Releases: zenml-io/zenml
0.7.3
📊 Experiment Tracking Components
PR #530 adds a new stack component to ZenMLs ever-growing list: experiment_trackers allows users to configure your experiment tracking tools with ZenML. Examples of experiment tracking tools are Weights&Biases, mlflow, Neptune, amongst others.
Existing users might be confused, as ZenML has had MLflow and wandb support for a while now without such a component. However, this component allows uses more control over the configuration of MLflow and wandb with the new MLFlowExperimentTracker and
WandbExperimentTracker components. This allows these tools to work in more scenarios than the currently limiting local use-cases.
🔎 XGBoost and LightGBM support
XGBoost and LightGBM are one of the most widely used boosting algorithm libraries out there. This release adds materializers for native objects for each library.
Check out both examples here and PR's #544 and #538 for more details.
📂 Parameterized S3FS support to enable non-AWS S3 storage (minio, ceph)
A big complaint of the S3 Artifact Store integration was that it was hard to parameterize it in a way that it supports non-AWS S3 storage like minio and ceph. The latest release
made this super simple! When you want to register an S3ArtifactStore from the CLI, you can now pass in client_kwargs, config_kwargs or s3_additional_kwargs as a JSON string. For example:
zenml artifact-store register my_s3_store --type=s3 --path=s3://my_bucket \
--client_kwargs='{"endpoint_url": "http://my-s3-endpoint"}'See PR #532 for more details.
🧱 New CLI commands to update stack components
We added functionality to allow users to update stacks that already exist. This shows the basic workflow:
zenml orchestrator register local_orchestrator2 -t local
zenml stack update default -o local_orchestrator2
zenml stack describe default
zenml container-registry register local_registry --type=default --uri=localhost:5000
zenml container-registry update local --uri='somethingelse.com'
zenml container-registry rename local local2
zenml container-registry describe local2
zenml stack rename default new_default
zenml stack update new_default -c local2
zenml stack describe new_default
zenml stack remove-component -cMore details are in the CLI docs.
Users can add new stack components to a pre-existing stack, or they can modify
already-present stack components. They can also rename their stack and individual stack components.
🐛 Seldon Core authentication through ZenML secrets
The Seldon Core Model Deployer stack component was updated in this release to allow the configuration of ZenML secrets with credentials that authenticate Seldon to access the Artifact Store. The Seldon Core integration provides 3 different secret schemas for the 3 flavors of Artifact Store: AWS, GCP, and Azure, but custom secrets can be used as well. For more information on how to use this feature please refer to our Seldon Core deployment example.
Lastly, we had numerous other changes such as ensuring the PyTorch materializer works across all artifact stores
and the Kubeflow Metadata Store can be easily queried locally.
Detailed Changelog
- Fix caching &
mypyerrors by @strickvl in #524 - Switch unit test from local_daemon to multiprocessing by @jwwwb in #508
- Change Pytorch materializer to support remote storage by @safoinme in #525
- Remove TODO from Feature Store
initdocstring by @strickvl in #527 - Fixed typo predicter -> predictor by @MateusGheorghe in #523
- Fix mypy errors by @strickvl in #528
- Replaced old local_* logic by @htahir1 in #531
- capitalize aws username in ECR docs by @wjayesh in #533
- Build docker base images quicker after release by @schustmi in #537
- Allow configuration of s3fs by @schustmi in #532
- Update contributing and fix ci badge to main by @htahir1 in #536
- Added XGboost integration by @htahir1 in #538
- Added fa9r to .github/teams.yml. by @fa9r in #539
- Secret Manager improvements and Seldon Core secret passing by @stefannica in #529
- User management by @schustmi in #500
- Update stack and stack components via the CLI by @strickvl in #497
- Added lightgbm integration by @htahir1 in #544
- Fix the Kubeflow metadata store and other stack management improvements by @stefannica in #542
- Experiment tracker stack components by @htahir1 in #530
New Contributors
- @MateusGheorghe made their first contribution in #523
- @fa9r made their first contribution in #539
Full Changelog: 0.7.2...0.7.3
Blog Post: https://blog.zenml.io/zero-seven-two-three-release/
Contributors
Assets 2
0.7.2
0.7.2 is a minor release which quickly patches some bugs found in the last release to do with Seldon and Mlflow deployment.
This release also features initial versions of two amazing new community-led integrations: HuggingFace and Weights&Biases!

