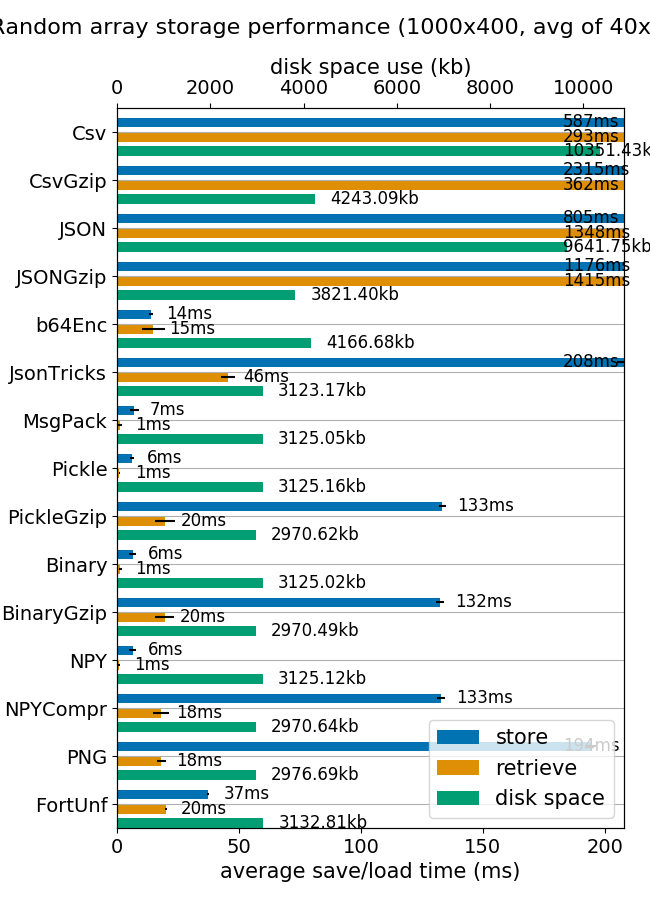
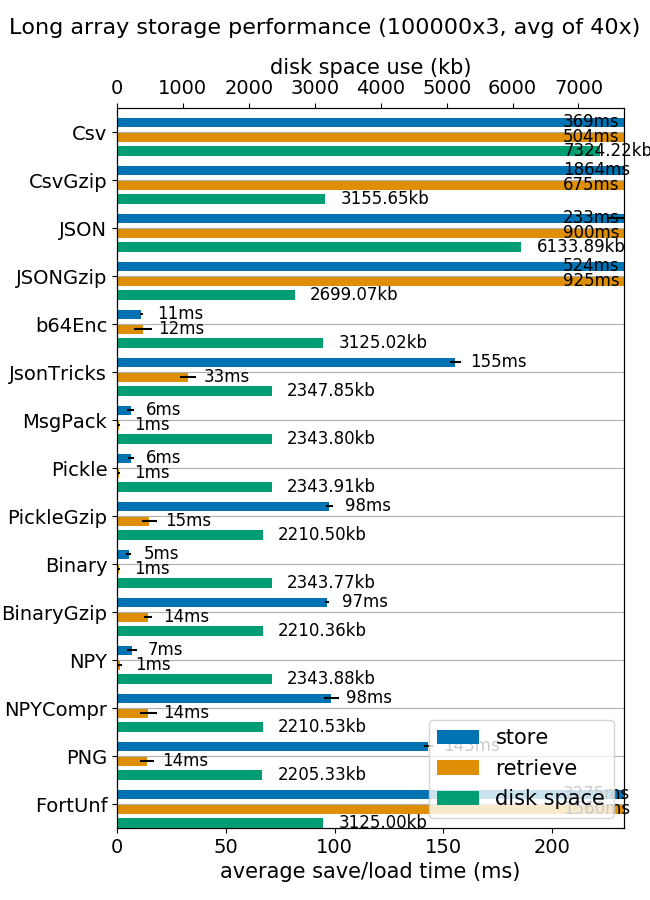
Compare the storage speed, retrieval speed and file size for various methods of storing 2D numpy arrays.
