
Este projeto foi realizado no workshop desenvolvido pelo Mulheres em Dados em parceria com Téo Me Why. Veja como apoiar estes projetos:
Apoia.se LivePix Assinante na Twitch Membros no YouTube GitHub Sponsors
Discord LinkedIn YouTube Instagram
O objetivo deste projeto é analisar o perfil dos assinantes de realizam do canal educativo Teo Me Why na Twitch e treinar um modelo de machine learning que estime a probabilidade de churn dos inscritos.
Início: 05/08/24
Entrega: 26/08/24
Avaliação: 30/08/24
Foi utilizado o framework Crisp-DM (Cross-Industry Standard Process for Data Mining) como orientador do passo-a-passo necessário para desenvolver este projeto.
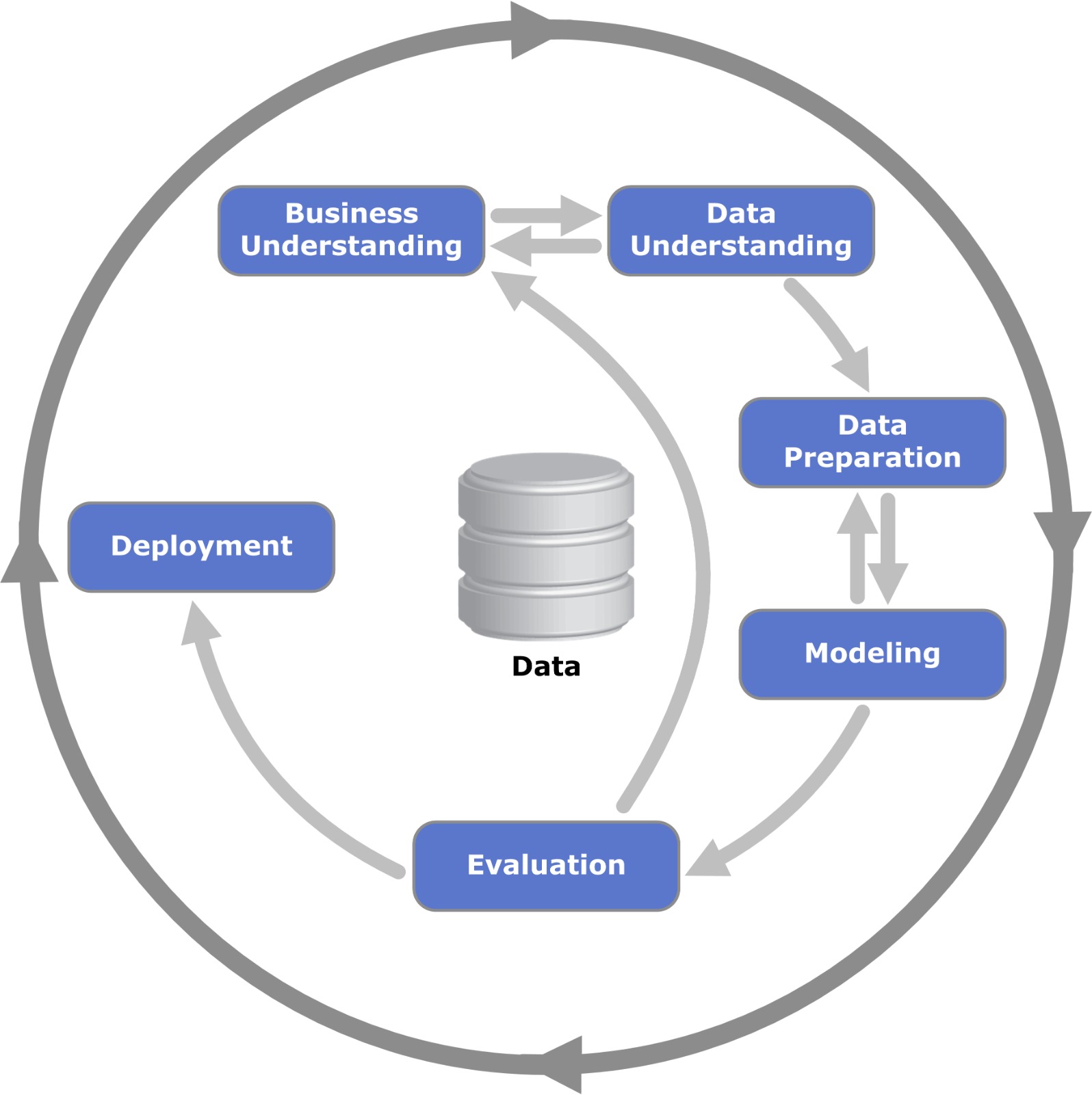
Portanto, este workshop nos proporcionou experiências de entendimento de negócios, engenharia de dados e ciência de dados para a execução de um projeto com dados reais do início ao fim.