- HuggingFace models are now supported to be passed through ZenML pipelines [see full example] -> Huge shoutout to @Ankur3107 for PR #467.
- You can now track your pipeline runs with Weights&Biases with the new
enable_wandbdecorator [see full example] -> Huge shoutout to @soumik12345 for PR #486.
Continuous model deployment with MLflow has been improved with ZenML 0.7.2. A new MLflow Model Deployer Stack component is now available and needs to be part of your stack to be able to deploy models:
zenml integration install mlflow
zenml model-deployer register mlflow --type=mlflow
zenml stack register local_with_mlflow -m default -a default -o default -d mlflow
zenml stack set local_with_mlflowThe MLflow Model Deployer is yet another addition to the list of Model Deployers available in ZenML. You can read more on deploying models to production with MLflow in our [Continuous Training and Deployment documentation section](https://docs.zenml.io/features/continuous training-and-deployment) and our MLflow deployment example.
What's Changed
- Fix the seldon deployment example by @htahir1 in #511
- Create base deployer and refactor MLflow deployer implementation by @wjayesh in #489
- Add nlp example by @Ankur3107 in #467
- Fix typos by @strickvl in #515
- Bugfix/hypothesis given doesnt work with fixture by @jwwwb in #513
- Bug: fix long Kubernetes labels in Seldon deployments by @stefannica in #514
- Change prediction_uri to prediction_url in MLflow deployer by @stefannica in #516
- Simplify HuggingFace Integration by @AlexejPenner in #517
- Weights & Biases Basic Integration by @htahir1 in #518
New Contributors
- @Ankur3107 made their first contribution to the HuggingFace integration in #467
- @soumik12345 from Weights&Biases also made their first contribution to the wandb integration in #486!
Full Changelog: 0.7.1...0.7.2
Contributors
Assets 2
0.7.1
0.7.1

The release introduces the Seldon Core ZenML integration, featuring the Seldon Core Model Deployer and a Seldon Core standard model deployer step. The Model Deployer is a new type of stack component that enables you to develop continuous model deployment pipelines that train models and continuously deploy them to an external model serving tool, service or platform. You can read more on deploying models to production with Seldon Core in our Continuous Training and Deployment documentation section and our Seldon Core deployment example.
We also see two new integrations with Feast as ZenML's first feature store integration. Feature stores allow data teams to serve data via an offline store and an online low-latency store where data is kept in sync between the two. It also offers a centralized registry where features (and feature schemas) are stored for use within a team or wider organization. ZenML now supports connecting to a Redis-backed Feast feature store as a stack component integration. Check out the full example to see it in action!
0.7.1 also brings an addition to ZenML training library integrations with NeuralProphet. Check out the new example for more details, and the docs for more further detail on all new features!
What's Changed
- Add linting of examples to
pre-commitby @strickvl in #490 - Remove dev-specific entries in
.gitignoreby @strickvl in #488 - Produce periodic mocked data for Segment/Mixpanel by @AlexejPenner in #487
- Abstractions for artifact stores by @bcdurak in #474
- enable and disable cache from runtime config by @AlexejPenner in #492
- Basic Seldon Core Deployment Service by @stefannica in #495
- Parallelise our test suite and make errors more readable by @alex-zenml in #378
- Provision local zenml service by @jwwwb in #496
- bugfix/optional-secrets-manager by @safoinme in #493
- Quick fix for copying folders by @bcdurak in #501
- Pin exact ml-pipelines-sdk version by @schustmi in #506
- Seldon Core model deployer stack component and standard step by @stefannica in #499
- Fix datetime test / bug by @strickvl in #507
- Added NeuralProphet integration by @htahir1 in #504
- Feature Store (Feast with Redis) by @strickvl in #498
Contributors
Assets 2
0.7.0
With ZenML 0.7.0, a lot has been revamped under the hood about how things are stored. Importantly what this means is that ZenML now has system-wide profiles that let you register stacks to share across several of your projects! If you still want to manage your stacks for each project folder individually, profiles still let you do that as well.
Most projects of any complexity will require passwords or tokens to access data and infrastructure, and for this purpose ZenML 0.7.0 introduces the Secrets Manager stack component to seamlessly pass around these values to your steps. Our AWS integration also allows you to use AWS Secrets Manager as a backend to handle all your secret persistence needs.
