|
| 1 | + |
| 2 | +# coding: utf-8 |
| 3 | + |
| 4 | +# # 基于统计规则的中文分词 |
| 5 | + |
| 6 | +# --- |
| 7 | + |
| 8 | +# ### 实验介绍 |
| 9 | + |
| 10 | +# 上节实验我们介绍了基于规则的分词方法,本次实验我们将带大家认识更成熟的分词方法,基于统计规则的分词方法。需要一定的概率统计基础,但是本实验将以最浅显的方法让你了解实验内容。 |
| 11 | + |
| 12 | +# ### 实验知识点 |
| 13 | + |
| 14 | +# - 语言模型 |
| 15 | +# - 隐马可夫模型 |
| 16 | +# - veterbi 算法 |
| 17 | +# - 中文分词工具 |
| 18 | + |
| 19 | +# ### 目录索引 |
| 20 | + |
| 21 | +# - <a href="#统计分词概述">统计分词</a> |
| 22 | +# - <a href="#语言模型">语言模型</a> |
| 23 | +# - <a href="#隐马可夫模型">隐马可夫模型</a> |
| 24 | +# - <a href="#jieba-工具">jieba 工具</a> |
| 25 | + |
| 26 | +# --- |
| 27 | + |
| 28 | +# |
| 29 | +# 随着语料库的大规模化,以及统计机器学习的蓬勃发展,基于统计规则的中文分词算法逐渐成为现在的主流分词方法。其目的是在给定大量已经分词的文本的前提下,利用统计机器学习的模型学习词语切分的规律。 |
| 30 | + |
| 31 | +# 统计分词可以这样理解:我们已经有一个由很多个文本组成的的语料库 `D` ,现在有一个文本需要我们分词, `我有一个苹果` ,其中两个相连的字 `苹` `果` 在不同的文本中连续出现的次数越多,就说明这两个相连字很可能构成一个词 `苹果`。与此同时 `个` `苹` 这两个相连的词在别的文本中连续出现的次数很少,就说明这两个相连的字不太可能构成一个词 `个苹` 。所以,我们就可以利用这个统计规则来反应字与字成词的可信度。当字连续组合的概率高过一个临界值时,就认为该组合构成了一个词语。 |
| 32 | + |
| 33 | +# 基于统计的分词,一般情况下有两个步骤: |
| 34 | + |
| 35 | +# 1. 建立统计语言模型。 |
| 36 | +# 2. 对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就需要用到统计学习算法,如隐马可夫,条件随机场等。 |
| 37 | + |
| 38 | +# ### 语言模型 |
| 39 | + |
| 40 | +# |
| 41 | +# 语言模型又叫做 N 元文法模型(N-gram)。按照书面解释来说,以长度为 m 的字符串,目的是确定其概率分布 $P\left (w_{1},w_{2}, \cdots ,w_{m}\right )$,其中 $w_{1}$ 到 $w_{m}$ 依次为文本中的每个词语。 |
| 42 | + |
| 43 | +# 这个概率可以用链式法则来求:即 |
| 44 | + |
| 45 | +# $$P\left (w_{1},w_{2}, \cdots ,w_{m}\right )=P\left ( w_{1} \right )*P\left ( w_{2}|w_{1} \right )*P\left ( w_{3}|w_{1},w_{2} \right )\cdots P\left ( w_{m}|w_{1},w_{2},\cdots ,w_{m-1} \right )$$ |
| 46 | + |
| 47 | +# 这里用到的是条件概率的公式 $P\left ( A|B\right )=\frac{P\left ( AB \right )}{P\left ( B \right )}$,即有 $P\left ( AB \right )=P\left ( A|B \right )*P\left ( B \right )$. |
| 48 | + |
| 49 | +# 因为我们是基于语料库的统计模型,所以上面的所有概率都可以通过对语料库的统计计算获得。但是,虽然采用的方法简单粗暴,但是观察上面的式子可以知道,当语料很大的时候,公式从第三项开始计算量就已经十分庞大了。 |
| 50 | + |
| 51 | +# 因此,在语言模型的基础上,衍生出了 $n$ 元模型。所谓的 $n$ 元就是在估算条件概率时,忽略掉大于 $n$ 个或者等于 $n$ 个上文词的的影响。即将上式子中的每一项简化 |
