R Packages
- Many useful R functions come in packages
- They increase the power of R by improving existing base R functionalities
- They bundle together code, data, documentation, and tests
- There are thousands of packages available on the Comprehensive R Archive Network, or CRAN
- Commonly used R Packages are: dplyr, tidyr, ggplot2, shiny etc.
To install an R Package, type the following in the command line

After it is installed, you can make its contents available by running:

You can also get help on them by
help(package =“<the package’s name>”)
A data set is called tidy when:
- Each column represents a variable, and
- Each row represents an observation
The opposite of tidy data is messy data, which corresponds to any other arrangement of the data.
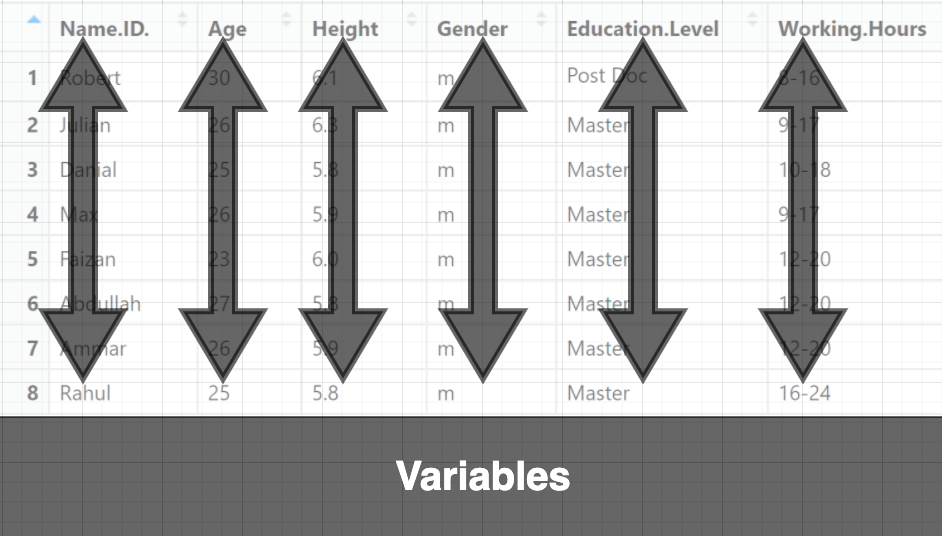
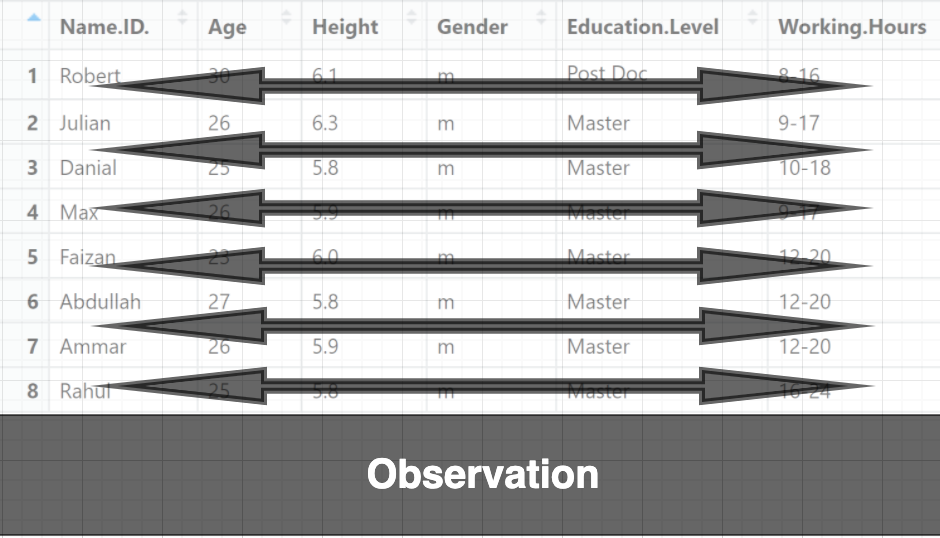

Organize (or reshape) your data in order to make the analysis easier. This process is called tidying your data.
- gather(): gather (collapse) columns into rows
- spread(): spread rows into columns.
- separate(): separate one column into multiple
- unite(): unite multiple columns into one
Let us consider the following dataset





-
Installing : install.packages("tidyr")
-
Loading : library("tidyr")
-
Load-Dataset : my-data <- USArrests[c(1, 10, 20, 30), ] # [c(1,10,20,30), ] means specific rows and all columns
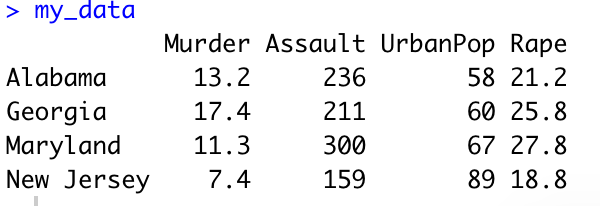
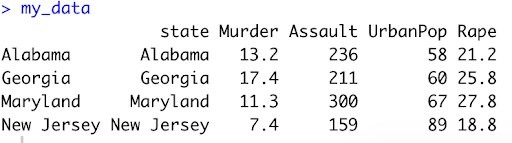
- Row names are states, so let’s use the function cbind() to add a column named “state”
- In the data. This will make the data tidy and the analysis easier.
My_data <- cbind(state = rownames(my_data), my_data)
my_data
Simplified format:
gather(data, key, value, ...)
data: A data frame
key: Names of key
value: Value columns to create in output
…: Specification of columns to gather.
Allowed values are: variable names
- if you want to select all variables between a and e, use a:e
- if you want to exclude a column name y use -y
- for more options, see: dplyr::select()
- The function spread() does the reverse of gather().
- It takes two columns (key and value) and Spreads into multiple columns. It produces a “wide” data format from a “long” one.
Simplified format:
spread(data, key, value, ...)
data: A data frame
key: The (unquoted) name of the column whose values will be used as column headings
value: The (unquoted) names of the column whose values will populate the cells
…: Specification of columns to gather.
Allowed values are: variable names
Simplified format:
unite(data, col, ..., sep = "_")
data: A data frame
col: The new (unquoted) name of column to add.
sep: Separator to use between values
…: Specification of columns to gather.
Allowed values are: variable names
separate() : separate one column into multiple : The function sperate() is the reverse of unite(). It takes values inside a single character column and separates them into multiple columns.
Simplified format:
separate(data, col, into, sep = "_")
data: A data frame
col: Unquoted column names
into: Character vector specifying the names of new variables to be created.
sep: Separator between columns: