월간슈도렉 9월호 작성공간 #6
Replies: 4 comments
-
Matrix Factorization은 어떻게 추천시스템이 될 수 있을까? - 34.5 Singular Value DecompositionSVD는 정방행렬뿐만 아니라 모든 행렬에 적용될 수 있기 때문에 선형대수학의 기본 정리라고도 불린다. Theorem 4.22 (SVD Theorem).
특이값 행렬 4.5.1 Geometric Intuitions for the SVD는 일단 패스! 4.5.2 Construction of the SVD왜 SVD가 존재하는지, 그리고 어떻게 계산하는지 알아보자. 일반적인 행렬의 SVD는 정방행렬을 eigendecomposition할 때와 몇 가지의 유사점을 갖는다. 아래 Symmetric Positive Definite 행렬의 eigendecomposition과 비교해보자. 이에 상응하는 SVD는 만약 위의 Theorem 4.22 (SVD Theorem)이 왜 만족하는지 알아보자. 행렬 처음 할 일은 right-singular vector인
Right-singular vector를 먼저 만들어보자. Spectral Theorem (Theorem 4.15)에 따라 symmetric 행렬은 고유 벡터의 ONB를 갖는다. 이는 대각화 될 수 있음을 의미한다. 잠깐, symmetric 행렬은 고유 벡터의 ONB를 갖고, 때문에 대각화 할 수 있다?Spectral Theorem : 만약
대칭행렬은 정규 직교 기저를 갖는다고 했다. 이 벡터들을 행렬 여기까지 해서 symmetric 행렬은 고유 벡터의 ONB를 갖고, 때문에 대각화 할 수 있다. 게다가, Theorem 4.14에 의해 모든 직사각행렬
둘을 비교함으로써, 그러므로,
Spectral Theorem에 의하면(엄청 자주나오네...) 마지막 스텝은 위에서 계산한 부분들을 연결하는 것이다. 현재 우리는 right-singular vectors의 ONB를 왜 중간에 SVD 구축을완료하기 위해 left-singular vectors가 orthonormal이 돼야 한다.
그러므로, right-singular vector인
|











Beta Was this translation helpful? Give feedback.
-
[Review] Large Language Models for User Interest Journeys안녕하세요. 이번 글은 구글 딥마인드 개발자가 RecSys '23 비디오 추천시스템 워크샵에서 발표한 "고객 관심사 여정을 위한 LLM"에 대한 리뷰를 하려고 합니다. 추천시스템에서 고객의 상호작용이력은 필수적으로 필요한 데이터입니다. 하지만 고객의 관심사는 하나로 귀결되는 것이 아니라 상황에 따라 다이나믹하게 변화하여 여러가지 관심사가 섞여 있을 수 있습니다. 고객의 시청의도를 파악하기 위한 방법으로 이전에는 인과추론 모델을 활용해 개인 관심사에 의한 시청인지 인기 콘텐츠 노출로 인한 동조효과에 의한 것인지를 분류하는 모델이 있었는데요[Disentangling User Interest and Conformity for Recommendation with Causal Embedding]. LLM 기술이 발전함에 따라 본 워크샵에서는 LLM을 활용해 관심사 여정을 분류하여 고객 임베딩을 하는 방법에 대해 논합니다. 실험하는 과정에서 Fine-Tuning과 Prompt Tuning, 데이터셋 생성과 LLM 평가 방식 등을 다양하게 기술하고 있어, LLM을 활용할때 참고하기 좋아보입니다.
workshop video: https://youtu.be/55KXlMSfklg?si=6hbXptcYVcsij21P User Intents and Journeys in Recommender Systems by Minmin ChenVideoRecSys Workshop | RecSys 2023 [Workshop Review] Introduction of User Intent Experimentsby Minmin Chen (Google DeepMind)
[Paper Review] Interest Journeys and Companion RecommendersAbstract
실험 전 군집화 모델링을 위한 사전조사
Journey Service본 연구에서는 Journey를 추출하고 네이밍 하는 것에만 목적을 두고, 추천모델에 활용하는 과정은 향후연구로 남겨 놓음 Two components
평가방식 *Lamda: Language models for dialog applications
Journey Extraction Modeling모든 유저-아이템 인터렉션 시퀀스를 분리하여 여정 클러스터 생성
Infinite Concepts
Infinite Concept Personalized Clustering (ICPC)ICPC

Journey Naming Modeling (using LLMs)추출된 여정을 설명, 분석, 활용 가능하게 이름을 생성 실험 모델
실험 종류
Journey Extraction Results실험 셋팅



Journey Naming Results
Conclusions and future work
Insights
|












Beta Was this translation helpful? Give feedback.
