In this scenario you will be working with the Scenario 2 PaaS infrastructure architecture. It was originally built and run on virtual machines on-prem before being migrated to Azure and refactored to leverage PaaS.
It has been configured to use Multi Zones for all the components/services. However, given the criticality of the workload and recent incidents of Service outage in the entire region, the use of “Multiple Regions” has been identified as critical to mitigating region level failures moving forward. Along with the services, we need a comprehensive architecture to support different scenarios with Multiple Regions – Active/Active and Active/Passive and so on.
There are multiple ways to achieve this requirement, the below is just one variation that would meet ACME’s requirements.

To begin the lab, your first step is to deploy the synthetic workload. This will deploy the Azure Infrastructure shown in the architecture above into a single resource group called rg-waf-mrn-lab-scenario-3. Ensure you have the prerequisites above complete before following the steps below.
- Navigate to the following Github Repo and either download or clone it to your local device.
- Open up the Github Repo Directory in VS Code and load up terminal, logging into Azure Powershell or Azure CLI.
- Ensure you are in the correct context for deploying resources.
- CD into the Labs\scenario-three directory If you dont want to deploy application gateway, please change the parameter “createAppGw” value to false in the main.bicep file
- Run the following deployment command.
- PS - New-azSubscriptionDeployment -Location -TemplateFile .\labs\scenario-three\main.bicep -verbose -name
- AZ CLI - az deployment sub create --location --template-file ./labs/scenario-three/main.bicep
- Once you run the command, it will ask you to provide the SQL Password. Please provide the password
For each critical flow, we need to consider their failure modes and how that would impact the user experience. So, let’s assume if a service like SQL goes down, how would that impact the user / dataflow. It would certainly cause timeouts, latency and therefore performance issues while increasing the response time in case of a partial failover, in this case SQL servicing from the secondary region.
Hence, it becomes important to consider if a critical service like SQL being down warrants a complete failover. We will be remediating at each component level to support failover scenarios, however before we go any further and start deploying configurations across services to support Multi Region Architecture, we need to understand certain pieces which are of utmost importance in deciding the SKUs, configurations and directly impacting your cost, resiliency and performance of the workload.
- Design Strategy
- Choosing the Secondary Region
- Load Balancing
There are multiple strategies one can take when it comes to implementing a multi-region design. In contrast, active-passive setups are configured to handle production loads in a primary region, with a secondary (passive) region taking over only in case of a failure. Choosing the optimal Azure regions for your workload is essential in designing a highly available multi-region environment.
-
Active/active – Both regions are actively serving users. Traffic routing can be based on performance, geographic source of the request etc. Active/active at capacity - Mirrored deployment stamps in two or more Azure regions, each configured to handle production workloads for the region or regions they serve and scalable to handle loads from other regions in case of a regional outage.
-
Active/active overprovisioned - Mirrored deployment stamps in two or more Azure regions, each overprovisioned to handle production workloads for the region or regions they serve and to handle loads from other regions in case of a regional outage.
-
Active/passive – Whilst the active region is serving users, the passive one is on available of standby in the event of a failure. There are multiple variations of this that can address requirements such as RTO, Cost, operational complexity etc. Warm spare - One primary region and one or more secondary regions. The secondary region is deployed with the minimum possible compute and data sizing and runs without load. This region is known as a warm spare region. Upon failover, the compute and data resources are scaled to handle the load from the primary region.
-
Cold spare - One primary region and one or more secondary regions. The secondary region is scaled to handle full load, but all compute resources are stopped. This region is known as a cold spare region. You need to start the resources before failover.
-
Redeploy - One primary region and one or more secondary regions. Only the necessary networking is deployed in the secondary region. Operators must run provisioning scripts in the secondary region to fail over the workloads. This design is known as redeploy on disaster. To read more on these strategies, following this link. Recommendations for highly available multi-region design - Microsoft Azure Well-Architected Framework | Microsoft Learn It is important to note that choosing the appropriate strategy will have multiple implications on cost, operational overhead, security and how you achieve your availability targets.