Finally, in addition to the new AzureML and Sagemaker Step Operators that version 0.6.3 brought, this release also adds the ability to run individual steps on GCP's Vertex AI.
Beyond this, some smaller bugfixes and documentation changes combine to make ZenML 0.7.0 a more pleasant user experience.
What's Changed
- Added quick mention of how to use dockerignore by @AlexejPenner in #468
- Made rich traceback optional with ENV variable by @htahir1 in #472
- Separate stack persistence from repo implementation by @jwwwb in #462
- Adding safoine username to github team by @safoinme in #475
- Fix
zenml stack describebug by @strickvl in #476 - ZenProfiles and centralized ZenML repositories by @stefannica in #471
- Add
examplesfolder to linting script by @strickvl in #482 - Vertex AI integration and numerous other changes by @htahir1 in #477
- Fix profile handing in the Azure ML step operator by @stefannica in #483
- Copy the entire stack configuration into containers by @stefannica in #480
- Improve some things with the Profiles CLI output by @stefannica in #484
- Secrets manager stack component and interface by @AlexejPenner in #470
- Update schedule.py (#485) by @avramdj in #485
New Contributors
Full Changelog: 0.6.3...0.7.0rc
Contributors
Assets 2
0.6.3
0.6.3

With ZenML 0.6.3, you can now run your ZenML steps on Sagemaker and AzureML! It's normal to have certain steps that require specific hardware on which to run model training, for example, and this latest release gives you the power to switch out hardware for individual steps to support this.
We added a new Tensorboard visualisation that you can make use of when using our Kubeflow Pipelines integration. We handle the background processes needed to spin up this interactive web interface that you can use to visualise your model's performance over time.
Behind the scenes we gave our integration testing suite a massive upgrade, fixed a number of smaller bugs and made documentation updates. For a detailed look at what's changed, see below:
What's Changed
- Fix typo by @wjayesh in #432
- Remove tabulate dependency (replaced by rich) by @jwwwb in #436
- Fix potential issue with local integration tests by @schustmi in #428
- Remove support for python 3.6 by @schustmi in #437
- Create clean test repos in separate folders by @michael-zenml in #430
- Copy explicit materializers before modifying, log correct class by @schustmi in #434
- Fix typo in mysql password parameter by @pafpixel in #438
- Pytest-fixture for separate virtual environments for each integration test by @AlexejPenner in #405
- Bugfix/fix failing tests due to comments step by @AlexejPenner in #444
- Added --use-virtualenvs option to allow choosing envs to run by @AlexejPenner in #445
- Log whether a step was cached by @strickvl in #435
- Added basic integration tests for remaining examples by @strickvl in #439
- Improve error message when provisioning local kubeflow resources with a non-local container registry. by @schustmi in #442
- Enable generic step inputs and outputs by @schustmi in #440
- Removed old reference to a step that no longer exists by @AlexejPenner in #452
- Correctly use custom kubernetes context if specified by @schustmi in #451
- Fix CLI stack component describe/list commands by @schustmi in #450
- Ignore type of any tfx proto file by @schustmi in #453
- Another boyscout pr on the gh actions by @AlexejPenner in #455
- Upgrade TFX to 1.6.1 by @jwwwb in #441
- Added ZenFiles to README by @htahir1 in #457
- Upgrade
richfrom 11.0 to 12.0 by @strickvl in #458 - Add Kubeflow tensorboard viz and fix tensorflow file IO for cloud back-ends by @stefannica in #447
- Implementing the
explainsubcommand by @bcdurak in #460 - Implement AzureML and Sagemaker step operators by @schustmi in #456
New Contributors
Contributors
Assets 2
0.6.2

ZenML 0.6.2 brings you the ability to serve models using MLflow deployments as well as an updated CLI interface! For a real continuous deployment cycle, we know that ZenML pipelines should be able to handle everything — from pre-processing to training to serving to monitoring and then potentially re-training and re-serving. The interfaces we created in this release are the foundation on which all of this will build.
We also improved how you interact with ZenML through the CLI. Everything looks so much smarter and readable now with the popular rich library integrated into our dependencies.
Smaller changes that you'll notice include updates to our cloud integrations and bug fixes for Windows users. For a detailed look at what's changed, see below.
