Недавно прочитал пост Максима Кульгина про то что они не успевали настроить парсинг продавцов Ozon и попросили сделать это "умного человека". К этому посту приложено видео с демонстрацией того как реализован парсер. На видео 2 окна браузера управляемых из скрипта. В среднем на обработку одного продавца уходило около 13 секунд. Быстренько прикинув я высчитал что потребуется сделать минимум 46248 запросов (42691 страницы магазинов и 3557 страниц списка). Посчитав примерное время работы вышло чуть более 3х суток. Продемонстрированное решение можно было оптимизировать, но как не оптимизируй, а 2 chromium браузера довольно прожорливы к ресурсам сервера и нет никаких гарантий что cloudflare не замучает тебя блоками. Я спросил почему не использовали API мобильного приложения ведь скорость там НАМНОГО лучше, на что мне пришло сообщение от одного из читателей
Нее, вы утрируете
Что я прочитал как
Нее, вы балаболите
Что бы не подразумевал тот человек меня уже было не остановить и я начал работать над PoC.
В первую очередь мне нужно было научится собирать список продавцов. Я открыл девтулзы браузера и начал смотреть откуда берутся данные на ozon.ru/seller/ Пролистав страницу я увидел endpoint в котором получалась информация о магазинах. www.ozon.ru/api/entrypoint-api.bx/page/json/v2
