SolrWayback bundle release 4.3.0 can be downloaded here: https://github.com/netarchivesuite/solrwayback/releases/tag/4.3.0
THIS VERSION HAS BEEN PATCHED AGAINST 'log4shell'
SolrWayback itself does not use log4j 2+ and is not directly affected by CVE-2021-44228.
The SolrWayback bundle uses Solr 7.7.3, which is affected by log4shell. Please follow the Solr log4shell mitigation guide if the bundled Solr is used before versio 4.2.3. The quickest fix, taken from the guide, is
- (Linux/MacOS) Edit your solr.in.sh file to include: SOLR_OPTS="$SOLR_OPTS -Dlog4j2.formatMsgNoLookups=true"
- (Windows) Edit your solr.in.cmd file to include: set SOLR_OPTS=%SOLR_OPTS% -Dlog4j2.formatMsgNoLookups=true
If another version of Solr is used, note that Solr >= 7.4 and < 8.11 are vulnerable. See the mitigation guide above for details.
SolrWayback is a web application for browsing historical harvested ARC/WARC files similar to the Internet Archive Wayback Machine. The SolrWayback uses on a Solr server with ARC/WARC files indexed using the warc-indexer.
SolrWayback comes with additional features:
- Free text search in all resources (HTML pages, PDFs, metadata for different media types, URLs, etc.)
- Interactive link graph (ingoing/outgoing) for domains.
- Export of search results to a WARC file. Streaming download, no limit of size of resultset.
- CSV text export of searc result with custom field selection.
- Wordcloud generation for domain.
- N-gram search visuzalisation.
- Visualization of search result by domain.