| 52 | + |
| 53 | +# $$P\left ( w_{m}|w_{1},w_{2},\cdots,w_{m-1} \right )\approx P\left ( w_{m}|w_{m-(n-1)},w_{m-(n-2))},\cdots,w_{m-1} \right )$$ |
| 54 | + |
| 55 | +# $n=1$ 时,称一元模型(unigram model),此时有: |
| 56 | + |
| 57 | +# $$P\left (w_{1},w_{2}, \cdots ,w_{m}\right )=P(w_{1})*P(w_{2})\cdots P(w_{m})$$ |
| 58 | + |
| 59 | +# $n=2$ 时,称二元模型(bi-gram model),此时有: |
| 60 | + |
| 61 | +# $$P\left (w_{1},w_{2}, \cdots ,w_{m}\right )=P(w_{1})*P(w_{2}|w_{1}) \cdots P(w_{m}|w_{m-1},w_{m-2})$$ |
| 62 | + |
| 63 | +# 可以看到,当 $n=1$ 时,词与词之间基本没有关系。随着 $n$ 逐渐增大,每个模型与上文的关系越密切,包含的次序信息也越丰富,但是与此同时计算量也随之大大增加。所以常用的一般为二元模型,三元模型。 |
| 64 | + |
| 65 | +# ### 隐马可夫模型 |
| 66 | + |
| 67 | +# 为了更好的解释隐马可夫,我们先从马可夫(Markov Method , MM)模型模型说起。我们来举个例子,在天气预测时候,假如我们知道晴雨云天气之间的相互转换概率,如下图。 |
| 68 | + |
| 69 | +# 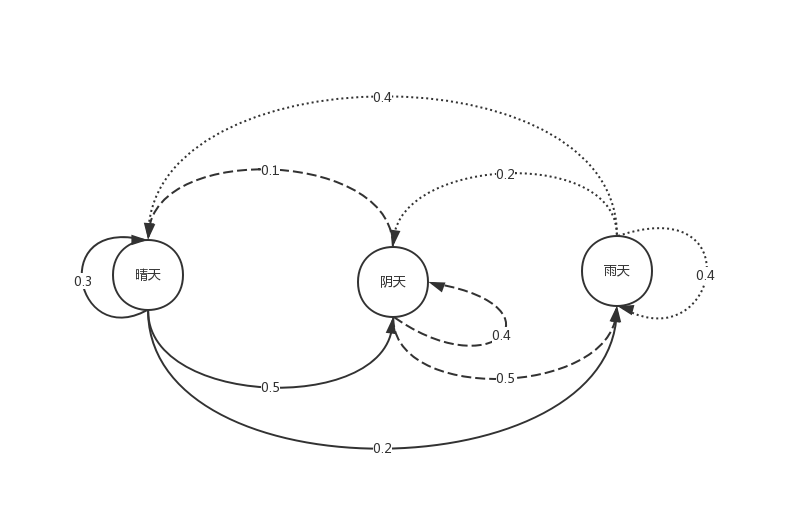 |
| 70 | + |
| 71 | +# 有了这个转移概率图,假如我们知道今天的天气情况的时候,我们就能推测出明天的天气状况。若今天为晴,那么明天推测为阴天(取其中概率最大的)。这样一种类型就是马可夫模型。 |
| 72 | + |
| 73 | +# #### 隐马可夫模型 |
| 74 | + |
| 75 | +# 隐马可夫(Hidden Markov Method , HMM)模型是在马可夫模型的特殊情况,更进一步的,我们在上面马尔可夫的模型中,添加更多的限制条件。 |
| 76 | + |
| 77 | +# 1. 假若我们不知道未来几天的天气情况。 |
| 78 | +# 2. 我们知道未来几天的空气湿度情况。 |
| 79 | +# 3. 我们知道第一天天气各种情况的概率。 |
| 80 | +# 4. 为我们知道某种天气状态条件下,空气湿度的概率。 |
| 81 | +# 5. 我们知道前一天天气情况转移到下一个天气情况的概率。 |
| 82 | + |
| 83 | +# |
| 84 | +# 在这个例子当中,未来几天天气状态的序列就叫做隐藏状态序列。而我们唯一能观测到的是,未来几天空气中的湿度,这些湿度状态就叫做可观测状态。 |
| 85 | + |
| 86 | +# 因为空气湿度与天气有关,因此我们想要通过可以观测到的空气湿度这一可观测状态序列来推测出未来三天的天气状态这一隐藏状态序列。这类型的问题,就叫做隐马可夫模型。 |
| 87 | + |
| 88 | +# #### HMM 应用于分词 |
| 89 | + |
| 90 | +# 首先,规定每个字在一个词语当中有着4个不同的位置,词首 B,词中 M,词尾 E,单字成词 S。我们通过给一句话中的每个字标记上述的属性,最后通过标注来确定分词结果。 |
| 91 | + |
| 92 | +# 例如:`我今天要去实验室` |
| 93 | +# |
| 94 | +# 标注后得到:`我/S 今/B 天/E 要/S 去/S 实/B 验/M 室/E` |
| 95 | +# |
| 96 | +# 标注序列是:`S B E S S B M E` |
| 97 | +# |
| 98 | +# 找到 `S 、B 、 E` 进行切词:`S / B E / S / S / B M E /` |
| 99 | +# |
| 100 | +# 所以得到的切词结果是:`我 / 今天 / 要 / 去 / 实验室` |
| 101 | + |
| 102 | +# 这就是一个 HMM 模型,因为我们要得到每个字的标注信息,但是我们只能看到的是每一个汉字,需要我们通过这些汉字来推断每个字在词中的位置,并且每个字的标注状态还与他前一个字的标注状态有关。 |
