Performance of popular deep learning frameworks and GPUs are compared, including the effect of adjusting the floating point precision (the new Volta architecture allows performance boost by utilizing half/mixed-precision calculations.)
Note: Docker images available from NVIDIA GPU Cloud were used so as to make benchmarking controlled and repeatable by anyone.
-
PyTorch 0.3.0
docker pull nvcr.io/nvidia/pytorch:17.12
-
PyTorch 1.0.0 (CUDA 10.0, cuDNN 7.4.2)
docker pull nvcr.io/nvidia/pytorch:19.01-py3(note: requires login API key to NGC registry)
-
Caffe2 0.8.1
docker pull nvcr.io/nvidia/caffe2:17.12
-
TensorFlow 1.4.0 (note: this is TensorFlow 1.4.0 compiled against CUDA 9 and CuDNN 7)
docker pull nvcr.io/nvidia/tensorflow:17.12
-
TensorFlow 1.5.0
-
TensorFlow 1.12.0 (CUDA 10.0, cuDNN 7.4.2)
docker pull nvcr.io/nvidia/tensorflow:19.01-py3(note: requires login API key to NGC registry)
-
MXNet 1.0.0 (anyone interested?)
docker pull nvcr.io/nvidia/mxnet:17.12
-
CNTK (anyone interested?)
docker pull nvcr.io/nvidia/cntk:17.12
| Model | Architecture | Memory | CUDA Cores | Tensor Cores | F32 TFLOPS | F16 TFLOPS* | Retail | Cloud |
|---|---|---|---|---|---|---|---|---|
| Tesla V100 | Volta | 16GB HBM2 | 5120 | 640 | 15.7 | 125 | $3.06/hr (p3.2xlarge) | |
| Titan V | Volta | 12GB HBM2 | 5120 | 640 | 15 | 110 | $2999 | N/A |
| 1080 Ti | Pascal | 11GB GDDR5 | 3584 | 0 | 11 | N/A | $699 | N/A |
| 2080 Ti | Turing | 11GB GDDR6 | 4352 | 544 | 13.4 | 56.9 | $1299 | N/A |
*: F16 (single precision) TFLOPS on TensorCores.
- CUDA 9.0.176
- CuDNN 7.0.0.5
- NVIDIA driver 387.34.
Except where noted.
- VGG16
- Resnet152
- Densenet161
- Any others you might be interested in?
The results are based on running the models with images of size 224 x 224 x 3 with a batch size of 16. "Eval" shows the duration for a single forward pass averaged over 20 passes. "Train" shows the duration for a pair of forward and backward passes averaged over 20 runs. In both scenarios, 20 runs of warm up is performed and those are not counted towards the measured numbers.
Titan V gets a significant speed up when going to half precision by utilizing its Tensor cores, while 1080 Ti gets a small speed up with half precision computation. Similarly, the numbers from V100 on an Amazon p3 instance is shown. It is faster than Titan V and the speed up when going to half-precision is similar to that of Titan V.
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 31.3ms | 108.8ms | 48.9ms | 180.2ms | 52.4ms | 174.1ms |