Selecting a secondary region in Azure for a multi-region architecture involves several key considerations to ensure high availability, disaster recovery, and optimal performance. Here's an example structured approach to making this decision: Here are some of the top considerations when you select a region. However, detailed information is available - Select Azure regions - Cloud Adoption Framework | Microsoft Learn
-
Geographic Distance
- Proximity to Primary Region: Select a secondary region that is geographically close enough to the primary region to minimize latency but far enough to avoid being impacted by the same regional disasters.
- Data Residency Requirements: Ensure compliance with data residency regulations, which may dictate the geographical location of your data.
-
Paired Regions
- Azure Region Pairs: Azure pairs certain regions to provide disaster recovery benefits, including data residency, priority recovery, and updates deployed sequentially to minimize downtime. Selecting a paired region can simplify configuration and enhance resilience. (add GRS capability available for PaaS)
Each Azure region is paired with another region within the same geography. In general, choose regions from the same regional pair (for example, East US 2 and Central US). Benefits of doing so include: If there's a broad outage, recovery of at least one region out of every pair is prioritized. Planned Azure system updates are rolled out to paired regions sequentially to minimize possible downtime. In most cases, regional pairs reside within the same geography to meet data residency requirements. Most PaaS services have geo replication capability which replicates only amongst paired regions.
- Compliance and Legal Requirement
- Service Availability
- Service Parity: Ensure that the secondary region supports all the services and features required by your workload. Some Azure services may not be available in all regions.
- Performance and Latency
- Network Latency: Consider the network latency between the primary and secondary regions to ensure that replication and failover processes meet your performance requirements.
- User Base Proximity: Factor in the proximity to your end-users if the secondary region might serve traffic during failover scenarios.
- Disaster Recovery Objectives
- Recovery Time Objective (RTO): Determine the acceptable downtime and choose a secondary region that can meet this RTO.
- Recovery Point Objective (RPO): Establish the maximum acceptable data loss and ensure that the secondary region can support the required data replication frequency.
Example Process:
- Identify Primary Region: Start with your primary region based on your user base, regulatory requirements, and service availability.
- Review Azure Region Pairs: Check if there is a paired region recommended by Azure for your primary region.
- Assess Compliance: Verify that the secondary region meets all compliance and legal requirements.
- Evaluate Latency and Performance: Measure network latency and performance metrics between the primary and secondary regions.
- Compare Costs: Analyze the cost implications of using the secondary region.
- Finalize Choice: Select the secondary region that best aligns with your disaster recovery objectives, performance needs, and budget constraints.
Azure Resources:
You also need to consider if you are selecting the Regions where we have restrictions by design or are non-paired regions:
- West US3 is paired in one direction with East US.
- East US is bidirectionally paired with West US.
- West India is paired in one direction only.
- West India's secondary region is South India, but South India's secondary region is Central India.
- Brazil South is unique because it's paired with a region outside of its geography.
- Brazil South's secondary region is South Central US. The secondary region of South Central US isn't Brazil South.
By following these steps, you can choose a secondary Azure region that ensures high availability, meets compliance requirements, and provides the necessary performance and cost-effectiveness for your multi-region architecture. In this lab, we are targeting any paired region which does not have any special considerations.
The first step is to identify a load balancer to support multiple regions. There are multiple 1st party options in Azure. When selecting a load balancer, ensure you have a clear understanding of your requirements to select the option with the appropriate features. The two primary options available are Azure Front Door and Azure Traffic Manager. Below are some key considerations and a decision tree to help guide you to the correct decision.