| 103 | + |
| 104 | +# 以上面的例子来说:根据可观察状态的序列(我今天要去实验室)找到一个最可能的隐藏状态的序列(`S B E S S B M E`)。 |
| 105 | + |
| 106 | +# 现在我们建模来表示中文分词问题:在这里令 $t = i$ 时刻的隐藏状态是 $O_{i}$ ,当 $i$ 时刻的可观测状态是 $S_{i}$ 。 |
| 107 | + |
| 108 | +# 初始状态:假设 $t=1$ 为初始时刻,每种隐藏状态的概率称为初始状态。下面是初始状态矩阵: |
| 109 | + |
| 110 | +# 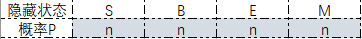 |
| 111 | + |
| 112 | +# 转移概率:在 $i$ 时刻隐藏状态 $(O_{i})$ 到下一个时刻 $i+1$ 的隐藏状态 $(O_{i+1})$ 的概率,记作 $P(O_{i+1}|O_{i})$ ,下面是转移概率矩阵: |
| 113 | + |
| 114 | +# 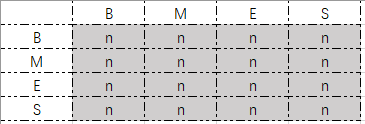 |
| 115 | + |
| 116 | +# 发射概率:在 $i$ 时刻隐藏状态 $(O_{i})$ 到当前时刻可观测状态 $(S_{i})$ 的概率,记作 $P(S_{i}|O_{i})$ ,下面是发射概率矩阵: |
| 117 | + |
| 118 | +#  |
| 119 | + |
| 120 | +# 我们的目标是求得一个在 可观测状态序 $S_{1}S_{2}\dots S_{n}$ 条件下最理想的一个 隐藏序列 $O_{1}O_{2}\dots O_{n}$ ,即求: |
| 121 | + |
| 122 | +# $$max{P \left (O_{1}O_{2}\dots O_{n} |S_{1}S_{2}\dots S_{n} \right )}$$ |
| 123 | + |
| 124 | +# 为了求解这样一个问题,我们需要作出两个假设来简化我们的计算流程。 |
| 125 | + |
| 126 | +# **独立输出假设** |
| 127 | + |
| 128 | +# 当前时刻的隐藏状态与当前时刻可观测状态有关,与之前的可观测状态无关,与之后的可观测状态无关。如:上面“天”的序列标注与“天”有关,与“今”无关,与“要”无关。这样: |
| 129 | + |
| 130 | +# $$P \left (O_{1}O_{2}\dots O_{n} |S_{1}S_{2}\dots S_{n} \right )$$ |
| 131 | +# 变成了: |
| 132 | +# $$P \left (O_{1}|S_{1}\right ) \left (O_{2}|S_{2}\right ) \dots \left (O_{n}|S_{n}\right )$$ |
| 133 | + |
| 134 | +# **有限历史性假设** |
| 135 | + |
| 136 | +# 当前时刻的隐藏状态与前一个隐藏状态有关,与前一个隐藏状态之前的隐藏状态 或者是 当前状态之后的隐藏状态都没有关系。如:上面例子当中,“天”的序列标注由“今”的序列标注决定,与“我”的序列标注无关,与“要”的序列标注无关。 |
| 137 | + |
| 138 | +# $$P\left ( O_{i}|O_{1},O_{2}\dots O_{i-1} \right )=P\left ( O_{i}|O_{i-1} \right )$$ |
| 139 | + |
| 140 | +# #### 维特比算法 |
| 141 | + |
| 142 | +# HMM 求解常用的有 Viterbi 算法。有了上面的假设,我们就能利用 Viterbi 算法求出最终的目标概率最大值。 |
| 143 | + |
| 144 | +# Verterbi 是一种动态规划的方法,动态规划有这样一个特性:如果最终的最优路径从某个结点 $i$ 经过,那么从初始结点到 $i-1$ 的这条路径也是一个最优路径。通俗一点来讲,对某一段序列做标注,以某种方式标注序列的前 $n$ 个词,如果这个序列是最优的标注方法,那么按照这个方式标注前 $n-1$ 个词也是最优的。 |
| 145 | + |
| 146 | +# 因此,依据这样一个特性,在考虑每个 $t$ 时刻时,只用求经过 $t-1$ 前一个时刻的最优路径,然后在于当前时刻的状态结合求出当前时刻的最优路径。这样从 $t=1$ 时刻开始逐步递推,就可以得到我们想要的最佳路径。 |