- Visualization of various domain statistics over time such as size, number of in and out going links.
- Large scale export of linkgraph in Gephi format. (See https://labs.statsbiblioteket.dk/linkgraph/)
- Image search similar to google images.
- Search by uploading a file. (e.g., image, PDF) See if the resource has been harvested and find HTML pages using the image.
- View all fields indexed for a resource and show warc-header for records.
- Configure alternative playback engine to any playback engine using the playback-API such as OpenWayback or pywb.
The National Széchényi Library of Hungary has kindly set up the following demo site for SolrWayback
https://webadmin.oszk.hu/solrwayback/
Warc-indexer: https://github.com/ukwa/webarchive-discovery/tree/master/warc-indexer
The Warc indexer is the indexing engine for documents in SolrWayback. It is maintained by the British Library.
Netsearch(Archon/Arctika): https://github.com/netarchivesuite/netsearch
Archon/Actika is a book keeping application for warc-files and can start multiple concurrent warc-indexer jobs for large scale netarchives.
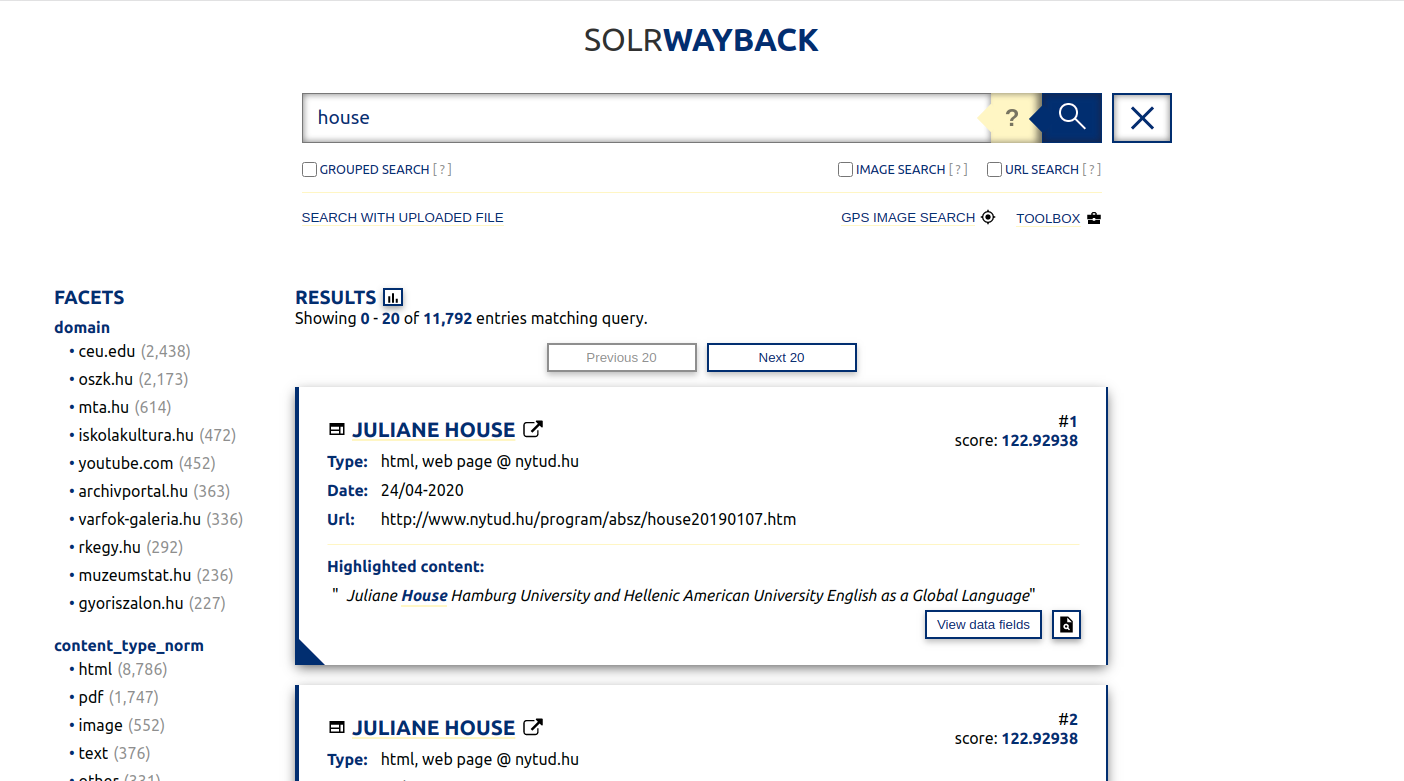
Lising of search results with facets.

Image search, show only images as results.

Solrwayback showing the playback of an archived webpage with playback toolbox overlay.
gui

Interactive domain link graph

Github like visualization of crawltimes
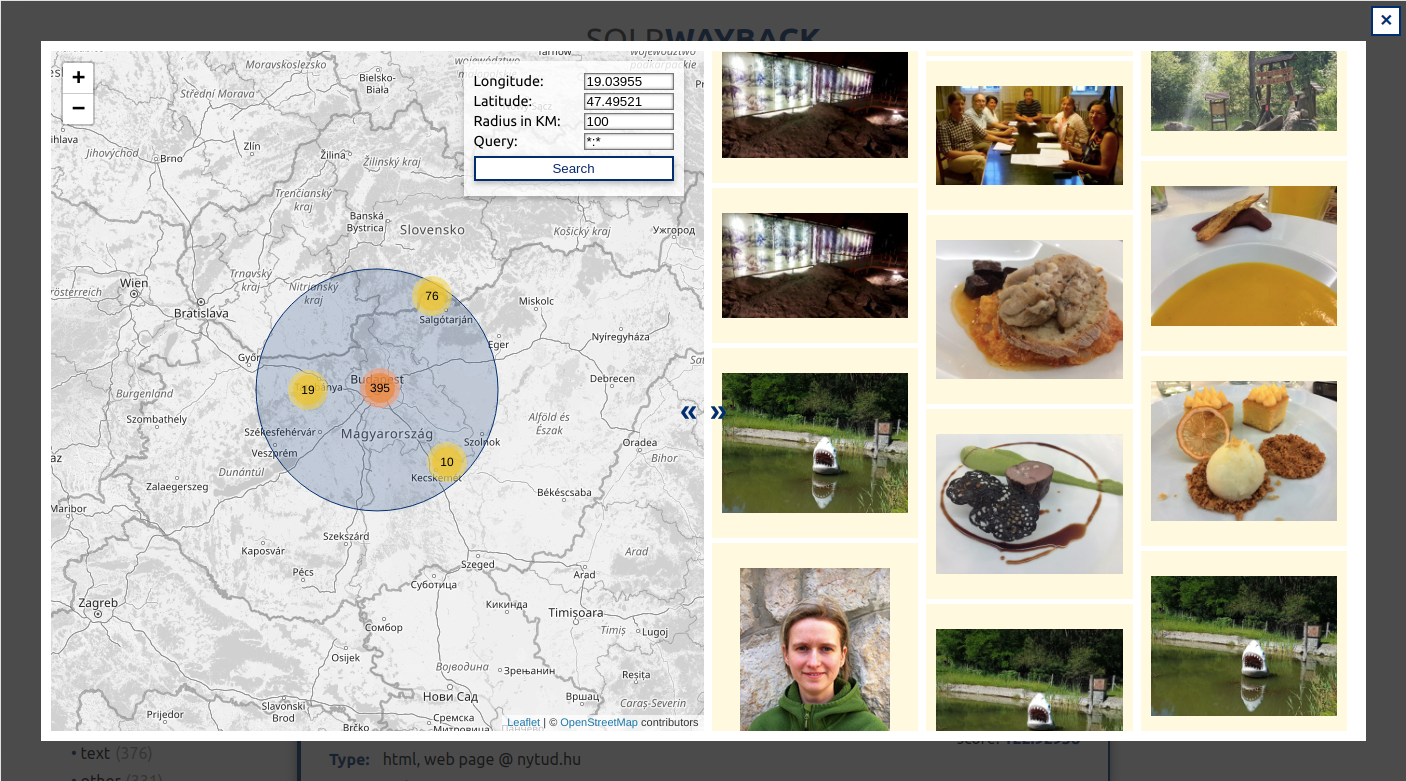
Search in images by gps location in images having exif location information about the location.
