Home
This is a training exercise for a training class that uses PySpark, AWS S3, Airflow and Snowflake
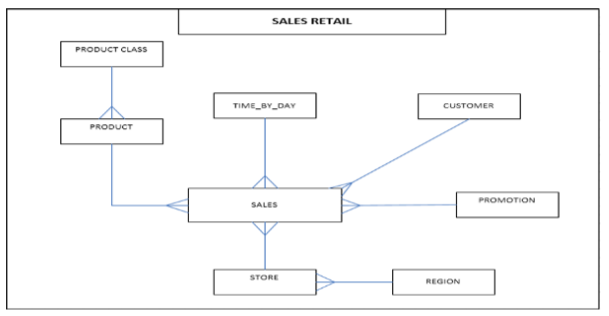
In this project, we will be migrating the existing Retail project to use the New Architecture using Spark, Airflow and Kafka.
{kind=link}
- Find total Promotion sales generated on weekdays and weekends for each region, year & month
- Find the most popular promotion which generated highest sales in each region
-
Create pySpark scripts for initial and incremental loads. The script will read sales and promotion tables based on last_update_date column from mysql and store them in AVRO format in S3 buckets. You might want to add a last_update_date in the tables
-
A second pySpark script will read the AVRO files, filter out all non-promotion records from input, join the promotion and sales tables and save the data in Parquet format in S3 buckets.
-
The Parquet file is aggregated by regionID, promotionID, sales_year, sales_month to generate total StoreSales for weekdays and weekends and the output is saved as a CSV file in S3 buckets.
-
The CSV file generated is loaded into a Snowflake database.
-
Following queries are executed on Snowflake table
- Query1: List the total weekday sales & weekend sales for each promotions: Region ID, Promotion ID, Promotion Cost, total weekday sales, total weekend sales
- Query 2: List promotions, which generated highest total sales (weekday + weekend) in each region. Following columns are required in output: Region ID, Promotion ID, Promotion Cost, total sales
-
Automate the workflow using Airflow scheduler