O canal da Twitch Teo Me Why possui um sistema de pontos.
Há 3 tipos de pontos: Datapoints, Pôneis e Cubos.
É possível termos pontos negativos, já que as transações em que os pontos são trocados por prêmios também são registradas.
O churn é caracterizado pela inatividade na conta dentro de um período de 28 dias. Portanto, denominaremos contas que deram "churn" como inativas, e as que não deram "churn" como ativas.
| Nome da Coluna | Tipo de Dados | Descrição |
|---|---|---|
| idCliente | string | Identificador único do cliente. Chave primária |
| nrPontosCliente | bigint | Número total de pontos acumulados pela pessoa inscrita no canal. |
| flEmailCliente | bigint | Indicador se a pessoa inscrita possui um email registrado. 1 para sim e 0 para não. |
| Nome da Coluna | Tipo de Dados | Descrição |
|---|---|---|
| descProduto | string | Descrição do produto, como nome, características e outras especificações. |
| Nome da Coluna | Tipo de Dados | Descrição |
|---|---|---|
| idTransacaoProduto | string | Identificador único da transação do produto. Chave primária |
| idTransacao | string | Identificador único da transação. Relaciona a transação do produto com uma transação global ou um pedido específico. |
| descNomeProduto | string | Nome ou descrição do produto na transação. |
| nrQuantidadeProduto | bigint | Indica o número de unidades do produto envolvidas na transação. |
| Nome da Coluna | Tipo de Dados | Descrição |
|---|---|---|
| idTransacao | string | Identificador único da transação. |
| idCliente | string | Identificador único do cliente associado à transação. Relaciona a transação a um cliente específico. |
| dtTransacao | string | Data em que a transação foi realizada. Pode ser armazenado como uma string no formato de data/hora. |
| nrPontosTransacao | bigint | Número de pontos acumulados ou usados durante a transação. Pode representar o valor em pontos de um programa de fidelidade. |
Os dados foram trabalhados diretamente no Databricks em todas as atapas do projeto. Para a criação da feature store, foi desenvolvido um script em Python que integra a query SQL de maneira a automatizar a coleta de dados para diferentes coortes.
Janela de observação: 28 dias
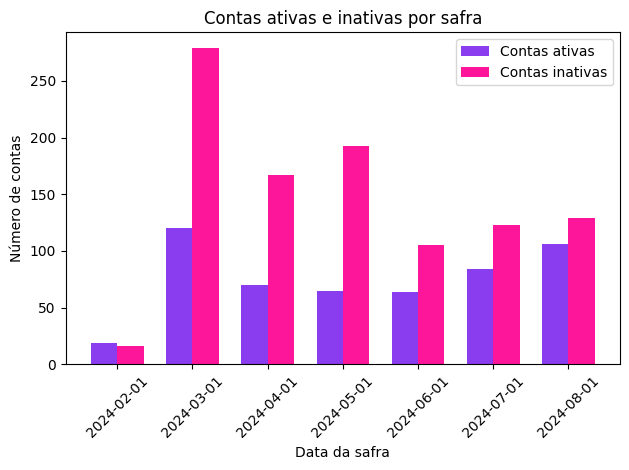
Número de coortes (safras): 7
Portanto, temos os seguinte elementos na nossa feature store: Partição
- dtRef: data da observação (coorte), ou seja, último dia da janela de observação. Id
- idCliente: código único do cliente. Features
- nrSomaPontos: número total de pontos do idCliente na dtRef.
