Capstone Project for Galvanize: Data Science Immersive
Reddit is the 4th most visited site in the US(Alexa). It is an aggregation of online discussion communities. Each content community is known as a subreddit; users can post links to other websites or create texts posts, which can be upvoted/downvoted based on the quality of the content. Then a discussion takes place, based on this post. There is a full spectrum of subreddits(topics) including science, politics, music, various image types, jokes, news, and gaming.
There are currently over 1 million subreddits. It can be overwhelming having to deal with a list of that many choices, so I thought it would be a great opportunity to make a recommender, since nobody has time to look through a list of a million subreddits to see what they might like.

This dataset was found on r/datasets It has all public comment data from 2007 to 2015, which is about 1.8 billion comments, totaling about 1 TB.

The approaches used in recommender systems are either: Collaborative filtering, Content-based filtering, or Hybrid recommender systems. Collaborative filtering makes recommendations on users by finding the most similar users and finding the mutual activity of these similar users. Content-based filtering recommends items that are similar to those that a user liked in the past, the technique commonly uses TF-IDF(term frequency–inverse document frequency) to find items that are similar. Hybrid recommender systems are usually better because they take the best of both worlds.
Collaborative filtering (CF) seemed like it would work the best under the time constraint and the mass amount of user data. It tends to fail when there are not many similar users compared to the desired user to make a recommendation on. If a user is into r/opera, r/machinelearning, r/Nickelback, and r/metal. There are very few users similar to this user therefore it will be difficult to make recommendations on this user.
Content-Based Filtering (CBF) seemed like it would not be very consistent considering how much sarcasm is on reddit, and it would not generalize many cases, where r/bird would be similar to r/eagles, when in reality the former subreddit is about birds and latter is about an NFL(football) team. Another case would be where users who are in communities with opposing views would probably not like a recommendation to a subreddit with completely opposite views. An example of that is r/The_Donald is a subreddit for users who like Trump, while r/MarchAgainstTrump is a subreddit for people who dislike Trump. Also since subreddits are always one word, it would also probably not always split at the correct words. Is r/Overwatch Over watch or Overwatch? Is r/AdviceAnimals Ad vice Animals or Advice Animals?
I would build a Hybrid recommender if I were deploying this in the industry, but given my time and financial constraints, I will stick to just the CF.
Given a user to make a recommendation on, I find the most similar users based on where people have comment activity(Jaccard similarity). Then aggregate where the 20 most similar users have comment activity in minus where the original user already has comment activity in and take votes for each user per subreddit. Whichever subreddits have the most votes, will be the top recommendations in a descending fashion by the number of votes.
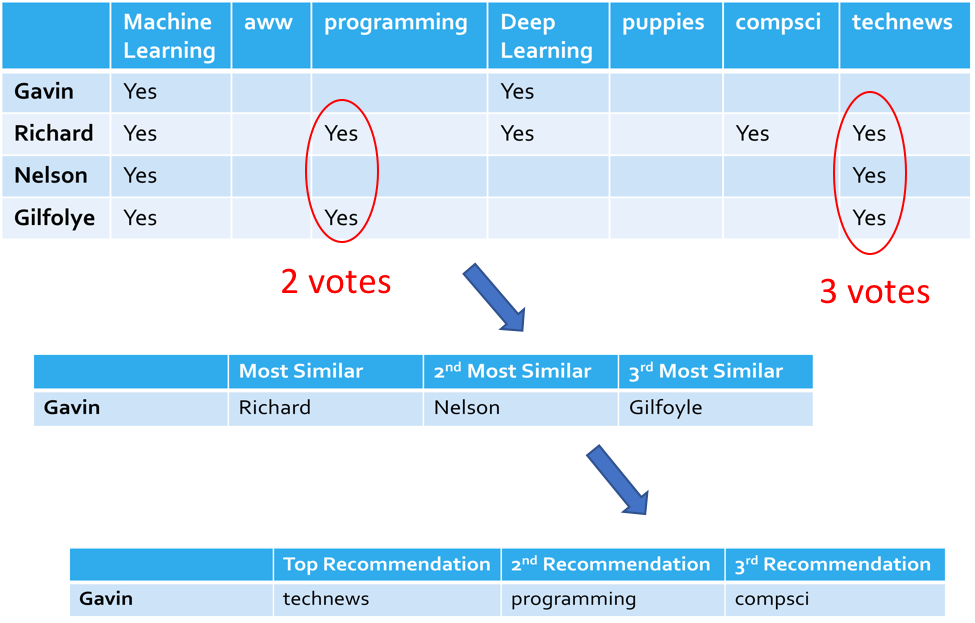
In the figure above, to make a recommendation for Gavin. Gavin is the most similar to Richard, Nelson, and Gilfoyle. The three of these guys together all have comment activity in technews, therefore technews would be the first recommendation. The next recommendation would be programming, because 2/3 have comment activity there. Last would be compsci, since Richard is the most similar user and has comment activity there. The recommendations for Gavin in ranked order would be technews, programming, and compsci.
- Torrent data onto an EC2 (I recommend this way, because it gets around the bottleneck of your ISP's upload speeds)
- Upload the unzipped data onto your S3 bucket all in the same directory
- Launch cluster(EMR) on AWS
bash launch_cluster.sh mybucket_name mypem 20
launch_cluster.sh Takes three arguments:
- bucket name - one that has already been created
- name of key file - without .pem extension
- number of slave instances
***Modify script as needed
- Run PySpark with jupyter kernel in EMR and create SSH tunnel
- Run Jupyspark kernel and connect on your tunneled Jupyter notebook
- Create an instance of Pyspk:
spark_data = Pyspk(INSERT S3 READ LINK, UTC TIME SPLIT)
UTC time split will split everything after the specified time to be test data, and everything before to be training data.
- After it has finished running (few hours), you can write to s3 by calling the method of the instance write_s3, AWS credentials need to be initialized also to write.
spark_data.write_s3(s3_write_link) - There will be many csv's that will need to be concatenated, use an EC2 instance to do this. It should be much quicker than the previous steps
-
Import csv of dataframe
df = pd.read_csv(concatenated_csv) -
Create an instance of Pndas
pandas_data = Pnds(df) -
This will create a Utility matrix where the rows are Users and columns are subreddits
-
Then it will compute the user-user similarity between each user using Jaccard Similarity
-
Find the most similar users
-
Get Recommendations based on where most similar users have comment activity, for a list of users by:
pandas_data.get_recommendations(user_list)which will return a dictionary of the user with its subreddit recomendations
- Spark 2.1
- Python 2.7.13
- Numpy
- Pandas
- Scipy