The paper written by Bretthorst (1993) "On the difference in means" is a full analytical solution to the Behrens-Fisher problem of same/ different means/ standard deviations from a Bayesian perspective. It works compared to R packages like BESTmcmc or brms without MCMC. Two implementations - very similar - are available, written in R.
| File | Description |
|---|---|
DiM_Bretthorst_UMS.r |
qualitative as well as quantitative version + input data plots after UM Studer (1998) |
DiM_Bretthorst_UMS_calls.r |
example calls |
DiM_Bretthorst_PG.r |
quantitative version + posterior plots after P Gregory (2005) |
DiM_Bretthorst_PG_calls.r |
example calls |
DiM_Bretthorst_helperfuncs-general.r |
helper functions |
| Function | Description |
|---|---|
DiM_Bretthorst_UMS.r |
Calculate posteriors, print results, plot input values (qual, quan) |
SucRatesIntBounds |
Calculate means and sds from successes/ failures |
PMV.hypo |
Bayesian hypothesis |
PMbarV.hypo |
Bayesian hypothesis |
PMVbar.hypo |
Bayesian hypothesis |
PMbarVbar.hypo |
Bayesian hypothesis |
.DiM_ccs |
create constants from initial values |
.DiM_callintegrals |
calculate integrals (MV, MbarV, MVbar, MbarVbar) |
.DiM_prepres |
prepare the resulting probabilities based on the integrals |
DiM |
meta function, compiles single steps together |
UMSplot |
plot input data (qualitative version) after UMS |
UMSprint |
print results in the original Bretthorst style |
.DiM_prout.short |
print out short and efficient report |
.DiM_speedtest |
small speed test to compare the methods by calculating the four integrals |
.DiM.quan.plot |
plot inpuit data (quantitative version: raw or simulated from normal distribution) |
DiM_Bretthorst_PG.r |
Calculate and plot posteriors (quan) |
ums2pg |
convert initial values from UMS style to PG style |
DiM.pg |
calculate posterior probabilities according to PG Mathematica code |
DiM.extract.limits |
extract and apply (new) limits for the posterior plots |
DiM.plot.calc.pg |
calculate posterior plot points resulting from DiM.pg |
DiM.plot.pg |
plot posteriors from DiM.plot.calc.pg |
DiM.print.pg |
print results from DiM.pg |
DiM_Bretthorst_helperfuncs-general.r |
Functions for log version, brob objects, and numerical integration |
.llog.2add.short |
log(x+y) |
.llog.2sub.short |
log(x-y) |
gamma_inc_gen |
(generalized) incomplete gamma function for brob objects |
scalarprod.brob |
scalar product for brob objects |
list2vec.brob |
convert a brob list to a brob vector |
brobgiveback |
extract and format a brob object nicely as a character vector |
simpsonrule.nlb |
numerical integration (Simpson rule) for normal, log, and brob objects |
The textual output is written as an hommage to the Bretthorst paper and mirrors the way results are reported in that paper. Originally this was invented by UM Studer (1998) in his Mathematica script. It looks like good old typewriter style.
The UMS version works with qualitative and quantitative input. Ie. either one uses successes/ failures or works with raw values to create summary statistics (means, standard deviations, sample sizes) for the calculations. The PG version works only quantitatively. Via the PG version posterior plots can be created. With initial values one can create plots of the input data - for successes/ failures as well as the quantitative version. The latter works with density plots of either the raw values or one can draw random points from normal distribution based on the summary statistics or draws the ideal curve via the density function of the normal distribution. Be aware that the normal distribution as a base can be misleading ie. the wrong model. If this is clear one should use a different model to plot the data. Plotting the raw data can be misleading too as it just gives a rough impression in case of small data sets. All this has no influence on the actual calculation of the Bayesian posterior probabilities (see Bretthorst, 1993). Plotting the data is useful to get an impression of the data and to use common sense, nothing else. It is very helpful as well if infinity errors occur while using the normal version. It often clarifies why infinity errors happen, e.g. in case of larger sample sizes or very clear effects for which one does not really need to calculate anything.