-
민상: “[Paper Review] Explainable and coherent complement recommendation based on large language models”About최근 Amazon Science에서는 LLM을 활용한 추천시스템 연구를 여럿 발표하고 있습니다. 이번 월간슈도렉에서는 Amazon Science의 논문 하나를 소개하려고 합니다. 제목은 Explainable and coherent complement recommendation based on large language models로, LLM의 정보 이해와 자연어 생성 기능을 활용하여 함께 사면 좋은 상품을 추천해주는 연구입니다. BackgroundCoherent complement recommendation이 연구에서 중점적으로 다루는 주제는 complementary item 추천입니다. 직역하자면 ‘상호보완적인 상품’이 될 텐데, 좀 더 부드럽게 번역하자면 **‘함께 사면 좋은 상품’**이 될 것 같습니다. 핸드폰과 액정보호 필름처럼 한 쪽이 다른 쪽의 액세서리인 경우, 서로 잘 어울리는 우산과 핸드백처럼 한 쌍으로 사용하기 좋은 상품들, 달콤한 코코아와 쌉쌀한 커피처럼 사람들의 구매욕을 자극할 만한 상품들이 이에 해당할 겁니다. 기존에는 complementary item을 추천할 때, 같이 구매한(co-purchase) 기록을 학습시켜 추천 모델을 만들었다고 합니다. 하지만 이런 방식은 한계도 있는데, 사람이 보기에 언뜻 이해가 가지 않는 상품을 연관지어 추천해줄 수도 있다는 겁니다. 상품명이나 상품 특성, 이미지를 이용한 추천시스템도 있었지만 마찬가지로 서로 맞지 않는 상품을 추천한 경우도 있다고 합니다. 이를 테면 카테고리만 보고 8인치 태블릿에 14인치 액정필름을 추천한다던지 하는 일이 생기는 거죠. 이 연구에서는 LLM을 이용해 밀접한 보완 상품 추천(coherent complement recommendation) 성능을 올리는 방법을 제안합니다.
complementary item이 얼마나 잘 어울리는지를 판단하기 위해, 여기서는 ‘밀접한(coherent)’ 정도를 두 가지 측면으로 나눠서 생각합니다. 바로 호환성(compatibility)와 연관성(relevance)입니다.
Data그럼 이런 complementary item 추천을 어떻게 형식화할 수 있을까요? 이 논문의 저자들은 두 개의 상품
$\mathcal{B}{cv}$와 $\mathcal{B}{vp}$의 경우, 유저가 상품 실제로 $(\mathcal{B}{cv}\cap \mathcal{B}{vp})-\mathcal{B}{cp}$의 데이터는 서로 대체 가능한 상품들을 찾는 product embedding에 사용된다고 합니다. 반대로 $\mathcal{B}{cp}-(\mathcal{B}{cv}\cap \mathcal{B}{vp})$는 complementary item을 모델링하는 데 사용할 수 있겠죠? 그래도 아직 애매모호합니다. 호환성과 연관성을 지닌 상품들의 학습 데이터가 필요할 텐데, 이걸 어떻게 구축해야 할까요? 저자들은 아래와 같은 집합들을 조합하여 CC, 즉 coherent complementary dataset을 구축했습니다.
이 집합들로부터, _CC_는 이렇게 구성됩니다. 기준 상품(anchor item) Complement \leftrightarrow (i_a, i_c)\in CP Compatible \leftrightarrow (i_a, i_c)\in COM Relevant \leftrightarrow \exists t \in \bigl( (I(PT(i_a)) \cap I(PT(i_c))\bigr) \wedge CAT(i_a, t)=CAT(i_c, t) 갑자기 수식이 튀어나오니 헷갈리죠? 말로 설명해보자면 이렇습니다.