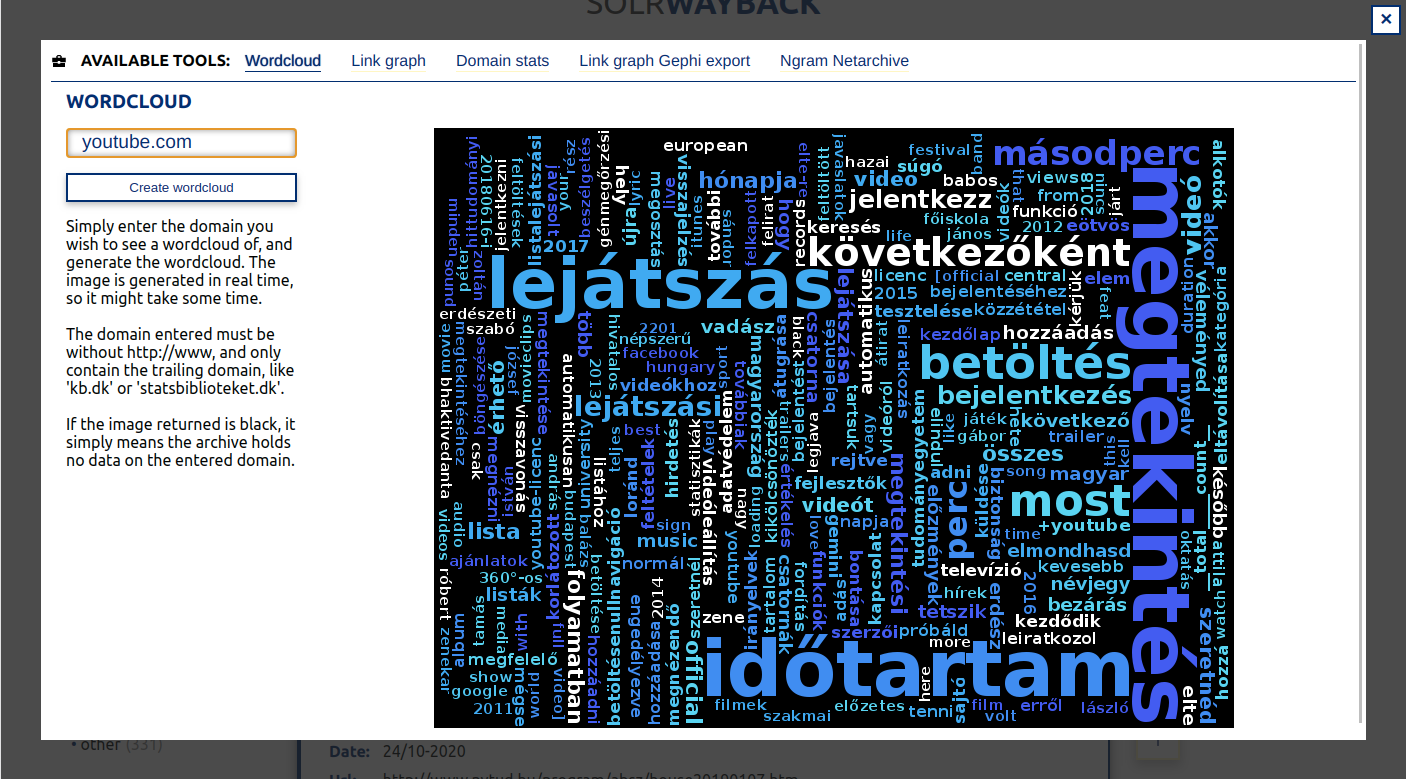
Generate a wordcloud for a domain
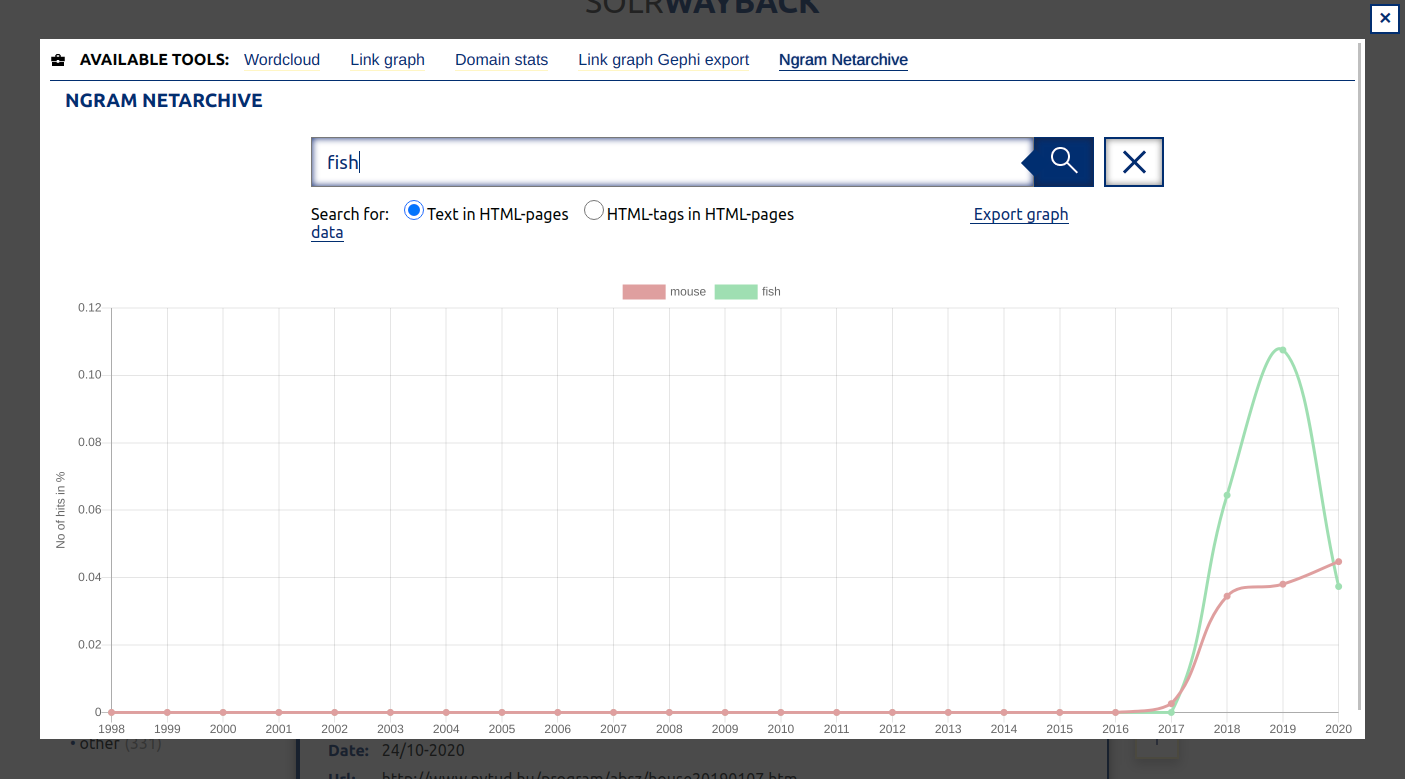
n-gram visualization of results by year, relative to the number of results that year.
The API for linking to and browsing archived webpages is the same as for Internet Archive:
- Internet Archive: https://web.archive.org/web/20080213093319/http://www.statsbiblioteket.dk/
- SolrWayback: http://server/solrwayback/services/web/20140515140841/http://statsbiblioteket.dk/
For moderne browsers that supports Serviceworkers, the root servlet will be obsolete. But for better playback in legacy browsers, the root servlet can improve the playbackback. See https://caniuse.com/serviceworkers if the browser supports serviceworkers.
