一般而言,关系数据库设计的目标是生成一组关系模式,使我们存储信息时避免不必要的冗余,并且可以让我们方便地获取信息。这是通过设计满足适当范式(normal form)的模式来实现的。
关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键。比如下面的三个表中(主键用下划线标注)。
- 学生表( 学号 ,姓名,性别,班级)
- 课程表( 课程编号 ,课程名,学分)
- 成绩表( 学号,课程号 ,成绩)
其中每个学生的学号是唯一的,学号就是一个主键。其中课程编号是唯一的,课程编号就是一个主键。成绩表中单一一个属性无法唯一标识一条记录,学号和课程号的组合才可以唯一标识一条记录,所以学号和课程号的属性组是一个主键。
成绩表中的学号不是成绩表的主键,但它和学生表中的学号相对应,并且学生表中的学号是学生表的主键,则称成绩表中的学号是学生表的外键。同理成绩表中的课程号是课程表的外键。外键用于与另一张表的关联,是能确定另一张表记录的字段,用于保持数据的一致性。
主键主要有两个用途:
- 惟一地标识一行。
- 作为一个可以被外键有效引用的对象。
一个域是原子的,如果该域的元素被认为是不可分的单元。如果 R 的所有属性的域都是原子的,则称关系模式 R 属于第一范式。
仅仅符合1NF的设计,会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如下表中的设计:
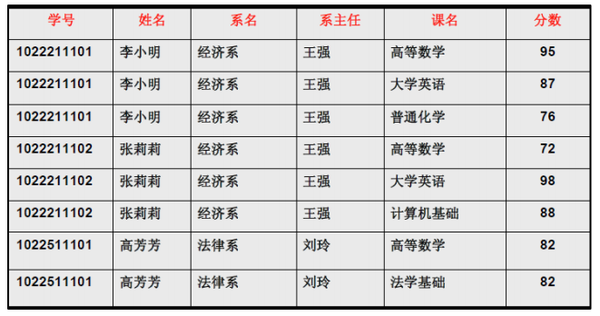
存在着下面的问题:
数据冗余过大:每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次。插入异常:假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的。删除异常:假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。修改异常:假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。
因为仅符合1NF的数据库设计存在着这样那样的问题,我们需要提高设计标准,去掉导致上述四种问题的因素,使其符合更高一级的范式(2NF)。
第二范式在第一范式的基础上,消除了非主属性对于候选码的部分函数依赖。
若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说 Y 函数依赖于 X,写作 X➞Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。
例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作“学号 ➞ 姓名”。
从“函数依赖”这个概念展开,还会有三个概念:
完全函数依赖:在一张表中,若 X➞Y,且对于X的任何一个真子集(假如属性组X包含超过一个属性的话)X'➞Y 不成立,那么我们称Y对于X完全函数依赖。部分函数依赖:假如Y函数依赖于X,但同时Y并不完全函数依赖于X,那么我们就称Y部分函数依赖于X。传递函数依赖:假如Z函数依赖于Y,且Y函数依赖于X (严格来说还有一个X不包含于Y,且Y不函数依赖于Z的前提条件),那么我们就称 Z 传递函数依赖于X。
**包含在任何一个候选中的属性称为主属性。**如果数据表中存在非主属性对于候选码的部分函数依赖,则数据表不符合 2NF 的要求,否则,符合2NF。
对于上面的表,所有的函数依赖关系如下图:
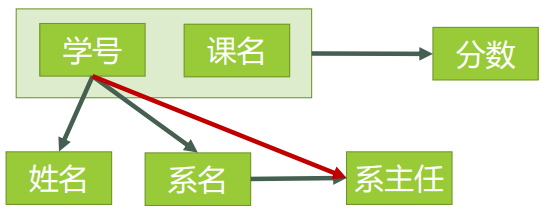
候选码为(学号,课名),主属性为(学号,课名),其它属性为非主属性。对于(学号,课名)➞姓名,有学号➞姓名,存在非主属性姓名对于候选码的部分函数依赖;同理还存在非主属性系名,系主任对于候选码的部分函数依赖。
为了使上面表格符合 2NF 要求,必须消除这些部分函数依赖。通过将大数据表拆分成两个或者多个更小的表。将数据表拆分,达到更高一级范式要求的过程,叫做模式分解,模式分解的结果并不唯一,下面是一种分解结果:
- 选课表( 学号,课名,分数)
- 学生 ( 学号,姓名,系名,系主任)
新的数据表格如下:
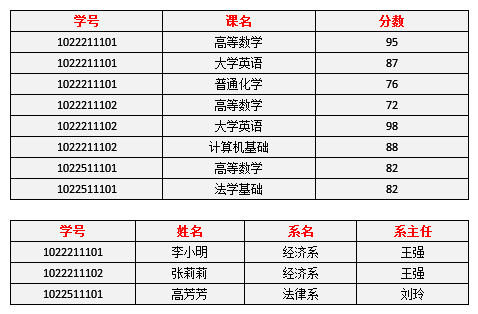
满足 2NF 后,之前的问题
- 数据冗余减少
- 李小明转系到法律系,只需要更改一次,有改进。
插入异常:学生表候选码是学号,所以插入没有学生的系失败。删除异常:假如将某个系中所有学生相关的记录都删除,那么系与系主任的数据也就随之消失了。
3NF 在 2NF 的基础上,消除了非主属性对于候选码的传递函数依赖。也就是说如果存在非主属性对于候选码的传递函数依赖,则不符合3NF的要求。
对于上面满足2NF的表,函数依赖关系如下图:
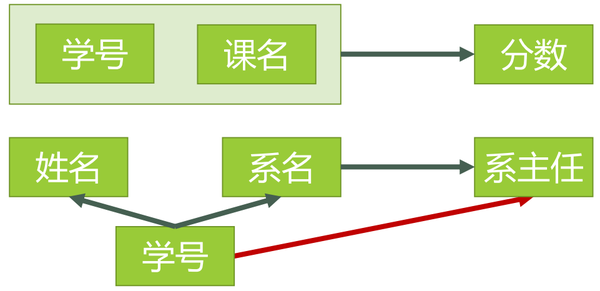
对于选课表,满足3NF。对于学生表,存在有传递函数依赖,学号➞系名,系名➞系主任,因此不符合 3NF。
为了让数据表设计达到 3NF,必须进一步进行模式分解如下:
- 选课表( 学号,课名,分数)
- 学生 ( 学号,姓名,系名)
- 系( 系名,系主任)
新的数据表如下:
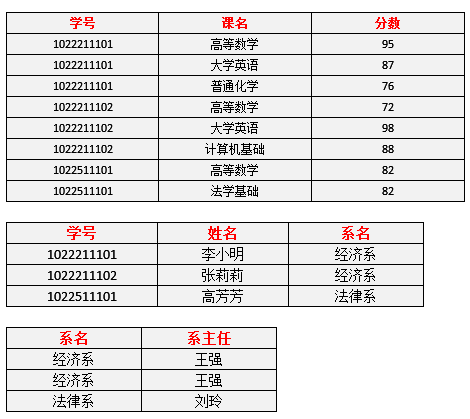
满足3NF后情况有了很大的改观,基本上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。
在 3NF 的基础上,消除了主属性对于候选码的部分函数依赖与传递函数依赖。
具体看下面的一个示例,某公司有若干个仓库,其中:
- 每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;
- 一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。
容易知道函数依赖集:仓库名➞管理员,管理员➞仓库名,(仓库名,物品名)➞数量,候选码有两个,分别是(管理员,物品名),(仓库名,物品名))。主属性:仓库名、管理员、物品名,非主属性:数量。
所以不存在非主属性对候选码的部分函数依赖和传递函数依赖,此关系模式属于3NF。基于此关系模式的关系(具体的数据)可能如图所示:
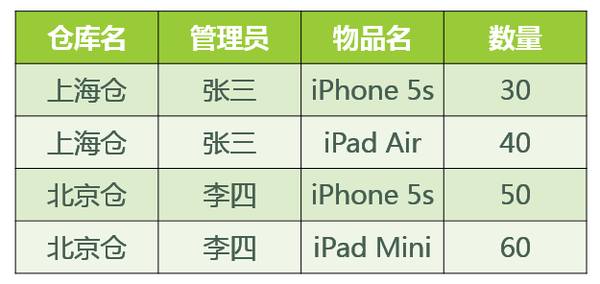
那么这个关系模式是否存在问题呢?我们来看以下几种操作:
- 先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。
- 某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。
从这里我们可以得出结论,在某些特殊情况下,即使关系模式符合 3NF 的要求,仍然存在着插入异常,修改异常与删除异常的问题,仍然不是好的设计。
造成此问题的原因:存在着主属性对于候选码的部分函数依赖与传递函数依赖。在此例中就是存在主属性【仓库名】对于候选码(管理员,物品名)的部分函数依赖。
解决办法就是要在 3NF 的基础上消除主属性对于候选码的部分函数依赖与传递函数依赖。如下:
- 仓库(仓库名,管理员)
- 库存(仓库名,物品名,数量)
在范式化的数据库中,每个事实数据出现并且只出现一次。相反,在反范式化的数据库中,信息是冗余的,可能会存储在多个地方。
范式化设计的好处:
- 范式化的更新操作通常比反范式化要快;
- 当数据较好地范式化时,就只有很少或者没有重复数据,所以只需要更改更少的数据;
- 范式化的表通常更小,可以更好地放在内存中,所以执行操作会快;
范式化设计的一个缺点是通常需要关联,稍微复杂一些的查询语句在符合范式的 schema 上都可能需要至少一次关联。不但代价昂贵,也可能使一些索引策略无效。
反范式化的 schema 因为所有数据都放在一张表中,可以很好地避免关联。单独的表也能使用更有效的索引策略。
实际应用中,可以使用部分 schema、缓存表等技巧。最常见的反范式化数据的方法是复制或者缓存,在不同的表中存储相同的特定列。在新版本的Mysql中,可以使用触发器更新缓存值。
解释一下关系数据库的第一第二第三范式?
数据库设计之概念结构设计:E-R图详解
数据库设计 Step by Step (1)
数据库设计 Step by Step (2)——数据库生命周期
数据库设计 Step by Step (3)——基本ER模型构件