The results here are obtained on a normal desktop PC that's several years old and running Ubuntu and has a SSD for storage. You can easily run the benchmarks on your own PC to get more relevant results. You can also apply it to your own data.
| Name | Description | Fast | Small^ | Portability | Ease of use | Human-readable | Flexible% | Notes |
|---|---|---|---|---|---|---|---|---|
| Csv~ | comma separated value | ☐ ☐ ☐ | ☐ ☐ ☐ | ☒ ☒ ☒ | ☒ ☒ ☒ | ☒ ☒ | ☒ ☐ | only 2D |
| JSON~ | js object notation | ☐ ☐ ☐ | ☐ ☐ ☐ | ☒ ☒ ☐ | ☒ ☒ ☐ ++ | ☒ ☐ | ☒ ☒ | any dim, unequal rows |
| b64Enc | base 64 encoding | ☒ ☒ ☒ | ☒ ☐ ☐ | ☒ ☒ ☐ | ☒ ☒ ☐ | ☐ ☐ | ☐ ☐ | more network, not files |
| Pickle~ | python pickle | ☒ ☒ ☐ | ☐ ☐ ☐ | ☐ ☐ ☐ | ☒ ☒ ☒ | ☐ ☐ | ☒ ☒ | any obj, not backw. comp |
| Binary~ | pure raw data | ☒ ☒ ☒ | ☒ ☒ ☐ | ☒ ☒ ☒ | ☒ ☐ ☐ | ☐ ☐ | ☐ ☐ | dim & type separately |
| NPY | numpy .npy (no pickle) | ☒ ☒ ☒ | ☒ ☒ ☐ | ☒ ☐ ☐ | ☒ ☒ ☒ | ☐ ☐ | ☒ ☐ | with pickle mode OFF |
| NPYCompr | numpy .npz | ☒ ☒ ☒ | ☒ ☒ ☒ | ☒ ☐ ☐ | ☒ ☒ ☒ | ☐ ☐ | ☒ ☐ | multiple matrices |
| PNG | encoded as png image | ☒ ☒ ☐ | ☒ ☒ ☒ | ☐ ☐ ☐ | ☐ ☐ ☐ ++ | ☐ ☐ | ☐ ☐ | only 2D; for fun but works |
| FortUnf | fortran unformatted | ☒ ☒ ☒ | ☒ ☒ ☐ | ☒ ☐ ☐ | ☒ ☐ ☐ + | ☐ ☐ | ☒ ☐ | often compiler dependent |
| MatFile | Matlab .mat file | ☒ ☒ ☒ | ☒ ☒ ☐ | ☒ ☒ ☐ | ☒ ☒ ☒ + | ☐ ☐ | ☒ ☐ | multiple matrices |
- ^ Two checks if it's small for dense data, three checks if also for sparse. All gzipped results are small for sparse data.
- % E.g. easily supports 3D or higher arrays, unequal columns, inhomogeneous type columns...
- ~ Also tested with gzip, stats refer to non-gzipped. Gzipped is always much slower to write, a slower to read, for text formats it's at least 50% smaller.
- Rating refers to using a semi-popular package (probably scipy), as opposed to only python and numpy.
- ++ Very easy (☒☒☒) with an unpopular and/or dedicated package, but the rating refers to only python and numpy.