What's Changed
- Updated notebook for quickstart by @htahir1 in #398
- Update tensorflow base image by @schustmi in #396
- Add cloud specific deployment guide + refactoring by @wjayesh in #400
- add cloud sub page to toc.md by @wjayesh in #401
- fix tab indent by @wjayesh in #402
- Bugfix for workflows failing due to modules not being found by @bcdurak in #390
- Improve github workflows by @schustmi in #406
- Add plausible script to docs.zenml.io pages by @alex-zenml in #414
- Add orchestrator and ECR docs by @wjayesh in #413
- Richify the CLI by @alex-zenml in #392
- Allow specification of required integrations for a pipeline by @schustmi in #408
- Update quickstart in docs to conform to examples by @htahir1 in #410
- Updated PR template with some more details by @htahir1 in #411
- Bugfix on the CLI to work without a git installation by @bcdurak in #412
- Added Ayush's Handle by @ayush714 in #417
- Adding an info message on Windows if there is no application associated to .sh files by @bcdurak in #419
- Catch
matplotlibcrash when running IPython in terminal by @strickvl in #416 - Automatically activate integrations when unable to find stack component by @schustmi in #420
- Fix some code inspections by @halvgaard in #422
- Prepare integration tests on kubeflow by @schustmi in #423
- Add concepts back into glossary by @strickvl in #425
- Make guide easier to follow by @wjayesh in #427
- Fix httplib to 0.19 and pyparsing to 2.4 by @jwwwb in #426
- Wrap context serialization in try blocks by @jwwwb in #397
- Track stack configuration when registering and running a pipeline by @schustmi in #429
- MLflow deployment integration by @stefannica in #415
Contributors
Assets 2
0.6.1
0.6.1
ZenML 0.6.1 is out and it's all about the cloud ☁️! We have improved AWS integration and a brand-new Azure integration! Run your pipelines on AWS and Azure now and let us know how it went on our Slack. To learn more, check out the new documentation page we just included to guide you in deploying your pipelines to AWS, GCP and/or Azure.
Smaller changes that you'll notice include much-awaited updates and fixes, including the first iterations of scheduling pipelines and tracking more reproducibility-relevant data in the metadata store.
For a detailed look at what's changed, see below.
What's Changed
- Update 0.6.0 release notes by @alex-zenml in #362
- Update 0.6.0 release notes (#362) by @alex-zenml in #364
- Fix cuda-dev base container image by @stefannica in #361
- [0.6.0] Fix cuda-dev base container image by @stefannica in #367
- Mark ZenML as typed package by @schustmi in #360
- Improve error message if ZenML repo is missing inside kubeflow container entrypoint by @schustmi in #363
- Spell whylogs and WhyLabs correctly in our docs by @stefannica in #369
- Feature/add readme for mkdocs by @AlexejPenner in #372
- Cleaning up the assets pushed by gitbook automatically by @bcdurak in #371
- Turn codecov off for patch updates by @htahir1 in #376
- Minor changes and fixes by @schustmi in #365
- Only include python files when building local docs by @schustmi in #377
- Prevent access to repo during step execution by @schustmi in #370
- Removed duplicated Section within docs by @AlexejPenner in #379
- Fixing the materializer registry to spot sub-classes of defined types by @bcdurak in #368
- Computing hash of step and materializer works in notebooks by @htahir1 in #375
- Sort requirements to improve docker build caching by @schustmi in #383
- Make sure the s3 artifact store is registered when the integration is activated by @schustmi in #382
- Make MLflow integration work with kubeflow and scheduled pipelines by @stefannica in #374
- Reset _has_been_called to False ahead of pipeline.connect by @AlexejPenner in #385
- Fix local airflow example by @schustmi in #366
- Improve and extend base materializer error messages by @schustmi in #380
- Windows CI issue by @schustmi in #389
- Add the ability to attach custom properties to the Metadata Store by @bcdurak in #355
- Handle case when return values do not match output by @AlexejPenner in #386
- Quickstart code in docs fixed by @AlexejPenner in #387
- Fix mlflow tracking example by @stefannica in #393
- Implement azure artifact store and fileio plugin by @schustmi in #388
- Create todo issues with separate issue type by @schustmi in #394
- Log that steps are cached while running pipeline by @alex-zenml in #381
- Schedule added to context for all orchestrators by @AlexejPenner in #391
- Fix lineage and statistics examples by @stefannica in #395
Full Changelog: 0.6.0...0.6.1
Contributors
Assets 2
0.6.0
ZenML 0.6.0 is out now. We've made some big changes under the hood, but our biggest public-facing addition is our new integration to support all your data logging needs: whylogs. Our core architecture was thoroughly reworked and is now in a much better place to support our ongoing development needs.
