
{kind=link}
pyimpute provides high-level python functions for bridging the gap between spatial data formats and machine learning software to facilitate supervised classification and regression on geospatial data. This allows you to create landscape-scale predictions based on sparse observations.
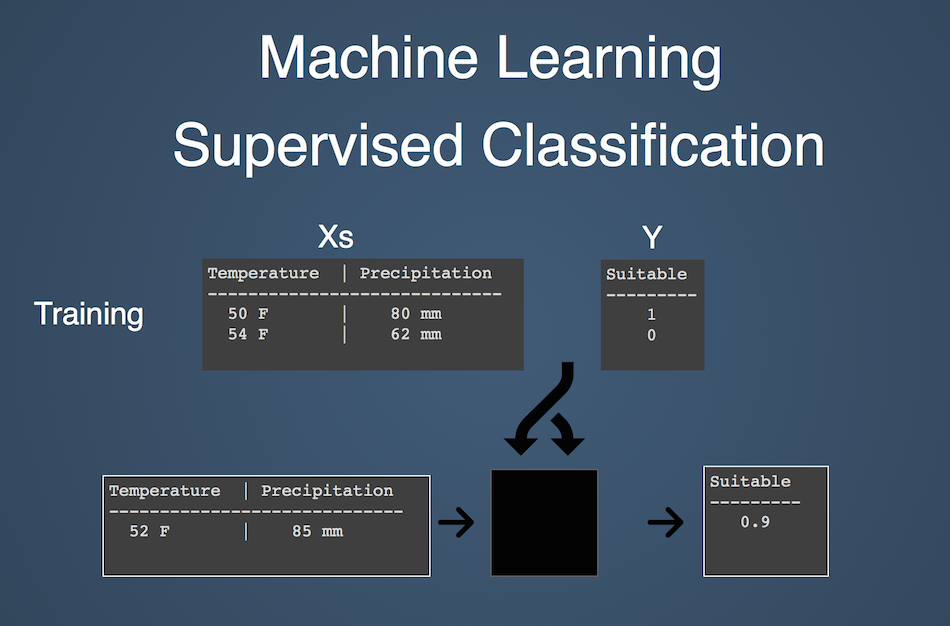
The observations, known as the training data, consists of:
- response variables: what we are trying to predict
- explanatory variables: variables which explain the spatial patterns of responses
The target data consists of explanatory variables represented by raster datasets. There are no response variables available for the target data; the goal is to predict a raster surface of responses. The responses can either be discrete (classification) or continuous (regression).
load_training_vector: Load training data where responses are vector data (explanatory variables are always raster)load_training_raster: Load training data where responses are raster datastratified_sample_raster: Random sampling of raster cells based on discrete classesevaluate_clf: Performs cross-validation and prints metrics to help tune your scikit-learn classifiers.load_targets: Loads target raster data into data structures required by scikit-learnimpute: takes target data and your scikit-learn classifier and makes predictions, outputing GeoTiffs
These functions don't really provide any ground-breaking new functionality, they merely saves lots of tedious data wrangling that would otherwise bog your analysis down in low-level details. In other words, pyimpute provides a high-level python workflow for spatial prediction, making it easier to:
- explore new variables more easily
- frequently update predictions with new information (e.g. new Landsat imagery as it becomes available)
- bring the technique to other disciplines and geographies
Here's what a pyimpute workflow might look like. In this example, we have two explanatory variables as rasters (temperature and precipitation) and a geojson with point observations of habitat suitability for a plant species. Our goal is to predict habitat suitability across the entire region based only on the explanatory variables.
from pyimpute import load_training_vector, load_targets, impute, evaluate_clf
from sklearn.ensemble import RandomForestClassifier
Load some training data
explanatory_rasters = ['temperature.tif', 'precipitation.tif']
response_data = 'point_observations.geojson'
train_xs, train_y = load_training_vector(response_data,
explanatory_rasters,
response_field="suitability")
Train a scikit-learn classifier
clf = RandomForestClassifier(n_estimators=10, n_jobs=1)
clf.fit(train_xs, train_y)
Evalute the classifier using several validation metrics, manually inspecting the output
evaluate_clf(clf, train_xs, train_y)
Load target raster data
target_xs, raster_info = load_targets(explanatory_rasters)
Make predictions, outputing geotiffs
impute(target_xs, clf, raster_info, outdir='/tmp',
linechunk=400, class_prob=True, certainty=True)
assert os.path.exists("/tmp/responses.tif")
assert os.path.exists("/tmp/certainty.tif")
assert os.path.exists("/tmp/probability_0.tif")
assert os.path.exists("/tmp/probability_1.tif")
Assuming you have libgdal and the scipy system dependencies installed, you can install with pip
pip install pyimpute
Alternatively, install from the source code
git clone https://github.com/perrygeo/pyimpute.git
cd pyimpute
pip install -e .
See the .travis.yml file for a working example on Ubuntu systems.
For an overview, watch my presentation at FOSS4G 2014: Spatial-Temporal Prediction of Climate Change Impacts using pyimpute, scikit-learn and GDAL — Matthew Perry
Also, check out the examples and the wiki