-
Notifications
You must be signed in to change notification settings - Fork 30
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
1 changed file
with
126 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,126 @@ | ||
| ### ICCV 2023: Transferable Decoding with Visual Entities for Zero-Shot Image Captioning | ||
|
|
||
| ### 1. 论文信息 | ||
|
|
||
|  | ||
|
|
||
| ### 2. 引言 | ||
|
|
||
| 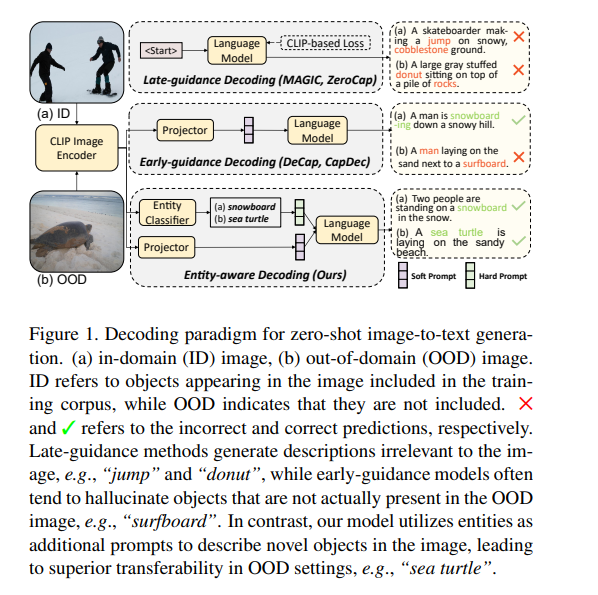 | ||
|
|
||
| 这篇论文的研究背景是图像描述生成任务,特别是零样本域适应的图像描述生成。现有通过直接适配预训练的视觉语言模型(如CLIP)到下游图像描述生成任务的方法存在两个主要问题: | ||
|
|
||
| 第一,在解码过程中,语言模型的先验知识会主导生成过程,导致生成的描述与图像无关。 | ||
|
|
||
| 第二,在描述未见域的图像时,模型容易产生对象幻象,即生成的描述包含图像中并不存在的对象。 | ||
|
|
||
| 针对这两个问题,论文提出了实体感知的解码方法ViECap。该方法在图像描述的生成过程中融合了基于实体的hard prompts和soft prompts来指导语言模型的解码。具体来说,hard prompts由图像中的显著对象实体通过CLIP的开放词汇量检索获得,可以明确指导语言模型关注图像中的视觉实体。而soft prompts则由图像描述的CLIP文本表达获得,提供整体的语义内容。为避免模型直接复制hard prompts的实体,论文采用了实体遮蔽策略。 | ||
|
|
||
| 通过在多个数据集上的大量实验,结果显示ViECap不仅在域内图像描述任务上性能强劲,与先前仅用文本训练的方法相当,更重要的是,它展现出了显著的迁移能力,在包含未见域的NoCaps数据集上明显优于其他方法。即使在低资源情况下,ViECap也表现出良好的性能。 | ||
|
|
||
| 也就是说,这篇论文对适配预训练模型到下游生成任务中存在的问题进行了深入分析,并通过实体感知的解码范式增强了模型的迁移性,为零样本域适应的图像描述生成任务提供了有价值的方法和见解。 | ||
|
|
||
| ### 3. 方法 | ||
|
|
||
| 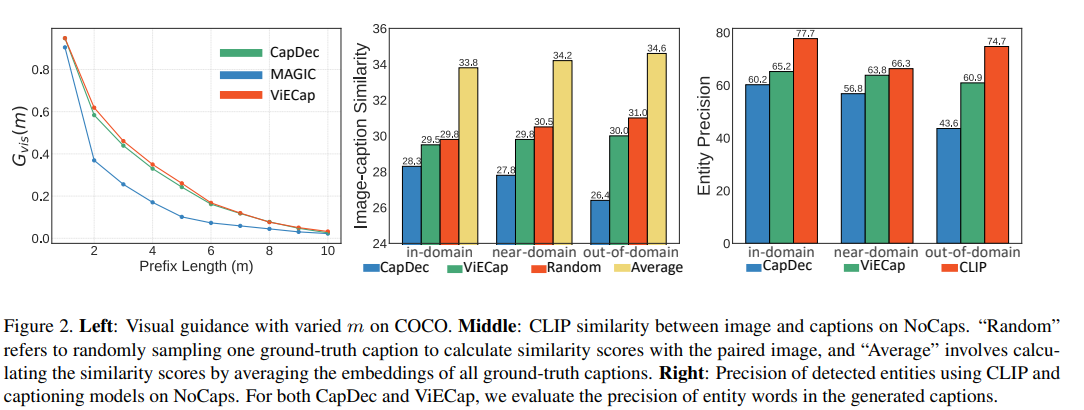 | ||
|
|
||
| #### 3.1 Empirical Observations | ||
|
|
||
| 首先,论文先用Empirical Observations这一节通过实验量化地验证了直接适配预训练视觉语言模型和语言模型到image captioning生成任务中存在的两个问题: | ||
|
|
||
| (1) Modality Bias(模态偏置):该节设计了一个两阶段的解码策略,先用图像描述模型生成部分词汇,然后用语言模型完成剩余的句子生成。通过调整第一个阶段生成的词汇数量,可以观察视觉指导的重要性。结果发现,late-guidance方法(如MAGIC)的视觉指导重要性很低,语言先验知识主导了整个生成过程。 | ||
|
|
||
|  | ||
|
|
||
| (2) Object Hallucination(对象幻象):该节计算了生成描述和对应的图像之间的CLIP相似度。结果发现,在未见域中,early-guidance方法的性能逐渐下降,而ViECap的性能较为稳定。这说明当前方法在迁移到未见域时会产生对象幻象,即生成的描述包含图像中不存在的对象。进一步分析实体检测的精度也支持了这一结论。CapDec从已见域到未见域的实体检测准确率大幅下降(60.2% → 43.6%),而ViECap只有很小的下降(4.3%)。 | ||
|
|
||
| 以上分析证明了适配预训练模型时存在的模态偏置和对象幻象问题,也为后续ViECap的设计提供了支撑。 | ||
|  | ||
|
|
||
| #### 3.2 ViECap | ||
|
|
||
