To extract the keyword from PDF, I use KeyLLM, an extension to KeyBERT for extracting keywords with Large Language Models like Mistral.
First use PyPDF2 to extract text contents and the page number from pdf, then do the cleaning to remove characters like specific quotation marks.
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf",
model_type="mistral",
gpu_layers=200,
device_map="auto",
hf=True,
config=config
)Here I load mistral 7B. It is a small language model but really accurate and instruct is a chat based model. gpu_layers=200 offload some of its layers to be used on the GPU.
config.config.context_length = 4096 Because the text contents in pdf are usually very long, so make sure to set this value very large.
login(token="---")
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
# Pipeline
generator = pipeline(
model=model.to('cuda'), tokenizer=tokenizer,
task='text-generation',
max_new_tokens=50,
repetition_penalty=1.1
)For security, I hide the login token of my huggingface. Tokenizer is also from Mistral 7B and max_new_tokens is set to 50 to tell the model to only generate 50 new tokens at a max because we just want a number of keywords.
The prompt template is as follows (https://newsletter.maartengrootendorst.com/p/introducing-keyllm-keyword-extraction):
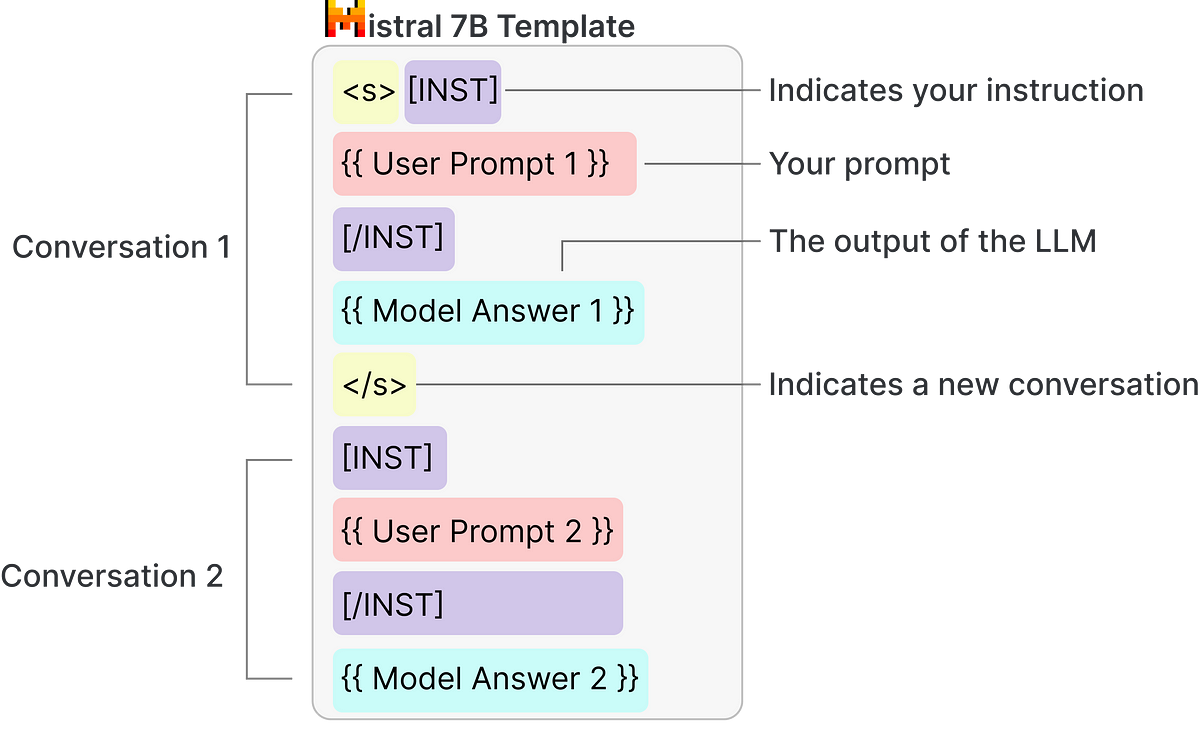
Example prompt- This will be used to show the LLM what a “good” output looks likeKeyword prompt- This will be used to ask the LLM to extract the keywords
We can show the large language model an example of how it should extract keywords and then it repeats that. Example prompt shows how a conversation should go. After that, Keyword prompt essentially is the samething but this time we can plug in any document that we want and our documents pdf for which we wnat our keywords to be extracted.
With the document and prompt, load them and model into KeyLLM
# Load it in KeyLLM
llm = TextGeneration(generator, prompt=prompt)
kw_model = KeyLLM(llm)
for grouped_text in grouped_texts_list:
keywords = kw_model.extract_keywords(grouped_text);
keywords_list = keywords_list + keywordsWhen the amount of text is particularly large, inputting the entire text directly into the model will cause the processing to be very slow, so here the text is input into the model in sections and a keywords list is obtained.
One problem with LLM extract keywords is that the keywords it outputs may not exist in the original text, so the last step is to remove these words and output the page number where each keyword is located.