今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显。关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。
一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重。
当MYSQL 收到一条查询请求时,会首先通过关键字对SQL语句进行解析,生成一颗“解析树”,然后预处理器会校验“解析树”是否合法(主要校验数据列和表明是否存在,别名是否有歧义等),当“解析树”被认为合法后,查询优化器会对这颗“解析树”进行优化,并确定它认为最完美的执行计划。
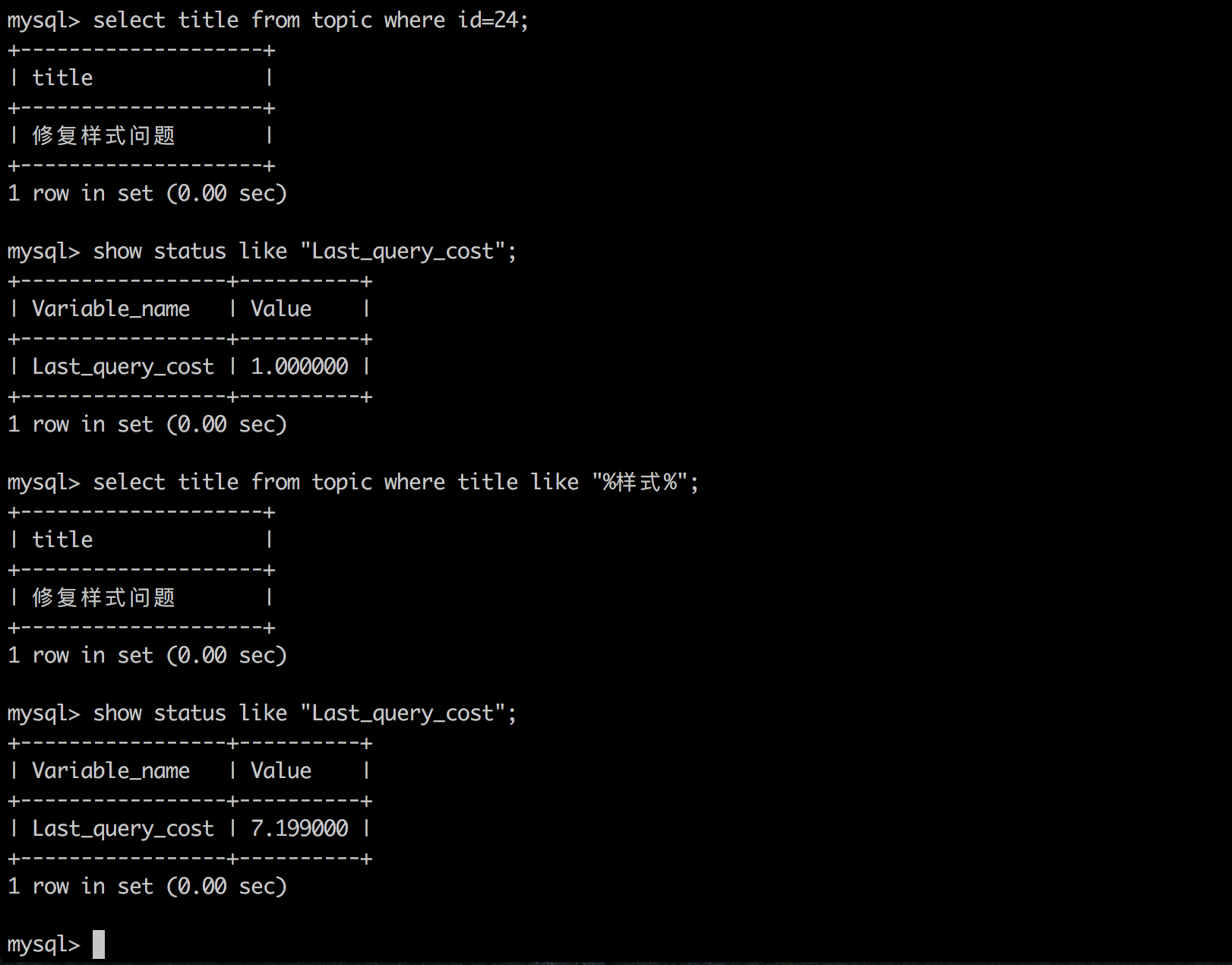
MYSQL查询优化器衡量某个执行计划是否完美的标准是使用该执行计划时的成本,该成本的最小单位是读取一个4K数据页的成本。下面图中的数据说明,当使用id为条件查询时,查询的成本只有一个数据页,而使用title查询时(非索引),成本将近是7个数据页(数据量比较小):
如何对查询进行优化是一个复杂的问题,在开始介绍查询优化前,需要先了解explain命令。使用 EXPLAIN 关键字可以让我们知道MySQL是如何处理SQL语句的,可以帮我们分析查询语句和表结构的性能瓶颈。EXPLAIN 的查询结果还会告诉我们索引主键被如何利用的,你的数据表是如何被搜索和排序的等等。
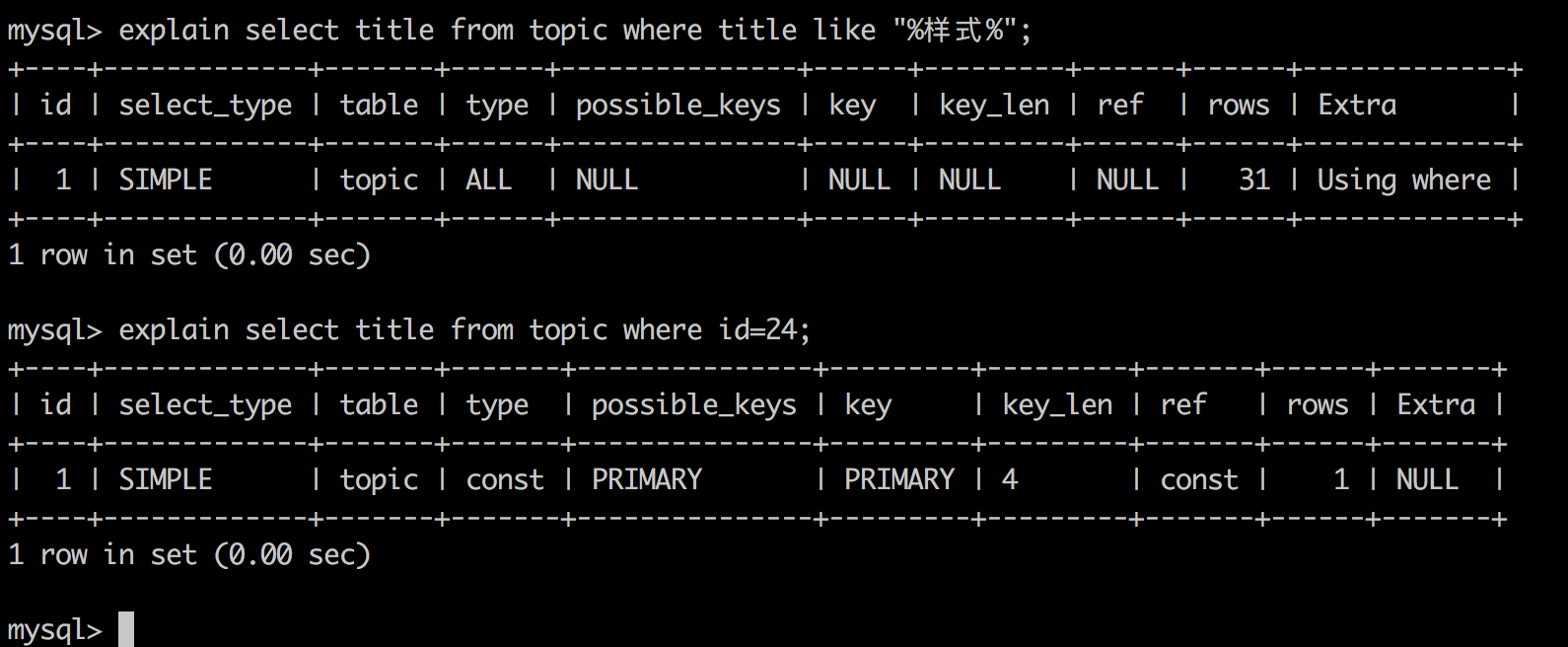
具体用法和字段含义可以参考官网explain-output,这里需要强调rows是核心指标,绝大部分rows小的语句执行一定很快(有例外),所以优化语句基本上都是在优化rows。
优化查询很大的一方面在于索引的使用,关于如何建立索引,并不只是简单地为搜索字段建立索引,有下面这些指导原则:
- 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a, b, d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式;
- 尽量选择区分度高的列作为索引, 区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段要求是0.1以上,即平均1条扫描10条记录。
- 索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
- 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
更多关于索引原理和建立索引的内容,可以参考 Index。
首先应考虑在 where 及 order by 涉及的列上建立索引,然后还要注意:
-
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
-
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
-
尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。
select id from t where num=10 or num=20可以这样查询:
select id from t where num=10 union all select id from t where num=20 -
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
-
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
-
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。所以,应该养成一个需要什么就取什么的好的习惯。
// 不推荐
$r = mysql_query("SELECT * FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
// 推荐
$r = mysql_query("SELECT username FROM user WHERE user_id = 1");
$d = mysql_fetch_assoc($r);
echo "Welcome {$d['username']}";
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
MySQL也有一个“建议”(见第十条)告诉你怎么去重新组织你的表结构。当你有一个 VARCHAR 字段时,这个建议会告诉你把其改成 ENUM 类型。使用 PROCEDURE ANALYSE() 你可以得到相关的建议。
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。首先,问问你自己“Empty”和“NULL”有多大的区别(如果是INT,那就是0和NULL)?如果你觉得它们之间没有什么区别,那么你就不要使用NULL。(你知道吗?在 Oracle 里,NULL 和 Empty 的字符串是一样的!)
不要以为 NULL 不需要空间,其需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
下面摘自MySQL自己的文档:
“NULL columns require additional space in the row to record whether their values are NULL. For MyISAM tables, each NULL column takes one bit extra, rounded up to the nearest byte.”
- 先运行看看是否真的很慢,注意设置SQL_NO_CACHE
- where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
- explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
- order by limit 形式的sql语句让排序的表优先查
- 了解业务方使用场景
- 加索引时参照建索引的几大原则
- 观察结果,不符合预期继续从0分析
MySQL性能优化的最佳20+条经验
Mysql处理海量数据时的一些优化查询速度方法
MySQL性能优化的最佳20+条经验
MySQL 对于千万级的大表要怎么优化?
MySQL索引原理及慢查询优化
mysql全文检索原理与实例分析