Mintos web scraper implemented in Python. (For research purposes only)
Warning: Mintos prohibit commercial use of web scrapers in their Terms & Conditions, so make sure you only utilise this project for personal use.
Mintos platform: https://www.mintos.com/en/
- Get portfolio data (Active funds, late funds, etc).
- Get Notes and Claims that you've invested in, with support for pagination and Mintos' filters.
- Get Notes that are listed on the Mintos primary and secondary marketplace, with support for pagination and Mintos' filters.
- Get details provided by Mintos on Notes and Claims.
- Returns Notes/Claims data in an easy-to-use Pandas DataFrame.
- Allows option to get raw data in JSON, instead of the parsed data in the Pandas DataFrame.
$ python -m pip install mintospyThis scraper uses audio transcription to automatically solve ReCAPTCHA challenges, so you need to have FFmpeg installed on your machine and in your PATH (If using windows) or just installed on your machine (For Linux or MacOS).
- Guide for installing FFmpeg on Windows: https://phoenixnap.com/kb/ffmpeg-windows
- Guide for installing FFmpeg on Linux: https://www.tecmint.com/install-ffmpeg-in-linux/
- Guide for installing FFmpeg on MacOS: https://phoenixnap.com/kb/ffmpeg-mac
Link to project used to solve ReCAPTCHA challenges: https://github.com/thicccat688/selenium-recaptcha-solver
from mintospy import API
mintos_api = API(
email='YOUR EMAIL HERE',
password='YOUR PASSWORD HERE',
tfa_secret='YOUR BASE32 TFA SECRET HERE', # This is only required if you have TFA enabled on your account (It should look something like this: PJJORHUYVGZVPQSF)
)
# Gets data for EUR (€) portfolio
print(mintos_api.get_portfolio_data(currency='EUR'))
# Gets 200 of the EUR (€) denominated notes from your "Current investments" section
print(mintos_api.get_investments(currency='EUR', quantity=200))
# Gets 300 of the EUR (€) denominated notes from your "Finished investments" section
print(mintos_api.get_investments(currency='EUR', quantity=300, claims=True))
# Gets 400 KZT (₸) denominated notes available in the primary marketplace for investment
print(mintos_api.get_loans(currency='KZT', quantity=400))
# Gets 400 KZT (₸) denominated notes available in the secondary marketplace for investment
print(mintos_api.get_loans(currency='KZT', quantity=400, secondary_market=True))You already have everything you need above, but if you're curious about how I've made this work, I've put the automation process below!
