Realzeitsystem
Das System soll Sprachkommandos in Echtzeit, also zur Laufzeit verarbeiten können. Dabei soll das System realzeitfähig sein. Das bedeutet, dass bestimmte Deadlines zur Verarbeitung der Kommandos eingehalten werden müssen. Zur Erkennung der Sprachkommandos wird die Bibliothek Pocketsphinx verwendet. Diese bietet neben bereits fertigen Akustikmodellen, auch die Möglichkeit eigene Sprachmodelle, also Wörterbücher für das Programm, zu verwenden.
Der Realzeitaspekt des sprachgesteuerten Systems soll anhand einer grafischen Simulation dargestellt werden. Hierbei handelt es sich um ein sehr rudimentäres Spiel, bei dem der Spieler, also derjenige, der Sprachbefehle eingibt, quasi 2 Straßenspuren hat, auf denen er sich bewegen kann. Auf jeder dieser Spuren kommen in periodischen Abständen Hindernisse auf den Spieler zu, denen er mit einem Sprachbefehl entkommen muss, indem er die Spur wechselt. Durch das periodische Auftreten ergeben sich sowohl Prozesszeiten als auch eine maximale Deadline für das Gesamtsystem (dazu später mehr). Die grafische Darstellung der Simulation wird mit der Grafikbibliothek Allegro 4 realisiert.
Die folgende Abbildung zeigt die grafische Oberfläche.

Die horizontalen Linien entsprechen den beiden Spuren, der blaue Kasten dem Spieler und die roten Kästen den Hindernissen. Die Hindernisse bewegen sich auf den Spieler zu. Der Spieler kann die Spur wechseln, um den Hindernissen auszuweichen.
Die Hauptkomponente der Hardware ist ein Raspberry Pi. Zusätzlich wird ein USB-Mikrofon verwendet, um die Sprachbefehle aufzunehmen. Da das Raspberry Pi keine Inputsoundgeräte unterstützt, muss ein USB-Gerät mit eigenem Soundchip verwendet werden.
Als Betriebssystem wird ein minimales Raspbian verwendet. Hierbei handelt es sich um ein Debiansystem, das sehr weit verbreitet ist und gut unterstützt wird. Da es viele Anleitungen, Hilfestellungen und hilfreiche Programme für Raspbian gibt, stellt es eine angenehme Umgebung zur Entwicklung dar. Außerdem ist es durch seine große Verbreitung gut getestet und erhält regelmäßig Updates. Der Performanceverlust durch die Verwendung eines general purpose Betriebssystem wie Raspbian ist nicht entscheidend für das Realzeitsystem. Außerdem ist das hier verwendete minimale Raspbian gerade einmal 20Mb größer als ein ArchLinux.
Das System besteht aus den folgenden Komponenten:
- Aufnahme der Daten
- Verarbeiten der Audiodaten
- Abbilden des Kommandos auf Funktionen
- Realzeitsimulation
- Visualisierung
Diese Komponenten werden auf verschiedene Tasks verteilt. Die Aufnahme der Daten übernimmt die Input Task, das Verarbeiten der Audiodaten die Interpreter Task, das Abbilden der Kommandos auf Funktionen die Mapper Task und die Realzeitsimulation, sowie deren Visualisierung werden von der Simulation Task erledigt. Die Tasks werden im nächsten Abschnitt näher beleuchtet.
Das Realzeitsystem umfasst insgesamte 4 Tasks, die als Threads realisiert wurden. Diese werden im Folgenden vorgestellt.
Wie bereits oben angesprochen werden in diesem Realzeitsystem Sprachbefehle in Echtzeit aufgenommen. Die Input Task nimmt dabei die rohen Audiodaten aus dem Mikrofon auf und speichert diese in einem Puffer. Dieser Puffer wird in eine Blocking Queue (im weiteren Verlauf Audioqueue genannt) eingereiht, sodass andere Tasks auf die Daten zugreifen und weiterverarbeiten können.
Mit dem Device Thread ist ein interner Thread von Pocketsphinx gemeint. Dieser wird bei der Initialisierung des Audiogeräts automatisch erzeugt.