- nrSomaPontosPos: número total de pontos positivos do idCliente na dtRef.
- nrSomaPontosNeg: número total de pontos negativos do idCliente na dtRef.
- nrTicketMedio: ticket médio (número médio de pontos por transação).
- nrTicketMedioPos: ticket médio considerando apenas pontos positivos (representa o valor médio de pontos ganhos).
- nrTicketMedioNeg: ticket médio considerando apenas pontos negativos (representa a média de gastos do cliente).
- nrPontosDia: número médio de pontos por dia de acesso.
- nrRecenciaDias: menor diferença entre a última transação e data da safra.
- nrQtdeDias: frequência de atividade em dias.
- nrQtdeTransacoes: frequência de transações.
- nrQtdeTransacaoDay2: frequência de transações no segundo dia da semana.
- nrQtdeTransacaoDay3: frequência de transações no terceiro dia da semana
- nrQtdeTransacaoDay4: frequência de transações no quarto dia da semana
- nrQtdeTransacaoDay5: frequência de transações no quinto dia da semana
- nrQtdeTransacaoDay6: frequência de transações no sexto dia da semana
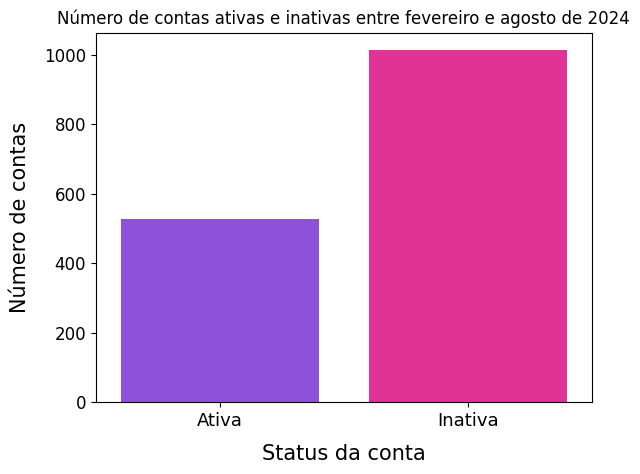
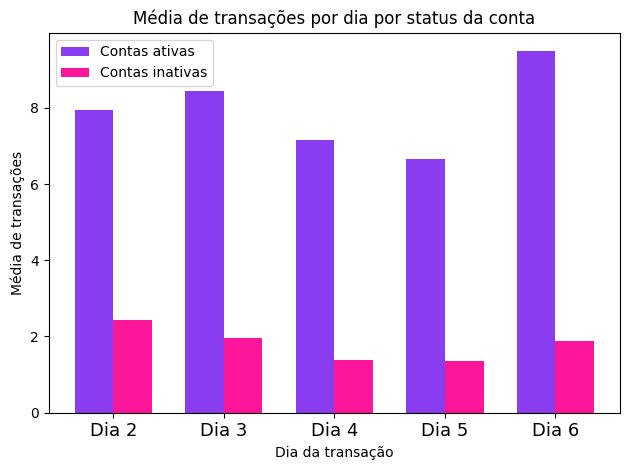
Embora a análise exploratória de dados seja feita normalmente na etapa de entendimento dos dados, realizamos uma EDA nesta etapa de preparação dos dados pois estamos interessadas em entender as features que foram construídas a partir dos dados brutos.