The calculation of the integrals can exceed the computer limits for very large or very small numbers which both result in infinity errors and a break of the script. Consequently, one can choose three methods to calculate integrals:
- normal
- log
- brob
Those differ in the sense that log and brob allow to calculate values without getting any infinite errors. This happens regularly for larger sample sizes as well as obvious outcomes. The brob version works with package Brobdingnag and is much slower than the log version. The latter uses an adjusted numerical integration method (Simpson rule) to work only on the log level. The relevant integrals are therefor tweaked to work on the log-level as well. The log version is not yet implemented to calculate posterior plots. However, as long as the normal version works, one should use that, because it is by far the fasted one.
The qualitative version allows to compare e.g. 4 of 5 vs. 8 of 10 (successes/ failures) regarding the same and/ or different means/ standard deviations (Studer, 1998, p.47-48). The function SucRatesIntBounds calculates means and standard deviations from such initial ratios as input values for further calculations of the posterior probabilities.
Example - we compare 11 of 15 vs. 10 of 16
# Load scripts into R
source("DiM_Bretthorst_UMS.r")
source("DiM_Bretthorst_helperfuncs-general.r")
# calculate means/ standard deviations + lower/ upperbounds from successes/ failures
inval <- SucRatesIntBounds(Si=11, Ni=15, Sii=10, Nii=16, smin=0, snames=c("male","female"))
# calculate constants
DiM.ccs <- .DiM_ccs(inval=inval)
# calculate the four integrals
DiM.integrals.normal <- .DiM_callintegrals(DiM.ccs, method="normal")
# calculate posterior porbabilities of the difference in means (UMS version)
# and prepare results
DiM.out <- .DiM_prepres(DiM.integrals.normal, method="normal", percfac=1)
# output results (long version)
UMSprint(results=DiM.out, ccs=DiM.ccs, inval=inval, dig=3)
# plot qualitative view based on initials values
UMSplot(inval=inval)

This results in:
Click here for Posterior Probabilities
#########################################################################################
###
### ON THE DIFFERENCE IN MEANS
### G.L. Bretthorst (1993)
###
### original Mathematica code by U.M. Studer (90s, Switzerland)
###
### methods = normal, log, brob
### log and brob are for large numbers and infinity errors
Note:
If any probability is printed as '1' (= one) or '0' (= zero), it means that the
probability is practically that value by giving respect to limited computer precision.
...based on METHOD = normal and CONVBACK = FALSE
-------------------------------- Data (Input) ------------------------------------------
s_1/N_1 = 11/15 : Mean_1 ± SD_1 = 0.706 ± 0.107
s_2/N_2 = 10/16 : Mean_2 ± SD_2 = 0.611 ± 0.112
N_total = N_1 + N_2 = 31 : Mean_comb ± SD_comb = 0.657 ± 0.118
Bounds on the Mean (s_min = 0): Mean_L = 0.05, Mean_H = 0.95
Bounds on the Standard Deviation: SD_L = 0.052, SD_H = 0.118
Mean_L - Mean_comb < 0 = TRUE (-> '+'-sign between Gamma-fcts o.k.)
-------------------------------- Results ------------------------------------------------
p(mv | D_1, D_2, I) = const. 1.4e+20
p(mbarv | D_1, D_2, I) = const. 3.45e+20
p(mvbar | D_1, D_2, I) = const. 5.25e+19
p(mbarvbar | D_1, D_2, I) = const. 1.53e+20
where const. = 1.44e-13 / p(D_1,D_2|I)
= 1.45e-21
--------------- Model --------------------------------- Probability ---------------------
mv: Same Mean, Same Variance: 0.203
mbarv: Different Mean, Same Variance: 0.5
mvbar: Same Mean, Different Variance: 0.0761
mbarvbar: Different Mean, Different Variance: 0.221
------------------------------ Odds Ratios ----------------------------------------------
The probability the means are the same is: 0.279
The probability the means are different is: 0.721
The odds ratio is 2.59 to 1 in favor of different means.