Experiments**밀접한 보완 상품 추천(coherent complement recommendation, 이하 CCR)**은 두 파트로 나눠집니다. 첫 번째로는 CC한 상품 쌍을 찾는 것이고, 두 번째는 왜 그렇게 판단했는지에 대한 설명을 제시하는 것입니다. 이 두 가지 과제를 모두 수행할 수 있도록 LLM 모델을 파인튜닝시켰다고 합니다. 백본 모델로는 T5-S, T5-B. LLaMA-3B를 사용했다네요! Task 1: Recommendation Task. 상품에 대한 CC 추천
Task 2: Explanation Task. CC한 상품 쌍에 대한 설명문 생성.
FindingsGeneral
시험을 해본 결과, 저자들의 방식은 다른 베이스라인에 비해 좋은 성능을 거뒀다고 합니다! Human Evaluation이 논문에서는 수치적인 평가 지표 외에도, 사람들이 직접 추천 결과와 설명문을 평가하는 인간 평가도 진행했다고 합니다. 한 가지 눈에 띄는 것은 온라인 A/B 테스트 결과입니다. 실제로 고객들을 대상으로 A/B 테스트를 해본 결과 연간 수익은 0.1%, 연간 판매량은 0.2%가 증가했다네요! Insight슈도렉 홈페이지에 LLM을 어떻게 적용하면 좋을까 고민하며 읽어본 논문이지만, 데이터를 모아서 LLM을 파인튜닝해야 하기 때문에 슈도렉에 진짜 적용하긴 어렵겠다는 생각이 듭니다. 그래도 그냥 브레인스토밍을 해보자면…
|



Beta Was this translation helpful? Give feedback.
-
LLM을 추천시스템으로 사용할 수 있을까 - 1
들어가기에 앞서안녕하세요! 처음 월간 슈도렉 컨텐츠을 고민하다가 최근 하고 있는 공모전과 시너지를 위해 LLM for rec, 다시 말해 추천을 위한 대형언어모델 연구를 전체적으로 리뷰해보려는 대형?! 프로젝트를 시작하려고 합니다. 메인 소스는 위에 언급한 서베이 논문을 두고, 핵심이 될 수 있는 논문를 추가적으로 리뷰하며 전체적인 연구 흐름을 이해해보려 합니다. 이번달에는 우선 서베이 논문에 대해서 개략적으로 살펴본 후 (개인적으로 논문 컨텐츠는 좋은데 논문 흐름이 매끄럽지 않은 느낌이 있어서 의역과 흐름을 제 나름대로 재구성했습니다!) 그리고 최근에 각광받고 있는 Generative LLM(GPT 계열)을 활용한 추천시스템 중 튜닝을 활용하지 않는 방법론에 대해 좀 더 이야기해보고자 합니다!
초록 및 서론LLM은 추천 분야에 있어서도 주목을 받고 있습니다.
기존 추천시스템과는 다르게, LLM 기반 모델은 유저 쿼리나 아이템 설명, 다른 텍스트 데이터를 효과적으로 통합할 수 있으며, LLM의 사전지식통해 추천과 관련된 사전정보가 없어도 특정 유저나 아이템에 추천할 수 있는 제로/퓨샷 추천 능력(가능성)을 갖추고 있습니다.