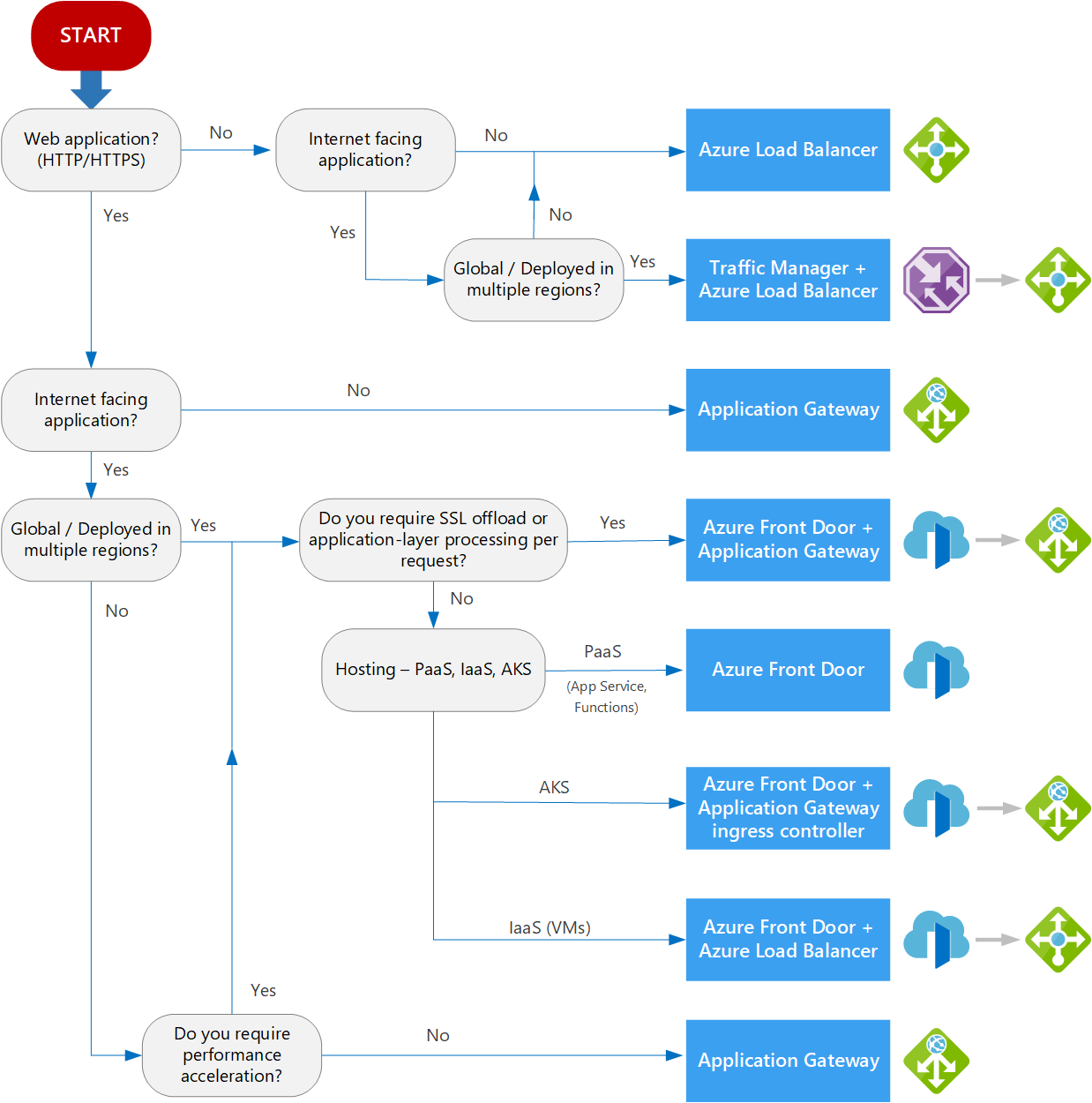
Front Door: Provides rapid failover with its Layer 7 capabilities, including SSL offload, path-based routing, and caching. This ensures high performance and availability, as well as quicker packet travel times since traffic is onboarded to the Azure network sooner.
Traffic Manager: Uses DNS-based load balancing, which inherently has slower failover due to DNS caching and the potential for systems to ignore DNS TTLs.
Front Door: Handles TLS offloading, which reduces the overhead for your services. However, it adds an additional hop and security considerations. Ensure that the architecture meets regulatory requirements and that Front Door's TLS cipher suites and backend service certificates align with your organization's security standards.
Traffic Manager: Does not handle TLS offloading, which means you must manage TLS certificates and termination within your backend services.
Front Door: The added cost can be justified by leveraging its full feature set beyond just failover, such as improved performance and availability.
Traffic Manager: More cost-effective and lightweight, suitable for scenarios where DNS-based failover speed is sufficient. Additional Considerations – If using AFD, can you explore not having AppGW?! Also, could you leverage CDN capability for your front-end and scale that layer of your architecture? How cost effective can it be to use AFD with WAF instead of Traffic Manager and Application Gateway with WAF? 1-2: Load-balancing options - Azure Architecture Center | Microsoft Learn
The objective of this lab is to implement and explore one or more of the common design strategies below around Multi-Region designs.
