
 -
- -
- -
- -
- -
-With the goal of making information digestion faster, we designed a concept graph generator that includes relevant information on a text’s main concepts and visually shows how topics relate to one another. To achieve this, our graph outputs nodes that represent article concepts, and edges that represent links between the concepts.
-
-We use Streamlit for the front end interface and a custom version of the Streamlit graphing libraries to display our graphs. The resulting graphs are interactive—users can move the graph and individual nodes as well as zoom in and out freely, or click a node to receive a digest of the topic in textual context.
-
-Additionally, we provide users with a threshold slider that allows users to decide how many nodes/connections they want their graph to provide. This customization doubles as an optimization for the shape and density of the graph. How this works is that connections between nodes are determined by a similarity score between the nodes (via cosine similarity on the word embeddings). A connection is drawn between two topics if the score is above the threshold from the slider. This means that as the slider moves further to the left, the lower threshold makes the graph generate more nodes, and the resulting graph would be more dense.
-
-### Working with Multiple Graphs
-
-Beyond generating graphs from a single text source, users can combine graphs they have previously generated to see how concepts from several articles interrelate. In the below example, we see how two related articles interact when graphed together. Here we have one from the Bitcoin Wikipedia page and the other from the Decentralized Finance page. We can distill from a quick glance that both articles discuss networking, bitcoin, privacy, blockchain and currency concepts (as indicated by green nodes), but diverge slightly as the Bitcoin article focuses on the system specification of Bitcoin and the Decentralized Finance article talks more about impacts of Bitcoin on markets. The multi-graph option allows users to not only assess the contents of several articles all at once with a single glance, but also reveals insights on larger concepts through visualizing the interconnections of the two sources. A user could use this tool to obtain a holistic view on any area of research they want to delve into.
-
-
-
-With the goal of making information digestion faster, we designed a concept graph generator that includes relevant information on a text’s main concepts and visually shows how topics relate to one another. To achieve this, our graph outputs nodes that represent article concepts, and edges that represent links between the concepts.
-
-We use Streamlit for the front end interface and a custom version of the Streamlit graphing libraries to display our graphs. The resulting graphs are interactive—users can move the graph and individual nodes as well as zoom in and out freely, or click a node to receive a digest of the topic in textual context.
-
-Additionally, we provide users with a threshold slider that allows users to decide how many nodes/connections they want their graph to provide. This customization doubles as an optimization for the shape and density of the graph. How this works is that connections between nodes are determined by a similarity score between the nodes (via cosine similarity on the word embeddings). A connection is drawn between two topics if the score is above the threshold from the slider. This means that as the slider moves further to the left, the lower threshold makes the graph generate more nodes, and the resulting graph would be more dense.
-
-### Working with Multiple Graphs
-
-Beyond generating graphs from a single text source, users can combine graphs they have previously generated to see how concepts from several articles interrelate. In the below example, we see how two related articles interact when graphed together. Here we have one from the Bitcoin Wikipedia page and the other from the Decentralized Finance page. We can distill from a quick glance that both articles discuss networking, bitcoin, privacy, blockchain and currency concepts (as indicated by green nodes), but diverge slightly as the Bitcoin article focuses on the system specification of Bitcoin and the Decentralized Finance article talks more about impacts of Bitcoin on markets. The multi-graph option allows users to not only assess the contents of several articles all at once with a single glance, but also reveals insights on larger concepts through visualizing the interconnections of the two sources. A user could use this tool to obtain a holistic view on any area of research they want to delve into.
-
- -
-### Visual Embedding Generation
-
-
-
-### Visual Embedding Generation
-
-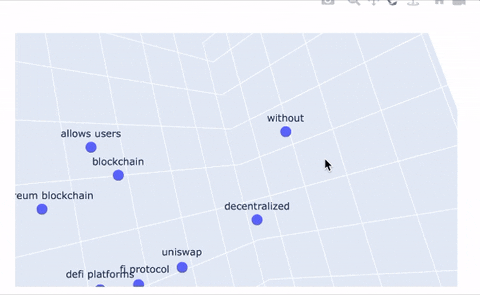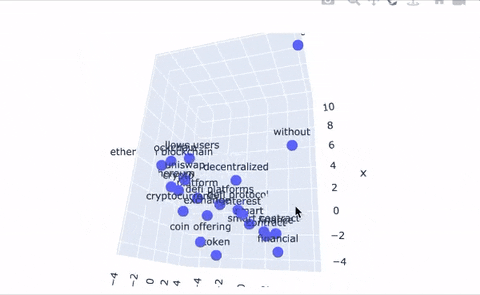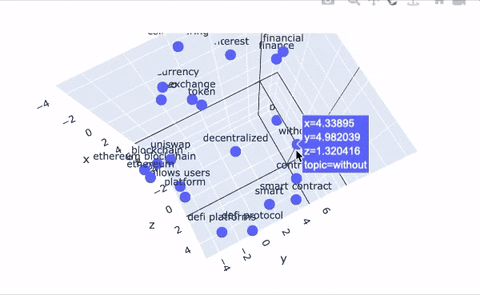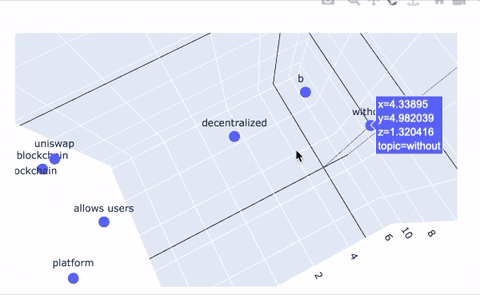 -
-An additional feature our system provides is a tool to plot topics in 2D and 3D space to provide a new way of representing topic relations. Even better, we use the Poltly library to make these plots interactive! The embedding tools simply take the embedding that corresponds to each topic node in our graph and projects it into 2D space. Topic clustering indicates high similarity or strong relationships between those topics, and large distances between topics indicates dissimilarity. The same logic applies to the 3D representation; we give users the ability to upgrade their 2D plots to 3D, if they're feeling especially adventurous.
-
-### Deployment and Caching
-
-We deployed our app on the Google Cloud Platform (GCP) via Docker. In particular, we sent a cloud built docker image to Google Cloud, and set up a powerful VM that launched the app from that Docker image. For any local updates to the application, redeploying was quite simple, requiring us to rebuild the image using Google Cloud Build and point the VM to the updated image.
-
-To speed up performance of our app, we cache graphs globally. Let’s say you are trying to graph an article about Taylor Swift’s incredible Folklore album, but another user had recently generated the same graph. Our caching system ensures that the cached graph would be quickly served instead of being re-generated, doing so by utilizing Streamlit’s global application cache. Our initial caching implementation resulted in User A’s generated and named graphs appearing in a User B’s application. To fix this, we updated each user’s session state individually instead of using one global state over all users, therefore preventing User A’s queries from interfering with User B’s experience.
-
-### Our Backend: Machine Learning for Concept Extraction and Graph Generation
-
-
-Our concept graph generation pipeline is displayed in Figure 1. Users are allowed to provide either custom input (arbitrarily-formatted text) or a web URL, which we parse and extract relevant textual information from. We next generate concepts from that text using numerous concept extraction techniques, including TF-IDF and PMI-based ranking over extracted n-grams: unigrams, bigrams, and trigrams. The resulting combined topics are culled to the most relevant ones, and subsequently contextualized by sentences that contain the topics. Finally, each topic is embedded according to its relevant context, and these final embeddings are used to compute (cosine) similarities. We then define edges among topics with a high enough similarity and present these outputs as a graph visualization. Our primary machine intelligence pipelines are introduced in (1) our TF-IDF concept extraction of relevant topics from the input text and (2) our generation of BERT embeddings of each topic using the contextual information of the topic within the input text.