Smaller changes that you'll notice include extensive documentation additions, updates and fixes. For a detailed look at what's changed, see below.
📊 Whylogs logging
Whylogs is an open source library that analyzes your data and creates statistical summaries called whylogs profiles. Whylogs profiles can be visualized locally or uploaded to the WhyLabs platform where more comprehensive analysis can be carried out.
ZenML integrates seamlessly with Whylogs and WhyLabs. This example shows how easy it is to enhance steps in an existing ML pipeline with Whylogs profiling features. Changes to the user code are minimal while ZenML takes care of all aspects related to Whylogs session initialization, profile serialization, versioning and persistence and even uploading generated profiles to Whylabs.
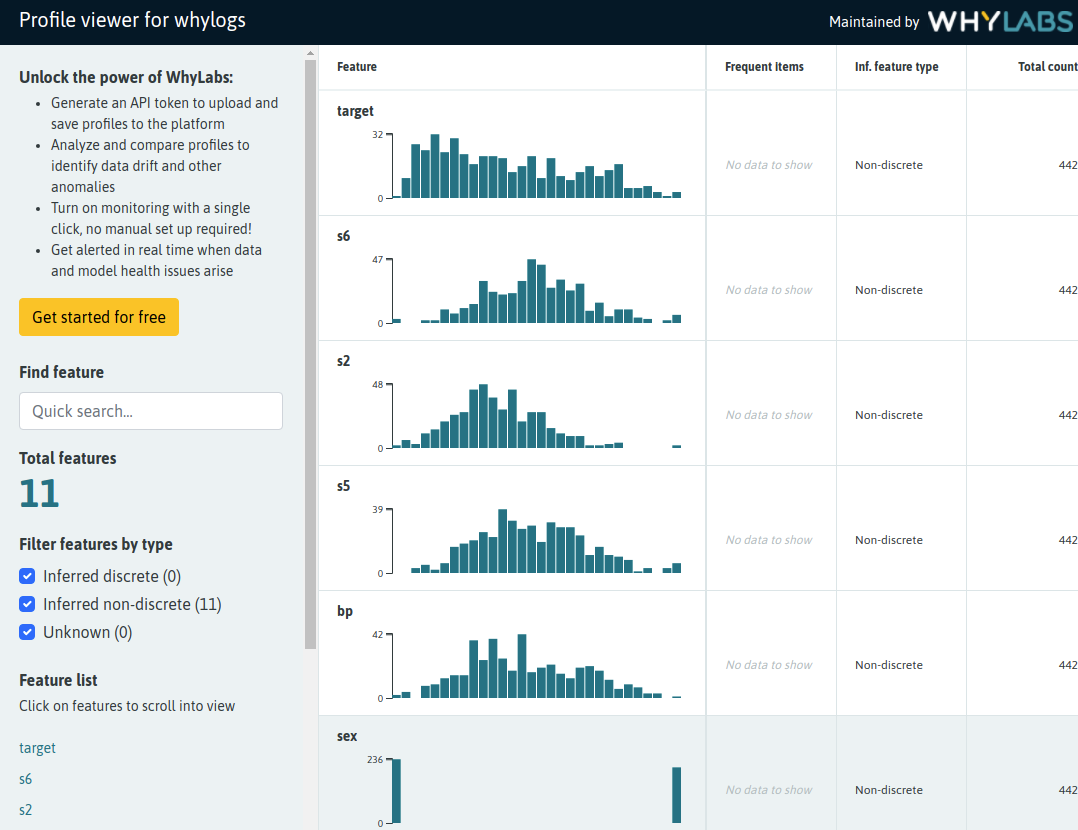
With our WhylogsVisualizer, as described in the associated example notes, you can visualize Whylogs profiles generated as part of a pipeline.
⛩ New Core Architecture
We implemented some fundamental changes to the core architecture to solve some of the issues we previously had and provide a more extensible design to support quicker implementations of different stack components and integrations. The main change was to refactor the Repository, Stack and StackComponent architectures. These changes had a pretty wide impact so involved changes in many files throughout the codebase, especially in the CLI which makes calls to all these pieces.
