In essence, predicting user behavior in a website or application is a difficult task, which requires the integration of multiple sources of information, such as geo-location, user profile or web surfing history.
For this usecase, we tackle the problem of predicting the user intent, based on the queries that were used to access a certain webpage. We make no additional assumptions, such as domain detection, device used or location and only use the word information embedded in the given query.
On a VM running the MorphL Orchestrator, clone repository under /opt/usi_csv. Run module installer using the following command: sudo -Hiu airflow bash /opt/usi_csv/install.sh
For keywords / queries classification, we have defined user intent as follows:
-
Informational / KNOW - find information on a topic. Examples: new york city population 2013, new york city.
-
Transactional / DO - accomplish a goal or engage in an activity. Examples: get candy crush game, buy citizen kane dvd.
-
Navigational / Visit website or in person - locate a specific website or a place nearby. Examples: H&M, gas stations, chinese restaurant nearby.
Some queries are ambiguous by default (as is natural language in general), where the context becomes very important in order to reach a final conclusion. Since we only work at query level, without any additional information, we allow queries to be part of multiple classes, thus transforming the problem into a multi-intent classification.
In order to build competitive classifiers, we have labelled a small fraction of the query intent prediction dataset, which is used as ground truth.
Then, using various rule-based approaches, we automatically labelled the rest of the dataset, trained the classifiers and evaluated the quality of the automatic labeling on the ground truth dataset. We used both recurrent and convolutional networks as the models, while representing the words in the query with multiple embedding methods (GloVe, FastText, one-hot encoding).
For English keywords, the best results were given by a RNN (non-linear) model, over a training set labelled with GloVe 100 embeddings.
You can read in detail about this process in our paper from arXiv.
This repository contains the code for the user search intent pipelines. The code runs on the MorphL Platform Orchestrator and creates 2 pipelines: Ingestion Pipeline and Prediction Pipeline.
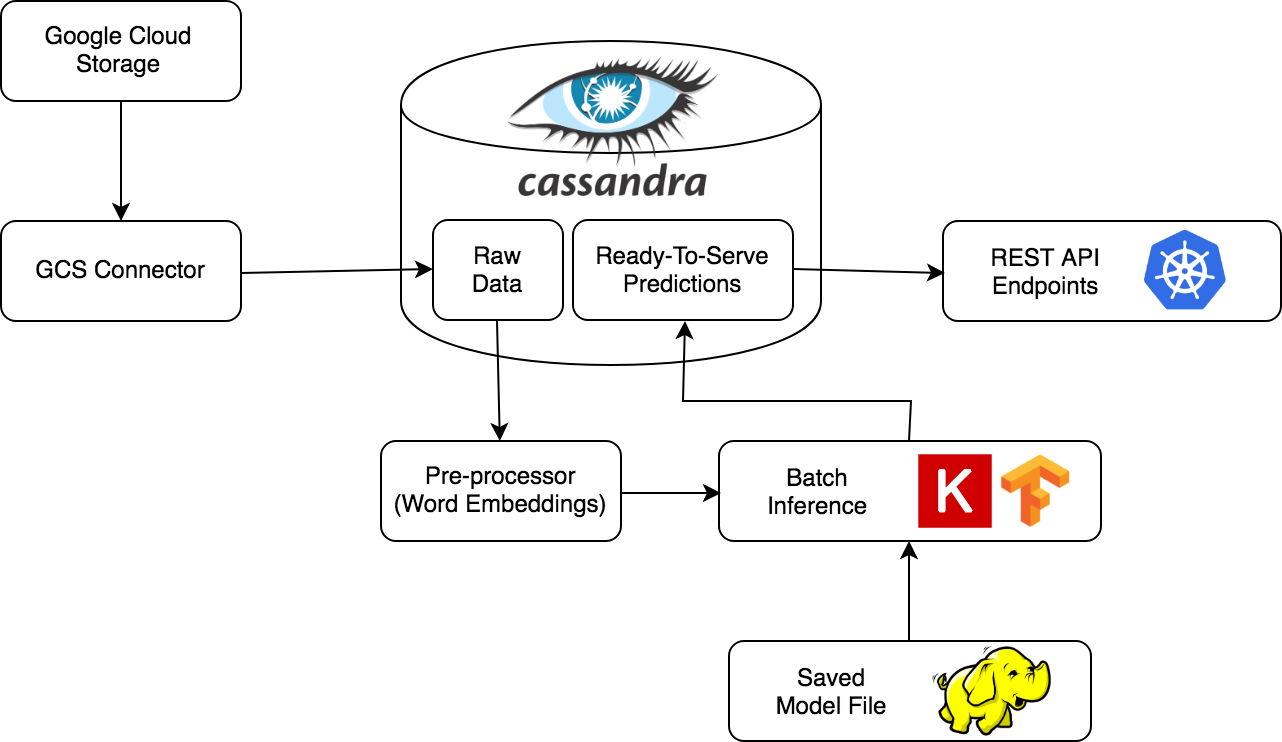
This pipeline is responsible for authenticating to a Google Cloud Storage bucket using a service account and downloading data composed of multiple csvs files.
The data from the csvs files is saved into Cassandra tables.
It is composed of several components:
-
Batch inference
It is used for making predictions and saving them in the Cassandra database. It uses the raw data (features), calculates the words embeddings for each keyword / query and generates predictions. For generating predictions, a pre-trained model is used. Since our features (words embeddings) do not evolve with time, we assume that model decay is minimal.
-
Endpoint
After the prediction pipeline is triggered, predictions can be accessed at an endpoint. See Wiki for details.
In addition to these two pipelines, we plan to develop a training pipeline. In this setup, the usecase will not require a pre-trained model to run.