KMeans_CUDA model (data, N, D, K); // Where data is AoS, N is number of data points, D is number of dimensions and K is number of clusters
model.one_epoch(); // Trains one epoch
model.print_predictions(); // Classify data// Updates each centroid using d_sum and d_count
// where the index is d * centroid number (out of k).
// d: number of dimensions
// k: number of clusters
__global__ void update_centroids(
float *d_centroids,
const float *d_sum,
const int *d_count,
int d,
int k
);// Computes the sum (d_sum) and count (d_count)
// for each of the k clusters labeled in d_centroids.
// n: number of data points
// d: number of dimensions
// k: number of clusters
// Uses shared memory of (k+2*k*d)
__global__ void sum_and_count(
const float *d_data,
const float *d_centroids,
float *d_sum,
int *d_count,
int n,
int d,
int k
);Go to: https://github.com/Tyler-Hilbert/CUDA-KMeans/tree/52db75728794449dc152989c648e03b632d24c08 for most recent performance tests.
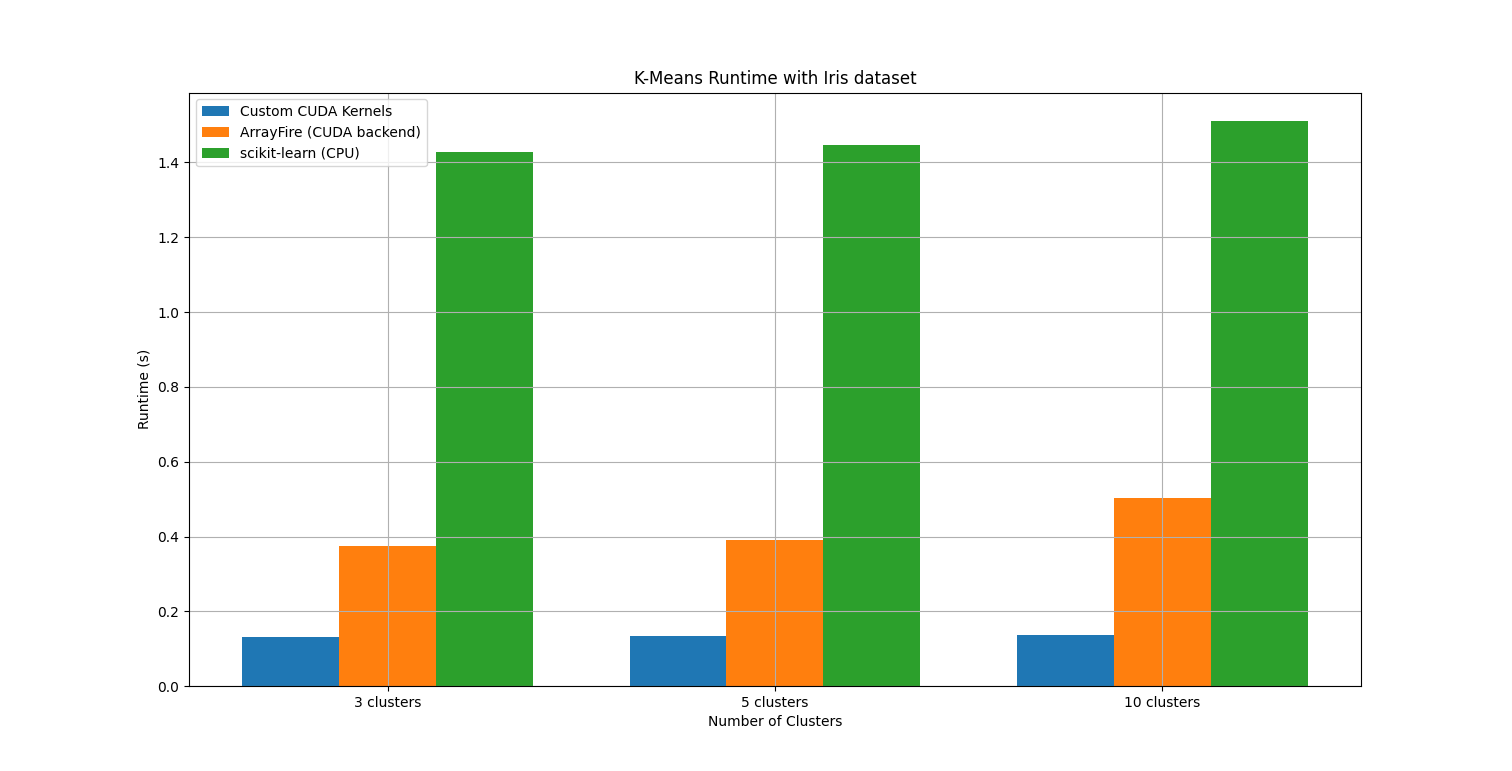
It is shown that this implementations of K-Means outperforms scitkit-learn and ArrayFire on a T4.