We've already seen how it helps us move faster in building integrations and we hope it helps making contributions as pain-free as possible!
🗒 Documentation and Example Updates
As the codebase and functionality of ZenML grows, we always want to make sure our documentation is clear, up-to-date and easy to use. We made a number of changes in this release that will improve your experience in this regard:
- added a number of new explainers on key ZenML concepts and how to use them in your code, notably on how to create a custom materializer and how to fetch historic pipeline runs using the
StepContext - fixed a number of typos and broken links
- added versioning to our API documentation so you can choose to view the reference appropriate to the version that you're using. We now use
mkdocsfor this so you'll notice a slight visual refresh as well. - added new examples highlighting specific use cases and integrations:
➕ Other updates, additions and fixes
As with most releases, we made a number of small but significant fixes and additions. The most import of these were that you can now access the metadata store via the step context. This enables a number of new possible workflows and pipeline patterns and we're really excited to have this in the release.
We added in a markdown parser for the zenml example info … command, so now when you want to use our CLI to learn more about specific examples you will see beautifully parsed text and not markdown markup.
We improved a few of our error messages, too, like for when the return type of a step function doesn’t match the expected type, or if step is called twice. We hope this makes ZenML just that little bit easier to use.
New Contributors
- @bhattbhuwan13 made their first contribution in #317
- @wjayesh made their first contribution in #324
[Full Changelog: https://github.com/zenml-io/zenml/compare/0.5.7...0.6.0]
Contributors
Assets 2
0.5.7
0.5.7
ZenML 0.5.7 is here 💯 and it brings not one, but 🔥TWO🔥 brand new integrations 🚀! ZenML now support MLFlow for tracking pipelines as experiments and Evidently for detecting drift in your ML pipelines in production!
New Features
- Introducing the MLFLow Tracking Integration, a first step towards our complete MLFlow Integration as described in the #115 poll. Full example found here.

- Introducing the Evidently integration. Use the standard Evidently drift detection step to calculate drift automatically in your pipeline. Full example found here.

Bugfixes
- Prevent KFP install timeouts during
stack upby @stefannica in #299 - Prevent naming parameters same name as inputs/outputs to prevent kwargs-errors by @bcdurak in #300
What's Changed
- Force pull overwrites local examples without user confirmation by @AlexejPenner in #278
- Updated README with latest features by @htahir1 in #280
- Integration test the examples within ci pipeline by @AlexejPenner in #282
- Add exception for missing system requirements by @kamalesh0406 in #281
- Examples are automatically pulled if not present before any example command is run by @AlexejPenner in #279
- Add pipeline error for passing the same step object twice by @kamalesh0406 in #283
- Create pytest fixture to use a temporary zenml repo in tests by @htahir1 in #287
- Additional example run implementations for standard interfaces, functional and class based api by @AlexejPenner in #286
- Make pull_request.yaml actually use os.runner instead of ubuntu by @htahir1 in #288
- In pytest return to previous workdir before tearing down tmp_dir fixture by @AlexejPenner in #289
- Don't raise an exception during integration installation if system requirement is not installed by @schustmi in #291
- Update starting page for the API docs by @alex-zenml in #294
- Add
stack upfailure prompts by @alex-zenml in #290 - Spelling fixes by @alex-zenml in #295
- Remove instructions to git init from docs by @bcdurak in #293
- Fix the
stack upandorchestrator upfailure prompts by @stefannica in #297 - Prevent KFP install timeouts during
stack upby @stefannica in #299 - Add stefannica to list of internal github users by @stefannica in #303
- Improve KFP UI daemon error messages by @schustmi in #292
- Replaced old diagrams with new ones in the docs by @AlexejPenner in #306
- Fix broken links & text formatting in docs by @alex-zenml in #302
- Run KFP container as local user/group if local by @stefannica in #304
- Add james to github team by @jwwwb in #308
- Implement integration of mlflow tracking by @AlexejPenner in #301
- Bugfix integration tests on windows by @jwwwb in #296
- Prevent naming parameters same name as inputs/outputs to prevent kwargs-errors by @bcdurak in #300
- Add tests for
fileioby @alex-zenml in #298 - Evidently integration (standard steps and example) by @alex-zenml in #307
- Implemented evidently integration by @stefannica in #310
- Make mlflow example faster by @AlexejPenner in #312
New Contributors
- @kamalesh0406 made their first contribution in #281
- @stefannica made their first contribution in #297
- @jwwwb made their first contribution in #308
Contributors
Assets 2
0.5.6
) * (
( /( ( ` )\ )
)\()) ( )\))( (()/(
((_)\ ))\ ( ((_)()\ /(_))
_((_) /((_) )\ ) (_()((_) (_))
|_ / (_)) _(_/( | \/ | | |
/ / / -_) | ' \)) | |\/| | | |__
/___| \___| |_||_| |_| |_| |____|
This release fixes some known bugs from previous releases and especially 0.5.5. Therefore, upgrading to 0.5.6 is a breaking change. You must do the following in order to proceed with this version:
cd zenml_enabled_repo
rm -rf .zen/
And then start again with ZenML init:
pip install --upgrade zenml
zenml init
New Features
- Added
zenml example run [EXAMPLE_RUN_NAME]feature: The ability to run an example with one command. In order to run this, dozenml example pullfirst and see all examples available by runningzenml example list. - Added ability to specify a
.dockerignorefile before running pipelines on Kubeflow. - Kubeflow Orchestrator is now leaner and faster.