The probability the variances are the same is: 0.702
The probability the variances are different is: 0.298
The odds ratio is 2.36 to 1 in favor of the same variances
The probability the data sets are the same is: 0.203
The probability the data sets are different is: 0.797
The odds ratio is 3.93 to 1 in favor of different means and/ or variances.
-------------------------------- End ----------------------------------------------------
#########################################################################################
One can do that shorter with less calls:
# UMS 1998, p.47
initials <- list(Si=11, Ni=15, Sii=10, Nii=16, snames=c("voluntary","non-voluntary"))
DiM.res <- DiM(initials=initials, cinput="qual", cmethod="normal", prout="long", convback=FALSE, plotti=FALSE)
The quantitative version is available for the UMS as well as for the PG version. One has to add lower and upper bounds for means and standard deviations as priors. Additionally, the actual empirical means, standard deviations, and sample sizes of the two sets that should be compared have to be given as input values along with the input type (invtyp can be UMS ums or PG pg). DiM does not take raw values. One has to calculate means and standard deviations beforehand manually. DiM.pg takes raw values for the two sets as well as priors.
The basic structure of the input values for DiM consists of summary statistics as well as priors, ie. lower/ upper bounds on the mean and on the standard deviation:
# input values for `DiM` after Studer (1998, p.47)
# empirical values from (Bretthorst, 1993, p.189 and here from Jaynes, 1976 + 1983)
inval <- list(
Si=NULL, # UMS specific -> successes group_1
Ni = 4, # N group_1
Sii=NULL, # UMS specific -> successes group_2
Nii = 9, # N group_2
smin = 0, # UMS specific -> bounds on the mean -> only for `SucRatesIntBounds`
Di = 50, # mean group_1
si = 6.48, # sd group_1
Dii = 42, # mean group_2
sii = 7.48, # sd group_2
L = 34, # mean lower bound
H = 58, # mean upper bound
sL = 3, # stdanrd deviation lower bound
sH = 10, # stdanrd deviation upper bound
snames = c("Jaynes.1","Jaynes.2")
)
The equivalent of DiM.pg is very similar:
# input values for `DiM.pg` after Gregory (2010)
inputvalues <- list(snames = c("riverB.1","riverB.2"),
# sample 1
d1 = c(13.2,13.8,8.7,9,8.6,9.9,14.2,9.7,10.7,8.3,8.5,9.2),
# sample 2
d2 = c(8.9,9.1,8.3,6,7.7,9.9,9.9,8.9),
# Input priors and no. of steps for numerical integration
# ndelta = number of steps in delta parameter (mean difference)
ndelta = 1000
# nr = number of steps in r parameter (ratio of the standard deviations)
nr = 1000
# Set prior limits on mean and standard deviation
# assumed that the data set is the same
# upper mean
high = 12,
# lower mean
low = 7,
# upper sd
sigma.high = 4,
# lower sd
sigma.low = 1
)
# calculate posterior porbabilities of the difference in means (PG version)
dim.res <- DiM.pg(invtyp="pg", inputvalues, print.res=FALSE)
# output results
DiM.print.pg(dim.res)
# extract limits for plot
DiM.extract.limits(dim.res.newlimits, change=FALSE)
# calculate plot values
dim.res.calc <- DiM.plot.calc.pg(dim.res.newlimits, method="normal")
# plot results
DiM.plot.pg(dim.res.calc, filling=FALSE, method="normal")
| mean difference | standard deviation ratio |
|---|---|
 |
 |
 |
 |
 |
 |
One can convert input values to be used within the other script.