Der Ablauf der Input Task sieht im Detail wie folgt aus:
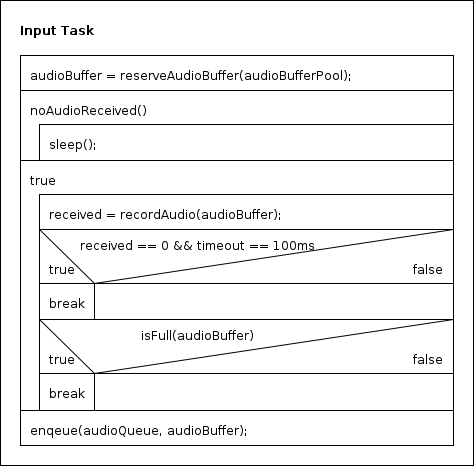
Erklärung:
Zuerst reserviert sich die Task einen Puffer für die Audiodaten (auch Audiopuffer). Diese werden aus einem Pufferpool (im weiteren Verlauf Audiopufferpool genannt) bereitgestellt. Dieser Pool reserviert bereits beim Start des Systems eine feste Anzahl an Puffer, die er dann auf Anfrage vergeben kann. So kann der unsichere Weg eines malloc/calloc über das Betriebssystem vermieden werden. Sind keine freien Puffer mehr vorhanden, blockiert die anfragende Task.
Im nächsten Schritt wartet die Task darauf, dass sie Audiodaten empfängt. Dies wird durch die While-Schleife "noAudioReceived()" realisiert. Die Task pollt also darauf, ob das Audiogerät irgendwelche Daten hat. Dabei wird Stille bereits herausgefiltert, sodass die Task wirklich erst reagiert, wenn in das Mikrofon hineingesprochen wird.
Hat die Task ihre ersten Audiodaten erhalten, geht sie in eine Endlosschleife über. In dieser werden immer wieder Audiodaten aus dem Audiogerät entnommen ("recordAudio()"), so lange bis entweder eine Ruhepause von 200ms ("timeout == 200") auftritt oder der Puffer für die Audiodaten voll ist. In beiden Fällen wird die Schleife durch ein break verlassen.
Im letzten Schritt wird der Puffer mit den gesammelten Audiodaten in die Audioqueue eingereiht.
Die Interpreter Task stellt den nächsten Schritt der Datenverarbeitung dar. Diese Task benötigt die von der Input Task aufgenommenen Audiodaten. Dazu entnimmt die Interpreter Task einen Audiopuffer aus der Audioqueue. Diese Audiodaten werden nun dem Audiodecoder von Pocketsphinx übergeben. Der Decoder wird beim Systemstart mit dem gewünschten Akustikmodell und dem Sprachmodell initialisiert. Das Akustikmodell gibt die Laute vor, die in unserer gewählten Sprach existieren. Mit diesem Modell kann der Decoder bestimmte Laute bestimmten Buchstaben zuordnen. Das Sprachmodell hingegen gibt an welche Worte es in unserer Applikation geben soll und welche Laute diese beinhalten. Es ist die Verknüpfung zwischen dem eigentlichen Wörterbuch (welche Worte gibt es?) und Akustikmodell (welche Laute gibt es?).
Aus den gesammelten Sprachdaten wird durch den Decoder ein String, eine sogenannte Hypothese, generiert. Die Hypothese wird in einem Characterpuffer gespeichert. Dieser wird wieder durch einen Pool bereit gestellt. Dieser Stringpool reserviert sich wie auch der Audiopufferpool bereits beim Systemstart eine feste Anzahl an Strings mit fester Länge. Diese können von den Tasks reserviert und genutzt werden. Ist kein String mehr frei, blockiert die anfragende Task. Die Hypothese, die von Pocketsphinx generiert wurde, wird wiederrum in eine Blocking Queue (die Hypothesenqueue) eingereiht. So können andere Tasks diese Hypothese entnehmen und weiterverarbeiten. Am Ende darf natürlich nicht vergessen werden den erhaltenen Audiopuffer im Audiopufferpool wieder freizugeben, damit er wieder verwendet werden kann.
Der eben beschriebene Ablauf wird auch noch mal in dem folgenden Struktogramm dargestellt.

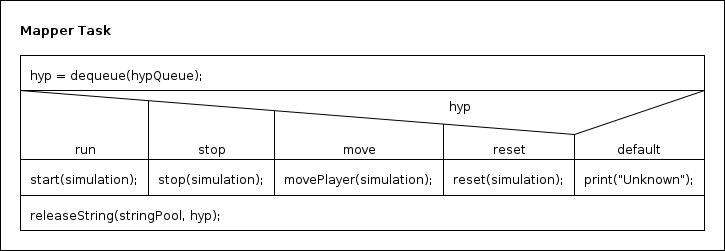
Die Mapper Task umfasst das Abbilden der erhaltenen Hypothesen auf entsprechende Kommandos / Funktionen. Zuerst entnimmt die Mapper Task eine Hypothese aus der Hypothesenqueue. Daraufhin wird über ein simples If-Else-Verfahren entschieden welche Aktion auszuführen ist. Dabei handelt es sich in allen Fällen um eine Aktion, die direkten Einfluss auf die Simulation (siehe nächster Abschnitt) hat. Damit ist die Mapper Task die simpelste Komponente des Systems.