-
-
-
-An additional feature our system provides is a tool to plot topics in 2D and 3D space to provide a new way of representing topic relations. Even better, we use the Poltly library to make these plots interactive! The embedding tools simply take the embedding that corresponds to each topic node in our graph and projects it into 2D space. Topic clustering indicates high similarity or strong relationships between those topics, and large distances between topics indicates dissimilarity. The same logic applies to the 3D representation; we give users the ability to upgrade their 2D plots to 3D, if they're feeling especially adventurous.
-
-### Deployment and Caching
-
-We deployed our app on the Google Cloud Platform (GCP) via Docker. In particular, we sent a cloud built docker image to Google Cloud, and set up a powerful VM that launched the app from that Docker image. For any local updates to the application, redeploying was quite simple, requiring us to rebuild the image using Google Cloud Build and point the VM to the updated image.
-
-To speed up performance of our app, we cache graphs globally. Let’s say you are trying to graph an article about Taylor Swift’s incredible Folklore album, but another user had recently generated the same graph. Our caching system ensures that the cached graph would be quickly served instead of being re-generated, doing so by utilizing Streamlit’s global application cache. Our initial caching implementation resulted in User A’s generated and named graphs appearing in a User B’s application. To fix this, we updated each user’s session state individually instead of using one global state over all users, therefore preventing User A’s queries from interfering with User B’s experience.
-
-### Our Backend: Machine Learning for Concept Extraction and Graph Generation
-
-
-Our concept graph generation pipeline is displayed in Figure 1. Users are allowed to provide either custom input (arbitrarily-formatted text) or a web URL, which we parse and extract relevant textual information from. We next generate concepts from that text using numerous concept extraction techniques, including TF-IDF and PMI-based ranking over extracted n-grams: unigrams, bigrams, and trigrams. The resulting combined topics are culled to the most relevant ones, and subsequently contextualized by sentences that contain the topics. Finally, each topic is embedded according to its relevant context, and these final embeddings are used to compute (cosine) similarities. We then define edges among topics with a high enough similarity and present these outputs as a graph visualization. Our primary machine intelligence pipelines are introduced in (1) our TF-IDF concept extraction of relevant topics from the input text and (2) our generation of BERT embeddings of each topic using the contextual information of the topic within the input text.
-
- -
-Pipeline Illustration: A diagram of our text-to-graph pipeline, which uses machine intelligence models to extract concepts from an arbitrary input span of text.
-
-Our concept extraction pipeline started with the most frequent unigrams and bigrams present in the input text, but we soon realized that doing so populated our graph with meaningless words that had little to do with the article and instead represented common terms and phrases broadly used in the English language. Although taking stopwords into account and further ranking bigrams by their pointwise mutual information partially resolved this issue, we were unable to consistently obtain concepts that accurately represented the input. We properly resolved this issue by pre-processing a large Wikipedia dataset consisting of 6 million examples to extract “inverse document frequencies'' for common unigrams, bigrams, and trigrams. We then rank each topic according to its term frequency-inverse document frequency (TF-IDF) ratio, representing the uniqueness of the term to the given article compared to the overall frequency of the term in a representative sample of English text. TF-IDF let us properly select topics that were unique to the input documents, significantly improving our graph quality.
-
-To embed extracted topics, we initially used pre-trained embeddings from GloVe and word2vec. Both of these algorithms embed words using neural networks trained on context windows that place similar words close to each other in the embedding space. A limitation with these representations is that they fail to consider larger surrounding context when making predictions. This was particularly problematic for our use-case, as using pre-trained context-independent word embeddings would yield identical graphs for a set of concepts. And when we asked users to evaluate the quality of the generated graphs, the primary feedback was that the graph represented abstract connections between concepts as opposed to being drawn from the text itself. Taking this into account, we knew that the graphs we wanted should be both meaningful and specific to their input articles.
-
-In order to resolve this issue and generate contextually-relevant graphs, we introduced a BERT embedding model that embeds each concept along with its surrounding context, producing an embedding for each concept that was influenced by the article it was present in. Our BERT model is pre-trained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia (excluding lists, tables and headers). We used embeddings from the final layer of the BERT model—averaged across all WordPiece-split tokens describing the input concept—to create our final 1024-dimensional embeddings for each concept. We implemented caching mechanisms to ensure that identical queries would have their associated embeddings and adjacency matrices cached for future use. This improves the efficiency of the overall process and even guarantees graph generation completes in under 30 seconds for user inputs of reasonable length (it’s usually faster than that).
-
-## System Evaluation
-
-Since we are working with unstructured data and unsupervised learning, we had to be a little more creative in how we evaluated our model’s performance. To start, we created a few metrics to gather for generated graphs that would help us better quantify the performance of our system. The metrics include:
-
-- The time to generate a novel, uncached graph
-- The number of nodes and edges generated, along with average node degree
-- Ratings of pop-up context digest quality
-- An graph-level label of whether it is informative overall
-- The number of generated topics that provide no insight
-- The number of topics that are substrings of another topic
-
-When designing metrics to track, our main goal was to capture the utility of our app to users. The runtime of graph generation is paramount, as users can easily grow impatient with wait times that are too long. The number of nodes shows how many topics we present to the user, the number of edges indicates how many connections our tool is able to find, and the average degree captures the synergy between those two. The pop-up context digests can either provide useful or irrelevant additional information. Having a general sense for the overall quality of information in graphs is important to note. Nodes generated based on irrelevant topics waste users’ time, so we want to minimize that. Similarly, nodes with topics that are substrings of other topics in the graph are also unwanted, as they indicate redundant information in our graph.
-
-With our metrics defined, we began generating graphs and annotating them by hand. We found that the average graph takes 20.4 seconds to generate and has 13.27 nodes and 13.55 edges, leading to an average node degree of 1.02. Overall, we are happy with the graph generation time that we measured — 20 seconds is a reasonable expectation for our users, especially considering we are not currently using a GPU. On average, we found that the graphs were informative 68% of the time. The times that they were not were caused either by too high of a threshold or poor topic generation. In particular, we noticed that performance was poor on articles that covered many different areas of a topic, such as articles discussing matchup predictions for March Madness. While the overarching theme of college basketball was the main focus of those articles, they discussed many different teams, which led the model to have a tough time parsing out common threads, such as the importance of an efficient offense and lockdown defense on good teams, throughout the article.
-
-Our default graph generation uses a threshold of 0.65 for the cosine similarity between topics to form an edge between them. For reference, we also tested our graph generation with thresholds of 0.6 and 0.7 for the edge cosine similarity and found that they yielded an average node degree of 1.71 and 0.81, respectively. An average node degree of 1.71 is too high and floods the user with many frivolous connections between topics. An average node degree of 0.81, on the other hand, doesn’t show enough of the connections that actually exist between topics. Therefore, a threshold of 0.65, with an average node degree of 1.02, provides a nice balance between topics presented and the connections between them.
-
-As for the errors we were scanning for, we found that on average, 12.33% of nodes in every graph were topics that added nothing and 17.81% of nodes were simply substrings of another topic in the graph. Therefore, about 69.86% of the nodes that we present to users are actually relevant. This tells us that users on our site may spend some time sifting through irrelevant topics, which we hope to improve in the future. We additionally rated the quality of the contextual information displayed in each node’s pop-up digest window, and found that (on a scale of 0-1) our ratings averaged 0.71. This was largely caused by lack of sufficient filtering applied to the sentences displayed. Filtering and curation heuristics for these digests is another potential area of growth.