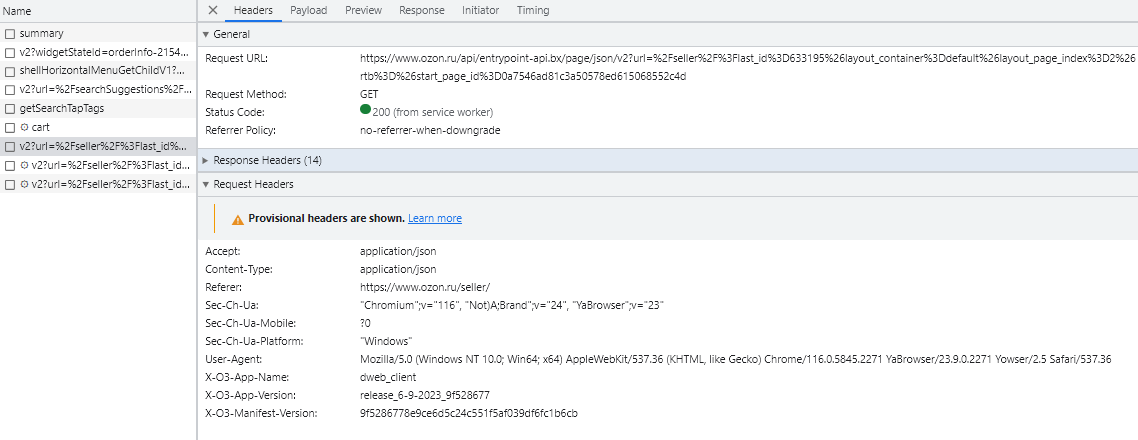
Единственным параметром был URL по которому получается HTML списка магазинов. В ответ мы получали JSON со списком компонентов и их состоянием. Повторив запрос с почти теми же заголовками я, как и ожидал, уперся в cloudflare
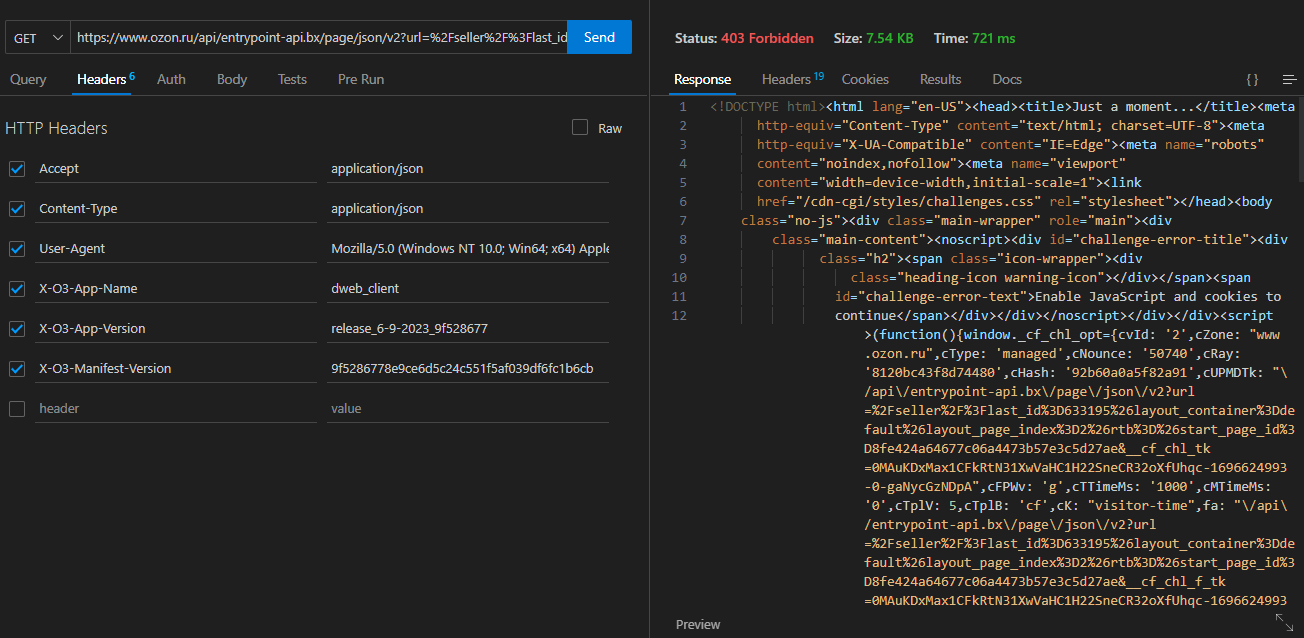
Варианты обхода CF мне известны, но я хотел более элегантного, менее ресурсозатратного и быстрого решения и я пошёл своим любимым путём.
Я буду сниффить приложение под android. В нем можно получить все те же данные и очень часто они менее защищены. Первым делом нужно преодолеть SSL pinning. Можно пропатчить APK приложения, можно попытаться подсунуть сертификат своего mitm-прокси, но я пойду другим путём. Я буду патчить приложение в момент работы при помощи Frida и скрипта Universal Android SSL Pinning Bypass
Настраиваю прокси в Burp Suite, устанавливаю прокси на телефоне и запускаю приложение со скриптом фриды и вот мы можем просматривать содержимое перехваченных пакетов
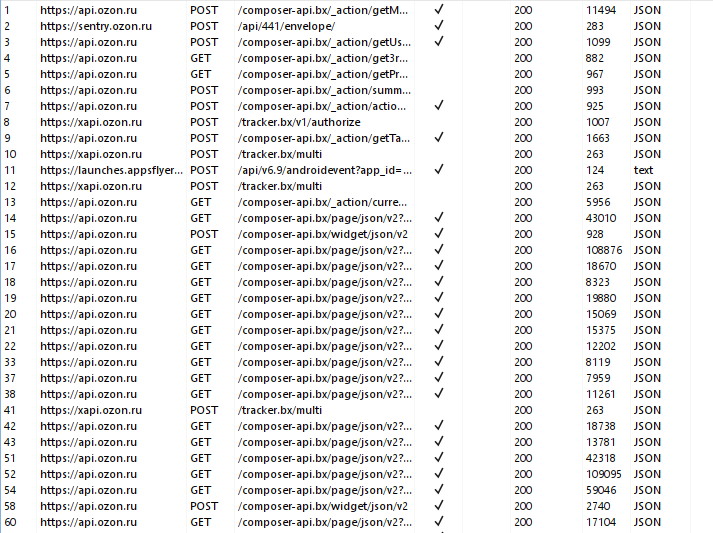
Сразу в глаза бросается что api.ozon.ru/composer-api.bx/page/json/v2 и www.ozon.ru/api/entrypoint-api.bx/page/json/v2 ОЧЕНЬ похожи. И после проверки я убедился что они выполняют одну и ту же функцию. Вот только CF не блочит запрос даже при том что я убрал все заголовки которые хоть как то намекали на прохождение защиты или аутентификацию