| ViECap是一个融合实体感知hard prompts和soft prompts的图像描述生成框架,可以仅通过文本数据进行训练,并可以零样本推理生成描述。在训练阶段,ViECap从文本数据中提取名词实体构建hard prompts,同时用CLIP对文本编码并通过projector获得soft prompts。这两个提示被拼接起来输入语言模型GPT-2进行训练,而CLIP文本编码器被冻结。为避免语言模型仅依赖hard prompts,还使用了实体遮蔽策略。在推理阶段,ViECap利用CLIP的图像编码器和实体分类器构建与图像相关的hard prompts,再将其与来自projector的soft prompts拼接,输入语言模型生成描述。通过训练阶段的策略,hard prompts具有强大的迁移性,而soft prompts提供整体语义内容,二者结合可以生成高质量的描述。这样,ViECap展现出了从已见域良好的泛化能力到未见域出色的迁移能力。 | ||
|
|
||
| ##### 3.2.1 Entity-aware Transferable Decoding | ||
|
|
||
| Entity-aware Transferable Decoding是ViECap的核心方法,它融合了基于实体的hard prompts和soft prompts来实现可迁移的语言解码。 | ||
|
|
||
| 具体来说,hard prompts由图像中的名词实体构成,这些实体可以捕捉图像中的静态视觉信息,如人、动物和对象等。实体通过开放词汇量的CLIP检索获得,构成对语言模型的强有力指导,使其关注特定的视觉实体。 | ||
|
|
||
| 而soft prompts则来自图像描述的CLIP文本表达,经过一个可学习的projector转换而来。soft prompts提供了跨图像更整体的语义内容,如场景和对象之间的交互等隐式的视觉语言对齐信息。 | ||
|
|
||
| 在训练中,冻结CLIP文本编码器以最大化迁移性,只优化projector和语言模型。在推理时,将图像的CLIP视觉表达直接输入训练好的解码器生成描述。 | ||
|
|
||
| 通过实体hard prompts的明确指导和soft prompts的整体语义补充,该方法实现了可迁移的视觉语言解码,既确保了准确描述显著实体的能力,又提供了丰富的上下文信息,使得最终生成的图像描述连贯性强且准确贴合具体图像。 | ||
|
|
||
| ##### 3.2.2 Zero-shot Inference | ||
|
|
||
| 给定一张测试图像,首先用CLIP图像编码器提取视觉嵌入。然后将其输入训练好的projector得到soft prompts。 | ||
|
|
||
| 对于hard prompts,使用手动模板“A photo of {entity}”构建各个类别的实体描述。计算这些描述与图像嵌入的相似度,选择相似度最高的前M个实体构建hard prompts。 | ||
|
|
||
| 最后将软hard prompts按顺序拼接,输入语言模型生成描述。 | ||
|
|
||
| 这里存在一个训练推理间的结构差异。为弥补这一差距,在训练中采用了两种策略: | ||
|
|
||
| 1) 在文本嵌入中注入噪声,弥合视觉文本间的鸿沟。 | ||
|
|
||
| 2) 设计实体遮蔽机制避免复制粘贴,迫使模型从soft prompts中复原实体。 | ||
|
|
||
| 在未见域中,projector可能过拟合已见域数据,导致soft prompts的效果下降。而基于CLIP的hard prompts继承了CLIP嵌入的强大迁移性。GPT可以灵活地融合软hard prompts进行解码。 | ||
|
|
||
| 总之,零样本推理通过soft prompts提供整体上下文,hard prompts关注特定实体,二者结合可以生成准确的图像描述。 | ||
|
|
||
| 总的来说,ViECap是一个实体感知的图像描述框架,通过对硬soft prompts的融合使用,既考虑了连贯性又确保了准确性,能够生成符合图像的高质量描述,在域间表现出色。 | ||
|
|
||
| ### 4. 实验 | ||
|
|
||
|  | ||
|
|
||
| Table 1展示了在NoCaps验证集上的跨域图像描述结果,模型在COCO训练集上训练,在NoCaps上测试。 | ||
|
|
||
| 从结果可以看出: | ||
|
|
||
| 1. ViECap在未见域(Out)和整体(Overall)上的CIDEr值明显优于其他只用文本训练的方法,如DeCap和CapDec,提升幅度可达39.2和36.3。这说明融合实体hard prompts对描述新颖实体是非常有效的。 | ||