-
-## Application Demonstration
-
-Interested users should visit our application at [this URL](http://104.199.124.26/), where they are presented with a clean, simple, and intuitive interface that allows them to either (a) input custom text to graph, (b) input a web URL to graph, or (c) generate a combined graph from two of their previously saved graphs. Upon entering custom text or a web URL, users are shown a progress bar estimating the time of graph generation (or an instant graph if the query has been cached from previous uses of the website). Generated graphs are interactive, allowing users to click on nodes to see the context in which they appear in the input document. We also present other modes of visualization, including a 2D and 3D PCA-based embedding of the concepts, which provide a different perspective of relationships between concepts. Users can also save graphs locally (to their local browser cache), and subsequently combine them to link concepts together across numerous distinct documents.
-
-Our team chose to use a web interface as it proved to be the most intuitive and straightforward way for users to provide custom input and interact with the produced graphs. We implemented our own customizations to the Streamlit default graphing library (in [this fork](https://github.com/mananshah99/streamlit-agraph)) to enable enhanced interactivity, and we employed Streamilit to ensure a seamless development process between our python backend and the frontend interface.
-
-Watch us demo our platform and [give it a try](http://104.199.124.26/) !
-
-
-
-## Reflection
-
-### What worked well?
-We had such a rewarding and exciting experience this quarter building out this application. From day one, we were all sold on the context graph idea and committed a lot of time and energy into it. We are so happy with the outcome that we want to continue working on it next quarter. We will soon reach out to some of the judges that were present at the demo but didn’t make it to our room.
-
-While nontrivial, building out the application was a smooth process for several reasons: technical decisions, use of Streamlit, great camaraderie. Let’s break these down.
-
-Our topic retrieval process is quite simple, with the use of highest frequency n-grams weighted by PMI scores, with n={1,2,3}. TF-IDF was a good addition to topic filtering (the graphs were more robust as a result), but because it was slower we added it as a checkbox option to the user. Sentence/context retrieval required carefully designed regular expressions, but proved to work incredibly efficiently once properly implemented. We then had to shape the topics and contexts correctly and after passing them through BERT, compute cosine similarities. For displaying graphs, we utilized a Streamlit component called streamilt-agraph. While it had all the basic functionality we needed, there were things we wanted to add on top of it (e.g. clicking on nodes to display context), which required forking the repo and making custom changes on our end.
-
-Due to the nature of our project, it was pretty feasible to build out the MVP on Streamlit and iterate by small performance improvements and new features. This made individual contributions easy to line up with Git issues and to execute on different branches. It also helped that we have an incredible camaraderie already, as we all met in Stanford’s study abroad program in Florence in 2019.
-
-### What didn't work as well?
-To be honest, nothing crazy here. We had some obscure bugs from BERT embeddings that would occur rarely but at random, as well as graph generation bugs if inputs were too small. We got around them with try/catch blocks, but could have looked into them with a little more attention.
-
-### If we had unlimited time & unlimited resources...
-Among the four of us, we made our best guesses as to what the best features would be for our application. Of course if time permitted, we could conduct serious user research about what people are looking for, and we could build exactly that. But apart from that, there are actual action items moving forward, discussed below.
-
-We wanted to create an accessible tutorial or perhaps some guides either on the website or an accessible location. This may actually no longer be necessary because we can point to the tutorial provided in this blog (see Application Demonstration). We saw in many cases that without any context of what our application does, users may not know what our app is for or how they could get the most out of it.
-
-On top of this, future work includes adding a better URL (i.e. contextgraph.io), including a Chrome extension, building more fluid topic digests in our pop-ups, and submitting a pull request to the streamlit-agraph component with our added functionality—in theory we could then deploy this for free via Streamlit.
-
-## Broader Impacts
-**Context Graph Generator Impacts**:
-
-- **Summarization**: Our ***intuitive interface*** combined with ***robust graph generation*** enables users to understand large bodies of text with a simple glance.
-
-- **Textual Insights**: The extensive features we offer from multi-graphing to TF-IDF topic generation to context summarization for each node enables users to ***generate analysis and insights*** for their inquiries on the fly.
-
-Our aim in creating this tool is to empower individuals to obtain the information they need with ease, so they are empowered to achieve their goals at work or in their personal lives. Whether the user has to synthesize large amounts of information for their business or simply seek to stay informed while on a busy schedule, our tool is here to help!
-
-When considering the ethical implications of such a tool, it becomes apparent that while a context graph largely positively impacts users, it’s important to consider how it could become a weapon of misinformation. When a user provides text for the graph generator to analyze, we do not perform fact checking of the provided text. We believe this is reasonable considering that our platform is an analysis tool. Additionally, because we are also operating only natively within our site and graphs are not shareable, there is no possibility of a generated graph object being shared to inform others (one could take a screenshot of the graph, however, most detailed information is embedded in the nodes’ pop-up). If we were to make graphs shareable or integrate our tool into other platforms, we run the risk of being a tool of misinformation if users were to share graphs that help people quickly digest information. As we continue to work on our platform, we will keep this scenario top of mind and work to find ways to prevent such an outcome.
-
-
-## Contributions
-- Blake: Worked on generating PCA projection plots from embeddings, saving graphs, graph combination, and Streamlit UI.
-- Ella: Worked on graph topic generation (primarily TF-IDF & data processing), reducing skew in embeddings of overlapping topics, and Streamlit UI
-- Lauren: Worked on graph topic generation, GCP deployment, and Streamlit UI
-- Manan: Worked on graph topic generation, embedding and overall graph generation, streamlit-agraph customization for node popup context digests, and Streamlit UI
-
-## References
-
-
-Our system was built using [Streamlit](https://streamlit.io), Plotly and [HuggingFace’s BERT model](https://huggingface.co/transformers/model_doc/bert.html). To deploy our system, we used Docker and GCP.
-
-We utilized the [Tensorflow Wikipedia English Dataset](https://www.tensorflow.org/datasets/catalog/wikipedia) for IDF preprocessing as well.
\ No newline at end of file
diff --git a/_posts/2021-03-18-stylify.markdown b/_posts/2021-03-18-stylify.markdown
deleted file mode 100644
index 3b3c306..0000000
--- a/_posts/2021-03-18-stylify.markdown
+++ /dev/null
@@ -1,157 +0,0 @@
----
-layout: post
-title: Stylify
-date: 2021-03-18 20:13:20 -0700
-description: Stylify
-img: # Add image post (optional)
-fig-caption: # Add figcaption (optional)
-tags: [Edge-ML]
-comments: true
----
-
-### The Team
-- Daniel Tan
-- Noah Jacobson
-- Jiatu Liu
-
-## Problem Definition
-
-Where photography is limited by its reliance on reality, art transcends the confines of the physical world. At the same time, art is a highly technical skill, relying on fine motor control and knowledge of materials to put one’s mental image to paper. Professional artists must study for years and hone their technical skills through repeated projects. As a result, while everyone has the capacity for creativity, far fewer have the ability to materialize their imagination on the canvas.
-
-We seek to bridge this gap with Stylify, our application for neural style transfer. With our app, anyone can create original art by combining the characteristics of multiple existing images. Everybody has an innate aesthetic sense; a latent capacity for art. Our lofty ambition is to allow the human mind to fully embrace its creativity by giving form to abstract thought.
-
-Implementation-wise, our application is backed by a state-of-the-art neural style transfer model. Whereas previous style transfer models are trained to learn a finite number of styles, our model is able to extract the style of arbitrary images, providing true creative freedom to end users. Our model is also extremely efficient. Where previous style transfer models arrive at the output by iterated minimization, requiring many forward passes, our model requires only a single forward pass through the architecture, saving time and compute resources. The fully-convolutional architecture also means that images of any size can be stylified.