The next layer we are going to focus on is the Data Layer, for this workload it consists of Azure Storage account and Azure SQL Single DB.
SQL Database Steps Azure SQL Databases are used to store information relating to the application, data such as projects, engineer profiles, capacity project, time logging etc. You can use SQL Management Studio to connect to the DB should you wish.
Active geo-replication is a feature that lets you continuously replicate data from a primary database to a readable secondary database. The readable secondary database might be in the same Azure region as the primary, or, more commonly, in a different region. This kind of readable secondary database is also known as a geo-secondary or geo-replica.
Active geo-replication is configured per database, and only supports manual failover. To fail over a group of databases, or if your application requires a stable connection endpoint, consider Failover groups instead.
The failover groups feature allows you to manage the replication and failover of databases to another Azure region. You can choose all, or a subset of, user databases in a logical server to be replicated to another logical server. It's a declarative abstraction on top of the active geo-replication feature, designed to simplify deployment and management of geo-replicated databases at scale.
Configure using Tutorial:
- Geo-replication & failover in portal - Azure SQL Database | Microsoft Learn
- Configure a failover group - Azure SQL Database | Microsoft Learn
In this lab, we are using an auto failover group to get a stable connection endpoint. Failover groups provide a read-write and a read-only listener endpoint. Configure your applications to use these endpoints. The listener endpoints automatically update DNS records during failover, redirecting traffic to the new primary database.
Use Failover groups overview & best practices to set it up. - Azure SQL Database | Microsoft Learn
The failovers can be managed by the customer or Microsoft. But if it's Microsoft, then it might take some time depending on the grace period and the failover policy for the secondary database to come up which might not suit the RTO & RPO requirements of the customer. So, a path to explore would be how to switch over within the RTO and RPO using customer managed failover.
- Failover groups overview & best practices- Azure SQL Database | Microsoft Learn
- Disaster recovery guidance - Azure SQL Database | Microsoft Learn
To learn how to perform a recovery drill, follow this documentation - Disaster recovery drills - Azure SQL Database | Microsoft Learn
For Active-Active, one alternative can be to utilize - Azure Cosmos DB. This service can globally distribute data by transparently replicate the data to all regions in your Azure Cosmos DB account. You can also configure Azure Cosmos DB with multiple write regions.
Storage Account Steps The storage account is used to store specific content related to the application, file uploads by users, generated reports etc. Follow the steps below to migrate the deployed storage account from its current state to our desired state. Use Azure Storage Explorer to understand any downtime implications.
Open Azure Storage explorer on your workstation and connect to the storage account that was deployed during the bicep deployment. Once you have successfully connected, ensure you can create, upload and download blobs.
Follow the steps here to migrate to Multi Region support. You will notice there are two migration options, follow ‘Option one – customer initiated’ for the purpose of this lab.
Migrate Azure Storage accounts to multi region support | Microsoft Learn
You will notice that for the option we selected, there will be no impact on the availability of the storage account, however, it is not immediate and could take up to 72 hours to complete. This is something to keep in mind when conducting a migration to from ZRS to another resiliency type as the timing may play a role in ones remediation strategy. There are failover considerations to go through if we use private endpoints.
Microsoft-managed failover can't be initiated for individual storage accounts, subscriptions, or tenants. For more details see Microsoft-managed failover. Your disaster recovery plan should be based on customer-managed failover. Do not rely on Microsoft-managed failover, which would only be used in extreme circumstances.Because geo-replication is asynchronous, it is possible that data written to the primary region has not yet been written to the secondary region at the time an outage occurs.
The Last Sync Time property indicates the most recent time that data from the primary region is guaranteed to have been written to the secondary region. For accounts that have a hierarchical namespace, the same Last Sync Time property also applies to the metadata managed by the hierarchical namespace, including ACLs. All data and metadata written prior to the last sync time is available on the secondary, while data and metadata written after the last sync time may not have been written to the secondary, and may be lost.