| 2. ViECap甚至超过了一些有监督方法的性能,显示了它对新实体的强大泛化能力。例如在Overall上,ViECap取得66.2的CIDEr,优于有监督方法OSCAR的63.8和ClipCap的65.8。 | ||
| 3. 其他方法从已见域到未见域会经历明显的性能下降,而ViECap在不同域间保持较小的波动,展现了强大的迁移性。 | ||
| 4. 在实际应用中,目标域往往是不确定的,所以Overall结果比较能反映模型的实际效果。从这个角度看,ViECap与有监督方法获得了可比的表现。 | ||
|
|
||
| 也就是说该实验验证了ViECap具有显著的零样本迁移能力,可以准确描述新颖的未见实体和场景,是一种高效可靠的跨域图像描述生成方法。 | ||
|
|
||
|  | ||
|
|
||
| 从Table 3的域内图像描述生成实验结果可以看出,ViECap整体上优于当前其他仅依靠文本进行训练的方法,如基准方法CapDec和MAGIC,在多个数据集和评估指标上均获得了state-of-the-art的表现。这充分证明了ViECap通过融合实体hard prompts和soft prompts的设计,不仅拥有卓越的迁移能力描述新颖概念,同时也具备良好的泛化能力,可以适应已见域的数据分布生成相关连贯的描述。即使是在处理不同文本样式的描述生成任务上,ViECap也展现出了强大的适应力。综上可以看出,ViECap是一个高效的文本训练框架,既确保了准确描述显著实体的能力,又提供了整体语义内容,使得生成的描述富有连贯性且准确贴合具体图像,证明了它在各类场景下的强大表达能力和迁移适应能力。 | ||
|
|
||
|  | ||
|
|
||
| 从具体的例子来看,论文提出的方法也的确有很强的代表性。 | ||
|
|
||
| ### 5. 讨论 | ||
|
|
||
| 这篇论文提出的ViECap方法有以下几点优点: | ||
|
|
||
| 1. 仅依靠文本数据进行训练,大大降低了数据标注的成本,展现了很强的数据效率。 | ||
| 2. 通过实体感知的hard prompts,明确地指导语言模型关注图像中的视觉实体,增强了模型的迁移性,使其可以准确描述新颖的未见概念。 | ||
| 3. soft prompts提供整体语义信息,使得生成的描述连贯自然,内容丰富。 | ||
| 4. 实体遮蔽策略避免模型依赖hard prompts,保证了模型的泛化能力。 | ||
| 5. 在多个数据集上获得了state-of-the-art的性能,验证了方法的有效性。 | ||
|
|
||
| 但是该方法也存在一些缺点: | ||
|
|
||
| 1. 生成的描述样式单一,缺乏多样性。 | ||
| 2. 对低频实体的描述不够准确。 | ||
| 3. 在真实场景的宽域适应性还需进一步验证。 | ||
|
|
||
| 因此未来的一些研究方向包括: | ||
|
|
||
| 1. 在描述样式上进行创新,如生成多样化或可控制的文本。 | ||
| 2. 通过记忆模块增强对长尾实体的建模。 | ||
| 3. 在更多实际应用场景中评估模型的适应性。 | ||
| 4. 探索在其他视觉语言任务中的适用性。 | ||
|
|
||
| 总体来说,这篇论文对适配预训练模型到生成任务的问题给出了新的视角,提出的ViECap方法展现了强大的迁移适应能力,为后续在这个方向的研究奠定了基础。但也还有一些可以改进的空间,需要后续的研究来进一步探索。 | ||
|
|
||
| ### 6. 结论 | ||
|
|
||
| 这篇论文提出的ViECap方法最大的优点在于展现了从已见域到未见域的强大迁移能力。通过实体感知的hard prompts,可以明确地指导语言模型关注图像中的视觉实体,准确描述新颖的未见概念,是当前文本训练方法中泛化性能最优的。同时,soft prompts提供的整体语义信息使生成描述连贯自然。实体遮蔽策略也避免了对hard prompts的依赖,保证了模型的泛化能力。该方法在多个数据集上都获得了state-of-the-art的性能,证明了其有效性。但是,该方法生成的描述样式还不够丰富多样,对长尾实体的建模也较弱。未来的研究可以在描述样式上进行创新,增强对长尾概念的建模,在更多实际场景中验证模型的适应性,并探索该方法在其他视觉语言任务中的扩展。总体上,这篇论文对预训练模型适配的问题给出了宝贵的分析和有效的方法,可为后续研究奠定基础。但也还存在可以改进的空间,需要后续工作进行探索。 |