Example:
# calculate means/ standard deviations + lower/ upperbounds from successes/ failures
res.SIB <- SucRatesIntBounds(Si=11, Ni=15, Sii=10, Nii=16, smin=0, snames=c("voluntary","non-voluntary"))
# use input values after UMS for PG version
DIM.pg.res <- DiM.pg(invtyp="ums", inputvalues=res.SIB, print.res=TRUE)
or
# insert successes/ failures manually and let the script calculate the rest
inputvalues.UMS <- list(snames=c("Jaynes.1","Jaynes.2"), si=6.48, Ni=4, sii=7.48, Nii=9, Di=50, Dii=42, L=34, H=58, sL=3, sH=10, ndelta=1000, nr=1000)
dim.res <- DiM.pg(invtyp="ums", inputvalues=inputvalues.UMS, print.res=TRUE)
Usage of R package Brobdingnag
The calculation of the posterior probabilities depend heavily on Gamma function calls used for numerical integration. With larger sample sizes (not the ones used in the original papers and books) this leads temporarily to numbers beyond normal computer capabilities. If that happens, the scripts contain a switch to use the R package Brobdingnag for very large numbers and the UMS version allows to work with a log-only variant. The work with Brobdingnag works well but leads to a substantial loss in speed. The work with log-only is much faster, but is not yet implemented for the posterior plots. In fututre, the UMS and PG versions will be merged and the log version will be available for posterior plots as well.
Example output that fails due to very large numbers:
# example when normal version fails due to infinite errors - requires a very large number version (log, Brobdingnag)
res.SIB.NRFtotal <- SucRatesIntBounds(Si=(20+13), Ni=(47+28), Sii=(338 %/% 4), Nii=338, smin=0, snames=c("male","female"))
# normal version - does not work
DiM.res <- DiM(initials=res.SIB.NRFtotal, cinput="qual", cmethod="normal", prout="long", convback=FALSE, plotti=FALSE)
# brob version
DiM.res <- DiM(initials=res.SIB.NRFtotal, cinput="qual", cmethod="brob", prout="long", convback=FALSE, plotti=FALSE)
# log version
DiM.res <- DiM(initials=res.SIB.NRFtotal, cinput="qual", cmethod="log", prout="long", convback=FALSE, plotti=FALSE)
# plot to see why it fails
UMSplot(inval=res.SIB.NRFtotal, pdfout=FALSE)

Looking at the plot makes it obvious why it fails - the differences with respect to means and standard deviations are clear. As a consequence it is very likely that very large numbers will occur at least temporarily during calculations or even as a result. But it should work nevertheless, because the results are human readable again as proabilities are bound between zero and one.
Be aware that the output of log values (log, brob) contains now the sign of the results exp(x). This is implemented for the UMS as well as for the PG version. This work solely on the log level avoids the problem of infinite values. However, thinking in probabilities becomes challenging if they are represented on the log scale. So a rule of thumb is that very large numbers either near zero or up to infinity just mark the limits of probabilities: zero or one. Both probabilities point towards very certain outcomes so that the exact probability here is of less importance. The corresponding odds ratios can achieve huge numbers, but one should not take those too serious - like we do not take very small p-values in classical statistics too serious. Better is to remember that the size of effects can be
- non-existent
- small but visible
- visible but still uncertain
- very likely, less uncertain
- existent and clear
The category in a concrete case has to be decided on the original scale of each effect, but such a rough distinction is sometimes easier and helps not to lose track of what is really important than sticking to numbers or several digits after the comma or believing in huge numbers. For the relationship of probabilities' limits and log values the following is valid:
> exp(0)
[1] 1
> exp(-Inf)
[1] 0
There is a graphical output for the qualitative version as well as for the quantitative one. The qualitative version with UMSplot plots
- successes/ failures of input values
The quantitative one with DiM.quan.plot plots density plots of input values of the type
- raw values
- summary statistics (mean, sd, N) based on simulation from normal distribution using
rnorm - summary statistics (mean, sd, N) based on densities taken from normal distribution using
