Flux.1, developed by Black Forest Labs and created by the original team behind Stable Diffusion, is a DiTs model featuring three variants: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell], all equipped with 12 billion parameters.
Deploying Flux.1 in real-time presents several challenges:
-
High Latency: Generating a 2048px image using the schnell variant with 4 sampling steps on a single A100 GPU takes approximately 10 seconds. This latency is significantly higher for the dev and pro versions, which require 30 to 50 steps.
-
VAE OOM: The VAE component experiences Out Of Memory (OOM) issues when attempting to generate images larger than 2048px on an A100 GPU with 80GB VRAM, despite the DiTs backbone's capability to handle higher resolutions.
To address these challenges, xDiT employs a hybrid sequence parallel USP, PipeFusion and VAE Parallel to scale Flux.1 inference across multiple GPUs. Since Flux.1 does not utilize Classifier-Free Guidance (CFG), it is not compatible with cfg parallel.
We conducted performance benchmarking using FLUX.1 [dev] with 28 diffusion steps.
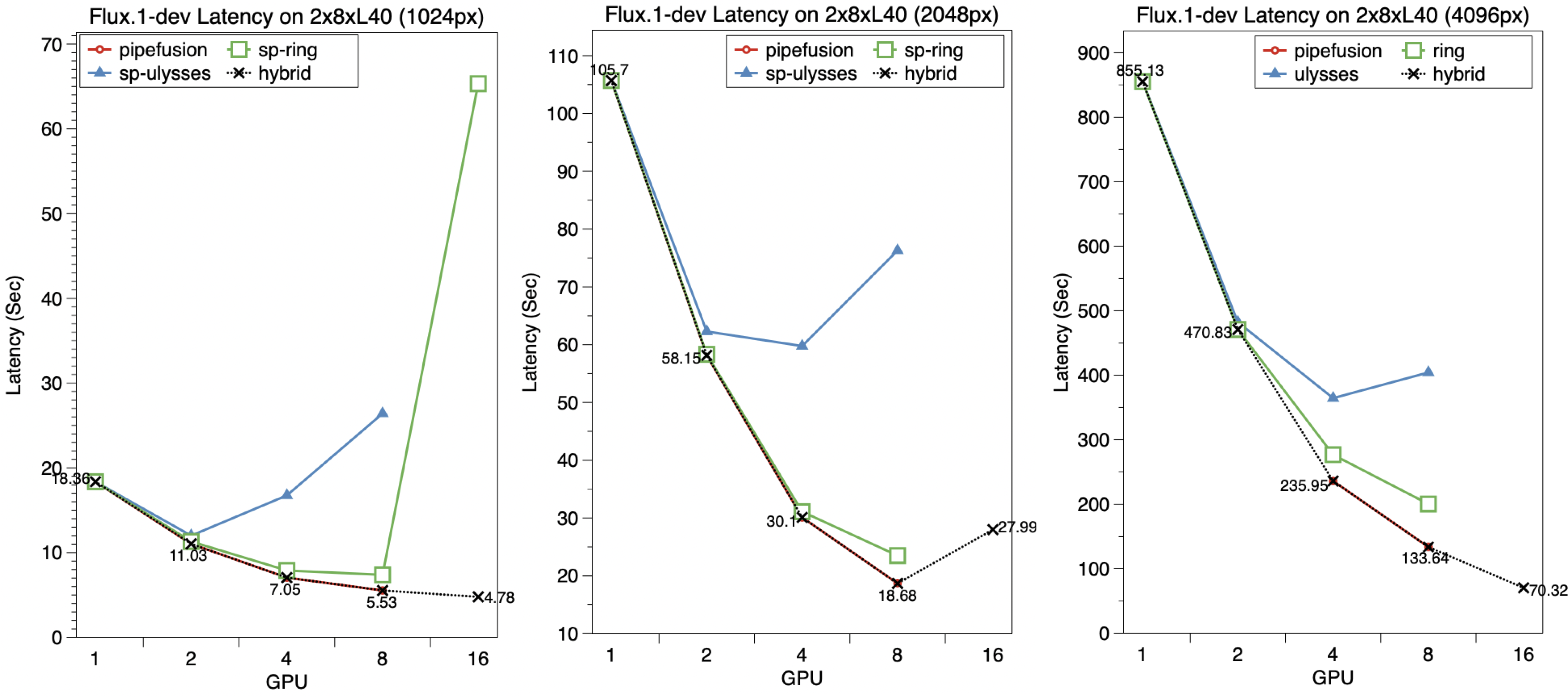