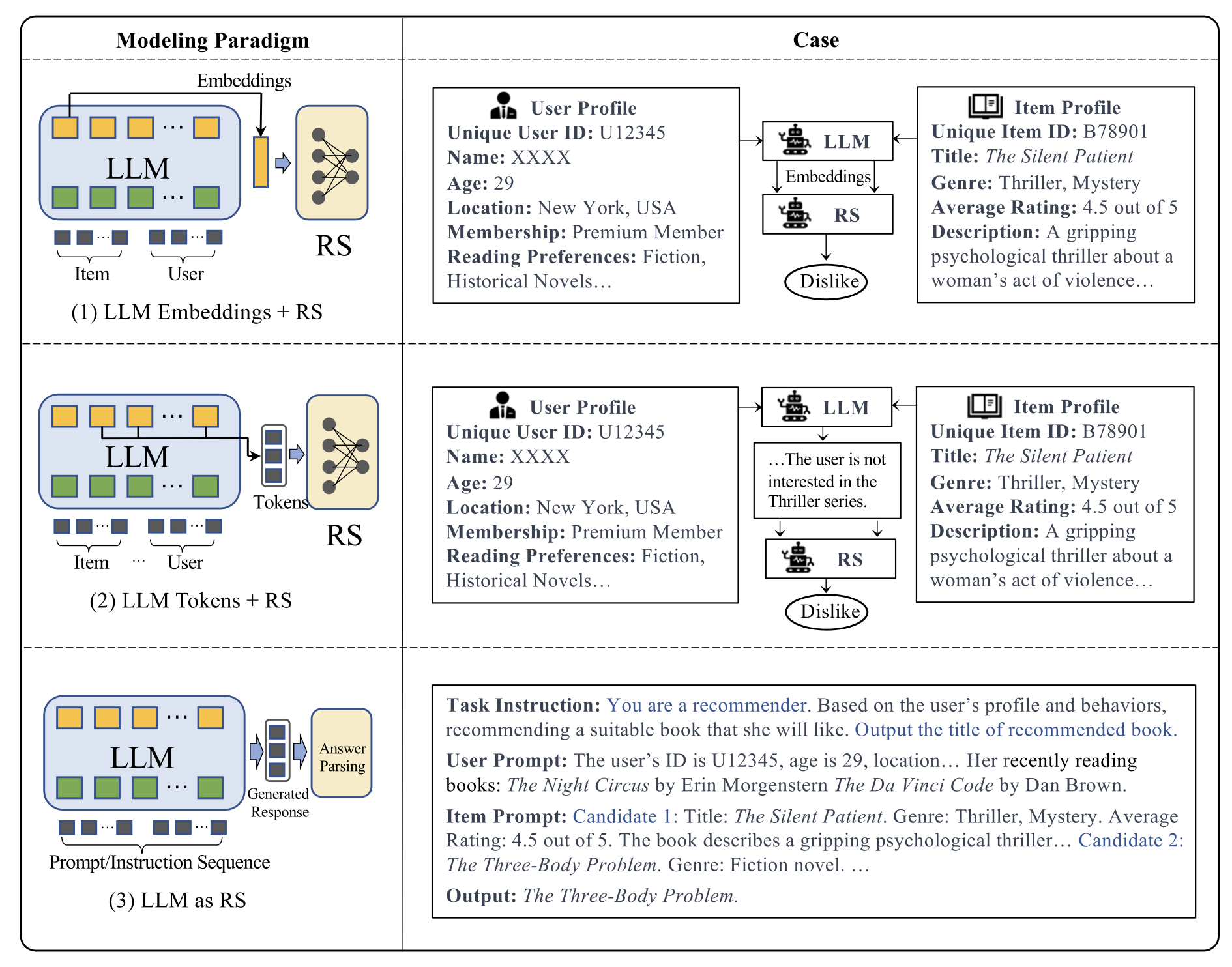
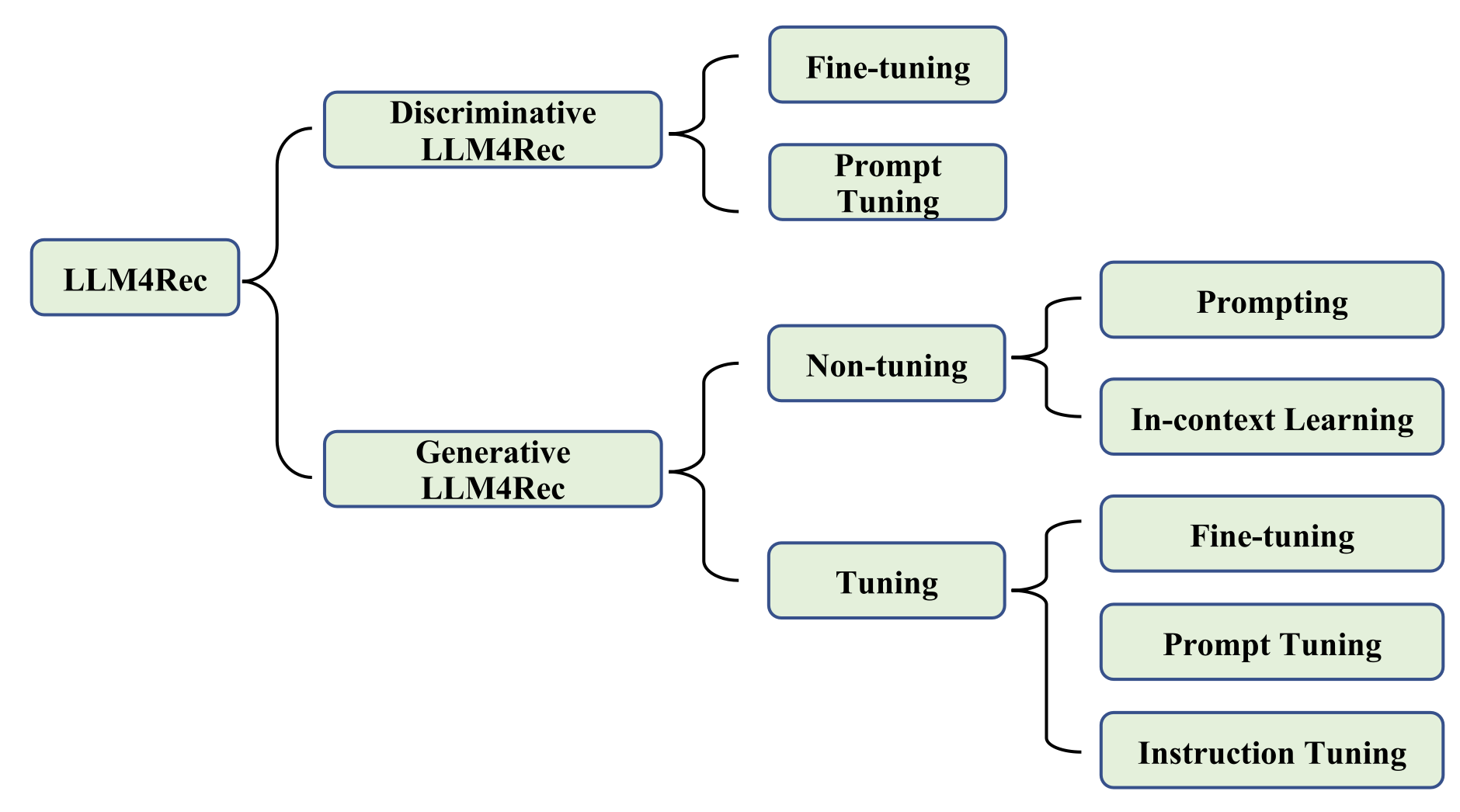
LLM 기반의 추천시스템 연구에 대한 이해를 돕기 위해, 이 논문에서는 분류체계를 소개합니다. 통합방법과 모델사용 관점에서 연구를 구분해볼 수 있습니다.
서베이 논문에 대한 추가적인 설명은 다음 슈도렉 컨텐츠로 미루고, 논문에서 소개된 Generative LLM(GPT 계열)을 활용한 추천시스템 중 튜닝을 활용하지 않는 연구 두개를 간략하게 살펴보도록 합시다. (1) Is ChatGPT a Good Recommender? A Preliminary Study 알리바바에서 발표한 논문(CIKM, 2023)입니다. 이 논문의 접근방법은 아래 그림을 보면 바로 이해가 되실겁니다.
이 논문에서 주장하는 컨트리뷰션은 추천 Task에서 ChatGPT를 평가하는 벤치마크를 구축한 것과 ChapGPT를 추천에 활용했을때의 장점과 단점에 대해 논의했다는 것입니다. 그래서 방법론 자체는 새로울 것이 없긴 합니다.
