主要介绍数据库的索引,及其实现,平衡多叉树
想象一下,假设db没有任何数据结构驻留在内存,其一切存储都放在disk,那么想找到一张表的一个行,就必须把表的所有页取到memory,逐个比较各行. 因此我们必须放置一些特定的数据结构在内存中,方便快速查找(但不是缓存)(也不总是在内存中)
对于一张表结构,它自身就记录自己在磁盘上的位置和大小,我们可以快速找到它,但是它包含很多页,我们无法确定某一行在哪一页,只能扫描全表.
索引完成了这样一个功能, 快速找到某一列的值所在的行的在磁盘上的页(os虚拟页,实际在磁盘); 注意,无法找到在那一页的哪一个位置,最终读到内存页后还是扫描整个页,因此文档也指出了,对于小表,加不加索引意义不大,对于要查出绝大部分数据的大表,也不要用索引,不如直接全表扫描
mysql 官方文档: mysql-indexes ,innodb-index-types
所谓索引(index),就是给定一个键,快速返回其在磁盘上的存储页(索引本身是一个键值存储数据结构),然后再根据这个位置磁盘的磁头快速旋转到对应扇区(一个扇区512B,但InnoDB的页16KB),读取一整块数据,通过DMA方式从磁盘缓冲区copy到内核缓冲区,然后中断,对应db进程被唤醒,read到用户缓冲区,遍历整页的数据,找到record(实际上页16KB,一条record如果1KB,就有16行,最差比较16次,其实是不慢的),通过tcp本机通信发送给client.
你可以将其理解为一个map,其键是某一列的取值,其值是对应页所在磁盘的位置.(索引树本身是要持久化在磁盘的,一个结点一页)
其实这更像是搜索引擎领域中的倒排索引(反向索引),给定关键词,返回其所在页;正向索引则是像普通目录一样,给定页,返回其关键词.
事实上,数据库的索引常见的实现算法就是hash和b/b+树,其本身就是一个存储型数据结构,可作为in-memory cache/db,当设置特殊的kv时,便可视作索引
hash分为静态hash和动态hash(依据其是否在runtime时会有分裂桶(增加桶数)的操作),redis作为一个in-memory cache/db,其dict结构就是用的动态哈希算法中的可拓展哈希
hash和b/b+树的各自特点:
-
hash表是无序的,在使用==时很快,对于不等号,有点无能为力
-
b/b+树是有序数据结构,在不等号时很快,但本质还是搜索树,判断相等要多分遍历,但也不慢
实际上索引的树的结点都需要持久化放在磁盘,并且一般来说每个结点一个页
高度为 3 的 B+ 树就能够存储千万级别的数据: 比如高度为2的树,满载时根节点有16KB/14B =1170个指针,这里14是指主键8B,指针6B,由于一条记录1KB,则一页只能存放16条记录,则总共:1170*16 = 18720 条记录; 高度为3时:1170*1170*16*21902400 条记录
ALTER TABLE students
ADD INDEX idx_name_score (name,score);这一段sql就为表students,添加了名为idx_name_score的索引,它是针对列name和score的索引.
我们常称为: 对列name,score创建索引
显然,它将列的值作为key,行的磁盘地址作为value,当key越不同时,冲突越少,效率越高. db会默认为主键创建索引.
对表的增删查改,显然也要及时更新索引,因此这是一个缺点,对于hash表和b/b+树,都可能触发整个数据结构的整形(hash是桶的分裂,b/b+树是平衡化),会拖慢速度,但没办法,没有银弹.