Use this property in the event of an outage to estimate the amount of data loss you may incur by initiating an account failover.
To initiate a storage account failover - Azure Storage | Microsoft Learn For Active-Active, you can also utilize RA-GRS. Considerations for Storage Account Failover with Private Endpoints - Failover considerations for storage accounts with private endpoints - Azure Storage | Microsoft Learn
API Management
Azure API Management serves as the gateway to the API Web App, it is there for security, performance and resiliency reasons, providing rate limiting, secure API access and circuit breaker functionality where required.
Azure API Management supports multi-region deployment, which enables API publishers to add regional API gateways to an existing API Management instance in one or more supported Azure regions. Multi-region deployment helps reduce request latency perceived by geographically distributed API consumers and improves service availability if one region goes offline.
Or By publishing and managing your APIs via Azure API Management, you're taking advantage of fault tolerance and infrastructure capabilities that you'd otherwise design, implement, and manage manually. The Azure platform mitigates a large fraction of potential failures at a fraction of the cost.
To recover from availability problems that affect your API Management service, be ready to reconstitute your service in another region at any time. Depending on your recovery time objective, you might want to keep a standby service in one or more regions. You might also try to maintain their configuration and content in sync with the active service according to your recovery point objective. The API management backup and restore capabilities provide the necessary building blocks for implementing disaster recovery strategy.
For testing downtime, leverage an application such as Postman to test API call to APIM whilst the migration is happening. For this lab, utilize option 1.
Active/Active - One alternative can be to utilize App Gateway with WAF to utilize security features, since APIM does not have its own inbuilt firewall, with an APIM instance running in each region as its backend and it would be able to redirect calls to an active APIM instance.
App Services
It is a fully managed platform for creating and deploying cloud applications. It lets you define a set of compute resources for a web app to run, deploy web apps, and configure deployment slots. We would be deploying another web app service in the secondary region and add it as an endpoint to Application Gateway.
Keep the app in stopped state for the lab for Active/Passive - Cold spare. For Active/Active, you can keep it running.
Application Gateway & Load balancing
In this lab, you can choose not to deploy the Application Gateway if you are using Azure Front Door with WAF. However, if you are using Traffic Manager, then you would want to keep it. Deploy another instance of Application Gateway in the secondary region. We would keep all its configs similar to the one in Primary region. Keep it stopped for Active/Passive - Cold.
- Tutorial: Create an application gateway with a Web Application Firewall using the Azure portal | Microsoft Learn
- Manage traffic to App Service - Azure Application Gateway | Microsoft Learn
For Active/Active - keep it running. Resource to configure and understand Traffic Manager:
- Azure Traffic Manager | Microsoft Learn
- Create a TM Profile - Quickstart: Create a profile for HA of applications - Azure portal - Azure Traffic Manager | Microsoft Learn
- Routing Method - Azure Traffic Manager - traffic routing methods | Microsoft Learn
- Endpoint - Manage endpoints in Azure Traffic Manager | Microsoft Learn
- Endpoint Monitoring - Azure Traffic Manager endpoint monitoring | Microsoft Learn
In case you opt for Azure Front Door:
- Quickstart: How to use Azure Front Door Service to enable high availability - Azure portal | Microsoft Learn
- Tutorial: Create a WAF policy for Azure Front Door - Azure portal | Microsoft Learn
- Traffic routing methods to origin - Azure Front Door | Microsoft Learn
- Health probes - Azure Front Door | Microsoft Learn
Azure Key Vault
For most Azure regions that are paired with another region, the contents of your key vault are replicated both within the region and to the paired region. The paired region is usually at least 150 miles away, but within the same geography. This approach ensures high durability of your keys and secrets. For more information about Azure region pairs, see Azure paired regions. Two exceptions are the Brazil South region, which is paired to a region in another geography, and the West US 3 region. When you create key vaults in Brazil South or West US 3, they aren't replicated across regions.
For non-paired Azure regions, as well as the Brazil South and West US 3 regions, Azure Key Vault uses zone redundant storage (ZRS) to replicate your data three times within the region, across independent availability zones. For Azure Key Vault Premium, two of the three zones are used to replicate the hardware security module (HSM) keys. You can also use the backup and restore feature to replicate the contents of your vault to another region of your choice.