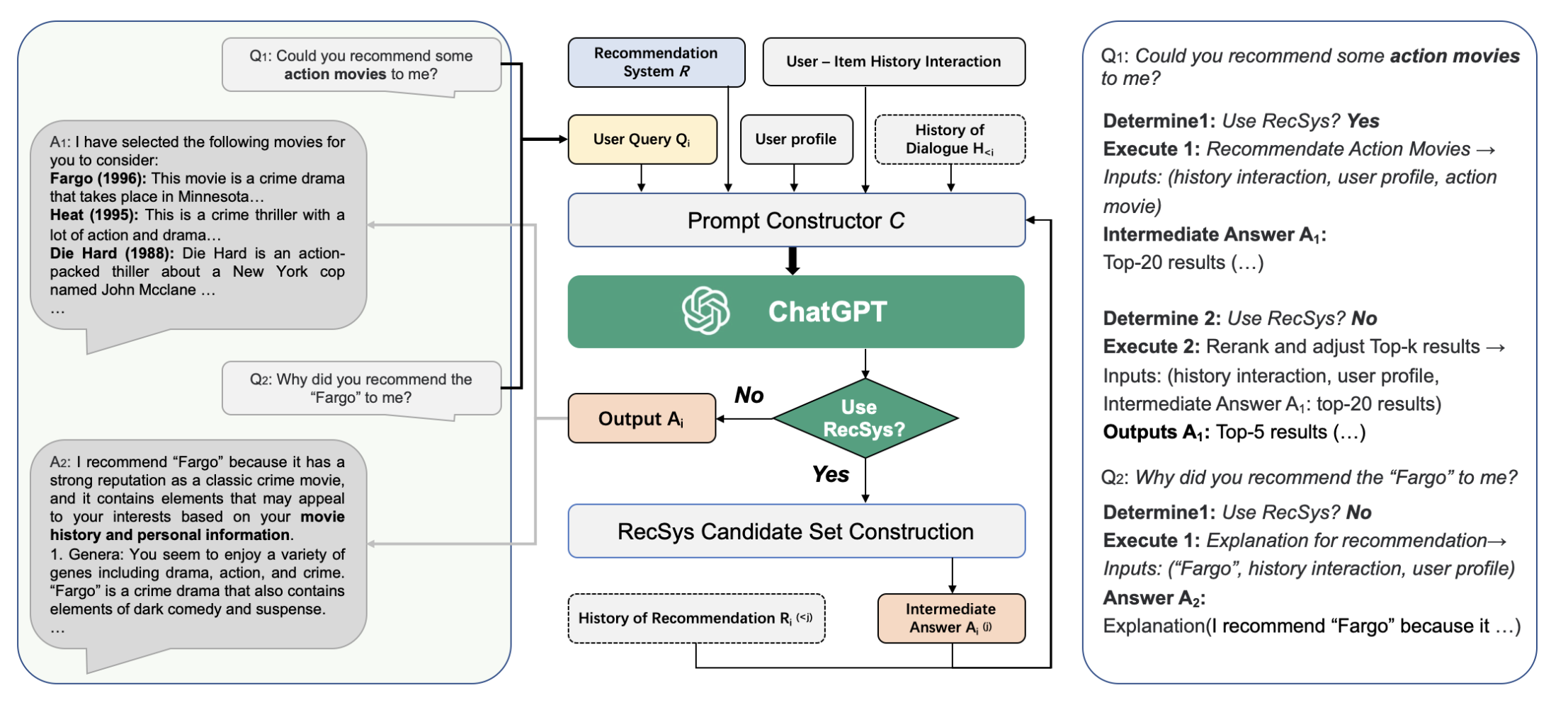
(2) Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System 두번째는 2023년에 arXiv에 올라온 논문으로, 기존 추천시스템을 프롬프트를 활용한 LLM과 연계하여 대화형 추천패러다임을 제안합니다. LLM은 별도로 추가 학습하지 않으며, In-context learning 만을 활용합니다.
논문에서 제시한 케이스 스터디를 보겠습니다.