-
-## System Design
-
-Our system consists of 4 main components:
-
-1. A ReactJS frontend, which provides the interface for end users to interact with our application
-2. An API endpoint deployed using Sagemaker. It provides access to the style transfer model, which accepts batches of content and style images and returns an image with the content of the former and the style of the latter
-3. A Python middleman server, which performs preprocessing on the inputs sent by the frontend, and queries the model through the endpoint. In order to support video input, the server unpacks videos into component frames and makes a batch query to the endpoint.
-4. An S3 bucket which is used for temporary file storage as well as logging of metrics
-
-Our system is summarized below.
-
-
-
-Pipeline Illustration: A diagram of our text-to-graph pipeline, which uses machine intelligence models to extract concepts from an arbitrary input span of text.
-
-Our concept extraction pipeline started with the most frequent unigrams and bigrams present in the input text, but we soon realized that doing so populated our graph with meaningless words that had little to do with the article and instead represented common terms and phrases broadly used in the English language. Although taking stopwords into account and further ranking bigrams by their pointwise mutual information partially resolved this issue, we were unable to consistently obtain concepts that accurately represented the input. We properly resolved this issue by pre-processing a large Wikipedia dataset consisting of 6 million examples to extract “inverse document frequencies'' for common unigrams, bigrams, and trigrams. We then rank each topic according to its term frequency-inverse document frequency (TF-IDF) ratio, representing the uniqueness of the term to the given article compared to the overall frequency of the term in a representative sample of English text. TF-IDF let us properly select topics that were unique to the input documents, significantly improving our graph quality.
-
-To embed extracted topics, we initially used pre-trained embeddings from GloVe and word2vec. Both of these algorithms embed words using neural networks trained on context windows that place similar words close to each other in the embedding space. A limitation with these representations is that they fail to consider larger surrounding context when making predictions. This was particularly problematic for our use-case, as using pre-trained context-independent word embeddings would yield identical graphs for a set of concepts. And when we asked users to evaluate the quality of the generated graphs, the primary feedback was that the graph represented abstract connections between concepts as opposed to being drawn from the text itself. Taking this into account, we knew that the graphs we wanted should be both meaningful and specific to their input articles.
-
-In order to resolve this issue and generate contextually-relevant graphs, we introduced a BERT embedding model that embeds each concept along with its surrounding context, producing an embedding for each concept that was influenced by the article it was present in. Our BERT model is pre-trained on BookCorpus, a dataset consisting of 11,038 unpublished books and English Wikipedia (excluding lists, tables and headers). We used embeddings from the final layer of the BERT model—averaged across all WordPiece-split tokens describing the input concept—to create our final 1024-dimensional embeddings for each concept. We implemented caching mechanisms to ensure that identical queries would have their associated embeddings and adjacency matrices cached for future use. This improves the efficiency of the overall process and even guarantees graph generation completes in under 30 seconds for user inputs of reasonable length (it’s usually faster than that).
-
-## System Evaluation
-
-Since we are working with unstructured data and unsupervised learning, we had to be a little more creative in how we evaluated our model’s performance. To start, we created a few metrics to gather for generated graphs that would help us better quantify the performance of our system. The metrics include:
-
-- The time to generate a novel, uncached graph
-- The number of nodes and edges generated, along with average node degree
-- Ratings of pop-up context digest quality
-- An graph-level label of whether it is informative overall
-- The number of generated topics that provide no insight
-- The number of topics that are substrings of another topic
-
-When designing metrics to track, our main goal was to capture the utility of our app to users. The runtime of graph generation is paramount, as users can easily grow impatient with wait times that are too long. The number of nodes shows how many topics we present to the user, the number of edges indicates how many connections our tool is able to find, and the average degree captures the synergy between those two. The pop-up context digests can either provide useful or irrelevant additional information. Having a general sense for the overall quality of information in graphs is important to note. Nodes generated based on irrelevant topics waste users’ time, so we want to minimize that. Similarly, nodes with topics that are substrings of other topics in the graph are also unwanted, as they indicate redundant information in our graph.
-
-With our metrics defined, we began generating graphs and annotating them by hand. We found that the average graph takes 20.4 seconds to generate and has 13.27 nodes and 13.55 edges, leading to an average node degree of 1.02. Overall, we are happy with the graph generation time that we measured — 20 seconds is a reasonable expectation for our users, especially considering we are not currently using a GPU. On average, we found that the graphs were informative 68% of the time. The times that they were not were caused either by too high of a threshold or poor topic generation. In particular, we noticed that performance was poor on articles that covered many different areas of a topic, such as articles discussing matchup predictions for March Madness. While the overarching theme of college basketball was the main focus of those articles, they discussed many different teams, which led the model to have a tough time parsing out common threads, such as the importance of an efficient offense and lockdown defense on good teams, throughout the article.
-
-Our default graph generation uses a threshold of 0.65 for the cosine similarity between topics to form an edge between them. For reference, we also tested our graph generation with thresholds of 0.6 and 0.7 for the edge cosine similarity and found that they yielded an average node degree of 1.71 and 0.81, respectively. An average node degree of 1.71 is too high and floods the user with many frivolous connections between topics. An average node degree of 0.81, on the other hand, doesn’t show enough of the connections that actually exist between topics. Therefore, a threshold of 0.65, with an average node degree of 1.02, provides a nice balance between topics presented and the connections between them.
-
-As for the errors we were scanning for, we found that on average, 12.33% of nodes in every graph were topics that added nothing and 17.81% of nodes were simply substrings of another topic in the graph. Therefore, about 69.86% of the nodes that we present to users are actually relevant. This tells us that users on our site may spend some time sifting through irrelevant topics, which we hope to improve in the future. We additionally rated the quality of the contextual information displayed in each node’s pop-up digest window, and found that (on a scale of 0-1) our ratings averaged 0.71. This was largely caused by lack of sufficient filtering applied to the sentences displayed. Filtering and curation heuristics for these digests is another potential area of growth.
-
-## Application Demonstration
-
-Interested users should visit our application at [this URL](http://104.199.124.26/), where they are presented with a clean, simple, and intuitive interface that allows them to either (a) input custom text to graph, (b) input a web URL to graph, or (c) generate a combined graph from two of their previously saved graphs. Upon entering custom text or a web URL, users are shown a progress bar estimating the time of graph generation (or an instant graph if the query has been cached from previous uses of the website). Generated graphs are interactive, allowing users to click on nodes to see the context in which they appear in the input document. We also present other modes of visualization, including a 2D and 3D PCA-based embedding of the concepts, which provide a different perspective of relationships between concepts. Users can also save graphs locally (to their local browser cache), and subsequently combine them to link concepts together across numerous distinct documents.
-
-Our team chose to use a web interface as it proved to be the most intuitive and straightforward way for users to provide custom input and interact with the produced graphs. We implemented our own customizations to the Streamlit default graphing library (in [this fork](https://github.com/mananshah99/streamlit-agraph)) to enable enhanced interactivity, and we employed Streamilit to ensure a seamless development process between our python backend and the frontend interface.
-
-Watch us demo our platform and [give it a try](http://104.199.124.26/) !
-
-
-
-## Reflection
-
-### What worked well?
-We had such a rewarding and exciting experience this quarter building out this application. From day one, we were all sold on the context graph idea and committed a lot of time and energy into it. We are so happy with the outcome that we want to continue working on it next quarter. We will soon reach out to some of the judges that were present at the demo but didn’t make it to our room.
-
-While nontrivial, building out the application was a smooth process for several reasons: technical decisions, use of Streamlit, great camaraderie. Let’s break these down.
-
-Our topic retrieval process is quite simple, with the use of highest frequency n-grams weighted by PMI scores, with n={1,2,3}. TF-IDF was a good addition to topic filtering (the graphs were more robust as a result), but because it was slower we added it as a checkbox option to the user. Sentence/context retrieval required carefully designed regular expressions, but proved to work incredibly efficiently once properly implemented. We then had to shape the topics and contexts correctly and after passing them through BERT, compute cosine similarities. For displaying graphs, we utilized a Streamlit component called streamilt-agraph. While it had all the basic functionality we needed, there were things we wanted to add on top of it (e.g. clicking on nodes to display context), which required forking the repo and making custom changes on our end.
-
-Due to the nature of our project, it was pretty feasible to build out the MVP on Streamlit and iterate by small performance improvements and new features. This made individual contributions easy to line up with Git issues and to execute on different branches. It also helped that we have an incredible camaraderie already, as we all met in Stanford’s study abroad program in Florence in 2019.
-
-### What didn't work as well?
-To be honest, nothing crazy here. We had some obscure bugs from BERT embeddings that would occur rarely but at random, as well as graph generation bugs if inputs were too small. We got around them with try/catch blocks, but could have looked into them with a little more attention.
-
-### If we had unlimited time & unlimited resources...
-Among the four of us, we made our best guesses as to what the best features would be for our application. Of course if time permitted, we could conduct serious user research about what people are looking for, and we could build exactly that. But apart from that, there are actual action items moving forward, discussed below.
-
-We wanted to create an accessible tutorial or perhaps some guides either on the website or an accessible location. This may actually no longer be necessary because we can point to the tutorial provided in this blog (see Application Demonstration). We saw in many cases that without any context of what our application does, users may not know what our app is for or how they could get the most out of it.
-
-On top of this, future work includes adding a better URL (i.e. contextgraph.io), including a Chrome extension, building more fluid topic digests in our pop-ups, and submitting a pull request to the streamlit-agraph component with our added functionality—in theory we could then deploy this for free via Streamlit.
-
-## Broader Impacts
-**Context Graph Generator Impacts**:
-
-- **Summarization**: Our ***intuitive interface*** combined with ***robust graph generation*** enables users to understand large bodies of text with a simple glance.
-
-- **Textual Insights**: The extensive features we offer from multi-graphing to TF-IDF topic generation to context summarization for each node enables users to ***generate analysis and insights*** for their inquiries on the fly.
-
-Our aim in creating this tool is to empower individuals to obtain the information they need with ease, so they are empowered to achieve their goals at work or in their personal lives. Whether the user has to synthesize large amounts of information for their business or simply seek to stay informed while on a busy schedule, our tool is here to help!
-
-When considering the ethical implications of such a tool, it becomes apparent that while a context graph largely positively impacts users, it’s important to consider how it could become a weapon of misinformation. When a user provides text for the graph generator to analyze, we do not perform fact checking of the provided text. We believe this is reasonable considering that our platform is an analysis tool. Additionally, because we are also operating only natively within our site and graphs are not shareable, there is no possibility of a generated graph object being shared to inform others (one could take a screenshot of the graph, however, most detailed information is embedded in the nodes’ pop-up). If we were to make graphs shareable or integrate our tool into other platforms, we run the risk of being a tool of misinformation if users were to share graphs that help people quickly digest information. As we continue to work on our platform, we will keep this scenario top of mind and work to find ways to prevent such an outcome.
-
-
-## Contributions
-- Blake: Worked on generating PCA projection plots from embeddings, saving graphs, graph combination, and Streamlit UI.
-- Ella: Worked on graph topic generation (primarily TF-IDF & data processing), reducing skew in embeddings of overlapping topics, and Streamlit UI
-- Lauren: Worked on graph topic generation, GCP deployment, and Streamlit UI
-- Manan: Worked on graph topic generation, embedding and overall graph generation, streamlit-agraph customization for node popup context digests, and Streamlit UI
-
-## References
-
-
-Our system was built using [Streamlit](https://streamlit.io), Plotly and [HuggingFace’s BERT model](https://huggingface.co/transformers/model_doc/bert.html). To deploy our system, we used Docker and GCP.
-
-We utilized the [Tensorflow Wikipedia English Dataset](https://www.tensorflow.org/datasets/catalog/wikipedia) for IDF preprocessing as well.
\ No newline at end of file
diff --git a/_posts/2021-03-18-stylify.markdown b/_posts/2021-03-18-stylify.markdown
deleted file mode 100644
index 3b3c306..0000000
--- a/_posts/2021-03-18-stylify.markdown
+++ /dev/null
@@ -1,157 +0,0 @@
----
-layout: post
-title: Stylify
-date: 2021-03-18 20:13:20 -0700
-description: Stylify
-img: # Add image post (optional)
-fig-caption: # Add figcaption (optional)
-tags: [Edge-ML]
-comments: true
----
-
-### The Team
-- Daniel Tan
-- Noah Jacobson
-- Jiatu Liu
-
-## Problem Definition
-
-Where photography is limited by its reliance on reality, art transcends the confines of the physical world. At the same time, art is a highly technical skill, relying on fine motor control and knowledge of materials to put one’s mental image to paper. Professional artists must study for years and hone their technical skills through repeated projects. As a result, while everyone has the capacity for creativity, far fewer have the ability to materialize their imagination on the canvas.
-
-We seek to bridge this gap with Stylify, our application for neural style transfer. With our app, anyone can create original art by combining the characteristics of multiple existing images. Everybody has an innate aesthetic sense; a latent capacity for art. Our lofty ambition is to allow the human mind to fully embrace its creativity by giving form to abstract thought.
-
-Implementation-wise, our application is backed by a state-of-the-art neural style transfer model. Whereas previous style transfer models are trained to learn a finite number of styles, our model is able to extract the style of arbitrary images, providing true creative freedom to end users. Our model is also extremely efficient. Where previous style transfer models arrive at the output by iterated minimization, requiring many forward passes, our model requires only a single forward pass through the architecture, saving time and compute resources. The fully-convolutional architecture also means that images of any size can be stylified.
-
-## System Design
-
-Our system consists of 4 main components:
-
-1. A ReactJS frontend, which provides the interface for end users to interact with our application
-2. An API endpoint deployed using Sagemaker. It provides access to the style transfer model, which accepts batches of content and style images and returns an image with the content of the former and the style of the latter
-3. A Python middleman server, which performs preprocessing on the inputs sent by the frontend, and queries the model through the endpoint. In order to support video input, the server unpacks videos into component frames and makes a batch query to the endpoint.
-4. An S3 bucket which is used for temporary file storage as well as logging of metrics
-
-Our system is summarized below.
-
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
- -
-[Covid Risk Evaluation - Hosted on GCP Cloud Run](https://covid-risk-evaluation-fynom42syq-uc.a.run.app/)
-
-### GitHub Link
-[CS 329S - Covid Risk Evaluation Repository](https://github.com/LukasHaas/cs329s-covid-prediction)
-
-### The Team
-- [Lukas Haas](https://www.linkedin.com/in/lukas-haas/)
-- [Dilara Soylu](https://www.linkedin.com/in/dilarasoylu/)
-- [John Spencer](https://www.linkedin.com/in/johnspe/)
-
-
-## **Problem Definition**
-
-Since the start of the COVID-19 pandemic, widespread testing has become a significant bottleneck in the efforts to monitor, model and prevent the spread of the disease. Obtaining accurate information about a person’s disease status is critical in order to isolate infected individuals and decrease the reproduction number of the virus. Unfortunately, we see four major issues with current testing regimes; first, oropharyngeal swab tests are invasive, expensive, and time consuming; second, the time required to receive test results is significant, ranging anywhere from 30 minutes for rapid swab tests to three days for PCR tests in a lab at the time of this writing; third, contamination risk is high when individuals travel to testing sites to obtain their tests, and last but not least, tests need to be administered by trained clinicians, severely limiting throughput.
-
-In order to address current issues with testing, we developed a machine learning system to instantly test for and collect data on COVID-19 using the cough sounds recorded on the users’ personal devices. The World Health Organization (WHO) has [reported](https://www.who.int/docs/default-source/searo/myanmar/documents/coronavirus-disease-factsheet-3.pdf?sfvrsn=471f4cf_0) that 5 out of 6 COVID-19 patients exhibit mild symptoms, most commonly a “dry cough” producing a unique audio signature in the lungs. Cough sound analyses have proven to be effective for diagnosing other respiratory diseases such as [pertussis](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0162128), [pneumonia, and asthma](https://ieeexplore.ieee.org/document/7311223).
-
-[Our system ](https://covid-risk-evaluation-fynom42syq-uc.a.run.app/)is deployed on **Google Cloud Platform (GCP)** and achieves a **ROC-AUC score of 71%**.
-
-## **System Design**
-
-There are three different user groups for our system:
-
-1. **Regular Users**
-
- The first group involves the regular users who would like to get pre-screened for COVID-19 to inform themselves. The goal of this group is to provide them a rough idea about whether the cough-like symptoms they are experiencing could be related to COVID-19. If the cough test results signal that COVID-19 is a high possibility, the users are encouraged to seek out medical help and isolate.
-
-2. **Medical Practitioners**
-
- The second group involves medical practitioners who would like to employ a test that is both faster and cheaper before they try out more expensive, and time consuming tests. Based on the results showing the likelihood of COVID, test takers are advised to take more rigorous tests.
-
-3. **Community Administrators**
-
- The third group involves the community admins who would like to ensure the safety of their community by employing a cheaper pre-screening test for COVID.
-
-All of our users access our app through the web using their mobile devices. For all of our users, a key consideration we kept in mind while designing our system was **interpretability**; we made sure to include both personalized and general explanations of how our model makes predictions. This not only informs our users but also encourages them to give back by donating their cough data for research. Interpretability is especially important for the medical practitioners using our app: even if our model fails to make the correct prediction, the methodologies and their interpretations that are being displayed can help the medical practitioners make more informed decisions.
-
-
-
-[Covid Risk Evaluation - Hosted on GCP Cloud Run](https://covid-risk-evaluation-fynom42syq-uc.a.run.app/)
-
-### GitHub Link
-[CS 329S - Covid Risk Evaluation Repository](https://github.com/LukasHaas/cs329s-covid-prediction)
-
-### The Team
-- [Lukas Haas](https://www.linkedin.com/in/lukas-haas/)
-- [Dilara Soylu](https://www.linkedin.com/in/dilarasoylu/)
-- [John Spencer](https://www.linkedin.com/in/johnspe/)
-
-
-## **Problem Definition**
-
-Since the start of the COVID-19 pandemic, widespread testing has become a significant bottleneck in the efforts to monitor, model and prevent the spread of the disease. Obtaining accurate information about a person’s disease status is critical in order to isolate infected individuals and decrease the reproduction number of the virus. Unfortunately, we see four major issues with current testing regimes; first, oropharyngeal swab tests are invasive, expensive, and time consuming; second, the time required to receive test results is significant, ranging anywhere from 30 minutes for rapid swab tests to three days for PCR tests in a lab at the time of this writing; third, contamination risk is high when individuals travel to testing sites to obtain their tests, and last but not least, tests need to be administered by trained clinicians, severely limiting throughput.
-
-In order to address current issues with testing, we developed a machine learning system to instantly test for and collect data on COVID-19 using the cough sounds recorded on the users’ personal devices. The World Health Organization (WHO) has [reported](https://www.who.int/docs/default-source/searo/myanmar/documents/coronavirus-disease-factsheet-3.pdf?sfvrsn=471f4cf_0) that 5 out of 6 COVID-19 patients exhibit mild symptoms, most commonly a “dry cough” producing a unique audio signature in the lungs. Cough sound analyses have proven to be effective for diagnosing other respiratory diseases such as [pertussis](https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0162128), [pneumonia, and asthma](https://ieeexplore.ieee.org/document/7311223).
-
-[Our system ](https://covid-risk-evaluation-fynom42syq-uc.a.run.app/)is deployed on **Google Cloud Platform (GCP)** and achieves a **ROC-AUC score of 71%**.
-
-## **System Design**
-
-There are three different user groups for our system:
-
-1. **Regular Users**
-
- The first group involves the regular users who would like to get pre-screened for COVID-19 to inform themselves. The goal of this group is to provide them a rough idea about whether the cough-like symptoms they are experiencing could be related to COVID-19. If the cough test results signal that COVID-19 is a high possibility, the users are encouraged to seek out medical help and isolate.
-
-2. **Medical Practitioners**
-
- The second group involves medical practitioners who would like to employ a test that is both faster and cheaper before they try out more expensive, and time consuming tests. Based on the results showing the likelihood of COVID, test takers are advised to take more rigorous tests.
-
-3. **Community Administrators**
-
- The third group involves the community admins who would like to ensure the safety of their community by employing a cheaper pre-screening test for COVID.
-
-All of our users access our app through the web using their mobile devices. For all of our users, a key consideration we kept in mind while designing our system was **interpretability**; we made sure to include both personalized and general explanations of how our model makes predictions. This not only informs our users but also encourages them to give back by donating their cough data for research. Interpretability is especially important for the medical practitioners using our app: even if our model fails to make the correct prediction, the methodologies and their interpretations that are being displayed can help the medical practitioners make more informed decisions.
-
- -
- -
-  -
-  -
-  -
-  -
- -
-  -
-  -
-  -
-  -
- -
- -
-
-
-
-
-
-
-
diff --git a/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html b/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html
deleted file mode 100644
index 1182253..0000000
--- a/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html
+++ /dev/null
@@ -1,507 +0,0 @@
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html b/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html
deleted file mode 100644
index 1182253..0000000
--- a/_site/Fact-Checking-Tool-for-Public-Health-Claims/index.html
+++ /dev/null
@@ -1,507 +0,0 @@
-
-
-
-
- Fact-Checking Tool for Public Health Claims
-The Team
--
-
- Alex Gui -
- Vivek Lam -
- Sathya Chitturi -
Problem Definition
- -Due to the nature and popularity of social networking sites, misinformation can propagate rapidly leading to widespread dissemination of misleading and even harmful information. A plethora of misinformation can make it hard for the public to understand what claims hold merit and which are baseless. The process of researching and validating claims can be time-consuming and difficult, leading to many users reading articles and never validating them. To tackle this issue, we made an easy-to-use tool that will help automate fact checking of various claims focusing on the area of public health. Based on the text the user puts into the search box, our system will generate a prediction that classifies the claim as one of True, False, Mixed or Unproven. Additionally, we develop a model which matches sentences in a news article against common claims that exist in a training set of fact-checking data. Much of the prior inspiration for this work can be found in Kotonya et al where the authors generated the dataset used in this project and developed a method to evaluate the veracity of claims and corresponding explanations. With this in mind we tried to address veracity prediction and explainability in our analysis of news articles.
- -System Design
- -Our system design used the following steps: 1) Development of ML models and integration with Streamlit 2) Packaging the application into a Docker container 3) Deployment of the application using Google App Engine.
- - -
--
-
- In order to allow users to have an interactive experience, we designed a web application using Streamlit for fake news detection and claim evaluation. We chose Streamlit for three primary reasons: amenability to rapid prototyping, ready integration with existing ML pipelines and clean user interface. Crucial to the interface design was allowing the users a number of different ways to interact with the platform. Here we allowed the users to either choose to enter text into text boxes directly or enter a URL from which the text could be automatically scraped using the Beautiful Soup python library. Therefore, using this design pipeline we were able to quickly get a ML-powered web-application working on a local host! -
- To begin the process of converting our locally hosted website to a searchable website, we used Docker containers. Docker is a tool that can help easily package a local project into an environment known as a container that can be run on another machine. For this project, our Docker container hosted the machine learning models, relevant training and testing data, the Streamlit application file (app.py) as well as a file named “requirements.txt” which contained a list of names of packages needed to run the application. -
- With our application packaged, we deployed our Docker container on Google App Engine using the Google Cloud SDK. Essentially, this created a CPU (or sets of CPUs) in the cloud to host the web-app and models. We opted for an auto-scaling option which means that the number of CPUs automatically scale with the number of requests. For example, many CPU cores will be used in periods of high traffic and few CPU cores will be used in periods of low traffic. Here, it is worth noting that we considered other choices for where to host the model including Amazon AWS and Heroku. We opted for Google App Engine over Heroku since we needed more than 500MB of storage; furthermore, we preferred App Engine to AWS in order to take advantage of the $300 free GCP credit! -
Machine Learning Component
- -We build our model to achieve two tasks: veracity prediction and relevant fact-check recommendation. The veracity prediction model is a classifier that takes in a text input and predicts it to be one of true, false, mixed and unproven with the corresponding probabilities. The model is trained on PUBHEALTH, an open source dataset of fact-checked health claims. The dataset contains 11.8k health claims, with the original texts and expert-annotated ground-truth labels and explanations. More details about the dataset can be found here.
- -We first trained a baseline LSTM (Long Short Term Memory Network), a recurrent neural network that’s widely used in text classification tasks. We fit the tokenizer and classification model from scratch using tensorflow and Keras. We trained the model for 3 epochs using an embedding dimension size of 32. With a very simple architecture, we were able to get decent results on the held-out test set (see Table 1).
- -In the next iterations, we improved the baseline model leveraging state-of-the-art language model DistilBERT with the huggingface API. Compared to the LSTM which learns one-directional sequentially, BERT makes use of Transformer which encodes the entire sequence at once, and is thus able to learn word embeddings with a deeper context. We used a lightweight pretrained model DistilBERT (a distilled version of BERT, more details can be found here and fine-tuned it on the same training dataset. We trained the model for 5 epochs using warm up steps of 500 and weight-decay of 0.02. All prediction metrics were improved on the test set. The DistilBERT model takes 5x longer time to train, however at inference step, both models are fast in generating online predictions.
- -
The supervised-learning approach is extremely efficient and has good precision to capture signals of misinformation. However, the end-to-end neural network is black-box in nature and the prediction is never perfect, it is very unsatisfying for users to only receive a prediction without knowing how models arrive at certain decisions. Additionally, users don’t gain new information or become better-informed from reading a single classifier result, which defeats the overall purpose of the application. Therefore, we implemented a relevant claim recommendation feature to promote explainability and trust. Based on the user input, our app would search for claims in the training data that are similar to the input sentences. This provides two additional benefits: 1) users will have proxy knowledge of what kind of signals our classifier learned 2) users can read relevant health claims that are fact-checked by reliable sources to better understand the subject-matter.
- -For implementation, we encode the data on a sentence level using Sentence-BERT. The top recommendations are generated by looking for the nearest neighbors in the embedding space. For each sentence in the user input, we look for most similar claims in the training dataset using cosine similarity. We returned the trigger sentence and most relevant claims with similarity scores above 0.8.
- -
System Evaluation
- -We conducted offline evaluation on the Pubhealth held-out test set (n = 1235). The first table showed the overall accuracy of the two models. Since our task is multi-label classification, we are interested in the performance per each class, particularly in how discriminative our model is in flagging false information.
- -| Model | -Accuracy (Overall) | -F1 (False) | -
|---|---|---|
| LSTM | -0.667 | -0.635 | -
| DistilBERT Fine Tuned | -0.685 | -0.674 | -
Table 1: Overall accuracy of the two models
- -| Label | -F1 | -Precision | -Recall | -
|---|---|---|---|
| False (n = 388 ) | -0.674 | -0.683 | -0.665 | -
| Mixed (n = 201) | -0.4 | -0.365 | -0.443 | -
| True (n = 599 ) | -0.829 | -0.846 | -0.813 | -
| Unproven (n = 47 ) | -0.286 | -0.324 | -0.255 | -
Table 2: F1, Precision and Recall per class of Fine-tuned BERT model
- -Our overall accuracy isn’t amazing, but it is consistent with the results we see in the original pubhealth paper. There are several explanations:
--
-
- Multi-label classification is inherently challenging, and since our class sizes are imbalanced, we sometimes suffer from poor performance in the minority classes. -
- Text embeddings themselves don’t provide rich enough signals to verify the veracity of content. Our model might be able to pick up certain writing styles and keywords, but they lack the power to predict things that are outside of what experts have fact-checked. -
- It is very hard to predict “mixed” and “unproven” (Table 2). -
However looking at the breakdown performance per class, we observe that the model did particularly well in predicting true information, meaning that most verified articles aren’t flagged as false or otherwise. This is good because it is equally damaging for the model to misclassify truthful information, and thus make users trust our platform less. It also means that if we count mixed and unproven as “potentially containing false information”, our classifier actually achieved good accuracy on a binary label prediction task (>80%).
- -Some interesting examples
- -In addition to system-level evaluation, we provide some interesting instances where the model did particularly well and poorly.
- -Case 1 (Success, DistilBERT): False information, Model prediction: mixture, p = 0.975
- -“The notion that the cancer industry isn’t truly looking for a ‘cure’ may seem crazy to many, but the proof seems to be in the numbers. As noted by Your News Wire, if any of the existing low-cost, natural and alternative cancer treatments were ever to be approved, then the healthcare industry’s cornerstone revenue producer would vanish within months. Sadly, it doesn’t appear that big pharma would ever want that to happen. The industry seems to be what is keeping us from a cure. Lets think about how big a business cancer has become over the years. In the 1940’s, before all of the technology and innovation that we have today, just one out of every 16 people was stricken with cancer; by the 70’s, that ratio fell to 1 in 10. Today, one in two males are at risk of developing some form of cancer, and for women that ratio is one in three.”
- -This is an example of a very successful prediction. The above article leveraged correct data to draw false conclusions. For example, that cancer rate has increased is true information that was included in the training database, but the writing itself is misleading. The model did a good job of predicting mixture.
- -Case 2 (Failure, DistilBERT): False information, Model prediction: true, p = 0.993
- -“WUHAN, China, December 23, 2020 (LifeSiteNews) – A study of almost 10 million people in Wuhan, China, found that asymptomatic spread of COVID-19 did not occur at all, thus undermining the need for lockdowns, which are built on the premise of the virus being unwittingly spread by infectious, asymptomatic people. Published in November in the scientific journal Nature Communications, the paper was compiled by 19 scientists, mainly from the Huazhong University of Science and Technology in Wuhan, but also from scientific institutions across China as well as in the U.K. and Australia. It focused on the residents of Wuhan, ground zero for COVID-19, where 9,899,828 people took part in a screening program between May 14 and June 1, which provided clear results as to the possibility of any asymptomatic transmission of the virus.”
- -This is a case of the model failing completely. We suspect that this is because the article is written very appropriately, and quoted prestigious scientific journals, which all made the claim look legitimate. Given that there is no exact similar claim matched in the training data, the model tends to classify it as true.
- -Slice analysis
- -We performed an analysis of the LSTM model performance on various testing dataset slices. Our rationale for doing these experiments was that the LSTM likely makes a number of predictions based on writing style or similar semantics rather than the correct content. Thus, it is very possible that a model written with a “non-standard” with True information might be predicted to be False. Our slices, which included word count, percentage of punctuation, average sentence length, and date published were intended to be style features that might help us learn more about our model’s biases.