The following figure shows the scalability of Flux.1 on two 8xL40 Nodes, 16xL40 GPUs in total. Althogh cfg parallel is not available, We can still achieve enhanced scalability by using PipeFusion as a method for parallel between nodes. For the 1024px task, hybrid parallel on 16xL40 is 1.16x lower than on 8xL40, where the best configuration is ulysses=4 and pipefusion=4. For the 4096px task, hybrid parallel still benefits on 16 L40s, 1.9x lower than 8 GPUs, where the configuration is ulysses=2, ring=2, and pipefusion=4. The performance improvement dose not achieved with 16 GPUs 2048px tasks.
The following figure demonstrates the scalability of Flux.1 on 8xA100 GPUs. For both the 1024px and the 2048px image generation tasks, SP-Ulysses exhibits the lowest latency among the single parallel methods. The optimal hybrid strategy also are SP-Ulysses in this case.
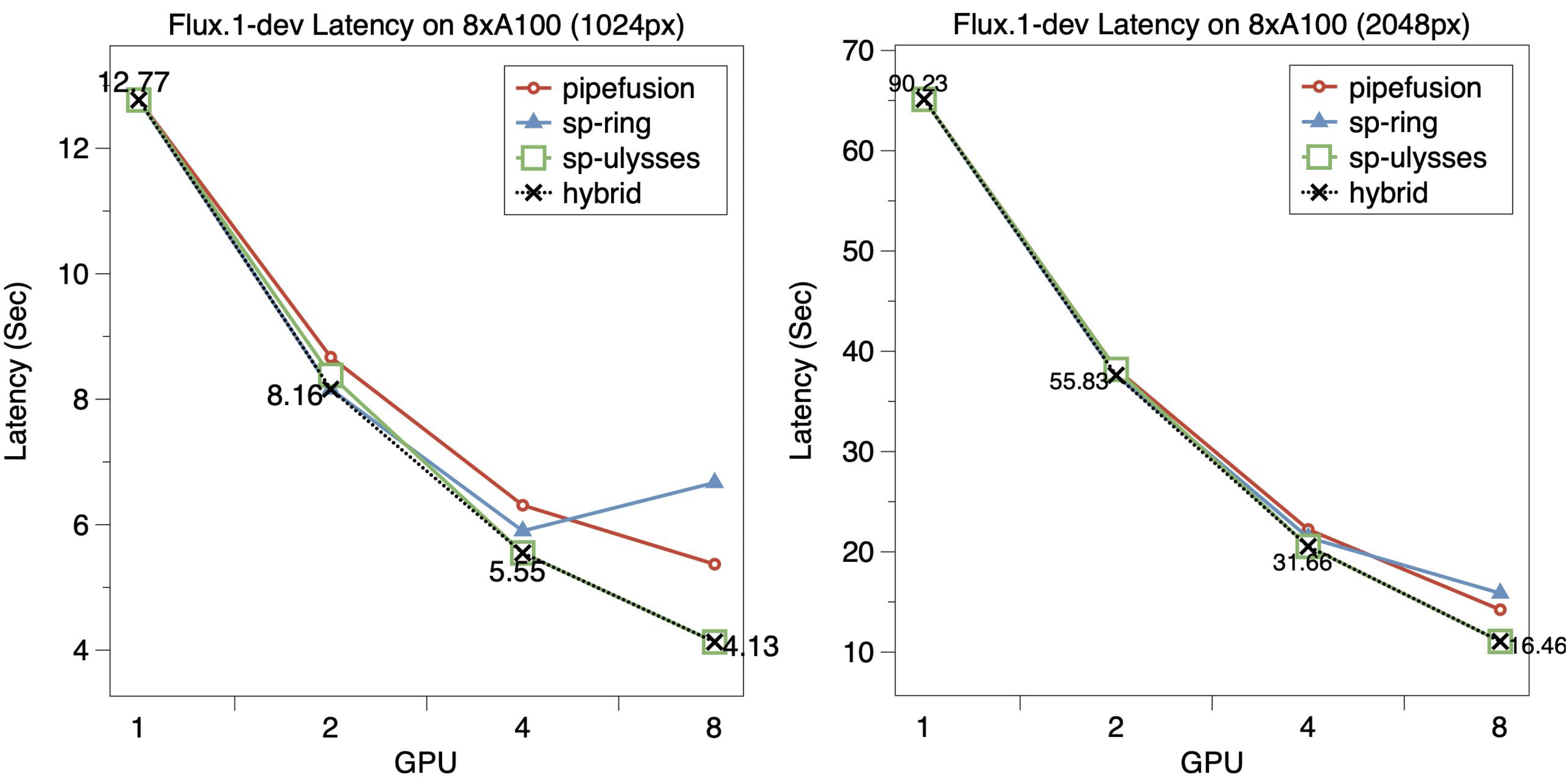
Note that the latency shown in the above figure does not yet include the use of torch.compile, which would provide further performance improvements.
We conducted performance benchmarking using FLUX.1 [schnell] with 4 steps. Since the step number is very small, we do not apply PipeFusion.