Azure Key Vault availability and redundancy - Azure Key Vault | Microsoft Learn
Azure Private DNS Zone
DNS private zones are resilient to regional outages because zone data is globally available. Resource records in a private zone are automatically replicated across regions. To make sure the secondary region can connect with the DNZ Zone, we need to link the secondary region v-net.
Quickstart - Create an Azure private DNS zone using the Azure portal | Microsoft Learn
This architecture uses functionality of private endpoints that may not be commonly encountered when doing single region deployments. First, an individual service can have multiple private endpoints attached to it. For example, a storage account could have a private endpoint for its blob containers located in multiple different virtual networks, and each one functions independently. However, this pattern isn't used often in hub and spoke scenarios because a Private DNS Zone can only have one record for a private endpoint. If you register your first private endpoint to your Private DNS Zone, other private endpoints would need to use other zones.
In addition, the private endpoints aren't required to be in the same region as the resource they're connecting to. A storage account in East US 2 can have a private endpoint deployed in Central US, to give one example.
So long as there's an alternate Private DNS Zone for that region, resources in the second can resolve and interact with the storage account. It's common to use private endpoints located in the same region to reduce costs. When considering failover, this functionality can allow regional private networking to work despite failures in one region.
Scenarios & Considerations
- If Application Gateway in the primary region goes down. In the current setup, Active/Passive, Cold Spare, the Application Gateway and App service in the secondary region is in stopped state. So, it needs to be turned on along with the App Service to perform the failover. The other services are up and running and their endpoints do not require any change in the application code. One consideration should be around the latency that will be uncurred due to the switchover of web app to the secondary region.
- If App service in the primary region is down – Refer Scenario 1
- If APIM in the primary region is down – Gateway configurations such as APIs and policy definitions are regularly synchronized between the primary and secondary regions you add. Propagation of updates to the regional gateways normally takes less than 10 seconds. Multi-region deployment provides availability of the API gateway in more than one region and provides service availability if one region goes offline. If a region goes offline, API requests are automatically routed around the failed region to the next closest gateway. If the primary region goes offline, the API Management management plane and developer portal become unavailable, but secondary regions continue to serve API requests using the most recent gateway configuration.
- Azure SQL in the primary region is down – We are utilizing an Auto-Failover group so, it would automatically failover to the secondary database, and nothing needs to be changed unless you have manual failover enabled. You might want to consider complete failover here, since latency can cause a degraded performance.
- Azure Storage Account is down – It is enabled with GRS. So, we need to initiate a failover Initiate a storage account failover - Azure Storage | Microsoft Learn
- Azure Key Vault is down – Nothing needs to be done
- Entire region is down – Manually start the AppGw and App service instances in secondary and perform manual failovers for other services like SQL and Storage Account.
Composite Availability Estimate
Availability Calculations are intended to be used as a rough-order-of-magnitude (ROM) estimate for the general availability of a workload based on the design and dependency chain of each critical flow. It is a great way to understand how design decisions relating to both the infrastructure in Azure and your application code play a role is a workloads level of potential availability.
Call to Action: Using the Microsoft Composite Availability Estimate Calculator (CATE), work out the Max Minutes of Downtime/month and the Composite Availability Target for the architecture and its critical flows to compare the before and after based on leveraging a single region & one of the multi-region strategies. For a table of details about the critical flows, read the workload preface.
Given that all services are now configured to handle regional failures, what would you need to perform a complete failover to the secondary region? Currently, you would need to manually failover or start/stop different components to play out the scenario. However, is this what you need in real-time? Wouldn’t you like to automate the failover completely? What would that need? How many or which services being down simultaneously would qualify for a complete failover? One alternative can be to utilize logs being sent to Event Hub which ingests it to Azure Stream Analytics to query the logs. Based on the result of the query, you can trigger an Azure Function to start/stop and initiate automatic failover to different services or maybe in turn trigger a Logic App workflow to send notifications to get approvals.
When you have finished with this scenario as part of the lab, simply delete the resource group named ‘rg-waf-mr-lab-scenario-3’. Everything that was deployed during the initial steps will reside within that resource group. If you deployed any additional resources outside of that resource group, be sure to do the same and clean them up also.