- Added the
describecommand group to the CLI for groupsstack,orchestrator,artifact-store, andmetadata-store. E.g.zenml stack describe
Bug fixes and minor improvements
- Adding
StepContextto a branch now invalidates caching by default. Disable explicitly withenable_cache=True. - Docs updated to reflect minor changes in CLI commands.
- CLI
listcommands now mentions active component. Tryzenml stack listto check this out. zenml versionnow has cooler art.
What's Changed
- Delete blog reference from release notes by @alex-zenml in #228
- Docs updates by @alex-zenml in #229
- Update kubeflow guide by @schustmi in #230
- Updated quickstart to reflect newest zenml version by @alexej-zenml in #231
- Add KFP GCP example readme by @schustmi in #233
- Baris/update docs with class api by @bcdurak in #232
- fixing a small typo [ci skip] by @bcdurak in #236
- Hamza/docs last min updates by @htahir1 in #234
- fix broken links by @alex-zenml in #237
- added one more page for standardized artifacts [ci skip] by @bcdurak in #238
- Unified use of cli_utils.print_table for all table format cli printouts by @AlexejPenner in #240
- Remove unused tfx kubeflow code by @schustmi in #239
- Relaxed typing requirements for cli_utils.print_table by @AlexejPenner in #241
- Pass input artifact types to kubeflow container entrypoint by @schustmi in #242
- Catch duplicate run name error and throw custom exception by @schustmi in #243
- Improved logs by @htahir1 in #244
- CLI active component highlighting by @alex-zenml in #245
- Baris/eng 244 clean up by @bcdurak in #246
- CLI describe command by @alex-zenml in #248
- Alexej/eng 35 run examples from cli by @AlexejPenner in #253
- CLI argument and option flag consistency improvements by @alex-zenml in #250
- Invalidate caching when a step requires a step context by @schustmi in #252
- Implement better error messages for custom step output artifact types by @schustmi in #254
- Small improvements by @schustmi in #251
- Kubeflow dockerignore by @schustmi in #249
- Rename container registry folder to be consistent with the other stack components by @schustmi in #257
- Update todo script by @schustmi in #256
- Update docs following CLI change by @alex-zenml in #255
- Bump mypy version by @schustmi in #258
- Kubeflow Windows daemon alternative by @schustmi in #259
- Run pre commit in local environment by @schustmi in #260
- Hamza/eng 269 move beam out by @htahir1 in #262
- Update docs by @alex-zenml in #261
- Hamza/update readme with contribitions by @htahir1 in #271
- Hamza/eng 256 backoff analytics by @htahir1 in #270
- Add spellcheck by @alex-zenml in #264
- Using the pipeline run name to explicitly access when explaining the … by @AlexejPenner in #263
- Import user main module in kubeflow entrypoint to make sure all components are registered by @schustmi in #273
- Fix cli version command by @schustmi in #272
- User is informed of version mismatch and example pull defaults to cod… by @AlexejPenner in #274
- Hamza/eng 274 telemetry by @htahir1 in #275
- Update docs with right commands and events by @htahir1 in #276
- Fixed type annotation for some python versions by @AlexejPenner in #277
Full Changelog: 0.5.5...0.5.6