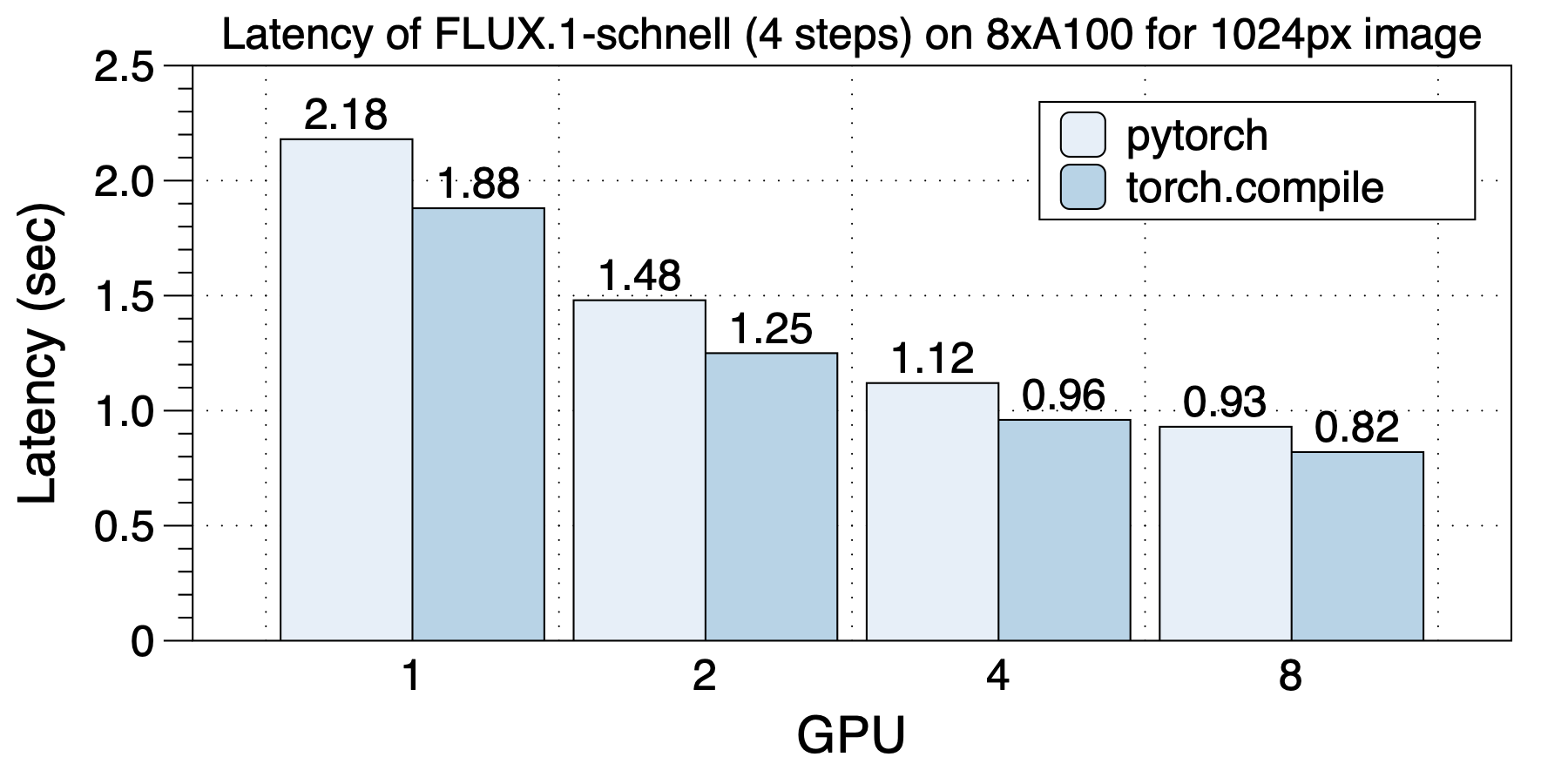
On a machine with 8xA100 (80GB) GPUs interconnected via NVLink, generating a 1024px image, the optimal strategy with USP is to apply ulysses_degree=#gpu. After using torch.compile, the generation of a 1024px image takes only 0.82 seconds!
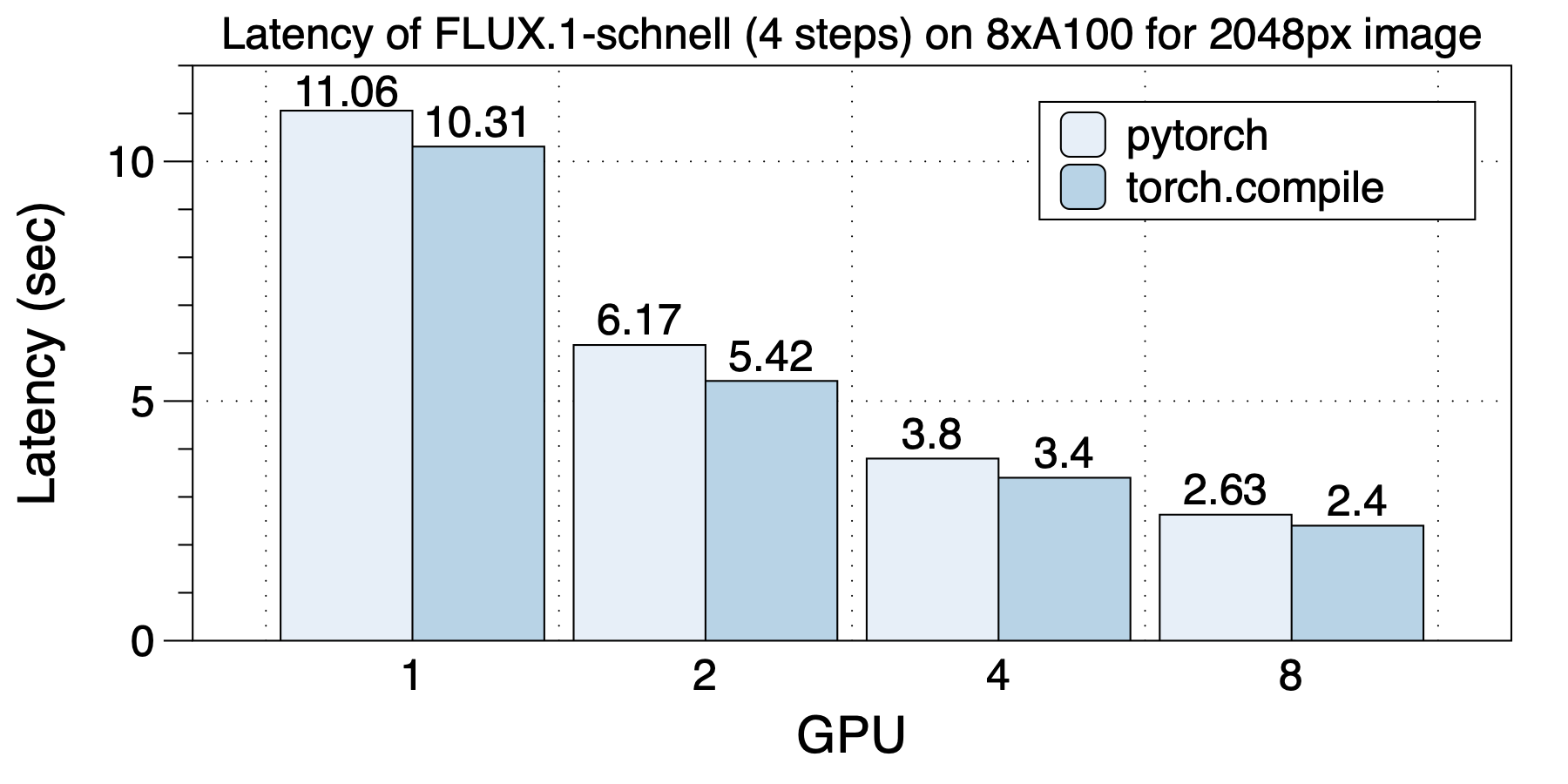
On the same 8xA100 (80GB) NVLink-interconnected machine, generating a 2048px image, after using torch.compile, the generation of a 2048px image takes only 2.4 seconds!
On a machine with 8xL40 GPUs interconnected via PCIe Gen4, even with a 4-card setup using xDiT, there is significant