Installing the root-servlet will improve playback of sites that are leaking URLs. The root-servlet will catch relative leaks (same domain) even without using proxy mode. The leaks will then be redirected back into SolrWayback to the correct URL and crawltime. The root-servlet is included in the bundle install. In Tomcat it must be named ROOT.war. Link to SolrWayback root proxy: https://github.com/netarchivesuite/solrwaybackrootproxy Absolute URL live-leaks (starting with http://domain...) will not be caught and can leak to the open web. Open network (F12) to see if any resources are leaking, or turn-off the internet connection to be sure there is no live leaks during playback.
- Works on macOS/Linux/Windows.
- JDK 8/9/10/11
- A nice collection of ARC/WARC files or harvest your own with Heritrix, Webrecorder, Brozzler, Wget, etc.
- Tomcat 8+ or another J2EE server for deploying the WAR-file
- A Solr 7.X server with the index build from the Arc/Warc files using the Warc-Indexer version 3.2.0-SNAPSHOT +
- (Optional) chrome/(chromium) installed for page previews to work. (headless chrome)
- Build the application with:
mvn package - Deploy the
target/solrwayback-*.warfile in a web-container - Copy
src/test/resources/properties/solrwayback.propertiesand/src/test/resources/properties/solrwaybackweb.propertiestouser/home/folder for the J2EE server - Modify the property files. (default all urls http://localhost:8080)
- Open search interface: http://localhost:8080/solrwayback
There is a Dockerfile that builds the SolrWayback WAR and deploys it via a containerised Tomcat server. This has been set up to allow configuration via environment variables as an alternative to supplying the properties file directly. There is also a docker-compose file that is intended to help with local building and testing of the SolrWayback Docker container. To use it:
- Run
docker-compose buildto build (or re-build) the container. - Run
docker-compose upto run the SolrWayback container along with a Solr instance that contains some test data.
After running docker-compose up you should see logs from three services (solrwayback, solr and populate). SolrWayback itself should be available on port 18080, at http://localhost:18080/solrwayback/
The Solr instance runs ukwa/webarchive-discovery-solr, which contains a suitable collection with the right schema. The Solr service itself should be available on port 18983, i.e. http://localhost:18983/solr/
The docker-compose up command also runs a helper service to populate the instance with some test data. This waits a few seconds (for Solr to start up) before sending 1000 records to it, and then exits. If needed, the test Solr instance can be run separately via docker-compose up solr populate.
Note that if you do not have direct internet access, you will need to set proxy variables including MAVEN_OPTS appropriately in order for the build to work.
Thomas Egense ([email protected]) Feel free to send emails with comments or questions.
With this download you will be able to index, search and playback web pages from your WARC files. The bundle contains Solr, the warc-indexer tool and SolrWayback installed on a Tomcat webserver. Just unzip the bundle and copy two files to your home directory and explore your WARC files.
Download : https://github.com/netarchivesuite/solrwayback/releases/download/4.3.0/solrwayback_package_4.3.0.zip
Unzip and follow the instructions below.
Properties:
Copy the two files properties/solrwayback.properties and properties/solrwaybackweb.properties to your HOME folder (or the home-folder for Tomcat user)
Optional: For screenshot previews to work you may have to edit solrwayback.properties and change the value of the last two properties : chrome.command and screenshot.temp.imagedir.
Chrome(Chromium) must has to be installed for screenshot preview images.
If there are errors when running a script, try change the permissions for the file (startup.sh etc). Linux: chmod +x filename.sh
SolrWayback requires both Solr and Tomcat to be running.
- Start tomcat:
apache-tomcat-8.5.60/bin/startup.sh - Stop tomcat:
apache-tomcat-8.5.60/bin/shutdown.sh - (For windows navigate to
apache-tomcat-8.5.60/bin/and typestartup.batorshutdown.bat) - To see Tomcat is running open: http://localhost:8080/solrwayback/
- Start solr:
solr-7.7.3/bin/solr start - Stop solr:
solr-7.7.3/bin/solr stop -all - (For windows navigate to
solr-7.7.3/bin/and typesolr.cmd startorsolr.cmd stop -all) - To see Solr is running open: http://localhost:8983/solr/#/netarchivebuilder
SolrWayback uses a Solr index of WARC files to support freetext search and more complex queries.
If you do not have existing WARC files, see steps below on harvesting with wget.
The script warc-indexer.sh in the indexing-folder allows for multi processing and keeps track of already
indexed files, so the collection can be extended by adding more WARCs and running the script again.