| 147 | + |
| 148 | +# ### jieba 中文分词 |
| 149 | + |
| 150 | +# 为了方便起见,我们可以在 Python 用第三方的中文分词工具 jieba,来替我们在实际应用中省掉训练分词马可夫模型的繁琐步骤。并且,jieba 工具用的 HMM算 法与数据结构算法结合使用的方法,比直接单独使用 HMM 来分词效率高很多,准确率也高很多。 |
| 151 | + |
| 152 | +# 另外,目前在实际应用中,jieba 分词是使用率很高的一款工具。不仅使用起来十分的方便、快速,而且分词效果也比较理想,首先需要下载第三方的 jieba 工具库:https://github.com/fxsjy/jieba |
| 153 | + |
| 154 | +# 下面我们就来通过例子看下 jieba 分词的方法: |
| 155 | +# |
| 156 | +# 1. 全模式 |
| 157 | +# 2. 精确模式 |
| 158 | +# 3. 搜索引擎模式 |
| 159 | + |
| 160 | +# 加载 jieba: |
| 161 | + |
| 162 | +# In[ ]: |
| 163 | + |
| 164 | + |
| 165 | +import jieba |
| 166 | + |
| 167 | + |
| 168 | +# 全模式: |
| 169 | + |
| 170 | +# In[ ]: |
| 171 | + |
| 172 | + |
| 173 | +string = '我来到北京清华大学' |
| 174 | +seg_list = jieba.cut(string, cut_all=True) |
| 175 | + |
| 176 | + |
| 177 | +# jieba 是将分词后的结果存放在生成器当中的。 |
| 178 | + |
| 179 | +# In[ ]: |
| 180 | + |
| 181 | + |
| 182 | +seg_list |
| 183 | + |
| 184 | + |
| 185 | +# 无法直接显示,若想要显示,可以下面这样。用 ‘/’ 把生成器中的词串起来显示。这个方法在下面提到的精确模式和搜索引擎模式中同样适用。 |
| 186 | + |
| 187 | +# In[ ]: |
| 188 | + |
| 189 | + |
| 190 | +'/'.join(seg_list) |
| 191 | + |
| 192 | + |
| 193 | +# 精确模式: |
| 194 | + |
| 195 | +# In[ ]: |
| 196 | + |
| 197 | + |
| 198 | +seg_list = jieba.cut(string, cut_all=False) |
| 199 | + |
| 200 | + |
| 201 | +# 显示精确模式分词结果: |
| 202 | + |
| 203 | +# In[ ]: |
| 204 | + |
| 205 | + |
| 206 | +'/'.join(seg_list) |
| 207 | + |
| 208 | + |
| 209 | +# 搜索引擎模式: |
| 210 | + |
| 211 | +# In[ ]: |
| 212 | + |
| 213 | + |
| 214 | +seg_list = jieba.cut_for_search(string) |
| 215 | + |
| 216 | + |
| 217 | +# 显示搜索引擎模式结果: |
| 218 | + |
| 219 | +# In[ ]: |
| 220 | + |
| 221 | + |
| 222 | +'/'.join(seg_list) |
| 223 | + |
| 224 | + |
| 225 | +# 可以看到,全模式和搜索引擎模式,jieba 会把全部可能组成的词都打印出来。在一般的任务当中,我们使用默认的精确模式就行了,在模糊匹配时,则需要用到全模式或者搜索引擎模式。 |
| 226 | + |
| 227 | +# 接下来,我们试着对一篇长文本作分词。首先,导入某一段文本。 |
| 228 | + |
| 229 | +# In[ ]: |
| 230 | + |
| 231 | + |
| 232 | +text = '市场有很多机遇但同时也充满杀机,野蛮生长和快速发展中如何慢慢稳住底盘,驾驭风险,保持起伏冲撞在合理的范围,特别是新兴行业,领军企业更得有胸怀和大局,需要在竞争中保持张弛有度,促成行业建立同盟和百花争艳的健康持续的多赢局面,而非最后比的是谁狠,比的是谁更有底线,劣币驱逐良币,最终谁都逃不了要还的。' |
