Python implementations of some of the fundamental Machine Learning models and algorithms from scratch.
The purpose of this project is not to produce as optimized and computationally efficient algorithms as possible but rather to present the inner workings of them in a transparent way. The reason the project uses scikit-learn is to evaluate the implementations on sklearn.datasets.
Feel free to reach out if you can think of ways to expand this project.
$ pip install mlfromscratch
or
$ python setup.py install
$ python mlfromscratch/supervised_learning/regression.py

Figure: Polynomial ridge regression of temperature data measured in
Linköping, Sweden 2016.
$ python mlfromscratch/supervised_learning/multilayer_perceptron.py
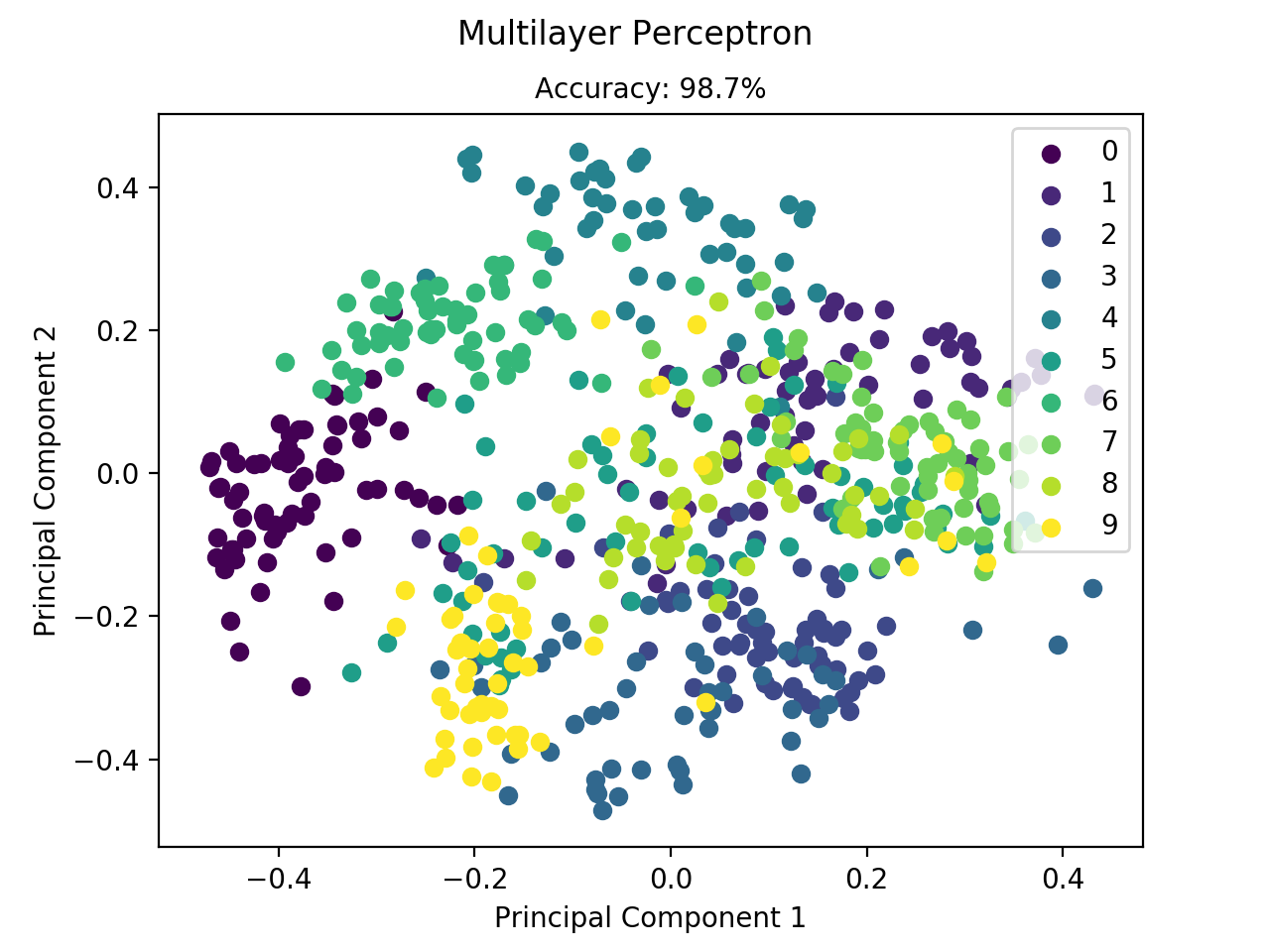
Figure: Classification of the digit dataset using an MLP with two
hidden layers.
$ python mlfromscratch/unsupervised_learning/dbscan.py

Figure: Clustering of the moons dataset using DBSCAN.
$ python mlfromscratch/unsupervised_learning/apriori.py
+-------------+
| Apriori |
+-------------+
Minimum Support: 0.25
Minimum Confidence: 0.8
Transactions:
[1, 2, 3, 4]
[1, 2, 4]
[1, 2]
[2, 3, 4]
[2, 3]
[3, 4]
[2, 4]
Frequent Itemsets:
[1, 2, 3, 4, [1, 2], [1, 4], [2, 3], [2, 4], [3, 4], [1, 2, 4], [2, 3, 4]]
Rules:
1 -> 2 (support: 0.43, confidence: 1.0)
4 -> 2 (support: 0.57, confidence: 0.8)
[1, 4] -> 2 (support: 0.29, confidence: 1.0)
- Adaboost
- Bayesian Regression
- Decision Tree
- Gradient Boosting
- K Nearest Neighbors
- Linear Discriminant Analysis
- Linear Regression
- Logistic Regression
- Multi-class Linear Discriminant Analysis
- Multilayer Perceptron
- Naive Bayes
- Perceptron
- Polynomial Regression
- Random Forest
- Ridge Regression
- Support Vector Machine
- XGBoost