acceleration. Generating a 1024px image with ulysses_degree=2 and ring_degree=2 results in lower latency compared to using Ulysses or ring alone, with a generation time of 1.41 seconds. Using 8xL40 actually slows down due to the need for QPI communication.
We anticipate that using PipeFusion will enhance the scalability of 8-card setups.
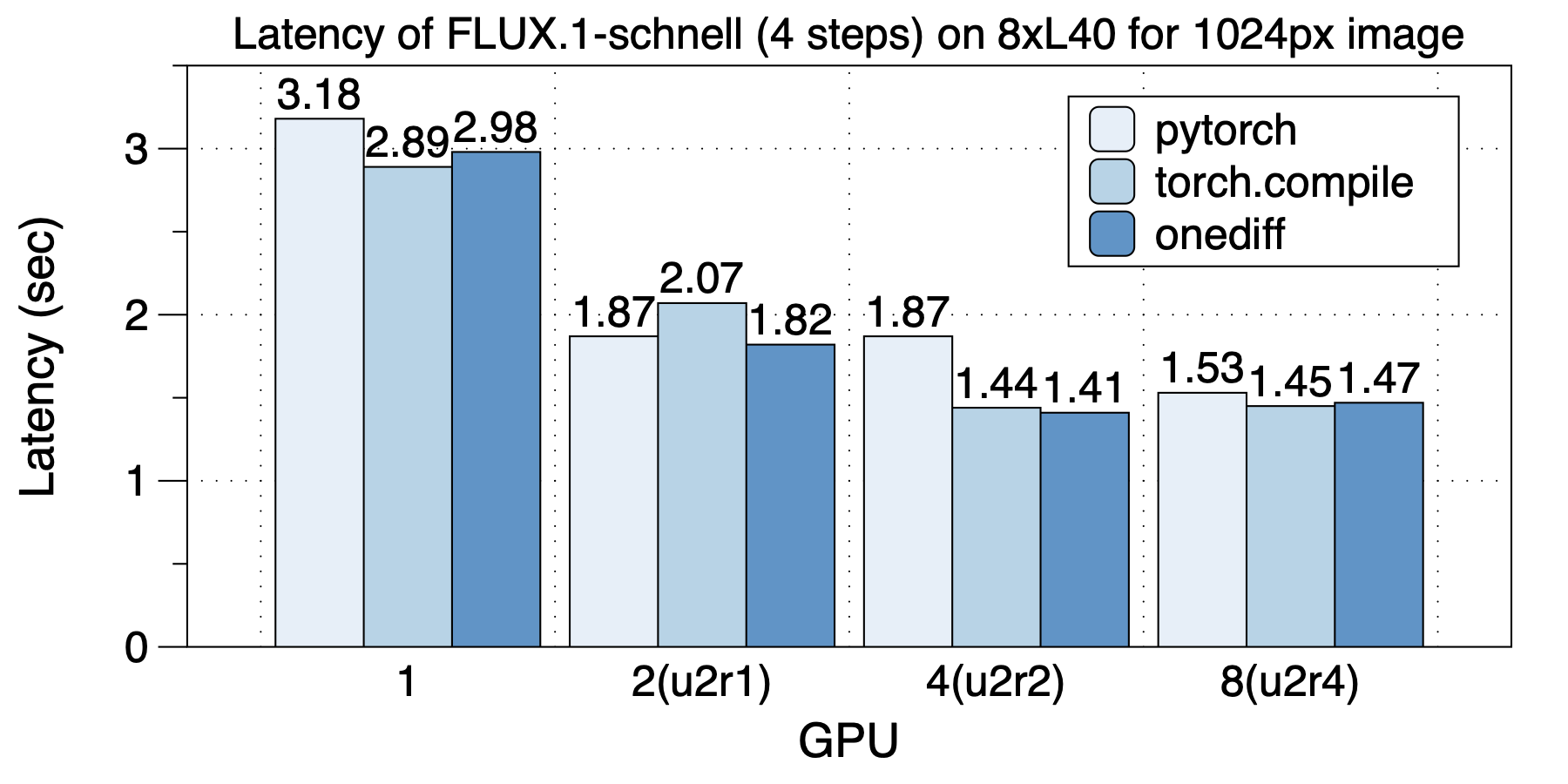
We compared the performance of torch.compile and onediff on 1024px image generation tasks. On 1 and 8 GPUs, torch.compile performs slightly better, while on 2 and 4 GPUs, onediff performs slightly better.