You can install all dependencies using pip install -r rements.pip. csv and NPY were done with numpy; json was done with pyjson_tricks; png was done with imgarray; fortran unformatted was done with fortranfile; matlab was done with scipy; pickle, base64 and gzipping were done with python built-ins. pandas is needed for stata (not ready yet) statai files. Seaborn is needed for plotting. You can install all dependencies using pip install requirements.pip
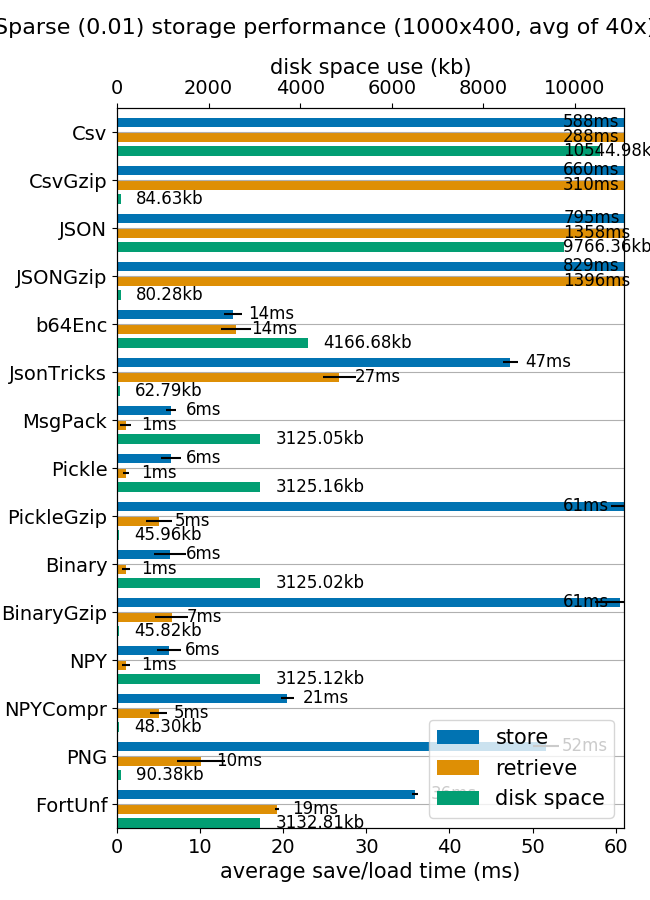
99% of values are zero, so compression ratios are very good.
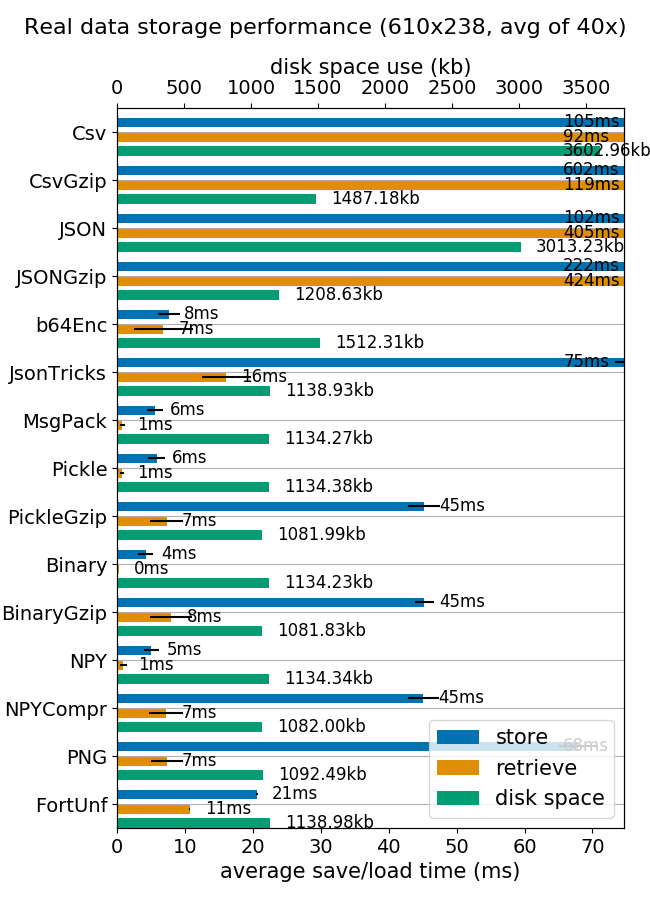
Scattering probabilities for hydrogen and carbon monoxide (many doubles between 0 and 1, most close to 0). You can easily overwrite this by your own file in testdata.csv.
Pull requests with other methods (serious or otherwise) are welcome! There might be some ideas in the issue tracker.