dnorm
This looks like
# example 1
# UMS, s.a.
# initial values
initials <- list(Ni=15, Di=0.7058824, si=0.1073966, Nii=16, Dii=0.6111111, sii=0.1118397,
L=0.05, H=0.95, sL=0.052, sH=0.118, snames=c("voluntary","non-voluntary"))
attach(initials)
xbar1 <- Di
sd1 <- si
n1 <- Ni
xbar2 <- Dii
sd2 <- sii
n2 <- Nii
groupnames <- snames
detach(initials)
# plots
# summary statistics, no simulation
DiM.quan.plot(stype="sumstat", xbar1=xbar1, sd1=sd1, n1=n1, xbar2=xbar2, sd2=sd2, n2=n2, simulate=FALSE, groupnames=groupnames)
# summary statistics, simulation
DiM.quan.plot(stype="sumstat", xbar1=xbar1, sd1=sd1, n1=n1, xbar2=xbar2, sd2=sd2, n2=n2, simulate=TRUE, groupnames=groupnames)
# larger sample size for simulation
nfac <- 100
DiM.quan.plot(stype="sumstat", xbar1=xbar1, sd1=sd1, n1=n1*nfac, xbar2=xbar2, sd2=sd2, n2=n2*nfac, simulate=TRUE, groupnames=groupnames)
# simulate values and plot them as raw
set.seed(1423)
v1 <- rnorm(n=n1, mean=xbar1, sd=sd1)
v2 <- rnorm(n=n2, mean=xbar2, sd=sd2)
DiM.quan.plot(stype="raw", v1=v1, v2=v2, groupnames=groupnames)
| Plot summary statistics | ...and raw/ simulated values |
|---|---|
| summary statistics and dnorm | raw values |
 |
 |
| simulation (rnorm) | simulation (rnorm, larger sample size) |
 |
 |
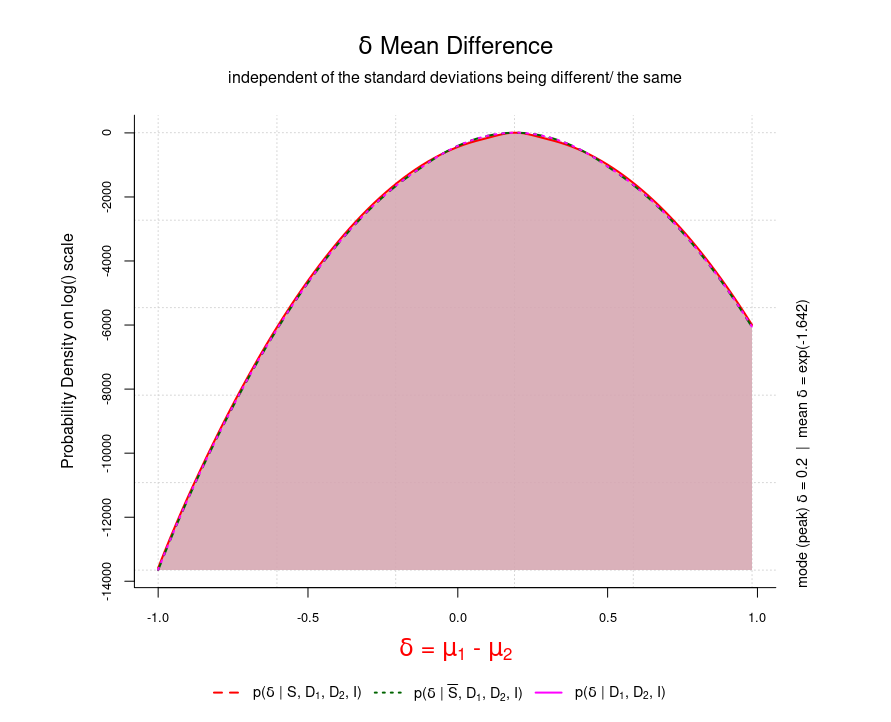
And the posterior plots via DiM.plot.pg are plotted in the following order:
- mean difference assuming the standard deviations are the same
- mean difference assuming the standard deviations are different
- mean difference independent of the standard deviations being different/ the same
- standard deviation ratio assuming the means are the same
- standard deviation ratio assuming the means are different
- standard deviation ratio independent of the means being different/ the same
It can happen that the limits of the last three plots are unfortunate and result in errors in case of very large numbers. For such purposes one can tweak the limits withDiM.extract.limits before calling DiM.plot.calc.pg. It either gives out the actual limits or takes scaling parameters for the lower/ upper limit so that a plot can be printed properly. A change can be introduced by the switch change=TRUE that allows to redefine the range. This does not change or re-calculates the posterior probabilities per se but changes the plot range values of the posterior plots so that their calculations succeed. Again, this happens only in case of very large (small) numbers. A view on such plots makes it obvious. Be aware - such plots contain log values on the y-axis which makes it harder to interpret. A little bit of experimentation is necessary to achieve the best results. The following example shows how to handle it.
Example:
# this example has very large numbers
res.SIB.NRFtotal
# calculate posteriors
DIM.pg.res.brob <- DiM.pg(invtyp="ums", inputvalues=res.SIB.NRFtotal, print.res=TRUE, method="brob")