Es können die Kommandos run, stop, reset und move angewendet werden.
Die Funktionsweise des Mappers wird auch in dem folgeden Struktogramm dargestellt.
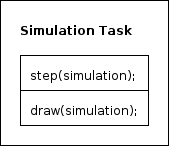
Die Simulation Task simuliert ein kleines Spiel (siehe Abschnitt Aufgabe des Systems), um dem sprachgesteuerten System einen zeitlichen Rahmen zu geben. Dabei besteht die Simulation Task nur aus 2 wesentlichen Schritten. Zuerst wird die Simulation um einen Zeitschritt weiterberechnet. Dabei werden immer die aktuellen Parameter der Simulation miteinbezogen. Im nächsten Schritt wird die neue Spielsituation mithilfe von Allegro visualisiert.
Das folgende Struktogramm zeigt diesen Ablauf nochmals.
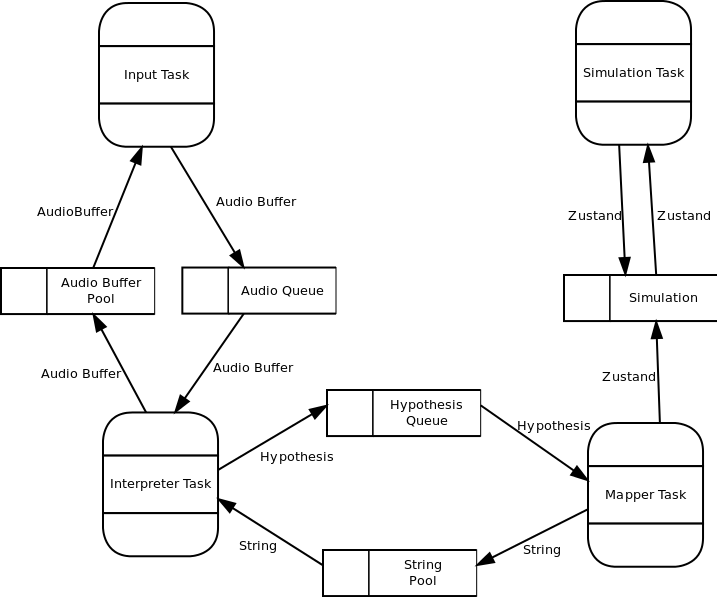
Das folgende Datenflussdiagramm zeigt nochmals den Datenfluss zwischen den Tasks. Der Datenfluss wird in den Taskbeschreibungen erläutert.
Die folgende Tabelle veranschaulicht nochmals, welche Task welche Resource verwendet. Die Zusammenhänge werden im Abschnitt Tasks beschrieben.
| Resource | Input Task | Interpreter Task | Mapper Task | Simulation Task |
|---|---|---|---|---|
| Audioqueue | X | X | ||
| Hypothesenqueue | X | X | ||
| Audiobufferpool | X | X | ||
| Stringpool | X | X | ||
| Simulation | X | X |
Der Simulationsteil des Systems gibt die zeitlichen Schranken des System vor. So läuft die Simulation mit einer Frequenz von 3 Hz. Das bedeutet, dass die Simulation alle 333 ms einen Zeitschritt fortschreitet. Daraus ergibt sich schon einmal die Prozesszeit für die Simulation Task - das Berechnen des nächsten Zeitschritts und das Visualisieren der neuen Spielsituation (siehe Abschnitt Simulation Task) werden innerhalb von 333 ms wiederholt.
Die Prozesszeit der Input Task, wie auch folglich die Prozesszeiten der Interpreter und Mapper Task, hängen vollständig vom Verhalten des Benutzers ab, wenn als Rechenzeitanforderung der Zeitpunkt des nächsten Input gewählt wird. Damit kann die Prozesszeit unendlich klein werden, was wiederrum nicht erfüllbar wäre. Daher macht es mehr Sinn ein anderes Ereignis zum Auslösen einer Rechenzeitanforderung zu wählen. In diesem Fall ist das Auftauchen eines neuen Hindernisses ein Ereignis, das dazu führt, dass der Benutzer ausweichen, also reagieren muss. Das Kommando des Benutzers führt zu einer Rechenzeitanforderung. Die Hindernisse, denen der Spieler ausweichen muss, erscheinen immer in Abständen von 7 Zeitschritten. Damit treten Rechenzeitanforderungen für die Input Task im Abstand von 7 * 333 ms = 2331ms auf. Interpreter und Mapper Task erhalten immer dann eine Rechenzeitanforderung, wenn die vorhergehende Task ihre Arbeit abgeschlossen hat. Damit haben die Tasks die gleiche Prozesszeit wie die Task von denen sie abhängig sind. Im Falle des Interpreters wäre die vorhergehende Task die Input Task und im Falle des Mappers der Interpreter. Damit haben alle 3 Tasks die Prozesszeit 2331 ms.