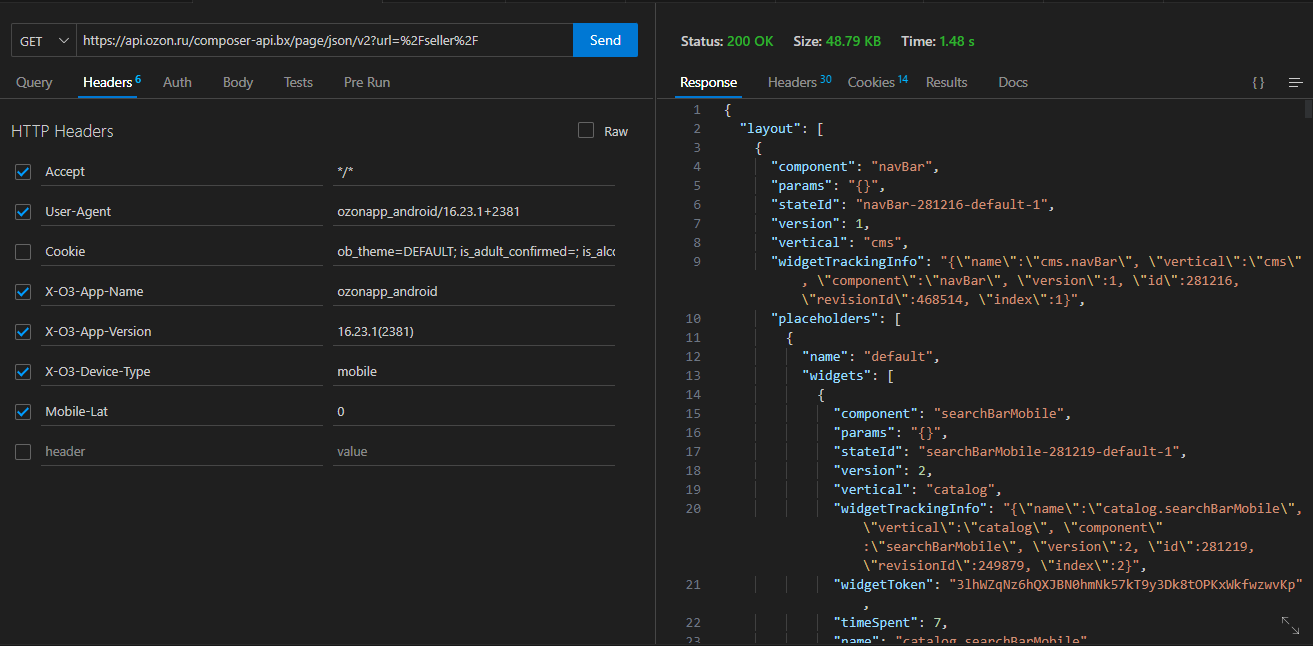
Я узнал конечные точки, необходимые параметры и разобрался со структурой ответа сервера. Теперь осталось только собрать данные.
Для быстрого написания парсера я использовал crawlee. Эта библиотека берёт на себя все рутинные вопросы и вам остается только выбирать данные которые вам нужны. Для описания этой библиотеки может не хватить отдельной статьи, поэтому напишу кратко что сделал я.
В настройках кравлера задаём preNavigationHook в котором добавляем необходимые заголовки и создаём "роутер". Если запрос не отмечен как запрос информации о магазине разбираем ответ как список магазинов иначе получаем инфу о магазине. Звучит просто? Так и есть. Написанный мной код занял ~100 строк и доступен в репозитории на github.
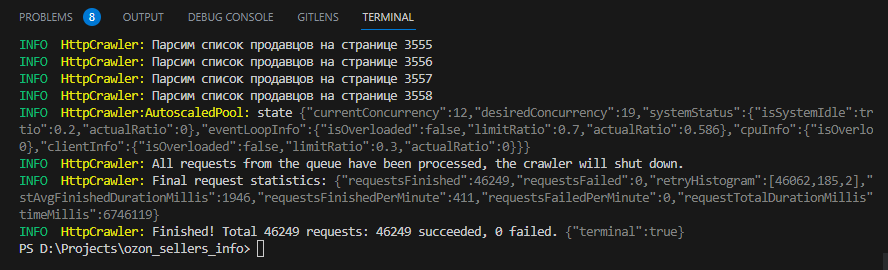
Наш парсер выбрал 19 потоков оптимальным количеством потоков и отработал чуть менее чем за 2 часа. Мы не использовали прокси. При этом мы не получили ни одной ошибки. Результат очень даже не плохой и я уверен что его можно улучшить. А чего я вообще всё это начал?
Подписывайтесь на мой Telegram. Там будет ещё много интересного)