-
Notifications
You must be signed in to change notification settings - Fork 3
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
e2b4c23
commit 4411ffa
Showing
6 changed files
with
207 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,3 @@ | ||
| /bot.session | ||
| /.idea | ||
| /__pycache__ |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,2 +1,63 @@ | ||
| # luoxu-bot | ||
| A Telegram bot to index Chinese and Japanese group contents with luoxu | ||
| luoxu-bot 是类似于 [luoxu-web](https://github.com/lilydjwg/luoxu-web) 的 CJK 友好的 Telegram Bot,依赖于 [luoxu](https://github.com/lilydjwg/luoxu) 所创建的后端。 | ||
|
|
||
| # 测试环境 | ||
| - Python 3.7.9 | ||
| - pip 21.1.2 | ||
| > 开发中使用到的 Telethon 需要 Python 3+ | ||
| # 配置 | ||
| - 前往 [luoxu](https://github.com/lilydjwg/luoxu) 根据相关内容配置并运行 luoxu,等待**消息索引完毕** | ||
| > **由于 Telegram 的消息样式问题,建议修改 luoxu 项目中的 `luoxu/db.py` 文件,将 `SEARCH_LIMIT` 修改为 `10`** | ||
| - 克隆 [本项目](https://github.com/TigerBeanst/luoxu-bot) , 并使用 `pip3 install -r requirements.txt` 等方式安装依赖 | ||
| - 前往 [My Telegram](https://my.telegram.org/) ,获取 `API development tools` 中的 `api_id` 和 `api_hash` | ||
| - 在 Telegram 中向 [@BotFather](https://t.me/botfather) 申请 Bot,获取 `bot token`(由`数字:数字字母`构成,如`1111122222:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA`) | ||
| - 在 Telegram 中向 [@getidsbot](https://t.me/getidsbot) 发送 `/start` 以获取你的 Telegram 账号 ID(`my_id`) | ||
| - 打开 `config.py` 并填写相关字段(如果你在 luoxu 中修改了接口的端口或者前缀等,请同步修改) | ||
| - 使用 `python3 main.py` 运行项目,当出现 `开摆` 时代表项目已启动,可以向自己的 Bot 尝试发送指令(请提前向自己的 Bot 激活 `/start`) | ||
|
|
||
| # 使用 | ||
| - `/list` 获取已索引群组的列表和相关信息 | ||
|
|
||
| 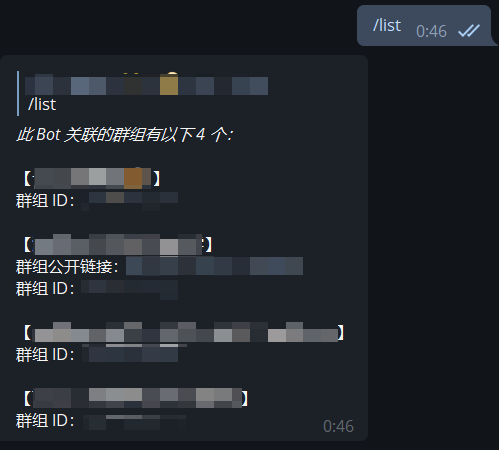 | ||
|
|
||
| - 直接发送关键词,如 `我是垃圾`,其后通过点选对应的群组或「所有已索引群组」 | ||
|
|
||
| 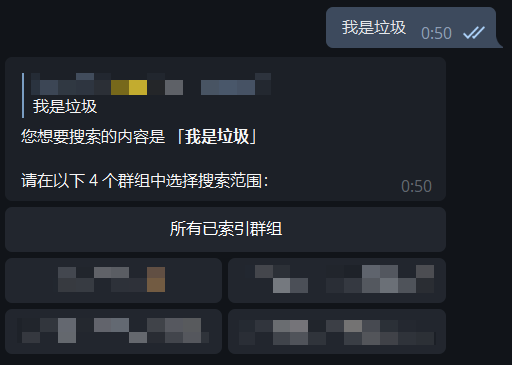 | ||
|
|
||
| - 搜索结果,点击「查看群组原消息」可以直接跳转到对应消息位置: | ||
|
|
||
| 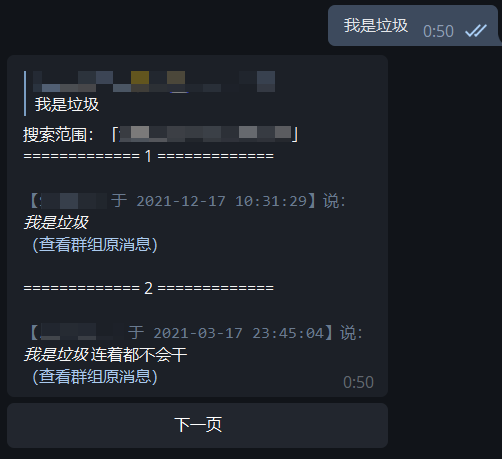 | ||
|
|
||
| 另外简单测试了一下,luoxu 作者提供的搜索字符串的功能应该是工作正常的(毕竟我没去注意过 URL 里的空格啥的……) | ||
| > 搜索消息时,搜索字符串不区分简繁(会使用 OpenCC 自动转换),也不进行分词(请手动将可能不连在一起的词语以空格分开)。 | ||
| > | ||
| > 搜索字符串支持以下功能: | ||
| > | ||
| > 1.以空格分开的多个搜索词是「与」的关系 | ||
| > | ||
| > 2.使用 `OR`(全大写)来表达「或」条件 | ||
| > | ||
| > 3.使用 `-` 来表达排除,如 `落絮 - 测试` | ||
| > | ||
| > 4.使用小括号来分组 | ||
| # 其他 | ||
| - **搜索结果只有一页时,可能会有多余的「下一页」按钮,问题不大,懒得修了** | ||
| - 部分数据量过大的消息可能会让 Bot 一直保持在「少女祈祷中…」,建议换个详细点的词。一般是搜什么 test 之类的很容易出现在一条长消息里的(有人在群里直接粘贴发带了关键词的 log 之类的) | ||
| - 请使用 `screen` 等程序保持 Bot 在终端关闭后亦持续运行 | ||
| - 可以使用已经配置在公网上的 API 吗?当然可以,但是这个项目出现的原因就是因为不想公开在公网上 | ||
| - 本项目没有代理字段的配置。经过各方面的考虑~~以及我懒得再改~~,我认为一般需要部署此项目的机器都已经能正常连接 Telegram | ||
|
|
||
| # 为什么会有这个项目 | ||
| luoxu 是一个很棒的项目,在此感谢 [@lilydjwg](https://github.com/lilydjwg) ( | ||
|
|
||
| luoxu 提供了 API 接口以供前端使用,但这也带来一个问题,如果索引的内容存在不想公开的私密群组,那么要不就将整套前后端部署在自己的内网上,要不就需要通过设置 Base Auth 等方式在保护接口( | ||
|
|
||
| 所以最后我选择摸一个 Telegram Bot(((( | ||
|
|
||
| # 鸣谢 | ||
| - [@lilydjwg](https://github.com/lilydjwg) ,给您磕头!!!!!! | ||