在InnoDB中,默认采用B+树作索引,对于主键的索引,以<primary_id,page>的方式,辅助索引以<col,primary_id>的方式,辅助索引(secondary index)指出了聚簇索引(clustered index)(一般的,主键索引)以外的所有索引
由于大多数db engine会采用b/b+树,比如innodb使用b+树作为索引,我们这里就不探讨动态哈希了,哈希由于对区间查找支持太差,更适合作为键值缓存数据库,比如redis
二叉搜索树(二叉排序树,查找树),相比都知道,其在结构上是类似一个二叉堆,但是满足左子节点<父节点<右子节点,相比之下,用来实现优先队列(大/小顶堆)的二叉堆结构,只需要满足左子节点<父节点,右子节点<父子节点
平衡化: 这意味着插入/删除元素的时候,不能直接简单的插入删除,需要对局部结构进行reshape(旋转),以满足插入/删除后仍然是平衡树
平衡树: 如果一棵树,其子节点都是平衡树,并且深度相差不超过1,则称为平衡树
平衡化的旋转操作比较复杂,如果不是专门去实现一个平衡树,我个人认为了解它需要平衡化就行了
有序性: 当对平衡二叉搜索树进行中序遍历时,将得到一个递增序列
B树是平衡二叉搜索树的进阶版,可以认为,B树是平衡多叉搜索树,在这里,平衡是严格平衡,不再是相差为1,而是都一样的高度
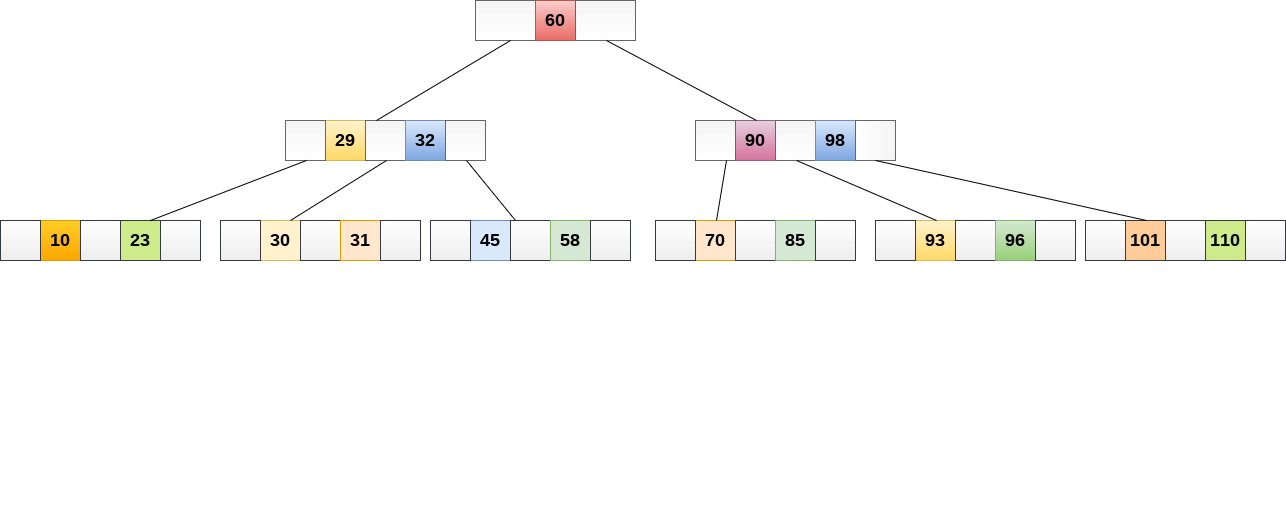
这是google/btree的go语言实现版
// degree指度数,一个node的最小item数是degree-1,最大是degree*2-1
// order指阶数,一个node的最大子树个数是order,最大item数是order-1,最小item数是order/2
// 所以: order-1 等于 degree*2-1 , 一个2度树是一个4阶数
type BTree struct {
degree int
length int
root *node
cow *copyOnWriteContext
}
// node指tree中的一个节点
type node struct {
items items
children children
cow *copyOnWriteContext
}
type items []Item
type children []Item
// 显然items代表父节点自己存储的值数组,而children代表指向子节点的指针数组
// Item represents a single object in the tree.
type Item interface {
// Less tests whether the current item is less than the given argument.