| 233 | +text |
| 234 | + |
| 235 | + |
| 236 | +# 适用精确模式对文本进行分词: |
| 237 | + |
| 238 | +# In[ ]: |
| 239 | + |
| 240 | + |
| 241 | +a = jieba.cut(text, cut_all=False) |
| 242 | + |
| 243 | + |
| 244 | +# 显示结果: |
| 245 | + |
| 246 | +# In[ ]: |
| 247 | + |
| 248 | + |
| 249 | +'/'.join(a) |
| 250 | + |
| 251 | + |
| 252 | +# jieba 在某些特定的情况下来分词,可能表现不是很好。比如一篇非常专业的医学论文,含有一些特定领域的专有名词。不过,为了解决此类问题, jieba 允许用户自己添加该领域的自定义词典,我们可以提前把这些词加进自定义词典当中,来增加分词的效果。调用的方法是:`jieba.load_userdic()`。 |
| 253 | + |
| 254 | +# 自定义词典的格式要求每一行一个词,有三个部分,词语,词频(词语出现的频率),词性(名词,动词……)。其中,词频和词性可省略。用户自定义词典可以直接用记事本创立即可,但是需要以 utf-8 编码模式保存。 |
| 255 | +# 格式像下面这样: |
| 256 | + |
| 257 | +# 凶许 1 a |
| 258 | +# 脑斧 2 b |
| 259 | +# 福蝶 c |
| 260 | +# 小局 4 |
| 261 | +# 海疼 |
| 262 | + |
| 263 | +# 对于结巴的词性标记集,可以参考 https://gist.github.com/hscspring/c985355e0814f01437eaf8fd55fd7998 |
| 264 | + |
| 265 | +# 除了使用 `jieba.load_userdic()` 函数在分词开始前加载自定义词典之外,还有两种方法在可以在程序中动态修改词典。 |
| 266 | + |
| 267 | +# * 使用 `add_word(word, freq=None, tag=None)` 和 `del_word(word)` 可在程序中动态修改词典。 |
| 268 | +# |
| 269 | +# * 使用 `suggest_freq(segment, tune=True)` 可调节单个词语的词频,使其能(或不能)被分出来。 |
| 270 | + |
| 271 | +# 使用自定义词典,有时候可以取得更好的效果,例如「今天天气不错」这句话,本应该分出「今天」、「天气」、「不错」三个词,而来看一下直接使用结巴分词的结果: |
| 272 | + |
| 273 | +# In[ ]: |
| 274 | + |
| 275 | + |
| 276 | +string = '今天天气不错' |
| 277 | +seg_list = jieba.cut(string, cut_all=False) |
| 278 | +'/'.join(seg_list) |
| 279 | + |
| 280 | + |
| 281 | +# 可以看到结果并没有被完整分割,这时候就可以加载自定义的词典了,将「今天」和「天气」两个词语添加到词典中,并重新分词: |
| 282 | + |
| 283 | +# In[ ]: |
| 284 | + |
| 285 | + |
| 286 | +jieba.suggest_freq(('今天', '天气'), True) |
| 287 | +seg_list = jieba.cut(string, cut_all=False) |
| 288 | +'/'.join(seg_list) |
| 289 | + |
| 290 | + |
| 291 | +# 也可以从词典直接删除该词语: |
| 292 | + |
| 293 | +# In[ ]: |
| 294 | + |
| 295 | + |
| 296 | +jieba.del_word('今天天气') |
| 297 | +seg_list = jieba.cut(string, cut_all=False) |
| 298 | +'/'.join(seg_list) |
| 299 | + |
| 300 | + |