| - [@LonamiWebs/Telethon](https://github.com/LonamiWebs/Telethon) | ||
| - 我那会使用搜索引擎的双手和大脑 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,10 @@ | ||
| my_id = 19260817 | ||
| api_id = 1145141919 | ||
| api_hash = 'gouliguojiashengsiyiqiyinhuofubiquzhi' | ||
| bot_token = '1111122222:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA' | ||
|
|
||
| BASE_URL = "http://localhost:9008" | ||
| BASE_URL_PREFIX = "luoxu" | ||
|
|
||
| GROUPS_LIST_URL = BASE_URL + "/" + BASE_URL_PREFIX + "/groups" | ||
| SEARCH_LIST_URL = BASE_URL + "/" + BASE_URL_PREFIX + "/search" |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,69 @@ | ||
| import logging | ||
|
|
||
| from telethon import Button | ||
| from telethon.sync import TelegramClient, events | ||
|
|
||
| import config | ||
| from utils.search_utils import group_list, search_list | ||
| from utils.search_utils import groups_button_list | ||
|
|
||
| logging.basicConfig(format='[%(levelname) 5s/%(asctime)s] %(name)s: %(message)s', | ||
| level=logging.WARNING) | ||
|
|
||
| bot = TelegramClient('bot', config.api_id, config.api_hash).start(bot_token=config.bot_token) | ||
|
|
||
| global_event = None | ||
| query_page = ["0"] | ||
|
|
||
|
|
||
| @bot.on(events.CallbackQuery) | ||
| async def click_button(event): | ||
| data = event.data.decode('utf-8').split('$') | ||
| await event.edit("少女祈祷中…") | ||
| reply_array = search_list(data, global_event.raw_text) | ||
|
|
||
| button_pre_next = [] | ||
| global query_page | ||
| if len(data) > 1: | ||
| if len(query_page) > 1 and query_page[-2] == data[1]: | ||
| query_page.pop() | ||
| else: | ||
| query_page.append(data[1]) | ||
| if reply_array[1] == 0 and len(query_page) == 1: # 单页 | ||
| await event.edit(reply_array[0], link_preview=False) | ||
| else: # 多页 | ||
| if len(query_page) > 1: | ||
| button_pre_next.append(Button.inline("上一页", data[0] + "$" + str(query_page[-2]))) | ||
| if reply_array[1] != 0: | ||
| button_pre_next.append(Button.inline("下一页", data[0] + "$" + str(reply_array[1]))) | ||
| await event.edit(reply_array[0], buttons=button_pre_next, link_preview=False) | ||
|
|
||
|
|
||
| async def reply_msg(event, reply_msg, button_list=None): | ||
| if event.sender_id == config.my_id: | ||
| markup = None | ||
| if button_list is not None: | ||
| markup = button_list | ||
| await event.reply(reply_msg, buttons=markup, link_preview=False) | ||
| else: | ||
| await event.reply("您并非此 Bot 的持有者,无法使用此功能") | ||
|
|
||
|
|
||
| @bot.on(events.NewMessage) | ||
| async def event_handler(event): | ||
| if '/list' == event.raw_text or '、list' == event.raw_text: | ||
| await reply_msg(event, group_list()) | ||
| else: | ||
| global query_page | ||
| query_page = ["0"] | ||
| button_list = groups_button_list() | ||
| list_length = (len(button_list) - 2) * 2 + len(button_list[-1]) | ||
| reply_word = "您想要搜索的内容是 「**" + event.raw_text + "**」\n\n" + \ | ||
| "请在以下 " + str(list_length) + " 个群组中选择搜索范围:\n" | ||