| 1080 Ti | 39.3ms | 131.9ms | 57.8ms | 206.4ms | 62.9ms | 211.9ms |
| V100 (Amazon p3, CUDA 9.0.176, CuDNN 7.0.0.3) | 26.2ms | 83.5ms | 38.7ms | 136.5ms | 48.3ms | 142.5ms |
| 2080 Ti | 30.5ms | 102.9ms | 41.9ms | 157.0ms | 47.3ms | 160.0ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 14.7ms | 74.1ms | 26.1ms | 115.9ms | 32.2ms | 118.9ms |
| 1080 Ti | 33.5ms | 117.6ms | 46.9ms | 193.5ms | 50.1ms | 191.0ms |
| V100 (Amazon p3, CUDA 9.0.176, CuDNN 7.0.0.3) | 12.6ms | 58.8ms | 21.7ms | 92.9ms | 35.7ms | 102.3ms |
| 2080 Ti | 23.6ms | 99.3ms | 31.3ms | 133.0ms | 35.5ms | 135.8ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| 2080 Ti (CUDA 10.0.130, CuDNN 7.4.2.24) | 28.0ms | 95.5ms | 41.8ms | 142.5ms | 45.4ms | 148.4ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| 2080 Ti (CUDA 10.0.130, CuDNN 7.4.2.24) | 19.1ms | 68.1ms | 25.0ms | 98.6ms | 30.1ms | 110.8ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 31.8ms | 157.2ms | 50.3ms | 269.8ms | ||
| 1080 Ti | 43.4ms | 131.3ms | 69.6ms | 300.6ms | ||
| 2080 Ti | 31.3ms | 99.4ms | 43.2ms | 187.7ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 16.1ms | 96.7ms | 28.4ms | 193.3ms | ||
| 1080 Ti | 38.6ms | 121.1ms | 53.9ms | 257.0ms | ||
| 2080 Ti | 24.9ms | 81.8ms | 31.9ms | 155.5ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| V100 | 24.0ms | 71.7ms | 39.4ms | 199.8ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| V100 | 13.6ms | 49.4ms | 22.6ms | 147.4ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| 2080 Ti (CUDA 10.0.130, CuDNN 7.4.2.24) | 28.8ms | 90.8ms | 43.6ms | 191.0ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| 2080 Ti (CUDA 10.0.130, CuDNN 7.4.2.24) | 18.7ms | 58.6ms | 25.8ms | 133.5ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 57.5ms | 185.4ms | 74.4ms | 214.1ms | ||
| 1080 Ti | 47.0ms | 158.9ms | 77.9ms | 223.9ms |
| Model | vgg16 eval | vgg16 train | resnet152 eval | resnet152 train | densenet161 eval | densenet161 train |
|---|---|---|---|---|---|---|
| Titan V | 41.6ms | 156.1ms | 56.9ms | 172.7ms | ||
| 1080 Ti | 40.1ms | 137.8ms | 61.7ms | 184.1ms |
Comparison of Titan V vs 1080 Ti, PyTorch 0.3.0 vs Tensorflow 1.4.0 vs Caffe2 0.8.1, and FP32 vs FP16 in terms of images processed per second:
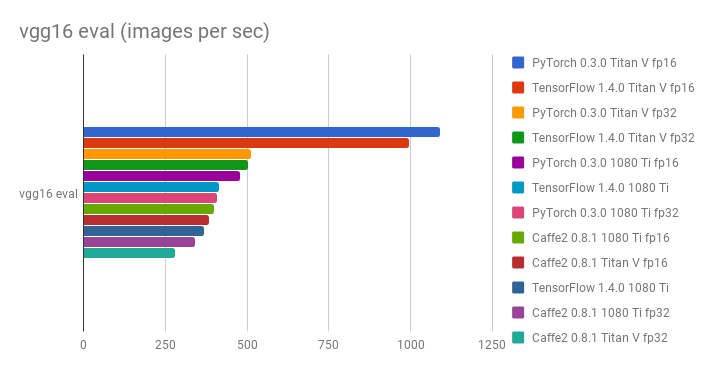
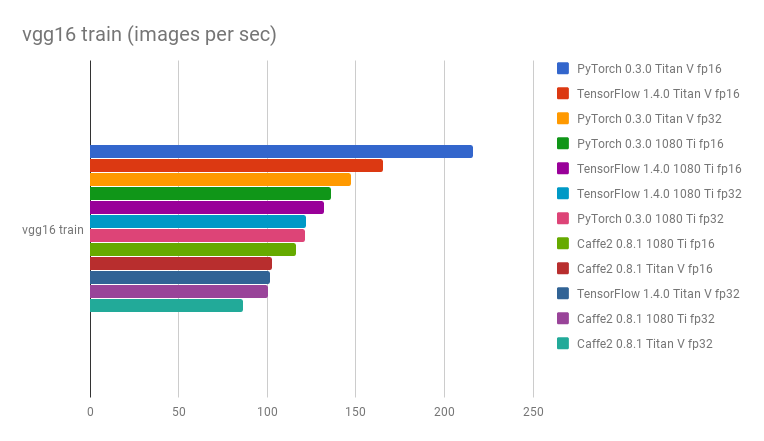
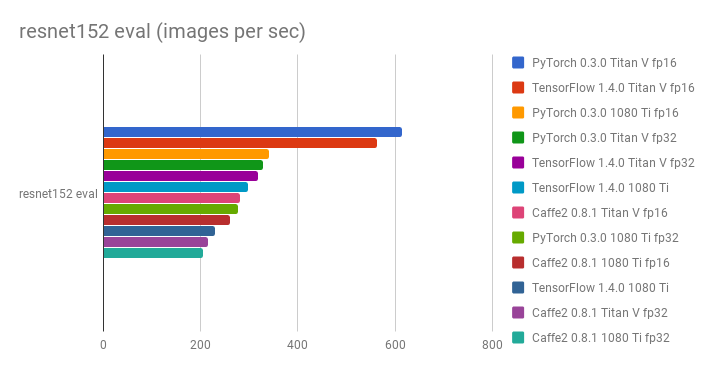
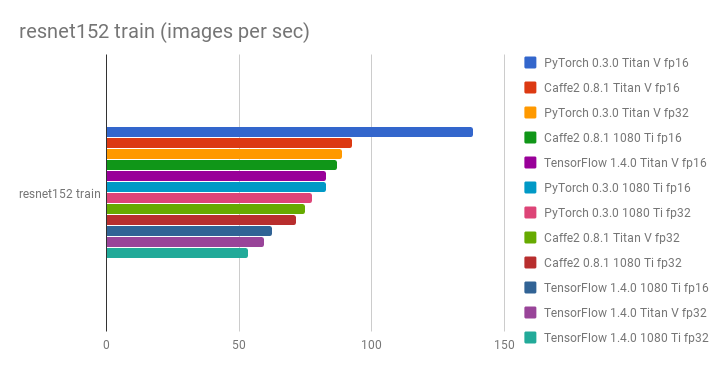
- Yusaku Sako
- Bartosz Ludwiczuk (thank you for supplying the V100 numbers)