Tamil Emotional Speech Dataset is a collection of recordings in Sri Lankan Tamil, representing the distinct dialects spoken in the northern, eastern, western, and central provinces. It aims to capture the linguistic and emotional diversity of these regions for use in speech and emotion recognition research.

EmoTa is the first emotional speech dataset in Tamil, designed to reflect the linguistic diversity of Sri Lankan Tamil speakers. It includes 936 utterances from 22 native Tamil speakers (11 male, 11 female), each articulating 19 semantically neutral sentences across five primary emotions: Anger, Happiness, Sadness, Fear, and Neutrality.
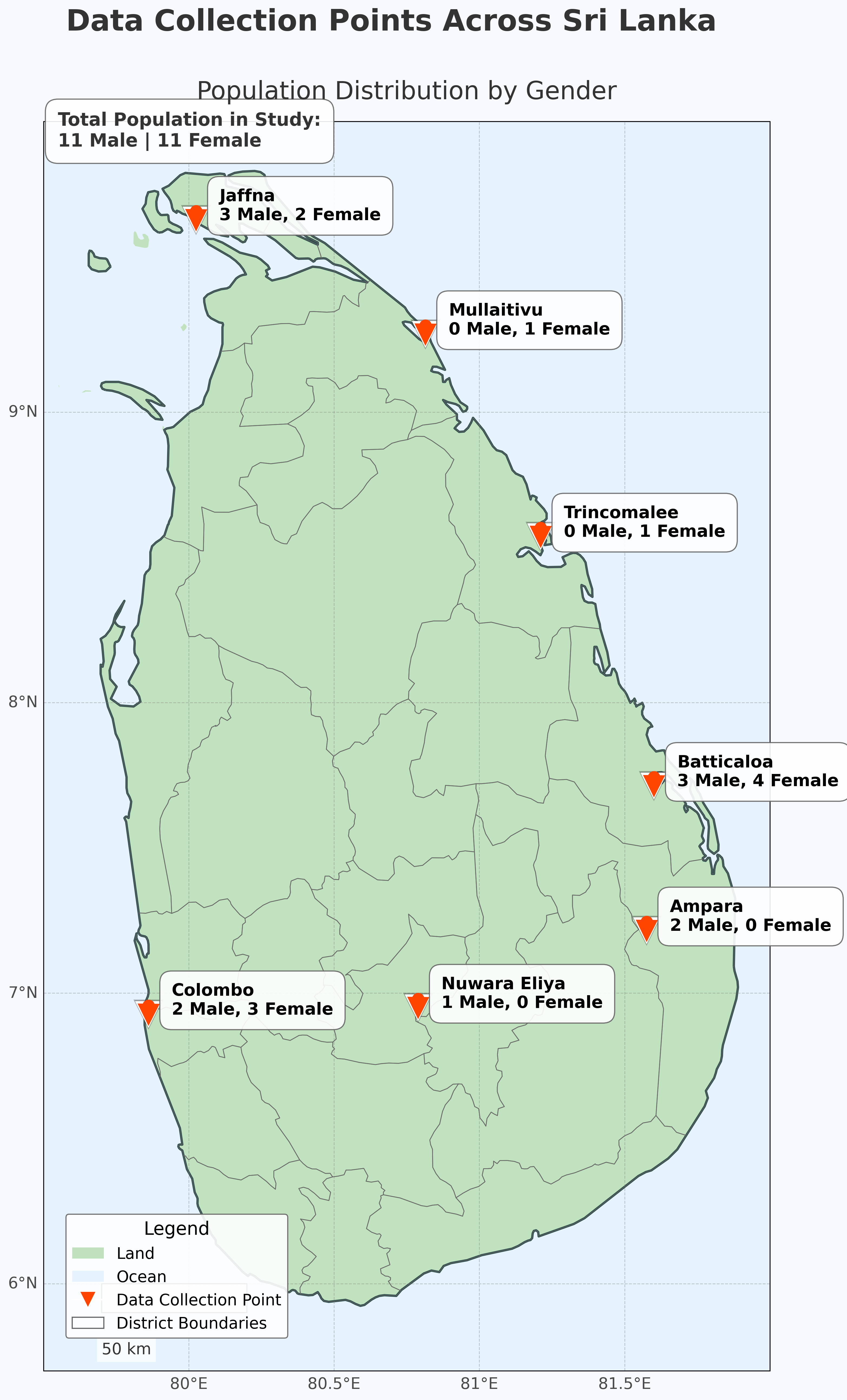
- Speakers: 22 native Tamil speakers (11 male, 11 female)
- Emotions: Anger, Happiness, Sadness, Fear, Neutrality
- Sentences: 19 semantically neutral sentences to reduce lexical bias
- Recording Quality: Captured in a controlled, soundproof environment with professional equipment
- Total Duration: Approx. 48 minutes of speech
The dataset is organized into emotion-based folders with the following naming convention:
EmoTa/
├── happy/
├── sad/
├── angry/
├── fear/
└── neutral/
└── <spkID>_<senID>_<emo[:3]>.wav
EmoTa aims to facilitate research in Speech Emotion Recognition (SER) for the Tamil language, offering a balanced and diverse representation of emotional expressions from native Tamil speakers. It is released as open-access to support further exploration of Tamil language processing.
If you use EmoTa: A Tamil Emotional Speech Dataset in your research, please cite:
@inproceedings{thevakumar-etal-2025-emota,
title = "{E}mo{T}a: A {T}amil Emotional Speech Dataset",
author = "Thevakumar, Jubeerathan and
Thavarasa, Luxshan and
Sivatheepan, Thanikan and
Kugarajah, Sajeev and
Thayasivam, Uthayasanker",
editor = "Sarveswaran, Kengatharaiyer and
Vaidya, Ashwini and
Krishna Bal, Bal and
Shams, Sana and
Thapa, Surendrabikram",
booktitle = "Proceedings of the First Workshop on Challenges in Processing South Asian Languages (CHiPSAL 2025)",
month = jan,
year = "2025",
address = "Abu Dhabi, UAE",
publisher = "International Committee on Computational Linguistics",
url = "https://aclanthology.org/2025.chipsal-1.19/",
pages = "193--201",
abstract = "This paper introduces EmoTa, the first emotional speech dataset in Tamil, designed to reflect the linguistic diversity of Sri Lankan Tamil speakers. EmoTa comprises 936 recorded utterances from 22 native Tamil speakers (11 male, 11 female), each articulating 19 semantically neutral sentences across five primary emotions: anger, happiness, sadness, fear, and neutrality. To ensure quality, inter-annotator agreement was assessed using Fleiss' Kappa, resulting in a substantial agreement score of 0.74. Initial evaluations using machine learning models, including XGBoost and Random Forest, yielded a high F1-score of 0.91 and 0.90 for emotion classification tasks. By releasing EmoTa, we aim to encourage further exploration of Tamil language processing and the development of innovative models for Tamil Speech Emotion Recognition."
}Paper: view
| 🏷️ Name | ||
|---|---|---|
| Jubeerathan Thevakumar | [email protected] | |
| Luxshan Thavarasa | [email protected] | |
| Thanikan Sivatheepan | [email protected] | |
| Uthayasanker Thayasivam | [email protected] |
Thanks to all the volunteers who provided samples to make EmoTa possible.
Special thanks to Braveenan Sritharan for his invaluable help and to Sajeev Kugarajah for his contribution to dataset collection.