Auch die maximalen Deadlines der Tasks werden durch die Simulation bestimmt. Wie oben schon angedeutet wurde ist die maximale Deadline der Simulation Task gleich ihrer Prozesszeit, also 333 ms.
Bei den restlichen Tasks sieht das schon anders aus. Da die Hindernisse in einem Abstand von 7 Zeitschritten erscheinen und ein Zeitschritt 333 ms dauert, hat das System genau 2331 ms Zeit, um auf dieses Hindernis zu reagieren. Diese Zeit wird von der Input Task, Interpreter Task und Mapper Task geteilt. Um die maximalen Deadlines der einzelnen Tasks zu bestimmen, muss diese Zeit aufgeteilt werden. Bei der Entscheidung, welche Task wieviel Zeit bekommt, wurde deren Ausführungszeit berücksichtigt. Es ergibt sich also für die Input Task eine maximale Deadline von 1900 ms, für die Interpreter Task eine maximale Deadline von 400 ms und für die Mapper Task eine maximale Deadline von 31ms (Summe ist 2331ms).
Die minimale Deadline beträgt für alle Tasks 0, da keine Task zu früh reagieren könnte.
Obwohl die Input, Interpreter und Mapper Tasks voneinander abhängen, beträgt ihre Phase zueinander 0, da sie nicht zeitlich, sondern funktional voneinander abhängen. Die Mapper Task läuft nämlich nicht zu einem bestimmten Zeitpunkt nach der Interpreter Task. So kann die Interpreter Task rein theoretisch auch mehrere Male laufen bevor sich die Mapper Task einschaltet. Dann befinden sich eben mehrere Hypothesen in der Hypothesenqueue, die der Mapper abarbeiten muss.
Die Werte sind übersichtshalber nochmal in folgender Tabelle aufgelistet.
| Wert | Mapper | Simulation | Interpreter | Input |
|---|---|---|---|---|
| tPMin | 2331ms | 333ms | 2331ms | 2331ms |
| tDMax | 31ms | 333ms | 400ms | 1900ms |
| tDMin | 0ms | 0ms | 0ms | 0ms |
| tPH | 0ms | 0ms | 0ms | 0ms |
Im Bereich Safety soll die Sprachsteuerung natürlich mit einer möglichst hohen Genauigkeit Befehle erkennen, um keine falschen Kommandos auszulösen, die wiederrum zum Verlieren des Spiels führen. Eine erhöhte Genauigkeit geht jedoch mit einer langsameren Verarbeitung einher. Daher muss ein guter Mittelweg gefunden werden. Eine sehr hohe Genauigkeit und schnelle Verarbeitung wäre nur mit einer entsprechend schnellen Hardware möglich.
Wünschenswert wäre auch eine Unabhängigkeit von der Hintergundgeräuschkulisse. Dies ist jedoch nur mit einem ständigen Rekalibrieren des Mikrofons möglich. Dieses Verfahren dauert jedoch im Vergleich zum Rest des System beinahe unendlich lange und ist daher nicht umsetzbar. Ändert sich die Geräuschkulisse schlagartig zwischen 2 Kalibrierungschritten, kann dies auch trotz ständigem Neukalibrieren zu Fehlverhalten führen.
Das System muss nicht an ein Netzwerk angeschlossen sein. Es kann also völlig isoliert vom Internet betrieben werden. Um Störungen des Systems durch den Benutzer zu verhindern, sollte ein eigener User für das Realzeitsystem erstellt werden, der nur genau über die Rechte verfügt, die er für den Betrieb des Systems benötigt. Dazu zählen Zugriff auf Audiogeräte und das Starten von Applikationen mit Realzeitprioritäten.
Für den Schutz kritischer Bereiche wird das Priority Inheritance Protokoll verwendet. Als Scheduling wird ein prioritätengesteuertes Round Robin Verfahren genutzt. Die Tasks laufen unter Echtzeitprioritäten. Die Prioritäten lauten wie folgt:
| Input Task | Interpreter Task | Simulation Task | Mapper Task |
|---|---|---|---|
| 96 | 97 | 98 | 99 |