| 301 | +# 还有一种情况是「台中」总是被切成「中」和「中」,因为 P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低,这时候可以添加词典,强制调高词频。 |
| 302 | + |
| 303 | +# In[ ]: |
| 304 | + |
| 305 | + |
| 306 | +string = '台中' |
| 307 | +seg_list = jieba.cut(string, cut_all=False) |
| 308 | +'/'.join(seg_list) |
| 309 | + |
| 310 | + |
| 311 | +# 强制调高「台中」的词频,使它被分为一个词: |
| 312 | + |
| 313 | +# In[ ]: |
| 314 | + |
| 315 | + |
| 316 | +jieba.add_word('台中') |
| 317 | +seg_list = jieba.cut(string, cut_all=False) |
| 318 | +'/'.join(seg_list) |
| 319 | + |
| 320 | + |
| 321 | +# 接下来我们利用 jiaba 来做一个简单过滤器,这个在实际的应用中十分常用。比如有的词“的”,“地”,“得”,对数据分析没有什么实际作用,但是文章中大量的这类词又会占据大量的存储资源,因此我们想要过滤掉这类词。 |
| 322 | + |
| 323 | +# 首先建立停用词表,为了便于理解,我们直接建立一个小型的停用词表。实际中常常需要一个由大量的停用词组成的词表。 |
| 324 | + |
| 325 | +# In[ ]: |
| 326 | + |
| 327 | + |
| 328 | +stopwords = ('的', '地', '得') |
| 329 | +stopwords |
| 330 | + |
| 331 | + |
| 332 | +# 自定义待过滤的文本: |
| 333 | + |
| 334 | +# In[ ]: |
| 335 | + |
| 336 | + |
| 337 | +string = '我喜欢的和你讨厌地以及最不想要得' |
| 338 | +string |
| 339 | + |
| 340 | + |
| 341 | +# 对 `string` 进行分词操作,并将结果存放在一个 `seg_list` 中: |
| 342 | + |
| 343 | +# In[ ]: |
| 344 | + |
| 345 | + |
| 346 | +seg_list = jieba.cut(string, cut_all=False) |
| 347 | +seg_list |
| 348 | + |
| 349 | + |
| 350 | +# 看看没过滤之前的分词结果: |
| 351 | + |
| 352 | +# In[ ]: |
| 353 | + |
| 354 | + |
| 355 | +'/'.join(seg_list) |
| 356 | + |
| 357 | + |
| 358 | +# 接下来,查看过滤后结果。首先创建一个空数组来存放过滤后的词语,然后通过循环迭代的方法,将过滤后的词语依次添加到刚刚建立的空数组当中。 |
| 359 | + |
| 360 | +# In[ ]: |
| 361 | + |
| 362 | + |
| 363 | +a = [] |
| 364 | +seg_list = jieba.cut(string, cut_all=False) |
| 365 | +for word in seg_list: |
| 366 | + if word not in stopwords: |
| 367 | + a.append(word) |
| 368 | +a |
| 369 | + |
| 370 | + |
| 371 | +# 这样,我们就实现了一个简单过滤器,来过滤掉不需要的文本信息。虽然很简单,但是这是在中文处理中非常实用的一个操作。 |
| 372 | + |
| 373 | +# ### 实验总结 |
| 374 | + |
| 375 | +# 本次实验,我们讲解了中文分词的基本原理,着重介绍了中文分词的相关技术,后面介绍了 jieba 分词工具,然后用一个例子,讲解了 jieba 的用法。分词是自然语言处理所有中文任务当中最基本的步骤,大部分任务都是建立在分词之后的文本上的,因此,掌握好分词将会对自然语言处理的理解有不小的帮助。 |
0 commit comments