Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alex Berg, Wan-Yen Lo, Piotr Dollar, Ross Girshick
[Paper] [Project] [Demo] [Dataset] [Blog] [BibTeX]
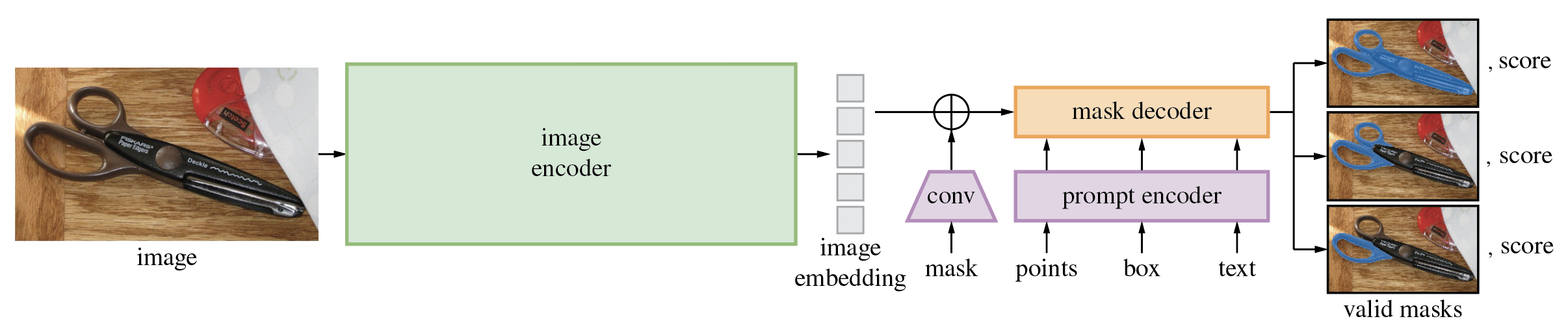
Segment Anything Model (SAM) 从诸如点或框之类的输入提示生成高质量的对象掩码,可用于为图像中的所有对象生成掩码。它已经在包含1100万张图像和11亿个掩码的数据集上进行了训练,并在各种分割任务上具有强大的零样本zero-shot性能。


代码要求python>=3.8,以及pytorch>=1.7和torchvision>=0.8。请按照这里的说明安装PyTorch和TorchVision的依赖项。强烈建议安装支持CUDA的PyTorch和TorchVision。
克隆存储库并在本地安装:
git clone https://github.com/facebookresearch/segment-anything.git
cd segment-anything
pip install -e .
建议先fork到自己仓库后再克隆
以下是必要的可选依赖项,用于掩码后处理、以COCO格式保存掩码、示例jupyter笔记本以及将模型导出为ONNX格式。运行示例jupyter笔记本还需要jupyter。
pip install opencv-python pycocotools matplotlib onnxruntime onnx
首先下载一个模型检查点。然后,可以使用以下几行代码从给定提示中获取掩码:
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
或者为整个图像生成掩码:
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)
此外,可以使用命令行为图像生成掩码:
python scripts/amg.py --checkpoint <path/to/checkpoint> --model-type <model_type> --input <image_or_folder> --output <path/to/output>
有关更多详细信息,请参阅使用提示生成掩码和自动生成对象掩码的示例笔记本。


SAM的轻量级掩码解码器可以导出为ONNX格式,以便在支持ONNX运行时的任何环境中运行,例如在演示中展示的浏览器中。使用以下命令导出模型:
python scripts/export_onnx_model.py --checkpoint <path/to/checkpoint> --model-type <model_type> --output <path/to/output>
请参阅示例笔记本以了解如何通过SAM的骨干进行图像预处理,然后使用ONNX模型进行掩码预测的详细信息。建议使用PyTorch的最新稳定版本进行ONNX导出。
demo/文件夹中有一个简单的单页React应用程序,展示了如何在支持多线程的Web浏览器中使用导出的ONNX模型运行掩码预测。请查看demo/README.md以获取更多详细信息。
提供了三个模型版本,具有不同的骨干大小。可以通过运行以下代码实例化这些模型:
from segment_anything import sam_model_registry
sam = sam_model_registry["<model_type>"](checkpoint="<path/to/checkpoint>")
单击下面的链接下载相应模型类型的检查点。
default或vit_h:ViT-H SAM模型。vit_l:ViT-L SAM模型。vit_b:ViT-B SAM模型。
b:base基础模型
l:large较大模型
h:huge最大的模型
请参阅此处以获取有关数据集的概述。可以在此处下载数据集。通过下载数据集,您同意已阅读并接受了SA-1B数据集研究许可条款。
每个图像的掩码保存为json文件。它可以在以下格式的Python字典中加载。
{
"image" : image_info,
"annotations" : [annotation],
}
image_info {
"image_id" : int, # 图像id
"width" : int, # 图像宽度
"height" : int, # 图像高度
"file_name" : str, # 图像文件名
}
annotation {
"id" : int, # 注释id
"segmentation" : dict, # 以COCO RLE格式保存的掩码。
"bbox" : [x, y, w, h], # 掩码周围的框,以XYWH格式表示
"area" : int, # 掩码的像素面积
"predicted_iou" : float, # 模型对掩码质量的自身预测
"stability_score" : float, # 掩码质量的度量
"crop_box" : [x, y, w, h], # 用于生成掩码的图像的裁剪,以XYWH格式表示
"point_coords" : [[x, y]], # 输入模型生成掩码的点坐标
}图像ID可以在sa_images_ids.txt中找到,可以使用上述链接下载。
要将COCO RLE格式的掩码解码为二进制:
from pycocotools import mask as mask_utils
mask = mask_utils.decode(annotation["segmentation"])
请参阅此处以获取有关如何操作以RLE格式存储的掩码的更多说明。
如果您在研究中使用SAM或SA-1B,请使用以下BibTeX条目。
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}