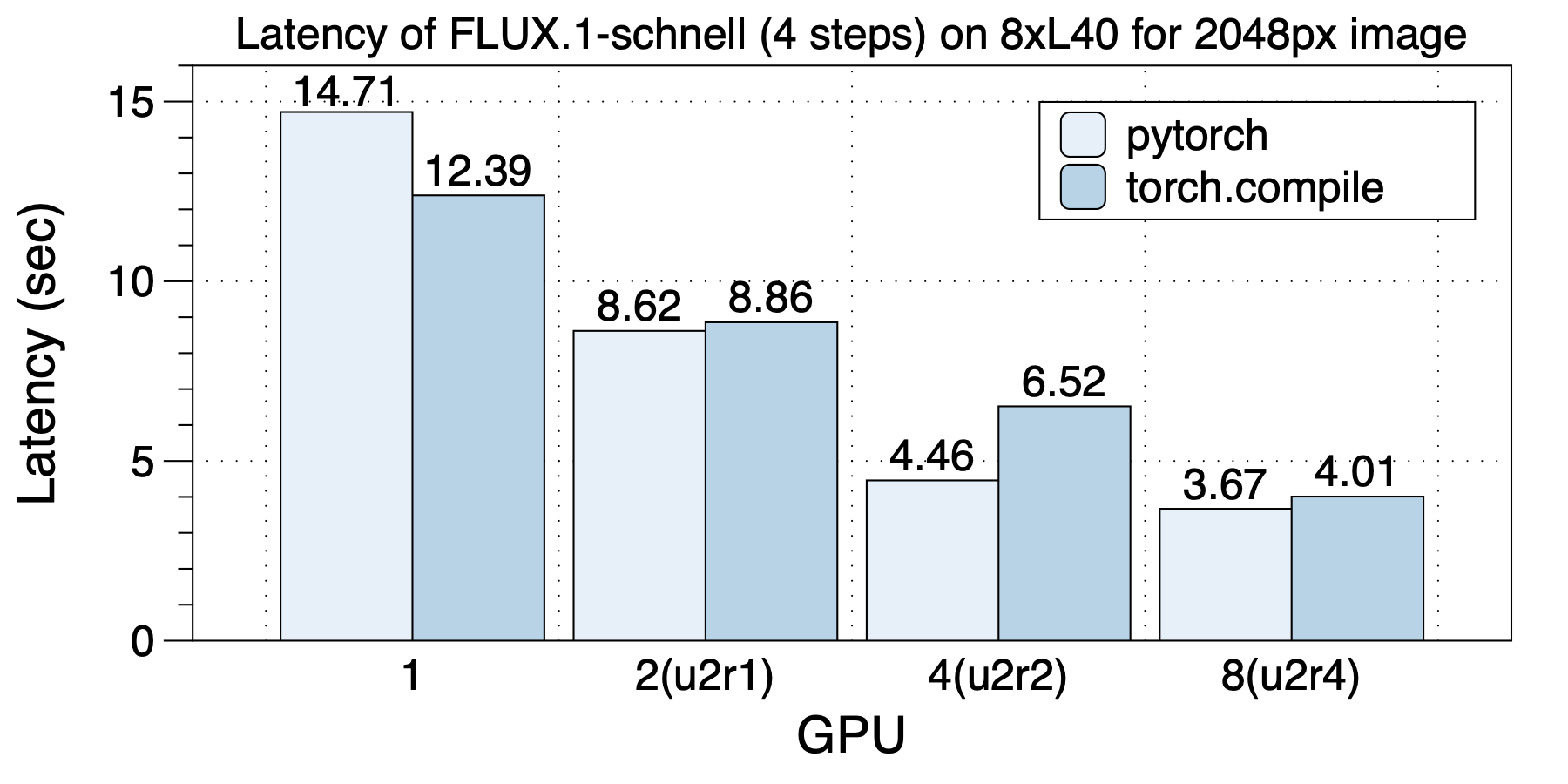
The performance of generating a 2048px image on 8xL40 GPUs is shown below. Due to the increased ratio of computation to communication, unlike the 1024px image generation tasks, using 8 GPUs results in lower latency compared to 4 cards, with the fastest image generation time reaching 3.67 seconds.
On an A100 GPU, using Flux.1 on a single card for resolutions above 2048px leads to an Out Of Memory (OOM) error. This is due to the increased memory requirements for activations, along with memory spikes caused by convolution operators, both of which collectively contribute to the issue.
By leveraging Parallel VAE, xDiT is able to demonstrate its capability for generating images at higher resolutions, enabling us to produce images with even greater detail and clarity. Applying --use_parallel_vae in the runing script.
prompt是"A hyperrealistic portrait of a weathered sailor in his 60s, with deep-set blue eyes, a salt-and-pepper beard, and sun-weathered skin. He’s wearing a faded blue captain’s hat and a thick wool sweater. The background shows a misty harbor at dawn, with fishing boats barely visible in the distance."
The quality of image generation at 2048px, 3072px, and 4096px resolutions is as follows. It is evident that the quality of the 4096px generated images is significantly lower.