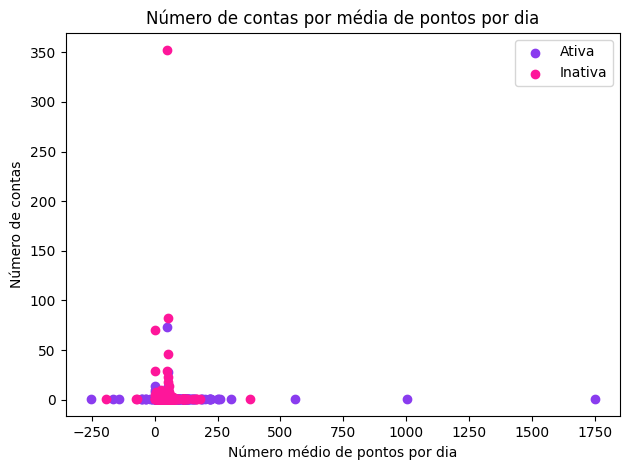
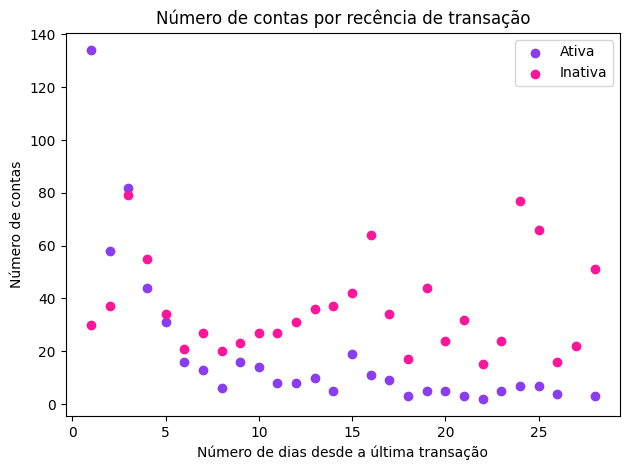
- Método IterativeImputer para valores NaN
Durante o processo de treinamento e validação dos modelos de árvore de decisão e random forest, foi identificado que alguns valores estavam ausentes nos dados. Para lidar com esses valores ausentes, foi utilizada a técnica de imputação avançada conhecida como IterativeImputer, a qual foi importada do pacote from sklearn.experimental import enable_iterative_imputer e from sklearn.impute import IterativeImputer.
O IterativeImputer realiza a imputação de valores ausentes de forma iterativa, usando um modelo de regressão para prever os valores que estão faltando com base nas características observadas no restante dos dados. Isso se diferencia da simples substituição por média, pois considera a relação entre variáveis para estimar os valores ausentes. Este método não apenas ajuda a preencher os dados incompletos, mas também preserva a integridade das relações entre as variáveis, minimizando o viés e melhorando a precisão dos modelos de machine learning.
- Decision Tree (Árvore de decisão)
É um modelo de machine learning que toma decisões com base em uma estrutura de árvore. Cada nó representa uma pergunta sobre uma característica dos dados, e cada ramo mostra a resposta. A árvore divide os dados em subconjuntos menores até chegar a uma previsão ou classificação.
- Random Forest (floresta aleatória)
Combina muitas árvores de decisão, em que cada uma traz uma recomendação para tomada de decisão.
A parte “aleatória” vem da forma como a floresta é construída. Cada árvore na floresta é treinada em um subconjunto diferente dos dados e usa características (perguntas) diferentes para fazer suas divisões. Essa aleatoriedade ajuda a criar uma variedade de árvores que juntas fazem melhores previsões.
Quando a floresta aleatória precisa fazer uma previsão, ela pergunta a todas as árvores suas opiniões. Para tarefas de classificação (como prever se um assinante vai cancelar), ela conta os votos e escolhe o resultado mais popular.
O modelo Random Forest foi testado para prever quais assinantes vão churnar. Ele teve um ótimo desempenho nos dados usados para treinar o modelo, com 96% de acurácia. No entanto, quando aplicamos o modelo a novos dados, a acurácia caiu para 72%, o que sugere que o modelo pode estar com overfit e não se sair tão bem em situações novas. A precisão (0,96) e o recall (0,99) também foram muito bons no treinamento, mas diminuíram na validação (0,76 e 0,84, respectivamente). De forma geral, vemos que o modelo identifica bem os assinantes que churnarão, mas precisa de ajustes para melhorar sua performance em dados que ainda não viu.
Esta etapa ficaremos devendo... Obrigada pela atenção!