| global global_event | ||
| global_event = event | ||
| await reply_msg(event, reply_word, button_list) | ||
|
|
||
|
|
||
| print('开摆') | ||
| bot.run_until_disconnected() |
Binary file not shown.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,63 @@ | ||
| import time | ||
| import requests | ||
| from telethon import Button | ||
| import config | ||
|
|
||
|
|
||
| def group_list(): | ||
| response = requests.get(config.GROUPS_LIST_URL).json()["groups"] | ||
| reply_msg = "__此 Bot 关联的群组有以下 " + str(len(response)) + " 个:__\n\n" | ||
| for group in response: | ||
| reply_msg += "【**" + group["name"] + "**】\n" | ||
| if group["pub_id"] is not None: | ||
| reply_msg += "群组公开链接:[@" + \ | ||
| str(group["pub_id"]) + "](https://t.me/" + str(group["pub_id"]) + ")" + \ | ||
| "\n" | ||
| reply_msg += "群组 ID:`" + str(group["group_id"]) + "`\n\n" | ||
| return reply_msg | ||
|
|
||
|
|
||
| def groups_button_list(): | ||
| response = requests.get(config.GROUPS_LIST_URL).json()["groups"] | ||
| button_list = [[Button.inline("所有已索引群组", str(0))]] | ||
| for i, group in enumerate(response): | ||
| one_button = Button.inline(group["name"], str(group["group_id"])) | ||
| if i % 2 != 0: | ||
| button_list[len(button_list) - 1].append(one_button) | ||
| else: | ||
| button_list.append([one_button]) | ||
| return button_list | ||
|
|
||
|
|
||
| def search_list(data, raw_text): | ||
| url = config.SEARCH_LIST_URL + "?q=" + raw_text | ||
| if data[0] != 0: | ||
| url += "&g=" + data[0] | ||
| if len(data) > 1 and data[1] != "0": | ||
| url += "&end=" + data[1] | ||
|
|
||
| print(url) | ||
| msg_response = requests.get(url).json() | ||
| msgs = msg_response["messages"] | ||
| reply_msg = "搜索范围:" | ||
| reply_msg += ("「" + msg_response["groupinfo"][str(data[0])][1] + "」\n") if data[0] != "0" else "所有已索引群组\n" | ||
| end_msg_t = "0" | ||
| for i, msg in enumerate(msgs): | ||
| msg["id"] = int(msg["id"]) | ||
| msg["from_id"] = int(msg["from_id"]) | ||
| msg["group_id"] = int(msg["group_id"]) | ||
| msg["t"] = int(msg["t"]) | ||
| time_string = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(msg["t"])) | ||
| msg_md = msg["html"].replace("<span class=\"keyword\">", "__").replace("</span>", "__") | ||
| msg_link = "https://t.me/c/" + str(msg["group_id"]) + "/" + str(msg["id"]) | ||
| group_name = (" " + msg_response["groupinfo"][str(msg["group_id"])][1] + " ") if data[0] == "0" else "" | ||
| reply_msg += "============= " + str(i + 1) + " =============\n\n" | ||
| reply_msg += "`【" + msg["from_name"] + " 于 " + time_string + "】说:`\n" + \ | ||
| msg_md + \ | ||
| "\n[(查看群组" + group_name + "原消息)](" + msg_link + ")\n\n" | ||
| # print(reply_msg) | ||
| if msg_response["has_more"]: | ||
| end_msg_t = msgs[-1]["t"] | ||
| reply_msg = "__剩余搜索结果大于 10 条,请点击末尾按钮翻页搜索。__\n\n\n" + reply_msg | ||
| reply_array = [reply_msg, end_msg_t] | ||
| return reply_array |