Call indexing/warc-indexer.sh -h for usage and how to adjust the number of processes to use for indexing.
Example usage:
THREADS=20 ./warc-indexer.sh warcs1
This will start indexing files from the warcs1 folder using 20 threads. Assigning a higher number of threads than CPU cores available will result in slower indexing. Each indexing job require 1GB ram, so this can also be a limiting factor.
The script keeps track of processed files by checking if a log from a previous analysis is available. The logs are stored
in the status-folder (this can be changed using the STATUS_ROOT variable). To re-index a WARC file, delete the
corresponding log file.
The script warc-indexer.sh is not available for Windows. For that platform only a more primitive script is provided that also works for Linux/MacOs.
- Copy ARC/WARC files into folder:
indexing/warcs1 - Start indexing: call
indexing/batch_warcs1_folder.sh(or batch_warcs1_folder.bat for windows)
Indexing can take up to 20 minutes for 1GB warc-files. After indexing, the warc-files must stay in the same folder since SolrWayback is using them during playback etc.
Having whitespace characters in WARC file names can result in pagepreviews and playback not working on some systems.
There can be up to 5 minutes delay before the indexed files are visible from search. Visit this url after index job have finished to commit them instantly: http://localhost:8983/solr/netarchivebuilder/update?commit=true
There is a batch_warcs2_folder.sh similar script to show how to easily add new WARC files to the collection without indexing the old ones again.
For more information about the warc-indexer see: https://github.com/ukwa/webarchive-discovery/wiki/Quick-Start
Renaming the solrwayback.war to collection1#solrwayback.war in the tomcat/webapps/ folder will have tomcat mapping the application from 'http://localhost:8080/solrwayback/' to 'http://localhost:8080/collection1/solrwayback/'. The requires defining the property in solrwaybackweb.properties: webapp.prefix=/collection1/solrwayback/ The 'wayback.baseurl' in solrwayback.properties also needs to be fixed to match. It will not work to try renaming a Tomcat deployment descriptor to collection1#solrwayback.xml. (hopefull fixed in a later release) The two property files must then be placed in the a /collection1 folder in the home-directory. This way multiple SolrWaybacks can be running in the same Tomcat server. None of the two property files must exist in the home-directory with this setup.
The stand alone Solr-server and indexing workflow using warc-indexer.sh can scale up to 20000 WARC files of size 1GB. Using 20 threads indexing a collection of this size can take up to 3 weeks. This will result in an index about 1TB having 500M documents and this will require to changing the Solr memory allocation to at least 12GB. Storing the index on a SSD drive is required to reach acceptable performance for searches. For collections larger than this limit Solr Cloud is required instead of the stand alone Solr that comes with the SolrWayback Bundle. A more advanced distributed indexing flow can handled by the archon/arctika index workflow. See: https://github.com/netarchivesuite/netsearch
If you want to index a new collection into solr and remove the old index.
- Stop solr
- Delete the folder
solr-7.7.3/server/solr/configsets/netarchivebuilder/netarchivebuilder_data/index(or rename toindex1etc, if you want to switch back later) - Start solr
- Start the indexing script
A powerful laptop can handle up to 8 simultaneous indexing processes with Solr running on the same laptop. Using an SSD for the Solr-index will speed up indexing and also improve search/playback performance drastically.
Click the question mark in the search-field to get help with the search syntax for more complex queries and using field queries.
The toolbar icon opens a menu with the available tools.
How to do your own web harvest websites (macOS/Linux only):
- Using the wget command is an easy way to harvest web sites and create WARC files. The WARC files can then be indexed into SolrWayback.
- Create a new folder, since there will be several files written in this folder. Navigate to that folder in a prompt.
- Create a text file call
url_list.txtwith one URL per line in that folder. - Type the following in a prompt:
wget --span-hosts --warc-cdx --page-requisites --warc-file=warcfilename --warc-max-size=1G -i url_list.txt
The script will harvest all pages in the url_list.txt file with all resources required for that page (images, CSS, etc.) and be written to a WARC file(s) called warcfilename.warc.
The optional --span-hosts parameter will also harvest resources outside the domain of the page and can be removed
- To perform a multi-level harvest:
wget --span-hosts --level=1 --recursive --warc-cdx --page-requisites --warc-file=warcfilename --warc-max-size=1G -i url_list.txt
wherelevel=1means "starting URLs and the first level of URLs linked from the starting URLs". This will substantially increase the size of the WARC file(s).