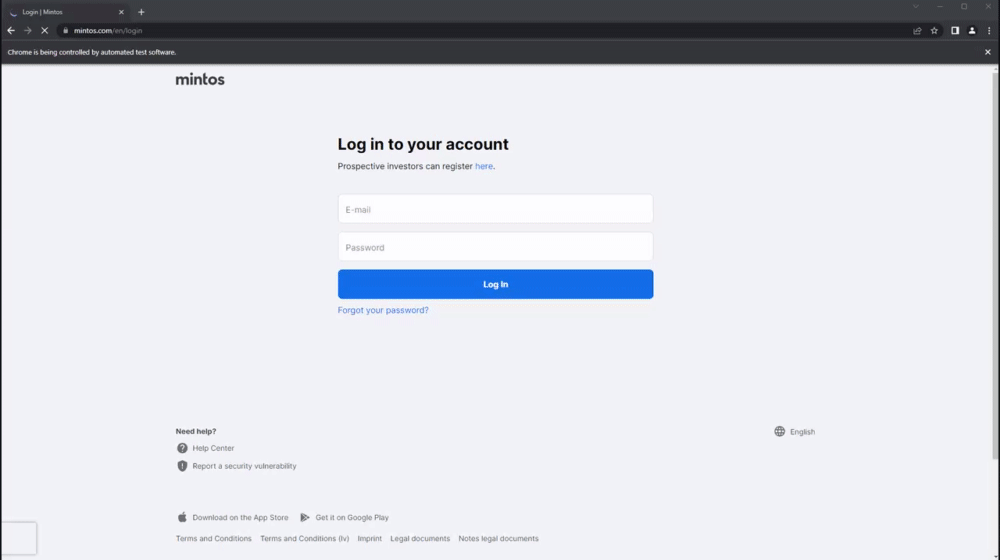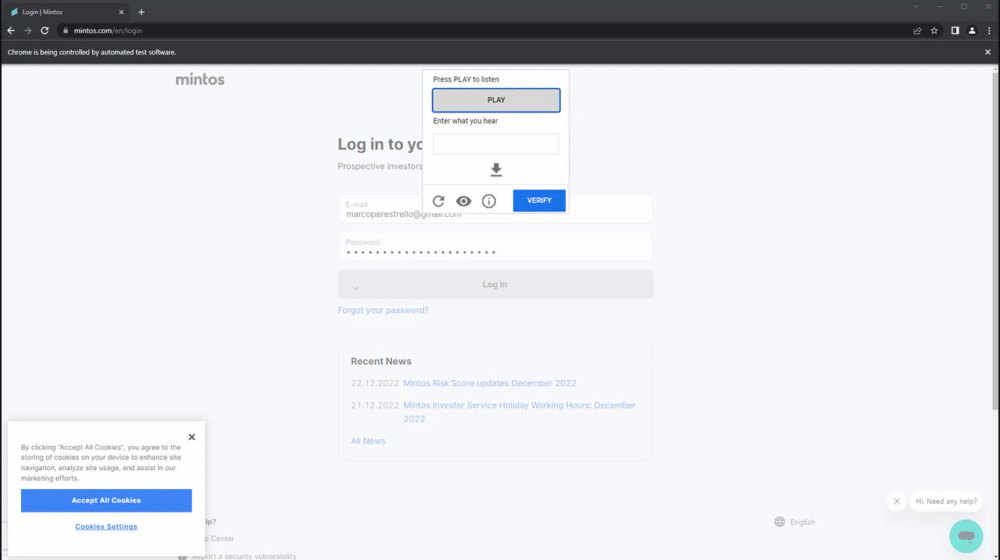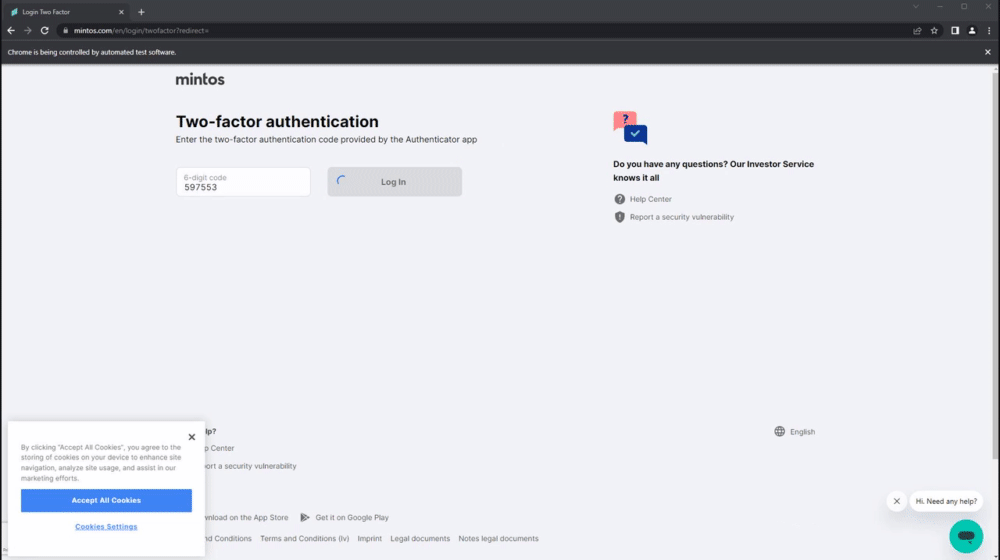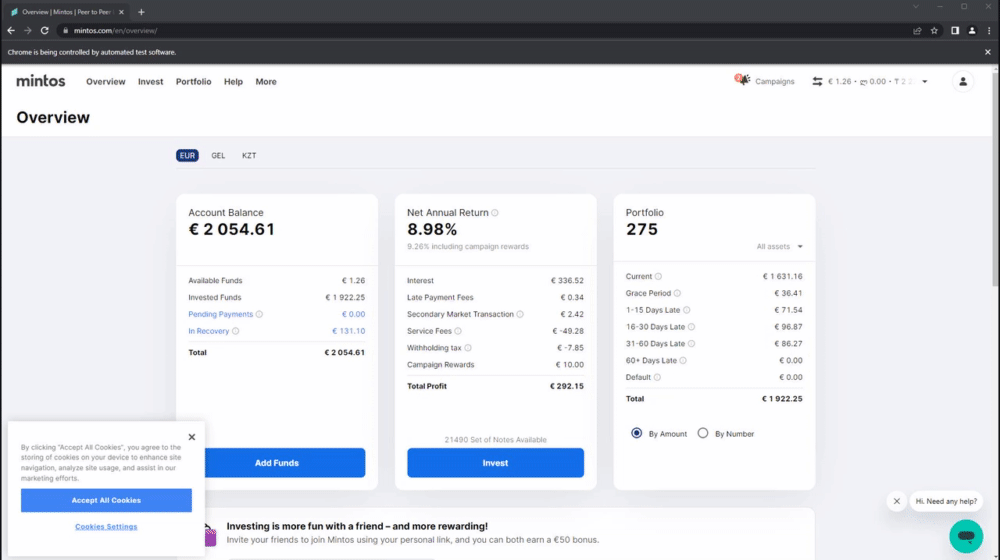
Authentication process:
- This part uses a headless browser to fill out the login form, resolve all the ReCAPTCHA challenges that appear, and, if applicable, generate the current TOTP token using the base32 secret provided by the user and fill out the TFA section.
- After a successful login, the driver pickles and saves the cookies, then load those cookies to avoid logging in again the next time the scraper is used (If the cookies haven't expired).
- To solve the ReCAPTCHA challenges, I'm using a package I made which works with Selenium. It solves the ReCAPTCHA challenges by using Google's speech recognition API to transcribe the audio and fill out the form as needed.
- If you're interested, here is the repository's URL: https://github.com/thicccat688/selenium-recaptcha-solver
Demonstration of the authentication process:
API request process and getting around Cloudflare:
- This part took a great deal of work to figure out and implement. On top of using ReCAPTCHA, Mintos uses Cloudflare to detect bots and secure their API.
- Cloudflare makes it so requests made by Python to Mintos' API endpoints, even given the correct headers, are rejected with a 403 HTTP response.
- Cloudflare runs a series of checks to guarantee the requestor is a legitimate browser, making it virtually impossible to make requests without a web driver to emulate a browser's properties.
- I went around this by constructing the request payloads in Python and using said payloads to execute the desired API calls using the Fetch API in the web driver's console.
- Due to performance constraints, I also made a function that can do this concurrently, which I use for mass retrieval of investments or loans.
- This workaround means there's no need to scrape Mintos' UI to get the data we need so that we can perform data extraction more efficiently and in a less error-prone way.
Final message:
If you've reached this far, thank you! If you have any criticism or ideas about what can be improved, please get in touch with me through discord (ThiccCat#3210). Thanks again, and I hope this package can be of use to you!