Less(than Item) bool
}对于m阶的b树,每个子节点不能有超过m-1个关键字,非根结点至少有Math.ceil(m/2)-1个关键字
插入节点时,首先寻路到了叶子节点(注意一定是叶子节点,否则是replace而不是insert),正常按顺序找到位置,插入,对于go实现,可以通过*items = copy((*items)[i:] , (*items)[i+1:]) 如果叶子节点关键字数超过了m-1,则将整个items二分,将中间的关键字append到父节点
当一层满了之后,才会插入到下一层!
B+树显然是B树的升级版
B+树的特点是,非叶子节点不保存(key-value),而只是保存key用于比较,所有的数据item都在叶子节点
叶子节点的最右指针将会指向临近的叶子节点
-
快速性: B+树的层级比B树小,查的更快(基本上看其他资料,都有提到这个,但我实在不懂为什么会更矮:2021/03/16更新:因为B+树的非叶子节点没有数据,而一个数据要1kb,至少相当于100个指针了,所以B+树每个节点能容纳的叉数更多(建立在一个节点存一个页的情况))
-
稳定性: B+树由于非叶子节点不存储值,所以每次查询必须一直查到叶子节点,对于不同的键查询时间差距不大(这个是建立在其本身和B树的查询速度差距不大的前提下)
-
有序性: 虽然B树作为搜索树也可以通过中序遍历获取有序列,但是B+树更加便捷,因为叶子节点之间是直接通过指针相连的(所以在查区间数据时很有优势)
有些地方说,B+树有利于全表扫描,但根据文档的建议,对于要查出大部分record的查询来说,不要用索引,直接全表扫描
2020/03/16更新,今天面试问了为什么稳定性是一个好的特性呢,可惜我不知道! 面试官说是和硬盘的特性有关,我搜索了一下,B+树比B树更满足硬盘的特性,因为硬盘读取慢,我们希望降低io次数,对于3层B+树,就可索引2kw个数据,这意味着4次io就可索引到2kw个数据,很恐怖! 反之对B树,由于数据要放在非叶子节点,所以一页最多16个指针,16^3远小于2kw
但是对于内存中的存储,多用B树,因为不再需要io
使用B/B+树时,不建议使用自增主键,因为自增主键由于主键的严格有序性,导致每插入一个元素(最终都会在最后一个叶子节点插入),就会触发一次分裂
2021/03/16更新,这句话就是在放屁,自己可以压测一下,无论是avl树还是rb树还是b树,在插入递增key时,绝对是比随机key性能好的
更何况b+树呢
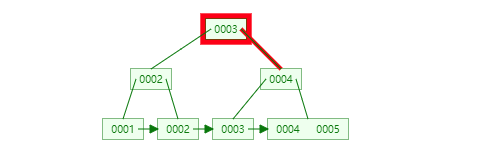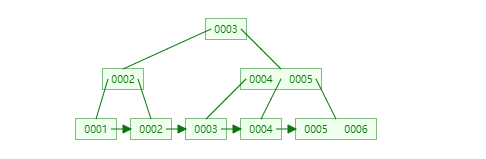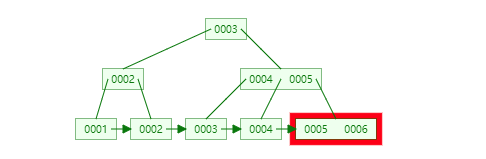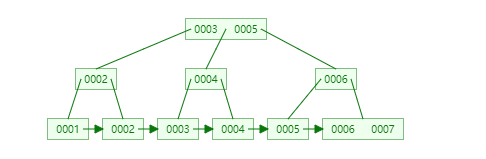
等价问题是,为什么InnoDB为什么采用B+树,而不是B树和动态哈希?
显然,对于OLTP来说,所有提到的优点在前文已经说明了.