# look at the results:
DiM.print.pg(DIM.pg.res.brob)
This gives the output:
Click here for Posterior Probabilities
##########################################################################
#
# On the 'Difference in means'
# original: G.L. Bretthorst (1993)
# R code after Mathematica code by Phil Gregory
# Descriptive values of samples
Data set Sample Size Standard Deviation Variance Mean
male 75 0.05622580 0.0031613408 0.4415584
female 338 0.02344895 0.0005498534 0.2500000
combined 413 0.08052561 0.0064843736 0.2847866
# Prior information
Type Value
Prior Mean lower bound 0.0e+00
Prior Mean upper bound 1.0e+00
Prior Standard Deviation lower bound 2.0e-03
Prior Standard Deviation upper bound 5.7e-02
Number of steps for plotting p(delta | D_1, D_2, I) 1.0e+03
Number of steps for plotting p(r | D_1, D_2, I) 1.0e+03
# Posterior probabilities
Total Probability: exp(881.156) [sign=TRUE]
short Hypothesis Probability exp(Probability) sign
C,S Same Mean, same Standard Deviation 7.779e-219 exp(-502.2) TRUE
Cbar,S Different Means, same Standard Deviation 2.436e-26 exp(-58.98) TRUE
C,Sbar Same Mean, different Standard Deviations 0.000e+00 exp(-Inf)
Cbar,Sbar Different Means, different Standard Deviations 1.000e+00 exp(0) TRUE
C The Means are the same 7.779e-219 exp(-502.2) TRUE
Cbar The Means are different 1.000e+00 exp(2.436e-26) TRUE
S The Standard Deviations are the same 2.436e-26 exp(-58.98) TRUE
Sbar The Standard Deviations are different 1.000e+00 exp(0) TRUE
C, S Same Means and Standard Deviations 7.779e-219 exp(-502.2) TRUE
Cbar, Sbar One or Both are different 1.000e+00 exp(-7.779e-219) TRUE
# Odds Ratios
Hypothesis Odds Ratio exp(Odds Ratio) sign
The odds Ratio in favour of a difference (means) 1.286e+218 exp(502.2) TRUE
The Odds Ratio in favour of a difference (standard deviations) 4.106e+25 exp(58.98) TRUE
The Odds Ratio in favour of a difference (means and standard deviations) 1.286e+218 exp(502.2) TRUE
The Odds Ratio in favour of the same (means) 7.779e-219 exp(-502.2) TRUE
The Odds Ratio in favour of the same (standard deviations) 2.436e-26 exp(-58.98) TRUE
The Odds Ratio in favour of the same (means and standard deviations) 7.779e-219 exp(-502.2) TRUE
##########################################################################
Obviously there are "certain probabilities," i.e. probabilities that are on the numerical level around zero or one and therefor at the limits. Let's go back to tweak the graphical output limits - this touches only the standard deviation ratios, not the difference in means:
# we can try out several limits before applying it
DiM.extract.limits(DIM.pg.res.brob, scaleL=5, scaleH=2, change=FALSE)
DiM.extract.limits(DIM.pg.res.brob, scaleL=10, scaleH=3, change=FALSE)
# apply new limits
DiM.newlimits <- DiM.extract.limits(DIM.pg.res.brob, scaleL=5, scaleH=2, change=TRUE)
# check
DiM.extract.limits(DiM.newlimits, change=FALSE)
# calculate plot values - this requires time ...
DiM.newlimits.calc.plot <- DiM.plot.calc.pg(DiM.newlimits, method="brob")
The last command gives the following output:
Calculate graphical output for the various probabilities...
Using log() and package 'Brobdingnag'
All results are expressed as log(RESULT)
Calculate pdel.SD1D2I and pdelA...
Calculate pdel.SbarD1D2I and pdelB...
Calculate average of pdelA and pdelB...
Calculate HDIs for the average of pdelA and pdelB...
Calculate pr.CD1D2I and prA...
Calculate pr.CbarD1D2I and prB...
Calculate average of prA and prB...
Calculate HDIs for the average of prA and prB...
Compile results...
and we plot the result on the log scale.
# plot results as usual
DiM.plot.pg(DiM.newlimits.calc.plot, filling=TRUE, by1=TRUE, method="brob")
| mean difference | standard deviation ratio |
|---|---|
 |
 |
 |
 |
 |
 |
In our case it gives out a warning which we keep in mind while looking on the plots:
In table 'pr.df' (ratios) are values of '-Inf' - those will be replaced for the graphical output by the minimum value of those vectors
Remember: exp(-Inf) = 0
An important future task is to merge the UMS and PG version so that only one version is left and the log version is available too to calculate the posterior plots. Another alternative would be to use the package Rmpfr. But this is slower than the log-only version. Better of course would be to write everything in C++.
Bretthorst, G.L. (1993). On the difference in means. In Physics & Probability Essays in honor of Edwin T. Jaynes, W. T. Grandy and P. W. Milonni Eds., Cambridge University Press, England.
Gregory, P. (2005). Bayesian logical data analysis for the physical sciences. A comparative approach with Mathematica support. Cambridge University Press.
Studer, U.M. (1998). Verlangen, Süchtigkeit und Tiefensystemik. Fallstudie des Suchttherapiezentrums für Drogensüchtige start again in Männedorf und Zürich von 1992 bis 1998. Bericht an das Bundesamt für Justiz (BAJ). Zürich.
The R code is based on two Mathematica scripts that acted as role models - very similar, but not identical implementations.
- (C) by UM Studer (1998). This Mathematica code is unpublished.
- (C) by P Gregory (2005). You can get his Mathematica notebook for free on the book's website.
- R code by LG (2005-2023): GPL >= v3
All R scripts should work under R >=v3.
The R code was tested carefully, and cross-checked against various publication results to ensure proper results. However, it is provided "as is". Use common sense to compare results with expectations. NO WARRANTY of any kind is involved here. There is no guarantee that the software is free of error or consistent with any standards or even meets your requirements. Do not use the software or rely on it to solve problems if incorrect results may lead to hurting or injurying living beings of any kind or if it can lead to loss of property or any other possible damage to the world. If you use the software in such a manner, you are on your own and it is your own risk.