- -Here we would like to highlight an example of the difficulty in interpreting the results of a slice based analysis for a multi-class problem. In this example, we slice the dataset by word count and create two datasets corresponding to whether the articles contain more than or less than 500 words. We found that the accuracy for the shorter articles was 0.77 while the accuracy for the larger articles was 0.60. Although this seems like a large difference in performance, there are some hidden subtleties that are worth considering further. In Table 3, we show the per-class performance for both splits as well as the number of samples in each split. Here, it is clear to see that class distributions of the two datasets are quite different, making a fair comparison challenging. For instance, it is likely that we do well on the lower split dataset because it contains a large fraction of True articles which is the class which is best predicted by our model.
- -| Labels | -Lower Split Accuracy | -Lower Split Nsamples | -Upper Split Accuracy | -Upper Split Nsamples | -
|---|---|---|---|---|
| False | -0.7320 | -97 | -0.7526 | -291 | -
| Mixture | -0.2041 | -49 | -0.2368 | -152 | -
| True | -0.8810 | -311 | -0.7118 | -288 | -
| Unproven | -0.3636 | -11 | -0.0588 | -34 | -
Table 3: Slice analysis on word count
- -Similarity Matching
- -To evaluate the quality of similarity matching, one proxy is to look at the cosine similarity score of the recommended claims. Since we only returned those with similarity scores of more than 0.8, the matching results should be close to each other in the embedding space. However it is less straightforward to evaluate the embedding quality. For the scope of this project, we did not conduct systematic evaluation of semantic similarities of the recommended claims. But we did observe empirically that the recommended claims are semantically relevant to the input article, but they don’t always provide correction to false information. We provide one example in our app demonstration section.
- -Application Demostration
- -To serve users, we opted to create a web application for deployment. We settled on this choice as it enabled a highly interactive and user friendly interface. In particular, it is easy to access the website URL via either a phone or a laptop.
- -
There are three core tabs in our streamlit web-application: Fake News Prediction, Similarity Matching and Testing.
- -Fake News Prediction Tab
- -The Fake News Prediction tab allows the user to make predictions as to whether a news article contains false claims (“False”) , true claims (“True”), claims of unknown veracity (“Unknown”) or claims which have both true and false elements (“Mixed”). Below, we show an example prediction on text from the following article: Asymptomatic transmission of COVID-19 didn’t occur at all, study of 10 million finds. Here, our LSTM model correctly identifies that this article contains false claims!
- - -
-Similarity Matching Tab
- -The Similarity Matching Tab compares sentences in a user input article to fact checked claims made in the PUBHEALTH fact-check dataset. Again we allow users the option of being able to enter either a URL or text. The following video demonstrates the web-app usage when provided the URL corresponding to the article: Study: Covid-19 deadlier than flu. Here, it is clear that the model identifies some relevant claims made in the article including the number of deaths from covid, as well as comparisons between covid and the flu.
- - -
-Testing Tab
- -Finally, our “Testing” tab allows users to see the impact of choosing different PUBHEALTH testing slices on the performance of the baseline LSTM model. For this tab, we allow the user to select the break point for the split. For instance, for the word count slicing type, if we select 200, this means that we create two datasets: one with only articles shorter than 200 words and another with only articles larger than 200 words. Check out the video below for a demo of splicing the dataset on the punctuation condition!
- - -
-Reflection
- -Overall, our project was quite successful as a proof of concept for the design of a larger ML driven fact-checking platform. We succeeded in developing two models (LSTM and DistilBERT) that can reasonably detect fake news on a wide range of user articles. We achieved promising results on a held-out testing set and found that our model was relatively stable to some common dataset slices. Furthermore, for some inputs, our Sentence-BERT was able to detect claims in the article which were similar to those contained within our training set. We were also able to allocate work and seamlessly integrate among our three team members. Although all members contributed significantly to each part of the project, Alex focused on the model training and validation while Vivek and Satya focused on the UI and deployment. Despite the successes of this project, there are several things that either don’t work or need improvement.
- -One major area for improvement is on the sentence claim matcher. Currently when certain articles make claims that are outside of the distribution of the training dataset there will be no relevant training claims that can be matched to. This is inherently due to the lack of training data needed for these types of applications. To address this issue it would be useful to periodically scrape fact-checked claims and evidence from websites such as snopes to keep the database up to date and expanding. Additionally, we could incorporate user feedback in our database after being reviewed by us or an external fact-checking group.
- -Another issue is that we have two separate features, one where the veracity of an article is predicted based primarily on style (LSTM and DistilBERT models), and one where we attempt to extract the content by matching with fact checked claims. An ideal model would be able to combine style and content. Additionally, the claims that we can match sentences to are limited by the data in our training set.
- -Another improvement we could make pertains to the testing tab. Currently we output the per-class accuracy, but we could additionally output several figures such as histograms and confusion matrices. Better visualization will help users understand quickly how the models perform on different slices.
- -Broader Impacts
- -Fake news poses a tremendous risk to the general public. With the high barrier required to fact check certain claims and articles we hope that this project will start to alleviate some of this burden from casual internet users and help people better decide what information they can trust. Although this is the intended use case of our project, we recognize that there is potential harm that can arise from the machine learning models predicting the wrong veracity for some articles. One can easily imagine that if our model predicts that an article has true information, but it is actually fake news this would only cause the user to further believe in the article. To try to mitigate this type of issue, we used the sentence claim matching algorithm where article sentences can be matched to fact-checked claims. If this approach is done correctly the user will in theory have access to training claims that are similar to those in the article and the label associated with the training claims. In addition, we chose to include a tab which showed how our model performed on different slices of the testing data. We believe showing this type of data to users could be a very useful tool for harm mitigation as it allows the users to more fully assess potential biases in the models. At the end of the day because these models are all imperfect we include a disclaimer that these predictions are not a substitute for professional fact-checking.
- -Contributions
- -All members contributed significantly to each part of the project. Alex focused more on model training and development. Vivek and Sathya focused more on UI and deployment. We gratefully acknowledge helpful discussions and feedback from Chip Huyen and Xi Yan throughout the project! In addition, special thanks to Navya Lam and Callista Wells for helping find errors and bugs in our UI.
- -References
- -We referred the the following models to guide ML model development:
- --
-
- Sanh, V., Debut, L., Chaumond, J. and Wolf, T., 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108. -
- Reimers, N. and Gurevych, I., 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084. -
We used data from the following dataset:
- --
-
- Kotonya, N. and Toni, F., 2020. Explainable automated fact-checking for public health claims. arXiv preprint arXiv:2010.09926. -
We found the following tutorials and code very helpful for model deployment via Streamlit/Docker/App Engine.
- --
-
- Jesse E. Agbe (2021), GitHub repository, https://github.com/Jcharis/Streamlit_DataScience_Apps -
- Daniel Bourke (2021), GitHub repository https://github.com/mrdbourke/cs329s-ml-deployment-tutorial -
Core technologies used:
- --
-
- Tensorflow, Pytorch, Keras, Streamlit, Docker, Google App Engine -
 -
- -
- -
-

 -Figure 4. CovidBot Demonstration for Personal and General Covid Question-Answering
-Figure 4. CovidBot Demonstration for Personal and General Covid Question-Answering -
- -
-
 is the empirical probability of each loss as shown in Figure 3,
is the empirical probability of each loss as shown in Figure 3, 
 -
-






 -
- -
-
 -
- -
-


 -
- -
-
 -
-

 -
-


 -
- -
-