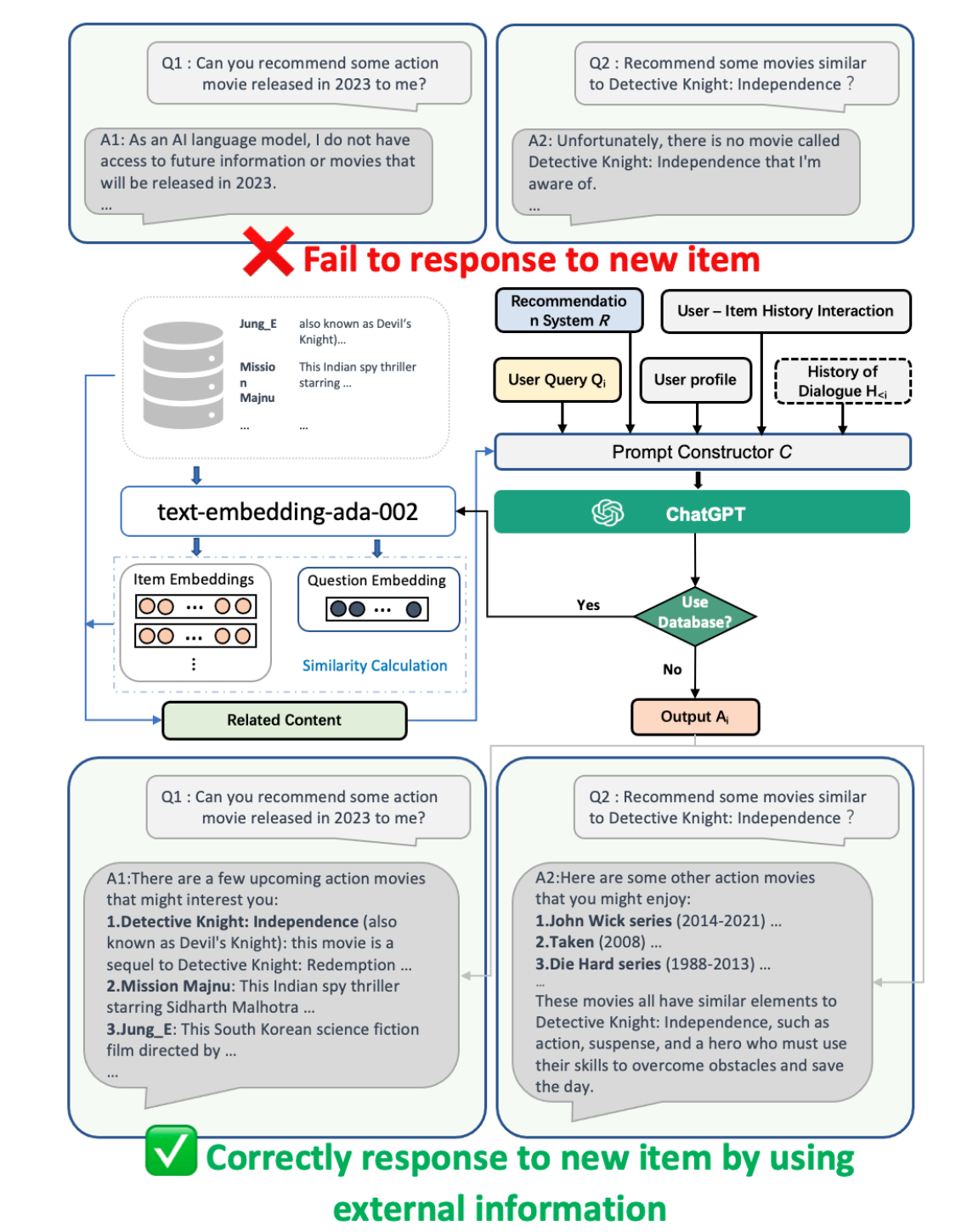
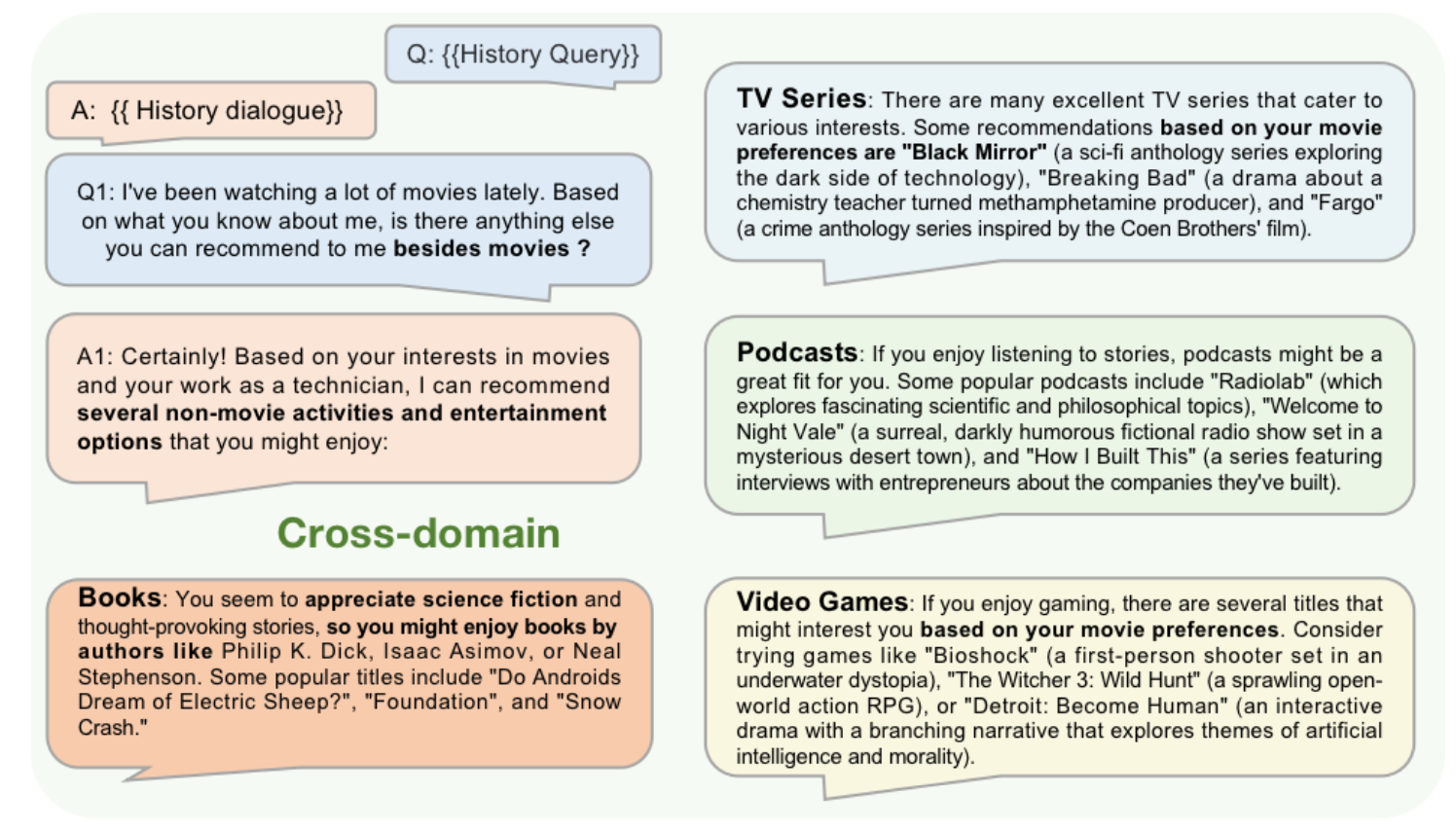
또한, 논문에서는 외부 데이터베이스 기반 RAG를 연계한 LLM을 활용해서 콜드스타트 문제를 개선할 수 있다는 주장과 크로스도메인 문제도 해결가능함을 주장합니다.
실험은 간략하게 설명드리면, 논문은 평점예측과 Top-5 예측 성능을 FM, GCN, MF, KNN 모델과 비교를 해서 성능 개선을 보여줍니다. (다만, 아쉬운 점은 구체적으로 연계한 추천모듈이 무엇인지, 앞서 주장했던 콜드스타트나 크로스도메인과 같은 task에서의 성능을 보여주지 않은 점입니다.) 위 두번째 논문은 LLM과 추천시스템을 연계하는 패러다임을 제안했습니다. 이를 기반으로 다양한 후속 연구, 최신 딥러닝 기반 추천시스템이나 크로스도메인 영역에서 LLM의 성능을 높이고 이를 검증하는 연구들이 기대되고 저도 한번 해보고 싶다는 생각이 듭니다. 끝까지 읽어주셔서 감사합니다. |




Beta Was this translation helpful? Give feedback.
-
월간슈도렉 9월호 작성공간입니다.
Beta Was this translation helpful? Give feedback.
All reactions