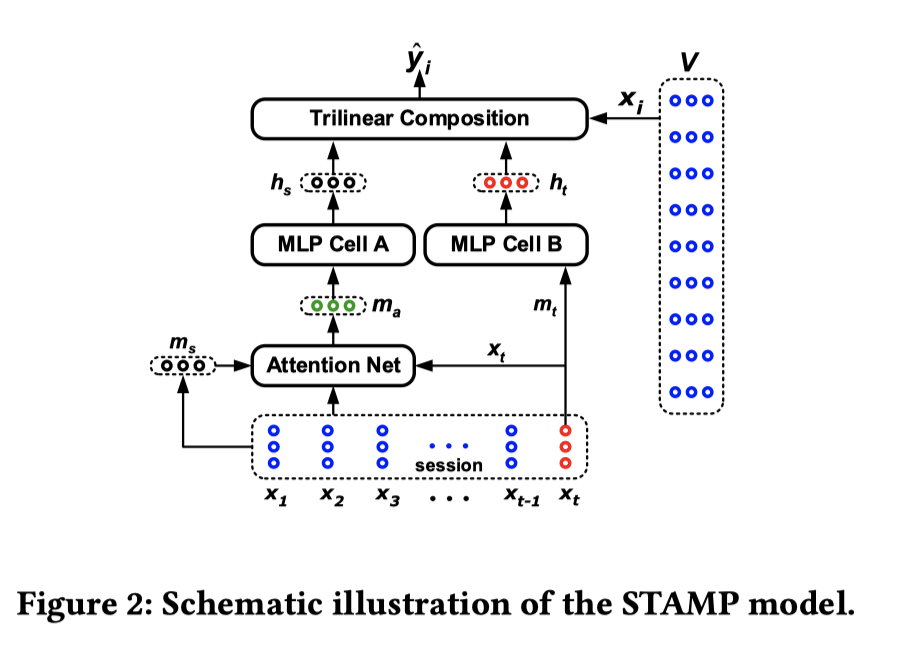
STAMP: Short-Term Attention/Memory Priority Model for Session-based Recommendation
创新:结合长期记忆(序列兴趣)和短期记忆(当前兴趣)
原文笔记:https://mp.weixin.qq.com/s/TXOSQAkwky1d27PciKjqtQ
采用Diginetica数据集进行测试,将其处理为用户序列。数据集的处理见utils文件,主要分为:
- 读取数据(可以取部分数据进行测试);
- 过滤掉session长度为1的样本;
- 过滤掉包含某物品(出现次数小于5)的样本;
- 对特征
itemId进行LabelEncoder,将其转化为0, 1,...范围; - 按照
evetdate、sessionId排序; - 按照
eventdate划分训练集、验证集、测试集; - 生成序列【无负样本】,生成新的数据,格式为
hist, label,因此需要使用tf.keras.preprocessing.sequence.pad_sequences方法进行填充/切割,此外,由于序列中只有一个特征item_id,经过填充/切割后,维度会缺失,所以需要进行增添维度; - 生成一个物品池
item pooling:物品池按序号排序; - 得到
feature_columns:无密集数据,稀疏数据为item_id; - 生成用户行为列表,方便后续序列Embedding的提取,在此处,即
item_id; - 最后返回
feature_columns, behavior_list, (train_X, train_y), (val_X, val_y), (test_X, test_y);
class STAMP(tf.keras.Model):
def __init__(self, feature_columns, behavior_feature_list, item_pooling, maxlen=40, activation='tanh', embed_reg=1e-4):
"""
STAMP
:param feature_columns: A list. dense_feature_columns + sparse_feature_columns
:param behavior_feature_list: A list. the list of behavior feature names
:param item_pooling: A Ndarray or Tensor, shape=(m, n),
m is the number of items, and n is the number of behavior feature. The item pooling.
:param activation: A String. The activation of FFN.
:param maxlen: A scalar. Maximum sequence length.
:param embed_reg: A scalar. The regularizer of embedding.
"""-
file:Amazon Electronic文件;
-
maxlen:最大序列长度,
40; -
embed_dim:Embedding维度,
100; -
K:评价指标的@K,
20; -
learning_rate:学习率,
0.005; -
batch_size:
128; -
epoch:
30;
采用Diginetica数据集数据,最终测试集的结果为: