

 、
+
+
、
+
+

 +
+
+
+## 开发环境
+
+- Python 3.5/3.6/3.7
+- Ubuntu 16.04
+- Numpy 1.14.3
+- Tensorflow1.12
+- Cuda 9.0
+- cuDNN 7.0
+
+## 安装、编译指南
+
+程序由两大部分组成:模型训练、微信小程序
+
+models实现宠物检测训练
+
+facenet 实现对比
+
+Flask_server实现模型接口封装
+
+wx 实现微信小程序开发
+
+## 团队介绍
+
+L-team
+
+项目利用以往课程学习经验,在此对相关课程表示感谢
\ No newline at end of file
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore"
new file mode 100644
index 00000000..99c0f969
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore"
@@ -0,0 +1,94 @@
+led / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*,cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# dotenv
+.env
+
+# virtualenv
+.venv
+venv/
+ENV/
+
+# Spyder project settings
+.spyderproject
+
+# Rope project settings
+.ropeproject
+
+# PyCharm project setting
+.idea
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project"
new file mode 100644
index 00000000..cb71a621
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project"
@@ -0,0 +1,17 @@
+
+
+
+
+
+## 开发环境
+
+- Python 3.5/3.6/3.7
+- Ubuntu 16.04
+- Numpy 1.14.3
+- Tensorflow1.12
+- Cuda 9.0
+- cuDNN 7.0
+
+## 安装、编译指南
+
+程序由两大部分组成:模型训练、微信小程序
+
+models实现宠物检测训练
+
+facenet 实现对比
+
+Flask_server实现模型接口封装
+
+wx 实现微信小程序开发
+
+## 团队介绍
+
+L-team
+
+项目利用以往课程学习经验,在此对相关课程表示感谢
\ No newline at end of file
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore"
new file mode 100644
index 00000000..99c0f969
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.gitignore"
@@ -0,0 +1,94 @@
+led / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+env/
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*,cover
+.hypothesis/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# dotenv
+.env
+
+# virtualenv
+.venv
+venv/
+ENV/
+
+# Spyder project settings
+.spyderproject
+
+# Rope project settings
+.ropeproject
+
+# PyCharm project setting
+.idea
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project"
new file mode 100644
index 00000000..cb71a621
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/facenet/.project"
@@ -0,0 +1,17 @@
+
+clean images | Accuracy on
`pgdll_16_1_20` | Accuracy on
`pgdll_16_2_10` | +| ----------- | ------------ | --------------- | --------------------------- | -------------- | +| [Baseline ResNet-v2-50](http://download.tensorflow.org/models/adversarial_logit_pairing/imagenet64_base_2018_06_26.ckpt.tar.gz) | ImageNet 64x64 | 60.5% | 1.8% | 3.5% | +| [ALP-trained ResNet-v2-50](http://download.tensorflow.org/models/adversarial_logit_pairing/imagenet64_alp025_2018_06_26.ckpt.tar.gz) | ImageNet 64x64 | 55.7% | 27.5% | 27.8% | +| [Baseline ResNet-v2-50](http://download.tensorflow.org/models/adversarial_logit_pairing/tiny_imagenet_base_2018_06_26.ckpt.tar.gz) | Tiny ImageNet | 69.2% | 0.1% | 0.3% | +| [ALP-trained ResNet-v2-50](http://download.tensorflow.org/models/adversarial_logit_pairing/tiny_imagenet_alp05_2018_06_26.ckpt.tar.gz) | Tiny ImageNet | 72.0% | 41.3% | 40.8% | + + +* All provided checkpoints were initially trained with exponential moving + average. However for ease of use they were re-saved without it. + So to load and use provided checkpoints you need to specify + `--moving_average_decay=-1` flag. +* All ALP models were trained with `pgdll_16_2_10` adversarial examples. +* All Tiny Imagenet models were obtained by fine tuning corresponding + ImageNet 64x64 models. ALP-trained models were fine tuned with ALP. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/adversarial_attack.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/adversarial_attack.py" new file mode 100644 index 00000000..804bd64b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/adversarial_attack.py" @@ -0,0 +1,219 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Library with adversarial attacks. + +This library designed to be self-contained and have no dependencies other +than TensorFlow. It only contains PGD / Iterative FGSM attacks, +see https://arxiv.org/abs/1706.06083 and https://arxiv.org/abs/1607.02533 +for details. + +For wider set of adversarial attacks refer to Cleverhans library: +https://github.com/tensorflow/cleverhans +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + + +def generate_pgd_common(x, + bounds, + model_fn, + attack_params, + one_hot_labels, + perturbation_multiplier): + """Common code for generating PGD adversarial examples. + + Args: + x: original examples. + bounds: tuple with bounds of image values, bounds[0] < bounds[1]. + model_fn: model function with signature model_fn(images). + attack_params: parameters of the attack. + one_hot_labels: one hot label vector to use in the loss. + perturbation_multiplier: multiplier of adversarial perturbation, + either +1.0 or -1.0. + + Returns: + Tensor with adversarial examples. + + Raises: + ValueError: if attack parameters are invalid. + """ + # parse attack_params + # Format of attack_params: 'EPS_STEP_NITER' + # where EPS - epsilon, STEP - step size, NITER - number of iterations + params_list = attack_params.split('_') + if len(params_list) != 3: + raise ValueError('Invalid parameters of PGD attack: %s' % attack_params) + epsilon = int(params_list[0]) + step_size = int(params_list[1]) + niter = int(params_list[2]) + + # rescale epsilon and step size to image bounds + epsilon = float(epsilon) / 255.0 * (bounds[1] - bounds[0]) + step_size = float(step_size) / 255.0 * (bounds[1] - bounds[0]) + + # clipping boundaries + clip_min = tf.maximum(x - epsilon, bounds[0]) + clip_max = tf.minimum(x + epsilon, bounds[1]) + + # compute starting point + start_x = x + tf.random_uniform(tf.shape(x), -epsilon, epsilon) + start_x = tf.clip_by_value(start_x, clip_min, clip_max) + + # main iteration of PGD + loop_vars = [0, start_x] + + def loop_cond(index, _): + return index < niter + + def loop_body(index, adv_images): + logits = model_fn(adv_images) + loss = tf.reduce_sum( + tf.nn.softmax_cross_entropy_with_logits_v2( + labels=one_hot_labels, + logits=logits)) + perturbation = step_size * tf.sign(tf.gradients(loss, adv_images)[0]) + new_adv_images = adv_images + perturbation_multiplier * perturbation + new_adv_images = tf.clip_by_value(new_adv_images, clip_min, clip_max) + return index + 1, new_adv_images + + with tf.control_dependencies([start_x]): + _, result = tf.while_loop( + loop_cond, + loop_body, + loop_vars, + back_prop=False, + parallel_iterations=1) + return result + + +def generate_pgd_ll(x, bounds, model_fn, attack_params): + # pylint: disable=g-doc-args + """Generats targeted PGD adversarial examples with least likely target class. + + See generate_pgd_common for description of arguments. + + Returns: + Tensor with adversarial examples. + """ + # pylint: enable=g-doc-args + + # compute one hot least likely class + logits = model_fn(x) + num_classes = tf.shape(logits)[1] + one_hot_labels = tf.one_hot(tf.argmin(model_fn(x), axis=1), num_classes) + + return generate_pgd_common(x, bounds, model_fn, attack_params, + one_hot_labels=one_hot_labels, + perturbation_multiplier=-1.0) + + +def generate_pgd_rand(x, bounds, model_fn, attack_params): + # pylint: disable=g-doc-args + """Generats targeted PGD adversarial examples with random target class. + + See generate_pgd_common for description of arguments. + + Returns: + Tensor with adversarial examples. + """ + # pylint: enable=g-doc-args + + # compute one hot random class + logits = model_fn(x) + batch_size = tf.shape(logits)[0] + num_classes = tf.shape(logits)[1] + random_labels = tf.random_uniform(shape=[batch_size], + minval=0, + maxval=num_classes, + dtype=tf.int32) + one_hot_labels = tf.one_hot(random_labels, num_classes) + + return generate_pgd_common(x, bounds, model_fn, attack_params, + one_hot_labels=one_hot_labels, + perturbation_multiplier=-1.0) + + +def generate_pgd(x, bounds, model_fn, attack_params): + # pylint: disable=g-doc-args + """Generats non-targeted PGD adversarial examples. + + See generate_pgd_common for description of arguments. + + Returns: + tensor with adversarial examples. + """ + # pylint: enable=g-doc-args + + # compute one hot predicted class + logits = model_fn(x) + num_classes = tf.shape(logits)[1] + one_hot_labels = tf.one_hot(tf.argmax(model_fn(x), axis=1), num_classes) + + return generate_pgd_common(x, bounds, model_fn, attack_params, + one_hot_labels=one_hot_labels, + perturbation_multiplier=1.0) + + +def generate_adversarial_examples(x, bounds, model_fn, attack_description): + """Generates adversarial examples. + + Args: + x: original examples. + bounds: tuple with bounds of image values, bounds[0] < bounds[1] + model_fn: model function with signature model_fn(images). + attack_description: string which describes an attack, see notes below for + details. + + Returns: + Tensor with adversarial examples. + + Raises: + ValueError: if attack description is invalid. + + + Attack description could be one of the following strings: + - "clean" - no attack, return original images. + - "pgd_EPS_STEP_NITER" - non-targeted PGD attack. + - "pgdll_EPS_STEP_NITER" - tageted PGD attack with least likely target class. + - "pgdrnd_EPS_STEP_NITER" - targetd PGD attack with random target class. + + Meaning of attack parameters is following: + - EPS - maximum size of adversarial perturbation, between 0 and 255. + - STEP - step size of one iteration of PGD, between 0 and 255. + - NITER - number of iterations. + """ + if attack_description == 'clean': + return x + idx = attack_description.find('_') + if idx < 0: + raise ValueError('Invalid value of attack description %s' + % attack_description) + attack_name = attack_description[:idx] + attack_params = attack_description[idx+1:] + if attack_name == 'pgdll': + return generate_pgd_ll(x, bounds, model_fn, attack_params) + elif attack_name == 'pgdrnd': + return generate_pgd_rand(x, bounds, model_fn, attack_params) + elif attack_name == 'pgd': + return generate_pgd(x, bounds, model_fn, attack_params) + else: + raise ValueError('Invalid value of attack description %s' + % attack_description) + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/dataset_factory.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/dataset_factory.py" new file mode 100644 index 00000000..01c36d4f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/dataset_factory.py" @@ -0,0 +1,62 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Library which creates datasets.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from datasets import imagenet_input +from datasets import tiny_imagenet_input + + +def get_dataset(dataset_name, split, batch_size, image_size, is_training): + """Returns dataset. + + Args: + dataset_name: name of the dataset, "imagenet" or "tiny_imagenet". + split: name of the split, "train" or "validation". + batch_size: size of the minibatch. + image_size: size of the one side of the image. Output images will be + resized to square shape image_size*image_size. + is_training: if True then training preprocessing is done, otherwise eval + preprocessing is done. + + Raises: + ValueError: if dataset_name is invalid. + + Returns: + dataset: instance of tf.data.Dataset with the dataset. + num_examples: number of examples in given split of the dataset. + num_classes: number of classes in the dataset. + bounds: tuple with bounds of image values. All returned image pixels + are between bounds[0] and bounds[1]. + """ + if dataset_name == 'tiny_imagenet': + dataset = tiny_imagenet_input.tiny_imagenet_input( + split, batch_size, image_size, is_training) + num_examples = tiny_imagenet_input.num_examples_per_epoch(split) + num_classes = 200 + bounds = (-1, 1) + elif dataset_name == 'imagenet': + dataset = imagenet_input.imagenet_input( + split, batch_size, image_size, is_training) + num_examples = imagenet_input.num_examples_per_epoch(split) + num_classes = 1001 + bounds = (-1, 1) + else: + raise ValueError('Invalid dataset %s' % dataset_name) + return dataset, num_examples, num_classes, bounds diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/imagenet_input.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/imagenet_input.py" new file mode 100644 index 00000000..f396e603 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/imagenet_input.py" @@ -0,0 +1,255 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Imagenet input.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +from absl import flags +import tensorflow as tf + +FLAGS = flags.FLAGS + + +flags.DEFINE_string('imagenet_data_dir', None, + 'Directory with Imagenet dataset in TFRecord format.') + + +def _decode_and_random_crop(image_buffer, bbox, image_size): + """Randomly crops image and then scales to target size.""" + with tf.name_scope('distorted_bounding_box_crop', + values=[image_buffer, bbox]): + sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box( + tf.image.extract_jpeg_shape(image_buffer), + bounding_boxes=bbox, + min_object_covered=0.1, + aspect_ratio_range=[0.75, 1.33], + area_range=[0.08, 1.0], + max_attempts=10, + use_image_if_no_bounding_boxes=True) + bbox_begin, bbox_size, _ = sample_distorted_bounding_box + + # Crop the image to the specified bounding box. + offset_y, offset_x, _ = tf.unstack(bbox_begin) + target_height, target_width, _ = tf.unstack(bbox_size) + crop_window = tf.stack([offset_y, offset_x, target_height, target_width]) + image = tf.image.decode_and_crop_jpeg(image_buffer, crop_window, channels=3) + image = tf.image.convert_image_dtype( + image, dtype=tf.float32) + + image = tf.image.resize_bicubic([image], + [image_size, image_size])[0] + + return image + + +def _decode_and_center_crop(image_buffer, image_size): + """Crops to center of image with padding then scales to target size.""" + shape = tf.image.extract_jpeg_shape(image_buffer) + image_height = shape[0] + image_width = shape[1] + + padded_center_crop_size = tf.cast( + 0.875 * tf.cast(tf.minimum(image_height, image_width), tf.float32), + tf.int32) + + offset_height = ((image_height - padded_center_crop_size) + 1) // 2 + offset_width = ((image_width - padded_center_crop_size) + 1) // 2 + crop_window = tf.stack([offset_height, offset_width, + padded_center_crop_size, padded_center_crop_size]) + image = tf.image.decode_and_crop_jpeg(image_buffer, crop_window, channels=3) + image = tf.image.convert_image_dtype( + image, dtype=tf.float32) + + image = tf.image.resize_bicubic([image], + [image_size, image_size])[0] + + return image + + +def _normalize(image): + """Rescale image to [-1, 1] range.""" + return tf.multiply(tf.subtract(image, 0.5), 2.0) + + +def image_preprocessing(image_buffer, bbox, image_size, is_training): + """Does image decoding and preprocessing. + + Args: + image_buffer: string tensor with encoded image. + bbox: bounding box of the object at the image. + image_size: image size. + is_training: whether to do training or eval preprocessing. + + Returns: + Tensor with the image. + """ + if is_training: + image = _decode_and_random_crop(image_buffer, bbox, image_size) + image = _normalize(image) + image = tf.image.random_flip_left_right(image) + else: + image = _decode_and_center_crop(image_buffer, image_size) + image = _normalize(image) + image = tf.reshape(image, [image_size, image_size, 3]) + return image + + +def imagenet_parser(value, image_size, is_training): + """Parse an ImageNet record from a serialized string Tensor. + + Args: + value: encoded example. + image_size: size of the output image. + is_training: if True then do training preprocessing, + otherwise do eval preprocessing. + + Returns: + image: tensor with the image. + label: true label of the image. + """ + keys_to_features = { + 'image/encoded': + tf.FixedLenFeature((), tf.string, ''), + 'image/format': + tf.FixedLenFeature((), tf.string, 'jpeg'), + 'image/class/label': + tf.FixedLenFeature([], tf.int64, -1), + 'image/class/text': + tf.FixedLenFeature([], tf.string, ''), + 'image/object/bbox/xmin': + tf.VarLenFeature(dtype=tf.float32), + 'image/object/bbox/ymin': + tf.VarLenFeature(dtype=tf.float32), + 'image/object/bbox/xmax': + tf.VarLenFeature(dtype=tf.float32), + 'image/object/bbox/ymax': + tf.VarLenFeature(dtype=tf.float32), + 'image/object/class/label': + tf.VarLenFeature(dtype=tf.int64), + } + + parsed = tf.parse_single_example(value, keys_to_features) + + image_buffer = tf.reshape(parsed['image/encoded'], shape=[]) + + xmin = tf.expand_dims(parsed['image/object/bbox/xmin'].values, 0) + ymin = tf.expand_dims(parsed['image/object/bbox/ymin'].values, 0) + xmax = tf.expand_dims(parsed['image/object/bbox/xmax'].values, 0) + ymax = tf.expand_dims(parsed['image/object/bbox/ymax'].values, 0) + # Note that ordering is (y, x) + bbox = tf.concat([ymin, xmin, ymax, xmax], 0) + # Force the variable number of bounding boxes into the shape + # [1, num_boxes, coords]. + bbox = tf.expand_dims(bbox, 0) + bbox = tf.transpose(bbox, [0, 2, 1]) + + image = image_preprocessing( + image_buffer=image_buffer, + bbox=bbox, + image_size=image_size, + is_training=is_training + ) + + # Labels are in [1, 1000] range + label = tf.cast( + tf.reshape(parsed['image/class/label'], shape=[]), dtype=tf.int32) + + return image, label + + +def imagenet_input(split, batch_size, image_size, is_training): + """Returns ImageNet dataset. + + Args: + split: name of the split, "train" or "validation". + batch_size: size of the minibatch. + image_size: size of the one side of the image. Output images will be + resized to square shape image_size*image_size. + is_training: if True then training preprocessing is done, otherwise eval + preprocessing is done. + + Raises: + ValueError: if name of the split is incorrect. + + Returns: + Instance of tf.data.Dataset with the dataset. + """ + if split.lower().startswith('train'): + file_pattern = os.path.join(FLAGS.imagenet_data_dir, 'train-*') + elif split.lower().startswith('validation'): + file_pattern = os.path.join(FLAGS.imagenet_data_dir, 'validation-*') + else: + raise ValueError('Invalid split: %s' % split) + + dataset = tf.data.Dataset.list_files(file_pattern, shuffle=is_training) + + if is_training: + dataset = dataset.repeat() + + def fetch_dataset(filename): + return tf.data.TFRecordDataset(filename, buffer_size=8*1024*1024) + + # Read the data from disk in parallel + dataset = dataset.apply( + tf.contrib.data.parallel_interleave( + fetch_dataset, cycle_length=4, sloppy=True)) + dataset = dataset.shuffle(1024) + + # Parse, preprocess, and batch the data in parallel + dataset = dataset.apply( + tf.contrib.data.map_and_batch( + lambda value: imagenet_parser(value, image_size, is_training), + batch_size=batch_size, + num_parallel_batches=4, + drop_remainder=True)) + + def set_shapes(images, labels): + """Statically set the batch_size dimension.""" + images.set_shape(images.get_shape().merge_with( + tf.TensorShape([batch_size, None, None, None]))) + labels.set_shape(labels.get_shape().merge_with( + tf.TensorShape([batch_size]))) + return images, labels + + # Assign static batch size dimension + dataset = dataset.map(set_shapes) + + # Prefetch overlaps in-feed with training + dataset = dataset.prefetch(tf.contrib.data.AUTOTUNE) + return dataset + + +def num_examples_per_epoch(split): + """Returns the number of examples in the data set. + + Args: + split: name of the split, "train" or "validation". + + Raises: + ValueError: if split name is incorrect. + + Returns: + Number of example in the split. + """ + if split.lower().startswith('train'): + return 1281167 + elif split.lower().startswith('validation'): + return 50000 + else: + raise ValueError('Invalid split: %s' % split) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/tiny_imagenet_input.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/tiny_imagenet_input.py" new file mode 100644 index 00000000..e3138919 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/datasets/tiny_imagenet_input.py" @@ -0,0 +1,157 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tiny imagenet input.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +from absl import flags +import tensorflow as tf + +FLAGS = flags.FLAGS + + +flags.DEFINE_string('tiny_imagenet_data_dir', None, + 'Directory with Tiny Imagenet dataset in TFRecord format.') + + +def tiny_imagenet_parser(value, image_size, is_training): + """Parses tiny imagenet example. + + Args: + value: encoded example. + image_size: size of the image. + is_training: if True then do training preprocessing (which includes + random cropping), otherwise do eval preprocessing. + + Returns: + image: tensor with the image. + label: true label of the image. + """ + keys_to_features = { + 'image/encoded': tf.FixedLenFeature((), tf.string, ''), + 'label/tiny_imagenet': tf.FixedLenFeature([], tf.int64, -1), + } + + parsed = tf.parse_single_example(value, keys_to_features) + + image_buffer = tf.reshape(parsed['image/encoded'], shape=[]) + image = tf.image.decode_image(image_buffer, channels=3) + image = tf.image.convert_image_dtype( + image, dtype=tf.float32) + + # Crop image + if is_training: + bbox_begin, bbox_size, _ = tf.image.sample_distorted_bounding_box( + tf.shape(image), + bounding_boxes=tf.constant([0.0, 0.0, 1.0, 1.0], + dtype=tf.float32, + shape=[1, 1, 4]), + min_object_covered=0.5, + aspect_ratio_range=[0.75, 1.33], + area_range=[0.5, 1.0], + max_attempts=20, + use_image_if_no_bounding_boxes=True) + image = tf.slice(image, bbox_begin, bbox_size) + + # resize image + image = tf.image.resize_bicubic([image], [image_size, image_size])[0] + + # Rescale image to [-1, 1] range. + image = tf.multiply(tf.subtract(image, 0.5), 2.0) + + image = tf.reshape(image, [image_size, image_size, 3]) + + # Labels are in [0, 199] range + label = tf.cast( + tf.reshape(parsed['label/tiny_imagenet'], shape=[]), dtype=tf.int32) + + return image, label + + +def tiny_imagenet_input(split, batch_size, image_size, is_training): + """Returns Tiny Imagenet Dataset. + + Args: + split: name of the split, "train" or "validation". + batch_size: size of the minibatch. + image_size: size of the one side of the image. Output images will be + resized to square shape image_size*image_size. + is_training: if True then training preprocessing is done, otherwise eval + preprocessing is done.instance of tf.data.Dataset with the dataset. + + Raises: + ValueError: if name of the split is incorrect. + + Returns: + Instance of tf.data.Dataset with the dataset. + """ + if split.lower().startswith('train'): + filepath = os.path.join(FLAGS.tiny_imagenet_data_dir, 'train.tfrecord') + elif split.lower().startswith('validation'): + filepath = os.path.join(FLAGS.tiny_imagenet_data_dir, 'validation.tfrecord') + else: + raise ValueError('Invalid split: %s' % split) + + dataset = tf.data.TFRecordDataset(filepath, buffer_size=8*1024*1024) + + if is_training: + dataset = dataset.shuffle(10000) + dataset = dataset.repeat() + + dataset = dataset.apply( + tf.contrib.data.map_and_batch( + lambda value: tiny_imagenet_parser(value, image_size, is_training), + batch_size=batch_size, + num_parallel_batches=4, + drop_remainder=True)) + + def set_shapes(images, labels): + """Statically set the batch_size dimension.""" + images.set_shape(images.get_shape().merge_with( + tf.TensorShape([batch_size, None, None, None]))) + labels.set_shape(labels.get_shape().merge_with( + tf.TensorShape([batch_size]))) + return images, labels + + # Assign static batch size dimension + dataset = dataset.map(set_shapes) + + dataset = dataset.prefetch(tf.contrib.data.AUTOTUNE) + + return dataset + + +def num_examples_per_epoch(split): + """Returns the number of examples in the data set. + + Args: + split: name of the split, "train" or "validation". + + Raises: + ValueError: if split name is incorrect. + + Returns: + Number of example in the split. + """ + if split.lower().startswith('train'): + return 100000 + elif split.lower().startswith('validation'): + return 10000 + else: + raise ValueError('Invalid split: %s' % split) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/eval.py" new file mode 100644 index 00000000..504cc0b0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/eval.py" @@ -0,0 +1,181 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Program which runs evaluation of Imagenet 64x64 and TinyImagenet models.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os + +from absl import app +from absl import flags + +import tensorflow as tf + +import adversarial_attack +import model_lib +from datasets import dataset_factory + +FLAGS = flags.FLAGS + + +flags.DEFINE_string('train_dir', None, + 'Training directory. If specified then this program ' + 'runs in continuous evaluation mode.') + +flags.DEFINE_string('checkpoint_path', None, + 'Path to the file with checkpoint. If specified then ' + 'this program evaluates only provided checkpoint one time.') + +flags.DEFINE_string('output_file', None, + 'Name of output file. Used only in single evaluation mode.') + +flags.DEFINE_string('eval_name', 'default', 'Name for eval subdirectory.') + +flags.DEFINE_string('master', '', 'Tensorflow master.') + +flags.DEFINE_string('model_name', 'resnet_v2_50', 'Name of the model.') + +flags.DEFINE_string('adv_method', 'clean', + 'Method which is used to generate adversarial examples.') + +flags.DEFINE_string('dataset', 'imagenet', + 'Dataset: "tiny_imagenet" or "imagenet".') + +flags.DEFINE_integer('dataset_image_size', 64, + 'Size of the images in the dataset.') + +flags.DEFINE_string('hparams', '', 'Hyper parameters.') + +flags.DEFINE_string('split_name', 'validation', 'Name of the split.') + +flags.DEFINE_float('moving_average_decay', 0.9999, + 'The decay to use for the moving average.') + +flags.DEFINE_integer('eval_interval_secs', 120, + 'The frequency, in seconds, with which evaluation is run.') + +flags.DEFINE_integer( + 'num_examples', -1, + 'If positive - maximum number of example to use for evaluation.') + +flags.DEFINE_bool('eval_once', False, + 'If true then evaluate model only once.') + +flags.DEFINE_string('trainable_scopes', None, + 'If set then it defines list of variable scopes for ' + 'trainable variables.') + + +def main(_): + if not FLAGS.train_dir and not FLAGS.checkpoint_path: + print('Either --train_dir or --checkpoint_path flags has to be provided.') + if FLAGS.train_dir and FLAGS.checkpoint_path: + print('Only one of --train_dir or --checkpoint_path should be provided.') + params = model_lib.default_hparams() + params.parse(FLAGS.hparams) + tf.logging.info('User provided hparams: %s', FLAGS.hparams) + tf.logging.info('All hyper parameters: %s', params) + batch_size = params.eval_batch_size + graph = tf.Graph() + with graph.as_default(): + # dataset + dataset, num_examples, num_classes, bounds = dataset_factory.get_dataset( + FLAGS.dataset, + FLAGS.split_name, + batch_size, + FLAGS.dataset_image_size, + is_training=False) + dataset_iterator = dataset.make_one_shot_iterator() + images, labels = dataset_iterator.get_next() + if FLAGS.num_examples > 0: + num_examples = min(num_examples, FLAGS.num_examples) + + # setup model + global_step = tf.train.get_or_create_global_step() + model_fn_two_args = model_lib.get_model(FLAGS.model_name, num_classes) + model_fn = lambda x: model_fn_two_args(x, is_training=False) + if not FLAGS.adv_method or FLAGS.adv_method == 'clean': + logits = model_fn(images) + else: + adv_examples = adversarial_attack.generate_adversarial_examples( + images, bounds, model_fn, FLAGS.adv_method) + logits = model_fn(adv_examples) + + # update trainable variables if fine tuning is used + model_lib.filter_trainable_variables(FLAGS.trainable_scopes) + + # Setup the moving averages + if FLAGS.moving_average_decay and (FLAGS.moving_average_decay > 0): + variable_averages = tf.train.ExponentialMovingAverage( + FLAGS.moving_average_decay, global_step) + variables_to_restore = variable_averages.variables_to_restore( + tf.contrib.framework.get_model_variables()) + variables_to_restore[global_step.op.name] = global_step + else: + variables_to_restore = tf.contrib.framework.get_variables_to_restore() + + # Setup evaluation metric + with tf.name_scope('Eval'): + names_to_values, names_to_updates = ( + tf.contrib.metrics.aggregate_metric_map({ + 'Accuracy': tf.metrics.accuracy(labels, tf.argmax(logits, 1)), + 'Top5': tf.metrics.recall_at_k(tf.to_int64(labels), logits, 5) + })) + + for name, value in names_to_values.iteritems(): + tf.summary.scalar(name, value) + + # Run evaluation + num_batches = int(num_examples / batch_size) + if FLAGS.train_dir: + output_dir = os.path.join(FLAGS.train_dir, FLAGS.eval_name) + if not tf.gfile.Exists(output_dir): + tf.gfile.MakeDirs(output_dir) + tf.contrib.training.evaluate_repeatedly( + FLAGS.train_dir, + master=FLAGS.master, + scaffold=tf.train.Scaffold( + saver=tf.train.Saver(variables_to_restore)), + eval_ops=names_to_updates.values(), + eval_interval_secs=FLAGS.eval_interval_secs, + hooks=[ + tf.contrib.training.StopAfterNEvalsHook(num_batches), + tf.contrib.training.SummaryAtEndHook(output_dir), + tf.train.LoggingTensorHook(names_to_values, at_end=True), + ], + max_number_of_evaluations=1 if FLAGS.eval_once else None) + else: + result = tf.contrib.training.evaluate_once( + FLAGS.checkpoint_path, + master=FLAGS.master, + scaffold=tf.train.Scaffold( + saver=tf.train.Saver(variables_to_restore)), + eval_ops=names_to_updates.values(), + final_ops=names_to_values, + hooks=[ + tf.contrib.training.StopAfterNEvalsHook(num_batches), + tf.train.LoggingTensorHook(names_to_values, at_end=True), + ]) + if FLAGS.output_file: + with tf.gfile.Open(FLAGS.output_file, 'a') as f: + f.write('%s,%.3f,%.3f\n' + % (FLAGS.eval_name, result['Accuracy'], result['Top5'])) + + +if __name__ == '__main__': + app.run(main) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/model_lib.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/model_lib.py" new file mode 100644 index 00000000..1499a378 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/model_lib.py" @@ -0,0 +1,189 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Library with common functions for training and eval.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import six + +import tensorflow as tf + +from tensorflow.contrib.slim.nets import resnet_v2 + + +def default_hparams(): + """Returns default hyperparameters.""" + return tf.contrib.training.HParams( + # Batch size for training and evaluation. + batch_size=32, + eval_batch_size=50, + + # General training parameters. + weight_decay=0.0001, + label_smoothing=0.1, + + # Parameters of the adversarial training. + train_adv_method='clean', # adversarial training method + train_lp_weight=0.0, # Weight of adversarial logit pairing loss + + # Parameters of the optimizer. + optimizer='rms', # possible values are: 'rms', 'momentum', 'adam' + momentum=0.9, # momentum + rmsprop_decay=0.9, # Decay term for RMSProp + rmsprop_epsilon=1.0, # Epsilon term for RMSProp + + # Parameters of learning rate schedule. + lr_schedule='exp_decay', # Possible values: 'exp_decay', 'step', 'fixed' + learning_rate=0.045, + lr_decay_factor=0.94, # Learning exponential decay + lr_num_epochs_per_decay=2.0, # Number of epochs per lr decay + lr_list=[1.0 / 6, 2.0 / 6, 3.0 / 6, + 4.0 / 6, 5.0 / 6, 1.0, 0.1, 0.01, + 0.001, 0.0001], + lr_decay_epochs=[1, 2, 3, 4, 5, 30, 60, 80, + 90]) + + +def get_lr_schedule(hparams, examples_per_epoch, replicas_to_aggregate=1): + """Returns TensorFlow op which compute learning rate. + + Args: + hparams: hyper parameters. + examples_per_epoch: number of training examples per epoch. + replicas_to_aggregate: number of training replicas running in parallel. + + Raises: + ValueError: if learning rate schedule specified in hparams is incorrect. + + Returns: + learning_rate: tensor with learning rate. + steps_per_epoch: number of training steps per epoch. + """ + global_step = tf.train.get_or_create_global_step() + steps_per_epoch = float(examples_per_epoch) / float(hparams.batch_size) + if replicas_to_aggregate > 0: + steps_per_epoch /= replicas_to_aggregate + + if hparams.lr_schedule == 'exp_decay': + decay_steps = long(steps_per_epoch * hparams.lr_num_epochs_per_decay) + learning_rate = tf.train.exponential_decay( + hparams.learning_rate, + global_step, + decay_steps, + hparams.lr_decay_factor, + staircase=True) + elif hparams.lr_schedule == 'step': + lr_decay_steps = [long(epoch * steps_per_epoch) + for epoch in hparams.lr_decay_epochs] + learning_rate = tf.train.piecewise_constant( + global_step, lr_decay_steps, hparams.lr_list) + elif hparams.lr_schedule == 'fixed': + learning_rate = hparams.learning_rate + else: + raise ValueError('Invalid value of lr_schedule: %s' % hparams.lr_schedule) + + if replicas_to_aggregate > 0: + learning_rate *= replicas_to_aggregate + + return learning_rate, steps_per_epoch + + +def get_optimizer(hparams, learning_rate): + """Returns optimizer. + + Args: + hparams: hyper parameters. + learning_rate: learning rate tensor. + + Raises: + ValueError: if type of optimizer specified in hparams is incorrect. + + Returns: + Instance of optimizer class. + """ + if hparams.optimizer == 'rms': + optimizer = tf.train.RMSPropOptimizer(learning_rate, + hparams.rmsprop_decay, + hparams.momentum, + hparams.rmsprop_epsilon) + elif hparams.optimizer == 'momentum': + optimizer = tf.train.MomentumOptimizer(learning_rate, + hparams.momentum) + elif hparams.optimizer == 'adam': + optimizer = tf.train.AdamOptimizer(learning_rate) + else: + raise ValueError('Invalid value of optimizer: %s' % hparams.optimizer) + return optimizer + + +RESNET_MODELS = {'resnet_v2_50': resnet_v2.resnet_v2_50} + + +def get_model(model_name, num_classes): + """Returns function which creates model. + + Args: + model_name: Name of the model. + num_classes: Number of classes. + + Raises: + ValueError: If model_name is invalid. + + Returns: + Function, which creates model when called. + """ + if model_name.startswith('resnet'): + def resnet_model(images, is_training, reuse=tf.AUTO_REUSE): + with tf.contrib.framework.arg_scope(resnet_v2.resnet_arg_scope()): + resnet_fn = RESNET_MODELS[model_name] + logits, _ = resnet_fn(images, num_classes, is_training=is_training, + reuse=reuse) + logits = tf.reshape(logits, [-1, num_classes]) + return logits + return resnet_model + else: + raise ValueError('Invalid model: %s' % model_name) + + +def filter_trainable_variables(trainable_scopes): + """Keep only trainable variables which are prefixed with given scopes. + + Args: + trainable_scopes: either list of trainable scopes or string with comma + separated list of trainable scopes. + + This function removes all variables which are not prefixed with given + trainable_scopes from collection of trainable variables. + Useful during network fine tuning, when you only need to train subset of + variables. + """ + if not trainable_scopes: + return + if isinstance(trainable_scopes, six.string_types): + trainable_scopes = [scope.strip() for scope in trainable_scopes.split(',')] + trainable_scopes = {scope for scope in trainable_scopes if scope} + if not trainable_scopes: + return + trainable_collection = tf.get_collection_ref( + tf.GraphKeys.TRAINABLE_VARIABLES) + non_trainable_vars = [ + v for v in trainable_collection + if not any([v.op.name.startswith(s) for s in trainable_scopes]) + ] + for v in non_trainable_vars: + trainable_collection.remove(v) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/tiny_imagenet_converter/converter.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/tiny_imagenet_converter/converter.py" new file mode 100644 index 00000000..4fdccc32 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/tiny_imagenet_converter/converter.py" @@ -0,0 +1,241 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Converts Tiny Imagenet dataset into TFRecord format. + +As an output this program generates following files in TFRecord format: +- train.tfrecord +- validation.tfrecord +- test.tfrecord + +Generated train and validation files will contain tf.Example entries with +following features: +- image/encoded - encoded image +- image/format - image format +- label/wnid - label WordNet ID +- label/imagenet - imagenet label [1 ... 1000] +- label/tiny_imagenet - tiny imagenet label [0 ... 199] +- bbox/xmin +- bbox/ymin +- bbox/xmax +- bbox/ymax + +Test file will contain entries with 'image/encoded' and 'image/format' features. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from collections import namedtuple +import os +import random + +from absl import app +from absl import flags +from absl import logging + +import pandas as pd + +import tensorflow as tf + + +FLAGS = flags.FLAGS + +flags.DEFINE_string('input_dir', '', 'Input directory') +flags.DEFINE_string('output_dir', '', 'Output directory') + +flags.DEFINE_string('imagenet_synsets_path', '', + 'Optional path to /imagenet_lsvrc_2015_synsets.txt') + + +ImageMetadata = namedtuple('ImageMetadata', ['label', 'x1', 'y1', 'x2', 'y2']) + + +class WnIdToNodeIdConverter(object): + """Converts WordNet IDs to numerical labels.""" + + def __init__(self, wnids_path, background_class): + self._wnid_to_node_id = {} + self._node_id_to_wnid = {} + with tf.gfile.Open(wnids_path) as f: + wnids_sequence = [wnid.strip() for wnid in f.readlines() if wnid.strip()] + node_id_offset = 1 if background_class else 0 + for i, label in enumerate(wnids_sequence): + self._wnid_to_node_id[label] = i + node_id_offset + self._node_id_to_wnid[i + node_id_offset] = label + + def to_node_id(self, wnid): + return self._wnid_to_node_id[wnid] + + def to_wnid(self, node_id): + return self._node_id_to_wnid[node_id] + + def all_wnids(self): + return self._wnid_to_node_id.keys() + + +def read_tiny_imagenet_annotations(annotations_filename, + images_dir, + one_label=None): + """Reads one file with Tiny Imagenet annotations.""" + result = [] + if one_label: + column_names = ['filename', 'x1', 'y1', 'x2', 'y2'] + else: + column_names = ['filename', 'label', 'x1', 'y1', 'x2', 'y2'] + with tf.gfile.Open(annotations_filename) as f: + data = pd.read_csv(f, sep='\t', names=column_names) + for row in data.itertuples(): + label = one_label if one_label else getattr(row, 'label') + full_filename = os.path.join(images_dir, getattr(row, 'filename')) + result.append((full_filename, + ImageMetadata(label=label, + x1=getattr(row, 'x1'), + y1=getattr(row, 'y1'), + x2=getattr(row, 'x2'), + y2=getattr(row, 'y2')))) + return result + + +def read_validation_annotations(validation_dir): + """Reads validation data annotations.""" + return read_tiny_imagenet_annotations( + os.path.join(validation_dir, 'val_annotations.txt'), + os.path.join(validation_dir, 'images')) + + +def read_training_annotations(training_dir): + """Reads training data annotations.""" + result = [] + sub_dirs = tf.gfile.ListDirectory(training_dir) + for sub_dir in sub_dirs: + if not sub_dir.startswith('n'): + logging.warning('Found non-class directory in training dir: %s', sub_dir) + continue + sub_dir_results = read_tiny_imagenet_annotations( + os.path.join(training_dir, sub_dir, sub_dir + '_boxes.txt'), + os.path.join(training_dir, sub_dir, 'images'), + one_label=sub_dir) + result.extend(sub_dir_results) + return result + + +def read_test_annotations(test_dir): + """Reads test data annotations.""" + files = tf.gfile.ListDirectory(os.path.join(test_dir, 'images')) + return [(os.path.join(test_dir, 'images', f), None) + for f in files if f.endswith('.JPEG')] + + +def get_image_format(filename): + """Returns image format from filename.""" + filename = filename.lower() + if filename.endswith('jpeg') or filename.endswith('jpg'): + return 'jpeg' + elif filename.endswith('png'): + return 'png' + else: + raise ValueError('Unrecognized file format: %s' % filename) + + +class TinyImagenetWriter(object): + """Helper class which writes Tiny Imagenet dataset into TFRecord file.""" + + def __init__(self, tiny_imagenet_wnid_conveter, imagenet_wnid_converter): + self.tiny_imagenet_wnid_conveter = tiny_imagenet_wnid_conveter + self.imagenet_wnid_converter = imagenet_wnid_converter + + def write_tf_record(self, + annotations, + output_file): + """Generates TFRecord file from given list of annotations.""" + with tf.python_io.TFRecordWriter(output_file) as writer: + for image_filename, image_metadata in annotations: + with tf.gfile.Open(image_filename) as f: + image_buffer = f.read() + image_format = get_image_format(image_filename) + features = { + 'image/encoded': tf.train.Feature( + bytes_list=tf.train.BytesList(value=[image_buffer])), + 'image/format': tf.train.Feature( + bytes_list=tf.train.BytesList(value=[image_format])) + } + if image_metadata: + # bounding box features + features['bbox/xmin'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[image_metadata.x1])) + features['bbox/ymin'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[image_metadata.y1])) + features['bbox/xmax'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[image_metadata.x2])) + features['bbox/ymax'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[image_metadata.y2])) + # tiny imagenet label, from [0, 200) iterval + tiny_imagenet_label = self.tiny_imagenet_wnid_conveter.to_node_id( + image_metadata.label) + features['label/wnid'] = tf.train.Feature( + bytes_list=tf.train.BytesList(value=image_metadata.label)) + features['label/tiny_imagenet'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[tiny_imagenet_label])) + # full imagenet label, from [1, 1001) interval + if self.imagenet_wnid_converter: + imagenet_label = self.imagenet_wnid_converter.to_node_id( + image_metadata.label) + features['label/imagenet'] = tf.train.Feature( + int64_list=tf.train.Int64List(value=[imagenet_label])) + example = tf.train.Example(features=tf.train.Features(feature=features)) + writer.write(example.SerializeToString()) + + +def main(_): + assert FLAGS.input_dir, 'Input directory must be provided' + assert FLAGS.output_dir, 'Output directory must be provided' + + # Create WordNet ID conveters for tiny imagenet and possibly for imagenet + tiny_imagenet_wnid_conveter = WnIdToNodeIdConverter( + os.path.join(FLAGS.input_dir, 'wnids.txt'), + background_class=False) + if FLAGS.imagenet_synsets_path: + imagenet_wnid_converter = WnIdToNodeIdConverter(FLAGS.imagenet_synsets_path, + background_class=True) + else: + imagenet_wnid_converter = None + + # read tiny imagenet annotations + train_annotations = read_training_annotations( + os.path.join(FLAGS.input_dir, 'train')) + random.shuffle(train_annotations) + val_annotations = read_validation_annotations( + os.path.join(FLAGS.input_dir, 'val')) + test_filenames = read_test_annotations(os.path.join(FLAGS.input_dir, 'test')) + + # Generate TFRecord files + writer = TinyImagenetWriter(tiny_imagenet_wnid_conveter, + imagenet_wnid_converter) + tf.logging.info('Converting %d training images', len(train_annotations)) + writer.write_tf_record(train_annotations, + os.path.join(FLAGS.output_dir, 'train.tfrecord')) + tf.logging.info('Converting %d validation images ', len(val_annotations)) + writer.write_tf_record(val_annotations, + os.path.join(FLAGS.output_dir, 'validation.tfrecord')) + tf.logging.info('Converting %d test images', len(test_filenames)) + writer.write_tf_record(test_filenames, + os.path.join(FLAGS.output_dir, 'test.tfrecord')) + tf.logging.info('All files are converted') + + +if __name__ == '__main__': + app.run(main) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/train.py" new file mode 100644 index 00000000..dd20969f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_logit_pairing/train.py" @@ -0,0 +1,288 @@ +# Copyright 2018 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Program which train models.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from absl import app +from absl import flags + +import tensorflow as tf + +import adversarial_attack +import model_lib +from datasets import dataset_factory + +FLAGS = flags.FLAGS + + +flags.DEFINE_integer('max_steps', -1, 'Number of steps to stop at.') + +flags.DEFINE_string('output_dir', None, + 'Training directory where checkpoints will be saved.') + +flags.DEFINE_integer('ps_tasks', 0, 'Number of parameter servers.') + +flags.DEFINE_integer('task', 0, 'Task ID for running distributed training.') + +flags.DEFINE_string('master', '', 'Tensorflow master.') + +flags.DEFINE_string('model_name', 'resnet_v2_50', 'Name of the model.') + +flags.DEFINE_string('dataset', 'imagenet', + 'Dataset: "tiny_imagenet" or "imagenet".') + +flags.DEFINE_integer('dataset_image_size', 64, + 'Size of the images in the dataset.') + +flags.DEFINE_integer('num_summary_images', 3, + 'Number of images to display in Tensorboard.') + +flags.DEFINE_integer( + 'save_summaries_steps', 100, + 'The frequency with which summaries are saved, in steps.') + +flags.DEFINE_integer( + 'save_summaries_secs', None, + 'The frequency with which summaries are saved, in seconds.') + +flags.DEFINE_integer( + 'save_model_steps', 500, + 'The frequency with which the model is saved, in steps.') + +flags.DEFINE_string('hparams', '', 'Hyper parameters.') + +flags.DEFINE_integer('replicas_to_aggregate', 1, + 'Number of gradients to collect before param updates.') + +flags.DEFINE_integer('worker_replicas', 1, 'Number of worker replicas.') + +flags.DEFINE_float('moving_average_decay', 0.9999, + 'The decay to use for the moving average.') + +# Flags to control fine tuning + +flags.DEFINE_string('finetune_checkpoint_path', None, + 'Path to checkpoint for fine tuning. ' + 'If None then no fine tuning is done.') + +flags.DEFINE_string('finetune_exclude_pretrained_scopes', '', + 'Variable scopes to exclude when loading checkpoint for ' + 'fine tuning.') + +flags.DEFINE_string('finetune_trainable_scopes', None, + 'If set then it defines list of variable scopes for ' + 'trainable variables.') + + +def _get_finetuning_init_fn(variable_averages): + """Returns an init functions, used for fine tuning.""" + if not FLAGS.finetune_checkpoint_path: + return None + + if tf.train.latest_checkpoint(FLAGS.output_dir): + return None + + if tf.gfile.IsDirectory(FLAGS.finetune_checkpoint_path): + checkpoint_path = tf.train.latest_checkpoint(FLAGS.finetune_checkpoint_path) + else: + checkpoint_path = FLAGS.finetune_checkpoint_path + + if not checkpoint_path: + tf.logging.warning('Not doing fine tuning, can not find checkpoint in %s', + FLAGS.finetune_checkpoint_path) + return None + + tf.logging.info('Fine-tuning from %s', checkpoint_path) + + if FLAGS.finetune_exclude_pretrained_scopes: + exclusions = { + scope.strip() + for scope in FLAGS.finetune_exclude_pretrained_scopes.split(',') + } + else: + exclusions = set() + + filtered_model_variables = [ + v for v in tf.contrib.framework.get_model_variables() + if not any([v.op.name.startswith(e) for e in exclusions]) + ] + + if variable_averages: + variables_to_restore = {} + for v in filtered_model_variables: + # variables_to_restore[variable_averages.average_name(v)] = v + if v in tf.trainable_variables(): + variables_to_restore[variable_averages.average_name(v)] = v + else: + variables_to_restore[v.op.name] = v + else: + variables_to_restore = {v.op.name: v for v in filtered_model_variables} + + assign_fn = tf.contrib.framework.assign_from_checkpoint_fn( + checkpoint_path, + variables_to_restore) + if assign_fn: + return lambda _, sess: assign_fn(sess) + else: + return None + + +def main(_): + assert FLAGS.output_dir, '--output_dir has to be provided' + if not tf.gfile.Exists(FLAGS.output_dir): + tf.gfile.MakeDirs(FLAGS.output_dir) + params = model_lib.default_hparams() + params.parse(FLAGS.hparams) + tf.logging.info('User provided hparams: %s', FLAGS.hparams) + tf.logging.info('All hyper parameters: %s', params) + batch_size = params.batch_size + graph = tf.Graph() + with graph.as_default(): + with tf.device(tf.train.replica_device_setter(ps_tasks=FLAGS.ps_tasks)): + # dataset + dataset, examples_per_epoch, num_classes, bounds = ( + dataset_factory.get_dataset( + FLAGS.dataset, + 'train', + batch_size, + FLAGS.dataset_image_size, + is_training=True)) + dataset_iterator = dataset.make_one_shot_iterator() + images, labels = dataset_iterator.get_next() + one_hot_labels = tf.one_hot(labels, num_classes) + + # set up model + global_step = tf.train.get_or_create_global_step() + model_fn = model_lib.get_model(FLAGS.model_name, num_classes) + if params.train_adv_method == 'clean': + logits = model_fn(images, is_training=True) + adv_examples = None + else: + model_fn_eval_mode = lambda x: model_fn(x, is_training=False) + adv_examples = adversarial_attack.generate_adversarial_examples( + images, bounds, model_fn_eval_mode, params.train_adv_method) + all_examples = tf.concat([images, adv_examples], axis=0) + logits = model_fn(all_examples, is_training=True) + one_hot_labels = tf.concat([one_hot_labels, one_hot_labels], axis=0) + + # update trainable variables if fine tuning is used + model_lib.filter_trainable_variables( + FLAGS.finetune_trainable_scopes) + + # set up losses + total_loss = tf.losses.softmax_cross_entropy( + onehot_labels=one_hot_labels, + logits=logits, + label_smoothing=params.label_smoothing) + tf.summary.scalar('loss_xent', total_loss) + + if params.train_lp_weight > 0: + images1, images2 = tf.split(logits, 2) + loss_lp = tf.losses.mean_squared_error( + images1, images2, weights=params.train_lp_weight) + tf.summary.scalar('loss_lp', loss_lp) + total_loss += loss_lp + + if params.weight_decay > 0: + loss_wd = ( + params.weight_decay + * tf.add_n([tf.nn.l2_loss(v) for v in tf.trainable_variables()]) + ) + tf.summary.scalar('loss_wd', loss_wd) + total_loss += loss_wd + + # Setup the moving averages: + if FLAGS.moving_average_decay and (FLAGS.moving_average_decay > 0): + with tf.name_scope('moving_average'): + moving_average_variables = tf.contrib.framework.get_model_variables() + variable_averages = tf.train.ExponentialMovingAverage( + FLAGS.moving_average_decay, global_step) + else: + moving_average_variables = None + variable_averages = None + + # set up optimizer and training op + learning_rate, steps_per_epoch = model_lib.get_lr_schedule( + params, examples_per_epoch, FLAGS.replicas_to_aggregate) + + optimizer = model_lib.get_optimizer(params, learning_rate) + + optimizer = tf.train.SyncReplicasOptimizer( + opt=optimizer, + replicas_to_aggregate=FLAGS.replicas_to_aggregate, + total_num_replicas=FLAGS.worker_replicas, + variable_averages=variable_averages, + variables_to_average=moving_average_variables) + + train_op = tf.contrib.training.create_train_op( + total_loss, optimizer, + update_ops=tf.get_collection(tf.GraphKeys.UPDATE_OPS)) + + tf.summary.image('images', images[0:FLAGS.num_summary_images]) + if adv_examples is not None: + tf.summary.image('adv_images', adv_examples[0:FLAGS.num_summary_images]) + tf.summary.scalar('total_loss', total_loss) + tf.summary.scalar('learning_rate', learning_rate) + tf.summary.scalar('current_epoch', + tf.to_double(global_step) / steps_per_epoch) + + # Training + is_chief = FLAGS.task == 0 + + scaffold = tf.train.Scaffold( + init_fn=_get_finetuning_init_fn(variable_averages)) + hooks = [ + tf.train.LoggingTensorHook({'total_loss': total_loss, + 'global_step': global_step}, + every_n_iter=1), + tf.train.NanTensorHook(total_loss), + ] + chief_only_hooks = [ + tf.train.SummarySaverHook(save_steps=FLAGS.save_summaries_steps, + save_secs=FLAGS.save_summaries_secs, + output_dir=FLAGS.output_dir, + scaffold=scaffold), + tf.train.CheckpointSaverHook(FLAGS.output_dir, + save_steps=FLAGS.save_model_steps, + scaffold=scaffold), + ] + + if FLAGS.max_steps > 0: + hooks.append( + tf.train.StopAtStepHook(last_step=FLAGS.max_steps)) + + # hook for sync replica training + hooks.append(optimizer.make_session_run_hook(is_chief)) + + with tf.train.MonitoredTrainingSession( + master=FLAGS.master, + is_chief=is_chief, + checkpoint_dir=FLAGS.output_dir, + scaffold=scaffold, + hooks=hooks, + chief_only_hooks=chief_only_hooks, + save_checkpoint_secs=None, + save_summaries_steps=None, + save_summaries_secs=None) as session: + while not session.should_stop(): + session.run([train_op]) + + +if __name__ == '__main__': + app.run(main) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_text/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_text/README.md" new file mode 100644 index 00000000..3e6dc3f6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/adversarial_text/README.md" @@ -0,0 +1,157 @@ +# Adversarial Text Classification + +Code for [*Adversarial Training Methods for Semi-Supervised Text Classification*](https://arxiv.org/abs/1605.07725) and [*Semi-Supervised Sequence Learning*](https://arxiv.org/abs/1511.01432). + +## Requirements + +* TensorFlow >= v1.3 + +## End-to-end IMDB Sentiment Classification + +### Fetch data + +```bash +$ wget http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz \ + -O /tmp/imdb.tar.gz +$ tar -xf /tmp/imdb.tar.gz -C /tmp +``` + +The directory `/tmp/aclImdb` contains the raw IMDB data. + +### Generate vocabulary + +```bash +$ IMDB_DATA_DIR=/tmp/imdb +$ python gen_vocab.py \ + --output_dir=$IMDB_DATA_DIR \ + --dataset=imdb \ + --imdb_input_dir=/tmp/aclImdb \ + --lowercase=False +``` + +Vocabulary and frequency files will be generated in `$IMDB_DATA_DIR`. + +### Generate training, validation, and test data + +```bash +$ python gen_data.py \ + --output_dir=$IMDB_DATA_DIR \ + --dataset=imdb \ + --imdb_input_dir=/tmp/aclImdb \ + --lowercase=False \ + --label_gain=False +``` + +`$IMDB_DATA_DIR` contains TFRecords files. + +### Pretrain IMDB Language Model + +```bash +$ PRETRAIN_DIR=/tmp/models/imdb_pretrain +$ python pretrain.py \ + --train_dir=$PRETRAIN_DIR \ + --data_dir=$IMDB_DATA_DIR \ + --vocab_size=86934 \ + --embedding_dims=256 \ + --rnn_cell_size=1024 \ + --num_candidate_samples=1024 \ + --batch_size=256 \ + --learning_rate=0.001 \ + --learning_rate_decay_factor=0.9999 \ + --max_steps=100000 \ + --max_grad_norm=1.0 \ + --num_timesteps=400 \ + --keep_prob_emb=0.5 \ + --normalize_embeddings +``` + +`$PRETRAIN_DIR` contains checkpoints of the pretrained language model. + +### Train classifier + +Most flags stay the same, save for the removal of candidate sampling and the +addition of `pretrained_model_dir`, from which the classifier will load the +pretrained embedding and LSTM variables, and flags related to adversarial +training and classification. + +```bash +$ TRAIN_DIR=/tmp/models/imdb_classify +$ python train_classifier.py \ + --train_dir=$TRAIN_DIR \ + --pretrained_model_dir=$PRETRAIN_DIR \ + --data_dir=$IMDB_DATA_DIR \ + --vocab_size=86934 \ + --embedding_dims=256 \ + --rnn_cell_size=1024 \ + --cl_num_layers=1 \ + --cl_hidden_size=30 \ + --batch_size=64 \ + --learning_rate=0.0005 \ + --learning_rate_decay_factor=0.9998 \ + --max_steps=15000 \ + --max_grad_norm=1.0 \ + --num_timesteps=400 \ + --keep_prob_emb=0.5 \ + --normalize_embeddings \ + --adv_training_method=vat \ + --perturb_norm_length=5.0 +``` + +### Evaluate on test data + +```bash +$ EVAL_DIR=/tmp/models/imdb_eval +$ python evaluate.py \ + --eval_dir=$EVAL_DIR \ + --checkpoint_dir=$TRAIN_DIR \ + --eval_data=test \ + --run_once \ + --num_examples=25000 \ + --data_dir=$IMDB_DATA_DIR \ + --vocab_size=86934 \ + --embedding_dims=256 \ + --rnn_cell_size=1024 \ + --batch_size=256 \ + --num_timesteps=400 \ + --normalize_embeddings +``` + +## Code Overview + +The main entry points are the binaries listed below. Each training binary builds +a `VatxtModel`, defined in `graphs.py`, which in turn uses graph building blocks +defined in `inputs.py` (defines input data reading and parsing), `layers.py` +(defines core model components), and `adversarial_losses.py` (defines +adversarial training losses). The training loop itself is defined in +`train_utils.py`. + +### Binaries + +* Pretraining: `pretrain.py` +* Classifier Training: `train_classifier.py` +* Evaluation: `evaluate.py` + +### Command-Line Flags + +Flags related to distributed training and the training loop itself are defined +in [`train_utils.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/train_utils.py). + +Flags related to model hyperparameters are defined in [`graphs.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/graphs.py). + +Flags related to adversarial training are defined in [`adversarial_losses.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/adversarial_losses.py). + +Flags particular to each job are defined in the main binary files. + +### Data Generation + +* Vocabulary generation: [`gen_vocab.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/gen_vocab.py) +* Data generation: [`gen_data.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/gen_data.py) + +Command-line flags defined in [`document_generators.py`](https://github.com/tensorflow/models/tree/master/research/adversarial_text/data/document_generators.py) +control which dataset is processed and how. + +## Contact for Issues + +* Ryan Sepassi, @rsepassi +* Andrew M. Dai, @a-dai
+
+
+
+
+
+
+Paper: [https://arxiv.org/abs/1805.06066](https://arxiv.org/abs/1805.06066)
+
+
+## 1. Installation
+
+### Requirements
+
+#### Python Packages
+
+```shell
+networkx
+gin-config
+```
+
+### Download cognitive_planning
+
+```shell
+git clone --depth 1 https://github.com/tensorflow/models.git
+```
+
+## 2. Datasets
+
+### Download ActiveVision Dataset
+We used Active Vision Dataset (AVD) which can be downloaded from [here](http://cs.unc.edu/~ammirato/active_vision_dataset_website/). To make our code faster and reduce memory footprint, we created the AVD Minimal dataset. AVD Minimal consists of low resolution images from the original AVD dataset. In addition, we added annotations for target views, predicted object detections from pre-trained object detector on MS-COCO dataset, and predicted semantic segmentation from pre-trained model on NYU-v2 dataset. AVD minimal can be downloaded from [here](https://storage.googleapis.com/active-vision-dataset/AVD_Minimal.zip). Set `$AVD_DIR` as the path to the downloaded AVD Minimal.
+
+### TODO: SUNCG Dataset
+Current version of the code does not support SUNCG dataset. It can be added by
+implementing necessary functions of `envs/task_env.py` using the public
+released code of SUNCG environment such as
+[House3d](https://github.com/facebookresearch/House3D) and
+[MINOS](https://github.com/minosworld/minos).
+
+### ActiveVisionDataset Demo
+
+
+If you wish to navigate the environment, to see how the AVD looks like you can use the following command:
+```shell
+python viz_active_vision_dataset_main -- \
+ --mode=human \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR'
+```
+
+## 3. Training
+Right now, the released version only supports training and inference using the real data from Active Vision Dataset.
+
+When RGB image modality is used, the Resnet embeddings are initialized. To start the training download pre-trained Resnet50 check point in the working directory ./resnet_v2_50_checkpoint/resnet_v2_50.ckpt
+
+```
+wget http://download.tensorflow.org/models/resnet_v2_50_2017_04_14.tar.gz
+```
+### Run training
+Use the following command for training:
+```shell
+# Train
+python train_supervised_active_vision.py \
+ --mode='train' \
+ --logdir=$CHECKPOINT_DIR \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR' \
+ --logtostderr
+```
+
+The training can be run for different modalities and modality combinations, including semantic segmentation, object detectors, RGB images, depth images. Low resolution images and outputs of detectors pretrained on COCO dataset and semantic segmenation pre trained on NYU dataset are provided as a part of this distribution and can be found in Meta directory of AVD_Minimal.
+Additional details are described in the comments of the code and in the paper.
+
+### Run Evaluation
+Use the following command for unrolling the policy on the eval environments. The inference code periodically check the checkpoint folder for new checkpoints to use it for unrolling the policy on the eval environments. After each evaluation, it will create a folder in the $CHECKPOINT_DIR/evals/$ITER where $ITER is the iteration number at which the checkpoint is stored.
+```shell
+# Eval
+python train_supervised_active_vision.py \
+ --mode='eval' \
+ --logdir=$CHECKPOINT_DIR \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR' \
+ --logtostderr
+```
+At any point, you can run the following command to compute statistics such as success rate over all the evaluations so far. It also generates gif images for unrolling of the best policy.
+```shell
+# Visualize and Compute Stats
+python viz_active_vision_dataset_main.py \
+ --mode=eval \
+ --eval_folder=$CHECKPOINT_DIR/evals/ \
+ --output_folder=$OUTPUT_GIFS_FOLDER \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root=$AVD_DIR'
+```
+## Contact
+
+To ask questions or report issues please open an issue on the tensorflow/models
+[issues tracker](https://github.com/tensorflow/models/issues).
+Please assign issues to @arsalan-mousavian.
+
+## Reference
+The details of the training and experiments can be found in the following paper. If you find our work useful in your research please consider citing our paper:
+
+```
+@inproceedings{MousavianECCVW18,
+ author = {A. Mousavian and A. Toshev and M. Fiser and J. Kosecka and J. Davidson},
+ title = {Visual Representations for Semantic Target Driven Navigation},
+ booktitle = {ECCV Workshop on Visual Learning and Embodied Agents in Simulation Environments},
+ year = {2018},
+}
+```
+
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/command" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/command"
new file mode 100644
index 00000000..daf634b3
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/command"
@@ -0,0 +1,14 @@
+python train_supervised_active_vision \
+ --mode='train' \
+ --logdir=/usr/local/google/home/kosecka/checkin_log_det/ \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=robotics/cognitive_planning/envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root="/usr/local/google/home/kosecka/AVD_minimal/"' \
+ --logtostderr
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/embedders.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/embedders.py"
new file mode 100644
index 00000000..91ed9f45
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/embedders.py"
@@ -0,0 +1,547 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Interface for different embedders for modalities."""
+
+import abc
+import numpy as np
+import tensorflow as tf
+import preprocessing
+from tensorflow.contrib.slim.nets import resnet_v2
+
+slim = tf.contrib.slim
+
+
+class Embedder(object):
+ """Represents the embedder for different modalities.
+
+ Modalities can be semantic segmentation, depth channel, object detection and
+ so on, which require specific embedder for them.
+ """
+ __metaclass__ = abc.ABCMeta
+
+ @abc.abstractmethod
+ def build(self, observation):
+ """Builds the model to embed the observation modality.
+
+ Args:
+ observation: tensor that contains the raw observation from modality.
+ Returns:
+ Embedding tensor for the given observation tensor.
+ """
+ raise NotImplementedError(
+ 'Needs to be implemented as part of Embedder Interface')
+
+
+class DetectionBoxEmbedder(Embedder):
+ """Represents the model that encodes the detection boxes from images."""
+
+ def __init__(self, rnn_state_size, scope=None):
+ self._rnn_state_size = rnn_state_size
+ self._scope = scope
+
+ def build(self, observations):
+ """Builds the model to embed object detection observations.
+
+ Args:
+ observations: a tuple of (dets, det_num).
+ dets is a tensor of BxTxLxE that has the detection boxes in all the
+ images of the batch. B is the batch size, T is the maximum length of
+ episode, L is the maximum number of detections per image in the batch
+ and E is the size of each detection embedding.
+ det_num is a tensor of BxT that contains the number of detected boxes
+ each image of each sequence in the batch.
+ Returns:
+ For each image in the batch, returns the accumulative embedding of all the
+ detection boxes in that image.
+ """
+ with tf.variable_scope(self._scope, default_name=''):
+ shape = observations[0].shape
+ dets = tf.reshape(observations[0], [-1, shape[-2], shape[-1]])
+ det_num = tf.reshape(observations[1], [-1])
+ lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self._rnn_state_size)
+ batch_size = tf.shape(dets)[0]
+ lstm_outputs, _ = tf.nn.dynamic_rnn(
+ cell=lstm_cell,
+ inputs=dets,
+ sequence_length=det_num,
+ initial_state=lstm_cell.zero_state(batch_size, dtype=tf.float32),
+ dtype=tf.float32)
+ # Gathering the last state of each sequence in the batch.
+ batch_range = tf.range(batch_size)
+ indices = tf.stack([batch_range, det_num - 1], axis=1)
+ last_lstm_outputs = tf.gather_nd(lstm_outputs, indices)
+ last_lstm_outputs = tf.reshape(last_lstm_outputs,
+ [-1, shape[1], self._rnn_state_size])
+ return last_lstm_outputs
+
+
+class ResNet(Embedder):
+ """Residual net embedder for image data."""
+
+ def __init__(self, params, *args, **kwargs):
+ super(ResNet, self).__init__(*args, **kwargs)
+ self._params = params
+ self._extra_train_ops = []
+
+ def build(self, images):
+ shape = images.get_shape().as_list()
+ if len(shape) == 5:
+ images = tf.reshape(images,
+ [shape[0] * shape[1], shape[2], shape[3], shape[4]])
+ embedding = self._build_model(images)
+ if len(shape) == 5:
+ embedding = tf.reshape(embedding, [shape[0], shape[1], -1])
+
+ return embedding
+
+ @property
+ def extra_train_ops(self):
+ return self._extra_train_ops
+
+ def _build_model(self, images):
+ """Builds the model."""
+
+ # Convert images to floats and normalize them.
+ images = tf.to_float(images)
+ bs = images.get_shape().as_list()[0]
+ images = [
+ tf.image.per_image_standardization(tf.squeeze(i))
+ for i in tf.split(images, bs)
+ ]
+ images = tf.concat([tf.expand_dims(i, axis=0) for i in images], axis=0)
+
+ with tf.variable_scope('init'):
+ x = self._conv('init_conv', images, 3, 3, 16, self._stride_arr(1))
+
+ strides = [1, 2, 2]
+ activate_before_residual = [True, False, False]
+ if self._params.use_bottleneck:
+ res_func = self._bottleneck_residual
+ filters = [16, 64, 128, 256]
+ else:
+ res_func = self._residual
+ filters = [16, 16, 32, 128]
+
+ with tf.variable_scope('unit_1_0'):
+ x = res_func(x, filters[0], filters[1], self._stride_arr(strides[0]),
+ activate_before_residual[0])
+ for i in xrange(1, self._params.num_residual_units):
+ with tf.variable_scope('unit_1_%d' % i):
+ x = res_func(x, filters[1], filters[1], self._stride_arr(1), False)
+
+ with tf.variable_scope('unit_2_0'):
+ x = res_func(x, filters[1], filters[2], self._stride_arr(strides[1]),
+ activate_before_residual[1])
+ for i in xrange(1, self._params.num_residual_units):
+ with tf.variable_scope('unit_2_%d' % i):
+ x = res_func(x, filters[2], filters[2], self._stride_arr(1), False)
+
+ with tf.variable_scope('unit_3_0'):
+ x = res_func(x, filters[2], filters[3], self._stride_arr(strides[2]),
+ activate_before_residual[2])
+ for i in xrange(1, self._params.num_residual_units):
+ with tf.variable_scope('unit_3_%d' % i):
+ x = res_func(x, filters[3], filters[3], self._stride_arr(1), False)
+
+ with tf.variable_scope('unit_last'):
+ x = self._batch_norm('final_bn', x)
+ x = self._relu(x, self._params.relu_leakiness)
+
+ with tf.variable_scope('pool_logit'):
+ x = self._global_avg_pooling(x)
+
+ return x
+
+ def _stride_arr(self, stride):
+ return [1, stride, stride, 1]
+
+ def _batch_norm(self, name, x):
+ """batch norm implementation."""
+ with tf.variable_scope(name):
+ params_shape = [x.shape[-1]]
+
+ beta = tf.get_variable(
+ 'beta',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(0.0, tf.float32))
+ gamma = tf.get_variable(
+ 'gamma',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(1.0, tf.float32))
+
+ if self._params.is_train:
+ mean, variance = tf.nn.moments(x, [0, 1, 2], name='moments')
+
+ moving_mean = tf.get_variable(
+ 'moving_mean',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(0.0, tf.float32),
+ trainable=False)
+ moving_variance = tf.get_variable(
+ 'moving_variance',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(1.0, tf.float32),
+ trainable=False)
+
+ self._extra_train_ops.append(
+ tf.assign_moving_average(moving_mean, mean, 0.9))
+ self._extra_train_ops.append(
+ tf.assign_moving_average(moving_variance, variance, 0.9))
+ else:
+ mean = tf.get_variable(
+ 'moving_mean',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(0.0, tf.float32),
+ trainable=False)
+ variance = tf.get_variable(
+ 'moving_variance',
+ params_shape,
+ tf.float32,
+ initializer=tf.constant_initializer(1.0, tf.float32),
+ trainable=False)
+ tf.summary.histogram(mean.op.name, mean)
+ tf.summary.histogram(variance.op.name, variance)
+ # elipson used to be 1e-5. Maybe 0.001 solves NaN problem in deeper net.
+ y = tf.nn.batch_normalization(x, mean, variance, beta, gamma, 0.001)
+ y.set_shape(x.shape)
+ return y
+
+ def _residual(self,
+ x,
+ in_filter,
+ out_filter,
+ stride,
+ activate_before_residual=False):
+ """Residual unit with 2 sub layers."""
+
+ if activate_before_residual:
+ with tf.variable_scope('shared_activation'):
+ x = self._batch_norm('init_bn', x)
+ x = self._relu(x, self._params.relu_leakiness)
+ orig_x = x
+ else:
+ with tf.variable_scope('residual_only_activation'):
+ orig_x = x
+ x = self._batch_norm('init_bn', x)
+ x = self._relu(x, self._params.relu_leakiness)
+
+ with tf.variable_scope('sub1'):
+ x = self._conv('conv1', x, 3, in_filter, out_filter, stride)
+
+ with tf.variable_scope('sub2'):
+ x = self._batch_norm('bn2', x)
+ x = self._relu(x, self._params.relu_leakiness)
+ x = self._conv('conv2', x, 3, out_filter, out_filter, [1, 1, 1, 1])
+
+ with tf.variable_scope('sub_add'):
+ if in_filter != out_filter:
+ orig_x = tf.nn.avg_pool(orig_x, stride, stride, 'VALID')
+ orig_x = tf.pad(
+ orig_x, [[0, 0], [0, 0], [0, 0], [(out_filter - in_filter) // 2,
+ (out_filter - in_filter) // 2]])
+ x += orig_x
+
+ return x
+
+ def _bottleneck_residual(self,
+ x,
+ in_filter,
+ out_filter,
+ stride,
+ activate_before_residual=False):
+ """A residual convolutional layer with a bottleneck.
+
+ The layer is a composite of three convolutional layers with a ReLU non-
+ linearity and batch normalization after each linear convolution. The depth
+ if the second and third layer is out_filter / 4 (hence it is a bottleneck).
+
+ Args:
+ x: a float 4 rank Tensor representing the input to the layer.
+ in_filter: a python integer representing depth of the input.
+ out_filter: a python integer representing depth of the output.
+ stride: a python integer denoting the stride of the layer applied before
+ the first convolution.
+ activate_before_residual: a python boolean. If True, then a ReLU is
+ applied as a first operation on the input x before everything else.
+ Returns:
+ A 4 rank Tensor with batch_size = batch size of input, width and height =
+ width / stride and height / stride of the input and depth = out_filter.
+ """
+ if activate_before_residual:
+ with tf.variable_scope('common_bn_relu'):
+ x = self._batch_norm('init_bn', x)
+ x = self._relu(x, self._params.relu_leakiness)
+ orig_x = x
+ else:
+ with tf.variable_scope('residual_bn_relu'):
+ orig_x = x
+ x = self._batch_norm('init_bn', x)
+ x = self._relu(x, self._params.relu_leakiness)
+
+ with tf.variable_scope('sub1'):
+ x = self._conv('conv1', x, 1, in_filter, out_filter / 4, stride)
+
+ with tf.variable_scope('sub2'):
+ x = self._batch_norm('bn2', x)
+ x = self._relu(x, self._params.relu_leakiness)
+ x = self._conv('conv2', x, 3, out_filter / 4, out_filter / 4,
+ [1, 1, 1, 1])
+
+ with tf.variable_scope('sub3'):
+ x = self._batch_norm('bn3', x)
+ x = self._relu(x, self._params.relu_leakiness)
+ x = self._conv('conv3', x, 1, out_filter / 4, out_filter, [1, 1, 1, 1])
+
+ with tf.variable_scope('sub_add'):
+ if in_filter != out_filter:
+ orig_x = self._conv('project', orig_x, 1, in_filter, out_filter, stride)
+ x += orig_x
+
+ return x
+
+ def _decay(self):
+ costs = []
+ for var in tf.trainable_variables():
+ if var.op.name.find(r'DW') > 0:
+ costs.append(tf.nn.l2_loss(var))
+
+ return tf.mul(self._params.weight_decay_rate, tf.add_n(costs))
+
+ def _conv(self, name, x, filter_size, in_filters, out_filters, strides):
+ """Convolution."""
+ with tf.variable_scope(name):
+ n = filter_size * filter_size * out_filters
+ kernel = tf.get_variable(
+ 'DW', [filter_size, filter_size, in_filters, out_filters],
+ tf.float32,
+ initializer=tf.random_normal_initializer(stddev=np.sqrt(2.0 / n)))
+ return tf.nn.conv2d(x, kernel, strides, padding='SAME')
+
+ def _relu(self, x, leakiness=0.0):
+ return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
+
+ def _fully_connected(self, x, out_dim):
+ x = tf.reshape(x, [self._params.batch_size, -1])
+ w = tf.get_variable(
+ 'DW', [x.get_shape()[1], out_dim],
+ initializer=tf.uniform_unit_scaling_initializer(factor=1.0))
+ b = tf.get_variable(
+ 'biases', [out_dim], initializer=tf.constant_initializer())
+ return tf.nn.xw_plus_b(x, w, b)
+
+ def _global_avg_pooling(self, x):
+ assert x.get_shape().ndims == 4
+ return tf.reduce_mean(x, [1, 2])
+
+
+class MLPEmbedder(Embedder):
+ """Embedder of vectorial data.
+
+ The net is a multi-layer perceptron, with ReLU nonlinearities in all layers
+ except the last one.
+ """
+
+ def __init__(self, layers, *args, **kwargs):
+ """Constructs MLPEmbedder.
+
+ Args:
+ layers: a list of python integers representing layer sizes.
+ *args: arguments for super constructor.
+ **kwargs: keyed arguments for super constructor.
+ """
+ super(MLPEmbedder, self).__init__(*args, **kwargs)
+ self._layers = layers
+
+ def build(self, features):
+ shape = features.get_shape().as_list()
+ if len(shape) == 3:
+ features = tf.reshape(features, [shape[0] * shape[1], shape[2]])
+ x = features
+ for i, dim in enumerate(self._layers):
+ with tf.variable_scope('layer_%i' % i):
+ x = self._fully_connected(x, dim)
+ if i < len(self._layers) - 1:
+ x = self._relu(x)
+
+ if len(shape) == 3:
+ x = tf.reshape(x, shape[:-1] + [self._layers[-1]])
+ return x
+
+ def _fully_connected(self, x, out_dim):
+ w = tf.get_variable(
+ 'DW', [x.get_shape()[1], out_dim],
+ initializer=tf.variance_scaling_initializer(distribution='uniform'))
+ b = tf.get_variable(
+ 'biases', [out_dim], initializer=tf.constant_initializer())
+ return tf.nn.xw_plus_b(x, w, b)
+
+ def _relu(self, x, leakiness=0.0):
+ return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu')
+
+
+class SmallNetworkEmbedder(Embedder):
+ """Embedder for image like observations.
+
+ The network is comprised of multiple conv layers and a fully connected layer
+ at the end. The number of conv layers and the parameters are configured from
+ params.
+ """
+
+ def __init__(self, params, *args, **kwargs):
+ """Constructs the small network.
+
+ Args:
+ params: params should be tf.hparams type. params need to have a list of
+ conv_sizes, conv_strides, conv_channels. The length of these lists
+ should be equal to each other and to the number of conv layers in the
+ network. Plus, it also needs to have boolean variable named to_one_hot
+ which indicates whether the input should be converted to one hot or not.
+ The size of the fully connected layer is specified by
+ params.embedding_size.
+
+ *args: The rest of the parameters.
+ **kwargs: the reset of the parameters.
+
+ Raises:
+ ValueError: If the length of params.conv_strides, params.conv_sizes, and
+ params.conv_channels are not equal.
+
+ """
+
+ super(SmallNetworkEmbedder, self).__init__(*args, **kwargs)
+ self._params = params
+ if len(self._params.conv_sizes) != len(self._params.conv_strides):
+ raise ValueError(
+ 'Conv sizes and strides should have the same length: {} != {}'.format(
+ len(self._params.conv_sizes), len(self._params.conv_strides)))
+
+ if len(self._params.conv_sizes) != len(self._params.conv_channels):
+ raise ValueError(
+ 'Conv sizes and channels should have the same length: {} != {}'.
+ format(len(self._params.conv_sizes), len(self._params.conv_channels)))
+
+ def build(self, images):
+ """Builds the embedder with the given speicifcation.
+
+ Args:
+ images: a tensor that contains the input images which has the shape of
+ NxTxHxWxC where N is the batch size, T is the maximum length of the
+ sequence, H and W are the height and width of the images and C is the
+ number of channels.
+
+ Returns:
+ A tensor that is the embedding of the images.
+ """
+
+ shape = images.get_shape().as_list()
+ images = tf.reshape(images,
+ [shape[0] * shape[1], shape[2], shape[3], shape[4]])
+
+ with slim.arg_scope(
+ [slim.conv2d, slim.fully_connected],
+ activation_fn=tf.nn.relu,
+ weights_regularizer=slim.l2_regularizer(self._params.weight_decay_rate),
+ biases_initializer=tf.zeros_initializer()):
+ with slim.arg_scope([slim.conv2d], padding='SAME'):
+ # convert the image to one hot if needed.
+ if self._params.to_one_hot:
+ net = tf.one_hot(
+ tf.squeeze(tf.to_int32(images), axis=[-1]),
+ self._params.one_hot_length)
+ else:
+ net = images
+
+ p = self._params
+ # Adding conv layers with the specified configurations.
+ for conv_id, kernel_stride_channel in enumerate(
+ zip(p.conv_sizes, p.conv_strides, p.conv_channels)):
+ kernel_size, stride, channels = kernel_stride_channel
+ net = slim.conv2d(
+ net,
+ channels, [kernel_size, kernel_size],
+ stride,
+ scope='conv_{}'.format(conv_id + 1))
+
+ net = slim.flatten(net)
+ net = slim.fully_connected(net, self._params.embedding_size, scope='fc')
+
+ output = tf.reshape(net, [shape[0], shape[1], -1])
+ return output
+
+
+class ResNet50Embedder(Embedder):
+ """Uses ResNet50 to embed input images."""
+
+ def build(self, images):
+ """Builds a ResNet50 embedder for the input images.
+
+ It assumes that the range of the pixel values in the images tensor is
+ [0,255] and should be castable to tf.uint8.
+
+ Args:
+ images: a tensor that contains the input images which has the shape of
+ NxTxHxWx3 where N is the batch size, T is the maximum length of the
+ sequence, H and W are the height and width of the images and C is the
+ number of channels.
+ Returns:
+ The embedding of the input image with the shape of NxTxL where L is the
+ embedding size of the output.
+
+ Raises:
+ ValueError: if the shape of the input does not agree with the expected
+ shape explained in the Args section.
+ """
+ shape = images.get_shape().as_list()
+ if len(shape) != 5:
+ raise ValueError(
+ 'The tensor shape should have 5 elements, {} is provided'.format(
+ len(shape)))
+ if shape[4] != 3:
+ raise ValueError('Three channels are expected for the input image')
+
+ images = tf.cast(images, tf.uint8)
+ images = tf.reshape(images,
+ [shape[0] * shape[1], shape[2], shape[3], shape[4]])
+ with slim.arg_scope(resnet_v2.resnet_arg_scope()):
+
+ def preprocess_fn(x):
+ x = tf.expand_dims(x, 0)
+ x = tf.image.resize_bilinear(x, [299, 299],
+ align_corners=False)
+ return(tf.squeeze(x, [0]))
+
+ images = tf.map_fn(preprocess_fn, images, dtype=tf.float32)
+
+ net, _ = resnet_v2.resnet_v2_50(
+ images, is_training=False, global_pool=True)
+ output = tf.reshape(net, [shape[0], shape[1], -1])
+ return output
+
+
+class IdentityEmbedder(Embedder):
+ """This embedder just returns the input as the output.
+
+ Used for modalitites that the embedding of the modality is the same as the
+ modality itself. For example, it can be used for one_hot goal.
+ """
+
+ def build(self, images):
+ return images
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/active_vision_dataset_env.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/active_vision_dataset_env.py"
new file mode 100644
index 00000000..507cde76
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/active_vision_dataset_env.py"
@@ -0,0 +1,1097 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Gym environment for the ActiveVision Dataset.
+
+ The dataset is captured with a robot moving around and taking picture in
+ multiple directions. The actions are moving in four directions, and rotate
+ clockwise or counter clockwise. The observations are the output of vision
+ pipelines such as object detectors. The goal is to find objects of interest
+ in each environment. For more details, refer:
+ http://cs.unc.edu/~ammirato/active_vision_dataset_website/.
+"""
+import tensorflow as tf
+import collections
+import copy
+import json
+import os
+from StringIO import StringIO
+import time
+import gym
+from gym.envs.registration import register
+import gym.spaces
+import networkx as nx
+import numpy as np
+import scipy.io as sio
+from absl import logging
+import gin
+import cv2
+import label_map_util
+import visualization_utils as vis_util
+from envs import task_env
+
+
+register(
+ id='active-vision-env-v0',
+ entry_point=
+ 'cognitive_planning.envs.active_vision_dataset_env:ActiveVisionDatasetEnv', # pylint: disable=line-too-long
+)
+
+_MAX_DEPTH_VALUE = 12102
+
+SUPPORTED_ACTIONS = [
+ 'right', 'rotate_cw', 'rotate_ccw', 'forward', 'left', 'backward', 'stop'
+]
+SUPPORTED_MODALITIES = [
+ task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
+ task_env.ModalityTypes.DEPTH,
+ task_env.ModalityTypes.OBJECT_DETECTION,
+ task_env.ModalityTypes.IMAGE,
+ task_env.ModalityTypes.GOAL,
+ task_env.ModalityTypes.PREV_ACTION,
+ task_env.ModalityTypes.DISTANCE,
+]
+
+# Data structure for storing the information related to the graph of the world.
+_Graph = collections.namedtuple('_Graph', [
+ 'graph', 'id_to_index', 'index_to_id', 'target_indexes', 'distance_to_goal'
+])
+
+
+def _init_category_index(label_map_path):
+ """Creates category index from class indexes to name of the classes.
+
+ Args:
+ label_map_path: path to the mapping.
+ Returns:
+ A map for mapping int keys to string categories.
+ """
+
+ label_map = label_map_util.load_labelmap(label_map_path)
+ num_classes = np.max(x.id for x in label_map.item)
+ categories = label_map_util.convert_label_map_to_categories(
+ label_map, max_num_classes=num_classes, use_display_name=True)
+ category_index = label_map_util.create_category_index(categories)
+ return category_index
+
+
+def _draw_detections(image_np, detections, category_index):
+ """Draws detections on to the image.
+
+ Args:
+ image_np: Image in the form of uint8 numpy array.
+ detections: a dictionary that contains the detection outputs.
+ category_index: contains the mapping between indexes and the category names.
+
+ Returns:
+ Does not return anything but draws the boxes on the
+ """
+ vis_util.visualize_boxes_and_labels_on_image_array(
+ image_np,
+ detections['detection_boxes'],
+ detections['detection_classes'],
+ detections['detection_scores'],
+ category_index,
+ use_normalized_coordinates=True,
+ max_boxes_to_draw=1000,
+ min_score_thresh=.0,
+ agnostic_mode=False)
+
+
+def generate_detection_image(detections,
+ image_size,
+ category_map,
+ num_classes,
+ is_binary=True):
+ """Generates one_hot vector of the image using the detection boxes.
+
+ Args:
+ detections: 2D object detections from the image. It's a dictionary that
+ contains detection_boxes, detection_classes, and detection_scores with
+ dimensions of nx4, nx1, nx1 where n is the number of detections.
+ image_size: The resolution of the output image.
+ category_map: dictionary that maps label names to index.
+ num_classes: Number of classes.
+ is_binary: If true, it sets the corresponding channels to 0 and 1.
+ Otherwise, sets the score in the corresponding channel.
+ Returns:
+ Returns image_size x image_size x num_classes image for the detection boxes.
+ """
+ res = np.zeros((image_size, image_size, num_classes), dtype=np.float32)
+ boxes = detections['detection_boxes']
+ labels = detections['detection_classes']
+ scores = detections['detection_scores']
+ for box, label, score in zip(boxes, labels, scores):
+ transformed_boxes = [int(round(t)) for t in box * image_size]
+ y1, x1, y2, x2 = transformed_boxes
+ # Detector returns fixed number of detections. Boxes with area of zero
+ # are equivalent of boxes that don't correspond to any detection box.
+ # So, we need to skip the boxes with area 0.
+ if (y2 - y1) * (x2 - x1) == 0:
+ continue
+ assert category_map[label] < num_classes, 'label = {}'.format(label)
+ value = score
+ if is_binary:
+ value = 1
+ res[y1:y2, x1:x2, category_map[label]] = value
+ return res
+
+
+def _get_detection_path(root, detection_folder_name, world):
+ return os.path.join(root, 'Meta', detection_folder_name, world + '.npy')
+
+
+def _get_image_folder(root, world):
+ return os.path.join(root, world, 'jpg_rgb')
+
+
+def _get_json_path(root, world):
+ return os.path.join(root, world, 'annotations.json')
+
+
+def _get_image_path(root, world, image_id):
+ return os.path.join(_get_image_folder(root, world), image_id + '.jpg')
+
+
+def _get_image_list(path, worlds):
+ """Builds a dictionary for all the worlds.
+
+ Args:
+ path: the path to the dataset on cns.
+ worlds: list of the worlds.
+
+ Returns:
+ dictionary where the key is the world names and the values
+ are the image_ids of that world.
+ """
+ world_id_dict = {}
+ for loc in worlds:
+ files = [t[:-4] for t in tf.gfile.ListDir(_get_image_folder(path, loc))]
+ world_id_dict[loc] = files
+ return world_id_dict
+
+
+def read_all_poses(dataset_root, world):
+ """Reads all the poses for each world.
+
+ Args:
+ dataset_root: the path to the root of the dataset.
+ world: string, name of the world.
+
+ Returns:
+ Dictionary of poses for all the images in each world. The key is the image
+ id of each view and the values are tuple of (x, z, R, scale). Where x and z
+ are the first and third coordinate of translation. R is the 3x3 rotation
+ matrix and scale is a float scalar that indicates the scale that needs to
+ be multipled to x and z in order to get the real world coordinates.
+
+ Raises:
+ ValueError: if the number of images do not match the number of poses read.
+ """
+ path = os.path.join(dataset_root, world, 'image_structs.mat')
+ with tf.gfile.Open(path) as f:
+ data = sio.loadmat(f)
+ xyz = data['image_structs']['world_pos']
+ image_names = data['image_structs']['image_name'][0]
+ rot = data['image_structs']['R'][0]
+ scale = data['scale'][0][0]
+ n = xyz.shape[1]
+ x = [xyz[0][i][0][0] for i in range(n)]
+ z = [xyz[0][i][2][0] for i in range(n)]
+ names = [name[0][:-4] for name in image_names]
+ if len(names) != len(x):
+ raise ValueError('number of image names are not equal to the number of '
+ 'poses {} != {}'.format(len(names), len(x)))
+ output = {}
+ for i in range(n):
+ if rot[i].shape[0] != 0:
+ assert rot[i].shape[0] == 3
+ assert rot[i].shape[1] == 3
+ output[names[i]] = (x[i], z[i], rot[i], scale)
+ else:
+ output[names[i]] = (x[i], z[i], None, scale)
+
+ return output
+
+
+def read_cached_data(should_load_images, dataset_root, segmentation_file_name,
+ targets_file_name, output_size):
+ """Reads all the necessary cached data.
+
+ Args:
+ should_load_images: whether to load the images or not.
+ dataset_root: path to the root of the dataset.
+ segmentation_file_name: The name of the file that contains semantic
+ segmentation annotations.
+ targets_file_name: The name of the file the contains targets annotated for
+ each world.
+ output_size: Size of the output images. This is used for pre-processing the
+ loaded images.
+ Returns:
+ Dictionary of all the cached data.
+ """
+
+ load_start = time.time()
+ result_data = {}
+
+ annotated_target_path = os.path.join(dataset_root, 'Meta',
+ targets_file_name + '.npy')
+
+ logging.info('loading targets: %s', annotated_target_path)
+ with tf.gfile.Open(annotated_target_path) as f:
+ result_data['targets'] = np.load(f).item()
+
+ depth_image_path = os.path.join(dataset_root, 'Meta/depth_imgs.npy')
+ logging.info('loading depth: %s', depth_image_path)
+ with tf.gfile.Open(depth_image_path) as f:
+ depth_data = np.load(f).item()
+
+ logging.info('processing depth')
+ for home_id in depth_data:
+ images = depth_data[home_id]
+ for image_id in images:
+ depth = images[image_id]
+ depth = cv2.resize(
+ depth / _MAX_DEPTH_VALUE, (output_size, output_size),
+ interpolation=cv2.INTER_NEAREST)
+ depth_mask = (depth > 0).astype(np.float32)
+ depth = np.dstack((depth, depth_mask))
+ images[image_id] = depth
+ result_data[task_env.ModalityTypes.DEPTH] = depth_data
+
+ sseg_path = os.path.join(dataset_root, 'Meta',
+ segmentation_file_name + '.npy')
+ logging.info('loading sseg: %s', sseg_path)
+ with tf.gfile.Open(sseg_path) as f:
+ sseg_data = np.load(f).item()
+
+ logging.info('processing sseg')
+ for home_id in sseg_data:
+ images = sseg_data[home_id]
+ for image_id in images:
+ sseg = images[image_id]
+ sseg = cv2.resize(
+ sseg, (output_size, output_size), interpolation=cv2.INTER_NEAREST)
+ images[image_id] = np.expand_dims(sseg, axis=-1).astype(np.float32)
+ result_data[task_env.ModalityTypes.SEMANTIC_SEGMENTATION] = sseg_data
+
+ if should_load_images:
+ image_path = os.path.join(dataset_root, 'Meta/imgs.npy')
+ logging.info('loading imgs: %s', image_path)
+ with tf.gfile.Open(image_path) as f:
+ image_data = np.load(f).item()
+
+ result_data[task_env.ModalityTypes.IMAGE] = image_data
+
+ with tf.gfile.Open(os.path.join(dataset_root, 'Meta/world_id_dict.npy')) as f:
+ result_data['world_id_dict'] = np.load(f).item()
+
+ logging.info('logging done in %f seconds', time.time() - load_start)
+ return result_data
+
+
+@gin.configurable
+def get_spec_dtype_map():
+ return {gym.spaces.Box: np.float32}
+
+
+@gin.configurable
+class ActiveVisionDatasetEnv(task_env.TaskEnv):
+ """Simulates the environment from ActiveVisionDataset."""
+ cached_data = None
+
+ def __init__(
+ self,
+ episode_length,
+ modality_types,
+ confidence_threshold,
+ output_size,
+ worlds,
+ targets,
+ compute_distance,
+ should_draw_detections,
+ dataset_root,
+ labelmap_path,
+ reward_collision,
+ reward_goal_range,
+ num_detection_classes,
+ segmentation_file_name,
+ detection_folder_name,
+ actions,
+ targets_file_name,
+ eval_init_points_file_name=None,
+ shaped_reward=False,
+ ):
+ """Instantiates the environment for ActiveVision Dataset.
+
+ Args:
+ episode_length: the length of each episode.
+ modality_types: a list of the strings where each entry indicates the name
+ of the modalities to be loaded. Valid entries are "sseg", "det",
+ "depth", "image", "distance", and "prev_action". "distance" should be
+ used for computing metrics in tf agents.
+ confidence_threshold: Consider detections more than confidence_threshold
+ for potential targets.
+ output_size: Resolution of the output image.
+ worlds: List of the name of the worlds.
+ targets: List of the target names. Each entry is a string label of the
+ target category (e.g. 'fridge', 'microwave', so on).
+ compute_distance: If True, outputs the distance of the view to the goal.
+ should_draw_detections (bool): If True, the image returned for the
+ observation will contains the bounding boxes.
+ dataset_root: the path to the root folder of the dataset.
+ labelmap_path: path to the dictionary that converts label strings to
+ indexes.
+ reward_collision: the reward the agents get after hitting an obstacle.
+ It should be a non-positive number.
+ reward_goal_range: the number of steps from goal, such that the agent is
+ considered to have reached the goal. If the agent's distance is less
+ than the specified goal range, the episode is also finishes by setting
+ done = True.
+ num_detection_classes: number of classes that detector outputs.
+ segmentation_file_name: the name of the file that contains the semantic
+ information. The file should be in the dataset_root/Meta/ folder.
+ detection_folder_name: Name of the folder that contains the detections
+ for each world. The folder should be under dataset_root/Meta/ folder.
+ actions: The list of the action names. Valid entries are listed in
+ SUPPORTED_ACTIONS.
+ targets_file_name: the name of the file that contains the annotated
+ targets. The file should be in the dataset_root/Meta/Folder
+ eval_init_points_file_name: The name of the file that contains the initial
+ points for evaluating the performance of the agent. If set to None,
+ episodes start at random locations. Should be only set for evaluation.
+ shaped_reward: Whether to add delta goal distance to the reward each step.
+
+ Raises:
+ ValueError: If one of the targets are not available in the annotated
+ targets or the modality names are not from the domain specified above.
+ ValueError: If one of the actions is not in SUPPORTED_ACTIONS.
+ ValueError: If the reward_collision is a positive number.
+ ValueError: If there is no action other than stop provided.
+ """
+ if reward_collision > 0:
+ raise ValueError('"reward" for collision should be non positive')
+
+ if reward_goal_range < 0:
+ logging.warning('environment does not terminate the episode if the agent '
+ 'is too close to the environment')
+
+ if not modality_types:
+ raise ValueError('modality names can not be empty')
+
+ for name in modality_types:
+ if name not in SUPPORTED_MODALITIES:
+ raise ValueError('invalid modality type: {}'.format(name))
+
+ actions_other_than_stop_found = False
+ for a in actions:
+ if a != 'stop':
+ actions_other_than_stop_found = True
+ if a not in SUPPORTED_ACTIONS:
+ raise ValueError('invalid action %s', a)
+
+ if not actions_other_than_stop_found:
+ raise ValueError('environment needs to have actions other than stop.')
+
+ super(ActiveVisionDatasetEnv, self).__init__()
+
+ self._episode_length = episode_length
+ self._modality_types = set(modality_types)
+ self._confidence_threshold = confidence_threshold
+ self._output_size = output_size
+ self._dataset_root = dataset_root
+ self._worlds = worlds
+ self._targets = targets
+ self._all_graph = {}
+ for world in self._worlds:
+ with tf.gfile.Open(_get_json_path(self._dataset_root, world), 'r') as f:
+ file_content = f.read()
+ file_content = file_content.replace('.jpg', '')
+ io = StringIO(file_content)
+ self._all_graph[world] = json.load(io)
+
+ self._cur_world = ''
+ self._cur_image_id = ''
+ self._cur_graph = None # Loaded by _update_graph
+ self._steps_taken = 0
+ self._last_action_success = True
+ self._category_index = _init_category_index(labelmap_path)
+ self._category_map = dict(
+ [(c, i) for i, c in enumerate(self._category_index)])
+ self._detection_cache = {}
+ if not ActiveVisionDatasetEnv.cached_data:
+ ActiveVisionDatasetEnv.cached_data = read_cached_data(
+ True, self._dataset_root, segmentation_file_name, targets_file_name,
+ self._output_size)
+ cached_data = ActiveVisionDatasetEnv.cached_data
+
+ self._world_id_dict = cached_data['world_id_dict']
+ self._depth_images = cached_data[task_env.ModalityTypes.DEPTH]
+ self._semantic_segmentations = cached_data[
+ task_env.ModalityTypes.SEMANTIC_SEGMENTATION]
+ self._annotated_targets = cached_data['targets']
+ self._cached_imgs = cached_data[task_env.ModalityTypes.IMAGE]
+ self._graph_cache = {}
+ self._compute_distance = compute_distance
+ self._should_draw_detections = should_draw_detections
+ self._reward_collision = reward_collision
+ self._reward_goal_range = reward_goal_range
+ self._num_detection_classes = num_detection_classes
+ self._actions = actions
+ self._detection_folder_name = detection_folder_name
+ self._shaped_reward = shaped_reward
+
+ self._eval_init_points = None
+ if eval_init_points_file_name is not None:
+ self._eval_init_index = 0
+ init_points_path = os.path.join(self._dataset_root, 'Meta',
+ eval_init_points_file_name + '.npy')
+ with tf.gfile.Open(init_points_path) as points_file:
+ data = np.load(points_file).item()
+ self._eval_init_points = []
+ for world in self._worlds:
+ for goal in self._targets:
+ if world in self._annotated_targets[goal]:
+ for image_id in data[world]:
+ self._eval_init_points.append((world, image_id[0], goal))
+ logging.info('loaded %d eval init points', len(self._eval_init_points))
+
+ self.action_space = gym.spaces.Discrete(len(self._actions))
+
+ obs_shapes = {}
+ if task_env.ModalityTypes.SEMANTIC_SEGMENTATION in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.SEMANTIC_SEGMENTATION] = gym.spaces.Box(
+ low=0, high=255, shape=(self._output_size, self._output_size, 1))
+ if task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.OBJECT_DETECTION] = gym.spaces.Box(
+ low=0,
+ high=255,
+ shape=(self._output_size, self._output_size,
+ self._num_detection_classes))
+ if task_env.ModalityTypes.DEPTH in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.DEPTH] = gym.spaces.Box(
+ low=0,
+ high=_MAX_DEPTH_VALUE,
+ shape=(self._output_size, self._output_size, 2))
+ if task_env.ModalityTypes.IMAGE in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.IMAGE] = gym.spaces.Box(
+ low=0, high=255, shape=(self._output_size, self._output_size, 3))
+ if task_env.ModalityTypes.GOAL in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.GOAL] = gym.spaces.Box(
+ low=0, high=1., shape=(len(self._targets),))
+ if task_env.ModalityTypes.PREV_ACTION in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.PREV_ACTION] = gym.spaces.Box(
+ low=0, high=1., shape=(len(self._actions) + 1,))
+ if task_env.ModalityTypes.DISTANCE in self._modality_types:
+ obs_shapes[task_env.ModalityTypes.DISTANCE] = gym.spaces.Box(
+ low=0, high=255, shape=(1,))
+ self.observation_space = gym.spaces.Dict(obs_shapes)
+
+ self._prev_action = np.zeros((len(self._actions) + 1), dtype=np.float32)
+
+ # Loading all the poses.
+ all_poses = {}
+ for world in self._worlds:
+ all_poses[world] = read_all_poses(self._dataset_root, world)
+ self._cached_poses = all_poses
+ self._vertex_to_pose = {}
+ self._pose_to_vertex = {}
+
+ @property
+ def actions(self):
+ """Returns list of actions for the env."""
+ return self._actions
+
+ def _next_image(self, image_id, action):
+ """Given the action, returns the name of the image that agent ends up in.
+
+ Args:
+ image_id: The image id of the current view.
+ action: valid actions are ['right', 'rotate_cw', 'rotate_ccw',
+ 'forward', 'left']. Each rotation is 30 degrees.
+
+ Returns:
+ The image name for the next location of the agent. If the action results
+ in collision or it is not possible for the agent to execute that action,
+ returns empty string.
+ """
+ assert action in self._actions, 'invalid action : {}'.format(action)
+ assert self._cur_world in self._all_graph, 'invalid world {}'.format(
+ self._cur_world)
+ assert image_id in self._all_graph[
+ self._cur_world], 'image_id {} is not in {}'.format(
+ image_id, self._cur_world)
+ return self._all_graph[self._cur_world][image_id][action]
+
+ def _largest_detection_for_image(self, image_id, detections_dict):
+ """Assigns area of the largest box for the view with given image id.
+
+ Args:
+ image_id: Image id of the view.
+ detections_dict: Detections for the view.
+ """
+ for cls, box, score in zip(detections_dict['detection_classes'],
+ detections_dict['detection_boxes'],
+ detections_dict['detection_scores']):
+ if cls not in self._targets:
+ continue
+ if score < self._confidence_threshold:
+ continue
+ ymin, xmin, ymax, xmax = box
+ area = (ymax - ymin) * (xmax - xmin)
+ if abs(area) < 1e-5:
+ continue
+ if image_id not in self._detection_area:
+ self._detection_area[image_id] = area
+ else:
+ self._detection_area[image_id] = max(self._detection_area[image_id],
+ area)
+
+ def _compute_goal_indexes(self):
+ """Computes the goal indexes for the environment.
+
+ Returns:
+ The indexes of the goals that are closest to target categories. A vertex
+ is goal vertice if the desired objects are detected in the image and the
+ target categories are not seen by moving forward from that vertice.
+ """
+ for image_id in self._world_id_dict[self._cur_world]:
+ detections_dict = self._detection_table[image_id]
+ self._largest_detection_for_image(image_id, detections_dict)
+ goal_indexes = []
+ for image_id in self._world_id_dict[self._cur_world]:
+ if image_id not in self._detection_area:
+ continue
+ # Detection box is large enough.
+ if self._detection_area[image_id] < 0.01:
+ continue
+ ok = True
+ next_image_id = self._next_image(image_id, 'forward')
+ if next_image_id:
+ if next_image_id in self._detection_area:
+ ok = False
+ if ok:
+ goal_indexes.append(self._cur_graph.id_to_index[image_id])
+ return goal_indexes
+
+ def to_image_id(self, vid):
+ """Converts vertex id to the image id.
+
+ Args:
+ vid: vertex id of the view.
+ Returns:
+ image id of the input vertex id.
+ """
+ return self._cur_graph.index_to_id[vid]
+
+ def to_vertex(self, image_id):
+ return self._cur_graph.id_to_index[image_id]
+
+ def observation(self, view_pose):
+ """Returns the observation at the given the vertex.
+
+ Args:
+ view_pose: pose of the view of interest.
+
+ Returns:
+ Observation at the given view point.
+
+ Raises:
+ ValueError: if the given view pose is not similar to any of the poses in
+ the current world.
+ """
+ vertex = self.pose_to_vertex(view_pose)
+ if vertex is None:
+ raise ValueError('The given found is not close enough to any of the poses'
+ ' in the environment.')
+ image_id = self._cur_graph.index_to_id[vertex]
+ output = collections.OrderedDict()
+
+ if task_env.ModalityTypes.SEMANTIC_SEGMENTATION in self._modality_types:
+ output[task_env.ModalityTypes.
+ SEMANTIC_SEGMENTATION] = self._semantic_segmentations[
+ self._cur_world][image_id]
+
+ detection = None
+ need_det = (
+ task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types or
+ (task_env.ModalityTypes.IMAGE in self._modality_types and
+ self._should_draw_detections))
+ if need_det:
+ detection = self._detection_table[image_id]
+ detection_image = generate_detection_image(
+ detection,
+ self._output_size,
+ self._category_map,
+ num_classes=self._num_detection_classes)
+
+ if task_env.ModalityTypes.OBJECT_DETECTION in self._modality_types:
+ output[task_env.ModalityTypes.OBJECT_DETECTION] = detection_image
+
+ if task_env.ModalityTypes.DEPTH in self._modality_types:
+ output[task_env.ModalityTypes.DEPTH] = self._depth_images[
+ self._cur_world][image_id]
+
+ if task_env.ModalityTypes.IMAGE in self._modality_types:
+ output_img = self._cached_imgs[self._cur_world][image_id]
+ if self._should_draw_detections:
+ output_img = output_img.copy()
+ _draw_detections(output_img, detection, self._category_index)
+ output[task_env.ModalityTypes.IMAGE] = output_img
+
+ if task_env.ModalityTypes.GOAL in self._modality_types:
+ goal = np.zeros((len(self._targets),), dtype=np.float32)
+ goal[self._targets.index(self._cur_goal)] = 1.
+ output[task_env.ModalityTypes.GOAL] = goal
+
+ if task_env.ModalityTypes.PREV_ACTION in self._modality_types:
+ output[task_env.ModalityTypes.PREV_ACTION] = self._prev_action
+
+ if task_env.ModalityTypes.DISTANCE in self._modality_types:
+ output[task_env.ModalityTypes.DISTANCE] = np.asarray(
+ [self.gt_value(self._cur_goal, vertex)], dtype=np.float32)
+
+ return output
+
+ def _step_no_reward(self, action):
+ """Performs a step in the environment with given action.
+
+ Args:
+ action: Action that is used to step in the environment. Action can be
+ string or integer. If the type is integer then it uses the ith element
+ from self._actions list. Otherwise, uses the string value as the action.
+
+ Returns:
+ observation, done, info
+ observation: dictonary that contains all the observations specified in
+ modality_types.
+ observation[task_env.ModalityTypes.OBJECT_DETECTION]: contains the
+ detection of the current view.
+ observation[task_env.ModalityTypes.IMAGE]: contains the
+ image of the current view. Note that if using the images for training,
+ should_load_images should be set to false.
+ observation[task_env.ModalityTypes.SEMANTIC_SEGMENTATION]: contains the
+ semantic segmentation of the current view.
+ observation[task_env.ModalityTypes.DEPTH]: If selected, returns the
+ depth map for the current view.
+ observation[task_env.ModalityTypes.PREV_ACTION]: If selected, returns
+ a numpy of (action_size + 1,). The first action_size elements indicate
+ the action and the last element indicates whether the previous action
+ was successful or not.
+ done: True after episode_length steps have been taken, False otherwise.
+ info: Empty dictionary.
+
+ Raises:
+ ValueError: for invalid actions.
+ """
+ # Primarily used for gym interface.
+ if not isinstance(action, str):
+ if not self.action_space.contains(action):
+ raise ValueError('Not a valid actions: %d', action)
+
+ action = self._actions[action]
+
+ if action not in self._actions:
+ raise ValueError('Not a valid action: %s', action)
+
+ action_index = self._actions.index(action)
+
+ if action == 'stop':
+ next_image_id = self._cur_image_id
+ done = True
+ success = True
+ else:
+ next_image_id = self._next_image(self._cur_image_id, action)
+ self._steps_taken += 1
+ done = False
+ success = True
+ if not next_image_id:
+ success = False
+ else:
+ self._cur_image_id = next_image_id
+
+ if self._steps_taken >= self._episode_length:
+ done = True
+
+ cur_vertex = self._cur_graph.id_to_index[self._cur_image_id]
+ observation = self.observation(self.vertex_to_pose(cur_vertex))
+
+ # Concatenation of one-hot prev action + a binary number for success of
+ # previous actions.
+ self._prev_action = np.zeros((len(self._actions) + 1,), dtype=np.float32)
+ self._prev_action[action_index] = 1.
+ self._prev_action[-1] = float(success)
+
+ distance_to_goal = self.gt_value(self._cur_goal, cur_vertex)
+ if success:
+ if distance_to_goal <= self._reward_goal_range:
+ done = True
+
+ return observation, done, {'success': success}
+
+ @property
+ def graph(self):
+ return self._cur_graph.graph
+
+ def state(self):
+ return self.vertex_to_pose(self.to_vertex(self._cur_image_id))
+
+ def gt_value(self, goal, v):
+ """Computes the distance to the goal from vertex v.
+
+ Args:
+ goal: name of the goal.
+ v: vertex id.
+
+ Returns:
+ Minimmum number of steps to the given goal.
+ """
+ assert goal in self._cur_graph.distance_to_goal, 'goal: {}'.format(goal)
+ assert v in self._cur_graph.distance_to_goal[goal]
+ res = self._cur_graph.distance_to_goal[goal][v]
+ return res
+
+ def _update_graph(self):
+ """Creates the graph for each environment and updates the _cur_graph."""
+ if self._cur_world not in self._graph_cache:
+ graph = nx.DiGraph()
+ id_to_index = {}
+ index_to_id = {}
+ image_list = self._world_id_dict[self._cur_world]
+ for i, image_id in enumerate(image_list):
+ id_to_index[image_id] = i
+ index_to_id[i] = image_id
+ graph.add_node(i)
+
+ for image_id in image_list:
+ for action in self._actions:
+ if action == 'stop':
+ continue
+ next_image = self._all_graph[self._cur_world][image_id][action]
+ if next_image:
+ graph.add_edge(
+ id_to_index[image_id], id_to_index[next_image], action=action)
+ target_indexes = {}
+ number_of_nodes_without_targets = graph.number_of_nodes()
+ distance_to_goal = {}
+ for goal in self._targets:
+ if self._cur_world not in self._annotated_targets[goal]:
+ continue
+ goal_indexes = [
+ id_to_index[i]
+ for i in self._annotated_targets[goal][self._cur_world]
+ if i
+ ]
+ super_source_index = graph.number_of_nodes()
+ target_indexes[goal] = super_source_index
+ graph.add_node(super_source_index)
+ index_to_id[super_source_index] = goal
+ id_to_index[goal] = super_source_index
+ for v in goal_indexes:
+ graph.add_edge(v, super_source_index, action='stop')
+ graph.add_edge(super_source_index, v, action='stop')
+ distance_to_goal[goal] = {}
+ for v in range(number_of_nodes_without_targets):
+ distance_to_goal[goal][v] = len(
+ nx.shortest_path(graph, v, super_source_index)) - 2
+
+ self._graph_cache[self._cur_world] = _Graph(
+ graph, id_to_index, index_to_id, target_indexes, distance_to_goal)
+ self._cur_graph = self._graph_cache[self._cur_world]
+
+ def reset_for_eval(self, new_world, new_goal, new_image_id):
+ """Resets to the given goal and image_id."""
+ return self._reset_env(new_world=new_world, new_goal=new_goal, new_image_id=new_image_id)
+
+ def get_init_config(self, path):
+ """Exposes the initial state of the agent for the given path.
+
+ Args:
+ path: sequences of the vertexes that the agent moves.
+
+ Returns:
+ image_id of the first view, world, and the goal.
+ """
+ return self._cur_graph.index_to_id[path[0]], self._cur_world, self._cur_goal
+
+ def _reset_env(
+ self,
+ new_world=None,
+ new_goal=None,
+ new_image_id=None,
+ ):
+ """Resets the agent in a random world and random id.
+
+ Args:
+ new_world: If not None, sets the new world to new_world.
+ new_goal: If not None, sets the new goal to new_goal.
+ new_image_id: If not None, sets the first image id to new_image_id.
+
+ Returns:
+ observation: dictionary of the observations. Content of the observation
+ is similar to that of the step function.
+ Raises:
+ ValueError: if it can't find a world and annotated goal.
+ """
+ self._steps_taken = 0
+ # The first prev_action is special all zero vector + success=1.
+ self._prev_action = np.zeros((len(self._actions) + 1,), dtype=np.float32)
+ self._prev_action[len(self._actions)] = 1.
+ if self._eval_init_points is not None:
+ if self._eval_init_index >= len(self._eval_init_points):
+ self._eval_init_index = 0
+ a = self._eval_init_points[self._eval_init_index]
+ self._cur_world, self._cur_image_id, self._cur_goal = a
+ self._eval_init_index += 1
+ elif not new_world:
+ attempts = 100
+ found = False
+ while attempts >= 0:
+ attempts -= 1
+ self._cur_goal = np.random.choice(self._targets)
+ available_worlds = list(
+ set(self._annotated_targets[self._cur_goal].keys()).intersection(
+ set(self._worlds)))
+ if available_worlds:
+ found = True
+ break
+ if not found:
+ raise ValueError('could not find a world that has a target annotated')
+ self._cur_world = np.random.choice(available_worlds)
+ else:
+ self._cur_world = new_world
+ self._cur_goal = new_goal
+ if new_world not in self._annotated_targets[new_goal]:
+ return None
+
+ self._cur_goal_index = self._targets.index(self._cur_goal)
+ if new_image_id:
+ self._cur_image_id = new_image_id
+ else:
+ self._cur_image_id = np.random.choice(
+ self._world_id_dict[self._cur_world])
+ if self._cur_world not in self._detection_cache:
+ with tf.gfile.Open(
+ _get_detection_path(self._dataset_root, self._detection_folder_name,
+ self._cur_world)) as f:
+ # Each file contains a dictionary with image ids as keys and detection
+ # dicts as values.
+ self._detection_cache[self._cur_world] = np.load(f).item()
+ self._detection_table = self._detection_cache[self._cur_world]
+ self._detection_area = {}
+ self._update_graph()
+ if self._cur_world not in self._vertex_to_pose:
+ # adding fake pose for the super nodes of each target categories.
+ self._vertex_to_pose[self._cur_world] = {
+ index: (-index,) for index in self._cur_graph.target_indexes.values()
+ }
+ # Calling vetex_to_pose for each vertex results in filling out the
+ # dictionaries that contain pose related data.
+ for image_id in self._world_id_dict[self._cur_world]:
+ self.vertex_to_pose(self.to_vertex(image_id))
+
+ # Filling out pose_to_vertex from vertex_to_pose.
+ self._pose_to_vertex[self._cur_world] = {
+ tuple(v): k
+ for k, v in self._vertex_to_pose[self._cur_world].iteritems()
+ }
+
+ cur_vertex = self._cur_graph.id_to_index[self._cur_image_id]
+ observation = self.observation(self.vertex_to_pose(cur_vertex))
+ return observation
+
+ def cur_vertex(self):
+ return self._cur_graph.id_to_index[self._cur_image_id]
+
+ def cur_image_id(self):
+ return self._cur_image_id
+
+ def path_to_goal(self, image_id=None):
+ """Returns the path from image_id to the self._cur_goal.
+
+ Args:
+ image_id: If set to None, computes the path from the current view.
+ Otherwise, sets the current view to the given image_id.
+ Returns:
+ The path to the goal.
+ Raises:
+ Exception if there's no path from the view to the goal.
+ """
+ if image_id is None:
+ image_id = self._cur_image_id
+ super_source = self._cur_graph.target_indexes[self._cur_goal]
+ try:
+ path = nx.shortest_path(self._cur_graph.graph,
+ self._cur_graph.id_to_index[image_id],
+ super_source)
+ except:
+ print 'path not found, image_id = ', self._cur_world, self._cur_image_id
+ raise
+ return path[:-1]
+
+ def targets(self):
+ return [self.vertex_to_pose(self._cur_graph.target_indexes[self._cur_goal])]
+
+ def vertex_to_pose(self, v):
+ """Returns pose of the view for a given vertex.
+
+ Args:
+ v: integer, vertex index.
+
+ Returns:
+ (x, z, dir_x, dir_z) where x and z are the tranlation and dir_x, dir_z are
+ a vector giving direction of the view.
+ """
+ if v in self._vertex_to_pose[self._cur_world]:
+ return np.copy(self._vertex_to_pose[self._cur_world][v])
+
+ x, z, rot, scale = self._cached_poses[self._cur_world][self.to_image_id(
+ v)]
+ if rot is None: # if rotation is not provided for the given vertex.
+ self._vertex_to_pose[self._cur_world][v] = np.asarray(
+ [x * scale, z * scale, v])
+ return np.copy(self._vertex_to_pose[self._cur_world][v])
+ # Multiply rotation matrix by [0,0,1] to get a vector of length 1 in the
+ # direction of the ray.
+ direction = np.zeros((3, 1), dtype=np.float32)
+ direction[2][0] = 1
+ direction = np.matmul(np.transpose(rot), direction)
+ direction = [direction[0][0], direction[2][0]]
+ self._vertex_to_pose[self._cur_world][v] = np.asarray(
+ [x * scale, z * scale, direction[0], direction[1]])
+ return np.copy(self._vertex_to_pose[self._cur_world][v])
+
+ def pose_to_vertex(self, pose):
+ """Returns the vertex id for the given pose."""
+ if tuple(pose) not in self._pose_to_vertex[self._cur_world]:
+ raise ValueError(
+ 'The given pose is not present in the dictionary: {}'.format(
+ tuple(pose)))
+
+ return self._pose_to_vertex[self._cur_world][tuple(pose)]
+
+ def check_scene_graph(self, world, goal):
+ """Checks the connectivity of the scene graph.
+
+ Goes over all the views. computes the shortest path to the goal. If it
+ crashes it means that it's not connected. Otherwise, the env graph is fine.
+
+ Args:
+ world: the string name of the world.
+ goal: the string label for the goal.
+ Returns:
+ Nothing.
+ """
+ obs = self._reset_env(new_world=world, new_goal=goal)
+ if not obs:
+ print '{} is not availble in {}'.format(goal, world)
+ return True
+ for image_id in self._world_id_dict[self._cur_world]:
+ print 'check image_id = {}'.format(image_id)
+ self._cur_image_id = image_id
+ path = self.path_to_goal()
+ actions = []
+ for i in range(len(path) - 2):
+ actions.append(self.action(path[i], path[i + 1]))
+ actions.append('stop')
+
+ @property
+ def goal_one_hot(self):
+ res = np.zeros((len(self._targets),), dtype=np.float32)
+ res[self._cur_goal_index] = 1.
+ return res
+
+ @property
+ def goal_index(self):
+ return self._cur_goal_index
+
+ @property
+ def goal_string(self):
+ return self._cur_goal
+
+ @property
+ def worlds(self):
+ return self._worlds
+
+ @property
+ def possible_targets(self):
+ return self._targets
+
+ def action(self, from_pose, to_pose):
+ """Returns the action that takes source vertex to destination vertex.
+
+ Args:
+ from_pose: pose of the source.
+ to_pose: pose of the destination.
+ Returns:
+ Returns the index of the action.
+ Raises:
+ ValueError: If it is not possible to go from the first vertice to second
+ vertice with one action, it raises value error.
+ """
+ from_index = self.pose_to_vertex(from_pose)
+ to_index = self.pose_to_vertex(to_pose)
+ if to_index not in self.graph[from_index]:
+ from_image_id = self.to_image_id(from_index)
+ to_image_id = self.to_image_id(to_index)
+ raise ValueError('{},{} is not connected to {},{}'.format(
+ from_index, from_image_id, to_index, to_image_id))
+ return self._actions.index(self.graph[from_index][to_index]['action'])
+
+ def random_step_sequence(self, min_len=None, max_len=None):
+ """Generates random step sequence that takes agent to the goal.
+
+ Args:
+ min_len: integer, minimum length of a step sequence. Not yet implemented.
+ max_len: integer, should be set to an integer and it is the maximum number
+ of observations and path length to be max_len.
+ Returns:
+ Tuple of (path, actions, states, step_outputs).
+ path: a random path from a random starting point and random environment.
+ actions: actions of the returned path.
+ states: viewpoints of all the states in between.
+ step_outputs: list of step() return tuples.
+ Raises:
+ ValueError: if first_n is not greater than zero; if min_len is different
+ from None.
+ """
+ if max_len is None:
+ raise ValueError('max_len can not be set as None')
+ if max_len < 1:
+ raise ValueError('first_n must be greater or equal to 1.')
+ if min_len is not None:
+ raise ValueError('min_len is not yet implemented.')
+
+ path = []
+ actions = []
+ states = []
+ step_outputs = []
+ obs = self.reset()
+ last_obs_tuple = [obs, 0, False, {}]
+ for _ in xrange(max_len):
+ action = np.random.choice(self._actions)
+ # We don't want to sample stop action because stop does not add new
+ # information.
+ while action == 'stop':
+ action = np.random.choice(self._actions)
+ path.append(self.to_vertex(self._cur_image_id))
+ onehot = np.zeros((len(self._actions),), dtype=np.float32)
+ onehot[self._actions.index(action)] = 1.
+ actions.append(onehot)
+ states.append(self.vertex_to_pose(path[-1]))
+ step_outputs.append(copy.deepcopy(last_obs_tuple))
+ last_obs_tuple = self.step(action)
+
+ return path, actions, states, step_outputs
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/configs/active_vision_config.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/configs/active_vision_config.gin"
new file mode 100644
index 00000000..edb10dc1
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/configs/active_vision_config.gin"
@@ -0,0 +1,27 @@
+#-*-Python-*-
+ActiveVisionDatasetEnv.episode_length = 200
+ActiveVisionDatasetEnv.actions = [
+ 'right', 'rotate_cw', 'rotate_ccw', 'forward', 'left', 'backward', 'stop'
+]
+ActiveVisionDatasetEnv.confidence_threshold = 0.5
+ActiveVisionDatasetEnv.output_size = 64
+ActiveVisionDatasetEnv.worlds = [
+ 'Home_001_1', 'Home_001_2', 'Home_002_1', 'Home_003_1', 'Home_003_2',
+ 'Home_004_1', 'Home_004_2', 'Home_005_1', 'Home_005_2', 'Home_006_1',
+ 'Home_007_1', 'Home_010_1', 'Home_011_1', 'Home_013_1', 'Home_014_1',
+ 'Home_014_2', 'Home_015_1', 'Home_016_1'
+]
+ActiveVisionDatasetEnv.targets = [
+ 'tv', 'dining_table', 'fridge', 'microwave', 'couch'
+]
+ActiveVisionDatasetEnv.compute_distance = False
+ActiveVisionDatasetEnv.should_draw_detections = False
+ActiveVisionDatasetEnv.dataset_root = '/usr/local/google/home/kosecka/AVD_Minimal/'
+ActiveVisionDatasetEnv.labelmap_path = 'label_map.txt'
+ActiveVisionDatasetEnv.reward_collision = 0
+ActiveVisionDatasetEnv.reward_goal_range = 2
+ActiveVisionDatasetEnv.num_detection_classes = 90
+ActiveVisionDatasetEnv.segmentation_file_name='sseg_crf'
+ActiveVisionDatasetEnv.detection_folder_name='Detections'
+ActiveVisionDatasetEnv.targets_file_name='annotated_targets'
+ActiveVisionDatasetEnv.shaped_reward=False
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/task_env.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/task_env.py"
new file mode 100644
index 00000000..84d527cd
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/task_env.py"
@@ -0,0 +1,218 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""An interface representing the topology of an environment.
+
+Allows for high level planning and high level instruction generation for
+navigation tasks.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import abc
+import enum
+import gym
+import gin
+
+
+@gin.config.constants_from_enum
+class ModalityTypes(enum.Enum):
+ """Types of the modalities that can be used."""
+ IMAGE = 0
+ SEMANTIC_SEGMENTATION = 1
+ OBJECT_DETECTION = 2
+ DEPTH = 3
+ GOAL = 4
+ PREV_ACTION = 5
+ PREV_SUCCESS = 6
+ STATE = 7
+ DISTANCE = 8
+ CAN_STEP = 9
+
+ def __lt__(self, other):
+ if self.__class__ is other.__class__:
+ return self.value < other.value
+ return NotImplemented
+
+
+class TaskEnvInterface(object):
+ """Interface for an environment topology.
+
+ An environment can implement this interface if there is a topological graph
+ underlying this environment. All paths below are defined as paths in this
+ graph. Using path_to_actions function one can translate a topological path
+ to a geometric path in the environment.
+ """
+
+ __metaclass__ = abc.ABCMeta
+
+ @abc.abstractmethod
+ def random_step_sequence(self, min_len=None, max_len=None):
+ """Generates a random sequence of actions and executes them.
+
+ Args:
+ min_len: integer, minimum length of a step sequence.
+ max_len: integer, if it is set to non-None, the method returns only
+ the first n steps of a random sequence. If the environment is
+ computationally heavy this argument should be set to speed up the
+ training and avoid unnecessary computations by the environment.
+
+ Returns:
+ A path, defined as a list of vertex indices, a list of actions, a list of
+ states, and a list of step() return tuples.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractmethod
+ def targets(self):
+ """A list of targets in the environment.
+
+ Returns:
+ A list of target locations.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractproperty
+ def state(self):
+ """Returns the position for the current location of agent."""
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractproperty
+ def graph(self):
+ """Returns a graph representing the environment topology.
+
+ Returns:
+ nx.Graph object.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractmethod
+ def vertex_to_pose(self, vertex_index):
+ """Maps a vertex index to a pose in the environment.
+
+ Pose of the camera can be represented by (x,y,theta) or (x,y,z,theta).
+ Args:
+ vertex_index: index of a vertex in the topology graph.
+
+ Returns:
+ A np.array of floats of size 3 or 4 representing the pose of the vertex.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractmethod
+ def pose_to_vertex(self, pose):
+ """Maps a coordinate in the maze to the closest vertex in topology graph.
+
+ Args:
+ pose: np.array of floats containing a the pose of the view.
+
+ Returns:
+ index of a vertex.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ @abc.abstractmethod
+ def observation(self, state):
+ """Returns observation at location xy and orientation theta.
+
+ Args:
+ state: a np.array of floats containing coordinates of a location and
+ orientation.
+
+ Returns:
+ Dictionary of observations in the case of multiple observations.
+ The keys are the modality names and the values are the np.array of float
+ of observations for corresponding modality.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+ def action(self, init_state, final_state):
+ """Computes the transition action from state1 to state2.
+
+ If the environment is discrete and the views are not adjacent in the
+ environment. i.e. it is not possible to move from the first view to the
+ second view with one action it should return None. In the continuous case,
+ it will be the continuous difference of first view and second view.
+
+ Args:
+ init_state: numpy array, the initial view of the agent.
+ final_state: numpy array, the final view of the agent.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of EnvTopology interface.')
+
+
+@gin.configurable
+class TaskEnv(gym.Env, TaskEnvInterface):
+ """An environment which uses a Task to compute reward.
+
+ The environment implements a a gym interface, as well as EnvTopology. The
+ former makes sure it can be used within an RL training, while the latter
+ makes sure it can be used by a Task.
+
+ This environment requires _step_no_reward to be implemented, which steps
+ through it but does not return reward. Instead, the reward calculation is
+ delegated to the Task object, which in return can access needed properties
+ of the environment. These properties are exposed via the EnvTopology
+ interface.
+ """
+
+ def __init__(self, task=None):
+ self._task = task
+
+ def set_task(self, task):
+ self._task = task
+
+ @abc.abstractmethod
+ def _step_no_reward(self, action):
+ """Same as _step without returning reward.
+
+ Args:
+ action: see _step.
+
+ Returns:
+ state, done, info as defined in _step.
+ """
+ raise NotImplementedError('Implement step.')
+
+ @abc.abstractmethod
+ def _reset_env(self):
+ """Resets the environment. Returns initial observation."""
+ raise NotImplementedError('Implement _reset. Must call super!')
+
+ def step(self, action):
+ obs, done, info = self._step_no_reward(action)
+
+ reward = 0.0
+ if self._task is not None:
+ obs, reward, done, info = self._task.reward(obs, done, info)
+
+ return obs, reward, done, info
+
+ def reset(self):
+ """Resets the environment. Gym API."""
+ obs = self._reset_env()
+ if self._task is not None:
+ self._task.reset(obs)
+ return obs
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/util.py"
new file mode 100644
index 00000000..32a384bc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/envs/util.py"
@@ -0,0 +1,55 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""A module with utility functions.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import numpy as np
+
+
+def trajectory_to_deltas(trajectory, state):
+ """Computes a sequence of deltas of a state to traverse a trajectory in 2D.
+
+ The initial state of the agent contains its pose -- location in 2D and
+ orientation. When the computed deltas are incrementally added to it, it
+ traverses the specified trajectory while keeping its orientation parallel to
+ the trajectory.
+
+ Args:
+ trajectory: a np.array of floats of shape n x 2. The n-th row contains the
+ n-th point.
+ state: a 3 element np.array of floats containing agent's location and
+ orientation in radians.
+
+ Returns:
+ A np.array of floats of size n x 3.
+ """
+ state = np.reshape(state, [-1])
+ init_xy = state[0:2]
+ init_theta = state[2]
+
+ delta_xy = trajectory - np.concatenate(
+ [np.reshape(init_xy, [1, 2]), trajectory[:-1, :]], axis=0)
+
+ thetas = np.reshape(np.arctan2(delta_xy[:, 1], delta_xy[:, 0]), [-1, 1])
+ thetas = np.concatenate([np.reshape(init_theta, [1, 1]), thetas], axis=0)
+ delta_thetas = thetas[1:] - thetas[:-1]
+
+ deltas = np.concatenate([delta_xy, delta_thetas], axis=1)
+ return deltas
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map.txt" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map.txt"
new file mode 100644
index 00000000..1f4872bd
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map.txt"
@@ -0,0 +1,400 @@
+item {
+ name: "/m/01g317"
+ id: 1
+ display_name: "person"
+}
+item {
+ name: "/m/0199g"
+ id: 2
+ display_name: "bicycle"
+}
+item {
+ name: "/m/0k4j"
+ id: 3
+ display_name: "car"
+}
+item {
+ name: "/m/04_sv"
+ id: 4
+ display_name: "motorcycle"
+}
+item {
+ name: "/m/05czz6l"
+ id: 5
+ display_name: "airplane"
+}
+item {
+ name: "/m/01bjv"
+ id: 6
+ display_name: "bus"
+}
+item {
+ name: "/m/07jdr"
+ id: 7
+ display_name: "train"
+}
+item {
+ name: "/m/07r04"
+ id: 8
+ display_name: "truck"
+}
+item {
+ name: "/m/019jd"
+ id: 9
+ display_name: "boat"
+}
+item {
+ name: "/m/015qff"
+ id: 10
+ display_name: "traffic light"
+}
+item {
+ name: "/m/01pns0"
+ id: 11
+ display_name: "fire hydrant"
+}
+item {
+ name: "/m/02pv19"
+ id: 13
+ display_name: "stop sign"
+}
+item {
+ name: "/m/015qbp"
+ id: 14
+ display_name: "parking meter"
+}
+item {
+ name: "/m/0cvnqh"
+ id: 15
+ display_name: "bench"
+}
+item {
+ name: "/m/015p6"
+ id: 16
+ display_name: "bird"
+}
+item {
+ name: "/m/01yrx"
+ id: 17
+ display_name: "cat"
+}
+item {
+ name: "/m/0bt9lr"
+ id: 18
+ display_name: "dog"
+}
+item {
+ name: "/m/03k3r"
+ id: 19
+ display_name: "horse"
+}
+item {
+ name: "/m/07bgp"
+ id: 20
+ display_name: "sheep"
+}
+item {
+ name: "/m/01xq0k1"
+ id: 21
+ display_name: "cow"
+}
+item {
+ name: "/m/0bwd_0j"
+ id: 22
+ display_name: "elephant"
+}
+item {
+ name: "/m/01dws"
+ id: 23
+ display_name: "bear"
+}
+item {
+ name: "/m/0898b"
+ id: 24
+ display_name: "zebra"
+}
+item {
+ name: "/m/03bk1"
+ id: 25
+ display_name: "giraffe"
+}
+item {
+ name: "/m/01940j"
+ id: 27
+ display_name: "backpack"
+}
+item {
+ name: "/m/0hnnb"
+ id: 28
+ display_name: "umbrella"
+}
+item {
+ name: "/m/080hkjn"
+ id: 31
+ display_name: "handbag"
+}
+item {
+ name: "/m/01rkbr"
+ id: 32
+ display_name: "tie"
+}
+item {
+ name: "/m/01s55n"
+ id: 33
+ display_name: "suitcase"
+}
+item {
+ name: "/m/02wmf"
+ id: 34
+ display_name: "frisbee"
+}
+item {
+ name: "/m/071p9"
+ id: 35
+ display_name: "skis"
+}
+item {
+ name: "/m/06__v"
+ id: 36
+ display_name: "snowboard"
+}
+item {
+ name: "/m/018xm"
+ id: 37
+ display_name: "sports ball"
+}
+item {
+ name: "/m/02zt3"
+ id: 38
+ display_name: "kite"
+}
+item {
+ name: "/m/03g8mr"
+ id: 39
+ display_name: "baseball bat"
+}
+item {
+ name: "/m/03grzl"
+ id: 40
+ display_name: "baseball glove"
+}
+item {
+ name: "/m/06_fw"
+ id: 41
+ display_name: "skateboard"
+}
+item {
+ name: "/m/019w40"
+ id: 42
+ display_name: "surfboard"
+}
+item {
+ name: "/m/0dv9c"
+ id: 43
+ display_name: "tennis racket"
+}
+item {
+ name: "/m/04dr76w"
+ id: 44
+ display_name: "bottle"
+}
+item {
+ name: "/m/09tvcd"
+ id: 46
+ display_name: "wine glass"
+}
+item {
+ name: "/m/08gqpm"
+ id: 47
+ display_name: "cup"
+}
+item {
+ name: "/m/0dt3t"
+ id: 48
+ display_name: "fork"
+}
+item {
+ name: "/m/04ctx"
+ id: 49
+ display_name: "knife"
+}
+item {
+ name: "/m/0cmx8"
+ id: 50
+ display_name: "spoon"
+}
+item {
+ name: "/m/04kkgm"
+ id: 51
+ display_name: "bowl"
+}
+item {
+ name: "/m/09qck"
+ id: 52
+ display_name: "banana"
+}
+item {
+ name: "/m/014j1m"
+ id: 53
+ display_name: "apple"
+}
+item {
+ name: "/m/0l515"
+ id: 54
+ display_name: "sandwich"
+}
+item {
+ name: "/m/0cyhj_"
+ id: 55
+ display_name: "orange"
+}
+item {
+ name: "/m/0hkxq"
+ id: 56
+ display_name: "broccoli"
+}
+item {
+ name: "/m/0fj52s"
+ id: 57
+ display_name: "carrot"
+}
+item {
+ name: "/m/01b9xk"
+ id: 58
+ display_name: "hot dog"
+}
+item {
+ name: "/m/0663v"
+ id: 59
+ display_name: "pizza"
+}
+item {
+ name: "/m/0jy4k"
+ id: 60
+ display_name: "donut"
+}
+item {
+ name: "/m/0fszt"
+ id: 61
+ display_name: "cake"
+}
+item {
+ name: "/m/01mzpv"
+ id: 62
+ display_name: "chair"
+}
+item {
+ name: "/m/02crq1"
+ id: 63
+ display_name: "couch"
+}
+item {
+ name: "/m/03fp41"
+ id: 64
+ display_name: "potted plant"
+}
+item {
+ name: "/m/03ssj5"
+ id: 65
+ display_name: "bed"
+}
+item {
+ name: "/m/04bcr3"
+ id: 67
+ display_name: "dining table"
+}
+item {
+ name: "/m/09g1w"
+ id: 70
+ display_name: "toilet"
+}
+item {
+ name: "/m/07c52"
+ id: 72
+ display_name: "tv"
+}
+item {
+ name: "/m/01c648"
+ id: 73
+ display_name: "laptop"
+}
+item {
+ name: "/m/020lf"
+ id: 74
+ display_name: "mouse"
+}
+item {
+ name: "/m/0qjjc"
+ id: 75
+ display_name: "remote"
+}
+item {
+ name: "/m/01m2v"
+ id: 76
+ display_name: "keyboard"
+}
+item {
+ name: "/m/050k8"
+ id: 77
+ display_name: "cell phone"
+}
+item {
+ name: "/m/0fx9l"
+ id: 78
+ display_name: "microwave"
+}
+item {
+ name: "/m/029bxz"
+ id: 79
+ display_name: "oven"
+}
+item {
+ name: "/m/01k6s3"
+ id: 80
+ display_name: "toaster"
+}
+item {
+ name: "/m/0130jx"
+ id: 81
+ display_name: "sink"
+}
+item {
+ name: "/m/040b_t"
+ id: 82
+ display_name: "refrigerator"
+}
+item {
+ name: "/m/0bt_c3"
+ id: 84
+ display_name: "book"
+}
+item {
+ name: "/m/01x3z"
+ id: 85
+ display_name: "clock"
+}
+item {
+ name: "/m/02s195"
+ id: 86
+ display_name: "vase"
+}
+item {
+ name: "/m/01lsmm"
+ id: 87
+ display_name: "scissors"
+}
+item {
+ name: "/m/0kmg4"
+ id: 88
+ display_name: "teddy bear"
+}
+item {
+ name: "/m/03wvsk"
+ id: 89
+ display_name: "hair drier"
+}
+item {
+ name: "/m/012xff"
+ id: 90
+ display_name: "toothbrush"
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map_util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map_util.py"
new file mode 100644
index 00000000..e258e3ab
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/label_map_util.py"
@@ -0,0 +1,181 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Label map utility functions."""
+
+import logging
+
+import tensorflow as tf
+from google.protobuf import text_format
+import string_int_label_map_pb2
+
+
+def _validate_label_map(label_map):
+ """Checks if a label map is valid.
+
+ Args:
+ label_map: StringIntLabelMap to validate.
+
+ Raises:
+ ValueError: if label map is invalid.
+ """
+ for item in label_map.item:
+ if item.id < 0:
+ raise ValueError('Label map ids should be >= 0.')
+ if (item.id == 0 and item.name != 'background' and
+ item.display_name != 'background'):
+ raise ValueError('Label map id 0 is reserved for the background label')
+
+
+def create_category_index(categories):
+ """Creates dictionary of COCO compatible categories keyed by category id.
+
+ Args:
+ categories: a list of dicts, each of which has the following keys:
+ 'id': (required) an integer id uniquely identifying this category.
+ 'name': (required) string representing category name
+ e.g., 'cat', 'dog', 'pizza'.
+
+ Returns:
+ category_index: a dict containing the same entries as categories, but keyed
+ by the 'id' field of each category.
+ """
+ category_index = {}
+ for cat in categories:
+ category_index[cat['id']] = cat
+ return category_index
+
+
+def get_max_label_map_index(label_map):
+ """Get maximum index in label map.
+
+ Args:
+ label_map: a StringIntLabelMapProto
+
+ Returns:
+ an integer
+ """
+ return max([item.id for item in label_map.item])
+
+
+def convert_label_map_to_categories(label_map,
+ max_num_classes,
+ use_display_name=True):
+ """Loads label map proto and returns categories list compatible with eval.
+
+ This function loads a label map and returns a list of dicts, each of which
+ has the following keys:
+ 'id': (required) an integer id uniquely identifying this category.
+ 'name': (required) string representing category name
+ e.g., 'cat', 'dog', 'pizza'.
+ We only allow class into the list if its id-label_id_offset is
+ between 0 (inclusive) and max_num_classes (exclusive).
+ If there are several items mapping to the same id in the label map,
+ we will only keep the first one in the categories list.
+
+ Args:
+ label_map: a StringIntLabelMapProto or None. If None, a default categories
+ list is created with max_num_classes categories.
+ max_num_classes: maximum number of (consecutive) label indices to include.
+ use_display_name: (boolean) choose whether to load 'display_name' field
+ as category name. If False or if the display_name field does not exist,
+ uses 'name' field as category names instead.
+ Returns:
+ categories: a list of dictionaries representing all possible categories.
+ """
+ categories = []
+ list_of_ids_already_added = []
+ if not label_map:
+ label_id_offset = 1
+ for class_id in range(max_num_classes):
+ categories.append({
+ 'id': class_id + label_id_offset,
+ 'name': 'category_{}'.format(class_id + label_id_offset)
+ })
+ return categories
+ for item in label_map.item:
+ if not 0 < item.id <= max_num_classes:
+ logging.info('Ignore item %d since it falls outside of requested '
+ 'label range.', item.id)
+ continue
+ if use_display_name and item.HasField('display_name'):
+ name = item.display_name
+ else:
+ name = item.name
+ if item.id not in list_of_ids_already_added:
+ list_of_ids_already_added.append(item.id)
+ categories.append({'id': item.id, 'name': name})
+ return categories
+
+
+def load_labelmap(path):
+ """Loads label map proto.
+
+ Args:
+ path: path to StringIntLabelMap proto text file.
+ Returns:
+ a StringIntLabelMapProto
+ """
+ with tf.gfile.GFile(path, 'r') as fid:
+ label_map_string = fid.read()
+ label_map = string_int_label_map_pb2.StringIntLabelMap()
+ try:
+ text_format.Merge(label_map_string, label_map)
+ except text_format.ParseError:
+ label_map.ParseFromString(label_map_string)
+ _validate_label_map(label_map)
+ return label_map
+
+
+def get_label_map_dict(label_map_path, use_display_name=False):
+ """Reads a label map and returns a dictionary of label names to id.
+
+ Args:
+ label_map_path: path to label_map.
+ use_display_name: whether to use the label map items' display names as keys.
+
+ Returns:
+ A dictionary mapping label names to id.
+ """
+ label_map = load_labelmap(label_map_path)
+ label_map_dict = {}
+ for item in label_map.item:
+ if use_display_name:
+ label_map_dict[item.display_name] = item.id
+ else:
+ label_map_dict[item.name] = item.id
+ return label_map_dict
+
+
+def create_category_index_from_labelmap(label_map_path):
+ """Reads a label map and returns a category index.
+
+ Args:
+ label_map_path: Path to `StringIntLabelMap` proto text file.
+
+ Returns:
+ A category index, which is a dictionary that maps integer ids to dicts
+ containing categories, e.g.
+ {1: {'id': 1, 'name': 'dog'}, 2: {'id': 2, 'name': 'cat'}, ...}
+ """
+ label_map = load_labelmap(label_map_path)
+ max_num_classes = max(item.id for item in label_map.item)
+ categories = convert_label_map_to_categories(label_map, max_num_classes)
+ return create_category_index(categories)
+
+
+def create_class_agnostic_category_index():
+ """Creates a category index with a single `object` class."""
+ return {1: {'id': 1, 'name': 'object'}}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/policies.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/policies.py"
new file mode 100644
index 00000000..5c7e2207
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/policies.py"
@@ -0,0 +1,474 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Interface for the policy of the agents use for navigation."""
+
+import abc
+import tensorflow as tf
+from absl import logging
+import embedders
+from envs import task_env
+
+slim = tf.contrib.slim
+
+def _print_debug_ios(history, goal, output):
+ """Prints sizes of history, goal and outputs."""
+ if history is not None:
+ shape = history.get_shape().as_list()
+ # logging.info('history embedding shape ')
+ # logging.info(shape)
+ if len(shape) != 3:
+ raise ValueError('history Tensor must have rank=3')
+ if goal is not None:
+ logging.info('goal embedding shape ')
+ logging.info(goal.get_shape().as_list())
+ if output is not None:
+ logging.info('targets shape ')
+ logging.info(output.get_shape().as_list())
+
+
+class Policy(object):
+ """Represents the policy of the agent for navigation tasks.
+
+ Instantiates a policy that takes embedders for each modality and builds a
+ model to infer the actions.
+ """
+ __metaclass__ = abc.ABCMeta
+
+ def __init__(self, embedders_dict, action_size):
+ """Instantiates the policy.
+
+ Args:
+ embedders_dict: Dictionary of embedders for different modalities. Keys
+ should be identical to keys of observation modality.
+ action_size: Number of possible actions.
+ """
+ self._embedders = embedders_dict
+ self._action_size = action_size
+
+ @abc.abstractmethod
+ def build(self, observations, prev_state):
+ """Builds the model that represents the policy of the agent.
+
+ Args:
+ observations: Dictionary of observations from different modalities. Keys
+ are the name of the modalities.
+ prev_state: The tensor of the previous state of the model. Should be set
+ to None if the policy is stateless
+ Returns:
+ Tuple of (action, state) where action is the action logits and state is
+ the state of the model after taking new observation.
+ """
+ raise NotImplementedError(
+ 'Needs implementation as part of Policy interface')
+
+
+class LSTMPolicy(Policy):
+ """Represents the implementation of the LSTM based policy.
+
+ The architecture of the model is as follows. It embeds all the observations
+ using the embedders, concatenates the embeddings of all the modalities. Feed
+ them through two fully connected layers. The lstm takes the features from
+ fully connected layer and the previous action and success of previous action
+ and feed them to LSTM. The value for each action is predicted afterwards.
+ Although the class name has the word LSTM in it, it also supports a mode that
+ builds the network without LSTM just for comparison purposes.
+ """
+
+ def __init__(self,
+ modality_names,
+ embedders_dict,
+ action_size,
+ params,
+ max_episode_length,
+ feedforward_mode=False):
+ """Instantiates the LSTM policy.
+
+ Args:
+ modality_names: List of modality names. Makes sure the ordering in
+ concatenation remains the same as modality_names list. Each modality
+ needs to be in the embedders_dict.
+ embedders_dict: Dictionary of embedders for different modalities. Keys
+ should be identical to keys of observation modality. Values should be
+ instance of Embedder class. All the observations except PREV_ACTION
+ requires embedder.
+ action_size: Number of possible actions.
+ params: is instance of tf.hparams and contains the hyperparameters for the
+ policy network.
+ max_episode_length: integer, specifying the maximum length of each
+ episode.
+ feedforward_mode: If True, it does not add LSTM to the model. It should
+ only be set True for comparison between LSTM and feedforward models.
+ """
+ super(LSTMPolicy, self).__init__(embedders_dict, action_size)
+
+ self._modality_names = modality_names
+
+ self._lstm_state_size = params.lstm_state_size
+ self._fc_channels = params.fc_channels
+ self._weight_decay = params.weight_decay
+ self._target_embedding_size = params.target_embedding_size
+ self._max_episode_length = max_episode_length
+ self._feedforward_mode = feedforward_mode
+
+ def _build_lstm(self, encoded_inputs, prev_state, episode_length,
+ prev_action=None):
+ """Builds an LSTM on top of the encoded inputs.
+
+ If prev_action is not None then it concatenates them to the input of LSTM.
+
+ Args:
+ encoded_inputs: The embedding of the observations and goal.
+ prev_state: previous state of LSTM.
+ episode_length: The tensor that contains the length of the sequence for
+ each element of the batch.
+ prev_action: tensor to previous chosen action and additional bit for
+ indicating whether the previous action was successful or not.
+
+ Returns:
+ a tuple of (lstm output, lstm state).
+ """
+
+ # Adding prev action and success in addition to the embeddings of the
+ # modalities.
+ if prev_action is not None:
+ encoded_inputs = tf.concat([encoded_inputs, prev_action], axis=-1)
+
+ with tf.variable_scope('LSTM'):
+ lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(self._lstm_state_size)
+ if prev_state is None:
+ # If prev state is set to None, a state of all zeros will be
+ # passed as a previous value for the cell. Should be used for the
+ # first step of each episode.
+ tf_prev_state = lstm_cell.zero_state(
+ encoded_inputs.get_shape().as_list()[0], dtype=tf.float32)
+ else:
+ tf_prev_state = tf.nn.rnn_cell.LSTMStateTuple(prev_state[0],
+ prev_state[1])
+
+ lstm_outputs, lstm_state = tf.nn.dynamic_rnn(
+ cell=lstm_cell,
+ inputs=encoded_inputs,
+ sequence_length=episode_length,
+ initial_state=tf_prev_state,
+ dtype=tf.float32,
+ )
+ lstm_outputs = tf.reshape(lstm_outputs, [-1, lstm_cell.output_size])
+ return lstm_outputs, lstm_state
+
+ def build(
+ self,
+ observations,
+ prev_state,
+ ):
+ """Builds the model that represents the policy of the agent.
+
+ Args:
+ observations: Dictionary of observations from different modalities. Keys
+ are the name of the modalities. Observation should have the following
+ key-values.
+ observations['goal']: One-hot tensor that indicates the semantic
+ category of the goal. The shape should be
+ (batch_size x max_sequence_length x goals).
+ observations[task_env.ModalityTypes.PREV_ACTION]: has action_size + 1
+ elements where the first action_size numbers are the one hot vector
+ of the previous action and the last element indicates whether the
+ previous action was successful or not. If
+ task_env.ModalityTypes.PREV_ACTION is not in the observation, it
+ will not be used in the policy.
+ prev_state: Previous state of the model. It should be a tuple of (c,h)
+ where c and h are the previous cell value and hidden state of the lstm.
+ Each element of tuple has shape of (batch_size x lstm_cell_size).
+ If it is set to None, then it initializes the state of the lstm with all
+ zeros.
+
+ Returns:
+ Tuple of (action, state) where action is the action logits and state is
+ the state of the model after taking new observation.
+ Raises:
+ ValueError: If any of the modality names is not in observations or
+ embedders_dict.
+ ValueError: If 'goal' is not in the observations.
+ """
+
+ for modality_name in self._modality_names:
+ if modality_name not in observations:
+ raise ValueError('modality name does not exist in observations: {} not '
+ 'in {}'.format(modality_name, observations.keys()))
+ if modality_name not in self._embedders:
+ if modality_name == task_env.ModalityTypes.PREV_ACTION:
+ continue
+ raise ValueError('modality name does not have corresponding embedder'
+ ' {} not in {}'.format(modality_name,
+ self._embedders.keys()))
+
+ if task_env.ModalityTypes.GOAL not in observations:
+ raise ValueError('goal should be provided in the observations')
+
+ goal = observations[task_env.ModalityTypes.GOAL]
+ prev_action = None
+ if task_env.ModalityTypes.PREV_ACTION in observations:
+ prev_action = observations[task_env.ModalityTypes.PREV_ACTION]
+
+ with tf.variable_scope('policy'):
+ with slim.arg_scope(
+ [slim.fully_connected],
+ activation_fn=tf.nn.relu,
+ weights_initializer=tf.truncated_normal_initializer(stddev=0.01),
+ weights_regularizer=slim.l2_regularizer(self._weight_decay)):
+ all_inputs = []
+
+ # Concatenating the embedding of each modality by applying the embedders
+ # to corresponding observations.
+ def embed(name):
+ with tf.variable_scope('embed_{}'.format(name)):
+ # logging.info('Policy uses embedding %s', name)
+ return self._embedders[name].build(observations[name])
+
+ all_inputs = map(embed, [
+ x for x in self._modality_names
+ if x != task_env.ModalityTypes.PREV_ACTION
+ ])
+
+ # Computing goal embedding.
+ shape = goal.get_shape().as_list()
+ with tf.variable_scope('embed_goal'):
+ encoded_goal = tf.reshape(goal, [shape[0] * shape[1], -1])
+ encoded_goal = slim.fully_connected(encoded_goal,
+ self._target_embedding_size)
+ encoded_goal = tf.reshape(encoded_goal, [shape[0], shape[1], -1])
+ all_inputs.append(encoded_goal)
+
+ # Concatenating all the modalities and goal.
+ all_inputs = tf.concat(all_inputs, axis=-1, name='concat_embeddings')
+
+ shape = all_inputs.get_shape().as_list()
+ all_inputs = tf.reshape(all_inputs, [shape[0] * shape[1], shape[2]])
+
+ # Applying fully connected layers.
+ encoded_inputs = slim.fully_connected(all_inputs, self._fc_channels)
+ encoded_inputs = slim.fully_connected(encoded_inputs, self._fc_channels)
+
+ if not self._feedforward_mode:
+ encoded_inputs = tf.reshape(encoded_inputs,
+ [shape[0], shape[1], self._fc_channels])
+ lstm_outputs, lstm_state = self._build_lstm(
+ encoded_inputs=encoded_inputs,
+ prev_state=prev_state,
+ episode_length=tf.ones((shape[0],), dtype=tf.float32) *
+ self._max_episode_length,
+ prev_action=prev_action,
+ )
+ else:
+ # If feedforward_mode=True, directly compute bypass the whole LSTM
+ # computations.
+ lstm_outputs = encoded_inputs
+
+ lstm_outputs = slim.fully_connected(lstm_outputs, self._fc_channels)
+ action_values = slim.fully_connected(
+ lstm_outputs, self._action_size, activation_fn=None)
+ action_values = tf.reshape(action_values, [shape[0], shape[1], -1])
+ if not self._feedforward_mode:
+ return action_values, lstm_state
+ else:
+ return action_values, None
+
+
+class TaskPolicy(Policy):
+ """A covenience abstract class providing functionality to deal with Tasks."""
+
+ def __init__(self,
+ task_config,
+ model_hparams=None,
+ embedder_hparams=None,
+ train_hparams=None):
+ """Constructs a policy which knows how to work with tasks (see tasks.py).
+
+ It allows to read task history, goal and outputs in consistency with the
+ task config.
+
+ Args:
+ task_config: an object of type tasks.TaskIOConfig (see tasks.py)
+ model_hparams: a tf.HParams object containing parameter pertaining to
+ model (these are implementation specific)
+ embedder_hparams: a tf.HParams object containing parameter pertaining to
+ history, goal embedders (these are implementation specific)
+ train_hparams: a tf.HParams object containing parameter pertaining to
+ trainin (these are implementation specific)`
+ """
+ super(TaskPolicy, self).__init__(None, None)
+ self._model_hparams = model_hparams
+ self._embedder_hparams = embedder_hparams
+ self._train_hparams = train_hparams
+ self._task_config = task_config
+ self._extra_train_ops = []
+
+ @property
+ def extra_train_ops(self):
+ """Training ops in addition to the loss, e.g. batch norm updates.
+
+ Returns:
+ A list of tf ops.
+ """
+ return self._extra_train_ops
+
+ def _embed_task_ios(self, streams):
+ """Embeds a list of heterogenous streams.
+
+ These streams correspond to task history, goal and output. The number of
+ streams is equal to the total number of history, plus one for the goal if
+ present, plus one for the output. If the number of history is k, then the
+ first k streams are the history.
+
+ The used embedders depend on the input (or goal) types. If an input is an
+ image, then a ResNet embedder is used, otherwise
+ MLPEmbedder (see embedders.py).
+
+ Args:
+ streams: a list of Tensors.
+ Returns:
+ Three float Tensors history, goal, output. If there are no history, or no
+ goal, then the corresponding returned values are None. The shape of the
+ embedded history is batch_size x sequence_length x sum of all embedding
+ dimensions for all history. The shape of the goal is embedding dimension.
+ """
+ # EMBED history.
+ index = 0
+ inps = []
+ scopes = []
+ for c in self._task_config.inputs:
+ if c == task_env.ModalityTypes.IMAGE:
+ scope_name = 'image_embedder/image'
+ reuse = scope_name in scopes
+ scopes.append(scope_name)
+ with tf.variable_scope(scope_name, reuse=reuse):
+ resnet_embedder = embedders.ResNet(self._embedder_hparams.image)
+ image_embeddings = resnet_embedder.build(streams[index])
+ # Uncover batch norm ops.
+ if self._embedder_hparams.image.is_train:
+ self._extra_train_ops += resnet_embedder.extra_train_ops
+ inps.append(image_embeddings)
+ index += 1
+ else:
+ scope_name = 'input_embedder/vector'
+ reuse = scope_name in scopes
+ scopes.append(scope_name)
+ with tf.variable_scope(scope_name, reuse=reuse):
+ input_vector_embedder = embedders.MLPEmbedder(
+ layers=self._embedder_hparams.vector)
+ vector_embedder = input_vector_embedder.build(streams[index])
+ inps.append(vector_embedder)
+ index += 1
+ history = tf.concat(inps, axis=2) if inps else None
+
+ # EMBED goal.
+ goal = None
+ if self._task_config.query is not None:
+ scope_name = 'image_embedder/query'
+ reuse = scope_name in scopes
+ scopes.append(scope_name)
+ with tf.variable_scope(scope_name, reuse=reuse):
+ resnet_goal_embedder = embedders.ResNet(self._embedder_hparams.goal)
+ goal = resnet_goal_embedder.build(streams[index])
+ if self._embedder_hparams.goal.is_train:
+ self._extra_train_ops += resnet_goal_embedder.extra_train_ops
+ index += 1
+
+ # Embed true targets if needed (tbd).
+ true_target = streams[index]
+
+ return history, goal, true_target
+
+ @abc.abstractmethod
+ def build(self, feeds, prev_state):
+ pass
+
+
+class ReactivePolicy(TaskPolicy):
+ """A policy which ignores history.
+
+ It processes only the current observation (last element in history) and the
+ goal to output a prediction.
+ """
+
+ def __init__(self, *args, **kwargs):
+ super(ReactivePolicy, self).__init__(*args, **kwargs)
+
+ # The current implementation ignores the prev_state as it is purely reactive.
+ # It returns None for the current state.
+ def build(self, feeds, prev_state):
+ history, goal, _ = self._embed_task_ios(feeds)
+ _print_debug_ios(history, goal, None)
+
+ with tf.variable_scope('output_decoder'):
+ # Concatenate the embeddings of the current observation and the goal.
+ reactive_input = tf.concat([tf.squeeze(history[:, -1, :]), goal], axis=1)
+ oconfig = self._task_config.output.shape
+ assert len(oconfig) == 1
+ decoder = embedders.MLPEmbedder(
+ layers=self._embedder_hparams.predictions.layer_sizes + oconfig)
+ predictions = decoder.build(reactive_input)
+
+ return predictions, None
+
+
+class RNNPolicy(TaskPolicy):
+ """A policy which takes into account the full history via RNN.
+
+ The implementation might and will change.
+ The history, together with the goal, is processed using a stacked LSTM. The
+ output of the last LSTM step is used to produce a prediction. Currently, only
+ a single step output is supported.
+ """
+
+ def __init__(self, lstm_hparams, *args, **kwargs):
+ super(RNNPolicy, self).__init__(*args, **kwargs)
+ self._lstm_hparams = lstm_hparams
+
+ # The prev_state is ignored as for now the full history is specified as first
+ # element of the feeds. It might turn out to be beneficial to keep the state
+ # as part of the policy object.
+ def build(self, feeds, state):
+ history, goal, _ = self._embed_task_ios(feeds)
+ _print_debug_ios(history, goal, None)
+
+ params = self._lstm_hparams
+ cell = lambda: tf.contrib.rnn.BasicLSTMCell(params.cell_size)
+ stacked_lstm = tf.contrib.rnn.MultiRNNCell(
+ [cell() for _ in range(params.num_layers)])
+ # history is of shape batch_size x seq_len x embedding_dimension
+ batch_size, seq_len, _ = tuple(history.get_shape().as_list())
+
+ if state is None:
+ state = stacked_lstm.zero_state(batch_size, tf.float32)
+ for t in range(seq_len):
+ if params.concat_goal_everywhere:
+ lstm_input = tf.concat([tf.squeeze(history[:, t, :]), goal], axis=1)
+ else:
+ lstm_input = tf.squeeze(history[:, t, :])
+ output, state = stacked_lstm(lstm_input, state)
+
+ with tf.variable_scope('output_decoder'):
+ oconfig = self._task_config.output.shape
+ assert len(oconfig) == 1
+ features = tf.concat([output, goal], axis=1)
+ assert len(output.get_shape().as_list()) == 2
+ assert len(goal.get_shape().as_list()) == 2
+ decoder = embedders.MLPEmbedder(
+ layers=self._embedder_hparams.predictions.layer_sizes + oconfig)
+ # Prediction is done off the last step lstm output and the goal.
+ predictions = decoder.build(features)
+
+ return predictions, state
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/__init__.py"
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/__init__.py"
@@ -0,0 +1 @@
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py"
new file mode 100644
index 00000000..0b5a88fa
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/cifarnet_preprocessing.py"
@@ -0,0 +1,128 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Provides utilities to preprocess images in CIFAR-10.
+
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+_PADDING = 4
+
+slim = tf.contrib.slim
+
+
+def preprocess_for_train(image,
+ output_height,
+ output_width,
+ padding=_PADDING,
+ add_image_summaries=True):
+ """Preprocesses the given image for training.
+
+ Note that the actual resizing scale is sampled from
+ [`resize_size_min`, `resize_size_max`].
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ padding: The amound of padding before and after each dimension of the image.
+ add_image_summaries: Enable image summaries.
+
+ Returns:
+ A preprocessed image.
+ """
+ if add_image_summaries:
+ tf.summary.image('image', tf.expand_dims(image, 0))
+
+ # Transform the image to floats.
+ image = tf.to_float(image)
+ if padding > 0:
+ image = tf.pad(image, [[padding, padding], [padding, padding], [0, 0]])
+ # Randomly crop a [height, width] section of the image.
+ distorted_image = tf.random_crop(image,
+ [output_height, output_width, 3])
+
+ # Randomly flip the image horizontally.
+ distorted_image = tf.image.random_flip_left_right(distorted_image)
+
+ if add_image_summaries:
+ tf.summary.image('distorted_image', tf.expand_dims(distorted_image, 0))
+
+ # Because these operations are not commutative, consider randomizing
+ # the order their operation.
+ distorted_image = tf.image.random_brightness(distorted_image,
+ max_delta=63)
+ distorted_image = tf.image.random_contrast(distorted_image,
+ lower=0.2, upper=1.8)
+ # Subtract off the mean and divide by the variance of the pixels.
+ return tf.image.per_image_standardization(distorted_image)
+
+
+def preprocess_for_eval(image, output_height, output_width,
+ add_image_summaries=True):
+ """Preprocesses the given image for evaluation.
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ add_image_summaries: Enable image summaries.
+
+ Returns:
+ A preprocessed image.
+ """
+ if add_image_summaries:
+ tf.summary.image('image', tf.expand_dims(image, 0))
+ # Transform the image to floats.
+ image = tf.to_float(image)
+
+ # Resize and crop if needed.
+ resized_image = tf.image.resize_image_with_crop_or_pad(image,
+ output_width,
+ output_height)
+ if add_image_summaries:
+ tf.summary.image('resized_image', tf.expand_dims(resized_image, 0))
+
+ # Subtract off the mean and divide by the variance of the pixels.
+ return tf.image.per_image_standardization(resized_image)
+
+
+def preprocess_image(image, output_height, output_width, is_training=False,
+ add_image_summaries=True):
+ """Preprocesses the given image.
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ is_training: `True` if we're preprocessing the image for training and
+ `False` otherwise.
+ add_image_summaries: Enable image summaries.
+
+ Returns:
+ A preprocessed image.
+ """
+ if is_training:
+ return preprocess_for_train(
+ image, output_height, output_width,
+ add_image_summaries=add_image_summaries)
+ else:
+ return preprocess_for_eval(
+ image, output_height, output_width,
+ add_image_summaries=add_image_summaries)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/inception_preprocessing.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/inception_preprocessing.py"
new file mode 100644
index 00000000..846b81b3
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/inception_preprocessing.py"
@@ -0,0 +1,318 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Provides utilities to preprocess images for the Inception networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from tensorflow.python.ops import control_flow_ops
+
+
+def apply_with_random_selector(x, func, num_cases):
+ """Computes func(x, sel), with sel sampled from [0...num_cases-1].
+
+ Args:
+ x: input Tensor.
+ func: Python function to apply.
+ num_cases: Python int32, number of cases to sample sel from.
+
+ Returns:
+ The result of func(x, sel), where func receives the value of the
+ selector as a python integer, but sel is sampled dynamically.
+ """
+ sel = tf.random_uniform([], maxval=num_cases, dtype=tf.int32)
+ # Pass the real x only to one of the func calls.
+ return control_flow_ops.merge([
+ func(control_flow_ops.switch(x, tf.equal(sel, case))[1], case)
+ for case in range(num_cases)])[0]
+
+
+def distort_color(image, color_ordering=0, fast_mode=True, scope=None):
+ """Distort the color of a Tensor image.
+
+ Each color distortion is non-commutative and thus ordering of the color ops
+ matters. Ideally we would randomly permute the ordering of the color ops.
+ Rather then adding that level of complication, we select a distinct ordering
+ of color ops for each preprocessing thread.
+
+ Args:
+ image: 3-D Tensor containing single image in [0, 1].
+ color_ordering: Python int, a type of distortion (valid values: 0-3).
+ fast_mode: Avoids slower ops (random_hue and random_contrast)
+ scope: Optional scope for name_scope.
+ Returns:
+ 3-D Tensor color-distorted image on range [0, 1]
+ Raises:
+ ValueError: if color_ordering not in [0, 3]
+ """
+ with tf.name_scope(scope, 'distort_color', [image]):
+ if fast_mode:
+ if color_ordering == 0:
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ else:
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ else:
+ if color_ordering == 0:
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ image = tf.image.random_hue(image, max_delta=0.2)
+ image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
+ elif color_ordering == 1:
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
+ image = tf.image.random_hue(image, max_delta=0.2)
+ elif color_ordering == 2:
+ image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
+ image = tf.image.random_hue(image, max_delta=0.2)
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ elif color_ordering == 3:
+ image = tf.image.random_hue(image, max_delta=0.2)
+ image = tf.image.random_saturation(image, lower=0.5, upper=1.5)
+ image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
+ image = tf.image.random_brightness(image, max_delta=32. / 255.)
+ else:
+ raise ValueError('color_ordering must be in [0, 3]')
+
+ # The random_* ops do not necessarily clamp.
+ return tf.clip_by_value(image, 0.0, 1.0)
+
+
+def distorted_bounding_box_crop(image,
+ bbox,
+ min_object_covered=0.1,
+ aspect_ratio_range=(0.75, 1.33),
+ area_range=(0.05, 1.0),
+ max_attempts=100,
+ scope=None):
+ """Generates cropped_image using a one of the bboxes randomly distorted.
+
+ See `tf.image.sample_distorted_bounding_box` for more documentation.
+
+ Args:
+ image: 3-D Tensor of image (it will be converted to floats in [0, 1]).
+ bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
+ where each coordinate is [0, 1) and the coordinates are arranged
+ as [ymin, xmin, ymax, xmax]. If num_boxes is 0 then it would use the whole
+ image.
+ min_object_covered: An optional `float`. Defaults to `0.1`. The cropped
+ area of the image must contain at least this fraction of any bounding box
+ supplied.
+ aspect_ratio_range: An optional list of `floats`. The cropped area of the
+ image must have an aspect ratio = width / height within this range.
+ area_range: An optional list of `floats`. The cropped area of the image
+ must contain a fraction of the supplied image within in this range.
+ max_attempts: An optional `int`. Number of attempts at generating a cropped
+ region of the image of the specified constraints. After `max_attempts`
+ failures, return the entire image.
+ scope: Optional scope for name_scope.
+ Returns:
+ A tuple, a 3-D Tensor cropped_image and the distorted bbox
+ """
+ with tf.name_scope(scope, 'distorted_bounding_box_crop', [image, bbox]):
+ # Each bounding box has shape [1, num_boxes, box coords] and
+ # the coordinates are ordered [ymin, xmin, ymax, xmax].
+
+ # A large fraction of image datasets contain a human-annotated bounding
+ # box delineating the region of the image containing the object of interest.
+ # We choose to create a new bounding box for the object which is a randomly
+ # distorted version of the human-annotated bounding box that obeys an
+ # allowed range of aspect ratios, sizes and overlap with the human-annotated
+ # bounding box. If no box is supplied, then we assume the bounding box is
+ # the entire image.
+ sample_distorted_bounding_box = tf.image.sample_distorted_bounding_box(
+ tf.shape(image),
+ bounding_boxes=bbox,
+ min_object_covered=min_object_covered,
+ aspect_ratio_range=aspect_ratio_range,
+ area_range=area_range,
+ max_attempts=max_attempts,
+ use_image_if_no_bounding_boxes=True)
+ bbox_begin, bbox_size, distort_bbox = sample_distorted_bounding_box
+
+ # Crop the image to the specified bounding box.
+ cropped_image = tf.slice(image, bbox_begin, bbox_size)
+ return cropped_image, distort_bbox
+
+
+def preprocess_for_train(image, height, width, bbox,
+ fast_mode=True,
+ scope=None,
+ add_image_summaries=True):
+ """Distort one image for training a network.
+
+ Distorting images provides a useful technique for augmenting the data
+ set during training in order to make the network invariant to aspects
+ of the image that do not effect the label.
+
+ Additionally it would create image_summaries to display the different
+ transformations applied to the image.
+
+ Args:
+ image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
+ [0, 1], otherwise it would converted to tf.float32 assuming that the range
+ is [0, MAX], where MAX is largest positive representable number for
+ int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
+ height: integer
+ width: integer
+ bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
+ where each coordinate is [0, 1) and the coordinates are arranged
+ as [ymin, xmin, ymax, xmax].
+ fast_mode: Optional boolean, if True avoids slower transformations (i.e.
+ bi-cubic resizing, random_hue or random_contrast).
+ scope: Optional scope for name_scope.
+ add_image_summaries: Enable image summaries.
+ Returns:
+ 3-D float Tensor of distorted image used for training with range [-1, 1].
+ """
+ with tf.name_scope(scope, 'distort_image', [image, height, width, bbox]):
+ if bbox is None:
+ bbox = tf.constant([0.0, 0.0, 1.0, 1.0],
+ dtype=tf.float32,
+ shape=[1, 1, 4])
+ if image.dtype != tf.float32:
+ image = tf.image.convert_image_dtype(image, dtype=tf.float32)
+ # Each bounding box has shape [1, num_boxes, box coords] and
+ # the coordinates are ordered [ymin, xmin, ymax, xmax].
+ image_with_box = tf.image.draw_bounding_boxes(tf.expand_dims(image, 0),
+ bbox)
+ if add_image_summaries:
+ tf.summary.image('image_with_bounding_boxes', image_with_box)
+
+ distorted_image, distorted_bbox = distorted_bounding_box_crop(image, bbox)
+ # Restore the shape since the dynamic slice based upon the bbox_size loses
+ # the third dimension.
+ distorted_image.set_shape([None, None, 3])
+ image_with_distorted_box = tf.image.draw_bounding_boxes(
+ tf.expand_dims(image, 0), distorted_bbox)
+ if add_image_summaries:
+ tf.summary.image('images_with_distorted_bounding_box',
+ image_with_distorted_box)
+
+ # This resizing operation may distort the images because the aspect
+ # ratio is not respected. We select a resize method in a round robin
+ # fashion based on the thread number.
+ # Note that ResizeMethod contains 4 enumerated resizing methods.
+
+ # We select only 1 case for fast_mode bilinear.
+ num_resize_cases = 1 if fast_mode else 4
+ distorted_image = apply_with_random_selector(
+ distorted_image,
+ lambda x, method: tf.image.resize_images(x, [height, width], method),
+ num_cases=num_resize_cases)
+
+ if add_image_summaries:
+ tf.summary.image('cropped_resized_image',
+ tf.expand_dims(distorted_image, 0))
+
+ # Randomly flip the image horizontally.
+ distorted_image = tf.image.random_flip_left_right(distorted_image)
+
+ # Randomly distort the colors. There are 1 or 4 ways to do it.
+ num_distort_cases = 1 if fast_mode else 4
+ distorted_image = apply_with_random_selector(
+ distorted_image,
+ lambda x, ordering: distort_color(x, ordering, fast_mode),
+ num_cases=num_distort_cases)
+
+ if add_image_summaries:
+ tf.summary.image('final_distorted_image',
+ tf.expand_dims(distorted_image, 0))
+ distorted_image = tf.subtract(distorted_image, 0.5)
+ distorted_image = tf.multiply(distorted_image, 2.0)
+ return distorted_image
+
+
+def preprocess_for_eval(image, height, width,
+ central_fraction=0.875, scope=None):
+ """Prepare one image for evaluation.
+
+ If height and width are specified it would output an image with that size by
+ applying resize_bilinear.
+
+ If central_fraction is specified it would crop the central fraction of the
+ input image.
+
+ Args:
+ image: 3-D Tensor of image. If dtype is tf.float32 then the range should be
+ [0, 1], otherwise it would converted to tf.float32 assuming that the range
+ is [0, MAX], where MAX is largest positive representable number for
+ int(8/16/32) data type (see `tf.image.convert_image_dtype` for details).
+ height: integer
+ width: integer
+ central_fraction: Optional Float, fraction of the image to crop.
+ scope: Optional scope for name_scope.
+ Returns:
+ 3-D float Tensor of prepared image.
+ """
+ with tf.name_scope(scope, 'eval_image', [image, height, width]):
+ if image.dtype != tf.float32:
+ image = tf.image.convert_image_dtype(image, dtype=tf.float32)
+ # Crop the central region of the image with an area containing 87.5% of
+ # the original image.
+ if central_fraction:
+ image = tf.image.central_crop(image, central_fraction=central_fraction)
+
+ if height and width:
+ # Resize the image to the specified height and width.
+ image = tf.expand_dims(image, 0)
+ image = tf.image.resize_bilinear(image, [height, width],
+ align_corners=False)
+ image = tf.squeeze(image, [0])
+ image = tf.subtract(image, 0.5)
+ image = tf.multiply(image, 2.0)
+ return image
+
+
+def preprocess_image(image, height, width,
+ is_training=False,
+ bbox=None,
+ fast_mode=True,
+ add_image_summaries=True):
+ """Pre-process one image for training or evaluation.
+
+ Args:
+ image: 3-D Tensor [height, width, channels] with the image. If dtype is
+ tf.float32 then the range should be [0, 1], otherwise it would converted
+ to tf.float32 assuming that the range is [0, MAX], where MAX is largest
+ positive representable number for int(8/16/32) data type (see
+ `tf.image.convert_image_dtype` for details).
+ height: integer, image expected height.
+ width: integer, image expected width.
+ is_training: Boolean. If true it would transform an image for train,
+ otherwise it would transform it for evaluation.
+ bbox: 3-D float Tensor of bounding boxes arranged [1, num_boxes, coords]
+ where each coordinate is [0, 1) and the coordinates are arranged as
+ [ymin, xmin, ymax, xmax].
+ fast_mode: Optional boolean, if True avoids slower transformations.
+ add_image_summaries: Enable image summaries.
+
+ Returns:
+ 3-D float Tensor containing an appropriately scaled image
+
+ Raises:
+ ValueError: if user does not provide bounding box
+ """
+ if is_training:
+ return preprocess_for_train(image, height, width, bbox, fast_mode,
+ add_image_summaries=add_image_summaries)
+ else:
+ return preprocess_for_eval(image, height, width)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/lenet_preprocessing.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/lenet_preprocessing.py"
new file mode 100644
index 00000000..ac5e71af
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/lenet_preprocessing.py"
@@ -0,0 +1,44 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Provides utilities for preprocessing."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+slim = tf.contrib.slim
+
+
+def preprocess_image(image, output_height, output_width, is_training):
+ """Preprocesses the given image.
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ is_training: `True` if we're preprocessing the image for training and
+ `False` otherwise.
+
+ Returns:
+ A preprocessed image.
+ """
+ image = tf.to_float(image)
+ image = tf.image.resize_image_with_crop_or_pad(
+ image, output_width, output_height)
+ image = tf.subtract(image, 128.0)
+ image = tf.div(image, 128.0)
+ return image
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/preprocessing_factory.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/preprocessing_factory.py"
new file mode 100644
index 00000000..1bd04c25
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/preprocessing_factory.py"
@@ -0,0 +1,81 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains a factory for building various models."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from preprocessing import cifarnet_preprocessing
+from preprocessing import inception_preprocessing
+from preprocessing import lenet_preprocessing
+from preprocessing import vgg_preprocessing
+
+slim = tf.contrib.slim
+
+
+def get_preprocessing(name, is_training=False):
+ """Returns preprocessing_fn(image, height, width, **kwargs).
+
+ Args:
+ name: The name of the preprocessing function.
+ is_training: `True` if the model is being used for training and `False`
+ otherwise.
+
+ Returns:
+ preprocessing_fn: A function that preprocessing a single image (pre-batch).
+ It has the following signature:
+ image = preprocessing_fn(image, output_height, output_width, ...).
+
+ Raises:
+ ValueError: If Preprocessing `name` is not recognized.
+ """
+ preprocessing_fn_map = {
+ 'cifarnet': cifarnet_preprocessing,
+ 'inception': inception_preprocessing,
+ 'inception_v1': inception_preprocessing,
+ 'inception_v2': inception_preprocessing,
+ 'inception_v3': inception_preprocessing,
+ 'inception_v4': inception_preprocessing,
+ 'inception_resnet_v2': inception_preprocessing,
+ 'lenet': lenet_preprocessing,
+ 'mobilenet_v1': inception_preprocessing,
+ 'nasnet_mobile': inception_preprocessing,
+ 'nasnet_large': inception_preprocessing,
+ 'pnasnet_large': inception_preprocessing,
+ 'resnet_v1_50': vgg_preprocessing,
+ 'resnet_v1_101': vgg_preprocessing,
+ 'resnet_v1_152': vgg_preprocessing,
+ 'resnet_v1_200': vgg_preprocessing,
+ 'resnet_v2_50': vgg_preprocessing,
+ 'resnet_v2_101': vgg_preprocessing,
+ 'resnet_v2_152': vgg_preprocessing,
+ 'resnet_v2_200': vgg_preprocessing,
+ 'vgg': vgg_preprocessing,
+ 'vgg_a': vgg_preprocessing,
+ 'vgg_16': vgg_preprocessing,
+ 'vgg_19': vgg_preprocessing,
+ }
+
+ if name not in preprocessing_fn_map:
+ raise ValueError('Preprocessing name [%s] was not recognized' % name)
+
+ def preprocessing_fn(image, output_height, output_width, **kwargs):
+ return preprocessing_fn_map[name].preprocess_image(
+ image, output_height, output_width, is_training=is_training, **kwargs)
+
+ return preprocessing_fn
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/vgg_preprocessing.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/vgg_preprocessing.py"
new file mode 100644
index 00000000..3bd50598
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/preprocessing/vgg_preprocessing.py"
@@ -0,0 +1,365 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Provides utilities to preprocess images.
+
+The preprocessing steps for VGG were introduced in the following technical
+report:
+
+ Very Deep Convolutional Networks For Large-Scale Image Recognition
+ Karen Simonyan and Andrew Zisserman
+ arXiv technical report, 2015
+ PDF: http://arxiv.org/pdf/1409.1556.pdf
+ ILSVRC 2014 Slides: http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
+ CC-BY-4.0
+
+More information can be obtained from the VGG website:
+www.robots.ox.ac.uk/~vgg/research/very_deep/
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+slim = tf.contrib.slim
+
+_R_MEAN = 123.68
+_G_MEAN = 116.78
+_B_MEAN = 103.94
+
+_RESIZE_SIDE_MIN = 256
+_RESIZE_SIDE_MAX = 512
+
+
+def _crop(image, offset_height, offset_width, crop_height, crop_width):
+ """Crops the given image using the provided offsets and sizes.
+
+ Note that the method doesn't assume we know the input image size but it does
+ assume we know the input image rank.
+
+ Args:
+ image: an image of shape [height, width, channels].
+ offset_height: a scalar tensor indicating the height offset.
+ offset_width: a scalar tensor indicating the width offset.
+ crop_height: the height of the cropped image.
+ crop_width: the width of the cropped image.
+
+ Returns:
+ the cropped (and resized) image.
+
+ Raises:
+ InvalidArgumentError: if the rank is not 3 or if the image dimensions are
+ less than the crop size.
+ """
+ original_shape = tf.shape(image)
+
+ rank_assertion = tf.Assert(
+ tf.equal(tf.rank(image), 3),
+ ['Rank of image must be equal to 3.'])
+ with tf.control_dependencies([rank_assertion]):
+ cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]])
+
+ size_assertion = tf.Assert(
+ tf.logical_and(
+ tf.greater_equal(original_shape[0], crop_height),
+ tf.greater_equal(original_shape[1], crop_width)),
+ ['Crop size greater than the image size.'])
+
+ offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0]))
+
+ # Use tf.slice instead of crop_to_bounding box as it accepts tensors to
+ # define the crop size.
+ with tf.control_dependencies([size_assertion]):
+ image = tf.slice(image, offsets, cropped_shape)
+ return tf.reshape(image, cropped_shape)
+
+
+def _random_crop(image_list, crop_height, crop_width):
+ """Crops the given list of images.
+
+ The function applies the same crop to each image in the list. This can be
+ effectively applied when there are multiple image inputs of the same
+ dimension such as:
+
+ image, depths, normals = _random_crop([image, depths, normals], 120, 150)
+
+ Args:
+ image_list: a list of image tensors of the same dimension but possibly
+ varying channel.
+ crop_height: the new height.
+ crop_width: the new width.
+
+ Returns:
+ the image_list with cropped images.
+
+ Raises:
+ ValueError: if there are multiple image inputs provided with different size
+ or the images are smaller than the crop dimensions.
+ """
+ if not image_list:
+ raise ValueError('Empty image_list.')
+
+ # Compute the rank assertions.
+ rank_assertions = []
+ for i in range(len(image_list)):
+ image_rank = tf.rank(image_list[i])
+ rank_assert = tf.Assert(
+ tf.equal(image_rank, 3),
+ ['Wrong rank for tensor %s [expected] [actual]',
+ image_list[i].name, 3, image_rank])
+ rank_assertions.append(rank_assert)
+
+ with tf.control_dependencies([rank_assertions[0]]):
+ image_shape = tf.shape(image_list[0])
+ image_height = image_shape[0]
+ image_width = image_shape[1]
+ crop_size_assert = tf.Assert(
+ tf.logical_and(
+ tf.greater_equal(image_height, crop_height),
+ tf.greater_equal(image_width, crop_width)),
+ ['Crop size greater than the image size.'])
+
+ asserts = [rank_assertions[0], crop_size_assert]
+
+ for i in range(1, len(image_list)):
+ image = image_list[i]
+ asserts.append(rank_assertions[i])
+ with tf.control_dependencies([rank_assertions[i]]):
+ shape = tf.shape(image)
+ height = shape[0]
+ width = shape[1]
+
+ height_assert = tf.Assert(
+ tf.equal(height, image_height),
+ ['Wrong height for tensor %s [expected][actual]',
+ image.name, height, image_height])
+ width_assert = tf.Assert(
+ tf.equal(width, image_width),
+ ['Wrong width for tensor %s [expected][actual]',
+ image.name, width, image_width])
+ asserts.extend([height_assert, width_assert])
+
+ # Create a random bounding box.
+ #
+ # Use tf.random_uniform and not numpy.random.rand as doing the former would
+ # generate random numbers at graph eval time, unlike the latter which
+ # generates random numbers at graph definition time.
+ with tf.control_dependencies(asserts):
+ max_offset_height = tf.reshape(image_height - crop_height + 1, [])
+ with tf.control_dependencies(asserts):
+ max_offset_width = tf.reshape(image_width - crop_width + 1, [])
+ offset_height = tf.random_uniform(
+ [], maxval=max_offset_height, dtype=tf.int32)
+ offset_width = tf.random_uniform(
+ [], maxval=max_offset_width, dtype=tf.int32)
+
+ return [_crop(image, offset_height, offset_width,
+ crop_height, crop_width) for image in image_list]
+
+
+def _central_crop(image_list, crop_height, crop_width):
+ """Performs central crops of the given image list.
+
+ Args:
+ image_list: a list of image tensors of the same dimension but possibly
+ varying channel.
+ crop_height: the height of the image following the crop.
+ crop_width: the width of the image following the crop.
+
+ Returns:
+ the list of cropped images.
+ """
+ outputs = []
+ for image in image_list:
+ image_height = tf.shape(image)[0]
+ image_width = tf.shape(image)[1]
+
+ offset_height = (image_height - crop_height) / 2
+ offset_width = (image_width - crop_width) / 2
+
+ outputs.append(_crop(image, offset_height, offset_width,
+ crop_height, crop_width))
+ return outputs
+
+
+def _mean_image_subtraction(image, means):
+ """Subtracts the given means from each image channel.
+
+ For example:
+ means = [123.68, 116.779, 103.939]
+ image = _mean_image_subtraction(image, means)
+
+ Note that the rank of `image` must be known.
+
+ Args:
+ image: a tensor of size [height, width, C].
+ means: a C-vector of values to subtract from each channel.
+
+ Returns:
+ the centered image.
+
+ Raises:
+ ValueError: If the rank of `image` is unknown, if `image` has a rank other
+ than three or if the number of channels in `image` doesn't match the
+ number of values in `means`.
+ """
+ if image.get_shape().ndims != 3:
+ raise ValueError('Input must be of size [height, width, C>0]')
+ num_channels = image.get_shape().as_list()[-1]
+ if len(means) != num_channels:
+ raise ValueError('len(means) must match the number of channels')
+
+ channels = tf.split(axis=2, num_or_size_splits=num_channels, value=image)
+ for i in range(num_channels):
+ channels[i] -= means[i]
+ return tf.concat(axis=2, values=channels)
+
+
+def _smallest_size_at_least(height, width, smallest_side):
+ """Computes new shape with the smallest side equal to `smallest_side`.
+
+ Computes new shape with the smallest side equal to `smallest_side` while
+ preserving the original aspect ratio.
+
+ Args:
+ height: an int32 scalar tensor indicating the current height.
+ width: an int32 scalar tensor indicating the current width.
+ smallest_side: A python integer or scalar `Tensor` indicating the size of
+ the smallest side after resize.
+
+ Returns:
+ new_height: an int32 scalar tensor indicating the new height.
+ new_width: and int32 scalar tensor indicating the new width.
+ """
+ smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
+
+ height = tf.to_float(height)
+ width = tf.to_float(width)
+ smallest_side = tf.to_float(smallest_side)
+
+ scale = tf.cond(tf.greater(height, width),
+ lambda: smallest_side / width,
+ lambda: smallest_side / height)
+ new_height = tf.to_int32(tf.rint(height * scale))
+ new_width = tf.to_int32(tf.rint(width * scale))
+ return new_height, new_width
+
+
+def _aspect_preserving_resize(image, smallest_side):
+ """Resize images preserving the original aspect ratio.
+
+ Args:
+ image: A 3-D image `Tensor`.
+ smallest_side: A python integer or scalar `Tensor` indicating the size of
+ the smallest side after resize.
+
+ Returns:
+ resized_image: A 3-D tensor containing the resized image.
+ """
+ smallest_side = tf.convert_to_tensor(smallest_side, dtype=tf.int32)
+
+ shape = tf.shape(image)
+ height = shape[0]
+ width = shape[1]
+ new_height, new_width = _smallest_size_at_least(height, width, smallest_side)
+ image = tf.expand_dims(image, 0)
+ resized_image = tf.image.resize_bilinear(image, [new_height, new_width],
+ align_corners=False)
+ resized_image = tf.squeeze(resized_image)
+ resized_image.set_shape([None, None, 3])
+ return resized_image
+
+
+def preprocess_for_train(image,
+ output_height,
+ output_width,
+ resize_side_min=_RESIZE_SIDE_MIN,
+ resize_side_max=_RESIZE_SIDE_MAX):
+ """Preprocesses the given image for training.
+
+ Note that the actual resizing scale is sampled from
+ [`resize_size_min`, `resize_size_max`].
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ resize_side_min: The lower bound for the smallest side of the image for
+ aspect-preserving resizing.
+ resize_side_max: The upper bound for the smallest side of the image for
+ aspect-preserving resizing.
+
+ Returns:
+ A preprocessed image.
+ """
+ resize_side = tf.random_uniform(
+ [], minval=resize_side_min, maxval=resize_side_max+1, dtype=tf.int32)
+
+ image = _aspect_preserving_resize(image, resize_side)
+ image = _random_crop([image], output_height, output_width)[0]
+ image.set_shape([output_height, output_width, 3])
+ image = tf.to_float(image)
+ image = tf.image.random_flip_left_right(image)
+ return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
+
+
+def preprocess_for_eval(image, output_height, output_width, resize_side):
+ """Preprocesses the given image for evaluation.
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ resize_side: The smallest side of the image for aspect-preserving resizing.
+
+ Returns:
+ A preprocessed image.
+ """
+ image = _aspect_preserving_resize(image, resize_side)
+ image = _central_crop([image], output_height, output_width)[0]
+ image.set_shape([output_height, output_width, 3])
+ image = tf.to_float(image)
+ return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
+
+
+def preprocess_image(image, output_height, output_width, is_training=False,
+ resize_side_min=_RESIZE_SIDE_MIN,
+ resize_side_max=_RESIZE_SIDE_MAX):
+ """Preprocesses the given image.
+
+ Args:
+ image: A `Tensor` representing an image of arbitrary size.
+ output_height: The height of the image after preprocessing.
+ output_width: The width of the image after preprocessing.
+ is_training: `True` if we're preprocessing the image for training and
+ `False` otherwise.
+ resize_side_min: The lower bound for the smallest side of the image for
+ aspect-preserving resizing. If `is_training` is `False`, then this value
+ is used for rescaling.
+ resize_side_max: The upper bound for the smallest side of the image for
+ aspect-preserving resizing. If `is_training` is `False`, this value is
+ ignored. Otherwise, the resize side is sampled from
+ [resize_size_min, resize_size_max].
+
+ Returns:
+ A preprocessed image.
+ """
+ if is_training:
+ return preprocess_for_train(image, output_height, output_width,
+ resize_side_min, resize_side_max)
+ else:
+ return preprocess_for_eval(image, output_height, output_width,
+ resize_side_min)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/standard_fields.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/standard_fields.py"
new file mode 100644
index 00000000..99e04e66
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/standard_fields.py"
@@ -0,0 +1,224 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Contains classes specifying naming conventions used for object detection.
+
+
+Specifies:
+ InputDataFields: standard fields used by reader/preprocessor/batcher.
+ DetectionResultFields: standard fields returned by object detector.
+ BoxListFields: standard field used by BoxList
+ TfExampleFields: standard fields for tf-example data format (go/tf-example).
+"""
+
+
+class InputDataFields(object):
+ """Names for the input tensors.
+
+ Holds the standard data field names to use for identifying input tensors. This
+ should be used by the decoder to identify keys for the returned tensor_dict
+ containing input tensors. And it should be used by the model to identify the
+ tensors it needs.
+
+ Attributes:
+ image: image.
+ image_additional_channels: additional channels.
+ original_image: image in the original input size.
+ key: unique key corresponding to image.
+ source_id: source of the original image.
+ filename: original filename of the dataset (without common path).
+ groundtruth_image_classes: image-level class labels.
+ groundtruth_boxes: coordinates of the ground truth boxes in the image.
+ groundtruth_classes: box-level class labels.
+ groundtruth_label_types: box-level label types (e.g. explicit negative).
+ groundtruth_is_crowd: [DEPRECATED, use groundtruth_group_of instead]
+ is the groundtruth a single object or a crowd.
+ groundtruth_area: area of a groundtruth segment.
+ groundtruth_difficult: is a `difficult` object
+ groundtruth_group_of: is a `group_of` objects, e.g. multiple objects of the
+ same class, forming a connected group, where instances are heavily
+ occluding each other.
+ proposal_boxes: coordinates of object proposal boxes.
+ proposal_objectness: objectness score of each proposal.
+ groundtruth_instance_masks: ground truth instance masks.
+ groundtruth_instance_boundaries: ground truth instance boundaries.
+ groundtruth_instance_classes: instance mask-level class labels.
+ groundtruth_keypoints: ground truth keypoints.
+ groundtruth_keypoint_visibilities: ground truth keypoint visibilities.
+ groundtruth_label_scores: groundtruth label scores.
+ groundtruth_weights: groundtruth weight factor for bounding boxes.
+ num_groundtruth_boxes: number of groundtruth boxes.
+ true_image_shapes: true shapes of images in the resized images, as resized
+ images can be padded with zeros.
+ multiclass_scores: the label score per class for each box.
+ """
+ image = 'image'
+ image_additional_channels = 'image_additional_channels'
+ original_image = 'original_image'
+ key = 'key'
+ source_id = 'source_id'
+ filename = 'filename'
+ groundtruth_image_classes = 'groundtruth_image_classes'
+ groundtruth_boxes = 'groundtruth_boxes'
+ groundtruth_classes = 'groundtruth_classes'
+ groundtruth_label_types = 'groundtruth_label_types'
+ groundtruth_is_crowd = 'groundtruth_is_crowd'
+ groundtruth_area = 'groundtruth_area'
+ groundtruth_difficult = 'groundtruth_difficult'
+ groundtruth_group_of = 'groundtruth_group_of'
+ proposal_boxes = 'proposal_boxes'
+ proposal_objectness = 'proposal_objectness'
+ groundtruth_instance_masks = 'groundtruth_instance_masks'
+ groundtruth_instance_boundaries = 'groundtruth_instance_boundaries'
+ groundtruth_instance_classes = 'groundtruth_instance_classes'
+ groundtruth_keypoints = 'groundtruth_keypoints'
+ groundtruth_keypoint_visibilities = 'groundtruth_keypoint_visibilities'
+ groundtruth_label_scores = 'groundtruth_label_scores'
+ groundtruth_weights = 'groundtruth_weights'
+ num_groundtruth_boxes = 'num_groundtruth_boxes'
+ true_image_shape = 'true_image_shape'
+ multiclass_scores = 'multiclass_scores'
+
+
+class DetectionResultFields(object):
+ """Naming conventions for storing the output of the detector.
+
+ Attributes:
+ source_id: source of the original image.
+ key: unique key corresponding to image.
+ detection_boxes: coordinates of the detection boxes in the image.
+ detection_scores: detection scores for the detection boxes in the image.
+ detection_classes: detection-level class labels.
+ detection_masks: contains a segmentation mask for each detection box.
+ detection_boundaries: contains an object boundary for each detection box.
+ detection_keypoints: contains detection keypoints for each detection box.
+ num_detections: number of detections in the batch.
+ """
+
+ source_id = 'source_id'
+ key = 'key'
+ detection_boxes = 'detection_boxes'
+ detection_scores = 'detection_scores'
+ detection_classes = 'detection_classes'
+ detection_masks = 'detection_masks'
+ detection_boundaries = 'detection_boundaries'
+ detection_keypoints = 'detection_keypoints'
+ num_detections = 'num_detections'
+
+
+class BoxListFields(object):
+ """Naming conventions for BoxLists.
+
+ Attributes:
+ boxes: bounding box coordinates.
+ classes: classes per bounding box.
+ scores: scores per bounding box.
+ weights: sample weights per bounding box.
+ objectness: objectness score per bounding box.
+ masks: masks per bounding box.
+ boundaries: boundaries per bounding box.
+ keypoints: keypoints per bounding box.
+ keypoint_heatmaps: keypoint heatmaps per bounding box.
+ is_crowd: is_crowd annotation per bounding box.
+ """
+ boxes = 'boxes'
+ classes = 'classes'
+ scores = 'scores'
+ weights = 'weights'
+ objectness = 'objectness'
+ masks = 'masks'
+ boundaries = 'boundaries'
+ keypoints = 'keypoints'
+ keypoint_heatmaps = 'keypoint_heatmaps'
+ is_crowd = 'is_crowd'
+
+
+class TfExampleFields(object):
+ """TF-example proto feature names for object detection.
+
+ Holds the standard feature names to load from an Example proto for object
+ detection.
+
+ Attributes:
+ image_encoded: JPEG encoded string
+ image_format: image format, e.g. "JPEG"
+ filename: filename
+ channels: number of channels of image
+ colorspace: colorspace, e.g. "RGB"
+ height: height of image in pixels, e.g. 462
+ width: width of image in pixels, e.g. 581
+ source_id: original source of the image
+ image_class_text: image-level label in text format
+ image_class_label: image-level label in numerical format
+ object_class_text: labels in text format, e.g. ["person", "cat"]
+ object_class_label: labels in numbers, e.g. [16, 8]
+ object_bbox_xmin: xmin coordinates of groundtruth box, e.g. 10, 30
+ object_bbox_xmax: xmax coordinates of groundtruth box, e.g. 50, 40
+ object_bbox_ymin: ymin coordinates of groundtruth box, e.g. 40, 50
+ object_bbox_ymax: ymax coordinates of groundtruth box, e.g. 80, 70
+ object_view: viewpoint of object, e.g. ["frontal", "left"]
+ object_truncated: is object truncated, e.g. [true, false]
+ object_occluded: is object occluded, e.g. [true, false]
+ object_difficult: is object difficult, e.g. [true, false]
+ object_group_of: is object a single object or a group of objects
+ object_depiction: is object a depiction
+ object_is_crowd: [DEPRECATED, use object_group_of instead]
+ is the object a single object or a crowd
+ object_segment_area: the area of the segment.
+ object_weight: a weight factor for the object's bounding box.
+ instance_masks: instance segmentation masks.
+ instance_boundaries: instance boundaries.
+ instance_classes: Classes for each instance segmentation mask.
+ detection_class_label: class label in numbers.
+ detection_bbox_ymin: ymin coordinates of a detection box.
+ detection_bbox_xmin: xmin coordinates of a detection box.
+ detection_bbox_ymax: ymax coordinates of a detection box.
+ detection_bbox_xmax: xmax coordinates of a detection box.
+ detection_score: detection score for the class label and box.
+ """
+ image_encoded = 'image/encoded'
+ image_format = 'image/format' # format is reserved keyword
+ filename = 'image/filename'
+ channels = 'image/channels'
+ colorspace = 'image/colorspace'
+ height = 'image/height'
+ width = 'image/width'
+ source_id = 'image/source_id'
+ image_class_text = 'image/class/text'
+ image_class_label = 'image/class/label'
+ object_class_text = 'image/object/class/text'
+ object_class_label = 'image/object/class/label'
+ object_bbox_ymin = 'image/object/bbox/ymin'
+ object_bbox_xmin = 'image/object/bbox/xmin'
+ object_bbox_ymax = 'image/object/bbox/ymax'
+ object_bbox_xmax = 'image/object/bbox/xmax'
+ object_view = 'image/object/view'
+ object_truncated = 'image/object/truncated'
+ object_occluded = 'image/object/occluded'
+ object_difficult = 'image/object/difficult'
+ object_group_of = 'image/object/group_of'
+ object_depiction = 'image/object/depiction'
+ object_is_crowd = 'image/object/is_crowd'
+ object_segment_area = 'image/object/segment/area'
+ object_weight = 'image/object/weight'
+ instance_masks = 'image/segmentation/object'
+ instance_boundaries = 'image/boundaries/object'
+ instance_classes = 'image/segmentation/object/class'
+ detection_class_label = 'image/detection/label'
+ detection_bbox_ymin = 'image/detection/bbox/ymin'
+ detection_bbox_xmin = 'image/detection/bbox/xmin'
+ detection_bbox_ymax = 'image/detection/bbox/ymax'
+ detection_bbox_xmax = 'image/detection/bbox/xmax'
+ detection_score = 'image/detection/score'
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/string_int_label_map_pb2.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/string_int_label_map_pb2.py"
new file mode 100644
index 00000000..44a46d7a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/string_int_label_map_pb2.py"
@@ -0,0 +1,138 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# Generated by the protocol buffer compiler. DO NOT EDIT!
+# source: object_detection/protos/string_int_label_map.proto
+
+import sys
+_b=sys.version_info[0]<3 and (lambda x:x) or (lambda x:x.encode('latin1'))
+from google.protobuf import descriptor as _descriptor
+from google.protobuf import message as _message
+from google.protobuf import reflection as _reflection
+from google.protobuf import symbol_database as _symbol_database
+from google.protobuf import descriptor_pb2
+# @@protoc_insertion_point(imports)
+
+_sym_db = _symbol_database.Default()
+
+
+
+
+DESCRIPTOR = _descriptor.FileDescriptor(
+ name='object_detection/protos/string_int_label_map.proto',
+ package='object_detection.protos',
+ syntax='proto2',
+ serialized_pb=_b('\n2object_detection/protos/string_int_label_map.proto\x12\x17object_detection.protos\"G\n\x15StringIntLabelMapItem\x12\x0c\n\x04name\x18\x01 \x01(\t\x12\n\n\x02id\x18\x02 \x01(\x05\x12\x14\n\x0c\x64isplay_name\x18\x03 \x01(\t\"Q\n\x11StringIntLabelMap\x12<\n\x04item\x18\x01 \x03(\x0b\x32..object_detection.protos.StringIntLabelMapItem')
+)
+
+
+
+
+_STRINGINTLABELMAPITEM = _descriptor.Descriptor(
+ name='StringIntLabelMapItem',
+ full_name='object_detection.protos.StringIntLabelMapItem',
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name='name', full_name='object_detection.protos.StringIntLabelMapItem.name', index=0,
+ number=1, type=9, cpp_type=9, label=1,
+ has_default_value=False, default_value=_b("").decode('utf-8'),
+ message_type=None, enum_type=None, containing_type=None,
+ is_extension=False, extension_scope=None,
+ options=None),
+ _descriptor.FieldDescriptor(
+ name='id', full_name='object_detection.protos.StringIntLabelMapItem.id', index=1,
+ number=2, type=5, cpp_type=1, label=1,
+ has_default_value=False, default_value=0,
+ message_type=None, enum_type=None, containing_type=None,
+ is_extension=False, extension_scope=None,
+ options=None),
+ _descriptor.FieldDescriptor(
+ name='display_name', full_name='object_detection.protos.StringIntLabelMapItem.display_name', index=2,
+ number=3, type=9, cpp_type=9, label=1,
+ has_default_value=False, default_value=_b("").decode('utf-8'),
+ message_type=None, enum_type=None, containing_type=None,
+ is_extension=False, extension_scope=None,
+ options=None),
+ ],
+ extensions=[
+ ],
+ nested_types=[],
+ enum_types=[
+ ],
+ options=None,
+ is_extendable=False,
+ syntax='proto2',
+ extension_ranges=[],
+ oneofs=[
+ ],
+ serialized_start=79,
+ serialized_end=150,
+)
+
+
+_STRINGINTLABELMAP = _descriptor.Descriptor(
+ name='StringIntLabelMap',
+ full_name='object_detection.protos.StringIntLabelMap',
+ filename=None,
+ file=DESCRIPTOR,
+ containing_type=None,
+ fields=[
+ _descriptor.FieldDescriptor(
+ name='item', full_name='object_detection.protos.StringIntLabelMap.item', index=0,
+ number=1, type=11, cpp_type=10, label=3,
+ has_default_value=False, default_value=[],
+ message_type=None, enum_type=None, containing_type=None,
+ is_extension=False, extension_scope=None,
+ options=None),
+ ],
+ extensions=[
+ ],
+ nested_types=[],
+ enum_types=[
+ ],
+ options=None,
+ is_extendable=False,
+ syntax='proto2',
+ extension_ranges=[],
+ oneofs=[
+ ],
+ serialized_start=152,
+ serialized_end=233,
+)
+
+_STRINGINTLABELMAP.fields_by_name['item'].message_type = _STRINGINTLABELMAPITEM
+DESCRIPTOR.message_types_by_name['StringIntLabelMapItem'] = _STRINGINTLABELMAPITEM
+DESCRIPTOR.message_types_by_name['StringIntLabelMap'] = _STRINGINTLABELMAP
+_sym_db.RegisterFileDescriptor(DESCRIPTOR)
+
+StringIntLabelMapItem = _reflection.GeneratedProtocolMessageType('StringIntLabelMapItem', (_message.Message,), dict(
+ DESCRIPTOR = _STRINGINTLABELMAPITEM,
+ __module__ = 'object_detection.protos.string_int_label_map_pb2'
+ # @@protoc_insertion_point(class_scope:object_detection.protos.StringIntLabelMapItem)
+ ))
+_sym_db.RegisterMessage(StringIntLabelMapItem)
+
+StringIntLabelMap = _reflection.GeneratedProtocolMessageType('StringIntLabelMap', (_message.Message,), dict(
+ DESCRIPTOR = _STRINGINTLABELMAP,
+ __module__ = 'object_detection.protos.string_int_label_map_pb2'
+ # @@protoc_insertion_point(class_scope:object_detection.protos.StringIntLabelMap)
+ ))
+_sym_db.RegisterMessage(StringIntLabelMap)
+
+
+# @@protoc_insertion_point(module_scope)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/tasks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/tasks.py"
new file mode 100644
index 00000000..c3ef6ca3
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/tasks.py"
@@ -0,0 +1,1507 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""A library of tasks.
+
+This interface is intended to implement a wide variety of navigation
+tasks. See go/navigation_tasks for a list.
+"""
+
+import abc
+import collections
+import math
+import threading
+import networkx as nx
+import numpy as np
+import tensorflow as tf
+#from pyglib import logging
+#import gin
+from envs import task_env
+from envs import util as envs_util
+
+
+# Utility functions.
+def _pad_or_clip_array(np_arr, arr_len, is_front_clip=True, output_mask=False):
+ """Make np_arr array to have length arr_len.
+
+ If the array is shorter than arr_len, then it is padded from the front with
+ zeros. If it is longer, then it is clipped either from the back or from the
+ front. Only the first dimension is modified.
+
+ Args:
+ np_arr: numpy array.
+ arr_len: integer scalar.
+ is_front_clip: a boolean. If true then clipping is done in the front,
+ otherwise in the back.
+ output_mask: If True, outputs a numpy array of rank 1 which represents
+ a mask of which values have been added (0 - added, 1 - actual output).
+
+ Returns:
+ A numpy array and the size of padding (as a python int32). This size is
+ negative is the array is clipped.
+ """
+ shape = list(np_arr.shape)
+ pad_size = arr_len - shape[0]
+ padded_or_clipped = None
+ if pad_size < 0:
+ if is_front_clip:
+ padded_or_clipped = np_arr[-pad_size:, :]
+ else:
+ padded_or_clipped = np_arr[:arr_len, :]
+ elif pad_size > 0:
+ padding = np.zeros([pad_size] + shape[1:], dtype=np_arr.dtype)
+ padded_or_clipped = np.concatenate([np_arr, padding], axis=0)
+ else:
+ padded_or_clipped = np_arr
+
+ if output_mask:
+ mask = np.ones((arr_len,), dtype=np.int)
+ if pad_size > 0:
+ mask[-pad_size:] = 0
+ return padded_or_clipped, pad_size, mask
+ else:
+ return padded_or_clipped, pad_size
+
+
+def classification_loss(truth, predicted, weights=None, is_one_hot=True):
+ """A cross entropy loss.
+
+ Computes the mean of cross entropy losses for all pairs of true labels and
+ predictions. It wraps around a tf implementation of the cross entropy loss
+ with additional reformating of the inputs. If the truth and predicted are
+ n-rank Tensors with n > 2, then these are reshaped to 2-rank Tensors. It
+ allows for truth to be specified as one hot vector or class indices. Finally,
+ a weight can be specified for each element in truth and predicted.
+
+ Args:
+ truth: an n-rank or (n-1)-rank Tensor containing labels. If is_one_hot is
+ True, then n-rank Tensor is expected, otherwise (n-1) rank one.
+ predicted: an n-rank float Tensor containing prediction probabilities.
+ weights: an (n-1)-rank float Tensor of weights
+ is_one_hot: a boolean.
+
+ Returns:
+ A TF float scalar.
+ """
+ num_labels = predicted.get_shape().as_list()[-1]
+ if not is_one_hot:
+ truth = tf.reshape(truth, [-1])
+ truth = tf.one_hot(
+ truth, depth=num_labels, on_value=1.0, off_value=0.0, axis=-1)
+ else:
+ truth = tf.reshape(truth, [-1, num_labels])
+ predicted = tf.reshape(predicted, [-1, num_labels])
+ losses = tf.nn.softmax_cross_entropy_with_logits(
+ labels=truth, logits=predicted)
+ if weights is not None:
+ losses = tf.boolean_mask(losses,
+ tf.cast(tf.reshape(weights, [-1]), dtype=tf.bool))
+ return tf.reduce_mean(losses)
+
+
+class UnrolledTaskIOConfig(object):
+ """Configuration of task inputs and outputs.
+
+ A task can have multiple inputs, which define the context, and a task query
+ which defines what is to be executed in this context. The desired execution
+ is encoded in an output. The config defines the shapes of the inputs, the
+ query and the outputs.
+ """
+
+ def __init__(self, inputs, output, query=None):
+ """Constructs a Task input/output config.
+
+ Args:
+ inputs: a list of tuples. Each tuple represents the configuration of an
+ input, with first element being the type (a string value) and the second
+ element the shape.
+ output: a tuple representing the configuration of the output.
+ query: a tuple representing the configuration of the query. If no query,
+ then None.
+ """
+ # A configuration of a single input, output or query. Consists of the type,
+ # which can be one of the three specified above, and a shape. The shape must
+ # be consistent with the type, e.g. if type == 'image', then shape is a 3
+ # valued list.
+ io_config = collections.namedtuple('IOConfig', ['type', 'shape'])
+
+ def assert_config(config):
+ if not isinstance(config, tuple):
+ raise ValueError('config must be a tuple. Received {}'.format(
+ type(config)))
+ if len(config) != 2:
+ raise ValueError('config must have 2 elements, has %d' % len(config))
+ if not isinstance(config[0], tf.DType):
+ raise ValueError('First element of config must be a tf.DType.')
+ if not isinstance(config[1], list):
+ raise ValueError('Second element of config must be a list.')
+
+ assert isinstance(inputs, collections.OrderedDict)
+ for modality_type in inputs:
+ assert_config(inputs[modality_type])
+ self._inputs = collections.OrderedDict(
+ [(k, io_config(*value)) for k, value in inputs.iteritems()])
+
+ if query is not None:
+ assert_config(query)
+ self._query = io_config(*query)
+ else:
+ self._query = None
+
+ assert_config(output)
+ self._output = io_config(*output)
+
+ @property
+ def inputs(self):
+ return self._inputs
+
+ @property
+ def output(self):
+ return self._output
+
+ @property
+ def query(self):
+ return self._query
+
+
+class UnrolledTask(object):
+ """An interface for a Task which can be unrolled during training.
+
+ Each example is called episode and consists of inputs and target output, where
+ the output can be considered as desired unrolled sequence of actions for the
+ inputs. For the specified tasks, these action sequences are to be
+ unambiguously definable.
+ """
+ __metaclass__ = abc.ABCMeta
+
+ def __init__(self, config):
+ assert isinstance(config, UnrolledTaskIOConfig)
+ self._config = config
+ # A dict of bookkeeping variables.
+ self.info = {}
+ # Tensorflow input is multithreaded and this lock is needed to prevent
+ # race condition in the environment. Without the lock, non-thread safe
+ # environments crash.
+ self._lock = threading.Lock()
+
+ @property
+ def config(self):
+ return self._config
+
+ @abc.abstractmethod
+ def episode(self):
+ """Returns data needed to train and test a single episode.
+
+ Each episode consists of inputs, which define the context of the task, a
+ query which defines the task, and a target output, which defines a
+ sequence of actions to be executed for this query. This sequence should not
+ require feedback, i.e. can be predicted purely from input and query.]
+
+ Returns:
+ inputs, query, output, where inputs is a list of numpy arrays and query
+ and output are numpy arrays. These arrays must be of shape and type as
+ specified in the task configuration.
+ """
+ pass
+
+ def reset(self, observation):
+ """Called after the environment is reset."""
+ pass
+
+ def episode_batch(self, batch_size):
+ """Returns a batch of episodes.
+
+ Args:
+ batch_size: size of batch.
+
+ Returns:
+ (inputs, query, output, masks) where inputs is list of numpy arrays and
+ query, output, and mask are numpy arrays. These arrays must be of shape
+ and type as specified in the task configuration with one additional
+ preceding dimension corresponding to the batch.
+
+ Raises:
+ ValueError: if self.episode() returns illegal values.
+ """
+ batched_inputs = collections.OrderedDict(
+ [[mtype, []] for mtype in self.config.inputs])
+ batched_queries = []
+ batched_outputs = []
+ batched_masks = []
+ for _ in range(int(batch_size)):
+ with self._lock:
+ # The episode function needs to be thread-safe. Since the current
+ # implementation for the envs are not thread safe we need to have lock
+ # the operations here.
+ inputs, query, outputs = self.episode()
+ if not isinstance(outputs, tuple):
+ raise ValueError('Outputs return value must be tuple.')
+ if len(outputs) != 2:
+ raise ValueError('Output tuple must be of size 2.')
+ if inputs is not None:
+ for modality_type in batched_inputs:
+ batched_inputs[modality_type].append(
+ np.expand_dims(inputs[modality_type], axis=0))
+
+ if query is not None:
+ batched_queries.append(np.expand_dims(query, axis=0))
+ batched_outputs.append(np.expand_dims(outputs[0], axis=0))
+ if outputs[1] is not None:
+ batched_masks.append(np.expand_dims(outputs[1], axis=0))
+
+ batched_inputs = {
+ k: np.concatenate(i, axis=0) for k, i in batched_inputs.iteritems()
+ }
+ if batched_queries:
+ batched_queries = np.concatenate(batched_queries, axis=0)
+ batched_outputs = np.concatenate(batched_outputs, axis=0)
+ if batched_masks:
+ batched_masks = np.concatenate(batched_masks, axis=0).astype(np.float32)
+ else:
+ # When the array is empty, the default np.dtype is float64 which causes
+ # py_func to crash in the tests.
+ batched_masks = np.array([], dtype=np.float32)
+ batched_inputs = [batched_inputs[k] for k in self._config.inputs]
+ return batched_inputs, batched_queries, batched_outputs, batched_masks
+
+ def tf_episode_batch(self, batch_size):
+ """A batch of episodes as TF Tensors.
+
+ Same as episode_batch with the difference that the return values are TF
+ Tensors.
+
+ Args:
+ batch_size: a python float for the batch size.
+
+ Returns:
+ inputs, query, output, mask where inputs is a dictionary of tf.Tensor
+ where the keys are the modality types specified in the config.inputs.
+ query, output, and mask are TF Tensors. These tensors must
+ be of shape and type as specified in the task configuration with one
+ additional preceding dimension corresponding to the batch. Both mask and
+ output have the same shape as output.
+ """
+
+ # Define TF outputs.
+ touts = []
+ shapes = []
+ for _, i in self._config.inputs.iteritems():
+ touts.append(i.type)
+ shapes.append(i.shape)
+ if self._config.query is not None:
+ touts.append(self._config.query.type)
+ shapes.append(self._config.query.shape)
+ # Shapes and types for batched_outputs.
+ touts.append(self._config.output.type)
+ shapes.append(self._config.output.shape)
+ # Shapes and types for batched_masks.
+ touts.append(self._config.output.type)
+ shapes.append(self._config.output.shape[0:1])
+
+ def episode_batch_func():
+ if self.config.query is None:
+ inp, _, output, masks = self.episode_batch(int(batch_size))
+ return tuple(inp) + (output, masks)
+ else:
+ inp, query, output, masks = self.episode_batch(int(batch_size))
+ return tuple(inp) + (query, output, masks)
+
+ tf_episode_batch = tf.py_func(episode_batch_func, [], touts,
+ stateful=True, name='taskdata')
+ for episode, shape in zip(tf_episode_batch, shapes):
+ episode.set_shape([batch_size] + shape)
+
+ tf_episode_batch_dict = collections.OrderedDict([
+ (mtype, episode)
+ for mtype, episode in zip(self.config.inputs.keys(), tf_episode_batch)
+ ])
+ cur_index = len(self.config.inputs.keys())
+ tf_query = None
+ if self.config.query is not None:
+ tf_query = tf_episode_batch[cur_index]
+ cur_index += 1
+ tf_outputs = tf_episode_batch[cur_index]
+ tf_masks = tf_episode_batch[cur_index + 1]
+
+ return tf_episode_batch_dict, tf_query, tf_outputs, tf_masks
+
+ @abc.abstractmethod
+ def target_loss(self, true_targets, targets, weights=None):
+ """A loss for training a task model.
+
+ This loss measures the discrepancy between the task outputs, the true and
+ predicted ones.
+
+ Args:
+ true_targets: tf.Tensor of shape and type as defined in the task config
+ containing the true outputs.
+ targets: tf.Tensor of shape and type as defined in the task config
+ containing the predicted outputs.
+ weights: a bool tf.Tensor of shape as targets. Only true values are
+ considered when formulating the loss.
+ """
+ pass
+
+ def reward(self, obs, done, info):
+ """Returns a reward.
+
+ The tasks has to compute a reward based on the state of the environment. The
+ reward computation, though, is task specific. The task is to use the
+ environment interface, as defined in task_env.py, to compute the reward. If
+ this interface does not expose enough information, it is to be updated.
+
+ Args:
+ obs: Observation from environment's step function.
+ done: Done flag from environment's step function.
+ info: Info dict from environment's step function.
+
+ Returns:
+ obs: Observation.
+ reward: Floating point value.
+ done: Done flag.
+ info: Info dict.
+ """
+ # Default implementation does not do anything.
+ return obs, 0.0, done, info
+
+
+class RandomExplorationBasedTask(UnrolledTask):
+ """A Task which starts with a random exploration of the environment."""
+
+ def __init__(self,
+ env,
+ seed,
+ add_query_noise=False,
+ query_noise_var=0.0,
+ *args,
+ **kwargs): # pylint: disable=keyword-arg-before-vararg
+ """Initializes a Task using a random exploration runs.
+
+ Args:
+ env: an instance of type TaskEnv and gym.Env.
+ seed: a random seed.
+ add_query_noise: boolean, if True then whatever queries are generated,
+ they are randomly perturbed. The semantics of the queries depends on the
+ concrete task implementation.
+ query_noise_var: float, the variance of Gaussian noise used for query
+ perturbation. Used iff add_query_noise==True.
+ *args: see super class.
+ **kwargs: see super class.
+ """
+ super(RandomExplorationBasedTask, self).__init__(*args, **kwargs)
+ assert isinstance(env, task_env.TaskEnv)
+ self._env = env
+ self._env.set_task(self)
+ self._rng = np.random.RandomState(seed)
+ self._add_query_noise = add_query_noise
+ self._query_noise_var = query_noise_var
+
+ # GoToStaticXTask can also take empty config but for the rest of the classes
+ # the number of modality types is 1.
+ if len(self.config.inputs.keys()) > 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type or less.')
+
+ def _exploration(self):
+ """Generates a random exploration run.
+
+ The function uses the environment to generate a run.
+
+ Returns:
+ A tuple of numpy arrays. The i-th array contains observation of type and
+ shape as specified in config.inputs[i].
+ A list of states along the exploration path.
+ A list of vertex indices corresponding to the path of the exploration.
+ """
+ in_seq_len = self._config.inputs.values()[0].shape[0]
+ path, _, states, step_outputs = self._env.random_step_sequence(
+ min_len=in_seq_len)
+ obs = {modality_type: [] for modality_type in self._config.inputs}
+ for o in step_outputs:
+ step_obs, _, done, _ = o
+ # It is expected that each value of step_obs is a dict of observations,
+ # whose dimensions are consistent with the config.inputs sizes.
+ for modality_type in self._config.inputs:
+ assert modality_type in step_obs, '{}'.format(type(step_obs))
+ o = step_obs[modality_type]
+ i = self._config.inputs[modality_type]
+ assert len(o.shape) == len(i.shape) - 1
+ for dim_o, dim_i in zip(o.shape, i.shape[1:]):
+ assert dim_o == dim_i, '{} != {}'.format(dim_o, dim_i)
+ obs[modality_type].append(o)
+ if done:
+ break
+
+ if not obs:
+ return obs, states, path
+
+ max_path_len = int(
+ round(in_seq_len * float(len(path)) / float(len(obs.values()[0]))))
+ path = path[-max_path_len:]
+ states = states[-in_seq_len:]
+
+ # The above obs is a list of tuples of np,array. Re-format them as tuple of
+ # np.array, each array containing all observations from all steps.
+ def regroup(obs, i):
+ """Regroups observations.
+
+ Args:
+ obs: a list of tuples of same size. The k-th tuple contains all the
+ observations from k-th step. Each observation is a numpy array.
+ i: the index of the observation in each tuple to be grouped.
+
+ Returns:
+ A numpy array of shape config.inputs[i] which contains all i-th
+ observations from all steps. These are concatenated along the first
+ dimension. In addition, if the number of observations is different from
+ the one specified in config.inputs[i].shape[0], then the array is either
+ padded from front or clipped.
+ """
+ grouped_obs = np.concatenate(
+ [np.expand_dims(o, axis=0) for o in obs[i]], axis=0)
+ in_seq_len = self._config.inputs[i].shape[0]
+ # pylint: disable=unbalanced-tuple-unpacking
+ grouped_obs, _ = _pad_or_clip_array(
+ grouped_obs, in_seq_len, is_front_clip=True)
+ return grouped_obs
+
+ all_obs = {i: regroup(obs, i) for i in self._config.inputs}
+
+ return all_obs, states, path
+
+ def _obs_to_state(self, path, states):
+ """Computes mapping between path nodes and states."""
+ # Generate a numpy array of locations corresponding to the path vertices.
+ path_coordinates = map(self._env.vertex_to_pose, path)
+ path_coordinates = np.concatenate(
+ [np.reshape(p, [1, 2]) for p in path_coordinates])
+
+ # The observations are taken along a smoothed trajectory following the path.
+ # We compute a mapping between the obeservations and the map vertices.
+ path_to_obs = collections.defaultdict(list)
+ obs_to_state = []
+ for i, s in enumerate(states):
+ location = np.reshape(s[0:2], [1, 2])
+ index = np.argmin(
+ np.reshape(
+ np.sum(np.power(path_coordinates - location, 2), axis=1), [-1]))
+ index = path[index]
+ path_to_obs[index].append(i)
+ obs_to_state.append(index)
+ return path_to_obs, obs_to_state
+
+ def _perturb_state(self, state, noise_var):
+ """Perturbes the state.
+
+ The location are purturbed using a Gaussian noise with variance
+ noise_var. The orientation is uniformly sampled.
+
+ Args:
+ state: a numpy array containing an env state (x, y locations).
+ noise_var: float
+ Returns:
+ The perturbed state.
+ """
+
+ def normal(v, std):
+ if std > 0:
+ n = self._rng.normal(0.0, std)
+ n = min(n, 2.0 * std)
+ n = max(n, -2.0 * std)
+ return v + n
+ else:
+ return v
+
+ state = state.copy()
+ state[0] = normal(state[0], noise_var)
+ state[1] = normal(state[1], noise_var)
+ if state.size > 2:
+ state[2] = self._rng.uniform(-math.pi, math.pi)
+ return state
+
+ def _sample_obs(self,
+ indices,
+ observations,
+ observation_states,
+ path_to_obs,
+ max_obs_index=None,
+ use_exploration_obs=True):
+ """Samples one observation which corresponds to vertex_index in path.
+
+ In addition, the sampled observation must have index in observations less
+ than max_obs_index. If these two conditions cannot be satisfied the
+ function returns None.
+
+ Args:
+ indices: a list of integers.
+ observations: a list of numpy arrays containing all the observations.
+ observation_states: a list of numpy arrays, each array representing the
+ state of the observation.
+ path_to_obs: a dict of path indices to lists of observation indices.
+ max_obs_index: an integer.
+ use_exploration_obs: if True, then the observation is sampled among the
+ specified observations, otherwise it is obtained from the environment.
+ Returns:
+ A tuple of:
+ -- A numpy array of size width x height x 3 representing the sampled
+ observation.
+ -- The index of the sampld observation among the input observations.
+ -- The state at which the observation is captured.
+ Raises:
+ ValueError: if the observation and observation_states lists are of
+ different lengths.
+ """
+ if len(observations) != len(observation_states):
+ raise ValueError('observation and observation_states lists must have '
+ 'equal lengths')
+ if not indices:
+ return None, None, None
+ vertex_index = self._rng.choice(indices)
+ if use_exploration_obs:
+ obs_indices = path_to_obs[vertex_index]
+
+ if max_obs_index is not None:
+ obs_indices = [i for i in obs_indices if i < max_obs_index]
+
+ if obs_indices:
+ index = self._rng.choice(obs_indices)
+ if self._add_query_noise:
+ xytheta = self._perturb_state(observation_states[index],
+ self._query_noise_var)
+ return self._env.observation(xytheta), index, xytheta
+ else:
+ return observations[index], index, observation_states[index]
+ else:
+ return None, None, None
+ else:
+ xy = self._env.vertex_to_pose(vertex_index)
+ xytheta = np.array([xy[0], xy[1], 0.0])
+ xytheta = self._perturb_state(xytheta, self._query_noise_var)
+ return self._env.observation(xytheta), None, xytheta
+
+
+class AreNearbyTask(RandomExplorationBasedTask):
+ """A task of identifying whether a query is nearby current location or not.
+
+ The query is guaranteed to be in proximity of an already visited location,
+ i.e. close to one of the observations. For each observation we have one
+ query, which is either close or not to this observation.
+ """
+
+ def __init__(
+ self,
+ max_distance=0,
+ *args,
+ **kwargs): # pylint: disable=keyword-arg-before-vararg
+ super(AreNearbyTask, self).__init__(*args, **kwargs)
+ self._max_distance = max_distance
+
+ if len(self.config.inputs.keys()) != 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type')
+
+ def episode(self):
+ """Episode data.
+
+ Returns:
+ observations: a tuple with one element. This element is a numpy array of
+ size in_seq_len x observation_size x observation_size x 3 containing
+ in_seq_len images.
+ query: a numpy array of size
+ in_seq_len x observation_size X observation_size x 3 containing a query
+ image.
+ A tuple of size two. First element is a in_seq_len x 2 numpy array of
+ either 1.0 or 0.0. The i-th element denotes whether the i-th query
+ image is neraby (value 1.0) or not (value 0.0) to the i-th observation.
+ The second element in the tuple is a mask, a numpy array of size
+ in_seq_len x 1 and values 1.0 or 0.0 denoting whether the query is
+ valid or not (it can happen that the query is not valid, e.g. there are
+ not enough observations to have a meaningful queries).
+ """
+ observations, states, path = self._exploration()
+ assert len(observations.values()[0]) == len(states)
+
+ # The observations are taken along a smoothed trajectory following the path.
+ # We compute a mapping between the obeservations and the map vertices.
+ path_to_obs, obs_to_path = self._obs_to_state(path, states)
+
+ # Go over all observations, and sample a query. With probability 0.5 this
+ # query is a nearby observation (defined as belonging to the same vertex
+ # in path).
+ g = self._env.graph
+ queries = []
+ labels = []
+ validity_masks = []
+ query_index_in_observations = []
+ for i, curr_o in enumerate(observations.values()[0]):
+ p = obs_to_path[i]
+ low = max(0, i - self._max_distance)
+
+ # A list of lists of vertex indices. Each list in this group corresponds
+ # to one possible label.
+ index_groups = [[], [], []]
+ # Nearby visited indices, label 1.
+ nearby_visited = [
+ ii for ii in path[low:i + 1] + g[p].keys() if ii in obs_to_path[:i]
+ ]
+ nearby_visited = [ii for ii in index_groups[1] if ii in path_to_obs]
+ # NOT Nearby visited indices, label 0.
+ not_nearby_visited = [ii for ii in path[:low] if ii not in g[p].keys()]
+ not_nearby_visited = [ii for ii in index_groups[0] if ii in path_to_obs]
+ # NOT visited indices, label 2.
+ not_visited = [
+ ii for ii in range(g.number_of_nodes()) if ii not in path[:i + 1]
+ ]
+
+ index_groups = [not_nearby_visited, nearby_visited, not_visited]
+
+ # Consider only labels for which there are indices.
+ allowed_labels = [ii for ii, group in enumerate(index_groups) if group]
+ label = self._rng.choice(allowed_labels)
+
+ indices = list(set(index_groups[label]))
+ max_obs_index = None if label == 2 else i
+ use_exploration_obs = False if label == 2 else True
+ o, obs_index, _ = self._sample_obs(
+ indices=indices,
+ observations=observations.values()[0],
+ observation_states=states,
+ path_to_obs=path_to_obs,
+ max_obs_index=max_obs_index,
+ use_exploration_obs=use_exploration_obs)
+ query_index_in_observations.append(obs_index)
+
+ # If we cannot sample a valid query, we mark it as not valid in mask.
+ if o is None:
+ label = 0.0
+ o = curr_o
+ validity_masks.append(0)
+ else:
+ validity_masks.append(1)
+
+ queries.append(o.values()[0])
+ labels.append(label)
+
+ query = np.concatenate([np.expand_dims(q, axis=0) for q in queries], axis=0)
+
+ def one_hot(label, num_labels=3):
+ a = np.zeros((num_labels,), dtype=np.float)
+ a[int(label)] = 1.0
+ return a
+
+ outputs = np.stack([one_hot(l) for l in labels], axis=0)
+ validity_mask = np.reshape(
+ np.array(validity_masks, dtype=np.int32), [-1, 1])
+
+ self.info['query_index_in_observations'] = query_index_in_observations
+ self.info['observation_states'] = states
+
+ return observations, query, (outputs, validity_mask)
+
+ def target_loss(self, truth, predicted, weights=None):
+ pass
+
+
+class NeighboringQueriesTask(RandomExplorationBasedTask):
+ """A task of identifying whether two queries are closeby or not.
+
+ The proximity between queries is defined by the length of the shorest path
+ between them.
+ """
+
+ def __init__(
+ self,
+ max_distance=1,
+ *args,
+ **kwargs): # pylint: disable=keyword-arg-before-vararg
+ """Initializes a NeighboringQueriesTask.
+
+ Args:
+ max_distance: integer, the maximum distance in terms of number of vertices
+ between the two queries, so that they are considered neighboring.
+ *args: for super class.
+ **kwargs: for super class.
+ """
+ super(NeighboringQueriesTask, self).__init__(*args, **kwargs)
+ self._max_distance = max_distance
+ if len(self.config.inputs.keys()) != 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type')
+
+ def episode(self):
+ """Episode data.
+
+ Returns:
+ observations: a tuple with one element. This element is a numpy array of
+ size in_seq_len x observation_size x observation_size x 3 containing
+ in_seq_len images.
+ query: a numpy array of size
+ 2 x observation_size X observation_size x 3 containing a pair of query
+ images.
+ A tuple of size two. First element is a numpy array of size 2 containing
+ a one hot vector of whether the two observations are neighobring. Second
+ element is a boolean numpy value denoting whether this is a valid
+ episode.
+ """
+ observations, states, path = self._exploration()
+ assert len(observations.values()[0]) == len(states)
+ path_to_obs, _ = self._obs_to_state(path, states)
+ # Restrict path to ones for which observations have been generated.
+ path = [p for p in path if p in path_to_obs]
+ # Sample first query.
+ query1_index = self._rng.choice(path)
+ # Sample label.
+ label = self._rng.randint(2)
+ # Sample second query.
+ # If label == 1, then second query must be nearby, otherwise not.
+ closest_indices = nx.single_source_shortest_path(
+ self._env.graph, query1_index, self._max_distance).keys()
+ if label == 0:
+ # Closest indices on the path.
+ indices = [p for p in path if p not in closest_indices]
+ else:
+ # Indices which are not closest on the path.
+ indices = [p for p in closest_indices if p in path]
+
+ query2_index = self._rng.choice(indices)
+ # Generate an observation.
+ query1, query1_index, _ = self._sample_obs(
+ [query1_index],
+ observations.values()[0],
+ states,
+ path_to_obs,
+ max_obs_index=None,
+ use_exploration_obs=True)
+ query2, query2_index, _ = self._sample_obs(
+ [query2_index],
+ observations.values()[0],
+ states,
+ path_to_obs,
+ max_obs_index=None,
+ use_exploration_obs=True)
+
+ queries = np.concatenate(
+ [np.expand_dims(q, axis=0) for q in [query1, query2]])
+ labels = np.array([0, 0])
+ labels[label] = 1
+ is_valid = np.array([1])
+
+ self.info['observation_states'] = states
+ self.info['query_indices_in_observations'] = [query1_index, query2_index]
+
+ return observations, queries, (labels, is_valid)
+
+ def target_loss(self, truth, predicted, weights=None):
+ pass
+
+
+#@gin.configurable
+class GotoStaticXTask(RandomExplorationBasedTask):
+ """Task go to a static X.
+
+ If continuous reward is used only one goal is allowed so that the reward can
+ be computed as a delta-distance to that goal..
+ """
+
+ def __init__(self,
+ step_reward=0.0,
+ goal_reward=1.0,
+ hit_wall_reward=-1.0,
+ done_at_target=False,
+ use_continuous_reward=False,
+ *args,
+ **kwargs): # pylint: disable=keyword-arg-before-vararg
+ super(GotoStaticXTask, self).__init__(*args, **kwargs)
+ if len(self.config.inputs.keys()) > 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type or less.')
+
+ self._step_reward = step_reward
+ self._goal_reward = goal_reward
+ self._hit_wall_reward = hit_wall_reward
+ self._done_at_target = done_at_target
+ self._use_continuous_reward = use_continuous_reward
+
+ self._previous_path_length = None
+
+ def episode(self):
+ observations, _, path = self._exploration()
+ if len(path) < 2:
+ raise ValueError('The exploration path has only one node.')
+
+ g = self._env.graph
+ start = path[-1]
+ while True:
+ goal = self._rng.choice(path[:-1])
+ if goal != start:
+ break
+ goal_path = nx.shortest_path(g, start, goal)
+
+ init_orientation = self._rng.uniform(0, np.pi, (1,))
+ trajectory = np.array(
+ [list(self._env.vertex_to_pose(p)) for p in goal_path])
+ init_xy = np.reshape(trajectory[0, :], [-1])
+ init_state = np.concatenate([init_xy, init_orientation], 0)
+
+ trajectory = trajectory[1:, :]
+ deltas = envs_util.trajectory_to_deltas(trajectory, init_state)
+ output_seq_len = self._config.output.shape[0]
+ arr = _pad_or_clip_array(deltas, output_seq_len, output_mask=True)
+ # pylint: disable=unbalanced-tuple-unpacking
+ thetas, _, thetas_mask = arr
+
+ query = self._env.observation(self._env.vertex_to_pose(goal)).values()[0]
+
+ return observations, query, (thetas, thetas_mask)
+
+ def reward(self, obs, done, info):
+ if 'wall_collision' in info and info['wall_collision']:
+ return obs, self._hit_wall_reward, done, info
+
+ reward = 0.0
+ current_vertex = self._env.pose_to_vertex(self._env.state)
+
+ if current_vertex in self._env.targets():
+ if self._done_at_target:
+ done = True
+ else:
+ obs = self._env.reset()
+ reward = self._goal_reward
+ else:
+ if self._use_continuous_reward:
+ if len(self._env.targets()) != 1:
+ raise ValueError(
+ 'FindX task with continuous reward is assuming only one target.')
+ goal_vertex = self._env.targets()[0]
+ path_length = self._compute_path_length(goal_vertex)
+ reward = self._previous_path_length - path_length
+ self._previous_path_length = path_length
+ else:
+ reward = self._step_reward
+
+ return obs, reward, done, info
+
+ def _compute_path_length(self, goal_vertex):
+ current_vertex = self._env.pose_to_vertex(self._env.state)
+ path = nx.shortest_path(self._env.graph, current_vertex, goal_vertex)
+ assert len(path) >= 2
+ curr_xy = np.array(self._env.state[:2])
+ next_xy = np.array(self._env.vertex_to_pose(path[1]))
+ last_step_distance = np.linalg.norm(next_xy - curr_xy)
+ return (len(path) - 2) * self._env.cell_size_px + last_step_distance
+
+ def reset(self, observation):
+ if self._use_continuous_reward:
+ if len(self._env.targets()) != 1:
+ raise ValueError(
+ 'FindX task with continuous reward is assuming only one target.')
+ goal_vertex = self._env.targets()[0]
+ self._previous_path_length = self._compute_path_length(goal_vertex)
+
+ def target_loss(self, truth, predicted, weights=None):
+ """Action classification loss.
+
+ Args:
+ truth: a batch_size x sequence length x number of labels float
+ Tensor containing a one hot vector for each label in each batch and
+ time.
+ predicted: a batch_size x sequence length x number of labels float
+ Tensor containing a predicted distribution over all actions.
+ weights: a batch_size x sequence_length float Tensor of bool
+ denoting which actions are valid.
+
+ Returns:
+ An average cross entropy over all batches and elements in sequence.
+ """
+ return classification_loss(
+ truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
+
+
+class RelativeLocationTask(RandomExplorationBasedTask):
+ """A task of estimating the relative location of a query w.r.t current.
+
+ It is to be used for debugging. It is designed such that the output is a
+ single value, out of a discrete set of values, so that it can be phrased as
+ a classification problem.
+ """
+
+ def __init__(self, num_labels, *args, **kwargs):
+ """Initializes a relative location task.
+
+ Args:
+ num_labels: integer, number of orientations to bin the relative
+ orientation into.
+ *args: see super class.
+ **kwargs: see super class.
+ """
+ super(RelativeLocationTask, self).__init__(*args, **kwargs)
+ self._num_labels = num_labels
+ if len(self.config.inputs.keys()) != 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type')
+
+ def episode(self):
+ observations, states, path = self._exploration()
+
+ # Select a random element from history.
+ path_to_obs, _ = self._obs_to_state(path, states)
+ use_exploration_obs = not self._add_query_noise
+ query, _, query_state = self._sample_obs(
+ path[:-1],
+ observations.values()[0],
+ states,
+ path_to_obs,
+ max_obs_index=None,
+ use_exploration_obs=use_exploration_obs)
+
+ x, y, theta = tuple(states[-1])
+ q_x, q_y, _ = tuple(query_state)
+ t_x, t_y = q_x - x, q_y - y
+ (rt_x, rt_y) = (np.sin(theta) * t_x - np.cos(theta) * t_y,
+ np.cos(theta) * t_x + np.sin(theta) * t_y)
+ # Bins are [a(i), a(i+1)] for a(i) = -pi + 0.5 * bin_size + i * bin_size.
+ shift = np.pi * (1 - 1.0 / (2.0 * self._num_labels))
+ orientation = np.arctan2(rt_y, rt_x) + shift
+ if orientation < 0:
+ orientation += 2 * np.pi
+ label = int(np.floor(self._num_labels * orientation / (2 * np.pi)))
+
+ out_shape = self._config.output.shape
+ if len(out_shape) != 1:
+ raise ValueError('Output shape should be of rank 1.')
+ if out_shape[0] != self._num_labels:
+ raise ValueError('Output shape must be of size %d' % self._num_labels)
+ output = np.zeros(out_shape, dtype=np.float32)
+ output[label] = 1
+
+ return observations, query, (output, None)
+
+ def target_loss(self, truth, predicted, weights=None):
+ return classification_loss(
+ truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
+
+
+class LocationClassificationTask(UnrolledTask):
+ """A task of classifying a location as one of several classes.
+
+ The task does not have an input, but just a query and an output. The query
+ is an observation of the current location, e.g. an image taken from the
+ current state. The output is a label classifying this location in one of
+ predefined set of locations (or landmarks).
+
+ The current implementation classifies locations as intersections based on the
+ number and directions of biforcations. It is expected that a location can have
+ at most 4 different directions, aligned with the axes. As each of these four
+ directions might be present or not, the number of possible intersections are
+ 2^4 = 16.
+ """
+
+ def __init__(self, env, seed, *args, **kwargs):
+ super(LocationClassificationTask, self).__init__(*args, **kwargs)
+ self._env = env
+ self._rng = np.random.RandomState(seed)
+ # A location property which can be set. If not set, a random one is
+ # generated.
+ self._location = None
+ if len(self.config.inputs.keys()) > 1:
+ raise NotImplementedError('current implementation supports input '
+ 'with only one modality type or less.')
+
+ @property
+ def location(self):
+ return self._location
+
+ @location.setter
+ def location(self, location):
+ self._location = location
+
+ def episode(self):
+ # Get a location. If not set, sample on at a vertex with a random
+ # orientation
+ location = self._location
+ if location is None:
+ num_nodes = self._env.graph.number_of_nodes()
+ vertex = int(math.floor(self._rng.uniform(0, num_nodes)))
+ xy = self._env.vertex_to_pose(vertex)
+ theta = self._rng.uniform(0, 2 * math.pi)
+ location = np.concatenate(
+ [np.reshape(xy, [-1]), np.array([theta])], axis=0)
+ else:
+ vertex = self._env.pose_to_vertex(location)
+
+ theta = location[2]
+ neighbors = self._env.graph.neighbors(vertex)
+ xy_s = [self._env.vertex_to_pose(n) for n in neighbors]
+
+ def rotate(xy, theta):
+ """Rotates a vector around the origin by angle theta.
+
+ Args:
+ xy: a numpy darray of shape (2, ) of floats containing the x and y
+ coordinates of a vector.
+ theta: a python float containing the rotation angle in radians.
+
+ Returns:
+ A numpy darray of floats of shape (2,) containing the x and y
+ coordinates rotated xy.
+ """
+ rotated_x = np.cos(theta) * xy[0] - np.sin(theta) * xy[1]
+ rotated_y = np.sin(theta) * xy[0] + np.cos(theta) * xy[1]
+ return np.array([rotated_x, rotated_y])
+
+ # Rotate all intersection biforcation by the orientation of the agent as the
+ # intersection label is defined in an agent centered fashion.
+ xy_s = [
+ rotate(xy - location[0:2], -location[2] - math.pi / 4) for xy in xy_s
+ ]
+ th_s = [np.arctan2(xy[1], xy[0]) for xy in xy_s]
+
+ out_shape = self._config.output.shape
+ if len(out_shape) != 1:
+ raise ValueError('Output shape should be of rank 1.')
+ num_labels = out_shape[0]
+ if num_labels != 16:
+ raise ValueError('Currently only 16 labels are supported '
+ '(there are 16 different 4 way intersection types).')
+
+ th_s = set([int(math.floor(4 * (th / (2 * np.pi) + 0.5))) for th in th_s])
+ one_hot_label = np.zeros((num_labels,), dtype=np.float32)
+ label = 0
+ for th in th_s:
+ label += pow(2, th)
+ one_hot_label[int(label)] = 1.0
+
+ query = self._env.observation(location).values()[0]
+ return [], query, (one_hot_label, None)
+
+ def reward(self, obs, done, info):
+ raise ValueError('Do not call.')
+
+ def target_loss(self, truth, predicted, weights=None):
+ return classification_loss(
+ truth=truth, predicted=predicted, weights=weights, is_one_hot=True)
+
+
+class GotoStaticXNoExplorationTask(UnrolledTask):
+ """An interface for findX tasks without exploration.
+
+ The agent is initialized a random location in a random world and a random goal
+ and the objective is for the agent to move toward the goal. This class
+ generates episode for such task. Each generates a sequence of observations x
+ and target outputs y. x is the observations and is an OrderedDict with keys
+ provided from config.inputs.keys() and the shapes provided in the
+ config.inputs. The output is a numpy arrays with the shape specified in the
+ config.output. The shape of the array is (sequence_length x action_size) where
+ action is the number of actions that can be done in the environment. Note that
+ config.output.shape should be set according to the number of actions that can
+ be done in the env.
+ target outputs y are the groundtruth value of each action that is computed
+ from the environment graph. The target output for each action is proportional
+ to the progress that each action makes. Target value of 1 means that the
+ action takes the agent one step closer, -1 means the action takes the agent
+ one step farther. Value of -2 means that action should not take place at all.
+ This can be because the action leads to collision or it wants to terminate the
+ episode prematurely.
+ """
+
+ def __init__(self, env, *args, **kwargs):
+ super(GotoStaticXNoExplorationTask, self).__init__(*args, **kwargs)
+
+ if self._config.query is not None:
+ raise ValueError('query should be None.')
+ if len(self._config.output.shape) != 2:
+ raise ValueError('output should only have two dimensions:'
+ '(sequence_length x number_of_actions)')
+ for input_config in self._config.inputs.values():
+ if input_config.shape[0] != self._config.output.shape[0]:
+ raise ValueError('the first dimension of the input and output should'
+ 'be the same.')
+ if len(self._config.output.shape) != 2:
+ raise ValueError('output shape should be '
+ '(sequence_length x number_of_actions)')
+
+ self._env = env
+
+ def _compute_shortest_path_length(self, vertex, target_vertices):
+ """Computes length of the shortest path from vertex to any target vertexes.
+
+ Args:
+ vertex: integer, index of the vertex in the environment graph.
+ target_vertices: list of the target vertexes
+
+ Returns:
+ integer, minimum distance from the vertex to any of the target_vertices.
+
+ Raises:
+ ValueError: if there is no path between the vertex and at least one of
+ the target_vertices.
+ """
+ try:
+ return np.min([
+ len(nx.shortest_path(self._env.graph, vertex, t))
+ for t in target_vertices
+ ])
+ except:
+ #logging.error('there is no path between vertex %d and at least one of '
+ # 'the targets %r', vertex, target_vertices)
+ raise
+
+ def _compute_gt_value(self, vertex, target_vertices):
+ """Computes groundtruth value of all the actions at the vertex.
+
+ The value of each action is the difference each action makes in the length
+ of the shortest path to the goal. If an action takes the agent one step
+ closer to the goal the value is 1. In case, it takes the agent one step away
+ from the goal it would be -1. If it leads to collision or if the agent uses
+ action stop before reaching to the goal it is -2. To avoid scale issues the
+ gt_values are multipled by 0.5.
+
+ Args:
+ vertex: integer, the index of current vertex.
+ target_vertices: list of the integer indexes of the target views.
+
+ Returns:
+ numpy array with shape (action_size,) and each element is the groundtruth
+ value of each action based on the progress each action makes.
+ """
+ action_size = self._config.output.shape[1]
+ output_value = np.ones((action_size), dtype=np.float32) * -2
+ my_distance = self._compute_shortest_path_length(vertex, target_vertices)
+ for adj in self._env.graph[vertex]:
+ adj_distance = self._compute_shortest_path_length(adj, target_vertices)
+ if adj_distance is None:
+ continue
+ action_index = self._env.action(
+ self._env.vertex_to_pose(vertex), self._env.vertex_to_pose(adj))
+ assert action_index is not None, ('{} is not adjacent to {}. There might '
+ 'be a problem in environment graph '
+ 'connectivity because there is no '
+ 'direct edge between the given '
+ 'vertices').format(
+ self._env.vertex_to_pose(vertex),
+ self._env.vertex_to_pose(adj))
+ output_value[action_index] = my_distance - adj_distance
+
+ return output_value * 0.5
+
+ def episode(self):
+ """Returns data needed to train and test a single episode.
+
+ Returns:
+ (inputs, None, output) where inputs is a dictionary of modality types to
+ numpy arrays. The second element is query but we assume that the goal
+ is also given as part of observation so it should be None for this task,
+ and the outputs is the tuple of ground truth action values with the
+ shape of (sequence_length x action_size) that is coming from
+ config.output.shape and a numpy array with the shape of
+ (sequence_length,) that is 1 if the corresponding element of the
+ input and output should be used in the training optimization.
+
+ Raises:
+ ValueError: If the output values for env.random_step_sequence is not
+ valid.
+ ValueError: If the shape of observations coming from the env is not
+ consistent with the config.
+ ValueError: If there is a modality type specified in the config but the
+ environment does not return that.
+ """
+ # Sequence length is the first dimension of any of the input tensors.
+ sequence_length = self._config.inputs.values()[0].shape[0]
+ modality_types = self._config.inputs.keys()
+
+ path, _, _, step_outputs = self._env.random_step_sequence(
+ max_len=sequence_length)
+ target_vertices = [self._env.pose_to_vertex(x) for x in self._env.targets()]
+
+ if len(path) != len(step_outputs):
+ raise ValueError('path, and step_outputs should have equal length'
+ ' {}!={}'.format(len(path), len(step_outputs)))
+
+ # Building up observations. observations will be a OrderedDict of
+ # modality types. The values are numpy arrays that follow the given shape
+ # in the input config for each modality type.
+ observations = collections.OrderedDict([k, []] for k in modality_types)
+ for step_output in step_outputs:
+ obs_dict = step_output[0]
+ # Only going over the modality types that are specified in the input
+ # config.
+ for modality_type in modality_types:
+ if modality_type not in obs_dict:
+ raise ValueError('modality type is not returned from the environment.'
+ '{} not in {}'.format(modality_type,
+ obs_dict.keys()))
+ obs = obs_dict[modality_type]
+ if np.any(
+ obs.shape != tuple(self._config.inputs[modality_type].shape[1:])):
+ raise ValueError(
+ 'The observations should have the same size as speicifed in'
+ 'config for modality type {}. {} != {}'.format(
+ modality_type, obs.shape,
+ self._config.inputs[modality_type].shape[1:]))
+ observations[modality_type].append(obs)
+
+ gt_value = [self._compute_gt_value(v, target_vertices) for v in path]
+
+ # pylint: disable=unbalanced-tuple-unpacking
+ gt_value, _, value_mask = _pad_or_clip_array(
+ np.array(gt_value),
+ sequence_length,
+ is_front_clip=False,
+ output_mask=True,
+ )
+ for modality_type, obs in observations.iteritems():
+ observations[modality_type], _, mask = _pad_or_clip_array(
+ np.array(obs), sequence_length, is_front_clip=False, output_mask=True)
+ assert np.all(mask == value_mask)
+
+ return observations, None, (gt_value, value_mask)
+
+ def reset(self, observation):
+ """Called after the environment is reset."""
+ pass
+
+ def target_loss(self, true_targets, targets, weights=None):
+ """A loss for training a task model.
+
+ This loss measures the discrepancy between the task outputs, the true and
+ predicted ones.
+
+ Args:
+ true_targets: tf.Tensor of tf.float32 with the shape of
+ (batch_size x sequence_length x action_size).
+ targets: tf.Tensor of tf.float32 with the shape of
+ (batch_size x sequence_length x action_size).
+ weights: tf.Tensor of tf.bool with the shape of
+ (batch_size x sequence_length).
+
+ Raises:
+ ValueError: if the shapes of the input tensors are not consistent.
+
+ Returns:
+ L2 loss between the predicted action values and true action values.
+ """
+ targets_shape = targets.get_shape().as_list()
+ true_targets_shape = true_targets.get_shape().as_list()
+ if len(targets_shape) != 3 or len(true_targets_shape) != 3:
+ raise ValueError('invalid shape for targets or true_targets_shape')
+ if np.any(targets_shape != true_targets_shape):
+ raise ValueError('the shape of targets and true_targets are not the same'
+ '{} != {}'.format(targets_shape, true_targets_shape))
+
+ if weights is not None:
+ # Filtering targets and true_targets using weights.
+ weights_shape = weights.get_shape().as_list()
+ if np.any(weights_shape != targets_shape[0:2]):
+ raise ValueError('The first two elements of weights shape should match'
+ 'target. {} != {}'.format(weights_shape,
+ targets_shape))
+ true_targets = tf.boolean_mask(true_targets, weights)
+ targets = tf.boolean_mask(targets, weights)
+
+ return tf.losses.mean_squared_error(tf.reshape(targets, [-1]),
+ tf.reshape(true_targets, [-1]))
+
+ def reward(self, obs, done, info):
+ raise NotImplementedError('reward is not implemented for this task')
+
+
+################################################################################
+class NewTask(UnrolledTask):
+ def __init__(self, env, *args, **kwargs):
+ super(NewTask, self).__init__(*args, **kwargs)
+ self._env = env
+
+ def _compute_shortest_path_length(self, vertex, target_vertices):
+ """Computes length of the shortest path from vertex to any target vertexes.
+
+ Args:
+ vertex: integer, index of the vertex in the environment graph.
+ target_vertices: list of the target vertexes
+
+ Returns:
+ integer, minimum distance from the vertex to any of the target_vertices.
+
+ Raises:
+ ValueError: if there is no path between the vertex and at least one of
+ the target_vertices.
+ """
+ try:
+ return np.min([
+ len(nx.shortest_path(self._env.graph, vertex, t))
+ for t in target_vertices
+ ])
+ except:
+ logging.error('there is no path between vertex %d and at least one of '
+ 'the targets %r', vertex, target_vertices)
+ raise
+
+ def _compute_gt_value(self, vertex, target_vertices):
+ """Computes groundtruth value of all the actions at the vertex.
+
+ The value of each action is the difference each action makes in the length
+ of the shortest path to the goal. If an action takes the agent one step
+ closer to the goal the value is 1. In case, it takes the agent one step away
+ from the goal it would be -1. If it leads to collision or if the agent uses
+ action stop before reaching to the goal it is -2. To avoid scale issues the
+ gt_values are multipled by 0.5.
+
+ Args:
+ vertex: integer, the index of current vertex.
+ target_vertices: list of the integer indexes of the target views.
+
+ Returns:
+ numpy array with shape (action_size,) and each element is the groundtruth
+ value of each action based on the progress each action makes.
+ """
+ action_size = self._config.output.shape[1]
+ output_value = np.ones((action_size), dtype=np.float32) * -2
+ # own compute _compute_shortest_path_length - returnts float
+ my_distance = self._compute_shortest_path_length(vertex, target_vertices)
+ for adj in self._env.graph[vertex]:
+ adj_distance = self._compute_shortest_path_length(adj, target_vertices)
+ if adj_distance is None:
+ continue
+ action_index = self._env.action(
+ self._env.vertex_to_pose(vertex), self._env.vertex_to_pose(adj))
+ assert action_index is not None, ('{} is not adjacent to {}. There might '
+ 'be a problem in environment graph '
+ 'connectivity because there is no '
+ 'direct edge between the given '
+ 'vertices').format(
+ self._env.vertex_to_pose(vertex),
+ self._env.vertex_to_pose(adj))
+ output_value[action_index] = my_distance - adj_distance
+
+ return output_value * 0.5
+
+ def episode(self):
+ """Returns data needed to train and test a single episode.
+
+ Returns:
+ (inputs, None, output) where inputs is a dictionary of modality types to
+ numpy arrays. The second element is query but we assume that the goal
+ is also given as part of observation so it should be None for this task,
+ and the outputs is the tuple of ground truth action values with the
+ shape of (sequence_length x action_size) that is coming from
+ config.output.shape and a numpy array with the shape of
+ (sequence_length,) that is 1 if the corresponding element of the
+ input and output should be used in the training optimization.
+
+ Raises:
+ ValueError: If the output values for env.random_step_sequence is not
+ valid.
+ ValueError: If the shape of observations coming from the env is not
+ consistent with the config.
+ ValueError: If there is a modality type specified in the config but the
+ environment does not return that.
+ """
+ # Sequence length is the first dimension of any of the input tensors.
+ sequence_length = self._config.inputs.values()[0].shape[0]
+ modality_types = self._config.inputs.keys()
+
+ path, _, _, step_outputs = self._env.random_step_sequence(
+ max_len=sequence_length)
+ target_vertices = [self._env.pose_to_vertex(x) for x in self._env.targets()]
+
+ if len(path) != len(step_outputs):
+ raise ValueError('path, and step_outputs should have equal length'
+ ' {}!={}'.format(len(path), len(step_outputs)))
+
+ # Building up observations. observations will be a OrderedDict of
+ # modality types. The values are numpy arrays that follow the given shape
+ # in the input config for each modality type.
+ observations = collections.OrderedDict([k, []] for k in modality_types)
+ for step_output in step_outputs:
+ obs_dict = step_output[0]
+ # Only going over the modality types that are specified in the input
+ # config.
+ for modality_type in modality_types:
+ if modality_type not in obs_dict:
+ raise ValueError('modality type is not returned from the environment.'
+ '{} not in {}'.format(modality_type,
+ obs_dict.keys()))
+ obs = obs_dict[modality_type]
+ if np.any(
+ obs.shape != tuple(self._config.inputs[modality_type].shape[1:])):
+ raise ValueError(
+ 'The observations should have the same size as speicifed in'
+ 'config for modality type {}. {} != {}'.format(
+ modality_type, obs.shape,
+ self._config.inputs[modality_type].shape[1:]))
+ observations[modality_type].append(obs)
+
+ gt_value = [self._compute_gt_value(v, target_vertices) for v in path]
+
+ # pylint: disable=unbalanced-tuple-unpacking
+ gt_value, _, value_mask = _pad_or_clip_array(
+ np.array(gt_value),
+ sequence_length,
+ is_front_clip=False,
+ output_mask=True,
+ )
+ for modality_type, obs in observations.iteritems():
+ observations[modality_type], _, mask = _pad_or_clip_array(
+ np.array(obs), sequence_length, is_front_clip=False, output_mask=True)
+ assert np.all(mask == value_mask)
+
+ return observations, None, (gt_value, value_mask)
+
+ def reset(self, observation):
+ """Called after the environment is reset."""
+ pass
+
+ def target_loss(self, true_targets, targets, weights=None):
+ """A loss for training a task model.
+
+ This loss measures the discrepancy between the task outputs, the true and
+ predicted ones.
+
+ Args:
+ true_targets: tf.Tensor of tf.float32 with the shape of
+ (batch_size x sequence_length x action_size).
+ targets: tf.Tensor of tf.float32 with the shape of
+ (batch_size x sequence_length x action_size).
+ weights: tf.Tensor of tf.bool with the shape of
+ (batch_size x sequence_length).
+
+ Raises:
+ ValueError: if the shapes of the input tensors are not consistent.
+
+ Returns:
+ L2 loss between the predicted action values and true action values.
+ """
+ targets_shape = targets.get_shape().as_list()
+ true_targets_shape = true_targets.get_shape().as_list()
+ if len(targets_shape) != 3 or len(true_targets_shape) != 3:
+ raise ValueError('invalid shape for targets or true_targets_shape')
+ if np.any(targets_shape != true_targets_shape):
+ raise ValueError('the shape of targets and true_targets are not the same'
+ '{} != {}'.format(targets_shape, true_targets_shape))
+
+ if weights is not None:
+ # Filtering targets and true_targets using weights.
+ weights_shape = weights.get_shape().as_list()
+ if np.any(weights_shape != targets_shape[0:2]):
+ raise ValueError('The first two elements of weights shape should match'
+ 'target. {} != {}'.format(weights_shape,
+ targets_shape))
+ true_targets = tf.boolean_mask(true_targets, weights)
+ targets = tf.boolean_mask(targets, weights)
+
+ return tf.losses.mean_squared_error(tf.reshape(targets, [-1]),
+ tf.reshape(true_targets, [-1]))
+
+ def reward(self, obs, done, info):
+ raise NotImplementedError('reward is not implemented for this task')
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.py"
new file mode 100644
index 00000000..5931a24e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.py"
@@ -0,0 +1,503 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# pylint: disable=line-too-long
+# pyformat: disable
+"""Train and eval for supervised navigation training.
+
+For training:
+python train_supervised_active_vision.py \
+ --mode='train' \
+ --logdir=$logdir/checkin_log_det/ \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root="$datadir"' \
+ --logtostderr
+
+For testing:
+python train_supervised_active_vision.py
+ --mode='eval' \
+ --logdir=$logdir/checkin_log_det/ \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root="$datadir"' \
+ --logtostderr
+"""
+
+import collections
+import os
+import time
+from absl import app
+from absl import flags
+from absl import logging
+import networkx as nx
+import numpy as np
+import tensorflow as tf
+import gin
+import embedders
+import policies
+import tasks
+from envs import active_vision_dataset_env
+from envs import task_env
+
+slim = tf.contrib.slim
+
+flags.DEFINE_string('logdir', '',
+ 'Path to a directory to write summaries and checkpoints')
+# Parameters controlling the training setup. In general one would not need to
+# modify them.
+flags.DEFINE_string('master', 'local',
+ 'BNS name of the TensorFlow master, or local.')
+flags.DEFINE_integer('task_id', 0,
+ 'Task id of the replica running the training.')
+flags.DEFINE_integer('ps_tasks', 0,
+ 'Number of tasks in the ps job. If 0 no ps job is used.')
+
+flags.DEFINE_integer('decay_steps', 1000,
+ 'Number of steps for exponential decay.')
+flags.DEFINE_float('learning_rate', 0.0001, 'Learning rate.')
+flags.DEFINE_integer('batch_size', 8, 'Batch size.')
+flags.DEFINE_integer('sequence_length', 20, 'sequence length')
+flags.DEFINE_integer('train_iters', 200000, 'number of training iterations.')
+flags.DEFINE_integer('save_summaries_secs', 300,
+ 'number of seconds between saving summaries')
+flags.DEFINE_integer('save_interval_secs', 300,
+ 'numer of seconds between saving variables')
+flags.DEFINE_integer('log_every_n_steps', 20, 'number of steps between logging')
+flags.DEFINE_string('modality_types', '',
+ 'modality names in _ separated format')
+flags.DEFINE_string('conv_window_sizes', '8_4_3',
+ 'conv window size in separated by _')
+flags.DEFINE_string('conv_strides', '4_2_1', '')
+flags.DEFINE_string('conv_channels', '8_16_16', '')
+flags.DEFINE_integer('embedding_fc_size', 128,
+ 'size of embedding for each modality')
+flags.DEFINE_integer('obs_resolution', 64,
+ 'resolution of the input observations')
+flags.DEFINE_integer('lstm_cell_size', 2048, 'size of lstm cell size')
+flags.DEFINE_integer('policy_fc_size', 2048,
+ 'size of fully connected layers for policy part')
+flags.DEFINE_float('weight_decay', 0.0002, 'weight decay')
+flags.DEFINE_integer('goal_category_count', 5, 'number of goal categories')
+flags.DEFINE_integer('action_size', 7, 'number of possible actions')
+flags.DEFINE_integer('max_eval_episode_length', 100,
+ 'maximum sequence length for evaluation.')
+flags.DEFINE_enum('mode', 'train', ['train', 'eval'],
+ 'indicates whether it is in training or evaluation')
+flags.DEFINE_integer('test_iters', 194,
+ 'number of iterations that the eval needs to be run')
+flags.DEFINE_multi_string('gin_config', [],
+ 'List of paths to a gin config files for the env.')
+flags.DEFINE_multi_string('gin_params', [],
+ 'Newline separated list of Gin parameter bindings.')
+flags.DEFINE_string(
+ 'resnet50_path', './resnet_v2_50_checkpoint/resnet_v2_50.ckpt', 'path to resnet50'
+ 'checkpoint')
+flags.DEFINE_bool('freeze_resnet_weights', True, '')
+flags.DEFINE_string(
+ 'eval_init_points_file_name', '',
+ 'Name of the file that containts the initial locations and'
+ 'worlds for each evalution point')
+
+FLAGS = flags.FLAGS
+TRAIN_WORLDS = [
+ 'Home_001_1', 'Home_001_2', 'Home_002_1', 'Home_003_1', 'Home_003_2',
+ 'Home_004_1', 'Home_004_2', 'Home_005_1', 'Home_005_2', 'Home_006_1',
+ 'Home_010_1'
+]
+
+TEST_WORLDS = ['Home_011_1', 'Home_013_1', 'Home_016_1']
+
+
+def create_modality_types():
+ """Parses the modality_types and returns a list of task_env.ModalityType."""
+ if not FLAGS.modality_types:
+ raise ValueError('there needs to be at least one modality type')
+ modality_types = FLAGS.modality_types.split('_')
+ for x in modality_types:
+ if x not in ['image', 'sseg', 'det', 'depth']:
+ raise ValueError('invalid modality type: {}'.format(x))
+
+ conversion_dict = {
+ 'image': task_env.ModalityTypes.IMAGE,
+ 'sseg': task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
+ 'depth': task_env.ModalityTypes.DEPTH,
+ 'det': task_env.ModalityTypes.OBJECT_DETECTION,
+ }
+ return [conversion_dict[k] for k in modality_types]
+
+
+def create_task_io_config(
+ modality_types,
+ goal_category_count,
+ action_size,
+ sequence_length,
+):
+ """Generates task io config."""
+ shape_prefix = [sequence_length, FLAGS.obs_resolution, FLAGS.obs_resolution]
+ shapes = {
+ task_env.ModalityTypes.IMAGE: [sequence_length, 224, 224, 3],
+ task_env.ModalityTypes.DEPTH: shape_prefix + [
+ 2,
+ ],
+ task_env.ModalityTypes.SEMANTIC_SEGMENTATION: shape_prefix + [
+ 1,
+ ],
+ task_env.ModalityTypes.OBJECT_DETECTION: shape_prefix + [
+ 90,
+ ]
+ }
+ types = {k: tf.float32 for k in shapes}
+ types[task_env.ModalityTypes.IMAGE] = tf.uint8
+ inputs = collections.OrderedDict(
+ [[mtype, (types[mtype], shapes[mtype])] for mtype in modality_types])
+ inputs[task_env.ModalityTypes.GOAL] = (tf.float32,
+ [sequence_length, goal_category_count])
+ inputs[task_env.ModalityTypes.PREV_ACTION] = (tf.float32, [
+ sequence_length, action_size + 1
+ ])
+ print inputs
+ return tasks.UnrolledTaskIOConfig(
+ inputs=inputs,
+ output=(tf.float32, [sequence_length, action_size]),
+ query=None)
+
+
+def map_to_embedder(modality_type):
+ """Maps modality_type to its corresponding embedder."""
+ if modality_type == task_env.ModalityTypes.PREV_ACTION:
+ return None
+ if modality_type == task_env.ModalityTypes.GOAL:
+ return embedders.IdentityEmbedder()
+ if modality_type == task_env.ModalityTypes.IMAGE:
+ return embedders.ResNet50Embedder()
+ conv_window_sizes = [int(x) for x in FLAGS.conv_window_sizes.split('_')]
+ conv_channels = [int(x) for x in FLAGS.conv_channels.split('_')]
+ conv_strides = [int(x) for x in FLAGS.conv_strides.split('_')]
+ params = tf.contrib.training.HParams(
+ to_one_hot=modality_type == task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
+ one_hot_length=10,
+ conv_sizes=conv_window_sizes,
+ conv_strides=conv_strides,
+ conv_channels=conv_channels,
+ embedding_size=FLAGS.embedding_fc_size,
+ weight_decay_rate=FLAGS.weight_decay,
+ )
+ return embedders.SmallNetworkEmbedder(params)
+
+
+def create_train_and_init_ops(policy, task):
+ """Creates training ops given the arguments.
+
+ Args:
+ policy: the policy for the task.
+ task: the task instance.
+
+ Returns:
+ train_op: the op that needs to be runned at each step.
+ summaries_op: the summary op that is executed.
+ init_fn: the op that initializes the variables if there is no previous
+ checkpoint. If Resnet50 is not used in the model it is None, otherwise
+ it reads the weights from FLAGS.resnet50_path and sets the init_fn
+ to the op that initializes the ResNet50 with the pre-trained weights.
+ """
+ assert isinstance(task, tasks.GotoStaticXNoExplorationTask)
+ assert isinstance(policy, policies.Policy)
+
+ inputs, _, gt_outputs, masks = task.tf_episode_batch(FLAGS.batch_size)
+ outputs, _ = policy.build(inputs, None)
+ loss = task.target_loss(gt_outputs, outputs, masks)
+
+ init_fn = None
+
+ # If resnet is added to the graph, init_fn should initialize resnet weights
+ # if there is no previous checkpoint.
+ variables_assign_dict = {}
+ vars_list = []
+ for v in slim.get_model_variables():
+ if v.name.find('resnet') >= 0:
+ if not FLAGS.freeze_resnet_weights:
+ vars_list.append(v)
+ variables_assign_dict[v.name[v.name.find('resnet'):-2]] = v
+ else:
+ vars_list.append(v)
+
+ global_step = tf.train.get_or_create_global_step()
+ learning_rate = tf.train.exponential_decay(
+ FLAGS.learning_rate,
+ global_step,
+ decay_steps=FLAGS.decay_steps,
+ decay_rate=0.98,
+ staircase=True)
+ optimizer = tf.train.AdamOptimizer(learning_rate)
+ train_op = slim.learning.create_train_op(
+ loss,
+ optimizer,
+ global_step=global_step,
+ variables_to_train=vars_list,
+ )
+
+ if variables_assign_dict:
+ init_fn = slim.assign_from_checkpoint_fn(
+ FLAGS.resnet50_path,
+ variables_assign_dict,
+ ignore_missing_vars=False)
+ scalar_summaries = {}
+ scalar_summaries['LR'] = learning_rate
+ scalar_summaries['loss'] = loss
+
+ for name, summary in scalar_summaries.iteritems():
+ tf.summary.scalar(name, summary)
+
+ return train_op, init_fn
+
+
+def create_eval_ops(policy, config, possible_targets):
+ """Creates the necessary ops for evaluation."""
+ inputs_feed = collections.OrderedDict([[
+ mtype,
+ tf.placeholder(config.inputs[mtype].type,
+ [1] + config.inputs[mtype].shape)
+ ] for mtype in config.inputs])
+ inputs_feed[task_env.ModalityTypes.PREV_ACTION] = tf.placeholder(
+ tf.float32, [1, 1] + [
+ config.output.shape[-1] + 1,
+ ])
+ prev_state_feed = [
+ tf.placeholder(
+ tf.float32, [1, FLAGS.lstm_cell_size], name='prev_state_{}'.format(i))
+ for i in range(2)
+ ]
+ policy_outputs = policy.build(inputs_feed, prev_state_feed)
+ summary_feed = {}
+ for c in possible_targets + ['mean']:
+ summary_feed[c] = tf.placeholder(
+ tf.float32, [], name='eval_in_range_{}_input'.format(c))
+ tf.summary.scalar('eval_in_range_{}'.format(c), summary_feed[c])
+
+ return inputs_feed, prev_state_feed, policy_outputs, (tf.summary.merge_all(),
+ summary_feed)
+
+
+def unroll_policy_for_eval(
+ sess,
+ env,
+ inputs_feed,
+ prev_state_feed,
+ policy_outputs,
+ number_of_steps,
+ output_folder,
+):
+ """unrolls the policy for testing.
+
+ Args:
+ sess: tf.Session
+ env: The environment.
+ inputs_feed: dictionary of placeholder for the input modalities.
+ prev_state_feed: placeholder for the input to the prev_state of the model.
+ policy_outputs: tensor that contains outputs of the policy.
+ number_of_steps: maximum number of unrolling steps.
+ output_folder: output_folder where the function writes a dictionary of
+ detailed information about the path. The dictionary keys are 'states' and
+ 'distance'. The value for 'states' is the list of states that the agent
+ goes along the path. The value for 'distance' contains the length of
+ shortest path to the goal at each step.
+
+ Returns:
+ states: list of states along the path.
+ distance: list of distances along the path.
+ """
+ prev_state = [
+ np.zeros((1, FLAGS.lstm_cell_size), dtype=np.float32) for _ in range(2)
+ ]
+ prev_action = np.zeros((1, 1, FLAGS.action_size + 1), dtype=np.float32)
+ obs = env.reset()
+ distances_to_goal = []
+ states = []
+ unique_id = '{}_{}'.format(env.cur_image_id(), env.goal_string)
+ for _ in range(number_of_steps):
+ distances_to_goal.append(
+ np.min([
+ len(
+ nx.shortest_path(env.graph, env.pose_to_vertex(env.state()),
+ env.pose_to_vertex(target_view)))
+ for target_view in env.targets()
+ ]))
+ states.append(env.state())
+ feed_dict = {inputs_feed[mtype]: [[obs[mtype]]] for mtype in inputs_feed}
+ feed_dict[prev_state_feed[0]] = prev_state[0]
+ feed_dict[prev_state_feed[1]] = prev_state[1]
+ action_values, prev_state = sess.run(policy_outputs, feed_dict=feed_dict)
+ chosen_action = np.argmax(action_values[0])
+ obs, _, done, info = env.step(np.int32(chosen_action))
+ prev_action[0][0][chosen_action] = 1.
+ prev_action[0][0][-1] = float(info['success'])
+ # If the agent chooses action stop or the number of steps exceeeded
+ # env._episode_length.
+ if done:
+ break
+
+ # logging.info('distance = %d, id = %s, #steps = %d', distances_to_goal[-1],
+ output_path = os.path.join(output_folder, unique_id + '.npy')
+ with tf.gfile.Open(output_path, 'w') as f:
+ print 'saving path information to {}'.format(output_path)
+ np.save(f, {'states': states, 'distance': distances_to_goal})
+ return states, distances_to_goal
+
+
+def init(sequence_length, eval_init_points_file_name, worlds):
+ """Initializes the common operations between train and test."""
+ modality_types = create_modality_types()
+ logging.info('modality types: %r', modality_types)
+ # negative reward_goal_range prevents the env from terminating early when the
+ # agent is close to the goal. The policy should keep the agent until the end
+ # of the 100 steps either through chosing stop action or oscilating around
+ # the target.
+
+ env = active_vision_dataset_env.ActiveVisionDatasetEnv(
+ modality_types=modality_types +
+ [task_env.ModalityTypes.GOAL, task_env.ModalityTypes.PREV_ACTION],
+ reward_goal_range=-1,
+ eval_init_points_file_name=eval_init_points_file_name,
+ worlds=worlds,
+ output_size=FLAGS.obs_resolution,
+ )
+
+ config = create_task_io_config(
+ modality_types=modality_types,
+ goal_category_count=FLAGS.goal_category_count,
+ action_size=FLAGS.action_size,
+ sequence_length=sequence_length,
+ )
+ task = tasks.GotoStaticXNoExplorationTask(env=env, config=config)
+ embedders_dict = {mtype: map_to_embedder(mtype) for mtype in config.inputs}
+ policy_params = tf.contrib.training.HParams(
+ lstm_state_size=FLAGS.lstm_cell_size,
+ fc_channels=FLAGS.policy_fc_size,
+ weight_decay=FLAGS.weight_decay,
+ target_embedding_size=FLAGS.embedding_fc_size,
+ )
+ policy = policies.LSTMPolicy(
+ modality_names=config.inputs.keys(),
+ embedders_dict=embedders_dict,
+ action_size=FLAGS.action_size,
+ params=policy_params,
+ max_episode_length=sequence_length)
+ return env, config, task, policy
+
+
+def test():
+ """Contains all the operations for testing policies."""
+ env, config, _, policy = init(1, 'all_init_configs', TEST_WORLDS)
+ inputs_feed, prev_state_feed, policy_outputs, summary_op = create_eval_ops(
+ policy, config, env.possible_targets)
+ sv = tf.train.Supervisor(logdir=FLAGS.logdir)
+ prev_checkpoint = None
+ with sv.managed_session(
+ start_standard_services=False,
+ config=tf.ConfigProto(allow_soft_placement=True)) as sess:
+ while not sv.should_stop():
+ while True:
+ new_checkpoint = tf.train.latest_checkpoint(FLAGS.logdir)
+ print 'new_checkpoint ', new_checkpoint
+ if not new_checkpoint:
+ time.sleep(1)
+ continue
+ if prev_checkpoint is None:
+ prev_checkpoint = new_checkpoint
+ break
+ if prev_checkpoint != new_checkpoint:
+ prev_checkpoint = new_checkpoint
+ break
+ else: # if prev_checkpoint == new_checkpoint, we have to wait more.
+ time.sleep(1)
+
+ checkpoint_step = int(new_checkpoint[new_checkpoint.rfind('-') + 1:])
+ sv.saver.restore(sess, new_checkpoint)
+ print '--------------------'
+ print 'evaluating checkpoint {}'.format(new_checkpoint)
+ folder_path = os.path.join(FLAGS.logdir, 'evals', str(checkpoint_step))
+ if not tf.gfile.Exists(folder_path):
+ tf.gfile.MakeDirs(folder_path)
+ eval_stats = {c: [] for c in env.possible_targets}
+ for test_iter in range(FLAGS.test_iters):
+ print 'evaluating {} of {}'.format(test_iter, FLAGS.test_iters)
+ _, distance_to_goal = unroll_policy_for_eval(
+ sess,
+ env,
+ inputs_feed,
+ prev_state_feed,
+ policy_outputs,
+ FLAGS.max_eval_episode_length,
+ folder_path,
+ )
+ print 'goal = {}'.format(env.goal_string)
+ eval_stats[env.goal_string].append(float(distance_to_goal[-1] <= 7))
+ eval_stats = {k: np.mean(v) for k, v in eval_stats.iteritems()}
+ eval_stats['mean'] = np.mean(eval_stats.values())
+ print eval_stats
+ feed_dict = {summary_op[1][c]: eval_stats[c] for c in eval_stats}
+ summary_str = sess.run(summary_op[0], feed_dict=feed_dict)
+ writer = sv.summary_writer
+ writer.add_summary(summary_str, checkpoint_step)
+ writer.flush()
+
+
+def train():
+ _, _, task, policy = init(FLAGS.sequence_length, None, TRAIN_WORLDS)
+ print(FLAGS.save_summaries_secs)
+ print(FLAGS.save_interval_secs)
+ print(FLAGS.logdir)
+
+ with tf.device(
+ tf.train.replica_device_setter(ps_tasks=FLAGS.ps_tasks, merge_devices=True)):
+ train_op, init_fn = create_train_and_init_ops(policy=policy, task=task)
+ print(FLAGS.logdir)
+ slim.learning.train(
+ train_op=train_op,
+ init_fn=init_fn,
+ logdir=FLAGS.logdir,
+ is_chief=FLAGS.task_id == 0,
+ number_of_steps=FLAGS.train_iters,
+ save_summaries_secs=FLAGS.save_summaries_secs,
+ save_interval_secs=FLAGS.save_interval_secs,
+ session_config=tf.ConfigProto(allow_soft_placement=True),
+ )
+
+
+def main(_):
+ gin.parse_config_files_and_bindings(FLAGS.gin_config, FLAGS.gin_params)
+ if FLAGS.mode == 'train':
+ train()
+ else:
+ test()
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.sh"
new file mode 100644
index 00000000..f2ea2275
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/train_supervised_active_vision.sh"
@@ -0,0 +1,32 @@
+#!/bin/bash
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+# blaze build -c opt train_supervised_active_vision
+# bazel build -c opt --config=cuda --copt=-mavx train_supervised_active_vision && \
+bazel-bin/research/cognitive_planning/train_supervised_active_vision \
+ --mode='train' \
+ --logdir=/usr/local/google/home/kosecka/local_avd_train/ \
+ --modality_types='det' \
+ --batch_size=8 \
+ --train_iters=200000 \
+ --lstm_cell_size=2048 \
+ --policy_fc_size=2048 \
+ --sequence_length=20 \
+ --max_eval_episode_length=100 \
+ --test_iters=194 \
+ --gin_config=envs/configs/active_vision_config.gin \
+ --gin_params='ActiveVisionDatasetEnv.dataset_root="/cns/jn-d/home/kosecka/AVD_Minimal/"' \
+ --logtostderr
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/visualization_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/visualization_utils.py"
new file mode 100644
index 00000000..7a7aeb50
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/visualization_utils.py"
@@ -0,0 +1,733 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""A set of functions that are used for visualization.
+
+These functions often receive an image, perform some visualization on the image.
+The functions do not return a value, instead they modify the image itself.
+
+"""
+import collections
+import functools
+# Set headless-friendly backend.
+import matplotlib; matplotlib.use('Agg') # pylint: disable=multiple-statements
+import matplotlib.pyplot as plt # pylint: disable=g-import-not-at-top
+import numpy as np
+import PIL.Image as Image
+import PIL.ImageColor as ImageColor
+import PIL.ImageDraw as ImageDraw
+import PIL.ImageFont as ImageFont
+import six
+import tensorflow as tf
+
+import standard_fields as fields
+
+
+_TITLE_LEFT_MARGIN = 10
+_TITLE_TOP_MARGIN = 10
+STANDARD_COLORS = [
+ 'AliceBlue', 'Chartreuse', 'Aqua', 'Aquamarine', 'Azure', 'Beige', 'Bisque',
+ 'BlanchedAlmond', 'BlueViolet', 'BurlyWood', 'CadetBlue', 'AntiqueWhite',
+ 'Chocolate', 'Coral', 'CornflowerBlue', 'Cornsilk', 'Crimson', 'Cyan',
+ 'DarkCyan', 'DarkGoldenRod', 'DarkGrey', 'DarkKhaki', 'DarkOrange',
+ 'DarkOrchid', 'DarkSalmon', 'DarkSeaGreen', 'DarkTurquoise', 'DarkViolet',
+ 'DeepPink', 'DeepSkyBlue', 'DodgerBlue', 'FireBrick', 'FloralWhite',
+ 'ForestGreen', 'Fuchsia', 'Gainsboro', 'GhostWhite', 'Gold', 'GoldenRod',
+ 'Salmon', 'Tan', 'HoneyDew', 'HotPink', 'IndianRed', 'Ivory', 'Khaki',
+ 'Lavender', 'LavenderBlush', 'LawnGreen', 'LemonChiffon', 'LightBlue',
+ 'LightCoral', 'LightCyan', 'LightGoldenRodYellow', 'LightGray', 'LightGrey',
+ 'LightGreen', 'LightPink', 'LightSalmon', 'LightSeaGreen', 'LightSkyBlue',
+ 'LightSlateGray', 'LightSlateGrey', 'LightSteelBlue', 'LightYellow', 'Lime',
+ 'LimeGreen', 'Linen', 'Magenta', 'MediumAquaMarine', 'MediumOrchid',
+ 'MediumPurple', 'MediumSeaGreen', 'MediumSlateBlue', 'MediumSpringGreen',
+ 'MediumTurquoise', 'MediumVioletRed', 'MintCream', 'MistyRose', 'Moccasin',
+ 'NavajoWhite', 'OldLace', 'Olive', 'OliveDrab', 'Orange', 'OrangeRed',
+ 'Orchid', 'PaleGoldenRod', 'PaleGreen', 'PaleTurquoise', 'PaleVioletRed',
+ 'PapayaWhip', 'PeachPuff', 'Peru', 'Pink', 'Plum', 'PowderBlue', 'Purple',
+ 'Red', 'RosyBrown', 'RoyalBlue', 'SaddleBrown', 'Green', 'SandyBrown',
+ 'SeaGreen', 'SeaShell', 'Sienna', 'Silver', 'SkyBlue', 'SlateBlue',
+ 'SlateGray', 'SlateGrey', 'Snow', 'SpringGreen', 'SteelBlue', 'GreenYellow',
+ 'Teal', 'Thistle', 'Tomato', 'Turquoise', 'Violet', 'Wheat', 'White',
+ 'WhiteSmoke', 'Yellow', 'YellowGreen'
+]
+
+
+def save_image_array_as_png(image, output_path):
+ """Saves an image (represented as a numpy array) to PNG.
+
+ Args:
+ image: a numpy array with shape [height, width, 3].
+ output_path: path to which image should be written.
+ """
+ image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
+ with tf.gfile.Open(output_path, 'w') as fid:
+ image_pil.save(fid, 'PNG')
+
+
+def encode_image_array_as_png_str(image):
+ """Encodes a numpy array into a PNG string.
+
+ Args:
+ image: a numpy array with shape [height, width, 3].
+
+ Returns:
+ PNG encoded image string.
+ """
+ image_pil = Image.fromarray(np.uint8(image))
+ output = six.BytesIO()
+ image_pil.save(output, format='PNG')
+ png_string = output.getvalue()
+ output.close()
+ return png_string
+
+
+def draw_bounding_box_on_image_array(image,
+ ymin,
+ xmin,
+ ymax,
+ xmax,
+ color='red',
+ thickness=4,
+ display_str_list=(),
+ use_normalized_coordinates=True):
+ """Adds a bounding box to an image (numpy array).
+
+ Bounding box coordinates can be specified in either absolute (pixel) or
+ normalized coordinates by setting the use_normalized_coordinates argument.
+
+ Args:
+ image: a numpy array with shape [height, width, 3].
+ ymin: ymin of bounding box.
+ xmin: xmin of bounding box.
+ ymax: ymax of bounding box.
+ xmax: xmax of bounding box.
+ color: color to draw bounding box. Default is red.
+ thickness: line thickness. Default value is 4.
+ display_str_list: list of strings to display in box
+ (each to be shown on its own line).
+ use_normalized_coordinates: If True (default), treat coordinates
+ ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
+ coordinates as absolute.
+ """
+ image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
+ draw_bounding_box_on_image(image_pil, ymin, xmin, ymax, xmax, color,
+ thickness, display_str_list,
+ use_normalized_coordinates)
+ np.copyto(image, np.array(image_pil))
+
+
+def draw_bounding_box_on_image(image,
+ ymin,
+ xmin,
+ ymax,
+ xmax,
+ color='red',
+ thickness=4,
+ display_str_list=(),
+ use_normalized_coordinates=True):
+ """Adds a bounding box to an image.
+
+ Bounding box coordinates can be specified in either absolute (pixel) or
+ normalized coordinates by setting the use_normalized_coordinates argument.
+
+ Each string in display_str_list is displayed on a separate line above the
+ bounding box in black text on a rectangle filled with the input 'color'.
+ If the top of the bounding box extends to the edge of the image, the strings
+ are displayed below the bounding box.
+
+ Args:
+ image: a PIL.Image object.
+ ymin: ymin of bounding box.
+ xmin: xmin of bounding box.
+ ymax: ymax of bounding box.
+ xmax: xmax of bounding box.
+ color: color to draw bounding box. Default is red.
+ thickness: line thickness. Default value is 4.
+ display_str_list: list of strings to display in box
+ (each to be shown on its own line).
+ use_normalized_coordinates: If True (default), treat coordinates
+ ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
+ coordinates as absolute.
+ """
+ draw = ImageDraw.Draw(image)
+ im_width, im_height = image.size
+ if use_normalized_coordinates:
+ (left, right, top, bottom) = (xmin * im_width, xmax * im_width,
+ ymin * im_height, ymax * im_height)
+ else:
+ (left, right, top, bottom) = (xmin, xmax, ymin, ymax)
+ draw.line([(left, top), (left, bottom), (right, bottom),
+ (right, top), (left, top)], width=thickness, fill=color)
+ try:
+ font = ImageFont.truetype('arial.ttf', 24)
+ except IOError:
+ font = ImageFont.load_default()
+
+ # If the total height of the display strings added to the top of the bounding
+ # box exceeds the top of the image, stack the strings below the bounding box
+ # instead of above.
+ display_str_heights = [font.getsize(ds)[1] for ds in display_str_list]
+ # Each display_str has a top and bottom margin of 0.05x.
+ total_display_str_height = (1 + 2 * 0.05) * sum(display_str_heights)
+
+ if top > total_display_str_height:
+ text_bottom = top
+ else:
+ text_bottom = bottom + total_display_str_height
+ # Reverse list and print from bottom to top.
+ for display_str in display_str_list[::-1]:
+ text_width, text_height = font.getsize(display_str)
+ margin = np.ceil(0.05 * text_height)
+ draw.rectangle(
+ [(left, text_bottom - text_height - 2 * margin), (left + text_width,
+ text_bottom)],
+ fill=color)
+ draw.text(
+ (left + margin, text_bottom - text_height - margin),
+ display_str,
+ fill='black',
+ font=font)
+ text_bottom -= text_height - 2 * margin
+
+
+def draw_bounding_boxes_on_image_array(image,
+ boxes,
+ color='red',
+ thickness=4,
+ display_str_list_list=()):
+ """Draws bounding boxes on image (numpy array).
+
+ Args:
+ image: a numpy array object.
+ boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
+ The coordinates are in normalized format between [0, 1].
+ color: color to draw bounding box. Default is red.
+ thickness: line thickness. Default value is 4.
+ display_str_list_list: list of list of strings.
+ a list of strings for each bounding box.
+ The reason to pass a list of strings for a
+ bounding box is that it might contain
+ multiple labels.
+
+ Raises:
+ ValueError: if boxes is not a [N, 4] array
+ """
+ image_pil = Image.fromarray(image)
+ draw_bounding_boxes_on_image(image_pil, boxes, color, thickness,
+ display_str_list_list)
+ np.copyto(image, np.array(image_pil))
+
+
+def draw_bounding_boxes_on_image(image,
+ boxes,
+ color='red',
+ thickness=4,
+ display_str_list_list=()):
+ """Draws bounding boxes on image.
+
+ Args:
+ image: a PIL.Image object.
+ boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
+ The coordinates are in normalized format between [0, 1].
+ color: color to draw bounding box. Default is red.
+ thickness: line thickness. Default value is 4.
+ display_str_list_list: list of list of strings.
+ a list of strings for each bounding box.
+ The reason to pass a list of strings for a
+ bounding box is that it might contain
+ multiple labels.
+
+ Raises:
+ ValueError: if boxes is not a [N, 4] array
+ """
+ boxes_shape = boxes.shape
+ if not boxes_shape:
+ return
+ if len(boxes_shape) != 2 or boxes_shape[1] != 4:
+ raise ValueError('Input must be of size [N, 4]')
+ for i in range(boxes_shape[0]):
+ display_str_list = ()
+ if display_str_list_list:
+ display_str_list = display_str_list_list[i]
+ draw_bounding_box_on_image(image, boxes[i, 0], boxes[i, 1], boxes[i, 2],
+ boxes[i, 3], color, thickness, display_str_list)
+
+
+def _visualize_boxes(image, boxes, classes, scores, category_index, **kwargs):
+ return visualize_boxes_and_labels_on_image_array(
+ image, boxes, classes, scores, category_index=category_index, **kwargs)
+
+
+def _visualize_boxes_and_masks(image, boxes, classes, scores, masks,
+ category_index, **kwargs):
+ return visualize_boxes_and_labels_on_image_array(
+ image,
+ boxes,
+ classes,
+ scores,
+ category_index=category_index,
+ instance_masks=masks,
+ **kwargs)
+
+
+def _visualize_boxes_and_keypoints(image, boxes, classes, scores, keypoints,
+ category_index, **kwargs):
+ return visualize_boxes_and_labels_on_image_array(
+ image,
+ boxes,
+ classes,
+ scores,
+ category_index=category_index,
+ keypoints=keypoints,
+ **kwargs)
+
+
+def _visualize_boxes_and_masks_and_keypoints(
+ image, boxes, classes, scores, masks, keypoints, category_index, **kwargs):
+ return visualize_boxes_and_labels_on_image_array(
+ image,
+ boxes,
+ classes,
+ scores,
+ category_index=category_index,
+ instance_masks=masks,
+ keypoints=keypoints,
+ **kwargs)
+
+
+def draw_bounding_boxes_on_image_tensors(images,
+ boxes,
+ classes,
+ scores,
+ category_index,
+ instance_masks=None,
+ keypoints=None,
+ max_boxes_to_draw=20,
+ min_score_thresh=0.2,
+ use_normalized_coordinates=True):
+ """Draws bounding boxes, masks, and keypoints on batch of image tensors.
+
+ Args:
+ images: A 4D uint8 image tensor of shape [N, H, W, C]. If C > 3, additional
+ channels will be ignored.
+ boxes: [N, max_detections, 4] float32 tensor of detection boxes.
+ classes: [N, max_detections] int tensor of detection classes. Note that
+ classes are 1-indexed.
+ scores: [N, max_detections] float32 tensor of detection scores.
+ category_index: a dict that maps integer ids to category dicts. e.g.
+ {1: {1: 'dog'}, 2: {2: 'cat'}, ...}
+ instance_masks: A 4D uint8 tensor of shape [N, max_detection, H, W] with
+ instance masks.
+ keypoints: A 4D float32 tensor of shape [N, max_detection, num_keypoints, 2]
+ with keypoints.
+ max_boxes_to_draw: Maximum number of boxes to draw on an image. Default 20.
+ min_score_thresh: Minimum score threshold for visualization. Default 0.2.
+ use_normalized_coordinates: Whether to assume boxes and kepoints are in
+ normalized coordinates (as opposed to absolute coordiantes).
+ Default is True.
+
+ Returns:
+ 4D image tensor of type uint8, with boxes drawn on top.
+ """
+ # Additional channels are being ignored.
+ images = images[:, :, :, 0:3]
+ visualization_keyword_args = {
+ 'use_normalized_coordinates': use_normalized_coordinates,
+ 'max_boxes_to_draw': max_boxes_to_draw,
+ 'min_score_thresh': min_score_thresh,
+ 'agnostic_mode': False,
+ 'line_thickness': 4
+ }
+
+ if instance_masks is not None and keypoints is None:
+ visualize_boxes_fn = functools.partial(
+ _visualize_boxes_and_masks,
+ category_index=category_index,
+ **visualization_keyword_args)
+ elems = [images, boxes, classes, scores, instance_masks]
+ elif instance_masks is None and keypoints is not None:
+ visualize_boxes_fn = functools.partial(
+ _visualize_boxes_and_keypoints,
+ category_index=category_index,
+ **visualization_keyword_args)
+ elems = [images, boxes, classes, scores, keypoints]
+ elif instance_masks is not None and keypoints is not None:
+ visualize_boxes_fn = functools.partial(
+ _visualize_boxes_and_masks_and_keypoints,
+ category_index=category_index,
+ **visualization_keyword_args)
+ elems = [images, boxes, classes, scores, instance_masks, keypoints]
+ else:
+ visualize_boxes_fn = functools.partial(
+ _visualize_boxes,
+ category_index=category_index,
+ **visualization_keyword_args)
+ elems = [images, boxes, classes, scores]
+
+ def draw_boxes(image_and_detections):
+ """Draws boxes on image."""
+ image_with_boxes = tf.py_func(visualize_boxes_fn, image_and_detections,
+ tf.uint8)
+ return image_with_boxes
+
+ images = tf.map_fn(draw_boxes, elems, dtype=tf.uint8, back_prop=False)
+ return images
+
+
+def draw_side_by_side_evaluation_image(eval_dict,
+ category_index,
+ max_boxes_to_draw=20,
+ min_score_thresh=0.2,
+ use_normalized_coordinates=True):
+ """Creates a side-by-side image with detections and groundtruth.
+
+ Bounding boxes (and instance masks, if available) are visualized on both
+ subimages.
+
+ Args:
+ eval_dict: The evaluation dictionary returned by
+ eval_util.result_dict_for_single_example().
+ category_index: A category index (dictionary) produced from a labelmap.
+ max_boxes_to_draw: The maximum number of boxes to draw for detections.
+ min_score_thresh: The minimum score threshold for showing detections.
+ use_normalized_coordinates: Whether to assume boxes and kepoints are in
+ normalized coordinates (as opposed to absolute coordiantes).
+ Default is True.
+
+ Returns:
+ A [1, H, 2 * W, C] uint8 tensor. The subimage on the left corresponds to
+ detections, while the subimage on the right corresponds to groundtruth.
+ """
+ detection_fields = fields.DetectionResultFields()
+ input_data_fields = fields.InputDataFields()
+ instance_masks = None
+ if detection_fields.detection_masks in eval_dict:
+ instance_masks = tf.cast(
+ tf.expand_dims(eval_dict[detection_fields.detection_masks], axis=0),
+ tf.uint8)
+ keypoints = None
+ if detection_fields.detection_keypoints in eval_dict:
+ keypoints = tf.expand_dims(
+ eval_dict[detection_fields.detection_keypoints], axis=0)
+ groundtruth_instance_masks = None
+ if input_data_fields.groundtruth_instance_masks in eval_dict:
+ groundtruth_instance_masks = tf.cast(
+ tf.expand_dims(
+ eval_dict[input_data_fields.groundtruth_instance_masks], axis=0),
+ tf.uint8)
+ images_with_detections = draw_bounding_boxes_on_image_tensors(
+ eval_dict[input_data_fields.original_image],
+ tf.expand_dims(eval_dict[detection_fields.detection_boxes], axis=0),
+ tf.expand_dims(eval_dict[detection_fields.detection_classes], axis=0),
+ tf.expand_dims(eval_dict[detection_fields.detection_scores], axis=0),
+ category_index,
+ instance_masks=instance_masks,
+ keypoints=keypoints,
+ max_boxes_to_draw=max_boxes_to_draw,
+ min_score_thresh=min_score_thresh,
+ use_normalized_coordinates=use_normalized_coordinates)
+ images_with_groundtruth = draw_bounding_boxes_on_image_tensors(
+ eval_dict[input_data_fields.original_image],
+ tf.expand_dims(eval_dict[input_data_fields.groundtruth_boxes], axis=0),
+ tf.expand_dims(eval_dict[input_data_fields.groundtruth_classes], axis=0),
+ tf.expand_dims(
+ tf.ones_like(
+ eval_dict[input_data_fields.groundtruth_classes],
+ dtype=tf.float32),
+ axis=0),
+ category_index,
+ instance_masks=groundtruth_instance_masks,
+ keypoints=None,
+ max_boxes_to_draw=None,
+ min_score_thresh=0.0,
+ use_normalized_coordinates=use_normalized_coordinates)
+ return tf.concat([images_with_detections, images_with_groundtruth], axis=2)
+
+
+def draw_keypoints_on_image_array(image,
+ keypoints,
+ color='red',
+ radius=2,
+ use_normalized_coordinates=True):
+ """Draws keypoints on an image (numpy array).
+
+ Args:
+ image: a numpy array with shape [height, width, 3].
+ keypoints: a numpy array with shape [num_keypoints, 2].
+ color: color to draw the keypoints with. Default is red.
+ radius: keypoint radius. Default value is 2.
+ use_normalized_coordinates: if True (default), treat keypoint values as
+ relative to the image. Otherwise treat them as absolute.
+ """
+ image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
+ draw_keypoints_on_image(image_pil, keypoints, color, radius,
+ use_normalized_coordinates)
+ np.copyto(image, np.array(image_pil))
+
+
+def draw_keypoints_on_image(image,
+ keypoints,
+ color='red',
+ radius=2,
+ use_normalized_coordinates=True):
+ """Draws keypoints on an image.
+
+ Args:
+ image: a PIL.Image object.
+ keypoints: a numpy array with shape [num_keypoints, 2].
+ color: color to draw the keypoints with. Default is red.
+ radius: keypoint radius. Default value is 2.
+ use_normalized_coordinates: if True (default), treat keypoint values as
+ relative to the image. Otherwise treat them as absolute.
+ """
+ draw = ImageDraw.Draw(image)
+ im_width, im_height = image.size
+ keypoints_x = [k[1] for k in keypoints]
+ keypoints_y = [k[0] for k in keypoints]
+ if use_normalized_coordinates:
+ keypoints_x = tuple([im_width * x for x in keypoints_x])
+ keypoints_y = tuple([im_height * y for y in keypoints_y])
+ for keypoint_x, keypoint_y in zip(keypoints_x, keypoints_y):
+ draw.ellipse([(keypoint_x - radius, keypoint_y - radius),
+ (keypoint_x + radius, keypoint_y + radius)],
+ outline=color, fill=color)
+
+
+def draw_mask_on_image_array(image, mask, color='red', alpha=0.4):
+ """Draws mask on an image.
+
+ Args:
+ image: uint8 numpy array with shape (img_height, img_height, 3)
+ mask: a uint8 numpy array of shape (img_height, img_height) with
+ values between either 0 or 1.
+ color: color to draw the keypoints with. Default is red.
+ alpha: transparency value between 0 and 1. (default: 0.4)
+
+ Raises:
+ ValueError: On incorrect data type for image or masks.
+ """
+ if image.dtype != np.uint8:
+ raise ValueError('`image` not of type np.uint8')
+ if mask.dtype != np.uint8:
+ raise ValueError('`mask` not of type np.uint8')
+ if np.any(np.logical_and(mask != 1, mask != 0)):
+ raise ValueError('`mask` elements should be in [0, 1]')
+ if image.shape[:2] != mask.shape:
+ raise ValueError('The image has spatial dimensions %s but the mask has '
+ 'dimensions %s' % (image.shape[:2], mask.shape))
+ rgb = ImageColor.getrgb(color)
+ pil_image = Image.fromarray(image)
+
+ solid_color = np.expand_dims(
+ np.ones_like(mask), axis=2) * np.reshape(list(rgb), [1, 1, 3])
+ pil_solid_color = Image.fromarray(np.uint8(solid_color)).convert('RGBA')
+ pil_mask = Image.fromarray(np.uint8(255.0*alpha*mask)).convert('L')
+ pil_image = Image.composite(pil_solid_color, pil_image, pil_mask)
+ np.copyto(image, np.array(pil_image.convert('RGB')))
+
+
+def visualize_boxes_and_labels_on_image_array(
+ image,
+ boxes,
+ classes,
+ scores,
+ category_index,
+ instance_masks=None,
+ instance_boundaries=None,
+ keypoints=None,
+ use_normalized_coordinates=False,
+ max_boxes_to_draw=20,
+ min_score_thresh=.5,
+ agnostic_mode=False,
+ line_thickness=4,
+ groundtruth_box_visualization_color='black',
+ skip_scores=False,
+ skip_labels=False):
+ """Overlay labeled boxes on an image with formatted scores and label names.
+
+ This function groups boxes that correspond to the same location
+ and creates a display string for each detection and overlays these
+ on the image. Note that this function modifies the image in place, and returns
+ that same image.
+
+ Args:
+ image: uint8 numpy array with shape (img_height, img_width, 3)
+ boxes: a numpy array of shape [N, 4]
+ classes: a numpy array of shape [N]. Note that class indices are 1-based,
+ and match the keys in the label map.
+ scores: a numpy array of shape [N] or None. If scores=None, then
+ this function assumes that the boxes to be plotted are groundtruth
+ boxes and plot all boxes as black with no classes or scores.
+ category_index: a dict containing category dictionaries (each holding
+ category index `id` and category name `name`) keyed by category indices.
+ instance_masks: a numpy array of shape [N, image_height, image_width] with
+ values ranging between 0 and 1, can be None.
+ instance_boundaries: a numpy array of shape [N, image_height, image_width]
+ with values ranging between 0 and 1, can be None.
+ keypoints: a numpy array of shape [N, num_keypoints, 2], can
+ be None
+ use_normalized_coordinates: whether boxes is to be interpreted as
+ normalized coordinates or not.
+ max_boxes_to_draw: maximum number of boxes to visualize. If None, draw
+ all boxes.
+ min_score_thresh: minimum score threshold for a box to be visualized
+ agnostic_mode: boolean (default: False) controlling whether to evaluate in
+ class-agnostic mode or not. This mode will display scores but ignore
+ classes.
+ line_thickness: integer (default: 4) controlling line width of the boxes.
+ groundtruth_box_visualization_color: box color for visualizing groundtruth
+ boxes
+ skip_scores: whether to skip score when drawing a single detection
+ skip_labels: whether to skip label when drawing a single detection
+
+ Returns:
+ uint8 numpy array with shape (img_height, img_width, 3) with overlaid boxes.
+ """
+ # Create a display string (and color) for every box location, group any boxes
+ # that correspond to the same location.
+ box_to_display_str_map = collections.defaultdict(list)
+ box_to_color_map = collections.defaultdict(str)
+ box_to_instance_masks_map = {}
+ box_to_instance_boundaries_map = {}
+ box_to_keypoints_map = collections.defaultdict(list)
+ if not max_boxes_to_draw:
+ max_boxes_to_draw = boxes.shape[0]
+ for i in range(min(max_boxes_to_draw, boxes.shape[0])):
+ if scores is None or scores[i] > min_score_thresh:
+ box = tuple(boxes[i].tolist())
+ if instance_masks is not None:
+ box_to_instance_masks_map[box] = instance_masks[i]
+ if instance_boundaries is not None:
+ box_to_instance_boundaries_map[box] = instance_boundaries[i]
+ if keypoints is not None:
+ box_to_keypoints_map[box].extend(keypoints[i])
+ if scores is None:
+ box_to_color_map[box] = groundtruth_box_visualization_color
+ else:
+ display_str = ''
+ if not skip_labels:
+ if not agnostic_mode:
+ if classes[i] in category_index.keys():
+ class_name = category_index[classes[i]]['name']
+ else:
+ class_name = 'N/A'
+ display_str = str(class_name)
+ if not skip_scores:
+ if not display_str:
+ display_str = '{}%'.format(int(100*scores[i]))
+ else:
+ display_str = '{}: {}%'.format(display_str, int(100*scores[i]))
+ box_to_display_str_map[box].append(display_str)
+ if agnostic_mode:
+ box_to_color_map[box] = 'DarkOrange'
+ else:
+ box_to_color_map[box] = STANDARD_COLORS[
+ classes[i] % len(STANDARD_COLORS)]
+
+ # Draw all boxes onto image.
+ for box, color in box_to_color_map.items():
+ ymin, xmin, ymax, xmax = box
+ if instance_masks is not None:
+ draw_mask_on_image_array(
+ image,
+ box_to_instance_masks_map[box],
+ color=color
+ )
+ if instance_boundaries is not None:
+ draw_mask_on_image_array(
+ image,
+ box_to_instance_boundaries_map[box],
+ color='red',
+ alpha=1.0
+ )
+ draw_bounding_box_on_image_array(
+ image,
+ ymin,
+ xmin,
+ ymax,
+ xmax,
+ color=color,
+ thickness=line_thickness,
+ display_str_list=box_to_display_str_map[box],
+ use_normalized_coordinates=use_normalized_coordinates)
+ if keypoints is not None:
+ draw_keypoints_on_image_array(
+ image,
+ box_to_keypoints_map[box],
+ color=color,
+ radius=line_thickness / 2,
+ use_normalized_coordinates=use_normalized_coordinates)
+
+ return image
+
+
+def add_cdf_image_summary(values, name):
+ """Adds a tf.summary.image for a CDF plot of the values.
+
+ Normalizes `values` such that they sum to 1, plots the cumulative distribution
+ function and creates a tf image summary.
+
+ Args:
+ values: a 1-D float32 tensor containing the values.
+ name: name for the image summary.
+ """
+ def cdf_plot(values):
+ """Numpy function to plot CDF."""
+ normalized_values = values / np.sum(values)
+ sorted_values = np.sort(normalized_values)
+ cumulative_values = np.cumsum(sorted_values)
+ fraction_of_examples = (np.arange(cumulative_values.size, dtype=np.float32)
+ / cumulative_values.size)
+ fig = plt.figure(frameon=False)
+ ax = fig.add_subplot('111')
+ ax.plot(fraction_of_examples, cumulative_values)
+ ax.set_ylabel('cumulative normalized values')
+ ax.set_xlabel('fraction of examples')
+ fig.canvas.draw()
+ width, height = fig.get_size_inches() * fig.get_dpi()
+ image = np.fromstring(fig.canvas.tostring_rgb(), dtype='uint8').reshape(
+ 1, int(height), int(width), 3)
+ return image
+ cdf_plot = tf.py_func(cdf_plot, [values], tf.uint8)
+ tf.summary.image(name, cdf_plot)
+
+
+def add_hist_image_summary(values, bins, name):
+ """Adds a tf.summary.image for a histogram plot of the values.
+
+ Plots the histogram of values and creates a tf image summary.
+
+ Args:
+ values: a 1-D float32 tensor containing the values.
+ bins: bin edges which will be directly passed to np.histogram.
+ name: name for the image summary.
+ """
+
+ def hist_plot(values, bins):
+ """Numpy function to plot hist."""
+ fig = plt.figure(frameon=False)
+ ax = fig.add_subplot('111')
+ y, x = np.histogram(values, bins=bins)
+ ax.plot(x[:-1], y)
+ ax.set_ylabel('count')
+ ax.set_xlabel('value')
+ fig.canvas.draw()
+ width, height = fig.get_size_inches() * fig.get_dpi()
+ image = np.fromstring(
+ fig.canvas.tostring_rgb(), dtype='uint8').reshape(
+ 1, int(height), int(width), 3)
+ return image
+ hist_plot = tf.py_func(hist_plot, [values, bins], tf.uint8)
+ tf.summary.image(name, hist_plot)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/viz_active_vision_dataset_main.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/viz_active_vision_dataset_main.py"
new file mode 100644
index 00000000..e6b7deef
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cognitive_planning/viz_active_vision_dataset_main.py"
@@ -0,0 +1,379 @@
+# Copyright 2018 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Initializes at random location and visualizes the optimal path.
+
+Different modes of execution:
+1) benchmark: It generates benchmark_iter sample trajectory to random goals
+ and plots the histogram of path lengths. It can be also used to see how fast
+ it runs.
+2) vis: It visualizes the generated paths by image, semantic segmentation, and
+ so on.
+3) human: allows the user to navigate through environment from keyboard input.
+
+python viz_active_vision_dataset_main -- \
+ --mode=benchmark --benchmark_iter=1000 --gin_config=envs/configs/active_vision_config.gin
+
+python viz_active_vision_dataset_main -- \
+ --mode=vis \
+ --gin_config=envs/configs/active_vision_config.gin
+
+python viz_active_vision_dataset_main -- \
+ --mode=human \
+ --gin_config=envs/configs/active_vision_config.gin
+
+python viz_active_vision_dataset_main.py --mode=eval --eval_folder=/usr/local/google/home/$USER/checkin_log_det/evals/ --output_folder=/usr/local/google/home/$USER/test_imgs/ --gin_config=envs/configs/active_vision_config.gin
+
+"""
+
+import matplotlib
+# pylint: disable=g-import-not-at-top
+# Need Tk for interactive plots.
+matplotlib.use('TkAgg')
+import tensorflow as tf
+from matplotlib import pyplot as plt
+import numpy as np
+import os
+from pyglib import app
+from pyglib import flags
+import gin
+import cv2
+from envs import active_vision_dataset_env
+from envs import task_env
+
+
+VIS_MODE = 'vis'
+HUMAN_MODE = 'human'
+BENCHMARK_MODE = 'benchmark'
+GRAPH_MODE = 'graph'
+EVAL_MODE = 'eval'
+
+flags.DEFINE_enum('mode', VIS_MODE,
+ [VIS_MODE, HUMAN_MODE, BENCHMARK_MODE, GRAPH_MODE, EVAL_MODE],
+ 'mode of the execution')
+flags.DEFINE_integer('benchmark_iter', 1000,
+ 'number of iterations for benchmarking')
+flags.DEFINE_string('eval_folder', '', 'the path to the eval folder')
+flags.DEFINE_string('output_folder', '',
+ 'the path to which the images and gifs are written')
+flags.DEFINE_multi_string('gin_config', [],
+ 'List of paths to a gin config files for the env.')
+flags.DEFINE_multi_string('gin_params', [],
+ 'Newline separated list of Gin parameter bindings.')
+
+mt = task_env.ModalityTypes
+FLAGS = flags.FLAGS
+
+def benchmark(env, targets):
+ """Benchmarks the speed of sequence generation by env.
+
+ Args:
+ env: environment.
+ targets: list of target classes.
+ """
+ episode_lengths = {}
+ all_init_configs = {}
+ all_actions = dict([(a, 0.) for a in env.actions])
+ for i in range(FLAGS.benchmark_iter):
+ path, actions, _, _ = env.random_step_sequence()
+ selected_actions = np.argmax(actions, axis=-1)
+ new_actions = dict([(a, 0.) for a in env.actions])
+ for a in selected_actions:
+ new_actions[env.actions[a]] += 1. / selected_actions.shape[0]
+ for a in new_actions:
+ all_actions[a] += new_actions[a] / FLAGS.benchmark_iter
+ start_image_id, world, goal = env.get_init_config(path)
+ print world
+ if world not in all_init_configs:
+ all_init_configs[world] = set()
+ all_init_configs[world].add((start_image_id, goal, len(actions)))
+ if env.goal_index not in episode_lengths:
+ episode_lengths[env.goal_index] = []
+ episode_lengths[env.goal_index].append(len(actions))
+ for i, cls in enumerate(episode_lengths):
+ plt.subplot(231 + i)
+ plt.hist(episode_lengths[cls])
+ plt.title(targets[cls])
+ plt.show()
+
+
+def human(env, targets):
+ """Lets user play around the env manually."""
+ string_key_map = {
+ 'a': 'left',
+ 'd': 'right',
+ 'w': 'forward',
+ 's': 'backward',
+ 'j': 'rotate_ccw',
+ 'l': 'rotate_cw',
+ 'n': 'stop'
+ }
+ integer_key_map = {
+ 'a': env.actions.index('left'),
+ 'd': env.actions.index('right'),
+ 'w': env.actions.index('forward'),
+ 's': env.actions.index('backward'),
+ 'j': env.actions.index('rotate_ccw'),
+ 'l': env.actions.index('rotate_cw'),
+ 'n': env.actions.index('stop')
+ }
+ for k in integer_key_map:
+ integer_key_map[k] = np.int32(integer_key_map[k])
+ plt.ion()
+ for _ in range(20):
+ obs = env.reset()
+ steps = -1
+ action = None
+ while True:
+ print 'distance = ', obs[task_env.ModalityTypes.DISTANCE]
+ steps += 1
+ depth_value = obs[task_env.ModalityTypes.DEPTH][:, :, 0]
+ depth_mask = obs[task_env.ModalityTypes.DEPTH][:, :, 1]
+ seg_mask = np.squeeze(obs[task_env.ModalityTypes.SEMANTIC_SEGMENTATION])
+ det_mask = np.argmax(
+ obs[task_env.ModalityTypes.OBJECT_DETECTION], axis=-1)
+ img = obs[task_env.ModalityTypes.IMAGE]
+ plt.subplot(231)
+ plt.title('steps = {}'.format(steps))
+ plt.imshow(img.astype(np.uint8))
+ plt.subplot(232)
+ plt.imshow(depth_value)
+ plt.title('depth value')
+ plt.subplot(233)
+ plt.imshow(depth_mask)
+ plt.title('depth mask')
+ plt.subplot(234)
+ plt.imshow(seg_mask)
+ plt.title('seg')
+ plt.subplot(235)
+ plt.imshow(det_mask)
+ plt.title('det')
+ plt.subplot(236)
+ plt.title('goal={}'.format(targets[env.goal_index]))
+ plt.draw()
+ while True:
+ s = raw_input('key = ')
+ if np.random.rand() > 0.5:
+ key_map = string_key_map
+ else:
+ key_map = integer_key_map
+ if s in key_map:
+ action = key_map[s]
+ break
+ else:
+ print 'invalid action'
+ print 'action = {}'.format(action)
+ if action == 'stop':
+ print 'dist to goal: {}'.format(len(env.path_to_goal()) - 2)
+ break
+ obs, reward, done, info = env.step(action)
+ print 'reward = {}, done = {}, success = {}'.format(
+ reward, done, info['success'])
+
+
+def visualize_random_step_sequence(env):
+ """Visualizes random sequence of steps."""
+ plt.ion()
+ for _ in range(20):
+ path, actions, _, step_outputs = env.random_step_sequence(max_len=30)
+ print 'path = {}'.format(path)
+ for action, step_output in zip(actions, step_outputs):
+ obs, _, done, _ = step_output
+ depth_value = obs[task_env.ModalityTypes.DEPTH][:, :, 0]
+ depth_mask = obs[task_env.ModalityTypes.DEPTH][:, :, 1]
+ seg_mask = np.squeeze(obs[task_env.ModalityTypes.SEMANTIC_SEGMENTATION])
+ det_mask = np.argmax(
+ obs[task_env.ModalityTypes.OBJECT_DETECTION], axis=-1)
+ img = obs[task_env.ModalityTypes.IMAGE]
+ plt.subplot(231)
+ plt.imshow(img.astype(np.uint8))
+ plt.subplot(232)
+ plt.imshow(depth_value)
+ plt.title('depth value')
+ plt.subplot(233)
+ plt.imshow(depth_mask)
+ plt.title('depth mask')
+ plt.subplot(234)
+ plt.imshow(seg_mask)
+ plt.title('seg')
+ plt.subplot(235)
+ plt.imshow(det_mask)
+ plt.title('det')
+ plt.subplot(236)
+ print 'action = {}'.format(action)
+ print 'done = {}'.format(done)
+ plt.draw()
+ if raw_input('press \'n\' to go to the next random sequence. Otherwise, '
+ 'press any key to continue...') == 'n':
+ break
+
+
+def visualize(env, input_folder, output_root_folder):
+ """visualizes images for sequence of steps from the evals folder."""
+ def which_env(file_name):
+ img_name = file_name.split('_')[0][2:5]
+ env_dict = {'161': 'Home_016_1', '131': 'Home_013_1', '111': 'Home_011_1'}
+ if img_name in env_dict:
+ return env_dict[img_name]
+ else:
+ raise ValueError('could not resolve env: {} {}'.format(
+ img_name, file_name))
+
+ def which_goal(file_name):
+ return file_name[file_name.find('_')+1:]
+
+ output_images_folder = os.path.join(output_root_folder, 'images')
+ output_gifs_folder = os.path.join(output_root_folder, 'gifs')
+ if not tf.gfile.IsDirectory(output_images_folder):
+ tf.gfile.MakeDirs(output_images_folder)
+ if not tf.gfile.IsDirectory(output_gifs_folder):
+ tf.gfile.MakeDirs(output_gifs_folder)
+ npy_files = [
+ os.path.join(input_folder, name)
+ for name in tf.gfile.ListDirectory(input_folder)
+ if name.find('npy') >= 0
+ ]
+ for i, npy_file in enumerate(npy_files):
+ print 'saving images {}/{}'.format(i, len(npy_files))
+ pure_name = npy_file[npy_file.rfind('/') + 1:-4]
+ output_folder = os.path.join(output_images_folder, pure_name)
+ if not tf.gfile.IsDirectory(output_folder):
+ tf.gfile.MakeDirs(output_folder)
+ print '*******'
+ print pure_name[0:pure_name.find('_')]
+ env.reset_for_eval(which_env(pure_name),
+ which_goal(pure_name),
+ pure_name[0:pure_name.find('_')],
+ )
+ with tf.gfile.Open(npy_file) as h:
+ states = np.load(h).item()['states']
+ images = [
+ env.observation(state)[mt.IMAGE] for state in states
+ ]
+ for j, img in enumerate(images):
+ cv2.imwrite(os.path.join(output_folder, '{0:03d}'.format(j) + '.jpg'),
+ img[:, :, ::-1])
+ print 'converting to gif'
+ os.system(
+ 'convert -set delay 20 -colors 256 -dispose 1 {}/*.jpg {}.gif'.format(
+ output_folder,
+ os.path.join(output_gifs_folder, pure_name + '.gif')
+ )
+ )
+
+def evaluate_folder(env, folder_path):
+ """Evaluates the performance from the evals folder."""
+ targets = ['fridge', 'dining_table', 'microwave', 'tv', 'couch']
+
+ def compute_acc(npy_file):
+ with tf.gfile.Open(npy_file) as h:
+ data = np.load(h).item()
+ if npy_file.find('dining_table') >= 0:
+ category = 'dining_table'
+ else:
+ category = npy_file[npy_file.rfind('_') + 1:-4]
+ return category, data['distance'][-1] - 2
+
+ def evaluate_iteration(folder):
+ """Evaluates the data from the folder of certain eval iteration."""
+ print folder
+ npy_files = [
+ os.path.join(folder, name)
+ for name in tf.gfile.ListDirectory(folder)
+ if name.find('npy') >= 0
+ ]
+ eval_stats = {c: [] for c in targets}
+ for npy_file in npy_files:
+ try:
+ category, dist = compute_acc(npy_file)
+ except: # pylint: disable=bare-except
+ continue
+ eval_stats[category].append(float(dist <= 5))
+ for c in eval_stats:
+ if not eval_stats[c]:
+ print 'incomplete eval {}: empty class {}'.format(folder_path, c)
+ return None
+ eval_stats[c] = np.mean(eval_stats[c])
+
+ eval_stats['mean'] = np.mean(eval_stats.values())
+ return eval_stats
+
+ checkpoint_folders = [
+ folder_path + x
+ for x in tf.gfile.ListDirectory(folder_path)
+ if tf.gfile.IsDirectory(folder_path + x)
+ ]
+
+ print '{} folders found'.format(len(checkpoint_folders))
+ print '------------------------'
+ all_iters = []
+ all_accs = []
+ for i, folder in enumerate(checkpoint_folders):
+ print 'processing {}/{}'.format(i, len(checkpoint_folders))
+ eval_stats = evaluate_iteration(folder)
+ if eval_stats is None:
+ continue
+ else:
+ iter_no = int(folder[folder.rfind('/') + 1:])
+ print 'result ', iter_no, eval_stats['mean']
+ all_accs.append(eval_stats['mean'])
+ all_iters.append(iter_no)
+
+ all_accs = np.asarray(all_accs)
+ all_iters = np.asarray(all_iters)
+ idx = np.argmax(all_accs)
+ print 'best result at iteration {} was {}'.format(all_iters[idx],
+ all_accs[idx])
+ order = np.argsort(all_iters)
+ all_iters = all_iters[order]
+ all_accs = all_accs[order]
+ #plt.plot(all_iters, all_accs)
+ #plt.show()
+ #print 'done plotting'
+
+ best_iteration_folder = os.path.join(folder_path, str(all_iters[idx]))
+
+ print 'generating gifs and images for {}'.format(best_iteration_folder)
+ visualize(env, best_iteration_folder, FLAGS.output_folder)
+
+
+def main(_):
+ gin.parse_config_files_and_bindings(FLAGS.gin_config, FLAGS.gin_params)
+ print('********')
+ print(FLAGS.mode)
+ print(FLAGS.gin_config)
+ print(FLAGS.gin_params)
+
+ env = active_vision_dataset_env.ActiveVisionDatasetEnv(modality_types=[
+ task_env.ModalityTypes.IMAGE,
+ task_env.ModalityTypes.SEMANTIC_SEGMENTATION,
+ task_env.ModalityTypes.OBJECT_DETECTION, task_env.ModalityTypes.DEPTH,
+ task_env.ModalityTypes.DISTANCE
+ ])
+
+ if FLAGS.mode == BENCHMARK_MODE:
+ benchmark(env, env.possible_targets)
+ elif FLAGS.mode == GRAPH_MODE:
+ for loc in env.worlds:
+ env.check_scene_graph(loc, 'fridge')
+ elif FLAGS.mode == HUMAN_MODE:
+ human(env, env.possible_targets)
+ elif FLAGS.mode == VIS_MODE:
+ visualize_random_step_sequence(env)
+ elif FLAGS.mode == EVAL_MODE:
+ evaluate_folder(env, FLAGS.eval_folder)
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/README.md"
new file mode 100644
index 00000000..4406b268
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/README.md"
@@ -0,0 +1,15 @@
+# Compression with Neural Networks
+
+This is a [TensorFlow](http://www.tensorflow.org/) model repo containing
+research on compression with neural networks. This repo currently contains
+code for the following papers:
+
+[Full Resolution Image Compression with Recurrent Neural Networks](https://arxiv.org/abs/1608.05148)
+
+## Organization
+[Image Encoder](image_encoder/): Encoding and decoding images into their binary representation.
+
+[Entropy Coder](entropy_coder/): Lossless compression of the binary representation.
+
+## Contact Info
+Model repository maintained by Nick Johnston ([nmjohn](https://github.com/nmjohn)).
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/README.md"
new file mode 100644
index 00000000..59e88999
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/README.md"
@@ -0,0 +1,109 @@
+# Neural net based entropy coding
+
+This is a [TensorFlow](http://www.tensorflow.org/) model for additional
+lossless compression of bitstreams generated by neural net based image
+encoders as described in
+[https://arxiv.org/abs/1703.10114](https://arxiv.org/abs/1703.10114).
+
+To be more specific, the entropy coder aims at compressing further binary
+codes which have a 3D tensor structure with:
+
+* the first two dimensions of the tensors corresponding to the height and
+the width of the binary codes,
+* the last dimension being the depth of the codes. The last dimension can be
+sliced into N groups of K, where each additional group is used by the image
+decoder to add more details to the reconstructed image.
+
+The code in this directory only contains the underlying code probability model
+but does not perform the actual compression using arithmetic coding.
+The code probability model is enough to compute the theoretical compression
+ratio.
+
+
+## Prerequisites
+The only software requirements for running the encoder and decoder is having
+Tensorflow installed.
+
+You will also need to add the top level source directory of the entropy coder
+to your `PYTHONPATH`, for example:
+
+`export PYTHONPATH=${PYTHONPATH}:/tmp/models/compression`
+
+
+## Training the entropy coder
+
+### Synthetic dataset
+If you do not have a training dataset, there is a simple code generative model
+that you can use to generate a dataset and play with the entropy coder.
+The generative model is located under dataset/gen\_synthetic\_dataset.py. Note
+that this simple generative model is not going to give good results on real
+images as it is not supposed to be close to the statistics of the binary
+representation of encoded images. Consider it as a toy dataset, no more, no
+less.
+
+To generate a synthetic dataset with 20000 samples:
+
+`mkdir -p /tmp/dataset`
+
+`python ./dataset/gen_synthetic_dataset.py --dataset_dir=/tmp/dataset/
+--count=20000`
+
+Note that the generator has not been optimized at all, generating the synthetic
+dataset is currently pretty slow.
+
+### Training
+
+If you just want to play with the entropy coder trainer, here is the command
+line that can be used to train the entropy coder on the synthetic dataset:
+
+`mkdir -p /tmp/entropy_coder_train`
+
+`python ./core/entropy_coder_train.py --task=0
+--train_dir=/tmp/entropy_coder_train/
+--model=progressive
+--model_config=./configs/synthetic/model_config.json
+--train_config=./configs/synthetic/train_config.json
+--input_config=./configs/synthetic/input_config.json
+`
+
+Training is configured using 3 files formatted using JSON:
+
+* One file is used to configure the underlying entropy coder model.
+ Currently, only the *progressive* model is supported.
+ This model takes 2 mandatory parameters and an optional one:
+ * `layer_depth`: the number of bits per layer (a.k.a. iteration).
+ Background: the image decoder takes each layer to add more detail
+ to the image.
+ * `layer_count`: the maximum number of layers that should be supported
+ by the model. This should be equal or greater than the maximum number
+ of layers in the input binary codes.
+ * `coded_layer_count`: This can be used to consider only partial codes,
+ keeping only the first `coded_layer_count` layers and ignoring the
+ remaining layers. If left empty, the binary codes are left unchanged.
+* One file to configure the training, including the learning rate, ...
+ The meaning of the parameters are pretty straightforward. Note that this
+ file is only used during training and is not needed during inference.
+* One file to specify the input dataset to use during training.
+ The dataset is formatted using tf.RecordIO.
+
+
+## Inference: file size after entropy coding.
+
+### Using a synthetic sample
+
+Here is the command line to generate a single synthetic sample formatted
+in the same way as what is provided by the image encoder:
+
+`python ./dataset/gen_synthetic_single.py
+--sample_filename=/tmp/dataset/sample_0000.npz`
+
+To actually compute the additional compression ratio using the entropy coder
+trained in the previous step:
+
+`python ./core/entropy_coder_single.py
+--model=progressive
+--model_config=./configs/synthetic/model_config.json
+--input_codes=/tmp/dataset/sample_0000.npz
+--checkpoint=/tmp/entropy_coder_train/model.ckpt-209078`
+
+where the checkpoint number should be adjusted accordingly.
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models.py"
new file mode 100644
index 00000000..e376dac7
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models.py"
@@ -0,0 +1,19 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Import and register all the entropy coder models."""
+
+# pylint: disable=unused-import
+from entropy_coder.progressive import progressive
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models_test.py"
new file mode 100644
index 00000000..b8aff504
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/all_models/all_models_test.py"
@@ -0,0 +1,68 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Basic test of all registered models."""
+
+import tensorflow as tf
+
+# pylint: disable=unused-import
+import all_models
+# pylint: enable=unused-import
+from entropy_coder.model import model_factory
+
+
+class AllModelsTest(tf.test.TestCase):
+
+ def testBuildModelForTraining(self):
+ factory = model_factory.GetModelRegistry()
+ model_names = factory.GetAvailableModels()
+
+ for m in model_names:
+ tf.reset_default_graph()
+
+ global_step = tf.Variable(tf.zeros([], dtype=tf.int64),
+ trainable=False,
+ name='global_step')
+
+ optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
+
+ batch_size = 3
+ height = 40
+ width = 20
+ depth = 5
+ binary_codes = tf.placeholder(dtype=tf.float32,
+ shape=[batch_size, height, width, depth])
+
+ # Create a model with the default configuration.
+ print('Creating model: {}'.format(m))
+ model = factory.CreateModel(m)
+ model.Initialize(global_step,
+ optimizer,
+ model.GetConfigStringForUnitTest())
+ self.assertTrue(model.loss is None, 'model: {}'.format(m))
+ self.assertTrue(model.train_op is None, 'model: {}'.format(m))
+ self.assertTrue(model.average_code_length is None, 'model: {}'.format(m))
+
+ # Build the Tensorflow graph corresponding to the model.
+ model.BuildGraph(binary_codes)
+ self.assertTrue(model.loss is not None, 'model: {}'.format(m))
+ self.assertTrue(model.average_code_length is not None,
+ 'model: {}'.format(m))
+ if model.train_op is None:
+ print('Model {} is not trainable'.format(m))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/gru_prime3/model_config.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/gru_prime3/model_config.json"
new file mode 100644
index 00000000..cf63a4c4
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/gru_prime3/model_config.json"
@@ -0,0 +1,4 @@
+{
+ "layer_count": 16,
+ "layer_depth": 32
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/input_config.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/input_config.json"
new file mode 100644
index 00000000..18455e65
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/input_config.json"
@@ -0,0 +1,4 @@
+{
+ "data": "/tmp/dataset/synthetic_dataset",
+ "unique_code_size": true
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/model_config.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/model_config.json"
new file mode 100644
index 00000000..c6f1f3e1
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/model_config.json"
@@ -0,0 +1,4 @@
+{
+ "layer_depth": 2,
+ "layer_count": 8
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/train_config.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/train_config.json"
new file mode 100644
index 00000000..79e4909f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/configs/synthetic/train_config.json"
@@ -0,0 +1,6 @@
+{
+ "batch_size": 4,
+ "learning_rate": 0.1,
+ "decay_rate": 0.9,
+ "samples_per_decay": 20000
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/code_loader.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/code_loader.py"
new file mode 100644
index 00000000..603ab724
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/code_loader.py"
@@ -0,0 +1,73 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Load binary codes stored as tf.Example in a TFRecord table."""
+
+import tensorflow as tf
+
+
+def ReadFirstCode(dataset):
+ """Read the first example from a binary code RecordIO table."""
+ for record in tf.python_io.tf_record_iterator(dataset):
+ tf_example = tf.train.Example()
+ tf_example.ParseFromString(record)
+ break
+ return tf_example
+
+
+def LoadBinaryCode(input_config, batch_size):
+ """Load a batch of binary codes from a tf.Example dataset.
+
+ Args:
+ input_config: An InputConfig proto containing the input configuration.
+ batch_size: Output batch size of examples.
+
+ Returns:
+ A batched tensor of binary codes.
+ """
+ data = input_config.data
+
+ # TODO: Possibly use multiple files (instead of just one).
+ file_list = [data]
+ filename_queue = tf.train.string_input_producer(file_list,
+ capacity=4)
+ reader = tf.TFRecordReader()
+ _, values = reader.read(filename_queue)
+
+ serialized_example = tf.reshape(values, shape=[1])
+ serialized_features = {
+ 'code_shape': tf.FixedLenFeature([3],
+ dtype=tf.int64),
+ 'code': tf.VarLenFeature(tf.float32),
+ }
+ example = tf.parse_example(serialized_example, serialized_features)
+
+ # 3D shape: height x width x binary_code_depth
+ z = example['code_shape']
+ code_shape = tf.reshape(tf.cast(z, tf.int32), [3])
+ # Un-flatten the binary codes.
+ code = tf.reshape(tf.sparse_tensor_to_dense(example['code']), code_shape)
+
+ queue_size = 10
+ queue = tf.PaddingFIFOQueue(
+ queue_size + 3 * batch_size,
+ dtypes=[code.dtype],
+ shapes=[[None, None, None]])
+ enqueue_op = queue.enqueue([code])
+ dequeue_code = queue.dequeue_many(batch_size)
+ queue_runner = tf.train.queue_runner.QueueRunner(queue, [enqueue_op])
+ tf.add_to_collection(tf.GraphKeys.QUEUE_RUNNERS, queue_runner)
+
+ return dequeue_code
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/config_helper.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/config_helper.py"
new file mode 100644
index 00000000..a7d949e3
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/config_helper.py"
@@ -0,0 +1,52 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Helper functions used in both train and inference."""
+
+import json
+import os.path
+
+import tensorflow as tf
+
+
+def GetConfigString(config_file):
+ config_string = ''
+ if config_file is not None:
+ config_string = open(config_file).read()
+ return config_string
+
+
+class InputConfig(object):
+
+ def __init__(self, config_string):
+ config = json.loads(config_string)
+ self.data = config["data"]
+ self.unique_code_size = config["unique_code_size"]
+
+
+class TrainConfig(object):
+
+ def __init__(self, config_string):
+ config = json.loads(config_string)
+ self.batch_size = config["batch_size"]
+ self.learning_rate = config["learning_rate"]
+ self.decay_rate = config["decay_rate"]
+ self.samples_per_decay = config["samples_per_decay"]
+
+
+def SaveConfig(directory, filename, config_string):
+ path = os.path.join(directory, filename)
+ with tf.gfile.Open(path, mode='w') as f:
+ f.write(config_string)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_single.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_single.py"
new file mode 100644
index 00000000..8a61b488
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_single.py"
@@ -0,0 +1,116 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Compute the additional compression ratio after entropy coding."""
+
+import io
+import os
+
+import numpy as np
+import tensorflow as tf
+
+import config_helper
+
+# pylint: disable=unused-import
+from entropy_coder.all_models import all_models
+# pylint: enable=unused-import
+from entropy_coder.model import model_factory
+
+
+# Checkpoint used to restore the model parameters.
+tf.app.flags.DEFINE_string('checkpoint', None,
+ """Model checkpoint.""")
+
+# Model selection and configuration.
+tf.app.flags.DEFINE_string('model', None, """Underlying encoder model.""")
+tf.app.flags.DEFINE_string('model_config', None,
+ """Model config protobuf given as text file.""")
+
+# File holding the binary codes.
+tf.flags.DEFINE_string('input_codes', None, 'Location of binary code file.')
+
+FLAGS = tf.flags.FLAGS
+
+
+def main(_):
+ if (FLAGS.input_codes is None or FLAGS.model is None):
+ print ('\nUsage: python entropy_coder_single.py --model=progressive '
+ '--model_config=model_config.json'
+ '--iteration=15\n\n')
+ return
+
+ #if FLAGS.iteration < -1 or FLAGS.iteration > 15:
+ # print ('\n--iteration must be between 0 and 15 inclusive, or -1 to infer '
+ # 'from file.\n')
+ # return
+ #iteration = FLAGS.iteration
+
+ if not tf.gfile.Exists(FLAGS.input_codes):
+ print('\nInput codes not found.\n')
+ return
+
+ with tf.gfile.FastGFile(FLAGS.input_codes, 'rb') as code_file:
+ contents = code_file.read()
+ loaded_codes = np.load(io.BytesIO(contents))
+ assert ['codes', 'shape'] not in loaded_codes.files
+ loaded_shape = loaded_codes['shape']
+ loaded_array = loaded_codes['codes']
+
+ # Unpack and recover code shapes.
+ unpacked_codes = np.reshape(np.unpackbits(loaded_array)
+ [:np.prod(loaded_shape)],
+ loaded_shape)
+
+ numpy_int_codes = unpacked_codes.transpose([1, 2, 3, 0, 4])
+ numpy_int_codes = numpy_int_codes.reshape([numpy_int_codes.shape[0],
+ numpy_int_codes.shape[1],
+ numpy_int_codes.shape[2],
+ -1])
+ numpy_codes = numpy_int_codes.astype(np.float32) * 2.0 - 1.0
+
+ with tf.Graph().as_default() as graph:
+ # TF tensor to hold the binary codes to losslessly compress.
+ batch_size = 1
+ codes = tf.placeholder(tf.float32, shape=numpy_codes.shape)
+
+ # Create the entropy coder model.
+ global_step = None
+ optimizer = None
+ model = model_factory.GetModelRegistry().CreateModel(FLAGS.model)
+ model_config_string = config_helper.GetConfigString(FLAGS.model_config)
+ model.Initialize(global_step, optimizer, model_config_string)
+ model.BuildGraph(codes)
+
+ saver = tf.train.Saver(sharded=True, keep_checkpoint_every_n_hours=12.0)
+
+ with tf.Session(graph=graph) as sess:
+ # Initialize local variables.
+ sess.run(tf.local_variables_initializer())
+
+ # Restore model variables.
+ saver.restore(sess, FLAGS.checkpoint)
+
+ tf_tensors = {
+ 'code_length': model.average_code_length
+ }
+ feed_dict = {codes: numpy_codes}
+ np_tensors = sess.run(tf_tensors, feed_dict=feed_dict)
+
+ print('Additional compression ratio: {}'.format(
+ np_tensors['code_length']))
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_train.py"
new file mode 100644
index 00000000..27c48903
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/core/entropy_coder_train.py"
@@ -0,0 +1,184 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Train an entropy coder model."""
+
+import time
+
+import tensorflow as tf
+
+import code_loader
+import config_helper
+
+# pylint: disable=unused-import
+from entropy_coder.all_models import all_models
+# pylint: enable=unused-import
+from entropy_coder.model import model_factory
+
+
+FLAGS = tf.app.flags.FLAGS
+
+# Hardware resources configuration.
+tf.app.flags.DEFINE_string('master', '',
+ """Name of the TensorFlow master to use.""")
+tf.app.flags.DEFINE_string('train_dir', None,
+ """Directory where to write event logs.""")
+tf.app.flags.DEFINE_integer('task', None,
+ """Task id of the replica running the training.""")
+tf.app.flags.DEFINE_integer('ps_tasks', 0, """Number of tasks in the ps job.
+ If 0 no ps job is used.""")
+
+# Model selection and configuration.
+tf.app.flags.DEFINE_string('model', None, """Underlying encoder model.""")
+tf.app.flags.DEFINE_string('model_config', None,
+ """Model config protobuf given as text file.""")
+
+# Training data and parameters configuration.
+tf.app.flags.DEFINE_string('input_config', None,
+ """Path to the training input config file.""")
+tf.app.flags.DEFINE_string('train_config', None,
+ """Path to the training experiment config file.""")
+
+
+def train():
+ if FLAGS.train_dir is None:
+ raise ValueError('Parameter train_dir must be provided')
+ if FLAGS.task is None:
+ raise ValueError('Parameter task must be provided')
+ if FLAGS.model is None:
+ raise ValueError('Parameter model must be provided')
+
+ input_config_string = config_helper.GetConfigString(FLAGS.input_config)
+ input_config = config_helper.InputConfig(input_config_string)
+
+ # Training parameters.
+ train_config_string = config_helper.GetConfigString(FLAGS.train_config)
+ train_config = config_helper.TrainConfig(train_config_string)
+
+ batch_size = train_config.batch_size
+ initial_learning_rate = train_config.learning_rate
+ decay_rate = train_config.decay_rate
+ samples_per_decay = train_config.samples_per_decay
+
+ # Parameters for learning-rate decay.
+ # The formula is decay_rate ** floor(steps / decay_steps).
+ decay_steps = samples_per_decay / batch_size
+ decay_steps = max(decay_steps, 1)
+
+ first_code = code_loader.ReadFirstCode(input_config.data)
+ first_code_height = (
+ first_code.features.feature['code_shape'].int64_list.value[0])
+ first_code_width = (
+ first_code.features.feature['code_shape'].int64_list.value[1])
+ max_bit_depth = (
+ first_code.features.feature['code_shape'].int64_list.value[2])
+ print('Maximum code depth: {}'.format(max_bit_depth))
+
+ with tf.Graph().as_default():
+ ps_ops = ["Variable", "VariableV2", "AutoReloadVariable", "VarHandleOp"]
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks,
+ ps_ops=ps_ops)):
+ codes = code_loader.LoadBinaryCode(
+ input_config=input_config,
+ batch_size=batch_size)
+ if input_config.unique_code_size:
+ print('Input code size: {} x {}'.format(first_code_height,
+ first_code_width))
+ codes.set_shape(
+ [batch_size, first_code_height, first_code_width, max_bit_depth])
+ else:
+ codes.set_shape([batch_size, None, None, max_bit_depth])
+ codes_effective_shape = tf.shape(codes)
+
+ global_step = tf.contrib.framework.create_global_step()
+
+ # Apply learning-rate decay.
+ learning_rate = tf.train.exponential_decay(
+ learning_rate=initial_learning_rate,
+ global_step=global_step,
+ decay_steps=decay_steps,
+ decay_rate=decay_rate,
+ staircase=True)
+ tf.summary.scalar('Learning Rate', learning_rate)
+ optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate,
+ epsilon=1.0)
+
+ # Create the entropy coder model.
+ model = model_factory.GetModelRegistry().CreateModel(FLAGS.model)
+ model_config_string = config_helper.GetConfigString(FLAGS.model_config)
+ model.Initialize(global_step, optimizer, model_config_string)
+ model.BuildGraph(codes)
+
+ summary_op = tf.summary.merge_all()
+
+ # Verify that the model can actually be trained.
+ if model.train_op is None:
+ raise ValueError('Input model {} is not trainable'.format(FLAGS.model))
+
+ # We disable the summary thread run by Supervisor class by passing
+ # summary_op=None. We still pass save_summaries_secs because it is used by
+ # the global step counter thread.
+ is_chief = (FLAGS.task == 0)
+ sv = tf.train.Supervisor(logdir=FLAGS.train_dir,
+ is_chief=is_chief,
+ global_step=global_step,
+ # saver=model.saver,
+ summary_op=None,
+ save_summaries_secs=120,
+ save_model_secs=600,
+ recovery_wait_secs=30)
+
+ sess = sv.PrepareSession(FLAGS.master)
+ sv.StartQueueRunners(sess)
+
+ step = sess.run(global_step)
+ print('Trainer initial step: {}.'.format(step))
+
+ # Once everything has been setup properly, save the configs.
+ if is_chief:
+ config_helper.SaveConfig(FLAGS.train_dir, 'input_config.json',
+ input_config_string)
+ config_helper.SaveConfig(FLAGS.train_dir, 'model_config.json',
+ model_config_string)
+ config_helper.SaveConfig(FLAGS.train_dir, 'train_config.json',
+ train_config_string)
+
+ # Train the model.
+ next_summary_time = time.time()
+ while not sv.ShouldStop():
+ feed_dict = None
+
+ # Once in a while, update the summaries on the chief worker.
+ if is_chief and next_summary_time < time.time():
+ summary_str = sess.run(summary_op, feed_dict=feed_dict)
+ sv.SummaryComputed(sess, summary_str)
+ next_summary_time = time.time() + sv.save_summaries_secs
+ else:
+ tf_tensors = {
+ 'train': model.train_op,
+ 'code_length': model.average_code_length
+ }
+ np_tensors = sess.run(tf_tensors, feed_dict=feed_dict)
+ print(np_tensors['code_length'])
+
+ sv.Stop()
+
+
+def main(argv=None): # pylint: disable=unused-argument
+ train()
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py"
new file mode 100644
index 00000000..de60aee3
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_dataset.py"
@@ -0,0 +1,89 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Generate a synthetic dataset."""
+
+import os
+
+import numpy as np
+from six.moves import xrange
+import tensorflow as tf
+
+import synthetic_model
+
+
+FLAGS = tf.app.flags.FLAGS
+
+tf.app.flags.DEFINE_string(
+ 'dataset_dir', None,
+ """Directory where to write the dataset and the configs.""")
+tf.app.flags.DEFINE_integer(
+ 'count', 1000,
+ """Number of samples to generate.""")
+
+
+def int64_feature(values):
+ """Returns a TF-Feature of int64s.
+
+ Args:
+ values: A scalar or list of values.
+
+ Returns:
+ A TF-Feature.
+ """
+ if not isinstance(values, (tuple, list)):
+ values = [values]
+ return tf.train.Feature(int64_list=tf.train.Int64List(value=values))
+
+
+def float_feature(values):
+ """Returns a TF-Feature of floats.
+
+ Args:
+ values: A scalar of list of values.
+
+ Returns:
+ A TF-Feature.
+ """
+ if not isinstance(values, (tuple, list)):
+ values = [values]
+ return tf.train.Feature(float_list=tf.train.FloatList(value=values))
+
+
+def AddToTFRecord(code, tfrecord_writer):
+ example = tf.train.Example(features=tf.train.Features(feature={
+ 'code_shape': int64_feature(code.shape),
+ 'code': float_feature(code.flatten().tolist()),
+ }))
+ tfrecord_writer.write(example.SerializeToString())
+
+
+def GenerateDataset(filename, count, code_shape):
+ with tf.python_io.TFRecordWriter(filename) as tfrecord_writer:
+ for _ in xrange(count):
+ code = synthetic_model.GenerateSingleCode(code_shape)
+ # Convert {0,1} codes to {-1,+1} codes.
+ code = 2.0 * code - 1.0
+ AddToTFRecord(code, tfrecord_writer)
+
+
+def main(argv=None): # pylint: disable=unused-argument
+ GenerateDataset(os.path.join(FLAGS.dataset_dir + '/synthetic_dataset'),
+ FLAGS.count,
+ [35, 48, 8])
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_single.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_single.py"
new file mode 100644
index 00000000..b8c3821c
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/gen_synthetic_single.py"
@@ -0,0 +1,72 @@
+# Copyright 2016 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Generate a single synthetic sample."""
+
+import io
+import os
+
+import numpy as np
+import tensorflow as tf
+
+import synthetic_model
+
+
+FLAGS = tf.app.flags.FLAGS
+
+tf.app.flags.DEFINE_string(
+ 'sample_filename', None,
+ """Output file to store the generated binary code.""")
+
+
+def GenerateSample(filename, code_shape, layer_depth):
+ # {0, +1} binary codes.
+ # No conversion since the output file is expected to store
+ # codes using {0, +1} codes (and not {-1, +1}).
+ code = synthetic_model.GenerateSingleCode(code_shape)
+ code = np.round(code)
+
+ # Reformat the code so as to be compatible with what is generated
+ # by the image encoder.
+ # The image encoder generates a tensor of size:
+ # iteration_count x batch_size x height x width x iteration_depth.
+ # Here: batch_size = 1
+ if code_shape[-1] % layer_depth != 0:
+ raise ValueError('Number of layers is not an integer')
+ height = code_shape[0]
+ width = code_shape[1]
+ code = code.reshape([1, height, width, -1, layer_depth])
+ code = np.transpose(code, [3, 0, 1, 2, 4])
+
+ int_codes = code.astype(np.int8)
+ exported_codes = np.packbits(int_codes.reshape(-1))
+
+ output = io.BytesIO()
+ np.savez_compressed(output, shape=int_codes.shape, codes=exported_codes)
+ with tf.gfile.FastGFile(filename, 'wb') as code_file:
+ code_file.write(output.getvalue())
+
+
+def main(argv=None): # pylint: disable=unused-argument
+ # Note: the height and the width is different from the training dataset.
+ # The main purpose is to show that the entropy coder model is fully
+ # convolutional and can be used on any image size.
+ layer_depth = 2
+ GenerateSample(FLAGS.sample_filename, [31, 36, 8], layer_depth)
+
+
+if __name__ == '__main__':
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/synthetic_model.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/synthetic_model.py"
new file mode 100644
index 00000000..9cccb64a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/dataset/synthetic_model.py"
@@ -0,0 +1,75 @@
+# Copyright 2016 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Binary code sample generator."""
+
+import numpy as np
+from six.moves import xrange
+
+
+_CRC_LINE = [
+ [0, 1, 0],
+ [1, 1, 0],
+ [1, 0, 0]
+]
+
+_CRC_DEPTH = [1, 1, 0, 1]
+
+
+def ComputeLineCrc(code, width, y, x, d):
+ crc = 0
+ for dy in xrange(len(_CRC_LINE)):
+ i = y - 1 - dy
+ if i < 0:
+ continue
+ for dx in xrange(len(_CRC_LINE[dy])):
+ j = x - 2 + dx
+ if j < 0 or j >= width:
+ continue
+ crc += 1 if (code[i, j, d] != _CRC_LINE[dy][dx]) else 0
+ return crc
+
+
+def ComputeDepthCrc(code, y, x, d):
+ crc = 0
+ for delta in xrange(len(_CRC_DEPTH)):
+ k = d - 1 - delta
+ if k < 0:
+ continue
+ crc += 1 if (code[y, x, k] != _CRC_DEPTH[delta]) else 0
+ return crc
+
+
+def GenerateSingleCode(code_shape):
+ code = np.zeros(code_shape, dtype=np.int)
+
+ keep_value_proba = 0.8
+
+ height = code_shape[0]
+ width = code_shape[1]
+ depth = code_shape[2]
+
+ for d in xrange(depth):
+ for y in xrange(height):
+ for x in xrange(width):
+ v1 = ComputeLineCrc(code, width, y, x, d)
+ v2 = ComputeDepthCrc(code, y, x, d)
+ v = 1 if (v1 + v2 >= 6) else 0
+ if np.random.rand() < keep_value_proba:
+ code[y, x, d] = v
+ else:
+ code[y, x, d] = 1 - v
+
+ return code
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/entropy_coder_model.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/entropy_coder_model.py"
new file mode 100644
index 00000000..67f7eb5b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/entropy_coder_model.py"
@@ -0,0 +1,55 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Entropy coder model."""
+
+
+class EntropyCoderModel(object):
+ """Entropy coder model."""
+
+ def __init__(self):
+ # Loss used for training the model.
+ self.loss = None
+
+ # Tensorflow op to run to train the model.
+ self.train_op = None
+
+ # Tensor corresponding to the average code length of the input bit field
+ # tensor. The average code length is a number of output bits per input bit.
+ # To get an effective compression, this number should be between 0.0
+ # and 1.0 (1.0 corresponds to no compression).
+ self.average_code_length = None
+
+ def Initialize(self, global_step, optimizer, config_string):
+ raise NotImplementedError()
+
+ def BuildGraph(self, input_codes):
+ """Build the Tensorflow graph corresponding to the entropy coder model.
+
+ Args:
+ input_codes: Tensor of size: batch_size x height x width x bit_depth
+ corresponding to the codes to compress.
+ The input codes are {-1, +1} codes.
+ """
+ # TODO:
+ # - consider switching to {0, 1} codes.
+ # - consider passing an extra tensor which gives for each (b, y, x)
+ # what is the actual depth (which would allow to use more or less bits
+ # for each (y, x) location.
+ raise NotImplementedError()
+
+ def GetConfigStringForUnitTest(self):
+ """Returns a default model configuration to be used for unit tests."""
+ return None
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/model_factory.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/model_factory.py"
new file mode 100644
index 00000000..e6f9902f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/model/model_factory.py"
@@ -0,0 +1,53 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Entropy coder model registrar."""
+
+
+class ModelFactory(object):
+ """Factory of encoder/decoder models."""
+
+ def __init__(self):
+ self._model_dictionary = dict()
+
+ def RegisterModel(self,
+ entropy_coder_model_name,
+ entropy_coder_model_factory):
+ self._model_dictionary[entropy_coder_model_name] = (
+ entropy_coder_model_factory)
+
+ def CreateModel(self, model_name):
+ current_model_factory = self._model_dictionary[model_name]
+ return current_model_factory()
+
+ def GetAvailableModels(self):
+ return self._model_dictionary.keys()
+
+
+_model_registry = ModelFactory()
+
+
+def GetModelRegistry():
+ return _model_registry
+
+
+class RegisterEntropyCoderModel(object):
+
+ def __init__(self, model_name):
+ self._model_name = model_name
+
+ def __call__(self, f):
+ _model_registry.RegisterModel(self._model_name, f)
+ return f
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/progressive/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/progressive/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/progressive/progressive.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/progressive/progressive.py"
new file mode 100644
index 00000000..7b03a07d
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/entropy_coder/progressive/progressive.py"
@@ -0,0 +1,242 @@
+# Copyright 2017 The TensorFlow Authors All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Code probability model used for entropy coding."""
+
+import json
+
+from six.moves import xrange
+import tensorflow as tf
+
+from entropy_coder.lib import blocks
+from entropy_coder.model import entropy_coder_model
+from entropy_coder.model import model_factory
+
+# pylint: disable=not-callable
+
+
+class BrnnPredictor(blocks.BlockBase):
+ """BRNN prediction applied on one layer."""
+
+ def __init__(self, code_depth, name=None):
+ super(BrnnPredictor, self).__init__(name)
+
+ with self._BlockScope():
+ hidden_depth = 2 * code_depth
+
+ # What is coming from the previous layer/iteration
+ # is going through a regular Conv2D layer as opposed to the binary codes
+ # of the current layer/iteration which are going through a masked
+ # convolution.
+ self._adaptation0 = blocks.RasterScanConv2D(
+ hidden_depth, [7, 7], [1, 1], 'SAME',
+ strict_order=True,
+ bias=blocks.Bias(0), act=tf.tanh)
+ self._adaptation1 = blocks.Conv2D(
+ hidden_depth, [3, 3], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh)
+ self._predictor = blocks.CompositionOperator([
+ blocks.LineOperator(
+ blocks.RasterScanConv2DLSTM(
+ depth=hidden_depth,
+ filter_size=[1, 3],
+ hidden_filter_size=[1, 3],
+ strides=[1, 1],
+ padding='SAME')),
+ blocks.Conv2D(hidden_depth, [1, 1], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh),
+ blocks.Conv2D(code_depth, [1, 1], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh)
+ ])
+
+ def _Apply(self, x, s):
+ # Code estimation using both:
+ # - the state from the previous iteration/layer,
+ # - the binary codes that are before in raster scan order.
+ h = tf.concat(values=[self._adaptation0(x), self._adaptation1(s)], axis=3)
+
+ estimated_codes = self._predictor(h)
+
+ return estimated_codes
+
+
+class LayerPrediction(blocks.BlockBase):
+ """Binary code prediction for one layer."""
+
+ def __init__(self, layer_count, code_depth, name=None):
+ super(LayerPrediction, self).__init__(name)
+
+ self._layer_count = layer_count
+
+ # No previous layer.
+ self._layer_state = None
+ self._current_layer = 0
+
+ with self._BlockScope():
+ # Layers used to do the conditional code prediction.
+ self._brnn_predictors = []
+ for _ in xrange(layer_count):
+ self._brnn_predictors.append(BrnnPredictor(code_depth))
+
+ # Layers used to generate the input of the LSTM operating on the
+ # iteration/depth domain.
+ hidden_depth = 2 * code_depth
+ self._state_blocks = []
+ for _ in xrange(layer_count):
+ self._state_blocks.append(blocks.CompositionOperator([
+ blocks.Conv2D(
+ hidden_depth, [3, 3], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh),
+ blocks.Conv2D(
+ code_depth, [3, 3], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh)
+ ]))
+
+ # Memory of the RNN is equivalent to the size of 2 layers of binary
+ # codes.
+ hidden_depth = 2 * code_depth
+ self._layer_rnn = blocks.CompositionOperator([
+ blocks.Conv2DLSTM(
+ depth=hidden_depth,
+ filter_size=[1, 1],
+ hidden_filter_size=[1, 1],
+ strides=[1, 1],
+ padding='SAME'),
+ blocks.Conv2D(hidden_depth, [1, 1], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh),
+ blocks.Conv2D(code_depth, [1, 1], [1, 1], 'SAME',
+ bias=blocks.Bias(0), act=tf.tanh)
+ ])
+
+ def _Apply(self, x):
+ assert self._current_layer < self._layer_count
+
+ # Layer state is set to 0 when there is no previous iteration.
+ if self._layer_state is None:
+ self._layer_state = tf.zeros_like(x, dtype=tf.float32)
+
+ # Code estimation using both:
+ # - the state from the previous iteration/layer,
+ # - the binary codes that are before in raster scan order.
+ estimated_codes = self._brnn_predictors[self._current_layer](
+ x, self._layer_state)
+
+ # Compute the updated layer state.
+ h = self._state_blocks[self._current_layer](x)
+ self._layer_state = self._layer_rnn(h)
+ self._current_layer += 1
+
+ return estimated_codes
+
+
+class ProgressiveModel(entropy_coder_model.EntropyCoderModel):
+ """Progressive BRNN entropy coder model."""
+
+ def __init__(self):
+ super(ProgressiveModel, self).__init__()
+
+ def Initialize(self, global_step, optimizer, config_string):
+ if config_string is None:
+ raise ValueError('The progressive model requires a configuration.')
+ config = json.loads(config_string)
+ if 'coded_layer_count' not in config:
+ config['coded_layer_count'] = 0
+
+ self._config = config
+ self._optimizer = optimizer
+ self._global_step = global_step
+
+ def BuildGraph(self, input_codes):
+ """Build the graph corresponding to the progressive BRNN model."""
+ layer_depth = self._config['layer_depth']
+ layer_count = self._config['layer_count']
+
+ code_shape = input_codes.get_shape()
+ code_depth = code_shape[-1].value
+ if self._config['coded_layer_count'] > 0:
+ prefix_depth = self._config['coded_layer_count'] * layer_depth
+ if code_depth < prefix_depth:
+ raise ValueError('Invalid prefix depth: {} VS {}'.format(
+ prefix_depth, code_depth))
+ input_codes = input_codes[:, :, :, :prefix_depth]
+
+ code_shape = input_codes.get_shape()
+ code_depth = code_shape[-1].value
+ if code_depth % layer_depth != 0:
+ raise ValueError(
+ 'Code depth must be a multiple of the layer depth: {} vs {}'.format(
+ code_depth, layer_depth))
+ code_layer_count = code_depth // layer_depth
+ if code_layer_count > layer_count:
+ raise ValueError('Input codes have too many layers: {}, max={}'.format(
+ code_layer_count, layer_count))
+
+ # Block used to estimate binary codes.
+ layer_prediction = LayerPrediction(layer_count, layer_depth)
+
+ # Block used to compute code lengths.
+ code_length_block = blocks.CodeLength()
+
+ # Loop over all the layers.
+ code_length = []
+ code_layers = tf.split(
+ value=input_codes, num_or_size_splits=code_layer_count, axis=3)
+ for k in xrange(code_layer_count):
+ x = code_layers[k]
+ predicted_x = layer_prediction(x)
+ # Saturate the prediction to avoid infinite code length.
+ epsilon = 0.001
+ predicted_x = tf.clip_by_value(
+ predicted_x, -1 + epsilon, +1 - epsilon)
+ code_length.append(code_length_block(
+ blocks.ConvertSignCodeToZeroOneCode(x),
+ blocks.ConvertSignCodeToZeroOneCode(predicted_x)))
+ tf.summary.scalar('code_length_layer_{:02d}'.format(k), code_length[-1])
+ code_length = tf.stack(code_length)
+ self.loss = tf.reduce_mean(code_length)
+ tf.summary.scalar('loss', self.loss)
+
+ # Loop over all the remaining layers just to make sure they are
+ # instantiated. Otherwise, loading model params could fail.
+ dummy_x = tf.zeros_like(code_layers[0])
+ for _ in xrange(layer_count - code_layer_count):
+ dummy_predicted_x = layer_prediction(dummy_x)
+
+ # Average bitrate over total_line_count.
+ self.average_code_length = tf.reduce_mean(code_length)
+
+ if self._optimizer:
+ optim_op = self._optimizer.minimize(self.loss,
+ global_step=self._global_step)
+ block_updates = blocks.CreateBlockUpdates()
+ if block_updates:
+ with tf.get_default_graph().control_dependencies([optim_op]):
+ self.train_op = tf.group(*block_updates)
+ else:
+ self.train_op = optim_op
+ else:
+ self.train_op = None
+
+ def GetConfigStringForUnitTest(self):
+ s = '{\n'
+ s += '"layer_depth": 1,\n'
+ s += '"layer_count": 8\n'
+ s += '}\n'
+ return s
+
+
+@model_factory.RegisterEntropyCoderModel('progressive')
+def CreateProgressiveModel():
+ return ProgressiveModel()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/README.md"
new file mode 100644
index 00000000..a47da977
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/README.md"
@@ -0,0 +1,105 @@
+# Image Compression with Neural Networks
+
+This is a [TensorFlow](http://www.tensorflow.org/) model for compressing and
+decompressing images using an already trained Residual GRU model as descibed
+in [Full Resolution Image Compression with Recurrent Neural Networks](https://arxiv.org/abs/1608.05148). Please consult the paper for more details
+on the architecture and compression results.
+
+This code will allow you to perform the lossy compression on an model
+already trained on compression. This code doesn't not currently contain the
+Entropy Coding portions of our paper.
+
+
+## Prerequisites
+The only software requirements for running the encoder and decoder is having
+Tensorflow installed. You will also need to [download](http://download.tensorflow.org/models/compression_residual_gru-2016-08-23.tar.gz)
+and extract the model residual_gru.pb.
+
+If you want to generate the perceptual similarity under MS-SSIM, you will also
+need to [Install SciPy](https://www.scipy.org/install.html).
+
+## Encoding
+The Residual GRU network is fully convolutional, but requires the images
+height and width in pixels by a multiple of 32. There is an image in this folder
+called example.png that is 768x1024 if one is needed for testing. We also
+rely on TensorFlow's built in decoding ops, which support only PNG and JPEG at
+time of release.
+
+To encode an image, simply run the following command:
+
+`python encoder.py --input_image=/your/image/here.png
+--output_codes=output_codes.npz --iteration=15
+--model=/path/to/model/residual_gru.pb
+`
+
+The iteration parameter specifies the lossy-quality to target for compression.
+The quality can be [0-15], where 0 corresponds to a target of 1/8 (bits per
+pixel) bpp and every increment results in an additional 1/8 bpp.
+
+| Iteration | BPP | Compression Ratio |
+|---: |---: |---: |
+|0 | 0.125 | 192:1|
+|1 | 0.250 | 96:1|
+|2 | 0.375 | 64:1|
+|3 | 0.500 | 48:1|
+|4 | 0.625 | 38.4:1|
+|5 | 0.750 | 32:1|
+|6 | 0.875 | 27.4:1|
+|7 | 1.000 | 24:1|
+|8 | 1.125 | 21.3:1|
+|9 | 1.250 | 19.2:1|
+|10 | 1.375 | 17.4:1|
+|11 | 1.500 | 16:1|
+|12 | 1.625 | 14.7:1|
+|13 | 1.750 | 13.7:1|
+|14 | 1.875 | 12.8:1|
+|15 | 2.000 | 12:1|
+
+The output_codes file contains the numpy shape and a flattened, bit-packed
+array of the codes. These can be inspected in python by using numpy.load().
+
+
+## Decoding
+After generating codes for an image, the lossy reconstructions for that image
+can be done as follows:
+
+`python decoder.py --input_codes=codes.npz --output_directory=/tmp/decoded/
+--model=residual_gru.pb`
+
+The output_directory will contain images decoded at each quality level.
+
+
+## Comparing Similarity
+One of our primary metrics for comparing how similar two images are
+is MS-SSIM.
+
+To generate these metrics on your images you can run:
+`python msssim.py --original_image=/path/to/your/image.png
+--compared_image=/tmp/decoded/image_15.png`
+
+
+## Results
+CSV results containing the post-entropy bitrates and MS-SSIM over Kodak can
+are available for reference. Each row of the CSV represents each of the Kodak
+images in their dataset number (1-24). Each column of the CSV represents each
+iteration of the model (1-16).
+
+[Post Entropy Bitrates](https://storage.googleapis.com/compression-ml/residual_gru_results/bitrate.csv)
+
+[MS-SSIM](https://storage.googleapis.com/compression-ml/residual_gru_results/msssim.csv)
+
+
+## FAQ
+
+#### How do I train my own compression network?
+We currently don't provide the code to build and train a compression
+graph from scratch.
+
+#### I get an InvalidArgumentError: Incompatible shapes.
+This is usually due to the fact that our network only supports images that are
+both height and width divisible by 32 pixel. Try padding your images to 32
+pixel boundaries.
+
+
+## Contact Info
+Model repository maintained by Nick Johnston ([nmjohn](https://github.com/nmjohn)).
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/decoder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/decoder.py"
new file mode 100644
index 00000000..75bc18ca
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/decoder.py"
@@ -0,0 +1,127 @@
+#!/usr/bin/python
+#
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+r"""Neural Network Image Compression Decoder.
+
+Decompress an image from the numpy's npz format generated by the encoder.
+
+Example usage:
+python decoder.py --input_codes=output_codes.pkl --iteration=15 \
+--output_directory=/tmp/compression_output/ --model=residual_gru.pb
+"""
+import io
+import os
+
+import numpy as np
+import tensorflow as tf
+
+tf.flags.DEFINE_string('input_codes', None, 'Location of binary code file.')
+tf.flags.DEFINE_integer('iteration', -1, 'The max quality level of '
+ 'the images to output. Use -1 to infer from loaded '
+ ' codes.')
+tf.flags.DEFINE_string('output_directory', None, 'Directory to save decoded '
+ 'images.')
+tf.flags.DEFINE_string('model', None, 'Location of compression model.')
+
+FLAGS = tf.flags.FLAGS
+
+
+def get_input_tensor_names():
+ name_list = ['GruBinarizer/SignBinarizer/Sign:0']
+ for i in range(1, 16):
+ name_list.append('GruBinarizer/SignBinarizer/Sign_{}:0'.format(i))
+ return name_list
+
+
+def get_output_tensor_names():
+ return ['loop_{0:02d}/add:0'.format(i) for i in range(0, 16)]
+
+
+def main(_):
+ if (FLAGS.input_codes is None or FLAGS.output_directory is None or
+ FLAGS.model is None):
+ print('\nUsage: python decoder.py --input_codes=output_codes.pkl '
+ '--iteration=15 --output_directory=/tmp/compression_output/ '
+ '--model=residual_gru.pb\n\n')
+ return
+
+ if FLAGS.iteration < -1 or FLAGS.iteration > 15:
+ print('\n--iteration must be between 0 and 15 inclusive, or -1 to infer '
+ 'from file.\n')
+ return
+ iteration = FLAGS.iteration
+
+ if not tf.gfile.Exists(FLAGS.output_directory):
+ tf.gfile.MkDir(FLAGS.output_directory)
+
+ if not tf.gfile.Exists(FLAGS.input_codes):
+ print('\nInput codes not found.\n')
+ return
+
+ contents = ''
+ with tf.gfile.FastGFile(FLAGS.input_codes, 'rb') as code_file:
+ contents = code_file.read()
+ loaded_codes = np.load(io.BytesIO(contents))
+ assert ['codes', 'shape'] not in loaded_codes.files
+ loaded_shape = loaded_codes['shape']
+ loaded_array = loaded_codes['codes']
+
+ # Unpack and recover code shapes.
+ unpacked_codes = np.reshape(np.unpackbits(loaded_array)
+ [:np.prod(loaded_shape)],
+ loaded_shape)
+
+ numpy_int_codes = np.split(unpacked_codes, len(unpacked_codes))
+ if iteration == -1:
+ iteration = len(unpacked_codes) - 1
+ # Convert back to float and recover scale.
+ numpy_codes = [np.squeeze(x.astype(np.float32), 0) * 2 - 1 for x in
+ numpy_int_codes]
+
+ with tf.Graph().as_default() as graph:
+ # Load the inference model for decoding.
+ with tf.gfile.FastGFile(FLAGS.model, 'rb') as model_file:
+ graph_def = tf.GraphDef()
+ graph_def.ParseFromString(model_file.read())
+ _ = tf.import_graph_def(graph_def, name='')
+
+ # For encoding the tensors into PNGs.
+ input_image = tf.placeholder(tf.uint8)
+ encoded_image = tf.image.encode_png(input_image)
+
+ input_tensors = [graph.get_tensor_by_name(name) for name in
+ get_input_tensor_names()][0:iteration+1]
+ outputs = [graph.get_tensor_by_name(name) for name in
+ get_output_tensor_names()][0:iteration+1]
+
+ feed_dict = {key: value for (key, value) in zip(input_tensors,
+ numpy_codes)}
+
+ with tf.Session(graph=graph) as sess:
+ results = sess.run(outputs, feed_dict=feed_dict)
+
+ for index, result in enumerate(results):
+ img = np.uint8(np.clip(result + 0.5, 0, 255))
+ img = img.squeeze()
+ png_img = sess.run(encoded_image, feed_dict={input_image: img})
+
+ with tf.gfile.FastGFile(os.path.join(FLAGS.output_directory,
+ 'image_{0:02d}.png'.format(index)),
+ 'w') as output_image:
+ output_image.write(png_img)
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/encoder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/encoder.py"
new file mode 100644
index 00000000..27754bda
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/encoder.py"
@@ -0,0 +1,105 @@
+#!/usr/bin/python
+#
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+r"""Neural Network Image Compression Encoder.
+
+Compresses an image to a binarized numpy array. The image must be padded to a
+multiple of 32 pixels in height and width.
+
+Example usage:
+python encoder.py --input_image=/your/image/here.png \
+--output_codes=output_codes.pkl --iteration=15 --model=residual_gru.pb
+"""
+import io
+import os
+
+import numpy as np
+import tensorflow as tf
+
+tf.flags.DEFINE_string('input_image', None, 'Location of input image. We rely '
+ 'on tf.image to decode the image, so only PNG and JPEG '
+ 'formats are currently supported.')
+tf.flags.DEFINE_integer('iteration', 15, 'Quality level for encoding image. '
+ 'Must be between 0 and 15 inclusive.')
+tf.flags.DEFINE_string('output_codes', None, 'File to save output encoding.')
+tf.flags.DEFINE_string('model', None, 'Location of compression model.')
+
+FLAGS = tf.flags.FLAGS
+
+
+def get_output_tensor_names():
+ name_list = ['GruBinarizer/SignBinarizer/Sign:0']
+ for i in range(1, 16):
+ name_list.append('GruBinarizer/SignBinarizer/Sign_{}:0'.format(i))
+ return name_list
+
+
+def main(_):
+ if (FLAGS.input_image is None or FLAGS.output_codes is None or
+ FLAGS.model is None):
+ print('\nUsage: python encoder.py --input_image=/your/image/here.png '
+ '--output_codes=output_codes.pkl --iteration=15 '
+ '--model=residual_gru.pb\n\n')
+ return
+
+ if FLAGS.iteration < 0 or FLAGS.iteration > 15:
+ print('\n--iteration must be between 0 and 15 inclusive.\n')
+ return
+
+ with tf.gfile.FastGFile(FLAGS.input_image, 'rb') as input_image:
+ input_image_str = input_image.read()
+
+ with tf.Graph().as_default() as graph:
+ # Load the inference model for encoding.
+ with tf.gfile.FastGFile(FLAGS.model, 'rb') as model_file:
+ graph_def = tf.GraphDef()
+ graph_def.ParseFromString(model_file.read())
+ _ = tf.import_graph_def(graph_def, name='')
+
+ input_tensor = graph.get_tensor_by_name('Placeholder:0')
+ outputs = [graph.get_tensor_by_name(name) for name in
+ get_output_tensor_names()]
+
+ input_image = tf.placeholder(tf.string)
+ _, ext = os.path.splitext(FLAGS.input_image)
+ if ext == '.png':
+ decoded_image = tf.image.decode_png(input_image, channels=3)
+ elif ext == '.jpeg' or ext == '.jpg':
+ decoded_image = tf.image.decode_jpeg(input_image, channels=3)
+ else:
+ assert False, 'Unsupported file format {}'.format(ext)
+ decoded_image = tf.expand_dims(decoded_image, 0)
+
+ with tf.Session(graph=graph) as sess:
+ img_array = sess.run(decoded_image, feed_dict={input_image:
+ input_image_str})
+ results = sess.run(outputs, feed_dict={input_tensor: img_array})
+
+ results = results[0:FLAGS.iteration + 1]
+ int_codes = np.asarray([x.astype(np.int8) for x in results])
+
+ # Convert int codes to binary.
+ int_codes = (int_codes + 1)//2
+ export = np.packbits(int_codes.reshape(-1))
+
+ output = io.BytesIO()
+ np.savez_compressed(output, shape=int_codes.shape, codes=export)
+ with tf.gfile.FastGFile(FLAGS.output_codes, 'w') as code_file:
+ code_file.write(output.getvalue())
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/example.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/example.png"
new file mode 100644
index 00000000..d3409b01
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/example.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/msssim.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/msssim.py"
new file mode 100644
index 00000000..f07a3712
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/compression/image_encoder/msssim.py"
@@ -0,0 +1,217 @@
+#!/usr/bin/python
+#
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+"""Python implementation of MS-SSIM.
+
+Usage:
+
+python msssim.py --original_image=original.png --compared_image=distorted.png
+"""
+import numpy as np
+from scipy import signal
+from scipy.ndimage.filters import convolve
+import tensorflow as tf
+
+
+tf.flags.DEFINE_string('original_image', None, 'Path to PNG image.')
+tf.flags.DEFINE_string('compared_image', None, 'Path to PNG image.')
+FLAGS = tf.flags.FLAGS
+
+
+def _FSpecialGauss(size, sigma):
+ """Function to mimic the 'fspecial' gaussian MATLAB function."""
+ radius = size // 2
+ offset = 0.0
+ start, stop = -radius, radius + 1
+ if size % 2 == 0:
+ offset = 0.5
+ stop -= 1
+ x, y = np.mgrid[offset + start:stop, offset + start:stop]
+ assert len(x) == size
+ g = np.exp(-((x**2 + y**2)/(2.0 * sigma**2)))
+ return g / g.sum()
+
+
+def _SSIMForMultiScale(img1, img2, max_val=255, filter_size=11,
+ filter_sigma=1.5, k1=0.01, k2=0.03):
+ """Return the Structural Similarity Map between `img1` and `img2`.
+
+ This function attempts to match the functionality of ssim_index_new.m by
+ Zhou Wang: http://www.cns.nyu.edu/~lcv/ssim/msssim.zip
+
+ Arguments:
+ img1: Numpy array holding the first RGB image batch.
+ img2: Numpy array holding the second RGB image batch.
+ max_val: the dynamic range of the images (i.e., the difference between the
+ maximum the and minimum allowed values).
+ filter_size: Size of blur kernel to use (will be reduced for small images).
+ filter_sigma: Standard deviation for Gaussian blur kernel (will be reduced
+ for small images).
+ k1: Constant used to maintain stability in the SSIM calculation (0.01 in
+ the original paper).
+ k2: Constant used to maintain stability in the SSIM calculation (0.03 in
+ the original paper).
+
+ Returns:
+ Pair containing the mean SSIM and contrast sensitivity between `img1` and
+ `img2`.
+
+ Raises:
+ RuntimeError: If input images don't have the same shape or don't have four
+ dimensions: [batch_size, height, width, depth].
+ """
+ if img1.shape != img2.shape:
+ raise RuntimeError('Input images must have the same shape (%s vs. %s).',
+ img1.shape, img2.shape)
+ if img1.ndim != 4:
+ raise RuntimeError('Input images must have four dimensions, not %d',
+ img1.ndim)
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+ _, height, width, _ = img1.shape
+
+ # Filter size can't be larger than height or width of images.
+ size = min(filter_size, height, width)
+
+ # Scale down sigma if a smaller filter size is used.
+ sigma = size * filter_sigma / filter_size if filter_size else 0
+
+ if filter_size:
+ window = np.reshape(_FSpecialGauss(size, sigma), (1, size, size, 1))
+ mu1 = signal.fftconvolve(img1, window, mode='valid')
+ mu2 = signal.fftconvolve(img2, window, mode='valid')
+ sigma11 = signal.fftconvolve(img1 * img1, window, mode='valid')
+ sigma22 = signal.fftconvolve(img2 * img2, window, mode='valid')
+ sigma12 = signal.fftconvolve(img1 * img2, window, mode='valid')
+ else:
+ # Empty blur kernel so no need to convolve.
+ mu1, mu2 = img1, img2
+ sigma11 = img1 * img1
+ sigma22 = img2 * img2
+ sigma12 = img1 * img2
+
+ mu11 = mu1 * mu1
+ mu22 = mu2 * mu2
+ mu12 = mu1 * mu2
+ sigma11 -= mu11
+ sigma22 -= mu22
+ sigma12 -= mu12
+
+ # Calculate intermediate values used by both ssim and cs_map.
+ c1 = (k1 * max_val) ** 2
+ c2 = (k2 * max_val) ** 2
+ v1 = 2.0 * sigma12 + c2
+ v2 = sigma11 + sigma22 + c2
+ ssim = np.mean((((2.0 * mu12 + c1) * v1) / ((mu11 + mu22 + c1) * v2)))
+ cs = np.mean(v1 / v2)
+ return ssim, cs
+
+
+def MultiScaleSSIM(img1, img2, max_val=255, filter_size=11, filter_sigma=1.5,
+ k1=0.01, k2=0.03, weights=None):
+ """Return the MS-SSIM score between `img1` and `img2`.
+
+ This function implements Multi-Scale Structural Similarity (MS-SSIM) Image
+ Quality Assessment according to Zhou Wang's paper, "Multi-scale structural
+ similarity for image quality assessment" (2003).
+ Link: https://ece.uwaterloo.ca/~z70wang/publications/msssim.pdf
+
+ Author's MATLAB implementation:
+ http://www.cns.nyu.edu/~lcv/ssim/msssim.zip
+
+ Arguments:
+ img1: Numpy array holding the first RGB image batch.
+ img2: Numpy array holding the second RGB image batch.
+ max_val: the dynamic range of the images (i.e., the difference between the
+ maximum the and minimum allowed values).
+ filter_size: Size of blur kernel to use (will be reduced for small images).
+ filter_sigma: Standard deviation for Gaussian blur kernel (will be reduced
+ for small images).
+ k1: Constant used to maintain stability in the SSIM calculation (0.01 in
+ the original paper).
+ k2: Constant used to maintain stability in the SSIM calculation (0.03 in
+ the original paper).
+ weights: List of weights for each level; if none, use five levels and the
+ weights from the original paper.
+
+ Returns:
+ MS-SSIM score between `img1` and `img2`.
+
+ Raises:
+ RuntimeError: If input images don't have the same shape or don't have four
+ dimensions: [batch_size, height, width, depth].
+ """
+ if img1.shape != img2.shape:
+ raise RuntimeError('Input images must have the same shape (%s vs. %s).',
+ img1.shape, img2.shape)
+ if img1.ndim != 4:
+ raise RuntimeError('Input images must have four dimensions, not %d',
+ img1.ndim)
+
+ # Note: default weights don't sum to 1.0 but do match the paper / matlab code.
+ weights = np.array(weights if weights else
+ [0.0448, 0.2856, 0.3001, 0.2363, 0.1333])
+ levels = weights.size
+ downsample_filter = np.ones((1, 2, 2, 1)) / 4.0
+ im1, im2 = [x.astype(np.float64) for x in [img1, img2]]
+ mssim = np.array([])
+ mcs = np.array([])
+ for _ in range(levels):
+ ssim, cs = _SSIMForMultiScale(
+ im1, im2, max_val=max_val, filter_size=filter_size,
+ filter_sigma=filter_sigma, k1=k1, k2=k2)
+ mssim = np.append(mssim, ssim)
+ mcs = np.append(mcs, cs)
+ filtered = [convolve(im, downsample_filter, mode='reflect')
+ for im in [im1, im2]]
+ im1, im2 = [x[:, ::2, ::2, :] for x in filtered]
+ return (np.prod(mcs[0:levels-1] ** weights[0:levels-1]) *
+ (mssim[levels-1] ** weights[levels-1]))
+
+
+def main(_):
+ if FLAGS.original_image is None or FLAGS.compared_image is None:
+ print('\nUsage: python msssim.py --original_image=original.png '
+ '--compared_image=distorted.png\n\n')
+ return
+
+ if not tf.gfile.Exists(FLAGS.original_image):
+ print('\nCannot find --original_image.\n')
+ return
+
+ if not tf.gfile.Exists(FLAGS.compared_image):
+ print('\nCannot find --compared_image.\n')
+ return
+
+ with tf.gfile.FastGFile(FLAGS.original_image) as image_file:
+ img1_str = image_file.read('rb')
+ with tf.gfile.FastGFile(FLAGS.compared_image) as image_file:
+ img2_str = image_file.read('rb')
+
+ input_img = tf.placeholder(tf.string)
+ decoded_image = tf.expand_dims(tf.image.decode_png(input_img, channels=3), 0)
+
+ with tf.Session() as sess:
+ img1 = sess.run(decoded_image, feed_dict={input_img: img1_str})
+ img2 = sess.run(decoded_image, feed_dict={input_img: img2_str})
+
+ print((MultiScaleSSIM(img1, img2, max_val=255)))
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cvt_text/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cvt_text/README.md"
new file mode 100644
index 00000000..1c0a415b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/cvt_text/README.md"
@@ -0,0 +1,38 @@
+# Cross-View Training
+
+This repository contains code for *Semi-Supervised Sequence Modeling with Cross-View Training*. Currently sequence tagging and dependency parsing tasks are supported.
+
+## Requirements
+* [Tensorflow](https://www.tensorflow.org/)
+* [Numpy](http://www.numpy.org/)
+
+This code has been run with TensorFlow 1.10.1 and Numpy 1.14.5; other versions may work, but have not been tested.
+
+## Fetching and Preprocessing Data
+Run `fetch_data.sh` to download and extract pretrained [GloVe](https://nlp.stanford.edu/projects/glove/) vectors, the [1 Billion Word Language Model Benchmark](http://www.statmt.org/lm-benchmark/) corpus of unlabeled data, and the CoNLL-2000 [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/) dataset. Unfortunately the other datasets from our paper are not freely available and so can't be included in this repository.
+
+To apply CVT to other datasets, the data should be placed in `data/raw_data/ |
+  |
+
| Target: Fridge | +Target: Television | +
 |
+  |
+
| Target: Microwave | +Target: Couch | +
+  +
+  +
+  +
+
+ +Running: + +* Installation.
+* Running DeepLab on PASCAL VOC 2012 semantic segmentation dataset.
+* Running DeepLab on Cityscapes semantic segmentation dataset.
+* Running DeepLab on ADE20K semantic segmentation dataset.
+ +Models: + +* Checkpoints and frozen inference graphs.
+ +Misc: + +* Please check FAQ if you have some questions before reporting the issues.
+ +## Getting Help + +To get help with issues you may encounter while using the DeepLab Tensorflow +implementation, create a new question on +[StackOverflow](https://stackoverflow.com/) with the tag "tensorflow". + +Please report bugs (i.e., broken code, not usage questions) to the +tensorflow/models GitHub [issue +tracker](https://github.com/tensorflow/models/issues), prefixing the issue name +with "deeplab". + +## Change Logs + +### October 1, 2018 + +Released MobileNet-v2 depth-multiplier = 0.5 COCO-pretrained checkpoints on +PASCAL VOC 2012, and Xception-65 COCO pretrained checkpoint (i.e., no PASCAL +pretrained). + + +### September 5, 2018 + +Released Cityscapes pretrained checkpoints with found best dense prediction cell. + + +### May 26, 2018 + +Updated ADE20K pretrained checkpoint. + + +### May 18, 2018 +1. Added builders for ResNet-v1 and Xception model variants. +1. Added ADE20K support, including colormap and pretrained Xception_65 checkpoint. +1. Fixed a bug on using non-default depth_multiplier for MobileNet-v2. + + +### March 22, 2018 + +Released checkpoints using MobileNet-V2 as network backbone and pretrained on +PASCAL VOC 2012 and Cityscapes. + + +### March 5, 2018 + +First release of DeepLab in TensorFlow including deeper Xception network +backbone. Included chekcpoints that have been pretrained on PASCAL VOC 2012 +and Cityscapes. + +## References + +1. **Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs**
+ Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, Alan L. Yuille (+ equal + contribution).
+ [[link]](https://arxiv.org/abs/1412.7062). In ICLR, 2015. + +2. **DeepLab: Semantic Image Segmentation with Deep Convolutional Nets,** + **Atrous Convolution, and Fully Connected CRFs**
+ Liang-Chieh Chen+, George Papandreou+, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille (+ equal + contribution).
+ [[link]](http://arxiv.org/abs/1606.00915). TPAMI 2017. + +3. **Rethinking Atrous Convolution for Semantic Image Segmentation**
+ Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam.
+ [[link]](http://arxiv.org/abs/1706.05587). arXiv: 1706.05587, 2017. + +4. **Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation**
+ Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam.
+ [[link]](https://arxiv.org/abs/1802.02611). In ECCV, 2018. + +5. **ParseNet: Looking Wider to See Better**
+ Wei Liu, Andrew Rabinovich, Alexander C Berg
+ [[link]](https://arxiv.org/abs/1506.04579). arXiv:1506.04579, 2015. + +6. **Pyramid Scene Parsing Network**
+ Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
+ [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. + +7. **Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate shift**
+ Sergey Ioffe, Christian Szegedy
+ [[link]](https://arxiv.org/abs/1502.03167). In ICML, 2015. + +8. **MobileNetV2: Inverted Residuals and Linear Bottlenecks**
+ Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
+ [[link]](https://arxiv.org/abs/1801.04381). In CVPR, 2018. + +9. **Xception: Deep Learning with Depthwise Separable Convolutions**
+ François Chollet
+ [[link]](https://arxiv.org/abs/1610.02357). In CVPR, 2017. + +10. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
+ Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
+ [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge + Workshop, 2017. + +11. **Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems**
+ M. Abadi, A. Agarwal, et al.
+ [[link]](https://arxiv.org/abs/1603.04467). arXiv:1603.04467, 2016. + +12. **The Pascal Visual Object Classes Challenge – A Retrospective,**
+ Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John + Winn, and Andrew Zisserma.
+ [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. + +13. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
+ Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
+ [[link]](https://www.cityscapes-dataset.com/). In CVPR, 2016. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common.py" new file mode 100644 index 00000000..83b73f07 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common.py" @@ -0,0 +1,173 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Provides flags that are common to scripts. + +Common flags from train/eval/vis/export_model.py are collected in this script. +""" +import collections +import copy +import json + +import tensorflow as tf + +flags = tf.app.flags + +# Flags for input preprocessing. + +flags.DEFINE_integer('min_resize_value', None, + 'Desired size of the smaller image side.') + +flags.DEFINE_integer('max_resize_value', None, + 'Maximum allowed size of the larger image side.') + +flags.DEFINE_integer('resize_factor', None, + 'Resized dimensions are multiple of factor plus one.') + +# Model dependent flags. + +flags.DEFINE_integer('logits_kernel_size', 1, + 'The kernel size for the convolutional kernel that ' + 'generates logits.') + +# When using 'mobilent_v2', we set atrous_rates = decoder_output_stride = None. +# When using 'xception_65' or 'resnet_v1' model variants, we set +# atrous_rates = [6, 12, 18] (output stride 16) and decoder_output_stride = 4. +# See core/feature_extractor.py for supported model variants. +flags.DEFINE_string('model_variant', 'mobilenet_v2', 'DeepLab model variant.') + +flags.DEFINE_multi_float('image_pyramid', None, + 'Input scales for multi-scale feature extraction.') + +flags.DEFINE_boolean('add_image_level_feature', True, + 'Add image level feature.') + +flags.DEFINE_multi_integer( + 'image_pooling_crop_size', None, + 'Image pooling crop size [height, width] used in the ASPP module. When ' + 'value is None, the model performs image pooling with "crop_size". This' + 'flag is useful when one likes to use different image pooling sizes.') + +flags.DEFINE_boolean('aspp_with_batch_norm', True, + 'Use batch norm parameters for ASPP or not.') + +flags.DEFINE_boolean('aspp_with_separable_conv', True, + 'Use separable convolution for ASPP or not.') + +# Defaults to None. Set multi_grid = [1, 2, 4] when using provided +# 'resnet_v1_{50,101}_beta' checkpoints. +flags.DEFINE_multi_integer('multi_grid', None, + 'Employ a hierarchy of atrous rates for ResNet.') + +flags.DEFINE_float('depth_multiplier', 1.0, + 'Multiplier for the depth (number of channels) for all ' + 'convolution ops used in MobileNet.') + +# For `xception_65`, use decoder_output_stride = 4. For `mobilenet_v2`, use +# decoder_output_stride = None. +flags.DEFINE_integer('decoder_output_stride', None, + 'The ratio of input to output spatial resolution when ' + 'employing decoder to refine segmentation results.') + +flags.DEFINE_boolean('decoder_use_separable_conv', True, + 'Employ separable convolution for decoder or not.') + +flags.DEFINE_enum('merge_method', 'max', ['max', 'avg'], + 'Scheme to merge multi scale features.') + +flags.DEFINE_string( + 'dense_prediction_cell_json', + '', + 'A JSON file that specifies the dense prediction cell.') + +FLAGS = flags.FLAGS + +# Constants + +# Perform semantic segmentation predictions. +OUTPUT_TYPE = 'semantic' + +# Semantic segmentation item names. +LABELS_CLASS = 'labels_class' +IMAGE = 'image' +HEIGHT = 'height' +WIDTH = 'width' +IMAGE_NAME = 'image_name' +LABEL = 'label' +ORIGINAL_IMAGE = 'original_image' + +# Test set name. +TEST_SET = 'test' + + +class ModelOptions( + collections.namedtuple('ModelOptions', [ + 'outputs_to_num_classes', + 'crop_size', + 'atrous_rates', + 'output_stride', + 'merge_method', + 'add_image_level_feature', + 'image_pooling_crop_size', + 'aspp_with_batch_norm', + 'aspp_with_separable_conv', + 'multi_grid', + 'decoder_output_stride', + 'decoder_use_separable_conv', + 'logits_kernel_size', + 'model_variant', + 'depth_multiplier', + 'dense_prediction_cell_config', + ])): + """Immutable class to hold model options.""" + + __slots__ = () + + def __new__(cls, + outputs_to_num_classes, + crop_size=None, + atrous_rates=None, + output_stride=8): + """Constructor to set default values. + + Args: + outputs_to_num_classes: A dictionary from output type to the number of + classes. For example, for the task of semantic segmentation with 21 + semantic classes, we would have outputs_to_num_classes['semantic'] = 21. + crop_size: A tuple [crop_height, crop_width]. + atrous_rates: A list of atrous convolution rates for ASPP. + output_stride: The ratio of input to output spatial resolution. + + Returns: + A new ModelOptions instance. + """ + dense_prediction_cell_config = None + if FLAGS.dense_prediction_cell_json: + with tf.gfile.Open(FLAGS.dense_prediction_cell_json, 'r') as f: + dense_prediction_cell_config = json.load(f) + + return super(ModelOptions, cls).__new__( + cls, outputs_to_num_classes, crop_size, atrous_rates, output_stride, + FLAGS.merge_method, FLAGS.add_image_level_feature, + FLAGS.image_pooling_crop_size, FLAGS.aspp_with_batch_norm, + FLAGS.aspp_with_separable_conv, FLAGS.multi_grid, + FLAGS.decoder_output_stride, FLAGS.decoder_use_separable_conv, + FLAGS.logits_kernel_size, FLAGS.model_variant, FLAGS.depth_multiplier, + dense_prediction_cell_config) + + def __deepcopy__(self, memo): + return ModelOptions(copy.deepcopy(self.outputs_to_num_classes), + self.crop_size, + self.atrous_rates, + self.output_stride) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common_test.py" new file mode 100644 index 00000000..45b64e50 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/common_test.py" @@ -0,0 +1,52 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for common.py.""" +import copy + +import tensorflow as tf + +from deeplab import common + + +class CommonTest(tf.test.TestCase): + + def testOutputsToNumClasses(self): + num_classes = 21 + model_options = common.ModelOptions( + outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) + self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], + num_classes) + + def testDeepcopy(self): + num_classes = 21 + model_options = common.ModelOptions( + outputs_to_num_classes={common.OUTPUT_TYPE: num_classes}) + model_options_new = copy.deepcopy(model_options) + self.assertEqual((model_options_new. + outputs_to_num_classes[common.OUTPUT_TYPE]), + num_classes) + + num_classes_new = 22 + model_options_new.outputs_to_num_classes[common.OUTPUT_TYPE] = ( + num_classes_new) + self.assertEqual(model_options.outputs_to_num_classes[common.OUTPUT_TYPE], + num_classes) + self.assertEqual((model_options_new. + outputs_to_num_classes[common.OUTPUT_TYPE]), + num_classes_new) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell.py" new file mode 100644 index 00000000..c1498586 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell.py" @@ -0,0 +1,288 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Dense Prediction Cell class that can be evolved in semantic segmentation. + +DensePredictionCell is used as a `layer` in semantic segmentation whose +architecture is determined by the `config`, a dictionary specifying +the architecture. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + +from deeplab.core import utils + +slim = tf.contrib.slim + +# Local constants. +_META_ARCHITECTURE_SCOPE = 'meta_architecture' +_CONCAT_PROJECTION_SCOPE = 'concat_projection' +_OP = 'op' +_CONV = 'conv' +_PYRAMID_POOLING = 'pyramid_pooling' +_KERNEL = 'kernel' +_RATE = 'rate' +_GRID_SIZE = 'grid_size' +_TARGET_SIZE = 'target_size' +_INPUT = 'input' + + +def dense_prediction_cell_hparams(): + """DensePredictionCell HParams. + + Returns: + A dictionary of hyper-parameters used for dense prediction cell with keys: + - reduction_size: Integer, the number of output filters for each operation + inside the cell. + - dropout_on_concat_features: Boolean, apply dropout on the concatenated + features or not. + - dropout_on_projection_features: Boolean, apply dropout on the projection + features or not. + - dropout_keep_prob: Float, when `dropout_on_concat_features' or + `dropout_on_projection_features' is True, the `keep_prob` value used + in the dropout operation. + - concat_channels: Integer, the concatenated features will be + channel-reduced to `concat_channels` channels. + - conv_rate_multiplier: Integer, used to multiply the convolution rates. + This is useful in the case when the output_stride is changed from 16 + to 8, we need to double the convolution rates correspondingly. + """ + return { + 'reduction_size': 256, + 'dropout_on_concat_features': True, + 'dropout_on_projection_features': False, + 'dropout_keep_prob': 0.9, + 'concat_channels': 256, + 'conv_rate_multiplier': 1, + } + + +class DensePredictionCell(object): + """DensePredictionCell class used as a 'layer' in semantic segmentation.""" + + def __init__(self, config, hparams=None): + """Initializes the dense prediction cell. + + Args: + config: A dictionary storing the architecture of a dense prediction cell. + hparams: A dictionary of hyper-parameters, provided by users. This + dictionary will be used to update the default dictionary returned by + dense_prediction_cell_hparams(). + + Raises: + ValueError: If `conv_rate_multiplier` has value < 1. + """ + self.hparams = dense_prediction_cell_hparams() + if hparams is not None: + self.hparams.update(hparams) + self.config = config + + # Check values in hparams are valid or not. + if self.hparams['conv_rate_multiplier'] < 1: + raise ValueError('conv_rate_multiplier cannot have value < 1.') + + def _get_pyramid_pooling_arguments( + self, crop_size, output_stride, image_grid, image_pooling_crop_size=None): + """Gets arguments for pyramid pooling. + + Args: + crop_size: A list of two integers, [crop_height, crop_width] specifying + whole patch crop size. + output_stride: Integer, output stride value for extracted features. + image_grid: A list of two integers, [image_grid_height, image_grid_width], + specifying the grid size of how the pyramid pooling will be performed. + image_pooling_crop_size: A list of two integers, [crop_height, crop_width] + specifying the crop size for image pooling operations. Note that we + decouple whole patch crop_size and image_pooling_crop_size as one could + perform the image_pooling with different crop sizes. + + Returns: + A list of (resize_value, pooled_kernel) + """ + resize_height = utils.scale_dimension(crop_size[0], 1. / output_stride) + resize_width = utils.scale_dimension(crop_size[1], 1. / output_stride) + # If image_pooling_crop_size is not specified, use crop_size. + if image_pooling_crop_size is None: + image_pooling_crop_size = crop_size + pooled_height = utils.scale_dimension( + image_pooling_crop_size[0], 1. / (output_stride * image_grid[0])) + pooled_width = utils.scale_dimension( + image_pooling_crop_size[1], 1. / (output_stride * image_grid[1])) + return ([resize_height, resize_width], [pooled_height, pooled_width]) + + def _parse_operation(self, config, crop_size, output_stride, + image_pooling_crop_size=None): + """Parses one operation. + + When 'operation' is 'pyramid_pooling', we compute the required + hyper-parameters and save in config. + + Args: + config: A dictionary storing required hyper-parameters for one + operation. + crop_size: A list of two integers, [crop_height, crop_width] specifying + whole patch crop size. + output_stride: Integer, output stride value for extracted features. + image_pooling_crop_size: A list of two integers, [crop_height, crop_width] + specifying the crop size for image pooling operations. Note that we + decouple whole patch crop_size and image_pooling_crop_size as one could + perform the image_pooling with different crop sizes. + + Returns: + A dictionary stores the related information for the operation. + """ + if config[_OP] == _PYRAMID_POOLING: + (config[_TARGET_SIZE], + config[_KERNEL]) = self._get_pyramid_pooling_arguments( + crop_size=crop_size, + output_stride=output_stride, + image_grid=config[_GRID_SIZE], + image_pooling_crop_size=image_pooling_crop_size) + + return config + + def build_cell(self, + features, + output_stride=16, + crop_size=None, + image_pooling_crop_size=None, + weight_decay=0.00004, + reuse=None, + is_training=False, + fine_tune_batch_norm=False, + scope=None): + """Builds the dense prediction cell based on the config. + + Args: + features: Input feature map of size [batch, height, width, channels]. + output_stride: Int, output stride at which the features were extracted. + crop_size: A list [crop_height, crop_width], determining the input + features resolution. + image_pooling_crop_size: A list of two integers, [crop_height, crop_width] + specifying the crop size for image pooling operations. Note that we + decouple whole patch crop_size and image_pooling_crop_size as one could + perform the image_pooling with different crop sizes. + weight_decay: Float, the weight decay for model variables. + reuse: Reuse the model variables or not. + is_training: Boolean, is training or not. + fine_tune_batch_norm: Boolean, fine-tuning batch norm parameters or not. + scope: Optional string, specifying the variable scope. + + Returns: + Features after passing through the constructed dense prediction cell with + shape = [batch, height, width, channels] where channels are determined + by `reduction_size` returned by dense_prediction_cell_hparams(). + + Raises: + ValueError: Use Convolution with kernel size not equal to 1x1 or 3x3 or + the operation is not recognized. + """ + batch_norm_params = { + 'is_training': is_training and fine_tune_batch_norm, + 'decay': 0.9997, + 'epsilon': 1e-5, + 'scale': True, + } + hparams = self.hparams + with slim.arg_scope( + [slim.conv2d, slim.separable_conv2d], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + padding='SAME', + stride=1, + reuse=reuse): + with slim.arg_scope([slim.batch_norm], **batch_norm_params): + with tf.variable_scope(scope, _META_ARCHITECTURE_SCOPE, [features]): + depth = hparams['reduction_size'] + branch_logits = [] + for i, current_config in enumerate(self.config): + scope = 'branch%d' % i + current_config = self._parse_operation( + config=current_config, + crop_size=crop_size, + output_stride=output_stride, + image_pooling_crop_size=image_pooling_crop_size) + tf.logging.info(current_config) + if current_config[_INPUT] < 0: + operation_input = features + else: + operation_input = branch_logits[current_config[_INPUT]] + if current_config[_OP] == _CONV: + if current_config[_KERNEL] == [1, 1] or current_config[ + _KERNEL] == 1: + branch_logits.append( + slim.conv2d(operation_input, depth, 1, scope=scope)) + else: + conv_rate = [r * hparams['conv_rate_multiplier'] + for r in current_config[_RATE]] + branch_logits.append( + utils.split_separable_conv2d( + operation_input, + filters=depth, + kernel_size=current_config[_KERNEL], + rate=conv_rate, + weight_decay=weight_decay, + scope=scope)) + elif current_config[_OP] == _PYRAMID_POOLING: + pooled_features = slim.avg_pool2d( + operation_input, + kernel_size=current_config[_KERNEL], + stride=[1, 1], + padding='VALID') + pooled_features = slim.conv2d( + pooled_features, + depth, + 1, + scope=scope) + pooled_features = tf.image.resize_bilinear( + pooled_features, + current_config[_TARGET_SIZE], + align_corners=True) + # Set shape for resize_height/resize_width if they are not Tensor. + resize_height = current_config[_TARGET_SIZE][0] + resize_width = current_config[_TARGET_SIZE][1] + if isinstance(resize_height, tf.Tensor): + resize_height = None + if isinstance(resize_width, tf.Tensor): + resize_width = None + pooled_features.set_shape( + [None, resize_height, resize_width, depth]) + branch_logits.append(pooled_features) + else: + raise ValueError('Unrecognized operation.') + # Merge branch logits. + concat_logits = tf.concat(branch_logits, 3) + if self.hparams['dropout_on_concat_features']: + concat_logits = slim.dropout( + concat_logits, + keep_prob=self.hparams['dropout_keep_prob'], + is_training=is_training, + scope=_CONCAT_PROJECTION_SCOPE + '_dropout') + concat_logits = slim.conv2d(concat_logits, + self.hparams['concat_channels'], + 1, + scope=_CONCAT_PROJECTION_SCOPE) + if self.hparams['dropout_on_projection_features']: + concat_logits = slim.dropout( + concat_logits, + keep_prob=self.hparams['dropout_keep_prob'], + is_training=is_training, + scope=_CONCAT_PROJECTION_SCOPE + '_dropout') + return concat_logits \ No newline at end of file diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json" new file mode 100644 index 00000000..12b093d0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json" @@ -0,0 +1 @@ +[{"kernel": 3, "rate": [1, 6], "op": "conv", "input": -1}, {"kernel": 3, "rate": [18, 15], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 3], "op": "conv", "input": 1}, {"kernel": 3, "rate": [1, 1], "op": "conv", "input": 0}, {"kernel": 3, "rate": [6, 21], "op": "conv", "input": 0}] \ No newline at end of file diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_test.py" new file mode 100644 index 00000000..9ae84ae8 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/dense_prediction_cell_test.py" @@ -0,0 +1,135 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for dense_prediction_cell.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + +from deeplab.core import dense_prediction_cell + + +class DensePredictionCellTest(tf.test.TestCase): + + def setUp(self): + self.segmentation_layer = dense_prediction_cell.DensePredictionCell( + config=[ + { + dense_prediction_cell._INPUT: -1, + dense_prediction_cell._OP: dense_prediction_cell._CONV, + dense_prediction_cell._KERNEL: 1, + }, + { + dense_prediction_cell._INPUT: 0, + dense_prediction_cell._OP: dense_prediction_cell._CONV, + dense_prediction_cell._KERNEL: 3, + dense_prediction_cell._RATE: [1, 3], + }, + { + dense_prediction_cell._INPUT: 1, + dense_prediction_cell._OP: ( + dense_prediction_cell._PYRAMID_POOLING), + dense_prediction_cell._GRID_SIZE: [1, 2], + }, + ], + hparams={'conv_rate_multiplier': 2}) + + def testPyramidPoolingArguments(self): + features_size, pooled_kernel = ( + self.segmentation_layer._get_pyramid_pooling_arguments( + crop_size=[513, 513], + output_stride=16, + image_grid=[4, 4])) + self.assertListEqual(features_size, [33, 33]) + self.assertListEqual(pooled_kernel, [9, 9]) + + def testPyramidPoolingArgumentsWithImageGrid1x1(self): + features_size, pooled_kernel = ( + self.segmentation_layer._get_pyramid_pooling_arguments( + crop_size=[257, 257], + output_stride=16, + image_grid=[1, 1])) + self.assertListEqual(features_size, [17, 17]) + self.assertListEqual(pooled_kernel, [17, 17]) + + def testParseOperationStringWithConv1x1(self): + operation = self.segmentation_layer._parse_operation( + config={ + dense_prediction_cell._OP: dense_prediction_cell._CONV, + dense_prediction_cell._KERNEL: [1, 1], + }, + crop_size=[513, 513], output_stride=16) + self.assertEqual(operation[dense_prediction_cell._OP], + dense_prediction_cell._CONV) + self.assertListEqual(operation[dense_prediction_cell._KERNEL], [1, 1]) + + def testParseOperationStringWithConv3x3(self): + operation = self.segmentation_layer._parse_operation( + config={ + dense_prediction_cell._OP: dense_prediction_cell._CONV, + dense_prediction_cell._KERNEL: [3, 3], + dense_prediction_cell._RATE: [9, 6], + }, + crop_size=[513, 513], output_stride=16) + self.assertEqual(operation[dense_prediction_cell._OP], + dense_prediction_cell._CONV) + self.assertListEqual(operation[dense_prediction_cell._KERNEL], [3, 3]) + self.assertEqual(operation[dense_prediction_cell._RATE], [9, 6]) + + def testParseOperationStringWithPyramidPooling2x2(self): + operation = self.segmentation_layer._parse_operation( + config={ + dense_prediction_cell._OP: dense_prediction_cell._PYRAMID_POOLING, + dense_prediction_cell._GRID_SIZE: [2, 2], + }, + crop_size=[513, 513], + output_stride=16) + self.assertEqual(operation[dense_prediction_cell._OP], + dense_prediction_cell._PYRAMID_POOLING) + # The feature maps of size [33, 33] should be covered by 2x2 kernels with + # size [17, 17]. + self.assertListEqual( + operation[dense_prediction_cell._TARGET_SIZE], [33, 33]) + self.assertListEqual(operation[dense_prediction_cell._KERNEL], [17, 17]) + + def testBuildCell(self): + with self.test_session(graph=tf.Graph()) as sess: + features = tf.random_normal([2, 33, 33, 5]) + concat_logits = self.segmentation_layer.build_cell( + features, + output_stride=8, + crop_size=[257, 257]) + sess.run(tf.global_variables_initializer()) + concat_logits = sess.run(concat_logits) + self.assertTrue(concat_logits.any()) + + def testBuildCellWithImagePoolingCropSize(self): + with self.test_session(graph=tf.Graph()) as sess: + features = tf.random_normal([2, 33, 33, 5]) + concat_logits = self.segmentation_layer.build_cell( + features, + output_stride=8, + crop_size=[257, 257], + image_pooling_crop_size=[129, 129]) + sess.run(tf.global_variables_initializer()) + concat_logits = sess.run(concat_logits) + self.assertTrue(concat_logits.any()) + + +if __name__ == '__main__': + tf.test.main() \ No newline at end of file diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/feature_extractor.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/feature_extractor.py" new file mode 100644 index 00000000..da89dfe9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/feature_extractor.py" @@ -0,0 +1,330 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Extracts features for different models.""" +import functools +import tensorflow as tf + +from deeplab.core import resnet_v1_beta +from deeplab.core import xception +from tensorflow.contrib.slim.nets import resnet_utils +from nets.mobilenet import mobilenet_v2 + + +slim = tf.contrib.slim + +# Default end point for MobileNetv2. +_MOBILENET_V2_FINAL_ENDPOINT = 'layer_18' + + +def _mobilenet_v2(net, + depth_multiplier, + output_stride, + reuse=None, + scope=None, + final_endpoint=None): + """Auxiliary function to add support for 'reuse' to mobilenet_v2. + + Args: + net: Input tensor of shape [batch_size, height, width, channels]. + depth_multiplier: Float multiplier for the depth (number of channels) + for all convolution ops. The value must be greater than zero. Typical + usage will be to set this value in (0, 1) to reduce the number of + parameters or computation cost of the model. + output_stride: An integer that specifies the requested ratio of input to + output spatial resolution. If not None, then we invoke atrous convolution + if necessary to prevent the network from reducing the spatial resolution + of the activation maps. Allowed values are 8 (accurate fully convolutional + mode), 16 (fast fully convolutional mode), 32 (classification mode). + reuse: Reuse model variables. + scope: Optional variable scope. + final_endpoint: The endpoint to construct the network up to. + + Returns: + Features extracted by MobileNetv2. + """ + with tf.variable_scope( + scope, 'MobilenetV2', [net], reuse=reuse) as scope: + return mobilenet_v2.mobilenet_base( + net, + conv_defs=mobilenet_v2.V2_DEF, + depth_multiplier=depth_multiplier, + min_depth=8 if depth_multiplier == 1.0 else 1, + divisible_by=8 if depth_multiplier == 1.0 else 1, + final_endpoint=final_endpoint or _MOBILENET_V2_FINAL_ENDPOINT, + output_stride=output_stride, + scope=scope) + + +# A map from network name to network function. +networks_map = { + 'mobilenet_v2': _mobilenet_v2, + 'resnet_v1_50': resnet_v1_beta.resnet_v1_50, + 'resnet_v1_50_beta': resnet_v1_beta.resnet_v1_50_beta, + 'resnet_v1_101': resnet_v1_beta.resnet_v1_101, + 'resnet_v1_101_beta': resnet_v1_beta.resnet_v1_101_beta, + 'xception_41': xception.xception_41, + 'xception_65': xception.xception_65, + 'xception_71': xception.xception_71, +} + +# A map from network name to network arg scope. +arg_scopes_map = { + 'mobilenet_v2': mobilenet_v2.training_scope, + 'resnet_v1_50': resnet_utils.resnet_arg_scope, + 'resnet_v1_50_beta': resnet_utils.resnet_arg_scope, + 'resnet_v1_101': resnet_utils.resnet_arg_scope, + 'resnet_v1_101_beta': resnet_utils.resnet_arg_scope, + 'xception_41': xception.xception_arg_scope, + 'xception_65': xception.xception_arg_scope, + 'xception_71': xception.xception_arg_scope, +} + +# Names for end point features. +DECODER_END_POINTS = 'decoder_end_points' + +# A dictionary from network name to a map of end point features. +networks_to_feature_maps = { + 'mobilenet_v2': { + DECODER_END_POINTS: ['layer_4/depthwise_output'], + }, + 'resnet_v1_50': { + DECODER_END_POINTS: ['block1/unit_2/bottleneck_v1/conv3'], + }, + 'resnet_v1_50_beta': { + DECODER_END_POINTS: ['block1/unit_2/bottleneck_v1/conv3'], + }, + 'resnet_v1_101': { + DECODER_END_POINTS: ['block1/unit_2/bottleneck_v1/conv3'], + }, + 'resnet_v1_101_beta': { + DECODER_END_POINTS: ['block1/unit_2/bottleneck_v1/conv3'], + }, + 'xception_41': { + DECODER_END_POINTS: [ + 'entry_flow/block2/unit_1/xception_module/' + 'separable_conv2_pointwise', + ], + }, + 'xception_65': { + DECODER_END_POINTS: [ + 'entry_flow/block2/unit_1/xception_module/' + 'separable_conv2_pointwise', + ], + }, + 'xception_71': { + DECODER_END_POINTS: [ + 'entry_flow/block3/unit_1/xception_module/' + 'separable_conv2_pointwise', + ], + }, +} + +# A map from feature extractor name to the network name scope used in the +# ImageNet pretrained versions of these models. +name_scope = { + 'mobilenet_v2': 'MobilenetV2', + 'resnet_v1_50': 'resnet_v1_50', + 'resnet_v1_50_beta': 'resnet_v1_50', + 'resnet_v1_101': 'resnet_v1_101', + 'resnet_v1_101_beta': 'resnet_v1_101', + 'xception_41': 'xception_41', + 'xception_65': 'xception_65', + 'xception_71': 'xception_71', +} + +# Mean pixel value. +_MEAN_RGB = [123.15, 115.90, 103.06] + + +def _preprocess_subtract_imagenet_mean(inputs): + """Subtract Imagenet mean RGB value.""" + mean_rgb = tf.reshape(_MEAN_RGB, [1, 1, 1, 3]) + return inputs - mean_rgb + + +def _preprocess_zero_mean_unit_range(inputs): + """Map image values from [0, 255] to [-1, 1].""" + return (2.0 / 255.0) * tf.to_float(inputs) - 1.0 + + +_PREPROCESS_FN = { + 'mobilenet_v2': _preprocess_zero_mean_unit_range, + 'resnet_v1_50': _preprocess_subtract_imagenet_mean, + 'resnet_v1_50_beta': _preprocess_zero_mean_unit_range, + 'resnet_v1_101': _preprocess_subtract_imagenet_mean, + 'resnet_v1_101_beta': _preprocess_zero_mean_unit_range, + 'xception_41': _preprocess_zero_mean_unit_range, + 'xception_65': _preprocess_zero_mean_unit_range, + 'xception_71': _preprocess_zero_mean_unit_range, +} + + +def mean_pixel(model_variant=None): + """Gets mean pixel value. + + This function returns different mean pixel value, depending on the input + model_variant which adopts different preprocessing functions. We currently + handle the following preprocessing functions: + (1) _preprocess_subtract_imagenet_mean. We simply return mean pixel value. + (2) _preprocess_zero_mean_unit_range. We return [127.5, 127.5, 127.5]. + The return values are used in a way that the padded regions after + pre-processing will contain value 0. + + Args: + model_variant: Model variant (string) for feature extraction. For + backwards compatibility, model_variant=None returns _MEAN_RGB. + + Returns: + Mean pixel value. + """ + if model_variant in ['resnet_v1_50', + 'resnet_v1_101'] or model_variant is None: + return _MEAN_RGB + else: + return [127.5, 127.5, 127.5] + + +def extract_features(images, + output_stride=8, + multi_grid=None, + depth_multiplier=1.0, + final_endpoint=None, + model_variant=None, + weight_decay=0.0001, + reuse=None, + is_training=False, + fine_tune_batch_norm=False, + regularize_depthwise=False, + preprocess_images=True, + num_classes=None, + global_pool=False): + """Extracts features by the particular model_variant. + + Args: + images: A tensor of size [batch, height, width, channels]. + output_stride: The ratio of input to output spatial resolution. + multi_grid: Employ a hierarchy of different atrous rates within network. + depth_multiplier: Float multiplier for the depth (number of channels) + for all convolution ops used in MobileNet. + final_endpoint: The MobileNet endpoint to construct the network up to. + model_variant: Model variant for feature extraction. + weight_decay: The weight decay for model variables. + reuse: Reuse the model variables or not. + is_training: Is training or not. + fine_tune_batch_norm: Fine-tune the batch norm parameters or not. + regularize_depthwise: Whether or not apply L2-norm regularization on the + depthwise convolution weights. + preprocess_images: Performs preprocessing on images or not. Defaults to + True. Set to False if preprocessing will be done by other functions. We + supprot two types of preprocessing: (1) Mean pixel substraction and (2) + Pixel values normalization to be [-1, 1]. + num_classes: Number of classes for image classification task. Defaults + to None for dense prediction tasks. + global_pool: Global pooling for image classification task. Defaults to + False, since dense prediction tasks do not use this. + + Returns: + features: A tensor of size [batch, feature_height, feature_width, + feature_channels], where feature_height/feature_width are determined + by the images height/width and output_stride. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: Unrecognized model variant. + """ + if 'resnet' in model_variant: + arg_scope = arg_scopes_map[model_variant]( + weight_decay=weight_decay, + batch_norm_decay=0.95, + batch_norm_epsilon=1e-5, + batch_norm_scale=True) + features, end_points = get_network( + model_variant, preprocess_images, arg_scope)( + inputs=images, + num_classes=num_classes, + is_training=(is_training and fine_tune_batch_norm), + global_pool=global_pool, + output_stride=output_stride, + multi_grid=multi_grid, + reuse=reuse, + scope=name_scope[model_variant]) + elif 'xception' in model_variant: + arg_scope = arg_scopes_map[model_variant]( + weight_decay=weight_decay, + batch_norm_decay=0.9997, + batch_norm_epsilon=1e-3, + batch_norm_scale=True, + regularize_depthwise=regularize_depthwise) + features, end_points = get_network( + model_variant, preprocess_images, arg_scope)( + inputs=images, + num_classes=num_classes, + is_training=(is_training and fine_tune_batch_norm), + global_pool=global_pool, + output_stride=output_stride, + regularize_depthwise=regularize_depthwise, + multi_grid=multi_grid, + reuse=reuse, + scope=name_scope[model_variant]) + elif 'mobilenet' in model_variant: + arg_scope = arg_scopes_map[model_variant]( + is_training=(is_training and fine_tune_batch_norm), + weight_decay=weight_decay) + features, end_points = get_network( + model_variant, preprocess_images, arg_scope)( + inputs=images, + depth_multiplier=depth_multiplier, + output_stride=output_stride, + reuse=reuse, + scope=name_scope[model_variant], + final_endpoint=final_endpoint) + else: + raise ValueError('Unknown model variant %s.' % model_variant) + + return features, end_points + + +def get_network(network_name, preprocess_images, arg_scope=None): + """Gets the network. + + Args: + network_name: Network name. + preprocess_images: Preprocesses the images or not. + arg_scope: Optional, arg_scope to build the network. If not provided the + default arg_scope of the network would be used. + + Returns: + A network function that is used to extract features. + + Raises: + ValueError: network is not supported. + """ + if network_name not in networks_map: + raise ValueError('Unsupported network %s.' % network_name) + arg_scope = arg_scope or arg_scopes_map[network_name]() + def _identity_function(inputs): + return inputs + if preprocess_images: + preprocess_function = _PREPROCESS_FN[network_name] + else: + preprocess_function = _identity_function + func = networks_map[network_name] + @functools.wraps(func) + def network_fn(inputs, *args, **kwargs): + with slim.arg_scope(arg_scope): + return func(preprocess_function(inputs), *args, **kwargs) + return network_fn diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils.py" new file mode 100644 index 00000000..f6026505 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils.py" @@ -0,0 +1,445 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Utility functions related to preprocessing inputs.""" +import tensorflow as tf + + +def flip_dim(tensor_list, prob=0.5, dim=1): + """Randomly flips a dimension of the given tensor. + + The decision to randomly flip the `Tensors` is made together. In other words, + all or none of the images pass in are flipped. + + Note that tf.random_flip_left_right and tf.random_flip_up_down isn't used so + that we can control for the probability as well as ensure the same decision + is applied across the images. + + Args: + tensor_list: A list of `Tensors` with the same number of dimensions. + prob: The probability of a left-right flip. + dim: The dimension to flip, 0, 1, .. + + Returns: + outputs: A list of the possibly flipped `Tensors` as well as an indicator + `Tensor` at the end whose value is `True` if the inputs were flipped and + `False` otherwise. + + Raises: + ValueError: If dim is negative or greater than the dimension of a `Tensor`. + """ + random_value = tf.random_uniform([]) + + def flip(): + flipped = [] + for tensor in tensor_list: + if dim < 0 or dim >= len(tensor.get_shape().as_list()): + raise ValueError('dim must represent a valid dimension.') + flipped.append(tf.reverse_v2(tensor, [dim])) + return flipped + + is_flipped = tf.less_equal(random_value, prob) + outputs = tf.cond(is_flipped, flip, lambda: tensor_list) + if not isinstance(outputs, (list, tuple)): + outputs = [outputs] + outputs.append(is_flipped) + + return outputs + + +def pad_to_bounding_box(image, offset_height, offset_width, target_height, + target_width, pad_value): + """Pads the given image with the given pad_value. + + Works like tf.image.pad_to_bounding_box, except it can pad the image + with any given arbitrary pad value and also handle images whose sizes are not + known during graph construction. + + Args: + image: 3-D tensor with shape [height, width, channels] + offset_height: Number of rows of zeros to add on top. + offset_width: Number of columns of zeros to add on the left. + target_height: Height of output image. + target_width: Width of output image. + pad_value: Value to pad the image tensor with. + + Returns: + 3-D tensor of shape [target_height, target_width, channels]. + + Raises: + ValueError: If the shape of image is incompatible with the offset_* or + target_* arguments. + """ + image_rank = tf.rank(image) + image_rank_assert = tf.Assert( + tf.equal(image_rank, 3), + ['Wrong image tensor rank [Expected] [Actual]', + 3, image_rank]) + with tf.control_dependencies([image_rank_assert]): + image -= pad_value + image_shape = tf.shape(image) + height, width = image_shape[0], image_shape[1] + target_width_assert = tf.Assert( + tf.greater_equal( + target_width, width), + ['target_width must be >= width']) + target_height_assert = tf.Assert( + tf.greater_equal(target_height, height), + ['target_height must be >= height']) + with tf.control_dependencies([target_width_assert]): + after_padding_width = target_width - offset_width - width + with tf.control_dependencies([target_height_assert]): + after_padding_height = target_height - offset_height - height + offset_assert = tf.Assert( + tf.logical_and( + tf.greater_equal(after_padding_width, 0), + tf.greater_equal(after_padding_height, 0)), + ['target size not possible with the given target offsets']) + + height_params = tf.stack([offset_height, after_padding_height]) + width_params = tf.stack([offset_width, after_padding_width]) + channel_params = tf.stack([0, 0]) + with tf.control_dependencies([offset_assert]): + paddings = tf.stack([height_params, width_params, channel_params]) + padded = tf.pad(image, paddings) + return padded + pad_value + + +def _crop(image, offset_height, offset_width, crop_height, crop_width): + """Crops the given image using the provided offsets and sizes. + + Note that the method doesn't assume we know the input image size but it does + assume we know the input image rank. + + Args: + image: an image of shape [height, width, channels]. + offset_height: a scalar tensor indicating the height offset. + offset_width: a scalar tensor indicating the width offset. + crop_height: the height of the cropped image. + crop_width: the width of the cropped image. + + Returns: + The cropped (and resized) image. + + Raises: + ValueError: if `image` doesn't have rank of 3. + InvalidArgumentError: if the rank is not 3 or if the image dimensions are + less than the crop size. + """ + original_shape = tf.shape(image) + + if len(image.get_shape().as_list()) != 3: + raise ValueError('input must have rank of 3') + original_channels = image.get_shape().as_list()[2] + + rank_assertion = tf.Assert( + tf.equal(tf.rank(image), 3), + ['Rank of image must be equal to 3.']) + with tf.control_dependencies([rank_assertion]): + cropped_shape = tf.stack([crop_height, crop_width, original_shape[2]]) + + size_assertion = tf.Assert( + tf.logical_and( + tf.greater_equal(original_shape[0], crop_height), + tf.greater_equal(original_shape[1], crop_width)), + ['Crop size greater than the image size.']) + + offsets = tf.to_int32(tf.stack([offset_height, offset_width, 0])) + + # Use tf.slice instead of crop_to_bounding box as it accepts tensors to + # define the crop size. + with tf.control_dependencies([size_assertion]): + image = tf.slice(image, offsets, cropped_shape) + image = tf.reshape(image, cropped_shape) + image.set_shape([crop_height, crop_width, original_channels]) + return image + + +def random_crop(image_list, crop_height, crop_width): + """Crops the given list of images. + + The function applies the same crop to each image in the list. This can be + effectively applied when there are multiple image inputs of the same + dimension such as: + + image, depths, normals = random_crop([image, depths, normals], 120, 150) + + Args: + image_list: a list of image tensors of the same dimension but possibly + varying channel. + crop_height: the new height. + crop_width: the new width. + + Returns: + the image_list with cropped images. + + Raises: + ValueError: if there are multiple image inputs provided with different size + or the images are smaller than the crop dimensions. + """ + if not image_list: + raise ValueError('Empty image_list.') + + # Compute the rank assertions. + rank_assertions = [] + for i in range(len(image_list)): + image_rank = tf.rank(image_list[i]) + rank_assert = tf.Assert( + tf.equal(image_rank, 3), + ['Wrong rank for tensor %s [expected] [actual]', + image_list[i].name, 3, image_rank]) + rank_assertions.append(rank_assert) + + with tf.control_dependencies([rank_assertions[0]]): + image_shape = tf.shape(image_list[0]) + image_height = image_shape[0] + image_width = image_shape[1] + crop_size_assert = tf.Assert( + tf.logical_and( + tf.greater_equal(image_height, crop_height), + tf.greater_equal(image_width, crop_width)), + ['Crop size greater than the image size.']) + + asserts = [rank_assertions[0], crop_size_assert] + + for i in range(1, len(image_list)): + image = image_list[i] + asserts.append(rank_assertions[i]) + with tf.control_dependencies([rank_assertions[i]]): + shape = tf.shape(image) + height = shape[0] + width = shape[1] + + height_assert = tf.Assert( + tf.equal(height, image_height), + ['Wrong height for tensor %s [expected][actual]', + image.name, height, image_height]) + width_assert = tf.Assert( + tf.equal(width, image_width), + ['Wrong width for tensor %s [expected][actual]', + image.name, width, image_width]) + asserts.extend([height_assert, width_assert]) + + # Create a random bounding box. + # + # Use tf.random_uniform and not numpy.random.rand as doing the former would + # generate random numbers at graph eval time, unlike the latter which + # generates random numbers at graph definition time. + with tf.control_dependencies(asserts): + max_offset_height = tf.reshape(image_height - crop_height + 1, []) + max_offset_width = tf.reshape(image_width - crop_width + 1, []) + offset_height = tf.random_uniform( + [], maxval=max_offset_height, dtype=tf.int32) + offset_width = tf.random_uniform( + [], maxval=max_offset_width, dtype=tf.int32) + + return [_crop(image, offset_height, offset_width, + crop_height, crop_width) for image in image_list] + + +def get_random_scale(min_scale_factor, max_scale_factor, step_size): + """Gets a random scale value. + + Args: + min_scale_factor: Minimum scale value. + max_scale_factor: Maximum scale value. + step_size: The step size from minimum to maximum value. + + Returns: + A random scale value selected between minimum and maximum value. + + Raises: + ValueError: min_scale_factor has unexpected value. + """ + if min_scale_factor < 0 or min_scale_factor > max_scale_factor: + raise ValueError('Unexpected value of min_scale_factor.') + + if min_scale_factor == max_scale_factor: + return tf.to_float(min_scale_factor) + + # When step_size = 0, we sample the value uniformly from [min, max). + if step_size == 0: + return tf.random_uniform([1], + minval=min_scale_factor, + maxval=max_scale_factor) + + # When step_size != 0, we randomly select one discrete value from [min, max]. + num_steps = int((max_scale_factor - min_scale_factor) / step_size + 1) + scale_factors = tf.lin_space(min_scale_factor, max_scale_factor, num_steps) + shuffled_scale_factors = tf.random_shuffle(scale_factors) + return shuffled_scale_factors[0] + + +def randomly_scale_image_and_label(image, label=None, scale=1.0): + """Randomly scales image and label. + + Args: + image: Image with shape [height, width, 3]. + label: Label with shape [height, width, 1]. + scale: The value to scale image and label. + + Returns: + Scaled image and label. + """ + # No random scaling if scale == 1. + if scale == 1.0: + return image, label + image_shape = tf.shape(image) + new_dim = tf.to_int32(tf.to_float([image_shape[0], image_shape[1]]) * scale) + + # Need squeeze and expand_dims because image interpolation takes + # 4D tensors as input. + image = tf.squeeze(tf.image.resize_bilinear( + tf.expand_dims(image, 0), + new_dim, + align_corners=True), [0]) + if label is not None: + label = tf.squeeze(tf.image.resize_nearest_neighbor( + tf.expand_dims(label, 0), + new_dim, + align_corners=True), [0]) + + return image, label + + +def resolve_shape(tensor, rank=None, scope=None): + """Fully resolves the shape of a Tensor. + + Use as much as possible the shape components already known during graph + creation and resolve the remaining ones during runtime. + + Args: + tensor: Input tensor whose shape we query. + rank: The rank of the tensor, provided that we know it. + scope: Optional name scope. + + Returns: + shape: The full shape of the tensor. + """ + with tf.name_scope(scope, 'resolve_shape', [tensor]): + if rank is not None: + shape = tensor.get_shape().with_rank(rank).as_list() + else: + shape = tensor.get_shape().as_list() + + if None in shape: + shape_dynamic = tf.shape(tensor) + for i in range(len(shape)): + if shape[i] is None: + shape[i] = shape_dynamic[i] + + return shape + + +def resize_to_range(image, + label=None, + min_size=None, + max_size=None, + factor=None, + align_corners=True, + label_layout_is_chw=False, + scope=None, + method=tf.image.ResizeMethod.BILINEAR): + """Resizes image or label so their sides are within the provided range. + + The output size can be described by two cases: + 1. If the image can be rescaled so its minimum size is equal to min_size + without the other side exceeding max_size, then do so. + 2. Otherwise, resize so the largest side is equal to max_size. + + An integer in `range(factor)` is added to the computed sides so that the + final dimensions are multiples of `factor` plus one. + + Args: + image: A 3D tensor of shape [height, width, channels]. + label: (optional) A 3D tensor of shape [height, width, channels] (default) + or [channels, height, width] when label_layout_is_chw = True. + min_size: (scalar) desired size of the smaller image side. + max_size: (scalar) maximum allowed size of the larger image side. Note + that the output dimension is no larger than max_size and may be slightly + smaller than min_size when factor is not None. + factor: Make output size multiple of factor plus one. + align_corners: If True, exactly align all 4 corners of input and output. + label_layout_is_chw: If true, the label has shape [channel, height, width]. + We support this case because for some instance segmentation dataset, the + instance segmentation is saved as [num_instances, height, width]. + scope: Optional name scope. + method: Image resize method. Defaults to tf.image.ResizeMethod.BILINEAR. + + Returns: + A 3-D tensor of shape [new_height, new_width, channels], where the image + has been resized (with the specified method) so that + min(new_height, new_width) == ceil(min_size) or + max(new_height, new_width) == ceil(max_size). + + Raises: + ValueError: If the image is not a 3D tensor. + """ + with tf.name_scope(scope, 'resize_to_range', [image]): + new_tensor_list = [] + min_size = tf.to_float(min_size) + if max_size is not None: + max_size = tf.to_float(max_size) + # Modify the max_size to be a multiple of factor plus 1 and make sure the + # max dimension after resizing is no larger than max_size. + if factor is not None: + max_size = (max_size + (factor - (max_size - 1) % factor) % factor + - factor) + + [orig_height, orig_width, _] = resolve_shape(image, rank=3) + orig_height = tf.to_float(orig_height) + orig_width = tf.to_float(orig_width) + orig_min_size = tf.minimum(orig_height, orig_width) + + # Calculate the larger of the possible sizes + large_scale_factor = min_size / orig_min_size + large_height = tf.to_int32(tf.ceil(orig_height * large_scale_factor)) + large_width = tf.to_int32(tf.ceil(orig_width * large_scale_factor)) + large_size = tf.stack([large_height, large_width]) + + new_size = large_size + if max_size is not None: + # Calculate the smaller of the possible sizes, use that if the larger + # is too big. + orig_max_size = tf.maximum(orig_height, orig_width) + small_scale_factor = max_size / orig_max_size + small_height = tf.to_int32(tf.ceil(orig_height * small_scale_factor)) + small_width = tf.to_int32(tf.ceil(orig_width * small_scale_factor)) + small_size = tf.stack([small_height, small_width]) + new_size = tf.cond( + tf.to_float(tf.reduce_max(large_size)) > max_size, + lambda: small_size, + lambda: large_size) + # Ensure that both output sides are multiples of factor plus one. + if factor is not None: + new_size += (factor - (new_size - 1) % factor) % factor + new_tensor_list.append(tf.image.resize_images( + image, new_size, method=method, align_corners=align_corners)) + if label is not None: + if label_layout_is_chw: + # Input label has shape [channel, height, width]. + resized_label = tf.expand_dims(label, 3) + resized_label = tf.image.resize_nearest_neighbor( + resized_label, new_size, align_corners=align_corners) + resized_label = tf.squeeze(resized_label, 3) + else: + # Input label has shape [height, width, channel]. + resized_label = tf.image.resize_images( + label, new_size, method=tf.image.ResizeMethod.NEAREST_NEIGHBOR, + align_corners=align_corners) + new_tensor_list.append(resized_label) + else: + new_tensor_list.append(None) + return new_tensor_list diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils_test.py" new file mode 100644 index 00000000..bca14d4b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/preprocess_utils_test.py" @@ -0,0 +1,432 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for preprocess_utils.""" +import numpy as np +import tensorflow as tf + +from tensorflow.python.framework import errors +from deeplab.core import preprocess_utils + + +class PreprocessUtilsTest(tf.test.TestCase): + + def testNoFlipWhenProbIsZero(self): + numpy_image = np.dstack([[[5., 6.], + [9., 0.]], + [[4., 3.], + [3., 5.]]]) + image = tf.convert_to_tensor(numpy_image) + + with self.test_session(): + actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=0) + self.assertAllEqual(numpy_image, actual.eval()) + self.assertAllEqual(False, is_flipped.eval()) + actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=1) + self.assertAllEqual(numpy_image, actual.eval()) + self.assertAllEqual(False, is_flipped.eval()) + actual, is_flipped = preprocess_utils.flip_dim([image], prob=0, dim=2) + self.assertAllEqual(numpy_image, actual.eval()) + self.assertAllEqual(False, is_flipped.eval()) + + def testFlipWhenProbIsOne(self): + numpy_image = np.dstack([[[5., 6.], + [9., 0.]], + [[4., 3.], + [3., 5.]]]) + dim0_flipped = np.dstack([[[9., 0.], + [5., 6.]], + [[3., 5.], + [4., 3.]]]) + dim1_flipped = np.dstack([[[6., 5.], + [0., 9.]], + [[3., 4.], + [5., 3.]]]) + dim2_flipped = np.dstack([[[4., 3.], + [3., 5.]], + [[5., 6.], + [9., 0.]]]) + image = tf.convert_to_tensor(numpy_image) + + with self.test_session(): + actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=0) + self.assertAllEqual(dim0_flipped, actual.eval()) + self.assertAllEqual(True, is_flipped.eval()) + actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=1) + self.assertAllEqual(dim1_flipped, actual.eval()) + self.assertAllEqual(True, is_flipped.eval()) + actual, is_flipped = preprocess_utils.flip_dim([image], prob=1, dim=2) + self.assertAllEqual(dim2_flipped, actual.eval()) + self.assertAllEqual(True, is_flipped.eval()) + + def testFlipMultipleImagesConsistentlyWhenProbIsOne(self): + numpy_image = np.dstack([[[5., 6.], + [9., 0.]], + [[4., 3.], + [3., 5.]]]) + numpy_label = np.dstack([[[0., 1.], + [2., 3.]]]) + image_dim1_flipped = np.dstack([[[6., 5.], + [0., 9.]], + [[3., 4.], + [5., 3.]]]) + label_dim1_flipped = np.dstack([[[1., 0.], + [3., 2.]]]) + image = tf.convert_to_tensor(numpy_image) + label = tf.convert_to_tensor(numpy_label) + + with self.test_session() as sess: + image, label, is_flipped = preprocess_utils.flip_dim( + [image, label], prob=1, dim=1) + actual_image, actual_label = sess.run([image, label]) + self.assertAllEqual(image_dim1_flipped, actual_image) + self.assertAllEqual(label_dim1_flipped, actual_label) + self.assertEqual(True, is_flipped.eval()) + + def testReturnRandomFlipsOnMultipleEvals(self): + numpy_image = np.dstack([[[5., 6.], + [9., 0.]], + [[4., 3.], + [3., 5.]]]) + dim1_flipped = np.dstack([[[6., 5.], + [0., 9.]], + [[3., 4.], + [5., 3.]]]) + image = tf.convert_to_tensor(numpy_image) + tf.set_random_seed(53) + + with self.test_session() as sess: + actual, is_flipped = preprocess_utils.flip_dim( + [image], prob=0.5, dim=1) + actual_image, actual_is_flipped = sess.run([actual, is_flipped]) + self.assertAllEqual(numpy_image, actual_image) + self.assertEqual(False, actual_is_flipped) + actual_image, actual_is_flipped = sess.run([actual, is_flipped]) + self.assertAllEqual(dim1_flipped, actual_image) + self.assertEqual(True, actual_is_flipped) + + def testReturnCorrectCropOfSingleImage(self): + np.random.seed(0) + + height, width = 10, 20 + image = np.random.randint(0, 256, size=(height, width, 3)) + + crop_height, crop_width = 2, 4 + + image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) + [cropped] = preprocess_utils.random_crop([image_placeholder], + crop_height, + crop_width) + + with self.test_session(): + cropped_image = cropped.eval(feed_dict={image_placeholder: image}) + + # Ensure we can find the cropped image in the original: + is_found = False + for x in range(0, width - crop_width + 1): + for y in range(0, height - crop_height + 1): + if np.isclose(image[y:y+crop_height, x:x+crop_width, :], + cropped_image).all(): + is_found = True + break + + self.assertTrue(is_found) + + def testRandomCropMaintainsNumberOfChannels(self): + np.random.seed(0) + + crop_height, crop_width = 10, 20 + image = np.random.randint(0, 256, size=(100, 200, 3)) + + tf.set_random_seed(37) + image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) + [cropped] = preprocess_utils.random_crop( + [image_placeholder], crop_height, crop_width) + + with self.test_session(): + cropped_image = cropped.eval(feed_dict={image_placeholder: image}) + self.assertTupleEqual(cropped_image.shape, (crop_height, crop_width, 3)) + + def testReturnDifferentCropAreasOnTwoEvals(self): + tf.set_random_seed(0) + + crop_height, crop_width = 2, 3 + image = np.random.randint(0, 256, size=(100, 200, 3)) + image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) + [cropped] = preprocess_utils.random_crop( + [image_placeholder], crop_height, crop_width) + + with self.test_session(): + crop0 = cropped.eval(feed_dict={image_placeholder: image}) + crop1 = cropped.eval(feed_dict={image_placeholder: image}) + self.assertFalse(np.isclose(crop0, crop1).all()) + + def testReturnConsistenCropsOfImagesInTheList(self): + tf.set_random_seed(0) + + height, width = 10, 20 + crop_height, crop_width = 2, 3 + labels = np.linspace(0, height * width-1, height * width) + labels = labels.reshape((height, width, 1)) + image = np.tile(labels, (1, 1, 3)) + + image_placeholder = tf.placeholder(tf.int32, shape=(None, None, 3)) + label_placeholder = tf.placeholder(tf.int32, shape=(None, None, 1)) + [cropped_image, cropped_label] = preprocess_utils.random_crop( + [image_placeholder, label_placeholder], crop_height, crop_width) + + with self.test_session() as sess: + cropped_image, cropped_labels = sess.run([cropped_image, cropped_label], + feed_dict={ + image_placeholder: image, + label_placeholder: labels}) + for i in range(3): + self.assertAllEqual(cropped_image[:, :, i], cropped_labels.squeeze()) + + def testDieOnRandomCropWhenImagesWithDifferentWidth(self): + crop_height, crop_width = 2, 3 + image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) + image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) + cropped = preprocess_utils.random_crop( + [image1, image2], crop_height, crop_width) + + with self.test_session() as sess: + with self.assertRaises(errors.InvalidArgumentError): + sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), + image2: np.random.rand(4, 6, 1)}) + + def testDieOnRandomCropWhenImagesWithDifferentHeight(self): + crop_height, crop_width = 2, 3 + image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) + image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) + cropped = preprocess_utils.random_crop( + [image1, image2], crop_height, crop_width) + + with self.test_session() as sess: + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'Wrong height for tensor'): + sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), + image2: np.random.rand(3, 5, 1)}) + + def testDieOnRandomCropWhenCropSizeIsGreaterThanImage(self): + crop_height, crop_width = 5, 9 + image1 = tf.placeholder(tf.float32, name='image1', shape=(None, None, 3)) + image2 = tf.placeholder(tf.float32, name='image2', shape=(None, None, 1)) + cropped = preprocess_utils.random_crop( + [image1, image2], crop_height, crop_width) + + with self.test_session() as sess: + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'Crop size greater than the image size.'): + sess.run(cropped, feed_dict={image1: np.random.rand(4, 5, 3), + image2: np.random.rand(4, 5, 1)}) + + def testReturnPaddedImageWithNonZeroPadValue(self): + for dtype in [np.int32, np.int64, np.float32, np.float64]: + image = np.dstack([[[5, 6], + [9, 0]], + [[4, 3], + [3, 5]]]).astype(dtype) + expected_image = np.dstack([[[255, 255, 255, 255, 255], + [255, 255, 255, 255, 255], + [255, 5, 6, 255, 255], + [255, 9, 0, 255, 255], + [255, 255, 255, 255, 255]], + [[255, 255, 255, 255, 255], + [255, 255, 255, 255, 255], + [255, 4, 3, 255, 255], + [255, 3, 5, 255, 255], + [255, 255, 255, 255, 255]]]).astype(dtype) + + with self.test_session(): + image_placeholder = tf.placeholder(tf.float32) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 2, 1, 5, 5, 255) + self.assertAllClose(padded_image.eval( + feed_dict={image_placeholder: image}), expected_image) + + def testReturnOriginalImageWhenTargetSizeIsEqualToImageSize(self): + image = np.dstack([[[5, 6], + [9, 0]], + [[4, 3], + [3, 5]]]) + + with self.test_session(): + image_placeholder = tf.placeholder(tf.float32) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 0, 0, 2, 2, 255) + self.assertAllClose(padded_image.eval( + feed_dict={image_placeholder: image}), image) + + def testDieOnTargetSizeGreaterThanImageSize(self): + image = np.dstack([[[5, 6], + [9, 0]], + [[4, 3], + [3, 5]]]) + with self.test_session(): + image_placeholder = tf.placeholder(tf.float32) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 0, 0, 2, 1, 255) + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'target_width must be >= width'): + padded_image.eval(feed_dict={image_placeholder: image}) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 0, 0, 1, 2, 255) + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'target_height must be >= height'): + padded_image.eval(feed_dict={image_placeholder: image}) + + def testDieIfTargetSizeNotPossibleWithGivenOffset(self): + image = np.dstack([[[5, 6], + [9, 0]], + [[4, 3], + [3, 5]]]) + with self.test_session(): + image_placeholder = tf.placeholder(tf.float32) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 3, 0, 4, 4, 255) + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'target size not possible with the given target offsets'): + padded_image.eval(feed_dict={image_placeholder: image}) + + def testDieIfImageTensorRankIsNotThree(self): + image = np.vstack([[5, 6], + [9, 0]]) + with self.test_session(): + image_placeholder = tf.placeholder(tf.float32) + padded_image = preprocess_utils.pad_to_bounding_box( + image_placeholder, 0, 0, 2, 2, 255) + with self.assertRaisesWithPredicateMatch( + errors.InvalidArgumentError, + 'Wrong image tensor rank'): + padded_image.eval(feed_dict={image_placeholder: image}) + + def testResizeTensorsToRange(self): + test_shapes = [[60, 40], + [15, 30], + [15, 50]] + min_size = 50 + max_size = 100 + factor = None + expected_shape_list = [(75, 50, 3), + (50, 100, 3), + (30, 100, 3)] + for i, test_shape in enumerate(test_shapes): + image = tf.random_normal([test_shape[0], test_shape[1], 3]) + new_tensor_list = preprocess_utils.resize_to_range( + image=image, + label=None, + min_size=min_size, + max_size=max_size, + factor=factor, + align_corners=True) + with self.test_session() as session: + resized_image = session.run(new_tensor_list[0]) + self.assertEqual(resized_image.shape, expected_shape_list[i]) + + def testResizeTensorsToRangeWithFactor(self): + test_shapes = [[60, 40], + [15, 30], + [15, 50]] + min_size = 50 + max_size = 98 + factor = 8 + expected_image_shape_list = [(81, 57, 3), + (49, 97, 3), + (33, 97, 3)] + expected_label_shape_list = [(81, 57, 1), + (49, 97, 1), + (33, 97, 1)] + for i, test_shape in enumerate(test_shapes): + image = tf.random_normal([test_shape[0], test_shape[1], 3]) + label = tf.random_normal([test_shape[0], test_shape[1], 1]) + new_tensor_list = preprocess_utils.resize_to_range( + image=image, + label=label, + min_size=min_size, + max_size=max_size, + factor=factor, + align_corners=True) + with self.test_session() as session: + new_tensor_list = session.run(new_tensor_list) + self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) + self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) + + def testResizeTensorsToRangeWithFactorAndLabelShapeCHW(self): + test_shapes = [[60, 40], + [15, 30], + [15, 50]] + min_size = 50 + max_size = 98 + factor = 8 + expected_image_shape_list = [(81, 57, 3), + (49, 97, 3), + (33, 97, 3)] + expected_label_shape_list = [(5, 81, 57), + (5, 49, 97), + (5, 33, 97)] + for i, test_shape in enumerate(test_shapes): + image = tf.random_normal([test_shape[0], test_shape[1], 3]) + label = tf.random_normal([5, test_shape[0], test_shape[1]]) + new_tensor_list = preprocess_utils.resize_to_range( + image=image, + label=label, + min_size=min_size, + max_size=max_size, + factor=factor, + align_corners=True, + label_layout_is_chw=True) + with self.test_session() as session: + new_tensor_list = session.run(new_tensor_list) + self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) + self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) + + def testResizeTensorsToRangeWithSimilarMinMaxSizes(self): + test_shapes = [[60, 40], + [15, 30], + [15, 50]] + # Values set so that one of the side = 97. + min_size = 96 + max_size = 98 + factor = 8 + expected_image_shape_list = [(97, 65, 3), + (49, 97, 3), + (33, 97, 3)] + expected_label_shape_list = [(97, 65, 1), + (49, 97, 1), + (33, 97, 1)] + for i, test_shape in enumerate(test_shapes): + image = tf.random_normal([test_shape[0], test_shape[1], 3]) + label = tf.random_normal([test_shape[0], test_shape[1], 1]) + new_tensor_list = preprocess_utils.resize_to_range( + image=image, + label=label, + min_size=min_size, + max_size=max_size, + factor=factor, + align_corners=True) + with self.test_session() as session: + new_tensor_list = session.run(new_tensor_list) + self.assertEqual(new_tensor_list[0].shape, expected_image_shape_list[i]) + self.assertEqual(new_tensor_list[1].shape, expected_label_shape_list[i]) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta.py" new file mode 100644 index 00000000..91b72e43 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta.py" @@ -0,0 +1,517 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Resnet v1 model variants. + +Code branched out from slim/nets/resnet_v1.py, and please refer to it for +more details. + +The original version ResNets-v1 were proposed by: +[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun + Deep Residual Learning for Image Recognition. arXiv:1512.03385 +""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import functools +import tensorflow as tf + +from tensorflow.contrib.slim.nets import resnet_utils + +slim = tf.contrib.slim + +_DEFAULT_MULTI_GRID = [1, 1, 1] + + +@slim.add_arg_scope +def bottleneck(inputs, + depth, + depth_bottleneck, + stride, + unit_rate=1, + rate=1, + outputs_collections=None, + scope=None): + """Bottleneck residual unit variant with BN after convolutions. + + This is the original residual unit proposed in [1]. See Fig. 1(a) of [2] for + its definition. Note that we use here the bottleneck variant which has an + extra bottleneck layer. + + When putting together two consecutive ResNet blocks that use this unit, one + should use stride = 2 in the last unit of the first block. + + Args: + inputs: A tensor of size [batch, height, width, channels]. + depth: The depth of the ResNet unit output. + depth_bottleneck: The depth of the bottleneck layers. + stride: The ResNet unit's stride. Determines the amount of downsampling of + the units output compared to its input. + unit_rate: An integer, unit rate for atrous convolution. + rate: An integer, rate for atrous convolution. + outputs_collections: Collection to add the ResNet unit output. + scope: Optional variable_scope. + + Returns: + The ResNet unit's output. + """ + with tf.variable_scope(scope, 'bottleneck_v1', [inputs]) as sc: + depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4) + if depth == depth_in: + shortcut = resnet_utils.subsample(inputs, stride, 'shortcut') + else: + shortcut = slim.conv2d( + inputs, + depth, + [1, 1], + stride=stride, + activation_fn=None, + scope='shortcut') + + residual = slim.conv2d(inputs, depth_bottleneck, [1, 1], stride=1, + scope='conv1') + residual = resnet_utils.conv2d_same(residual, depth_bottleneck, 3, stride, + rate=rate*unit_rate, scope='conv2') + residual = slim.conv2d(residual, depth, [1, 1], stride=1, + activation_fn=None, scope='conv3') + output = tf.nn.relu(shortcut + residual) + + return slim.utils.collect_named_outputs(outputs_collections, + sc.name, + output) + + +def root_block_fn_for_beta_variant(net): + """Gets root_block_fn for beta variant. + + ResNet-v1 beta variant modifies the first original 7x7 convolution to three + 3x3 convolutions. + + Args: + net: A tensor of size [batch, height, width, channels], input to the model. + + Returns: + A tensor after three 3x3 convolutions. + """ + net = resnet_utils.conv2d_same(net, 64, 3, stride=2, scope='conv1_1') + net = resnet_utils.conv2d_same(net, 64, 3, stride=1, scope='conv1_2') + net = resnet_utils.conv2d_same(net, 128, 3, stride=1, scope='conv1_3') + + return net + + +def resnet_v1_beta(inputs, + blocks, + num_classes=None, + is_training=None, + global_pool=True, + output_stride=None, + root_block_fn=None, + reuse=None, + scope=None): + """Generator for v1 ResNet models (beta variant). + + This function generates a family of modified ResNet v1 models. In particular, + the first original 7x7 convolution is replaced with three 3x3 convolutions. + See the resnet_v1_*() methods for specific model instantiations, obtained by + selecting different block instantiations that produce ResNets of various + depths. + + The code is modified from slim/nets/resnet_v1.py, and please refer to it for + more details. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + blocks: A list of length equal to the number of ResNet blocks. Each element + is a resnet_utils.Block object describing the units in the block. + num_classes: Number of predicted classes for classification tasks. If None + we return the features before the logit layer. + is_training: Enable/disable is_training for batch normalization. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + root_block_fn: The function consisting of convolution operations applied to + the root input. If root_block_fn is None, use the original setting of + RseNet-v1, which is simply one convolution with 7x7 kernel and stride=2. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is None, then + net is the output of the last ResNet block, potentially after global + average pooling. If num_classes is not None, net contains the pre-softmax + activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: If the target output_stride is not valid. + """ + if root_block_fn is None: + root_block_fn = functools.partial(resnet_utils.conv2d_same, + num_outputs=64, + kernel_size=7, + stride=2, + scope='conv1') + with tf.variable_scope(scope, 'resnet_v1', [inputs], reuse=reuse) as sc: + end_points_collection = sc.original_name_scope + '_end_points' + with slim.arg_scope([slim.conv2d, bottleneck, + resnet_utils.stack_blocks_dense], + outputs_collections=end_points_collection): + if is_training is not None: + arg_scope = slim.arg_scope([slim.batch_norm], is_training=is_training) + else: + arg_scope = slim.arg_scope([]) + with arg_scope: + net = inputs + if output_stride is not None: + if output_stride % 4 != 0: + raise ValueError('The output_stride needs to be a multiple of 4.') + output_stride /= 4 + net = root_block_fn(net) + net = slim.max_pool2d(net, 3, stride=2, padding='SAME', scope='pool1') + net = resnet_utils.stack_blocks_dense(net, blocks, output_stride) + + if global_pool: + # Global average pooling. + net = tf.reduce_mean(net, [1, 2], name='pool5', keepdims=True) + if num_classes is not None: + net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, + normalizer_fn=None, scope='logits') + # Convert end_points_collection into a dictionary of end_points. + end_points = slim.utils.convert_collection_to_dict( + end_points_collection) + if num_classes is not None: + end_points['predictions'] = slim.softmax(net, scope='predictions') + return net, end_points + + +def resnet_v1_beta_block(scope, base_depth, num_units, stride): + """Helper function for creating a resnet_v1 beta variant bottleneck block. + + Args: + scope: The scope of the block. + base_depth: The depth of the bottleneck layer for each unit. + num_units: The number of units in the block. + stride: The stride of the block, implemented as a stride in the last unit. + All other units have stride=1. + + Returns: + A resnet_v1 bottleneck block. + """ + return resnet_utils.Block(scope, bottleneck, [{ + 'depth': base_depth * 4, + 'depth_bottleneck': base_depth, + 'stride': 1, + 'unit_rate': 1 + }] * (num_units - 1) + [{ + 'depth': base_depth * 4, + 'depth_bottleneck': base_depth, + 'stride': stride, + 'unit_rate': 1 + }]) + + +def resnet_v1_50(inputs, + num_classes=None, + is_training=None, + global_pool=False, + output_stride=None, + multi_grid=None, + reuse=None, + scope='resnet_v1_50'): + """Resnet v1 50. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + num_classes: Number of predicted classes for classification tasks. If None + we return the features before the logit layer. + is_training: Enable/disable is_training for batch normalization. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + multi_grid: Employ a hierarchy of different atrous rates within network. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is None, then + net is the output of the last ResNet block, potentially after global + average pooling. If num_classes is not None, net contains the pre-softmax + activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: if multi_grid is not None and does not have length = 3. + """ + if multi_grid is None: + multi_grid = _DEFAULT_MULTI_GRID + else: + if len(multi_grid) != 3: + raise ValueError('Expect multi_grid to have length 3.') + + blocks = [ + resnet_v1_beta_block( + 'block1', base_depth=64, num_units=3, stride=2), + resnet_v1_beta_block( + 'block2', base_depth=128, num_units=4, stride=2), + resnet_v1_beta_block( + 'block3', base_depth=256, num_units=6, stride=2), + resnet_utils.Block('block4', bottleneck, [ + {'depth': 2048, + 'depth_bottleneck': 512, + 'stride': 1, + 'unit_rate': rate} for rate in multi_grid]), + ] + return resnet_v1_beta( + inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + +def resnet_v1_50_beta(inputs, + num_classes=None, + is_training=None, + global_pool=False, + output_stride=None, + multi_grid=None, + reuse=None, + scope='resnet_v1_50'): + """Resnet v1 50 beta variant. + + This variant modifies the first convolution layer of ResNet-v1-50. In + particular, it changes the original one 7x7 convolution to three 3x3 + convolutions. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + num_classes: Number of predicted classes for classification tasks. If None + we return the features before the logit layer. + is_training: Enable/disable is_training for batch normalization. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + multi_grid: Employ a hierarchy of different atrous rates within network. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is None, then + net is the output of the last ResNet block, potentially after global + average pooling. If num_classes is not None, net contains the pre-softmax + activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: if multi_grid is not None and does not have length = 3. + """ + if multi_grid is None: + multi_grid = _DEFAULT_MULTI_GRID + else: + if len(multi_grid) != 3: + raise ValueError('Expect multi_grid to have length 3.') + + blocks = [ + resnet_v1_beta_block( + 'block1', base_depth=64, num_units=3, stride=2), + resnet_v1_beta_block( + 'block2', base_depth=128, num_units=4, stride=2), + resnet_v1_beta_block( + 'block3', base_depth=256, num_units=6, stride=2), + resnet_utils.Block('block4', bottleneck, [ + {'depth': 2048, + 'depth_bottleneck': 512, + 'stride': 1, + 'unit_rate': rate} for rate in multi_grid]), + ] + return resnet_v1_beta( + inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + root_block_fn=functools.partial(root_block_fn_for_beta_variant), + reuse=reuse, + scope=scope) + + +def resnet_v1_101(inputs, + num_classes=None, + is_training=None, + global_pool=False, + output_stride=None, + multi_grid=None, + reuse=None, + scope='resnet_v1_101'): + """Resnet v1 101. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + num_classes: Number of predicted classes for classification tasks. If None + we return the features before the logit layer. + is_training: Enable/disable is_training for batch normalization. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + multi_grid: Employ a hierarchy of different atrous rates within network. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is None, then + net is the output of the last ResNet block, potentially after global + average pooling. If num_classes is not None, net contains the pre-softmax + activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: if multi_grid is not None and does not have length = 3. + """ + if multi_grid is None: + multi_grid = _DEFAULT_MULTI_GRID + else: + if len(multi_grid) != 3: + raise ValueError('Expect multi_grid to have length 3.') + + blocks = [ + resnet_v1_beta_block( + 'block1', base_depth=64, num_units=3, stride=2), + resnet_v1_beta_block( + 'block2', base_depth=128, num_units=4, stride=2), + resnet_v1_beta_block( + 'block3', base_depth=256, num_units=23, stride=2), + resnet_utils.Block('block4', bottleneck, [ + {'depth': 2048, + 'depth_bottleneck': 512, + 'stride': 1, + 'unit_rate': rate} for rate in multi_grid]), + ] + return resnet_v1_beta( + inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + +def resnet_v1_101_beta(inputs, + num_classes=None, + is_training=None, + global_pool=False, + output_stride=None, + multi_grid=None, + reuse=None, + scope='resnet_v1_101'): + """Resnet v1 101 beta variant. + + This variant modifies the first convolution layer of ResNet-v1-101. In + particular, it changes the original one 7x7 convolution to three 3x3 + convolutions. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + num_classes: Number of predicted classes for classification tasks. If None + we return the features before the logit layer. + is_training: Enable/disable is_training for batch normalization. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + multi_grid: Employ a hierarchy of different atrous rates within network. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is None, then + net is the output of the last ResNet block, potentially after global + average pooling. If num_classes is not None, net contains the pre-softmax + activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: if multi_grid is not None and does not have length = 3. + """ + if multi_grid is None: + multi_grid = _DEFAULT_MULTI_GRID + else: + if len(multi_grid) != 3: + raise ValueError('Expect multi_grid to have length 3.') + + blocks = [ + resnet_v1_beta_block( + 'block1', base_depth=64, num_units=3, stride=2), + resnet_v1_beta_block( + 'block2', base_depth=128, num_units=4, stride=2), + resnet_v1_beta_block( + 'block3', base_depth=256, num_units=23, stride=2), + resnet_utils.Block('block4', bottleneck, [ + {'depth': 2048, + 'depth_bottleneck': 512, + 'stride': 1, + 'unit_rate': rate} for rate in multi_grid]), + ] + return resnet_v1_beta( + inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + root_block_fn=functools.partial(root_block_fn_for_beta_variant), + reuse=reuse, + scope=scope) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta_test.py" new file mode 100644 index 00000000..49ea3eeb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/resnet_v1_beta_test.py" @@ -0,0 +1,274 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for resnet_v1_beta module.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import functools + +import numpy as np +import tensorflow as tf + +from deeplab.core import resnet_v1_beta +from tensorflow.contrib.slim.nets import resnet_utils + +slim = tf.contrib.slim + + +def create_test_input(batch, height, width, channels): + """Create test input tensor.""" + if None in [batch, height, width, channels]: + return tf.placeholder(tf.float32, (batch, height, width, channels)) + else: + return tf.to_float( + np.tile( + np.reshape( + np.reshape(np.arange(height), [height, 1]) + + np.reshape(np.arange(width), [1, width]), + [1, height, width, 1]), + [batch, 1, 1, channels])) + + +class ResnetCompleteNetworkTest(tf.test.TestCase): + """Tests with complete small ResNet v1 networks.""" + + def _resnet_small(self, + inputs, + num_classes=None, + is_training=True, + global_pool=True, + output_stride=None, + multi_grid=None, + reuse=None, + scope='resnet_v1_small'): + """A shallow and thin ResNet v1 for faster tests.""" + if multi_grid is None: + multi_grid = [1, 1, 1] + else: + if len(multi_grid) != 3: + raise ValueError('Expect multi_grid to have length 3.') + + block = resnet_v1_beta.resnet_v1_beta_block + blocks = [ + block('block1', base_depth=1, num_units=3, stride=2), + block('block2', base_depth=2, num_units=3, stride=2), + block('block3', base_depth=4, num_units=3, stride=2), + resnet_utils.Block('block4', resnet_v1_beta.bottleneck, [ + {'depth': 32, + 'depth_bottleneck': 8, + 'stride': 1, + 'unit_rate': rate} for rate in multi_grid])] + + return resnet_v1_beta.resnet_v1_beta( + inputs, + blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + root_block_fn=functools.partial( + resnet_v1_beta.root_block_fn_for_beta_variant), + reuse=reuse, + scope=scope) + + def testClassificationEndPoints(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + logits, end_points = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + scope='resnet') + + self.assertTrue(logits.op.name.startswith('resnet/logits')) + self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) + self.assertTrue('predictions' in end_points) + self.assertListEqual(end_points['predictions'].get_shape().as_list(), + [2, 1, 1, num_classes]) + + def testClassificationEndPointsWithMultigrid(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + multi_grid = [1, 2, 4] + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + logits, end_points = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + multi_grid=multi_grid, + scope='resnet') + + self.assertTrue(logits.op.name.startswith('resnet/logits')) + self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) + self.assertTrue('predictions' in end_points) + self.assertListEqual(end_points['predictions'].get_shape().as_list(), + [2, 1, 1, num_classes]) + + def testClassificationShapes(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + _, end_points = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + scope='resnet') + endpoint_to_shape = { + 'resnet/conv1_1': [2, 112, 112, 64], + 'resnet/conv1_2': [2, 112, 112, 64], + 'resnet/conv1_3': [2, 112, 112, 128], + 'resnet/block1': [2, 28, 28, 4], + 'resnet/block2': [2, 14, 14, 8], + 'resnet/block3': [2, 7, 7, 16], + 'resnet/block4': [2, 7, 7, 32]} + for endpoint, shape in endpoint_to_shape.iteritems(): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testFullyConvolutionalEndpointShapes(self): + global_pool = False + num_classes = 10 + inputs = create_test_input(2, 321, 321, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + _, end_points = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + scope='resnet') + endpoint_to_shape = { + 'resnet/conv1_1': [2, 161, 161, 64], + 'resnet/conv1_2': [2, 161, 161, 64], + 'resnet/conv1_3': [2, 161, 161, 128], + 'resnet/block1': [2, 41, 41, 4], + 'resnet/block2': [2, 21, 21, 8], + 'resnet/block3': [2, 11, 11, 16], + 'resnet/block4': [2, 11, 11, 32]} + for endpoint, shape in endpoint_to_shape.iteritems(): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testAtrousFullyConvolutionalEndpointShapes(self): + global_pool = False + num_classes = 10 + output_stride = 8 + inputs = create_test_input(2, 321, 321, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + _, end_points = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + output_stride=output_stride, + scope='resnet') + endpoint_to_shape = { + 'resnet/conv1_1': [2, 161, 161, 64], + 'resnet/conv1_2': [2, 161, 161, 64], + 'resnet/conv1_3': [2, 161, 161, 128], + 'resnet/block1': [2, 41, 41, 4], + 'resnet/block2': [2, 41, 41, 8], + 'resnet/block3': [2, 41, 41, 16], + 'resnet/block4': [2, 41, 41, 32]} + for endpoint, shape in endpoint_to_shape.iteritems(): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testAtrousFullyConvolutionalValues(self): + """Verify dense feature extraction with atrous convolution.""" + nominal_stride = 32 + for output_stride in [4, 8, 16, 32, None]: + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + with tf.Graph().as_default(): + with self.test_session() as sess: + tf.set_random_seed(0) + inputs = create_test_input(2, 81, 81, 3) + # Dense feature extraction followed by subsampling. + output, _ = self._resnet_small(inputs, + None, + is_training=False, + global_pool=False, + output_stride=output_stride) + if output_stride is None: + factor = 1 + else: + factor = nominal_stride // output_stride + output = resnet_utils.subsample(output, factor) + # Make the two networks use the same weights. + tf.get_variable_scope().reuse_variables() + # Feature extraction at the nominal network rate. + expected, _ = self._resnet_small(inputs, + None, + is_training=False, + global_pool=False) + sess.run(tf.global_variables_initializer()) + self.assertAllClose(output.eval(), expected.eval(), + atol=1e-4, rtol=1e-4) + + def testUnknownBatchSize(self): + batch = 2 + height, width = 65, 65 + global_pool = True + num_classes = 10 + inputs = create_test_input(None, height, width, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + logits, _ = self._resnet_small(inputs, + num_classes, + global_pool=global_pool, + scope='resnet') + self.assertTrue(logits.op.name.startswith('resnet/logits')) + self.assertListEqual(logits.get_shape().as_list(), + [None, 1, 1, num_classes]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(logits, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 1, 1, num_classes)) + + def testFullyConvolutionalUnknownHeightWidth(self): + batch = 2 + height, width = 65, 65 + global_pool = False + inputs = create_test_input(batch, None, None, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + output, _ = self._resnet_small(inputs, + None, + global_pool=global_pool) + self.assertListEqual(output.get_shape().as_list(), + [batch, None, None, 32]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(output, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 3, 3, 32)) + + def testAtrousFullyConvolutionalUnknownHeightWidth(self): + batch = 2 + height, width = 65, 65 + global_pool = False + output_stride = 8 + inputs = create_test_input(batch, None, None, 3) + with slim.arg_scope(resnet_utils.resnet_arg_scope()): + output, _ = self._resnet_small(inputs, + None, + global_pool=global_pool, + output_stride=output_stride) + self.assertListEqual(output.get_shape().as_list(), + [batch, None, None, 32]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(output, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 9, 9, 32)) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils.py" new file mode 100644 index 00000000..60a87430 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils.py" @@ -0,0 +1,84 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""This script contains utility functions.""" +import tensorflow as tf + +slim = tf.contrib.slim + + +def scale_dimension(dim, scale): + """Scales the input dimension. + + Args: + dim: Input dimension (a scalar or a scalar Tensor). + scale: The amount of scaling applied to the input. + + Returns: + Scaled dimension. + """ + if isinstance(dim, tf.Tensor): + return tf.cast((tf.to_float(dim) - 1.0) * scale + 1.0, dtype=tf.int32) + else: + return int((float(dim) - 1.0) * scale + 1.0) + + +def split_separable_conv2d(inputs, + filters, + kernel_size=3, + rate=1, + weight_decay=0.00004, + depthwise_weights_initializer_stddev=0.33, + pointwise_weights_initializer_stddev=0.06, + scope=None): + """Splits a separable conv2d into depthwise and pointwise conv2d. + + This operation differs from `tf.layers.separable_conv2d` as this operation + applies activation function between depthwise and pointwise conv2d. + + Args: + inputs: Input tensor with shape [batch, height, width, channels]. + filters: Number of filters in the 1x1 pointwise convolution. + kernel_size: A list of length 2: [kernel_height, kernel_width] of + of the filters. Can be an int if both values are the same. + rate: Atrous convolution rate for the depthwise convolution. + weight_decay: The weight decay to use for regularizing the model. + depthwise_weights_initializer_stddev: The standard deviation of the + truncated normal weight initializer for depthwise convolution. + pointwise_weights_initializer_stddev: The standard deviation of the + truncated normal weight initializer for pointwise convolution. + scope: Optional scope for the operation. + + Returns: + Computed features after split separable conv2d. + """ + outputs = slim.separable_conv2d( + inputs, + None, + kernel_size=kernel_size, + depth_multiplier=1, + rate=rate, + weights_initializer=tf.truncated_normal_initializer( + stddev=depthwise_weights_initializer_stddev), + weights_regularizer=None, + scope=scope + '_depthwise') + return slim.conv2d( + outputs, + filters, + 1, + weights_initializer=tf.truncated_normal_initializer( + stddev=pointwise_weights_initializer_stddev), + weights_regularizer=slim.l2_regularizer(weight_decay), + scope=scope + '_pointwise') \ No newline at end of file diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils_test.py" new file mode 100644 index 00000000..83843282 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/utils_test.py" @@ -0,0 +1,32 @@ + +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for utils.py.""" + +import tensorflow as tf + +from deeplab.core import utils + + +class UtilsTest(tf.test.TestCase): + + def testScaleDimensionOutput(self): + self.assertEqual(161, utils.scale_dimension(321, 0.5)) + self.assertEqual(193, utils.scale_dimension(321, 0.6)) + self.assertEqual(241, utils.scale_dimension(321, 0.75)) + + +if __name__ == '__main__': + tf.test.main() \ No newline at end of file diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception.py" new file mode 100644 index 00000000..6fd306cb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception.py" @@ -0,0 +1,761 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +r"""Xception model. + +"Xception: Deep Learning with Depthwise Separable Convolutions" +Fran{\c{c}}ois Chollet +https://arxiv.org/abs/1610.02357 + +We implement the modified version by Jifeng Dai et al. for their COCO 2017 +detection challenge submission, where the model is made deeper and has aligned +features for dense prediction tasks. See their slides for details: + +"Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge +2017 Entry" +Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei and Jifeng Dai +ICCV 2017 COCO Challenge workshop +http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf + +We made a few more changes on top of MSRA's modifications: +1. Fully convolutional: All the max-pooling layers are replaced with separable + conv2d with stride = 2. This allows us to use atrous convolution to extract + feature maps at any resolution. + +2. We support adding ReLU and BatchNorm after depthwise convolution, motivated + by the design of MobileNetv1. + +"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision +Applications" +Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, +Tobias Weyand, Marco Andreetto, Hartwig Adam +https://arxiv.org/abs/1704.04861 +""" +import collections +import tensorflow as tf + +from tensorflow.contrib.slim.nets import resnet_utils + +slim = tf.contrib.slim + + +_DEFAULT_MULTI_GRID = [1, 1, 1] + + +class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])): + """A named tuple describing an Xception block. + + Its parts are: + scope: The scope of the block. + unit_fn: The Xception unit function which takes as input a tensor and + returns another tensor with the output of the Xception unit. + args: A list of length equal to the number of units in the block. The list + contains one dictionary for each unit in the block to serve as argument to + unit_fn. + """ + + +def fixed_padding(inputs, kernel_size, rate=1): + """Pads the input along the spatial dimensions independently of input size. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. + kernel_size: The kernel to be used in the conv2d or max_pool2d operation. + Should be a positive integer. + rate: An integer, rate for atrous convolution. + + Returns: + output: A tensor of size [batch, height_out, width_out, channels] with the + input, either intact (if kernel_size == 1) or padded (if kernel_size > 1). + """ + kernel_size_effective = kernel_size + (kernel_size - 1) * (rate - 1) + pad_total = kernel_size_effective - 1 + pad_beg = pad_total // 2 + pad_end = pad_total - pad_beg + padded_inputs = tf.pad(inputs, [[0, 0], [pad_beg, pad_end], + [pad_beg, pad_end], [0, 0]]) + return padded_inputs + + +@slim.add_arg_scope +def separable_conv2d_same(inputs, + num_outputs, + kernel_size, + depth_multiplier, + stride, + rate=1, + use_explicit_padding=True, + regularize_depthwise=False, + scope=None, + **kwargs): + """Strided 2-D separable convolution with 'SAME' padding. + + If stride > 1 and use_explicit_padding is True, then we do explicit zero- + padding, followed by conv2d with 'VALID' padding. + + Note that + + net = separable_conv2d_same(inputs, num_outputs, 3, + depth_multiplier=1, stride=stride) + + is equivalent to + + net = slim.separable_conv2d(inputs, num_outputs, 3, + depth_multiplier=1, stride=1, padding='SAME') + net = resnet_utils.subsample(net, factor=stride) + + whereas + + net = slim.separable_conv2d(inputs, num_outputs, 3, stride=stride, + depth_multiplier=1, padding='SAME') + + is different when the input's height or width is even, which is why we add the + current function. + + Consequently, if the input feature map has even height or width, setting + `use_explicit_padding=False` will result in feature misalignment by one pixel + along the corresponding dimension. + + Args: + inputs: A 4-D tensor of size [batch, height_in, width_in, channels]. + num_outputs: An integer, the number of output filters. + kernel_size: An int with the kernel_size of the filters. + depth_multiplier: The number of depthwise convolution output channels for + each input channel. The total number of depthwise convolution output + channels will be equal to `num_filters_in * depth_multiplier`. + stride: An integer, the output stride. + rate: An integer, rate for atrous convolution. + use_explicit_padding: If True, use explicit padding to make the model fully + compatible with the open source version, otherwise use the native + Tensorflow 'SAME' padding. + regularize_depthwise: Whether or not apply L2-norm regularization on the + depthwise convolution weights. + scope: Scope. + **kwargs: additional keyword arguments to pass to slim.conv2d + + Returns: + output: A 4-D tensor of size [batch, height_out, width_out, channels] with + the convolution output. + """ + def _separable_conv2d(padding): + """Wrapper for separable conv2d.""" + return slim.separable_conv2d(inputs, + num_outputs, + kernel_size, + depth_multiplier=depth_multiplier, + stride=stride, + rate=rate, + padding=padding, + scope=scope, + **kwargs) + def _split_separable_conv2d(padding): + """Splits separable conv2d into depthwise and pointwise conv2d.""" + outputs = slim.separable_conv2d(inputs, + None, + kernel_size, + depth_multiplier=depth_multiplier, + stride=stride, + rate=rate, + padding=padding, + scope=scope + '_depthwise', + **kwargs) + return slim.conv2d(outputs, + num_outputs, + 1, + scope=scope + '_pointwise', + **kwargs) + if stride == 1 or not use_explicit_padding: + if regularize_depthwise: + outputs = _separable_conv2d(padding='SAME') + else: + outputs = _split_separable_conv2d(padding='SAME') + else: + inputs = fixed_padding(inputs, kernel_size, rate) + if regularize_depthwise: + outputs = _separable_conv2d(padding='VALID') + else: + outputs = _split_separable_conv2d(padding='VALID') + return outputs + + +@slim.add_arg_scope +def xception_module(inputs, + depth_list, + skip_connection_type, + stride, + unit_rate_list=None, + rate=1, + activation_fn_in_separable_conv=False, + regularize_depthwise=False, + outputs_collections=None, + scope=None): + """An Xception module. + + The output of one Xception module is equal to the sum of `residual` and + `shortcut`, where `residual` is the feature computed by three separable + convolution. The `shortcut` is the feature computed by 1x1 convolution with + or without striding. In some cases, the `shortcut` path could be a simple + identity function or none (i.e, no shortcut). + + Note that we replace the max pooling operations in the Xception module with + another separable convolution with striding, since atrous rate is not properly + supported in current TensorFlow max pooling implementation. + + Args: + inputs: A tensor of size [batch, height, width, channels]. + depth_list: A list of three integers specifying the depth values of one + Xception module. + skip_connection_type: Skip connection type for the residual path. Only + supports 'conv', 'sum', or 'none'. + stride: The block unit's stride. Determines the amount of downsampling of + the units output compared to its input. + unit_rate_list: A list of three integers, determining the unit rate for + each separable convolution in the xception module. + rate: An integer, rate for atrous convolution. + activation_fn_in_separable_conv: Includes activation function in the + separable convolution or not. + regularize_depthwise: Whether or not apply L2-norm regularization on the + depthwise convolution weights. + outputs_collections: Collection to add the Xception unit output. + scope: Optional variable_scope. + + Returns: + The Xception module's output. + + Raises: + ValueError: If depth_list and unit_rate_list do not contain three elements, + or if stride != 1 for the third separable convolution operation in the + residual path, or unsupported skip connection type. + """ + if len(depth_list) != 3: + raise ValueError('Expect three elements in depth_list.') + if unit_rate_list: + if len(unit_rate_list) != 3: + raise ValueError('Expect three elements in unit_rate_list.') + + with tf.variable_scope(scope, 'xception_module', [inputs]) as sc: + residual = inputs + + def _separable_conv(features, depth, kernel_size, depth_multiplier, + regularize_depthwise, rate, stride, scope): + if activation_fn_in_separable_conv: + activation_fn = tf.nn.relu + else: + activation_fn = None + features = tf.nn.relu(features) + return separable_conv2d_same(features, + depth, + kernel_size, + depth_multiplier=depth_multiplier, + stride=stride, + rate=rate, + activation_fn=activation_fn, + regularize_depthwise=regularize_depthwise, + scope=scope) + for i in range(3): + residual = _separable_conv(residual, + depth_list[i], + kernel_size=3, + depth_multiplier=1, + regularize_depthwise=regularize_depthwise, + rate=rate*unit_rate_list[i], + stride=stride if i == 2 else 1, + scope='separable_conv' + str(i+1)) + if skip_connection_type == 'conv': + shortcut = slim.conv2d(inputs, + depth_list[-1], + [1, 1], + stride=stride, + activation_fn=None, + scope='shortcut') + outputs = residual + shortcut + elif skip_connection_type == 'sum': + outputs = residual + inputs + elif skip_connection_type == 'none': + outputs = residual + else: + raise ValueError('Unsupported skip connection type.') + + return slim.utils.collect_named_outputs(outputs_collections, + sc.name, + outputs) + + +@slim.add_arg_scope +def stack_blocks_dense(net, + blocks, + output_stride=None, + outputs_collections=None): + """Stacks Xception blocks and controls output feature density. + + First, this function creates scopes for the Xception in the form of + 'block_name/unit_1', 'block_name/unit_2', etc. + + Second, this function allows the user to explicitly control the output + stride, which is the ratio of the input to output spatial resolution. This + is useful for dense prediction tasks such as semantic segmentation or + object detection. + + Control of the output feature density is implemented by atrous convolution. + + Args: + net: A tensor of size [batch, height, width, channels]. + blocks: A list of length equal to the number of Xception blocks. Each + element is an Xception Block object describing the units in the block. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution, which needs to be equal to + the product of unit strides from the start up to some level of Xception. + For example, if the Xception employs units with strides 1, 2, 1, 3, 4, 1, + then valid values for the output_stride are 1, 2, 6, 24 or None (which + is equivalent to output_stride=24). + outputs_collections: Collection to add the Xception block outputs. + + Returns: + net: Output tensor with stride equal to the specified output_stride. + + Raises: + ValueError: If the target output_stride is not valid. + """ + # The current_stride variable keeps track of the effective stride of the + # activations. This allows us to invoke atrous convolution whenever applying + # the next residual unit would result in the activations having stride larger + # than the target output_stride. + current_stride = 1 + + # The atrous convolution rate parameter. + rate = 1 + + for block in blocks: + with tf.variable_scope(block.scope, 'block', [net]) as sc: + for i, unit in enumerate(block.args): + if output_stride is not None and current_stride > output_stride: + raise ValueError('The target output_stride cannot be reached.') + with tf.variable_scope('unit_%d' % (i + 1), values=[net]): + # If we have reached the target output_stride, then we need to employ + # atrous convolution with stride=1 and multiply the atrous rate by the + # current unit's stride for use in subsequent layers. + if output_stride is not None and current_stride == output_stride: + net = block.unit_fn(net, rate=rate, **dict(unit, stride=1)) + rate *= unit.get('stride', 1) + else: + net = block.unit_fn(net, rate=1, **unit) + current_stride *= unit.get('stride', 1) + + # Collect activations at the block's end before performing subsampling. + net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net) + + if output_stride is not None and current_stride != output_stride: + raise ValueError('The target output_stride cannot be reached.') + + return net + + +def xception(inputs, + blocks, + num_classes=None, + is_training=True, + global_pool=True, + keep_prob=0.5, + output_stride=None, + reuse=None, + scope=None): + """Generator for Xception models. + + This function generates a family of Xception models. See the xception_*() + methods for specific model instantiations, obtained by selecting different + block instantiations that produce Xception of various depths. + + Args: + inputs: A tensor of size [batch, height_in, width_in, channels]. Must be + floating point. If a pretrained checkpoint is used, pixel values should be + the same as during training (see go/slim-classification-models for + specifics). + blocks: A list of length equal to the number of Xception blocks. Each + element is an Xception Block object describing the units in the block. + num_classes: Number of predicted classes for classification tasks. + If 0 or None, we return the features before the logit layer. + is_training: whether batch_norm layers are in training mode. + global_pool: If True, we perform global average pooling before computing the + logits. Set to True for image classification, False for dense prediction. + keep_prob: Keep probability used in the pre-logits dropout layer. + output_stride: If None, then the output will be computed at the nominal + network stride. If output_stride is not None, it specifies the requested + ratio of input to output spatial resolution. + reuse: whether or not the network and its variables should be reused. To be + able to reuse 'scope' must be given. + scope: Optional variable_scope. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is False, then height_out and width_out are reduced by a + factor of output_stride compared to the respective height_in and width_in, + else both height_out and width_out equal one. If num_classes is 0 or None, + then net is the output of the last Xception block, potentially after + global average pooling. If num_classes is a non-zero integer, net contains + the pre-softmax activations. + end_points: A dictionary from components of the network to the corresponding + activation. + + Raises: + ValueError: If the target output_stride is not valid. + """ + with tf.variable_scope( + scope, 'xception', [inputs], reuse=reuse) as sc: + end_points_collection = sc.original_name_scope + 'end_points' + with slim.arg_scope([slim.conv2d, + slim.separable_conv2d, + xception_module, + stack_blocks_dense], + outputs_collections=end_points_collection): + with slim.arg_scope([slim.batch_norm], is_training=is_training): + net = inputs + if output_stride is not None: + if output_stride % 2 != 0: + raise ValueError('The output_stride needs to be a multiple of 2.') + output_stride /= 2 + # Root block function operated on inputs. + net = resnet_utils.conv2d_same(net, 32, 3, stride=2, + scope='entry_flow/conv1_1') + net = resnet_utils.conv2d_same(net, 64, 3, stride=1, + scope='entry_flow/conv1_2') + + # Extract features for entry_flow, middle_flow, and exit_flow. + net = stack_blocks_dense(net, blocks, output_stride) + + # Convert end_points_collection into a dictionary of end_points. + end_points = slim.utils.convert_collection_to_dict( + end_points_collection, clear_collection=True) + + if global_pool: + # Global average pooling. + net = tf.reduce_mean(net, [1, 2], name='global_pool', keepdims=True) + end_points['global_pool'] = net + if num_classes: + net = slim.dropout(net, keep_prob=keep_prob, is_training=is_training, + scope='prelogits_dropout') + net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None, + normalizer_fn=None, scope='logits') + end_points[sc.name + '/logits'] = net + end_points['predictions'] = slim.softmax(net, scope='predictions') + return net, end_points + + +def xception_block(scope, + depth_list, + skip_connection_type, + activation_fn_in_separable_conv, + regularize_depthwise, + num_units, + stride, + unit_rate_list=None): + """Helper function for creating a Xception block. + + Args: + scope: The scope of the block. + depth_list: The depth of the bottleneck layer for each unit. + skip_connection_type: Skip connection type for the residual path. Only + supports 'conv', 'sum', or 'none'. + activation_fn_in_separable_conv: Includes activation function in the + separable convolution or not. + regularize_depthwise: Whether or not apply L2-norm regularization on the + depthwise convolution weights. + num_units: The number of units in the block. + stride: The stride of the block, implemented as a stride in the last unit. + All other units have stride=1. + unit_rate_list: A list of three integers, determining the unit rate in the + corresponding xception block. + + Returns: + An Xception block. + """ + if unit_rate_list is None: + unit_rate_list = _DEFAULT_MULTI_GRID + return Block(scope, xception_module, [{ + 'depth_list': depth_list, + 'skip_connection_type': skip_connection_type, + 'activation_fn_in_separable_conv': activation_fn_in_separable_conv, + 'regularize_depthwise': regularize_depthwise, + 'stride': stride, + 'unit_rate_list': unit_rate_list, + }] * num_units) + + +def xception_41(inputs, + num_classes=None, + is_training=True, + global_pool=True, + keep_prob=0.5, + output_stride=None, + regularize_depthwise=False, + multi_grid=None, + reuse=None, + scope='xception_41'): + """Xception-41 model.""" + blocks = [ + xception_block('entry_flow/block1', + depth_list=[128, 128, 128], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block2', + depth_list=[256, 256, 256], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block3', + depth_list=[728, 728, 728], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('middle_flow/block1', + depth_list=[728, 728, 728], + skip_connection_type='sum', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=8, + stride=1), + xception_block('exit_flow/block1', + depth_list=[728, 1024, 1024], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('exit_flow/block2', + depth_list=[1536, 1536, 2048], + skip_connection_type='none', + activation_fn_in_separable_conv=True, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1, + unit_rate_list=multi_grid), + ] + return xception(inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + keep_prob=keep_prob, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + +def xception_65(inputs, + num_classes=None, + is_training=True, + global_pool=True, + keep_prob=0.5, + output_stride=None, + regularize_depthwise=False, + multi_grid=None, + reuse=None, + scope='xception_65'): + """Xception-65 model.""" + blocks = [ + xception_block('entry_flow/block1', + depth_list=[128, 128, 128], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block2', + depth_list=[256, 256, 256], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block3', + depth_list=[728, 728, 728], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('middle_flow/block1', + depth_list=[728, 728, 728], + skip_connection_type='sum', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=16, + stride=1), + xception_block('exit_flow/block1', + depth_list=[728, 1024, 1024], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('exit_flow/block2', + depth_list=[1536, 1536, 2048], + skip_connection_type='none', + activation_fn_in_separable_conv=True, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1, + unit_rate_list=multi_grid), + ] + return xception(inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + keep_prob=keep_prob, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + +def xception_71(inputs, + num_classes=None, + is_training=True, + global_pool=True, + keep_prob=0.5, + output_stride=None, + regularize_depthwise=False, + multi_grid=None, + reuse=None, + scope='xception_71'): + """Xception-71 model.""" + blocks = [ + xception_block('entry_flow/block1', + depth_list=[128, 128, 128], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block2', + depth_list=[256, 256, 256], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1), + xception_block('entry_flow/block3', + depth_list=[256, 256, 256], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('entry_flow/block4', + depth_list=[728, 728, 728], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1), + xception_block('entry_flow/block5', + depth_list=[728, 728, 728], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('middle_flow/block1', + depth_list=[728, 728, 728], + skip_connection_type='sum', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=16, + stride=1), + xception_block('exit_flow/block1', + depth_list=[728, 1024, 1024], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + xception_block('exit_flow/block2', + depth_list=[1536, 1536, 2048], + skip_connection_type='none', + activation_fn_in_separable_conv=True, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1, + unit_rate_list=multi_grid), + ] + return xception(inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + keep_prob=keep_prob, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + +def xception_arg_scope(weight_decay=0.00004, + batch_norm_decay=0.9997, + batch_norm_epsilon=0.001, + batch_norm_scale=True, + weights_initializer_stddev=0.09, + activation_fn=tf.nn.relu, + regularize_depthwise=False, + use_batch_norm=True): + """Defines the default Xception arg scope. + + Args: + weight_decay: The weight decay to use for regularizing the model. + batch_norm_decay: The moving average decay when estimating layer activation + statistics in batch normalization. + batch_norm_epsilon: Small constant to prevent division by zero when + normalizing activations by their variance in batch normalization. + batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the + activations in the batch normalization layer. + weights_initializer_stddev: The standard deviation of the trunctated normal + weight initializer. + activation_fn: The activation function in Xception. + regularize_depthwise: Whether or not apply L2-norm regularization on the + depthwise convolution weights. + use_batch_norm: Whether or not to use batch normalization. + + Returns: + An `arg_scope` to use for the Xception models. + """ + batch_norm_params = { + 'decay': batch_norm_decay, + 'epsilon': batch_norm_epsilon, + 'scale': batch_norm_scale, + } + if regularize_depthwise: + depthwise_regularizer = slim.l2_regularizer(weight_decay) + else: + depthwise_regularizer = None + with slim.arg_scope( + [slim.conv2d, slim.separable_conv2d], + weights_initializer=tf.truncated_normal_initializer( + stddev=weights_initializer_stddev), + activation_fn=activation_fn, + normalizer_fn=slim.batch_norm if use_batch_norm else None): + with slim.arg_scope([slim.batch_norm], **batch_norm_params): + with slim.arg_scope( + [slim.conv2d], + weights_regularizer=slim.l2_regularizer(weight_decay)): + with slim.arg_scope( + [slim.separable_conv2d], + weights_regularizer=depthwise_regularizer) as arg_sc: + return arg_sc diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception_test.py" new file mode 100644 index 00000000..4ef25ba5 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/core/xception_test.py" @@ -0,0 +1,467 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for xception.py.""" +import numpy as np +import six +import tensorflow as tf + +from deeplab.core import xception +from tensorflow.contrib.slim.nets import resnet_utils + +slim = tf.contrib.slim + + +def create_test_input(batch, height, width, channels): + """Create test input tensor.""" + if None in [batch, height, width, channels]: + return tf.placeholder(tf.float32, (batch, height, width, channels)) + else: + return tf.to_float( + np.tile( + np.reshape( + np.reshape(np.arange(height), [height, 1]) + + np.reshape(np.arange(width), [1, width]), + [1, height, width, 1]), + [batch, 1, 1, channels])) + + +class UtilityFunctionTest(tf.test.TestCase): + + def testSeparableConv2DSameWithInputEvenSize(self): + n, n2 = 4, 2 + + # Input image. + x = create_test_input(1, n, n, 1) + + # Convolution kernel. + dw = create_test_input(1, 3, 3, 1) + dw = tf.reshape(dw, [3, 3, 1, 1]) + + tf.get_variable('Conv/depthwise_weights', initializer=dw) + tf.get_variable('Conv/pointwise_weights', + initializer=tf.ones([1, 1, 1, 1])) + tf.get_variable('Conv/biases', initializer=tf.zeros([1])) + tf.get_variable_scope().reuse_variables() + + y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, + stride=1, scope='Conv') + y1_expected = tf.to_float([[14, 28, 43, 26], + [28, 48, 66, 37], + [43, 66, 84, 46], + [26, 37, 46, 22]]) + y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) + + y2 = resnet_utils.subsample(y1, 2) + y2_expected = tf.to_float([[14, 43], + [43, 84]]) + y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) + + y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, + regularize_depthwise=True, + stride=2, scope='Conv') + y3_expected = y2_expected + + y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, + stride=2, scope='Conv') + y4_expected = tf.to_float([[48, 37], + [37, 22]]) + y4_expected = tf.reshape(y4_expected, [1, n2, n2, 1]) + + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + self.assertAllClose(y1.eval(), y1_expected.eval()) + self.assertAllClose(y2.eval(), y2_expected.eval()) + self.assertAllClose(y3.eval(), y3_expected.eval()) + self.assertAllClose(y4.eval(), y4_expected.eval()) + + def testSeparableConv2DSameWithInputOddSize(self): + n, n2 = 5, 3 + + # Input image. + x = create_test_input(1, n, n, 1) + + # Convolution kernel. + dw = create_test_input(1, 3, 3, 1) + dw = tf.reshape(dw, [3, 3, 1, 1]) + + tf.get_variable('Conv/depthwise_weights', initializer=dw) + tf.get_variable('Conv/pointwise_weights', + initializer=tf.ones([1, 1, 1, 1])) + tf.get_variable('Conv/biases', initializer=tf.zeros([1])) + tf.get_variable_scope().reuse_variables() + + y1 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, + stride=1, scope='Conv') + y1_expected = tf.to_float([[14, 28, 43, 58, 34], + [28, 48, 66, 84, 46], + [43, 66, 84, 102, 55], + [58, 84, 102, 120, 64], + [34, 46, 55, 64, 30]]) + y1_expected = tf.reshape(y1_expected, [1, n, n, 1]) + + y2 = resnet_utils.subsample(y1, 2) + y2_expected = tf.to_float([[14, 43, 34], + [43, 84, 55], + [34, 55, 30]]) + y2_expected = tf.reshape(y2_expected, [1, n2, n2, 1]) + + y3 = xception.separable_conv2d_same(x, 1, 3, depth_multiplier=1, + regularize_depthwise=True, + stride=2, scope='Conv') + y3_expected = y2_expected + + y4 = slim.separable_conv2d(x, 1, [3, 3], depth_multiplier=1, + stride=2, scope='Conv') + y4_expected = y2_expected + + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + self.assertAllClose(y1.eval(), y1_expected.eval()) + self.assertAllClose(y2.eval(), y2_expected.eval()) + self.assertAllClose(y3.eval(), y3_expected.eval()) + self.assertAllClose(y4.eval(), y4_expected.eval()) + + +class XceptionNetworkTest(tf.test.TestCase): + """Tests with small Xception network.""" + + def _xception_small(self, + inputs, + num_classes=None, + is_training=True, + global_pool=True, + output_stride=None, + regularize_depthwise=True, + reuse=None, + scope='xception_small'): + """A shallow and thin Xception for faster tests.""" + block = xception.xception_block + blocks = [ + block('entry_flow/block1', + depth_list=[1, 1, 1], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + block('entry_flow/block2', + depth_list=[2, 2, 2], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + block('entry_flow/block3', + depth_list=[4, 4, 4], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1), + block('entry_flow/block4', + depth_list=[4, 4, 4], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + block('middle_flow/block1', + depth_list=[4, 4, 4], + skip_connection_type='sum', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=2, + stride=1), + block('exit_flow/block1', + depth_list=[8, 8, 8], + skip_connection_type='conv', + activation_fn_in_separable_conv=False, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=2), + block('exit_flow/block2', + depth_list=[16, 16, 16], + skip_connection_type='none', + activation_fn_in_separable_conv=True, + regularize_depthwise=regularize_depthwise, + num_units=1, + stride=1), + ] + return xception.xception(inputs, + blocks=blocks, + num_classes=num_classes, + is_training=is_training, + global_pool=global_pool, + output_stride=output_stride, + reuse=reuse, + scope=scope) + + def testClassificationEndPoints(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + with slim.arg_scope(xception.xception_arg_scope()): + logits, end_points = self._xception_small( + inputs, + num_classes=num_classes, + global_pool=global_pool, + scope='xception') + self.assertTrue( + logits.op.name.startswith('xception/logits')) + self.assertListEqual(logits.get_shape().as_list(), [2, 1, 1, num_classes]) + self.assertTrue('predictions' in end_points) + self.assertListEqual(end_points['predictions'].get_shape().as_list(), + [2, 1, 1, num_classes]) + self.assertTrue('global_pool' in end_points) + self.assertListEqual(end_points['global_pool'].get_shape().as_list(), + [2, 1, 1, 16]) + + def testEndpointNames(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points = self._xception_small( + inputs, + num_classes=num_classes, + global_pool=global_pool, + scope='xception') + expected = [ + 'xception/entry_flow/conv1_1', + 'xception/entry_flow/conv1_2', + 'xception/entry_flow/block1/unit_1/xception_module/separable_conv1', + 'xception/entry_flow/block1/unit_1/xception_module/separable_conv2', + 'xception/entry_flow/block1/unit_1/xception_module/separable_conv3', + 'xception/entry_flow/block1/unit_1/xception_module/shortcut', + 'xception/entry_flow/block1/unit_1/xception_module', + 'xception/entry_flow/block1', + 'xception/entry_flow/block2/unit_1/xception_module/separable_conv1', + 'xception/entry_flow/block2/unit_1/xception_module/separable_conv2', + 'xception/entry_flow/block2/unit_1/xception_module/separable_conv3', + 'xception/entry_flow/block2/unit_1/xception_module/shortcut', + 'xception/entry_flow/block2/unit_1/xception_module', + 'xception/entry_flow/block2', + 'xception/entry_flow/block3/unit_1/xception_module/separable_conv1', + 'xception/entry_flow/block3/unit_1/xception_module/separable_conv2', + 'xception/entry_flow/block3/unit_1/xception_module/separable_conv3', + 'xception/entry_flow/block3/unit_1/xception_module/shortcut', + 'xception/entry_flow/block3/unit_1/xception_module', + 'xception/entry_flow/block3', + 'xception/entry_flow/block4/unit_1/xception_module/separable_conv1', + 'xception/entry_flow/block4/unit_1/xception_module/separable_conv2', + 'xception/entry_flow/block4/unit_1/xception_module/separable_conv3', + 'xception/entry_flow/block4/unit_1/xception_module/shortcut', + 'xception/entry_flow/block4/unit_1/xception_module', + 'xception/entry_flow/block4', + 'xception/middle_flow/block1/unit_1/xception_module/separable_conv1', + 'xception/middle_flow/block1/unit_1/xception_module/separable_conv2', + 'xception/middle_flow/block1/unit_1/xception_module/separable_conv3', + 'xception/middle_flow/block1/unit_1/xception_module', + 'xception/middle_flow/block1/unit_2/xception_module/separable_conv1', + 'xception/middle_flow/block1/unit_2/xception_module/separable_conv2', + 'xception/middle_flow/block1/unit_2/xception_module/separable_conv3', + 'xception/middle_flow/block1/unit_2/xception_module', + 'xception/middle_flow/block1', + 'xception/exit_flow/block1/unit_1/xception_module/separable_conv1', + 'xception/exit_flow/block1/unit_1/xception_module/separable_conv2', + 'xception/exit_flow/block1/unit_1/xception_module/separable_conv3', + 'xception/exit_flow/block1/unit_1/xception_module/shortcut', + 'xception/exit_flow/block1/unit_1/xception_module', + 'xception/exit_flow/block1', + 'xception/exit_flow/block2/unit_1/xception_module/separable_conv1', + 'xception/exit_flow/block2/unit_1/xception_module/separable_conv2', + 'xception/exit_flow/block2/unit_1/xception_module/separable_conv3', + 'xception/exit_flow/block2/unit_1/xception_module', + 'xception/exit_flow/block2', + 'global_pool', + 'xception/logits', + 'predictions', + ] + self.assertItemsEqual(end_points.keys(), expected) + + def testClassificationShapes(self): + global_pool = True + num_classes = 10 + inputs = create_test_input(2, 224, 224, 3) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points = self._xception_small( + inputs, + num_classes, + global_pool=global_pool, + scope='xception') + endpoint_to_shape = { + 'xception/entry_flow/conv1_1': [2, 112, 112, 32], + 'xception/entry_flow/block1': [2, 56, 56, 1], + 'xception/entry_flow/block2': [2, 28, 28, 2], + 'xception/entry_flow/block4': [2, 14, 14, 4], + 'xception/middle_flow/block1': [2, 14, 14, 4], + 'xception/exit_flow/block1': [2, 7, 7, 8], + 'xception/exit_flow/block2': [2, 7, 7, 16]} + for endpoint, shape in six.iteritems(endpoint_to_shape): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testFullyConvolutionalEndpointShapes(self): + global_pool = False + num_classes = 10 + inputs = create_test_input(2, 321, 321, 3) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points = self._xception_small( + inputs, + num_classes, + global_pool=global_pool, + scope='xception') + endpoint_to_shape = { + 'xception/entry_flow/conv1_1': [2, 161, 161, 32], + 'xception/entry_flow/block1': [2, 81, 81, 1], + 'xception/entry_flow/block2': [2, 41, 41, 2], + 'xception/entry_flow/block4': [2, 21, 21, 4], + 'xception/middle_flow/block1': [2, 21, 21, 4], + 'xception/exit_flow/block1': [2, 11, 11, 8], + 'xception/exit_flow/block2': [2, 11, 11, 16]} + for endpoint, shape in six.iteritems(endpoint_to_shape): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testAtrousFullyConvolutionalEndpointShapes(self): + global_pool = False + num_classes = 10 + output_stride = 8 + inputs = create_test_input(2, 321, 321, 3) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points = self._xception_small( + inputs, + num_classes, + global_pool=global_pool, + output_stride=output_stride, + scope='xception') + endpoint_to_shape = { + 'xception/entry_flow/block1': [2, 81, 81, 1], + 'xception/entry_flow/block2': [2, 41, 41, 2], + 'xception/entry_flow/block4': [2, 41, 41, 4], + 'xception/middle_flow/block1': [2, 41, 41, 4], + 'xception/exit_flow/block1': [2, 41, 41, 8], + 'xception/exit_flow/block2': [2, 41, 41, 16]} + for endpoint, shape in six.iteritems(endpoint_to_shape): + self.assertListEqual(end_points[endpoint].get_shape().as_list(), shape) + + def testAtrousFullyConvolutionalValues(self): + """Verify dense feature extraction with atrous convolution.""" + nominal_stride = 32 + for output_stride in [4, 8, 16, 32, None]: + with slim.arg_scope(xception.xception_arg_scope()): + with tf.Graph().as_default(): + with self.test_session() as sess: + tf.set_random_seed(0) + inputs = create_test_input(2, 96, 97, 3) + # Dense feature extraction followed by subsampling. + output, _ = self._xception_small( + inputs, + None, + is_training=False, + global_pool=False, + output_stride=output_stride) + if output_stride is None: + factor = 1 + else: + factor = nominal_stride // output_stride + output = resnet_utils.subsample(output, factor) + # Make the two networks use the same weights. + tf.get_variable_scope().reuse_variables() + # Feature extraction at the nominal network rate. + expected, _ = self._xception_small( + inputs, + None, + is_training=False, + global_pool=False) + sess.run(tf.global_variables_initializer()) + self.assertAllClose(output.eval(), expected.eval(), + atol=1e-5, rtol=1e-5) + + def testUnknownBatchSize(self): + batch = 2 + height, width = 65, 65 + global_pool = True + num_classes = 10 + inputs = create_test_input(None, height, width, 3) + with slim.arg_scope(xception.xception_arg_scope()): + logits, _ = self._xception_small( + inputs, + num_classes, + global_pool=global_pool, + scope='xception') + self.assertTrue(logits.op.name.startswith('xception/logits')) + self.assertListEqual(logits.get_shape().as_list(), + [None, 1, 1, num_classes]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(logits, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 1, 1, num_classes)) + + def testFullyConvolutionalUnknownHeightWidth(self): + batch = 2 + height, width = 65, 65 + global_pool = False + inputs = create_test_input(batch, None, None, 3) + with slim.arg_scope(xception.xception_arg_scope()): + output, _ = self._xception_small( + inputs, + None, + global_pool=global_pool) + self.assertListEqual(output.get_shape().as_list(), + [batch, None, None, 16]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(output, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 3, 3, 16)) + + def testAtrousFullyConvolutionalUnknownHeightWidth(self): + batch = 2 + height, width = 65, 65 + global_pool = False + output_stride = 8 + inputs = create_test_input(batch, None, None, 3) + with slim.arg_scope(xception.xception_arg_scope()): + output, _ = self._xception_small( + inputs, + None, + global_pool=global_pool, + output_stride=output_stride) + self.assertListEqual(output.get_shape().as_list(), + [batch, None, None, 16]) + images = create_test_input(batch, height, width, 3) + with self.test_session() as sess: + sess.run(tf.global_variables_initializer()) + output = sess.run(output, {inputs: images.eval()}) + self.assertEquals(output.shape, (batch, 9, 9, 16)) + + def testEndpointsReuse(self): + inputs = create_test_input(2, 32, 32, 3) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points0 = xception.xception_65( + inputs, + num_classes=10, + reuse=False) + with slim.arg_scope(xception.xception_arg_scope()): + _, end_points1 = xception.xception_65( + inputs, + num_classes=10, + reuse=True) + self.assertItemsEqual(end_points0.keys(), end_points1.keys()) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_ade20k_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_ade20k_data.py" new file mode 100644 index 00000000..b637fb43 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_ade20k_data.py" @@ -0,0 +1,118 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Converts ADE20K data to TFRecord file format with Example protos.""" + +import math +import os +import random +import sys +import build_data +import tensorflow as tf + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_string( + 'train_image_folder', + './ADE20K/ADEChallengeData2016/images/training', + 'Folder containing trainng images') +tf.app.flags.DEFINE_string( + 'train_image_label_folder', + './ADE20K/ADEChallengeData2016/annotations/training', + 'Folder containing annotations for trainng images') + +tf.app.flags.DEFINE_string( + 'val_image_folder', + './ADE20K/ADEChallengeData2016/images/validation', + 'Folder containing validation images') + +tf.app.flags.DEFINE_string( + 'val_image_label_folder', + './ADE20K/ADEChallengeData2016/annotations/validation', + 'Folder containing annotations for validation') + +tf.app.flags.DEFINE_string( + 'output_dir', './ADE20K/tfrecord', + 'Path to save converted tfrecord of Tensorflow example') + +_NUM_SHARDS = 4 + + +def _convert_dataset(dataset_split, dataset_dir, dataset_label_dir): + """Converts the ADE20k dataset into into tfrecord format. + + Args: + dataset_split: Dataset split (e.g., train, val). + dataset_dir: Dir in which the dataset locates. + dataset_label_dir: Dir in which the annotations locates. + + Raises: + RuntimeError: If loaded image and label have different shape. + """ + + img_names = tf.gfile.Glob(os.path.join(dataset_dir, '*.jpg')) + random.shuffle(img_names) + seg_names = [] + for f in img_names: + # get the filename without the extension + basename = os.path.basename(f).split('.')[0] + # cover its corresponding *_seg.png + seg = os.path.join(dataset_label_dir, basename+'.png') + seg_names.append(seg) + + num_images = len(img_names) + num_per_shard = int(math.ceil(num_images / float(_NUM_SHARDS))) + + image_reader = build_data.ImageReader('jpeg', channels=3) + label_reader = build_data.ImageReader('png', channels=1) + + for shard_id in range(_NUM_SHARDS): + output_filename = os.path.join( + FLAGS.output_dir, + '%s-%05d-of-%05d.tfrecord' % (dataset_split, shard_id, _NUM_SHARDS)) + with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: + start_idx = shard_id * num_per_shard + end_idx = min((shard_id + 1) * num_per_shard, num_images) + for i in range(start_idx, end_idx): + sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( + i + 1, num_images, shard_id)) + sys.stdout.flush() + # Read the image. + image_filename = img_names[i] + image_data = tf.gfile.FastGFile(image_filename, 'r').read() + height, width = image_reader.read_image_dims(image_data) + # Read the semantic segmentation annotation. + seg_filename = seg_names[i] + seg_data = tf.gfile.FastGFile(seg_filename, 'r').read() + seg_height, seg_width = label_reader.read_image_dims(seg_data) + if height != seg_height or width != seg_width: + raise RuntimeError('Shape mismatched between image and label.') + # Convert to tf example. + example = build_data.image_seg_to_tfexample( + image_data, img_names[i], height, width, seg_data) + tfrecord_writer.write(example.SerializeToString()) + sys.stdout.write('\n') + sys.stdout.flush() + + +def main(unused_argv): + tf.gfile.MakeDirs(FLAGS.output_dir) + _convert_dataset( + 'train', FLAGS.train_image_folder, FLAGS.train_image_label_folder) + _convert_dataset('val', FLAGS.val_image_folder, FLAGS.val_image_label_folder) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_cityscapes_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_cityscapes_data.py" new file mode 100644 index 00000000..df7fec65 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_cityscapes_data.py" @@ -0,0 +1,183 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Converts Cityscapes data to TFRecord file format with Example protos. + +The Cityscapes dataset is expected to have the following directory structure: + + + cityscapes + - build_cityscapes_data.py (current working directiory). + - build_data.py + + cityscapesscripts + + annotation + + evaluation + + helpers + + preparation + + viewer + + gtFine + + train + + val + + test + + leftImg8bit + + train + + val + + test + + tfrecord + +This script converts data into sharded data files and save at tfrecord folder. + +Note that before running this script, the users should (1) register the +Cityscapes dataset website at https://www.cityscapes-dataset.com to +download the dataset, and (2) run the script provided by Cityscapes +`preparation/createTrainIdLabelImgs.py` to generate the training groundtruth. + +Also note that the tensorflow model will be trained with `TrainId' instead +of `EvalId' used on the evaluation server. Thus, the users need to convert +the predicted labels to `EvalId` for evaluation on the server. See the +vis.py for more details. + +The Example proto contains the following fields: + + image/encoded: encoded image content. + image/filename: image filename. + image/format: image file format. + image/height: image height. + image/width: image width. + image/channels: image channels. + image/segmentation/class/encoded: encoded semantic segmentation content. + image/segmentation/class/format: semantic segmentation file format. +""" +import glob +import math +import os.path +import re +import sys +import build_data +import tensorflow as tf + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_string('cityscapes_root', + './cityscapes', + 'Cityscapes dataset root folder.') + +tf.app.flags.DEFINE_string( + 'output_dir', + './tfrecord', + 'Path to save converted SSTable of TensorFlow examples.') + + +_NUM_SHARDS = 10 + +# A map from data type to folder name that saves the data. +_FOLDERS_MAP = { + 'image': 'leftImg8bit', + 'label': 'gtFine', +} + +# A map from data type to filename postfix. +_POSTFIX_MAP = { + 'image': '_leftImg8bit', + 'label': '_gtFine_labelTrainIds', +} + +# A map from data type to data format. +_DATA_FORMAT_MAP = { + 'image': 'png', + 'label': 'png', +} + +# Image file pattern. +_IMAGE_FILENAME_RE = re.compile('(.+)' + _POSTFIX_MAP['image']) + + +def _get_files(data, dataset_split): + """Gets files for the specified data type and dataset split. + + Args: + data: String, desired data ('image' or 'label'). + dataset_split: String, dataset split ('train', 'val', 'test') + + Returns: + A list of sorted file names or None when getting label for + test set. + """ + if data == 'label' and dataset_split == 'test': + return None + pattern = '*%s.%s' % (_POSTFIX_MAP[data], _DATA_FORMAT_MAP[data]) + search_files = os.path.join( + FLAGS.cityscapes_root, _FOLDERS_MAP[data], dataset_split, '*', pattern) + filenames = glob.glob(search_files) + return sorted(filenames) + + +def _convert_dataset(dataset_split): + """Converts the specified dataset split to TFRecord format. + + Args: + dataset_split: The dataset split (e.g., train, val). + + Raises: + RuntimeError: If loaded image and label have different shape, or if the + image file with specified postfix could not be found. + """ + image_files = _get_files('image', dataset_split) + label_files = _get_files('label', dataset_split) + + num_images = len(image_files) + num_per_shard = int(math.ceil(num_images / float(_NUM_SHARDS))) + + image_reader = build_data.ImageReader('png', channels=3) + label_reader = build_data.ImageReader('png', channels=1) + + for shard_id in range(_NUM_SHARDS): + shard_filename = '%s-%05d-of-%05d.tfrecord' % ( + dataset_split, shard_id, _NUM_SHARDS) + output_filename = os.path.join(FLAGS.output_dir, shard_filename) + with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: + start_idx = shard_id * num_per_shard + end_idx = min((shard_id + 1) * num_per_shard, num_images) + for i in range(start_idx, end_idx): + sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( + i + 1, num_images, shard_id)) + sys.stdout.flush() + # Read the image. + image_data = tf.gfile.FastGFile(image_files[i], 'rb').read() + height, width = image_reader.read_image_dims(image_data) + # Read the semantic segmentation annotation. + seg_data = tf.gfile.FastGFile(label_files[i], 'rb').read() + seg_height, seg_width = label_reader.read_image_dims(seg_data) + if height != seg_height or width != seg_width: + raise RuntimeError('Shape mismatched between image and label.') + # Convert to tf example. + re_match = _IMAGE_FILENAME_RE.search(image_files[i]) + if re_match is None: + raise RuntimeError('Invalid image filename: ' + image_files[i]) + filename = os.path.basename(re_match.group(1)) + example = build_data.image_seg_to_tfexample( + image_data, filename, height, width, seg_data) + tfrecord_writer.write(example.SerializeToString()) + sys.stdout.write('\n') + sys.stdout.flush() + + +def main(unused_argv): + # Only support converting 'train' and 'val' sets for now. + for dataset_split in ['train', 'val']: + _convert_dataset(dataset_split) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_data.py" new file mode 100644 index 00000000..45628674 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_data.py" @@ -0,0 +1,161 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Contains common utility functions and classes for building dataset. + +This script contains utility functions and classes to converts dataset to +TFRecord file format with Example protos. + +The Example proto contains the following fields: + + image/encoded: encoded image content. + image/filename: image filename. + image/format: image file format. + image/height: image height. + image/width: image width. + image/channels: image channels. + image/segmentation/class/encoded: encoded semantic segmentation content. + image/segmentation/class/format: semantic segmentation file format. +""" +import collections +import six +import tensorflow as tf + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_enum('image_format', 'png', ['jpg', 'jpeg', 'png'], + 'Image format.') + +tf.app.flags.DEFINE_enum('label_format', 'png', ['png'], + 'Segmentation label format.') + +# A map from image format to expected data format. +_IMAGE_FORMAT_MAP = { + 'jpg': 'jpeg', + 'jpeg': 'jpeg', + 'png': 'png', +} + + +class ImageReader(object): + """Helper class that provides TensorFlow image coding utilities.""" + + def __init__(self, image_format='jpeg', channels=3): + """Class constructor. + + Args: + image_format: Image format. Only 'jpeg', 'jpg', or 'png' are supported. + channels: Image channels. + """ + with tf.Graph().as_default(): + self._decode_data = tf.placeholder(dtype=tf.string) + self._image_format = image_format + self._session = tf.Session() + if self._image_format in ('jpeg', 'jpg'): + self._decode = tf.image.decode_jpeg(self._decode_data, + channels=channels) + elif self._image_format == 'png': + self._decode = tf.image.decode_png(self._decode_data, + channels=channels) + + def read_image_dims(self, image_data): + """Reads the image dimensions. + + Args: + image_data: string of image data. + + Returns: + image_height and image_width. + """ + image = self.decode_image(image_data) + return image.shape[:2] + + def decode_image(self, image_data): + """Decodes the image data string. + + Args: + image_data: string of image data. + + Returns: + Decoded image data. + + Raises: + ValueError: Value of image channels not supported. + """ + image = self._session.run(self._decode, + feed_dict={self._decode_data: image_data}) + if len(image.shape) != 3 or image.shape[2] not in (1, 3): + raise ValueError('The image channels not supported.') + + return image + + +def _int64_list_feature(values): + """Returns a TF-Feature of int64_list. + + Args: + values: A scalar or list of values. + + Returns: + A TF-Feature. + """ + if not isinstance(values, collections.Iterable): + values = [values] + + return tf.train.Feature(int64_list=tf.train.Int64List(value=values)) + + +def _bytes_list_feature(values): + """Returns a TF-Feature of bytes. + + Args: + values: A string. + + Returns: + A TF-Feature. + """ + def norm2bytes(value): + return value.encode() if isinstance(value, str) and six.PY3 else value + + return tf.train.Feature( + bytes_list=tf.train.BytesList(value=[norm2bytes(values)])) + + +def image_seg_to_tfexample(image_data, filename, height, width, seg_data): + """Converts one image/segmentation pair to tf example. + + Args: + image_data: string of image data. + filename: image filename. + height: image height. + width: image width. + seg_data: string of semantic segmentation data. + + Returns: + tf example of one image/segmentation pair. + """ + return tf.train.Example(features=tf.train.Features(feature={ + 'image/encoded': _bytes_list_feature(image_data), + 'image/filename': _bytes_list_feature(filename), + 'image/format': _bytes_list_feature( + _IMAGE_FORMAT_MAP[FLAGS.image_format]), + 'image/height': _int64_list_feature(height), + 'image/width': _int64_list_feature(width), + 'image/channels': _int64_list_feature(3), + 'image/segmentation/class/encoded': ( + _bytes_list_feature(seg_data)), + 'image/segmentation/class/format': _bytes_list_feature( + FLAGS.label_format), + })) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_voc2012_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_voc2012_data.py" new file mode 100644 index 00000000..94ad3191 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/build_voc2012_data.py" @@ -0,0 +1,141 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Converts PASCAL VOC 2012 data to TFRecord file format with Example protos. + +PASCAL VOC 2012 dataset is expected to have the following directory structure: + + + pascal_voc_seg + - build_data.py + - build_voc2012_data.py (current working directory). + + VOCdevkit + + VOC2012 + + JPEGImages + + SegmentationClass + + ImageSets + + Segmentation + + tfrecord + +Image folder: + ./VOCdevkit/VOC2012/JPEGImages + +Semantic segmentation annotations: + ./VOCdevkit/VOC2012/SegmentationClass + +list folder: + ./VOCdevkit/VOC2012/ImageSets/Segmentation + +This script converts data into sharded data files and save at tfrecord folder. + +The Example proto contains the following fields: + + image/encoded: encoded image content. + image/filename: image filename. + image/format: image file format. + image/height: image height. + image/width: image width. + image/channels: image channels. + image/segmentation/class/encoded: encoded semantic segmentation content. + image/segmentation/class/format: semantic segmentation file format. +""" +import math +import os.path +import sys +import build_data +import tensorflow as tf + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_string('image_folder', + './VOCdevkit/VOC2012/JPEGImages', + 'Folder containing images.') + +tf.app.flags.DEFINE_string( + 'semantic_segmentation_folder', + './VOCdevkit/VOC2012/SegmentationClassRaw', + 'Folder containing semantic segmentation annotations.') + +tf.app.flags.DEFINE_string( + 'list_folder', + './VOCdevkit/VOC2012/ImageSets/Segmentation', + 'Folder containing lists for training and validation') + +tf.app.flags.DEFINE_string( + 'output_dir', + './tfrecord', + 'Path to save converted SSTable of TensorFlow examples.') + + +_NUM_SHARDS = 4 + + +def _convert_dataset(dataset_split): + """Converts the specified dataset split to TFRecord format. + + Args: + dataset_split: The dataset split (e.g., train, test). + + Raises: + RuntimeError: If loaded image and label have different shape. + """ + dataset = os.path.basename(dataset_split)[:-4] + sys.stdout.write('Processing ' + dataset) + filenames = [x.strip('\n') for x in open(dataset_split, 'r')] + num_images = len(filenames) + num_per_shard = int(math.ceil(num_images / float(_NUM_SHARDS))) + + image_reader = build_data.ImageReader('jpeg', channels=3) + label_reader = build_data.ImageReader('png', channels=1) + + for shard_id in range(_NUM_SHARDS): + output_filename = os.path.join( + FLAGS.output_dir, + '%s-%05d-of-%05d.tfrecord' % (dataset, shard_id, _NUM_SHARDS)) + with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: + start_idx = shard_id * num_per_shard + end_idx = min((shard_id + 1) * num_per_shard, num_images) + for i in range(start_idx, end_idx): + sys.stdout.write('\r>> Converting image %d/%d shard %d' % ( + i + 1, len(filenames), shard_id)) + sys.stdout.flush() + # Read the image. + image_filename = os.path.join( + FLAGS.image_folder, filenames[i] + '.' + FLAGS.image_format) + image_data = tf.gfile.FastGFile(image_filename, 'rb').read() + height, width = image_reader.read_image_dims(image_data) + # Read the semantic segmentation annotation. + seg_filename = os.path.join( + FLAGS.semantic_segmentation_folder, + filenames[i] + '.' + FLAGS.label_format) + seg_data = tf.gfile.FastGFile(seg_filename, 'rb').read() + seg_height, seg_width = label_reader.read_image_dims(seg_data) + if height != seg_height or width != seg_width: + raise RuntimeError('Shape mismatched between image and label.') + # Convert to tf example. + example = build_data.image_seg_to_tfexample( + image_data, filenames[i], height, width, seg_data) + tfrecord_writer.write(example.SerializeToString()) + sys.stdout.write('\n') + sys.stdout.flush() + + +def main(unused_argv): + dataset_splits = tf.gfile.Glob(os.path.join(FLAGS.list_folder, '*.txt')) + for dataset_split in dataset_splits: + _convert_dataset(dataset_split) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/convert_cityscapes.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/convert_cityscapes.sh" new file mode 100644 index 00000000..9945e121 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/convert_cityscapes.sh" @@ -0,0 +1,58 @@ +#!/bin/bash +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +# +# Script to preprocess the Cityscapes dataset. Note (1) the users should +# register the Cityscapes dataset website at +# https://www.cityscapes-dataset.com/downloads/ to download the dataset, +# and (2) the users should download the utility scripts provided by +# Cityscapes at https://github.com/mcordts/cityscapesScripts. +# +# Usage: +# bash ./preprocess_cityscapes.sh +# +# The folder structure is assumed to be: +# + datasets +# - build_cityscapes_data.py +# - convert_cityscapes.sh +# + cityscapes +# + cityscapesscripts (downloaded scripts) +# + gtFine +# + leftImg8bit +# + +# Exit immediately if a command exits with a non-zero status. +set -e + +CURRENT_DIR=$(pwd) +WORK_DIR="." + +# Root path for Cityscapes dataset. +CITYSCAPES_ROOT="${WORK_DIR}/cityscapes" + +# Create training labels. +python "${CITYSCAPES_ROOT}/cityscapesscripts/preparation/createTrainIdLabelImgs.py" + +# Build TFRecords of the dataset. +# First, create output directory for storing TFRecords. +OUTPUT_DIR="${CITYSCAPES_ROOT}/tfrecord" +mkdir -p "${OUTPUT_DIR}" + +BUILD_SCRIPT="${CURRENT_DIR}/build_cityscapes_data.py" + +echo "Converting Cityscapes dataset..." +python "${BUILD_SCRIPT}" \ + --cityscapes_root="${CITYSCAPES_ROOT}" \ + --output_dir="${OUTPUT_DIR}" \ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_ade20k.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_ade20k.sh" new file mode 100644 index 00000000..aa684b41 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_ade20k.sh" @@ -0,0 +1,80 @@ +#!/bin/bash +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +# +# Script to download and preprocess the PASCAL VOC 2012 dataset. +# +# Usage: +# bash ./download_and_convert_ade20k.sh +# +# The folder structure is assumed to be: +# + datasets +# - build_data.py +# - build_ade20k_data.py +# - download_and_convert_ade20k.sh +# + ADE20K +# + tfrecord +# + ADEChallengeData2016 +# + annotations +# + training +# + validation +# + images +# + training +# + validation + +# Exit immediately if a command exits with a non-zero status. +set -e + +CURRENT_DIR=$(pwd) +WORK_DIR="./ADE20K" +mkdir -p "${WORK_DIR}" +cd "${WORK_DIR}" + +# Helper function to download and unpack ADE20K dataset. +download_and_uncompress() { + local BASE_URL=${1} + local FILENAME=${2} + + if [ ! -f "${FILENAME}" ]; then + echo "Downloading ${FILENAME} to ${WORK_DIR}" + wget -nd -c "${BASE_URL}/${FILENAME}" + fi + echo "Uncompressing ${FILENAME}" + unzip "${FILENAME}" +} + +# Download the images. +BASE_URL="http://data.csail.mit.edu/places/ADEchallenge" +FILENAME="ADEChallengeData2016.zip" + +download_and_uncompress "${BASE_URL}" "${FILENAME}" + +cd "${CURRENT_DIR}" + +# Root path for ADE20K dataset. +ADE20K_ROOT="${WORK_DIR}/ADEChallengeData2016" + +# Build TFRecords of the dataset. +# First, create output directory for storing TFRecords. +OUTPUT_DIR="${WORK_DIR}/tfrecord" +mkdir -p "${OUTPUT_DIR}" + +echo "Converting ADE20K dataset..." +python ./build_ade20k_data.py \ + --train_image_folder="${ADE20K_ROOT}/images/training/" \ + --train_image_label_folder="${ADE20K_ROOT}/annotations/training/" \ + --val_image_folder="${ADE20K_ROOT}/images/validation/" \ + --val_image_label_folder="${ADE20K_ROOT}/annotations/validation/" \ + --output_dir="${OUTPUT_DIR}" diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_voc2012.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_voc2012.sh" new file mode 100644 index 00000000..30eec7f7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/download_and_convert_voc2012.sh" @@ -0,0 +1,90 @@ +#!/bin/bash +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +# +# Script to download and preprocess the PASCAL VOC 2012 dataset. +# +# Usage: +# bash ./download_and_convert_voc2012.sh +# +# The folder structure is assumed to be: +# + datasets +# - build_data.py +# - build_voc2012_data.py +# - download_and_convert_voc2012.sh +# - remove_gt_colormap.py +# + pascal_voc_seg +# + VOCdevkit +# + VOC2012 +# + JPEGImages +# + SegmentationClass +# + +# Exit immediately if a command exits with a non-zero status. +set -e + +CURRENT_DIR=$(pwd) +WORK_DIR="./pascal_voc_seg" +mkdir -p "${WORK_DIR}" +cd "${WORK_DIR}" + +# Helper function to download and unpack VOC 2012 dataset. +download_and_uncompress() { + local BASE_URL=${1} + local FILENAME=${2} + + if [ ! -f "${FILENAME}" ]; then + echo "Downloading ${FILENAME} to ${WORK_DIR}" + wget -nd -c "${BASE_URL}/${FILENAME}" + fi + echo "Uncompressing ${FILENAME}" + tar -xf "${FILENAME}" +} + +# Download the images. +BASE_URL="http://host.robots.ox.ac.uk/pascal/VOC/voc2012/" +FILENAME="VOCtrainval_11-May-2012.tar" + +download_and_uncompress "${BASE_URL}" "${FILENAME}" + +cd "${CURRENT_DIR}" + +# Root path for PASCAL VOC 2012 dataset. +PASCAL_ROOT="${WORK_DIR}/VOCdevkit/VOC2012" + +# Remove the colormap in the ground truth annotations. +SEG_FOLDER="${PASCAL_ROOT}/SegmentationClass" +SEMANTIC_SEG_FOLDER="${PASCAL_ROOT}/SegmentationClassRaw" + +echo "Removing the color map in ground truth annotations..." +python ./remove_gt_colormap.py \ + --original_gt_folder="${SEG_FOLDER}" \ + --output_dir="${SEMANTIC_SEG_FOLDER}" + +# Build TFRecords of the dataset. +# First, create output directory for storing TFRecords. +OUTPUT_DIR="${WORK_DIR}/tfrecord" +mkdir -p "${OUTPUT_DIR}" + +IMAGE_FOLDER="${PASCAL_ROOT}/JPEGImages" +LIST_FOLDER="${PASCAL_ROOT}/ImageSets/Segmentation" + +echo "Converting PASCAL VOC 2012 dataset..." +python ./build_voc2012_data.py \ + --image_folder="${IMAGE_FOLDER}" \ + --semantic_segmentation_folder="${SEMANTIC_SEG_FOLDER}" \ + --list_folder="${LIST_FOLDER}" \ + --image_format="jpg" \ + --output_dir="${OUTPUT_DIR}" diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/remove_gt_colormap.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/remove_gt_colormap.py" new file mode 100644 index 00000000..7bd68b02 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/remove_gt_colormap.py" @@ -0,0 +1,83 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Removes the color map from segmentation annotations. + +Removes the color map from the ground truth segmentation annotations and save +the results to output_dir. +""" +import glob +import os.path +import numpy as np + +from PIL import Image + +import tensorflow as tf + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_string('original_gt_folder', + './VOCdevkit/VOC2012/SegmentationClass', + 'Original ground truth annotations.') + +tf.app.flags.DEFINE_string('segmentation_format', 'png', 'Segmentation format.') + +tf.app.flags.DEFINE_string('output_dir', + './VOCdevkit/VOC2012/SegmentationClassRaw', + 'folder to save modified ground truth annotations.') + + +def _remove_colormap(filename): + """Removes the color map from the annotation. + + Args: + filename: Ground truth annotation filename. + + Returns: + Annotation without color map. + """ + return np.array(Image.open(filename)) + + +def _save_annotation(annotation, filename): + """Saves the annotation as png file. + + Args: + annotation: Segmentation annotation. + filename: Output filename. + """ + pil_image = Image.fromarray(annotation.astype(dtype=np.uint8)) + with tf.gfile.Open(filename, mode='w') as f: + pil_image.save(f, 'PNG') + + +def main(unused_argv): + # Create the output directory if not exists. + if not tf.gfile.IsDirectory(FLAGS.output_dir): + tf.gfile.MakeDirs(FLAGS.output_dir) + + annotations = glob.glob(os.path.join(FLAGS.original_gt_folder, + '*.' + FLAGS.segmentation_format)) + for annotation in annotations: + raw_annotation = _remove_colormap(annotation) + filename = os.path.splitext(os.path.basename(annotation))[0] + _save_annotation(raw_annotation, + os.path.join( + FLAGS.output_dir, + filename + '.' + FLAGS.segmentation_format)) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/segmentation_dataset.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/segmentation_dataset.py" new file mode 100644 index 00000000..65c06041 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/datasets/segmentation_dataset.py" @@ -0,0 +1,198 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Provides data from semantic segmentation datasets. + +The SegmentationDataset class provides both images and annotations (semantic +segmentation and/or instance segmentation) for TensorFlow. Currently, we +support the following datasets: + +1. PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). + +PASCAL VOC 2012 semantic segmentation dataset annotates 20 foreground objects +(e.g., bike, person, and so on) and leaves all the other semantic classes as +one background class. The dataset contains 1464, 1449, and 1456 annotated +images for the training, validation and test respectively. + +2. Cityscapes dataset (https://www.cityscapes-dataset.com) + +The Cityscapes dataset contains 19 semantic labels (such as road, person, car, +and so on) for urban street scenes. + +3. ADE20K dataset (http://groups.csail.mit.edu/vision/datasets/ADE20K) + +The ADE20K dataset contains 150 semantic labels both urban street scenes and +indoor scenes. + +References: + M. Everingham, S. M. A. Eslami, L. V. Gool, C. K. I. Williams, J. Winn, + and A. Zisserman, The pascal visual object classes challenge a retrospective. + IJCV, 2014. + + M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, + U. Franke, S. Roth, and B. Schiele, "The cityscapes dataset for semantic urban + scene understanding," In Proc. of CVPR, 2016. + + B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba, "Scene Parsing + through ADE20K dataset", In Proc. of CVPR, 2017. +""" +import collections +import os.path +import tensorflow as tf + +slim = tf.contrib.slim + +dataset = slim.dataset + +tfexample_decoder = slim.tfexample_decoder + + +_ITEMS_TO_DESCRIPTIONS = { + 'image': 'A color image of varying height and width.', + 'labels_class': ('A semantic segmentation label whose size matches image.' + 'Its values range from 0 (background) to num_classes.'), +} + +# Named tuple to describe the dataset properties. +DatasetDescriptor = collections.namedtuple( + 'DatasetDescriptor', + ['splits_to_sizes', # Splits of the dataset into training, val, and test. + 'num_classes', # Number of semantic classes, including the background + # class (if exists). For example, there are 20 + # foreground classes + 1 background class in the PASCAL + # VOC 2012 dataset. Thus, we set num_classes=21. + 'ignore_label', # Ignore label value. + ] +) + +_CITYSCAPES_INFORMATION = DatasetDescriptor( + splits_to_sizes={ + 'train': 2975, + 'val': 500, + }, + num_classes=19, + ignore_label=255, +) + +_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor( + splits_to_sizes={ + 'train': 1464, + 'train_aug': 10582, + 'trainval': 2913, + 'val': 1449, + }, + num_classes=21, + ignore_label=255, +) + +# These number (i.e., 'train'/'test') seems to have to be hard coded +# You are required to figure it out for your training/testing example. +_ADE20K_INFORMATION = DatasetDescriptor( + splits_to_sizes={ + 'train': 20210, # num of samples in images/training + 'val': 2000, # num of samples in images/validation + }, + num_classes=151, + ignore_label=0, +) + + +_DATASETS_INFORMATION = { + 'cityscapes': _CITYSCAPES_INFORMATION, + 'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION, + 'ade20k': _ADE20K_INFORMATION, +} + +# Default file pattern of TFRecord of TensorFlow Example. +_FILE_PATTERN = '%s-*' + + +def get_cityscapes_dataset_name(): + return 'cityscapes' + + +def get_dataset(dataset_name, split_name, dataset_dir): + """Gets an instance of slim Dataset. + + Args: + dataset_name: Dataset name. + split_name: A train/val Split name. + dataset_dir: The directory of the dataset sources. + + Returns: + An instance of slim Dataset. + + Raises: + ValueError: if the dataset_name or split_name is not recognized. + """ + if dataset_name not in _DATASETS_INFORMATION: + raise ValueError('The specified dataset is not supported yet.') + + splits_to_sizes = _DATASETS_INFORMATION[dataset_name].splits_to_sizes + + if split_name not in splits_to_sizes: + raise ValueError('data split name %s not recognized' % split_name) + + # Prepare the variables for different datasets. + num_classes = _DATASETS_INFORMATION[dataset_name].num_classes + ignore_label = _DATASETS_INFORMATION[dataset_name].ignore_label + + file_pattern = _FILE_PATTERN + file_pattern = os.path.join(dataset_dir, file_pattern % split_name) + + # Specify how the TF-Examples are decoded. + keys_to_features = { + 'image/encoded': tf.FixedLenFeature( + (), tf.string, default_value=''), + 'image/filename': tf.FixedLenFeature( + (), tf.string, default_value=''), + 'image/format': tf.FixedLenFeature( + (), tf.string, default_value='jpeg'), + 'image/height': tf.FixedLenFeature( + (), tf.int64, default_value=0), + 'image/width': tf.FixedLenFeature( + (), tf.int64, default_value=0), + 'image/segmentation/class/encoded': tf.FixedLenFeature( + (), tf.string, default_value=''), + 'image/segmentation/class/format': tf.FixedLenFeature( + (), tf.string, default_value='png'), + } + items_to_handlers = { + 'image': tfexample_decoder.Image( + image_key='image/encoded', + format_key='image/format', + channels=3), + 'image_name': tfexample_decoder.Tensor('image/filename'), + 'height': tfexample_decoder.Tensor('image/height'), + 'width': tfexample_decoder.Tensor('image/width'), + 'labels_class': tfexample_decoder.Image( + image_key='image/segmentation/class/encoded', + format_key='image/segmentation/class/format', + channels=1), + } + + decoder = tfexample_decoder.TFExampleDecoder( + keys_to_features, items_to_handlers) + + return dataset.Dataset( + data_sources=file_pattern, + reader=tf.TFRecordReader, + decoder=decoder, + num_samples=splits_to_sizes[split_name], + items_to_descriptions=_ITEMS_TO_DESCRIPTIONS, + ignore_label=ignore_label, + num_classes=num_classes, + name=dataset_name, + multi_label=True) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/deeplab_demo.ipynb" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/deeplab_demo.ipynb" new file mode 100644 index 00000000..84728fe1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/deeplab_demo.ipynb" @@ -0,0 +1,348 @@ +{ + "cells": [ + { + "cell_type": "markdown", + "metadata": { + "colab_type": "text", + "id": "KFPcBuVFw61h" + }, + "source": [ + "# DeepLab Demo\n", + "\n", + "This demo will demostrate the steps to run deeplab semantic segmentation model on sample input images." + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "cellView": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "kAbdmRmvq0Je" + }, + "outputs": [], + "source": [ + "#@title Imports\n", + "\n", + "import os\n", + "from io import BytesIO\n", + "import tarfile\n", + "import tempfile\n", + "from six.moves import urllib\n", + "\n", + "from matplotlib import gridspec\n", + "from matplotlib import pyplot as plt\n", + "import numpy as np\n", + "from PIL import Image\n", + "\n", + "import tensorflow as tf" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "cellView": "code", + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "vN0kU6NJ1Ye5" + }, + "outputs": [], + "source": [ + "#@title Helper methods\n", + "\n", + "\n", + "class DeepLabModel(object):\n", + " \"\"\"Class to load deeplab model and run inference.\"\"\"\n", + "\n", + " INPUT_TENSOR_NAME = 'ImageTensor:0'\n", + " OUTPUT_TENSOR_NAME = 'SemanticPredictions:0'\n", + " INPUT_SIZE = 513\n", + " FROZEN_GRAPH_NAME = 'frozen_inference_graph'\n", + "\n", + " def __init__(self, tarball_path):\n", + " \"\"\"Creates and loads pretrained deeplab model.\"\"\"\n", + " self.graph = tf.Graph()\n", + "\n", + " graph_def = None\n", + " # Extract frozen graph from tar archive.\n", + " tar_file = tarfile.open(tarball_path)\n", + " for tar_info in tar_file.getmembers():\n", + " if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name):\n", + " file_handle = tar_file.extractfile(tar_info)\n", + " graph_def = tf.GraphDef.FromString(file_handle.read())\n", + " break\n", + "\n", + " tar_file.close()\n", + "\n", + " if graph_def is None:\n", + " raise RuntimeError('Cannot find inference graph in tar archive.')\n", + "\n", + " with self.graph.as_default():\n", + " tf.import_graph_def(graph_def, name='')\n", + "\n", + " self.sess = tf.Session(graph=self.graph)\n", + "\n", + " def run(self, image):\n", + " \"\"\"Runs inference on a single image.\n", + "\n", + " Args:\n", + " image: A PIL.Image object, raw input image.\n", + "\n", + " Returns:\n", + " resized_image: RGB image resized from original input image.\n", + " seg_map: Segmentation map of `resized_image`.\n", + " \"\"\"\n", + " width, height = image.size\n", + " resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height)\n", + " target_size = (int(resize_ratio * width), int(resize_ratio * height))\n", + " resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS)\n", + " batch_seg_map = self.sess.run(\n", + " self.OUTPUT_TENSOR_NAME,\n", + " feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]})\n", + " seg_map = batch_seg_map[0]\n", + " return resized_image, seg_map\n", + "\n", + "\n", + "def create_pascal_label_colormap():\n", + " \"\"\"Creates a label colormap used in PASCAL VOC segmentation benchmark.\n", + "\n", + " Returns:\n", + " A Colormap for visualizing segmentation results.\n", + " \"\"\"\n", + " colormap = np.zeros((256, 3), dtype=int)\n", + " ind = np.arange(256, dtype=int)\n", + "\n", + " for shift in reversed(range(8)):\n", + " for channel in range(3):\n", + " colormap[:, channel] |= ((ind \u003e\u003e channel) \u0026 1) \u003c\u003c shift\n", + " ind \u003e\u003e= 3\n", + "\n", + " return colormap\n", + "\n", + "\n", + "def label_to_color_image(label):\n", + " \"\"\"Adds color defined by the dataset colormap to the label.\n", + "\n", + " Args:\n", + " label: A 2D array with integer type, storing the segmentation label.\n", + "\n", + " Returns:\n", + " result: A 2D array with floating type. The element of the array\n", + " is the color indexed by the corresponding element in the input label\n", + " to the PASCAL color map.\n", + "\n", + " Raises:\n", + " ValueError: If label is not of rank 2 or its value is larger than color\n", + " map maximum entry.\n", + " \"\"\"\n", + " if label.ndim != 2:\n", + " raise ValueError('Expect 2-D input label')\n", + "\n", + " colormap = create_pascal_label_colormap()\n", + "\n", + " if np.max(label) \u003e= len(colormap):\n", + " raise ValueError('label value too large.')\n", + "\n", + " return colormap[label]\n", + "\n", + "\n", + "def vis_segmentation(image, seg_map):\n", + " \"\"\"Visualizes input image, segmentation map and overlay view.\"\"\"\n", + " plt.figure(figsize=(15, 5))\n", + " grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1])\n", + "\n", + " plt.subplot(grid_spec[0])\n", + " plt.imshow(image)\n", + " plt.axis('off')\n", + " plt.title('input image')\n", + "\n", + " plt.subplot(grid_spec[1])\n", + " seg_image = label_to_color_image(seg_map).astype(np.uint8)\n", + " plt.imshow(seg_image)\n", + " plt.axis('off')\n", + " plt.title('segmentation map')\n", + "\n", + " plt.subplot(grid_spec[2])\n", + " plt.imshow(image)\n", + " plt.imshow(seg_image, alpha=0.7)\n", + " plt.axis('off')\n", + " plt.title('segmentation overlay')\n", + "\n", + " unique_labels = np.unique(seg_map)\n", + " ax = plt.subplot(grid_spec[3])\n", + " plt.imshow(\n", + " FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest')\n", + " ax.yaxis.tick_right()\n", + " plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels])\n", + " plt.xticks([], [])\n", + " ax.tick_params(width=0.0)\n", + " plt.grid('off')\n", + " plt.show()\n", + "\n", + "\n", + "LABEL_NAMES = np.asarray([\n", + " 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus',\n", + " 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike',\n", + " 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv'\n", + "])\n", + "\n", + "FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1)\n", + "FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP)" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "c4oXKmnjw6i_" + }, + "outputs": [], + "source": [ + "#@title Select and download models {display-mode: \"form\"}\n", + "\n", + "MODEL_NAME = 'mobilenetv2_coco_voctrainaug' # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval']\n", + "\n", + "_DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/'\n", + "_MODEL_URLS = {\n", + " 'mobilenetv2_coco_voctrainaug':\n", + " 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz',\n", + " 'mobilenetv2_coco_voctrainval':\n", + " 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz',\n", + " 'xception_coco_voctrainaug':\n", + " 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz',\n", + " 'xception_coco_voctrainval':\n", + " 'deeplabv3_pascal_trainval_2018_01_04.tar.gz',\n", + "}\n", + "_TARBALL_NAME = 'deeplab_model.tar.gz'\n", + "\n", + "model_dir = tempfile.mkdtemp()\n", + "tf.gfile.MakeDirs(model_dir)\n", + "\n", + "download_path = os.path.join(model_dir, _TARBALL_NAME)\n", + "print('downloading model, this might take a while...')\n", + "urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME],\n", + " download_path)\n", + "print('download completed! loading DeepLab model...')\n", + "\n", + "MODEL = DeepLabModel(download_path)\n", + "print('model loaded successfully!')" + ] + }, + { + "cell_type": "markdown", + "metadata": { + "colab_type": "text", + "id": "SZst78N-4OKO" + }, + "source": [ + "## Run on sample images\n", + "\n", + "Select one of sample images (leave `IMAGE_URL` empty) or feed any internet image\n", + "url for inference.\n", + "\n", + "Note that we are using single scale inference in the demo for fast computation,\n", + "so the results may slightly differ from the visualizations in\n", + "[README](https://github.com/tensorflow/models/blob/master/research/deeplab/README.md),\n", + "which uses multi-scale and left-right flipped inputs." + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "edGukUHXyymr" + }, + "outputs": [], + "source": [ + "#@title Run on sample images {display-mode: \"form\"}\n", + "\n", + "SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3']\n", + "IMAGE_URL = '' #@param {type:\"string\"}\n", + "\n", + "_SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/'\n", + " 'deeplab/g3doc/img/%s.jpg?raw=true')\n", + "\n", + "\n", + "def run_visualization(url):\n", + " \"\"\"Inferences DeepLab model and visualizes result.\"\"\"\n", + " try:\n", + " f = urllib.request.urlopen(url)\n", + " jpeg_str = f.read()\n", + " original_im = Image.open(BytesIO(jpeg_str))\n", + " except IOError:\n", + " print('Cannot retrieve image. Please check url: ' + url)\n", + " return\n", + "\n", + " print('running deeplab on image %s...' % url)\n", + " resized_im, seg_map = MODEL.run(original_im)\n", + "\n", + " vis_segmentation(resized_im, seg_map)\n", + "\n", + "\n", + "image_url = IMAGE_URL or _SAMPLE_URL % SAMPLE_IMAGE\n", + "run_visualization(image_url)" + ] + }, + { + "cell_type": "code", + "execution_count": 0, + "metadata": { + "colab": { + "autoexec": { + "startup": false, + "wait_interval": 0 + } + }, + "colab_type": "code", + "id": "7XrFNGsxzSIB" + }, + "outputs": [], + "source": [ + "" + ] + } + ], + "metadata": { + "colab": { + "collapsed_sections": [], + "default_view": {}, + "name": "DeepLab Demo.ipynb", + "provenance": [], + "version": "0.3.2", + "views": {} + }, + "kernelspec": { + "display_name": "Python 2", + "name": "python2" + } + }, + "nbformat": 4, + "nbformat_minor": 0 +} + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/eval.py" new file mode 100644 index 00000000..600bb5f7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/eval.py" @@ -0,0 +1,176 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Evaluation script for the DeepLab model. + +See model.py for more details and usage. +""" + +import math +import six +import tensorflow as tf +from deeplab import common +from deeplab import model +from deeplab.datasets import segmentation_dataset +from deeplab.utils import input_generator + +slim = tf.contrib.slim + +flags = tf.app.flags + +FLAGS = flags.FLAGS + +flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') + +# Settings for log directories. + +flags.DEFINE_string('eval_logdir', None, 'Where to write the event logs.') + +flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') + +# Settings for evaluating the model. + +flags.DEFINE_integer('eval_batch_size', 1, + 'The number of images in each batch during evaluation.') + +flags.DEFINE_multi_integer('eval_crop_size', [513, 513], + 'Image crop size [height, width] for evaluation.') + +flags.DEFINE_integer('eval_interval_secs', 60 * 5, + 'How often (in seconds) to run evaluation.') + +# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or +# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note +# one could use different atrous_rates/output_stride during training/evaluation. +flags.DEFINE_multi_integer('atrous_rates', None, + 'Atrous rates for atrous spatial pyramid pooling.') + +flags.DEFINE_integer('output_stride', 16, + 'The ratio of input to output spatial resolution.') + +# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. +flags.DEFINE_multi_float('eval_scales', [1.0], + 'The scales to resize images for evaluation.') + +# Change to True for adding flipped images during test. +flags.DEFINE_bool('add_flipped_images', False, + 'Add flipped images for evaluation or not.') + +# Dataset settings. + +flags.DEFINE_string('dataset', 'pascal_voc_seg', + 'Name of the segmentation dataset.') + +flags.DEFINE_string('eval_split', 'val', + 'Which split of the dataset used for evaluation') + +flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') + +flags.DEFINE_integer('max_number_of_evaluations', 0, + 'Maximum number of eval iterations. Will loop ' + 'indefinitely upon nonpositive values.') + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + # Get dataset-dependent information. + dataset = segmentation_dataset.get_dataset( + FLAGS.dataset, FLAGS.eval_split, dataset_dir=FLAGS.dataset_dir) + + tf.gfile.MakeDirs(FLAGS.eval_logdir) + tf.logging.info('Evaluating on %s set', FLAGS.eval_split) + + with tf.Graph().as_default(): + samples = input_generator.get( + dataset, + FLAGS.eval_crop_size, + FLAGS.eval_batch_size, + min_resize_value=FLAGS.min_resize_value, + max_resize_value=FLAGS.max_resize_value, + resize_factor=FLAGS.resize_factor, + dataset_split=FLAGS.eval_split, + is_training=False, + model_variant=FLAGS.model_variant) + + model_options = common.ModelOptions( + outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_classes}, + crop_size=FLAGS.eval_crop_size, + atrous_rates=FLAGS.atrous_rates, + output_stride=FLAGS.output_stride) + + if tuple(FLAGS.eval_scales) == (1.0,): + tf.logging.info('Performing single-scale test.') + predictions = model.predict_labels(samples[common.IMAGE], model_options, + image_pyramid=FLAGS.image_pyramid) + else: + tf.logging.info('Performing multi-scale test.') + predictions = model.predict_labels_multi_scale( + samples[common.IMAGE], + model_options=model_options, + eval_scales=FLAGS.eval_scales, + add_flipped_images=FLAGS.add_flipped_images) + predictions = predictions[common.OUTPUT_TYPE] + predictions = tf.reshape(predictions, shape=[-1]) + labels = tf.reshape(samples[common.LABEL], shape=[-1]) + weights = tf.to_float(tf.not_equal(labels, dataset.ignore_label)) + + # Set ignore_label regions to label 0, because metrics.mean_iou requires + # range of labels = [0, dataset.num_classes). Note the ignore_label regions + # are not evaluated since the corresponding regions contain weights = 0. + labels = tf.where( + tf.equal(labels, dataset.ignore_label), tf.zeros_like(labels), labels) + + predictions_tag = 'miou' + for eval_scale in FLAGS.eval_scales: + predictions_tag += '_' + str(eval_scale) + if FLAGS.add_flipped_images: + predictions_tag += '_flipped' + + # Define the evaluation metric. + metric_map = {} + metric_map[predictions_tag] = tf.metrics.mean_iou( + predictions, labels, dataset.num_classes, weights=weights) + + metrics_to_values, metrics_to_updates = ( + tf.contrib.metrics.aggregate_metric_map(metric_map)) + + for metric_name, metric_value in six.iteritems(metrics_to_values): + slim.summaries.add_scalar_summary( + metric_value, metric_name, print_summary=True) + + num_batches = int( + math.ceil(dataset.num_samples / float(FLAGS.eval_batch_size))) + + tf.logging.info('Eval num images %d', dataset.num_samples) + tf.logging.info('Eval batch size %d and num batch %d', + FLAGS.eval_batch_size, num_batches) + + num_eval_iters = None + if FLAGS.max_number_of_evaluations > 0: + num_eval_iters = FLAGS.max_number_of_evaluations + slim.evaluation.evaluation_loop( + master=FLAGS.master, + checkpoint_dir=FLAGS.checkpoint_dir, + logdir=FLAGS.eval_logdir, + num_evals=num_batches, + eval_op=list(metrics_to_updates.values()), + max_number_of_evaluations=num_eval_iters, + eval_interval_secs=FLAGS.eval_interval_secs) + + +if __name__ == '__main__': + flags.mark_flag_as_required('checkpoint_dir') + flags.mark_flag_as_required('eval_logdir') + flags.mark_flag_as_required('dataset_dir') + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/export_model.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/export_model.py" new file mode 100644 index 00000000..c2ad6a61 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/export_model.py" @@ -0,0 +1,166 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Exports trained model to TensorFlow frozen graph.""" + +import os +import tensorflow as tf + +from tensorflow.python.tools import freeze_graph +from deeplab import common +from deeplab import input_preprocess +from deeplab import model + +slim = tf.contrib.slim +flags = tf.app.flags + +FLAGS = flags.FLAGS + +flags.DEFINE_string('checkpoint_path', None, 'Checkpoint path') + +flags.DEFINE_string('export_path', None, + 'Path to output Tensorflow frozen graph.') + +flags.DEFINE_integer('num_classes', 21, 'Number of classes.') + +flags.DEFINE_multi_integer('crop_size', [513, 513], + 'Crop size [height, width].') + +# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or +# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note +# one could use different atrous_rates/output_stride during training/evaluation. +flags.DEFINE_multi_integer('atrous_rates', None, + 'Atrous rates for atrous spatial pyramid pooling.') + +flags.DEFINE_integer('output_stride', 8, + 'The ratio of input to output spatial resolution.') + +# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale inference. +flags.DEFINE_multi_float('inference_scales', [1.0], + 'The scales to resize images for inference.') + +flags.DEFINE_bool('add_flipped_images', False, + 'Add flipped images during inference or not.') + +# Input name of the exported model. +_INPUT_NAME = 'ImageTensor' + +# Output name of the exported model. +_OUTPUT_NAME = 'SemanticPredictions' + + +def _create_input_tensors(): + """Creates and prepares input tensors for DeepLab model. + + This method creates a 4-D uint8 image tensor 'ImageTensor' with shape + [1, None, None, 3]. The actual input tensor name to use during inference is + 'ImageTensor:0'. + + Returns: + image: Preprocessed 4-D float32 tensor with shape [1, crop_height, + crop_width, 3]. + original_image_size: Original image shape tensor [height, width]. + resized_image_size: Resized image shape tensor [height, width]. + """ + # input_preprocess takes 4-D image tensor as input. + input_image = tf.placeholder(tf.uint8, [1, None, None, 3], name=_INPUT_NAME) + original_image_size = tf.shape(input_image)[1:3] + + # Squeeze the dimension in axis=0 since `preprocess_image_and_label` assumes + # image to be 3-D. + image = tf.squeeze(input_image, axis=0) + resized_image, image, _ = input_preprocess.preprocess_image_and_label( + image, + label=None, + crop_height=FLAGS.crop_size[0], + crop_width=FLAGS.crop_size[1], + min_resize_value=FLAGS.min_resize_value, + max_resize_value=FLAGS.max_resize_value, + resize_factor=FLAGS.resize_factor, + is_training=False, + model_variant=FLAGS.model_variant) + resized_image_size = tf.shape(resized_image)[:2] + + # Expand the dimension in axis=0, since the following operations assume the + # image to be 4-D. + image = tf.expand_dims(image, 0) + + return image, original_image_size, resized_image_size + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + tf.logging.info('Prepare to export model to: %s', FLAGS.export_path) + + with tf.Graph().as_default(): + image, image_size, resized_image_size = _create_input_tensors() + + model_options = common.ModelOptions( + outputs_to_num_classes={common.OUTPUT_TYPE: FLAGS.num_classes}, + crop_size=FLAGS.crop_size, + atrous_rates=FLAGS.atrous_rates, + output_stride=FLAGS.output_stride) + + if tuple(FLAGS.inference_scales) == (1.0,): + tf.logging.info('Exported model performs single-scale inference.') + predictions = model.predict_labels( + image, + model_options=model_options, + image_pyramid=FLAGS.image_pyramid) + else: + tf.logging.info('Exported model performs multi-scale inference.') + predictions = model.predict_labels_multi_scale( + image, + model_options=model_options, + eval_scales=FLAGS.inference_scales, + add_flipped_images=FLAGS.add_flipped_images) + + predictions = tf.cast(predictions[common.OUTPUT_TYPE], tf.float32) + # Crop the valid regions from the predictions. + semantic_predictions = tf.slice( + predictions, + [0, 0, 0], + [1, resized_image_size[0], resized_image_size[1]]) + # Resize back the prediction to the original image size. + def _resize_label(label, label_size): + # Expand dimension of label to [1, height, width, 1] for resize operation. + label = tf.expand_dims(label, 3) + resized_label = tf.image.resize_images( + label, + label_size, + method=tf.image.ResizeMethod.NEAREST_NEIGHBOR, + align_corners=True) + return tf.cast(tf.squeeze(resized_label, 3), tf.int32) + semantic_predictions = _resize_label(semantic_predictions, image_size) + semantic_predictions = tf.identity(semantic_predictions, name=_OUTPUT_NAME) + + saver = tf.train.Saver(tf.model_variables()) + + tf.gfile.MakeDirs(os.path.dirname(FLAGS.export_path)) + freeze_graph.freeze_graph_with_def_protos( + tf.get_default_graph().as_graph_def(add_shapes=True), + saver.as_saver_def(), + FLAGS.checkpoint_path, + _OUTPUT_NAME, + restore_op_name=None, + filename_tensor_name=None, + output_graph=FLAGS.export_path, + clear_devices=True, + initializer_nodes=None) + + +if __name__ == '__main__': + flags.mark_flag_as_required('checkpoint_path') + flags.mark_flag_as_required('export_path') + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/ade20k.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/ade20k.md" new file mode 100644 index 00000000..d7d8a382 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/ade20k.md" @@ -0,0 +1,108 @@ +# Running DeepLab on ADE20K Semantic Segmentation Dataset + +This page walks through the steps required to run DeepLab on ADE20K dataset on a +local machine. + +## Download dataset and convert to TFRecord + +We have prepared the script (under the folder `datasets`) to download and +convert ADE20K semantic segmentation dataset to TFRecord. + +```bash +# From the tensorflow/models/research/deeplab/datasets directory. +bash download_and_convert_ade20k.sh +``` + +The converted dataset will be saved at ./deeplab/datasets/ADE20K/tfrecord + +## Recommended Directory Structure for Training and Evaluation + +``` ++ datasets + - build_data.py + - build_ade20k_data.py + - download_and_convert_ade20k.sh + + ADE20K + + tfrecord + + exp + + train_on_train_set + + train + + eval + + vis + + ADEChallengeData2016 + + annotations + + training + + validation + + images + + training + + validation +``` + +where the folder `train_on_train_set` stores the train/eval/vis events and +results (when training DeepLab on the ADE20K train set). + +## Running the train/eval/vis jobs + +A local training job using `xception_65` can be run with the following command: + +```bash +# From tensorflow/models/research/ +python deeplab/train.py \ + --logtostderr \ + --training_number_of_steps=150000 \ + --train_split="train" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --train_crop_size=513 \ + --train_crop_size=513 \ + --train_batch_size=4 \ + --min_resize_value=513 \ + --max_resize_value=513 \ + --resize_factor=16 \ + --dataset="ade20k" \ + --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \ + --train_logdir=${PATH_TO_TRAIN_DIR}\ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH\_TO\_INITIAL\_CHECKPOINT} is the path to the initial checkpoint. +${PATH\_TO\_TRAIN\_DIR} is the directory in which training checkpoints and +events will be written to (it is recommended to set it to the +`train_on_train_set/train` above), and ${PATH\_TO\_DATASET} is the directory in +which the ADE20K dataset resides (the `tfrecord` above) + +**Note that for train.py:** + +1. In order to fine tune the BN layers, one needs to use large batch size (> + 12), and set fine_tune_batch_norm = True. Here, we simply use small batch + size during training for the purpose of demonstration. If the users have + limited GPU memory at hand, please fine-tune from our provided checkpoints + whose batch norm parameters have been trained, and use smaller learning rate + with fine_tune_batch_norm = False. + +2. User should fine tune the `min_resize_value` and `max_resize_value` to get + better result. Note that `resize_factor` has to be equal to `output_stride`. + +3. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if + setting output_stride=8. + +4. The users could skip the flag, `decoder_output_stride`, if you do not want + to use the decoder structure. + +## Running Tensorboard + +Progress for training and evaluation jobs can be inspected using Tensorboard. If +using the recommended directory structure, Tensorboard can be run using the +following command: + +```bash +tensorboard --logdir=${PATH_TO_LOG_DIRECTORY} +``` + +where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the train +directorie (e.g., the folder `train_on_train_set` in the above example). Please +note it may take Tensorboard a couple minutes to populate with data. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/cityscapes.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/cityscapes.md" new file mode 100644 index 00000000..8e897031 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/cityscapes.md" @@ -0,0 +1,160 @@ +# Running DeepLab on Cityscapes Semantic Segmentation Dataset + +This page walks through the steps required to run DeepLab on Cityscapes on a +local machine. + +## Download dataset and convert to TFRecord + +We have prepared the script (under the folder `datasets`) to convert Cityscapes +dataset to TFRecord. The users are required to download the dataset beforehand +by registering the [website](https://www.cityscapes-dataset.com/). + +```bash +# From the tensorflow/models/research/deeplab/datasets directory. +sh convert_cityscapes.sh +``` + +The converted dataset will be saved at ./deeplab/datasets/cityscapes/tfrecord. + +## Recommended Directory Structure for Training and Evaluation + +``` ++ datasets + + cityscapes + + leftImg8bit + + gtFine + + tfrecord + + exp + + train_on_train_set + + train + + eval + + vis +``` + +where the folder `train_on_train_set` stores the train/eval/vis events and +results (when training DeepLab on the Cityscapes train set). + +## Running the train/eval/vis jobs + +A local training job using `xception_65` can be run with the following command: + +```bash +# From tensorflow/models/research/ +python deeplab/train.py \ + --logtostderr \ + --training_number_of_steps=90000 \ + --train_split="train" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --train_crop_size=769 \ + --train_crop_size=769 \ + --train_batch_size=1 \ + --dataset="cityscapes" \ + --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \ + --train_logdir=${PATH_TO_TRAIN_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_INITIAL_CHECKPOINT} is the path to the initial checkpoint +(usually an ImageNet pretrained checkpoint), ${PATH_TO_TRAIN_DIR} is the +directory in which training checkpoints and events will be written to, and +${PATH_TO_DATASET} is the directory in which the Cityscapes dataset resides. + +**Note that for {train,eval,vis}.py**: + +1. In order to reproduce our results, one needs to use large batch size (> 8), + and set fine_tune_batch_norm = True. Here, we simply use small batch size + during training for the purpose of demonstration. If the users have limited + GPU memory at hand, please fine-tune from our provided checkpoints whose + batch norm parameters have been trained, and use smaller learning rate with + fine_tune_batch_norm = False. + +2. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if + setting output_stride=8. + +3. The users could skip the flag, `decoder_output_stride`, if you do not want + to use the decoder structure. + +4. Change and add the following flags in order to use the provided dense prediction cell. + +```bash +--model_variant="xception_71" +--dense_prediction_cell_json="deeplab/core/dense_prediction_cell_branch5_top1_cityscapes.json" + +``` + +A local evaluation job using `xception_65` can be run with the following +command: + +```bash +# From tensorflow/models/research/ +python deeplab/eval.py \ + --logtostderr \ + --eval_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --eval_crop_size=1025 \ + --eval_crop_size=2049 \ + --dataset="cityscapes" \ + --checkpoint_dir=${PATH_TO_CHECKPOINT} \ + --eval_logdir=${PATH_TO_EVAL_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the +path to train_logdir), ${PATH_TO_EVAL_DIR} is the directory in which evaluation +events will be written to, and ${PATH_TO_DATASET} is the directory in which the +Cityscapes dataset resides. + +A local visualization job using `xception_65` can be run with the following +command: + +```bash +# From tensorflow/models/research/ +python deeplab/vis.py \ + --logtostderr \ + --vis_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --vis_crop_size=1025 \ + --vis_crop_size=2049 \ + --dataset="cityscapes" \ + --colormap_type="cityscapes" \ + --checkpoint_dir=${PATH_TO_CHECKPOINT} \ + --vis_logdir=${PATH_TO_VIS_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the +path to train_logdir), ${PATH_TO_VIS_DIR} is the directory in which evaluation +events will be written to, and ${PATH_TO_DATASET} is the directory in which the +Cityscapes dataset resides. Note that if the users would like to save the +segmentation results for evaluation server, set also_save_raw_predictions = +True. + +## Running Tensorboard + +Progress for training and evaluation jobs can be inspected using Tensorboard. If +using the recommended directory structure, Tensorboard can be run using the +following command: + +```bash +tensorboard --logdir=${PATH_TO_LOG_DIRECTORY} +``` + +where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the +train, eval, and vis directories (e.g., the folder `train_on_train_set` in the +above example). Please note it may take Tensorboard a couple minutes to populate +with data. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/export_model.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/export_model.md" new file mode 100644 index 00000000..c41649e6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/export_model.md" @@ -0,0 +1,23 @@ +# Export trained deeplab model to frozen inference graph + +After model training finishes, you could export it to a frozen TensorFlow +inference graph proto. Your trained model checkpoint usually includes the +following files: + +* model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001, +* model.ckpt-${CHECKPOINT_NUMBER}.index +* model.ckpt-${CHECKPOINT_NUMBER}.meta + +After you have identified a candidate checkpoint to export, you can run the +following commandline to export to a frozen graph: + +```bash +# From tensorflow/models/research/ +# Assume all checkpoint files share the same path prefix `${CHECKPOINT_PATH}`. +python deeplab/export_model.py \ + --checkpoint_path=${CHECKPOINT_PATH} \ + --export_path=${OUTPUT_DIR}/frozen_inference_graph.pb +``` + +Please also add other model specific flags as you use for training, such as +`model_variant`, `add_image_level_feature`, etc. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/faq.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/faq.md" new file mode 100644 index 00000000..c8162497 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/faq.md" @@ -0,0 +1,82 @@ +# FAQ +___ +Q1: What if I want to use other network backbones, such as ResNet [1], instead of only those provided ones (e.g., Xception)? + +A: The users could modify the provided core/feature_extractor.py to support more network backbones. +___ +Q2: What if I want to train the model on other datasets? + +A: The users could modify the provided dataset/build_{cityscapes,voc2012}_data.py and dataset/segmentation_dataset.py to build their own dataset. +___ +Q3: Where can I download the PASCAL VOC augmented training set? + +A: The PASCAL VOC augmented training set is provided by Bharath Hariharan et al. [2] Please refer to their [website](http://home.bharathh.info/pubs/codes/SBD/download.html) for details and consider citing their paper if using the dataset. +___ +Q4: Why the implementation does not include DenseCRF [3]? + +A: We have not tried this. The interested users could take a look at Philipp Krähenbühl's [website](http://graphics.stanford.edu/projects/densecrf/) and [paper](https://arxiv.org/abs/1210.5644) for details. +___ +Q5: What if I want to train the model and fine-tune the batch normalization parameters? + +A: If given the limited resource at hand, we would suggest you simply fine-tune +from our provided checkpoint whose batch-norm parameters have been trained (i.e., +train with a smaller learning rate, set `fine_tune_batch_norm = false`, and +employ longer training iterations since the learning rate is small). If +you really would like to train by yourself, we would suggest + +1. Set `output_stride = 16` or maybe even `32` (remember to change the flag +`atrous_rates` accordingly, e.g., `atrous_rates = [3, 6, 9]` for +`output_stride = 32`). + +2. Use as many GPUs as possible (change the flag `num_clones` in train.py) and +set `train_batch_size` as large as possible. + +3. Adjust the `train_crop_size` in train.py. Maybe set it to be smaller, e.g., +513x513 (or even 321x321), so that you could use a larger batch size. + +4. Use a smaller network backbone, such as MobileNet-v2. + +___ +Q6: How can I train the model asynchronously? + +A: In the train.py, the users could set `num_replicas` (number of machines for training) and `num_ps_tasks` (we usually set `num_ps_tasks` = `num_replicas` / 2). See slim.deployment.model_deploy for more details. +___ +Q7: I could not reproduce the performance even with the provided checkpoints. + +A: Please try running + +```bash +# Run the simple test with Xception_65 as network backbone. +sh local_test.sh +``` + +or + +```bash +# Run the simple test with MobileNet-v2 as network backbone. +sh local_test_mobilenetv2.sh +``` + +First, make sure you could reproduce the results with our provided setting. +After that, you could start to make a new change one at a time to help debug. +___ +Q8: What value of `eval_crop_size` should I use? + +A: Our model uses whole-image inference, meaning that we need to set `eval_crop_size` equal to `output_stride` * k + 1, where k is an integer and set k so that the resulting `eval_crop_size` is slightly larger the largest +image dimension in the dataset. For example, we have `eval_crop_size` = 513x513 for PASCAL dataset whose largest image dimension is 512. Similarly, we set `eval_crop_size` = 1025x2049 for Cityscapes images whose +image dimension is all equal to 1024x2048. +___ + +## References + +1. **Deep Residual Learning for Image Recognition**
+ Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
+ [[link]](https://arxiv.org/abs/1512.03385), In CVPR, 2016. + +2. **Semantic Contours from Inverse Detectors**
+ Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
+ [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html), In ICCV, 2011. + +3. **Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials**
+ Philipp Krähenbühl, Vladlen Koltun
+ [[link]](http://graphics.stanford.edu/projects/densecrf/), In NIPS, 2011. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image1.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image1.jpg" new file mode 100644 index 00000000..939b6f9c Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image1.jpg" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image2.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image2.jpg" new file mode 100644 index 00000000..5ec1b8ac Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image2.jpg" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image3.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image3.jpg" new file mode 100644 index 00000000..d788e3dc Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image3.jpg" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image_info.txt" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image_info.txt" new file mode 100644 index 00000000..583d113e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/image_info.txt" @@ -0,0 +1,13 @@ +Image provenance: + +image1.jpg: Philippe Put, + https://www.flickr.com/photos/34547181@N00/14499172124 + +image2.jpg: Peretz Partensky + https://www.flickr.com/photos/ifl/3926001309 + +image3.jpg: Peter Harrison + https://www.flickr.com/photos/devcentre/392585679 + + +vis[1-3].png: Showing original image together with DeepLab segmentation map. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis1.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis1.png" new file mode 100644 index 00000000..41b8ecd8 Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis1.png" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis2.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis2.png" new file mode 100644 index 00000000..7fa7a4ca Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis2.png" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis3.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis3.png" new file mode 100644 index 00000000..813b6340 Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/img/vis3.png" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/installation.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/installation.md" new file mode 100644 index 00000000..481015e9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/installation.md" @@ -0,0 +1,66 @@ +# Installation + +## Dependencies + +DeepLab depends on the following libraries: + +* Numpy +* Pillow 1.0 +* tf Slim (which is included in the "tensorflow/models/research/" checkout) +* Jupyter notebook +* Matplotlib +* Tensorflow + +For detailed steps to install Tensorflow, follow the [Tensorflow installation +instructions](https://www.tensorflow.org/install/). A typical user can install +Tensorflow using one of the following commands: + +```bash +# For CPU +pip install tensorflow +# For GPU +pip install tensorflow-gpu +``` + +The remaining libraries can be installed on Ubuntu 14.04 using via apt-get: + +```bash +sudo apt-get install python-pil python-numpy +sudo pip install jupyter +sudo pip install matplotlib +``` + +## Add Libraries to PYTHONPATH + +When running locally, the tensorflow/models/research/ and slim directories +should be appended to PYTHONPATH. This can be done by running the following from +tensorflow/models/research/: + +```bash +# From tensorflow/models/research/ +export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim +``` + +Note: This command needs to run from every new terminal you start. If you wish +to avoid running this manually, you can add it as a new line to the end of your +~/.bashrc file. + +# Testing the Installation + +You can test if you have successfully installed the Tensorflow DeepLab by +running the following commands: + +Quick test by running model_test.py: + +```bash +# From tensorflow/models/research/ +python deeplab/model_test.py +``` + +Quick running the whole code on the PASCAL VOC 2012 dataset: + +```bash +# From tensorflow/models/research/deeplab +sh local_test.sh +``` + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/model_zoo.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/model_zoo.md" new file mode 100644 index 00000000..12e026dc --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/model_zoo.md" @@ -0,0 +1,185 @@ +# TensorFlow DeepLab Model Zoo + +We provide deeplab models pretrained several datasets, including (1) PASCAL VOC +2012, (2) Cityscapes, and (3) ADE20K for reproducing our results, as well as +some checkpoints that are only pretrained on ImageNet for training your own +models. + +## DeepLab models trained on PASCAL VOC 2012 + +Un-tar'ed directory includes: + +* a frozen inference graph (`frozen_inference_graph.pb`). All frozen inference + graphs use output stride of 8 and a single eval scale of 1.0. No left-right + flips are used, and MobileNet-v2 based models do not include the decoder + module. + +* a checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`) + +### Model details + +We provide several checkpoints that have been pretrained on VOC 2012 train_aug +set or train_aug + trainval set. In the former case, one could train their model +with smaller batch size and freeze batch normalization when limited GPU memory +is available, since we have already fine-tuned the batch normalization for you. +In the latter case, one could directly evaluate the checkpoints on VOC 2012 test +set or use this checkpoint for demo. Note *MobileNet-v2* based models do not +employ ASPP and decoder modules for fast computation. + +Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder +--------------------------- | :--------------: | :-----------------: | :---: | :-----: +mobilenetv2_dm05_coco_voc_trainaug | MobileNet-v2
Depth-Multiplier = 0.5 | MS-COCO
VOC 2012 train_aug set| N/A | N/A +mobilenetv2_dm05_coco_voc_trainval | MobileNet-v2
Depth-Multiplier = 0.5 | MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A +mobilenetv2_coco_voc_trainaug | MobileNet-v2 | MS-COCO
VOC 2012 train_aug set| N/A | N/A +mobilenetv2_coco_voc_trainval | MobileNet-v2 | MS-COCO
VOC 2012 train_aug + trainval sets | N/A | N/A +xception65_coco_voc_trainaug | Xception_65 | MS-COCO
VOC 2012 train_aug set| [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 +xception65_coco_voc_trainval | Xception_65 | MS-COCO
VOC 2012 train_aug + trainval sets | [6,12,18] for OS=16
[12,24,36] for OS=8 | OS = 4 + +In the table, **OS** denotes output stride. + +Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | PASCAL mIOU | File Size +------------------------------------------------------------------------------------------------------------------------ | :-------: | :------------------------: | :-------------: | :------------------: | :------------: | :----------------------------: | :-------: +[mobilenetv2_dm05_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz) | 16 | [1.0] | No | 0.88B | - | 70.19% (val) | 7.6MB +[mobilenetv2_dm05_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz) | 8 | [1.0] | No | 2.84B | - | 71.83% (test) | 7.6MB +[mobilenetv2_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 2.75B
152.59B | 0.1
26.9 | 75.32% (val)
77.33 (val) | 23MB +[mobilenetv2_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 152.59B | 26.9 | 80.25% (**test**) | 23MB +[xception65_coco_voc_trainaug](http://download.tensorflow.org/models/deeplabv3_pascal_train_aug_2018_01_04.tar.gz) | 16
8 | [1.0]
[0.5:0.25:1.75] | No
Yes | 54.17B
3055.35B | 0.7
223.2 | 82.20% (val)
83.58% (val) | 439MB +[xception65_coco_voc_trainval](http://download.tensorflow.org/models/deeplabv3_pascal_trainval_2018_01_04.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 3055.35B | 223.2 | 87.80% (**test**) | 439MB + +In the table, we report both computation complexity (in terms of Multiply-Adds +and CPU Runtime) and segmentation performance (in terms of mIOU) on the PASCAL +VOC val or test set. The reported runtime is calculated by tfprof on a +workstation with CPU E5-1650 v3 @ 3.50GHz and 32GB memory. Note that applying +multi-scale inputs and left-right flips increases the segmentation performance +but also significantly increases the computation and thus may not be suitable +for real-time applications. + +## DeepLab models trained on Cityscapes + +### Model details + +We provide several checkpoints that have been pretrained on Cityscapes +train_fine set. Note *MobileNet-v2* based model has been pretrained on MS-COCO +dataset and does not employ ASPP and decoder modules for fast computation. + +Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder +------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: +mobilenetv2_coco_cityscapes_trainfine | MobileNet-v2 | MS-COCO
Cityscapes train_fine set | N/A | N/A +xception65_cityscapes_trainfine | Xception_65 | ImageNet
Cityscapes train_fine set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 +xception71_dpc_cityscapes_trainfine | Xception_71 | ImageNet
MS-COCO
Cityscapes train_fine set | Dense Prediction Cell | OS = 4 +xception71_dpc_cityscapes_trainval | Xception_71 | ImageNet
MS-COCO
Cityscapes trainval_fine and coarse set | Dense Prediction Cell | OS = 4 + +In the table, **OS** denotes output stride. + +Checkpoint name | Eval OS | Eval scales | Left-right Flip | Multiply-Adds | Runtime (sec) | Cityscapes mIOU | File Size +-------------------------------------------------------------------------------------------------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :------------: | :----------------------------: | :-------: +[mobilenetv2_coco_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_mnv2_cityscapes_train_2018_02_05.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 21.27B
433.24B | 0.8
51.12 | 70.71% (val)
73.57% (val) | 23MB +[xception65_cityscapes_trainfine](http://download.tensorflow.org/models/deeplabv3_cityscapes_train_2018_02_06.tar.gz) | 16
8 | [1.0]
[0.75:0.25:1.25] | No
Yes | 418.64B
8677.92B | 5.0
422.8 | 78.79% (val)
80.42% (val) | 439MB +[xception71_dpc_cityscapes_trainfine](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainfine_2018_09_08.tar.gz) | 16 | [1.0] | No | 502.07B | - | 80.31% (val) | 445MB +[xception71_dpc_cityscapes_trainval](http://download.tensorflow.org/models/deeplab_cityscapes_xception71_trainvalfine_2018_09_08.tar.gz) | 8 | [0.75:0.25:2] | Yes | - | - | 82.66% (**test**) | 446MB + + + +## DeepLab models trained on ADE20K + +### Model details + +We provide some checkpoints that have been pretrained on ADE20K training set. +Note that the model has only been pretrained on ImageNet, following the +dataset rule. + +Checkpoint name | Network backbone | Pretrained dataset | ASPP | Decoder +------------------------------------- | :--------------: | :-------------------------------------: | :----------------------------------------------: | :-----: +xception65_ade20k_train | Xception_65 | ImageNet
ADE20K training set | [6, 12, 18] for OS=16
[12, 24, 36] for OS=8 | OS = 4 + +Checkpoint name | Eval OS | Eval scales | Left-right Flip | mIOU | Pixel-wise Accuracy | File Size +------------------------------------- | :-------: | :-------------------------: | :-------------: | :-------------------: | :-------------------: | :-------: +[xception65_ade20k_train](http://download.tensorflow.org/models/deeplabv3_xception_ade20k_train_2018_05_29.tar.gz) | 8 | [0.5:0.25:1.75] | Yes | 45.65% (val) | 82.52% (val) | 439MB + +## Checkpoints pretrained on ImageNet + +Un-tar'ed directory includes: + +* model checkpoint (`model.ckpt.data-00000-of-00001`, `model.ckpt.index`). + +### Model details + +We also provide some checkpoints that are pretrained on ImageNet and/or COCO (as +post-fixed in the model name) so that one could use this for training your own +models. + +* mobilenet_v2: We refer the interested users to the TensorFlow open source + [MobileNet-V2](https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet) + for details. + +* xception_{41,65,71}: We adapt the original Xception model to the task of + semantic segmentation with the following changes: (1) more layers, (2) all + max pooling operations are replaced by strided (atrous) separable + convolutions, and (3) extra batch-norm and ReLU after each 3x3 depthwise + convolution are added. We provide three Xception model variants with + different network depths. + +* resnet_v1_{50,101}_beta: We modify the original ResNet-101 [10], similar to + PSPNet [11] by replacing the first 7x7 convolution with three 3x3 + convolutions. See resnet_v1_beta.py for more details. + +Model name | File Size +-------------------------------------------------------------------------------------- | :-------: +[xception_41_imagenet](http://download.tensorflow.org/models/xception_41_2018_05_09.tar.gz ) | 288MB +[xception_65_imagenet](http://download.tensorflow.org/models/deeplabv3_xception_2018_01_04.tar.gz) | 447MB +[xception_65_imagenet_coco](http://download.tensorflow.org/models/xception_65_coco_pretrained_2018_10_02.tar.gz) | 292MB +[xception_71_imagenet](http://download.tensorflow.org/models/xception_71_2018_05_09.tar.gz ) | 474MB +[resnet_v1_50_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_50_2018_05_04.tar.gz) | 274MB +[resnet_v1_101_beta_imagenet](http://download.tensorflow.org/models/resnet_v1_101_2018_05_04.tar.gz) | 477MB + +## References + +1. **Mobilenets: Efficient convolutional neural networks for mobile vision applications**
+ Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, Hartwig Adam
+ [[link]](https://arxiv.org/abs/1704.04861). arXiv:1704.04861, 2017. + +2. **Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification, Detection and Segmentation**
+ Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
+ [[link]](https://arxiv.org/abs/1801.04381). arXiv:1801.04381, 2018. + +3. **Xception: Deep Learning with Depthwise Separable Convolutions**
+ François Chollet
+ [[link]](https://arxiv.org/abs/1610.02357). In the Proc. of CVPR, 2017. + +4. **Deformable Convolutional Networks -- COCO Detection and Segmentation Challenge 2017 Entry**
+ Haozhi Qi, Zheng Zhang, Bin Xiao, Han Hu, Bowen Cheng, Yichen Wei, Jifeng Dai
+ [[link]](http://presentations.cocodataset.org/COCO17-Detect-MSRA.pdf). ICCV COCO Challenge + Workshop, 2017. + +5. **The Pascal Visual Object Classes Challenge: A Retrospective**
+ Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John M. Winn, Andrew Zisserman
+ [[link]](http://host.robots.ox.ac.uk/pascal/VOC/voc2012/). IJCV, 2014. + +6. **Semantic Contours from Inverse Detectors**
+ Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, Subhransu Maji, Jitendra Malik
+ [[link]](http://home.bharathh.info/pubs/codes/SBD/download.html). In the Proc. of ICCV, 2011. + +7. **The Cityscapes Dataset for Semantic Urban Scene Understanding**
+ Cordts, Marius, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, Bernt Schiele.
+ [[link]](https://www.cityscapes-dataset.com/). In the Proc. of CVPR, 2016. + +8. **Microsoft COCO: Common Objects in Context**
+ Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollar
+ [[link]](http://cocodataset.org/). In the Proc. of ECCV, 2014. + +9. **ImageNet Large Scale Visual Recognition Challenge**
+ Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, Li Fei-Fei
+ [[link]](http://www.image-net.org/). IJCV, 2015. + +10. **Deep Residual Learning for Image Recognition**
+ Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
+ [[link]](https://arxiv.org/abs/1512.03385). CVPR, 2016. + +11. **Pyramid Scene Parsing Network**
+ Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
+ [[link]](https://arxiv.org/abs/1612.01105). In CVPR, 2017. + +12. **Scene Parsing through ADE20K Dataset**
+ Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, Antonio Torralba
+ [[link]](http://groups.csail.mit.edu/vision/datasets/ADE20K/). In CVPR, + 2017. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/pascal.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/pascal.md" new file mode 100644 index 00000000..de627182 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/g3doc/pascal.md" @@ -0,0 +1,164 @@ +# Running DeepLab on PASCAL VOC 2012 Semantic Segmentation Dataset + +This page walks through the steps required to run DeepLab on PASCAL VOC 2012 on +a local machine. + +## Download dataset and convert to TFRecord + +We have prepared the script (under the folder `datasets`) to download and +convert PASCAL VOC 2012 semantic segmentation dataset to TFRecord. + +```bash +# From the tensorflow/models/research/deeplab/datasets directory. +sh download_and_convert_voc2012.sh +``` + +The converted dataset will be saved at +./deeplab/datasets/pascal_voc_seg/tfrecord + +## Recommended Directory Structure for Training and Evaluation + +``` ++ datasets + + pascal_voc_seg + + VOCdevkit + + VOC2012 + + JPEGImages + + SegmentationClass + + tfrecord + + exp + + train_on_train_set + + train + + eval + + vis +``` + +where the folder `train_on_train_set` stores the train/eval/vis events and +results (when training DeepLab on the PASCAL VOC 2012 train set). + +## Running the train/eval/vis jobs + +A local training job using `xception_65` can be run with the following command: + +```bash +# From tensorflow/models/research/ +python deeplab/train.py \ + --logtostderr \ + --training_number_of_steps=30000 \ + --train_split="train" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --train_crop_size=513 \ + --train_crop_size=513 \ + --train_batch_size=1 \ + --dataset="pascal_voc_seg" \ + --tf_initial_checkpoint=${PATH_TO_INITIAL_CHECKPOINT} \ + --train_logdir=${PATH_TO_TRAIN_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_INITIAL_CHECKPOINT} is the path to the initial checkpoint +(usually an ImageNet pretrained checkpoint), ${PATH_TO_TRAIN_DIR} is the +directory in which training checkpoints and events will be written to, and +${PATH_TO_DATASET} is the directory in which the PASCAL VOC 2012 dataset +resides. + +**Note that for {train,eval,vis}.py:** + +1. In order to reproduce our results, one needs to use large batch size (> 12), + and set fine_tune_batch_norm = True. Here, we simply use small batch size + during training for the purpose of demonstration. If the users have limited + GPU memory at hand, please fine-tune from our provided checkpoints whose + batch norm parameters have been trained, and use smaller learning rate with + fine_tune_batch_norm = False. + +2. The users should change atrous_rates from [6, 12, 18] to [12, 24, 36] if + setting output_stride=8. + +3. The users could skip the flag, `decoder_output_stride`, if you do not want + to use the decoder structure. + +A local evaluation job using `xception_65` can be run with the following +command: + +```bash +# From tensorflow/models/research/ +python deeplab/eval.py \ + --logtostderr \ + --eval_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --eval_crop_size=513 \ + --eval_crop_size=513 \ + --dataset="pascal_voc_seg" \ + --checkpoint_dir=${PATH_TO_CHECKPOINT} \ + --eval_logdir=${PATH_TO_EVAL_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the +path to train_logdir), ${PATH_TO_EVAL_DIR} is the directory in which evaluation +events will be written to, and ${PATH_TO_DATASET} is the directory in which the +PASCAL VOC 2012 dataset resides. + +A local visualization job using `xception_65` can be run with the following +command: + +```bash +# From tensorflow/models/research/ +python deeplab/vis.py \ + --logtostderr \ + --vis_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --vis_crop_size=513 \ + --vis_crop_size=513 \ + --dataset="pascal_voc_seg" \ + --checkpoint_dir=${PATH_TO_CHECKPOINT} \ + --vis_logdir=${PATH_TO_VIS_DIR} \ + --dataset_dir=${PATH_TO_DATASET} +``` + +where ${PATH_TO_CHECKPOINT} is the path to the trained checkpoint (i.e., the +path to train_logdir), ${PATH_TO_VIS_DIR} is the directory in which evaluation +events will be written to, and ${PATH_TO_DATASET} is the directory in which the +PASCAL VOC 2012 dataset resides. Note that if the users would like to save the +segmentation results for evaluation server, set also_save_raw_predictions = +True. + +## Running Tensorboard + +Progress for training and evaluation jobs can be inspected using Tensorboard. If +using the recommended directory structure, Tensorboard can be run using the +following command: + +```bash +tensorboard --logdir=${PATH_TO_LOG_DIRECTORY} +``` + +where `${PATH_TO_LOG_DIRECTORY}` points to the directory that contains the +train, eval, and vis directories (e.g., the folder `train_on_train_set` in the +above example). Please note it may take Tensorboard a couple minutes to populate +with data. + +## Example + +We provide a script to run the {train,eval,vis,export_model}.py on the PASCAL VOC +2012 dataset as an example. See the code in local_test.sh for details. + +```bash +# From tensorflow/models/research/deeplab +sh local_test.sh +``` diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/input_preprocess.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/input_preprocess.py" new file mode 100644 index 00000000..135e24cf --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/input_preprocess.py" @@ -0,0 +1,138 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Prepares the data used for DeepLab training/evaluation.""" +import tensorflow as tf +from deeplab.core import feature_extractor +from deeplab.core import preprocess_utils + + +# The probability of flipping the images and labels +# left-right during training +_PROB_OF_FLIP = 0.5 + + +def preprocess_image_and_label(image, + label, + crop_height, + crop_width, + min_resize_value=None, + max_resize_value=None, + resize_factor=None, + min_scale_factor=1., + max_scale_factor=1., + scale_factor_step_size=0, + ignore_label=255, + is_training=True, + model_variant=None): + """Preprocesses the image and label. + + Args: + image: Input image. + label: Ground truth annotation label. + crop_height: The height value used to crop the image and label. + crop_width: The width value used to crop the image and label. + min_resize_value: Desired size of the smaller image side. + max_resize_value: Maximum allowed size of the larger image side. + resize_factor: Resized dimensions are multiple of factor plus one. + min_scale_factor: Minimum scale factor value. + max_scale_factor: Maximum scale factor value. + scale_factor_step_size: The step size from min scale factor to max scale + factor. The input is randomly scaled based on the value of + (min_scale_factor, max_scale_factor, scale_factor_step_size). + ignore_label: The label value which will be ignored for training and + evaluation. + is_training: If the preprocessing is used for training or not. + model_variant: Model variant (string) for choosing how to mean-subtract the + images. See feature_extractor.network_map for supported model variants. + + Returns: + original_image: Original image (could be resized). + processed_image: Preprocessed image. + label: Preprocessed ground truth segmentation label. + + Raises: + ValueError: Ground truth label not provided during training. + """ + if is_training and label is None: + raise ValueError('During training, label must be provided.') + if model_variant is None: + tf.logging.warning('Default mean-subtraction is performed. Please specify ' + 'a model_variant. See feature_extractor.network_map for ' + 'supported model variants.') + + # Keep reference to original image. + original_image = image + + processed_image = tf.cast(image, tf.float32) + + if label is not None: + label = tf.cast(label, tf.int32) + + # Resize image and label to the desired range. + if min_resize_value is not None or max_resize_value is not None: + [processed_image, label] = ( + preprocess_utils.resize_to_range( + image=processed_image, + label=label, + min_size=min_resize_value, + max_size=max_resize_value, + factor=resize_factor, + align_corners=True)) + # The `original_image` becomes the resized image. + original_image = tf.identity(processed_image) + + # Data augmentation by randomly scaling the inputs. + if is_training: + scale = preprocess_utils.get_random_scale( + min_scale_factor, max_scale_factor, scale_factor_step_size) + processed_image, label = preprocess_utils.randomly_scale_image_and_label( + processed_image, label, scale) + processed_image.set_shape([None, None, 3]) + + # Pad image and label to have dimensions >= [crop_height, crop_width] + image_shape = tf.shape(processed_image) + image_height = image_shape[0] + image_width = image_shape[1] + + target_height = image_height + tf.maximum(crop_height - image_height, 0) + target_width = image_width + tf.maximum(crop_width - image_width, 0) + + # Pad image with mean pixel value. + mean_pixel = tf.reshape( + feature_extractor.mean_pixel(model_variant), [1, 1, 3]) + processed_image = preprocess_utils.pad_to_bounding_box( + processed_image, 0, 0, target_height, target_width, mean_pixel) + + if label is not None: + label = preprocess_utils.pad_to_bounding_box( + label, 0, 0, target_height, target_width, ignore_label) + + # Randomly crop the image and label. + if is_training and label is not None: + processed_image, label = preprocess_utils.random_crop( + [processed_image, label], crop_height, crop_width) + + processed_image.set_shape([crop_height, crop_width, 3]) + + if label is not None: + label.set_shape([crop_height, crop_width, 1]) + + if is_training: + # Randomly left-right flip the image and label. + processed_image, label, _ = preprocess_utils.flip_dim( + [processed_image, label], _PROB_OF_FLIP, dim=1) + + return original_image, processed_image, label diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test.sh" new file mode 100644 index 00000000..65c827af --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test.sh" @@ -0,0 +1,150 @@ +#!/bin/bash +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +# +# This script is used to run local test on PASCAL VOC 2012. Users could also +# modify from this script for their use case. +# +# Usage: +# # From the tensorflow/models/research/deeplab directory. +# sh ./local_test.sh +# +# + +# Exit immediately if a command exits with a non-zero status. +set -e + +# Move one-level up to tensorflow/models/research directory. +cd .. + +# Update PYTHONPATH. +export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim + +# Set up the working environment. +CURRENT_DIR=$(pwd) +WORK_DIR="${CURRENT_DIR}/deeplab" + +# Run model_test first to make sure the PYTHONPATH is correctly set. +python "${WORK_DIR}"/model_test.py -v + +# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. +DATASET_DIR="datasets" +cd "${WORK_DIR}/${DATASET_DIR}" +sh download_and_convert_voc2012.sh + +# Go back to original directory. +cd "${CURRENT_DIR}" + +# Set up the working directories. +PASCAL_FOLDER="pascal_voc_seg" +EXP_FOLDER="exp/train_on_trainval_set" +INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" +TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" +EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" +VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" +EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" +mkdir -p "${INIT_FOLDER}" +mkdir -p "${TRAIN_LOGDIR}" +mkdir -p "${EVAL_LOGDIR}" +mkdir -p "${VIS_LOGDIR}" +mkdir -p "${EXPORT_DIR}" + +# Copy locally the trained checkpoint as the initial checkpoint. +TF_INIT_ROOT="http://download.tensorflow.org/models" +TF_INIT_CKPT="deeplabv3_pascal_train_aug_2018_01_04.tar.gz" +cd "${INIT_FOLDER}" +wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" +tar -xf "${TF_INIT_CKPT}" +cd "${CURRENT_DIR}" + +PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" + +# Train 10 iterations. +NUM_ITERATIONS=10 +python "${WORK_DIR}"/train.py \ + --logtostderr \ + --train_split="trainval" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --train_crop_size=513 \ + --train_crop_size=513 \ + --train_batch_size=4 \ + --training_number_of_steps="${NUM_ITERATIONS}" \ + --fine_tune_batch_norm=true \ + --tf_initial_checkpoint="${INIT_FOLDER}/deeplabv3_pascal_train_aug/model.ckpt" \ + --train_logdir="${TRAIN_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" + +# Run evaluation. This performs eval over the full val split (1449 images) and +# will take a while. +# Using the provided checkpoint, one should expect mIOU=82.20%. +python "${WORK_DIR}"/eval.py \ + --logtostderr \ + --eval_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --eval_crop_size=513 \ + --eval_crop_size=513 \ + --checkpoint_dir="${TRAIN_LOGDIR}" \ + --eval_logdir="${EVAL_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" \ + --max_number_of_evaluations=1 + +# Visualize the results. +python "${WORK_DIR}"/vis.py \ + --logtostderr \ + --vis_split="val" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --vis_crop_size=513 \ + --vis_crop_size=513 \ + --checkpoint_dir="${TRAIN_LOGDIR}" \ + --vis_logdir="${VIS_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" \ + --max_number_of_iterations=1 + +# Export the trained checkpoint. +CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" +EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" + +python "${WORK_DIR}"/export_model.py \ + --logtostderr \ + --checkpoint_path="${CKPT_PATH}" \ + --export_path="${EXPORT_PATH}" \ + --model_variant="xception_65" \ + --atrous_rates=6 \ + --atrous_rates=12 \ + --atrous_rates=18 \ + --output_stride=16 \ + --decoder_output_stride=4 \ + --num_classes=21 \ + --crop_size=513 \ + --crop_size=513 \ + --inference_scales=1.0 + +# Run inference with the exported checkpoint. +# Please refer to the provided deeplab_demo.ipynb for an example. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test_mobilenetv2.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test_mobilenetv2.sh" new file mode 100644 index 00000000..1f0bc846 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/local_test_mobilenetv2.sh" @@ -0,0 +1,132 @@ +#!/bin/bash +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +# +# This script is used to run local test on PASCAL VOC 2012 using MobileNet-v2. +# Users could also modify from this script for their use case. +# +# Usage: +# # From the tensorflow/models/research/deeplab directory. +# sh ./local_test_mobilenetv2.sh +# +# + +# Exit immediately if a command exits with a non-zero status. +set -e + +# Move one-level up to tensorflow/models/research directory. +cd .. + +# Update PYTHONPATH. +export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim + +# Set up the working environment. +CURRENT_DIR=$(pwd) +WORK_DIR="${CURRENT_DIR}/deeplab" + +# Run model_test first to make sure the PYTHONPATH is correctly set. +python "${WORK_DIR}"/model_test.py -v + +# Go to datasets folder and download PASCAL VOC 2012 segmentation dataset. +DATASET_DIR="datasets" +cd "${WORK_DIR}/${DATASET_DIR}" +sh download_and_convert_voc2012.sh + +# Go back to original directory. +cd "${CURRENT_DIR}" + +# Set up the working directories. +PASCAL_FOLDER="pascal_voc_seg" +EXP_FOLDER="exp/train_on_trainval_set_mobilenetv2" +INIT_FOLDER="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/init_models" +TRAIN_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/train" +EVAL_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/eval" +VIS_LOGDIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/vis" +EXPORT_DIR="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/${EXP_FOLDER}/export" +mkdir -p "${INIT_FOLDER}" +mkdir -p "${TRAIN_LOGDIR}" +mkdir -p "${EVAL_LOGDIR}" +mkdir -p "${VIS_LOGDIR}" +mkdir -p "${EXPORT_DIR}" + +# Copy locally the trained checkpoint as the initial checkpoint. +TF_INIT_ROOT="http://download.tensorflow.org/models" +CKPT_NAME="deeplabv3_mnv2_pascal_train_aug" +TF_INIT_CKPT="${CKPT_NAME}_2018_01_29.tar.gz" +cd "${INIT_FOLDER}" +wget -nd -c "${TF_INIT_ROOT}/${TF_INIT_CKPT}" +tar -xf "${TF_INIT_CKPT}" +cd "${CURRENT_DIR}" + +PASCAL_DATASET="${WORK_DIR}/${DATASET_DIR}/${PASCAL_FOLDER}/tfrecord" + +# Train 10 iterations. +NUM_ITERATIONS=10 +python "${WORK_DIR}"/train.py \ + --logtostderr \ + --train_split="trainval" \ + --model_variant="mobilenet_v2" \ + --output_stride=16 \ + --train_crop_size=513 \ + --train_crop_size=513 \ + --train_batch_size=4 \ + --training_number_of_steps="${NUM_ITERATIONS}" \ + --fine_tune_batch_norm=true \ + --tf_initial_checkpoint="${INIT_FOLDER}/${CKPT_NAME}/model.ckpt-30000" \ + --train_logdir="${TRAIN_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" + +# Run evaluation. This performs eval over the full val split (1449 images) and +# will take a while. +# Using the provided checkpoint, one should expect mIOU=75.34%. +python "${WORK_DIR}"/eval.py \ + --logtostderr \ + --eval_split="val" \ + --model_variant="mobilenet_v2" \ + --eval_crop_size=513 \ + --eval_crop_size=513 \ + --checkpoint_dir="${TRAIN_LOGDIR}" \ + --eval_logdir="${EVAL_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" \ + --max_number_of_evaluations=1 + +# Visualize the results. +python "${WORK_DIR}"/vis.py \ + --logtostderr \ + --vis_split="val" \ + --model_variant="mobilenet_v2" \ + --vis_crop_size=513 \ + --vis_crop_size=513 \ + --checkpoint_dir="${TRAIN_LOGDIR}" \ + --vis_logdir="${VIS_LOGDIR}" \ + --dataset_dir="${PASCAL_DATASET}" \ + --max_number_of_iterations=1 + +# Export the trained checkpoint. +CKPT_PATH="${TRAIN_LOGDIR}/model.ckpt-${NUM_ITERATIONS}" +EXPORT_PATH="${EXPORT_DIR}/frozen_inference_graph.pb" + +python "${WORK_DIR}"/export_model.py \ + --logtostderr \ + --checkpoint_path="${CKPT_PATH}" \ + --export_path="${EXPORT_PATH}" \ + --model_variant="mobilenet_v2" \ + --num_classes=21 \ + --crop_size=513 \ + --crop_size=513 \ + --inference_scales=1.0 + +# Run inference with the exported checkpoint. +# Please refer to the provided deeplab_demo.ipynb for an example. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model.py" new file mode 100644 index 00000000..8a687395 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model.py" @@ -0,0 +1,709 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +r"""Provides DeepLab model definition and helper functions. + +DeepLab is a deep learning system for semantic image segmentation with +the following features: + +(1) Atrous convolution to explicitly control the resolution at which +feature responses are computed within Deep Convolutional Neural Networks. + +(2) Atrous spatial pyramid pooling (ASPP) to robustly segment objects at +multiple scales with filters at multiple sampling rates and effective +fields-of-views. + +(3) ASPP module augmented with image-level feature and batch normalization. + +(4) A simple yet effective decoder module to recover the object boundaries. + +See the following papers for more details: + +"Encoder-Decoder with Atrous Separable Convolution for Semantic Image +Segmentation" +Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, Hartwig Adam. +(https://arxiv.org/abs/1802.02611) + +"Rethinking Atrous Convolution for Semantic Image Segmentation," +Liang-Chieh Chen, George Papandreou, Florian Schroff, Hartwig Adam +(https://arxiv.org/abs/1706.05587) + +"DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, +Atrous Convolution, and Fully Connected CRFs", +Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, +Alan L Yuille (* equal contribution) +(https://arxiv.org/abs/1606.00915) + +"Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected +CRFs" +Liang-Chieh Chen*, George Papandreou*, Iasonas Kokkinos, Kevin Murphy, +Alan L. Yuille (* equal contribution) +(https://arxiv.org/abs/1412.7062) +""" +import tensorflow as tf +from deeplab.core import dense_prediction_cell +from deeplab.core import feature_extractor +from deeplab.core import utils + + +slim = tf.contrib.slim + +LOGITS_SCOPE_NAME = 'logits' +MERGED_LOGITS_SCOPE = 'merged_logits' +IMAGE_POOLING_SCOPE = 'image_pooling' +ASPP_SCOPE = 'aspp' +CONCAT_PROJECTION_SCOPE = 'concat_projection' +DECODER_SCOPE = 'decoder' +META_ARCHITECTURE_SCOPE = 'meta_architecture' + +scale_dimension = utils.scale_dimension +split_separable_conv2d = utils.split_separable_conv2d + +def get_extra_layer_scopes(last_layers_contain_logits_only=False): + """Gets the scopes for extra layers. + + Args: + last_layers_contain_logits_only: Boolean, True if only consider logits as + the last layer (i.e., exclude ASPP module, decoder module and so on) + + Returns: + A list of scopes for extra layers. + """ + if last_layers_contain_logits_only: + return [LOGITS_SCOPE_NAME] + else: + return [ + LOGITS_SCOPE_NAME, + IMAGE_POOLING_SCOPE, + ASPP_SCOPE, + CONCAT_PROJECTION_SCOPE, + DECODER_SCOPE, + META_ARCHITECTURE_SCOPE, + ] + + +def predict_labels_multi_scale(images, + model_options, + eval_scales=(1.0,), + add_flipped_images=False): + """Predicts segmentation labels. + + Args: + images: A tensor of size [batch, height, width, channels]. + model_options: A ModelOptions instance to configure models. + eval_scales: The scales to resize images for evaluation. + add_flipped_images: Add flipped images for evaluation or not. + + Returns: + A dictionary with keys specifying the output_type (e.g., semantic + prediction) and values storing Tensors representing predictions (argmax + over channels). Each prediction has size [batch, height, width]. + """ + outputs_to_predictions = { + output: [] + for output in model_options.outputs_to_num_classes + } + + for i, image_scale in enumerate(eval_scales): + with tf.variable_scope(tf.get_variable_scope(), reuse=True if i else None): + outputs_to_scales_to_logits = multi_scale_logits( + images, + model_options=model_options, + image_pyramid=[image_scale], + is_training=False, + fine_tune_batch_norm=False) + + if add_flipped_images: + with tf.variable_scope(tf.get_variable_scope(), reuse=True): + outputs_to_scales_to_logits_reversed = multi_scale_logits( + tf.reverse_v2(images, [2]), + model_options=model_options, + image_pyramid=[image_scale], + is_training=False, + fine_tune_batch_norm=False) + + for output in sorted(outputs_to_scales_to_logits): + scales_to_logits = outputs_to_scales_to_logits[output] + logits = tf.image.resize_bilinear( + scales_to_logits[MERGED_LOGITS_SCOPE], + tf.shape(images)[1:3], + align_corners=True) + outputs_to_predictions[output].append( + tf.expand_dims(tf.nn.softmax(logits), 4)) + + if add_flipped_images: + scales_to_logits_reversed = ( + outputs_to_scales_to_logits_reversed[output]) + logits_reversed = tf.image.resize_bilinear( + tf.reverse_v2(scales_to_logits_reversed[MERGED_LOGITS_SCOPE], [2]), + tf.shape(images)[1:3], + align_corners=True) + outputs_to_predictions[output].append( + tf.expand_dims(tf.nn.softmax(logits_reversed), 4)) + + for output in sorted(outputs_to_predictions): + predictions = outputs_to_predictions[output] + # Compute average prediction across different scales and flipped images. + predictions = tf.reduce_mean(tf.concat(predictions, 4), axis=4) + outputs_to_predictions[output] = tf.argmax(predictions, 3) + + return outputs_to_predictions + + +def predict_labels(images, model_options, image_pyramid=None): + """Predicts segmentation labels. + + Args: + images: A tensor of size [batch, height, width, channels]. + model_options: A ModelOptions instance to configure models. + image_pyramid: Input image scales for multi-scale feature extraction. + + Returns: + A dictionary with keys specifying the output_type (e.g., semantic + prediction) and values storing Tensors representing predictions (argmax + over channels). Each prediction has size [batch, height, width]. + """ + outputs_to_scales_to_logits = multi_scale_logits( + images, + model_options=model_options, + image_pyramid=image_pyramid, + is_training=False, + fine_tune_batch_norm=False) + + predictions = {} + for output in sorted(outputs_to_scales_to_logits): + scales_to_logits = outputs_to_scales_to_logits[output] + logits = tf.image.resize_bilinear( + scales_to_logits[MERGED_LOGITS_SCOPE], + tf.shape(images)[1:3], + align_corners=True) + predictions[output] = tf.argmax(logits, 3) + + return predictions + + +def _resize_bilinear(images, size, output_dtype=tf.float32): + """Returns resized images as output_type. + + Args: + images: A tensor of size [batch, height_in, width_in, channels]. + size: A 1-D int32 Tensor of 2 elements: new_height, new_width. The new size + for the images. + output_dtype: The destination type. + Returns: + A tensor of size [batch, height_out, width_out, channels] as a dtype of + output_dtype. + """ + images = tf.image.resize_bilinear(images, size, align_corners=True) + return tf.cast(images, dtype=output_dtype) + + +def multi_scale_logits(images, + model_options, + image_pyramid, + weight_decay=0.0001, + is_training=False, + fine_tune_batch_norm=False): + """Gets the logits for multi-scale inputs. + + The returned logits are all downsampled (due to max-pooling layers) + for both training and evaluation. + + Args: + images: A tensor of size [batch, height, width, channels]. + model_options: A ModelOptions instance to configure models. + image_pyramid: Input image scales for multi-scale feature extraction. + weight_decay: The weight decay for model variables. + is_training: Is training or not. + fine_tune_batch_norm: Fine-tune the batch norm parameters or not. + + Returns: + outputs_to_scales_to_logits: A map of maps from output_type (e.g., + semantic prediction) to a dictionary of multi-scale logits names to + logits. For each output_type, the dictionary has keys which + correspond to the scales and values which correspond to the logits. + For example, if `scales` equals [1.0, 1.5], then the keys would + include 'merged_logits', 'logits_1.00' and 'logits_1.50'. + + Raises: + ValueError: If model_options doesn't specify crop_size and its + add_image_level_feature = True, since add_image_level_feature requires + crop_size information. + """ + # Setup default values. + if not image_pyramid: + image_pyramid = [1.0] + crop_height = ( + model_options.crop_size[0] + if model_options.crop_size else tf.shape(images)[1]) + crop_width = ( + model_options.crop_size[1] + if model_options.crop_size else tf.shape(images)[2]) + + # Compute the height, width for the output logits. + logits_output_stride = ( + model_options.decoder_output_stride or model_options.output_stride) + + logits_height = scale_dimension( + crop_height, + max(1.0, max(image_pyramid)) / logits_output_stride) + logits_width = scale_dimension( + crop_width, + max(1.0, max(image_pyramid)) / logits_output_stride) + + # Compute the logits for each scale in the image pyramid. + outputs_to_scales_to_logits = { + k: {} + for k in model_options.outputs_to_num_classes + } + + for image_scale in image_pyramid: + if image_scale != 1.0: + scaled_height = scale_dimension(crop_height, image_scale) + scaled_width = scale_dimension(crop_width, image_scale) + scaled_crop_size = [scaled_height, scaled_width] + scaled_images = tf.image.resize_bilinear( + images, scaled_crop_size, align_corners=True) + if model_options.crop_size: + scaled_images.set_shape([None, scaled_height, scaled_width, 3]) + else: + scaled_crop_size = model_options.crop_size + scaled_images = images + + updated_options = model_options._replace(crop_size=scaled_crop_size) + outputs_to_logits = _get_logits( + scaled_images, + updated_options, + weight_decay=weight_decay, + reuse=tf.AUTO_REUSE, + is_training=is_training, + fine_tune_batch_norm=fine_tune_batch_norm) + + # Resize the logits to have the same dimension before merging. + for output in sorted(outputs_to_logits): + outputs_to_logits[output] = tf.image.resize_bilinear( + outputs_to_logits[output], [logits_height, logits_width], + align_corners=True) + + # Return when only one input scale. + if len(image_pyramid) == 1: + for output in sorted(model_options.outputs_to_num_classes): + outputs_to_scales_to_logits[output][ + MERGED_LOGITS_SCOPE] = outputs_to_logits[output] + return outputs_to_scales_to_logits + + # Save logits to the output map. + for output in sorted(model_options.outputs_to_num_classes): + outputs_to_scales_to_logits[output][ + 'logits_%.2f' % image_scale] = outputs_to_logits[output] + + # Merge the logits from all the multi-scale inputs. + for output in sorted(model_options.outputs_to_num_classes): + # Concatenate the multi-scale logits for each output type. + all_logits = [ + tf.expand_dims(logits, axis=4) + for logits in outputs_to_scales_to_logits[output].values() + ] + all_logits = tf.concat(all_logits, 4) + merge_fn = ( + tf.reduce_max + if model_options.merge_method == 'max' else tf.reduce_mean) + outputs_to_scales_to_logits[output][MERGED_LOGITS_SCOPE] = merge_fn( + all_logits, axis=4) + + return outputs_to_scales_to_logits + + +def extract_features(images, + model_options, + weight_decay=0.0001, + reuse=None, + is_training=False, + fine_tune_batch_norm=False): + """Extracts features by the particular model_variant. + + Args: + images: A tensor of size [batch, height, width, channels]. + model_options: A ModelOptions instance to configure models. + weight_decay: The weight decay for model variables. + reuse: Reuse the model variables or not. + is_training: Is training or not. + fine_tune_batch_norm: Fine-tune the batch norm parameters or not. + + Returns: + concat_logits: A tensor of size [batch, feature_height, feature_width, + feature_channels], where feature_height/feature_width are determined by + the images height/width and output_stride. + end_points: A dictionary from components of the network to the corresponding + activation. + """ + features, end_points = feature_extractor.extract_features( + images, + output_stride=model_options.output_stride, + multi_grid=model_options.multi_grid, + model_variant=model_options.model_variant, + depth_multiplier=model_options.depth_multiplier, + weight_decay=weight_decay, + reuse=reuse, + is_training=is_training, + fine_tune_batch_norm=fine_tune_batch_norm) + + if not model_options.aspp_with_batch_norm: + return features, end_points + else: + if model_options.dense_prediction_cell_config is not None: + tf.logging.info('Using dense prediction cell config.') + dense_prediction_layer = dense_prediction_cell.DensePredictionCell( + config=model_options.dense_prediction_cell_config, + hparams={ + 'conv_rate_multiplier': 16 // model_options.output_stride, + }) + concat_logits = dense_prediction_layer.build_cell( + features, + output_stride=model_options.output_stride, + crop_size=model_options.crop_size, + image_pooling_crop_size=model_options.image_pooling_crop_size, + weight_decay=weight_decay, + reuse=reuse, + is_training=is_training, + fine_tune_batch_norm=fine_tune_batch_norm) + return concat_logits, end_points + else: + # The following codes employ the DeepLabv3 ASPP module. Note that We + # could express the ASPP module as one particular dense prediction + # cell architecture. We do not do so but leave the following codes in + # order for backward compatibility. + batch_norm_params = { + 'is_training': is_training and fine_tune_batch_norm, + 'decay': 0.9997, + 'epsilon': 1e-5, + 'scale': True, + } + + with slim.arg_scope( + [slim.conv2d, slim.separable_conv2d], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + padding='SAME', + stride=1, + reuse=reuse): + with slim.arg_scope([slim.batch_norm], **batch_norm_params): + depth = 256 + branch_logits = [] + + if model_options.add_image_level_feature: + if model_options.crop_size is not None: + image_pooling_crop_size = model_options.image_pooling_crop_size + # If image_pooling_crop_size is not specified, use crop_size. + if image_pooling_crop_size is None: + image_pooling_crop_size = model_options.crop_size + pool_height = scale_dimension( + image_pooling_crop_size[0], + 1. / model_options.output_stride) + pool_width = scale_dimension( + image_pooling_crop_size[1], + 1. / model_options.output_stride) + image_feature = slim.avg_pool2d( + features, [pool_height, pool_width], [1, 1], padding='VALID') + resize_height = scale_dimension( + model_options.crop_size[0], + 1. / model_options.output_stride) + resize_width = scale_dimension( + model_options.crop_size[1], + 1. / model_options.output_stride) + else: + # If crop_size is None, we simply do global pooling. + pool_height = tf.shape(features)[1] + pool_width = tf.shape(features)[2] + image_feature = tf.reduce_mean( + features, axis=[1, 2], keepdims=True) + resize_height = pool_height + resize_width = pool_width + image_feature = slim.conv2d( + image_feature, depth, 1, scope=IMAGE_POOLING_SCOPE) + image_feature = _resize_bilinear( + image_feature, + [resize_height, resize_width], + image_feature.dtype) + # Set shape for resize_height/resize_width if they are not Tensor. + if isinstance(resize_height, tf.Tensor): + resize_height = None + if isinstance(resize_width, tf.Tensor): + resize_width = None + image_feature.set_shape([None, resize_height, resize_width, depth]) + branch_logits.append(image_feature) + + # Employ a 1x1 convolution. + branch_logits.append(slim.conv2d(features, depth, 1, + scope=ASPP_SCOPE + str(0))) + + if model_options.atrous_rates: + # Employ 3x3 convolutions with different atrous rates. + for i, rate in enumerate(model_options.atrous_rates, 1): + scope = ASPP_SCOPE + str(i) + if model_options.aspp_with_separable_conv: + aspp_features = split_separable_conv2d( + features, + filters=depth, + rate=rate, + weight_decay=weight_decay, + scope=scope) + else: + aspp_features = slim.conv2d( + features, depth, 3, rate=rate, scope=scope) + branch_logits.append(aspp_features) + + # Merge branch logits. + concat_logits = tf.concat(branch_logits, 3) + concat_logits = slim.conv2d( + concat_logits, depth, 1, scope=CONCAT_PROJECTION_SCOPE) + concat_logits = slim.dropout( + concat_logits, + keep_prob=0.9, + is_training=is_training, + scope=CONCAT_PROJECTION_SCOPE + '_dropout') + + return concat_logits, end_points + + +def _get_logits(images, + model_options, + weight_decay=0.0001, + reuse=None, + is_training=False, + fine_tune_batch_norm=False): + """Gets the logits by atrous/image spatial pyramid pooling. + + Args: + images: A tensor of size [batch, height, width, channels]. + model_options: A ModelOptions instance to configure models. + weight_decay: The weight decay for model variables. + reuse: Reuse the model variables or not. + is_training: Is training or not. + fine_tune_batch_norm: Fine-tune the batch norm parameters or not. + + Returns: + outputs_to_logits: A map from output_type to logits. + """ + features, end_points = extract_features( + images, + model_options, + weight_decay=weight_decay, + reuse=reuse, + is_training=is_training, + fine_tune_batch_norm=fine_tune_batch_norm) + + if model_options.decoder_output_stride is not None: + if model_options.crop_size is None: + height = tf.shape(images)[1] + width = tf.shape(images)[2] + else: + height, width = model_options.crop_size + decoder_height = scale_dimension(height, + 1.0 / model_options.decoder_output_stride) + decoder_width = scale_dimension(width, + 1.0 / model_options.decoder_output_stride) + features = refine_by_decoder( + features, + end_points, + decoder_height=decoder_height, + decoder_width=decoder_width, + decoder_use_separable_conv=model_options.decoder_use_separable_conv, + model_variant=model_options.model_variant, + weight_decay=weight_decay, + reuse=reuse, + is_training=is_training, + fine_tune_batch_norm=fine_tune_batch_norm) + + outputs_to_logits = {} + for output in sorted(model_options.outputs_to_num_classes): + outputs_to_logits[output] = get_branch_logits( + features, + model_options.outputs_to_num_classes[output], + model_options.atrous_rates, + aspp_with_batch_norm=model_options.aspp_with_batch_norm, + kernel_size=model_options.logits_kernel_size, + weight_decay=weight_decay, + reuse=reuse, + scope_suffix=output) + + return outputs_to_logits + + +def refine_by_decoder(features, + end_points, + decoder_height, + decoder_width, + decoder_use_separable_conv=False, + model_variant=None, + weight_decay=0.0001, + reuse=None, + is_training=False, + fine_tune_batch_norm=False): + """Adds the decoder to obtain sharper segmentation results. + + Args: + features: A tensor of size [batch, features_height, features_width, + features_channels]. + end_points: A dictionary from components of the network to the corresponding + activation. + decoder_height: The height of decoder feature maps. + decoder_width: The width of decoder feature maps. + decoder_use_separable_conv: Employ separable convolution for decoder or not. + model_variant: Model variant for feature extraction. + weight_decay: The weight decay for model variables. + reuse: Reuse the model variables or not. + is_training: Is training or not. + fine_tune_batch_norm: Fine-tune the batch norm parameters or not. + + Returns: + Decoder output with size [batch, decoder_height, decoder_width, + decoder_channels]. + """ + batch_norm_params = { + 'is_training': is_training and fine_tune_batch_norm, + 'decay': 0.9997, + 'epsilon': 1e-5, + 'scale': True, + } + + with slim.arg_scope( + [slim.conv2d, slim.separable_conv2d], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + padding='SAME', + stride=1, + reuse=reuse): + with slim.arg_scope([slim.batch_norm], **batch_norm_params): + with tf.variable_scope(DECODER_SCOPE, DECODER_SCOPE, [features]): + feature_list = feature_extractor.networks_to_feature_maps[ + model_variant][feature_extractor.DECODER_END_POINTS] + if feature_list is None: + tf.logging.info('Not found any decoder end points.') + return features + else: + decoder_features = features + for i, name in enumerate(feature_list): + decoder_features_list = [decoder_features] + + # MobileNet variants use different naming convention. + if 'mobilenet' in model_variant: + feature_name = name + else: + feature_name = '{}/{}'.format( + feature_extractor.name_scope[model_variant], name) + decoder_features_list.append( + slim.conv2d( + end_points[feature_name], + 48, + 1, + scope='feature_projection' + str(i))) + # Resize to decoder_height/decoder_width. + for j, feature in enumerate(decoder_features_list): + decoder_features_list[j] = tf.image.resize_bilinear( + feature, [decoder_height, decoder_width], align_corners=True) + h = (None if isinstance(decoder_height, tf.Tensor) + else decoder_height) + w = (None if isinstance(decoder_width, tf.Tensor) + else decoder_width) + decoder_features_list[j].set_shape([None, h, w, None]) + decoder_depth = 256 + if decoder_use_separable_conv: + decoder_features = split_separable_conv2d( + tf.concat(decoder_features_list, 3), + filters=decoder_depth, + rate=1, + weight_decay=weight_decay, + scope='decoder_conv0') + decoder_features = split_separable_conv2d( + decoder_features, + filters=decoder_depth, + rate=1, + weight_decay=weight_decay, + scope='decoder_conv1') + else: + num_convs = 2 + decoder_features = slim.repeat( + tf.concat(decoder_features_list, 3), + num_convs, + slim.conv2d, + decoder_depth, + 3, + scope='decoder_conv' + str(i)) + return decoder_features + + +def get_branch_logits(features, + num_classes, + atrous_rates=None, + aspp_with_batch_norm=False, + kernel_size=1, + weight_decay=0.0001, + reuse=None, + scope_suffix=''): + """Gets the logits from each model's branch. + + The underlying model is branched out in the last layer when atrous + spatial pyramid pooling is employed, and all branches are sum-merged + to form the final logits. + + Args: + features: A float tensor of shape [batch, height, width, channels]. + num_classes: Number of classes to predict. + atrous_rates: A list of atrous convolution rates for last layer. + aspp_with_batch_norm: Use batch normalization layers for ASPP. + kernel_size: Kernel size for convolution. + weight_decay: Weight decay for the model variables. + reuse: Reuse model variables or not. + scope_suffix: Scope suffix for the model variables. + + Returns: + Merged logits with shape [batch, height, width, num_classes]. + + Raises: + ValueError: Upon invalid input kernel_size value. + """ + # When using batch normalization with ASPP, ASPP has been applied before + # in extract_features, and thus we simply apply 1x1 convolution here. + if aspp_with_batch_norm or atrous_rates is None: + if kernel_size != 1: + raise ValueError('Kernel size must be 1 when atrous_rates is None or ' + 'using aspp_with_batch_norm. Gets %d.' % kernel_size) + atrous_rates = [1] + + with slim.arg_scope( + [slim.conv2d], + weights_regularizer=slim.l2_regularizer(weight_decay), + weights_initializer=tf.truncated_normal_initializer(stddev=0.01), + reuse=reuse): + with tf.variable_scope(LOGITS_SCOPE_NAME, LOGITS_SCOPE_NAME, [features]): + branch_logits = [] + for i, rate in enumerate(atrous_rates): + scope = scope_suffix + if i: + scope += '_%d' % i + + branch_logits.append( + slim.conv2d( + features, + num_classes, + kernel_size=kernel_size, + rate=rate, + activation_fn=None, + normalizer_fn=None, + scope=scope)) + + return tf.add_n(branch_logits) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model_test.py" new file mode 100644 index 00000000..50471c27 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/model_test.py" @@ -0,0 +1,146 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for DeepLab model and some helper functions.""" + +import tensorflow as tf + +from deeplab import common +from deeplab import model + + +class DeeplabModelTest(tf.test.TestCase): + + def testWrongDeepLabVariant(self): + model_options = common.ModelOptions([])._replace( + model_variant='no_such_variant') + with self.assertRaises(ValueError): + model._get_logits(images=[], model_options=model_options) + + def testBuildDeepLabv2(self): + batch_size = 2 + crop_size = [41, 41] + + # Test with two image_pyramids. + image_pyramids = [[1], [0.5, 1]] + + # Test two model variants. + model_variants = ['xception_65', 'mobilenet_v2'] + + # Test with two output_types. + outputs_to_num_classes = {'semantic': 3, + 'direction': 2} + + expected_endpoints = [['merged_logits'], + ['merged_logits', + 'logits_0.50', + 'logits_1.00']] + expected_num_logits = [1, 3] + + for model_variant in model_variants: + model_options = common.ModelOptions(outputs_to_num_classes)._replace( + add_image_level_feature=False, + aspp_with_batch_norm=False, + aspp_with_separable_conv=False, + model_variant=model_variant) + + for i, image_pyramid in enumerate(image_pyramids): + g = tf.Graph() + with g.as_default(): + with self.test_session(graph=g): + inputs = tf.random_uniform( + (batch_size, crop_size[0], crop_size[1], 3)) + outputs_to_scales_to_logits = model.multi_scale_logits( + inputs, model_options, image_pyramid=image_pyramid) + + # Check computed results for each output type. + for output in outputs_to_num_classes: + scales_to_logits = outputs_to_scales_to_logits[output] + self.assertListEqual(sorted(scales_to_logits.keys()), + sorted(expected_endpoints[i])) + + # Expected number of logits = len(image_pyramid) + 1, since the + # last logits is merged from all the scales. + self.assertEqual(len(scales_to_logits), expected_num_logits[i]) + + def testForwardpassDeepLabv3plus(self): + crop_size = [33, 33] + outputs_to_num_classes = {'semantic': 3} + + model_options = common.ModelOptions( + outputs_to_num_classes, + crop_size, + output_stride=16 + )._replace( + add_image_level_feature=True, + aspp_with_batch_norm=True, + logits_kernel_size=1, + model_variant='mobilenet_v2') # Employ MobileNetv2 for fast test. + + g = tf.Graph() + with g.as_default(): + with self.test_session(graph=g) as sess: + inputs = tf.random_uniform( + (1, crop_size[0], crop_size[1], 3)) + outputs_to_scales_to_logits = model.multi_scale_logits( + inputs, + model_options, + image_pyramid=[1.0]) + + sess.run(tf.global_variables_initializer()) + outputs_to_scales_to_logits = sess.run(outputs_to_scales_to_logits) + + # Check computed results for each output type. + for output in outputs_to_num_classes: + scales_to_logits = outputs_to_scales_to_logits[output] + # Expect only one output. + self.assertEqual(len(scales_to_logits), 1) + for logits in scales_to_logits.values(): + self.assertTrue(logits.any()) + + def testBuildDeepLabWithDensePredictionCell(self): + batch_size = 1 + crop_size = [33, 33] + outputs_to_num_classes = {'semantic': 2} + expected_endpoints = ['merged_logits'] + dense_prediction_cell_config = [ + {'kernel': 3, 'rate': [1, 6], 'op': 'conv', 'input': -1}, + {'kernel': 3, 'rate': [18, 15], 'op': 'conv', 'input': 0}, + ] + model_options = common.ModelOptions( + outputs_to_num_classes, + crop_size, + output_stride=16)._replace( + aspp_with_batch_norm=True, + model_variant='mobilenet_v2', + dense_prediction_cell_config=dense_prediction_cell_config) + g = tf.Graph() + with g.as_default(): + with self.test_session(graph=g): + inputs = tf.random_uniform( + (batch_size, crop_size[0], crop_size[1], 3)) + outputs_to_scales_to_model_results = model.multi_scale_logits( + inputs, + model_options, + image_pyramid=[1.0]) + for output in outputs_to_num_classes: + scales_to_model_results = outputs_to_scales_to_model_results[output] + self.assertListEqual(scales_to_model_results.keys(), + expected_endpoints) + self.assertEqual(len(scales_to_model_results), 1) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/train.py" new file mode 100644 index 00000000..bf362922 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/train.py" @@ -0,0 +1,394 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Training script for the DeepLab model. + +See model.py for more details and usage. +""" + +import six +import tensorflow as tf +from deeplab import common +from deeplab import model +from deeplab.datasets import segmentation_dataset +from deeplab.utils import input_generator +from deeplab.utils import train_utils +from deployment import model_deploy + +slim = tf.contrib.slim + +prefetch_queue = slim.prefetch_queue + +flags = tf.app.flags + +FLAGS = flags.FLAGS + +# Settings for multi-GPUs/multi-replicas training. + +flags.DEFINE_integer('num_clones', 1, 'Number of clones to deploy.') + +flags.DEFINE_boolean('clone_on_cpu', False, 'Use CPUs to deploy clones.') + +flags.DEFINE_integer('num_replicas', 1, 'Number of worker replicas.') + +flags.DEFINE_integer('startup_delay_steps', 15, + 'Number of training steps between replicas startup.') + +flags.DEFINE_integer('num_ps_tasks', 0, + 'The number of parameter servers. If the value is 0, then ' + 'the parameters are handled locally by the worker.') + +flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') + +flags.DEFINE_integer('task', 0, 'The task ID.') + +# Settings for logging. + +flags.DEFINE_string('train_logdir', None, + 'Where the checkpoint and logs are stored.') + +flags.DEFINE_integer('log_steps', 10, + 'Display logging information at every log_steps.') + +flags.DEFINE_integer('save_interval_secs', 1200, + 'How often, in seconds, we save the model to disk.') + +flags.DEFINE_integer('save_summaries_secs', 600, + 'How often, in seconds, we compute the summaries.') + +flags.DEFINE_boolean('save_summaries_images', False, + 'Save sample inputs, labels, and semantic predictions as ' + 'images to summary.') + +# Settings for training strategy. + +flags.DEFINE_enum('learning_policy', 'poly', ['poly', 'step'], + 'Learning rate policy for training.') + +# Use 0.007 when training on PASCAL augmented training set, train_aug. When +# fine-tuning on PASCAL trainval set, use learning rate=0.0001. +flags.DEFINE_float('base_learning_rate', .0001, + 'The base learning rate for model training.') + +flags.DEFINE_float('learning_rate_decay_factor', 0.1, + 'The rate to decay the base learning rate.') + +flags.DEFINE_integer('learning_rate_decay_step', 2000, + 'Decay the base learning rate at a fixed step.') + +flags.DEFINE_float('learning_power', 0.9, + 'The power value used in the poly learning policy.') + +flags.DEFINE_integer('training_number_of_steps', 30000, + 'The number of steps used for training') + +flags.DEFINE_float('momentum', 0.9, 'The momentum value to use') + +# When fine_tune_batch_norm=True, use at least batch size larger than 12 +# (batch size more than 16 is better). Otherwise, one could use smaller batch +# size and set fine_tune_batch_norm=False. +flags.DEFINE_integer('train_batch_size', 8, + 'The number of images in each batch during training.') + +# For weight_decay, use 0.00004 for MobileNet-V2 or Xcpetion model variants. +# Use 0.0001 for ResNet model variants. +flags.DEFINE_float('weight_decay', 0.00004, + 'The value of the weight decay for training.') + +flags.DEFINE_multi_integer('train_crop_size', [513, 513], + 'Image crop size [height, width] during training.') + +flags.DEFINE_float('last_layer_gradient_multiplier', 1.0, + 'The gradient multiplier for last layers, which is used to ' + 'boost the gradient of last layers if the value > 1.') + +flags.DEFINE_boolean('upsample_logits', True, + 'Upsample logits during training.') + +# Settings for fine-tuning the network. + +flags.DEFINE_string('tf_initial_checkpoint', None, + 'The initial checkpoint in tensorflow format.') + +# Set to False if one does not want to re-use the trained classifier weights. +flags.DEFINE_boolean('initialize_last_layer', True, + 'Initialize the last layer.') + +flags.DEFINE_boolean('last_layers_contain_logits_only', False, + 'Only consider logits as last layers or not.') + +flags.DEFINE_integer('slow_start_step', 0, + 'Training model with small learning rate for few steps.') + +flags.DEFINE_float('slow_start_learning_rate', 1e-4, + 'Learning rate employed during slow start.') + +# Set to True if one wants to fine-tune the batch norm parameters in DeepLabv3. +# Set to False and use small batch size to save GPU memory. +flags.DEFINE_boolean('fine_tune_batch_norm', True, + 'Fine tune the batch norm parameters or not.') + +flags.DEFINE_float('min_scale_factor', 0.5, + 'Mininum scale factor for data augmentation.') + +flags.DEFINE_float('max_scale_factor', 2., + 'Maximum scale factor for data augmentation.') + +flags.DEFINE_float('scale_factor_step_size', 0.25, + 'Scale factor step size for data augmentation.') + +# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or +# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note +# one could use different atrous_rates/output_stride during training/evaluation. +flags.DEFINE_multi_integer('atrous_rates', None, + 'Atrous rates for atrous spatial pyramid pooling.') + +flags.DEFINE_integer('output_stride', 16, + 'The ratio of input to output spatial resolution.') + +# Dataset settings. +flags.DEFINE_string('dataset', 'pascal_voc_seg', + 'Name of the segmentation dataset.') + +flags.DEFINE_string('train_split', 'train', + 'Which split of the dataset to be used for training') + +flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') + + +def _build_deeplab(inputs_queue, outputs_to_num_classes, ignore_label): + """Builds a clone of DeepLab. + + Args: + inputs_queue: A prefetch queue for images and labels. + outputs_to_num_classes: A map from output type to the number of classes. + For example, for the task of semantic segmentation with 21 semantic + classes, we would have outputs_to_num_classes['semantic'] = 21. + ignore_label: Ignore label. + + Returns: + A map of maps from output_type (e.g., semantic prediction) to a + dictionary of multi-scale logits names to logits. For each output_type, + the dictionary has keys which correspond to the scales and values which + correspond to the logits. For example, if `scales` equals [1.0, 1.5], + then the keys would include 'merged_logits', 'logits_1.00' and + 'logits_1.50'. + """ + samples = inputs_queue.dequeue() + + # Add name to input and label nodes so we can add to summary. + samples[common.IMAGE] = tf.identity( + samples[common.IMAGE], name=common.IMAGE) + samples[common.LABEL] = tf.identity( + samples[common.LABEL], name=common.LABEL) + + model_options = common.ModelOptions( + outputs_to_num_classes=outputs_to_num_classes, + crop_size=FLAGS.train_crop_size, + atrous_rates=FLAGS.atrous_rates, + output_stride=FLAGS.output_stride) + outputs_to_scales_to_logits = model.multi_scale_logits( + samples[common.IMAGE], + model_options=model_options, + image_pyramid=FLAGS.image_pyramid, + weight_decay=FLAGS.weight_decay, + is_training=True, + fine_tune_batch_norm=FLAGS.fine_tune_batch_norm) + + # Add name to graph node so we can add to summary. + output_type_dict = outputs_to_scales_to_logits[common.OUTPUT_TYPE] + output_type_dict[model.MERGED_LOGITS_SCOPE] = tf.identity( + output_type_dict[model.MERGED_LOGITS_SCOPE], + name=common.OUTPUT_TYPE) + + for output, num_classes in six.iteritems(outputs_to_num_classes): + train_utils.add_softmax_cross_entropy_loss_for_each_scale( + outputs_to_scales_to_logits[output], + samples[common.LABEL], + num_classes, + ignore_label, + loss_weight=1.0, + upsample_logits=FLAGS.upsample_logits, + scope=output) + + return outputs_to_scales_to_logits + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + # Set up deployment (i.e., multi-GPUs and/or multi-replicas). + config = model_deploy.DeploymentConfig( + num_clones=FLAGS.num_clones, + clone_on_cpu=FLAGS.clone_on_cpu, + replica_id=FLAGS.task, + num_replicas=FLAGS.num_replicas, + num_ps_tasks=FLAGS.num_ps_tasks) + + # Split the batch across GPUs. + assert FLAGS.train_batch_size % config.num_clones == 0, ( + 'Training batch size not divisble by number of clones (GPUs).') + + clone_batch_size = FLAGS.train_batch_size // config.num_clones + + # Get dataset-dependent information. + dataset = segmentation_dataset.get_dataset( + FLAGS.dataset, FLAGS.train_split, dataset_dir=FLAGS.dataset_dir) + + tf.gfile.MakeDirs(FLAGS.train_logdir) + tf.logging.info('Training on %s set', FLAGS.train_split) + + with tf.Graph().as_default() as graph: + with tf.device(config.inputs_device()): + samples = input_generator.get( + dataset, + FLAGS.train_crop_size, + clone_batch_size, + min_resize_value=FLAGS.min_resize_value, + max_resize_value=FLAGS.max_resize_value, + resize_factor=FLAGS.resize_factor, + min_scale_factor=FLAGS.min_scale_factor, + max_scale_factor=FLAGS.max_scale_factor, + scale_factor_step_size=FLAGS.scale_factor_step_size, + dataset_split=FLAGS.train_split, + is_training=True, + model_variant=FLAGS.model_variant) + inputs_queue = prefetch_queue.prefetch_queue( + samples, capacity=128 * config.num_clones) + + # Create the global step on the device storing the variables. + with tf.device(config.variables_device()): + global_step = tf.train.get_or_create_global_step() + + # Define the model and create clones. + model_fn = _build_deeplab + model_args = (inputs_queue, { + common.OUTPUT_TYPE: dataset.num_classes + }, dataset.ignore_label) + clones = model_deploy.create_clones(config, model_fn, args=model_args) + + # Gather update_ops from the first clone. These contain, for example, + # the updates for the batch_norm variables created by model_fn. + first_clone_scope = config.clone_scope(0) + update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, first_clone_scope) + + # Gather initial summaries. + summaries = set(tf.get_collection(tf.GraphKeys.SUMMARIES)) + + # Add summaries for model variables. + for model_var in slim.get_model_variables(): + summaries.add(tf.summary.histogram(model_var.op.name, model_var)) + + # Add summaries for images, labels, semantic predictions + if FLAGS.save_summaries_images: + summary_image = graph.get_tensor_by_name( + ('%s/%s:0' % (first_clone_scope, common.IMAGE)).strip('/')) + summaries.add( + tf.summary.image('samples/%s' % common.IMAGE, summary_image)) + + first_clone_label = graph.get_tensor_by_name( + ('%s/%s:0' % (first_clone_scope, common.LABEL)).strip('/')) + # Scale up summary image pixel values for better visualization. + pixel_scaling = max(1, 255 // dataset.num_classes) + summary_label = tf.cast(first_clone_label * pixel_scaling, tf.uint8) + summaries.add( + tf.summary.image('samples/%s' % common.LABEL, summary_label)) + + first_clone_output = graph.get_tensor_by_name( + ('%s/%s:0' % (first_clone_scope, common.OUTPUT_TYPE)).strip('/')) + predictions = tf.expand_dims(tf.argmax(first_clone_output, 3), -1) + + summary_predictions = tf.cast(predictions * pixel_scaling, tf.uint8) + summaries.add( + tf.summary.image( + 'samples/%s' % common.OUTPUT_TYPE, summary_predictions)) + + # Add summaries for losses. + for loss in tf.get_collection(tf.GraphKeys.LOSSES, first_clone_scope): + summaries.add(tf.summary.scalar('losses/%s' % loss.op.name, loss)) + + # Build the optimizer based on the device specification. + with tf.device(config.optimizer_device()): + learning_rate = train_utils.get_model_learning_rate( + FLAGS.learning_policy, FLAGS.base_learning_rate, + FLAGS.learning_rate_decay_step, FLAGS.learning_rate_decay_factor, + FLAGS.training_number_of_steps, FLAGS.learning_power, + FLAGS.slow_start_step, FLAGS.slow_start_learning_rate) + optimizer = tf.train.MomentumOptimizer(learning_rate, FLAGS.momentum) + summaries.add(tf.summary.scalar('learning_rate', learning_rate)) + + startup_delay_steps = FLAGS.task * FLAGS.startup_delay_steps + for variable in slim.get_model_variables(): + summaries.add(tf.summary.histogram(variable.op.name, variable)) + + with tf.device(config.variables_device()): + total_loss, grads_and_vars = model_deploy.optimize_clones( + clones, optimizer) + total_loss = tf.check_numerics(total_loss, 'Loss is inf or nan.') + summaries.add(tf.summary.scalar('total_loss', total_loss)) + + # Modify the gradients for biases and last layer variables. + last_layers = model.get_extra_layer_scopes( + FLAGS.last_layers_contain_logits_only) + grad_mult = train_utils.get_model_gradient_multipliers( + last_layers, FLAGS.last_layer_gradient_multiplier) + if grad_mult: + grads_and_vars = slim.learning.multiply_gradients( + grads_and_vars, grad_mult) + + # Create gradient update op. + grad_updates = optimizer.apply_gradients( + grads_and_vars, global_step=global_step) + update_ops.append(grad_updates) + update_op = tf.group(*update_ops) + with tf.control_dependencies([update_op]): + train_tensor = tf.identity(total_loss, name='train_op') + + # Add the summaries from the first clone. These contain the summaries + # created by model_fn and either optimize_clones() or _gather_clone_loss(). + summaries |= set( + tf.get_collection(tf.GraphKeys.SUMMARIES, first_clone_scope)) + + # Merge all summaries together. + summary_op = tf.summary.merge(list(summaries)) + + # Soft placement allows placing on CPU ops without GPU implementation. + session_config = tf.ConfigProto( + allow_soft_placement=True, log_device_placement=False) + + # Start the training. + slim.learning.train( + train_tensor, + logdir=FLAGS.train_logdir, + log_every_n_steps=FLAGS.log_steps, + master=FLAGS.master, + number_of_steps=FLAGS.training_number_of_steps, + is_chief=(FLAGS.task == 0), + session_config=session_config, + startup_delay_steps=startup_delay_steps, + init_fn=train_utils.get_model_init_fn( + FLAGS.train_logdir, + FLAGS.tf_initial_checkpoint, + FLAGS.initialize_last_layer, + last_layers, + ignore_missing_vars=True), + summary_op=summary_op, + save_summaries_secs=FLAGS.save_summaries_secs, + save_interval_secs=FLAGS.save_interval_secs) + + +if __name__ == '__main__': + flags.mark_flag_as_required('train_logdir') + flags.mark_flag_as_required('tf_initial_checkpoint') + flags.mark_flag_as_required('dataset_dir') + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap.py" new file mode 100644 index 00000000..eff9b195 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap.py" @@ -0,0 +1,405 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Visualizes the segmentation results via specified color map. + +Visualizes the semantic segmentation results by the color map +defined by the different datasets. Supported colormaps are: + +* ADE20K (http://groups.csail.mit.edu/vision/datasets/ADE20K/). + +* Cityscapes dataset (https://www.cityscapes-dataset.com). + +* Mapillary Vistas (https://research.mapillary.com). + +* PASCAL VOC 2012 (http://host.robots.ox.ac.uk/pascal/VOC/). +""" + +import numpy as np + +# Dataset names. +_ADE20K = 'ade20k' +_CITYSCAPES = 'cityscapes' +_MAPILLARY_VISTAS = 'mapillary_vistas' +_PASCAL = 'pascal' + +# Max number of entries in the colormap for each dataset. +_DATASET_MAX_ENTRIES = { + _ADE20K: 151, + _CITYSCAPES: 19, + _MAPILLARY_VISTAS: 66, + _PASCAL: 256, +} + + +def create_ade20k_label_colormap(): + """Creates a label colormap used in ADE20K segmentation benchmark. + + Returns: + A colormap for visualizing segmentation results. + """ + return np.asarray([ + [0, 0, 0], + [120, 120, 120], + [180, 120, 120], + [6, 230, 230], + [80, 50, 50], + [4, 200, 3], + [120, 120, 80], + [140, 140, 140], + [204, 5, 255], + [230, 230, 230], + [4, 250, 7], + [224, 5, 255], + [235, 255, 7], + [150, 5, 61], + [120, 120, 70], + [8, 255, 51], + [255, 6, 82], + [143, 255, 140], + [204, 255, 4], + [255, 51, 7], + [204, 70, 3], + [0, 102, 200], + [61, 230, 250], + [255, 6, 51], + [11, 102, 255], + [255, 7, 71], + [255, 9, 224], + [9, 7, 230], + [220, 220, 220], + [255, 9, 92], + [112, 9, 255], + [8, 255, 214], + [7, 255, 224], + [255, 184, 6], + [10, 255, 71], + [255, 41, 10], + [7, 255, 255], + [224, 255, 8], + [102, 8, 255], + [255, 61, 6], + [255, 194, 7], + [255, 122, 8], + [0, 255, 20], + [255, 8, 41], + [255, 5, 153], + [6, 51, 255], + [235, 12, 255], + [160, 150, 20], + [0, 163, 255], + [140, 140, 140], + [250, 10, 15], + [20, 255, 0], + [31, 255, 0], + [255, 31, 0], + [255, 224, 0], + [153, 255, 0], + [0, 0, 255], + [255, 71, 0], + [0, 235, 255], + [0, 173, 255], + [31, 0, 255], + [11, 200, 200], + [255, 82, 0], + [0, 255, 245], + [0, 61, 255], + [0, 255, 112], + [0, 255, 133], + [255, 0, 0], + [255, 163, 0], + [255, 102, 0], + [194, 255, 0], + [0, 143, 255], + [51, 255, 0], + [0, 82, 255], + [0, 255, 41], + [0, 255, 173], + [10, 0, 255], + [173, 255, 0], + [0, 255, 153], + [255, 92, 0], + [255, 0, 255], + [255, 0, 245], + [255, 0, 102], + [255, 173, 0], + [255, 0, 20], + [255, 184, 184], + [0, 31, 255], + [0, 255, 61], + [0, 71, 255], + [255, 0, 204], + [0, 255, 194], + [0, 255, 82], + [0, 10, 255], + [0, 112, 255], + [51, 0, 255], + [0, 194, 255], + [0, 122, 255], + [0, 255, 163], + [255, 153, 0], + [0, 255, 10], + [255, 112, 0], + [143, 255, 0], + [82, 0, 255], + [163, 255, 0], + [255, 235, 0], + [8, 184, 170], + [133, 0, 255], + [0, 255, 92], + [184, 0, 255], + [255, 0, 31], + [0, 184, 255], + [0, 214, 255], + [255, 0, 112], + [92, 255, 0], + [0, 224, 255], + [112, 224, 255], + [70, 184, 160], + [163, 0, 255], + [153, 0, 255], + [71, 255, 0], + [255, 0, 163], + [255, 204, 0], + [255, 0, 143], + [0, 255, 235], + [133, 255, 0], + [255, 0, 235], + [245, 0, 255], + [255, 0, 122], + [255, 245, 0], + [10, 190, 212], + [214, 255, 0], + [0, 204, 255], + [20, 0, 255], + [255, 255, 0], + [0, 153, 255], + [0, 41, 255], + [0, 255, 204], + [41, 0, 255], + [41, 255, 0], + [173, 0, 255], + [0, 245, 255], + [71, 0, 255], + [122, 0, 255], + [0, 255, 184], + [0, 92, 255], + [184, 255, 0], + [0, 133, 255], + [255, 214, 0], + [25, 194, 194], + [102, 255, 0], + [92, 0, 255], + ]) + + +def create_cityscapes_label_colormap(): + """Creates a label colormap used in CITYSCAPES segmentation benchmark. + + Returns: + A colormap for visualizing segmentation results. + """ + return np.asarray([ + [128, 64, 128], + [244, 35, 232], + [70, 70, 70], + [102, 102, 156], + [190, 153, 153], + [153, 153, 153], + [250, 170, 30], + [220, 220, 0], + [107, 142, 35], + [152, 251, 152], + [70, 130, 180], + [220, 20, 60], + [255, 0, 0], + [0, 0, 142], + [0, 0, 70], + [0, 60, 100], + [0, 80, 100], + [0, 0, 230], + [119, 11, 32], + ]) + + +def create_mapillary_vistas_label_colormap(): + """Creates a label colormap used in Mapillary Vistas segmentation benchmark. + + Returns: + A colormap for visualizing segmentation results. + """ + return np.asarray([ + [165, 42, 42], + [0, 192, 0], + [196, 196, 196], + [190, 153, 153], + [180, 165, 180], + [102, 102, 156], + [102, 102, 156], + [128, 64, 255], + [140, 140, 200], + [170, 170, 170], + [250, 170, 160], + [96, 96, 96], + [230, 150, 140], + [128, 64, 128], + [110, 110, 110], + [244, 35, 232], + [150, 100, 100], + [70, 70, 70], + [150, 120, 90], + [220, 20, 60], + [255, 0, 0], + [255, 0, 0], + [255, 0, 0], + [200, 128, 128], + [255, 255, 255], + [64, 170, 64], + [128, 64, 64], + [70, 130, 180], + [255, 255, 255], + [152, 251, 152], + [107, 142, 35], + [0, 170, 30], + [255, 255, 128], + [250, 0, 30], + [0, 0, 0], + [220, 220, 220], + [170, 170, 170], + [222, 40, 40], + [100, 170, 30], + [40, 40, 40], + [33, 33, 33], + [170, 170, 170], + [0, 0, 142], + [170, 170, 170], + [210, 170, 100], + [153, 153, 153], + [128, 128, 128], + [0, 0, 142], + [250, 170, 30], + [192, 192, 192], + [220, 220, 0], + [180, 165, 180], + [119, 11, 32], + [0, 0, 142], + [0, 60, 100], + [0, 0, 142], + [0, 0, 90], + [0, 0, 230], + [0, 80, 100], + [128, 64, 64], + [0, 0, 110], + [0, 0, 70], + [0, 0, 192], + [32, 32, 32], + [0, 0, 0], + [0, 0, 0], + ]) + + +def create_pascal_label_colormap(): + """Creates a label colormap used in PASCAL VOC segmentation benchmark. + + Returns: + A colormap for visualizing segmentation results. + """ + colormap = np.zeros((_DATASET_MAX_ENTRIES[_PASCAL], 3), dtype=int) + ind = np.arange(_DATASET_MAX_ENTRIES[_PASCAL], dtype=int) + + for shift in reversed(range(8)): + for channel in range(3): + colormap[:, channel] |= bit_get(ind, channel) << shift + ind >>= 3 + + return colormap + + +def get_ade20k_name(): + return _ADE20K + + +def get_cityscapes_name(): + return _CITYSCAPES + + +def get_mapillary_vistas_name(): + return _MAPILLARY_VISTAS + + +def get_pascal_name(): + return _PASCAL + + +def bit_get(val, idx): + """Gets the bit value. + + Args: + val: Input value, int or numpy int array. + idx: Which bit of the input val. + + Returns: + The "idx"-th bit of input val. + """ + return (val >> idx) & 1 + + +def create_label_colormap(dataset=_PASCAL): + """Creates a label colormap for the specified dataset. + + Args: + dataset: The colormap used in the dataset. + + Returns: + A numpy array of the dataset colormap. + + Raises: + ValueError: If the dataset is not supported. + """ + if dataset == _ADE20K: + return create_ade20k_label_colormap() + elif dataset == _CITYSCAPES: + return create_cityscapes_label_colormap() + elif dataset == _MAPILLARY_VISTAS: + return create_mapillary_vistas_label_colormap() + elif dataset == _PASCAL: + return create_pascal_label_colormap() + else: + raise ValueError('Unsupported dataset.') + + +def label_to_color_image(label, dataset=_PASCAL): + """Adds color defined by the dataset colormap to the label. + + Args: + label: A 2D array with integer type, storing the segmentation label. + dataset: The colormap used in the dataset. + + Returns: + result: A 2D array with floating type. The element of the array + is the color indexed by the corresponding element in the input label + to the dataset color map. + + Raises: + ValueError: If label is not of rank 2 or its value is larger than color + map maximum entry. + """ + if label.ndim != 2: + raise ValueError('Expect 2-D input label') + + if np.max(label) >= _DATASET_MAX_ENTRIES[dataset]: + raise ValueError('label value too large.') + + colormap = create_label_colormap(dataset) + return colormap[label] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap_test.py" new file mode 100644 index 00000000..676beb11 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/get_dataset_colormap_test.py" @@ -0,0 +1,96 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for get_dataset_colormap.py.""" + +import numpy as np +import tensorflow as tf + +from deeplab.utils import get_dataset_colormap + + +class VisualizationUtilTest(tf.test.TestCase): + + def testBitGet(self): + """Test that if the returned bit value is correct.""" + self.assertEqual(1, get_dataset_colormap.bit_get(9, 0)) + self.assertEqual(0, get_dataset_colormap.bit_get(9, 1)) + self.assertEqual(0, get_dataset_colormap.bit_get(9, 2)) + self.assertEqual(1, get_dataset_colormap.bit_get(9, 3)) + + def testPASCALLabelColorMapValue(self): + """Test the getd color map value.""" + colormap = get_dataset_colormap.create_pascal_label_colormap() + + # Only test a few sampled entries in the color map. + self.assertTrue(np.array_equal([128., 0., 128.], colormap[5, :])) + self.assertTrue(np.array_equal([128., 192., 128.], colormap[23, :])) + self.assertTrue(np.array_equal([128., 0., 192.], colormap[37, :])) + self.assertTrue(np.array_equal([224., 192., 192.], colormap[127, :])) + self.assertTrue(np.array_equal([192., 160., 192.], colormap[175, :])) + + def testLabelToPASCALColorImage(self): + """Test the value of the converted label value.""" + label = np.array([[0, 16, 16], [52, 7, 52]]) + expected_result = np.array([ + [[0, 0, 0], [0, 64, 0], [0, 64, 0]], + [[0, 64, 192], [128, 128, 128], [0, 64, 192]] + ]) + colored_label = get_dataset_colormap.label_to_color_image( + label, get_dataset_colormap.get_pascal_name()) + self.assertTrue(np.array_equal(expected_result, colored_label)) + + def testUnExpectedLabelValueForLabelToPASCALColorImage(self): + """Raise ValueError when input value exceeds range.""" + label = np.array([[120], [300]]) + with self.assertRaises(ValueError): + get_dataset_colormap.label_to_color_image( + label, get_dataset_colormap.get_pascal_name()) + + def testUnExpectedLabelDimensionForLabelToPASCALColorImage(self): + """Raise ValueError if input dimension is not correct.""" + label = np.array([120]) + with self.assertRaises(ValueError): + get_dataset_colormap.label_to_color_image( + label, get_dataset_colormap.get_pascal_name()) + + def testGetColormapForUnsupportedDataset(self): + with self.assertRaises(ValueError): + get_dataset_colormap.create_label_colormap('unsupported_dataset') + + def testUnExpectedLabelDimensionForLabelToADE20KColorImage(self): + label = np.array([250]) + with self.assertRaises(ValueError): + get_dataset_colormap.label_to_color_image( + label, get_dataset_colormap.get_ade20k_name()) + + def testFirstColorInADE20KColorMap(self): + label = np.array([[1, 3], [10, 20]]) + expected_result = np.array([ + [[120, 120, 120], [6, 230, 230]], + [[4, 250, 7], [204, 70, 3]] + ]) + colored_label = get_dataset_colormap.label_to_color_image( + label, get_dataset_colormap.get_ade20k_name()) + self.assertTrue(np.array_equal(colored_label, expected_result)) + + def testMapillaryVistasColorMapValue(self): + colormap = get_dataset_colormap.create_mapillary_vistas_label_colormap() + self.assertTrue(np.array_equal([190, 153, 153], colormap[3, :])) + self.assertTrue(np.array_equal([102, 102, 156], colormap[6, :])) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/input_generator.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/input_generator.py" new file mode 100644 index 00000000..4d4d09a5 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/input_generator.py" @@ -0,0 +1,168 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Wrapper for providing semantic segmentation data.""" + +import tensorflow as tf +from deeplab import common +from deeplab import input_preprocess + +slim = tf.contrib.slim + +dataset_data_provider = slim.dataset_data_provider + + +def _get_data(data_provider, dataset_split): + """Gets data from data provider. + + Args: + data_provider: An object of slim.data_provider. + dataset_split: Dataset split. + + Returns: + image: Image Tensor. + label: Label Tensor storing segmentation annotations. + image_name: Image name. + height: Image height. + width: Image width. + + Raises: + ValueError: Failed to find label. + """ + if common.LABELS_CLASS not in data_provider.list_items(): + raise ValueError('Failed to find labels.') + + image, height, width = data_provider.get( + [common.IMAGE, common.HEIGHT, common.WIDTH]) + + # Some datasets do not contain image_name. + if common.IMAGE_NAME in data_provider.list_items(): + image_name, = data_provider.get([common.IMAGE_NAME]) + else: + image_name = tf.constant('') + + label = None + if dataset_split != common.TEST_SET: + label, = data_provider.get([common.LABELS_CLASS]) + + return image, label, image_name, height, width + + +def get(dataset, + crop_size, + batch_size, + min_resize_value=None, + max_resize_value=None, + resize_factor=None, + min_scale_factor=1., + max_scale_factor=1., + scale_factor_step_size=0, + num_readers=1, + num_threads=1, + dataset_split=None, + is_training=True, + model_variant=None): + """Gets the dataset split for semantic segmentation. + + This functions gets the dataset split for semantic segmentation. In + particular, it is a wrapper of (1) dataset_data_provider which returns the raw + dataset split, (2) input_preprcess which preprocess the raw data, and (3) the + Tensorflow operation of batching the preprocessed data. Then, the output could + be directly used by training, evaluation or visualization. + + Args: + dataset: An instance of slim Dataset. + crop_size: Image crop size [height, width]. + batch_size: Batch size. + min_resize_value: Desired size of the smaller image side. + max_resize_value: Maximum allowed size of the larger image side. + resize_factor: Resized dimensions are multiple of factor plus one. + min_scale_factor: Minimum scale factor value. + max_scale_factor: Maximum scale factor value. + scale_factor_step_size: The step size from min scale factor to max scale + factor. The input is randomly scaled based on the value of + (min_scale_factor, max_scale_factor, scale_factor_step_size). + num_readers: Number of readers for data provider. + num_threads: Number of threads for batching data. + dataset_split: Dataset split. + is_training: Is training or not. + model_variant: Model variant (string) for choosing how to mean-subtract the + images. See feature_extractor.network_map for supported model variants. + + Returns: + A dictionary of batched Tensors for semantic segmentation. + + Raises: + ValueError: dataset_split is None, failed to find labels, or label shape + is not valid. + """ + if dataset_split is None: + raise ValueError('Unknown dataset split.') + if model_variant is None: + tf.logging.warning('Please specify a model_variant. See ' + 'feature_extractor.network_map for supported model ' + 'variants.') + + data_provider = dataset_data_provider.DatasetDataProvider( + dataset, + num_readers=num_readers, + num_epochs=None if is_training else 1, + shuffle=is_training) + image, label, image_name, height, width = _get_data(data_provider, + dataset_split) + if label is not None: + if label.shape.ndims == 2: + label = tf.expand_dims(label, 2) + elif label.shape.ndims == 3 and label.shape.dims[2] == 1: + pass + else: + raise ValueError('Input label shape must be [height, width], or ' + '[height, width, 1].') + + label.set_shape([None, None, 1]) + original_image, image, label = input_preprocess.preprocess_image_and_label( + image, + label, + crop_height=crop_size[0], + crop_width=crop_size[1], + min_resize_value=min_resize_value, + max_resize_value=max_resize_value, + resize_factor=resize_factor, + min_scale_factor=min_scale_factor, + max_scale_factor=max_scale_factor, + scale_factor_step_size=scale_factor_step_size, + ignore_label=dataset.ignore_label, + is_training=is_training, + model_variant=model_variant) + sample = { + common.IMAGE: image, + common.IMAGE_NAME: image_name, + common.HEIGHT: height, + common.WIDTH: width + } + if label is not None: + sample[common.LABEL] = label + + if not is_training: + # Original image is only used during visualization. + sample[common.ORIGINAL_IMAGE] = original_image, + num_threads = 1 + + return tf.train.batch( + sample, + batch_size=batch_size, + num_threads=num_threads, + capacity=32 * batch_size, + allow_smaller_final_batch=not is_training, + dynamic_pad=True) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/save_annotation.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/save_annotation.py" new file mode 100644 index 00000000..9f3c7e78 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/save_annotation.py" @@ -0,0 +1,52 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Saves an annotation as one png image. + +This script saves an annotation as one png image, and has the option to add +colormap to the png image for better visualization. +""" + +import numpy as np +import PIL.Image as img +import tensorflow as tf + +from deeplab.utils import get_dataset_colormap + + +def save_annotation(label, + save_dir, + filename, + add_colormap=True, + colormap_type=get_dataset_colormap.get_pascal_name()): + """Saves the given label to image on disk. + + Args: + label: The numpy array to be saved. The data will be converted + to uint8 and saved as png image. + save_dir: The directory to which the results will be saved. + filename: The image filename. + add_colormap: Add color map to the label or not. + colormap_type: Colormap type for visualization. + """ + # Add colormap for visualizing the prediction. + if add_colormap: + colored_label = get_dataset_colormap.label_to_color_image( + label, colormap_type) + else: + colored_label = label + + pil_image = img.fromarray(colored_label.astype(dtype=np.uint8)) + with tf.gfile.Open('%s/%s.png' % (save_dir, filename), mode='w') as f: + pil_image.save(f, 'PNG') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/train_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/train_utils.py" new file mode 100644 index 00000000..4eeffb1e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/utils/train_utils.py" @@ -0,0 +1,211 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Utility functions for training.""" + +import six + +import tensorflow as tf +from deeplab.core import preprocess_utils + +slim = tf.contrib.slim + + +def add_softmax_cross_entropy_loss_for_each_scale(scales_to_logits, + labels, + num_classes, + ignore_label, + loss_weight=1.0, + upsample_logits=True, + scope=None): + """Adds softmax cross entropy loss for logits of each scale. + + Args: + scales_to_logits: A map from logits names for different scales to logits. + The logits have shape [batch, logits_height, logits_width, num_classes]. + labels: Groundtruth labels with shape [batch, image_height, image_width, 1]. + num_classes: Integer, number of target classes. + ignore_label: Integer, label to ignore. + loss_weight: Float, loss weight. + upsample_logits: Boolean, upsample logits or not. + scope: String, the scope for the loss. + + Raises: + ValueError: Label or logits is None. + """ + if labels is None: + raise ValueError('No label for softmax cross entropy loss.') + + for scale, logits in six.iteritems(scales_to_logits): + loss_scope = None + if scope: + loss_scope = '%s_%s' % (scope, scale) + + if upsample_logits: + # Label is not downsampled, and instead we upsample logits. + logits = tf.image.resize_bilinear( + logits, + preprocess_utils.resolve_shape(labels, 4)[1:3], + align_corners=True) + scaled_labels = labels + else: + # Label is downsampled to the same size as logits. + scaled_labels = tf.image.resize_nearest_neighbor( + labels, + preprocess_utils.resolve_shape(logits, 4)[1:3], + align_corners=True) + + scaled_labels = tf.reshape(scaled_labels, shape=[-1]) + not_ignore_mask = tf.to_float(tf.not_equal(scaled_labels, + ignore_label)) * loss_weight + one_hot_labels = slim.one_hot_encoding( + scaled_labels, num_classes, on_value=1.0, off_value=0.0) + tf.losses.softmax_cross_entropy( + one_hot_labels, + tf.reshape(logits, shape=[-1, num_classes]), + weights=not_ignore_mask, + scope=loss_scope) + + +def get_model_init_fn(train_logdir, + tf_initial_checkpoint, + initialize_last_layer, + last_layers, + ignore_missing_vars=False): + """Gets the function initializing model variables from a checkpoint. + + Args: + train_logdir: Log directory for training. + tf_initial_checkpoint: TensorFlow checkpoint for initialization. + initialize_last_layer: Initialize last layer or not. + last_layers: Last layers of the model. + ignore_missing_vars: Ignore missing variables in the checkpoint. + + Returns: + Initialization function. + """ + if tf_initial_checkpoint is None: + tf.logging.info('Not initializing the model from a checkpoint.') + return None + + if tf.train.latest_checkpoint(train_logdir): + tf.logging.info('Ignoring initialization; other checkpoint exists') + return None + + tf.logging.info('Initializing model from path: %s', tf_initial_checkpoint) + + # Variables that will not be restored. + exclude_list = ['global_step'] + if not initialize_last_layer: + exclude_list.extend(last_layers) + + variables_to_restore = slim.get_variables_to_restore(exclude=exclude_list) + + if variables_to_restore: + return slim.assign_from_checkpoint_fn( + tf_initial_checkpoint, + variables_to_restore, + ignore_missing_vars=ignore_missing_vars) + return None + + +def get_model_gradient_multipliers(last_layers, last_layer_gradient_multiplier): + """Gets the gradient multipliers. + + The gradient multipliers will adjust the learning rates for model + variables. For the task of semantic segmentation, the models are + usually fine-tuned from the models trained on the task of image + classification. To fine-tune the models, we usually set larger (e.g., + 10 times larger) learning rate for the parameters of last layer. + + Args: + last_layers: Scopes of last layers. + last_layer_gradient_multiplier: The gradient multiplier for last layers. + + Returns: + The gradient multiplier map with variables as key, and multipliers as value. + """ + gradient_multipliers = {} + + for var in slim.get_model_variables(): + # Double the learning rate for biases. + if 'biases' in var.op.name: + gradient_multipliers[var.op.name] = 2. + + # Use larger learning rate for last layer variables. + for layer in last_layers: + if layer in var.op.name and 'biases' in var.op.name: + gradient_multipliers[var.op.name] = 2 * last_layer_gradient_multiplier + break + elif layer in var.op.name: + gradient_multipliers[var.op.name] = last_layer_gradient_multiplier + break + + return gradient_multipliers + + +def get_model_learning_rate( + learning_policy, base_learning_rate, learning_rate_decay_step, + learning_rate_decay_factor, training_number_of_steps, learning_power, + slow_start_step, slow_start_learning_rate): + """Gets model's learning rate. + + Computes the model's learning rate for different learning policy. + Right now, only "step" and "poly" are supported. + (1) The learning policy for "step" is computed as follows: + current_learning_rate = base_learning_rate * + learning_rate_decay_factor ^ (global_step / learning_rate_decay_step) + See tf.train.exponential_decay for details. + (2) The learning policy for "poly" is computed as follows: + current_learning_rate = base_learning_rate * + (1 - global_step / training_number_of_steps) ^ learning_power + + Args: + learning_policy: Learning rate policy for training. + base_learning_rate: The base learning rate for model training. + learning_rate_decay_step: Decay the base learning rate at a fixed step. + learning_rate_decay_factor: The rate to decay the base learning rate. + training_number_of_steps: Number of steps for training. + learning_power: Power used for 'poly' learning policy. + slow_start_step: Training model with small learning rate for the first + few steps. + slow_start_learning_rate: The learning rate employed during slow start. + + Returns: + Learning rate for the specified learning policy. + + Raises: + ValueError: If learning policy is not recognized. + """ + global_step = tf.train.get_or_create_global_step() + if learning_policy == 'step': + learning_rate = tf.train.exponential_decay( + base_learning_rate, + global_step, + learning_rate_decay_step, + learning_rate_decay_factor, + staircase=True) + elif learning_policy == 'poly': + learning_rate = tf.train.polynomial_decay( + base_learning_rate, + global_step, + training_number_of_steps, + end_learning_rate=0, + power=learning_power) + else: + raise ValueError('Unknown learning policy.') + + # Employ small learning rate at the first few steps for warm start. + return tf.where(global_step < slow_start_step, slow_start_learning_rate, + learning_rate) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/vis.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/vis.py" new file mode 100644 index 00000000..9f75d104 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/deeplab/vis.py" @@ -0,0 +1,320 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Segmentation results visualization on a given set of images. + +See model.py for more details and usage. +""" +import math +import os.path +import time +import numpy as np +import tensorflow as tf +from deeplab import common +from deeplab import model +from deeplab.datasets import segmentation_dataset +from deeplab.utils import input_generator +from deeplab.utils import save_annotation + +slim = tf.contrib.slim + +flags = tf.app.flags + +FLAGS = flags.FLAGS + +flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') + +# Settings for log directories. + +flags.DEFINE_string('vis_logdir', None, 'Where to write the event logs.') + +flags.DEFINE_string('checkpoint_dir', None, 'Directory of model checkpoints.') + +# Settings for visualizing the model. + +flags.DEFINE_integer('vis_batch_size', 1, + 'The number of images in each batch during evaluation.') + +flags.DEFINE_multi_integer('vis_crop_size', [513, 513], + 'Crop size [height, width] for visualization.') + +flags.DEFINE_integer('eval_interval_secs', 60 * 5, + 'How often (in seconds) to run evaluation.') + +# For `xception_65`, use atrous_rates = [12, 24, 36] if output_stride = 8, or +# rates = [6, 12, 18] if output_stride = 16. For `mobilenet_v2`, use None. Note +# one could use different atrous_rates/output_stride during training/evaluation. +flags.DEFINE_multi_integer('atrous_rates', None, + 'Atrous rates for atrous spatial pyramid pooling.') + +flags.DEFINE_integer('output_stride', 16, + 'The ratio of input to output spatial resolution.') + +# Change to [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] for multi-scale test. +flags.DEFINE_multi_float('eval_scales', [1.0], + 'The scales to resize images for evaluation.') + +# Change to True for adding flipped images during test. +flags.DEFINE_bool('add_flipped_images', False, + 'Add flipped images for evaluation or not.') + +# Dataset settings. + +flags.DEFINE_string('dataset', 'pascal_voc_seg', + 'Name of the segmentation dataset.') + +flags.DEFINE_string('vis_split', 'val', + 'Which split of the dataset used for visualizing results') + +flags.DEFINE_string('dataset_dir', None, 'Where the dataset reside.') + +flags.DEFINE_enum('colormap_type', 'pascal', ['pascal', 'cityscapes'], + 'Visualization colormap type.') + +flags.DEFINE_boolean('also_save_raw_predictions', False, + 'Also save raw predictions.') + +flags.DEFINE_integer('max_number_of_iterations', 0, + 'Maximum number of visualization iterations. Will loop ' + 'indefinitely upon nonpositive values.') + +# The folder where semantic segmentation predictions are saved. +_SEMANTIC_PREDICTION_SAVE_FOLDER = 'segmentation_results' + +# The folder where raw semantic segmentation predictions are saved. +_RAW_SEMANTIC_PREDICTION_SAVE_FOLDER = 'raw_segmentation_results' + +# The format to save image. +_IMAGE_FORMAT = '%06d_image' + +# The format to save prediction +_PREDICTION_FORMAT = '%06d_prediction' + +# To evaluate Cityscapes results on the evaluation server, the labels used +# during training should be mapped to the labels for evaluation. +_CITYSCAPES_TRAIN_ID_TO_EVAL_ID = [7, 8, 11, 12, 13, 17, 19, 20, 21, 22, + 23, 24, 25, 26, 27, 28, 31, 32, 33] + + +def _convert_train_id_to_eval_id(prediction, train_id_to_eval_id): + """Converts the predicted label for evaluation. + + There are cases where the training labels are not equal to the evaluation + labels. This function is used to perform the conversion so that we could + evaluate the results on the evaluation server. + + Args: + prediction: Semantic segmentation prediction. + train_id_to_eval_id: A list mapping from train id to evaluation id. + + Returns: + Semantic segmentation prediction whose labels have been changed. + """ + converted_prediction = prediction.copy() + for train_id, eval_id in enumerate(train_id_to_eval_id): + converted_prediction[prediction == train_id] = eval_id + + return converted_prediction + + +def _process_batch(sess, original_images, semantic_predictions, image_names, + image_heights, image_widths, image_id_offset, save_dir, + raw_save_dir, train_id_to_eval_id=None): + """Evaluates one single batch qualitatively. + + Args: + sess: TensorFlow session. + original_images: One batch of original images. + semantic_predictions: One batch of semantic segmentation predictions. + image_names: Image names. + image_heights: Image heights. + image_widths: Image widths. + image_id_offset: Image id offset for indexing images. + save_dir: The directory where the predictions will be saved. + raw_save_dir: The directory where the raw predictions will be saved. + train_id_to_eval_id: A list mapping from train id to eval id. + """ + (original_images, + semantic_predictions, + image_names, + image_heights, + image_widths) = sess.run([original_images, semantic_predictions, + image_names, image_heights, image_widths]) + + num_image = semantic_predictions.shape[0] + for i in range(num_image): + image_height = np.squeeze(image_heights[i]) + image_width = np.squeeze(image_widths[i]) + original_image = np.squeeze(original_images[i]) + semantic_prediction = np.squeeze(semantic_predictions[i]) + crop_semantic_prediction = semantic_prediction[:image_height, :image_width] + + # Save image. + save_annotation.save_annotation( + original_image, save_dir, _IMAGE_FORMAT % (image_id_offset + i), + add_colormap=False) + + # Save prediction. + save_annotation.save_annotation( + crop_semantic_prediction, save_dir, + _PREDICTION_FORMAT % (image_id_offset + i), add_colormap=True, + colormap_type=FLAGS.colormap_type) + + if FLAGS.also_save_raw_predictions: + image_filename = os.path.basename(image_names[i]) + + if train_id_to_eval_id is not None: + crop_semantic_prediction = _convert_train_id_to_eval_id( + crop_semantic_prediction, + train_id_to_eval_id) + save_annotation.save_annotation( + crop_semantic_prediction, raw_save_dir, image_filename, + add_colormap=False) + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + # Get dataset-dependent information. + dataset = segmentation_dataset.get_dataset( + FLAGS.dataset, FLAGS.vis_split, dataset_dir=FLAGS.dataset_dir) + train_id_to_eval_id = None + if dataset.name == segmentation_dataset.get_cityscapes_dataset_name(): + tf.logging.info('Cityscapes requires converting train_id to eval_id.') + train_id_to_eval_id = _CITYSCAPES_TRAIN_ID_TO_EVAL_ID + + # Prepare for visualization. + tf.gfile.MakeDirs(FLAGS.vis_logdir) + save_dir = os.path.join(FLAGS.vis_logdir, _SEMANTIC_PREDICTION_SAVE_FOLDER) + tf.gfile.MakeDirs(save_dir) + raw_save_dir = os.path.join( + FLAGS.vis_logdir, _RAW_SEMANTIC_PREDICTION_SAVE_FOLDER) + tf.gfile.MakeDirs(raw_save_dir) + + tf.logging.info('Visualizing on %s set', FLAGS.vis_split) + + g = tf.Graph() + with g.as_default(): + samples = input_generator.get(dataset, + FLAGS.vis_crop_size, + FLAGS.vis_batch_size, + min_resize_value=FLAGS.min_resize_value, + max_resize_value=FLAGS.max_resize_value, + resize_factor=FLAGS.resize_factor, + dataset_split=FLAGS.vis_split, + is_training=False, + model_variant=FLAGS.model_variant) + + model_options = common.ModelOptions( + outputs_to_num_classes={common.OUTPUT_TYPE: dataset.num_classes}, + crop_size=FLAGS.vis_crop_size, + atrous_rates=FLAGS.atrous_rates, + output_stride=FLAGS.output_stride) + + if tuple(FLAGS.eval_scales) == (1.0,): + tf.logging.info('Performing single-scale test.') + predictions = model.predict_labels( + samples[common.IMAGE], + model_options=model_options, + image_pyramid=FLAGS.image_pyramid) + else: + tf.logging.info('Performing multi-scale test.') + predictions = model.predict_labels_multi_scale( + samples[common.IMAGE], + model_options=model_options, + eval_scales=FLAGS.eval_scales, + add_flipped_images=FLAGS.add_flipped_images) + predictions = predictions[common.OUTPUT_TYPE] + + if FLAGS.min_resize_value and FLAGS.max_resize_value: + # Only support batch_size = 1, since we assume the dimensions of original + # image after tf.squeeze is [height, width, 3]. + assert FLAGS.vis_batch_size == 1 + + # Reverse the resizing and padding operations performed in preprocessing. + # First, we slice the valid regions (i.e., remove padded region) and then + # we reisze the predictions back. + original_image = tf.squeeze(samples[common.ORIGINAL_IMAGE]) + original_image_shape = tf.shape(original_image) + predictions = tf.slice( + predictions, + [0, 0, 0], + [1, original_image_shape[0], original_image_shape[1]]) + resized_shape = tf.to_int32([tf.squeeze(samples[common.HEIGHT]), + tf.squeeze(samples[common.WIDTH])]) + predictions = tf.squeeze( + tf.image.resize_images(tf.expand_dims(predictions, 3), + resized_shape, + method=tf.image.ResizeMethod.NEAREST_NEIGHBOR, + align_corners=True), 3) + + tf.train.get_or_create_global_step() + saver = tf.train.Saver(slim.get_variables_to_restore()) + sv = tf.train.Supervisor(graph=g, + logdir=FLAGS.vis_logdir, + init_op=tf.global_variables_initializer(), + summary_op=None, + summary_writer=None, + global_step=None, + saver=saver) + num_batches = int(math.ceil( + dataset.num_samples / float(FLAGS.vis_batch_size))) + last_checkpoint = None + + # Loop to visualize the results when new checkpoint is created. + num_iters = 0 + while (FLAGS.max_number_of_iterations <= 0 or + num_iters < FLAGS.max_number_of_iterations): + num_iters += 1 + last_checkpoint = slim.evaluation.wait_for_new_checkpoint( + FLAGS.checkpoint_dir, last_checkpoint) + start = time.time() + tf.logging.info( + 'Starting visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', + time.gmtime())) + tf.logging.info('Visualizing with model %s', last_checkpoint) + + with sv.managed_session(FLAGS.master, + start_standard_services=False) as sess: + sv.start_queue_runners(sess) + sv.saver.restore(sess, last_checkpoint) + + image_id_offset = 0 + for batch in range(num_batches): + tf.logging.info('Visualizing batch %d / %d', batch + 1, num_batches) + _process_batch(sess=sess, + original_images=samples[common.ORIGINAL_IMAGE], + semantic_predictions=predictions, + image_names=samples[common.IMAGE_NAME], + image_heights=samples[common.HEIGHT], + image_widths=samples[common.WIDTH], + image_id_offset=image_id_offset, + save_dir=save_dir, + raw_save_dir=raw_save_dir, + train_id_to_eval_id=train_id_to_eval_id) + image_id_offset += FLAGS.vis_batch_size + + tf.logging.info( + 'Finished visualization at ' + time.strftime('%Y-%m-%d-%H:%M:%S', + time.gmtime())) + time_to_next_eval = start + FLAGS.eval_interval_secs - time.time() + if time_to_next_eval > 0: + time.sleep(time_to_next_eval) + + +if __name__ == '__main__': + flags.mark_flag_as_required('checkpoint_dir') + flags.mark_flag_as_required('vis_logdir') + flags.mark_flag_as_required('dataset_dir') + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/.gitignore" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/.gitignore" new file mode 100644 index 00000000..b61ddd10 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/.gitignore" @@ -0,0 +1,4 @@ +*pyc +*~ +*pb2.py +*pb2.pyc diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/EXTRACTION_MATCHING.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/EXTRACTION_MATCHING.md" new file mode 100644 index 00000000..399eb730 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/EXTRACTION_MATCHING.md" @@ -0,0 +1,67 @@ +## Quick start: DELF extraction and matching + +To illustrate DELF usage, please download the Oxford buildings dataset. To +follow these instructions closely, please download the dataset to the +`tensorflow/models/research/delf/delf/python/examples` directory, as in the +following commands: + +```bash +# From tensorflow/models/research/delf/delf/python/examples/ +mkdir data && cd data +wget http://www.robots.ox.ac.uk/~vgg/data/oxbuildings/oxbuild_images.tgz +mkdir oxford5k_images oxford5k_features +tar -xvzf oxbuild_images.tgz -C oxford5k_images/ +cd ../ +echo data/oxford5k_images/hertford_000056.jpg >> list_images.txt +echo data/oxford5k_images/oxford_000317.jpg >> list_images.txt +``` + +Also, you will need to download the trained DELF model: + +```bash +# From tensorflow/models/research/delf/delf/python/examples/ +mkdir parameters && cd parameters +wget http://download.tensorflow.org/models/delf_v1_20171026.tar.gz +tar -xvzf delf_v1_20171026.tar.gz +``` + +### DELF feature extraction + +Now that you have everything in place, running this command should extract DELF +features for the images `hertford_000056.jpg` and `oxford_000317.jpg`: + +```bash +# From tensorflow/models/research/delf/delf/python/examples/ +python extract_features.py \ + --config_path delf_config_example.pbtxt \ + --list_images_path list_images.txt \ + --output_dir data/oxford5k_features +``` + +### Image matching using DELF features + +After feature extraction, run this command to perform feature matching between +the images `hertford_000056.jpg` and `oxford_000317.jpg`: + +```bash +python match_images.py \ + --image_1_path data/oxford5k_images/hertford_000056.jpg \ + --image_2_path data/oxford5k_images/oxford_000317.jpg \ + --features_1_path data/oxford5k_features/hertford_000056.delf \ + --features_2_path data/oxford5k_features/oxford_000317.delf \ + --output_image matched_images.png +``` + +The image `matched_images.png` is generated and should look similar to this one: + + + +### Troubleshooting + +#### `matplotlib` + +`matplotlib` may complain with a message such as `no display name and no +$DISPLAY environment variable`. To fix this, one option is add the line +`backend : Agg` to the file `.config/matplotlib/matplotlibrc`. On this problem, +see the discussion +[here](https://stackoverflow.com/questions/37604289/tkinter-tclerror-no-display-name-and-no-display-environment-variable). diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/INSTALL_INSTRUCTIONS.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/INSTALL_INSTRUCTIONS.md" new file mode 100644 index 00000000..0b47f2f8 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/INSTALL_INSTRUCTIONS.md" @@ -0,0 +1,98 @@ +## DELF installation + +### Tensorflow + +For detailed steps to install Tensorflow, follow the [Tensorflow installation +instructions](https://www.tensorflow.org/install/). A typical user can install +Tensorflow using one of the following commands: + +```bash +# For CPU: +pip install tensorflow +# For GPU: +pip install tensorflow-gpu +``` + +### Protobuf + +The DELF library uses [protobuf](https://github.com/google/protobuf) (the python +version) to configure feature extraction and its format. You will need the +`protoc` compiler, version >= 3.3. The easiest way to get it is to download +directly. For Linux, this can be done as (see +[here](https://github.com/google/protobuf/releases) for other platforms): + +```bash +wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip +unzip protoc-3.3.0-linux-x86_64.zip +PATH_TO_PROTOC=`pwd` +``` + +### Python dependencies + +Install python library dependencies: + +```bash +sudo pip install matplotlib +sudo pip install numpy +sudo pip install scikit-image +sudo pip install scipy +``` + +### `tensorflow/models` + +Now, clone `tensorflow/models`, and install required libraries: (note that the +`object_detection` library requires you to add `tensorflow/models/research/` to +your `PYTHONPATH`, as instructed +[here](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md)) + +```bash +git clone https://github.com/tensorflow/models + +# First, install slim's "nets" package. +cd models/research/slim/ +sudo pip install -e . + +# Second, setup the object_detection module by editing PYTHONPATH. +cd .. +# From tensorflow/models/research/ +export PYTHONPATH=$PYTHONPATH:`pwd` +``` + +Then, compile DELF's protobufs. Use `PATH_TO_PROTOC` as the directory where you +downloaded the `protoc` compiler. + +```bash +# From tensorflow/models/research/delf/ +${PATH_TO_PROTOC?}/bin/protoc delf/protos/*.proto --python_out=. +``` + +Finally, install the DELF package. + +```bash +# From tensorflow/models/research/delf/ +sudo pip install -e . # Install "delf" package. +``` + +At this point, running + +```bash +python -c 'import delf' +``` + +should just return without complaints. This indicates that the DELF package is +loaded successfully. + +### Troubleshooting + +#### Python version + +Installation issues may happen if multiple python versions are mixed. The +instructions above assume python2.7 version is used; if using python3.X, be sure +to use `pip3` instead of `pip`, and all should work. + +#### `pip install` + +Issues might be observed if using `pip install` with `-e` option (editable +mode). You may try out to simply remove the `-e` from the commands above. Also, +depending on your machine setup, you might need to run the `pip install` command +without `sudo` at the beginning. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/README.md" new file mode 100644 index 00000000..56032a47 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/README.md" @@ -0,0 +1,103 @@ +# DELF: DEep Local Features + +This project presents code for extracting DELF features, which were introduced +with the paper ["Large-Scale Image Retrieval with Attentive Deep Local +Features"](https://arxiv.org/abs/1612.06321). A simple application is also +illustrated, where two images containing the same landmark can be matched to +each other, to obtain local image correspondences. + +DELF is particularly useful for large-scale instance-level image recognition. It +detects and describes semantic local features which can be geometrically +verified between images showing the same object instance. The pre-trained model +released here has been optimized for landmark recognition, so expect it to work +well in this area. We also provide tensorflow code for building the DELF model, +which could then be used to train models for other types of objects. + +If you make use of this code, please consider citing: + +``` +"Large-Scale Image Retrieval with Attentive Deep Local Features", +Hyeonwoo Noh, Andre Araujo, Jack Sim, Tobias Weyand, Bohyung Han, +Proc. ICCV'17 +``` + +## News + +- DELF achieved state-of-the-art results in a CVPR'18 image retrieval paper: + [Radenovic et al., "Revisiting Oxford and Paris: Large-Scale Image Retrieval + Benchmarking"](https://arxiv.org/abs/1803.11285). +- DELF was featured in + [ModelDepot](https://modeldepot.io/mikeshi/delf/overview) +- DELF is now available in + [TF-Hub](https://www.tensorflow.org/hub/modules/google/delf/1) + +## Dataset + +The Google-Landmarks dataset has been released as part of two Kaggle challenges: +[Landmark Recognition](https://www.kaggle.com/c/landmark-recognition-challenge) +and [Landmark Retrieval](https://www.kaggle.com/c/landmark-retrieval-challenge). +If you make use of the dataset in your research, please consider citing the +paper mentioned above. + +## Installation + +To be able to use this code, please follow [these +instructions](INSTALL_INSTRUCTIONS.md) to properly install the DELF library. + +## Quick start: DELF extraction and matching + +Please follow [these instructions](EXTRACTION_MATCHING.md). At the end, you +should obtain a nice figure showing local feature matches, as: + + + +## Code overview + +DELF's code is located under the `delf` directory. There are two directories +therein, `protos` and `python`. + +### `delf/protos` + +This directory contains three protobufs: + +- `datum.proto`: general-purpose protobuf for serializing float tensors. +- `feature.proto`: protobuf for serializing DELF features. +- `delf_config.proto`: protobuf for configuring DELF extraction. + +### `delf/python` + +This directory contains files for several different purposes: + +- `datum_io.py`, `feature_io.py` are helper files for reading and writing + tensors and features. +- `delf_v1.py` contains the code to create DELF models. +- `feature_extractor.py` contains the code to extract features using DELF. + This is particularly useful for extracting features over multiple scales, + with keypoint selection based on attention scores, and PCA/whitening + post-processing. + +Besides these, other files in this directory contain tests for different +modules. + +The subdirectory `delf/python/examples` contains sample scripts to run DELF +feature extraction and matching: + +- `extract_features.py` enables DELF extraction from a list of images. +- `match_images.py` supports image matching using DELF features extracted + using `extract_features.py`. +- `delf_config_example.pbtxt` shows an example instantiation of the DelfConfig + proto, used for DELF feature extraction. + +## Maintainers + +André Araujo (@andrefaraujo) + +## Release history + +### October 26, 2017 + +Initial release containing DELF-v1 code, including feature extraction and +matching examples. + +**Thanks to contributors**: André Araujo, Hyeonwoo Noh, Youlong Cheng, +Jack Sim. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/__init__.py" new file mode 100644 index 00000000..2c20f4c2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/__init__.py" @@ -0,0 +1,29 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Module to extract deep local features.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +# pylint: disable=unused-import +from delf.protos import datum_pb2 +from delf.protos import delf_config_pb2 +from delf.protos import feature_pb2 +from delf.python import datum_io +from delf.python import delf_v1 +from delf.python import feature_extractor +from delf.python import feature_io +# pylint: enable=unused-import diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/datum.proto" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/datum.proto" new file mode 100644 index 00000000..66960dfc --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/datum.proto" @@ -0,0 +1,53 @@ +// Protocol buffer for serializing arbitrary float tensors. +// Note: Currently only floating point feature is supported. + +syntax = "proto2"; + +package delf.protos; + +// A DatumProto is a data structure used to serialize tensor with arbitrary +// shape. DatumProto contains an array of floating point values and its shape +// is represented as a sequence of integer values. Values are contained in +// row major order. +// +// Example: +// 3 x 2 array +// +// [1.1, 2.2] +// [3.3, 4.4] +// [5.5, 6.6] +// +// can be represented with the following DatumProto: +// +// DatumProto { +// shape { +// dim: 3 +// dim: 2 +// } +// float_list { +// value: 1.1 +// value: 2.2 +// value: 3.3 +// value: 4.4 +// value: 5.5 +// value: 6.6 +// } +// } + +// DatumShape is array of dimension of the tensor. +message DatumShape { + repeated int64 dim = 1 [packed = true]; +} + +// FloatList is the container of tensor values. The tensor values are saved as +// a list of floating point values. +message FloatList { + repeated float value = 1 [packed = true]; +} + +message DatumProto { + optional DatumShape shape = 1; + oneof kind_oneof { + FloatList float_list = 2; + } +} diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/delf_config.proto" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/delf_config.proto" new file mode 100644 index 00000000..40aaaf73 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/delf_config.proto" @@ -0,0 +1,64 @@ +// Protocol buffer for configuring DELF feature extraction. + +syntax = "proto2"; + +package delf.protos; + +message DelfPcaParameters { + // Path to PCA mean file. + optional string mean_path = 1; // Required. + + // Path to PCA matrix file. + optional string projection_matrix_path = 2; // Required. + + // Dimensionality of feature after PCA. + optional int32 pca_dim = 3; // Required. + + // If whitening is to be used, this must be set to true. + optional bool use_whitening = 4 [default = false]; + + // Path to PCA variances file, used for whitening. This is used only if + // use_whitening is set to true. + optional string pca_variances_path = 5; +} + +message DelfLocalFeatureConfig { + // If PCA is to be used, this must be set to true. + optional bool use_pca = 1 [default = true]; + + // Target layer name for DELF model. This is used to obtain receptive field + // parameters used for localizing features with respect to the input image. + optional string layer_name = 2 [default = ""]; + + // Intersection over union threshold for the non-max suppression (NMS) + // operation. If two features overlap by at most this amount, both are kept. + // Otherwise, the one with largest attention score is kept. This should be a + // number between 0.0 (no region is selected) and 1.0 (all regions are + // selected and NMS is not performed). + optional float iou_threshold = 3 [default = 1.0]; + + // Maximum number of features that will be selected. The features with largest + // scores (eg, largest attention score if score_type is "Att") are the + // selected ones. + optional int32 max_feature_num = 4 [default = 1000]; + + // Threshold to be used for feature selection: no feature with score lower + // than this number will be selected). + optional float score_threshold = 5 [default = 100.0]; + + // PCA parameters for DELF local feature. This is used only if use_pca is + // true. + optional DelfPcaParameters pca_parameters = 6; +} + +message DelfConfig { + // Path to DELF model. + optional string model_path = 1; // Required. + + // Image scales to be used. + repeated float image_scales = 2; + + // Configuration used for DELF local features. + optional DelfLocalFeatureConfig delf_local_config = 3; + +} diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/feature.proto" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/feature.proto" new file mode 100644 index 00000000..64c342fe --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/protos/feature.proto" @@ -0,0 +1,22 @@ +// Protocol buffer for serializing the DELF feature information. + +syntax = "proto2"; + +package delf.protos; + +import "delf/protos/datum.proto"; + +// FloatList is the container of tensor values. The tensor values are saved as +// a list of floating point values. +message DelfFeature { + optional DatumProto descriptor = 1; + optional float x = 2; + optional float y = 3; + optional float scale = 4; + optional float orientation = 5; + optional float strength = 6; +} + +message DelfFeatures { + repeated DelfFeature feature = 1; +} diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io.py" new file mode 100644 index 00000000..5602667a --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io.py" @@ -0,0 +1,109 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Python interface for DatumProto. + +DatumProto is protocol buffer used to serialize tensor with arbitrary shape. +Please refer to datum.proto for details. + +Support read and write of DatumProto from/to numpy array and file. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np +import tensorflow as tf + +from delf import datum_pb2 + + +def ArrayToDatum(arr): + """Converts numpy array to DatumProto. + + Args: + arr: Numpy array of arbitrary shape. + + Returns: + datum: DatumProto object. + """ + datum = datum_pb2.DatumProto() + datum.float_list.value.extend(arr.astype(float).flat) + datum.shape.dim.extend(arr.shape) + return datum + + +def DatumToArray(datum): + """Converts data saved in DatumProto to numpy array. + + Args: + datum: DatumProto object. + + Returns: + Numpy array of arbitrary shape. + """ + return np.array(datum.float_list.value).astype(float).reshape(datum.shape.dim) + + +def SerializeToString(arr): + """Converts numpy array to serialized DatumProto. + + Args: + arr: Numpy array of arbitrary shape. + + Returns: + Serialized DatumProto string. + """ + datum = ArrayToDatum(arr) + return datum.SerializeToString() + + +def ParseFromString(string): + """Converts serialized DatumProto string to numpy array. + + Args: + string: Serialized DatumProto string. + + Returns: + Numpy array. + """ + datum = datum_pb2.DatumProto() + datum.ParseFromString(string) + return DatumToArray(datum) + + +def ReadFromFile(file_path): + """Helper function to load data from a DatumProto format in a file. + + Args: + file_path: Path to file containing data. + + Returns: + data: Numpy array. + """ + with tf.gfile.FastGFile(file_path, 'rb') as f: + return ParseFromString(f.read()) + + +def WriteToFile(data, file_path): + """Helper function to write data to a file in DatumProto format. + + Args: + data: Numpy array. + file_path: Path to file that will be written. + """ + serialized_data = SerializeToString(data) + with tf.gfile.FastGFile(file_path, 'w') as f: + f.write(serialized_data) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io_test.py" new file mode 100644 index 00000000..5cee0c3d --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/datum_io_test.py" @@ -0,0 +1,72 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for datum_io, the python interface of DatumProto.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os + +import numpy as np +import tensorflow as tf + +from delf import datum_io + + +class DatumIoTest(tf.test.TestCase): + + def Conversion2dTestWithType(self, dtype): + original_data = np.arange(9).reshape(3, 3).astype(dtype) + serialized = datum_io.SerializeToString(original_data) + retrieved_data = datum_io.ParseFromString(serialized) + self.assertTrue(np.array_equal(original_data, retrieved_data)) + + def Conversion3dTestWithType(self, dtype): + original_data = np.arange(24).reshape(2, 3, 4).astype(dtype) + serialized = datum_io.SerializeToString(original_data) + retrieved_data = datum_io.ParseFromString(serialized) + self.assertTrue(np.array_equal(original_data, retrieved_data)) + + def testConversion2dWithType(self): + self.Conversion2dTestWithType(np.int8) + self.Conversion2dTestWithType(np.int16) + self.Conversion2dTestWithType(np.int32) + self.Conversion2dTestWithType(np.int64) + self.Conversion2dTestWithType(np.float16) + self.Conversion2dTestWithType(np.float32) + self.Conversion2dTestWithType(np.float64) + + def testConversion3dWithType(self): + self.Conversion3dTestWithType(np.int8) + self.Conversion3dTestWithType(np.int16) + self.Conversion3dTestWithType(np.int32) + self.Conversion3dTestWithType(np.int64) + self.Conversion3dTestWithType(np.float16) + self.Conversion3dTestWithType(np.float32) + self.Conversion3dTestWithType(np.float64) + + def testWriteAndReadToFile(self): + data = np.array([[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], + [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]]) + tmpdir = tf.test.get_temp_dir() + filename = os.path.join(tmpdir, 'test.datum') + datum_io.WriteToFile(data, filename) + data_read = datum_io.ReadFromFile(filename) + self.assertAllEqual(data_read, data) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/delf_v1.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/delf_v1.py" new file mode 100644 index 00000000..7fcf44fe --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/delf_v1.py" @@ -0,0 +1,398 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""DELF model implementation based on the following paper. + + Large-Scale Image Retrieval with Attentive Deep Local Features + https://arxiv.org/abs/1612.06321 + +Please refer to the README.md file for detailed explanations on using the DELF +model. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + +from nets import resnet_v1 + +slim = tf.contrib.slim + +_SUPPORTED_TARGET_LAYER = ['resnet_v1_50/block3', 'resnet_v1_50/block4'] + +# The variable scope for the attention portion of the model. +_ATTENTION_VARIABLE_SCOPE = 'attention_block' + +# The attention_type determines whether the attention based feature aggregation +# is performed on the L2-normalized feature map or on the default feature map +# where L2-normalization is not applied. Note that in both cases, attention +# functions are built on the un-normalized feature map. This is only relevant +# for the training stage. +# Currently supported options are as follows: +# * use_l2_normalized_feature: +# The option use_l2_normalized_feature first applies L2-normalization on the +# feature map and then applies attention based feature aggregation. This +# option is used for the DELF+FT+Att model in the paper. +# * use_default_input_feature: +# The option use_default_input_feature aggregates unnormalized feature map +# directly. +_SUPPORTED_ATTENTION_TYPES = [ + 'use_l2_normalized_feature', 'use_default_input_feature' +] + +# Supported types of non-lineary for the attention score function. +_SUPPORTED_ATTENTION_NONLINEARITY = ['softplus'] + + +class DelfV1(object): + """Creates a DELF model. + + Args: + target_layer_type: The name of target CNN architecture and its layer. + + Raises: + ValueError: If an unknown target_layer_type is provided. + """ + + def __init__(self, target_layer_type=_SUPPORTED_TARGET_LAYER[0]): + tf.logging.info('Creating model %s ', target_layer_type) + + self._target_layer_type = target_layer_type + if self._target_layer_type not in _SUPPORTED_TARGET_LAYER: + raise ValueError('Unknown model type.') + + @property + def target_layer_type(self): + return self._target_layer_type + + def _PerformAttention(self, + attention_feature_map, + feature_map, + attention_nonlinear, + kernel=1): + """Helper function to construct the attention part of the model. + + Computes attention score map and aggregates the input feature map based on + the attention score map. + + Args: + attention_feature_map: Potentially normalized feature map that will + be aggregated with attention score map. + feature_map: Unnormalized feature map that will be used to compute + attention score map. + attention_nonlinear: Type of non-linearity that will be applied to + attention value. + kernel: Convolutional kernel to use in attention layers (eg: 1, [3, 3]). + + Returns: + attention_feat: Aggregated feature vector. + attention_prob: Attention score map after the non-linearity. + attention_score: Attention score map before the non-linearity. + + Raises: + ValueError: If unknown attention non-linearity type is provided. + """ + with tf.variable_scope( + 'attention', values=[attention_feature_map, feature_map]): + with tf.variable_scope('compute', values=[feature_map]): + activation_fn_conv1 = tf.nn.relu + feature_map_conv1 = slim.conv2d( + feature_map, + 512, + kernel, + rate=1, + activation_fn=activation_fn_conv1, + scope='conv1') + + attention_score = slim.conv2d( + feature_map_conv1, + 1, + kernel, + rate=1, + activation_fn=None, + normalizer_fn=None, + scope='conv2') + + # Set activation of conv2 layer of attention model. + with tf.variable_scope( + 'merge', values=[attention_feature_map, attention_score]): + if attention_nonlinear not in _SUPPORTED_ATTENTION_NONLINEARITY: + raise ValueError('Unknown attention non-linearity.') + if attention_nonlinear == 'softplus': + with tf.variable_scope( + 'softplus_attention', + values=[attention_feature_map, attention_score]): + attention_prob = tf.nn.softplus(attention_score) + attention_feat = tf.reduce_mean( + tf.multiply(attention_feature_map, attention_prob), [1, 2]) + attention_feat = tf.expand_dims(tf.expand_dims(attention_feat, 1), 2) + return attention_feat, attention_prob, attention_score + + def _GetAttentionSubnetwork( + self, + feature_map, + end_points, + attention_nonlinear=_SUPPORTED_ATTENTION_NONLINEARITY[0], + attention_type=_SUPPORTED_ATTENTION_TYPES[0], + kernel=1, + reuse=False): + """Constructs the part of the model performing attention. + + Args: + feature_map: A tensor of size [batch, height, width, channels]. Usually it + corresponds to the output feature map of a fully-convolutional network. + end_points: Set of activations of the network constructed so far. + attention_nonlinear: Type of non-linearity on top of the attention + function. + attention_type: Type of the attention structure. + kernel: Convolutional kernel to use in attention layers (eg, [3, 3]). + reuse: Whether or not the layer and its variables should be reused. + + Returns: + prelogits: A tensor of size [batch, 1, 1, channels]. + attention_prob: Attention score after the non-linearity. + attention_score: Attention score before the non-linearity. + end_points: Updated set of activations, for external use. + Raises: + ValueError: If unknown attention_type is provided. + """ + with tf.variable_scope( + _ATTENTION_VARIABLE_SCOPE, + values=[feature_map, end_points], + reuse=reuse): + if attention_type not in _SUPPORTED_ATTENTION_TYPES: + raise ValueError('Unknown attention_type.') + if attention_type == 'use_l2_normalized_feature': + attention_feature_map = tf.nn.l2_normalize( + feature_map, 3, name='l2_normalize') + elif attention_type == 'use_default_input_feature': + attention_feature_map = feature_map + end_points['attention_feature_map'] = attention_feature_map + + attention_outputs = self._PerformAttention( + attention_feature_map, feature_map, attention_nonlinear, kernel) + prelogits, attention_prob, attention_score = attention_outputs + end_points['prelogits'] = prelogits + end_points['attention_prob'] = attention_prob + end_points['attention_score'] = attention_score + return prelogits, attention_prob, attention_score, end_points + + def GetResnet50Subnetwork(self, + images, + is_training=False, + global_pool=False, + reuse=None): + """Constructs resnet_v1_50 part of the DELF model. + + Args: + images: A tensor of size [batch, height, width, channels]. + is_training: Whether or not the model is in training mode. + global_pool: If True, perform global average pooling after feature + extraction. This may be useful for DELF's descriptor fine-tuning stage. + reuse: Whether or not the layer and its variables should be reused. + + Returns: + net: A rank-4 tensor of size [batch, height_out, width_out, channels_out]. + If global_pool is True, height_out = width_out = 1. + end_points: A set of activations for external use. + """ + block = resnet_v1.resnet_v1_block + blocks = [ + block('block1', base_depth=64, num_units=3, stride=2), + block('block2', base_depth=128, num_units=4, stride=2), + block('block3', base_depth=256, num_units=6, stride=2), + ] + if self._target_layer_type == 'resnet_v1_50/block4': + blocks.append(block('block4', base_depth=512, num_units=3, stride=1)) + net, end_points = resnet_v1.resnet_v1( + images, + blocks, + is_training=is_training, + global_pool=global_pool, + reuse=reuse, + scope='resnet_v1_50') + return net, end_points + + def GetAttentionPrelogit( + self, + images, + weight_decay=0.0001, + attention_nonlinear=_SUPPORTED_ATTENTION_NONLINEARITY[0], + attention_type=_SUPPORTED_ATTENTION_TYPES[0], + kernel=1, + training_resnet=False, + training_attention=False, + reuse=False, + use_batch_norm=True): + """Constructs attention model on resnet_v1_50. + + Args: + images: A tensor of size [batch, height, width, channels]. + weight_decay: The parameters for weight_decay regularizer. + attention_nonlinear: Type of non-linearity on top of the attention + function. + attention_type: Type of the attention structure. + kernel: Convolutional kernel to use in attention layers (eg, [3, 3]). + training_resnet: Whether or not the Resnet blocks from the model are in + training mode. + training_attention: Whether or not the attention part of the model is + in training mode. + reuse: Whether or not the layer and its variables should be reused. + use_batch_norm: Whether or not to use batch normalization. + + Returns: + prelogits: A tensor of size [batch, 1, 1, channels]. + attention_prob: Attention score after the non-linearity. + attention_score: Attention score before the non-linearity. + feature_map: Features extracted from the model, which are not + l2-normalized. + end_points: Set of activations for external use. + """ + # Construct Resnet50 features. + with slim.arg_scope( + resnet_v1.resnet_arg_scope(use_batch_norm=use_batch_norm)): + _, end_points = self.GetResnet50Subnetwork( + images, is_training=training_resnet, reuse=reuse) + + feature_map = end_points[self._target_layer_type] + + # Construct attention subnetwork on top of features. + with slim.arg_scope( + resnet_v1.resnet_arg_scope( + weight_decay=weight_decay, use_batch_norm=use_batch_norm)): + with slim.arg_scope([slim.batch_norm], is_training=training_attention): + (prelogits, attention_prob, attention_score, + end_points) = self._GetAttentionSubnetwork( + feature_map, + end_points, + attention_nonlinear=attention_nonlinear, + attention_type=attention_type, + kernel=kernel, + reuse=reuse) + + return prelogits, attention_prob, attention_score, feature_map, end_points + + def _GetAttentionModel( + self, + images, + num_classes, + weight_decay=0.0001, + attention_nonlinear=_SUPPORTED_ATTENTION_NONLINEARITY[0], + attention_type=_SUPPORTED_ATTENTION_TYPES[0], + kernel=1, + training_resnet=False, + training_attention=False, + reuse=False): + """Constructs attention model on resnet_v1_50. + + Args: + images: A tensor of size [batch, height, width, channels] + num_classes: The number of output classes. + weight_decay: The parameters for weight_decay regularizer. + attention_nonlinear: Type of non-linearity on top of the attention + function. + attention_type: Type of the attention structure. + kernel: Convolutional kernel to use in attention layers (eg, [3, 3]). + training_resnet: Whether or not the Resnet blocks from the model are in + training mode. + training_attention: Whether or not the attention part of the model is in + training mode. + reuse: Whether or not the layer and its variables should be reused. + + Returns: + logits: A tensor of size [batch, num_classes]. + attention_prob: Attention score after the non-linearity. + attention_score: Attention score before the non-linearity. + feature_map: Features extracted from the model, which are not + l2-normalized. + """ + + attention_feat, attention_prob, attention_score, feature_map, _ = ( + self.GetAttentionPrelogit( + images, + weight_decay, + attention_nonlinear=attention_nonlinear, + attention_type=attention_type, + kernel=kernel, + training_resnet=training_resnet, + training_attention=training_attention, + reuse=reuse)) + with slim.arg_scope( + resnet_v1.resnet_arg_scope( + weight_decay=weight_decay, batch_norm_scale=True)): + with slim.arg_scope([slim.batch_norm], is_training=training_attention): + with tf.variable_scope( + _ATTENTION_VARIABLE_SCOPE, values=[attention_feat], reuse=reuse): + logits = slim.conv2d( + attention_feat, + num_classes, [1, 1], + activation_fn=None, + normalizer_fn=None, + scope='logits') + logits = tf.squeeze(logits, [1, 2], name='spatial_squeeze') + return logits, attention_prob, attention_score, feature_map + + def AttentionModel(self, + images, + num_classes, + weight_decay=0.0001, + attention_nonlinear=_SUPPORTED_ATTENTION_NONLINEARITY[0], + attention_type=_SUPPORTED_ATTENTION_TYPES[0], + kernel=1, + training_resnet=False, + training_attention=False, + reuse=False): + """Constructs attention based classification model for training. + + Args: + images: A tensor of size [batch, height, width, channels] + num_classes: The number of output classes. + weight_decay: The parameters for weight_decay regularizer. + attention_nonlinear: Type of non-linearity on top of the attention + function. + attention_type: Type of the attention structure. + kernel: Convolutional kernel to use in attention layers (eg, [3, 3]). + training_resnet: Whether or not the Resnet blocks from the model are in + training mode. + training_attention: Whether or not the model is in training mode. Note + that this function only supports training the attention part of the + model, ie, the feature extraction layers are not trained. + reuse: Whether or not the layer and its variables should be reused. + + Returns: + logit: A tensor of size [batch, num_classes] + attention: Attention score after the non-linearity. + feature_map: Features extracted from the model, which are not + l2-normalized. + + Raises: + ValueError: If unknown target_layer_type is provided. + """ + if 'resnet_v1_50' in self._target_layer_type: + net_outputs = self._GetAttentionModel( + images, + num_classes, + weight_decay, + attention_nonlinear=attention_nonlinear, + attention_type=attention_type, + kernel=kernel, + training_resnet=training_resnet, + training_attention=training_attention, + reuse=reuse) + logits, attention, _, feature_map = net_outputs + else: + raise ValueError('Unknown target_layer_type.') + return logits, attention, feature_map diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/delf_config_example.pbtxt" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/delf_config_example.pbtxt" new file mode 100644 index 00000000..7765551c --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/delf_config_example.pbtxt" @@ -0,0 +1,25 @@ +model_path: "parameters/delf_v1_20171026/model/" +image_scales: .25 +image_scales: .3536 +image_scales: .5 +image_scales: .7071 +image_scales: 1.0 +image_scales: 1.4142 +image_scales: 2.0 +delf_local_config { + use_pca: true + # Note that for the exported model provided as an example, layer_name and + # iou_threshold are hard-coded in the checkpoint. So, the layer_name and + # iou_threshold variables here have no effect on the provided + # extract_features.py script. + layer_name: "resnet_v1_50/block3" + iou_threshold: 1.0 + max_feature_num: 1000 + score_threshold: 100.0 + pca_parameters { + mean_path: "parameters/delf_v1_20171026/pca/mean.datum" + projection_matrix_path: "parameters/delf_v1_20171026/pca/pca_proj_mat.datum" + pca_dim: 40 + use_whitening: false + } +} diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/extract_features.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/extract_features.py" new file mode 100644 index 00000000..7a32a861 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/extract_features.py" @@ -0,0 +1,189 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Extracts DELF features from a list of images, saving them to file. + +The images must be in JPG format. The program checks if descriptors already +exist, and skips computation for those. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import argparse +import os +import sys +import time + +import tensorflow as tf + +from google.protobuf import text_format +from tensorflow.python.platform import app +from delf import delf_config_pb2 +from delf import feature_extractor +from delf import feature_io + +cmd_args = None + +# Extension of feature files. +_DELF_EXT = '.delf' + +# Pace to report extraction log. +_STATUS_CHECK_ITERATIONS = 100 + + +def _ReadImageList(list_path): + """Helper function to read image paths. + + Args: + list_path: Path to list of images, one image path per line. + + Returns: + image_paths: List of image paths. + """ + with tf.gfile.GFile(list_path, 'r') as f: + image_paths = f.readlines() + image_paths = [entry.rstrip() for entry in image_paths] + return image_paths + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + + # Read list of images. + tf.logging.info('Reading list of images...') + image_paths = _ReadImageList(cmd_args.list_images_path) + num_images = len(image_paths) + tf.logging.info('done! Found %d images', num_images) + + # Parse DelfConfig proto. + config = delf_config_pb2.DelfConfig() + with tf.gfile.FastGFile(cmd_args.config_path, 'r') as f: + text_format.Merge(f.read(), config) + + # Create output directory if necessary. + if not os.path.exists(cmd_args.output_dir): + os.makedirs(cmd_args.output_dir) + + # Tell TensorFlow that the model will be built into the default Graph. + with tf.Graph().as_default(): + # Reading list of images. + filename_queue = tf.train.string_input_producer(image_paths, shuffle=False) + reader = tf.WholeFileReader() + _, value = reader.read(filename_queue) + image_tf = tf.image.decode_jpeg(value, channels=3) + + with tf.Session() as sess: + # Initialize variables. + init_op = tf.global_variables_initializer() + sess.run(init_op) + + # Loading model that will be used. + tf.saved_model.loader.load(sess, [tf.saved_model.tag_constants.SERVING], + config.model_path) + graph = tf.get_default_graph() + input_image = graph.get_tensor_by_name('input_image:0') + input_score_threshold = graph.get_tensor_by_name('input_abs_thres:0') + input_image_scales = graph.get_tensor_by_name('input_scales:0') + input_max_feature_num = graph.get_tensor_by_name( + 'input_max_feature_num:0') + boxes = graph.get_tensor_by_name('boxes:0') + raw_descriptors = graph.get_tensor_by_name('features:0') + feature_scales = graph.get_tensor_by_name('scales:0') + attention_with_extra_dim = graph.get_tensor_by_name('scores:0') + attention = tf.reshape(attention_with_extra_dim, + [tf.shape(attention_with_extra_dim)[0]]) + + locations, descriptors = feature_extractor.DelfFeaturePostProcessing( + boxes, raw_descriptors, config) + + # Start input enqueue threads. + coord = tf.train.Coordinator() + threads = tf.train.start_queue_runners(sess=sess, coord=coord) + start = time.clock() + for i in range(num_images): + # Write to log-info once in a while. + if i == 0: + tf.logging.info('Starting to extract DELF features from images...') + elif i % _STATUS_CHECK_ITERATIONS == 0: + elapsed = (time.clock() - start) + tf.logging.info('Processing image %d out of %d, last %d ' + 'images took %f seconds', i, num_images, + _STATUS_CHECK_ITERATIONS, elapsed) + start = time.clock() + + # # Get next image. + im = sess.run(image_tf) + + # If descriptor already exists, skip its computation. + out_desc_filename = os.path.splitext(os.path.basename( + image_paths[i]))[0] + _DELF_EXT + out_desc_fullpath = os.path.join(cmd_args.output_dir, out_desc_filename) + if tf.gfile.Exists(out_desc_fullpath): + tf.logging.info('Skipping %s', image_paths[i]) + continue + + # Extract and save features. + (locations_out, descriptors_out, feature_scales_out, + attention_out) = sess.run( + [locations, descriptors, feature_scales, attention], + feed_dict={ + input_image: + im, + input_score_threshold: + config.delf_local_config.score_threshold, + input_image_scales: + list(config.image_scales), + input_max_feature_num: + config.delf_local_config.max_feature_num + }) + + feature_io.WriteToFile(out_desc_fullpath, locations_out, + feature_scales_out, descriptors_out, + attention_out) + + # Finalize enqueue threads. + coord.request_stop() + coord.join(threads) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.register('type', 'bool', lambda v: v.lower() == 'true') + parser.add_argument( + '--config_path', + type=str, + default='delf_config_example.pbtxt', + help=""" + Path to DelfConfig proto text file with configuration to be used for DELF + extraction. + """) + parser.add_argument( + '--list_images_path', + type=str, + default='list_images.txt', + help=""" + Path to list of images whose DELF features will be extracted. + """) + parser.add_argument( + '--output_dir', + type=str, + default='test_features', + help=""" + Directory where DELF features will be written to. Each image's features + will be written to a file with same name, and extension replaced by .delf. + """) + cmd_args, unparsed = parser.parse_known_args() + app.run(main=main, argv=[sys.argv[0]] + unparsed) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/match_images.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/match_images.py" new file mode 100644 index 00000000..6aa8ce37 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/match_images.py" @@ -0,0 +1,144 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Matches two images using their DELF features. + +The matching is done using feature-based nearest-neighbor search, followed by +geometric verification using RANSAC. + +The DELF features can be extracted using the extract_features.py script. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import argparse +import sys + +import matplotlib.image as mpimg +import matplotlib.pyplot as plt +import numpy as np +from scipy.spatial import cKDTree +from skimage.feature import plot_matches +from skimage.measure import ransac +from skimage.transform import AffineTransform +import tensorflow as tf + +from tensorflow.python.platform import app +from delf import feature_io + +cmd_args = None + +_DISTANCE_THRESHOLD = 0.8 + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + + # Read features. + locations_1, _, descriptors_1, _, _ = feature_io.ReadFromFile( + cmd_args.features_1_path) + num_features_1 = locations_1.shape[0] + tf.logging.info("Loaded image 1's %d features" % num_features_1) + locations_2, _, descriptors_2, _, _ = feature_io.ReadFromFile( + cmd_args.features_2_path) + num_features_2 = locations_2.shape[0] + tf.logging.info("Loaded image 2's %d features" % num_features_2) + + # Find nearest-neighbor matches using a KD tree. + d1_tree = cKDTree(descriptors_1) + _, indices = d1_tree.query( + descriptors_2, distance_upper_bound=_DISTANCE_THRESHOLD) + + # Select feature locations for putative matches. + locations_2_to_use = np.array([ + locations_2[i,] + for i in range(num_features_2) + if indices[i] != num_features_1 + ]) + locations_1_to_use = np.array([ + locations_1[indices[i],] + for i in range(num_features_2) + if indices[i] != num_features_1 + ]) + + # Perform geometric verification using RANSAC. + _, inliers = ransac( + (locations_1_to_use, locations_2_to_use), + AffineTransform, + min_samples=3, + residual_threshold=20, + max_trials=1000) + + tf.logging.info('Found %d inliers' % sum(inliers)) + + # Visualize correspondences, and save to file. + _, ax = plt.subplots() + img_1 = mpimg.imread(cmd_args.image_1_path) + img_2 = mpimg.imread(cmd_args.image_2_path) + inlier_idxs = np.nonzero(inliers)[0] + plot_matches( + ax, + img_1, + img_2, + locations_1_to_use, + locations_2_to_use, + np.column_stack((inlier_idxs, inlier_idxs)), + matches_color='b') + ax.axis('off') + ax.set_title('DELF correspondences') + plt.savefig(cmd_args.output_image) + + +if __name__ == '__main__': + parser = argparse.ArgumentParser() + parser.register('type', 'bool', lambda v: v.lower() == 'true') + parser.add_argument( + '--image_1_path', + type=str, + default='test_images/image_1.jpg', + help=""" + Path to test image 1. + """) + parser.add_argument( + '--image_2_path', + type=str, + default='test_images/image_2.jpg', + help=""" + Path to test image 2. + """) + parser.add_argument( + '--features_1_path', + type=str, + default='test_features/image_1.delf', + help=""" + Path to DELF features from image 1. + """) + parser.add_argument( + '--features_2_path', + type=str, + default='test_features/image_2.delf', + help=""" + Path to DELF features from image 2. + """) + parser.add_argument( + '--output_image', + type=str, + default='test_match.png', + help=""" + Path where an image showing the matches will be saved. + """) + cmd_args, unparsed = parser.parse_known_args() + app.run(main=main, argv=[sys.argv[0]] + unparsed) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/matched_images_example.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/matched_images_example.png" new file mode 100644 index 00000000..2430e003 Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/examples/matched_images_example.png" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor.py" new file mode 100644 index 00000000..6eca9c6c --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor.py" @@ -0,0 +1,384 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""DELF feature extractor. +""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf + +from delf import datum_io +from delf import delf_v1 +from object_detection.core import box_list +from object_detection.core import box_list_ops + + +def NormalizePixelValues(image, + pixel_value_offset=128.0, + pixel_value_scale=128.0): + """Normalize image pixel values. + + Args: + image: a uint8 tensor. + pixel_value_offset: a Python float, offset for normalizing pixel values. + pixel_value_scale: a Python float, scale for normalizing pixel values. + + Returns: + image: a float32 tensor of the same shape as the input image. + """ + image = tf.to_float(image) + image = tf.div(tf.subtract(image, pixel_value_offset), pixel_value_scale) + return image + + +def CalculateReceptiveBoxes(height, width, rf, stride, padding): + """Calculate receptive boxes for each feature point. + + Args: + height: The height of feature map. + width: The width of feature map. + rf: The receptive field size. + stride: The effective stride between two adjacent feature points. + padding: The effective padding size. + Returns: + rf_boxes: [N, 4] receptive boxes tensor. Here N equals to height x width. + Each box is represented by [ymin, xmin, ymax, xmax]. + """ + x, y = tf.meshgrid(tf.range(width), tf.range(height)) + coordinates = tf.reshape(tf.stack([y, x], axis=2), [-1, 2]) + # [y,x,y,x] + point_boxes = tf.to_float(tf.concat([coordinates, coordinates], 1)) + bias = [-padding, -padding, -padding + rf - 1, -padding + rf - 1] + rf_boxes = stride * point_boxes + bias + return rf_boxes + + +def CalculateKeypointCenters(boxes): + """Helper function to compute feature centers, from RF boxes. + + Args: + boxes: [N, 4] float tensor. + + Returns: + centers: [N, 2] float tensor. + """ + return tf.divide( + tf.add( + tf.gather(boxes, [0, 1], axis=1), tf.gather(boxes, [2, 3], axis=1)), + 2.0) + + +def ExtractKeypointDescriptor(image, layer_name, image_scales, iou, + max_feature_num, abs_thres, model_fn): + """Extract keypoint descriptor for input image. + + Args: + image: A image tensor with shape [h, w, channels]. + layer_name: The endpoint of feature extraction layer. + image_scales: A 1D float tensor which contains the scales. + iou: A float scalar denoting the IOU threshold for NMS. + max_feature_num: An int tensor denoting the maximum selected feature points. + abs_thres: A float tensor denoting the score threshold for feature + selection. + model_fn: Model function. Follows the signature: + + * Args: + * `images`: Image tensor which is re-scaled. + * `normalized_image`: Whether or not the images are normalized. + * `reuse`: Whether or not the layer and its variables should be reused. + + * Returns: + * `attention`: Attention score after the non-linearity. + * `feature_map`: Feature map obtained from the ResNet model. + + Returns: + boxes: [N, 4] float tensor which denotes the selected receptive box. N is + the number of final feature points which pass through keypoint selection + and NMS steps. + feature_scales: [N] float tensor. It is the inverse of the input image + scales such that larger image scales correspond to larger image regions, + which is compatible with scale-space keypoint detection convention. + features: [N, depth] float tensor with feature descriptors. + scores: [N, 1] float tensor denoting the attention score. + + Raises: + ValueError: If the layer_name is unsupported. + """ + original_image_shape_float = tf.gather(tf.to_float(tf.shape(image)), [0, 1]) + image_tensor = NormalizePixelValues(image) + image_tensor = tf.expand_dims(image_tensor, 0, name='image/expand_dims') + + # Feature depth and receptive field parameters for each network version. + if layer_name == 'resnet_v1_50/block3': + feature_depth = 1024 + rf, stride, padding = [291.0, 32.0, 145.0] + elif layer_name == 'resnet_v1_50/block4': + feature_depth = 2048 + rf, stride, padding = [483.0, 32.0, 241.0] + else: + raise ValueError('Unsupported layer_name.') + + def _ProcessSingleScale(scale_index, + boxes, + features, + scales, + scores, + reuse=True): + """Resize the image and run feature extraction and keypoint selection. + + This function will be passed into tf.while_loop() and be called + repeatedly. The input boxes are collected from the previous iteration + [0: scale_index -1]. We get the current scale by + image_scales[scale_index], and run image resizing, feature extraction and + keypoint selection. Then we will get a new set of selected_boxes for + current scale. In the end, we concat the previous boxes with current + selected_boxes as the output. + + Args: + scale_index: A valid index in the image_scales. + boxes: Box tensor with the shape of [N, 4]. + features: Feature tensor with the shape of [N, depth]. + scales: Scale tensor with the shape of [N]. + scores: Attention score tensor with the shape of [N]. + reuse: Whether or not the layer and its variables should be reused. + + Returns: + scale_index: The next scale index for processing. + boxes: Concatenated box tensor with the shape of [K, 4]. K >= N. + features: Concatenated feature tensor with the shape of [K, depth]. + scales: Concatenated scale tensor with the shape of [K]. + scores: Concatenated attention score tensor with the shape of [K]. + """ + scale = tf.gather(image_scales, scale_index) + new_image_size = tf.to_int32(tf.round(original_image_shape_float * scale)) + resized_image = tf.image.resize_bilinear(image_tensor, new_image_size) + + attention, feature_map = model_fn( + resized_image, normalized_image=True, reuse=reuse) + + rf_boxes = CalculateReceptiveBoxes( + tf.shape(feature_map)[1], + tf.shape(feature_map)[2], rf, stride, padding) + # Re-project back to the original image space. + rf_boxes = tf.divide(rf_boxes, scale) + attention = tf.reshape(attention, [-1]) + feature_map = tf.reshape(feature_map, [-1, feature_depth]) + + # Use attention score to select feature vectors. + indices = tf.reshape(tf.where(attention >= abs_thres), [-1]) + selected_boxes = tf.gather(rf_boxes, indices) + selected_features = tf.gather(feature_map, indices) + selected_scores = tf.gather(attention, indices) + selected_scales = tf.ones_like(selected_scores, tf.float32) / scale + + # Concat with the previous result from different scales. + boxes = tf.concat([boxes, selected_boxes], 0) + features = tf.concat([features, selected_features], 0) + scales = tf.concat([scales, selected_scales], 0) + scores = tf.concat([scores, selected_scores], 0) + + return scale_index + 1, boxes, features, scales, scores + + output_boxes = tf.zeros([0, 4], dtype=tf.float32) + output_features = tf.zeros([0, feature_depth], dtype=tf.float32) + output_scales = tf.zeros([0], dtype=tf.float32) + output_scores = tf.zeros([0], dtype=tf.float32) + + # Process the first scale separately, the following scales will reuse the + # graph variables. + (_, output_boxes, output_features, output_scales, + output_scores) = _ProcessSingleScale( + 0, + output_boxes, + output_features, + output_scales, + output_scores, + reuse=False) + i = tf.constant(1, dtype=tf.int32) + num_scales = tf.shape(image_scales)[0] + keep_going = lambda j, boxes, features, scales, scores: tf.less(j, num_scales) + + (_, output_boxes, output_features, output_scales, + output_scores) = tf.while_loop( + cond=keep_going, + body=_ProcessSingleScale, + loop_vars=[ + i, output_boxes, output_features, output_scales, output_scores + ], + shape_invariants=[ + i.get_shape(), + tf.TensorShape([None, 4]), + tf.TensorShape([None, feature_depth]), + tf.TensorShape([None]), + tf.TensorShape([None]) + ], + back_prop=False) + + feature_boxes = box_list.BoxList(output_boxes) + feature_boxes.add_field('features', output_features) + feature_boxes.add_field('scales', output_scales) + feature_boxes.add_field('scores', output_scores) + + nms_max_boxes = tf.minimum(max_feature_num, feature_boxes.num_boxes()) + final_boxes = box_list_ops.non_max_suppression(feature_boxes, iou, + nms_max_boxes) + + return (final_boxes.get(), final_boxes.get_field('scales'), + final_boxes.get_field('features'), + tf.expand_dims(final_boxes.get_field('scores'), 1)) + + +def BuildModel(layer_name, attention_nonlinear, attention_type, + attention_kernel_size): + """Build the DELF model. + + This function is helpful for constructing the model function which will be fed + to ExtractKeypointDescriptor(). + + Args: + layer_name: the endpoint of feature extraction layer. + attention_nonlinear: Type of the non-linearity for the attention function. + Currently, only 'softplus' is supported. + attention_type: Type of the attention used. Options are: + 'use_l2_normalized_feature' and 'use_default_input_feature'. Note that + this is irrelevant during inference time. + attention_kernel_size: Size of attention kernel (kernel is square). + + Returns: + Attention model function. + """ + + def _ModelFn(images, normalized_image, reuse): + """Attention model to get feature map and attention score map. + + Args: + images: Image tensor. + normalized_image: Whether or not the images are normalized. + reuse: Whether or not the layer and its variables should be reused. + Returns: + attention: Attention score after the non-linearity. + feature_map: Feature map after ResNet convolution. + """ + if normalized_image: + image_tensor = images + else: + image_tensor = NormalizePixelValues(images) + + # Extract features and attention scores. + model = delf_v1.DelfV1(layer_name) + _, attention, _, feature_map, _ = model.GetAttentionPrelogit( + image_tensor, + attention_nonlinear=attention_nonlinear, + attention_type=attention_type, + kernel=[attention_kernel_size, attention_kernel_size], + training_resnet=False, + training_attention=False, + reuse=reuse) + return attention, feature_map + + return _ModelFn + + +def ApplyPcaAndWhitening(data, + pca_matrix, + pca_mean, + output_dim, + use_whitening=False, + pca_variances=None): + """Applies PCA/whitening to data. + + Args: + data: [N, dim] float tensor containing data which undergoes PCA/whitening. + pca_matrix: [dim, dim] float tensor PCA matrix, row-major. + pca_mean: [dim] float tensor, mean to subtract before projection. + output_dim: Number of dimensions to use in output data, of type int. + use_whitening: Whether whitening is to be used. + pca_variances: [dim] float tensor containing PCA variances. Only used if + use_whitening is True. + + Returns: + output: [N, output_dim] float tensor with output of PCA/whitening operation. + """ + output = tf.matmul( + tf.subtract(data, pca_mean), + tf.slice(pca_matrix, [0, 0], [output_dim, -1]), + transpose_b=True, + name='pca_matmul') + + # Apply whitening if desired. + if use_whitening: + output = tf.divide( + output, + tf.sqrt(tf.slice(pca_variances, [0], [output_dim])), + name='whitening') + + return output + + +def DelfFeaturePostProcessing(boxes, descriptors, config): + """Extract DELF features from input image. + + Args: + boxes: [N, 4] float tensor which denotes the selected receptive box. N is + the number of final feature points which pass through keypoint selection + and NMS steps. + descriptors: [N, input_dim] float tensor. + config: DelfConfig proto with DELF extraction options. + + Returns: + locations: [N, 2] float tensor which denotes the selected keypoint + locations. + final_descriptors: [N, output_dim] float tensor with DELF descriptors after + normalization and (possibly) PCA/whitening. + """ + + # Get center of descriptor boxes, corresponding to feature locations. + locations = CalculateKeypointCenters(boxes) + + # Post-process descriptors: L2-normalize, and if desired apply PCA (followed + # by L2-normalization). + with tf.variable_scope('postprocess'): + final_descriptors = tf.nn.l2_normalize( + descriptors, dim=1, name='l2_normalization') + + if config.delf_local_config.use_pca: + # Load PCA parameters. + pca_mean = tf.constant( + datum_io.ReadFromFile( + config.delf_local_config.pca_parameters.mean_path), + dtype=tf.float32) + pca_matrix = tf.constant( + datum_io.ReadFromFile( + config.delf_local_config.pca_parameters.projection_matrix_path), + dtype=tf.float32) + pca_dim = config.delf_local_config.pca_parameters.pca_dim + pca_variances = None + if config.delf_local_config.pca_parameters.use_whitening: + pca_variances = tf.constant( + datum_io.ReadFromFile( + config.delf_local_config.pca_parameters.pca_variances_path), + dtype=tf.float32) + + # Apply PCA, and whitening if desired. + final_descriptors = ApplyPcaAndWhitening( + final_descriptors, pca_matrix, pca_mean, pca_dim, + config.delf_local_config.pca_parameters.use_whitening, pca_variances) + + # Re-normalize. + final_descriptors = tf.nn.l2_normalize( + final_descriptors, dim=1, name='pca_l2_normalization') + + return locations, final_descriptors diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor_test.py" new file mode 100644 index 00000000..882dc9e1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_extractor_test.py" @@ -0,0 +1,133 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for DELF feature extractor.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np +import tensorflow as tf + +from delf import feature_extractor + + +class FeatureExtractorTest(tf.test.TestCase): + + def testNormalizePixelValues(self): + image = tf.constant( + [[[3, 255, 0], [34, 12, 5]], [[45, 5, 65], [56, 77, 89]]], + dtype=tf.uint8) + normalized_image = feature_extractor.NormalizePixelValues( + image, pixel_value_offset=5.0, pixel_value_scale=2.0) + exp_normalized_image = [[[-1.0, 125.0, -2.5], [14.5, 3.5, 0.0]], + [[20.0, 0.0, 30.0], [25.5, 36.0, 42.0]]] + with self.test_session() as sess: + normalized_image_out = sess.run(normalized_image) + + self.assertAllEqual(normalized_image_out, exp_normalized_image) + + def testCalculateReceptiveBoxes(self): + boxes = feature_extractor.CalculateReceptiveBoxes( + height=1, width=2, rf=291, stride=32, padding=145) + exp_boxes = [[-145., -145., 145., 145.], [-145., -113., 145., 177.]] + with self.test_session() as sess: + boxes_out = sess.run(boxes) + + self.assertAllEqual(exp_boxes, boxes_out) + + def testCalculateKeypointCenters(self): + boxes = [[-10.0, 0.0, 11.0, 21.0], [-2.5, 5.0, 18.5, 26.0], + [45.0, -2.5, 66.0, 18.5]] + centers = feature_extractor.CalculateKeypointCenters(boxes) + with self.test_session() as sess: + centers_out = sess.run(centers) + + exp_centers = [[0.5, 10.5], [8.0, 15.5], [55.5, 8.0]] + + self.assertAllEqual(exp_centers, centers_out) + + def testExtractKeypointDescriptor(self): + image = tf.constant( + [[[0, 255, 255], [128, 64, 196]], [[0, 0, 32], [32, 128, 16]]], + dtype=tf.uint8) + + # Arbitrary model function used to test ExtractKeypointDescriptor. The + # generated feature_map is a replicated version of the image, concatenated + # with zeros to achieve the required dimensionality. The attention is simply + # the norm of the input image pixels. + def _test_model_fn(image, normalized_image, reuse): + del normalized_image, reuse # Unused variables in the test. + image_shape = tf.shape(image) + attention = tf.squeeze(tf.norm(image, axis=3)) + feature_map = tf.concat( + [ + tf.tile(image, [1, 1, 1, 341]), + tf.zeros([1, image_shape[1], image_shape[2], 1]) + ], + axis=3) + return attention, feature_map + + boxes, feature_scales, features, scores = ( + feature_extractor.ExtractKeypointDescriptor( + image, + layer_name='resnet_v1_50/block3', + image_scales=tf.constant([1.0]), + iou=1.0, + max_feature_num=10, + abs_thres=1.5, + model_fn=_test_model_fn)) + + exp_boxes = [[-145.0, -145.0, 145.0, 145.0], [-113.0, -145.0, 177.0, 145.0]] + exp_feature_scales = [1.0, 1.0] + exp_features = np.array( + np.concatenate( + (np.tile([[-1.0, 127.0 / 128.0, 127.0 / 128.0], [-1.0, -1.0, -0.75] + ], [1, 341]), np.zeros([2, 1])), + axis=1)) + exp_scores = [[1.723042], [1.600781]] + + with self.test_session() as sess: + boxes_out, feature_scales_out, features_out, scores_out = sess.run( + [boxes, feature_scales, features, scores]) + + self.assertAllEqual(exp_boxes, boxes_out) + self.assertAllEqual(exp_feature_scales, feature_scales_out) + self.assertAllClose(exp_features, features_out) + self.assertAllClose(exp_scores, scores_out) + + def testPcaWhitening(self): + data = tf.constant([[1.0, 2.0, -2.0], [-5.0, 0.0, 3.0], [-1.0, 2.0, 0.0], + [0.0, 4.0, -1.0]]) + pca_matrix = tf.constant([[2.0, 0.0, -1.0], [0.0, 1.0, 1.0], + [-1.0, 1.0, 3.0]]) + pca_mean = tf.constant([1.0, 2.0, 3.0]) + output_dim = 2 + use_whitening = True + pca_variances = tf.constant([4.0, 1.0]) + + output = feature_extractor.ApplyPcaAndWhitening( + data, pca_matrix, pca_mean, output_dim, use_whitening, pca_variances) + + exp_output = [[2.5, -5.0], [-6.0, -2.0], [-0.5, -3.0], [1.0, -2.0]] + + with self.test_session() as sess: + output_out = sess.run(output) + + self.assertAllEqual(exp_output, output_out) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io.py" new file mode 100644 index 00000000..8f7a02bb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io.py" @@ -0,0 +1,197 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Python interface for DelfFeatures proto. + +Support read and write of DelfFeatures from/to numpy arrays and file. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np +from six.moves import xrange +import tensorflow as tf + +from delf import feature_pb2 +from delf import datum_io + + +def ArraysToDelfFeatures(locations, + scales, + descriptors, + attention, + orientations=None): + """Converts DELF features to DelfFeatures proto. + + Args: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. If None, all orientations + are set to zero. + + Returns: + delf_features: DelfFeatures object. + """ + num_features = len(attention) + assert num_features == locations.shape[0] + assert num_features == len(scales) + assert num_features == descriptors.shape[0] + + if orientations is None: + orientations = np.zeros([num_features], dtype=np.float32) + else: + assert num_features == len(orientations) + + delf_features = feature_pb2.DelfFeatures() + for i in range(num_features): + delf_feature = delf_features.feature.add() + delf_feature.y = locations[i, 0] + delf_feature.x = locations[i, 1] + delf_feature.scale = scales[i] + delf_feature.orientation = orientations[i] + delf_feature.strength = attention[i] + delf_feature.descriptor.CopyFrom(datum_io.ArrayToDatum(descriptors[i,])) + + return delf_features + + +def DelfFeaturesToArrays(delf_features): + """Converts data saved in DelfFeatures to numpy arrays. + + If there are no features, the function returns four empty arrays. + + Args: + delf_features: DelfFeatures object. + + Returns: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. + """ + num_features = len(delf_features.feature) + if num_features == 0: + return np.array([]), np.array([]), np.array([]), np.array([]) + + # Figure out descriptor dimensionality by parsing first one. + descriptor_dim = len( + datum_io.DatumToArray(delf_features.feature[0].descriptor)) + locations = np.zeros([num_features, 2]) + scales = np.zeros([num_features]) + descriptors = np.zeros([num_features, descriptor_dim]) + attention = np.zeros([num_features]) + orientations = np.zeros([num_features]) + + for i in range(num_features): + delf_feature = delf_features.feature[i] + locations[i, 0] = delf_feature.y + locations[i, 1] = delf_feature.x + scales[i] = delf_feature.scale + descriptors[i,] = datum_io.DatumToArray(delf_feature.descriptor) + attention[i] = delf_feature.strength + orientations[i] = delf_feature.orientation + + return locations, scales, descriptors, attention, orientations + + +def SerializeToString(locations, + scales, + descriptors, + attention, + orientations=None): + """Converts numpy arrays to serialized DelfFeatures. + + Args: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. If None, all orientations + are set to zero. + + Returns: + Serialized DelfFeatures string. + """ + delf_features = ArraysToDelfFeatures(locations, scales, descriptors, + attention, orientations) + return delf_features.SerializeToString() + + +def ParseFromString(string): + """Converts serialized DelfFeatures string to numpy arrays. + + Args: + string: Serialized DelfFeatures string. + + Returns: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. + """ + delf_features = feature_pb2.DelfFeatures() + delf_features.ParseFromString(string) + return DelfFeaturesToArrays(delf_features) + + +def ReadFromFile(file_path): + """Helper function to load data from a DelfFeatures format in a file. + + Args: + file_path: Path to file containing data. + + Returns: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. + """ + with tf.gfile.FastGFile(file_path, 'rb') as f: + return ParseFromString(f.read()) + + +def WriteToFile(file_path, + locations, + scales, + descriptors, + attention, + orientations=None): + """Helper function to write data to a file in DelfFeatures format. + + Args: + file_path: Path to file that will be written. + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. If None, all orientations + are set to zero. + """ + serialized_data = SerializeToString(locations, scales, descriptors, attention, + orientations) + with tf.gfile.FastGFile(file_path, 'w') as f: + f.write(serialized_data) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io_test.py" new file mode 100644 index 00000000..377c6a58 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/delf/python/feature_io_test.py" @@ -0,0 +1,98 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for feature_io, the python interface of DelfFeatures.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os + +import numpy as np +import tensorflow as tf + +from delf import feature_io + + +def create_data(): + """Creates data to be used in tests. + + Returns: + locations: [N, 2] float array which denotes the selected keypoint + locations. N is the number of features. + scales: [N] float array with feature scales. + descriptors: [N, depth] float array with DELF descriptors. + attention: [N] float array with attention scores. + orientations: [N] float array with orientations. + """ + locations = np.arange(8, dtype=np.float32).reshape(4, 2) + scales = np.arange(4, dtype=np.float32) + attention = np.arange(4, dtype=np.float32) + orientations = np.arange(4, dtype=np.float32) + descriptors = np.zeros([4, 1024]) + descriptors[0,] = np.arange(1024) + descriptors[1,] = np.zeros([1024]) + descriptors[2,] = np.ones([1024]) + descriptors[3,] = -np.ones([1024]) + + return locations, scales, descriptors, attention, orientations + + +class DelfFeaturesIoTest(tf.test.TestCase): + + def testConversionAndBack(self): + locations, scales, descriptors, attention, orientations = create_data() + + serialized = feature_io.SerializeToString(locations, scales, descriptors, + attention, orientations) + parsed_data = feature_io.ParseFromString(serialized) + + self.assertAllEqual(locations, parsed_data[0]) + self.assertAllEqual(scales, parsed_data[1]) + self.assertAllEqual(descriptors, parsed_data[2]) + self.assertAllEqual(attention, parsed_data[3]) + self.assertAllEqual(orientations, parsed_data[4]) + + def testConversionAndBackNoOrientations(self): + locations, scales, descriptors, attention, _ = create_data() + + serialized = feature_io.SerializeToString(locations, scales, descriptors, + attention) + parsed_data = feature_io.ParseFromString(serialized) + + self.assertAllEqual(locations, parsed_data[0]) + self.assertAllEqual(scales, parsed_data[1]) + self.assertAllEqual(descriptors, parsed_data[2]) + self.assertAllEqual(attention, parsed_data[3]) + self.assertAllEqual(np.zeros([4]), parsed_data[4]) + + def testWriteAndReadToFile(self): + locations, scales, descriptors, attention, orientations = create_data() + + tmpdir = tf.test.get_temp_dir() + filename = os.path.join(tmpdir, 'test.delf') + feature_io.WriteToFile(filename, locations, scales, descriptors, attention, + orientations) + data_read = feature_io.ReadFromFile(filename) + + self.assertAllEqual(locations, data_read[0]) + self.assertAllEqual(scales, data_read[1]) + self.assertAllEqual(descriptors, data_read[2]) + self.assertAllEqual(attention, data_read[3]) + self.assertAllEqual(orientations, data_read[4]) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/setup.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/setup.py" new file mode 100644 index 00000000..61b0ac50 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/delf/setup.py" @@ -0,0 +1,25 @@ +# Copyright 2017 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Setup script for delf.""" + +from setuptools import setup, find_packages + +setup( + name='delf', + version='0.1', + include_package_data=True, + packages=find_packages(), + description='DELF (DEep Local Features)', +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/differential_privacy/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/differential_privacy/README.md" new file mode 100644 index 00000000..9cd41749 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/differential_privacy/README.md" @@ -0,0 +1,3 @@ +# Deep Learning with Differential Privacy + +All of the content from this directory has moved to the [tensorflow/privacy](https://github.com/tensorflow/privacy) repository, which is dedicated to learning with (differential) privacy. diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/README.md" new file mode 100644 index 00000000..7fec0bb0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/README.md" @@ -0,0 +1,123 @@ +## Introduction +This is the code used for two domain adaptation papers. + +The `domain_separation` directory contains code for the "Domain Separation +Networks" paper by Bousmalis K., Trigeorgis G., et al. which was presented at +NIPS 2016. The paper can be found here: https://arxiv.org/abs/1608.06019. + +The `pixel_domain_adaptation` directory contains the code used for the +"Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial +Networks" paper by Bousmalis K., et al. (presented at CVPR 2017). The paper can +be found here: https://arxiv.org/abs/1612.05424. PixelDA aims to perform domain +adaptation by transfering the visual style of the target domain (which has few +or no labels) to a source domain (which has many labels). This is accomplished +using a Generative Adversarial Network (GAN). + +## Contact +The domain separation code was open-sourced +by [Konstantinos Bousmalis](https://github.com/bousmalis) +(konstantinos@google.com), while the pixel level domain adaptation code was +open-sourced by [David Dohan](https://github.com/dmrd) (ddohan@google.com). + +## Installation +You will need to have the following installed on your machine before trying out the DSN code. + +* Tensorflow: https://www.tensorflow.org/install/ +* Bazel: https://bazel.build/ + +## Important Note +We are working to open source the pose estimation dataset. For now, the MNIST to +MNIST-M dataset is available. Check back here in a few weeks or wait for a +relevant announcement from [@bousmalis](https://twitter.com/bousmalis). + +## Initial setup +In order to run the MNIST to MNIST-M experiments, you will need to set the +data directory: + +``` +$ export DSN_DATA_DIR=/your/dir +``` + +Add models and models/slim to your `$PYTHONPATH` (assumes $PWD is /models): + +``` +$ export PYTHONPATH=$PYTHONPATH:$PWD:$PWD/slim +``` + +## Getting the datasets + +You can fetch the MNIST data by running + +``` + $ bazel run slim:download_and_convert_data -- --dataset_dir $DSN_DATA_DIR --dataset_name=mnist +``` + +The MNIST-M dataset is available online [here](http://bit.ly/2nrlUAJ). Once it is downloaded and extracted into your data directory, create TFRecord files by running: +``` +$ bazel run domain_adaptation/datasets:download_and_convert_mnist_m -- --dataset_dir $DSN_DATA_DIR +``` + + + +# Running PixelDA from MNIST to MNIST-M +You can run PixelDA as follows (using Tensorboard to examine the results): + +``` +$ bazel run domain_adaptation/pixel_domain_adaptation:pixelda_train -- --dataset_dir $DSN_DATA_DIR --source_dataset mnist --target_dataset mnist_m +``` + +And evaluation as: +``` +$ bazel run domain_adaptation/pixel_domain_adaptation:pixelda_eval -- --dataset_dir $DSN_DATA_DIR --source_dataset mnist --target_dataset mnist_m --target_split_name test +``` + +The MNIST-M results in the paper were run with the following hparams flag: +``` +--hparams arch=resnet,domain_loss_weight=0.135603587834,num_training_examples=16000000,style_transfer_loss_weight=0.0113173311334,task_loss_in_g_weight=0.0100959947002,task_tower=mnist,task_tower_in_g_step=true +``` + +### A note on terminology/language of the code: + +The components of the network can be grouped into two parts +which correspond to elements which are jointly optimized: The generator +component and the discriminator component. + +The generator component takes either an image or noise vector and produces an +output image. + +The discriminator component takes the generated images and the target images +and attempts to discriminate between them. + +## Running DSN code for adapting MNIST to MNIST-M + +Then you need to build the binaries with Bazel: + +``` +$ bazel build -c opt domain_adaptation/domain_separation/... +``` + +You can then train with the following command: + +``` +$ ./bazel-bin/domain_adaptation/domain_separation/dsn_train \ + --similarity_loss=dann_loss \ + --basic_tower=dann_mnist \ + --source_dataset=mnist \ + --target_dataset=mnist_m \ + --learning_rate=0.0117249 \ + --gamma_weight=0.251175 \ + --weight_decay=1e-6 \ + --layers_to_regularize=fc3 \ + --nouse_separation \ + --master="" \ + --dataset_dir=${DSN_DATA_DIR} \ + -v --use_logging +``` + +Evaluation can be invoked with the following command: + +``` +$ ./bazel-bin/domain_adaptation/domain_separation/dsn_eval \ + -v --dataset mnist_m --split test --num_examples=9001 \ + --dataset_dir=${DSN_DATA_DIR} +``` diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/WORKSPACE" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/WORKSPACE" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/BUILD" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/BUILD" new file mode 100644 index 00000000..067a7937 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/BUILD" @@ -0,0 +1,45 @@ +# Domain Adaptation Scenarios Datasets + +package( + default_visibility = [ + ":internal", + ], +) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +package_group( + name = "internal", + packages = [ + "//domain_adaptation/...", + ], +) + +py_library( + name = "dataset_factory", + srcs = ["dataset_factory.py"], + deps = [ + ":mnist_m", + "//slim:mnist", + ], +) + +py_binary( + name = "download_and_convert_mnist_m", + srcs = ["download_and_convert_mnist_m.py"], + deps = [ + + "//slim:dataset_utils", + ], +) + +py_binary( + name = "mnist_m", + srcs = ["mnist_m.py"], + deps = [ + + "//slim:dataset_utils", + ], +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/dataset_factory.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/dataset_factory.py" new file mode 100644 index 00000000..4ca1b41c --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/dataset_factory.py" @@ -0,0 +1,107 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""A factory-pattern class which returns image/label pairs.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +# Dependency imports +import tensorflow as tf + +from slim.datasets import mnist +from domain_adaptation.datasets import mnist_m + +slim = tf.contrib.slim + + +def get_dataset(dataset_name, + split_name, + dataset_dir, + file_pattern=None, + reader=None): + """Given a dataset name and a split_name returns a Dataset. + + Args: + dataset_name: String, the name of the dataset. + split_name: A train/test split name. + dataset_dir: The directory where the dataset files are stored. + file_pattern: The file pattern to use for matching the dataset source files. + reader: The subclass of tf.ReaderBase. If left as `None`, then the default + reader defined by each dataset is used. + + Returns: + A tf-slim `Dataset` class. + + Raises: + ValueError: if `dataset_name` isn't recognized. + """ + dataset_name_to_module = {'mnist': mnist, 'mnist_m': mnist_m} + if dataset_name not in dataset_name_to_module: + raise ValueError('Name of dataset unknown %s.' % dataset_name) + + return dataset_name_to_module[dataset_name].get_split(split_name, dataset_dir, + file_pattern, reader) + + +def provide_batch(dataset_name, split_name, dataset_dir, num_readers, + batch_size, num_preprocessing_threads): + """Provides a batch of images and corresponding labels. + + Args: + dataset_name: String, the name of the dataset. + split_name: A train/test split name. + dataset_dir: The directory where the dataset files are stored. + num_readers: The number of readers used by DatasetDataProvider. + batch_size: The size of the batch requested. + num_preprocessing_threads: The number of preprocessing threads for + tf.train.batch. + file_pattern: The file pattern to use for matching the dataset source files. + reader: The subclass of tf.ReaderBase. If left as `None`, then the default + reader defined by each dataset is used. + + Returns: + A batch of + images: tensor of [batch_size, height, width, channels]. + labels: dictionary of labels. + """ + dataset = get_dataset(dataset_name, split_name, dataset_dir) + provider = slim.dataset_data_provider.DatasetDataProvider( + dataset, + num_readers=num_readers, + common_queue_capacity=20 * batch_size, + common_queue_min=10 * batch_size) + [image, label] = provider.get(['image', 'label']) + + # Convert images to float32 + image = tf.image.convert_image_dtype(image, tf.float32) + image -= 0.5 + image *= 2 + + # Load the data. + labels = {} + images, labels['classes'] = tf.train.batch( + [image, label], + batch_size=batch_size, + num_threads=num_preprocessing_threads, + capacity=5 * batch_size) + labels['classes'] = slim.one_hot_encoding(labels['classes'], + dataset.num_classes) + + # Convert mnist to RGB and 32x32 so that it can match mnist_m. + if dataset_name == 'mnist': + images = tf.image.grayscale_to_rgb(images) + images = tf.image.resize_images(images, [32, 32]) + return images, labels diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/download_and_convert_mnist_m.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/download_and_convert_mnist_m.py" new file mode 100644 index 00000000..3b5004d3 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/download_and_convert_mnist_m.py" @@ -0,0 +1,237 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +r"""Downloads and converts MNIST-M data to TFRecords of TF-Example protos. + +This module downloads the MNIST-M data, uncompresses it, reads the files +that make up the MNIST-M data and creates two TFRecord datasets: one for train +and one for test. Each TFRecord dataset is comprised of a set of TF-Example +protocol buffers, each of which contain a single image and label. + +The script should take about a minute to run. + +""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +import random +import sys + +# Dependency imports +import numpy as np +from six.moves import urllib +import tensorflow as tf + +from slim.datasets import dataset_utils + +tf.app.flags.DEFINE_string( + 'dataset_dir', None, + 'The directory where the output TFRecords and temporary files are saved.') + +FLAGS = tf.app.flags.FLAGS + +_IMAGE_SIZE = 32 +_NUM_CHANNELS = 3 + +# The number of images in the training set. +_NUM_TRAIN_SAMPLES = 59001 + +# The number of images to be kept from the training set for the validation set. +_NUM_VALIDATION = 1000 + +# The number of images in the test set. +_NUM_TEST_SAMPLES = 9001 + +# Seed for repeatability. +_RANDOM_SEED = 0 + +# The names of the classes. +_CLASS_NAMES = [ + 'zero', + 'one', + 'two', + 'three', + 'four', + 'five', + 'size', + 'seven', + 'eight', + 'nine', +] + + +class ImageReader(object): + """Helper class that provides TensorFlow image coding utilities.""" + + def __init__(self): + # Initializes function that decodes RGB PNG data. + self._decode_png_data = tf.placeholder(dtype=tf.string) + self._decode_png = tf.image.decode_png(self._decode_png_data, channels=3) + + def read_image_dims(self, sess, image_data): + image = self.decode_png(sess, image_data) + return image.shape[0], image.shape[1] + + def decode_png(self, sess, image_data): + image = sess.run( + self._decode_png, feed_dict={self._decode_png_data: image_data}) + assert len(image.shape) == 3 + assert image.shape[2] == 3 + return image + + +def _convert_dataset(split_name, filenames, filename_to_class_id, dataset_dir): + """Converts the given filenames to a TFRecord dataset. + + Args: + split_name: The name of the dataset, either 'train' or 'valid'. + filenames: A list of absolute paths to png images. + filename_to_class_id: A dictionary from filenames (strings) to class ids + (integers). + dataset_dir: The directory where the converted datasets are stored. + """ + print('Converting the {} split.'.format(split_name)) + # Train and validation splits are both in the train directory. + if split_name in ['train', 'valid']: + png_directory = os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train') + elif split_name == 'test': + png_directory = os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test') + + with tf.Graph().as_default(): + image_reader = ImageReader() + + with tf.Session('') as sess: + output_filename = _get_output_filename(dataset_dir, split_name) + + with tf.python_io.TFRecordWriter(output_filename) as tfrecord_writer: + for filename in filenames: + # Read the filename: + image_data = tf.gfile.FastGFile( + os.path.join(png_directory, filename), 'r').read() + height, width = image_reader.read_image_dims(sess, image_data) + + class_id = filename_to_class_id[filename] + example = dataset_utils.image_to_tfexample(image_data, 'png', height, + width, class_id) + tfrecord_writer.write(example.SerializeToString()) + + sys.stdout.write('\n') + sys.stdout.flush() + + +def _extract_labels(label_filename): + """Extract the labels into a dict of filenames to int labels. + + Args: + labels_filename: The filename of the MNIST-M labels. + + Returns: + A dictionary of filenames to int labels. + """ + print('Extracting labels from: ', label_filename) + label_file = tf.gfile.FastGFile(label_filename, 'r').readlines() + label_lines = [line.rstrip('\n').split() for line in label_file] + labels = {} + for line in label_lines: + assert len(line) == 2 + labels[line[0]] = int(line[1]) + return labels + + +def _get_output_filename(dataset_dir, split_name): + """Creates the output filename. + + Args: + dataset_dir: The directory where the temporary files are stored. + split_name: The name of the train/test split. + + Returns: + An absolute file path. + """ + return '%s/mnist_m_%s.tfrecord' % (dataset_dir, split_name) + + +def _get_filenames(dataset_dir): + """Returns a list of filenames and inferred class names. + + Args: + dataset_dir: A directory containing a set PNG encoded MNIST-M images. + + Returns: + A list of image file paths, relative to `dataset_dir`. + """ + photo_filenames = [] + for filename in os.listdir(dataset_dir): + photo_filenames.append(filename) + return photo_filenames + + +def run(dataset_dir): + """Runs the download and conversion operation. + + Args: + dataset_dir: The dataset directory where the dataset is stored. + """ + if not tf.gfile.Exists(dataset_dir): + tf.gfile.MakeDirs(dataset_dir) + + train_filename = _get_output_filename(dataset_dir, 'train') + testing_filename = _get_output_filename(dataset_dir, 'test') + + if tf.gfile.Exists(train_filename) and tf.gfile.Exists(testing_filename): + print('Dataset files already exist. Exiting without re-creating them.') + return + + # TODO(konstantinos): Add download and cleanup functionality + + train_validation_filenames = _get_filenames( + os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train')) + test_filenames = _get_filenames( + os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test')) + + # Divide into train and validation: + random.seed(_RANDOM_SEED) + random.shuffle(train_validation_filenames) + train_filenames = train_validation_filenames[_NUM_VALIDATION:] + validation_filenames = train_validation_filenames[:_NUM_VALIDATION] + + train_validation_filenames_to_class_ids = _extract_labels( + os.path.join(dataset_dir, 'mnist_m', 'mnist_m_train_labels.txt')) + test_filenames_to_class_ids = _extract_labels( + os.path.join(dataset_dir, 'mnist_m', 'mnist_m_test_labels.txt')) + + # Convert the train, validation, and test sets. + _convert_dataset('train', train_filenames, + train_validation_filenames_to_class_ids, dataset_dir) + _convert_dataset('valid', validation_filenames, + train_validation_filenames_to_class_ids, dataset_dir) + _convert_dataset('test', test_filenames, test_filenames_to_class_ids, + dataset_dir) + + # Finally, write the labels file: + labels_to_class_names = dict(zip(range(len(_CLASS_NAMES)), _CLASS_NAMES)) + dataset_utils.write_label_file(labels_to_class_names, dataset_dir) + + print('\nFinished converting the MNIST-M dataset!') + + +def main(_): + assert FLAGS.dataset_dir + run(FLAGS.dataset_dir) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/mnist_m.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/mnist_m.py" new file mode 100644 index 00000000..fab6c443 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/datasets/mnist_m.py" @@ -0,0 +1,98 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Provides data for the MNIST-M dataset. + +The dataset scripts used to create the dataset can be found at: +tensorflow_models/domain_adaptation_/datasets/download_and_convert_mnist_m_dataset.py +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os +# Dependency imports +import tensorflow as tf + +from slim.datasets import dataset_utils + +slim = tf.contrib.slim + +_FILE_PATTERN = 'mnist_m_%s.tfrecord' + +_SPLITS_TO_SIZES = {'train': 58001, 'valid': 1000, 'test': 9001} + +_NUM_CLASSES = 10 + +_ITEMS_TO_DESCRIPTIONS = { + 'image': 'A [32 x 32 x 1] RGB image.', + 'label': 'A single integer between 0 and 9', +} + + +def get_split(split_name, dataset_dir, file_pattern=None, reader=None): + """Gets a dataset tuple with instructions for reading MNIST. + + Args: + split_name: A train/test split name. + dataset_dir: The base directory of the dataset sources. + + Returns: + A `Dataset` namedtuple. + + Raises: + ValueError: if `split_name` is not a valid train/test split. + """ + if split_name not in _SPLITS_TO_SIZES: + raise ValueError('split name %s was not recognized.' % split_name) + + if not file_pattern: + file_pattern = _FILE_PATTERN + file_pattern = os.path.join(dataset_dir, file_pattern % split_name) + + # Allowing None in the signature so that dataset_factory can use the default. + if reader is None: + reader = tf.TFRecordReader + + keys_to_features = { + 'image/encoded': + tf.FixedLenFeature((), tf.string, default_value=''), + 'image/format': + tf.FixedLenFeature((), tf.string, default_value='png'), + 'image/class/label': + tf.FixedLenFeature( + [1], tf.int64, default_value=tf.zeros([1], dtype=tf.int64)), + } + + items_to_handlers = { + 'image': slim.tfexample_decoder.Image(shape=[32, 32, 3], channels=3), + 'label': slim.tfexample_decoder.Tensor('image/class/label', shape=[]), + } + + decoder = slim.tfexample_decoder.TFExampleDecoder( + keys_to_features, items_to_handlers) + + labels_to_names = None + if dataset_utils.has_labels(dataset_dir): + labels_to_names = dataset_utils.read_label_file(dataset_dir) + + return slim.dataset.Dataset( + data_sources=file_pattern, + reader=reader, + decoder=decoder, + num_samples=_SPLITS_TO_SIZES[split_name], + num_classes=_NUM_CLASSES, + items_to_descriptions=_ITEMS_TO_DESCRIPTIONS, + labels_to_names=labels_to_names) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/BUILD" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/BUILD" new file mode 100644 index 00000000..14dceda2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/BUILD" @@ -0,0 +1,157 @@ +# Domain Separation Networks + +package( + default_visibility = [ + ":internal", + ], +) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +package_group( + name = "internal", + packages = [ + "//domain_adaptation/...", + ], +) + +py_library( + name = "models", + srcs = [ + "models.py", + ], + deps = [ + ":utils", + ], +) + +py_library( + name = "losses", + srcs = [ + "losses.py", + ], + deps = [ + ":grl_op_grads_py", + ":grl_op_shapes_py", + ":grl_ops", + ":utils", + ], +) + +py_test( + name = "losses_test", + srcs = [ + "losses_test.py", + ], + deps = [ + ":losses", + ":utils", + ], +) + +py_library( + name = "dsn", + srcs = [ + "dsn.py", + ], + deps = [ + ":grl_op_grads_py", + ":grl_op_shapes_py", + ":grl_ops", + ":losses", + ":models", + ":utils", + ], +) + +py_test( + name = "dsn_test", + srcs = [ + "dsn_test.py", + ], + deps = [ + ":dsn", + ], +) + +py_binary( + name = "dsn_train", + srcs = [ + "dsn_train.py", + ], + deps = [ + ":dsn", + ":models", + "//domain_adaptation/datasets:dataset_factory", + ], +) + +py_binary( + name = "dsn_eval", + srcs = [ + "dsn_eval.py", + ], + deps = [ + ":dsn", + ":models", + "//domain_adaptation/datasets:dataset_factory", + ], +) + +py_test( + name = "models_test", + srcs = [ + "models_test.py", + ], + deps = [ + ":models", + "//domain_adaptation/datasets:dataset_factory", + ], +) + +py_library( + name = "utils", + srcs = [ + "utils.py", + ], + deps = [ + ], +) + +py_library( + name = "grl_op_grads_py", + srcs = [ + "grl_op_grads.py", + ], + deps = [ + ":grl_ops", + ], +) + +py_library( + name = "grl_op_shapes_py", + srcs = [ + "grl_op_shapes.py", + ], + deps = [ + ], +) + +py_library( + name = "grl_ops", + srcs = ["grl_ops.py"], + data = ["_grl_ops.so"], +) + +py_test( + name = "grl_ops_test", + size = "small", + srcs = ["grl_ops_test.py"], + deps = [ + ":grl_op_grads_py", + ":grl_op_shapes_py", + ":grl_ops", + ], +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn.py" new file mode 100644 index 00000000..3018e8a7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn.py" @@ -0,0 +1,355 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Functions to create a DSN model and add the different losses to it. + +Specifically, in this file we define the: + - Shared Encoding Similarity Loss Module, with: + - The MMD Similarity method + - The Correlation Similarity method + - The Gradient Reversal (Domain-Adversarial) method + - Difference Loss Module + - Reconstruction Loss Module + - Task Loss Module +""" +from functools import partial + +import tensorflow as tf + +import losses +import models +import utils + +slim = tf.contrib.slim + + +################################################################################ +# HELPER FUNCTIONS +################################################################################ +def dsn_loss_coefficient(params): + """The global_step-dependent weight that specifies when to kick in DSN losses. + + Args: + params: A dictionary of parameters. Expecting 'domain_separation_startpoint' + + Returns: + A weight to that effectively enables or disables the DSN-related losses, + i.e. similarity, difference, and reconstruction losses. + """ + return tf.where( + tf.less(slim.get_or_create_global_step(), + params['domain_separation_startpoint']), 1e-10, 1.0) + + +################################################################################ +# MODEL CREATION +################################################################################ +def create_model(source_images, source_labels, domain_selection_mask, + target_images, target_labels, similarity_loss, params, + basic_tower_name): + """Creates a DSN model. + + Args: + source_images: images from the source domain, a tensor of size + [batch_size, height, width, channels] + source_labels: a dictionary with the name, tensor pairs. 'classes' is one- + hot for the number of classes. + domain_selection_mask: a boolean tensor of size [batch_size, ] which denotes + the labeled images that belong to the source domain. + target_images: images from the target domain, a tensor of size + [batch_size, height width, channels]. + target_labels: a dictionary with the name, tensor pairs. + similarity_loss: The type of method to use for encouraging + the codes from the shared encoder to be similar. + params: A dictionary of parameters. Expecting 'weight_decay', + 'layers_to_regularize', 'use_separation', 'domain_separation_startpoint', + 'alpha_weight', 'beta_weight', 'gamma_weight', 'recon_loss_name', + 'decoder_name', 'encoder_name' + basic_tower_name: the name of the tower to use for the shared encoder. + + Raises: + ValueError: if the arch is not one of the available architectures. + """ + network = getattr(models, basic_tower_name) + num_classes = source_labels['classes'].get_shape().as_list()[1] + + # Make sure we are using the appropriate number of classes. + network = partial(network, num_classes=num_classes) + + # Add the classification/pose estimation loss to the source domain. + source_endpoints = add_task_loss(source_images, source_labels, network, + params) + + if similarity_loss == 'none': + # No domain adaptation, we can stop here. + return + + with tf.variable_scope('towers', reuse=True): + target_logits, target_endpoints = network( + target_images, weight_decay=params['weight_decay'], prefix='target') + + # Plot target accuracy of the train set. + target_accuracy = utils.accuracy( + tf.argmax(target_logits, 1), tf.argmax(target_labels['classes'], 1)) + + if 'quaternions' in target_labels: + target_quaternion_loss = losses.log_quaternion_loss( + target_labels['quaternions'], target_endpoints['quaternion_pred'], + params) + tf.summary.scalar('eval/Target quaternions', target_quaternion_loss) + + tf.summary.scalar('eval/Target accuracy', target_accuracy) + + source_shared = source_endpoints[params['layers_to_regularize']] + target_shared = target_endpoints[params['layers_to_regularize']] + + # When using the semisupervised model we include labeled target data in the + # source classifier. We do not want to include these target domain when + # we use the similarity loss. + indices = tf.range(0, source_shared.get_shape().as_list()[0]) + indices = tf.boolean_mask(indices, domain_selection_mask) + add_similarity_loss(similarity_loss, + tf.gather(source_shared, indices), + tf.gather(target_shared, indices), params) + + if params['use_separation']: + add_autoencoders( + source_images, + source_shared, + target_images, + target_shared, + params=params,) + + +def add_similarity_loss(method_name, + source_samples, + target_samples, + params, + scope=None): + """Adds a loss encouraging the shared encoding from each domain to be similar. + + Args: + method_name: the name of the encoding similarity method to use. Valid + options include `dann_loss', `mmd_loss' or `correlation_loss'. + source_samples: a tensor of shape [num_samples, num_features]. + target_samples: a tensor of shape [num_samples, num_features]. + params: a dictionary of parameters. Expecting 'gamma_weight'. + scope: optional name scope for summary tags. + Raises: + ValueError: if `method_name` is not recognized. + """ + weight = dsn_loss_coefficient(params) * params['gamma_weight'] + method = getattr(losses, method_name) + method(source_samples, target_samples, weight, scope) + + +def add_reconstruction_loss(recon_loss_name, images, recons, weight, domain): + """Adds a reconstruction loss. + + Args: + recon_loss_name: The name of the reconstruction loss. + images: A `Tensor` of size [batch_size, height, width, 3]. + recons: A `Tensor` whose size matches `images`. + weight: A scalar coefficient for the loss. + domain: The name of the domain being reconstructed. + + Raises: + ValueError: If `recon_loss_name` is not recognized. + """ + if recon_loss_name == 'sum_of_pairwise_squares': + loss_fn = tf.contrib.losses.mean_pairwise_squared_error + elif recon_loss_name == 'sum_of_squares': + loss_fn = tf.contrib.losses.mean_squared_error + else: + raise ValueError('recon_loss_name value [%s] not recognized.' % + recon_loss_name) + + loss = loss_fn(recons, images, weight) + assert_op = tf.Assert(tf.is_finite(loss), [loss]) + with tf.control_dependencies([assert_op]): + tf.summary.scalar('losses/%s Recon Loss' % domain, loss) + + +def add_autoencoders(source_data, source_shared, target_data, target_shared, + params): + """Adds the encoders/decoders for our domain separation model w/ incoherence. + + Args: + source_data: images from the source domain, a tensor of size + [batch_size, height, width, channels] + source_shared: a tensor with first dimension batch_size + target_data: images from the target domain, a tensor of size + [batch_size, height, width, channels] + target_shared: a tensor with first dimension batch_size + params: A dictionary of parameters. Expecting 'layers_to_regularize', + 'beta_weight', 'alpha_weight', 'recon_loss_name', 'decoder_name', + 'encoder_name', 'weight_decay' + """ + + def normalize_images(images): + images -= tf.reduce_min(images) + return images / tf.reduce_max(images) + + def concat_operation(shared_repr, private_repr): + return shared_repr + private_repr + + mu = dsn_loss_coefficient(params) + + # The layer to concatenate the networks at. + concat_layer = params['layers_to_regularize'] + + # The coefficient for modulating the private/shared difference loss. + difference_loss_weight = params['beta_weight'] * mu + + # The reconstruction weight. + recon_loss_weight = params['alpha_weight'] * mu + + # The reconstruction loss to use. + recon_loss_name = params['recon_loss_name'] + + # The decoder/encoder to use. + decoder_name = params['decoder_name'] + encoder_name = params['encoder_name'] + + _, height, width, _ = source_data.get_shape().as_list() + code_size = source_shared.get_shape().as_list()[-1] + weight_decay = params['weight_decay'] + + encoder_fn = getattr(models, encoder_name) + # Target Auto-encoding. + with tf.variable_scope('source_encoder'): + source_endpoints = encoder_fn( + source_data, code_size, weight_decay=weight_decay) + + with tf.variable_scope('target_encoder'): + target_endpoints = encoder_fn( + target_data, code_size, weight_decay=weight_decay) + + decoder_fn = getattr(models, decoder_name) + + decoder = partial( + decoder_fn, + height=height, + width=width, + channels=source_data.get_shape().as_list()[-1], + weight_decay=weight_decay) + + # Source Auto-encoding. + source_private = source_endpoints[concat_layer] + target_private = target_endpoints[concat_layer] + with tf.variable_scope('decoder'): + source_recons = decoder(concat_operation(source_shared, source_private)) + + with tf.variable_scope('decoder', reuse=True): + source_private_recons = decoder( + concat_operation(tf.zeros_like(source_private), source_private)) + source_shared_recons = decoder( + concat_operation(source_shared, tf.zeros_like(source_shared))) + + with tf.variable_scope('decoder', reuse=True): + target_recons = decoder(concat_operation(target_shared, target_private)) + target_shared_recons = decoder( + concat_operation(target_shared, tf.zeros_like(target_shared))) + target_private_recons = decoder( + concat_operation(tf.zeros_like(target_private), target_private)) + + losses.difference_loss( + source_private, + source_shared, + weight=difference_loss_weight, + name='Source') + losses.difference_loss( + target_private, + target_shared, + weight=difference_loss_weight, + name='Target') + + add_reconstruction_loss(recon_loss_name, source_data, source_recons, + recon_loss_weight, 'source') + add_reconstruction_loss(recon_loss_name, target_data, target_recons, + recon_loss_weight, 'target') + + # Add summaries + source_reconstructions = tf.concat( + axis=2, + values=map(normalize_images, [ + source_data, source_recons, source_shared_recons, + source_private_recons + ])) + target_reconstructions = tf.concat( + axis=2, + values=map(normalize_images, [ + target_data, target_recons, target_shared_recons, + target_private_recons + ])) + tf.summary.image( + 'Source Images:Recons:RGB', + source_reconstructions[:, :, :, :3], + max_outputs=10) + tf.summary.image( + 'Target Images:Recons:RGB', + target_reconstructions[:, :, :, :3], + max_outputs=10) + + if source_reconstructions.get_shape().as_list()[3] == 4: + tf.summary.image( + 'Source Images:Recons:Depth', + source_reconstructions[:, :, :, 3:4], + max_outputs=10) + tf.summary.image( + 'Target Images:Recons:Depth', + target_reconstructions[:, :, :, 3:4], + max_outputs=10) + + +def add_task_loss(source_images, source_labels, basic_tower, params): + """Adds a classification and/or pose estimation loss to the model. + + Args: + source_images: images from the source domain, a tensor of size + [batch_size, height, width, channels] + source_labels: labels from the source domain, a tensor of size [batch_size]. + or a tuple of (quaternions, class_labels) + basic_tower: a function that creates the single tower of the model. + params: A dictionary of parameters. Expecting 'weight_decay', 'pose_weight'. + Returns: + The source endpoints. + + Raises: + RuntimeError: if basic tower does not support pose estimation. + """ + with tf.variable_scope('towers'): + source_logits, source_endpoints = basic_tower( + source_images, weight_decay=params['weight_decay'], prefix='Source') + + if 'quaternions' in source_labels: # We have pose estimation as well + if 'quaternion_pred' not in source_endpoints: + raise RuntimeError('Please use a model for estimation e.g. pose_mini') + + loss = losses.log_quaternion_loss(source_labels['quaternions'], + source_endpoints['quaternion_pred'], + params) + + assert_op = tf.Assert(tf.is_finite(loss), [loss]) + with tf.control_dependencies([assert_op]): + quaternion_loss = loss + tf.summary.histogram('log_quaternion_loss_hist', quaternion_loss) + slim.losses.add_loss(quaternion_loss * params['pose_weight']) + tf.summary.scalar('losses/quaternion_loss', quaternion_loss) + + classification_loss = tf.losses.softmax_cross_entropy( + source_labels['classes'], source_logits) + + tf.summary.scalar('losses/classification_loss', classification_loss) + return source_endpoints diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_eval.py" new file mode 100644 index 00000000..b6cccdfc --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_eval.py" @@ -0,0 +1,161 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +# pylint: disable=line-too-long +"""Evaluation for Domain Separation Networks (DSNs).""" +# pylint: enable=line-too-long +import math + +import numpy as np +from six.moves import xrange +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +from domain_adaptation.domain_separation import losses +from domain_adaptation.domain_separation import models + +slim = tf.contrib.slim + +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_integer('batch_size', 32, + 'The number of images in each batch.') + +tf.app.flags.DEFINE_string('master', '', + 'BNS name of the TensorFlow master to use.') + +tf.app.flags.DEFINE_string('checkpoint_dir', '/tmp/da/', + 'Directory where the model was written to.') + +tf.app.flags.DEFINE_string( + 'eval_dir', '/tmp/da/', + 'Directory where we should write the tf summaries to.') + +tf.app.flags.DEFINE_string('dataset_dir', None, + 'The directory where the dataset files are stored.') + +tf.app.flags.DEFINE_string('dataset', 'mnist_m', + 'Which dataset to test on: "mnist", "mnist_m".') + +tf.app.flags.DEFINE_string('split', 'valid', + 'Which portion to test on: "valid", "test".') + +tf.app.flags.DEFINE_integer('num_examples', 1000, 'Number of test examples.') + +tf.app.flags.DEFINE_string('basic_tower', 'dann_mnist', + 'The basic tower building block.') + +tf.app.flags.DEFINE_bool('enable_precision_recall', False, + 'If True, precision and recall for each class will ' + 'be added to the metrics.') + +tf.app.flags.DEFINE_bool('use_logging', False, 'Debugging messages.') + + +def quaternion_metric(predictions, labels): + params = {'batch_size': FLAGS.batch_size, 'use_logging': False} + logcost = losses.log_quaternion_loss_batch(predictions, labels, params) + return slim.metrics.streaming_mean(logcost) + + +def angle_diff(true_q, pred_q): + angles = 2 * ( + 180.0 / + np.pi) * np.arccos(np.abs(np.sum(np.multiply(pred_q, true_q), axis=1))) + return angles + + +def provide_batch_fn(): + """ The provide_batch function to use. """ + return dataset_factory.provide_batch + + +def main(_): + g = tf.Graph() + with g.as_default(): + # Load the data. + images, labels = provide_batch_fn()( + FLAGS.dataset, FLAGS.split, FLAGS.dataset_dir, 4, FLAGS.batch_size, 4) + + num_classes = labels['classes'].get_shape().as_list()[1] + + tf.summary.image('eval_images', images, max_outputs=3) + + # Define the model: + with tf.variable_scope('towers'): + basic_tower = getattr(models, FLAGS.basic_tower) + predictions, endpoints = basic_tower( + images, + num_classes=num_classes, + is_training=False, + batch_norm_params=None) + metric_names_to_values = {} + + # Define the metrics: + if 'quaternions' in labels: # Also have to evaluate pose estimation! + quaternion_loss = quaternion_metric(labels['quaternions'], + endpoints['quaternion_pred']) + + angle_errors, = tf.py_func( + angle_diff, [labels['quaternions'], endpoints['quaternion_pred']], + [tf.float32]) + + metric_names_to_values[ + 'Angular mean error'] = slim.metrics.streaming_mean(angle_errors) + metric_names_to_values['Quaternion Loss'] = quaternion_loss + + accuracy = tf.contrib.metrics.streaming_accuracy( + tf.argmax(predictions, 1), tf.argmax(labels['classes'], 1)) + + predictions = tf.argmax(predictions, 1) + labels = tf.argmax(labels['classes'], 1) + metric_names_to_values['Accuracy'] = accuracy + + if FLAGS.enable_precision_recall: + for i in xrange(num_classes): + index_map = tf.one_hot(i, depth=num_classes) + name = 'PR/Precision_{}'.format(i) + metric_names_to_values[name] = slim.metrics.streaming_precision( + tf.gather(index_map, predictions), tf.gather(index_map, labels)) + name = 'PR/Recall_{}'.format(i) + metric_names_to_values[name] = slim.metrics.streaming_recall( + tf.gather(index_map, predictions), tf.gather(index_map, labels)) + + names_to_values, names_to_updates = slim.metrics.aggregate_metric_map( + metric_names_to_values) + + # Create the summary ops such that they also print out to std output: + summary_ops = [] + for metric_name, metric_value in names_to_values.iteritems(): + op = tf.summary.scalar(metric_name, metric_value) + op = tf.Print(op, [metric_value], metric_name) + summary_ops.append(op) + + # This ensures that we make a single pass over all of the data. + num_batches = math.ceil(FLAGS.num_examples / float(FLAGS.batch_size)) + + # Setup the global step. + slim.get_or_create_global_step() + slim.evaluation.evaluation_loop( + FLAGS.master, + checkpoint_dir=FLAGS.checkpoint_dir, + logdir=FLAGS.eval_dir, + num_evals=num_batches, + eval_op=names_to_updates.values(), + summary_op=tf.summary.merge(summary_ops)) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_test.py" new file mode 100644 index 00000000..3d687398 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_test.py" @@ -0,0 +1,157 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for DSN model assembly functions.""" + +import numpy as np +import tensorflow as tf + +import dsn + + +class HelperFunctionsTest(tf.test.TestCase): + + def testBasicDomainSeparationStartPoint(self): + with self.test_session() as sess: + # Test for when global_step < domain_separation_startpoint + step = tf.contrib.slim.get_or_create_global_step() + sess.run(tf.global_variables_initializer()) # global_step = 0 + params = {'domain_separation_startpoint': 2} + weight = dsn.dsn_loss_coefficient(params) + weight_np = sess.run(weight) + self.assertAlmostEqual(weight_np, 1e-10) + + step_op = tf.assign_add(step, 1) + step_np = sess.run(step_op) # global_step = 1 + weight = dsn.dsn_loss_coefficient(params) + weight_np = sess.run(weight) + self.assertAlmostEqual(weight_np, 1e-10) + + # Test for when global_step >= domain_separation_startpoint + step_np = sess.run(step_op) # global_step = 2 + tf.logging.info(step_np) + weight = dsn.dsn_loss_coefficient(params) + weight_np = sess.run(weight) + self.assertAlmostEqual(weight_np, 1.0) + + +class DsnModelAssemblyTest(tf.test.TestCase): + + def _testBuildDefaultModel(self): + images = tf.to_float(np.random.rand(32, 28, 28, 1)) + labels = {} + labels['classes'] = tf.one_hot( + tf.to_int32(np.random.randint(0, 9, (32))), 10) + + params = { + 'use_separation': True, + 'layers_to_regularize': 'fc3', + 'weight_decay': 0.0, + 'ps_tasks': 1, + 'domain_separation_startpoint': 1, + 'alpha_weight': 1, + 'beta_weight': 1, + 'gamma_weight': 1, + 'recon_loss_name': 'sum_of_squares', + 'decoder_name': 'small_decoder', + 'encoder_name': 'default_encoder', + } + return images, labels, params + + def testBuildModelDann(self): + images, labels, params = self._testBuildDefaultModel() + + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'dann_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 6) + + def testBuildModelDannSumOfPairwiseSquares(self): + images, labels, params = self._testBuildDefaultModel() + + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'dann_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 6) + + def testBuildModelDannMultiPSTasks(self): + images, labels, params = self._testBuildDefaultModel() + params['ps_tasks'] = 10 + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'dann_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 6) + + def testBuildModelMmd(self): + images, labels, params = self._testBuildDefaultModel() + + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'mmd_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 6) + + def testBuildModelCorr(self): + images, labels, params = self._testBuildDefaultModel() + + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'correlation_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 6) + + def testBuildModelNoDomainAdaptation(self): + images, labels, params = self._testBuildDefaultModel() + params['use_separation'] = False + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, 'none', + params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 1) + self.assertEqual(len(tf.contrib.losses.get_regularization_losses()), 0) + + def testBuildModelNoAdaptationWeightDecay(self): + images, labels, params = self._testBuildDefaultModel() + params['use_separation'] = False + params['weight_decay'] = 1e-5 + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, 'none', + params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 1) + self.assertTrue(len(tf.contrib.losses.get_regularization_losses()) >= 1) + + def testBuildModelNoSeparation(self): + images, labels, params = self._testBuildDefaultModel() + params['use_separation'] = False + with self.test_session(): + dsn.create_model(images, labels, + tf.cast(tf.ones([32,]), tf.bool), images, labels, + 'dann_loss', params, 'dann_mnist') + loss_tensors = tf.contrib.losses.get_losses() + self.assertEqual(len(loss_tensors), 2) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_train.py" new file mode 100644 index 00000000..5e364ad3 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/dsn_train.py" @@ -0,0 +1,278 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Training for Domain Separation Networks (DSNs).""" +from __future__ import division + +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +import dsn + +slim = tf.contrib.slim +FLAGS = tf.app.flags.FLAGS + +tf.app.flags.DEFINE_integer('batch_size', 32, + 'The number of images in each batch.') + +tf.app.flags.DEFINE_string('source_dataset', 'pose_synthetic', + 'Source dataset to train on.') + +tf.app.flags.DEFINE_string('target_dataset', 'pose_real', + 'Target dataset to train on.') + +tf.app.flags.DEFINE_string('target_labeled_dataset', 'none', + 'Target dataset to train on.') + +tf.app.flags.DEFINE_string('dataset_dir', None, + 'The directory where the dataset files are stored.') + +tf.app.flags.DEFINE_string('master', '', + 'BNS name of the TensorFlow master to use.') + +tf.app.flags.DEFINE_string('train_log_dir', '/tmp/da/', + 'Directory where to write event logs.') + +tf.app.flags.DEFINE_string( + 'layers_to_regularize', 'fc3', + 'Comma-separated list of layer names to use MMD regularization on.') + +tf.app.flags.DEFINE_float('learning_rate', .01, 'The learning rate') + +tf.app.flags.DEFINE_float('alpha_weight', 1e-6, + 'The coefficient for scaling the reconstruction ' + 'loss.') + +tf.app.flags.DEFINE_float( + 'beta_weight', 1e-6, + 'The coefficient for scaling the private/shared difference loss.') + +tf.app.flags.DEFINE_float( + 'gamma_weight', 1e-6, + 'The coefficient for scaling the shared encoding similarity loss.') + +tf.app.flags.DEFINE_float('pose_weight', 0.125, + 'The coefficient for scaling the pose loss.') + +tf.app.flags.DEFINE_float( + 'weight_decay', 1e-6, + 'The coefficient for the L2 regularization applied for all weights.') + +tf.app.flags.DEFINE_integer( + 'save_summaries_secs', 60, + 'The frequency with which summaries are saved, in seconds.') + +tf.app.flags.DEFINE_integer( + 'save_interval_secs', 60, + 'The frequency with which the model is saved, in seconds.') + +tf.app.flags.DEFINE_integer( + 'max_number_of_steps', None, + 'The maximum number of gradient steps. Use None to train indefinitely.') + +tf.app.flags.DEFINE_integer( + 'domain_separation_startpoint', 1, + 'The global step to add the domain separation losses.') + +tf.app.flags.DEFINE_integer( + 'bipartite_assignment_top_k', 3, + 'The number of top-k matches to use in bipartite matching adaptation.') + +tf.app.flags.DEFINE_float('decay_rate', 0.95, 'Learning rate decay factor.') + +tf.app.flags.DEFINE_integer('decay_steps', 20000, 'Learning rate decay steps.') + +tf.app.flags.DEFINE_float('momentum', 0.9, 'The momentum value.') + +tf.app.flags.DEFINE_bool('use_separation', False, + 'Use our domain separation model.') + +tf.app.flags.DEFINE_bool('use_logging', False, 'Debugging messages.') + +tf.app.flags.DEFINE_integer( + 'ps_tasks', 0, + 'The number of parameter servers. If the value is 0, then the parameters ' + 'are handled locally by the worker.') + +tf.app.flags.DEFINE_integer( + 'num_readers', 4, + 'The number of parallel readers that read data from the dataset.') + +tf.app.flags.DEFINE_integer('num_preprocessing_threads', 4, + 'The number of threads used to create the batches.') + +tf.app.flags.DEFINE_integer( + 'task', 0, + 'The Task ID. This value is used when training with multiple workers to ' + 'identify each worker.') + +tf.app.flags.DEFINE_string('decoder_name', 'small_decoder', + 'The decoder to use.') +tf.app.flags.DEFINE_string('encoder_name', 'default_encoder', + 'The encoder to use.') + +################################################################################ +# Flags that control the architecture and losses +################################################################################ +tf.app.flags.DEFINE_string( + 'similarity_loss', 'grl', + 'The method to use for encouraging the common encoder codes to be ' + 'similar, one of "grl", "mmd", "corr".') + +tf.app.flags.DEFINE_string('recon_loss_name', 'sum_of_pairwise_squares', + 'The name of the reconstruction loss.') + +tf.app.flags.DEFINE_string('basic_tower', 'pose_mini', + 'The basic tower building block.') + +def provide_batch_fn(): + """ The provide_batch function to use. """ + return dataset_factory.provide_batch + +def main(_): + model_params = { + 'use_separation': FLAGS.use_separation, + 'domain_separation_startpoint': FLAGS.domain_separation_startpoint, + 'layers_to_regularize': FLAGS.layers_to_regularize, + 'alpha_weight': FLAGS.alpha_weight, + 'beta_weight': FLAGS.beta_weight, + 'gamma_weight': FLAGS.gamma_weight, + 'pose_weight': FLAGS.pose_weight, + 'recon_loss_name': FLAGS.recon_loss_name, + 'decoder_name': FLAGS.decoder_name, + 'encoder_name': FLAGS.encoder_name, + 'weight_decay': FLAGS.weight_decay, + 'batch_size': FLAGS.batch_size, + 'use_logging': FLAGS.use_logging, + 'ps_tasks': FLAGS.ps_tasks, + 'task': FLAGS.task, + } + g = tf.Graph() + with g.as_default(): + with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)): + # Load the data. + source_images, source_labels = provide_batch_fn()( + FLAGS.source_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers, + FLAGS.batch_size, FLAGS.num_preprocessing_threads) + target_images, target_labels = provide_batch_fn()( + FLAGS.target_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers, + FLAGS.batch_size, FLAGS.num_preprocessing_threads) + + # In the unsupervised case all the samples in the labeled + # domain are from the source domain. + domain_selection_mask = tf.fill((source_images.get_shape().as_list()[0],), + True) + + # When using the semisupervised model we include labeled target data in + # the source labelled data. + if FLAGS.target_labeled_dataset != 'none': + # 1000 is the maximum number of labelled target samples that exists in + # the datasets. + target_semi_images, target_semi_labels = provide_batch_fn()( + FLAGS.target_labeled_dataset, 'train', FLAGS.batch_size) + + # Calculate the proportion of source domain samples in the semi- + # supervised setting, so that the proportion is set accordingly in the + # batches. + proportion = float(source_labels['num_train_samples']) / ( + source_labels['num_train_samples'] + + target_semi_labels['num_train_samples']) + + rnd_tensor = tf.random_uniform( + (target_semi_images.get_shape().as_list()[0],)) + + domain_selection_mask = rnd_tensor < proportion + source_images = tf.where(domain_selection_mask, source_images, + target_semi_images) + source_class_labels = tf.where(domain_selection_mask, + source_labels['classes'], + target_semi_labels['classes']) + + if 'quaternions' in source_labels: + source_pose_labels = tf.where(domain_selection_mask, + source_labels['quaternions'], + target_semi_labels['quaternions']) + (source_images, source_class_labels, source_pose_labels, + domain_selection_mask) = tf.train.shuffle_batch( + [ + source_images, source_class_labels, source_pose_labels, + domain_selection_mask + ], + FLAGS.batch_size, + 50000, + 5000, + num_threads=1, + enqueue_many=True) + + else: + (source_images, source_class_labels, + domain_selection_mask) = tf.train.shuffle_batch( + [source_images, source_class_labels, domain_selection_mask], + FLAGS.batch_size, + 50000, + 5000, + num_threads=1, + enqueue_many=True) + source_labels = {} + source_labels['classes'] = source_class_labels + if 'quaternions' in source_labels: + source_labels['quaternions'] = source_pose_labels + + slim.get_or_create_global_step() + tf.summary.image('source_images', source_images, max_outputs=3) + tf.summary.image('target_images', target_images, max_outputs=3) + + dsn.create_model( + source_images, + source_labels, + domain_selection_mask, + target_images, + target_labels, + FLAGS.similarity_loss, + model_params, + basic_tower_name=FLAGS.basic_tower) + + # Configure the optimization scheme: + learning_rate = tf.train.exponential_decay( + FLAGS.learning_rate, + slim.get_or_create_global_step(), + FLAGS.decay_steps, + FLAGS.decay_rate, + staircase=True, + name='learning_rate') + + tf.summary.scalar('learning_rate', learning_rate) + tf.summary.scalar('total_loss', tf.losses.get_total_loss()) + + opt = tf.train.MomentumOptimizer(learning_rate, FLAGS.momentum) + tf.logging.set_verbosity(tf.logging.INFO) + # Run training. + loss_tensor = slim.learning.create_train_op( + slim.losses.get_total_loss(), + opt, + summarize_gradients=True, + colocate_gradients_with_ops=True) + slim.learning.train( + train_op=loss_tensor, + logdir=FLAGS.train_log_dir, + master=FLAGS.master, + is_chief=FLAGS.task == 0, + number_of_steps=FLAGS.max_number_of_steps, + save_summaries_secs=FLAGS.save_summaries_secs, + save_interval_secs=FLAGS.save_interval_secs) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_grads.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_grads.py" new file mode 100644 index 00000000..fcd85ba2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_grads.py" @@ -0,0 +1,34 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Gradients for operators defined in grl_ops.py.""" +import tensorflow as tf + + +@tf.RegisterGradient("GradientReversal") +def _GradientReversalGrad(_, grad): + """The gradients for `gradient_reversal`. + + Args: + _: The `gradient_reversal` `Operation` that we are differentiating, + which we can use to find the inputs and outputs of the original op. + grad: Gradient with respect to the output of the `gradient_reversal` op. + + Returns: + Gradient with respect to the input of `gradient_reversal`, which is simply + the negative of the input gradient. + + """ + return tf.negative(grad) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_kernels.cc" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_kernels.cc" new file mode 100644 index 00000000..ba30128f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_kernels.cc" @@ -0,0 +1,47 @@ +/* Copyright 2016 The TensorFlow Authors All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// This file contains the implementations of the ops registered in +// grl_ops.cc. + +#include "tensorflow/core/framework/op_kernel.h" +#include "tensorflow/core/framework/types.pb.h" + +namespace tensorflow { + +// The gradient reversal op is used in domain adversarial training. It behaves +// as the identity op during forward propagation, and multiplies its input by -1 +// during backward propagation. +class GradientReversalOp : public OpKernel { + public: + explicit GradientReversalOp(OpKernelConstruction* context) + : OpKernel(context) {} + + // Gradient reversal op behaves as the identity op during forward + // propagation. Compute() function copied from the IdentityOp::Compute() + // function here: third_party/tensorflow/core/kernels/identity_op.h. + void Compute(OpKernelContext* context) override { + if (IsRefType(context->input_dtype(0))) { + context->forward_ref_input_to_ref_output(0, 0); + } else { + context->set_output(0, context->input(0)); + } + } +}; + +REGISTER_KERNEL_BUILDER(Name("GradientReversal").Device(DEVICE_CPU), + GradientReversalOp); + +} // namespace tensorflow diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_shapes.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_shapes.py" new file mode 100644 index 00000000..52773c68 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_op_shapes.py" @@ -0,0 +1,16 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Shape inference for operators defined in grl_ops.cc.""" diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.cc" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.cc" new file mode 100644 index 00000000..d441c2b4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.cc" @@ -0,0 +1,36 @@ +/* Copyright 2016 The TensorFlow Authors All Rights Reserved. + +Licensed under the Apache License, Version 2.0 (the "License"); +you may not use this file except in compliance with the License. +You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, software +distributed under the License is distributed on an "AS IS" BASIS, +WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +See the License for the specific language governing permissions and +limitations under the License. +==============================================================================*/ + +// Contains custom ops. + +#include "tensorflow/core/framework/common_shape_fns.h" +#include "tensorflow/core/framework/op.h" + +namespace tensorflow { + +// This custom op is used by adversarial training. +REGISTER_OP("GradientReversal") + .Input("input: float") + .Output("output: float") + .SetShapeFn(shape_inference::UnchangedShape) + .Doc(R"doc( +This op copies the input to the output during forward propagation, and +negates the input during backward propagation. + +input: Tensor. +output: Tensor, copied from input. +)doc"); + +} // namespace tensorflow diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.py" new file mode 100644 index 00000000..50447247 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops.py" @@ -0,0 +1,28 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""GradientReversal op Python library.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import os.path + +import tensorflow as tf + +tf.logging.info(tf.resource_loader.get_data_files_path()) +_grl_ops_module = tf.load_op_library( + os.path.join(tf.resource_loader.get_data_files_path(), + '_grl_ops.so')) +gradient_reversal = _grl_ops_module.gradient_reversal diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops_test.py" new file mode 100644 index 00000000..b431a6c0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/grl_ops_test.py" @@ -0,0 +1,73 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for grl_ops.""" + +#from models.domain_adaptation.domain_separation import grl_op_grads # pylint: disable=unused-import +#from models.domain_adaptation.domain_separation import grl_op_shapes # pylint: disable=unused-import +import tensorflow as tf + +import grl_op_grads +import grl_ops + +FLAGS = tf.app.flags.FLAGS + + +class GRLOpsTest(tf.test.TestCase): + + def testGradientReversalOp(self): + with tf.Graph().as_default(): + with self.test_session(): + # Test that in forward prop, gradient reversal op acts as the + # identity operation. + examples = tf.constant([5.0, 4.0, 3.0, 2.0, 1.0]) + output = grl_ops.gradient_reversal(examples) + expected_output = examples + self.assertAllEqual(output.eval(), expected_output.eval()) + + # Test that shape inference works as expected. + self.assertAllEqual(output.get_shape(), expected_output.get_shape()) + + # Test that in backward prop, gradient reversal op multiplies + # gradients by -1. + examples = tf.constant([[1.0]]) + w = tf.get_variable(name='w', shape=[1, 1]) + b = tf.get_variable(name='b', shape=[1]) + init_op = tf.global_variables_initializer() + init_op.run() + features = tf.nn.xw_plus_b(examples, w, b) + # Construct two outputs: features layer passes directly to output1, but + # features layer passes through a gradient reversal layer before + # reaching output2. + output1 = features + output2 = grl_ops.gradient_reversal(features) + gold = tf.constant([1.0]) + loss1 = gold - output1 + loss2 = gold - output2 + opt = tf.train.GradientDescentOptimizer(learning_rate=0.01) + grads_and_vars_1 = opt.compute_gradients(loss1, + tf.trainable_variables()) + grads_and_vars_2 = opt.compute_gradients(loss2, + tf.trainable_variables()) + self.assertAllEqual(len(grads_and_vars_1), len(grads_and_vars_2)) + for i in range(len(grads_and_vars_1)): + g1 = grads_and_vars_1[i][0] + g2 = grads_and_vars_2[i][0] + # Verify that gradients of loss1 are the negative of gradients of + # loss2. + self.assertAllEqual(tf.negative(g1).eval(), g2.eval()) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses.py" new file mode 100644 index 00000000..0d882340 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses.py" @@ -0,0 +1,290 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Domain Adaptation Loss Functions. + +The following domain adaptation loss functions are defined: + +- Maximum Mean Discrepancy (MMD). + Relevant paper: + Gretton, Arthur, et al., + "A kernel two-sample test." + The Journal of Machine Learning Research, 2012 + +- Correlation Loss on a batch. +""" +from functools import partial +import tensorflow as tf + +import grl_op_grads # pylint: disable=unused-import +import grl_op_shapes # pylint: disable=unused-import +import grl_ops +import utils +slim = tf.contrib.slim + + +################################################################################ +# SIMILARITY LOSS +################################################################################ +def maximum_mean_discrepancy(x, y, kernel=utils.gaussian_kernel_matrix): + r"""Computes the Maximum Mean Discrepancy (MMD) of two samples: x and y. + + Maximum Mean Discrepancy (MMD) is a distance-measure between the samples of + the distributions of x and y. Here we use the kernel two sample estimate + using the empirical mean of the two distributions. + + MMD^2(P, Q) = || \E{\phi(x)} - \E{\phi(y)} ||^2 + = \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) }, + + where K = <\phi(x), \phi(y)>, + is the desired kernel function, in this case a radial basis kernel. + + Args: + x: a tensor of shape [num_samples, num_features] + y: a tensor of shape [num_samples, num_features] + kernel: a function which computes the kernel in MMD. Defaults to the + GaussianKernelMatrix. + + Returns: + a scalar denoting the squared maximum mean discrepancy loss. + """ + with tf.name_scope('MaximumMeanDiscrepancy'): + # \E{ K(x, x) } + \E{ K(y, y) } - 2 \E{ K(x, y) } + cost = tf.reduce_mean(kernel(x, x)) + cost += tf.reduce_mean(kernel(y, y)) + cost -= 2 * tf.reduce_mean(kernel(x, y)) + + # We do not allow the loss to become negative. + cost = tf.where(cost > 0, cost, 0, name='value') + return cost + + +def mmd_loss(source_samples, target_samples, weight, scope=None): + """Adds a similarity loss term, the MMD between two representations. + + This Maximum Mean Discrepancy (MMD) loss is calculated with a number of + different Gaussian kernels. + + Args: + source_samples: a tensor of shape [num_samples, num_features]. + target_samples: a tensor of shape [num_samples, num_features]. + weight: the weight of the MMD loss. + scope: optional name scope for summary tags. + + Returns: + a scalar tensor representing the MMD loss value. + """ + sigmas = [ + 1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1, 5, 10, 15, 20, 25, 30, 35, 100, + 1e3, 1e4, 1e5, 1e6 + ] + gaussian_kernel = partial( + utils.gaussian_kernel_matrix, sigmas=tf.constant(sigmas)) + + loss_value = maximum_mean_discrepancy( + source_samples, target_samples, kernel=gaussian_kernel) + loss_value = tf.maximum(1e-4, loss_value) * weight + assert_op = tf.Assert(tf.is_finite(loss_value), [loss_value]) + with tf.control_dependencies([assert_op]): + tag = 'MMD Loss' + if scope: + tag = scope + tag + tf.summary.scalar(tag, loss_value) + tf.losses.add_loss(loss_value) + + return loss_value + + +def correlation_loss(source_samples, target_samples, weight, scope=None): + """Adds a similarity loss term, the correlation between two representations. + + Args: + source_samples: a tensor of shape [num_samples, num_features] + target_samples: a tensor of shape [num_samples, num_features] + weight: a scalar weight for the loss. + scope: optional name scope for summary tags. + + Returns: + a scalar tensor representing the correlation loss value. + """ + with tf.name_scope('corr_loss'): + source_samples -= tf.reduce_mean(source_samples, 0) + target_samples -= tf.reduce_mean(target_samples, 0) + + source_samples = tf.nn.l2_normalize(source_samples, 1) + target_samples = tf.nn.l2_normalize(target_samples, 1) + + source_cov = tf.matmul(tf.transpose(source_samples), source_samples) + target_cov = tf.matmul(tf.transpose(target_samples), target_samples) + + corr_loss = tf.reduce_mean(tf.square(source_cov - target_cov)) * weight + + assert_op = tf.Assert(tf.is_finite(corr_loss), [corr_loss]) + with tf.control_dependencies([assert_op]): + tag = 'Correlation Loss' + if scope: + tag = scope + tag + tf.summary.scalar(tag, corr_loss) + tf.losses.add_loss(corr_loss) + + return corr_loss + + +def dann_loss(source_samples, target_samples, weight, scope=None): + """Adds the domain adversarial (DANN) loss. + + Args: + source_samples: a tensor of shape [num_samples, num_features]. + target_samples: a tensor of shape [num_samples, num_features]. + weight: the weight of the loss. + scope: optional name scope for summary tags. + + Returns: + a scalar tensor representing the correlation loss value. + """ + with tf.variable_scope('dann'): + batch_size = tf.shape(source_samples)[0] + samples = tf.concat(axis=0, values=[source_samples, target_samples]) + samples = slim.flatten(samples) + + domain_selection_mask = tf.concat( + axis=0, values=[tf.zeros((batch_size, 1)), tf.ones((batch_size, 1))]) + + # Perform the gradient reversal and be careful with the shape. + grl = grl_ops.gradient_reversal(samples) + grl = tf.reshape(grl, (-1, samples.get_shape().as_list()[1])) + + grl = slim.fully_connected(grl, 100, scope='fc1') + logits = slim.fully_connected(grl, 1, activation_fn=None, scope='fc2') + + domain_predictions = tf.sigmoid(logits) + + domain_loss = tf.losses.log_loss( + domain_selection_mask, domain_predictions, weights=weight) + + domain_accuracy = utils.accuracy( + tf.round(domain_predictions), domain_selection_mask) + + assert_op = tf.Assert(tf.is_finite(domain_loss), [domain_loss]) + with tf.control_dependencies([assert_op]): + tag_loss = 'losses/domain_loss' + tag_accuracy = 'losses/domain_accuracy' + if scope: + tag_loss = scope + tag_loss + tag_accuracy = scope + tag_accuracy + + tf.summary.scalar(tag_loss, domain_loss) + tf.summary.scalar(tag_accuracy, domain_accuracy) + + return domain_loss + + +################################################################################ +# DIFFERENCE LOSS +################################################################################ +def difference_loss(private_samples, shared_samples, weight=1.0, name=''): + """Adds the difference loss between the private and shared representations. + + Args: + private_samples: a tensor of shape [num_samples, num_features]. + shared_samples: a tensor of shape [num_samples, num_features]. + weight: the weight of the incoherence loss. + name: the name of the tf summary. + """ + private_samples -= tf.reduce_mean(private_samples, 0) + shared_samples -= tf.reduce_mean(shared_samples, 0) + + private_samples = tf.nn.l2_normalize(private_samples, 1) + shared_samples = tf.nn.l2_normalize(shared_samples, 1) + + correlation_matrix = tf.matmul( + private_samples, shared_samples, transpose_a=True) + + cost = tf.reduce_mean(tf.square(correlation_matrix)) * weight + cost = tf.where(cost > 0, cost, 0, name='value') + + tf.summary.scalar('losses/Difference Loss {}'.format(name), + cost) + assert_op = tf.Assert(tf.is_finite(cost), [cost]) + with tf.control_dependencies([assert_op]): + tf.losses.add_loss(cost) + + +################################################################################ +# TASK LOSS +################################################################################ +def log_quaternion_loss_batch(predictions, labels, params): + """A helper function to compute the error between quaternions. + + Args: + predictions: A Tensor of size [batch_size, 4]. + labels: A Tensor of size [batch_size, 4]. + params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'. + + Returns: + A Tensor of size [batch_size], denoting the error between the quaternions. + """ + use_logging = params['use_logging'] + assertions = [] + if use_logging: + assertions.append( + tf.Assert( + tf.reduce_all( + tf.less( + tf.abs(tf.reduce_sum(tf.square(predictions), [1]) - 1), + 1e-4)), + ['The l2 norm of each prediction quaternion vector should be 1.'])) + assertions.append( + tf.Assert( + tf.reduce_all( + tf.less( + tf.abs(tf.reduce_sum(tf.square(labels), [1]) - 1), 1e-4)), + ['The l2 norm of each label quaternion vector should be 1.'])) + + with tf.control_dependencies(assertions): + product = tf.multiply(predictions, labels) + internal_dot_products = tf.reduce_sum(product, [1]) + + if use_logging: + internal_dot_products = tf.Print( + internal_dot_products, + [internal_dot_products, tf.shape(internal_dot_products)], + 'internal_dot_products:') + + logcost = tf.log(1e-4 + 1 - tf.abs(internal_dot_products)) + return logcost + + +def log_quaternion_loss(predictions, labels, params): + """A helper function to compute the mean error between batches of quaternions. + + The caller is expected to add the loss to the graph. + + Args: + predictions: A Tensor of size [batch_size, 4]. + labels: A Tensor of size [batch_size, 4]. + params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'. + + Returns: + A Tensor of size 1, denoting the mean error between batches of quaternions. + """ + use_logging = params['use_logging'] + logcost = log_quaternion_loss_batch(predictions, labels, params) + logcost = tf.reduce_sum(logcost, [0]) + batch_size = params['batch_size'] + logcost = tf.multiply(logcost, 1.0 / batch_size, name='log_quaternion_loss') + if use_logging: + logcost = tf.Print( + logcost, [logcost], '[logcost]', name='log_quaternion_loss_print') + return logcost diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses_test.py" new file mode 100644 index 00000000..46e50301 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/losses_test.py" @@ -0,0 +1,110 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for DSN losses.""" +from functools import partial + +import numpy as np +import tensorflow as tf + +import losses +import utils + + +def MaximumMeanDiscrepancySlow(x, y, sigmas): + num_samples = x.get_shape().as_list()[0] + + def AverageGaussianKernel(x, y, sigmas): + result = 0 + for sigma in sigmas: + dist = tf.reduce_sum(tf.square(x - y)) + result += tf.exp((-1.0 / (2.0 * sigma)) * dist) + return result / num_samples**2 + + total = 0 + + for i in range(num_samples): + for j in range(num_samples): + total += AverageGaussianKernel(x[i, :], x[j, :], sigmas) + total += AverageGaussianKernel(y[i, :], y[j, :], sigmas) + total += -2 * AverageGaussianKernel(x[i, :], y[j, :], sigmas) + + return total + + +class LogQuaternionLossTest(tf.test.TestCase): + + def test_log_quaternion_loss_batch(self): + with self.test_session(): + predictions = tf.random_uniform((10, 4), seed=1) + predictions = tf.nn.l2_normalize(predictions, 1) + labels = tf.random_uniform((10, 4), seed=1) + labels = tf.nn.l2_normalize(labels, 1) + params = {'batch_size': 10, 'use_logging': False} + x = losses.log_quaternion_loss_batch(predictions, labels, params) + self.assertTrue(((10,) == tf.shape(x).eval()).all()) + + +class MaximumMeanDiscrepancyTest(tf.test.TestCase): + + def test_mmd_name(self): + with self.test_session(): + x = tf.random_uniform((2, 3), seed=1) + kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.])) + loss = losses.maximum_mean_discrepancy(x, x, kernel) + + self.assertEquals(loss.op.name, 'MaximumMeanDiscrepancy/value') + + def test_mmd_is_zero_when_inputs_are_same(self): + with self.test_session(): + x = tf.random_uniform((2, 3), seed=1) + kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.])) + self.assertEquals(0, losses.maximum_mean_discrepancy(x, x, kernel).eval()) + + def test_fast_mmd_is_similar_to_slow_mmd(self): + with self.test_session(): + x = tf.constant(np.random.normal(size=(2, 3)), tf.float32) + y = tf.constant(np.random.rand(2, 3), tf.float32) + + cost_old = MaximumMeanDiscrepancySlow(x, y, [1.]).eval() + kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([1.])) + cost_new = losses.maximum_mean_discrepancy(x, y, kernel).eval() + + self.assertAlmostEqual(cost_old, cost_new, delta=1e-5) + + def test_multiple_sigmas(self): + with self.test_session(): + x = tf.constant(np.random.normal(size=(2, 3)), tf.float32) + y = tf.constant(np.random.rand(2, 3), tf.float32) + + sigmas = tf.constant([2., 5., 10, 20, 30]) + kernel = partial(utils.gaussian_kernel_matrix, sigmas=sigmas) + cost_old = MaximumMeanDiscrepancySlow(x, y, [2., 5., 10, 20, 30]).eval() + cost_new = losses.maximum_mean_discrepancy(x, y, kernel=kernel).eval() + + self.assertAlmostEqual(cost_old, cost_new, delta=1e-5) + + def test_mmd_is_zero_when_distributions_are_same(self): + + with self.test_session(): + x = tf.random_uniform((1000, 10), seed=1) + y = tf.random_uniform((1000, 10), seed=3) + + kernel = partial(utils.gaussian_kernel_matrix, sigmas=tf.constant([100.])) + loss = losses.maximum_mean_discrepancy(x, y, kernel=kernel).eval() + + self.assertAlmostEqual(0, loss, delta=1e-4) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models.py" new file mode 100644 index 00000000..04ccaf82 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models.py" @@ -0,0 +1,443 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Contains different architectures for the different DSN parts. + +We define here the modules that can be used in the different parts of the DSN +model. +- shared encoder (dsn_cropped_linemod, dann_xxxx) +- private encoder (default_encoder) +- decoder (large_decoder, gtsrb_decoder, small_decoder) +""" +import tensorflow as tf + +#from models.domain_adaptation.domain_separation +import utils + +slim = tf.contrib.slim + + +def default_batch_norm_params(is_training=False): + """Returns default batch normalization parameters for DSNs. + + Args: + is_training: whether or not the model is training. + + Returns: + a dictionary that maps batch norm parameter names (strings) to values. + """ + return { + # Decay for the moving averages. + 'decay': 0.5, + # epsilon to prevent 0s in variance. + 'epsilon': 0.001, + 'is_training': is_training + } + + +################################################################################ +# PRIVATE ENCODERS +################################################################################ +def default_encoder(images, code_size, batch_norm_params=None, + weight_decay=0.0): + """Encodes the given images to codes of the given size. + + Args: + images: a tensor of size [batch_size, height, width, 1]. + code_size: the number of hidden units in the code layer of the classifier. + batch_norm_params: a dictionary that maps batch norm parameter names to + values. + weight_decay: the value for the weight decay coefficient. + + Returns: + end_points: the code of the input. + """ + end_points = {} + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + normalizer_params=batch_norm_params): + with slim.arg_scope([slim.conv2d], kernel_size=[5, 5], padding='SAME'): + net = slim.conv2d(images, 32, scope='conv1') + net = slim.max_pool2d(net, [2, 2], 2, scope='pool1') + net = slim.conv2d(net, 64, scope='conv2') + net = slim.max_pool2d(net, [2, 2], 2, scope='pool2') + + net = slim.flatten(net) + end_points['flatten'] = net + net = slim.fully_connected(net, code_size, scope='fc1') + end_points['fc3'] = net + return end_points + + +################################################################################ +# DECODERS +################################################################################ +def large_decoder(codes, + height, + width, + channels, + batch_norm_params=None, + weight_decay=0.0): + """Decodes the codes to a fixed output size. + + Args: + codes: a tensor of size [batch_size, code_size]. + height: the height of the output images. + width: the width of the output images. + channels: the number of the output channels. + batch_norm_params: a dictionary that maps batch norm parameter names to + values. + weight_decay: the value for the weight decay coefficient. + + Returns: + recons: the reconstruction tensor of shape [batch_size, height, width, 3]. + """ + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + normalizer_params=batch_norm_params): + net = slim.fully_connected(codes, 600, scope='fc1') + batch_size = net.get_shape().as_list()[0] + net = tf.reshape(net, [batch_size, 10, 10, 6]) + + net = slim.conv2d(net, 32, [5, 5], scope='conv1_1') + + net = tf.image.resize_nearest_neighbor(net, (16, 16)) + + net = slim.conv2d(net, 32, [5, 5], scope='conv2_1') + + net = tf.image.resize_nearest_neighbor(net, (32, 32)) + + net = slim.conv2d(net, 32, [5, 5], scope='conv3_2') + + output_size = [height, width] + net = tf.image.resize_nearest_neighbor(net, output_size) + + with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]): + net = slim.conv2d(net, channels, activation_fn=None, scope='conv4_1') + + return net + + +def gtsrb_decoder(codes, + height, + width, + channels, + batch_norm_params=None, + weight_decay=0.0): + """Decodes the codes to a fixed output size. This decoder is specific to GTSRB + + Args: + codes: a tensor of size [batch_size, 100]. + height: the height of the output images. + width: the width of the output images. + channels: the number of the output channels. + batch_norm_params: a dictionary that maps batch norm parameter names to + values. + weight_decay: the value for the weight decay coefficient. + + Returns: + recons: the reconstruction tensor of shape [batch_size, height, width, 3]. + + Raises: + ValueError: When the input code size is not 100. + """ + batch_size, code_size = codes.get_shape().as_list() + if code_size != 100: + raise ValueError('The code size used as an input to the GTSRB decoder is ' + 'expected to be 100.') + + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + normalizer_params=batch_norm_params): + net = codes + net = tf.reshape(net, [batch_size, 10, 10, 1]) + net = slim.conv2d(net, 32, [3, 3], scope='conv1_1') + + # First upsampling 20x20 + net = tf.image.resize_nearest_neighbor(net, [20, 20]) + + net = slim.conv2d(net, 32, [3, 3], scope='conv2_1') + + output_size = [height, width] + # Final upsampling 40 x 40 + net = tf.image.resize_nearest_neighbor(net, output_size) + + with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]): + net = slim.conv2d(net, 16, scope='conv3_1') + net = slim.conv2d(net, channels, activation_fn=None, scope='conv3_2') + + return net + + +def small_decoder(codes, + height, + width, + channels, + batch_norm_params=None, + weight_decay=0.0): + """Decodes the codes to a fixed output size. + + Args: + codes: a tensor of size [batch_size, code_size]. + height: the height of the output images. + width: the width of the output images. + channels: the number of the output channels. + batch_norm_params: a dictionary that maps batch norm parameter names to + values. + weight_decay: the value for the weight decay coefficient. + + Returns: + recons: the reconstruction tensor of shape [batch_size, height, width, 3]. + """ + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm, + normalizer_params=batch_norm_params): + net = slim.fully_connected(codes, 300, scope='fc1') + batch_size = net.get_shape().as_list()[0] + net = tf.reshape(net, [batch_size, 10, 10, 3]) + + net = slim.conv2d(net, 16, [3, 3], scope='conv1_1') + net = slim.conv2d(net, 16, [3, 3], scope='conv1_2') + + output_size = [height, width] + net = tf.image.resize_nearest_neighbor(net, output_size) + + with slim.arg_scope([slim.conv2d], kernel_size=[3, 3]): + net = slim.conv2d(net, 16, scope='conv2_1') + net = slim.conv2d(net, channels, activation_fn=None, scope='conv2_2') + + return net + + +################################################################################ +# SHARED ENCODERS +################################################################################ +def dann_mnist(images, + weight_decay=0.0, + prefix='model', + num_classes=10, + **kwargs): + """Creates a convolution MNIST model. + + Note that this model implements the architecture for MNIST proposed in: + Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN), + JMLR 2015 + + Args: + images: the MNIST digits, a tensor of size [batch_size, 28, 28, 1]. + weight_decay: the value for the weight decay coefficient. + prefix: name of the model to use when prefixing tags. + num_classes: the number of output classes to use. + **kwargs: Placeholder for keyword arguments used by other shared encoders. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + end_points = {} + + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu,): + with slim.arg_scope([slim.conv2d], padding='SAME'): + end_points['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1') + end_points['pool1'] = slim.max_pool2d( + end_points['conv1'], [2, 2], 2, scope='pool1') + end_points['conv2'] = slim.conv2d( + end_points['pool1'], 48, [5, 5], scope='conv2') + end_points['pool2'] = slim.max_pool2d( + end_points['conv2'], [2, 2], 2, scope='pool2') + end_points['fc3'] = slim.fully_connected( + slim.flatten(end_points['pool2']), 100, scope='fc3') + end_points['fc4'] = slim.fully_connected( + slim.flatten(end_points['fc3']), 100, scope='fc4') + + logits = slim.fully_connected( + end_points['fc4'], num_classes, activation_fn=None, scope='fc5') + + return logits, end_points + + +def dann_svhn(images, + weight_decay=0.0, + prefix='model', + num_classes=10, + **kwargs): + """Creates the convolutional SVHN model. + + Note that this model implements the architecture for MNIST proposed in: + Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN), + JMLR 2015 + + Args: + images: the SVHN digits, a tensor of size [batch_size, 32, 32, 3]. + weight_decay: the value for the weight decay coefficient. + prefix: name of the model to use when prefixing tags. + num_classes: the number of output classes to use. + **kwargs: Placeholder for keyword arguments used by other shared encoders. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + end_points = {} + + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu,): + with slim.arg_scope([slim.conv2d], padding='SAME'): + + end_points['conv1'] = slim.conv2d(images, 64, [5, 5], scope='conv1') + end_points['pool1'] = slim.max_pool2d( + end_points['conv1'], [3, 3], 2, scope='pool1') + end_points['conv2'] = slim.conv2d( + end_points['pool1'], 64, [5, 5], scope='conv2') + end_points['pool2'] = slim.max_pool2d( + end_points['conv2'], [3, 3], 2, scope='pool2') + end_points['conv3'] = slim.conv2d( + end_points['pool2'], 128, [5, 5], scope='conv3') + + end_points['fc3'] = slim.fully_connected( + slim.flatten(end_points['conv3']), 3072, scope='fc3') + end_points['fc4'] = slim.fully_connected( + slim.flatten(end_points['fc3']), 2048, scope='fc4') + + logits = slim.fully_connected( + end_points['fc4'], num_classes, activation_fn=None, scope='fc5') + + return logits, end_points + + +def dann_gtsrb(images, + weight_decay=0.0, + prefix='model', + num_classes=43, + **kwargs): + """Creates the convolutional GTSRB model. + + Note that this model implements the architecture for MNIST proposed in: + Y. Ganin et al., Domain-Adversarial Training of Neural Networks (DANN), + JMLR 2015 + + Args: + images: the GTSRB images, a tensor of size [batch_size, 40, 40, 3]. + weight_decay: the value for the weight decay coefficient. + prefix: name of the model to use when prefixing tags. + num_classes: the number of output classes to use. + **kwargs: Placeholder for keyword arguments used by other shared encoders. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + end_points = {} + + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu,): + with slim.arg_scope([slim.conv2d], padding='SAME'): + + end_points['conv1'] = slim.conv2d(images, 96, [5, 5], scope='conv1') + end_points['pool1'] = slim.max_pool2d( + end_points['conv1'], [2, 2], 2, scope='pool1') + end_points['conv2'] = slim.conv2d( + end_points['pool1'], 144, [3, 3], scope='conv2') + end_points['pool2'] = slim.max_pool2d( + end_points['conv2'], [2, 2], 2, scope='pool2') + end_points['conv3'] = slim.conv2d( + end_points['pool2'], 256, [5, 5], scope='conv3') + end_points['pool3'] = slim.max_pool2d( + end_points['conv3'], [2, 2], 2, scope='pool3') + + end_points['fc3'] = slim.fully_connected( + slim.flatten(end_points['pool3']), 512, scope='fc3') + + logits = slim.fully_connected( + end_points['fc3'], num_classes, activation_fn=None, scope='fc4') + + return logits, end_points + + +def dsn_cropped_linemod(images, + weight_decay=0.0, + prefix='model', + num_classes=11, + batch_norm_params=None, + is_training=False): + """Creates the convolutional pose estimation model for Cropped Linemod. + + Args: + images: the Cropped Linemod samples, a tensor of size + [batch_size, 64, 64, 4]. + weight_decay: the value for the weight decay coefficient. + prefix: name of the model to use when prefixing tags. + num_classes: the number of output classes to use. + batch_norm_params: a dictionary that maps batch norm parameter names to + values. + is_training: specifies whether or not we're currently training the model. + This variable will determine the behaviour of the dropout layer. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + end_points = {} + + tf.summary.image('{}/input_images'.format(prefix), images) + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + weights_regularizer=slim.l2_regularizer(weight_decay), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm if batch_norm_params else None, + normalizer_params=batch_norm_params): + with slim.arg_scope([slim.conv2d], padding='SAME'): + end_points['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1') + end_points['pool1'] = slim.max_pool2d( + end_points['conv1'], [2, 2], 2, scope='pool1') + end_points['conv2'] = slim.conv2d( + end_points['pool1'], 64, [5, 5], scope='conv2') + end_points['pool2'] = slim.max_pool2d( + end_points['conv2'], [2, 2], 2, scope='pool2') + net = slim.flatten(end_points['pool2']) + end_points['fc3'] = slim.fully_connected(net, 128, scope='fc3') + net = slim.dropout( + end_points['fc3'], 0.5, is_training=is_training, scope='dropout') + + with tf.variable_scope('quaternion_prediction'): + predicted_quaternion = slim.fully_connected( + net, 4, activation_fn=tf.nn.tanh) + predicted_quaternion = tf.nn.l2_normalize(predicted_quaternion, 1) + logits = slim.fully_connected( + net, num_classes, activation_fn=None, scope='fc4') + end_points['quaternion_pred'] = predicted_quaternion + + return logits, end_points diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models_test.py" new file mode 100644 index 00000000..69d1a272 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/models_test.py" @@ -0,0 +1,167 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for DSN components.""" + +import numpy as np +import tensorflow as tf + +#from models.domain_adaptation.domain_separation +import models + + +class SharedEncodersTest(tf.test.TestCase): + + def _testSharedEncoder(self, + input_shape=[5, 28, 28, 1], + model=models.dann_mnist, + is_training=True): + images = tf.to_float(np.random.rand(*input_shape)) + + with self.test_session() as sess: + logits, _ = model(images) + sess.run(tf.global_variables_initializer()) + logits_np = sess.run(logits) + return logits_np + + def testBuildGRLMnistModel(self): + logits = self._testSharedEncoder(model=getattr(models, + 'dann_mnist')) + self.assertEqual(logits.shape, (5, 10)) + self.assertTrue(np.any(logits)) + + def testBuildGRLSvhnModel(self): + logits = self._testSharedEncoder(model=getattr(models, + 'dann_svhn')) + self.assertEqual(logits.shape, (5, 10)) + self.assertTrue(np.any(logits)) + + def testBuildGRLGtsrbModel(self): + logits = self._testSharedEncoder([5, 40, 40, 3], + getattr(models, 'dann_gtsrb')) + self.assertEqual(logits.shape, (5, 43)) + self.assertTrue(np.any(logits)) + + def testBuildPoseModel(self): + logits = self._testSharedEncoder([5, 64, 64, 4], + getattr(models, 'dsn_cropped_linemod')) + self.assertEqual(logits.shape, (5, 11)) + self.assertTrue(np.any(logits)) + + def testBuildPoseModelWithBatchNorm(self): + images = tf.to_float(np.random.rand(10, 64, 64, 4)) + + with self.test_session() as sess: + logits, _ = getattr(models, 'dsn_cropped_linemod')( + images, batch_norm_params=models.default_batch_norm_params(True)) + sess.run(tf.global_variables_initializer()) + logits_np = sess.run(logits) + self.assertEqual(logits_np.shape, (10, 11)) + self.assertTrue(np.any(logits_np)) + + +class EncoderTest(tf.test.TestCase): + + def _testEncoder(self, batch_norm_params=None, channels=1): + images = tf.to_float(np.random.rand(10, 28, 28, channels)) + + with self.test_session() as sess: + end_points = models.default_encoder( + images, 128, batch_norm_params=batch_norm_params) + sess.run(tf.global_variables_initializer()) + private_code = sess.run(end_points['fc3']) + self.assertEqual(private_code.shape, (10, 128)) + self.assertTrue(np.any(private_code)) + self.assertTrue(np.all(np.isfinite(private_code))) + + def testEncoder(self): + self._testEncoder() + + def testEncoderMultiChannel(self): + self._testEncoder(None, 4) + + def testEncoderIsTrainingBatchNorm(self): + self._testEncoder(models.default_batch_norm_params(True)) + + def testEncoderBatchNorm(self): + self._testEncoder(models.default_batch_norm_params(False)) + + +class DecoderTest(tf.test.TestCase): + + def _testDecoder(self, + height=64, + width=64, + channels=4, + batch_norm_params=None, + decoder=models.small_decoder): + codes = tf.to_float(np.random.rand(32, 100)) + + with self.test_session() as sess: + output = decoder( + codes, + height=height, + width=width, + channels=channels, + batch_norm_params=batch_norm_params) + sess.run(tf.global_variables_initializer()) + output_np = sess.run(output) + self.assertEqual(output_np.shape, (32, height, width, channels)) + self.assertTrue(np.any(output_np)) + self.assertTrue(np.all(np.isfinite(output_np))) + + def testSmallDecoder(self): + self._testDecoder(28, 28, 4, None, getattr(models, 'small_decoder')) + + def testSmallDecoderThreeChannels(self): + self._testDecoder(28, 28, 3) + + def testSmallDecoderBatchNorm(self): + self._testDecoder(28, 28, 4, models.default_batch_norm_params(False)) + + def testSmallDecoderIsTrainingBatchNorm(self): + self._testDecoder(28, 28, 4, models.default_batch_norm_params(True)) + + def testLargeDecoder(self): + self._testDecoder(32, 32, 4, None, getattr(models, 'large_decoder')) + + def testLargeDecoderThreeChannels(self): + self._testDecoder(32, 32, 3, None, getattr(models, 'large_decoder')) + + def testLargeDecoderBatchNorm(self): + self._testDecoder(32, 32, 4, + models.default_batch_norm_params(False), + getattr(models, 'large_decoder')) + + def testLargeDecoderIsTrainingBatchNorm(self): + self._testDecoder(32, 32, 4, + models.default_batch_norm_params(True), + getattr(models, 'large_decoder')) + + def testGtsrbDecoder(self): + self._testDecoder(40, 40, 3, None, getattr(models, 'large_decoder')) + + def testGtsrbDecoderBatchNorm(self): + self._testDecoder(40, 40, 4, + models.default_batch_norm_params(False), + getattr(models, 'gtsrb_decoder')) + + def testGtsrbDecoderIsTrainingBatchNorm(self): + self._testDecoder(40, 40, 4, + models.default_batch_norm_params(True), + getattr(models, 'gtsrb_decoder')) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/utils.py" new file mode 100644 index 00000000..e144ee86 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/domain_separation/utils.py" @@ -0,0 +1,183 @@ +# Copyright 2016 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Auxiliary functions for domain adaptation related losses. +""" +import math +import tensorflow as tf + + +def create_summaries(end_points, prefix='', max_images=3, use_op_name=False): + """Creates a tf summary per endpoint. + + If the endpoint is a 4 dimensional tensor it displays it as an image + otherwise if it is a two dimensional one it creates a histogram summary. + + Args: + end_points: a dictionary of name, tf tensor pairs. + prefix: an optional string to prefix the summary with. + max_images: the maximum number of images to display per summary. + use_op_name: Use the op name as opposed to the shorter end_points key. + """ + for layer_name in end_points: + if use_op_name: + name = end_points[layer_name].op.name + else: + name = layer_name + if len(end_points[layer_name].get_shape().as_list()) == 4: + # if it's an actual image do not attempt to reshape it + if end_points[layer_name].get_shape().as_list()[-1] == 1 or end_points[ + layer_name].get_shape().as_list()[-1] == 3: + visualization_image = end_points[layer_name] + else: + visualization_image = reshape_feature_maps(end_points[layer_name]) + tf.summary.image( + '{}/{}'.format(prefix, name), + visualization_image, + max_outputs=max_images) + elif len(end_points[layer_name].get_shape().as_list()) == 3: + images = tf.expand_dims(end_points[layer_name], 3) + tf.summary.image( + '{}/{}'.format(prefix, name), + images, + max_outputs=max_images) + elif len(end_points[layer_name].get_shape().as_list()) == 2: + tf.summary.histogram('{}/{}'.format(prefix, name), end_points[layer_name]) + + +def reshape_feature_maps(features_tensor): + """Reshape activations for tf.summary.image visualization. + + Arguments: + features_tensor: a tensor of activations with a square number of feature + maps, eg 4, 9, 16, etc. + Returns: + A composite image with all the feature maps that can be passed as an + argument to tf.summary.image. + """ + assert len(features_tensor.get_shape().as_list()) == 4 + num_filters = features_tensor.get_shape().as_list()[-1] + assert num_filters > 0 + num_filters_sqrt = math.sqrt(num_filters) + assert num_filters_sqrt.is_integer( + ), 'Number of filters should be a square number but got {}'.format( + num_filters) + num_filters_sqrt = int(num_filters_sqrt) + conv_summary = tf.unstack(features_tensor, axis=3) + conv_one_row = tf.concat(axis=2, values=conv_summary[0:num_filters_sqrt]) + ind = 1 + conv_final = conv_one_row + for ind in range(1, num_filters_sqrt): + conv_one_row = tf.concat(axis=2, + values=conv_summary[ + ind * num_filters_sqrt + 0:ind * num_filters_sqrt + num_filters_sqrt]) + conv_final = tf.concat( + axis=1, values=[tf.squeeze(conv_final), tf.squeeze(conv_one_row)]) + conv_final = tf.expand_dims(conv_final, -1) + return conv_final + + +def accuracy(predictions, labels): + """Calculates the classificaton accuracy. + + Args: + predictions: the predicted values, a tensor whose size matches 'labels'. + labels: the ground truth values, a tensor of any size. + + Returns: + a tensor whose value on evaluation returns the total accuracy. + """ + return tf.reduce_mean(tf.cast(tf.equal(predictions, labels), tf.float32)) + + +def compute_upsample_values(input_tensor, upsample_height, upsample_width): + """Compute values for an upsampling op (ops.BatchCropAndResize). + + Args: + input_tensor: image tensor with shape [batch, height, width, in_channels] + upsample_height: integer + upsample_width: integer + + Returns: + grid_centers: tensor with shape [batch, 1] + crop_sizes: tensor with shape [batch, 1] + output_height: integer + output_width: integer + """ + batch, input_height, input_width, _ = input_tensor.shape + + height_half = input_height / 2. + width_half = input_width / 2. + grid_centers = tf.constant(batch * [[height_half, width_half]]) + crop_sizes = tf.constant(batch * [[input_height, input_width]]) + output_height = input_height * upsample_height + output_width = input_width * upsample_width + + return grid_centers, tf.to_float(crop_sizes), output_height, output_width + + +def compute_pairwise_distances(x, y): + """Computes the squared pairwise Euclidean distances between x and y. + + Args: + x: a tensor of shape [num_x_samples, num_features] + y: a tensor of shape [num_y_samples, num_features] + + Returns: + a distance matrix of dimensions [num_x_samples, num_y_samples]. + + Raises: + ValueError: if the inputs do no matched the specified dimensions. + """ + + if not len(x.get_shape()) == len(y.get_shape()) == 2: + raise ValueError('Both inputs should be matrices.') + + if x.get_shape().as_list()[1] != y.get_shape().as_list()[1]: + raise ValueError('The number of features should be the same.') + + norm = lambda x: tf.reduce_sum(tf.square(x), 1) + + # By making the `inner' dimensions of the two matrices equal to 1 using + # broadcasting then we are essentially substracting every pair of rows + # of x and y. + # x will be num_samples x num_features x 1, + # and y will be 1 x num_features x num_samples (after broadcasting). + # After the substraction we will get a + # num_x_samples x num_features x num_y_samples matrix. + # The resulting dist will be of shape num_y_samples x num_x_samples. + # and thus we need to transpose it again. + return tf.transpose(norm(tf.expand_dims(x, 2) - tf.transpose(y))) + + +def gaussian_kernel_matrix(x, y, sigmas): + r"""Computes a Guassian Radial Basis Kernel between the samples of x and y. + + We create a sum of multiple gaussian kernels each having a width sigma_i. + + Args: + x: a tensor of shape [num_samples, num_features] + y: a tensor of shape [num_samples, num_features] + sigmas: a tensor of floats which denote the widths of each of the + gaussians in the kernel. + Returns: + A tensor of shape [num_samples{x}, num_samples{y}] with the RBF kernel. + """ + beta = 1. / (2. * (tf.expand_dims(sigmas, 1))) + + dist = compute_pairwise_distances(x, y) + + s = tf.matmul(beta, tf.reshape(dist, (1, -1))) + + return tf.reshape(tf.reduce_sum(tf.exp(-s), 0), tf.shape(dist)) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/BUILD" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/BUILD" new file mode 100644 index 00000000..2bc8d4a4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/BUILD" @@ -0,0 +1,90 @@ +# Description: +# Contains code for domain-adaptation style transfer. + +package( + default_visibility = [ + ":internal", + ], +) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +package_group( + name = "internal", + packages = [ + "//domain_adaptation/...", + ], +) + +py_library( + name = "pixelda_preprocess", + srcs = ["pixelda_preprocess.py"], + deps = [ + + ], +) + +py_test( + name = "pixelda_preprocess_test", + srcs = ["pixelda_preprocess_test.py"], + deps = [ + ":pixelda_preprocess", + + ], +) + +py_library( + name = "pixelda_model", + srcs = [ + "pixelda_model.py", + "pixelda_task_towers.py", + "hparams.py", + ], + deps = [ + + ], +) + +py_library( + name = "pixelda_utils", + srcs = ["pixelda_utils.py"], + deps = [ + + ], +) + +py_library( + name = "pixelda_losses", + srcs = ["pixelda_losses.py"], + deps = [ + + ], +) + +py_binary( + name = "pixelda_train", + srcs = ["pixelda_train.py"], + deps = [ + ":pixelda_losses", + ":pixelda_model", + ":pixelda_preprocess", + ":pixelda_utils", + + "//domain_adaptation/datasets:dataset_factory", + ], +) + +py_binary( + name = "pixelda_eval", + srcs = ["pixelda_eval.py"], + deps = [ + ":pixelda_losses", + ":pixelda_model", + ":pixelda_preprocess", + ":pixelda_utils", + + "//domain_adaptation/datasets:dataset_factory", + ], +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/README.md" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD" new file mode 100644 index 00000000..c41a4ffe --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/BUILD" @@ -0,0 +1,23 @@ +licenses(["notice"]) # Apache 2.0 + +py_binary( + name = "baseline_train", + srcs = ["baseline_train.py"], + deps = [ + + "//domain_adaptation/datasets:dataset_factory", + "//domain_adaptation/pixel_domain_adaptation:pixelda_model", + "//domain_adaptation/pixel_domain_adaptation:pixelda_preprocess", + ], +) + +py_binary( + name = "baseline_eval", + srcs = ["baseline_eval.py"], + deps = [ + + "//domain_adaptation/datasets:dataset_factory", + "//domain_adaptation/pixel_domain_adaptation:pixelda_model", + "//domain_adaptation/pixel_domain_adaptation:pixelda_preprocess", + ], +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md" new file mode 100644 index 00000000..d61195ad --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/README.md" @@ -0,0 +1,60 @@ +The best baselines are obtainable via the following configuration: + + +## MNIST => MNIST_M + +Accuracy: +MNIST-Train: 99.9 +MNIST_M-Train: 63.9 +MNIST_M-Valid: 63.9 +MNIST_M-Test: 63.6 + +Learning Rate = 0.0001 +Weight Decay = 0.0 +Number of Steps: 105,000 + +## MNIST => USPS + +Accuracy: +MNIST-Train: 100.0 +USPS-Train: 82.8 +USPS-Valid: 82.8 +USPS-Test: 78.9 + +Learning Rate = 0.0001 +Weight Decay = 0.0 +Number of Steps: 22,000 + +## MNIST_M => MNIST + +Accuracy: +MNIST_M-Train: 100 +MNIST-Train: 98.5 +MNIST-Valid: 98.5 +MNIST-Test: 98.1 + +Learning Rate = 0.001 +Weight Decay = 0.0 +Number of Steps: 604,400 + +## MNIST_M => MNIST_M + +Accuracy: +MNIST_M-Train: 100.0 +MNIST_M-Valid: 96.6 +MNIST_M-Test: 96.4 + +Learning Rate = 0.001 +Weight Decay = 0.0 +Number of Steps: 139,400 + +## USPS => USPS + +Accuracy: +USPS-Train: 100.0 +USPS-Valid: 100.0 +USPS-Test: 96.5 + +Learning Rate = 0.001 +Weight Decay = 0.0 +Number of Steps: 67,000 diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py" new file mode 100644 index 00000000..6b7ef645 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_eval.py" @@ -0,0 +1,141 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +r"""Evals the classification/pose baselines.""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from functools import partial + +import math + +# Dependency imports + +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess +from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers + +flags = tf.app.flags +FLAGS = flags.FLAGS + +slim = tf.contrib.slim + +flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') + +flags.DEFINE_string( + 'checkpoint_dir', None, 'The location of the checkpoint files.') + +flags.DEFINE_string( + 'eval_dir', None, 'The directory where evaluation logs are written.') + +flags.DEFINE_integer('batch_size', 32, 'The number of samples per batch.') + +flags.DEFINE_string('dataset_name', None, 'The name of the dataset.') + +flags.DEFINE_string('dataset_dir', None, + 'The directory where the data is stored.') + +flags.DEFINE_string('split_name', None, 'The name of the train/test split.') + +flags.DEFINE_integer('eval_interval_secs', 60 * 5, + 'How often (in seconds) to run evaluation.') + +flags.DEFINE_integer( + 'num_readers', 4, + 'The number of parallel readers that read data from the dataset.') + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + hparams = tf.contrib.training.HParams() + hparams.weight_decay_task_classifier = 0.0 + + if FLAGS.dataset_name in ['mnist', 'mnist_m', 'usps']: + hparams.task_tower = 'mnist' + else: + raise ValueError('Unknown dataset %s' % FLAGS.dataset_name) + + if not tf.gfile.Exists(FLAGS.eval_dir): + tf.gfile.MakeDirs(FLAGS.eval_dir) + + with tf.Graph().as_default(): + dataset = dataset_factory.get_dataset(FLAGS.dataset_name, FLAGS.split_name, + FLAGS.dataset_dir) + num_classes = dataset.num_classes + num_samples = dataset.num_samples + + preprocess_fn = partial(pixelda_preprocess.preprocess_classification, + is_training=False) + + images, labels = dataset_factory.provide_batch( + FLAGS.dataset_name, + FLAGS.split_name, + dataset_dir=FLAGS.dataset_dir, + num_readers=FLAGS.num_readers, + batch_size=FLAGS.batch_size, + num_preprocessing_threads=FLAGS.num_readers) + + # Define the model + logits, _ = pixelda_task_towers.add_task_specific_model( + images, hparams, num_classes=num_classes, is_training=True) + + ##################### + # Define the losses # + ##################### + if 'classes' in labels: + one_hot_labels = labels['classes'] + loss = tf.losses.softmax_cross_entropy( + onehot_labels=one_hot_labels, logits=logits) + tf.summary.scalar('losses/Classification_Loss', loss) + else: + raise ValueError('Only support classification for now.') + + total_loss = tf.losses.get_total_loss() + + predictions = tf.reshape(tf.argmax(logits, 1), shape=[-1]) + class_labels = tf.argmax(labels['classes'], 1) + + metrics_to_values, metrics_to_updates = slim.metrics.aggregate_metric_map({ + 'Mean_Loss': + tf.contrib.metrics.streaming_mean(total_loss), + 'Accuracy': + tf.contrib.metrics.streaming_accuracy(predictions, + tf.reshape( + class_labels, + shape=[-1])), + 'Recall_at_5': + tf.contrib.metrics.streaming_recall_at_k(logits, class_labels, 5), + }) + + tf.summary.histogram('outputs/Predictions', predictions) + tf.summary.histogram('outputs/Ground_Truth', class_labels) + + for name, value in metrics_to_values.iteritems(): + tf.summary.scalar(name, value) + + num_batches = int(math.ceil(num_samples / float(FLAGS.batch_size))) + + slim.evaluation.evaluation_loop( + master=FLAGS.master, + checkpoint_dir=FLAGS.checkpoint_dir, + logdir=FLAGS.eval_dir, + num_evals=num_batches, + eval_op=metrics_to_updates.values(), + eval_interval_secs=FLAGS.eval_interval_secs) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py" new file mode 100644 index 00000000..8c92bd81 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/baselines/baseline_train.py" @@ -0,0 +1,161 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +r"""Trains the classification/pose baselines.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from functools import partial + +# Dependency imports + +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess +from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers + +flags = tf.app.flags +FLAGS = flags.FLAGS + +slim = tf.contrib.slim + +flags.DEFINE_string('master', '', 'BNS name of the tensorflow server') + +flags.DEFINE_integer('task', 0, 'The task ID.') + +flags.DEFINE_integer('num_ps_tasks', 0, + 'The number of parameter servers. If the value is 0, then ' + 'the parameters are handled locally by the worker.') + +flags.DEFINE_integer('batch_size', 32, 'The number of samples per batch.') + +flags.DEFINE_string('dataset_name', None, 'The name of the dataset.') + +flags.DEFINE_string('dataset_dir', None, + 'The directory where the data is stored.') + +flags.DEFINE_string('split_name', None, 'The name of the train/test split.') + +flags.DEFINE_float('learning_rate', 0.001, 'The initial learning rate.') + +flags.DEFINE_integer( + 'learning_rate_decay_steps', 20000, + 'The frequency, in steps, at which the learning rate is decayed.') + +flags.DEFINE_float('learning_rate_decay_factor', + 0.95, + 'The factor with which the learning rate is decayed.') + +flags.DEFINE_float('adam_beta1', 0.5, 'The beta1 value for the AdamOptimizer') + +flags.DEFINE_float('weight_decay', 1e-5, + 'The L2 coefficient on the model weights.') + +flags.DEFINE_string( + 'logdir', None, 'The location of the logs and checkpoints.') + +flags.DEFINE_integer('save_interval_secs', 600, + 'How often, in seconds, we save the model to disk.') + +flags.DEFINE_integer('save_summaries_secs', 600, + 'How often, in seconds, we compute the summaries.') + +flags.DEFINE_integer( + 'num_readers', 4, + 'The number of parallel readers that read data from the dataset.') + +flags.DEFINE_float( + 'moving_average_decay', 0.9999, + 'The amount of decay to use for moving averages.') + + +def main(unused_argv): + tf.logging.set_verbosity(tf.logging.INFO) + hparams = tf.contrib.training.HParams() + hparams.weight_decay_task_classifier = FLAGS.weight_decay + + if FLAGS.dataset_name in ['mnist', 'mnist_m', 'usps']: + hparams.task_tower = 'mnist' + else: + raise ValueError('Unknown dataset %s' % FLAGS.dataset_name) + + with tf.Graph().as_default(): + with tf.device( + tf.train.replica_device_setter(FLAGS.num_ps_tasks, merge_devices=True)): + dataset = dataset_factory.get_dataset(FLAGS.dataset_name, + FLAGS.split_name, FLAGS.dataset_dir) + num_classes = dataset.num_classes + + preprocess_fn = partial(pixelda_preprocess.preprocess_classification, + is_training=True) + + images, labels = dataset_factory.provide_batch( + FLAGS.dataset_name, + FLAGS.split_name, + dataset_dir=FLAGS.dataset_dir, + num_readers=FLAGS.num_readers, + batch_size=FLAGS.batch_size, + num_preprocessing_threads=FLAGS.num_readers) + # preprocess_fn=preprocess_fn) + + # Define the model + logits, _ = pixelda_task_towers.add_task_specific_model( + images, hparams, num_classes=num_classes, is_training=True) + + # Define the losses + if 'classes' in labels: + one_hot_labels = labels['classes'] + loss = tf.losses.softmax_cross_entropy( + onehot_labels=one_hot_labels, logits=logits) + tf.summary.scalar('losses/Classification_Loss', loss) + else: + raise ValueError('Only support classification for now.') + + total_loss = tf.losses.get_total_loss() + tf.summary.scalar('losses/Total_Loss', total_loss) + + # Setup the moving averages + moving_average_variables = slim.get_model_variables() + variable_averages = tf.train.ExponentialMovingAverage( + FLAGS.moving_average_decay, slim.get_or_create_global_step()) + tf.add_to_collection( + tf.GraphKeys.UPDATE_OPS, + variable_averages.apply(moving_average_variables)) + + # Specify the optimization scheme: + learning_rate = tf.train.exponential_decay( + FLAGS.learning_rate, + slim.get_or_create_global_step(), + FLAGS.learning_rate_decay_steps, + FLAGS.learning_rate_decay_factor, + staircase=True) + + optimizer = tf.train.AdamOptimizer(learning_rate, beta1=FLAGS.adam_beta1) + + train_op = slim.learning.create_train_op(total_loss, optimizer) + + slim.learning.train( + train_op, + FLAGS.logdir, + master=FLAGS.master, + is_chief=(FLAGS.task == 0), + save_summaries_secs=FLAGS.save_summaries_secs, + save_interval_secs=FLAGS.save_interval_secs) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/hparams.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/hparams.py" new file mode 100644 index 00000000..ba9539f7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/hparams.py" @@ -0,0 +1,201 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Define model HParams.""" +import tensorflow as tf + + +def create_hparams(hparam_string=None): + """Create model hyperparameters. Parse nondefault from given string.""" + hparams = tf.contrib.training.HParams( + # The name of the architecture to use. + arch='resnet', + lrelu_leakiness=0.2, + batch_norm_decay=0.9, + weight_decay=1e-5, + normal_init_std=0.02, + generator_kernel_size=3, + discriminator_kernel_size=3, + + # Stop training after this many examples are processed + # If none, train indefinitely + num_training_examples=0, + + # Apply data augmentation to datasets + # Applies only in training job + augment_source_images=False, + augment_target_images=False, + + # Discriminator + # Number of filters in first layer of discriminator + num_discriminator_filters=64, + discriminator_conv_block_size=1, # How many convs to have at each size + discriminator_filter_factor=2.0, # Multiply # filters by this each layer + # Add gaussian noise with this stddev to every hidden layer of D + discriminator_noise_stddev=0.2, # lmetz: Start seeing results at >= 0.1 + # If true, add this gaussian noise to input images to D as well + discriminator_image_noise=False, + discriminator_first_stride=1, # Stride in first conv of discriminator + discriminator_do_pooling=False, # If true, replace stride 2 with avg pool + discriminator_dropout_keep_prob=0.9, # keep probability for dropout + + # DCGAN Generator + # Number of filters in generator decoder last layer (repeatedly halved + # from 1st layer) + num_decoder_filters=64, + # Number of filters in generator encoder 1st layer (repeatedly doubled + # after 1st layer) + num_encoder_filters=64, + + # This is the shape to which the noise vector is projected (if we're + # transferring from noise). + # Write this way instead of [4, 4, 64] for hparam search flexibility + projection_shape_size=4, + projection_shape_channels=64, + + # Indicates the method by which we enlarge the spatial representation + # of an image. Possible values include: + # - resize_conv: Performs a nearest neighbor resize followed by a conv. + # - conv2d_transpose: Performs a conv2d_transpose. + upsample_method='resize_conv', + + # Visualization + summary_steps=500, # Output image summary every N steps + + ################################### + # Task Classifier Hyperparameters # + ################################### + + # Which task-specific prediction tower to use. Possible choices are: + # none: No task tower. + # doubling_pose_estimator: classifier + quaternion regressor. + # [conv + pool]* + FC + # Classifiers used in DSN paper: + # gtsrb: Classifier used for GTSRB + # svhn: Classifier used for SVHN + # mnist: Classifier used for MNIST + # pose_mini: Classifier + regressor used for pose_mini + task_tower='doubling_pose_estimator', + weight_decay_task_classifier=1e-5, + source_task_loss_weight=1.0, + transferred_task_loss_weight=1.0, + + # Number of private layers in doubling_pose_estimator task tower + num_private_layers=2, + + # The weight for the log quaternion loss we use for source and transferred + # samples of the cropped_linemod dataset. + # In the DSN work, 1/8 of the classifier weight worked well for our log + # quaternion loss + source_pose_weight=0.125 * 2.0, + transferred_pose_weight=0.125 * 1.0, + + # If set to True, the style transfer network also attempts to change its + # weights to maximize the performance of the task tower. If set to False, + # then the style transfer network only attempts to change its weights to + # make the transferred images more likely according to the domain + # classifier. + task_tower_in_g_step=True, + task_loss_in_g_weight=1.0, # Weight of task loss in G + + ######################################### + # 'simple` generator arch model hparams # + ######################################### + simple_num_conv_layers=1, + simple_conv_filters=8, + + ######################### + # Resnet Hyperparameters# + ######################### + resnet_blocks=6, # Number of resnet blocks + resnet_filters=64, # Number of filters per conv in resnet blocks + # If true, add original input back to result of convolutions inside the + # resnet arch. If false, it turns into a simple stack of conv/relu/BN + # layers. + resnet_residuals=True, + + ####################################### + # The residual / interpretable model. # + ####################################### + res_int_blocks=2, # The number of residual blocks. + res_int_convs=2, # The number of conv calls inside each block. + res_int_filters=64, # The number of filters used by each convolution. + + #################### + # Latent variables # + #################### + # if true, then generate random noise and project to input for generator + noise_channel=True, + # The number of dimensions in the input noise vector. + noise_dims=10, + + # If true, then one hot encode source image class and project as an + # additional channel for the input to generator. This gives the generator + # access to the class, which may help generation performance. + condition_on_source_class=False, + + ######################## + # Loss Hyperparameters # + ######################## + domain_loss_weight=1.0, + style_transfer_loss_weight=1.0, + + ######################################################################## + # Encourages the transferred images to be similar to the source images # + # using a configurable metric. # + ######################################################################## + + # The weight of the loss function encouraging the source and transferred + # images to be similar. If set to 0, then the loss function is not used. + transferred_similarity_loss_weight=0.0, + + # The type of loss used to encourage transferred and source image + # similarity. Valid values include: + # mpse: Mean Pairwise Squared Error + # mse: Mean Squared Error + # hinged_mse: Computes the mean squared error using squared differences + # greater than hparams.transferred_similarity_max_diff + # hinged_mae: Computes the mean absolute error using absolute + # differences greater than hparams.transferred_similarity_max_diff. + transferred_similarity_loss='mpse', + + # The maximum allowable difference between the source and target images. + # This value is used, in effect, to produce a hinge loss. Note that the + # range of values should be between 0 and 1. + transferred_similarity_max_diff=0.4, + + ################################ + # Optimization Hyperparameters # + ################################ + learning_rate=0.001, + batch_size=32, + lr_decay_steps=20000, + lr_decay_rate=0.95, + + # Recomendation from the DCGAN paper: + adam_beta1=0.5, + clip_gradient_norm=5.0, + + # The number of times we run the discriminator train_op in a row. + discriminator_steps=1, + + # The number of times we run the generator train_op in a row. + generator_steps=1) + + if hparam_string: + tf.logging.info('Parsing command line hparams: %s', hparam_string) + hparams.parse(hparam_string) + + tf.logging.info('Final parsed hparams: %s', hparams.values()) + return hparams diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py" new file mode 100644 index 00000000..23824249 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_eval.py" @@ -0,0 +1,298 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +r"""Evaluates the PIXELDA model. + +-- Compiles the model for CPU. +$ bazel build -c opt third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation:pixelda_eval + +-- Compile the model for GPU. +$ bazel build -c opt --copt=-mavx --config=cuda \ + third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation:pixelda_eval + +-- Runs the training. +$ ./bazel-bin/third_party/tensorflow_models/domain_adaptation/pixel_domain_adaptation/pixelda_eval \ + --source_dataset=mnist \ + --target_dataset=mnist_m \ + --dataset_dir=/tmp/datasets/ \ + --alsologtostderr + +-- Visualize the results. +$ bash learning/brain/tensorboard/tensorboard.sh \ + --port 2222 --logdir=/tmp/pixelda/ +""" +from functools import partial +import math + +# Dependency imports + +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +from domain_adaptation.pixel_domain_adaptation import pixelda_model +from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess +from domain_adaptation.pixel_domain_adaptation import pixelda_utils +from domain_adaptation.pixel_domain_adaptation import pixelda_losses +from domain_adaptation.pixel_domain_adaptation.hparams import create_hparams + +slim = tf.contrib.slim + +flags = tf.app.flags +FLAGS = flags.FLAGS + +flags.DEFINE_string('master', '', 'BNS name of the TensorFlow master to use.') + +flags.DEFINE_string('checkpoint_dir', '/tmp/pixelda/', + 'Directory where the model was written to.') + +flags.DEFINE_string('eval_dir', '/tmp/pixelda/', + 'Directory where the results are saved to.') + +flags.DEFINE_integer('eval_interval_secs', 60, + 'The frequency, in seconds, with which evaluation is run.') + +flags.DEFINE_string('target_split_name', 'test', + 'The name of the train/test split.') +flags.DEFINE_string('source_split_name', 'train', 'Split for source dataset.' + ' Defaults to train.') + +flags.DEFINE_string('source_dataset', 'mnist', + 'The name of the source dataset.') + +flags.DEFINE_string('target_dataset', 'mnist_m', + 'The name of the target dataset.') + +flags.DEFINE_string( + 'dataset_dir', + '', # None, + 'The directory where the datasets can be found.') + +flags.DEFINE_integer( + 'num_readers', 4, + 'The number of parallel readers that read data from the dataset.') + +flags.DEFINE_integer('num_preprocessing_threads', 4, + 'The number of threads used to create the batches.') + +# HParams + +flags.DEFINE_string('hparams', '', 'Comma separated hyperparameter values') + + +def run_eval(run_dir, checkpoint_dir, hparams): + """Runs the eval loop. + + Args: + run_dir: The directory where eval specific logs are placed + checkpoint_dir: The directory where the checkpoints are stored + hparams: The hyperparameters struct. + + Raises: + ValueError: if hparams.arch is not recognized. + """ + for checkpoint_path in slim.evaluation.checkpoints_iterator( + checkpoint_dir, FLAGS.eval_interval_secs): + with tf.Graph().as_default(): + ######################### + # Preprocess the inputs # + ######################### + target_dataset = dataset_factory.get_dataset( + FLAGS.target_dataset, + split_name=FLAGS.target_split_name, + dataset_dir=FLAGS.dataset_dir) + target_images, target_labels = dataset_factory.provide_batch( + FLAGS.target_dataset, FLAGS.target_split_name, FLAGS.dataset_dir, + FLAGS.num_readers, hparams.batch_size, + FLAGS.num_preprocessing_threads) + num_target_classes = target_dataset.num_classes + target_labels['class'] = tf.argmax(target_labels['classes'], 1) + del target_labels['classes'] + + if hparams.arch not in ['dcgan']: + source_dataset = dataset_factory.get_dataset( + FLAGS.source_dataset, + split_name=FLAGS.source_split_name, + dataset_dir=FLAGS.dataset_dir) + num_source_classes = source_dataset.num_classes + source_images, source_labels = dataset_factory.provide_batch( + FLAGS.source_dataset, FLAGS.source_split_name, FLAGS.dataset_dir, + FLAGS.num_readers, hparams.batch_size, + FLAGS.num_preprocessing_threads) + source_labels['class'] = tf.argmax(source_labels['classes'], 1) + del source_labels['classes'] + if num_source_classes != num_target_classes: + raise ValueError( + 'Input and output datasets must have same number of classes') + else: + source_images = None + source_labels = None + + #################### + # Define the model # + #################### + end_points = pixelda_model.create_model( + hparams, + target_images, + source_images=source_images, + source_labels=source_labels, + is_training=False, + num_classes=num_target_classes) + + ####################### + # Metrics & Summaries # + ####################### + names_to_values, names_to_updates = create_metrics(end_points, + source_labels, + target_labels, hparams) + pixelda_utils.summarize_model(end_points) + pixelda_utils.summarize_transferred_grid( + end_points['transferred_images'], source_images, name='Transferred') + if 'source_images_recon' in end_points: + pixelda_utils.summarize_transferred_grid( + end_points['source_images_recon'], + source_images, + name='Source Reconstruction') + pixelda_utils.summarize_images(target_images, 'Target') + + for name, value in names_to_values.iteritems(): + tf.summary.scalar(name, value) + + # Use the entire split by default + num_examples = target_dataset.num_samples + + num_batches = math.ceil(num_examples / float(hparams.batch_size)) + global_step = slim.get_or_create_global_step() + + result = slim.evaluation.evaluate_once( + master=FLAGS.master, + checkpoint_path=checkpoint_path, + logdir=run_dir, + num_evals=num_batches, + eval_op=names_to_updates.values(), + final_op=names_to_values) + + +def to_degrees(log_quaternion_loss): + """Converts a log quaternion distance to an angle. + + Args: + log_quaternion_loss: The log quaternion distance between two + unit quaternions (or a batch of pairs of quaternions). + + Returns: + The angle in degrees of the implied angle-axis representation. + """ + return tf.acos(-(tf.exp(log_quaternion_loss) - 1)) * 2 * 180 / math.pi + + +def create_metrics(end_points, source_labels, target_labels, hparams): + """Create metrics for the model. + + Args: + end_points: A dictionary of end point name to tensor + source_labels: Labels for source images. batch_size x 1 + target_labels: Labels for target images. batch_size x 1 + hparams: The hyperparameters struct. + + Returns: + Tuple of (names_to_values, names_to_updates), dictionaries that map a metric + name to its value and update op, respectively + + """ + ########################################### + # Evaluate the Domain Prediction Accuracy # + ########################################### + batch_size = hparams.batch_size + names_to_values, names_to_updates = slim.metrics.aggregate_metric_map({ + ('eval/Domain_Accuracy-Transferred'): + tf.contrib.metrics.streaming_accuracy( + tf.to_int32( + tf.round(tf.sigmoid(end_points[ + 'transferred_domain_logits']))), + tf.zeros(batch_size, dtype=tf.int32)), + ('eval/Domain_Accuracy-Target'): + tf.contrib.metrics.streaming_accuracy( + tf.to_int32( + tf.round(tf.sigmoid(end_points['target_domain_logits']))), + tf.ones(batch_size, dtype=tf.int32)) + }) + + ################################ + # Evaluate the task classifier # + ################################ + if 'source_task_logits' in end_points: + metric_name = 'eval/Task_Accuracy-Source' + names_to_values[metric_name], names_to_updates[ + metric_name] = tf.contrib.metrics.streaming_accuracy( + tf.argmax(end_points['source_task_logits'], 1), + source_labels['class']) + + if 'transferred_task_logits' in end_points: + metric_name = 'eval/Task_Accuracy-Transferred' + names_to_values[metric_name], names_to_updates[ + metric_name] = tf.contrib.metrics.streaming_accuracy( + tf.argmax(end_points['transferred_task_logits'], 1), + source_labels['class']) + + if 'target_task_logits' in end_points: + metric_name = 'eval/Task_Accuracy-Target' + names_to_values[metric_name], names_to_updates[ + metric_name] = tf.contrib.metrics.streaming_accuracy( + tf.argmax(end_points['target_task_logits'], 1), + target_labels['class']) + + ########################################################################## + # Pose data-specific losses. + ########################################################################## + if 'quaternion' in source_labels.keys(): + params = {} + params['use_logging'] = False + params['batch_size'] = batch_size + + angle_loss_source = to_degrees( + pixelda_losses.log_quaternion_loss_batch(end_points[ + 'source_quaternion'], source_labels['quaternion'], params)) + angle_loss_transferred = to_degrees( + pixelda_losses.log_quaternion_loss_batch(end_points[ + 'transferred_quaternion'], source_labels['quaternion'], params)) + angle_loss_target = to_degrees( + pixelda_losses.log_quaternion_loss_batch(end_points[ + 'target_quaternion'], target_labels['quaternion'], params)) + + metric_name = 'eval/Angle_Loss-Source' + names_to_values[metric_name], names_to_updates[ + metric_name] = slim.metrics.mean(angle_loss_source) + + metric_name = 'eval/Angle_Loss-Transferred' + names_to_values[metric_name], names_to_updates[ + metric_name] = slim.metrics.mean(angle_loss_transferred) + + metric_name = 'eval/Angle_Loss-Target' + names_to_values[metric_name], names_to_updates[ + metric_name] = slim.metrics.mean(angle_loss_target) + + return names_to_values, names_to_updates + + +def main(_): + tf.logging.set_verbosity(tf.logging.INFO) + hparams = create_hparams(FLAGS.hparams) + run_eval( + run_dir=FLAGS.eval_dir, + checkpoint_dir=FLAGS.checkpoint_dir, + hparams=hparams) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py" new file mode 100644 index 00000000..cf39765d --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_losses.py" @@ -0,0 +1,385 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Defines the various loss functions in use by the PIXELDA model.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +# Dependency imports + +import tensorflow as tf + +slim = tf.contrib.slim + + +def add_domain_classifier_losses(end_points, hparams): + """Adds losses related to the domain-classifier. + + Args: + end_points: A map of network end point names to `Tensors`. + hparams: The hyperparameters struct. + + Returns: + loss: A `Tensor` representing the total task-classifier loss. + """ + if hparams.domain_loss_weight == 0: + tf.logging.info( + 'Domain classifier loss weight is 0, so not creating losses.') + return 0 + + # The domain prediction loss is minimized with respect to the domain + # classifier features only. Its aim is to predict the domain of the images. + # Note: 1 = 'real image' label, 0 = 'fake image' label + transferred_domain_loss = tf.losses.sigmoid_cross_entropy( + multi_class_labels=tf.zeros_like(end_points['transferred_domain_logits']), + logits=end_points['transferred_domain_logits']) + tf.summary.scalar('Domain_loss_transferred', transferred_domain_loss) + + target_domain_loss = tf.losses.sigmoid_cross_entropy( + multi_class_labels=tf.ones_like(end_points['target_domain_logits']), + logits=end_points['target_domain_logits']) + tf.summary.scalar('Domain_loss_target', target_domain_loss) + + # Compute the total domain loss: + total_domain_loss = transferred_domain_loss + target_domain_loss + total_domain_loss *= hparams.domain_loss_weight + tf.summary.scalar('Domain_loss_total', total_domain_loss) + + return total_domain_loss + +def log_quaternion_loss_batch(predictions, labels, params): + """A helper function to compute the error between quaternions. + + Args: + predictions: A Tensor of size [batch_size, 4]. + labels: A Tensor of size [batch_size, 4]. + params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'. + + Returns: + A Tensor of size [batch_size], denoting the error between the quaternions. + """ + use_logging = params['use_logging'] + assertions = [] + if use_logging: + assertions.append( + tf.Assert( + tf.reduce_all( + tf.less( + tf.abs(tf.reduce_sum(tf.square(predictions), [1]) - 1), + 1e-4)), + ['The l2 norm of each prediction quaternion vector should be 1.'])) + assertions.append( + tf.Assert( + tf.reduce_all( + tf.less( + tf.abs(tf.reduce_sum(tf.square(labels), [1]) - 1), 1e-4)), + ['The l2 norm of each label quaternion vector should be 1.'])) + + with tf.control_dependencies(assertions): + product = tf.multiply(predictions, labels) + internal_dot_products = tf.reduce_sum(product, [1]) + + if use_logging: + internal_dot_products = tf.Print(internal_dot_products, [ + internal_dot_products, + tf.shape(internal_dot_products) + ], 'internal_dot_products:') + + logcost = tf.log(1e-4 + 1 - tf.abs(internal_dot_products)) + return logcost + + +def log_quaternion_loss(predictions, labels, params): + """A helper function to compute the mean error between batches of quaternions. + + The caller is expected to add the loss to the graph. + + Args: + predictions: A Tensor of size [batch_size, 4]. + labels: A Tensor of size [batch_size, 4]. + params: A dictionary of parameters. Expecting 'use_logging', 'batch_size'. + + Returns: + A Tensor of size 1, denoting the mean error between batches of quaternions. + """ + use_logging = params['use_logging'] + logcost = log_quaternion_loss_batch(predictions, labels, params) + logcost = tf.reduce_sum(logcost, [0]) + batch_size = params['batch_size'] + logcost = tf.multiply(logcost, 1.0 / batch_size, name='log_quaternion_loss') + if use_logging: + logcost = tf.Print( + logcost, [logcost], '[logcost]', name='log_quaternion_loss_print') + return logcost + +def _quaternion_loss(labels, predictions, weight, batch_size, domain, + add_summaries): + """Creates a Quaternion Loss. + + Args: + labels: The true quaternions. + predictions: The predicted quaternions. + weight: A scalar weight. + batch_size: The size of the batches. + domain: The name of the domain from which the labels were taken. + add_summaries: Whether or not to add summaries for the losses. + + Returns: + A `Tensor` representing the loss. + """ + assert domain in ['Source', 'Transferred'] + + params = {'use_logging': False, 'batch_size': batch_size} + loss = weight * log_quaternion_loss(labels, predictions, params) + + if add_summaries: + assert_op = tf.Assert(tf.is_finite(loss), [loss]) + with tf.control_dependencies([assert_op]): + tf.summary.histogram( + 'Log_Quaternion_Loss_%s' % domain, loss, collections='losses') + tf.summary.scalar( + 'Task_Quaternion_Loss_%s' % domain, loss, collections='losses') + + return loss + + +def _add_task_specific_losses(end_points, source_labels, num_classes, hparams, + add_summaries=False): + """Adds losses related to the task-classifier. + + Args: + end_points: A map of network end point names to `Tensors`. + source_labels: A dictionary of output labels to `Tensors`. + num_classes: The number of classes used by the classifier. + hparams: The hyperparameters struct. + add_summaries: Whether or not to add the summaries. + + Returns: + loss: A `Tensor` representing the total task-classifier loss. + """ + # TODO(ddohan): Make sure the l2 regularization is added to the loss + + one_hot_labels = slim.one_hot_encoding(source_labels['class'], num_classes) + total_loss = 0 + + if 'source_task_logits' in end_points: + loss = tf.losses.softmax_cross_entropy( + onehot_labels=one_hot_labels, + logits=end_points['source_task_logits'], + weights=hparams.source_task_loss_weight) + if add_summaries: + tf.summary.scalar('Task_Classifier_Loss_Source', loss) + total_loss += loss + + if 'transferred_task_logits' in end_points: + loss = tf.losses.softmax_cross_entropy( + onehot_labels=one_hot_labels, + logits=end_points['transferred_task_logits'], + weights=hparams.transferred_task_loss_weight) + if add_summaries: + tf.summary.scalar('Task_Classifier_Loss_Transferred', loss) + total_loss += loss + + ######################### + # Pose specific losses. # + ######################### + if 'quaternion' in source_labels: + total_loss += _quaternion_loss( + source_labels['quaternion'], + end_points['source_quaternion'], + hparams.source_pose_weight, + hparams.batch_size, + 'Source', + add_summaries) + + total_loss += _quaternion_loss( + source_labels['quaternion'], + end_points['transferred_quaternion'], + hparams.transferred_pose_weight, + hparams.batch_size, + 'Transferred', + add_summaries) + + if add_summaries: + tf.summary.scalar('Task_Loss_Total', total_loss) + + return total_loss + + +def _transferred_similarity_loss(reconstructions, + source_images, + weight=1.0, + method='mse', + max_diff=0.4, + name='similarity'): + """Computes a loss encouraging similarity between source and transferred. + + Args: + reconstructions: A `Tensor` of shape [batch_size, height, width, channels] + source_images: A `Tensor` of shape [batch_size, height, width, channels]. + weight: Multiple similarity loss by this weight before returning + method: One of: + mpse = Mean Pairwise Squared Error + mse = Mean Squared Error + hinged_mse = Computes the mean squared error using squared differences + greater than hparams.transferred_similarity_max_diff + hinged_mae = Computes the mean absolute error using absolute + differences greater than hparams.transferred_similarity_max_diff. + max_diff: Maximum unpenalized difference for hinged losses + name: Identifying name to use for creating summaries + + + Returns: + A `Tensor` representing the transferred similarity loss. + + Raises: + ValueError: if `method` is not recognized. + """ + if weight == 0: + return 0 + + source_channels = source_images.shape.as_list()[-1] + reconstruction_channels = reconstructions.shape.as_list()[-1] + + # Convert grayscale source to RGB if target is RGB + if source_channels == 1 and reconstruction_channels != 1: + source_images = tf.tile(source_images, [1, 1, 1, reconstruction_channels]) + if reconstruction_channels == 1 and source_channels != 1: + reconstructions = tf.tile(reconstructions, [1, 1, 1, source_channels]) + + if method == 'mpse': + reconstruction_similarity_loss_fn = ( + tf.contrib.losses.mean_pairwise_squared_error) + elif method == 'masked_mpse': + + def masked_mpse(predictions, labels, weight): + """Masked mpse assuming we have a depth to create a mask from.""" + assert labels.shape.as_list()[-1] == 4 + mask = tf.to_float(tf.less(labels[:, :, :, 3:4], 0.99)) + mask = tf.tile(mask, [1, 1, 1, 4]) + predictions *= mask + labels *= mask + tf.image_summary('masked_pred', predictions) + tf.image_summary('masked_label', labels) + return tf.contrib.losses.mean_pairwise_squared_error( + predictions, labels, weight) + + reconstruction_similarity_loss_fn = masked_mpse + elif method == 'mse': + reconstruction_similarity_loss_fn = tf.contrib.losses.mean_squared_error + elif method == 'hinged_mse': + + def hinged_mse(predictions, labels, weight): + diffs = tf.square(predictions - labels) + diffs = tf.maximum(0.0, diffs - max_diff) + return tf.reduce_mean(diffs) * weight + + reconstruction_similarity_loss_fn = hinged_mse + elif method == 'hinged_mae': + + def hinged_mae(predictions, labels, weight): + diffs = tf.abs(predictions - labels) + diffs = tf.maximum(0.0, diffs - max_diff) + return tf.reduce_mean(diffs) * weight + + reconstruction_similarity_loss_fn = hinged_mae + else: + raise ValueError('Unknown reconstruction loss %s' % method) + + reconstruction_similarity_loss = reconstruction_similarity_loss_fn( + reconstructions, source_images, weight) + + name = '%s_Similarity_(%s)' % (name, method) + tf.summary.scalar(name, reconstruction_similarity_loss) + return reconstruction_similarity_loss + + +def g_step_loss(source_images, source_labels, end_points, hparams, num_classes): + """Configures the loss function which runs during the g-step. + + Args: + source_images: A `Tensor` of shape [batch_size, height, width, channels]. + source_labels: A dictionary of `Tensors` of shape [batch_size]. Valid keys + are 'class' and 'quaternion'. + end_points: A map of the network end points. + hparams: The hyperparameters struct. + num_classes: Number of classes for classifier loss + + Returns: + A `Tensor` representing a loss function. + + Raises: + ValueError: if hparams.transferred_similarity_loss_weight is non-zero but + hparams.transferred_similarity_loss is invalid. + """ + generator_loss = 0 + + ################################################################ + # Adds a loss which encourages the discriminator probabilities # + # to be high (near one). + ################################################################ + + # As per the GAN paper, maximize the log probs, instead of minimizing + # log(1-probs). Since we're minimizing, we'll minimize -log(probs) which is + # the same thing. + style_transfer_loss = tf.losses.sigmoid_cross_entropy( + logits=end_points['transferred_domain_logits'], + multi_class_labels=tf.ones_like(end_points['transferred_domain_logits']), + weights=hparams.style_transfer_loss_weight) + tf.summary.scalar('Style_transfer_loss', style_transfer_loss) + generator_loss += style_transfer_loss + + # Optimizes the style transfer network to produce transferred images similar + # to the source images. + generator_loss += _transferred_similarity_loss( + end_points['transferred_images'], + source_images, + weight=hparams.transferred_similarity_loss_weight, + method=hparams.transferred_similarity_loss, + name='transferred_similarity') + + # Optimizes the style transfer network to maximize classification accuracy. + if source_labels is not None and hparams.task_tower_in_g_step: + generator_loss += _add_task_specific_losses( + end_points, source_labels, num_classes, + hparams) * hparams.task_loss_in_g_weight + + return generator_loss + + +def d_step_loss(end_points, source_labels, num_classes, hparams): + """Configures the losses during the D-Step. + + Note that during the D-step, the model optimizes both the domain (binary) + classifier and the task classifier. + + Args: + end_points: A map of the network end points. + source_labels: A dictionary of output labels to `Tensors`. + num_classes: The number of classes used by the classifier. + hparams: The hyperparameters struct. + + Returns: + A `Tensor` representing the value of the D-step loss. + """ + domain_classifier_loss = add_domain_classifier_losses(end_points, hparams) + + task_classifier_loss = 0 + if source_labels is not None: + task_classifier_loss = _add_task_specific_losses( + end_points, source_labels, num_classes, hparams, add_summaries=True) + + return domain_classifier_loss + task_classifier_loss diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py" new file mode 100644 index 00000000..16b550a6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_model.py" @@ -0,0 +1,713 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Contains the Domain Adaptation via Style Transfer (PixelDA) model components. + +A number of details in the implementation make reference to one of the following +works: + +- "Unsupervised Representation Learning with Deep Convolutional + Generative Adversarial Networks"" + https://arxiv.org/abs/1511.06434 + +This paper makes several architecture recommendations: +1. Use strided convs in discriminator, fractional-strided convs in generator +2. batchnorm everywhere +3. remove fully connected layers for deep models +4. ReLu for all layers in generator, except tanh on output +5. LeakyReLu for everything in discriminator +""" +import functools +import math + +# Dependency imports +import numpy as np + +import tensorflow as tf + +slim = tf.contrib.slim + +from domain_adaptation.pixel_domain_adaptation import pixelda_task_towers + + +def create_model(hparams, + target_images, + source_images=None, + source_labels=None, + is_training=False, + noise=None, + num_classes=None): + """Create a GAN model. + + Arguments: + hparams: HParam object specifying model params + target_images: A `Tensor` of size [batch_size, height, width, channels]. It + is assumed that the images are [-1, 1] normalized. + source_images: A `Tensor` of size [batch_size, height, width, channels]. It + is assumed that the images are [-1, 1] normalized. + source_labels: A `Tensor` of size [batch_size] of categorical labels between + [0, num_classes] + is_training: whether model is currently training + noise: If None, model generates its own noise. Otherwise use provided. + num_classes: Number of classes for classification + + Returns: + end_points dict with model outputs + + Raises: + ValueError: unknown hparams.arch setting + """ + if num_classes is None and hparams.arch in ['resnet', 'simple']: + raise ValueError('Num classes must be provided to create task classifier') + + if target_images.dtype != tf.float32: + raise ValueError('target_images must be tf.float32 and [-1, 1] normalized.') + if source_images is not None and source_images.dtype != tf.float32: + raise ValueError('source_images must be tf.float32 and [-1, 1] normalized.') + + ########################### + # Create latent variables # + ########################### + latent_vars = dict() + + if hparams.noise_channel: + noise_shape = [hparams.batch_size, hparams.noise_dims] + if noise is not None: + assert noise.shape.as_list() == noise_shape + tf.logging.info('Using provided noise') + else: + tf.logging.info('Using random noise') + noise = tf.random_uniform( + shape=noise_shape, + minval=-1, + maxval=1, + dtype=tf.float32, + name='random_noise') + latent_vars['noise'] = noise + + #################### + # Create generator # + #################### + + with slim.arg_scope( + [slim.conv2d, slim.conv2d_transpose, slim.fully_connected], + normalizer_params=batch_norm_params(is_training, + hparams.batch_norm_decay), + weights_initializer=tf.random_normal_initializer( + stddev=hparams.normal_init_std), + weights_regularizer=tf.contrib.layers.l2_regularizer( + hparams.weight_decay)): + with slim.arg_scope([slim.conv2d], padding='SAME'): + if hparams.arch == 'dcgan': + end_points = dcgan( + target_images, latent_vars, hparams, scope='generator') + elif hparams.arch == 'resnet': + end_points = resnet_generator( + source_images, + target_images.shape.as_list()[1:4], + hparams=hparams, + latent_vars=latent_vars) + elif hparams.arch == 'residual_interpretation': + end_points = residual_interpretation_generator( + source_images, is_training=is_training, hparams=hparams) + elif hparams.arch == 'simple': + end_points = simple_generator( + source_images, + target_images, + is_training=is_training, + hparams=hparams, + latent_vars=latent_vars) + elif hparams.arch == 'identity': + # Pass through unmodified, besides changing # channels + # Used to calculate baseline numbers + # Also set `generator_steps=0` for baseline + if hparams.generator_steps: + raise ValueError('Must set generator_steps=0 for identity arch. Is %s' + % hparams.generator_steps) + transferred_images = source_images + source_channels = source_images.shape.as_list()[-1] + target_channels = target_images.shape.as_list()[-1] + if source_channels == 1 and target_channels == 3: + transferred_images = tf.tile(source_images, [1, 1, 1, 3]) + if source_channels == 3 and target_channels == 1: + transferred_images = tf.image.rgb_to_grayscale(source_images) + end_points = {'transferred_images': transferred_images} + else: + raise ValueError('Unknown architecture: %s' % hparams.arch) + + ##################### + # Domain Classifier # + ##################### + if hparams.arch in [ + 'dcgan', 'resnet', 'residual_interpretation', 'simple', 'identity', + ]: + + # Add a discriminator for these architectures + end_points['transferred_domain_logits'] = predict_domain( + end_points['transferred_images'], + hparams, + is_training=is_training, + reuse=False) + end_points['target_domain_logits'] = predict_domain( + target_images, + hparams, + is_training=is_training, + reuse=True) + + ################### + # Task Classifier # + ################### + if hparams.task_tower != 'none' and hparams.arch in [ + 'resnet', 'residual_interpretation', 'simple', 'identity', + ]: + with tf.variable_scope('discriminator'): + with tf.variable_scope('task_tower'): + end_points['source_task_logits'], end_points[ + 'source_quaternion'] = pixelda_task_towers.add_task_specific_model( + source_images, + hparams, + num_classes=num_classes, + is_training=is_training, + reuse_private=False, + private_scope='source_task_classifier', + reuse_shared=False) + end_points['transferred_task_logits'], end_points[ + 'transferred_quaternion'] = ( + pixelda_task_towers.add_task_specific_model( + end_points['transferred_images'], + hparams, + num_classes=num_classes, + is_training=is_training, + reuse_private=False, + private_scope='transferred_task_classifier', + reuse_shared=True)) + end_points['target_task_logits'], end_points[ + 'target_quaternion'] = pixelda_task_towers.add_task_specific_model( + target_images, + hparams, + num_classes=num_classes, + is_training=is_training, + reuse_private=True, + private_scope='transferred_task_classifier', + reuse_shared=True) + # Remove any endpoints with None values + return dict((k, v) for k, v in end_points.iteritems() if v is not None) + + +def batch_norm_params(is_training, batch_norm_decay): + return { + 'is_training': is_training, + # Decay for the moving averages. + 'decay': batch_norm_decay, + # epsilon to prevent 0s in variance. + 'epsilon': 0.001, + } + + +def lrelu(x, leakiness=0.2): + """Relu, with optional leaky support.""" + return tf.where(tf.less(x, 0.0), leakiness * x, x, name='leaky_relu') + + +def upsample(net, num_filters, scale=2, method='resize_conv', scope=None): + """Performs spatial upsampling of the given features. + + Args: + net: A `Tensor` of shape [batch_size, height, width, filters]. + num_filters: The number of output filters. + scale: The scale of the upsampling. Must be a positive integer greater or + equal to two. + method: The method by which the features are upsampled. Valid options + include 'resize_conv' and 'conv2d_transpose'. + scope: An optional variable scope. + + Returns: + A new set of features of shape + [batch_size, height*scale, width*scale, num_filters]. + + Raises: + ValueError: if `method` is not valid or + """ + if scale < 2: + raise ValueError('scale must be greater or equal to two.') + + with tf.variable_scope(scope, 'upsample', [net]): + if method == 'resize_conv': + net = tf.image.resize_nearest_neighbor( + net, [net.shape.as_list()[1] * scale, + net.shape.as_list()[2] * scale], + align_corners=True, + name='resize') + return slim.conv2d(net, num_filters, stride=1, scope='conv') + elif method == 'conv2d_transpose': + return slim.conv2d_transpose(net, num_filters, scope='deconv') + else: + raise ValueError('Upsample method [%s] was not recognized.' % method) + + +def project_latent_vars(hparams, proj_shape, latent_vars, combine_method='sum'): + """Generate noise and project to input volume size. + + Args: + hparams: The hyperparameter HParams struct. + proj_shape: Shape to project noise (not including batch size). + latent_vars: dictionary of `'key': Tensor of shape [batch_size, N]` + combine_method: How to combine the projected values. + sum = project to volume then sum + concat = concatenate along last dimension (i.e. channel) + + Returns: + If combine_method=sum, a `Tensor` of size `hparams.projection_shape` + If combine_method=concat and there are N latent vars, a `Tensor` of size + `hparams.projection_shape`, with the last channel multiplied by N + + + Raises: + ValueError: combine_method is not one of sum/concat + """ + values = [] + for var in latent_vars: + with tf.variable_scope(var): + # Project & reshape noise to a HxWxC input + projected = slim.fully_connected( + latent_vars[var], + np.prod(proj_shape), + activation_fn=tf.nn.relu, + normalizer_fn=slim.batch_norm) + values.append(tf.reshape(projected, [hparams.batch_size] + proj_shape)) + + if combine_method == 'sum': + result = values[0] + for value in values[1:]: + result += value + elif combine_method == 'concat': + # Concatenate along last axis + result = tf.concat(values, len(proj_shape)) + else: + raise ValueError('Unknown combine_method %s' % combine_method) + + tf.logging.info('Latent variables projected to size %s volume', result.shape) + + return result + + +def resnet_block(net, hparams): + """Create a resnet block.""" + net_in = net + net = slim.conv2d( + net, + hparams.resnet_filters, + stride=1, + normalizer_fn=slim.batch_norm, + activation_fn=tf.nn.relu) + net = slim.conv2d( + net, + hparams.resnet_filters, + stride=1, + normalizer_fn=slim.batch_norm, + activation_fn=None) + if hparams.resnet_residuals: + net += net_in + return net + + +def resnet_stack(images, output_shape, hparams, scope=None): + """Create a resnet style transfer block. + + Args: + images: [batch-size, height, width, channels] image tensor to feed as input + output_shape: output image shape in form [height, width, channels] + hparams: hparams objects + scope: Variable scope + + Returns: + Images after processing with resnet blocks. + """ + end_points = {} + if hparams.noise_channel: + # separate the noise for visualization + end_points['noise'] = images[:, :, :, -1] + assert images.shape.as_list()[1:3] == output_shape[0:2] + + with tf.variable_scope(scope, 'resnet_style_transfer', [images]): + with slim.arg_scope( + [slim.conv2d], + normalizer_fn=slim.batch_norm, + kernel_size=[hparams.generator_kernel_size] * 2, + stride=1): + net = slim.conv2d( + images, + hparams.resnet_filters, + normalizer_fn=None, + activation_fn=tf.nn.relu) + for block in range(hparams.resnet_blocks): + net = resnet_block(net, hparams) + end_points['resnet_block_{}'.format(block)] = net + + net = slim.conv2d( + net, + output_shape[-1], + kernel_size=[1, 1], + normalizer_fn=None, + activation_fn=tf.nn.tanh, + scope='conv_out') + end_points['transferred_images'] = net + return net, end_points + + +def predict_domain(images, + hparams, + is_training=False, + reuse=False, + scope='discriminator'): + """Creates a discriminator for a GAN. + + Args: + images: A `Tensor` of size [batch_size, height, width, channels]. It is + assumed that the images are centered between -1 and 1. + hparams: hparam object with params for discriminator + is_training: Specifies whether or not we're training or testing. + reuse: Whether to reuse variable scope + scope: An optional variable_scope. + + Returns: + [batch size, 1] - logit output of discriminator. + """ + with tf.variable_scope(scope, 'discriminator', [images], reuse=reuse): + lrelu_partial = functools.partial(lrelu, leakiness=hparams.lrelu_leakiness) + with slim.arg_scope( + [slim.conv2d], + kernel_size=[hparams.discriminator_kernel_size] * 2, + activation_fn=lrelu_partial, + stride=2, + normalizer_fn=slim.batch_norm): + + def add_noise(hidden, scope_num=None): + if scope_num: + hidden = slim.dropout( + hidden, + hparams.discriminator_dropout_keep_prob, + is_training=is_training, + scope='dropout_%s' % scope_num) + if hparams.discriminator_noise_stddev == 0: + return hidden + return hidden + tf.random_normal( + hidden.shape.as_list(), + mean=0.0, + stddev=hparams.discriminator_noise_stddev) + + # As per the recommendation of the DCGAN paper, we don't use batch norm + # on the discriminator input (https://arxiv.org/pdf/1511.06434v2.pdf). + if hparams.discriminator_image_noise: + images = add_noise(images) + net = slim.conv2d( + images, + hparams.num_discriminator_filters, + normalizer_fn=None, + stride=hparams.discriminator_first_stride, + scope='conv1_stride%s' % hparams.discriminator_first_stride) + net = add_noise(net, 1) + + block_id = 2 + # Repeatedly stack + # discriminator_conv_block_size-1 conv layers with stride 1 + # followed by a stride 2 layer + # Add (optional) noise at every point + while net.shape.as_list()[1] > hparams.projection_shape_size: + num_filters = int(hparams.num_discriminator_filters * + (hparams.discriminator_filter_factor**(block_id - 1))) + for conv_id in range(1, hparams.discriminator_conv_block_size): + net = slim.conv2d( + net, + num_filters, + stride=1, + scope='conv_%s_%s' % (block_id, conv_id)) + if hparams.discriminator_do_pooling: + net = slim.conv2d( + net, num_filters, scope='conv_%s_prepool' % block_id) + net = slim.avg_pool2d( + net, kernel_size=[2, 2], stride=2, scope='pool_%s' % block_id) + else: + net = slim.conv2d( + net, num_filters, scope='conv_%s_stride2' % block_id) + net = add_noise(net, block_id) + block_id += 1 + net = slim.flatten(net) + net = slim.fully_connected( + net, + 1, + # Models with BN here generally produce noise + normalizer_fn=None, + activation_fn=None, + scope='fc_logit_out') # Returns logits! + return net + + +def dcgan_generator(images, output_shape, hparams, scope=None): + """Transforms the visual style of the input images. + + Args: + images: A `Tensor` of shape [batch_size, height, width, channels]. + output_shape: A list or tuple of 3 elements: the output height, width and + number of channels. + hparams: hparams object with generator parameters + scope: Scope to place generator inside + + Returns: + A `Tensor` of shape [batch_size, height, width, output_channels] which + represents the result of style transfer. + + Raises: + ValueError: If `output_shape` is not a list or tuple or if it doesn't have + three elements or if `output_shape` or `images` arent square. + """ + if not isinstance(output_shape, (tuple, list)): + raise ValueError('output_shape must be a tuple or list.') + elif len(output_shape) != 3: + raise ValueError('output_shape must have three elements.') + + if output_shape[0] != output_shape[1]: + raise ValueError('output_shape must be square') + if images.shape.as_list()[1] != images.shape.as_list()[2]: + raise ValueError('images height and width must match.') + + outdim = output_shape[0] + indim = images.shape.as_list()[1] + num_iterations = int(math.ceil(math.log(float(outdim) / float(indim), 2.0))) + + with slim.arg_scope( + [slim.conv2d, slim.conv2d_transpose], + kernel_size=[hparams.generator_kernel_size] * 2, + stride=2): + with tf.variable_scope(scope or 'generator'): + + net = images + + # Repeatedly halve # filters until = hparams.decode_filters in last layer + for i in range(num_iterations): + num_filters = hparams.num_decoder_filters * 2**(num_iterations - i - 1) + net = slim.conv2d_transpose(net, num_filters, scope='deconv_%s' % i) + + # Crop down to desired size (e.g. 32x32 -> 28x28) + dif = net.shape.as_list()[1] - outdim + low = dif / 2 + high = net.shape.as_list()[1] - low + net = net[:, low:high, low:high, :] + + # No batch norm on generator output + net = slim.conv2d( + net, + output_shape[2], + kernel_size=[1, 1], + stride=1, + normalizer_fn=None, + activation_fn=tf.tanh, + scope='conv_out') + return net + + +def dcgan(target_images, latent_vars, hparams, scope='dcgan'): + """Creates the PixelDA model. + + Args: + target_images: A `Tensor` of shape [batch_size, height, width, 3] + sampled from the image domain to which we want to transfer. + latent_vars: dictionary of 'key': Tensor of shape [batch_size, N] + hparams: The hyperparameter map. + scope: Surround generator component with this scope + + Returns: + A dictionary of model outputs. + """ + proj_shape = [ + hparams.projection_shape_size, hparams.projection_shape_size, + hparams.projection_shape_channels + ] + source_volume = project_latent_vars( + hparams, proj_shape, latent_vars, combine_method='concat') + + ################################################### + # Transfer the source images to the target style. # + ################################################### + with tf.variable_scope(scope, 'generator', [target_images]): + transferred_images = dcgan_generator( + source_volume, + output_shape=target_images.shape.as_list()[1:4], + hparams=hparams) + assert transferred_images.shape.as_list() == target_images.shape.as_list() + + return {'transferred_images': transferred_images} + + +def resnet_generator(images, output_shape, hparams, latent_vars=None): + """Creates a ResNet-based generator. + + Args: + images: A `Tensor` of shape [batch_size, height, width, num_channels] + sampled from the image domain from which we want to transfer + output_shape: A length-3 array indicating the height, width and channels of + the output. + hparams: The hyperparameter map. + latent_vars: dictionary of 'key': Tensor of shape [batch_size, N] + + Returns: + A dictionary of model outputs. + """ + with tf.variable_scope('generator'): + if latent_vars: + noise_channel = project_latent_vars( + hparams, + proj_shape=images.shape.as_list()[1:3] + [1], + latent_vars=latent_vars, + combine_method='concat') + images = tf.concat([images, noise_channel], 3) + + transferred_images, end_points = resnet_stack( + images, + output_shape=output_shape, + hparams=hparams, + scope='resnet_stack') + end_points['transferred_images'] = transferred_images + + return end_points + + +def residual_interpretation_block(images, hparams, scope): + """Learns a residual image which is added to the incoming image. + + Args: + images: A `Tensor` of size [batch_size, height, width, 3] + hparams: The hyperparameters struct. + scope: The name of the variable op scope. + + Returns: + The updated images. + """ + with tf.variable_scope(scope): + with slim.arg_scope( + [slim.conv2d], + normalizer_fn=None, + kernel_size=[hparams.generator_kernel_size] * 2): + + net = images + for _ in range(hparams.res_int_convs): + net = slim.conv2d( + net, hparams.res_int_filters, activation_fn=tf.nn.relu) + net = slim.conv2d(net, 3, activation_fn=tf.nn.tanh) + + # Add the residual + images += net + + # Clip the output + images = tf.maximum(images, -1.0) + images = tf.minimum(images, 1.0) + return images + + +def residual_interpretation_generator(images, + is_training, + hparams, + latent_vars=None): + """Creates a generator producing purely residual transformations. + + A residual generator differs from the resnet generator in that each 'block' of + the residual generator produces a residual image. Consequently, the 'progress' + of the model generation process can be directly observed at inference time, + making it easier to diagnose and understand. + + Args: + images: A `Tensor` of shape [batch_size, height, width, num_channels] + sampled from the image domain from which we want to transfer. It is + assumed that the images are centered between -1 and 1. + is_training: whether or not the model is training. + hparams: The hyperparameter map. + latent_vars: dictionary of 'key': Tensor of shape [batch_size, N] + + Returns: + A dictionary of model outputs. + """ + end_points = {} + + with tf.variable_scope('generator'): + if latent_vars: + projected_latent = project_latent_vars( + hparams, + proj_shape=images.shape.as_list()[1:3] + [images.shape.as_list()[-1]], + latent_vars=latent_vars, + combine_method='sum') + images += projected_latent + with tf.variable_scope(None, 'residual_style_transfer', [images]): + for i in range(hparams.res_int_blocks): + images = residual_interpretation_block(images, hparams, + 'residual_%d' % i) + end_points['transferred_images_%d' % i] = images + + end_points['transferred_images'] = images + + return end_points + + +def simple_generator(source_images, target_images, is_training, hparams, + latent_vars): + """Simple generator architecture (stack of convs) for trying small models.""" + end_points = {} + with tf.variable_scope('generator'): + feed_source_images = source_images + + if latent_vars: + projected_latent = project_latent_vars( + hparams, + proj_shape=source_images.shape.as_list()[1:3] + [1], + latent_vars=latent_vars, + combine_method='concat') + feed_source_images = tf.concat([source_images, projected_latent], 3) + + end_points = {} + + ################################################### + # Transfer the source images to the target style. # + ################################################### + with slim.arg_scope( + [slim.conv2d], + normalizer_fn=slim.batch_norm, + stride=1, + kernel_size=[hparams.generator_kernel_size] * 2): + net = feed_source_images + + # N convolutions + for i in range(1, hparams.simple_num_conv_layers): + normalizer_fn = None + if i != 0: + normalizer_fn = slim.batch_norm + net = slim.conv2d( + net, + hparams.simple_conv_filters, + normalizer_fn=normalizer_fn, + activation_fn=tf.nn.relu) + + # Project back to right # image channels + net = slim.conv2d( + net, + target_images.shape.as_list()[-1], + kernel_size=[1, 1], + stride=1, + normalizer_fn=None, + activation_fn=tf.tanh, + scope='conv_out') + + transferred_images = net + assert transferred_images.shape.as_list() == target_images.shape.as_list() + end_points['transferred_images'] = transferred_images + + return end_points diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py" new file mode 100644 index 00000000..747c17b1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess.py" @@ -0,0 +1,129 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Contains functions for preprocessing the inputs.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +# Dependency imports + +import tensorflow as tf + + +def preprocess_classification(image, labels, is_training=False): + """Preprocesses the image and labels for classification purposes. + + Preprocessing includes shifting the images to be 0-centered between -1 and 1. + This is not only a popular method of preprocessing (inception) but is also + the mechanism used by DSNs. + + Args: + image: A `Tensor` of size [height, width, 3]. + labels: A dictionary of labels. + is_training: Whether or not we're training the model. + + Returns: + The preprocessed image and labels. + """ + # If the image is uint8, this will scale it to 0-1. + image = tf.image.convert_image_dtype(image, tf.float32) + image -= 0.5 + image *= 2 + + return image, labels + + +def preprocess_style_transfer(image, + labels, + augment=False, + size=None, + is_training=False): + """Preprocesses the image and labels for style transfer purposes. + + Args: + image: A `Tensor` of size [height, width, 3]. + labels: A dictionary of labels. + augment: Whether to apply data augmentation to inputs + size: The height and width to which images should be resized. If left as + `None`, then no resizing is performed + is_training: Whether or not we're training the model + + Returns: + The preprocessed image and labels. Scaled to [-1, 1] + """ + # If the image is uint8, this will scale it to 0-1. + image = tf.image.convert_image_dtype(image, tf.float32) + if augment and is_training: + image = image_augmentation(image) + + if size: + image = resize_image(image, size) + + image -= 0.5 + image *= 2 + + return image, labels + + +def image_augmentation(image): + """Performs data augmentation by randomly permuting the inputs. + + Args: + image: A float `Tensor` of size [height, width, channels] with values + in range[0,1]. + + Returns: + The mutated batch of images + """ + # Apply photometric data augmentation (contrast etc.) + num_channels = image.shape_as_list()[-1] + if num_channels == 4: + # Only augment image part + image, depth = image[:, :, 0:3], image[:, :, 3:4] + elif num_channels == 1: + image = tf.image.grayscale_to_rgb(image) + image = tf.image.random_brightness(image, max_delta=0.1) + image = tf.image.random_saturation(image, lower=0.5, upper=1.5) + image = tf.image.random_hue(image, max_delta=0.032) + image = tf.image.random_contrast(image, lower=0.5, upper=1.5) + image = tf.clip_by_value(image, 0, 1.0) + if num_channels == 4: + image = tf.concat(2, [image, depth]) + elif num_channels == 1: + image = tf.image.rgb_to_grayscale(image) + return image + + +def resize_image(image, size=None): + """Resize image to target size. + + Args: + image: A `Tensor` of size [height, width, 3]. + size: (height, width) to resize image to. + + Returns: + resized image + """ + if size is None: + raise ValueError('Must specify size') + + if image.shape_as_list()[:2] == size: + # Don't resize if not necessary + return image + image = tf.expand_dims(image, 0) + image = tf.image.resize_images(image, size) + image = tf.squeeze(image, 0) + return image diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py" new file mode 100644 index 00000000..73f8c7ff --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_preprocess_test.py" @@ -0,0 +1,69 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Tests for domain_adaptation.pixel_domain_adaptation.pixelda_preprocess.""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +# Dependency imports + +import tensorflow as tf + +from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess + + +class PixelDAPreprocessTest(tf.test.TestCase): + + def assert_preprocess_classification_is_centered(self, dtype, is_training): + tf.set_random_seed(0) + + if dtype == tf.uint8: + image = tf.random_uniform((100, 200, 3), maxval=255, dtype=tf.int64) + image = tf.cast(image, tf.uint8) + else: + image = tf.random_uniform((100, 200, 3), maxval=1.0, dtype=dtype) + + labels = {} + image, labels = pixelda_preprocess.preprocess_classification( + image, labels, is_training=is_training) + + with self.test_session() as sess: + np_image = sess.run(image) + + self.assertTrue(np_image.min() <= -0.95) + self.assertTrue(np_image.min() >= -1.0) + self.assertTrue(np_image.max() >= 0.95) + self.assertTrue(np_image.max() <= 1.0) + + def testPreprocessClassificationZeroCentersUint8DuringTrain(self): + self.assert_preprocess_classification_is_centered( + tf.uint8, is_training=True) + + def testPreprocessClassificationZeroCentersUint8DuringTest(self): + self.assert_preprocess_classification_is_centered( + tf.uint8, is_training=False) + + def testPreprocessClassificationZeroCentersFloatDuringTrain(self): + self.assert_preprocess_classification_is_centered( + tf.float32, is_training=True) + + def testPreprocessClassificationZeroCentersFloatDuringTest(self): + self.assert_preprocess_classification_is_centered( + tf.float32, is_training=False) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py" new file mode 100644 index 00000000..1cb42e2d --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_task_towers.py" @@ -0,0 +1,317 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Task towers for PixelDA model.""" +import tensorflow as tf + +slim = tf.contrib.slim + + +def add_task_specific_model(images, + hparams, + num_classes=10, + is_training=False, + reuse_private=False, + private_scope=None, + reuse_shared=False, + shared_scope=None): + """Create a classifier for the given images. + + The classifier is composed of a few 'private' layers followed by a few + 'shared' layers. This lets us account for different image 'style', while + sharing the last few layers as 'content' layers. + + Args: + images: A `Tensor` of size [batch_size, height, width, 3]. + hparams: model hparams + num_classes: The number of output classes. + is_training: whether model is training + reuse_private: Whether or not to reuse the private weights, which are the + first few layers in the classifier + private_scope: The name of the variable_scope for the private (unshared) + components of the classifier. + reuse_shared: Whether or not to reuse the shared weights, which are the last + few layers in the classifier + shared_scope: The name of the variable_scope for the shared components of + the classifier. + + Returns: + The logits, a `Tensor` of shape [batch_size, num_classes]. + + Raises: + ValueError: If hparams.task_classifier is an unknown value + """ + + model = hparams.task_tower + # Make sure the classifier name shows up in graph + shared_scope = shared_scope or (model + '_shared') + kwargs = { + 'num_classes': num_classes, + 'is_training': is_training, + 'reuse_private': reuse_private, + 'reuse_shared': reuse_shared, + } + + if private_scope: + kwargs['private_scope'] = private_scope + if shared_scope: + kwargs['shared_scope'] = shared_scope + + quaternion_pred = None + with slim.arg_scope( + [slim.conv2d, slim.fully_connected], + activation_fn=tf.nn.relu, + weights_regularizer=tf.contrib.layers.l2_regularizer( + hparams.weight_decay_task_classifier)): + with slim.arg_scope([slim.conv2d], padding='SAME'): + if model == 'doubling_pose_estimator': + logits, quaternion_pred = doubling_cnn_class_and_quaternion( + images, num_private_layers=hparams.num_private_layers, **kwargs) + elif model == 'mnist': + logits, _ = mnist_classifier(images, **kwargs) + elif model == 'svhn': + logits, _ = svhn_classifier(images, **kwargs) + elif model == 'gtsrb': + logits, _ = gtsrb_classifier(images, **kwargs) + elif model == 'pose_mini': + logits, quaternion_pred = pose_mini_tower(images, **kwargs) + else: + raise ValueError('Unknown task classifier %s' % model) + + return logits, quaternion_pred + + +##################################### +# Classifiers used in the DSN paper # +##################################### + + +def mnist_classifier(images, + is_training=False, + num_classes=10, + reuse_private=False, + private_scope='mnist', + reuse_shared=False, + shared_scope='task_model'): + """Creates the convolutional MNIST model from the gradient reversal paper. + + Note that since the output is a set of 'logits', the values fall in the + interval of (-infinity, infinity). Consequently, to convert the outputs to a + probability distribution over the characters, one will need to convert them + using the softmax function: + logits, endpoints = conv_mnist(images, is_training=False) + predictions = tf.nn.softmax(logits) + + Args: + images: the MNIST digits, a tensor of size [batch_size, 28, 28, 1]. + is_training: specifies whether or not we're currently training the model. + This variable will determine the behaviour of the dropout layer. + num_classes: the number of output classes to use. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + net = {} + + with tf.variable_scope(private_scope, reuse=reuse_private): + net['conv1'] = slim.conv2d(images, 32, [5, 5], scope='conv1') + net['pool1'] = slim.max_pool2d(net['conv1'], [2, 2], 2, scope='pool1') + + with tf.variable_scope(shared_scope, reuse=reuse_shared): + net['conv2'] = slim.conv2d(net['pool1'], 48, [5, 5], scope='conv2') + net['pool2'] = slim.max_pool2d(net['conv2'], [2, 2], 2, scope='pool2') + net['fc3'] = slim.fully_connected( + slim.flatten(net['pool2']), 100, scope='fc3') + net['fc4'] = slim.fully_connected( + slim.flatten(net['fc3']), 100, scope='fc4') + logits = slim.fully_connected( + net['fc4'], num_classes, activation_fn=None, scope='fc5') + return logits, net + + +def svhn_classifier(images, + is_training=False, + num_classes=10, + reuse_private=False, + private_scope=None, + reuse_shared=False, + shared_scope='task_model'): + """Creates the convolutional SVHN model from the gradient reversal paper. + + Note that since the output is a set of 'logits', the values fall in the + interval of (-infinity, infinity). Consequently, to convert the outputs to a + probability distribution over the characters, one will need to convert them + using the softmax function: + logits = mnist.Mnist(images, is_training=False) + predictions = tf.nn.softmax(logits) + + Args: + images: the SVHN digits, a tensor of size [batch_size, 40, 40, 3]. + is_training: specifies whether or not we're currently training the model. + This variable will determine the behaviour of the dropout layer. + num_classes: the number of output classes to use. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + net = {} + + with tf.variable_scope(private_scope, reuse=reuse_private): + net['conv1'] = slim.conv2d(images, 64, [5, 5], scope='conv1') + net['pool1'] = slim.max_pool2d(net['conv1'], [3, 3], 2, scope='pool1') + + with tf.variable_scope(shared_scope, reuse=reuse_shared): + net['conv2'] = slim.conv2d(net['pool1'], 64, [5, 5], scope='conv2') + net['pool2'] = slim.max_pool2d(net['conv2'], [3, 3], 2, scope='pool2') + net['conv3'] = slim.conv2d(net['pool2'], 128, [5, 5], scope='conv3') + + net['fc3'] = slim.fully_connected( + slim.flatten(net['conv3']), 3072, scope='fc3') + net['fc4'] = slim.fully_connected( + slim.flatten(net['fc3']), 2048, scope='fc4') + + logits = slim.fully_connected( + net['fc4'], num_classes, activation_fn=None, scope='fc5') + + return logits, net + + +def gtsrb_classifier(images, + is_training=False, + num_classes=43, + reuse_private=False, + private_scope='gtsrb', + reuse_shared=False, + shared_scope='task_model'): + """Creates the convolutional GTSRB model from the gradient reversal paper. + + Note that since the output is a set of 'logits', the values fall in the + interval of (-infinity, infinity). Consequently, to convert the outputs to a + probability distribution over the characters, one will need to convert them + using the softmax function: + logits = mnist.Mnist(images, is_training=False) + predictions = tf.nn.softmax(logits) + + Args: + images: the SVHN digits, a tensor of size [batch_size, 40, 40, 3]. + is_training: specifies whether or not we're currently training the model. + This variable will determine the behaviour of the dropout layer. + num_classes: the number of output classes to use. + reuse_private: Whether or not to reuse the private components of the model. + private_scope: The name of the private scope. + reuse_shared: Whether or not to reuse the shared components of the model. + shared_scope: The name of the shared scope. + + Returns: + the output logits, a tensor of size [batch_size, num_classes]. + a dictionary with key/values the layer names and tensors. + """ + + net = {} + + with tf.variable_scope(private_scope, reuse=reuse_private): + net['conv1'] = slim.conv2d(images, 96, [5, 5], scope='conv1') + net['pool1'] = slim.max_pool2d(net['conv1'], [2, 2], 2, scope='pool1') + with tf.variable_scope(shared_scope, reuse=reuse_shared): + net['conv2'] = slim.conv2d(net['pool1'], 144, [3, 3], scope='conv2') + net['pool2'] = slim.max_pool2d(net['conv2'], [2, 2], 2, scope='pool2') + net['conv3'] = slim.conv2d(net['pool2'], 256, [5, 5], scope='conv3') + net['pool3'] = slim.max_pool2d(net['conv3'], [2, 2], 2, scope='pool3') + + net['fc3'] = slim.fully_connected( + slim.flatten(net['pool3']), 512, scope='fc3') + logits = slim.fully_connected( + net['fc3'], num_classes, activation_fn=None, scope='fc4') + + return logits, net + + +######################### +# pose_mini task towers # +######################### + + +def pose_mini_tower(images, + num_classes=11, + is_training=False, + reuse_private=False, + private_scope='pose_mini', + reuse_shared=False, + shared_scope='task_model'): + """Task tower for the pose_mini dataset.""" + + with tf.variable_scope(private_scope, reuse=reuse_private): + net = slim.conv2d(images, 32, [5, 5], scope='conv1') + net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool1') + with tf.variable_scope(shared_scope, reuse=reuse_shared): + net = slim.conv2d(net, 64, [5, 5], scope='conv2') + net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool2') + net = slim.flatten(net) + + net = slim.fully_connected(net, 128, scope='fc3') + net = slim.dropout(net, 0.5, is_training=is_training, scope='dropout') + with tf.variable_scope('quaternion_prediction'): + quaternion_pred = slim.fully_connected( + net, 4, activation_fn=tf.tanh, scope='fc_q') + quaternion_pred = tf.nn.l2_normalize(quaternion_pred, 1) + + logits = slim.fully_connected( + net, num_classes, activation_fn=None, scope='fc4') + + return logits, quaternion_pred + + +def doubling_cnn_class_and_quaternion(images, + num_private_layers=1, + num_classes=10, + is_training=False, + reuse_private=False, + private_scope='doubling_cnn', + reuse_shared=False, + shared_scope='task_model'): + """Alternate conv, pool while doubling filter count.""" + net = images + depth = 32 + layer_id = 1 + + with tf.variable_scope(private_scope, reuse=reuse_private): + while num_private_layers > 0 and net.shape.as_list()[1] > 5: + net = slim.conv2d(net, depth, [3, 3], scope='conv%s' % layer_id) + net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool%s' % layer_id) + depth *= 2 + layer_id += 1 + num_private_layers -= 1 + + with tf.variable_scope(shared_scope, reuse=reuse_shared): + while net.shape.as_list()[1] > 5: + net = slim.conv2d(net, depth, [3, 3], scope='conv%s' % layer_id) + net = slim.max_pool2d(net, [2, 2], stride=2, scope='pool%s' % layer_id) + depth *= 2 + layer_id += 1 + + net = slim.flatten(net) + net = slim.fully_connected(net, 100, scope='fc1') + net = slim.dropout(net, 0.5, is_training=is_training, scope='dropout') + quaternion_pred = slim.fully_connected( + net, 4, activation_fn=tf.tanh, scope='fc_q') + quaternion_pred = tf.nn.l2_normalize(quaternion_pred, 1) + + logits = slim.fully_connected( + net, num_classes, activation_fn=None, scope='fc_logits') + + return logits, quaternion_pred diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py" new file mode 100644 index 00000000..4ca072cc --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_train.py" @@ -0,0 +1,409 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +r"""Trains the PixelDA model.""" + +from functools import partial +import os + +# Dependency imports + +import tensorflow as tf + +from domain_adaptation.datasets import dataset_factory +from domain_adaptation.pixel_domain_adaptation import pixelda_losses +from domain_adaptation.pixel_domain_adaptation import pixelda_model +from domain_adaptation.pixel_domain_adaptation import pixelda_preprocess +from domain_adaptation.pixel_domain_adaptation import pixelda_utils +from domain_adaptation.pixel_domain_adaptation.hparams import create_hparams + +slim = tf.contrib.slim + +flags = tf.app.flags +FLAGS = flags.FLAGS + +flags.DEFINE_string('master', '', 'BNS name of the TensorFlow master to use.') + +flags.DEFINE_integer( + 'ps_tasks', 0, + 'The number of parameter servers. If the value is 0, then the parameters ' + 'are handled locally by the worker.') + +flags.DEFINE_integer( + 'task', 0, + 'The Task ID. This value is used when training with multiple workers to ' + 'identify each worker.') + +flags.DEFINE_string('train_log_dir', '/tmp/pixelda/', + 'Directory where to write event logs.') + +flags.DEFINE_integer( + 'save_summaries_steps', 500, + 'The frequency with which summaries are saved, in seconds.') + +flags.DEFINE_integer('save_interval_secs', 300, + 'The frequency with which the model is saved, in seconds.') + +flags.DEFINE_boolean('summarize_gradients', False, + 'Whether to summarize model gradients') + +flags.DEFINE_integer( + 'print_loss_steps', 100, + 'The frequency with which the losses are printed, in steps.') + +flags.DEFINE_string('source_dataset', 'mnist', 'The name of the source dataset.' + ' If hparams="arch=dcgan", this flag is ignored.') + +flags.DEFINE_string('target_dataset', 'mnist_m', + 'The name of the target dataset.') + +flags.DEFINE_string('source_split_name', 'train', + 'Name of the train split for the source.') + +flags.DEFINE_string('target_split_name', 'train', + 'Name of the train split for the target.') + +flags.DEFINE_string('dataset_dir', '', + 'The directory where the datasets can be found.') + +flags.DEFINE_integer( + 'num_readers', 4, + 'The number of parallel readers that read data from the dataset.') + +flags.DEFINE_integer('num_preprocessing_threads', 4, + 'The number of threads used to create the batches.') + +# HParams + +flags.DEFINE_string('hparams', '', 'Comma separated hyperparameter values') + + +def _get_vars_and_update_ops(hparams, scope): + """Returns the variables and update ops for a particular variable scope. + + Args: + hparams: The hyperparameters struct. + scope: The variable scope. + + Returns: + A tuple consisting of trainable variables and update ops. + """ + is_trainable = lambda x: x in tf.trainable_variables() + var_list = filter(is_trainable, slim.get_model_variables(scope)) + global_step = slim.get_or_create_global_step() + + update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope) + + tf.logging.info('All variables for scope: %s', + slim.get_model_variables(scope)) + tf.logging.info('Trainable variables for scope: %s', var_list) + + return var_list, update_ops + + +def _train(discriminator_train_op, + generator_train_op, + logdir, + master='', + is_chief=True, + scaffold=None, + hooks=None, + chief_only_hooks=None, + save_checkpoint_secs=600, + save_summaries_steps=100, + hparams=None): + """Runs the training loop. + + Args: + discriminator_train_op: A `Tensor` that, when executed, will apply the + gradients and return the loss value for the discriminator. + generator_train_op: A `Tensor` that, when executed, will apply the + gradients and return the loss value for the generator. + logdir: The directory where the graph and checkpoints are saved. + master: The URL of the master. + is_chief: Specifies whether or not the training is being run by the primary + replica during replica training. + scaffold: An tf.train.Scaffold instance. + hooks: List of `tf.train.SessionRunHook` callbacks which are run inside the + training loop. + chief_only_hooks: List of `tf.train.SessionRunHook` instances which are run + inside the training loop for the chief trainer only. + save_checkpoint_secs: The frequency, in seconds, that a checkpoint is saved + using a default checkpoint saver. If `save_checkpoint_secs` is set to + `None`, then the default checkpoint saver isn't used. + save_summaries_steps: The frequency, in number of global steps, that the + summaries are written to disk using a default summary saver. If + `save_summaries_steps` is set to `None`, then the default summary saver + isn't used. + hparams: The hparams struct. + + Returns: + the value of the loss function after training. + + Raises: + ValueError: if `logdir` is `None` and either `save_checkpoint_secs` or + `save_summaries_steps` are `None. + """ + global_step = slim.get_or_create_global_step() + + scaffold = scaffold or tf.train.Scaffold() + + hooks = hooks or [] + + if is_chief: + session_creator = tf.train.ChiefSessionCreator( + scaffold=scaffold, checkpoint_dir=logdir, master=master) + + if chief_only_hooks: + hooks.extend(chief_only_hooks) + hooks.append(tf.train.StepCounterHook(output_dir=logdir)) + + if save_summaries_steps: + if logdir is None: + raise ValueError( + 'logdir cannot be None when save_summaries_steps is None') + hooks.append( + tf.train.SummarySaverHook( + scaffold=scaffold, + save_steps=save_summaries_steps, + output_dir=logdir)) + + if save_checkpoint_secs: + if logdir is None: + raise ValueError( + 'logdir cannot be None when save_checkpoint_secs is None') + hooks.append( + tf.train.CheckpointSaverHook( + logdir, save_secs=save_checkpoint_secs, scaffold=scaffold)) + else: + session_creator = tf.train.WorkerSessionCreator( + scaffold=scaffold, master=master) + + with tf.train.MonitoredSession( + session_creator=session_creator, hooks=hooks) as session: + loss = None + while not session.should_stop(): + # Run the domain classifier op X times. + for _ in range(hparams.discriminator_steps): + if session.should_stop(): + return loss + loss, np_global_step = session.run( + [discriminator_train_op, global_step]) + if np_global_step % FLAGS.print_loss_steps == 0: + tf.logging.info('Step %d: Discriminator Loss = %.2f', np_global_step, + loss) + + # Run the generator op X times. + for _ in range(hparams.generator_steps): + if session.should_stop(): + return loss + loss, np_global_step = session.run([generator_train_op, global_step]) + if np_global_step % FLAGS.print_loss_steps == 0: + tf.logging.info('Step %d: Generator Loss = %.2f', np_global_step, + loss) + return loss + + +def run_training(run_dir, checkpoint_dir, hparams): + """Runs the training loop. + + Args: + run_dir: The directory where training specific logs are placed + checkpoint_dir: The directory where the checkpoints and log files are + stored. + hparams: The hyperparameters struct. + + Raises: + ValueError: if hparams.arch is not recognized. + """ + for path in [run_dir, checkpoint_dir]: + if not tf.gfile.Exists(path): + tf.gfile.MakeDirs(path) + + # Serialize hparams to log dir + hparams_filename = os.path.join(checkpoint_dir, 'hparams.json') + with tf.gfile.FastGFile(hparams_filename, 'w') as f: + f.write(hparams.to_json()) + + with tf.Graph().as_default(): + with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)): + global_step = slim.get_or_create_global_step() + + ######################### + # Preprocess the inputs # + ######################### + target_dataset = dataset_factory.get_dataset( + FLAGS.target_dataset, + split_name='train', + dataset_dir=FLAGS.dataset_dir) + target_images, _ = dataset_factory.provide_batch( + FLAGS.target_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers, + hparams.batch_size, FLAGS.num_preprocessing_threads) + num_target_classes = target_dataset.num_classes + + if hparams.arch not in ['dcgan']: + source_dataset = dataset_factory.get_dataset( + FLAGS.source_dataset, + split_name='train', + dataset_dir=FLAGS.dataset_dir) + num_source_classes = source_dataset.num_classes + source_images, source_labels = dataset_factory.provide_batch( + FLAGS.source_dataset, 'train', FLAGS.dataset_dir, FLAGS.num_readers, + hparams.batch_size, FLAGS.num_preprocessing_threads) + # Data provider provides 1 hot labels, but we expect categorical. + source_labels['class'] = tf.argmax(source_labels['classes'], 1) + del source_labels['classes'] + if num_source_classes != num_target_classes: + raise ValueError( + 'Source and Target datasets must have same number of classes. ' + 'Are %d and %d' % (num_source_classes, num_target_classes)) + else: + source_images = None + source_labels = None + + #################### + # Define the model # + #################### + end_points = pixelda_model.create_model( + hparams, + target_images, + source_images=source_images, + source_labels=source_labels, + is_training=True, + num_classes=num_target_classes) + + ################################# + # Get the variables to optimize # + ################################# + generator_vars, generator_update_ops = _get_vars_and_update_ops( + hparams, 'generator') + discriminator_vars, discriminator_update_ops = _get_vars_and_update_ops( + hparams, 'discriminator') + + ######################## + # Configure the losses # + ######################## + generator_loss = pixelda_losses.g_step_loss( + source_images, + source_labels, + end_points, + hparams, + num_classes=num_target_classes) + discriminator_loss = pixelda_losses.d_step_loss( + end_points, source_labels, num_target_classes, hparams) + + ########################### + # Create the training ops # + ########################### + learning_rate = hparams.learning_rate + if hparams.lr_decay_steps: + learning_rate = tf.train.exponential_decay( + learning_rate, + slim.get_or_create_global_step(), + decay_steps=hparams.lr_decay_steps, + decay_rate=hparams.lr_decay_rate, + staircase=True) + tf.summary.scalar('Learning_rate', learning_rate) + + + if hparams.discriminator_steps == 0: + discriminator_train_op = tf.no_op() + else: + discriminator_optimizer = tf.train.AdamOptimizer( + learning_rate, beta1=hparams.adam_beta1) + + discriminator_train_op = slim.learning.create_train_op( + discriminator_loss, + discriminator_optimizer, + update_ops=discriminator_update_ops, + variables_to_train=discriminator_vars, + clip_gradient_norm=hparams.clip_gradient_norm, + summarize_gradients=FLAGS.summarize_gradients) + + if hparams.generator_steps == 0: + generator_train_op = tf.no_op() + else: + generator_optimizer = tf.train.AdamOptimizer( + learning_rate, beta1=hparams.adam_beta1) + generator_train_op = slim.learning.create_train_op( + generator_loss, + generator_optimizer, + update_ops=generator_update_ops, + variables_to_train=generator_vars, + clip_gradient_norm=hparams.clip_gradient_norm, + summarize_gradients=FLAGS.summarize_gradients) + + ############# + # Summaries # + ############# + pixelda_utils.summarize_model(end_points) + pixelda_utils.summarize_transferred_grid( + end_points['transferred_images'], source_images, name='Transferred') + if 'source_images_recon' in end_points: + pixelda_utils.summarize_transferred_grid( + end_points['source_images_recon'], + source_images, + name='Source Reconstruction') + pixelda_utils.summaries_color_distributions(end_points['transferred_images'], + 'Transferred') + pixelda_utils.summaries_color_distributions(target_images, 'Target') + + if source_images is not None: + pixelda_utils.summarize_transferred(source_images, + end_points['transferred_images']) + pixelda_utils.summaries_color_distributions(source_images, 'Source') + pixelda_utils.summaries_color_distributions( + tf.abs(source_images - end_points['transferred_images']), + 'Abs(Source_minus_Transferred)') + + number_of_steps = None + if hparams.num_training_examples: + # Want to control by amount of data seen, not # steps + number_of_steps = hparams.num_training_examples / hparams.batch_size + + hooks = [tf.train.StepCounterHook(),] + + chief_only_hooks = [ + tf.train.CheckpointSaverHook( + saver=tf.train.Saver(), + checkpoint_dir=run_dir, + save_secs=FLAGS.save_interval_secs) + ] + + if number_of_steps: + hooks.append(tf.train.StopAtStepHook(last_step=number_of_steps)) + + _train( + discriminator_train_op, + generator_train_op, + logdir=run_dir, + master=FLAGS.master, + is_chief=FLAGS.task == 0, + hooks=hooks, + chief_only_hooks=chief_only_hooks, + save_checkpoint_secs=None, + save_summaries_steps=FLAGS.save_summaries_steps, + hparams=hparams) + +def main(_): + tf.logging.set_verbosity(tf.logging.INFO) + hparams = create_hparams(FLAGS.hparams) + run_training( + run_dir=FLAGS.train_log_dir, + checkpoint_dir=FLAGS.train_log_dir, + hparams=hparams) + + +if __name__ == '__main__': + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py" new file mode 100644 index 00000000..28e8006f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/domain_adaptation/pixel_domain_adaptation/pixelda_utils.py" @@ -0,0 +1,195 @@ +# Copyright 2017 Google Inc. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. + +"""Utilities for PixelDA model.""" +import math + +# Dependency imports + +import tensorflow as tf + +slim = tf.contrib.slim + +flags = tf.app.flags +FLAGS = flags.FLAGS + + +def remove_depth(images): + """Takes a batch of images and remove depth channel if present.""" + if images.shape.as_list()[-1] == 4: + return images[:, :, :, 0:3] + return images + + +def image_grid(images, max_grid_size=4): + """Given images and N, return first N^2 images as an NxN image grid. + + Args: + images: a `Tensor` of size [batch_size, height, width, channels] + max_grid_size: Maximum image grid height/width + + Returns: + Single image batch, of dim [1, h*n, w*n, c] + """ + images = remove_depth(images) + batch_size = images.shape.as_list()[0] + grid_size = min(int(math.sqrt(batch_size)), max_grid_size) + assert images.shape.as_list()[0] >= grid_size * grid_size + + # If we have a depth channel + if images.shape.as_list()[-1] == 4: + images = images[:grid_size * grid_size, :, :, 0:3] + depth = tf.image.grayscale_to_rgb(images[:grid_size * grid_size, :, :, 3:4]) + + images = tf.reshape(images, [-1, images.shape.as_list()[2], 3]) + split = tf.split(0, grid_size, images) + depth = tf.reshape(depth, [-1, images.shape.as_list()[2], 3]) + depth_split = tf.split(0, grid_size, depth) + grid = tf.concat(split + depth_split, 1) + return tf.expand_dims(grid, 0) + else: + images = images[:grid_size * grid_size, :, :, :] + images = tf.reshape( + images, [-1, images.shape.as_list()[2], + images.shape.as_list()[3]]) + split = tf.split(images, grid_size, 0) + grid = tf.concat(split, 1) + return tf.expand_dims(grid, 0) + + +def source_and_output_image_grid(output_images, + source_images=None, + max_grid_size=4): + """Create NxN image grid for output, concatenate source grid if given. + + Makes grid out of output_images and, if provided, source_images, and + concatenates them. + + Args: + output_images: [batch_size, h, w, c] tensor of images + source_images: optional[batch_size, h, w, c] tensor of images + max_grid_size: Image grid height/width + + Returns: + Single image batch, of dim [1, h*n, w*n, c] + + + """ + output_grid = image_grid(output_images, max_grid_size=max_grid_size) + if source_images is not None: + source_grid = image_grid(source_images, max_grid_size=max_grid_size) + # Make sure they have the same # of channels before concat + # Assumes either 1 or 3 channels + if output_grid.shape.as_list()[-1] != source_grid.shape.as_list()[-1]: + if output_grid.shape.as_list()[-1] == 1: + output_grid = tf.tile(output_grid, [1, 1, 1, 3]) + if source_grid.shape.as_list()[-1] == 1: + source_grid = tf.tile(source_grid, [1, 1, 1, 3]) + output_grid = tf.concat([output_grid, source_grid], 1) + return output_grid + + +def summarize_model(end_points): + """Summarizes the given model via its end_points. + + Args: + end_points: A dictionary of end_point names to `Tensor`. + """ + tf.summary.histogram('domain_logits_transferred', + tf.sigmoid(end_points['transferred_domain_logits'])) + + tf.summary.histogram('domain_logits_target', + tf.sigmoid(end_points['target_domain_logits'])) + + +def summarize_transferred_grid(transferred_images, + source_images=None, + name='Transferred'): + """Produces a visual grid summarization of the image transferrence. + + Args: + transferred_images: A `Tensor` of size [batch_size, height, width, c]. + source_images: A `Tensor` of size [batch_size, height, width, c]. + name: Name to use in summary name + """ + if source_images is not None: + grid = source_and_output_image_grid(transferred_images, source_images) + else: + grid = image_grid(transferred_images) + tf.summary.image('%s_Images_Grid' % name, grid, max_outputs=1) + + +def summarize_transferred(source_images, + transferred_images, + max_images=20, + name='Transferred'): + """Produces a visual summary of the image transferrence. + + This summary displays the source image, transferred image, and a grayscale + difference image which highlights the differences between input and output. + + Args: + source_images: A `Tensor` of size [batch_size, height, width, channels]. + transferred_images: A `Tensor` of size [batch_size, height, width, channels] + max_images: The number of images to show. + name: Name to use in summary name + + Raises: + ValueError: If number of channels in source and target are incompatible + """ + source_channels = source_images.shape.as_list()[-1] + transferred_channels = transferred_images.shape.as_list()[-1] + if source_channels < transferred_channels: + if source_channels != 1: + raise ValueError( + 'Source must be 1 channel or same # of channels as target') + source_images = tf.tile(source_images, [1, 1, 1, transferred_channels]) + if transferred_channels < source_channels: + if transferred_channels != 1: + raise ValueError( + 'Target must be 1 channel or same # of channels as source') + transferred_images = tf.tile(transferred_images, [1, 1, 1, source_channels]) + diffs = tf.abs(source_images - transferred_images) + diffs = tf.reduce_max(diffs, reduction_indices=[3], keep_dims=True) + diffs = tf.tile(diffs, [1, 1, 1, max(source_channels, transferred_channels)]) + + transition_images = tf.concat([ + source_images, + transferred_images, + diffs, + ], 2) + + tf.summary.image( + '%s_difference' % name, transition_images, max_outputs=max_images) + + +def summaries_color_distributions(images, name): + """Produces a histogram of the color distributions of the images. + + Args: + images: A `Tensor` of size [batch_size, height, width, 3]. + name: The name of the images being summarized. + """ + tf.summary.histogram('color_values/%s' % name, images) + + +def summarize_images(images, name): + """Produces a visual summary of the given images. + + Args: + images: A `Tensor` of size [batch_size, height, width, 3]. + name: The name of the images being summarized. + """ + grid = image_grid(images) + tf.summary.image('%s_Images' % name, grid, max_outputs=1) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/README.md" new file mode 100644 index 00000000..6ea4918e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/README.md" @@ -0,0 +1,62 @@ +Code for performing Hierarchical RL based on the following publications: + +"Data-Efficient Hierarchical Reinforcement Learning" by +Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, and Sergey Levine +(https://arxiv.org/abs/1805.08296). + +"Near-Optimal Representation Learning for Hierarchical Reinforcement Learning" +by Ofir Nachum, Shixiang (Shane) Gu, Honglak Lee, and Sergey Levine +(https://arxiv.org/abs/1810.01257). + + +Requirements: +* TensorFlow (see http://www.tensorflow.org for how to install/upgrade) +* Gin Config (see https://github.com/google/gin-config) +* Tensorflow Agents (see https://github.com/tensorflow/agents) +* OpenAI Gym (see http://gym.openai.com/docs, be sure to install MuJoCo as well) +* NumPy (see http://www.numpy.org/) + + +Quick Start: + +Run a training job based on the original HIRO paper on Ant Maze: + +``` +python scripts/local_train.py test1 hiro_orig ant_maze base_uvf suite +``` + +Run a continuous evaluation job for that experiment: + +``` +python scripts/local_eval.py test1 hiro_orig ant_maze base_uvf suite +``` + +To run the same experiment with online representation learning (the +"Near-Optimal" paper), change `hiro_orig` to `hiro_repr`. +You can also run with `hiro_xy` to run the same experiment with HIRO on only the +xy coordinates of the agent. + +To run on other environments, change `ant_maze` to something else; e.g., +`ant_push_multi`, `ant_fall_multi`, etc. See `context/configs/*` for other options. + + +Basic Code Guide: + +The code for training resides in train.py. The code trains a lower-level policy +(a UVF agent in the code) and a higher-level policy (a MetaAgent in the code) +concurrently. The higher-level policy communicates goals to the lower-level +policy. In the code, this is called a context. Not only does the lower-level +policy act with respect to a context (a higher-level specified goal), but the +higher-level policy also acts with respect to an environment-specified context +(corresponding to the navigation target location associated with the task). +Therefore, in `context/configs/*` you will find both specifications for task setup +as well as goal configurations. Most remaining hyperparameters used for +training/evaluation may be found in `configs/*`. + +NOTE: Not all the code corresponding to the "Near-Optimal" paper is included. +Namely, changes to low-level policy training proposed in the paper (discounting +and auxiliary rewards) are not implemented here. Performance should not change +significantly. + + +Maintained by Ofir Nachum (ofirnachum). diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agent.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agent.py" new file mode 100644 index 00000000..cb02b51f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agent.py" @@ -0,0 +1,774 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A UVF agent. +""" + +import tensorflow as tf +import gin.tf +from agents import ddpg_agent +# pylint: disable=unused-import +import cond_fn +from utils import utils as uvf_utils +from context import gin_imports +# pylint: enable=unused-import +slim = tf.contrib.slim + + +@gin.configurable +class UvfAgentCore(object): + """Defines basic functions for UVF agent. Must be inherited with an RL agent. + + Used as lower-level agent. + """ + + def __init__(self, + observation_spec, + action_spec, + tf_env, + tf_context, + step_cond_fn=cond_fn.env_transition, + reset_episode_cond_fn=cond_fn.env_restart, + reset_env_cond_fn=cond_fn.false_fn, + metrics=None, + **base_agent_kwargs): + """Constructs a UVF agent. + + Args: + observation_spec: A TensorSpec defining the observations. + action_spec: A BoundedTensorSpec defining the actions. + tf_env: A Tensorflow environment object. + tf_context: A Context class. + step_cond_fn: A function indicating whether to increment the num of steps. + reset_episode_cond_fn: A function indicating whether to restart the + episode, resampling the context. + reset_env_cond_fn: A function indicating whether to perform a manual reset + of the environment. + metrics: A list of functions that evaluate metrics of the agent. + **base_agent_kwargs: A dictionary of parameters for base RL Agent. + Raises: + ValueError: If 'dqda_clipping' is < 0. + """ + self._step_cond_fn = step_cond_fn + self._reset_episode_cond_fn = reset_episode_cond_fn + self._reset_env_cond_fn = reset_env_cond_fn + self.metrics = metrics + + # expose tf_context methods + self.tf_context = tf_context(tf_env=tf_env) + self.set_replay = self.tf_context.set_replay + self.sample_contexts = self.tf_context.sample_contexts + self.compute_rewards = self.tf_context.compute_rewards + self.gamma_index = self.tf_context.gamma_index + self.context_specs = self.tf_context.context_specs + self.context_as_action_specs = self.tf_context.context_as_action_specs + self.init_context_vars = self.tf_context.create_vars + + self.env_observation_spec = observation_spec[0] + merged_observation_spec = (uvf_utils.merge_specs( + (self.env_observation_spec,) + self.context_specs),) + self._context_vars = dict() + self._action_vars = dict() + + self.BASE_AGENT_CLASS.__init__( + self, + observation_spec=merged_observation_spec, + action_spec=action_spec, + **base_agent_kwargs + ) + + def set_meta_agent(self, agent=None): + self._meta_agent = agent + + @property + def meta_agent(self): + return self._meta_agent + + def actor_loss(self, states, actions, rewards, discounts, + next_states): + """Returns the next action for the state. + + Args: + state: A [num_state_dims] tensor representing a state. + context: A list of [num_context_dims] tensor representing a context. + Returns: + A [num_action_dims] tensor representing the action. + """ + return self.BASE_AGENT_CLASS.actor_loss(self, states) + + def action(self, state, context=None): + """Returns the next action for the state. + + Args: + state: A [num_state_dims] tensor representing a state. + context: A list of [num_context_dims] tensor representing a context. + Returns: + A [num_action_dims] tensor representing the action. + """ + merged_state = self.merged_state(state, context) + return self.BASE_AGENT_CLASS.action(self, merged_state) + + def actions(self, state, context=None): + """Returns the next action for the state. + + Args: + state: A [-1, num_state_dims] tensor representing a state. + context: A list of [-1, num_context_dims] tensor representing a context. + Returns: + A [-1, num_action_dims] tensor representing the action. + """ + merged_states = self.merged_states(state, context) + return self.BASE_AGENT_CLASS.actor_net(self, merged_states) + + def log_probs(self, states, actions, state_reprs, contexts=None): + assert contexts is not None + batch_dims = [tf.shape(states)[0], tf.shape(states)[1]] + contexts = self.tf_context.context_multi_transition_fn( + contexts, states=tf.to_float(state_reprs)) + + flat_states = tf.reshape(states, + [batch_dims[0] * batch_dims[1], states.shape[-1]]) + flat_contexts = [tf.reshape(tf.cast(context, states.dtype), + [batch_dims[0] * batch_dims[1], context.shape[-1]]) + for context in contexts] + flat_pred_actions = self.actions(flat_states, flat_contexts) + pred_actions = tf.reshape(flat_pred_actions, + batch_dims + [flat_pred_actions.shape[-1]]) + + error = tf.square(actions - pred_actions) + spec_range = (self._action_spec.maximum - self._action_spec.minimum) / 2 + normalized_error = error / tf.constant(spec_range) ** 2 + return -normalized_error + + @gin.configurable('uvf_add_noise_fn') + def add_noise_fn(self, action_fn, stddev=1.0, debug=False, + clip=True, global_step=None): + """Returns the action_fn with additive Gaussian noise. + + Args: + action_fn: A callable(`state`, `context`) which returns a + [num_action_dims] tensor representing a action. + stddev: stddev for the Ornstein-Uhlenbeck noise. + debug: Print debug messages. + Returns: + A [num_action_dims] action tensor. + """ + if global_step is not None: + stddev *= tf.maximum( # Decay exploration during training. + tf.train.exponential_decay(1.0, global_step, 1e6, 0.8), 0.5) + def noisy_action_fn(state, context=None): + """Noisy action fn.""" + action = action_fn(state, context) + if debug: + action = uvf_utils.tf_print( + action, [action], + message='[add_noise_fn] pre-noise action', + first_n=100) + noise_dist = tf.distributions.Normal(tf.zeros_like(action), + tf.ones_like(action) * stddev) + noise = noise_dist.sample() + action += noise + if debug: + action = uvf_utils.tf_print( + action, [action], + message='[add_noise_fn] post-noise action', + first_n=100) + if clip: + action = uvf_utils.clip_to_spec(action, self._action_spec) + return action + return noisy_action_fn + + def merged_state(self, state, context=None): + """Returns the merged state from the environment state and contexts. + + Args: + state: A [num_state_dims] tensor representing a state. + context: A list of [num_context_dims] tensor representing a context. + If None, use the internal context. + Returns: + A [num_merged_state_dims] tensor representing the merged state. + """ + if context is None: + context = list(self.context_vars) + state = tf.concat([state,] + context, axis=-1) + self._validate_states(self._batch_state(state)) + return state + + def merged_states(self, states, contexts=None): + """Returns the batch merged state from the batch env state and contexts. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + contexts: A list of [batch_size, num_context_dims] tensor + representing a batch of contexts. If None, + use the internal context. + Returns: + A [batch_size, num_merged_state_dims] tensor representing the batch + of merged states. + """ + if contexts is None: + contexts = [tf.tile(tf.expand_dims(context, axis=0), + (tf.shape(states)[0], 1)) for + context in self.context_vars] + states = tf.concat([states,] + contexts, axis=-1) + self._validate_states(states) + return states + + def unmerged_states(self, merged_states): + """Returns the batch state and contexts from the batch merged state. + + Args: + merged_states: A [batch_size, num_merged_state_dims] tensor + representing a batch of merged states. + Returns: + A [batch_size, num_state_dims] tensor and a list of + [batch_size, num_context_dims] tensors representing the batch state + and contexts respectively. + """ + self._validate_states(merged_states) + num_state_dims = self.env_observation_spec.shape.as_list()[0] + num_context_dims_list = [c.shape.as_list()[0] for c in self.context_specs] + states = merged_states[:, :num_state_dims] + contexts = [] + i = num_state_dims + for num_context_dims in num_context_dims_list: + contexts.append(merged_states[:, i: i+num_context_dims]) + i += num_context_dims + return states, contexts + + def sample_random_actions(self, batch_size=1): + """Return random actions. + + Args: + batch_size: Batch size. + Returns: + A [batch_size, num_action_dims] tensor representing the batch of actions. + """ + actions = tf.concat( + [ + tf.random_uniform( + shape=(batch_size, 1), + minval=self._action_spec.minimum[i], + maxval=self._action_spec.maximum[i]) + for i in range(self._action_spec.shape[0].value) + ], + axis=1) + return actions + + def clip_actions(self, actions): + """Clip actions to spec. + + Args: + actions: A [batch_size, num_action_dims] tensor representing + the batch of actions. + Returns: + A [batch_size, num_action_dims] tensor representing the batch + of clipped actions. + """ + actions = tf.concat( + [ + tf.clip_by_value( + actions[:, i:i+1], + self._action_spec.minimum[i], + self._action_spec.maximum[i]) + for i in range(self._action_spec.shape[0].value) + ], + axis=1) + return actions + + def mix_contexts(self, contexts, insert_contexts, indices): + """Mix two contexts based on indices. + + Args: + contexts: A list of [batch_size, num_context_dims] tensor representing + the batch of contexts. + insert_contexts: A list of [batch_size, num_context_dims] tensor + representing the batch of contexts to be inserted. + indices: A list of a list of integers denoting indices to replace. + Returns: + A list of resulting contexts. + """ + if indices is None: indices = [[]] * len(contexts) + assert len(contexts) == len(indices) + assert all([spec.shape.ndims == 1 for spec in self.context_specs]) + mix_contexts = [] + for contexts_, insert_contexts_, indices_, spec in zip( + contexts, insert_contexts, indices, self.context_specs): + mix_contexts.append( + tf.concat( + [ + insert_contexts_[:, i:i + 1] if i in indices_ else + contexts_[:, i:i + 1] for i in range(spec.shape.as_list()[0]) + ], + axis=1)) + return mix_contexts + + def begin_episode_ops(self, mode, action_fn=None, state=None): + """Returns ops that reset agent at beginning of episodes. + + Args: + mode: a string representing the mode=[train, explore, eval]. + Returns: + A list of ops. + """ + all_ops = [] + for _, action_var in sorted(self._action_vars.items()): + sample_action = self.sample_random_actions(1)[0] + all_ops.append(tf.assign(action_var, sample_action)) + all_ops += self.tf_context.reset(mode=mode, agent=self._meta_agent, + action_fn=action_fn, state=state) + return all_ops + + def cond_begin_episode_op(self, cond, input_vars, mode, meta_action_fn): + """Returns op that resets agent at beginning of episodes. + + A new episode is begun if the cond op evalues to `False`. + + Args: + cond: a Boolean tensor variable. + input_vars: A list of tensor variables. + mode: a string representing the mode=[train, explore, eval]. + Returns: + Conditional begin op. + """ + (state, action, reward, next_state, + state_repr, next_state_repr) = input_vars + def continue_fn(): + """Continue op fn.""" + items = [state, action, reward, next_state, + state_repr, next_state_repr] + list(self.context_vars) + batch_items = [tf.expand_dims(item, 0) for item in items] + (states, actions, rewards, next_states, + state_reprs, next_state_reprs) = batch_items[:6] + context_reward = self.compute_rewards( + mode, state_reprs, actions, rewards, next_state_reprs, + batch_items[6:])[0][0] + context_reward = tf.cast(context_reward, dtype=reward.dtype) + if self.meta_agent is not None: + meta_action = tf.concat(self.context_vars, -1) + items = [state, meta_action, reward, next_state, + state_repr, next_state_repr] + list(self.meta_agent.context_vars) + batch_items = [tf.expand_dims(item, 0) for item in items] + (states, meta_actions, rewards, next_states, + state_reprs, next_state_reprs) = batch_items[:6] + meta_reward = self.meta_agent.compute_rewards( + mode, states, meta_actions, rewards, + next_states, batch_items[6:])[0][0] + meta_reward = tf.cast(meta_reward, dtype=reward.dtype) + else: + meta_reward = tf.constant(0, dtype=reward.dtype) + + with tf.control_dependencies([context_reward, meta_reward]): + step_ops = self.tf_context.step(mode=mode, agent=self._meta_agent, + state=state, + next_state=next_state, + state_repr=state_repr, + next_state_repr=next_state_repr, + action_fn=meta_action_fn) + with tf.control_dependencies(step_ops): + context_reward, meta_reward = map(tf.identity, [context_reward, meta_reward]) + return context_reward, meta_reward + def begin_episode_fn(): + """Begin op fn.""" + begin_ops = self.begin_episode_ops(mode=mode, action_fn=meta_action_fn, state=state) + with tf.control_dependencies(begin_ops): + return tf.zeros_like(reward), tf.zeros_like(reward) + with tf.control_dependencies(input_vars): + cond_begin_episode_op = tf.cond(cond, continue_fn, begin_episode_fn) + return cond_begin_episode_op + + def get_env_base_wrapper(self, env_base, **begin_kwargs): + """Create a wrapper around env_base, with agent-specific begin/end_episode. + + Args: + env_base: A python environment base. + **begin_kwargs: Keyword args for begin_episode_ops. + Returns: + An object with begin_episode() and end_episode(). + """ + begin_ops = self.begin_episode_ops(**begin_kwargs) + return uvf_utils.get_contextual_env_base(env_base, begin_ops) + + def init_action_vars(self, name, i=None): + """Create and return a tensorflow Variable holding an action. + + Args: + name: Name of the variables. + i: Integer id. + Returns: + A [num_action_dims] tensor. + """ + if i is not None: + name += '_%d' % i + assert name not in self._action_vars, ('Conflict! %s is already ' + 'initialized.') % name + self._action_vars[name] = tf.Variable( + self.sample_random_actions(1)[0], name='%s_action' % (name)) + self._validate_actions(tf.expand_dims(self._action_vars[name], 0)) + return self._action_vars[name] + + @gin.configurable('uvf_critic_function') + def critic_function(self, critic_vals, states, critic_fn=None): + """Computes q values based on outputs from the critic net. + + Args: + critic_vals: A tf.float32 [batch_size, ...] tensor representing outputs + from the critic net. + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + critic_fn: A callable that process outputs from critic_net and + outputs a [batch_size] tensor representing q values. + Returns: + A tf.float32 [batch_size] tensor representing q values. + """ + if critic_fn is not None: + env_states, contexts = self.unmerged_states(states) + critic_vals = critic_fn(critic_vals, env_states, contexts) + critic_vals.shape.assert_has_rank(1) + return critic_vals + + def get_action_vars(self, key): + return self._action_vars[key] + + def get_context_vars(self, key): + return self.tf_context.context_vars[key] + + def step_cond_fn(self, *args): + return self._step_cond_fn(self, *args) + + def reset_episode_cond_fn(self, *args): + return self._reset_episode_cond_fn(self, *args) + + def reset_env_cond_fn(self, *args): + return self._reset_env_cond_fn(self, *args) + + @property + def context_vars(self): + return self.tf_context.vars + + +@gin.configurable +class MetaAgentCore(UvfAgentCore): + """Defines basic functions for UVF Meta-agent. Must be inherited with an RL agent. + + Used as higher-level agent. + """ + + def __init__(self, + observation_spec, + action_spec, + tf_env, + tf_context, + sub_context, + step_cond_fn=cond_fn.env_transition, + reset_episode_cond_fn=cond_fn.env_restart, + reset_env_cond_fn=cond_fn.false_fn, + metrics=None, + actions_reg=0., + k=2, + **base_agent_kwargs): + """Constructs a Meta agent. + + Args: + observation_spec: A TensorSpec defining the observations. + action_spec: A BoundedTensorSpec defining the actions. + tf_env: A Tensorflow environment object. + tf_context: A Context class. + step_cond_fn: A function indicating whether to increment the num of steps. + reset_episode_cond_fn: A function indicating whether to restart the + episode, resampling the context. + reset_env_cond_fn: A function indicating whether to perform a manual reset + of the environment. + metrics: A list of functions that evaluate metrics of the agent. + **base_agent_kwargs: A dictionary of parameters for base RL Agent. + Raises: + ValueError: If 'dqda_clipping' is < 0. + """ + self._step_cond_fn = step_cond_fn + self._reset_episode_cond_fn = reset_episode_cond_fn + self._reset_env_cond_fn = reset_env_cond_fn + self.metrics = metrics + self._actions_reg = actions_reg + self._k = k + + # expose tf_context methods + self.tf_context = tf_context(tf_env=tf_env) + self.sub_context = sub_context(tf_env=tf_env) + self.set_replay = self.tf_context.set_replay + self.sample_contexts = self.tf_context.sample_contexts + self.compute_rewards = self.tf_context.compute_rewards + self.gamma_index = self.tf_context.gamma_index + self.context_specs = self.tf_context.context_specs + self.context_as_action_specs = self.tf_context.context_as_action_specs + self.sub_context_as_action_specs = self.sub_context.context_as_action_specs + self.init_context_vars = self.tf_context.create_vars + + self.env_observation_spec = observation_spec[0] + merged_observation_spec = (uvf_utils.merge_specs( + (self.env_observation_spec,) + self.context_specs),) + self._context_vars = dict() + self._action_vars = dict() + + assert len(self.context_as_action_specs) == 1 + self.BASE_AGENT_CLASS.__init__( + self, + observation_spec=merged_observation_spec, + action_spec=self.sub_context_as_action_specs, + **base_agent_kwargs + ) + + @gin.configurable('meta_add_noise_fn') + def add_noise_fn(self, action_fn, stddev=1.0, debug=False, + global_step=None): + noisy_action_fn = super(MetaAgentCore, self).add_noise_fn( + action_fn, stddev, + clip=True, global_step=global_step) + return noisy_action_fn + + def actor_loss(self, states, actions, rewards, discounts, + next_states): + """Returns the next action for the state. + + Args: + state: A [num_state_dims] tensor representing a state. + context: A list of [num_context_dims] tensor representing a context. + Returns: + A [num_action_dims] tensor representing the action. + """ + actions = self.actor_net(states, stop_gradients=False) + regularizer = self._actions_reg * tf.reduce_mean( + tf.reduce_sum(tf.abs(actions[:, self._k:]), -1), 0) + loss = self.BASE_AGENT_CLASS.actor_loss(self, states) + return regularizer + loss + + +@gin.configurable +class UvfAgent(UvfAgentCore, ddpg_agent.TD3Agent): + """A DDPG agent with UVF. + """ + BASE_AGENT_CLASS = ddpg_agent.TD3Agent + ACTION_TYPE = 'continuous' + + def __init__(self, *args, **kwargs): + UvfAgentCore.__init__(self, *args, **kwargs) + + +@gin.configurable +class MetaAgent(MetaAgentCore, ddpg_agent.TD3Agent): + """A DDPG meta-agent. + """ + BASE_AGENT_CLASS = ddpg_agent.TD3Agent + ACTION_TYPE = 'continuous' + + def __init__(self, *args, **kwargs): + MetaAgentCore.__init__(self, *args, **kwargs) + + +@gin.configurable() +def state_preprocess_net( + states, + num_output_dims=2, + states_hidden_layers=(100,), + normalizer_fn=None, + activation_fn=tf.nn.relu, + zero_time=True, + images=False): + """Creates a simple feed forward net for embedding states. + """ + with slim.arg_scope( + [slim.fully_connected], + activation_fn=activation_fn, + normalizer_fn=normalizer_fn, + weights_initializer=slim.variance_scaling_initializer( + factor=1.0/3.0, mode='FAN_IN', uniform=True)): + + states_shape = tf.shape(states) + states_dtype = states.dtype + states = tf.to_float(states) + if images: # Zero-out x-y + states *= tf.constant([0.] * 2 + [1.] * (states.shape[-1] - 2), dtype=states.dtype) + if zero_time: + states *= tf.constant([1.] * (states.shape[-1] - 1) + [0.], dtype=states.dtype) + orig_states = states + embed = states + if states_hidden_layers: + embed = slim.stack(embed, slim.fully_connected, states_hidden_layers, + scope='states') + + with slim.arg_scope([slim.fully_connected], + weights_regularizer=None, + weights_initializer=tf.random_uniform_initializer( + minval=-0.003, maxval=0.003)): + embed = slim.fully_connected(embed, num_output_dims, + activation_fn=None, + normalizer_fn=None, + scope='value') + + output = embed + output = tf.cast(output, states_dtype) + return output + + +@gin.configurable() +def action_embed_net( + actions, + states=None, + num_output_dims=2, + hidden_layers=(400, 300), + normalizer_fn=None, + activation_fn=tf.nn.relu, + zero_time=True, + images=False): + """Creates a simple feed forward net for embedding actions. + """ + with slim.arg_scope( + [slim.fully_connected], + activation_fn=activation_fn, + normalizer_fn=normalizer_fn, + weights_initializer=slim.variance_scaling_initializer( + factor=1.0/3.0, mode='FAN_IN', uniform=True)): + + actions = tf.to_float(actions) + if states is not None: + if images: # Zero-out x-y + states *= tf.constant([0.] * 2 + [1.] * (states.shape[-1] - 2), dtype=states.dtype) + if zero_time: + states *= tf.constant([1.] * (states.shape[-1] - 1) + [0.], dtype=states.dtype) + actions = tf.concat([actions, tf.to_float(states)], -1) + + embed = actions + if hidden_layers: + embed = slim.stack(embed, slim.fully_connected, hidden_layers, + scope='hidden') + + with slim.arg_scope([slim.fully_connected], + weights_regularizer=None, + weights_initializer=tf.random_uniform_initializer( + minval=-0.003, maxval=0.003)): + embed = slim.fully_connected(embed, num_output_dims, + activation_fn=None, + normalizer_fn=None, + scope='value') + if num_output_dims == 1: + return embed[:, 0, ...] + else: + return embed + + +def huber(x, kappa=0.1): + return (0.5 * tf.square(x) * tf.to_float(tf.abs(x) <= kappa) + + kappa * (tf.abs(x) - 0.5 * kappa) * tf.to_float(tf.abs(x) > kappa) + ) / kappa + + +@gin.configurable() +class StatePreprocess(object): + STATE_PREPROCESS_NET_SCOPE = 'state_process_net' + ACTION_EMBED_NET_SCOPE = 'action_embed_net' + + def __init__(self, trainable=False, + state_preprocess_net=lambda states: states, + action_embed_net=lambda actions, *args, **kwargs: actions, + ndims=None): + self.trainable = trainable + self._scope = tf.get_variable_scope().name + self._ndims = ndims + self._state_preprocess_net = tf.make_template( + self.STATE_PREPROCESS_NET_SCOPE, state_preprocess_net, + create_scope_now_=True) + self._action_embed_net = tf.make_template( + self.ACTION_EMBED_NET_SCOPE, action_embed_net, + create_scope_now_=True) + + def __call__(self, states): + batched = states.get_shape().ndims != 1 + if not batched: + states = tf.expand_dims(states, 0) + embedded = self._state_preprocess_net(states) + if self._ndims is not None: + embedded = embedded[..., :self._ndims] + if not batched: + return embedded[0] + return embedded + + def loss(self, states, next_states, low_actions, low_states): + batch_size = tf.shape(states)[0] + d = int(low_states.shape[1]) + # Sample indices into meta-transition to train on. + probs = 0.99 ** tf.range(d, dtype=tf.float32) + probs *= tf.constant([1.0] * (d - 1) + [1.0 / (1 - 0.99)], + dtype=tf.float32) + probs /= tf.reduce_sum(probs) + index_dist = tf.distributions.Categorical(probs=probs, dtype=tf.int64) + indices = index_dist.sample(batch_size) + batch_size = tf.cast(batch_size, tf.int64) + next_indices = tf.concat( + [tf.range(batch_size, dtype=tf.int64)[:, None], + (1 + indices[:, None]) % d], -1) + new_next_states = tf.where(indices < d - 1, + tf.gather_nd(low_states, next_indices), + next_states) + next_states = new_next_states + + embed1 = tf.to_float(self._state_preprocess_net(states)) + embed2 = tf.to_float(self._state_preprocess_net(next_states)) + action_embed = self._action_embed_net( + tf.layers.flatten(low_actions), states=states) + + tau = 2.0 + fn = lambda z: tau * tf.reduce_sum(huber(z), -1) + all_embed = tf.get_variable('all_embed', [1024, int(embed1.shape[-1])], + initializer=tf.zeros_initializer()) + upd = all_embed.assign(tf.concat([all_embed[batch_size:], embed2], 0)) + with tf.control_dependencies([upd]): + close = 1 * tf.reduce_mean(fn(embed1 + action_embed - embed2)) + prior_log_probs = tf.reduce_logsumexp( + -fn((embed1 + action_embed)[:, None, :] - all_embed[None, :, :]), + axis=-1) - tf.log(tf.to_float(all_embed.shape[0])) + far = tf.reduce_mean(tf.exp(-fn((embed1 + action_embed)[1:] - embed2[:-1]) + - tf.stop_gradient(prior_log_probs[1:]))) + repr_log_probs = tf.stop_gradient( + -fn(embed1 + action_embed - embed2) - prior_log_probs) / tau + return close + far, repr_log_probs, indices + + def get_trainable_vars(self): + return ( + slim.get_trainable_variables( + uvf_utils.join_scope(self._scope, self.STATE_PREPROCESS_NET_SCOPE)) + + slim.get_trainable_variables( + uvf_utils.join_scope(self._scope, self.ACTION_EMBED_NET_SCOPE))) + + +@gin.configurable() +class InverseDynamics(object): + INVERSE_DYNAMICS_NET_SCOPE = 'inverse_dynamics' + + def __init__(self, spec): + self._spec = spec + + def sample(self, states, next_states, num_samples, orig_goals, sc=0.5): + goal_dim = orig_goals.shape[-1] + spec_range = (self._spec.maximum - self._spec.minimum) / 2 * tf.ones([goal_dim]) + loc = tf.cast(next_states - states, tf.float32)[:, :goal_dim] + scale = sc * tf.tile(tf.reshape(spec_range, [1, goal_dim]), + [tf.shape(states)[0], 1]) + dist = tf.distributions.Normal(loc, scale) + if num_samples == 1: + return dist.sample() + samples = tf.concat([dist.sample(num_samples - 2), + tf.expand_dims(loc, 0), + tf.expand_dims(orig_goals, 0)], 0) + return uvf_utils.clip_to_spec(samples, self._spec) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/__init__.py" new file mode 100644 index 00000000..8b137891 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/__init__.py" @@ -0,0 +1 @@ + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/circular_buffer.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/circular_buffer.py" new file mode 100644 index 00000000..17b6304b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/circular_buffer.py" @@ -0,0 +1,289 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A circular buffer where each element is a list of tensors. + +Each element of the buffer is a list of tensors. An example use case is a replay +buffer in reinforcement learning, where each element is a list of tensors +representing the state, action, reward etc. + +New elements are added sequentially, and once the buffer is full, we +start overwriting them in a circular fashion. Reading does not remove any +elements, only adding new elements does. +""" + +import collections +import numpy as np +import tensorflow as tf + +import gin.tf + + +@gin.configurable +class CircularBuffer(object): + """A circular buffer where each element is a list of tensors.""" + + def __init__(self, buffer_size=1000, scope='replay_buffer'): + """Circular buffer of list of tensors. + + Args: + buffer_size: (integer) maximum number of tensor lists the buffer can hold. + scope: (string) variable scope for creating the variables. + """ + self._buffer_size = np.int64(buffer_size) + self._scope = scope + self._tensors = collections.OrderedDict() + with tf.variable_scope(self._scope): + self._num_adds = tf.Variable(0, dtype=tf.int64, name='num_adds') + self._num_adds_cs = tf.contrib.framework.CriticalSection(name='num_adds') + + @property + def buffer_size(self): + return self._buffer_size + + @property + def scope(self): + return self._scope + + @property + def num_adds(self): + return self._num_adds + + def _create_variables(self, tensors): + with tf.variable_scope(self._scope): + for name in tensors.keys(): + tensor = tensors[name] + self._tensors[name] = tf.get_variable( + name='BufferVariable_' + name, + shape=[self._buffer_size] + tensor.get_shape().as_list(), + dtype=tensor.dtype, + trainable=False) + + def _validate(self, tensors): + """Validate shapes of tensors.""" + if len(tensors) != len(self._tensors): + raise ValueError('Expected tensors to have %d elements. Received %d ' + 'instead.' % (len(self._tensors), len(tensors))) + if self._tensors.keys() != tensors.keys(): + raise ValueError('The keys of tensors should be the always the same.' + 'Received %s instead %s.' % + (tensors.keys(), self._tensors.keys())) + for name, tensor in tensors.items(): + if tensor.get_shape().as_list() != self._tensors[ + name].get_shape().as_list()[1:]: + raise ValueError('Tensor %s has incorrect shape.' % name) + if not tensor.dtype.is_compatible_with(self._tensors[name].dtype): + raise ValueError( + 'Tensor %s has incorrect data type. Expected %s, received %s' % + (name, self._tensors[name].read_value().dtype, tensor.dtype)) + + def add(self, tensors): + """Adds an element (list/tuple/dict of tensors) to the buffer. + + Args: + tensors: (list/tuple/dict of tensors) to be added to the buffer. + Returns: + An add operation that adds the input `tensors` to the buffer. Similar to + an enqueue_op. + Raises: + ValueError: If the shapes and data types of input `tensors' are not the + same across calls to the add function. + """ + return self.maybe_add(tensors, True) + + def maybe_add(self, tensors, condition): + """Adds an element (tensors) to the buffer based on the condition.. + + Args: + tensors: (list/tuple of tensors) to be added to the buffer. + condition: A boolean Tensor controlling whether the tensors would be added + to the buffer or not. + Returns: + An add operation that adds the input `tensors` to the buffer. Similar to + an maybe_enqueue_op. + Raises: + ValueError: If the shapes and data types of input `tensors' are not the + same across calls to the add function. + """ + if not isinstance(tensors, dict): + names = [str(i) for i in range(len(tensors))] + tensors = collections.OrderedDict(zip(names, tensors)) + if not isinstance(tensors, collections.OrderedDict): + tensors = collections.OrderedDict( + sorted(tensors.items(), key=lambda t: t[0])) + if not self._tensors: + self._create_variables(tensors) + else: + self._validate(tensors) + + #@tf.critical_section(self._position_mutex) + def _increment_num_adds(): + # Adding 0 to the num_adds variable is a trick to read the value of the + # variable and return a read-only tensor. Doing this in a critical + # section allows us to capture a snapshot of the variable that will + # not be affected by other threads updating num_adds. + return self._num_adds.assign_add(1) + 0 + def _add(): + num_adds_inc = self._num_adds_cs.execute(_increment_num_adds) + current_pos = tf.mod(num_adds_inc - 1, self._buffer_size) + update_ops = [] + for name in self._tensors.keys(): + update_ops.append( + tf.scatter_update(self._tensors[name], current_pos, tensors[name])) + return tf.group(*update_ops) + + return tf.contrib.framework.smart_cond(condition, _add, tf.no_op) + + def get_random_batch(self, batch_size, keys=None, num_steps=1): + """Samples a batch of tensors from the buffer with replacement. + + Args: + batch_size: (integer) number of elements to sample. + keys: List of keys of tensors to retrieve. If None retrieve all. + num_steps: (integer) length of trajectories to return. If > 1 will return + a list of lists, where each internal list represents a trajectory of + length num_steps. + Returns: + A list of tensors, where each element in the list is a batch sampled from + one of the tensors in the buffer. + Raises: + ValueError: If get_random_batch is called before calling the add function. + tf.errors.InvalidArgumentError: If this operation is executed before any + items are added to the buffer. + """ + if not self._tensors: + raise ValueError('The add function must be called before get_random_batch.') + if keys is None: + keys = self._tensors.keys() + + latest_start_index = self.get_num_adds() - num_steps + 1 + empty_buffer_assert = tf.Assert( + tf.greater(latest_start_index, 0), + ['Not enough elements have been added to the buffer.']) + with tf.control_dependencies([empty_buffer_assert]): + max_index = tf.minimum(self._buffer_size, latest_start_index) + indices = tf.random_uniform( + [batch_size], + minval=0, + maxval=max_index, + dtype=tf.int64) + if num_steps == 1: + return self.gather(indices, keys) + else: + return self.gather_nstep(num_steps, indices, keys) + + def gather(self, indices, keys=None): + """Returns elements at the specified indices from the buffer. + + Args: + indices: (list of integers or rank 1 int Tensor) indices in the buffer to + retrieve elements from. + keys: List of keys of tensors to retrieve. If None retrieve all. + Returns: + A list of tensors, where each element in the list is obtained by indexing + one of the tensors in the buffer. + Raises: + ValueError: If gather is called before calling the add function. + tf.errors.InvalidArgumentError: If indices are bigger than the number of + items in the buffer. + """ + if not self._tensors: + raise ValueError('The add function must be called before calling gather.') + if keys is None: + keys = self._tensors.keys() + with tf.name_scope('Gather'): + index_bound_assert = tf.Assert( + tf.less( + tf.to_int64(tf.reduce_max(indices)), + tf.minimum(self.get_num_adds(), self._buffer_size)), + ['Index out of bounds.']) + with tf.control_dependencies([index_bound_assert]): + indices = tf.convert_to_tensor(indices) + + batch = [] + for key in keys: + batch.append(tf.gather(self._tensors[key], indices, name=key)) + return batch + + def gather_nstep(self, num_steps, indices, keys=None): + """Returns elements at the specified indices from the buffer. + + Args: + num_steps: (integer) length of trajectories to return. + indices: (list of rank num_steps int Tensor) indices in the buffer to + retrieve elements from for multiple trajectories. Each Tensor in the + list represents the indices for a trajectory. + keys: List of keys of tensors to retrieve. If None retrieve all. + Returns: + A list of list-of-tensors, where each element in the list is obtained by + indexing one of the tensors in the buffer. + Raises: + ValueError: If gather is called before calling the add function. + tf.errors.InvalidArgumentError: If indices are bigger than the number of + items in the buffer. + """ + if not self._tensors: + raise ValueError('The add function must be called before calling gather.') + if keys is None: + keys = self._tensors.keys() + with tf.name_scope('Gather'): + index_bound_assert = tf.Assert( + tf.less_equal( + tf.to_int64(tf.reduce_max(indices) + num_steps), + self.get_num_adds()), + ['Trajectory indices go out of bounds.']) + with tf.control_dependencies([index_bound_assert]): + indices = tf.map_fn( + lambda x: tf.mod(tf.range(x, x + num_steps), self._buffer_size), + indices, + dtype=tf.int64) + + batch = [] + for key in keys: + + def SampleTrajectories(trajectory_indices, key=key, + num_steps=num_steps): + trajectory_indices.set_shape([num_steps]) + return tf.gather(self._tensors[key], trajectory_indices, name=key) + + batch.append(tf.map_fn(SampleTrajectories, indices, + dtype=self._tensors[key].dtype)) + return batch + + def get_position(self): + """Returns the position at which the last element was added. + + Returns: + An int tensor representing the index at which the last element was added + to the buffer or -1 if no elements were added. + """ + return tf.cond(self.get_num_adds() < 1, + lambda: self.get_num_adds() - 1, + lambda: tf.mod(self.get_num_adds() - 1, self._buffer_size)) + + def get_num_adds(self): + """Returns the number of additions to the buffer. + + Returns: + An int tensor representing the number of elements that were added. + """ + def num_adds(): + return self._num_adds.value() + + return self._num_adds_cs.execute(num_adds) + + def get_num_tensors(self): + """Returns the number of tensors (slots) in the buffer.""" + return len(self._tensors) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_agent.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_agent.py" new file mode 100644 index 00000000..904eb650 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_agent.py" @@ -0,0 +1,739 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A DDPG/NAF agent. + +Implements the Deep Deterministic Policy Gradient (DDPG) algorithm from +"Continuous control with deep reinforcement learning" - Lilicrap et al. +https://arxiv.org/abs/1509.02971, and the Normalized Advantage Functions (NAF) +algorithm "Continuous Deep Q-Learning with Model-based Acceleration" - Gu et al. +https://arxiv.org/pdf/1603.00748. +""" + +import tensorflow as tf +slim = tf.contrib.slim +import gin.tf +from utils import utils +from agents import ddpg_networks as networks + + +@gin.configurable +class DdpgAgent(object): + """An RL agent that learns using the DDPG algorithm. + + Example usage: + + def critic_net(states, actions): + ... + def actor_net(states, num_action_dims): + ... + + Given a tensorflow environment tf_env, + (of type learning.deepmind.rl.environments.tensorflow.python.tfpyenvironment) + + obs_spec = tf_env.observation_spec() + action_spec = tf_env.action_spec() + + ddpg_agent = agent.DdpgAgent(obs_spec, + action_spec, + actor_net=actor_net, + critic_net=critic_net) + + we can perform actions on the environment as follows: + + state = tf_env.observations()[0] + action = ddpg_agent.actor_net(tf.expand_dims(state, 0))[0, :] + transition_type, reward, discount = tf_env.step([action]) + + Train: + + critic_loss = ddpg_agent.critic_loss(states, actions, rewards, discounts, + next_states) + actor_loss = ddpg_agent.actor_loss(states) + + critic_train_op = slim.learning.create_train_op( + critic_loss, + critic_optimizer, + variables_to_train=ddpg_agent.get_trainable_critic_vars(), + ) + + actor_train_op = slim.learning.create_train_op( + actor_loss, + actor_optimizer, + variables_to_train=ddpg_agent.get_trainable_actor_vars(), + ) + """ + + ACTOR_NET_SCOPE = 'actor_net' + CRITIC_NET_SCOPE = 'critic_net' + TARGET_ACTOR_NET_SCOPE = 'target_actor_net' + TARGET_CRITIC_NET_SCOPE = 'target_critic_net' + + def __init__(self, + observation_spec, + action_spec, + actor_net=networks.actor_net, + critic_net=networks.critic_net, + td_errors_loss=tf.losses.huber_loss, + dqda_clipping=0., + actions_regularizer=0., + target_q_clipping=None, + residual_phi=0.0, + debug_summaries=False): + """Constructs a DDPG agent. + + Args: + observation_spec: A TensorSpec defining the observations. + action_spec: A BoundedTensorSpec defining the actions. + actor_net: A callable that creates the actor network. Must take the + following arguments: states, num_actions. Please see networks.actor_net + for an example. + critic_net: A callable that creates the critic network. Must take the + following arguments: states, actions. Please see networks.critic_net + for an example. + td_errors_loss: A callable defining the loss function for the critic + td error. + dqda_clipping: (float) clips the gradient dqda element-wise between + [-dqda_clipping, dqda_clipping]. Does not perform clipping if + dqda_clipping == 0. + actions_regularizer: A scalar, when positive penalizes the norm of the + actions. This can prevent saturation of actions for the actor_loss. + target_q_clipping: (tuple of floats) clips target q values within + (low, high) values when computing the critic loss. + residual_phi: (float) [0.0, 1.0] Residual algorithm parameter that + interpolates between Q-learning and residual gradient algorithm. + http://www.leemon.com/papers/1995b.pdf + debug_summaries: If True, add summaries to help debug behavior. + Raises: + ValueError: If 'dqda_clipping' is < 0. + """ + self._observation_spec = observation_spec[0] + self._action_spec = action_spec[0] + self._state_shape = tf.TensorShape([None]).concatenate( + self._observation_spec.shape) + self._action_shape = tf.TensorShape([None]).concatenate( + self._action_spec.shape) + self._num_action_dims = self._action_spec.shape.num_elements() + + self._scope = tf.get_variable_scope().name + self._actor_net = tf.make_template( + self.ACTOR_NET_SCOPE, actor_net, create_scope_now_=True) + self._critic_net = tf.make_template( + self.CRITIC_NET_SCOPE, critic_net, create_scope_now_=True) + self._target_actor_net = tf.make_template( + self.TARGET_ACTOR_NET_SCOPE, actor_net, create_scope_now_=True) + self._target_critic_net = tf.make_template( + self.TARGET_CRITIC_NET_SCOPE, critic_net, create_scope_now_=True) + self._td_errors_loss = td_errors_loss + if dqda_clipping < 0: + raise ValueError('dqda_clipping must be >= 0.') + self._dqda_clipping = dqda_clipping + self._actions_regularizer = actions_regularizer + self._target_q_clipping = target_q_clipping + self._residual_phi = residual_phi + self._debug_summaries = debug_summaries + + def _batch_state(self, state): + """Convert state to a batched state. + + Args: + state: Either a list/tuple with an state tensor [num_state_dims]. + Returns: + A tensor [1, num_state_dims] + """ + if isinstance(state, (tuple, list)): + state = state[0] + if state.get_shape().ndims == 1: + state = tf.expand_dims(state, 0) + return state + + def action(self, state): + """Returns the next action for the state. + + Args: + state: A [num_state_dims] tensor representing a state. + Returns: + A [num_action_dims] tensor representing the action. + """ + return self.actor_net(self._batch_state(state), stop_gradients=True)[0, :] + + @gin.configurable('ddpg_sample_action') + def sample_action(self, state, stddev=1.0): + """Returns the action for the state with additive noise. + + Args: + state: A [num_state_dims] tensor representing a state. + stddev: stddev for the Ornstein-Uhlenbeck noise. + Returns: + A [num_action_dims] action tensor. + """ + agent_action = self.action(state) + agent_action += tf.random_normal(tf.shape(agent_action)) * stddev + return utils.clip_to_spec(agent_action, self._action_spec) + + def actor_net(self, states, stop_gradients=False): + """Returns the output of the actor network. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + stop_gradients: (boolean) if true, gradients cannot be propogated through + this operation. + Returns: + A [batch_size, num_action_dims] tensor of actions. + Raises: + ValueError: If `states` does not have the expected dimensions. + """ + self._validate_states(states) + actions = self._actor_net(states, self._action_spec) + if stop_gradients: + actions = tf.stop_gradient(actions) + return actions + + def critic_net(self, states, actions, for_critic_loss=False): + """Returns the output of the critic network. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] tensor representing a batch + of actions. + Returns: + q values: A [batch_size] tensor of q values. + Raises: + ValueError: If `states` or `actions' do not have the expected dimensions. + """ + self._validate_states(states) + self._validate_actions(actions) + return self._critic_net(states, actions, + for_critic_loss=for_critic_loss) + + def target_actor_net(self, states): + """Returns the output of the target actor network. + + The target network is used to compute stable targets for training. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + A [batch_size, num_action_dims] tensor of actions. + Raises: + ValueError: If `states` does not have the expected dimensions. + """ + self._validate_states(states) + actions = self._target_actor_net(states, self._action_spec) + return tf.stop_gradient(actions) + + def target_critic_net(self, states, actions, for_critic_loss=False): + """Returns the output of the target critic network. + + The target network is used to compute stable targets for training. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] tensor representing a batch + of actions. + Returns: + q values: A [batch_size] tensor of q values. + Raises: + ValueError: If `states` or `actions' do not have the expected dimensions. + """ + self._validate_states(states) + self._validate_actions(actions) + return tf.stop_gradient( + self._target_critic_net(states, actions, + for_critic_loss=for_critic_loss)) + + def value_net(self, states, for_critic_loss=False): + """Returns the output of the critic evaluated with the actor. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + q values: A [batch_size] tensor of q values. + """ + actions = self.actor_net(states) + return self.critic_net(states, actions, + for_critic_loss=for_critic_loss) + + def target_value_net(self, states, for_critic_loss=False): + """Returns the output of the target critic evaluated with the target actor. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + q values: A [batch_size] tensor of q values. + """ + target_actions = self.target_actor_net(states) + return self.target_critic_net(states, target_actions, + for_critic_loss=for_critic_loss) + + def critic_loss(self, states, actions, rewards, discounts, + next_states): + """Computes a loss for training the critic network. + + The loss is the mean squared error between the Q value predictions of the + critic and Q values estimated using TD-lambda. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] tensor representing a batch + of actions. + rewards: A [batch_size, ...] tensor representing a batch of rewards, + broadcastable to the critic net output. + discounts: A [batch_size, ...] tensor representing a batch of discounts, + broadcastable to the critic net output. + next_states: A [batch_size, num_state_dims] tensor representing a batch + of next states. + Returns: + A rank-0 tensor representing the critic loss. + Raises: + ValueError: If any of the inputs do not have the expected dimensions, or + if their batch_sizes do not match. + """ + self._validate_states(states) + self._validate_actions(actions) + self._validate_states(next_states) + + target_q_values = self.target_value_net(next_states, for_critic_loss=True) + td_targets = target_q_values * discounts + rewards + if self._target_q_clipping is not None: + td_targets = tf.clip_by_value(td_targets, self._target_q_clipping[0], + self._target_q_clipping[1]) + q_values = self.critic_net(states, actions, for_critic_loss=True) + td_errors = td_targets - q_values + if self._debug_summaries: + gen_debug_td_error_summaries( + target_q_values, q_values, td_targets, td_errors) + + loss = self._td_errors_loss(td_targets, q_values) + + if self._residual_phi > 0.0: # compute residual gradient loss + residual_q_values = self.value_net(next_states, for_critic_loss=True) + residual_td_targets = residual_q_values * discounts + rewards + if self._target_q_clipping is not None: + residual_td_targets = tf.clip_by_value(residual_td_targets, + self._target_q_clipping[0], + self._target_q_clipping[1]) + residual_td_errors = residual_td_targets - q_values + residual_loss = self._td_errors_loss( + residual_td_targets, residual_q_values) + loss = (loss * (1.0 - self._residual_phi) + + residual_loss * self._residual_phi) + return loss + + def actor_loss(self, states): + """Computes a loss for training the actor network. + + Note that output does not represent an actual loss. It is called a loss only + in the sense that its gradient w.r.t. the actor network weights is the + correct gradient for training the actor network, + i.e. dloss/dweights = (dq/da)*(da/dweights) + which is the gradient used in Algorithm 1 of Lilicrap et al. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + A rank-0 tensor representing the actor loss. + Raises: + ValueError: If `states` does not have the expected dimensions. + """ + self._validate_states(states) + actions = self.actor_net(states, stop_gradients=False) + critic_values = self.critic_net(states, actions) + q_values = self.critic_function(critic_values, states) + dqda = tf.gradients([q_values], [actions])[0] + dqda_unclipped = dqda + if self._dqda_clipping > 0: + dqda = tf.clip_by_value(dqda, -self._dqda_clipping, self._dqda_clipping) + + actions_norm = tf.norm(actions) + if self._debug_summaries: + with tf.name_scope('dqda'): + tf.summary.scalar('actions_norm', actions_norm) + tf.summary.histogram('dqda', dqda) + tf.summary.histogram('dqda_unclipped', dqda_unclipped) + tf.summary.histogram('actions', actions) + for a in range(self._num_action_dims): + tf.summary.histogram('dqda_unclipped_%d' % a, dqda_unclipped[:, a]) + tf.summary.histogram('dqda_%d' % a, dqda[:, a]) + + actions_norm *= self._actions_regularizer + return slim.losses.mean_squared_error(tf.stop_gradient(dqda + actions), + actions, + scope='actor_loss') + actions_norm + + @gin.configurable('ddpg_critic_function') + def critic_function(self, critic_values, states, weights=None): + """Computes q values based on critic_net outputs, states, and weights. + + Args: + critic_values: A tf.float32 [batch_size, ...] tensor representing outputs + from the critic net. + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + weights: A list or Numpy array or tensor with a shape broadcastable to + `critic_values`. + Returns: + A tf.float32 [batch_size] tensor representing q values. + """ + del states # unused args + if weights is not None: + weights = tf.convert_to_tensor(weights, dtype=critic_values.dtype) + critic_values *= weights + if critic_values.shape.ndims > 1: + critic_values = tf.reduce_sum(critic_values, + range(1, critic_values.shape.ndims)) + critic_values.shape.assert_has_rank(1) + return critic_values + + @gin.configurable('ddpg_update_targets') + def update_targets(self, tau=1.0): + """Performs a soft update of the target network parameters. + + For each weight w_s in the actor/critic networks, and its corresponding + weight w_t in the target actor/critic networks, a soft update is: + w_t = (1- tau) x w_t + tau x ws + + Args: + tau: A float scalar in [0, 1] + Returns: + An operation that performs a soft update of the target network parameters. + Raises: + ValueError: If `tau` is not in [0, 1]. + """ + if tau < 0 or tau > 1: + raise ValueError('Input `tau` should be in [0, 1].') + update_actor = utils.soft_variables_update( + slim.get_trainable_variables( + utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)), + slim.get_trainable_variables( + utils.join_scope(self._scope, self.TARGET_ACTOR_NET_SCOPE)), + tau) + update_critic = utils.soft_variables_update( + slim.get_trainable_variables( + utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)), + slim.get_trainable_variables( + utils.join_scope(self._scope, self.TARGET_CRITIC_NET_SCOPE)), + tau) + return tf.group(update_actor, update_critic, name='update_targets') + + def get_trainable_critic_vars(self): + """Returns a list of trainable variables in the critic network. + + Returns: + A list of trainable variables in the critic network. + """ + return slim.get_trainable_variables( + utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)) + + def get_trainable_actor_vars(self): + """Returns a list of trainable variables in the actor network. + + Returns: + A list of trainable variables in the actor network. + """ + return slim.get_trainable_variables( + utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)) + + def get_critic_vars(self): + """Returns a list of all variables in the critic network. + + Returns: + A list of trainable variables in the critic network. + """ + return slim.get_model_variables( + utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)) + + def get_actor_vars(self): + """Returns a list of all variables in the actor network. + + Returns: + A list of trainable variables in the actor network. + """ + return slim.get_model_variables( + utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)) + + def _validate_states(self, states): + """Raises a value error if `states` does not have the expected shape. + + Args: + states: A tensor. + Raises: + ValueError: If states.shape or states.dtype are not compatible with + observation_spec. + """ + states.shape.assert_is_compatible_with(self._state_shape) + if not states.dtype.is_compatible_with(self._observation_spec.dtype): + raise ValueError('states.dtype={} is not compatible with' + ' observation_spec.dtype={}'.format( + states.dtype, self._observation_spec.dtype)) + + def _validate_actions(self, actions): + """Raises a value error if `actions` does not have the expected shape. + + Args: + actions: A tensor. + Raises: + ValueError: If actions.shape or actions.dtype are not compatible with + action_spec. + """ + actions.shape.assert_is_compatible_with(self._action_shape) + if not actions.dtype.is_compatible_with(self._action_spec.dtype): + raise ValueError('actions.dtype={} is not compatible with' + ' action_spec.dtype={}'.format( + actions.dtype, self._action_spec.dtype)) + + +@gin.configurable +class TD3Agent(DdpgAgent): + """An RL agent that learns using the TD3 algorithm.""" + + ACTOR_NET_SCOPE = 'actor_net' + CRITIC_NET_SCOPE = 'critic_net' + CRITIC_NET2_SCOPE = 'critic_net2' + TARGET_ACTOR_NET_SCOPE = 'target_actor_net' + TARGET_CRITIC_NET_SCOPE = 'target_critic_net' + TARGET_CRITIC_NET2_SCOPE = 'target_critic_net2' + + def __init__(self, + observation_spec, + action_spec, + actor_net=networks.actor_net, + critic_net=networks.critic_net, + td_errors_loss=tf.losses.huber_loss, + dqda_clipping=0., + actions_regularizer=0., + target_q_clipping=None, + residual_phi=0.0, + debug_summaries=False): + """Constructs a TD3 agent. + + Args: + observation_spec: A TensorSpec defining the observations. + action_spec: A BoundedTensorSpec defining the actions. + actor_net: A callable that creates the actor network. Must take the + following arguments: states, num_actions. Please see networks.actor_net + for an example. + critic_net: A callable that creates the critic network. Must take the + following arguments: states, actions. Please see networks.critic_net + for an example. + td_errors_loss: A callable defining the loss function for the critic + td error. + dqda_clipping: (float) clips the gradient dqda element-wise between + [-dqda_clipping, dqda_clipping]. Does not perform clipping if + dqda_clipping == 0. + actions_regularizer: A scalar, when positive penalizes the norm of the + actions. This can prevent saturation of actions for the actor_loss. + target_q_clipping: (tuple of floats) clips target q values within + (low, high) values when computing the critic loss. + residual_phi: (float) [0.0, 1.0] Residual algorithm parameter that + interpolates between Q-learning and residual gradient algorithm. + http://www.leemon.com/papers/1995b.pdf + debug_summaries: If True, add summaries to help debug behavior. + Raises: + ValueError: If 'dqda_clipping' is < 0. + """ + self._observation_spec = observation_spec[0] + self._action_spec = action_spec[0] + self._state_shape = tf.TensorShape([None]).concatenate( + self._observation_spec.shape) + self._action_shape = tf.TensorShape([None]).concatenate( + self._action_spec.shape) + self._num_action_dims = self._action_spec.shape.num_elements() + + self._scope = tf.get_variable_scope().name + self._actor_net = tf.make_template( + self.ACTOR_NET_SCOPE, actor_net, create_scope_now_=True) + self._critic_net = tf.make_template( + self.CRITIC_NET_SCOPE, critic_net, create_scope_now_=True) + self._critic_net2 = tf.make_template( + self.CRITIC_NET2_SCOPE, critic_net, create_scope_now_=True) + self._target_actor_net = tf.make_template( + self.TARGET_ACTOR_NET_SCOPE, actor_net, create_scope_now_=True) + self._target_critic_net = tf.make_template( + self.TARGET_CRITIC_NET_SCOPE, critic_net, create_scope_now_=True) + self._target_critic_net2 = tf.make_template( + self.TARGET_CRITIC_NET2_SCOPE, critic_net, create_scope_now_=True) + self._td_errors_loss = td_errors_loss + if dqda_clipping < 0: + raise ValueError('dqda_clipping must be >= 0.') + self._dqda_clipping = dqda_clipping + self._actions_regularizer = actions_regularizer + self._target_q_clipping = target_q_clipping + self._residual_phi = residual_phi + self._debug_summaries = debug_summaries + + def get_trainable_critic_vars(self): + """Returns a list of trainable variables in the critic network. + NOTE: This gets the vars of both critic networks. + + Returns: + A list of trainable variables in the critic network. + """ + return ( + slim.get_trainable_variables( + utils.join_scope(self._scope, self.CRITIC_NET_SCOPE))) + + def critic_net(self, states, actions, for_critic_loss=False): + """Returns the output of the critic network. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] tensor representing a batch + of actions. + Returns: + q values: A [batch_size] tensor of q values. + Raises: + ValueError: If `states` or `actions' do not have the expected dimensions. + """ + values1 = self._critic_net(states, actions, + for_critic_loss=for_critic_loss) + values2 = self._critic_net2(states, actions, + for_critic_loss=for_critic_loss) + if for_critic_loss: + return values1, values2 + return values1 + + def target_critic_net(self, states, actions, for_critic_loss=False): + """Returns the output of the target critic network. + + The target network is used to compute stable targets for training. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] tensor representing a batch + of actions. + Returns: + q values: A [batch_size] tensor of q values. + Raises: + ValueError: If `states` or `actions' do not have the expected dimensions. + """ + self._validate_states(states) + self._validate_actions(actions) + values1 = tf.stop_gradient( + self._target_critic_net(states, actions, + for_critic_loss=for_critic_loss)) + values2 = tf.stop_gradient( + self._target_critic_net2(states, actions, + for_critic_loss=for_critic_loss)) + if for_critic_loss: + return values1, values2 + return values1 + + def value_net(self, states, for_critic_loss=False): + """Returns the output of the critic evaluated with the actor. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + q values: A [batch_size] tensor of q values. + """ + actions = self.actor_net(states) + return self.critic_net(states, actions, + for_critic_loss=for_critic_loss) + + def target_value_net(self, states, for_critic_loss=False): + """Returns the output of the target critic evaluated with the target actor. + + Args: + states: A [batch_size, num_state_dims] tensor representing a batch + of states. + Returns: + q values: A [batch_size] tensor of q values. + """ + target_actions = self.target_actor_net(states) + noise = tf.clip_by_value( + tf.random_normal(tf.shape(target_actions), stddev=0.2), -0.5, 0.5) + values1, values2 = self.target_critic_net( + states, target_actions + noise, + for_critic_loss=for_critic_loss) + values = tf.minimum(values1, values2) + return values, values + + @gin.configurable('td3_update_targets') + def update_targets(self, tau=1.0): + """Performs a soft update of the target network parameters. + + For each weight w_s in the actor/critic networks, and its corresponding + weight w_t in the target actor/critic networks, a soft update is: + w_t = (1- tau) x w_t + tau x ws + + Args: + tau: A float scalar in [0, 1] + Returns: + An operation that performs a soft update of the target network parameters. + Raises: + ValueError: If `tau` is not in [0, 1]. + """ + if tau < 0 or tau > 1: + raise ValueError('Input `tau` should be in [0, 1].') + update_actor = utils.soft_variables_update( + slim.get_trainable_variables( + utils.join_scope(self._scope, self.ACTOR_NET_SCOPE)), + slim.get_trainable_variables( + utils.join_scope(self._scope, self.TARGET_ACTOR_NET_SCOPE)), + tau) + # NOTE: This updates both critic networks. + update_critic = utils.soft_variables_update( + slim.get_trainable_variables( + utils.join_scope(self._scope, self.CRITIC_NET_SCOPE)), + slim.get_trainable_variables( + utils.join_scope(self._scope, self.TARGET_CRITIC_NET_SCOPE)), + tau) + return tf.group(update_actor, update_critic, name='update_targets') + + +def gen_debug_td_error_summaries( + target_q_values, q_values, td_targets, td_errors): + """Generates debug summaries for critic given a set of batch samples. + + Args: + target_q_values: set of predicted next stage values. + q_values: current predicted value for the critic network. + td_targets: discounted target_q_values with added next stage reward. + td_errors: the different between td_targets and q_values. + """ + with tf.name_scope('td_errors'): + tf.summary.histogram('td_targets', td_targets) + tf.summary.histogram('q_values', q_values) + tf.summary.histogram('target_q_values', target_q_values) + tf.summary.histogram('td_errors', td_errors) + with tf.name_scope('td_targets'): + tf.summary.scalar('mean', tf.reduce_mean(td_targets)) + tf.summary.scalar('max', tf.reduce_max(td_targets)) + tf.summary.scalar('min', tf.reduce_min(td_targets)) + with tf.name_scope('q_values'): + tf.summary.scalar('mean', tf.reduce_mean(q_values)) + tf.summary.scalar('max', tf.reduce_max(q_values)) + tf.summary.scalar('min', tf.reduce_min(q_values)) + with tf.name_scope('target_q_values'): + tf.summary.scalar('mean', tf.reduce_mean(target_q_values)) + tf.summary.scalar('max', tf.reduce_max(target_q_values)) + tf.summary.scalar('min', tf.reduce_min(target_q_values)) + with tf.name_scope('td_errors'): + tf.summary.scalar('mean', tf.reduce_mean(td_errors)) + tf.summary.scalar('max', tf.reduce_max(td_errors)) + tf.summary.scalar('min', tf.reduce_min(td_errors)) + tf.summary.scalar('mean_abs', tf.reduce_mean(tf.abs(td_errors))) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_networks.py" new file mode 100644 index 00000000..63074dfb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/agents/ddpg_networks.py" @@ -0,0 +1,150 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Sample actor(policy) and critic(q) networks to use with DDPG/NAF agents. + +The DDPG networks are defined in "Section 7: Experiment Details" of +"Continuous control with deep reinforcement learning" - Lilicrap et al. +https://arxiv.org/abs/1509.02971 + +The NAF critic network is based on "Section 4" of "Continuous deep Q-learning +with model-based acceleration" - Gu et al. https://arxiv.org/pdf/1603.00748. +""" + +import tensorflow as tf +slim = tf.contrib.slim +import gin.tf + + +@gin.configurable('ddpg_critic_net') +def critic_net(states, actions, + for_critic_loss=False, + num_reward_dims=1, + states_hidden_layers=(400,), + actions_hidden_layers=None, + joint_hidden_layers=(300,), + weight_decay=0.0001, + normalizer_fn=None, + activation_fn=tf.nn.relu, + zero_obs=False, + images=False): + """Creates a critic that returns q values for the given states and actions. + + Args: + states: (castable to tf.float32) a [batch_size, num_state_dims] tensor + representing a batch of states. + actions: (castable to tf.float32) a [batch_size, num_action_dims] tensor + representing a batch of actions. + num_reward_dims: Number of reward dimensions. + states_hidden_layers: tuple of hidden layers units for states. + actions_hidden_layers: tuple of hidden layers units for actions. + joint_hidden_layers: tuple of hidden layers units after joining states + and actions using tf.concat(). + weight_decay: Weight decay for l2 weights regularizer. + normalizer_fn: Normalizer function, i.e. slim.layer_norm, + activation_fn: Activation function, i.e. tf.nn.relu, slim.leaky_relu, ... + Returns: + A tf.float32 [batch_size] tensor of q values, or a tf.float32 + [batch_size, num_reward_dims] tensor of vector q values if + num_reward_dims > 1. + """ + with slim.arg_scope( + [slim.fully_connected], + activation_fn=activation_fn, + normalizer_fn=normalizer_fn, + weights_regularizer=slim.l2_regularizer(weight_decay), + weights_initializer=slim.variance_scaling_initializer( + factor=1.0/3.0, mode='FAN_IN', uniform=True)): + + orig_states = tf.to_float(states) + #states = tf.to_float(states) + states = tf.concat([tf.to_float(states), tf.to_float(actions)], -1) #TD3 + if images or zero_obs: + states *= tf.constant([0.0] * 2 + [1.0] * (states.shape[1] - 2)) #LALA + actions = tf.to_float(actions) + if states_hidden_layers: + states = slim.stack(states, slim.fully_connected, states_hidden_layers, + scope='states') + if actions_hidden_layers: + actions = slim.stack(actions, slim.fully_connected, actions_hidden_layers, + scope='actions') + joint = tf.concat([states, actions], 1) + if joint_hidden_layers: + joint = slim.stack(joint, slim.fully_connected, joint_hidden_layers, + scope='joint') + with slim.arg_scope([slim.fully_connected], + weights_regularizer=None, + weights_initializer=tf.random_uniform_initializer( + minval=-0.003, maxval=0.003)): + value = slim.fully_connected(joint, num_reward_dims, + activation_fn=None, + normalizer_fn=None, + scope='q_value') + if num_reward_dims == 1: + value = tf.reshape(value, [-1]) + if not for_critic_loss and num_reward_dims > 1: + value = tf.reduce_sum( + value * tf.abs(orig_states[:, -num_reward_dims:]), -1) + return value + + +@gin.configurable('ddpg_actor_net') +def actor_net(states, action_spec, + hidden_layers=(400, 300), + normalizer_fn=None, + activation_fn=tf.nn.relu, + zero_obs=False, + images=False): + """Creates an actor that returns actions for the given states. + + Args: + states: (castable to tf.float32) a [batch_size, num_state_dims] tensor + representing a batch of states. + action_spec: (BoundedTensorSpec) A tensor spec indicating the shape + and range of actions. + hidden_layers: tuple of hidden layers units. + normalizer_fn: Normalizer function, i.e. slim.layer_norm, + activation_fn: Activation function, i.e. tf.nn.relu, slim.leaky_relu, ... + Returns: + A tf.float32 [batch_size, num_action_dims] tensor of actions. + """ + + with slim.arg_scope( + [slim.fully_connected], + activation_fn=activation_fn, + normalizer_fn=normalizer_fn, + weights_initializer=slim.variance_scaling_initializer( + factor=1.0/3.0, mode='FAN_IN', uniform=True)): + + states = tf.to_float(states) + orig_states = states + if images or zero_obs: # Zero-out x, y position. Hacky. + states *= tf.constant([0.0] * 2 + [1.0] * (states.shape[1] - 2)) + if hidden_layers: + states = slim.stack(states, slim.fully_connected, hidden_layers, + scope='states') + with slim.arg_scope([slim.fully_connected], + weights_initializer=tf.random_uniform_initializer( + minval=-0.003, maxval=0.003)): + actions = slim.fully_connected(states, + action_spec.shape.num_elements(), + scope='actions', + normalizer_fn=None, + activation_fn=tf.nn.tanh) + action_means = (action_spec.maximum + action_spec.minimum) / 2.0 + action_magnitudes = (action_spec.maximum - action_spec.minimum) / 2.0 + actions = action_means + action_magnitudes * actions + + return actions diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/cond_fn.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/cond_fn.py" new file mode 100644 index 00000000..cd1a276e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/cond_fn.py" @@ -0,0 +1,244 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Defines many boolean functions indicating when to step and reset. +""" + +import tensorflow as tf +import gin.tf + + +@gin.configurable +def env_transition(agent, state, action, transition_type, environment_steps, + num_episodes): + """True if the transition_type is TRANSITION or FINAL_TRANSITION. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + Returns: + cond: Returns an op that evaluates to true if the transition type is + not RESTARTING + """ + del agent, state, action, num_episodes, environment_steps + cond = tf.logical_not(transition_type) + return cond + + +@gin.configurable +def env_restart(agent, state, action, transition_type, environment_steps, + num_episodes): + """True if the transition_type is RESTARTING. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + Returns: + cond: Returns an op that evaluates to true if the transition type equals + RESTARTING. + """ + del agent, state, action, num_episodes, environment_steps + cond = tf.identity(transition_type) + return cond + + +@gin.configurable +def every_n_steps(agent, + state, + action, + transition_type, + environment_steps, + num_episodes, + n=150): + """True once every n steps. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + n: Return true once every n steps. + Returns: + cond: Returns an op that evaluates to true if environment_steps + equals 0 mod n. We increment the step before checking this condition, so + we do not need to add one to environment_steps. + """ + del agent, state, action, transition_type, num_episodes + cond = tf.equal(tf.mod(environment_steps, n), 0) + return cond + + +@gin.configurable +def every_n_episodes(agent, + state, + action, + transition_type, + environment_steps, + num_episodes, + n=2, + steps_per_episode=None): + """True once every n episodes. + + Specifically, evaluates to True on the 0th step of every nth episode. + Unlike environment_steps, num_episodes starts at 0, so we do want to add + one to ensure it does not reset on the first call. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + n: Return true once every n episodes. + steps_per_episode: How many steps per episode. Needed to determine when a + new episode starts. + Returns: + cond: Returns an op that evaluates to true on the last step of the episode + (i.e. if num_episodes equals 0 mod n). + """ + assert steps_per_episode is not None + del agent, action, transition_type + ant_fell = tf.logical_or(state[2] < 0.2, state[2] > 1.0) + cond = tf.logical_and( + tf.logical_or( + ant_fell, + tf.equal(tf.mod(num_episodes + 1, n), 0)), + tf.equal(tf.mod(environment_steps, steps_per_episode), 0)) + return cond + + +@gin.configurable +def failed_reset_after_n_episodes(agent, + state, + action, + transition_type, + environment_steps, + num_episodes, + steps_per_episode=None, + reset_state=None, + max_dist=1.0, + epsilon=1e-10): + """Every n episodes, returns True if the reset agent fails to return. + + Specifically, evaluates to True if the distance between the state and the + reset state is greater than max_dist at the end of the episode. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + steps_per_episode: How many steps per episode. Needed to determine when a + new episode starts. + reset_state: State to which the reset controller should return. + max_dist: Agent is considered to have successfully reset if its distance + from the reset_state is less than max_dist. + epsilon: small offset to ensure non-negative/zero distance. + Returns: + cond: Returns an op that evaluates to true if num_episodes+1 equals 0 + mod n. We add one to the num_episodes so the environment is not reset after + the 0th step. + """ + assert steps_per_episode is not None + assert reset_state is not None + del agent, state, action, transition_type, num_episodes + dist = tf.sqrt( + tf.reduce_sum(tf.squared_difference(state, reset_state)) + epsilon) + cond = tf.logical_and( + tf.greater(dist, tf.constant(max_dist)), + tf.equal(tf.mod(environment_steps, steps_per_episode), 0)) + return cond + + +@gin.configurable +def q_too_small(agent, + state, + action, + transition_type, + environment_steps, + num_episodes, + q_min=0.5): + """True of q is too small. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + q_min: Returns true if the qval is less than q_min + Returns: + cond: Returns an op that evaluates to true if qval is less than q_min. + """ + del transition_type, environment_steps, num_episodes + state_for_reset_agent = tf.stack(state[:-1], tf.constant([0], dtype=tf.float)) + qval = agent.BASE_AGENT_CLASS.critic_net( + tf.expand_dims(state_for_reset_agent, 0), tf.expand_dims(action, 0))[0, :] + cond = tf.greater(tf.constant(q_min), qval) + return cond + + +@gin.configurable +def true_fn(agent, state, action, transition_type, environment_steps, + num_episodes): + """Returns an op that evaluates to true. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + Returns: + cond: op that always evaluates to True. + """ + del agent, state, action, transition_type, environment_steps, num_episodes + cond = tf.constant(True, dtype=tf.bool) + return cond + + +@gin.configurable +def false_fn(agent, state, action, transition_type, environment_steps, + num_episodes): + """Returns an op that evaluates to false. + + Args: + agent: RL agent. + state: A [num_state_dims] tensor representing a state. + action: Action performed. + transition_type: Type of transition after action + environment_steps: Number of steps performed by environment. + num_episodes: Number of episodes. + Returns: + cond: op that always evaluates to False. + """ + del agent, state, action, transition_type, environment_steps, num_episodes + cond = tf.constant(False, dtype=tf.bool) + return cond diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/base_uvf.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/base_uvf.gin" new file mode 100644 index 00000000..2f3f47b6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/base_uvf.gin" @@ -0,0 +1,68 @@ +#-*-Python-*- +import gin.tf.external_configurables + +create_maze_env.top_down_view = %IMAGES +## Create the agent +AGENT_CLASS = @UvfAgent +UvfAgent.tf_context = %CONTEXT +UvfAgent.actor_net = @agent/ddpg_actor_net +UvfAgent.critic_net = @agent/ddpg_critic_net +UvfAgent.dqda_clipping = 0.0 +UvfAgent.td_errors_loss = @tf.losses.huber_loss +UvfAgent.target_q_clipping = %TARGET_Q_CLIPPING + +# Create meta agent +META_CLASS = @MetaAgent +MetaAgent.tf_context = %META_CONTEXT +MetaAgent.sub_context = %CONTEXT +MetaAgent.actor_net = @meta/ddpg_actor_net +MetaAgent.critic_net = @meta/ddpg_critic_net +MetaAgent.dqda_clipping = 0.0 +MetaAgent.td_errors_loss = @tf.losses.huber_loss +MetaAgent.target_q_clipping = %TARGET_Q_CLIPPING + +# Create state preprocess +STATE_PREPROCESS_CLASS = @StatePreprocess +StatePreprocess.ndims = %SUBGOAL_DIM +state_preprocess_net.states_hidden_layers = (100, 100) +state_preprocess_net.num_output_dims = %SUBGOAL_DIM +state_preprocess_net.images = %IMAGES +action_embed_net.num_output_dims = %SUBGOAL_DIM +INVERSE_DYNAMICS_CLASS = @InverseDynamics + +# actor_net +ACTOR_HIDDEN_SIZE_1 = 300 +ACTOR_HIDDEN_SIZE_2 = 300 +agent/ddpg_actor_net.hidden_layers = (%ACTOR_HIDDEN_SIZE_1, %ACTOR_HIDDEN_SIZE_2) +agent/ddpg_actor_net.activation_fn = @tf.nn.relu +agent/ddpg_actor_net.zero_obs = %ZERO_OBS +agent/ddpg_actor_net.images = %IMAGES +meta/ddpg_actor_net.hidden_layers = (%ACTOR_HIDDEN_SIZE_1, %ACTOR_HIDDEN_SIZE_2) +meta/ddpg_actor_net.activation_fn = @tf.nn.relu +meta/ddpg_actor_net.zero_obs = False +meta/ddpg_actor_net.images = %IMAGES +# critic_net +CRITIC_HIDDEN_SIZE_1 = 300 +CRITIC_HIDDEN_SIZE_2 = 300 +agent/ddpg_critic_net.states_hidden_layers = (%CRITIC_HIDDEN_SIZE_1,) +agent/ddpg_critic_net.actions_hidden_layers = None +agent/ddpg_critic_net.joint_hidden_layers = (%CRITIC_HIDDEN_SIZE_2,) +agent/ddpg_critic_net.weight_decay = 0.0 +agent/ddpg_critic_net.activation_fn = @tf.nn.relu +agent/ddpg_critic_net.zero_obs = %ZERO_OBS +agent/ddpg_critic_net.images = %IMAGES +meta/ddpg_critic_net.states_hidden_layers = (%CRITIC_HIDDEN_SIZE_1,) +meta/ddpg_critic_net.actions_hidden_layers = None +meta/ddpg_critic_net.joint_hidden_layers = (%CRITIC_HIDDEN_SIZE_2,) +meta/ddpg_critic_net.weight_decay = 0.0 +meta/ddpg_critic_net.activation_fn = @tf.nn.relu +meta/ddpg_critic_net.zero_obs = False +meta/ddpg_critic_net.images = %IMAGES + +tf.losses.huber_loss.delta = 1.0 +# Sample action +uvf_add_noise_fn.stddev = 1.0 +meta_add_noise_fn.stddev = %META_EXPLORE_NOISE +# Update targets +ddpg_update_targets.tau = 0.001 +td3_update_targets.tau = 0.005 diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/eval_uvf.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/eval_uvf.gin" new file mode 100644 index 00000000..7a58241e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/eval_uvf.gin" @@ -0,0 +1,14 @@ +#-*-Python-*- +# Config eval +evaluate.environment = @create_maze_env() +evaluate.agent_class = %AGENT_CLASS +evaluate.meta_agent_class = %META_CLASS +evaluate.state_preprocess_class = %STATE_PREPROCESS_CLASS +evaluate.num_episodes_eval = 50 +evaluate.num_episodes_videos = 1 +evaluate.gamma = 1.0 +evaluate.eval_interval_secs = 1 +evaluate.generate_videos = False +evaluate.generate_summaries = True +evaluate.eval_modes = %EVAL_MODES +evaluate.max_steps_per_episode = %RESET_EPISODE_PERIOD diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/train_uvf.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/train_uvf.gin" new file mode 100644 index 00000000..8b02d7a6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/configs/train_uvf.gin" @@ -0,0 +1,52 @@ +#-*-Python-*- +# Create replay_buffer +agent/CircularBuffer.buffer_size = 200000 +meta/CircularBuffer.buffer_size = 200000 +agent/CircularBuffer.scope = "agent" +meta/CircularBuffer.scope = "meta" + +# Config train +train_uvf.environment = @create_maze_env() +train_uvf.agent_class = %AGENT_CLASS +train_uvf.meta_agent_class = %META_CLASS +train_uvf.state_preprocess_class = %STATE_PREPROCESS_CLASS +train_uvf.inverse_dynamics_class = %INVERSE_DYNAMICS_CLASS +train_uvf.replay_buffer = @agent/CircularBuffer() +train_uvf.meta_replay_buffer = @meta/CircularBuffer() +train_uvf.critic_optimizer = @critic/AdamOptimizer() +train_uvf.actor_optimizer = @actor/AdamOptimizer() +train_uvf.meta_critic_optimizer = @meta_critic/AdamOptimizer() +train_uvf.meta_actor_optimizer = @meta_actor/AdamOptimizer() +train_uvf.repr_optimizer = @repr/AdamOptimizer() +train_uvf.num_episodes_train = 25000 +train_uvf.batch_size = 100 +train_uvf.initial_episodes = 5 +train_uvf.gamma = 0.99 +train_uvf.meta_gamma = 0.99 +train_uvf.reward_scale_factor = 1.0 +train_uvf.target_update_period = 2 +train_uvf.num_updates_per_observation = 1 +train_uvf.num_collect_per_update = 1 +train_uvf.num_collect_per_meta_update = 10 +train_uvf.debug_summaries = False +train_uvf.log_every_n_steps = 1000 +train_uvf.save_policy_every_n_steps =100000 + +# Config Optimizers +critic/AdamOptimizer.learning_rate = 0.001 +critic/AdamOptimizer.beta1 = 0.9 +critic/AdamOptimizer.beta2 = 0.999 +actor/AdamOptimizer.learning_rate = 0.0001 +actor/AdamOptimizer.beta1 = 0.9 +actor/AdamOptimizer.beta2 = 0.999 + +meta_critic/AdamOptimizer.learning_rate = 0.001 +meta_critic/AdamOptimizer.beta1 = 0.9 +meta_critic/AdamOptimizer.beta2 = 0.999 +meta_actor/AdamOptimizer.learning_rate = 0.0001 +meta_actor/AdamOptimizer.beta1 = 0.9 +meta_actor/AdamOptimizer.beta2 = 0.999 + +repr/AdamOptimizer.learning_rate = 0.0001 +repr/AdamOptimizer.beta1 = 0.9 +repr/AdamOptimizer.beta2 = 0.999 diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/__init__.py" new file mode 100644 index 00000000..8b137891 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/__init__.py" @@ -0,0 +1 @@ + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block.gin" new file mode 100644 index 00000000..d5bd4f01 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block.gin" @@ -0,0 +1,67 @@ +#-*-Python-*- +create_maze_env.env_name = "AntBlock" +ZERO_OBS = False +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4), (20, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1", "eval2", "eval3"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], + "eval2": [@eval2/ConstantSampler], + "eval3": [@eval3/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [3, 4] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [16, 0] +eval2/ConstantSampler.value = [16, 16] +eval3/ConstantSampler.value = [0, 16] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block_maze.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block_maze.gin" new file mode 100644 index 00000000..cebf775b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_block_maze.gin" @@ -0,0 +1,67 @@ +#-*-Python-*- +create_maze_env.env_name = "AntBlockMaze" +ZERO_OBS = False +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4), (12, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1", "eval2", "eval3"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], + "eval2": [@eval2/ConstantSampler], + "eval3": [@eval3/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [3, 4] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [8, 0] +eval2/ConstantSampler.value = [8, 16] +eval3/ConstantSampler.value = [0, 16] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi.gin" new file mode 100644 index 00000000..eb89ad0c --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi.gin" @@ -0,0 +1,62 @@ +#-*-Python-*- +create_maze_env.env_name = "AntFall" +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4, 0), (12, 28, 5)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [3] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1, 2] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [0, 27, 4.5] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi_img.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi_img.gin" new file mode 100644 index 00000000..b54fb7c9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_multi_img.gin" @@ -0,0 +1,68 @@ +#-*-Python-*- +create_maze_env.env_name = "AntFall" +IMAGES = True + +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4, 0), (12, 28, 5)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [3] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], +} +meta/Context.context_transition_fn = @task/relative_context_transition_fn +meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1, 2] +task/negative_distance.relative_context = True +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +task/relative_context_transition_fn.k = 3 +task/relative_context_multi_transition_fn.k = 3 +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [0, 27, 0] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_single.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_single.gin" new file mode 100644 index 00000000..56bbc070 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_fall_single.gin" @@ -0,0 +1,62 @@ +#-*-Python-*- +create_maze_env.env_name = "AntFall" +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4, 0), (12, 28, 5)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [3] +meta/Context.samplers = { + "train": [@eval1/ConstantSampler], + "explore": [@eval1/ConstantSampler], + "eval1": [@eval1/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1, 2] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [0, 27, 4.5] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze.gin" new file mode 100644 index 00000000..3a0b73e3 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze.gin" @@ -0,0 +1,66 @@ +#-*-Python-*- +create_maze_env.env_name = "AntMaze" +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4), (20, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1", "eval2", "eval3"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], + "eval2": [@eval2/ConstantSampler], + "eval3": [@eval3/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [16, 0] +eval2/ConstantSampler.value = [16, 16] +eval3/ConstantSampler.value = [0, 16] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze_img.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze_img.gin" new file mode 100644 index 00000000..ceed65a0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_maze_img.gin" @@ -0,0 +1,72 @@ +#-*-Python-*- +create_maze_env.env_name = "AntMaze" +IMAGES = True + +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-4, -4), (20, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1", "eval2", "eval3"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], + "eval2": [@eval2/ConstantSampler], + "eval3": [@eval3/ConstantSampler], +} +meta/Context.context_transition_fn = @task/relative_context_transition_fn +meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = True +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +task/relative_context_transition_fn.k = 2 +task/relative_context_multi_transition_fn.k = 2 +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [16, 0] +eval2/ConstantSampler.value = [16, 16] +eval3/ConstantSampler.value = [0, 16] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi.gin" new file mode 100644 index 00000000..db9b4ed7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi.gin" @@ -0,0 +1,62 @@ +#-*-Python-*- +create_maze_env.env_name = "AntPush" +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-16, -4), (16, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval2"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval2": [@eval2/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval2/ConstantSampler.value = [0, 19] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi_img.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi_img.gin" new file mode 100644 index 00000000..abdc4340 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_multi_img.gin" @@ -0,0 +1,68 @@ +#-*-Python-*- +create_maze_env.env_name = "AntPush" +IMAGES = True + +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-16, -4), (16, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval2"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval2": [@eval2/ConstantSampler], +} +meta/Context.context_transition_fn = @task/relative_context_transition_fn +meta/Context.context_multi_transition_fn = @task/relative_context_multi_transition_fn +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = True +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +task/relative_context_transition_fn.k = 2 +task/relative_context_multi_transition_fn.k = 2 +MetaAgent.k = %SUBGOAL_DIM + +eval2/ConstantSampler.value = [0, 19] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_single.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_single.gin" new file mode 100644 index 00000000..e85c5dfb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/ant_push_single.gin" @@ -0,0 +1,62 @@ +#-*-Python-*- +create_maze_env.env_name = "AntPush" +context_range = (%CONTEXT_RANGE_MIN, %CONTEXT_RANGE_MAX) +meta_context_range = ((-16, -4), (16, 20)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval2"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@eval2/ConstantSampler], + "explore": [@eval2/ConstantSampler], + "eval2": [@eval2/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval2/ConstantSampler.value = [0, 19] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/default.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/default.gin" new file mode 100644 index 00000000..65f91e52 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/default.gin" @@ -0,0 +1,12 @@ +#-*-Python-*- +ENV_CONTEXT = None +EVAL_MODES = ["eval"] +TARGET_Q_CLIPPING = None +RESET_EPISODE_PERIOD = None +ZERO_OBS = False +CONTEXT_RANGE_MIN = -10 +CONTEXT_RANGE_MAX = 10 +SUBGOAL_DIM = 2 + +uvf/negative_distance.summarize = False +uvf/negative_distance.relative_context = True diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_orig.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_orig.gin" new file mode 100644 index 00000000..e39ba96b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_orig.gin" @@ -0,0 +1,14 @@ +#-*-Python-*- +ENV_CONTEXT = None +EVAL_MODES = ["eval"] +TARGET_Q_CLIPPING = None +RESET_EPISODE_PERIOD = None +ZERO_OBS = True +IMAGES = False +CONTEXT_RANGE_MIN = (-10, -10, -0.5, -1, -1, -1, -1, -0.5, -0.3, -0.5, -0.3, -0.5, -0.3, -0.5, -0.3) +CONTEXT_RANGE_MAX = ( 10, 10, 0.5, 1, 1, 1, 1, 0.5, 0.3, 0.5, 0.3, 0.5, 0.3, 0.5, 0.3) +SUBGOAL_DIM = 15 +META_EXPLORE_NOISE = 1.0 + +uvf/negative_distance.summarize = False +uvf/negative_distance.relative_context = True diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_repr.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_repr.gin" new file mode 100644 index 00000000..a0a8057b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_repr.gin" @@ -0,0 +1,18 @@ +#-*-Python-*- +ENV_CONTEXT = None +EVAL_MODES = ["eval"] +TARGET_Q_CLIPPING = None +RESET_EPISODE_PERIOD = None +ZERO_OBS = False +IMAGES = False +CONTEXT_RANGE_MIN = -10 +CONTEXT_RANGE_MAX = 10 +SUBGOAL_DIM = 2 +META_EXPLORE_NOISE = 5.0 + +StatePreprocess.trainable = True +StatePreprocess.state_preprocess_net = @state_preprocess_net +StatePreprocess.action_embed_net = @action_embed_net + +uvf/negative_distance.summarize = False +uvf/negative_distance.relative_context = True diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_xy.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_xy.gin" new file mode 100644 index 00000000..f35026c9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/hiro_xy.gin" @@ -0,0 +1,14 @@ +#-*-Python-*- +ENV_CONTEXT = None +EVAL_MODES = ["eval"] +TARGET_Q_CLIPPING = None +RESET_EPISODE_PERIOD = None +ZERO_OBS = False +IMAGES = False +CONTEXT_RANGE_MIN = -10 +CONTEXT_RANGE_MAX = 10 +SUBGOAL_DIM = 2 +META_EXPLORE_NOISE = 1.0 + +uvf/negative_distance.summarize = False +uvf/negative_distance.relative_context = True diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/point_maze.gin" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/point_maze.gin" new file mode 100644 index 00000000..0ea67d2d --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/configs/point_maze.gin" @@ -0,0 +1,73 @@ +#-*-Python-*- +# NOTE: For best training, low-level exploration (uvf_add_noise_fn.stddev) +# should be reduced to around 0.1. +create_maze_env.env_name = "PointMaze" +context_range_min = -10 +context_range_max = 10 +context_range = (%context_range_min, %context_range_max) +meta_context_range = ((-2, -2), (10, 10)) + +RESET_EPISODE_PERIOD = 500 +RESET_ENV_PERIOD = 1 +# End episode every N steps +UvfAgent.reset_episode_cond_fn = @every_n_steps +every_n_steps.n = %RESET_EPISODE_PERIOD +train_uvf.max_steps_per_episode = %RESET_EPISODE_PERIOD +# Do a manual reset every N episodes +UvfAgent.reset_env_cond_fn = @every_n_episodes +every_n_episodes.n = %RESET_ENV_PERIOD +every_n_episodes.steps_per_episode = %RESET_EPISODE_PERIOD + +## Config defaults +EVAL_MODES = ["eval1", "eval2", "eval3"] + +## Config agent +CONTEXT = @agent/Context +META_CONTEXT = @meta/Context + +## Config agent context +agent/Context.context_ranges = [%context_range] +agent/Context.context_shapes = [%SUBGOAL_DIM] +agent/Context.meta_action_every_n = 10 +agent/Context.samplers = { + "train": [@train/DirectionSampler], + "explore": [@train/DirectionSampler], + "eval1": [@uvf_eval1/ConstantSampler], + "eval2": [@uvf_eval2/ConstantSampler], + "eval3": [@uvf_eval3/ConstantSampler], +} + +agent/Context.context_transition_fn = @relative_context_transition_fn +agent/Context.context_multi_transition_fn = @relative_context_multi_transition_fn + +agent/Context.reward_fn = @uvf/negative_distance + +## Config meta context +meta/Context.context_ranges = [%meta_context_range] +meta/Context.context_shapes = [2] +meta/Context.samplers = { + "train": [@train/RandomSampler], + "explore": [@train/RandomSampler], + "eval1": [@eval1/ConstantSampler], + "eval2": [@eval2/ConstantSampler], + "eval3": [@eval3/ConstantSampler], +} +meta/Context.reward_fn = @task/negative_distance + +## Config rewards +task/negative_distance.state_indices = [0, 1] +task/negative_distance.relative_context = False +task/negative_distance.diff = False +task/negative_distance.offset = 0.0 + +## Config samplers +train/RandomSampler.context_range = %meta_context_range +train/DirectionSampler.context_range = %context_range +train/DirectionSampler.k = %SUBGOAL_DIM +relative_context_transition_fn.k = %SUBGOAL_DIM +relative_context_multi_transition_fn.k = %SUBGOAL_DIM +MetaAgent.k = %SUBGOAL_DIM + +eval1/ConstantSampler.value = [8, 0] +eval2/ConstantSampler.value = [8, 8] +eval3/ConstantSampler.value = [0, 8] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context.py" new file mode 100644 index 00000000..76be00b4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context.py" @@ -0,0 +1,467 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Context for Universal Value Function agents. + +A context specifies a list of contextual variables, each with + own sampling and reward computation methods. + +Examples of contextual variables include + goal states, reward combination vectors, etc. +""" +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function +import numpy as np +import tensorflow as tf +from tf_agents import specs +import gin.tf +from utils import utils as uvf_utils + + +@gin.configurable +class Context(object): + """Base context.""" + VAR_NAME = 'action' + + def __init__(self, + tf_env, + context_ranges=None, + context_shapes=None, + state_indices=None, + variable_indices=None, + gamma_index=None, + settable_context=False, + timers=None, + samplers=None, + reward_weights=None, + reward_fn=None, + random_sampler_mode='random', + normalizers=None, + context_transition_fn=None, + context_multi_transition_fn=None, + meta_action_every_n=None): + self._tf_env = tf_env + self.variable_indices = variable_indices + self.gamma_index = gamma_index + self._settable_context = settable_context + self.timers = timers + self._context_transition_fn = context_transition_fn + self._context_multi_transition_fn = context_multi_transition_fn + self._random_sampler_mode = random_sampler_mode + + # assign specs + self._obs_spec = self._tf_env.observation_spec() + self._context_shapes = tuple([ + shape if shape is not None else self._obs_spec.shape + for shape in context_shapes + ]) + self.context_specs = tuple([ + specs.TensorSpec(dtype=self._obs_spec.dtype, shape=shape) + for shape in self._context_shapes + ]) + if context_ranges is not None: + self.context_ranges = context_ranges + else: + self.context_ranges = [None] * len(self._context_shapes) + + self.context_as_action_specs = tuple([ + specs.BoundedTensorSpec( + shape=shape, + dtype=(tf.float32 if self._obs_spec.dtype in + [tf.float32, tf.float64] else self._obs_spec.dtype), + minimum=context_range[0], + maximum=context_range[-1]) + for shape, context_range in zip(self._context_shapes, self.context_ranges) + ]) + + if state_indices is not None: + self.state_indices = state_indices + else: + self.state_indices = [None] * len(self._context_shapes) + if self.variable_indices is not None and self.n != len( + self.variable_indices): + raise ValueError( + 'variable_indices (%s) must have the same length as contexts (%s).' % + (self.variable_indices, self.context_specs)) + assert self.n == len(self.context_ranges) + assert self.n == len(self.state_indices) + + # assign reward/sampler fns + self._sampler_fns = dict() + self._samplers = dict() + self._reward_fns = dict() + + # assign reward fns + self._add_custom_reward_fns() + reward_weights = reward_weights or None + self._reward_fn = self._make_reward_fn(reward_fn, reward_weights) + + # assign samplers + self._add_custom_sampler_fns() + for mode, sampler_fns in samplers.items(): + self._make_sampler_fn(sampler_fns, mode) + + # create normalizers + if normalizers is None: + self._normalizers = [None] * len(self.context_specs) + else: + self._normalizers = [ + normalizer(tf.zeros(shape=spec.shape, dtype=spec.dtype)) + if normalizer is not None else None + for normalizer, spec in zip(normalizers, self.context_specs) + ] + assert self.n == len(self._normalizers) + + self.meta_action_every_n = meta_action_every_n + + # create vars + self.context_vars = {} + self.timer_vars = {} + self.create_vars(self.VAR_NAME) + self.t = tf.Variable( + tf.zeros(shape=(), dtype=tf.int32), name='num_timer_steps') + + def _add_custom_reward_fns(self): + pass + + def _add_custom_sampler_fns(self): + pass + + def sample_random_contexts(self, batch_size): + """Sample random batch contexts.""" + assert self._random_sampler_mode is not None + return self.sample_contexts(self._random_sampler_mode, batch_size)[0] + + def sample_contexts(self, mode, batch_size, state=None, next_state=None, + **kwargs): + """Sample a batch of contexts. + + Args: + mode: A string representing the mode [`train`, `explore`, `eval`]. + batch_size: Batch size. + Returns: + Two lists of [batch_size, num_context_dims] contexts. + """ + contexts, next_contexts = self._sampler_fns[mode]( + batch_size, state=state, next_state=next_state, + **kwargs) + self._validate_contexts(contexts) + self._validate_contexts(next_contexts) + return contexts, next_contexts + + def compute_rewards(self, mode, states, actions, rewards, next_states, + contexts): + """Compute context-based rewards. + + Args: + mode: A string representing the mode ['uvf', 'task']. + states: A [batch_size, num_state_dims] tensor. + actions: A [batch_size, num_action_dims] tensor. + rewards: A [batch_size] tensor representing unmodified rewards. + next_states: A [batch_size, num_state_dims] tensor. + contexts: A list of [batch_size, num_context_dims] tensors. + Returns: + A [batch_size] tensor representing rewards. + """ + return self._reward_fn(states, actions, rewards, next_states, + contexts) + + def _make_reward_fn(self, reward_fns_list, reward_weights): + """Returns a fn that computes rewards. + + Args: + reward_fns_list: A fn or a list of reward fns. + mode: A string representing the operating mode. + reward_weights: A list of reward weights. + """ + if not isinstance(reward_fns_list, (list, tuple)): + reward_fns_list = [reward_fns_list] + if reward_weights is None: + reward_weights = [1.0] * len(reward_fns_list) + assert len(reward_fns_list) == len(reward_weights) + + reward_fns_list = [ + self._custom_reward_fns[fn] if isinstance(fn, (str,)) else fn + for fn in reward_fns_list + ] + + def reward_fn(*args, **kwargs): + """Returns rewards, discounts.""" + reward_tuples = [ + reward_fn(*args, **kwargs) for reward_fn in reward_fns_list + ] + rewards_list = [reward_tuple[0] for reward_tuple in reward_tuples] + discounts_list = [reward_tuple[1] for reward_tuple in reward_tuples] + ndims = max([r.shape.ndims for r in rewards_list]) + if ndims > 1: # expand reward shapes to allow broadcasting + for i in range(len(rewards_list)): + for _ in range(rewards_list[i].shape.ndims - ndims): + rewards_list[i] = tf.expand_dims(rewards_list[i], axis=-1) + for _ in range(discounts_list[i].shape.ndims - ndims): + discounts_list[i] = tf.expand_dims(discounts_list[i], axis=-1) + rewards = tf.add_n( + [r * tf.to_float(w) for r, w in zip(rewards_list, reward_weights)]) + discounts = discounts_list[0] + for d in discounts_list[1:]: + discounts *= d + + return rewards, discounts + + return reward_fn + + def _make_sampler_fn(self, sampler_cls_list, mode): + """Returns a fn that samples a list of context vars. + + Args: + sampler_cls_list: A list of sampler classes. + mode: A string representing the operating mode. + """ + if not isinstance(sampler_cls_list, (list, tuple)): + sampler_cls_list = [sampler_cls_list] + + self._samplers[mode] = [] + sampler_fns = [] + for spec, sampler in zip(self.context_specs, sampler_cls_list): + if isinstance(sampler, (str,)): + sampler_fn = self._custom_sampler_fns[sampler] + else: + sampler_fn = sampler(context_spec=spec) + self._samplers[mode].append(sampler_fn) + sampler_fns.append(sampler_fn) + + def batch_sampler_fn(batch_size, state=None, next_state=None, **kwargs): + """Sampler fn.""" + contexts_tuples = [ + sampler(batch_size, state=state, next_state=next_state, **kwargs) + for sampler in sampler_fns] + contexts = [c[0] for c in contexts_tuples] + next_contexts = [c[1] for c in contexts_tuples] + contexts = [ + normalizer.update_apply(c) if normalizer is not None else c + for normalizer, c in zip(self._normalizers, contexts) + ] + next_contexts = [ + normalizer.apply(c) if normalizer is not None else c + for normalizer, c in zip(self._normalizers, next_contexts) + ] + return contexts, next_contexts + + self._sampler_fns[mode] = batch_sampler_fn + + def set_env_context_op(self, context, disable_unnormalizer=False): + """Returns a TensorFlow op that sets the environment context. + + Args: + context: A list of context Tensor variables. + disable_unnormalizer: Disable unnormalization. + Returns: + A TensorFlow op that sets the environment context. + """ + ret_val = np.array(1.0, dtype=np.float32) + if not self._settable_context: + return tf.identity(ret_val) + + if not disable_unnormalizer: + context = [ + normalizer.unapply(tf.expand_dims(c, 0))[0] + if normalizer is not None else c + for normalizer, c in zip(self._normalizers, context) + ] + + def set_context_func(*env_context_values): + tf.logging.info('[set_env_context_op] Setting gym environment context.') + # pylint: disable=protected-access + self.gym_env.set_context(*env_context_values) + return ret_val + # pylint: enable=protected-access + + with tf.name_scope('set_env_context'): + set_op = tf.py_func(set_context_func, context, tf.float32, + name='set_env_context_py_func') + set_op.set_shape([]) + return set_op + + def set_replay(self, replay): + """Set replay buffer for samplers. + + Args: + replay: A replay buffer. + """ + for _, samplers in self._samplers.items(): + for sampler in samplers: + sampler.set_replay(replay) + + def get_clip_fns(self): + """Returns a list of clip fns for contexts. + + Returns: + A list of fns that clip context tensors. + """ + clip_fns = [] + for context_range in self.context_ranges: + def clip_fn(var_, range_=context_range): + """Clip a tensor.""" + if range_ is None: + clipped_var = tf.identity(var_) + elif isinstance(range_[0], (int, long, float, list, np.ndarray)): + clipped_var = tf.clip_by_value( + var_, + range_[0], + range_[1],) + else: raise NotImplementedError(range_) + return clipped_var + clip_fns.append(clip_fn) + return clip_fns + + def _validate_contexts(self, contexts): + """Validate if contexts have right specs. + + Args: + contexts: A list of [batch_size, num_context_dim] tensors. + Raises: + ValueError: If shape or dtype mismatches that of spec. + """ + for i, (context, spec) in enumerate(zip(contexts, self.context_specs)): + if context[0].shape != spec.shape: + raise ValueError('contexts[%d] has invalid shape %s wrt spec shape %s' % + (i, context[0].shape, spec.shape)) + if context.dtype != spec.dtype: + raise ValueError('contexts[%d] has invalid dtype %s wrt spec dtype %s' % + (i, context.dtype, spec.dtype)) + + def context_multi_transition_fn(self, contexts, **kwargs): + """Returns multiple future contexts starting from a batch.""" + assert self._context_multi_transition_fn + return self._context_multi_transition_fn(contexts, None, None, **kwargs) + + def step(self, mode, agent=None, action_fn=None, **kwargs): + """Returns [next_contexts..., next_timer] list of ops. + + Args: + mode: a string representing the mode=[train, explore, eval]. + **kwargs: kwargs for context_transition_fn. + Returns: + a list of ops that set the context. + """ + if agent is None: + ops = [] + if self._context_transition_fn is not None: + def sampler_fn(): + samples = self.sample_contexts(mode, 1)[0] + return [s[0] for s in samples] + values = self._context_transition_fn(self.vars, self.t, sampler_fn, **kwargs) + ops += [tf.assign(var, value) for var, value in zip(self.vars, values)] + ops.append(tf.assign_add(self.t, 1)) # increment timer + return ops + else: + ops = agent.tf_context.step(mode, **kwargs) + state = kwargs['state'] + next_state = kwargs['next_state'] + state_repr = kwargs['state_repr'] + next_state_repr = kwargs['next_state_repr'] + with tf.control_dependencies(ops): # Step high level context before computing low level one. + # Get the context transition function output. + values = self._context_transition_fn(self.vars, self.t, None, + state=state_repr, + next_state=next_state_repr) + # Select a new goal every C steps, otherwise use context transition. + low_level_context = [ + tf.cond(tf.equal(self.t % self.meta_action_every_n, 0), + lambda: tf.cast(action_fn(next_state, context=None), tf.float32), + lambda: values)] + ops = [tf.assign(var, value) + for var, value in zip(self.vars, low_level_context)] + with tf.control_dependencies(ops): + return [tf.assign_add(self.t, 1)] # increment timer + return ops + + def reset(self, mode, agent=None, action_fn=None, state=None): + """Returns ops that reset the context. + + Args: + mode: a string representing the mode=[train, explore, eval]. + Returns: + a list of ops that reset the context. + """ + if agent is None: + values = self.sample_contexts(mode=mode, batch_size=1)[0] + if values is None: + return [] + values = [value[0] for value in values] + values[0] = uvf_utils.tf_print( + values[0], + values, + message='context:reset, mode=%s' % mode, + first_n=10, + name='context:reset:%s' % mode) + all_ops = [] + for _, context_vars in sorted(self.context_vars.items()): + ops = [tf.assign(var, value) for var, value in zip(context_vars, values)] + all_ops += ops + all_ops.append(self.set_env_context_op(values)) + all_ops.append(tf.assign(self.t, 0)) # reset timer + return all_ops + else: + ops = agent.tf_context.reset(mode) + # NOTE: The code is currently written in such a way that the higher level + # policy does not provide a low-level context until the second + # observation. Insead, we just zero-out low-level contexts. + for key, context_vars in sorted(self.context_vars.items()): + ops += [tf.assign(var, tf.zeros_like(var)) for var, meta_var in + zip(context_vars, agent.tf_context.context_vars[key])] + + ops.append(tf.assign(self.t, 0)) # reset timer + return ops + + def create_vars(self, name, agent=None): + """Create tf variables for contexts. + + Args: + name: Name of the variables. + Returns: + A list of [num_context_dims] tensors. + """ + if agent is not None: + meta_vars = agent.create_vars(name) + else: + meta_vars = {} + assert name not in self.context_vars, ('Conflict! %s is already ' + 'initialized.') % name + self.context_vars[name] = tuple([ + tf.Variable( + tf.zeros(shape=spec.shape, dtype=spec.dtype), + name='%s_context_%d' % (name, i)) + for i, spec in enumerate(self.context_specs) + ]) + return self.context_vars[name], meta_vars + + @property + def n(self): + return len(self.context_specs) + + @property + def vars(self): + return self.context_vars[self.VAR_NAME] + + # pylint: disable=protected-access + @property + def gym_env(self): + return self._tf_env.pyenv._gym_env + + @property + def tf_env(self): + return self._tf_env + # pylint: enable=protected-access diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context_transition_functions.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context_transition_functions.py" new file mode 100644 index 00000000..70326deb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/context_transition_functions.py" @@ -0,0 +1,123 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Context functions. + +Given the current contexts, timer and context sampler, returns new contexts + after an environment step. This can be used to define a high-level policy + that controls contexts as its actions. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf +import gin.tf +import utils as uvf_utils + + +@gin.configurable +def periodic_context_fn(contexts, timer, sampler_fn, period=1): + """Periodically samples contexts. + + Args: + contexts: a list of [num_context_dims] tensor variables representing + current contexts. + timer: a scalar integer tensor variable holding the current time step. + sampler_fn: a sampler function that samples a list of [num_context_dims] + tensors. + period: (integer) period of update. + Returns: + a list of [num_context_dims] tensors. + """ + contexts = list(contexts[:]) # create copy + return tf.cond(tf.mod(timer, period) == 0, sampler_fn, lambda: contexts) + + +@gin.configurable +def timer_context_fn(contexts, + timer, + sampler_fn, + period=1, + timer_index=-1, + debug=False): + """Samples contexts based on timer in contexts. + + Args: + contexts: a list of [num_context_dims] tensor variables representing + current contexts. + timer: a scalar integer tensor variable holding the current time step. + sampler_fn: a sampler function that samples a list of [num_context_dims] + tensors. + period: (integer) period of update; actual period = `period` + 1. + timer_index: (integer) Index of context list that present timer. + debug: (boolean) Print debug messages. + Returns: + a list of [num_context_dims] tensors. + """ + contexts = list(contexts[:]) # create copy + cond = tf.equal(contexts[timer_index][0], 0) + def reset(): + """Sample context and reset the timer.""" + new_contexts = sampler_fn() + new_contexts[timer_index] = tf.zeros_like( + contexts[timer_index]) + period + return new_contexts + def update(): + """Decrement the timer.""" + contexts[timer_index] -= 1 + return contexts + values = tf.cond(cond, reset, update) + if debug: + values[0] = uvf_utils.tf_print( + values[0], + values + [timer], + 'timer_context_fn', + first_n=200, + name='timer_context_fn:contexts') + return values + + +@gin.configurable +def relative_context_transition_fn( + contexts, timer, sampler_fn, + k=2, state=None, next_state=None, + **kwargs): + """Contexts updated to be relative to next state. + """ + contexts = list(contexts[:]) # create copy + assert len(contexts) == 1 + new_contexts = [ + tf.concat( + [contexts[0][:k] + state[:k] - next_state[:k], + contexts[0][k:]], -1)] + return new_contexts + + +@gin.configurable +def relative_context_multi_transition_fn( + contexts, timer, sampler_fn, + k=2, states=None, + **kwargs): + """Given contexts at first state and sequence of states, derives sequence of all contexts. + """ + contexts = list(contexts[:]) # create copy + assert len(contexts) == 1 + contexts = [ + tf.concat( + [tf.expand_dims(contexts[0][:, :k] + states[:, 0, :k], 1) - states[:, :, :k], + contexts[0][:, None, k:] * tf.ones_like(states[:, :, :1])], -1)] + return contexts diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_imports.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_imports.py" new file mode 100644 index 00000000..94512cef --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_imports.py" @@ -0,0 +1,25 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Import gin configurable modules. +""" + +# pylint: disable=unused-import +from context import context +from context import context_transition_functions +from context import gin_utils +from context import rewards_functions +from context import samplers +# pylint: disable=unused-import diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_utils.py" new file mode 100644 index 00000000..ab7c1b2d --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/gin_utils.py" @@ -0,0 +1,45 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Gin configurable utility functions. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np +import gin.tf + + +@gin.configurable +def gin_sparse_array(size, values, indices, fill_value=0): + arr = np.zeros(size) + arr.fill(fill_value) + arr[indices] = values + return arr + + +@gin.configurable +def gin_sum(values): + result = values[0] + for value in values[1:]: + result += value + return result + + +@gin.configurable +def gin_range(n): + return range(n) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/rewards_functions.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/rewards_functions.py" new file mode 100644 index 00000000..ab560a7f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/rewards_functions.py" @@ -0,0 +1,741 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Reward shaping functions used by Contexts. + + Each reward function should take the following inputs and return new rewards, + and discounts. + + new_rewards, discounts = reward_fn(states, actions, rewards, + next_states, contexts) +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import tensorflow as tf +import gin.tf + + +def summarize_stats(stats): + """Summarize a dictionary of variables. + + Args: + stats: a dictionary of {name: tensor} to compute stats over. + """ + for name, stat in stats.items(): + mean = tf.reduce_mean(stat) + tf.summary.scalar('mean_%s' % name, mean) + tf.summary.scalar('max_%s' % name, tf.reduce_max(stat)) + tf.summary.scalar('min_%s' % name, tf.reduce_min(stat)) + std = tf.sqrt(tf.reduce_mean(tf.square(stat)) - tf.square(mean) + 1e-10) + tf.summary.scalar('std_%s' % name, std) + tf.summary.histogram(name, stat) + + +def index_states(states, indices): + """Return indexed states. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + indices: (a list of Numpy integer array) Indices of states dimensions + to be mapped. + Returns: + A [batch_size, num_indices] Tensor representing the batch of indexed states. + """ + if indices is None: + return states + indices = tf.constant(indices, dtype=tf.int32) + return tf.gather(states, indices=indices, axis=1) + + +def record_tensor(tensor, indices, stats, name='states'): + """Record specified tensor dimensions into stats. + + Args: + tensor: A [batch_size, num_dims] Tensor. + indices: (a list of integers) Indices of dimensions to record. + stats: A dictionary holding stats. + name: (string) Name of tensor. + """ + if indices is None: + indices = range(tensor.shape.as_list()[1]) + for index in indices: + stats['%s_%02d' % (name, index)] = tensor[:, index] + + +@gin.configurable +def potential_rewards(states, + actions, + rewards, + next_states, + contexts, + gamma=1.0, + reward_fn=None): + """Return the potential-based rewards. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + gamma: Reward discount. + reward_fn: A reward function. + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del actions # unused args + gamma = tf.to_float(gamma) + rewards_tp1, discounts = reward_fn(None, None, rewards, next_states, contexts) + rewards, _ = reward_fn(None, None, rewards, states, contexts) + return -rewards + gamma * rewards_tp1, discounts + + +@gin.configurable +def timed_rewards(states, + actions, + rewards, + next_states, + contexts, + reward_fn=None, + dense=False, + timer_index=-1): + """Return the timed rewards. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + reward_fn: A reward function. + dense: (boolean) Provide dense rewards or sparse rewards at time = 0. + timer_index: (integer) The context list index that specifies timer. + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + assert contexts[timer_index].get_shape().as_list()[1] == 1 + timers = contexts[timer_index][:, 0] + rewards, discounts = reward_fn(states, actions, rewards, next_states, + contexts) + terminates = tf.to_float(timers <= 0) # if terminate set 1, else set 0 + for _ in range(rewards.shape.ndims - 1): + terminates = tf.expand_dims(terminates, axis=-1) + if not dense: + rewards *= terminates # if terminate, return rewards, else return 0 + discounts *= (tf.to_float(1.0) - terminates) + return rewards, discounts + + +@gin.configurable +def reset_rewards(states, + actions, + rewards, + next_states, + contexts, + reset_index=0, + reset_state=None, + reset_reward_function=None, + include_forward_rewards=True, + include_reset_rewards=True): + """Returns the rewards for a forward/reset agent. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + reset_index: (integer) The context list index that specifies reset. + reset_state: Reset state. + reset_reward_function: Reward function for reset step. + include_forward_rewards: Include the rewards from the forward pass. + include_reset_rewards: Include the rewards from the reset pass. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + reset_state = tf.constant( + reset_state, dtype=next_states.dtype, shape=next_states.shape) + reset_states = tf.expand_dims(reset_state, 0) + + def true_fn(): + if include_reset_rewards: + return reset_reward_function(states, actions, rewards, next_states, + [reset_states] + contexts[1:]) + else: + return tf.zeros_like(rewards), tf.ones_like(rewards) + + def false_fn(): + if include_forward_rewards: + return plain_rewards(states, actions, rewards, next_states, contexts) + else: + return tf.zeros_like(rewards), tf.ones_like(rewards) + + rewards, discounts = tf.cond( + tf.cast(contexts[reset_index][0, 0], dtype=tf.bool), true_fn, false_fn) + return rewards, discounts + + +@gin.configurable +def tanh_similarity(states, + actions, + rewards, + next_states, + contexts, + mse_scale=1.0, + state_scales=1.0, + goal_scales=1.0, + summarize=False): + """Returns the similarity between next_states and contexts using tanh and mse. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + mse_scale: A float, to scale mse before tanh. + state_scales: multiplicative scale for (next) states. A scalar or 1D tensor, + must be broadcastable to number of state dimensions. + goal_scales: multiplicative scale for contexts. A scalar or 1D tensor, + must be broadcastable to number of goal dimensions. + summarize: (boolean) enable summary ops. + + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, actions, rewards # Unused + mse = tf.reduce_mean(tf.squared_difference(next_states * state_scales, + contexts[0] * goal_scales), -1) + tanh = tf.tanh(mse_scale * mse) + if summarize: + with tf.name_scope('RewardFn/'): + tf.summary.scalar('mean_mse', tf.reduce_mean(mse)) + tf.summary.histogram('mse', mse) + tf.summary.scalar('mean_tanh', tf.reduce_mean(tanh)) + tf.summary.histogram('tanh', tanh) + rewards = tf.to_float(1 - tanh) + return rewards, tf.ones_like(rewards) + + +@gin.configurable +def negative_mse(states, + actions, + rewards, + next_states, + contexts, + state_scales=1.0, + goal_scales=1.0, + summarize=False): + """Returns the negative mean square error between next_states and contexts. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + state_scales: multiplicative scale for (next) states. A scalar or 1D tensor, + must be broadcastable to number of state dimensions. + goal_scales: multiplicative scale for contexts. A scalar or 1D tensor, + must be broadcastable to number of goal dimensions. + summarize: (boolean) enable summary ops. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, actions, rewards # Unused + mse = tf.reduce_mean(tf.squared_difference(next_states * state_scales, + contexts[0] * goal_scales), -1) + if summarize: + with tf.name_scope('RewardFn/'): + tf.summary.scalar('mean_mse', tf.reduce_mean(mse)) + tf.summary.histogram('mse', mse) + rewards = tf.to_float(-mse) + return rewards, tf.ones_like(rewards) + + +@gin.configurable +def negative_distance(states, + actions, + rewards, + next_states, + contexts, + state_scales=1.0, + goal_scales=1.0, + reward_scales=1.0, + weight_index=None, + weight_vector=None, + summarize=False, + termination_epsilon=1e-4, + state_indices=None, + goal_indices=None, + vectorize=False, + relative_context=False, + diff=False, + norm='L2', + epsilon=1e-10, + bonus_epsilon=0., #5., + offset=0.0): + """Returns the negative euclidean distance between next_states and contexts. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + state_scales: multiplicative scale for (next) states. A scalar or 1D tensor, + must be broadcastable to number of state dimensions. + goal_scales: multiplicative scale for goals. A scalar or 1D tensor, + must be broadcastable to number of goal dimensions. + reward_scales: multiplicative scale for rewards. A scalar or 1D tensor, + must be broadcastable to number of reward dimensions. + weight_index: (integer) The context list index that specifies weight. + weight_vector: (a number or a list or Numpy array) The weighting vector, + broadcastable to `next_states`. + summarize: (boolean) enable summary ops. + termination_epsilon: terminate if dist is less than this quantity. + state_indices: (a list of integers) list of state indices to select. + goal_indices: (a list of integers) list of goal indices to select. + vectorize: Return a vectorized form. + norm: L1 or L2. + epsilon: small offset to ensure non-negative/zero distance. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del actions, rewards # Unused + stats = {} + record_tensor(next_states, state_indices, stats, 'next_states') + states = index_states(states, state_indices) + next_states = index_states(next_states, state_indices) + goals = index_states(contexts[0], goal_indices) + if relative_context: + goals = states + goals + sq_dists = tf.squared_difference(next_states * state_scales, + goals * goal_scales) + old_sq_dists = tf.squared_difference(states * state_scales, + goals * goal_scales) + record_tensor(sq_dists, None, stats, 'sq_dists') + if weight_vector is not None: + sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype) + old_sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype) + if weight_index is not None: + #sq_dists *= contexts[weight_index] + weights = tf.abs(index_states(contexts[0], weight_index)) + #weights /= tf.reduce_sum(weights, -1, keepdims=True) + sq_dists *= weights + old_sq_dists *= weights + if norm == 'L1': + dist = tf.sqrt(sq_dists + epsilon) + old_dist = tf.sqrt(old_sq_dists + epsilon) + if not vectorize: + dist = tf.reduce_sum(dist, -1) + old_dist = tf.reduce_sum(old_dist, -1) + elif norm == 'L2': + if vectorize: + dist = sq_dists + old_dist = old_sq_dists + else: + dist = tf.reduce_sum(sq_dists, -1) + old_dist = tf.reduce_sum(old_sq_dists, -1) + dist = tf.sqrt(dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0) + old_dist = tf.sqrt(old_dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0) + else: + raise NotImplementedError(norm) + discounts = dist > termination_epsilon + if summarize: + with tf.name_scope('RewardFn/'): + tf.summary.scalar('mean_dist', tf.reduce_mean(dist)) + tf.summary.histogram('dist', dist) + summarize_stats(stats) + bonus = tf.to_float(dist < bonus_epsilon) + dist *= reward_scales + old_dist *= reward_scales + if diff: + return bonus + offset + tf.to_float(old_dist - dist), tf.to_float(discounts) + return bonus + offset + tf.to_float(-dist), tf.to_float(discounts) + + +@gin.configurable +def cosine_similarity(states, + actions, + rewards, + next_states, + contexts, + state_scales=1.0, + goal_scales=1.0, + reward_scales=1.0, + normalize_states=True, + normalize_goals=True, + weight_index=None, + weight_vector=None, + summarize=False, + state_indices=None, + goal_indices=None, + offset=0.0): + """Returns the cosine similarity between next_states - states and contexts. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + state_scales: multiplicative scale for (next) states. A scalar or 1D tensor, + must be broadcastable to number of state dimensions. + goal_scales: multiplicative scale for goals. A scalar or 1D tensor, + must be broadcastable to number of goal dimensions. + reward_scales: multiplicative scale for rewards. A scalar or 1D tensor, + must be broadcastable to number of reward dimensions. + weight_index: (integer) The context list index that specifies weight. + weight_vector: (a number or a list or Numpy array) The weighting vector, + broadcastable to `next_states`. + summarize: (boolean) enable summary ops. + termination_epsilon: terminate if dist is less than this quantity. + state_indices: (a list of integers) list of state indices to select. + goal_indices: (a list of integers) list of goal indices to select. + vectorize: Return a vectorized form. + norm: L1 or L2. + epsilon: small offset to ensure non-negative/zero distance. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del actions, rewards # Unused + stats = {} + record_tensor(next_states, state_indices, stats, 'next_states') + states = index_states(states, state_indices) + next_states = index_states(next_states, state_indices) + goals = index_states(contexts[0], goal_indices) + + if weight_vector is not None: + goals *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype) + if weight_index is not None: + weights = tf.abs(index_states(contexts[0], weight_index)) + goals *= weights + + direction_vec = next_states - states + if normalize_states: + direction_vec = tf.nn.l2_normalize(direction_vec, -1) + goal_vec = goals + if normalize_goals: + goal_vec = tf.nn.l2_normalize(goal_vec, -1) + + similarity = tf.reduce_sum(goal_vec * direction_vec, -1) + discounts = tf.ones_like(similarity) + return offset + tf.to_float(similarity), tf.to_float(discounts) + + +@gin.configurable +def diff_distance(states, + actions, + rewards, + next_states, + contexts, + state_scales=1.0, + goal_scales=1.0, + reward_scales=1.0, + weight_index=None, + weight_vector=None, + summarize=False, + termination_epsilon=1e-4, + state_indices=None, + goal_indices=None, + norm='L2', + epsilon=1e-10): + """Returns the difference in euclidean distance between states/next_states and contexts. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + state_scales: multiplicative scale for (next) states. A scalar or 1D tensor, + must be broadcastable to number of state dimensions. + goal_scales: multiplicative scale for goals. A scalar or 1D tensor, + must be broadcastable to number of goal dimensions. + reward_scales: multiplicative scale for rewards. A scalar or 1D tensor, + must be broadcastable to number of reward dimensions. + weight_index: (integer) The context list index that specifies weight. + weight_vector: (a number or a list or Numpy array) The weighting vector, + broadcastable to `next_states`. + summarize: (boolean) enable summary ops. + termination_epsilon: terminate if dist is less than this quantity. + state_indices: (a list of integers) list of state indices to select. + goal_indices: (a list of integers) list of goal indices to select. + vectorize: Return a vectorized form. + norm: L1 or L2. + epsilon: small offset to ensure non-negative/zero distance. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del actions, rewards # Unused + stats = {} + record_tensor(next_states, state_indices, stats, 'next_states') + next_states = index_states(next_states, state_indices) + states = index_states(states, state_indices) + goals = index_states(contexts[0], goal_indices) + next_sq_dists = tf.squared_difference(next_states * state_scales, + goals * goal_scales) + sq_dists = tf.squared_difference(states * state_scales, + goals * goal_scales) + record_tensor(sq_dists, None, stats, 'sq_dists') + if weight_vector is not None: + next_sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype) + sq_dists *= tf.convert_to_tensor(weight_vector, dtype=next_states.dtype) + if weight_index is not None: + next_sq_dists *= contexts[weight_index] + sq_dists *= contexts[weight_index] + if norm == 'L1': + next_dist = tf.sqrt(next_sq_dists + epsilon) + dist = tf.sqrt(sq_dists + epsilon) + next_dist = tf.reduce_sum(next_dist, -1) + dist = tf.reduce_sum(dist, -1) + elif norm == 'L2': + next_dist = tf.reduce_sum(next_sq_dists, -1) + next_dist = tf.sqrt(next_dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0) + dist = tf.reduce_sum(sq_dists, -1) + dist = tf.sqrt(dist + epsilon) # tf.gradients fails when tf.sqrt(-0.0) + else: + raise NotImplementedError(norm) + discounts = next_dist > termination_epsilon + if summarize: + with tf.name_scope('RewardFn/'): + tf.summary.scalar('mean_dist', tf.reduce_mean(dist)) + tf.summary.histogram('dist', dist) + summarize_stats(stats) + diff = dist - next_dist + diff *= reward_scales + return tf.to_float(diff), tf.to_float(discounts) + + +@gin.configurable +def binary_indicator(states, + actions, + rewards, + next_states, + contexts, + termination_epsilon=1e-4, + offset=0, + epsilon=1e-10, + state_indices=None, + summarize=False): + """Returns 0/1 by checking if next_states and contexts overlap. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + termination_epsilon: terminate if dist is less than this quantity. + offset: Offset the rewards. + epsilon: small offset to ensure non-negative/zero distance. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, actions # unused args + next_states = index_states(next_states, state_indices) + dist = tf.reduce_sum(tf.squared_difference(next_states, contexts[0]), -1) + dist = tf.sqrt(dist + epsilon) + discounts = dist > termination_epsilon + rewards = tf.logical_not(discounts) + rewards = tf.to_float(rewards) + offset + return tf.to_float(rewards), tf.ones_like(tf.to_float(discounts)) #tf.to_float(discounts) + + +@gin.configurable +def plain_rewards(states, actions, rewards, next_states, contexts): + """Returns the given rewards. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, actions, next_states, contexts # Unused + return rewards, tf.ones_like(rewards) + + +@gin.configurable +def ctrl_rewards(states, + actions, + rewards, + next_states, + contexts, + reward_scales=1.0): + """Returns the negative control cost. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + reward_scales: multiplicative scale for rewards. A scalar or 1D tensor, + must be broadcastable to number of reward dimensions. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, rewards, contexts # Unused + if actions is None: + rewards = tf.to_float(tf.zeros(shape=next_states.shape[:1])) + else: + rewards = -tf.reduce_sum(tf.square(actions), axis=1) + rewards *= reward_scales + rewards = tf.to_float(rewards) + return rewards, tf.ones_like(rewards) + + +@gin.configurable +def diff_rewards( + states, + actions, + rewards, + next_states, + contexts, + state_indices=None, + goal_index=0,): + """Returns (next_states - goals) as a batched vector reward.""" + del states, rewards, actions # Unused + if state_indices is not None: + next_states = index_states(next_states, state_indices) + rewards = tf.to_float(next_states - contexts[goal_index]) + return rewards, tf.ones_like(rewards) + + +@gin.configurable +def state_rewards(states, + actions, + rewards, + next_states, + contexts, + weight_index=None, + state_indices=None, + weight_vector=1.0, + offset_vector=0.0, + summarize=False): + """Returns the rewards that are linear mapping of next_states. + + Args: + states: A [batch_size, num_state_dims] Tensor representing a batch + of states. + actions: A [batch_size, num_action_dims] Tensor representing a batch + of actions. + rewards: A [batch_size] Tensor representing a batch of rewards. + next_states: A [batch_size, num_state_dims] Tensor representing a batch + of next states. + contexts: A list of [batch_size, num_context_dims] Tensor representing + a batch of contexts. + weight_index: (integer) Index of contexts lists that specify weighting. + state_indices: (a list of Numpy integer array) Indices of states dimensions + to be mapped. + weight_vector: (a number or a list or Numpy array) The weighting vector, + broadcastable to `next_states`. + offset_vector: (a number or a list of Numpy array) The off vector. + summarize: (boolean) enable summary ops. + + Returns: + A new tf.float32 [batch_size] rewards Tensor, and + tf.float32 [batch_size] discounts tensor. + """ + del states, actions, rewards # unused args + stats = {} + record_tensor(next_states, state_indices, stats) + next_states = index_states(next_states, state_indices) + weight = tf.constant( + weight_vector, dtype=next_states.dtype, shape=next_states[0].shape) + weights = tf.expand_dims(weight, 0) + offset = tf.constant( + offset_vector, dtype=next_states.dtype, shape=next_states[0].shape) + offsets = tf.expand_dims(offset, 0) + if weight_index is not None: + weights *= contexts[weight_index] + rewards = tf.to_float(tf.reduce_sum(weights * (next_states+offsets), axis=1)) + if summarize: + with tf.name_scope('RewardFn/'): + summarize_stats(stats) + return rewards, tf.ones_like(rewards) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/samplers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/samplers.py" new file mode 100644 index 00000000..15a22df5 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/context/samplers.py" @@ -0,0 +1,445 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Samplers for Contexts. + + Each sampler class should define __call__(batch_size). +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import numpy as np +import tensorflow as tf +slim = tf.contrib.slim +import gin.tf + + +@gin.configurable +class BaseSampler(object): + """Base sampler.""" + + def __init__(self, context_spec, context_range=None, k=2, scope='sampler'): + """Construct a base sampler. + + Args: + context_spec: A context spec. + context_range: A tuple of (minval, max), where minval, maxval are floats + or Numpy arrays with the same shape as the context. + scope: A string denoting scope. + """ + self._context_spec = context_spec + self._context_range = context_range + self._k = k + self._scope = scope + + def __call__(self, batch_size, **kwargs): + raise NotImplementedError + + def set_replay(self, replay=None): + pass + + def _validate_contexts(self, contexts): + """Validate if contexts have right spec. + + Args: + contexts: A [batch_size, num_contexts_dim] tensor. + Raises: + ValueError: If shape or dtype mismatches that of spec. + """ + if contexts[0].shape != self._context_spec.shape: + raise ValueError('contexts has invalid shape %s wrt spec shape %s' % + (contexts[0].shape, self._context_spec.shape)) + if contexts.dtype != self._context_spec.dtype: + raise ValueError('contexts has invalid dtype %s wrt spec dtype %s' % + (contexts.dtype, self._context_spec.dtype)) + + +@gin.configurable +class ZeroSampler(BaseSampler): + """Zero sampler.""" + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + contexts = tf.zeros( + dtype=self._context_spec.dtype, + shape=[ + batch_size, + ] + self._context_spec.shape.as_list()) + return contexts, contexts + + +@gin.configurable +class BinarySampler(BaseSampler): + """Binary sampler.""" + + def __init__(self, probs=0.5, *args, **kwargs): + """Constructor.""" + super(BinarySampler, self).__init__(*args, **kwargs) + self._probs = probs + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context.""" + spec = self._context_spec + contexts = tf.random_uniform( + shape=[ + batch_size, + ] + spec.shape.as_list(), dtype=tf.float32) + contexts = tf.cast(tf.greater(contexts, self._probs), dtype=spec.dtype) + return contexts, contexts + + +@gin.configurable +class RandomSampler(BaseSampler): + """Random sampler.""" + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + spec = self._context_spec + context_range = self._context_range + if isinstance(context_range[0], (int, float)): + contexts = tf.random_uniform( + shape=[ + batch_size, + ] + spec.shape.as_list(), + minval=context_range[0], + maxval=context_range[1], + dtype=spec.dtype) + elif isinstance(context_range[0], (list, tuple, np.ndarray)): + assert len(spec.shape.as_list()) == 1 + assert spec.shape.as_list()[0] == len(context_range[0]) + assert spec.shape.as_list()[0] == len(context_range[1]) + contexts = tf.concat( + [ + tf.random_uniform( + shape=[ + batch_size, 1, + ] + spec.shape.as_list()[1:], + minval=context_range[0][i], + maxval=context_range[1][i], + dtype=spec.dtype) for i in range(spec.shape.as_list()[0]) + ], + axis=1) + else: raise NotImplementedError(context_range) + self._validate_contexts(contexts) + state, next_state = kwargs['state'], kwargs['next_state'] + if state is not None and next_state is not None: + pass + #contexts = tf.concat( + # [tf.random_normal(tf.shape(state[:, :self._k]), dtype=tf.float64) + + # tf.random_shuffle(state[:, :self._k]), + # contexts[:, self._k:]], 1) + + return contexts, contexts + + +@gin.configurable +class ScheduledSampler(BaseSampler): + """Scheduled sampler.""" + + def __init__(self, + scope='default', + values=None, + scheduler='cycle', + scheduler_params=None, + *args, **kwargs): + """Construct sampler. + + Args: + scope: Scope name. + values: A list of numbers or [num_context_dim] Numpy arrays + representing the values to cycle. + scheduler: scheduler type. + scheduler_params: scheduler parameters. + *args: arguments. + **kwargs: keyword arguments. + """ + super(ScheduledSampler, self).__init__(*args, **kwargs) + self._scope = scope + self._values = values + self._scheduler = scheduler + self._scheduler_params = scheduler_params or {} + assert self._values is not None and len( + self._values), 'must provide non-empty values.' + self._n = len(self._values) + # TODO(shanegu): move variable creation outside. resolve tf.cond problem. + self._count = 0 + self._i = tf.Variable( + tf.zeros(shape=(), dtype=tf.int32), + name='%s-scheduled_sampler_%d' % (self._scope, self._count)) + self._values = tf.constant(self._values, dtype=self._context_spec.dtype) + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + spec = self._context_spec + next_op = self._next(self._i) + with tf.control_dependencies([next_op]): + value = self._values[self._i] + if value.get_shape().as_list(): + values = tf.tile( + tf.expand_dims(value, 0), (batch_size,) + (1,) * spec.shape.ndims) + else: + values = value + tf.zeros( + shape=[ + batch_size, + ] + spec.shape.as_list(), dtype=spec.dtype) + self._validate_contexts(values) + self._count += 1 + return values, values + + def _next(self, i): + """Return op that increments pointer to next value. + + Args: + i: A tensorflow integer variable. + Returns: + Op that increments pointer. + """ + if self._scheduler == 'cycle': + inc = ('inc' in self._scheduler_params and + self._scheduler_params['inc']) or 1 + return tf.assign(i, tf.mod(i+inc, self._n)) + else: + raise NotImplementedError(self._scheduler) + + +@gin.configurable +class ReplaySampler(BaseSampler): + """Replay sampler.""" + + def __init__(self, + prefetch_queue_capacity=2, + override_indices=None, + state_indices=None, + *args, + **kwargs): + """Construct sampler. + + Args: + prefetch_queue_capacity: Capacity for prefetch queue. + override_indices: Override indices. + state_indices: Select certain indices from state dimension. + *args: arguments. + **kwargs: keyword arguments. + """ + super(ReplaySampler, self).__init__(*args, **kwargs) + self._prefetch_queue_capacity = prefetch_queue_capacity + self._override_indices = override_indices + self._state_indices = state_indices + + def set_replay(self, replay): + """Set replay. + + Args: + replay: A replay buffer. + """ + self._replay = replay + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + batch = self._replay.GetRandomBatch(batch_size) + next_states = batch[4] + if self._prefetch_queue_capacity > 0: + batch_queue = slim.prefetch_queue.prefetch_queue( + [next_states], + capacity=self._prefetch_queue_capacity, + name='%s/batch_context_queue' % self._scope) + next_states = batch_queue.dequeue() + if self._override_indices is not None: + assert self._context_range is not None and isinstance( + self._context_range[0], (int, long, float)) + next_states = tf.concat( + [ + tf.random_uniform( + shape=next_states[:, :1].shape, + minval=self._context_range[0], + maxval=self._context_range[1], + dtype=next_states.dtype) + if i in self._override_indices else next_states[:, i:i + 1] + for i in range(self._context_spec.shape.as_list()[0]) + ], + axis=1) + if self._state_indices is not None: + next_states = tf.concat( + [ + next_states[:, i:i + 1] + for i in range(self._context_spec.shape.as_list()[0]) + ], + axis=1) + self._validate_contexts(next_states) + return next_states, next_states + + +@gin.configurable +class TimeSampler(BaseSampler): + """Time Sampler.""" + + def __init__(self, minval=0, maxval=1, timestep=-1, *args, **kwargs): + """Construct sampler. + + Args: + minval: Min value integer. + maxval: Max value integer. + timestep: Time step between states and next_states. + *args: arguments. + **kwargs: keyword arguments. + """ + super(TimeSampler, self).__init__(*args, **kwargs) + assert self._context_spec.shape.as_list() == [1] + self._minval = minval + self._maxval = maxval + self._timestep = timestep + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + if self._maxval == self._minval: + contexts = tf.constant( + self._maxval, shape=[batch_size, 1], dtype=tf.int32) + else: + contexts = tf.random_uniform( + shape=[batch_size, 1], + dtype=tf.int32, + maxval=self._maxval, + minval=self._minval) + next_contexts = tf.maximum(contexts + self._timestep, 0) + + return tf.cast( + contexts, dtype=self._context_spec.dtype), tf.cast( + next_contexts, dtype=self._context_spec.dtype) + + +@gin.configurable +class ConstantSampler(BaseSampler): + """Constant sampler.""" + + def __init__(self, value=None, *args, **kwargs): + """Construct sampler. + + Args: + value: A list or Numpy array for values of the constant. + *args: arguments. + **kwargs: keyword arguments. + """ + super(ConstantSampler, self).__init__(*args, **kwargs) + self._value = value + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + spec = self._context_spec + value_ = tf.constant(self._value, shape=spec.shape, dtype=spec.dtype) + values = tf.tile( + tf.expand_dims(value_, 0), (batch_size,) + (1,) * spec.shape.ndims) + self._validate_contexts(values) + return values, values + + +@gin.configurable +class DirectionSampler(RandomSampler): + """Direction sampler.""" + + def __call__(self, batch_size, **kwargs): + """Sample a batch of context. + + Args: + batch_size: Batch size. + Returns: + Two [batch_size, num_context_dims] tensors. + """ + spec = self._context_spec + context_range = self._context_range + if isinstance(context_range[0], (int, float)): + contexts = tf.random_uniform( + shape=[ + batch_size, + ] + spec.shape.as_list(), + minval=context_range[0], + maxval=context_range[1], + dtype=spec.dtype) + elif isinstance(context_range[0], (list, tuple, np.ndarray)): + assert len(spec.shape.as_list()) == 1 + assert spec.shape.as_list()[0] == len(context_range[0]) + assert spec.shape.as_list()[0] == len(context_range[1]) + contexts = tf.concat( + [ + tf.random_uniform( + shape=[ + batch_size, 1, + ] + spec.shape.as_list()[1:], + minval=context_range[0][i], + maxval=context_range[1][i], + dtype=spec.dtype) for i in range(spec.shape.as_list()[0]) + ], + axis=1) + else: raise NotImplementedError(context_range) + self._validate_contexts(contexts) + if 'sampler_fn' in kwargs: + other_contexts = kwargs['sampler_fn']() + else: + other_contexts = contexts + state, next_state = kwargs['state'], kwargs['next_state'] + if state is not None and next_state is not None: + my_context_range = (np.array(context_range[1]) - np.array(context_range[0])) / 2 * np.ones(spec.shape.as_list()) + contexts = tf.concat( + [0.1 * my_context_range[:self._k] * + tf.random_normal(tf.shape(state[:, :self._k]), dtype=state.dtype) + + tf.random_shuffle(state[:, :self._k]) - state[:, :self._k], + other_contexts[:, self._k:]], 1) + #contexts = tf.Print(contexts, + # [contexts, tf.reduce_max(contexts, 0), + # tf.reduce_min(state, 0), tf.reduce_max(state, 0)], 'contexts', summarize=15) + next_contexts = tf.concat( #LALA + [state[:, :self._k] + contexts[:, :self._k] - next_state[:, :self._k], + other_contexts[:, self._k:]], 1) + next_contexts = contexts #LALA cosine + else: + next_contexts = contexts + return tf.stop_gradient(contexts), tf.stop_gradient(next_contexts) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/__init__.py" new file mode 100644 index 00000000..8b137891 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/__init__.py" @@ -0,0 +1 @@ + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant.py" new file mode 100644 index 00000000..bea9b209 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant.py" @@ -0,0 +1,134 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Wrapper for creating the ant environment in gym_mujoco.""" + +import math +import numpy as np +from gym import utils +from gym.envs.mujoco import mujoco_env + + +def q_inv(a): + return [a[0], -a[1], -a[2], -a[3]] + + +def q_mult(a, b): # multiply two quaternion + w = a[0] * b[0] - a[1] * b[1] - a[2] * b[2] - a[3] * b[3] + i = a[0] * b[1] + a[1] * b[0] + a[2] * b[3] - a[3] * b[2] + j = a[0] * b[2] - a[1] * b[3] + a[2] * b[0] + a[3] * b[1] + k = a[0] * b[3] + a[1] * b[2] - a[2] * b[1] + a[3] * b[0] + return [w, i, j, k] + + +class AntEnv(mujoco_env.MujocoEnv, utils.EzPickle): + FILE = "ant.xml" + ORI_IND = 3 + + def __init__(self, file_path=None, expose_all_qpos=True, + expose_body_coms=None, expose_body_comvels=None): + self._expose_all_qpos = expose_all_qpos + self._expose_body_coms = expose_body_coms + self._expose_body_comvels = expose_body_comvels + self._body_com_indices = {} + self._body_comvel_indices = {} + + mujoco_env.MujocoEnv.__init__(self, file_path, 5) + utils.EzPickle.__init__(self) + + @property + def physics(self): + return self.model + + def _step(self, a): + return self.step(a) + + def step(self, a): + xposbefore = self.get_body_com("torso")[0] + self.do_simulation(a, self.frame_skip) + xposafter = self.get_body_com("torso")[0] + forward_reward = (xposafter - xposbefore) / self.dt + ctrl_cost = .5 * np.square(a).sum() + survive_reward = 1.0 + reward = forward_reward - ctrl_cost + survive_reward + state = self.state_vector() + done = False + ob = self._get_obs() + return ob, reward, done, dict( + reward_forward=forward_reward, + reward_ctrl=-ctrl_cost, + reward_survive=survive_reward) + + def _get_obs(self): + # No cfrc observation + if self._expose_all_qpos: + obs = np.concatenate([ + self.physics.data.qpos.flat[:15], # Ensures only ant obs. + self.physics.data.qvel.flat[:14], + ]) + else: + obs = np.concatenate([ + self.physics.data.qpos.flat[2:15], + self.physics.data.qvel.flat[:14], + ]) + + if self._expose_body_coms is not None: + for name in self._expose_body_coms: + com = self.get_body_com(name) + if name not in self._body_com_indices: + indices = range(len(obs), len(obs) + len(com)) + self._body_com_indices[name] = indices + obs = np.concatenate([obs, com]) + + if self._expose_body_comvels is not None: + for name in self._expose_body_comvels: + comvel = self.get_body_comvel(name) + if name not in self._body_comvel_indices: + indices = range(len(obs), len(obs) + len(comvel)) + self._body_comvel_indices[name] = indices + obs = np.concatenate([obs, comvel]) + return obs + + def reset_model(self): + qpos = self.init_qpos + self.np_random.uniform( + size=self.model.nq, low=-.1, high=.1) + qvel = self.init_qvel + self.np_random.randn(self.model.nv) * .1 + + # Set everything other than ant to original position and 0 velocity. + qpos[15:] = self.init_qpos[15:] + qvel[14:] = 0. + self.set_state(qpos, qvel) + return self._get_obs() + + def viewer_setup(self): + self.viewer.cam.distance = self.model.stat.extent * 0.5 + + def get_ori(self): + ori = [0, 1, 0, 0] + rot = self.model.data.qpos[self.__class__.ORI_IND:self.__class__.ORI_IND + 4] # take the quaternion + ori = q_mult(q_mult(rot, ori), q_inv(rot))[1:3] # project onto x-y plane + ori = math.atan2(ori[1], ori[0]) + return ori + + def set_xy(self, xy): + qpos = np.copy(self.physics.data.qpos) + qpos[0] = xy[0] + qpos[1] = xy[1] + + qvel = self.physics.data.qvel + self.set_state(qpos, qvel) + + def get_xy(self): + return self.physics.data.qpos[:2] diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant_maze_env.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant_maze_env.py" new file mode 100644 index 00000000..69a10663 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/ant_maze_env.py" @@ -0,0 +1,21 @@ +# Copyright 2018 The TensorFlow Authors All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +from environments.maze_env import MazeEnv +from environments.ant import AntEnv + + +class AntMazeEnv(MazeEnv): + MODEL_CLASS = AntEnv diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/assets/ant.xml" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/assets/ant.xml" new file mode 100644 index 00000000..5a49d7f5 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/efficient-hrl/environments/assets/ant.xml" @@ -0,0 +1,81 @@ +
 +
+### Conditional MNIST
+
+
+### Conditional MNIST
+ +
+### InfoGAN MNIST
+
+
+### InfoGAN MNIST
+ +
+## MNIST with GANEstimator
+
+
+This setup is exactly the same as in the [unconditional MNIST example](#mnist), but
+uses the `tf.Learn` `GANEstimator`.
+
+
+
+## MNIST with GANEstimator
+
+
+This setup is exactly the same as in the [unconditional MNIST example](#mnist), but
+uses the `tf.Learn` `GANEstimator`.
+
+ +
+## CIFAR10
+
+
+We train a [DCGAN generator](https://arxiv.org/abs/1511.06434) to produce [CIFAR10 images](https://www.cs.toronto.edu/~kriz/cifar.html).
+The unconditional case maps noise to CIFAR10 images. The conditional case maps
+noise and image class to CIFAR10 images. The
+network architectures are defined [here](https://github.com/tensorflow/models/tree/master/research/gan/cifar/networks.py).
+
+We use the [Inception Score](https://arxiv.org/abs/1606.03498) to evaluate the images.
+
+### Unconditional CIFAR10
+
+
+## CIFAR10
+
+
+We train a [DCGAN generator](https://arxiv.org/abs/1511.06434) to produce [CIFAR10 images](https://www.cs.toronto.edu/~kriz/cifar.html).
+The unconditional case maps noise to CIFAR10 images. The conditional case maps
+noise and image class to CIFAR10 images. The
+network architectures are defined [here](https://github.com/tensorflow/models/tree/master/research/gan/cifar/networks.py).
+
+We use the [Inception Score](https://arxiv.org/abs/1606.03498) to evaluate the images.
+
+### Unconditional CIFAR10
+ +
+### Conditional CIFAR10
+
+
+### Conditional CIFAR10
+ +
+## Image compression
+
+
+In neural image compression, we attempt to reduce an image to a smaller representation
+such that we can recreate the original image as closely as possible. See [`Full Resolution Image Compression with Recurrent Neural Networks`](https://arxiv.org/abs/1608.05148) for more details on using neural networks
+for image compression.
+
+In this example, we train an encoder to compress images to a compressed binary
+representation and a decoder to map the binary representation back to the image.
+We treat both systems together (encoder -> decoder) as the generator.
+
+A typical image compression trained on L1 pixel loss will decode into
+blurry images. We use an adversarial loss to force the outputs to be more
+plausible.
+
+This example also highlights the following infrastructure challenges:
+
+* When you have custom code to keep track of your variables
+
+Some other notes on the problem:
+
+* Since the network is fully convolutional, we train on image patches.
+* Bottleneck layer is floating point during training and binarized during
+ evaluation.
+
+### Results
+
+#### No adversarial loss
+
+
+## Image compression
+
+
+In neural image compression, we attempt to reduce an image to a smaller representation
+such that we can recreate the original image as closely as possible. See [`Full Resolution Image Compression with Recurrent Neural Networks`](https://arxiv.org/abs/1608.05148) for more details on using neural networks
+for image compression.
+
+In this example, we train an encoder to compress images to a compressed binary
+representation and a decoder to map the binary representation back to the image.
+We treat both systems together (encoder -> decoder) as the generator.
+
+A typical image compression trained on L1 pixel loss will decode into
+blurry images. We use an adversarial loss to force the outputs to be more
+plausible.
+
+This example also highlights the following infrastructure challenges:
+
+* When you have custom code to keep track of your variables
+
+Some other notes on the problem:
+
+* Since the network is fully convolutional, we train on image patches.
+* Bottleneck layer is floating point during training and binarized during
+ evaluation.
+
+### Results
+
+#### No adversarial loss
+ +
+#### Adversarial loss
+
+
+#### Adversarial loss
+ +
+### Architectures
+
+#### Compression Network
+
+The compression network is a DCGAN discriminator for the encoder and a DCGAN
+generator for the decoder from [`Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks`](https://arxiv.org/abs/1511.06434).
+The binarizer adds uniform noise during training then binarizes during eval, as in
+[`End-to-end Optimized Image Compression`](https://arxiv.org/abs/1611.01704).
+
+#### Discriminator
+
+The discriminator looks at 70x70 patches, as in
+[`Image-to-Image Translation with Conditional Adversarial Networks`](https://arxiv.org/abs/1611.07004).
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py"
new file mode 100644
index 00000000..329f86b8
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py"
@@ -0,0 +1,94 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the CIFAR data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(batch_size, dataset_dir, dataset_name='cifar10',
+ split_name='train', one_hot=True):
+ """Provides batches of CIFAR data.
+
+ Args:
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the CIFAR10 data can be found. If `None`,
+ use default.
+ dataset_name: Name of the dataset.
+ split_name: Should be either 'train' or 'test'.
+ one_hot: Output one hot vector instead of int32 label.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, 32, 32, 3]. Output pixel values are
+ in [-1, 1].
+ labels: Either (1) one_hot_labels if `one_hot` is `True`
+ A `Tensor` of size [batch_size, num_classes], where each row has a
+ single element set to one and the rest set to zeros.
+ Or (2) labels if `one_hot` is `False`
+ A `Tensor` of size [batch_size], holding the labels as integers.
+ num_samples: The number of total samples in the dataset.
+ num_classes: The number of classes in the dataset.
+
+ Raises:
+ ValueError: if the split_name is not either 'train' or 'test'.
+ """
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=(split_name == 'train'))
+ [image, label] = provider.get(['image', 'label'])
+
+ # Preprocess the images.
+ image = (tf.to_float(image) - 128.0) / 128.0
+
+ # Creates a QueueRunner for the pre-fetching operation.
+ images, labels = tf.train.batch(
+ [image, label],
+ batch_size=batch_size,
+ num_threads=32,
+ capacity=5 * batch_size)
+
+ labels = tf.reshape(labels, [-1])
+
+ if one_hot:
+ labels = tf.one_hot(labels, dataset.num_classes)
+
+ return images, labels, dataset.num_samples, dataset.num_classes
+
+
+def float_image_to_uint8(image):
+ """Convert float image in [-1, 1) to [0, 255] uint8.
+
+ Note that `1` gets mapped to `0`, but `1 - epsilon` gets mapped to 255.
+
+ Args:
+ image: An image tensor. Values should be in [-1, 1).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 128.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py"
new file mode 100644
index 00000000..c9f18008
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py"
@@ -0,0 +1,54 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def test_cifar10_train_set(self):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cifar/testdata')
+
+ batch_size = 4
+ images, labels, num_samples, num_classes = data_provider.provide_data(
+ batch_size, dataset_dir)
+ self.assertEqual(50000, num_samples)
+ self.assertEqual(10, num_classes)
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_out, labels_out = sess.run([images, labels])
+ self.assertEqual(images_out.shape, (batch_size, 32, 32, 3))
+ expected_label_shape = (batch_size, 10)
+ self.assertEqual(expected_label_shape, labels_out.shape)
+ # Check range.
+ self.assertTrue(np.all(np.abs(images_out) <= 1))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py"
new file mode 100644
index 00000000..6addd5e1
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py"
@@ -0,0 +1,170 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained CIFAR model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/cifar10/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/cifar10/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('num_images_generated', 100,
+ 'Number of images to generate at once.')
+
+flags.DEFINE_integer('num_inception_images', 10,
+ 'The number of images to run through Inception at once.')
+
+flags.DEFINE_boolean('eval_real_images', False,
+ 'If `True`, run Inception network on real images.')
+
+flags.DEFINE_boolean('conditional_eval', False,
+ 'If `True`, set up a conditional GAN.')
+
+flags.DEFINE_boolean('eval_frechet_inception_distance', True,
+ 'If `True`, compute Frechet Inception distance using real '
+ 'images and generated images.')
+
+flags.DEFINE_integer('num_images_per_class', 10,
+ 'When a conditional generator is used, this is the number '
+ 'of images to display per class.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+flags.DEFINE_integer(
+ 'inter_op_parallelism_threads', 0,
+ 'Number of threads to use for inter-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+flags.DEFINE_integer(
+ 'intra_op_parallelism_threads', 0,
+ 'Number of threads to use for intra-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+def main(_, run_eval_loop=True):
+ # Fetch and generate images to run through Inception.
+ with tf.name_scope('inputs'):
+ real_data, num_classes = _get_real_data(
+ FLAGS.num_images_generated, FLAGS.dataset_dir)
+ generated_data = _get_generated_data(
+ FLAGS.num_images_generated, FLAGS.conditional_eval, num_classes)
+
+ # Compute Frechet Inception Distance.
+ if FLAGS.eval_frechet_inception_distance:
+ fid = util.get_frechet_inception_distance(
+ real_data, generated_data, FLAGS.num_images_generated,
+ FLAGS.num_inception_images)
+ tf.summary.scalar('frechet_inception_distance', fid)
+
+ # Compute normal Inception scores.
+ if FLAGS.eval_real_images:
+ inc_score = util.get_inception_scores(
+ real_data, FLAGS.num_images_generated, FLAGS.num_inception_images)
+ else:
+ inc_score = util.get_inception_scores(
+ generated_data, FLAGS.num_images_generated, FLAGS.num_inception_images)
+ tf.summary.scalar('inception_score', inc_score)
+
+ # If conditional, display an image grid of difference classes.
+ if FLAGS.conditional_eval and not FLAGS.eval_real_images:
+ reshaped_imgs = util.get_image_grid(
+ generated_data, FLAGS.num_images_generated, num_classes,
+ FLAGS.num_images_per_class)
+ tf.summary.image('generated_data', reshaped_imgs, max_outputs=1)
+
+ # Create ops that write images to disk.
+ image_write_ops = None
+ if FLAGS.conditional_eval and FLAGS.write_to_disk:
+ reshaped_imgs = util.get_image_grid(
+ generated_data, FLAGS.num_images_generated, num_classes,
+ FLAGS.num_images_per_class)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_imgs)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'conditional_cifar10.png'),
+ tf.image.encode_png(uint8_images[0]))
+ else:
+ if FLAGS.num_images_generated >= 100 and FLAGS.write_to_disk:
+ reshaped_imgs = tfgan.eval.image_reshaper(
+ generated_data[:100], num_cols=FLAGS.num_images_per_class)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_imgs)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'unconditional_cifar10.png'),
+ tf.image.encode_png(uint8_images[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ sess_config = tf.ConfigProto(
+ inter_op_parallelism_threads=FLAGS.inter_op_parallelism_threads,
+ intra_op_parallelism_threads=FLAGS.intra_op_parallelism_threads)
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ master=FLAGS.master,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ config=sess_config,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _get_real_data(num_images_generated, dataset_dir):
+ """Get real images."""
+ data, _, _, num_classes = data_provider.provide_data(
+ num_images_generated, dataset_dir)
+ return data, num_classes
+
+
+def _get_generated_data(num_images_generated, conditional_eval, num_classes):
+ """Get generated images."""
+ noise = tf.random_normal([num_images_generated, 64])
+ # If conditional, generate class-specific images.
+ if conditional_eval:
+ conditioning = util.get_generator_conditioning(
+ num_images_generated, num_classes)
+ generator_inputs = (noise, conditioning)
+ generator_fn = networks.conditional_generator
+ else:
+ generator_inputs = noise
+ generator_fn = networks.generator
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('Generator'):
+ data = generator_fn(generator_inputs, is_training=False)
+
+ return data
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py"
new file mode 100644
index 00000000..f8c644ea
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py"
@@ -0,0 +1,51 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.cifar.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import tensorflow as tf
+import eval # pylint:disable=redefined-builtin
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class EvalTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('RealData', True, False),
+ ('GeneratedData', False, False),
+ ('GeneratedDataConditional', False, True))
+ def test_build_graph(self, eval_real_images, conditional_eval):
+ FLAGS.eval_real_images = eval_real_images
+ FLAGS.conditional_eval = conditional_eval
+ # Mock `frechet_inception_distance` and `inception_score`, which are
+ # expensive.
+ with mock.patch.object(
+ eval.util, 'get_frechet_inception_distance') as mock_fid:
+ with mock.patch.object(eval.util, 'get_inception_scores') as mock_iscore:
+ mock_fid.return_value = 1.0
+ mock_iscore.return_value = 1.0
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh"
new file mode 100644
index 00000000..89313da5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh"
@@ -0,0 +1,121 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the CIFAR dataset.
+# 2. Trains an unconditional or conditional model on the CIFAR training set.
+# 3. Evaluates the models and writes sample images to disk.
+#
+#
+# With the default batch size and number of steps, train times are:
+#
+# Usage:
+# cd models/research/gan/cifar
+# ./launch_jobs.sh ${gan_type} ${git_repo}
+set -e
+
+# Type of GAN to run. Right now, options are `unconditional`, `conditional`, or
+# `infogan`.
+gan_type=$1
+if ! [[ "$gan_type" =~ ^(unconditional|conditional) ]]; then
+ echo "'gan_type' must be one of: 'unconditional', 'conditional'."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/cifar-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/cifar-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/cifar-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/gan:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=cifar10 \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+if [[ "$gan_type" == "unconditional" ]]; then
+ UNCONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/unconditional"
+ UNCONDITIONAL_EVAL_DIR="${EVAL_DIR}/unconditional"
+ NUM_STEPS=10000
+ # Run training.
+ Banner "Starting training unconditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/cifar/train.py" \
+ --train_log_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="unconditional" \
+ --alsologtostderr
+ Banner "Finished training unconditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of unconditional GAN..."
+ python "${git_repo}/research/gan/cifar/eval.py" \
+ --checkpoint_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${UNCONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --conditional_eval=false \
+ --max_number_of_evaluations=1
+ Banner "Finished unconditional evaluation. See ${UNCONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run conditional GAN.
+if [[ "$gan_type" == "conditional" ]]; then
+ CONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/conditional"
+ CONDITIONAL_EVAL_DIR="${EVAL_DIR}/conditional"
+ NUM_STEPS=10000
+ # Run training.
+ Banner "Starting training conditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/cifar/train.py" \
+ --train_log_dir=${CONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="conditional" \
+ --alsologtostderr
+ Banner "Finished training conditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of conditional GAN..."
+ python "${git_repo}/research/gan/cifar/eval.py" \
+ --checkpoint_dir=${CONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${CONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --conditional_eval=true \
+ --max_number_of_evaluations=1
+ Banner "Finished conditional evaluation. See ${CONDITIONAL_EVAL_DIR} for output images."
+fi
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py"
new file mode 100644
index 00000000..f50b1ce9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py"
@@ -0,0 +1,130 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN CIFAR example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import dcgan
+
+tfgan = tf.contrib.gan
+
+
+def _last_conv_layer(end_points):
+ """"Returns the last convolutional layer from an endpoints dictionary."""
+ conv_list = [k if k[:4] == 'conv' else None for k in end_points.keys()]
+ conv_list.sort()
+ return end_points[conv_list[-1]]
+
+
+def generator(noise, is_training=True):
+ """Generator to produce CIFAR images.
+
+ Args:
+ noise: A 2D Tensor of shape [batch size, noise dim]. Since this example
+ does not use conditioning, this Tensor represents a noise vector of some
+ kind that will be reshaped by the generator into CIFAR examples.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A single Tensor with a batch of generated CIFAR images.
+ """
+ images, _ = dcgan.generator(noise, is_training=is_training, fused_batch_norm=True)
+
+ # Make sure output lies between [-1, 1].
+ return tf.tanh(images)
+
+
+def conditional_generator(inputs, is_training=True):
+ """Generator to produce CIFAR images.
+
+ Args:
+ inputs: A 2-tuple of Tensors (noise, one_hot_labels) and creates a
+ conditional generator.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A single Tensor with a batch of generated CIFAR images.
+ """
+ noise, one_hot_labels = inputs
+ noise = tfgan.features.condition_tensor_from_onehot(noise, one_hot_labels)
+
+ images, _ = dcgan.generator(noise, is_training=is_training, fused_batch_norm=True)
+
+ # Make sure output lies between [-1, 1].
+ return tf.tanh(images)
+
+
+def discriminator(img, unused_conditioning, is_training=True):
+ """Discriminator for CIFAR images.
+
+ Args:
+ img: A Tensor of shape [batch size, width, height, channels], that can be
+ either real or generated. It is the discriminator's goal to distinguish
+ between the two.
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A 1D Tensor of shape [batch size] representing the confidence that the
+ images are real. The output can lie in [-inf, inf], with positive values
+ indicating high confidence that the images are real.
+ """
+ logits, _ = dcgan.discriminator(img, is_training=is_training, fused_batch_norm=True)
+ return logits
+
+
+# (joelshor): This discriminator creates variables that aren't used, and
+# causes logging warnings. Improve `dcgan` nets to accept a target end layer,
+# so extraneous variables aren't created.
+def conditional_discriminator(img, conditioning, is_training=True):
+ """Discriminator for CIFAR images.
+
+ Args:
+ img: A Tensor of shape [batch size, width, height, channels], that can be
+ either real or generated. It is the discriminator's goal to distinguish
+ between the two.
+ conditioning: A 2-tuple of Tensors representing (noise, one_hot_labels).
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A 1D Tensor of shape [batch size] representing the confidence that the
+ images are real. The output can lie in [-inf, inf], with positive values
+ indicating high confidence that the images are real.
+ """
+ logits, end_points = dcgan.discriminator(img, is_training=is_training, fused_batch_norm=True)
+
+ # Condition the last convolution layer.
+ _, one_hot_labels = conditioning
+ net = _last_conv_layer(end_points)
+ net = tfgan.features.condition_tensor_from_onehot(
+ tf.contrib.layers.flatten(net), one_hot_labels)
+ logits = tf.contrib.layers.linear(net, 1)
+
+ return logits
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py"
new file mode 100644
index 00000000..1893d164
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py"
@@ -0,0 +1,78 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.cifar.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+import networks
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_generator(self):
+ tf.set_random_seed(1234)
+ batch_size = 100
+ noise = tf.random_normal([batch_size, 64])
+ image = networks.generator(noise)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ image_np = image.eval()
+
+ self.assertAllEqual([batch_size, 32, 32, 3], image_np.shape)
+ self.assertTrue(np.all(np.abs(image_np) <= 1))
+
+ def test_generator_conditional(self):
+ tf.set_random_seed(1234)
+ batch_size = 100
+ noise = tf.random_normal([batch_size, 64])
+ conditioning = tf.one_hot([0] * batch_size, 10)
+ image = networks.conditional_generator((noise, conditioning))
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ image_np = image.eval()
+
+ self.assertAllEqual([batch_size, 32, 32, 3], image_np.shape)
+ self.assertTrue(np.all(np.abs(image_np) <= 1))
+
+ def test_discriminator(self):
+ batch_size = 5
+ image = tf.random_uniform([batch_size, 32, 32, 3], -1, 1)
+ dis_output = networks.discriminator(image, None)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ dis_output_np = dis_output.eval()
+
+ self.assertAllEqual([batch_size, 1], dis_output_np.shape)
+
+ def test_discriminator_conditional(self):
+ batch_size = 5
+ image = tf.random_uniform([batch_size, 32, 32, 3], -1, 1)
+ conditioning = (None, tf.one_hot([0] * batch_size, 10))
+ dis_output = networks.conditional_discriminator(image, conditioning)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ dis_output_np = dis_output.eval()
+
+ self.assertAllEqual([batch_size, 1], dis_output_np.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord"
new file mode 100644
index 00000000..93402244
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py"
new file mode 100644
index 00000000..f08f7955
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py"
@@ -0,0 +1,190 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a generator on CIFAR data."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/cifar/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_boolean(
+ 'conditional', False,
+ 'If `True`, set up a conditional GAN. If False, it is unconditional.')
+
+# Sync replicas flags.
+flags.DEFINE_boolean(
+ 'use_sync_replicas', True,
+ 'If `True`, use sync replicas. Otherwise use async.')
+
+flags.DEFINE_integer(
+ 'worker_replicas', 10,
+ 'The number of gradients to collect before updating params. Only used '
+ 'with sync replicas.')
+
+flags.DEFINE_integer(
+ 'backup_workers', 1,
+ 'Number of workers to be kept as backup in the sync replicas case.')
+
+flags.DEFINE_integer(
+ 'inter_op_parallelism_threads', 0,
+ 'Number of threads to use for inter-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+flags.DEFINE_integer(
+ 'intra_op_parallelism_threads', 0,
+ 'Number of threads to use for intra-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+FLAGS = flags.FLAGS
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Force all input processing onto CPU in order to reserve the GPU for
+ # the forward inference and back-propagation.
+ with tf.name_scope('inputs'):
+ with tf.device('/cpu:0'):
+ images, one_hot_labels, _, _ = data_provider.provide_data(
+ FLAGS.batch_size, FLAGS.dataset_dir)
+
+ # Define the GANModel tuple.
+ noise = tf.random_normal([FLAGS.batch_size, 64])
+ if FLAGS.conditional:
+ generator_fn = networks.conditional_generator
+ discriminator_fn = networks.conditional_discriminator
+ generator_inputs = (noise, one_hot_labels)
+ else:
+ generator_fn = networks.generator
+ discriminator_fn = networks.discriminator
+ generator_inputs = noise
+ gan_model = tfgan.gan_model(
+ generator_fn,
+ discriminator_fn,
+ real_data=images,
+ generator_inputs=generator_inputs)
+ tfgan.eval.add_gan_model_image_summaries(gan_model)
+
+ # Get the GANLoss tuple. Use the selected GAN loss functions.
+ # (joelshor): Put this block in `with tf.name_scope('loss'):` when
+ # cl/171610946 goes into the opensource release.
+ gan_loss = tfgan.gan_loss(gan_model,
+ gradient_penalty_weight=1.0,
+ add_summaries=True)
+
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ with tf.name_scope('train'):
+ gen_lr, dis_lr = _learning_rate()
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr, FLAGS.use_sync_replicas)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ sync_hooks = ([gen_opt.make_session_run_hook(FLAGS.task == 0),
+ dis_opt.make_session_run_hook(FLAGS.task == 0)]
+ if FLAGS.use_sync_replicas else [])
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ sess_config = tf.ConfigProto(
+ inter_op_parallelism_threads=FLAGS.inter_op_parallelism_threads,
+ intra_op_parallelism_threads=FLAGS.intra_op_parallelism_threads)
+ tfgan.gan_train(
+ train_ops,
+ hooks=(
+ [tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)] +
+ sync_hooks),
+ logdir=FLAGS.train_log_dir,
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0,
+ config=sess_config)
+
+
+def _learning_rate():
+ generator_lr = tf.train.exponential_decay(
+ learning_rate=0.0001,
+ global_step=tf.train.get_or_create_global_step(),
+ decay_steps=100000,
+ decay_rate=0.9,
+ staircase=True)
+ discriminator_lr = 0.001
+ return generator_lr, discriminator_lr
+
+
+def _optimizer(gen_lr, dis_lr, use_sync_replicas):
+ """Get an optimizer, that's optionally synchronous."""
+ generator_opt = tf.train.RMSPropOptimizer(gen_lr, decay=.9, momentum=0.1)
+ discriminator_opt = tf.train.RMSPropOptimizer(dis_lr, decay=.95, momentum=0.1)
+
+ def _make_sync(opt):
+ return tf.train.SyncReplicasOptimizer(
+ opt,
+ replicas_to_aggregate=FLAGS.worker_replicas-FLAGS.backup_workers,
+ total_num_replicas=FLAGS.worker_replicas)
+ if use_sync_replicas:
+ generator_opt = _make_sync(generator_opt)
+ discriminator_opt = _make_sync(discriminator_opt)
+
+ return generator_opt, discriminator_opt
+
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py"
new file mode 100644
index 00000000..6f0fbc3d
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py"
@@ -0,0 +1,56 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('Unconditional', False, False),
+ ('Conditional', True, False),
+ ('SyncReplicas', False, True))
+ def test_build_graph(self, conditional, use_sync_replicas):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.conditional = conditional
+ FLAGS.use_sync_replicas = use_sync_replicas
+ FLAGS.batch_size = 16
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 32, 32, 3], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = (
+ mock_imgs, mock_lbls, None, None)
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py"
new file mode 100644
index 00000000..02f344de
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py"
@@ -0,0 +1,156 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Convenience functions for training and evaluating a TFGAN CIFAR example."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+tfgan = tf.contrib.gan
+
+
+def get_generator_conditioning(batch_size, num_classes):
+ """Generates TFGAN conditioning inputs for evaluation.
+
+ Args:
+ batch_size: A Python integer. The desired batch size.
+ num_classes: A Python integer. The number of classes.
+
+ Returns:
+ A Tensor of one-hot vectors corresponding to an even distribution over
+ classes.
+
+ Raises:
+ ValueError: If `batch_size` isn't evenly divisible by `num_classes`.
+ """
+ if batch_size % num_classes != 0:
+ raise ValueError('`batch_size` %i must be evenly divisible by '
+ '`num_classes` %i.' % (batch_size, num_classes))
+ labels = [lbl for lbl in xrange(num_classes)
+ for _ in xrange(batch_size // num_classes)]
+ return tf.one_hot(tf.constant(labels), num_classes)
+
+
+def get_image_grid(images, batch_size, num_classes, num_images_per_class):
+ """Combines images from each class in a single summary image.
+
+ Args:
+ images: Tensor of images that are arranged by class. The first
+ `batch_size / num_classes` images belong to the first class, the second
+ group belong to the second class, etc. Shape is
+ [batch, width, height, channels].
+ batch_size: Python integer. Batch dimension.
+ num_classes: Number of classes to show.
+ num_images_per_class: Number of image examples per class to show.
+
+ Raises:
+ ValueError: If the batch dimension of `images` is known at graph
+ construction, and it isn't `batch_size`.
+ ValueError: If there aren't enough images to show
+ `num_classes * num_images_per_class` images.
+ ValueError: If `batch_size` isn't divisible by `num_classes`.
+
+ Returns:
+ A single image.
+ """
+ # Validate inputs.
+ images.shape[0:1].assert_is_compatible_with([batch_size])
+ if batch_size < num_classes * num_images_per_class:
+ raise ValueError('Not enough images in batch to show the desired number of '
+ 'images.')
+ if batch_size % num_classes != 0:
+ raise ValueError('`batch_size` must be divisible by `num_classes`.')
+
+ # Only get a certain number of images per class.
+ num_batches = batch_size // num_classes
+ indices = [i * num_batches + j for i in xrange(num_classes)
+ for j in xrange(num_images_per_class)]
+ sampled_images = tf.gather(images, indices)
+ return tfgan.eval.image_reshaper(
+ sampled_images, num_cols=num_images_per_class)
+
+
+def get_inception_scores(images, batch_size, num_inception_images):
+ """Get Inception score for some images.
+
+ Args:
+ images: Image minibatch. Shape [batch size, width, height, channels]. Values
+ are in [-1, 1].
+ batch_size: Python integer. Batch dimension.
+ num_inception_images: Number of images to run through Inception at once.
+
+ Returns:
+ Inception scores. Tensor shape is [batch size].
+
+ Raises:
+ ValueError: If `batch_size` is incompatible with the first dimension of
+ `images`.
+ ValueError: If `batch_size` isn't divisible by `num_inception_images`.
+ """
+ # Validate inputs.
+ images.shape[0:1].assert_is_compatible_with([batch_size])
+ if batch_size % num_inception_images != 0:
+ raise ValueError(
+ '`batch_size` must be divisible by `num_inception_images`.')
+
+ # Resize images.
+ size = 299
+ resized_images = tf.image.resize_bilinear(images, [size, size])
+
+ # Run images through Inception.
+ num_batches = batch_size // num_inception_images
+ inc_score = tfgan.eval.inception_score(
+ resized_images, num_batches=num_batches)
+
+ return inc_score
+
+
+def get_frechet_inception_distance(real_images, generated_images, batch_size,
+ num_inception_images):
+ """Get Frechet Inception Distance between real and generated images.
+
+ Args:
+ real_images: Real images minibatch. Shape [batch size, width, height,
+ channels. Values are in [-1, 1].
+ generated_images: Generated images minibatch. Shape [batch size, width,
+ height, channels]. Values are in [-1, 1].
+ batch_size: Python integer. Batch dimension.
+ num_inception_images: Number of images to run through Inception at once.
+
+ Returns:
+ Frechet Inception distance. A floating-point scalar.
+
+ Raises:
+ ValueError: If the minibatch size is known at graph construction time, and
+ doesn't batch `batch_size`.
+ """
+ # Validate input dimensions.
+ real_images.shape[0:1].assert_is_compatible_with([batch_size])
+ generated_images.shape[0:1].assert_is_compatible_with([batch_size])
+
+ # Resize input images.
+ size = 299
+ resized_real_images = tf.image.resize_bilinear(real_images, [size, size])
+ resized_generated_images = tf.image.resize_bilinear(
+ generated_images, [size, size])
+
+ # Compute Frechet Inception Distance.
+ num_batches = batch_size // num_inception_images
+ fid = tfgan.eval.frechet_inception_distance(
+ resized_real_images, resized_generated_images, num_batches=num_batches)
+
+ return fid
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py"
new file mode 100644
index 00000000..b1847489
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py"
@@ -0,0 +1,62 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.cifar.util."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import util
+
+mock = tf.test.mock
+
+
+class UtilTest(tf.test.TestCase):
+
+ def test_get_generator_conditioning(self):
+ conditioning = util.get_generator_conditioning(12, 4)
+ self.assertEqual([12, 4], conditioning.shape.as_list())
+
+ def test_get_image_grid(self):
+ util.get_image_grid(
+ tf.zeros([6, 28, 28, 1]),
+ batch_size=6,
+ num_classes=3,
+ num_images_per_class=1)
+
+ # Mock `inception_score` which is expensive.
+ @mock.patch.object(util.tfgan.eval, 'inception_score', autospec=True)
+ def test_get_inception_scores(self, mock_inception_score):
+ mock_inception_score.return_value = 1.0
+ util.get_inception_scores(
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ batch_size=100,
+ num_inception_images=10)
+
+ # Mock `frechet_inception_distance` which is expensive.
+ @mock.patch.object(util.tfgan.eval, 'frechet_inception_distance',
+ autospec=True)
+ def test_get_frechet_inception_distance(self, mock_fid):
+ mock_fid.return_value = 1.0
+ util.get_frechet_inception_distance(
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ batch_size=100,
+ num_inception_images=10)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py"
new file mode 100644
index 00000000..bed09a3f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py"
@@ -0,0 +1,185 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+
+def normalize_image(image):
+ """Rescale from range [0, 255] to [-1, 1]."""
+ return (tf.to_float(image) - 127.5) / 127.5
+
+
+def undo_normalize_image(normalized_image):
+ """Convert to a numpy array that can be read by PIL."""
+ # Convert from NHWC to HWC.
+ normalized_image = np.squeeze(normalized_image, axis=0)
+ return np.uint8(normalized_image * 127.5 + 127.5)
+
+
+def _sample_patch(image, patch_size):
+ """Crop image to square shape and resize it to `patch_size`.
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_size: A Python scalar. The output image size.
+
+ Returns:
+ A 3D `Tensor` of HWC format which has the shape of
+ [patch_size, patch_size, 3].
+ """
+ image_shape = tf.shape(image)
+ height, width = image_shape[0], image_shape[1]
+ target_size = tf.minimum(height, width)
+ image = tf.image.resize_image_with_crop_or_pad(image, target_size,
+ target_size)
+ # tf.image.resize_area only accepts 4D tensor, so expand dims first.
+ image = tf.expand_dims(image, axis=0)
+ image = tf.image.resize_images(image, [patch_size, patch_size])
+ image = tf.squeeze(image, axis=0)
+ # Force image num_channels = 3
+ image = tf.tile(image, [1, 1, tf.maximum(1, 4 - tf.shape(image)[2])])
+ image = tf.slice(image, [0, 0, 0], [patch_size, patch_size, 3])
+ return image
+
+
+def full_image_to_patch(image, patch_size):
+ image = normalize_image(image)
+ # Sample a patch of fixed size.
+ image_patch = _sample_patch(image, patch_size)
+ image_patch.shape.assert_is_compatible_with([patch_size, patch_size, 3])
+ return image_patch
+
+
+def _provide_custom_dataset(image_file_pattern,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides batches of custom image data.
+
+ Args:
+ image_file_pattern: A string of glob pattern of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of mapping threads. Defaults to 1.
+ patch_size: Size of the path to extract from the image. Defaults to 128.
+
+ Returns:
+ A tf.data.Dataset with Tensors of shape
+ [batch_size, patch_size, patch_size, 3] representing a batch of images.
+
+ Raises:
+ ValueError: If no files match `image_file_pattern`.
+ """
+ if not tf.gfile.Glob(image_file_pattern):
+ raise ValueError('No file patterns found.')
+ filenames_ds = tf.data.Dataset.list_files(image_file_pattern)
+ bytes_ds = filenames_ds.map(tf.io.read_file, num_parallel_calls=num_threads)
+ images_ds = bytes_ds.map(
+ tf.image.decode_image, num_parallel_calls=num_threads)
+ patches_ds = images_ds.map(
+ lambda img: full_image_to_patch(img, patch_size),
+ num_parallel_calls=num_threads)
+ patches_ds = patches_ds.repeat()
+
+ if shuffle:
+ patches_ds = patches_ds.shuffle(5 * batch_size)
+
+ patches_ds = patches_ds.prefetch(5 * batch_size)
+ patches_ds = patches_ds.batch(batch_size)
+
+ return patches_ds
+
+
+def provide_custom_datasets(image_file_patterns,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides multiple batches of custom image data.
+
+ Args:
+ image_file_patterns: A list of glob patterns of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_size: Size of the patch to extract from the image. Defaults to 128.
+
+ Returns:
+ A list of tf.data.Datasets the same number as `image_file_patterns`. Each
+ of the datasets have `Tensor`'s in the list has a shape of
+ [batch_size, patch_size, patch_size, 3] representing a batch of images.
+
+ Raises:
+ ValueError: If image_file_patterns is not a list or tuple.
+ """
+ if not isinstance(image_file_patterns, (list, tuple)):
+ raise ValueError(
+ '`image_file_patterns` should be either list or tuple, but was {}.'.
+ format(type(image_file_patterns)))
+ custom_datasets = []
+ for pattern in image_file_patterns:
+ custom_datasets.append(
+ _provide_custom_dataset(
+ pattern,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads,
+ patch_size=patch_size))
+
+ return custom_datasets
+
+
+def provide_custom_data(image_file_patterns,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides multiple batches of custom image data.
+
+ Args:
+ image_file_patterns: A list of glob patterns of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_size: Size of the patch to extract from the image. Defaults to 128.
+
+ Returns:
+ A list of float `Tensor`s with the same size of `image_file_patterns`. Each
+ of the `Tensor` in the list has a shape of
+ [batch_size, patch_size, patch_size, 3] representing a batch of images. As a
+ side effect, the tf.Dataset initializer is added to the
+ tf.GraphKeys.TABLE_INITIALIZERS collection.
+
+ Raises:
+ ValueError: If image_file_patterns is not a list or tuple.
+ """
+ datasets = provide_custom_datasets(
+ image_file_patterns, batch_size, shuffle, num_threads, patch_size)
+
+ tensors = []
+ for ds in datasets:
+ iterator = ds.make_initializable_iterator()
+ tf.add_to_collection(tf.GraphKeys.TABLE_INITIALIZERS, iterator.initializer)
+ tensors.append(iterator.get_next())
+
+ return tensors
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py"
new file mode 100644
index 00000000..c4c44b38
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py"
@@ -0,0 +1,129 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+mock = tf.test.mock
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def setUp(self):
+ super(DataProviderTest, self).setUp()
+ self.testdata_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cyclegan/testdata')
+
+ def test_normalize_image(self):
+ image = tf.random_uniform(shape=(8, 8, 3), maxval=256, dtype=tf.int32)
+ rescaled_image = data_provider.normalize_image(image)
+ self.assertEqual(tf.float32, rescaled_image.dtype)
+ self.assertListEqual(image.shape.as_list(), rescaled_image.shape.as_list())
+ with self.test_session(use_gpu=True) as sess:
+ rescaled_image_out = sess.run(rescaled_image)
+ self.assertTrue(np.all(np.abs(rescaled_image_out) <= 1.0))
+
+ def test_sample_patch(self):
+ image = tf.zeros(shape=(8, 8, 3))
+ patch1 = data_provider._sample_patch(image, 7)
+ patch2 = data_provider._sample_patch(image, 10)
+ image = tf.zeros(shape=(8, 8, 1))
+ patch3 = data_provider._sample_patch(image, 10)
+ with self.test_session(use_gpu=True) as sess:
+ self.assertTupleEqual((7, 7, 3), sess.run(patch1).shape)
+ self.assertTupleEqual((10, 10, 3), sess.run(patch2).shape)
+ self.assertTupleEqual((10, 10, 3), sess.run(patch3).shape)
+
+ def test_custom_dataset_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_ds = data_provider._provide_custom_dataset(
+ file_pattern, batch_size=batch_size, patch_size=patch_size)
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images_ds.output_shapes.as_list())
+ self.assertEqual(tf.float32, images_ds.output_types)
+
+ iterator = images_ds.make_initializable_iterator()
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(iterator.initializer)
+ images_out = sess.run(iterator.get_next())
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+ def test_custom_datasets_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_ds_list = data_provider.provide_custom_datasets(
+ [file_pattern, file_pattern],
+ batch_size=batch_size,
+ patch_size=patch_size)
+ for images_ds in images_ds_list:
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images_ds.output_shapes.as_list())
+ self.assertEqual(tf.float32, images_ds.output_types)
+
+ iterators = [x.make_initializable_iterator() for x in images_ds_list]
+ initialiers = [x.initializer for x in iterators]
+ img_tensors = [x.get_next() for x in iterators]
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(initialiers)
+ images_out_list = sess.run(img_tensors)
+ for images_out in images_out_list:
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+ def test_custom_data_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_list = data_provider.provide_custom_data(
+ [file_pattern, file_pattern],
+ batch_size=batch_size,
+ patch_size=patch_size)
+ for images in images_list:
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images.shape.as_list())
+ self.assertEqual(tf.float32, images.dtype)
+
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(tf.tables_initializer())
+ images_out_list = sess.run(images_list)
+ for images_out in images_out_list:
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py"
new file mode 100644
index 00000000..9eaaa111
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py"
@@ -0,0 +1,151 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+r"""Demo that makes inference requests against a running inference server."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import app
+from absl import flags
+import numpy as np
+import PIL
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('checkpoint_path', '',
+ 'CycleGAN checkpoint path created by train.py. '
+ '(e.g. "/mylogdir/model.ckpt-18442")')
+
+flags.DEFINE_string(
+ 'image_set_x_glob', '',
+ 'Optional: Glob path to images of class X to feed through the CycleGAN.')
+
+flags.DEFINE_string(
+ 'image_set_y_glob', '',
+ 'Optional: Glob path to images of class Y to feed through the CycleGAN.')
+
+flags.DEFINE_string(
+ 'generated_x_dir', '/tmp/generated_x/',
+ 'If image_set_y_glob is defined, where to output the generated X '
+ 'images.')
+
+flags.DEFINE_string(
+ 'generated_y_dir', '/tmp/generated_y/',
+ 'If image_set_x_glob is defined, where to output the generated Y '
+ 'images.')
+
+flags.DEFINE_integer('patch_dim', 128,
+ 'The patch size of images that was used in train.py.')
+
+FLAGS = flags.FLAGS
+
+
+def _make_dir_if_not_exists(dir_path):
+ """Make a directory if it does not exist."""
+ if not tf.gfile.Exists(dir_path):
+ tf.gfile.MakeDirs(dir_path)
+
+
+def _file_output_path(dir_path, input_file_path):
+ """Create output path for an individual file."""
+ return os.path.join(dir_path, os.path.basename(input_file_path))
+
+
+def make_inference_graph(model_name, patch_dim):
+ """Build the inference graph for either the X2Y or Y2X GAN.
+
+ Args:
+ model_name: The var scope name 'ModelX2Y' or 'ModelY2X'.
+ patch_dim: An integer size of patches to feed to the generator.
+
+ Returns:
+ Tuple of (input_placeholder, generated_tensor).
+ """
+ input_hwc_pl = tf.placeholder(tf.float32, [None, None, 3])
+
+ # Expand HWC to NHWC
+ images_x = tf.expand_dims(
+ data_provider.full_image_to_patch(input_hwc_pl, patch_dim), 0)
+
+ with tf.variable_scope(model_name):
+ with tf.variable_scope('Generator'):
+ generated = networks.generator(images_x)
+ return input_hwc_pl, generated
+
+
+def export(sess, input_pl, output_tensor, input_file_pattern, output_dir):
+ """Exports inference outputs to an output directory.
+
+ Args:
+ sess: tf.Session with variables already loaded.
+ input_pl: tf.Placeholder for input (HWC format).
+ output_tensor: Tensor for generated outut images.
+ input_file_pattern: Glob file pattern for input images.
+ output_dir: Output directory.
+ """
+ if output_dir:
+ _make_dir_if_not_exists(output_dir)
+
+ if input_file_pattern:
+ for file_path in tf.gfile.Glob(input_file_pattern):
+ # Grab a single image and run it through inference
+ input_np = np.asarray(PIL.Image.open(file_path))
+ output_np = sess.run(output_tensor, feed_dict={input_pl: input_np})
+ image_np = data_provider.undo_normalize_image(output_np)
+ output_path = _file_output_path(output_dir, file_path)
+ PIL.Image.fromarray(image_np).save(output_path)
+
+
+def _validate_flags():
+ flags.register_validator('checkpoint_path', bool,
+ 'Must provide `checkpoint_path`.')
+ flags.register_validator(
+ 'generated_x_dir',
+ lambda x: False if (FLAGS.image_set_y_glob and not x) else True,
+ 'Must provide `generated_x_dir`.')
+ flags.register_validator(
+ 'generated_y_dir',
+ lambda x: False if (FLAGS.image_set_x_glob and not x) else True,
+ 'Must provide `generated_y_dir`.')
+
+
+def main(_):
+ _validate_flags()
+ images_x_hwc_pl, generated_y = make_inference_graph('ModelX2Y',
+ FLAGS.patch_dim)
+ images_y_hwc_pl, generated_x = make_inference_graph('ModelY2X',
+ FLAGS.patch_dim)
+
+ # Restore all the variables that were saved in the checkpoint.
+ saver = tf.train.Saver()
+ with tf.Session() as sess:
+ saver.restore(sess, FLAGS.checkpoint_path)
+
+ export(sess, images_x_hwc_pl, generated_y, FLAGS.image_set_x_glob,
+ FLAGS.generated_y_dir)
+ export(sess, images_y_hwc_pl, generated_x, FLAGS.image_set_y_glob,
+ FLAGS.generated_x_dir)
+
+
+if __name__ == '__main__':
+ app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py"
new file mode 100644
index 00000000..4474693e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py"
@@ -0,0 +1,106 @@
+"""Tests for CycleGAN inference demo."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+from absl import logging
+import numpy as np
+import PIL
+
+import tensorflow as tf
+
+import inference_demo
+import train
+
+FLAGS = tf.flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _basenames_from_glob(file_glob):
+ return [os.path.basename(file_path) for file_path in tf.gfile.Glob(file_glob)]
+
+
+class InferenceDemoTest(tf.test.TestCase):
+
+ def setUp(self):
+ self._export_dir = os.path.join(FLAGS.test_tmpdir, 'export')
+ self._ckpt_path = os.path.join(self._export_dir, 'model.ckpt')
+ self._image_glob = os.path.join(
+ FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cyclegan/testdata', '*.jpg')
+ self._genx_dir = os.path.join(FLAGS.test_tmpdir, 'genx')
+ self._geny_dir = os.path.join(FLAGS.test_tmpdir, 'geny')
+
+ @mock.patch.object(tfgan, 'gan_train', autospec=True)
+ @mock.patch.object(
+ train.data_provider, 'provide_custom_data', autospec=True)
+ def testTrainingAndInferenceGraphsAreCompatible(
+ self, mock_provide_custom_data, unused_mock_gan_train):
+ # Training and inference graphs can get out of sync if changes are made
+ # to one but not the other. This test will keep them in sync.
+
+ # Save the training graph
+ train_sess = tf.Session()
+ FLAGS.image_set_x_file_pattern = '/tmp/x/*.jpg'
+ FLAGS.image_set_y_file_pattern = '/tmp/y/*.jpg'
+ FLAGS.batch_size = 3
+ FLAGS.patch_size = 128
+ FLAGS.generator_lr = 0.02
+ FLAGS.discriminator_lr = 0.3
+ FLAGS.train_log_dir = self._export_dir
+ FLAGS.master = 'master'
+ FLAGS.task = 0
+ FLAGS.cycle_consistency_loss_weight = 2.0
+ FLAGS.max_number_of_steps = 1
+ mock_provide_custom_data.return_value = (
+ tf.zeros([3, 4, 4, 3,]), tf.zeros([3, 4, 4, 3]))
+ train.main(None)
+ init_op = tf.global_variables_initializer()
+ train_sess.run(init_op)
+ train_saver = tf.train.Saver()
+ train_saver.save(train_sess, save_path=self._ckpt_path)
+
+ # Create inference graph
+ tf.reset_default_graph()
+ FLAGS.patch_dim = FLAGS.patch_size
+ logging.info('dir_path: %s', os.listdir(self._export_dir))
+ FLAGS.checkpoint_path = self._ckpt_path
+ FLAGS.image_set_x_glob = self._image_glob
+ FLAGS.image_set_y_glob = self._image_glob
+ FLAGS.generated_x_dir = self._genx_dir
+ FLAGS.generated_y_dir = self._geny_dir
+
+ inference_demo.main(None)
+ logging.info('gen x: %s', os.listdir(self._genx_dir))
+
+ # Check that the image names match
+ self.assertSetEqual(
+ set(_basenames_from_glob(FLAGS.image_set_x_glob)),
+ set(os.listdir(FLAGS.generated_y_dir)))
+ self.assertSetEqual(
+ set(_basenames_from_glob(FLAGS.image_set_y_glob)),
+ set(os.listdir(FLAGS.generated_x_dir)))
+
+ # Check that each image in the directory looks as expected
+ for directory in [FLAGS.generated_x_dir, FLAGS.generated_x_dir]:
+ for base_name in os.listdir(directory):
+ image_path = os.path.join(directory, base_name)
+ self.assertRealisticImage(image_path)
+
+ def assertRealisticImage(self, image_path):
+ logging.info('Testing %s for realism.', image_path)
+ # If the normalization is off or forgotten, then the generated image is
+ # all one pixel value. This tests that different pixel values are achieved.
+ input_np = np.asarray(PIL.Image.open(image_path))
+ self.assertEqual(len(input_np.shape), 3)
+ self.assertGreaterEqual(input_np.shape[0], 50)
+ self.assertGreaterEqual(input_np.shape[1], 50)
+ self.assertGreater(np.mean(input_np), 20)
+ self.assertGreater(np.var(input_np), 100)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg"
new file mode 100644
index 00000000..f465f6b4
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py"
new file mode 100644
index 00000000..63523cee
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py"
@@ -0,0 +1,217 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a CycleGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('image_set_x_file_pattern', None,
+ 'File pattern of images in image set X')
+
+flags.DEFINE_string('image_set_y_file_pattern', None,
+ 'File pattern of images in image set Y')
+
+flags.DEFINE_integer('batch_size', 1, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 64, 'The patch size of images.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/cyclegan/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 0.0002,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 0.0001,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 500000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float('cycle_consistency_loss_weight', 10.0,
+ 'The weight of cycle consistency loss')
+
+
+FLAGS = flags.FLAGS
+
+
+def _define_model(images_x, images_y):
+ """Defines a CycleGAN model that maps between images_x and images_y.
+
+ Args:
+ images_x: A 4D float `Tensor` of NHWC format. Images in set X.
+ images_y: A 4D float `Tensor` of NHWC format. Images in set Y.
+
+ Returns:
+ A `CycleGANModel` namedtuple.
+ """
+ cyclegan_model = tfgan.cyclegan_model(
+ generator_fn=networks.generator,
+ discriminator_fn=networks.discriminator,
+ data_x=images_x,
+ data_y=images_y)
+
+ # Add summaries for generated images.
+ tfgan.eval.add_cyclegan_image_summaries(cyclegan_model)
+
+ return cyclegan_model
+
+
+def _get_lr(base_lr):
+ """Returns a learning rate `Tensor`.
+
+ Args:
+ base_lr: A scalar float `Tensor` or a Python number. The base learning
+ rate.
+
+ Returns:
+ A scalar float `Tensor` of learning rate which equals `base_lr` when the
+ global training step is less than FLAGS.max_number_of_steps / 2, afterwards
+ it linearly decays to zero.
+ """
+ global_step = tf.train.get_or_create_global_step()
+ lr_constant_steps = FLAGS.max_number_of_steps // 2
+
+ def _lr_decay():
+ return tf.train.polynomial_decay(
+ learning_rate=base_lr,
+ global_step=(global_step - lr_constant_steps),
+ decay_steps=(FLAGS.max_number_of_steps - lr_constant_steps),
+ end_learning_rate=0.0)
+
+ return tf.cond(global_step < lr_constant_steps, lambda: base_lr, _lr_decay)
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ # beta1 follows
+ # https://github.com/junyanz/CycleGAN/blob/master/options.lua
+ gen_opt = tf.train.AdamOptimizer(gen_lr, beta1=0.5, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(dis_lr, beta1=0.5, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_ops(cyclegan_model, cyclegan_loss):
+ """Defines train ops that trains `cyclegan_model` with `cyclegan_loss`.
+
+ Args:
+ cyclegan_model: A `CycleGANModel` namedtuple.
+ cyclegan_loss: A `CycleGANLoss` namedtuple containing all losses for
+ `cyclegan_model`.
+
+ Returns:
+ A `GANTrainOps` namedtuple.
+ """
+ gen_lr = _get_lr(FLAGS.generator_lr)
+ dis_lr = _get_lr(FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _get_optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ cyclegan_model,
+ cyclegan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+ return train_ops
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ with tf.name_scope('inputs'):
+ images_x, images_y = data_provider.provide_custom_data(
+ [FLAGS.image_set_x_file_pattern, FLAGS.image_set_y_file_pattern],
+ batch_size=FLAGS.batch_size,
+ patch_size=FLAGS.patch_size)
+ # Set batch size for summaries.
+ images_x.set_shape([FLAGS.batch_size, None, None, None])
+ images_y.set_shape([FLAGS.batch_size, None, None, None])
+
+ # Define CycleGAN model.
+ cyclegan_model = _define_model(images_x, images_y)
+
+ # Define CycleGAN loss.
+ cyclegan_loss = tfgan.cyclegan_loss(
+ cyclegan_model,
+ cycle_consistency_loss_weight=FLAGS.cycle_consistency_loss_weight,
+ tensor_pool_fn=tfgan.features.tensor_pool)
+
+ # Define CycleGAN train ops.
+ train_ops = _define_train_ops(cyclegan_model, cyclegan_loss)
+
+ # Training
+ train_steps = tfgan.GANTrainSteps(1, 1)
+ status_message = tf.string_join(
+ [
+ 'Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())
+ ],
+ name='status_message')
+ if not FLAGS.max_number_of_steps:
+ return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[
+ tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)
+ ],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_set_x_file_pattern')
+ tf.flags.mark_flag_as_required('image_set_y_file_pattern')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py"
new file mode 100644
index 00000000..5d27d377
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py"
@@ -0,0 +1,155 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for cyclegan.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _test_generator(input_images):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(image_batch, unused_conditioning=None):
+ """Simple discriminator function."""
+ return tf.contrib.layers.flatten(
+ image_batch * tf.get_variable('dummy_d', initializer=2.0))
+
+
+train.networks.generator = _test_generator
+train.networks.discriminator = _test_discriminator
+
+
+class TrainTest(tf.test.TestCase):
+
+ @mock.patch.object(tfgan, 'eval', autospec=True)
+ def test_define_model(self, mock_eval):
+ FLAGS.batch_size = 2
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_x_np = np.zeros(shape=images_shape)
+ images_y_np = np.zeros(shape=images_shape)
+ images_x = tf.constant(images_x_np, dtype=tf.float32)
+ images_y = tf.constant(images_y_np, dtype=tf.float32)
+
+ cyclegan_model = train._define_model(images_x, images_y)
+ self.assertIsInstance(cyclegan_model, tfgan.CycleGANModel)
+ self.assertShapeEqual(images_x_np, cyclegan_model.reconstructed_x)
+ self.assertShapeEqual(images_y_np, cyclegan_model.reconstructed_y)
+
+ @mock.patch.object(train.networks, 'generator', autospec=True)
+ @mock.patch.object(train.networks, 'discriminator', autospec=True)
+ @mock.patch.object(
+ tf.train, 'get_or_create_global_step', autospec=True)
+ def test_get_lr(self, mock_get_or_create_global_step,
+ unused_mock_discriminator, unused_mock_generator):
+ FLAGS.max_number_of_steps = 10
+ base_lr = 0.01
+ with self.test_session(use_gpu=True) as sess:
+ mock_get_or_create_global_step.return_value = tf.constant(2)
+ lr_step2 = sess.run(train._get_lr(base_lr))
+ mock_get_or_create_global_step.return_value = tf.constant(9)
+ lr_step9 = sess.run(train._get_lr(base_lr))
+
+ self.assertAlmostEqual(base_lr, lr_step2)
+ self.assertAlmostEqual(base_lr * 0.2, lr_step9)
+
+ @mock.patch.object(tf.train, 'AdamOptimizer', autospec=True)
+ def test_get_optimizer(self, mock_adam_optimizer):
+ gen_lr, dis_lr = 0.1, 0.01
+ train._get_optimizer(gen_lr=gen_lr, dis_lr=dis_lr)
+ mock_adam_optimizer.assert_has_calls([
+ mock.call(gen_lr, beta1=mock.ANY, use_locking=True),
+ mock.call(dis_lr, beta1=mock.ANY, use_locking=True)
+ ])
+
+ @mock.patch.object(tf.summary, 'scalar', autospec=True)
+ def test_define_train_ops(self, mock_summary_scalar):
+ FLAGS.batch_size = 2
+ FLAGS.generator_lr = 0.1
+ FLAGS.discriminator_lr = 0.01
+
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_x = tf.zeros(images_shape, dtype=tf.float32)
+ images_y = tf.zeros(images_shape, dtype=tf.float32)
+
+ cyclegan_model = train._define_model(images_x, images_y)
+ cyclegan_loss = tfgan.cyclegan_loss(
+ cyclegan_model, cycle_consistency_loss_weight=10.0)
+ train_ops = train._define_train_ops(cyclegan_model, cyclegan_loss)
+
+ self.assertIsInstance(train_ops, tfgan.GANTrainOps)
+ mock_summary_scalar.assert_has_calls([
+ mock.call('generator_lr', mock.ANY),
+ mock.call('discriminator_lr', mock.ANY)
+ ])
+
+ @mock.patch.object(tf, 'gfile', autospec=True)
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ @mock.patch.object(train, '_define_model', autospec=True)
+ @mock.patch.object(tfgan, 'cyclegan_loss', autospec=True)
+ @mock.patch.object(train, '_define_train_ops', autospec=True)
+ @mock.patch.object(tfgan, 'gan_train', autospec=True)
+ def test_main(self, mock_gan_train, mock_define_train_ops, mock_cyclegan_loss,
+ mock_define_model, mock_data_provider, mock_gfile):
+ FLAGS.image_set_x_file_pattern = '/tmp/x/*.jpg'
+ FLAGS.image_set_y_file_pattern = '/tmp/y/*.jpg'
+ FLAGS.batch_size = 3
+ FLAGS.patch_size = 8
+ FLAGS.generator_lr = 0.02
+ FLAGS.discriminator_lr = 0.3
+ FLAGS.train_log_dir = '/tmp/foo'
+ FLAGS.master = 'master'
+ FLAGS.task = 0
+ FLAGS.cycle_consistency_loss_weight = 2.0
+ FLAGS.max_number_of_steps = 1
+
+ mock_data_provider.provide_custom_data.return_value = (
+ tf.zeros([3, 2, 2, 3], dtype=tf.float32),
+ tf.zeros([3, 2, 2, 3], dtype=tf.float32))
+
+ train.main(None)
+ mock_data_provider.provide_custom_data.assert_called_once_with(
+ ['/tmp/x/*.jpg', '/tmp/y/*.jpg'], batch_size=3, patch_size=8)
+ mock_define_model.assert_called_once_with(mock.ANY, mock.ANY)
+ mock_cyclegan_loss.assert_called_once_with(
+ mock_define_model.return_value,
+ cycle_consistency_loss_weight=2.0,
+ tensor_pool_fn=mock.ANY)
+ mock_define_train_ops.assert_called_once_with(
+ mock_define_model.return_value, mock_cyclegan_loss.return_value)
+ mock_gan_train.assert_called_once_with(
+ mock_define_train_ops.return_value,
+ '/tmp/foo',
+ get_hooks_fn=mock.ANY,
+ hooks=mock.ANY,
+ master='master',
+ is_chief=True)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png"
new file mode 100644
index 00000000..954c339c
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png"
new file mode 100644
index 00000000..481a6e80
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png"
new file mode 100644
index 00000000..4b39eda9
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png"
new file mode 100644
index 00000000..ed74069f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png"
new file mode 100644
index 00000000..7f47b3c0
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png"
new file mode 100644
index 00000000..4aeab789
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png"
new file mode 100644
index 00000000..fcc488fb
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png"
new file mode 100644
index 00000000..624bcf7c
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py"
new file mode 100644
index 00000000..da14741f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py"
@@ -0,0 +1,93 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the compression image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(split_name, batch_size, dataset_dir,
+ dataset_name='imagenet', num_readers=1, num_threads=1,
+ patch_size=128):
+ """Provides batches of image data for compression.
+
+ Args:
+ split_name: Either 'train' or 'validation'.
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the data can be found. If `None`, use
+ default.
+ dataset_name: Name of the dataset.
+ num_readers: Number of dataset readers.
+ num_threads: Number of prefetching threads.
+ patch_size: Size of the path to extract from the image.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, patch_size, patch_size, channels]
+ """
+ randomize = split_name == 'train'
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=num_readers,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=randomize)
+ [image] = provider.get(['image'])
+
+ # Sample a patch of fixed size.
+ patch = tf.image.resize_image_with_crop_or_pad(image, patch_size, patch_size)
+ patch.shape.assert_is_compatible_with([patch_size, patch_size, 3])
+
+ # Preprocess the images. Make the range lie in a strictly smaller range than
+ # [-1, 1], so that network outputs aren't forced to the extreme ranges.
+ patch = (tf.to_float(patch) - 128.0) / 142.0
+
+ if randomize:
+ image_batch = tf.train.shuffle_batch(
+ [patch],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size,
+ min_after_dequeue=batch_size)
+ else:
+ image_batch = tf.train.batch(
+ [patch],
+ batch_size=batch_size,
+ num_threads=1, # no threads so it's deterministic
+ capacity=5 * batch_size)
+
+ return image_batch
+
+
+def float_image_to_uint8(image):
+ """Convert float image in ~[-0.9, 0.9) to [0, 255] uint8.
+
+ Args:
+ image: An image tensor. Values should be in [-0.9, 0.9).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 142.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py"
new file mode 100644
index 00000000..1d9e54bc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py"
@@ -0,0 +1,59 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('train', 'train'),
+ ('validation', 'validation'))
+ def test_data_provider(self, split_name):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/image_compression/testdata/')
+
+ batch_size = 3
+ patch_size = 8
+ images = data_provider.provide_data(
+ split_name, batch_size, dataset_dir, patch_size=8)
+ self.assertListEqual([batch_size, patch_size, patch_size, 3],
+ images.shape.as_list())
+
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_out = sess.run(images)
+ self.assertEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ # Check range.
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py"
new file mode 100644
index 00000000..240f9ef5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py"
@@ -0,0 +1,102 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained compression model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import summaries
+
+FLAGS = flags.FLAGS
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/compression/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/compression/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+# Compression-specific flags.
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_integer('bits_per_patch', 1230,
+ 'The number of bits to produce per patch.')
+
+flags.DEFINE_integer('model_depth', 64,
+ 'Number of filters for compression model')
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ images = data_provider.provide_data(
+ 'validation', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('generator'):
+ reconstructions, _, prebinary = networks.compression_model(
+ images,
+ num_bits=FLAGS.bits_per_patch,
+ depth=FLAGS.model_depth,
+ is_training=False)
+ summaries.add_reconstruction_summaries(images, reconstructions, prebinary)
+
+ # Visualize losses.
+ pixel_loss_per_example = tf.reduce_mean(
+ tf.abs(images - reconstructions), axis=[1, 2, 3])
+ pixel_loss = tf.reduce_mean(pixel_loss_per_example)
+ tf.summary.histogram('pixel_l1_loss_hist', pixel_loss_per_example)
+ tf.summary.scalar('pixel_l1_loss', pixel_loss)
+
+ # Create ops to write images to disk.
+ uint8_images = data_provider.float_image_to_uint8(images)
+ uint8_reconstructions = data_provider.float_image_to_uint8(reconstructions)
+ uint8_reshaped = summaries.stack_images(uint8_images, uint8_reconstructions)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'compression.png'),
+ tf.image.encode_png(uint8_reshaped[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ master=FLAGS.master,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+if __name__ == '__main__':
+ app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py"
new file mode 100644
index 00000000..89b3f1b5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py"
@@ -0,0 +1,32 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.image_compression.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import eval # pylint:disable=redefined-builtin
+
+
+class EvalTest(tf.test.TestCase):
+
+ def test_build_graph(self):
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh"
new file mode 100644
index 00000000..e7fa2ec4
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh"
@@ -0,0 +1,85 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the Imagenet dataset.
+# 2. Trains image compression model on patches from Imagenet.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# Usage:
+# cd models/research/gan/image_compression
+# ./launch_jobs.sh ${weight_factor} ${git_repo}
+set -e
+
+# Weight of the adversarial loss.
+weight_factor=$1
+if [[ "$weight_factor" == "" ]]; then
+ echo "'weight_factor' must not be empty."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/compression-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/compression-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/imagenet-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim:$git_repo/research/slim/nets
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset. You will be asked for an ImageNet username and password.
+# To get one, register at http://www.image-net.org/.
+bazel build "${git_repo}/research/slim:download_and_convert_imagenet"
+"./bazel-bin/download_and_convert_imagenet" ${DATASET_DIR}
+
+# Run the compression model.
+NUM_STEPS=10000
+MODEL_TRAIN_DIR="${TRAIN_DIR}/wt${weight_factor}"
+Banner "Starting training an image compression model for ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/image_compression/train.py" \
+ --train_log_dir=${MODEL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --weight_factor=${weight_factor} \
+ --alsologtostderr
+Banner "Finished training image compression model ${NUM_STEPS} steps."
+
+# Run evaluation.
+MODEL_EVAL_DIR="${TRAIN_DIR}/eval/wt${weight_factor}"
+Banner "Starting evaluation of image compression model..."
+python "${git_repo}/research/gan/image_compression/eval.py" \
+ --checkpoint_dir=${MODEL_TRAIN_DIR} \
+ --eval_dir=${MODEL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_evaluations=1
+Banner "Finished evaluation. See ${MODEL_EVAL_DIR} for output images."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py"
new file mode 100644
index 00000000..ff44d84a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py"
@@ -0,0 +1,145 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN compression example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import dcgan
+from slim.nets import pix2pix
+
+
+def _last_conv_layer(end_points):
+ """"Returns the last convolutional layer from an endpoints dictionary."""
+ conv_list = [k if k[:4] == 'conv' else None for k in end_points.keys()]
+ conv_list.sort()
+ return end_points[conv_list[-1]]
+
+
+def _encoder(img_batch, is_training=True, bits=64, depth=64):
+ """Maps images to internal representation.
+
+ Args:
+ img_batch: Stuff
+ is_training: Stuff
+ bits: Number of bits per patch.
+ depth: Stuff
+
+ Returns:
+ Real-valued 2D Tensor of size [batch_size, bits].
+ """
+ _, end_points = dcgan.discriminator(
+ img_batch, depth=depth, is_training=is_training, scope='Encoder')
+
+ # (joelshor): Make the DCGAN convolutional layer that converts to logits
+ # not trainable, since it doesn't affect the encoder output.
+
+ # Get the pre-logit layer, which is the last conv.
+ net = _last_conv_layer(end_points)
+
+ # Transform the features to the proper number of bits.
+ with tf.variable_scope('EncoderTransformer'):
+ encoded = tf.contrib.layers.conv2d(net, bits, kernel_size=1, stride=1,
+ padding='VALID', normalizer_fn=None,
+ activation_fn=None)
+ encoded = tf.squeeze(encoded, [1, 2])
+ encoded.shape.assert_has_rank(2)
+
+ # Map encoded to the range [-1, 1].
+ return tf.nn.softsign(encoded)
+
+
+def _binarizer(prebinary_codes, is_training):
+ """Binarize compression logits.
+
+ During training, add noise, as in https://arxiv.org/pdf/1611.01704.pdf. During
+ eval, map [-1, 1] -> {-1, 1}.
+
+ Args:
+ prebinary_codes: Floating-point tensors corresponding to pre-binary codes.
+ Shape is [batch, code_length].
+ is_training: A python bool. If True, add noise. If false, binarize.
+
+ Returns:
+ Binarized codes. Shape is [batch, code_length].
+
+ Raises:
+ ValueError: If the shape of `prebinary_codes` isn't static.
+ """
+ if is_training:
+ # In order to train codes that can be binarized during eval, we add noise as
+ # in https://arxiv.org/pdf/1611.01704.pdf. Another option is to use a
+ # stochastic node, as in https://arxiv.org/abs/1608.05148.
+ noise = tf.random_uniform(
+ prebinary_codes.shape,
+ minval=-1.0,
+ maxval=1.0)
+ return prebinary_codes + noise
+ else:
+ return tf.sign(prebinary_codes)
+
+
+def _decoder(codes, final_size, is_training, depth=64):
+ """Compression decoder."""
+ decoded_img, _ = dcgan.generator(
+ codes,
+ depth=depth,
+ final_size=final_size,
+ num_outputs=3,
+ is_training=is_training,
+ scope='Decoder')
+
+ # Map output to [-1, 1].
+ # Use softsign instead of tanh, as per empirical results of
+ # http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf.
+ return tf.nn.softsign(decoded_img)
+
+
+def _validate_image_inputs(image_batch):
+ image_batch.shape.assert_has_rank(4)
+ image_batch.shape[1:].assert_is_fully_defined()
+
+
+def compression_model(image_batch, num_bits=64, depth=64, is_training=True):
+ """Image compression model.
+
+ Args:
+ image_batch: A batch of images to compress and reconstruct. Images should
+ be normalized already. Shape is [batch, height, width, channels].
+ num_bits: Desired number of bits per image in the compressed representation.
+ depth: The base number of filters for the encoder and decoder networks.
+ is_training: A python bool. If False, run in evaluation mode.
+
+ Returns:
+ uncompressed images, binary codes, prebinary codes
+ """
+ image_batch = tf.convert_to_tensor(image_batch)
+ _validate_image_inputs(image_batch)
+ final_size = image_batch.shape.as_list()[1]
+
+ prebinary_codes = _encoder(image_batch, is_training, num_bits, depth)
+ binary_codes = _binarizer(prebinary_codes, is_training)
+ uncompressed_imgs = _decoder(binary_codes, final_size, is_training, depth)
+ return uncompressed_imgs, binary_codes, prebinary_codes
+
+
+def discriminator(image_batch, unused_conditioning=None, depth=64):
+ """A thin wrapper around the pix2pix discriminator to conform to TFGAN API."""
+ logits, _ = pix2pix.pix2pix_discriminator(
+ image_batch, num_filters=[depth, 2 * depth, 4 * depth, 8 * depth])
+ return tf.layers.flatten(logits)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py"
new file mode 100644
index 00000000..222f7e8a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py"
@@ -0,0 +1,99 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.image_compression.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+import networks
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_last_conv_layer(self):
+ x = tf.constant(1.0)
+ y = tf.constant(0.0)
+ end_points = {
+ 'silly': y,
+ 'conv2': y,
+ 'conv4': x,
+ 'logits': y,
+ 'conv-1': y,
+ }
+ self.assertEqual(x, networks._last_conv_layer(end_points))
+
+ def test_generator_run(self):
+ img_batch = tf.zeros([3, 16, 16, 3])
+ model_output = networks.compression_model(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_graph(self):
+ for i, batch_size in zip(xrange(3, 7), xrange(3, 11, 2)):
+ tf.reset_default_graph()
+ patch_size = 2 ** i
+ bits = 2 ** i
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ uncompressed, binary_codes, prebinary = networks.compression_model(
+ img, bits)
+
+ self.assertAllEqual([batch_size, patch_size, patch_size, 3],
+ uncompressed.shape.as_list())
+ self.assertEqual([batch_size, bits], binary_codes.shape.as_list())
+ self.assertEqual([batch_size, bits], prebinary.shape.as_list())
+
+ def test_generator_invalid_input(self):
+ wrong_dim_input = tf.zeros([5, 32, 32])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* must have rank 4'):
+ networks.compression_model(wrong_dim_input)
+
+ not_fully_defined = tf.placeholder(tf.float32, [3, None, 32, 3])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* is not fully defined'):
+ networks.compression_model(not_fully_defined)
+
+ def test_discriminator_run(self):
+ img_batch = tf.zeros([3, 70, 70, 3])
+ disc_output = networks.discriminator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(disc_output)
+
+ def test_discriminator_graph(self):
+ # Check graph construction for a number of image size/depths and batch
+ # sizes.
+ for batch_size, patch_size in zip([3, 6], [70, 128]):
+ tf.reset_default_graph()
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ disc_output = networks.discriminator(img)
+
+ self.assertEqual(2, disc_output.shape.ndims)
+ self.assertEqual(batch_size, disc_output.shape[0])
+
+ def test_discriminator_invalid_input(self):
+ wrong_dim_input = tf.zeros([5, 32, 32])
+ with self.assertRaisesRegexp(ValueError, 'Shape must be rank 4'):
+ networks.discriminator(wrong_dim_input)
+
+ not_fully_defined = tf.placeholder(tf.float32, [3, None, 32, 3])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* is not fully defined'):
+ networks.compression_model(not_fully_defined)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py"
new file mode 100644
index 00000000..f85a780c
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py"
@@ -0,0 +1,44 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Summaries utility file to share between train and eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+tfgan = tf.contrib.gan
+
+
+def add_reconstruction_summaries(images, reconstructions, prebinary,
+ num_imgs_to_visualize=8):
+ """Adds image summaries."""
+ reshaped_img = stack_images(images, reconstructions, num_imgs_to_visualize)
+
+ tf.summary.image('real_vs_reconstruction', reshaped_img, max_outputs=1)
+ if prebinary is not None:
+ tf.summary.histogram('prebinary_codes', prebinary)
+
+
+def stack_images(images, reconstructions, num_imgs_to_visualize=8):
+ """Stack and reshape images to see compression effects."""
+ to_reshape = (tf.unstack(images)[:num_imgs_to_visualize] +
+ tf.unstack(reconstructions)[:num_imgs_to_visualize])
+ reshaped_img = tfgan.eval.image_reshaper(
+ to_reshape, num_cols=num_imgs_to_visualize)
+ return reshaped_img
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt"
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt"
@@ -0,0 +1 @@
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py"
new file mode 100644
index 00000000..70aed9fc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py"
@@ -0,0 +1,217 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint:disable=line-too-long
+"""Trains an image compression network with an adversarial loss."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+import summaries
+
+
+tfgan = tf.contrib.gan
+FLAGS = flags.FLAGS
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_integer('bits_per_patch', 1230,
+ 'The number of bits to produce per patch.')
+
+flags.DEFINE_integer('model_depth', 64,
+ 'Number of filters for compression model')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/compression/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 1e-5,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 1e-6,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 2000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float(
+ 'weight_factor', 10000.0,
+ 'How much to weight the adversarial loss relative to pixel loss.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Put input pipeline on CPU to reserve GPU for training.
+ with tf.name_scope('inputs'), tf.device('/cpu:0'):
+ images = data_provider.provide_data(
+ 'train', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+
+ # Manually define a GANModel tuple. This is useful when we have custom
+ # code to track variables. Note that we could replace all of this with a
+ # call to `tfgan.gan_model`, but we don't in order to demonstrate some of
+ # TFGAN's flexibility.
+ with tf.variable_scope('generator') as gen_scope:
+ reconstructions, _, prebinary = networks.compression_model(
+ images,
+ num_bits=FLAGS.bits_per_patch,
+ depth=FLAGS.model_depth)
+ gan_model = _get_gan_model(
+ generator_inputs=images,
+ generated_data=reconstructions,
+ real_data=images,
+ generator_scope=gen_scope)
+ summaries.add_reconstruction_summaries(images, reconstructions, prebinary)
+ tfgan.eval.add_gan_model_summaries(gan_model)
+
+ # Define the GANLoss tuple using standard library functions.
+ with tf.name_scope('loss'):
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.least_squares_generator_loss,
+ discriminator_loss_fn=tfgan.losses.least_squares_discriminator_loss,
+ add_summaries=FLAGS.weight_factor > 0)
+
+ # Define the standard pixel loss.
+ l1_pixel_loss = tf.norm(gan_model.real_data - gan_model.generated_data,
+ ord=1)
+
+ # Modify the loss tuple to include the pixel loss. Add summaries as well.
+ gan_loss = tfgan.losses.combine_adversarial_loss(
+ gan_loss, gan_model, l1_pixel_loss, weight_factor=FLAGS.weight_factor)
+
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ with tf.name_scope('train_ops'):
+ gen_lr, dis_lr = _lr(FLAGS.generator_lr, FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Determine the number of generator vs discriminator steps.
+ train_steps = tfgan.GANTrainSteps(
+ generator_train_steps=1,
+ discriminator_train_steps=int(FLAGS.weight_factor > 0))
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+def _optimizer(gen_lr, dis_lr):
+ # First is generator optimizer, second is discriminator.
+ adam_kwargs = {
+ 'epsilon': 1e-8,
+ 'beta1': 0.5,
+ }
+ return (tf.train.AdamOptimizer(gen_lr, **adam_kwargs),
+ tf.train.AdamOptimizer(dis_lr, **adam_kwargs))
+
+
+def _lr(gen_lr_base, dis_lr_base):
+ """Return the generator and discriminator learning rates."""
+ gen_lr_kwargs = {
+ 'decay_steps': 60000,
+ 'decay_rate': 0.9,
+ 'staircase': True,
+ }
+ gen_lr = tf.train.exponential_decay(
+ learning_rate=gen_lr_base,
+ global_step=tf.train.get_or_create_global_step(),
+ **gen_lr_kwargs)
+ dis_lr = dis_lr_base
+
+ return gen_lr, dis_lr
+
+
+def _get_gan_model(generator_inputs, generated_data, real_data,
+ generator_scope):
+ """Manually construct and return a GANModel tuple."""
+ generator_vars = tf.contrib.framework.get_trainable_variables(generator_scope)
+
+ discriminator_fn = networks.discriminator
+ with tf.variable_scope('discriminator') as dis_scope:
+ discriminator_gen_outputs = discriminator_fn(generated_data)
+ with tf.variable_scope(dis_scope, reuse=True):
+ discriminator_real_outputs = discriminator_fn(real_data)
+ discriminator_vars = tf.contrib.framework.get_trainable_variables(
+ dis_scope)
+
+ # Manually construct GANModel tuple.
+ gan_model = tfgan.GANModel(
+ generator_inputs=generator_inputs,
+ generated_data=generated_data,
+ generator_variables=generator_vars,
+ generator_scope=generator_scope,
+ generator_fn=None, # not necessary
+ real_data=real_data,
+ discriminator_real_outputs=discriminator_real_outputs,
+ discriminator_gen_outputs=discriminator_gen_outputs,
+ discriminator_variables=discriminator_vars,
+ discriminator_scope=dis_scope,
+ discriminator_fn=discriminator_fn)
+
+ return gan_model
+
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py"
new file mode 100644
index 00000000..a76f9b06
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py"
@@ -0,0 +1,56 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for image_compression.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('NoAdversarialLoss', 0.0),
+ ('AdversarialLoss', 1.0))
+ def test_build_graph(self, weight_factor):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.weight_factor = weight_factor
+
+ batch_size = 3
+ patch_size = 16
+
+ FLAGS.batch_size = batch_size
+ FLAGS.patch_size = patch_size
+ mock_imgs = np.zeros([batch_size, patch_size, patch_size, 3],
+ dtype=np.float32)
+
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = mock_imgs
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py"
new file mode 100644
index 00000000..9fbd640f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py"
@@ -0,0 +1,111 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a conditional TFGAN trained MNIST model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('num_images_per_class', 10,
+ 'Number of images to generate per class.')
+
+flags.DEFINE_integer('noise_dims', 64,
+ 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+FLAGS = flags.FLAGS
+NUM_CLASSES = 10
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ noise, one_hot_labels = _get_generator_inputs(
+ FLAGS.num_images_per_class, NUM_CLASSES, FLAGS.noise_dims)
+
+ # Generate images.
+ with tf.variable_scope('Generator'): # Same scope as in train job.
+ images = networks.conditional_generator(
+ (noise, one_hot_labels), is_training=False)
+
+ # Visualize images.
+ reshaped_img = tfgan.eval.image_reshaper(
+ images, num_cols=FLAGS.num_images_per_class)
+ tf.summary.image('generated_images', reshaped_img, max_outputs=1)
+
+ # Calculate evaluation metrics.
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(images, FLAGS.classifier_filename))
+ tf.summary.scalar('MNIST_Cross_entropy',
+ util.mnist_cross_entropy(
+ images, one_hot_labels, FLAGS.classifier_filename))
+
+ # Write images to disk.
+ image_write_ops = None
+ if FLAGS.write_to_disk:
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'conditional_gan.png'),
+ tf.image.encode_png(data_provider.float_image_to_uint8(
+ reshaped_img[0])))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _get_generator_inputs(num_images_per_class, num_classes, noise_dims):
+ # Since we want a grid of numbers for the conditional generator, manually
+ # construct the desired class labels.
+ num_images_generated = num_images_per_class * num_classes
+ noise = tf.random_normal([num_images_generated, noise_dims])
+ labels = [lbl for lbl in range(num_classes) for _
+ in range(num_images_per_class)]
+ one_hot_labels = tf.one_hot(tf.constant(labels), num_classes)
+ return noise, one_hot_labels
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py"
new file mode 100644
index 00000000..1bb96a24
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py"
@@ -0,0 +1,32 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.conditional_eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from absl.testing import absltest
+import conditional_eval
+
+
+class ConditionalEvalTest(absltest.TestCase):
+
+ def test_build_graph(self):
+ conditional_eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py"
new file mode 100644
index 00000000..afbc3809
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py"
@@ -0,0 +1,85 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(split_name, batch_size, dataset_dir, num_readers=1,
+ num_threads=1):
+ """Provides batches of MNIST digits.
+
+ Args:
+ split_name: Either 'train' or 'test'.
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the MNIST data can be found.
+ num_readers: Number of dataset readers.
+ num_threads: Number of prefetching threads.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, 28, 28, 1]
+ one_hot_labels: A `Tensor` of size [batch_size, mnist.NUM_CLASSES], where
+ each row has a single element set to one and the rest set to zeros.
+ num_samples: The number of total samples in the dataset.
+
+ Raises:
+ ValueError: If `split_name` is not either 'train' or 'test'.
+ """
+ dataset = datasets.get_dataset('mnist', split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=num_readers,
+ common_queue_capacity=2 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=(split_name == 'train'))
+ [image, label] = provider.get(['image', 'label'])
+
+ # Preprocess the images.
+ image = (tf.to_float(image) - 128.0) / 128.0
+
+ # Creates a QueueRunner for the pre-fetching operation.
+ images, labels = tf.train.batch(
+ [image, label],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size)
+
+ one_hot_labels = tf.one_hot(labels, dataset.num_classes)
+ return images, one_hot_labels, dataset.num_samples
+
+
+def float_image_to_uint8(image):
+ """Convert float image in [-1, 1) to [0, 255] uint8.
+
+ Note that `1` gets mapped to `0`, but `1 - epsilon` gets mapped to 255.
+
+ Args:
+ image: An image tensor. Values should be in [-1, 1).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 128.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py"
new file mode 100644
index 00000000..463ecfdc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py"
@@ -0,0 +1,49 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def test_mnist_data_reading(self):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/mnist/testdata')
+
+ batch_size = 5
+ images, labels, num_samples = data_provider.provide_data(
+ 'test', batch_size, dataset_dir)
+ self.assertEqual(num_samples, 10000)
+
+ with self.test_session() as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images, labels = sess.run([images, labels])
+ self.assertEqual(images.shape, (batch_size, 28, 28, 1))
+ self.assertEqual(labels.shape, (batch_size, 10))
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py"
new file mode 100644
index 00000000..b7f50f3a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py"
@@ -0,0 +1,104 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained MNIST model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('num_images_generated', 1000,
+ 'Number of images to generate at once.')
+
+flags.DEFINE_boolean('eval_real_images', False,
+ 'If `True`, run Inception network on real images.')
+
+flags.DEFINE_integer('noise_dims', 64,
+ 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+
+def main(_, run_eval_loop=True):
+ # Fetch real images.
+ with tf.name_scope('inputs'):
+ real_images, _, _ = data_provider.provide_data(
+ 'train', FLAGS.num_images_generated, FLAGS.dataset_dir)
+
+ image_write_ops = None
+ if FLAGS.eval_real_images:
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(real_images, FLAGS.classifier_filename))
+ else:
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('Generator'):
+ images = networks.unconditional_generator(
+ tf.random_normal([FLAGS.num_images_generated, FLAGS.noise_dims]),
+ is_training=False)
+ tf.summary.scalar('MNIST_Frechet_distance',
+ util.mnist_frechet_distance(
+ real_images, images, FLAGS.classifier_filename))
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(images, FLAGS.classifier_filename))
+ if FLAGS.num_images_generated >= 100 and FLAGS.write_to_disk:
+ reshaped_images = tfgan.eval.image_reshaper(
+ images[:100, ...], num_cols=10)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_images)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'unconditional_gan.png'),
+ tf.image.encode_png(uint8_images[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py"
new file mode 100644
index 00000000..1a7d4ca8
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py"
@@ -0,0 +1,40 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import flags
+from absl.testing import absltest
+from absl.testing import parameterized
+import eval # pylint:disable=redefined-builtin
+
+
+class EvalTest(parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('RealData', True),
+ ('GeneratedData', False))
+ def test_build_graph(self, eval_real_images):
+ flags.FLAGS.eval_real_images = eval_real_images
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py"
new file mode 100644
index 00000000..ef2eae01
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py"
@@ -0,0 +1,160 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates an InfoGAN TFGAN trained MNIST model.
+
+The image visualizations, as in https://arxiv.org/abs/1606.03657, show the
+effect of varying a specific latent variable on the image. Each visualization
+focuses on one of the three structured variables. Columns have two of the three
+variables fixed, while the third one is varied. Different rows have different
+random samples from the remaining latents.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import app
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('noise_samples', 6,
+ 'Number of samples to draw from the continuous structured '
+ 'noise.')
+
+flags.DEFINE_integer('unstructured_noise_dims', 62,
+ 'The number of dimensions of the unstructured noise.')
+
+flags.DEFINE_integer('continuous_noise_dims', 2,
+ 'The number of dimensions of the continuous noise.')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+CAT_SAMPLE_POINTS = np.arange(0, 10)
+CONT_SAMPLE_POINTS = np.linspace(-2.0, 2.0, 10)
+FLAGS = flags.FLAGS
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ noise_args = (FLAGS.noise_samples, CAT_SAMPLE_POINTS, CONT_SAMPLE_POINTS,
+ FLAGS.unstructured_noise_dims, FLAGS.continuous_noise_dims)
+ # Use fixed noise vectors to illustrate the effect of each dimension.
+ display_noise1 = util.get_eval_noise_categorical(*noise_args)
+ display_noise2 = util.get_eval_noise_continuous_dim1(*noise_args)
+ display_noise3 = util.get_eval_noise_continuous_dim2(*noise_args)
+ _validate_noises([display_noise1, display_noise2, display_noise3])
+
+ # Visualize the effect of each structured noise dimension on the generated
+ # image.
+ def generator_fn(inputs):
+ return networks.infogan_generator(
+ inputs, len(CAT_SAMPLE_POINTS), is_training=False)
+ with tf.variable_scope('Generator') as genscope: # Same scope as in training.
+ categorical_images = generator_fn(display_noise1)
+ reshaped_categorical_img = tfgan.eval.image_reshaper(
+ categorical_images, num_cols=len(CAT_SAMPLE_POINTS))
+ tf.summary.image('categorical', reshaped_categorical_img, max_outputs=1)
+
+ with tf.variable_scope(genscope, reuse=True):
+ continuous1_images = generator_fn(display_noise2)
+ reshaped_continuous1_img = tfgan.eval.image_reshaper(
+ continuous1_images, num_cols=len(CONT_SAMPLE_POINTS))
+ tf.summary.image('continuous1', reshaped_continuous1_img, max_outputs=1)
+
+ with tf.variable_scope(genscope, reuse=True):
+ continuous2_images = generator_fn(display_noise3)
+ reshaped_continuous2_img = tfgan.eval.image_reshaper(
+ continuous2_images, num_cols=len(CONT_SAMPLE_POINTS))
+ tf.summary.image('continuous2', reshaped_continuous2_img, max_outputs=1)
+
+ # Evaluate image quality.
+ all_images = tf.concat(
+ [categorical_images, continuous1_images, continuous2_images], 0)
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(all_images, FLAGS.classifier_filename))
+
+ # Write images to disk.
+ image_write_ops = []
+ if FLAGS.write_to_disk:
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'categorical_infogan.png', reshaped_categorical_img[0]))
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'continuous1_infogan.png', reshaped_continuous1_img[0]))
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'continuous2_infogan.png', reshaped_continuous2_img[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _validate_noises(noises):
+ """Sanity check on constructed noise tensors.
+
+ Args:
+ noises: List of 3-tuples of noise vectors.
+ """
+ assert isinstance(noises, (list, tuple))
+ for noise_l in noises:
+ assert len(noise_l) == 3
+ assert isinstance(noise_l[0], np.ndarray)
+ batch_dim = noise_l[0].shape[0]
+ for i, noise in enumerate(noise_l):
+ assert isinstance(noise, np.ndarray)
+ # Check that batch dimensions are all the same.
+ assert noise.shape[0] == batch_dim
+
+ # Check that shapes for corresponding noises are the same.
+ assert noise.shape == noises[0][i].shape
+
+
+def _get_write_image_ops(eval_dir, filename, images):
+ """Create Ops that write images to disk."""
+ return tf.write_file(
+ '%s/%s'% (eval_dir, filename),
+ tf.image.encode_png(data_provider.float_image_to_uint8(images)))
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py"
new file mode 100644
index 00000000..741465fc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py"
@@ -0,0 +1,33 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.infogan_eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl.testing import absltest
+import infogan_eval
+
+
+class MnistInfoGANEvalTest(absltest.TestCase):
+
+ def test_build_graph(self):
+ infogan_eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh"
new file mode 100644
index 00000000..8bccb12f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh"
@@ -0,0 +1,157 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the MNIST dataset.
+# 2. Trains an unconditional, conditional, or InfoGAN model on the MNIST
+# training set.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# These examples are intended to be fast. For better final results, tune
+# hyperparameters or train longer.
+#
+# NOTE: Each training step takes about 0.5 second with a batch size of 32 on
+# CPU. On GPU, it takes ~5 milliseconds.
+#
+# With the default batch size and number of steps, train times are:
+#
+# unconditional: CPU: 800 steps, ~10 min GPU: 800 steps, ~1 min
+# conditional: CPU: 2000 steps, ~20 min GPU: 2000 steps, ~2 min
+# infogan: CPU: 3000 steps, ~20 min GPU: 3000 steps, ~6 min
+#
+# Usage:
+# cd models/research/gan/mnist
+# ./launch_jobs.sh ${gan_type} ${git_repo}
+set -e
+
+# Type of GAN to run. Right now, options are `unconditional`, `conditional`, or
+# `infogan`.
+gan_type=$1
+if ! [[ "$gan_type" =~ ^(unconditional|conditional|infogan) ]]; then
+ echo "'gan_type' must be one of: 'unconditional', 'conditional', 'infogan'."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/mnist-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/mnist-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/mnist-data
+
+# Location of the classifier frozen graph used for evaluation.
+FROZEN_GRAPH="${git_repo}/research/gan/mnist/data/classify_mnist_graph_def.pb"
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=mnist \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+if [[ "$gan_type" == "unconditional" ]]; then
+ UNCONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/unconditional"
+ UNCONDITIONAL_EVAL_DIR="${EVAL_DIR}/unconditional"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training unconditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="unconditional" \
+ --alsologtostderr
+ Banner "Finished training unconditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of unconditional GAN..."
+ python "${git_repo}/research/gan/mnist/eval.py" \
+ --checkpoint_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${UNCONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished unconditional evaluation. See ${UNCONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run conditional GAN.
+if [[ "$gan_type" == "conditional" ]]; then
+ CONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/conditional"
+ CONDITIONAL_EVAL_DIR="${EVAL_DIR}/conditional"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training conditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${CONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="conditional" \
+ --alsologtostderr
+ Banner "Finished training conditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of conditional GAN..."
+ python "${git_repo}/research/gan/mnist/conditional_eval.py" \
+ --checkpoint_dir=${CONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${CONDITIONAL_EVAL_DIR} \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished conditional evaluation. See ${CONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run InfoGAN.
+if [[ "$gan_type" == "infogan" ]]; then
+ INFOGAN_TRAIN_DIR="${TRAIN_DIR}/infogan"
+ INFOGAN_EVAL_DIR="${EVAL_DIR}/infogan"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training infogan GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${INFOGAN_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="infogan" \
+ --alsologtostderr
+ Banner "Finished training InfoGAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of infogan..."
+ python "${git_repo}/research/gan/mnist/infogan_eval.py" \
+ --checkpoint_dir=${INFOGAN_TRAIN_DIR} \
+ --eval_dir=${INFOGAN_EVAL_DIR} \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished InfoGAN evaluation. See ${INFOGAN_EVAL_DIR} for output images."
+fi
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py"
new file mode 100644
index 00000000..72f78c83
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py"
@@ -0,0 +1,235 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for MNIST example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+ds = tf.contrib.distributions
+layers = tf.contrib.layers
+tfgan = tf.contrib.gan
+
+
+def _generator_helper(
+ noise, is_conditional, one_hot_labels, weight_decay, is_training):
+ """Core MNIST generator.
+
+ This function is reused between the different GAN modes (unconditional,
+ conditional, etc).
+
+ Args:
+ noise: A 2D Tensor of shape [batch size, noise dim].
+ is_conditional: Whether to condition on labels.
+ one_hot_labels: Optional labels for conditioning.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ with tf.contrib.framework.arg_scope(
+ [layers.fully_connected, layers.conv2d_transpose],
+ activation_fn=tf.nn.relu, normalizer_fn=layers.batch_norm,
+ weights_regularizer=layers.l2_regularizer(weight_decay)):
+ with tf.contrib.framework.arg_scope(
+ [layers.batch_norm], is_training=is_training):
+ net = layers.fully_connected(noise, 1024)
+ if is_conditional:
+ net = tfgan.features.condition_tensor_from_onehot(net, one_hot_labels)
+ net = layers.fully_connected(net, 7 * 7 * 128)
+ net = tf.reshape(net, [-1, 7, 7, 128])
+ net = layers.conv2d_transpose(net, 64, [4, 4], stride=2)
+ net = layers.conv2d_transpose(net, 32, [4, 4], stride=2)
+ # Make sure that generator output is in the same range as `inputs`
+ # ie [-1, 1].
+ net = layers.conv2d(
+ net, 1, [4, 4], normalizer_fn=None, activation_fn=tf.tanh)
+
+ return net
+
+
+def unconditional_generator(noise, weight_decay=2.5e-5, is_training=True):
+ """Generator to produce unconditional MNIST images.
+
+ Args:
+ noise: A single Tensor representing noise.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ return _generator_helper(noise, False, None, weight_decay, is_training)
+
+
+def conditional_generator(inputs, weight_decay=2.5e-5, is_training=True):
+ """Generator to produce MNIST images conditioned on class.
+
+ Args:
+ inputs: A 2-tuple of Tensors (noise, one_hot_labels).
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ noise, one_hot_labels = inputs
+ return _generator_helper(
+ noise, True, one_hot_labels, weight_decay, is_training)
+
+
+def infogan_generator(inputs, categorical_dim, weight_decay=2.5e-5,
+ is_training=True):
+ """InfoGAN generator network on MNIST digits.
+
+ Based on a paper https://arxiv.org/abs/1606.03657, their code
+ https://github.com/openai/InfoGAN, and code by pooleb@.
+
+ Args:
+ inputs: A 3-tuple of Tensors (unstructured_noise, categorical structured
+ noise, continuous structured noise). `inputs[0]` and `inputs[2]` must be
+ 2D, and `inputs[1]` must be 1D. All must have the same first dimension.
+ categorical_dim: Dimensions of the incompressible categorical noise.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ unstructured_noise, cat_noise, cont_noise = inputs
+ cat_noise_onehot = tf.one_hot(cat_noise, categorical_dim)
+ all_noise = tf.concat(
+ [unstructured_noise, cat_noise_onehot, cont_noise], axis=1)
+ return _generator_helper(all_noise, False, None, weight_decay, is_training)
+
+
+_leaky_relu = lambda x: tf.nn.leaky_relu(x, alpha=0.01)
+
+
+def _discriminator_helper(img, is_conditional, one_hot_labels, weight_decay):
+ """Core MNIST discriminator.
+
+ This function is reused between the different GAN modes (unconditional,
+ conditional, etc).
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ is_conditional: Whether to condition on labels.
+ one_hot_labels: Labels to optionally condition the network on.
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Final fully connected discriminator layer. [batch_size, 1024].
+ """
+ with tf.contrib.framework.arg_scope(
+ [layers.conv2d, layers.fully_connected],
+ activation_fn=_leaky_relu, normalizer_fn=None,
+ weights_regularizer=layers.l2_regularizer(weight_decay),
+ biases_regularizer=layers.l2_regularizer(weight_decay)):
+ net = layers.conv2d(img, 64, [4, 4], stride=2)
+ net = layers.conv2d(net, 128, [4, 4], stride=2)
+ net = layers.flatten(net)
+ if is_conditional:
+ net = tfgan.features.condition_tensor_from_onehot(net, one_hot_labels)
+ net = layers.fully_connected(net, 1024, normalizer_fn=layers.layer_norm)
+
+ return net
+
+
+def unconditional_discriminator(img, unused_conditioning, weight_decay=2.5e-5):
+ """Discriminator network on unconditional MNIST digits.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Logits for the probability that the image is real.
+ """
+ net = _discriminator_helper(img, False, None, weight_decay)
+ return layers.linear(net, 1)
+
+
+def conditional_discriminator(img, conditioning, weight_decay=2.5e-5):
+ """Conditional discriminator network on MNIST digits.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ conditioning: A 2-tuple of Tensors representing (noise, one_hot_labels).
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Logits for the probability that the image is real.
+ """
+ _, one_hot_labels = conditioning
+ net = _discriminator_helper(img, True, one_hot_labels, weight_decay)
+ return layers.linear(net, 1)
+
+
+def infogan_discriminator(img, unused_conditioning, weight_decay=2.5e-5,
+ categorical_dim=10, continuous_dim=2):
+ """InfoGAN discriminator network on MNIST digits.
+
+ Based on a paper https://arxiv.org/abs/1606.03657, their code
+ https://github.com/openai/InfoGAN, and code by pooleb@.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ weight_decay: The L2 weight decay.
+ categorical_dim: Dimensions of the incompressible categorical noise.
+ continuous_dim: Dimensions of the incompressible continuous noise.
+
+ Returns:
+ Logits for the probability that the image is real, and a list of posterior
+ distributions for each of the noise vectors.
+ """
+ net = _discriminator_helper(img, False, None, weight_decay)
+ logits_real = layers.fully_connected(net, 1, activation_fn=None)
+
+ # Recognition network for latent variables has an additional layer
+ with tf.contrib.framework.arg_scope([layers.batch_norm], is_training=False):
+ encoder = layers.fully_connected(net, 128, normalizer_fn=layers.batch_norm,
+ activation_fn=_leaky_relu)
+
+ # Compute logits for each category of categorical latent.
+ logits_cat = layers.fully_connected(
+ encoder, categorical_dim, activation_fn=None)
+ q_cat = ds.Categorical(logits_cat)
+
+ # Compute mean for Gaussian posterior of continuous latents.
+ mu_cont = layers.fully_connected(encoder, continuous_dim, activation_fn=None)
+ sigma_cont = tf.ones_like(mu_cont)
+ q_cont = ds.Normal(loc=mu_cont, scale=sigma_cont)
+
+ return logits_real, [q_cat, q_cont]
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py"
new file mode 100644
index 00000000..b51f2812
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py"
@@ -0,0 +1,151 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a generator on MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import functools
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/mnist/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('max_number_of_steps', 20000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_string(
+ 'gan_type', 'unconditional',
+ 'Either `unconditional`, `conditional`, or `infogan`.')
+
+flags.DEFINE_integer(
+ 'grid_size', 5, 'Grid size for image visualization.')
+
+
+flags.DEFINE_integer(
+ 'noise_dims', 64, 'Dimensions of the generator noise vector.')
+
+FLAGS = flags.FLAGS
+
+
+def _learning_rate(gan_type):
+ # First is generator learning rate, second is discriminator learning rate.
+ return {
+ 'unconditional': (1e-3, 1e-4),
+ 'conditional': (1e-5, 1e-4),
+ 'infogan': (0.001, 9e-5),
+ }[gan_type]
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ # Force all input processing onto CPU in order to reserve the GPU for
+ # the forward inference and back-propagation.
+ with tf.name_scope('inputs'):
+ with tf.device('/cpu:0'):
+ images, one_hot_labels, _ = data_provider.provide_data(
+ 'train', FLAGS.batch_size, FLAGS.dataset_dir, num_threads=4)
+
+ # Define the GANModel tuple. Optionally, condition the GAN on the label or
+ # use an InfoGAN to learn a latent representation.
+ if FLAGS.gan_type == 'unconditional':
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.unconditional_generator,
+ discriminator_fn=networks.unconditional_discriminator,
+ real_data=images,
+ generator_inputs=tf.random_normal(
+ [FLAGS.batch_size, FLAGS.noise_dims]))
+ elif FLAGS.gan_type == 'conditional':
+ noise = tf.random_normal([FLAGS.batch_size, FLAGS.noise_dims])
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.conditional_generator,
+ discriminator_fn=networks.conditional_discriminator,
+ real_data=images,
+ generator_inputs=(noise, one_hot_labels))
+ elif FLAGS.gan_type == 'infogan':
+ cat_dim, cont_dim = 10, 2
+ generator_fn = functools.partial(
+ networks.infogan_generator, categorical_dim=cat_dim)
+ discriminator_fn = functools.partial(
+ networks.infogan_discriminator, categorical_dim=cat_dim,
+ continuous_dim=cont_dim)
+ unstructured_inputs, structured_inputs = util.get_infogan_noise(
+ FLAGS.batch_size, cat_dim, cont_dim, FLAGS.noise_dims)
+ gan_model = tfgan.infogan_model(
+ generator_fn=generator_fn,
+ discriminator_fn=discriminator_fn,
+ real_data=images,
+ unstructured_generator_inputs=unstructured_inputs,
+ structured_generator_inputs=structured_inputs)
+ tfgan.eval.add_gan_model_image_summaries(gan_model, FLAGS.grid_size)
+
+ # Get the GANLoss tuple. You can pass a custom function, use one of the
+ # already-implemented losses from the losses library, or use the defaults.
+ with tf.name_scope('loss'):
+ mutual_information_penalty_weight = (1.0 if FLAGS.gan_type == 'infogan'
+ else 0.0)
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ gradient_penalty_weight=1.0,
+ mutual_information_penalty_weight=mutual_information_penalty_weight,
+ add_summaries=True)
+ tfgan.eval.add_regularization_loss_summaries(gan_model)
+
+ # Get the GANTrain ops using custom optimizers.
+ with tf.name_scope('train'):
+ gen_lr, dis_lr = _learning_rate(FLAGS.gan_type)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=tf.train.AdamOptimizer(gen_lr, 0.5),
+ discriminator_optimizer=tf.train.AdamOptimizer(dis_lr, 0.5),
+ summarize_gradients=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ logdir=FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_joint_train_hooks())
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py"
new file mode 100644
index 00000000..a75f858b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py"
@@ -0,0 +1,71 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ def test_run_one_train_step(self, mock_data_provider):
+ FLAGS.max_number_of_steps = 1
+ FLAGS.gan_type = 'unconditional'
+ FLAGS.batch_size = 5
+ FLAGS.grid_size = 1
+ tf.set_random_seed(1234)
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ mock_data_provider.provide_data.return_value = (mock_imgs, mock_lbls, None)
+
+ train.main(None)
+
+ @parameterized.named_parameters(
+ ('Unconditional', 'unconditional'),
+ ('Conditional', 'conditional'),
+ ('InfoGAN', 'infogan'))
+ def test_build_graph(self, gan_type):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.gan_type = gan_type
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = (
+ mock_imgs, mock_lbls, None)
+ train.main(None)
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py"
new file mode 100644
index 00000000..0cf6b00e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py"
@@ -0,0 +1,323 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""A utility for evaluating MNIST generative models.
+
+These functions use a pretrained MNIST classifier with ~99% eval accuracy to
+measure various aspects of the quality of generated MNIST digits.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+
+ds = tf.contrib.distributions
+tfgan = tf.contrib.gan
+
+
+__all__ = [
+ 'mnist_score',
+ 'mnist_frechet_distance',
+ 'mnist_cross_entropy',
+ 'get_eval_noise_categorical',
+ 'get_eval_noise_continuous_dim1',
+ 'get_eval_noise_continuous_dim2',
+ 'get_infogan_noise',
+]
+
+
+# Prepend `../`, since paths start from `third_party/tensorflow`.
+MODEL_GRAPH_DEF = '../tensorflow_models/gan/mnist/data/classify_mnist_graph_def.pb'
+INPUT_TENSOR = 'inputs:0'
+OUTPUT_TENSOR = 'logits:0'
+
+
+def mnist_score(images, graph_def_filename=None, input_tensor=INPUT_TENSOR,
+ output_tensor=OUTPUT_TENSOR, num_batches=1):
+ """Get MNIST logits of a fully-trained classifier.
+
+ Args:
+ images: A minibatch tensor of MNIST digits. Shape must be
+ [batch, 28, 28, 1].
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+ num_batches: Number of batches to split `generated_images` in to in order to
+ efficiently run them through Inception.
+
+ Returns:
+ A logits tensor of [batch, 10].
+ """
+ images.shape.assert_is_compatible_with([None, 28, 28, 1])
+
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+ mnist_classifier_fn = lambda x: tfgan.eval.run_image_classifier( # pylint: disable=g-long-lambda
+ x, graph_def, input_tensor, output_tensor)
+
+ score = tfgan.eval.classifier_score(
+ images, mnist_classifier_fn, num_batches)
+ score.shape.assert_is_compatible_with([])
+
+ return score
+
+
+def mnist_frechet_distance(real_images, generated_images,
+ graph_def_filename=None, input_tensor=INPUT_TENSOR,
+ output_tensor=OUTPUT_TENSOR, num_batches=1):
+ """Frechet distance between real and generated images.
+
+ This technique is described in detail in https://arxiv.org/abs/1706.08500.
+ Please see TFGAN for implementation details
+ (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/
+ python/eval/python/classifier_metrics_impl.py).
+
+ Args:
+ real_images: Real images to use to compute Frechet Inception distance.
+ generated_images: Generated images to use to compute Frechet Inception
+ distance.
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+ num_batches: Number of batches to split images into in order to
+ efficiently run them through the classifier network.
+
+ Returns:
+ The Frechet distance. A floating-point scalar.
+ """
+ real_images.shape.assert_is_compatible_with([None, 28, 28, 1])
+ generated_images.shape.assert_is_compatible_with([None, 28, 28, 1])
+
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+ mnist_classifier_fn = lambda x: tfgan.eval.run_image_classifier( # pylint: disable=g-long-lambda
+ x, graph_def, input_tensor, output_tensor)
+
+ frechet_distance = tfgan.eval.frechet_classifier_distance(
+ real_images, generated_images, mnist_classifier_fn, num_batches)
+ frechet_distance.shape.assert_is_compatible_with([])
+
+ return frechet_distance
+
+
+def mnist_cross_entropy(images, one_hot_labels, graph_def_filename=None,
+ input_tensor=INPUT_TENSOR, output_tensor=OUTPUT_TENSOR):
+ """Returns the cross entropy loss of the classifier on images.
+
+ Args:
+ images: A minibatch tensor of MNIST digits. Shape must be
+ [batch, 28, 28, 1].
+ one_hot_labels: The one hot label of the examples. Tensor size is
+ [batch, 10].
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph embedded in the par file.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+
+ Returns:
+ A scalar Tensor representing the cross entropy of the image minibatch.
+ """
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+
+ logits = tfgan.eval.run_image_classifier(
+ images, graph_def, input_tensor, output_tensor)
+ return tf.losses.softmax_cross_entropy(
+ one_hot_labels, logits, loss_collection=None)
+
+
+# (joelshor): Refactor the `eval_noise` functions to reuse code.
+def get_eval_noise_categorical(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims):
+ """Create noise showing impact of categorical noise in InfoGAN.
+
+ Categorical noise is constant across columns. Other noise is constant across
+ rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays. Each
+ should have shape [noise_samples, ?].
+ """
+ rows, cols = noise_samples, len(categorical_sample_points)
+
+ # Take random draws for non-categorical noise, making sure they are constant
+ # across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ continuous_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(
+ continuous_sample_points, size=[1, continuous_noise_dims])
+ continuous_noise.extend([cur_sample] * cols)
+ continuous_noise = np.concatenate(continuous_noise)
+
+ # Increase categorical noise from left to right, making sure they are constant
+ # across rows.
+ categorical_noise = np.tile(categorical_sample_points, rows)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_eval_noise_continuous_dim1(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims): # pylint:disable=unused-argument
+ """Create noise showing impact of first dim continuous noise in InfoGAN.
+
+ First dimension of continuous noise is constant across columns. Other noise is
+ constant across rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays.
+ """
+ rows, cols = noise_samples, len(continuous_sample_points)
+
+ # Take random draws for non-first-dim-continuous noise, making sure they are
+ # constant across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ categorical_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(categorical_sample_points)
+ categorical_noise.extend([cur_sample] * cols)
+ categorical_noise = np.array(categorical_noise)
+
+ cont_noise_dim2 = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(continuous_sample_points, size=[1, 1])
+ cont_noise_dim2.extend([cur_sample] * cols)
+ cont_noise_dim2 = np.concatenate(cont_noise_dim2)
+
+ # Increase first dimension of continuous noise from left to right, making sure
+ # they are constant across rows.
+ cont_noise_dim1 = np.expand_dims(np.tile(continuous_sample_points, rows), 1)
+
+ continuous_noise = np.concatenate((cont_noise_dim1, cont_noise_dim2), 1)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_eval_noise_continuous_dim2(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims): # pylint:disable=unused-argument
+ """Create noise showing impact of second dim of continuous noise in InfoGAN.
+
+ Second dimension of continuous noise is constant across columns. Other noise
+ is constant across rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays.
+ """
+ rows, cols = noise_samples, len(continuous_sample_points)
+
+ # Take random draws for non-first-dim-continuous noise, making sure they are
+ # constant across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ categorical_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(categorical_sample_points)
+ categorical_noise.extend([cur_sample] * cols)
+ categorical_noise = np.array(categorical_noise)
+
+ cont_noise_dim1 = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(continuous_sample_points, size=[1, 1])
+ cont_noise_dim1.extend([cur_sample] * cols)
+ cont_noise_dim1 = np.concatenate(cont_noise_dim1)
+
+ # Increase first dimension of continuous noise from left to right, making sure
+ # they are constant across rows.
+ cont_noise_dim2 = np.expand_dims(np.tile(continuous_sample_points, rows), 1)
+
+ continuous_noise = np.concatenate((cont_noise_dim1, cont_noise_dim2), 1)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_infogan_noise(batch_size, categorical_dim, structured_continuous_dim,
+ total_continuous_noise_dims):
+ """Get unstructured and structured noise for InfoGAN.
+
+ Args:
+ batch_size: The number of noise vectors to generate.
+ categorical_dim: The number of categories in the categorical noise.
+ structured_continuous_dim: The number of dimensions of the uniform
+ continuous noise.
+ total_continuous_noise_dims: The number of continuous noise dimensions. This
+ number includes the structured and unstructured noise.
+
+ Returns:
+ A 2-tuple of structured and unstructured noise. First element is the
+ unstructured noise, and the second is a 2-tuple of
+ (categorical structured noise, continuous structured noise).
+ """
+ # Get unstructurd noise.
+ unstructured_noise = tf.random_normal(
+ [batch_size, total_continuous_noise_dims - structured_continuous_dim])
+
+ # Get categorical noise Tensor.
+ categorical_dist = ds.Categorical(logits=tf.zeros([categorical_dim]))
+ categorical_noise = categorical_dist.sample([batch_size])
+
+ # Get continuous noise Tensor.
+ continuous_dist = ds.Uniform(-tf.ones([structured_continuous_dim]),
+ tf.ones([structured_continuous_dim]))
+ continuous_noise = continuous_dist.sample([batch_size])
+
+ return [unstructured_noise], [categorical_noise, continuous_noise]
+
+
+def _graph_def_from_par_or_disk(filename):
+ if filename is None:
+ return tfgan.eval.get_graph_def_from_resource(MODEL_GRAPH_DEF)
+ else:
+ return tfgan.eval.get_graph_def_from_disk(filename)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py"
new file mode 100644
index 00000000..53b851b6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py"
@@ -0,0 +1,229 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist.util."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import numpy as np
+
+import tensorflow as tf
+from google3.third_party.tensorflow_models.gan.mnist import util
+
+
+# pylint: disable=line-too-long
+# This is a real digit `5` from MNIST.
+REAL_DIGIT = [[-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.9765625, -0.859375, -0.859375, -0.859375, -0.015625, 0.0625, 0.3671875, -0.796875, 0.296875, 0.9921875, 0.9296875, -0.0078125, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.765625, -0.71875, -0.265625, 0.203125, 0.328125, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.7578125, 0.34375, 0.9765625, 0.890625, 0.5234375, -0.5, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6171875, 0.859375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9609375, -0.2734375, -0.359375, -0.359375, -0.5625, -0.6953125, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.859375, 0.7109375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.546875, 0.421875, 0.9296875, 0.8828125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.375, 0.21875, -0.1640625, 0.9765625, 0.9765625, 0.6015625, -0.9140625, -1.0, -0.6640625, 0.203125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.890625, -0.9921875, 0.203125, 0.9765625, -0.296875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 0.0859375, 0.9765625, 0.484375, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.9140625, 0.484375, 0.9765625, -0.453125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.7265625, 0.8828125, 0.7578125, 0.25, -0.15625, -0.9921875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.3671875, 0.875, 0.9765625, 0.9765625, -0.0703125, -0.8046875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6484375, 0.453125, 0.9765625, 0.9765625, 0.171875, -0.7890625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.875, -0.2734375, 0.96875, 0.9765625, 0.4609375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 0.9453125, 0.9765625, 0.9453125, -0.5, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.640625, 0.015625, 0.4296875, 0.9765625, 0.9765625, 0.6171875, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6953125, 0.15625, 0.7890625, 0.9765625, 0.9765625, 0.9765625, 0.953125, 0.421875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.8125, -0.109375, 0.7265625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.5703125, -0.390625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.8203125, -0.484375, 0.6640625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.546875, -0.3671875, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.859375, 0.3359375, 0.7109375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.5234375, -0.375, -0.9296875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -0.5703125, 0.34375, 0.765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.90625, 0.0390625, -0.9140625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, 0.0625, 0.9765625, 0.9765625, 0.9765625, 0.65625, 0.0546875, 0.03125, -0.875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0]]
+ONE_HOT = [[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0]]
+
+# Uniform noise in [-1, 1].
+FAKE_DIGIT = [[0.778958797454834, 0.8792028427124023, 0.07099628448486328, 0.8518857955932617, -0.3541288375854492, -0.7431280612945557, -0.12607860565185547, 0.17328786849975586, 0.6749839782714844, -0.5402040481567383, 0.9034252166748047, 0.2420203685760498, 0.3455841541290283, 0.1937558650970459, 0.9989571571350098, 0.9039363861083984, -0.955411434173584, 0.6228537559509277, -0.33131909370422363, 0.9653763771057129, 0.864208459854126, -0.05056142807006836, 0.12686634063720703, -0.09225749969482422, 0.49758028984069824, 0.08698725700378418, 0.5533185005187988, 0.20227980613708496], [0.8400616645812988, 0.7409703731536865, -0.6215496063232422, -0.53228759765625, -0.20184636116027832, -0.8568699359893799, -0.8662903308868408, -0.8735041618347168, -0.11022663116455078, -0.8418543338775635, 0.8193502426147461, -0.901512622833252, -0.7680232524871826, 0.6209826469421387, 0.06459426879882812, 0.5341305732727051, -0.4078702926635742, -0.13658642768859863, 0.6602437496185303, 0.848508358001709, -0.23431801795959473, 0.5995683670043945, -0.9807922840118408, 0.2657158374786377, -0.8068397045135498, 0.2438051700592041, -0.2116842269897461, 0.011460304260253906], [0.00040912628173828125, -0.058798789978027344, 0.3239307403564453, 0.5040378570556641, -0.03192305564880371, -0.4816470146179199, -0.14559340476989746, -0.9231269359588623, -0.6602556705474854, -0.2537086009979248, -0.11059761047363281, -0.8174862861633301, 0.6180260181427002, 0.7245023250579834, 0.5007762908935547, -0.1575303077697754, -0.0167086124420166, 0.7173266410827637, 0.1126704216003418, -0.9878268241882324, 0.4538843631744385, -0.4422755241394043, -0.7899672985076904, 0.7349567413330078, -0.4448075294494629, -0.7548923492431641, -0.5739786624908447, 0.30504918098449707], [-0.8488152027130127, 0.43424463272094727, 0.7724254131317139, 0.43314504623413086, 0.7352848052978516, -0.26010799407958984, 0.43951940536499023, -0.7642686367034912, -0.657184362411499, -0.9933960437774658, -0.47258639335632324, 0.10390830039978027, 0.11454653739929199, -0.6156411170959473, -0.23431062698364258, -0.6897118091583252, -0.5721850395202637, -0.3574075698852539, 0.13927006721496582, -0.6530766487121582, 0.32231855392456055, 0.6294634342193604, 0.5507853031158447, -0.4867420196533203, 0.4329197406768799, 0.6168341636657715, -0.8720219135284424, 0.8639121055603027], [0.02407360076904297, -0.11185193061828613, -0.38637852668762207, -0.8244953155517578, -0.648916482925415, 0.44907593727111816, -0.368192195892334, 0.0190126895904541, -0.9450500011444092, 0.41033458709716797, -0.7877917289733887, 0.617938756942749, 0.551692008972168, -0.48288512229919434, 0.019921541213989258, -0.8765170574188232, 0.5651748180389404, 0.850874662399292, -0.5792787075042725, 0.1748213768005371, -0.6905481815338135, -0.521310567855835, 0.062479496002197266, 0.17763280868530273, -0.4628307819366455, 0.8870463371276855, -0.8685822486877441, -0.29169774055480957], [-0.14687561988830566, 0.8801963329315186, 0.11353135108947754, -0.6009430885314941, 0.8818719387054443, -0.8621203899383545, -0.48749589920043945, 0.5224916934967041, 0.7050364017486572, -0.9968757629394531, 0.7235188484191895, 0.662771463394165, 0.588390588760376, -0.9624209403991699, 0.39203453063964844, -0.2210233211517334, 0.9266352653503418, -0.9132544994354248, -0.5175333023071289, 0.7251780033111572, 0.3030557632446289, 0.5743863582611084, 0.14350247383117676, -0.3735086917877197, -0.6299927234649658, 0.5088682174682617, -0.6953752040863037, 0.23583650588989258], [0.25864362716674805, 0.5736973285675049, -0.3975222110748291, -0.6369199752807617, 0.5376672744750977, -0.19951462745666504, 0.6843924522399902, 0.6296660900115967, 0.36865997314453125, -0.7243289947509766, 0.5768749713897705, -0.5493001937866211, 0.31238412857055664, 0.21019506454467773, -0.368206262588501, -0.33148622512817383, -0.3421964645385742, -0.15616083145141602, 0.6617193222045898, 0.4400820732116699, 0.7893157005310059, -0.2935945987701416, 0.6241741180419922, -0.26036930084228516, -0.6958446502685547, 0.27047157287597656, -0.9095940589904785, 0.9525108337402344], [-0.5233585834503174, -0.45003342628479004, 0.15099048614501953, 0.6257956027984619, 0.9017877578735352, -0.18155455589294434, -0.20237135887145996, -0.014468908309936523, 0.01797318458557129, -0.5453977584838867, 0.21428155899047852, -0.9678947925567627, 0.5137600898742676, -0.1094369888305664, -0.13572359085083008, -0.1704423427581787, -0.9122319221496582, 0.8274900913238525, -0.11746454238891602, -0.8701446056365967, -0.9545385837554932, -0.6735866069793701, 0.9445557594299316, -0.3842940330505371, -0.6240942478179932, -0.1673595905303955, -0.3959221839904785, -0.05602693557739258], [0.8833198547363281, 0.14288711547851562, -0.9623878002166748, -0.26968836784362793, 0.9689288139343262, -0.3792128562927246, 0.2520296573638916, 0.1477947235107422, -0.24453139305114746, 0.94329833984375, 0.8014910221099854, 0.5443501472473145, 0.8486857414245605, -0.0795745849609375, -0.30250096321105957, -0.909733772277832, 0.8387842178344727, -0.41989898681640625, -0.8364224433898926, 0.04792976379394531, -0.38036274909973145, 0.12747883796691895, -0.5356688499450684, -0.04269552230834961, -0.2070469856262207, -0.6911153793334961, 0.33954668045043945, 0.25260138511657715], [0.3128373622894287, 0.36142778396606445, -0.2512378692626953, -0.6497259140014648, -0.21787405014038086, -0.9972476959228516, -0.026904821395874023, -0.4214746952056885, -0.3354766368865967, -0.6112637519836426, -0.7594058513641357, 0.09093379974365234, -0.7331845760345459, 0.5222046375274658, -0.8997514247894287, -0.3749384880065918, -0.0775001049041748, -0.26296448707580566, 0.404325008392334, -0.25776195526123047, 0.9136955738067627, 0.2623283863067627, -0.6411356925964355, 0.6646602153778076, -0.12833356857299805, -0.4184732437133789, -0.3663449287414551, -0.5468103885650635], [0.3770618438720703, 0.5572817325592041, -0.3657073974609375, -0.5056321620941162, 0.6555137634277344, 0.9557509422302246, -0.6900768280029297, -0.4980638027191162, 0.05510354042053223, -0.610318660736084, 0.9753992557525635, 0.7569930553436279, 0.4011664390563965, 0.8439173698425293, -0.5921270847320557, -0.2775266170501709, -0.061129093170166016, -0.49707984924316406, 0.5820951461791992, 0.008175849914550781, 0.06372833251953125, 0.3061811923980713, -0.5091361999511719, 0.9751057624816895, 0.4571402072906494, 0.6769094467163086, -0.46695923805236816, 0.44080281257629395], [-0.6510493755340576, -0.032715559005737305, 0.3482983112335205, -0.8135421276092529, 0.1506943702697754, 0.5220685005187988, -0.8834004402160645, -0.908900260925293, 0.3211519718170166, 0.896381139755249, -0.9448244571685791, -0.6193962097167969, -0.009401559829711914, 0.38227057456970215, -0.9219558238983154, -0.029483318328857422, -0.3889012336730957, 0.5242419242858887, 0.7338912487030029, -0.8713808059692383, -0.04948568344116211, -0.797940731048584, -0.9933724403381348, -0.262890100479126, -0.7165846824645996, -0.9763388633728027, -0.4105076789855957, 0.5907857418060303], [-0.6091890335083008, 0.7921168804168701, -0.033307790756225586, -0.9177074432373047, 0.4553513526916504, 0.5754055976867676, 0.6747269630432129, 0.0015664100646972656, -0.36865878105163574, -0.7999486923217773, 0.993431568145752, -0.7310445308685303, -0.49965715408325195, -0.028263330459594727, -0.20190834999084473, -0.7398116588592529, 0.10513901710510254, 0.22136950492858887, 0.42579007148742676, -0.4703383445739746, -0.8729751110076904, 0.28951215744018555, -0.3110074996948242, 0.9935362339019775, -0.29533815383911133, -0.3384673595428467, -0.07292437553405762, 0.8471579551696777], [-0.04648447036743164, -0.6876633167266846, -0.4921104907989502, -0.1925184726715088, -0.5843420028686523, -0.2852492332458496, 0.1251826286315918, -0.5709969997406006, 0.6744673252105713, 0.17812824249267578, 0.675086259841919, 0.1219022274017334, 0.6496286392211914, 0.05892682075500488, 0.33709263801574707, -0.9087743759155273, -0.4785141944885254, 0.2689247131347656, 0.3600578308105469, -0.6822943687438965, -0.0801839828491211, 0.9234893321990967, 0.5037875175476074, -0.8148105144500732, 0.6820621490478516, -0.8345451354980469, 0.9400079250335693, -0.752265453338623], [0.4599113464355469, 0.0292510986328125, -0.7475054264068604, -0.4074263572692871, 0.8800950050354004, 0.41760849952697754, 0.3225588798522949, 0.8359887599945068, -0.8655965328216553, 0.17258906364440918, 0.752063512802124, -0.48968982696533203, -0.9149389266967773, -0.46224403381347656, -0.26379919052124023, -0.9342350959777832, -0.5444085597991943, -0.4576752185821533, -0.12544608116149902, -0.3810274600982666, -0.5277583599090576, 0.3267025947570801, 0.4762594699859619, 0.09010529518127441, -0.2434844970703125, -0.8013439178466797, -0.23540687561035156, 0.8844473361968994], [-0.8922028541564941, -0.7912418842315674, -0.14429497718811035, -0.3925011157989502, 0.1870102882385254, -0.28865933418273926, 0.11481523513793945, -0.9174098968505859, -0.5264348983764648, -0.7296302318572998, 0.44644737243652344, 0.11140275001525879, 0.08105874061584473, 0.3871574401855469, -0.5030152797698975, -0.9560322761535645, -0.07085466384887695, 0.7949709892272949, 0.37600183486938477, -0.8664641380310059, -0.08428549766540527, 0.9169652462005615, 0.9479010105133057, 0.3576698303222656, 0.6677501201629639, -0.34919166564941406, -0.11635351181030273, -0.05966901779174805], [-0.9716870784759521, -0.7901370525360107, 0.9152195453643799, -0.42171406745910645, 0.20472931861877441, -0.9847748279571533, 0.9935972690582275, -0.5975158214569092, 0.9557573795318604, 0.41234254837036133, -0.26670074462890625, 0.869682788848877, 0.4443938732147217, -0.13968205451965332, -0.7745835781097412, -0.5692052841186523, 0.321591854095459, -0.3146944046020508, -0.3921670913696289, -0.36029601097106934, 0.33528995513916016, 0.029220104217529297, -0.8788590431213379, 0.6883881092071533, -0.8260040283203125, -0.43041515350341797, 0.42810845375061035, 0.40050792694091797], [0.6319584846496582, 0.32369279861450195, -0.6308813095092773, 0.07861590385437012, 0.5387494564056396, -0.902024507522583, -0.5346510410308838, 0.10787153244018555, 0.36048197746276855, 0.7801573276519775, -0.39187049865722656, 0.409869909286499, 0.5972449779510498, -0.7578165531158447, 0.30403685569763184, -0.7885205745697021, 0.01341390609741211, -0.023469209671020508, -0.11588907241821289, -0.941727876663208, -0.09618496894836426, 0.8042230606079102, 0.4683551788330078, -0.6497313976287842, 0.7443571090698242, 0.7150907516479492, -0.5759801864624023, -0.6523513793945312], [0.3150167465209961, -0.1853046417236328, 0.1839759349822998, -0.9234504699707031, -0.666614294052124, -0.740748405456543, 0.5700008869171143, 0.4091987609863281, -0.8912513256072998, 0.027419567108154297, 0.07219696044921875, -0.3128829002380371, 0.9465951919555664, 0.8715424537658691, -0.4559173583984375, -0.5862705707550049, -0.6734106540679932, 0.8419013023376465, -0.5523068904876709, -0.5019669532775879, -0.4969966411590576, -0.030994892120361328, 0.7572557926177979, 0.3824281692504883, 0.6366133689880371, -0.13271117210388184, 0.632627010345459, -0.9462625980377197], [-0.3923935890197754, 0.5466675758361816, -0.9815363883972168, -0.12867975234985352, 0.9932572841644287, -0.712486743927002, -0.17107725143432617, -0.41582536697387695, 0.10990118980407715, 0.11867499351501465, -0.7774863243103027, -0.9382553100585938, 0.4290587902069092, -0.1412363052368164, -0.498490571975708, 0.7793624401092529, 0.9015710353851318, -0.5107312202453613, 0.12394595146179199, 0.4988982677459717, -0.5731511116027832, -0.8105146884918213, 0.19758391380310059, 0.4081540107727051, -0.20432400703430176, 0.9924988746643066, -0.16952204704284668, 0.45574188232421875], [-0.023319005966186523, -0.3514130115509033, 0.4652390480041504, 0.7690563201904297, 0.7906622886657715, 0.9922001361846924, -0.6670932769775391, -0.5720524787902832, 0.3491201400756836, -0.18706512451171875, 0.4899415969848633, -0.5637645721435547, 0.8986928462982178, -0.7359066009521484, -0.6342356204986572, 0.6608924865722656, 0.6014213562011719, 0.7906208038330078, 0.19034814834594727, 0.16884255409240723, -0.8803558349609375, 0.4060337543487549, 0.9862797260284424, -0.48758840560913086, 0.3894319534301758, 0.4226539134979248, 0.00042724609375, -0.3623659610748291], [0.7065057754516602, -0.4103825092315674, 0.3343489170074463, -0.9341757297515869, -0.20749878883361816, -0.3589310646057129, -0.9470062255859375, 0.7851138114929199, -0.74678635597229, -0.05102086067199707, 0.16727972030639648, 0.12385678291320801, -0.41132497787475586, 0.5856695175170898, 0.06311273574829102, 0.8238284587860107, 0.2257852554321289, -0.6452250480651855, -0.6373245716094971, -0.1247873306274414, 0.0021851062774658203, -0.5648598670959473, 0.8261771202087402, 0.3713812828063965, -0.7185893058776855, 0.45911359786987305, 0.6722264289855957, -0.31804966926574707], [-0.2952606678009033, -0.12052011489868164, 0.9074821472167969, -0.9850583076477051, 0.6732273101806641, 0.7954013347625732, 0.938248872756958, -0.35915136337280273, -0.8291504383087158, 0.6020793914794922, -0.30096912384033203, 0.6136975288391113, 0.46443629264831543, -0.9057025909423828, 0.43993186950683594, -0.11653375625610352, 0.9514555931091309, 0.7985148429870605, -0.6911783218383789, -0.931948184967041, 0.06829452514648438, 0.711458683013916, 0.17953252792358398, 0.19076848030090332, 0.6339912414550781, -0.38822221755981445, 0.09893226623535156, -0.7663829326629639], [0.2640511989593506, 0.16821074485778809, 0.9845118522644043, 0.13789963722229004, -0.1097862720489502, 0.24889636039733887, 0.12135696411132812, 0.4419589042663574, -0.022361040115356445, 0.3793671131134033, 0.7053709030151367, 0.5814387798309326, 0.24962759017944336, -0.40136122703552246, -0.364804744720459, -0.2518625259399414, 0.25757312774658203, 0.6828348636627197, -0.08237361907958984, -0.07745933532714844, -0.9299273490905762, -0.3066704273223877, 0.22127842903137207, -0.6690163612365723, 0.7477891445159912, 0.5738682746887207, -0.9027633666992188, 0.33333301544189453], [0.44417595863342285, 0.5279359817504883, 0.36589932441711426, -0.049490928649902344, -0.3003063201904297, 0.8447706699371338, 0.8139019012451172, -0.4958505630493164, -0.3640005588531494, -0.7731854915618896, 0.4138674736022949, 0.3080577850341797, -0.5615301132202148, -0.4247474670410156, -0.25992918014526367, -0.7983508110046387, -0.4926283359527588, 0.08595061302185059, 0.9205574989318848, 0.6025278568267822, 0.37128734588623047, -0.1856670379638672, 0.9658422470092773, -0.6652145385742188, -0.2217710018157959, 0.8311929702758789, 0.9117603302001953, 0.4660191535949707], [-0.6164810657501221, -0.9509942531585693, 0.30228447914123535, 0.39792585372924805, -0.45194506645202637, -0.3315877914428711, 0.5393261909484863, 0.030223369598388672, 0.6013507843017578, 0.020318031311035156, 0.17352747917175293, -0.25470709800720215, -0.7904071807861328, 0.5383470058441162, -0.43855953216552734, -0.350492000579834, -0.5038156509399414, 0.0511777400970459, 0.9628784656524658, -0.520085334777832, 0.33083176612854004, 0.3698580265045166, 0.9121549129486084, -0.664802074432373, -0.45629024505615234, -0.44208550453186035, 0.6502475738525391, -0.597346305847168], [-0.5405080318450928, 0.2640984058380127, -0.2119138240814209, 0.04504036903381348, -0.10604047775268555, -0.8093295097351074, 0.20915007591247559, 0.08994936943054199, 0.5347979068756104, -0.550915002822876, 0.3008608818054199, 0.2416989803314209, 0.025292158126831055, -0.2790646553039551, 0.5850257873535156, 0.7020430564880371, -0.9527721405029297, 0.8273317813873291, -0.8028199672698975, 0.3686351776123047, -0.9391682147979736, -0.4261181354522705, 0.1674947738647461, 0.27993154525756836, 0.7567532062530518, 0.9245085716247559, 0.9245762825012207, -0.296356201171875], [-0.7747671604156494, 0.7632861137390137, 0.10236740112304688, 0.14044547080993652, 0.9318621158599854, -0.5622165203094482, -0.6605725288391113, -0.8286299705505371, 0.8717818260192871, -0.22177672386169434, -0.6030778884887695, 0.20917797088623047, 0.31551361083984375, 0.7741527557373047, -0.3320643901824951, -0.9014863967895508, 0.44268250465393066, 0.25649309158325195, -0.5621528625488281, -0.6077632904052734, 0.21485304832458496, -0.658627986907959, -0.9116294384002686, -0.294114351272583, 0.0452420711517334, 0.8542745113372803, 0.7148771286010742, 0.3244490623474121]]
+# pylint: enable=line-too-long
+
+
+def real_digit():
+ return tf.expand_dims(tf.expand_dims(REAL_DIGIT, 0), -1)
+
+
+def fake_digit():
+ return tf.expand_dims(tf.expand_dims(FAKE_DIGIT, 0), -1)
+
+
+def one_hot_real():
+ return tf.constant(ONE_HOT)
+
+
+def one_hot1():
+ return tf.constant([[1.0] + [0.0] * 9])
+
+
+class MnistScoreTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ mscore = util.mnist_score(inputs)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(mscore, feed_dict={inputs: np.zeros([batch_size, 28, 28, 1])})
+
+ def test_deterministic(self):
+ m_score = util.mnist_score(real_digit())
+ with self.test_session():
+ m_score1 = m_score.eval()
+ m_score2 = m_score.eval()
+ self.assertEqual(m_score1, m_score2)
+
+ with self.test_session():
+ m_score3 = m_score.eval()
+ self.assertEqual(m_score1, m_score3)
+
+ def test_single_example_correct(self):
+ real_score = util.mnist_score(real_digit())
+ fake_score = util.mnist_score(fake_digit())
+ with self.test_session():
+ self.assertNear(1.0, real_score.eval(), 1e-6)
+ self.assertNear(1.0, fake_score.eval(), 1e-6)
+
+ def test_minibatch_correct(self):
+ mscore = util.mnist_score(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0))
+ with self.test_session():
+ self.assertNear(1.612828, mscore.eval(), 1e-6)
+
+ def test_batch_splitting_doesnt_change_value(self):
+ for num_batches in [1, 2, 4, 8]:
+ mscore = util.mnist_score(
+ tf.concat([real_digit()] * 4 + [fake_digit()] * 4, 0),
+ num_batches=num_batches)
+ with self.test_session():
+ self.assertNear(1.649209, mscore.eval(), 1e-6)
+
+
+class MnistFrechetDistanceTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ fdistance = util.mnist_frechet_distance(inputs, inputs)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(fdistance,
+ feed_dict={inputs: np.zeros([batch_size, 28, 28, 1])})
+
+ def test_deterministic(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 2, 0),
+ tf.concat([fake_digit()] * 2, 0))
+ with self.test_session():
+ fdistance1 = fdistance.eval()
+ fdistance2 = fdistance.eval()
+ self.assertNear(fdistance1, fdistance2, 2e-1)
+
+ with self.test_session():
+ fdistance3 = fdistance.eval()
+ self.assertNear(fdistance1, fdistance3, 2e-1)
+
+ def test_single_example_correct(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 2, 0),
+ tf.concat([real_digit()] * 2, 0))
+ with self.test_session():
+ self.assertNear(0.0, fdistance.eval(), 2e-1)
+
+ def test_minibatch_correct(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0),
+ tf.concat([real_digit(), fake_digit(), fake_digit()], 0))
+ with self.test_session():
+ self.assertNear(43.5, fdistance.eval(), 2e-1)
+
+ def test_batch_splitting_doesnt_change_value(self):
+ for num_batches in [1, 2, 4, 8]:
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 6 + [fake_digit()] * 2, 0),
+ tf.concat([real_digit()] * 2 + [fake_digit()] * 6, 0),
+ num_batches=num_batches)
+ with self.test_session():
+ self.assertNear(97.8, fdistance.eval(), 2e-1)
+
+
+class MnistCrossEntropyTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ num_classes = 10
+ one_label = np.array([[1] + [0] * (num_classes - 1)])
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ one_hot_label = tf.placeholder(tf.int32, shape=[None, num_classes])
+ entropy = util.mnist_cross_entropy(inputs, one_hot_label)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(entropy, feed_dict={
+ inputs: np.zeros([batch_size, 28, 28, 1]),
+ one_hot_label: np.concatenate([one_label] * batch_size)})
+
+ def test_deterministic(self):
+ xent = util.mnist_cross_entropy(real_digit(), one_hot_real())
+ with self.test_session():
+ ent1 = xent.eval()
+ ent2 = xent.eval()
+ self.assertEqual(ent1, ent2)
+
+ with self.test_session():
+ ent3 = xent.eval()
+ self.assertEqual(ent1, ent3)
+
+ def test_single_example_correct(self):
+ # The correct label should have low cross entropy.
+ correct_xent = util.mnist_cross_entropy(real_digit(), one_hot_real())
+ # The incorrect label should have high cross entropy.
+ wrong_xent = util.mnist_cross_entropy(real_digit(), one_hot1())
+ # A random digit should have medium cross entropy for any label.
+ fake_xent1 = util.mnist_cross_entropy(fake_digit(), one_hot_real())
+ fake_xent6 = util.mnist_cross_entropy(fake_digit(), one_hot1())
+ with self.test_session():
+ self.assertNear(0.00996, correct_xent.eval(), 1e-5)
+ self.assertNear(18.63073, wrong_xent.eval(), 1e-5)
+ self.assertNear(2.2, fake_xent1.eval(), 1e-1)
+ self.assertNear(2.2, fake_xent6.eval(), 1e-1)
+
+ def test_minibatch_correct(self):
+ # Reorded minibatches should have the same value.
+ xent1 = util.mnist_cross_entropy(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0),
+ tf.concat([one_hot_real(), one_hot1(), one_hot1()], 0))
+ xent2 = util.mnist_cross_entropy(
+ tf.concat([real_digit(), fake_digit(), real_digit()], 0),
+ tf.concat([one_hot_real(), one_hot1(), one_hot1()], 0))
+ with self.test_session():
+ self.assertNear(6.972539, xent1.eval(), 1e-5)
+ self.assertNear(xent1.eval(), xent2.eval(), 1e-5)
+
+
+class GetNoiseTest(tf.test.TestCase):
+
+ def test_get_noise_categorical_syntax(self):
+ util.get_eval_noise_categorical(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_noise_continuous_dim1_syntax(self):
+ util.get_eval_noise_continuous_dim1(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_noise_continuous_dim2_syntax(self):
+ util.get_eval_noise_continuous_dim2(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_infogan_syntax(self):
+ util.get_infogan_noise(
+ batch_size=4,
+ categorical_dim=10,
+ structured_continuous_dim=3,
+ total_continuous_noise_dims=62)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh"
new file mode 100644
index 00000000..fcc5131f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh"
@@ -0,0 +1,65 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the MNIST dataset.
+# 2. Trains an unconditional model on the MNIST training set using a
+# tf.Estimator.
+# 3. Evaluates the models and writes sample images to disk.
+#
+#
+# Usage:
+# cd models/research/gan/mnist_estimator
+# ./launch_jobs.sh ${git_repo}
+set -e
+
+# Location of the git repository.
+git_repo=$1
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/mnist-estimator
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/mnist-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/gan:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=mnist \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+NUM_STEPS=1600
+Banner "Starting training GANEstimator ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/mnist_estimator/train.py" \
+ --max_number_of_steps=${NUM_STEPS} \
+ --eval_dir=${EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --alsologtostderr
+Banner "Finished training GANEstimator ${NUM_STEPS} steps. See ${EVAL_DIR} for output images."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py"
new file mode 100644
index 00000000..d2c8ea34
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py"
@@ -0,0 +1,109 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a GANEstimator on MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+import scipy.misc
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+
+from mnist import data_provider
+from mnist import networks
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_integer('batch_size', 32,
+ 'The number of images in each train batch.')
+
+flags.DEFINE_integer('max_number_of_steps', 20000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'noise_dims', 64, 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist-estimator/',
+ 'Directory where the results are saved to.')
+
+FLAGS = flags.FLAGS
+
+
+def _get_train_input_fn(batch_size, noise_dims, dataset_dir=None,
+ num_threads=4):
+ def train_input_fn():
+ with tf.device('/cpu:0'):
+ images, _, _ = data_provider.provide_data(
+ 'train', batch_size, dataset_dir, num_threads=num_threads)
+ noise = tf.random_normal([batch_size, noise_dims])
+ return noise, images
+ return train_input_fn
+
+
+def _get_predict_input_fn(batch_size, noise_dims):
+ def predict_input_fn():
+ noise = tf.random_normal([batch_size, noise_dims])
+ return noise
+ return predict_input_fn
+
+
+def _unconditional_generator(noise, mode):
+ """MNIST generator with extra argument for tf.Estimator's `mode`."""
+ is_training = (mode == tf.estimator.ModeKeys.TRAIN)
+ return networks.unconditional_generator(noise, is_training=is_training)
+
+
+def main(_):
+ # Initialize GANEstimator with options and hyperparameters.
+ gan_estimator = tfgan.estimator.GANEstimator(
+ generator_fn=_unconditional_generator,
+ discriminator_fn=networks.unconditional_discriminator,
+ generator_loss_fn=tfgan.losses.wasserstein_generator_loss,
+ discriminator_loss_fn=tfgan.losses.wasserstein_discriminator_loss,
+ generator_optimizer=tf.train.AdamOptimizer(0.001, 0.5),
+ discriminator_optimizer=tf.train.AdamOptimizer(0.0001, 0.5),
+ add_summaries=tfgan.estimator.SummaryType.IMAGES)
+
+ # Train estimator.
+ train_input_fn = _get_train_input_fn(
+ FLAGS.batch_size, FLAGS.noise_dims, FLAGS.dataset_dir)
+ gan_estimator.train(train_input_fn, max_steps=FLAGS.max_number_of_steps)
+
+ # Run inference.
+ predict_input_fn = _get_predict_input_fn(36, FLAGS.noise_dims)
+ prediction_iterable = gan_estimator.predict(predict_input_fn)
+ predictions = [prediction_iterable.next() for _ in xrange(36)]
+
+ # Nicely tile.
+ image_rows = [np.concatenate(predictions[i:i+6], axis=0) for i in
+ range(0, 36, 6)]
+ tiled_image = np.concatenate(image_rows, axis=1)
+
+ # Write to disk.
+ if not tf.gfile.Exists(FLAGS.eval_dir):
+ tf.gfile.MakeDirs(FLAGS.eval_dir)
+ scipy.misc.imsave(os.path.join(FLAGS.eval_dir, 'unconditional_gan.png'),
+ np.squeeze(tiled_image, axis=2))
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py"
new file mode 100644
index 00000000..5bec5db6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py"
@@ -0,0 +1,52 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist_estimator.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase):
+
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ def test_full_flow(self, mock_data_provider):
+ FLAGS.eval_dir = self.get_temp_dir()
+ FLAGS.batch_size = 16
+ FLAGS.max_number_of_steps = 2
+ FLAGS.noise_dims = 3
+
+ # Construct mock inputs.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ mock_data_provider.provide_data.return_value = (mock_imgs, mock_lbls, None)
+
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh"
new file mode 100644
index 00000000..9302b99b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh"
@@ -0,0 +1,74 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the Imagenet dataset.
+# 2. Trains image compression model on patches from Imagenet.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# Usage:
+# cd models/research/gan/image_compression
+# ./launch_jobs.sh ${weight_factor} ${git_repo}
+set -e
+
+# Weight of the adversarial loss.
+weight_factor=$1
+if [[ "$weight_factor" == "" ]]; then
+ echo "'weight_factor' must not be empty."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/compression-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/compression-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/imagenet-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim:$git_repo/research/slim/nets
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+bazel build "${git_repo}/research/slim:download_and_convert_imagenet"
+"./bazel-bin/download_and_convert_imagenet" ${DATASET_DIR}
+
+# Run the pix2pix model.
+NUM_STEPS=10000
+MODEL_TRAIN_DIR="${TRAIN_DIR}/wt${weight_factor}"
+Banner "Starting training an image compression model for ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/image_compression/train.py" \
+ --train_log_dir=${MODEL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --weight_factor=${weight_factor} \
+ --alsologtostderr
+Banner "Finished training pix2pix model ${NUM_STEPS} steps."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py"
new file mode 100644
index 00000000..3a59d41a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py"
@@ -0,0 +1,61 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN Pix2Pix example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import cyclegan
+from slim.nets import pix2pix
+
+
+def generator(input_images):
+ """Thin wrapper around CycleGAN generator to conform to the TFGAN API.
+
+ Args:
+ input_images: A batch of images to translate. Images should be normalized
+ already. Shape is [batch, height, width, channels].
+
+ Returns:
+ Returns generated image batch.
+
+ Raises:
+ ValueError: If shape of last dimension (channels) is not defined.
+ """
+ input_images.shape.assert_has_rank(4)
+ input_size = input_images.shape.as_list()
+ channels = input_size[-1]
+ if channels is None:
+ raise ValueError(
+ 'Last dimension shape must be known but is None: %s' % input_size)
+ with tf.contrib.framework.arg_scope(cyclegan.cyclegan_arg_scope()):
+ output_images, _ = cyclegan.cyclegan_generator_resnet(input_images,
+ num_outputs=channels)
+ return output_images
+
+
+def discriminator(image_batch, unused_conditioning=None):
+ """A thin wrapper around the Pix2Pix discriminator to conform to TFGAN API."""
+ with tf.contrib.framework.arg_scope(pix2pix.pix2pix_arg_scope()):
+ logits_4d, _ = pix2pix.pix2pix_discriminator(
+ image_batch, num_filters=[64, 128, 256, 512])
+ logits_4d.shape.assert_has_rank(4)
+ # Output of logits is 4D. Reshape to 2D, for TFGAN.
+ logits_2d = tf.contrib.layers.flatten(logits_4d)
+
+ return logits_2d
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py"
new file mode 100644
index 00000000..7b94173a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py"
@@ -0,0 +1,89 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.networks.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import networks
+
+
+class Pix2PixTest(tf.test.TestCase):
+
+ def test_generator_run(self):
+ img_batch = tf.zeros([3, 128, 128, 3])
+ model_output = networks.generator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_graph(self):
+ for shape in ([4, 32, 32], [3, 128, 128], [2, 80, 400]):
+ tf.reset_default_graph()
+ img = tf.ones(shape + [3])
+ output_imgs = networks.generator(img)
+
+ self.assertAllEqual(shape + [3], output_imgs.shape.as_list())
+
+ def test_generator_graph_unknown_batch_dim(self):
+ img = tf.placeholder(tf.float32, shape=[None, 32, 32, 3])
+ output_imgs = networks.generator(img)
+
+ self.assertAllEqual([None, 32, 32, 3], output_imgs.shape.as_list())
+
+ def test_generator_invalid_input(self):
+ with self.assertRaisesRegexp(ValueError, 'must have rank 4'):
+ networks.generator(tf.zeros([28, 28, 3]))
+
+ def test_generator_run_multi_channel(self):
+ img_batch = tf.zeros([3, 128, 128, 5])
+ model_output = networks.generator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_invalid_channels(self):
+ with self.assertRaisesRegexp(
+ ValueError, 'Last dimension shape must be known but is None'):
+ img = tf.placeholder(tf.float32, shape=[4, 32, 32, None])
+ networks.generator(img)
+
+ def test_discriminator_run(self):
+ img_batch = tf.zeros([3, 70, 70, 3])
+ disc_output = networks.discriminator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(disc_output)
+
+ def test_discriminator_graph(self):
+ # Check graph construction for a number of image size/depths and batch
+ # sizes.
+ for batch_size, patch_size in zip([3, 6], [70, 128]):
+ tf.reset_default_graph()
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ disc_output = networks.discriminator(img)
+
+ self.assertEqual(2, disc_output.shape.ndims)
+ self.assertEqual(batch_size, disc_output.shape.as_list()[0])
+
+ def test_discriminator_invalid_input(self):
+ with self.assertRaisesRegexp(ValueError, 'Shape must be rank 4'):
+ networks.discriminator(tf.zeros([28, 28, 3]))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py"
new file mode 100644
index 00000000..2b0d5e36
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py"
@@ -0,0 +1,177 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains an image-to-image translation network with an adversarial loss."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_integer('batch_size', 10, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/pix2pix/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 0.00001,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 0.00001,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 2000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float(
+ 'weight_factor', 0.0,
+ 'How much to weight the adversarial loss relative to pixel loss.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+
+FLAGS = flags.FLAGS
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Get real and distorted images.
+ with tf.device('/cpu:0'), tf.name_scope('inputs'):
+ real_images = data_provider.provide_data(
+ 'train', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+ distorted_images = _distort_images(
+ real_images, downscale_size=int(FLAGS.patch_size / 2),
+ upscale_size=FLAGS.patch_size)
+
+ # Create a GANModel tuple.
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.generator,
+ discriminator_fn=networks.discriminator,
+ real_data=real_images,
+ generator_inputs=distorted_images)
+ tfgan.eval.add_image_comparison_summaries(
+ gan_model, num_comparisons=3, display_diffs=True)
+ tfgan.eval.add_gan_model_image_summaries(gan_model, grid_size=3)
+
+ # Define the GANLoss tuple using standard library functions.
+ with tf.name_scope('losses'):
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.least_squares_generator_loss,
+ discriminator_loss_fn=tfgan.losses.least_squares_discriminator_loss)
+
+ # Define the standard L1 pixel loss.
+ l1_pixel_loss = tf.norm(gan_model.real_data - gan_model.generated_data,
+ ord=1) / FLAGS.patch_size ** 2
+
+ # Modify the loss tuple to include the pixel loss. Add summaries as well.
+ gan_loss = tfgan.losses.combine_adversarial_loss(
+ gan_loss, gan_model, l1_pixel_loss,
+ weight_factor=FLAGS.weight_factor)
+
+ with tf.name_scope('train_ops'):
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ gen_lr, dis_lr = _lr(FLAGS.generator_lr, FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N,
+ transform_grads_fn=tf.contrib.training.clip_gradient_norms_fn(1e3))
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Use GAN train step function if using adversarial loss, otherwise
+ # only train the generator.
+ train_steps = tfgan.GANTrainSteps(
+ generator_train_steps=1,
+ discriminator_train_steps=int(FLAGS.weight_factor > 0))
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+def _optimizer(gen_lr, dis_lr):
+ kwargs = {'beta1': 0.5, 'beta2': 0.999}
+ generator_opt = tf.train.AdamOptimizer(gen_lr, **kwargs)
+ discriminator_opt = tf.train.AdamOptimizer(dis_lr, **kwargs)
+ return generator_opt, discriminator_opt
+
+
+def _lr(gen_lr_base, dis_lr_base):
+ """Return the generator and discriminator learning rates."""
+ gen_lr = tf.train.exponential_decay(
+ learning_rate=gen_lr_base,
+ global_step=tf.train.get_or_create_global_step(),
+ decay_steps=100000,
+ decay_rate=0.8,
+ staircase=True,)
+ dis_lr = dis_lr_base
+
+ return gen_lr, dis_lr
+
+
+def _distort_images(images, downscale_size, upscale_size):
+ downscaled = tf.image.resize_area(images, [downscale_size] * 2)
+ upscaled = tf.image.resize_area(downscaled, [upscale_size] * 2)
+ return upscaled
+
+
+if __name__ == '__main__':
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py"
new file mode 100644
index 00000000..02c6d5b9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py"
@@ -0,0 +1,52 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for pix2pix.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('NoAdversarialLoss', 0.0),
+ ('AdversarialLoss', 1.0))
+ def test_build_graph(self, weight_factor):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.weight_factor = weight_factor
+ FLAGS.batch_size = 9
+ FLAGS.patch_size = 32
+
+ mock_imgs = np.zeros(
+ [FLAGS.batch_size, FLAGS.patch_size, FLAGS.patch_size, 3],
+ dtype=np.float32)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = mock_imgs
+ train.main(None)
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py"
new file mode 100644
index 00000000..6e1563bc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py"
@@ -0,0 +1,189 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Loading and preprocessing image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+
+def normalize_image(image):
+ """Rescales image from range [0, 255] to [-1, 1]."""
+ return (tf.to_float(image) - 127.5) / 127.5
+
+
+def sample_patch(image, patch_height, patch_width, colors):
+ """Crops image to the desired aspect ratio shape and resizes it.
+
+ If the image has shape H x W, crops a square in the center of
+ shape min(H,W) x min(H,W).
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_height: A Python integer. The output images height.
+ patch_width: A Python integer. The output images width.
+ colors: Number of output image channels. Defaults to 3.
+
+ Returns:
+ A 3D `Tensor` of HWC format with shape [patch_height, patch_width, colors].
+ """
+ image_shape = tf.shape(image)
+ h, w = image_shape[0], image_shape[1]
+
+ h_major_target_h = h
+ h_major_target_w = tf.maximum(1, tf.to_int32(
+ (h * patch_width) / patch_height))
+ w_major_target_h = tf.maximum(1, tf.to_int32(
+ (w * patch_height) / patch_width))
+ w_major_target_w = w
+ target_hw = tf.cond(
+ h_major_target_w <= w,
+ lambda: tf.convert_to_tensor([h_major_target_h, h_major_target_w]),
+ lambda: tf.convert_to_tensor([w_major_target_h, w_major_target_w]))
+ # Cut a patch of shape (target_h, target_w).
+ image = tf.image.resize_image_with_crop_or_pad(image, target_hw[0],
+ target_hw[1])
+ # Resize the cropped image to (patch_h, patch_w).
+ image = tf.image.resize_images([image], [patch_height, patch_width])[0]
+ # Force number of channels: repeat the channel dimension enough
+ # number of times and then slice the first `colors` channels.
+ num_repeats = tf.to_int32(tf.ceil(colors / image_shape[2]))
+ image = tf.tile(image, [1, 1, num_repeats])
+ image = tf.slice(image, [0, 0, 0], [-1, -1, colors])
+ image.set_shape([patch_height, patch_width, colors])
+ return image
+
+
+def batch_images(image, patch_height, patch_width, colors, batch_size, shuffle,
+ num_threads):
+ """Creates a batch of images.
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_height: A Python integer. The output images height.
+ patch_width: A Python integer. The output images width.
+ colors: Number of channels.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images.
+ num_threads: Number of prefetching threads.
+
+ Returns:
+ A float `Tensor`s with shape [batch_size, patch_height, patch_width, colors]
+ representing a batch of images.
+ """
+ image = sample_patch(image, patch_height, patch_width, colors)
+ images = None
+ if shuffle:
+ images = tf.train.shuffle_batch(
+ [image],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size,
+ min_after_dequeue=batch_size)
+ else:
+ images = tf.train.batch(
+ [image],
+ batch_size=batch_size,
+ num_threads=1, # no threads so it's deterministic
+ capacity=5 * batch_size)
+ images.set_shape([batch_size, patch_height, patch_width, colors])
+ return images
+
+
+def provide_data(dataset_name='cifar10',
+ split_name='train',
+ dataset_dir,
+ batch_size=32,
+ shuffle=True,
+ num_threads=1,
+ patch_height=32,
+ patch_width=32,
+ colors=3):
+ """Provides a batch of image data from predefined dataset.
+
+ Args:
+ dataset_name: A string of dataset name. Defaults to 'cifar10'.
+ split_name: Either 'train' or 'validation'. Defaults to 'train'.
+ dataset_dir: The directory where the data can be found. If `None`, use
+ default.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_height: A Python integer. The read images height. Defaults to 32.
+ patch_width: A Python integer. The read images width. Defaults to 32.
+ colors: Number of channels. Defaults to 3.
+
+ Returns:
+ A float `Tensor`s with shape [batch_size, patch_height, patch_width, colors]
+ representing a batch of images.
+ """
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = tf.contrib.slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=1,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=shuffle)
+ return batch_images(
+ image=normalize_image(provider.get(['image'])[0]),
+ patch_height=patch_height,
+ patch_width=patch_width,
+ colors=colors,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads)
+
+
+def provide_data_from_image_files(file_pattern,
+ batch_size=32,
+ shuffle=True,
+ num_threads=1,
+ patch_height=32,
+ patch_width=32,
+ colors=3):
+ """Provides a batch of image data from image files.
+
+ Args:
+ file_pattern: A file pattern (glob), or 1D `Tensor` of file patterns.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_height: A Python integer. The read images height. Defaults to 32.
+ patch_width: A Python integer. The read images width. Defaults to 32.
+ colors: Number of channels. Defaults to 3.
+
+ Returns:
+ A float `Tensor` of shape [batch_size, patch_height, patch_width, 3]
+ representing a batch of images.
+ """
+ filename_queue = tf.train.string_input_producer(
+ tf.train.match_filenames_once(file_pattern),
+ shuffle=shuffle,
+ capacity=5 * batch_size)
+ _, image_bytes = tf.WholeFileReader().read(filename_queue)
+ return batch_images(
+ image=normalize_image(tf.image.decode_image(image_bytes)),
+ patch_height=patch_height,
+ patch_width=patch_width,
+ colors=colors,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py"
new file mode 100644
index 00000000..86dc93a6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py"
@@ -0,0 +1,136 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def setUp(self):
+ super(DataProviderTest, self).setUp()
+ self.testdata_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/progressive_gan/testdata/')
+
+ def test_normalize_image(self):
+ image_np = np.asarray([0, 255, 210], dtype=np.uint8)
+ normalized_image = data_provider.normalize_image(tf.constant(image_np))
+ self.assertEqual(normalized_image.dtype, tf.float32)
+ self.assertEqual(normalized_image.shape.as_list(), [3])
+ with self.test_session(use_gpu=True) as sess:
+ normalized_image_np = sess.run(normalized_image)
+ self.assertNDArrayNear(normalized_image_np, [-1, 1, 0.6470588235], 1.0e-6)
+
+ def test_sample_patch_large_patch_returns_upscaled_image(self):
+ image_np = np.reshape(np.arange(2 * 2), [2, 2, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ image_patch = data_provider.sample_patch(
+ image, patch_height=3, patch_width=3, colors=1)
+ with self.test_session(use_gpu=True) as sess:
+ image_patch_np = sess.run(image_patch)
+ expected_np = np.asarray([[[0.], [0.66666669], [1.]], [[1.33333337], [2.],
+ [2.33333349]],
+ [[2.], [2.66666675], [3.]]])
+ self.assertNDArrayNear(image_patch_np, expected_np, 1.0e-6)
+
+ def test_sample_patch_small_patch_returns_downscaled_image(self):
+ image_np = np.reshape(np.arange(3 * 3), [3, 3, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ image_patch = data_provider.sample_patch(
+ image, patch_height=2, patch_width=2, colors=1)
+ with self.test_session(use_gpu=True) as sess:
+ image_patch_np = sess.run(image_patch)
+ expected_np = np.asarray([[[0.], [1.5]], [[4.5], [6.]]])
+ self.assertNDArrayNear(image_patch_np, expected_np, 1.0e-6)
+
+ def test_batch_images(self):
+ image_np = np.reshape(np.arange(3 * 3), [3, 3, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ images = data_provider.batch_images(
+ image,
+ patch_height=2,
+ patch_width=2,
+ colors=1,
+ batch_size=2,
+ shuffle=False,
+ num_threads=1)
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ expected_np = np.asarray([[[[0.], [1.5]], [[4.5], [6.]]], [[[0.], [1.5]],
+ [[4.5], [6.]]]])
+ self.assertNDArrayNear(images_np, expected_np, 1.0e-6)
+
+ def test_provide_data(self):
+ images = data_provider.provide_data(
+ 'mnist',
+ 'train',
+ dataset_dir=self.testdata_dir,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+ def test_provide_data_from_image_files_a_single_pattern(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ images = data_provider.provide_data_from_image_files(
+ file_pattern,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+ def test_provide_data_from_image_files_a_list_of_patterns(self):
+ file_pattern = [os.path.join(self.testdata_dir, '*.jpg')]
+ images = data_provider.provide_data_from_image_files(
+ file_pattern,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py"
new file mode 100644
index 00000000..5bf0d804
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py"
@@ -0,0 +1,293 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Layers for a progressive GAN model.
+
+This module contains basic building blocks to build a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+
+def pixel_norm(images, epsilon=1.0e-8):
+ """Pixel normalization.
+
+ For each pixel a[i,j,k] of image in HWC format, normalize its value to
+ b[i,j,k] = a[i,j,k] / SQRT(SUM_k(a[i,j,k]^2) / C + eps).
+
+ Args:
+ images: A 4D `Tensor` of NHWC format.
+ epsilon: A small positive number to avoid division by zero.
+
+ Returns:
+ A 4D `Tensor` with pixel-wise normalized channels.
+ """
+ return images * tf.rsqrt(
+ tf.reduce_mean(tf.square(images), axis=3, keepdims=True) + epsilon)
+
+
+def _get_validated_scale(scale):
+ """Returns the scale guaranteed to be a positive integer."""
+ scale = int(scale)
+ if scale <= 0:
+ raise ValueError('`scale` must be a positive integer.')
+ return scale
+
+
+def downscale(images, scale):
+ """Box downscaling of images.
+
+ Args:
+ images: A 4D `Tensor` in NHWC format.
+ scale: A positive integer scale.
+
+ Returns:
+ A 4D `Tensor` of `images` down scaled by a factor `scale`.
+
+ Raises:
+ ValueError: If `scale` is not a positive integer.
+ """
+ scale = _get_validated_scale(scale)
+ if scale == 1:
+ return images
+ return tf.nn.avg_pool(
+ images,
+ ksize=[1, scale, scale, 1],
+ strides=[1, scale, scale, 1],
+ padding='VALID')
+
+
+def upscale(images, scale):
+ """Box upscaling (also called nearest neighbors) of images.
+
+ Args:
+ images: A 4D `Tensor` in NHWC format.
+ scale: A positive integer scale.
+
+ Returns:
+ A 4D `Tensor` of `images` up scaled by a factor `scale`.
+
+ Raises:
+ ValueError: If `scale` is not a positive integer.
+ """
+ scale = _get_validated_scale(scale)
+ if scale == 1:
+ return images
+ return tf.batch_to_space(
+ tf.tile(images, [scale**2, 1, 1, 1]),
+ crops=[[0, 0], [0, 0]],
+ block_size=scale)
+
+
+def minibatch_mean_stddev(x):
+ """Computes the standard deviation average.
+
+ This is used by the discriminator as a form of batch discrimination.
+
+ Args:
+ x: A `Tensor` for which to compute the standard deviation average. The first
+ dimension must be batch size.
+
+ Returns:
+ A scalar `Tensor` which is the mean variance of variable x.
+ """
+ mean, var = tf.nn.moments(x, axes=[0])
+ del mean
+ return tf.reduce_mean(tf.sqrt(var))
+
+
+def scalar_concat(tensor, scalar):
+ """Concatenates a scalar to the last dimension of a tensor.
+
+ Args:
+ tensor: A `Tensor`.
+ scalar: a scalar `Tensor` to concatenate to tensor `tensor`.
+
+ Returns:
+ A `Tensor`. If `tensor` has shape [...,N], the result R has shape
+ [...,N+1] and R[...,N] = scalar.
+
+ Raises:
+ ValueError: If `tensor` is a scalar `Tensor`.
+ """
+ ndims = tensor.shape.ndims
+ if ndims < 1:
+ raise ValueError('`tensor` must have number of dimensions >= 1.')
+ shape = tf.shape(tensor)
+ return tf.concat(
+ [tensor, tf.ones([shape[i] for i in range(ndims - 1)] + [1]) * scalar],
+ axis=ndims - 1)
+
+
+def he_initializer_scale(shape, slope=1.0):
+ """The scale of He neural network initializer.
+
+ Args:
+ shape: A list of ints representing the dimensions of a tensor.
+ slope: A float representing the slope of the ReLu following the layer.
+
+ Returns:
+ A float of he initializer scale.
+ """
+ fan_in = np.prod(shape[:-1])
+ return np.sqrt(2. / ((1. + slope**2) * fan_in))
+
+
+def _custom_layer_impl(apply_kernel, kernel_shape, bias_shape, activation,
+ he_initializer_slope, use_weight_scaling):
+ """Helper function to implement custom_xxx layer.
+
+ Args:
+ apply_kernel: A function that transforms kernel to output.
+ kernel_shape: An integer tuple or list of the kernel shape.
+ bias_shape: An integer tuple or list of the bias shape.
+ activation: An activation function to be applied. None means no
+ activation.
+ he_initializer_slope: A float slope for the He initializer.
+ use_weight_scaling: Whether to apply weight scaling.
+
+ Returns:
+ A `Tensor` computed as apply_kernel(kernel) + bias where kernel is a
+ `Tensor` variable with shape `kernel_shape`, bias is a `Tensor` variable
+ with shape `bias_shape`.
+ """
+ kernel_scale = he_initializer_scale(kernel_shape, he_initializer_slope)
+ init_scale, post_scale = kernel_scale, 1.0
+ if use_weight_scaling:
+ init_scale, post_scale = post_scale, init_scale
+
+ kernel_initializer = tf.random_normal_initializer(stddev=init_scale)
+
+ bias = tf.get_variable(
+ 'bias', shape=bias_shape, initializer=tf.zeros_initializer())
+
+ output = post_scale * apply_kernel(kernel_shape, kernel_initializer) + bias
+
+ if activation is not None:
+ output = activation(output)
+ return output
+
+
+def custom_conv2d(x,
+ filters,
+ kernel_size,
+ strides=(1, 1),
+ padding='SAME',
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True,
+ scope='custom_conv2d',
+ reuse=None):
+ """Custom conv2d layer.
+
+ In comparison with tf.layers.conv2d this implementation use the He initializer
+ to initialize convolutional kernel and the weight scaling trick (if
+ `use_weight_scaling` is True) to equalize learning rates. See
+ https://arxiv.org/abs/1710.10196 for more details.
+
+ Args:
+ x: A `Tensor` of NHWC format.
+ filters: An int of output channels.
+ kernel_size: An integer or a int tuple of [kernel_height, kernel_width].
+ strides: A list of strides.
+ padding: One of "VALID" or "SAME".
+ activation: An activation function to be applied. None means no
+ activation. Defaults to None.
+ he_initializer_slope: A float slope for the He initializer. Defaults to 1.0.
+ use_weight_scaling: Whether to apply weight scaling. Defaults to True.
+ scope: A string or variable scope.
+ reuse: Whether to reuse the weights. Defaults to None.
+
+ Returns:
+ A `Tensor` of NHWC format where the last dimension has size `filters`.
+ """
+ if not isinstance(kernel_size, (list, tuple)):
+ kernel_size = [kernel_size] * 2
+ kernel_size = list(kernel_size)
+
+ def _apply_kernel(kernel_shape, kernel_initializer):
+ return tf.layers.conv2d(
+ x,
+ filters=filters,
+ kernel_size=kernel_shape[0:2],
+ strides=strides,
+ padding=padding,
+ use_bias=False,
+ kernel_initializer=kernel_initializer)
+
+ with tf.variable_scope(scope, reuse=reuse):
+ return _custom_layer_impl(
+ _apply_kernel,
+ kernel_shape=kernel_size + [x.shape.as_list()[3], filters],
+ bias_shape=(filters,),
+ activation=activation,
+ he_initializer_slope=he_initializer_slope,
+ use_weight_scaling=use_weight_scaling)
+
+
+def custom_dense(x,
+ units,
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True,
+ scope='custom_dense',
+ reuse=None):
+ """Custom dense layer.
+
+ In comparison with tf.layers.dense This implementation use the He
+ initializer to initialize weights and the weight scaling trick
+ (if `use_weight_scaling` is True) to equalize learning rates. See
+ https://arxiv.org/abs/1710.10196 for more details.
+
+ Args:
+ x: A `Tensor`.
+ units: An int of the last dimension size of output.
+ activation: An activation function to be applied. None means no
+ activation. Defaults to None.
+ he_initializer_slope: A float slope for the He initializer. Defaults to 1.0.
+ use_weight_scaling: Whether to apply weight scaling. Defaults to True.
+ scope: A string or variable scope.
+ reuse: Whether to reuse the weights. Defaults to None.
+
+ Returns:
+ A `Tensor` where the last dimension has size `units`.
+ """
+ x = tf.contrib.layers.flatten(x)
+
+ def _apply_kernel(kernel_shape, kernel_initializer):
+ return tf.layers.dense(
+ x,
+ kernel_shape[1],
+ use_bias=False,
+ kernel_initializer=kernel_initializer)
+
+ with tf.variable_scope(scope, reuse=reuse):
+ return _custom_layer_impl(
+ _apply_kernel,
+ kernel_shape=(x.shape.as_list()[-1], units),
+ bias_shape=(units,),
+ activation=activation,
+ he_initializer_slope=he_initializer_slope,
+ use_weight_scaling=use_weight_scaling)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py"
new file mode 100644
index 00000000..73d8fecf
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py"
@@ -0,0 +1,282 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+import layers
+
+mock = tf.test.mock
+
+
+def dummy_apply_kernel(kernel_shape, kernel_initializer):
+ kernel = tf.get_variable(
+ 'kernel', shape=kernel_shape, initializer=kernel_initializer)
+ return tf.reduce_sum(kernel) + 1.5
+
+
+class LayersTest(tf.test.TestCase):
+
+ def test_pixel_norm_4d_images_returns_channel_normalized_images(self):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.pixel_norm(x))
+
+ expected_np = [[[[0.46291006, 0.92582011, 1.38873017],
+ [0.78954202, 0.98692751, 1.18431306]],
+ [[0.87047803, 0.99483204, 1.11918604],
+ [0.90659684, 0.99725652, 1.08791625]]],
+ [[[0., 0., 0.], [-0.46291006, -0.92582011, -1.38873017]],
+ [[0.57735026, -1.15470052, 1.15470052],
+ [0.56195146, 1.40487862, 0.84292722]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ def test_get_validated_scale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers._get_validated_scale(0)
+
+ def test_get_validated_scale_float_scale_returns_integer(self):
+ self.assertEqual(layers._get_validated_scale(5.5), 5)
+
+ def test_downscale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers.downscale(tf.constant([]), -1)
+
+ def test_downscale_4d_images_returns_downscaled_images(self):
+ x_np = np.array(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=np.float32)
+ with self.test_session(use_gpu=True) as sess:
+ x1_np, x2_np = sess.run(
+ [layers.downscale(tf.constant(x_np), n) for n in [1, 2]])
+
+ expected2_np = [[[[5.5, 6.5, 7.5]]], [[[0.5, 0.25, 0.5]]]]
+
+ self.assertNDArrayNear(x1_np, x_np, 1.0e-5)
+ self.assertNDArrayNear(x2_np, expected2_np, 1.0e-5)
+
+ def test_upscale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ self.assertRaises(layers.upscale(tf.constant([]), -1))
+
+ def test_upscale_4d_images_returns_upscaled_images(self):
+ x_np = np.array([[[[1, 2, 3]]], [[[4, 5, 6]]]], dtype=np.float32)
+ with self.test_session(use_gpu=True) as sess:
+ x1_np, x2_np = sess.run(
+ [layers.upscale(tf.constant(x_np), n) for n in [1, 2]])
+
+ expected2_np = [[[[1, 2, 3], [1, 2, 3]], [[1, 2, 3], [1, 2, 3]]],
+ [[[4, 5, 6], [4, 5, 6]], [[4, 5, 6], [4, 5, 6]]]]
+
+ self.assertNDArrayNear(x1_np, x_np, 1.0e-5)
+ self.assertNDArrayNear(x2_np, expected2_np, 1.0e-5)
+
+ def test_minibatch_mean_stddev_4d_images_returns_scalar(self):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.minibatch_mean_stddev(x))
+
+ self.assertAlmostEqual(output_np, 3.0416667, 5)
+
+ def test_scalar_concat_invalid_input_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers.scalar_concat(tf.constant(1.2), 2.0)
+
+ def test_scalar_concat_4d_images_and_scalar(self):
+ x = tf.constant(
+ [[[[1, 2], [4, 5]], [[7, 8], [10, 11]]], [[[0, 0], [-1, -2]],
+ [[1, -2], [2, 5]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.scalar_concat(x, 7))
+
+ expected_np = [[[[1, 2, 7], [4, 5, 7]], [[7, 8, 7], [10, 11, 7]]],
+ [[[0, 0, 7], [-1, -2, 7]], [[1, -2, 7], [2, 5, 7]]]]
+
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ def test_he_initializer_scale_slope_linear(self):
+ self.assertAlmostEqual(
+ layers.he_initializer_scale([3, 4, 5, 6], 1.0), 0.1290994, 5)
+
+ def test_he_initializer_scale_slope_relu(self):
+ self.assertAlmostEqual(
+ layers.he_initializer_scale([3, 4, 5, 6], 0.0), 0.1825742, 5)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_layer_impl_with_weight_scaling(
+ self, mock_zeros_initializer, mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ output = layers._custom_layer_impl(
+ apply_kernel=dummy_apply_kernel,
+ kernel_shape=(25, 6),
+ bias_shape=(),
+ activation=lambda x: 2.0 * x,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+ mock_zeros_initializer.assert_called_once_with()
+ mock_random_normal_initializer.assert_called_once_with(stddev=1.0)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ self.assertAlmostEqual(output_np, 182.6, 3)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_layer_impl_no_weight_scaling(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ output = layers._custom_layer_impl(
+ apply_kernel=dummy_apply_kernel,
+ kernel_shape=(25, 6),
+ bias_shape=(),
+ activation=lambda x: 2.0 * x,
+ he_initializer_slope=1.0,
+ use_weight_scaling=False)
+ mock_zeros_initializer.assert_called_once_with()
+ mock_random_normal_initializer.assert_called_once_with(stddev=0.2)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ self.assertAlmostEqual(output_np, 905.0, 3)
+
+ @mock.patch.object(tf.layers, 'conv2d', autospec=True)
+ def test_custom_conv2d_passes_conv2d_options(self, mock_conv2d):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_conv2d(x, 1, 2)
+ mock_conv2d.assert_called_once_with(
+ x,
+ filters=1,
+ kernel_size=[2, 2],
+ strides=(1, 1),
+ padding='SAME',
+ use_bias=False,
+ kernel_initializer=mock.ANY)
+
+ @mock.patch.object(layers, '_custom_layer_impl', autospec=True)
+ def test_custom_conv2d_passes_custom_layer_options(self,
+ mock_custom_layer_impl):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_conv2d(x, 1, 2)
+ mock_custom_layer_impl.assert_called_once_with(
+ mock.ANY,
+ kernel_shape=[2, 2, 3, 1],
+ bias_shape=(1,),
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_conv2d_scalar_kernel_size(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_conv2d(x, 1, 2)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[[[68.54998016], [42.56921768]], [[50.36344528],
+ [29.57883835]]],
+ [[[5.33012676], [4.46410179]], [[10.52627945],
+ [9.66025352]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_conv2d_list_kernel_size(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_conv2d(x, 1, [2, 3])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[
+ [[56.15432739], [56.15432739]],
+ [[41.30508804], [41.30508804]],
+ ], [[[4.53553391], [4.53553391]], [[8.7781744], [8.7781744]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ @mock.patch.object(layers, '_custom_layer_impl', autospec=True)
+ def test_custom_dense_passes_custom_layer_options(self,
+ mock_custom_layer_impl):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_dense(x, 3)
+ mock_custom_layer_impl.assert_called_once_with(
+ mock.ANY,
+ kernel_shape=(12, 3),
+ bias_shape=(3,),
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_dense_output_is_correct(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_dense(x, 3)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[68.54998016, 68.54998016, 68.54998016],
+ [5.33012676, 5.33012676, 5.33012676]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py"
new file mode 100644
index 00000000..0561ea65
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py"
@@ -0,0 +1,412 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Generator and discriminator for a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+
+import tensorflow as tf
+
+import layers
+
+
+class ResolutionSchedule(object):
+ """Image resolution upscaling schedule."""
+
+ def __init__(self, start_resolutions=(4, 4), scale_base=2, num_resolutions=4):
+ """Initializer.
+
+ Args:
+ start_resolutions: An tuple of integers of HxW format for start image
+ resolutions. Defaults to (4, 4).
+ scale_base: An integer of resolution base multiplier. Defaults to 2.
+ num_resolutions: An integer of how many progressive resolutions (including
+ `start_resolutions`). Defaults to 4.
+ """
+ self._start_resolutions = start_resolutions
+ self._scale_base = scale_base
+ self._num_resolutions = num_resolutions
+
+ @property
+ def start_resolutions(self):
+ return tuple(self._start_resolutions)
+
+ @property
+ def scale_base(self):
+ return self._scale_base
+
+ @property
+ def num_resolutions(self):
+ return self._num_resolutions
+
+ @property
+ def final_resolutions(self):
+ """Returns the final resolutions."""
+ return tuple([
+ r * self._scale_base**(self._num_resolutions - 1)
+ for r in self._start_resolutions
+ ])
+
+ def scale_factor(self, block_id):
+ """Returns the scale factor for network block `block_id`."""
+ if block_id < 1 or block_id > self._num_resolutions:
+ raise ValueError('`block_id` must be in [1, {}]'.format(
+ self._num_resolutions))
+ return self._scale_base**(self._num_resolutions - block_id)
+
+
+def block_name(block_id):
+ """Returns the scope name for the network block `block_id`."""
+ return 'progressive_gan_block_{}'.format(block_id)
+
+
+def min_total_num_images(stable_stage_num_images, transition_stage_num_images,
+ num_blocks):
+ """Returns the minimum total number of images.
+
+ Computes the minimum total number of images required to reach the desired
+ `resolution`.
+
+ Args:
+ stable_stage_num_images: Number of images in the stable stage.
+ transition_stage_num_images: Number of images in the transition stage.
+ num_blocks: Number of network blocks.
+
+ Returns:
+ An integer of the minimum total number of images.
+ """
+ return (num_blocks * stable_stage_num_images +
+ (num_blocks - 1) * transition_stage_num_images)
+
+
+def compute_progress(current_image_id, stable_stage_num_images,
+ transition_stage_num_images, num_blocks):
+ """Computes the training progress.
+
+ The training alternates between stable phase and transition phase.
+ The `progress` indicates the training progress, i.e. the training is at
+ - a stable phase p if progress = p
+ - a transition stage between p and p + 1 if progress = p + fraction
+ where p = 0,1,2.,...
+
+ Note the max value of progress is `num_blocks` - 1.
+
+ In terms of LOD (of the original implementation):
+ progress = `num_blocks` - 1 - LOD
+
+ Args:
+ current_image_id: An scalar integer `Tensor` of the current image id, count
+ from 0.
+ stable_stage_num_images: An integer representing the number of images in
+ each stable stage.
+ transition_stage_num_images: An integer representing the number of images in
+ each transition stage.
+ num_blocks: Number of network blocks.
+
+ Returns:
+ A scalar float `Tensor` of the training progress.
+ """
+ # Note when current_image_id >= min_total_num_images - 1 (which means we
+ # are already at the highest resolution), we want to keep progress constant.
+ # Therefore, cap current_image_id here.
+ capped_current_image_id = tf.minimum(
+ current_image_id,
+ min_total_num_images(stable_stage_num_images, transition_stage_num_images,
+ num_blocks) - 1)
+
+ stage_num_images = stable_stage_num_images + transition_stage_num_images
+ progress_integer = tf.floordiv(capped_current_image_id, stage_num_images)
+ progress_fraction = tf.maximum(
+ 0.0,
+ tf.to_float(
+ tf.mod(capped_current_image_id, stage_num_images) -
+ stable_stage_num_images) / tf.to_float(transition_stage_num_images))
+ return tf.to_float(progress_integer) + progress_fraction
+
+
+def _generator_alpha(block_id, progress):
+ """Returns the block output parameter for the generator network.
+
+ The generator has N blocks with `block_id` = 1,2,...,N. Each block
+ block_id outputs a fake data output(block_id). The generator output is a
+ linear combination of all block outputs, i.e.
+ SUM_block_id(output(block_id) * alpha(block_id, progress)) where
+ alpha(block_id, progress) = _generator_alpha(block_id, progress). Note it
+ garantees that SUM_block_id(alpha(block_id, progress)) = 1 for any progress.
+
+ With a fixed block_id, the plot of alpha(block_id, progress) against progress
+ is a 'triangle' with its peak at (block_id - 1, 1).
+
+ Args:
+ block_id: An integer of generator block id.
+ progress: A scalar float `Tensor` of training progress.
+
+ Returns:
+ A scalar float `Tensor` of block output parameter.
+ """
+ return tf.maximum(0.0,
+ tf.minimum(progress - (block_id - 2), block_id - progress))
+
+
+def _discriminator_alpha(block_id, progress):
+ """Returns the block input parameter for discriminator network.
+
+ The discriminator has N blocks with `block_id` = 1,2,...,N. Each block
+ block_id accepts an
+ - input(block_id) transformed from the real data and
+ - the output of block block_id + 1, i.e. output(block_id + 1)
+ The final input is a linear combination of them,
+ i.e. alpha * input(block_id) + (1 - alpha) * output(block_id + 1)
+ where alpha = _discriminator_alpha(block_id, progress).
+
+ With a fixed block_id, alpha(block_id, progress) stays to be 1
+ when progress <= block_id - 1, then linear decays to 0 when
+ block_id - 1 < progress <= block_id, and finally stays at 0
+ when progress > block_id.
+
+ Args:
+ block_id: An integer of generator block id.
+ progress: A scalar float `Tensor` of training progress.
+
+ Returns:
+ A scalar float `Tensor` of block input parameter.
+ """
+ return tf.clip_by_value(block_id - progress, 0.0, 1.0)
+
+
+def blend_images(x, progress, resolution_schedule, num_blocks):
+ """Blends images of different resolutions according to `progress`.
+
+ When training `progress` is at a stable stage for resolution r, returns
+ image `x` downscaled to resolution r and then upscaled to `final_resolutions`,
+ call it x'(r).
+
+ Otherwise when training `progress` is at a transition stage from resolution
+ r to 2r, returns a linear combination of x'(r) and x'(2r).
+
+ Args:
+ x: An image `Tensor` of NHWC format with resolution `final_resolutions`.
+ progress: A scalar float `Tensor` of training progress.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks.
+
+ Returns:
+ An image `Tensor` which is a blend of images of different resolutions.
+ """
+ x_blend = []
+ for block_id in range(1, num_blocks + 1):
+ alpha = _generator_alpha(block_id, progress)
+ scale = resolution_schedule.scale_factor(block_id)
+ x_blend.append(alpha * layers.upscale(layers.downscale(x, scale), scale))
+ return tf.add_n(x_blend)
+
+
+def num_filters(block_id, fmap_base=4096, fmap_decay=1.0, fmap_max=256):
+ """Computes number of filters of block `block_id`."""
+ return int(min(fmap_base / math.pow(2.0, block_id * fmap_decay), fmap_max))
+
+
+def generator(z,
+ progress,
+ num_filters_fn,
+ resolution_schedule,
+ num_blocks=None,
+ kernel_size=3,
+ colors=3,
+ to_rgb_activation=None,
+ scope='progressive_gan_generator',
+ reuse=None):
+ """Generator network for the progressive GAN model.
+
+ Args:
+ z: A `Tensor` of latent vector. The first dimension must be batch size.
+ progress: A scalar float `Tensor` of training progress.
+ num_filters_fn: A function that maps `block_id` to # of filters for the
+ block.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks. None means maximum number of
+ blocks, i.e. `resolution.schedule.num_resolutions`. Defaults to None.
+ kernel_size: An integer of convolution kernel size.
+ colors: Number of output color channels. Defaults to 3.
+ to_rgb_activation: Activation function applied when output rgb.
+ scope: A string or variable scope.
+ reuse: Whether to reuse `scope`. Defaults to None which means to inherit
+ the reuse option of the parent scope.
+
+ Returns:
+ A `Tensor` of model output and a dictionary of model end points.
+ """
+ if num_blocks is None:
+ num_blocks = resolution_schedule.num_resolutions
+
+ start_h, start_w = resolution_schedule.start_resolutions
+ final_h, final_w = resolution_schedule.final_resolutions
+
+ def _conv2d(scope, x, kernel_size, filters, padding='SAME'):
+ return layers.custom_conv2d(
+ x=x,
+ filters=filters,
+ kernel_size=kernel_size,
+ padding=padding,
+ activation=lambda x: layers.pixel_norm(tf.nn.leaky_relu(x)),
+ he_initializer_slope=0.0,
+ scope=scope)
+
+ def _to_rgb(x):
+ return layers.custom_conv2d(
+ x=x,
+ filters=colors,
+ kernel_size=1,
+ padding='SAME',
+ activation=to_rgb_activation,
+ scope='to_rgb')
+
+ end_points = {}
+
+ with tf.variable_scope(scope, reuse=reuse):
+ with tf.name_scope('input'):
+ x = tf.contrib.layers.flatten(z)
+ end_points['latent_vector'] = x
+
+ with tf.variable_scope(block_name(1)):
+ x = tf.expand_dims(tf.expand_dims(x, 1), 1)
+ x = layers.pixel_norm(x)
+ # Pad the 1 x 1 image to 2 * (start_h - 1) x 2 * (start_w - 1)
+ # with zeros for the next conv.
+ x = tf.pad(x, [[0] * 2, [start_h - 1] * 2, [start_w - 1] * 2, [0] * 2])
+ # The output is start_h x start_w x num_filters_fn(1).
+ x = _conv2d('conv0', x, (start_h, start_w), num_filters_fn(1), 'VALID')
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(1))
+ lods = [x]
+
+ for block_id in range(2, num_blocks + 1):
+ with tf.variable_scope(block_name(block_id)):
+ x = layers.upscale(x, resolution_schedule.scale_base)
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(block_id))
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(block_id))
+ lods.append(x)
+
+ outputs = []
+ for block_id in range(1, num_blocks + 1):
+ with tf.variable_scope(block_name(block_id)):
+ lod = _to_rgb(lods[block_id - 1])
+ scale = resolution_schedule.scale_factor(block_id)
+ lod = layers.upscale(lod, scale)
+ end_points['upscaled_rgb_{}'.format(block_id)] = lod
+
+ # alpha_i is used to replace lod_select. Note sum(alpha_i) is
+ # garanteed to be 1.
+ alpha = _generator_alpha(block_id, progress)
+ end_points['alpha_{}'.format(block_id)] = alpha
+
+ outputs.append(lod * alpha)
+
+ predictions = tf.add_n(outputs)
+ batch_size = z.shape[0].value
+ predictions.set_shape([batch_size, final_h, final_w, colors])
+ end_points['predictions'] = predictions
+
+ return predictions, end_points
+
+
+def discriminator(x,
+ progress,
+ num_filters_fn,
+ resolution_schedule,
+ num_blocks=None,
+ kernel_size=3,
+ scope='progressive_gan_discriminator',
+ reuse=None):
+ """Discriminator network for the progressive GAN model.
+
+ Args:
+ x: A `Tensor`of NHWC format representing images of size `resolution`.
+ progress: A scalar float `Tensor` of training progress.
+ num_filters_fn: A function that maps `block_id` to # of filters for the
+ block.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks. None means maximum number of
+ blocks, i.e. `resolution.schedule.num_resolutions`. Defaults to None.
+ kernel_size: An integer of convolution kernel size.
+ scope: A string or variable scope.
+ reuse: Whether to reuse `scope`. Defaults to None which means to inherit
+ the reuse option of the parent scope.
+
+ Returns:
+ A `Tensor` of model output and a dictionary of model end points.
+ """
+ if num_blocks is None:
+ num_blocks = resolution_schedule.num_resolutions
+
+ def _conv2d(scope, x, kernel_size, filters, padding='SAME'):
+ return layers.custom_conv2d(
+ x=x,
+ filters=filters,
+ kernel_size=kernel_size,
+ padding=padding,
+ activation=tf.nn.leaky_relu,
+ he_initializer_slope=0.0,
+ scope=scope)
+
+ def _from_rgb(x, block_id):
+ return _conv2d('from_rgb', x, 1, num_filters_fn(block_id))
+
+ end_points = {}
+
+ with tf.variable_scope(scope, reuse=reuse):
+ x0 = x
+ end_points['rgb'] = x0
+
+ lods = []
+ for block_id in range(num_blocks, 0, -1):
+ with tf.variable_scope(block_name(block_id)):
+ scale = resolution_schedule.scale_factor(block_id)
+ lod = layers.downscale(x0, scale)
+ end_points['downscaled_rgb_{}'.format(block_id)] = lod
+ lod = _from_rgb(lod, block_id)
+ # alpha_i is used to replace lod_select.
+ alpha = _discriminator_alpha(block_id, progress)
+ end_points['alpha_{}'.format(block_id)] = alpha
+ lods.append((lod, alpha))
+
+ lods_iter = iter(lods)
+ x, _ = lods_iter.next()
+ for block_id in range(num_blocks, 1, -1):
+ with tf.variable_scope(block_name(block_id)):
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(block_id))
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(block_id - 1))
+ x = layers.downscale(x, resolution_schedule.scale_base)
+ lod, alpha = lods_iter.next()
+ x = alpha * lod + (1.0 - alpha) * x
+
+ with tf.variable_scope(block_name(1)):
+ x = layers.scalar_concat(x, layers.minibatch_mean_stddev(x))
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(1))
+ x = _conv2d('conv1', x, resolution_schedule.start_resolutions,
+ num_filters_fn(0), 'VALID')
+ end_points['last_conv'] = x
+ logits = layers.custom_dense(x=x, units=1, scope='logits')
+ end_points['logits'] = logits
+
+ return logits, end_points
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py"
new file mode 100644
index 00000000..5e0f7374
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py"
@@ -0,0 +1,248 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+import layers
+import networks
+
+
+def _get_grad_norm(ys, xs):
+ """Compute 2-norm of dys / dxs."""
+ return tf.sqrt(
+ tf.add_n([tf.reduce_sum(tf.square(g)) for g in tf.gradients(ys, xs)]))
+
+
+def _num_filters_stub(block_id):
+ return networks.num_filters(block_id, 8, 1, 8)
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_resolution_schedule_correct(self):
+ rs = networks.ResolutionSchedule(
+ start_resolutions=[5, 3], scale_base=2, num_resolutions=3)
+ self.assertEqual(rs.start_resolutions, (5, 3))
+ self.assertEqual(rs.scale_base, 2)
+ self.assertEqual(rs.num_resolutions, 3)
+ self.assertEqual(rs.final_resolutions, (20, 12))
+ self.assertEqual(rs.scale_factor(1), 4)
+ self.assertEqual(rs.scale_factor(2), 2)
+ self.assertEqual(rs.scale_factor(3), 1)
+ with self.assertRaises(ValueError):
+ rs.scale_factor(0)
+ with self.assertRaises(ValueError):
+ rs.scale_factor(4)
+
+ def test_block_name(self):
+ self.assertEqual(networks.block_name(10), 'progressive_gan_block_10')
+
+ def test_min_total_num_images(self):
+ self.assertEqual(networks.min_total_num_images(7, 8, 4), 52)
+
+ def test_compute_progress(self):
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images=7,
+ transition_stage_num_images=8,
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ progress_output = [
+ sess.run(progress, feed_dict={current_image_id_ph: current_image_id})
+ for current_image_id in [0, 3, 6, 7, 8, 10, 15, 29, 100]
+ ]
+ self.assertArrayNear(progress_output,
+ [0.0, 0.0, 0.0, 0.0, 0.125, 0.375, 1.0, 1.0, 1.0],
+ 1.0e-6)
+
+ def test_generator_alpha(self):
+ with self.test_session(use_gpu=True) as sess:
+ alpha_fixed_block_id = [
+ sess.run(
+ networks._generator_alpha(2, tf.constant(progress, tf.float32)))
+ for progress in [0, 0.2, 1, 1.2, 2, 2.2, 3]
+ ]
+ alpha_fixed_progress = [
+ sess.run(
+ networks._generator_alpha(block_id, tf.constant(1.2, tf.float32)))
+ for block_id in range(1, 5)
+ ]
+
+ self.assertArrayNear(alpha_fixed_block_id, [0, 0.2, 1, 0.8, 0, 0, 0],
+ 1.0e-6)
+ self.assertArrayNear(alpha_fixed_progress, [0, 0.8, 0.2, 0], 1.0e-6)
+
+ def test_discriminator_alpha(self):
+ with self.test_session(use_gpu=True) as sess:
+ alpha_fixed_block_id = [
+ sess.run(
+ networks._discriminator_alpha(2, tf.constant(
+ progress, tf.float32)))
+ for progress in [0, 0.2, 1, 1.2, 2, 2.2, 3]
+ ]
+ alpha_fixed_progress = [
+ sess.run(
+ networks._discriminator_alpha(block_id,
+ tf.constant(1.2, tf.float32)))
+ for block_id in range(1, 5)
+ ]
+
+ self.assertArrayNear(alpha_fixed_block_id, [1, 1, 1, 0.8, 0, 0, 0], 1.0e-6)
+ self.assertArrayNear(alpha_fixed_progress, [0, 0.8, 1, 1], 1.0e-6)
+
+ def test_blend_images_in_stable_stage(self):
+ x_np = np.random.normal(size=[2, 8, 8, 3])
+ x = tf.constant(x_np, tf.float32)
+ x_blend = networks.blend_images(
+ x,
+ progress=tf.constant(0.0),
+ resolution_schedule=networks.ResolutionSchedule(
+ scale_base=2, num_resolutions=2),
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ x_blend_np = sess.run(x_blend)
+ x_blend_expected_np = sess.run(layers.upscale(layers.downscale(x, 2), 2))
+ self.assertNDArrayNear(x_blend_np, x_blend_expected_np, 1.0e-6)
+
+ def test_blend_images_in_transition_stage(self):
+ x_np = np.random.normal(size=[2, 8, 8, 3])
+ x = tf.constant(x_np, tf.float32)
+ x_blend = networks.blend_images(
+ x,
+ tf.constant(0.2),
+ resolution_schedule=networks.ResolutionSchedule(
+ scale_base=2, num_resolutions=2),
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ x_blend_np = sess.run(x_blend)
+ x_blend_expected_np = 0.8 * sess.run(
+ layers.upscale(layers.downscale(x, 2), 2)) + 0.2 * x_np
+ self.assertNDArrayNear(x_blend_np, x_blend_expected_np, 1.0e-6)
+
+ def test_num_filters(self):
+ self.assertEqual(networks.num_filters(1, 4096, 1, 256), 256)
+ self.assertEqual(networks.num_filters(5, 4096, 1, 256), 128)
+
+ def test_generator_grad_norm_progress(self):
+ stable_stage_num_images = 2
+ transition_stage_num_images = 3
+
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images,
+ transition_stage_num_images,
+ num_blocks=3)
+ z = tf.random_normal([2, 10], dtype=tf.float32)
+ x, _ = networks.generator(
+ z, progress, _num_filters_stub,
+ networks.ResolutionSchedule(
+ start_resolutions=(4, 4), scale_base=2, num_resolutions=3))
+ fake_loss = tf.reduce_sum(tf.square(x))
+ grad_norms = [
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_1/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_2/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_3/.*'))
+ ]
+
+ grad_norms_output = None
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ x1_np = sess.run(x, feed_dict={current_image_id_ph: 0.12})
+ x2_np = sess.run(x, feed_dict={current_image_id_ph: 1.8})
+ grad_norms_output = np.array([
+ sess.run(grad_norms, feed_dict={current_image_id_ph: i})
+ for i in range(15) # total num of images
+ ])
+
+ self.assertEqual((2, 16, 16, 3), x1_np.shape)
+ self.assertEqual((2, 16, 16, 3), x2_np.shape)
+ # The gradient of block_1 is always on.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 0] > 0), 0,
+ 'gradient norms {} for block 1 is not always on'.format(
+ grad_norms_output[:, 0]))
+ # The gradient of block_2 is on after 1 stable stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 1] > 0), 3,
+ 'gradient norms {} for block 2 is not on at step 3'.format(
+ grad_norms_output[:, 1]))
+ # The gradient of block_3 is on after 2 stable stage + 1 transition stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 2] > 0), 8,
+ 'gradient norms {} for block 3 is not on at step 8'.format(
+ grad_norms_output[:, 2]))
+
+ def test_discriminator_grad_norm_progress(self):
+ stable_stage_num_images = 2
+ transition_stage_num_images = 3
+
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images,
+ transition_stage_num_images,
+ num_blocks=3)
+ x = tf.random_normal([2, 16, 16, 3])
+ logits, _ = networks.discriminator(
+ x, progress, _num_filters_stub,
+ networks.ResolutionSchedule(
+ start_resolutions=(4, 4), scale_base=2, num_resolutions=3))
+ fake_loss = tf.reduce_sum(tf.square(logits))
+ grad_norms = [
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_1/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_2/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_3/.*'))
+ ]
+
+ grad_norms_output = None
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ grad_norms_output = np.array([
+ sess.run(grad_norms, feed_dict={current_image_id_ph: i})
+ for i in range(15) # total num of images
+ ])
+
+ # The gradient of block_1 is always on.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 0] > 0), 0,
+ 'gradient norms {} for block 1 is not always on'.format(
+ grad_norms_output[:, 0]))
+ # The gradient of block_2 is on after 1 stable stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 1] > 0), 3,
+ 'gradient norms {} for block 2 is not on at step 3'.format(
+ grad_norms_output[:, 1]))
+ # The gradient of block_3 is on after 2 stable stage + 1 transition stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 2] > 0), 8,
+ 'gradient norms {} for block 3 is not on at step 8'.format(
+ grad_norms_output[:, 2]))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg"
new file mode 100644
index 00000000..edf90ef6
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py"
new file mode 100644
index 00000000..66f9e1cb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py"
@@ -0,0 +1,589 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Train a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import logging
+import numpy as np
+import tensorflow as tf
+
+import networks
+
+tfgan = tf.contrib.gan
+
+
+def make_train_sub_dir(stage_id, **kwargs):
+ """Returns the log directory for training stage `stage_id`."""
+ return os.path.join(kwargs['train_root_dir'], 'stage_{:05d}'.format(stage_id))
+
+
+def make_resolution_schedule(**kwargs):
+ """Returns an object of `ResolutionSchedule`."""
+ return networks.ResolutionSchedule(
+ start_resolutions=(kwargs['start_height'], kwargs['start_width']),
+ scale_base=kwargs['scale_base'],
+ num_resolutions=kwargs['num_resolutions'])
+
+
+def get_stage_ids(**kwargs):
+ """Returns a list of stage ids.
+
+ Args:
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ """
+ train_sub_dirs = [
+ sub_dir for sub_dir in tf.gfile.ListDirectory(kwargs['train_root_dir'])
+ if sub_dir.startswith('stage_')
+ ]
+
+ # If fresh start, start with start_stage_id = 0
+ # If has been trained for n = len(train_sub_dirs) stages, start with the last
+ # stage, i.e. start_stage_id = n - 1.
+ start_stage_id = max(0, len(train_sub_dirs) - 1)
+
+ return range(start_stage_id, get_total_num_stages(**kwargs))
+
+
+def get_total_num_stages(**kwargs):
+ """Returns total number of training stages."""
+ return 2 * kwargs['num_resolutions'] - 1
+
+
+def get_batch_size(stage_id, **kwargs):
+ """Returns batch size for each stage.
+
+ It is expected that `len(batch_size_schedule) == num_resolutions`. Each stage
+ corresponds to a resolution and hence a batch size. However if
+ `len(batch_size_schedule) < num_resolutions`, pad `batch_size_schedule` in the
+ beginning with the first batch size.
+
+ Args:
+ stage_id: An integer of training stage index.
+ **kwargs: A dictionary of
+ 'batch_size_schedule': A list of integer, each element is the batch size
+ for the current training image resolution.
+ 'num_resolutions': An integer of number of progressive resolutions.
+
+ Returns:
+ An integer batch size for the `stage_id`.
+ """
+ batch_size_schedule = kwargs['batch_size_schedule']
+ num_resolutions = kwargs['num_resolutions']
+ if len(batch_size_schedule) < num_resolutions:
+ batch_size_schedule = (
+ [batch_size_schedule[0]] * (num_resolutions - len(batch_size_schedule))
+ + batch_size_schedule)
+
+ return int(batch_size_schedule[(stage_id + 1) // 2])
+
+
+def get_stage_info(stage_id, **kwargs):
+ """Returns information for a training stage.
+
+ Args:
+ stage_id: An integer of training stage index.
+ **kwargs: A dictionary of
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+
+ Returns:
+ A tuple of integers. The first entry is the number of blocks. The second
+ entry is the accumulated total number of training images when stage
+ `stage_id` is finished.
+
+ Raises:
+ ValueError: If `stage_id` is not in [0, total number of stages).
+ """
+ total_num_stages = get_total_num_stages(**kwargs)
+ if not (stage_id >= 0 and stage_id < total_num_stages):
+ raise ValueError(
+ '`stage_id` must be in [0, {0}), but instead was {1}'.format(
+ total_num_stages, stage_id))
+
+ # Even stage_id: stable training stage.
+ # Odd stage_id: transition training stage.
+ num_blocks = (stage_id + 1) // 2 + 1
+ num_images = ((stage_id // 2 + 1) * kwargs['stable_stage_num_images'] + (
+ (stage_id + 1) // 2) * kwargs['transition_stage_num_images'])
+
+ total_num_images = kwargs['total_num_images']
+ if stage_id >= total_num_stages - 1:
+ num_images = total_num_images
+ num_images = min(num_images, total_num_images)
+
+ return num_blocks, num_images
+
+
+def make_latent_vectors(num, **kwargs):
+ """Returns a batch of `num` random latent vectors."""
+ return tf.random_normal([num, kwargs['latent_vector_size']], dtype=tf.float32)
+
+
+def make_interpolated_latent_vectors(num_rows, num_columns, **kwargs):
+ """Returns a batch of linearly interpolated latent vectors.
+
+ Given two randomly generated latent vector za and zb, it can generate
+ a row of `num_columns` interpolated latent vectors, i.e.
+ [..., za + (zb - za) * i / (num_columns - 1), ...] where
+ i = 0, 1, ..., `num_columns` - 1.
+
+ This function produces `num_rows` such rows and returns a (flattened)
+ batch of latent vectors with batch size `num_rows * num_columns`.
+
+ Args:
+ num_rows: An integer. Number of rows of interpolated latent vectors.
+ num_columns: An integer. Number of interpolated latent vectors in each row.
+ **kwargs: A dictionary of
+ 'latent_vector_size': An integer of latent vector size.
+
+ Returns:
+ A `Tensor` of shape `[num_rows * num_columns, latent_vector_size]`.
+ """
+ ans = []
+ for _ in range(num_rows):
+ z = tf.random_normal([2, kwargs['latent_vector_size']])
+ r = tf.reshape(
+ tf.to_float(tf.range(num_columns)) / (num_columns - 1), [-1, 1])
+ dz = z[1] - z[0]
+ ans.append(z[0] + tf.stack([dz] * num_columns) * r)
+ return tf.concat(ans, axis=0)
+
+
+def define_loss(gan_model, **kwargs):
+ """Defines progressive GAN losses.
+
+ The generator and discriminator both use wasserstein loss. In addition,
+ a small penalty term is added to the discriminator loss to prevent it getting
+ too large.
+
+ Args:
+ gan_model: A `GANModel` namedtuple.
+ **kwargs: A dictionary of
+ 'gradient_penalty_weight': A float of gradient norm target for
+ wasserstein loss.
+ 'gradient_penalty_target': A float of gradient penalty weight for
+ wasserstein loss.
+ 'real_score_penalty_weight': A float of Additional penalty to keep
+ the scores from drifting too far from zero.
+
+ Returns:
+ A `GANLoss` namedtuple.
+ """
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.wasserstein_generator_loss,
+ discriminator_loss_fn=tfgan.losses.wasserstein_discriminator_loss,
+ gradient_penalty_weight=kwargs['gradient_penalty_weight'],
+ gradient_penalty_target=kwargs['gradient_penalty_target'],
+ gradient_penalty_epsilon=0.0)
+
+ real_score_penalty = tf.reduce_mean(
+ tf.square(gan_model.discriminator_real_outputs))
+ tf.summary.scalar('real_score_penalty', real_score_penalty)
+
+ return gan_loss._replace(
+ discriminator_loss=(
+ gan_loss.discriminator_loss +
+ kwargs['real_score_penalty_weight'] * real_score_penalty))
+
+
+def define_train_ops(gan_model, gan_loss, **kwargs):
+ """Defines progressive GAN train ops.
+
+ Args:
+ gan_model: A `GANModel` namedtuple.
+ gan_loss: A `GANLoss` namedtuple.
+ **kwargs: A dictionary of
+ 'adam_beta1': A float of Adam optimizer beta1.
+ 'adam_beta2': A float of Adam optimizer beta2.
+ 'generator_learning_rate': A float of generator learning rate.
+ 'discriminator_learning_rate': A float of discriminator learning rate.
+
+ Returns:
+ A tuple of `GANTrainOps` namedtuple and a list variables tracking the state
+ of optimizers.
+ """
+ with tf.variable_scope('progressive_gan_train_ops') as var_scope:
+ beta1, beta2 = kwargs['adam_beta1'], kwargs['adam_beta2']
+ gen_opt = tf.train.AdamOptimizer(kwargs['generator_learning_rate'], beta1,
+ beta2)
+ dis_opt = tf.train.AdamOptimizer(kwargs['discriminator_learning_rate'],
+ beta1, beta2)
+ gan_train_ops = tfgan.gan_train_ops(gan_model, gan_loss, gen_opt, dis_opt)
+ return gan_train_ops, tf.get_collection(
+ tf.GraphKeys.GLOBAL_VARIABLES, scope=var_scope.name)
+
+
+def add_generator_smoothing_ops(generator_ema, gan_model, gan_train_ops):
+ """Adds generator smoothing ops."""
+ with tf.control_dependencies([gan_train_ops.generator_train_op]):
+ new_generator_train_op = generator_ema.apply(gan_model.generator_variables)
+
+ gan_train_ops = gan_train_ops._replace(
+ generator_train_op=new_generator_train_op)
+ generator_vars_to_restore = generator_ema.variables_to_restore(
+ gan_model.generator_variables)
+ return gan_train_ops, generator_vars_to_restore
+
+
+def build_model(stage_id, batch_size, real_images, **kwargs):
+ """Builds progressive GAN model.
+
+ Args:
+ stage_id: An integer of training stage index.
+ batch_size: Number of training images in each minibatch.
+ real_images: A 4D `Tensor` of NHWC format.
+ **kwargs: A dictionary of
+ 'start_height': An integer of start image height.
+ 'start_width': An integer of start image width.
+ 'scale_base': An integer of resolution multiplier.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+ 'kernel_size': Convolution kernel size.
+ 'colors': Number of image channels.
+ 'to_rgb_use_tanh_activation': Whether to apply tanh activation when
+ output rgb.
+ 'fmap_base': Base number of filters.
+ 'fmap_decay': Decay of number of filters.
+ 'fmap_max': Max number of filters.
+ 'latent_vector_size': An integer of latent vector size.
+ 'gradient_penalty_weight': A float of gradient norm target for
+ wasserstein loss.
+ 'gradient_penalty_target': A float of gradient penalty weight for
+ wasserstein loss.
+ 'real_score_penalty_weight': A float of Additional penalty to keep
+ the scores from drifting too far from zero.
+ 'adam_beta1': A float of Adam optimizer beta1.
+ 'adam_beta2': A float of Adam optimizer beta2.
+ 'generator_learning_rate': A float of generator learning rate.
+ 'discriminator_learning_rate': A float of discriminator learning rate.
+
+ Returns:
+ An inernal object that wraps all information about the model.
+ """
+ kernel_size = kwargs['kernel_size']
+ colors = kwargs['colors']
+ resolution_schedule = make_resolution_schedule(**kwargs)
+
+ num_blocks, num_images = get_stage_info(stage_id, **kwargs)
+
+ current_image_id = tf.train.get_or_create_global_step()
+ current_image_id_inc_op = current_image_id.assign_add(batch_size)
+ tf.summary.scalar('current_image_id', current_image_id)
+
+ progress = networks.compute_progress(
+ current_image_id, kwargs['stable_stage_num_images'],
+ kwargs['transition_stage_num_images'], num_blocks)
+ tf.summary.scalar('progress', progress)
+
+ real_images = networks.blend_images(
+ real_images, progress, resolution_schedule, num_blocks=num_blocks)
+
+ def _num_filters_fn(block_id):
+ """Computes number of filters of block `block_id`."""
+ return networks.num_filters(block_id, kwargs['fmap_base'],
+ kwargs['fmap_decay'], kwargs['fmap_max'])
+
+ def _generator_fn(z):
+ """Builds generator network."""
+ return networks.generator(
+ z,
+ progress,
+ _num_filters_fn,
+ resolution_schedule,
+ num_blocks=num_blocks,
+ kernel_size=kernel_size,
+ colors=colors,
+ to_rgb_activation=(tf.tanh
+ if kwargs['to_rgb_use_tanh_activation'] else None))
+
+ def _discriminator_fn(x):
+ """Builds discriminator network."""
+ return networks.discriminator(
+ x,
+ progress,
+ _num_filters_fn,
+ resolution_schedule,
+ num_blocks=num_blocks,
+ kernel_size=kernel_size)
+
+ ########## Define model.
+ z = make_latent_vectors(batch_size, **kwargs)
+
+ gan_model = tfgan.gan_model(
+ generator_fn=lambda z: _generator_fn(z)[0],
+ discriminator_fn=lambda x, unused_z: _discriminator_fn(x)[0],
+ real_data=real_images,
+ generator_inputs=z)
+
+ ########## Define loss.
+ gan_loss = define_loss(gan_model, **kwargs)
+
+ ########## Define train ops.
+ gan_train_ops, optimizer_var_list = define_train_ops(gan_model, gan_loss,
+ **kwargs)
+ gan_train_ops = gan_train_ops._replace(
+ global_step_inc_op=current_image_id_inc_op)
+
+ ########## Generator smoothing.
+ generator_ema = tf.train.ExponentialMovingAverage(decay=0.999)
+ gan_train_ops, generator_vars_to_restore = add_generator_smoothing_ops(
+ generator_ema, gan_model, gan_train_ops)
+
+ class Model(object):
+ pass
+
+ model = Model()
+ model.stage_id = stage_id
+ model.batch_size = batch_size
+ model.resolution_schedule = resolution_schedule
+ model.num_images = num_images
+ model.num_blocks = num_blocks
+ model.current_image_id = current_image_id
+ model.progress = progress
+ model.num_filters_fn = _num_filters_fn
+ model.generator_fn = _generator_fn
+ model.discriminator_fn = _discriminator_fn
+ model.gan_model = gan_model
+ model.gan_loss = gan_loss
+ model.gan_train_ops = gan_train_ops
+ model.optimizer_var_list = optimizer_var_list
+ model.generator_ema = generator_ema
+ model.generator_vars_to_restore = generator_vars_to_restore
+ return model
+
+
+def make_var_scope_custom_getter_for_ema(ema):
+ """Makes variable scope custom getter."""
+ def _custom_getter(getter, name, *args, **kwargs):
+ var = getter(name, *args, **kwargs)
+ ema_var = ema.average(var)
+ return ema_var if ema_var else var
+ return _custom_getter
+
+
+def add_model_summaries(model, **kwargs):
+ """Adds model summaries.
+
+ This function adds several useful summaries during training:
+ - fake_images: A grid of fake images based on random latent vectors.
+ - interp_images: A grid of fake images based on interpolated latent vectors.
+ - real_images_blend: A grid of real images.
+ - summaries for `gan_model` losses, variable distributions etc.
+
+ Args:
+ model: An model object having all information of progressive GAN model,
+ e.g. the return of build_model().
+ **kwargs: A dictionary of
+ 'fake_grid_size': The fake image grid size for summaries.
+ 'interp_grid_size': The latent space interpolated image grid size for
+ summaries.
+ 'colors': Number of image channels.
+ 'latent_vector_size': An integer of latent vector size.
+ """
+ fake_grid_size = kwargs['fake_grid_size']
+ interp_grid_size = kwargs['interp_grid_size']
+ colors = kwargs['colors']
+
+ image_shape = list(model.resolution_schedule.final_resolutions)
+
+ fake_batch_size = fake_grid_size**2
+ fake_images_shape = [fake_batch_size] + image_shape + [colors]
+
+ interp_batch_size = interp_grid_size**2
+ interp_images_shape = [interp_batch_size] + image_shape + [colors]
+
+ # When making prediction, use the ema smoothed generator vars.
+ with tf.variable_scope(
+ model.gan_model.generator_scope,
+ reuse=True,
+ custom_getter=make_var_scope_custom_getter_for_ema(model.generator_ema)):
+ z_fake = make_latent_vectors(fake_batch_size, **kwargs)
+ fake_images = model.gan_model.generator_fn(z_fake)
+ fake_images.set_shape(fake_images_shape)
+
+ z_interp = make_interpolated_latent_vectors(interp_grid_size,
+ interp_grid_size, **kwargs)
+ interp_images = model.gan_model.generator_fn(z_interp)
+ interp_images.set_shape(interp_images_shape)
+
+ tf.summary.image(
+ 'fake_images',
+ tfgan.eval.eval_utils.image_grid(
+ fake_images,
+ grid_shape=[fake_grid_size] * 2,
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ tf.summary.image(
+ 'interp_images',
+ tfgan.eval.eval_utils.image_grid(
+ interp_images,
+ grid_shape=[interp_grid_size] * 2,
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ real_grid_size = int(np.sqrt(model.batch_size))
+ tf.summary.image(
+ 'real_images_blend',
+ tfgan.eval.eval_utils.image_grid(
+ model.gan_model.real_data[:real_grid_size**2],
+ grid_shape=(real_grid_size, real_grid_size),
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ tfgan.eval.add_gan_model_summaries(model.gan_model)
+
+
+def make_scaffold(stage_id, optimizer_var_list, **kwargs):
+ """Makes a custom scaffold.
+
+ The scaffold
+ - restores variables from the last training stage.
+ - initializes new variables in the new block.
+
+ Args:
+ stage_id: An integer of stage id.
+ optimizer_var_list: A list of optimizer variables.
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+
+ Returns:
+ A `Scaffold` object.
+ """
+ # Holds variables that from the previous stage and need to be restored.
+ restore_var_list = []
+ prev_ckpt = None
+ curr_ckpt = tf.train.latest_checkpoint(make_train_sub_dir(stage_id, **kwargs))
+ if stage_id > 0 and curr_ckpt is None:
+ prev_ckpt = tf.train.latest_checkpoint(
+ make_train_sub_dir(stage_id - 1, **kwargs))
+
+ num_blocks, _ = get_stage_info(stage_id, **kwargs)
+ prev_num_blocks, _ = get_stage_info(stage_id - 1, **kwargs)
+
+ # Holds variables created in the new block of the current stage. If the
+ # current stage is a stable stage (except the initial stage), this list
+ # will be empty.
+ new_block_var_list = []
+ for block_id in range(prev_num_blocks + 1, num_blocks + 1):
+ new_block_var_list.extend(
+ tf.get_collection(
+ tf.GraphKeys.GLOBAL_VARIABLES,
+ scope='.*/{}/'.format(networks.block_name(block_id))))
+
+ # Every variables that are 1) not for optimizers and 2) from the new block
+ # need to be restored.
+ restore_var_list = [
+ var for var in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
+ if var not in set(optimizer_var_list + new_block_var_list)
+ ]
+
+ # Add saver op to graph. This saver is used to restore variables from the
+ # previous stage.
+ saver_for_restore = tf.train.Saver(
+ var_list=restore_var_list, allow_empty=True)
+ # Add the op to graph that initializes all global variables.
+ init_op = tf.global_variables_initializer()
+
+ def _init_fn(unused_scaffold, sess):
+ # First initialize every variables.
+ sess.run(init_op)
+ logging.info('\n'.join([var.name for var in restore_var_list]))
+ # Then overwrite variables saved in previous stage.
+ if prev_ckpt is not None:
+ saver_for_restore.restore(sess, prev_ckpt)
+
+ # Use a dummy init_op here as all initialization is done in init_fn.
+ return tf.train.Scaffold(init_op=tf.constant([]), init_fn=_init_fn)
+
+
+def make_status_message(model):
+ """Makes a string `Tensor` of training status."""
+ return tf.string_join(
+ [
+ 'Starting train step: current_image_id: ',
+ tf.as_string(model.current_image_id), ', progress: ',
+ tf.as_string(model.progress), ', num_blocks: {}'.format(
+ model.num_blocks), ', batch_size: {}'.format(model.batch_size)
+ ],
+ name='status_message')
+
+
+def train(model, **kwargs):
+ """Trains progressive GAN for stage `stage_id`.
+
+ Args:
+ model: An model object having all information of progressive GAN model,
+ e.g. the return of build_model().
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'master': Name of the TensorFlow master to use.
+ 'task': The Task ID. This value is used when training with multiple
+ workers to identify each worker.
+ 'save_summaries_num_images': Save summaries in this number of images.
+ Returns:
+ None.
+ """
+ logging.info('stage_id=%d, num_blocks=%d, num_images=%d', model.stage_id,
+ model.num_blocks, model.num_images)
+
+ scaffold = make_scaffold(model.stage_id, model.optimizer_var_list, **kwargs)
+
+ tfgan.gan_train(
+ model.gan_train_ops,
+ logdir=make_train_sub_dir(model.stage_id, **kwargs),
+ get_hooks_fn=tfgan.get_sequential_train_hooks(tfgan.GANTrainSteps(1, 1)),
+ hooks=[
+ tf.train.StopAtStepHook(last_step=model.num_images),
+ tf.train.LoggingTensorHook(
+ [make_status_message(model)], every_n_iter=10)
+ ],
+ master=kwargs['master'],
+ is_chief=(kwargs['task'] == 0),
+ scaffold=scaffold,
+ save_checkpoint_secs=600,
+ save_summaries_steps=(kwargs['save_summaries_num_images']))
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py"
new file mode 100644
index 00000000..645d20cf
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py"
@@ -0,0 +1,174 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Train a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import sys
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import train
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('dataset_name', 'cifar10', 'Dataset name.')
+
+flags.DEFINE_string('dataset_file_pattern', '', 'Dataset file pattern.')
+
+flags.DEFINE_integer('start_height', 4, 'Start image height.')
+
+flags.DEFINE_integer('start_width', 4, 'Start image width.')
+
+flags.DEFINE_integer('scale_base', 2, 'Resolution multiplier.')
+
+flags.DEFINE_integer('num_resolutions', 4, 'Number of progressive resolutions.')
+
+flags.DEFINE_list(
+ 'batch_size_schedule', [8, 8, 4],
+ 'A list of batch sizes for each resolution, if '
+ 'len(batch_size_schedule) < num_resolutions, pad the schedule in the '
+ 'beginning with the first batch size.')
+
+flags.DEFINE_integer('kernel_size', 3, 'Convolution kernel size.')
+
+flags.DEFINE_integer('colors', 3, 'Number of image channels.')
+
+flags.DEFINE_bool('to_rgb_use_tanh_activation', False,
+ 'Whether to apply tanh activation when output rgb.')
+
+flags.DEFINE_integer('stable_stage_num_images', 1000,
+ 'Number of images in the stable stage.')
+
+flags.DEFINE_integer('transition_stage_num_images', 1000,
+ 'Number of images in the transition stage.')
+
+flags.DEFINE_integer('total_num_images', 10000, 'Total number of images.')
+
+flags.DEFINE_integer('save_summaries_num_images', 100,
+ 'Save summaries in this number of images.')
+
+flags.DEFINE_integer('latent_vector_size', 128, 'Latent vector size.')
+
+flags.DEFINE_integer('fmap_base', 4096, 'Base number of filters.')
+
+flags.DEFINE_float('fmap_decay', 1.0, 'Decay of number of filters.')
+
+flags.DEFINE_integer('fmap_max', 128, 'Max number of filters.')
+
+flags.DEFINE_float('gradient_penalty_target', 1.0,
+ 'Gradient norm target for wasserstein loss.')
+
+flags.DEFINE_float('gradient_penalty_weight', 10.0,
+ 'Gradient penalty weight for wasserstein loss.')
+
+flags.DEFINE_float('real_score_penalty_weight', 0.001,
+ 'Additional penalty to keep the scores from drifting too '
+ 'far from zero.')
+
+flags.DEFINE_float('generator_learning_rate', 0.001, 'Learning rate.')
+
+flags.DEFINE_float('discriminator_learning_rate', 0.001, 'Learning rate.')
+
+flags.DEFINE_float('adam_beta1', 0.0, 'Adam beta 1.')
+
+flags.DEFINE_float('adam_beta2', 0.99, 'Adam beta 2.')
+
+flags.DEFINE_integer('fake_grid_size', 8, 'The fake image grid size for eval.')
+
+flags.DEFINE_integer('interp_grid_size', 8,
+ 'The interp image grid size for eval.')
+
+flags.DEFINE_string('train_root_dir', '/tmp/progressive_gan/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+
+
+def _make_config_from_flags():
+ """Makes a config dictionary from commandline flags."""
+ return dict([(flag.name, flag.value)
+ for flag in FLAGS.get_key_flags_for_module(sys.argv[0])])
+
+
+def _provide_real_images(batch_size, **kwargs):
+ """Provides real images."""
+ dataset_name = kwargs.get('dataset_name')
+ dataset_file_pattern = kwargs.get('dataset_file_pattern')
+ colors = kwargs['colors']
+ final_height, final_width = train.make_resolution_schedule(
+ **kwargs).final_resolutions
+ if dataset_name is not None:
+ return data_provider.provide_data(
+ dataset_name=dataset_name,
+ split_name='train',
+ batch_size=batch_size,
+ patch_height=final_height,
+ patch_width=final_width,
+ colors=colors)
+ elif dataset_file_pattern is not None:
+ return data_provider.provide_data_from_image_files(
+ file_pattern=dataset_file_pattern,
+ batch_size=batch_size,
+ patch_height=final_height,
+ patch_width=final_width,
+ colors=colors)
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_root_dir):
+ tf.gfile.MakeDirs(FLAGS.train_root_dir)
+
+ config = _make_config_from_flags()
+ logging.info('\n'.join(['{}={}'.format(k, v) for k, v in config.iteritems()]))
+
+ for stage_id in train.get_stage_ids(**config):
+ batch_size = train.get_batch_size(stage_id, **config)
+ tf.reset_default_graph()
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ real_images = None
+ with tf.device('/cpu:0'), tf.name_scope('inputs'):
+ real_images = _provide_real_images(batch_size, **config)
+ model = train.build_model(stage_id, batch_size, real_images, **config)
+ train.add_model_summaries(model, **config)
+ train.train(model, **config)
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py"
new file mode 100644
index 00000000..67f47899
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py"
@@ -0,0 +1,93 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+from absl.testing import absltest
+import tensorflow as tf
+
+import train
+
+
+FLAGS = flags.FLAGS
+
+
+def provide_random_data(batch_size=2, patch_size=4, colors=1, **unused_kwargs):
+ return tf.random_normal([batch_size, patch_size, patch_size, colors])
+
+
+class TrainTest(absltest.TestCase):
+
+ def setUp(self):
+ self._config = {
+ 'start_height': 2,
+ 'start_width': 2,
+ 'scale_base': 2,
+ 'num_resolutions': 2,
+ 'batch_size_schedule': [2],
+ 'colors': 1,
+ 'to_rgb_use_tanh_activation': True,
+ 'kernel_size': 3,
+ 'stable_stage_num_images': 1,
+ 'transition_stage_num_images': 1,
+ 'total_num_images': 3,
+ 'save_summaries_num_images': 2,
+ 'latent_vector_size': 2,
+ 'fmap_base': 8,
+ 'fmap_decay': 1.0,
+ 'fmap_max': 8,
+ 'gradient_penalty_target': 1.0,
+ 'gradient_penalty_weight': 10.0,
+ 'real_score_penalty_weight': 0.001,
+ 'generator_learning_rate': 0.001,
+ 'discriminator_learning_rate': 0.001,
+ 'adam_beta1': 0.0,
+ 'adam_beta2': 0.99,
+ 'fake_grid_size': 2,
+ 'interp_grid_size': 2,
+ 'train_root_dir': os.path.join(FLAGS.test_tmpdir, 'progressive_gan'),
+ 'master': '',
+ 'task': 0
+ }
+
+ def test_train_success(self):
+ train_root_dir = self._config['train_root_dir']
+ if not tf.gfile.Exists(train_root_dir):
+ tf.gfile.MakeDirs(train_root_dir)
+
+ for stage_id in train.get_stage_ids(**self._config):
+ batch_size = train.get_batch_size(stage_id, **self._config)
+ tf.reset_default_graph()
+ real_images = provide_random_data(batch_size=batch_size)
+ model = train.build_model(stage_id, batch_size, real_images,
+ **self._config)
+ train.add_model_summaries(model, **self._config)
+ train.train(model, **self._config)
+
+ def test_get_batch_size(self):
+ config = {'num_resolutions': 5, 'batch_size_schedule': [8, 4, 2]}
+ # batch_size_schedule is expanded to [8, 8, 8, 4, 2]
+ # At stage level it is [8, 8, 8, 8, 8, 4, 4, 2, 2]
+ for i, expected_batch_size in enumerate([8, 8, 8, 8, 8, 4, 4, 2, 2]):
+ self.assertEqual(train.get_batch_size(i, **config), expected_batch_size)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py"
new file mode 100644
index 00000000..5e136cf9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py"
@@ -0,0 +1,33 @@
+"""StarGAN data provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import data_provider
+
+
+def provide_data(image_file_patterns, batch_size, patch_size):
+ """Data provider wrapper on for the data_provider in gan/cyclegan.
+
+ Args:
+ image_file_patterns: A list of file pattern globs.
+ batch_size: Python int. Batch size.
+ patch_size: Python int. The patch size to extract.
+
+ Returns:
+ List of `Tensor` of shape (N, H, W, C) representing the images.
+ List of `Tensor` of shape (N, num_domains) representing the labels.
+ """
+
+ images = data_provider.provide_custom_data(
+ image_file_patterns,
+ batch_size=batch_size,
+ patch_size=patch_size)
+
+ num_domains = len(images)
+ labels = [tf.one_hot([idx] * batch_size, num_domains) for idx in
+ range(num_domains)]
+
+ return images, labels
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py"
new file mode 100644
index 00000000..cdd0927b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py"
@@ -0,0 +1,42 @@
+"""Tests for google3.third_party.tensorflow_models.gan.stargan.data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from google3.testing.pybase import googletest
+import data_provider
+
+mock = tf.test.mock
+
+
+class DataProviderTest(googletest.TestCase):
+
+ @mock.patch.object(
+ data_provider.data_provider, 'provide_custom_data', autospec=True)
+ def test_data_provider(self, mock_provide_custom_data):
+
+ batch_size = 2
+ patch_size = 8
+ num_domains = 3
+
+ images_shape = [batch_size, patch_size, patch_size, 3]
+ mock_provide_custom_data.return_value = [
+ tf.zeros(images_shape) for _ in range(num_domains)
+ ]
+
+ images, labels = data_provider.provide_data(
+ image_file_patterns=None, batch_size=batch_size, patch_size=patch_size)
+
+ self.assertEqual(num_domains, len(images))
+ self.assertEqual(num_domains, len(labels))
+ for label in labels:
+ self.assertListEqual([batch_size, num_domains], label.shape.as_list())
+ for image in images:
+ self.assertListEqual(images_shape, image.shape.as_list())
+
+
+if __name__ == '__main__':
+ googletest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py"
new file mode 100644
index 00000000..c92430f5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py"
@@ -0,0 +1,392 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Layers for a StarGAN model.
+
+This module contains basic layers to build a StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorvh implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+import ops
+
+
+def generator_down_sample(input_net, final_num_outputs=256):
+ """Down-sampling module in Generator.
+
+ Down sampling pathway of the Generator Architecture:
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L32
+
+ Notes:
+ We require dimension 1 and dimension 2 of the input_net to be fully defined
+ for the correct down sampling.
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, c + num_class).
+ final_num_outputs: (int) Number of hidden unit for the final layer.
+
+ Returns:
+ Tensor of shape (batch_size, h / 4, w / 4, 256).
+
+ Raises:
+ ValueError: If final_num_outputs are not divisible by 4,
+ or input_net does not have a rank of 4,
+ or dimension 1 and dimension 2 of input_net are not defined at graph
+ construction time,
+ or dimension 1 and dimension 2 of input_net are not divisible by 4.
+ """
+
+ if final_num_outputs % 4 != 0:
+ raise ValueError('Final number outputs need to be divisible by 4.')
+
+ # Check the rank of input_net.
+ input_net.shape.assert_has_rank(4)
+
+ # Check dimension 1 and dimension 2 are defined and divisible by 4.
+ if input_net.shape[1]:
+ if input_net.shape[1] % 4 != 0:
+ raise ValueError(
+ 'Dimension 1 of the input should be divisible by 4, but is {} '
+ 'instead.'.
+ format(input_net.shape[1]))
+ else:
+ raise ValueError('Dimension 1 of the input should be explicitly defined.')
+
+ # Check dimension 1 and dimension 2 are defined and divisible by 4.
+ if input_net.shape[2]:
+ if input_net.shape[2] % 4 != 0:
+ raise ValueError(
+ 'Dimension 2 of the input should be divisible by 4, but is {} '
+ 'instead.'.
+ format(input_net.shape[2]))
+ else:
+ raise ValueError('Dimension 2 of the input should be explicitly defined.')
+
+ with tf.variable_scope('generator_down_sample'):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d],
+ padding='VALID',
+ biases_initializer=None,
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ activation_fn=tf.nn.relu):
+
+ down_sample = ops.pad(input_net, 3)
+ down_sample = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs / 4,
+ kernel_size=7,
+ stride=1,
+ scope='conv_0')
+
+ down_sample = ops.pad(down_sample, 1)
+ down_sample = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs / 2,
+ kernel_size=4,
+ stride=2,
+ scope='conv_1')
+
+ down_sample = ops.pad(down_sample, 1)
+ output_net = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs,
+ kernel_size=4,
+ stride=2,
+ scope='conv_2')
+
+ return output_net
+
+
+def _residual_block(input_net,
+ num_outputs,
+ kernel_size,
+ stride=1,
+ padding_size=0,
+ activation_fn=tf.nn.relu,
+ normalizer_fn=None,
+ name='residual_block'):
+ """Residual Block.
+
+ Input Tensor X - > Conv1 -> IN -> ReLU -> Conv2 -> IN + X
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L7
+
+ Args:
+ input_net: Tensor as input.
+ num_outputs: (int) number of output channels for Convolution.
+ kernel_size: (int) size of the square kernel for Convolution.
+ stride: (int) stride for Convolution. Default to 1.
+ padding_size: (int) padding size for Convolution. Default to 0.
+ activation_fn: Activation function.
+ normalizer_fn: Normalization function.
+ name: Name scope
+
+ Returns:
+ Residual Tensor with the same shape as the input tensor.
+ """
+
+ with tf.variable_scope(name):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d],
+ num_outputs=num_outputs,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding='VALID',
+ normalizer_fn=normalizer_fn,
+ activation_fn=None):
+
+ res_block = ops.pad(input_net, padding_size)
+ res_block = tf.contrib.layers.conv2d(inputs=res_block, scope='conv_0')
+
+ res_block = activation_fn(res_block, name='activation_0')
+
+ res_block = ops.pad(res_block, padding_size)
+ res_block = tf.contrib.layers.conv2d(inputs=res_block, scope='conv_1')
+
+ output_net = res_block + input_net
+
+ return output_net
+
+
+def generator_bottleneck(input_net, residual_block_num=6, num_outputs=256):
+ """Bottleneck module in Generator.
+
+ Residual bottleneck pathway in Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L40
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 4, w / 4, 256).
+ residual_block_num: (int) Number of residual_block_num. Default to 6 per the
+ original implementation.
+ num_outputs: (int) Number of hidden unit in the residual bottleneck. Default
+ to 256 per the original implementation.
+
+ Returns:
+ Tensor of shape (batch_size, h / 4, w / 4, 256).
+
+ Raises:
+ ValueError: If the rank of the input tensor is not 4,
+ or the last channel of the input_tensor is not explicitly defined,
+ or the last channel of the input_tensor is not the same as num_outputs.
+ """
+
+ # Check the rank of input_net.
+ input_net.shape.assert_has_rank(4)
+
+ # Check dimension 4 of the input_net.
+ if input_net.shape[-1]:
+ if input_net.shape[-1] != num_outputs:
+ raise ValueError(
+ 'The last dimension of the input_net should be the same as '
+ 'num_outputs: but {} vs. {} instead.'.format(input_net.shape[-1],
+ num_outputs))
+ else:
+ raise ValueError(
+ 'The last dimension of the input_net should be explicitly defined.')
+
+ with tf.variable_scope('generator_bottleneck'):
+
+ bottleneck = input_net
+
+ for i in range(residual_block_num):
+
+ bottleneck = _residual_block(
+ input_net=bottleneck,
+ num_outputs=num_outputs,
+ kernel_size=3,
+ stride=1,
+ padding_size=1,
+ activation_fn=tf.nn.relu,
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ name='residual_block_{}'.format(i))
+
+ return bottleneck
+
+
+def generator_up_sample(input_net, num_outputs):
+ """Up-sampling module in Generator.
+
+ Up sampling path for image generation in the Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L44
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 4, w / 4, 256).
+ num_outputs: (int) Number of channel for the output tensor.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, num_outputs).
+ """
+
+ with tf.variable_scope('generator_up_sample'):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d_transpose],
+ kernel_size=4,
+ stride=2,
+ padding='VALID',
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ activation_fn=tf.nn.relu):
+
+ up_sample = tf.contrib.layers.conv2d_transpose(
+ inputs=input_net, num_outputs=128, scope='deconv_0')
+ up_sample = up_sample[:, 1:-1, 1:-1, :]
+
+ up_sample = tf.contrib.layers.conv2d_transpose(
+ inputs=up_sample, num_outputs=64, scope='deconv_1')
+ up_sample = up_sample[:, 1:-1, 1:-1, :]
+
+ output_net = ops.pad(up_sample, 3)
+ output_net = tf.contrib.layers.conv2d(
+ inputs=output_net,
+ num_outputs=num_outputs,
+ kernel_size=7,
+ stride=1,
+ padding='VALID',
+ activation_fn=tf.nn.tanh,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='conv_0')
+
+ return output_net
+
+
+def discriminator_input_hidden(input_net, hidden_layer=6, init_num_outputs=64):
+ """Input Layer + Hidden Layer in the Discriminator.
+
+ Feature extraction pathway in the Discriminator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L68
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, 3) as batch of images.
+ hidden_layer: (int) Number of hidden layers. Default to 6 per the original
+ implementation.
+ init_num_outputs: (int) Number of hidden unit in the first hidden layer. The
+ number of hidden unit double after each layer. Default to 64 per the
+ original implementation.
+
+ Returns:
+ Tensor of shape (batch_size, h / 64, w / 64, 2048) as features.
+ """
+
+ num_outputs = init_num_outputs
+
+ with tf.variable_scope('discriminator_input_hidden'):
+
+ hidden = input_net
+
+ for i in range(hidden_layer):
+
+ hidden = ops.pad(hidden, 1)
+ hidden = tf.contrib.layers.conv2d(
+ inputs=hidden,
+ num_outputs=num_outputs,
+ kernel_size=4,
+ stride=2,
+ padding='VALID',
+ activation_fn=None,
+ normalizer_fn=None,
+ scope='conv_{}'.format(i))
+ hidden = tf.nn.leaky_relu(hidden, alpha=0.01)
+
+ num_outputs = 2 * num_outputs
+
+ return hidden
+
+
+def discriminator_output_source(input_net):
+ """Output Layer for Source in the Discriminator.
+
+ Determine if the image is real/fake based on the feature extracted. We follow
+ the original paper design where the output is not a simple (batch_size) shape
+ Tensor but rather a (batch_size, 2, 2, 2048) shape Tensor. We will get the
+ correct shape later when we piece things together.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L79
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 64, w / 64, 2048) as features.
+
+ Returns:
+ Tensor of shape (batch_size, h / 64, w / 64, 1) as the score.
+ """
+
+ with tf.variable_scope('discriminator_output_source'):
+
+ output_src = ops.pad(input_net, 1)
+ output_src = tf.contrib.layers.conv2d(
+ inputs=output_src,
+ num_outputs=1,
+ kernel_size=3,
+ stride=1,
+ padding='VALID',
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='conv')
+
+ return output_src
+
+
+def discriminator_output_class(input_net, class_num):
+ """Output Layer for Domain Classification in the Discriminator.
+
+ The original paper use convolution layer where the kernel size is the height
+ and width of the Tensor. We use an equivalent operation here where we first
+ flatten the Tensor to shape (batch_size, K) and a fully connected layer.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L80https
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 64, w / 64, 2028).
+ class_num: Number of output classes to be predicted.
+
+ Returns:
+ Tensor of shape (batch_size, class_num).
+ """
+
+ with tf.variable_scope('discriminator_output_class'):
+
+ output_cls = tf.contrib.layers.flatten(input_net, scope='flatten')
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=output_cls,
+ num_outputs=class_num,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='fully_connected')
+
+ return output_cls
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py"
new file mode 100644
index 00000000..faaf8297
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py"
@@ -0,0 +1,137 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import layers
+
+
+class LayersTest(tf.test.TestCase):
+
+ def test_residual_block(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers._residual_block(
+ input_net=input_tensor,
+ num_outputs=c,
+ kernel_size=3,
+ stride=1,
+ padding_size=1)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_generator_down_sample(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3 + 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_down_sample(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h // 4, w // 4, 256), output.shape)
+
+ def test_generator_bottleneck(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_bottleneck(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_generator_up_sample(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+ c_out = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_up_sample(input_tensor, c_out)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h * 4, w * 4, c_out), output.shape)
+
+ def test_discriminator_input_hidden(self):
+
+ n = 2
+ h = 128
+ w = 128
+ c = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_input_hidden(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, 2, 2, 2048), output.shape)
+
+ def test_discriminator_output_source(self):
+
+ n = 2
+ h = 2
+ w = 2
+ c = 2048
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_output_source(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, 1), output.shape)
+
+ def test_discriminator_output_class(self):
+
+ n = 2
+ h = 2
+ w = 2
+ c = 2048
+ num_domain = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_output_class(input_tensor, num_domain)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, num_domain), output.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py"
new file mode 100644
index 00000000..6d4d0790
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py"
@@ -0,0 +1,102 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Neural network for a StarGAN model.
+
+This module contains the Generator and Discriminator Neural Network to build a
+StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorch implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+import layers
+import ops
+
+
+def generator(inputs, targets):
+ """Generator module.
+
+ Piece everything together for the Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L22
+
+ Args:
+ inputs: Tensor of shape (batch_size, h, w, c) representing the
+ images/information that we want to transform.
+ targets: Tensor of shape (batch_size, num_domains) representing the target
+ domain the generator should transform the image/information to.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, c) as the inputs.
+ """
+
+ with tf.variable_scope('generator'):
+
+ input_with_condition = ops.condition_input_with_pixel_padding(
+ inputs, targets)
+
+ down_sample = layers.generator_down_sample(input_with_condition)
+
+ bottleneck = layers.generator_bottleneck(down_sample)
+
+ up_sample = layers.generator_up_sample(bottleneck, inputs.shape[-1])
+
+ return up_sample
+
+
+def discriminator(input_net, class_num):
+ """Discriminator Module.
+
+ Piece everything together and reshape the output source tensor
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L63
+
+ Notes:
+ The PyTorch Version run the reduce_mean operation later in their solver:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/solver.py#L245
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, c) as batch of images.
+ class_num: (int) number of domain to be predicted
+
+ Returns:
+ output_src: Tensor of shape (batch_size) where each value is a logit
+ representing whether the image is real of fake.
+ output_cls: Tensor of shape (batch_size, class_um) where each value is a
+ logit representing whether the image is in the associated domain.
+ """
+
+ with tf.variable_scope('discriminator'):
+
+ hidden = layers.discriminator_input_hidden(input_net)
+
+ output_src = layers.discriminator_output_source(hidden)
+ output_src = tf.contrib.layers.flatten(output_src)
+ output_src = tf.reduce_mean(output_src, axis=1)
+
+ output_cls = layers.discriminator_output_class(hidden, class_num)
+
+ return output_src, output_cls
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py"
new file mode 100644
index 00000000..a89c0156
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py"
@@ -0,0 +1,61 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import network
+
+
+class NetworkTest(tf.test.TestCase):
+
+ def test_generator(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 4
+ class_num = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ target_tensor = tf.random_uniform((n, class_num))
+ output_tensor = network.generator(input_tensor, target_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_discriminator(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3
+ class_num = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_src_tensor, output_cls_tensor = network.discriminator(
+ input_tensor, class_num)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output_src, output_cls = sess.run([output_src_tensor, output_cls_tensor])
+ self.assertEqual(1, len(output_src.shape))
+ self.assertEqual(n, output_src.shape[0])
+ self.assertTupleEqual((n, class_num), output_cls.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py"
new file mode 100644
index 00000000..c2c1797e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py"
@@ -0,0 +1,106 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Ops for a StarGAN model.
+
+This module contains basic ops to build a StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorvh implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+
+def _padding_arg(h, w, input_format):
+ """Calculate the padding shape for tf.pad().
+
+ Args:
+ h: (int) padding on the height dim.
+ w: (int) padding on the width dim.
+ input_format: (string) the input format as in 'NHWC' or 'HWC'.
+ Raises:
+ ValueError: If input_format is not 'NHWC' or 'HWC'.
+
+ Returns:
+ A two dimension array representing the padding argument.
+ """
+ if input_format == 'NHWC':
+ return [[0, 0], [h, h], [w, w], [0, 0]]
+ elif input_format == 'HWC':
+ return [[h, h], [w, w], [0, 0]]
+ else:
+ raise ValueError('Input Format %s is not supported.' % input_format)
+
+
+def pad(input_net, padding_size):
+ """Padding the tensor with padding_size on both the height and width dim.
+
+ Args:
+ input_net: Tensor in 3D ('HWC') or 4D ('NHWC').
+ padding_size: (int) the size of the padding.
+
+ Notes:
+ Original StarGAN use zero padding instead of mirror padding.
+
+ Raises:
+ ValueError: If input_net Tensor is not 3D or 4D.
+
+ Returns:
+ Tensor with same rank as input_net but with padding on the height and width
+ dim.
+ """
+ if len(input_net.shape) == 4:
+ return tf.pad(input_net, _padding_arg(padding_size, padding_size, 'NHWC'))
+ elif len(input_net.shape) == 3:
+ return tf.pad(input_net, _padding_arg(padding_size, padding_size, 'HWC'))
+ else:
+ raise ValueError('The input tensor need to be either 3D or 4D.')
+
+
+def condition_input_with_pixel_padding(input_tensor, condition_tensor):
+ """Pad image tensor with condition tensor as additional color channel.
+
+ Args:
+ input_tensor: Tensor of shape (batch_size, h, w, c) representing images.
+ condition_tensor: Tensor of shape (batch_size, num_domains) representing the
+ associated domain for the image in input_tensor.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, c + num_domains) representing the
+ conditioned data.
+
+ Raises:
+ ValueError: If `input_tensor` isn't rank 4.
+ ValueError: If `condition_tensor` isn't rank 2.
+ ValueError: If dimension 1 of the input_tensor and condition_tensor is not
+ the same.
+ """
+
+ input_tensor.shape.assert_has_rank(4)
+ condition_tensor.shape.assert_has_rank(2)
+ input_tensor.shape[:1].assert_is_compatible_with(condition_tensor.shape[:1])
+ condition_tensor = tf.expand_dims(condition_tensor, axis=1)
+ condition_tensor = tf.expand_dims(condition_tensor, axis=1)
+ condition_tensor = tf.tile(
+ condition_tensor, [1, input_tensor.shape[1], input_tensor.shape[2], 1])
+
+ return tf.concat([input_tensor, condition_tensor], -1)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py"
new file mode 100644
index 00000000..580a8edb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py"
@@ -0,0 +1,113 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import ops
+
+
+class OpsTest(tf.test.TestCase):
+
+ def test_padding_arg(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ self.assertListEqual([[0, 0], [pad_h, pad_h], [pad_w, pad_w], [0, 0]],
+ ops._padding_arg(pad_h, pad_w, 'NHWC'))
+
+ def test_padding_arg_specify_format(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ self.assertListEqual([[pad_h, pad_h], [pad_w, pad_w], [0, 0]],
+ ops._padding_arg(pad_h, pad_w, 'HWC'))
+
+ def test_padding_arg_invalid_format(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ with self.assertRaises(ValueError):
+ ops._padding_arg(pad_h, pad_w, 'INVALID')
+
+ def test_padding(self):
+
+ n = 2
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((n, h, w, c))
+ test_output_tensor = ops.pad(test_input_tensor, padding_size=pad)
+
+ with self.test_session() as sess:
+ output = sess.run(test_output_tensor)
+ self.assertTupleEqual((n, h + pad * 2, w + pad * 2, c), output.shape)
+
+ def test_padding_with_3D_tensor(self):
+
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((h, w, c))
+ test_output_tensor = ops.pad(test_input_tensor, padding_size=pad)
+
+ with self.test_session() as sess:
+ output = sess.run(test_output_tensor)
+ self.assertTupleEqual((h + pad * 2, w + pad * 2, c), output.shape)
+
+ def test_padding_with_tensor_of_invalid_shape(self):
+
+ n = 2
+ invalid_rank = 1
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((n, invalid_rank, h, w, c))
+
+ with self.assertRaises(ValueError):
+ ops.pad(test_input_tensor, padding_size=pad)
+
+ def test_condition_input_with_pixel_padding(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3
+ num_label = 5
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ label_tensor = tf.random_uniform((n, num_label))
+ output_tensor = ops.condition_input_with_pixel_padding(
+ input_tensor, label_tensor)
+
+ with self.test_session() as sess:
+ labels, outputs = sess.run([label_tensor, output_tensor])
+ self.assertTupleEqual((n, h, w, c + num_label), outputs.shape)
+ for label, output in zip(labels, outputs):
+ for i in range(output.shape[0]):
+ for j in range(output.shape[1]):
+ self.assertListEqual(label.tolist(), output[i, j, c:].tolist())
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py"
new file mode 100644
index 00000000..a959da71
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py"
@@ -0,0 +1,228 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a StarGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import network
+
+# FLAGS for data.
+flags.DEFINE_multi_string(
+ 'image_file_patterns', None,
+ 'List of file pattern for different domain of images. '
+ '(e.g.[\'black_hair\', \'blond_hair\', \'brown_hair\']')
+flags.DEFINE_integer('batch_size', 6, 'The number of images in each batch.')
+flags.DEFINE_integer('patch_size', 128, 'The patch size of images.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/stargan/',
+ 'Directory where to write event logs.')
+
+# FLAGS for training hyper-parameters.
+flags.DEFINE_float('generator_lr', 1e-4, 'The generator learning rate.')
+flags.DEFINE_float('discriminator_lr', 1e-4, 'The discriminator learning rate.')
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+flags.DEFINE_float('adam_beta1', 0.5, 'Adam Beta 1 for the Adam optimizer.')
+flags.DEFINE_float('adam_beta2', 0.999, 'Adam Beta 2 for the Adam optimizer.')
+flags.DEFINE_float('gen_disc_step_ratio', 0.2,
+ 'Generator:Discriminator training step ratio.')
+
+# FLAGS for distributed training.
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+def _define_model(images, labels):
+ """Create the StarGAN Model.
+
+ Args:
+ images: `Tensor` or list of `Tensor` of shape (N, H, W, C).
+ labels: `Tensor` or list of `Tensor` of shape (N, num_domains).
+
+ Returns:
+ `StarGANModel` namedtuple.
+ """
+
+ return tfgan.stargan_model(
+ generator_fn=network.generator,
+ discriminator_fn=network.discriminator,
+ input_data=images,
+ input_data_domain_label=labels)
+
+
+def _get_lr(base_lr):
+ """Returns a learning rate `Tensor`.
+
+ Args:
+ base_lr: A scalar float `Tensor` or a Python number. The base learning
+ rate.
+
+ Returns:
+ A scalar float `Tensor` of learning rate which equals `base_lr` when the
+ global training step is less than FLAGS.max_number_of_steps / 2, afterwards
+ it linearly decays to zero.
+ """
+ global_step = tf.train.get_or_create_global_step()
+ lr_constant_steps = FLAGS.max_number_of_steps // 2
+
+ def _lr_decay():
+ return tf.train.polynomial_decay(
+ learning_rate=base_lr,
+ global_step=(global_step - lr_constant_steps),
+ decay_steps=(FLAGS.max_number_of_steps - lr_constant_steps),
+ end_learning_rate=0.0)
+
+ return tf.cond(global_step < lr_constant_steps, lambda: base_lr, _lr_decay)
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ gen_opt = tf.train.AdamOptimizer(
+ gen_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(
+ dis_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_ops(model, loss):
+ """Defines train ops that trains `stargan_model` with `stargan_loss`.
+
+ Args:
+ model: A `StarGANModel` namedtuple.
+ loss: A `StarGANLoss` namedtuple containing all losses for
+ `stargan_model`.
+
+ Returns:
+ A `GANTrainOps` namedtuple.
+ """
+
+ gen_lr = _get_lr(FLAGS.generator_lr)
+ dis_lr = _get_lr(FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _get_optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ model,
+ loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ return train_ops
+
+
+def _define_train_step():
+ """Get the training step for generator and discriminator for each GAN step.
+
+ Returns:
+ GANTrainSteps namedtuple representing the training step configuration.
+ """
+
+ if FLAGS.gen_disc_step_ratio <= 1:
+ discriminator_step = int(1 / FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(1, discriminator_step)
+ else:
+ generator_step = int(FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(generator_step, 1)
+
+
+def main(_):
+
+ # Create the log_dir if not exist.
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ # Shard the model to different parameter servers.
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+
+ # Create the input dataset.
+ with tf.name_scope('inputs'):
+ images, labels = data_provider.provide_data(
+ FLAGS.image_file_patterns, FLAGS.batch_size, FLAGS.patch_size)
+
+ # Define the model.
+ with tf.name_scope('model'):
+ model = _define_model(images, labels)
+
+ # Add image summary.
+ tfgan.eval.add_stargan_image_summaries(
+ model,
+ num_images=len(FLAGS.image_file_patterns) * FLAGS.batch_size,
+ display_diffs=True)
+
+ # Define the model loss.
+ loss = tfgan.stargan_loss(model)
+
+ # Define the train ops.
+ with tf.name_scope('train_ops'):
+ train_ops = _define_train_ops(model, loss)
+
+ # Define the train steps.
+ train_steps = _define_train_step()
+
+ # Define a status message.
+ status_message = tf.string_join(
+ [
+ 'Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())
+ ],
+ name='status_message')
+
+ # Train the model.
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[
+ tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)
+ ],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_file_patterns')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py"
new file mode 100644
index 00000000..b35c7deb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py"
@@ -0,0 +1,141 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for stargan.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _test_generator(input_images, _):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(inputs, num_domains):
+ """Differentiable dummy discriminator for StarGAN."""
+
+ hidden = tf.contrib.layers.flatten(inputs)
+
+ output_src = tf.reduce_mean(hidden, axis=1)
+
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=hidden,
+ num_outputs=num_domains,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None)
+ return output_src, output_cls
+
+
+train.network.generator = _test_generator
+train.network.discriminator = _test_discriminator
+
+
+class TrainTest(tf.test.TestCase):
+
+ def test_define_model(self):
+ FLAGS.batch_size = 2
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_np = np.zeros(shape=images_shape)
+ images = tf.constant(images_np, dtype=tf.float32)
+ labels = tf.one_hot([0] * FLAGS.batch_size, 2)
+
+ model = train._define_model(images, labels)
+ self.assertIsInstance(model, tfgan.StarGANModel)
+ self.assertShapeEqual(images_np, model.generated_data)
+ self.assertShapeEqual(images_np, model.reconstructed_data)
+ self.assertTrue(isinstance(model.discriminator_variables, list))
+ self.assertTrue(isinstance(model.generator_variables, list))
+ self.assertIsInstance(model.discriminator_scope, tf.VariableScope)
+ self.assertTrue(model.generator_scope, tf.VariableScope)
+ self.assertTrue(callable(model.discriminator_fn))
+ self.assertTrue(callable(model.generator_fn))
+
+ @mock.patch.object(tf.train, 'get_or_create_global_step', autospec=True)
+ def test_get_lr(self, mock_get_or_create_global_step):
+ FLAGS.max_number_of_steps = 10
+ base_lr = 0.01
+ with self.test_session(use_gpu=True) as sess:
+ mock_get_or_create_global_step.return_value = tf.constant(2)
+ lr_step2 = sess.run(train._get_lr(base_lr))
+ mock_get_or_create_global_step.return_value = tf.constant(9)
+ lr_step9 = sess.run(train._get_lr(base_lr))
+
+ self.assertAlmostEqual(base_lr, lr_step2)
+ self.assertAlmostEqual(base_lr * 0.2, lr_step9)
+
+ @mock.patch.object(tf.summary, 'scalar', autospec=True)
+ def test_define_train_ops(self, mock_summary_scalar):
+
+ FLAGS.batch_size = 2
+ FLAGS.generator_lr = 0.1
+ FLAGS.discriminator_lr = 0.01
+
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images = tf.zeros(images_shape, dtype=tf.float32)
+ labels = tf.one_hot([0] * FLAGS.batch_size, 2)
+
+ model = train._define_model(images, labels)
+ loss = tfgan.stargan_loss(model)
+ train_ops = train._define_train_ops(model, loss)
+
+ self.assertIsInstance(train_ops, tfgan.GANTrainOps)
+ mock_summary_scalar.assert_has_calls([
+ mock.call('generator_lr', mock.ANY),
+ mock.call('discriminator_lr', mock.ANY)
+ ])
+
+ def test_get_train_step(self):
+
+ FLAGS.gen_disc_step_ratio = 0.5
+ train_steps = train._define_train_step()
+ self.assertEqual(1, train_steps.generator_train_steps)
+ self.assertEqual(2, train_steps.discriminator_train_steps)
+
+ FLAGS.gen_disc_step_ratio = 3
+ train_steps = train._define_train_step()
+ self.assertEqual(3, train_steps.generator_train_steps)
+ self.assertEqual(1, train_steps.discriminator_train_steps)
+
+ @mock.patch.object(
+ train.data_provider, 'provide_data', autospec=True)
+ def test_main(self, mock_provide_data):
+ FLAGS.image_file_patterns = ['/tmp/A/*.jpg', '/tmp/B/*.jpg', '/tmp/C/*.jpg']
+ FLAGS.max_number_of_steps = 10
+ FLAGS.batch_size = 2
+ num_domains = 3
+
+ images_shape = [FLAGS.batch_size, FLAGS.patch_size, FLAGS.patch_size, 3]
+ img_list = [tf.zeros(images_shape)] * num_domains
+ lbl_list = [tf.one_hot([0] * FLAGS.batch_size, num_domains)] * num_domains
+ mock_provide_data.return_value = (img_list, lbl_list)
+
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy"
new file mode 100644
index 00000000..8288ba0e
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy"
new file mode 100644
index 00000000..8288ba0e
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py"
new file mode 100644
index 00000000..53a11238
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py"
@@ -0,0 +1,37 @@
+"""StarGAN Estimator data provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+import numpy as np
+import data_provider
+from google3.pyglib import resources
+
+
+provide_data = data_provider.provide_data
+
+
+def provide_celeba_test_set():
+ """Provide one example of every class, and labels.
+
+ Returns:
+ An `np.array` of shape (num_domains, H, W, C) representing the images.
+ Values are in [-1, 1].
+ An `np.array` of shape (num_domains, num_domains) representing the labels.
+
+ Raises:
+ ValueError: If test data is inconsistent or malformed.
+ """
+ base_dir = 'google3/third_party/tensorflow_models/gan/stargan_estimator/data'
+ images_fn = os.path.join(base_dir, 'celeba_test_split_images.npy')
+ with resources.GetResourceAsFile(images_fn) as f:
+ images_np = np.load(f)
+ labels_fn = os.path.join(base_dir, 'celeba_test_split_labels.npy')
+ with resources.GetResourceAsFile(labels_fn) as f:
+ labels_np = np.load(f)
+ if images_np.shape[0] != labels_np.shape[0]:
+ raise ValueError('Test data is malformed.')
+
+ return images_np, labels_np
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg"
new file mode 100644
index 00000000..4bcdba0f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg"
new file mode 100644
index 00000000..1421bf9f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg"
new file mode 100644
index 00000000..da8b5ab0
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py"
new file mode 100644
index 00000000..51e5c7e7
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py"
@@ -0,0 +1,184 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a StarGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import io
+import os
+
+from absl import flags
+import numpy as np
+import scipy.misc
+import tensorflow as tf
+
+import network
+import data_provider
+
+# FLAGS for data.
+flags.DEFINE_multi_string(
+ 'image_file_patterns', None,
+ 'List of file pattern for different domain of images. '
+ '(e.g.[\'black_hair\', \'blond_hair\', \'brown_hair\']')
+flags.DEFINE_integer('batch_size', 6, 'The number of images in each batch.')
+flags.DEFINE_integer('patch_size', 128, 'The patch size of images.')
+
+# Write-to-disk flags.
+flags.DEFINE_string('output_dir', '/tmp/stargan/out/',
+ 'Directory where to write summary image.')
+
+# FLAGS for training hyper-parameters.
+flags.DEFINE_float('generator_lr', 1e-4, 'The generator learning rate.')
+flags.DEFINE_float('discriminator_lr', 1e-4, 'The discriminator learning rate.')
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+flags.DEFINE_integer('steps_per_eval', 1000,
+ 'The number of steps after which we write eval to disk.')
+flags.DEFINE_float('adam_beta1', 0.5, 'Adam Beta 1 for the Adam optimizer.')
+flags.DEFINE_float('adam_beta2', 0.999, 'Adam Beta 2 for the Adam optimizer.')
+flags.DEFINE_float('gen_disc_step_ratio', 0.2,
+ 'Generator:Discriminator training step ratio.')
+
+# FLAGS for distributed training.
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ gen_opt = tf.train.AdamOptimizer(
+ gen_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(
+ dis_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_step():
+ """Get the training step for generator and discriminator for each GAN step.
+
+ Returns:
+ GANTrainSteps namedtuple representing the training step configuration.
+ """
+
+ if FLAGS.gen_disc_step_ratio <= 1:
+ discriminator_step = int(1 / FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(1, discriminator_step)
+ else:
+ generator_step = int(FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(generator_step, 1)
+
+
+def _get_summary_image(estimator, test_images_np):
+ """Returns a numpy image of the generate on the test images."""
+ num_domains = len(test_images_np)
+
+ img_rows = []
+ for img_np in test_images_np:
+ def test_input_fn():
+ dataset_imgs = [img_np] * num_domains # pylint:disable=cell-var-from-loop
+ dataset_lbls = [tf.one_hot([d], num_domains) for d in xrange(num_domains)]
+
+ # Make into a dataset.
+ dataset_imgs = np.stack(dataset_imgs)
+ dataset_imgs = np.expand_dims(dataset_imgs, 1)
+ dataset_lbls = tf.stack(dataset_lbls)
+ unused_tensor = tf.zeros(num_domains)
+ return tf.data.Dataset.from_tensor_slices(
+ ((dataset_imgs, dataset_lbls), unused_tensor))
+
+ prediction_iterable = estimator.predict(test_input_fn)
+ predictions = [prediction_iterable.next() for _ in xrange(num_domains)]
+ transform_row = np.concatenate([img_np] + predictions, 1)
+ img_rows.append(transform_row)
+
+ all_rows = np.concatenate(img_rows, 0)
+ # Normalize` [-1, 1] to [0, 1].
+ normalized_summary = (all_rows + 1.0) / 2.0
+ return normalized_summary
+
+
+def _write_to_disk(summary_image, filename):
+ """Write to disk."""
+ buf = io.BytesIO()
+ scipy.misc.imsave(buf, summary_image, format='png')
+ buf.seek(0)
+ with tf.gfile.GFile(filename, 'w') as f:
+ f.write(buf.getvalue())
+
+
+def main(_, override_generator_fn=None, override_discriminator_fn=None):
+ # Create directories if not exist.
+ if not tf.gfile.Exists(FLAGS.output_dir):
+ tf.gfile.MakeDirs(FLAGS.output_dir)
+
+ # Make sure steps integers are consistent.
+ if FLAGS.max_number_of_steps % FLAGS.steps_per_eval != 0:
+ raise ValueError('`max_number_of_steps` must be divisible by '
+ '`steps_per_eval`.')
+
+ # Create optimizers.
+ gen_opt, dis_opt = _get_optimizer(FLAGS.generator_lr, FLAGS.discriminator_lr)
+
+ # Create estimator.
+ # (joelshor): Add optional distribution strategy here.
+ stargan_estimator = tfgan.estimator.StarGANEstimator(
+ generator_fn=override_generator_fn or network.generator,
+ discriminator_fn=override_discriminator_fn or network.discriminator,
+ loss_fn=tfgan.stargan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(_define_train_step()),
+ add_summaries=tfgan.estimator.SummaryType.IMAGES)
+
+ # Get input function for training and test images.
+ train_input_fn = lambda: data_provider.provide_data( # pylint:disable=g-long-lambda
+ FLAGS.image_file_patterns, FLAGS.batch_size, FLAGS.patch_size)
+ test_images_np, _ = data_provider.provide_celeba_test_set()
+ filename_str = os.path.join(FLAGS.output_dir, 'summary_image_%i.png')
+
+ # Periodically train and write prediction output to disk.
+ cur_step = 0
+ while cur_step < FLAGS.max_number_of_steps:
+ stargan_estimator.train(train_input_fn, steps=FLAGS.steps_per_eval)
+ cur_step += FLAGS.steps_per_eval
+ summary_img = _get_summary_image(stargan_estimator, test_images_np)
+ _write_to_disk(summary_img, filename_str % cur_step)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_file_patterns')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py"
new file mode 100644
index 00000000..7bc69191
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py"
@@ -0,0 +1,73 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for stargan_estimator.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+TESTDATA_DIR = 'google3/third_party/tensorflow_models/gan/stargan_estimator/testdata/celeba'
+
+
+def _test_generator(input_images, _):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(inputs, num_domains):
+ """Differentiable dummy discriminator for StarGAN."""
+
+ hidden = tf.contrib.layers.flatten(inputs)
+
+ output_src = tf.reduce_mean(hidden, axis=1)
+
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=hidden,
+ num_outputs=num_domains,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None)
+ return output_src, output_cls
+
+
+class TrainTest(tf.test.TestCase):
+
+ def test_main(self):
+
+ FLAGS.image_file_patterns = [
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'black/*.jpg'),
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'blond/*.jpg'),
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'brown/*.jpg'),
+ ]
+ FLAGS.max_number_of_steps = 1
+ FLAGS.steps_per_eval = 1
+ FLAGS.batch_size = 1
+ train.main(None, _test_generator, _test_discriminator)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb"
new file mode 100644
index 00000000..164b433d
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb"
@@ -0,0 +1,2256 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# TFGAN Tutorial\n",
+ "\n",
+ "## Authors: Joel Shor, joel-shor\n",
+ "\n",
+ "### More complex examples, see [`tensorflow/models/gan`](https://github.com/tensorflow/models/tree/master/research/gan)\n",
+ "\n",
+ "\n",
+ "This notebook will walk you through the basics of using [TFGAN](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/gan) to define, train, and evaluate Generative Adversarial Networks. We describe the library's core features as well as some extra features. This colab assumes a familiarity with TensorFlow's Python API. For more on TensorFlow, please see [TensorFlow tutorials](https://www.tensorflow.org/tutorials/).\n",
+ "\n",
+ "Please note that running on GPU will significantly speed up the training steps, but is not required.\n",
+ "\n",
+ "Last update: 2018-02-10."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Table of Contents\n",
+ "Installation and Setup
+
+### Architectures
+
+#### Compression Network
+
+The compression network is a DCGAN discriminator for the encoder and a DCGAN
+generator for the decoder from [`Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks`](https://arxiv.org/abs/1511.06434).
+The binarizer adds uniform noise during training then binarizes during eval, as in
+[`End-to-end Optimized Image Compression`](https://arxiv.org/abs/1611.01704).
+
+#### Discriminator
+
+The discriminator looks at 70x70 patches, as in
+[`Image-to-Image Translation with Conditional Adversarial Networks`](https://arxiv.org/abs/1611.07004).
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py"
new file mode 100644
index 00000000..329f86b8
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider.py"
@@ -0,0 +1,94 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the CIFAR data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(batch_size, dataset_dir, dataset_name='cifar10',
+ split_name='train', one_hot=True):
+ """Provides batches of CIFAR data.
+
+ Args:
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the CIFAR10 data can be found. If `None`,
+ use default.
+ dataset_name: Name of the dataset.
+ split_name: Should be either 'train' or 'test'.
+ one_hot: Output one hot vector instead of int32 label.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, 32, 32, 3]. Output pixel values are
+ in [-1, 1].
+ labels: Either (1) one_hot_labels if `one_hot` is `True`
+ A `Tensor` of size [batch_size, num_classes], where each row has a
+ single element set to one and the rest set to zeros.
+ Or (2) labels if `one_hot` is `False`
+ A `Tensor` of size [batch_size], holding the labels as integers.
+ num_samples: The number of total samples in the dataset.
+ num_classes: The number of classes in the dataset.
+
+ Raises:
+ ValueError: if the split_name is not either 'train' or 'test'.
+ """
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=(split_name == 'train'))
+ [image, label] = provider.get(['image', 'label'])
+
+ # Preprocess the images.
+ image = (tf.to_float(image) - 128.0) / 128.0
+
+ # Creates a QueueRunner for the pre-fetching operation.
+ images, labels = tf.train.batch(
+ [image, label],
+ batch_size=batch_size,
+ num_threads=32,
+ capacity=5 * batch_size)
+
+ labels = tf.reshape(labels, [-1])
+
+ if one_hot:
+ labels = tf.one_hot(labels, dataset.num_classes)
+
+ return images, labels, dataset.num_samples, dataset.num_classes
+
+
+def float_image_to_uint8(image):
+ """Convert float image in [-1, 1) to [0, 255] uint8.
+
+ Note that `1` gets mapped to `0`, but `1 - epsilon` gets mapped to 255.
+
+ Args:
+ image: An image tensor. Values should be in [-1, 1).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 128.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py"
new file mode 100644
index 00000000..c9f18008
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/data_provider_test.py"
@@ -0,0 +1,54 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def test_cifar10_train_set(self):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cifar/testdata')
+
+ batch_size = 4
+ images, labels, num_samples, num_classes = data_provider.provide_data(
+ batch_size, dataset_dir)
+ self.assertEqual(50000, num_samples)
+ self.assertEqual(10, num_classes)
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_out, labels_out = sess.run([images, labels])
+ self.assertEqual(images_out.shape, (batch_size, 32, 32, 3))
+ expected_label_shape = (batch_size, 10)
+ self.assertEqual(expected_label_shape, labels_out.shape)
+ # Check range.
+ self.assertTrue(np.all(np.abs(images_out) <= 1))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py"
new file mode 100644
index 00000000..6addd5e1
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval.py"
@@ -0,0 +1,170 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained CIFAR model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/cifar10/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/cifar10/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('num_images_generated', 100,
+ 'Number of images to generate at once.')
+
+flags.DEFINE_integer('num_inception_images', 10,
+ 'The number of images to run through Inception at once.')
+
+flags.DEFINE_boolean('eval_real_images', False,
+ 'If `True`, run Inception network on real images.')
+
+flags.DEFINE_boolean('conditional_eval', False,
+ 'If `True`, set up a conditional GAN.')
+
+flags.DEFINE_boolean('eval_frechet_inception_distance', True,
+ 'If `True`, compute Frechet Inception distance using real '
+ 'images and generated images.')
+
+flags.DEFINE_integer('num_images_per_class', 10,
+ 'When a conditional generator is used, this is the number '
+ 'of images to display per class.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+flags.DEFINE_integer(
+ 'inter_op_parallelism_threads', 0,
+ 'Number of threads to use for inter-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+flags.DEFINE_integer(
+ 'intra_op_parallelism_threads', 0,
+ 'Number of threads to use for intra-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+def main(_, run_eval_loop=True):
+ # Fetch and generate images to run through Inception.
+ with tf.name_scope('inputs'):
+ real_data, num_classes = _get_real_data(
+ FLAGS.num_images_generated, FLAGS.dataset_dir)
+ generated_data = _get_generated_data(
+ FLAGS.num_images_generated, FLAGS.conditional_eval, num_classes)
+
+ # Compute Frechet Inception Distance.
+ if FLAGS.eval_frechet_inception_distance:
+ fid = util.get_frechet_inception_distance(
+ real_data, generated_data, FLAGS.num_images_generated,
+ FLAGS.num_inception_images)
+ tf.summary.scalar('frechet_inception_distance', fid)
+
+ # Compute normal Inception scores.
+ if FLAGS.eval_real_images:
+ inc_score = util.get_inception_scores(
+ real_data, FLAGS.num_images_generated, FLAGS.num_inception_images)
+ else:
+ inc_score = util.get_inception_scores(
+ generated_data, FLAGS.num_images_generated, FLAGS.num_inception_images)
+ tf.summary.scalar('inception_score', inc_score)
+
+ # If conditional, display an image grid of difference classes.
+ if FLAGS.conditional_eval and not FLAGS.eval_real_images:
+ reshaped_imgs = util.get_image_grid(
+ generated_data, FLAGS.num_images_generated, num_classes,
+ FLAGS.num_images_per_class)
+ tf.summary.image('generated_data', reshaped_imgs, max_outputs=1)
+
+ # Create ops that write images to disk.
+ image_write_ops = None
+ if FLAGS.conditional_eval and FLAGS.write_to_disk:
+ reshaped_imgs = util.get_image_grid(
+ generated_data, FLAGS.num_images_generated, num_classes,
+ FLAGS.num_images_per_class)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_imgs)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'conditional_cifar10.png'),
+ tf.image.encode_png(uint8_images[0]))
+ else:
+ if FLAGS.num_images_generated >= 100 and FLAGS.write_to_disk:
+ reshaped_imgs = tfgan.eval.image_reshaper(
+ generated_data[:100], num_cols=FLAGS.num_images_per_class)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_imgs)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'unconditional_cifar10.png'),
+ tf.image.encode_png(uint8_images[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ sess_config = tf.ConfigProto(
+ inter_op_parallelism_threads=FLAGS.inter_op_parallelism_threads,
+ intra_op_parallelism_threads=FLAGS.intra_op_parallelism_threads)
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ master=FLAGS.master,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ config=sess_config,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _get_real_data(num_images_generated, dataset_dir):
+ """Get real images."""
+ data, _, _, num_classes = data_provider.provide_data(
+ num_images_generated, dataset_dir)
+ return data, num_classes
+
+
+def _get_generated_data(num_images_generated, conditional_eval, num_classes):
+ """Get generated images."""
+ noise = tf.random_normal([num_images_generated, 64])
+ # If conditional, generate class-specific images.
+ if conditional_eval:
+ conditioning = util.get_generator_conditioning(
+ num_images_generated, num_classes)
+ generator_inputs = (noise, conditioning)
+ generator_fn = networks.conditional_generator
+ else:
+ generator_inputs = noise
+ generator_fn = networks.generator
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('Generator'):
+ data = generator_fn(generator_inputs, is_training=False)
+
+ return data
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py"
new file mode 100644
index 00000000..f8c644ea
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/eval_test.py"
@@ -0,0 +1,51 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.cifar.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import tensorflow as tf
+import eval # pylint:disable=redefined-builtin
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class EvalTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('RealData', True, False),
+ ('GeneratedData', False, False),
+ ('GeneratedDataConditional', False, True))
+ def test_build_graph(self, eval_real_images, conditional_eval):
+ FLAGS.eval_real_images = eval_real_images
+ FLAGS.conditional_eval = conditional_eval
+ # Mock `frechet_inception_distance` and `inception_score`, which are
+ # expensive.
+ with mock.patch.object(
+ eval.util, 'get_frechet_inception_distance') as mock_fid:
+ with mock.patch.object(eval.util, 'get_inception_scores') as mock_iscore:
+ mock_fid.return_value = 1.0
+ mock_iscore.return_value = 1.0
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh"
new file mode 100644
index 00000000..89313da5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/launch_jobs.sh"
@@ -0,0 +1,121 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the CIFAR dataset.
+# 2. Trains an unconditional or conditional model on the CIFAR training set.
+# 3. Evaluates the models and writes sample images to disk.
+#
+#
+# With the default batch size and number of steps, train times are:
+#
+# Usage:
+# cd models/research/gan/cifar
+# ./launch_jobs.sh ${gan_type} ${git_repo}
+set -e
+
+# Type of GAN to run. Right now, options are `unconditional`, `conditional`, or
+# `infogan`.
+gan_type=$1
+if ! [[ "$gan_type" =~ ^(unconditional|conditional) ]]; then
+ echo "'gan_type' must be one of: 'unconditional', 'conditional'."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/cifar-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/cifar-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/cifar-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/gan:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=cifar10 \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+if [[ "$gan_type" == "unconditional" ]]; then
+ UNCONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/unconditional"
+ UNCONDITIONAL_EVAL_DIR="${EVAL_DIR}/unconditional"
+ NUM_STEPS=10000
+ # Run training.
+ Banner "Starting training unconditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/cifar/train.py" \
+ --train_log_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="unconditional" \
+ --alsologtostderr
+ Banner "Finished training unconditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of unconditional GAN..."
+ python "${git_repo}/research/gan/cifar/eval.py" \
+ --checkpoint_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${UNCONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --conditional_eval=false \
+ --max_number_of_evaluations=1
+ Banner "Finished unconditional evaluation. See ${UNCONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run conditional GAN.
+if [[ "$gan_type" == "conditional" ]]; then
+ CONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/conditional"
+ CONDITIONAL_EVAL_DIR="${EVAL_DIR}/conditional"
+ NUM_STEPS=10000
+ # Run training.
+ Banner "Starting training conditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/cifar/train.py" \
+ --train_log_dir=${CONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="conditional" \
+ --alsologtostderr
+ Banner "Finished training conditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of conditional GAN..."
+ python "${git_repo}/research/gan/cifar/eval.py" \
+ --checkpoint_dir=${CONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${CONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --conditional_eval=true \
+ --max_number_of_evaluations=1
+ Banner "Finished conditional evaluation. See ${CONDITIONAL_EVAL_DIR} for output images."
+fi
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py"
new file mode 100644
index 00000000..f50b1ce9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks.py"
@@ -0,0 +1,130 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN CIFAR example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import dcgan
+
+tfgan = tf.contrib.gan
+
+
+def _last_conv_layer(end_points):
+ """"Returns the last convolutional layer from an endpoints dictionary."""
+ conv_list = [k if k[:4] == 'conv' else None for k in end_points.keys()]
+ conv_list.sort()
+ return end_points[conv_list[-1]]
+
+
+def generator(noise, is_training=True):
+ """Generator to produce CIFAR images.
+
+ Args:
+ noise: A 2D Tensor of shape [batch size, noise dim]. Since this example
+ does not use conditioning, this Tensor represents a noise vector of some
+ kind that will be reshaped by the generator into CIFAR examples.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A single Tensor with a batch of generated CIFAR images.
+ """
+ images, _ = dcgan.generator(noise, is_training=is_training, fused_batch_norm=True)
+
+ # Make sure output lies between [-1, 1].
+ return tf.tanh(images)
+
+
+def conditional_generator(inputs, is_training=True):
+ """Generator to produce CIFAR images.
+
+ Args:
+ inputs: A 2-tuple of Tensors (noise, one_hot_labels) and creates a
+ conditional generator.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A single Tensor with a batch of generated CIFAR images.
+ """
+ noise, one_hot_labels = inputs
+ noise = tfgan.features.condition_tensor_from_onehot(noise, one_hot_labels)
+
+ images, _ = dcgan.generator(noise, is_training=is_training, fused_batch_norm=True)
+
+ # Make sure output lies between [-1, 1].
+ return tf.tanh(images)
+
+
+def discriminator(img, unused_conditioning, is_training=True):
+ """Discriminator for CIFAR images.
+
+ Args:
+ img: A Tensor of shape [batch size, width, height, channels], that can be
+ either real or generated. It is the discriminator's goal to distinguish
+ between the two.
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A 1D Tensor of shape [batch size] representing the confidence that the
+ images are real. The output can lie in [-inf, inf], with positive values
+ indicating high confidence that the images are real.
+ """
+ logits, _ = dcgan.discriminator(img, is_training=is_training, fused_batch_norm=True)
+ return logits
+
+
+# (joelshor): This discriminator creates variables that aren't used, and
+# causes logging warnings. Improve `dcgan` nets to accept a target end layer,
+# so extraneous variables aren't created.
+def conditional_discriminator(img, conditioning, is_training=True):
+ """Discriminator for CIFAR images.
+
+ Args:
+ img: A Tensor of shape [batch size, width, height, channels], that can be
+ either real or generated. It is the discriminator's goal to distinguish
+ between the two.
+ conditioning: A 2-tuple of Tensors representing (noise, one_hot_labels).
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A 1D Tensor of shape [batch size] representing the confidence that the
+ images are real. The output can lie in [-inf, inf], with positive values
+ indicating high confidence that the images are real.
+ """
+ logits, end_points = dcgan.discriminator(img, is_training=is_training, fused_batch_norm=True)
+
+ # Condition the last convolution layer.
+ _, one_hot_labels = conditioning
+ net = _last_conv_layer(end_points)
+ net = tfgan.features.condition_tensor_from_onehot(
+ tf.contrib.layers.flatten(net), one_hot_labels)
+ logits = tf.contrib.layers.linear(net, 1)
+
+ return logits
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py"
new file mode 100644
index 00000000..1893d164
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/networks_test.py"
@@ -0,0 +1,78 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.cifar.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+import networks
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_generator(self):
+ tf.set_random_seed(1234)
+ batch_size = 100
+ noise = tf.random_normal([batch_size, 64])
+ image = networks.generator(noise)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ image_np = image.eval()
+
+ self.assertAllEqual([batch_size, 32, 32, 3], image_np.shape)
+ self.assertTrue(np.all(np.abs(image_np) <= 1))
+
+ def test_generator_conditional(self):
+ tf.set_random_seed(1234)
+ batch_size = 100
+ noise = tf.random_normal([batch_size, 64])
+ conditioning = tf.one_hot([0] * batch_size, 10)
+ image = networks.conditional_generator((noise, conditioning))
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ image_np = image.eval()
+
+ self.assertAllEqual([batch_size, 32, 32, 3], image_np.shape)
+ self.assertTrue(np.all(np.abs(image_np) <= 1))
+
+ def test_discriminator(self):
+ batch_size = 5
+ image = tf.random_uniform([batch_size, 32, 32, 3], -1, 1)
+ dis_output = networks.discriminator(image, None)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ dis_output_np = dis_output.eval()
+
+ self.assertAllEqual([batch_size, 1], dis_output_np.shape)
+
+ def test_discriminator_conditional(self):
+ batch_size = 5
+ image = tf.random_uniform([batch_size, 32, 32, 3], -1, 1)
+ conditioning = (None, tf.one_hot([0] * batch_size, 10))
+ dis_output = networks.conditional_discriminator(image, conditioning)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ dis_output_np = dis_output.eval()
+
+ self.assertAllEqual([batch_size, 1], dis_output_np.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord"
new file mode 100644
index 00000000..93402244
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/testdata/cifar10_train.tfrecord" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py"
new file mode 100644
index 00000000..f08f7955
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train.py"
@@ -0,0 +1,190 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a generator on CIFAR data."""
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/cifar/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_boolean(
+ 'conditional', False,
+ 'If `True`, set up a conditional GAN. If False, it is unconditional.')
+
+# Sync replicas flags.
+flags.DEFINE_boolean(
+ 'use_sync_replicas', True,
+ 'If `True`, use sync replicas. Otherwise use async.')
+
+flags.DEFINE_integer(
+ 'worker_replicas', 10,
+ 'The number of gradients to collect before updating params. Only used '
+ 'with sync replicas.')
+
+flags.DEFINE_integer(
+ 'backup_workers', 1,
+ 'Number of workers to be kept as backup in the sync replicas case.')
+
+flags.DEFINE_integer(
+ 'inter_op_parallelism_threads', 0,
+ 'Number of threads to use for inter-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+flags.DEFINE_integer(
+ 'intra_op_parallelism_threads', 0,
+ 'Number of threads to use for intra-op parallelism. If left as default value of 0, the system will pick an appropriate number.')
+
+FLAGS = flags.FLAGS
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Force all input processing onto CPU in order to reserve the GPU for
+ # the forward inference and back-propagation.
+ with tf.name_scope('inputs'):
+ with tf.device('/cpu:0'):
+ images, one_hot_labels, _, _ = data_provider.provide_data(
+ FLAGS.batch_size, FLAGS.dataset_dir)
+
+ # Define the GANModel tuple.
+ noise = tf.random_normal([FLAGS.batch_size, 64])
+ if FLAGS.conditional:
+ generator_fn = networks.conditional_generator
+ discriminator_fn = networks.conditional_discriminator
+ generator_inputs = (noise, one_hot_labels)
+ else:
+ generator_fn = networks.generator
+ discriminator_fn = networks.discriminator
+ generator_inputs = noise
+ gan_model = tfgan.gan_model(
+ generator_fn,
+ discriminator_fn,
+ real_data=images,
+ generator_inputs=generator_inputs)
+ tfgan.eval.add_gan_model_image_summaries(gan_model)
+
+ # Get the GANLoss tuple. Use the selected GAN loss functions.
+ # (joelshor): Put this block in `with tf.name_scope('loss'):` when
+ # cl/171610946 goes into the opensource release.
+ gan_loss = tfgan.gan_loss(gan_model,
+ gradient_penalty_weight=1.0,
+ add_summaries=True)
+
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ with tf.name_scope('train'):
+ gen_lr, dis_lr = _learning_rate()
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr, FLAGS.use_sync_replicas)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ sync_hooks = ([gen_opt.make_session_run_hook(FLAGS.task == 0),
+ dis_opt.make_session_run_hook(FLAGS.task == 0)]
+ if FLAGS.use_sync_replicas else [])
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ sess_config = tf.ConfigProto(
+ inter_op_parallelism_threads=FLAGS.inter_op_parallelism_threads,
+ intra_op_parallelism_threads=FLAGS.intra_op_parallelism_threads)
+ tfgan.gan_train(
+ train_ops,
+ hooks=(
+ [tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)] +
+ sync_hooks),
+ logdir=FLAGS.train_log_dir,
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0,
+ config=sess_config)
+
+
+def _learning_rate():
+ generator_lr = tf.train.exponential_decay(
+ learning_rate=0.0001,
+ global_step=tf.train.get_or_create_global_step(),
+ decay_steps=100000,
+ decay_rate=0.9,
+ staircase=True)
+ discriminator_lr = 0.001
+ return generator_lr, discriminator_lr
+
+
+def _optimizer(gen_lr, dis_lr, use_sync_replicas):
+ """Get an optimizer, that's optionally synchronous."""
+ generator_opt = tf.train.RMSPropOptimizer(gen_lr, decay=.9, momentum=0.1)
+ discriminator_opt = tf.train.RMSPropOptimizer(dis_lr, decay=.95, momentum=0.1)
+
+ def _make_sync(opt):
+ return tf.train.SyncReplicasOptimizer(
+ opt,
+ replicas_to_aggregate=FLAGS.worker_replicas-FLAGS.backup_workers,
+ total_num_replicas=FLAGS.worker_replicas)
+ if use_sync_replicas:
+ generator_opt = _make_sync(generator_opt)
+ discriminator_opt = _make_sync(discriminator_opt)
+
+ return generator_opt, discriminator_opt
+
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py"
new file mode 100644
index 00000000..6f0fbc3d
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/train_test.py"
@@ -0,0 +1,56 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('Unconditional', False, False),
+ ('Conditional', True, False),
+ ('SyncReplicas', False, True))
+ def test_build_graph(self, conditional, use_sync_replicas):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.conditional = conditional
+ FLAGS.use_sync_replicas = use_sync_replicas
+ FLAGS.batch_size = 16
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 32, 32, 3], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = (
+ mock_imgs, mock_lbls, None, None)
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py"
new file mode 100644
index 00000000..02f344de
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util.py"
@@ -0,0 +1,156 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Convenience functions for training and evaluating a TFGAN CIFAR example."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+tfgan = tf.contrib.gan
+
+
+def get_generator_conditioning(batch_size, num_classes):
+ """Generates TFGAN conditioning inputs for evaluation.
+
+ Args:
+ batch_size: A Python integer. The desired batch size.
+ num_classes: A Python integer. The number of classes.
+
+ Returns:
+ A Tensor of one-hot vectors corresponding to an even distribution over
+ classes.
+
+ Raises:
+ ValueError: If `batch_size` isn't evenly divisible by `num_classes`.
+ """
+ if batch_size % num_classes != 0:
+ raise ValueError('`batch_size` %i must be evenly divisible by '
+ '`num_classes` %i.' % (batch_size, num_classes))
+ labels = [lbl for lbl in xrange(num_classes)
+ for _ in xrange(batch_size // num_classes)]
+ return tf.one_hot(tf.constant(labels), num_classes)
+
+
+def get_image_grid(images, batch_size, num_classes, num_images_per_class):
+ """Combines images from each class in a single summary image.
+
+ Args:
+ images: Tensor of images that are arranged by class. The first
+ `batch_size / num_classes` images belong to the first class, the second
+ group belong to the second class, etc. Shape is
+ [batch, width, height, channels].
+ batch_size: Python integer. Batch dimension.
+ num_classes: Number of classes to show.
+ num_images_per_class: Number of image examples per class to show.
+
+ Raises:
+ ValueError: If the batch dimension of `images` is known at graph
+ construction, and it isn't `batch_size`.
+ ValueError: If there aren't enough images to show
+ `num_classes * num_images_per_class` images.
+ ValueError: If `batch_size` isn't divisible by `num_classes`.
+
+ Returns:
+ A single image.
+ """
+ # Validate inputs.
+ images.shape[0:1].assert_is_compatible_with([batch_size])
+ if batch_size < num_classes * num_images_per_class:
+ raise ValueError('Not enough images in batch to show the desired number of '
+ 'images.')
+ if batch_size % num_classes != 0:
+ raise ValueError('`batch_size` must be divisible by `num_classes`.')
+
+ # Only get a certain number of images per class.
+ num_batches = batch_size // num_classes
+ indices = [i * num_batches + j for i in xrange(num_classes)
+ for j in xrange(num_images_per_class)]
+ sampled_images = tf.gather(images, indices)
+ return tfgan.eval.image_reshaper(
+ sampled_images, num_cols=num_images_per_class)
+
+
+def get_inception_scores(images, batch_size, num_inception_images):
+ """Get Inception score for some images.
+
+ Args:
+ images: Image minibatch. Shape [batch size, width, height, channels]. Values
+ are in [-1, 1].
+ batch_size: Python integer. Batch dimension.
+ num_inception_images: Number of images to run through Inception at once.
+
+ Returns:
+ Inception scores. Tensor shape is [batch size].
+
+ Raises:
+ ValueError: If `batch_size` is incompatible with the first dimension of
+ `images`.
+ ValueError: If `batch_size` isn't divisible by `num_inception_images`.
+ """
+ # Validate inputs.
+ images.shape[0:1].assert_is_compatible_with([batch_size])
+ if batch_size % num_inception_images != 0:
+ raise ValueError(
+ '`batch_size` must be divisible by `num_inception_images`.')
+
+ # Resize images.
+ size = 299
+ resized_images = tf.image.resize_bilinear(images, [size, size])
+
+ # Run images through Inception.
+ num_batches = batch_size // num_inception_images
+ inc_score = tfgan.eval.inception_score(
+ resized_images, num_batches=num_batches)
+
+ return inc_score
+
+
+def get_frechet_inception_distance(real_images, generated_images, batch_size,
+ num_inception_images):
+ """Get Frechet Inception Distance between real and generated images.
+
+ Args:
+ real_images: Real images minibatch. Shape [batch size, width, height,
+ channels. Values are in [-1, 1].
+ generated_images: Generated images minibatch. Shape [batch size, width,
+ height, channels]. Values are in [-1, 1].
+ batch_size: Python integer. Batch dimension.
+ num_inception_images: Number of images to run through Inception at once.
+
+ Returns:
+ Frechet Inception distance. A floating-point scalar.
+
+ Raises:
+ ValueError: If the minibatch size is known at graph construction time, and
+ doesn't batch `batch_size`.
+ """
+ # Validate input dimensions.
+ real_images.shape[0:1].assert_is_compatible_with([batch_size])
+ generated_images.shape[0:1].assert_is_compatible_with([batch_size])
+
+ # Resize input images.
+ size = 299
+ resized_real_images = tf.image.resize_bilinear(real_images, [size, size])
+ resized_generated_images = tf.image.resize_bilinear(
+ generated_images, [size, size])
+
+ # Compute Frechet Inception Distance.
+ num_batches = batch_size // num_inception_images
+ fid = tfgan.eval.frechet_inception_distance(
+ resized_real_images, resized_generated_images, num_batches=num_batches)
+
+ return fid
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py"
new file mode 100644
index 00000000..b1847489
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cifar/util_test.py"
@@ -0,0 +1,62 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.cifar.util."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import util
+
+mock = tf.test.mock
+
+
+class UtilTest(tf.test.TestCase):
+
+ def test_get_generator_conditioning(self):
+ conditioning = util.get_generator_conditioning(12, 4)
+ self.assertEqual([12, 4], conditioning.shape.as_list())
+
+ def test_get_image_grid(self):
+ util.get_image_grid(
+ tf.zeros([6, 28, 28, 1]),
+ batch_size=6,
+ num_classes=3,
+ num_images_per_class=1)
+
+ # Mock `inception_score` which is expensive.
+ @mock.patch.object(util.tfgan.eval, 'inception_score', autospec=True)
+ def test_get_inception_scores(self, mock_inception_score):
+ mock_inception_score.return_value = 1.0
+ util.get_inception_scores(
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ batch_size=100,
+ num_inception_images=10)
+
+ # Mock `frechet_inception_distance` which is expensive.
+ @mock.patch.object(util.tfgan.eval, 'frechet_inception_distance',
+ autospec=True)
+ def test_get_frechet_inception_distance(self, mock_fid):
+ mock_fid.return_value = 1.0
+ util.get_frechet_inception_distance(
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ tf.placeholder(tf.float32, shape=[None, 28, 28, 3]),
+ batch_size=100,
+ num_inception_images=10)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py"
new file mode 100644
index 00000000..bed09a3f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider.py"
@@ -0,0 +1,185 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+
+def normalize_image(image):
+ """Rescale from range [0, 255] to [-1, 1]."""
+ return (tf.to_float(image) - 127.5) / 127.5
+
+
+def undo_normalize_image(normalized_image):
+ """Convert to a numpy array that can be read by PIL."""
+ # Convert from NHWC to HWC.
+ normalized_image = np.squeeze(normalized_image, axis=0)
+ return np.uint8(normalized_image * 127.5 + 127.5)
+
+
+def _sample_patch(image, patch_size):
+ """Crop image to square shape and resize it to `patch_size`.
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_size: A Python scalar. The output image size.
+
+ Returns:
+ A 3D `Tensor` of HWC format which has the shape of
+ [patch_size, patch_size, 3].
+ """
+ image_shape = tf.shape(image)
+ height, width = image_shape[0], image_shape[1]
+ target_size = tf.minimum(height, width)
+ image = tf.image.resize_image_with_crop_or_pad(image, target_size,
+ target_size)
+ # tf.image.resize_area only accepts 4D tensor, so expand dims first.
+ image = tf.expand_dims(image, axis=0)
+ image = tf.image.resize_images(image, [patch_size, patch_size])
+ image = tf.squeeze(image, axis=0)
+ # Force image num_channels = 3
+ image = tf.tile(image, [1, 1, tf.maximum(1, 4 - tf.shape(image)[2])])
+ image = tf.slice(image, [0, 0, 0], [patch_size, patch_size, 3])
+ return image
+
+
+def full_image_to_patch(image, patch_size):
+ image = normalize_image(image)
+ # Sample a patch of fixed size.
+ image_patch = _sample_patch(image, patch_size)
+ image_patch.shape.assert_is_compatible_with([patch_size, patch_size, 3])
+ return image_patch
+
+
+def _provide_custom_dataset(image_file_pattern,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides batches of custom image data.
+
+ Args:
+ image_file_pattern: A string of glob pattern of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of mapping threads. Defaults to 1.
+ patch_size: Size of the path to extract from the image. Defaults to 128.
+
+ Returns:
+ A tf.data.Dataset with Tensors of shape
+ [batch_size, patch_size, patch_size, 3] representing a batch of images.
+
+ Raises:
+ ValueError: If no files match `image_file_pattern`.
+ """
+ if not tf.gfile.Glob(image_file_pattern):
+ raise ValueError('No file patterns found.')
+ filenames_ds = tf.data.Dataset.list_files(image_file_pattern)
+ bytes_ds = filenames_ds.map(tf.io.read_file, num_parallel_calls=num_threads)
+ images_ds = bytes_ds.map(
+ tf.image.decode_image, num_parallel_calls=num_threads)
+ patches_ds = images_ds.map(
+ lambda img: full_image_to_patch(img, patch_size),
+ num_parallel_calls=num_threads)
+ patches_ds = patches_ds.repeat()
+
+ if shuffle:
+ patches_ds = patches_ds.shuffle(5 * batch_size)
+
+ patches_ds = patches_ds.prefetch(5 * batch_size)
+ patches_ds = patches_ds.batch(batch_size)
+
+ return patches_ds
+
+
+def provide_custom_datasets(image_file_patterns,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides multiple batches of custom image data.
+
+ Args:
+ image_file_patterns: A list of glob patterns of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_size: Size of the patch to extract from the image. Defaults to 128.
+
+ Returns:
+ A list of tf.data.Datasets the same number as `image_file_patterns`. Each
+ of the datasets have `Tensor`'s in the list has a shape of
+ [batch_size, patch_size, patch_size, 3] representing a batch of images.
+
+ Raises:
+ ValueError: If image_file_patterns is not a list or tuple.
+ """
+ if not isinstance(image_file_patterns, (list, tuple)):
+ raise ValueError(
+ '`image_file_patterns` should be either list or tuple, but was {}.'.
+ format(type(image_file_patterns)))
+ custom_datasets = []
+ for pattern in image_file_patterns:
+ custom_datasets.append(
+ _provide_custom_dataset(
+ pattern,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads,
+ patch_size=patch_size))
+
+ return custom_datasets
+
+
+def provide_custom_data(image_file_patterns,
+ batch_size,
+ shuffle=True,
+ num_threads=1,
+ patch_size=128):
+ """Provides multiple batches of custom image data.
+
+ Args:
+ image_file_patterns: A list of glob patterns of image files.
+ batch_size: The number of images in each batch.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_size: Size of the patch to extract from the image. Defaults to 128.
+
+ Returns:
+ A list of float `Tensor`s with the same size of `image_file_patterns`. Each
+ of the `Tensor` in the list has a shape of
+ [batch_size, patch_size, patch_size, 3] representing a batch of images. As a
+ side effect, the tf.Dataset initializer is added to the
+ tf.GraphKeys.TABLE_INITIALIZERS collection.
+
+ Raises:
+ ValueError: If image_file_patterns is not a list or tuple.
+ """
+ datasets = provide_custom_datasets(
+ image_file_patterns, batch_size, shuffle, num_threads, patch_size)
+
+ tensors = []
+ for ds in datasets:
+ iterator = ds.make_initializable_iterator()
+ tf.add_to_collection(tf.GraphKeys.TABLE_INITIALIZERS, iterator.initializer)
+ tensors.append(iterator.get_next())
+
+ return tensors
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py"
new file mode 100644
index 00000000..c4c44b38
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/data_provider_test.py"
@@ -0,0 +1,129 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+mock = tf.test.mock
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def setUp(self):
+ super(DataProviderTest, self).setUp()
+ self.testdata_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cyclegan/testdata')
+
+ def test_normalize_image(self):
+ image = tf.random_uniform(shape=(8, 8, 3), maxval=256, dtype=tf.int32)
+ rescaled_image = data_provider.normalize_image(image)
+ self.assertEqual(tf.float32, rescaled_image.dtype)
+ self.assertListEqual(image.shape.as_list(), rescaled_image.shape.as_list())
+ with self.test_session(use_gpu=True) as sess:
+ rescaled_image_out = sess.run(rescaled_image)
+ self.assertTrue(np.all(np.abs(rescaled_image_out) <= 1.0))
+
+ def test_sample_patch(self):
+ image = tf.zeros(shape=(8, 8, 3))
+ patch1 = data_provider._sample_patch(image, 7)
+ patch2 = data_provider._sample_patch(image, 10)
+ image = tf.zeros(shape=(8, 8, 1))
+ patch3 = data_provider._sample_patch(image, 10)
+ with self.test_session(use_gpu=True) as sess:
+ self.assertTupleEqual((7, 7, 3), sess.run(patch1).shape)
+ self.assertTupleEqual((10, 10, 3), sess.run(patch2).shape)
+ self.assertTupleEqual((10, 10, 3), sess.run(patch3).shape)
+
+ def test_custom_dataset_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_ds = data_provider._provide_custom_dataset(
+ file_pattern, batch_size=batch_size, patch_size=patch_size)
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images_ds.output_shapes.as_list())
+ self.assertEqual(tf.float32, images_ds.output_types)
+
+ iterator = images_ds.make_initializable_iterator()
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(iterator.initializer)
+ images_out = sess.run(iterator.get_next())
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+ def test_custom_datasets_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_ds_list = data_provider.provide_custom_datasets(
+ [file_pattern, file_pattern],
+ batch_size=batch_size,
+ patch_size=patch_size)
+ for images_ds in images_ds_list:
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images_ds.output_shapes.as_list())
+ self.assertEqual(tf.float32, images_ds.output_types)
+
+ iterators = [x.make_initializable_iterator() for x in images_ds_list]
+ initialiers = [x.initializer for x in iterators]
+ img_tensors = [x.get_next() for x in iterators]
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(initialiers)
+ images_out_list = sess.run(img_tensors)
+ for images_out in images_out_list:
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+ def test_custom_data_provider(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ batch_size = 3
+ patch_size = 8
+ images_list = data_provider.provide_custom_data(
+ [file_pattern, file_pattern],
+ batch_size=batch_size,
+ patch_size=patch_size)
+ for images in images_list:
+ self.assertListEqual([None, patch_size, patch_size, 3],
+ images.shape.as_list())
+ self.assertEqual(tf.float32, images.dtype)
+
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ sess.run(tf.tables_initializer())
+ images_out_list = sess.run(images_list)
+ for images_out in images_out_list:
+ self.assertTupleEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py"
new file mode 100644
index 00000000..9eaaa111
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo.py"
@@ -0,0 +1,151 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+r"""Demo that makes inference requests against a running inference server."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import app
+from absl import flags
+import numpy as np
+import PIL
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('checkpoint_path', '',
+ 'CycleGAN checkpoint path created by train.py. '
+ '(e.g. "/mylogdir/model.ckpt-18442")')
+
+flags.DEFINE_string(
+ 'image_set_x_glob', '',
+ 'Optional: Glob path to images of class X to feed through the CycleGAN.')
+
+flags.DEFINE_string(
+ 'image_set_y_glob', '',
+ 'Optional: Glob path to images of class Y to feed through the CycleGAN.')
+
+flags.DEFINE_string(
+ 'generated_x_dir', '/tmp/generated_x/',
+ 'If image_set_y_glob is defined, where to output the generated X '
+ 'images.')
+
+flags.DEFINE_string(
+ 'generated_y_dir', '/tmp/generated_y/',
+ 'If image_set_x_glob is defined, where to output the generated Y '
+ 'images.')
+
+flags.DEFINE_integer('patch_dim', 128,
+ 'The patch size of images that was used in train.py.')
+
+FLAGS = flags.FLAGS
+
+
+def _make_dir_if_not_exists(dir_path):
+ """Make a directory if it does not exist."""
+ if not tf.gfile.Exists(dir_path):
+ tf.gfile.MakeDirs(dir_path)
+
+
+def _file_output_path(dir_path, input_file_path):
+ """Create output path for an individual file."""
+ return os.path.join(dir_path, os.path.basename(input_file_path))
+
+
+def make_inference_graph(model_name, patch_dim):
+ """Build the inference graph for either the X2Y or Y2X GAN.
+
+ Args:
+ model_name: The var scope name 'ModelX2Y' or 'ModelY2X'.
+ patch_dim: An integer size of patches to feed to the generator.
+
+ Returns:
+ Tuple of (input_placeholder, generated_tensor).
+ """
+ input_hwc_pl = tf.placeholder(tf.float32, [None, None, 3])
+
+ # Expand HWC to NHWC
+ images_x = tf.expand_dims(
+ data_provider.full_image_to_patch(input_hwc_pl, patch_dim), 0)
+
+ with tf.variable_scope(model_name):
+ with tf.variable_scope('Generator'):
+ generated = networks.generator(images_x)
+ return input_hwc_pl, generated
+
+
+def export(sess, input_pl, output_tensor, input_file_pattern, output_dir):
+ """Exports inference outputs to an output directory.
+
+ Args:
+ sess: tf.Session with variables already loaded.
+ input_pl: tf.Placeholder for input (HWC format).
+ output_tensor: Tensor for generated outut images.
+ input_file_pattern: Glob file pattern for input images.
+ output_dir: Output directory.
+ """
+ if output_dir:
+ _make_dir_if_not_exists(output_dir)
+
+ if input_file_pattern:
+ for file_path in tf.gfile.Glob(input_file_pattern):
+ # Grab a single image and run it through inference
+ input_np = np.asarray(PIL.Image.open(file_path))
+ output_np = sess.run(output_tensor, feed_dict={input_pl: input_np})
+ image_np = data_provider.undo_normalize_image(output_np)
+ output_path = _file_output_path(output_dir, file_path)
+ PIL.Image.fromarray(image_np).save(output_path)
+
+
+def _validate_flags():
+ flags.register_validator('checkpoint_path', bool,
+ 'Must provide `checkpoint_path`.')
+ flags.register_validator(
+ 'generated_x_dir',
+ lambda x: False if (FLAGS.image_set_y_glob and not x) else True,
+ 'Must provide `generated_x_dir`.')
+ flags.register_validator(
+ 'generated_y_dir',
+ lambda x: False if (FLAGS.image_set_x_glob and not x) else True,
+ 'Must provide `generated_y_dir`.')
+
+
+def main(_):
+ _validate_flags()
+ images_x_hwc_pl, generated_y = make_inference_graph('ModelX2Y',
+ FLAGS.patch_dim)
+ images_y_hwc_pl, generated_x = make_inference_graph('ModelY2X',
+ FLAGS.patch_dim)
+
+ # Restore all the variables that were saved in the checkpoint.
+ saver = tf.train.Saver()
+ with tf.Session() as sess:
+ saver.restore(sess, FLAGS.checkpoint_path)
+
+ export(sess, images_x_hwc_pl, generated_y, FLAGS.image_set_x_glob,
+ FLAGS.generated_y_dir)
+ export(sess, images_y_hwc_pl, generated_x, FLAGS.image_set_y_glob,
+ FLAGS.generated_x_dir)
+
+
+if __name__ == '__main__':
+ app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py"
new file mode 100644
index 00000000..4474693e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/inference_demo_test.py"
@@ -0,0 +1,106 @@
+"""Tests for CycleGAN inference demo."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+from absl import logging
+import numpy as np
+import PIL
+
+import tensorflow as tf
+
+import inference_demo
+import train
+
+FLAGS = tf.flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _basenames_from_glob(file_glob):
+ return [os.path.basename(file_path) for file_path in tf.gfile.Glob(file_glob)]
+
+
+class InferenceDemoTest(tf.test.TestCase):
+
+ def setUp(self):
+ self._export_dir = os.path.join(FLAGS.test_tmpdir, 'export')
+ self._ckpt_path = os.path.join(self._export_dir, 'model.ckpt')
+ self._image_glob = os.path.join(
+ FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/cyclegan/testdata', '*.jpg')
+ self._genx_dir = os.path.join(FLAGS.test_tmpdir, 'genx')
+ self._geny_dir = os.path.join(FLAGS.test_tmpdir, 'geny')
+
+ @mock.patch.object(tfgan, 'gan_train', autospec=True)
+ @mock.patch.object(
+ train.data_provider, 'provide_custom_data', autospec=True)
+ def testTrainingAndInferenceGraphsAreCompatible(
+ self, mock_provide_custom_data, unused_mock_gan_train):
+ # Training and inference graphs can get out of sync if changes are made
+ # to one but not the other. This test will keep them in sync.
+
+ # Save the training graph
+ train_sess = tf.Session()
+ FLAGS.image_set_x_file_pattern = '/tmp/x/*.jpg'
+ FLAGS.image_set_y_file_pattern = '/tmp/y/*.jpg'
+ FLAGS.batch_size = 3
+ FLAGS.patch_size = 128
+ FLAGS.generator_lr = 0.02
+ FLAGS.discriminator_lr = 0.3
+ FLAGS.train_log_dir = self._export_dir
+ FLAGS.master = 'master'
+ FLAGS.task = 0
+ FLAGS.cycle_consistency_loss_weight = 2.0
+ FLAGS.max_number_of_steps = 1
+ mock_provide_custom_data.return_value = (
+ tf.zeros([3, 4, 4, 3,]), tf.zeros([3, 4, 4, 3]))
+ train.main(None)
+ init_op = tf.global_variables_initializer()
+ train_sess.run(init_op)
+ train_saver = tf.train.Saver()
+ train_saver.save(train_sess, save_path=self._ckpt_path)
+
+ # Create inference graph
+ tf.reset_default_graph()
+ FLAGS.patch_dim = FLAGS.patch_size
+ logging.info('dir_path: %s', os.listdir(self._export_dir))
+ FLAGS.checkpoint_path = self._ckpt_path
+ FLAGS.image_set_x_glob = self._image_glob
+ FLAGS.image_set_y_glob = self._image_glob
+ FLAGS.generated_x_dir = self._genx_dir
+ FLAGS.generated_y_dir = self._geny_dir
+
+ inference_demo.main(None)
+ logging.info('gen x: %s', os.listdir(self._genx_dir))
+
+ # Check that the image names match
+ self.assertSetEqual(
+ set(_basenames_from_glob(FLAGS.image_set_x_glob)),
+ set(os.listdir(FLAGS.generated_y_dir)))
+ self.assertSetEqual(
+ set(_basenames_from_glob(FLAGS.image_set_y_glob)),
+ set(os.listdir(FLAGS.generated_x_dir)))
+
+ # Check that each image in the directory looks as expected
+ for directory in [FLAGS.generated_x_dir, FLAGS.generated_x_dir]:
+ for base_name in os.listdir(directory):
+ image_path = os.path.join(directory, base_name)
+ self.assertRealisticImage(image_path)
+
+ def assertRealisticImage(self, image_path):
+ logging.info('Testing %s for realism.', image_path)
+ # If the normalization is off or forgotten, then the generated image is
+ # all one pixel value. This tests that different pixel values are achieved.
+ input_np = np.asarray(PIL.Image.open(image_path))
+ self.assertEqual(len(input_np.shape), 3)
+ self.assertGreaterEqual(input_np.shape[0], 50)
+ self.assertGreaterEqual(input_np.shape[1], 50)
+ self.assertGreater(np.mean(input_np), 20)
+ self.assertGreater(np.var(input_np), 100)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg"
new file mode 100644
index 00000000..f465f6b4
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/testdata/00500.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py"
new file mode 100644
index 00000000..63523cee
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train.py"
@@ -0,0 +1,217 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a CycleGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('image_set_x_file_pattern', None,
+ 'File pattern of images in image set X')
+
+flags.DEFINE_string('image_set_y_file_pattern', None,
+ 'File pattern of images in image set Y')
+
+flags.DEFINE_integer('batch_size', 1, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 64, 'The patch size of images.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/cyclegan/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 0.0002,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 0.0001,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 500000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float('cycle_consistency_loss_weight', 10.0,
+ 'The weight of cycle consistency loss')
+
+
+FLAGS = flags.FLAGS
+
+
+def _define_model(images_x, images_y):
+ """Defines a CycleGAN model that maps between images_x and images_y.
+
+ Args:
+ images_x: A 4D float `Tensor` of NHWC format. Images in set X.
+ images_y: A 4D float `Tensor` of NHWC format. Images in set Y.
+
+ Returns:
+ A `CycleGANModel` namedtuple.
+ """
+ cyclegan_model = tfgan.cyclegan_model(
+ generator_fn=networks.generator,
+ discriminator_fn=networks.discriminator,
+ data_x=images_x,
+ data_y=images_y)
+
+ # Add summaries for generated images.
+ tfgan.eval.add_cyclegan_image_summaries(cyclegan_model)
+
+ return cyclegan_model
+
+
+def _get_lr(base_lr):
+ """Returns a learning rate `Tensor`.
+
+ Args:
+ base_lr: A scalar float `Tensor` or a Python number. The base learning
+ rate.
+
+ Returns:
+ A scalar float `Tensor` of learning rate which equals `base_lr` when the
+ global training step is less than FLAGS.max_number_of_steps / 2, afterwards
+ it linearly decays to zero.
+ """
+ global_step = tf.train.get_or_create_global_step()
+ lr_constant_steps = FLAGS.max_number_of_steps // 2
+
+ def _lr_decay():
+ return tf.train.polynomial_decay(
+ learning_rate=base_lr,
+ global_step=(global_step - lr_constant_steps),
+ decay_steps=(FLAGS.max_number_of_steps - lr_constant_steps),
+ end_learning_rate=0.0)
+
+ return tf.cond(global_step < lr_constant_steps, lambda: base_lr, _lr_decay)
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ # beta1 follows
+ # https://github.com/junyanz/CycleGAN/blob/master/options.lua
+ gen_opt = tf.train.AdamOptimizer(gen_lr, beta1=0.5, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(dis_lr, beta1=0.5, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_ops(cyclegan_model, cyclegan_loss):
+ """Defines train ops that trains `cyclegan_model` with `cyclegan_loss`.
+
+ Args:
+ cyclegan_model: A `CycleGANModel` namedtuple.
+ cyclegan_loss: A `CycleGANLoss` namedtuple containing all losses for
+ `cyclegan_model`.
+
+ Returns:
+ A `GANTrainOps` namedtuple.
+ """
+ gen_lr = _get_lr(FLAGS.generator_lr)
+ dis_lr = _get_lr(FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _get_optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ cyclegan_model,
+ cyclegan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+ return train_ops
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ with tf.name_scope('inputs'):
+ images_x, images_y = data_provider.provide_custom_data(
+ [FLAGS.image_set_x_file_pattern, FLAGS.image_set_y_file_pattern],
+ batch_size=FLAGS.batch_size,
+ patch_size=FLAGS.patch_size)
+ # Set batch size for summaries.
+ images_x.set_shape([FLAGS.batch_size, None, None, None])
+ images_y.set_shape([FLAGS.batch_size, None, None, None])
+
+ # Define CycleGAN model.
+ cyclegan_model = _define_model(images_x, images_y)
+
+ # Define CycleGAN loss.
+ cyclegan_loss = tfgan.cyclegan_loss(
+ cyclegan_model,
+ cycle_consistency_loss_weight=FLAGS.cycle_consistency_loss_weight,
+ tensor_pool_fn=tfgan.features.tensor_pool)
+
+ # Define CycleGAN train ops.
+ train_ops = _define_train_ops(cyclegan_model, cyclegan_loss)
+
+ # Training
+ train_steps = tfgan.GANTrainSteps(1, 1)
+ status_message = tf.string_join(
+ [
+ 'Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())
+ ],
+ name='status_message')
+ if not FLAGS.max_number_of_steps:
+ return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[
+ tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)
+ ],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_set_x_file_pattern')
+ tf.flags.mark_flag_as_required('image_set_y_file_pattern')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py"
new file mode 100644
index 00000000..5d27d377
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/cyclegan/train_test.py"
@@ -0,0 +1,155 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for cyclegan.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _test_generator(input_images):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(image_batch, unused_conditioning=None):
+ """Simple discriminator function."""
+ return tf.contrib.layers.flatten(
+ image_batch * tf.get_variable('dummy_d', initializer=2.0))
+
+
+train.networks.generator = _test_generator
+train.networks.discriminator = _test_discriminator
+
+
+class TrainTest(tf.test.TestCase):
+
+ @mock.patch.object(tfgan, 'eval', autospec=True)
+ def test_define_model(self, mock_eval):
+ FLAGS.batch_size = 2
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_x_np = np.zeros(shape=images_shape)
+ images_y_np = np.zeros(shape=images_shape)
+ images_x = tf.constant(images_x_np, dtype=tf.float32)
+ images_y = tf.constant(images_y_np, dtype=tf.float32)
+
+ cyclegan_model = train._define_model(images_x, images_y)
+ self.assertIsInstance(cyclegan_model, tfgan.CycleGANModel)
+ self.assertShapeEqual(images_x_np, cyclegan_model.reconstructed_x)
+ self.assertShapeEqual(images_y_np, cyclegan_model.reconstructed_y)
+
+ @mock.patch.object(train.networks, 'generator', autospec=True)
+ @mock.patch.object(train.networks, 'discriminator', autospec=True)
+ @mock.patch.object(
+ tf.train, 'get_or_create_global_step', autospec=True)
+ def test_get_lr(self, mock_get_or_create_global_step,
+ unused_mock_discriminator, unused_mock_generator):
+ FLAGS.max_number_of_steps = 10
+ base_lr = 0.01
+ with self.test_session(use_gpu=True) as sess:
+ mock_get_or_create_global_step.return_value = tf.constant(2)
+ lr_step2 = sess.run(train._get_lr(base_lr))
+ mock_get_or_create_global_step.return_value = tf.constant(9)
+ lr_step9 = sess.run(train._get_lr(base_lr))
+
+ self.assertAlmostEqual(base_lr, lr_step2)
+ self.assertAlmostEqual(base_lr * 0.2, lr_step9)
+
+ @mock.patch.object(tf.train, 'AdamOptimizer', autospec=True)
+ def test_get_optimizer(self, mock_adam_optimizer):
+ gen_lr, dis_lr = 0.1, 0.01
+ train._get_optimizer(gen_lr=gen_lr, dis_lr=dis_lr)
+ mock_adam_optimizer.assert_has_calls([
+ mock.call(gen_lr, beta1=mock.ANY, use_locking=True),
+ mock.call(dis_lr, beta1=mock.ANY, use_locking=True)
+ ])
+
+ @mock.patch.object(tf.summary, 'scalar', autospec=True)
+ def test_define_train_ops(self, mock_summary_scalar):
+ FLAGS.batch_size = 2
+ FLAGS.generator_lr = 0.1
+ FLAGS.discriminator_lr = 0.01
+
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_x = tf.zeros(images_shape, dtype=tf.float32)
+ images_y = tf.zeros(images_shape, dtype=tf.float32)
+
+ cyclegan_model = train._define_model(images_x, images_y)
+ cyclegan_loss = tfgan.cyclegan_loss(
+ cyclegan_model, cycle_consistency_loss_weight=10.0)
+ train_ops = train._define_train_ops(cyclegan_model, cyclegan_loss)
+
+ self.assertIsInstance(train_ops, tfgan.GANTrainOps)
+ mock_summary_scalar.assert_has_calls([
+ mock.call('generator_lr', mock.ANY),
+ mock.call('discriminator_lr', mock.ANY)
+ ])
+
+ @mock.patch.object(tf, 'gfile', autospec=True)
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ @mock.patch.object(train, '_define_model', autospec=True)
+ @mock.patch.object(tfgan, 'cyclegan_loss', autospec=True)
+ @mock.patch.object(train, '_define_train_ops', autospec=True)
+ @mock.patch.object(tfgan, 'gan_train', autospec=True)
+ def test_main(self, mock_gan_train, mock_define_train_ops, mock_cyclegan_loss,
+ mock_define_model, mock_data_provider, mock_gfile):
+ FLAGS.image_set_x_file_pattern = '/tmp/x/*.jpg'
+ FLAGS.image_set_y_file_pattern = '/tmp/y/*.jpg'
+ FLAGS.batch_size = 3
+ FLAGS.patch_size = 8
+ FLAGS.generator_lr = 0.02
+ FLAGS.discriminator_lr = 0.3
+ FLAGS.train_log_dir = '/tmp/foo'
+ FLAGS.master = 'master'
+ FLAGS.task = 0
+ FLAGS.cycle_consistency_loss_weight = 2.0
+ FLAGS.max_number_of_steps = 1
+
+ mock_data_provider.provide_custom_data.return_value = (
+ tf.zeros([3, 2, 2, 3], dtype=tf.float32),
+ tf.zeros([3, 2, 2, 3], dtype=tf.float32))
+
+ train.main(None)
+ mock_data_provider.provide_custom_data.assert_called_once_with(
+ ['/tmp/x/*.jpg', '/tmp/y/*.jpg'], batch_size=3, patch_size=8)
+ mock_define_model.assert_called_once_with(mock.ANY, mock.ANY)
+ mock_cyclegan_loss.assert_called_once_with(
+ mock_define_model.return_value,
+ cycle_consistency_loss_weight=2.0,
+ tensor_pool_fn=mock.ANY)
+ mock_define_train_ops.assert_called_once_with(
+ mock_define_model.return_value, mock_cyclegan_loss.return_value)
+ mock_gan_train.assert_called_once_with(
+ mock_define_train_ops.return_value,
+ '/tmp/foo',
+ get_hooks_fn=mock.ANY,
+ hooks=mock.ANY,
+ master='master',
+ is_chief=True)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png"
new file mode 100644
index 00000000..954c339c
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_conditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png"
new file mode 100644
index 00000000..481a6e80
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/cifar_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png"
new file mode 100644
index 00000000..4b39eda9
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf0.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png"
new file mode 100644
index 00000000..ed74069f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/compression_wf10000.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png"
new file mode 100644
index 00000000..7f47b3c0
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_conditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png"
new file mode 100644
index 00000000..4aeab789
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_estimator_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png"
new file mode 100644
index 00000000..fcc488fb
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_infogan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png"
new file mode 100644
index 00000000..624bcf7c
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/g3doc/mnist_unconditional_gan.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py"
new file mode 100644
index 00000000..da14741f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider.py"
@@ -0,0 +1,93 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the compression image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(split_name, batch_size, dataset_dir,
+ dataset_name='imagenet', num_readers=1, num_threads=1,
+ patch_size=128):
+ """Provides batches of image data for compression.
+
+ Args:
+ split_name: Either 'train' or 'validation'.
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the data can be found. If `None`, use
+ default.
+ dataset_name: Name of the dataset.
+ num_readers: Number of dataset readers.
+ num_threads: Number of prefetching threads.
+ patch_size: Size of the path to extract from the image.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, patch_size, patch_size, channels]
+ """
+ randomize = split_name == 'train'
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=num_readers,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=randomize)
+ [image] = provider.get(['image'])
+
+ # Sample a patch of fixed size.
+ patch = tf.image.resize_image_with_crop_or_pad(image, patch_size, patch_size)
+ patch.shape.assert_is_compatible_with([patch_size, patch_size, 3])
+
+ # Preprocess the images. Make the range lie in a strictly smaller range than
+ # [-1, 1], so that network outputs aren't forced to the extreme ranges.
+ patch = (tf.to_float(patch) - 128.0) / 142.0
+
+ if randomize:
+ image_batch = tf.train.shuffle_batch(
+ [patch],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size,
+ min_after_dequeue=batch_size)
+ else:
+ image_batch = tf.train.batch(
+ [patch],
+ batch_size=batch_size,
+ num_threads=1, # no threads so it's deterministic
+ capacity=5 * batch_size)
+
+ return image_batch
+
+
+def float_image_to_uint8(image):
+ """Convert float image in ~[-0.9, 0.9) to [0, 255] uint8.
+
+ Args:
+ image: An image tensor. Values should be in [-0.9, 0.9).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 142.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py"
new file mode 100644
index 00000000..1d9e54bc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/data_provider_test.py"
@@ -0,0 +1,59 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('train', 'train'),
+ ('validation', 'validation'))
+ def test_data_provider(self, split_name):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/image_compression/testdata/')
+
+ batch_size = 3
+ patch_size = 8
+ images = data_provider.provide_data(
+ split_name, batch_size, dataset_dir, patch_size=8)
+ self.assertListEqual([batch_size, patch_size, patch_size, 3],
+ images.shape.as_list())
+
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_out = sess.run(images)
+ self.assertEqual((batch_size, patch_size, patch_size, 3),
+ images_out.shape)
+ # Check range.
+ self.assertTrue(np.all(np.abs(images_out) <= 1.0))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py"
new file mode 100644
index 00000000..240f9ef5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval.py"
@@ -0,0 +1,102 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained compression model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import summaries
+
+FLAGS = flags.FLAGS
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/compression/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/compression/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+# Compression-specific flags.
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_integer('bits_per_patch', 1230,
+ 'The number of bits to produce per patch.')
+
+flags.DEFINE_integer('model_depth', 64,
+ 'Number of filters for compression model')
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ images = data_provider.provide_data(
+ 'validation', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('generator'):
+ reconstructions, _, prebinary = networks.compression_model(
+ images,
+ num_bits=FLAGS.bits_per_patch,
+ depth=FLAGS.model_depth,
+ is_training=False)
+ summaries.add_reconstruction_summaries(images, reconstructions, prebinary)
+
+ # Visualize losses.
+ pixel_loss_per_example = tf.reduce_mean(
+ tf.abs(images - reconstructions), axis=[1, 2, 3])
+ pixel_loss = tf.reduce_mean(pixel_loss_per_example)
+ tf.summary.histogram('pixel_l1_loss_hist', pixel_loss_per_example)
+ tf.summary.scalar('pixel_l1_loss', pixel_loss)
+
+ # Create ops to write images to disk.
+ uint8_images = data_provider.float_image_to_uint8(images)
+ uint8_reconstructions = data_provider.float_image_to_uint8(reconstructions)
+ uint8_reshaped = summaries.stack_images(uint8_images, uint8_reconstructions)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'compression.png'),
+ tf.image.encode_png(uint8_reshaped[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ master=FLAGS.master,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+if __name__ == '__main__':
+ app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py"
new file mode 100644
index 00000000..89b3f1b5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/eval_test.py"
@@ -0,0 +1,32 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.image_compression.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import eval # pylint:disable=redefined-builtin
+
+
+class EvalTest(tf.test.TestCase):
+
+ def test_build_graph(self):
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh"
new file mode 100644
index 00000000..e7fa2ec4
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/launch_jobs.sh"
@@ -0,0 +1,85 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the Imagenet dataset.
+# 2. Trains image compression model on patches from Imagenet.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# Usage:
+# cd models/research/gan/image_compression
+# ./launch_jobs.sh ${weight_factor} ${git_repo}
+set -e
+
+# Weight of the adversarial loss.
+weight_factor=$1
+if [[ "$weight_factor" == "" ]]; then
+ echo "'weight_factor' must not be empty."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/compression-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/compression-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/imagenet-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim:$git_repo/research/slim/nets
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset. You will be asked for an ImageNet username and password.
+# To get one, register at http://www.image-net.org/.
+bazel build "${git_repo}/research/slim:download_and_convert_imagenet"
+"./bazel-bin/download_and_convert_imagenet" ${DATASET_DIR}
+
+# Run the compression model.
+NUM_STEPS=10000
+MODEL_TRAIN_DIR="${TRAIN_DIR}/wt${weight_factor}"
+Banner "Starting training an image compression model for ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/image_compression/train.py" \
+ --train_log_dir=${MODEL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --weight_factor=${weight_factor} \
+ --alsologtostderr
+Banner "Finished training image compression model ${NUM_STEPS} steps."
+
+# Run evaluation.
+MODEL_EVAL_DIR="${TRAIN_DIR}/eval/wt${weight_factor}"
+Banner "Starting evaluation of image compression model..."
+python "${git_repo}/research/gan/image_compression/eval.py" \
+ --checkpoint_dir=${MODEL_TRAIN_DIR} \
+ --eval_dir=${MODEL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_evaluations=1
+Banner "Finished evaluation. See ${MODEL_EVAL_DIR} for output images."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py"
new file mode 100644
index 00000000..ff44d84a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks.py"
@@ -0,0 +1,145 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN compression example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import dcgan
+from slim.nets import pix2pix
+
+
+def _last_conv_layer(end_points):
+ """"Returns the last convolutional layer from an endpoints dictionary."""
+ conv_list = [k if k[:4] == 'conv' else None for k in end_points.keys()]
+ conv_list.sort()
+ return end_points[conv_list[-1]]
+
+
+def _encoder(img_batch, is_training=True, bits=64, depth=64):
+ """Maps images to internal representation.
+
+ Args:
+ img_batch: Stuff
+ is_training: Stuff
+ bits: Number of bits per patch.
+ depth: Stuff
+
+ Returns:
+ Real-valued 2D Tensor of size [batch_size, bits].
+ """
+ _, end_points = dcgan.discriminator(
+ img_batch, depth=depth, is_training=is_training, scope='Encoder')
+
+ # (joelshor): Make the DCGAN convolutional layer that converts to logits
+ # not trainable, since it doesn't affect the encoder output.
+
+ # Get the pre-logit layer, which is the last conv.
+ net = _last_conv_layer(end_points)
+
+ # Transform the features to the proper number of bits.
+ with tf.variable_scope('EncoderTransformer'):
+ encoded = tf.contrib.layers.conv2d(net, bits, kernel_size=1, stride=1,
+ padding='VALID', normalizer_fn=None,
+ activation_fn=None)
+ encoded = tf.squeeze(encoded, [1, 2])
+ encoded.shape.assert_has_rank(2)
+
+ # Map encoded to the range [-1, 1].
+ return tf.nn.softsign(encoded)
+
+
+def _binarizer(prebinary_codes, is_training):
+ """Binarize compression logits.
+
+ During training, add noise, as in https://arxiv.org/pdf/1611.01704.pdf. During
+ eval, map [-1, 1] -> {-1, 1}.
+
+ Args:
+ prebinary_codes: Floating-point tensors corresponding to pre-binary codes.
+ Shape is [batch, code_length].
+ is_training: A python bool. If True, add noise. If false, binarize.
+
+ Returns:
+ Binarized codes. Shape is [batch, code_length].
+
+ Raises:
+ ValueError: If the shape of `prebinary_codes` isn't static.
+ """
+ if is_training:
+ # In order to train codes that can be binarized during eval, we add noise as
+ # in https://arxiv.org/pdf/1611.01704.pdf. Another option is to use a
+ # stochastic node, as in https://arxiv.org/abs/1608.05148.
+ noise = tf.random_uniform(
+ prebinary_codes.shape,
+ minval=-1.0,
+ maxval=1.0)
+ return prebinary_codes + noise
+ else:
+ return tf.sign(prebinary_codes)
+
+
+def _decoder(codes, final_size, is_training, depth=64):
+ """Compression decoder."""
+ decoded_img, _ = dcgan.generator(
+ codes,
+ depth=depth,
+ final_size=final_size,
+ num_outputs=3,
+ is_training=is_training,
+ scope='Decoder')
+
+ # Map output to [-1, 1].
+ # Use softsign instead of tanh, as per empirical results of
+ # http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf.
+ return tf.nn.softsign(decoded_img)
+
+
+def _validate_image_inputs(image_batch):
+ image_batch.shape.assert_has_rank(4)
+ image_batch.shape[1:].assert_is_fully_defined()
+
+
+def compression_model(image_batch, num_bits=64, depth=64, is_training=True):
+ """Image compression model.
+
+ Args:
+ image_batch: A batch of images to compress and reconstruct. Images should
+ be normalized already. Shape is [batch, height, width, channels].
+ num_bits: Desired number of bits per image in the compressed representation.
+ depth: The base number of filters for the encoder and decoder networks.
+ is_training: A python bool. If False, run in evaluation mode.
+
+ Returns:
+ uncompressed images, binary codes, prebinary codes
+ """
+ image_batch = tf.convert_to_tensor(image_batch)
+ _validate_image_inputs(image_batch)
+ final_size = image_batch.shape.as_list()[1]
+
+ prebinary_codes = _encoder(image_batch, is_training, num_bits, depth)
+ binary_codes = _binarizer(prebinary_codes, is_training)
+ uncompressed_imgs = _decoder(binary_codes, final_size, is_training, depth)
+ return uncompressed_imgs, binary_codes, prebinary_codes
+
+
+def discriminator(image_batch, unused_conditioning=None, depth=64):
+ """A thin wrapper around the pix2pix discriminator to conform to TFGAN API."""
+ logits, _ = pix2pix.pix2pix_discriminator(
+ image_batch, num_filters=[depth, 2 * depth, 4 * depth, 8 * depth])
+ return tf.layers.flatten(logits)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py"
new file mode 100644
index 00000000..222f7e8a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/networks_test.py"
@@ -0,0 +1,99 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for gan.image_compression.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+import networks
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_last_conv_layer(self):
+ x = tf.constant(1.0)
+ y = tf.constant(0.0)
+ end_points = {
+ 'silly': y,
+ 'conv2': y,
+ 'conv4': x,
+ 'logits': y,
+ 'conv-1': y,
+ }
+ self.assertEqual(x, networks._last_conv_layer(end_points))
+
+ def test_generator_run(self):
+ img_batch = tf.zeros([3, 16, 16, 3])
+ model_output = networks.compression_model(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_graph(self):
+ for i, batch_size in zip(xrange(3, 7), xrange(3, 11, 2)):
+ tf.reset_default_graph()
+ patch_size = 2 ** i
+ bits = 2 ** i
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ uncompressed, binary_codes, prebinary = networks.compression_model(
+ img, bits)
+
+ self.assertAllEqual([batch_size, patch_size, patch_size, 3],
+ uncompressed.shape.as_list())
+ self.assertEqual([batch_size, bits], binary_codes.shape.as_list())
+ self.assertEqual([batch_size, bits], prebinary.shape.as_list())
+
+ def test_generator_invalid_input(self):
+ wrong_dim_input = tf.zeros([5, 32, 32])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* must have rank 4'):
+ networks.compression_model(wrong_dim_input)
+
+ not_fully_defined = tf.placeholder(tf.float32, [3, None, 32, 3])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* is not fully defined'):
+ networks.compression_model(not_fully_defined)
+
+ def test_discriminator_run(self):
+ img_batch = tf.zeros([3, 70, 70, 3])
+ disc_output = networks.discriminator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(disc_output)
+
+ def test_discriminator_graph(self):
+ # Check graph construction for a number of image size/depths and batch
+ # sizes.
+ for batch_size, patch_size in zip([3, 6], [70, 128]):
+ tf.reset_default_graph()
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ disc_output = networks.discriminator(img)
+
+ self.assertEqual(2, disc_output.shape.ndims)
+ self.assertEqual(batch_size, disc_output.shape[0])
+
+ def test_discriminator_invalid_input(self):
+ wrong_dim_input = tf.zeros([5, 32, 32])
+ with self.assertRaisesRegexp(ValueError, 'Shape must be rank 4'):
+ networks.discriminator(wrong_dim_input)
+
+ not_fully_defined = tf.placeholder(tf.float32, [3, None, 32, 3])
+ with self.assertRaisesRegexp(ValueError, 'Shape .* is not fully defined'):
+ networks.compression_model(not_fully_defined)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py"
new file mode 100644
index 00000000..f85a780c
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/summaries.py"
@@ -0,0 +1,44 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Summaries utility file to share between train and eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+tfgan = tf.contrib.gan
+
+
+def add_reconstruction_summaries(images, reconstructions, prebinary,
+ num_imgs_to_visualize=8):
+ """Adds image summaries."""
+ reshaped_img = stack_images(images, reconstructions, num_imgs_to_visualize)
+
+ tf.summary.image('real_vs_reconstruction', reshaped_img, max_outputs=1)
+ if prebinary is not None:
+ tf.summary.histogram('prebinary_codes', prebinary)
+
+
+def stack_images(images, reconstructions, num_imgs_to_visualize=8):
+ """Stack and reshape images to see compression effects."""
+ to_reshape = (tf.unstack(images)[:num_imgs_to_visualize] +
+ tf.unstack(reconstructions)[:num_imgs_to_visualize])
+ reshaped_img = tfgan.eval.image_reshaper(
+ to_reshape, num_cols=num_imgs_to_visualize)
+ return reshaped_img
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt"
new file mode 100644
index 00000000..8b137891
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/testdata/labels.txt"
@@ -0,0 +1 @@
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py"
new file mode 100644
index 00000000..70aed9fc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train.py"
@@ -0,0 +1,217 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+# pylint:disable=line-too-long
+"""Trains an image compression network with an adversarial loss."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+import summaries
+
+
+tfgan = tf.contrib.gan
+FLAGS = flags.FLAGS
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_integer('bits_per_patch', 1230,
+ 'The number of bits to produce per patch.')
+
+flags.DEFINE_integer('model_depth', 64,
+ 'Number of filters for compression model')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/compression/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 1e-5,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 1e-6,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 2000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float(
+ 'weight_factor', 10000.0,
+ 'How much to weight the adversarial loss relative to pixel loss.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Put input pipeline on CPU to reserve GPU for training.
+ with tf.name_scope('inputs'), tf.device('/cpu:0'):
+ images = data_provider.provide_data(
+ 'train', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+
+ # Manually define a GANModel tuple. This is useful when we have custom
+ # code to track variables. Note that we could replace all of this with a
+ # call to `tfgan.gan_model`, but we don't in order to demonstrate some of
+ # TFGAN's flexibility.
+ with tf.variable_scope('generator') as gen_scope:
+ reconstructions, _, prebinary = networks.compression_model(
+ images,
+ num_bits=FLAGS.bits_per_patch,
+ depth=FLAGS.model_depth)
+ gan_model = _get_gan_model(
+ generator_inputs=images,
+ generated_data=reconstructions,
+ real_data=images,
+ generator_scope=gen_scope)
+ summaries.add_reconstruction_summaries(images, reconstructions, prebinary)
+ tfgan.eval.add_gan_model_summaries(gan_model)
+
+ # Define the GANLoss tuple using standard library functions.
+ with tf.name_scope('loss'):
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.least_squares_generator_loss,
+ discriminator_loss_fn=tfgan.losses.least_squares_discriminator_loss,
+ add_summaries=FLAGS.weight_factor > 0)
+
+ # Define the standard pixel loss.
+ l1_pixel_loss = tf.norm(gan_model.real_data - gan_model.generated_data,
+ ord=1)
+
+ # Modify the loss tuple to include the pixel loss. Add summaries as well.
+ gan_loss = tfgan.losses.combine_adversarial_loss(
+ gan_loss, gan_model, l1_pixel_loss, weight_factor=FLAGS.weight_factor)
+
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ with tf.name_scope('train_ops'):
+ gen_lr, dis_lr = _lr(FLAGS.generator_lr, FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Determine the number of generator vs discriminator steps.
+ train_steps = tfgan.GANTrainSteps(
+ generator_train_steps=1,
+ discriminator_train_steps=int(FLAGS.weight_factor > 0))
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+def _optimizer(gen_lr, dis_lr):
+ # First is generator optimizer, second is discriminator.
+ adam_kwargs = {
+ 'epsilon': 1e-8,
+ 'beta1': 0.5,
+ }
+ return (tf.train.AdamOptimizer(gen_lr, **adam_kwargs),
+ tf.train.AdamOptimizer(dis_lr, **adam_kwargs))
+
+
+def _lr(gen_lr_base, dis_lr_base):
+ """Return the generator and discriminator learning rates."""
+ gen_lr_kwargs = {
+ 'decay_steps': 60000,
+ 'decay_rate': 0.9,
+ 'staircase': True,
+ }
+ gen_lr = tf.train.exponential_decay(
+ learning_rate=gen_lr_base,
+ global_step=tf.train.get_or_create_global_step(),
+ **gen_lr_kwargs)
+ dis_lr = dis_lr_base
+
+ return gen_lr, dis_lr
+
+
+def _get_gan_model(generator_inputs, generated_data, real_data,
+ generator_scope):
+ """Manually construct and return a GANModel tuple."""
+ generator_vars = tf.contrib.framework.get_trainable_variables(generator_scope)
+
+ discriminator_fn = networks.discriminator
+ with tf.variable_scope('discriminator') as dis_scope:
+ discriminator_gen_outputs = discriminator_fn(generated_data)
+ with tf.variable_scope(dis_scope, reuse=True):
+ discriminator_real_outputs = discriminator_fn(real_data)
+ discriminator_vars = tf.contrib.framework.get_trainable_variables(
+ dis_scope)
+
+ # Manually construct GANModel tuple.
+ gan_model = tfgan.GANModel(
+ generator_inputs=generator_inputs,
+ generated_data=generated_data,
+ generator_variables=generator_vars,
+ generator_scope=generator_scope,
+ generator_fn=None, # not necessary
+ real_data=real_data,
+ discriminator_real_outputs=discriminator_real_outputs,
+ discriminator_gen_outputs=discriminator_gen_outputs,
+ discriminator_variables=discriminator_vars,
+ discriminator_scope=dis_scope,
+ discriminator_fn=discriminator_fn)
+
+ return gan_model
+
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py"
new file mode 100644
index 00000000..a76f9b06
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/image_compression/train_test.py"
@@ -0,0 +1,56 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for image_compression.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('NoAdversarialLoss', 0.0),
+ ('AdversarialLoss', 1.0))
+ def test_build_graph(self, weight_factor):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.weight_factor = weight_factor
+
+ batch_size = 3
+ patch_size = 16
+
+ FLAGS.batch_size = batch_size
+ FLAGS.patch_size = patch_size
+ mock_imgs = np.zeros([batch_size, patch_size, patch_size, 3],
+ dtype=np.float32)
+
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = mock_imgs
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/__init__.py"
new file mode 100644
index 00000000..e69de29b
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py"
new file mode 100644
index 00000000..9fbd640f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval.py"
@@ -0,0 +1,111 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a conditional TFGAN trained MNIST model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('num_images_per_class', 10,
+ 'Number of images to generate per class.')
+
+flags.DEFINE_integer('noise_dims', 64,
+ 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+FLAGS = flags.FLAGS
+NUM_CLASSES = 10
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ noise, one_hot_labels = _get_generator_inputs(
+ FLAGS.num_images_per_class, NUM_CLASSES, FLAGS.noise_dims)
+
+ # Generate images.
+ with tf.variable_scope('Generator'): # Same scope as in train job.
+ images = networks.conditional_generator(
+ (noise, one_hot_labels), is_training=False)
+
+ # Visualize images.
+ reshaped_img = tfgan.eval.image_reshaper(
+ images, num_cols=FLAGS.num_images_per_class)
+ tf.summary.image('generated_images', reshaped_img, max_outputs=1)
+
+ # Calculate evaluation metrics.
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(images, FLAGS.classifier_filename))
+ tf.summary.scalar('MNIST_Cross_entropy',
+ util.mnist_cross_entropy(
+ images, one_hot_labels, FLAGS.classifier_filename))
+
+ # Write images to disk.
+ image_write_ops = None
+ if FLAGS.write_to_disk:
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'conditional_gan.png'),
+ tf.image.encode_png(data_provider.float_image_to_uint8(
+ reshaped_img[0])))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _get_generator_inputs(num_images_per_class, num_classes, noise_dims):
+ # Since we want a grid of numbers for the conditional generator, manually
+ # construct the desired class labels.
+ num_images_generated = num_images_per_class * num_classes
+ noise = tf.random_normal([num_images_generated, noise_dims])
+ labels = [lbl for lbl in range(num_classes) for _
+ in range(num_images_per_class)]
+ one_hot_labels = tf.one_hot(tf.constant(labels), num_classes)
+ return noise, one_hot_labels
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py"
new file mode 100644
index 00000000..1bb96a24
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/conditional_eval_test.py"
@@ -0,0 +1,32 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.conditional_eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from absl.testing import absltest
+import conditional_eval
+
+
+class ConditionalEvalTest(absltest.TestCase):
+
+ def test_build_graph(self):
+ conditional_eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py"
new file mode 100644
index 00000000..afbc3809
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider.py"
@@ -0,0 +1,85 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Contains code for loading and preprocessing the MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+slim = tf.contrib.slim
+
+
+def provide_data(split_name, batch_size, dataset_dir, num_readers=1,
+ num_threads=1):
+ """Provides batches of MNIST digits.
+
+ Args:
+ split_name: Either 'train' or 'test'.
+ batch_size: The number of images in each batch.
+ dataset_dir: The directory where the MNIST data can be found.
+ num_readers: Number of dataset readers.
+ num_threads: Number of prefetching threads.
+
+ Returns:
+ images: A `Tensor` of size [batch_size, 28, 28, 1]
+ one_hot_labels: A `Tensor` of size [batch_size, mnist.NUM_CLASSES], where
+ each row has a single element set to one and the rest set to zeros.
+ num_samples: The number of total samples in the dataset.
+
+ Raises:
+ ValueError: If `split_name` is not either 'train' or 'test'.
+ """
+ dataset = datasets.get_dataset('mnist', split_name, dataset_dir=dataset_dir)
+ provider = slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=num_readers,
+ common_queue_capacity=2 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=(split_name == 'train'))
+ [image, label] = provider.get(['image', 'label'])
+
+ # Preprocess the images.
+ image = (tf.to_float(image) - 128.0) / 128.0
+
+ # Creates a QueueRunner for the pre-fetching operation.
+ images, labels = tf.train.batch(
+ [image, label],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size)
+
+ one_hot_labels = tf.one_hot(labels, dataset.num_classes)
+ return images, one_hot_labels, dataset.num_samples
+
+
+def float_image_to_uint8(image):
+ """Convert float image in [-1, 1) to [0, 255] uint8.
+
+ Note that `1` gets mapped to `0`, but `1 - epsilon` gets mapped to 255.
+
+ Args:
+ image: An image tensor. Values should be in [-1, 1).
+
+ Returns:
+ Input image cast to uint8 and with integer values in [0, 255].
+ """
+ image = (image * 128.0) + 128.0
+ return tf.cast(image, tf.uint8)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py"
new file mode 100644
index 00000000..463ecfdc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/data_provider_test.py"
@@ -0,0 +1,49 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def test_mnist_data_reading(self):
+ dataset_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/mnist/testdata')
+
+ batch_size = 5
+ images, labels, num_samples = data_provider.provide_data(
+ 'test', batch_size, dataset_dir)
+ self.assertEqual(num_samples, 10000)
+
+ with self.test_session() as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images, labels = sess.run([images, labels])
+ self.assertEqual(images.shape, (batch_size, 28, 28, 1))
+ self.assertEqual(labels.shape, (batch_size, 10))
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py"
new file mode 100644
index 00000000..b7f50f3a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval.py"
@@ -0,0 +1,104 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates a TFGAN trained MNIST model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import app
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('num_images_generated', 1000,
+ 'Number of images to generate at once.')
+
+flags.DEFINE_boolean('eval_real_images', False,
+ 'If `True`, run Inception network on real images.')
+
+flags.DEFINE_integer('noise_dims', 64,
+ 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+
+def main(_, run_eval_loop=True):
+ # Fetch real images.
+ with tf.name_scope('inputs'):
+ real_images, _, _ = data_provider.provide_data(
+ 'train', FLAGS.num_images_generated, FLAGS.dataset_dir)
+
+ image_write_ops = None
+ if FLAGS.eval_real_images:
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(real_images, FLAGS.classifier_filename))
+ else:
+ # In order for variables to load, use the same variable scope as in the
+ # train job.
+ with tf.variable_scope('Generator'):
+ images = networks.unconditional_generator(
+ tf.random_normal([FLAGS.num_images_generated, FLAGS.noise_dims]),
+ is_training=False)
+ tf.summary.scalar('MNIST_Frechet_distance',
+ util.mnist_frechet_distance(
+ real_images, images, FLAGS.classifier_filename))
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(images, FLAGS.classifier_filename))
+ if FLAGS.num_images_generated >= 100 and FLAGS.write_to_disk:
+ reshaped_images = tfgan.eval.image_reshaper(
+ images[:100, ...], num_cols=10)
+ uint8_images = data_provider.float_image_to_uint8(reshaped_images)
+ image_write_ops = tf.write_file(
+ '%s/%s'% (FLAGS.eval_dir, 'unconditional_gan.png'),
+ tf.image.encode_png(uint8_images[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py"
new file mode 100644
index 00000000..1a7d4ca8
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/eval_test.py"
@@ -0,0 +1,40 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+from absl import flags
+from absl.testing import absltest
+from absl.testing import parameterized
+import eval # pylint:disable=redefined-builtin
+
+
+class EvalTest(parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('RealData', True),
+ ('GeneratedData', False))
+ def test_build_graph(self, eval_real_images):
+ flags.FLAGS.eval_real_images = eval_real_images
+ eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py"
new file mode 100644
index 00000000..ef2eae01
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval.py"
@@ -0,0 +1,160 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Evaluates an InfoGAN TFGAN trained MNIST model.
+
+The image visualizations, as in https://arxiv.org/abs/1606.03657, show the
+effect of varying a specific latent variable on the image. Each visualization
+focuses on one of the three structured variables. Columns have two of the three
+variables fixed, while the third one is varied. Different rows have different
+random samples from the remaining latents.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import app
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_string('checkpoint_dir', '/tmp/mnist/',
+ 'Directory where the model was written to.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist/',
+ 'Directory where the results are saved to.')
+
+flags.DEFINE_integer('noise_samples', 6,
+ 'Number of samples to draw from the continuous structured '
+ 'noise.')
+
+flags.DEFINE_integer('unstructured_noise_dims', 62,
+ 'The number of dimensions of the unstructured noise.')
+
+flags.DEFINE_integer('continuous_noise_dims', 2,
+ 'The number of dimensions of the continuous noise.')
+
+flags.DEFINE_string('classifier_filename', None,
+ 'Location of the pretrained classifier. If `None`, use '
+ 'default.')
+
+flags.DEFINE_integer('max_number_of_evaluations', None,
+ 'Number of times to run evaluation. If `None`, run '
+ 'forever.')
+
+flags.DEFINE_boolean('write_to_disk', True, 'If `True`, run images to disk.')
+
+CAT_SAMPLE_POINTS = np.arange(0, 10)
+CONT_SAMPLE_POINTS = np.linspace(-2.0, 2.0, 10)
+FLAGS = flags.FLAGS
+
+
+def main(_, run_eval_loop=True):
+ with tf.name_scope('inputs'):
+ noise_args = (FLAGS.noise_samples, CAT_SAMPLE_POINTS, CONT_SAMPLE_POINTS,
+ FLAGS.unstructured_noise_dims, FLAGS.continuous_noise_dims)
+ # Use fixed noise vectors to illustrate the effect of each dimension.
+ display_noise1 = util.get_eval_noise_categorical(*noise_args)
+ display_noise2 = util.get_eval_noise_continuous_dim1(*noise_args)
+ display_noise3 = util.get_eval_noise_continuous_dim2(*noise_args)
+ _validate_noises([display_noise1, display_noise2, display_noise3])
+
+ # Visualize the effect of each structured noise dimension on the generated
+ # image.
+ def generator_fn(inputs):
+ return networks.infogan_generator(
+ inputs, len(CAT_SAMPLE_POINTS), is_training=False)
+ with tf.variable_scope('Generator') as genscope: # Same scope as in training.
+ categorical_images = generator_fn(display_noise1)
+ reshaped_categorical_img = tfgan.eval.image_reshaper(
+ categorical_images, num_cols=len(CAT_SAMPLE_POINTS))
+ tf.summary.image('categorical', reshaped_categorical_img, max_outputs=1)
+
+ with tf.variable_scope(genscope, reuse=True):
+ continuous1_images = generator_fn(display_noise2)
+ reshaped_continuous1_img = tfgan.eval.image_reshaper(
+ continuous1_images, num_cols=len(CONT_SAMPLE_POINTS))
+ tf.summary.image('continuous1', reshaped_continuous1_img, max_outputs=1)
+
+ with tf.variable_scope(genscope, reuse=True):
+ continuous2_images = generator_fn(display_noise3)
+ reshaped_continuous2_img = tfgan.eval.image_reshaper(
+ continuous2_images, num_cols=len(CONT_SAMPLE_POINTS))
+ tf.summary.image('continuous2', reshaped_continuous2_img, max_outputs=1)
+
+ # Evaluate image quality.
+ all_images = tf.concat(
+ [categorical_images, continuous1_images, continuous2_images], 0)
+ tf.summary.scalar('MNIST_Classifier_score',
+ util.mnist_score(all_images, FLAGS.classifier_filename))
+
+ # Write images to disk.
+ image_write_ops = []
+ if FLAGS.write_to_disk:
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'categorical_infogan.png', reshaped_categorical_img[0]))
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'continuous1_infogan.png', reshaped_continuous1_img[0]))
+ image_write_ops.append(_get_write_image_ops(
+ FLAGS.eval_dir, 'continuous2_infogan.png', reshaped_continuous2_img[0]))
+
+ # For unit testing, use `run_eval_loop=False`.
+ if not run_eval_loop: return
+ tf.contrib.training.evaluate_repeatedly(
+ FLAGS.checkpoint_dir,
+ hooks=[tf.contrib.training.SummaryAtEndHook(FLAGS.eval_dir),
+ tf.contrib.training.StopAfterNEvalsHook(1)],
+ eval_ops=image_write_ops,
+ max_number_of_evaluations=FLAGS.max_number_of_evaluations)
+
+
+def _validate_noises(noises):
+ """Sanity check on constructed noise tensors.
+
+ Args:
+ noises: List of 3-tuples of noise vectors.
+ """
+ assert isinstance(noises, (list, tuple))
+ for noise_l in noises:
+ assert len(noise_l) == 3
+ assert isinstance(noise_l[0], np.ndarray)
+ batch_dim = noise_l[0].shape[0]
+ for i, noise in enumerate(noise_l):
+ assert isinstance(noise, np.ndarray)
+ # Check that batch dimensions are all the same.
+ assert noise.shape[0] == batch_dim
+
+ # Check that shapes for corresponding noises are the same.
+ assert noise.shape == noises[0][i].shape
+
+
+def _get_write_image_ops(eval_dir, filename, images):
+ """Create Ops that write images to disk."""
+ return tf.write_file(
+ '%s/%s'% (eval_dir, filename),
+ tf.image.encode_png(data_provider.float_image_to_uint8(images)))
+
+
+if __name__ == '__main__':
+ app.run(main)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py"
new file mode 100644
index 00000000..741465fc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/infogan_eval_test.py"
@@ -0,0 +1,33 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.mnist.infogan_eval."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl.testing import absltest
+import infogan_eval
+
+
+class MnistInfoGANEvalTest(absltest.TestCase):
+
+ def test_build_graph(self):
+ infogan_eval.main(None, run_eval_loop=False)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh"
new file mode 100644
index 00000000..8bccb12f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/launch_jobs.sh"
@@ -0,0 +1,157 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the MNIST dataset.
+# 2. Trains an unconditional, conditional, or InfoGAN model on the MNIST
+# training set.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# These examples are intended to be fast. For better final results, tune
+# hyperparameters or train longer.
+#
+# NOTE: Each training step takes about 0.5 second with a batch size of 32 on
+# CPU. On GPU, it takes ~5 milliseconds.
+#
+# With the default batch size and number of steps, train times are:
+#
+# unconditional: CPU: 800 steps, ~10 min GPU: 800 steps, ~1 min
+# conditional: CPU: 2000 steps, ~20 min GPU: 2000 steps, ~2 min
+# infogan: CPU: 3000 steps, ~20 min GPU: 3000 steps, ~6 min
+#
+# Usage:
+# cd models/research/gan/mnist
+# ./launch_jobs.sh ${gan_type} ${git_repo}
+set -e
+
+# Type of GAN to run. Right now, options are `unconditional`, `conditional`, or
+# `infogan`.
+gan_type=$1
+if ! [[ "$gan_type" =~ ^(unconditional|conditional|infogan) ]]; then
+ echo "'gan_type' must be one of: 'unconditional', 'conditional', 'infogan'."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/mnist-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/mnist-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/mnist-data
+
+# Location of the classifier frozen graph used for evaluation.
+FROZEN_GRAPH="${git_repo}/research/gan/mnist/data/classify_mnist_graph_def.pb"
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=mnist \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+if [[ "$gan_type" == "unconditional" ]]; then
+ UNCONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/unconditional"
+ UNCONDITIONAL_EVAL_DIR="${EVAL_DIR}/unconditional"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training unconditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="unconditional" \
+ --alsologtostderr
+ Banner "Finished training unconditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of unconditional GAN..."
+ python "${git_repo}/research/gan/mnist/eval.py" \
+ --checkpoint_dir=${UNCONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${UNCONDITIONAL_EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --eval_real_images=false \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished unconditional evaluation. See ${UNCONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run conditional GAN.
+if [[ "$gan_type" == "conditional" ]]; then
+ CONDITIONAL_TRAIN_DIR="${TRAIN_DIR}/conditional"
+ CONDITIONAL_EVAL_DIR="${EVAL_DIR}/conditional"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training conditional GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${CONDITIONAL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="conditional" \
+ --alsologtostderr
+ Banner "Finished training conditional GAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of conditional GAN..."
+ python "${git_repo}/research/gan/mnist/conditional_eval.py" \
+ --checkpoint_dir=${CONDITIONAL_TRAIN_DIR} \
+ --eval_dir=${CONDITIONAL_EVAL_DIR} \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished conditional evaluation. See ${CONDITIONAL_EVAL_DIR} for output images."
+fi
+
+# Run InfoGAN.
+if [[ "$gan_type" == "infogan" ]]; then
+ INFOGAN_TRAIN_DIR="${TRAIN_DIR}/infogan"
+ INFOGAN_EVAL_DIR="${EVAL_DIR}/infogan"
+ NUM_STEPS=3000
+ # Run training.
+ Banner "Starting training infogan GAN for ${NUM_STEPS} steps..."
+ python "${git_repo}/research/gan/mnist/train.py" \
+ --train_log_dir=${INFOGAN_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --gan_type="infogan" \
+ --alsologtostderr
+ Banner "Finished training InfoGAN ${NUM_STEPS} steps."
+
+ # Run evaluation.
+ Banner "Starting evaluation of infogan..."
+ python "${git_repo}/research/gan/mnist/infogan_eval.py" \
+ --checkpoint_dir=${INFOGAN_TRAIN_DIR} \
+ --eval_dir=${INFOGAN_EVAL_DIR} \
+ --classifier_filename=${FROZEN_GRAPH} \
+ --max_number_of_evaluations=1
+ Banner "Finished InfoGAN evaluation. See ${INFOGAN_EVAL_DIR} for output images."
+fi
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py"
new file mode 100644
index 00000000..72f78c83
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/networks.py"
@@ -0,0 +1,235 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for MNIST example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+ds = tf.contrib.distributions
+layers = tf.contrib.layers
+tfgan = tf.contrib.gan
+
+
+def _generator_helper(
+ noise, is_conditional, one_hot_labels, weight_decay, is_training):
+ """Core MNIST generator.
+
+ This function is reused between the different GAN modes (unconditional,
+ conditional, etc).
+
+ Args:
+ noise: A 2D Tensor of shape [batch size, noise dim].
+ is_conditional: Whether to condition on labels.
+ one_hot_labels: Optional labels for conditioning.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ with tf.contrib.framework.arg_scope(
+ [layers.fully_connected, layers.conv2d_transpose],
+ activation_fn=tf.nn.relu, normalizer_fn=layers.batch_norm,
+ weights_regularizer=layers.l2_regularizer(weight_decay)):
+ with tf.contrib.framework.arg_scope(
+ [layers.batch_norm], is_training=is_training):
+ net = layers.fully_connected(noise, 1024)
+ if is_conditional:
+ net = tfgan.features.condition_tensor_from_onehot(net, one_hot_labels)
+ net = layers.fully_connected(net, 7 * 7 * 128)
+ net = tf.reshape(net, [-1, 7, 7, 128])
+ net = layers.conv2d_transpose(net, 64, [4, 4], stride=2)
+ net = layers.conv2d_transpose(net, 32, [4, 4], stride=2)
+ # Make sure that generator output is in the same range as `inputs`
+ # ie [-1, 1].
+ net = layers.conv2d(
+ net, 1, [4, 4], normalizer_fn=None, activation_fn=tf.tanh)
+
+ return net
+
+
+def unconditional_generator(noise, weight_decay=2.5e-5, is_training=True):
+ """Generator to produce unconditional MNIST images.
+
+ Args:
+ noise: A single Tensor representing noise.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ return _generator_helper(noise, False, None, weight_decay, is_training)
+
+
+def conditional_generator(inputs, weight_decay=2.5e-5, is_training=True):
+ """Generator to produce MNIST images conditioned on class.
+
+ Args:
+ inputs: A 2-tuple of Tensors (noise, one_hot_labels).
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ noise, one_hot_labels = inputs
+ return _generator_helper(
+ noise, True, one_hot_labels, weight_decay, is_training)
+
+
+def infogan_generator(inputs, categorical_dim, weight_decay=2.5e-5,
+ is_training=True):
+ """InfoGAN generator network on MNIST digits.
+
+ Based on a paper https://arxiv.org/abs/1606.03657, their code
+ https://github.com/openai/InfoGAN, and code by pooleb@.
+
+ Args:
+ inputs: A 3-tuple of Tensors (unstructured_noise, categorical structured
+ noise, continuous structured noise). `inputs[0]` and `inputs[2]` must be
+ 2D, and `inputs[1]` must be 1D. All must have the same first dimension.
+ categorical_dim: Dimensions of the incompressible categorical noise.
+ weight_decay: The value of the l2 weight decay.
+ is_training: If `True`, batch norm uses batch statistics. If `False`, batch
+ norm uses the exponential moving average collected from population
+ statistics.
+
+ Returns:
+ A generated image in the range [-1, 1].
+ """
+ unstructured_noise, cat_noise, cont_noise = inputs
+ cat_noise_onehot = tf.one_hot(cat_noise, categorical_dim)
+ all_noise = tf.concat(
+ [unstructured_noise, cat_noise_onehot, cont_noise], axis=1)
+ return _generator_helper(all_noise, False, None, weight_decay, is_training)
+
+
+_leaky_relu = lambda x: tf.nn.leaky_relu(x, alpha=0.01)
+
+
+def _discriminator_helper(img, is_conditional, one_hot_labels, weight_decay):
+ """Core MNIST discriminator.
+
+ This function is reused between the different GAN modes (unconditional,
+ conditional, etc).
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ is_conditional: Whether to condition on labels.
+ one_hot_labels: Labels to optionally condition the network on.
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Final fully connected discriminator layer. [batch_size, 1024].
+ """
+ with tf.contrib.framework.arg_scope(
+ [layers.conv2d, layers.fully_connected],
+ activation_fn=_leaky_relu, normalizer_fn=None,
+ weights_regularizer=layers.l2_regularizer(weight_decay),
+ biases_regularizer=layers.l2_regularizer(weight_decay)):
+ net = layers.conv2d(img, 64, [4, 4], stride=2)
+ net = layers.conv2d(net, 128, [4, 4], stride=2)
+ net = layers.flatten(net)
+ if is_conditional:
+ net = tfgan.features.condition_tensor_from_onehot(net, one_hot_labels)
+ net = layers.fully_connected(net, 1024, normalizer_fn=layers.layer_norm)
+
+ return net
+
+
+def unconditional_discriminator(img, unused_conditioning, weight_decay=2.5e-5):
+ """Discriminator network on unconditional MNIST digits.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Logits for the probability that the image is real.
+ """
+ net = _discriminator_helper(img, False, None, weight_decay)
+ return layers.linear(net, 1)
+
+
+def conditional_discriminator(img, conditioning, weight_decay=2.5e-5):
+ """Conditional discriminator network on MNIST digits.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ conditioning: A 2-tuple of Tensors representing (noise, one_hot_labels).
+ weight_decay: The L2 weight decay.
+
+ Returns:
+ Logits for the probability that the image is real.
+ """
+ _, one_hot_labels = conditioning
+ net = _discriminator_helper(img, True, one_hot_labels, weight_decay)
+ return layers.linear(net, 1)
+
+
+def infogan_discriminator(img, unused_conditioning, weight_decay=2.5e-5,
+ categorical_dim=10, continuous_dim=2):
+ """InfoGAN discriminator network on MNIST digits.
+
+ Based on a paper https://arxiv.org/abs/1606.03657, their code
+ https://github.com/openai/InfoGAN, and code by pooleb@.
+
+ Args:
+ img: Real or generated MNIST digits. Should be in the range [-1, 1].
+ unused_conditioning: The TFGAN API can help with conditional GANs, which
+ would require extra `condition` information to both the generator and the
+ discriminator. Since this example is not conditional, we do not use this
+ argument.
+ weight_decay: The L2 weight decay.
+ categorical_dim: Dimensions of the incompressible categorical noise.
+ continuous_dim: Dimensions of the incompressible continuous noise.
+
+ Returns:
+ Logits for the probability that the image is real, and a list of posterior
+ distributions for each of the noise vectors.
+ """
+ net = _discriminator_helper(img, False, None, weight_decay)
+ logits_real = layers.fully_connected(net, 1, activation_fn=None)
+
+ # Recognition network for latent variables has an additional layer
+ with tf.contrib.framework.arg_scope([layers.batch_norm], is_training=False):
+ encoder = layers.fully_connected(net, 128, normalizer_fn=layers.batch_norm,
+ activation_fn=_leaky_relu)
+
+ # Compute logits for each category of categorical latent.
+ logits_cat = layers.fully_connected(
+ encoder, categorical_dim, activation_fn=None)
+ q_cat = ds.Categorical(logits_cat)
+
+ # Compute mean for Gaussian posterior of continuous latents.
+ mu_cont = layers.fully_connected(encoder, continuous_dim, activation_fn=None)
+ sigma_cont = tf.ones_like(mu_cont)
+ q_cont = ds.Normal(loc=mu_cont, scale=sigma_cont)
+
+ return logits_real, [q_cat, q_cont]
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py"
new file mode 100644
index 00000000..b51f2812
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train.py"
@@ -0,0 +1,151 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a generator on MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import functools
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import networks
+import util
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_integer('batch_size', 32, 'The number of images in each batch.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/mnist/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_integer('max_number_of_steps', 20000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_string(
+ 'gan_type', 'unconditional',
+ 'Either `unconditional`, `conditional`, or `infogan`.')
+
+flags.DEFINE_integer(
+ 'grid_size', 5, 'Grid size for image visualization.')
+
+
+flags.DEFINE_integer(
+ 'noise_dims', 64, 'Dimensions of the generator noise vector.')
+
+FLAGS = flags.FLAGS
+
+
+def _learning_rate(gan_type):
+ # First is generator learning rate, second is discriminator learning rate.
+ return {
+ 'unconditional': (1e-3, 1e-4),
+ 'conditional': (1e-5, 1e-4),
+ 'infogan': (0.001, 9e-5),
+ }[gan_type]
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ # Force all input processing onto CPU in order to reserve the GPU for
+ # the forward inference and back-propagation.
+ with tf.name_scope('inputs'):
+ with tf.device('/cpu:0'):
+ images, one_hot_labels, _ = data_provider.provide_data(
+ 'train', FLAGS.batch_size, FLAGS.dataset_dir, num_threads=4)
+
+ # Define the GANModel tuple. Optionally, condition the GAN on the label or
+ # use an InfoGAN to learn a latent representation.
+ if FLAGS.gan_type == 'unconditional':
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.unconditional_generator,
+ discriminator_fn=networks.unconditional_discriminator,
+ real_data=images,
+ generator_inputs=tf.random_normal(
+ [FLAGS.batch_size, FLAGS.noise_dims]))
+ elif FLAGS.gan_type == 'conditional':
+ noise = tf.random_normal([FLAGS.batch_size, FLAGS.noise_dims])
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.conditional_generator,
+ discriminator_fn=networks.conditional_discriminator,
+ real_data=images,
+ generator_inputs=(noise, one_hot_labels))
+ elif FLAGS.gan_type == 'infogan':
+ cat_dim, cont_dim = 10, 2
+ generator_fn = functools.partial(
+ networks.infogan_generator, categorical_dim=cat_dim)
+ discriminator_fn = functools.partial(
+ networks.infogan_discriminator, categorical_dim=cat_dim,
+ continuous_dim=cont_dim)
+ unstructured_inputs, structured_inputs = util.get_infogan_noise(
+ FLAGS.batch_size, cat_dim, cont_dim, FLAGS.noise_dims)
+ gan_model = tfgan.infogan_model(
+ generator_fn=generator_fn,
+ discriminator_fn=discriminator_fn,
+ real_data=images,
+ unstructured_generator_inputs=unstructured_inputs,
+ structured_generator_inputs=structured_inputs)
+ tfgan.eval.add_gan_model_image_summaries(gan_model, FLAGS.grid_size)
+
+ # Get the GANLoss tuple. You can pass a custom function, use one of the
+ # already-implemented losses from the losses library, or use the defaults.
+ with tf.name_scope('loss'):
+ mutual_information_penalty_weight = (1.0 if FLAGS.gan_type == 'infogan'
+ else 0.0)
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ gradient_penalty_weight=1.0,
+ mutual_information_penalty_weight=mutual_information_penalty_weight,
+ add_summaries=True)
+ tfgan.eval.add_regularization_loss_summaries(gan_model)
+
+ # Get the GANTrain ops using custom optimizers.
+ with tf.name_scope('train'):
+ gen_lr, dis_lr = _learning_rate(FLAGS.gan_type)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=tf.train.AdamOptimizer(gen_lr, 0.5),
+ discriminator_optimizer=tf.train.AdamOptimizer(dis_lr, 0.5),
+ summarize_gradients=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ logdir=FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_joint_train_hooks())
+
+if __name__ == '__main__':
+ logging.set_verbosity(logging.INFO)
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py"
new file mode 100644
index 00000000..a75f858b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/train_test.py"
@@ -0,0 +1,71 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ def test_run_one_train_step(self, mock_data_provider):
+ FLAGS.max_number_of_steps = 1
+ FLAGS.gan_type = 'unconditional'
+ FLAGS.batch_size = 5
+ FLAGS.grid_size = 1
+ tf.set_random_seed(1234)
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ mock_data_provider.provide_data.return_value = (mock_imgs, mock_lbls, None)
+
+ train.main(None)
+
+ @parameterized.named_parameters(
+ ('Unconditional', 'unconditional'),
+ ('Conditional', 'conditional'),
+ ('InfoGAN', 'infogan'))
+ def test_build_graph(self, gan_type):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.gan_type = gan_type
+
+ # Mock input pipeline.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = (
+ mock_imgs, mock_lbls, None)
+ train.main(None)
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py"
new file mode 100644
index 00000000..0cf6b00e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util.py"
@@ -0,0 +1,323 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""A utility for evaluating MNIST generative models.
+
+These functions use a pretrained MNIST classifier with ~99% eval accuracy to
+measure various aspects of the quality of generated MNIST digits.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+
+ds = tf.contrib.distributions
+tfgan = tf.contrib.gan
+
+
+__all__ = [
+ 'mnist_score',
+ 'mnist_frechet_distance',
+ 'mnist_cross_entropy',
+ 'get_eval_noise_categorical',
+ 'get_eval_noise_continuous_dim1',
+ 'get_eval_noise_continuous_dim2',
+ 'get_infogan_noise',
+]
+
+
+# Prepend `../`, since paths start from `third_party/tensorflow`.
+MODEL_GRAPH_DEF = '../tensorflow_models/gan/mnist/data/classify_mnist_graph_def.pb'
+INPUT_TENSOR = 'inputs:0'
+OUTPUT_TENSOR = 'logits:0'
+
+
+def mnist_score(images, graph_def_filename=None, input_tensor=INPUT_TENSOR,
+ output_tensor=OUTPUT_TENSOR, num_batches=1):
+ """Get MNIST logits of a fully-trained classifier.
+
+ Args:
+ images: A minibatch tensor of MNIST digits. Shape must be
+ [batch, 28, 28, 1].
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+ num_batches: Number of batches to split `generated_images` in to in order to
+ efficiently run them through Inception.
+
+ Returns:
+ A logits tensor of [batch, 10].
+ """
+ images.shape.assert_is_compatible_with([None, 28, 28, 1])
+
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+ mnist_classifier_fn = lambda x: tfgan.eval.run_image_classifier( # pylint: disable=g-long-lambda
+ x, graph_def, input_tensor, output_tensor)
+
+ score = tfgan.eval.classifier_score(
+ images, mnist_classifier_fn, num_batches)
+ score.shape.assert_is_compatible_with([])
+
+ return score
+
+
+def mnist_frechet_distance(real_images, generated_images,
+ graph_def_filename=None, input_tensor=INPUT_TENSOR,
+ output_tensor=OUTPUT_TENSOR, num_batches=1):
+ """Frechet distance between real and generated images.
+
+ This technique is described in detail in https://arxiv.org/abs/1706.08500.
+ Please see TFGAN for implementation details
+ (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/
+ python/eval/python/classifier_metrics_impl.py).
+
+ Args:
+ real_images: Real images to use to compute Frechet Inception distance.
+ generated_images: Generated images to use to compute Frechet Inception
+ distance.
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+ num_batches: Number of batches to split images into in order to
+ efficiently run them through the classifier network.
+
+ Returns:
+ The Frechet distance. A floating-point scalar.
+ """
+ real_images.shape.assert_is_compatible_with([None, 28, 28, 1])
+ generated_images.shape.assert_is_compatible_with([None, 28, 28, 1])
+
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+ mnist_classifier_fn = lambda x: tfgan.eval.run_image_classifier( # pylint: disable=g-long-lambda
+ x, graph_def, input_tensor, output_tensor)
+
+ frechet_distance = tfgan.eval.frechet_classifier_distance(
+ real_images, generated_images, mnist_classifier_fn, num_batches)
+ frechet_distance.shape.assert_is_compatible_with([])
+
+ return frechet_distance
+
+
+def mnist_cross_entropy(images, one_hot_labels, graph_def_filename=None,
+ input_tensor=INPUT_TENSOR, output_tensor=OUTPUT_TENSOR):
+ """Returns the cross entropy loss of the classifier on images.
+
+ Args:
+ images: A minibatch tensor of MNIST digits. Shape must be
+ [batch, 28, 28, 1].
+ one_hot_labels: The one hot label of the examples. Tensor size is
+ [batch, 10].
+ graph_def_filename: Location of a frozen GraphDef binary file on disk. If
+ `None`, uses a default graph embedded in the par file.
+ input_tensor: GraphDef's input tensor name.
+ output_tensor: GraphDef's output tensor name.
+
+ Returns:
+ A scalar Tensor representing the cross entropy of the image minibatch.
+ """
+ graph_def = _graph_def_from_par_or_disk(graph_def_filename)
+
+ logits = tfgan.eval.run_image_classifier(
+ images, graph_def, input_tensor, output_tensor)
+ return tf.losses.softmax_cross_entropy(
+ one_hot_labels, logits, loss_collection=None)
+
+
+# (joelshor): Refactor the `eval_noise` functions to reuse code.
+def get_eval_noise_categorical(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims):
+ """Create noise showing impact of categorical noise in InfoGAN.
+
+ Categorical noise is constant across columns. Other noise is constant across
+ rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays. Each
+ should have shape [noise_samples, ?].
+ """
+ rows, cols = noise_samples, len(categorical_sample_points)
+
+ # Take random draws for non-categorical noise, making sure they are constant
+ # across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ continuous_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(
+ continuous_sample_points, size=[1, continuous_noise_dims])
+ continuous_noise.extend([cur_sample] * cols)
+ continuous_noise = np.concatenate(continuous_noise)
+
+ # Increase categorical noise from left to right, making sure they are constant
+ # across rows.
+ categorical_noise = np.tile(categorical_sample_points, rows)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_eval_noise_continuous_dim1(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims): # pylint:disable=unused-argument
+ """Create noise showing impact of first dim continuous noise in InfoGAN.
+
+ First dimension of continuous noise is constant across columns. Other noise is
+ constant across rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays.
+ """
+ rows, cols = noise_samples, len(continuous_sample_points)
+
+ # Take random draws for non-first-dim-continuous noise, making sure they are
+ # constant across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ categorical_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(categorical_sample_points)
+ categorical_noise.extend([cur_sample] * cols)
+ categorical_noise = np.array(categorical_noise)
+
+ cont_noise_dim2 = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(continuous_sample_points, size=[1, 1])
+ cont_noise_dim2.extend([cur_sample] * cols)
+ cont_noise_dim2 = np.concatenate(cont_noise_dim2)
+
+ # Increase first dimension of continuous noise from left to right, making sure
+ # they are constant across rows.
+ cont_noise_dim1 = np.expand_dims(np.tile(continuous_sample_points, rows), 1)
+
+ continuous_noise = np.concatenate((cont_noise_dim1, cont_noise_dim2), 1)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_eval_noise_continuous_dim2(
+ noise_samples, categorical_sample_points, continuous_sample_points,
+ unstructured_noise_dims, continuous_noise_dims): # pylint:disable=unused-argument
+ """Create noise showing impact of second dim of continuous noise in InfoGAN.
+
+ Second dimension of continuous noise is constant across columns. Other noise
+ is constant across rows.
+
+ Args:
+ noise_samples: Number of non-categorical noise samples to use.
+ categorical_sample_points: Possible categorical noise points to sample.
+ continuous_sample_points: Possible continuous noise points to sample.
+ unstructured_noise_dims: Dimensions of the unstructured noise.
+ continuous_noise_dims: Dimensions of the continuous noise.
+
+ Returns:
+ Unstructured noise, categorical noise, continuous noise numpy arrays.
+ """
+ rows, cols = noise_samples, len(continuous_sample_points)
+
+ # Take random draws for non-first-dim-continuous noise, making sure they are
+ # constant across columns.
+ unstructured_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.normal(size=[1, unstructured_noise_dims])
+ unstructured_noise.extend([cur_sample] * cols)
+ unstructured_noise = np.concatenate(unstructured_noise)
+
+ categorical_noise = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(categorical_sample_points)
+ categorical_noise.extend([cur_sample] * cols)
+ categorical_noise = np.array(categorical_noise)
+
+ cont_noise_dim1 = []
+ for _ in xrange(rows):
+ cur_sample = np.random.choice(continuous_sample_points, size=[1, 1])
+ cont_noise_dim1.extend([cur_sample] * cols)
+ cont_noise_dim1 = np.concatenate(cont_noise_dim1)
+
+ # Increase first dimension of continuous noise from left to right, making sure
+ # they are constant across rows.
+ cont_noise_dim2 = np.expand_dims(np.tile(continuous_sample_points, rows), 1)
+
+ continuous_noise = np.concatenate((cont_noise_dim1, cont_noise_dim2), 1)
+
+ return unstructured_noise, categorical_noise, continuous_noise
+
+
+def get_infogan_noise(batch_size, categorical_dim, structured_continuous_dim,
+ total_continuous_noise_dims):
+ """Get unstructured and structured noise for InfoGAN.
+
+ Args:
+ batch_size: The number of noise vectors to generate.
+ categorical_dim: The number of categories in the categorical noise.
+ structured_continuous_dim: The number of dimensions of the uniform
+ continuous noise.
+ total_continuous_noise_dims: The number of continuous noise dimensions. This
+ number includes the structured and unstructured noise.
+
+ Returns:
+ A 2-tuple of structured and unstructured noise. First element is the
+ unstructured noise, and the second is a 2-tuple of
+ (categorical structured noise, continuous structured noise).
+ """
+ # Get unstructurd noise.
+ unstructured_noise = tf.random_normal(
+ [batch_size, total_continuous_noise_dims - structured_continuous_dim])
+
+ # Get categorical noise Tensor.
+ categorical_dist = ds.Categorical(logits=tf.zeros([categorical_dim]))
+ categorical_noise = categorical_dist.sample([batch_size])
+
+ # Get continuous noise Tensor.
+ continuous_dist = ds.Uniform(-tf.ones([structured_continuous_dim]),
+ tf.ones([structured_continuous_dim]))
+ continuous_noise = continuous_dist.sample([batch_size])
+
+ return [unstructured_noise], [categorical_noise, continuous_noise]
+
+
+def _graph_def_from_par_or_disk(filename):
+ if filename is None:
+ return tfgan.eval.get_graph_def_from_resource(MODEL_GRAPH_DEF)
+ else:
+ return tfgan.eval.get_graph_def_from_disk(filename)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py"
new file mode 100644
index 00000000..53b851b6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist/util_test.py"
@@ -0,0 +1,229 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist.util."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import numpy as np
+
+import tensorflow as tf
+from google3.third_party.tensorflow_models.gan.mnist import util
+
+
+# pylint: disable=line-too-long
+# This is a real digit `5` from MNIST.
+REAL_DIGIT = [[-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.9765625, -0.859375, -0.859375, -0.859375, -0.015625, 0.0625, 0.3671875, -0.796875, 0.296875, 0.9921875, 0.9296875, -0.0078125, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.765625, -0.71875, -0.265625, 0.203125, 0.328125, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.7578125, 0.34375, 0.9765625, 0.890625, 0.5234375, -0.5, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6171875, 0.859375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9609375, -0.2734375, -0.359375, -0.359375, -0.5625, -0.6953125, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.859375, 0.7109375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.546875, 0.421875, 0.9296875, 0.8828125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.375, 0.21875, -0.1640625, 0.9765625, 0.9765625, 0.6015625, -0.9140625, -1.0, -0.6640625, 0.203125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.890625, -0.9921875, 0.203125, 0.9765625, -0.296875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 0.0859375, 0.9765625, 0.484375, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.9140625, 0.484375, 0.9765625, -0.453125, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.7265625, 0.8828125, 0.7578125, 0.25, -0.15625, -0.9921875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.3671875, 0.875, 0.9765625, 0.9765625, -0.0703125, -0.8046875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6484375, 0.453125, 0.9765625, 0.9765625, 0.171875, -0.7890625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.875, -0.2734375, 0.96875, 0.9765625, 0.4609375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, 0.9453125, 0.9765625, 0.9453125, -0.5, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.640625, 0.015625, 0.4296875, 0.9765625, 0.9765625, 0.6171875, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.6953125, 0.15625, 0.7890625, 0.9765625, 0.9765625, 0.9765625, 0.953125, 0.421875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.8125, -0.109375, 0.7265625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.5703125, -0.390625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.8203125, -0.484375, 0.6640625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.546875, -0.3671875, -0.984375, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -0.859375, 0.3359375, 0.7109375, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.5234375, -0.375, -0.9296875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -0.5703125, 0.34375, 0.765625, 0.9765625, 0.9765625, 0.9765625, 0.9765625, 0.90625, 0.0390625, -0.9140625, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, 0.0625, 0.9765625, 0.9765625, 0.9765625, 0.65625, 0.0546875, 0.03125, -0.875, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0], [-1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0, -1.0]]
+ONE_HOT = [[0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0]]
+
+# Uniform noise in [-1, 1].
+FAKE_DIGIT = [[0.778958797454834, 0.8792028427124023, 0.07099628448486328, 0.8518857955932617, -0.3541288375854492, -0.7431280612945557, -0.12607860565185547, 0.17328786849975586, 0.6749839782714844, -0.5402040481567383, 0.9034252166748047, 0.2420203685760498, 0.3455841541290283, 0.1937558650970459, 0.9989571571350098, 0.9039363861083984, -0.955411434173584, 0.6228537559509277, -0.33131909370422363, 0.9653763771057129, 0.864208459854126, -0.05056142807006836, 0.12686634063720703, -0.09225749969482422, 0.49758028984069824, 0.08698725700378418, 0.5533185005187988, 0.20227980613708496], [0.8400616645812988, 0.7409703731536865, -0.6215496063232422, -0.53228759765625, -0.20184636116027832, -0.8568699359893799, -0.8662903308868408, -0.8735041618347168, -0.11022663116455078, -0.8418543338775635, 0.8193502426147461, -0.901512622833252, -0.7680232524871826, 0.6209826469421387, 0.06459426879882812, 0.5341305732727051, -0.4078702926635742, -0.13658642768859863, 0.6602437496185303, 0.848508358001709, -0.23431801795959473, 0.5995683670043945, -0.9807922840118408, 0.2657158374786377, -0.8068397045135498, 0.2438051700592041, -0.2116842269897461, 0.011460304260253906], [0.00040912628173828125, -0.058798789978027344, 0.3239307403564453, 0.5040378570556641, -0.03192305564880371, -0.4816470146179199, -0.14559340476989746, -0.9231269359588623, -0.6602556705474854, -0.2537086009979248, -0.11059761047363281, -0.8174862861633301, 0.6180260181427002, 0.7245023250579834, 0.5007762908935547, -0.1575303077697754, -0.0167086124420166, 0.7173266410827637, 0.1126704216003418, -0.9878268241882324, 0.4538843631744385, -0.4422755241394043, -0.7899672985076904, 0.7349567413330078, -0.4448075294494629, -0.7548923492431641, -0.5739786624908447, 0.30504918098449707], [-0.8488152027130127, 0.43424463272094727, 0.7724254131317139, 0.43314504623413086, 0.7352848052978516, -0.26010799407958984, 0.43951940536499023, -0.7642686367034912, -0.657184362411499, -0.9933960437774658, -0.47258639335632324, 0.10390830039978027, 0.11454653739929199, -0.6156411170959473, -0.23431062698364258, -0.6897118091583252, -0.5721850395202637, -0.3574075698852539, 0.13927006721496582, -0.6530766487121582, 0.32231855392456055, 0.6294634342193604, 0.5507853031158447, -0.4867420196533203, 0.4329197406768799, 0.6168341636657715, -0.8720219135284424, 0.8639121055603027], [0.02407360076904297, -0.11185193061828613, -0.38637852668762207, -0.8244953155517578, -0.648916482925415, 0.44907593727111816, -0.368192195892334, 0.0190126895904541, -0.9450500011444092, 0.41033458709716797, -0.7877917289733887, 0.617938756942749, 0.551692008972168, -0.48288512229919434, 0.019921541213989258, -0.8765170574188232, 0.5651748180389404, 0.850874662399292, -0.5792787075042725, 0.1748213768005371, -0.6905481815338135, -0.521310567855835, 0.062479496002197266, 0.17763280868530273, -0.4628307819366455, 0.8870463371276855, -0.8685822486877441, -0.29169774055480957], [-0.14687561988830566, 0.8801963329315186, 0.11353135108947754, -0.6009430885314941, 0.8818719387054443, -0.8621203899383545, -0.48749589920043945, 0.5224916934967041, 0.7050364017486572, -0.9968757629394531, 0.7235188484191895, 0.662771463394165, 0.588390588760376, -0.9624209403991699, 0.39203453063964844, -0.2210233211517334, 0.9266352653503418, -0.9132544994354248, -0.5175333023071289, 0.7251780033111572, 0.3030557632446289, 0.5743863582611084, 0.14350247383117676, -0.3735086917877197, -0.6299927234649658, 0.5088682174682617, -0.6953752040863037, 0.23583650588989258], [0.25864362716674805, 0.5736973285675049, -0.3975222110748291, -0.6369199752807617, 0.5376672744750977, -0.19951462745666504, 0.6843924522399902, 0.6296660900115967, 0.36865997314453125, -0.7243289947509766, 0.5768749713897705, -0.5493001937866211, 0.31238412857055664, 0.21019506454467773, -0.368206262588501, -0.33148622512817383, -0.3421964645385742, -0.15616083145141602, 0.6617193222045898, 0.4400820732116699, 0.7893157005310059, -0.2935945987701416, 0.6241741180419922, -0.26036930084228516, -0.6958446502685547, 0.27047157287597656, -0.9095940589904785, 0.9525108337402344], [-0.5233585834503174, -0.45003342628479004, 0.15099048614501953, 0.6257956027984619, 0.9017877578735352, -0.18155455589294434, -0.20237135887145996, -0.014468908309936523, 0.01797318458557129, -0.5453977584838867, 0.21428155899047852, -0.9678947925567627, 0.5137600898742676, -0.1094369888305664, -0.13572359085083008, -0.1704423427581787, -0.9122319221496582, 0.8274900913238525, -0.11746454238891602, -0.8701446056365967, -0.9545385837554932, -0.6735866069793701, 0.9445557594299316, -0.3842940330505371, -0.6240942478179932, -0.1673595905303955, -0.3959221839904785, -0.05602693557739258], [0.8833198547363281, 0.14288711547851562, -0.9623878002166748, -0.26968836784362793, 0.9689288139343262, -0.3792128562927246, 0.2520296573638916, 0.1477947235107422, -0.24453139305114746, 0.94329833984375, 0.8014910221099854, 0.5443501472473145, 0.8486857414245605, -0.0795745849609375, -0.30250096321105957, -0.909733772277832, 0.8387842178344727, -0.41989898681640625, -0.8364224433898926, 0.04792976379394531, -0.38036274909973145, 0.12747883796691895, -0.5356688499450684, -0.04269552230834961, -0.2070469856262207, -0.6911153793334961, 0.33954668045043945, 0.25260138511657715], [0.3128373622894287, 0.36142778396606445, -0.2512378692626953, -0.6497259140014648, -0.21787405014038086, -0.9972476959228516, -0.026904821395874023, -0.4214746952056885, -0.3354766368865967, -0.6112637519836426, -0.7594058513641357, 0.09093379974365234, -0.7331845760345459, 0.5222046375274658, -0.8997514247894287, -0.3749384880065918, -0.0775001049041748, -0.26296448707580566, 0.404325008392334, -0.25776195526123047, 0.9136955738067627, 0.2623283863067627, -0.6411356925964355, 0.6646602153778076, -0.12833356857299805, -0.4184732437133789, -0.3663449287414551, -0.5468103885650635], [0.3770618438720703, 0.5572817325592041, -0.3657073974609375, -0.5056321620941162, 0.6555137634277344, 0.9557509422302246, -0.6900768280029297, -0.4980638027191162, 0.05510354042053223, -0.610318660736084, 0.9753992557525635, 0.7569930553436279, 0.4011664390563965, 0.8439173698425293, -0.5921270847320557, -0.2775266170501709, -0.061129093170166016, -0.49707984924316406, 0.5820951461791992, 0.008175849914550781, 0.06372833251953125, 0.3061811923980713, -0.5091361999511719, 0.9751057624816895, 0.4571402072906494, 0.6769094467163086, -0.46695923805236816, 0.44080281257629395], [-0.6510493755340576, -0.032715559005737305, 0.3482983112335205, -0.8135421276092529, 0.1506943702697754, 0.5220685005187988, -0.8834004402160645, -0.908900260925293, 0.3211519718170166, 0.896381139755249, -0.9448244571685791, -0.6193962097167969, -0.009401559829711914, 0.38227057456970215, -0.9219558238983154, -0.029483318328857422, -0.3889012336730957, 0.5242419242858887, 0.7338912487030029, -0.8713808059692383, -0.04948568344116211, -0.797940731048584, -0.9933724403381348, -0.262890100479126, -0.7165846824645996, -0.9763388633728027, -0.4105076789855957, 0.5907857418060303], [-0.6091890335083008, 0.7921168804168701, -0.033307790756225586, -0.9177074432373047, 0.4553513526916504, 0.5754055976867676, 0.6747269630432129, 0.0015664100646972656, -0.36865878105163574, -0.7999486923217773, 0.993431568145752, -0.7310445308685303, -0.49965715408325195, -0.028263330459594727, -0.20190834999084473, -0.7398116588592529, 0.10513901710510254, 0.22136950492858887, 0.42579007148742676, -0.4703383445739746, -0.8729751110076904, 0.28951215744018555, -0.3110074996948242, 0.9935362339019775, -0.29533815383911133, -0.3384673595428467, -0.07292437553405762, 0.8471579551696777], [-0.04648447036743164, -0.6876633167266846, -0.4921104907989502, -0.1925184726715088, -0.5843420028686523, -0.2852492332458496, 0.1251826286315918, -0.5709969997406006, 0.6744673252105713, 0.17812824249267578, 0.675086259841919, 0.1219022274017334, 0.6496286392211914, 0.05892682075500488, 0.33709263801574707, -0.9087743759155273, -0.4785141944885254, 0.2689247131347656, 0.3600578308105469, -0.6822943687438965, -0.0801839828491211, 0.9234893321990967, 0.5037875175476074, -0.8148105144500732, 0.6820621490478516, -0.8345451354980469, 0.9400079250335693, -0.752265453338623], [0.4599113464355469, 0.0292510986328125, -0.7475054264068604, -0.4074263572692871, 0.8800950050354004, 0.41760849952697754, 0.3225588798522949, 0.8359887599945068, -0.8655965328216553, 0.17258906364440918, 0.752063512802124, -0.48968982696533203, -0.9149389266967773, -0.46224403381347656, -0.26379919052124023, -0.9342350959777832, -0.5444085597991943, -0.4576752185821533, -0.12544608116149902, -0.3810274600982666, -0.5277583599090576, 0.3267025947570801, 0.4762594699859619, 0.09010529518127441, -0.2434844970703125, -0.8013439178466797, -0.23540687561035156, 0.8844473361968994], [-0.8922028541564941, -0.7912418842315674, -0.14429497718811035, -0.3925011157989502, 0.1870102882385254, -0.28865933418273926, 0.11481523513793945, -0.9174098968505859, -0.5264348983764648, -0.7296302318572998, 0.44644737243652344, 0.11140275001525879, 0.08105874061584473, 0.3871574401855469, -0.5030152797698975, -0.9560322761535645, -0.07085466384887695, 0.7949709892272949, 0.37600183486938477, -0.8664641380310059, -0.08428549766540527, 0.9169652462005615, 0.9479010105133057, 0.3576698303222656, 0.6677501201629639, -0.34919166564941406, -0.11635351181030273, -0.05966901779174805], [-0.9716870784759521, -0.7901370525360107, 0.9152195453643799, -0.42171406745910645, 0.20472931861877441, -0.9847748279571533, 0.9935972690582275, -0.5975158214569092, 0.9557573795318604, 0.41234254837036133, -0.26670074462890625, 0.869682788848877, 0.4443938732147217, -0.13968205451965332, -0.7745835781097412, -0.5692052841186523, 0.321591854095459, -0.3146944046020508, -0.3921670913696289, -0.36029601097106934, 0.33528995513916016, 0.029220104217529297, -0.8788590431213379, 0.6883881092071533, -0.8260040283203125, -0.43041515350341797, 0.42810845375061035, 0.40050792694091797], [0.6319584846496582, 0.32369279861450195, -0.6308813095092773, 0.07861590385437012, 0.5387494564056396, -0.902024507522583, -0.5346510410308838, 0.10787153244018555, 0.36048197746276855, 0.7801573276519775, -0.39187049865722656, 0.409869909286499, 0.5972449779510498, -0.7578165531158447, 0.30403685569763184, -0.7885205745697021, 0.01341390609741211, -0.023469209671020508, -0.11588907241821289, -0.941727876663208, -0.09618496894836426, 0.8042230606079102, 0.4683551788330078, -0.6497313976287842, 0.7443571090698242, 0.7150907516479492, -0.5759801864624023, -0.6523513793945312], [0.3150167465209961, -0.1853046417236328, 0.1839759349822998, -0.9234504699707031, -0.666614294052124, -0.740748405456543, 0.5700008869171143, 0.4091987609863281, -0.8912513256072998, 0.027419567108154297, 0.07219696044921875, -0.3128829002380371, 0.9465951919555664, 0.8715424537658691, -0.4559173583984375, -0.5862705707550049, -0.6734106540679932, 0.8419013023376465, -0.5523068904876709, -0.5019669532775879, -0.4969966411590576, -0.030994892120361328, 0.7572557926177979, 0.3824281692504883, 0.6366133689880371, -0.13271117210388184, 0.632627010345459, -0.9462625980377197], [-0.3923935890197754, 0.5466675758361816, -0.9815363883972168, -0.12867975234985352, 0.9932572841644287, -0.712486743927002, -0.17107725143432617, -0.41582536697387695, 0.10990118980407715, 0.11867499351501465, -0.7774863243103027, -0.9382553100585938, 0.4290587902069092, -0.1412363052368164, -0.498490571975708, 0.7793624401092529, 0.9015710353851318, -0.5107312202453613, 0.12394595146179199, 0.4988982677459717, -0.5731511116027832, -0.8105146884918213, 0.19758391380310059, 0.4081540107727051, -0.20432400703430176, 0.9924988746643066, -0.16952204704284668, 0.45574188232421875], [-0.023319005966186523, -0.3514130115509033, 0.4652390480041504, 0.7690563201904297, 0.7906622886657715, 0.9922001361846924, -0.6670932769775391, -0.5720524787902832, 0.3491201400756836, -0.18706512451171875, 0.4899415969848633, -0.5637645721435547, 0.8986928462982178, -0.7359066009521484, -0.6342356204986572, 0.6608924865722656, 0.6014213562011719, 0.7906208038330078, 0.19034814834594727, 0.16884255409240723, -0.8803558349609375, 0.4060337543487549, 0.9862797260284424, -0.48758840560913086, 0.3894319534301758, 0.4226539134979248, 0.00042724609375, -0.3623659610748291], [0.7065057754516602, -0.4103825092315674, 0.3343489170074463, -0.9341757297515869, -0.20749878883361816, -0.3589310646057129, -0.9470062255859375, 0.7851138114929199, -0.74678635597229, -0.05102086067199707, 0.16727972030639648, 0.12385678291320801, -0.41132497787475586, 0.5856695175170898, 0.06311273574829102, 0.8238284587860107, 0.2257852554321289, -0.6452250480651855, -0.6373245716094971, -0.1247873306274414, 0.0021851062774658203, -0.5648598670959473, 0.8261771202087402, 0.3713812828063965, -0.7185893058776855, 0.45911359786987305, 0.6722264289855957, -0.31804966926574707], [-0.2952606678009033, -0.12052011489868164, 0.9074821472167969, -0.9850583076477051, 0.6732273101806641, 0.7954013347625732, 0.938248872756958, -0.35915136337280273, -0.8291504383087158, 0.6020793914794922, -0.30096912384033203, 0.6136975288391113, 0.46443629264831543, -0.9057025909423828, 0.43993186950683594, -0.11653375625610352, 0.9514555931091309, 0.7985148429870605, -0.6911783218383789, -0.931948184967041, 0.06829452514648438, 0.711458683013916, 0.17953252792358398, 0.19076848030090332, 0.6339912414550781, -0.38822221755981445, 0.09893226623535156, -0.7663829326629639], [0.2640511989593506, 0.16821074485778809, 0.9845118522644043, 0.13789963722229004, -0.1097862720489502, 0.24889636039733887, 0.12135696411132812, 0.4419589042663574, -0.022361040115356445, 0.3793671131134033, 0.7053709030151367, 0.5814387798309326, 0.24962759017944336, -0.40136122703552246, -0.364804744720459, -0.2518625259399414, 0.25757312774658203, 0.6828348636627197, -0.08237361907958984, -0.07745933532714844, -0.9299273490905762, -0.3066704273223877, 0.22127842903137207, -0.6690163612365723, 0.7477891445159912, 0.5738682746887207, -0.9027633666992188, 0.33333301544189453], [0.44417595863342285, 0.5279359817504883, 0.36589932441711426, -0.049490928649902344, -0.3003063201904297, 0.8447706699371338, 0.8139019012451172, -0.4958505630493164, -0.3640005588531494, -0.7731854915618896, 0.4138674736022949, 0.3080577850341797, -0.5615301132202148, -0.4247474670410156, -0.25992918014526367, -0.7983508110046387, -0.4926283359527588, 0.08595061302185059, 0.9205574989318848, 0.6025278568267822, 0.37128734588623047, -0.1856670379638672, 0.9658422470092773, -0.6652145385742188, -0.2217710018157959, 0.8311929702758789, 0.9117603302001953, 0.4660191535949707], [-0.6164810657501221, -0.9509942531585693, 0.30228447914123535, 0.39792585372924805, -0.45194506645202637, -0.3315877914428711, 0.5393261909484863, 0.030223369598388672, 0.6013507843017578, 0.020318031311035156, 0.17352747917175293, -0.25470709800720215, -0.7904071807861328, 0.5383470058441162, -0.43855953216552734, -0.350492000579834, -0.5038156509399414, 0.0511777400970459, 0.9628784656524658, -0.520085334777832, 0.33083176612854004, 0.3698580265045166, 0.9121549129486084, -0.664802074432373, -0.45629024505615234, -0.44208550453186035, 0.6502475738525391, -0.597346305847168], [-0.5405080318450928, 0.2640984058380127, -0.2119138240814209, 0.04504036903381348, -0.10604047775268555, -0.8093295097351074, 0.20915007591247559, 0.08994936943054199, 0.5347979068756104, -0.550915002822876, 0.3008608818054199, 0.2416989803314209, 0.025292158126831055, -0.2790646553039551, 0.5850257873535156, 0.7020430564880371, -0.9527721405029297, 0.8273317813873291, -0.8028199672698975, 0.3686351776123047, -0.9391682147979736, -0.4261181354522705, 0.1674947738647461, 0.27993154525756836, 0.7567532062530518, 0.9245085716247559, 0.9245762825012207, -0.296356201171875], [-0.7747671604156494, 0.7632861137390137, 0.10236740112304688, 0.14044547080993652, 0.9318621158599854, -0.5622165203094482, -0.6605725288391113, -0.8286299705505371, 0.8717818260192871, -0.22177672386169434, -0.6030778884887695, 0.20917797088623047, 0.31551361083984375, 0.7741527557373047, -0.3320643901824951, -0.9014863967895508, 0.44268250465393066, 0.25649309158325195, -0.5621528625488281, -0.6077632904052734, 0.21485304832458496, -0.658627986907959, -0.9116294384002686, -0.294114351272583, 0.0452420711517334, 0.8542745113372803, 0.7148771286010742, 0.3244490623474121]]
+# pylint: enable=line-too-long
+
+
+def real_digit():
+ return tf.expand_dims(tf.expand_dims(REAL_DIGIT, 0), -1)
+
+
+def fake_digit():
+ return tf.expand_dims(tf.expand_dims(FAKE_DIGIT, 0), -1)
+
+
+def one_hot_real():
+ return tf.constant(ONE_HOT)
+
+
+def one_hot1():
+ return tf.constant([[1.0] + [0.0] * 9])
+
+
+class MnistScoreTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ mscore = util.mnist_score(inputs)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(mscore, feed_dict={inputs: np.zeros([batch_size, 28, 28, 1])})
+
+ def test_deterministic(self):
+ m_score = util.mnist_score(real_digit())
+ with self.test_session():
+ m_score1 = m_score.eval()
+ m_score2 = m_score.eval()
+ self.assertEqual(m_score1, m_score2)
+
+ with self.test_session():
+ m_score3 = m_score.eval()
+ self.assertEqual(m_score1, m_score3)
+
+ def test_single_example_correct(self):
+ real_score = util.mnist_score(real_digit())
+ fake_score = util.mnist_score(fake_digit())
+ with self.test_session():
+ self.assertNear(1.0, real_score.eval(), 1e-6)
+ self.assertNear(1.0, fake_score.eval(), 1e-6)
+
+ def test_minibatch_correct(self):
+ mscore = util.mnist_score(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0))
+ with self.test_session():
+ self.assertNear(1.612828, mscore.eval(), 1e-6)
+
+ def test_batch_splitting_doesnt_change_value(self):
+ for num_batches in [1, 2, 4, 8]:
+ mscore = util.mnist_score(
+ tf.concat([real_digit()] * 4 + [fake_digit()] * 4, 0),
+ num_batches=num_batches)
+ with self.test_session():
+ self.assertNear(1.649209, mscore.eval(), 1e-6)
+
+
+class MnistFrechetDistanceTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ fdistance = util.mnist_frechet_distance(inputs, inputs)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(fdistance,
+ feed_dict={inputs: np.zeros([batch_size, 28, 28, 1])})
+
+ def test_deterministic(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 2, 0),
+ tf.concat([fake_digit()] * 2, 0))
+ with self.test_session():
+ fdistance1 = fdistance.eval()
+ fdistance2 = fdistance.eval()
+ self.assertNear(fdistance1, fdistance2, 2e-1)
+
+ with self.test_session():
+ fdistance3 = fdistance.eval()
+ self.assertNear(fdistance1, fdistance3, 2e-1)
+
+ def test_single_example_correct(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 2, 0),
+ tf.concat([real_digit()] * 2, 0))
+ with self.test_session():
+ self.assertNear(0.0, fdistance.eval(), 2e-1)
+
+ def test_minibatch_correct(self):
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0),
+ tf.concat([real_digit(), fake_digit(), fake_digit()], 0))
+ with self.test_session():
+ self.assertNear(43.5, fdistance.eval(), 2e-1)
+
+ def test_batch_splitting_doesnt_change_value(self):
+ for num_batches in [1, 2, 4, 8]:
+ fdistance = util.mnist_frechet_distance(
+ tf.concat([real_digit()] * 6 + [fake_digit()] * 2, 0),
+ tf.concat([real_digit()] * 2 + [fake_digit()] * 6, 0),
+ num_batches=num_batches)
+ with self.test_session():
+ self.assertNear(97.8, fdistance.eval(), 2e-1)
+
+
+class MnistCrossEntropyTest(tf.test.TestCase):
+
+ def test_any_batch_size(self):
+ num_classes = 10
+ one_label = np.array([[1] + [0] * (num_classes - 1)])
+ inputs = tf.placeholder(tf.float32, shape=[None, 28, 28, 1])
+ one_hot_label = tf.placeholder(tf.int32, shape=[None, num_classes])
+ entropy = util.mnist_cross_entropy(inputs, one_hot_label)
+ for batch_size in [4, 16, 30]:
+ with self.test_session() as sess:
+ sess.run(entropy, feed_dict={
+ inputs: np.zeros([batch_size, 28, 28, 1]),
+ one_hot_label: np.concatenate([one_label] * batch_size)})
+
+ def test_deterministic(self):
+ xent = util.mnist_cross_entropy(real_digit(), one_hot_real())
+ with self.test_session():
+ ent1 = xent.eval()
+ ent2 = xent.eval()
+ self.assertEqual(ent1, ent2)
+
+ with self.test_session():
+ ent3 = xent.eval()
+ self.assertEqual(ent1, ent3)
+
+ def test_single_example_correct(self):
+ # The correct label should have low cross entropy.
+ correct_xent = util.mnist_cross_entropy(real_digit(), one_hot_real())
+ # The incorrect label should have high cross entropy.
+ wrong_xent = util.mnist_cross_entropy(real_digit(), one_hot1())
+ # A random digit should have medium cross entropy for any label.
+ fake_xent1 = util.mnist_cross_entropy(fake_digit(), one_hot_real())
+ fake_xent6 = util.mnist_cross_entropy(fake_digit(), one_hot1())
+ with self.test_session():
+ self.assertNear(0.00996, correct_xent.eval(), 1e-5)
+ self.assertNear(18.63073, wrong_xent.eval(), 1e-5)
+ self.assertNear(2.2, fake_xent1.eval(), 1e-1)
+ self.assertNear(2.2, fake_xent6.eval(), 1e-1)
+
+ def test_minibatch_correct(self):
+ # Reorded minibatches should have the same value.
+ xent1 = util.mnist_cross_entropy(
+ tf.concat([real_digit(), real_digit(), fake_digit()], 0),
+ tf.concat([one_hot_real(), one_hot1(), one_hot1()], 0))
+ xent2 = util.mnist_cross_entropy(
+ tf.concat([real_digit(), fake_digit(), real_digit()], 0),
+ tf.concat([one_hot_real(), one_hot1(), one_hot1()], 0))
+ with self.test_session():
+ self.assertNear(6.972539, xent1.eval(), 1e-5)
+ self.assertNear(xent1.eval(), xent2.eval(), 1e-5)
+
+
+class GetNoiseTest(tf.test.TestCase):
+
+ def test_get_noise_categorical_syntax(self):
+ util.get_eval_noise_categorical(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_noise_continuous_dim1_syntax(self):
+ util.get_eval_noise_continuous_dim1(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_noise_continuous_dim2_syntax(self):
+ util.get_eval_noise_continuous_dim2(
+ noise_samples=4,
+ categorical_sample_points=np.arange(0, 10),
+ continuous_sample_points=np.linspace(-2.0, 2.0, 10),
+ unstructured_noise_dims=62,
+ continuous_noise_dims=2)
+
+ def test_get_infogan_syntax(self):
+ util.get_infogan_noise(
+ batch_size=4,
+ categorical_dim=10,
+ structured_continuous_dim=3,
+ total_continuous_noise_dims=62)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh"
new file mode 100644
index 00000000..fcc5131f
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/launch_jobs.sh"
@@ -0,0 +1,65 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the MNIST dataset.
+# 2. Trains an unconditional model on the MNIST training set using a
+# tf.Estimator.
+# 3. Evaluates the models and writes sample images to disk.
+#
+#
+# Usage:
+# cd models/research/gan/mnist_estimator
+# ./launch_jobs.sh ${git_repo}
+set -e
+
+# Location of the git repository.
+git_repo=$1
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/mnist-estimator
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/mnist-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/gan:$git_repo/research/slim
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+python "${git_repo}/research/slim/download_and_convert_data.py" \
+ --dataset_name=mnist \
+ --dataset_dir=${DATASET_DIR}
+
+# Run unconditional GAN.
+NUM_STEPS=1600
+Banner "Starting training GANEstimator ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/mnist_estimator/train.py" \
+ --max_number_of_steps=${NUM_STEPS} \
+ --eval_dir=${EVAL_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --alsologtostderr
+Banner "Finished training GANEstimator ${NUM_STEPS} steps. See ${EVAL_DIR} for output images."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py"
new file mode 100644
index 00000000..d2c8ea34
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train.py"
@@ -0,0 +1,109 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a GANEstimator on MNIST data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import numpy as np
+import scipy.misc
+from six.moves import xrange # pylint: disable=redefined-builtin
+import tensorflow as tf
+
+from mnist import data_provider
+from mnist import networks
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_integer('batch_size', 32,
+ 'The number of images in each train batch.')
+
+flags.DEFINE_integer('max_number_of_steps', 20000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'noise_dims', 64, 'Dimensions of the generator noise vector')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+flags.DEFINE_string('eval_dir', '/tmp/mnist-estimator/',
+ 'Directory where the results are saved to.')
+
+FLAGS = flags.FLAGS
+
+
+def _get_train_input_fn(batch_size, noise_dims, dataset_dir=None,
+ num_threads=4):
+ def train_input_fn():
+ with tf.device('/cpu:0'):
+ images, _, _ = data_provider.provide_data(
+ 'train', batch_size, dataset_dir, num_threads=num_threads)
+ noise = tf.random_normal([batch_size, noise_dims])
+ return noise, images
+ return train_input_fn
+
+
+def _get_predict_input_fn(batch_size, noise_dims):
+ def predict_input_fn():
+ noise = tf.random_normal([batch_size, noise_dims])
+ return noise
+ return predict_input_fn
+
+
+def _unconditional_generator(noise, mode):
+ """MNIST generator with extra argument for tf.Estimator's `mode`."""
+ is_training = (mode == tf.estimator.ModeKeys.TRAIN)
+ return networks.unconditional_generator(noise, is_training=is_training)
+
+
+def main(_):
+ # Initialize GANEstimator with options and hyperparameters.
+ gan_estimator = tfgan.estimator.GANEstimator(
+ generator_fn=_unconditional_generator,
+ discriminator_fn=networks.unconditional_discriminator,
+ generator_loss_fn=tfgan.losses.wasserstein_generator_loss,
+ discriminator_loss_fn=tfgan.losses.wasserstein_discriminator_loss,
+ generator_optimizer=tf.train.AdamOptimizer(0.001, 0.5),
+ discriminator_optimizer=tf.train.AdamOptimizer(0.0001, 0.5),
+ add_summaries=tfgan.estimator.SummaryType.IMAGES)
+
+ # Train estimator.
+ train_input_fn = _get_train_input_fn(
+ FLAGS.batch_size, FLAGS.noise_dims, FLAGS.dataset_dir)
+ gan_estimator.train(train_input_fn, max_steps=FLAGS.max_number_of_steps)
+
+ # Run inference.
+ predict_input_fn = _get_predict_input_fn(36, FLAGS.noise_dims)
+ prediction_iterable = gan_estimator.predict(predict_input_fn)
+ predictions = [prediction_iterable.next() for _ in xrange(36)]
+
+ # Nicely tile.
+ image_rows = [np.concatenate(predictions[i:i+6], axis=0) for i in
+ range(0, 36, 6)]
+ tiled_image = np.concatenate(image_rows, axis=1)
+
+ # Write to disk.
+ if not tf.gfile.Exists(FLAGS.eval_dir):
+ tf.gfile.MakeDirs(FLAGS.eval_dir)
+ scipy.misc.imsave(os.path.join(FLAGS.eval_dir, 'unconditional_gan.png'),
+ np.squeeze(tiled_image, axis=2))
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py"
new file mode 100644
index 00000000..5bec5db6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/mnist_estimator/train_test.py"
@@ -0,0 +1,52 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for mnist_estimator.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase):
+
+ @mock.patch.object(train, 'data_provider', autospec=True)
+ def test_full_flow(self, mock_data_provider):
+ FLAGS.eval_dir = self.get_temp_dir()
+ FLAGS.batch_size = 16
+ FLAGS.max_number_of_steps = 2
+ FLAGS.noise_dims = 3
+
+ # Construct mock inputs.
+ mock_imgs = np.zeros([FLAGS.batch_size, 28, 28, 1], dtype=np.float32)
+ mock_lbls = np.concatenate(
+ (np.ones([FLAGS.batch_size, 1], dtype=np.int32),
+ np.zeros([FLAGS.batch_size, 9], dtype=np.int32)), axis=1)
+ mock_data_provider.provide_data.return_value = (mock_imgs, mock_lbls, None)
+
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh"
new file mode 100644
index 00000000..9302b99b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/launch_jobs.sh"
@@ -0,0 +1,74 @@
+# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+#!/bin/bash
+#
+# This script performs the following operations:
+# 1. Downloads the Imagenet dataset.
+# 2. Trains image compression model on patches from Imagenet.
+# 3. Evaluates the models and writes sample images to disk.
+#
+# Usage:
+# cd models/research/gan/image_compression
+# ./launch_jobs.sh ${weight_factor} ${git_repo}
+set -e
+
+# Weight of the adversarial loss.
+weight_factor=$1
+if [[ "$weight_factor" == "" ]]; then
+ echo "'weight_factor' must not be empty."
+ exit
+fi
+
+# Location of the git repository.
+git_repo=$2
+if [[ "$git_repo" == "" ]]; then
+ echo "'git_repo' must not be empty."
+ exit
+fi
+
+# Base name for where the checkpoint and logs will be saved to.
+TRAIN_DIR=/tmp/compression-model
+
+# Base name for where the evaluation images will be saved to.
+EVAL_DIR=/tmp/compression-model/eval
+
+# Where the dataset is saved to.
+DATASET_DIR=/tmp/imagenet-data
+
+export PYTHONPATH=$PYTHONPATH:$git_repo:$git_repo/research:$git_repo/research/slim:$git_repo/research/slim/nets
+
+# A helper function for printing pretty output.
+Banner () {
+ local text=$1
+ local green='\033[0;32m'
+ local nc='\033[0m' # No color.
+ echo -e "${green}${text}${nc}"
+}
+
+# Download the dataset.
+bazel build "${git_repo}/research/slim:download_and_convert_imagenet"
+"./bazel-bin/download_and_convert_imagenet" ${DATASET_DIR}
+
+# Run the pix2pix model.
+NUM_STEPS=10000
+MODEL_TRAIN_DIR="${TRAIN_DIR}/wt${weight_factor}"
+Banner "Starting training an image compression model for ${NUM_STEPS} steps..."
+python "${git_repo}/research/gan/image_compression/train.py" \
+ --train_log_dir=${MODEL_TRAIN_DIR} \
+ --dataset_dir=${DATASET_DIR} \
+ --max_number_of_steps=${NUM_STEPS} \
+ --weight_factor=${weight_factor} \
+ --alsologtostderr
+Banner "Finished training pix2pix model ${NUM_STEPS} steps."
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py"
new file mode 100644
index 00000000..3a59d41a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks.py"
@@ -0,0 +1,61 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Networks for GAN Pix2Pix example using TFGAN."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from slim.nets import cyclegan
+from slim.nets import pix2pix
+
+
+def generator(input_images):
+ """Thin wrapper around CycleGAN generator to conform to the TFGAN API.
+
+ Args:
+ input_images: A batch of images to translate. Images should be normalized
+ already. Shape is [batch, height, width, channels].
+
+ Returns:
+ Returns generated image batch.
+
+ Raises:
+ ValueError: If shape of last dimension (channels) is not defined.
+ """
+ input_images.shape.assert_has_rank(4)
+ input_size = input_images.shape.as_list()
+ channels = input_size[-1]
+ if channels is None:
+ raise ValueError(
+ 'Last dimension shape must be known but is None: %s' % input_size)
+ with tf.contrib.framework.arg_scope(cyclegan.cyclegan_arg_scope()):
+ output_images, _ = cyclegan.cyclegan_generator_resnet(input_images,
+ num_outputs=channels)
+ return output_images
+
+
+def discriminator(image_batch, unused_conditioning=None):
+ """A thin wrapper around the Pix2Pix discriminator to conform to TFGAN API."""
+ with tf.contrib.framework.arg_scope(pix2pix.pix2pix_arg_scope()):
+ logits_4d, _ = pix2pix.pix2pix_discriminator(
+ image_batch, num_filters=[64, 128, 256, 512])
+ logits_4d.shape.assert_has_rank(4)
+ # Output of logits is 4D. Reshape to 2D, for TFGAN.
+ logits_2d = tf.contrib.layers.flatten(logits_4d)
+
+ return logits_2d
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py"
new file mode 100644
index 00000000..7b94173a
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/networks_test.py"
@@ -0,0 +1,89 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for tfgan.examples.networks.networks."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import networks
+
+
+class Pix2PixTest(tf.test.TestCase):
+
+ def test_generator_run(self):
+ img_batch = tf.zeros([3, 128, 128, 3])
+ model_output = networks.generator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_graph(self):
+ for shape in ([4, 32, 32], [3, 128, 128], [2, 80, 400]):
+ tf.reset_default_graph()
+ img = tf.ones(shape + [3])
+ output_imgs = networks.generator(img)
+
+ self.assertAllEqual(shape + [3], output_imgs.shape.as_list())
+
+ def test_generator_graph_unknown_batch_dim(self):
+ img = tf.placeholder(tf.float32, shape=[None, 32, 32, 3])
+ output_imgs = networks.generator(img)
+
+ self.assertAllEqual([None, 32, 32, 3], output_imgs.shape.as_list())
+
+ def test_generator_invalid_input(self):
+ with self.assertRaisesRegexp(ValueError, 'must have rank 4'):
+ networks.generator(tf.zeros([28, 28, 3]))
+
+ def test_generator_run_multi_channel(self):
+ img_batch = tf.zeros([3, 128, 128, 5])
+ model_output = networks.generator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(model_output)
+
+ def test_generator_invalid_channels(self):
+ with self.assertRaisesRegexp(
+ ValueError, 'Last dimension shape must be known but is None'):
+ img = tf.placeholder(tf.float32, shape=[4, 32, 32, None])
+ networks.generator(img)
+
+ def test_discriminator_run(self):
+ img_batch = tf.zeros([3, 70, 70, 3])
+ disc_output = networks.discriminator(img_batch)
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ sess.run(disc_output)
+
+ def test_discriminator_graph(self):
+ # Check graph construction for a number of image size/depths and batch
+ # sizes.
+ for batch_size, patch_size in zip([3, 6], [70, 128]):
+ tf.reset_default_graph()
+ img = tf.ones([batch_size, patch_size, patch_size, 3])
+ disc_output = networks.discriminator(img)
+
+ self.assertEqual(2, disc_output.shape.ndims)
+ self.assertEqual(batch_size, disc_output.shape.as_list()[0])
+
+ def test_discriminator_invalid_input(self):
+ with self.assertRaisesRegexp(ValueError, 'Shape must be rank 4'):
+ networks.discriminator(tf.zeros([28, 28, 3]))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py"
new file mode 100644
index 00000000..2b0d5e36
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train.py"
@@ -0,0 +1,177 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains an image-to-image translation network with an adversarial loss."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import networks
+
+tfgan = tf.contrib.gan
+
+
+flags.DEFINE_integer('batch_size', 10, 'The number of images in each batch.')
+
+flags.DEFINE_integer('patch_size', 32, 'The size of the patches to train on.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/pix2pix/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_float('generator_lr', 0.00001,
+ 'The compression model learning rate.')
+
+flags.DEFINE_float('discriminator_lr', 0.00001,
+ 'The discriminator learning rate.')
+
+flags.DEFINE_integer('max_number_of_steps', 2000000,
+ 'The maximum number of gradient steps.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+flags.DEFINE_float(
+ 'weight_factor', 0.0,
+ 'How much to weight the adversarial loss relative to pixel loss.')
+
+flags.DEFINE_string('dataset_dir', None, 'Location of data.')
+
+
+FLAGS = flags.FLAGS
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ # Get real and distorted images.
+ with tf.device('/cpu:0'), tf.name_scope('inputs'):
+ real_images = data_provider.provide_data(
+ 'train', FLAGS.batch_size, dataset_dir=FLAGS.dataset_dir,
+ patch_size=FLAGS.patch_size)
+ distorted_images = _distort_images(
+ real_images, downscale_size=int(FLAGS.patch_size / 2),
+ upscale_size=FLAGS.patch_size)
+
+ # Create a GANModel tuple.
+ gan_model = tfgan.gan_model(
+ generator_fn=networks.generator,
+ discriminator_fn=networks.discriminator,
+ real_data=real_images,
+ generator_inputs=distorted_images)
+ tfgan.eval.add_image_comparison_summaries(
+ gan_model, num_comparisons=3, display_diffs=True)
+ tfgan.eval.add_gan_model_image_summaries(gan_model, grid_size=3)
+
+ # Define the GANLoss tuple using standard library functions.
+ with tf.name_scope('losses'):
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.least_squares_generator_loss,
+ discriminator_loss_fn=tfgan.losses.least_squares_discriminator_loss)
+
+ # Define the standard L1 pixel loss.
+ l1_pixel_loss = tf.norm(gan_model.real_data - gan_model.generated_data,
+ ord=1) / FLAGS.patch_size ** 2
+
+ # Modify the loss tuple to include the pixel loss. Add summaries as well.
+ gan_loss = tfgan.losses.combine_adversarial_loss(
+ gan_loss, gan_model, l1_pixel_loss,
+ weight_factor=FLAGS.weight_factor)
+
+ with tf.name_scope('train_ops'):
+ # Get the GANTrain ops using the custom optimizers and optional
+ # discriminator weight clipping.
+ gen_lr, dis_lr = _lr(FLAGS.generator_lr, FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ gan_model,
+ gan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N,
+ transform_grads_fn=tf.contrib.training.clip_gradient_norms_fn(1e3))
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ # Use GAN train step function if using adversarial loss, otherwise
+ # only train the generator.
+ train_steps = tfgan.GANTrainSteps(
+ generator_train_steps=1,
+ discriminator_train_steps=int(FLAGS.weight_factor > 0))
+
+ # Run the alternating training loop. Skip it if no steps should be taken
+ # (used for graph construction tests).
+ status_message = tf.string_join(
+ ['Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())],
+ name='status_message')
+ if FLAGS.max_number_of_steps == 0: return
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+def _optimizer(gen_lr, dis_lr):
+ kwargs = {'beta1': 0.5, 'beta2': 0.999}
+ generator_opt = tf.train.AdamOptimizer(gen_lr, **kwargs)
+ discriminator_opt = tf.train.AdamOptimizer(dis_lr, **kwargs)
+ return generator_opt, discriminator_opt
+
+
+def _lr(gen_lr_base, dis_lr_base):
+ """Return the generator and discriminator learning rates."""
+ gen_lr = tf.train.exponential_decay(
+ learning_rate=gen_lr_base,
+ global_step=tf.train.get_or_create_global_step(),
+ decay_steps=100000,
+ decay_rate=0.8,
+ staircase=True,)
+ dis_lr = dis_lr_base
+
+ return gen_lr, dis_lr
+
+
+def _distort_images(images, downscale_size, upscale_size):
+ downscaled = tf.image.resize_area(images, [downscale_size] * 2)
+ upscaled = tf.image.resize_area(downscaled, [upscale_size] * 2)
+ return upscaled
+
+
+if __name__ == '__main__':
+ tf.app.run()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py"
new file mode 100644
index 00000000..02c6d5b9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/pix2pix/train_test.py"
@@ -0,0 +1,52 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for pix2pix.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+from absl.testing import parameterized
+import numpy as np
+import tensorflow as tf
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+
+
+class TrainTest(tf.test.TestCase, parameterized.TestCase):
+
+ @parameterized.named_parameters(
+ ('NoAdversarialLoss', 0.0),
+ ('AdversarialLoss', 1.0))
+ def test_build_graph(self, weight_factor):
+ FLAGS.max_number_of_steps = 0
+ FLAGS.weight_factor = weight_factor
+ FLAGS.batch_size = 9
+ FLAGS.patch_size = 32
+
+ mock_imgs = np.zeros(
+ [FLAGS.batch_size, FLAGS.patch_size, FLAGS.patch_size, 3],
+ dtype=np.float32)
+ with mock.patch.object(train, 'data_provider') as mock_data_provider:
+ mock_data_provider.provide_data.return_value = mock_imgs
+ train.main(None)
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py"
new file mode 100644
index 00000000..6e1563bc
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider.py"
@@ -0,0 +1,189 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Loading and preprocessing image data."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import tensorflow as tf
+
+from slim.datasets import dataset_factory as datasets
+
+
+def normalize_image(image):
+ """Rescales image from range [0, 255] to [-1, 1]."""
+ return (tf.to_float(image) - 127.5) / 127.5
+
+
+def sample_patch(image, patch_height, patch_width, colors):
+ """Crops image to the desired aspect ratio shape and resizes it.
+
+ If the image has shape H x W, crops a square in the center of
+ shape min(H,W) x min(H,W).
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_height: A Python integer. The output images height.
+ patch_width: A Python integer. The output images width.
+ colors: Number of output image channels. Defaults to 3.
+
+ Returns:
+ A 3D `Tensor` of HWC format with shape [patch_height, patch_width, colors].
+ """
+ image_shape = tf.shape(image)
+ h, w = image_shape[0], image_shape[1]
+
+ h_major_target_h = h
+ h_major_target_w = tf.maximum(1, tf.to_int32(
+ (h * patch_width) / patch_height))
+ w_major_target_h = tf.maximum(1, tf.to_int32(
+ (w * patch_height) / patch_width))
+ w_major_target_w = w
+ target_hw = tf.cond(
+ h_major_target_w <= w,
+ lambda: tf.convert_to_tensor([h_major_target_h, h_major_target_w]),
+ lambda: tf.convert_to_tensor([w_major_target_h, w_major_target_w]))
+ # Cut a patch of shape (target_h, target_w).
+ image = tf.image.resize_image_with_crop_or_pad(image, target_hw[0],
+ target_hw[1])
+ # Resize the cropped image to (patch_h, patch_w).
+ image = tf.image.resize_images([image], [patch_height, patch_width])[0]
+ # Force number of channels: repeat the channel dimension enough
+ # number of times and then slice the first `colors` channels.
+ num_repeats = tf.to_int32(tf.ceil(colors / image_shape[2]))
+ image = tf.tile(image, [1, 1, num_repeats])
+ image = tf.slice(image, [0, 0, 0], [-1, -1, colors])
+ image.set_shape([patch_height, patch_width, colors])
+ return image
+
+
+def batch_images(image, patch_height, patch_width, colors, batch_size, shuffle,
+ num_threads):
+ """Creates a batch of images.
+
+ Args:
+ image: A 3D `Tensor` of HWC format.
+ patch_height: A Python integer. The output images height.
+ patch_width: A Python integer. The output images width.
+ colors: Number of channels.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images.
+ num_threads: Number of prefetching threads.
+
+ Returns:
+ A float `Tensor`s with shape [batch_size, patch_height, patch_width, colors]
+ representing a batch of images.
+ """
+ image = sample_patch(image, patch_height, patch_width, colors)
+ images = None
+ if shuffle:
+ images = tf.train.shuffle_batch(
+ [image],
+ batch_size=batch_size,
+ num_threads=num_threads,
+ capacity=5 * batch_size,
+ min_after_dequeue=batch_size)
+ else:
+ images = tf.train.batch(
+ [image],
+ batch_size=batch_size,
+ num_threads=1, # no threads so it's deterministic
+ capacity=5 * batch_size)
+ images.set_shape([batch_size, patch_height, patch_width, colors])
+ return images
+
+
+def provide_data(dataset_name='cifar10',
+ split_name='train',
+ dataset_dir,
+ batch_size=32,
+ shuffle=True,
+ num_threads=1,
+ patch_height=32,
+ patch_width=32,
+ colors=3):
+ """Provides a batch of image data from predefined dataset.
+
+ Args:
+ dataset_name: A string of dataset name. Defaults to 'cifar10'.
+ split_name: Either 'train' or 'validation'. Defaults to 'train'.
+ dataset_dir: The directory where the data can be found. If `None`, use
+ default.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_height: A Python integer. The read images height. Defaults to 32.
+ patch_width: A Python integer. The read images width. Defaults to 32.
+ colors: Number of channels. Defaults to 3.
+
+ Returns:
+ A float `Tensor`s with shape [batch_size, patch_height, patch_width, colors]
+ representing a batch of images.
+ """
+ dataset = datasets.get_dataset(
+ dataset_name, split_name, dataset_dir=dataset_dir)
+ provider = tf.contrib.slim.dataset_data_provider.DatasetDataProvider(
+ dataset,
+ num_readers=1,
+ common_queue_capacity=5 * batch_size,
+ common_queue_min=batch_size,
+ shuffle=shuffle)
+ return batch_images(
+ image=normalize_image(provider.get(['image'])[0]),
+ patch_height=patch_height,
+ patch_width=patch_width,
+ colors=colors,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads)
+
+
+def provide_data_from_image_files(file_pattern,
+ batch_size=32,
+ shuffle=True,
+ num_threads=1,
+ patch_height=32,
+ patch_width=32,
+ colors=3):
+ """Provides a batch of image data from image files.
+
+ Args:
+ file_pattern: A file pattern (glob), or 1D `Tensor` of file patterns.
+ batch_size: The number of images in each minibatch. Defaults to 32.
+ shuffle: Whether to shuffle the read images. Defaults to True.
+ num_threads: Number of prefetching threads. Defaults to 1.
+ patch_height: A Python integer. The read images height. Defaults to 32.
+ patch_width: A Python integer. The read images width. Defaults to 32.
+ colors: Number of channels. Defaults to 3.
+
+ Returns:
+ A float `Tensor` of shape [batch_size, patch_height, patch_width, 3]
+ representing a batch of images.
+ """
+ filename_queue = tf.train.string_input_producer(
+ tf.train.match_filenames_once(file_pattern),
+ shuffle=shuffle,
+ capacity=5 * batch_size)
+ _, image_bytes = tf.WholeFileReader().read(filename_queue)
+ return batch_images(
+ image=normalize_image(tf.image.decode_image(image_bytes)),
+ patch_height=patch_height,
+ patch_width=patch_width,
+ colors=colors,
+ batch_size=batch_size,
+ shuffle=shuffle,
+ num_threads=num_threads)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py"
new file mode 100644
index 00000000..86dc93a6
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/data_provider_test.py"
@@ -0,0 +1,136 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import data_provider
+
+
+class DataProviderTest(tf.test.TestCase):
+
+ def setUp(self):
+ super(DataProviderTest, self).setUp()
+ self.testdata_dir = os.path.join(
+ flags.FLAGS.test_srcdir,
+ 'google3/third_party/tensorflow_models/gan/progressive_gan/testdata/')
+
+ def test_normalize_image(self):
+ image_np = np.asarray([0, 255, 210], dtype=np.uint8)
+ normalized_image = data_provider.normalize_image(tf.constant(image_np))
+ self.assertEqual(normalized_image.dtype, tf.float32)
+ self.assertEqual(normalized_image.shape.as_list(), [3])
+ with self.test_session(use_gpu=True) as sess:
+ normalized_image_np = sess.run(normalized_image)
+ self.assertNDArrayNear(normalized_image_np, [-1, 1, 0.6470588235], 1.0e-6)
+
+ def test_sample_patch_large_patch_returns_upscaled_image(self):
+ image_np = np.reshape(np.arange(2 * 2), [2, 2, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ image_patch = data_provider.sample_patch(
+ image, patch_height=3, patch_width=3, colors=1)
+ with self.test_session(use_gpu=True) as sess:
+ image_patch_np = sess.run(image_patch)
+ expected_np = np.asarray([[[0.], [0.66666669], [1.]], [[1.33333337], [2.],
+ [2.33333349]],
+ [[2.], [2.66666675], [3.]]])
+ self.assertNDArrayNear(image_patch_np, expected_np, 1.0e-6)
+
+ def test_sample_patch_small_patch_returns_downscaled_image(self):
+ image_np = np.reshape(np.arange(3 * 3), [3, 3, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ image_patch = data_provider.sample_patch(
+ image, patch_height=2, patch_width=2, colors=1)
+ with self.test_session(use_gpu=True) as sess:
+ image_patch_np = sess.run(image_patch)
+ expected_np = np.asarray([[[0.], [1.5]], [[4.5], [6.]]])
+ self.assertNDArrayNear(image_patch_np, expected_np, 1.0e-6)
+
+ def test_batch_images(self):
+ image_np = np.reshape(np.arange(3 * 3), [3, 3, 1])
+ image = tf.constant(image_np, dtype=tf.float32)
+ images = data_provider.batch_images(
+ image,
+ patch_height=2,
+ patch_width=2,
+ colors=1,
+ batch_size=2,
+ shuffle=False,
+ num_threads=1)
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ expected_np = np.asarray([[[[0.], [1.5]], [[4.5], [6.]]], [[[0.], [1.5]],
+ [[4.5], [6.]]]])
+ self.assertNDArrayNear(images_np, expected_np, 1.0e-6)
+
+ def test_provide_data(self):
+ images = data_provider.provide_data(
+ 'mnist',
+ 'train',
+ dataset_dir=self.testdata_dir,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+ def test_provide_data_from_image_files_a_single_pattern(self):
+ file_pattern = os.path.join(self.testdata_dir, '*.jpg')
+ images = data_provider.provide_data_from_image_files(
+ file_pattern,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+ def test_provide_data_from_image_files_a_list_of_patterns(self):
+ file_pattern = [os.path.join(self.testdata_dir, '*.jpg')]
+ images = data_provider.provide_data_from_image_files(
+ file_pattern,
+ batch_size=2,
+ shuffle=False,
+ patch_height=3,
+ patch_width=3,
+ colors=1)
+ self.assertEqual(images.shape.as_list(), [2, 3, 3, 1])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.local_variables_initializer())
+ with tf.contrib.slim.queues.QueueRunners(sess):
+ images_np = sess.run(images)
+ self.assertEqual(images_np.shape, (2, 3, 3, 1))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py"
new file mode 100644
index 00000000..5bf0d804
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers.py"
@@ -0,0 +1,293 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Layers for a progressive GAN model.
+
+This module contains basic building blocks to build a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+
+def pixel_norm(images, epsilon=1.0e-8):
+ """Pixel normalization.
+
+ For each pixel a[i,j,k] of image in HWC format, normalize its value to
+ b[i,j,k] = a[i,j,k] / SQRT(SUM_k(a[i,j,k]^2) / C + eps).
+
+ Args:
+ images: A 4D `Tensor` of NHWC format.
+ epsilon: A small positive number to avoid division by zero.
+
+ Returns:
+ A 4D `Tensor` with pixel-wise normalized channels.
+ """
+ return images * tf.rsqrt(
+ tf.reduce_mean(tf.square(images), axis=3, keepdims=True) + epsilon)
+
+
+def _get_validated_scale(scale):
+ """Returns the scale guaranteed to be a positive integer."""
+ scale = int(scale)
+ if scale <= 0:
+ raise ValueError('`scale` must be a positive integer.')
+ return scale
+
+
+def downscale(images, scale):
+ """Box downscaling of images.
+
+ Args:
+ images: A 4D `Tensor` in NHWC format.
+ scale: A positive integer scale.
+
+ Returns:
+ A 4D `Tensor` of `images` down scaled by a factor `scale`.
+
+ Raises:
+ ValueError: If `scale` is not a positive integer.
+ """
+ scale = _get_validated_scale(scale)
+ if scale == 1:
+ return images
+ return tf.nn.avg_pool(
+ images,
+ ksize=[1, scale, scale, 1],
+ strides=[1, scale, scale, 1],
+ padding='VALID')
+
+
+def upscale(images, scale):
+ """Box upscaling (also called nearest neighbors) of images.
+
+ Args:
+ images: A 4D `Tensor` in NHWC format.
+ scale: A positive integer scale.
+
+ Returns:
+ A 4D `Tensor` of `images` up scaled by a factor `scale`.
+
+ Raises:
+ ValueError: If `scale` is not a positive integer.
+ """
+ scale = _get_validated_scale(scale)
+ if scale == 1:
+ return images
+ return tf.batch_to_space(
+ tf.tile(images, [scale**2, 1, 1, 1]),
+ crops=[[0, 0], [0, 0]],
+ block_size=scale)
+
+
+def minibatch_mean_stddev(x):
+ """Computes the standard deviation average.
+
+ This is used by the discriminator as a form of batch discrimination.
+
+ Args:
+ x: A `Tensor` for which to compute the standard deviation average. The first
+ dimension must be batch size.
+
+ Returns:
+ A scalar `Tensor` which is the mean variance of variable x.
+ """
+ mean, var = tf.nn.moments(x, axes=[0])
+ del mean
+ return tf.reduce_mean(tf.sqrt(var))
+
+
+def scalar_concat(tensor, scalar):
+ """Concatenates a scalar to the last dimension of a tensor.
+
+ Args:
+ tensor: A `Tensor`.
+ scalar: a scalar `Tensor` to concatenate to tensor `tensor`.
+
+ Returns:
+ A `Tensor`. If `tensor` has shape [...,N], the result R has shape
+ [...,N+1] and R[...,N] = scalar.
+
+ Raises:
+ ValueError: If `tensor` is a scalar `Tensor`.
+ """
+ ndims = tensor.shape.ndims
+ if ndims < 1:
+ raise ValueError('`tensor` must have number of dimensions >= 1.')
+ shape = tf.shape(tensor)
+ return tf.concat(
+ [tensor, tf.ones([shape[i] for i in range(ndims - 1)] + [1]) * scalar],
+ axis=ndims - 1)
+
+
+def he_initializer_scale(shape, slope=1.0):
+ """The scale of He neural network initializer.
+
+ Args:
+ shape: A list of ints representing the dimensions of a tensor.
+ slope: A float representing the slope of the ReLu following the layer.
+
+ Returns:
+ A float of he initializer scale.
+ """
+ fan_in = np.prod(shape[:-1])
+ return np.sqrt(2. / ((1. + slope**2) * fan_in))
+
+
+def _custom_layer_impl(apply_kernel, kernel_shape, bias_shape, activation,
+ he_initializer_slope, use_weight_scaling):
+ """Helper function to implement custom_xxx layer.
+
+ Args:
+ apply_kernel: A function that transforms kernel to output.
+ kernel_shape: An integer tuple or list of the kernel shape.
+ bias_shape: An integer tuple or list of the bias shape.
+ activation: An activation function to be applied. None means no
+ activation.
+ he_initializer_slope: A float slope for the He initializer.
+ use_weight_scaling: Whether to apply weight scaling.
+
+ Returns:
+ A `Tensor` computed as apply_kernel(kernel) + bias where kernel is a
+ `Tensor` variable with shape `kernel_shape`, bias is a `Tensor` variable
+ with shape `bias_shape`.
+ """
+ kernel_scale = he_initializer_scale(kernel_shape, he_initializer_slope)
+ init_scale, post_scale = kernel_scale, 1.0
+ if use_weight_scaling:
+ init_scale, post_scale = post_scale, init_scale
+
+ kernel_initializer = tf.random_normal_initializer(stddev=init_scale)
+
+ bias = tf.get_variable(
+ 'bias', shape=bias_shape, initializer=tf.zeros_initializer())
+
+ output = post_scale * apply_kernel(kernel_shape, kernel_initializer) + bias
+
+ if activation is not None:
+ output = activation(output)
+ return output
+
+
+def custom_conv2d(x,
+ filters,
+ kernel_size,
+ strides=(1, 1),
+ padding='SAME',
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True,
+ scope='custom_conv2d',
+ reuse=None):
+ """Custom conv2d layer.
+
+ In comparison with tf.layers.conv2d this implementation use the He initializer
+ to initialize convolutional kernel and the weight scaling trick (if
+ `use_weight_scaling` is True) to equalize learning rates. See
+ https://arxiv.org/abs/1710.10196 for more details.
+
+ Args:
+ x: A `Tensor` of NHWC format.
+ filters: An int of output channels.
+ kernel_size: An integer or a int tuple of [kernel_height, kernel_width].
+ strides: A list of strides.
+ padding: One of "VALID" or "SAME".
+ activation: An activation function to be applied. None means no
+ activation. Defaults to None.
+ he_initializer_slope: A float slope for the He initializer. Defaults to 1.0.
+ use_weight_scaling: Whether to apply weight scaling. Defaults to True.
+ scope: A string or variable scope.
+ reuse: Whether to reuse the weights. Defaults to None.
+
+ Returns:
+ A `Tensor` of NHWC format where the last dimension has size `filters`.
+ """
+ if not isinstance(kernel_size, (list, tuple)):
+ kernel_size = [kernel_size] * 2
+ kernel_size = list(kernel_size)
+
+ def _apply_kernel(kernel_shape, kernel_initializer):
+ return tf.layers.conv2d(
+ x,
+ filters=filters,
+ kernel_size=kernel_shape[0:2],
+ strides=strides,
+ padding=padding,
+ use_bias=False,
+ kernel_initializer=kernel_initializer)
+
+ with tf.variable_scope(scope, reuse=reuse):
+ return _custom_layer_impl(
+ _apply_kernel,
+ kernel_shape=kernel_size + [x.shape.as_list()[3], filters],
+ bias_shape=(filters,),
+ activation=activation,
+ he_initializer_slope=he_initializer_slope,
+ use_weight_scaling=use_weight_scaling)
+
+
+def custom_dense(x,
+ units,
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True,
+ scope='custom_dense',
+ reuse=None):
+ """Custom dense layer.
+
+ In comparison with tf.layers.dense This implementation use the He
+ initializer to initialize weights and the weight scaling trick
+ (if `use_weight_scaling` is True) to equalize learning rates. See
+ https://arxiv.org/abs/1710.10196 for more details.
+
+ Args:
+ x: A `Tensor`.
+ units: An int of the last dimension size of output.
+ activation: An activation function to be applied. None means no
+ activation. Defaults to None.
+ he_initializer_slope: A float slope for the He initializer. Defaults to 1.0.
+ use_weight_scaling: Whether to apply weight scaling. Defaults to True.
+ scope: A string or variable scope.
+ reuse: Whether to reuse the weights. Defaults to None.
+
+ Returns:
+ A `Tensor` where the last dimension has size `units`.
+ """
+ x = tf.contrib.layers.flatten(x)
+
+ def _apply_kernel(kernel_shape, kernel_initializer):
+ return tf.layers.dense(
+ x,
+ kernel_shape[1],
+ use_bias=False,
+ kernel_initializer=kernel_initializer)
+
+ with tf.variable_scope(scope, reuse=reuse):
+ return _custom_layer_impl(
+ _apply_kernel,
+ kernel_shape=(x.shape.as_list()[-1], units),
+ bias_shape=(units,),
+ activation=activation,
+ he_initializer_slope=he_initializer_slope,
+ use_weight_scaling=use_weight_scaling)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py"
new file mode 100644
index 00000000..73d8fecf
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/layers_test.py"
@@ -0,0 +1,282 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+import layers
+
+mock = tf.test.mock
+
+
+def dummy_apply_kernel(kernel_shape, kernel_initializer):
+ kernel = tf.get_variable(
+ 'kernel', shape=kernel_shape, initializer=kernel_initializer)
+ return tf.reduce_sum(kernel) + 1.5
+
+
+class LayersTest(tf.test.TestCase):
+
+ def test_pixel_norm_4d_images_returns_channel_normalized_images(self):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.pixel_norm(x))
+
+ expected_np = [[[[0.46291006, 0.92582011, 1.38873017],
+ [0.78954202, 0.98692751, 1.18431306]],
+ [[0.87047803, 0.99483204, 1.11918604],
+ [0.90659684, 0.99725652, 1.08791625]]],
+ [[[0., 0., 0.], [-0.46291006, -0.92582011, -1.38873017]],
+ [[0.57735026, -1.15470052, 1.15470052],
+ [0.56195146, 1.40487862, 0.84292722]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ def test_get_validated_scale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers._get_validated_scale(0)
+
+ def test_get_validated_scale_float_scale_returns_integer(self):
+ self.assertEqual(layers._get_validated_scale(5.5), 5)
+
+ def test_downscale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers.downscale(tf.constant([]), -1)
+
+ def test_downscale_4d_images_returns_downscaled_images(self):
+ x_np = np.array(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=np.float32)
+ with self.test_session(use_gpu=True) as sess:
+ x1_np, x2_np = sess.run(
+ [layers.downscale(tf.constant(x_np), n) for n in [1, 2]])
+
+ expected2_np = [[[[5.5, 6.5, 7.5]]], [[[0.5, 0.25, 0.5]]]]
+
+ self.assertNDArrayNear(x1_np, x_np, 1.0e-5)
+ self.assertNDArrayNear(x2_np, expected2_np, 1.0e-5)
+
+ def test_upscale_invalid_scale_throws_exception(self):
+ with self.assertRaises(ValueError):
+ self.assertRaises(layers.upscale(tf.constant([]), -1))
+
+ def test_upscale_4d_images_returns_upscaled_images(self):
+ x_np = np.array([[[[1, 2, 3]]], [[[4, 5, 6]]]], dtype=np.float32)
+ with self.test_session(use_gpu=True) as sess:
+ x1_np, x2_np = sess.run(
+ [layers.upscale(tf.constant(x_np), n) for n in [1, 2]])
+
+ expected2_np = [[[[1, 2, 3], [1, 2, 3]], [[1, 2, 3], [1, 2, 3]]],
+ [[[4, 5, 6], [4, 5, 6]], [[4, 5, 6], [4, 5, 6]]]]
+
+ self.assertNDArrayNear(x1_np, x_np, 1.0e-5)
+ self.assertNDArrayNear(x2_np, expected2_np, 1.0e-5)
+
+ def test_minibatch_mean_stddev_4d_images_returns_scalar(self):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.minibatch_mean_stddev(x))
+
+ self.assertAlmostEqual(output_np, 3.0416667, 5)
+
+ def test_scalar_concat_invalid_input_throws_exception(self):
+ with self.assertRaises(ValueError):
+ layers.scalar_concat(tf.constant(1.2), 2.0)
+
+ def test_scalar_concat_4d_images_and_scalar(self):
+ x = tf.constant(
+ [[[[1, 2], [4, 5]], [[7, 8], [10, 11]]], [[[0, 0], [-1, -2]],
+ [[1, -2], [2, 5]]]],
+ dtype=tf.float32)
+ with self.test_session(use_gpu=True) as sess:
+ output_np = sess.run(layers.scalar_concat(x, 7))
+
+ expected_np = [[[[1, 2, 7], [4, 5, 7]], [[7, 8, 7], [10, 11, 7]]],
+ [[[0, 0, 7], [-1, -2, 7]], [[1, -2, 7], [2, 5, 7]]]]
+
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ def test_he_initializer_scale_slope_linear(self):
+ self.assertAlmostEqual(
+ layers.he_initializer_scale([3, 4, 5, 6], 1.0), 0.1290994, 5)
+
+ def test_he_initializer_scale_slope_relu(self):
+ self.assertAlmostEqual(
+ layers.he_initializer_scale([3, 4, 5, 6], 0.0), 0.1825742, 5)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_layer_impl_with_weight_scaling(
+ self, mock_zeros_initializer, mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ output = layers._custom_layer_impl(
+ apply_kernel=dummy_apply_kernel,
+ kernel_shape=(25, 6),
+ bias_shape=(),
+ activation=lambda x: 2.0 * x,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+ mock_zeros_initializer.assert_called_once_with()
+ mock_random_normal_initializer.assert_called_once_with(stddev=1.0)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ self.assertAlmostEqual(output_np, 182.6, 3)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_layer_impl_no_weight_scaling(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ output = layers._custom_layer_impl(
+ apply_kernel=dummy_apply_kernel,
+ kernel_shape=(25, 6),
+ bias_shape=(),
+ activation=lambda x: 2.0 * x,
+ he_initializer_slope=1.0,
+ use_weight_scaling=False)
+ mock_zeros_initializer.assert_called_once_with()
+ mock_random_normal_initializer.assert_called_once_with(stddev=0.2)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ self.assertAlmostEqual(output_np, 905.0, 3)
+
+ @mock.patch.object(tf.layers, 'conv2d', autospec=True)
+ def test_custom_conv2d_passes_conv2d_options(self, mock_conv2d):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_conv2d(x, 1, 2)
+ mock_conv2d.assert_called_once_with(
+ x,
+ filters=1,
+ kernel_size=[2, 2],
+ strides=(1, 1),
+ padding='SAME',
+ use_bias=False,
+ kernel_initializer=mock.ANY)
+
+ @mock.patch.object(layers, '_custom_layer_impl', autospec=True)
+ def test_custom_conv2d_passes_custom_layer_options(self,
+ mock_custom_layer_impl):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_conv2d(x, 1, 2)
+ mock_custom_layer_impl.assert_called_once_with(
+ mock.ANY,
+ kernel_shape=[2, 2, 3, 1],
+ bias_shape=(1,),
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_conv2d_scalar_kernel_size(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_conv2d(x, 1, 2)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[[[68.54998016], [42.56921768]], [[50.36344528],
+ [29.57883835]]],
+ [[[5.33012676], [4.46410179]], [[10.52627945],
+ [9.66025352]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_conv2d_list_kernel_size(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_conv2d(x, 1, [2, 3])
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[
+ [[56.15432739], [56.15432739]],
+ [[41.30508804], [41.30508804]],
+ ], [[[4.53553391], [4.53553391]], [[8.7781744], [8.7781744]]]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+ @mock.patch.object(layers, '_custom_layer_impl', autospec=True)
+ def test_custom_dense_passes_custom_layer_options(self,
+ mock_custom_layer_impl):
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ layers.custom_dense(x, 3)
+ mock_custom_layer_impl.assert_called_once_with(
+ mock.ANY,
+ kernel_shape=(12, 3),
+ bias_shape=(3,),
+ activation=None,
+ he_initializer_slope=1.0,
+ use_weight_scaling=True)
+
+ @mock.patch.object(tf, 'random_normal_initializer', autospec=True)
+ @mock.patch.object(tf, 'zeros_initializer', autospec=True)
+ def test_custom_dense_output_is_correct(self, mock_zeros_initializer,
+ mock_random_normal_initializer):
+ mock_zeros_initializer.return_value = tf.constant_initializer(1.0)
+ mock_random_normal_initializer.return_value = tf.constant_initializer(3.0)
+ x = tf.constant(
+ [[[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]],
+ [[[0, 0, 0], [-1, -2, -3]], [[1, -2, 2], [2, 5, 3]]]],
+ dtype=tf.float32)
+ output = layers.custom_dense(x, 3)
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ output_np = sess.run(output)
+
+ expected_np = [[68.54998016, 68.54998016, 68.54998016],
+ [5.33012676, 5.33012676, 5.33012676]]
+ self.assertNDArrayNear(output_np, expected_np, 1.0e-5)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py"
new file mode 100644
index 00000000..0561ea65
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks.py"
@@ -0,0 +1,412 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Generator and discriminator for a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+
+import tensorflow as tf
+
+import layers
+
+
+class ResolutionSchedule(object):
+ """Image resolution upscaling schedule."""
+
+ def __init__(self, start_resolutions=(4, 4), scale_base=2, num_resolutions=4):
+ """Initializer.
+
+ Args:
+ start_resolutions: An tuple of integers of HxW format for start image
+ resolutions. Defaults to (4, 4).
+ scale_base: An integer of resolution base multiplier. Defaults to 2.
+ num_resolutions: An integer of how many progressive resolutions (including
+ `start_resolutions`). Defaults to 4.
+ """
+ self._start_resolutions = start_resolutions
+ self._scale_base = scale_base
+ self._num_resolutions = num_resolutions
+
+ @property
+ def start_resolutions(self):
+ return tuple(self._start_resolutions)
+
+ @property
+ def scale_base(self):
+ return self._scale_base
+
+ @property
+ def num_resolutions(self):
+ return self._num_resolutions
+
+ @property
+ def final_resolutions(self):
+ """Returns the final resolutions."""
+ return tuple([
+ r * self._scale_base**(self._num_resolutions - 1)
+ for r in self._start_resolutions
+ ])
+
+ def scale_factor(self, block_id):
+ """Returns the scale factor for network block `block_id`."""
+ if block_id < 1 or block_id > self._num_resolutions:
+ raise ValueError('`block_id` must be in [1, {}]'.format(
+ self._num_resolutions))
+ return self._scale_base**(self._num_resolutions - block_id)
+
+
+def block_name(block_id):
+ """Returns the scope name for the network block `block_id`."""
+ return 'progressive_gan_block_{}'.format(block_id)
+
+
+def min_total_num_images(stable_stage_num_images, transition_stage_num_images,
+ num_blocks):
+ """Returns the minimum total number of images.
+
+ Computes the minimum total number of images required to reach the desired
+ `resolution`.
+
+ Args:
+ stable_stage_num_images: Number of images in the stable stage.
+ transition_stage_num_images: Number of images in the transition stage.
+ num_blocks: Number of network blocks.
+
+ Returns:
+ An integer of the minimum total number of images.
+ """
+ return (num_blocks * stable_stage_num_images +
+ (num_blocks - 1) * transition_stage_num_images)
+
+
+def compute_progress(current_image_id, stable_stage_num_images,
+ transition_stage_num_images, num_blocks):
+ """Computes the training progress.
+
+ The training alternates between stable phase and transition phase.
+ The `progress` indicates the training progress, i.e. the training is at
+ - a stable phase p if progress = p
+ - a transition stage between p and p + 1 if progress = p + fraction
+ where p = 0,1,2.,...
+
+ Note the max value of progress is `num_blocks` - 1.
+
+ In terms of LOD (of the original implementation):
+ progress = `num_blocks` - 1 - LOD
+
+ Args:
+ current_image_id: An scalar integer `Tensor` of the current image id, count
+ from 0.
+ stable_stage_num_images: An integer representing the number of images in
+ each stable stage.
+ transition_stage_num_images: An integer representing the number of images in
+ each transition stage.
+ num_blocks: Number of network blocks.
+
+ Returns:
+ A scalar float `Tensor` of the training progress.
+ """
+ # Note when current_image_id >= min_total_num_images - 1 (which means we
+ # are already at the highest resolution), we want to keep progress constant.
+ # Therefore, cap current_image_id here.
+ capped_current_image_id = tf.minimum(
+ current_image_id,
+ min_total_num_images(stable_stage_num_images, transition_stage_num_images,
+ num_blocks) - 1)
+
+ stage_num_images = stable_stage_num_images + transition_stage_num_images
+ progress_integer = tf.floordiv(capped_current_image_id, stage_num_images)
+ progress_fraction = tf.maximum(
+ 0.0,
+ tf.to_float(
+ tf.mod(capped_current_image_id, stage_num_images) -
+ stable_stage_num_images) / tf.to_float(transition_stage_num_images))
+ return tf.to_float(progress_integer) + progress_fraction
+
+
+def _generator_alpha(block_id, progress):
+ """Returns the block output parameter for the generator network.
+
+ The generator has N blocks with `block_id` = 1,2,...,N. Each block
+ block_id outputs a fake data output(block_id). The generator output is a
+ linear combination of all block outputs, i.e.
+ SUM_block_id(output(block_id) * alpha(block_id, progress)) where
+ alpha(block_id, progress) = _generator_alpha(block_id, progress). Note it
+ garantees that SUM_block_id(alpha(block_id, progress)) = 1 for any progress.
+
+ With a fixed block_id, the plot of alpha(block_id, progress) against progress
+ is a 'triangle' with its peak at (block_id - 1, 1).
+
+ Args:
+ block_id: An integer of generator block id.
+ progress: A scalar float `Tensor` of training progress.
+
+ Returns:
+ A scalar float `Tensor` of block output parameter.
+ """
+ return tf.maximum(0.0,
+ tf.minimum(progress - (block_id - 2), block_id - progress))
+
+
+def _discriminator_alpha(block_id, progress):
+ """Returns the block input parameter for discriminator network.
+
+ The discriminator has N blocks with `block_id` = 1,2,...,N. Each block
+ block_id accepts an
+ - input(block_id) transformed from the real data and
+ - the output of block block_id + 1, i.e. output(block_id + 1)
+ The final input is a linear combination of them,
+ i.e. alpha * input(block_id) + (1 - alpha) * output(block_id + 1)
+ where alpha = _discriminator_alpha(block_id, progress).
+
+ With a fixed block_id, alpha(block_id, progress) stays to be 1
+ when progress <= block_id - 1, then linear decays to 0 when
+ block_id - 1 < progress <= block_id, and finally stays at 0
+ when progress > block_id.
+
+ Args:
+ block_id: An integer of generator block id.
+ progress: A scalar float `Tensor` of training progress.
+
+ Returns:
+ A scalar float `Tensor` of block input parameter.
+ """
+ return tf.clip_by_value(block_id - progress, 0.0, 1.0)
+
+
+def blend_images(x, progress, resolution_schedule, num_blocks):
+ """Blends images of different resolutions according to `progress`.
+
+ When training `progress` is at a stable stage for resolution r, returns
+ image `x` downscaled to resolution r and then upscaled to `final_resolutions`,
+ call it x'(r).
+
+ Otherwise when training `progress` is at a transition stage from resolution
+ r to 2r, returns a linear combination of x'(r) and x'(2r).
+
+ Args:
+ x: An image `Tensor` of NHWC format with resolution `final_resolutions`.
+ progress: A scalar float `Tensor` of training progress.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks.
+
+ Returns:
+ An image `Tensor` which is a blend of images of different resolutions.
+ """
+ x_blend = []
+ for block_id in range(1, num_blocks + 1):
+ alpha = _generator_alpha(block_id, progress)
+ scale = resolution_schedule.scale_factor(block_id)
+ x_blend.append(alpha * layers.upscale(layers.downscale(x, scale), scale))
+ return tf.add_n(x_blend)
+
+
+def num_filters(block_id, fmap_base=4096, fmap_decay=1.0, fmap_max=256):
+ """Computes number of filters of block `block_id`."""
+ return int(min(fmap_base / math.pow(2.0, block_id * fmap_decay), fmap_max))
+
+
+def generator(z,
+ progress,
+ num_filters_fn,
+ resolution_schedule,
+ num_blocks=None,
+ kernel_size=3,
+ colors=3,
+ to_rgb_activation=None,
+ scope='progressive_gan_generator',
+ reuse=None):
+ """Generator network for the progressive GAN model.
+
+ Args:
+ z: A `Tensor` of latent vector. The first dimension must be batch size.
+ progress: A scalar float `Tensor` of training progress.
+ num_filters_fn: A function that maps `block_id` to # of filters for the
+ block.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks. None means maximum number of
+ blocks, i.e. `resolution.schedule.num_resolutions`. Defaults to None.
+ kernel_size: An integer of convolution kernel size.
+ colors: Number of output color channels. Defaults to 3.
+ to_rgb_activation: Activation function applied when output rgb.
+ scope: A string or variable scope.
+ reuse: Whether to reuse `scope`. Defaults to None which means to inherit
+ the reuse option of the parent scope.
+
+ Returns:
+ A `Tensor` of model output and a dictionary of model end points.
+ """
+ if num_blocks is None:
+ num_blocks = resolution_schedule.num_resolutions
+
+ start_h, start_w = resolution_schedule.start_resolutions
+ final_h, final_w = resolution_schedule.final_resolutions
+
+ def _conv2d(scope, x, kernel_size, filters, padding='SAME'):
+ return layers.custom_conv2d(
+ x=x,
+ filters=filters,
+ kernel_size=kernel_size,
+ padding=padding,
+ activation=lambda x: layers.pixel_norm(tf.nn.leaky_relu(x)),
+ he_initializer_slope=0.0,
+ scope=scope)
+
+ def _to_rgb(x):
+ return layers.custom_conv2d(
+ x=x,
+ filters=colors,
+ kernel_size=1,
+ padding='SAME',
+ activation=to_rgb_activation,
+ scope='to_rgb')
+
+ end_points = {}
+
+ with tf.variable_scope(scope, reuse=reuse):
+ with tf.name_scope('input'):
+ x = tf.contrib.layers.flatten(z)
+ end_points['latent_vector'] = x
+
+ with tf.variable_scope(block_name(1)):
+ x = tf.expand_dims(tf.expand_dims(x, 1), 1)
+ x = layers.pixel_norm(x)
+ # Pad the 1 x 1 image to 2 * (start_h - 1) x 2 * (start_w - 1)
+ # with zeros for the next conv.
+ x = tf.pad(x, [[0] * 2, [start_h - 1] * 2, [start_w - 1] * 2, [0] * 2])
+ # The output is start_h x start_w x num_filters_fn(1).
+ x = _conv2d('conv0', x, (start_h, start_w), num_filters_fn(1), 'VALID')
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(1))
+ lods = [x]
+
+ for block_id in range(2, num_blocks + 1):
+ with tf.variable_scope(block_name(block_id)):
+ x = layers.upscale(x, resolution_schedule.scale_base)
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(block_id))
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(block_id))
+ lods.append(x)
+
+ outputs = []
+ for block_id in range(1, num_blocks + 1):
+ with tf.variable_scope(block_name(block_id)):
+ lod = _to_rgb(lods[block_id - 1])
+ scale = resolution_schedule.scale_factor(block_id)
+ lod = layers.upscale(lod, scale)
+ end_points['upscaled_rgb_{}'.format(block_id)] = lod
+
+ # alpha_i is used to replace lod_select. Note sum(alpha_i) is
+ # garanteed to be 1.
+ alpha = _generator_alpha(block_id, progress)
+ end_points['alpha_{}'.format(block_id)] = alpha
+
+ outputs.append(lod * alpha)
+
+ predictions = tf.add_n(outputs)
+ batch_size = z.shape[0].value
+ predictions.set_shape([batch_size, final_h, final_w, colors])
+ end_points['predictions'] = predictions
+
+ return predictions, end_points
+
+
+def discriminator(x,
+ progress,
+ num_filters_fn,
+ resolution_schedule,
+ num_blocks=None,
+ kernel_size=3,
+ scope='progressive_gan_discriminator',
+ reuse=None):
+ """Discriminator network for the progressive GAN model.
+
+ Args:
+ x: A `Tensor`of NHWC format representing images of size `resolution`.
+ progress: A scalar float `Tensor` of training progress.
+ num_filters_fn: A function that maps `block_id` to # of filters for the
+ block.
+ resolution_schedule: An object of `ResolutionSchedule`.
+ num_blocks: An integer of number of blocks. None means maximum number of
+ blocks, i.e. `resolution.schedule.num_resolutions`. Defaults to None.
+ kernel_size: An integer of convolution kernel size.
+ scope: A string or variable scope.
+ reuse: Whether to reuse `scope`. Defaults to None which means to inherit
+ the reuse option of the parent scope.
+
+ Returns:
+ A `Tensor` of model output and a dictionary of model end points.
+ """
+ if num_blocks is None:
+ num_blocks = resolution_schedule.num_resolutions
+
+ def _conv2d(scope, x, kernel_size, filters, padding='SAME'):
+ return layers.custom_conv2d(
+ x=x,
+ filters=filters,
+ kernel_size=kernel_size,
+ padding=padding,
+ activation=tf.nn.leaky_relu,
+ he_initializer_slope=0.0,
+ scope=scope)
+
+ def _from_rgb(x, block_id):
+ return _conv2d('from_rgb', x, 1, num_filters_fn(block_id))
+
+ end_points = {}
+
+ with tf.variable_scope(scope, reuse=reuse):
+ x0 = x
+ end_points['rgb'] = x0
+
+ lods = []
+ for block_id in range(num_blocks, 0, -1):
+ with tf.variable_scope(block_name(block_id)):
+ scale = resolution_schedule.scale_factor(block_id)
+ lod = layers.downscale(x0, scale)
+ end_points['downscaled_rgb_{}'.format(block_id)] = lod
+ lod = _from_rgb(lod, block_id)
+ # alpha_i is used to replace lod_select.
+ alpha = _discriminator_alpha(block_id, progress)
+ end_points['alpha_{}'.format(block_id)] = alpha
+ lods.append((lod, alpha))
+
+ lods_iter = iter(lods)
+ x, _ = lods_iter.next()
+ for block_id in range(num_blocks, 1, -1):
+ with tf.variable_scope(block_name(block_id)):
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(block_id))
+ x = _conv2d('conv1', x, kernel_size, num_filters_fn(block_id - 1))
+ x = layers.downscale(x, resolution_schedule.scale_base)
+ lod, alpha = lods_iter.next()
+ x = alpha * lod + (1.0 - alpha) * x
+
+ with tf.variable_scope(block_name(1)):
+ x = layers.scalar_concat(x, layers.minibatch_mean_stddev(x))
+ x = _conv2d('conv0', x, kernel_size, num_filters_fn(1))
+ x = _conv2d('conv1', x, resolution_schedule.start_resolutions,
+ num_filters_fn(0), 'VALID')
+ end_points['last_conv'] = x
+ logits = layers.custom_dense(x=x, units=1, scope='logits')
+ end_points['logits'] = logits
+
+ return logits, end_points
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py"
new file mode 100644
index 00000000..5e0f7374
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/networks_test.py"
@@ -0,0 +1,248 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+import numpy as np
+import tensorflow as tf
+
+import layers
+import networks
+
+
+def _get_grad_norm(ys, xs):
+ """Compute 2-norm of dys / dxs."""
+ return tf.sqrt(
+ tf.add_n([tf.reduce_sum(tf.square(g)) for g in tf.gradients(ys, xs)]))
+
+
+def _num_filters_stub(block_id):
+ return networks.num_filters(block_id, 8, 1, 8)
+
+
+class NetworksTest(tf.test.TestCase):
+
+ def test_resolution_schedule_correct(self):
+ rs = networks.ResolutionSchedule(
+ start_resolutions=[5, 3], scale_base=2, num_resolutions=3)
+ self.assertEqual(rs.start_resolutions, (5, 3))
+ self.assertEqual(rs.scale_base, 2)
+ self.assertEqual(rs.num_resolutions, 3)
+ self.assertEqual(rs.final_resolutions, (20, 12))
+ self.assertEqual(rs.scale_factor(1), 4)
+ self.assertEqual(rs.scale_factor(2), 2)
+ self.assertEqual(rs.scale_factor(3), 1)
+ with self.assertRaises(ValueError):
+ rs.scale_factor(0)
+ with self.assertRaises(ValueError):
+ rs.scale_factor(4)
+
+ def test_block_name(self):
+ self.assertEqual(networks.block_name(10), 'progressive_gan_block_10')
+
+ def test_min_total_num_images(self):
+ self.assertEqual(networks.min_total_num_images(7, 8, 4), 52)
+
+ def test_compute_progress(self):
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images=7,
+ transition_stage_num_images=8,
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ progress_output = [
+ sess.run(progress, feed_dict={current_image_id_ph: current_image_id})
+ for current_image_id in [0, 3, 6, 7, 8, 10, 15, 29, 100]
+ ]
+ self.assertArrayNear(progress_output,
+ [0.0, 0.0, 0.0, 0.0, 0.125, 0.375, 1.0, 1.0, 1.0],
+ 1.0e-6)
+
+ def test_generator_alpha(self):
+ with self.test_session(use_gpu=True) as sess:
+ alpha_fixed_block_id = [
+ sess.run(
+ networks._generator_alpha(2, tf.constant(progress, tf.float32)))
+ for progress in [0, 0.2, 1, 1.2, 2, 2.2, 3]
+ ]
+ alpha_fixed_progress = [
+ sess.run(
+ networks._generator_alpha(block_id, tf.constant(1.2, tf.float32)))
+ for block_id in range(1, 5)
+ ]
+
+ self.assertArrayNear(alpha_fixed_block_id, [0, 0.2, 1, 0.8, 0, 0, 0],
+ 1.0e-6)
+ self.assertArrayNear(alpha_fixed_progress, [0, 0.8, 0.2, 0], 1.0e-6)
+
+ def test_discriminator_alpha(self):
+ with self.test_session(use_gpu=True) as sess:
+ alpha_fixed_block_id = [
+ sess.run(
+ networks._discriminator_alpha(2, tf.constant(
+ progress, tf.float32)))
+ for progress in [0, 0.2, 1, 1.2, 2, 2.2, 3]
+ ]
+ alpha_fixed_progress = [
+ sess.run(
+ networks._discriminator_alpha(block_id,
+ tf.constant(1.2, tf.float32)))
+ for block_id in range(1, 5)
+ ]
+
+ self.assertArrayNear(alpha_fixed_block_id, [1, 1, 1, 0.8, 0, 0, 0], 1.0e-6)
+ self.assertArrayNear(alpha_fixed_progress, [0, 0.8, 1, 1], 1.0e-6)
+
+ def test_blend_images_in_stable_stage(self):
+ x_np = np.random.normal(size=[2, 8, 8, 3])
+ x = tf.constant(x_np, tf.float32)
+ x_blend = networks.blend_images(
+ x,
+ progress=tf.constant(0.0),
+ resolution_schedule=networks.ResolutionSchedule(
+ scale_base=2, num_resolutions=2),
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ x_blend_np = sess.run(x_blend)
+ x_blend_expected_np = sess.run(layers.upscale(layers.downscale(x, 2), 2))
+ self.assertNDArrayNear(x_blend_np, x_blend_expected_np, 1.0e-6)
+
+ def test_blend_images_in_transition_stage(self):
+ x_np = np.random.normal(size=[2, 8, 8, 3])
+ x = tf.constant(x_np, tf.float32)
+ x_blend = networks.blend_images(
+ x,
+ tf.constant(0.2),
+ resolution_schedule=networks.ResolutionSchedule(
+ scale_base=2, num_resolutions=2),
+ num_blocks=2)
+ with self.test_session(use_gpu=True) as sess:
+ x_blend_np = sess.run(x_blend)
+ x_blend_expected_np = 0.8 * sess.run(
+ layers.upscale(layers.downscale(x, 2), 2)) + 0.2 * x_np
+ self.assertNDArrayNear(x_blend_np, x_blend_expected_np, 1.0e-6)
+
+ def test_num_filters(self):
+ self.assertEqual(networks.num_filters(1, 4096, 1, 256), 256)
+ self.assertEqual(networks.num_filters(5, 4096, 1, 256), 128)
+
+ def test_generator_grad_norm_progress(self):
+ stable_stage_num_images = 2
+ transition_stage_num_images = 3
+
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images,
+ transition_stage_num_images,
+ num_blocks=3)
+ z = tf.random_normal([2, 10], dtype=tf.float32)
+ x, _ = networks.generator(
+ z, progress, _num_filters_stub,
+ networks.ResolutionSchedule(
+ start_resolutions=(4, 4), scale_base=2, num_resolutions=3))
+ fake_loss = tf.reduce_sum(tf.square(x))
+ grad_norms = [
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_1/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_2/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_3/.*'))
+ ]
+
+ grad_norms_output = None
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ x1_np = sess.run(x, feed_dict={current_image_id_ph: 0.12})
+ x2_np = sess.run(x, feed_dict={current_image_id_ph: 1.8})
+ grad_norms_output = np.array([
+ sess.run(grad_norms, feed_dict={current_image_id_ph: i})
+ for i in range(15) # total num of images
+ ])
+
+ self.assertEqual((2, 16, 16, 3), x1_np.shape)
+ self.assertEqual((2, 16, 16, 3), x2_np.shape)
+ # The gradient of block_1 is always on.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 0] > 0), 0,
+ 'gradient norms {} for block 1 is not always on'.format(
+ grad_norms_output[:, 0]))
+ # The gradient of block_2 is on after 1 stable stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 1] > 0), 3,
+ 'gradient norms {} for block 2 is not on at step 3'.format(
+ grad_norms_output[:, 1]))
+ # The gradient of block_3 is on after 2 stable stage + 1 transition stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 2] > 0), 8,
+ 'gradient norms {} for block 3 is not on at step 8'.format(
+ grad_norms_output[:, 2]))
+
+ def test_discriminator_grad_norm_progress(self):
+ stable_stage_num_images = 2
+ transition_stage_num_images = 3
+
+ current_image_id_ph = tf.placeholder(tf.int32, [])
+ progress = networks.compute_progress(
+ current_image_id_ph,
+ stable_stage_num_images,
+ transition_stage_num_images,
+ num_blocks=3)
+ x = tf.random_normal([2, 16, 16, 3])
+ logits, _ = networks.discriminator(
+ x, progress, _num_filters_stub,
+ networks.ResolutionSchedule(
+ start_resolutions=(4, 4), scale_base=2, num_resolutions=3))
+ fake_loss = tf.reduce_sum(tf.square(logits))
+ grad_norms = [
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_1/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_2/.*')),
+ _get_grad_norm(
+ fake_loss, tf.trainable_variables('.*/progressive_gan_block_3/.*'))
+ ]
+
+ grad_norms_output = None
+ with self.test_session(use_gpu=True) as sess:
+ sess.run(tf.global_variables_initializer())
+ grad_norms_output = np.array([
+ sess.run(grad_norms, feed_dict={current_image_id_ph: i})
+ for i in range(15) # total num of images
+ ])
+
+ # The gradient of block_1 is always on.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 0] > 0), 0,
+ 'gradient norms {} for block 1 is not always on'.format(
+ grad_norms_output[:, 0]))
+ # The gradient of block_2 is on after 1 stable stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 1] > 0), 3,
+ 'gradient norms {} for block 2 is not on at step 3'.format(
+ grad_norms_output[:, 1]))
+ # The gradient of block_3 is on after 2 stable stage + 1 transition stage.
+ self.assertEqual(
+ np.argmax(grad_norms_output[:, 2] > 0), 8,
+ 'gradient norms {} for block 3 is not on at step 8'.format(
+ grad_norms_output[:, 2]))
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg"
new file mode 100644
index 00000000..edf90ef6
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/testdata/test.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py"
new file mode 100644
index 00000000..66f9e1cb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train.py"
@@ -0,0 +1,589 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Train a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import logging
+import numpy as np
+import tensorflow as tf
+
+import networks
+
+tfgan = tf.contrib.gan
+
+
+def make_train_sub_dir(stage_id, **kwargs):
+ """Returns the log directory for training stage `stage_id`."""
+ return os.path.join(kwargs['train_root_dir'], 'stage_{:05d}'.format(stage_id))
+
+
+def make_resolution_schedule(**kwargs):
+ """Returns an object of `ResolutionSchedule`."""
+ return networks.ResolutionSchedule(
+ start_resolutions=(kwargs['start_height'], kwargs['start_width']),
+ scale_base=kwargs['scale_base'],
+ num_resolutions=kwargs['num_resolutions'])
+
+
+def get_stage_ids(**kwargs):
+ """Returns a list of stage ids.
+
+ Args:
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ """
+ train_sub_dirs = [
+ sub_dir for sub_dir in tf.gfile.ListDirectory(kwargs['train_root_dir'])
+ if sub_dir.startswith('stage_')
+ ]
+
+ # If fresh start, start with start_stage_id = 0
+ # If has been trained for n = len(train_sub_dirs) stages, start with the last
+ # stage, i.e. start_stage_id = n - 1.
+ start_stage_id = max(0, len(train_sub_dirs) - 1)
+
+ return range(start_stage_id, get_total_num_stages(**kwargs))
+
+
+def get_total_num_stages(**kwargs):
+ """Returns total number of training stages."""
+ return 2 * kwargs['num_resolutions'] - 1
+
+
+def get_batch_size(stage_id, **kwargs):
+ """Returns batch size for each stage.
+
+ It is expected that `len(batch_size_schedule) == num_resolutions`. Each stage
+ corresponds to a resolution and hence a batch size. However if
+ `len(batch_size_schedule) < num_resolutions`, pad `batch_size_schedule` in the
+ beginning with the first batch size.
+
+ Args:
+ stage_id: An integer of training stage index.
+ **kwargs: A dictionary of
+ 'batch_size_schedule': A list of integer, each element is the batch size
+ for the current training image resolution.
+ 'num_resolutions': An integer of number of progressive resolutions.
+
+ Returns:
+ An integer batch size for the `stage_id`.
+ """
+ batch_size_schedule = kwargs['batch_size_schedule']
+ num_resolutions = kwargs['num_resolutions']
+ if len(batch_size_schedule) < num_resolutions:
+ batch_size_schedule = (
+ [batch_size_schedule[0]] * (num_resolutions - len(batch_size_schedule))
+ + batch_size_schedule)
+
+ return int(batch_size_schedule[(stage_id + 1) // 2])
+
+
+def get_stage_info(stage_id, **kwargs):
+ """Returns information for a training stage.
+
+ Args:
+ stage_id: An integer of training stage index.
+ **kwargs: A dictionary of
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+
+ Returns:
+ A tuple of integers. The first entry is the number of blocks. The second
+ entry is the accumulated total number of training images when stage
+ `stage_id` is finished.
+
+ Raises:
+ ValueError: If `stage_id` is not in [0, total number of stages).
+ """
+ total_num_stages = get_total_num_stages(**kwargs)
+ if not (stage_id >= 0 and stage_id < total_num_stages):
+ raise ValueError(
+ '`stage_id` must be in [0, {0}), but instead was {1}'.format(
+ total_num_stages, stage_id))
+
+ # Even stage_id: stable training stage.
+ # Odd stage_id: transition training stage.
+ num_blocks = (stage_id + 1) // 2 + 1
+ num_images = ((stage_id // 2 + 1) * kwargs['stable_stage_num_images'] + (
+ (stage_id + 1) // 2) * kwargs['transition_stage_num_images'])
+
+ total_num_images = kwargs['total_num_images']
+ if stage_id >= total_num_stages - 1:
+ num_images = total_num_images
+ num_images = min(num_images, total_num_images)
+
+ return num_blocks, num_images
+
+
+def make_latent_vectors(num, **kwargs):
+ """Returns a batch of `num` random latent vectors."""
+ return tf.random_normal([num, kwargs['latent_vector_size']], dtype=tf.float32)
+
+
+def make_interpolated_latent_vectors(num_rows, num_columns, **kwargs):
+ """Returns a batch of linearly interpolated latent vectors.
+
+ Given two randomly generated latent vector za and zb, it can generate
+ a row of `num_columns` interpolated latent vectors, i.e.
+ [..., za + (zb - za) * i / (num_columns - 1), ...] where
+ i = 0, 1, ..., `num_columns` - 1.
+
+ This function produces `num_rows` such rows and returns a (flattened)
+ batch of latent vectors with batch size `num_rows * num_columns`.
+
+ Args:
+ num_rows: An integer. Number of rows of interpolated latent vectors.
+ num_columns: An integer. Number of interpolated latent vectors in each row.
+ **kwargs: A dictionary of
+ 'latent_vector_size': An integer of latent vector size.
+
+ Returns:
+ A `Tensor` of shape `[num_rows * num_columns, latent_vector_size]`.
+ """
+ ans = []
+ for _ in range(num_rows):
+ z = tf.random_normal([2, kwargs['latent_vector_size']])
+ r = tf.reshape(
+ tf.to_float(tf.range(num_columns)) / (num_columns - 1), [-1, 1])
+ dz = z[1] - z[0]
+ ans.append(z[0] + tf.stack([dz] * num_columns) * r)
+ return tf.concat(ans, axis=0)
+
+
+def define_loss(gan_model, **kwargs):
+ """Defines progressive GAN losses.
+
+ The generator and discriminator both use wasserstein loss. In addition,
+ a small penalty term is added to the discriminator loss to prevent it getting
+ too large.
+
+ Args:
+ gan_model: A `GANModel` namedtuple.
+ **kwargs: A dictionary of
+ 'gradient_penalty_weight': A float of gradient norm target for
+ wasserstein loss.
+ 'gradient_penalty_target': A float of gradient penalty weight for
+ wasserstein loss.
+ 'real_score_penalty_weight': A float of Additional penalty to keep
+ the scores from drifting too far from zero.
+
+ Returns:
+ A `GANLoss` namedtuple.
+ """
+ gan_loss = tfgan.gan_loss(
+ gan_model,
+ generator_loss_fn=tfgan.losses.wasserstein_generator_loss,
+ discriminator_loss_fn=tfgan.losses.wasserstein_discriminator_loss,
+ gradient_penalty_weight=kwargs['gradient_penalty_weight'],
+ gradient_penalty_target=kwargs['gradient_penalty_target'],
+ gradient_penalty_epsilon=0.0)
+
+ real_score_penalty = tf.reduce_mean(
+ tf.square(gan_model.discriminator_real_outputs))
+ tf.summary.scalar('real_score_penalty', real_score_penalty)
+
+ return gan_loss._replace(
+ discriminator_loss=(
+ gan_loss.discriminator_loss +
+ kwargs['real_score_penalty_weight'] * real_score_penalty))
+
+
+def define_train_ops(gan_model, gan_loss, **kwargs):
+ """Defines progressive GAN train ops.
+
+ Args:
+ gan_model: A `GANModel` namedtuple.
+ gan_loss: A `GANLoss` namedtuple.
+ **kwargs: A dictionary of
+ 'adam_beta1': A float of Adam optimizer beta1.
+ 'adam_beta2': A float of Adam optimizer beta2.
+ 'generator_learning_rate': A float of generator learning rate.
+ 'discriminator_learning_rate': A float of discriminator learning rate.
+
+ Returns:
+ A tuple of `GANTrainOps` namedtuple and a list variables tracking the state
+ of optimizers.
+ """
+ with tf.variable_scope('progressive_gan_train_ops') as var_scope:
+ beta1, beta2 = kwargs['adam_beta1'], kwargs['adam_beta2']
+ gen_opt = tf.train.AdamOptimizer(kwargs['generator_learning_rate'], beta1,
+ beta2)
+ dis_opt = tf.train.AdamOptimizer(kwargs['discriminator_learning_rate'],
+ beta1, beta2)
+ gan_train_ops = tfgan.gan_train_ops(gan_model, gan_loss, gen_opt, dis_opt)
+ return gan_train_ops, tf.get_collection(
+ tf.GraphKeys.GLOBAL_VARIABLES, scope=var_scope.name)
+
+
+def add_generator_smoothing_ops(generator_ema, gan_model, gan_train_ops):
+ """Adds generator smoothing ops."""
+ with tf.control_dependencies([gan_train_ops.generator_train_op]):
+ new_generator_train_op = generator_ema.apply(gan_model.generator_variables)
+
+ gan_train_ops = gan_train_ops._replace(
+ generator_train_op=new_generator_train_op)
+ generator_vars_to_restore = generator_ema.variables_to_restore(
+ gan_model.generator_variables)
+ return gan_train_ops, generator_vars_to_restore
+
+
+def build_model(stage_id, batch_size, real_images, **kwargs):
+ """Builds progressive GAN model.
+
+ Args:
+ stage_id: An integer of training stage index.
+ batch_size: Number of training images in each minibatch.
+ real_images: A 4D `Tensor` of NHWC format.
+ **kwargs: A dictionary of
+ 'start_height': An integer of start image height.
+ 'start_width': An integer of start image width.
+ 'scale_base': An integer of resolution multiplier.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+ 'kernel_size': Convolution kernel size.
+ 'colors': Number of image channels.
+ 'to_rgb_use_tanh_activation': Whether to apply tanh activation when
+ output rgb.
+ 'fmap_base': Base number of filters.
+ 'fmap_decay': Decay of number of filters.
+ 'fmap_max': Max number of filters.
+ 'latent_vector_size': An integer of latent vector size.
+ 'gradient_penalty_weight': A float of gradient norm target for
+ wasserstein loss.
+ 'gradient_penalty_target': A float of gradient penalty weight for
+ wasserstein loss.
+ 'real_score_penalty_weight': A float of Additional penalty to keep
+ the scores from drifting too far from zero.
+ 'adam_beta1': A float of Adam optimizer beta1.
+ 'adam_beta2': A float of Adam optimizer beta2.
+ 'generator_learning_rate': A float of generator learning rate.
+ 'discriminator_learning_rate': A float of discriminator learning rate.
+
+ Returns:
+ An inernal object that wraps all information about the model.
+ """
+ kernel_size = kwargs['kernel_size']
+ colors = kwargs['colors']
+ resolution_schedule = make_resolution_schedule(**kwargs)
+
+ num_blocks, num_images = get_stage_info(stage_id, **kwargs)
+
+ current_image_id = tf.train.get_or_create_global_step()
+ current_image_id_inc_op = current_image_id.assign_add(batch_size)
+ tf.summary.scalar('current_image_id', current_image_id)
+
+ progress = networks.compute_progress(
+ current_image_id, kwargs['stable_stage_num_images'],
+ kwargs['transition_stage_num_images'], num_blocks)
+ tf.summary.scalar('progress', progress)
+
+ real_images = networks.blend_images(
+ real_images, progress, resolution_schedule, num_blocks=num_blocks)
+
+ def _num_filters_fn(block_id):
+ """Computes number of filters of block `block_id`."""
+ return networks.num_filters(block_id, kwargs['fmap_base'],
+ kwargs['fmap_decay'], kwargs['fmap_max'])
+
+ def _generator_fn(z):
+ """Builds generator network."""
+ return networks.generator(
+ z,
+ progress,
+ _num_filters_fn,
+ resolution_schedule,
+ num_blocks=num_blocks,
+ kernel_size=kernel_size,
+ colors=colors,
+ to_rgb_activation=(tf.tanh
+ if kwargs['to_rgb_use_tanh_activation'] else None))
+
+ def _discriminator_fn(x):
+ """Builds discriminator network."""
+ return networks.discriminator(
+ x,
+ progress,
+ _num_filters_fn,
+ resolution_schedule,
+ num_blocks=num_blocks,
+ kernel_size=kernel_size)
+
+ ########## Define model.
+ z = make_latent_vectors(batch_size, **kwargs)
+
+ gan_model = tfgan.gan_model(
+ generator_fn=lambda z: _generator_fn(z)[0],
+ discriminator_fn=lambda x, unused_z: _discriminator_fn(x)[0],
+ real_data=real_images,
+ generator_inputs=z)
+
+ ########## Define loss.
+ gan_loss = define_loss(gan_model, **kwargs)
+
+ ########## Define train ops.
+ gan_train_ops, optimizer_var_list = define_train_ops(gan_model, gan_loss,
+ **kwargs)
+ gan_train_ops = gan_train_ops._replace(
+ global_step_inc_op=current_image_id_inc_op)
+
+ ########## Generator smoothing.
+ generator_ema = tf.train.ExponentialMovingAverage(decay=0.999)
+ gan_train_ops, generator_vars_to_restore = add_generator_smoothing_ops(
+ generator_ema, gan_model, gan_train_ops)
+
+ class Model(object):
+ pass
+
+ model = Model()
+ model.stage_id = stage_id
+ model.batch_size = batch_size
+ model.resolution_schedule = resolution_schedule
+ model.num_images = num_images
+ model.num_blocks = num_blocks
+ model.current_image_id = current_image_id
+ model.progress = progress
+ model.num_filters_fn = _num_filters_fn
+ model.generator_fn = _generator_fn
+ model.discriminator_fn = _discriminator_fn
+ model.gan_model = gan_model
+ model.gan_loss = gan_loss
+ model.gan_train_ops = gan_train_ops
+ model.optimizer_var_list = optimizer_var_list
+ model.generator_ema = generator_ema
+ model.generator_vars_to_restore = generator_vars_to_restore
+ return model
+
+
+def make_var_scope_custom_getter_for_ema(ema):
+ """Makes variable scope custom getter."""
+ def _custom_getter(getter, name, *args, **kwargs):
+ var = getter(name, *args, **kwargs)
+ ema_var = ema.average(var)
+ return ema_var if ema_var else var
+ return _custom_getter
+
+
+def add_model_summaries(model, **kwargs):
+ """Adds model summaries.
+
+ This function adds several useful summaries during training:
+ - fake_images: A grid of fake images based on random latent vectors.
+ - interp_images: A grid of fake images based on interpolated latent vectors.
+ - real_images_blend: A grid of real images.
+ - summaries for `gan_model` losses, variable distributions etc.
+
+ Args:
+ model: An model object having all information of progressive GAN model,
+ e.g. the return of build_model().
+ **kwargs: A dictionary of
+ 'fake_grid_size': The fake image grid size for summaries.
+ 'interp_grid_size': The latent space interpolated image grid size for
+ summaries.
+ 'colors': Number of image channels.
+ 'latent_vector_size': An integer of latent vector size.
+ """
+ fake_grid_size = kwargs['fake_grid_size']
+ interp_grid_size = kwargs['interp_grid_size']
+ colors = kwargs['colors']
+
+ image_shape = list(model.resolution_schedule.final_resolutions)
+
+ fake_batch_size = fake_grid_size**2
+ fake_images_shape = [fake_batch_size] + image_shape + [colors]
+
+ interp_batch_size = interp_grid_size**2
+ interp_images_shape = [interp_batch_size] + image_shape + [colors]
+
+ # When making prediction, use the ema smoothed generator vars.
+ with tf.variable_scope(
+ model.gan_model.generator_scope,
+ reuse=True,
+ custom_getter=make_var_scope_custom_getter_for_ema(model.generator_ema)):
+ z_fake = make_latent_vectors(fake_batch_size, **kwargs)
+ fake_images = model.gan_model.generator_fn(z_fake)
+ fake_images.set_shape(fake_images_shape)
+
+ z_interp = make_interpolated_latent_vectors(interp_grid_size,
+ interp_grid_size, **kwargs)
+ interp_images = model.gan_model.generator_fn(z_interp)
+ interp_images.set_shape(interp_images_shape)
+
+ tf.summary.image(
+ 'fake_images',
+ tfgan.eval.eval_utils.image_grid(
+ fake_images,
+ grid_shape=[fake_grid_size] * 2,
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ tf.summary.image(
+ 'interp_images',
+ tfgan.eval.eval_utils.image_grid(
+ interp_images,
+ grid_shape=[interp_grid_size] * 2,
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ real_grid_size = int(np.sqrt(model.batch_size))
+ tf.summary.image(
+ 'real_images_blend',
+ tfgan.eval.eval_utils.image_grid(
+ model.gan_model.real_data[:real_grid_size**2],
+ grid_shape=(real_grid_size, real_grid_size),
+ image_shape=image_shape,
+ num_channels=colors),
+ max_outputs=1)
+
+ tfgan.eval.add_gan_model_summaries(model.gan_model)
+
+
+def make_scaffold(stage_id, optimizer_var_list, **kwargs):
+ """Makes a custom scaffold.
+
+ The scaffold
+ - restores variables from the last training stage.
+ - initializes new variables in the new block.
+
+ Args:
+ stage_id: An integer of stage id.
+ optimizer_var_list: A list of optimizer variables.
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'num_resolutions': An integer of number of progressive resolutions.
+ 'stable_stage_num_images': An integer of number of training images in
+ the stable stage.
+ 'transition_stage_num_images': An integer of number of training images
+ in the transition stage.
+ 'total_num_images': An integer of total number of training images.
+
+ Returns:
+ A `Scaffold` object.
+ """
+ # Holds variables that from the previous stage and need to be restored.
+ restore_var_list = []
+ prev_ckpt = None
+ curr_ckpt = tf.train.latest_checkpoint(make_train_sub_dir(stage_id, **kwargs))
+ if stage_id > 0 and curr_ckpt is None:
+ prev_ckpt = tf.train.latest_checkpoint(
+ make_train_sub_dir(stage_id - 1, **kwargs))
+
+ num_blocks, _ = get_stage_info(stage_id, **kwargs)
+ prev_num_blocks, _ = get_stage_info(stage_id - 1, **kwargs)
+
+ # Holds variables created in the new block of the current stage. If the
+ # current stage is a stable stage (except the initial stage), this list
+ # will be empty.
+ new_block_var_list = []
+ for block_id in range(prev_num_blocks + 1, num_blocks + 1):
+ new_block_var_list.extend(
+ tf.get_collection(
+ tf.GraphKeys.GLOBAL_VARIABLES,
+ scope='.*/{}/'.format(networks.block_name(block_id))))
+
+ # Every variables that are 1) not for optimizers and 2) from the new block
+ # need to be restored.
+ restore_var_list = [
+ var for var in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
+ if var not in set(optimizer_var_list + new_block_var_list)
+ ]
+
+ # Add saver op to graph. This saver is used to restore variables from the
+ # previous stage.
+ saver_for_restore = tf.train.Saver(
+ var_list=restore_var_list, allow_empty=True)
+ # Add the op to graph that initializes all global variables.
+ init_op = tf.global_variables_initializer()
+
+ def _init_fn(unused_scaffold, sess):
+ # First initialize every variables.
+ sess.run(init_op)
+ logging.info('\n'.join([var.name for var in restore_var_list]))
+ # Then overwrite variables saved in previous stage.
+ if prev_ckpt is not None:
+ saver_for_restore.restore(sess, prev_ckpt)
+
+ # Use a dummy init_op here as all initialization is done in init_fn.
+ return tf.train.Scaffold(init_op=tf.constant([]), init_fn=_init_fn)
+
+
+def make_status_message(model):
+ """Makes a string `Tensor` of training status."""
+ return tf.string_join(
+ [
+ 'Starting train step: current_image_id: ',
+ tf.as_string(model.current_image_id), ', progress: ',
+ tf.as_string(model.progress), ', num_blocks: {}'.format(
+ model.num_blocks), ', batch_size: {}'.format(model.batch_size)
+ ],
+ name='status_message')
+
+
+def train(model, **kwargs):
+ """Trains progressive GAN for stage `stage_id`.
+
+ Args:
+ model: An model object having all information of progressive GAN model,
+ e.g. the return of build_model().
+ **kwargs: A dictionary of
+ 'train_root_dir': A string of root directory of training logs.
+ 'master': Name of the TensorFlow master to use.
+ 'task': The Task ID. This value is used when training with multiple
+ workers to identify each worker.
+ 'save_summaries_num_images': Save summaries in this number of images.
+ Returns:
+ None.
+ """
+ logging.info('stage_id=%d, num_blocks=%d, num_images=%d', model.stage_id,
+ model.num_blocks, model.num_images)
+
+ scaffold = make_scaffold(model.stage_id, model.optimizer_var_list, **kwargs)
+
+ tfgan.gan_train(
+ model.gan_train_ops,
+ logdir=make_train_sub_dir(model.stage_id, **kwargs),
+ get_hooks_fn=tfgan.get_sequential_train_hooks(tfgan.GANTrainSteps(1, 1)),
+ hooks=[
+ tf.train.StopAtStepHook(last_step=model.num_images),
+ tf.train.LoggingTensorHook(
+ [make_status_message(model)], every_n_iter=10)
+ ],
+ master=kwargs['master'],
+ is_chief=(kwargs['task'] == 0),
+ scaffold=scaffold,
+ save_checkpoint_secs=600,
+ save_summaries_steps=(kwargs['save_summaries_num_images']))
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py"
new file mode 100644
index 00000000..645d20cf
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_main.py"
@@ -0,0 +1,174 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Train a progressive GAN model.
+
+See https://arxiv.org/abs/1710.10196 for details about the model.
+
+See https://github.com/tkarras/progressive_growing_of_gans for the original
+theano implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import sys
+
+
+from absl import flags
+from absl import logging
+import tensorflow as tf
+
+import data_provider
+import train
+
+tfgan = tf.contrib.gan
+
+flags.DEFINE_string('dataset_name', 'cifar10', 'Dataset name.')
+
+flags.DEFINE_string('dataset_file_pattern', '', 'Dataset file pattern.')
+
+flags.DEFINE_integer('start_height', 4, 'Start image height.')
+
+flags.DEFINE_integer('start_width', 4, 'Start image width.')
+
+flags.DEFINE_integer('scale_base', 2, 'Resolution multiplier.')
+
+flags.DEFINE_integer('num_resolutions', 4, 'Number of progressive resolutions.')
+
+flags.DEFINE_list(
+ 'batch_size_schedule', [8, 8, 4],
+ 'A list of batch sizes for each resolution, if '
+ 'len(batch_size_schedule) < num_resolutions, pad the schedule in the '
+ 'beginning with the first batch size.')
+
+flags.DEFINE_integer('kernel_size', 3, 'Convolution kernel size.')
+
+flags.DEFINE_integer('colors', 3, 'Number of image channels.')
+
+flags.DEFINE_bool('to_rgb_use_tanh_activation', False,
+ 'Whether to apply tanh activation when output rgb.')
+
+flags.DEFINE_integer('stable_stage_num_images', 1000,
+ 'Number of images in the stable stage.')
+
+flags.DEFINE_integer('transition_stage_num_images', 1000,
+ 'Number of images in the transition stage.')
+
+flags.DEFINE_integer('total_num_images', 10000, 'Total number of images.')
+
+flags.DEFINE_integer('save_summaries_num_images', 100,
+ 'Save summaries in this number of images.')
+
+flags.DEFINE_integer('latent_vector_size', 128, 'Latent vector size.')
+
+flags.DEFINE_integer('fmap_base', 4096, 'Base number of filters.')
+
+flags.DEFINE_float('fmap_decay', 1.0, 'Decay of number of filters.')
+
+flags.DEFINE_integer('fmap_max', 128, 'Max number of filters.')
+
+flags.DEFINE_float('gradient_penalty_target', 1.0,
+ 'Gradient norm target for wasserstein loss.')
+
+flags.DEFINE_float('gradient_penalty_weight', 10.0,
+ 'Gradient penalty weight for wasserstein loss.')
+
+flags.DEFINE_float('real_score_penalty_weight', 0.001,
+ 'Additional penalty to keep the scores from drifting too '
+ 'far from zero.')
+
+flags.DEFINE_float('generator_learning_rate', 0.001, 'Learning rate.')
+
+flags.DEFINE_float('discriminator_learning_rate', 0.001, 'Learning rate.')
+
+flags.DEFINE_float('adam_beta1', 0.0, 'Adam beta 1.')
+
+flags.DEFINE_float('adam_beta2', 0.99, 'Adam beta 2.')
+
+flags.DEFINE_integer('fake_grid_size', 8, 'The fake image grid size for eval.')
+
+flags.DEFINE_integer('interp_grid_size', 8,
+ 'The interp image grid size for eval.')
+
+flags.DEFINE_string('train_root_dir', '/tmp/progressive_gan/',
+ 'Directory where to write event logs.')
+
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+
+
+def _make_config_from_flags():
+ """Makes a config dictionary from commandline flags."""
+ return dict([(flag.name, flag.value)
+ for flag in FLAGS.get_key_flags_for_module(sys.argv[0])])
+
+
+def _provide_real_images(batch_size, **kwargs):
+ """Provides real images."""
+ dataset_name = kwargs.get('dataset_name')
+ dataset_file_pattern = kwargs.get('dataset_file_pattern')
+ colors = kwargs['colors']
+ final_height, final_width = train.make_resolution_schedule(
+ **kwargs).final_resolutions
+ if dataset_name is not None:
+ return data_provider.provide_data(
+ dataset_name=dataset_name,
+ split_name='train',
+ batch_size=batch_size,
+ patch_height=final_height,
+ patch_width=final_width,
+ colors=colors)
+ elif dataset_file_pattern is not None:
+ return data_provider.provide_data_from_image_files(
+ file_pattern=dataset_file_pattern,
+ batch_size=batch_size,
+ patch_height=final_height,
+ patch_width=final_width,
+ colors=colors)
+
+
+def main(_):
+ if not tf.gfile.Exists(FLAGS.train_root_dir):
+ tf.gfile.MakeDirs(FLAGS.train_root_dir)
+
+ config = _make_config_from_flags()
+ logging.info('\n'.join(['{}={}'.format(k, v) for k, v in config.iteritems()]))
+
+ for stage_id in train.get_stage_ids(**config):
+ batch_size = train.get_batch_size(stage_id, **config)
+ tf.reset_default_graph()
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+ real_images = None
+ with tf.device('/cpu:0'), tf.name_scope('inputs'):
+ real_images = _provide_real_images(batch_size, **config)
+ model = train.build_model(stage_id, batch_size, real_images, **config)
+ train.add_model_summaries(model, **config)
+ train.train(model, **config)
+
+
+if __name__ == '__main__':
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py"
new file mode 100644
index 00000000..67f47899
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/progressive_gan/train_test.py"
@@ -0,0 +1,93 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+
+from absl import flags
+from absl.testing import absltest
+import tensorflow as tf
+
+import train
+
+
+FLAGS = flags.FLAGS
+
+
+def provide_random_data(batch_size=2, patch_size=4, colors=1, **unused_kwargs):
+ return tf.random_normal([batch_size, patch_size, patch_size, colors])
+
+
+class TrainTest(absltest.TestCase):
+
+ def setUp(self):
+ self._config = {
+ 'start_height': 2,
+ 'start_width': 2,
+ 'scale_base': 2,
+ 'num_resolutions': 2,
+ 'batch_size_schedule': [2],
+ 'colors': 1,
+ 'to_rgb_use_tanh_activation': True,
+ 'kernel_size': 3,
+ 'stable_stage_num_images': 1,
+ 'transition_stage_num_images': 1,
+ 'total_num_images': 3,
+ 'save_summaries_num_images': 2,
+ 'latent_vector_size': 2,
+ 'fmap_base': 8,
+ 'fmap_decay': 1.0,
+ 'fmap_max': 8,
+ 'gradient_penalty_target': 1.0,
+ 'gradient_penalty_weight': 10.0,
+ 'real_score_penalty_weight': 0.001,
+ 'generator_learning_rate': 0.001,
+ 'discriminator_learning_rate': 0.001,
+ 'adam_beta1': 0.0,
+ 'adam_beta2': 0.99,
+ 'fake_grid_size': 2,
+ 'interp_grid_size': 2,
+ 'train_root_dir': os.path.join(FLAGS.test_tmpdir, 'progressive_gan'),
+ 'master': '',
+ 'task': 0
+ }
+
+ def test_train_success(self):
+ train_root_dir = self._config['train_root_dir']
+ if not tf.gfile.Exists(train_root_dir):
+ tf.gfile.MakeDirs(train_root_dir)
+
+ for stage_id in train.get_stage_ids(**self._config):
+ batch_size = train.get_batch_size(stage_id, **self._config)
+ tf.reset_default_graph()
+ real_images = provide_random_data(batch_size=batch_size)
+ model = train.build_model(stage_id, batch_size, real_images,
+ **self._config)
+ train.add_model_summaries(model, **self._config)
+ train.train(model, **self._config)
+
+ def test_get_batch_size(self):
+ config = {'num_resolutions': 5, 'batch_size_schedule': [8, 4, 2]}
+ # batch_size_schedule is expanded to [8, 8, 8, 4, 2]
+ # At stage level it is [8, 8, 8, 8, 8, 4, 4, 2, 2]
+ for i, expected_batch_size in enumerate([8, 8, 8, 8, 8, 4, 4, 2, 2]):
+ self.assertEqual(train.get_batch_size(i, **config), expected_batch_size)
+
+
+if __name__ == '__main__':
+ absltest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py"
new file mode 100644
index 00000000..5e136cf9
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider.py"
@@ -0,0 +1,33 @@
+"""StarGAN data provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+import data_provider
+
+
+def provide_data(image_file_patterns, batch_size, patch_size):
+ """Data provider wrapper on for the data_provider in gan/cyclegan.
+
+ Args:
+ image_file_patterns: A list of file pattern globs.
+ batch_size: Python int. Batch size.
+ patch_size: Python int. The patch size to extract.
+
+ Returns:
+ List of `Tensor` of shape (N, H, W, C) representing the images.
+ List of `Tensor` of shape (N, num_domains) representing the labels.
+ """
+
+ images = data_provider.provide_custom_data(
+ image_file_patterns,
+ batch_size=batch_size,
+ patch_size=patch_size)
+
+ num_domains = len(images)
+ labels = [tf.one_hot([idx] * batch_size, num_domains) for idx in
+ range(num_domains)]
+
+ return images, labels
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py"
new file mode 100644
index 00000000..cdd0927b
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/data_provider_test.py"
@@ -0,0 +1,42 @@
+"""Tests for google3.third_party.tensorflow_models.gan.stargan.data_provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import tensorflow as tf
+
+from google3.testing.pybase import googletest
+import data_provider
+
+mock = tf.test.mock
+
+
+class DataProviderTest(googletest.TestCase):
+
+ @mock.patch.object(
+ data_provider.data_provider, 'provide_custom_data', autospec=True)
+ def test_data_provider(self, mock_provide_custom_data):
+
+ batch_size = 2
+ patch_size = 8
+ num_domains = 3
+
+ images_shape = [batch_size, patch_size, patch_size, 3]
+ mock_provide_custom_data.return_value = [
+ tf.zeros(images_shape) for _ in range(num_domains)
+ ]
+
+ images, labels = data_provider.provide_data(
+ image_file_patterns=None, batch_size=batch_size, patch_size=patch_size)
+
+ self.assertEqual(num_domains, len(images))
+ self.assertEqual(num_domains, len(labels))
+ for label in labels:
+ self.assertListEqual([batch_size, num_domains], label.shape.as_list())
+ for image in images:
+ self.assertListEqual(images_shape, image.shape.as_list())
+
+
+if __name__ == '__main__':
+ googletest.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py"
new file mode 100644
index 00000000..c92430f5
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers.py"
@@ -0,0 +1,392 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Layers for a StarGAN model.
+
+This module contains basic layers to build a StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorvh implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+import ops
+
+
+def generator_down_sample(input_net, final_num_outputs=256):
+ """Down-sampling module in Generator.
+
+ Down sampling pathway of the Generator Architecture:
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L32
+
+ Notes:
+ We require dimension 1 and dimension 2 of the input_net to be fully defined
+ for the correct down sampling.
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, c + num_class).
+ final_num_outputs: (int) Number of hidden unit for the final layer.
+
+ Returns:
+ Tensor of shape (batch_size, h / 4, w / 4, 256).
+
+ Raises:
+ ValueError: If final_num_outputs are not divisible by 4,
+ or input_net does not have a rank of 4,
+ or dimension 1 and dimension 2 of input_net are not defined at graph
+ construction time,
+ or dimension 1 and dimension 2 of input_net are not divisible by 4.
+ """
+
+ if final_num_outputs % 4 != 0:
+ raise ValueError('Final number outputs need to be divisible by 4.')
+
+ # Check the rank of input_net.
+ input_net.shape.assert_has_rank(4)
+
+ # Check dimension 1 and dimension 2 are defined and divisible by 4.
+ if input_net.shape[1]:
+ if input_net.shape[1] % 4 != 0:
+ raise ValueError(
+ 'Dimension 1 of the input should be divisible by 4, but is {} '
+ 'instead.'.
+ format(input_net.shape[1]))
+ else:
+ raise ValueError('Dimension 1 of the input should be explicitly defined.')
+
+ # Check dimension 1 and dimension 2 are defined and divisible by 4.
+ if input_net.shape[2]:
+ if input_net.shape[2] % 4 != 0:
+ raise ValueError(
+ 'Dimension 2 of the input should be divisible by 4, but is {} '
+ 'instead.'.
+ format(input_net.shape[2]))
+ else:
+ raise ValueError('Dimension 2 of the input should be explicitly defined.')
+
+ with tf.variable_scope('generator_down_sample'):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d],
+ padding='VALID',
+ biases_initializer=None,
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ activation_fn=tf.nn.relu):
+
+ down_sample = ops.pad(input_net, 3)
+ down_sample = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs / 4,
+ kernel_size=7,
+ stride=1,
+ scope='conv_0')
+
+ down_sample = ops.pad(down_sample, 1)
+ down_sample = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs / 2,
+ kernel_size=4,
+ stride=2,
+ scope='conv_1')
+
+ down_sample = ops.pad(down_sample, 1)
+ output_net = tf.contrib.layers.conv2d(
+ inputs=down_sample,
+ num_outputs=final_num_outputs,
+ kernel_size=4,
+ stride=2,
+ scope='conv_2')
+
+ return output_net
+
+
+def _residual_block(input_net,
+ num_outputs,
+ kernel_size,
+ stride=1,
+ padding_size=0,
+ activation_fn=tf.nn.relu,
+ normalizer_fn=None,
+ name='residual_block'):
+ """Residual Block.
+
+ Input Tensor X - > Conv1 -> IN -> ReLU -> Conv2 -> IN + X
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L7
+
+ Args:
+ input_net: Tensor as input.
+ num_outputs: (int) number of output channels for Convolution.
+ kernel_size: (int) size of the square kernel for Convolution.
+ stride: (int) stride for Convolution. Default to 1.
+ padding_size: (int) padding size for Convolution. Default to 0.
+ activation_fn: Activation function.
+ normalizer_fn: Normalization function.
+ name: Name scope
+
+ Returns:
+ Residual Tensor with the same shape as the input tensor.
+ """
+
+ with tf.variable_scope(name):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d],
+ num_outputs=num_outputs,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding='VALID',
+ normalizer_fn=normalizer_fn,
+ activation_fn=None):
+
+ res_block = ops.pad(input_net, padding_size)
+ res_block = tf.contrib.layers.conv2d(inputs=res_block, scope='conv_0')
+
+ res_block = activation_fn(res_block, name='activation_0')
+
+ res_block = ops.pad(res_block, padding_size)
+ res_block = tf.contrib.layers.conv2d(inputs=res_block, scope='conv_1')
+
+ output_net = res_block + input_net
+
+ return output_net
+
+
+def generator_bottleneck(input_net, residual_block_num=6, num_outputs=256):
+ """Bottleneck module in Generator.
+
+ Residual bottleneck pathway in Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L40
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 4, w / 4, 256).
+ residual_block_num: (int) Number of residual_block_num. Default to 6 per the
+ original implementation.
+ num_outputs: (int) Number of hidden unit in the residual bottleneck. Default
+ to 256 per the original implementation.
+
+ Returns:
+ Tensor of shape (batch_size, h / 4, w / 4, 256).
+
+ Raises:
+ ValueError: If the rank of the input tensor is not 4,
+ or the last channel of the input_tensor is not explicitly defined,
+ or the last channel of the input_tensor is not the same as num_outputs.
+ """
+
+ # Check the rank of input_net.
+ input_net.shape.assert_has_rank(4)
+
+ # Check dimension 4 of the input_net.
+ if input_net.shape[-1]:
+ if input_net.shape[-1] != num_outputs:
+ raise ValueError(
+ 'The last dimension of the input_net should be the same as '
+ 'num_outputs: but {} vs. {} instead.'.format(input_net.shape[-1],
+ num_outputs))
+ else:
+ raise ValueError(
+ 'The last dimension of the input_net should be explicitly defined.')
+
+ with tf.variable_scope('generator_bottleneck'):
+
+ bottleneck = input_net
+
+ for i in range(residual_block_num):
+
+ bottleneck = _residual_block(
+ input_net=bottleneck,
+ num_outputs=num_outputs,
+ kernel_size=3,
+ stride=1,
+ padding_size=1,
+ activation_fn=tf.nn.relu,
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ name='residual_block_{}'.format(i))
+
+ return bottleneck
+
+
+def generator_up_sample(input_net, num_outputs):
+ """Up-sampling module in Generator.
+
+ Up sampling path for image generation in the Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L44
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 4, w / 4, 256).
+ num_outputs: (int) Number of channel for the output tensor.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, num_outputs).
+ """
+
+ with tf.variable_scope('generator_up_sample'):
+
+ with tf.contrib.framework.arg_scope(
+ [tf.contrib.layers.conv2d_transpose],
+ kernel_size=4,
+ stride=2,
+ padding='VALID',
+ normalizer_fn=tf.contrib.layers.instance_norm,
+ activation_fn=tf.nn.relu):
+
+ up_sample = tf.contrib.layers.conv2d_transpose(
+ inputs=input_net, num_outputs=128, scope='deconv_0')
+ up_sample = up_sample[:, 1:-1, 1:-1, :]
+
+ up_sample = tf.contrib.layers.conv2d_transpose(
+ inputs=up_sample, num_outputs=64, scope='deconv_1')
+ up_sample = up_sample[:, 1:-1, 1:-1, :]
+
+ output_net = ops.pad(up_sample, 3)
+ output_net = tf.contrib.layers.conv2d(
+ inputs=output_net,
+ num_outputs=num_outputs,
+ kernel_size=7,
+ stride=1,
+ padding='VALID',
+ activation_fn=tf.nn.tanh,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='conv_0')
+
+ return output_net
+
+
+def discriminator_input_hidden(input_net, hidden_layer=6, init_num_outputs=64):
+ """Input Layer + Hidden Layer in the Discriminator.
+
+ Feature extraction pathway in the Discriminator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L68
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, 3) as batch of images.
+ hidden_layer: (int) Number of hidden layers. Default to 6 per the original
+ implementation.
+ init_num_outputs: (int) Number of hidden unit in the first hidden layer. The
+ number of hidden unit double after each layer. Default to 64 per the
+ original implementation.
+
+ Returns:
+ Tensor of shape (batch_size, h / 64, w / 64, 2048) as features.
+ """
+
+ num_outputs = init_num_outputs
+
+ with tf.variable_scope('discriminator_input_hidden'):
+
+ hidden = input_net
+
+ for i in range(hidden_layer):
+
+ hidden = ops.pad(hidden, 1)
+ hidden = tf.contrib.layers.conv2d(
+ inputs=hidden,
+ num_outputs=num_outputs,
+ kernel_size=4,
+ stride=2,
+ padding='VALID',
+ activation_fn=None,
+ normalizer_fn=None,
+ scope='conv_{}'.format(i))
+ hidden = tf.nn.leaky_relu(hidden, alpha=0.01)
+
+ num_outputs = 2 * num_outputs
+
+ return hidden
+
+
+def discriminator_output_source(input_net):
+ """Output Layer for Source in the Discriminator.
+
+ Determine if the image is real/fake based on the feature extracted. We follow
+ the original paper design where the output is not a simple (batch_size) shape
+ Tensor but rather a (batch_size, 2, 2, 2048) shape Tensor. We will get the
+ correct shape later when we piece things together.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L79
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 64, w / 64, 2048) as features.
+
+ Returns:
+ Tensor of shape (batch_size, h / 64, w / 64, 1) as the score.
+ """
+
+ with tf.variable_scope('discriminator_output_source'):
+
+ output_src = ops.pad(input_net, 1)
+ output_src = tf.contrib.layers.conv2d(
+ inputs=output_src,
+ num_outputs=1,
+ kernel_size=3,
+ stride=1,
+ padding='VALID',
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='conv')
+
+ return output_src
+
+
+def discriminator_output_class(input_net, class_num):
+ """Output Layer for Domain Classification in the Discriminator.
+
+ The original paper use convolution layer where the kernel size is the height
+ and width of the Tensor. We use an equivalent operation here where we first
+ flatten the Tensor to shape (batch_size, K) and a fully connected layer.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L80https
+
+ Args:
+ input_net: Tensor of shape (batch_size, h / 64, w / 64, 2028).
+ class_num: Number of output classes to be predicted.
+
+ Returns:
+ Tensor of shape (batch_size, class_num).
+ """
+
+ with tf.variable_scope('discriminator_output_class'):
+
+ output_cls = tf.contrib.layers.flatten(input_net, scope='flatten')
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=output_cls,
+ num_outputs=class_num,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None,
+ scope='fully_connected')
+
+ return output_cls
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py"
new file mode 100644
index 00000000..faaf8297
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/layers_test.py"
@@ -0,0 +1,137 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import layers
+
+
+class LayersTest(tf.test.TestCase):
+
+ def test_residual_block(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers._residual_block(
+ input_net=input_tensor,
+ num_outputs=c,
+ kernel_size=3,
+ stride=1,
+ padding_size=1)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_generator_down_sample(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3 + 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_down_sample(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h // 4, w // 4, 256), output.shape)
+
+ def test_generator_bottleneck(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_bottleneck(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_generator_up_sample(self):
+
+ n = 2
+ h = 32
+ w = h
+ c = 256
+ c_out = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.generator_up_sample(input_tensor, c_out)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h * 4, w * 4, c_out), output.shape)
+
+ def test_discriminator_input_hidden(self):
+
+ n = 2
+ h = 128
+ w = 128
+ c = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_input_hidden(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, 2, 2, 2048), output.shape)
+
+ def test_discriminator_output_source(self):
+
+ n = 2
+ h = 2
+ w = 2
+ c = 2048
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_output_source(input_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, 1), output.shape)
+
+ def test_discriminator_output_class(self):
+
+ n = 2
+ h = 2
+ w = 2
+ c = 2048
+ num_domain = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_tensor = layers.discriminator_output_class(input_tensor, num_domain)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, num_domain), output.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py"
new file mode 100644
index 00000000..6d4d0790
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network.py"
@@ -0,0 +1,102 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Neural network for a StarGAN model.
+
+This module contains the Generator and Discriminator Neural Network to build a
+StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorch implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+import layers
+import ops
+
+
+def generator(inputs, targets):
+ """Generator module.
+
+ Piece everything together for the Generator.
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L22
+
+ Args:
+ inputs: Tensor of shape (batch_size, h, w, c) representing the
+ images/information that we want to transform.
+ targets: Tensor of shape (batch_size, num_domains) representing the target
+ domain the generator should transform the image/information to.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, c) as the inputs.
+ """
+
+ with tf.variable_scope('generator'):
+
+ input_with_condition = ops.condition_input_with_pixel_padding(
+ inputs, targets)
+
+ down_sample = layers.generator_down_sample(input_with_condition)
+
+ bottleneck = layers.generator_bottleneck(down_sample)
+
+ up_sample = layers.generator_up_sample(bottleneck, inputs.shape[-1])
+
+ return up_sample
+
+
+def discriminator(input_net, class_num):
+ """Discriminator Module.
+
+ Piece everything together and reshape the output source tensor
+
+ PyTorch Version:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/model.py#L63
+
+ Notes:
+ The PyTorch Version run the reduce_mean operation later in their solver:
+ https://github.com/yunjey/StarGAN/blob/fbdb6a6ce2a4a92e1dc034faec765e0dbe4b8164/solver.py#L245
+
+ Args:
+ input_net: Tensor of shape (batch_size, h, w, c) as batch of images.
+ class_num: (int) number of domain to be predicted
+
+ Returns:
+ output_src: Tensor of shape (batch_size) where each value is a logit
+ representing whether the image is real of fake.
+ output_cls: Tensor of shape (batch_size, class_um) where each value is a
+ logit representing whether the image is in the associated domain.
+ """
+
+ with tf.variable_scope('discriminator'):
+
+ hidden = layers.discriminator_input_hidden(input_net)
+
+ output_src = layers.discriminator_output_source(hidden)
+ output_src = tf.contrib.layers.flatten(output_src)
+ output_src = tf.reduce_mean(output_src, axis=1)
+
+ output_cls = layers.discriminator_output_class(hidden, class_num)
+
+ return output_src, output_cls
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py"
new file mode 100644
index 00000000..a89c0156
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/network_test.py"
@@ -0,0 +1,61 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import network
+
+
+class NetworkTest(tf.test.TestCase):
+
+ def test_generator(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 4
+ class_num = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ target_tensor = tf.random_uniform((n, class_num))
+ output_tensor = network.generator(input_tensor, target_tensor)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output = sess.run(output_tensor)
+ self.assertTupleEqual((n, h, w, c), output.shape)
+
+ def test_discriminator(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3
+ class_num = 3
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ output_src_tensor, output_cls_tensor = network.discriminator(
+ input_tensor, class_num)
+
+ with self.test_session() as sess:
+ sess.run(tf.global_variables_initializer())
+ output_src, output_cls = sess.run([output_src_tensor, output_cls_tensor])
+ self.assertEqual(1, len(output_src.shape))
+ self.assertEqual(n, output_src.shape[0])
+ self.assertTupleEqual((n, class_num), output_cls.shape)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py"
new file mode 100644
index 00000000..c2c1797e
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops.py"
@@ -0,0 +1,106 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Ops for a StarGAN model.
+
+This module contains basic ops to build a StarGAN model.
+
+See https://arxiv.org/abs/1711.09020 for details about the model.
+
+See https://github.com/yunjey/StarGAN for the original pytorvh implementation.
+"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+
+import tensorflow as tf
+
+
+def _padding_arg(h, w, input_format):
+ """Calculate the padding shape for tf.pad().
+
+ Args:
+ h: (int) padding on the height dim.
+ w: (int) padding on the width dim.
+ input_format: (string) the input format as in 'NHWC' or 'HWC'.
+ Raises:
+ ValueError: If input_format is not 'NHWC' or 'HWC'.
+
+ Returns:
+ A two dimension array representing the padding argument.
+ """
+ if input_format == 'NHWC':
+ return [[0, 0], [h, h], [w, w], [0, 0]]
+ elif input_format == 'HWC':
+ return [[h, h], [w, w], [0, 0]]
+ else:
+ raise ValueError('Input Format %s is not supported.' % input_format)
+
+
+def pad(input_net, padding_size):
+ """Padding the tensor with padding_size on both the height and width dim.
+
+ Args:
+ input_net: Tensor in 3D ('HWC') or 4D ('NHWC').
+ padding_size: (int) the size of the padding.
+
+ Notes:
+ Original StarGAN use zero padding instead of mirror padding.
+
+ Raises:
+ ValueError: If input_net Tensor is not 3D or 4D.
+
+ Returns:
+ Tensor with same rank as input_net but with padding on the height and width
+ dim.
+ """
+ if len(input_net.shape) == 4:
+ return tf.pad(input_net, _padding_arg(padding_size, padding_size, 'NHWC'))
+ elif len(input_net.shape) == 3:
+ return tf.pad(input_net, _padding_arg(padding_size, padding_size, 'HWC'))
+ else:
+ raise ValueError('The input tensor need to be either 3D or 4D.')
+
+
+def condition_input_with_pixel_padding(input_tensor, condition_tensor):
+ """Pad image tensor with condition tensor as additional color channel.
+
+ Args:
+ input_tensor: Tensor of shape (batch_size, h, w, c) representing images.
+ condition_tensor: Tensor of shape (batch_size, num_domains) representing the
+ associated domain for the image in input_tensor.
+
+ Returns:
+ Tensor of shape (batch_size, h, w, c + num_domains) representing the
+ conditioned data.
+
+ Raises:
+ ValueError: If `input_tensor` isn't rank 4.
+ ValueError: If `condition_tensor` isn't rank 2.
+ ValueError: If dimension 1 of the input_tensor and condition_tensor is not
+ the same.
+ """
+
+ input_tensor.shape.assert_has_rank(4)
+ condition_tensor.shape.assert_has_rank(2)
+ input_tensor.shape[:1].assert_is_compatible_with(condition_tensor.shape[:1])
+ condition_tensor = tf.expand_dims(condition_tensor, axis=1)
+ condition_tensor = tf.expand_dims(condition_tensor, axis=1)
+ condition_tensor = tf.tile(
+ condition_tensor, [1, input_tensor.shape[1], input_tensor.shape[2], 1])
+
+ return tf.concat([input_tensor, condition_tensor], -1)
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py"
new file mode 100644
index 00000000..580a8edb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/ops_test.py"
@@ -0,0 +1,113 @@
+# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+
+import tensorflow as tf
+
+import ops
+
+
+class OpsTest(tf.test.TestCase):
+
+ def test_padding_arg(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ self.assertListEqual([[0, 0], [pad_h, pad_h], [pad_w, pad_w], [0, 0]],
+ ops._padding_arg(pad_h, pad_w, 'NHWC'))
+
+ def test_padding_arg_specify_format(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ self.assertListEqual([[pad_h, pad_h], [pad_w, pad_w], [0, 0]],
+ ops._padding_arg(pad_h, pad_w, 'HWC'))
+
+ def test_padding_arg_invalid_format(self):
+
+ pad_h = 2
+ pad_w = 3
+
+ with self.assertRaises(ValueError):
+ ops._padding_arg(pad_h, pad_w, 'INVALID')
+
+ def test_padding(self):
+
+ n = 2
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((n, h, w, c))
+ test_output_tensor = ops.pad(test_input_tensor, padding_size=pad)
+
+ with self.test_session() as sess:
+ output = sess.run(test_output_tensor)
+ self.assertTupleEqual((n, h + pad * 2, w + pad * 2, c), output.shape)
+
+ def test_padding_with_3D_tensor(self):
+
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((h, w, c))
+ test_output_tensor = ops.pad(test_input_tensor, padding_size=pad)
+
+ with self.test_session() as sess:
+ output = sess.run(test_output_tensor)
+ self.assertTupleEqual((h + pad * 2, w + pad * 2, c), output.shape)
+
+ def test_padding_with_tensor_of_invalid_shape(self):
+
+ n = 2
+ invalid_rank = 1
+ h = 128
+ w = 64
+ c = 3
+ pad = 3
+
+ test_input_tensor = tf.random_uniform((n, invalid_rank, h, w, c))
+
+ with self.assertRaises(ValueError):
+ ops.pad(test_input_tensor, padding_size=pad)
+
+ def test_condition_input_with_pixel_padding(self):
+
+ n = 2
+ h = 128
+ w = h
+ c = 3
+ num_label = 5
+
+ input_tensor = tf.random_uniform((n, h, w, c))
+ label_tensor = tf.random_uniform((n, num_label))
+ output_tensor = ops.condition_input_with_pixel_padding(
+ input_tensor, label_tensor)
+
+ with self.test_session() as sess:
+ labels, outputs = sess.run([label_tensor, output_tensor])
+ self.assertTupleEqual((n, h, w, c + num_label), outputs.shape)
+ for label, output in zip(labels, outputs):
+ for i in range(output.shape[0]):
+ for j in range(output.shape[1]):
+ self.assertListEqual(label.tolist(), output[i, j, c:].tolist())
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py"
new file mode 100644
index 00000000..a959da71
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train.py"
@@ -0,0 +1,228 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a StarGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import tensorflow as tf
+
+import data_provider
+import network
+
+# FLAGS for data.
+flags.DEFINE_multi_string(
+ 'image_file_patterns', None,
+ 'List of file pattern for different domain of images. '
+ '(e.g.[\'black_hair\', \'blond_hair\', \'brown_hair\']')
+flags.DEFINE_integer('batch_size', 6, 'The number of images in each batch.')
+flags.DEFINE_integer('patch_size', 128, 'The patch size of images.')
+
+flags.DEFINE_string('train_log_dir', '/tmp/stargan/',
+ 'Directory where to write event logs.')
+
+# FLAGS for training hyper-parameters.
+flags.DEFINE_float('generator_lr', 1e-4, 'The generator learning rate.')
+flags.DEFINE_float('discriminator_lr', 1e-4, 'The discriminator learning rate.')
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+flags.DEFINE_float('adam_beta1', 0.5, 'Adam Beta 1 for the Adam optimizer.')
+flags.DEFINE_float('adam_beta2', 0.999, 'Adam Beta 2 for the Adam optimizer.')
+flags.DEFINE_float('gen_disc_step_ratio', 0.2,
+ 'Generator:Discriminator training step ratio.')
+
+# FLAGS for distributed training.
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+def _define_model(images, labels):
+ """Create the StarGAN Model.
+
+ Args:
+ images: `Tensor` or list of `Tensor` of shape (N, H, W, C).
+ labels: `Tensor` or list of `Tensor` of shape (N, num_domains).
+
+ Returns:
+ `StarGANModel` namedtuple.
+ """
+
+ return tfgan.stargan_model(
+ generator_fn=network.generator,
+ discriminator_fn=network.discriminator,
+ input_data=images,
+ input_data_domain_label=labels)
+
+
+def _get_lr(base_lr):
+ """Returns a learning rate `Tensor`.
+
+ Args:
+ base_lr: A scalar float `Tensor` or a Python number. The base learning
+ rate.
+
+ Returns:
+ A scalar float `Tensor` of learning rate which equals `base_lr` when the
+ global training step is less than FLAGS.max_number_of_steps / 2, afterwards
+ it linearly decays to zero.
+ """
+ global_step = tf.train.get_or_create_global_step()
+ lr_constant_steps = FLAGS.max_number_of_steps // 2
+
+ def _lr_decay():
+ return tf.train.polynomial_decay(
+ learning_rate=base_lr,
+ global_step=(global_step - lr_constant_steps),
+ decay_steps=(FLAGS.max_number_of_steps - lr_constant_steps),
+ end_learning_rate=0.0)
+
+ return tf.cond(global_step < lr_constant_steps, lambda: base_lr, _lr_decay)
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ gen_opt = tf.train.AdamOptimizer(
+ gen_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(
+ dis_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_ops(model, loss):
+ """Defines train ops that trains `stargan_model` with `stargan_loss`.
+
+ Args:
+ model: A `StarGANModel` namedtuple.
+ loss: A `StarGANLoss` namedtuple containing all losses for
+ `stargan_model`.
+
+ Returns:
+ A `GANTrainOps` namedtuple.
+ """
+
+ gen_lr = _get_lr(FLAGS.generator_lr)
+ dis_lr = _get_lr(FLAGS.discriminator_lr)
+ gen_opt, dis_opt = _get_optimizer(gen_lr, dis_lr)
+ train_ops = tfgan.gan_train_ops(
+ model,
+ loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ summarize_gradients=True,
+ colocate_gradients_with_ops=True,
+ aggregation_method=tf.AggregationMethod.EXPERIMENTAL_ACCUMULATE_N)
+
+ tf.summary.scalar('generator_lr', gen_lr)
+ tf.summary.scalar('discriminator_lr', dis_lr)
+
+ return train_ops
+
+
+def _define_train_step():
+ """Get the training step for generator and discriminator for each GAN step.
+
+ Returns:
+ GANTrainSteps namedtuple representing the training step configuration.
+ """
+
+ if FLAGS.gen_disc_step_ratio <= 1:
+ discriminator_step = int(1 / FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(1, discriminator_step)
+ else:
+ generator_step = int(FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(generator_step, 1)
+
+
+def main(_):
+
+ # Create the log_dir if not exist.
+ if not tf.gfile.Exists(FLAGS.train_log_dir):
+ tf.gfile.MakeDirs(FLAGS.train_log_dir)
+
+ # Shard the model to different parameter servers.
+ with tf.device(tf.train.replica_device_setter(FLAGS.ps_tasks)):
+
+ # Create the input dataset.
+ with tf.name_scope('inputs'):
+ images, labels = data_provider.provide_data(
+ FLAGS.image_file_patterns, FLAGS.batch_size, FLAGS.patch_size)
+
+ # Define the model.
+ with tf.name_scope('model'):
+ model = _define_model(images, labels)
+
+ # Add image summary.
+ tfgan.eval.add_stargan_image_summaries(
+ model,
+ num_images=len(FLAGS.image_file_patterns) * FLAGS.batch_size,
+ display_diffs=True)
+
+ # Define the model loss.
+ loss = tfgan.stargan_loss(model)
+
+ # Define the train ops.
+ with tf.name_scope('train_ops'):
+ train_ops = _define_train_ops(model, loss)
+
+ # Define the train steps.
+ train_steps = _define_train_step()
+
+ # Define a status message.
+ status_message = tf.string_join(
+ [
+ 'Starting train step: ',
+ tf.as_string(tf.train.get_or_create_global_step())
+ ],
+ name='status_message')
+
+ # Train the model.
+ tfgan.gan_train(
+ train_ops,
+ FLAGS.train_log_dir,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(train_steps),
+ hooks=[
+ tf.train.StopAtStepHook(num_steps=FLAGS.max_number_of_steps),
+ tf.train.LoggingTensorHook([status_message], every_n_iter=10)
+ ],
+ master=FLAGS.master,
+ is_chief=FLAGS.task == 0)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_file_patterns')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py"
new file mode 100644
index 00000000..b35c7deb
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan/train_test.py"
@@ -0,0 +1,141 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for stargan.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+
+from absl import flags
+import numpy as np
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+
+def _test_generator(input_images, _):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(inputs, num_domains):
+ """Differentiable dummy discriminator for StarGAN."""
+
+ hidden = tf.contrib.layers.flatten(inputs)
+
+ output_src = tf.reduce_mean(hidden, axis=1)
+
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=hidden,
+ num_outputs=num_domains,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None)
+ return output_src, output_cls
+
+
+train.network.generator = _test_generator
+train.network.discriminator = _test_discriminator
+
+
+class TrainTest(tf.test.TestCase):
+
+ def test_define_model(self):
+ FLAGS.batch_size = 2
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images_np = np.zeros(shape=images_shape)
+ images = tf.constant(images_np, dtype=tf.float32)
+ labels = tf.one_hot([0] * FLAGS.batch_size, 2)
+
+ model = train._define_model(images, labels)
+ self.assertIsInstance(model, tfgan.StarGANModel)
+ self.assertShapeEqual(images_np, model.generated_data)
+ self.assertShapeEqual(images_np, model.reconstructed_data)
+ self.assertTrue(isinstance(model.discriminator_variables, list))
+ self.assertTrue(isinstance(model.generator_variables, list))
+ self.assertIsInstance(model.discriminator_scope, tf.VariableScope)
+ self.assertTrue(model.generator_scope, tf.VariableScope)
+ self.assertTrue(callable(model.discriminator_fn))
+ self.assertTrue(callable(model.generator_fn))
+
+ @mock.patch.object(tf.train, 'get_or_create_global_step', autospec=True)
+ def test_get_lr(self, mock_get_or_create_global_step):
+ FLAGS.max_number_of_steps = 10
+ base_lr = 0.01
+ with self.test_session(use_gpu=True) as sess:
+ mock_get_or_create_global_step.return_value = tf.constant(2)
+ lr_step2 = sess.run(train._get_lr(base_lr))
+ mock_get_or_create_global_step.return_value = tf.constant(9)
+ lr_step9 = sess.run(train._get_lr(base_lr))
+
+ self.assertAlmostEqual(base_lr, lr_step2)
+ self.assertAlmostEqual(base_lr * 0.2, lr_step9)
+
+ @mock.patch.object(tf.summary, 'scalar', autospec=True)
+ def test_define_train_ops(self, mock_summary_scalar):
+
+ FLAGS.batch_size = 2
+ FLAGS.generator_lr = 0.1
+ FLAGS.discriminator_lr = 0.01
+
+ images_shape = [FLAGS.batch_size, 4, 4, 3]
+ images = tf.zeros(images_shape, dtype=tf.float32)
+ labels = tf.one_hot([0] * FLAGS.batch_size, 2)
+
+ model = train._define_model(images, labels)
+ loss = tfgan.stargan_loss(model)
+ train_ops = train._define_train_ops(model, loss)
+
+ self.assertIsInstance(train_ops, tfgan.GANTrainOps)
+ mock_summary_scalar.assert_has_calls([
+ mock.call('generator_lr', mock.ANY),
+ mock.call('discriminator_lr', mock.ANY)
+ ])
+
+ def test_get_train_step(self):
+
+ FLAGS.gen_disc_step_ratio = 0.5
+ train_steps = train._define_train_step()
+ self.assertEqual(1, train_steps.generator_train_steps)
+ self.assertEqual(2, train_steps.discriminator_train_steps)
+
+ FLAGS.gen_disc_step_ratio = 3
+ train_steps = train._define_train_step()
+ self.assertEqual(3, train_steps.generator_train_steps)
+ self.assertEqual(1, train_steps.discriminator_train_steps)
+
+ @mock.patch.object(
+ train.data_provider, 'provide_data', autospec=True)
+ def test_main(self, mock_provide_data):
+ FLAGS.image_file_patterns = ['/tmp/A/*.jpg', '/tmp/B/*.jpg', '/tmp/C/*.jpg']
+ FLAGS.max_number_of_steps = 10
+ FLAGS.batch_size = 2
+ num_domains = 3
+
+ images_shape = [FLAGS.batch_size, FLAGS.patch_size, FLAGS.patch_size, 3]
+ img_list = [tf.zeros(images_shape)] * num_domains
+ lbl_list = [tf.one_hot([0] * FLAGS.batch_size, num_domains)] * num_domains
+ mock_provide_data.return_value = (img_list, lbl_list)
+
+ train.main(None)
+
+
+if __name__ == '__main__':
+ tf.test.main()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy"
new file mode 100644
index 00000000..8288ba0e
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_images.npy" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy"
new file mode 100644
index 00000000..8288ba0e
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data/celeba_test_split_labels.npy" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py"
new file mode 100644
index 00000000..53a11238
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/data_provider.py"
@@ -0,0 +1,37 @@
+"""StarGAN Estimator data provider."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+import numpy as np
+import data_provider
+from google3.pyglib import resources
+
+
+provide_data = data_provider.provide_data
+
+
+def provide_celeba_test_set():
+ """Provide one example of every class, and labels.
+
+ Returns:
+ An `np.array` of shape (num_domains, H, W, C) representing the images.
+ Values are in [-1, 1].
+ An `np.array` of shape (num_domains, num_domains) representing the labels.
+
+ Raises:
+ ValueError: If test data is inconsistent or malformed.
+ """
+ base_dir = 'google3/third_party/tensorflow_models/gan/stargan_estimator/data'
+ images_fn = os.path.join(base_dir, 'celeba_test_split_images.npy')
+ with resources.GetResourceAsFile(images_fn) as f:
+ images_np = np.load(f)
+ labels_fn = os.path.join(base_dir, 'celeba_test_split_labels.npy')
+ with resources.GetResourceAsFile(labels_fn) as f:
+ labels_np = np.load(f)
+ if images_np.shape[0] != labels_np.shape[0]:
+ raise ValueError('Test data is malformed.')
+
+ return images_np, labels_np
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg"
new file mode 100644
index 00000000..4bcdba0f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/black/202598.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg"
new file mode 100644
index 00000000..1421bf9f
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/blond/202599.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg"
new file mode 100644
index 00000000..da8b5ab0
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/testdata/celeba/brown/202587.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py"
new file mode 100644
index 00000000..51e5c7e7
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train.py"
@@ -0,0 +1,184 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Trains a StarGAN model."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import io
+import os
+
+from absl import flags
+import numpy as np
+import scipy.misc
+import tensorflow as tf
+
+import network
+import data_provider
+
+# FLAGS for data.
+flags.DEFINE_multi_string(
+ 'image_file_patterns', None,
+ 'List of file pattern for different domain of images. '
+ '(e.g.[\'black_hair\', \'blond_hair\', \'brown_hair\']')
+flags.DEFINE_integer('batch_size', 6, 'The number of images in each batch.')
+flags.DEFINE_integer('patch_size', 128, 'The patch size of images.')
+
+# Write-to-disk flags.
+flags.DEFINE_string('output_dir', '/tmp/stargan/out/',
+ 'Directory where to write summary image.')
+
+# FLAGS for training hyper-parameters.
+flags.DEFINE_float('generator_lr', 1e-4, 'The generator learning rate.')
+flags.DEFINE_float('discriminator_lr', 1e-4, 'The discriminator learning rate.')
+flags.DEFINE_integer('max_number_of_steps', 1000000,
+ 'The maximum number of gradient steps.')
+flags.DEFINE_integer('steps_per_eval', 1000,
+ 'The number of steps after which we write eval to disk.')
+flags.DEFINE_float('adam_beta1', 0.5, 'Adam Beta 1 for the Adam optimizer.')
+flags.DEFINE_float('adam_beta2', 0.999, 'Adam Beta 2 for the Adam optimizer.')
+flags.DEFINE_float('gen_disc_step_ratio', 0.2,
+ 'Generator:Discriminator training step ratio.')
+
+# FLAGS for distributed training.
+flags.DEFINE_string('master', '', 'Name of the TensorFlow master to use.')
+flags.DEFINE_integer(
+ 'ps_tasks', 0,
+ 'The number of parameter servers. If the value is 0, then the parameters '
+ 'are handled locally by the worker.')
+flags.DEFINE_integer(
+ 'task', 0,
+ 'The Task ID. This value is used when training with multiple workers to '
+ 'identify each worker.')
+
+FLAGS = flags.FLAGS
+tfgan = tf.contrib.gan
+
+
+def _get_optimizer(gen_lr, dis_lr):
+ """Returns generator optimizer and discriminator optimizer.
+
+ Args:
+ gen_lr: A scalar float `Tensor` or a Python number. The Generator learning
+ rate.
+ dis_lr: A scalar float `Tensor` or a Python number. The Discriminator
+ learning rate.
+
+ Returns:
+ A tuple of generator optimizer and discriminator optimizer.
+ """
+ gen_opt = tf.train.AdamOptimizer(
+ gen_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ dis_opt = tf.train.AdamOptimizer(
+ dis_lr, beta1=FLAGS.adam_beta1, beta2=FLAGS.adam_beta2, use_locking=True)
+ return gen_opt, dis_opt
+
+
+def _define_train_step():
+ """Get the training step for generator and discriminator for each GAN step.
+
+ Returns:
+ GANTrainSteps namedtuple representing the training step configuration.
+ """
+
+ if FLAGS.gen_disc_step_ratio <= 1:
+ discriminator_step = int(1 / FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(1, discriminator_step)
+ else:
+ generator_step = int(FLAGS.gen_disc_step_ratio)
+ return tfgan.GANTrainSteps(generator_step, 1)
+
+
+def _get_summary_image(estimator, test_images_np):
+ """Returns a numpy image of the generate on the test images."""
+ num_domains = len(test_images_np)
+
+ img_rows = []
+ for img_np in test_images_np:
+ def test_input_fn():
+ dataset_imgs = [img_np] * num_domains # pylint:disable=cell-var-from-loop
+ dataset_lbls = [tf.one_hot([d], num_domains) for d in xrange(num_domains)]
+
+ # Make into a dataset.
+ dataset_imgs = np.stack(dataset_imgs)
+ dataset_imgs = np.expand_dims(dataset_imgs, 1)
+ dataset_lbls = tf.stack(dataset_lbls)
+ unused_tensor = tf.zeros(num_domains)
+ return tf.data.Dataset.from_tensor_slices(
+ ((dataset_imgs, dataset_lbls), unused_tensor))
+
+ prediction_iterable = estimator.predict(test_input_fn)
+ predictions = [prediction_iterable.next() for _ in xrange(num_domains)]
+ transform_row = np.concatenate([img_np] + predictions, 1)
+ img_rows.append(transform_row)
+
+ all_rows = np.concatenate(img_rows, 0)
+ # Normalize` [-1, 1] to [0, 1].
+ normalized_summary = (all_rows + 1.0) / 2.0
+ return normalized_summary
+
+
+def _write_to_disk(summary_image, filename):
+ """Write to disk."""
+ buf = io.BytesIO()
+ scipy.misc.imsave(buf, summary_image, format='png')
+ buf.seek(0)
+ with tf.gfile.GFile(filename, 'w') as f:
+ f.write(buf.getvalue())
+
+
+def main(_, override_generator_fn=None, override_discriminator_fn=None):
+ # Create directories if not exist.
+ if not tf.gfile.Exists(FLAGS.output_dir):
+ tf.gfile.MakeDirs(FLAGS.output_dir)
+
+ # Make sure steps integers are consistent.
+ if FLAGS.max_number_of_steps % FLAGS.steps_per_eval != 0:
+ raise ValueError('`max_number_of_steps` must be divisible by '
+ '`steps_per_eval`.')
+
+ # Create optimizers.
+ gen_opt, dis_opt = _get_optimizer(FLAGS.generator_lr, FLAGS.discriminator_lr)
+
+ # Create estimator.
+ # (joelshor): Add optional distribution strategy here.
+ stargan_estimator = tfgan.estimator.StarGANEstimator(
+ generator_fn=override_generator_fn or network.generator,
+ discriminator_fn=override_discriminator_fn or network.discriminator,
+ loss_fn=tfgan.stargan_loss,
+ generator_optimizer=gen_opt,
+ discriminator_optimizer=dis_opt,
+ get_hooks_fn=tfgan.get_sequential_train_hooks(_define_train_step()),
+ add_summaries=tfgan.estimator.SummaryType.IMAGES)
+
+ # Get input function for training and test images.
+ train_input_fn = lambda: data_provider.provide_data( # pylint:disable=g-long-lambda
+ FLAGS.image_file_patterns, FLAGS.batch_size, FLAGS.patch_size)
+ test_images_np, _ = data_provider.provide_celeba_test_set()
+ filename_str = os.path.join(FLAGS.output_dir, 'summary_image_%i.png')
+
+ # Periodically train and write prediction output to disk.
+ cur_step = 0
+ while cur_step < FLAGS.max_number_of_steps:
+ stargan_estimator.train(train_input_fn, steps=FLAGS.steps_per_eval)
+ cur_step += FLAGS.steps_per_eval
+ summary_img = _get_summary_image(stargan_estimator, test_images_np)
+ _write_to_disk(summary_img, filename_str % cur_step)
+
+
+if __name__ == '__main__':
+ tf.flags.mark_flag_as_required('image_file_patterns')
+ tf.app.run()
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py"
new file mode 100644
index 00000000..7bc69191
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/stargan_estimator/train_test.py"
@@ -0,0 +1,73 @@
+# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+# ==============================================================================
+"""Tests for stargan_estimator.train."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import os
+
+from absl import flags
+import tensorflow as tf
+
+import train
+
+FLAGS = flags.FLAGS
+mock = tf.test.mock
+tfgan = tf.contrib.gan
+
+TESTDATA_DIR = 'google3/third_party/tensorflow_models/gan/stargan_estimator/testdata/celeba'
+
+
+def _test_generator(input_images, _):
+ """Simple generator function."""
+ return input_images * tf.get_variable('dummy_g', initializer=2.0)
+
+
+def _test_discriminator(inputs, num_domains):
+ """Differentiable dummy discriminator for StarGAN."""
+
+ hidden = tf.contrib.layers.flatten(inputs)
+
+ output_src = tf.reduce_mean(hidden, axis=1)
+
+ output_cls = tf.contrib.layers.fully_connected(
+ inputs=hidden,
+ num_outputs=num_domains,
+ activation_fn=None,
+ normalizer_fn=None,
+ biases_initializer=None)
+ return output_src, output_cls
+
+
+class TrainTest(tf.test.TestCase):
+
+ def test_main(self):
+
+ FLAGS.image_file_patterns = [
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'black/*.jpg'),
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'blond/*.jpg'),
+ os.path.join(FLAGS.test_srcdir, TESTDATA_DIR, 'brown/*.jpg'),
+ ]
+ FLAGS.max_number_of_steps = 1
+ FLAGS.steps_per_eval = 1
+ FLAGS.batch_size = 1
+ train.main(None, _test_generator, _test_discriminator)
+
+
+if __name__ == '__main__':
+ tf.test.main()
+
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb"
new file mode 100644
index 00000000..164b433d
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/gan/tutorial.ipynb"
@@ -0,0 +1,2256 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# TFGAN Tutorial\n",
+ "\n",
+ "## Authors: Joel Shor, joel-shor\n",
+ "\n",
+ "### More complex examples, see [`tensorflow/models/gan`](https://github.com/tensorflow/models/tree/master/research/gan)\n",
+ "\n",
+ "\n",
+ "This notebook will walk you through the basics of using [TFGAN](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/gan) to define, train, and evaluate Generative Adversarial Networks. We describe the library's core features as well as some extra features. This colab assumes a familiarity with TensorFlow's Python API. For more on TensorFlow, please see [TensorFlow tutorials](https://www.tensorflow.org/tutorials/).\n",
+ "\n",
+ "Please note that running on GPU will significantly speed up the training steps, but is not required.\n",
+ "\n",
+ "Last update: 2018-02-10."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Table of Contents\n",
+ "Installation and Setup\n", + " Download Data
\n", + "Unconditional GAN example
\n", + " Input pipeline
\n", + " Model
\n", + " Loss
\n", + " Train and evaluation
\n", + "GANEstimator example
\n", + " Input pipeline
\n", + " Train
\n", + " Eval
\n", + "Conditional GAN example
\n", + " Input pipeline
\n", + " Model
\n", + " Loss
\n", + " Train and evaluation
\n", + "InfoGAN example
\n", + " Input pipeline
\n", + " Model
\n", + " Loss
\n", + " Train and evaluation
" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "\n", + "## Installation and setup\n", + "\n", + "To make sure that your version of TensorFlow has TFGAN included, run\n", + "\n", + "```\n", + "python -c \"import tensorflow.contrib.gan as tfgan\"\n", + "```\n", + "\n", + "You also need to install the TFGAN models library.\n", + "\n", + "To check that these two steps work, execute the [`Imports`](#imports) cell. If it complains about unknown modules, restart the notebook after moving to the TFGAN models directory." + ] + }, + { + "cell_type": "code", + "execution_count": null, + "metadata": {}, + "outputs": [], + "source": [ + "# Make TFGAN models and TF-Slim models discoverable.\n", + "import sys\n", + "import os\n", + "# This is needed since the notebook is stored in the `tensorflow/models/gan` folder.\n", + "sys.path.append('..')\n", + "sys.path.append(os.path.join('..', 'slim'))" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "\n", + "### Imports" + ] + }, + { + "cell_type": "code", + "execution_count": 3, + "metadata": {}, + "outputs": [], + "source": [ + "from __future__ import absolute_import\n", + "from __future__ import division\n", + "from __future__ import print_function\n", + "\n", + "%matplotlib inline\n", + "import matplotlib.pyplot as plt\n", + "import numpy as np\n", + "import time\n", + "import functools\n", + "from six.moves import xrange # pylint: disable=redefined-builtin\n", + "\n", + "import tensorflow as tf\n", + "\n", + "# Main TFGAN library.\n", + "tfgan = tf.contrib.gan\n", + "\n", + "# TFGAN MNIST examples from `tensorflow/models`.\n", + "from mnist import data_provider\n", + "from mnist import util\n", + "\n", + "# TF-Slim data provider.\n", + "from datasets import download_and_convert_mnist\n", + "\n", + "# Shortcuts for later.\n", + "queues = tf.contrib.slim.queues\n", + "layers = tf.contrib.layers\n", + "ds = tf.contrib.distributions\n", + "framework = tf.contrib.framework" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "### Common functions\n", + "\n", + "These functions are used by many examples, so we define them here." + ] + }, + { + "cell_type": "code", + "execution_count": 4, + "metadata": {}, + "outputs": [], + "source": [ + "leaky_relu = lambda net: tf.nn.leaky_relu(net, alpha=0.01)\n", + " \n", + "\n", + "def visualize_training_generator(train_step_num, start_time, data_np):\n", + " \"\"\"Visualize generator outputs during training.\n", + " \n", + " Args:\n", + " train_step_num: The training step number. A python integer.\n", + " start_time: Time when training started. The output of `time.time()`. A\n", + " python float.\n", + " data: Data to plot. A numpy array, most likely from an evaluated TensorFlow\n", + " tensor.\n", + " \"\"\"\n", + " print('Training step: %i' % train_step_num)\n", + " time_since_start = (time.time() - start_time) / 60.0\n", + " print('Time since start: %f m' % time_since_start)\n", + " print('Steps per min: %f' % (train_step_num / time_since_start))\n", + " plt.axis('off')\n", + " plt.imshow(np.squeeze(data_np), cmap='gray')\n", + " plt.show()\n", + "\n", + "def visualize_digits(tensor_to_visualize):\n", + " \"\"\"Visualize an image once. Used to visualize generator before training.\n", + " \n", + " Args:\n", + " tensor_to_visualize: An image tensor to visualize. A python Tensor.\n", + " \"\"\"\n", + " with tf.Session() as sess:\n", + " sess.run(tf.global_variables_initializer())\n", + " with queues.QueueRunners(sess):\n", + " images_np = sess.run(tensor_to_visualize)\n", + " plt.axis('off')\n", + " plt.imshow(np.squeeze(images_np), cmap='gray')\n", + "\n", + "def evaluate_tfgan_loss(gan_loss, name=None):\n", + " \"\"\"Evaluate GAN losses. Used to check that the graph is correct.\n", + " \n", + " Args:\n", + " gan_loss: A GANLoss tuple.\n", + " name: Optional. If present, append to debug output.\n", + " \"\"\"\n", + " with tf.Session() as sess:\n", + " sess.run(tf.global_variables_initializer())\n", + " with queues.QueueRunners(sess):\n", + " gen_loss_np = sess.run(gan_loss.generator_loss)\n", + " dis_loss_np = sess.run(gan_loss.discriminator_loss)\n", + " if name:\n", + " print('%s generator loss: %f' % (name, gen_loss_np))\n", + " print('%s discriminator loss: %f'% (name, dis_loss_np))\n", + " else:\n", + " print('Generator loss: %f' % gen_loss_np)\n", + " print('Discriminator loss: %f'% dis_loss_np)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "\n", + "### Download data" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "metadata": {}, + "outputs": [ + { + "name": "stdout", + "output_type": "stream", + "text": [ + "Dataset files already exist. Exiting without re-creating them.\n" + ] + } + ], + "source": [ + "MNIST_DATA_DIR = '/tmp/mnist-data'\n", + "\n", + "if not tf.gfile.Exists(MNIST_DATA_DIR):\n", + " tf.gfile.MakeDirs(MNIST_DATA_DIR)\n", + "\n", + "download_and_convert_mnist.run(MNIST_DATA_DIR)" + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "\n", + "# Unconditional GAN Example\n", + "\n", + "With unconditional GANs, we want a generator network to produce realistic-looking digits. During training, the generator tries to produce realistic-enough digits to 'fool' a discriminator network, while the discriminator tries to distinguish real digits from generated ones. See the paper ['NIPS 2016 Tutorial: Generative Adversarial Networks'](https://arxiv.org/pdf/1701.00160.pdf) by Goodfellow or ['Generative Adversarial Networks'](https://arxiv.org/abs/1406.2661) by Goodfellow et al. for more details.\n", + "\n", + "The steps to using TFGAN to set up an unconditional GAN, in the simplest case, are as follows:\n", + "\n", + "1. **Model**: Set up the generator and discriminator graphs with a [`GANModel`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/namedtuples.py#L39) tuple. Use [`tfgan.gan_model`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/train.py#L64) or create one manually.\n", + "1. **Losses**: Set up the generator and discriminator losses with a [`GANLoss`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/namedtuples.py#L115) tuple. Use [`tfgan.gan_loss`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/train.py#L328) or create one manually.\n", + "1. **Train ops**: Set up TensorFlow ops that compute the loss, calculate the gradients, and update the weights with a [`GANTrainOps`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/namedtuples.py#L128) tuple. Use [`tfgan.gan_train_ops`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/train.py#L476) or create one manually.\n", + "1. **Run alternating train loop**: Run the training Ops. This can be done with [`tfgan.gan_train`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/gan/python/train.py#L661), or done manually.\n", + "\n", + "Each step can be performed by a TFGAN library call, or can be constructed manually for more control." + ] + }, + { + "cell_type": "markdown", + "metadata": {}, + "source": [ + "\n", + "## Data input pipeline" + ] + }, + { + "cell_type": "code", + "execution_count": 5, + "metadata": {}, + "outputs": [ + { + "data": { + "image/png": "iVBORw0KGgoAAAANSUhEUgAAAfkAAACHCAYAAAAV6SDhAAAABHNCSVQICAgIfAhkiAAAAAlwSFlz\nAAAPYQAAD2EBqD+naQAAIABJREFUeJzsnedznNeVp5/OGZ0TGjkDRCBIgCQYRIqkKInyrsayZXs8\noWZqtrZqq2b/mP2wtbVTW96tqd3ZGc/Ya82MbEqkxASIJEAQAJFzTt0I3Wh0QAMN7AfUew0wiCKN\nRM37VKnsIhhuA+97z73n/M7vgIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyM\njIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyMjIyM\njIyMjIyMjIyMjIyMjMzbg+IQ/+2tQ/y3ZWRkZGRk3nZeGcOVB7EKGRkZGRkZmYNHDvIyMjIyMjLf\nU+QgLyMjIyMj8z1FDvIyMjIyMjLfU9SHvYCDQKFQkJGRgd/vp7y8HLPZzObmJj09PYyPj7OyssLG\nxsZhL1NGRkZG5i1Fq9ViMBiw2+04HA48Hg8KhYLV1VXi8TjJZBKAcDjM3Nwcm5ubbG3tv/7830yQ\n9/l8XLp0if/8n/8zeXl5rK+v81/+y3/h17/+NYODg3KQl5GRkZF5Y4xGIz6fj2PHjlFbW8vZs2dR\nKpWMj48zNTXF4uIiAD09PSwsLLC+vi4H+b3A6/WSn5/PqVOnOHv2LG63G71ej0aj4dSpU6RSKdrb\n2+nv72dkZIStra0D+cZ/GyqVCo1Gg1qtxmKx4Pf7MZlMKJVKBgYGCAaDpNPpQ12jjMyrMJvNOBwO\n6uvrKS0txWazEYlEmJycpKWlheHh4QPb6F4XlUqF2WzG5/NRUlJCWVkZNpsNg8Hw3O+dm5ujpaWF\nSCTC+vo6AKlUitXVVVZWVohGo3u2Lo/HQ1ZWFsXFxWRnZ+PxeFCrX7yNr6+vMz09zezsLLOzs8zP\nz7O4uIhOp2NjY4PV1VVSqZS8l/yBGI1GCgsLRWD3+/34/X4CgYC4YFZUVJBIJABwOp2MjY0xNzdH\nOBze9/V9b4O8SqXCYDCQn59PQ0MDFy5coKamBqPRyNbWFkqlksrKSkwmE16vF5VKxdTUFOvr64fy\n0KtUKnQ6HSaTCbPZjNlsxmg04vV6KSkpwWazoVQqUalUbGxssLy8LGcfZI4kSqUStVqN3++nqqqK\nH/7wh5w/fx6v18v8/Dzd3d3E43GCwSCRSOTQnmOVSoVarcZkMqHT6XZ9TavV4vF4qKys5Ny5c1y4\ncAGfz4fFYnnu7xkaGsLlcjE/Py9SstLnGxoaYmRkhHQ6zebm5huvVa1Wo9PpKCoq4syZM5w5c4aq\nqiry8/PRarUoFIrnDktra2v09vYyMDDA4OAg/f39TExMYDQaWV9fJxgMkkwmSaVS4vdHo1HW1tbk\nveU10Gq1+P1+6uvr+fTTTzGZTGi1WvF1n8+36/en02n6+vpoa2tjbW2NtbW1P+jZeBXf2yBvsVio\nrKykrq6O06dPU1JSgtvtRqPRANspfLvdjk6nIzMzk5WVFR49esTKyoo4cR0USqUSi8VCXl4e9fX1\nFBQUEAgEcLvd2O12zGYzarWajY0NLBYLVquVr776ipWVlQNdp4zMd0EKkBcvXuRP/uRPyMvLw+Vy\noVAocDgc1NTUUFZWRn9/P4lE4tACitFoxO12c+rUKXJzc5/7DH6/n9raWvx+Pw6HA51O98Ksg9/v\n54c//OGuzXp1dZW5uTlu3LhBNBpleXn5D9pXLBYLRUVFfPDBB3z00Ue43W5sNhtqtfql2Ue1Wk1+\nfj4ej4fa2lpmZ2cJhULiJr+yskIqlRLf/9HRUe7cucPY2BihUOiN1/pvjUQiQX9/P5WVlaRSqRdm\ne3ZSVlbGf/yP/5F/+qd/YnNzk/HxcWKx2L6t73sR5BUKBWq1Gr1ej8lkIj8/n6KiIioqKigtLaWk\npASfz4dWqyUej4ubvE6nw263Y7fb8Xq96HQ6lMqDaTiQ1utyufD5fOTl5VFaWsrx48fJzs7G7XZj\nMpnQaDSk02m0Wi0qlYpYLEYkEqGjo0OcAvcKpVIp/tPr9dhsNkwm0ysf2mdZXV1lfn6eeDwu0pdH\nEZVKhV6vFyKZzMxMdDqdSH+Gw2GmpqaYnZ0V9bSjhCT0MZvNOJ1OcnNzMZlMwPY7sb6+TiQSYWFh\ngfn5ecLhMPF4fN/XpdPpCAQCVFRUcPLkSdRqNZFIhKdPn6LVavF6vZSWlnLu3DlWVlaYnZ0Vt8mD\npKCggHfeeYe6ujpycnJ2fU2tVmO328nPz0ev13/r32M0GikoKNj1a8lkkpycHDY2NlAqlYyMjDA6\nOsr4+PgbfVa9Xo/f76ewsJDy8nI0Gs0r9yqlUklGRgYZGRnA9o0yFouhUqnY3NwUN3bpYDI+Po7B\nYKCxsZEnT54Qi8UO7f1VKBSoVCry8/PJzc0lIyNj1+14a2uL9fV1VlZWCIVCbG1tkUqlCIVCrK6u\n7um++CqkrMjw8DAdHR2UlZURCARQKpWk02lSqRRarVbsK06nE4vFIkrEwWBQDvKvQgrYbrebnJwc\nfv7zn3PhwgWsVitGoxGdTodKpSKZTLK4uEgqlUKlUuF2u1+YfjsItFotbreb+vp6Ll68SF1dHQUF\nBRgMBtRqNQqFgkgkwuLiImtra0KxWVBQwLFjxwgEAqysrOzpw6xSqdBqtWg0GrxeL8eOHSMnJwev\n1/taf8/o6Cj37t1jdnaWSCSyZ+vba7RaLQ6Hg9raWi5cuMB7772H0+kUgbK7u5vPP/+cmzdvHskg\nbzQa8fv95Ofnc+LECT799FMRrBQKBdFolL6+Ph49esTdu3fp7e09kCCv1+vJzs4WWpJEIsHQ0BD/\n9b/+VywWC5cvX6aqqgqPx0NfX5+4UR40J06c4K//+q93/cwlFAqFCDRvgk6nw+v1cu3aNerq6nj0\n6BG3bt3i17/+9Rt9VqmsYDQaRXr+dZH+vMSzt3+Px0N+fj5qtZr5+XkmJycPLchLe9E777zDp59+\nKjQd0prT6TTRaJSBgQEePnwoAv6DBw8YHR0llUodmNZjc3OTZDLJ0NAQn3/+OWq1Go/Hg1arZW1t\njeXlZWw2G2azGdj+WapUKrKzsykoKKCtrW1f1/dWB3mFQkFmZiY5OTkUFxdTVFREcXExlZWVZGZm\notFoUKlU4sQbiUR49OgR4XAYjUbD+fPnDzTIS7f3qqoqkWUoKiqisLAQv99PRkYGSqWSZDLJ8vIy\nt27dor+/n83NTS5dusS1a9cwmUxYrVYyMjKeqyO+yXqys7Px+Xy4XC7cbjcejwe73Y7T6cTlcmG1\nWp/bAF9FKBSiqKiIW7du0dTURDKZPFLiHqPRKIJ7bW0t5eXlFBcXk5OTg8FgECWdoqIirl+/jsVi\nwePx8Pjx40NPYwYCAfFfQUEBRUVFuFwu8R5ItzaFQoFer0ehUGAwGMjMzOTu3bu0tLTse3pQCo5S\ngBwZGaGtrY2RkRE8Hg9LS0uo1Wp8Ph+VlZUsLi6yvLy8b+t5GeFwmJGREUwmE3a7fdfXpNtZX18f\nNpuN3NxczGbzd37npEOC0WhEqVRSWFjIxMQEfr+f9fV1VldXX2utPp+PDz/8kIqKijcK8DvX9DIM\nBgMej4erV6/idrsZGhqis7OT5uZmVldX972sIumSXC4XFRUVnD17lrq6OioqKnA6neKiJv1el8uF\nWq0mIyODzc1NVlZWcDgcNDY2cvfu3QMtA21tbTE7O8u9e/coLy+nvLwch8NBOp0mkUiIAC+hUCgY\nGxujq6trX99FeIuDvEajwWAwUFFRwalTp6irq6O8vJzCwkIR1J+tVa2urtLV1cXMzAxarZaysjKK\ni4sPbM16vR6Px8OFCxe4cuUKVVVV2Gw2kYba2toinU4TDAbp7e3lX/7lX3j8+LG49b///vtotVqM\nRqO48f8haLVaKisrqa2tJTc3l9zc3F2lAoCNjQ2R0kun0y8N1pKIyWAwkEqlqKysZHV1lb6+PhYW\nFg7kBvldUCqVOBwOKisruXbtGu+++y6BQACdTsfa2horKyuk02n0ej0ZGRk0NDRgMpnQ6/WMj4+z\nsLBwKGpwjUaDTqejtLSU+vp6qqqqKC4uJi8vTzzn0vqlTgyNRoPf78dut1NcXCzqsPudHtzJ1tYW\nk5OT9Pf3s7CwgNFoFM+C1WqlqKiI/v5+Ojs7D2Q9O5mbm+Px48eiRr1zzclkkpGREW7dukVWVhb1\n9fVkZ2djNptJJBLo9XosFsuuEteLkEpCPp+PnJwcfD4fS0tLrx3krVYr1dXV+Hw+cbve3NxkfX19\nV9lOeg91Op04kEiHrlcdDtRqNWq1WjxfQ0NDfPnllwwPD++q3e81CoUCpVKJ1WrF7XZTWlrK1atX\n+eM//mMRHGOxGMvLyywsLKBQKNDpdOJC4vf7ReZKrVYTCoVobGw8cK3H0tISS0tL9Pf3MzU1tWtf\nfxFTU1P09/fv+9741gZ5r9dLRUUFP/7xjzl79ix2u128dC97mHf+unSqlX7tTU/Hr4MkgDlz5gzV\n1dVkZGTsCtSpVIpIJMLdu3f51a9+RXd3N9FoFJvNti/rMRgMXL16lWvXrqHX6zEYDOh0OlKplEhP\nB4NB5ubmSCQSrKyssLy8/MJAb7PZ8Pl8HD9+HLfbjdPppKSkhNraWlpaWo5EkFcqlRgMBsrKyvjZ\nz35GdXU1mZmZIhANDw8zPDxMOBwWmZbi4mIcDgfZ2dniVnYYWQmXy0VZWRnXr1/n/PnzeDwe4vE4\nbW1tTExMsLCwgEqloqysjPPnz4u0Lmwf5jIyMrDZbM89cwfFUWyTm56e5s6dO3R0dDynO1lfXxc3\nfZvNRnNzMw0NDRiNRp48eUJNTQ1Xr17FYrGIQ+DLAr1CoRAZOIvFsqu2/F2Zn5/n5s2bnDx5ksLC\nQgCi0Shzc3P09fUxNDQEbLcter1ekZ2C7cuF1WoVZcBXIQXRvLw8CgoKcDgcLC8v79s7rNVqMZvN\nNDQ0cO7cOY4fP05RURFms5l0Os3CwgL37t2jpaWFrq4ulEolLpeL8+fPU19fz/Hjx1Gr1UJncBil\nn510d3dz+/ZtNjY2yM3NFVqfZ5G6pfY79rx1QV4Sy9XU1HD58mVOnz5NWVmZuGnGYjFR89hZT5Nu\nydKt9DA2HY/Hw/HjxykoKMDtdgPbm0kikSAWizE3N0dvby9ff/01Dx48IBaLodVqX9jisxeoVCq8\nXi+BQEC8TNIpVKqlS6KtZDJJNBolHA7vCnJST39JSQkqlYq1tTXRvii1Ah5GUHkRBoOB6upqzp8/\nz5kzZzCZTCwuLtLV1cXg4KAQRkWjUSEGy87OFm2WDocDg8FALBY78OfH4/Fw+vRpTpw4QUFBAYuL\ni/T29tLU1CQyDGq1mqWlJbxeLzk5ObhcLnHLlHwXvu0QfNBIh643CXp7wfr6OtFolNHR0ecyG5ub\nm6LXXafTMTU1xcrKClqtlqdPnxIMBlGpVFRVVZGXl4dWq31hkJf+nvHxcYaGhlhaWhIp59chFArx\n9ddfMzMzQ15eHrCdmQwGg+LZhe1SlMfjYXBwUBwG7HY7RUVFuw4ikgeAJOjdiXTzl1xC8/PzWVxc\nZGlp6bXX/W1IN3ifz0dtbS2XLl2ioaGBvLw81Go1MzMzTE9PMzg4yFdffUVbWxsDAwOYTCby8vKo\nrq4WosFoNMr09LRwMd3PlrRXMTw8jEajIZlMcvr0aU6fPv3CZzwzM5OioiJWVlbe6Jn4rhyN3fc1\nMJvNVFdXc/XqVT755BNsNptIW8XjcfFS6vV6jEajeIA3NjZIpVIkk0nW19fR6/W70vkHsWlLN12H\nwyF+LZFIsLi4yOTkJK2trfzLv/wLg4ODhMNhtra2sFgs+yYQ3NzcFBaLGxsbPHjwgK+//pq2tjZm\nZ2fF70mn0+J79ezLI6nwvV7vcyWEeDzO8vLyoZ+sJaxWKx9//DHXrl0jOzubiYkJHj9+zN/8zd/Q\n2dkpShNqtZrZ2Vl0Oh3nz58Xpi4ejwebzSY6NA4Sj8fDmTNnyM3NZX19nfv373Pr1i1u374t2tCk\ndiqv1yvSnztThuvr66RSqUPdAHei0WhwOBzP1SsPioyMDLKysggGgywsLOz6mvTz3dzcJJFIsLa2\nxu3bt0XXQiKRYG5ujj/7sz/DbreLm/KzbG5uEo1GuXPnDr/73e/o7Ox8I3OcUCjE7du3aWxsFP/O\n5uYmm5ub4rmF3wfOnb8vJyeH8+fPk5GRIfQmBQUFXL16FYfD8a3iQpvNRk1NDdPT04yMjLz2ur8N\nhUKBRqOhvLycv/qrv6K8vByfz0cqlWJycpLOzk6amppobm5mfHycSCRCOp3GZDLh9/upqKggLy8P\npVLJ3NwcbW1t3Lhxg/b29kPt85+cnCQUCtHT00MwGBQammcDfXV1NfPz84yMjOyrJuWtCfKSc1B1\ndTV/9Ed/RH19PU6nE7VazdraGsFgkMePH3P//n3y8/MpLy/n1KlTWK1WNjc36erqorGxkY6ODtGX\nftCMjIzwu9/9joWFBVwuF8FgkFAoJG7LExMT9Pf3E4lExEYsud69qo3nTYjFYnz22We0t7ezubnJ\nxMQEIyMjzM7OvnIjUiqVGI1G8vLyuHDhAqdPn6ayspKMjAyRRuzv73/hLemwkNKQUpvc/Pw8PT09\nzM7O7nKe0mg0YmPf2toSB8T9rEu+Co1GI8SWW1tbonwSiURwOp1YrVYhRPV6vSKDolAoxCGyubmZ\njo6O164Hvy5S1kzK+NjtdnJzcykvLyc/P5+KigrhHpeXl0dmZiZ6vf7AjagWFxfp6+t7aQlKCkJS\nNk2qy8O2Ut3lcnHs2DEcDsdzAV46HPf29tLS0sK9e/fo7e0lFou90WeUvp/f9ca38/dJmUupywi2\nyz9dXV2YzWasVqsw1vF6vbtu9xaLhdLSUpqbm197zd+GSqXCarVy4sQJ3n33XcrLy7HZbITDYZqa\nmmhra6Onp4fR0VGmp6eJRqNsbGyIktTFixfJz88nIyMDhULB4OAgjY2NTExMsLq6eqjlIa/XS2Zm\nJh6Ph4KCApxO5wv379XVVcLh8L7vKW9FkJdER2VlZVy4cIHr168TCATEKTYSiTA4OMgXX3zB//pf\n/4uzZ88Si8UoKSlBo9EQj8dFC8vTp09xu91kZWWxtrbG+vr6gaWTh4eHWVpaYn5+noyMDAYHB4XV\nZCwWe2E7nEajeamd5h9KIpHgd7/73Wv9GcmTwGAwEAgEOHXqFJ9++inFxcV4PB5g+yTb3t5Od3c3\n4+PjB9qz+m3sDD5bW1sEg0FGRkaIx+OiPiYJG+12O0ajUWQ7ZmdnhaHJYWwgkouclG6VBmF4vV6K\niopEX25FRQWFhYU4HA6USqW4Fd2/f58HDx7Q1dW172uV2pui0SjxeBybzUZpaSnhcJisrCxKSkow\nGAwoFAqys7PJysoSlrcHaUS1sLDw3A1eQjoQSj4aPp+PTz75hJMnTwLbdWTJ5+LZ7hNJBLm0tERL\nSwv/7//9Pzo6OpiZmdn3z/QiJI+CnajVar7++muhZv/Rj37E5cuXsVgsu0qd0tdft8PmVWi1Wlwu\nF5cuXeLixYsEAgEikQhDQ0P89re/pbGxkbGxMdLptCgfmM1mMjIyOHHiBBcvXiQrK0sEz7GxMZ48\neSI84Q8SaX16vR6z2UxNTQ3Hjh0TZQgps/YswWCQ8fHxfU3Vw1sS5CWR3UcffcSFCxew2+0iRT83\nN0dPTw+/+93vdvUbplIp5ufnGR8fp6enh5s3b9Le3k48HicUCtHW1saZM2coLCx87T7wN0Xq03/4\n8CEajYbV1VVhK/my05zBYCA7O3tXiv+w2GlXWlRUxPvvvy/cBKXWLdhWLX/xxRf09PTsu2Xj67BT\nZCmlXZPJJAqFQtxoJLGdFIwSiQR3794V7YyHkaqH7edZ6id3uVycO3eOvLw8PvzwQ2GHbLVacTqd\nojsikUgwMjLCnTt3+OUvf8nY2NiBrDUajdLZ2Ynf76egoIDs7GzhA5FMJonH4wwPD2M0GkVXx/Hj\nx+nq6mJqaupA1vgqpPbS9957j+rqakpLS8nJyRGtdjsPhTuRTFlGR0e5efMmd+/epa2t7UA8yl+H\ndDotzHDUajXj4+NMT09TXV29S7MRCoW4f//+nj87Usq9qqqKwsJCVCoVT5484fPPP6e1tZX5+Xmx\nb6hUKpxOJzU1NVy5coVTp05RXFy85wePN0UyTqqvr+f69evk5+fj8/nEZeFlGhhJb7DfB9u3Ishn\nZWVx+fJlGhoaKC0tRavVsrS0JOo2ra2tNDU1MTExAWynoScmJmhsbGRhYYHu7m66urqYnZ0Vdayp\nqSmCwSArKyu4XK4D+RxSz+T09PSuX5fUomaz+TlhVGFhIbm5ucIIIhaLsbS09AfbZL4JFouF7Oxs\nqqurqaur491336WoqEjcynZ+Hq1WS3Z2tiiLSJqJcDhMJBI5lMEYUt+y1D9us9koKCgQp2xpGElW\nVhaJREJ4Fdy5c4cHDx6wtLR0aOYgCwsLtLa2YrFYyMjIIDs7m0AgwPr6Ouvr6yiVSmw2m6i5wnY6\ncGhoiKdPn/L06dMDW3sqlWJ2dpa2tjZsNhvHjx8XJj2hUIipqSkUCgV+v198jrq6Oubm5pienj50\nJb6Upvf7/cKoShK7vYp0Os3Y2BjNzc3cunWLzs5O5ubm9nfBb4CU1QKE3bDL5RICws3NTeLxOFNT\nUzx58mTPsxCS8E/yB1lfX2doaIiWlhampqZESUnq2jl27BgNDQ1cuXIFj8cj9FaSPkIaBHQY5TS1\nWo3T6eTYsWN88MEHOJ1OzGbzK30JJMfK/XZZfSuCfE5ODh9++CF+v1+4PU1MTHDjxg1u3rzJ06dP\nSSQSYqLV/Pw8a2trPH78WLR97bxRSqdYqQZ42JuKWq2msrKSwsLC51S6Pp9P1J7S6bQQauy3WONF\neL1erl69ytWrV2loaBDK6Gcf5KysLH74wx8SiUREKmplZYWpqSna29t5+vTpS+ug+4n0Mkqn6+Li\nYrRaLRsbG9hsNrKzs9Hr9SwvL/P3f//33Lt3j66uLqLR6KEb+oyMjPD3f//36PV6UW4ymUy7nt1n\nN4tkMilqmpK+4CCQAkhfXx8zMzPcu3cPp9MJbB88IpEI+fn5nDlzhrNnz+Lz+aivr6e5uVkEmMN+\nJyUHzaqqKgKBwHf+c6lUigcPHvD555/T0tJyKCY/r4N0C718+TIXL14UQSeVSjE3N8fw8DADAwN7\nrqyXBMVarVZ0OYRCIbF3S+Tl5XHu3DmuX78uJgGura0RDoex2+0kk0mmp6eZnJxkbm7uUEqDGo0G\np9OJ1+vF6XR+58BdVlbGqVOnmJ6e3tc5JEc6yEtiI4/HI755MzMzfP755zx58oS+vj6hRN+JVNuT\nBFPP/uCfNck56JYiydlJGkpTVlbG6dOnRevIzvVI1qVGo5Hl5WXu37/PnTt3DmUKncFgICsrC5/P\n9629+xkZGZSXl++6rSeTScLhsBj20dTUxOTk5IFu5pKIbn19nY2NDRwOxy5XOEmkGQ6HCQaDIttz\nFNz6YrEYU1NTfPHFF0xNTeF0OkVbpd/vJy8vT5grAeJA1dzcLEYoHzRSKSqVSonslWTekkwmMZlM\nDAwMkJubS1lZGUVFRfT29jI/P3/oHRlSz7W0l+zMkHwbarWawsJCjh07Rm9vL4lEYt+Fjm+CtAdV\nV1dz7tw5CgsLRfpb0hQMDAzQ09NDKBTa86yhlDUzm81i7K1UvnG73VitVvLy8igpKRHzR5aWlvjn\nf/5nvF4veXl56PV6YrGYGKiTSCQO5V1dW1tjamqKjo4O7ty5Q2VlJbm5ua9sV83IyMDpdH7nZ+tN\nObJBXhJaSBPZ9Ho9KpWK6elp/tt/+2/f6pAVi8VeqejeaYbzqrTKXiG5UUm1U5/Px9mzZ7l8+TJl\nZWW4XC7S6bToPX/WrW96epqWlhZhLnPQG7fUb51KpV56speEeS6XS7T2SH9Ouh1ZrVYxS3l1dfXA\navYbGxsEg0FmZmZIpVLioGU0GkX7mbSxB4NB0cZ4FJDS8nfv3qWpqWmXF8SZM2e4fPmyGOSxsbHB\nwMAA33zzDa2traKMddBIN/oX3WaTySQGg4HOzk4cDocQDGZnZxMOhw89yO8U9BqNRrKysnZ9Xa/X\nv1AxrdFoqKmpIZlM0tHRQSwWO1JBXqFQiG4Bh8PBuXPn+OEPf0hmZibwe03B8vIynZ2ddHd3s7Ky\nsuelHpvNJroqJH2Vx+PhxIkTAOTn53P+/HkhOk6lUrS3t/Pf//t/55133uGDDz4gJydH/IxCodCh\nldLW1tYYGxsTQ2i2trbEuNmdN3rJF0IywNHpdMJgaz85skHeZrNRXl7OJ598wtmzZ0UNZi82Xcn2\nUZrk9LJRjXuF1Ltqs9nw+/1cv36d2tpaUQdzOp2i13Nubg6Hw0EgENilppZezoKCAoqLi0XrxUGK\n2ubm5vjyyy/p7u5+oRBQeoj9fj8lJSVMTU0xMTGBxWKhsLCQhoYGfD4fDQ0NKJVKsrKy+Oyzz4hG\nowcSTJeWlvjbv/1bGhsbyc7Oxmq1kpmZybVr10TNeGZmhs7OTsbHx49UkJeQNkSpX1iyOz19+jRW\nq5VIJMLMzAx37tzh1q1bLCwsHBnh406k4N/W1kZWVhalpaW43W4CgQB9fX2HujbpsDcyMsIvf/lL\nWltbnwvydXV1nDt37oW3NekdqK2tZWFh4dAOWc8izTMoKyujoqKCqqoq6urqKC4uxmKxiENZf38/\njx494s6dO/T29u5L8BweHubhw4eUlpbidDrx+/2888471NTUANvCPLfbTTQaZXBwkBs3bvDo0SMW\nFxfR6XQ4nU42NjaE9uooCDZnZ2e5c+cO8Xiczs5OcTGF7e+9y+XiwoULoux8UBzJIK9QKCgoKKCh\noYELFy5QWFgoUhp7semazWYyMzOFycybTpr6LkgntoyMDOGzf/36dYqLi4nFYqysrDA8PMzy8jKL\ni4sEg0Hdls5aAAAgAElEQVSqqqrEYBgpJatSqTCZTFRVVREOh8WUqJWVlX0/pEiEw2Ha29vp7+9/\nzoFP8nrPz88nFosxPz/PwMAAQ0NDWCwWKioqSKfTFBYW4nK5OHv2LKurq9y7d2/PR+a+jEQiQVtb\nG8PDw2Ioj+SnIAX50dFRWlpamJ2dPXBh43dha2tLtOw4HA5KSkqorKykuLgYvV7PyMgITU1NtLS0\n0NfXRzKZPHIHFdg+rEitXWVlZUSjUVwuF7m5uaKEcpjr3tjYYGFhgebmZkZHR4WmQCIYDJJIJAgE\nAni9Xux2uyi1aTQaMWFyYmKCnp6eQx3bKpGRkUEgEBC+FhUVFQQCAfHZ1tbWiEajtLe38+WXX9LV\n1UUwGNyXtczPz9Pd3c3g4CA2mw2r1Up2djb5+fnAdjZ2cXGRnp4eWlpauHHjBlNTU2KIjsfjIZ1O\nMzs7S3d390tbIQ8SqW10Y2ODkZGRXb4ECoVCtIqqVCrR/idlEjUazb49H0c2yNfX1/P+++/vmpG9\nV7jdbmpraykpKcHv9+9rn7w007mkpIR//+//PT/96U+xWCyEQiHu3r1LT08Pw8PDjI2Niel4P/7x\njyktLRUpbvj9WFQpqzE3NycUsBsbGweyIUqmQy8qb0iHpurqalKpFJ999hnj4+MsLS2hVCrp6+uj\ns7OTjz76iPfeew+Px0Nubi4+n49oNHqggpnV1VXGxsZIJpO4XK5dqeG+vj7u3bu350KjvUSyHC0u\nLubKlSuUlZWJzMrIyAi//vWv6evrI5FIHMlbvEQsFqO3t5f+/n7m5+dxuVyiNeqwgzwgylKRSOS5\nFrL+/n5u3LjBv/t3/47Lly9z6tSpXfuIlAofGxujra2N8fHxQxfhZWdni/R8TU2NyGZKxONxJiYm\nhKfIfs6biMViTE9P09TUxNbWFrW1tcLcDLYPUd988w03btygsbGRpaUl4bdQVFSE3+8XHiNzc3NH\nxnALtm/0oVDoudkok5OTuN1udDodgUAAu91OIBDA7XYzOTm5b22WRzLIAyIVKdU1tra26Ovro7W1\n9Y1rXGq1GrPZTGVlJdevXycvLw+FQsHq6uqeB0vpRF9aWkpNTQ1nzpzh9OnTuN1uQqEQvb293Lt3\nj/7+fubm5ohGozidThoaGoSASvIiHx0dFYcFyfzk448/Jj8/n+7uboaGhggGg6K7QBq7uNeBU2o/\n3Ilka3vs2DGOHz8u1js6OrrLp3tjY4NkMklmZiaZmZlYLBYKCgr4yU9+wj//8z9z9+7dPV3rqz5H\nKpVCq9VitVrFRqdQKIRH/1EQ270MrVZLIBCgqqqK8+fPi5a//v5+njx5wujo6C7XxKOKNIc7GAwy\nNDQk9DcZGRlotdp9Nwl5FZJQc2Nj47l3SRLUtbe34/P5KCsrE06KgJgVII2n3e+664vQarXk5+eT\nl5dHbm4uhYWFYvKm1WoFtssmS0tLNDU10dfXRzAY5MmTJ/uq9obt79/s7Cz3799nYmKCpqamXZnL\nhYUFRkZGhBATEPtFVVUVCoWC+fl5IdI8Ss+6pJ/ZiTRDQtKdSL8mjULfz+fjyAb5Z9na2qKzs5Nv\nvvnmjbyfJRvWrKwsTp48yfvvv49er2dtbY25uTkWFxdZX1/fs4dFmvx16tQpPvjgA959911MJhPR\naJShoSEeP37MgwcPmJmZEUrvyspKfv7zn1NZWYnD4SCRSDA+Ps7XX3+NRqMhEAhQU1NDIBDgvffe\no6Kigv7+fm7fvk1fXx/xeJx0Ok0qlWJoaOhAbseSOPLUqVOcPHmSX/7ylzx8+PA5IUwymRRWtzk5\nOWIs8J/+6Z8yMTFxoEF+59p3qtR3ahwO+xb5MpRKJSaTicLCQmpqaqivryedTjM1NcX9+/dpbm5m\ncXHx0APk6xCJRBgZGRGuiVarFb1ef6Q/g6S+HxkZYWBggGg0KlL20telTo6DbNOVSjmSwLeuro5L\nly5x4cIFnE6nSA1L9fdYLMbk5CR/93d/J8azHoRQcG1tjVAoRCgUeqVlrkqlwmg0Ulpayk9+8hMx\nWGp8fJyZmZkjFeBfhk6nw+v1ioFqsJ0pkrrA9vMzvDVBHrYfjDdJQSoUCqxWK2VlZXz88cdcuHAB\no9HI+vo6IyMj/OY3v+HOnTusrKz8wW1pUoqmqKiIM2fO8OGHH1JbW4taraarq4vm5maePHlCZ2cn\nwWBQ1JikF7GsrAyNRiM27QcPHvDkyRMUCgV2u120k0gbYnl5OW63m9XVVdLpNPF4nLm5OX7xi1+I\ncbH7idvt5uLFi5SUlKBUKolEIoTD4Zf+jJaXl5mcnCQWi6FUKsVN5zCQphKm02lWVlaYnp5mcXHx\nSHgnvAybzSae44aGBgAGBwd5+PChqKPGYrFDHdDxh6DVavF6vcLH/CiztbXF6uqqUJ/vfOaXl5fp\n7e2lo6ODiYmJAxu1LE1MLC8vp7KykvLyckpLS/F4PELZrVQqicViBINBnj59SnNzM729vSwvL4vs\nxVFCo9GIka0KhYJYLMbMzAyPHz+mt7f3SGfdJKqrq7l48eKu1uORkRFhNLSfz8dbEeSlwOnxeMjK\nyvpOykRJ0e5wOMjMzCQnJ4fa2lquXr1KTk4OGxsbDA4O8uDBA7766iv6+/v35OYr+V3X1tbywQcf\nUFtbi81mY2xsjIcPH3Lr1i0mJiZYWVkRvt0lJSVcuXKF0tJS1tfXmZqaYmhoiC+++IKWlhbRT67X\n6xkbG2NgYICysjJqamqoqqrC6/UKwYo0JnY/xYQ7sVgslJWVkZ2djUqlEul4aQOUbmNSu5rNZhOq\n050jUA8StVqNVqvFbrcLj/dQKMTTp0+Zmpo6krVsqV0uPz+fkydPUl9fTyAQECnjr776io6ODpHa\nfFvRarW43e5dNslHEbVajdFoFM/7syn5eDzO6Ogok5OTLC0tHVgg0uv1+Hw+6urquHz5Mi6XS0z6\nUyqVrK+vi1twV1cXLS0ttLa2iuf+KGIwGCgvL6eoqAiVSsXU1JRwMZ2cnDywd1Uaoe33+1EoFKys\nrLCysvKtAVp6bysrK2loaBBlEtj223/69ClLS0v72jJ6pIP8zh52pVLJuXPnALh9+/YrrSKllrPa\n2lo++eQTKisryc/Px2q1ihT9b37zG27cuMHQ0NCepah2psjeffddNBoNY2Nj/OY3v+HRo0f09vbi\ndrs5efIktbW1HDt2jLKyMux2uzC7efToEU+ePGFqaorl5WWR9o7H44yNjTE7O0traysdHR3U1dVR\nU1OD3+8H4P79+3zxxRcMDQ3tyed5FdJm53a7cTqd/NEf/RFut5s7d+4wODgo7DBtNhuVlZVUVVVx\n/PhxXC7XgR1EnkUaLHLs2DFqa2vRaDSiFae/v59wOHzkbgcajQaLxUJ9fT2XL1/G4XAQj8dF284X\nX3zxRmWso8Zhj5/9rphMJjIzM/nBD37A1atX8fl8uzJSku7joNP1Go0Gq9VKQUEBx48fF34KSqWS\njY0NotEora2t3L9/n6+++oqZmRnC4fCRGSL1IoxGIw0NDZw4cQK1Wk1vby9fffUVw8PDorvoINBq\ntWRlZfHJJ5+gVCqFXfS3+fpL721FRQUnTpzYNf10cnKS/v7+fRcNHtkgPzIyQmdnp1AjSiNXi4qK\n+Oijj6iqqmJra4tQKMTS0hLxeByn00lubi6AMJQ5ceKEsM5UKpVifOHQ0BCNjY0MDQ3tqdDK4XBw\n4cIFampqsNlspFIp9Ho9gUCA+vp6MfwkJydHjNl0OByMjY3R2trKl19+SU9Pj0jx7axrSxPUpBey\np6eH1dVVhoeHRRpoYGCA/v7+AzPgkIwzUqkUZrNZCJC8Xi9TU1OEQiHxfZGmpQUCAWw2mxj1Ojw8\nfCBrlYx6CgsLuXbtmnAZnJiYoLm5mZaWFqGROGrk5+dz6dIlLl26JGp6AwMD3L17l66urkNXbu8V\nkmB1Pw6Akkd7IBCgrKwMo9Eovra0tERPT48YAgTb6fj19XVx0ZDGo0pCtoKCAtHiK7X97UQSqh5k\n6cfpdHLmzJkXDnCZm5tjYGCAJ0+e0NXVJWa0H7bx0LchiWOlThxAmFVJGqSDorS0lHPnznHhwgXU\narVYj+SqmkgkiMfjWCwWLBYLJpOJ7OxsysrKOH78uNBsLCwsMDY2xvDwMIuLi/82R81ubW3R1dWF\nzWYT1ocWiwWFQoHX6+VnP/sZ8Xiczc1NOjs7GRwcJBgMUl5ezqVLl8RLqVarhcGG5Er01Vdf0dzc\nLGrie60itdvtnD17luLiYmBbKOV0Ojl79qxIuTscDgwGwy7xi9QLevPmzW+tae9EUpe2tLTs6Wd4\nHaS2m52tLT6fj5MnTxKPx0UKUK/XY7VaRWpemrX9T//0T3R3dx/IWiXRWlVVFX/5l3+Jz+cjFotx\n9+5d7t27R0dHx5Hb8KTgUlFRwV/91V+Rk5ODyWRifn6e9vZ2/vEf//HImK08y04RmGRkJc1ZT6fT\nB14SUSqVwozpZz/7mRiNDNu6hn/4h38Q88hhW4gZi8XE59DpdOTn53P58mWqq6spKSkRI4l3kk6n\nD20uhtvtFoOjnmV2dpaOjg6GhoZEX/mzrmyA+BkdhRkCRqNR+MJLg2zi8bjQIB0kFRUVXLlyhZqa\nGvR6Pbm5uSJdv9PnJDMzk6ysLDweDydPnuTKlSuizLy5ucnk5CQ3b95kcHDwQD7HkQ3yc3NzNDc3\no9PpuHLlClevXhUznHNzc0W7mMvl4uTJkySTSaxWKz6fb1eaP5FIMDAwwMDAAO3t7dy9e5eJiQmW\nl5f3Rb2bTqdFLVqqgxmNRnHqg+0e0GAwyNzcHJOTk4yNjdHX18fIyAixWOzQX6zXYXZ2lt/+9rds\nbm6iVCopLS3F4XCIzUOy/tw5ozqVStHX18c333zDo0ePnpvKt1+YzWYuXLjA+fPncblcBINBurq6\nuHPnDl1dXUfuBq9QKISSvrKyUhhoLC8v09zcTHNzMxMTE0c2TS/dms+dO0dBQQGJRILJyUkGBwfp\n7+9ndnb2QNcjlfAsFgter3fXO2kymbDZbKyurornQBJ4SdMLbTYbbrcbn8+Hw+EQrX47kSyFOzs7\n6e/vPxDxq4RSqRTalxeJWQsKCjCZTJw6dYqJiQm6u7tfaNIj3TKl2zJwKIcygNzcXE6cOIHVaiUe\njxMMBg88WykxNDTEN998g81mo6ioCI/Hw0cffURNTY0I8HNzc+Tn55OVlUVGRgYulwu/34/JZGJ9\nfZ1wOExXVxeff/45o6OjB+JxciSDPGynZIaHh0mlUmxtbWGxWPB4PMIGVmoD2Xkal5DqYdKmIqnZ\nu7q66O7u3teHY2Vlhfb2dmB7ep7keiQF/3A4zNDQkBDlDA8PMzIyIgZhHDXB16uIRCJ0dnZiMplQ\nqVQEg0Fyc3NF//mzt4S1tTWWl5dpamqisbGRwcHBAzGyMBgM4hZXW1uLyWSip6dHpC4P6qDxOuh0\nOjweD/X19cIFcWFhgb6+PhobG+no6GBxcfHIHgrtdjsVFRVcunSJmpoaMQJackxUKBREo1F0Ot0L\nb5T7gUqlEk5jO0VQkuPaTiTDFinIv+jWDogMxdbWFolEgu7ubh48eCCGuxwEko+G3W7HZDK9cOiJ\ny+USY7UXFxfFwevZw+3AwAC9vb2iXp9MJgmFQiwsLAg/kf1GygAVFhZy/PhxLBYLwWCQhw8f0tPT\ncyjjeycmJmhra6OoqEgIRKV24EgkwtLSEouLi8LgZucznU6nWVxc5PHjxzQ1NdHe3r5rMup+cmSD\nPGz3Vo+Pj/Pb3/6Wnp4e6urqaGho4J133nmhd7pEIpEQCtJbt27x2Wefsby8zMrKyr4rSCcmJvjF\nL35BWVkZx44dIzMzE4PBQCwWo6+vj6dPnxIOh4lGoyQSCZLJJGtrawfuQ79XSJtbZ2cnU1NT/Ou/\n/isFBQXU1dUJJf1O5ufnGRsbo6WlhdHRURKJxIEEKY/HQ0VFBSdPnqSgoICtrS1xmzlKA0R2YrPZ\nKC4u5r333qOmpob19XXa2tq4desWX3/9NePj40c2wMN2kC8rK8NqtQrf9GPHjnHixAnsdjtOp5OO\njg6cTucuU6KjgsFgEHbHSqXypV0g6XSaZDIpTKiePHnC3bt3mZqaOjAnNqnNLC8v7zuNOrVarVRW\nVr4wJV9dXU0ikRB6m+npae7du8f9+/eF0dJ+o9VqhcPd8ePHxTCjX/ziF/T39+/7v/8iFhcXGR0d\nZWRkRJQM3n//ferq6oQNueRLv3PuCGxnL8fHx/mbv/kbHj58eKB200c6yEuOWLOzs0QiEVZXV4WL\nWnl5OdnZ2WJwjaQ0npiYIBwOMzc3x+DgIB0dHQwPD4sa2X6TSCQYGxsT/ep2ux2dTifmHo+Pj4tR\np0dNwf2mbG1tsbKywurqqrB0XFhYEJOYdhIOh8XQjv121YLtzU+v11NXV8eHH35Ifn4+kUiEb775\nhqamJnp7e49culuaTnXu3DmuXLlCVVUVKpWKzs5OmpubaW1tZWZm5khZeb4IaS5DJBIR08TKyso4\nceIENTU1OBwOjh8/Lg5gJpOJubk5RkZG9uUGLN20Q6EQAwMDKJVKPB7PS6dQ7iw3PYuUnt3a2hIe\n69FolNXVVZqamkQZ5aDe8XQ6LbKf9+/fp6SkRLT2Sf/t/IySG9+L0Ov1oqc+IyMDjUZDOp3GYrHw\nq1/96kCCfFZWFu+++y6nTp0iMzMTrVZLOBzel9n235X19XUWFhZ4+PAhJpOJeDwuJuTB9vfNbDYL\nnwf4vVi6tbWVW7duCS3YQXKkg7yENJO6tbWV8fFxQqEQly5d4vLly3i9XrRaLfPz8zx69Iivv/6a\nUCjEzMyMOHEdJFKpYGpq6khMRjooJCXxxsbGkfrsOp1OTH/65JNPUKvVPHz4kP/7f/8vjx8/PrBW\nw9fBaDQSCAT44IMP+NGPfoTRaKSnp0c42vX19R35AA/beo3GxkaWl5dJp9N4vV7ef/997HY7BQUF\nYqyoFGRXV1eFTmJycnLP17O1tUU0GmViYoKWlhbhCqfVar9Vzb/Tzlm6fUmp283NTQYGBvj1r3/N\n7Ozsobn0bWxsMDY2Ji4P58+fp76+HofDgc1mE4NR4PceIs8ebHZaYofDYbRarWgDrK6uprCwkAcP\nHuzrTVqyeC0pKeHP//zPKSoqwm63i6znfth1vw4rKyvcu3dPlBO0Wq3QljgcDuGoajAYgO3YlUwm\nuXnzJv/4j/94KD4Wb0WQ38nq6iodHR0Eg0Hu378vTpyJRIJgMChetHg8fuSU0jIHh6SIloRfxcXF\nKJVKYUDR3t5+4CfqVyGZAx07doxPPvmE2tpalEol09PTtLe3c+fOHeHp8DZkgRKJBAsLC6ytrbG1\ntUUwGOT27dtMTk5y5swZ6urqqK6uxm63i77jpqYmgsHgvmzkW1tbLC0t0dnZSSgUYnJykvn5eerr\n60Va/kUMDw/T1dUlWnVhe0BNV1eXmKa3sLBw6FPmYNtpTzK3uXPnDpmZmfj9frxeL2q1Go1GQ1ZW\nFtnZ2eTk5OwqQczOztLW1kZfXx+Tk5Po9XpSqRSLi4tkZ2eLro79wmQy4fP5uHjxIpcuXRLDyaLR\nKHfv3qWpqenIiGOlC013d7cI8jqdDpPJxGeffSbMnKROhZ6eHmZnZw8lJr11QT6ZTDI5ObkvJ32Z\n7w/SKNbS0lIuXrxIIBAgEonQ1tbG48ePxRS6o4KUPs3Ly+Ps2bO89957mM1mZmdnaW9v58GDB3R0\ndBx545KdPDuoY319nd7eXgYGBlhYWGBhYYGVlRXcbjdKpZLbt2/z8OFDlpaW9mUzl1wYV1dXRb08\nFouRSCREy+uLePr0KQ8fPiQYDIrSztTUlNBEHCVdhPSZxsbGUKvVIsB7PB7RBlhYWEhRURHFxcW7\nymmjo6Pcu3ePnp4eEeQlRXh2djYul2tfR7pKz/+1a9doaGjA5XKJ8ue9e/doa2s7MkFean+emZkR\nhl9HlecLUQfH0XkzZL53mM1m6uvr+eCDD/jpT38qhvZIwpdgMHikhI7SOOI///M/FyY9AwMDPH78\nmH/913+lr6+PUCj01go0d6JQKIRhiMViQaPRoFAoCIfDrKysHFgt22g0CpX9y2rvsO0FEY1GSaVS\nYl2SAcpRCvDPIrUMajQa8T2WdAZS3X1nyn5tbY1IJCKyoNK433Q6Lf6eF7Xc7RXl5eWcPXuW//Af\n/gM1NTVoNBra29u5d+8e//AP/0B3dzfxePxIf88PgVfG8LfuJi8j8yrMZjNZWVmcPn2agoICZmdn\nRcDs6uoiFAodmUAp1aMLCws5efIkmZmZou7X1tZGa2srnZ2dLCwsHJk1/6FIQs2DEF5+G/F4nHg8\n/tb7/b+Mra0t1tbW9iTzcxClCI1Gg8FgwGg0CkHjkydPuH37NmNjY2+FDuUoIgd5me8ddrud4uJi\nzp8/j9ls5vbt2zQ2NvLkyRMhAjtKKJVKMcAimUzS09PDN998Q3d3t1yWkvk3g3RD39zcJBqNMj4+\nzsOHD/nqq69kfdUfgJyul/neIc2JLy8vR6PRMD8/z9zcnBCBHaUgv/MmHwgEUCqVrKysMD8/z/Ly\n8pHt4ZeR2WscDgd+v1/MFVhdXRWzLY7y+OdD5pUxXA7yMjIyMjIybyevjOH77yMpIyMjIyMjcyjI\nQV5GRkZGRuZ7ihzkZWRkZGRkvqfIQV5GRkZGRuZ7ihzkZWRkZGRkvqfIQV5GRkZGRuZ7imyGI3Mg\nWCwWMjMzycrKwm63Mzk5yfT0NLOzs0eqb/2o43A4sFgswp5UmmFtNptZWVkRI1ATiQTxeJxYLHZk\n/L5lDh+VSoXNZiMrK4uysjIUCgWxWIyRkRGCwSCrq6tiFPZholar0ev1GI1GdDrdrq9tbGywtrZG\nNBo9EkOBjjpykJc5EDweDxcvXuTDDz+kqqqKzz//nC+//JLFxUUSicRhL++tITs7m4KCAjQaDW63\nm5ycHC5dukR+fj6Dg4O0trby4MEDZmdnmZ2dZXJy8tA3bJmjg1qtJjc3l+vXr/Of/tN/QqlUMjU1\nxd/93d/xzTffMDExQSQSOfRnRqfT4XQ6yczMxOVy7fpaLBZjaWmJkZEROch/B+QgL7MnmM1mzGYz\nSuXvK0DpdJpUKsXq6ioKhQK1Wo3BYMDpdFJZWcnY2Bj3798/1CCvVqtxOBxUV1fz3nvvodFonnPW\n6u/vp7u7m56eHpaXlw9sbSqVCq1Wi8ViIT8/n8rKSiorK8nLy0Oj0WA0GsnIyCA7Oxur1UpBQQEm\nk4mioiKCwSAzMzMMDQ3R09PD06dPxQ1Ndg57ORaLhYyMDJaXl8VY2ddBpVKRnZ2NRqMhFAoduZHX\n0pAatVqNTqfDaDSiVCr5+OOPKS0tpa+vj8bGRh4/fnxga8rMzKS6uhqTySSm4lksFjweDzk5OXi9\n3l2/PxqNMjk5yZdffklvb++RGzZ11Pg3E+RVKpUIMMlkknA4zMbGhpwq/gOQUsYWi4VAIIDf70el\nUonJVlJKbXBwUMytVqlU6PV6AoEAPp9v16HgMNBqteTl5XHlyhX++q//GoPB8FwQbGxs5NatW6yt\nrTEyMkIymSSVSu35bUehUIiJYRqNBrPZjNVqJRAIUFdXx+XLlyksLMTv96NWq3dNEIPtbInH46Gq\nqopwOMz8/Dyjo6NkZmayubnJ4uIi4XCYRCKxZ+vXaDTYbDaUSiXpdJq1tbXvfLuSJpxtbm4e+iYt\njWHNycmhsLCQyclJYYX8XT+PVqslIyOD6upqMjIyxFz2wx6AI1knS3bPPp8Pu90unjeHw8G5c+fI\ny8vD7XYzNja2b0FeOmBI/2swGDh27Bg/+MEPcDgcYhqgyWTC7XYTCARwu91sbm6K9zIWizE5OSmm\nAMbjcRKJhHyrfwn/JoK8QqHAZDJx7Ngxfv7znzM8PMxvfvMbFhYWZG/wN0ShUKDX6ykuLubdd9+l\npqaG4uLiXcEnkUgwOzvL//yf/5Pl5WUR0Dc3N8VI0cO+VZpMJs6cOUNtbS0qleqFwaa8vByDwYDJ\nZKKtrY2BgQGmpqYIhUJ7uhYpBe/3+wkEAuTn51NUVERpaSmBQACXy4XRaHxhgH/R58rKysLhcFBQ\nUMC1a9doamri8ePHDA4OMjMzsyezwd1uN9evX8dsNhOJRBgaGvrOQW19fZ1oNCpmuh8mJpOJvLw8\n3nvvPT788EOWlpZobW3lb//2b5mfn/9OhxC/309VVRU/+tGP8Pv9dHZ2cuPGDW7evHkAn+DlSAeY\n06dP884771BaWkpJSclz43UTiQSTk5NEIpF9W4ter8dut2MymURG79SpU7zzzjsYjUZUKhWwnWHT\narXo9Xo2NzeJx+PiUKrRaMjOzubHP/4xTqdTHL4P+zB1VHlrg7xWq0Wn07G5uSnSwi97ERUKBSUl\nJZw7d44zZ86wtbWFVqs99Fvky3A6nbjdbnHSll4Mu90ObAtPkskkg4OD9Pf3H/j6jEYjdrudgoIC\n6urquHbtGiUlJWRlZYmb/NbWFqlUiqmpKW7cuIFCoSA3Nxez2Uw0GuXp06f09PQcyulb2kCKioo4\nfvw4586do7CwUDwPzx487HY7Op2OdDqNwWBgfX2dSCSy50Feq9Xi9/upra3l9OnTZGdnk5WVRXZ2\nNiaTCdieY/5taWSVSoVGo0GtVqPRaMSNqKSkBKPRiNVqRa1Ws7a2tidB3mw2U1lZSW5uLpubm4yN\njX3nv3dtbY2lpSVx4BsZGWFubo5EInFgN3uFQoHVaqWoqIgLFy7w7rvvUldXRzKZZGtri1/96lev\nPFBJGAwG3G43+fn5lJSUkJGRQTQaZXl5mZGREZaWlvb507wYrVaLw+GgrKyMc+fOkZubi8vlQqPR\nPLf+nJwccnJy8Pl8hMNhksnknqxBqVRiMBjIy8vjxIkTIutUWlpKcXExeXl5JJNJVlZWiEQiu8bj\nbmhfgCgAACAASURBVGxssLy8LMoe5eXl5OfnU1xcTCwWY3p6mlQqJQf5l/DWBnnphVpfXyeRSLC8\nvPzSjUGlUnHmzBmuXr2K2WwmlUqxtrZ26CnCl5GXl8fZs2dRqVSYzWZ8Ph9VVVVUVVUBiBnY/+N/\n/I9DCfIOh4Py8nI+/PBDGhoaxE13Z6oeEHVjvV6P1+ulrq4Ot9tNKBTiyy+/5M6dO3u2ibwO0qb3\n8ccf8+Mf/xiXy0VGRsa3HvoMBgO1tbWk02mGh4cZGhral3VlZWVx+vRpPv30U3EQlW43sP2zlzIg\nL8qCGAwGMjIy0Gg0u/4cQFVVFRaLhcXFRWZmZvbk2dFoNLhcLiorKwkEAmxsbLC5uSmeg62trRf+\nf/h9kI9Go4TDYf73//7ffP3118zPzx9YHVulUpGVlcWZM2f44z/+YwoLCzGbzZhMJhwOx3Pfw29j\nc3NTfH6TyURhYSFXrlzBbDbzf/7P/zm0IK/X6/H7/SKASxmhZ/H7/Vy7do2lpSUmJyfp7Ozcs/dT\nrVbjdDo5efIkf/EXf0F+fj5utxuVSoVKpUKtVjMxMUF/fz+9vb27vlfr6+vi8KdQKPjTP/1T8vPz\nhYjwBz/4AaOjo7S2tu7JWr9vvHVB3mg0kpmZycmTJzl//jxdXV10dnbS2dn5wluhJOAoKyvD6/WK\nDXp5eXnXafGwsNlsOJ1OrFYrdrsdl8vFiRMnqKurQ6lUotVqMZlMeDweMjIygO2NXKfT8cEHH6BQ\nKLh58yaDg4P7vlaz2YzX6+XSpUtcvnxZpJENBoNQcisUCoxGIy6Xi/b2dpqbm8W89OzsbNHqdZjp\neqke6HA4yMrKQvf/2zuvp7ayLY1/SiijjECInEQONtiAE263w7i7b9+avqHufZmaqflr5mn+gHm6\nU9137oRut+1xO2EbY5IJBhFEEBJIAgkJlLOE5sG1d4ON3XYbJOw5vyqXqyzAR+KcvfZe61vf4vPB\n4/FoBuIg9tbLX93MHBYsFgscDgeRSASrq6vQ6/WQy+WIRqNwOp2wWq2YmZmBxWJBMpk8cJOq1+vR\n2NiItrY2VFRU7HuNiK1ITfQwcLlc+Otf/4qlpSW0tLRAKpVCJpNBrVZTEdWb2N3dBYfDgVqtRmFh\nIa5cuQIul4ubN29ia2vrUK7vbRCdDllL9Ho9xGIx0uk0VldXsbCwgGg0+s73qMfjwfz8PJxOJ+Lx\nOIRCIYqKilBTUwOlUgkej5cT4SOXy4VIJIJIJIJQKKTlnlevg81mg8/no729HbFYDCKRCC9evDiU\nNlepVIovv/wSly5dolkONpuNUCgEi8WCqakpWCwWrK2tYWNjA+FwmH5vOp1GOBwGm82GSCSCz+ej\nG0ZSinifzVguIWXOVzdZiUSCZrAO+/D5UQZ5g8GACxcu4KuvvgKbzYbD4aDCrleRy+WoqalBZWUl\nJBIJTCYTlpeXEQgEsnbNRNEqEolojzNZZHU6HSoqKlBYWAi9Xk/TUKRN6qDFmMfjQSaTobu7GwUF\nBVhZWclKkFcoFDh58iSuXr2Ka9eugcViIR6PY3NzE5OTk5iZmQGPx4NWq0VdXR2ePXuGR48e4eLF\ni2hubkZBQQHi8TitweZKKENO8kqlkm6c9gbtdDqNUCiEdDpN+3V/KWAdBru7u4hGo1hfX8fIyAga\nGxtRXFyMYDAIk8mEsbExPH36FEaj8Y3lKYPBgHPnzkGlUr0W5DOZDF1EDivQeDwe3Lp1C4uLi1hZ\nWYFarUZRURHKy8shFArf+r0k+Oj1euj1enR2diIYDKK/v/9Qru2XEIvF0Ol0OHnyJE6ePAmFQkH1\nIpOTk5iYmEA4HH7nz2pnZwfpdBoejwfxeBxSqRRKpRIlJSXQaDR0g5sNsa9IJIJYLKan+PLycqjV\nahoQ37ahra2thVQqhcvlgtvthtvt/uBrFolE6OrqwokTJyAQCBAKhRAKhbC5uYmRkRH8+OOPcDgc\ntKX2IFGoQqFASUnJod6/BHKgymQyH3z4I5sPHo8HPp8PgUBAxY9sNhsymQwFBQX7vsfr9WJzcxOB\nQODQ9SkfXZCXSCRobm6GRCLBixcv8PTpU4yPj79RQKdWq9HS0gKVSoVoNIqFhQXY7fasXjOXy4VY\nLEZPTw8uXboEmUxGRS9SqRRyuZy2oIlEIiSTSTgcDhQUFEAikRz4M0kaN5vagoqKCvzjP/4jGhsb\nweFw4PF4MDk5ie+//x5msxk+nw96vR7V1dVIpVIoKirCN998Q0V5eXl5sNvtWFpayqngsbi4GNeu\nXUNVVdWBrwcCATx48AB+vx8FBQVoampCZWXlkV9XJBLB/Pw8HA4HBgcHUVhYCJlMhng8jq2tLayv\nr1O195sWuVAoBKvVimAw+NprxEQkHA4feplkY2MDAwMDVCy1V0T1JoRCIQoLC3H9+nWUl5fD5/PB\n4/FkrUfbYDDgypUrOHHiBLRaLU0ZT09P4+bNm3j27NkHZ5tEIhEKCwtRX18Ps9mM2dnZrIgMGxsb\ncfbsWbS2tqK0tBRSqRRarRYSiYSe5Nls9oHvTSAQID8/HwqFAlKp9FCyVrFYDEajEZlMBlwuF4FA\nAC6XC1NTUzCbzdjc3KRdK2/aUOj1enz11Veoq6s79GyaQCBAZWUlYrEYVldXP+g0zePxkJ+fj9LS\nUtTV1aGxsZFmzzgcDgoKClBeXr7ve0wmEwYGBjA6OoqlpaUPfDf7+eiCvEgkQnV1NaRSKdbX17G+\nvg6n0/nGr5dKpTRNvLcGmA1YLBakUimKiopQX1+Pvr4+XLp0Cfn5+dTFicfjIS8vDzweDz6fDwsL\nC7DZbNje3kZRURFkMhl4PB51i9tba02lUohEIllrA5TJZGhqakJRURFisRi2t7exsLCAJ0+e0JRe\nIBBAPB4Hi8VCa2srmpqaoNPpIBQKsbOzgxcvXmBgYODQRWu/hFQqhUqlQlVVFbq6utDX14eSkhK6\nUJBFZ2NjA2azGU+ePEEmk0FDQwN0Oh3dEJAd+VGQTCbp6SmTyWBlZQV5eXlIp9O0Fn8QLBYLQqGQ\nXmddXR0Vae7FbrfDaDRiZWUF29vbh3rt4XB4X4r1XSAdBBKJBJlMBk6nEzab7cjr8SSDUFtbi3Pn\nzqGsrAxCoRCpVApra2t49uwZZmZmYLPZPvj/IuJHpVIJuVyetbSySqVCQ0MDbY0jkPuX6JiCwSDi\n8TgkEgny8/PpNQqFQhQXF9NnN5lMftA6E41GMTExAYfDAeDlZnR7exsmk+kXtQocDgf5+fmorq5G\nT08P9Ho9fQZ9Ph/m5uY+WERKNC7vu6EjJbD8/HwIhUIIBAIolUq6sTMYDKirq6Pp+GAwCI1Gg7q6\nOojFYhoHtFothEIhHA4HE+QFAgFKSkrA5XKxuLj4iylfPp8PuVyOvLy8rNfg2Ww2iouL0dvbiz/8\n4Q+oq6uDRqMBm82mN+nev1dXV/Gv//qvWF5eRiQSocYcMpkMV69exW9+85t9C0UoFILL5cpa+xFJ\n95L+5q2tLfr/p9NppFIpOBwOJJNJsFgsnDx5Es3NzeBwOPSBvnv3Lv7rv/4r678LrVaLU6dO4Z/+\n6Z/Q1ta2rw4PAJubm3jw4AHu3r2LkZERxONxVFZWQqlUUsHP3gB/FIF+d3d33wk7FovtE629CTab\nDaVSiYsXL6KnpwcdHR3Q6XSvfd3U1BRu3bpFHfFyTXFxMf75n/8Zra2tyGQyWF9fx/Ly8pGLMUkK\nu6amBg0NDZDJZEin04hGozCbzRgcHMyKJuCoOShwZTIZsNls+Hw+zMzMYGVlBW63G5WVlTAYDGhp\naaGalcrKStTU1EAmkyEWi33QOhMOhzE8PLyvg2V3d/edSnbEy6KhoQH19fVQqVT0NZvNhh9++OGD\nA2M8HofVan3vmrhAIIBarabdRRqNBlVVVaiurkZNTQ0UCgW4XC42NjZgsViwvr4On89H4xgJ8iUl\nJVCpVHjw4MEHvY+D+KiCvEAggEQioYYl71KbUalUaGxshFQqxc7ODlW/ZgMul4umpiZ0d3ejurqa\nim+An2/y1dVVmEwmeL1eGI1GzMzMYGtrC6lUCtvb2yguLkZVVRU0Gg3EYjG4XC7tKJiYmMCNGzey\nVn7Y2dnB8+fP0d7ejsLCQlRUVODs2bNgsViYmpqCyWQCANTU1ODq1aswGAzg8XiIxWJYW1vDgwcP\nsLCw8N4nvsOACHTkcjmtwwM/B0+Hw4GffvoJs7Oz9GQRj8fp/UK+7tW/D5tXF+S3IZVKoVarUV1d\njebmZpw7dw61tbUoKira1wMdj8cRiUSwtLSEubk5agSVK1gsFurq6tDZ2QmtVkszQmNjY0ca5Fks\nFuRyOQwGA65evYpz585BJpMhLy8PW1tbGB4extDQEKxW668uJ+3u7sLtdmNrawtyuZy2Mra0tMBu\nt2NqaupISlUkm5Ofnw+VSoXW1lY0NDQgPz+fbsATiQQ1ApudncW9e/dgt9vpfa7RaOhpncvlori4\nmGZBPzTzk8lkftXvlbyv2tpa1NbW0gNbMpnE9vY2LBYLzGbzB/f2/9rr6+npwdmzZ1FeXg6VSgWJ\nREL1PkqlEpFIBGtra3j69CkmJiawvr4OrVaLYDCI8+fPU8tev9+P1dVV+Hy+D3ofB/FRBXlS7+Ny\nufRmJKerNy2IpD+UBEYi6njb9xwGpA7f1NSEEydOQKPR0IWXnNj8fj8mJibw008/YX19HTabDXa7\nnaYrI5EIioqKUF1dTetqwMtd8dbWFiYmJnD79u1fZb/5a3C73Xj8+DFtXywtLYVSqaROWUT82NHR\ngS+++AJFRUVIJBJwOp2Ym5vDo0ePYLFYsnKtr0Kc+Tgczmu/993dXTidTgwODtKUOKlZ7j15kHsm\n1wY+RAVdXFyM5uZmnDlzBl1dXTAYDPs2MOl0mpZVXC4XFhcXsbq6mlPjmby8PEgkEpw8eRKnT58G\nn8/HysoK7t69SxfBo4LNZkOj0aCtrQ2/+93vUF5eDj6fj1Qqhc3NTZrF+ZB+63Q6jbW1NZjNZhQX\nF9OOjKamJjgcjtcMaA4Dos0pKipCWVkZqqur0dXVhYaGBggEAiSTSap3cLvdsNvtGBsbw+3btxEI\nBCCVSlFXV7cvHc/lclFQUEDTyG8SNh81IpEIWq0WjY2NqKmpgVgsBovFQjAYxNLSEkwmE5xO5wcf\nHEh28n3p6urCn/70J2i1WurbEo1GEY/H4fV6sba2BqPRiJs3b2J4eBjpdBq1tbVQqVRob2+n68nG\nxgYGBwffWnr+tXxUQT4ajSIQCCAcDlNDE1KjTqfTBy6+JPXk8/mwtbVF/aTJRuGoTvVKpRI1NTWo\nrq5GYWEhfUgymQxCoRCWlpZw7949jI2NwWg0IhKJ7HN1IhAl/V6lcjAYxMLCAtbX1xEOh7NWk3c6\nnbh79y41WCkvL4dYLEZZWRmuXLmCxsZGsFgs2hKVyWSwubmJGzduoL+/H2azOatdDXtpaGhAX1/f\na8MuSHtOJBKh9w8J8CQgZUNZ/z6IxWLU19fjwoUL+OKLL1BQUACVSvWamj0QCGBsbAyzs7MwmUyY\nnJzM6v1yEBUVFeju7sa1a9fQ2tqKcDgMo9FIdR1HCZvNhk6nQ3l5OaRSKXg8HrX7tVgstP3tQ0gk\nEhgcHASHw4FOp0NNTQ3kcvmRajmI7uj69es4ceIESkpKoNPpIBAIwOFw4Ha7MTU1hadPn2J0dBTR\naBQ7Ozvwer0QCAQoLCxEd3c32tvbj829Tp5BkqG6cOECampqaOlveXkZP/zwA54+fYpgMJizzBTJ\nyKZSKUSjUXg8HkxMTGB+fh7b29twOp3Y2NiA3W4Hh8NBe3s7zp07h6tXr6K8vJzqmObn53H79m2s\nra0d+jV+VEGe2GA6HA6q4m5ubkYoFILdbkcoFHpNtEPaGYCf2+92d3fh8Xjg9/uP7BSs0+nQ1dWF\n8vJyyGQycDgcxGIxBINBrKysYHR0FHfv3sXy8vJr9T82mw0ej0c94YuLi5Gfn49MJoNwOIzNzU2q\nws5mG1ooFKLXLpfL0dnZidraWiokKS8v3zcAg0xFe/ToESYnJ7G9vZ2zAENsNF91+YrFYjCZTFhZ\nWaHXRtoAa2tr0dDQsK8GmCt4PB5Nx5aUlODChQu4cOECTp06tU9pTE4GgUAAFosFw8PDeP78ORYX\nF+HxeHI2LIUYInV1deHv/u7vaCvV48ePMTw8jOXl5SPPMHA4HFRVVaG+vh5isZimaJeWljA9PY31\n9fUP3oSmUilYrVYUFhZie3ubijvJMy0UCsHj8Q71uVUoFKiursbp06dx+vRpKJXKfcr5WCyGzc1N\nzMzM4OnTp/u+l8/n0zXyIFGgRCJBdXU1vF5vVoczkYPEqVOncOnSJRgMBvocut1uzM/PY3x8HEtL\nS9TDPhdsbm5ienoafD4fgUAAGxsbmJiYwMLCAra3txEIBBAKhSCVSlFZWYmzZ8/i/PnzaGlpQSaT\noRuwoaEhGI3GIyllflRBHniZql5YWIBOp8OFCxcgEolQUFCAO3fuvNE6kqjcGxoa8A//8A8YGhrC\n48ePsbS0dGRBvqysDH19fSguLqYtKz6fD2azGffu3cPg4CDm5uYOVEyTAF9bW4u2tjbU1dVBpVIh\nnU7D5XJheXkZc3NzWbdxJCmtyclJuFwuuFwuXLx4EefOnaOLF4vFotarg4OD+O6777CysgKPx5PT\nE6TP58PGxgbKysr2/XswGMT9+/fx7NkzuvASd7vPPvsMV69epWWSXELmxjc0NODkyZO4du0aKisr\nX2slIqeK9fV1TE5OYnR0FHNzc9ja2srp569QKHDmzBlcu3YNV65cAZ/Px+zsLL799lvaAnvUCzWH\nw0FjYyPa29tpq6rf78fIyAiePn0Kv99/KJ9ROp2mE/9IppAMc1IoFNja2jpUf3ilUonq6mro9Xoo\nFIr3aqmNxWLweDx48eIFtFotTp8+vS81X1hYiM8//xxer/dIXB7fhEajQU9PD/r6+tDT07NvpvzG\nxgbm5uawubn5Xj4GR8GLFy/oBohoMfa2AhIhH/FjuHLlChoaGpCXlwefz4fl5WX85S9/wejoKPx+\n/5Fklj+6IE8eSjKdq6ioCFeuXEFZWRmWlpawurqKdDoNDocDkUiE06dPAwA1gfD7/XA6nXA4HEda\ny97Z2cHS0hK1xkwmkxgfH8ejR49gNBphNpvfmDotKiqifa5dXV0oKChAOp3GxsYGHjx4gMHBQczM\nzGS9DY1ATCzMZjOt5ZHTCovFwu7uLh0Huby8fGiL54dQWFiIurq6fb4Dbrcbi4uLMJlMcDgc9AET\niURoaWlBc3Mz9XrPBcRlj1zPZ599RpW7paWlND2/t1TlcDiwsLCAkZERjI+PY3FxEV6vN2fGQywW\nC5WVlejo6MC1a9fQ2NiIVCqFsbExPHnyhIpOsyGGJT71CoUCHA6H1kzn5+exsrLyqwV/RNS51zRJ\nqVTuc2IjCvFvvvkG//u//4vHjx9/8PshfddyuRyFhYVUmMtisRAOh+F2uzEyMoIXL17AZDJhdXX1\ntZ9BNu7xeJxmefY+w2traxgfH6etb0cNi8VCXl4edDodTp8+jYqKCuTl5VErZqvVioGBAQwNDWF7\nezvn1uQ2mw1er5e2kL56Ei8oKEBVVRXOnj1L2xl5PB6CwSAGBgbw8OFDTE9PH+km/KML8oFAABMT\nE/Rk09bWhqamJnR0dGBtbQ1zc3NIpVLg8XhQqVQoLS0F8LJWtr29jbm5OczNzR14wx8mDocDz549\ng0AgQCAQQCwWw8OHD/Hf//3ftDf1Vfa2rly8eBFXrlyBwWAAABpU79+/j8ePHyMYDOYscJLT4qu1\nbOJZTgRfgUCAuoDliry8POqt0NzcvM/1zWq1YmJiAmazGTs7O/R98Pl81NXVoaKigi7SmUwGyWQS\nsVjsQO3EUSAQCCCTyaDT6dDb24s//vGPKCgogFQqpZ8x6b8lC/TMzAzu3r2LgYEBzM3NHfk1/hIs\nFgs1NTU4d+4c+vr6IJFI4Ha78eTJE/z000/w+XxU/0C6GI7C0Yxci1AohEgkoiNKnU4nXC4XtUo9\nKGVNgumbHChJ14ZcLqdZn8rKSjpDgGzWysrK8M0332Bzc/NQgjwxXSFumcQqlcViwe/3Y3FxEd9+\n+y0GBwcRCAQODIgkVS8QCCAQCGiaP5FIwOFwYHp6Gvfv38fGxsYHX+8vQe4D0jFy8uRJFBYW0msZ\nHR1Ff38/pqenYTabcy6ABUAdAV+F/M7Ly8tx+fJlXL58GW1tbdQIyOl04v79+/jhhx+wvb19pC3F\nH12QJ+pFkiY5ceIEmpqaUFVVBaFQiIKCAuqqJJVKIRQKkU6n0d/fj4cPH2J4eBhWq/XIr3NrawvP\nnz/H+vo6JBIJ0uk0nE7nW0UiEokE5eXl6O3txeXLl1FUVERrrMSkg4jtcrmDlcvl9OY9c+YMBAIB\n4vE4NcFJpVLIz8+HRqOBVqvFzs5OzhTdNTU1tAZM0tqJRAI+nw+PHj3C3/72N9hsNjp1bC97e+MT\niQRsNhsmJycxMDCQlUWvvr4ep06dwpkzZ9DY2IjCwkLw+XxqJWy1WrG8vIzZ2VmqSvf5fNjc3MxZ\nludVyOlZqVSCy+XSz1gmk9EhJX6/H16vF7FYDKFQCD6fLyuZB6lUioqKCpw/fx4cDgezs7MH1kTl\ncjkKCgpQXV39mnAT+FkBrtVq6evE8WxvqYfL5UIikexLPX8IWq0Wvb29uHTpErq6uqBQKOgmaW1t\nDcPDw7DZbG9NafP5fKjVarS2tsJgMNAgZLfbcevWLTx69AhbW1tZ8bUQi8UoKSnBF198gfPnz6Oy\nshJSqRTRaBQWiwXT09OYmJiAx+M5Fl0ub4NM3Ovt7cVXX30FvV4PNpuNQCCA6elpPHz4EJOTk1nJ\nsn10QT6TySCVSmFjYwNOpxM7OzuwWq2orq6GRqOhD5VQKIRWqwWPx4NSqaQKXpImP2qIN/P79LCr\n1WpcuHABvb29qK2tBZvNRjgcht1ux/j4OIaGhrC5uZmz1Cvxca+rq0NPTw+6u7tRWVlJT8Xr6+uQ\nyWR0VG5paSkMBgOMRmPWgzybzYZYLEZlZSX6+vr21eKJU+Dq6iqmp6f3fR8ZaPSqLWssFsPi4iKM\nRiNWV1ePZNEjGwrigtjY2Ii+vj6cPXuWel2Hw2E4nU6MjY3Rcb1Go/FIVLmHQSaToWpum81GjWfK\nysqo1ScZxxqNRhEKheD1erGxsQGbzUazYId1LWRDIZVKqXd9d3c3ZDIZSkpK3hjkiRBTo9G89rpA\nIIBKpYJKpTrQaRB4eTjx+XxYXFw8tDYpuVyO9vZ2NDY2Qq/X73uNnBZDodBbh+KQVt+ioiJ6j5EN\nwpMnTzA9PU3nOBw1arUa9fX1OH/+PFpbW8HhcLC5uYn19XWMjY1henoaNpstpx4P74JEIoFer8eZ\nM2foBh146U8/PT2NgYEBPHjwAFarNSvr4kcX5Alkx2qxWOBwODA0NLRvupZKpUJHRwe+/PJLVFRU\nwOPxUH/kXNdx3oRer8ef//xnGAwGWt92Op24ffs2Hjx4gOHh4ZyMZiWQqVqfffYZfv/730On0yEv\nLw+hUAhPnjzBvXv30Nraiq6uLuoo1t3dDYfDkXUHMTK2lQz/ISnaV/+8SnFxMZqamqDRaMDn8+nX\nRCIRWts8qgWP1COJoUlzczNaWlr26Qi2trYwOTmJv/3tbzAajfB4PDm9J36JTCYDi8WCkZERJBIJ\nVFdXo6SkBG1tbejp6aFDQYiugJSC+vv78de//hVzc3OHljVJp9OwWq1YWVlBQ0MDhEIhlEolTp48\niaamJvzmN785cG0gyvM3TTsj6fw3WdaSUs/Kygr+7d/+DaOjo4fyfoj1rEwme+01Mr2SlBje556d\nmprCf/zHf2BxcTGr5Ta9Xo/29nY6RnZ1dRUzMzMYHx/HkydPsLa2lnNtz7ug0+lw6tQp/P73v0dL\nSwt4PB78fj/MZjO+/fZbjI6OYn19PWuHtY82yAOgE4PedKrau+NLpVJvHeyRS7hcLmpra3Hy5Eno\n9fp9i3ooFML8/DzW1tZyOtQFePkQ/va3v8WFCxdoa5DFYsHQ0BD6+/sxPz8PnU5H0/YkxalQKKhL\nVbY+f2LmodPpoFarf3EiGlmo9Xo9DAYDlEol8vLywGKxqBvb6Ogotb48CsiQjJaWFnR2duLUqVPQ\narV0I7Wzs4P+/n709/fDaDTSTetxh8w1cDqd0Gg0UKlUKCwshFqtpoOZiL+7Wq2GVqtFS0sLXC4X\ndnZ2Di3Ip1IpDA4Ogs1mIx6Po7q6mg6mOWi++rtCDId2dnaoY5lUKqXPMpvNxsbGBkwmE4xG46Gd\n5KPRKBwOB2pqal57TS6Xo6SkhM6+IDoHNpsNoVBISxAKhQIVFRWQSqUIhUJU+c/lcumG66iRSCQo\nKChAZ2cnenp6oFKpEAgEYDKZMDIygtHRUdjt9qyZfv1aSIny888/x6VLl1BfX09H4z59+hSPHj3C\nxMQE7HZ7VjObH3WQfxs8Ho8uIqSV4TgGeODltba3t+PUqVMQiURU3ZpIJOD1emG1Wg99oMj7wGKx\nwOfzUVNTgz/96U8oKysDj8eD2+2G0WjEt99+i8XFRcRisX0bLplMRmei5+XlZXWWNofDgUKhgEaj\ngVwu31cHJZ7Ze4M1aVssLy9HfX39Pgtio9GIW7duYWJi4sjaFtlsNqRSKVpaWvDll1/i7//+76k7\nHxlfOj8/jzt37uDu3buIx+MHnmr26ghIb/bbJnYlEgn6WRzF7yaTycDj8dDrJ9dYUFAAjUZDf0da\nrRY1NTXUglqv1+PcuXN49uzZoV1LMpnEs2fP4PF4IBaLsbu7Cz6fDy6XSz+jvZ/T3gwDCZCkXLj3\nsyKnNLPZTMsmJSUltNYvEAiwvr6OxcVFWoI4DCKRCGw22z4rVJINISUEcppPJBL0PeTn59OOZydZ\nqQAAEfxJREFUB6VSSZ8Rv9+P2dlZBIPBfff/UaNUKtHW1obu7m50dnaCw+HAYrFgdnYWk5OTMBqN\nWbmOXwsRL2q1WrS1teH69eu4fPkyWCwWvF4vbDYb7ty5gxs3bmBnZyfrXhWfZJAnU4vq6uogk8mw\nsbEBv9//xhncuYQsxBqNBhqNhi7siUQCQ0NDuHfvHtbW1nLi904QCoW4cOECLl++DLVajby8PEQi\nEQwMDODu3bvUO/pVQRGZ0JSXl5e16VvvAvHu3ltCIIvypUuX0NLSsk8wRaZHHWWqkGwwzpw5g6am\nJhps4vE4HT37448/vnWWPPBSSCWVSsHlcqFWq9HZ2QmdTvdarz/p5SaOeC6XK2tZAVIbJyN0rVYr\nRCIRPfGTUcZHhdPpxP/8z/9gaGgIWq0WDQ0NKCkpobbHBKK+J7oAtVqNRCIBk8m07yQWj8cRCATg\n8/mo70VzczPq6uposLTb7YeeolUqlTh16tQ+vUkkEsH29jaePHmC27dv01kAZFPCZrOhUCjQ2NiI\nr7/+GnK5HAKBABqNBqurqxgZGcHU1BSWlpayZn5TUlKCr7/+Gk1NTeDxeIhEIrBYLHj48GFWRNIf\nikAgQFlZGc6fP4/f/va3qK+vpxvG+fl5/Pu//zvtg8+FnuCTDPJcLhf5+fmoqKgAn8/H6uoqvF4v\n3c0eB8hNkJ+fT602i4qKwOVyEQ6H4XK5MDIygpGREXg8nqxPbSMQEcnZs2dx+vRp5OfnIxKJwGq1\nYmhoCM+fP8fW1haSyST4fP4+v3cyv/y4ba52dnYwNTUFp9NJMz5tbW24cuUKWltb6QS3eDyOUCgE\nt9t9ZDtwHo8HPp8Pg8GA7u5udHR0oKSkhH6GiUQCm5ubWF5ehtFopMOLgJ8H1Ow9fapUKtpOVVRU\nhN7eXhrA9n6d2+2mU98Oezb3uxCLxfZtKjgcDlQqFaLRKHZ3dxEOh4+sREUUzrOzsxAIBFheXkZF\nRQXy8/P3eSKEQiFsbGzA5/MhGo1Cq9UiHo+/JiQlLZkkY8jn81FQUEDXm93dXSr4O8znIC8vD0ql\nkmb/COl0mpZ3OBwOzWjK5XKoVCpUVFTg9OnTaG9vh0QiQSqVgtfrhdlsxuTkJObn57M6pZAcyMgh\nh7yHN2WrjhNcLhcKhQLt7e04c+YMent7weVy6YTQsbEx3L9/H263O2cdRp9ckCepZRI8k8kkZmdn\n4Xa7s5ou/iWIirqkpASdnZ1obW1FaWkp8vLyYLPZMDExgbGxMZhMpgPbu7KFXq/H6dOn0d3dDYPB\nAD6fj8XFRTx58gTj4+OwWCw06LBYLDp1i/Tq2u12bG9v57ztby9utxtDQ0NwOBwQi8Xo6emhU8n2\nnni9Xi9MJhOWl5exsbFxJBstEoyvXbuG69evo7KyEmKxmL5OFuBkMgmNRoNgMEhPi6Wlpejr66MG\nKABQXl6O9vZ2KJVKyGQyiMVi5OXlvdbfTXwcZmdns26PfBAsFosOV+Hz+VhYWMC9e/eOxIRlr1dC\nOp3GixcvMD8/v28ENPBzWYcEb9KbfZB499WTcmFh4YHzBA4TUpMvKyujG1ORSISSkhKcPHkSwWCQ\nlkgMBgNOnDiB5uZm8Pl8iMViOuwlkUjAaDRiaGho3xTGbEGcB2OxGBQKBcRiMaqqqnDlyhX09/dj\namoqq9fzPpDPu6+vj1o1R6NR2Gw23Lx5Ew8fPsxpRxTwCQZ54KXLUGlpKcRiMe2v3Gt2kmuIKKy5\nuRknTpxAZ2cnKioqqIJ7dHQUw8PDmJ+fz7lbHElnarVaCAQCZDIZOlWOWDgCoPbCBoMBJSUliMfj\nmJ2dRX9/P1wuV04C/N769N5phaT+3tjYCJVKhStXrqCzs5O6E5I+9ImJCdy7dw9TU1MIBAJHkmoj\nc8zJqWVvJgR4mQqsqKhAJpNBYWEhNW4BXgb0jo6OfcFJrVajtLQUIpHorf3YpGc9kUjkLEtEINfc\n2dmJ+vp6JJNJWCwWjI+Pw+PxHMn/SdYCcuo9zJ9LyjuRSATJZPLISg/JZBJer3efIRURkFZVVYHF\nYqG+vh4AaLaQ9GsTnUEikUAgEMDCwgJMJhMCgUDWA9Lm5iYePnwIoVAInU5Hsw+tra3w+/3Uwc/r\n9cLj8UCn00GpVMLr9cLv9yMYDNIpkVwuF0qlkr7PV1lfXz8UXQ2Z/NfT04OLFy/ixIkTUKvVCIfD\nmJqawsjICPr7+2EymXLqrQ98gkGexWKhuLgYlZWVEAgEcLvdNMgfB8gJvrS0FF9//TV6enrQ2NiI\nTCYDk8mEO3fu4MGDBxgbGzsWhg9qtRq1tbWQSCT0BOR2u2GxWBCLxegpkrhUdXR0oLKykk5junPn\nTs4mzwEHB3qZTEbnAdTU1KC3txc6nY5uAuLxOEwmE+7fv4+//OUvRxoEiXe4xWLB8vIyioqKIBaL\n9w1VampqQm1tLSKRCGKxGF2ExWIxFArFO6faU6kU3TBmMpmcjhAlkOf17Nmz6O7uRk1NDex2O1ZX\nV4+FY9/7Qvrht7a2sLOzg0gkAh6PdyTiX+L3cFAQKS4upqf7vex1FNzd3aUW1QsLC/uyctnEZrPh\nxo0bqKqqogOX5HI56urqkEwmoVAo4HK5qPVwQ0MDDAYDlpaWYLVaYbfbsbu7CzabDZFIRJ/pveZL\nhPv37x9KkCcHhc8//xx//vOfIZfLEY1G4XQ60d/fj1u3bmFlZeXA2STZ5pMM8iqVihrhEA/1XArX\n9sJisaj5RHNzM4qLi+nUMKvVisHBQZoWzHWAB35ubyGzkuPxOJLJJFgsFvR6PR2K0dnZid7eXlRX\nVyMajWJjYwNbW1s5HQMJ/DyVbe+fsrIy/OEPf6A96fn5+XSRyGQyCAaDGBoawtTU1JFnUchn+vz5\ncySTSXC5XJw4cQKVlZX7gjdp8yK/B/Jv74PRaMTy8jLi8ThmZmbQ39+fNU/ygyDK84qKCvT09KCg\noAChUAgLCwvvZSJ1HCEjjLe2tuD1erG0tASbzXaop2Ry8j2oT/5NkO6AeDyOcDhMh3WNjo7C6XTm\nJGtILMcXFhYwMTFBDxUVFRVQKBRoamqiA6bW1tZgMBig1+up/4bH46HPL5/PR3FxMerr62kL4N61\ndHl5Gc+fP//gayZlNrVaDalUCjabjcXFRfzwww8YGhrC2trasWlv/aSCPBnmUVZWhtLSUqRSKfh8\nvmNziudyuRAKhdDr9aiqqkJZWRkkEgmdD//8+XMsLCwcG0tS4OVCvLfmC7w83Tc3NwN4ebOrVCp0\ndXWhra0N4XAYq6ureP78OaxWa85udNL+RE6vZBEAXqqSlUrlvq8nXvB+vx/Ly8t48eIFHXZ0lOz1\n0U8mkygrK4NUKqW1SZJyJ77eb4IYrni9XjidTsTj8dc2V2TyIbEJnZ+fz+kGTCQSoaqqCs3NzWht\nbQWXy8Xa2hrGxsaOfLbEURMMBmEymWgq2WQyweVyHer9FI/H4Xa76UhTkUj01rY34ijo9/vhdrvh\ncDjQ39+Px48fY3NzM2c+HGSE+MrKCiYnJ8Hn86HX65GXl4fS0lJUVlYiGo3C7/djZ2cHWq0Wcrkc\ntbW1CAaD9Lp3d3cRi8UgFAqh0Wjg8XioLzz53A9LPEucAoVCITgcDu3r/+mnn7C+vn5sYg7wiQV5\niUSC4uJidHR0wGAwYHt7O6f95a8iFotRWFiIzs5OdHR0QCgUIhwOw+Fw4Pvvv8e9e/cOdQTlYRAM\nBrG1tUVrZUKhEL29vTTIk6E6xI9gfn6etu9YLJacXTdJu5PefTJ8403EYjF4vV5MTk5iaGgIq6ur\nWRl/SiBTv+bm5qBQKCCXy1FZWQmtVvtO359KpRAMBjEyMoL//M//hNvtfq1MQoIBUS7n2hxKo9Hg\n+vXrdCSzyWTCs2fPcOfOnayONT0KNjc3cePGDeq0SDoFDlObsr6+ju+++w6RSAQSiQRlZWVvtNUF\nXrYOLi4uYmVlBUajEaOjo/Q+yaUwjHiC2O12vHjxAmw2G263G2q1Gnq9HhqNho6yVigU4HK54HK5\ndCAQCeCRSIRupsxmM4aHhzE5OYnt7W162Dgs5810Ok3LZ4FAAGazGQsLCzCbzTlT0b+JTyrI5+Xl\nQSaTUfMVp9N5rIK8Xq9Hd3c3zp49i+bmZggEAqytreH58+eYnp6G1WrNulHCL2G32zEyMoJUKoX6\n+nq6kOTn59PFgc1mw2g0YmZmBnNzc5idncXS0lJOSySJRAJWqxWTk5MoLi5Ga2srKioq3vj1ZrMZ\nN2/epIugy+XK6imXCLaWlpao7qGhoQHl5eXUTpik8GOxGBwOBzweDxXhkZTn8+fPMTIyAr/f/5pD\nGMlq5LoMxGaz0dDQgJ6eHurLb7PZ8PjxY+rpnWt3xw8lGo1ibW2NaisikcihZ4VIP/nw8DAEAgH6\n+vpgMBggk8nAYrGotsTlciEej2N1dRVLS0tYX1+H1WqF2WzOeVcF8HNJjYhdnU4n9dIvLS1FYWHh\nO/2cUCiE2dlZOJ1OOmvCYrEgGAwe+vuMRqPY2trC48eP4fF44HA4MDk5eay6iAifVJDn8Xh0pjJZ\nCI9L2oTFYqGiogKXL19GZ2cn9Ho93eEPDg7Sm/G4YbVa0d/fT3uFlUolxGIxEokENjY2EAqFwOPx\n8OOPP+K7777D9vb2sdjJxuNxLC4uUjc3gUCA0tJSWnbY20YFvKxX/8u//EtOg0ssFoPFYoHNZsPQ\n0BCamppQU1MDlUqF06dPQ6fTgc1m04zD7OwsVlZWaNaCLDa5zKAcBFH/k8+ew+Hg7Nmz+Prrr9HR\n0QG3243x8XHcvHkTAwMDOb7awyGVSh35vZRKpZBKpehkNqIv4fF44HK58Pv96O/vx/j4OPx+PxwO\nBxwOB8Lh8LE7TAAvMw1OpxOTk5PU5lin0x04FOggIpEIlpaWqK/IUW5mI5EIIpEIvv/+e/z000+I\nRqPU4+G48UkFeZVKhcbGRgiFQlpvOg6WiGTetFKppGljn8+HpaUlTExMYHl5OacK9Lfh8/mwsrJC\nXeJu3rxJvbBDoRA9yVsslqyMTXxfSE+8QqEAm81GW1sb8vPzEY1GMTY2RhXcU1NTx+baiRhvdXUV\n29vb4PP5mJ6exp07d+gJzeVywev1IhAI0A0LmXV/nGCxWGhoaEBVVRUKCgpo8Dt//jx0Oh2MRiMd\nQPKx1+FzRTQahd1ux3fffYfHjx9Tv/x4PA6z2QyPx4NkMolwOIxIJHLsp7gBLzfpOzs7iMVi7zy7\nIJ1Ow+/3Z7UMRbobiP7nOPJJBXlSk2exWHC5XJiZmYHNZsv1ZdHZwqWlpVCr1eBwOHC73RgdHcXU\n1FTObWvfBtmhbm1tUWONjwliHkM80EOhEJRKJUKhEB4+fEgngm1vbx+bh5RkGNxu97ESYf4aWCwW\nlEolNWNJJBJwOByQy+Vwu90YGBjA0NAQRkdHj0UG6GMkkUhgZ2cHIyMjub6UQ4NkKY7rukjItcfE\nu/BJBXmC3++Hx+OhZhS5RiaToa2tjQoC4/E4TdNPT09TW1iGo8NkMmFjYwN3796lE7b2eo2nUqlj\nmWr72MlkMnC5XHC73dBqtUin09jZ2cHjx4+xurqK6elpuFwuhMPhY29hysDwMfJJBXmn04mhoSEs\nLS0hGAzC6/XmXGQE/KzEBF6e6o1GI4aHh/eJYhiOllAoRL3IGbKLx+PB7Owsbt++jd3dXdjtdths\nNjgcDmxubjL3PwPDEfJJBXky7vG4EQ6HsbKyQvuXR0ZG8ODBg2OdpmdgOAwymQxtZR0bG8v15TAw\n/L8ju6On9pP7I3aWIMK7mpoaVFdXY2Fhgc6IPy51YAYGBgaGj45fjOFMkGdgYGBgYPg4yWUMZ2Bg\nYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBg\nYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBg\nYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBg\nYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGBgYGD4f83/AWvhJbdqo4fI\nAAAAAElFTkSuQmCC\n", + "text/plain": [ + "
+ 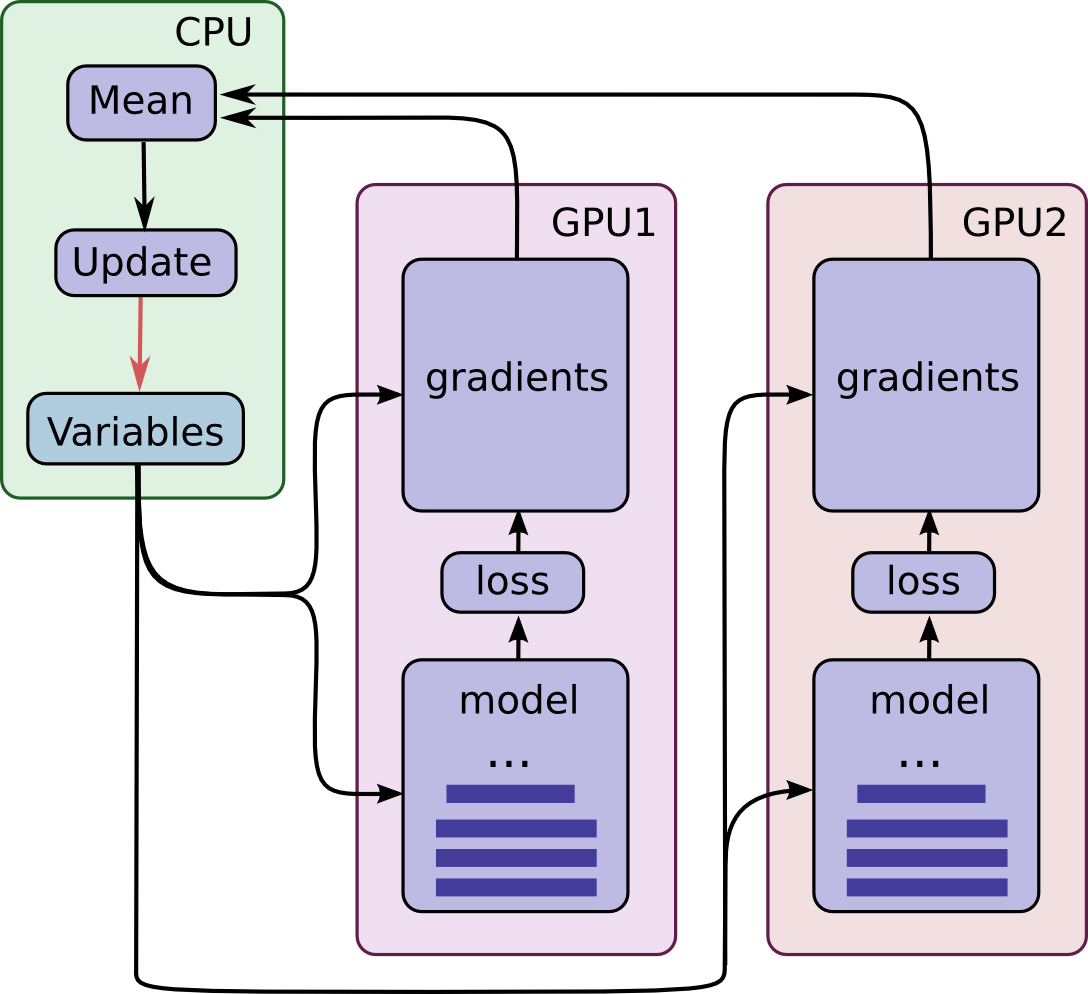 +
+
+
+Each tower computes the gradients for a portion of the batch and the gradients
+are combined and averaged across the multiple towers in order to provide a
+single update of the Variables stored on the CPU.
+
+A crucial aspect of training a network of this size is *training speed* in terms
+of wall-clock time. The training speed is dictated by many factors -- most
+importantly the batch size and the learning rate schedule. Both of these
+parameters are heavily coupled to the hardware set up.
+
+Generally speaking, a batch size is a difficult parameter to tune as it requires
+balancing memory demands of the model, memory available on the GPU and speed of
+computation. Generally speaking, employing larger batch sizes leads to more
+efficient computation and potentially more efficient training steps.
+
+We have tested several hardware setups for training this model from scratch but
+we emphasize that depending your hardware set up, you may need to adapt the
+batch size and learning rate schedule.
+
+Please see the comments in `inception_train.py` for a few selected learning rate
+plans based on some selected hardware setups.
+
+To train this model, you simply need to specify the following:
+
+```shell
+# Build the model. Note that we need to make sure the TensorFlow is ready to
+# use before this as this command will not build TensorFlow.
+cd tensorflow-models/inception
+bazel build //inception:imagenet_train
+
+# run it
+bazel-bin/inception/imagenet_train --num_gpus=1 --batch_size=32 --train_dir=/tmp/imagenet_train --data_dir=/tmp/imagenet_data
+```
+
+The model reads in the ImageNet training data from `--data_dir`. If you followed
+the instructions in [Getting Started](#getting-started), then set
+`--data_dir="${DATA_DIR}"`. The script assumes that there exists a set of
+sharded TFRecord files containing the ImageNet data. If you have not created
+TFRecord files, please refer to [Getting Started](#getting-started)
+
+Here is the output of the above command line when running on a Tesla K40c:
+
+```shell
+2016-03-07 12:24:59.922898: step 0, loss = 13.11 (5.3 examples/sec; 6.064 sec/batch)
+2016-03-07 12:25:55.206783: step 10, loss = 13.71 (9.4 examples/sec; 3.394 sec/batch)
+2016-03-07 12:26:28.905231: step 20, loss = 14.81 (9.5 examples/sec; 3.380 sec/batch)
+2016-03-07 12:27:02.699719: step 30, loss = 14.45 (9.5 examples/sec; 3.378 sec/batch)
+2016-03-07 12:27:36.515699: step 40, loss = 13.98 (9.5 examples/sec; 3.376 sec/batch)
+2016-03-07 12:28:10.220956: step 50, loss = 13.92 (9.6 examples/sec; 3.327 sec/batch)
+2016-03-07 12:28:43.658223: step 60, loss = 13.28 (9.6 examples/sec; 3.350 sec/batch)
+...
+```
+
+In this example, a log entry is printed every 10 step and the line includes the
+total loss (starts around 13.0-14.0) and the speed of processing in terms of
+throughput (examples / sec) and batch speed (sec/batch).
+
+The number of GPU devices is specified by `--num_gpus` (which defaults to 1).
+Specifying `--num_gpus` greater then 1 splits the batch evenly split across the
+GPU cards.
+
+```shell
+# Build the model. Note that we need to make sure the TensorFlow is ready to
+# use before this as this command will not build TensorFlow.
+cd tensorflow-models/inception
+bazel build //inception:imagenet_train
+
+# run it
+bazel-bin/inception/imagenet_train --num_gpus=2 --batch_size=64 --train_dir=/tmp/imagenet_train
+```
+
+This model splits the batch of 64 images across 2 GPUs and calculates the
+average gradient by waiting for both GPUs to finish calculating the gradients
+from their respective data (See diagram above). Generally speaking, using larger
+numbers of GPUs leads to higher throughput as well as the opportunity to use
+larger batch sizes. In turn, larger batch sizes imply better estimates of the
+gradient enabling the usage of higher learning rates. In summary, using more
+GPUs results in simply faster training speed.
+
+Note that selecting a batch size is a difficult parameter to tune as it requires
+balancing memory demands of the model, memory available on the GPU and speed of
+computation. Generally speaking, employing larger batch sizes leads to more
+efficient computation and potentially more efficient training steps.
+
+Note that there is considerable noise in the loss function on individual steps
+in the previous log. Because of this noise, it is difficult to discern how well
+a model is learning. The solution to the last problem is to launch TensorBoard
+pointing to the directory containing the events log.
+
+```shell
+tensorboard --logdir=/tmp/imagenet_train
+```
+
+TensorBoard has access to the many Summaries produced by the model that describe
+multitudes of statistics tracking the model behavior and the quality of the
+learned model. In particular, TensorBoard tracks a exponentially smoothed
+version of the loss. In practice, it is far easier to judge how well a model
+learns by monitoring the smoothed version of the loss.
+
+## How to Train from Scratch in a Distributed Setting
+
+**NOTE** Distributed TensorFlow requires version 0.8 or later.
+
+Distributed TensorFlow lets us use multiple machines to train a model faster.
+This is quite different from the training with multiple GPU towers on a single
+machine where all parameters and gradients computation are in the same place. We
+coordinate the computation across multiple machines by employing a centralized
+repository for parameters that maintains a unified, single copy of model
+parameters. Each individual machine sends gradient updates to the centralized
+parameter repository which coordinates these updates and sends back updated
+parameters to the individual machines running the model training.
+
+We term each machine that runs a copy of the training a `worker` or `replica`.
+We term each machine that maintains model parameters a `ps`, short for
+`parameter server`. Note that we might have more than one machine acting as a
+`ps` as the model parameters may be sharded across multiple machines.
+
+Variables may be updated with synchronous or asynchronous gradient updates. One
+may construct a an [`Optimizer`](https://www.tensorflow.org/api_docs/python/train.html#optimizers) in TensorFlow
+that constructs the necessary graph for either case diagrammed below from the
+TensorFlow [Whitepaper](http://download.tensorflow.org/paper/whitepaper2015.pdf):
+
+
+
+ 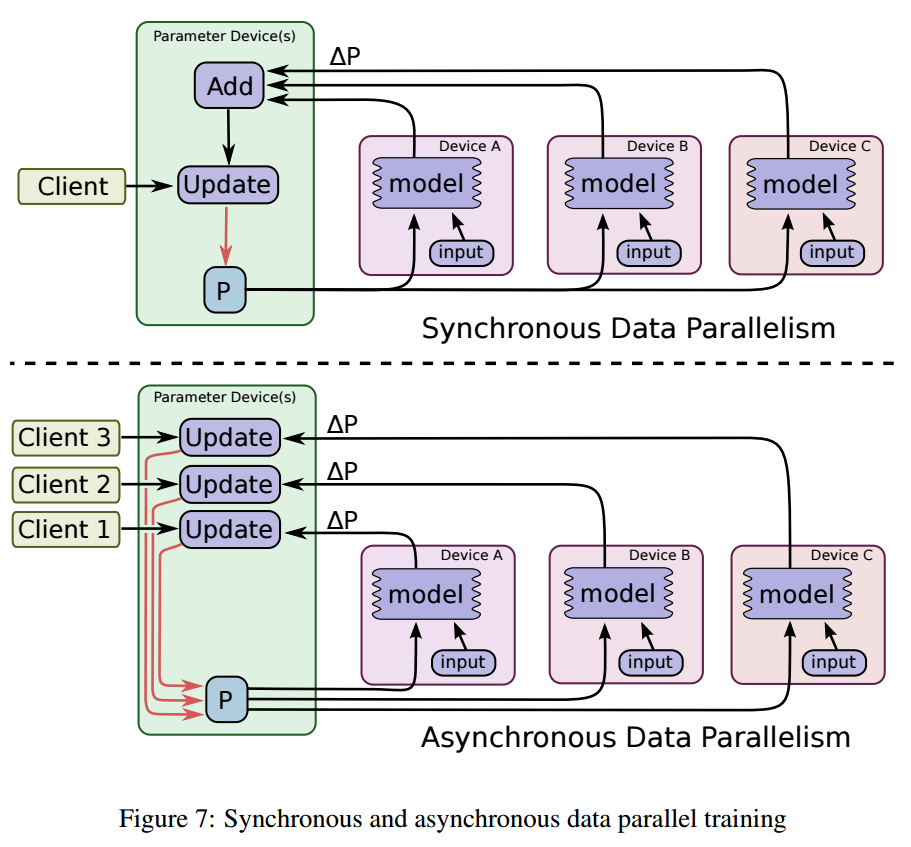 +
+
+
+In [a recent paper](https://arxiv.org/abs/1604.00981), synchronous gradient
+updates have demonstrated to reach higher accuracy in a shorter amount of time.
+In this distributed Inception example we employ synchronous gradient updates.
+
+Note that in this example each replica has a single tower that uses one GPU.
+
+The command-line flags `worker_hosts` and `ps_hosts` specify available servers.
+The same binary will be used for both the `worker` jobs and the `ps` jobs.
+Command line flag `job_name` will be used to specify what role a task will be
+playing and `task_id` will be used to identify which one of the jobs it is
+running. Several things to note here:
+
+* The numbers of `ps` and `worker` tasks are inferred from the lists of hosts
+ specified in the flags. The `task_id` should be within the range `[0,
+ num_ps_tasks)` for `ps` tasks and `[0, num_worker_tasks)` for `worker`
+ tasks.
+* `ps` and `worker` tasks can run on the same machine, as long as that machine
+ has sufficient resources to handle both tasks. Note that the `ps` task does
+ not benefit from a GPU, so it should not attempt to use one (see below).
+* Multiple `worker` tasks can run on the same machine with multiple GPUs so
+ machine_A with 2 GPUs may have 2 workers while machine_B with 1 GPU just has
+ 1 worker.
+* The default learning rate schedule works well for a wide range of number of
+ replicas [25, 50, 100] but feel free to tune it for even better results.
+* The command line of both `ps` and `worker` tasks should include the complete
+ list of `ps_hosts` and `worker_hosts`.
+* There is a chief `worker` among all workers which defaults to `worker` 0.
+ The chief will be in charge of initializing all the parameters, writing out
+ the summaries and the checkpoint. The checkpoint and summary will be in the
+ `train_dir` of the host for `worker` 0.
+* Each worker processes a batch_size number of examples but each gradient
+ update is computed from all replicas. Hence, the effective batch size of
+ this model is batch_size * num_workers.
+
+```shell
+# Build the model. Note that we need to make sure the TensorFlow is ready to
+# use before this as this command will not build TensorFlow.
+cd tensorflow-models/inception
+bazel build //inception:imagenet_distributed_train
+
+# To start worker 0, go to the worker0 host and run the following (Note that
+# task_id should be in the range [0, num_worker_tasks):
+bazel-bin/inception/imagenet_distributed_train \
+--batch_size=32 \
+--data_dir=$HOME/imagenet-data \
+--job_name='worker' \
+--task_id=0 \
+--ps_hosts='ps0.example.com:2222' \
+--worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
+
+# To start worker 1, go to the worker1 host and run the following (Note that
+# task_id should be in the range [0, num_worker_tasks):
+bazel-bin/inception/imagenet_distributed_train \
+--batch_size=32 \
+--data_dir=$HOME/imagenet-data \
+--job_name='worker' \
+--task_id=1 \
+--ps_hosts='ps0.example.com:2222' \
+--worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
+
+# To start the parameter server (ps), go to the ps host and run the following (Note
+# that task_id should be in the range [0, num_ps_tasks):
+bazel-bin/inception/imagenet_distributed_train \
+--job_name='ps' \
+--task_id=0 \
+--ps_hosts='ps0.example.com:2222' \
+--worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
+```
+
+If you have installed a GPU-compatible version of TensorFlow, the `ps` will also
+try to allocate GPU memory although it is not helpful. This could potentially
+crash the worker on the same machine as it has little to no GPU memory to
+allocate. To avoid this, you can prepend the previous command to start `ps`
+with: `CUDA_VISIBLE_DEVICES=''`
+
+```shell
+CUDA_VISIBLE_DEVICES='' bazel-bin/inception/imagenet_distributed_train \
+--job_name='ps' \
+--task_id=0 \
+--ps_hosts='ps0.example.com:2222' \
+--worker_hosts='worker0.example.com:2222,worker1.example.com:2222'
+```
+
+If you have run everything correctly, you should see a log in each `worker` job
+that looks like the following. Note the training speed varies depending on your
+hardware and the first several steps could take much longer.
+
+```shell
+INFO:tensorflow:PS hosts are: ['ps0.example.com:2222', 'ps1.example.com:2222']
+INFO:tensorflow:Worker hosts are: ['worker0.example.com:2222', 'worker1.example.com:2222']
+I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job ps -> {ps0.example.com:2222, ps1.example.com:2222}
+I tensorflow/core/distributed_runtime/rpc/grpc_channel.cc:206] Initialize HostPortsGrpcChannelCache for job worker -> {localhost:2222, worker1.example.com:2222}
+I tensorflow/core/distributed_runtime/rpc/grpc_server_lib.cc:202] Started server with target: grpc://localhost:2222
+INFO:tensorflow:Created variable global_step:0 with shape () and init
++$ export PYTHONPATH=$PYTHONPATH:/path/to/your/directory/lfads/ ++ +where "path/to/your/directory" is replaced with the path to the LFADS repository (you can get this path by using the `pwd` command). This allows the nested directories to access modules from their parent directory. + +## Generate synthetic data + +In order to generate the synthetic datasets first, from the top-level lfads directory, run: + +```sh +$ cd synth_data +$ ./run_generate_synth_data.sh +$ cd .. +``` + +These synthetic datasets are provided 1. to gain insight into how the LFADS algorithm operates, and 2. to give reasonable starting points for analyses you might be interested for your own data. + +## Train an LFADS model + +Now that we have our example datasets, we can train some models! To spin up an LFADS model on the synthetic data, run any of the following commands. For the examples that are in the paper, the important hyperparameters are roughly replicated. Most hyperparameters are insensitive to small changes or won't ever be changed unless you want a very fine level of control. In the first example, all hyperparameter flags are enumerated for easy copy-pasting, but for the rest of the examples only the most important flags (~the first 9) are specified for brevity. For a full list of flags, their descriptions, and their default values, refer to the top of `run_lfads.py`. Please see Table 1 in the Online Methods of the associated paper for definitions of the most important hyperparameters. + +```sh +# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with spiking noise +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_no_inputs \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_no_inputs \ +--co_dim=0 \ +--factors_dim=20 \ +--ext_input_dim=0 \ +--controller_input_lag=1 \ +--output_dist=poisson \ +--do_causal_controller=false \ +--batch_size=128 \ +--learning_rate_init=0.01 \ +--learning_rate_stop=1e-05 \ +--learning_rate_decay_factor=0.95 \ +--learning_rate_n_to_compare=6 \ +--do_reset_learning_rate=false \ +--keep_prob=0.95 \ +--con_dim=128 \ +--gen_dim=200 \ +--ci_enc_dim=128 \ +--ic_dim=64 \ +--ic_enc_dim=128 \ +--ic_prior_var_min=0.1 \ +--gen_cell_input_weight_scale=1.0 \ +--cell_weight_scale=1.0 \ +--do_feed_factors_to_controller=true \ +--kl_start_step=0 \ +--kl_increase_steps=2000 \ +--kl_ic_weight=1.0 \ +--l2_con_scale=0.0 \ +--l2_gen_scale=2000.0 \ +--l2_start_step=0 \ +--l2_increase_steps=2000 \ +--ic_prior_var_scale=0.1 \ +--ic_post_var_min=0.0001 \ +--kl_co_weight=1.0 \ +--prior_ar_nvar=0.1 \ +--cell_clip_value=5.0 \ +--max_ckpt_to_keep_lve=5 \ +--do_train_prior_ar_atau=true \ +--co_prior_var_scale=0.1 \ +--csv_log=fitlog \ +--feedback_factors_or_rates=factors \ +--do_train_prior_ar_nvar=true \ +--max_grad_norm=200.0 \ +--device=gpu:0 \ +--num_steps_for_gen_ic=100000000 \ +--ps_nexamples_to_process=100000000 \ +--checkpoint_name=lfads_vae \ +--temporal_spike_jitter_width=0 \ +--checkpoint_pb_load_name=checkpoint \ +--inject_ext_input_to_gen=false \ +--co_mean_corr_scale=0.0 \ +--gen_cell_rec_weight_scale=1.0 \ +--max_ckpt_to_keep=5 \ +--output_filename_stem="" \ +--ic_prior_var_max=0.1 \ +--prior_ar_atau=10.0 \ +--do_train_io_only=false \ +--do_train_encoder_only=false + +# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with Gaussian noise +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=gaussian_chaotic_rnn_no_inputs \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ +--co_dim=1 \ +--factors_dim=20 \ +--output_dist=gaussian + + +# Run LFADS on chaotic rnn data with input pulses (g = 2.5) +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_inputs_g2p5 \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ +--co_dim=1 \ +--factors_dim=20 \ +--output_dist=poisson + +# Run LFADS on multi-session RNN data +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_multisession \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_multisession \ +--factors_dim=10 \ +--output_dist=poisson + +# Run LFADS on integration to bound model data +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=itb_rnn \ +--lfads_save_dir=/tmp/lfads_itb_rnn \ +--co_dim=1 \ +--factors_dim=20 \ +--controller_input_lag=0 \ +--output_dist=poisson + +# Run LFADS on chaotic RNN data with labels +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnns_labeled \ +--lfads_save_dir=/tmp/lfads_chaotic_rnns_labeled \ +--co_dim=0 \ +--factors_dim=20 \ +--controller_input_lag=0 \ +--ext_input_dim=1 \ +--output_dist=poisson + +# Run LFADS on chaotic rnn data with no input pulses (g = 1.5) with Gaussian noise +$ python run_lfads.py --kind=train \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_no_inputs \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_no_inputs \ +--co_dim=0 \ +--factors_dim=20 \ +--ext_input_dim=0 \ +--controller_input_lag=1 \ +--output_dist=gaussian \ + + +``` + +**Tip**: If you are running LFADS on GPU and would like to run more than one model concurrently, set the `--allow_gpu_growth=True` flag on each job, otherwise one model will take up the entire GPU for performance purposes. Also, one needs to install the TensorFlow libraries with GPU support. + + +## Visualize a training model + +To visualize training curves and various other metrics while training and LFADS model, run the following command on your model directory. To launch a tensorboard on the chaotic RNN data with input pulses, for example: + +```sh +tensorboard --logdir=/tmp/lfads_chaotic_rnn_inputs_g2p5 +``` + +## Evaluate a trained model + +Once your model is finished training, there are multiple ways you can evaluate +it. Below are some sample commands to evaluate an LFADS model trained on the +chaotic rnn data with input pulses (g = 2.5). The key differences here are +setting the `--kind` flag to the appropriate mode, as well as the +`--checkpoint_pb_load_name` flag to `checkpoint_lve` and the `--batch_size` flag +(if you'd like to make it larger or smaller). All other flags should be the +same as used in training, so that the same model architecture is built. + +```sh +# Take samples from posterior then average (denoising operation) +$ python run_lfads.py --kind=posterior_sample_and_average \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_inputs_g2p5 \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ +--co_dim=1 \ +--factors_dim=20 \ +--batch_size=1024 \ +--checkpoint_pb_load_name=checkpoint_lve + +# Sample from prior (generation of completely new samples) +$ python run_lfads.py --kind=prior_sample \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_inputs_g2p5 \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ +--co_dim=1 \ +--factors_dim=20 \ +--batch_size=50 \ +--checkpoint_pb_load_name=checkpoint_lve + +# Write down model parameters +$ python run_lfads.py --kind=write_model_params \ +--data_dir=/tmp/rnn_synth_data_v1.0/ \ +--data_filename_stem=chaotic_rnn_inputs_g2p5 \ +--lfads_save_dir=/tmp/lfads_chaotic_rnn_inputs_g2p5 \ +--co_dim=1 \ +--factors_dim=20 \ +--checkpoint_pb_load_name=checkpoint_lve +``` + +## Contact + +File any issues with the [issue tracker](https://github.com/tensorflow/models/issues). For any questions or problems, this code is maintained by [@sussillo](https://github.com/sussillo) and [@jazcollins](https://github.com/jazcollins). + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/distributions.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/distributions.py" new file mode 100644 index 00000000..351d019a --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/distributions.py" @@ -0,0 +1,493 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +import numpy as np +import tensorflow as tf +from utils import linear, log_sum_exp + +class Poisson(object): + """Poisson distributon + + Computes the log probability under the model. + + """ + def __init__(self, log_rates): + """ Create Poisson distributions with log_rates parameters. + + Args: + log_rates: a tensor-like list of log rates underlying the Poisson dist. + """ + self.logr = log_rates + + def logp(self, bin_counts): + """Compute the log probability for the counts in the bin, under the model. + + Args: + bin_counts: array-like integer counts + + Returns: + The log-probability under the Poisson models for each element of + bin_counts. + """ + k = tf.to_float(bin_counts) + # log poisson(k, r) = log(r^k * e^(-r) / k!) = k log(r) - r - log k! + # log poisson(k, r=exp(x)) = k * x - exp(x) - lgamma(k + 1) + return k * self.logr - tf.exp(self.logr) - tf.lgamma(k + 1) + + +def diag_gaussian_log_likelihood(z, mu=0.0, logvar=0.0): + """Log-likelihood under a Gaussian distribution with diagonal covariance. + Returns the log-likelihood for each dimension. One should sum the + results for the log-likelihood under the full multidimensional model. + + Args: + z: The value to compute the log-likelihood. + mu: The mean of the Gaussian + logvar: The log variance of the Gaussian. + + Returns: + The log-likelihood under the Gaussian model. + """ + + return -0.5 * (logvar + np.log(2*np.pi) + \ + tf.square((z-mu)/tf.exp(0.5*logvar))) + + +def gaussian_pos_log_likelihood(unused_mean, logvar, noise): + """Gaussian log-likelihood function for a posterior in VAE + + Note: This function is specialized for a posterior distribution, that has the + form of z = mean + sigma * noise. + + Args: + unused_mean: ignore + logvar: The log variance of the distribution + noise: The noise used in the sampling of the posterior. + + Returns: + The log-likelihood under the Gaussian model. + """ + # ln N(z; mean, sigma) = - ln(sigma) - 0.5 ln 2pi - noise^2 / 2 + return - 0.5 * (logvar + np.log(2 * np.pi) + tf.square(noise)) + + +class Gaussian(object): + """Base class for Gaussian distribution classes.""" + pass + + +class DiagonalGaussian(Gaussian): + """Diagonal Gaussian with different constant mean and variances in each + dimension. + """ + + def __init__(self, batch_size, z_size, mean, logvar): + """Create a diagonal gaussian distribution. + + Args: + batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. + z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. + mean: The N-D mean of the distribution. + logvar: The N-D log variance of the diagonal distribution. + """ + size__xz = [None, z_size] + self.mean = mean # bxn already + self.logvar = logvar # bxn already + self.noise = noise = tf.random_normal(tf.shape(logvar)) + self.sample = mean + tf.exp(0.5 * logvar) * noise + mean.set_shape(size__xz) + logvar.set_shape(size__xz) + self.sample.set_shape(size__xz) + + def logp(self, z=None): + """Compute the log-likelihood under the distribution. + + Args: + z (optional): value to compute likelihood for, if None, use sample. + + Returns: + The likelihood of z under the model. + """ + if z is None: + z = self.sample + + # This is needed to make sure that the gradients are simple. + # The value of the function shouldn't change. + if z == self.sample: + return gaussian_pos_log_likelihood(self.mean, self.logvar, self.noise) + + return diag_gaussian_log_likelihood(z, self.mean, self.logvar) + + +class LearnableDiagonalGaussian(Gaussian): + """Diagonal Gaussian whose mean and variance are learned parameters.""" + + def __init__(self, batch_size, z_size, name, mean_init=0.0, + var_init=1.0, var_min=0.0, var_max=1000000.0): + """Create a learnable diagonal gaussian distribution. + + Args: + batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. + z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. + name: prefix name for the mean and log TF variables. + mean_init (optional): The N-D mean initialization of the distribution. + var_init (optional): The N-D variance initialization of the diagonal + distribution. + var_min (optional): The minimum value the learned variance can take in any + dimension. + var_max (optional): The maximum value the learned variance can take in any + dimension. + """ + + size_1xn = [1, z_size] + size__xn = [None, z_size] + size_bx1 = tf.stack([batch_size, 1]) + assert var_init > 0.0, "Problems" + assert var_max >= var_min, "Problems" + assert var_init >= var_min, "Problems" + assert var_max >= var_init, "Problems" + + + z_mean_1xn = tf.get_variable(name=name+"/mean", shape=size_1xn, + initializer=tf.constant_initializer(mean_init)) + self.mean_bxn = mean_bxn = tf.tile(z_mean_1xn, size_bx1) + mean_bxn.set_shape(size__xn) # tile loses shape + + log_var_init = np.log(var_init) + if var_max > var_min: + var_is_trainable = True + else: + var_is_trainable = False + + z_logvar_1xn = \ + tf.get_variable(name=(name+"/logvar"), shape=size_1xn, + initializer=tf.constant_initializer(log_var_init), + trainable=var_is_trainable) + + if var_is_trainable: + z_logit_var_1xn = tf.exp(z_logvar_1xn) + z_var_1xn = tf.nn.sigmoid(z_logit_var_1xn)*(var_max-var_min) + var_min + z_logvar_1xn = tf.log(z_var_1xn) + + logvar_bxn = tf.tile(z_logvar_1xn, size_bx1) + self.logvar_bxn = logvar_bxn + self.noise_bxn = noise_bxn = tf.random_normal(tf.shape(logvar_bxn)) + self.sample_bxn = mean_bxn + tf.exp(0.5 * logvar_bxn) * noise_bxn + + def logp(self, z=None): + """Compute the log-likelihood under the distribution. + + Args: + z (optional): value to compute likelihood for, if None, use sample. + + Returns: + The likelihood of z under the model. + """ + if z is None: + z = self.sample + + # This is needed to make sure that the gradients are simple. + # The value of the function shouldn't change. + if z == self.sample_bxn: + return gaussian_pos_log_likelihood(self.mean_bxn, self.logvar_bxn, + self.noise_bxn) + + return diag_gaussian_log_likelihood(z, self.mean_bxn, self.logvar_bxn) + + @property + def mean(self): + return self.mean_bxn + + @property + def logvar(self): + return self.logvar_bxn + + @property + def sample(self): + return self.sample_bxn + + +class DiagonalGaussianFromInput(Gaussian): + """Diagonal Gaussian whose mean and variance are conditioned on other + variables. + + Note: the parameters to convert from input to the learned mean and log + variance are held in this class. + """ + + def __init__(self, x_bxu, z_size, name, var_min=0.0): + """Create an input dependent diagonal Gaussian distribution. + + Args: + x: The input tensor from which the mean and variance are computed, + via a linear transformation of x. I.e. + mu = Wx + b, log(var) = Mx + c + z_size: The size of the distribution. + name: The name to prefix to learned variables. + var_min (optional): Minimal variance allowed. This is an additional + way to control the amount of information getting through the stochastic + layer. + """ + size_bxn = tf.stack([tf.shape(x_bxu)[0], z_size]) + self.mean_bxn = mean_bxn = linear(x_bxu, z_size, name=(name+"/mean")) + logvar_bxn = linear(x_bxu, z_size, name=(name+"/logvar")) + if var_min > 0.0: + logvar_bxn = tf.log(tf.exp(logvar_bxn) + var_min) + self.logvar_bxn = logvar_bxn + + self.noise_bxn = noise_bxn = tf.random_normal(size_bxn) + self.noise_bxn.set_shape([None, z_size]) + self.sample_bxn = mean_bxn + tf.exp(0.5 * logvar_bxn) * noise_bxn + + def logp(self, z=None): + """Compute the log-likelihood under the distribution. + + Args: + z (optional): value to compute likelihood for, if None, use sample. + + Returns: + The likelihood of z under the model. + """ + + if z is None: + z = self.sample + + # This is needed to make sure that the gradients are simple. + # The value of the function shouldn't change. + if z == self.sample_bxn: + return gaussian_pos_log_likelihood(self.mean_bxn, + self.logvar_bxn, self.noise_bxn) + + return diag_gaussian_log_likelihood(z, self.mean_bxn, self.logvar_bxn) + + @property + def mean(self): + return self.mean_bxn + + @property + def logvar(self): + return self.logvar_bxn + + @property + def sample(self): + return self.sample_bxn + + +class GaussianProcess: + """Base class for Gaussian processes.""" + pass + + +class LearnableAutoRegressive1Prior(GaussianProcess): + """AR(1) model where autocorrelation and process variance are learned + parameters. Assumed zero mean. + + """ + + def __init__(self, batch_size, z_size, + autocorrelation_taus, noise_variances, + do_train_prior_ar_atau, do_train_prior_ar_nvar, + num_steps, name): + """Create a learnable autoregressive (1) process. + + Args: + batch_size: The size of the batch, i.e. 0th dim in 2D tensor of samples. + z_size: The dimension of the distribution, i.e. 1st dim in 2D tensor. + autocorrelation_taus: The auto correlation time constant of the AR(1) + process. + A value of 0 is uncorrelated gaussian noise. + noise_variances: The variance of the additive noise, *not* the process + variance. + do_train_prior_ar_atau: Train or leave as constant, the autocorrelation? + do_train_prior_ar_nvar: Train or leave as constant, the noise variance? + num_steps: Number of steps to run the process. + name: The name to prefix to learned TF variables. + """ + + # Note the use of the plural in all of these quantities. This is intended + # to mark that even though a sample z_t from the posterior is thought of a + # single sample of a multidimensional gaussian, the prior is actually + # thought of as U AR(1) processes, where U is the dimension of the inferred + # input. + size_bx1 = tf.stack([batch_size, 1]) + size__xu = [None, z_size] + # process variance, the variance at time t over all instantiations of AR(1) + # with these parameters. + log_evar_inits_1xu = tf.expand_dims(tf.log(noise_variances), 0) + self.logevars_1xu = logevars_1xu = \ + tf.Variable(log_evar_inits_1xu, name=name+"/logevars", dtype=tf.float32, + trainable=do_train_prior_ar_nvar) + self.logevars_bxu = logevars_bxu = tf.tile(logevars_1xu, size_bx1) + logevars_bxu.set_shape(size__xu) # tile loses shape + + # \tau, which is the autocorrelation time constant of the AR(1) process + log_atau_inits_1xu = tf.expand_dims(tf.log(autocorrelation_taus), 0) + self.logataus_1xu = logataus_1xu = \ + tf.Variable(log_atau_inits_1xu, name=name+"/logatau", dtype=tf.float32, + trainable=do_train_prior_ar_atau) + + # phi in x_t = \mu + phi x_tm1 + \eps + # phi = exp(-1/tau) + # phi = exp(-1/exp(logtau)) + # phi = exp(-exp(-logtau)) + phis_1xu = tf.exp(-tf.exp(-logataus_1xu)) + self.phis_bxu = phis_bxu = tf.tile(phis_1xu, size_bx1) + phis_bxu.set_shape(size__xu) + + # process noise + # pvar = evar / (1- phi^2) + # logpvar = log ( exp(logevar) / (1 - phi^2) ) + # logpvar = logevar - log(1-phi^2) + # logpvar = logevar - (log(1-phi) + log(1+phi)) + self.logpvars_1xu = \ + logevars_1xu - tf.log(1.0-phis_1xu) - tf.log(1.0+phis_1xu) + self.logpvars_bxu = logpvars_bxu = tf.tile(self.logpvars_1xu, size_bx1) + logpvars_bxu.set_shape(size__xu) + + # process mean (zero but included in for completeness) + self.pmeans_bxu = pmeans_bxu = tf.zeros_like(phis_bxu) + + # For sampling from the prior during de-novo generation. + self.means_t = means_t = [None] * num_steps + self.logvars_t = logvars_t = [None] * num_steps + self.samples_t = samples_t = [None] * num_steps + self.gaussians_t = gaussians_t = [None] * num_steps + sample_bxu = tf.zeros_like(phis_bxu) + for t in range(num_steps): + # process variance used here to make process completely stationary + if t == 0: + logvar_pt_bxu = self.logpvars_bxu + else: + logvar_pt_bxu = self.logevars_bxu + + z_mean_pt_bxu = pmeans_bxu + phis_bxu * sample_bxu + gaussians_t[t] = DiagonalGaussian(batch_size, z_size, + mean=z_mean_pt_bxu, + logvar=logvar_pt_bxu) + sample_bxu = gaussians_t[t].sample + samples_t[t] = sample_bxu + logvars_t[t] = logvar_pt_bxu + means_t[t] = z_mean_pt_bxu + + def logp_t(self, z_t_bxu, z_tm1_bxu=None): + """Compute the log-likelihood under the distribution for a given time t, + not the whole sequence. + + Args: + z_t_bxu: sample to compute likelihood for at time t. + z_tm1_bxu (optional): sample condition probability of z_t upon. + + Returns: + The likelihood of p_t under the model at time t. i.e. + p(z_t|z_tm1_bxu) = N(z_tm1_bxu * phis, eps^2) + + """ + if z_tm1_bxu is None: + return diag_gaussian_log_likelihood(z_t_bxu, self.pmeans_bxu, + self.logpvars_bxu) + else: + means_t_bxu = self.pmeans_bxu + self.phis_bxu * z_tm1_bxu + logp_tgtm1_bxu = diag_gaussian_log_likelihood(z_t_bxu, + means_t_bxu, + self.logevars_bxu) + return logp_tgtm1_bxu + + +class KLCost_GaussianGaussian(object): + """log p(x|z) + KL(q||p) terms for Gaussian posterior and Gaussian prior. See + eqn 10 and Appendix B in VAE for latter term, + http://arxiv.org/abs/1312.6114 + + The log p(x|z) term is the reconstruction error under the model. + The KL term represents the penalty for passing information from the encoder + to the decoder. + To sample KL(q||p), we simply sample + ln q - ln p + by drawing samples from q and averaging. + """ + + def __init__(self, zs, prior_zs): + """Create a lower bound in three parts, normalized reconstruction + cost, normalized KL divergence cost, and their sum. + + E_q[ln p(z_i | z_{i+1}) / q(z_i | x) + \int q(z) ln p(z) dz = - 0.5 ln(2pi) - 0.5 \sum (ln(sigma_p^2) + \ + sigma_q^2 / sigma_p^2 + (mean_p - mean_q)^2 / sigma_p^2) + + \int q(z) ln q(z) dz = - 0.5 ln(2pi) - 0.5 \sum (ln(sigma_q^2) + 1) + + Args: + zs: posterior z ~ q(z|x) + prior_zs: prior zs + """ + # L = -KL + log p(x|z), to maximize bound on likelihood + # -L = KL - log p(x|z), to minimize bound on NLL + # so 'KL cost' is postive KL divergence + kl_b = 0.0 + for z, prior_z in zip(zs, prior_zs): + assert isinstance(z, Gaussian) + assert isinstance(prior_z, Gaussian) + # ln(2pi) terms cancel + kl_b += 0.5 * tf.reduce_sum( + prior_z.logvar - z.logvar + + tf.exp(z.logvar - prior_z.logvar) + + tf.square((z.mean - prior_z.mean) / tf.exp(0.5 * prior_z.logvar)) + - 1.0, [1]) + + self.kl_cost_b = kl_b + self.kl_cost = tf.reduce_mean(kl_b) + + +class KLCost_GaussianGaussianProcessSampled(object): + """ log p(x|z) + KL(q||p) terms for Gaussian posterior and Gaussian process + prior via sampling. + + The log p(x|z) term is the reconstruction error under the model. + The KL term represents the penalty for passing information from the encoder + to the decoder. + To sample KL(q||p), we simply sample + ln q - ln p + by drawing samples from q and averaging. + """ + + def __init__(self, post_zs, prior_z_process): + """Create a lower bound in three parts, normalized reconstruction + cost, normalized KL divergence cost, and their sum. + + Args: + post_zs: posterior z ~ q(z|x) + prior_z_process: prior AR(1) process + """ + assert len(post_zs) > 1, "GP is for time, need more than 1 time step." + assert isinstance(prior_z_process, GaussianProcess), "Must use GP." + + # L = -KL + log p(x|z), to maximize bound on likelihood + # -L = KL - log p(x|z), to minimize bound on NLL + # so 'KL cost' is postive KL divergence + z0_bxu = post_zs[0].sample + logq_bxu = post_zs[0].logp(z0_bxu) + logp_bxu = prior_z_process.logp_t(z0_bxu) + z_tm1_bxu = z0_bxu + for z_t in post_zs[1:]: + # posterior is independent in time, prior is not + z_t_bxu = z_t.sample + logq_bxu += z_t.logp(z_t_bxu) + logp_bxu += prior_z_process.logp_t(z_t_bxu, z_tm1_bxu) + z_tm1_bxu = z_t_bxu + + kl_bxu = logq_bxu - logp_bxu + kl_b = tf.reduce_sum(kl_bxu, [1]) + self.kl_cost_b = kl_b + self.kl_cost = tf.reduce_mean(kl_b) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/lfads.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/lfads.py" new file mode 100644 index 00000000..0bbb0a3b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/lfads.py" @@ -0,0 +1,2170 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +""" +LFADS - Latent Factor Analysis via Dynamical Systems. + +LFADS is an unsupervised method to decompose time series data into +various factors, such as an initial condition, a generative +dynamical system, control inputs to that generator, and a low +dimensional description of the observed data, called the factors. +Additionally, the observations have a noise model (in this case +Poisson), so a denoised version of the observations is also created +(e.g. underlying rates of a Poisson distribution given the observed +event counts). + +The main data structure being passed around is a dataset. This is a dictionary +of data dictionaries. + +DATASET: The top level dictionary is simply name (string -> dictionary). +The nested dictionary is the DATA DICTIONARY, which has the following keys: + 'train_data' and 'valid_data', whose values are the corresponding training + and validation data with shape + ExTxD, E - # examples, T - # time steps, D - # dimensions in data. + The data dictionary also has a few more keys: + 'train_ext_input' and 'valid_ext_input', if there are know external inputs + to the system being modeled, these take on dimensions: + ExTxI, E - # examples, T - # time steps, I = # dimensions in input. + 'alignment_matrix_cxf' - If you are using multiple days data, it's possible + that one can align the channels (see manuscript). If so each dataset will + contain this matrix, which will be used for both the input adapter and the + output adapter for each dataset. These matrices, if provided, must be of + size [data_dim x factors] where data_dim is the number of neurons recorded + on that day, and factors is chosen and set through the '--factors' flag. + 'alignment_bias_c' - See alignment_matrix_cxf. This bias will used to + the offset for the alignment transformation. It will *subtract* off the + bias from the data, so pca style inits can align factors across sessions. + + + If one runs LFADS on data where the true rates are known for some trials, + (say simulated, testing data, as in the example shipped with the paper), then + one can add three more fields for plotting purposes. These are 'train_truth' + and 'valid_truth', and 'conversion_factor'. These have the same dimensions as + 'train_data', and 'valid_data' but represent the underlying rates of the + observations. Finally, if one needs to convert scale for plotting the true + underlying firing rates, there is the 'conversion_factor' key. +""" + +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + + +import numpy as np +import os +import tensorflow as tf +from distributions import LearnableDiagonalGaussian, DiagonalGaussianFromInput +from distributions import diag_gaussian_log_likelihood +from distributions import KLCost_GaussianGaussian, Poisson +from distributions import LearnableAutoRegressive1Prior +from distributions import KLCost_GaussianGaussianProcessSampled + +from utils import init_linear, linear, list_t_bxn_to_tensor_bxtxn, write_data +from utils import log_sum_exp, flatten +from plot_lfads import plot_lfads + + +class GRU(object): + """Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078). + + """ + def __init__(self, num_units, forget_bias=1.0, weight_scale=1.0, + clip_value=np.inf, collections=None): + """Create a GRU object. + + Args: + num_units: Number of units in the GRU + forget_bias (optional): Hack to help learning. + weight_scale (optional): weights are scaled by ws/sqrt(#inputs), with + ws being the weight scale. + clip_value (optional): if the recurrent values grow above this value, + clip them. + collections (optional): List of additonal collections variables should + belong to. + """ + self._num_units = num_units + self._forget_bias = forget_bias + self._weight_scale = weight_scale + self._clip_value = clip_value + self._collections = collections + + @property + def state_size(self): + return self._num_units + + @property + def output_size(self): + return self._num_units + + @property + def state_multiplier(self): + return 1 + + def output_from_state(self, state): + """Return the output portion of the state.""" + return state + + def __call__(self, inputs, state, scope=None): + """Gated recurrent unit (GRU) function. + + Args: + inputs: A 2D batch x input_dim tensor of inputs. + state: The previous state from the last time step. + scope (optional): TF variable scope for defined GRU variables. + + Returns: + A tuple (state, state), where state is the newly computed state at time t. + It is returned twice to respect an interface that works for LSTMs. + """ + + x = inputs + h = state + if inputs is not None: + xh = tf.concat(axis=1, values=[x, h]) + else: + xh = h + + with tf.variable_scope(scope or type(self).__name__): # "GRU" + with tf.variable_scope("Gates"): # Reset gate and update gate. + # We start with bias of 1.0 to not reset and not update. + r, u = tf.split(axis=1, num_or_size_splits=2, value=linear(xh, + 2 * self._num_units, + alpha=self._weight_scale, + name="xh_2_ru", + collections=self._collections)) + r, u = tf.sigmoid(r), tf.sigmoid(u + self._forget_bias) + with tf.variable_scope("Candidate"): + xrh = tf.concat(axis=1, values=[x, r * h]) + c = tf.tanh(linear(xrh, self._num_units, name="xrh_2_c", + collections=self._collections)) + new_h = u * h + (1 - u) * c + new_h = tf.clip_by_value(new_h, -self._clip_value, self._clip_value) + + return new_h, new_h + + +class GenGRU(object): + """Gated Recurrent Unit cell (cf. http://arxiv.org/abs/1406.1078). + + This version is specialized for the generator, but isn't as fast, so + we have two. Note this allows for l2 regularization on the recurrent + weights, but also implicitly rescales the inputs via the 1/sqrt(input) + scaling in the linear helper routine to be large magnitude, if there are + fewer inputs than recurrent state. + + """ + def __init__(self, num_units, forget_bias=1.0, + input_weight_scale=1.0, rec_weight_scale=1.0, clip_value=np.inf, + input_collections=None, recurrent_collections=None): + """Create a GRU object. + + Args: + num_units: Number of units in the GRU + forget_bias (optional): Hack to help learning. + input_weight_scale (optional): weights are scaled ws/sqrt(#inputs), with + ws being the weight scale. + rec_weight_scale (optional): weights are scaled ws/sqrt(#inputs), + with ws being the weight scale. + clip_value (optional): if the recurrent values grow above this value, + clip them. + input_collections (optional): List of additonal collections variables + that input->rec weights should belong to. + recurrent_collections (optional): List of additonal collections variables + that rec->rec weights should belong to. + """ + self._num_units = num_units + self._forget_bias = forget_bias + self._input_weight_scale = input_weight_scale + self._rec_weight_scale = rec_weight_scale + self._clip_value = clip_value + self._input_collections = input_collections + self._rec_collections = recurrent_collections + + @property + def state_size(self): + return self._num_units + + @property + def output_size(self): + return self._num_units + + @property + def state_multiplier(self): + return 1 + + def output_from_state(self, state): + """Return the output portion of the state.""" + return state + + def __call__(self, inputs, state, scope=None): + """Gated recurrent unit (GRU) function. + + Args: + inputs: A 2D batch x input_dim tensor of inputs. + state: The previous state from the last time step. + scope (optional): TF variable scope for defined GRU variables. + + Returns: + A tuple (state, state), where state is the newly computed state at time t. + It is returned twice to respect an interface that works for LSTMs. + """ + + x = inputs + h = state + with tf.variable_scope(scope or type(self).__name__): # "GRU" + with tf.variable_scope("Gates"): # Reset gate and update gate. + # We start with bias of 1.0 to not reset and not update. + r_x = u_x = 0.0 + if x is not None: + r_x, u_x = tf.split(axis=1, num_or_size_splits=2, value=linear(x, + 2 * self._num_units, + alpha=self._input_weight_scale, + do_bias=False, + name="x_2_ru", + normalized=False, + collections=self._input_collections)) + + r_h, u_h = tf.split(axis=1, num_or_size_splits=2, value=linear(h, + 2 * self._num_units, + do_bias=True, + alpha=self._rec_weight_scale, + name="h_2_ru", + collections=self._rec_collections)) + r = r_x + r_h + u = u_x + u_h + r, u = tf.sigmoid(r), tf.sigmoid(u + self._forget_bias) + + with tf.variable_scope("Candidate"): + c_x = 0.0 + if x is not None: + c_x = linear(x, self._num_units, name="x_2_c", do_bias=False, + alpha=self._input_weight_scale, + normalized=False, + collections=self._input_collections) + c_rh = linear(r*h, self._num_units, name="rh_2_c", do_bias=True, + alpha=self._rec_weight_scale, + collections=self._rec_collections) + c = tf.tanh(c_x + c_rh) + + new_h = u * h + (1 - u) * c + new_h = tf.clip_by_value(new_h, -self._clip_value, self._clip_value) + + return new_h, new_h + + +class LFADS(object): + """LFADS - Latent Factor Analysis via Dynamical Systems. + + LFADS is an unsupervised method to decompose time series data into + various factors, such as an initial condition, a generative + dynamical system, inferred inputs to that generator, and a low + dimensional description of the observed data, called the factors. + Additoinally, the observations have a noise model (in this case + Poisson), so a denoised version of the observations is also created + (e.g. underlying rates of a Poisson distribution given the observed + event counts). + """ + + def __init__(self, hps, kind="train", datasets=None): + """Create an LFADS model. + + train - a model for training, sampling of posteriors is used + posterior_sample_and_average - sample from the posterior, this is used + for evaluating the expected value of the outputs of LFADS, given a + specific input, by averaging over multiple samples from the approx + posterior. Also used for the lower bound on the negative + log-likelihood using IWAE error (Importance Weighed Auto-encoder). + This is the denoising operation. + prior_sample - a model for generation - sampling from priors is used + + Args: + hps: The dictionary of hyper parameters. + kind: the type of model to build (see above). + datasets: a dictionary of named data_dictionaries, see top of lfads.py + """ + print("Building graph...") + all_kinds = ['train', 'posterior_sample_and_average', 'posterior_push_mean', + 'prior_sample'] + assert kind in all_kinds, 'Wrong kind' + if hps.feedback_factors_or_rates == "rates": + assert len(hps.dataset_names) == 1, \ + "Multiple datasets not supported for rate feedback." + num_steps = hps.num_steps + ic_dim = hps.ic_dim + co_dim = hps.co_dim + ext_input_dim = hps.ext_input_dim + cell_class = GRU + gen_cell_class = GenGRU + + def makelambda(v): # Used with tf.case + return lambda: v + + # Define the data placeholder, and deal with all parts of the graph + # that are dataset dependent. + self.dataName = tf.placeholder(tf.string, shape=()) + # The batch_size to be inferred from data, as normal. + # Additionally, the data_dim will be inferred as well, allowing for a + # single placeholder for all datasets, regardless of data dimension. + if hps.output_dist == 'poisson': + # Enforce correct dtype + assert np.issubdtype( + datasets[hps.dataset_names[0]]['train_data'].dtype, int), \ + "Data dtype must be int for poisson output distribution" + data_dtype = tf.int32 + elif hps.output_dist == 'gaussian': + assert np.issubdtype( + datasets[hps.dataset_names[0]]['train_data'].dtype, float), \ + "Data dtype must be float for gaussian output dsitribution" + data_dtype = tf.float32 + else: + assert False, "NIY" + self.dataset_ph = dataset_ph = tf.placeholder(data_dtype, + [None, num_steps, None], + name="data") + self.train_step = tf.get_variable("global_step", [], tf.int64, + tf.zeros_initializer(), + trainable=False) + self.hps = hps + ndatasets = hps.ndatasets + factors_dim = hps.factors_dim + self.preds = preds = [None] * ndatasets + self.fns_in_fac_Ws = fns_in_fac_Ws = [None] * ndatasets + self.fns_in_fatcor_bs = fns_in_fac_bs = [None] * ndatasets + self.fns_out_fac_Ws = fns_out_fac_Ws = [None] * ndatasets + self.fns_out_fac_bs = fns_out_fac_bs = [None] * ndatasets + self.datasetNames = dataset_names = hps.dataset_names + self.ext_inputs = ext_inputs = None + + if len(dataset_names) == 1: # single session + if 'alignment_matrix_cxf' in datasets[dataset_names[0]].keys(): + used_in_factors_dim = factors_dim + in_identity_if_poss = False + else: + used_in_factors_dim = hps.dataset_dims[dataset_names[0]] + in_identity_if_poss = True + else: # multisession + used_in_factors_dim = factors_dim + in_identity_if_poss = False + + for d, name in enumerate(dataset_names): + data_dim = hps.dataset_dims[name] + in_mat_cxf = None + in_bias_1xf = None + align_bias_1xc = None + + if datasets and 'alignment_matrix_cxf' in datasets[name].keys(): + dataset = datasets[name] + if hps.do_train_readin: + print("Initializing trainable readin matrix with alignment matrix" \ + " provided for dataset:", name) + else: + print("Setting non-trainable readin matrix to alignment matrix" \ + " provided for dataset:", name) + in_mat_cxf = dataset['alignment_matrix_cxf'].astype(np.float32) + if in_mat_cxf.shape != (data_dim, factors_dim): + raise ValueError("""Alignment matrix must have dimensions %d x %d + (data_dim x factors_dim), but currently has %d x %d."""% + (data_dim, factors_dim, in_mat_cxf.shape[0], + in_mat_cxf.shape[1])) + if datasets and 'alignment_bias_c' in datasets[name].keys(): + dataset = datasets[name] + if hps.do_train_readin: + print("Initializing trainable readin bias with alignment bias " \ + "provided for dataset:", name) + else: + print("Setting non-trainable readin bias to alignment bias " \ + "provided for dataset:", name) + align_bias_c = dataset['alignment_bias_c'].astype(np.float32) + align_bias_1xc = np.expand_dims(align_bias_c, axis=0) + if align_bias_1xc.shape[1] != data_dim: + raise ValueError("""Alignment bias must have dimensions %d + (data_dim), but currently has %d."""% + (data_dim, in_mat_cxf.shape[0])) + if in_mat_cxf is not None and align_bias_1xc is not None: + # (data - alignment_bias) * W_in + # data * W_in - alignment_bias * W_in + # So b = -alignment_bias * W_in to accommodate PCA style offset. + in_bias_1xf = -np.dot(align_bias_1xc, in_mat_cxf) + + if hps.do_train_readin: + # only add to IO transformations collection only if we want it to be + # learnable, because IO_transformations collection will be trained + # when do_train_io_only + collections_readin=['IO_transformations'] + else: + collections_readin=None + + in_fac_lin = init_linear(data_dim, used_in_factors_dim, + do_bias=True, + mat_init_value=in_mat_cxf, + bias_init_value=in_bias_1xf, + identity_if_possible=in_identity_if_poss, + normalized=False, name="x_2_infac_"+name, + collections=collections_readin, + trainable=hps.do_train_readin) + in_fac_W, in_fac_b = in_fac_lin + fns_in_fac_Ws[d] = makelambda(in_fac_W) + fns_in_fac_bs[d] = makelambda(in_fac_b) + + with tf.variable_scope("glm"): + out_identity_if_poss = False + if len(dataset_names) == 1 and \ + factors_dim == hps.dataset_dims[dataset_names[0]]: + out_identity_if_poss = True + for d, name in enumerate(dataset_names): + data_dim = hps.dataset_dims[name] + in_mat_cxf = None + if datasets and 'alignment_matrix_cxf' in datasets[name].keys(): + dataset = datasets[name] + in_mat_cxf = dataset['alignment_matrix_cxf'].astype(np.float32) + + if datasets and 'alignment_bias_c' in datasets[name].keys(): + dataset = datasets[name] + align_bias_c = dataset['alignment_bias_c'].astype(np.float32) + align_bias_1xc = np.expand_dims(align_bias_c, axis=0) + + out_mat_fxc = None + out_bias_1xc = None + if in_mat_cxf is not None: + out_mat_fxc = in_mat_cxf.T + if align_bias_1xc is not None: + out_bias_1xc = align_bias_1xc + + if hps.output_dist == 'poisson': + out_fac_lin = init_linear(factors_dim, data_dim, do_bias=True, + mat_init_value=out_mat_fxc, + bias_init_value=out_bias_1xc, + identity_if_possible=out_identity_if_poss, + normalized=False, + name="fac_2_logrates_"+name, + collections=['IO_transformations']) + out_fac_W, out_fac_b = out_fac_lin + + elif hps.output_dist == 'gaussian': + out_fac_lin_mean = \ + init_linear(factors_dim, data_dim, do_bias=True, + mat_init_value=out_mat_fxc, + bias_init_value=out_bias_1xc, + normalized=False, + name="fac_2_means_"+name, + collections=['IO_transformations']) + out_fac_W_mean, out_fac_b_mean = out_fac_lin_mean + + mat_init_value = np.zeros([factors_dim, data_dim]).astype(np.float32) + bias_init_value = np.ones([1, data_dim]).astype(np.float32) + out_fac_lin_logvar = \ + init_linear(factors_dim, data_dim, do_bias=True, + mat_init_value=mat_init_value, + bias_init_value=bias_init_value, + normalized=False, + name="fac_2_logvars_"+name, + collections=['IO_transformations']) + out_fac_W_mean, out_fac_b_mean = out_fac_lin_mean + out_fac_W_logvar, out_fac_b_logvar = out_fac_lin_logvar + out_fac_W = tf.concat( + axis=1, values=[out_fac_W_mean, out_fac_W_logvar]) + out_fac_b = tf.concat( + axis=1, values=[out_fac_b_mean, out_fac_b_logvar]) + else: + assert False, "NIY" + + preds[d] = tf.equal(tf.constant(name), self.dataName) + data_dim = hps.dataset_dims[name] + fns_out_fac_Ws[d] = makelambda(out_fac_W) + fns_out_fac_bs[d] = makelambda(out_fac_b) + + pf_pairs_in_fac_Ws = zip(preds, fns_in_fac_Ws) + pf_pairs_in_fac_bs = zip(preds, fns_in_fac_bs) + pf_pairs_out_fac_Ws = zip(preds, fns_out_fac_Ws) + pf_pairs_out_fac_bs = zip(preds, fns_out_fac_bs) + + this_in_fac_W = tf.case(pf_pairs_in_fac_Ws, exclusive=True) + this_in_fac_b = tf.case(pf_pairs_in_fac_bs, exclusive=True) + this_out_fac_W = tf.case(pf_pairs_out_fac_Ws, exclusive=True) + this_out_fac_b = tf.case(pf_pairs_out_fac_bs, exclusive=True) + + # External inputs (not changing by dataset, by definition). + if hps.ext_input_dim > 0: + self.ext_input = tf.placeholder(tf.float32, + [None, num_steps, ext_input_dim], + name="ext_input") + else: + self.ext_input = None + ext_input_bxtxi = self.ext_input + + self.keep_prob = keep_prob = tf.placeholder(tf.float32, [], "keep_prob") + self.batch_size = batch_size = int(hps.batch_size) + self.learning_rate = tf.Variable(float(hps.learning_rate_init), + trainable=False, name="learning_rate") + self.learning_rate_decay_op = self.learning_rate.assign( + self.learning_rate * hps.learning_rate_decay_factor) + + # Dropout the data. + dataset_do_bxtxd = tf.nn.dropout(tf.to_float(dataset_ph), keep_prob) + if hps.ext_input_dim > 0: + ext_input_do_bxtxi = tf.nn.dropout(ext_input_bxtxi, keep_prob) + else: + ext_input_do_bxtxi = None + + # ENCODERS + def encode_data(dataset_bxtxd, enc_cell, name, forward_or_reverse, + num_steps_to_encode): + """Encode data for LFADS + Args: + dataset_bxtxd - the data to encode, as a 3 tensor, with dims + time x batch x data dims. + enc_cell: encoder cell + name: name of encoder + forward_or_reverse: string, encode in forward or reverse direction + num_steps_to_encode: number of steps to encode, 0:num_steps_to_encode + Returns: + encoded data as a list with num_steps_to_encode items, in order + """ + if forward_or_reverse == "forward": + dstr = "_fwd" + time_fwd_or_rev = range(num_steps_to_encode) + else: + dstr = "_rev" + time_fwd_or_rev = reversed(range(num_steps_to_encode)) + + with tf.variable_scope(name+"_enc"+dstr, reuse=False): + enc_state = tf.tile( + tf.Variable(tf.zeros([1, enc_cell.state_size]), + name=name+"_enc_t0"+dstr), tf.stack([batch_size, 1])) + enc_state.set_shape([None, enc_cell.state_size]) # tile loses shape + + enc_outs = [None] * num_steps_to_encode + for i, t in enumerate(time_fwd_or_rev): + with tf.variable_scope(name+"_enc"+dstr, reuse=True if i > 0 else None): + dataset_t_bxd = dataset_bxtxd[:,t,:] + in_fac_t_bxf = tf.matmul(dataset_t_bxd, this_in_fac_W) + this_in_fac_b + in_fac_t_bxf.set_shape([None, used_in_factors_dim]) + if ext_input_dim > 0 and not hps.inject_ext_input_to_gen: + ext_input_t_bxi = ext_input_do_bxtxi[:,t,:] + enc_input_t_bxfpe = tf.concat( + axis=1, values=[in_fac_t_bxf, ext_input_t_bxi]) + else: + enc_input_t_bxfpe = in_fac_t_bxf + enc_out, enc_state = enc_cell(enc_input_t_bxfpe, enc_state) + enc_outs[t] = enc_out + + return enc_outs + + # Encode initial condition means and variances + # ([x_T, x_T-1, ... x_0] and [x_0, x_1, ... x_T] -> g0/c0) + self.ic_enc_fwd = [None] * num_steps + self.ic_enc_rev = [None] * num_steps + if ic_dim > 0: + enc_ic_cell = cell_class(hps.ic_enc_dim, + weight_scale=hps.cell_weight_scale, + clip_value=hps.cell_clip_value) + ic_enc_fwd = encode_data(dataset_do_bxtxd, enc_ic_cell, + "ic", "forward", + hps.num_steps_for_gen_ic) + ic_enc_rev = encode_data(dataset_do_bxtxd, enc_ic_cell, + "ic", "reverse", + hps.num_steps_for_gen_ic) + self.ic_enc_fwd = ic_enc_fwd + self.ic_enc_rev = ic_enc_rev + + # Encoder control input means and variances, bi-directional encoding so: + # ([x_T, x_T-1, ..., x_0] and [x_0, x_1 ... x_T] -> u_t) + self.ci_enc_fwd = [None] * num_steps + self.ci_enc_rev = [None] * num_steps + if co_dim > 0: + enc_ci_cell = cell_class(hps.ci_enc_dim, + weight_scale=hps.cell_weight_scale, + clip_value=hps.cell_clip_value) + ci_enc_fwd = encode_data(dataset_do_bxtxd, enc_ci_cell, + "ci", "forward", + hps.num_steps) + if hps.do_causal_controller: + ci_enc_rev = None + else: + ci_enc_rev = encode_data(dataset_do_bxtxd, enc_ci_cell, + "ci", "reverse", + hps.num_steps) + self.ci_enc_fwd = ci_enc_fwd + self.ci_enc_rev = ci_enc_rev + + # STOCHASTIC LATENT VARIABLES, priors and posteriors + # (initial conditions g0, and control inputs, u_t) + # Note that zs represent all the stochastic latent variables. + with tf.variable_scope("z", reuse=False): + self.prior_zs_g0 = None + self.posterior_zs_g0 = None + self.g0s_val = None + if ic_dim > 0: + self.prior_zs_g0 = \ + LearnableDiagonalGaussian(batch_size, ic_dim, name="prior_g0", + mean_init=0.0, + var_min=hps.ic_prior_var_min, + var_init=hps.ic_prior_var_scale, + var_max=hps.ic_prior_var_max) + ic_enc = tf.concat(axis=1, values=[ic_enc_fwd[-1], ic_enc_rev[0]]) + ic_enc = tf.nn.dropout(ic_enc, keep_prob) + self.posterior_zs_g0 = \ + DiagonalGaussianFromInput(ic_enc, ic_dim, "ic_enc_2_post_g0", + var_min=hps.ic_post_var_min) + if kind in ["train", "posterior_sample_and_average", + "posterior_push_mean"]: + zs_g0 = self.posterior_zs_g0 + else: + zs_g0 = self.prior_zs_g0 + if kind in ["train", "posterior_sample_and_average", "prior_sample"]: + self.g0s_val = zs_g0.sample + else: + self.g0s_val = zs_g0.mean + + # Priors for controller, 'co' for controller output + self.prior_zs_co = prior_zs_co = [None] * num_steps + self.posterior_zs_co = posterior_zs_co = [None] * num_steps + self.zs_co = zs_co = [None] * num_steps + self.prior_zs_ar_con = None + if co_dim > 0: + # Controller outputs + autocorrelation_taus = [hps.prior_ar_atau for x in range(hps.co_dim)] + noise_variances = [hps.prior_ar_nvar for x in range(hps.co_dim)] + self.prior_zs_ar_con = prior_zs_ar_con = \ + LearnableAutoRegressive1Prior(batch_size, hps.co_dim, + autocorrelation_taus, + noise_variances, + hps.do_train_prior_ar_atau, + hps.do_train_prior_ar_nvar, + num_steps, "u_prior_ar1") + + # CONTROLLER -> GENERATOR -> RATES + # (u(t) -> gen(t) -> factors(t) -> rates(t) -> p(x_t|z_t) ) + self.controller_outputs = u_t = [None] * num_steps + self.con_ics = con_state = None + self.con_states = con_states = [None] * num_steps + self.con_outs = con_outs = [None] * num_steps + self.gen_inputs = gen_inputs = [None] * num_steps + if co_dim > 0: + # gen_cell_class here for l2 penalty recurrent weights + # didn't split the cell_weight scale here, because I doubt it matters + con_cell = gen_cell_class(hps.con_dim, + input_weight_scale=hps.cell_weight_scale, + rec_weight_scale=hps.cell_weight_scale, + clip_value=hps.cell_clip_value, + recurrent_collections=['l2_con_reg']) + with tf.variable_scope("con", reuse=False): + self.con_ics = tf.tile( + tf.Variable(tf.zeros([1, hps.con_dim*con_cell.state_multiplier]), + name="c0"), + tf.stack([batch_size, 1])) + self.con_ics.set_shape([None, con_cell.state_size]) # tile loses shape + con_states[-1] = self.con_ics + + gen_cell = gen_cell_class(hps.gen_dim, + input_weight_scale=hps.gen_cell_input_weight_scale, + rec_weight_scale=hps.gen_cell_rec_weight_scale, + clip_value=hps.cell_clip_value, + recurrent_collections=['l2_gen_reg']) + with tf.variable_scope("gen", reuse=False): + if ic_dim == 0: + self.gen_ics = tf.tile( + tf.Variable(tf.zeros([1, gen_cell.state_size]), name="g0"), + tf.stack([batch_size, 1])) + else: + self.gen_ics = linear(self.g0s_val, gen_cell.state_size, + identity_if_possible=True, + name="g0_2_gen_ic") + + self.gen_states = gen_states = [None] * num_steps + self.gen_outs = gen_outs = [None] * num_steps + gen_states[-1] = self.gen_ics + gen_outs[-1] = gen_cell.output_from_state(gen_states[-1]) + self.factors = factors = [None] * num_steps + factors[-1] = linear(gen_outs[-1], factors_dim, do_bias=False, + normalized=True, name="gen_2_fac") + + self.rates = rates = [None] * num_steps + # rates[-1] is collected to potentially feed back to controller + with tf.variable_scope("glm", reuse=False): + if hps.output_dist == 'poisson': + log_rates_t0 = tf.matmul(factors[-1], this_out_fac_W) + this_out_fac_b + log_rates_t0.set_shape([None, None]) + rates[-1] = tf.exp(log_rates_t0) # rate + rates[-1].set_shape([None, hps.dataset_dims[hps.dataset_names[0]]]) + elif hps.output_dist == 'gaussian': + mean_n_logvars = tf.matmul(factors[-1],this_out_fac_W) + this_out_fac_b + mean_n_logvars.set_shape([None, None]) + means_t_bxd, logvars_t_bxd = tf.split(axis=1, num_or_size_splits=2, + value=mean_n_logvars) + rates[-1] = means_t_bxd + else: + assert False, "NIY" + + # We support multiple output distributions, for example Poisson, and also + # Gaussian. In these two cases respectively, there are one and two + # parameters (rates vs. mean and variance). So the output_dist_params + # tensor will variable sizes via tf.concat and tf.split, along the 1st + # dimension. So in the case of gaussian, for example, it'll be + # batch x (D+D), where each D dims is the mean, and then variances, + # respectively. For a distribution with 3 parameters, it would be + # batch x (D+D+D). + self.output_dist_params = dist_params = [None] * num_steps + self.log_p_xgz_b = log_p_xgz_b = 0.0 # log P(x|z) + for t in range(num_steps): + # Controller + if co_dim > 0: + # Build inputs for controller + tlag = t - hps.controller_input_lag + if tlag < 0: + con_in_f_t = tf.zeros_like(ci_enc_fwd[0]) + else: + con_in_f_t = ci_enc_fwd[tlag] + if hps.do_causal_controller: + # If controller is causal (wrt to data generation process), then it + # cannot see future data. Thus, excluding ci_enc_rev[t] is obvious. + # Less obvious is the need to exclude factors[t-1]. This arises + # because information flows from g0 through factors to the controller + # input. The g0 encoding is backwards, so we must necessarily exclude + # the factors in order to keep the controller input purely from a + # forward encoding (however unlikely it is that + # g0->factors->controller channel might actually be used in this way). + con_in_list_t = [con_in_f_t] + else: + tlag_rev = t + hps.controller_input_lag + if tlag_rev >= num_steps: + # better than zeros + con_in_r_t = tf.zeros_like(ci_enc_rev[0]) + else: + con_in_r_t = ci_enc_rev[tlag_rev] + con_in_list_t = [con_in_f_t, con_in_r_t] + + if hps.do_feed_factors_to_controller: + if hps.feedback_factors_or_rates == "factors": + con_in_list_t.append(factors[t-1]) + elif hps.feedback_factors_or_rates == "rates": + con_in_list_t.append(rates[t-1]) + else: + assert False, "NIY" + + con_in_t = tf.concat(axis=1, values=con_in_list_t) + con_in_t = tf.nn.dropout(con_in_t, keep_prob) + with tf.variable_scope("con", reuse=True if t > 0 else None): + con_outs[t], con_states[t] = con_cell(con_in_t, con_states[t-1]) + posterior_zs_co[t] = \ + DiagonalGaussianFromInput(con_outs[t], co_dim, + name="con_to_post_co") + if kind == "train": + u_t[t] = posterior_zs_co[t].sample + elif kind == "posterior_sample_and_average": + u_t[t] = posterior_zs_co[t].sample + elif kind == "posterior_push_mean": + u_t[t] = posterior_zs_co[t].mean + else: + u_t[t] = prior_zs_ar_con.samples_t[t] + + # Inputs to the generator (controller output + external input) + if ext_input_dim > 0 and hps.inject_ext_input_to_gen: + ext_input_t_bxi = ext_input_do_bxtxi[:,t,:] + if co_dim > 0: + gen_inputs[t] = tf.concat(axis=1, values=[u_t[t], ext_input_t_bxi]) + else: + gen_inputs[t] = ext_input_t_bxi + else: + gen_inputs[t] = u_t[t] + + # Generator + data_t_bxd = dataset_ph[:,t,:] + with tf.variable_scope("gen", reuse=True if t > 0 else None): + gen_outs[t], gen_states[t] = gen_cell(gen_inputs[t], gen_states[t-1]) + gen_outs[t] = tf.nn.dropout(gen_outs[t], keep_prob) + with tf.variable_scope("gen", reuse=True): # ic defined it above + factors[t] = linear(gen_outs[t], factors_dim, do_bias=False, + normalized=True, name="gen_2_fac") + with tf.variable_scope("glm", reuse=True if t > 0 else None): + if hps.output_dist == 'poisson': + log_rates_t = tf.matmul(factors[t], this_out_fac_W) + this_out_fac_b + log_rates_t.set_shape([None, None]) + rates[t] = dist_params[t] = tf.exp(log_rates_t) # rates feed back + rates[t].set_shape([None, hps.dataset_dims[hps.dataset_names[0]]]) + loglikelihood_t = Poisson(log_rates_t).logp(data_t_bxd) + + elif hps.output_dist == 'gaussian': + mean_n_logvars = tf.matmul(factors[t],this_out_fac_W) + this_out_fac_b + mean_n_logvars.set_shape([None, None]) + means_t_bxd, logvars_t_bxd = tf.split(axis=1, num_or_size_splits=2, + value=mean_n_logvars) + rates[t] = means_t_bxd # rates feed back to controller + dist_params[t] = tf.concat( + axis=1, values=[means_t_bxd, tf.exp(logvars_t_bxd)]) + loglikelihood_t = \ + diag_gaussian_log_likelihood(data_t_bxd, + means_t_bxd, logvars_t_bxd) + else: + assert False, "NIY" + + log_p_xgz_b += tf.reduce_sum(loglikelihood_t, [1]) + + # Correlation of inferred inputs cost. + self.corr_cost = tf.constant(0.0) + if hps.co_mean_corr_scale > 0.0: + all_sum_corr = [] + for i in range(hps.co_dim): + for j in range(i+1, hps.co_dim): + sum_corr_ij = tf.constant(0.0) + for t in range(num_steps): + u_mean_t = posterior_zs_co[t].mean + sum_corr_ij += u_mean_t[:,i]*u_mean_t[:,j] + all_sum_corr.append(0.5 * tf.square(sum_corr_ij)) + self.corr_cost = tf.reduce_mean(all_sum_corr) # div by batch and by n*(n-1)/2 pairs + + # Variational Lower Bound on posterior, p(z|x), plus reconstruction cost. + # KL and reconstruction costs are normalized only by batch size, not by + # dimension, or by time steps. + kl_cost_g0_b = tf.zeros_like(batch_size, dtype=tf.float32) + kl_cost_co_b = tf.zeros_like(batch_size, dtype=tf.float32) + self.kl_cost = tf.constant(0.0) # VAE KL cost + self.recon_cost = tf.constant(0.0) # VAE reconstruction cost + self.nll_bound_vae = tf.constant(0.0) + self.nll_bound_iwae = tf.constant(0.0) # for eval with IWAE cost. + if kind in ["train", "posterior_sample_and_average", "posterior_push_mean"]: + kl_cost_g0_b = 0.0 + kl_cost_co_b = 0.0 + if ic_dim > 0: + g0_priors = [self.prior_zs_g0] + g0_posts = [self.posterior_zs_g0] + kl_cost_g0_b = KLCost_GaussianGaussian(g0_posts, g0_priors).kl_cost_b + kl_cost_g0_b = hps.kl_ic_weight * kl_cost_g0_b + if co_dim > 0: + kl_cost_co_b = \ + KLCost_GaussianGaussianProcessSampled( + posterior_zs_co, prior_zs_ar_con).kl_cost_b + kl_cost_co_b = hps.kl_co_weight * kl_cost_co_b + + # L = -KL + log p(x|z), to maximize bound on likelihood + # -L = KL - log p(x|z), to minimize bound on NLL + # so 'reconstruction cost' is negative log likelihood + self.recon_cost = - tf.reduce_mean(log_p_xgz_b) + self.kl_cost = tf.reduce_mean(kl_cost_g0_b + kl_cost_co_b) + + lb_on_ll_b = log_p_xgz_b - kl_cost_g0_b - kl_cost_co_b + + # VAE error averages outside the log + self.nll_bound_vae = -tf.reduce_mean(lb_on_ll_b) + + # IWAE error averages inside the log + k = tf.cast(tf.shape(log_p_xgz_b)[0], tf.float32) + iwae_lb_on_ll = -tf.log(k) + log_sum_exp(lb_on_ll_b) + self.nll_bound_iwae = -iwae_lb_on_ll + + # L2 regularization on the generator, normalized by number of parameters. + self.l2_cost = tf.constant(0.0) + if self.hps.l2_gen_scale > 0.0 or self.hps.l2_con_scale > 0.0: + l2_costs = [] + l2_numels = [] + l2_reg_var_lists = [tf.get_collection('l2_gen_reg'), + tf.get_collection('l2_con_reg')] + l2_reg_scales = [self.hps.l2_gen_scale, self.hps.l2_con_scale] + for l2_reg_vars, l2_scale in zip(l2_reg_var_lists, l2_reg_scales): + for v in l2_reg_vars: + numel = tf.reduce_prod(tf.concat(axis=0, values=tf.shape(v))) + numel_f = tf.cast(numel, tf.float32) + l2_numels.append(numel_f) + v_l2 = tf.reduce_sum(v*v) + l2_costs.append(0.5 * l2_scale * v_l2) + self.l2_cost = tf.add_n(l2_costs) / tf.add_n(l2_numels) + + # Compute the cost for training, part of the graph regardless. + # The KL cost can be problematic at the beginning of optimization, + # so we allow an exponential increase in weighting the KL from 0 + # to 1. + self.kl_decay_step = tf.maximum(self.train_step - hps.kl_start_step, 0) + self.l2_decay_step = tf.maximum(self.train_step - hps.l2_start_step, 0) + kl_decay_step_f = tf.cast(self.kl_decay_step, tf.float32) + l2_decay_step_f = tf.cast(self.l2_decay_step, tf.float32) + kl_increase_steps_f = tf.cast(hps.kl_increase_steps, tf.float32) + l2_increase_steps_f = tf.cast(hps.l2_increase_steps, tf.float32) + self.kl_weight = kl_weight = \ + tf.minimum(kl_decay_step_f / kl_increase_steps_f, 1.0) + self.l2_weight = l2_weight = \ + tf.minimum(l2_decay_step_f / l2_increase_steps_f, 1.0) + + self.timed_kl_cost = kl_weight * self.kl_cost + self.timed_l2_cost = l2_weight * self.l2_cost + self.weight_corr_cost = hps.co_mean_corr_scale * self.corr_cost + self.cost = self.recon_cost + self.timed_kl_cost + \ + self.timed_l2_cost + self.weight_corr_cost + + if kind != "train": + # save every so often + self.seso_saver = tf.train.Saver(tf.global_variables(), + max_to_keep=hps.max_ckpt_to_keep) + # lowest validation error + self.lve_saver = tf.train.Saver(tf.global_variables(), + max_to_keep=hps.max_ckpt_to_keep_lve) + + return + + # OPTIMIZATION + # train the io matrices only + if self.hps.do_train_io_only: + self.train_vars = tvars = \ + tf.get_collection('IO_transformations', + scope=tf.get_variable_scope().name) + # train the encoder only + elif self.hps.do_train_encoder_only: + tvars1 = \ + tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, + scope='LFADS/ic_enc_*') + tvars2 = \ + tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, + scope='LFADS/z/ic_enc_*') + + self.train_vars = tvars = tvars1 + tvars2 + # train all variables + else: + self.train_vars = tvars = \ + tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, + scope=tf.get_variable_scope().name) + print("done.") + print("Model Variables (to be optimized): ") + total_params = 0 + for i in range(len(tvars)): + shape = tvars[i].get_shape().as_list() + print(" ", i, tvars[i].name, shape) + total_params += np.prod(shape) + print("Total model parameters: ", total_params) + + grads = tf.gradients(self.cost, tvars) + grads, grad_global_norm = tf.clip_by_global_norm(grads, hps.max_grad_norm) + opt = tf.train.AdamOptimizer(self.learning_rate, beta1=0.9, beta2=0.999, + epsilon=1e-01) + self.grads = grads + self.grad_global_norm = grad_global_norm + self.train_op = opt.apply_gradients( + zip(grads, tvars), global_step=self.train_step) + + self.seso_saver = tf.train.Saver(tf.global_variables(), + max_to_keep=hps.max_ckpt_to_keep) + + # lowest validation error + self.lve_saver = tf.train.Saver(tf.global_variables(), + max_to_keep=hps.max_ckpt_to_keep) + + # SUMMARIES, used only during training. + # example summary + self.example_image = tf.placeholder(tf.float32, shape=[1,None,None,3], + name='image_tensor') + self.example_summ = tf.summary.image("LFADS example", self.example_image, + collections=["example_summaries"]) + + # general training summaries + self.lr_summ = tf.summary.scalar("Learning rate", self.learning_rate) + self.kl_weight_summ = tf.summary.scalar("KL weight", self.kl_weight) + self.l2_weight_summ = tf.summary.scalar("L2 weight", self.l2_weight) + self.corr_cost_summ = tf.summary.scalar("Corr cost", self.weight_corr_cost) + self.grad_global_norm_summ = tf.summary.scalar("Gradient global norm", + self.grad_global_norm) + if hps.co_dim > 0: + self.atau_summ = [None] * hps.co_dim + self.pvar_summ = [None] * hps.co_dim + for c in range(hps.co_dim): + self.atau_summ[c] = \ + tf.summary.scalar("AR Autocorrelation taus " + str(c), + tf.exp(self.prior_zs_ar_con.logataus_1xu[0,c])) + self.pvar_summ[c] = \ + tf.summary.scalar("AR Variances " + str(c), + tf.exp(self.prior_zs_ar_con.logpvars_1xu[0,c])) + + # cost summaries, separated into different collections for + # training vs validation. We make placeholders for these, because + # even though the graph computes these costs on a per-batch basis, + # we want to report the more reliable metric of per-epoch cost. + kl_cost_ph = tf.placeholder(tf.float32, shape=[], name='kl_cost_ph') + self.kl_t_cost_summ = tf.summary.scalar("KL cost (train)", kl_cost_ph, + collections=["train_summaries"]) + self.kl_v_cost_summ = tf.summary.scalar("KL cost (valid)", kl_cost_ph, + collections=["valid_summaries"]) + l2_cost_ph = tf.placeholder(tf.float32, shape=[], name='l2_cost_ph') + self.l2_cost_summ = tf.summary.scalar("L2 cost", l2_cost_ph, + collections=["train_summaries"]) + + recon_cost_ph = tf.placeholder(tf.float32, shape=[], name='recon_cost_ph') + self.recon_t_cost_summ = tf.summary.scalar("Reconstruction cost (train)", + recon_cost_ph, + collections=["train_summaries"]) + self.recon_v_cost_summ = tf.summary.scalar("Reconstruction cost (valid)", + recon_cost_ph, + collections=["valid_summaries"]) + + total_cost_ph = tf.placeholder(tf.float32, shape=[], name='total_cost_ph') + self.cost_t_summ = tf.summary.scalar("Total cost (train)", total_cost_ph, + collections=["train_summaries"]) + self.cost_v_summ = tf.summary.scalar("Total cost (valid)", total_cost_ph, + collections=["valid_summaries"]) + + self.kl_cost_ph = kl_cost_ph + self.l2_cost_ph = l2_cost_ph + self.recon_cost_ph = recon_cost_ph + self.total_cost_ph = total_cost_ph + + # Merged summaries, for easy coding later. + self.merged_examples = tf.summary.merge_all(key="example_summaries") + self.merged_generic = tf.summary.merge_all() # default key is 'summaries' + self.merged_train = tf.summary.merge_all(key="train_summaries") + self.merged_valid = tf.summary.merge_all(key="valid_summaries") + + session = tf.get_default_session() + self.logfile = os.path.join(hps.lfads_save_dir, "lfads_log") + self.writer = tf.summary.FileWriter(self.logfile) + + def build_feed_dict(self, train_name, data_bxtxd, ext_input_bxtxi=None, + keep_prob=None): + """Build the feed dictionary, handles cases where there is no value defined. + + Args: + train_name: The key into the datasets, to set the tf.case statement for + the proper readin / readout matrices. + data_bxtxd: The data tensor + ext_input_bxtxi (optional): The external input tensor + keep_prob: The drop out keep probability. + + Returns: + The feed dictionary with TF tensors as keys and data as values, for use + with tf.Session.run() + + """ + feed_dict = {} + B, T, _ = data_bxtxd.shape + feed_dict[self.dataName] = train_name + feed_dict[self.dataset_ph] = data_bxtxd + + if self.ext_input is not None and ext_input_bxtxi is not None: + feed_dict[self.ext_input] = ext_input_bxtxi + + if keep_prob is None: + feed_dict[self.keep_prob] = self.hps.keep_prob + else: + feed_dict[self.keep_prob] = keep_prob + + return feed_dict + + @staticmethod + def get_batch(data_extxd, ext_input_extxi=None, batch_size=None, + example_idxs=None): + """Get a batch of data, either randomly chosen, or specified directly. + + Args: + data_extxd: The data to model, numpy tensors with shape: + # examples x # time steps x # dimensions + ext_input_extxi (optional): The external inputs, numpy tensor with shape: + # examples x # time steps x # external input dimensions + batch_size: The size of the batch to return + example_idxs (optional): The example indices used to select examples. + + Returns: + A tuple with two parts: + 1. Batched data numpy tensor with shape: + batch_size x # time steps x # dimensions + 2. Batched external input numpy tensor with shape: + batch_size x # time steps x # external input dims + """ + assert batch_size is not None or example_idxs is not None, "Problems" + E, T, D = data_extxd.shape + if example_idxs is None: + example_idxs = np.random.choice(E, batch_size) + + ext_input_bxtxi = None + if ext_input_extxi is not None: + ext_input_bxtxi = ext_input_extxi[example_idxs,:,:] + + return data_extxd[example_idxs,:,:], ext_input_bxtxi + + @staticmethod + def example_idxs_mod_batch_size(nexamples, batch_size): + """Given a number of examples, E, and a batch_size, B, generate indices + [0, 1, 2, ... B-1; + [B, B+1, ... 2*B-1; + ... + ] + returning those indices as a 2-dim tensor shaped like E/B x B. Note that + shape is only correct if E % B == 0. If not, then an extra row is generated + so that the remainder of examples is included. The extra examples are + explicitly to to the zero index (see randomize_example_idxs_mod_batch_size) + for randomized behavior. + + Args: + nexamples: The number of examples to batch up. + batch_size: The size of the batch. + Returns: + 2-dim tensor as described above. + """ + bmrem = batch_size - (nexamples % batch_size) + bmrem_examples = [] + if bmrem < batch_size: + #bmrem_examples = np.zeros(bmrem, dtype=np.int32) + ridxs = np.random.permutation(nexamples)[0:bmrem].astype(np.int32) + bmrem_examples = np.sort(ridxs) + example_idxs = range(nexamples) + list(bmrem_examples) + example_idxs_e_x_edivb = np.reshape(example_idxs, [-1, batch_size]) + return example_idxs_e_x_edivb, bmrem + + @staticmethod + def randomize_example_idxs_mod_batch_size(nexamples, batch_size): + """Indices 1:nexamples, randomized, in 2D form of + shape = (nexamples / batch_size) x batch_size. The remainder + is managed by drawing randomly from 1:nexamples. + + Args: + nexamples: number of examples to randomize + batch_size: number of elements in batch + + Returns: + The randomized, properly shaped indicies. + """ + assert nexamples > batch_size, "Problems" + bmrem = batch_size - nexamples % batch_size + bmrem_examples = [] + if bmrem < batch_size: + bmrem_examples = np.random.choice(range(nexamples), + size=bmrem, replace=False) + example_idxs = range(nexamples) + list(bmrem_examples) + mixed_example_idxs = np.random.permutation(example_idxs) + example_idxs_e_x_edivb = np.reshape(mixed_example_idxs, [-1, batch_size]) + return example_idxs_e_x_edivb, bmrem + + def shuffle_spikes_in_time(self, data_bxtxd): + """Shuffle the spikes in the temporal dimension. This is useful to + help the LFADS system avoid overfitting to individual spikes or fast + oscillations found in the data that are irrelevant to behavior. A + pure 'tabula rasa' approach would avoid this, but LFADS is sensitive + enough to pick up dynamics that you may not want. + + Args: + data_bxtxd: numpy array of spike count data to be shuffled. + Returns: + S_bxtxd, a numpy array with the same dimensions and contents as + data_bxtxd, but shuffled appropriately. + + """ + + B, T, N = data_bxtxd.shape + w = self.hps.temporal_spike_jitter_width + + if w == 0: + return data_bxtxd + + max_counts = np.max(data_bxtxd) + S_bxtxd = np.zeros([B,T,N]) + + # Intuitively, shuffle spike occurances, 0 or 1, but since we have counts, + # Do it over and over again up to the max count. + for mc in range(1,max_counts+1): + idxs = np.nonzero(data_bxtxd >= mc) + + data_ones = np.zeros_like(data_bxtxd) + data_ones[data_bxtxd >= mc] = 1 + + nfound = len(idxs[0]) + shuffles_incrs_in_time = np.random.randint(-w, w, size=nfound) + + shuffle_tidxs = idxs[1].copy() + shuffle_tidxs += shuffles_incrs_in_time + + # Reflect on the boundaries to not lose mass. + shuffle_tidxs[shuffle_tidxs < 0] = -shuffle_tidxs[shuffle_tidxs < 0] + shuffle_tidxs[shuffle_tidxs > T-1] = \ + (T-1)-(shuffle_tidxs[shuffle_tidxs > T-1] -(T-1)) + + for iii in zip(idxs[0], shuffle_tidxs, idxs[2]): + S_bxtxd[iii] += 1 + + return S_bxtxd + + def shuffle_and_flatten_datasets(self, datasets, kind='train'): + """Since LFADS supports multiple datasets in the same dynamical model, + we have to be careful to use all the data in a single training epoch. But + since the datasets my have different data dimensionality, we cannot batch + examples from data dictionaries together. Instead, we generate random + batches within each data dictionary, and then randomize these batches + while holding onto the dataname, so that when it's time to feed + the graph, the correct in/out matrices can be selected, per batch. + + Args: + datasets: A dict of data dicts. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + kind: 'train' or 'valid' + + Returns: + A flat list, in which each element is a pair ('name', indices). + """ + batch_size = self.hps.batch_size + ndatasets = len(datasets) + random_example_idxs = {} + epoch_idxs = {} + all_name_example_idx_pairs = [] + kind_data = kind + '_data' + for name, data_dict in datasets.items(): + nexamples, ntime, data_dim = data_dict[kind_data].shape + epoch_idxs[name] = 0 + random_example_idxs, _ = \ + self.randomize_example_idxs_mod_batch_size(nexamples, batch_size) + + epoch_size = random_example_idxs.shape[0] + names = [name] * epoch_size + all_name_example_idx_pairs += zip(names, random_example_idxs) + + np.random.shuffle(all_name_example_idx_pairs) # shuffle in place + + return all_name_example_idx_pairs + + def train_epoch(self, datasets, batch_size=None, do_save_ckpt=True): + """Train the model through the entire dataset once. + + Args: + datasets: A dict of data dicts. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + batch_size (optional): The batch_size to use + do_save_ckpt (optional): Should the routine save a checkpoint on this + training epoch? + + Returns: + A tuple with 6 float values: + (total cost of the epoch, epoch reconstruction cost, + epoch kl cost, KL weight used this training epoch, + total l2 cost on generator, and the corresponding weight). + """ + ops_to_eval = [self.cost, self.recon_cost, + self.kl_cost, self.kl_weight, + self.l2_cost, self.l2_weight, + self.train_op] + collected_op_values = self.run_epoch(datasets, ops_to_eval, kind="train") + + total_cost = total_recon_cost = total_kl_cost = 0.0 + # normalizing by batch done in distributions.py + epoch_size = len(collected_op_values) + for op_values in collected_op_values: + total_cost += op_values[0] + total_recon_cost += op_values[1] + total_kl_cost += op_values[2] + + kl_weight = collected_op_values[-1][3] + l2_cost = collected_op_values[-1][4] + l2_weight = collected_op_values[-1][5] + + epoch_total_cost = total_cost / epoch_size + epoch_recon_cost = total_recon_cost / epoch_size + epoch_kl_cost = total_kl_cost / epoch_size + + if do_save_ckpt: + session = tf.get_default_session() + checkpoint_path = os.path.join(self.hps.lfads_save_dir, + self.hps.checkpoint_name + '.ckpt') + self.seso_saver.save(session, checkpoint_path, + global_step=self.train_step) + + return epoch_total_cost, epoch_recon_cost, epoch_kl_cost, \ + kl_weight, l2_cost, l2_weight + + + def run_epoch(self, datasets, ops_to_eval, kind="train", batch_size=None, + do_collect=True, keep_prob=None): + """Run the model through the entire dataset once. + + Args: + datasets: A dict of data dicts. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + ops_to_eval: A list of tensorflow operations that will be evaluated in + the tf.session.run() call. + batch_size (optional): The batch_size to use + do_collect (optional): Should the routine collect all session.run + output as a list, and return it? + keep_prob (optional): The dropout keep probability. + + Returns: + A list of lists, the internal list is the return for the ops for each + session.run() call. The outer list collects over the epoch. + """ + hps = self.hps + all_name_example_idx_pairs = \ + self.shuffle_and_flatten_datasets(datasets, kind) + + kind_data = kind + '_data' + kind_ext_input = kind + '_ext_input' + + total_cost = total_recon_cost = total_kl_cost = 0.0 + session = tf.get_default_session() + epoch_size = len(all_name_example_idx_pairs) + evaled_ops_list = [] + for name, example_idxs in all_name_example_idx_pairs: + data_dict = datasets[name] + data_extxd = data_dict[kind_data] + if hps.output_dist == 'poisson' and hps.temporal_spike_jitter_width > 0: + data_extxd = self.shuffle_spikes_in_time(data_extxd) + + ext_input_extxi = data_dict[kind_ext_input] + data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, ext_input_extxi, + example_idxs=example_idxs) + + feed_dict = self.build_feed_dict(name, data_bxtxd, ext_input_bxtxi, + keep_prob=keep_prob) + evaled_ops_np = session.run(ops_to_eval, feed_dict=feed_dict) + if do_collect: + evaled_ops_list.append(evaled_ops_np) + + return evaled_ops_list + + def summarize_all(self, datasets, summary_values): + """Plot and summarize stuff in tensorboard. + + Note that everything done in the current function is otherwise done on + a single, randomly selected dataset (except for summary_values, which are + passed in.) + + Args: + datasets, the dictionary of datasets used in the study. + summary_values: These summary values are created from the training loop, + and so summarize the entire set of datasets. + """ + hps = self.hps + tr_kl_cost = summary_values['tr_kl_cost'] + tr_recon_cost = summary_values['tr_recon_cost'] + tr_total_cost = summary_values['tr_total_cost'] + kl_weight = summary_values['kl_weight'] + l2_weight = summary_values['l2_weight'] + l2_cost = summary_values['l2_cost'] + has_any_valid_set = summary_values['has_any_valid_set'] + i = summary_values['nepochs'] + + session = tf.get_default_session() + train_summ, train_step = session.run([self.merged_train, + self.train_step], + feed_dict={self.l2_cost_ph:l2_cost, + self.kl_cost_ph:tr_kl_cost, + self.recon_cost_ph:tr_recon_cost, + self.total_cost_ph:tr_total_cost}) + self.writer.add_summary(train_summ, train_step) + if has_any_valid_set: + ev_kl_cost = summary_values['ev_kl_cost'] + ev_recon_cost = summary_values['ev_recon_cost'] + ev_total_cost = summary_values['ev_total_cost'] + eval_summ = session.run(self.merged_valid, + feed_dict={self.kl_cost_ph:ev_kl_cost, + self.recon_cost_ph:ev_recon_cost, + self.total_cost_ph:ev_total_cost}) + self.writer.add_summary(eval_summ, train_step) + print("Epoch:%d, step:%d (TRAIN, VALID): total: %.2f, %.2f\ + recon: %.2f, %.2f, kl: %.2f, %.2f, l2: %.5f,\ + kl weight: %.2f, l2 weight: %.2f" % \ + (i, train_step, tr_total_cost, ev_total_cost, + tr_recon_cost, ev_recon_cost, tr_kl_cost, ev_kl_cost, + l2_cost, kl_weight, l2_weight)) + + csv_outstr = "epoch,%d, step,%d, total,%.2f,%.2f, \ + recon,%.2f,%.2f, kl,%.2f,%.2f, l2,%.5f, \ + klweight,%.2f, l2weight,%.2f\n"% \ + (i, train_step, tr_total_cost, ev_total_cost, + tr_recon_cost, ev_recon_cost, tr_kl_cost, ev_kl_cost, + l2_cost, kl_weight, l2_weight) + + else: + print("Epoch:%d, step:%d TRAIN: total: %.2f recon: %.2f, kl: %.2f,\ + l2: %.5f, kl weight: %.2f, l2 weight: %.2f" % \ + (i, train_step, tr_total_cost, tr_recon_cost, tr_kl_cost, + l2_cost, kl_weight, l2_weight)) + csv_outstr = "epoch,%d, step,%d, total,%.2f, recon,%.2f, kl,%.2f, \ + l2,%.5f, klweight,%.2f, l2weight,%.2f\n"% \ + (i, train_step, tr_total_cost, tr_recon_cost, + tr_kl_cost, l2_cost, kl_weight, l2_weight) + + if self.hps.csv_log: + csv_file = os.path.join(self.hps.lfads_save_dir, self.hps.csv_log+'.csv') + with open(csv_file, "a") as myfile: + myfile.write(csv_outstr) + + + def plot_single_example(self, datasets): + """Plot an image relating to a randomly chosen, specific example. We use + posterior sample and average by taking one example, and filling a whole + batch with that example, sample from the posterior, and then average the + quantities. + + """ + hps = self.hps + all_data_names = datasets.keys() + data_name = np.random.permutation(all_data_names)[0] + data_dict = datasets[data_name] + has_valid_set = True if data_dict['valid_data'] is not None else False + cf = 1.0 # plotting concern + + # posterior sample and average here + E, _, _ = data_dict['train_data'].shape + eidx = np.random.choice(E) + example_idxs = eidx * np.ones(hps.batch_size, dtype=np.int32) + + train_data_bxtxd, train_ext_input_bxtxi = \ + self.get_batch(data_dict['train_data'], data_dict['train_ext_input'], + example_idxs=example_idxs) + + truth_train_data_bxtxd = None + if 'train_truth' in data_dict and data_dict['train_truth'] is not None: + truth_train_data_bxtxd, _ = self.get_batch(data_dict['train_truth'], + example_idxs=example_idxs) + cf = data_dict['conversion_factor'] + + # plotter does averaging + train_model_values = self.eval_model_runs_batch(data_name, + train_data_bxtxd, + train_ext_input_bxtxi, + do_average_batch=False) + + train_step = train_model_values['train_steps'] + feed_dict = self.build_feed_dict(data_name, train_data_bxtxd, + train_ext_input_bxtxi, keep_prob=1.0) + + session = tf.get_default_session() + generic_summ = session.run(self.merged_generic, feed_dict=feed_dict) + self.writer.add_summary(generic_summ, train_step) + + valid_data_bxtxd = valid_model_values = valid_ext_input_bxtxi = None + truth_valid_data_bxtxd = None + if has_valid_set: + E, _, _ = data_dict['valid_data'].shape + eidx = np.random.choice(E) + example_idxs = eidx * np.ones(hps.batch_size, dtype=np.int32) + valid_data_bxtxd, valid_ext_input_bxtxi = \ + self.get_batch(data_dict['valid_data'], + data_dict['valid_ext_input'], + example_idxs=example_idxs) + if 'valid_truth' in data_dict and data_dict['valid_truth'] is not None: + truth_valid_data_bxtxd, _ = self.get_batch(data_dict['valid_truth'], + example_idxs=example_idxs) + else: + truth_valid_data_bxtxd = None + + # plotter does averaging + valid_model_values = self.eval_model_runs_batch(data_name, + valid_data_bxtxd, + valid_ext_input_bxtxi, + do_average_batch=False) + + example_image = plot_lfads(train_bxtxd=train_data_bxtxd, + train_model_vals=train_model_values, + train_ext_input_bxtxi=train_ext_input_bxtxi, + train_truth_bxtxd=truth_train_data_bxtxd, + valid_bxtxd=valid_data_bxtxd, + valid_model_vals=valid_model_values, + valid_ext_input_bxtxi=valid_ext_input_bxtxi, + valid_truth_bxtxd=truth_valid_data_bxtxd, + bidx=None, cf=cf, output_dist=hps.output_dist) + example_image = np.expand_dims(example_image, axis=0) + example_summ = session.run(self.merged_examples, + feed_dict={self.example_image : example_image}) + self.writer.add_summary(example_summ) + + def train_model(self, datasets): + """Train the model, print per-epoch information, and save checkpoints. + + Loop over training epochs. The function that actually does the + training is train_epoch. This function iterates over the training + data, one epoch at a time. The learning rate schedule is such + that it will stay the same until the cost goes up in comparison to + the last few values, then it will drop. + + Args: + datasets: A dict of data dicts. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + """ + hps = self.hps + has_any_valid_set = False + for data_dict in datasets.values(): + if data_dict['valid_data'] is not None: + has_any_valid_set = True + break + + session = tf.get_default_session() + lr = session.run(self.learning_rate) + lr_stop = hps.learning_rate_stop + i = -1 + train_costs = [] + valid_costs = [] + ev_total_cost = ev_recon_cost = ev_kl_cost = 0.0 + lowest_ev_cost = np.Inf + while True: + i += 1 + do_save_ckpt = True if i % 10 ==0 else False + tr_total_cost, tr_recon_cost, tr_kl_cost, kl_weight, l2_cost, l2_weight = \ + self.train_epoch(datasets, do_save_ckpt=do_save_ckpt) + + # Evaluate the validation cost, and potentially save. Note that this + # routine will not save a validation checkpoint until the kl weight and + # l2 weights are equal to 1.0. + if has_any_valid_set: + ev_total_cost, ev_recon_cost, ev_kl_cost = \ + self.eval_cost_epoch(datasets, kind='valid') + valid_costs.append(ev_total_cost) + + # > 1 may give more consistent results, but not the actual lowest vae. + # == 1 gives the lowest vae seen so far. + n_lve = 1 + run_avg_lve = np.mean(valid_costs[-n_lve:]) + + # conditions for saving checkpoints: + # KL weight must have finished stepping (>=1.0), AND + # L2 weight must have finished stepping OR L2 is not being used, AND + # the current run has a lower LVE than previous runs AND + # len(valid_costs > n_lve) (not sure what that does) + if kl_weight >= 1.0 and \ + (l2_weight >= 1.0 or \ + (self.hps.l2_gen_scale == 0.0 and self.hps.l2_con_scale == 0.0)) \ + and (len(valid_costs) > n_lve and run_avg_lve < lowest_ev_cost): + + lowest_ev_cost = run_avg_lve + checkpoint_path = os.path.join(self.hps.lfads_save_dir, + self.hps.checkpoint_name + '_lve.ckpt') + self.lve_saver.save(session, checkpoint_path, + global_step=self.train_step, + latest_filename='checkpoint_lve') + + # Plot and summarize. + values = {'nepochs':i, 'has_any_valid_set': has_any_valid_set, + 'tr_total_cost':tr_total_cost, 'ev_total_cost':ev_total_cost, + 'tr_recon_cost':tr_recon_cost, 'ev_recon_cost':ev_recon_cost, + 'tr_kl_cost':tr_kl_cost, 'ev_kl_cost':ev_kl_cost, + 'l2_weight':l2_weight, 'kl_weight':kl_weight, + 'l2_cost':l2_cost} + self.summarize_all(datasets, values) + self.plot_single_example(datasets) + + # Manage learning rate. + train_res = tr_total_cost + n_lr = hps.learning_rate_n_to_compare + if len(train_costs) > n_lr and train_res > np.max(train_costs[-n_lr:]): + _ = session.run(self.learning_rate_decay_op) + lr = session.run(self.learning_rate) + print(" Decreasing learning rate to %f." % lr) + # Force the system to run n_lr times while at this lr. + train_costs.append(np.inf) + else: + train_costs.append(train_res) + + if lr < lr_stop: + print("Stopping optimization based on learning rate criteria.") + break + + def eval_cost_epoch(self, datasets, kind='train', ext_input_extxi=None, + batch_size=None): + """Evaluate the cost of the epoch. + + Args: + data_dict: The dictionary of data (training and validation) used for + training and evaluation of the model, respectively. + + Returns: + a 3 tuple of costs: + (epoch total cost, epoch reconstruction cost, epoch KL cost) + """ + ops_to_eval = [self.cost, self.recon_cost, self.kl_cost] + collected_op_values = self.run_epoch(datasets, ops_to_eval, kind=kind, + keep_prob=1.0) + + total_cost = total_recon_cost = total_kl_cost = 0.0 + # normalizing by batch done in distributions.py + epoch_size = len(collected_op_values) + for op_values in collected_op_values: + total_cost += op_values[0] + total_recon_cost += op_values[1] + total_kl_cost += op_values[2] + + epoch_total_cost = total_cost / epoch_size + epoch_recon_cost = total_recon_cost / epoch_size + epoch_kl_cost = total_kl_cost / epoch_size + + return epoch_total_cost, epoch_recon_cost, epoch_kl_cost + + def eval_model_runs_batch(self, data_name, data_bxtxd, ext_input_bxtxi=None, + do_eval_cost=False, do_average_batch=False): + """Returns all the goodies for the entire model, per batch. + + If data_bxtxd and ext_input_bxtxi can have fewer than batch_size along dim 1 + in which case this handles the padding and truncating automatically + + Args: + data_name: The name of the data dict, to select which in/out matrices + to use. + data_bxtxd: Numpy array training data with shape: + batch_size x # time steps x # dimensions + ext_input_bxtxi: Numpy array training external input with shape: + batch_size x # time steps x # external input dims + do_eval_cost (optional): If true, the IWAE (Importance Weighted + Autoencoder) log likeihood bound, instead of the VAE version. + do_average_batch (optional): average over the batch, useful for getting + good IWAE costs, and model outputs for a single data point. + + Returns: + A dictionary with the outputs of the model decoder, namely: + prior g0 mean, prior g0 variance, approx. posterior mean, approx + posterior mean, the generator initial conditions, the control inputs (if + enabled), the state of the generator, the factors, and the rates. + """ + session = tf.get_default_session() + + # if fewer than batch_size provided, pad to batch_size + hps = self.hps + batch_size = hps.batch_size + E, _, _ = data_bxtxd.shape + if E < hps.batch_size: + data_bxtxd = np.pad(data_bxtxd, ((0, hps.batch_size-E), (0, 0), (0, 0)), + mode='constant', constant_values=0) + if ext_input_bxtxi is not None: + ext_input_bxtxi = np.pad(ext_input_bxtxi, + ((0, hps.batch_size-E), (0, 0), (0, 0)), + mode='constant', constant_values=0) + + feed_dict = self.build_feed_dict(data_name, data_bxtxd, + ext_input_bxtxi, keep_prob=1.0) + + # Non-temporal signals will be batch x dim. + # Temporal signals are list length T with elements batch x dim. + tf_vals = [self.gen_ics, self.gen_states, self.factors, + self.output_dist_params] + tf_vals.append(self.cost) + tf_vals.append(self.nll_bound_vae) + tf_vals.append(self.nll_bound_iwae) + tf_vals.append(self.train_step) # not train_op! + if self.hps.ic_dim > 0: + tf_vals += [self.prior_zs_g0.mean, self.prior_zs_g0.logvar, + self.posterior_zs_g0.mean, self.posterior_zs_g0.logvar] + if self.hps.co_dim > 0: + tf_vals.append(self.controller_outputs) + tf_vals_flat, fidxs = flatten(tf_vals) + + np_vals_flat = session.run(tf_vals_flat, feed_dict=feed_dict) + + ff = 0 + gen_ics = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + gen_states = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + factors = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + out_dist_params = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + costs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + nll_bound_vaes = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + nll_bound_iwaes = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 + train_steps = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 + if self.hps.ic_dim > 0: + prior_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff +=1 + prior_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + post_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + post_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + if self.hps.co_dim > 0: + controller_outputs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + + # [0] are to take out the non-temporal items from lists + gen_ics = gen_ics[0] + costs = costs[0] + nll_bound_vaes = nll_bound_vaes[0] + nll_bound_iwaes = nll_bound_iwaes[0] + train_steps = train_steps[0] + + # Convert to full tensors, not lists of tensors in time dim. + gen_states = list_t_bxn_to_tensor_bxtxn(gen_states) + factors = list_t_bxn_to_tensor_bxtxn(factors) + out_dist_params = list_t_bxn_to_tensor_bxtxn(out_dist_params) + if self.hps.ic_dim > 0: + # select first time point + prior_g0_mean = prior_g0_mean[0] + prior_g0_logvar = prior_g0_logvar[0] + post_g0_mean = post_g0_mean[0] + post_g0_logvar = post_g0_logvar[0] + if self.hps.co_dim > 0: + controller_outputs = list_t_bxn_to_tensor_bxtxn(controller_outputs) + + # slice out the trials in case < batch_size provided + if E < hps.batch_size: + idx = np.arange(E) + gen_ics = gen_ics[idx, :] + gen_states = gen_states[idx, :] + factors = factors[idx, :, :] + out_dist_params = out_dist_params[idx, :, :] + if self.hps.ic_dim > 0: + prior_g0_mean = prior_g0_mean[idx, :] + prior_g0_logvar = prior_g0_logvar[idx, :] + post_g0_mean = post_g0_mean[idx, :] + post_g0_logvar = post_g0_logvar[idx, :] + if self.hps.co_dim > 0: + controller_outputs = controller_outputs[idx, :, :] + + if do_average_batch: + gen_ics = np.mean(gen_ics, axis=0) + gen_states = np.mean(gen_states, axis=0) + factors = np.mean(factors, axis=0) + out_dist_params = np.mean(out_dist_params, axis=0) + if self.hps.ic_dim > 0: + prior_g0_mean = np.mean(prior_g0_mean, axis=0) + prior_g0_logvar = np.mean(prior_g0_logvar, axis=0) + post_g0_mean = np.mean(post_g0_mean, axis=0) + post_g0_logvar = np.mean(post_g0_logvar, axis=0) + if self.hps.co_dim > 0: + controller_outputs = np.mean(controller_outputs, axis=0) + + model_vals = {} + model_vals['gen_ics'] = gen_ics + model_vals['gen_states'] = gen_states + model_vals['factors'] = factors + model_vals['output_dist_params'] = out_dist_params + model_vals['costs'] = costs + model_vals['nll_bound_vaes'] = nll_bound_vaes + model_vals['nll_bound_iwaes'] = nll_bound_iwaes + model_vals['train_steps'] = train_steps + if self.hps.ic_dim > 0: + model_vals['prior_g0_mean'] = prior_g0_mean + model_vals['prior_g0_logvar'] = prior_g0_logvar + model_vals['post_g0_mean'] = post_g0_mean + model_vals['post_g0_logvar'] = post_g0_logvar + if self.hps.co_dim > 0: + model_vals['controller_outputs'] = controller_outputs + + return model_vals + + def eval_model_runs_avg_epoch(self, data_name, data_extxd, + ext_input_extxi=None): + """Returns all the expected value for goodies for the entire model. + + The expected value is taken over hidden (z) variables, namely the initial + conditions and the control inputs. The expected value is approximate, and + accomplished via sampling (batch_size) samples for every examples. + + Args: + data_name: The name of the data dict, to select which in/out matrices + to use. + data_extxd: Numpy array training data with shape: + # examples x # time steps x # dimensions + ext_input_extxi (optional): Numpy array training external input with + shape: # examples x # time steps x # external input dims + + Returns: + A dictionary with the averaged outputs of the model decoder, namely: + prior g0 mean, prior g0 variance, approx. posterior mean, approx + posterior mean, the generator initial conditions, the control inputs (if + enabled), the state of the generator, the factors, and the output + distribution parameters, e.g. (rates or mean and variances). + """ + hps = self.hps + batch_size = hps.batch_size + E, T, D = data_extxd.shape + E_to_process = hps.ps_nexamples_to_process + if E_to_process > E: + E_to_process = E + + if hps.ic_dim > 0: + prior_g0_mean = np.zeros([E_to_process, hps.ic_dim]) + prior_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) + post_g0_mean = np.zeros([E_to_process, hps.ic_dim]) + post_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) + + if hps.co_dim > 0: + controller_outputs = np.zeros([E_to_process, T, hps.co_dim]) + gen_ics = np.zeros([E_to_process, hps.gen_dim]) + gen_states = np.zeros([E_to_process, T, hps.gen_dim]) + factors = np.zeros([E_to_process, T, hps.factors_dim]) + + if hps.output_dist == 'poisson': + out_dist_params = np.zeros([E_to_process, T, D]) + elif hps.output_dist == 'gaussian': + out_dist_params = np.zeros([E_to_process, T, D+D]) + else: + assert False, "NIY" + + costs = np.zeros(E_to_process) + nll_bound_vaes = np.zeros(E_to_process) + nll_bound_iwaes = np.zeros(E_to_process) + train_steps = np.zeros(E_to_process) + for es_idx in range(E_to_process): + print("Running %d of %d." % (es_idx+1, E_to_process)) + example_idxs = es_idx * np.ones(batch_size, dtype=np.int32) + data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, + ext_input_extxi, + batch_size=batch_size, + example_idxs=example_idxs) + model_values = self.eval_model_runs_batch(data_name, data_bxtxd, + ext_input_bxtxi, + do_eval_cost=True, + do_average_batch=True) + + if self.hps.ic_dim > 0: + prior_g0_mean[es_idx,:] = model_values['prior_g0_mean'] + prior_g0_logvar[es_idx,:] = model_values['prior_g0_logvar'] + post_g0_mean[es_idx,:] = model_values['post_g0_mean'] + post_g0_logvar[es_idx,:] = model_values['post_g0_logvar'] + gen_ics[es_idx,:] = model_values['gen_ics'] + + if self.hps.co_dim > 0: + controller_outputs[es_idx,:,:] = model_values['controller_outputs'] + gen_states[es_idx,:,:] = model_values['gen_states'] + factors[es_idx,:,:] = model_values['factors'] + out_dist_params[es_idx,:,:] = model_values['output_dist_params'] + costs[es_idx] = model_values['costs'] + nll_bound_vaes[es_idx] = model_values['nll_bound_vaes'] + nll_bound_iwaes[es_idx] = model_values['nll_bound_iwaes'] + train_steps[es_idx] = model_values['train_steps'] + print('bound nll(vae): %.3f, bound nll(iwae): %.3f' \ + % (nll_bound_vaes[es_idx], nll_bound_iwaes[es_idx])) + + model_runs = {} + if self.hps.ic_dim > 0: + model_runs['prior_g0_mean'] = prior_g0_mean + model_runs['prior_g0_logvar'] = prior_g0_logvar + model_runs['post_g0_mean'] = post_g0_mean + model_runs['post_g0_logvar'] = post_g0_logvar + model_runs['gen_ics'] = gen_ics + + if self.hps.co_dim > 0: + model_runs['controller_outputs'] = controller_outputs + model_runs['gen_states'] = gen_states + model_runs['factors'] = factors + model_runs['output_dist_params'] = out_dist_params + model_runs['costs'] = costs + model_runs['nll_bound_vaes'] = nll_bound_vaes + model_runs['nll_bound_iwaes'] = nll_bound_iwaes + model_runs['train_steps'] = train_steps + return model_runs + + def eval_model_runs_push_mean(self, data_name, data_extxd, + ext_input_extxi=None): + """Returns values of interest for the model by pushing the means through + + The mean values for both initial conditions and the control inputs are + pushed through the model instead of sampling (as is done in + eval_model_runs_avg_epoch). + This is a quick and approximate version of estimating these values instead + of sampling from the posterior many times and then averaging those values of + interest. + + Internally, a total of batch_size trials are run through the model at once. + + Args: + data_name: The name of the data dict, to select which in/out matrices + to use. + data_extxd: Numpy array training data with shape: + # examples x # time steps x # dimensions + ext_input_extxi (optional): Numpy array training external input with + shape: # examples x # time steps x # external input dims + + Returns: + A dictionary with the estimated outputs of the model decoder, namely: + prior g0 mean, prior g0 variance, approx. posterior mean, approx + posterior mean, the generator initial conditions, the control inputs (if + enabled), the state of the generator, the factors, and the output + distribution parameters, e.g. (rates or mean and variances). + """ + hps = self.hps + batch_size = hps.batch_size + E, T, D = data_extxd.shape + E_to_process = hps.ps_nexamples_to_process + if E_to_process > E: + print("Setting number of posterior samples to process to : ", E) + E_to_process = E + + if hps.ic_dim > 0: + prior_g0_mean = np.zeros([E_to_process, hps.ic_dim]) + prior_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) + post_g0_mean = np.zeros([E_to_process, hps.ic_dim]) + post_g0_logvar = np.zeros([E_to_process, hps.ic_dim]) + + if hps.co_dim > 0: + controller_outputs = np.zeros([E_to_process, T, hps.co_dim]) + gen_ics = np.zeros([E_to_process, hps.gen_dim]) + gen_states = np.zeros([E_to_process, T, hps.gen_dim]) + factors = np.zeros([E_to_process, T, hps.factors_dim]) + + if hps.output_dist == 'poisson': + out_dist_params = np.zeros([E_to_process, T, D]) + elif hps.output_dist == 'gaussian': + out_dist_params = np.zeros([E_to_process, T, D+D]) + else: + assert False, "NIY" + + costs = np.zeros(E_to_process) + nll_bound_vaes = np.zeros(E_to_process) + nll_bound_iwaes = np.zeros(E_to_process) + train_steps = np.zeros(E_to_process) + + # generator that will yield 0:N in groups of per items, e.g. + # (0:per-1), (per:2*per-1), ..., with the last group containing <= per items + # this will be used to feed per=batch_size trials into the model at a time + def trial_batches(N, per): + for i in range(0, N, per): + yield np.arange(i, min(i+per, N), dtype=np.int32) + + for batch_idx, es_idx in enumerate(trial_batches(E_to_process, + hps.batch_size)): + print("Running trial batch %d with %d trials" % (batch_idx+1, + len(es_idx))) + data_bxtxd, ext_input_bxtxi = self.get_batch(data_extxd, + ext_input_extxi, + batch_size=batch_size, + example_idxs=es_idx) + model_values = self.eval_model_runs_batch(data_name, data_bxtxd, + ext_input_bxtxi, + do_eval_cost=True, + do_average_batch=False) + + if self.hps.ic_dim > 0: + prior_g0_mean[es_idx,:] = model_values['prior_g0_mean'] + prior_g0_logvar[es_idx,:] = model_values['prior_g0_logvar'] + post_g0_mean[es_idx,:] = model_values['post_g0_mean'] + post_g0_logvar[es_idx,:] = model_values['post_g0_logvar'] + gen_ics[es_idx,:] = model_values['gen_ics'] + + if self.hps.co_dim > 0: + controller_outputs[es_idx,:,:] = model_values['controller_outputs'] + gen_states[es_idx,:,:] = model_values['gen_states'] + factors[es_idx,:,:] = model_values['factors'] + out_dist_params[es_idx,:,:] = model_values['output_dist_params'] + + # TODO + # model_values['costs'] and other costs come out as scalars, summed over + # all the trials in the batch. what we want is the per-trial costs + costs[es_idx] = model_values['costs'] + nll_bound_vaes[es_idx] = model_values['nll_bound_vaes'] + nll_bound_iwaes[es_idx] = model_values['nll_bound_iwaes'] + + train_steps[es_idx] = model_values['train_steps'] + + model_runs = {} + if self.hps.ic_dim > 0: + model_runs['prior_g0_mean'] = prior_g0_mean + model_runs['prior_g0_logvar'] = prior_g0_logvar + model_runs['post_g0_mean'] = post_g0_mean + model_runs['post_g0_logvar'] = post_g0_logvar + model_runs['gen_ics'] = gen_ics + + if self.hps.co_dim > 0: + model_runs['controller_outputs'] = controller_outputs + model_runs['gen_states'] = gen_states + model_runs['factors'] = factors + model_runs['output_dist_params'] = out_dist_params + + # You probably do not want the LL associated values when pushing the mean + # instead of sampling. + model_runs['costs'] = costs + model_runs['nll_bound_vaes'] = nll_bound_vaes + model_runs['nll_bound_iwaes'] = nll_bound_iwaes + model_runs['train_steps'] = train_steps + return model_runs + + def write_model_runs(self, datasets, output_fname=None, push_mean=False): + """Run the model on the data in data_dict, and save the computed values. + + LFADS generates a number of outputs for each examples, and these are all + saved. They are: + The mean and variance of the prior of g0. + The mean and variance of approximate posterior of g0. + The control inputs (if enabled) + The initial conditions, g0, for all examples. + The generator states for all time. + The factors for all time. + The output distribution parameters (e.g. rates) for all time. + + Args: + datasets: a dictionary of named data_dictionaries, see top of lfads.py + output_fname: a file name stem for the output files. + push_mean: if False (default), generates batch_size samples for each trial + and averages the results. if True, runs each trial once without noise, + pushing the posterior mean initial conditions and control inputs through + the trained model. False is used for posterior_sample_and_average, True + is used for posterior_push_mean. + """ + hps = self.hps + kind = hps.kind + + for data_name, data_dict in datasets.items(): + data_tuple = [('train', data_dict['train_data'], + data_dict['train_ext_input']), + ('valid', data_dict['valid_data'], + data_dict['valid_ext_input'])] + for data_kind, data_extxd, ext_input_extxi in data_tuple: + if not output_fname: + fname = "model_runs_" + data_name + '_' + data_kind + '_' + kind + else: + fname = output_fname + data_name + '_' + data_kind + '_' + kind + + print("Writing data for %s data and kind %s." % (data_name, data_kind)) + if push_mean: + model_runs = self.eval_model_runs_push_mean(data_name, data_extxd, + ext_input_extxi) + else: + model_runs = self.eval_model_runs_avg_epoch(data_name, data_extxd, + ext_input_extxi) + full_fname = os.path.join(hps.lfads_save_dir, fname) + write_data(full_fname, model_runs, compression='gzip') + print("Done.") + + def write_model_samples(self, dataset_name, output_fname=None): + """Use the prior distribution to generate batch_size number of samples + from the model. + + LFADS generates a number of outputs for each sample, and these are all + saved. They are: + The mean and variance of the prior of g0. + The control inputs (if enabled) + The initial conditions, g0, for all examples. + The generator states for all time. + The factors for all time. + The output distribution parameters (e.g. rates) for all time. + + Args: + dataset_name: The name of the dataset to grab the factors -> rates + alignment matrices from. + output_fname: The name of the file in which to save the generated + samples. + """ + hps = self.hps + batch_size = hps.batch_size + + print("Generating %d samples" % (batch_size)) + tf_vals = [self.factors, self.gen_states, self.gen_ics, + self.cost, self.output_dist_params] + if hps.ic_dim > 0: + tf_vals += [self.prior_zs_g0.mean, self.prior_zs_g0.logvar] + if hps.co_dim > 0: + tf_vals += [self.prior_zs_ar_con.samples_t] + tf_vals_flat, fidxs = flatten(tf_vals) + + session = tf.get_default_session() + feed_dict = {} + feed_dict[self.dataName] = dataset_name + feed_dict[self.keep_prob] = 1.0 + + np_vals_flat = session.run(tf_vals_flat, feed_dict=feed_dict) + + ff = 0 + factors = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + gen_states = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + gen_ics = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + costs = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + output_dist_params = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + if hps.ic_dim > 0: + prior_g0_mean = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + prior_g0_logvar = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + if hps.co_dim > 0: + prior_zs_ar_con = [np_vals_flat[f] for f in fidxs[ff]]; ff += 1 + + # [0] are to take out the non-temporal items from lists + gen_ics = gen_ics[0] + costs = costs[0] + + # Convert to full tensors, not lists of tensors in time dim. + gen_states = list_t_bxn_to_tensor_bxtxn(gen_states) + factors = list_t_bxn_to_tensor_bxtxn(factors) + output_dist_params = list_t_bxn_to_tensor_bxtxn(output_dist_params) + if hps.ic_dim > 0: + prior_g0_mean = prior_g0_mean[0] + prior_g0_logvar = prior_g0_logvar[0] + if hps.co_dim > 0: + prior_zs_ar_con = list_t_bxn_to_tensor_bxtxn(prior_zs_ar_con) + + model_vals = {} + model_vals['gen_ics'] = gen_ics + model_vals['gen_states'] = gen_states + model_vals['factors'] = factors + model_vals['output_dist_params'] = output_dist_params + model_vals['costs'] = costs.reshape(1) + if hps.ic_dim > 0: + model_vals['prior_g0_mean'] = prior_g0_mean + model_vals['prior_g0_logvar'] = prior_g0_logvar + if hps.co_dim > 0: + model_vals['prior_zs_ar_con'] = prior_zs_ar_con + + full_fname = os.path.join(hps.lfads_save_dir, output_fname) + write_data(full_fname, model_vals, compression='gzip') + print("Done.") + + @staticmethod + def eval_model_parameters(use_nested=True, include_strs=None): + """Evaluate and return all of the TF variables in the model. + + Args: + use_nested (optional): For returning values, use a nested dictoinary, based + on variable scoping, or return all variables in a flat dictionary. + include_strs (optional): A list of strings to use as a filter, to reduce the + number of variables returned. A variable name must contain at least one + string in include_strs as a sub-string in order to be returned. + + Returns: + The parameters of the model. This can be in a flat + dictionary, or a nested dictionary, where the nesting is by variable + scope. + """ + all_tf_vars = tf.global_variables() + session = tf.get_default_session() + all_tf_vars_eval = session.run(all_tf_vars) + vars_dict = {} + strs = ["LFADS"] + if include_strs: + strs += include_strs + + for i, (var, var_eval) in enumerate(zip(all_tf_vars, all_tf_vars_eval)): + if any(s in include_strs for s in var.name): + if not isinstance(var_eval, np.ndarray): # for H5PY + print(var.name, """ is not numpy array, saving as numpy array + with value: """, var_eval, type(var_eval)) + e = np.array(var_eval) + print(e, type(e)) + else: + e = var_eval + vars_dict[var.name] = e + + if not use_nested: + return vars_dict + + var_names = vars_dict.keys() + nested_vars_dict = {} + current_dict = nested_vars_dict + for v, var_name in enumerate(var_names): + var_split_name_list = var_name.split('/') + split_name_list_len = len(var_split_name_list) + current_dict = nested_vars_dict + for p, part in enumerate(var_split_name_list): + if p < split_name_list_len - 1: + if part in current_dict: + current_dict = current_dict[part] + else: + current_dict[part] = {} + current_dict = current_dict[part] + else: + current_dict[part] = vars_dict[var_name] + + return nested_vars_dict + + @staticmethod + def spikify_rates(rates_bxtxd): + """Randomly spikify underlying rates according a Poisson distribution + + Args: + rates_bxtxd: a numpy tensor with shape: + + Returns: + A numpy array with the same shape as rates_bxtxd, but with the event + counts. + """ + + B,T,N = rates_bxtxd.shape + assert all([B > 0, N > 0]), "problems" + + # Because the rates are changing, there is nesting + spikes_bxtxd = np.zeros([B,T,N], dtype=np.int32) + for b in range(B): + for t in range(T): + for n in range(N): + rate = rates_bxtxd[b,t,n] + count = np.random.poisson(rate) + spikes_bxtxd[b,t,n] = count + + return spikes_bxtxd diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/plot_lfads.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/plot_lfads.py" new file mode 100644 index 00000000..c4e1a033 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/plot_lfads.py" @@ -0,0 +1,181 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +import matplotlib +matplotlib.use('Agg') +from matplotlib import pyplot as plt +import numpy as np +import tensorflow as tf + +def _plot_item(W, name, full_name, nspaces): + plt.figure() + if W.shape == (): + print(name, ": ", W) + elif W.shape[0] == 1: + plt.stem(W.T) + plt.title(full_name) + elif W.shape[1] == 1: + plt.stem(W) + plt.title(full_name) + else: + plt.imshow(np.abs(W), interpolation='nearest', cmap='jet'); + plt.colorbar() + plt.title(full_name) + + +def all_plot(d, full_name="", exclude="", nspaces=0): + """Recursively plot all the LFADS model parameters in the nested + dictionary.""" + for k, v in d.iteritems(): + this_name = full_name+"/"+k + if isinstance(v, dict): + all_plot(v, full_name=this_name, exclude=exclude, nspaces=nspaces+4) + else: + if exclude == "" or exclude not in this_name: + _plot_item(v, name=k, full_name=full_name+"/"+k, nspaces=nspaces+4) + + + +def plot_time_series(vals_bxtxn, bidx=None, n_to_plot=np.inf, scale=1.0, + color='r', title=None): + + if bidx is None: + vals_txn = np.mean(vals_bxtxn, axis=0) + else: + vals_txn = vals_bxtxn[bidx,:,:] + + T, N = vals_txn.shape + if n_to_plot > N: + n_to_plot = N + + plt.plot(vals_txn[:,0:n_to_plot] + scale*np.array(range(n_to_plot)), + color=color, lw=1.0) + plt.axis('tight') + if title: + plt.title(title) + + +def plot_lfads_timeseries(data_bxtxn, model_vals, ext_input_bxtxi=None, + truth_bxtxn=None, bidx=None, output_dist="poisson", + conversion_factor=1.0, subplot_cidx=0, + col_title=None): + + n_to_plot = 10 + scale = 1.0 + nrows = 7 + plt.subplot(nrows,2,1+subplot_cidx) + + if output_dist == 'poisson': + rates = means = conversion_factor * model_vals['output_dist_params'] + plot_time_series(rates, bidx, n_to_plot=n_to_plot, scale=scale, + title=col_title + " rates (LFADS - red, Truth - black)") + elif output_dist == 'gaussian': + means_vars = model_vals['output_dist_params'] + means, vars = np.split(means_vars,2, axis=2) # bxtxn + stds = np.sqrt(vars) + plot_time_series(means, bidx, n_to_plot=n_to_plot, scale=scale, + title=col_title + " means (LFADS - red, Truth - black)") + plot_time_series(means+stds, bidx, n_to_plot=n_to_plot, scale=scale, + color='c') + plot_time_series(means-stds, bidx, n_to_plot=n_to_plot, scale=scale, + color='c') + else: + assert 'NIY' + + + if truth_bxtxn is not None: + plot_time_series(truth_bxtxn, bidx, n_to_plot=n_to_plot, color='k', + scale=scale) + + input_title = "" + if "controller_outputs" in model_vals.keys(): + input_title += " Controller Output" + plt.subplot(nrows,2,3+subplot_cidx) + u_t = model_vals['controller_outputs'][0:-1] + plot_time_series(u_t, bidx, n_to_plot=n_to_plot, color='c', scale=1.0, + title=col_title + input_title) + + if ext_input_bxtxi is not None: + input_title += " External Input" + plot_time_series(ext_input_bxtxi, n_to_plot=n_to_plot, color='b', + scale=scale, title=col_title + input_title) + + plt.subplot(nrows,2,5+subplot_cidx) + plot_time_series(means, bidx, + n_to_plot=n_to_plot, scale=1.0, + title=col_title + " Spikes (LFADS - red, Spikes - black)") + plot_time_series(data_bxtxn, bidx, n_to_plot=n_to_plot, color='k', scale=1.0) + + plt.subplot(nrows,2,7+subplot_cidx) + plot_time_series(model_vals['factors'], bidx, n_to_plot=n_to_plot, color='b', + scale=2.0, title=col_title + " Factors") + + plt.subplot(nrows,2,9+subplot_cidx) + plot_time_series(model_vals['gen_states'], bidx, n_to_plot=n_to_plot, + color='g', scale=1.0, title=col_title + " Generator State") + + if bidx is not None: + data_nxt = data_bxtxn[bidx,:,:].T + params_nxt = model_vals['output_dist_params'][bidx,:,:].T + else: + data_nxt = np.mean(data_bxtxn, axis=0).T + params_nxt = np.mean(model_vals['output_dist_params'], axis=0).T + if output_dist == 'poisson': + means_nxt = params_nxt + elif output_dist == 'gaussian': # (means+vars) x time + means_nxt = np.vsplit(params_nxt,2)[0] # get means + else: + assert "NIY" + + plt.subplot(nrows,2,11+subplot_cidx) + plt.imshow(data_nxt, aspect='auto', interpolation='nearest') + plt.title(col_title + ' Data') + + plt.subplot(nrows,2,13+subplot_cidx) + plt.imshow(means_nxt, aspect='auto', interpolation='nearest') + plt.title(col_title + ' Means') + + +def plot_lfads(train_bxtxd, train_model_vals, + train_ext_input_bxtxi=None, train_truth_bxtxd=None, + valid_bxtxd=None, valid_model_vals=None, + valid_ext_input_bxtxi=None, valid_truth_bxtxd=None, + bidx=None, cf=1.0, output_dist='poisson'): + + # Plotting + f = plt.figure(figsize=(18,20), tight_layout=True) + plot_lfads_timeseries(train_bxtxd, train_model_vals, + train_ext_input_bxtxi, + truth_bxtxn=train_truth_bxtxd, + conversion_factor=cf, bidx=bidx, + output_dist=output_dist, col_title='Train') + plot_lfads_timeseries(valid_bxtxd, valid_model_vals, + valid_ext_input_bxtxi, + truth_bxtxn=valid_truth_bxtxd, + conversion_factor=cf, bidx=bidx, + output_dist=output_dist, + subplot_cidx=1, col_title='Valid') + + # Convert from figure to an numpy array width x height x 3 (last for RGB) + f.canvas.draw() + data = np.fromstring(f.canvas.tostring_rgb(), dtype=np.uint8, sep='') + data_wxhx3 = data.reshape(f.canvas.get_width_height()[::-1] + (3,)) + plt.close() + + return data_wxhx3 diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/run_lfads.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/run_lfads.py" new file mode 100644 index 00000000..6e81b0bc --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/run_lfads.py" @@ -0,0 +1,814 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import absolute_import +from __future__ import division +from __future__ import print_function + +from lfads import LFADS +import numpy as np +import os +import tensorflow as tf +import re +import utils +import sys +MAX_INT = sys.maxsize + +# Lots of hyperparameters, but most are pretty insensitive. The +# explanation of these hyperparameters is found below, in the flags +# session. + +CHECKPOINT_PB_LOAD_NAME = "checkpoint" +CHECKPOINT_NAME = "lfads_vae" +CSV_LOG = "fitlog" +OUTPUT_FILENAME_STEM = "" +DEVICE = "gpu:0" # "cpu:0", or other gpus, e.g. "gpu:1" +MAX_CKPT_TO_KEEP = 5 +MAX_CKPT_TO_KEEP_LVE = 5 +PS_NEXAMPLES_TO_PROCESS = MAX_INT # if larger than number of examples, process all +EXT_INPUT_DIM = 0 +IC_DIM = 64 +FACTORS_DIM = 50 +IC_ENC_DIM = 128 +GEN_DIM = 200 +GEN_CELL_INPUT_WEIGHT_SCALE = 1.0 +GEN_CELL_REC_WEIGHT_SCALE = 1.0 +CELL_WEIGHT_SCALE = 1.0 +BATCH_SIZE = 128 +LEARNING_RATE_INIT = 0.01 +LEARNING_RATE_DECAY_FACTOR = 0.95 +LEARNING_RATE_STOP = 0.00001 +LEARNING_RATE_N_TO_COMPARE = 6 +INJECT_EXT_INPUT_TO_GEN = False +DO_TRAIN_IO_ONLY = False +DO_TRAIN_ENCODER_ONLY = False +DO_RESET_LEARNING_RATE = False +FEEDBACK_FACTORS_OR_RATES = "factors" +DO_TRAIN_READIN = True + +# Calibrated just above the average value for the rnn synthetic data. +MAX_GRAD_NORM = 200.0 +CELL_CLIP_VALUE = 5.0 +KEEP_PROB = 0.95 +TEMPORAL_SPIKE_JITTER_WIDTH = 0 +OUTPUT_DISTRIBUTION = 'poisson' # 'poisson' or 'gaussian' +NUM_STEPS_FOR_GEN_IC = MAX_INT # set to num_steps if greater than num_steps + +DATA_DIR = "/tmp/rnn_synth_data_v1.0/" +DATA_FILENAME_STEM = "chaotic_rnn_inputs_g1p5" +LFADS_SAVE_DIR = "/tmp/lfads_chaotic_rnn_inputs_g1p5/" +CO_DIM = 1 +DO_CAUSAL_CONTROLLER = False +DO_FEED_FACTORS_TO_CONTROLLER = True +CONTROLLER_INPUT_LAG = 1 +PRIOR_AR_AUTOCORRELATION = 10.0 +PRIOR_AR_PROCESS_VAR = 0.1 +DO_TRAIN_PRIOR_AR_ATAU = True +DO_TRAIN_PRIOR_AR_NVAR = True +CI_ENC_DIM = 128 +CON_DIM = 128 +CO_PRIOR_VAR_SCALE = 0.1 +KL_INCREASE_STEPS = 2000 +L2_INCREASE_STEPS = 2000 +L2_GEN_SCALE = 2000.0 +L2_CON_SCALE = 0.0 +# scale of regularizer on time correlation of inferred inputs +CO_MEAN_CORR_SCALE = 0.0 +KL_IC_WEIGHT = 1.0 +KL_CO_WEIGHT = 1.0 +KL_START_STEP = 0 +L2_START_STEP = 0 +IC_PRIOR_VAR_MIN = 0.1 +IC_PRIOR_VAR_SCALE = 0.1 +IC_PRIOR_VAR_MAX = 0.1 +IC_POST_VAR_MIN = 0.0001 # protection from KL blowing up + +flags = tf.app.flags +flags.DEFINE_string("kind", "train", + "Type of model to build {train, \ + posterior_sample_and_average, \ + posterior_push_mean, \ + prior_sample, write_model_params") +flags.DEFINE_string("output_dist", OUTPUT_DISTRIBUTION, + "Type of output distribution, 'poisson' or 'gaussian'") +flags.DEFINE_boolean("allow_gpu_growth", False, + "If true, only allocate amount of memory needed for \ + Session. Otherwise, use full GPU memory.") + +# DATA +flags.DEFINE_string("data_dir", DATA_DIR, "Data for training") +flags.DEFINE_string("data_filename_stem", DATA_FILENAME_STEM, + "Filename stem for data dictionaries.") +flags.DEFINE_string("lfads_save_dir", LFADS_SAVE_DIR, "model save dir") +flags.DEFINE_string("checkpoint_pb_load_name", CHECKPOINT_PB_LOAD_NAME, + "Name of checkpoint files, use 'checkpoint_lve' for best \ + error") +flags.DEFINE_string("checkpoint_name", CHECKPOINT_NAME, + "Name of checkpoint files (.ckpt appended)") +flags.DEFINE_string("output_filename_stem", OUTPUT_FILENAME_STEM, + "Name of output file (postfix will be added)") +flags.DEFINE_string("device", DEVICE, + "Which device to use (default: \"gpu:0\", can also be \ + \"cpu:0\", \"gpu:1\", etc)") +flags.DEFINE_string("csv_log", CSV_LOG, + "Name of file to keep running log of fit likelihoods, \ + etc (.csv appended)") +flags.DEFINE_integer("max_ckpt_to_keep", MAX_CKPT_TO_KEEP, + "Max # of checkpoints to keep (rolling)") +flags.DEFINE_integer("ps_nexamples_to_process", PS_NEXAMPLES_TO_PROCESS, + "Number of examples to process for posterior sample and \ + average (not number of samples to average over).") +flags.DEFINE_integer("max_ckpt_to_keep_lve", MAX_CKPT_TO_KEEP_LVE, + "Max # of checkpoints to keep for lowest validation error \ + models (rolling)") +flags.DEFINE_integer("ext_input_dim", EXT_INPUT_DIM, "Dimension of external \ +inputs") +flags.DEFINE_integer("num_steps_for_gen_ic", NUM_STEPS_FOR_GEN_IC, + "Number of steps to train the generator initial conditon.") + + +# If there are observed inputs, there are two ways to add that observed +# input to the model. The first is by treating as something to be +# inferred, and thus encoding the observed input via the encoders, and then +# input to the generator via the "inferred inputs" channel. Second, one +# can input the input directly into the generator. This has the downside +# of making the generation process strictly dependent on knowing the +# observed input for any generated trial. +flags.DEFINE_boolean("inject_ext_input_to_gen", + INJECT_EXT_INPUT_TO_GEN, + "Should observed inputs be input to model via encoders, \ + or injected directly into generator?") + +# CELL + +# The combined recurrent and input weights of the encoder and +# controller cells are by default set to scale at ws/sqrt(#inputs), +# with ws=1.0. You can change this scaling with this parameter. +flags.DEFINE_float("cell_weight_scale", CELL_WEIGHT_SCALE, + "Input scaling for input weights in generator.") + + +# GENERATION + +# Note that the dimension of the initial conditions is separated from the +# dimensions of the generator initial conditions (and a linear matrix will +# adapt the shapes if necessary). This is just another way to control +# complexity. In all likelihood, setting the ic dims to the size of the +# generator hidden state is just fine. +flags.DEFINE_integer("ic_dim", IC_DIM, "Dimension of h0") +# Setting the dimensions of the factors to something smaller than the data +# dimension is a way to get a reduced dimensionality representation of your +# data. +flags.DEFINE_integer("factors_dim", FACTORS_DIM, + "Number of factors from generator") +flags.DEFINE_integer("ic_enc_dim", IC_ENC_DIM, + "Cell hidden size, encoder of h0") + +# Controlling the size of the generator is one way to control complexity of +# the dynamics (there is also l2, which will squeeze out unnecessary +# dynamics also). The modern deep learning approach is to make these cells +# as large as tolerable (from a waiting perspective), and then regularize +# them to death with drop out or whatever. I don't know if this is correct +# for the LFADS application or not. +flags.DEFINE_integer("gen_dim", GEN_DIM, + "Cell hidden size, generator.") +# The weights of the generator cell by default set to scale at +# ws/sqrt(#inputs), with ws=1.0. You can change ws for +# the input weights or the recurrent weights with these hyperparameters. +flags.DEFINE_float("gen_cell_input_weight_scale", GEN_CELL_INPUT_WEIGHT_SCALE, + "Input scaling for input weights in generator.") +flags.DEFINE_float("gen_cell_rec_weight_scale", GEN_CELL_REC_WEIGHT_SCALE, + "Input scaling for rec weights in generator.") + +# KL DISTRIBUTIONS +# If you don't know what you are donig here, please leave alone, the +# defaults should be fine for most cases, irregardless of other parameters. +# +# If you don't want the prior variance to be learned, set the +# following values to the same thing: ic_prior_var_min, +# ic_prior_var_scale, ic_prior_var_max. The prior mean will be +# learned regardless. +flags.DEFINE_float("ic_prior_var_min", IC_PRIOR_VAR_MIN, + "Minimum variance in posterior h0 codes.") +flags.DEFINE_float("ic_prior_var_scale", IC_PRIOR_VAR_SCALE, + "Variance of ic prior distribution") +flags.DEFINE_float("ic_prior_var_max", IC_PRIOR_VAR_MAX, + "Maximum variance of IC prior distribution.") +# If you really want to limit the information from encoder to decoder, +# Increase ic_post_var_min above 0.0. +flags.DEFINE_float("ic_post_var_min", IC_POST_VAR_MIN, + "Minimum variance of IC posterior distribution.") +flags.DEFINE_float("co_prior_var_scale", CO_PRIOR_VAR_SCALE, + "Variance of control input prior distribution.") + + +flags.DEFINE_float("prior_ar_atau", PRIOR_AR_AUTOCORRELATION, + "Initial autocorrelation of AR(1) priors.") +flags.DEFINE_float("prior_ar_nvar", PRIOR_AR_PROCESS_VAR, + "Initial noise variance for AR(1) priors.") +flags.DEFINE_boolean("do_train_prior_ar_atau", DO_TRAIN_PRIOR_AR_ATAU, + "Is the value for atau an init, or the constant value?") +flags.DEFINE_boolean("do_train_prior_ar_nvar", DO_TRAIN_PRIOR_AR_NVAR, + "Is the value for noise variance an init, or the constant \ + value?") + +# CONTROLLER +# This parameter critically controls whether or not there is a controller +# (along with controller encoders placed into the LFADS graph. If CO_DIM > +# 1, that means there is a 1 dimensional controller outputs, if equal to 0, +# then no controller. +flags.DEFINE_integer("co_dim", CO_DIM, + "Number of control net outputs (>0 builds that graph).") + +# The controller will be more powerful if it can see the encoding of the entire +# trial. However, this allows the controller to create inferred inputs that are +# acausal with respect to the actual data generation process. E.g. the data +# generator could have an input at time t, but the controller, after seeing the +# entirety of the trial could infer that the input is coming a little before +# time t, because there are no restrictions on the data the controller sees. +# One can force the controller to be causal (with respect to perturbations in +# the data generator) so that it only sees forward encodings of the data at time +# t that originate at times before or at time t. One can also control the data +# the controller sees by using an input lag (forward encoding at time [t-tlag] +# for controller input at time t. The same can be done in the reverse direction +# (controller input at time t from reverse encoding at time [t+tlag], in the +# case of an acausal controller). Setting this lag > 0 (even lag=1) can be a +# powerful way of avoiding very spiky decodes. Finally, one can manually control +# whether the factors at time t-1 are fed to the controller at time t. +# +# If you don't care about any of this, and just want to smooth your data, set +# do_causal_controller = False +# do_feed_factors_to_controller = True +# causal_input_lag = 0 +flags.DEFINE_boolean("do_causal_controller", + DO_CAUSAL_CONTROLLER, + "Restrict the controller create only causal inferred \ + inputs?") +# Strictly speaking, feeding either the factors or the rates to the controller +# violates causality, since the g0 gets to see all the data. This may or may not +# be only a theoretical concern. +flags.DEFINE_boolean("do_feed_factors_to_controller", + DO_FEED_FACTORS_TO_CONTROLLER, + "Should factors[t-1] be input to controller at time t?") +flags.DEFINE_string("feedback_factors_or_rates", FEEDBACK_FACTORS_OR_RATES, + "Feedback the factors or the rates to the controller? \ + Acceptable values: 'factors' or 'rates'.") +flags.DEFINE_integer("controller_input_lag", CONTROLLER_INPUT_LAG, + "Time lag on the encoding to controller t-lag for \ + forward, t+lag for reverse.") + +flags.DEFINE_integer("ci_enc_dim", CI_ENC_DIM, + "Cell hidden size, encoder of control inputs") +flags.DEFINE_integer("con_dim", CON_DIM, + "Cell hidden size, controller") + + +# OPTIMIZATION +flags.DEFINE_integer("batch_size", BATCH_SIZE, + "Batch size to use during training.") +flags.DEFINE_float("learning_rate_init", LEARNING_RATE_INIT, + "Learning rate initial value") +flags.DEFINE_float("learning_rate_decay_factor", LEARNING_RATE_DECAY_FACTOR, + "Learning rate decay, decay by this fraction every so \ + often.") +flags.DEFINE_float("learning_rate_stop", LEARNING_RATE_STOP, + "The lr is adaptively reduced, stop training at this value.") +# Rather put the learning rate on an exponentially decreasiong schedule, +# the current algorithm pays attention to the learning rate, and if it +# isn't regularly decreasing, it will decrease the learning rate. So far, +# it works fine, though it is not perfect. +flags.DEFINE_integer("learning_rate_n_to_compare", LEARNING_RATE_N_TO_COMPARE, + "Number of previous costs current cost has to be worse \ + than, to lower learning rate.") + +# This sets a value, above which, the gradients will be clipped. This hp +# is extremely useful to avoid an infrequent, but highly pathological +# problem whereby the gradient is so large that it destroys the +# optimziation by setting parameters too large, leading to a vicious cycle +# that ends in NaNs. If it's too large, it's useless, if it's too small, +# it essentially becomes the learning rate. It's pretty insensitive, though. +flags.DEFINE_float("max_grad_norm", MAX_GRAD_NORM, + "Max norm of gradient before clipping.") + +# If your optimizations start "NaN-ing out", reduce this value so that +# the values of the network don't grow out of control. Typically, once +# this parameter is set to a reasonable value, one stops having numerical +# problems. +flags.DEFINE_float("cell_clip_value", CELL_CLIP_VALUE, + "Max value recurrent cell can take before being clipped.") + +# This flag is used for an experiment where one sees if training a model with +# many days data can be used to learn the dynamics from a held-out days data. +# If you don't care about that particular experiment, this flag should always be +# false. +flags.DEFINE_boolean("do_train_io_only", DO_TRAIN_IO_ONLY, + "Train only the input (readin) and output (readout) \ + affine functions.") + +# This flag is used for an experiment where one wants to know if the dynamics +# learned by the generator generalize across conditions. In that case, you might +# train up a model on one set of data, and then only further train the encoder +# on another set of data (the conditions to be tested) so that the model is +# forced to use the same dynamics to describe that data. If you don't care about +# that particular experiment, this flag should always be false. +flags.DEFINE_boolean("do_train_encoder_only", DO_TRAIN_ENCODER_ONLY, + "Train only the encoder weights.") + +flags.DEFINE_boolean("do_reset_learning_rate", DO_RESET_LEARNING_RATE, + "Reset the learning rate to initial value.") + + +# for multi-session "stitching" models, the per-session readin matrices map from +# neurons to input factors which are fed into the shared encoder. These are +# initialized by alignment_matrix_cxf and alignment_bias_c in the input .h5 +# files. They can be fixed or made trainable. +flags.DEFINE_boolean("do_train_readin", DO_TRAIN_READIN, "Whether to train the \ + readin matrices and bias vectors. False leaves them fixed \ + at their initial values specified by the alignment \ + matrices and vectors.") + + +# OVERFITTING +# Dropout is done on the input data, on controller inputs (from +# encoder), on outputs from generator to factors. +flags.DEFINE_float("keep_prob", KEEP_PROB, "Dropout keep probability.") +# It appears that the system will happily fit spikes (blessing or +# curse, depending). You may not want this. Jittering the spikes a +# bit will help (-/+ bin size, as specified here). +flags.DEFINE_integer("temporal_spike_jitter_width", + TEMPORAL_SPIKE_JITTER_WIDTH, + "Shuffle spikes around this window.") + +# General note about helping ascribe controller inputs vs dynamics: +# +# If controller is heavily penalized, then it won't have any output. +# If dynamics are heavily penalized, then generator won't make +# dynamics. Note this l2 penalty is only on the recurrent portion of +# the RNNs, as dropout is also available, penalizing the feed-forward +# connections. +flags.DEFINE_float("l2_gen_scale", L2_GEN_SCALE, + "L2 regularization cost for the generator only.") +flags.DEFINE_float("l2_con_scale", L2_CON_SCALE, + "L2 regularization cost for the controller only.") +flags.DEFINE_float("co_mean_corr_scale", CO_MEAN_CORR_SCALE, + "Cost of correlation (thru time)in the means of \ + controller output.") + +# UNDERFITTING +# If the primary task of LFADS is "filtering" of data and not +# generation, then it is possible that the KL penalty is too strong. +# Empirically, we have found this to be the case. So we add a +# hyperparameter in front of the the two KL terms (one for the initial +# conditions to the generator, the other for the controller outputs). +# You should always think of the the default values as 1.0, and that +# leads to a standard VAE formulation whereby the numbers that are +# optimized are a lower-bound on the log-likelihood of the data. When +# these 2 HPs deviate from 1.0, one cannot make any statement about +# what those LL lower bounds mean anymore, and they cannot be compared +# (AFAIK). +flags.DEFINE_float("kl_ic_weight", KL_IC_WEIGHT, + "Strength of KL weight on initial conditions KL penatly.") +flags.DEFINE_float("kl_co_weight", KL_CO_WEIGHT, + "Strength of KL weight on controller output KL penalty.") + +# Sometimes the task can be sufficiently hard to learn that the +# optimizer takes the 'easy route', and simply minimizes the KL +# divergence, setting it to near zero, and the optimization gets +# stuck. These two parameters will help avoid that by by getting the +# optimization to 'latch' on to the main optimization, and only +# turning in the regularizers later. +flags.DEFINE_integer("kl_start_step", KL_START_STEP, + "Start increasing weight after this many steps.") +# training passes, not epochs, increase by 0.5 every kl_increase_steps +flags.DEFINE_integer("kl_increase_steps", KL_INCREASE_STEPS, + "Increase weight of kl cost to avoid local minimum.") +# Same story for l2 regularizer. One wants a simple generator, for scientific +# reasons, but not at the expense of hosing the optimization. +flags.DEFINE_integer("l2_start_step", L2_START_STEP, + "Start increasing l2 weight after this many steps.") +flags.DEFINE_integer("l2_increase_steps", L2_INCREASE_STEPS, + "Increase weight of l2 cost to avoid local minimum.") + +FLAGS = flags.FLAGS + + +def build_model(hps, kind="train", datasets=None): + """Builds a model from either random initialization, or saved parameters. + + Args: + hps: The hyper parameters for the model. + kind: (optional) The kind of model to build. Training vs inference require + different graphs. + datasets: The datasets structure (see top of lfads.py). + + Returns: + an LFADS model. + """ + + build_kind = kind + if build_kind == "write_model_params": + build_kind = "train" + with tf.variable_scope("LFADS", reuse=None): + model = LFADS(hps, kind=build_kind, datasets=datasets) + + if not os.path.exists(hps.lfads_save_dir): + print("Save directory %s does not exist, creating it." % hps.lfads_save_dir) + os.makedirs(hps.lfads_save_dir) + + cp_pb_ln = hps.checkpoint_pb_load_name + cp_pb_ln = 'checkpoint' if cp_pb_ln == "" else cp_pb_ln + if cp_pb_ln == 'checkpoint': + print("Loading latest training checkpoint in: ", hps.lfads_save_dir) + saver = model.seso_saver + elif cp_pb_ln == 'checkpoint_lve': + print("Loading lowest validation checkpoint in: ", hps.lfads_save_dir) + saver = model.lve_saver + else: + print("Loading checkpoint: ", cp_pb_ln, ", in: ", hps.lfads_save_dir) + saver = model.seso_saver + + ckpt = tf.train.get_checkpoint_state(hps.lfads_save_dir, + latest_filename=cp_pb_ln) + + session = tf.get_default_session() + print("ckpt: ", ckpt) + if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path): + print("Reading model parameters from %s" % ckpt.model_checkpoint_path) + saver.restore(session, ckpt.model_checkpoint_path) + else: + print("Created model with fresh parameters.") + if kind in ["posterior_sample_and_average", "posterior_push_mean", + "prior_sample", "write_model_params"]: + print("Possible error!!! You are running ", kind, " on a newly \ + initialized model!") + # cannot print ckpt.model_check_point path if no ckpt + print("Are you sure you sure a checkpoint in ", hps.lfads_save_dir, + " exists?") + + tf.global_variables_initializer().run() + + if ckpt: + train_step_str = re.search('-[0-9]+$', ckpt.model_checkpoint_path).group() + else: + train_step_str = '-0' + + fname = 'hyperparameters' + train_step_str + '.txt' + hp_fname = os.path.join(hps.lfads_save_dir, fname) + hps_for_saving = jsonify_dict(hps) + utils.write_data(hp_fname, hps_for_saving, use_json=True) + + return model + + +def jsonify_dict(d): + """Turns python booleans into strings so hps dict can be written in json. + Creates a shallow-copied dictionary first, then accomplishes string + conversion. + + Args: + d: hyperparameter dictionary + + Returns: hyperparameter dictionary with bool's as strings + """ + + d2 = d.copy() # shallow copy is fine by assumption of d being shallow + def jsonify_bool(boolean_value): + if boolean_value: + return "true" + else: + return "false" + + for key in d2.keys(): + if isinstance(d2[key], bool): + d2[key] = jsonify_bool(d2[key]) + return d2 + + +def build_hyperparameter_dict(flags): + """Simple script for saving hyper parameters. Under the hood the + flags structure isn't a dictionary, so it has to be simplified since we + want to be able to view file as text. + + Args: + flags: From tf.app.flags + + Returns: + dictionary of hyper parameters (ignoring other flag types). + """ + d = {} + # Data + d['output_dist'] = flags.output_dist + d['data_dir'] = flags.data_dir + d['lfads_save_dir'] = flags.lfads_save_dir + d['checkpoint_pb_load_name'] = flags.checkpoint_pb_load_name + d['checkpoint_name'] = flags.checkpoint_name + d['output_filename_stem'] = flags.output_filename_stem + d['max_ckpt_to_keep'] = flags.max_ckpt_to_keep + d['max_ckpt_to_keep_lve'] = flags.max_ckpt_to_keep_lve + d['ps_nexamples_to_process'] = flags.ps_nexamples_to_process + d['ext_input_dim'] = flags.ext_input_dim + d['data_filename_stem'] = flags.data_filename_stem + d['device'] = flags.device + d['csv_log'] = flags.csv_log + d['num_steps_for_gen_ic'] = flags.num_steps_for_gen_ic + d['inject_ext_input_to_gen'] = flags.inject_ext_input_to_gen + # Cell + d['cell_weight_scale'] = flags.cell_weight_scale + # Generation + d['ic_dim'] = flags.ic_dim + d['factors_dim'] = flags.factors_dim + d['ic_enc_dim'] = flags.ic_enc_dim + d['gen_dim'] = flags.gen_dim + d['gen_cell_input_weight_scale'] = flags.gen_cell_input_weight_scale + d['gen_cell_rec_weight_scale'] = flags.gen_cell_rec_weight_scale + # KL distributions + d['ic_prior_var_min'] = flags.ic_prior_var_min + d['ic_prior_var_scale'] = flags.ic_prior_var_scale + d['ic_prior_var_max'] = flags.ic_prior_var_max + d['ic_post_var_min'] = flags.ic_post_var_min + d['co_prior_var_scale'] = flags.co_prior_var_scale + d['prior_ar_atau'] = flags.prior_ar_atau + d['prior_ar_nvar'] = flags.prior_ar_nvar + d['do_train_prior_ar_atau'] = flags.do_train_prior_ar_atau + d['do_train_prior_ar_nvar'] = flags.do_train_prior_ar_nvar + # Controller + d['do_causal_controller'] = flags.do_causal_controller + d['controller_input_lag'] = flags.controller_input_lag + d['do_feed_factors_to_controller'] = flags.do_feed_factors_to_controller + d['feedback_factors_or_rates'] = flags.feedback_factors_or_rates + d['co_dim'] = flags.co_dim + d['ci_enc_dim'] = flags.ci_enc_dim + d['con_dim'] = flags.con_dim + d['co_mean_corr_scale'] = flags.co_mean_corr_scale + # Optimization + d['batch_size'] = flags.batch_size + d['learning_rate_init'] = flags.learning_rate_init + d['learning_rate_decay_factor'] = flags.learning_rate_decay_factor + d['learning_rate_stop'] = flags.learning_rate_stop + d['learning_rate_n_to_compare'] = flags.learning_rate_n_to_compare + d['max_grad_norm'] = flags.max_grad_norm + d['cell_clip_value'] = flags.cell_clip_value + d['do_train_io_only'] = flags.do_train_io_only + d['do_train_encoder_only'] = flags.do_train_encoder_only + d['do_reset_learning_rate'] = flags.do_reset_learning_rate + d['do_train_readin'] = flags.do_train_readin + + # Overfitting + d['keep_prob'] = flags.keep_prob + d['temporal_spike_jitter_width'] = flags.temporal_spike_jitter_width + d['l2_gen_scale'] = flags.l2_gen_scale + d['l2_con_scale'] = flags.l2_con_scale + # Underfitting + d['kl_ic_weight'] = flags.kl_ic_weight + d['kl_co_weight'] = flags.kl_co_weight + d['kl_start_step'] = flags.kl_start_step + d['kl_increase_steps'] = flags.kl_increase_steps + d['l2_start_step'] = flags.l2_start_step + d['l2_increase_steps'] = flags.l2_increase_steps + + return d + + +class hps_dict_to_obj(dict): + """Helper class allowing us to access hps dictionary more easily.""" + + def __getattr__(self, key): + if key in self: + return self[key] + else: + assert False, ("%s does not exist." % key) + def __setattr__(self, key, value): + self[key] = value + + +def train(hps, datasets): + """Train the LFADS model. + + Args: + hps: The dictionary of hyperparameters. + datasets: A dictionary of data dictionaries. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + """ + model = build_model(hps, kind="train", datasets=datasets) + if hps.do_reset_learning_rate: + sess = tf.get_default_session() + sess.run(model.learning_rate.initializer) + + model.train_model(datasets) + + +def write_model_runs(hps, datasets, output_fname=None, push_mean=False): + """Run the model on the data in data_dict, and save the computed values. + + LFADS generates a number of outputs for each examples, and these are all + saved. They are: + The mean and variance of the prior of g0. + The mean and variance of approximate posterior of g0. + The control inputs (if enabled) + The initial conditions, g0, for all examples. + The generator states for all time. + The factors for all time. + The rates for all time. + + Args: + hps: The dictionary of hyperparameters. + datasets: A dictionary of data dictionaries. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + output_fname (optional): output filename stem to write the model runs. + push_mean: if False (default), generates batch_size samples for each trial + and averages the results. if True, runs each trial once without noise, + pushing the posterior mean initial conditions and control inputs through + the trained model. False is used for posterior_sample_and_average, True + is used for posterior_push_mean. + """ + model = build_model(hps, kind=hps.kind, datasets=datasets) + model.write_model_runs(datasets, output_fname, push_mean) + + +def write_model_samples(hps, datasets, dataset_name=None, output_fname=None): + """Use the prior distribution to generate samples from the model. + Generates batch_size number of samples (set through FLAGS). + + LFADS generates a number of outputs for each examples, and these are all + saved. They are: + The mean and variance of the prior of g0. + The control inputs (if enabled) + The initial conditions, g0, for all examples. + The generator states for all time. + The factors for all time. + The output distribution parameters (e.g. rates) for all time. + + Args: + hps: The dictionary of hyperparameters. + datasets: A dictionary of data dictionaries. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + dataset_name: The name of the dataset to grab the factors -> rates + alignment matrices from. Only a concern with models trained on + multi-session data. By default, uses the first dataset in the data dict. + output_fname: The name prefix of the file in which to save the generated + samples. + """ + if not output_fname: + output_fname = "model_runs_" + hps.kind + else: + output_fname = output_fname + "model_runs_" + hps.kind + if not dataset_name: + dataset_name = datasets.keys()[0] + else: + if dataset_name not in datasets.keys(): + raise ValueError("Invalid dataset name '%s'."%(dataset_name)) + model = build_model(hps, kind=hps.kind, datasets=datasets) + model.write_model_samples(dataset_name, output_fname) + + +def write_model_parameters(hps, output_fname=None, datasets=None): + """Save all the model parameters + + Save all the parameters to hps.lfads_save_dir. + + Args: + hps: The dictionary of hyperparameters. + output_fname: The prefix of the file in which to save the generated + samples. + datasets: A dictionary of data dictionaries. The dataset dict is simply a + name(string)-> data dictionary mapping (See top of lfads.py). + """ + if not output_fname: + output_fname = "model_params" + else: + output_fname = output_fname + "_model_params" + fname = os.path.join(hps.lfads_save_dir, output_fname) + print("Writing model parameters to: ", fname) + # save the optimizer params as well + model = build_model(hps, kind="write_model_params", datasets=datasets) + model_params = model.eval_model_parameters(use_nested=False, + include_strs="LFADS") + utils.write_data(fname, model_params, compression=None) + print("Done.") + + +def clean_data_dict(data_dict): + """Add some key/value pairs to the data dict, if they are missing. + Args: + data_dict - dictionary containing data for LFADS + Returns: + data_dict with some keys filled in, if they are absent. + """ + + keys = ['train_truth', 'train_ext_input', 'valid_data', + 'valid_truth', 'valid_ext_input', 'valid_train'] + for k in keys: + if k not in data_dict: + data_dict[k] = None + + return data_dict + + +def load_datasets(data_dir, data_filename_stem): + """Load the datasets from a specified directory. + + Example files look like + >data_dir/my_dataset_first_day + >data_dir/my_dataset_second_day + + If my_dataset (filename) stem is in the directory, the read routine will try + and load it. The datasets dictionary will then look like + dataset['first_day'] -> (first day data dictionary) + dataset['second_day'] -> (first day data dictionary) + + Args: + data_dir: The directory from which to load the datasets. + data_filename_stem: The stem of the filename for the datasets. + + Returns: + datasets: a dataset dictionary, with one name->data dictionary pair for + each dataset file. + """ + print("Reading data from ", data_dir) + datasets = utils.read_datasets(data_dir, data_filename_stem) + for k, data_dict in datasets.items(): + datasets[k] = clean_data_dict(data_dict) + + train_total_size = len(data_dict['train_data']) + if train_total_size == 0: + print("Did not load training set.") + else: + print("Found training set with number examples: ", train_total_size) + + valid_total_size = len(data_dict['valid_data']) + if valid_total_size == 0: + print("Did not load validation set.") + else: + print("Found validation set with number examples: ", valid_total_size) + + return datasets + + +def main(_): + """Get this whole shindig off the ground.""" + d = build_hyperparameter_dict(FLAGS) + hps = hps_dict_to_obj(d) # hyper parameters + kind = FLAGS.kind + + # Read the data, if necessary. + train_set = valid_set = None + if kind in ["train", "posterior_sample_and_average", "posterior_push_mean", + "prior_sample", "write_model_params"]: + datasets = load_datasets(hps.data_dir, hps.data_filename_stem) + else: + raise ValueError('Kind {} is not supported.'.format(kind)) + + # infer the dataset names and dataset dimensions from the loaded files + hps.kind = kind # needs to be added here, cuz not saved as hyperparam + hps.dataset_names = [] + hps.dataset_dims = {} + for key in datasets: + hps.dataset_names.append(key) + hps.dataset_dims[key] = datasets[key]['data_dim'] + + # also store down the dimensionality of the data + # - just pull from one set, required to be same for all sets + hps.num_steps = datasets.values()[0]['num_steps'] + hps.ndatasets = len(hps.dataset_names) + + if hps.num_steps_for_gen_ic > hps.num_steps: + hps.num_steps_for_gen_ic = hps.num_steps + + # Build and run the model, for varying purposes. + config = tf.ConfigProto(allow_soft_placement=True, + log_device_placement=False) + if FLAGS.allow_gpu_growth: + config.gpu_options.allow_growth = True + sess = tf.Session(config=config) + with sess.as_default(): + with tf.device(hps.device): + if kind == "train": + train(hps, datasets) + elif kind == "posterior_sample_and_average": + write_model_runs(hps, datasets, hps.output_filename_stem, + push_mean=False) + elif kind == "posterior_push_mean": + write_model_runs(hps, datasets, hps.output_filename_stem, + push_mean=True) + elif kind == "prior_sample": + write_model_samples(hps, datasets, hps.output_filename_stem) + elif kind == "write_model_params": + write_model_parameters(hps, hps.output_filename_stem, datasets) + else: + assert False, ("Kind %s is not implemented. " % kind) + + +if __name__ == "__main__": + tf.app.run() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_chaotic_rnn_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_chaotic_rnn_data.py" new file mode 100644 index 00000000..3de72e58 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_chaotic_rnn_data.py" @@ -0,0 +1,200 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import print_function + +import h5py +import numpy as np +import os +import tensorflow as tf # used for flags here + +from utils import write_datasets +from synthetic_data_utils import add_alignment_projections, generate_data +from synthetic_data_utils import generate_rnn, get_train_n_valid_inds +from synthetic_data_utils import nparray_and_transpose +from synthetic_data_utils import spikify_data, gaussify_data, split_list_by_inds +import matplotlib +import matplotlib.pyplot as plt +import scipy.signal + +matplotlib.rcParams['image.interpolation'] = 'nearest' +DATA_DIR = "rnn_synth_data_v1.0" + +flags = tf.app.flags +flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", + "Directory for saving data.") +flags.DEFINE_string("datafile_name", "thits_data", + "Name of data file for input case.") +flags.DEFINE_string("noise_type", "poisson", "Noise type for data.") +flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") +flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") +flags.DEFINE_integer("C", 100, "Number of conditions") +flags.DEFINE_integer("N", 50, "Number of units for the RNN") +flags.DEFINE_integer("S", 50, "Number of sampled units from RNN") +flags.DEFINE_integer("npcs", 10, "Number of PCS for multi-session case.") +flags.DEFINE_float("train_percentage", 4.0/5.0, + "Percentage of train vs validation trials") +flags.DEFINE_integer("nreplications", 40, + "Number of noise replications of the same underlying rates.") +flags.DEFINE_float("g", 1.5, "Complexity of dynamics") +flags.DEFINE_float("x0_std", 1.0, + "Volume from which to pull initial conditions (affects diversity of dynamics.") +flags.DEFINE_float("tau", 0.025, "Time constant of RNN") +flags.DEFINE_float("dt", 0.010, "Time bin") +flags.DEFINE_float("input_magnitude", 20.0, + "For the input case, what is the value of the input?") +flags.DEFINE_float("max_firing_rate", 30.0, "Map 1.0 of RNN to a spikes per second") +FLAGS = flags.FLAGS + + +# Note that with N small, (as it is 25 above), the finite size effects +# will have pretty dramatic effects on the dynamics of the random RNN. +# If you want more complex dynamics, you'll have to run the script a +# lot, or increase N (or g). + +# Getting hard vs. easy data can be a little stochastic, so we set the seed. + +# Pull out some commonly used parameters. +# These are user parameters (configuration) +rng = np.random.RandomState(seed=FLAGS.synth_data_seed) +T = FLAGS.T +C = FLAGS.C +N = FLAGS.N +S = FLAGS.S +input_magnitude = FLAGS.input_magnitude +nreplications = FLAGS.nreplications +E = nreplications * C # total number of trials +# S is the number of measurements in each datasets, w/ each +# dataset having a different set of observations. +ndatasets = N/S # ok if rounded down +train_percentage = FLAGS.train_percentage +ntime_steps = int(T / FLAGS.dt) +# End of user parameters + +rnn = generate_rnn(rng, N, FLAGS.g, FLAGS.tau, FLAGS.dt, FLAGS.max_firing_rate) + +# Check to make sure the RNN is the one we used in the paper. +if N == 50: + assert abs(rnn['W'][0,0] - 0.06239899) < 1e-8, 'Error in random seed?' + rem_check = nreplications * train_percentage + assert abs(rem_check - int(rem_check)) < 1e-8, \ + 'Train percentage * nreplications should be integral number.' + + +# Initial condition generation, and condition label generation. This +# happens outside of the dataset loop, so that all datasets have the +# same conditions, which is similar to a neurophys setup. +condition_number = 0 +x0s = [] +condition_labels = [] +for c in range(C): + x0 = FLAGS.x0_std * rng.randn(N, 1) + x0s.append(np.tile(x0, nreplications)) # replicate x0 nreplications times + # replicate the condition label nreplications times + for ns in range(nreplications): + condition_labels.append(condition_number) + condition_number += 1 +x0s = np.concatenate(x0s, axis=1) + +# Containers for storing data across data. +datasets = {} +for n in range(ndatasets): + print(n+1, " of ", ndatasets) + + # First generate all firing rates. in the next loop, generate all + # replications this allows the random state for rate generation to be + # independent of n_replications. + dataset_name = 'dataset_N' + str(N) + '_S' + str(S) + if S < N: + dataset_name += '_n' + str(n+1) + + # Sample neuron subsets. The assumption is the PC axes of the RNN + # are not unit aligned, so sampling units is adequate to sample all + # the high-variance PCs. + P_sxn = np.eye(S,N) + for m in range(n): + P_sxn = np.roll(P_sxn, S, axis=1) + + if input_magnitude > 0.0: + # time of "hits" randomly chosen between [1/4 and 3/4] of total time + input_times = rng.choice(int(ntime_steps/2), size=[E]) + int(ntime_steps/4) + else: + input_times = None + + rates, x0s, inputs = \ + generate_data(rnn, T=T, E=E, x0s=x0s, P_sxn=P_sxn, + input_magnitude=input_magnitude, + input_times=input_times) + + if FLAGS.noise_type == "poisson": + noisy_data = spikify_data(rates, rng, rnn['dt'], rnn['max_firing_rate']) + elif FLAGS.noise_type == "gaussian": + noisy_data = gaussify_data(rates, rng, rnn['dt'], rnn['max_firing_rate']) + else: + raise ValueError("Only noise types supported are poisson or gaussian") + + # split into train and validation sets + train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, + nreplications) + + # Split the data, inputs, labels and times into train vs. validation. + rates_train, rates_valid = \ + split_list_by_inds(rates, train_inds, valid_inds) + noisy_data_train, noisy_data_valid = \ + split_list_by_inds(noisy_data, train_inds, valid_inds) + input_train, inputs_valid = \ + split_list_by_inds(inputs, train_inds, valid_inds) + condition_labels_train, condition_labels_valid = \ + split_list_by_inds(condition_labels, train_inds, valid_inds) + input_times_train, input_times_valid = \ + split_list_by_inds(input_times, train_inds, valid_inds) + + # Turn rates, noisy_data, and input into numpy arrays. + rates_train = nparray_and_transpose(rates_train) + rates_valid = nparray_and_transpose(rates_valid) + noisy_data_train = nparray_and_transpose(noisy_data_train) + noisy_data_valid = nparray_and_transpose(noisy_data_valid) + input_train = nparray_and_transpose(input_train) + inputs_valid = nparray_and_transpose(inputs_valid) + + # Note that we put these 'truth' rates and input into this + # structure, the only data that is used in LFADS are the noisy + # data e.g. spike trains. The rest is either for printing or posterity. + data = {'train_truth': rates_train, + 'valid_truth': rates_valid, + 'input_train_truth' : input_train, + 'input_valid_truth' : inputs_valid, + 'train_data' : noisy_data_train, + 'valid_data' : noisy_data_valid, + 'train_percentage' : train_percentage, + 'nreplications' : nreplications, + 'dt' : rnn['dt'], + 'input_magnitude' : input_magnitude, + 'input_times_train' : input_times_train, + 'input_times_valid' : input_times_valid, + 'P_sxn' : P_sxn, + 'condition_labels_train' : condition_labels_train, + 'condition_labels_valid' : condition_labels_valid, + 'conversion_factor': 1.0 / rnn['conversion_factor']} + datasets[dataset_name] = data + +if S < N: + # Note that this isn't necessary for this synthetic example, but + # it's useful to see how the input factor matrices were initialized + # for actual neurophysiology data. + datasets = add_alignment_projections(datasets, npcs=FLAGS.npcs) + +# Write out the datasets. +write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_itb_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_itb_data.py" new file mode 100644 index 00000000..66bc45d0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_itb_data.py" @@ -0,0 +1,209 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import print_function + +import h5py +import numpy as np +import os +from six.moves import xrange +import tensorflow as tf + +from utils import write_datasets +from synthetic_data_utils import normalize_rates +from synthetic_data_utils import get_train_n_valid_inds, nparray_and_transpose +from synthetic_data_utils import spikify_data, split_list_by_inds + +DATA_DIR = "rnn_synth_data_v1.0" + +flags = tf.app.flags +flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", + "Directory for saving data.") +flags.DEFINE_string("datafile_name", "itb_rnn", + "Name of data file for input case.") +flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") +flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") +flags.DEFINE_integer("C", 800, "Number of conditions") +flags.DEFINE_integer("N", 50, "Number of units for the RNN") +flags.DEFINE_float("train_percentage", 4.0/5.0, + "Percentage of train vs validation trials") +flags.DEFINE_integer("nreplications", 5, + "Number of spikifications of the same underlying rates.") +flags.DEFINE_float("tau", 0.025, "Time constant of RNN") +flags.DEFINE_float("dt", 0.010, "Time bin") +flags.DEFINE_float("max_firing_rate", 30.0, + "Map 1.0 of RNN to a spikes per second") +flags.DEFINE_float("u_std", 0.25, + "Std dev of input to integration to bound model") +flags.DEFINE_string("checkpoint_path", "SAMPLE_CHECKPOINT", + """Path to directory with checkpoints of model + trained on integration to bound task. Currently this + is a placeholder which tells the code to grab the + checkpoint that is provided with the code + (in /trained_itb/..). If you have your own checkpoint + you would like to restore, you would point it to + that path.""") +FLAGS = flags.FLAGS + + +class IntegrationToBoundModel: + def __init__(self, N): + scale = 0.8 / float(N**0.5) + self.N = N + self.Wh_nxn = tf.Variable(tf.random_normal([N, N], stddev=scale)) + self.b_1xn = tf.Variable(tf.zeros([1, N])) + self.Bu_1xn = tf.Variable(tf.zeros([1, N])) + self.Wro_nxo = tf.Variable(tf.random_normal([N, 1], stddev=scale)) + self.bro_o = tf.Variable(tf.zeros([1])) + + def call(self, h_tm1_bxn, u_bx1): + act_t_bxn = tf.matmul(h_tm1_bxn, self.Wh_nxn) + self.b_1xn + u_bx1 * self.Bu_1xn + h_t_bxn = tf.nn.tanh(act_t_bxn) + z_t = tf.nn.xw_plus_b(h_t_bxn, self.Wro_nxo, self.bro_o) + return z_t, h_t_bxn + +def get_data_batch(batch_size, T, rng, u_std): + u_bxt = rng.randn(batch_size, T) * u_std + running_sum_b = np.zeros([batch_size]) + labels_bxt = np.zeros([batch_size, T]) + for t in xrange(T): + running_sum_b += u_bxt[:, t] + labels_bxt[:, t] += running_sum_b + labels_bxt = np.clip(labels_bxt, -1, 1) + return u_bxt, labels_bxt + + +rng = np.random.RandomState(seed=FLAGS.synth_data_seed) +u_rng = np.random.RandomState(seed=FLAGS.synth_data_seed+1) +T = FLAGS.T +C = FLAGS.C +N = FLAGS.N # must be same N as in trained model (provided example is N = 50) +nreplications = FLAGS.nreplications +E = nreplications * C # total number of trials +train_percentage = FLAGS.train_percentage +ntimesteps = int(T / FLAGS.dt) +batch_size = 1 # gives one example per ntrial + +model = IntegrationToBoundModel(N) +inputs_ph_t = [tf.placeholder(tf.float32, + shape=[None, 1]) for _ in range(ntimesteps)] +state = tf.zeros([batch_size, N]) +saver = tf.train.Saver() + +P_nxn = rng.randn(N,N) / np.sqrt(N) # random projections + +# unroll RNN for T timesteps +outputs_t = [] +states_t = [] + +for inp in inputs_ph_t: + output, state = model.call(state, inp) + outputs_t.append(output) + states_t.append(state) + +with tf.Session() as sess: + # restore the latest model ckpt + if FLAGS.checkpoint_path == "SAMPLE_CHECKPOINT": + dir_path = os.path.dirname(os.path.realpath(__file__)) + model_checkpoint_path = os.path.join(dir_path, "trained_itb/model-65000") + else: + model_checkpoint_path = FLAGS.checkpoint_path + try: + saver.restore(sess, model_checkpoint_path) + print ('Model restored from', model_checkpoint_path) + except: + assert False, ("No checkpoints to restore from, is the path %s correct?" + %model_checkpoint_path) + + # generate data for trials + data_e = [] + u_e = [] + outs_e = [] + for c in range(C): + u_1xt, outs_1xt = get_data_batch(batch_size, ntimesteps, u_rng, FLAGS.u_std) + + feed_dict = {} + for t in xrange(ntimesteps): + feed_dict[inputs_ph_t[t]] = np.reshape(u_1xt[:,t], (batch_size,-1)) + + states_t_bxn, outputs_t_bxn = sess.run([states_t, outputs_t], + feed_dict=feed_dict) + states_nxt = np.transpose(np.squeeze(np.asarray(states_t_bxn))) + outputs_t_bxn = np.squeeze(np.asarray(outputs_t_bxn)) + r_sxt = np.dot(P_nxn, states_nxt) + + for s in xrange(nreplications): + data_e.append(r_sxt) + u_e.append(u_1xt) + outs_e.append(outputs_t_bxn) + + truth_data_e = normalize_rates(data_e, E, N) + +spiking_data_e = spikify_data(truth_data_e, rng, dt=FLAGS.dt, + max_firing_rate=FLAGS.max_firing_rate) +train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, + nreplications) + +data_train_truth, data_valid_truth = split_list_by_inds(truth_data_e, + train_inds, + valid_inds) +data_train_spiking, data_valid_spiking = split_list_by_inds(spiking_data_e, + train_inds, + valid_inds) + +data_train_truth = nparray_and_transpose(data_train_truth) +data_valid_truth = nparray_and_transpose(data_valid_truth) +data_train_spiking = nparray_and_transpose(data_train_spiking) +data_valid_spiking = nparray_and_transpose(data_valid_spiking) + +# save down the inputs used to generate this data +train_inputs_u, valid_inputs_u = split_list_by_inds(u_e, + train_inds, + valid_inds) +train_inputs_u = nparray_and_transpose(train_inputs_u) +valid_inputs_u = nparray_and_transpose(valid_inputs_u) + +# save down the network outputs (may be useful later) +train_outputs_u, valid_outputs_u = split_list_by_inds(outs_e, + train_inds, + valid_inds) +train_outputs_u = np.array(train_outputs_u) +valid_outputs_u = np.array(valid_outputs_u) + + +data = { 'train_truth': data_train_truth, + 'valid_truth': data_valid_truth, + 'train_data' : data_train_spiking, + 'valid_data' : data_valid_spiking, + 'train_percentage' : train_percentage, + 'nreplications' : nreplications, + 'dt' : FLAGS.dt, + 'u_std' : FLAGS.u_std, + 'max_firing_rate': FLAGS.max_firing_rate, + 'train_inputs_u': train_inputs_u, + 'valid_inputs_u': valid_inputs_u, + 'train_outputs_u': train_outputs_u, + 'valid_outputs_u': valid_outputs_u, + 'conversion_factor' : FLAGS.max_firing_rate/(1.0/FLAGS.dt) } + +# just one dataset here +datasets = {} +dataset_name = 'dataset_N' + str(N) +datasets[dataset_name] = data + +# write out the dataset +write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) +print ('Saved to ', os.path.join(FLAGS.save_dir, + FLAGS.datafile_name + '_' + dataset_name)) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_labeled_rnn_data.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_labeled_rnn_data.py" new file mode 100644 index 00000000..06955854 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/generate_labeled_rnn_data.py" @@ -0,0 +1,147 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import print_function + +import os +import h5py +import numpy as np +from six.moves import xrange + +from synthetic_data_utils import generate_data, generate_rnn +from synthetic_data_utils import get_train_n_valid_inds +from synthetic_data_utils import nparray_and_transpose +from synthetic_data_utils import spikify_data, split_list_by_inds +import tensorflow as tf +from utils import write_datasets + +DATA_DIR = "rnn_synth_data_v1.0" + +flags = tf.app.flags +flags.DEFINE_string("save_dir", "/tmp/" + DATA_DIR + "/", + "Directory for saving data.") +flags.DEFINE_string("datafile_name", "conditioned_rnn_data", + "Name of data file for input case.") +flags.DEFINE_integer("synth_data_seed", 5, "Random seed for RNN generation.") +flags.DEFINE_float("T", 1.0, "Time in seconds to generate.") +flags.DEFINE_integer("C", 400, "Number of conditions") +flags.DEFINE_integer("N", 50, "Number of units for the RNN") +flags.DEFINE_float("train_percentage", 4.0/5.0, + "Percentage of train vs validation trials") +flags.DEFINE_integer("nreplications", 10, + "Number of spikifications of the same underlying rates.") +flags.DEFINE_float("g", 1.5, "Complexity of dynamics") +flags.DEFINE_float("x0_std", 1.0, + "Volume from which to pull initial conditions (affects diversity of dynamics.") +flags.DEFINE_float("tau", 0.025, "Time constant of RNN") +flags.DEFINE_float("dt", 0.010, "Time bin") +flags.DEFINE_float("max_firing_rate", 30.0, "Map 1.0 of RNN to a spikes per second") +FLAGS = flags.FLAGS + +rng = np.random.RandomState(seed=FLAGS.synth_data_seed) +rnn_rngs = [np.random.RandomState(seed=FLAGS.synth_data_seed+1), + np.random.RandomState(seed=FLAGS.synth_data_seed+2)] +T = FLAGS.T +C = FLAGS.C +N = FLAGS.N +nreplications = FLAGS.nreplications +E = nreplications * C +train_percentage = FLAGS.train_percentage +ntimesteps = int(T / FLAGS.dt) + +rnn_a = generate_rnn(rnn_rngs[0], N, FLAGS.g, FLAGS.tau, FLAGS.dt, + FLAGS.max_firing_rate) +rnn_b = generate_rnn(rnn_rngs[1], N, FLAGS.g, FLAGS.tau, FLAGS.dt, + FLAGS.max_firing_rate) +rnns = [rnn_a, rnn_b] + +# pick which RNN is used on each trial +rnn_to_use = rng.randint(2, size=E) +ext_input = np.repeat(np.expand_dims(rnn_to_use, axis=1), ntimesteps, axis=1) +ext_input = np.expand_dims(ext_input, axis=2) # these are "a's" in the paper + +x0s = [] +condition_labels = [] +condition_number = 0 +for c in range(C): + x0 = FLAGS.x0_std * rng.randn(N, 1) + x0s.append(np.tile(x0, nreplications)) + for ns in range(nreplications): + condition_labels.append(condition_number) + condition_number += 1 +x0s = np.concatenate(x0s, axis=1) + +P_nxn = rng.randn(N, N) / np.sqrt(N) + +# generate trials for both RNNs +rates_a, x0s_a, _ = generate_data(rnn_a, T=T, E=E, x0s=x0s, P_sxn=P_nxn, + input_magnitude=0.0, input_times=None) +spikes_a = spikify_data(rates_a, rng, rnn_a['dt'], rnn_a['max_firing_rate']) + +rates_b, x0s_b, _ = generate_data(rnn_b, T=T, E=E, x0s=x0s, P_sxn=P_nxn, + input_magnitude=0.0, input_times=None) +spikes_b = spikify_data(rates_b, rng, rnn_b['dt'], rnn_b['max_firing_rate']) + +# not the best way to do this but E is small enough +rates = [] +spikes = [] +for trial in xrange(E): + if rnn_to_use[trial] == 0: + rates.append(rates_a[trial]) + spikes.append(spikes_a[trial]) + else: + rates.append(rates_b[trial]) + spikes.append(spikes_b[trial]) + +# split into train and validation sets +train_inds, valid_inds = get_train_n_valid_inds(E, train_percentage, + nreplications) + +rates_train, rates_valid = split_list_by_inds(rates, train_inds, valid_inds) +spikes_train, spikes_valid = split_list_by_inds(spikes, train_inds, valid_inds) +condition_labels_train, condition_labels_valid = split_list_by_inds( + condition_labels, train_inds, valid_inds) +ext_input_train, ext_input_valid = split_list_by_inds( + ext_input, train_inds, valid_inds) + +rates_train = nparray_and_transpose(rates_train) +rates_valid = nparray_and_transpose(rates_valid) +spikes_train = nparray_and_transpose(spikes_train) +spikes_valid = nparray_and_transpose(spikes_valid) + +# add train_ext_input and valid_ext input +data = {'train_truth': rates_train, + 'valid_truth': rates_valid, + 'train_data' : spikes_train, + 'valid_data' : spikes_valid, + 'train_ext_input' : np.array(ext_input_train), + 'valid_ext_input': np.array(ext_input_valid), + 'train_percentage' : train_percentage, + 'nreplications' : nreplications, + 'dt' : FLAGS.dt, + 'P_sxn' : P_nxn, + 'condition_labels_train' : condition_labels_train, + 'condition_labels_valid' : condition_labels_valid, + 'conversion_factor': 1.0 / rnn_a['conversion_factor']} + +# just one dataset here +datasets = {} +dataset_name = 'dataset_N' + str(N) +datasets[dataset_name] = data + +# write out the dataset +write_datasets(FLAGS.save_dir, FLAGS.datafile_name, datasets) +print ('Saved to ', os.path.join(FLAGS.save_dir, + FLAGS.datafile_name + '_' + dataset_name)) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/run_generate_synth_data.sh" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/run_generate_synth_data.sh" new file mode 100644 index 00000000..9ebc8ce2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/run_generate_synth_data.sh" @@ -0,0 +1,40 @@ +#!/bin/bash + +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== + +SYNTH_PATH=/tmp/rnn_synth_data_v1.0/ + + echo "Generating chaotic rnn data with no input pulses (g=1.5) with spiking noise" + python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_no_inputs --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='poisson' + +echo "Generating chaotic rnn data with no input pulses (g=1.5) with Gaussian noise" +python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=gaussian_chaotic_rnn_no_inputs --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='gaussian' + + echo "Generating chaotic rnn data with input pulses (g=1.5)" + python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_inputs_g1p5 --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=20.0 --max_firing_rate=30.0 --noise_type='poisson' + + echo "Generating chaotic rnn data with input pulses (g=2.5)" + python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_inputs_g2p5 --synth_data_seed=5 --T=1.0 --C=400 --N=50 --S=50 --train_percentage=0.8 --nreplications=10 --g=2.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=20.0 --max_firing_rate=30.0 --noise_type='poisson' + + echo "Generate the multi-session RNN data (no multi-session synth example in paper)" + python generate_chaotic_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnn_multisession --synth_data_seed=5 --T=1.0 --C=150 --N=100 --S=20 --npcs=10 --train_percentage=0.8 --nreplications=40 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --input_magnitude=0.0 --max_firing_rate=30.0 --noise_type='poisson' + + echo "Generating Integration-to-bound RNN data" + python generate_itb_data.py --save_dir=$SYNTH_PATH --datafile_name=itb_rnn --u_std=0.25 --checkpoint_path=SAMPLE_CHECKPOINT --synth_data_seed=5 --T=1.0 --C=800 --N=50 --train_percentage=0.8 --nreplications=5 --tau=0.025 --dt=0.01 --max_firing_rate=30.0 + + echo "Generating chaotic rnn data with external input labels (no external input labels example in paper)" + python generate_labeled_rnn_data.py --save_dir=$SYNTH_PATH --datafile_name=chaotic_rnns_labeled --synth_data_seed=5 --T=1.0 --C=400 --N=50 --train_percentage=0.8 --nreplications=10 --g=1.5 --x0_std=1.0 --tau=0.025 --dt=0.01 --max_firing_rate=30.0 diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/synthetic_data_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/synthetic_data_utils.py" new file mode 100644 index 00000000..cc264ee4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/synthetic_data_utils.py" @@ -0,0 +1,348 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import print_function + +import h5py +import numpy as np +import os + +from utils import write_datasets +import matplotlib +import matplotlib.pyplot as plt +import scipy.signal + + +def generate_rnn(rng, N, g, tau, dt, max_firing_rate): + """Create a (vanilla) RNN with a bunch of hyper parameters for generating +chaotic data. + Args: + rng: numpy random number generator + N: number of hidden units + g: scaling of recurrent weight matrix in g W, with W ~ N(0,1/N) + tau: time scale of individual unit dynamics + dt: time step for equation updates + max_firing_rate: how to resecale the -1,1 firing rates + Returns: + the dictionary of these parameters, plus some others. +""" + rnn = {} + rnn['N'] = N + rnn['W'] = rng.randn(N,N)/np.sqrt(N) + rnn['Bin'] = rng.randn(N)/np.sqrt(1.0) + rnn['Bin2'] = rng.randn(N)/np.sqrt(1.0) + rnn['b'] = np.zeros(N) + rnn['g'] = g + rnn['tau'] = tau + rnn['dt'] = dt + rnn['max_firing_rate'] = max_firing_rate + mfr = rnn['max_firing_rate'] # spikes / sec + nbins_per_sec = 1.0/rnn['dt'] # bins / sec + # Used for plotting in LFADS + rnn['conversion_factor'] = mfr / nbins_per_sec # spikes / bin + return rnn + + +def generate_data(rnn, T, E, x0s=None, P_sxn=None, input_magnitude=0.0, + input_times=None): + """ Generates data from an randomly initialized RNN. + Args: + rnn: the rnn + T: Time in seconds to run (divided by rnn['dt'] to get steps, rounded down. + E: total number of examples + S: number of samples (subsampling N) + Returns: + A list of length E of NxT tensors of the network being run. + """ + N = rnn['N'] + def run_rnn(rnn, x0, ntime_steps, input_time=None): + rs = np.zeros([N,ntime_steps]) + x_tm1 = x0 + r_tm1 = np.tanh(x0) + tau = rnn['tau'] + dt = rnn['dt'] + alpha = (1.0-dt/tau) + W = dt/tau*rnn['W']*rnn['g'] + Bin = dt/tau*rnn['Bin'] + Bin2 = dt/tau*rnn['Bin2'] + b = dt/tau*rnn['b'] + + us = np.zeros([1, ntime_steps]) + for t in range(ntime_steps): + x_t = alpha*x_tm1 + np.dot(W,r_tm1) + b + if input_time is not None and t == input_time: + us[0,t] = input_magnitude + x_t += Bin * us[0,t] # DCS is this what was used? + r_t = np.tanh(x_t) + x_tm1 = x_t + r_tm1 = r_t + rs[:,t] = r_t + return rs, us + + if P_sxn is None: + P_sxn = np.eye(N) + ntime_steps = int(T / rnn['dt']) + data_e = [] + inputs_e = [] + for e in range(E): + input_time = input_times[e] if input_times is not None else None + r_nxt, u_uxt = run_rnn(rnn, x0s[:,e], ntime_steps, input_time) + r_sxt = np.dot(P_sxn, r_nxt) + inputs_e.append(u_uxt) + data_e.append(r_sxt) + + S = P_sxn.shape[0] + data_e = normalize_rates(data_e, E, S) + + return data_e, x0s, inputs_e + + +def normalize_rates(data_e, E, S): + # Normalization, made more complex because of the P matrices. + # Normalize by min and max in each channel. This normalization will + # cause offset differences between identical rnn runs, but different + # t hits. + for e in range(E): + r_sxt = data_e[e] + for i in range(S): + rmin = np.min(r_sxt[i,:]) + rmax = np.max(r_sxt[i,:]) + assert rmax - rmin != 0, 'Something wrong' + r_sxt[i,:] = (r_sxt[i,:] - rmin)/(rmax-rmin) + data_e[e] = r_sxt + return data_e + + +def spikify_data(data_e, rng, dt=1.0, max_firing_rate=100): + """ Apply spikes to a continuous dataset whose values are between 0.0 and 1.0 + Args: + data_e: nexamples length list of NxT trials + dt: how often the data are sampled + max_firing_rate: the firing rate that is associated with a value of 1.0 + Returns: + spikified_e: a list of length b of the data represented as spikes, + sampled from the underlying poisson process. + """ + + E = len(data_e) + spikes_e = [] + for e in range(E): + data = data_e[e] + N,T = data.shape + data_s = np.zeros([N,T]).astype(np.int) + for n in range(N): + f = data[n,:] + s = rng.poisson(f*max_firing_rate*dt, size=T) + data_s[n,:] = s + spikes_e.append(data_s) + + return spikes_e + + +def gaussify_data(data_e, rng, dt=1.0, max_firing_rate=100): + """ Apply gaussian noise to a continuous dataset whose values are between + 0.0 and 1.0 + + Args: + data_e: nexamples length list of NxT trials + dt: how often the data are sampled + max_firing_rate: the firing rate that is associated with a value of 1.0 + Returns: + gauss_e: a list of length b of the data with noise. + """ + + E = len(data_e) + mfr = max_firing_rate + gauss_e = [] + for e in range(E): + data = data_e[e] + N,T = data.shape + noisy_data = data * mfr + np.random.randn(N,T) * (5.0*mfr) * np.sqrt(dt) + gauss_e.append(noisy_data) + + return gauss_e + + + +def get_train_n_valid_inds(num_trials, train_fraction, nreplications): + """Split the numbers between 0 and num_trials-1 into two portions for + training and validation, based on the train fraction. + Args: + num_trials: the number of trials + train_fraction: (e.g. .80) + nreplications: the number of spiking trials per initial condition + Returns: + a 2-tuple of two lists: the training indices and validation indices + """ + train_inds = [] + valid_inds = [] + for i in range(num_trials): + # This line divides up the trials so that within one initial condition, + # the randomness of spikifying the condition is shared among both + # training and validation data splits. + if (i % nreplications)+1 > train_fraction * nreplications: + valid_inds.append(i) + else: + train_inds.append(i) + + return train_inds, valid_inds + + +def split_list_by_inds(data, inds1, inds2): + """Take the data, a list, and split it up based on the indices in inds1 and + inds2. + Args: + data: the list of data to split + inds1, the first list of indices + inds2, the second list of indices + Returns: a 2-tuple of two lists. + """ + if data is None or len(data) == 0: + return [], [] + else: + dout1 = [data[i] for i in inds1] + dout2 = [data[i] for i in inds2] + return dout1, dout2 + + +def nparray_and_transpose(data_a_b_c): + """Convert the list of items in data to a numpy array, and transpose it + Args: + data: data_asbsc: a nested, nested list of length a, with sublist length + b, with sublist length c. + Returns: + a numpy 3-tensor with dimensions a x c x b +""" + data_axbxc = np.array([datum_b_c for datum_b_c in data_a_b_c]) + data_axcxb = np.transpose(data_axbxc, axes=[0,2,1]) + return data_axcxb + + +def add_alignment_projections(datasets, npcs, ntime=None, nsamples=None): + """Create a matrix that aligns the datasets a bit, under + the assumption that each dataset is observing the same underlying dynamical + system. + + Args: + datasets: The dictionary of dataset structures. + npcs: The number of pcs for each, basically like lfads factors. + nsamples (optional): Number of samples to take for each dataset. + ntime (optional): Number of time steps to take in each sample. + + Returns: + The dataset structures, with the field alignment_matrix_cxf added. + This is # channels x npcs dimension +""" + nchannels_all = 0 + channel_idxs = {} + conditions_all = {} + nconditions_all = 0 + for name, dataset in datasets.items(): + cidxs = np.where(dataset['P_sxn'])[1] # non-zero entries in columns + channel_idxs[name] = [cidxs[0], cidxs[-1]+1] + nchannels_all += cidxs[-1]+1 - cidxs[0] + conditions_all[name] = np.unique(dataset['condition_labels_train']) + + all_conditions_list = \ + np.unique(np.ndarray.flatten(np.array(conditions_all.values()))) + nconditions_all = all_conditions_list.shape[0] + + if ntime is None: + ntime = dataset['train_data'].shape[1] + if nsamples is None: + nsamples = dataset['train_data'].shape[0] + + # In the data workup in the paper, Chethan did intra condition + # averaging, so let's do that here. + avg_data_all = {} + for name, conditions in conditions_all.items(): + dataset = datasets[name] + avg_data_all[name] = {} + for cname in conditions: + td_idxs = np.argwhere(np.array(dataset['condition_labels_train'])==cname) + data = np.squeeze(dataset['train_data'][td_idxs,:,:], axis=1) + avg_data = np.mean(data, axis=0) + avg_data_all[name][cname] = avg_data + + # Visualize this in the morning. + all_data_nxtc = np.zeros([nchannels_all, ntime * nconditions_all]) + for name, dataset in datasets.items(): + cidx_s = channel_idxs[name][0] + cidx_f = channel_idxs[name][1] + for cname in conditions_all[name]: + cidxs = np.argwhere(all_conditions_list == cname) + if cidxs.shape[0] > 0: + cidx = cidxs[0][0] + all_tidxs = np.arange(0, ntime+1) + cidx*ntime + all_data_nxtc[cidx_s:cidx_f, all_tidxs[0]:all_tidxs[-1]] = \ + avg_data_all[name][cname].T + + # A bit of filtering. We don't care about spectral properties, or + # filtering artifacts, simply correlate time steps a bit. + filt_len = 6 + bc_filt = np.ones([filt_len])/float(filt_len) + for c in range(nchannels_all): + all_data_nxtc[c,:] = scipy.signal.filtfilt(bc_filt, [1.0], all_data_nxtc[c,:]) + + # Compute the PCs. + all_data_mean_nx1 = np.mean(all_data_nxtc, axis=1, keepdims=True) + all_data_zm_nxtc = all_data_nxtc - all_data_mean_nx1 + corr_mat_nxn = np.dot(all_data_zm_nxtc, all_data_zm_nxtc.T) + evals_n, evecs_nxn = np.linalg.eigh(corr_mat_nxn) + sidxs = np.flipud(np.argsort(evals_n)) # sort such that 0th is highest + evals_n = evals_n[sidxs] + evecs_nxn = evecs_nxn[:,sidxs] + + # Project all the channels data onto the low-D PCA basis, where + # low-d is the npcs parameter. + all_data_pca_pxtc = np.dot(evecs_nxn[:, 0:npcs].T, all_data_zm_nxtc) + + # Now for each dataset, we regress the channel data onto the top + # pcs, and this will be our alignment matrix for that dataset. + # |B - A*W|^2 + for name, dataset in datasets.items(): + cidx_s = channel_idxs[name][0] + cidx_f = channel_idxs[name][1] + all_data_zm_chxtc = all_data_zm_nxtc[cidx_s:cidx_f,:] # ch for channel + W_chxp, _, _, _ = \ + np.linalg.lstsq(all_data_zm_chxtc.T, all_data_pca_pxtc.T) + dataset['alignment_matrix_cxf'] = W_chxp + alignment_bias_cx1 = all_data_mean_nx1[cidx_s:cidx_f] + dataset['alignment_bias_c'] = np.squeeze(alignment_bias_cx1, axis=1) + + do_debug_plot = False + if do_debug_plot: + pc_vecs = evecs_nxn[:,0:npcs] + ntoplot = 400 + + plt.figure() + plt.plot(np.log10(evals_n), '-x') + plt.figure() + plt.subplot(311) + plt.imshow(all_data_pca_pxtc) + plt.colorbar() + + plt.subplot(312) + plt.imshow(np.dot(W_chxp.T, all_data_zm_chxtc)) + plt.colorbar() + + plt.subplot(313) + plt.imshow(np.dot(all_data_zm_chxtc.T, W_chxp).T - all_data_pca_pxtc) + plt.colorbar() + + import pdb + pdb.set_trace() + + return datasets diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001" new file mode 100644 index 00000000..9459a2a1 Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.data-00000-of-00001" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.index" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.index" new file mode 100644 index 00000000..dd9c793a Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.index" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.meta" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.meta" new file mode 100644 index 00000000..07bd2b96 Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/synth_data/trained_itb/model-65000.meta" differ diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/utils.py" new file mode 100644 index 00000000..b9d3f7f9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lfads/utils.py" @@ -0,0 +1,367 @@ +# Copyright 2017 Google Inc. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# +# ============================================================================== +from __future__ import print_function + +import os +import h5py +import json + +import numpy as np +import tensorflow as tf + + +def log_sum_exp(x_k): + """Computes log \sum exp in a numerically stable way. + log ( sum_i exp(x_i) ) + log ( sum_i exp(x_i - m + m) ), with m = max(x_i) + log ( sum_i exp(x_i - m)*exp(m) ) + log ( sum_i exp(x_i - m) + m + + Args: + x_k - k -dimensional list of arguments to log_sum_exp. + + Returns: + log_sum_exp of the arguments. + """ + m = tf.reduce_max(x_k) + x1_k = x_k - m + u_k = tf.exp(x1_k) + z = tf.reduce_sum(u_k) + return tf.log(z) + m + + +def linear(x, out_size, do_bias=True, alpha=1.0, identity_if_possible=False, + normalized=False, name=None, collections=None): + """Linear (affine) transformation, y = x W + b, for a variety of + configurations. + + Args: + x: input The tensor to tranformation. + out_size: The integer size of non-batch output dimension. + do_bias (optional): Add a learnable bias vector to the operation. + alpha (optional): A multiplicative scaling for the weight initialization + of the matrix, in the form \alpha * 1/\sqrt{x.shape[1]}. + identity_if_possible (optional): just return identity, + if x.shape[1] == out_size. + normalized (optional): Option to divide out by the norms of the rows of W. + name (optional): The name prefix to add to variables. + collections (optional): List of additional collections. (Placed in + tf.GraphKeys.GLOBAL_VARIABLES already, so no need for that.) + + Returns: + In the equation, y = x W + b, returns the tensorflow op that yields y. + """ + in_size = int(x.get_shape()[1]) # from Dimension(10) -> 10 + stddev = alpha/np.sqrt(float(in_size)) + mat_init = tf.random_normal_initializer(0.0, stddev) + wname = (name + "/W") if name else "/W" + + if identity_if_possible and in_size == out_size: + # Sometimes linear layers are nothing more than size adapters. + return tf.identity(x, name=(wname+'_ident')) + + W,b = init_linear(in_size, out_size, do_bias=do_bias, alpha=alpha, + normalized=normalized, name=name, collections=collections) + + if do_bias: + return tf.matmul(x, W) + b + else: + return tf.matmul(x, W) + + +def init_linear(in_size, out_size, do_bias=True, mat_init_value=None, + bias_init_value=None, alpha=1.0, identity_if_possible=False, + normalized=False, name=None, collections=None, trainable=True): + """Linear (affine) transformation, y = x W + b, for a variety of + configurations. + + Args: + in_size: The integer size of the non-batc input dimension. [(x),y] + out_size: The integer size of non-batch output dimension. [x,(y)] + do_bias (optional): Add a (learnable) bias vector to the operation, + if false, b will be None + mat_init_value (optional): numpy constant for matrix initialization, if None + , do random, with additional parameters. + alpha (optional): A multiplicative scaling for the weight initialization + of the matrix, in the form \alpha * 1/\sqrt{x.shape[1]}. + identity_if_possible (optional): just return identity, + if x.shape[1] == out_size. + normalized (optional): Option to divide out by the norms of the rows of W. + name (optional): The name prefix to add to variables. + collections (optional): List of additional collections. (Placed in + tf.GraphKeys.GLOBAL_VARIABLES already, so no need for that.) + + Returns: + In the equation, y = x W + b, returns the pair (W, b). + """ + + if mat_init_value is not None and mat_init_value.shape != (in_size, out_size): + raise ValueError( + 'Provided mat_init_value must have shape [%d, %d].'%(in_size, out_size)) + if bias_init_value is not None and bias_init_value.shape != (1,out_size): + raise ValueError( + 'Provided bias_init_value must have shape [1,%d].'%(out_size,)) + + if mat_init_value is None: + stddev = alpha/np.sqrt(float(in_size)) + mat_init = tf.random_normal_initializer(0.0, stddev) + + wname = (name + "/W") if name else "/W" + + if identity_if_possible and in_size == out_size: + return (tf.constant(np.eye(in_size).astype(np.float32)), + tf.zeros(in_size)) + + # Note the use of get_variable vs. tf.Variable. this is because get_variable + # does not allow the initialization of the variable with a value. + if normalized: + w_collections = [tf.GraphKeys.GLOBAL_VARIABLES, "norm-variables"] + if collections: + w_collections += collections + if mat_init_value is not None: + w = tf.Variable(mat_init_value, name=wname, collections=w_collections, + trainable=trainable) + else: + w = tf.get_variable(wname, [in_size, out_size], initializer=mat_init, + collections=w_collections, trainable=trainable) + w = tf.nn.l2_normalize(w, dim=0) # x W, so xW_j = \sum_i x_bi W_ij + else: + w_collections = [tf.GraphKeys.GLOBAL_VARIABLES] + if collections: + w_collections += collections + if mat_init_value is not None: + w = tf.Variable(mat_init_value, name=wname, collections=w_collections, + trainable=trainable) + else: + w = tf.get_variable(wname, [in_size, out_size], initializer=mat_init, + collections=w_collections, trainable=trainable) + b = None + if do_bias: + b_collections = [tf.GraphKeys.GLOBAL_VARIABLES] + if collections: + b_collections += collections + bname = (name + "/b") if name else "/b" + if bias_init_value is None: + b = tf.get_variable(bname, [1, out_size], + initializer=tf.zeros_initializer(), + collections=b_collections, + trainable=trainable) + else: + b = tf.Variable(bias_init_value, name=bname, + collections=b_collections, + trainable=trainable) + + return (w, b) + + +def write_data(data_fname, data_dict, use_json=False, compression=None): + """Write data in HD5F format. + + Args: + data_fname: The filename of teh file in which to write the data. + data_dict: The dictionary of data to write. The keys are strings + and the values are numpy arrays. + use_json (optional): human readable format for simple items + compression (optional): The compression to use for h5py (disabled by + default because the library borks on scalars, otherwise try 'gzip'). + """ + + dir_name = os.path.dirname(data_fname) + if not os.path.exists(dir_name): + os.makedirs(dir_name) + + if use_json: + the_file = open(data_fname,'w') + json.dump(data_dict, the_file) + the_file.close() + else: + try: + with h5py.File(data_fname, 'w') as hf: + for k, v in data_dict.items(): + clean_k = k.replace('/', '_') + if clean_k is not k: + print('Warning: saving variable with name: ', k, ' as ', clean_k) + else: + print('Saving variable with name: ', clean_k) + hf.create_dataset(clean_k, data=v, compression=compression) + except IOError: + print("Cannot open %s for writing.", data_fname) + raise + + +def read_data(data_fname): + """ Read saved data in HDF5 format. + + Args: + data_fname: The filename of the file from which to read the data. + Returns: + A dictionary whose keys will vary depending on dataset (but should + always contain the keys 'train_data' and 'valid_data') and whose + values are numpy arrays. + """ + + try: + with h5py.File(data_fname, 'r') as hf: + data_dict = {k: np.array(v) for k, v in hf.items()} + return data_dict + except IOError: + print("Cannot open %s for reading." % data_fname) + raise + + +def write_datasets(data_path, data_fname_stem, dataset_dict, compression=None): + """Write datasets in HD5F format. + + This function assumes the dataset_dict is a mapping ( string -> + to data_dict ). It calls write_data for each data dictionary, + post-fixing the data filename with the key of the dataset. + + Args: + data_path: The path to the save directory. + data_fname_stem: The filename stem of the file in which to write the data. + dataset_dict: The dictionary of datasets. The keys are strings + and the values data dictionaries (str -> numpy arrays) associations. + compression (optional): The compression to use for h5py (disabled by + default because the library borks on scalars, otherwise try 'gzip'). + """ + + full_name_stem = os.path.join(data_path, data_fname_stem) + for s, data_dict in dataset_dict.items(): + write_data(full_name_stem + "_" + s, data_dict, compression=compression) + + +def read_datasets(data_path, data_fname_stem): + """Read dataset sin HD5F format. + + This function assumes the dataset_dict is a mapping ( string -> + to data_dict ). It calls write_data for each data dictionary, + post-fixing the data filename with the key of the dataset. + + Args: + data_path: The path to the save directory. + data_fname_stem: The filename stem of the file in which to write the data. + """ + + dataset_dict = {} + fnames = os.listdir(data_path) + + print ('loading data from ' + data_path + ' with stem ' + data_fname_stem) + for fname in fnames: + if fname.startswith(data_fname_stem): + data_dict = read_data(os.path.join(data_path,fname)) + idx = len(data_fname_stem) + 1 + key = fname[idx:] + data_dict['data_dim'] = data_dict['train_data'].shape[2] + data_dict['num_steps'] = data_dict['train_data'].shape[1] + dataset_dict[key] = data_dict + + if len(dataset_dict) == 0: + raise ValueError("Failed to load any datasets, are you sure that the " + "'--data_dir' and '--data_filename_stem' flag values " + "are correct?") + + print (str(len(dataset_dict)) + ' datasets loaded') + return dataset_dict + + +# NUMPY utility functions +def list_t_bxn_to_list_b_txn(values_t_bxn): + """Convert a length T list of BxN numpy tensors of length B list of TxN numpy + tensors. + + Args: + values_t_bxn: The length T list of BxN numpy tensors. + + Returns: + The length B list of TxN numpy tensors. + """ + T = len(values_t_bxn) + B, N = values_t_bxn[0].shape + values_b_txn = [] + for b in range(B): + values_pb_txn = np.zeros([T,N]) + for t in range(T): + values_pb_txn[t,:] = values_t_bxn[t][b,:] + values_b_txn.append(values_pb_txn) + + return values_b_txn + + +def list_t_bxn_to_tensor_bxtxn(values_t_bxn): + """Convert a length T list of BxN numpy tensors to single numpy tensor with + shape BxTxN. + + Args: + values_t_bxn: The length T list of BxN numpy tensors. + + Returns: + values_bxtxn: The BxTxN numpy tensor. + """ + + T = len(values_t_bxn) + B, N = values_t_bxn[0].shape + values_bxtxn = np.zeros([B,T,N]) + for t in range(T): + values_bxtxn[:,t,:] = values_t_bxn[t] + + return values_bxtxn + + +def tensor_bxtxn_to_list_t_bxn(tensor_bxtxn): + """Convert a numpy tensor with shape BxTxN to a length T list of numpy tensors + with shape BxT. + + Args: + tensor_bxtxn: The BxTxN numpy tensor. + + Returns: + A length T list of numpy tensors with shape BxT. + """ + + values_t_bxn = [] + B, T, N = tensor_bxtxn.shape + for t in range(T): + values_t_bxn.append(np.squeeze(tensor_bxtxn[:,t,:])) + + return values_t_bxn + + +def flatten(list_of_lists): + """Takes a list of lists and returns a list of the elements. + + Args: + list_of_lists: List of lists. + + Returns: + flat_list: Flattened list. + flat_list_idxs: Flattened list indices. + """ + flat_list = [] + flat_list_idxs = [] + start_idx = 0 + for item in list_of_lists: + if isinstance(item, list): + flat_list += item + l = len(item) + idxs = range(start_idx, start_idx+l) + start_idx = start_idx+l + else: # a value + flat_list.append(item) + idxs = [start_idx] + start_idx += 1 + flat_list_idxs.append(idxs) + + return flat_list, flat_list_idxs diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/BUILD" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/BUILD" new file mode 100644 index 00000000..ca5bc1f6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/BUILD" @@ -0,0 +1,27 @@ +package(default_visibility = [":internal"]) + +licenses(["notice"]) # Apache 2.0 + +exports_files(["LICENSE"]) + +package_group( + name = "internal", + packages = [ + "//lm_1b/...", + ], +) + +py_library( + name = "data_utils", + srcs = ["data_utils.py"], +) + +py_binary( + name = "lm_1b_eval", + srcs = [ + "lm_1b_eval.py", + ], + deps = [ + ":data_utils", + ], +) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/README.md" new file mode 100644 index 00000000..88bdedc1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/README.md" @@ -0,0 +1,194 @@ +Language Model on One Billion Word Benchmark + +Authors: + +Oriol Vinyals (vinyals@google.com, github: OriolVinyals), +Xin Pan + +Paper Authors: + +Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, Yonghui Wu + +TL;DR + +This is a pretrained model on One Billion Word Benchmark. +If you use this model in your publication, please cite the original paper: + +@article{jozefowicz2016exploring, + title={Exploring the Limits of Language Modeling}, + author={Jozefowicz, Rafal and Vinyals, Oriol and Schuster, Mike + and Shazeer, Noam and Wu, Yonghui}, + journal={arXiv preprint arXiv:1602.02410}, + year={2016} +} + +Introduction + +In this release, we open source a model trained on the One Billion Word +Benchmark (http://arxiv.org/abs/1312.3005), a large language corpus in English +which was released in 2013. This dataset contains about one billion words, and +has a vocabulary size of about 800K words. It contains mostly news data. Since +sentences in the training set are shuffled, models can ignore the context and +focus on sentence level language modeling. + +In the original release and subsequent work, people have used the same test set +to train models on this dataset as a standard benchmark for language modeling. +Recently, we wrote an article (http://arxiv.org/abs/1602.02410) describing a +model hybrid between character CNN, a large and deep LSTM, and a specific +Softmax architecture which allowed us to train the best model on this dataset +thus far, almost halving the best perplexity previously obtained by others. + +Code Release + +The open-sourced components include: + +* TensorFlow GraphDef proto buffer text file. +* TensorFlow pre-trained checkpoint shards. +* Code used to evaluate the pre-trained model. +* Vocabulary file. +* Test set from LM-1B evaluation. + +The code supports 4 evaluation modes: + +* Given provided dataset, calculate the model's perplexity. +* Given a prefix sentence, predict the next words. +* Dump the softmax embedding, character-level CNN word embeddings. +* Give a sentence, dump the embedding from the LSTM state. + +Results + +Model | Test Perplexity | Number of Params [billions] +------|-----------------|---------------------------- +Sigmoid-RNN-2048 [Blackout] | 68.3 | 4.1 +Interpolated KN 5-gram, 1.1B n-grams [chelba2013one] | 67.6 | 1.76 +Sparse Non-Negative Matrix LM [shazeer2015sparse] | 52.9 | 33 +RNN-1024 + MaxEnt 9-gram features [chelba2013one] | 51.3 | 20 +LSTM-512-512 | 54.1 | 0.82 +LSTM-1024-512 | 48.2 | 0.82 +LSTM-2048-512 | 43.7 | 0.83 +LSTM-8192-2048 (No Dropout) | 37.9 | 3.3 +LSTM-8192-2048 (50\% Dropout) | 32.2 | 3.3 +2-Layer LSTM-8192-1024 (BIG LSTM) | 30.6 | 1.8 +(THIS RELEASE) BIG LSTM+CNN Inputs | 30.0 | 1.04 + +How To Run + +Prerequisites: + +* Install TensorFlow. +* Install Bazel. +* Download the data files: + * Model GraphDef file: + [link](http://download.tensorflow.org/models/LM_LSTM_CNN/graph-2016-09-10.pbtxt) + * Model Checkpoint sharded file: + [1](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-base) + [2](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-char-embedding) + [3](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-lstm) + [4](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax0) + [5](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax1) + [6](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax2) + [7](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax3) + [8](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax4) + [9](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax5) + [10](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax6) + [11](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax7) + [12](http://download.tensorflow.org/models/LM_LSTM_CNN/all_shards-2016-09-10/ckpt-softmax8) + * Vocabulary file: + [link](http://download.tensorflow.org/models/LM_LSTM_CNN/vocab-2016-09-10.txt) + * test dataset: link + [link](http://download.tensorflow.org/models/LM_LSTM_CNN/test/news.en.heldout-00000-of-00050) +* It is recommended to run on a modern desktop instead of a laptop. + +```shell +# 1. Clone the code to your workspace. +# 2. Download the data to your workspace. +# 3. Create an empty WORKSPACE file in your workspace. +# 4. Create an empty output directory in your workspace. +# Example directory structure below: +$ ls -R +.: +data lm_1b output WORKSPACE + +./data: +ckpt-base ckpt-lstm ckpt-softmax1 ckpt-softmax3 ckpt-softmax5 +ckpt-softmax7 graph-2016-09-10.pbtxt vocab-2016-09-10.txt +ckpt-char-embedding ckpt-softmax0 ckpt-softmax2 ckpt-softmax4 ckpt-softmax6 +ckpt-softmax8 news.en.heldout-00000-of-00050 + +./lm_1b: +BUILD data_utils.py lm_1b_eval.py README.md + +./output: + +# Build the codes. +$ bazel build -c opt lm_1b/... +# Run sample mode: +$ bazel-bin/lm_1b/lm_1b_eval --mode sample \ + --prefix "I love that I" \ + --pbtxt data/graph-2016-09-10.pbtxt \ + --vocab_file data/vocab-2016-09-10.txt \ + --ckpt 'data/ckpt-*' +...(omitted some TensorFlow output) +I love +I love that +I love that I +I love that I find +I love that I find that +I love that I find that amazing +...(omitted) + +# Run eval mode: +$ bazel-bin/lm_1b/lm_1b_eval --mode eval \ + --pbtxt data/graph-2016-09-10.pbtxt \ + --vocab_file data/vocab-2016-09-10.txt \ + --input_data data/news.en.heldout-00000-of-00050 \ + --ckpt 'data/ckpt-*' +...(omitted some TensorFlow output) +Loaded step 14108582. +# perplexity is high initially because words without context are harder to +# predict. +Eval Step: 0, Average Perplexity: 2045.512297. +Eval Step: 1, Average Perplexity: 229.478699. +Eval Step: 2, Average Perplexity: 208.116787. +Eval Step: 3, Average Perplexity: 338.870601. +Eval Step: 4, Average Perplexity: 228.950107. +Eval Step: 5, Average Perplexity: 197.685857. +Eval Step: 6, Average Perplexity: 156.287063. +Eval Step: 7, Average Perplexity: 124.866189. +Eval Step: 8, Average Perplexity: 147.204975. +Eval Step: 9, Average Perplexity: 90.124864. +Eval Step: 10, Average Perplexity: 59.897914. +Eval Step: 11, Average Perplexity: 42.591137. +...(omitted) +Eval Step: 4529, Average Perplexity: 29.243668. +Eval Step: 4530, Average Perplexity: 29.302362. +Eval Step: 4531, Average Perplexity: 29.285674. +...(omitted. At convergence, it should be around 30.) + +# Run dump_emb mode: +$ bazel-bin/lm_1b/lm_1b_eval --mode dump_emb \ + --pbtxt data/graph-2016-09-10.pbtxt \ + --vocab_file data/vocab-2016-09-10.txt \ + --ckpt 'data/ckpt-*' \ + --save_dir output +...(omitted some TensorFlow output) +Finished softmax weights +Finished word embedding 0/793471 +Finished word embedding 1/793471 +Finished word embedding 2/793471 +...(omitted) +$ ls output/ +embeddings_softmax.npy ... + +# Run dump_lstm_emb mode: +$ bazel-bin/lm_1b/lm_1b_eval --mode dump_lstm_emb \ + --pbtxt data/graph-2016-09-10.pbtxt \ + --vocab_file data/vocab-2016-09-10.txt \ + --ckpt 'data/ckpt-*' \ + --sentence "I love who I am ." \ + --save_dir output +$ ls output/ +lstm_emb_step_0.npy lstm_emb_step_2.npy lstm_emb_step_4.npy +lstm_emb_step_6.npy lstm_emb_step_1.npy lstm_emb_step_3.npy +lstm_emb_step_5.npy +``` diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/data_utils.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/data_utils.py" new file mode 100644 index 00000000..ad8d3391 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/lm_1b/data_utils.py" @@ -0,0 +1,279 @@ +# Copyright 2016 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A library for loading 1B word benchmark dataset.""" + +import random + +import numpy as np +import tensorflow as tf + + +class Vocabulary(object): + """Class that holds a vocabulary for the dataset.""" + + def __init__(self, filename): + """Initialize vocabulary. + + Args: + filename: Vocabulary file name. + """ + + self._id_to_word = [] + self._word_to_id = {} + self._unk = -1 + self._bos = -1 + self._eos = -1 + + with tf.gfile.Open(filename) as f: + idx = 0 + for line in f: + word_name = line.strip() + if word_name == '
 +
+It classifies it as belonging to one of four categories: crystals, precipitate, clear, or 'others'.
+
+The model is a variant of [Inception-v3](https://arxiv.org/abs/1512.00567) trained on data from the [MARCO](http://marco.ccr.buffalo.edu) repository.
+
+Model
+-----
+
+The model can be downloaded from:
+
+https://storage.googleapis.com/marco-168219-model/savedmodel.zip
+
+Example
+-------
+
+1. Install TensorFlow and the [Google Cloud SDK](https://cloud.google.com/sdk/gcloud/).
+
+2. Download and unzip the model:
+
+ ```bash
+ unzip savedmodel.zip
+ ```
+
+3. A sample image can be downloaded from:
+
+ https://storage.googleapis.com/marco-168219-model/002s_C6_ImagerDefaults_9.jpg
+
+ Convert your image into a JSON request using:
+
+ ```bash
+ python jpeg2json.py 002s_C6_ImagerDefaults_9.jpg > request.json
+ ```
+
+4. To issue a prediction, run:
+
+ ```bash
+ gcloud ml-engine local predict --model-dir=savedmodel --json-instances=request.json
+ ```
+
+The request should return normalized scores for each class:
+
+
+
+It classifies it as belonging to one of four categories: crystals, precipitate, clear, or 'others'.
+
+The model is a variant of [Inception-v3](https://arxiv.org/abs/1512.00567) trained on data from the [MARCO](http://marco.ccr.buffalo.edu) repository.
+
+Model
+-----
+
+The model can be downloaded from:
+
+https://storage.googleapis.com/marco-168219-model/savedmodel.zip
+
+Example
+-------
+
+1. Install TensorFlow and the [Google Cloud SDK](https://cloud.google.com/sdk/gcloud/).
+
+2. Download and unzip the model:
+
+ ```bash
+ unzip savedmodel.zip
+ ```
+
+3. A sample image can be downloaded from:
+
+ https://storage.googleapis.com/marco-168219-model/002s_C6_ImagerDefaults_9.jpg
+
+ Convert your image into a JSON request using:
+
+ ```bash
+ python jpeg2json.py 002s_C6_ImagerDefaults_9.jpg > request.json
+ ```
+
+4. To issue a prediction, run:
+
+ ```bash
+ gcloud ml-engine local predict --model-dir=savedmodel --json-instances=request.json
+ ```
+
+The request should return normalized scores for each class:
+
++CLASSES SCORES +[u'Crystals', u'Other', u'Precipitate', u'Clear'] [0.926338255405426, 0.026199858635663986, 0.026074528694152832, 0.021387407556176186] ++ +CloudML Endpoint +---------------- + +The model can also be accessed on [Google CloudML](https://cloud.google.com/ml-engine/) by issuing: + +```bash +gcloud ml-engine predict --model marco_168219_model --json-instances request.json +``` + +Ask the author for access privileges to the CloudML instance. + +Note +---- + +`002s_C6_ImagerDefaults_9.jpg` is a sample from the +[MARCO](http://marco.ccr.buffalo.edu) repository, contributed to the dataset under the [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license. + +Author +------ + +[Vincent Vanhoucke](mailto:vanhoucke@google.com) (github: vincentvanhoucke) + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/jpeg2json.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/jpeg2json.py" new file mode 100644 index 00000000..db795e05 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/jpeg2json.py" @@ -0,0 +1,35 @@ +#!/usr/bin/python +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""jpeg2json.py: Converts a JPEG image into a json request to CloudML. + +Usage: +python jpeg2json.py 002s_C6_ImagerDefaults_9.jpg > request.json + +See: +https://cloud.google.com/ml-engine/docs/concepts/prediction-overview#online_prediction_input_data +""" + +import base64 +import sys + + +def to_json(data): + return '{"image_bytes":{"b64": "%s"}}' % base64.b64encode(data) + + +if __name__ == '__main__': + file = open(sys.argv[1]) if len(sys.argv) > 1 else sys.stdin + print(to_json(file.read())) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/request.json" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/request.json" new file mode 100644 index 00000000..338a0091 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/marco/request.json" @@ -0,0 +1 @@ +{"image_bytes":{"b64": "/9j/4AAQSkZJRgABAQEAYABgAAD/2wBDAAYEBQYFBAYGBQYHBwYIChAKCgkJChQODwwQFxQYGBcUFhYaHSUfGhsjHBYWICwgIyYnKSopGR8tMC0oMCUoKSj/2wBDAQcHBwoIChMKChMoGhYaKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCgoKCj/wAARCAPABQADASIAAhEBAxEB/8QAHwAAAQUBAQEBAQEAAAAAAAAAAAECAwQFBgcICQoL/8QAtRAAAgEDAwIEAwUFBAQAAAF9AQIDAAQRBRIhMUEGE1FhByJxFDKBkaEII0KxwRVS0fAkM2JyggkKFhcYGRolJicoKSo0NTY3ODk6Q0RFRkdISUpTVFVWV1hZWmNkZWZnaGlqc3R1dnd4eXqDhIWGh4iJipKTlJWWl5iZmqKjpKWmp6ipqrKztLW2t7i5usLDxMXGx8jJytLT1NXW19jZ2uHi4+Tl5ufo6erx8vP09fb3+Pn6/8QAHwEAAwEBAQEBAQEBAQAAAAAAAAECAwQFBgcICQoL/8QAtREAAgECBAQDBAcFBAQAAQJ3AAECAxEEBSExBhJBUQdhcRMiMoEIFEKRobHBCSMzUvAVYnLRChYkNOEl8RcYGRomJygpKjU2Nzg5OkNERUZHSElKU1RVVldYWVpjZGVmZ2hpanN0dXZ3eHl6goOEhYaHiImKkpOUlZaXmJmaoqOkpaanqKmqsrO0tba3uLm6wsPExcbHyMnK0tPU1dbX2Nna4uPk5ebn6Onq8vP09fb3+Pn6/9oADAMBAAIRAxEAPwD0iPg4J47VKB0FNAPUVIORius9ERRxyacvTJpB1GOpqVMY4GKBEeOfalGQcdqd04xR1IzQFhe3P05pyg9zSOMAHH40hOF60mIjcAjIJyPSoMke1TnGPfrVWd8nAHNBLEkKsKpk4JHbPFOkl29etUpJsE0bEMsTOFBBP41kXdwFPX9addXqYIDVy+t6rFbq21gz46Vk5Ethrd6gyOpPbJrjdRmVhnHP1NOmupLiYtIevYVk6tKYzhazb6Gb1M6+mUSYUc/U1QlYNyP50yV2eUk9KbCQ0h3HpTdiSRVJHp9KrXG3POcj1NPaf5GORWdJKSxJ5qQFlK+p/CqzkHuabJIc9aibt3qhEsTHouMUr4yRn9ahDYHFG4kmkAjDrg/gKapKt9KCSBTQOeRTAs7t67s8+lMbGOaaWwAM0EjPJpANNGfWkY/NTW60wJPwFHT0pVGQKNtACYzwOab04xzUpG1eKjYE9aAFUkGnn14FRrhakA3dKAG9u1AznpSlSOv5VLEny5P50ARnI+tHIOR+NSbcHmmyN2HSgBhHpxSoSTwMmgDJzUiDHSgAPGPyp/PFSwQruy3FEyqw+WlcCDODUhOVyeKjVR3qQ4K8UANQEngA+5qxnKYYkH271FGQvXmnPJxjpQ9QIm4anAjA5UfSnou8+op4RBgcUXERBuepp8JO7jH9aawA6U6MEjgc0AEhBBHNMGfxqXyj1OcUgUhccYoAhbrTkJ3U9YsnFSGMLQBE0meO9KGyQDTXC9e9M3fMaaVwLGflFIzcVEpOPanhC3AzVqArjWPNNCk9quwWbP2NatppDnkIfyqrJDSbMOK3duxq5BYO3YgV00Gk7BjGDVxLDHAFK/YfL3OYh0w8Zq7Fp6jrg10Caa7dBV630SVv4OKYaHNx2qqen6VZS3JPyrxXWQaC3939KuxaCwx8tK6A4tbORj6e9TJpjNjiu5TRD/dq0mjYAyBRzIRwqaVzkjr1qzFpA4yufrXdR6SBjip00tRxtpc4jh49I4GFqZdI5AC813C6ZjAxUi6cMdKXMBw6aSOygfSpRo/qK7VdPA7U4aeoHI5o5hHFDSM4yOPT0p40oD+H9K7NbFcdKcLIADgYouwOJ/skenvTRpQzytdwbJT2Gab9g44x60cwjhzpI/ujApG0kf3a7c2A/u0n2AY6UXA4VtJGBxUb6QM/cGK7s2IxyM9qjOnjuPei4HANpAPbpVZtIB7HmvQzp4OcioTp2ewp8wjzt9IA6D8KryaS46DBr0Z9LB/hFV30r/Z4o5wPOH06RfUiq0ltIvVc/hXo8mk/7NVJdHPZc/hT5kFzzuS3z1WqstkrenNd9Nouc/J+lZ9xorA5Cn8qNBcxw02nHsKoy2jp2/Su7fTmXqBioH01HGMU72HzHAtEynkU3B712N1opwSq8fWse60t4zyho0ZXMYzdeaZjrVua2dSeDiq7Ls+lJxKTGg4OKeaiJ5pwbjmpcRpjh6UPmkBNKzVIxADjFGDmlGQOKkXnrRcBpBKj0pD0qRWwp3VGxz1HWgGKjAHqalEg9W+lVs84NSBcDOaGgJi47k/jVctuYnrQxHU1GWXPBzRYCYtx1OaZk5pVUuM5pPLbBNAg5xkDNM2nHSpAfWl3fJ0oATado4GKYVPXAp2444pMnJ7ZoGQ9zQc+macFO4daklgYDd2oERA47nNMY+oyfanYPenYOc4oAg7d8mm/yqaZR2qHtgdqAHD1pyimjpThkCgY/PcHPtUTEk96cp60hKkDPWgCP64NKPSlYYPHWgZ4oAeAe/SnA00df60uMcmgCeNsfWrVtKFPP86oKakVuc00xHSWl2Aa3bS5BwR3rhopyMd61LO+KHrT3Gd9azKVAz+tbFnMoI964axvwSOea3bS9GRzUONxpncWU4Dr6D3robWRSuQRiuEsLrewyRXTabOSMcGs3oWtTdc5BqOQ7h8tAIMfXmk5I/rW0JESiV3BBpIyM89ae/Qk1AWweCK6E7madmXIyM9cVcixxisyN898mr0L5HH5VLRpuaCVIPwqvCxIIJqb6UjKcRSee1SIwBqNsYOKaCQaGrnHONjRicZFXY5FHB9KxkkIPJq3FJyCT+Fc04GXNY2Y5BjipVcY68VlpN71MswzyawaNYTL+7J60hb8qqrLxmneZ7mhM6IzJWbgZP4UjNxnrUTPxxmkL8YqkzVSJSenPvSFzj0NQh/em7/enc1UiUn8qRicfyqNn6CmbwenWnctSKAPTFSbiOOxqDqeDUkeTXedZLuwPTFOjPy8jmoic8cD6UKWB5oEWFGTj1p/CkdKihkGeuKkd1bAyM9aQxW75qF+vBqYsAPpUEyjII6UhMgkDMcKelRsmIycc09uM7eBVO+vQIWUHDYxxSbIehQubgvL5aYJ/lWRrt6tlaEs3zHoB60+S5WC3lmBweTXF6xdNITcXUh4PyL2qW9TKT0Hy3spjZiTuP6Vzc08MAkluW3OScKamvdVkeQRL8oIrAvY1dnadiD2PrWUnrqZk41SISB2GKx9Tv8AzZdxOF7VT1CZdmF7VXmX7Sq7PugUcq3JuSvcKSpH3aglIiBbPJ9Kqu5AESjJBpkrMh+fqe1FhAZy5KgUE/u+BUWRjvzTgHSNj296bEQYJbnvSmNgM0+AgNlzwKLiYOcKcCgCDvRtPamjlvapVYZ5FAEZHSjOOtSSJjk8VD1OO9ADkAJyTmnhC3OKjGFq1FINtDArsmGo206Zhu460zdnrQA9FPYUvRgD1pnnYXC0hbGCTzQA98s2OwpGHFNDkngcU8DjBoAWOIkbiODUqDjillcLEq/rSL/qyaQD0iLHP60jnGBnjNILn5dq8VCWyffvQA6VsHj6VGCc89aU53DPU0pOBx1pgTMu0AnFNVvmzSEtKADQo2MDnOaALABK5NNHPy0s0pChTj6iohLjvSAPLO8imhGJwM8UGQ7s8k1KW2x5BwTTAiV9jYpWYkA0zcGPrSnJwMHFFgLFtISNvelnBQ5PApYk8o7qbNKZm29KXURD5nzVcjkULx371CLUsm5WG3NJ5L8heQKNGBaW4XgMeKYzBxhartFtAOas2cqRklkBOOKEuwhqkxgnGD703fnk5qa4kMrDA/KprKwnuHwkZNaKHVgURGXORzQLeRm4Fdnp3heR8Gf5V71v2WhWNtjcvmOPaqukUoNnA2GjXNwRhD+VdJY+FmwGnYKPeu0trORgFt4Qi+o4rQt9DlmwZWOKLtlcqRytvpVrbgADefYVfgs3k4iiIHrXZWegxIclAc9a1oNMRMDaKWgORxFtoc0mN/Falt4fQY3LmuxjslGPlAqwlsB0FK/Ym5zMGjImML+lXYtLUHoK6FLX25qVLb1oEYSaeqgkj9KmSxGeBW2IAM5FL5IBGBzSEZAshxwPyp4s1GcitgQc4A5p3k4PSgZkC0XI6ipBaj0zWr5OBwKTyjnpRYVjMFqPSni2HoK0TFxnB5oSPPGMe9FgM42xA5Wj7N7VppESMn8qGQqBxxRYLGZ9nGOB1oW2xjitDy+c0KpzTsBn+Rg9DQbYHAI6VoPF6fWlEYwKLBYzTbDHTrSfZxjGK0RGR9KDHmiwGYbYelM+zAnpWqyYPPSlaMelFgsYxtwcjGBTTakHkcetaphzT/IxwB0osFjEa0yegqJrMf3elbxhC9qa0C4ziiwrGA1kOPlqNrJf7oroGtxjPWo2txjkUuULHOSacvYCq8mmqQcLXTmAY6cGo2t+vHNFibHHz6RE+dyCs+50BGyVGDXdyW4weKryWwIzijUTiecXOiyJ9zms24s9pImh49a9Qlsweo4qlcaeHGCgNHqS4voeU3WjW0+dvDHtWDf+GJcloxmvXbvQ4pM4XB9RWTcaNPHkwsfpTTa2YczR4vdabNA2HQjHtVF0ZTXsVxbN927tg49axbzw/YXIPlfu29MfSq5u6KVTuebFio5pm/mun1Lwvcw5MYDr7H6Vz81nJE2HRh+FHKnqjRSTIVc5q0hxg+tVvL21NEwwM8YqHEpMtyRqY92KgRMnmjzcnGcipFXIzgjHtU7FELxjfgU18/d9Kmd4wMgnfTQruVIXNAio5bJxSRxFiTirs0iBSpQbvWo4pQoIwDRcBsY2Ec1K5d14AxVV92SxzyakjlcDBHFKwDZCcBR19qVVdR8wp8bhW981NJFI8e4MMfWncCHeBUZUu/HSnxKrEiT8MVC29GOATQIl3hWwetSeePL2nkVVYEjcahYk8A0rDuWHcHIXvSlsrVcH3qVH28GiwDCf/wBVMZKc+S2QKcpH8XamIYvSnbqdJgKCOagyQaBj+pOaAoPIpAafuFAiNgRiinZyOaQDJ9TQAozgUMaUnt0pNuevWgBVIx7U4MDimY5xS9MUDHhiD1qxC/qaqdWPrUidRzQBr285TkH6Vq2t5Iu05rn4mOMLVj7SwAAGMdcU0wO/0u9GzJbB+tdVo2pgMuTkGvH7e+YsDk4rqtI1NQoG/kUpRuioux7BBdo7YzitCFlcHB6V53pWqFnG45ArttOkBhD7hj0zWXwGi94szJ6VQmUqSSa2ZNvljbzWdcpkY71vTncxnCxTinweTgVoW8w3DniseePac96La4IYA9a3eqIjKz1OrgfPSrac4xWNYT7sDtWzDzg9jWexrox+PYUx+BU2B25psiZHrVrUwqQuV1apVlIOaikGOv51EW9OlEoXR59SLRoxzEnkipklrLWQnFSrLgjmuWcDNSsayy8cHmpBL2rNWXsakWT3rBo2jMvmTjkmmtJz6VUEh9aaZKSN4zLZfnGcUm+qqyZPNL5naqRqplnzPzpN/Wqxcg88+lG+maKQ1epp4OCaaD3pTn6V6B6Y8YBGelKXHIpmegPWhid3bJoAlAzj0p+QeMVEucECkjDBuelIRZUjBBOapXk/lR1ZOOtZmsMqpljjFJCZVur9hGQoO7Fc7NemR/K3jOck1YuLwMr4HbGaw/JjhEk8zkKMk+9DaijBu5Hrt6kVuEzwOTXGT34u78B8eSgzxVrxBe+ajEHCPwM9q5We5W1tikRDO3U+lYbkNliS/S61QL0jU4ArJ1zUDJdkRj5E4ApiIdplDfN1qndyKrAcE9SfWpdrkFW5uN2cj8altBItu0zcIOnvVGd90megqR71jGIh9wVT2sIWKQIxlxk9hVaWQO+WOTSFzLJhQcVNcWvlxg96AIUYZBxmpHkZj83Sm2ZEZZ5OcVFLIWbd2pCFYbnOKYyEDJpY2457808tujx2pgQgD15oyQacSFBxUbdBQBIWLdaiTh6DnoKApGKAHhNzZJwKXocLTA3r6U9GHagAdQo68mmA5FSMhkHyn8ab5e3A/OgBhAyKc+CcY4ApGB61JAuASeTQA+BgFI21IgBbntRFHlck4GaDIiqQM0gGz/PyBwKUofLHX6UzJ2/WrDcBRntTAqgFiT6VNEF3DI5p4cZxildkB+UCgCKdVViRzUflkhWGaldw5wB1qaMbmWPgAUAOs7Xz2LE4VetSTwRgYU8imzSbMpF931pS67QvUmlqBnyYwOmaEwelTNbky7QRmr1tYKFLOR9TTvYCpawhnUscCtu70iGO1Ry/LDOPSqIgVblAzYTGatTSrcR7UY7R0FKTfQRiyqsTYABwauQRrIgfuBmqdxCyOec02O4ZOBnAoeuwE805U7AOtRxgtk5xUUkpZt2PpSxSNnnkU0gJPOKkDPy1MtzjIAHPFRbPNcYBrY0vQbm8YbYzt9SK0VPuG+xlsrOeh57Vpabol1dOCqHb713Gm+F7e0Aa5YM4/hrobOxdwFt4gq/TFUn2LVPucnp/heCEBrj5m9K6Oz08IoW1gA9yK6Wx0Mkgycmt+00pUUYXAqX5lXS2OTtdGllx5rH6Vt2WhRpglRn1rpoLEAD5eaux2mByBRclyMO301U6KMVfislAHH4VrJAM9KnSDp2FIkzI7TGPl/Op1teuRzWmkIHXrThEcikBnrbcc1PHCAPu9quGMZB9KcE4NAioIz/CKf5PfpU4U1JszwevWmwKgiwDnmpo0ABwKk24PTil2UAV2XnKgD0oKEqOanKkCnIvXkU2IgKYWjbn+lTlOlNK5JpAM25HAphj/A1OuQOOBQy5wKLWAhVc9qHXIx+NTBcGmlfamtR2K4TJ/pQFw2alCknkUEcCgBm3oaXYAc4/+tT+Dg07kigCApgjvSFO44FTuOOKbj5aaCxCQCvvQU9OlSYpBw1MLEIUdKcmD1qQAbs4696VVweBigdiF155696jK4PQ1aZQeQBnvTMA9RQ9AsQBMUeWe9WSOKawyMgc0bisVjGD2ppi9quBRg8fhSsmRz3pWCxnND3qAwDHvWmy89s1BIvPToaLCsZ7QDHAqCS39K1dmaYUyelKwrGLLbDnpVR7QHtXQvBkVWeDtgUWFY5m409G+8tYt7oMUvO3B9a7prfIqtLb/KBj8aVmtiXFM8zuNJurbiI709DWPd2ltMSt1b4PrivWJ7Pd1H4Vk3mkJIpDIM/Slp1I5WtjxzUvC6uu60bcPSuYvdNntTiRG/KvbLrQWQkxZU+1Yt9ZkDbcwhl9cVab9RqbW54/kxtg9qsrfMq4IHpXaX/hmC4DPakBv7prldR0i4tWO+JsD2otGRqplGTym+YZ3UqXAVNoJDVXcMvUYNM6npzUOBdyYRSTyYXkmpms5oWBkX5T3pltIyMCCRVm4vHdQpYkd6nW49CKYDygByahVSODV2PY0Y3HBqHPmSADAA4BoTANoCsSMDFQyTADAHtU8u7oG4NVZYGCjHNCERqST157U4uysM0oj7dKa55Cn86AJA/mDGBSG1KnJ6GpEi+XcMU52Y4254pDIhZv97bxUTpjK8Zq1vmA2hjg9s0xrKXy2kyPpmn6iKh3cjNAHqOtIGIPekLZwDQBNEgc4Y0jxbGIzkUsKhj15qN9ysQ3agY5gAlMUZNICSDxxSxvg+9AD3j+XIqFW2nFTO5PtULKepOOaBE0bKeGpSnXbzUA61KhI4FAxrgg9KOanZjgZA4quwOScYoESBMcg0v3SKjDcYNKMk+1AywhOcjipVm2ocgEmoFYYA70Ow3AUCJY5Pm61o2MzeYOcVkqOOas2p+cc1SYHfaVdlGXdj8a7TT9RfA8tsg9RXmOnXKjBcnAre0/VBHIRGeO1TJcxadj1Wwvy4CSHg1cxvyc8elcjpeoiZAv8eOtdLpRkYAtgjNZp8pe4XMYYYA6VnSwlWyBXSPAoGetZ91ECSAOldEJ3MJxsVbG4ZWUd/5V0llNuUVyoQxvuArUsbjGMGnIISOoQgjP60/Gc5/OqVvLuTBPNWlOQM0QkWxkiDBx1qlIhWtVBkc4JqvPH1xW0Wc1WFzNPBGaVXO4U+VCDxUByDRKFzgnGxaWXJx1qRZOnNUd/wClOD8e1csqZCdjQEnv9KUv61QWQ5wPyp5k/wAmsXA1jItiXHFLuqkr+pp6ydOaLG0ZFrd0yaN4qtv9+fegvnvRY0UjSUDPPSncZ4pinP5UAH8K7j3BW65xmkyep60EEinBcjANADo85B7d6V3+YAjGKapwTzjHFQyPzjt61IhZLjbkHgVn38sbx4kIINVb+5ZXIBFZl3KVQySOFA6ZpSsjJsztVuY4BIw6CuV1OWSdY98mxC2duetW/EV8rRBItpGcsa5bXbtjJDHGTuCj8Kyk2zFlXX5PtF1FaRD0yao61bwWNosatumIy1RKsk138smHB+8TVHWWYAgnew75zUbNK5FyjJOzQ4BwtU2dSQoOTnmmszlMH1qLYRkk4qrE3JpkTI5471EAgOeq0juGU81CWO3AFAE1o6ifc33RU15deaMc4qkq4HJpG4/GjcBQ55FIwJPFAG0k0rOAPc0AMyUOO9KJOmaYRwCc80DGMgfSgQrEknvR2FJn5QfzpV5UkUAKeg9aUAtj0qNietOjlOMd6AHFMtxSJGWfCmg7gDxVmwdFcMw+tAEbBosD1prOMD1qa6cSzZUcVAwABoGPjUbcn9amUBUzUUbbyM8Cp5U3uqpznigRFuLE4zxUbx4Gea0GhECEEfNjNQMVcqvagCJGAQcc1MFDR7j1PFJOQABtAApJJFKYHGKQEewKDzmlg24IahAGQ881GEI5zx60wLYUyfLEvI7gUxUeJsyA5q7pdwkMeMZPUmkvLhLhnZVCmlfWwFSBWlkzjCjrUlzGUAI7jtTrcs37peM9TTZXwwUnPFPqA21jZyW5+tXTIqwlZGJPYiqskhVAqqRUIilnb5fypPUCSSbnk5pYCdpKnBqCaAwthup61IJcAIqjFP0ESSkGPGMk96gCIfT3qy8LGMEAgfzpbHTbi7lCxIWJ9BVxhcCqLfPI79BWppWg3V84EcbbfUiux0bwqkKrLft/wGuqsrVyoisYNqj+LFWnbYtU+rOc0rwrbWYV7ohn9K6mzs3lwlpD5aHvitvTfD3zbpyWb3rqbPS1TAC4HtSfmXdLY5mw0AZ3SfOx9a6K00tEAwuK2oLQLjAq7FbcDjAobZLZmQ2K8YA4q7Fa4GAPzq8kIAHFTpEO9IkpLDjnFSrEM9M1bEYB9KURjjFJiI0iGRkCn+WKlRSBg04oTyOuKBMhI54FOC5I4pwGCc88Up4ziiwr2G7Rt4NLtwcVKo+XB/KlIA4xxUhcgKHrzQmOanK8VGyBTnPHencBrD5qaBg9eKZ9ohMhQPk/WpsfKMUxBt3AdqRU6mpFI4OaXI7UuoyJhUZGD71K3DdKaykjIqmAwdSD0p+OOKaRkZGOOtOXp1osA0A9O9GeMGn/AMXNNbkgigZH2NNBHIqXA6A0wjB9qdrDsJt6c8U5R8vvTkXOacRjpzQgI26YHNJgDtxTj3ozjrTeobDdmDnOKYVwfTNTE5HTmk60tSiMKCoxS44HNOUdqD931ppCIyDimbSM55qU/dqMigGJjjmgcCnDkCjpxTsISgk8c4pp56ikz19aqwmI3Uc1GeakOev4Uw9e5+tKwxgHak2+1TdQcDFIR6Ac0rARlO3rUTxjcatEZP4daaQuPehhYoPFzxULRdBWmyDpTWi+vFSKxkvDySR9arSQde9bM0XAqsYuOR+VKxNjEltQVII5rNu9NWRSGTNdS0XFVngzn+tIlpM891HQActBlG9q56/s5ovku4fMT+9jNesz2oOeKy7zTldSCoI+lHqQ4djxXU/D1vcgvanDelcpfaXNZuQ8Z+uK9s1Tw8Mlocox9OK5y+smVTHeRBl6BsU9fUFNrc8qZtoxRGUOS1dZq3htXVpbQj1xXMXFlLbyFZEK/hRZS2NVO4yVgV+XNRCQADrzV2BFxtk4zwKhazfcxjG4ZzUWsWMhR5ThTn2qSSGWI4bNRo0kMvHBBqzNdtJGd5B4pO6ApNnOeaSUqwGBzVqKBnRmBBx2qrM+RsAwc8mgCzAR5XFR/wAX+FRxblI+YYrXtkhWHdJtI/Wlew9zN3AMF5yKhmmkCkZYD09auzCIy7oiDVa9bd94L+FMRWhQOeankijVMnB9KrLwwwcZq/FFGytuPTpikxlBTtOQacxBYknJqxLbKBlTmodgFMQhQbOOtQopBzVjoD/KmoR+H8qBipEZB+tDwnHXOO1OJMbZB4qMykuTnrSERD0p4yRxS5Xj3p3ABPQdqYwdyF60zzPlI4+tMk5XINMB6Ciwh4IPFPDYB9aaqgjOOaXac9RQA6LJPSpGGMEiokO1sGpd27g8igBU3dQOKlUlO1NBwn3T9aYzswHNAF+1uMMA5OK1dPu1SXnpXNgkHaetXLWQ5GTxTQ7npej30ZOQ2CK7fSdQ2oAhPPUntXlWjeWQHMwBHbNdro98g/d7h061nNJlxbPSIJ45bZTuyaSWLgkDmuf0u58sbWOR2ro4JDMhJ+UelKDsOSujLuIxycc4qpG5RsE1qTiNdwzlqzJFBLEcYrpT0MHoblhPkLzWvE+celclYzFGwTj0zW/aTgkcis3oy07mrEfm4FTum4HjtVSJuRVxTn6VpGYmZ88eCaoSLg5rcmjz07VnzxYzxXRF3OSrAzW4NM3YNTyofpVZwRnH4mqcLnHKNh+/v3pwYZ5xmoM8UoJ696xlSEThvm+tO3cmqykhvapQ3fNYuBaZNvOSTRv/ABqEtgCjfnFLlNFI3I+CR608tgD0pMYIoxn2Fbn0g4kbaFYAZPSmkcZ7U0PkhcdqTEDncc5wKpXsywQu5OMD9atSsMHtj1rmtUuDJKYx90etLciTsRQSPIGdsnPIFcn4n1GQSNASQK37u+jsLN5HOSBwK4iSQ3Mkl1d4KtyKzb1cjGT6GVqMk32eOKLJldsj6VQhtLmS9Ac5bGGz6VpWF15t/NLIFxGPkBqIX/lSSO2zdITjiolJozsjn9WuBZSukZyzZGfSsO4uw5A/n3qzrkvn3RIGOayQheXAznPFEV1Zm2XJZFMWcAfhUccDS5Z/lQdzTJQVID8ACo/OZxtGSoo9AGzICcRDI9aMCNckc+9SPIq44OaqsS3XikAkjZIAFHAGOppo5z6UsPDAnGBTEK/3feoS3t+dSv8AMS2cYqPpnrQA6M+YSD0FLwFz2pigAZ701s8CgCSMbzzTipx8o49aWCPIIzk+1SM5SPaRgnrQMquDnH501eHBParOwFOeD1qArxmgRKWLj1pAxXsc09BsT5sZpQm8EgGgB8UmxSMAseKHjyO3HJpmAjLzSzMc8Hg+lAyNSVbj86uRTFFDdxVdkXC7c5PXNWYkDr8/HFADHuGl3Zp9kmSzEZI5qeyhRi/uKRpUhBVOfei/RCK8qtLMOB70jqoyF5PanGQs2eQKYjKJCe/oaAIwCjH+VAYkAEdKtR2xmyxOD6UpjRY1UDLZ5NAFUsy84OKVJMZyetWr1N6BY1JA74qkUKNz+dCAuLvyG9fSpfLjlbAzkdKhQu0ee3algDeZknGOaQhZ3EbFetPs5zGzEYBPemXCo/ziolViOnWqUeYCW5zKwYNkmnW9o7SJsG4ntV7R9JuL11Eanb/eNegaNoVvYqrSKHlrRRURxi5GFo3hqa7CyXfyRj1rr7CwgtF8qxhDt/exWxp+kzXZXcpSL0AxXX6ZosUAUKn4kU/U2UVE5vTfD8k7B7rJ/wBmutsdKSIAKoA9hWvbWSr2+laUVqAOmPwovclsyo7cRn5Y8mr1vaMcFyfwrSit1B4A5qxHAMVJJUSHHQfjVlYMirCxgDAFSx8elJiuVkhAHOCMU7YAcgVaUfNjikaPIBHWjYVyvsDH+VJswamxhqcFz9aTYrkGORSgEmpWXYKaOmR1pITZFKmTx170gX1qVuM+tN70xXGA5Ge1OJyPUCnYFIQeRxQmAo+YVDcRNIpUHGe9TIPTin/lQBj2mlJBL5jMWY+taBXYRipiBnFIRmi7e4ETjutKD9M0/wBqaAMniqQDG55OMU1SehqQYxSFM0dRkQyp5FOCgHNKw4yOlOZc89TR1GR8mlz044pwAHXj2pxA2imAwAdT0pCuG9qeQSB6UDleO1IYijbyfrQ2OSe9OHHFNY8AkfhTQEZGQfXrTQDmpMEN2+tMIxzVDDikxgUoOKTPPNUA0YDc0ueBSkAHpQPzoWwWEFBTqT3pw+8aMcYPNIZGAaTbTsc0rYByM0kBGwBppUetPPFNOe4ouA3GTj8aay5OcVIehHSjt+FNhYjP3cDFKBtABzTyvGPWnIo70XHYjIGaTb+FTAZJpjD0oFYjxg88+tI2AAOOafjpgDmlwM9KdhWInUcDvUJi44/GrJ69eKbjHpj0qbBYqNFzULwg8dK0QMrheM1HKig8ikS0Zbw9qqyQjnI5rXaMc8VBJEPSlYVjCuLMEcDrWPfaXHKhBQH6iuteIHjFVZYOpA496WxLjc8y1HQZIHZoM467a53UdOiuQ0dxEEkHQ4r2Ce1VwcjIPrWDqejRzKcrj3Ao33M3FrY8R1XRZ7Ukou6POQQM+tYxmkgJAzketeuanpcttv8Al8yLngjOK5TVNEgulZ4Rsk5yPz9qfqVGocSV887icGoZ4zGcHn6VfvbGa1lwynA9qpsTn56lxNU7iQucY3EeuDULoSxI71YkMOwbMhj15qJWJGD+dQMQowIwCR3qzBD56kBirfWlUErxj3qu0jwyddoNLcAkgeJzuJqFYzKxwwB96tSzeapGOfWolXy1+YcnvTAYItqBn5z0qRSqjC9asu1vIQCGUYqk6YJ2NgUtwHxsQcSECmS4HeomLM3PFHzAc5/GmA9fmYVNIi+X8mNxqBC3b8qA7A9ce1KwxGRxw2eKaUHXvUrSbuD1okgaOPeelAiueuKVmOAPWmFjn1qRAGxupgR9uelSIoIxjinFRnpx7UPhcbaBgF25OelMByeaTnPSnYIoENqRCFPPWomBPFKVOaALqSDaVOMVX3DPApijkZp4jGM/lQAu7PTtU8OV57VXCY5BpyykDbxmgDbtLoRAVu6dqb7ly2K4uJz1GfzrZ06cAqrHAHrVDR6lpGoSOU2tnHOD6V31nexzwDkBsc4rxvTroxSKUbr3zXd+Hr3dKFYggj1rCUbamsX0OqMAkUsG5qp9mIc56VNbmTcdn3c4qd2JXB9K1jLoZyiZcy7GyBV6zuOmTyPSq065YgkfQ1VR2jlHpnpWjVzNHX2k27HOT2rThOQMEVzNhcdOePWt61kBGQc1jezKL5OQarTJyeKnXPHpSsnHNb05Gc1cx5ojg4qm6cmtmdPUY9qz5ose1dsHc5ZRM5lx1poHHFWJFqLArRwuYuIwcHOKcTTee1BrKVMmwuc0Bs+1Jnjikbr1rNwGdKDkc8EU4EYOar52nrkVJvyPSsrn04rEgZ7VU8xmlznAqdmJG3pUE2I1JXrRcTKl/dAkoueOprC1J0jjLMSOO1Wrycbi7EDmuR1S9lnmkQOAg6A96iXkZSkZ2pXLX1xyT5a8AHvXOarcFnNvASW7Cr2sXYtLYmM5lbjFc5b3Lxb5GGZm6VjdswbLNxiyswkrZmc8gelYVzeHzTk89quXc/Pm3BDP2FYNyWlkLqO/QULXclsluHTYA2S55NVrZxHMGI+lQPuHLHJJwKmMQWEOxwT0xT2J3JL6VXztx0rPBcfd60kpxxnNKuRii1gGkkHJP50wMQeeRUkiHHXmoCCCSfyFAh2/t+tOzhQTTApYc08Y3AUABB2fKOtQnk1bY/LtXrURRe45oAYvABPJHpTgC/zKc06OLecZwBT+Nm0daBjYWKAnvTXO9qU8cCkX3oEORS5CrktS7SjENww9alicRhm4yelJkHLN1NAyMlnGcfpUiuAnApY1VlJ6Y61G4Gfl6UAI6lyMkcmppYjkBfXFRRsC6g+tSTEq/HTNADGUq2CeasW0TO2AxHue1IuGcBRnjrWoWiitAuPnPehuwJFE/uA2W5PFU5G3OfappgXOc1XKknAGaEhE0YXC5bn61YgjQNlxkVWSJ1wSDinyy7BtFAFiW4IJ2DGeOKbbMcjPTuarpvkyQDj1q6XxAFCjNGwFhJfPPloASe+Ky7jKOwOD26VYjuPKB2nDHimvEsiFy3PakBFETnr8uO9P3ggY5NQHOeOlXtOsZryRVjUnn0rRRvqIgijaRgqgk5rr9A8NSTkTXXyp1wc1r6D4ditFWS4XMnXBrtdL0eW7K71KxDooq/Q0jDqzN03TwuIbOLA7tiut0jw8NytKCW681uaToyRKoCYA9RXRWtkFwMc0Ghn2enhNvy4xWvBa46gCrcNtgHIq3HFgYxSJZBHAB0FWUi9c1MseADipUQZ4oJZGsXA9KeEAPIzUyL0z1pzLUktjGUDOOajxg8dDUpHHBqJuDg00Sxx4P0pd2M80wHGCOlOIyBjvzQSKw3Dgc03aQcUq4z7U85HNQ0FxvDA5PNRMhHuKmcdx1puc8YzRsgTIsA9RTQMdRU7AdqY6+1FwGKOOKULnrSgcZpwPpQA3ZjntRj8akbGcdqb1zihAMII6ik6CpCM/jQADnmquBFj5qQ5z9acynHtTR074pDEIGOBRtpRTiuRz0oQyIDJ6UFSO1SAClx+VMCEjvR+FPIAGDSEdu1UgE600rhifypxHHHWgdMHqKYxmex60u4Z6dutDLzntQ4wOOlPcAYegqPB/On4GAcn6Ug6Akd6BoiHB5FB4/GnOpJ6YppzimgAdKRjzxR0Xikp2AVSQM96d1HPWmc5NOQYNFrjAgd6M5OKCPrTtpoGRnHemnoakK84PQ0mM9KQDQvAzSAcEU8D3pSuT70DsNWlHUGjGOMc08ZCnHemkA3gnimEZ6U9RnPakHNJqwxhXAxSAHPSpMZz6UBaBWI9o5NIU460/vRwRTERgYHFRScHPX61OenFQtjHI70MViFgPzqN1yDnpUxpm3IxUtCsQlBgdKhki5PpnirrDp6Uwp8vtSaJsZkkPOcVUltwQeK2XQYz1qB4e4GR1pNCOavbBZEOVBz7VyWseHjuaSAYbngcDNekyxd6o3FsrdR+NJaEygmeMalpwdWjuogD0ziuO1jQniLPHll/P+le86ro8cysCnHsK4rVNHkg3YXcnuKa8jPWG541LE6nB60ioRyTXbatoaybnhXDdxXLXNpJCxUg5HtQ0maxlcgRuPTFRSN5ko4qTCn5W4zUR2qeOfes7WLLkBSNQdvHfPNQSkPnjp2pPMBXC0x1kHIBwalAOeMlQQetRuOR7VMhyRkUSYC/dwc0wIwh8vOO9IzjGG5xU6uFU549KgdEKkjrSAhGN2CTj2obAbg5pwBHXHSlSJ2bpk0wECgkEnmnylmXb2qN1KHHfNKruhPFAETRkDgdKcuSvT2qYHcvIGKEAycEdaAIQDnBqQDGQRSTAhj0/CmuWHI70DAAE4px4XJxjpTVDAf0pWz359qACPAzjFJtYEHqKZtPPYUbm6E0CHZ59vSnoQwOTUTZ6ikVuTQMlYkdM4poGCCach7cUrEbh7UCH/dxjrU8Ltu461TZ8sfbinxyYPWhAdLpt228K7cCuy0W8MTgh/mx615taz4bIzXTaXeElfmwKbVykz1vQNVZWPmHg+prpgodMnqa8x0e8wyHOK9A0e8EybJThh0rBvldzVaqxPNGuCBj3rKu0PRcnHoK2JVzJx0qndx966IswmitYz4IXdXRafcAgAnkda5I5imH90mtqxmIwR26jNTUXUlM62J90eKsKfWsqzmBA5HSr6NkCs4SsKQ+RC3FVJo+vHH0q+Dmo5EyOK7qUzJoxpo++OKqsnNa80fJzVSSLArvg7kOJmlCDSEEDpVl0x2phT1qmjJxKxHU44o7ZqYrg5z+FMK+1ZuJm0a24kjI/GjzOgpmQM+9I3XPpXnn0orykP7VUupw7EZpbidQvNYWsah5aBY8B36GlchuxnazfIboW8Z6dTXJeJroQzIUHbBxWrqfl2cJurhvmPT3Ned6/eXF1IZBkJWT956GE3YW4k81zJkmqktykUJbPznIFWoI86SXc4ftWKys/LdM1Oj0M2QQsZ5iXJIzSyuoD469qgJMbPtPuKhdyEO48GmyQZQSMnrSTuZDgZwKiBOcn8KfGw35OM0ARtHgYPNIn3gM0sjF2wDT1AXnPSgCJ2O44HA71Fgs9W4yNhAAOagY7WIweKEA4jahApsQy3HU05XGwr/EaZuMZJzzQAu3bk5zUbtl+OKcXyoFJt56c0AAcquB+NK52r71KigQgtjNRuAWIoAkgxs3NyDTHGOneljXMZJP4UojJYAmgBQAIwT1PQUqJu5NMkXLYU5AqUH7qL+NAE3lKsRO76CqwBJOBxjvT+Q2CcilcnGR0oArxnbJ8wqby2kG4dKikUhqt2kihTG4yM5oAWLEUR4+Y8fSpkR5NoAOO5qCNx52X6elW5btdp8sYyOKAIpEA4Xn1pitGhzjLe9PX5Eyx5YZxQsCMm5jy3QUAKkhuZdgAG7inXNpFHJgPu4pGha3BZOGxnNRSE43ZOcUegFhAsMJAwSajIG0cn3qFGcgkg4pzSgjpgUWERybSxwMAU0M2AAcgUpXexCium8NeG5r11kmUpEO571pGPViWuiKWhaLNqEq4UhO5xXoelaTFZIsUKBpT3q9p1gq4tbKMYBwWFdvoGgLEFZxk+tV6m0YWM7Q9BZysk/J4/Cu507TkjUALirdjYhQMDA+lbEFvjGBijcor29oF7VfjgxgGp4ouBxVhIvxNBLZGkYz0/SpQnP1qZU/KnmPI5pCZXVNp56VIoz1p+BmlK8+lJsliBe/eg84pQSMd6UDPTgUEXGjBHPWmmPPWptuQSOKaR0zUXFch2bRjqKQL3WpSeoph74OB6UCbIySG4pQ4/E08DjHeonXnmncVhw5yB0puCM4pV+7mnE4FDAapGOfwpxAbrQV6YpyjHHakMiYY980wgZ4Jqf2qE8ZA9aaAXkcmjOad2pSAcYouFhmd1JjBpxGMelIRnmmAnt2pmOakx1xTCPXrQMQDBPpTu3JpgOKkxkZotcY3rnA5oGSeaTdg4pQ3NVYQ08mk9fWnMMUwHJ9KBoPT1pD9KWg4xmgYhw3FB4NIBS9eO9MZGvDfWjOOD0p+Oc96GXcBRcYEZGKhZOBU5PGaY6+lF7DREVz1pCncVMvIwevtTdpJHpVXCxDt9cinKARnmpNgNMwRnFCY7CqOtLkEdcYpQ2evajHNMAVcjrTW4py8HAoPXkA0JDGKOTnFAJpGyelA9sUAKw44pOce3SnEcDAyaQ5zTQWGH5c5pRnginZBx60vFK47AVB/rRgY5pccUY55osBE64P0pCCBUj9Mn8qZ169aNhWuRnnikI4xUhAB96GAIxSCxUZOcUiipyAM+tNxjoOtJMGiIrz9KMEkdakK4x3pSvQmhk2K5T8aYy9ABVph6cCoyvPvSJaKMsXPH0qBo859K0XTJqJk54FKwrGRNACp71kX+nLIrZHX2rp5IsD1NVpYc5yKVhWvoeYavoxiYvGvy1yGraOk6uUUB69rvbRZAVx19q5LWdDY5khGD6etPcxlBx1R4RqlhLA5DLj3xWSysODmvWtU0uO5DRTLskHQkVwGsaTLYSHcpK56099OpUJ3MUIf4etXIWkHG3I+lVxtD89qDcEE4PaspI1THxuVkLHAI6UskokJ3Y98VBuDHnpR5ZUbs8UrAPcqGAXmnNGWAOQMVAXDNUkZZmOc4oAbj97zzUsrEMCgIpqxl3OOgqzA6Iu2UZ9DSApuJN24jrQ2ecitCWQFNq49uKqptJIencCoH5xihBkkE4FTShQDgD2quv3s+lAEnltkjOSKbnA+cUrHCk/nSK27/wCvQA+BlHQcmknO0ntSjCLuWmSSecwyBQBFkkd6cCCcnt0p6oBgHjPemyL83SgY1gD3GKFUnkClxngU4ZTB70CJYoyw+brUB4PXpUpkLLx+OKYwIoQEXc81Io4BxSIhLcVY2iNVJ6+lADolfnA4rSsrhkcAnGPeqEbnIINSFz5mTTTA7fSLw/Lk++a7nSb1jhi3I9DXlGmXRUjdkD612mi3v3STxUTiXFnp1nfCRgCMnFWJPmDHGc1zumXKkq3YmuoAVrfevQ1nGXK7FNXVzEuI8k8HiktJtkgGfapr0MCx7Vl7ijj0roaujnOrsLjoM1t2824cHmuMs7jGDk10VhPkAZrmkrA9Ub0TAgd6l6iqcLZq2nNbU5kEUkeRVaWHHpWiVFRvHXo0pjSuZEsXPSq5THatWWLHIqs0fNdaZMolBk46UwqQcYq40Z9ue1RMnPTmnYxlAcD7UxslCSalIyRmq92+IsAc9K8ls90xr6Vg2T9wd65Sd3v9TVx/qouOK3temMFmwzy3SvP9U1WTT7f93neeTUu72MJu24/xbOJrhFZ/lTgCsHUnhitkRSC5+ZqqxyXGoNNcS5wDms6VlKl5HJOelZNW0uZ3vqNuNQkZDHtAQdMVnm8wePypl7IRkrwDVJAXPc45NNJENlidyBuJ5aq0jHPNOZi7YPQUyRwc4/OgQ2Q7gAKAjDvRngAdaeZCA30oAgZtrZ6mnq+Y/XNQu2T2+tNVgGBNAicOyjjg0m4596crgryMmm5PagYK3zHNKF3Hr1pkalnJ7Chjg8HvQApXbyBScuaex+QZpig47gCgCRNzfeIwKiJOSRzmpApZTjpTkwqYNAECu2fap1y7fLURA3VPD8pG3uKACJeSMcChyAwK/nU4wq5z1qPaNhLde1AERJzkHr1qcD5MfxVHaqHmAY4FXZAkQLDpjihgiuI8quepp08SxhdvpyaYZN2MZpXBYAmgBqrmRQxwKt3CRKo8rqeKjaIJGuep5pMhJFJOQOTRuACOV3CkVM6CNcfeYU+Kblifv0yRkUhmb5qAsKzN5W0/efrUXy9DzikaUEE55qN1YKG9aBEjy/LtX7tMWMu2ADkninW8bSsAoLMeAK7vwz4cESi4uwPUCtFFLVgk2VPDHhrewuLsEJ1wa7/T7B7orDbrshHUgVPpWmyXsiKEKwjpXoWiaQkESgLVebNoxKmg6HHbIo2c/qa6yzslUcDjtUtrbBMACtKKLJAFFu5Y23gAxV6KLoMYFLHBwOM1bij9qCWRrH6VKiY6/jTyoHsaUYPHamRcbt7CgZyCKsRqDxxTJo9rZHSovqSxgAJ9KULkYoQgn3qQqV5BpMTZAyjI703BU4FTSDpxg0wDg0iRq9eaVsfiKMcAg80E4PPGe9BLQxvaowQCQanI4JxULLg0BYF605kyAQM4pq8nB61MnGQRUsHoVynUgc07HBB6ipsHdTXGDwaPIZGeBn9KQjj2pXPB/pUZY+4HpVCHN17gVG3IOKkAOPakwBkAc0Ahh9CcUq9CCaAOxHWlYY5HXNCAaceuaOo460q9eaGBGcUxjeOmaTqOtKRkdaTkCgBjDAzTgflxSn2H4U2mgEYelIOtKe56UgGef0pjAHdmmlTnPanYGelLgk9KBjTnrRjrTsde1Jj3pjsMwMDrTu/NJSDntTGJ9cUr5HI9aDzxRj9KAAkUvYegqMZ79KfkYBNFhjcc8UvBHFBOc5oXHQUWuMUcGmPy3v0p/J4pp9OelO1gTGhefrSn9aO1KP1oGNAwRR6g0HuAeKaT2qkAwgfhR0U44p3agc0kMFPqaUjnIo6daOADigBv8We1NHt3oY+gNKAMD1p3Acp9e9OPXHr3pjcHOKdklR60BsDEY5qM9RxTweucUwvjOKTQCHrTTjr+lKefpTc460CDgmkPFIWweBkUu4Y56UrANPHvS4yOtHvS/WiwEbHB4ppHJ5p5+lN75JosKw0rnOOvpTNoqRl+uaMcdKViStIvJNQumRV1lz+NRsh7YpCaM6SP2qhc2wYZxW0yEgiq8kfbGRSsI4bXNDS5jJUbZOxFcFqdkObe9j47MRXtNxbhl/pXN63o0d5EwK/MOho30ZlOn1R8+6/oUlozSRZMZ7j8Kw4FUON44zzXrWoWL2cjQ3S7oz3xXF+INBa3PnQDKH0/Ch9mKE+jMjyYWVtowe1ULtWUbRT/ADjHkEHB/SoTKWPXPpWbi0bXuQxo2Ru4z0q+kagYk4HrVUP83sKfJvIHPymkwJ1eNW4Hy0jMkjHHA7VHHjacjJqaUReSuF2sOvvSAjIBx6dqSTCfMDTFlCsCO1STXAlUjAoAqOxY5PNQknPFSMcHHYU0kk5IyKYCDkYJODUsQGfm6VGOWA7VIACnoc0DGyfNnHSmgbTTlBBqxGgIG6i9hEBJZQKeFORnt2pkqGNjjpSbs4yaAFdgCMcetIQM8U4oOMflUZbHXpQAoOBxTlIZsntTVOelGCOgoGTOfk44NMPzDLUCQ4x1zU0Me8gA8mjYQ1cjGOaexwwJNTtbvGeegqJyGYZ4oQFi1kJIBrq9FmKsoY5rkYFHmjJwK3tNlEcqgninuho9K0uUYXnk13Gnyq9uFJzxXl+k3Y454rt9JvU+UHpiueaNovoat5GCp9KwbtQGY1vzOsi5XpWNeJyeOoreErowmrEFpMVPoK6LT7nlckYNcdvKSAH8s1uadPkDntioqIz8zt7aQMAxNX4nz1rA0+bgDOfati3c8ZNYxlZkM0FOVp5UY4zmooiKsx4bNdtOZcCpLHkHHSoGi/OtJ0zg1A8eBXfTnc05bma8eByPaozFnrWi8fPp7VH5RJ5FdCZlKJkSPgZHX+VUbmUDOT71NK/yk1harMwUgdTXk7npt2MLxBc/aZtqnCR9TXF36C73luEHGT3rotauDaWh3D55D1rh9S1LGyBBx3rFy10MJPuV768W3t2ghIBY1ivFsYM7ZXGcVNqePNDD7xGcVRuWd1BPQDGKSM2xsp8zLfwjiqrNsXCjGaaZSqkGnAGYZxwKqxJET1C9fWliUYOeppsgaMHA4NQkkDJ4NAFiNDJIVXrUUwIJA60RStGDtGM8ZpRmQjA+tAFdlI70RrubJqaXGcAdutRLmgAVecZ4pw4IUHinIoGDTuACetAAX2oVGADUQ+Y5FOOWJzTkwqkY5NACbs4HSpHPyADgetRICSS3SnyuCMCgBYuUI79aVVzktTUO1SB3p5VsEnpQAoC46U9CBknsKhjXOe1WIYlHzufwoAf5B8rzG4HvVV2yOOlWnmaXCgYA6CqsisjZYYoAdGrBgTVt2LgKvSqyvuAHQ1aDqke1RljQBDHG5bPYd6JHZjgCrDtt2oBwRzU0MUZkO77oGaYWKf7wx/OOe1PAAVVYck8mrspjIAwAo6Gq8kZlJkBwo6UrjsV2kVVIHWhAZevAqOZfnAyOavlUjtiRy2MUySpJEu3IbJ9KfEjzsqICT0xTYYnmfYmSSa9B8MaBFZxi5uxuc8gEVpFW1YJXegeGPDyWsS3N2Pm7Ka7vRtLkvpFZ1IjHQU7Q9JlvpFlmGIh0WvRtK01YkUBeKfXU3hAi0jSxCihUArpLaALhMfSnWlv8oHvWpDBwOKdiyOCDjGKuJFjkVNHHhSMYqVVxgdqdhDYxtGKkUgEcUpUHpxSYxSsZtkpUEZHWmFPm600OU6GnBgcenvTtoRckjzjg8fSldty4brSRuVbGeKeygjNQvMTsVxwePyqQZP8AhSlDzjinIcHB61LENPK46n3qLP51Oy5B9ag570rEgqnsKc6DoOfehCVGOxqUjcCFFILkG30NQsCCcirDAg0x+e1MRCeCCDUi4znNGPlJ/OmjqKSAcenHSkIwhOM0KcH2pGYDNNITGHnNRPktz0qXnmgjPtQURKSfoKc33s4zQoIzxxTsdSPpQFhpHcUA+nT1pwH40jDr7UIBhxk5zQOBz+lKeQSRzRxt9aYDe3rimkHNOA+XnOaD056dqYxOCBjrUTdakIKmmtn8KYDT05HNC8UpwTzzQeBzSGLgH60Ac0q8gHFAAHWmhicZzxQAMU7HcUZwKY7jCvfrim9sVIw44PFJgDHFAyFhg/WlA/8Ar045FNHWmA0rhjSHAHapDyeOlMxnrQAmefWlI9OtCjn1pGGfrTAWmnjn8Kcppr4Ix3pjQd6QdSaYM5zmnAjPtQMUnIppyRxUhA9OKZxnigaGkY47UdCOaCOxoC9c/hQANyM+lITilIAxmkPOeadxCcHBNI3XNKB04pxAI78Uhjd2UpVYBT0NAGAcdfSmk4JA+lNBYG6+55pp4PFKwx3oJ6Y9elFwGFsEg0h+tK5GRmkIBIx/+qlcAIz3oOSM0DpTjx0ouA3HQ0oHrRnt3FKKQDSM8Gkx34p/UHtSL6Gl1ERkenSggg1KQCfalIwBRcLEDJz0/GgrjJIqcrmmMvBFK4miqyc9MVFImRxVorg5pjDIoJaM94wKqTQBicitWReeBUEiUWEcjrGkRXkbLIozivONSsZNNmMVwm6BuhNe0zwgnBGMc1gaxpcd3EY5Fz6UJ9GZzhfVHz94j0LywZ7UZT0/KuUEZ3YI5r2LVdPl0ycxyDdCTxXF+IdEA/0i1GV9PyoatoyITtozlPJCkMatAEx5UDiqku/OOmKdC+Fwf51lKNjYVJPmJxTZiXXjoPSmOcM2BgVJCE2jccGkA2KFXxuOKRrUhuD0qcqudoaq7ZOQG4FADMLu2kZNXEt43hILYfqKgtygY7hmlnkBdQhxSYEZjVWO7tTHAByDRyzYJ4zUzKhgwD8+f0pgV9wLAkdKsR4Zc5waj2DHJx61Ecr0/CluBPne2CB71FcIqj5PxpEBLZqSZWxnj6UAVQ7KBT0IOcjrTjCzLkHp2oXG3OKYAABgj8qe+NnHJqI54pYz60DF8plGW6VNb8HOaYz/ACADoBUe89AcUAXjcMwIc5zUDcc1DuJNPDBhg8GjYC1GQFznpVu1my6gn6VlZYfSrNqSWApoDutIlDAZbkV2ujEO20NzXmOnT+Xtwea63Sr5o5EbJFZzTLi0ehicxBY2NR3rEqMDrVC1uVuVVs/NmtVgGgHpjrURdhyV0c9drhs4NWNOmw4HNLerubgcAVRjcJL6HOcVvLVHOdppk+cEnFdJaycLg8+tcRptwCFP511NhLkAA1yS0ZDN6Ft1aEJGBz7VkW7Z68VpWzdj17VpCQQepbUZHTimtHmpI+g9aeUwCK7aczqjqigyf/rprRke1XSlNKe1dsZilE4G6kIXqPzrn9QnCrvboK1L+QKnPWuR1662xlc9R0rzW9Dokzl/GGpGQLsP3elcTcs5Ifv61sa6XILnkE1gm6LBs8gDpUJWRzyd3qNExeVi54A6GqUkpZ+R71PDkgsQck1Dc/7P44oJKrAvJhsdavxhYrdiOc8CqJUqMnvUok/dBe5psENuJRjjHSq4G9Qx4GaeYt74HNOZAGVO1AEeN3HYU7ftJ46inMEjJHU9sVA5OcdKAHAA5yfzqFiAacctwvT1ocbOM5oAejAKexpjZxmo2bOOtSA71A9KAFTnj86eBwR+VKAFTpUaNlwD2oAcRtbHNI2CamdBjJPNQugGOeT1oAljGSO6npViTDYB4A4qAfJjH3RTxIOSaAGyEKcACnwrJOdq9qiLbiMda0rPbbwSM33jwBRsCJtMt0yWcg4NVNQdXlfABA4FPhmxGw7dcVSYlmYAdaLa3G3pYYkbE5XpVuzA88eaflzzUWCMKCOatFQsIBxz3oEizNscsykcfd4o0vyyzmc/L/OqudpOPSoojuZieg6UdLDvqWbp0aRynAzgYpk9wqRrGvQDNVJFJkAFNmI6A5A65osK4rnOGHNWYEebCAEk9qrQxmQgfpXd+FNEEarcTjqOBWsVbUW+hY8MaGlrGs9woL9QCK9B0HSHvJVlnB2DotR6FpLXcgeRfk7LXpekacI1GF5A+lM3hANM05Y1UKuAK6G1tsD9KdaW4GOK04IcYNNI1EghwOnIq0g5zSKPbFTxgZHrT2JHr27VIOnHSkVAfbFKFK5wKdyWhQOQRTSMZJ7U5DngcVMAGGCBUt2IZWABzSbecDrU8keOR1pig+/FJsWwAZ78075l4PJpwXJBAGKfjJ4x9DSbIYiNuGBx2pDke5pwUZ470jKRipExrNxxjNRdep5qU8cgVG69MdP5UxIQAdMnHpUm4AdMHFNAyuAcgUZzgdMUkhAecdD71Ew5z271Jj+9wKUgEZHOKQiEfNxjimkY4Ap+O4HBoAznmgYwAGmkc88fSngYzTWJz7UIBmMHJpMYGAPwpzDgEHil789aAGD249qCMH2pxGD7elIw70IAIzzim05Tk+1L14pgMxzwKUAelL0oPHTp2oQxmCc5NJjI+tPPsfwpMEHrx60xjCMkimyAdRUrfTHrUbcHnNMCLjr3FLgnjrSsMc0oweaQxE6+uKepyeRTQAG4pwIHtTQBjFN/lUgw4HtTWGDVDGfSkJ607v8ASo25oAUncMgUzrTwe3WmnigaE7ZowPpThSMSCOKAExTQMDnpTvqaDgmgZGAR9KQjHPrT8dqRhkYNMCNhzzQc+lOyNvTPpTQaChV59aCMHpSrkZA5pGIxTAaw5x+VKB70EAKKM85BpAGBTcetKTnij86YxMnPtS+3ekz1JNA6jFACDjI/GmtjPvUhpp6jNIBnf09qaxw3+eakxye9BxjnFO4EB5+o9aco47UoBH86Mc9qLisJ3xT+MZpCPxo7frQA3HNGD1B4NIT2GOKFPP1oQCg8e1A7Z60p5owM8UuoAc0vJxQe2elJkDFFhC5wfWmvhh6U4jP/ANakIP5UPQViE+gzkU1jkkVMQB16moyMnsKSYNERXdmoivPFWD/k0zGRQKxVkjz16VUngBA4z71pleP6VC65+lKwjkda0uO7hZXXOf8A61eaapYSaZcmORd0LdD+Ve23MII5/Sub1zSo72JlkUdODQn0exnUp31R4B4k0Xyc3FsMxnrXKMPLbpXr+o2T6fM0E4zE3ANcR4g0cQTGROYm5+n60mraMiEujOXYZB9abGr7sAZqaYeWSOo9aIJPLcMpxWbVjVBLu2424NLFblgMnk1PdXCTAcfN61CGVVHODUgRSwmGTDcj0FOeJXhVkxuzjGaWb5ud2TUHmMMD0pgMcFGwevpSM2T84pWJJB70o/2uc0ATQ9PXioZAd/y1LgKflPGKSXEbAk5pICEsVOccVLHKrN8wOKjJ3tz0FG7jA6U2ArMFc7SalWMeWSfyqADdyDz9cUbyM+gpAPEDsm4UiR5bHQ1LBcGM8njHSonlxIT6+lPUY2RNjlSaiUHdmpGPmHPc0gQ/lQIM460AA85pUHOTyalmRPL3Kee9ADA3btUicEZ71CV+XI605GIxuoGa1jLhhzXVadIzbQpJNcPBLtYZ4rpdJvNpB/Kh7DR3GnzMhAJPFdhpzedb5LZrzuzuzIwOMV1Wj3mxsE8HisZ+RcX0NS+j27iM4x0rEmyrFuOa37h/Mj46GsW9Xg8Yx6VrB3RhNWZY0mbDYJ5z0rsNLnztyeK89s3KzZrstKm4U9vasqsSWjr7eTpWpbP0xWHayZArVtm4GOaiLsQtGbUPJFWgPUVRt26c81fTketbxnY64O6IylJsGas7T2HNIE5rqhU0NLHiGr3GDgcYrhdeuWkcgGug1q6xuJauK1G4DliOa576Eyeph6xNJIojGSB1NY5QQodx5JrWu5MNtHzHuayLyQMwLcn09KSfQzYrv8m2PntVVQeWbqPzqeylVXaRhwB0qGeQNlwMA0CK8rmRximS4U8Hkd6ecgZUgVGowCTjFMAjYoCe5pxIIyMe5qB33HHvT8HGOM9aAE5bkfhUbsQTnrUwBAwKZjLZbigBigr8x707G7lqOS2OwqTIUHI4oAiC5bAo27ODT93IweaTnJ6E0AI/IwBzREh5JOKE+VuQKnOWwBQAwtn5efpQrcE1IUC4PU03YD15oAhLkngcetWIYt4/xpFjUPj1p7OYyAOnpQAGEowIHXpT2c+WFPNPXe6bwMD3qOKEu5LHAzQBLCpYrGBjPU1cMEcSMeMjvVQv5c2I+T0zUc8sgJU/zo3HsRSPh89fenks+1agzx75qzbqGQs3JHTNMRLLE0cYO/k9qjZQkIIOXPahd8zYJIA71FKhQjJyKQDt5RSCTk/pUYUu2eaMFz9K6Dw1orX1wCynyxyTirjHqxF7wnopncTzriJecGvTNE01rqVTsxEv3Riquj6d5zxwW64jXr716ZoOmLCqYUccYq/M1pwuWdF04RquABXU20AGBio7S2AAAA4rVgj7YppHSlYkgixjgfSrgj24x+RpIkxgdvWp1HP9apEsQJntxRtOKnC+nNGzJzQyRFb2qUIMcH8KaEYHPIFSodvcVIpERBU8inqAQM05lHJPWkUAdCfxpMjccAP60wkA+h9qcoHfj0NIyDuT7UrEsQkZPPFSZx/T3qEEng8iphjA6/jSe5LDv0/I0xycHkg/nT146ce1IQCOePxoRLRGp4HPB9qXHBB6UjrxjHFNBIxk9KQAAw+7/OmHr1+bNSlsjOeKY6g5IoRI0DIPSkB2kjHNNORyPypdx64/KiwWuDdM80zgZzUit2PIpkgG7HagLC4Bz+maawB4FCn5e9BPbOAfWkAzGBTSOTin9STmmtyx60wE9PalxwaD04HtQPSkMYPrTueOcUjf/qpVP6UwBsd+KAeoob3ppOKYDj2xSZ7HigHP1pCeOlFgAjA4PSm4z1IxS4JxnNIcjB6j1pjGN3zzTV46VIDx6+tNORRYYHkA8YpCenFBAIxTR15HNMBQfSlbOaQ8c96Qn/a4qkAm7tTTz0oPXqaAxBAycUhjl4GSabnBGKO3WkPTigYYyeBR9T3oB7UHp6UAIetHXignHWjn6igYD0Oaae+TmlOeeeKTsKaAjbPIPTNKAPXinHHqDTSMdKBjgcf4imv69aBwOxobp2zQgG59KRaPbvSrgUIoTGT9KBg0p6Hn6U3tzQIU9DikHTr+VGfloXrzTGBOCOaG9aVufrTVIB+tACZyaRjlsU7JA9qaTnJ9PWkA09PpSjke9KSenNIOmDzQAh6elGR0Uc0hz2pyjH/16LgN245o2ggYwKU5JOR+dJjrSAG5ApwXjrSA8cGggk4qhAzAgZpQhY8U0ZLYNLvI6VIDtgGcdfamYPSlzg+1JnnrQDYEc+/SmFePepCcfWm9SaQETgg9Mg00g4x0FSnHQcijGPrQmJkJXJNNZQBzjmrGABz3qIqc+1ArFV0wCOc1SuYAw6dK1nj+Wq0iYGKLAcR4h0dLyBlKjcORXm1/aNAz2tyMr0Fe43UAZcVxvinRluYy6j5xzTWqszGpDqjwDxBpTWs5Kj92en+c1ipleCOa9SvrMTxvbzrhl6Zrz/VrF7KdlbIx0NS09mTGRmScNkip4YfNzgjOMjNRIjSnrSgtG2RyelZNWNCPy2EhXnOetTGApy/ekLHO5uallmMkAA42/wAqGwK8xXACjp6VCWPOT07U9mUxYx8wNEODyQCaAIzkHhuaVlIxv61ZuEi2K6gg9CKhDbuvJH6UAMbAwKgY5Per8cKsMN1NU2Qq5GelCYCbDwcnAoXGfmqXeFjIK81FuAPHFAEu4Yzjio2AJG09aQMQeKdwrAigZJGAEwTyaWYhPlBNNdeAQaY+W69BQIA2akxgc8ioVFTMT0oGWLdlz8wBX3qC7ZTIdgwBUTSYIApM5NCEOQ4Na+myHcBWTGPWtGxbawx+FMaOtsZSpGBXR6c+8qR1rj7OYnAJrpdKfCcN06is5FI7K0nJh2tyRxVS7Od27mmWoJiDKc06R8rjHNKGmxM0Ze4pICOK6TRrnKAE9K5q6O1icYq1pF2ElAz3qpq6M90ekWEgIHNblq/I965HS7gHbzjPauktJBxXNszNnRWrcCtOJuBzxWLavyK1rdgR/Wq5jopl1Onv60uPamockYBqUelbwmdMT5V1y4LIctz9a469uFJ2qfetXWLrO7B4FcpLIdxZqq2hg3qO3Z3E9aybkkEk8k1fkmUR44BNUCu9iQeKSEyBZNikE9ajZzkDPSlkXYeDTQuVJNMkcW3EDvUcxycDoKbkinBMgluPegYxOME09mbrjrT4gAOeTUtyqgAd8ZouBBHIBgt1pHffyDULH5vXFSqMqO2O1ADA2DzmpWO4diKhZOM1NBEXQkdutAEJbjjFShSFyaRY/mx6dakGWYKKAI36+1TwtwKV0DDaORSRLgjNAE7gBcnrUMR+YkjtUz4L801ABuJHAoAYGywB788U94yWGBkVEhw+TUkUpjbJoGTtIyoFxwarmQr0p7yGVgelJMAoAAGRQgCF8yqXHeprkBnynSmIiDbk8mtG6CGAFQAQOtDBIy9g3AGpHwnyKOKhPLgnNPkOOM0CJN22EY4OarPIXb5qezMV4NOs7d551RASScVUY3E2X9C02S/u1jReCeTivUdOsFtY47S3XLn7xql4e0xdNs0CqGuHrvPDmkMp8yVcu36Vpv6Fwjc2PDOkrDGoIyx6mu4sbbaBxiqGl2gjVcCuitYadjrikkS28WAO1aMSDA6CoYl2gADNWEIBHvV2Bkyp26U8DB4pFJ4qZcNTJYijHTNPA9P0ppyDg08AEnFSyRwQ846+lKUwwz26UhPHfil35GGPzVNiWxCM9F6ZzSZw3I4pwbcCOnvTWHzZoJHZzx296XovI4pm71HWngggnmlYkAAfp1xijO0e1KSKThu2anqJjW46GkOcZIpSCue9NVjyGFMhiFiQPbtSggjk4pNmeaMZGPx6UnYdgX7uB0+tMYHbjp9KcDjPp6UknTIzQTYh5XjqPXNJ2OfyqQYI5zTGXD0MaQ7BxTX6U8DoM5FNcHoeKSFYjBOcGl4zg0nfI70rYHSgBrAjketNbk0/JNNGcnFACHoaQHk7acO5prD2oCwHkEGjFIKeRjNA7DTyMGmkAnFOPSkIA6cUwEFIeBmg5GCTSigAyTzmkPTGf1oJ+bnpTSQQT0NMYmD6cUnIz604Hgdc0nbPrQAxe5zn+lHuP/10YORnpSnrTAb0xjmhvwzSnr7+tJj1psdhpPbrSdeD0p/+cU3HpSGN/nR+NKeo44pDjFACZpT1pM9uaXk0wGkUAngd6U03kHrQMOaXgdDzSnp0pMCgYnT2zSY5zk0p4pvc0wQnTg896TPrwKUnBwKCDnmgY08HmgkdeKUgCmMcmgBTz3prHBpcUEe/FFwGkk0uOaCOeeaOlADmxtqP2JpxPGfypOpBOKLjFBPIBxQ2Ce9J1ApdvuaAEwDTiOKbQXAxxTAMDPI5FIeD3pSRg4701hkAj86lAPBA696jPFGCAfWkA7ZpgL2pueacMFj6U3HzUXAXtTfenZ7Gk6jJ5obEHJNLyVpQc0vGMUXCwyj8etLt465puKTCwYzTgpHSmrknjpUqD2pCIyo/Gm445qdh6f8A6qjbjk//AK6OoMjcflio2QEZ6jNTHJPpRt+X3piKEsecis27tgykECtuRKqTKO4yKLAeW+LNDIzPEPmFefa1Yrf2zcYlUV77f2qyKwYdR0ry/wATaQ1jcmWNf3TH8qfxepz1IcuqPFLiJ7WZlYYIqMgyHcOK7TxJpYljM8S89xXGOhR2zxUNX1HF3AptTOOOpNM3gpjFDM20+hqNMK/qvesrFiovcjHc/SlUr5hwMVYlmQxrxyOKgPIBpIBJG42kcdqjTg9PxqeSLdjaaiwVyCM0wJt24DB5FVmRsliaduK8jimNKTketCQDpU+UMCDmqzL7VKhbpjNWFVRGcjmjYCosbnBPAHepTEUAIwakI/d4HQVG75VVHSgBrFht6YNIVbJ9KmyCi+lJIwXDLzxQMhyT0pVb1pN2X46U4jc+BxQIa3XI4pVOB/Wl8snO0HNMYFeGwDQBIGxxVi2fDiqa5IqeLg5BxQM3rKTJGOtdHpkhQ4JPNcnp8m1x04robWXLgg1LGjtLKVoFUqcgitRSJE3dzzXN2VyXRUPT1rchcLGKzRTsylqK5rPhby5VPvWxeruTsKwZmKsc1undGGzO70SbcF56119i/AwT715t4euuzHkV32mybkBrnqKzJaOqtHyBWvamsCybOOa2LU9BmsjSBqxtjFWFGQKqRtjFTLJge5qos6os+LLpizHd35rFvCApA5rYvXxGT0rnLliSTXTe5gVZX45NMR9q/Wmyc89KaoLUySVQHyzDiq8jnPHTtTpXYKFzgVCxyRg0gEJyc04vkYqJj83rU0Cc7mHFMBAGRgevenEsSSx60+4YZG3pUJbK8jpQMHwH4FG4bTTGByPej2oEKx45q5BJiHavGTzUCwnHPNSINqN2J9aBhI2M4qMOd2c4pyjIOe1KyAD3NAD0fsMZNBBDZzUUfD80/OTigByk78nOKkeTIIpEQFSSTQiBnOMYoAjXPy/rVgKCcHpio4gDIDzgU525IDGgY+OAupbsKbLEcZ61NCzLbn3pI28xgg70AQxxlyOcYrWLRraYGC3vVeWJYMgfMcVQ3t5oLcUbhsXIwuDkDNQzRYUv2J4pC3zYB4PXNLLL5mFUfKtCQNkKAthR613ngzR1jT7ZcLkg/KDWH4V0lr+7UsP3ack16pptmJHjjRcRrjGPWtdtEEVfU0fD+nGebzpBz2HpXoem2iqi+tZejWQjC5ArrLKEccc/yqkdcI2LVpCAorWhXAGRUNrF8oq8inr2q0rFgv8A+qpUHGSCKao5FWE5FDE7CxYPFTBcYx+tMVF7HBqYKQPpSuSxp5HNLHnBBzinlc8k0xiQaNyGObj3zTe+en4UuQeBximE4PSggkTkEZxSgdR2pgPUdQRTkbceevekxMcwBAGKQHHHalYHBx2qNlxyeKRI9zwaQOCB/Kq0pJ4ByadGuBu5pdbE2LIOaTo3HNNTGOMkUvQnFILADjPPeg8ckU1/vZHHenZDLxSEMY5BI7UzfnP8qVzt/wDrVASPxp6CsTE/Lg9e1IQSOetJG+evIqXhl7ikA1Rjp0ND9OtD/d47dqaWGPSkgIsc46UrAEdaU88ikU/lRYCPkGnAZB9KTaCaATkg/lQAYI6UdeD0pQOvehlJ57UAMKkE+lHO7tTnOTzSNmhIBpHXFIO+TSn0FIf8mqAQ84NNHv3o+6Tim9D1oGh5+71GKbj1zijcfrSn7xIoAbjA9KAccUp65pPXvTGJ7HikORSnOeaTBwaAEJJ+tIDS9CD6UhGBxzQAHoKQ0Z9fwpG65oGGMDimn0BpevJ5pDzzQAYyD6+lNxTh9aQjpTQxDjBxQMHt0o/ClGCefSkMQ5xSEDPWnY980jdRimIOKb2I5p3Y80hPWmMYcY+lIPanA5HHFAXrnFK4xjHIx3+tIAO9PIHOP1pv86BiAdeuaD05NKOF96ME5pgMI3Z9aQ9OKf7U3t9aAsIfu4OMGgDK4oIz9DQfXoaQhwPHsaO3WmbqUcN1NMdx2OD71GyjbnOR61Jnt1oPT2FAEK8dakAyvY5o2gilGccdPWkloA0gjtSAZPGKc3UUnoScUAHGfWmcknFPzjntSMcDFADeMY70Uh460ZoAUmgD1oHA56e9LkZ4oAQjgYoGMc07OaUgdD0pdQGgjOMYAp275eO9Iy88dKMVWgrAWz0603GQadjj0p+BgfyqLjI8Yx796Q47YqVgcVGQefWqFYY4zxUMiZGCO3FTBSKYwO7NCEZ0ycEGsHW9OS7t3Rx1rqJo6pXMWVPFHmFk1Znh+rWL2Nw8Ug/dk8E+lcD4k0vynMsQ+Q88V794p0hL2Anb84HFeYXlqQZLedfUc0S/mRytODseWFioKckU4bMdMGtLXdPa0mbA+U8jFYxU884qJK+paY8jc+B0pzkxkAimKSnBHFSBDOfp61mUNWUZGani2ty3SotqKG9RTg4VQMcd6QDmWNjjpVcwFn2gfiKfIQSSB1psUhRuetMC1bwEMqnqKryOxd1GCKnky2ZEP3RVFS27dzk0ICZIzn5jgUyaBcAoalcgxgk8ioAx+b0NICJwyqMHr70wbsDdUzMCNucn1pECs3zHAFMCPgdKlQbmyvU0skKqgYEYNLCyq+c8UDL0duQm4sBiqNyn7481LJcMrED7pqA5ZtxpLQGKuFOCBS7hmkbP8X6U3jOe1MRetXG9cV0FlJ8o9a5a3fD981u2Mu4A0MaOt09wcc8V0enSK7FG6VxljMcjB4rfsZGJBB5rJotM37qMFTjpXOX6YkPrXQqxeIZPasfUowDkVdNmU1ZkOkTGKdee9ekaJcB1XB4IryeKQpLXfeGLnfGvPNFWOlxbnotjIMD0rbtnP1Fc1p7cDPNb9s3ArlY4mvGSVzjJqwvYYzVODt1xV1Me9JOx0I+Hr24yCKxZmyTz1q1dPknnmqbjucgV2JGBC65/ChCvTn3prMOMU3d2pgOlQEccmq7qU4AqZZME+tRyHceec0DIlGXBqwuTkdKhGNwAqfzAiketAiFxtJySaYctT/vHpTW6HtmgB2dwzwcUvC9uTTR90cVIVwoPc+tAx8b8ZJ5xQzg8CmsoC49qbEnyseaADJAO08U6IktyaVBhcYpu4hsigCQgqc4/OlBBfnrULs3cn601X+brQBfZlA9j2pgkCucDjGKjQbgDnr0pGTrk80AWEbGdoyTUcpwSTiiJ9i89aAA4O7pQA+CYlNgGalt42DgrgHOaigjAHXGf0p6eYvzA8UDL1zNGny9Wxkn3qiMTNg4qCQkud2fxoBKcjgGhIG7j5xtchegqfTbV7mdY0BJY9qgjy5wOSa9B8GaQIY1uJR8xPyg1a91XFa7N/QNOWytUiVcMRljiu60Ky2qGxk1jaZbb5Bkd67XSrbAUAU4rudFOJsabD93I610NpFuIxVCyhxjity0iAHpWqR0JE8SbcDNWY+vPNNRefSpQhHI/OrCw/aD0poDKRTx154qTrS2JEB7kc1MmCDjr6UxAOg/OnhRjrUktBnmj7w/zzSuCe3WmqTmmRYDlTQP73alY5+tAbOQKGSLtBXIGaAuOmOKUEA8flSlSTxUiY0sV5zmnAg8Dk/Sk2kZGOlIq4b1pMmw0Lhzx171JtXbgijHA45BpW4HFIVhgHTHJpT196HGORQBkdcHFAhhJI70inBweM08A4weKR1G3gUhWIJgxIPamBVJz09qnxleaQKFJzQ1fcBqjBx2p6kg9eKQqDz37iggZ4HGMUMQ4nJwRUVL0J65pCeBn8KewkIScEDmk6H096UtlqTIxUjFxzxQcCkU8Gn8EnJ4pAMBAbHFLjBxSOuM/zpRwuKaQDHXByOlITx605j1YHtTR0zQAw8D1o7U5vUU0dxQAxhgdKQ4OPSnnk4pMcHnNAyP1FG4enNL/AJ5pP50wFz05oyfQYpMYOKU9KYCDk5o68HNJj3xRyKAAjj3pOlHXrmjrx3oGNwKafzFOI4pMUAN6YoJ5pQPzpPxoGID60lHej+dAA3BpAfpS/wA6TH50DFHPUUHg+1IDk07tTAb04Pem9j0pSfmoH60MENXjgmjODinYpp4A6EUDF69KTHB5py8Ckz+VADV4IyAaQjmnkYz70Y7UDIyKTBp7DnpSdxQAwjAIpuMk8kmnsOe+KaRxzQAhI6gc0h/zmnbTTec0CFHH1oBySKaeuaMn8aYDsgdaTOBikPqen86QjHHrQA4nPOaTtQeOgpR0waQXEOM0Dp9aXikJBOBQMYeeBSheTS4PbjFOxkUgGgZ696MUvvS4yeKAEB9OlO49cGkHv1oI4GKYCsc9O9GcAYppXAHY0o6ikAvSnDpTcYHYnvSqcdadhDz+lRt1p+TkjtTT9KWwxm3rzSHg8U8jFIRk07EleRc/Sq8iZ/GrzgYxUMi4XjmgZiXtuGUjbmvOfFuk/OZo1wQea9WnQkdK53V7MTIwYA5prQmpHmR4PrFmLmCRSPnXOK4O6t2hmZWGCDXsXiXTTZ3TOq/KTk1wfiawBX7RGvB6/rUuPKzmi7HLFgw2t1HNPUqijk+1V2ba54pu4nkmspRNVqPz8/BPJqw0n7kLtBOetPsoY3OHOCaiuY2jkYA5Uc1N7sLWEbGzJWmQxGSRQvU1LHhhnPShW2NuTNMBZEeJyh71TdHXk5GavzEmIODkmqjTB1CkZPrQgIQxYHJpCcgKO1K+Am3+IUxR05/GgAIwcd6B7VKyFQDgHNAiy/BwD60XAjbcVx2oRc9xwKnKYXA9ahdW6cAGgBm8k8/SnB8Ag0qR9c9aa6hT70DFd+KaTk+9AGTz1p+AOn50CHRtyMYzWxp3IHIxWQowc1o2DY5zQNHS2I2mui0ztXK2coyOfrXR6fOigelZyHE6dBlB6Vm6mvymr0MqNENp/WqWoNlDgUQ3JqI5yVsOcGui8JXZW5VSeDXMXTYkIq3oly0d0o962kroUT2/TJQyqc10dm5IFcVoU4eJOe1ddZNkCuKaGlqbluTwM4rQhbgVlW5461oQnAxWTZtE+EXUk5HaoJiCwB6VK7+lQEE43d69AxIWT1NN2cc1JJkVAz9T1oAY/wArcChVO0k0INz85xT5NqjAPAoAiAABJHJpFGSSe1IAzHjpUqYTIzQBESQ2FyKcVyRnrQepPakD85xQA51wMAjNPxhAWPNFuuXwabNnpnIoGSoQQelSRoFByeKiiXC55z6U4v8AL0oAeq5VtuB+FVzwx7g8VKzHZgdD3pwwEGcZzQBG6fLgdajEfzDdxUxOG5PXtUYJZhjmgCQcY5FSCIv+J4piJuJboBVuBCBuz06ZoHYjuIFjIGee9Vy2FxU9yCXJZhk81UxuYdaEJl2AN5YJHWpQ+35ABkCoVcoioegpU3HLDpQMhlPzHik3b+CRx2p0rcUWsJmkVFBJNVFXEbnhbTDe3is3+rXk8V6hZRKgVVHA4ArH8P6eLCwjBxvYZNdLpcW9wcHihPmfkaRidBoluflz3rsrCHAHBFY+kQfKDjmuqsIeF5rVHVBGnYwcjjFbEUeAMVWtE2ge9aMY6Yq0agi7mwamAxxjilAH0pRlT7UyWG31FLsPY08HjmkPQEUEMFyKcMfnSBsmlI5wAc0iWPAPBpCucFaRTg+gp4PHvikySMg9DTQTnkVKVJzUbAg+1BI7qRj6U8DAGfzqNQSeOg71IM9DzSYmPGSc9fakIB6dc801TnkGnNkge1TYkRvTvQ3QZoBIxTvegQwYOcilxz1HNB75oVuvSlYQjgH8KavTFSbRyKjHymgQx1HUHvTVORjtUj9elMPy9qBCcrmm7jnjpTzyMjGabgAkUANY55oOR9aVh2/Gmng0AIeR70mOppkMflh8MW3Etg1I1FhDcY5p27pj8qQc0o6cdKEAsjBmx0ph9OTSvluaYchsUwsObOOKYfqc07PNBANIBpIB6U0+3WnMMGkP3aBjGXnI7UAjHNKcd/rTcDdk/lQAMOmORTeg9qU9PrTR1oAcCCATR1UYNMPUU5en1pjEPByaQkk+1OPOKT2HX1oAQ9PrR7ijr6YoI5x70ANOB60g7E07pnNNX3oAQcDmkIx2607HajqRQMYfWk7e1ObtTe1ABwetGPekX3o6UDExyTR+dBPtRQAdc00/Q0v1pSMfSgBB0HpQTxSUEfLQAY5FJg5+tLjikNMBSePWk6d/ypCcmlz1HegYpPJpMetAoY5xQAh/HPao+3NPOcZJoP5UDGHOcikOM07HFIRz9KAGHg96Mj8aeRxTMZODzSEKoz0oYevWk6D0FKT6UwG+vPFAPJ6/jQcY96MeppDQY7UEYNOUetDdMCgLCDrnpS/qRTe3NOzjFAC8fl60p5PHX1ppPHTmlIxg/pQABckd6XBHalXH50DpQwsNzkc4pBxz1p23v0pH44xQAhb5cDApQP5Uz8OacueD6elMB+AOnagigYxz1px9KkY3jpTTjpinkccc4pmOvNVcVhGGe+KicZyDwKkIJpvXntRcCs6cEGs67iBU8VsEZHFVJ4sqeRTA898Vad59u/y8gHtXmF5bf623k+62QPY17nqVtvVs/lXl3irTvIuiQMKxz+NO3MrHPVhZ8x41rVi1rduuOMkg49zVOGNXzuwPSu58SWIubYyKv7xBz+GfauFkLRuQeDk4rLdExY4bkOATVmB1Y4l/HNUvMIyepoL7nBPGf1rNos0LmJNn7gZHfFOjCfYzu4b3qCKcLGRjmq0ryI3zHrSXYCwZB5eMDjtVWbKvnGBTox5ufmxSXCFCAxyPWmBG3znIpjDaQO1KvHOaQDPrQBIp+U5PTtUjvgKRj1zUWxgOBwR1oXdxgZoAUyfPkn6Uu8MRxyKibLDBGMdxT4lXBzkY6ZoAHJWQHtTZD8+aViH47im8buRQhilx2GaUtkAUFlZcAANQgGcEUAP9DVu2foDVFuGx2qeBsHvQBt2j9Md627WTgckVz9q42qffpWtA2cbc1LA6vT5OBhs+2asXjfIaydNduvatO4P7kk1K0YS1RzF99/GKZZzbJgR1pdRb5jVCOTa4OelbkRPavC05kgjbtXeae2QK8o8BXm5Nmf8APNeo6adyjBriqblvc6C3OK0IW4zWXbMOM1oxHjisWVFnwnMoHQ1CSQSeatmLJz1AqC4xjC16BmVJXYj3qMe9SDoSaacbAOhoGM3kA4FRZLVMRkEDFQ4wc+tAEy4UCkxnLCo9xBHqas4HlgAjd1NAyHIA75NRnG72qYKAM9agYEscUCJoD++yOvpTmAMh3flSQ/Icnr0o8wZLHBoGTKu84A4pHjKjpUayspyKkRvNYZ5AoAVFBPOQBTXwD8tMbdk7etKmTndigBZCCAB1qLDAfL3qxGgEZZup6UzeMDA5oAWOTOE5q60mwDBBI9qopkc/xdhU8Tc/McmhjQ2YtIeRjNLEgx15FJIS7Niot7bcZxQBPC4JI70pk52/wiq6Ern1oY46GiwDm+Y5Ga6/wPpXnTm5mH7tOa5fT7Z7m4SJckk16va2y6dpsVsgw5GWqpOysuoRV3ctq3myjHQ8D6V1OiW/Q45Nc1pURklBx0ru9Jt8hdoqoqysbwV9ToNMgwF4rp7BNoHGMVmabCNqgAZrobSHaMfnWqR1RRbjGFHGKsoce1RIMcVOgyO9VcbRMjA8HrTxjrUIGCM1IASvNVoQ9BxfmlDbutQ4z1py9cigm1yXbg1IBke9NFOBx7elQJi7d3UU/HrSBscmnkc5pEsYQc80NSkg8UDA46CkSNUYzzRgDGMmnMMDqMU0H5c9qCWIOp6U44PWkQndR0NAmCk4waeDkZzyKacHkUgOGpCHkE9Kjx+lSbs9Kb3PFIQEn049aQrnBPNL0HHI9KTPGT+VAhjdx+VRkHHANTP1yBTSfbjvSERjgYpMDmnZGBjrmm+uRTAQ/wA6bjIwOtOJB6DtSHI6daQhvQ45ocd+9KTkmkz9aYCDA70p5HBpre1IvA9qQDjxSEdQTTTwevWgnDUABODxSAn6ZpW700c8AUAKxHr+NNJ4pxqMk/WgAY8YxTScHp0pew9e9N+tAwPfB/A0zt1zTj14pM57UAHejJFJgZG3rRimAE0u8fWmmjHp3oAdnjik7cYz6UCk5B44oAdxgUnegcik5K9qAEJ9OtH1peSOtNJweeaBiEkGmntSjvR05oAaeDQf50uaTIz6DNIYnb1pRkUNjOKO3WmITqaKM0gpjCl+tHejsaQCYHWkPrilyce1NPWgA4/GjvmkPb29KCfT/wDVQMOho6Z7+9JnAyaQngCgBxPI7A0w9aU56ntQDznNMYDgc0nUk5pwGQc0hAyPWkA3rxTcDt1p+CR6UFcc0AR9qXGfrTyvAA4oOBxQBHj6GndBxShaXoKAGAcHPFJg1IcdPWkA46UXCwwEZ5pxXP0pCpHenDpigBPQU7BH0pAeTSn6nigBe+FpMcc9aUf5NBwDjvQxjcHt1poHFS/Wm8H6UMBnuKcpwp4pcDtRimmKwv8AnFKQe9GO9Kd3egdhp79s0h+makAyOeDTdvpxSGMxntSMPlxjFSYAFIASM0bCIW+U1FKvpmrJXPOcU0qTyapBYxL+MFfTNcT4n09bi2faPnAJBx9favRLyIFTxnjjiuZ1WDcp44poUldWPF7uPazI445Vga8/8Sad9nuiyg7DyD+ftXrniax8q5aRBhG6/rXG63Zi6s3+UeYgJHHNRLR37nJZp2PPUUd+tKI8n5TzSXMbRykHjnFIm4Hk8e1ZyRaY4ZQ4PH4UXD+awOOBUmMgFxz05p0VuGBPbtUjIwcL8uAabMSyZIpGR0PIwKeWTb/SgCsgyQKtLGCp6cVW6yHAI9KtRRllBLUMAkB8g4xxUEZK5JB/GrLxsAf7p64quSWQkUAOkO9QQMAelAChQevtUBY5HOaljTJ+bIFADWYB+B+NNkI35HQ0k0ZWQgUD5uowaAE5BPH0oLFT0waNxDYpUyc5oAGfcQe9SxZ3DjIqNULNgVNHlHwaBmpbEFQFzWvbZIUjqKyLMA8nrWxbAKoqWCNmxcrx1rUZiYTngYrM0+RcjpW5MF+z54PFQ3qU1ocjqfDGskt83tWtqhy7VjSHnr0rfoYo7PwNe+VfRpnvj+de46VIQBg9RXzboU5hvo3zwDzX0RocgeCNgc5Fctbc0e1zqrY9Oa0YWxisu2IwMdO1aMJ6YrAEz4maIhWqpIhIAxWmSDUckQPSu65JhygioJGzjmt/+zzKp4rIvLfYxGKdxlQNikbnBPSjbjNBPH6UANDfNkflUm4gf0qNRlqkdicdOPagCRWAjII60xPmf26U1AWY56U9FHOScUDCQg5xxioc4Izk1Mo+VjigJu68UACrnHuanU7GIHpTFXa2TnApehB65NAATj+tC8ZK0jqXfriprGIPI6t0xxQBWkLbwueKVF+dQOtOIwzA9RTo4sYbkgdaAJCgWUDHTvTmAJG0Utuu9ixPyjrQ7BAQBzQMgJIBqMgkDIqwE3Rlu+abOy8AY4FADHOFHY00Lls0xiScY4rQ0q1a6u44lH3jVRXUk67wFpQy15KPlTpXSyuZ589cnj6UqRLY2EVrGADjLYqSwi3yjA4qU+Z8xslZWOg0K3wASD1rvdIg+6eg61zWiwYCV2+lQbQpxWyR0QRuafFtANbUA+UCqVnGQg6VpR4GB3rVLQ3sSqB2qZeO1RKBjjpTsnHU0WAm+lKp5oTpTwvHvTIYhUnpSKvenqcHFDAhutIkFyKeCCOlM5HUUucUrEscD2pynkgg8U337U4kkD1oJZIelJjtTVY/WlJ9ue9SSHPTtTVYA7TTv6UOAeSBQITo39aXjPWkI+U+lAxj3oEHQ/SkJ5zjmnAZHzfnTScnjtSJDGRnt7U4AN1OKQZFJkKeQaAA8ZpgPTv6U58c4NMyc8CgQpzhsZFMzjkjNPDAcjmgEHknn0pAM9PSk7YxyalIzjt70zgPx+dIQwrzxxRyG5p3qelNbnimDGngikPXig/ewD2oPrQITqOlMPGfSn96aehpANPzAYowaOAcHijPP9aAFzxTSOaA3PSndv6UABGR6VEwP1qTI6Z+tNPH40wGEHHtTD0/xqZxkZFR49RQMZjnFB704qBx3FGO/PtmkBGMilY5oPNIODQIQke1KPpQAOwI780e9ADsYGaaaM4Oadj0FAxlKuKUZxzSenp7VQCd+aaRzTuSKa2ePSkAnWjrRmgH16UDGmm49acD+FB6A4pAJ/Kig+tJQAHikycUp5pDxx3p3AB1obp70nOeKOlAAOTQQAc0E88de9ITxzQMTjjvQeuOtGSelNyetABikIzwM5p2OOtJ0HTvSGGMUdOKUcUg9qYC8d6RsZoUcmlPf2oAQUY79qUD8zQDjrQAhH5UEelKc/nSE9hQAdDxQRxRig9fagBKUDH0pTTSSxoAccY60gHOcU3GKeGPGKAE+tIDn0pTz1pMDigBQM9OfpSA4zSr19qCaAADPFBAFGfSg460DG5NOHXnpRSgd89KBCqckj1px7E0wEYGKd6etMY4HA+tJuJH0pQcjB4/CgDnFIBrZJ5pME+tSAZ6U8DHvQO5AEORxShOuasEDtxTH4GOKrYRRmXPGOKwNVhI3cda6SRc9BWZqMIkiJPahDPM/Edp5kTgD8a4C7jw5z2OGFesazDlW4wB/wDXrzvWbby7okjCtxRJXVjCrHqeZeJ9P8ifzUHyNz/OsCNvmwfWvR9Ysxc2boV+YZxXns0XkzMpGCCayWqMo9ia4IZAFxmoPNZECngClQlm+lLMoAHINRtoWNaVnTB60sEQYjdzk1CMhqn34+YdaALF9bxxTbIz2FVyGjFTIfMcFs4qGR/m2kULsBLE+VOTweuap3H7tiB0qUOqkgiorltzLihAQE+lTRuwHPP1pmNy4HFIMD5TQA5n3HpzTZF2hTzzQRsAJpSwcjNADc5OKcv1GO9IygHABxQwwKBksRwcjjFSA7ucc1WV8DFSxkE4HWgDVtOV9K0oC2Bisaz3etasBZSM85pMDVst25ea6Qk/ZhzkY5rlreUg8HArcgkLW5GSazkUtjF1RhuOKw5SNxrY1TIc1iSnnrW62MkWLWXY4I7V718PNQ+2aRESeV4P5mvn2JhnrXrXwhvwVmtyemMDP1rCsvduX0Pa7VvlFaEbDgg8Vk2bZUdq04TxjtXKiUz42RMmpQnSokOCaljbnJ6V3MC1GdiE96xb23Llz0A61q9RVe9kxblV61KBHKyqUY0zaDzVuWJi7FhgGq7ptqxkaHBzUhA2n3pirg59KXOevFADckLingHbkH600/KpPrTonzgdqBgWwuKfGMLnOaV0APNMCMAOe9ACs52465p0XHJoX/VkdTTo1AVt3pQAwt83FTwEowC9TUaIN3JoyTIdtACvky4A4qYHbEy460sKqvLcmhF80sT2oGMiYIhGevao2Ys3NSPGEan2kAmlA6DrR5iHYBU88DtUMkeY92KsbNspDH5eoqKeUMhUHrSGVApJxmu88DadsU3ko4XpmuU0qza7u44lHOa9QSEWtpFbR4G1ctVzdlYIK7uNmYu5Y9TWzo0HzLWNAnmTCut0e3wV4JpxVjaCuzqNFt8hcCuz02LgZ61g6RCFC4HaursYwFGRzWsUdUUacC4UCrcY54NVohxU8YPrzV2NCyMCnK35YqIN69adkZ4NUkSyRScjBJqUEd6hwcAAcU5O+etIlkjDnrT1ORTFcYwcinL1oJJFGep4oI4GaTd+VKeQMn6VJLE9jThnk5pABjBoIwQP1oEPI+XgUHnmjPAzS9uOtIkRecg0+PBODUbcfSmB8du9FrkslZduRyeaZnDfWpCRnvyKYcA8/nSELu/woz2pF6Y5pCexH40CFznj0ppwaUDHShhwD+tAhCuOeopuD3xTxnpnOaQ9CCMUmA0Lk4FNYEZx+tSDkcdv1pykNxilcREpOOaDgnNOIHfj0ph4zmgBT+lMYjPFO6Y7CmEYP60xDWxnI603dnofwp+SMZphXk4xSAUnrimd+M8045x3pp9qBBjpR7etLzzSHrnIpDG4wSRyKPp1p46E01uc4piDtnFNPT2pynilK/nSGN4xUfQU8sBkDimnkcCgAPfNNI4yO1KeV4FIelADSvOaQjHNOJOOOc03AA70IYuOfpSH3pSeKQE4piDjoaFOB60vc4pvJJAoQCnr7UmST7UhOORSA4z1oAXHFN4xzyacTzTCcUABH1Bph69KcDnjrQTn/GkMaccZpcUfjRnjHSgBvSk/Cndu5o5NADRx2pTyeaPrQf0oAZj0o6ilI4FNoAOw4NNP3uKeelN6ZouMTjGR1pG7D0pexFGPWgAOeO9GcmmmnY7jjigYgGR9KTuSaft4oIoAO1NLc80uOeaae9AhwOKQZz/jSKeM07PTn6cU0MPX1pCOcUoAwCaQkn60ALx3pCO56Ug5oIIpIBeCOKAOcetNHNLTAVvTI+lNBwelOpR785pANAOcmgDmlz+VISc4pgGcHGKP5Uo569qVRzxz7UhhjtSFSOfWnYPBo68mmA0DA5NIw/CnhcjJ700jNFwEX0zT/amY6gGnAZNMEKuT07elSAHcf0xTFGO9PBPSgA57YpSSKCR60Y3CmmAm70phP51IVx1pu3npQBG31qtcIXVhiruzvimsuOaaHucTrNvjdkZFcB4it8q5x06V6xrUCujEDmvPvEEBIfHbNNEyWh51OuMMBx0NcR4psvJuTIowrciu/uU/fMhBGawtdtPtOnupGXTJFc8vdmczVjzpWIyKfywHrTZkKSMpHINKFOBzRJDQ+OJmbIqxBEkm7edpHSpLGIOMt09agu0a3kK561G+gy1aGME7xuI6VWuXQy8DGO1MhlK5x1psifvQ/rT6iHXDIzDjBA7VXfDJ1HFWZfLIGOeKogHPFAxV9aMgN1z3p444qQxoI8MCG7UAQP8AvGzSDj1p4U4xjOaDGfSgBATjpzQeVPtT1wMZpz4wdvQ0DK4PpxUsfvTePxpVOTigDUsjkAZrSRtvANZFqTuBHGK04iTSYF+3yMZrWgfahyeayLc9PStJCdhyOKhjM7U3yxrElPzHFauokBs5rHk9a1WxmKrYI7123wzvTba9Fk4RyQfyNcKp54rd8LXHkatC2cYapmrxaLR9T2DDYK1YjXP6VLvhQ5681uwnncDXBEzPjiElnGPSrax5qtbYAJ78VN5vU13yZVicptUDrURjDsSRkD9ahluD602OVnOOwHNCTAZqUKvCCi4IrnpAd5B4FdRaRNPcYboelVdYsxBuGBkHrRtoNGFtAYDPGKicnOPyp7ZJ9qaevH60wGkCiPhs0r8cZzTOx+U0ATK4YndmpNw28iq5G3oetPjDNjNAyaBVJJJz6UuQWKgc01EIfgdaRz5cmR1oAJUZMkjmljyibzwTTw4lwW5NOnK+WoBxigBsbHBY1NDISVVBz3qsysq5z1qzppWIPJJ06A0PYa3EucZ5+97U22ZowxFQSk7zjnNSISVwBmjoFyeabO7sTVVVLHjtQ/3RnvVnT4TNPGg6scVUES2dn4F07ar3co6cCuiuMnJ/iY1PYWq2emQwgckc1C43yHHIHAqE+aVza3Kkixp0O5xxXbaJDkrkVzWlwHI712+iQ4xWqNaaOn0mHG2ult0IQD+lZWlxYANbcPAGa2R1JEyLgVOnT0pijpUijPtTGLuweRinYPUGkxlc0zJBzzVIgsIxyAak4NQg5wRzUuBwaSEx/GORzT0PFRgnvTue1IRKeR60h+vIpoBHWnckfjQTYetOPQ5FMXgDinscUiWA6GkOcjFHBz2OKY2R04NBI8DP1NNYdMil3dcYoz3pCHDlcUgHH0pVPGefejA6rzSENyPwpSOmP1prdcj9aUcjkUCE6GnMMrwRTCT3pQ3AyKBAR0K/lTiNwzjmmgjrxQDkntSEBwOufrQBtPTrQe386GOPwoEKWFNcg0nGQe5pGznkUWABjvz9aYfz9KVsUnX8KQDTyPpTOx5p5PBx0prKOooEIeO/FIemSacccik6Y4oAaQeSDwaD14605uRxR6Y4pAC/dwfrSZODS57E01vvcdaLANbg0rZ7GkYc9KTIOaLABzg5ppxxRu4pvGM0ALnGaTP0ppYUgYZ9qAuPyO1J1qGSeOL5pJFUe5rLu/EWnWynzLpOKaV9hXSNn3/Wm+u6uTm8Z2IYiFWl+h61Rl8YzOD5MG0HuTT5H1DmXQ7neO9IW9wK83u/E2puT5TImfbNUDqmqXDjzbg4PYDFFl1YubyPUmnRerKPxqu2oW6H5pV/OvPIprgn5pHOepJNTKrMckk/jRePcLs7Z9XtUyfNX8/8+lRPrdqPuyA1yPkkrnBzxU0Vv83Ipc8SrM6Y61Ao6n8qF1qAnABzWDHbkqMDk1NDb/NyKXPELM2xqsbMQEapUvVb+EisyGE8etWkXGAOAKXMhl9bng8U7zlA5qn79aWlcRY+2QDgyAH3NSLIjgEMCMVlPaozbsZNWIvlIxwBxTuNF7IPTmjtUAY4NPQkjr+dAyQmkxzzSbsn07Ude9OwBwDzRxzSjpScd+ppBcQemKO5wM0pGB/WgDKkUwD+KkGB2px4I5waPWgBrZHTpQRntTm5GRim8ZOO1AxMflQTwad1z1xTe2MYoEKDgY7Uh55Gce9LjNG04oGJ0xTe/NOOcCjGe1ADQe+OKd0HvQF47UEYoAXt70n50KMmlIoAAAB1zRsznmlUc85/KlY80AIV5wORS44/kKBxmnYz9fWgYhHHrQAM89cUqjnA7UopgIOaMZHSnKOe1LjJ560gI2XmhRx9acRzS4wTTQDVTsDzTscUoBHNPXG3GPwoGMCDmpFRQOtL9BxSnBp2AYwJPFLt4HGakUYFLtwPahDIWqIjg1ZK+vSmMh5xTuOxmX0QaMjFcJr9tw+enP4V6FcLlSBXK6/AAGOM+1MTPHNbiMU+e2azHAJ9Vbg10vieDJY4/CuYT51Ze4rOrG8bnPJHAeI7T7NetxhTyKyA/wA3Fdz4ttPPs1mUfMvWuEK/Nipi+aJmuxo2Eqqw3Hiqt6zGYsTle1RoWUHBp5yY+elZpWZQQ44OeKWccgr0NJEoTGTVuNY2OHPHancCpsDMuelBRRu/SkmXbIQDxTXbpigB8LL0IBqKcFXAPSlwAQR3pLjIYAnpQA+JsKSelPYqFDj05qGM5BGKWQDYKQETv8xxTQ+QOeadsyOvNL5e0HNMBVBPFP2Y5HSmLwM04vxg0DLVr1rThbNZdsQelXrc455FDA1LY4IzWqj/ACcism0IYitWFcoQDWbKMbUzySOTWNJ1zWxqYO4gmsaTrWy2MhoOau6dIY7qNh2NUBVq0IEopIo+nvB919p0uB85JWuutm+Uep5rzT4a3Yl0+NcdB6fX2r0i2PAAJrz7csmiJbnx0smF4oacLyDWYLg9M0GXcOvSu+xRceVmPBzmtLSrdpwcZ4rItG3Nk1v2JMcBIO0k9ap7AatjbrG6sQBtpviG2V43lxw3Sr+mbJLdVfqe9WfESRQaWpxyeMVhJ2kUkeVXKeW7Cq7AoAe9X75t05IPyiqchBxxWzERgNkGpox+7JxmkIyOnAFG8KmOxpDEkTgetW0RViBIBJqtkN9RTzuwAucCgCdCGYKvWo5ouueppbMfvBmnAvLcBTyCaBlbymHfA/Knxplvm6CtK5jRRtwOBzVWZkWNVTr3pXuFrFVyTwf0qcMRGsQxjqaImTzFyBjvT3KZYjrTAghhLygHgelWzDjKpj61GsoViQBk9KZLMMEL1NJgRzgb8L2rovBNl9p1RGYcLzXNIcn1969I8B2nk2L3DDluBmtPhg2KKvI6a4Yc47cCq1vHvcd6kmH3UHXvVywh3NmogrI23Zq6ZBjZ713GjQ4ArltLi+ccV3ekRL8uRWqOimjfsYsIO9aaJx0qtbpwo6VcVcY5rU6B6L79KeG9qavHWnYGc1QmPUk+mKcw9e9IFxwOlOzng079CWMB2+/vUyHI6/hTFWnquDz0qQaH4JHWnDI6mhak4I5FBAgJ6U4Ed6TqDiigkfjkcilxnIx1puSMe9KSQf8A61IliZxQec01sdR60gz2piFGO9PXGBTFBbkdqeo/P2qWIdjjNNBPXtT+eKacAdKESJuGORTT/k0MBxxTTyeOhoELyOaQj0pOo5pvQ5oAfnpSbuenNHXnvQeaBNDieKQng9aaQeTik7ZzSEO6fT1ozzj+lIM4wabkgHP6UgHH1BGKbu9e9KcEj1pCM57CgQhOOOKQ8fjQQPxpmfxoAcfXGaQkjHegjB9s0g/UUgA9Pal7cc0gx6dab0zzQA4nDUHkHPWmE8ehpu8KCSaBCk5OKjz7dKzNT16wsB+/nXf/AHRXKal44d2KWMW0f3m5pqLZLkkdzLKEGWYAfWsu78QWNsWDTKWHUCvPZ9Svb07ppW+gOKrhGfIbOfU0m4rcV29jq7vxkoVjbwknsTXOXnijV7piqSLGp7AVXjhwMEZpVtgCOM0vaJbILX3KUs11dOTNPI3/AAI0gtyxG7Jz681qrbDgYx/Wp4rXn3+lS6smPlRl29sdwA61cjtiVHGKvx2+GGBVqODtjAqHJspIzPsh3AAZFSQ2mGArWEA3cDk1Mtv8w9KQWM5bYDbkVbjt+en41eEA4OOnFTrFgj1pDsUFtx3FTRw8jAq4Yhkccnk04KBggYH0oSGQLFkfSnRxirO0AUKuMnpzVJCGquB049aULyPpTs4FCAfjTSBgeop4Gf8AGm456VIAMDP1oBDGHFIgxznilk/rSjgVSAcDjp1p/TjmmJ1+lOP1poYbveoLm5aAhsbk747VMRwO496jkQMuCOKd7AS29zFOoMbA+tTnmspbRFkDoSD7GtGFuADSfkA/AxwKUeooPfPSgDAz2pgBA29PyoODzRjNJ9P1oACOMc0N1z/KlJ456Uh5Hy5zSAZjnvS4/Glxk0AcZNMA46CjP5fzpee3WgjI7UgEHvSc4z0FI3UcZp68/SmMb260uMH1pcZ6YpQKAGAEduacF70vtQD2AoAUc0oA7ijjsBSc8cc0xAMelKevAoVhR35HNIYDPAoBx/8AXoGfSlUfN0+gpgL+FHOc07H6UoHPIpDGAU7BFOLDk8U0ZJpgIvPuPSnr+lBHb0pGBx6fSqQEwGKdgcdMVXwQOc0qs2O1Fhp2JT1459qUNke1R456/hS8dc02gH9eaaw596Pxp3QUrWKTK0qg81g6vBvibjPB/CukZcg88VnXkO+JxjqKEDPIPEdsMPn3rzyX91eMCcAmvXfE1r9/gd68p1yLyrjIxnNNrSxjJEF1EJoZYiPlZeK801GEwXMinsa9OVt8auP4eprjfGFqI7nzFHDf59a5qbtJxMZKzOdHAHqadIzFPL6iohljz+FSxgLyTTkrMZGVYGnx5/iOPrU8xTcAoqKUgpgcAUrgCFPJfd1qBCCcgUqgBW3fhSRMQOBye9AD5F8sAg9aRcMPm/OpThkVT1A61CoIJVulCAQblJxRjcSOhqZVUDrjNRuNsmGPSgBgUg57UjtlsHmrCSqM71+XHFVXIOSelADlIU1JlTkVAoPrSjgZNAF62ALVowrx6msy3YhR2FaEDZHvSY0X7YYIrWgxt561k25FasG0p6ECpkNGVq2M1iSk5NbWqfe4rEk6mtVsZkYPPtUsRAYVCetOBORzmktxntPwkvNwZDgFehH4+1ez2pG0Cvm74Y33kauiEcNnt7H2r6LspMqMgY7VxVlaoKfRnxGWweTTlfvmovcmlTk12oo0bI7pAtdxFaqNLQKPmPJrhbRtjA9TXaW11v05ULYIonfSwI09JXZEN5O76VZ1CCS5s3GcharaXMVjx1+tdDpUYmglUg5KkmsqmmpSPIdWg8mUjPU81QAwwyMV1PimER3D8Ywe1cu5rW91cWwkrBuFpJFHyr3pEOAT1qRFyN2eAKQEe3DBep9qtW6qFc85AqqrbWJFTxMBE5PJbgUMEM34Y4HJqxbssWX5ziqzKV57VNGymP5uSKHsBLdTB0B9arxgBGYnmlkUlN3YdKYqFgece1HQYpTcpboaW3gaRjg8DvSfMvyk8CpbabylOOtAhskGxiN3I61VcHJPf3q1LKSCx4PtVZmJI9KEDJ7GIySoo6k17HpVr9l0yCEDGFycV5t4PsvterxjGQvPSvWpV2jaOi8VVXpEumtGysib5S3ataxiwuaq28PT1rWgQbVHOaEaRRsaNDkg13GlQ4VcD8a5nQoSQuOa7SwTaoyOa1idcFoXosgVaRs5z1qFcEe9OVccE1pYssA/nSqx70xeDg1IvuKdxD0fnmn8Z44pu0AinBWHTmi4Eg+bkccdaVT2NMXG4dafn86TJY4e1SKwqLqvFOQ4WglkhxmjORTTz9KTP5UyR5IOaBz14xUZPcGmGXH1oJuWOh9+lJ19qh80NjNPUgHrSYiQE5HHPSnBsDI6elRfePPalXrUiJ8+9NPByM0zPX1oz04oJFzxx940c/iKaSaAeOelIBMZoPTFIGHINLnPFIAHp6d6Xg+tMJAPWgt60hNj89utIeOO/YVGWOKTcd3SmTcfuI4zTWwDkdaRiN2RSbgAR70ALuJoOecVGST0/lS7vWkIXNIeaaWx2xTWYbf8KAJMjacUn1zUW8DI9RUN1dxW0ZkmkWNAM7mPFAi0W46/hUFxdRW6F5WVVHUscVwXiH4i2dqWj07/AEiXpuHK1wGpa9qWrSlrmdgh6IpwKrk6yIc+x6hrPjiytWK2585/RegrjtU8WajfhlVvKibsvX865qGJmxnNaUFv7H8aTnFbInV7kKxs7ZZmY+rHNX7e3yOanhgxgAdKtwxYIOPwrGU3LcpJIhgiKnFWjDtcHsamjhO4cYFXBBuXPcVmykUFi5GBzUptzu9q0Uh46VIsI9OaaGUUt/lz+lWI7focVciiGamijB4xTApLByOlWUiAOTU5j6dvapgOBiiw7kAiGF4/Sn+WFIJqX+EcUrDBGKaQMTaOmKeF6Yo5696ce1FguMYDIHFLySM0rH5qVeH6UbDAjjr7Ug6c09/amDp700IQjPFOXj1zTRyfSnDpTAFHNPJwKRcc5FNJODSGgHWlJ7Ui+/pThknrVCHqMAg0gJzyOKTFOPFA7DQMscUpoHByKYSScAimMVQCcmpEOGJ7dqjzjAp2dq9KBoS4mKKWHJHam2d5Hcr8rDcOCPSq902VOK5+XzbW486AkHuOxqo2ejEzsscfjTsZrI0vVUuUCMdsvQqeM1qKwI45pNNbiF70oGSf6UYoyB0FIA4FNB5peo9u9J6cYpgHcDFIfYU7Az6Uck0AIOvFKTnpSGl4pDE6c4pcc+1HXGOKOnWgAX8BQeMYH5Uc9aMcc9aYB+BxRg0DpxSnGPSgBB9acMnvTR1zg08HvQA7p8v86XAyOMU0Ng5NODggDnFMBQCWJH50MeOv5UZH/wCqnBhgcYoGgUDHA/OkXPbinqCcY6elDYHQfnQMZz9Ce9Az06inEc04AUwG57cc00rk0/AzwOaciYXmgZFt46kfWnYwOvNSYwORzSZU9RTuFho+vFG/3pCMHrSBevpVXCwrEEVXlHy1OFycimMnHNIo4rxLbZDkDj3NeP8Aiq3w7npg/wCe9e863DviNePeLYTukOPWmZTRxVi+d6HpVDxHD51g395aswnZPnPerN0gljZWHDCuSouWVzGSujytwyuQfWnJkjHOc1a1aEwXTKQetVkY9hWkiUT+SwjMhIwPeqiMx4qdA0ibQeO4phxGSMc1CGKV3JsUc0kaMrcgYFS27rlsj5quXojisYtmN7dfzpX1sBVLKVx0IqPKspPekeIsAQajClWpgOO/oKhkDZznmrTcIWXr61Dk9z1oTAhy3rTgrYBJz70qjcTT0HBXFADcZHuKIxkHFBG1vemqDuHpQBatxwQRVyLrVWBqtRYDUMZo2xAIz09K04CMFunFYsRIYfzrQST5QO9SxlbUzk8VjSDrWpfNnOay5DzirWxBGaBweRSGgnmkM3vDNwYNSicdQ1fUejy+ZaxOOQwr5M0x9tyh9DzX034Eu/tGiQMD0H9T7Vz4pbSFL4T5DXvTkPOKbnmhTzXShl2zG6UV1ML5jSNeK5axbDA10dhICMntTYI6XSIfMJA7DNdJoziATFzwVrA0aYKrbACzcc1Z1O6FnZFSwEp64NYVHf3Slpqcj4xnEl5KAeAa5HPzelamrXBuJ2Oc81lYJJFapWVidxzfKmAOTSJKQpFIVbYTzxT0QCLnqaALUEKm2Zm601CA4PGAaZFK3CdBUzlFOO4FIoa5Dxc9z1pIo8A+lV5JCowDxUkbloyM80xE7OpUL0ApFdQ4AxgVW2ktjNSiLGCx60WAkbMoJQcVCqYOH7VY84IhA6UyEFjk9KAIpB1HQVGnJ/rVm477BkVDBHudVHOTVU1diZ6L8NLIBZbpwQF4z+ddsi+ZJk8g81l+G7T7FoUKAYZ8E1v2UOfmx1qW7ybN0rJImgi6ACrsaZnUDtSwxgHOKmsl3XGT61UTSKOt0CHhT6V1tshxxWDokO2MNXQW+R6GtonVHREoUnGRUmMU4YPtT8etWyhijHrUikcUmBRtIoETjk9aVWwcc0xQccUZIpkseeTS8gZPSo92CKlyDjjNBLFU5Ape/Smgc+1OwccA0rksepI60hOOvSk6H0pG6elBLFJBYVBMhbgfXNOPrnpQWJOCDQ9iRIEI+8eKnHBwelRjGeOnanhh0/WpirKwmO9uQe1AyGNNH3hn8Kd0YZzQwH88YGKMnPvTfoKTJoJFLfSkLH2xQeeR+tNPU4oExSR24pc+1R9wSD+dFIQ7JxxzTCxx7UNxxmkbn60EgW460hNIeOtAzwKAED+vSkySTjpSE47UwkDPGaLASBiMkdOnNIzEnP8Ak0xSPXH1prt64xS2EOZ8cmopZlRGZ2AHvWD4g8U2OlIy7xLOOka15lr3ibUdXYqXMUPZFNUlfchz7HceI/HNpYbo7Miecdh0FeZavrOqazKTczssZ6IpwKijtWJ5q/b2Rz61LqKPwkWb3Mq2tMnGMe/rWlBagEZya0oLAowLDArQjtRkEAVk5ORSRTgtzgcYrQgt/UVZhg6YFW47c8HpUjIIoOM4q3FbgfU1bitxjpxViOIA4qSrFVIMgZq5FCCoGKmjiyDgdKniXHaiwIrJCAcYzinBBkjirWzB4FJj5u3NUkMhWPGMnFKAA9S4wSMUEdKpEoYy5BFLjjin4/KjHFOwDDnBHrTu3FG3JwacAe/WgYgzxnrTj6Uij5qdg4pMY1+DnilXrTXHNOjHQfrR0AVifpTcnaKcw/GmUIQqZ60ufakUelLjj3psAB601jxzTumfWmEE9DTSHcehz1pc4pOmO9O6cetAAuSeaUkk0oHGaTHBz9eaTY9RCeMUijGeKCufalAB57U0CYmOp7fypCc9KDycDPFKqk84oGiJlyDjvWfcwcGtYrjpVeVC2allo5ySEq26MlXHcVraXqhGIrrqOA3amTwAZxVOSIjtxWkZ6WZLXY61JAwBXoaceeeRXL2uqGzkRJcmI8Z9K6S3lWaJXRsqRnNDjbURJS8e9IDigd+tSAdc9MUnanUhoGIBzyKQjHanDB6fhRnHH60CE5xjJpG6ZoHJ5pQOaBh1pfrTT2wM0oYY96bAcQTjn9KaTgDA5pwx0xSHGcUAJz3pw68UKBTsdDQA09ev0oAwOetOweM0AgjmncLDl6D0HelHXNAAIxThxjIoQx38NLu9iaTGenGaAPemMU9Pem554pT35pCCBigB3BOfSnhs4qLJHbin9OtMB7cjoBTGXnjGaUcGjdyKGhoZsOf8aXn05p+fpSAZz2pjG8gdKYxxnFT7flNRsueOlFxpGZfoHjYDrivKfGdttMmPrXr06jbnFcB41tMo7dyKZEkeGXS7Lsj3q2T8qnOKTWY/Luc4706EhoD9KwrIxtocX4uttk+8DrXMgkCu98UQedYCTGSua4gIATmlB3gZLckikVfSoJTvkOMU8qCSAOKYU2zbRk+9SUTW4AJzgkUjnzGPotLHGUfBpQuAegoQDRISccUj7iDn71CrtYZGakkA5brmgCqT8mAcGmBjx37VY+zlgCDTxaMIPMABAPNAFZSc1Juy31FPSLfx3pjoUfGOlACn1NOTG2kk5QZHNRkHcPSgCzEOTjgVZiBz9arRZx7VZiySKBlyFcmtKGMNHnvWfb/eFacDrsII59qiRSMzUMqTWS/WtfUsFjjmsh+tarYzIycGm9RyaU8mmE/nUgWrRsSjI6V9B/CW783TDGcjaB2+vtXzvEcSA+lez/By6IkMf97/AAPtWeIV6Y+jPBD7E0q0rClVe561oBNAdoGK07S4OAOnrWPvqaKXY4PNVcDutOvltIix5wO9Yutas05YA9az1mdoyxJ2ntVWbn61CSTuA12IHJ+Y0wYRe2TTTyDnrTYwWlHt60wJZG+QL0GaapycdqbOckj8KfaKfMwRke9AxJD5Z47U3l1J9qluUXnHX3ojYLARwCaAK7DKdeRUkZIAA6UmN3A/OpI/kOO/SgBM7ev4Yq0VPkFzyTwKTyf3YduWpruSQOlC1Au2tqnkeZKOvQVXkAGQuABVqaQi3BFZ28u3fFK1xsPukkmtHw9bG61KGPtmsvHz/ePFdt8ObPzL55mHC9/wraOkWxJXaR6KUCmKJQdqjFbVlDhORxWbaJ5kpfsTxXQwx4iGRyaxR0bsjZdkRbNWdHi3Sg9ar3ZIjUY61r+H4d0i4A461pE0gtTsdOj2wqB2FaSKwUbeaoWQIQda0UbICjpWyOglRcADmpVPrTATxx+NKMZ5/KqGSgjIyaeBzxyKjqRcetMQ4Ajp0oII7daAMUoOR0xSExOooAOaApBzxipEGV5HGfShskcB0IpQeMEUoHoKCOMigliLwaHHII6UtNJ/LFBLGdSPeg5IAFL94jPWgDPTilIQuMIDTj6UIMcZzmjbg1KBi96UZNJjpxzS9KZLCkB79qU8g460xjtPoKCWBJz703JDfKDmlDdM4pMjdkZIoExSefWmZz0pXHHHWojwc9D70hbkm4Ac0hPGaaB15yaaTzQKwp9aaW4xnBpCcGmE9hQIfmmE4PP6U122jJNc3rniA24MdsMuf4vSjcTdjX1HU7fT4i9xIAew9a4HX/FV3eBorTMUR43dzVLUJpb2QvKSWNVVt89RxSc1HYzd2ZIgd2JclmPcmp4rTGPX6Vqpaj+7VmO3z1GKylNsEjOitR1AxjtVyGHaeFyRV+K3wcqtXI7bBqB2KNrbTOpNxIHPXAGMVcith0HSr8Fvz04qysHHTimOxShtwrYI4NW0hAHvUwi2jOKsxp04FAFeNO1WAmGBpwTBFSquRTsNCKuMU4Lhj6Ui9MEU4HJ5FFhgRgUw53e1TYyBmonAxkdKaHYeVx0ximsOPb1qWP5k6VG3OeOKa0E0MUc0pHNOAGf8KPrQJCFeQaTHPHepNuVBoAycigdhmPWlx3oI+Yjnij+lDGMYfNTkBH0o2nPFPXqaQIawGfrTSPapGGcU0LzzTQWEUYFH4U4jA96QDt1FHULDNvPegjHpTyMdKQDkDtVBYFBPPFOIJOcU4fL15oPTjpUjsNGSff2p2CeBzQoyfepAMDnrR1HYiI4IxUIlVmKKeasMOPrUDIoYHABpoSQ5Rng08jA460KMfjTsfnQUNwfzpjKTxipRwMmjB/Ok0Mpypnp1qjcR8YxitYr1qrNHkehpDMOaIEYIB9jTLbUprC5Xq0BwCPT3rSmiyPeqE8HU45qozsJxOotLhLiJXQ5B561aAyfauFt7m4sbhXjy0efmX29q66yu1njDKeccg1Uo9UQXDxgUwinAg+9HUYFSAmBQeetH4UHpQMb0HelHTkdaOP8A61BIx9KBCYyOlL9AKTORQKQxw4oBGDikzx7ChcHmmCHAcU7GQMHj0pFHPanDk+gpjA9evSnEDt+lIq46mnpx05oAMe1GO3Wjnt0pRjjsaaGOHHejJC0AevWl79KaAABjOOaM4PIpSeeTTGBJGKAHMKQDmhQe4zTwucU0MQ9AOxpeOnalxtOMZpdmQMUDI9vXFOUdOakWPABI6Uu3NMCPBJAzSFSOP1qQxsM4PNAPGGB+tFrjRUmj4IFcp4rti9k5A5Arsmx6Via7DutpB6j0prQHqj5y8TQbJmJ55rPs2ymMfhXTeMINs0gI9a5ax6svf1rOqtDBDb6LzrKaP2zivNLgFJmX0Neqov78g8hhjmvOtft/s+oyKc4JrKl1RjLczgWxwDmkjYq+W61JG4C/XpRIQzbunrQ9xlu3ZN6bwDnrQYFM5GcrmoY0LsQvB7U6KQxvtYnPWpS7ATajD9nwAQQaolsrj0p9zPK7bXJKjpUIJ64ppCJYyyKPQ0+S7KRmJRwetRgN5YJzihQGDFhmiwxIZgr5HWnht5JOKrEFT04qaMfLkGgB5XcR7Uph3ozimhyBznFPSQlSoPXtQMkgTI57VYVQACDVeJvlK9DU0ZbPSgC1FnitC35HrWamc1cilK+1S0UivqPBJrHfmtTUH3Ek1lydTVrYzIz65phpxqNgc+vNIZJEcPnFemfCq68vVo1x68/gfavMFOD7mux8B3Bh1eNh7/yNElzRaDqcIRzxQpHSg4z/AIUmc9RzQApI7UFiMcH60gIwB6UE89sUAW1lJiAHQUIwwWzzUEZwpzSfwHFADshmFOkkVT8tRD2pVUk4oGMdgTirMDHhhkYoNvtRSR1qMHY2COM0bgTOjMN5GATxmmOuMA5zU3nghQRwKEIJLnGBzSAiKMigjoKAQXHpSsSUJPTtTAC3I70wLRuOwyBVq0hEwLNjd2rP24GOpq1aStHKhOaLaaDTNC8VYYxGck4rJk/dj5R1q9f3AlnyDxis+Y/MM96UQkNQktXq3gK1+z6KZiPmcjrXl1qu90XuTXtmi23laVawL6A/rW09I2HS+K50OlW3yoCD0rdEeAB6VW06LHPY1oNjP61ibRMu++aZRjgV0fh2PnjtXOSfPekmuu8Op8pJraOxtDc6S3T92M8VZiUgZANQRdqux4A561aNxVPrThtznpQMeg5pdoJxVAOGM0vJ6cUwAL9acCPoaZLHKSuM1IpDZ4z9aZjgdPypUz6c+1FxEgAAGRipVXjjmoh2yMn1qRW2j7vFITHgjOKUAcdqbkDkZ/ClY8UyWHeowBkjOaew46/lTcZFBIncd6UDFLgH2FOQen/6qlisLs4BB6UHkA9Kd6elIBgmhCGgdsc0hxnHenFTScAn+tAhrfL3NBAbtTjzxSgDvQKxHt9qNv0qTj8KRhyDjIpCGEcdeajZc896mI55FDLkA8UCsVwhzxTH689asbRg461GVz1zSvYCDHNQXU8VpG0szBVHrTdWv4NNtnnncKF6Dua8x1nXbjVp8klIB0X1p76szlK2iNnV/ED3c2y3JSEH86ypnMzAk5NUoByBV6BCDk9D2rKc77EIRYcjmpBAOuKsKmQSOatwxZ6Csh2KccDH+GrK23PI+tXI4W4zxVqKEdhQOxUjtx1xVmOEL2qykODzVhYsj6VQFVIz2qykYIqREAyDUgUAAUxoh2dyKVVwasKnzGh09KEDRGQAMt0oX6VMgBXH6UpiFNMLFcjB9PajGD9akdMjNCgHGTzTAROT05pjDBIPOKlxtYEDinSrxuoDcht8kFTSsuGwce9PiABzTpBg5p9RoiwBSkdyMU/Azx1pwX5cUgGAcY/pQoIP+FPUcYPNKRk9MCgZCV5PApNp9MVYxzyfzpm3nnpQIYgyeRSKPm9qlAx25pMc/wCNAxCpApoXjkYqXGAOmfajGOfzoAhIoC55xUhHOP1pyqT1x+VCGQspPbmlVakK0bQO3NO4IYFyelBHORUwGAfemMOcClce4iKSeuPwpzjrmnoAFycUjdMEY70LUZA/GMU1RnmpXXJOBSqo28imJDOhzilxipNoAx2poUljQMaBxkikPXnrTz+gpDgUxkbAY571Ew6j9alwcnvRsAGTSsFynJFkEkcVUli3gjHFarLu57fzqF03c+lIe5km3GcYxV62AjAxwadIuOAOagZtmc9aaYmjWglEi4JwR1xU3pXNm/8AIl3Hp3rftpluIlkRhgjNU11IZKeTzRyD05oPOKOv09qkQhyO1IOaUgd6DjFAxcjt1pvbOD9KjldIyN5xuOBUnUe1ABkYBpwP5UEDqetC+1MB4OKeOaYtSDOfSmCBcZ65p64HAHNAwMUYNBQ4Yx70YB7cGmj1oxg8UwHgcUAE444ozgelJnjr1oGLj1HWgDHTrQeg9qXOR9aAHA8cDn1pPu5pFH6U8ZOCeRTAQZH+Jp4yBz1oyMjilGPxpoYgyeKce3HFIOuKeufqKdgQKc8jpQVyOlKAKX6dfWixRXli9AcVm6hHujPHatdskHNUL5fkIApXK3PCvHtuUu3GOK4C0wt2R2Jr1f4i22H34x+FeUP+7vgeOtFRaHLsy5cLskDVx3jq32XSyY4YV3F0peIGuc8ZQedp0UuMkZzXLB2kjKojzzPapBkgYxTXTGT6Uq9ucYq56MEWopfKlUjtSTtvlZxjrTCmVDg/hUcW85HY1KAnlBMYJXGeacqLsXOOakL7kSIj7vemMp3fLyooAibcMxnoKaMjjH5VcZlIJON2KzzIA5IPFCAkfJA45p2dpUGmK+45zjFMlcsxOOlACvJtJHHNRxth8ilTDN82KUABuOlAFuL5sVahUg9earxJgA1YiYn6UDLkK/MKsrHz6iqsOdwxWjCPlOallGXfrjt0rKl69K19R6kc1kv1q1sZkRqN+vtUjc9KjakMaOv+Nb/hqXy71D3Gfw4Nc/24rT0iTZcIfSqiJmGeenWk5HWjFIPQ1IxT7U4DPSmYoDEe1AEvbHeg4xjNNGWPXNNJwelADwMcVNFIEcHrVccHg4qReQR0oAt7zMwA+lOubYAqBg8ZJqvbybDn05p7XBZtzDnFIYhiAUDPzZpufm29B0pUJaUbu9STRgOFTJ4zkUwJpFUqFQY9agddjAfjzUkB2kZ6D1qKZsybgfx9KQEqbV6nPvSBwwZugqFnBGBmkHOAKYBIzFuM5NIQTyTT4hh8t2qYbSTwD6U1uIueHYPP1OBeOte6aVH+9UAcIuK8l8CwCXVlbH3RXseix5DsehPatKvRGlPZs6PTkAiGRU742sc8AU63TbGPXFR3fy27HvWJsjKgJM7E812/h5MQg4/GuMsk3E+5ruNEUi2A5FbrY1gbcY7k1MhwOTUKcDrzUi4/izVG1ywD0zTs4qvkgjtTlb5ulUImByKeBkUxOlPwcUXAcnHXrT1xxyKZn2p/APpQwH9emDihc4yMe9MPH3TkUK204PfrQSyQDaeeadkk8daaCMcHNLtwMiglik880d+e/rSdeo6U4kduaLiFXjHFPwMehpuelOxkcmkxC47ilweKQAgc0H26UxMXimkU3PGe9O9OlIkQdaQ9Tmg9aM8YPWgQoPOO1GQOtJjI4pCDnikAuQD60nQ/hQOOveg5NAhucH0rL1/WbfSbQzXEgBH3QO5pviHWbbR7J57lgCBwvcmvGNY1a512+NxOx8v+BOwFFlu9jKc7aIt6vrFzrV60szERA/IlNgjOBgcVDbRZxitW3iBIrGc2yEghi7Y4q/FGT+FLDGM4FXYYj0qBpBBHhRxVxItuMcg0qQ45q3CgPWgYsUQOPSp449pB606JdvFWvLXGR3oKsRlBinR4B7ZpVG0+tKI1EhYD5qoBXTuKTAxkZqUn2qNh83P1oQApPB796k6qD1NRjg5A4qROAaYCKcEU+mOMdKeGyOaQxrLg896YFAb0NTldy59KjK5zTRIki7gMdRTzho+nIpFPODxSgYyKChgHI46U51zTQMMKfxxxTER4xjPanjkegoYdcCkXpQAg6nB4NOIIA7UmOfbNPPIxxQMaMYpGALDI6UoIPPNI3JHegBf5UgHPIpfSlxQAh+lJ396d0FN78UwGgZ6cU/GB70Y4xjFLjBGaAEx370qjj/GgAdM0/wBvbikMjPbjj1pAPnpx4FKqjNMBGBxjNIx96ecZz0qFkJJPvQA4BetOUdSwoC5OM07kt+lAxhBb6U5h2FSYAGO9RN8uTQAhbHJHNQEFjwKecseBxT8BR7mq2KGAADpQRnJPcU7HHP6U3uaBDSCST0FNcZzxxUoUnr0NNdjuIHJpFFScbBx970qhOCQcda1JE+UmqNwuM4HTmpBnOaoSqEd6q+FddayvDZXjHynb5GPqTWlfQZDZ6VyOrWpbJXIYHgitIvozKXc9fRw4DLyDTs449K4fwV4gMqCxvWxMvCk9x0FdsCDzxzUtWGtRSMjI+nFIOpBo6AD2oz+dIAZQcZHApw4AxTSM5BpR0xmgLDs8Uo4pvXBApw/UU0AoOOlO5zmkGBj9KdnFMBwzxmnio808dadhij6UYwOBzRyQDjOaBk47UFBwOtHA/wAaX69aAOO30oAABjOOaXIPX8qaRz14pwAFNDH4wM460oz93tQuW69Kk2js2aAsR5PIAxTgOMUo4NLkZ4pgIEOc0oYDrSFxnHp6U3ryBTv0CxKWzyOBQhBI/wAKjXB4PWpApXp1qkrjHYU/1qrcxZU1Mc9c8g0yQ5Xnk1LVikzy74jW7GANt55/z0rxXUVKXYPQZr3/AOIMIewJxyPb/wCtXg2uJiVjjHNN6xOeatIvH57VGHpWNrUXm6XKmOV6VtWB8yxUHtVC7jyJY8cEVxPRk1UeUyr+9IPrimyKFQjPNWNUQx3bgDoapnLHnNbTRkiaJio55FPjfBOF/SpLZQBh+9N3KhIIJrNDHjqrMMZpzfLHlTk1WdiwAJOBwKEYkEZyKAEQM5IB/CmNGvbg0u4r06mnhMqDnn0oAhTO7n9KeRhju71YZFUA96jucFlKjtQMr+WcnFOUYPNSLnvTlHz9KBEsDnAU9KtRcZqkpO4irUJY9aBmhD1yOavwMMYrMhYirsb4XJqWikU9SPJxWU+Mk1p3/OazJBVrYzIjUL1MRj/CoZOvApDI8/gav6ef3vpVDPNW7M/MPUd6qO4mZoHNBAFPprc9KkYzNJg5+tOI/lSoD3oAkB29KYx44pzKQajPcdaAJY0yhY0oHHpSxAuAvQCpTHtX8aBjSAqjPWnnAUbcc9eKruSeSM08NgAUATQjdMPQVbQRgNkjJ4yaplgrAZ5zzTpzuPy+nNICa9ZcAJjgdqrPl1CjHvSxoTG2evvSI+0kYzTsBGIzyPSpYxs5PNKy4IOODSuyk/X0oAmRA0BbHU1G4A6HHvSiXbEVz+NRo2etVTWomd/8OYcGWTIr1jQYsWikjljXm/w/h22DPjhsV6npEYWGIAHIp1Xqax0ijcRQIee1UtSOLbHTNaDACMZ65rM1c4jUHuazjuarYj08cqK7bSxshWuN05cyoBXbWkeEX6VumawNGE7sDIqdkI5FVolxyOlXB0Ao5tTWxHypweRUyAE8CgAEjNPTg1QChcHIp6sR1pRjGKXYDTQMXqcg0Dr60m0g9aOhpkjyVNI4yKTODxilXB46GgTEUkH2qROD9elRgc461J6cc0XYtCRuRjvR09j/ADpq55PengHkEUrkgD1Hanjj8ahyQeKkB7c+1Ah+eSD0pQwxim57mk4HSmIccYBpuefUUBhnB6GlPNIQ3nn0pB+tPyKjbof6UCHKcjGKXPNRse44oznpxSAecc5rN13V7bSrGS4uXACjgdyak1PUYdNsnubpgiIO/evFvEWvS67ds7kiEH5E7YoXd7GVSdtEUtd1a68QagZ7gkQg/InYCnW0HAyKbbQ5AI5rWtojisZzcmZJC28PGa04YxkcfhTYIQOnJrRhix2qChYIhuzitCOPvTIY9varcaeg4pWGgjTJwOKsJHg59aciBQCPyqZVDjHpTKsNUZFToex9KjA5HrT8YbI/GqsA/HODSElWpvOc9qcDvBB607AP4I65zTeh56UxCUO08j+VSHLDjGaQXE6dehpwPXPSm+9H6CgQ8jPemrw1CnOQaDjOaY2SofxFNZdrYxSKfzFSN93cOaQyJhyDTgOfak544pV7iqEA74opy88UhHegAIyuM01fSngdKTGG9qaAQClWlHH40DrQwGj2oNOx6009KQxB/KnDO7FIM5pe+adgCkIxSnpgUi9KAFUZAzQAcmnKOeKAM9qLhYQD0pQDijHajIFHUY09etKuMc9KABzml7dePSgYh6elJ+tOPc0Ih60xIQKevSpAvSjGaRj2AoKGyMOfSoT87Yp7jP0pp45HU8U0IXp8oHNAAA9aVVxyetB5PrihjuNY5PPApUQYDGlRORkZ9qc5wcD86Q+gx27L1qPGOnNPGCTgcUYCqMU7ARuvHzVUnTdzirjDJ+Y5NRSIWz2pNBcxbmLcDxn3rDvrXIOBXWTQ4B61mXUAKnOBUg0cZPZtHKJYvldTkEV23hvVvtdusNxgTJx9RWNPByeMCo7dfKmDp8rL3q076Mi1jvQQce1APJ9Ko6ddrcQqT94cGr4XvSasAvX1peOKUD3pOp9qQxcUDrilA5xjNKQBx+dMAGOuelKOaQKT34py8c9qAHD6U/HpUecYp4OVAqhirn149KXk8YoGOueKUdOKLDAgYpmew4qQcZJpOD060ACr6mnrk8cdOppAnBzQASRjp60wH4HGKeo9aYvOcde9PXAxzQNCsOSc00jBBp+e/wClNGCSKYxh/lTgpxmnlcCkHAJHAoGKE/OpOgqJiQM07fnGTV2AQAc8VHKpzntU3X2qOQDHPSpZSOQ8axh9NkHGR7V8/wDiCPDv9a+jvE0G+wkwMnFfPXiFcyuSKa1iYVfiItBbfbsvpUV4Ck+OlHhw/M6Hv2qbVEw5OOlcclq0TP4Uzy/xLB5eoPxgZzWbEACM8iuh8aRbLoMOh9vpXNAEg4FavWKZzonndVChecVBJIryBsY+lQEnPOacBlRjrWexRMvJBI61JjY2AR7VXbchHrUqyAgbhjA4pASR4IYuRimqd7daZINqYz1pI+MDt7UwJJgQm7nIqLrzzx2qdm3DA6U3jNAEe89ORTw2DzSShdwxikXnjFAE8bDr3NWomB+tVI0yBircULgbh0oGWI25wKtRN+AqlGDmrAIB5pMZDeHNZsnWr143NZ7Gq6EDKhc1Ke9RP6ZpARmrNofnAPSq2KmtzhqaAqbvekJJ5Apmfxp+D2pDFAzTlU9hUtsu5uR9a1Le2Tq3SmBlFWzgikKbQTith7FpizRAflVFrZ0DBwQc9DSAqRMY8mp2fMOMZOaY0RGajG4A5PAoGDYHXrSrjYWPaneSzDceAelAUZ2nmgALAnigPtOPypdg3e4pjqSc4/GgCVGOAACalSDOOxJqKGYKBgc08TkOGoAu3ceyJV+XP0rP2Mrc8d60pWDIjvyaqN+9lO3gUkNjdoEQzyWqOLO7j1pJTiTGeBUtspaZQO5rWluQz13wbF5ejRnnnFel6cvC8ZxXC6DEI9KtIzzkCu/sRjH0rObuzfZJGi3AA7msnWD8yAdK1W7HpxWNqp/0hRSjuWi5oy5uE/Cu6t0woritCU/aU9Aa7mI5HTrW25tB2RMmKmQgnA71CAR9akjGTT2NLkwOKk569qjUdutSj600wAH1p6nng0jbeoxmkAqhEjHJyOtNPA9cUAnNOIyfamIbgnqKQ5Bp6kdCaXHPI4pITBW46YNPByMZ96YEA57Gn+WDk5oExw4we1OJ4pFHGDRyMcUgYv8A+qhW7YNIpPSlIG6glj+D1pvIPNAo9zTENzjgHvTgcjjmgn2/ClUelK4gOSBimk5zTjxTWIzg0xDc4PXioZ50gieSQhUUZJNPc7QT2715L8TvFhnk/srTnwo4lZf5UkrmcpcqMrx54pbXr829sxWziOOD941k2kXTiqWn22TnHNbttDheKynO+iMUurJrSLgVr28WMe9V7eEZxitSCPFZlEsMXHBFaEEQReeajhTpV2JeetAxyRkEVcjSmxp6elWVXuKBoQJxnFAG05FSYB6fSkOSMntVJDYuN2CODQG45FIrbTQ4B5B5pgIxPQHihWIYY/Gm7smhSN2D1oEydxuAIpoOOtCsQcHpSugJpeQxxxjNNbgj0pUYcg0jcjrQAjHHzDrTu+ajLH8qcegz0FMB3RuKmjbBIPQ1ChyOmKeD0oYIVupzR3zTjyM9qaKaAcoHWg4zjsaF5P0pxpgMwaUnvS0Yz14pAJ1NLS8ntS49aYEZ5pGHHpT8d8UhGcUhjR6/pTsYANC9cmjPFMBMcUvH5UuOQKMDaMUwEXp70oHoDSqOaXn8akoQHJ9TTThj0p4GKMYHvTAbjJ46UEfQU7GBTcfnTEGNxx7U/oKRRxQRmixQMM8Uhx0FDNxTf/10ANc9vypwGBlqVecmlJ46ZoAafSgLk0uAT3p2MZ9aBoR8KMCoSM9P/wBdSsvc96QgAZpiY3BA9Kbxnj86eASeaUL6DJphYjCcgnr6UjJgEd/epyoUHuaifPbjmluUVZl4PAJ9qz54/WtbYSDge1QvD3IwKnYdrmBcQc5HU1nXA8s+/aujukABC1iX0Z5pIloz49YOn3KM/wDqs4au6tZlnt0kQggjINea6jDvRlI61r+CtWMTGwuW5H+rJ7+1av3kZ9TuhjtR34pFOelKDt+tQUPHAye1OGCfemA88GlHegCTbnpzSHoOKQD3NP7cUxjMFunBp6gCgUozg4NMLB3p2RSLg9e1O288UIYoUYOaWPGfelIzz3pwAU0DEJwRkUoIxjGKdgY+al8sAUwEUCnHngDFIfzpwzxkcUDEU07GDn1pehpQeMfrVIYgPtQAfSnHOeBS5wKAGEYGTSZx0p3P4UYGadyrDM+opu7cDj1waew4+lVI92+T0zRoBT1dC9s47Fa+d/FEOy4lXHQ19G3uTCwxkYrwLxtEE1CcEYGaFszGrujldBbZd7T3rS1VflyvesfS3Camo9TW1qfC1yT+ImWsTgPGkeVjYjPHWuXt1BIBya7LxcgNhEQPX+dcQjkMBWkdYHMtGSXFthiV6etVWPlvjqKsyzH7p6CqrqCM1mUIzmQjNSxLlc9hSwx7uOM1KNoQjPzCgCF1LEYySP0oQEfWpEcHoeKbuBYnbxQAqMQf8aCpYZHUGmlgDkDrSo4AOeuaAEZSp5609MGkGXfOKcnDc9RQCLduiZ56VYE6j5cfKDVFGO7jkVKiHbnHB9aLDuWRIC3HAqcAnHaq8K8c81dgXOM0noNFC7UrVB+prUvhjg1mv3xVLYghPTrUTHmpiOfeoZeuaQyLvUsB+YZqI1LDjdTAqKufbFPJ59hSjA4A5p23P1pATWx5966K0jU26+p7VzkPDCtrTpy08SY4zVctxM67T9PC+VlQAe9VPE2lhNzbcDrkDrXXW1sWsoT+tXvEdgkmkI5AJC4rmcrSRpFXPCZ/lYg1CTzgc1tajZgzyDGME81jSKI3PoK6GSPkm4C4wAKiQMxz+dRu3zZqzAwEWfXpS2AYQVJU96txQ7ogG6d6iK+Ypf0pPNZSAPWgAmh8sjbToLbchY8VPNFlgxOQFBqI3PVQKWoxZXJUIucigDy4G3cMaSBxuJYU6QNODtHAoEVyNw3EVd0lN97EvqapEEDBrV8Npv1SAehrekS9z2zSY8GzjHZa7OzyTXKaYP8ATYP9lT/KursyQDXO2bzZdJ4FYuonN8c88CtkkYGPSsS5+e+Y9acdxo2/Dqf6QK7SLBUdq5Dw8Ns2T6V18JyBjJrY3hsTBc8mnkYHAojzmlcZPNC1LbHrIOvp1qRXBxnvVcYVu9TDDCqvYCRSM08jGKiTjvmpBkU7gL0PvTsZA5pvNAHegTHdPSnA4GRTRzzTlODg0xDsn6ipF7mmA/Sl7elIQ7nH1oz9RSZGQBxS5z3zTFcaOtPJxx2pOlAI6kdaQhwPJB7UjZHIPFDECmseaBMcCCRkc9qbuIPpTSQH570pbI5oFcdu6GmE8800nb05rF8U65Boely3UzYYDCrnqaGTJ8quc/8AEnxSNKtDaWrj7ZKMcfwivILKIyOXlyzscsT6065up9X1KW9uiWkc557VpWkBA6VM5cq5Uc7bbuy1aQZIxxWzbQ9BVeyh6YFbMEQ9MVzjQ6CHnjitCGPkd8UW8fTPAq7HHjoMU0UOiQd+DVuNMCmRJkYAFW1Tj/69MSFjHcdKsKpPIxmolGOtSK3FOxSJCKYxApwwfakYc4o2KI24zjH50zcV69DTiCOtN/x6UyQbA5HSgYJx0PakyRkHvRkYx37UAySMjgHk9qlzkYJ/GoGGcEU5JO2OaGCYrDawIpxOWGDxSsAOp4pFHUZ6jNBQjgnIHehN38QoXgYp5J7UAIhw1SY6mo+/vUinNDEOXpg0Y9KXtSjlTz1poBvH/wBangccUmMHFKCOlMA6HpSkYNLjP4UuMgZ/GgY3OD9aDmmCHEmSc+1SkdO9IBhGCDSD2xTiMAZ5oGM80DGr1HpS4FOXpyKABVCsIB6HrSke1Lj04FA6/wA6BjfrSD3pwHNKB3pDD3ApTxyKQD1o+tMBDntSKppwHf1pwHGaBoQ8Dimtnt0p2eOetNPNMBowDk0AEj60uMnOKdjnk/hQFhAOMdqQjIxTiePSkzzmkNIABzg07APTrSA9KUY/Ggqwm3JppALYzwKe2QKb8o6daBWFCHBA4FBwBhfzoyT1pjHseB6U7DGk7sgfnQqj+I5NKOnAwO5o3ADA6UwSQMAP8KhmwT0x7U4k5HOT600KWJPalYdyjNHnPp2FZt1ED2rdeM5PJqrPGAOKlitc5G8tiGJ7GsDUI3gkWWLIdDkYruLyDNYl5aEhvT0pxdmZyidB4U1pNVsEYH96vysvcVvHryK8rsPM0fURPFkKT849RXpthdR3lqksZBB5qpLqhIsU5cCjt1oFJDH9vrT1GAaYvB6cU8CgYHBFO25AxSfU04egpjQgHTjFKD0ppIzzSjBximA9Tzk04nknt7U3BA6UL1PagYqnnrTw59aaQM+9KM9sU0FiQAf/AFqXOe2KRT0zTj6kc0FB2PSlUEc01Tjg08dc9qYCls470vPJyKQDgUEDPBoGOGc+tKBwaaOOQeKN+O1OwIRgM9MCq4G2U+h61ZDBuoxTGUck01puVoyndrmM4GeK8J+IkeNUnwOv+Fe7z5wee1eJfElP+JnIcdRmhdTKtsjzS0OzUlJ9a3tSHyVz+7bfKfeuivgTGCPSuWp8Rn9g47xYudKQ9x/jXnxch69J8Sx50hu+3/GvN5FBbjrTh8JzdSYFWJbggdagKgnp36U6NTtPapjbkKCOagoVFEZyOhFVpI2LDHepFUiQBqv22wbmYdKWwGUQyZDdaaWyas3RDHeO9VgN7cGmA6ULtG3pTUXvSFCCck1KR8gGMZoAUNsPAp2cnPc0/wAtfKHPNRiLB9BQgLEWPlq5GM/SqUYOeBVuPcq5YUDJ1BXpViBypqtG2fcelW7f7xz0pMaKl8+7rWa5rQv/ALxrOeqWxAwnioXxUpNQvSGRd85qSI4PBqI/rT4utMBrD1qRBzzxQVxUqqNmcUgCEbmrf0Kz33KOegNZVnCSNxHSus0KP5o8YzWqdkKx6FbMP7OAXGVFV9Ruml0WXLY206CIiHngEZNQa2n2fRSuMmTnr2rkaRojyjUZi9xJngd6yJmBcAc1oasTHOwHFZkXzNk/rW7IInTnGO9PUYGSeKmnIGKiDbjxSGOSYqrr6jFBfKjHY0iqGOAeaHAHAGKaA1YlNxAvGeMVmXMflyEDmtOwYi154xyB61VuV/eA9jUrcbKnIA65q8k/lwFCMEjrULY3jNJdMPM46Yoeohkj5I4xW14RXdq0X1rFLKR710PglM6tGevNb0/hYup7TpS5vlz2FdTbcKa5nSR/pZPoK6W2+7nNczNZ7lxjxWNH814enJrZk5JI/KsWA/6QSaqI0dHoY/ftXU25JUe1czoYyxb1NdPbgKo5rQ3g9C0rYxRuJOT3pucj+tKPTNWtCr3JBzQCQwGcYpUAA96XHzZpDJFP51Ipyeeo9ajA96cvDCqAcDTgeOKAM45pNuMYpiFBx24p3IJOKjpwyOM0CJAwwO1OB6A9ai6+1L260CJe+DSHrx0pAQR6Ypc5z6GgTFBJGfwpM800dDg/hTgeOuc0CHt0yOtNJx1FJkgYI4ozx/SjYQMM4PXFIGGB3ppzj+tMZsDNAhLiVYYWkkYKiAsSTXgXjjxBJ4i1dljY/Y4jhB2PvXY/FPxM0UX9lWb/ADv/AK0g9PavOLK34HHNF+VXZhOXM7FqzgGAABW3ZwnjI/Gq9pAPlrYt4+QDn8K53qIt2sXFalvFnjrVa2iyRita3XAqWNE0aYA4GKnjjpY0BxVqNMcjmhDFRRgHHFSoCDj19KVV9cVIRjgZqkMaenuaVcZ4596VlPbk0zHPXj2qguPZsE/40KwPB60m/Iw1NcdxRYCUgMPWomByQDyKVJOeakzuB5pbBuVnH50nO7pz7VNIuO/Woj8ppoB6HPGcU1hjkUDnH507qOaY9ySNtyc9qQZDc0wDnAxipCQVJakA4j0of1/ChGOOOlL0PrmkMQU5TjkdaTHpTl6fpTEScYHrSrwTjrSDnFPGKEMQg9c80ZI5yKUYz14pCfxqhjvQfrS8A0KBwc/hSjnijoAgxQ2c8U4dfakbngUhjOe9AxS4yOtAGPpTAUjAGBQOtH45pB1znimIF/SlpB6ml5OKBiAEdqdgY70g9cU8eueaQxuKQjindTz0pO+KYgAz3oz69KU+1NbNMYmc0f54oPTmlGAPegAxg8GgnjJxmlJBPvTenfNIY0DJJJp1KBz2p34UDGdvTNKMgf1p386RiFGTQMbgn2pvC8/lTiSeabjqT1phYjlmCAbsjJx0p6YIDE/SnHaecZzTGz04p7iegjtuzg0wIxxg/jUioe5qTZj6CnsCRGIwvv7UpUnrwKkJVOnWm5LcngUbjRG47A5qvLEe/wCFXBj+GmPgDLYqGi7GZLDnPHHrVC4tuwFbbgHoKheMnORUtCaOWubDfnjmptAMlhMUbmFu3pW4YAaQWyjGa0i7aEOJpIQcEd6eOOtVLZlWQRk9elWjzSaJsO75605TmkGcUoHPJpjJAARnrQRyMHFIB6U7p3oGIMA8UE5Pv3pSAQcHB6ik7+5700A9SSOR06044xg1HubGDSq3IoGPB28dKl2k4IqIHnBB+tPySOOKdgJAuPelNRiTGA1Sj9KBoZjjNOH3aXtxwaMUxgOlBA79KFOc7hS7sAZpjGc546UdRzTifekwOx4poCPJB65oZsdaeQB0JFMkGBx/OhjVivOcpx1xXjnxMQ/bCepxXsE4+U4615N8SsiZCevNEDOtseQXHy3a/WukujmAfSubvv8Aj5H1roZv+PVPpXLU3RkvhZz+uDOkzCvM5Fwxz+den60MaRKfX/GvMJD8+TTp/Czne43Ow81ZSf5SvrVYqXO6ljUhsk8VDGWJwCikDB7024LLCmOCetLdSZK7RgVXdmcAUIGMc5GGNOhiyeD3phBz7VatnMfIHHU0MCGRTvweCKkKARg5xTrhxIxcYGaZvyu0ngUAJCeTzxTy4aTnnFVwQuaVR1IPWgC4hAxirsf7wemKzojxkdelXLfOM96GNMnRMMa0LdQV6dqpxDnJ61ehPNTIpGZfr81ZzjitPUSd5rNetFsZkJ56VDIOTU9QSYzUgQkc+1PiGCO9MPTrzT4uT60xkuCSB2qcJkgHpTQADzU6j7uaEIuQIPKGO3Na2gXGLtcdAax423HauefStrS7F1cFVrRWtqB6VBOJkiVcZPUUzxfCBYoB6cnNZmlRTrLFuAySKseNr8CPykONq4P1rllFqSSNYvTU8l1wjzn74rKP3R9au3x3zMzHqarTYG1VPbpW0jMiYBtwJ7cUwDYOOasSKqpnvjJqsFLcj7tShksY3E9OKtwxKY8sAWJ4qpnj5elTWxK7c5PNMC0CVIXsfSoZQxfmpZpAAuF6HOfSoPNLOSOaENiTINmSCDVMklvWtHynmidx2qkYmByR0oQgC4xXVeBEB1VcVyxJ711XgIj+1F4/StofCxdUez6Io+0OeuP04rpIPu8VzOjNm7lDHpjmumtvu1zGk9y02e9YcQzO31rdkPDE+lYcH+uY+9OA0dZ4fX5eldJEMKM1znh8jBOc810sZBHXmtTeJID+dOHIyaQYpy4yRxmmVceuc8H61NtyOOKiXn3ApckdzmmFyQEpQSeCKaST0oU460xEoY468+tAZs4PSkyPxpc8U7gLwBkHmlU8800EelBPNAEp9ugpw5HvUat29KcGxwTQIcAOvegH1xRuBNKCOc9KBC89qaevtTvUA9qTrx3oEAPbPtSdOh5pR9RQeeaLgNYYPtWL4o1eLRdImupSA2NqDPUnpWuXwDu6DrXifxH1xtV1k2kL5tbc7QezHihaszqSsjmZZJL67e4nJaWQ7iTWlZ2+ACRVa1iz16963bOLCDisqk7swSJraLpkc1q2sZ/+tUNvH6VqWsOTz17VmUWLWLHSr0SDJNQxptIq4iAtkDn61SGTRL07Vdj4GO1QIuB3qZR6Hii1wTsSAKBT8DnmkGCKM9OtModTGXjg08N3Jp2PYYo2AgHPQc+lIxIPT8KmZA3Tg1C3DEfnTTDYafmOe/WlDdcjmmsTnK5znrS7tw5HNMETZyCDzTGTd9aYrYJ3ZAp5PPTiiw7kJUpmnjkZFOPzDB60nOT6UCDkHtmnj7nGKjbr7CnID14GOaBkgOWOT0/SnnOajB4PvUgPvmhhcB2pw64xx7Uh605f0+tIZIOmAcUvB69Kbxjk8inqOuOtACY9KDzn+VPPoKaetUAo45FO5wcU0c/hTh60xjTwDijt796XGfr2pB0x1pAhAOMGnY554oIx1oHXrigYuAT3zSEdMU9fQmjqAPancLDPSinYwOKB0wKAEAOKUenWgc+mKUY4zSGGM/UUmOSDxT19qQkjjqaaAZRzmlJJ60dF5oGITgU0c9ad34oGfamgGgDnFKOegpQOORRkigYE8YBpQOuKb0pCQScfzosArHA460z1+vNOwT2pSAP/AK1MBgznrj2oGOval6+tPCgZDEdOlAxpGePXvQExyTT8YxnuKGOB1zQOwdulIT70ZwPakClj7UhjSQDkc0bSclqlCKBz+VN4707iGEcYFN8vPLHmnluflowT1zQVYYdoGBzUZTOOw+tWCoHfFJtGOelKwFYx/wB0fjThB/eNWSAOO1HIA9R6U7AVmtEJB7joaeBjg1KxOPSmuOadiZIaOM08HP0pmeCO/tT19+aRA4DjvSigYB44FB5x60DDjPPUUoHAORzSqO+c0uMKBnn6UxjcEcmlXA6jmjPYnp3pdwwdtADs8DFKc59BSLuA4x9c1JuyKaQXARrwcdKeOKTP4ClPTgcUxhkmnD1NAbjpSbiOhNMY4EAdaCfpmmH5j1pMH8qVhihd3PSk5z0pyigtzVIYHpzTCD14p24ZpCRjn86ARUnA6GvKPiavzJzzz/nrXrM3KnH4mvLPifwIwDnr/T3pxWpFbY8W1D/j4GPWt8jNoh9uawdR5m59fWt0H/Q06jiuSr0MVszG1of8SSY9Px968rnOWI7V6trPGhz57/415RNndk06Xws55fEJvwcEnAp7SFuAPyqIRk8+vekyUfGKgZoIAwUHnHetGS2gfTfMjwJF4NYcc+AfWrUMrlSFJ2t1pNMZW2HI4zUi5QFc8VYZVUIR1FNuAZlLDjHWm9RFMnPHamHnj9KeBzyc0qpzTAiUkdc4qRQB0p5ClT69qVFzwKQFiNBjOetWoV7Dmq0YwvNW4uBxQMsxDketXoV496pwrk8VfRSF59KllIydQOCeePas2Q1o3/3jWa/WtOhmR+1QyHjnvUx5qCT9KkZCetOj6009afH1FMC+y9MfzpWJwQKkK8c02NSzYFNCLekIGuVBr0jRoYy0ajjceeK89sImWUFRXovhyMmLzXH3RRV2uOJ0MiiArGhBJbAzXEePpkjkIV8kDB/zmuhnuxGzTE/KoP515f4q1Fri7bnjNY04vmuW3oYF1Idx9OtQofmBY0yQ7pOnFOfgj6VqyB80nPXrRvHlhSKgcYI71NHGW69O1ICQMoVQPX0qWJ93yr1J5oWHbGS1PgjxG75AI6UXGEzADZnj+VMQbUJFMfOSx6Ui7tp7ChAaenzeVbur96jmXzU3J+dQ7CYy+enWrML7Ygrd6lrqhmW+d3OeK6bwOcaqmcf5/CubnwZCVOR2re8GMBqqeua6Kfwsnqe2aRgXTn1ArqLU/LxXK6Sf9KfPoK6e0OVGAcVzMue5el5BArFg/wBeeeM1tOep9qw4f9ecetOIROs0Fvl565rpYeetczoWVQEiulgfj+Va3N4llRkelAAHXH+FAJx7fWjI780Iq49T6H86VXznJ59KjJ6ilA6ZNUguTBs9+aenI5IBqIenFSoBj3pXBD8Up6cikBwOaTPbJqlqDYpPfPSkzk0ueeQDR3yKBXADPPpTlxzyaTPPtS9aQ7jhknBPSnjPP+NMPGM5pQfc07kiknd1zStj680wnJ/nSZ55zg0wJBhep6+tDEeuTTCSRknntTJnCIWc4AGSSelJ2Qnoct8Q9fGjaKwjcC6n+VAOuO5rxOLmRQSWZjk+tbPjXVn8QeInkU/6LBlIsd+nNV9Ktdt9DcFiNgIxj1ok+VWOZvmdy/aW5BwevpW3bxEYGB6Y7VFFGpY7BgdhnrWlaxYI9652BPBFkjuK1bePA561DboRir6JwOOaQxwTOOOnvVlExgmkiXA+vrVpVGMdaq47CKSCM81KufUU0CngcDHA9apAOGfxpTwOopF6euaXPamFwAznHWlBIPBxQBTtoYUAGc9ODTJOeuKdhl/xpc7hg0irlVxg/WmgZ74qeVKi2k9evbmqTEKe+OtKBj7p4NNZTkE8VIh9fzphqKOhoIHXPFOwfwpCCDSGRlcAnnBpo46jIqYEHOetRuOecjFNDJFYADninj0HPtUKnPFTA0WEO5NIDgHNA6AinY4OKLDHZ9+KcvOaYvSngcf/AF6Vhjl6jr+NOPX6UwHk05TjmmCFBwe3NKOxGKQc9s0px9aaAOnekbj607rzSHrikMOlAbt+tKAMnml+8OvFIoVcEdSBRjnOKAP85pOcghsY7UxAR6nFAGCDS5Ocik3DqTnNMYN15pw644/Om8EHn8KUfdx0/GkMdjjtTeSRxxSg+vI9aQduv500Ah4Jx36imjr70/GMHNNb680AIwwPegdM0oyQN3X2NBHTnFMYhPHek7c0vNHXrQAnBAp2OnNIenFJnnB5zQMcDxgdaT0A4pQcZyaDQAcLznJpCfU/lSYycmnHHrTGISThQf1oA9OvrSn0HSgsAOKBocFAGSaaXAHBpCWNJtJOWNFgbEZyw4oSPd17U/IA4o5PSmNCrgDgUAk9DigDBOTmlz+FIoQADvmg4J4FHHt+dBPH+BpisJjJ5NOx74ppak30w0Hgd6DgI2TmowxzwcUErtOT+tA7DFPfvTuTn+dRRtk8fdqUNSasYi/U/jTl/wB7FID/APWpRgnk4oAcFByKft9Tj3zTAcN6gU/cfUUAKF685pNoHpQGGaAeaChVVs8HFPC+p60gzt4pw9DjjvmmAvT6U4YC8ZpvTFOB2nBp2GHX/Cl257Upx1H6UFuKYxoIHDDijOelHUUKOec0DF/H9aaV54Jp+MdTmg/jTGRgZ4oKnqf50/B6g8UE02BTuAcHNeWfE/IWIEnoePy969YnGQeePrXk/wAUj80Qz0Df096cdGZ1tUeMajgzY9620P8AoSViajjzhj1rcTIsl69K463QxjszK1zA0OUdj/jXlMwBfjFeo60f+JHICf8AOa8ukGX565p0/hZzv4hORHTHyTyKmMeY6bgsRgdqgZFHGCw5rRjjEcYY9arxQbnA7n3qa7VomCnkClu7DEZsNuycVEJt2cEjPao3k3k5NQA4binYRcgClzuH0p6p+86dTVeBucE1M0pzx0pDCQICw7iogw7HFIQXYnNAUdqYi4jfJjGanhIxg1UTg1aQHAx19qBl+BsdKvIVKAjrWbCCQee1XYgSvJqWVcz77ljjvWY+c81pXv3iKznPPFadDMiPWq8o5qz2OMVXl61IyA9aki6jtUbfeqWHJYUwNNjmp7WLLZxUA4NXLV8dKOmgkbujWw8wFx8tddFcJBCY0OO1cPa35jBGfxqxLqhVcluBUNNvUpOxq65fJHYSKrfNnFee3hErFzVrVdUM7lQcrWW8xOF7etUlyoW5VcENxzSqMMN1OLAOT09KazkjPWgBzhS3Tk0/zQsg9Bio4zxk1OtuZIS4HSgZJ5vmD0FJ5m/5FHyjmo3A27R0AzRbyLGCx70AWGUqAGXtTXIYccYo80TTcn5QKW5UBRt6mgCVziNVU8HrSBiysfTpUMKsGDOangHUg8mh6AUXDbsmtzwkSNVi44J9KxpgfOIx0rV8MnbqkP1ransT1PcNMbF0eOCK6myPyYrkLBv9LTnqtdXpxzjFc3QupuacnOfpWHD/AK81tk8cdaxAMXBHTBogCOn0NjtZR+ldHA2QM1zOgHlveuli6DHP1rQ2iy2G9TTuG75NRLipB9KpMolBAGP1pwzjrUY570/JB69aLjbHKDjJOMe9Sp04FRqQQepIpw46ZoFcdnHB6+1KQM89KQHjpQCapMCQDk5xtpdoxnFNU9u1OGaEFxR+lJnFGetIR3NMLi5J5p4ODTFGORxSnrzQK4rGmk4peMGmnr9KYDicjiuO+JGtnTtI+zQv/pNxwuOoXua6qWQRxs7EAKMkmvFPFGpHWddlmUkwxnbHnpj1pLuzKpLSxk21vhR3PvW1ZwYGB1zVa2jJI4rZtoscYOM1hKV3cysWbWPOM9TWvbw4Ud/aq9tGOwrUgXBqLjQ+NMD2q5ChBB602JOatIuBxxVIY5KkA7jmmjtxTwTVWBDkf86kHX0qLgjtmhSw64oKJ+vXrSgYHFMV8++DUgYetAJXFH6GlHA9qaCDn+tBPHtTAeBx7/WmOCTwOlODYAz0pep5oAhORnOajI5JBxVllBBqIpk+9UgGE44PX2pODnbmpCvTNM2/Nzn60bDHK5xt5p/H503v+NLjOOaLAIV5zTcbuvJqbtSFd3K8Gi4EWP0p6Dn/ABpcc+1OA5+lMQA/5FSAYGaaDk8cU8dMZoGIRyMjBNL247UoOT15oZvegYEcZOKM5bnpSAZODTsEjr0oGhV9RT15pqccd6digYvqO1Nx0oXO4mnHBbOKBjR79KX+Hg5ox2J70vA4yaBijtzxSk889M0igAADvSkndQgDA7UHPfkUo9setNJP4CmAmOfpSgEAHNKPUc+lHbk4NIYmT6DFHQ5yeaXOPpSKc0AIDkUd/wCgo74Xn1pwOBjODQOwg+v60nYk804jn39qbn8qYAp44xmkbHHtRjJ460AYPrTAOeo/Kj370pOFxmkyevGaBh65pewBHJ5ppzRzn3qkgFJ46UgGDgmndcdaXG3tQMaOTz0oKjvn6Up4PB5o5b60DEyBn0o59Tg0oUjnrUm3HGTQNIiA4yMU7HqTink/3Rig8gilcZH9KTrUoxjqBTT75x7U0wsMPoeRSYP0p+fSkZuKGxpDSozkmo2cJTZGINVJpO5NTcb0JJLjA61RnuyVOGxmoLq4ODg/lWPd3e0EgmnHciTOq0ty0AyavoQaxfDM/wBpsC3vitracCqluZoXgE0H2HNKBjOafkcUkMaM59/epFHGOM03d1wKQMewoCxIFB54o4GTjmhSCvFHbkd6Yx3zHNOAxyeabuyRjp6Upbn2oXcY5j+VBPzU0YPPanDpmmgHr93FKG9fzpobg4o6gHmmxodx6ikyR0/nTMbT61IhBNMYq80hPrTqQnpxQMFYY4prd/WmOTnNNDNjDDj1p2DYjmbDf4V5L8VHzMmO2f6V6vMeDg1498TJN92VJ5GacdzOtseS3+DMM+tbsf8Ax4LnPSsG8G64GSOveugbIsQB6d64qvQxWzMDWDjR7jPt3ry9ziTP869M159ukTY74615jISXOaun8LOd/EPR9zAN0qRASx9BUUYIGetT7gCFFZjJlUKm/JyDxSSnz0LPkGmmUhRH29adOyuiKh+6OfegCr5e4kY6UGIBfrUwQqhYHFRlt/X8KAIdoA5p288AChkycZ5qeGHc+CO1AEKqT0P4VJGduRU0wWNfl64qsSOKEBZjzxmrSEAVTRuAO1WYvu+1Ay5EenFX4mAB4rNiJFXY2yv4VLGilfn5zz+NZj9etXr0jJxVB+tadCBuTmq8nfNTfSoJOSakZHUsAy1Rd6ntvvCmhF4sMipoicfKazi/NWrWYA5Pb1pDLm/ywcdxVK4umZNueKbd3JIODWc0hpoAJy9EgIbrSIMuCae2NxyKVwKzEk1MFAj6dalCAHkc02RSOP0oGNRQTg8Vp2jp5ToTjis5cqckU5XLS7R0PFDVwvYdKp6DByaaU5PpVlVLg/Lz0qMgoDnk0APW32QBwcknFMZThdx71PET5LBs461AwZjnPApIB8rjcFFXbdUQ5bjFZhjcNk59avKC8XJ4pvYERzKGbJNTaKdupxHPfrVdtwyDmpNObF6h6c1rSJZ7fpzZmtmP92us005rjdLbMdqw9DXXaeefr6Vgy57mzmsR+Lxq2/4V+lYt0AL09amG4kzoNBb94SfSurgxt4/OuP0M4mPvXWwt8o9a1NYstBeevFPBx3qNWxgmpHGQSD+tMu4hk4x3p4I9cmqV45jUNjPPrVmFiyqe1DaQJ3J1bnnFSjk1EBg8inrmi4Eig/hS9Dg0ijvmlZuc96oQ5SM57UpIzxUYO7tThgH0o2He4/OKTODSfXpQ3TFMGxQQTyaUdOTTMjt1pwPrQK4p+U9KYxxn1p5IqNmC5L8Ack0XEcp8QNWNhpbQxN+/m+Uewry+3iOfetbxbqTanrspU5jiJRfzqrbRFm6daU3yqxzt8zuXLOLAyea2LaPkYJwaqW0Y6dAK1IIx6cVgBct04G2tCIdsYFVYBgjtmr0IweaLAWYVxVhQO/WmIuFp44xmmkUOAycZpQME8U3JHFOBNWguVdRnkgtg0K7nLBcelW4RIF+cgj1oO0jB59adHwu0YwOwovoCFxxwcDvRklcqMinZB6U4HHvSuOxWMuGDMtSpMh71J1z6U0xIwwQKLgPDKeQQR9aXPpUAgQk7crj9aPLccq5pjLH86GB5x19KrZmXsGFKJz0ZSKdguT5zSMoIpnnKfXP0p6sp4zyelUA3G0nPNKp560/r3ppTBzQA4+xozz1470i8cU4gfjRYdwxxzRg/gKTnk9aep9KLAIMdBTwBzimnjp0pwORgcUDQNnt1oAxz3pVyOvWjryelIYYwc8Ype1KOOtBFO4wHXnkUtJ0603djpzSQEnbAoB5NNj5GW4NPxmmMaT+dHfHf1pQOelKB81NjQoPGT1Jpxb14HpQME55pG5GO1JagAOMk0gbnilIwMYz2pOg44ppAKDzg0cE0zHINL909SKdhgRz04pR8ooLcA03vnNIYp9jSlu1IOTQeeBRYAHPSk/z1peelAHPPNMYAcHtSr04oA9SacRkUAN6D1NNI684p5HuB/WlyAMYwKYDFBxQeeMmn/wARpAR1PWgYAECjtjJozn8eaXqOOKBiY/T0pcjtRxn60m7kkdaYx49qQkY6kmmlu2TSbs8+9Fhji2O+cUZGD296Znj0pQMn/GgYuSOuabmnc44oYZ5PagBneo3YAc4zUjdO9QvnvikwRXldj34qhcHg561cmBPU1RnHy1IMzb2TCnkVzt/ccEd63L04Q965LVX+QmiO5jN2Ox+Htz51rOo/heuzU4xmvLfhDeGWW+iY4IbI+leoKMk1o3rYI6ok3cHIpMZHHQUY+uKUZAODSQxoOM54pdxBwKceo6Gj5e1MYA5wf0p45wAfzpg6EgcUp+XnrQMecbeKUZIyahVucCnMx4GadgJVzjnpTh161FuP3akUcDOaYxVyO+KkUg/hTMZwTTwBnrQPYXGabtI6U8ED6U4kHpTAjUnNKRmlppXJ96BoNoprqCBSjjqaaT+FMZVmGAcmvE/iNKG1afHQHA/SvbLvDBvYV4J4+k/4nF0PRsfoKa6mNboefT4a5H1roZ+LQ59BXPDLXgHfNdDdcWrEdBXFV3Rl9k5bxI3/ABKXOMZrzgjLGu/8VvjSl9/8a4A85Jq4fCc7+IngACMSePSoepHNOVD5eR19KRACDWYx27OMnFAUq+e5piD58sOKtuUEe4HntQBAXJyp9akS2Jbg54zVQSHdk81YF4V6dcYodwQTAJIMU9J8E8fjVRpN7Enk5p0WCDRYCaUb1zUXJ6Cngkt7U5gQ9FwHxKfSrESkAYqKNsH8KsxtnGcUDJYQSPerUaHaeahj9RVuJh9aljMu8+8aoOOK0b/79Z79elX0IIz9agfrUxqFsZ5pDI+hwas2g+eq9XLJfmA71SEyoW5pd56jpUeeaQ5xxUjHNIW4pNopgJJp7N0JFAACd2KkVsP81QqfmyTUqkeZk9BQBJnc/FK2MHJ5pqShWJqN2BbPSkBLH8+eKbEpSccd6WEhCMkGpoSvnZbHtTGWw6xhi2MkVCMMpYDgVE5D557mtK1jjWwfIyzUnohrUzC5JO38qZFJ+9G4cZpzkeaVWmxJy2TyKZJeuJo2IVRxgVFI5jC7fyqtyx4ByDU75kizt6cUrWHuMknBzjrRaPidD3zULrwB6UsXyyDtWtPclntuhSeZp9u2c4rstOPK/SvPvB83maWoJyRjvXeaa4IB6dqxlo2VLZHQ54UelZV8MXX1rUQkpzWbqQxMhzUx3EjQ0ltk6+4rrrY5UVxdk379PyrsrM5RfXFao0TLoNTDkVGi/XNSlcYHfrxQWiORA4wfrU6LhRTQpx70/kUPUaHgDFLigEdSaODQhNjhwOKUjPNNFOBqkFwAwacOc0zf29aXIyKAuPB696ac9utJkDJ70uSRTBi4Gc0hPIzQDSEimK4ZIX1NYni7URp+iTuDh3BVR7kVs54rzn4hXvn30VmpO2P529O9C31Im7I5G2TcdzA5Y5P1rYtIgWqpbRZI+tbNtH04rGbuzIsW8Y9K0oY8kAZqC3TgcVehXk4NQMniXHarsC47darwpyOauRjB+lUBIuMU/rTRgZp3OKpDuB5PHalB+bvQBzS46g0wHHGM5oBO3g03P40o46UDFUkDrTxn8cU0HnnFPAHWgQ7JA4oDep5pPp2p2MigYobApQeuaZjvSd8+lFh3JO/Bo4PUUzPf14p3GBTsFxdinOAMmmSQLnpjNSZGM4pc+ozQhkSxuh+9kVMOAcjtSDmndRTTAQjIyOtKFIpwH8qdx0J4pgRnrjGRSEDtUhA9aacbsY5qrjE69acuAOKUKByc8U7j0o3AaAcetL0yCaX+LHSgjnNTYdw/WhfckijtkUnIORzSsUKcGg9elNYnIOKdn86dgFGT0pwT36UwHH1NSLkY96LDEAJPWlAAIPNKOuaa2QcDvQMeMg9OTRxnrzTQSCM0uACCOR3oAXjscU1eppx5HFCgdutNAJ6Y4pCP507ORjkYpuOQKdx2GnnjNA+lKBkkelOUjpjigY1uegxijH5kU/tjik6kHOKAE/h5yaXOAc9qUdMmg4xyaLjEQgjPenZqInY+c/KacT6dKAA889aUY5yaaTg8dDShcHpTGKCOfegnB6/hQOB70YLdqQxN3OOnakLcn3pSoJ470u0Z6ZqkFhpJIA7UoVs81IODxil7HrRcoYFxnJz3pMcdsU89DikIGKAG9fpQcYOaVs4xzQFJ4zTGIzfL2zTdxzzzUgRR1oIVfSlcZESTnHSopB6VMzD6VDIwGRUtjKcuATg4FUbjkGrspBziqU/NSJmPeDg8/XFcnqyHY1djcqCD61zWrxHaeKEzGaMj4YXDW3iqSJuFkQ17cvIHvXz9o9wbLxVbN0UuF/WvoCIhowfXmtHuTT1ViQ/d549KOcUnf6U7PynrmgsO3IyaOBjA5pNxJwOaec8cUxijB5ppAPPag5PSnYAHrQCIymOlJtOcj9KmIyOtGD07U0MEG7rxUq8YzTAD2pwqgQ5gOtIAaRSGHrindqBihCPencge1CnAGaGINACEjFNGM8GgikA5yKaKFPSoXGDwetTHgetQydOooTGineSAROxzkCvnzxpOZNTuX6gua971SUR2sxAH3T/KvnHxDLulkY85NO/us5626MG1G++X0zW3qbbbFjzzisjS1DXi56CtTXW2Wij1rhqO8jJ6ROK8XuRYwoK4rGTgV1vi5yfLUdMVyyqSCQOc1pH4DDqx27yvl9RQgyvHU1HODvBPQ0qZzkE1mMtyRD7Pk4/CqagthSflFTrvY4OeajcLEvPX0oQCSweWwwc5qvMhQ4PBqwJd8i7ugpLwl5N2BjFAFUDNTwrzSIBj5qMY6NQA8sRJx0p2/wCc1GOlO7g4BoAsRkkg1aQcZqrHj86vx4K+9DYySIdM1cj4XJqpHyelW0Q1LGjOvSSxrPf3rRveDis2TrWi2IGEflUDGpj0qF+vFSMaOTWhpiZlUVQHQEGtfRIi91GMVUdxMxMGmZ5qRqjP3sVIwbGBR/yzyaPanD7vsaAEQU5hg8dKfs+UYp20MRmi4yr1Oe1SxqXOKe0YDH0ojbZ2PsaAHSLsYDoMVIi7zkdFHaos5TJGaEkIBA4B60ATIpKnj3p6PNtx29KZBJsfJ5HSpxcRqNvvk5ouBDCjBnds8d6iPzScE1NLcKY9qfxHmmxRsp3MOtCAs2iEN8/A96n8vccIOKiYlxtXHNWLF1UgueelDGUmhKoxP3j61XBAbArWu3RssAMdBist02tVU2KSPTPAUoexZc8j/wCvXomktwpz1ryr4ez4JTOMjufrXpmlPwKmoveYnrE62I7ohiqWqrwjVatTlPpUepLm3BxWS3JTI7JuUOa7TTDuiXPpXC2jYAAPNdror7oAenatehombcPHp061Jg7s1Ajd8VI0hxzihIq5OOOlKOh9agR9x61IDTGOI4yKXOD0pvfr9aUcmmA4GlY8e9J6Uv1oQAAO4o7UY9aD29aBgfel4FJ2zxRjmmFwB556UFsc9qQ9OlIemKLgQ3UwhhdycbR+leSajK13qNxMxzliB9K7/wAX3H2fTJQv8Q2ivPoEw2MfWm3aJhN6lu1i4HX6VqQryOKqW6cDqK0rdORXOSXIlGKuRryO3rUEK9KuQrmgEyaJcAEjNWF/KmRjC461KMDFUhiqMelOXPakBH4Uo+tUA8deBRj3oHX3pR1oGKBnvzS7SKAQTyKUN65pjG4NKDz34p6kEk/hQByKLgAzjrxTs9gKCBn3oPT60DQbvTpTic8imY460cn8KB3Hd+1L0JppBx70bjnmncB4AH1p2eOvFMU8UucH3osMfgEcdaUZFIDjnNLnvSAAevNKc9qaBk5o3HJJqhkgPr0NO2ggZ6+tRj7wOaeeeKdwHMvHFAx+VKpwOeRRwcZoGLgZ5xg96Q4PNKRjOaTPHFAxp4z6UgHze9PI49aMc5/lQMj7804dulKRxjFIP0pgLjJpVbI5pB6U/oB70hjc5IzRuIYe9GM9etDDuOtMYueMZ+lPDdAegqI84NOByMnrSsA/PHHT0pOAfT0pu7PPU00nmmkMkzzmkBwD/WmK4ztOfpSqc0DHA5X0pcdMU0EdutO4HIpBYQ9adj8aUD2o6U0AmPSkA5zT8U3vyOfWqGNbBBB4zUcZAJU5zUx6Yxk0yVTnI6jmgY/AOc+lLnjrTVwygjFKeBQAhORwOtOPt6Ug/MU4AdzTKsN9cfpQAccZpwwaXPYUBYQg8/ypBz0zTuwPWkPegYdO/wCVKR155prMMcZphfnpRYLj8gKcCmliM7c00uSBTcnn1NUkK45mPuOaRj680nJ70pAweaGWiNz1qvKT+dWHIHSoJMnNQx2Kz5waqSg4NW2HFQMvGKRJQlj3DpWRqFuWQ4HtXQPGeOKhktt3UcUmJo8r1y1a0u4bpVPySAn869r0G6F5pFrMpyWjBNcpqGjR3MTKwBBrb8KwvaWn2ZzwnC/SrWqM0uVnRDqMdaMdxQjD1xTsgEjIIoKEA259e1OXPX86QDg7aeoyDTAB7daOgOKcoAGMYPtRt4z6U0MaAQfenA5IzShSR0FJtJ5I5FCGPHemltqnHagZ6AUFCe2KoCK0Y4bOeuanDADp1oRNopWUN1pJ9xjgScelBBpF44p4NMBhBxQO1PprDmhAhD6VDJwuBUp4JzUMhxyOtMpHNeK5TBpk0i5A24r551p8u2K90+IVxs0mRBwWIrwTWGy5olpA5aushuiJm4LVPr7ZbaB0p2gpwWHJqnq7Fro+2c1wS1k2RLZI4nxRJm4AyOKw5VKBSOh5q54glL3h9M1nEls8k4rZ6RRgu5PKwkCjjHrTVAVsHHFQ53DC9RUTOxPv61mMvSzKjnbUHlNOSxPPtTI1yeeSeatwSeUCAuc9c0bbAU0Q7jyKdcnAAWrDMu4tx0qEAO3PHegCsNzdeBUiDJwcU4A5bp+VSRwlwT0xQMaORgDNAU5GDQMKxFPQ4YZoESoNv0qzGx2j0qH0xjmpkHA70DLUKk1oIDt6VTtiAea0PMHl44zUMpGPf/eNZjnmtG9bLms1+ta9DMa1QMfSpT1qJ+T061IwXlun1ro/CsJkvkx74/KudQEsABxXcfD+3M2rwjBI55x04NVeyuJnCjk9SajYc5qZRycHNRtjvUDIacTwAKQ4HfNNJ+bnpTAsB/kx3pm7qOQai5z7VPGmVzQAoJKD8qG4TNTCMCMGkKqVyCMCkMYMiMe5phQj588VIMHjPApsj5Ax2pgHYc856UrxnzFHrSIu6Qe3NShgsoY57UAIqBJxu+6KvzSp5akKBniqk6Z+ZeaZligGeKNw2LRwU3xsBUMjHOO9RxllJHOKmCb3GThjQA/GyMHPPvVWV8k8jrVqQI+FDYI9TUEsezFOL1EzpPA8/l36qxxnP9fevWdIkG9h+XNeJ+G5zFqEZz3r2LSJcXCnH3uaqruC2O5s3yOnWn3a7oCOtVbFuF71dm5Rh0rme5CMu2znmuy8PuDEAa4yE4Yiuo0GTAxnpWpaOqTBxRJ14FRwvlan61S3KuMDc8cVMhyf1qHGD8tSA+tJ7lJkm4Uqk5qPPX1qRRjGeaARJ/OjNLjIyDSn3FO4XAUHOPemj26UucUBcCTgDGaD1o460n06UwFzikIPamn8xSOSAfagDjPHMwZ44f8AgVcxAmWB9a1PE03n6pJjoo2iqcK4HSlUeiRzt6lu3XpWhB1qpADtHf3q/AuCRx65rIm5ch5xxV6FeAaqQLnFX4h3oBMlXpx1p2MduaF/WnDmmixuOKcOlH4Ud/SquA4Zp30pv5U4dKLgOH604DdgnpnpTQehx+VKMH0/Gi4xxUHpxQqnv+VHGBz+VEfbnmncY5c45Bpw7Z5poYHqfenDrnrmgAApee/SjI7UHFMYEcUbQeO9KMj6UqnJpXGM2kZpRntT8+tNJGeKYxQfwoBHalHJ4xRjGDQMU9DxSA9aRs8YpD1xzVICVRzmnMCRnuKjHHfOKcCScmmND1JyQepp2eeR+VMPX196CwyetTYaJC2RzzQSB0x9Kj2knJxTlUgdKv1C4uACetH86UKd2cUd+OKkpBg5zR06UoPGKBngUwDkDjrRikPqe1AOfzpjHL6H86acn6Up4PFI3A4pDGpwcGg9Rx+VDdBSDIbJxTAXPPFMJ5OM0Mew/OgYA9+9AxQoC88+9OUjOBTFGfpTh14oGSDH5U4e3SmLzkGnqCBQMUdM+9O700dPrSbvm96dgHk45IpCfrTcnnOaMkn2p2GL06ZpCenX3pOOc5+lGSeoGKYIiJ8t+B8p/nUo6A5/CkdQ2Rjr3pkWQdrfeHH1ouOxPn9aUmmnn/ClPQd/pSKAjJFAPJxz70vT1+lNJABx3oAM4B4NIQR360A7uwzQQce5qgEI696GGMZFOwRSdiKBoUgD0owB9aFTJGfpShDnrSuVYYTzgU1sf/rqZkH4+tRtHgZobCxA/FQyHg1PIpGKqy5x7VLC5CTmmHBpWzzUefU0CuLjnFORAe1NU/TFWICu4dMVSVwHx2wOAyjFWBbBCGQHI4p8ZXHrUxIKnqKtKwNaEa9vapV6DAqLn0p4Py1JBJx27UoOc4pq/dz2pRhST0FAxw6nP4U4k8+lN6kClJwOODTAdk5wKATn5qMgAUvXGaaACSKcD8vzUuMjmm4AHQ0xjgeOaTcCcUgx0NNIGeKBj896kDLjmoATn2p5PTA/Om0IeQO1Nx1xSnnigY6GgBjemKrTH04qw45wPzqpdsNh5/GkWtjzb4mz/uo0HuT+leK6k4aU4716j8SrjN0FyPlrye4O+5H1oqO0UjilrJm5palLXOKwb1yWmbP3e9dCP3VmfpXJ6vL5Wmyv0LGuFakTZwuoAzXLEc5PWoNjKGAFS+Z85c4pY5BvJYcn1raZlErCNlXcenal8sYyanu3HCoOBUCqTjOdprMYRnYeuM1a81AgDYzjqKriHL+wFRAYfk8D3otcCwg3Nz0pr5JO3gUrEBsqeMUoKkccUAMjGOMZz7UskjINvrShwqkg9arysG+tADgcHJ71IrDbk1Wzk0obBwOhoA0VYEirAOAMZxVKLGBmri9BQMtwsT1PNXlxtrOh68nirYchT3FSxlC9xuwOtZz9cmr94ck1QY81p0II2zUbe/ankGmH696kY+Llq9P+E1v5mrxNjOAe3sfavM7cZfn17V7X8HLMeY0xGAvQ4+vtSqu1NivY8L3YprGk701ucUxjM+tHtinYzTQKAHAYHpVqNh5eKqgZBz1qSNsD5umKAJS+fpSBgynioi29wB9KkaPyyB68mgCIbiwUdKldCp9DTC2wgjtzUm4yHI+tAye3TMYJ6k4qO44YZHA/nSwSeW4J6DpSysOe560dQEdz5YB602Bxkk/lSMQabAuZApoAtEE4OOvpR5wSTpVhwqIfXFVGQuwNCAUEli+KkbEqZx0FQF9o46CkSQhGA70CLFk5iukYV67os4aGCXOB3NeNxsd+R2r07wrcGfSwM5K4rSprG4lueoWLnC56Vr9QAB2rndKm8yBGz7VvxnKKx6etcrIMwjbcsPet3RXIfrxWLejZOG7GtDSJP36+/WtFsWjtYH+Uc1aTp61RtOVGaupx9KbKJQO1OAGfQ+lIhqTGTmjcdxjrxxmlUkZHNBzuzmkyQe1PoFyVG6D86kbnHTNQg4P9akVuKEwF4HFBA7GkGTzQPSmMPrilzgUjdM96Rj2poLinkdMVXu2Edu7E9BU3QcdayvEU/laZMfajdibsjgrgmW5kY9WYmpoU+n0qvGctk/Wr0PHHvWc3qc5agTgcVehX8arwjgYzV+AcDjIrO4iwiYAxVtF4FQxDpmpxyPWmmOw5eRxTgeOlNJ7Cl6iqKHUoIwOMU0ce1LgepNMBwFLz0HSkBFOzRcYZbOKUdaTPbvS5zxTuAvNPUAD39aYOOvSlyegoGSbfbApegHftTAcAGjd2OPrTGSDt2xS9Bn1qMEZ65NLjPGSBQMlyP/rUvbpxUS8dKeDjpxQMcBnrzS47frTUPU070oGJtGDRkd6XnpjP0pCfUHPtTGGe1KRgdD9KarYPel3DPNO4CrweBwe1OIwOaYGABPSlVh0/SmA85xgUvb3pu70NA55zQkO48fnTgcnC9femBeevFKFFMaJKcfXGBTQCKB+JFAwA9PzpQcUnUd6d6dBQMaQODTQPSn8kAY+lIOvNMYAcCl9uxo5JzzmkI6YzmhAJyOvaoQSwwCcetOOWOB09aUgbhgYFDGhFG3p+NKBtPHSjp060KeO1IYo7evpSjnoOlMGckdvWnY5poY8EgdqevfnJqEnA6Z+lHmAcHI780bjuWMjOBSYBz61H5qjHzCjcCOCMVSQD2ycDr3pAc4FMLHik3dqeiGkSEgfX1NBHTimcGnjpzSckUkOAxnH0pjrzuAwak9qDwDzSuOwKQVzil4xzTFwpOMYNPLAjGOtAxCBzRgdhQOvOKUsBVCEwMHA6UrLxznrxQp5PNIeetBSFA49+lJ34zx7UHO40nJNMB3ufypdwHemEYPHNHuKVhpj9/wAvpUbsOnUUEZ4pjcCk0MZI+OgNVJXzU8hA69KpyEAZNSDZHITzVZj81SSNjPpVV32twaZJJuwODT45egzVGSYVA10FzyKaYrnSW10ucE8VcWZWOAQa4eXVBGMk4rV8J3v9pNLIDlIzs61otri5+h06n0xTwD1piYzzmn44OM4qRIXnIBzz6UvXnpikxg89KPlFMew/cOBxmlDDv96oyoPT8KcPcH8qYxSWz0zUmCVz3pucj+VOyOh60AOXPHr6Uvfmox94jvSg4PNMBSAOaAQB2pGpmMnFA7D8+3NAbPb8aaqjvkYp+Bx60wHA980pwfqKgdiB0P1piueKFqOxMzBeTWdqL7YHI7VaZ8H3rF8Q3SxWMh44HHFG4S0R4r48uvN1GVs8dK4e1UyXqjuTW54luPNupWzxuNZuhx77ouT0rKvKyOJasv6o+yED14rivF0nl2EcXc5rrNXbfN5Y7VwPjK43XQjByF7Vz0lqjOo9Dn098VHK58zC9O1PiwSPX3psuFIIq5vUks28QlOJKSQLGTzmo4t2flPLVFKGDkHk56VAFiIZYAnANRyRbZSByM0iOV5z0pwyV3Z5PWkAkmAcHpUB4Jx0qZxtAPrTAoJ9qYEZz60jRnr2p+OTmpGJkQADAFAysRjp1pyg54pWBHFOjBJoEWoVJFXY0+UeveqsYwPar0f3RigZNCnOKuCMbeOlVoRVzPyemKljMe9TD96z3FaN8fnNZ78HitOhBEentTCM/SpD9KZipAtWSbpFHc19CfCu18nTfMx97GOPr7V4LosPm3aADvX0t4Itfs+jwjAHGenuazxHwpETdonyZmlAx9KdxTSOa0NBPWmgc4pe5Hekx81ADgBnGaJOQMdqQDHOaVOc5PWgBI8KwapXl3nkioSMZ9Kap+bjkUAWCobk9hQrhc4PtQuPKJzUeO/btQMlLZwe2ac5+UeppgJGadGSQSaAH7dqqD3pOkmR2o3lnGRxT0IG48UIRo2cP2rrwcU5bIq7DPSqNrPJCxZW4Bqy1455z170NPoUmrEE1uRGSarLEfLJPHNWROzqyt0pSjIikjg9KNhblbbtHcGu38B3ed8LHg//AF6424IHpmtTwndeRqCDOATzWq96LRL0Z7VoMv7sx5+7XU2zbk29utcRpMoS5xnAPpXYWT8DJ5rlkiXuLqCYCsBwOKfpzbJVJp1yu6L1OearQuBJlTTgwTO90+QeWv0rQjyRWFpUgaIc54rct2OASau5RMDzUytntios5PrTlbBoHck4xyKa3sKdnIpuMH2poBqgkHPSnhSMd6Qc854p45pMdwDYxS5Ipo6471IRx70x3AEGmnlvT0oBHrSMOM5HFAhD71z3i+TFiEPG41v7sdelcz4xb93Cp9TTjuKb0OYQAdquQjgGqsQGeauQ4z6VjLc5y9COavwdqoQ9sflV+A+hqQLcYqYE+uBUCYxUg7Ypool3UZ+uaYMYOacKsLj8/lSjtjikHXA5oblSF4PY0XAeBnr0peBVIi5H3XU/WgPdj+FCPWixSLvFKMepqkZ515aLP0FNjvskh4ZAR7U7MDRB4pV69KqLeRn+Fh+FWUYNyKYyROfcelKOTz1+lM5wO1IWI6A5pjJQO/Y0uQM9M1B8x5FSKo/i5PpRcBxl2g00O7cIMD1NLtWndOO1BQRgqpyc1KvTJqMj8KcpBJGKLDuPBPf8KacjPGaXIAoOSeOlUhpijJHSkKk9RR06U7POeKGgAqAKCOnApXYYPt603qMmpRQoxnpxThjPNMzg0oIxzirQEnuO1PyCPwqNc+1OGNvA+tN6Aheh6U9T2/pR2GMGm8fjUosecYHNL0xnp2qPcaA3r+NUA/6daXrng0wHIoLZ+tAx2c8cYFMyWOOQPX1o+8w44pxwBz1pjEI/ugYFNPSn4z04pOTQgGAdCTmkYAnFOJx7ikzwTimNEfzL0ORT0bI4pQBxikI4460h2Hjn6UpXI5xUYJxyeKcpz0ouMYI0DEbevNKY8cAkU8gkZA6Uo+ancdiIKwPJyKeo45qQLxRt6YFMaAL6c0ds84pxBz6Uo5zg0WGhpBz7UjDnAp5HB9aYoLMen5UWHcaHVX2E/MegqYDPU1Xmtg8ySHhl71YXsOvpSGGM0mDyCOKfg96THBFOwxOg4NGMA9+aBgUvGPXmqAQ5pD1p2O1I2MDNAwx1xSdDRkYz0FNY/lTsFxcjHNRueKUmoJjwTUtDuRzNgVScjNSynrk1TduOamwiKVgCcGqUj81PO2AfSs+d+M9qCGiC4mxkA9OlZl1d4U81Ley4yc1hX0+A3WkRIzPEOqNFC53Y4r074ZRbPDEE3ef95wfWvFtWZJJAspyrHFfQPguNYPDWnKv3RCuPyrSTskkRS1bbNkc9Kfs785+tOC46Dmndj2BoNhgHtz6UuAV6dPWlYntjFMDcmmhjgQpJI5p+QR8p60wrk5HX0xSqMnnANMCQHIx1xSEZGT1oAx35PWpKY0RnnPPNJ3x3p+0Y7UuB1pDEC469aQg9sU8DH0ppweDQAwuQeetPHIHpTJPl6Dr3pgYjPWqCxKVJ9KiIIPNKshPBoJFGwyvKcfSuL8dXXladJgkEqa7G4O0E9RXlfxKvuBED+FNaMxqvQ8q1eUu5/vE1b0KPbAznOayb598uOp9q3rZfJ0wdiRXHXd9DnRl3bgzu57V5nrMxmvpG684rvdVmEdpPLnBIwK83lJaRmPOadPqzGW6Qm0qn16VHwUPc1IHGAMc04RrvGOBiobAbby+WBnk0v33LN0p/ljy/ftVQkgkZNAEryL82KRXwuO9MKZFNAO73oAkkkGwKeTUaEn2qXy89agHUjtQgJiucN2p+4BeKjZvlCimMeAKAJFyxFXYIkYEk/hWerEYqxHLggetFho0zEghB7U9BgACqqysVA7Vci+6PWlsMtQDn2qywwh7iqsZOTirQxtxSYGPe/frPkHNaF7jccdaznrToQM70ijsaKcnLrxSQHS+D7YzajGMd/SvpXRojDaxJjGBjFeFfDSyMt+jFeh9K9+s1IUDpgdaxq6zSMqr0SPjEjHSkXngU7qaRenFamxGRj6Uq8nNB5pVHGeMUAPfk4FNXJGMUoPPNOUcYFAET4BOaaDxx3qWRckA1E4w2PSgCcgCFfekBBC+1ITuTjtTVPPSgZPIB1B5PFRhwBgHk0h559aQoVznrQImA3OoFOkwHwOeKZFwhOcVKhHlEnBNCGWhH/owIGc0hUlApGBSQ3arDtHUVIJgE3dSaNR6FVX2McjgVNLcq6jA6VG6lkZgOKpkHoM0bi2Hs2/5jViwk8m5VunNVyjog3DrSI2DmtKbJZ7PpFz5kFvMDXcWMmcc/WvK/B9z5+nmInlen616LpM26FSetYTVnYmWp0TAlT6VlqSkuCOhrSiIZBis66G2fPTPNTF6iR1OhyjYvPtXTWpridElIIBOM9BXZWLZUGrKL5PHtR3yKTr/jQvBqugEozg5pG4AIzmgEFD6d8U4jI6gD2pILjFPJGcAVKMgZ71Dgg8c09X46UNjQ8dc4p5PvUYb86UHn60wbFHDHFJ0oJyOKQHigLit3x+Vcf4xYtNCoPTJrrWOAATiuN8XsRdxj2prcmb0MWPP61bhPQ1TUg9Ks2/TnNYswuaMJq9CcVQhHAq/DyKi4XLcfIB71OgqCLjFTq2eadxj1HenY7GmFvalU+n1qkxjwDSgUme4py0x3FwMc0uBjikXn2FLu4oKQox3NV7gbZFdQD2NS5GKVhuUg0ILiqFYfdH5U8DAwMCq1u+MxseR+tWQcgVQx3tmkA60nGeetOHGKYxRj/wCsKUDGc9fSk4/+vSkgYoC48Dj2oHXNNBGMYpQeM9qYx+e5paZnilHPbimO4/Pc0o5PGKTooo60ikKDS5HQdaQcdB0pBwO9MaBxlTn0pVOUA9qQ9xjimxnKe+cUDHngClY/lSdBz1pQc46VSGKpPfpUoAxUXGcAU8dOetMESe45NKOvOM00AY5pUyc8UkUBzj3poGWOelKw5HNNzgkDgimMf06imkZOTwKNucHP4UoHABoGOHsOaYxIFKSSQB1oI3jkfhTAbG+VzTlORz+VIEG3HQUqjAGaCkOI5BxzTcc809c/jS4yBxQMjAweO/akxjrUgUj60EE9qYxMj0FKODwM0hJHA796VBgnigY/HGCOKbH8pxxThng01+SCPxoHYkHTjpQBk8Ui8nNKAB060BYUjjNIQMHA5xRgZwetK2Rz270xkcp4xzTlGFwelIFyS2cjt9KlI9qY0MxnseaUdPpS8d+9IQSaY0Gcgd6OnUZoJGT9KQniiwDiRzk+1NYZPTBo7Y/GkK54zTHYKa2cHHIpSOo5+hoK9BTAZjHBzTfpUuB600r6d6LhykdRSAH6VKenOagmbjipZaKk3J9KpyDnmrMzc9KpTNjJ61DFcr3B+U5NZVy2FNX7hsg1kXbc461JDM29k4yCa53UZvlb69a1759oPWuX1SYgH0poxkzNbE+oRRsN2ZAK+k9Ej8nSrSPH3Y1H6V8yaFK1z4psYUPBmXI/GvqaEbI1XsBim9JJDpaxbJ0JIxmhs8g0ikcYpWwx/wAKs1SA9OT7UgYbfelwDTQO2PrTAk3fL+nFKDlQTTep6cd6U4xgHimgsOzyc8/hTuSOaYe3FKORjnFO40iTP50DOKaMj7vOKdzjPagYnzc8cUh6Z6GnqcikJA+lIZHg8Z59KcAM/wCNKRkelNB6c1XQCKUYPSoXJxVl1z1qu/GaSKsUryUCJjnHFeF+O70z6lKQflXivYNeuVgtJXJAwD3r5/8AEV15lzM2c5Y1TdkclZ3djHt18+9UA8Zre1F9luqjHSsvQYt0pkI6Vc1GTdMe6ivPm7yMuljj/Ftx5VqsOeTya4pmyuQcVteLLvzr8gcovFYABNbJcsLGG7bDJLA1b2gwMzfhUG3P0qRvlQKe1ZsYxXOBkYxSAB3J7U7PzH0xUWecDkUAOkBXHNPTbxkVEzF2BxwKsRYYsT0ApAOLjyGAqrEATyKGPU+vSmqOOuKYEgx5xyeKjcjcQBTnwF460wcnmgY70p8eMjFM+9jFTR4Bx+NAFyFPkya0oBwAKowqTGMGrkZKgUmMvLDtIwalWM7MmoYmPFXPmETAjFSxmBfDDms1h9K1L4fO2RWZJ1rboZEff2qSAZkApmKns/8AXKDk80luM9j+FVltXzSvHv8AjXr1omdv+c1wXw8tfK0uOTAG4f416DadBnrXPvNs56jvI+KG+nNNz6U/nNNPWtjpG1Iv3eajPSl38CgCXaCvB/ClJVV4696jXPFDKc8UWAMksCTxmklA3nmpSoAAFRso346UDEQqENES7n/WgY2kZ5p1u+xy3YDpQBKkWx/X0qOZssalklDAHOM1A2DxQAkbZOD0pRkEjNCJjJ6YpAOTigQ9EJOe9WniKqvPFWdOtWkQn1qWaAkEOelF+g7EBYLatjqaqpgHcR096sMA0fl9xUHlZXI6UWAkkO9Nw6kYqoQQenA7Vb3BUA6GmEZI9O9OOgmdD4NuzDd+XnAb/wCvXq2iy4yuOeteIabOILpGXjmvWtGut3lSqeGp1V1IZ39o+UAJOai1FcqG44qvp8ucZ596vXA3wtjk1z7MhEemzbWXnBBrtdMn3YGa88t5Nr4PUV1ujzkgVqizr1bNOJI5qvA2VFWOo5FAh6nA7c1IuSORUajJHFSlcnIGKm4xD/OlHP4UoAxjrilxxz0NMBO3rSdetOPHPemHjpTQXELEHnGKU4I4o4YZ7+9MyB9Kdxi1xXjJ8XyLjtXaEjaccVxPjA4vIyfShbkTehlJzj3q3AMdapRNxVuLp9KxZhc0IiavQn1/OqEPQVehxx24qRltD3qfBIPPNQQ9s5qZT6DigEyRRwMnPFPUc0wGlBPWqTHclAA7UufSowcDGc0vB+tNFIcT7cUhPXAoA5pVGO1UO4DJAzThgd+tKCDyOtOGO4FAIo3wZGSeMcqcN9PWrcciyKGXkEZBpzAFCrKMHrUFqBGTGenYe1PoUizznJBpQeehpM5HTmnfWmFxMjOKcOT0pOMjANOyehwKY7inNKAO9ITzg8D2pc5YdKY7ju2B2pR9aYH9elJg7gfXvSGSkjHJ5pwqIsA2MUoYdxTGSk8cUg9TTM7s4py5PBpFIOMY61GrYYjHQ5p5Xk46+lMAAds8kimMk3Z+hpRx0GaZgHkVIOnrVDFH0qVG9Kip69BTGSr14oUYzTVPJo8xQOetFh3HEDFIBjJFRPMACRyaFZ2XKjjtmkUibORzxSHOOtRqG3ZboalI60xjM9MU4MMDjFGPUUHOAKYw3DoetOHUU1cE54pwxkY5FBSHjk8HilGBznrSDHBHWlxjGD9aQxSoPTrSMpyaXPbr70hIABHWqQDQvAzTgajeVEH7xwoPrUJvI84TL/7ozRuNMtMc8YpMAj3oHzANjHsaeCPTpQhjVGD3pwY5wetC46ilIGc9adhhkdcZprZJ29R/KlIIHFIOX5//AF00gHH0/pS8ADimknGaMk5yMCnYY485puO+Mn2oJ6+nvTS3AA6daaAU80FWx6/4UgOe2PejPJNMYnoRwBS5PT9aMf40hXn2oGkO3DmgHjHpQRjHHNN/iwBigsU89elNbuRR1GKGPr+lS2FiJ+evFVJh8xOatueCc8VTmPoc1IFSWqMxwauTnjqKoz89etIkpTtjNY18+M4PPpWpcH2rFvT1qSJMxtQfKmuV1NshhnvXSXzcHngVzV9973oTMZIrfDi3M/ju2Ug/Kd/5V9QqMjmvBfhZp6nxck47RmvfV6DFNvmnc1pq0Ehy/KeeKkwO/emgc8enSn9uwrUoacHNG1scUvTIp+Plx/KmMaRj06U36ipGAwc5qM5BzjikMDnsakAwMnrSbfSncgciqAMEDnij+dIX7UbwfegYoHp0p20Hn07Uwtjp0qJ2xytDYWFdsNmoy/PTrTXY4pBQhskEnGO9RyMCDjgUxmIz/KqV3OUibBqhXscV8RNQ+z2RjDDLe/1rw7VJS8hx3Nd/8QdRE12yK3yr7154oNxeKoHGaio7KxwyfNK5uaXGILPeeM81l6rcCK1mlY844rWvW8m3SJeCR0Fcd4zuxDbiBWwT15riguaRM3ZHFXpM07Oe5qJk2cetODhiM4pLlt7D2rab1sZJDoPnYCkuQcgY+tPt/kGcdaWUbm56+9ZdRkCpg880BcZIFTSkA9cA0ZAAUdTTAgfAQY696iLEdzU8iBFBJ5NQ43N6ihAIhJND5B9qcylR9aXbuAAoGRgkketSKtMPykCngkDigBu3B5/OpogAcmohknntzinpuL9OKANKFsqKvxjgZ61nQDAAB57VpQdB60mCLluvzc1osB5B7cVStVOeauuCIiKl7j6HOX3MjVmuOfxrUvx+8PrWa/WtuhmiIDPWrmmReZeRKOpNVVGTmt7wjbfaNXtwBk7hSWmoz6D8M23kafbxgdFHtXU2gx6ZrK0yPCAeg7VtQAYxgkGueBxyd2fEuznOc0xh81TOMjmo2HPNbHaMbFNC4TIqVunbmo8/LjNACBttOLYGeee1QnJOM8Uqnn6UASliemaaAxYbqmjGc8UjkbjQAwp82cUjRlEz61LG65I7ikd94wBQAxUyo5pAuGIY1MjDy8cbulIOCe5PagZJDEWUlulM8oBjUsUh27RSORjHc0IC3DO0MS4JouZxKgwTmq7PhAuBxT7cKXG84p2W4XLMCKiDcOT+lS7EMKhce9MdwUcA8Cqcc5Hy560rXC9iUwb5gg6etLdQrGpCdQcU63kXzTnJNBG4FjkrmlrcZQ+6eRyK9C8H3vnWnllvmX/69cHdKFJPOTzWt4SvPs94oJ4Nav3ombR7VpU+9F5roI23r+GK4rSbjEhB6Hpiuss5MqAT1rmkjMq3I8uc4ra0a4wwBNZ2ooNm+madLtYVUXdFHpdg+Y1Pf3q+uMdDWBo84eIe1bsT/LyaqwmSA+vFSA4+lMBB9804jNKwXH5yfenHjioSCpJ7U9HyMj8aYDuR1NRMDzUp5+lNJGMHpTuBGCfxFNPU4p+BzzSMQf8AGkO4zOfwrivG3/H5AeeQa7U/dzjiuO8cEb7Y+uf6UR3JnsYULZI+lXYeSMms2B+Rjir8R+YZ71kznNGI9OO1XYSMDms63PuQKvQnKA9qgdy/ESPerCduwqvGe9Tq1CBEoHNKG/Cmqccd6ARmrQx4pytUYGetOH6Ux3JFpwpg7EYp3QUxocT6D9KNw9KZ/KgZ9KaKuP8AvHr0qOYELvXqPbtTh+FKeeOtO4xYn3oDn8qkyTVdVKORztNS49aLjRITwOeaAR603FIBg800xjsgilB7mkwD0HWnDOPei5Vhy++OaXOD7UgJxmhQRz0p3GKG57mnZAGBn/Cl74pehoGNUcknpT8+lJn0NIQMYoKQDIbr+NI3MwIpTjHr7UjdAe+aaAd0PT8KXePXHsaafu8UwRZ6nimNEhmUeppBK7fcXj3pyooA9qeBiquOwKJGHzMPwpdgC55Jp4PPTFIfvfSh3Y0ATCEAZptqSYgO461ID9BmoYm2yOp4xilYosdOfwpw6elMVi2QBShe/emUh24dO9IMgYpQoo6n0FMYEjFKv5Cmjpg0/qKTKF4z0oB9OlNIO7mhlJBAOM96dgGSziMYxmq264l5TCj1Iq3HCijPUjvSkelO47dysLRCQ0pZ29CeKsxxomNiKv4YoCjv2p4xjB+uaBpDWcqRnv61IDwM9aidQyHHXtT4m3ovHPf2pjHcUuM8UnTPvS8/WmMCQB82eKUcjPX8KQjpnpQvsefamMaVPvSHJqYdOtMcckHigdhnXgdqXBGfSlwQP/rUmcdqYAO44/KjjJBBpcDseKTtjjFA0BOAeOaCeenNLkH05pCATntTGNLHoc0pbuRmhsdM005BxQMXPf8ApTW47UE4prEGpY0iKXJ+lVJieatSdD0qpOwyeoqGBSmPbv61SnPYircnf3qlPgjFDJM+5P8Ak1h3zc9a2blhtOf0rCvT14qSGYeotgHmuW1CZVOTXR6ietcVrxYk7Dk+lVFXZzzbR6X8FYxc6vNc87UQrXtyKPyryD9ny2K6FeTMPmabGfbFeuoPXn6Uo/EzoivdRKzA9zUfb1p+M8Z4oPA65zWqLEXJP0qTd68VHjnFPUAg0xEmAQcU3G0kHmnduaRj6mgYuMjigZIIzzQBjpxSgnv+dMBuykKBeak5PSkY460DIWB6nn0pobOc8VMcEc0wqDTQDCARzUTDb0HFSsD60wkYx2oGVpidpwRWB4guxa2cjk4wvBrcuG2A8jBrzr4i6iIoTCp6jHB+tMyqS5UeWeIrwy3Er7s5JNUtDh8yUysOBzVbUJPMlK571q2yi104nozDiuavLoci7iTyCS5eRj8kY6dq8x8S3putQkOc4OAO1dt4huvsOlMM/PJmvNJn3yMxOOamkrLmM5u7sRM2CKemScDqajK5xjrUijaQMc1L1ESRq6nHp3qQKckseB61IoXlmwMdKrNIzNj0pARynL/N0qUMARjrTGjO4Me/vUkbAPkc0MCCU4PNNDBTnsKsOAxJIwO1V5Vx7ZoAbv8AmyxwKlhcDJIqBY8kc/hUuMEDPSgYN8zZH05pDkHrUyj5TioW4Y9aAJEAOcnHarChflC81Tzxmp4HywoA0o02gdq0IQAoP86pQsCgq/EflAxmkxl23bOBirUxJi+U8VDbICK0ZYwtv0GakdtDlL3lzWawrW1AfOay2GWrYyQxRXc/Cq1NxrqsR8kYya4pFycV658KLEQWMlwRhpTgfhUz+EU3yxZ6xYY2g9617cc9Kx7EDaK2YPXtWaRxrc+J3HHFRkY71akTjgVVcHNWd4xh6VG4xUx6fhULHJ5oARVIBbvTRnOafzzQvHXvQA8PgVFIWY/WhhhvapIwM5OMYoAZEcAipIuWx096h/iPTrUmMNntQA8OFcgDinMwJBHU1GCOnHNKRghjQMsW7qoIK5Y1YeDcu8cH0qkDgjHWrRchdpPJFDAgUEsAeaV3ORUoZQMetK6KTkdMUAQbnwR1pIY2dhtHenoME5OKsWrIo54NMQ6OIxzjd1qYHbGy7sE1HKCxDZ4qUKrx78A4FJjKd83I7/4VFZSmKdW7g09wZGz2HU1Bja3Wrg7Es9Y0K8823jkU845rt9LuMoOma8i8HX3WImvRtLuMYIPFZTWpkzrZMSRH6VmQkxyEe9X7WQMue1UrxCk25e9ZxetgR1mgXPOCeDXVWzbl5rzrSJyjqeBXdabLvQHtWrGzWQkkYqVW45FQIfQ1KrYGOc1KE2Pxk/rQB6UisfWnFvQUxCEZHHSgHtTsnFM3c89qY7gTgnPTtQ2fxpDkdDkfypACuck0Bca3cVyPj2M+RbOP4WNdgTuHfiub8bpu0dnH8JH86E9QlscRD1HPetCMnI/nWbEeKvRnOM9qzluc7NKFvzq5Cw6VnQnJx2q5ARn2qBGpEx6VZVqpQn9atoex6UBcl7/WngAVGD+JpwODnNMZIO3oaeT0qJTmng4pjTHg96M5600ZyKcB69qaKuOA9T1pVGeaQdOetOxyKZSGlRnJFPA4yaT6c0vegoDzThwBnrTWHoeacnQZpgOFAHI96B1oB7UxjugooHSjrzTKRIo/Kn4B61CTkYzTyxJ6dqQ0x+MdKXoOtM3ZOB+FKTxTKuIBycUp/SjOcilPp2ouMQY6/rSEZGAKdgAnFKvIplIaATgdxTgeDk4pc54PFBUZy3UUwHAZFOxk0isNvFGen6UxjsUhIBppznjpSqBz6mncYpJI+UVHtxLnrmph046+tRvkc56UFE46dBTjjFMRh6U8cmmUA6cUo5HPWk5+lKOOvSmMBSgZIxQTgc0gIHHY0WKHE4x6Clx696aOvGadkg85/KgYmCBwOtJnnPemyTKhyTye1R4km/2U+nNNIBXmVWCqM5NT46YFCQqq4HX1pQNuMnihlDSuMH8KjhJR3X1ORUjnnBqOb5WVxn0pjJ+owetJvCjnpVW8uDBEGCliTgAVWhjublSZ/wB2D0Aql3JvrZGpHIsmSpDAUrjiq9tAtsjCPOCcmrGcjpQWJ6cUjLuAyehpcAjkUFcDg8CmUGcjHFIfTinY64pMYoQ7DfSj19acRzmm4IzimAduO9NOead34+lJgdDQAn60jHjpR2x2oxigdhpJ+pNRnGOakbgVBI3JIxxUspEUjYzwAPWqk7DBGKsyHI68VSlI5A/OpYMrM6n6+hqlKeSeasy8ZPcVSnPX+lSSyhcnjjoKxL0n5jWvcNWTeAbTSM5HN6ieDXIajjzDnvXaX6ZVjjmuI1pHWYYHWrhqznqaHvHwftfsvhWNsY81t/1r0Bc5yDXOeBLcW/hDS0wAxhBIroQTU0tbs67WHjqfSl5OeOaBzgU9QOSa1EJ396eML3pODnFJkE4yMVS0GSjlc5pWUEc1GD7+1OD9c9qLAL9Kdjim+9ODdqAEL4NBYMO1MYc5IqNuDzQOxIWxnBqJuSdtAOO1NJwKCkIWz160xjjp1pXwRx1qCWTZ19ODTuJlXUpRFEzsegzXhXjvUvPvX+YnGf616l4z1IW2nSfNgkE14Hrl200ztnqaHtc5K8tbFSyT7RejjvWzdNukSIfdXrVbRYhHC07DnsahvbkQ2087kZwcVwzfNLQy2WpyPjS+8668oHKrXLAAntmrF/cme5d25yeKpNuGSK2l7q5TFa6ltYxgkU1gMj1piS8D9aZ5jbqxGWCnzYzmosAUb85p6fd+bgmmASyZiUIOBUDMAQR1FTswweeBVVgCx4IoAk83PzE/hTGbdksPpUJBBz0qROR1zigBYmAOe9O27yTTNgz0p4POKBjoZMZ/rTJTls9aQoQCaCeMHpQAg5+gqeBefaoRgGrETD15oA0LfoCenpWrb9OT+VZlvjArShHygjpSYzVs0DMK0LgYgrOsiRg9DWhOMwZweal7jb0OXv8A7xrLYfMa1L7O8k1nlQWyK3MkLboXkVR1Jr3zwnai10u3iXoFrxjw/ame+iABPNe7aRHtiRfQAVEzKs9DpLIYArXtycAisuzAKgVqwDjrUHMtT4xlHGM1VZa0JNp6dRVJxzTPQKzZz7VEy/nVllPaonAxTAb1j5po5NNdugpM4PWgCZkwuT+VQnqAD1NSFiVyeoqFgQc0ADjnNP3g4xwabyQC1IwJGR0oAfEMtknpVmcABcYxVVDhvanMd2TzQBJGR5q45Heps+bNheM8VVibA7getTQZV9wJxQMtPF5bgHn3p8u0RZXg0yeXewJ6DqKilcAf0oAAoZl3dM9afcjEvHAH60wPiJTimzMZCB0zTEaFsEdAAx5qJ2aJmC9M4qmpaJ8E1q29uJArE5LUnpqNa6EDAJbjHU9c1SmAzxVy83AjgZNV2iPl5zyaE+oMm0m5Ntcq2SOa9S0W7EsSMDwRXj6khq7nwfqGV8ljz2q5q6uYyR6zpkwaMCrl2vmRE45rndLuPu84ro4mDR1zPR3JTK1lJhwpNdrol0doB61wk4MU2fxrf0e4zgg/MOorRaopnoUT7gDUu4j6Vm6fPuVa0lO4DFMgenPOOKeDjt1qMDB5607OMc1IXHDPSmk9eePrQTk4oYYFO4XEBGeM+9KG3ZFMJwAOaCcnNFxjicjnjFZPiSLztGuIxzwD+taobnFQXSCSCRB/EMUXBnlMZweD0q5C4zgis9iVuJIyMFWINW4W5HSpqKzOdmnCelXYOtUIDjG6r0Rw3J/GsmI0YeMY5PvVlG5HOapRnPSrMZzigCyvJqQcCmJUg9KpMB69OeKcBz0po/lTgTigpMeMetL0PHX3po6ZNO79aY0O5zyaQexoOMCgnHFNFXHDrzSZyODmmk980DFMdyTNLkZpgI5xTJJPLwSM544podyfP50opqYIB7U7qaY0KOtBIHrQSBjtSigpMN3P9afj3pgNOznPNOxSYoPPp70rdyPzpF5HGcUdhQMfHSEnf7UoYDjIOabvy5A60ykSKScnsOlKDnJpBjtTh15GaEMDk9Dx708cHoKQDIzxmngY570IpMao4x0GaUjaSRTgOc0HkYzTGhh69aAc4Hb1pXUY+lGM00UGeeOaSTkH1p2PwFJ9eaoY2NjtVhVhWAFVYTlWHoalXsOtMZMxoXpzTF4ahFYFiTkHpQUiX0zwaa2OM0mRtz0AqNp8kqgy30pjHtKqDLMARUQlklOI12g9zUYgyweU5PpVpSNg4xjqBRsMbDboDk/M/qasKe1MAx+FKG+Yeh70blIk/i9CKM568UwN+dKMU7DFK5bkcCiVdyn6VIuMYzTT1yBSsUV4cFcEdOKfjnFNYbZ+PukfrTDcIZ/LU5Y8n2qrAixxx9aXv/SmkkEjrRniixSHn6Ucd/ypuTnANL069KY0GB1xS4zSZ9zSBgSQKaGKRTSTnj86CfmHelI6+9ADT3x1pGzilOdvHWkPT2phYaT+dIxpxGT60w9D6UMYyQn61Wc8GrDYxVWQAZyeahjIZmPaqshwM9zVhgOc1TmIx9KQmVJ3Izzn2qnO+0YPQ1POeWbPNZ0rdc81LJK05BDY71nXIB+npVuR8t9KpympIZlXse5ABwaxJdPW4uYldSQXAFdNIm/oKm07TzcajbYHAkBI/GqhuTy3Z6to0Ig0q0hXjZGBir+QMdabGu0AAcKMU4jOMVUFZGz1HAg80u7J9vSo8Yz6U8EZ4FaJisPyc0m0FqUAHGKU8GhDFUegpxI44pB04JFKSM5pgDDA60Bjjmg5IyOcU3PJzQMXOc+lNYHnnNLxz2FLu455osBE4yuRUZ5PvUzmom7mkMhZtrHmqV7KAh54q3NyCK5rxJfLa2cpJwQDQTN2Vzzz4i6sJJGiUnGeefrXmLnz7oD3rW8SX5uLmVyepP8AWqOjw5cyt255qa0uVHBe7uzRn/dW6Qr3rkfGN+I4vs6H64rpbu4CiSd+Ao4rzHWrs3N5IxOeeK56MdbkVH0M8tzmmliQQKGxjmnoB5Z9TTk9SRkXXHIqWaPoQKci4YZHX1qzLIrj5QMAVAFSHaWwadP97K9BULAhuO/WpVbdwKYEBbJBNSoFbqaQJhsn7tMUkE56UAOkiG3dng0wcfKBx61JI2Y1A4pnHYUDEwR05pvQ5NPbMeCRyaiZsHNAEkhJFNHAx1pw55pRtPWgBoU8kdqmgByMjimqw544qWE/MMDjNAGpaodo9BWrAPlGKy4TwMnjFalufkFJjNS1jOQQK0bpCLbk9qpWLEkYFaN1n7NyMVPUb2OQvh85BqkAd1aF8vzmqsUeWGfWtzNHWeBrPfcq5HC816xpvGOa4XwZbCK0Dkct7V32mDGMVMtzlqu7OitRhRmtWEcCsu0HC+tacPSpMkfGcinJzUBXDVcuEOapSqQN1DPQGSAAnmonGUNPdwQc1GjdAKVgK5XjNMHWrUgGGqsBkcU0BKQNgJqFupp4B249OabigBjcYGDVjZ+5yKjQAnDDrUqoeQT8ooAjjXJ6ZpHXr9anRdrnP6U4R5yaLjIMDYDSo7AfSpCm1fbNMxycc0CJACRuJolOUz3qIs2MdqceYxnk5oAcW3hVAwBVxogqxscdOapBvmXA6VrWcX2t1Q8Gh6DRRZRJLhRxVqG4MbBc/KOKSaA20jh/vCqnJY0boNiSRi0pJPB6ZpjSn/VilLqE2kciiUBUDDr1oAY0WEz3q1o90be6Rs45qp5u4HrUathwRVxfRktXPYtFvBJErevrXXafNuUZNeU+E78PEI2bkV32lXX59KxnG2hg9Gb18mU3DtS6XOY5B/WnIwkhx6iqOfKmwfXilB9Ckz0PSbkFRjjNdHAcoOcV5/ot4CAGPSu10+UMnvVMTNEdu9Ox70xTnGacGHI70iRSSaaSfx9DRnrk4NOHND0AjIPNNzx1qTGevJprLj6UBcSmtkjg0Hil7Aikxnl/iaD7Nrc4HAJB+vFVoGOP1rf+INuVubedR97Ib9K5qB+gFOWqTMZaM2IXBUCr8GCBWTbMPf8ACtCF8YHasiGaULZ71cRsdxWdE2OtW4nzx0pAX4yc81MDg+1VI36CrEZzTQideB0p1RKcdKeGH1pjuSbh1o3ZqMtimuXLIVOFHWmkUmTZwRRnHJpmcDjJozn8apDuPySe2KVfvZ45po9/zp64HJ70FJigYNPOTwOnrTByck/lTwcZAFBSHDtSnPPY03PNOBHHFMq4oP596XnOM5ozx0/OkyPxpjHHA60hYY64pD60A/lVFIcGOadg568UwcgYzUmQO/SgYh44PWhcBqB8xJP50HOQVOOeadhkvPGOtSZJ61H6mlB5PqaLFXJeAOuKN2KYcke9C89aZSHZ+bnNOPr2prD0JoLYGKLlIcOtKcZ5zSA5FLntSKQg6ZP5UoPHqKD7GkJIGTwapDIx8kzj8RUi5BycVGw/exn14NS855H5U7jQ7PA4pw9e9NB6AU9cGncqxC6MzDnC06NQvQfjTv1zQo2j+tPUaHE5/GomLIwI5HpUnIxg/WlUZ60yrXFVsgYxRk/SoiuxsgnaetSjkdfegaHduTThwuec0zOBk0oPHemUScggAinE5br0qLcOtQyTeWCzZwOaAY+4uNiHHL9hUNhasjNLKcyvyT6e1V7RmnnM825VB+RPX3rQEmDxmnboCXVj2Jx05pp6cdacDzkUnc+lUirCcHnp70ueoz+NJnk4PFKcfh6CkUO5pCKTP0oz9aBi54z3ppIzxSluOKCAeB1poAJ/Kkbpx/OkznjtSd/880DQHjimMetOJz9aikYeppMpEbnuOtVpDzknmpZDVSYkDk9ahgRyv1GKpzN1qaR+ME4NUZn+9zxSJZVuXAbJPGOazLmTanB61YuW+Y5NZdzL830pENjZH5qo8mWI5xUdxNtzz0qk1yA3pSIuakJDHmus8K26vcq5GdvOa4WC6AYdK9N8FxF7ETFcbunuKqK6lQZ0w56cU7p7GhRt6CnHGc81ZYwD16U5eRQBnGc0Yx0qkgHg0p5pFOB7UjH8KY0B4GaQE5pQRwaH5HGKAAHrnilyMY6ioiDmgEgjuaYyTb0wc57U3GM5PNOUnHP40jcnPApbAMY8dQajZsrStgVC7fKf60AV7uTaD9K8r+ImrlVMKnrwa73xBeC2tXZiAcE8V4N4s1H7VcyNnjJAprTU5a8+hz1yxnuNvqe1a2Bb2qqv3nqjpcPmTGV/urzU11cAeZM33U6Vx1Zc0rGC8zC8WX3k2ohRsE9a4STczZx1rR1u8N1dsc8Z4qpCCcZxgVfwRsY/E7lbaT1HFS5AwCOlPYZc7elQSgqeaz3GStIGYYo8wKpUDmoEY7uhzU8Y+Uk8mgBjMc5IxmnIoAJFMOWBPpTdxztzxQA9pAQAAOPWmDLtu9etN78c05WwT6dKAGkZz6UxWKn6VJIdo6dai68d6AFkkLkHtQATjgUBeOlIjc+goGSjjjsBSqNw9qYX6gYpwf5SKAHYOOKlgySKhMny7RUtuMsBQhGrbgnHrWvax5x61l2o+7xW7Y4GOM1MikjX06IKeeRVy9GYTjOMVXs8lhxirl4P3B+lJLUqexx98MselNs4TJMi9yanukJkPA+tXtEtt9wCR3rpRj0O+0ONVgjQDAFdbp4xt44rmtLXaqjFdPYgAj2rJnHPc37Xoo7VpQ8gHHNZtp0FaUWcCkSj5Iu4Nrcisa7T94fSuz1618qQ8e9cndLubIoR6BmTKB+NQxghquMnPsahKjmgCJm3HGDTY8cg8HtSsuBketNAz7UAWQyiIYA3dDVc4DdRSxqdrHNQv6mlYBy8v1p4l2grwar5OM/rRtzznrTAtSDhSppBIVcc8Ug4i56k8UkgwAcc96AHvL1AqON9oOe9JG2TzTyOe3FACuQStDL0wafIBhSKjBy200IZYiQAbjVy1d45leM9PSqsagMFbOOtWrR/Llbd0p3Al1R/ObzAOtZzkoxz1Iqe5ly5VemaHjEuCvJA5FJaBuVYlLyZOSBUko+XHWpU2onynkHml8suuQOCaGBWWPinGElN/QCpJk2YByKswyKICpAOemaL9RCaPdta3SkHC969K0u8DbHVvlavKJAUfI611/hi+82LymbkdM1UldXMZo9XsbjcBjGKW+Xo47c1iaLd7gFY8j3rf3eZHgn6cVhsyYsdpdxtYAn613ui3QKgE15ipMM+Peus0O8+569K13Gz0ON9yg55p44IxVKxm3Jzwavbs9KTRAA4OT0qUEGoOCaevBGe9SwJCQeaTbnqcinAAr70nGKAuR4ySKCMGlJHPHFKT8ue1JoLnM+ObVrnQ5miGZEIK+vUV5xA3SvZr2FZYJEYAhhg145cQtaXcsL9UPSqWsbET7l+3fDDHFacTgjrWLC/HPWtG1fIwcVkzNmpC/PPNXIn+Y84rLifB61ajekSakbd81ajfPfFZsT5xzVyI5PNFgLgbNOBx2qFDxUmcdDVIZICcYoBA60zNOA5A7Ux3F544qQDpzj0oTGAadnJ6cUXHccoAPNGP50gPPANKMk9uaC7i9TkHrSrz70ijr2xS7sfSmNMeKAeQBUZPA5Ip2RjrTKQ8nHfmjtTATjANKD3zTKHMeB2NOUE9aaOv9akB45607DuKcADHJphO58DpSsewpUHrTKQ8AYPIFCjJ7UmMn/Gk5JPpTuUSA4/xpwwW+lRgc4PSnAgE88dKZQ9jzjNOz6daaFBpw/Si5SF+lL164oUflS9+lBSDoaAfypDg5zRnP8AhTGh/TueKB830pM89OKAxHehFDZeUyM5BGKkU5wc00gtkZx7UqZEYDcGkykORgWIyMjinAc89aqQ8XUv4Yq0DwOf1popC45yTSjk45pyjvjvRgZPr7VVxobjBpQM/SlU4FHT6UXKD261CP3fH8PanuxHSmSSxqv7xgMnHWmmNkgbPelByT60wDDZHSpMdx0pjQm7j0qh5hupyin92h+Y+p9KfqEkhUQ2+DI3U/3RU1rbrbwhRySPmPqfWnfQErsmGABtAAHalAGSehFBz06UE4B70IsdkdD0pfvA+vamAhjx2pGLYOOo6CrBDnUc4zmoXkMYOenrSC5ABEuVI6+lNj/0li5P7teg96NgJ0cEfWlyMD1FMZQeOajbcAR1FBROSQODTvfn86rQyhlIPGKmBGODQMDyeOtDe9Ge/emn1zzSGIzcEgfhUMp6H9KlJ96rSNycmkykRyN1wapXDZzg4qd2wD6VRuJMZzUiZDLJwc9az7iQZHfipZ5enPOKzZZRgH8jSIbILqT5TzWPcS4U56VZu5z81YN9PtBXPFIybIry6xxmsi5vcNljTL65KkknJ7VzGo3xDn5ufSqjG5hKVjtNBkk1DUoraIbizAH6V9BaVarZ2UMCABUUCvHfgVo5uHn1WZSNnyICOua9vTGM9QaL3nZdDppxtDXqPyQetO+gpp9qVMnGfyrRFjsEdOKaRg96kOM8UhIxyM5pjIyccg0gBY4JoY+gpytgYoAUKegp20+lIDtIp2/mhjsNJAYYNIQD0prEE1GWOcGlcCQNjg4qNjgZzUbkgn1pN+eD1o3AezZXNU7mUKCewp8z8cHAFc94g1AW1sxJ/GgmUlFHGfEHWdsbRI/LcV5Bdyma4wOQTW94s1I3V45zkZwKxrCIZLuPlHNKrLljY4G+Z3ZcwILQIo+Z+vtXNeKb8QQ+QjcnqK2r25WKF534A4ArzvU7o3Vy7k9+K5qcbu7Im9LFJ+Tk85qxChx14quRk8GrcB+Xb39ac3clIj3kN0xUcke8j1NSSMCfemq4RsnOakCNozG1TZEcbE8se1O2eZ8/Qe9V53BYAc4o3GRsT+fSm9D70pG4HB6UwEjr0oAXIPbihTxSoMrmkZcZx1NAC8uuSeKPLwu6kBKjBHFBbt2oAUk44/GmAZNPbB4XmnmPagJ60ARKMnFOxlsZ4oPCknihc4PFACKOe4q9bKMjHIqqgyRV+1TpmgDSg7bRyK2rBRjnvxWbZx5I5HNbtlGqkD9ahlo1bFGZvlHFT3o/dkd6ksWAGFApb1T5Z4pxWo6mxy00e6Tit7Qbfb8xFZyRB5uPWuj02Py0AzXQ9jlk9DodPHSujsevSsDT1GetdBZdazOWW5vWg6cVpQg+1Z1qOBWlD05pWFE+fvFFuvORyOn6V57dw4dua9j8VaeSrAcjjGT9PevLNWtzGzZHIqY7Hovc55lycVDOm3HNXVUnOBzVaeM7vmNF9RFcMuMGm7QynpUUnDcU1XIbPWnYCRQQrdMVXYZBq0CGjx0NRSgA4oAijQgEmlxwSfwqRAChpjE4GR37UAKTkgH8/SlfDL64pSnGT6VGSQSKBgoxJk05dxOByKQfMAcVPDtRiW6GgCwkQZQW7VAqqswJ5XNAnKnb/Caa5DJ6YoQF26VcK6EYaoBPkHPX1qPz8xqD/DUR557mhAWoWDklsY/WrFk8aRSbjz2rNGVOF4qWEYkIbOO9DQrj2fzJfl6e1SxOVBBJ9qfbomWzgCmzbASB60eQ7DXYtjdyaswwFsbRgVAqMW2gE96mgnaNyOooe2gIr3SjecA8dak0y5a2uUcHAzzT22sCeCetVZBwGA5qovoTJXPTNKu9wjlU8HqQa7CwuRJGCCK8m8Nahx5Lvj05rvdIusEKTWc4nO1Zm9eJzuFT6XdGKQAnHNMVhLFxzVNgYZcj1pQl0KWp6do95vCHPHSukhYMK830C9ztBPNdzp8+4Alqtolo1CO/f0qVVwOaarAqCBSgnd7VD1JbHgAUxulOzzjvTXxjrRohDVHPYn0o5BwOKTPNKM8ZFJlAwPtXmPj2yNprCTxr8lwOSBxkAe1eoMMgdu1cz450032jOyDdLCQVwOeoz2oi7Mlq55zExH41fgkwQayoWBUY6fzq3E/OOaUlZmVjYR+hFWonzWXE5x2q7A+VHtUiNW3bmr0TdPSsiB8GtCKTIFIRoo3pUoOcZ5qpE3NWkHA6VQXJFx+FSA4FMXHGaAeaBkue46U4dOKjyO1KD0pgmSDkY6UFiqEjk03fzS5yOKCkxxOcZpeMcdKYBye9P79uaaLAnOPypW4wB0pFwTmlBOTx+dMpMVR78U4elNByeKUHjiqGiQHAoLY6U3r0pVHzZP4UFIUEgc96eCMUzqRThy360XKQ/nHP5UDjIpOvAp2CAT6Uy0xw9+46in4GMVEM9u9SqOOlNjQvYgU4AgU0kkccc0oPy0FD/XtR70zOD6igEgmgpDj1pTmmc5BFKx4xVFCk/wD6qQnLfSkU4OMU2aQIvuO1BSJAcY4+tK8qgcHJqsPNnGc7E9asRRCPtzSKRUjDtfHJ2AitFVAGB1qpKP8AS4TzyDVwY6dxTQ1oKpwRTx69Pao0Oc9c08H8jVFoUcCmSlto2DJzzUgPHFMxyTk80hkcpIhkI6qpP6Vxmn6Tc61bvd3d9Mjs52xqOBjpXaOm9ChPBGDTLW2S2t44YhtRB0FNScVoHLd6kelpPDZRxXTGSROC/wDe96t5xnBpnI6dDTwM00WRQxiMsT8zN1NS54po5J9RS4IOO9OwxTk0DpzwaQn86TPHXNMYqoqA475peAMGm57EmoZnLN5UfUjk+gpoYyUfapDHnMY6+9L5DRMWgfC/3O1SqgRNqjp+tRSxPIhAldD6gUwSHrOPuvw3vThIjD76n8apnTyVKvcyN+FVxpAXCpcSBAc49aLoNS5O0auCzrz700zhOUkRh6FqrNpUDoQ7OaSLTLT7jxDcPWi6HZlqO/hJIMigjqM0r38A58xfwOaiGl2JXm3Sm/2faJ923SldFJMnjmSeHfGcqehqN2O33pVCxoFRQqj0qCZgQRmpuUQSuSD6Vm3D/MeeBVmaTGcdKzLl+Cc0rkMhuZAO/Ssm7m2pwenUVYvJgO56ViXUpOcmkZyZWurkDdya5+9uOpzn2q1e3G4/L+tYN/PgdeaDGTKGp3J2nmuaw91eIi7iWbGM1e1G4BYgkV0Pws0T+2fFFuCMxRsHfjtVOXIrmUI+0mkfQ3w/0gaP4Zs4CoDlNzd+tdQg44x+VRIuEVQcADFTDAGCOKmjGyuz0HuKABzxinEZ5AFGMjpTeQePyra4hQQx7nNLgZJoz6Co3bnFDGh33jz0o2gkimg+lAYj60wHFcDk9PSmkEDrmjdxzTWbPSkxjS2aTeT701gc5pOMUIQ4kN7Gq04xkjrTnbae9RSzAqc8H1oYXKdzNtQ7sj3ry3x3rXMkaMceldj4r1UWsDANzivDtdv2uLl2znJpruzjrTvojPkcz3H1NW24AjHT+KoLUGNDI2Nx6CqusXgsbJiT+8cd65Jy55WRitFdmD4t1IM32eJgFUc4Fct94ZqS5kaaZnY5JNRxkbuat+6rIz3d2SBNoGcc0oyQArD60yWQuwC9BUkalRnFZjHGIBuuaryhgdwzxU5k+fHaopZdw2gUCASny9uflqJsc0jZ6Cm7S1ADwcd6YefqKcEI570Y5OaBjolJJxyKHOHHFSRHJwBjNJdxgBSMZIoAikYGmE8YzRsPGeadgEZFACxD3qedwVX2FVNxA46UoYt160AKx56VKhAHPT3oAB4IJ+lOOM4529aAEQ/NkVoWbFmA6VQHDdwKv2hHy8dO9MDdtccAVuWEYJ+bNYljgEE810enoXwMVnIuJrWSAfNg4p94AVIyKmtoWCnt6UyeIgnNVDVhU2KNrB8+SMGte2QAgVVgTBHGa0LdfmGa2kckjasFxg1vWHUA8CsSxHAFbtkMnNQc8jctenA6VpQjIz3rOteBwa04enSgS3OB8SWxZNwHOP8ACvK/Edph+R19Pwr2/U4d8eG57V5v4r0/IYKOR0/Ss1oem0eSTqIpiKr3igN1GDWnqtm4k4HNY1ykg+U5yKbRJn3CAHioNvrVtlLcnk01oyAeKYiBwQBtOaR+VyakVSWx2pZV2DANFwKwbaMEUq/OyrjFGBn3p6Dy2z+VAE8rLuwOMcVUZhu6c0ssgycDmmY4B7mhASo2SAPxp0nNQqSh6dachOTQAoG1xU8i8k9jUDjkZ/OpnPyDnpQwGnGD2qSCLILHoKi3Aj5qkSViNoFAEoCtKoXkVI8YD7R1NNtHCSbnHGKsOS65XqKNhoTb5S4PWq4UsxJ+7TpZGK4YHipraMyr04FGwtyKNmB6HHTNKkgOQcZ7VcYxKqqcdO1Z8qDfx60LUGTCFtoc9KiuDheKvSyKbaMAYYDFU3h8xwB3oT7g/IjtJWilVgT19a7/AES9FxAGDfOBzXBPGYwcgjFXdE1FrS4Xc3yE81TXMjKpG569pN4HAU9RV+4XcuRz3rk7K6H7uaM5RuvtXTWc6zQjnINYNWdzKLLOl3BilAJwfQ13ujXu9VyeRXm8oMUuR+db+hX2GUFsGtNy2eqWswZAc1aGDzXPaXdqygZrcR9yjnilYzZKM5pHzS5/D3pwJI5FIkhxzUgJ2gUEfNjjHpSjOT2oY0xAcYBpkqK6lWXIYYNOxjmhicc1LVwPF9ZsW0zU57QghUI2e4IzUMTGu2+JGml7ePUIl5j4fA65xXAQyc8GqfvRuQ0asD5HXpV6B8EVkRvz1q7A/IrNkmtG+CD3rQjbGMVjo+RnvWhbMCvJGfSgTNeFulXI2G0etZEcuOhq3FJ6ikkI0Q3HXmlBzVdHzxUwOQKpCuSdelOHqO9MBHanKfSmUO5yecmnj1HFMHt0pwOfpQNDgfT05pRxx3pqjkUoYD8apFXHdOvSjJb6UzP1FOWmO47OSKd1FNxzT0Bplocq0/gYx1pB2prHAPpSLQq55Pan96Yp+UY6YpepzTHckByOKd2Pt1pmfSnDjrVFIeOnI4PWnBuaYDzgg805up9h0p+pQ8HAx+tCn5qRc4waVaRSHHmkyBn1oYZ4FAHNBaYpHT0pGPc9qCcDNIpLD2plEYZ3OEGB61IsIXluT6mnH6UpIOBQUKjDpipARjNMCgjgU7IXFOxSZBPxPAT05zVkcmq1x1RvQ1ZQ5OTTGhy/N160AYPPSlHC4FJk556Uy0OjIGRk07qOKYPf9KcDwaaGM3E5A4p3QUhPpxRjp3oKQY+tAPvilGe9J196ZQH6Um7NOZSeKaRzTHYM5OO9NPHfmlA+akkcIpZugpoBk8mxMAZY9BRDH5YJP3m6mmxqcmRxyeg9qlP5UxoUjngmkOOc0pPFNPHvQUH0opATikY+tADiQahkBVlkHbrTyeOKTJ+62MUx2AsD3PPtTH4GRzjtSKcfKTyKY7YU1DLRHK3B5qjNJznFWJn4x2rMuZeSM9aklsinfqfX0rKupsAjJ5FWbiXGfWsi6my2OOKRm2VbubYhJwT6Vz93OWcnJwOlXL6fjBPSufvJwXbHAH60GUmV72cLnFc9fT5yf51cvZcknP51gX1x1GRnFNIwkzKuJS87fXFfR/wL8Pf2foTX8yETXBwuf7vBBrwjwnpD6xr9naquRLKFb6V9f6TaJZ6fBbRLhIowg49Bis6r5pKCN8NCyc2W+hFTIBxUJHPJ61KowT7V0RVjckAIpjAYpT9cE0xuKYwJA4oxkdcU3BPJpyKfWhdwAgZx0pG7VIU4zUZU5OcUANJqIsQcinmmEdcc0ABPBPrTA3Jz+VO3Y69KrTZzkHNDuA5znINZmpXC28TP6cVNLIyAknArg/Guui3t5EQ4PTrSvdmVSfKjj/G2sGadkDZwa4UEyy7jyB3qbUbh7iYsT1plvGSQAfrUVp8qsjiSbZOzBIzI+Aij864PxFqJvLk4PyjitrxRqYjT7NC3Trg1yG0u57k1nTXKuZkTfM7IRMZJPT1qJs5O3pUzDsPpT4otwGalu4iBDgggcetW0bKnNMkjCrjvURViNwzgUtxgW5IHWmNgAY60+NRgt1qM5JyPyoEIpyak4Lciq54J605CQcmgY6Q/Pz0ozleO9NdtzZxQzDAI4oESE+WRilmk3lQewqA5YZpgJU0WGTd+O1PX5uO5qEvTkJFACyIA5A7VGoKt14qRmIJzyaaAOcigB4yTg0N96hSOgzUgjJ6jigAUgnrWpYrlgMVmRJhiPStayDKy8UwR0NhHyPlxXXaZEAgO3Fcvp+4jJA4FdLppdtoJIFZNXNYm+qKIhjr61XmjA6805pCEULwaaTleTWtJWJqshVfSrlqvzAkVXUdu1XLbrWkjkZsWC4HNbtiBnp1rGsh+lbVn1FRY55m1ajgetaMI96z7U1ow+uM0hRMe6TcCBXIeILbep4rtJweufrWJqdruViO4pNHpni2swGGUh1+UdK5m8tzJPmPnI5r0XxJZF5SCM4/+tXHLbhJ2DcA96jzJOTMflTNkZqvcH5uK19UjVJWBHU1jTgB6a11EyNiUGcZqOR9y8fSpGJ2H9KgU4+9TAj7/AEpznPIp8YyzdKHA5GOaYFYZJJqfIMQ5ppX5AaY2Vx70AKBk9aenEnTio8kH3NKGOcGgBzHg/pUkPzR5NVznPtUkblc+9AD2UlvapbdhGxyPxqCQ9xxSZJAGfpQBdmUBMgcnvTbeYp1PFETF1CMPpUcseF4o8gJnYSZCmrWnyAMU9RVa3j2455PWpmTyn30eQBcKFlwBmmSMCQcCh5gSWI7YqFTkZ9KYFmUhQrAZpqXBZsgYxT4lDqfaq0yhPumlvoBJc3HnLt4B71Uwyn6Gn243TZ6ip7iIIee9NPl0Dc6Hwvqo4t5TweBn8K7XT7loZQpPymvI4pDFIHGQQcjFd7oOoreWqqT+8Uf4Upx6o5pxtqd6ds0WeOeait5mgmGDjniqOmXOV8tzz61buVwNw+tRF2dhxdzu9CvzKqYPzjt612Wn3IeMd68f0e/aCRcEg16DpN8JVR1OD/EKtqwSR2CkHrTsnIqnbTBgOasg56VLRBN70o7Gowe2acGKg5qBMexB5ppHvz2pC3y8Cmg7uvAqkSQXtvHd2rwSKGRxXiOo2kmmahNaSD5ozgH14r3JlwARXB/ErSvMhTUYF+aPiTHfOBSi7St3KepxcchIGDVyGUjnPFYsU46k1dhlxQ1bQzsbcMnc1egkxisWCQd6uwy4PPeoJNxXyBircUmeBWRG+e/FXYWGB1piNVHxgirSPu61nRvxVyJu1IRaTGKkXioFapARVDuSgnuRS9OKi3Clz71SQ7jwTjml3Yx3Paow2frUiKSeaewxwy2PWpB8vXHpScAetKvJyetBSHKM81IBimj16UFuKNy0KetMk+430p45NIxBGMUyiO0fdCM9qsA5+lUNPk3GZVPCNg1fH6U7WZdx49qVTkYPApo/Sne46GgaHfj0pc8k4pp6Hin8EH9KZaEyTnnFSA4FRdT/ADpxODjPFMpEvQHvTHyeRxQxwvWonnVFyTSKRJ64yTTlyOhrLa9eRysCk+4rQt43UFm7jvTtbctE5JGCOaAOOOtJ1HWjBHIoGPxjjr9KG/GmhjTlOOT1qykIMEfMOO1Kr/h3prnkDtQevFJFEiybulOJ4HNV4wy8YzUqtyM9apaopEvagMcA/hTA2BjvSb8dRQhkh4OaVTzmolY5wafkZxmqZSH5HU9aXgjjpUfU89acPlpNFpjjnk5pucGlDA/1pWAx0oGhrDP1pjKGwHGcGnZwT1IoI4poY3OeKrajJLHayPCPnAyKsY7ikYBlKsAR0NUOxDZTGa2SRxgkcips+lJsCKAv3R2oPIJpFAeOlNJyORQDuXpTXJzzn6UwFb2PNMJP1pW4PpUZ79qYIc3JzVaZvkIp7NjJzxVWeTPFQyiCd8Dk1l3Eg5zVi5kxWVcycHFSQ2V7ubA681jXc5A6jNWbqXdn0FYV9PtGM8mkZSZQvJ8g85rBvrj0/OrV7PhiAa52+ueGyce1NIwlIgvLrjr061hzS735p13OTwDUmg6fLqurW1pCNzSuEH41SajqzKzm7I9p+AfhziXWJ14H7uPI6Hg5r3NRhaxvDGlR6RolrZxAL5cahsd2xya2l4AJPFY0U5NzfU9KyilFdByjd2pW4OaQEEEqaQnHXrXSJBnJxTjkim/xdaXc2MEUwFLY60bgMg0pIxSEce9K5Vh+7K5HpUTSA/WkOV4BqJ/mIx2pbsBzHg1ETjgdaepwcHrUcnqPxqgGSHP4dqgeQKOaWVqydSu1t42djjHSpbIk7alDxDqa21s7E4bBrxDxJqjXdw/zZGa6DxprzTSvGjVwjNuLMeaL8iuzhnPnYirubPc9BTdWu10+yOG/esKnDrbQtcTYGOlcPrWoNeXDMWOM8CuZLnldkzfKrIz7ydpp2ZiTk0sJwD9OtV2IJGKnjXgk9MVU5XM0hTja2ajExUfLRP8AKgx61CORUWAcZS55qfzgYggqKOMnoCaUQ5lCng0aDGEkd+KaW5yKkkX5ioNMkUjAXpQIj4OfSkBy1Ozgcim54GetAx74C5prfdBGOe1K7ZGBUbbgOaAJB90HPaox8zemaF4HzH8KdkHnGBQAEAH1pAdpwTxS54yORSdTk0AKzktxThyfw5pV29aVCN1ACsu3HPWpN/alYDihV3HnpQBJb4LZP41tWPLr7dKyoI+duOtbWmR/MBigaR0enRlmUIPauvs7cRxKD1NYejw/dAH412lnaEqjMO3NYyep0QjoVDAFXkVXbitm5QbOOtZk6Y61001oY1Ssoq5arluarLz7VbtRnGDVSORm3ZDnjrW3aLyKxbPpyMVt2nUVG5zyNi2HA960YemR2qhbdBmtGIHGc5osKO5lyZPBH61RuVBUk1ot8ynOarzJgYODQ1c9JHCeIbLduMYzxXnt8kUwdSNkqV65qURJwe9ebeLLF4pmaIc98VlbWxTPO9WySd3BHFZjwlotw7Vvanay+aBIuARmsqc7QUTPpmqIMp22rgjioCNx4HNXjCWJGKpkGNzimIRRhsd6bLz9RTycneAc1G+D689aAFjfIwe1MkA6jmkUEEY+lOYYzigZGSc4H4Gn44z3ojTcevNKw6gGgQ3aTyKeD2PX1pyYZQPSmMOcgUAOIwgJ60sZDOAKa7AgAA01MrzQMtFtkwx1FFw+6XAPWoSxJ3HqamxlVJ+8aBDYy6SAZ6Vblc5+Y9etVZARgt1NSxDcp396AIZX9OlSWgDEg0yVduBTYw6nKnimBftGxOR2amX8RBPpTYJEVt7feqS5uVmQAde9T1DoRWQUg56ipWOUOe1V1kVVIXrVi3KsDk8H1oYFGXjpVvS7t7WdXB71FIqmRh2BpXj2qD2q4slq6PRNNvVniWVDzgZH5V0VtN5sYHcivKtE1BrWYKT8h4P6V3lhdAorqcqelZzjY5muVmyxMUuRXR+H9RKuoJ4rmwfMjBHXFJbzNFJkGqi7qxondHsmn3auoIOK3beTcvavM9A1XKqp6mu3066DADNDRDRubqN2OKhjcMOKf1/nUEihj9KUEZ5NMIz0PSj6daTuA9snoeagurdZ4HhlGVdcYNTDFObOefrUyV0B4J4g099F1aW1fO0H5GPcYH+NV7ebBHNepfEbQ/7T00XFuoNzB09xxmvHUmIOD+RrRPnjfqJnRW8wxg9far8EowK5u3n6c1q282QKholo3oJOmDWjBJ61g28mDwa0beTPOSaRDNu3fJx2q/E1Y8MmQO1X4pB0zigRoo2B161IrcVSRyTVhG4qloIsAg+1OFRqcVIOnpVIEOA5qccCokqQD3NA0OHzZp4GDSLgCgHnFItDyfypBzTcfN06U4cDpTRaY7PzY9qOmOtN6cnFOwccUMtGfp48u+u06ZfcPyrSBBOOayfMEet7Cf8AWJn8q1x7VbZQ9e/pS0g9utHbNBQ4dyBR0Pak3cZNRySN/AuSe1MpFgleckiq7TqMhSCfQVGIHl/1r/gDVmGFIx8qjPSjRFIhkEswwgKj3piWOeJHJ9s1fHHQUADHYGldl6EcEKRLhVAqx0HPWowwNKOvNBQ5elKCB70hIFJ05HSqRSYrLk8cGmbmU4apA3vTZMMuD1NMpAvTPWng9ARzUKkp7iplYNzxTKQ8H26U0nLcd6F45pCdwB6YplAchs5GO9Y2qS6jDIxtVVkPAz1raHGe/PNRyAkgDpTTsO1xlj5gtoxOR5uOcetWelMAxwOvrS5yOKZSHryc9D0o3Z6c+1R7ivJpVIJBHWgpEg+U0/cO1REEse1CnDc0MpEhwSeaaeD7UjONvagncD3NMoOmeKT9c9aUggZ/SkYcEc0XGJ3pp68daaFwxOcnFK2O3WgYdOKaDS7vzppznjigoR+Rz+lMbp3pze3Wo2Ye9DAgmfGQDiqE0p2nirN05I4x9ay7hyM9ai4mVrqTOfSsm7lxkd6tXcuFPOax7iQDn+dIybKd3LtVjXN6hcDJOeK072bqCa5bUrnGcdqZjJlDUrnDMQa5jULrLEd6ualcnDAGuduJSzcmqOaTHF979a9s+AHhvzrmXV7hf3UfyR5H8frXkfhfSZta1i2s4FJMrhAcdMmvsLwzpEWh6NbWUAH7tQGPq2OTWFV3tBdTqwsLe+zaiTapqQ45qMHsfSnEnp61vBWR0sXp7UooXg5oyc4NWAuaUnnmmE56UZx1pgSHgAimucc55pC9NIDZ5pMZHI5HTk0qtx05proQ2aRiTjsaa2B6ivgg9eKrs2DjvT3k59RVO5lA5HFJuwmyK7nCrnOAK818beINgdEbHatrxVrS2sDgNzXjer373lw5ZiRmiK+0zjrVL+6indztPKXdutNiXOWbhRUYXc2OazNf1NbeEwxn5u5Fc9STm7Iy0irsoeJdVMshhiPyDjiubPzfWmyyF3JJ60gJpv3VZGW+rAjDdKlRzjB6U0Lk4PWpBGACWOAKzGExUgAdajJVXHcUxxtGfWm4z1oAuCQKvWo1kxlu/aoMkmnMCFxRYADZJPepdwCkkjcars3A9qM7vcUAK2M5qJ2yR+lTMny+9QuMnihAKhwPenKoI5pjDAAHWlDcgfjQA9488iom44q15gKAfnUPBY5/GgCIknjtQOT9al2bug4qMjLYGKBD40z9KXBDcVJF1CmpJ1UYwecUDIxkkc1Mj8YqE9RUioRzjNAF2CTn3xW1pAZ5AM9TXP2ykuOOc11egW7M4Jzinsio6nceH4uVB5rubWMGEZ44HFYHh6z8uMFRknvXVwxYT5uvasN2dcVZGXfJgHHpWLOM9a3tQHp0rEnXJrshsclXcroM9RxVy1A3DjiqwUj6VatsbhxSZzSNuzxj2rXtF+YVlWK/Litm2GGGelQjnma9scjpWjD0ArOt+2K0YsY4602StzNz+dNfB9jT9tMfjjimegjKvog+Sa4XxFZvJLhR1PNejTQl+g5rC1ayVlJHDAVD0L3PLdVt45LZyF+ZPlIri9Rsfs7Ag53DIr0m4s3aecgfKTXP6/p6Pag52yLWT91huefO21ypOCBVOUF92a0biBjOy+hqK7i8qHnrVkGYRsTHSkjQNk05/mGe/akiVgTimA1kGSelNB4GKlwdrE81GeOQKAGhgh6cmmM/YUp5570gXJBOaAJFJXBHAp5be1MbgDHNCgAZ7UAOVRkimY5FOXLtwaftXaSTzQArHauMdqQOfyoB3gseopUXKk44oAk3HaAe1Sr8yAgc1CjDBBp8XzSKIyeKAHyx8qDjnvVhI1WMlevpVS5diwx1HekVyvLHrStoArqpJGKj+4pxzSmYKcYp0jqQD7U9QIkwCfSpBnscCnW8YkiY55HSnJEVGetFwGBQW/nVvyw1vlR8w6io43RQcjBPSiF8OQT8pHekBXIKc+9dB4e1TYywSN8p4Ht0rCvCB93oTUMLMrAgcirWqsyJRuj1qxuQCBnr0q5J83K81xHh/U/NAhlPPQV1lpcgqFfv3rJpxZz3cXY09PuzBJ1xg16BoepCQKpNeZv8uSv1rV0i/aFwCcAVonzI03PZbK434FaQOPeuJ0XUg6KCeK621mEiD1pMzasWuaUcdeTTQc9D+FOGD2qWTYXvTh055NN7elAHc1Ihsg+UrgYPBrw74i6E2jawbiAH7LcEkY6KeBjrXursGBx+NYviXSYtY0qa2l5LDKn3HTuKlS9nK/QaPn+Cb5uDWra3HHX86wtQgl0zUJbScYkjbacVPa3PI5reURtHV2824A1p20vTBxXNWk44HrWtbyj16Vk0ZtHQwyj1NXoJNx61gQSE4IrUt5AQCKRLRsxP6kZq2jHOKzIH4GccVdRsAHNMRfVumKlT2qnE2WBOKux9PU072ETJ6dqePamjpTx60hoVT6/hR3oPWkzmmix3JB/lThwKaeD7Ucnn0plJinJBp2cj6UyQ4QnPWnLycmmUjD1xzBqtlL7EfqK6FegrF8QWvnxRuDjyznn8K07JxJbRuMEMM1WjSNFsWQ3PBo75/Km5GacvWkNC4zin4x05poFBOMYHA96opMcWx6D6UobABPfjimnnFKy/KCD0oLRLRkU0HIJzims3JGeMetIpDlxyR0pcbQcc96a/CDaOtB+X/wDXVFocr7j/AEp4x1qNBkU9TjH8qZSFBwcd6UdetNJ78/jSAgYyaBokXBHNMI28pyPSnAg+tOAoLG7t33e9KnA78U106svWgv2b8aZSHhsfSmF8nHanjAHA4pnygk96pFIcSAOaE6nPTtSEcZ7elJF05/KgpDyBnBo54xSHBwQelLj1pjHMeBjr601vUYzTc4z/ADpRn+LFMY/gj0NLnFRgH1yKU9MigslzkdqY+enY02NzyDTz1pFEeMLikxzz+FPwQvA4pjdePzoGhMnPGPxpCfzpG+tNJx35pjFqCVvl4HIqRzge1VJ2wp5qWMqXL4zxWRcvye4q9dvwT1zWPdSYUipM5MpXcgBIGKxbuXBPIq7eOOeRWHqMu3PNBlJmZqU4HcVympT9cmtbVJs59q5TVZyRwcDFUjmmzI1C5y5FZ2SzU+Z9zk1r+EdGk1vW7S0jUnzXAJHYZok0tWZRi5ysj2r9n/wssNm+s3SfvGPlxgj8c17gntjArN0LTY9L0y2soQAsCBR25rVC8HuaxormfO+p6llFcq6DsAknPWpljGOmaiUdeKkDsD7V1aIQ50xUTbSOTzTgxHPamyMCfalcpIjJIpG6Gms2OvSkzlaAEZj0H60iyEHgcU0n65qMnAJoAshgR7e9QyBsZWofMPUHFMlnKjg0XAY85A+YYNc7r+qraROSwDH36VZ1jUUtoi7sM4ryHxbrrXEzrGxI+tKK5mc1WpyqyMzxPrD3ty6hjtrAVdxyevagZZtx61Df3aWkRPG4jgZqKtS/uxOZK2rK+qXy2sJAPz1xV5M80rMxJzVm8uzcysXPFQOV2YHNQvdRm3zO5VCg1IF2KM0qgZOaJXLduB2qQHHJQY60wqwODnmrEEiqvIyccCmGQGQFh+FICMQF1JPAAqILjIq1JMXUj+ECqqkZoAawwwwenWrSKrQ5PWqrDc/FPyRwDQBFNjJAzQp4/lT5F+QnGKgB6ZPFAhzsxB7Ck7e9KDzx0ppILGgYpXjNNXIIJp+/gcYAoP8Aq/rQAqMpb5ulDnL5HSogfX0pQfloEPDgjBNIODnHNIAfWnY2qO1AyRG5zSlmZ6ijNSrjGT2oAkUZYDvV7CsoRce9UlG5cirlqh3jvQCNPTbT5xx2ru9AtI44csOSa5bTVUBWPfgV23h5PNaPOQM81LV0bw8js9JGIkAXAxitPawzkkUWUYSNAAeB6VbOGB6UoRN2Yt5k5FZEw59xW7ejINY1wPmOK6kcdQrD8OKs2681CAOg61at8g81Mkc8jYsQQBj862LbtisqzGMZ59K1rbrnNQjnma9vjj+VaMXQGs625FaEPIpkR3KANJtBHFKef5UqnGMjBpnfEix2z17mqWq2/wC4LDritI8kelMuMFCvWpZqjgAikyAjOOK5TXYxtaMfezzXpV7poUvJGPvda4TXbUpc5bHrms5JN3QbHlWqp5dwxAztODWdqDieEFBjHBNdl4lskEbMh5fnP+TXI7QIXVuaSd1cl6GakYCEnHtQioZBin+WxYgdBRDGFclulWSRTL+AqsAc89BzV59ufm6daicKm4/wt0pAVHVSARSNjAFPzjgdKRv85pgNPfIzS5Gwr3pGYY44NRMSc4oAmU7ScdaGzkkjApi545yalYfhQAsYABOeTR5jpwBxTS+0Db070pJIGKAIz82cGrFg5iYueg4pgVRwAOamQbFZSOKGA8lHO7bxVeduwHB7U5JgpIAyDSSDADdc9aAGqgK8c57UbGJ29KIsMSCfpVxEAhOetDYFYqYgCO9OMzBeD14ps+7hR0xmiNxtwR0oEI5c84qXeXRc8Ed6SRwUAXqKYrBYyD160APWMtLhhwankiCDBUDFRxbn5Y9qSWV/utzRrcBscpikDL97PFdjoOqLcxLHIf3g6ZrkDFiMN2NMgmaGYMpwQarSSsZzhc9Vt7jI2Meam3FGznPeuZ0XU1uogrnEg71vQy8YbrWabi9TGLcXZnU6HqZicBmrv9F1QMoDHj0rxxZDE+5a6fQtV8sgFua0tc0auexW0ocA9qtDAxmuQ0rUt+05zXTWs3mqCP1rNozaLgI6Cjg9KbkgmkDcZotYkkLYB5+oqM4NGOOmcGgc9TzUSV0CPNPi14ZN7bjU7Nf38Qw6juO5OT/SvHYJirYPrX1VcRiSNlbJBGDzXz78SvDL6JqrT2y/6NMdwx/D7dTVUJ/8u5fIpFCxucDngelblrKGAOQK4y1lIIFbtlcdMVco2E0dTbygYB61p28nQg8GudtZemK1LaXBx296zsZs6KCT5eKuxSehBrDglwQAeDWlavTIZswN8uavxNxyayoJM4z0q9C/FSybF9DnHen5AqBGAANOX5jzTRaJAcn6U8HHpTBgL2oA3ds1QDsknjpTicAY60DAHHWkHOeKZSI7gEJuyfpVlB61Dd8WxxUq5IA5o6FpkOoLutmA6ngAVDonyWIhJy8R2NzV7GF68U1ESMsVADPyfemtrFoePwxTs01cAU7PH1plIcOcUYI9KQAAfSl+8M0FoN2DzwD3qRGB5J/+vSAcYodV57GnuUgdw30HvTCik+mOaYQV78deaYLhfMwM5+lNIpFkg4ADHH0pN5B5Gfxpm52XgY/GnCPco3sTz0oLQhnA4YEfQU8SE8qOPU0mwBcjinOyLjuTTLQcs4BOcdRUi4GBUFuS5ZhwM9alaLfyx5FBSHGQbsA804kn61HgBgcVIpzxk0yh5OQAKY4DDDde3tTjwO2f501uvGCe+e1MaGoSCFPPvUg7j34piEmjPzDFMoGJLYHalb26eooc8DIpCwoLQvOOMYFAYE4xTSxB4FNOetNDHk44Ip33uM4xTONtG7rmmUkP3DpijHWos5APSnhtvPWmNDuAflGaVX7YFMDDHoMUm4n6UikTKRzmmP7AcUxTgc9aUsNo5oKGE9sUx6eevtUch9etK4+gx275qjcPgEg1PK+MjNZ1zL161LFcqXknB5xWJeSZ5wMVevHJJ9BWPdy880iGZ93KACcGuf1CXr6VqX0gGe2K53UZeDmgwkYupzYUnNclqUpJIzW5qswJIXpXMXrkuavY5psqgFmxX0L+z/4WNvBJrN3Fh3BjiBHb1rxnwToUuv69bWUakhmG/wBlzzX2Nomnxabp1vZ26gRQoEUDjpWFV3agup1YWnZc7NCMYxwPxqXP401QMHPWlBxzW8UkrHQOzSgg/SmA8kUhGM4xVjHPj8KiOCead2pjUAGPpTCQpPP4UrPj6VE5B5yM0n5AIXz6VDI2Bk0jyCMc9PaoJJ125Xmi5LYszjAJPFZl/eJCjszAClvbpUUszfKO1eceMPEQUMkbcmkldmFWpyoqeMPEHmO6Ix56V59PKZXyxJJp9xM9xMSSTmmXEkdjCZZcb/Q0qk7e6jlSv7zIry4S0ty8hG7sK4jU9Qa5mY5qbV9RkvJic8VjvxWaXLqyJS5h6Z5yM08uFTGKIF34HFEycnaDgVDd2FhquTx2xTk5+lSQJleTSbMMQKQWHZRFB6mkQeZzSNH+7J6elMUtt47UASzoqgAnH0qqeQdtPkLFsE84pGwOM0ANIC555qPkcsMmn8E5JpzY25H4UAQs7MAO1IMHjp704c5P8qaSM8GgQ4oMcmoyvPFDOSMDGKeDgADrQMMhV/2qXBYd8VE3DZpwkx1oARwo6dab79v505hvwelNYHj0FAEqH0pZOTjPFMiBzkdakUE80AKkZJGalEfpigAlhipSHWgAUYIBrStyiRncPmNVbePLh3qxw0nygYoWo0bekRvLOmAdleueGdPCxRFlHJzivNvCysHX5cnPXFev+HoH2I756VMzqoo3VtzswBgY4pJICi8CtCHG3kdBzUN0MLn+VaQT2Ln3OfvuRyeax5xzWxfhuSCax5AcknoO9bI45kIGAc1YgHIPBqEj2zU1v196hmDNmzPQVr246YrIsz0rYt+oPT6UrHLM1bYAgelX4TwPWs+3z74rQh/P3pNExKWBzig89BQtLj0pHchOVX1qoz/Nz1q43C4zWZNw4+tOKuaXsTP8wx+lcrr1kJhIAvuK6o5ABX0rMulaRyMketKxVzyfW7EvA0RGG6iuDnt/LuHjHTOCa9j8R6XJ5vmR5wRXE32kKLjDDLNyfWs9hNHGNCqShf4TVS7i8qUrj5fatXXLWSKUgKVI4HuKzGWRocPzihdySjJHuGagZWCnP4VPuZJscgUtyv8AF2psRQ55WkYE9T0qVlwc9qTCkZHamBEFyM8ZpSgVR696erAdsYochxuFAETNzThLkHNM2ZyDSEH0AoAcf1qUZVFJFMhXdJz0qWUhhtU/hQAxT849Kndt4x0amRqGDBjjA4ogXDZbmgBJY+m3r3pu4hSpFTXBIPy4ANREfJz1oAZCoZ+nPvU8rlRjnIqugw+d1SuzHk9qAGSFiop0IHcZzQo3ocdqI2KH5gM0ATmLbIOOMVHOg6U+SUtHk8mopJC4A60gJYXIwD17UpJMm5sUioCo9RTmTeMjORTEXvka0LAfhWVcLzkVPFM8asgPympUjWWAufvUl7o9yra3L28gZTXc6LqiXcQRzhxXn8g2vxU9pctAyujYIq2lJGU4XPUVfs3SpopTE4weveuf0TVUu0EcpAcVs57H9KzTcXZmSbi7M7PQdVKgKWNegaRqe4LzXiME7ROCDxXX6Fq/K5J/zmtWr6lvU9ghuFYdf1qZSTXLaffrIF55rftp1fHzYNZszaLgo6jk4oyOMdKcMdMcUibDDyAaxvEukw61pktrKMnGVPv2rc6elRPjPHArKceqGfLeuadNpGpy20y4KN19afZTevSvZfiT4WTV7JruBf8ASYlz16gZ968RdHtZTGwKspxg10wmqkb9SjprOfAHJrXgmOBzwa5OynJUcjIrcsps4z2qGiGjpbWXcBmtSCXGMVz1tL0rUtnHBqWZ2Ogt5DitCKTvmsS3fB571fiftU2FY1oX6VaRuQRWbExO05q4j596aAsryeB+NSg44qFDgD1qUZzmqQC/Tn1qVRjqelMTjJpSw709xojueYmqWP7gqNgSDnFODbY+TTLiPLHnA+tCk55pgNP3HbgYplkg/WnDjk0wYB+tO+8QPSgtCjnNOwc4zxQBjmlGOc0yhC3ovIpG3NxwPpUhPOKT1oRaI2jGeSWp4QAY4x1peM4600gknHFMpCMoB4OKPMYDgbsU7aM880/AxxwBTLRHHmRcnIz2p8oCISoGR3pVbHGOtJMRgKO9HUsW3UrEoIxUqA9CelIvYYoyecUFIGHGSckU1CAQeaC3WgDdyeD2plIkAGCfWmHPHpTkPGAefSmHriqKQquM8daTdzxikAA7YzTSBnAGPagY7JJJJP0p3bp1pqbsk9qXk54yKCkLkkHnGOlKp4pucDBpucGmWh+MZ7Gm9vcUOcgf0pGIpoYp5GaXdzkimE4pQ3NMpC560meopG6nsKbnrz9aBkmcGjOCcUzcCOaTOOo6UikPJ65qGQkZ6Upb14qvIwA7+9SxkM54PNZV1Jg8VbuXOSBWZdMOeeakllK5b5T61iXcmPpWjdyY9axbx/U0GTZlX8nOK5vU5tqnnJrV1CfBbnk9K5u9f5Tk9KDCTMXUZNoJJ4rAcmST6960tTkDHArS8CaBJr3iC2tkQsm8F/Ze9XoldmMYucuVHsXwC8L/AGKwk1a6TbNN8kRPXb617Oi7R14qnpdlFYWUNrAAsUShQB6VfUDAyOKxpLmbm+p6duVcq6C/TkUHg5HJoDAHGKecduldNtRDVbGTjmkJ4OKdjg4qM8UMEN3dc5o3jHrSNgjFQsdpNIZI7emPaq8jYBIod/mGelVppByCc0mJsZPJuB9Kz7q5WJMsQAKbe3axKSWrz/xP4hADpG34UJX2MKlRRRJ4p8RBEZEb8jXl9/dyXU5IJZmNSaheSXUhAySarSyxadCZJiC/XFEpqCstzltze9LYkeWLT4DJMRvxwK43VdRe9lZ3J2+lR6vqUl7KSW+XsKzcsQfSskravciUub0I5D81M344IpS2T0pSuTn1qW7iJIhjkc1MZSw2AYFRBgqgYoD4bOOO9SBIF8vt1pobYcHrTppwygAdKriTe2SKAJyN3XgY6U5ACdqECqkkjZ44pysdhOeaAuSXIwMdTVULg4NSqS2Qac6lVVvWjYCI+nagneQB0prsBgDqTTUJHI60ASzAJHgHmq6ghuTjNOkJY8mmtQISQgvxRnHvR1pyJxzxQAxjzzTTnGae4J5PQU3Gef0oGSRncRipX2jjNV0+XkVLyVoAci8e9WoICxGAKrx4wM8VopeLHDtRRmk/IBsICTHd0okfzZCEqFfmYsxqe0UbyR9adrBuWIYumT83pWpZ2OWGR1qrbIpkBb1rrtLsi6K7ABe1S3Y0irm94T00SPGcbQvWvV9ItwkIBHauL8NWqxBd2BnpXoFkQIxgYxx0pqLudkLJFlYwqkiqdzyCDWg0gZBt61nXfetkiZmHfdxiseUHBxWxe8k1lyjB4qzkmU8EVNAOR0qM9Tnipohz71LOdmtZjpzWvbE59KyrTjAI5rWtx+dTc55mnb9sDrWhCeKzoK0YD2oIjuViB680qAZOaPwpSRj3qTsQyRAQRVZoQRz+FWge56elBxinsWiDy8ID14qnNAu7Pc1edii57dqz72bMYK/eJ7Uldl3M7UkXZ90EDivPvEVs1rdNOoO3GelejOpa3ycbvQ1i6zAsts6uoOR0qZRsO9zyrWmS8CTEbWHy1gXcASJ2HUDoK7vUdMje0cIuHUk1yWpWjCU7D0HI/OostkJnMCJZcnow5xVOdsBlPUVo+Q4uGIBHJ4qjdRkyEkfWq6kFRXJzn8KbEw3kHjNSlOeOtQFfmpgLIuG9qQEbD3IqYkPFgj5hUflbQSaAI1IOc8UYGSfwBpyjcDx9KjJxwTQA5SYzkY5pYziXLDI9KYW5GOlPMg3dOaAHygE8cVJ91KrmQA8fSpdw2CgCdIDImV5x1pCAFIJ/Go4LtoSQOQfSnSOGUkDFKzArFSXIXnFPLMFw1PgKiT5uKSQgk98UwHQMu3aepprheSfWnRqrEEdaSYFWxnNICJjg4HenxxnZu6mpHRdo9SKcnyoe1MCwsRW2DADk4pI5lAIYc9KktpM27K3IFUZMh8DuaSAmIDMfQ1JJIYkK8YIpiuCm3uKiuTujAB5o3EV8GRiQKcYip5qS2IClTTm5kx0p3ALaV4pA6Egiux0bV1uUEcpw471yjRARqVxnvVZJmim3IcGq0mrMznC56aGGMHpVi2uGgbKng1y+i6ysyiKcjPqa6ANwSpBFQm4OzMU3F6nb6LrOGAZsf5NdxpephlBYgn3rxaGZonyp4FdTour/ADAFsVo0mro03PZrWcSAE1bBNcVo+rBgBurqLa6EigA/rWdiWi7270hGVOOuaajZJ559Kf34pMixBIMjaw4ryD4qeFGik/tKxj+Rj86r68nNezMob3qpd2y3NvJDMoZHBBBrNXpy5kNM+XrdijcituymBAq9498NyaLqLvGh+zSNuUgcDJPFYVm5Ugdq6XaS5kD1OrtJQwB6VrW8o4ORzXM2kvQ/hWxby8DmsmiGjoYJd3Gea0LduetYNs5PIPNatq/TOakho24X9TxVyJ6yYn4FXYWz60CNSN/SrKngDOfeqEcgXA5NONwQOF69KaAvu4AzUe4Ek9qoG5Gc80onBxzT5iki+XGeKjD5qt5gLc5NShgadiywrd6kBqFB1J5H8qlT2OaEUPSQbsGp4xk57VVeEyHKnBp/mPEoEgOOmRVehaLR54HSl6AepqJHDDKnOafnPPWnYY4HJpGP50ZwDTe/egtCmlHtSH5uPSlHAPpTuWhepNOz8o5xTQTjjvSE8e1BaHr8o46+9G0HDc5FMBJI/lUpOMCmUh6n1oXJJ7elImCOtB57cUFiADcfWjJxj9aO3WjkDpTKHJ0wODmo2JzTlIC5brUZJJODVIYoOeKU9fSmoADzT2x1ploVT1pN2OlIpxSMOPegpDt2aQjue1MBIapDkjNBSE6Dr1pGHH68UmcZ9KQ5pjE6cZzS9D7UmR0pGboBTKRIMHvTGHWkB60p5xSKtcapAPqKcx4PBqN84PagsccGhjQjN3FVpm4zmpJTVOd8DGfpUFMqyvway7hxyT1q7cP1xWRdvwcUjJlG8kHJFc/fTehrVvHABrn72TAJP50GUmY+oSAZLVzWoTHJrW1GYkt6Vzl/LnjvTSOaTKDIZ5gFBr6I+DHhgaTpQv50H2iYZUkcgGvLvhh4ZfW9ZjaVCYYiGY44+lfTNlarFGiIAkajAX0FZVm21TXzOrDQ5Vzsso4AzjOasK3PFQgAD5f1oX5ffmt4KysbvXcnA6mgtioy5UHPSk35GMjFNvsCHF9tKzDGQeKhZgRz1FReYV4PIoTBkrnGearSSjnJ5pJ5evNZ88wU8k/WjYlsnnnwP8KytQv0hiLZGP1qpqOpLAjF2ArzrxL4kLllRqSTkc9Sryl7xN4i5Koxx7GvPr27e5lJYk1FcXMlzIeSRVG/vYrKI8gy0Snb3YnPa/vSJ7q7isoizYLkcCuL1e/kupSXJx6U3UNQeeUl2yKz3bce9ZrTVkSlzAGyRmnk4zjmmKucYp4+9UN3EMZdvzHpTM5NSuc9f/100RZOVPFIBshzgA9KUbj1pJVKgelPUEKCTxQAbgCB19adEFVmZunYVEuPM5JNOY5Y+hoAjkIJJz1pm7jHannHI7VCx+bApgTKw69qW4lJwvaolJAAwDQwLLk96QDfvfhT1HHXmmIDjNByrd6AFkGCKCBjmgtkZo3CgBF6UrH5iOopmcZI6ZpcZ/nQAbs8cYpO3FBUYFOjXLdc0ACcCnKdx9qUqFBpF696AHqpIPHFOB4wBUqLlcetEkRXaRQARke+TVu2B3be9PsYEX55O3apo08yfIGKL3HY1LC2DvGX65Brv9Fs5braiDCevtWD4Z07zWUyivTdIsxCiqg5qL3eh0wh3NLTLBIRGM9P1rqLSI8Z44FZFnbSM4bHGa6CMbI8V0JWRuhkiqueOnSqM4H4Vdmbt3qhcg446U9TOZjX3X3rKlPJrUvRWVNwDVHJMrsMsealh7cZqMgbsGpIeWqGYs1rTtWvb9qybMdM9a17ftipOeZpW+Soz1q/EOnrVC36Dpmr0PFJma3IgOaDwfSjI7daByOlCOtMjc+tM3E5HYU5wQDxzUCA59qZaC6YmIqvWqcEBbhx0rQMJZc96fGm0Ypc1kWigbYZPPSs+4sfO3HkDpWvu/eMveoZH2Z3dM9qWpSscNd6a0UsiOPvZwa43WNKkiu1Crwzdfzr1vUbcSruxlu1cpqsDMSzL9zNQ73A8p1ixa1vMuMIR/jXPX4xIcD5O1ena/HFf2JQAeapz+HNcPqmn/ZoyX5z0/WpT7ia7HLTfIcCodwwatSxsWJquYiGOR8prQgjLcjNOd8rsxyKHXHIxikQF2APfpQBHu2nnvTGG7nFWDGd20imYEbnPSgCLbhcZpjZ65qQrgkDvSeX8vOcUAIV3YNTgp5W09aRVxFmo2bJNADtvGR0pytgGmhyY8Ht6VGWz9KACRyTxUkHXnkU0xkfN2oU4NAFoEK3YcVFI53DoaiBJPXNKvr3oSAnyeOKkUBupqASFWGRUiyqDjHvQBYjKrGVyCc1A/ykng0qkcg8ClZDKQFOMUCGwnb82OBTZJAzkAdalkZQuwdaYqDDZ+9SGLbBeckdabMy7vlphHJ5xTQhHJpgSM52dSDUUg6EUA/OBipmUAj+7RsIjikZDnkHrXTaLrew+XOfl9T+NcuRuPHUU9VZRwarSWjJlFM9NjaOZd8TZHtSrM0TgrwRXEaRq8tpIAWyvcfn/jXY29zBexbo2APpmou4ehztOLOr0XWSGAJ5HFd9o2r7iuWGMeteL5eIjqPcVt6RrjW7Ksh49a2spq6KUkz3a0uhIM5rQVsr2PuK850TXY5Qu1x9M119pehsc1k1YrlNkHPSlfpVeOZelS7w2OetS1fcjlMrX9Jh1iwkt7hByDtJ7HnFeH+I9Dl0a+kiZW2AnafUZP8AhX0KeTzgGue8WaEmsWLrtXzQPlb3wf8AGohL2b8gPErd+Qc8VsWkmStZupadNpl5JFKpBBI6cHk1NZyHA9utbyXVEs6O1f14rVtpOOv0rBtXPGa1bd849ayIsbduxOM1pwEYrGtmxz2rSjf5aBGgjc8VaiUGqUP51eiHSgRYEKY+YYNRmzjbkinqSeBzUy56CmkVcgWzVTx+dSCAKeefpUwx3pw+76U7DuRiPC89aeqjrjmlGSefwFSBeaZSFRdo96bJgg55Bp+femN1oSLIhDtH7vK57VYUEDnrTV7804EAf41RSFIycCk9c84oHQnNJ7DvTLQgzjNLgn3pQMj2pygdjnmlY0QHsKXvSE8k+lGQBziqRSBPvHmpB0zxUa4JOadyTgUFocFwCetKSc4pD2x2pCeeaZQ8MAOlMkfaBzik3EDOOtMc5PzflTHcep3DpxScD6U4HPPrUYB4zVIocGHelJyKYc5pQ2BSLQoOOD1pc8YpvakAyKChWPNKG44600kKaaWAOe1A0yQnGSaaWBGT2qNpo0++4A9zUD3cQyF+fPZeae5SZaBBX3oz2xVSOZ26Iw+tWUPtTKQpOOfelJ7+nSmE5GO9NOfYkUFIkbHPrULnAOO9PJNRSnipKI5GwDmqMxzU8z8GqFwxwT+VJhcrXT4BFY13JyQe1aFyxIOTWReMTnFSZyMy+l71zOpTZBHGa2r9+uDXN38nLHjiqRzyZiahIADzzWdYWUl/fRxICxdgBUt6xaTaBnJr1j4R+FdxGo3ScD7oIqpP2ceYzpw9pKx3PgPw/HoWjRx4HnOAzketdZEwB5GcVEBgYxilPHIrClF35md78i0pDcAe/wBKXpnI+tV1fbyKeZck7jjNdJKYrMOR2phbA5NMZuc96glmC9Dk+lJiuTNJwearST4ORmqstxtzWbd6gsYJZuaVyXNF64uMBsnGO9c9q+spBGxLcj3rD13xJHAGCvnHHWvOdZ12a7kYITtNUoX1ZzTrX0ibHiHxI9wzqrfL061yru87MWJx71Dy2XmOFrG1bVwAYrc4HrUyqX92BnZR1luW9T1aO1UxwkF/WuVvL1pSWc5NV55WkYknJqEgkeorPSJm25biuxY57U3Oc46UuzPTmlCHGf0qGwJEcgbRj0q0Ihs5IzVLaQal3kDaRmlYBHBzkjihZAsZBA570+SUbACKjZQUyOlADXfcgXHFO3ERbaYF+XJ6UqyDac9ulAEYGG54okJb7vNP3ZxxTGIxgCgBvBXnNNOD3p2Mgdu+aFXnnGKAI+/0p4cFcE0uAQahC5PHagCQHAPpTXYHAFObIT0qIj169qAAn5cY5pM44p3oaRcZHegQZz2pxyBRjBI5zTwBjOaBjSfWnRHnmmkZ6VJCpYjHSgAfJHShFOKtmDAyadBHl8HFFwsOtl2g7uvar1valyGY5HpUDYDgJg1q2q7rfAHIHJqWUiosW6Ty0HOa3LCzCSKpTc/oBWfpsLPdcA59a7jSbWO3dHPzSHtQ+xcVc3PDWmOEjeYbR2Fd5YQKHGR0rO0OzklUO/yg9BXUWtpgHJBxzxVU49zsjGyJII2RgUPBq2d2zkU+GIKAQDVgAEYYYrcqxnyIRyRxVK6Iwa1LgAA4rLuSCCM0GEzFvDycVkzHDHNat7jcaypF5pnLIh7k9qmhGcdKixg1PCOR3qGYs1bPoOBWrbg4FZVnzWtbnkVJzzNGHBAq5CeKpW56VciNBktyBG9eKkVhgD0rNhmBfrmrqOD06dKk6kyRxUYGDz0qTcM80u8dMdaZaGO4RfeoBPuHANLdqdvAPNV4gxOMYxQloXcVQTOc9alWAMTn8qd5ZDBqlXnpQ2UmV5rQKvv0waybzT0ljkVhyQf610T4PXBxWe7BpmBGBU2bLPL9X0lra9KjoehH41zniTTgbUkoxXGM46HmvVde04XOSn3xypHbr7VyOo2kz2k0UifMASOKiavZhY8hnsgQ3l8YrHvkaNMDmu1u7IW85MmQWJ4Nc5qUQVnBXOeR7U+pHQ5856c1LAjD5lycU4RsQx2mngFY1wOKokimmH0aq5bcQamnj5zUSoCQaAFlXgEUw5JxUqjrnpUbKcnBH1oAaJSYyhBo24xnPtTWwpBxxU8bBh79qAK5JHFKq/OCakP3iTxTHHAPX3oAWVznA70i9PmpoUk0/wBwaABGHPvSrgNkUirwT3p2QFx3NACSEnJHNMBOR6mg/dxTh0FAE27KAHr60qSMr/LnmoEyWx+VWoUAwz9QcUANkDFwcYJpJWKHJ61NKwJG0dO9QT5bn+dAhNytjH41ZKgqCDkVDHD8nI49aVVKn5vu0MBjArJuwDSSMrKoAOae4BUgGmqm0/MMehoASNdrDNTNtx6YpGG3bx9KZw5xg8mgCPdhsg8Vcs7+S2kBjYgDsTSw2XmEkcheoqvNCY+cECqUlsJq6O50zWIbyMJIQG9zVuaMjkEY9q85inaN8qSD7HFdPpGujiO55Hrn/wCvU8ri7xMJU7bHR2WpT2T5jLY9K7nw74vRmVJpArD1P/164IBJo98Lbh6CqksTA5UlW9RWsakamkhKTR9Eabq0VwimORWJ962YpwwBUivmrTfE19pTqHLFAeoz/jXoPhv4g2s+2O4cIT1yR7e9OVGS1jqWmnuevJIGHOOlPOCeeBXOafrMF2oaGVGUjsc1rR3Csg55HrXO49GOxheMfDseqWpkiQCZe+OvB9vevLbmxlsLhopFKsDjnvXu5dCBnvXM+KNBj1AGWFQJQPTr19qVOXL7r2IlHqeeWxOQCa1rY9wM1Sls5LWZo5lKsOnGM1atcjk/pVSRmzZtXDHHStGI54BrIgwehrRt9wxj8aRJrQNhcZq7Cx6DrWbC3A6/SrsRPFArF+LjvU64wPWqsZIPNWEYnJ7U0MlGc9qOv0pO3WnAA/4VQ0PUfWpB04NMX3+lKx20FoHbt3po64pOetOA6Uy0Lxmg80neng5GcUykI/AxSKOM5oY8UowF/pQWhSfanqABkVGDk09jxgdKCkBNIcEc1m3uqxWkojmDD0NLaalDcttUEVXK9yk0zRQ89akB5qFMZ4/WnIfmyTzSNESZ554NIenrUeT6UoPHcYplJgucnJ4o703cS2e9Ln6UxoeAAPrUYPOKeOlR00V1F98013VTzSjnio5IwTk/lQUHnDGScj2pjXDEnYjHHtUixrtHyjj2py8KeKCiq32iQjaFA96Ps8j/AH5GH+6cVa7c4oAzxTuxpIgS0jxhgW/3ualWKNT8igeuBT+c+lKuOvekzRDT17YpAcmnN1zTT1OCaaGhcZJPemnqachHrzTGHU9zQWJnuKjkJxinNx0qGQ9c8UmMrXBI44rPuHwDVyckg1mznk5pEso3Lkk88VlXLEkgVo3DZzgVQmGVJqWQzDvUwGJrlNSkwzBB3rrdSRmyFHHTisD7C9xdLGqkljxgVUFcwmr6EPhDw9Jq+qx7lJQHLelfQ2l2sdhaRwQgBEGOKwvB2hx6VYruUCVhycV0a4UYY8VnNupLyR0QioRsSkAc5+lRseppu8A+38qid89Oa1SC5IZCDj+VBkI5/SqjyANz1xVS5vljGWbkVXMQ2aE1xzwD0rPuLhV5Y4rntY8T2tnGxaZQfc151r3xADs0dqCxPfPFOMJS2MZ14xPQ9Y8QQWqMWkUEH1rzvXPGDTMy25P1rjrrUbu/YvO7YPbNRovy5PCj1pvkp+bMPeqblqe6numJkZsGq800Nom6QjPpmqd7qsdspSPlsdc1zV/ePO2WY1lKcpvXYG1HSJe1TWHnJVDhB2FZG8seT1qA5bPJp8Le2ahu2xnvqyUQk8npSOu0E08yY4HU024+bhOfWo3GRRPirLYEfAyfaqqIQamL4BA6n1oYETNtOc81JG696gc7eWOTSKcigETO6s1NZzgjoKj3ADPJozuBoAcM4pgHNKvoafIuEPvQAwkZOMVGO+abyDR60ASM4Apmcn2puMjoacCAMUAA7c/nRyDwRjNNYYxQORQA9uRj0pHwMADPvSZGaM89aAEOO1Nzz8oxSk/pQ3txQIMnPPNOJ47VGF9c1IF55oGIoJ+mKsW6ktjdgCogOP6U5CVBxkZ60AXJ5iAFXpjFRwuwORSRoXYKe9TCHEu1SaFZAWbdMuNxrobSIyQhQAqDqayhayQqhKk7j1rrNFst8aCUn1wKiUtLmkUT6LpeZd+PkBzn1rudH06LzBLMuSPugVR0m2UNl+ABhR0rq9FtA0gdiSOwpwTerN4RNnS0IA+Qity0BJwQMVBbxDACr+VacUYC55FdEUrHSkAOMjrSngc0j464qGWQ568VdhNjJ3ABA7VnTAMDirEs2Tjiq0n3TipehhJ3Me+GDWXKBnj8q1b5c9azZF9elHQ5ZlVuTUsI5A71GRg1ND1zUsyZqWuep6VqQZ4xWZa5yDitSEcUjmmXosEVdiHHSqUI9eKvQHHrQzJbnKQzfNnPNalvcAKK5mGbDda0beb1NS0bJm+smeTUqOCetZ9tJ5i9eavQAcUI1THyDIBxxUcijgrxU7EHioyMEccUkWNZcJkg4qMOQuTwKlc4HHSoyA69xjpTRSY4McDALZ/Sq8vyOdwxn2qZFKHt9TUd2pLAjnjmi+pRnyyABsjOeKyrvy3kJKDOMdK2xACOQTn1rK1O2kCkxDlecYptJ6DTOU8Q6FBPF5oQbh8wIA/wrzfXNLZXO2MkE46dK9oglSaIpKvzdGBrmfEumbnJiT5D3x0/SueScWVpLU8YMX2aYo4z6ioZ4tsm6MZXuK6nVtHbezbfmHU461XsLSOWGWOQgNjg1TkrXIsczOmEJx1rPIIPrWzdIyM0TjofSsx1AyO9UiWVHbLU0H34qSSPaoIqIjn60wCXGRg0gO0Zyc9qac4GalUAx0AM39j3qQdMHpUW0kmnZO3BFACk4z6UisMYNNLZHFCYJ5oAVyQeOlGSV9/SmMcU4dM9qAFDcc/yp8ZUnBOKj47807ZxmgCeLAcYxg1ZkX5cY+lUYwd/Bq7vGBk/WhgRlsqcDB96jL88809sEnb0NMUgEg0CHQT7flbke9XEYSDGAR61msOeDzViEkDg5FDQD3IVzkflULMScKOlLI5yT3qSNNybgMUANZiV+br2qKFmD5XtU5cFsECmMNjEDnNCAvWd6YXbKgA9QRVe9mE8nGOew4qMZIwaSKLL5J6UrK9wEeDaDkfjUCkp3xV1ssAjVG8Chcg4pqVgLum6vNauBuJX0/ya6q01C3vUHzBZPQ4rgGyD0x71NBPJEwKMePQ05RUjOUL7HezQAqdygg+1Zd3YMh8y3Zgw9KraZrxUKk/I9f8AJroIJYbld0TAg+/NKNSdLczs0Z2meJtT0iRR5sm1T0YnHb39q7/w/wDE5SES9ODxk/l7/WuHv9PjmVuMH6VgXemywElckdutdMa1Op8SGvI+mdI8YaffxqI7iPkDjIz2/wAa6OC9ilQFHXBr4/tb+6snBilkVh/tH/H2rqdG+IOoWRRZHLqpGc5Pp7+1TLDRl8DKu1ufQmtabDexlkA8wcggf/WrlGtHt5Crqc544rn9F+KcEm1bsBSfp7e9djZa/pWsoPKmj3kdMisnTnDdaGckuhFbofl9q1IAABjrTI7Zc/uyCD+NXIYDuGRWZFixboO47VdiTAHrUUSkdRVuIcc9adhEiD0FTKKYg9KkwfxNNILDhzx/KnqppFXjng1IoplJCgYXPao+rewp0pGCBTV9qaRQoPJ7Uv0pp5OO9OUbjgdKZSHAY57mlYDp+NAzu9qRzljikaIbj5jTm5IHekGfr9KdgA5NMpACM+2cUp659aaOM8UoGSM0FIr3VtDO2ZIlY+6imw2cUbblUA+1WT97mhjjHB/CjUtAp47CpF74FRL61MDgD0plIj53U5sY4600EZzR3ODTKQ3nOe9L2pO1HYU0NEmeARUefU0uTtOeaZ2pooePyo4+tNBO6jp0oKQq9CBQOmfwoB60LwM0FIUnB96b3yKRh60oyBz1pooXdnjilXpgHp1zUbeoGPwp+TtoLQrHAphH508/d+tNP6Uihh+vSl3DA56UEDJIGB7UmMEkUykNcnmq8pwPSp36Hio5Bn1pMdihNyDWVdZJPPFatyCD1rMuRnNSJmZM2MgVRlJdsCrdwPmOKqJxKAoyP5U0rmRdi0ky25cJkn0FWfDGhJHcvNMv3emRWtpOViBYYFWpLyKJf4VB/CpbaVipcq1NRZFAA7jtio5psqQRg5rmb3xLY2gYy3EYI7bq5TWfiXptsGEcquw7Ag1cKb6IwnXit2ekvdKoJ3Csu81i3gRi8yg9eteH6x8U7iYsLVNo9/8A9dcXqXivU74nfOwU9lJH9a29j/M7HPLEt/Cj3XXPH1jaBv3ylvQEV5xrnxFubosloSAfT/8AXXnqie6OZGdvcmtK1sQOvJ9aTlTpke/U3ZJcXl9qDlriVyD2yasW9uF5Pf1pwRYl+bAHqaoX2qJECIyCaxnXlPRFqEYbmnLPDbplyM9hWHqGsNIdqHAFZdzeSTMSScVUYlsdazStqyZTciZpHdySc/WmyA7eeKWGMueuKmng2oDnPvQ5E2K8ZH8VIfvfL1pzLgcHNMLc4AqQFDYPXmrKAADPWq6DHPFSSOWjGB0oAkkZf4SKrscnA4pyKWOSaa5AyB16UAQuOcHpUiYIoCZFNI280AOcD0phO3vSs3HFRM+ScUASq3NSjDjLHiqwYcc1IXG3AoAZIQGOOlMGc0H/ADmkzTAVs4wf0pq5PFDHI5py8dOtIAJwwNB/PNI1KPl680AL05P40pXd0/Kmsx3elSBhjFAEWMHFKQT2qTbkA05kYLntQBCoIP8AQ1Io3HnNJtOelOQMOgoAk24Az1NWYLYuOgquvLD1q9ayMDgcZ9aTuCJIbZsMRwR3qzpECy3PzsAB1NW32xWeFALt1NXNJsFWMNI3WpvoWlqaLKkrDy1DgcDAro9Js2hiDclz2qPw/p8eN2MovrXW6Zai4m+RMKvc0oroaxRJplk3yNLjJ7Yrr7G38oqVXg1Rs7QqybscV0dtGABxXQkdEFYmhA3DOPwq6gDKcVUA/wDrVPCGySa1SNESFRjmq0sG5uDirJbPB61HI204GKNRNGfLbhSSeapy9CM1oSk4P51n3Jz2qXqYT8jLvCMc1nP0PNXbw8ms5zyc0WOWTISKlh61F1NTQfexUszZq2nStSE8d6zLXtWnAeKRzTL0Q6Yq5C2R6VThPpVyPihoyW55bHOwbJrRtLn5uuazZYiDxzUSzGNxTTUth7HZWM2CPSt6BhtB71x+lXIYgZznvXU2swYDGDxUS3Noss9j78im9QeeaXORUO47gMjaaNzRMB1Pv605yAB7d6CoXJHWoXyQKW5SYM25sg9DSK+9SD16VGAeamgQKwx0qikx8I3AqR0qG6jUZy3OKsswV/eqtyp3Bj0qUrsq5g3dkyzb4lIJ61TvFwhWUdeK6kKCMlQao6rZq6Bgv4AU3roxo821qBYslV3Z9q5e7tRLETbLtkHJr1S70QXMLlfv44rhRplxZ3kizjg+1YuKV7D9TzbUIpC754esOfcX54Ndzq1gDfSLztzXO6lYmOT7vB71UWQ0ZGCwx6VEYW6nrV/ywnQZpsu1owR24piKHl84IwPek2E8CrD9vSm8HgUwIDkdRUTkY4zVp05x2qN4+elFwIUwc80jcdKcw2n3pp5oAaWzjNSA4AFM2HPH508ggUAAIJIP6VYEgEe0jIFV14HvS7sdaLASAgH0FSMDjFRRkE1MzYHI5FADBwT14pjEk09nBB9ahY4P1oAcmS49KsfdBzTIV+bP6VKWx8uKAExnnv6U4EgEUbTyR1qWFQcbuvegQ1oS3OPm7mmBypG8fXitQNGIyGIBNZ90UBIHakmBJI8ZAK4FVpJMPkcVCpI9805TzzzTsBZgnJbpk0+dlYDAwarx/uznIpzuWxnrSsBVkBLEYp4X5cA8+9TCLq3FRNwfrTuBECQ3oau2l7NbsCjnr61AqBvr60MuAOearmBpM6vT9bSTak5w3rWruinTjayn0rz4MVI61cs9RlgwN5xnkGs5U09UZuHY6i80uKYFogM+341g3mmyxMSvIrUs9XSQDecN39K0PNSZeQGz3FJTnASbRxbq8bdCKu6dqU9nKrxTMpHYMRW5c2EUoJA59qx7jTHQkpzXTTr33Hoz1rwJ45SXZBeOA3ADE/8A169c0+6guEDRMDx2r5CiaW2kBUspHevSPBHjqS1kSG8clRwCT/8AXq6lBT96BlKNj6FWMHkdKmQZxgcetc9omuw30CssqlSOxrfibzMbcEe1c22jIsTBTj0A71Ii4ALf/qpUHAJp3DHGeKdykKPWgnaM0nGcZprksRjkU0hiZ3EUvT2JoA780ZxVFJBn881JGODzzTAOOTTx0yOlDKSHDABpvbihunH1pGByAPrSLQq5zQx5INKvLEmmnqcUF9BfTNL6mmpk53Up+UUxoQctyaDwSTRSMeKCkgXpink4WmL36U9jxjrTKQwE+1KT06fSk7mgGgpAevSjtQ3UdKTqQPTvTLQ8HjHao9x3Y7UoYEY9ec0wcnPpTSGSdMZo70gABpO3oaCh3NCmmjOME8etCdDQUhT1/WlHPPemsM9acuD0/GmNASB7UqnKnnimOelOU8cUFoVe4PGeBSMOMZoztIwMipMZ6UilqM7/AEpG5zmn4GMdKXblSOlBaIGXk1Gcen4VZZOvtUMi8HI/KgZSuEyM/pWTdR46VuSr06Vl3rbVJOBUNgzAukI6nisi+1qy0iJnuWG4DgU3xZr0Om27szjdjge9eF+Idfn1G6eSRjszwK2p07rmexwVq/K+WO56Jq3xUeNTHaxHjp09/euO1P4g6pdk4l2D/wDX71xc8zOSc8VGuSenNN1Ix2RyO8t2ad5rV3dMWlnkOfc1SaZ3bqSfenQWjyc4wDWnbWAGABk1nLEMqNIz4YHl9RWlbWQHJHNX4rYIMtiia5hizlhx2rB1JS2NVBR3HRRgDgDHrTbi+it165YVlXWpO5Ii4FZkheQksSaFC+rE6n8pdu9RknYjOB6VRJLA560ir+lJ6jNVe2xkI3Wnqh+tA2jgmrChVTI61LYyMbUYVK8ofAPSoQhLE4NNYlevWiw7jpyo4TpURUAZJ5puTnrzSck80CFPSng9KjcnApQfl96AJgyoDzmmBSx46UzHembjnGeKAJzgdaglfrjpTS5OaaBk80ALnt60ypcccU11AAoAYpJ4pTSjjpSgZoAYevWmk88cVK4xUY4JoEJjHel+7R1OT1p2OKBiDnqaeVGaaOMelP3Y5NAAUz1oC4PpTg49KOT2oAlgUF+elWZSrKFjHSoIojjPOKswAIdx+9SArmPa3PWniLAG6niTfLk1Y2k/NjP4UAVCQ0nAxWhZWjO24D5V71Xji3TZrdsYpLkrBCOvWlJ2HFEVnBLcTqqoWFdvpWjl3G/lF7CmQWsemWaoiBpcYPFdRosEi2ymUYZvbpU3ctUbRSWhJptkJnMaLtQd667SYo4YxFjkfrVDS7cRrhV575rodPhAIIArZRN4IfHCAd3Q9cVfhBOCKUQAkHHFTRIRkAfjWqNErEsaAsTnmraAbTkc1UhBGSe/aplIHGaqxSFZDuz/ACqGZB19KsZJPvSTKNpz6U2D2MyZtoIxWbdvkEAdav3JIYgVl3CkE1NjmmZd0etUG5/pV+6HX+lUR1ORQc0txgHPJqWJeRjqKZ0bAqeIYOahmcjRtumD1rSh+6DWdbDAHrWnCOBxQjmmXIO5q7Fgjk1Sizjp1q7ERjmmzJbnmjMGNULxQDkcA96keQbzjiqN1Mc4rCndMto09KuMMMkV2WnyblHI5rzvTZCZhg8HtXfaPzGOK2qaIFozXRietKvpnj6Ug+6KQkqeKyTNEySQHbxUW7I57VITkYPWoUHzkHp60y0SIoZcnpT1+UheophG08GlQ7mz3oLTCUHdu7EYqM/OCD1qyuDRsVeelNMaIY4yODSXIyCMDAqZ+nXBqIgsPc0y7lNotoytcvqlsJpHJUBh04rtJYsr8vasDUodkgZh8vrU8qY7nl2uWYS9Ylcetc1rtnugEkXOOtep67piXO1k+9XKapprOrqOMcY9axasG55WwIkwRxVa5BQkrx9K6PU7Aw3GwptJNZlxaEcAZrRNMmxkxqzREkU3Zz6cVq20aBSrjk1TuF2MVHQUX1EUXyCMUNICOetD4L/SmOozkd+1MBjtkZHNEY54pQnegDt3oAcRimtyB60pY96iJP4UASDAprnjim8+tGD3oAdHwasHGMnmq+CBxT9xAxzQA75Ryabs55oPIFSxkk80ANycZGTiph80ZY9aacAYxg5oDcYFAChypp6NhuKRgCB0zURJ4HSgRYZ9w5PNRSqcZ60Rjdk56U53ZVxQBX3HGBzQpwcHrUgQjkjg05EDHk0DGgFjipFToTTVJV808SHccdu1AhzOMHjioiBjk1NHhjgiiSMdDSAjQ8HGOlMKNnPehuuVPWnqRjDdaYERDHtzSFSvWp2I2cdaikcEc0XGMWQg5U81etNSkhIGfzqgq5HWmHiqvclq51tnqkcgUOcGtHcsi8YYe1cIjsv3c+1Xra/lhIwxFQ6fYlxOmmto3HIBqlJYFSTF1os9ZjYATfnWpG8M4zGwqoVJU2TYt+GfEN3pE6q5Yx59a9p8MeLbe8iTDj35rwl48HDCrFhdS2MgaGQrz0rqbhWWu5DVj6ktbxJ1XDe9W9/TuOleJ+G/GLLtSdjn/wDXXo+m67FcLy4Oa55U5QZSszpOp9qcBjBzmq0NwrruBBFWUcHr3pXuWoigUhBHNSLg0bc00x8omM/jTgML7fWnAcUEZGKCrDByfxpD98+gFO6CgDHNMpICMVExznHapWqLjnFCHYUAFSeeaG/u0uOOtNHLfSmNLUUnHFI3Q05uGxUchz6UyrDgflzmnk8DAqLoBT1PA96CkhR6Gm55pNw9T70dScGmMQsNxPUU4HnHamLyR+tPHQcUFJB1HXimDrxTm+7jPApg4YetCKHZ+bpRnnijPcnAoI5wKChPrTo/p+NM6fWnqO1MYhb0pyE8/Wmjng05OM+1BSFYdTTlA9eKXaOx4oApFIRhzkdKVeBkdKf1oA4I70FAenAoHAoA6UHAAo0GmNY8n2qJjkH9BT5GUHkis3UNQigQlnAx0oE5Jai3cwijLEgYrzzxj4mj0+CQs43dhVfxl40itEdIn3Pjsa8T1zU7rVbhnkZiCfWtYUftTOKtiG/dgQ+I9dn1S6dnY7ewzWAQ7nitBbYZ+bmrMVrgcACoq1uiMIU3uZkNkzY3Vft7JRjirqxxQgGRsEVDPqcUYIiArku5bGtox3LUVqqjLnApJruC3XAPNYk2oSSE8kCqU8pJ5P1pqn3E6vY1LvVGkGE4FZskrMSSSfrVcMSeaUscYAq9FsZu73J0Oe1SMVVeBzUEBIqWQ4+719aQEb8jik6Yx0pxHAFIQAOvNIAUZcccVYQY57VDEQCcjipVZduB3oAVpCFOOlV3cu1WTHlCScDFMt4Qx5IA70XArZweachBOB1qW6Vd2EqNVIXPegAlXiouegqRjximhsL70ARkkkCkxzQDycUpxn3oAY2e/wCVPUVG780gY49qAHlueKM5xmmN0FANADiM9KBkd+acMd6QnngGgBpb160gB/AUcnr3py9xQAw8HjpSg5OaU+tIAe1ADuPSjOee1PC8c9aOAfagAVQOtTRgZ56VF+lSKMDJNAF5JI1UAdBTpZRJhVAHvVBclutXbVctgDmi1tQWoyOMCTkVswJGIhhTTbSyM0qjHfmtm5WIbYolBZfapcruxSVkYi2TyXA2dTXX6NaNbsscSFnI5NR6HY+STNKMueme1dvoFtGy+YVyalts0hETStKMr75xnHIyK6azs8oMDn+VSwRoEAHUdK1LNAXGFrSMXubpIgtLVkODWtZqEUetSwwjbnGKRkLMB3raOpdrbGhGw2DipI/aoIw3lqDUynC4qki7kgUZJA5oVTv5pgyelSrV7D3FyFIpHYYI7U8gcnIqGTgHmpYnoUrk5J45rLuQMYrQnJ5OKz5sYyaTOeZl3QBOapMoUnHFX7j5m57dqqSDAxSOeRUPX3qxCO2KhYZfAqeHg1JkzSthnFaUQxj1rMgPygmtOE8ZoRzTLcRzirsPQCqUQ7irkdNmKPIZM7TiqhUuTxWqYCQKfFZkkHHJ71C0NHIqaZbHzAcd673S12xD1rCsLLDA/jXRWybAMVMpX0JvqXAMHk0kg5FIDwBSZ7VKZaYqn5h2qXHXHSoenTrS7j7iqLTHN3wTTYuCSaUZ9cmhVOeOlO5aJI+GOelPkJKkjp0qMDnmgkkY6UFpkbuc4p65HOODTCpJ6VMOV5GOKbGmDHCk54NZ9zEJ1ZW6GtDGQSelQSx5PTApIq5zZtWSVk6j1rJ8QaPL5HmwcsOvFdm1uNxOOaJY9yYIGBSn3GjxLWrKS7QEJ+8WuRZdkrRzrtf0r3a80XdK0irjPbFeeeJ9AYXxdkPPQ4/z6VktHYGjz29j53L2rMn+YZHXvXU6ppkiE4GBXPXVuUPIzVolmaqgEkimPHzxVlojmkK4HTNMCAIAMEUyRQM1YKg8g1G45pAVSpzTSMnjpUzLxTStMCPHNOBFKBQRigBQcUcYpO1HQ0ALyKduxgjr60zNKBk0AKSWbJNSL1qMCnduetAEj/d6/hULNmnl8jB61EwBoQDopCD1q2F8wgnpVFRzViNscUMC4ANhDVUm4Jx0qUykgdDUMrZNJCGAkgE5yKdznNNUcc9KlTkEUxjgxVs5qQyBl5qGnr1x0FAhpQjmjdzUu0YqMrnFACt82OOtRuuOcYxVpIyE5pGRTSApoMNyKJEwferAjweBmnOuRnFFxlVAAfanMV2j1odCB7UzBJA5pgOA461NFdSwt8rEU1SPoaY6mqTE0bVnrbqMSjPvWtb31vN3AJri+lSpIVPUimkuhDid3HnO6J81tabrdzZuOSR6V5za6hLEepNa1tq+7Ac1tGb2epDiez6T40QYEjAf5Ndhpvi21lABkBNfO8V6rjINTR37xnKsR+NPkpyGnJH1Ha6vbTr8sig9+aupdRN0dTmvluHW7lPu3DCtiw8WX0RH+kEjpS+r9mUqj6o+k1YHnr9KdkH3JrxXSfHk6lRI+6uw07xtFIAHIqXSnE0U4s7np060E5GDWFb+IraX+Ic1ej1K3kHD1G25orPYuN/KkAHXqaYs8bgYINP3DrTuilED2HYUKM5zS8etKPXNFx2EI5FQyKQTirBwaaxBoRVisd/HAxT4t2BnpUhIx2pFO3ApphYaDjnvQOjHt0pWIINIOnJp3Q7CJkY4qQdKQemacpGMUmy0hj8DH4U0DmpG+Y4zTR256U7jSDaM/rQxx3pwI654pHwetIdhg9KevTgUi9qcOvp+NNsaAc59aXbj3pNwHpSNKqnIIxSchomHSlPoe1U5L+CLJaVfzrL1DxTp9qp3yihXewnOMdzfyByc9Kgub6C3XdI6gCvMtb+JcESsttkmvNde8bX+oOQspRfTNaxoyfxaGMsSvsnuGseOtN08Nl1Jrgta+Lx3stmmfevHri5eZiZHZj7moC+BnOK0/dU/Mwc6k92d1d/ErXLhv3cmwH2rKu/F+rXQIuLknPYDFcxu3d6XzETqc1DxKWyFyd2W555bhyWJJPUmoCn96q0t8q8LVKW8Zz14rGdWUxrljsaTzRxgliDVOfUyAVjFZ0khYnJqIjNZcqBzbJZriSX7zVD35opfr0p3JHDkZFMKgmlzj6UHpSuA3AzUgXPSmDHrTlOKQDtoA461JGB1JqPPHHSlUHAoAHbDfSoict7U6Xjp+tMHSgB/TpSFiDkUKeKawA5zQBIZmK4ycUqMV6GocipA4AoAeSc+9Rk4PWkZyRmoy/egB7HAqJmNBORn1pKYC5/OkLZ9qO9GN2cUgGnnNA4FL3wKUYzigBB156Up9qTmgHuaAFz8tAFAwaXGKAFzgUh6ilHuaQ8daAALxmnYwB60A8U4DLUAIFJFPWMnipAtTQoQTxSuBCUwBgUuw5/pU5xu4p0SFnyBmgCJV2/WtGygY4K8miG182YZ/Gt6ytFiyU6ngUmykhtqhRRn71bOn6c0zglfmNWNJ0uV2V2UkHpXZ6bprRBfkAPtS9DSMOpnWeiOVVSeWrr9H0xbW2C/xU6wt2D5K8it62g+TvmrjF7G0Yle0tsEZ5atOGEKc4wakiiCAcc1YVSW6ZFbJGiQKvPWniP5snFOAz2p6rxTSKQ5fQ0pAwfWlC4PtSt1xVoYi8HnpT93OMUzvxwKUn1psB+eKq3DkZ5qZjxxVW455pEyZVnNULjNXJeRVScfnUmEjOlGT3zVeQfLzVyQc+lVpQcHPNIwkUGHOBU8XOO1ROOaljwGGelJmLNC3JAGa0Ys4HFZ1vjbWlD0H0pHNMuQnjHvV2KqMJq7F+lNmUdzhkthgVZit1AHSrSwc4P86nEQHbJrmchEUEQVs4xir0XSo1GMYp4yBx+VG40SA8UmSBSE9+9A5+lUjRD0OTS9TUecEU4c9eKopMeuMj0p45IxUaAnmnL1pFpj2J6GgUMOh6CjtyKEVccNoGB1oP3cd6Ewe2MUuATnnJp3LQoI2gCkYdMUjfex2pc8D3p7DuIVPHFMZfUdam/iwORSHHU9qRSKckQPGKxtVsFljIKA/hXQuAScdKryIG68iplEo8t1vRVKttFcFq2l+Wx4r3bUrESKSMH/ACPeuL1fSyysSox/n3pJktHj01sQTkc1QkhIzxmu11TTmR2GP1rnbm3weasRiuuM1G3TmtGaEDvVV4xnrSApsPTpTSBjFTMpzimMKAGAetMbrzUmPemjnrQBGQeOtIcmnkY70nagBnsacO2aMc/Wlxg0AAznFO9j0pCKKAA03GTmloxQAgHSnq2etJ9etLjIzjFAD88U1uT1pCeaXvQAoPt+FSZ/CmDOcelOIyPpQAmTnnFOVsHqKaPzoIxj3oAsA56U0Zz82KjBIIwadk4yaBFpXUjjrQSB9aq7iKeHOM0WAsooPNJKhHNQq5FTK24YOealoZXlqIDODU064J54quTg8VSEOI5waaTz605GJ4NBHPFIZG3PJB5oUY4pSOc04c5p3AQHnGeakRyOQaZjHHalxj6VSkKxaiumQjDHHpVyK9GMGsjvTlYnNVzCsbizA/danCV1OQxx9axBIR3OalS5YVSqNCsbkd5IpGCePQ1oW+ryR4+Y1zK3We3NTC4X1rVVu4uU7ix8Syxn/WEYrdsvGMiYzIeK8tWbPQ1IJmB61XNF7is0e0WvjZxj94PwrUg8csMDf+teFJdSKBz+tTLfyA4JNHLBlKUke/Q+Nl/ibNXYvGKHHIOK+fU1WQdGNWo9blUEhjU+yiUqkkfQS+L4zyePxqQeKovWvA08QPg5Y1YTxCwOcmp9kUqrPdG8SxMeCBTT4jjz1NeLL4hPqfapB4g56nn60ezH7U9l/wCEjj9eKd/wkkY968a/4SD1Y4pTr/X5jR7Maqnso8Rx/jR/wkae2a8ZbX+eGPNNbxAR/EcUeyH7Y9mPiNR0PFJ/wkyDqR9K8XbxFgHDGo28RNz8xo9kHtme1jxRGCeRxUUni2Jf4q8Rk8RsecmqsviGRs8mmqQe3Z7hJ4yTPDA1Tn8a44DAV4jJrkv941XfWJXB+Ymn7KIvbSPZLrxxIucSCsO98dzkELJ+teXSajIwwSfzqs107dz+dUowRDnJnc33i+5lB/fEVz95rEsxJaVjz61gPMe5qJpfeh1EthcvcvTXe7r1qs8x9s1VeYCommrKVRspaFsyn1phmweTVJ5ielRF2JrJu4+YuPcHtVd5iT1JqHJpeeM80hCliaQHNCjmnChsQjAU085wKU00ZBIpXGN9aO49KdjvTggNIBmOeKCOhqZV60w/eoAYBSgHNOC54py0AJgdTR5nFOYflTT34oAjY5PNM705854pg5PvQA/IxxTCaOe1IRigAJNJk96OtNPBoAUnNGOODTcUvI6UwE7AdKUdaQg7qeOg70gF6dqOKKCSeo70AMoxznmnH0pO/NADD70o60EZGaVQfxoAUZ7Zp2MjmkApQOOKAEIoIp2KMZNAAOnSpFGDSDtUirwaAJY+RU7EhcUyEDb71OsYbn8qVgGQRb26Vq2toSen6UafbBsciun0uwVsA4oZaRnWWnFnG1evpXWaR4fLbWcVqaPpaggkCuusLNRjOKTZrGCKOn6UEQDb0rbt7PC/1q7BCqrwPwq9CgHQfhVRia2K9pahCMj3rRij65HHaiMDPGKmXjGRWti0AXHHfFPQelJt5BzUiD86pIaDpTwaQ9aVOfoKuwx4+gNAznnpQDnPvS9qaHcQjn2pp6c04/rSelMBjdM1Xl6HFWSOKrTcqRipZEilLiqkwOKtyfSqk2fTNIxkVH7ZNVpjVhz6iqkpOKlowkVH4bHrzT4+ue1MkxnJHFSR/hQzBmhb8gVoRHKjms63NX4SR0qTnkXoj2OfpVyI5z6VRgIBOTV2LmqZmkf/2Q=="}} diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/maskgan/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/maskgan/README.md" new file mode 100644 index 00000000..17a5763f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/maskgan/README.md" @@ -0,0 +1,91 @@ +# MaskGAN: Better Text Generation via Filling in the ______ + +Code for [*MaskGAN: Better Text Generation via Filling in the +______*](https://arxiv.org/abs/1801.07736) published at ICLR 2018. + +## Requirements + +* TensorFlow >= v1.5 + +## Instructions + +Warning: The open-source version of this code is still in the process of being +tested. Pretraining may not work correctly. + +For training on PTB: + +1. Pretrain a LM on PTB and store the checkpoint in `/tmp/pretrain-lm/`. +Instructions WIP. + +2. Run MaskGAN in MLE pretraining mode. If step 1 was not run, set +`language_model_ckpt_dir` to empty. + +```bash +python train_mask_gan.py \ + --data_dir='/tmp/ptb' \ + --batch_size=20 \ + --sequence_length=20 \ + --base_directory='/tmp/maskGAN' \ + --hparams="gen_rnn_size=650,dis_rnn_size=650,gen_num_layers=2,dis_num_layers=2,gen_learning_rate=0.00074876,dis_learning_rate=5e-4,baseline_decay=0.99,dis_train_iterations=1,gen_learning_rate_decay=0.95" \ + --mode='TRAIN' \ + --max_steps=100000 \ + --language_model_ckpt_dir=/tmp/pretrain-lm/ \ + --generator_model='seq2seq_vd' \ + --discriminator_model='rnn_zaremba' \ + --is_present_rate=0.5 \ + --summaries_every=10 \ + --print_every=250 \ + --max_num_to_print=3 \ + --gen_training_strategy=cross_entropy \ + --seq2seq_share_embedding +``` + +3. Run MaskGAN in GAN mode. If step 2 was not run, set `maskgan_ckpt` to empty. +```bash +python train_mask_gan.py \ + --data_dir='/tmp/ptb' \ + --batch_size=128 \ + --sequence_length=20 \ + --base_directory='/tmp/maskGAN' \ + --mask_strategy=contiguous \ + --maskgan_ckpt='/tmp/maskGAN' \ + --hparams="gen_rnn_size=650,dis_rnn_size=650,gen_num_layers=2,dis_num_layers=2,gen_learning_rate=0.000038877,gen_learning_rate_decay=1.0,gen_full_learning_rate_steps=2000000,gen_vd_keep_prob=0.33971,rl_discount_rate=0.89072,dis_learning_rate=5e-4,baseline_decay=0.99,dis_train_iterations=2,dis_pretrain_learning_rate=0.005,critic_learning_rate=5.1761e-7,dis_vd_keep_prob=0.71940" \ + --mode='TRAIN' \ + --max_steps=100000 \ + --generator_model='seq2seq_vd' \ + --discriminator_model='seq2seq_vd' \ + --is_present_rate=0.5 \ + --summaries_every=250 \ + --print_every=250 \ + --max_num_to_print=3 \ + --gen_training_strategy='reinforce' \ + --seq2seq_share_embedding=true \ + --baseline_method=critic \ + --attention_option=luong +``` + +4. Generate samples: +```bash +python generate_samples.py \ + --data_dir /tmp/ptb/ \ + --data_set=ptb \ + --batch_size=256 \ + --sequence_length=20 \ + --base_directory /tmp/imdbsample/ \ + --hparams="gen_rnn_size=650,dis_rnn_size=650,gen_num_layers=2,gen_vd_keep_prob=0.33971" \ + --generator_model=seq2seq_vd \ + --discriminator_model=seq2seq_vd \ + --is_present_rate=0.0 \ + --maskgan_ckpt=/tmp/maskGAN \ + --seq2seq_share_embedding=True \ + --dis_share_embedding=True \ + --attention_option=luong \ + --mask_strategy=contiguous \ + --baseline_method=critic \ + --number_epochs=4 +``` + +## Contact for Issues + +* Liam Fedus, @liamb315
| \n",
+ " | \n",
+ " \n",
+ "  View source on GitHub\n",
+ " View source on GitHub\n",
+ " | \n",
+ "
 \n",
+ "
\n",
+ " \n",
+ "\n",
+ "[Image of Green Sea Turtle](https://commons.wikimedia.org/wiki/File:Green_Sea_Turtle_grazing_seagrass.jpg)\n",
+ "-By P.Lindgren [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], from Wikimedia Common\n",
+ "\n",
+ "\n",
+ "Now how would it look like if Hokusai decided to paint the picture of this Turtle exclusively with this style? Something like this?\n",
+ "\n",
+ "
\n",
+ "\n",
+ "[Image of Green Sea Turtle](https://commons.wikimedia.org/wiki/File:Green_Sea_Turtle_grazing_seagrass.jpg)\n",
+ "-By P.Lindgren [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], from Wikimedia Common\n",
+ "\n",
+ "\n",
+ "Now how would it look like if Hokusai decided to paint the picture of this Turtle exclusively with this style? Something like this?\n",
+ "\n",
+ " \n",
+ "\n",
+ "Is this magic or just deep learning? Fortunately, this doesn’t involve any witchcraft: style transfer is a fun and interesting technique that showcases the capabilities and internal representations of neural networks. \n",
+ "\n",
+ "The principle of neural style transfer is to define two distance functions, one that describes how different the content of two images are , $L_{content}$, and one that describes the difference between two images in terms of their style, $L_{style}$. Then, given three images, a desired style image, a desired content image, and the input image (initialized with the content image), we try to transform the input image to minimize the content distance with the content image and its style distance with the style image. \n",
+ "In summary, we’ll take the base input image, a content image that we want to match, and the style image that we want to match. We’ll transform the base input image by minimizing the content and style distances (losses) with backpropagation, creating an image that matches the content of the content image and the style of the style image. \n",
+ "\n",
+ "### Specific concepts that will be covered:\n",
+ "In the process, we will build practical experience and develop intuition around the following concepts\n",
+ "\n",
+ "* **Eager Execution** - use TensorFlow's imperative programming environment that evaluates operations immediately \n",
+ " * [Learn more about eager execution](https://www.tensorflow.org/programmers_guide/eager)\n",
+ " * [See it in action](https://www.tensorflow.org/get_started/eager)\n",
+ "* ** Using [Functional API](https://keras.io/getting-started/functional-api-guide/) to define a model** - we'll build a subset of our model that will give us access to the necessary intermediate activations using the Functional API \n",
+ "* **Leveraging feature maps of a pretrained model** - Learn how to use pretrained models and their feature maps \n",
+ "* **Create custom training loops** - we'll examine how to set up an optimizer to minimize a given loss with respect to input parameters\n",
+ "\n",
+ "### We will follow the general steps to perform style transfer:\n",
+ "\n",
+ "1. Visualize data\n",
+ "2. Basic Preprocessing/preparing our data\n",
+ "3. Set up loss functions \n",
+ "4. Create model\n",
+ "5. Optimize for loss function\n",
+ "\n",
+ "**Audience:** This post is geared towards intermediate users who are comfortable with basic machine learning concepts. To get the most out of this post, you should: \n",
+ "* Read [Gatys' paper](https://arxiv.org/abs/1508.06576) - we'll explain along the way, but the paper will provide a more thorough understanding of the task\n",
+ "* [Understand reducing loss with gradient descent](https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent)\n",
+ "\n",
+ "**Time Estimated**: 30 min\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "U8ajP_u73s6m",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Setup\n",
+ "\n",
+ "### Download Images"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "riWE_b8k3s6o",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import os\n",
+ "img_dir = '/tmp/nst'\n",
+ "if not os.path.exists(img_dir):\n",
+ " os.makedirs(img_dir)\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/d/d7/Green_Sea_Turtle_grazing_seagrass.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/0/0a/The_Great_Wave_off_Kanagawa.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/b/b4/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/0/00/Tuebingen_Neckarfront.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/6/68/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "eqxUicSPUOP6",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Import and configure modules"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "sc1OLbOWhPCO",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import matplotlib as mpl\n",
+ "mpl.rcParams['figure.figsize'] = (10,10)\n",
+ "mpl.rcParams['axes.grid'] = False\n",
+ "\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "import time\n",
+ "import functools"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "RYEjlrYk3s6w",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow.contrib.eager as tfe\n",
+ "\n",
+ "from tensorflow.python.keras.preprocessing import image as kp_image\n",
+ "from tensorflow.python.keras import models \n",
+ "from tensorflow.python.keras import losses\n",
+ "from tensorflow.python.keras import layers\n",
+ "from tensorflow.python.keras import backend as K"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "L7sjDODq67HQ",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "We’ll begin by enabling [eager execution](https://www.tensorflow.org/guide/eager). Eager execution allows us to work through this technique in the clearest and most readable way. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "sfjsSAtNrqQx",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "tf.enable_eager_execution()\n",
+ "print(\"Eager execution: {}\".format(tf.executing_eagerly()))"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "IOiGrIV1iERH",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "# Set up some global values here\n",
+ "content_path = '/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg'\n",
+ "style_path = '/tmp/nst/The_Great_Wave_off_Kanagawa.jpg'"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "xE4Yt8nArTeR",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Visualize the input"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "3TLljcwv5qZs",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def load_img(path_to_img):\n",
+ " max_dim = 512\n",
+ " img = Image.open(path_to_img)\n",
+ " long = max(img.size)\n",
+ " scale = max_dim/long\n",
+ " img = img.resize((round(img.size[0]*scale), round(img.size[1]*scale)), Image.ANTIALIAS)\n",
+ " \n",
+ " img = kp_image.img_to_array(img)\n",
+ " \n",
+ " # We need to broadcast the image array such that it has a batch dimension \n",
+ " img = np.expand_dims(img, axis=0)\n",
+ " return img"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "vupl0CI18aAG",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def imshow(img, title=None):\n",
+ " # Remove the batch dimension\n",
+ " out = np.squeeze(img, axis=0)\n",
+ " # Normalize for display \n",
+ " out = out.astype('uint8')\n",
+ " plt.imshow(out)\n",
+ " if title is not None:\n",
+ " plt.title(title)\n",
+ " plt.imshow(out)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "2yAlRzJZrWM3",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "These are input content and style images. We hope to \"create\" an image with the content of our content image, but with the style of the style image. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "_UWQmeEaiKkP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "plt.figure(figsize=(10,10))\n",
+ "\n",
+ "content = load_img(content_path).astype('uint8')\n",
+ "style = load_img(style_path).astype('uint8')\n",
+ "\n",
+ "plt.subplot(1, 2, 1)\n",
+ "imshow(content, 'Content Image')\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "imshow(style, 'Style Image')\n",
+ "plt.show()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "7qMVNvEsK-_D",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Prepare the data\n",
+ "Let's create methods that will allow us to load and preprocess our images easily. We perform the same preprocessing process as are expected according to the VGG training process. VGG networks are trained on image with each channel normalized by `mean = [103.939, 116.779, 123.68]`and with channels BGR."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "hGwmTwJNmv2a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def load_and_process_img(path_to_img):\n",
+ " img = load_img(path_to_img)\n",
+ " img = tf.keras.applications.vgg19.preprocess_input(img)\n",
+ " return img"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "xCgooqs6tAka",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In order to view the outputs of our optimization, we are required to perform the inverse preprocessing step. Furthermore, since our optimized image may take its values anywhere between $- \\infty$ and $\\infty$, we must clip to maintain our values from within the 0-255 range. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "mjzlKRQRs_y2",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def deprocess_img(processed_img):\n",
+ " x = processed_img.copy()\n",
+ " if len(x.shape) == 4:\n",
+ " x = np.squeeze(x, 0)\n",
+ " assert len(x.shape) == 3, (\"Input to deprocess image must be an image of \"\n",
+ " \"dimension [1, height, width, channel] or [height, width, channel]\")\n",
+ " if len(x.shape) != 3:\n",
+ " raise ValueError(\"Invalid input to deprocessing image\")\n",
+ " \n",
+ " # perform the inverse of the preprocessiing step\n",
+ " x[:, :, 0] += 103.939\n",
+ " x[:, :, 1] += 116.779\n",
+ " x[:, :, 2] += 123.68\n",
+ " x = x[:, :, ::-1]\n",
+ "\n",
+ " x = np.clip(x, 0, 255).astype('uint8')\n",
+ " return x"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "GEwZ7FlwrjoZ",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Define content and style representations\n",
+ "In order to get both the content and style representations of our image, we will look at some intermediate layers within our model. As we go deeper into the model, these intermediate layers represent higher and higher order features. In this case, we are using the network architecture VGG19, a pretrained image classification network. These intermediate layers are necessary to define the representation of content and style from our images. For an input image, we will try to match the corresponding style and content target representations at these intermediate layers. \n",
+ "\n",
+ "#### Why intermediate layers?\n",
+ "\n",
+ "You may be wondering why these intermediate outputs within our pretrained image classification network allow us to define style and content representations. At a high level, this phenomenon can be explained by the fact that in order for a network to perform image classification (which our network has been trained to do), it must understand the image. This involves taking the raw image as input pixels and building an internal representation through transformations that turn the raw image pixels into a complex understanding of the features present within the image. This is also partly why convolutional neural networks are able to generalize well: they’re able to capture the invariances and defining features within classes (e.g., cats vs. dogs) that are agnostic to background noise and other nuisances. Thus, somewhere between where the raw image is fed in and the classification label is output, the model serves as a complex feature extractor; hence by accessing intermediate layers, we’re able to describe the content and style of input images. \n",
+ "\n",
+ "\n",
+ "Specifically we’ll pull out these intermediate layers from our network: \n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "N4-8eUp_Kc-j",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "# Content layer where will pull our feature maps\n",
+ "content_layers = ['block5_conv2'] \n",
+ "\n",
+ "# Style layer we are interested in\n",
+ "style_layers = ['block1_conv1',\n",
+ " 'block2_conv1',\n",
+ " 'block3_conv1', \n",
+ " 'block4_conv1', \n",
+ " 'block5_conv1'\n",
+ " ]\n",
+ "\n",
+ "num_content_layers = len(content_layers)\n",
+ "num_style_layers = len(style_layers)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "Jt3i3RRrJiOX",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Build the Model \n",
+ "In this case, we load [VGG19](https://keras.io/applications/#vgg19), and feed in our input tensor to the model. This will allow us to extract the feature maps (and subsequently the content and style representations) of the content, style, and generated images.\n",
+ "\n",
+ "We use VGG19, as suggested in the paper. In addition, since VGG19 is a relatively simple model (compared with ResNet, Inception, etc) the feature maps actually work better for style transfer. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "v9AnzEUU6hhx",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In order to access the intermediate layers corresponding to our style and content feature maps, we get the corresponding outputs and using the Keras [**Functional API**](https://keras.io/getting-started/functional-api-guide/), we define our model with the desired output activations. \n",
+ "\n",
+ "With the Functional API defining a model simply involves defining the input and output: \n",
+ "\n",
+ "`model = Model(inputs, outputs)`"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "nfec6MuMAbPx",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_model():\n",
+ " \"\"\" Creates our model with access to intermediate layers. \n",
+ " \n",
+ " This function will load the VGG19 model and access the intermediate layers. \n",
+ " These layers will then be used to create a new model that will take input image\n",
+ " and return the outputs from these intermediate layers from the VGG model. \n",
+ " \n",
+ " Returns:\n",
+ " returns a keras model that takes image inputs and outputs the style and \n",
+ " content intermediate layers. \n",
+ " \"\"\"\n",
+ " # Load our model. We load pretrained VGG, trained on imagenet data\n",
+ " vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet')\n",
+ " vgg.trainable = False\n",
+ " # Get output layers corresponding to style and content layers \n",
+ " style_outputs = [vgg.get_layer(name).output for name in style_layers]\n",
+ " content_outputs = [vgg.get_layer(name).output for name in content_layers]\n",
+ " model_outputs = style_outputs + content_outputs\n",
+ " # Build model \n",
+ " return models.Model(vgg.input, model_outputs)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "kl6eFGa7-OtV",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In the above code snippet, we’ll load our pretrained image classification network. Then we grab the layers of interest as we defined earlier. Then we define a Model by setting the model’s inputs to an image and the outputs to the outputs of the style and content layers. In other words, we created a model that will take an input image and output the content and style intermediate layers! \n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "vJdYvJTZ4bdS",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Define and create our loss functions (content and style distances)"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "F2Hcepii7_qh",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Content Loss"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "1FvH-gwXi4nq",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Our content loss definition is actually quite simple. We’ll pass the network both the desired content image and our base input image. This will return the intermediate layer outputs (from the layers defined above) from our model. Then we simply take the euclidean distance between the two intermediate representations of those images. \n",
+ "\n",
+ "More formally, content loss is a function that describes the distance of content from our output image $x$ and our content image, $p$. Let $C_{nn}$ be a pre-trained deep convolutional neural network. Again, in this case we use [VGG19](https://keras.io/applications/#vgg19). Let $X$ be any image, then $C_{nn}(X)$ is the network fed by X. Let $F^l_{ij}(x) \\in C_{nn}(x)$ and $P^l_{ij}(p) \\in C_{nn}(p)$ describe the respective intermediate feature representation of the network with inputs $x$ and $p$ at layer $l$. Then we describe the content distance (loss) formally as: $$L^l_{content}(p, x) = \\sum_{i, j} (F^l_{ij}(x) - P^l_{ij}(p))^2$$\n",
+ "\n",
+ "We perform backpropagation in the usual way such that we minimize this content loss. We thus change the initial image until it generates a similar response in a certain layer (defined in content_layer) as the original content image.\n",
+ "\n",
+ "This can be implemented quite simply. Again it will take as input the feature maps at a layer L in a network fed by x, our input image, and p, our content image, and return the content distance.\n",
+ "\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "6KsbqPA8J9DY",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing content loss\n",
+ "We will actually add our content losses at each desired layer. This way, each iteration when we feed our input image through the model (which in eager is simply `model(input_image)`!) all the content losses through the model will be properly compute and because we are executing eagerly, all the gradients will be computed. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "d2mf7JwRMkCd",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_content_loss(base_content, target):\n",
+ " return tf.reduce_mean(tf.square(base_content - target))"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "lGUfttK9F8d5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Style Loss"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "I6XtkGK_YGD1",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Computing style loss is a bit more involved, but follows the same principle, this time feeding our network the base input image and the style image. However, instead of comparing the raw intermediate outputs of the base input image and the style image, we instead compare the Gram matrices of the two outputs. \n",
+ "\n",
+ "Mathematically, we describe the style loss of the base input image, $x$, and the style image, $a$, as the distance between the style representation (the gram matrices) of these images. We describe the style representation of an image as the correlation between different filter responses given by the Gram matrix $G^l$, where $G^l_{ij}$ is the inner product between the vectorized feature map $i$ and $j$ in layer $l$. We can see that $G^l_{ij}$ generated over the feature map for a given image represents the correlation between feature maps $i$ and $j$. \n",
+ "\n",
+ "To generate a style for our base input image, we perform gradient descent from the content image to transform it into an image that matches the style representation of the original image. We do so by minimizing the mean squared distance between the feature correlation map of the style image and the input image. The contribution of each layer to the total style loss is described by\n",
+ "$$E_l = \\frac{1}{4N_l^2M_l^2} \\sum_{i,j}(G^l_{ij} - A^l_{ij})^2$$\n",
+ "\n",
+ "where $G^l_{ij}$ and $A^l_{ij}$ are the respective style representation in layer $l$ of $x$ and $a$. $N_l$ describes the number of feature maps, each of size $M_l = height * width$. Thus, the total style loss across each layer is \n",
+ "$$L_{style}(a, x) = \\sum_{l \\in L} w_l E_l$$\n",
+ "where we weight the contribution of each layer's loss by some factor $w_l$. In our case, we weight each layer equally ($w_l =\\frac{1}{|L|}$)"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "F21Hm61yLKk5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing style loss\n",
+ "Again, we implement our loss as a distance metric . "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "N7MOqwKLLke8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def gram_matrix(input_tensor):\n",
+ " # We make the image channels first \n",
+ " channels = int(input_tensor.shape[-1])\n",
+ " a = tf.reshape(input_tensor, [-1, channels])\n",
+ " n = tf.shape(a)[0]\n",
+ " gram = tf.matmul(a, a, transpose_a=True)\n",
+ " return gram / tf.cast(n, tf.float32)\n",
+ "\n",
+ "def get_style_loss(base_style, gram_target):\n",
+ " \"\"\"Expects two images of dimension h, w, c\"\"\"\n",
+ " # height, width, num filters of each layer\n",
+ " # We scale the loss at a given layer by the size of the feature map and the number of filters\n",
+ " height, width, channels = base_style.get_shape().as_list()\n",
+ " gram_style = gram_matrix(base_style)\n",
+ " \n",
+ " return tf.reduce_mean(tf.square(gram_style - gram_target))# / (4. * (channels ** 2) * (width * height) ** 2)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "pXIUX6czZABh",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Apply style transfer to our images\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "y9r8Lyjb_m0u",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Run Gradient Descent \n",
+ "If you aren't familiar with gradient descent/backpropagation or need a refresher, you should definitely check out this [awesome resource](https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent).\n",
+ "\n",
+ "In this case, we use the [Adam](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam)* optimizer in order to minimize our loss. We iteratively update our output image such that it minimizes our loss: we don't update the weights associated with our network, but instead we train our input image to minimize loss. In order to do this, we must know how we calculate our loss and gradients. \n",
+ "\n",
+ "\\* Note that L-BFGS, which if you are familiar with this algorithm is recommended, isn’t used in this tutorial because a primary motivation behind this tutorial was to illustrate best practices with eager execution, and, by using Adam, we can demonstrate the autograd/gradient tape functionality with custom training loops.\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "-kGzV6LTp4CU",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "We’ll define a little helper function that will load our content and style image, feed them forward through our network, which will then output the content and style feature representations from our model. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "O-lj5LxgtmnI",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_feature_representations(model, content_path, style_path):\n",
+ " \"\"\"Helper function to compute our content and style feature representations.\n",
+ "\n",
+ " This function will simply load and preprocess both the content and style \n",
+ " images from their path. Then it will feed them through the network to obtain\n",
+ " the outputs of the intermediate layers. \n",
+ " \n",
+ " Arguments:\n",
+ " model: The model that we are using.\n",
+ " content_path: The path to the content image.\n",
+ " style_path: The path to the style image\n",
+ " \n",
+ " Returns:\n",
+ " returns the style features and the content features. \n",
+ " \"\"\"\n",
+ " # Load our images in \n",
+ " content_image = load_and_process_img(content_path)\n",
+ " style_image = load_and_process_img(style_path)\n",
+ " \n",
+ " # batch compute content and style features\n",
+ " style_outputs = model(style_image)\n",
+ " content_outputs = model(content_image)\n",
+ " \n",
+ " \n",
+ " # Get the style and content feature representations from our model \n",
+ " style_features = [style_layer[0] for style_layer in style_outputs[:num_style_layers]]\n",
+ " content_features = [content_layer[0] for content_layer in content_outputs[num_style_layers:]]\n",
+ " return style_features, content_features"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "3DopXw7-lFHa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing the loss and gradients\n",
+ "Here we use [**tf.GradientTape**](https://www.tensorflow.org/programmers_guide/eager#computing_gradients) to compute the gradient. It allows us to take advantage of the automatic differentiation available by tracing operations for computing the gradient later. It records the operations during the forward pass and then is able to compute the gradient of our loss function with respect to our input image for the backwards pass."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "oVDhSo8iJunf",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def compute_loss(model, loss_weights, init_image, gram_style_features, content_features):\n",
+ " \"\"\"This function will compute the loss total loss.\n",
+ " \n",
+ " Arguments:\n",
+ " model: The model that will give us access to the intermediate layers\n",
+ " loss_weights: The weights of each contribution of each loss function. \n",
+ " (style weight, content weight, and total variation weight)\n",
+ " init_image: Our initial base image. This image is what we are updating with \n",
+ " our optimization process. We apply the gradients wrt the loss we are \n",
+ " calculating to this image.\n",
+ " gram_style_features: Precomputed gram matrices corresponding to the \n",
+ " defined style layers of interest.\n",
+ " content_features: Precomputed outputs from defined content layers of \n",
+ " interest.\n",
+ " \n",
+ " Returns:\n",
+ " returns the total loss, style loss, content loss, and total variational loss\n",
+ " \"\"\"\n",
+ " style_weight, content_weight = loss_weights\n",
+ " \n",
+ " # Feed our init image through our model. This will give us the content and \n",
+ " # style representations at our desired layers. Since we're using eager\n",
+ " # our model is callable just like any other function!\n",
+ " model_outputs = model(init_image)\n",
+ " \n",
+ " style_output_features = model_outputs[:num_style_layers]\n",
+ " content_output_features = model_outputs[num_style_layers:]\n",
+ " \n",
+ " style_score = 0\n",
+ " content_score = 0\n",
+ "\n",
+ " # Accumulate style losses from all layers\n",
+ " # Here, we equally weight each contribution of each loss layer\n",
+ " weight_per_style_layer = 1.0 / float(num_style_layers)\n",
+ " for target_style, comb_style in zip(gram_style_features, style_output_features):\n",
+ " style_score += weight_per_style_layer * get_style_loss(comb_style[0], target_style)\n",
+ " \n",
+ " # Accumulate content losses from all layers \n",
+ " weight_per_content_layer = 1.0 / float(num_content_layers)\n",
+ " for target_content, comb_content in zip(content_features, content_output_features):\n",
+ " content_score += weight_per_content_layer* get_content_loss(comb_content[0], target_content)\n",
+ " \n",
+ " style_score *= style_weight\n",
+ " content_score *= content_weight\n",
+ "\n",
+ " # Get total loss\n",
+ " loss = style_score + content_score \n",
+ " return loss, style_score, content_score"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "r5XTvbP6nJQa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Then computing the gradients is easy:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "fwzYeOqOUH9_",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def compute_grads(cfg):\n",
+ " with tf.GradientTape() as tape: \n",
+ " all_loss = compute_loss(**cfg)\n",
+ " # Compute gradients wrt input image\n",
+ " total_loss = all_loss[0]\n",
+ " return tape.gradient(total_loss, cfg['init_image']), all_loss"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "T9yKu2PLlBIE",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Optimization loop"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "pj_enNo6tACQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import IPython.display\n",
+ "\n",
+ "def run_style_transfer(content_path, \n",
+ " style_path,\n",
+ " num_iterations=1000,\n",
+ " content_weight=1e3, \n",
+ " style_weight=1e-2): \n",
+ " # We don't need to (or want to) train any layers of our model, so we set their\n",
+ " # trainable to false. \n",
+ " model = get_model() \n",
+ " for layer in model.layers:\n",
+ " layer.trainable = False\n",
+ " \n",
+ " # Get the style and content feature representations (from our specified intermediate layers) \n",
+ " style_features, content_features = get_feature_representations(model, content_path, style_path)\n",
+ " gram_style_features = [gram_matrix(style_feature) for style_feature in style_features]\n",
+ " \n",
+ " # Set initial image\n",
+ " init_image = load_and_process_img(content_path)\n",
+ " init_image = tfe.Variable(init_image, dtype=tf.float32)\n",
+ " # Create our optimizer\n",
+ " opt = tf.train.AdamOptimizer(learning_rate=5, beta1=0.99, epsilon=1e-1)\n",
+ "\n",
+ " # For displaying intermediate images \n",
+ " iter_count = 1\n",
+ " \n",
+ " # Store our best result\n",
+ " best_loss, best_img = float('inf'), None\n",
+ " \n",
+ " # Create a nice config \n",
+ " loss_weights = (style_weight, content_weight)\n",
+ " cfg = {\n",
+ " 'model': model,\n",
+ " 'loss_weights': loss_weights,\n",
+ " 'init_image': init_image,\n",
+ " 'gram_style_features': gram_style_features,\n",
+ " 'content_features': content_features\n",
+ " }\n",
+ " \n",
+ " # For displaying\n",
+ " num_rows = 2\n",
+ " num_cols = 5\n",
+ " display_interval = num_iterations/(num_rows*num_cols)\n",
+ " start_time = time.time()\n",
+ " global_start = time.time()\n",
+ " \n",
+ " norm_means = np.array([103.939, 116.779, 123.68])\n",
+ " min_vals = -norm_means\n",
+ " max_vals = 255 - norm_means \n",
+ " \n",
+ " imgs = []\n",
+ " for i in range(num_iterations):\n",
+ " grads, all_loss = compute_grads(cfg)\n",
+ " loss, style_score, content_score = all_loss\n",
+ " opt.apply_gradients([(grads, init_image)])\n",
+ " clipped = tf.clip_by_value(init_image, min_vals, max_vals)\n",
+ " init_image.assign(clipped)\n",
+ " end_time = time.time() \n",
+ " \n",
+ " if loss < best_loss:\n",
+ " # Update best loss and best image from total loss. \n",
+ " best_loss = loss\n",
+ " best_img = deprocess_img(init_image.numpy())\n",
+ "\n",
+ " if i % display_interval== 0:\n",
+ " start_time = time.time()\n",
+ " \n",
+ " # Use the .numpy() method to get the concrete numpy array\n",
+ " plot_img = init_image.numpy()\n",
+ " plot_img = deprocess_img(plot_img)\n",
+ " imgs.append(plot_img)\n",
+ " IPython.display.clear_output(wait=True)\n",
+ " IPython.display.display_png(Image.fromarray(plot_img))\n",
+ " print('Iteration: {}'.format(i)) \n",
+ " print('Total loss: {:.4e}, ' \n",
+ " 'style loss: {:.4e}, '\n",
+ " 'content loss: {:.4e}, '\n",
+ " 'time: {:.4f}s'.format(loss, style_score, content_score, time.time() - start_time))\n",
+ " print('Total time: {:.4f}s'.format(time.time() - global_start))\n",
+ " IPython.display.clear_output(wait=True)\n",
+ " plt.figure(figsize=(14,4))\n",
+ " for i,img in enumerate(imgs):\n",
+ " plt.subplot(num_rows,num_cols,i+1)\n",
+ " plt.imshow(img)\n",
+ " plt.xticks([])\n",
+ " plt.yticks([])\n",
+ " \n",
+ " return best_img, best_loss "
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "vSVMx4burydi",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best, best_loss = run_style_transfer(content_path, \n",
+ " style_path, num_iterations=1000)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "dzJTObpsO3TZ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "Image.fromarray(best)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "dCXQ9vSnQbDy",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "To download the image from Colab uncomment the following code:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "SSH6OpyyQn7w",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "#from google.colab import files\n",
+ "#files.download('wave_turtle.png')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "LwiZfCW0AZwt",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Visualize outputs\n",
+ "We \"deprocess\" the output image in order to remove the processing that was applied to it. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "lqTQN1PjulV9",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def show_results(best_img, content_path, style_path, show_large_final=True):\n",
+ " plt.figure(figsize=(10, 5))\n",
+ " content = load_img(content_path) \n",
+ " style = load_img(style_path)\n",
+ "\n",
+ " plt.subplot(1, 2, 1)\n",
+ " imshow(content, 'Content Image')\n",
+ "\n",
+ " plt.subplot(1, 2, 2)\n",
+ " imshow(style, 'Style Image')\n",
+ "\n",
+ " if show_large_final: \n",
+ " plt.figure(figsize=(10, 10))\n",
+ "\n",
+ " plt.imshow(best_img)\n",
+ " plt.title('Output Image')\n",
+ " plt.show()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "i6d6O50Yvs6a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best, content_path, style_path)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "tyGMmWh2Pss8",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Try it on other images\n",
+ "Image of Tuebingen \n",
+ "\n",
+ "Photo By: Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)], from Wikimedia Commons"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "x2TePU39k9lb",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Starry night + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "ES9dC6ZyJBD2",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_starry_night, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "X8w8WLkKvzXu",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_starry_night, '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "QcXwvViek4Br",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Pillars of Creation + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "vJ3u2U-gGmgP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_poc_tubingen, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg', \n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "pQUq3KxpGv2O",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_poc_tubingen, \n",
+ " '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "bTZdTOdW3s8H",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Kandinsky Composition 7 + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "bt9mbQfl7exl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_kandinsky_tubingen, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg', \n",
+ " '/tmp/nst/Vassily_Kandinsky,_1913_-_Composition_7.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "Qnz8HeXSXg6P",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_kandinsky_tubingen, \n",
+ " '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/Vassily_Kandinsky,_1913_-_Composition_7.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "cg68lW2A3s8N",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Pillars of Creation + Sea Turtle"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "dl0DUot_bFST",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_poc_turtle, best_loss = run_style_transfer('/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg', \n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "UzJfE0I1bQn8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_poc_turtle, \n",
+ " '/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg',\n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "sElaeNX-4Vnc",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Key Takeaways\n",
+ "\n",
+ "### What we covered:\n",
+ "\n",
+ "* We built several different loss functions and used backpropagation to transform our input image in order to minimize these losses\n",
+ " * In order to do this we had to load in a **pretrained model** and use its learned feature maps to describe the content and style representation of our images.\n",
+ " * Our main loss functions were primarily computing the distance in terms of these different representations\n",
+ "* We implemented this with a custom model and **eager execution**\n",
+ " * We built our custom model with the Functional API \n",
+ " * Eager execution allows us to dynamically work with tensors, using a natural python control flow\n",
+ " * We manipulated tensors directly, which makes debugging and working with tensors easier. \n",
+ "* We iteratively updated our image by applying our optimizers update rules using **tf.gradient**. The optimizer minimized a given loss with respect to our input image. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "U-y02GWonqnD",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "**[Image of Tuebingen](https://commons.wikimedia.org/wiki/File:Tuebingen_Neckarfront.jpg)** \n",
+ "Photo By: Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)], from Wikimedia Commons\n",
+ "\n",
+ "**[Image of Green Sea Turtle](https://commons.wikimedia.org/wiki/File:Green_Sea_Turtle_grazing_seagrass.jpg)**\n",
+ "By P.Lindgren [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], from Wikimedia Commons\n",
+ "\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "IpUD9W6ZkeyM",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ ""
+ ],
+ "execution_count": 0,
+ "outputs": []
+ }
+ ]
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg"
new file mode 100644
index 00000000..c98791b8
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg"
new file mode 100644
index 00000000..5d3475c9
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png"
new file mode 100644
index 00000000..d15ee0fc
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md"
new file mode 100644
index 00000000..e3d87e3c
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md"
@@ -0,0 +1,13 @@
+# Contributing to the Tensorflow Object Detection API
+
+Patches to Tensorflow Object Detection API are welcome!
+
+We require contributors to fill out either the individual or corporate
+Contributor License Agreement (CLA).
+
+ * If you are an individual writing original source code and you're sure you own the intellectual property, then you'll need to sign an [individual CLA](http://code.google.com/legal/individual-cla-v1.0.html).
+ * If you work for a company that wants to allow you to contribute your work, then you'll need to sign a [corporate CLA](http://code.google.com/legal/corporate-cla-v1.0.html).
+
+Please follow the
+[Tensorflow contributing guidelines](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md)
+when submitting pull requests.
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md"
new file mode 100644
index 00000000..2fd23408
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md"
@@ -0,0 +1,245 @@
+
+# Tensorflow Object Detection API
+Creating accurate machine learning models capable of localizing and identifying
+multiple objects in a single image remains a core challenge in computer vision.
+The TensorFlow Object Detection API is an open source framework built on top of
+TensorFlow that makes it easy to construct, train and deploy object detection
+models. At Google we’ve certainly found this codebase to be useful for our
+computer vision needs, and we hope that you will as well.
+
\n",
+ "\n",
+ "Is this magic or just deep learning? Fortunately, this doesn’t involve any witchcraft: style transfer is a fun and interesting technique that showcases the capabilities and internal representations of neural networks. \n",
+ "\n",
+ "The principle of neural style transfer is to define two distance functions, one that describes how different the content of two images are , $L_{content}$, and one that describes the difference between two images in terms of their style, $L_{style}$. Then, given three images, a desired style image, a desired content image, and the input image (initialized with the content image), we try to transform the input image to minimize the content distance with the content image and its style distance with the style image. \n",
+ "In summary, we’ll take the base input image, a content image that we want to match, and the style image that we want to match. We’ll transform the base input image by minimizing the content and style distances (losses) with backpropagation, creating an image that matches the content of the content image and the style of the style image. \n",
+ "\n",
+ "### Specific concepts that will be covered:\n",
+ "In the process, we will build practical experience and develop intuition around the following concepts\n",
+ "\n",
+ "* **Eager Execution** - use TensorFlow's imperative programming environment that evaluates operations immediately \n",
+ " * [Learn more about eager execution](https://www.tensorflow.org/programmers_guide/eager)\n",
+ " * [See it in action](https://www.tensorflow.org/get_started/eager)\n",
+ "* ** Using [Functional API](https://keras.io/getting-started/functional-api-guide/) to define a model** - we'll build a subset of our model that will give us access to the necessary intermediate activations using the Functional API \n",
+ "* **Leveraging feature maps of a pretrained model** - Learn how to use pretrained models and their feature maps \n",
+ "* **Create custom training loops** - we'll examine how to set up an optimizer to minimize a given loss with respect to input parameters\n",
+ "\n",
+ "### We will follow the general steps to perform style transfer:\n",
+ "\n",
+ "1. Visualize data\n",
+ "2. Basic Preprocessing/preparing our data\n",
+ "3. Set up loss functions \n",
+ "4. Create model\n",
+ "5. Optimize for loss function\n",
+ "\n",
+ "**Audience:** This post is geared towards intermediate users who are comfortable with basic machine learning concepts. To get the most out of this post, you should: \n",
+ "* Read [Gatys' paper](https://arxiv.org/abs/1508.06576) - we'll explain along the way, but the paper will provide a more thorough understanding of the task\n",
+ "* [Understand reducing loss with gradient descent](https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent)\n",
+ "\n",
+ "**Time Estimated**: 30 min\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "U8ajP_u73s6m",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Setup\n",
+ "\n",
+ "### Download Images"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "riWE_b8k3s6o",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import os\n",
+ "img_dir = '/tmp/nst'\n",
+ "if not os.path.exists(img_dir):\n",
+ " os.makedirs(img_dir)\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/d/d7/Green_Sea_Turtle_grazing_seagrass.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/0/0a/The_Great_Wave_off_Kanagawa.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/b/b4/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/0/00/Tuebingen_Neckarfront.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/6/68/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg\n",
+ "!wget --quiet -P /tmp/nst/ https://upload.wikimedia.org/wikipedia/commons/thumb/e/ea/Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "eqxUicSPUOP6",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Import and configure modules"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "sc1OLbOWhPCO",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import matplotlib.pyplot as plt\n",
+ "import matplotlib as mpl\n",
+ "mpl.rcParams['figure.figsize'] = (10,10)\n",
+ "mpl.rcParams['axes.grid'] = False\n",
+ "\n",
+ "import numpy as np\n",
+ "from PIL import Image\n",
+ "import time\n",
+ "import functools"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "RYEjlrYk3s6w",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import tensorflow as tf\n",
+ "import tensorflow.contrib.eager as tfe\n",
+ "\n",
+ "from tensorflow.python.keras.preprocessing import image as kp_image\n",
+ "from tensorflow.python.keras import models \n",
+ "from tensorflow.python.keras import losses\n",
+ "from tensorflow.python.keras import layers\n",
+ "from tensorflow.python.keras import backend as K"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "L7sjDODq67HQ",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "We’ll begin by enabling [eager execution](https://www.tensorflow.org/guide/eager). Eager execution allows us to work through this technique in the clearest and most readable way. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "sfjsSAtNrqQx",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "tf.enable_eager_execution()\n",
+ "print(\"Eager execution: {}\".format(tf.executing_eagerly()))"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "IOiGrIV1iERH",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "# Set up some global values here\n",
+ "content_path = '/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg'\n",
+ "style_path = '/tmp/nst/The_Great_Wave_off_Kanagawa.jpg'"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "xE4Yt8nArTeR",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Visualize the input"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "3TLljcwv5qZs",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def load_img(path_to_img):\n",
+ " max_dim = 512\n",
+ " img = Image.open(path_to_img)\n",
+ " long = max(img.size)\n",
+ " scale = max_dim/long\n",
+ " img = img.resize((round(img.size[0]*scale), round(img.size[1]*scale)), Image.ANTIALIAS)\n",
+ " \n",
+ " img = kp_image.img_to_array(img)\n",
+ " \n",
+ " # We need to broadcast the image array such that it has a batch dimension \n",
+ " img = np.expand_dims(img, axis=0)\n",
+ " return img"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "vupl0CI18aAG",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def imshow(img, title=None):\n",
+ " # Remove the batch dimension\n",
+ " out = np.squeeze(img, axis=0)\n",
+ " # Normalize for display \n",
+ " out = out.astype('uint8')\n",
+ " plt.imshow(out)\n",
+ " if title is not None:\n",
+ " plt.title(title)\n",
+ " plt.imshow(out)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "2yAlRzJZrWM3",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "These are input content and style images. We hope to \"create\" an image with the content of our content image, but with the style of the style image. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "_UWQmeEaiKkP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "plt.figure(figsize=(10,10))\n",
+ "\n",
+ "content = load_img(content_path).astype('uint8')\n",
+ "style = load_img(style_path).astype('uint8')\n",
+ "\n",
+ "plt.subplot(1, 2, 1)\n",
+ "imshow(content, 'Content Image')\n",
+ "\n",
+ "plt.subplot(1, 2, 2)\n",
+ "imshow(style, 'Style Image')\n",
+ "plt.show()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "7qMVNvEsK-_D",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Prepare the data\n",
+ "Let's create methods that will allow us to load and preprocess our images easily. We perform the same preprocessing process as are expected according to the VGG training process. VGG networks are trained on image with each channel normalized by `mean = [103.939, 116.779, 123.68]`and with channels BGR."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "hGwmTwJNmv2a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def load_and_process_img(path_to_img):\n",
+ " img = load_img(path_to_img)\n",
+ " img = tf.keras.applications.vgg19.preprocess_input(img)\n",
+ " return img"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "xCgooqs6tAka",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In order to view the outputs of our optimization, we are required to perform the inverse preprocessing step. Furthermore, since our optimized image may take its values anywhere between $- \\infty$ and $\\infty$, we must clip to maintain our values from within the 0-255 range. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "mjzlKRQRs_y2",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def deprocess_img(processed_img):\n",
+ " x = processed_img.copy()\n",
+ " if len(x.shape) == 4:\n",
+ " x = np.squeeze(x, 0)\n",
+ " assert len(x.shape) == 3, (\"Input to deprocess image must be an image of \"\n",
+ " \"dimension [1, height, width, channel] or [height, width, channel]\")\n",
+ " if len(x.shape) != 3:\n",
+ " raise ValueError(\"Invalid input to deprocessing image\")\n",
+ " \n",
+ " # perform the inverse of the preprocessiing step\n",
+ " x[:, :, 0] += 103.939\n",
+ " x[:, :, 1] += 116.779\n",
+ " x[:, :, 2] += 123.68\n",
+ " x = x[:, :, ::-1]\n",
+ "\n",
+ " x = np.clip(x, 0, 255).astype('uint8')\n",
+ " return x"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "GEwZ7FlwrjoZ",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Define content and style representations\n",
+ "In order to get both the content and style representations of our image, we will look at some intermediate layers within our model. As we go deeper into the model, these intermediate layers represent higher and higher order features. In this case, we are using the network architecture VGG19, a pretrained image classification network. These intermediate layers are necessary to define the representation of content and style from our images. For an input image, we will try to match the corresponding style and content target representations at these intermediate layers. \n",
+ "\n",
+ "#### Why intermediate layers?\n",
+ "\n",
+ "You may be wondering why these intermediate outputs within our pretrained image classification network allow us to define style and content representations. At a high level, this phenomenon can be explained by the fact that in order for a network to perform image classification (which our network has been trained to do), it must understand the image. This involves taking the raw image as input pixels and building an internal representation through transformations that turn the raw image pixels into a complex understanding of the features present within the image. This is also partly why convolutional neural networks are able to generalize well: they’re able to capture the invariances and defining features within classes (e.g., cats vs. dogs) that are agnostic to background noise and other nuisances. Thus, somewhere between where the raw image is fed in and the classification label is output, the model serves as a complex feature extractor; hence by accessing intermediate layers, we’re able to describe the content and style of input images. \n",
+ "\n",
+ "\n",
+ "Specifically we’ll pull out these intermediate layers from our network: \n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "N4-8eUp_Kc-j",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "# Content layer where will pull our feature maps\n",
+ "content_layers = ['block5_conv2'] \n",
+ "\n",
+ "# Style layer we are interested in\n",
+ "style_layers = ['block1_conv1',\n",
+ " 'block2_conv1',\n",
+ " 'block3_conv1', \n",
+ " 'block4_conv1', \n",
+ " 'block5_conv1'\n",
+ " ]\n",
+ "\n",
+ "num_content_layers = len(content_layers)\n",
+ "num_style_layers = len(style_layers)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "Jt3i3RRrJiOX",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Build the Model \n",
+ "In this case, we load [VGG19](https://keras.io/applications/#vgg19), and feed in our input tensor to the model. This will allow us to extract the feature maps (and subsequently the content and style representations) of the content, style, and generated images.\n",
+ "\n",
+ "We use VGG19, as suggested in the paper. In addition, since VGG19 is a relatively simple model (compared with ResNet, Inception, etc) the feature maps actually work better for style transfer. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "v9AnzEUU6hhx",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In order to access the intermediate layers corresponding to our style and content feature maps, we get the corresponding outputs and using the Keras [**Functional API**](https://keras.io/getting-started/functional-api-guide/), we define our model with the desired output activations. \n",
+ "\n",
+ "With the Functional API defining a model simply involves defining the input and output: \n",
+ "\n",
+ "`model = Model(inputs, outputs)`"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "nfec6MuMAbPx",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_model():\n",
+ " \"\"\" Creates our model with access to intermediate layers. \n",
+ " \n",
+ " This function will load the VGG19 model and access the intermediate layers. \n",
+ " These layers will then be used to create a new model that will take input image\n",
+ " and return the outputs from these intermediate layers from the VGG model. \n",
+ " \n",
+ " Returns:\n",
+ " returns a keras model that takes image inputs and outputs the style and \n",
+ " content intermediate layers. \n",
+ " \"\"\"\n",
+ " # Load our model. We load pretrained VGG, trained on imagenet data\n",
+ " vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet')\n",
+ " vgg.trainable = False\n",
+ " # Get output layers corresponding to style and content layers \n",
+ " style_outputs = [vgg.get_layer(name).output for name in style_layers]\n",
+ " content_outputs = [vgg.get_layer(name).output for name in content_layers]\n",
+ " model_outputs = style_outputs + content_outputs\n",
+ " # Build model \n",
+ " return models.Model(vgg.input, model_outputs)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "kl6eFGa7-OtV",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "In the above code snippet, we’ll load our pretrained image classification network. Then we grab the layers of interest as we defined earlier. Then we define a Model by setting the model’s inputs to an image and the outputs to the outputs of the style and content layers. In other words, we created a model that will take an input image and output the content and style intermediate layers! \n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "vJdYvJTZ4bdS",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Define and create our loss functions (content and style distances)"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "F2Hcepii7_qh",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Content Loss"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "1FvH-gwXi4nq",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Our content loss definition is actually quite simple. We’ll pass the network both the desired content image and our base input image. This will return the intermediate layer outputs (from the layers defined above) from our model. Then we simply take the euclidean distance between the two intermediate representations of those images. \n",
+ "\n",
+ "More formally, content loss is a function that describes the distance of content from our output image $x$ and our content image, $p$. Let $C_{nn}$ be a pre-trained deep convolutional neural network. Again, in this case we use [VGG19](https://keras.io/applications/#vgg19). Let $X$ be any image, then $C_{nn}(X)$ is the network fed by X. Let $F^l_{ij}(x) \\in C_{nn}(x)$ and $P^l_{ij}(p) \\in C_{nn}(p)$ describe the respective intermediate feature representation of the network with inputs $x$ and $p$ at layer $l$. Then we describe the content distance (loss) formally as: $$L^l_{content}(p, x) = \\sum_{i, j} (F^l_{ij}(x) - P^l_{ij}(p))^2$$\n",
+ "\n",
+ "We perform backpropagation in the usual way such that we minimize this content loss. We thus change the initial image until it generates a similar response in a certain layer (defined in content_layer) as the original content image.\n",
+ "\n",
+ "This can be implemented quite simply. Again it will take as input the feature maps at a layer L in a network fed by x, our input image, and p, our content image, and return the content distance.\n",
+ "\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "6KsbqPA8J9DY",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing content loss\n",
+ "We will actually add our content losses at each desired layer. This way, each iteration when we feed our input image through the model (which in eager is simply `model(input_image)`!) all the content losses through the model will be properly compute and because we are executing eagerly, all the gradients will be computed. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "d2mf7JwRMkCd",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_content_loss(base_content, target):\n",
+ " return tf.reduce_mean(tf.square(base_content - target))"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "lGUfttK9F8d5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Style Loss"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "I6XtkGK_YGD1",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Computing style loss is a bit more involved, but follows the same principle, this time feeding our network the base input image and the style image. However, instead of comparing the raw intermediate outputs of the base input image and the style image, we instead compare the Gram matrices of the two outputs. \n",
+ "\n",
+ "Mathematically, we describe the style loss of the base input image, $x$, and the style image, $a$, as the distance between the style representation (the gram matrices) of these images. We describe the style representation of an image as the correlation between different filter responses given by the Gram matrix $G^l$, where $G^l_{ij}$ is the inner product between the vectorized feature map $i$ and $j$ in layer $l$. We can see that $G^l_{ij}$ generated over the feature map for a given image represents the correlation between feature maps $i$ and $j$. \n",
+ "\n",
+ "To generate a style for our base input image, we perform gradient descent from the content image to transform it into an image that matches the style representation of the original image. We do so by minimizing the mean squared distance between the feature correlation map of the style image and the input image. The contribution of each layer to the total style loss is described by\n",
+ "$$E_l = \\frac{1}{4N_l^2M_l^2} \\sum_{i,j}(G^l_{ij} - A^l_{ij})^2$$\n",
+ "\n",
+ "where $G^l_{ij}$ and $A^l_{ij}$ are the respective style representation in layer $l$ of $x$ and $a$. $N_l$ describes the number of feature maps, each of size $M_l = height * width$. Thus, the total style loss across each layer is \n",
+ "$$L_{style}(a, x) = \\sum_{l \\in L} w_l E_l$$\n",
+ "where we weight the contribution of each layer's loss by some factor $w_l$. In our case, we weight each layer equally ($w_l =\\frac{1}{|L|}$)"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "F21Hm61yLKk5",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing style loss\n",
+ "Again, we implement our loss as a distance metric . "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "N7MOqwKLLke8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def gram_matrix(input_tensor):\n",
+ " # We make the image channels first \n",
+ " channels = int(input_tensor.shape[-1])\n",
+ " a = tf.reshape(input_tensor, [-1, channels])\n",
+ " n = tf.shape(a)[0]\n",
+ " gram = tf.matmul(a, a, transpose_a=True)\n",
+ " return gram / tf.cast(n, tf.float32)\n",
+ "\n",
+ "def get_style_loss(base_style, gram_target):\n",
+ " \"\"\"Expects two images of dimension h, w, c\"\"\"\n",
+ " # height, width, num filters of each layer\n",
+ " # We scale the loss at a given layer by the size of the feature map and the number of filters\n",
+ " height, width, channels = base_style.get_shape().as_list()\n",
+ " gram_style = gram_matrix(base_style)\n",
+ " \n",
+ " return tf.reduce_mean(tf.square(gram_style - gram_target))# / (4. * (channels ** 2) * (width * height) ** 2)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "pXIUX6czZABh",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Apply style transfer to our images\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "y9r8Lyjb_m0u",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Run Gradient Descent \n",
+ "If you aren't familiar with gradient descent/backpropagation or need a refresher, you should definitely check out this [awesome resource](https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent).\n",
+ "\n",
+ "In this case, we use the [Adam](https://www.tensorflow.org/api_docs/python/tf/keras/optimizers/Adam)* optimizer in order to minimize our loss. We iteratively update our output image such that it minimizes our loss: we don't update the weights associated with our network, but instead we train our input image to minimize loss. In order to do this, we must know how we calculate our loss and gradients. \n",
+ "\n",
+ "\\* Note that L-BFGS, which if you are familiar with this algorithm is recommended, isn’t used in this tutorial because a primary motivation behind this tutorial was to illustrate best practices with eager execution, and, by using Adam, we can demonstrate the autograd/gradient tape functionality with custom training loops.\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "-kGzV6LTp4CU",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "We’ll define a little helper function that will load our content and style image, feed them forward through our network, which will then output the content and style feature representations from our model. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "O-lj5LxgtmnI",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def get_feature_representations(model, content_path, style_path):\n",
+ " \"\"\"Helper function to compute our content and style feature representations.\n",
+ "\n",
+ " This function will simply load and preprocess both the content and style \n",
+ " images from their path. Then it will feed them through the network to obtain\n",
+ " the outputs of the intermediate layers. \n",
+ " \n",
+ " Arguments:\n",
+ " model: The model that we are using.\n",
+ " content_path: The path to the content image.\n",
+ " style_path: The path to the style image\n",
+ " \n",
+ " Returns:\n",
+ " returns the style features and the content features. \n",
+ " \"\"\"\n",
+ " # Load our images in \n",
+ " content_image = load_and_process_img(content_path)\n",
+ " style_image = load_and_process_img(style_path)\n",
+ " \n",
+ " # batch compute content and style features\n",
+ " style_outputs = model(style_image)\n",
+ " content_outputs = model(content_image)\n",
+ " \n",
+ " \n",
+ " # Get the style and content feature representations from our model \n",
+ " style_features = [style_layer[0] for style_layer in style_outputs[:num_style_layers]]\n",
+ " content_features = [content_layer[0] for content_layer in content_outputs[num_style_layers:]]\n",
+ " return style_features, content_features"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "3DopXw7-lFHa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Computing the loss and gradients\n",
+ "Here we use [**tf.GradientTape**](https://www.tensorflow.org/programmers_guide/eager#computing_gradients) to compute the gradient. It allows us to take advantage of the automatic differentiation available by tracing operations for computing the gradient later. It records the operations during the forward pass and then is able to compute the gradient of our loss function with respect to our input image for the backwards pass."
+ ]
+ },
+ {
+ "metadata": {
+ "id": "oVDhSo8iJunf",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def compute_loss(model, loss_weights, init_image, gram_style_features, content_features):\n",
+ " \"\"\"This function will compute the loss total loss.\n",
+ " \n",
+ " Arguments:\n",
+ " model: The model that will give us access to the intermediate layers\n",
+ " loss_weights: The weights of each contribution of each loss function. \n",
+ " (style weight, content weight, and total variation weight)\n",
+ " init_image: Our initial base image. This image is what we are updating with \n",
+ " our optimization process. We apply the gradients wrt the loss we are \n",
+ " calculating to this image.\n",
+ " gram_style_features: Precomputed gram matrices corresponding to the \n",
+ " defined style layers of interest.\n",
+ " content_features: Precomputed outputs from defined content layers of \n",
+ " interest.\n",
+ " \n",
+ " Returns:\n",
+ " returns the total loss, style loss, content loss, and total variational loss\n",
+ " \"\"\"\n",
+ " style_weight, content_weight = loss_weights\n",
+ " \n",
+ " # Feed our init image through our model. This will give us the content and \n",
+ " # style representations at our desired layers. Since we're using eager\n",
+ " # our model is callable just like any other function!\n",
+ " model_outputs = model(init_image)\n",
+ " \n",
+ " style_output_features = model_outputs[:num_style_layers]\n",
+ " content_output_features = model_outputs[num_style_layers:]\n",
+ " \n",
+ " style_score = 0\n",
+ " content_score = 0\n",
+ "\n",
+ " # Accumulate style losses from all layers\n",
+ " # Here, we equally weight each contribution of each loss layer\n",
+ " weight_per_style_layer = 1.0 / float(num_style_layers)\n",
+ " for target_style, comb_style in zip(gram_style_features, style_output_features):\n",
+ " style_score += weight_per_style_layer * get_style_loss(comb_style[0], target_style)\n",
+ " \n",
+ " # Accumulate content losses from all layers \n",
+ " weight_per_content_layer = 1.0 / float(num_content_layers)\n",
+ " for target_content, comb_content in zip(content_features, content_output_features):\n",
+ " content_score += weight_per_content_layer* get_content_loss(comb_content[0], target_content)\n",
+ " \n",
+ " style_score *= style_weight\n",
+ " content_score *= content_weight\n",
+ "\n",
+ " # Get total loss\n",
+ " loss = style_score + content_score \n",
+ " return loss, style_score, content_score"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "r5XTvbP6nJQa",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "Then computing the gradients is easy:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "fwzYeOqOUH9_",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def compute_grads(cfg):\n",
+ " with tf.GradientTape() as tape: \n",
+ " all_loss = compute_loss(**cfg)\n",
+ " # Compute gradients wrt input image\n",
+ " total_loss = all_loss[0]\n",
+ " return tape.gradient(total_loss, cfg['init_image']), all_loss"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "T9yKu2PLlBIE",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Optimization loop"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "pj_enNo6tACQ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "import IPython.display\n",
+ "\n",
+ "def run_style_transfer(content_path, \n",
+ " style_path,\n",
+ " num_iterations=1000,\n",
+ " content_weight=1e3, \n",
+ " style_weight=1e-2): \n",
+ " # We don't need to (or want to) train any layers of our model, so we set their\n",
+ " # trainable to false. \n",
+ " model = get_model() \n",
+ " for layer in model.layers:\n",
+ " layer.trainable = False\n",
+ " \n",
+ " # Get the style and content feature representations (from our specified intermediate layers) \n",
+ " style_features, content_features = get_feature_representations(model, content_path, style_path)\n",
+ " gram_style_features = [gram_matrix(style_feature) for style_feature in style_features]\n",
+ " \n",
+ " # Set initial image\n",
+ " init_image = load_and_process_img(content_path)\n",
+ " init_image = tfe.Variable(init_image, dtype=tf.float32)\n",
+ " # Create our optimizer\n",
+ " opt = tf.train.AdamOptimizer(learning_rate=5, beta1=0.99, epsilon=1e-1)\n",
+ "\n",
+ " # For displaying intermediate images \n",
+ " iter_count = 1\n",
+ " \n",
+ " # Store our best result\n",
+ " best_loss, best_img = float('inf'), None\n",
+ " \n",
+ " # Create a nice config \n",
+ " loss_weights = (style_weight, content_weight)\n",
+ " cfg = {\n",
+ " 'model': model,\n",
+ " 'loss_weights': loss_weights,\n",
+ " 'init_image': init_image,\n",
+ " 'gram_style_features': gram_style_features,\n",
+ " 'content_features': content_features\n",
+ " }\n",
+ " \n",
+ " # For displaying\n",
+ " num_rows = 2\n",
+ " num_cols = 5\n",
+ " display_interval = num_iterations/(num_rows*num_cols)\n",
+ " start_time = time.time()\n",
+ " global_start = time.time()\n",
+ " \n",
+ " norm_means = np.array([103.939, 116.779, 123.68])\n",
+ " min_vals = -norm_means\n",
+ " max_vals = 255 - norm_means \n",
+ " \n",
+ " imgs = []\n",
+ " for i in range(num_iterations):\n",
+ " grads, all_loss = compute_grads(cfg)\n",
+ " loss, style_score, content_score = all_loss\n",
+ " opt.apply_gradients([(grads, init_image)])\n",
+ " clipped = tf.clip_by_value(init_image, min_vals, max_vals)\n",
+ " init_image.assign(clipped)\n",
+ " end_time = time.time() \n",
+ " \n",
+ " if loss < best_loss:\n",
+ " # Update best loss and best image from total loss. \n",
+ " best_loss = loss\n",
+ " best_img = deprocess_img(init_image.numpy())\n",
+ "\n",
+ " if i % display_interval== 0:\n",
+ " start_time = time.time()\n",
+ " \n",
+ " # Use the .numpy() method to get the concrete numpy array\n",
+ " plot_img = init_image.numpy()\n",
+ " plot_img = deprocess_img(plot_img)\n",
+ " imgs.append(plot_img)\n",
+ " IPython.display.clear_output(wait=True)\n",
+ " IPython.display.display_png(Image.fromarray(plot_img))\n",
+ " print('Iteration: {}'.format(i)) \n",
+ " print('Total loss: {:.4e}, ' \n",
+ " 'style loss: {:.4e}, '\n",
+ " 'content loss: {:.4e}, '\n",
+ " 'time: {:.4f}s'.format(loss, style_score, content_score, time.time() - start_time))\n",
+ " print('Total time: {:.4f}s'.format(time.time() - global_start))\n",
+ " IPython.display.clear_output(wait=True)\n",
+ " plt.figure(figsize=(14,4))\n",
+ " for i,img in enumerate(imgs):\n",
+ " plt.subplot(num_rows,num_cols,i+1)\n",
+ " plt.imshow(img)\n",
+ " plt.xticks([])\n",
+ " plt.yticks([])\n",
+ " \n",
+ " return best_img, best_loss "
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "vSVMx4burydi",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best, best_loss = run_style_transfer(content_path, \n",
+ " style_path, num_iterations=1000)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "dzJTObpsO3TZ",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "Image.fromarray(best)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "dCXQ9vSnQbDy",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "To download the image from Colab uncomment the following code:"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "SSH6OpyyQn7w",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "#from google.colab import files\n",
+ "#files.download('wave_turtle.png')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "LwiZfCW0AZwt",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Visualize outputs\n",
+ "We \"deprocess\" the output image in order to remove the processing that was applied to it. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "lqTQN1PjulV9",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "def show_results(best_img, content_path, style_path, show_large_final=True):\n",
+ " plt.figure(figsize=(10, 5))\n",
+ " content = load_img(content_path) \n",
+ " style = load_img(style_path)\n",
+ "\n",
+ " plt.subplot(1, 2, 1)\n",
+ " imshow(content, 'Content Image')\n",
+ "\n",
+ " plt.subplot(1, 2, 2)\n",
+ " imshow(style, 'Style Image')\n",
+ "\n",
+ " if show_large_final: \n",
+ " plt.figure(figsize=(10, 10))\n",
+ "\n",
+ " plt.imshow(best_img)\n",
+ " plt.title('Output Image')\n",
+ " plt.show()"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "i6d6O50Yvs6a",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best, content_path, style_path)"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "tyGMmWh2Pss8",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Try it on other images\n",
+ "Image of Tuebingen \n",
+ "\n",
+ "Photo By: Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)], from Wikimedia Commons"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "x2TePU39k9lb",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Starry night + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "ES9dC6ZyJBD2",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_starry_night, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "X8w8WLkKvzXu",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_starry_night, '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/1024px-Van_Gogh_-_Starry_Night_-_Google_Art_Project.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "QcXwvViek4Br",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Pillars of Creation + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "vJ3u2U-gGmgP",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_poc_tubingen, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg', \n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "pQUq3KxpGv2O",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_poc_tubingen, \n",
+ " '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "bTZdTOdW3s8H",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Kandinsky Composition 7 + Tuebingen"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "bt9mbQfl7exl",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_kandinsky_tubingen, best_loss = run_style_transfer('/tmp/nst/Tuebingen_Neckarfront.jpg', \n",
+ " '/tmp/nst/Vassily_Kandinsky,_1913_-_Composition_7.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "Qnz8HeXSXg6P",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_kandinsky_tubingen, \n",
+ " '/tmp/nst/Tuebingen_Neckarfront.jpg',\n",
+ " '/tmp/nst/Vassily_Kandinsky,_1913_-_Composition_7.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "cg68lW2A3s8N",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "### Pillars of Creation + Sea Turtle"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "dl0DUot_bFST",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "best_poc_turtle, best_loss = run_style_transfer('/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg', \n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "UzJfE0I1bQn8",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ "show_results(best_poc_turtle, \n",
+ " '/tmp/nst/Green_Sea_Turtle_grazing_seagrass.jpg',\n",
+ " '/tmp/nst/Pillars_of_creation_2014_HST_WFC3-UVIS_full-res_denoised.jpg')"
+ ],
+ "execution_count": 0,
+ "outputs": []
+ },
+ {
+ "metadata": {
+ "id": "sElaeNX-4Vnc",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "## Key Takeaways\n",
+ "\n",
+ "### What we covered:\n",
+ "\n",
+ "* We built several different loss functions and used backpropagation to transform our input image in order to minimize these losses\n",
+ " * In order to do this we had to load in a **pretrained model** and use its learned feature maps to describe the content and style representation of our images.\n",
+ " * Our main loss functions were primarily computing the distance in terms of these different representations\n",
+ "* We implemented this with a custom model and **eager execution**\n",
+ " * We built our custom model with the Functional API \n",
+ " * Eager execution allows us to dynamically work with tensors, using a natural python control flow\n",
+ " * We manipulated tensors directly, which makes debugging and working with tensors easier. \n",
+ "* We iteratively updated our image by applying our optimizers update rules using **tf.gradient**. The optimizer minimized a given loss with respect to our input image. "
+ ]
+ },
+ {
+ "metadata": {
+ "id": "U-y02GWonqnD",
+ "colab_type": "text"
+ },
+ "cell_type": "markdown",
+ "source": [
+ "\n",
+ "**[Image of Tuebingen](https://commons.wikimedia.org/wiki/File:Tuebingen_Neckarfront.jpg)** \n",
+ "Photo By: Andreas Praefcke [GFDL (http://www.gnu.org/copyleft/fdl.html) or CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)], from Wikimedia Commons\n",
+ "\n",
+ "**[Image of Green Sea Turtle](https://commons.wikimedia.org/wiki/File:Green_Sea_Turtle_grazing_seagrass.jpg)**\n",
+ "By P.Lindgren [CC BY-SA 3.0 (https://creativecommons.org/licenses/by-sa/3.0)], from Wikimedia Commons\n",
+ "\n"
+ ]
+ },
+ {
+ "metadata": {
+ "id": "IpUD9W6ZkeyM",
+ "colab_type": "code",
+ "colab": {}
+ },
+ "cell_type": "code",
+ "source": [
+ ""
+ ],
+ "execution_count": 0,
+ "outputs": []
+ }
+ ]
+}
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg"
new file mode 100644
index 00000000..c98791b8
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/Green_Sea_Turtle_grazing_seagrass.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg"
new file mode 100644
index 00000000..5d3475c9
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/The_Great_Wave_off_Kanagawa.jpg" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png"
new file mode 100644
index 00000000..d15ee0fc
Binary files /dev/null and "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/nst_blogpost/wave_turtle.png" differ
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md"
new file mode 100644
index 00000000..e3d87e3c
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/CONTRIBUTING.md"
@@ -0,0 +1,13 @@
+# Contributing to the Tensorflow Object Detection API
+
+Patches to Tensorflow Object Detection API are welcome!
+
+We require contributors to fill out either the individual or corporate
+Contributor License Agreement (CLA).
+
+ * If you are an individual writing original source code and you're sure you own the intellectual property, then you'll need to sign an [individual CLA](http://code.google.com/legal/individual-cla-v1.0.html).
+ * If you work for a company that wants to allow you to contribute your work, then you'll need to sign a [corporate CLA](http://code.google.com/legal/corporate-cla-v1.0.html).
+
+Please follow the
+[Tensorflow contributing guidelines](https://github.com/tensorflow/tensorflow/blob/master/CONTRIBUTING.md)
+when submitting pull requests.
diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md"
new file mode 100644
index 00000000..2fd23408
--- /dev/null
+++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/README.md"
@@ -0,0 +1,245 @@
+
+# Tensorflow Object Detection API
+Creating accurate machine learning models capable of localizing and identifying
+multiple objects in a single image remains a core challenge in computer vision.
+The TensorFlow Object Detection API is an open source framework built on top of
+TensorFlow that makes it easy to construct, train and deploy object detection
+models. At Google we’ve certainly found this codebase to be useful for our
+computer vision needs, and we hope that you will as well.
+
+  +
+
+ ![]() +
+
+ +Quick Start: + + * + Quick Start: Jupyter notebook for off-the-shelf inference
+ * Quick Start: Training a pet detector
+ +Customizing a Pipeline: + + * + Configuring an object detection pipeline
+ * Preparing inputs
+ +Running: + + * Running locally
+ * Running on the cloud
+ +Extras: + + * Tensorflow detection model zoo
+ * + Exporting a trained model for inference
+ * + Defining your own model architecture
+ * + Bringing in your own dataset
+ * + Supported object detection evaluation protocols
+ * + Inference and evaluation on the Open Images dataset
+ * + Run an instance segmentation model
+ * + Run the evaluation for the Open Images Challenge 2018
+ * + TPU compatible detection pipelines
+ * + Running object detection on mobile devices with TensorFlow Lite
+ +## Getting Help + +To get help with issues you may encounter using the Tensorflow Object Detection +API, create a new question on [StackOverflow](https://stackoverflow.com/) with +the tags "tensorflow" and "object-detection". + +Please report bugs (actually broken code, not usage questions) to the +tensorflow/models GitHub +[issue tracker](https://github.com/tensorflow/models/issues), prefixing the +issue name with "object_detection". + +Please check [FAQ](g3doc/faq.md) for frequently asked questions before +reporting an issue. + + +## Release information + +### Sep 17, 2018 + +We have released Faster R-CNN detectors with ResNet-50 / ResNet-101 feature +extractors trained on the [iNaturalist Species Detection Dataset](https://github.com/visipedia/inat_comp/blob/master/2017/README.md#bounding-boxes). +The models are trained on the training split of the iNaturalist data for 4M +iterations, they achieve 55% and 58% mean AP@.5 over 2854 classes respectively. +For more details please refer to this [paper](https://arxiv.org/abs/1707.06642). + +Thanks to contributors: Chen Sun + +### July 13, 2018 + +There are many new updates in this release, extending the functionality and +capability of the API: + +* Moving from slim-based training to [Estimator](https://www.tensorflow.org/api_docs/python/tf/estimator/Estimator)-based +training. +* Support for [RetinaNet](https://arxiv.org/abs/1708.02002), and a [MobileNet](https://ai.googleblog.com/2017/06/mobilenets-open-source-models-for.html) +adaptation of RetinaNet. +* A novel SSD-based architecture called the [Pooling Pyramid Network](https://arxiv.org/abs/1807.03284) (PPN). +* Releasing several [TPU](https://cloud.google.com/tpu/)-compatible models. +These can be found in the `samples/configs/` directory with a comment in the +pipeline configuration files indicating TPU compatibility. +* Support for quantized training. +* Updated documentation for new binaries, Cloud training, and [Tensorflow Lite](https://www.tensorflow.org/mobile/tflite/). + +See also our [expanded announcement blogpost](https://ai.googleblog.com/2018/07/accelerated-training-and-inference-with.html) and accompanying tutorial at the [TensorFlow blog](https://medium.com/tensorflow/training-and-serving-a-realtime-mobile-object-detector-in-30-minutes-with-cloud-tpus-b78971cf1193). + +Thanks to contributors: Sara Robinson, Aakanksha Chowdhery, Derek Chow, +Pengchong Jin, Jonathan Huang, Vivek Rathod, Zhichao Lu, Ronny Votel + + +### June 25, 2018 + +Additional evaluation tools for the [Open Images Challenge 2018](https://storage.googleapis.com/openimages/web/challenge.html) are out. +Check out our short tutorial on data preparation and running evaluation [here](g3doc/challenge_evaluation.md)! + +Thanks to contributors: Alina Kuznetsova + +### June 5, 2018 + +We have released the implementation of evaluation metrics for both tracks of the [Open Images Challenge 2018](https://storage.googleapis.com/openimages/web/challenge.html) as a part of the Object Detection API - see the [evaluation protocols](g3doc/evaluation_protocols.md) for more details. +Additionally, we have released a tool for hierarchical labels expansion for the Open Images Challenge: check out [oid_hierarchical_labels_expansion.py](dataset_tools/oid_hierarchical_labels_expansion.py). + +Thanks to contributors: Alina Kuznetsova, Vittorio Ferrari, Jasper Uijlings + +### April 30, 2018 + +We have released a Faster R-CNN detector with ResNet-101 feature extractor trained on [AVA](https://research.google.com/ava/) v2.1. +Compared with other commonly used object detectors, it changes the action classification loss function to per-class Sigmoid loss to handle boxes with multiple labels. +The model is trained on the training split of AVA v2.1 for 1.5M iterations, it achieves mean AP of 11.25% over 60 classes on the validation split of AVA v2.1. +For more details please refer to this [paper](https://arxiv.org/abs/1705.08421). + +Thanks to contributors: Chen Sun, David Ross + +### April 2, 2018 + +Supercharge your mobile phones with the next generation mobile object detector! +We are adding support for MobileNet V2 with SSDLite presented in +[MobileNetV2: Inverted Residuals and Linear Bottlenecks](https://arxiv.org/abs/1801.04381). +This model is 35% faster than Mobilenet V1 SSD on a Google Pixel phone CPU (200ms vs. 270ms) at the same accuracy. +Along with the model definition, we are also releasing a model checkpoint trained on the COCO dataset. + +Thanks to contributors: Menglong Zhu, Mark Sandler, Zhichao Lu, Vivek Rathod, Jonathan Huang + +### February 9, 2018 + +We now support instance segmentation!! In this API update we support a number of instance segmentation models similar to those discussed in the [Mask R-CNN paper](https://arxiv.org/abs/1703.06870). For further details refer to +[our slides](http://presentations.cocodataset.org/Places17-GMRI.pdf) from the 2017 Coco + Places Workshop. +Refer to the section on [Running an Instance Segmentation Model](g3doc/instance_segmentation.md) for instructions on how to configure a model +that predicts masks in addition to object bounding boxes. + +Thanks to contributors: Alireza Fathi, Zhichao Lu, Vivek Rathod, Ronny Votel, Jonathan Huang + +### November 17, 2017 + +As a part of the Open Images V3 release we have released: + +* An implementation of the Open Images evaluation metric and the [protocol](g3doc/evaluation_protocols.md#open-images). +* Additional tools to separate inference of detection and evaluation (see [this tutorial](g3doc/oid_inference_and_evaluation.md)). +* A new detection model trained on the Open Images V2 data release (see [Open Images model](g3doc/detection_model_zoo.md#open-images-models)). + +See more information on the [Open Images website](https://github.com/openimages/dataset)! + +Thanks to contributors: Stefan Popov, Alina Kuznetsova + +### November 6, 2017 + +We have re-released faster versions of our (pre-trained) models in the +model zoo. In addition to what +was available before, we are also adding Faster R-CNN models trained on COCO +with Inception V2 and Resnet-50 feature extractors, as well as a Faster R-CNN +with Resnet-101 model trained on the KITTI dataset. + +Thanks to contributors: Jonathan Huang, Vivek Rathod, Derek Chow, +Tal Remez, Chen Sun. + +### October 31, 2017 + +We have released a new state-of-the-art model for object detection using +the Faster-RCNN with the +[NASNet-A image featurization](https://arxiv.org/abs/1707.07012). This +model achieves mAP of 43.1% on the test-dev validation dataset for COCO, +improving on the best available model in the zoo by 6% in terms +of absolute mAP. + +Thanks to contributors: Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc Le + +### August 11, 2017 + +We have released an update to the [Android Detect +demo](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/android) +which will now run models trained using the Tensorflow Object +Detection API on an Android device. By default, it currently runs a +frozen SSD w/Mobilenet detector trained on COCO, but we encourage +you to try out other detection models! + +Thanks to contributors: Jonathan Huang, Andrew Harp + + +### June 15, 2017 + +In addition to our base Tensorflow detection model definitions, this +release includes: + +* A selection of trainable detection models, including: + * Single Shot Multibox Detector (SSD) with MobileNet, + * SSD with Inception V2, + * Region-Based Fully Convolutional Networks (R-FCN) with Resnet 101, + * Faster RCNN with Resnet 101, + * Faster RCNN with Inception Resnet v2 +* Frozen weights (trained on the COCO dataset) for each of the above models to + be used for out-of-the-box inference purposes. +* A [Jupyter notebook](object_detection_tutorial.ipynb) for performing + out-of-the-box inference with one of our released models +* Convenient [local training](g3doc/running_locally.md) scripts as well as + distributed training and evaluation pipelines via + [Google Cloud](g3doc/running_on_cloud.md). + + +Thanks to contributors: Jonathan Huang, Vivek Rathod, Derek Chow, +Chen Sun, Menglong Zhu, Matthew Tang, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, Jasper Uijlings, +Viacheslav Kovalevskyi, Kevin Murphy + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator.py" new file mode 100644 index 00000000..ba43f013 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator.py" @@ -0,0 +1,205 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Generates grid anchors on the fly as used in Faster RCNN. + +Generates grid anchors on the fly as described in: +"Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks" +Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. +""" + +import tensorflow as tf + +from object_detection.core import anchor_generator +from object_detection.core import box_list +from object_detection.utils import ops + + +class GridAnchorGenerator(anchor_generator.AnchorGenerator): + """Generates a grid of anchors at given scales and aspect ratios.""" + + def __init__(self, + scales=(0.5, 1.0, 2.0), + aspect_ratios=(0.5, 1.0, 2.0), + base_anchor_size=None, + anchor_stride=None, + anchor_offset=None): + """Constructs a GridAnchorGenerator. + + Args: + scales: a list of (float) scales, default=(0.5, 1.0, 2.0) + aspect_ratios: a list of (float) aspect ratios, default=(0.5, 1.0, 2.0) + base_anchor_size: base anchor size as height, width ( + (length-2 float32 list or tensor, default=[256, 256]) + anchor_stride: difference in centers between base anchors for adjacent + grid positions (length-2 float32 list or tensor, + default=[16, 16]) + anchor_offset: center of the anchor with scale and aspect ratio 1 for the + upper left element of the grid, this should be zero for + feature networks with only VALID padding and even receptive + field size, but may need additional calculation if other + padding is used (length-2 float32 list or tensor, + default=[0, 0]) + """ + # Handle argument defaults + if base_anchor_size is None: + base_anchor_size = [256, 256] + base_anchor_size = tf.to_float(tf.convert_to_tensor(base_anchor_size)) + if anchor_stride is None: + anchor_stride = [16, 16] + anchor_stride = tf.to_float(tf.convert_to_tensor(anchor_stride)) + if anchor_offset is None: + anchor_offset = [0, 0] + anchor_offset = tf.to_float(tf.convert_to_tensor(anchor_offset)) + + self._scales = scales + self._aspect_ratios = aspect_ratios + self._base_anchor_size = base_anchor_size + self._anchor_stride = anchor_stride + self._anchor_offset = anchor_offset + + def name_scope(self): + return 'GridAnchorGenerator' + + def num_anchors_per_location(self): + """Returns the number of anchors per spatial location. + + Returns: + a list of integers, one for each expected feature map to be passed to + the `generate` function. + """ + return [len(self._scales) * len(self._aspect_ratios)] + + def _generate(self, feature_map_shape_list): + """Generates a collection of bounding boxes to be used as anchors. + + Args: + feature_map_shape_list: list of pairs of convnet layer resolutions in the + format [(height_0, width_0)]. For example, setting + feature_map_shape_list=[(8, 8)] asks for anchors that correspond + to an 8x8 layer. For this anchor generator, only lists of length 1 are + allowed. + + Returns: + boxes_list: a list of BoxLists each holding anchor boxes corresponding to + the input feature map shapes. + + Raises: + ValueError: if feature_map_shape_list, box_specs_list do not have the same + length. + ValueError: if feature_map_shape_list does not consist of pairs of + integers + """ + if not (isinstance(feature_map_shape_list, list) + and len(feature_map_shape_list) == 1): + raise ValueError('feature_map_shape_list must be a list of length 1.') + if not all([isinstance(list_item, tuple) and len(list_item) == 2 + for list_item in feature_map_shape_list]): + raise ValueError('feature_map_shape_list must be a list of pairs.') + grid_height, grid_width = feature_map_shape_list[0] + scales_grid, aspect_ratios_grid = ops.meshgrid(self._scales, + self._aspect_ratios) + scales_grid = tf.reshape(scales_grid, [-1]) + aspect_ratios_grid = tf.reshape(aspect_ratios_grid, [-1]) + anchors = tile_anchors(grid_height, + grid_width, + scales_grid, + aspect_ratios_grid, + self._base_anchor_size, + self._anchor_stride, + self._anchor_offset) + + num_anchors = anchors.num_boxes_static() + if num_anchors is None: + num_anchors = anchors.num_boxes() + anchor_indices = tf.zeros([num_anchors]) + anchors.add_field('feature_map_index', anchor_indices) + return [anchors] + + +def tile_anchors(grid_height, + grid_width, + scales, + aspect_ratios, + base_anchor_size, + anchor_stride, + anchor_offset): + """Create a tiled set of anchors strided along a grid in image space. + + This op creates a set of anchor boxes by placing a "basis" collection of + boxes with user-specified scales and aspect ratios centered at evenly + distributed points along a grid. The basis collection is specified via the + scale and aspect_ratios arguments. For example, setting scales=[.1, .2, .2] + and aspect ratios = [2,2,1/2] means that we create three boxes: one with scale + .1, aspect ratio 2, one with scale .2, aspect ratio 2, and one with scale .2 + and aspect ratio 1/2. Each box is multiplied by "base_anchor_size" before + placing it over its respective center. + + Grid points are specified via grid_height, grid_width parameters as well as + the anchor_stride and anchor_offset parameters. + + Args: + grid_height: size of the grid in the y direction (int or int scalar tensor) + grid_width: size of the grid in the x direction (int or int scalar tensor) + scales: a 1-d (float) tensor representing the scale of each box in the + basis set. + aspect_ratios: a 1-d (float) tensor representing the aspect ratio of each + box in the basis set. The length of the scales and aspect_ratios tensors + must be equal. + base_anchor_size: base anchor size as [height, width] + (float tensor of shape [2]) + anchor_stride: difference in centers between base anchors for adjacent grid + positions (float tensor of shape [2]) + anchor_offset: center of the anchor with scale and aspect ratio 1 for the + upper left element of the grid, this should be zero for + feature networks with only VALID padding and even receptive + field size, but may need some additional calculation if other + padding is used (float tensor of shape [2]) + Returns: + a BoxList holding a collection of N anchor boxes + """ + ratio_sqrts = tf.sqrt(aspect_ratios) + heights = scales / ratio_sqrts * base_anchor_size[0] + widths = scales * ratio_sqrts * base_anchor_size[1] + + # Get a grid of box centers + y_centers = tf.to_float(tf.range(grid_height)) + y_centers = y_centers * anchor_stride[0] + anchor_offset[0] + x_centers = tf.to_float(tf.range(grid_width)) + x_centers = x_centers * anchor_stride[1] + anchor_offset[1] + x_centers, y_centers = ops.meshgrid(x_centers, y_centers) + + widths_grid, x_centers_grid = ops.meshgrid(widths, x_centers) + heights_grid, y_centers_grid = ops.meshgrid(heights, y_centers) + bbox_centers = tf.stack([y_centers_grid, x_centers_grid], axis=3) + bbox_sizes = tf.stack([heights_grid, widths_grid], axis=3) + bbox_centers = tf.reshape(bbox_centers, [-1, 2]) + bbox_sizes = tf.reshape(bbox_sizes, [-1, 2]) + bbox_corners = _center_size_bbox_to_corners_bbox(bbox_centers, bbox_sizes) + return box_list.BoxList(bbox_corners) + + +def _center_size_bbox_to_corners_bbox(centers, sizes): + """Converts bbox center-size representation to corners representation. + + Args: + centers: a tensor with shape [N, 2] representing bounding box centers + sizes: a tensor with shape [N, 2] representing bounding boxes + + Returns: + corners: tensor with shape [N, 4] representing bounding boxes in corners + representation + """ + return tf.concat([centers - .5 * sizes, centers + .5 * sizes], 1) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator_test.py" new file mode 100644 index 00000000..8de74aa7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/grid_anchor_generator_test.py" @@ -0,0 +1,104 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.grid_anchor_generator.""" +import numpy as np +import tensorflow as tf + +from object_detection.anchor_generators import grid_anchor_generator +from object_detection.utils import test_case + + +class GridAnchorGeneratorTest(test_case.TestCase): + + def test_construct_single_anchor(self): + """Builds a 1x1 anchor grid to test the size of the output boxes.""" + def graph_fn(): + scales = [0.5, 1.0, 2.0] + aspect_ratios = [0.25, 1.0, 4.0] + anchor_offset = [7, -3] + anchor_generator = grid_anchor_generator.GridAnchorGenerator( + scales, aspect_ratios, anchor_offset=anchor_offset) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(1, 1)]) + anchor_corners = anchors_list[0].get() + return (anchor_corners,) + exp_anchor_corners = [[-121, -35, 135, 29], [-249, -67, 263, 61], + [-505, -131, 519, 125], [-57, -67, 71, 61], + [-121, -131, 135, 125], [-249, -259, 263, 253], + [-25, -131, 39, 125], [-57, -259, 71, 253], + [-121, -515, 135, 509]] + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_anchor_grid(self): + def graph_fn(): + base_anchor_size = [10, 10] + anchor_stride = [19, 19] + anchor_offset = [0, 0] + scales = [0.5, 1.0, 2.0] + aspect_ratios = [1.0] + + anchor_generator = grid_anchor_generator.GridAnchorGenerator( + scales, + aspect_ratios, + base_anchor_size=base_anchor_size, + anchor_stride=anchor_stride, + anchor_offset=anchor_offset) + + anchors_list = anchor_generator.generate(feature_map_shape_list=[(2, 2)]) + anchor_corners = anchors_list[0].get() + return (anchor_corners,) + exp_anchor_corners = [[-2.5, -2.5, 2.5, 2.5], [-5., -5., 5., 5.], + [-10., -10., 10., 10.], [-2.5, 16.5, 2.5, 21.5], + [-5., 14., 5, 24], [-10., 9., 10, 29], + [16.5, -2.5, 21.5, 2.5], [14., -5., 24, 5], + [9., -10., 29, 10], [16.5, 16.5, 21.5, 21.5], + [14., 14., 24, 24], [9., 9., 29, 29]] + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_anchor_grid_with_dynamic_feature_map_shapes(self): + def graph_fn(feature_map_height, feature_map_width): + base_anchor_size = [10, 10] + anchor_stride = [19, 19] + anchor_offset = [0, 0] + scales = [0.5, 1.0, 2.0] + aspect_ratios = [1.0] + anchor_generator = grid_anchor_generator.GridAnchorGenerator( + scales, + aspect_ratios, + base_anchor_size=base_anchor_size, + anchor_stride=anchor_stride, + anchor_offset=anchor_offset) + + anchors_list = anchor_generator.generate( + feature_map_shape_list=[(feature_map_height, feature_map_width)]) + anchor_corners = anchors_list[0].get() + return (anchor_corners,) + + exp_anchor_corners = [[-2.5, -2.5, 2.5, 2.5], [-5., -5., 5., 5.], + [-10., -10., 10., 10.], [-2.5, 16.5, 2.5, 21.5], + [-5., 14., 5, 24], [-10., 9., 10, 29], + [16.5, -2.5, 21.5, 2.5], [14., -5., 24, 5], + [9., -10., 29, 10], [16.5, 16.5, 21.5, 21.5], + [14., 14., 24, 24], [9., 9., 29, 29]] + anchor_corners_out = self.execute_cpu(graph_fn, + [np.array(2, dtype=np.int32), + np.array(2, dtype=np.int32)]) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator.py" new file mode 100644 index 00000000..b870adce --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator.py" @@ -0,0 +1,334 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Generates grid anchors on the fly corresponding to multiple CNN layers. + +Generates grid anchors on the fly corresponding to multiple CNN layers as +described in: +"SSD: Single Shot MultiBox Detector" +Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, +Cheng-Yang Fu, Alexander C. Berg +(see Section 2.2: Choosing scales and aspect ratios for default boxes) +""" + +import numpy as np + +import tensorflow as tf + +from object_detection.anchor_generators import grid_anchor_generator +from object_detection.core import anchor_generator +from object_detection.core import box_list_ops + + +class MultipleGridAnchorGenerator(anchor_generator.AnchorGenerator): + """Generate a grid of anchors for multiple CNN layers.""" + + def __init__(self, + box_specs_list, + base_anchor_size=None, + anchor_strides=None, + anchor_offsets=None, + clip_window=None): + """Constructs a MultipleGridAnchorGenerator. + + To construct anchors, at multiple grid resolutions, one must provide a + list of feature_map_shape_list (e.g., [(8, 8), (4, 4)]), and for each grid + size, a corresponding list of (scale, aspect ratio) box specifications. + + For example: + box_specs_list = [[(.1, 1.0), (.1, 2.0)], # for 8x8 grid + [(.2, 1.0), (.3, 1.0), (.2, 2.0)]] # for 4x4 grid + + To support the fully convolutional setting, we pass grid sizes in at + generation time, while scale and aspect ratios are fixed at construction + time. + + Args: + box_specs_list: list of list of (scale, aspect ratio) pairs with the + outside list having the same number of entries as feature_map_shape_list + (which is passed in at generation time). + base_anchor_size: base anchor size as [height, width] + (length-2 float tensor, default=[1.0, 1.0]). + The height and width values are normalized to the + minimum dimension of the input height and width, so that + when the base anchor height equals the base anchor + width, the resulting anchor is square even if the input + image is not square. + anchor_strides: list of pairs of strides in pixels (in y and x directions + respectively). For example, setting anchor_strides=[(25, 25), (50, 50)] + means that we want the anchors corresponding to the first layer to be + strided by 25 pixels and those in the second layer to be strided by 50 + pixels in both y and x directions. If anchor_strides=None, they are set + to be the reciprocal of the corresponding feature map shapes. + anchor_offsets: list of pairs of offsets in pixels (in y and x directions + respectively). The offset specifies where we want the center of the + (0, 0)-th anchor to lie for each layer. For example, setting + anchor_offsets=[(10, 10), (20, 20)]) means that we want the + (0, 0)-th anchor of the first layer to lie at (10, 10) in pixel space + and likewise that we want the (0, 0)-th anchor of the second layer to + lie at (25, 25) in pixel space. If anchor_offsets=None, then they are + set to be half of the corresponding anchor stride. + clip_window: a tensor of shape [4] specifying a window to which all + anchors should be clipped. If clip_window is None, then no clipping + is performed. + + Raises: + ValueError: if box_specs_list is not a list of list of pairs + ValueError: if clip_window is not either None or a tensor of shape [4] + """ + if isinstance(box_specs_list, list) and all( + [isinstance(list_item, list) for list_item in box_specs_list]): + self._box_specs = box_specs_list + else: + raise ValueError('box_specs_list is expected to be a ' + 'list of lists of pairs') + if base_anchor_size is None: + base_anchor_size = tf.constant([256, 256], dtype=tf.float32) + self._base_anchor_size = base_anchor_size + self._anchor_strides = anchor_strides + self._anchor_offsets = anchor_offsets + if clip_window is not None and clip_window.get_shape().as_list() != [4]: + raise ValueError('clip_window must either be None or a shape [4] tensor') + self._clip_window = clip_window + self._scales = [] + self._aspect_ratios = [] + for box_spec in self._box_specs: + if not all([isinstance(entry, tuple) and len(entry) == 2 + for entry in box_spec]): + raise ValueError('box_specs_list is expected to be a ' + 'list of lists of pairs') + scales, aspect_ratios = zip(*box_spec) + self._scales.append(scales) + self._aspect_ratios.append(aspect_ratios) + + for arg, arg_name in zip([self._anchor_strides, self._anchor_offsets], + ['anchor_strides', 'anchor_offsets']): + if arg and not (isinstance(arg, list) and + len(arg) == len(self._box_specs)): + raise ValueError('%s must be a list with the same length ' + 'as self._box_specs' % arg_name) + if arg and not all([ + isinstance(list_item, tuple) and len(list_item) == 2 + for list_item in arg + ]): + raise ValueError('%s must be a list of pairs.' % arg_name) + + def name_scope(self): + return 'MultipleGridAnchorGenerator' + + def num_anchors_per_location(self): + """Returns the number of anchors per spatial location. + + Returns: + a list of integers, one for each expected feature map to be passed to + the Generate function. + """ + return [len(box_specs) for box_specs in self._box_specs] + + def _generate(self, feature_map_shape_list, im_height=1, im_width=1): + """Generates a collection of bounding boxes to be used as anchors. + + The number of anchors generated for a single grid with shape MxM where we + place k boxes over each grid center is k*M^2 and thus the total number of + anchors is the sum over all grids. In our box_specs_list example + (see the constructor docstring), we would place two boxes over each grid + point on an 8x8 grid and three boxes over each grid point on a 4x4 grid and + thus end up with 2*8^2 + 3*4^2 = 176 anchors in total. The layout of the + output anchors follows the order of how the grid sizes and box_specs are + specified (with box_spec index varying the fastest, followed by width + index, then height index, then grid index). + + Args: + feature_map_shape_list: list of pairs of convnet layer resolutions in the + format [(height_0, width_0), (height_1, width_1), ...]. For example, + setting feature_map_shape_list=[(8, 8), (7, 7)] asks for anchors that + correspond to an 8x8 layer followed by a 7x7 layer. + im_height: the height of the image to generate the grid for. If both + im_height and im_width are 1, the generated anchors default to + absolute coordinates, otherwise normalized coordinates are produced. + im_width: the width of the image to generate the grid for. If both + im_height and im_width are 1, the generated anchors default to + absolute coordinates, otherwise normalized coordinates are produced. + + Returns: + boxes_list: a list of BoxLists each holding anchor boxes corresponding to + the input feature map shapes. + + Raises: + ValueError: if feature_map_shape_list, box_specs_list do not have the same + length. + ValueError: if feature_map_shape_list does not consist of pairs of + integers + """ + if not (isinstance(feature_map_shape_list, list) + and len(feature_map_shape_list) == len(self._box_specs)): + raise ValueError('feature_map_shape_list must be a list with the same ' + 'length as self._box_specs') + if not all([isinstance(list_item, tuple) and len(list_item) == 2 + for list_item in feature_map_shape_list]): + raise ValueError('feature_map_shape_list must be a list of pairs.') + + im_height = tf.to_float(im_height) + im_width = tf.to_float(im_width) + + if not self._anchor_strides: + anchor_strides = [(1.0 / tf.to_float(pair[0]), 1.0 / tf.to_float(pair[1])) + for pair in feature_map_shape_list] + else: + anchor_strides = [(tf.to_float(stride[0]) / im_height, + tf.to_float(stride[1]) / im_width) + for stride in self._anchor_strides] + if not self._anchor_offsets: + anchor_offsets = [(0.5 * stride[0], 0.5 * stride[1]) + for stride in anchor_strides] + else: + anchor_offsets = [(tf.to_float(offset[0]) / im_height, + tf.to_float(offset[1]) / im_width) + for offset in self._anchor_offsets] + + for arg, arg_name in zip([anchor_strides, anchor_offsets], + ['anchor_strides', 'anchor_offsets']): + if not (isinstance(arg, list) and len(arg) == len(self._box_specs)): + raise ValueError('%s must be a list with the same length ' + 'as self._box_specs' % arg_name) + if not all([isinstance(list_item, tuple) and len(list_item) == 2 + for list_item in arg]): + raise ValueError('%s must be a list of pairs.' % arg_name) + + anchor_grid_list = [] + min_im_shape = tf.minimum(im_height, im_width) + scale_height = min_im_shape / im_height + scale_width = min_im_shape / im_width + base_anchor_size = [ + scale_height * self._base_anchor_size[0], + scale_width * self._base_anchor_size[1] + ] + for feature_map_index, (grid_size, scales, aspect_ratios, stride, + offset) in enumerate( + zip(feature_map_shape_list, self._scales, + self._aspect_ratios, anchor_strides, + anchor_offsets)): + tiled_anchors = grid_anchor_generator.tile_anchors( + grid_height=grid_size[0], + grid_width=grid_size[1], + scales=scales, + aspect_ratios=aspect_ratios, + base_anchor_size=base_anchor_size, + anchor_stride=stride, + anchor_offset=offset) + if self._clip_window is not None: + tiled_anchors = box_list_ops.clip_to_window( + tiled_anchors, self._clip_window, filter_nonoverlapping=False) + num_anchors_in_layer = tiled_anchors.num_boxes_static() + if num_anchors_in_layer is None: + num_anchors_in_layer = tiled_anchors.num_boxes() + anchor_indices = feature_map_index * tf.ones([num_anchors_in_layer]) + tiled_anchors.add_field('feature_map_index', anchor_indices) + anchor_grid_list.append(tiled_anchors) + + return anchor_grid_list + + +def create_ssd_anchors(num_layers=6, + min_scale=0.2, + max_scale=0.95, + scales=None, + aspect_ratios=(1.0, 2.0, 3.0, 1.0 / 2, 1.0 / 3), + interpolated_scale_aspect_ratio=1.0, + base_anchor_size=None, + anchor_strides=None, + anchor_offsets=None, + reduce_boxes_in_lowest_layer=True): + """Creates MultipleGridAnchorGenerator for SSD anchors. + + This function instantiates a MultipleGridAnchorGenerator that reproduces + ``default box`` construction proposed by Liu et al in the SSD paper. + See Section 2.2 for details. Grid sizes are assumed to be passed in + at generation time from finest resolution to coarsest resolution --- this is + used to (linearly) interpolate scales of anchor boxes corresponding to the + intermediate grid sizes. + + Anchors that are returned by calling the `generate` method on the returned + MultipleGridAnchorGenerator object are always in normalized coordinates + and clipped to the unit square: (i.e. all coordinates lie in [0, 1]x[0, 1]). + + Args: + num_layers: integer number of grid layers to create anchors for (actual + grid sizes passed in at generation time) + min_scale: scale of anchors corresponding to finest resolution (float) + max_scale: scale of anchors corresponding to coarsest resolution (float) + scales: As list of anchor scales to use. When not None and not empty, + min_scale and max_scale are not used. + aspect_ratios: list or tuple of (float) aspect ratios to place on each + grid point. + interpolated_scale_aspect_ratio: An additional anchor is added with this + aspect ratio and a scale interpolated between the scale for a layer + and the scale for the next layer (1.0 for the last layer). + This anchor is not included if this value is 0. + base_anchor_size: base anchor size as [height, width]. + The height and width values are normalized to the minimum dimension of the + input height and width, so that when the base anchor height equals the + base anchor width, the resulting anchor is square even if the input image + is not square. + anchor_strides: list of pairs of strides in pixels (in y and x directions + respectively). For example, setting anchor_strides=[(25, 25), (50, 50)] + means that we want the anchors corresponding to the first layer to be + strided by 25 pixels and those in the second layer to be strided by 50 + pixels in both y and x directions. If anchor_strides=None, they are set to + be the reciprocal of the corresponding feature map shapes. + anchor_offsets: list of pairs of offsets in pixels (in y and x directions + respectively). The offset specifies where we want the center of the + (0, 0)-th anchor to lie for each layer. For example, setting + anchor_offsets=[(10, 10), (20, 20)]) means that we want the + (0, 0)-th anchor of the first layer to lie at (10, 10) in pixel space + and likewise that we want the (0, 0)-th anchor of the second layer to lie + at (25, 25) in pixel space. If anchor_offsets=None, then they are set to + be half of the corresponding anchor stride. + reduce_boxes_in_lowest_layer: a boolean to indicate whether the fixed 3 + boxes per location is used in the lowest layer. + + Returns: + a MultipleGridAnchorGenerator + """ + if base_anchor_size is None: + base_anchor_size = [1.0, 1.0] + base_anchor_size = tf.constant(base_anchor_size, dtype=tf.float32) + box_specs_list = [] + if scales is None or not scales: + scales = [min_scale + (max_scale - min_scale) * i / (num_layers - 1) + for i in range(num_layers)] + [1.0] + else: + # Add 1.0 to the end, which will only be used in scale_next below and used + # for computing an interpolated scale for the largest scale in the list. + scales += [1.0] + + for layer, scale, scale_next in zip( + range(num_layers), scales[:-1], scales[1:]): + layer_box_specs = [] + if layer == 0 and reduce_boxes_in_lowest_layer: + layer_box_specs = [(0.1, 1.0), (scale, 2.0), (scale, 0.5)] + else: + for aspect_ratio in aspect_ratios: + layer_box_specs.append((scale, aspect_ratio)) + # Add one more anchor, with a scale between the current scale, and the + # scale for the next layer, with a specified aspect ratio (1.0 by + # default). + if interpolated_scale_aspect_ratio > 0.0: + layer_box_specs.append((np.sqrt(scale*scale_next), + interpolated_scale_aspect_ratio)) + box_specs_list.append(layer_box_specs) + + return MultipleGridAnchorGenerator(box_specs_list, base_anchor_size, + anchor_strides, anchor_offsets) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator_test.py" new file mode 100644 index 00000000..070d81d3 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiple_grid_anchor_generator_test.py" @@ -0,0 +1,289 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for anchor_generators.multiple_grid_anchor_generator_test.py.""" + +import numpy as np + +import tensorflow as tf + +from object_detection.anchor_generators import multiple_grid_anchor_generator as ag +from object_detection.utils import test_case + + +class MultipleGridAnchorGeneratorTest(test_case.TestCase): + + def test_construct_single_anchor_grid(self): + """Builds a 1x1 anchor grid to test the size of the output boxes.""" + def graph_fn(): + + box_specs_list = [[(.5, .25), (1.0, .25), (2.0, .25), + (.5, 1.0), (1.0, 1.0), (2.0, 1.0), + (.5, 4.0), (1.0, 4.0), (2.0, 4.0)]] + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([256, 256], dtype=tf.float32), + anchor_strides=[(16, 16)], + anchor_offsets=[(7, -3)]) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(1, 1)]) + return anchors_list[0].get() + exp_anchor_corners = [[-121, -35, 135, 29], [-249, -67, 263, 61], + [-505, -131, 519, 125], [-57, -67, 71, 61], + [-121, -131, 135, 125], [-249, -259, 263, 253], + [-25, -131, 39, 125], [-57, -259, 71, 253], + [-121, -515, 135, 509]] + + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_anchor_grid(self): + def graph_fn(): + box_specs_list = [[(0.5, 1.0), (1.0, 1.0), (2.0, 1.0)]] + + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([10, 10], dtype=tf.float32), + anchor_strides=[(19, 19)], + anchor_offsets=[(0, 0)]) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(2, 2)]) + return anchors_list[0].get() + exp_anchor_corners = [[-2.5, -2.5, 2.5, 2.5], [-5., -5., 5., 5.], + [-10., -10., 10., 10.], [-2.5, 16.5, 2.5, 21.5], + [-5., 14., 5, 24], [-10., 9., 10, 29], + [16.5, -2.5, 21.5, 2.5], [14., -5., 24, 5], + [9., -10., 29, 10], [16.5, 16.5, 21.5, 21.5], + [14., 14., 24, 24], [9., 9., 29, 29]] + + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_anchor_grid_non_square(self): + + def graph_fn(): + box_specs_list = [[(1.0, 1.0)]] + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, base_anchor_size=tf.constant([1, 1], + dtype=tf.float32)) + anchors_list = anchor_generator.generate(feature_map_shape_list=[( + tf.constant(1, dtype=tf.int32), tf.constant(2, dtype=tf.int32))]) + return anchors_list[0].get() + + exp_anchor_corners = [[0., -0.25, 1., 0.75], [0., 0.25, 1., 1.25]] + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_dynamic_size_anchor_grid(self): + + def graph_fn(height, width): + box_specs_list = [[(1.0, 1.0)]] + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, base_anchor_size=tf.constant([1, 1], + dtype=tf.float32)) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(height, + width)]) + return anchors_list[0].get() + + exp_anchor_corners = [[0., -0.25, 1., 0.75], [0., 0.25, 1., 1.25]] + + anchor_corners_out = self.execute_cpu(graph_fn, + [np.array(1, dtype=np.int32), + np.array(2, dtype=np.int32)]) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_anchor_grid_normalized(self): + def graph_fn(): + box_specs_list = [[(1.0, 1.0)]] + + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, base_anchor_size=tf.constant([1, 1], + dtype=tf.float32)) + anchors_list = anchor_generator.generate( + feature_map_shape_list=[(tf.constant(1, dtype=tf.int32), tf.constant( + 2, dtype=tf.int32))], + im_height=320, + im_width=640) + return anchors_list[0].get() + + exp_anchor_corners = [[0., 0., 1., 0.5], [0., 0.5, 1., 1.]] + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_multiple_grids(self): + + def graph_fn(): + box_specs_list = [[(1.0, 1.0), (2.0, 1.0), (1.0, 0.5)], + [(1.0, 1.0), (1.0, 0.5)]] + + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25), (.5, .5)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(4, 4), ( + 2, 2)]) + return [anchors.get() for anchors in anchors_list] + # height and width of box with .5 aspect ratio + h = np.sqrt(2) + w = 1.0/np.sqrt(2) + exp_small_grid_corners = [[-.25, -.25, .75, .75], + [.25-.5*h, .25-.5*w, .25+.5*h, .25+.5*w], + [-.25, .25, .75, 1.25], + [.25-.5*h, .75-.5*w, .25+.5*h, .75+.5*w], + [.25, -.25, 1.25, .75], + [.75-.5*h, .25-.5*w, .75+.5*h, .25+.5*w], + [.25, .25, 1.25, 1.25], + [.75-.5*h, .75-.5*w, .75+.5*h, .75+.5*w]] + # only test first entry of larger set of anchors + exp_big_grid_corners = [[.125-.5, .125-.5, .125+.5, .125+.5], + [.125-1.0, .125-1.0, .125+1.0, .125+1.0], + [.125-.5*h, .125-.5*w, .125+.5*h, .125+.5*w],] + + anchor_corners_out = np.concatenate(self.execute(graph_fn, []), axis=0) + self.assertEquals(anchor_corners_out.shape, (56, 4)) + big_grid_corners = anchor_corners_out[0:3, :] + small_grid_corners = anchor_corners_out[48:, :] + self.assertAllClose(small_grid_corners, exp_small_grid_corners) + self.assertAllClose(big_grid_corners, exp_big_grid_corners) + + def test_construct_multiple_grids_with_clipping(self): + + def graph_fn(): + box_specs_list = [[(1.0, 1.0), (2.0, 1.0), (1.0, 0.5)], + [(1.0, 1.0), (1.0, 0.5)]] + + clip_window = tf.constant([0, 0, 1, 1], dtype=tf.float32) + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + clip_window=clip_window) + anchors_list = anchor_generator.generate(feature_map_shape_list=[(4, 4), ( + 2, 2)]) + return [anchors.get() for anchors in anchors_list] + # height and width of box with .5 aspect ratio + h = np.sqrt(2) + w = 1.0/np.sqrt(2) + exp_small_grid_corners = [[0, 0, .75, .75], + [0, 0, .25+.5*h, .25+.5*w], + [0, .25, .75, 1], + [0, .75-.5*w, .25+.5*h, 1], + [.25, 0, 1, .75], + [.75-.5*h, 0, 1, .25+.5*w], + [.25, .25, 1, 1], + [.75-.5*h, .75-.5*w, 1, 1]] + + anchor_corners_out = np.concatenate(self.execute(graph_fn, []), axis=0) + small_grid_corners = anchor_corners_out[48:, :] + self.assertAllClose(small_grid_corners, exp_small_grid_corners) + + def test_invalid_box_specs(self): + # not all box specs are pairs + box_specs_list = [[(1.0, 1.0), (2.0, 1.0), (1.0, 0.5)], + [(1.0, 1.0), (1.0, 0.5, .3)]] + with self.assertRaises(ValueError): + ag.MultipleGridAnchorGenerator(box_specs_list) + + # box_specs_list is not a list of lists + box_specs_list = [(1.0, 1.0), (2.0, 1.0), (1.0, 0.5)] + with self.assertRaises(ValueError): + ag.MultipleGridAnchorGenerator(box_specs_list) + + def test_invalid_generate_arguments(self): + box_specs_list = [[(1.0, 1.0), (2.0, 1.0), (1.0, 0.5)], + [(1.0, 1.0), (1.0, 0.5)]] + + # incompatible lengths with box_specs_list + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4, 4), (2, 2)]) + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25), (.5, .5)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4, 4), (2, 2), (1, 1)]) + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.5, .5)], + anchor_offsets=[(.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4, 4), (2, 2)]) + + # not pairs + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25), (.5, .5)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4, 4, 4), (2, 2)]) + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25, .1), (.5, .5)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4, 4), (2, 2)]) + with self.assertRaises(ValueError): + anchor_generator = ag.MultipleGridAnchorGenerator( + box_specs_list, + base_anchor_size=tf.constant([1.0, 1.0], dtype=tf.float32), + anchor_strides=[(.25, .25), (.5, .5)], + anchor_offsets=[(.125, .125), (.25, .25)]) + anchor_generator.generate(feature_map_shape_list=[(4), (2, 2)]) + + +class CreateSSDAnchorsTest(test_case.TestCase): + + def test_create_ssd_anchors_returns_correct_shape(self): + + def graph_fn1(): + anchor_generator = ag.create_ssd_anchors( + num_layers=6, + min_scale=0.2, + max_scale=0.95, + aspect_ratios=(1.0, 2.0, 3.0, 1.0 / 2, 1.0 / 3), + reduce_boxes_in_lowest_layer=True) + + feature_map_shape_list = [(38, 38), (19, 19), (10, 10), + (5, 5), (3, 3), (1, 1)] + anchors_list = anchor_generator.generate( + feature_map_shape_list=feature_map_shape_list) + return [anchors.get() for anchors in anchors_list] + anchor_corners_out = np.concatenate(self.execute(graph_fn1, []), axis=0) + self.assertEquals(anchor_corners_out.shape, (7308, 4)) + + def graph_fn2(): + anchor_generator = ag.create_ssd_anchors( + num_layers=6, min_scale=0.2, max_scale=0.95, + aspect_ratios=(1.0, 2.0, 3.0, 1.0/2, 1.0/3), + reduce_boxes_in_lowest_layer=False) + + feature_map_shape_list = [(38, 38), (19, 19), (10, 10), + (5, 5), (3, 3), (1, 1)] + anchors_list = anchor_generator.generate( + feature_map_shape_list=feature_map_shape_list) + return [anchors.get() for anchors in anchors_list] + anchor_corners_out = np.concatenate(self.execute(graph_fn2, []), axis=0) + self.assertEquals(anchor_corners_out.shape, (11640, 4)) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator.py" new file mode 100644 index 00000000..cd2440a4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator.py" @@ -0,0 +1,145 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Generates grid anchors on the fly corresponding to multiple CNN layers. + +Generates grid anchors on the fly corresponding to multiple CNN layers as +described in: +"Focal Loss for Dense Object Detection" (https://arxiv.org/abs/1708.02002) +T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollar +""" + +from object_detection.anchor_generators import grid_anchor_generator +from object_detection.core import anchor_generator +from object_detection.core import box_list_ops + + +class MultiscaleGridAnchorGenerator(anchor_generator.AnchorGenerator): + """Generate a grid of anchors for multiple CNN layers of different scale.""" + + def __init__(self, min_level, max_level, anchor_scale, aspect_ratios, + scales_per_octave, normalize_coordinates=True): + """Constructs a MultiscaleGridAnchorGenerator. + + To construct anchors, at multiple scale resolutions, one must provide a + the minimum level and maximum levels on a scale pyramid. To define the size + of anchor, the anchor scale is provided to decide the size relatively to the + stride of the corresponding feature map. The generator allows one pixel + location on feature map maps to multiple anchors, that have different aspect + ratios and intermediate scales. + + Args: + min_level: minimum level in feature pyramid. + max_level: maximum level in feature pyramid. + anchor_scale: anchor scale and feature stride define the size of the base + anchor on an image. For example, given a feature pyramid with strides + [2^3, ..., 2^7] and anchor scale 4. The base anchor size is + 4 * [2^3, ..., 2^7]. + aspect_ratios: list or tuple of (float) aspect ratios to place on each + grid point. + scales_per_octave: integer number of intermediate scales per scale octave. + normalize_coordinates: whether to produce anchors in normalized + coordinates. (defaults to True). + """ + self._anchor_grid_info = [] + self._aspect_ratios = aspect_ratios + self._scales_per_octave = scales_per_octave + self._normalize_coordinates = normalize_coordinates + + scales = [2**(float(scale) / scales_per_octave) + for scale in range(scales_per_octave)] + aspects = list(aspect_ratios) + + for level in range(min_level, max_level + 1): + anchor_stride = [2**level, 2**level] + base_anchor_size = [2**level * anchor_scale, 2**level * anchor_scale] + self._anchor_grid_info.append({ + 'level': level, + 'info': [scales, aspects, base_anchor_size, anchor_stride] + }) + + def name_scope(self): + return 'MultiscaleGridAnchorGenerator' + + def num_anchors_per_location(self): + """Returns the number of anchors per spatial location. + + Returns: + a list of integers, one for each expected feature map to be passed to + the Generate function. + """ + return len(self._anchor_grid_info) * [ + len(self._aspect_ratios) * self._scales_per_octave] + + def _generate(self, feature_map_shape_list, im_height=1, im_width=1): + """Generates a collection of bounding boxes to be used as anchors. + + Currently we require the input image shape to be statically defined. That + is, im_height and im_width should be integers rather than tensors. + + Args: + feature_map_shape_list: list of pairs of convnet layer resolutions in the + format [(height_0, width_0), (height_1, width_1), ...]. For example, + setting feature_map_shape_list=[(8, 8), (7, 7)] asks for anchors that + correspond to an 8x8 layer followed by a 7x7 layer. + im_height: the height of the image to generate the grid for. If both + im_height and im_width are 1, anchors can only be generated in + absolute coordinates. + im_width: the width of the image to generate the grid for. If both + im_height and im_width are 1, anchors can only be generated in + absolute coordinates. + + Returns: + boxes_list: a list of BoxLists each holding anchor boxes corresponding to + the input feature map shapes. + Raises: + ValueError: if im_height and im_width are not integers. + ValueError: if im_height and im_width are 1, but normalized coordinates + were requested. + """ + anchor_grid_list = [] + for feat_shape, grid_info in zip(feature_map_shape_list, + self._anchor_grid_info): + # TODO(rathodv) check the feature_map_shape_list is consistent with + # self._anchor_grid_info + level = grid_info['level'] + stride = 2**level + scales, aspect_ratios, base_anchor_size, anchor_stride = grid_info['info'] + feat_h = feat_shape[0] + feat_w = feat_shape[1] + anchor_offset = [0, 0] + if isinstance(im_height, int) and isinstance(im_width, int): + if im_height % 2.0**level == 0 or im_height == 1: + anchor_offset[0] = stride / 2.0 + if im_width % 2.0**level == 0 or im_width == 1: + anchor_offset[1] = stride / 2.0 + ag = grid_anchor_generator.GridAnchorGenerator( + scales, + aspect_ratios, + base_anchor_size=base_anchor_size, + anchor_stride=anchor_stride, + anchor_offset=anchor_offset) + (anchor_grid,) = ag.generate(feature_map_shape_list=[(feat_h, feat_w)]) + + if self._normalize_coordinates: + if im_height == 1 or im_width == 1: + raise ValueError( + 'Normalized coordinates were requested upon construction of the ' + 'MultiscaleGridAnchorGenerator, but a subsequent call to ' + 'generate did not supply dimension information.') + anchor_grid = box_list_ops.to_normalized_coordinates( + anchor_grid, im_height, im_width, check_range=False) + anchor_grid_list.append(anchor_grid) + + return anchor_grid_list diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator_test.py" new file mode 100644 index 00000000..178705c1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/anchor_generators/multiscale_grid_anchor_generator_test.py" @@ -0,0 +1,302 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for anchor_generators.multiscale_grid_anchor_generator_test.py.""" +import numpy as np +import tensorflow as tf + +from object_detection.anchor_generators import multiscale_grid_anchor_generator as mg +from object_detection.utils import test_case + + +class MultiscaleGridAnchorGeneratorTest(test_case.TestCase): + + def test_construct_single_anchor(self): + min_level = 5 + max_level = 5 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 64 + im_width = 64 + feature_map_shape_list = [(2, 2)] + exp_anchor_corners = [[-48, -48, 80, 80], + [-48, -16, 80, 112], + [-16, -48, 112, 80], + [-16, -16, 112, 112]] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate( + feature_map_shape_list, im_height=im_height, im_width=im_width) + anchor_corners = anchors_list[0].get() + + with self.test_session(): + anchor_corners_out = anchor_corners.eval() + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchor_unit_dimensions(self): + min_level = 5 + max_level = 5 + anchor_scale = 1.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 1 + im_width = 1 + feature_map_shape_list = [(2, 2)] + # Positive offsets are produced. + exp_anchor_corners = [[0, 0, 32, 32], + [0, 32, 32, 64], + [32, 0, 64, 32], + [32, 32, 64, 64]] + + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate( + feature_map_shape_list, im_height=im_height, im_width=im_width) + anchor_corners = anchors_list[0].get() + + with self.test_session(): + anchor_corners_out = anchor_corners.eval() + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_normalized_anchors_fails_with_unit_dimensions(self): + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level=5, max_level=5, anchor_scale=1.0, aspect_ratios=[1.0], + scales_per_octave=1, normalize_coordinates=True) + with self.assertRaisesRegexp(ValueError, 'Normalized coordinates'): + anchor_generator.generate( + feature_map_shape_list=[(2, 2)], im_height=1, im_width=1) + + def test_construct_single_anchor_in_normalized_coordinates(self): + min_level = 5 + max_level = 5 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 64 + im_width = 128 + feature_map_shape_list = [(2, 2)] + exp_anchor_corners = [[-48./64, -48./128, 80./64, 80./128], + [-48./64, -16./128, 80./64, 112./128], + [-16./64, -48./128, 112./64, 80./128], + [-16./64, -16./128, 112./64, 112./128]] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=True) + anchors_list = anchor_generator.generate( + feature_map_shape_list, im_height=im_height, im_width=im_width) + anchor_corners = anchors_list[0].get() + + with self.test_session(): + anchor_corners_out = anchor_corners.eval() + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_num_anchors_per_location(self): + min_level = 5 + max_level = 6 + anchor_scale = 4.0 + aspect_ratios = [1.0, 2.0] + scales_per_octave = 3 + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + self.assertEqual(anchor_generator.num_anchors_per_location(), [6, 6]) + + def test_construct_single_anchor_dynamic_size(self): + min_level = 5 + max_level = 5 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = tf.constant(64) + im_width = tf.constant(64) + feature_map_shape_list = [(2, 2)] + # Zero offsets are used. + exp_anchor_corners = [[-64, -64, 64, 64], + [-64, -32, 64, 96], + [-32, -64, 96, 64], + [-32, -32, 96, 96]] + + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate( + feature_map_shape_list, im_height=im_height, im_width=im_width) + anchor_corners = anchors_list[0].get() + + with self.test_session(): + anchor_corners_out = anchor_corners.eval() + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchor_with_odd_input_dimension(self): + + def graph_fn(): + min_level = 5 + max_level = 5 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 65 + im_width = 65 + feature_map_shape_list = [(3, 3)] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate( + feature_map_shape_list, im_height=im_height, im_width=im_width) + anchor_corners = anchors_list[0].get() + return (anchor_corners,) + anchor_corners_out = self.execute(graph_fn, []) + exp_anchor_corners = [[-64, -64, 64, 64], + [-64, -32, 64, 96], + [-64, 0, 64, 128], + [-32, -64, 96, 64], + [-32, -32, 96, 96], + [-32, 0, 96, 128], + [0, -64, 128, 64], + [0, -32, 128, 96], + [0, 0, 128, 128]] + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchor_on_two_feature_maps(self): + + def graph_fn(): + min_level = 5 + max_level = 6 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 64 + im_width = 64 + feature_map_shape_list = [(2, 2), (1, 1)] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate(feature_map_shape_list, + im_height=im_height, + im_width=im_width) + anchor_corners = [anchors.get() for anchors in anchors_list] + return anchor_corners + + anchor_corners_out = np.concatenate(self.execute(graph_fn, []), axis=0) + exp_anchor_corners = [[-48, -48, 80, 80], + [-48, -16, 80, 112], + [-16, -48, 112, 80], + [-16, -16, 112, 112], + [-96, -96, 160, 160]] + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchor_with_two_scales_per_octave(self): + + def graph_fn(): + min_level = 6 + max_level = 6 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 2 + im_height = 64 + im_width = 64 + feature_map_shape_list = [(1, 1)] + + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate(feature_map_shape_list, + im_height=im_height, + im_width=im_width) + anchor_corners = [anchors.get() for anchors in anchors_list] + return anchor_corners + # There are 4 set of anchors in this configuration. The order is: + # [[2**0.0 intermediate scale + 1.0 aspect], + # [2**0.5 intermediate scale + 1.0 aspect]] + exp_anchor_corners = [[-96., -96., 160., 160.], + [-149.0193, -149.0193, 213.0193, 213.0193]] + + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchor_with_two_scales_per_octave_and_aspect(self): + def graph_fn(): + min_level = 6 + max_level = 6 + anchor_scale = 4.0 + aspect_ratios = [1.0, 2.0] + scales_per_octave = 2 + im_height = 64 + im_width = 64 + feature_map_shape_list = [(1, 1)] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate(feature_map_shape_list, + im_height=im_height, + im_width=im_width) + anchor_corners = [anchors.get() for anchors in anchors_list] + return anchor_corners + # There are 4 set of anchors in this configuration. The order is: + # [[2**0.0 intermediate scale + 1.0 aspect], + # [2**0.5 intermediate scale + 1.0 aspect], + # [2**0.0 intermediate scale + 2.0 aspect], + # [2**0.5 intermediate scale + 2.0 aspect]] + + exp_anchor_corners = [[-96., -96., 160., 160.], + [-149.0193, -149.0193, 213.0193, 213.0193], + [-58.50967, -149.0193, 122.50967, 213.0193], + [-96., -224., 160., 288.]] + anchor_corners_out = self.execute(graph_fn, []) + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + def test_construct_single_anchors_on_feature_maps_with_dynamic_shape(self): + + def graph_fn(feature_map1_height, feature_map1_width, feature_map2_height, + feature_map2_width): + min_level = 5 + max_level = 6 + anchor_scale = 4.0 + aspect_ratios = [1.0] + scales_per_octave = 1 + im_height = 64 + im_width = 64 + feature_map_shape_list = [(feature_map1_height, feature_map1_width), + (feature_map2_height, feature_map2_width)] + anchor_generator = mg.MultiscaleGridAnchorGenerator( + min_level, max_level, anchor_scale, aspect_ratios, scales_per_octave, + normalize_coordinates=False) + anchors_list = anchor_generator.generate(feature_map_shape_list, + im_height=im_height, + im_width=im_width) + anchor_corners = [anchors.get() for anchors in anchors_list] + return anchor_corners + + anchor_corners_out = np.concatenate( + self.execute_cpu(graph_fn, [ + np.array(2, dtype=np.int32), + np.array(2, dtype=np.int32), + np.array(1, dtype=np.int32), + np.array(1, dtype=np.int32) + ]), + axis=0) + exp_anchor_corners = [[-48, -48, 80, 80], + [-48, -16, 80, 112], + [-16, -48, 112, 80], + [-16, -16, 112, 112], + [-96, -96, 160, 160]] + self.assertAllClose(anchor_corners_out, exp_anchor_corners) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder.py" new file mode 100644 index 00000000..af25e21a --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder.py" @@ -0,0 +1,118 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Faster RCNN box coder. + +Faster RCNN box coder follows the coding schema described below: + ty = (y - ya) / ha + tx = (x - xa) / wa + th = log(h / ha) + tw = log(w / wa) + where x, y, w, h denote the box's center coordinates, width and height + respectively. Similarly, xa, ya, wa, ha denote the anchor's center + coordinates, width and height. tx, ty, tw and th denote the anchor-encoded + center, width and height respectively. + + See http://arxiv.org/abs/1506.01497 for details. +""" + +import tensorflow as tf + +from object_detection.core import box_coder +from object_detection.core import box_list + +EPSILON = 1e-8 + + +class FasterRcnnBoxCoder(box_coder.BoxCoder): + """Faster RCNN box coder.""" + + def __init__(self, scale_factors=None): + """Constructor for FasterRcnnBoxCoder. + + Args: + scale_factors: List of 4 positive scalars to scale ty, tx, th and tw. + If set to None, does not perform scaling. For Faster RCNN, + the open-source implementation recommends using [10.0, 10.0, 5.0, 5.0]. + """ + if scale_factors: + assert len(scale_factors) == 4 + for scalar in scale_factors: + assert scalar > 0 + self._scale_factors = scale_factors + + @property + def code_size(self): + return 4 + + def _encode(self, boxes, anchors): + """Encode a box collection with respect to anchor collection. + + Args: + boxes: BoxList holding N boxes to be encoded. + anchors: BoxList of anchors. + + Returns: + a tensor representing N anchor-encoded boxes of the format + [ty, tx, th, tw]. + """ + # Convert anchors to the center coordinate representation. + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + ycenter, xcenter, h, w = boxes.get_center_coordinates_and_sizes() + # Avoid NaN in division and log below. + ha += EPSILON + wa += EPSILON + h += EPSILON + w += EPSILON + + tx = (xcenter - xcenter_a) / wa + ty = (ycenter - ycenter_a) / ha + tw = tf.log(w / wa) + th = tf.log(h / ha) + # Scales location targets as used in paper for joint training. + if self._scale_factors: + ty *= self._scale_factors[0] + tx *= self._scale_factors[1] + th *= self._scale_factors[2] + tw *= self._scale_factors[3] + return tf.transpose(tf.stack([ty, tx, th, tw])) + + def _decode(self, rel_codes, anchors): + """Decode relative codes to boxes. + + Args: + rel_codes: a tensor representing N anchor-encoded boxes. + anchors: BoxList of anchors. + + Returns: + boxes: BoxList holding N bounding boxes. + """ + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + + ty, tx, th, tw = tf.unstack(tf.transpose(rel_codes)) + if self._scale_factors: + ty /= self._scale_factors[0] + tx /= self._scale_factors[1] + th /= self._scale_factors[2] + tw /= self._scale_factors[3] + w = tf.exp(tw) * wa + h = tf.exp(th) * ha + ycenter = ty * ha + ycenter_a + xcenter = tx * wa + xcenter_a + ymin = ycenter - h / 2. + xmin = xcenter - w / 2. + ymax = ycenter + h / 2. + xmax = xcenter + w / 2. + return box_list.BoxList(tf.transpose(tf.stack([ymin, xmin, ymax, xmax]))) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder_test.py" new file mode 100644 index 00000000..b2135f06 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/faster_rcnn_box_coder_test.py" @@ -0,0 +1,94 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.box_coder.faster_rcnn_box_coder.""" + +import tensorflow as tf + +from object_detection.box_coders import faster_rcnn_box_coder +from object_detection.core import box_list + + +class FasterRcnnBoxCoderTest(tf.test.TestCase): + + def test_get_correct_relative_codes_after_encoding(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + expected_rel_codes = [[-0.5, -0.416666, -0.405465, -0.182321], + [-0.083333, -0.222222, -0.693147, -1.098612]] + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = faster_rcnn_box_coder.FasterRcnnBoxCoder() + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_get_correct_relative_codes_after_encoding_with_scaling(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + scale_factors = [2, 3, 4, 5] + expected_rel_codes = [[-1., -1.25, -1.62186, -0.911608], + [-0.166667, -0.666667, -2.772588, -5.493062]] + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = faster_rcnn_box_coder.FasterRcnnBoxCoder( + scale_factors=scale_factors) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_get_correct_boxes_after_decoding(self): + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + rel_codes = [[-0.5, -0.416666, -0.405465, -0.182321], + [-0.083333, -0.222222, -0.693147, -1.098612]] + expected_boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = box_list.BoxList(tf.constant(anchors)) + coder = faster_rcnn_box_coder.FasterRcnnBoxCoder() + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + boxes_out, = sess.run([boxes.get()]) + self.assertAllClose(boxes_out, expected_boxes) + + def test_get_correct_boxes_after_decoding_with_scaling(self): + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + rel_codes = [[-1., -1.25, -1.62186, -0.911608], + [-0.166667, -0.666667, -2.772588, -5.493062]] + scale_factors = [2, 3, 4, 5] + expected_boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = box_list.BoxList(tf.constant(anchors)) + coder = faster_rcnn_box_coder.FasterRcnnBoxCoder( + scale_factors=scale_factors) + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + boxes_out, = sess.run([boxes.get()]) + self.assertAllClose(boxes_out, expected_boxes) + + def test_very_small_Width_nan_after_encoding(self): + boxes = [[10.0, 10.0, 10.0000001, 20.0]] + anchors = [[15.0, 12.0, 30.0, 18.0]] + expected_rel_codes = [[-0.833333, 0., -21.128731, 0.510826]] + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = faster_rcnn_box_coder.FasterRcnnBoxCoder() + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder.py" new file mode 100644 index 00000000..67df3b82 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder.py" @@ -0,0 +1,171 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Keypoint box coder. + +The keypoint box coder follows the coding schema described below (this is +similar to the FasterRcnnBoxCoder, except that it encodes keypoints in addition +to box coordinates): + ty = (y - ya) / ha + tx = (x - xa) / wa + th = log(h / ha) + tw = log(w / wa) + tky0 = (ky0 - ya) / ha + tkx0 = (kx0 - xa) / wa + tky1 = (ky1 - ya) / ha + tkx1 = (kx1 - xa) / wa + ... + where x, y, w, h denote the box's center coordinates, width and height + respectively. Similarly, xa, ya, wa, ha denote the anchor's center + coordinates, width and height. tx, ty, tw and th denote the anchor-encoded + center, width and height respectively. ky0, kx0, ky1, kx1, ... denote the + keypoints' coordinates, and tky0, tkx0, tky1, tkx1, ... denote the + anchor-encoded keypoint coordinates. +""" + +import tensorflow as tf + +from object_detection.core import box_coder +from object_detection.core import box_list +from object_detection.core import standard_fields as fields + +EPSILON = 1e-8 + + +class KeypointBoxCoder(box_coder.BoxCoder): + """Keypoint box coder.""" + + def __init__(self, num_keypoints, scale_factors=None): + """Constructor for KeypointBoxCoder. + + Args: + num_keypoints: Number of keypoints to encode/decode. + scale_factors: List of 4 positive scalars to scale ty, tx, th and tw. + In addition to scaling ty and tx, the first 2 scalars are used to scale + the y and x coordinates of the keypoints as well. If set to None, does + not perform scaling. + """ + self._num_keypoints = num_keypoints + + if scale_factors: + assert len(scale_factors) == 4 + for scalar in scale_factors: + assert scalar > 0 + self._scale_factors = scale_factors + self._keypoint_scale_factors = None + if scale_factors is not None: + self._keypoint_scale_factors = tf.expand_dims(tf.tile( + [tf.to_float(scale_factors[0]), tf.to_float(scale_factors[1])], + [num_keypoints]), 1) + + @property + def code_size(self): + return 4 + self._num_keypoints * 2 + + def _encode(self, boxes, anchors): + """Encode a box and keypoint collection with respect to anchor collection. + + Args: + boxes: BoxList holding N boxes and keypoints to be encoded. Boxes are + tensors with the shape [N, 4], and keypoints are tensors with the shape + [N, num_keypoints, 2]. + anchors: BoxList of anchors. + + Returns: + a tensor representing N anchor-encoded boxes of the format + [ty, tx, th, tw, tky0, tkx0, tky1, tkx1, ...] where tky0 and tkx0 + represent the y and x coordinates of the first keypoint, tky1 and tkx1 + represent the y and x coordinates of the second keypoint, and so on. + """ + # Convert anchors to the center coordinate representation. + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + ycenter, xcenter, h, w = boxes.get_center_coordinates_and_sizes() + keypoints = boxes.get_field(fields.BoxListFields.keypoints) + keypoints = tf.transpose(tf.reshape(keypoints, + [-1, self._num_keypoints * 2])) + num_boxes = boxes.num_boxes() + + # Avoid NaN in division and log below. + ha += EPSILON + wa += EPSILON + h += EPSILON + w += EPSILON + + tx = (xcenter - xcenter_a) / wa + ty = (ycenter - ycenter_a) / ha + tw = tf.log(w / wa) + th = tf.log(h / ha) + + tiled_anchor_centers = tf.tile( + tf.stack([ycenter_a, xcenter_a]), [self._num_keypoints, 1]) + tiled_anchor_sizes = tf.tile( + tf.stack([ha, wa]), [self._num_keypoints, 1]) + tkeypoints = (keypoints - tiled_anchor_centers) / tiled_anchor_sizes + + # Scales location targets as used in paper for joint training. + if self._scale_factors: + ty *= self._scale_factors[0] + tx *= self._scale_factors[1] + th *= self._scale_factors[2] + tw *= self._scale_factors[3] + tkeypoints *= tf.tile(self._keypoint_scale_factors, [1, num_boxes]) + + tboxes = tf.stack([ty, tx, th, tw]) + return tf.transpose(tf.concat([tboxes, tkeypoints], 0)) + + def _decode(self, rel_codes, anchors): + """Decode relative codes to boxes and keypoints. + + Args: + rel_codes: a tensor with shape [N, 4 + 2 * num_keypoints] representing N + anchor-encoded boxes and keypoints + anchors: BoxList of anchors. + + Returns: + boxes: BoxList holding N bounding boxes and keypoints. + """ + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + + num_codes = tf.shape(rel_codes)[0] + result = tf.unstack(tf.transpose(rel_codes)) + ty, tx, th, tw = result[:4] + tkeypoints = result[4:] + if self._scale_factors: + ty /= self._scale_factors[0] + tx /= self._scale_factors[1] + th /= self._scale_factors[2] + tw /= self._scale_factors[3] + tkeypoints /= tf.tile(self._keypoint_scale_factors, [1, num_codes]) + + w = tf.exp(tw) * wa + h = tf.exp(th) * ha + ycenter = ty * ha + ycenter_a + xcenter = tx * wa + xcenter_a + ymin = ycenter - h / 2. + xmin = xcenter - w / 2. + ymax = ycenter + h / 2. + xmax = xcenter + w / 2. + decoded_boxes_keypoints = box_list.BoxList( + tf.transpose(tf.stack([ymin, xmin, ymax, xmax]))) + + tiled_anchor_centers = tf.tile( + tf.stack([ycenter_a, xcenter_a]), [self._num_keypoints, 1]) + tiled_anchor_sizes = tf.tile( + tf.stack([ha, wa]), [self._num_keypoints, 1]) + keypoints = tkeypoints * tiled_anchor_sizes + tiled_anchor_centers + keypoints = tf.reshape(tf.transpose(keypoints), + [-1, self._num_keypoints, 2]) + decoded_boxes_keypoints.add_field(fields.BoxListFields.keypoints, keypoints) + return decoded_boxes_keypoints diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder_test.py" new file mode 100644 index 00000000..330641e5 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/keypoint_box_coder_test.py" @@ -0,0 +1,140 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.box_coder.keypoint_box_coder.""" + +import tensorflow as tf + +from object_detection.box_coders import keypoint_box_coder +from object_detection.core import box_list +from object_detection.core import standard_fields as fields + + +class KeypointBoxCoderTest(tf.test.TestCase): + + def test_get_correct_relative_codes_after_encoding(self): + boxes = [[10., 10., 20., 15.], + [0.2, 0.1, 0.5, 0.4]] + keypoints = [[[15., 12.], [10., 15.]], + [[0.5, 0.3], [0.2, 0.4]]] + num_keypoints = len(keypoints[0]) + anchors = [[15., 12., 30., 18.], + [0.1, 0.0, 0.7, 0.9]] + expected_rel_codes = [ + [-0.5, -0.416666, -0.405465, -0.182321, + -0.5, -0.5, -0.833333, 0.], + [-0.083333, -0.222222, -0.693147, -1.098612, + 0.166667, -0.166667, -0.333333, -0.055556] + ] + boxes = box_list.BoxList(tf.constant(boxes)) + boxes.add_field(fields.BoxListFields.keypoints, tf.constant(keypoints)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = keypoint_box_coder.KeypointBoxCoder(num_keypoints) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_get_correct_relative_codes_after_encoding_with_scaling(self): + boxes = [[10., 10., 20., 15.], + [0.2, 0.1, 0.5, 0.4]] + keypoints = [[[15., 12.], [10., 15.]], + [[0.5, 0.3], [0.2, 0.4]]] + num_keypoints = len(keypoints[0]) + anchors = [[15., 12., 30., 18.], + [0.1, 0.0, 0.7, 0.9]] + scale_factors = [2, 3, 4, 5] + expected_rel_codes = [ + [-1., -1.25, -1.62186, -0.911608, + -1.0, -1.5, -1.666667, 0.], + [-0.166667, -0.666667, -2.772588, -5.493062, + 0.333333, -0.5, -0.666667, -0.166667] + ] + boxes = box_list.BoxList(tf.constant(boxes)) + boxes.add_field(fields.BoxListFields.keypoints, tf.constant(keypoints)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = keypoint_box_coder.KeypointBoxCoder( + num_keypoints, scale_factors=scale_factors) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_get_correct_boxes_after_decoding(self): + anchors = [[15., 12., 30., 18.], + [0.1, 0.0, 0.7, 0.9]] + rel_codes = [ + [-0.5, -0.416666, -0.405465, -0.182321, + -0.5, -0.5, -0.833333, 0.], + [-0.083333, -0.222222, -0.693147, -1.098612, + 0.166667, -0.166667, -0.333333, -0.055556] + ] + expected_boxes = [[10., 10., 20., 15.], + [0.2, 0.1, 0.5, 0.4]] + expected_keypoints = [[[15., 12.], [10., 15.]], + [[0.5, 0.3], [0.2, 0.4]]] + num_keypoints = len(expected_keypoints[0]) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = keypoint_box_coder.KeypointBoxCoder(num_keypoints) + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + boxes_out, keypoints_out = sess.run( + [boxes.get(), boxes.get_field(fields.BoxListFields.keypoints)]) + self.assertAllClose(boxes_out, expected_boxes) + self.assertAllClose(keypoints_out, expected_keypoints) + + def test_get_correct_boxes_after_decoding_with_scaling(self): + anchors = [[15., 12., 30., 18.], + [0.1, 0.0, 0.7, 0.9]] + rel_codes = [ + [-1., -1.25, -1.62186, -0.911608, + -1.0, -1.5, -1.666667, 0.], + [-0.166667, -0.666667, -2.772588, -5.493062, + 0.333333, -0.5, -0.666667, -0.166667] + ] + scale_factors = [2, 3, 4, 5] + expected_boxes = [[10., 10., 20., 15.], + [0.2, 0.1, 0.5, 0.4]] + expected_keypoints = [[[15., 12.], [10., 15.]], + [[0.5, 0.3], [0.2, 0.4]]] + num_keypoints = len(expected_keypoints[0]) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = keypoint_box_coder.KeypointBoxCoder( + num_keypoints, scale_factors=scale_factors) + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + boxes_out, keypoints_out = sess.run( + [boxes.get(), boxes.get_field(fields.BoxListFields.keypoints)]) + self.assertAllClose(boxes_out, expected_boxes) + self.assertAllClose(keypoints_out, expected_keypoints) + + def test_very_small_width_nan_after_encoding(self): + boxes = [[10., 10., 10.0000001, 20.]] + keypoints = [[[10., 10.], [10.0000001, 20.]]] + anchors = [[15., 12., 30., 18.]] + expected_rel_codes = [[-0.833333, 0., -21.128731, 0.510826, + -0.833333, -0.833333, -0.833333, 0.833333]] + boxes = box_list.BoxList(tf.constant(boxes)) + boxes.add_field(fields.BoxListFields.keypoints, tf.constant(keypoints)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = keypoint_box_coder.KeypointBoxCoder(2) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + rel_codes_out, = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder.py" new file mode 100644 index 00000000..256f53fd --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder.py" @@ -0,0 +1,79 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Mean stddev box coder. + +This box coder use the following coding schema to encode boxes: +rel_code = (box_corner - anchor_corner_mean) / anchor_corner_stddev. +""" +from object_detection.core import box_coder +from object_detection.core import box_list + + +class MeanStddevBoxCoder(box_coder.BoxCoder): + """Mean stddev box coder.""" + + def __init__(self, stddev=0.01): + """Constructor for MeanStddevBoxCoder. + + Args: + stddev: The standard deviation used to encode and decode boxes. + """ + self._stddev = stddev + + @property + def code_size(self): + return 4 + + def _encode(self, boxes, anchors): + """Encode a box collection with respect to anchor collection. + + Args: + boxes: BoxList holding N boxes to be encoded. + anchors: BoxList of N anchors. + + Returns: + a tensor representing N anchor-encoded boxes + + Raises: + ValueError: if the anchors still have deprecated stddev field. + """ + box_corners = boxes.get() + if anchors.has_field('stddev'): + raise ValueError("'stddev' is a parameter of MeanStddevBoxCoder and " + "should not be specified in the box list.") + means = anchors.get() + return (box_corners - means) / self._stddev + + def _decode(self, rel_codes, anchors): + """Decode. + + Args: + rel_codes: a tensor representing N anchor-encoded boxes. + anchors: BoxList of anchors. + + Returns: + boxes: BoxList holding N bounding boxes + + Raises: + ValueError: if the anchors still have deprecated stddev field and expects + the decode method to use stddev value from that field. + """ + means = anchors.get() + if anchors.has_field('stddev'): + raise ValueError("'stddev' is a parameter of MeanStddevBoxCoder and " + "should not be specified in the box list.") + box_corners = rel_codes * self._stddev + means + return box_list.BoxList(box_corners) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder_test.py" new file mode 100644 index 00000000..3e0eba93 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/mean_stddev_box_coder_test.py" @@ -0,0 +1,54 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.box_coder.mean_stddev_boxcoder.""" + +import tensorflow as tf + +from object_detection.box_coders import mean_stddev_box_coder +from object_detection.core import box_list + + +class MeanStddevBoxCoderTest(tf.test.TestCase): + + def testGetCorrectRelativeCodesAfterEncoding(self): + box_corners = [[0.0, 0.0, 0.5, 0.5], [0.0, 0.0, 0.5, 0.5]] + boxes = box_list.BoxList(tf.constant(box_corners)) + expected_rel_codes = [[0.0, 0.0, 0.0, 0.0], [-5.0, -5.0, -5.0, -3.0]] + prior_means = tf.constant([[0.0, 0.0, 0.5, 0.5], [0.5, 0.5, 1.0, 0.8]]) + priors = box_list.BoxList(prior_means) + + coder = mean_stddev_box_coder.MeanStddevBoxCoder(stddev=0.1) + rel_codes = coder.encode(boxes, priors) + with self.test_session() as sess: + rel_codes_out = sess.run(rel_codes) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def testGetCorrectBoxesAfterDecoding(self): + rel_codes = tf.constant([[0.0, 0.0, 0.0, 0.0], [-5.0, -5.0, -5.0, -3.0]]) + expected_box_corners = [[0.0, 0.0, 0.5, 0.5], [0.0, 0.0, 0.5, 0.5]] + prior_means = tf.constant([[0.0, 0.0, 0.5, 0.5], [0.5, 0.5, 1.0, 0.8]]) + priors = box_list.BoxList(prior_means) + + coder = mean_stddev_box_coder.MeanStddevBoxCoder(stddev=0.1) + decoded_boxes = coder.decode(rel_codes, priors) + decoded_box_corners = decoded_boxes.get() + with self.test_session() as sess: + decoded_out = sess.run(decoded_box_corners) + self.assertAllClose(decoded_out, expected_box_corners) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder.py" new file mode 100644 index 00000000..ee46b689 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder.py" @@ -0,0 +1,126 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Square box coder. + +Square box coder follows the coding schema described below: +l = sqrt(h * w) +la = sqrt(ha * wa) +ty = (y - ya) / la +tx = (x - xa) / la +tl = log(l / la) +where x, y, w, h denote the box's center coordinates, width, and height, +respectively. Similarly, xa, ya, wa, ha denote the anchor's center +coordinates, width and height. tx, ty, tl denote the anchor-encoded +center, and length, respectively. Because the encoded box is a square, only +one length is encoded. + +This has shown to provide performance improvements over the Faster RCNN box +coder when the objects being detected tend to be square (e.g. faces) and when +the input images are not distorted via resizing. +""" + +import tensorflow as tf + +from object_detection.core import box_coder +from object_detection.core import box_list + +EPSILON = 1e-8 + + +class SquareBoxCoder(box_coder.BoxCoder): + """Encodes a 3-scalar representation of a square box.""" + + def __init__(self, scale_factors=None): + """Constructor for SquareBoxCoder. + + Args: + scale_factors: List of 3 positive scalars to scale ty, tx, and tl. + If set to None, does not perform scaling. For faster RCNN, + the open-source implementation recommends using [10.0, 10.0, 5.0]. + + Raises: + ValueError: If scale_factors is not length 3 or contains values less than + or equal to 0. + """ + if scale_factors: + if len(scale_factors) != 3: + raise ValueError('The argument scale_factors must be a list of length ' + '3.') + if any(scalar <= 0 for scalar in scale_factors): + raise ValueError('The values in scale_factors must all be greater ' + 'than 0.') + self._scale_factors = scale_factors + + @property + def code_size(self): + return 3 + + def _encode(self, boxes, anchors): + """Encodes a box collection with respect to an anchor collection. + + Args: + boxes: BoxList holding N boxes to be encoded. + anchors: BoxList of anchors. + + Returns: + a tensor representing N anchor-encoded boxes of the format + [ty, tx, tl]. + """ + # Convert anchors to the center coordinate representation. + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + la = tf.sqrt(ha * wa) + ycenter, xcenter, h, w = boxes.get_center_coordinates_and_sizes() + l = tf.sqrt(h * w) + # Avoid NaN in division and log below. + la += EPSILON + l += EPSILON + + tx = (xcenter - xcenter_a) / la + ty = (ycenter - ycenter_a) / la + tl = tf.log(l / la) + # Scales location targets for joint training. + if self._scale_factors: + ty *= self._scale_factors[0] + tx *= self._scale_factors[1] + tl *= self._scale_factors[2] + return tf.transpose(tf.stack([ty, tx, tl])) + + def _decode(self, rel_codes, anchors): + """Decodes relative codes to boxes. + + Args: + rel_codes: a tensor representing N anchor-encoded boxes. + anchors: BoxList of anchors. + + Returns: + boxes: BoxList holding N bounding boxes. + """ + ycenter_a, xcenter_a, ha, wa = anchors.get_center_coordinates_and_sizes() + la = tf.sqrt(ha * wa) + + ty, tx, tl = tf.unstack(tf.transpose(rel_codes)) + if self._scale_factors: + ty /= self._scale_factors[0] + tx /= self._scale_factors[1] + tl /= self._scale_factors[2] + l = tf.exp(tl) * la + ycenter = ty * la + ycenter_a + xcenter = tx * la + xcenter_a + ymin = ycenter - l / 2. + xmin = xcenter - l / 2. + ymax = ycenter + l / 2. + xmax = xcenter + l / 2. + return box_list.BoxList(tf.transpose(tf.stack([ymin, xmin, ymax, xmax]))) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder_test.py" new file mode 100644 index 00000000..7f739c6b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/box_coders/square_box_coder_test.py" @@ -0,0 +1,97 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.box_coder.square_box_coder.""" + +import tensorflow as tf + +from object_detection.box_coders import square_box_coder +from object_detection.core import box_list + + +class SquareBoxCoderTest(tf.test.TestCase): + + def test_correct_relative_codes_with_default_scale(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + scale_factors = None + expected_rel_codes = [[-0.790569, -0.263523, -0.293893], + [-0.068041, -0.272166, -0.89588]] + + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = square_box_coder.SquareBoxCoder(scale_factors=scale_factors) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + (rel_codes_out,) = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_correct_relative_codes_with_non_default_scale(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + scale_factors = [2, 3, 4] + expected_rel_codes = [[-1.581139, -0.790569, -1.175573], + [-0.136083, -0.816497, -3.583519]] + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = square_box_coder.SquareBoxCoder(scale_factors=scale_factors) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + (rel_codes_out,) = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_correct_relative_codes_with_small_width(self): + boxes = [[10.0, 10.0, 10.0000001, 20.0]] + anchors = [[15.0, 12.0, 30.0, 18.0]] + scale_factors = None + expected_rel_codes = [[-1.317616, 0., -20.670586]] + boxes = box_list.BoxList(tf.constant(boxes)) + anchors = box_list.BoxList(tf.constant(anchors)) + coder = square_box_coder.SquareBoxCoder(scale_factors=scale_factors) + rel_codes = coder.encode(boxes, anchors) + with self.test_session() as sess: + (rel_codes_out,) = sess.run([rel_codes]) + self.assertAllClose(rel_codes_out, expected_rel_codes) + + def test_correct_boxes_with_default_scale(self): + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + rel_codes = [[-0.5, -0.416666, -0.405465], + [-0.083333, -0.222222, -0.693147]] + scale_factors = None + expected_boxes = [[14.594306, 7.884875, 20.918861, 14.209432], + [0.155051, 0.102989, 0.522474, 0.470412]] + anchors = box_list.BoxList(tf.constant(anchors)) + coder = square_box_coder.SquareBoxCoder(scale_factors=scale_factors) + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + (boxes_out,) = sess.run([boxes.get()]) + self.assertAllClose(boxes_out, expected_boxes) + + def test_correct_boxes_with_non_default_scale(self): + anchors = [[15.0, 12.0, 30.0, 18.0], [0.1, 0.0, 0.7, 0.9]] + rel_codes = [[-1., -1.25, -1.62186], [-0.166667, -0.666667, -2.772588]] + scale_factors = [2, 3, 4] + expected_boxes = [[14.594306, 7.884875, 20.918861, 14.209432], + [0.155051, 0.102989, 0.522474, 0.470412]] + anchors = box_list.BoxList(tf.constant(anchors)) + coder = square_box_coder.SquareBoxCoder(scale_factors=scale_factors) + boxes = coder.decode(rel_codes, anchors) + with self.test_session() as sess: + (boxes_out,) = sess.run([boxes.get()]) + self.assertAllClose(boxes_out, expected_boxes) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/__init__.py" new file mode 100644 index 00000000..e69de29b diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder.py" new file mode 100644 index 00000000..54cec3a1 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder.py" @@ -0,0 +1,94 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A function to build an object detection anchor generator from config.""" + +from object_detection.anchor_generators import grid_anchor_generator +from object_detection.anchor_generators import multiple_grid_anchor_generator +from object_detection.anchor_generators import multiscale_grid_anchor_generator +from object_detection.protos import anchor_generator_pb2 + + +def build(anchor_generator_config): + """Builds an anchor generator based on the config. + + Args: + anchor_generator_config: An anchor_generator.proto object containing the + config for the desired anchor generator. + + Returns: + Anchor generator based on the config. + + Raises: + ValueError: On empty anchor generator proto. + """ + if not isinstance(anchor_generator_config, + anchor_generator_pb2.AnchorGenerator): + raise ValueError('anchor_generator_config not of type ' + 'anchor_generator_pb2.AnchorGenerator') + if anchor_generator_config.WhichOneof( + 'anchor_generator_oneof') == 'grid_anchor_generator': + grid_anchor_generator_config = anchor_generator_config.grid_anchor_generator + return grid_anchor_generator.GridAnchorGenerator( + scales=[float(scale) for scale in grid_anchor_generator_config.scales], + aspect_ratios=[float(aspect_ratio) + for aspect_ratio + in grid_anchor_generator_config.aspect_ratios], + base_anchor_size=[grid_anchor_generator_config.height, + grid_anchor_generator_config.width], + anchor_stride=[grid_anchor_generator_config.height_stride, + grid_anchor_generator_config.width_stride], + anchor_offset=[grid_anchor_generator_config.height_offset, + grid_anchor_generator_config.width_offset]) + elif anchor_generator_config.WhichOneof( + 'anchor_generator_oneof') == 'ssd_anchor_generator': + ssd_anchor_generator_config = anchor_generator_config.ssd_anchor_generator + anchor_strides = None + if ssd_anchor_generator_config.height_stride: + anchor_strides = zip(ssd_anchor_generator_config.height_stride, + ssd_anchor_generator_config.width_stride) + anchor_offsets = None + if ssd_anchor_generator_config.height_offset: + anchor_offsets = zip(ssd_anchor_generator_config.height_offset, + ssd_anchor_generator_config.width_offset) + return multiple_grid_anchor_generator.create_ssd_anchors( + num_layers=ssd_anchor_generator_config.num_layers, + min_scale=ssd_anchor_generator_config.min_scale, + max_scale=ssd_anchor_generator_config.max_scale, + scales=[float(scale) for scale in ssd_anchor_generator_config.scales], + aspect_ratios=ssd_anchor_generator_config.aspect_ratios, + interpolated_scale_aspect_ratio=( + ssd_anchor_generator_config.interpolated_scale_aspect_ratio), + base_anchor_size=[ + ssd_anchor_generator_config.base_anchor_height, + ssd_anchor_generator_config.base_anchor_width + ], + anchor_strides=anchor_strides, + anchor_offsets=anchor_offsets, + reduce_boxes_in_lowest_layer=( + ssd_anchor_generator_config.reduce_boxes_in_lowest_layer)) + elif anchor_generator_config.WhichOneof( + 'anchor_generator_oneof') == 'multiscale_anchor_generator': + cfg = anchor_generator_config.multiscale_anchor_generator + return multiscale_grid_anchor_generator.MultiscaleGridAnchorGenerator( + cfg.min_level, + cfg.max_level, + cfg.anchor_scale, + [float(aspect_ratio) for aspect_ratio in cfg.aspect_ratios], + cfg.scales_per_octave, + cfg.normalize_coordinates + ) + else: + raise ValueError('Empty anchor generator.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder_test.py" new file mode 100644 index 00000000..2a23c2d9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/anchor_generator_builder_test.py" @@ -0,0 +1,300 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for anchor_generator_builder.""" + +import math + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.anchor_generators import grid_anchor_generator +from object_detection.anchor_generators import multiple_grid_anchor_generator +from object_detection.anchor_generators import multiscale_grid_anchor_generator +from object_detection.builders import anchor_generator_builder +from object_detection.protos import anchor_generator_pb2 + + +class AnchorGeneratorBuilderTest(tf.test.TestCase): + + def assert_almost_list_equal(self, expected_list, actual_list, delta=None): + self.assertEqual(len(expected_list), len(actual_list)) + for expected_item, actual_item in zip(expected_list, actual_list): + self.assertAlmostEqual(expected_item, actual_item, delta=delta) + + def test_build_grid_anchor_generator_with_defaults(self): + anchor_generator_text_proto = """ + grid_anchor_generator { + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + grid_anchor_generator.GridAnchorGenerator)) + self.assertListEqual(anchor_generator_object._scales, []) + self.assertListEqual(anchor_generator_object._aspect_ratios, []) + with self.test_session() as sess: + base_anchor_size, anchor_offset, anchor_stride = sess.run( + [anchor_generator_object._base_anchor_size, + anchor_generator_object._anchor_offset, + anchor_generator_object._anchor_stride]) + self.assertAllEqual(anchor_offset, [0, 0]) + self.assertAllEqual(anchor_stride, [16, 16]) + self.assertAllEqual(base_anchor_size, [256, 256]) + + def test_build_grid_anchor_generator_with_non_default_parameters(self): + anchor_generator_text_proto = """ + grid_anchor_generator { + height: 128 + width: 512 + height_stride: 10 + width_stride: 20 + height_offset: 30 + width_offset: 40 + scales: [0.4, 2.2] + aspect_ratios: [0.3, 4.5] + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + grid_anchor_generator.GridAnchorGenerator)) + self.assert_almost_list_equal(anchor_generator_object._scales, + [0.4, 2.2]) + self.assert_almost_list_equal(anchor_generator_object._aspect_ratios, + [0.3, 4.5]) + with self.test_session() as sess: + base_anchor_size, anchor_offset, anchor_stride = sess.run( + [anchor_generator_object._base_anchor_size, + anchor_generator_object._anchor_offset, + anchor_generator_object._anchor_stride]) + self.assertAllEqual(anchor_offset, [30, 40]) + self.assertAllEqual(anchor_stride, [10, 20]) + self.assertAllEqual(base_anchor_size, [128, 512]) + + def test_build_ssd_anchor_generator_with_defaults(self): + anchor_generator_text_proto = """ + ssd_anchor_generator { + aspect_ratios: [1.0] + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiple_grid_anchor_generator. + MultipleGridAnchorGenerator)) + for actual_scales, expected_scales in zip( + list(anchor_generator_object._scales), + [(0.1, 0.2, 0.2), + (0.35, 0.418), + (0.499, 0.570), + (0.649, 0.721), + (0.799, 0.871), + (0.949, 0.974)]): + self.assert_almost_list_equal(expected_scales, actual_scales, delta=1e-2) + for actual_aspect_ratio, expected_aspect_ratio in zip( + list(anchor_generator_object._aspect_ratios), + [(1.0, 2.0, 0.5)] + 5 * [(1.0, 1.0)]): + self.assert_almost_list_equal(expected_aspect_ratio, actual_aspect_ratio) + + with self.test_session() as sess: + base_anchor_size = sess.run(anchor_generator_object._base_anchor_size) + self.assertAllClose(base_anchor_size, [1.0, 1.0]) + + def test_build_ssd_anchor_generator_with_custom_scales(self): + anchor_generator_text_proto = """ + ssd_anchor_generator { + aspect_ratios: [1.0] + scales: [0.1, 0.15, 0.2, 0.4, 0.6, 0.8] + reduce_boxes_in_lowest_layer: false + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiple_grid_anchor_generator. + MultipleGridAnchorGenerator)) + for actual_scales, expected_scales in zip( + list(anchor_generator_object._scales), + [(0.1, math.sqrt(0.1 * 0.15)), + (0.15, math.sqrt(0.15 * 0.2)), + (0.2, math.sqrt(0.2 * 0.4)), + (0.4, math.sqrt(0.4 * 0.6)), + (0.6, math.sqrt(0.6 * 0.8)), + (0.8, math.sqrt(0.8 * 1.0))]): + self.assert_almost_list_equal(expected_scales, actual_scales, delta=1e-2) + + def test_build_ssd_anchor_generator_with_custom_interpolated_scale(self): + anchor_generator_text_proto = """ + ssd_anchor_generator { + aspect_ratios: [0.5] + interpolated_scale_aspect_ratio: 0.5 + reduce_boxes_in_lowest_layer: false + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiple_grid_anchor_generator. + MultipleGridAnchorGenerator)) + for actual_aspect_ratio, expected_aspect_ratio in zip( + list(anchor_generator_object._aspect_ratios), + 6 * [(0.5, 0.5)]): + self.assert_almost_list_equal(expected_aspect_ratio, actual_aspect_ratio) + + def test_build_ssd_anchor_generator_without_reduced_boxes(self): + anchor_generator_text_proto = """ + ssd_anchor_generator { + aspect_ratios: [1.0] + reduce_boxes_in_lowest_layer: false + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiple_grid_anchor_generator. + MultipleGridAnchorGenerator)) + + for actual_scales, expected_scales in zip( + list(anchor_generator_object._scales), + [(0.2, 0.264), + (0.35, 0.418), + (0.499, 0.570), + (0.649, 0.721), + (0.799, 0.871), + (0.949, 0.974)]): + self.assert_almost_list_equal(expected_scales, actual_scales, delta=1e-2) + + for actual_aspect_ratio, expected_aspect_ratio in zip( + list(anchor_generator_object._aspect_ratios), + 6 * [(1.0, 1.0)]): + self.assert_almost_list_equal(expected_aspect_ratio, actual_aspect_ratio) + + with self.test_session() as sess: + base_anchor_size = sess.run(anchor_generator_object._base_anchor_size) + self.assertAllClose(base_anchor_size, [1.0, 1.0]) + + def test_build_ssd_anchor_generator_with_non_default_parameters(self): + anchor_generator_text_proto = """ + ssd_anchor_generator { + num_layers: 2 + min_scale: 0.3 + max_scale: 0.8 + aspect_ratios: [2.0] + height_stride: 16 + height_stride: 32 + width_stride: 20 + width_stride: 30 + height_offset: 8 + height_offset: 16 + width_offset: 0 + width_offset: 10 + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiple_grid_anchor_generator. + MultipleGridAnchorGenerator)) + + for actual_scales, expected_scales in zip( + list(anchor_generator_object._scales), + [(0.1, 0.3, 0.3), (0.8, 0.894)]): + self.assert_almost_list_equal(expected_scales, actual_scales, delta=1e-2) + + for actual_aspect_ratio, expected_aspect_ratio in zip( + list(anchor_generator_object._aspect_ratios), + [(1.0, 2.0, 0.5), (2.0, 1.0)]): + self.assert_almost_list_equal(expected_aspect_ratio, actual_aspect_ratio) + + for actual_strides, expected_strides in zip( + list(anchor_generator_object._anchor_strides), [(16, 20), (32, 30)]): + self.assert_almost_list_equal(expected_strides, actual_strides) + + for actual_offsets, expected_offsets in zip( + list(anchor_generator_object._anchor_offsets), [(8, 0), (16, 10)]): + self.assert_almost_list_equal(expected_offsets, actual_offsets) + + with self.test_session() as sess: + base_anchor_size = sess.run(anchor_generator_object._base_anchor_size) + self.assertAllClose(base_anchor_size, [1.0, 1.0]) + + def test_raise_value_error_on_empty_anchor_genertor(self): + anchor_generator_text_proto = """ + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + with self.assertRaises(ValueError): + anchor_generator_builder.build(anchor_generator_proto) + + def test_build_multiscale_anchor_generator_custom_aspect_ratios(self): + anchor_generator_text_proto = """ + multiscale_anchor_generator { + aspect_ratios: [1.0] + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiscale_grid_anchor_generator. + MultiscaleGridAnchorGenerator)) + for level, anchor_grid_info in zip( + range(3, 8), anchor_generator_object._anchor_grid_info): + self.assertEqual(set(anchor_grid_info.keys()), set(['level', 'info'])) + self.assertTrue(level, anchor_grid_info['level']) + self.assertEqual(len(anchor_grid_info['info']), 4) + self.assertAllClose(anchor_grid_info['info'][0], [2**0, 2**0.5]) + self.assertTrue(anchor_grid_info['info'][1], 1.0) + self.assertAllClose(anchor_grid_info['info'][2], + [4.0 * 2**level, 4.0 * 2**level]) + self.assertAllClose(anchor_grid_info['info'][3], [2**level, 2**level]) + self.assertTrue(anchor_generator_object._normalize_coordinates) + + def test_build_multiscale_anchor_generator_with_anchors_in_pixel_coordinates( + self): + anchor_generator_text_proto = """ + multiscale_anchor_generator { + aspect_ratios: [1.0] + normalize_coordinates: false + } + """ + anchor_generator_proto = anchor_generator_pb2.AnchorGenerator() + text_format.Merge(anchor_generator_text_proto, anchor_generator_proto) + anchor_generator_object = anchor_generator_builder.build( + anchor_generator_proto) + self.assertTrue(isinstance(anchor_generator_object, + multiscale_grid_anchor_generator. + MultiscaleGridAnchorGenerator)) + self.assertFalse(anchor_generator_object._normalize_coordinates) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder.py" new file mode 100644 index 00000000..cc13d5a2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder.py" @@ -0,0 +1,66 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A function to build an object detection box coder from configuration.""" +from object_detection.box_coders import faster_rcnn_box_coder +from object_detection.box_coders import keypoint_box_coder +from object_detection.box_coders import mean_stddev_box_coder +from object_detection.box_coders import square_box_coder +from object_detection.protos import box_coder_pb2 + + +def build(box_coder_config): + """Builds a box coder object based on the box coder config. + + Args: + box_coder_config: A box_coder.proto object containing the config for the + desired box coder. + + Returns: + BoxCoder based on the config. + + Raises: + ValueError: On empty box coder proto. + """ + if not isinstance(box_coder_config, box_coder_pb2.BoxCoder): + raise ValueError('box_coder_config not of type box_coder_pb2.BoxCoder.') + + if box_coder_config.WhichOneof('box_coder_oneof') == 'faster_rcnn_box_coder': + return faster_rcnn_box_coder.FasterRcnnBoxCoder(scale_factors=[ + box_coder_config.faster_rcnn_box_coder.y_scale, + box_coder_config.faster_rcnn_box_coder.x_scale, + box_coder_config.faster_rcnn_box_coder.height_scale, + box_coder_config.faster_rcnn_box_coder.width_scale + ]) + if box_coder_config.WhichOneof('box_coder_oneof') == 'keypoint_box_coder': + return keypoint_box_coder.KeypointBoxCoder( + box_coder_config.keypoint_box_coder.num_keypoints, + scale_factors=[ + box_coder_config.keypoint_box_coder.y_scale, + box_coder_config.keypoint_box_coder.x_scale, + box_coder_config.keypoint_box_coder.height_scale, + box_coder_config.keypoint_box_coder.width_scale + ]) + if (box_coder_config.WhichOneof('box_coder_oneof') == + 'mean_stddev_box_coder'): + return mean_stddev_box_coder.MeanStddevBoxCoder( + stddev=box_coder_config.mean_stddev_box_coder.stddev) + if box_coder_config.WhichOneof('box_coder_oneof') == 'square_box_coder': + return square_box_coder.SquareBoxCoder(scale_factors=[ + box_coder_config.square_box_coder.y_scale, + box_coder_config.square_box_coder.x_scale, + box_coder_config.square_box_coder.length_scale + ]) + raise ValueError('Empty box coder.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder_test.py" new file mode 100644 index 00000000..286012e9 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_coder_builder_test.py" @@ -0,0 +1,136 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for box_coder_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.box_coders import faster_rcnn_box_coder +from object_detection.box_coders import keypoint_box_coder +from object_detection.box_coders import mean_stddev_box_coder +from object_detection.box_coders import square_box_coder +from object_detection.builders import box_coder_builder +from object_detection.protos import box_coder_pb2 + + +class BoxCoderBuilderTest(tf.test.TestCase): + + def test_build_faster_rcnn_box_coder_with_defaults(self): + box_coder_text_proto = """ + faster_rcnn_box_coder { + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertIsInstance(box_coder_object, + faster_rcnn_box_coder.FasterRcnnBoxCoder) + self.assertEqual(box_coder_object._scale_factors, [10.0, 10.0, 5.0, 5.0]) + + def test_build_faster_rcnn_box_coder_with_non_default_parameters(self): + box_coder_text_proto = """ + faster_rcnn_box_coder { + y_scale: 6.0 + x_scale: 3.0 + height_scale: 7.0 + width_scale: 8.0 + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertIsInstance(box_coder_object, + faster_rcnn_box_coder.FasterRcnnBoxCoder) + self.assertEqual(box_coder_object._scale_factors, [6.0, 3.0, 7.0, 8.0]) + + def test_build_keypoint_box_coder_with_defaults(self): + box_coder_text_proto = """ + keypoint_box_coder { + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertIsInstance(box_coder_object, keypoint_box_coder.KeypointBoxCoder) + self.assertEqual(box_coder_object._scale_factors, [10.0, 10.0, 5.0, 5.0]) + + def test_build_keypoint_box_coder_with_non_default_parameters(self): + box_coder_text_proto = """ + keypoint_box_coder { + num_keypoints: 6 + y_scale: 6.0 + x_scale: 3.0 + height_scale: 7.0 + width_scale: 8.0 + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertIsInstance(box_coder_object, keypoint_box_coder.KeypointBoxCoder) + self.assertEqual(box_coder_object._num_keypoints, 6) + self.assertEqual(box_coder_object._scale_factors, [6.0, 3.0, 7.0, 8.0]) + + def test_build_mean_stddev_box_coder(self): + box_coder_text_proto = """ + mean_stddev_box_coder { + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertTrue( + isinstance(box_coder_object, + mean_stddev_box_coder.MeanStddevBoxCoder)) + + def test_build_square_box_coder_with_defaults(self): + box_coder_text_proto = """ + square_box_coder { + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertTrue( + isinstance(box_coder_object, square_box_coder.SquareBoxCoder)) + self.assertEqual(box_coder_object._scale_factors, [10.0, 10.0, 5.0]) + + def test_build_square_box_coder_with_non_default_parameters(self): + box_coder_text_proto = """ + square_box_coder { + y_scale: 6.0 + x_scale: 3.0 + length_scale: 7.0 + } + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + box_coder_object = box_coder_builder.build(box_coder_proto) + self.assertTrue( + isinstance(box_coder_object, square_box_coder.SquareBoxCoder)) + self.assertEqual(box_coder_object._scale_factors, [6.0, 3.0, 7.0]) + + def test_raise_error_on_empty_box_coder(self): + box_coder_text_proto = """ + """ + box_coder_proto = box_coder_pb2.BoxCoder() + text_format.Merge(box_coder_text_proto, box_coder_proto) + with self.assertRaises(ValueError): + box_coder_builder.build(box_coder_proto) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder.py" new file mode 100644 index 00000000..53a88daa --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder.py" @@ -0,0 +1,633 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Function to build box predictor from configuration.""" + +import collections +import tensorflow as tf +from object_detection.predictors import convolutional_box_predictor +from object_detection.predictors import convolutional_keras_box_predictor +from object_detection.predictors import mask_rcnn_box_predictor +from object_detection.predictors import rfcn_box_predictor +from object_detection.predictors.heads import box_head +from object_detection.predictors.heads import class_head +from object_detection.predictors.heads import keras_box_head +from object_detection.predictors.heads import keras_class_head +from object_detection.predictors.heads import mask_head +from object_detection.protos import box_predictor_pb2 + + +def build_convolutional_box_predictor(is_training, + num_classes, + conv_hyperparams_fn, + min_depth, + max_depth, + num_layers_before_predictor, + use_dropout, + dropout_keep_prob, + kernel_size, + box_code_size, + apply_sigmoid_to_scores=False, + add_background_class=True, + class_prediction_bias_init=0.0, + use_depthwise=False,): + """Builds the ConvolutionalBoxPredictor from the arguments. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + conv_hyperparams_fn: A function to generate tf-slim arg_scope with + hyperparameters for convolution ops. + min_depth: Minimum feature depth prior to predicting box encodings + and class predictions. + max_depth: Maximum feature depth prior to predicting box encodings + and class predictions. If max_depth is set to 0, no additional + feature map will be inserted before location and class predictions. + num_layers_before_predictor: Number of the additional conv layers before + the predictor. + use_dropout: Option to use dropout or not. Note that a single dropout + op is applied here prior to both box and class predictions, which stands + in contrast to the ConvolutionalBoxPredictor below. + dropout_keep_prob: Keep probability for dropout. + This is only used if use_dropout is True. + kernel_size: Size of final convolution kernel. If the + spatial resolution of the feature map is smaller than the kernel size, + then the kernel size is automatically set to be + min(feature_width, feature_height). + box_code_size: Size of encoding for each box. + apply_sigmoid_to_scores: If True, apply the sigmoid on the output + class_predictions. + add_background_class: Whether to add an implicit background class. + class_prediction_bias_init: Constant value to initialize bias of the last + conv2d layer before class prediction. + use_depthwise: Whether to use depthwise convolutions for prediction + steps. Default is False. + + Returns: + A ConvolutionalBoxPredictor class. + """ + box_prediction_head = box_head.ConvolutionalBoxHead( + is_training=is_training, + box_code_size=box_code_size, + kernel_size=kernel_size, + use_depthwise=use_depthwise) + class_prediction_head = class_head.ConvolutionalClassHead( + is_training=is_training, + num_class_slots=num_classes + 1 if add_background_class else num_classes, + use_dropout=use_dropout, + dropout_keep_prob=dropout_keep_prob, + kernel_size=kernel_size, + apply_sigmoid_to_scores=apply_sigmoid_to_scores, + class_prediction_bias_init=class_prediction_bias_init, + use_depthwise=use_depthwise) + other_heads = {} + return convolutional_box_predictor.ConvolutionalBoxPredictor( + is_training=is_training, + num_classes=num_classes, + box_prediction_head=box_prediction_head, + class_prediction_head=class_prediction_head, + other_heads=other_heads, + conv_hyperparams_fn=conv_hyperparams_fn, + num_layers_before_predictor=num_layers_before_predictor, + min_depth=min_depth, + max_depth=max_depth) + + +def build_convolutional_keras_box_predictor(is_training, + num_classes, + conv_hyperparams, + freeze_batchnorm, + inplace_batchnorm_update, + num_predictions_per_location_list, + min_depth, + max_depth, + num_layers_before_predictor, + use_dropout, + dropout_keep_prob, + kernel_size, + box_code_size, + add_background_class=True, + class_prediction_bias_init=0.0, + use_depthwise=False, + name='BoxPredictor'): + """Builds the Keras ConvolutionalBoxPredictor from the arguments. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + conv_hyperparams: A `hyperparams_builder.KerasLayerHyperparams` object + containing hyperparameters for convolution ops. + freeze_batchnorm: Whether to freeze batch norm parameters during + training or not. When training with a small batch size (e.g. 1), it is + desirable to freeze batch norm update and use pretrained batch norm + params. + inplace_batchnorm_update: Whether to update batch norm moving average + values inplace. When this is false train op must add a control + dependency on tf.graphkeys.UPDATE_OPS collection in order to update + batch norm statistics. + num_predictions_per_location_list: A list of integers representing the + number of box predictions to be made per spatial location for each + feature map. + min_depth: Minimum feature depth prior to predicting box encodings + and class predictions. + max_depth: Maximum feature depth prior to predicting box encodings + and class predictions. If max_depth is set to 0, no additional + feature map will be inserted before location and class predictions. + num_layers_before_predictor: Number of the additional conv layers before + the predictor. + use_dropout: Option to use dropout or not. Note that a single dropout + op is applied here prior to both box and class predictions, which stands + in contrast to the ConvolutionalBoxPredictor below. + dropout_keep_prob: Keep probability for dropout. + This is only used if use_dropout is True. + kernel_size: Size of final convolution kernel. If the + spatial resolution of the feature map is smaller than the kernel size, + then the kernel size is automatically set to be + min(feature_width, feature_height). + box_code_size: Size of encoding for each box. + add_background_class: Whether to add an implicit background class. + class_prediction_bias_init: constant value to initialize bias of the last + conv2d layer before class prediction. + use_depthwise: Whether to use depthwise convolutions for prediction + steps. Default is False. + name: A string name scope to assign to the box predictor. If `None`, Keras + will auto-generate one from the class name. + + Returns: + A Keras ConvolutionalBoxPredictor class. + """ + box_prediction_heads = [] + class_prediction_heads = [] + other_heads = {} + + for stack_index, num_predictions_per_location in enumerate( + num_predictions_per_location_list): + box_prediction_heads.append( + keras_box_head.ConvolutionalBoxHead( + is_training=is_training, + box_code_size=box_code_size, + kernel_size=kernel_size, + conv_hyperparams=conv_hyperparams, + freeze_batchnorm=freeze_batchnorm, + num_predictions_per_location=num_predictions_per_location, + use_depthwise=use_depthwise, + name='ConvolutionalBoxHead_%d' % stack_index)) + class_prediction_heads.append( + keras_class_head.ConvolutionalClassHead( + is_training=is_training, + num_class_slots=( + num_classes + 1 if add_background_class else num_classes), + use_dropout=use_dropout, + dropout_keep_prob=dropout_keep_prob, + kernel_size=kernel_size, + conv_hyperparams=conv_hyperparams, + freeze_batchnorm=freeze_batchnorm, + num_predictions_per_location=num_predictions_per_location, + class_prediction_bias_init=class_prediction_bias_init, + use_depthwise=use_depthwise, + name='ConvolutionalClassHead_%d' % stack_index)) + + return convolutional_keras_box_predictor.ConvolutionalBoxPredictor( + is_training=is_training, + num_classes=num_classes, + box_prediction_heads=box_prediction_heads, + class_prediction_heads=class_prediction_heads, + other_heads=other_heads, + conv_hyperparams=conv_hyperparams, + num_layers_before_predictor=num_layers_before_predictor, + min_depth=min_depth, + max_depth=max_depth, + freeze_batchnorm=freeze_batchnorm, + inplace_batchnorm_update=inplace_batchnorm_update, + name=name) + + +def build_weight_shared_convolutional_box_predictor( + is_training, + num_classes, + conv_hyperparams_fn, + depth, + num_layers_before_predictor, + box_code_size, + kernel_size=3, + add_background_class=True, + class_prediction_bias_init=0.0, + use_dropout=False, + dropout_keep_prob=0.8, + share_prediction_tower=False, + apply_batch_norm=True, + use_depthwise=False, + score_converter_fn=tf.identity, + box_encodings_clip_range=None): + """Builds and returns a WeightSharedConvolutionalBoxPredictor class. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + conv_hyperparams_fn: A function to generate tf-slim arg_scope with + hyperparameters for convolution ops. + depth: depth of conv layers. + num_layers_before_predictor: Number of the additional conv layers before + the predictor. + box_code_size: Size of encoding for each box. + kernel_size: Size of final convolution kernel. + add_background_class: Whether to add an implicit background class. + class_prediction_bias_init: constant value to initialize bias of the last + conv2d layer before class prediction. + use_dropout: Whether to apply dropout to class prediction head. + dropout_keep_prob: Probability of keeping activiations. + share_prediction_tower: Whether to share the multi-layer tower between box + prediction and class prediction heads. + apply_batch_norm: Whether to apply batch normalization to conv layers in + this predictor. + use_depthwise: Whether to use depthwise separable conv2d instead of conv2d. + score_converter_fn: Callable score converter to perform elementwise op on + class scores. + box_encodings_clip_range: Min and max values for clipping the box_encodings. + + Returns: + A WeightSharedConvolutionalBoxPredictor class. + """ + box_prediction_head = box_head.WeightSharedConvolutionalBoxHead( + box_code_size=box_code_size, + kernel_size=kernel_size, + use_depthwise=use_depthwise, + box_encodings_clip_range=box_encodings_clip_range) + class_prediction_head = ( + class_head.WeightSharedConvolutionalClassHead( + num_class_slots=( + num_classes + 1 if add_background_class else num_classes), + kernel_size=kernel_size, + class_prediction_bias_init=class_prediction_bias_init, + use_dropout=use_dropout, + dropout_keep_prob=dropout_keep_prob, + use_depthwise=use_depthwise, + score_converter_fn=score_converter_fn)) + other_heads = {} + return convolutional_box_predictor.WeightSharedConvolutionalBoxPredictor( + is_training=is_training, + num_classes=num_classes, + box_prediction_head=box_prediction_head, + class_prediction_head=class_prediction_head, + other_heads=other_heads, + conv_hyperparams_fn=conv_hyperparams_fn, + depth=depth, + num_layers_before_predictor=num_layers_before_predictor, + kernel_size=kernel_size, + apply_batch_norm=apply_batch_norm, + share_prediction_tower=share_prediction_tower, + use_depthwise=use_depthwise) + + +def build_mask_rcnn_box_predictor(is_training, + num_classes, + fc_hyperparams_fn, + use_dropout, + dropout_keep_prob, + box_code_size, + add_background_class=True, + share_box_across_classes=False, + predict_instance_masks=False, + conv_hyperparams_fn=None, + mask_height=14, + mask_width=14, + mask_prediction_num_conv_layers=2, + mask_prediction_conv_depth=256, + masks_are_class_agnostic=False, + convolve_then_upsample_masks=False): + """Builds and returns a MaskRCNNBoxPredictor class. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + fc_hyperparams_fn: A function to generate tf-slim arg_scope with + hyperparameters for fully connected ops. + use_dropout: Option to use dropout or not. Note that a single dropout + op is applied here prior to both box and class predictions, which stands + in contrast to the ConvolutionalBoxPredictor below. + dropout_keep_prob: Keep probability for dropout. + This is only used if use_dropout is True. + box_code_size: Size of encoding for each box. + add_background_class: Whether to add an implicit background class. + share_box_across_classes: Whether to share boxes across classes rather + than use a different box for each class. + predict_instance_masks: If True, will add a third stage mask prediction + to the returned class. + conv_hyperparams_fn: A function to generate tf-slim arg_scope with + hyperparameters for convolution ops. + mask_height: Desired output mask height. The default value is 14. + mask_width: Desired output mask width. The default value is 14. + mask_prediction_num_conv_layers: Number of convolution layers applied to + the image_features in mask prediction branch. + mask_prediction_conv_depth: The depth for the first conv2d_transpose op + applied to the image_features in the mask prediction branch. If set + to 0, the depth of the convolution layers will be automatically chosen + based on the number of object classes and the number of channels in the + image features. + masks_are_class_agnostic: Boolean determining if the mask-head is + class-agnostic or not. + convolve_then_upsample_masks: Whether to apply convolutions on mask + features before upsampling using nearest neighbor resizing. Otherwise, + mask features are resized to [`mask_height`, `mask_width`] using + bilinear resizing before applying convolutions. + + Returns: + A MaskRCNNBoxPredictor class. + """ + box_prediction_head = box_head.MaskRCNNBoxHead( + is_training=is_training, + num_classes=num_classes, + fc_hyperparams_fn=fc_hyperparams_fn, + use_dropout=use_dropout, + dropout_keep_prob=dropout_keep_prob, + box_code_size=box_code_size, + share_box_across_classes=share_box_across_classes) + class_prediction_head = class_head.MaskRCNNClassHead( + is_training=is_training, + num_class_slots=num_classes + 1 if add_background_class else num_classes, + fc_hyperparams_fn=fc_hyperparams_fn, + use_dropout=use_dropout, + dropout_keep_prob=dropout_keep_prob) + third_stage_heads = {} + if predict_instance_masks: + third_stage_heads[ + mask_rcnn_box_predictor. + MASK_PREDICTIONS] = mask_head.MaskRCNNMaskHead( + num_classes=num_classes, + conv_hyperparams_fn=conv_hyperparams_fn, + mask_height=mask_height, + mask_width=mask_width, + mask_prediction_num_conv_layers=mask_prediction_num_conv_layers, + mask_prediction_conv_depth=mask_prediction_conv_depth, + masks_are_class_agnostic=masks_are_class_agnostic, + convolve_then_upsample=convolve_then_upsample_masks) + return mask_rcnn_box_predictor.MaskRCNNBoxPredictor( + is_training=is_training, + num_classes=num_classes, + box_prediction_head=box_prediction_head, + class_prediction_head=class_prediction_head, + third_stage_heads=third_stage_heads) + + +def build_score_converter(score_converter_config, is_training): + """Builds score converter based on the config. + + Builds one of [tf.identity, tf.sigmoid] score converters based on the config + and whether the BoxPredictor is for training or inference. + + Args: + score_converter_config: + box_predictor_pb2.WeightSharedConvolutionalBoxPredictor.score_converter. + is_training: Indicates whether the BoxPredictor is in training mode. + + Returns: + Callable score converter op. + + Raises: + ValueError: On unknown score converter. + """ + if score_converter_config == ( + box_predictor_pb2.WeightSharedConvolutionalBoxPredictor.IDENTITY): + return tf.identity + if score_converter_config == ( + box_predictor_pb2.WeightSharedConvolutionalBoxPredictor.SIGMOID): + return tf.identity if is_training else tf.sigmoid + raise ValueError('Unknown score converter.') + + +BoxEncodingsClipRange = collections.namedtuple('BoxEncodingsClipRange', + ['min', 'max']) + + +def build(argscope_fn, box_predictor_config, is_training, num_classes, + add_background_class=True): + """Builds box predictor based on the configuration. + + Builds box predictor based on the configuration. See box_predictor.proto for + configurable options. Also, see box_predictor.py for more details. + + Args: + argscope_fn: A function that takes the following inputs: + * hyperparams_pb2.Hyperparams proto + * a boolean indicating if the model is in training mode. + and returns a tf slim argscope for Conv and FC hyperparameters. + box_predictor_config: box_predictor_pb2.BoxPredictor proto containing + configuration. + is_training: Whether the models is in training mode. + num_classes: Number of classes to predict. + add_background_class: Whether to add an implicit background class. + + Returns: + box_predictor: box_predictor.BoxPredictor object. + + Raises: + ValueError: On unknown box predictor. + """ + if not isinstance(box_predictor_config, box_predictor_pb2.BoxPredictor): + raise ValueError('box_predictor_config not of type ' + 'box_predictor_pb2.BoxPredictor.') + + box_predictor_oneof = box_predictor_config.WhichOneof('box_predictor_oneof') + + if box_predictor_oneof == 'convolutional_box_predictor': + config_box_predictor = box_predictor_config.convolutional_box_predictor + conv_hyperparams_fn = argscope_fn(config_box_predictor.conv_hyperparams, + is_training) + return build_convolutional_box_predictor( + is_training=is_training, + num_classes=num_classes, + add_background_class=add_background_class, + conv_hyperparams_fn=conv_hyperparams_fn, + use_dropout=config_box_predictor.use_dropout, + dropout_keep_prob=config_box_predictor.dropout_keep_probability, + box_code_size=config_box_predictor.box_code_size, + kernel_size=config_box_predictor.kernel_size, + num_layers_before_predictor=( + config_box_predictor.num_layers_before_predictor), + min_depth=config_box_predictor.min_depth, + max_depth=config_box_predictor.max_depth, + apply_sigmoid_to_scores=config_box_predictor.apply_sigmoid_to_scores, + class_prediction_bias_init=( + config_box_predictor.class_prediction_bias_init), + use_depthwise=config_box_predictor.use_depthwise) + + if box_predictor_oneof == 'weight_shared_convolutional_box_predictor': + config_box_predictor = ( + box_predictor_config.weight_shared_convolutional_box_predictor) + conv_hyperparams_fn = argscope_fn(config_box_predictor.conv_hyperparams, + is_training) + apply_batch_norm = config_box_predictor.conv_hyperparams.HasField( + 'batch_norm') + # During training phase, logits are used to compute the loss. Only apply + # sigmoid at inference to make the inference graph TPU friendly. + score_converter_fn = build_score_converter( + config_box_predictor.score_converter, is_training) + # Optionally apply clipping to box encodings, when box_encodings_clip_range + # is set. + box_encodings_clip_range = ( + BoxEncodingsClipRange( + min=config_box_predictor.box_encodings_clip_range.min, + max=config_box_predictor.box_encodings_clip_range.max) + if config_box_predictor.HasField('box_encodings_clip_range') else None) + + return build_weight_shared_convolutional_box_predictor( + is_training=is_training, + num_classes=num_classes, + add_background_class=add_background_class, + conv_hyperparams_fn=conv_hyperparams_fn, + depth=config_box_predictor.depth, + num_layers_before_predictor=( + config_box_predictor.num_layers_before_predictor), + box_code_size=config_box_predictor.box_code_size, + kernel_size=config_box_predictor.kernel_size, + class_prediction_bias_init=( + config_box_predictor.class_prediction_bias_init), + use_dropout=config_box_predictor.use_dropout, + dropout_keep_prob=config_box_predictor.dropout_keep_probability, + share_prediction_tower=config_box_predictor.share_prediction_tower, + apply_batch_norm=apply_batch_norm, + use_depthwise=config_box_predictor.use_depthwise, + score_converter_fn=score_converter_fn, + box_encodings_clip_range=box_encodings_clip_range) + + if box_predictor_oneof == 'mask_rcnn_box_predictor': + config_box_predictor = box_predictor_config.mask_rcnn_box_predictor + fc_hyperparams_fn = argscope_fn(config_box_predictor.fc_hyperparams, + is_training) + conv_hyperparams_fn = None + if config_box_predictor.HasField('conv_hyperparams'): + conv_hyperparams_fn = argscope_fn( + config_box_predictor.conv_hyperparams, is_training) + return build_mask_rcnn_box_predictor( + is_training=is_training, + num_classes=num_classes, + add_background_class=add_background_class, + fc_hyperparams_fn=fc_hyperparams_fn, + use_dropout=config_box_predictor.use_dropout, + dropout_keep_prob=config_box_predictor.dropout_keep_probability, + box_code_size=config_box_predictor.box_code_size, + share_box_across_classes=( + config_box_predictor.share_box_across_classes), + predict_instance_masks=config_box_predictor.predict_instance_masks, + conv_hyperparams_fn=conv_hyperparams_fn, + mask_height=config_box_predictor.mask_height, + mask_width=config_box_predictor.mask_width, + mask_prediction_num_conv_layers=( + config_box_predictor.mask_prediction_num_conv_layers), + mask_prediction_conv_depth=( + config_box_predictor.mask_prediction_conv_depth), + masks_are_class_agnostic=( + config_box_predictor.masks_are_class_agnostic), + convolve_then_upsample_masks=( + config_box_predictor.convolve_then_upsample_masks)) + + if box_predictor_oneof == 'rfcn_box_predictor': + config_box_predictor = box_predictor_config.rfcn_box_predictor + conv_hyperparams_fn = argscope_fn(config_box_predictor.conv_hyperparams, + is_training) + box_predictor_object = rfcn_box_predictor.RfcnBoxPredictor( + is_training=is_training, + num_classes=num_classes, + conv_hyperparams_fn=conv_hyperparams_fn, + crop_size=[config_box_predictor.crop_height, + config_box_predictor.crop_width], + num_spatial_bins=[config_box_predictor.num_spatial_bins_height, + config_box_predictor.num_spatial_bins_width], + depth=config_box_predictor.depth, + box_code_size=config_box_predictor.box_code_size) + return box_predictor_object + raise ValueError('Unknown box predictor: {}'.format(box_predictor_oneof)) + + +def build_keras(conv_hyperparams_fn, freeze_batchnorm, inplace_batchnorm_update, + num_predictions_per_location_list, box_predictor_config, + is_training, num_classes, add_background_class=True): + """Builds a Keras-based box predictor based on the configuration. + + Builds Keras-based box predictor based on the configuration. + See box_predictor.proto for configurable options. Also, see box_predictor.py + for more details. + + Args: + conv_hyperparams_fn: A function that takes a hyperparams_pb2.Hyperparams + proto and returns a `hyperparams_builder.KerasLayerHyperparams` + for Conv or FC hyperparameters. + freeze_batchnorm: Whether to freeze batch norm parameters during + training or not. When training with a small batch size (e.g. 1), it is + desirable to freeze batch norm update and use pretrained batch norm + params. + inplace_batchnorm_update: Whether to update batch norm moving average + values inplace. When this is false train op must add a control + dependency on tf.graphkeys.UPDATE_OPS collection in order to update + batch norm statistics. + num_predictions_per_location_list: A list of integers representing the + number of box predictions to be made per spatial location for each + feature map. + box_predictor_config: box_predictor_pb2.BoxPredictor proto containing + configuration. + is_training: Whether the models is in training mode. + num_classes: Number of classes to predict. + add_background_class: Whether to add an implicit background class. + + Returns: + box_predictor: box_predictor.KerasBoxPredictor object. + + Raises: + ValueError: On unknown box predictor, or one with no Keras box predictor. + """ + if not isinstance(box_predictor_config, box_predictor_pb2.BoxPredictor): + raise ValueError('box_predictor_config not of type ' + 'box_predictor_pb2.BoxPredictor.') + + box_predictor_oneof = box_predictor_config.WhichOneof('box_predictor_oneof') + + if box_predictor_oneof == 'convolutional_box_predictor': + config_box_predictor = box_predictor_config.convolutional_box_predictor + conv_hyperparams = conv_hyperparams_fn( + config_box_predictor.conv_hyperparams) + return build_convolutional_keras_box_predictor( + is_training=is_training, + num_classes=num_classes, + add_background_class=add_background_class, + conv_hyperparams=conv_hyperparams, + freeze_batchnorm=freeze_batchnorm, + inplace_batchnorm_update=inplace_batchnorm_update, + num_predictions_per_location_list=num_predictions_per_location_list, + use_dropout=config_box_predictor.use_dropout, + dropout_keep_prob=config_box_predictor.dropout_keep_probability, + box_code_size=config_box_predictor.box_code_size, + kernel_size=config_box_predictor.kernel_size, + num_layers_before_predictor=( + config_box_predictor.num_layers_before_predictor), + min_depth=config_box_predictor.min_depth, + max_depth=config_box_predictor.max_depth, + class_prediction_bias_init=( + config_box_predictor.class_prediction_bias_init), + use_depthwise=config_box_predictor.use_depthwise) + + raise ValueError( + 'Unknown box predictor for Keras: {}'.format(box_predictor_oneof)) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder_test.py" new file mode 100644 index 00000000..08029df7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/box_predictor_builder_test.py" @@ -0,0 +1,658 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for box_predictor_builder.""" + +import mock +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.builders import box_predictor_builder +from object_detection.builders import hyperparams_builder +from object_detection.predictors import mask_rcnn_box_predictor +from object_detection.protos import box_predictor_pb2 +from object_detection.protos import hyperparams_pb2 + + +class ConvolutionalBoxPredictorBuilderTest(tf.test.TestCase): + + def test_box_predictor_calls_conv_argscope_fn(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.0003 + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.3 + } + } + activation: RELU_6 + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.convolutional_box_predictor.conv_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10) + (conv_hyperparams_actual, is_training) = box_predictor._conv_hyperparams_fn + self.assertAlmostEqual((hyperparams_proto.regularizer. + l1_regularizer.weight), + (conv_hyperparams_actual.regularizer.l1_regularizer. + weight)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.stddev), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.stddev)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.mean), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.mean)) + self.assertEqual(hyperparams_proto.activation, + conv_hyperparams_actual.activation) + self.assertFalse(is_training) + + def test_construct_non_default_conv_box_predictor(self): + box_predictor_text_proto = """ + convolutional_box_predictor { + min_depth: 2 + max_depth: 16 + num_layers_before_predictor: 2 + use_dropout: false + dropout_keep_probability: 0.4 + kernel_size: 3 + box_code_size: 3 + apply_sigmoid_to_scores: true + class_prediction_bias_init: 4.0 + use_depthwise: true + } + """ + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor_proto.convolutional_box_predictor.conv_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10, + add_background_class=False) + class_head = box_predictor._class_prediction_head + self.assertEqual(box_predictor._min_depth, 2) + self.assertEqual(box_predictor._max_depth, 16) + self.assertEqual(box_predictor._num_layers_before_predictor, 2) + self.assertFalse(class_head._use_dropout) + self.assertAlmostEqual(class_head._dropout_keep_prob, 0.4) + self.assertTrue(class_head._apply_sigmoid_to_scores) + self.assertAlmostEqual(class_head._class_prediction_bias_init, 4.0) + self.assertEqual(class_head._num_class_slots, 10) + self.assertEqual(box_predictor.num_classes, 10) + self.assertFalse(box_predictor._is_training) + self.assertTrue(class_head._use_depthwise) + + def test_construct_default_conv_box_predictor(self): + box_predictor_text_proto = """ + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + }""" + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=hyperparams_builder.build, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + class_head = box_predictor._class_prediction_head + self.assertEqual(box_predictor._min_depth, 0) + self.assertEqual(box_predictor._max_depth, 0) + self.assertEqual(box_predictor._num_layers_before_predictor, 0) + self.assertTrue(class_head._use_dropout) + self.assertAlmostEqual(class_head._dropout_keep_prob, 0.8) + self.assertFalse(class_head._apply_sigmoid_to_scores) + self.assertEqual(class_head._num_class_slots, 91) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertFalse(class_head._use_depthwise) + + +class WeightSharedConvolutionalBoxPredictorBuilderTest(tf.test.TestCase): + + def test_box_predictor_calls_conv_argscope_fn(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.0003 + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.3 + } + } + activation: RELU_6 + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + (box_predictor_proto.weight_shared_convolutional_box_predictor + .conv_hyperparams.CopyFrom(hyperparams_proto)) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10) + (conv_hyperparams_actual, is_training) = box_predictor._conv_hyperparams_fn + self.assertAlmostEqual((hyperparams_proto.regularizer. + l1_regularizer.weight), + (conv_hyperparams_actual.regularizer.l1_regularizer. + weight)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.stddev), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.stddev)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.mean), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.mean)) + self.assertEqual(hyperparams_proto.activation, + conv_hyperparams_actual.activation) + self.assertFalse(is_training) + + def test_construct_non_default_conv_box_predictor(self): + box_predictor_text_proto = """ + weight_shared_convolutional_box_predictor { + depth: 2 + num_layers_before_predictor: 2 + kernel_size: 7 + box_code_size: 3 + class_prediction_bias_init: 4.0 + } + """ + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + (box_predictor_proto.weight_shared_convolutional_box_predictor. + conv_hyperparams.CopyFrom(hyperparams_proto)) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10, + add_background_class=False) + class_head = box_predictor._class_prediction_head + self.assertEqual(box_predictor._depth, 2) + self.assertEqual(box_predictor._num_layers_before_predictor, 2) + self.assertAlmostEqual(class_head._class_prediction_bias_init, 4.0) + self.assertEqual(box_predictor.num_classes, 10) + self.assertFalse(box_predictor._is_training) + self.assertEqual(box_predictor._apply_batch_norm, False) + + def test_construct_non_default_depthwise_conv_box_predictor(self): + box_predictor_text_proto = """ + weight_shared_convolutional_box_predictor { + depth: 2 + num_layers_before_predictor: 2 + kernel_size: 7 + box_code_size: 3 + class_prediction_bias_init: 4.0 + use_depthwise: true + } + """ + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + (box_predictor_proto.weight_shared_convolutional_box_predictor. + conv_hyperparams.CopyFrom(hyperparams_proto)) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10, + add_background_class=False) + class_head = box_predictor._class_prediction_head + self.assertEqual(box_predictor._depth, 2) + self.assertEqual(box_predictor._num_layers_before_predictor, 2) + self.assertEqual(box_predictor._apply_batch_norm, False) + self.assertEqual(box_predictor._use_depthwise, True) + self.assertAlmostEqual(class_head._class_prediction_bias_init, 4.0) + self.assertEqual(box_predictor.num_classes, 10) + self.assertFalse(box_predictor._is_training) + + def test_construct_default_conv_box_predictor(self): + box_predictor_text_proto = """ + weight_shared_convolutional_box_predictor { + conv_hyperparams { + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + }""" + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=hyperparams_builder.build, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + self.assertEqual(box_predictor._depth, 0) + self.assertEqual(box_predictor._num_layers_before_predictor, 0) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_predictor._apply_batch_norm, False) + + def test_construct_default_conv_box_predictor_with_batch_norm(self): + box_predictor_text_proto = """ + weight_shared_convolutional_box_predictor { + conv_hyperparams { + regularizer { + l1_regularizer { + } + } + batch_norm { + train: true + } + initializer { + truncated_normal_initializer { + } + } + } + }""" + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=hyperparams_builder.build, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + self.assertEqual(box_predictor._depth, 0) + self.assertEqual(box_predictor._num_layers_before_predictor, 0) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_predictor._apply_batch_norm, True) + + +class MaskRCNNBoxPredictorBuilderTest(tf.test.TestCase): + + def test_box_predictor_builder_calls_fc_argscope_fn(self): + fc_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.0003 + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.3 + } + } + activation: RELU_6 + op: FC + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(fc_hyperparams_text_proto, hyperparams_proto) + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams.CopyFrom( + hyperparams_proto) + mock_argscope_fn = mock.Mock(return_value='arg_scope') + box_predictor = box_predictor_builder.build( + argscope_fn=mock_argscope_fn, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10) + mock_argscope_fn.assert_called_with(hyperparams_proto, False) + self.assertEqual(box_predictor._box_prediction_head._fc_hyperparams_fn, + 'arg_scope') + self.assertEqual(box_predictor._class_prediction_head._fc_hyperparams_fn, + 'arg_scope') + + def test_non_default_mask_rcnn_box_predictor(self): + fc_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + op: FC + """ + box_predictor_text_proto = """ + mask_rcnn_box_predictor { + use_dropout: true + dropout_keep_probability: 0.8 + box_code_size: 3 + share_box_across_classes: true + } + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(fc_hyperparams_text_proto, hyperparams_proto) + def mock_fc_argscope_builder(fc_hyperparams_arg, is_training): + return (fc_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_fc_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + box_head = box_predictor._box_prediction_head + class_head = box_predictor._class_prediction_head + self.assertTrue(box_head._use_dropout) + self.assertTrue(class_head._use_dropout) + self.assertAlmostEqual(box_head._dropout_keep_prob, 0.8) + self.assertAlmostEqual(class_head._dropout_keep_prob, 0.8) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_head._box_code_size, 3) + self.assertEqual(box_head._share_box_across_classes, True) + + def test_build_default_mask_rcnn_box_predictor(self): + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams.op = ( + hyperparams_pb2.Hyperparams.FC) + box_predictor = box_predictor_builder.build( + argscope_fn=mock.Mock(return_value='arg_scope'), + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + box_head = box_predictor._box_prediction_head + class_head = box_predictor._class_prediction_head + self.assertFalse(box_head._use_dropout) + self.assertFalse(class_head._use_dropout) + self.assertAlmostEqual(box_head._dropout_keep_prob, 0.5) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_head._box_code_size, 4) + self.assertEqual(len(box_predictor._third_stage_heads.keys()), 0) + + def test_build_box_predictor_with_mask_branch(self): + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams.op = ( + hyperparams_pb2.Hyperparams.FC) + box_predictor_proto.mask_rcnn_box_predictor.conv_hyperparams.op = ( + hyperparams_pb2.Hyperparams.CONV) + box_predictor_proto.mask_rcnn_box_predictor.predict_instance_masks = True + box_predictor_proto.mask_rcnn_box_predictor.mask_prediction_conv_depth = 512 + box_predictor_proto.mask_rcnn_box_predictor.mask_height = 16 + box_predictor_proto.mask_rcnn_box_predictor.mask_width = 16 + mock_argscope_fn = mock.Mock(return_value='arg_scope') + box_predictor = box_predictor_builder.build( + argscope_fn=mock_argscope_fn, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + mock_argscope_fn.assert_has_calls( + [mock.call(box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams, + True), + mock.call(box_predictor_proto.mask_rcnn_box_predictor.conv_hyperparams, + True)], any_order=True) + box_head = box_predictor._box_prediction_head + class_head = box_predictor._class_prediction_head + third_stage_heads = box_predictor._third_stage_heads + self.assertFalse(box_head._use_dropout) + self.assertFalse(class_head._use_dropout) + self.assertAlmostEqual(box_head._dropout_keep_prob, 0.5) + self.assertAlmostEqual(class_head._dropout_keep_prob, 0.5) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_head._box_code_size, 4) + self.assertTrue( + mask_rcnn_box_predictor.MASK_PREDICTIONS in third_stage_heads) + self.assertEqual( + third_stage_heads[mask_rcnn_box_predictor.MASK_PREDICTIONS] + ._mask_prediction_conv_depth, 512) + + def test_build_box_predictor_with_convlve_then_upsample_masks(self): + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams.op = ( + hyperparams_pb2.Hyperparams.FC) + box_predictor_proto.mask_rcnn_box_predictor.conv_hyperparams.op = ( + hyperparams_pb2.Hyperparams.CONV) + box_predictor_proto.mask_rcnn_box_predictor.predict_instance_masks = True + box_predictor_proto.mask_rcnn_box_predictor.mask_prediction_conv_depth = 512 + box_predictor_proto.mask_rcnn_box_predictor.mask_height = 24 + box_predictor_proto.mask_rcnn_box_predictor.mask_width = 24 + box_predictor_proto.mask_rcnn_box_predictor.convolve_then_upsample_masks = ( + True) + + mock_argscope_fn = mock.Mock(return_value='arg_scope') + box_predictor = box_predictor_builder.build( + argscope_fn=mock_argscope_fn, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + mock_argscope_fn.assert_has_calls( + [mock.call(box_predictor_proto.mask_rcnn_box_predictor.fc_hyperparams, + True), + mock.call(box_predictor_proto.mask_rcnn_box_predictor.conv_hyperparams, + True)], any_order=True) + box_head = box_predictor._box_prediction_head + class_head = box_predictor._class_prediction_head + third_stage_heads = box_predictor._third_stage_heads + self.assertFalse(box_head._use_dropout) + self.assertFalse(class_head._use_dropout) + self.assertAlmostEqual(box_head._dropout_keep_prob, 0.5) + self.assertAlmostEqual(class_head._dropout_keep_prob, 0.5) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_head._box_code_size, 4) + self.assertTrue( + mask_rcnn_box_predictor.MASK_PREDICTIONS in third_stage_heads) + self.assertEqual( + third_stage_heads[mask_rcnn_box_predictor.MASK_PREDICTIONS] + ._mask_prediction_conv_depth, 512) + self.assertTrue(third_stage_heads[mask_rcnn_box_predictor.MASK_PREDICTIONS] + ._convolve_then_upsample) + + +class RfcnBoxPredictorBuilderTest(tf.test.TestCase): + + def test_box_predictor_calls_fc_argscope_fn(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.0003 + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.3 + } + } + activation: RELU_6 + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.rfcn_box_predictor.conv_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=False, + num_classes=10) + (conv_hyperparams_actual, is_training) = box_predictor._conv_hyperparams_fn + self.assertAlmostEqual((hyperparams_proto.regularizer. + l1_regularizer.weight), + (conv_hyperparams_actual.regularizer.l1_regularizer. + weight)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.stddev), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.stddev)) + self.assertAlmostEqual((hyperparams_proto.initializer. + truncated_normal_initializer.mean), + (conv_hyperparams_actual.initializer. + truncated_normal_initializer.mean)) + self.assertEqual(hyperparams_proto.activation, + conv_hyperparams_actual.activation) + self.assertFalse(is_training) + + def test_non_default_rfcn_box_predictor(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + """ + box_predictor_text_proto = """ + rfcn_box_predictor { + num_spatial_bins_height: 4 + num_spatial_bins_width: 4 + depth: 4 + box_code_size: 3 + crop_height: 16 + crop_width: 16 + } + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + text_format.Merge(box_predictor_text_proto, box_predictor_proto) + box_predictor_proto.rfcn_box_predictor.conv_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_predictor._box_code_size, 3) + self.assertEqual(box_predictor._num_spatial_bins, [4, 4]) + self.assertEqual(box_predictor._crop_size, [16, 16]) + + def test_default_rfcn_box_predictor(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + """ + hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, hyperparams_proto) + def mock_conv_argscope_builder(conv_hyperparams_arg, is_training): + return (conv_hyperparams_arg, is_training) + + box_predictor_proto = box_predictor_pb2.BoxPredictor() + box_predictor_proto.rfcn_box_predictor.conv_hyperparams.CopyFrom( + hyperparams_proto) + box_predictor = box_predictor_builder.build( + argscope_fn=mock_conv_argscope_builder, + box_predictor_config=box_predictor_proto, + is_training=True, + num_classes=90) + self.assertEqual(box_predictor.num_classes, 90) + self.assertTrue(box_predictor._is_training) + self.assertEqual(box_predictor._box_code_size, 4) + self.assertEqual(box_predictor._num_spatial_bins, [3, 3]) + self.assertEqual(box_predictor._crop_size, [12, 12]) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder.py" new file mode 100644 index 00000000..b46d5f7f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder.py" @@ -0,0 +1,152 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""tf.data.Dataset builder. + +Creates data sources for DetectionModels from an InputReader config. See +input_reader.proto for options. + +Note: If users wishes to also use their own InputReaders with the Object +Detection configuration framework, they should define their own builder function +that wraps the build function. +""" +import functools +import tensorflow as tf + +from object_detection.data_decoders import tf_example_decoder +from object_detection.protos import input_reader_pb2 + + +def make_initializable_iterator(dataset): + """Creates an iterator, and initializes tables. + + This is useful in cases where make_one_shot_iterator wouldn't work because + the graph contains a hash table that needs to be initialized. + + Args: + dataset: A `tf.data.Dataset` object. + + Returns: + A `tf.data.Iterator`. + """ + iterator = dataset.make_initializable_iterator() + tf.add_to_collection(tf.GraphKeys.TABLE_INITIALIZERS, iterator.initializer) + return iterator + + +def read_dataset(file_read_func, input_files, config): + """Reads a dataset, and handles repetition and shuffling. + + Args: + file_read_func: Function to use in tf.contrib.data.parallel_interleave, to + read every individual file into a tf.data.Dataset. + input_files: A list of file paths to read. + config: A input_reader_builder.InputReader object. + + Returns: + A tf.data.Dataset of (undecoded) tf-records based on config. + """ + # Shard, shuffle, and read files. + filenames = tf.gfile.Glob(input_files) + num_readers = config.num_readers + if num_readers > len(filenames): + num_readers = len(filenames) + tf.logging.warning('num_readers has been reduced to %d to match input file ' + 'shards.' % num_readers) + filename_dataset = tf.data.Dataset.from_tensor_slices(filenames) + if config.shuffle: + filename_dataset = filename_dataset.shuffle( + config.filenames_shuffle_buffer_size) + elif num_readers > 1: + tf.logging.warning('`shuffle` is false, but the input data stream is ' + 'still slightly shuffled since `num_readers` > 1.') + filename_dataset = filename_dataset.repeat(config.num_epochs or None) + records_dataset = filename_dataset.apply( + tf.contrib.data.parallel_interleave( + file_read_func, + cycle_length=num_readers, + block_length=config.read_block_length, + sloppy=config.shuffle)) + if config.shuffle: + records_dataset = records_dataset.shuffle(config.shuffle_buffer_size) + return records_dataset + + +def build(input_reader_config, batch_size=None, transform_input_data_fn=None): + """Builds a tf.data.Dataset. + + Builds a tf.data.Dataset by applying the `transform_input_data_fn` on all + records. Applies a padded batch to the resulting dataset. + + Args: + input_reader_config: A input_reader_pb2.InputReader object. + batch_size: Batch size. If batch size is None, no batching is performed. + transform_input_data_fn: Function to apply transformation to all records, + or None if no extra decoding is required. + + Returns: + A tf.data.Dataset based on the input_reader_config. + + Raises: + ValueError: On invalid input reader proto. + ValueError: If no input paths are specified. + """ + if not isinstance(input_reader_config, input_reader_pb2.InputReader): + raise ValueError('input_reader_config not of type ' + 'input_reader_pb2.InputReader.') + + if input_reader_config.WhichOneof('input_reader') == 'tf_record_input_reader': + config = input_reader_config.tf_record_input_reader + if not config.input_path: + raise ValueError('At least one input path must be specified in ' + '`input_reader_config`.') + + label_map_proto_file = None + if input_reader_config.HasField('label_map_path'): + label_map_proto_file = input_reader_config.label_map_path + decoder = tf_example_decoder.TfExampleDecoder( + load_instance_masks=input_reader_config.load_instance_masks, + instance_mask_type=input_reader_config.mask_type, + label_map_proto_file=label_map_proto_file, + use_display_name=input_reader_config.use_display_name, + num_additional_channels=input_reader_config.num_additional_channels) + + def process_fn(value): + """Sets up tf graph that decodes, transforms and pads input data.""" + processed_tensors = decoder.decode(value) + if transform_input_data_fn is not None: + processed_tensors = transform_input_data_fn(processed_tensors) + return processed_tensors + + dataset = read_dataset( + functools.partial(tf.data.TFRecordDataset, buffer_size=8 * 1000 * 1000), + config.input_path[:], input_reader_config) + if input_reader_config.sample_1_of_n_examples > 1: + dataset = dataset.shard(input_reader_config.sample_1_of_n_examples, 0) + # TODO(rathodv): make batch size a required argument once the old binaries + # are deleted. + if batch_size: + num_parallel_calls = batch_size * input_reader_config.num_parallel_batches + else: + num_parallel_calls = input_reader_config.num_parallel_map_calls + dataset = dataset.map( + process_fn, + num_parallel_calls=num_parallel_calls) + if batch_size: + dataset = dataset.apply( + tf.contrib.data.batch_and_drop_remainder(batch_size)) + dataset = dataset.prefetch(input_reader_config.num_prefetch_batches) + return dataset + + raise ValueError('Unsupported input_reader_config.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder_test.py" new file mode 100644 index 00000000..78677310 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/dataset_builder_test.py" @@ -0,0 +1,356 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for dataset_builder.""" + +import os +import numpy as np +import tensorflow as tf + +from google.protobuf import text_format + +from object_detection.builders import dataset_builder +from object_detection.core import standard_fields as fields +from object_detection.protos import input_reader_pb2 +from object_detection.utils import dataset_util + + +class DatasetBuilderTest(tf.test.TestCase): + + def create_tf_record(self, has_additional_channels=False, num_examples=1): + path = os.path.join(self.get_temp_dir(), 'tfrecord') + writer = tf.python_io.TFRecordWriter(path) + + image_tensor = np.random.randint(255, size=(4, 5, 3)).astype(np.uint8) + additional_channels_tensor = np.random.randint( + 255, size=(4, 5, 1)).astype(np.uint8) + flat_mask = (4 * 5) * [1.0] + with self.test_session(): + encoded_jpeg = tf.image.encode_jpeg(tf.constant(image_tensor)).eval() + encoded_additional_channels_jpeg = tf.image.encode_jpeg( + tf.constant(additional_channels_tensor)).eval() + for i in range(num_examples): + features = { + 'image/source_id': dataset_util.bytes_feature(str(i)), + 'image/encoded': dataset_util.bytes_feature(encoded_jpeg), + 'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')), + 'image/height': dataset_util.int64_feature(4), + 'image/width': dataset_util.int64_feature(5), + 'image/object/bbox/xmin': dataset_util.float_list_feature([0.0]), + 'image/object/bbox/xmax': dataset_util.float_list_feature([1.0]), + 'image/object/bbox/ymin': dataset_util.float_list_feature([0.0]), + 'image/object/bbox/ymax': dataset_util.float_list_feature([1.0]), + 'image/object/class/label': dataset_util.int64_list_feature([2]), + 'image/object/mask': dataset_util.float_list_feature(flat_mask), + } + if has_additional_channels: + additional_channels_key = 'image/additional_channels/encoded' + features[additional_channels_key] = dataset_util.bytes_list_feature( + [encoded_additional_channels_jpeg] * 2) + example = tf.train.Example(features=tf.train.Features(feature=features)) + writer.write(example.SerializeToString()) + writer.close() + + return path + + def test_build_tf_record_input_reader(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build(input_reader_proto, batch_size=1)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + + self.assertTrue( + fields.InputDataFields.groundtruth_instance_masks not in output_dict) + self.assertEquals((1, 4, 5, 3), + output_dict[fields.InputDataFields.image].shape) + self.assertAllEqual([[2]], + output_dict[fields.InputDataFields.groundtruth_classes]) + self.assertEquals( + (1, 1, 4), output_dict[fields.InputDataFields.groundtruth_boxes].shape) + self.assertAllEqual( + [0.0, 0.0, 1.0, 1.0], + output_dict[fields.InputDataFields.groundtruth_boxes][0][0]) + + def test_build_tf_record_input_reader_and_load_instance_masks(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + load_instance_masks: true + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build(input_reader_proto, batch_size=1)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + self.assertAllEqual( + (1, 1, 4, 5), + output_dict[fields.InputDataFields.groundtruth_instance_masks].shape) + + def test_build_tf_record_input_reader_with_batch_size_two(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + + def one_hot_class_encoding_fn(tensor_dict): + tensor_dict[fields.InputDataFields.groundtruth_classes] = tf.one_hot( + tensor_dict[fields.InputDataFields.groundtruth_classes] - 1, depth=3) + return tensor_dict + + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build( + input_reader_proto, + transform_input_data_fn=one_hot_class_encoding_fn, + batch_size=2)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + + self.assertAllEqual([2, 4, 5, 3], + output_dict[fields.InputDataFields.image].shape) + self.assertAllEqual( + [2, 1, 3], + output_dict[fields.InputDataFields.groundtruth_classes].shape) + self.assertAllEqual( + [2, 1, 4], output_dict[fields.InputDataFields.groundtruth_boxes].shape) + self.assertAllEqual([[[0.0, 0.0, 1.0, 1.0]], [[0.0, 0.0, 1.0, 1.0]]], + output_dict[fields.InputDataFields.groundtruth_boxes]) + + def test_build_tf_record_input_reader_with_batch_size_two_and_masks(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + load_instance_masks: true + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + + def one_hot_class_encoding_fn(tensor_dict): + tensor_dict[fields.InputDataFields.groundtruth_classes] = tf.one_hot( + tensor_dict[fields.InputDataFields.groundtruth_classes] - 1, depth=3) + return tensor_dict + + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build( + input_reader_proto, + transform_input_data_fn=one_hot_class_encoding_fn, + batch_size=2)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + + self.assertAllEqual( + [2, 1, 4, 5], + output_dict[fields.InputDataFields.groundtruth_instance_masks].shape) + + def test_raises_error_with_no_input_paths(self): + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + load_instance_masks: true + """ + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + with self.assertRaises(ValueError): + dataset_builder.build(input_reader_proto, batch_size=1) + + def test_sample_all_data(self): + tf_record_path = self.create_tf_record(num_examples=2) + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + sample_1_of_n_examples: 1 + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build(input_reader_proto, batch_size=1)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + self.assertAllEqual(['0'], output_dict[fields.InputDataFields.source_id]) + output_dict = sess.run(tensor_dict) + self.assertEquals(['1'], output_dict[fields.InputDataFields.source_id]) + + def test_sample_one_of_n_shards(self): + tf_record_path = self.create_tf_record(num_examples=4) + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + sample_1_of_n_examples: 2 + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = dataset_builder.make_initializable_iterator( + dataset_builder.build(input_reader_proto, batch_size=1)).get_next() + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + self.assertAllEqual(['0'], output_dict[fields.InputDataFields.source_id]) + output_dict = sess.run(tensor_dict) + self.assertEquals(['2'], output_dict[fields.InputDataFields.source_id]) + + +class ReadDatasetTest(tf.test.TestCase): + + def setUp(self): + self._path_template = os.path.join(self.get_temp_dir(), 'examples_%s.txt') + + for i in range(5): + path = self._path_template % i + with tf.gfile.Open(path, 'wb') as f: + f.write('\n'.join([str(i + 1), str((i + 1) * 10)])) + + self._shuffle_path_template = os.path.join(self.get_temp_dir(), + 'shuffle_%s.txt') + for i in range(2): + path = self._shuffle_path_template % i + with tf.gfile.Open(path, 'wb') as f: + f.write('\n'.join([str(i)] * 5)) + + def _get_dataset_next(self, files, config, batch_size): + + def decode_func(value): + return [tf.string_to_number(value, out_type=tf.int32)] + + dataset = dataset_builder.read_dataset(tf.data.TextLineDataset, files, + config) + dataset = dataset.map(decode_func) + dataset = dataset.batch(batch_size) + return dataset.make_one_shot_iterator().get_next() + + def test_make_initializable_iterator_with_hashTable(self): + keys = [1, 0, -1] + dataset = tf.data.Dataset.from_tensor_slices([[1, 2, -1, 5]]) + table = tf.contrib.lookup.HashTable( + initializer=tf.contrib.lookup.KeyValueTensorInitializer( + keys=keys, values=list(reversed(keys))), + default_value=100) + dataset = dataset.map(table.lookup) + data = dataset_builder.make_initializable_iterator(dataset).get_next() + init = tf.tables_initializer() + + with self.test_session() as sess: + sess.run(init) + self.assertAllEqual(sess.run(data), [-1, 100, 1, 100]) + + def test_read_dataset(self): + config = input_reader_pb2.InputReader() + config.num_readers = 1 + config.shuffle = False + + data = self._get_dataset_next( + [self._path_template % '*'], config, batch_size=20) + with self.test_session() as sess: + self.assertAllEqual( + sess.run(data), [[ + 1, 10, 2, 20, 3, 30, 4, 40, 5, 50, 1, 10, 2, 20, 3, 30, 4, 40, 5, + 50 + ]]) + + def test_reduce_num_reader(self): + config = input_reader_pb2.InputReader() + config.num_readers = 10 + config.shuffle = False + + data = self._get_dataset_next( + [self._path_template % '*'], config, batch_size=20) + with self.test_session() as sess: + self.assertAllEqual( + sess.run(data), [[ + 1, 10, 2, 20, 3, 30, 4, 40, 5, 50, 1, 10, 2, 20, 3, 30, 4, 40, 5, + 50 + ]]) + + def test_enable_shuffle(self): + config = input_reader_pb2.InputReader() + config.num_readers = 1 + config.shuffle = True + + tf.set_random_seed(1) # Set graph level seed. + data = self._get_dataset_next( + [self._shuffle_path_template % '*'], config, batch_size=10) + expected_non_shuffle_output = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] + + with self.test_session() as sess: + self.assertTrue( + np.any(np.not_equal(sess.run(data), expected_non_shuffle_output))) + + def test_disable_shuffle_(self): + config = input_reader_pb2.InputReader() + config.num_readers = 1 + config.shuffle = False + + data = self._get_dataset_next( + [self._shuffle_path_template % '*'], config, batch_size=10) + expected_non_shuffle_output = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] + + with self.test_session() as sess: + self.assertAllEqual(sess.run(data), [expected_non_shuffle_output]) + + def test_read_dataset_single_epoch(self): + config = input_reader_pb2.InputReader() + config.num_epochs = 1 + config.num_readers = 1 + config.shuffle = False + + data = self._get_dataset_next( + [self._path_template % '0'], config, batch_size=30) + with self.test_session() as sess: + # First batch will retrieve as much as it can, second batch will fail. + self.assertAllEqual(sess.run(data), [[1, 10]]) + self.assertRaises(tf.errors.OutOfRangeError, sess.run, data) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder.py" new file mode 100644 index 00000000..77e60479 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder.py" @@ -0,0 +1,42 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Functions for quantized training and evaluation.""" + +import tensorflow as tf + + +def build(graph_rewriter_config, is_training): + """Returns a function that modifies default graph based on options. + + Args: + graph_rewriter_config: graph_rewriter_pb2.GraphRewriter proto. + is_training: whether in training of eval mode. + """ + def graph_rewrite_fn(): + """Function to quantize weights and activation of the default graph.""" + if (graph_rewriter_config.quantization.weight_bits != 8 or + graph_rewriter_config.quantization.activation_bits != 8): + raise ValueError('Only 8bit quantization is supported') + + # Quantize the graph by inserting quantize ops for weights and activations + if is_training: + tf.contrib.quantize.create_training_graph( + input_graph=tf.get_default_graph(), + quant_delay=graph_rewriter_config.quantization.delay) + else: + tf.contrib.quantize.create_eval_graph(input_graph=tf.get_default_graph()) + + tf.contrib.layers.summarize_collection('quant_vars') + return graph_rewrite_fn diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder_test.py" new file mode 100644 index 00000000..5f38d5a2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/graph_rewriter_builder_test.py" @@ -0,0 +1,57 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for graph_rewriter_builder.""" +import mock +import tensorflow as tf +from object_detection.builders import graph_rewriter_builder +from object_detection.protos import graph_rewriter_pb2 + + +class QuantizationBuilderTest(tf.test.TestCase): + + def testQuantizationBuilderSetsUpCorrectTrainArguments(self): + with mock.patch.object( + tf.contrib.quantize, 'create_training_graph') as mock_quant_fn: + with mock.patch.object(tf.contrib.layers, + 'summarize_collection') as mock_summarize_col: + graph_rewriter_proto = graph_rewriter_pb2.GraphRewriter() + graph_rewriter_proto.quantization.delay = 10 + graph_rewriter_proto.quantization.weight_bits = 8 + graph_rewriter_proto.quantization.activation_bits = 8 + graph_rewrite_fn = graph_rewriter_builder.build( + graph_rewriter_proto, is_training=True) + graph_rewrite_fn() + _, kwargs = mock_quant_fn.call_args + self.assertEqual(kwargs['input_graph'], tf.get_default_graph()) + self.assertEqual(kwargs['quant_delay'], 10) + mock_summarize_col.assert_called_with('quant_vars') + + def testQuantizationBuilderSetsUpCorrectEvalArguments(self): + with mock.patch.object(tf.contrib.quantize, + 'create_eval_graph') as mock_quant_fn: + with mock.patch.object(tf.contrib.layers, + 'summarize_collection') as mock_summarize_col: + graph_rewriter_proto = graph_rewriter_pb2.GraphRewriter() + graph_rewriter_proto.quantization.delay = 10 + graph_rewrite_fn = graph_rewriter_builder.build( + graph_rewriter_proto, is_training=False) + graph_rewrite_fn() + _, kwargs = mock_quant_fn.call_args + self.assertEqual(kwargs['input_graph'], tf.get_default_graph()) + mock_summarize_col.assert_called_with('quant_vars') + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder.py" new file mode 100644 index 00000000..cd503e22 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder.py" @@ -0,0 +1,418 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Builder function to construct tf-slim arg_scope for convolution, fc ops.""" +import tensorflow as tf + +from object_detection.core import freezable_batch_norm +from object_detection.protos import hyperparams_pb2 +from object_detection.utils import context_manager + +slim = tf.contrib.slim + + +class KerasLayerHyperparams(object): + """ + A hyperparameter configuration object for Keras layers used in + Object Detection models. + """ + + def __init__(self, hyperparams_config): + """Builds keras hyperparameter config for layers based on the proto config. + + It automatically converts from Slim layer hyperparameter configs to + Keras layer hyperparameters. Namely, it: + - Builds Keras initializers/regularizers instead of Slim ones + - sets weights_regularizer/initializer to kernel_regularizer/initializer + - converts batchnorm decay to momentum + - converts Slim l2 regularizer weights to the equivalent Keras l2 weights + + Contains a hyperparameter configuration for ops that specifies kernel + initializer, kernel regularizer, activation. Also contains parameters for + batch norm operators based on the configuration. + + Note that if the batch_norm parameters are not specified in the config + (i.e. left to default) then batch norm is excluded from the config. + + Args: + hyperparams_config: hyperparams.proto object containing + hyperparameters. + + Raises: + ValueError: if hyperparams_config is not of type hyperparams.Hyperparams. + """ + if not isinstance(hyperparams_config, + hyperparams_pb2.Hyperparams): + raise ValueError('hyperparams_config not of type ' + 'hyperparams_pb.Hyperparams.') + + self._batch_norm_params = None + if hyperparams_config.HasField('batch_norm'): + self._batch_norm_params = _build_keras_batch_norm_params( + hyperparams_config.batch_norm) + + self._activation_fn = _build_activation_fn(hyperparams_config.activation) + # TODO(kaftan): Unclear if these kwargs apply to separable & depthwise conv + # (Those might use depthwise_* instead of kernel_*) + # We should probably switch to using build_conv2d_layer and + # build_depthwise_conv2d_layer methods instead. + self._op_params = { + 'kernel_regularizer': _build_keras_regularizer( + hyperparams_config.regularizer), + 'kernel_initializer': _build_initializer( + hyperparams_config.initializer, build_for_keras=True), + 'activation': _build_activation_fn(hyperparams_config.activation) + } + + def use_batch_norm(self): + return self._batch_norm_params is not None + + def batch_norm_params(self, **overrides): + """Returns a dict containing batchnorm layer construction hyperparameters. + + Optionally overrides values in the batchnorm hyperparam dict. Overrides + only apply to individual calls of this method, and do not affect + future calls. + + Args: + **overrides: keyword arguments to override in the hyperparams dictionary + + Returns: dict containing the layer construction keyword arguments, with + values overridden by the `overrides` keyword arguments. + """ + if self._batch_norm_params is None: + new_batch_norm_params = dict() + else: + new_batch_norm_params = self._batch_norm_params.copy() + new_batch_norm_params.update(overrides) + return new_batch_norm_params + + def build_batch_norm(self, training=None, **overrides): + """Returns a Batch Normalization layer with the appropriate hyperparams. + + If the hyperparams are configured to not use batch normalization, + this will return a Keras Lambda layer that only applies tf.Identity, + without doing any normalization. + + Optionally overrides values in the batch_norm hyperparam dict. Overrides + only apply to individual calls of this method, and do not affect + future calls. + + Args: + training: if True, the normalization layer will normalize using the batch + statistics. If False, the normalization layer will be frozen and will + act as if it is being used for inference. If None, the layer + will look up the Keras learning phase at `call` time to decide what to + do. + **overrides: batch normalization construction args to override from the + batch_norm hyperparams dictionary. + + Returns: Either a FreezableBatchNorm layer (if use_batch_norm() is True), + or a Keras Lambda layer that applies the identity (if use_batch_norm() + is False) + """ + if self.use_batch_norm(): + return freezable_batch_norm.FreezableBatchNorm( + training=training, + **self.batch_norm_params(**overrides) + ) + else: + return tf.keras.layers.Lambda(tf.identity) + + def build_activation_layer(self, name='activation'): + """Returns a Keras layer that applies the desired activation function. + + Args: + name: The name to assign the Keras layer. + Returns: A Keras lambda layer that applies the activation function + specified in the hyperparam config, or applies the identity if the + activation function is None. + """ + if self._activation_fn: + return tf.keras.layers.Lambda(self._activation_fn, name=name) + else: + return tf.keras.layers.Lambda(tf.identity, name=name) + + def params(self, include_activation=False, **overrides): + """Returns a dict containing the layer construction hyperparameters to use. + + Optionally overrides values in the returned dict. Overrides + only apply to individual calls of this method, and do not affect + future calls. + + Args: + include_activation: If False, activation in the returned dictionary will + be set to `None`, and the activation must be applied via a separate + layer created by `build_activation_layer`. If True, `activation` in the + output param dictionary will be set to the activation function + specified in the hyperparams config. + **overrides: keyword arguments to override in the hyperparams dictionary. + + Returns: dict containing the layer construction keyword arguments, with + values overridden by the `overrides` keyword arguments. + """ + new_params = self._op_params.copy() + new_params['activation'] = None + if include_activation: + new_params['activation'] = self._activation_fn + if self.use_batch_norm() and self.batch_norm_params()['center']: + new_params['use_bias'] = False + else: + new_params['use_bias'] = True + new_params.update(**overrides) + return new_params + + +def build(hyperparams_config, is_training): + """Builds tf-slim arg_scope for convolution ops based on the config. + + Returns an arg_scope to use for convolution ops containing weights + initializer, weights regularizer, activation function, batch norm function + and batch norm parameters based on the configuration. + + Note that if no normalization parameters are specified in the config, + (i.e. left to default) then both batch norm and group norm are excluded + from the arg_scope. + + The batch norm parameters are set for updates based on `is_training` argument + and conv_hyperparams_config.batch_norm.train parameter. During training, they + are updated only if batch_norm.train parameter is true. However, during eval, + no updates are made to the batch norm variables. In both cases, their current + values are used during forward pass. + + Args: + hyperparams_config: hyperparams.proto object containing + hyperparameters. + is_training: Whether the network is in training mode. + + Returns: + arg_scope_fn: A function to construct tf-slim arg_scope containing + hyperparameters for ops. + + Raises: + ValueError: if hyperparams_config is not of type hyperparams.Hyperparams. + """ + if not isinstance(hyperparams_config, + hyperparams_pb2.Hyperparams): + raise ValueError('hyperparams_config not of type ' + 'hyperparams_pb.Hyperparams.') + + normalizer_fn = None + batch_norm_params = None + if hyperparams_config.HasField('batch_norm'): + normalizer_fn = slim.batch_norm + batch_norm_params = _build_batch_norm_params( + hyperparams_config.batch_norm, is_training) + if hyperparams_config.HasField('group_norm'): + normalizer_fn = tf.contrib.layers.group_norm + affected_ops = [slim.conv2d, slim.separable_conv2d, slim.conv2d_transpose] + if hyperparams_config.HasField('op') and ( + hyperparams_config.op == hyperparams_pb2.Hyperparams.FC): + affected_ops = [slim.fully_connected] + def scope_fn(): + with (slim.arg_scope([slim.batch_norm], **batch_norm_params) + if batch_norm_params is not None else + context_manager.IdentityContextManager()): + with slim.arg_scope( + affected_ops, + weights_regularizer=_build_slim_regularizer( + hyperparams_config.regularizer), + weights_initializer=_build_initializer( + hyperparams_config.initializer), + activation_fn=_build_activation_fn(hyperparams_config.activation), + normalizer_fn=normalizer_fn) as sc: + return sc + + return scope_fn + + +def _build_activation_fn(activation_fn): + """Builds a callable activation from config. + + Args: + activation_fn: hyperparams_pb2.Hyperparams.activation + + Returns: + Callable activation function. + + Raises: + ValueError: On unknown activation function. + """ + if activation_fn == hyperparams_pb2.Hyperparams.NONE: + return None + if activation_fn == hyperparams_pb2.Hyperparams.RELU: + return tf.nn.relu + if activation_fn == hyperparams_pb2.Hyperparams.RELU_6: + return tf.nn.relu6 + raise ValueError('Unknown activation function: {}'.format(activation_fn)) + + +def _build_slim_regularizer(regularizer): + """Builds a tf-slim regularizer from config. + + Args: + regularizer: hyperparams_pb2.Hyperparams.regularizer proto. + + Returns: + tf-slim regularizer. + + Raises: + ValueError: On unknown regularizer. + """ + regularizer_oneof = regularizer.WhichOneof('regularizer_oneof') + if regularizer_oneof == 'l1_regularizer': + return slim.l1_regularizer(scale=float(regularizer.l1_regularizer.weight)) + if regularizer_oneof == 'l2_regularizer': + return slim.l2_regularizer(scale=float(regularizer.l2_regularizer.weight)) + if regularizer_oneof is None: + return None + raise ValueError('Unknown regularizer function: {}'.format(regularizer_oneof)) + + +def _build_keras_regularizer(regularizer): + """Builds a keras regularizer from config. + + Args: + regularizer: hyperparams_pb2.Hyperparams.regularizer proto. + + Returns: + Keras regularizer. + + Raises: + ValueError: On unknown regularizer. + """ + regularizer_oneof = regularizer.WhichOneof('regularizer_oneof') + if regularizer_oneof == 'l1_regularizer': + return tf.keras.regularizers.l1(float(regularizer.l1_regularizer.weight)) + if regularizer_oneof == 'l2_regularizer': + # The Keras L2 regularizer weight differs from the Slim L2 regularizer + # weight by a factor of 2 + return tf.keras.regularizers.l2( + float(regularizer.l2_regularizer.weight * 0.5)) + raise ValueError('Unknown regularizer function: {}'.format(regularizer_oneof)) + + +def _build_initializer(initializer, build_for_keras=False): + """Build a tf initializer from config. + + Args: + initializer: hyperparams_pb2.Hyperparams.regularizer proto. + build_for_keras: Whether the initializers should be built for Keras + operators. If false builds for Slim. + + Returns: + tf initializer. + + Raises: + ValueError: On unknown initializer. + """ + initializer_oneof = initializer.WhichOneof('initializer_oneof') + if initializer_oneof == 'truncated_normal_initializer': + return tf.truncated_normal_initializer( + mean=initializer.truncated_normal_initializer.mean, + stddev=initializer.truncated_normal_initializer.stddev) + if initializer_oneof == 'random_normal_initializer': + return tf.random_normal_initializer( + mean=initializer.random_normal_initializer.mean, + stddev=initializer.random_normal_initializer.stddev) + if initializer_oneof == 'variance_scaling_initializer': + enum_descriptor = (hyperparams_pb2.VarianceScalingInitializer. + DESCRIPTOR.enum_types_by_name['Mode']) + mode = enum_descriptor.values_by_number[initializer. + variance_scaling_initializer. + mode].name + if build_for_keras: + if initializer.variance_scaling_initializer.uniform: + return tf.variance_scaling_initializer( + scale=initializer.variance_scaling_initializer.factor, + mode=mode.lower(), + distribution='uniform') + else: + # In TF 1.9 release and earlier, the truncated_normal distribution was + # not supported correctly. So, in these earlier versions of tensorflow, + # the ValueError will be raised, and we manually truncate the + # distribution scale. + # + # It is insufficient to just set distribution to `normal` from the + # start, because the `normal` distribution in newer Tensorflow versions + # creates a truncated distribution, whereas it created untruncated + # distributions in older versions. + try: + return tf.variance_scaling_initializer( + scale=initializer.variance_scaling_initializer.factor, + mode=mode.lower(), + distribution='truncated_normal') + except ValueError: + truncate_constant = 0.87962566103423978 + truncated_scale = initializer.variance_scaling_initializer.factor / ( + truncate_constant * truncate_constant + ) + return tf.variance_scaling_initializer( + scale=truncated_scale, + mode=mode.lower(), + distribution='normal') + + else: + return slim.variance_scaling_initializer( + factor=initializer.variance_scaling_initializer.factor, + mode=mode, + uniform=initializer.variance_scaling_initializer.uniform) + raise ValueError('Unknown initializer function: {}'.format( + initializer_oneof)) + + +def _build_batch_norm_params(batch_norm, is_training): + """Build a dictionary of batch_norm params from config. + + Args: + batch_norm: hyperparams_pb2.ConvHyperparams.batch_norm proto. + is_training: Whether the models is in training mode. + + Returns: + A dictionary containing batch_norm parameters. + """ + batch_norm_params = { + 'decay': batch_norm.decay, + 'center': batch_norm.center, + 'scale': batch_norm.scale, + 'epsilon': batch_norm.epsilon, + # Remove is_training parameter from here and deprecate it in the proto + # once we refactor Faster RCNN models to set is_training through an outer + # arg_scope in the meta architecture. + 'is_training': is_training and batch_norm.train, + } + return batch_norm_params + + +def _build_keras_batch_norm_params(batch_norm): + """Build a dictionary of Keras BatchNormalization params from config. + + Args: + batch_norm: hyperparams_pb2.ConvHyperparams.batch_norm proto. + + Returns: + A dictionary containing Keras BatchNormalization parameters. + """ + # Note: Although decay is defined to be 1 - momentum in batch_norm, + # decay in the slim batch_norm layers was erroneously defined and is + # actually the same as momentum in the Keras batch_norm layers. + # For context, see: github.com/keras-team/keras/issues/6839 + batch_norm_params = { + 'momentum': batch_norm.decay, + 'center': batch_norm.center, + 'scale': batch_norm.scale, + 'epsilon': batch_norm.epsilon, + } + return batch_norm_params diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder_test.py" new file mode 100644 index 00000000..a83b9eea --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/hyperparams_builder_test.py" @@ -0,0 +1,865 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests object_detection.core.hyperparams_builder.""" + +import numpy as np +import tensorflow as tf + +from google.protobuf import text_format + +from object_detection.builders import hyperparams_builder +from object_detection.core import freezable_batch_norm +from object_detection.protos import hyperparams_pb2 + +slim = tf.contrib.slim + + +def _get_scope_key(op): + return getattr(op, '_key_op', str(op)) + + +class HyperparamsBuilderTest(tf.test.TestCase): + + def test_default_arg_scope_has_conv2d_op(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + self.assertTrue(_get_scope_key(slim.conv2d) in scope) + + def test_default_arg_scope_has_separable_conv2d_op(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + self.assertTrue(_get_scope_key(slim.separable_conv2d) in scope) + + def test_default_arg_scope_has_conv2d_transpose_op(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + self.assertTrue(_get_scope_key(slim.conv2d_transpose) in scope) + + def test_explicit_fc_op_arg_scope_has_fully_connected_op(self): + conv_hyperparams_text_proto = """ + op: FC + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + self.assertTrue(_get_scope_key(slim.fully_connected) in scope) + + def test_separable_conv2d_and_conv2d_and_transpose_have_same_parameters(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + kwargs_1, kwargs_2, kwargs_3 = scope.values() + self.assertDictEqual(kwargs_1, kwargs_2) + self.assertDictEqual(kwargs_1, kwargs_3) + + def test_return_l1_regularized_weights(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.5 + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope.values()[0] + regularizer = conv_scope_arguments['weights_regularizer'] + weights = np.array([1., -1, 4., 2.]) + with self.test_session() as sess: + result = sess.run(regularizer(tf.constant(weights))) + self.assertAllClose(np.abs(weights).sum() * 0.5, result) + + def test_return_l1_regularized_weights_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l1_regularizer { + weight: 0.5 + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + + regularizer = keras_config.params()['kernel_regularizer'] + weights = np.array([1., -1, 4., 2.]) + with self.test_session() as sess: + result = sess.run(regularizer(tf.constant(weights))) + self.assertAllClose(np.abs(weights).sum() * 0.5, result) + + def test_return_l2_regularizer_weights(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + weight: 0.42 + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + + regularizer = conv_scope_arguments['weights_regularizer'] + weights = np.array([1., -1, 4., 2.]) + with self.test_session() as sess: + result = sess.run(regularizer(tf.constant(weights))) + self.assertAllClose(np.power(weights, 2).sum() / 2.0 * 0.42, result) + + def test_return_l2_regularizer_weights_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + weight: 0.42 + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + + regularizer = keras_config.params()['kernel_regularizer'] + weights = np.array([1., -1, 4., 2.]) + with self.test_session() as sess: + result = sess.run(regularizer(tf.constant(weights))) + self.assertAllClose(np.power(weights, 2).sum() / 2.0 * 0.42, result) + + def test_return_non_default_batch_norm_params_with_train_during_train(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + batch_norm { + decay: 0.7 + center: false + scale: true + epsilon: 0.03 + train: true + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['normalizer_fn'], slim.batch_norm) + batch_norm_params = scope[_get_scope_key(slim.batch_norm)] + self.assertAlmostEqual(batch_norm_params['decay'], 0.7) + self.assertAlmostEqual(batch_norm_params['epsilon'], 0.03) + self.assertFalse(batch_norm_params['center']) + self.assertTrue(batch_norm_params['scale']) + self.assertTrue(batch_norm_params['is_training']) + + def test_return_non_default_batch_norm_params_keras( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + batch_norm { + decay: 0.7 + center: false + scale: true + epsilon: 0.03 + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + + self.assertTrue(keras_config.use_batch_norm()) + batch_norm_params = keras_config.batch_norm_params() + self.assertAlmostEqual(batch_norm_params['momentum'], 0.7) + self.assertAlmostEqual(batch_norm_params['epsilon'], 0.03) + self.assertFalse(batch_norm_params['center']) + self.assertTrue(batch_norm_params['scale']) + + batch_norm_layer = keras_config.build_batch_norm() + self.assertTrue(isinstance(batch_norm_layer, + freezable_batch_norm.FreezableBatchNorm)) + + def test_return_non_default_batch_norm_params_keras_override( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + batch_norm { + decay: 0.7 + center: false + scale: true + epsilon: 0.03 + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + + self.assertTrue(keras_config.use_batch_norm()) + batch_norm_params = keras_config.batch_norm_params(momentum=0.4) + self.assertAlmostEqual(batch_norm_params['momentum'], 0.4) + self.assertAlmostEqual(batch_norm_params['epsilon'], 0.03) + self.assertFalse(batch_norm_params['center']) + self.assertTrue(batch_norm_params['scale']) + + def test_return_batch_norm_params_with_notrain_during_eval(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + batch_norm { + decay: 0.7 + center: false + scale: true + epsilon: 0.03 + train: true + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=False) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['normalizer_fn'], slim.batch_norm) + batch_norm_params = scope[_get_scope_key(slim.batch_norm)] + self.assertAlmostEqual(batch_norm_params['decay'], 0.7) + self.assertAlmostEqual(batch_norm_params['epsilon'], 0.03) + self.assertFalse(batch_norm_params['center']) + self.assertTrue(batch_norm_params['scale']) + self.assertFalse(batch_norm_params['is_training']) + + def test_return_batch_norm_params_with_notrain_when_train_is_false(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + batch_norm { + decay: 0.7 + center: false + scale: true + epsilon: 0.03 + train: false + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['normalizer_fn'], slim.batch_norm) + batch_norm_params = scope[_get_scope_key(slim.batch_norm)] + self.assertAlmostEqual(batch_norm_params['decay'], 0.7) + self.assertAlmostEqual(batch_norm_params['epsilon'], 0.03) + self.assertFalse(batch_norm_params['center']) + self.assertTrue(batch_norm_params['scale']) + self.assertFalse(batch_norm_params['is_training']) + + def test_do_not_use_batch_norm_if_default(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['normalizer_fn'], None) + + def test_do_not_use_batch_norm_if_default_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + self.assertFalse(keras_config.use_batch_norm()) + self.assertEqual(keras_config.batch_norm_params(), {}) + + # The batch norm builder should build an identity Lambda layer + identity_layer = keras_config.build_batch_norm() + self.assertTrue(isinstance(identity_layer, + tf.keras.layers.Lambda)) + + def test_use_none_activation(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: NONE + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['activation_fn'], None) + + def test_use_none_activation_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: NONE + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + self.assertEqual(keras_config.params()['activation'], None) + self.assertEqual( + keras_config.params(include_activation=True)['activation'], None) + activation_layer = keras_config.build_activation_layer() + self.assertTrue(isinstance(activation_layer, tf.keras.layers.Lambda)) + self.assertEqual(activation_layer.function, tf.identity) + + def test_use_relu_activation(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['activation_fn'], tf.nn.relu) + + def test_use_relu_activation_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + self.assertEqual(keras_config.params()['activation'], None) + self.assertEqual( + keras_config.params(include_activation=True)['activation'], tf.nn.relu) + activation_layer = keras_config.build_activation_layer() + self.assertTrue(isinstance(activation_layer, tf.keras.layers.Lambda)) + self.assertEqual(activation_layer.function, tf.nn.relu) + + def test_use_relu_6_activation(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + self.assertEqual(conv_scope_arguments['activation_fn'], tf.nn.relu6) + + def test_use_relu_6_activation_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + self.assertEqual(keras_config.params()['activation'], None) + self.assertEqual( + keras_config.params(include_activation=True)['activation'], tf.nn.relu6) + activation_layer = keras_config.build_activation_layer() + self.assertTrue(isinstance(activation_layer, tf.keras.layers.Lambda)) + self.assertEqual(activation_layer.function, tf.nn.relu6) + + def test_override_activation_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + activation: RELU_6 + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + new_params = keras_config.params(activation=tf.nn.relu) + self.assertEqual(new_params['activation'], tf.nn.relu) + + def _assert_variance_in_range(self, initializer, shape, variance, + tol=1e-2): + with tf.Graph().as_default() as g: + with self.test_session(graph=g) as sess: + var = tf.get_variable( + name='test', + shape=shape, + dtype=tf.float32, + initializer=initializer) + sess.run(tf.global_variables_initializer()) + values = sess.run(var) + self.assertAllClose(np.var(values), variance, tol, tol) + + def test_variance_in_range_with_variance_scaling_initializer_fan_in(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_IN + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 100.) + + def test_variance_in_range_with_variance_scaling_initializer_fan_in_keras( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_IN + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 100.) + + def test_variance_in_range_with_variance_scaling_initializer_fan_out(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_OUT + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 40.) + + def test_variance_in_range_with_variance_scaling_initializer_fan_out_keras( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_OUT + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 40.) + + def test_variance_in_range_with_variance_scaling_initializer_fan_avg(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_AVG + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=4. / (100. + 40.)) + + def test_variance_in_range_with_variance_scaling_initializer_fan_avg_keras( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_AVG + uniform: false + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=4. / (100. + 40.)) + + def test_variance_in_range_with_variance_scaling_initializer_uniform(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_IN + uniform: true + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 100.) + + def test_variance_in_range_with_variance_scaling_initializer_uniform_keras( + self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + variance_scaling_initializer { + factor: 2.0 + mode: FAN_IN + uniform: true + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=2. / 100.) + + def test_variance_in_range_with_truncated_normal_initializer(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.8 + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=0.49, tol=1e-1) + + def test_variance_in_range_with_truncated_normal_initializer_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + mean: 0.0 + stddev: 0.8 + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=0.49, tol=1e-1) + + def test_variance_in_range_with_random_normal_initializer(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + random_normal_initializer { + mean: 0.0 + stddev: 0.8 + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + scope_fn = hyperparams_builder.build(conv_hyperparams_proto, + is_training=True) + scope = scope_fn() + conv_scope_arguments = scope[_get_scope_key(slim.conv2d)] + initializer = conv_scope_arguments['weights_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=0.64, tol=1e-1) + + def test_variance_in_range_with_random_normal_initializer_keras(self): + conv_hyperparams_text_proto = """ + regularizer { + l2_regularizer { + } + } + initializer { + random_normal_initializer { + mean: 0.0 + stddev: 0.8 + } + } + """ + conv_hyperparams_proto = hyperparams_pb2.Hyperparams() + text_format.Merge(conv_hyperparams_text_proto, conv_hyperparams_proto) + keras_config = hyperparams_builder.KerasLayerHyperparams( + conv_hyperparams_proto) + initializer = keras_config.params()['kernel_initializer'] + self._assert_variance_in_range(initializer, shape=[100, 40], + variance=0.64, tol=1e-1) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder.py" new file mode 100644 index 00000000..243c84dd --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder.py" @@ -0,0 +1,140 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Builder function for image resizing operations.""" +import functools +import tensorflow as tf + +from object_detection.core import preprocessor +from object_detection.protos import image_resizer_pb2 + + +def _tf_resize_method(resize_method): + """Maps image resize method from enumeration type to TensorFlow. + + Args: + resize_method: The resize_method attribute of keep_aspect_ratio_resizer or + fixed_shape_resizer. + + Returns: + method: The corresponding TensorFlow ResizeMethod. + + Raises: + ValueError: if `resize_method` is of unknown type. + """ + dict_method = { + image_resizer_pb2.BILINEAR: + tf.image.ResizeMethod.BILINEAR, + image_resizer_pb2.NEAREST_NEIGHBOR: + tf.image.ResizeMethod.NEAREST_NEIGHBOR, + image_resizer_pb2.BICUBIC: + tf.image.ResizeMethod.BICUBIC, + image_resizer_pb2.AREA: + tf.image.ResizeMethod.AREA + } + if resize_method in dict_method: + return dict_method[resize_method] + else: + raise ValueError('Unknown resize_method') + + +def build(image_resizer_config): + """Builds callable for image resizing operations. + + Args: + image_resizer_config: image_resizer.proto object containing parameters for + an image resizing operation. + + Returns: + image_resizer_fn: Callable for image resizing. This callable always takes + a rank-3 image tensor (corresponding to a single image) and returns a + rank-3 image tensor, possibly with new spatial dimensions. + + Raises: + ValueError: if `image_resizer_config` is of incorrect type. + ValueError: if `image_resizer_config.image_resizer_oneof` is of expected + type. + ValueError: if min_dimension > max_dimension when keep_aspect_ratio_resizer + is used. + """ + if not isinstance(image_resizer_config, image_resizer_pb2.ImageResizer): + raise ValueError('image_resizer_config not of type ' + 'image_resizer_pb2.ImageResizer.') + + image_resizer_oneof = image_resizer_config.WhichOneof('image_resizer_oneof') + if image_resizer_oneof == 'keep_aspect_ratio_resizer': + keep_aspect_ratio_config = image_resizer_config.keep_aspect_ratio_resizer + if not (keep_aspect_ratio_config.min_dimension <= + keep_aspect_ratio_config.max_dimension): + raise ValueError('min_dimension > max_dimension') + method = _tf_resize_method(keep_aspect_ratio_config.resize_method) + per_channel_pad_value = (0, 0, 0) + if keep_aspect_ratio_config.per_channel_pad_value: + per_channel_pad_value = tuple(keep_aspect_ratio_config. + per_channel_pad_value) + image_resizer_fn = functools.partial( + preprocessor.resize_to_range, + min_dimension=keep_aspect_ratio_config.min_dimension, + max_dimension=keep_aspect_ratio_config.max_dimension, + method=method, + pad_to_max_dimension=keep_aspect_ratio_config.pad_to_max_dimension, + per_channel_pad_value=per_channel_pad_value) + if not keep_aspect_ratio_config.convert_to_grayscale: + return image_resizer_fn + elif image_resizer_oneof == 'fixed_shape_resizer': + fixed_shape_resizer_config = image_resizer_config.fixed_shape_resizer + method = _tf_resize_method(fixed_shape_resizer_config.resize_method) + image_resizer_fn = functools.partial( + preprocessor.resize_image, + new_height=fixed_shape_resizer_config.height, + new_width=fixed_shape_resizer_config.width, + method=method) + if not fixed_shape_resizer_config.convert_to_grayscale: + return image_resizer_fn + else: + raise ValueError( + 'Invalid image resizer option: \'%s\'.' % image_resizer_oneof) + + def grayscale_image_resizer(image, masks=None): + """Convert to grayscale before applying image_resizer_fn. + + Args: + image: A 3D tensor of shape [height, width, 3] + masks: (optional) rank 3 float32 tensor with shape [num_instances, height, + width] containing instance masks. + + Returns: + Note that the position of the resized_image_shape changes based on whether + masks are present. + resized_image: A 3D tensor of shape [new_height, new_width, 1], + where the image has been resized (with bilinear interpolation) so that + min(new_height, new_width) == min_dimension or + max(new_height, new_width) == max_dimension. + resized_masks: If masks is not None, also outputs masks. A 3D tensor of + shape [num_instances, new_height, new_width]. + resized_image_shape: A 1D tensor of shape [3] containing shape of the + resized image. + """ + # image_resizer_fn returns [resized_image, resized_image_shape] if + # mask==None, otherwise it returns + # [resized_image, resized_mask, resized_image_shape]. In either case, we + # only deal with first and last element of the returned list. + retval = image_resizer_fn(image, masks) + resized_image = retval[0] + resized_image_shape = retval[-1] + retval[0] = preprocessor.rgb_to_gray(resized_image) + retval[-1] = tf.concat([resized_image_shape[:-1], [1]], 0) + return retval + + return functools.partial(grayscale_image_resizer) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder_test.py" new file mode 100644 index 00000000..f7da1912 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/image_resizer_builder_test.py" @@ -0,0 +1,141 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Tests for object_detection.builders.image_resizer_builder.""" +import numpy as np +import tensorflow as tf +from google.protobuf import text_format +from object_detection.builders import image_resizer_builder +from object_detection.protos import image_resizer_pb2 + + +class ImageResizerBuilderTest(tf.test.TestCase): + + def _shape_of_resized_random_image_given_text_proto(self, input_shape, + text_proto): + image_resizer_config = image_resizer_pb2.ImageResizer() + text_format.Merge(text_proto, image_resizer_config) + image_resizer_fn = image_resizer_builder.build(image_resizer_config) + images = tf.to_float( + tf.random_uniform(input_shape, minval=0, maxval=255, dtype=tf.int32)) + resized_images, _ = image_resizer_fn(images) + with self.test_session() as sess: + return sess.run(resized_images).shape + + def test_build_keep_aspect_ratio_resizer_returns_expected_shape(self): + image_resizer_text_proto = """ + keep_aspect_ratio_resizer { + min_dimension: 10 + max_dimension: 20 + } + """ + input_shape = (50, 25, 3) + expected_output_shape = (20, 10, 3) + output_shape = self._shape_of_resized_random_image_given_text_proto( + input_shape, image_resizer_text_proto) + self.assertEqual(output_shape, expected_output_shape) + + def test_build_keep_aspect_ratio_resizer_grayscale(self): + image_resizer_text_proto = """ + keep_aspect_ratio_resizer { + min_dimension: 10 + max_dimension: 20 + convert_to_grayscale: true + } + """ + input_shape = (50, 25, 3) + expected_output_shape = (20, 10, 1) + output_shape = self._shape_of_resized_random_image_given_text_proto( + input_shape, image_resizer_text_proto) + self.assertEqual(output_shape, expected_output_shape) + + def test_build_keep_aspect_ratio_resizer_with_padding(self): + image_resizer_text_proto = """ + keep_aspect_ratio_resizer { + min_dimension: 10 + max_dimension: 20 + pad_to_max_dimension: true + per_channel_pad_value: 3 + per_channel_pad_value: 4 + per_channel_pad_value: 5 + } + """ + input_shape = (50, 25, 3) + expected_output_shape = (20, 20, 3) + output_shape = self._shape_of_resized_random_image_given_text_proto( + input_shape, image_resizer_text_proto) + self.assertEqual(output_shape, expected_output_shape) + + def test_built_fixed_shape_resizer_returns_expected_shape(self): + image_resizer_text_proto = """ + fixed_shape_resizer { + height: 10 + width: 20 + } + """ + input_shape = (50, 25, 3) + expected_output_shape = (10, 20, 3) + output_shape = self._shape_of_resized_random_image_given_text_proto( + input_shape, image_resizer_text_proto) + self.assertEqual(output_shape, expected_output_shape) + + def test_built_fixed_shape_resizer_grayscale(self): + image_resizer_text_proto = """ + fixed_shape_resizer { + height: 10 + width: 20 + convert_to_grayscale: true + } + """ + input_shape = (50, 25, 3) + expected_output_shape = (10, 20, 1) + output_shape = self._shape_of_resized_random_image_given_text_proto( + input_shape, image_resizer_text_proto) + self.assertEqual(output_shape, expected_output_shape) + + def test_raises_error_on_invalid_input(self): + invalid_input = 'invalid_input' + with self.assertRaises(ValueError): + image_resizer_builder.build(invalid_input) + + def _resized_image_given_text_proto(self, image, text_proto): + image_resizer_config = image_resizer_pb2.ImageResizer() + text_format.Merge(text_proto, image_resizer_config) + image_resizer_fn = image_resizer_builder.build(image_resizer_config) + image_placeholder = tf.placeholder(tf.uint8, [1, None, None, 3]) + resized_image, _ = image_resizer_fn(image_placeholder) + with self.test_session() as sess: + return sess.run(resized_image, feed_dict={image_placeholder: image}) + + def test_fixed_shape_resizer_nearest_neighbor_method(self): + image_resizer_text_proto = """ + fixed_shape_resizer { + height: 1 + width: 1 + resize_method: NEAREST_NEIGHBOR + } + """ + image = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) + image = np.expand_dims(image, axis=2) + image = np.tile(image, (1, 1, 3)) + image = np.expand_dims(image, axis=0) + resized_image = self._resized_image_given_text_proto( + image, image_resizer_text_proto) + vals = np.unique(resized_image).tolist() + self.assertEqual(len(vals), 1) + self.assertEqual(vals[0], 1) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder.py" new file mode 100644 index 00000000..8cb5e2f0 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder.py" @@ -0,0 +1,76 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Input reader builder. + +Creates data sources for DetectionModels from an InputReader config. See +input_reader.proto for options. + +Note: If users wishes to also use their own InputReaders with the Object +Detection configuration framework, they should define their own builder function +that wraps the build function. +""" + +import tensorflow as tf + +from object_detection.data_decoders import tf_example_decoder +from object_detection.protos import input_reader_pb2 + +parallel_reader = tf.contrib.slim.parallel_reader + + +def build(input_reader_config): + """Builds a tensor dictionary based on the InputReader config. + + Args: + input_reader_config: A input_reader_pb2.InputReader object. + + Returns: + A tensor dict based on the input_reader_config. + + Raises: + ValueError: On invalid input reader proto. + ValueError: If no input paths are specified. + """ + if not isinstance(input_reader_config, input_reader_pb2.InputReader): + raise ValueError('input_reader_config not of type ' + 'input_reader_pb2.InputReader.') + + if input_reader_config.WhichOneof('input_reader') == 'tf_record_input_reader': + config = input_reader_config.tf_record_input_reader + if not config.input_path: + raise ValueError('At least one input path must be specified in ' + '`input_reader_config`.') + _, string_tensor = parallel_reader.parallel_read( + config.input_path[:], # Convert `RepeatedScalarContainer` to list. + reader_class=tf.TFRecordReader, + num_epochs=(input_reader_config.num_epochs + if input_reader_config.num_epochs else None), + num_readers=input_reader_config.num_readers, + shuffle=input_reader_config.shuffle, + dtypes=[tf.string, tf.string], + capacity=input_reader_config.queue_capacity, + min_after_dequeue=input_reader_config.min_after_dequeue) + + label_map_proto_file = None + if input_reader_config.HasField('label_map_path'): + label_map_proto_file = input_reader_config.label_map_path + decoder = tf_example_decoder.TfExampleDecoder( + load_instance_masks=input_reader_config.load_instance_masks, + instance_mask_type=input_reader_config.mask_type, + label_map_proto_file=label_map_proto_file) + return decoder.decode(string_tensor) + + raise ValueError('Unsupported input_reader_config.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder_test.py" new file mode 100644 index 00000000..c2c8ef4f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/input_reader_builder_test.py" @@ -0,0 +1,129 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for input_reader_builder.""" + +import os +import numpy as np +import tensorflow as tf + +from google.protobuf import text_format + +from object_detection.builders import input_reader_builder +from object_detection.core import standard_fields as fields +from object_detection.protos import input_reader_pb2 +from object_detection.utils import dataset_util + + +class InputReaderBuilderTest(tf.test.TestCase): + + def create_tf_record(self): + path = os.path.join(self.get_temp_dir(), 'tfrecord') + writer = tf.python_io.TFRecordWriter(path) + + image_tensor = np.random.randint(255, size=(4, 5, 3)).astype(np.uint8) + flat_mask = (4 * 5) * [1.0] + with self.test_session(): + encoded_jpeg = tf.image.encode_jpeg(tf.constant(image_tensor)).eval() + example = tf.train.Example(features=tf.train.Features(feature={ + 'image/encoded': dataset_util.bytes_feature(encoded_jpeg), + 'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')), + 'image/height': dataset_util.int64_feature(4), + 'image/width': dataset_util.int64_feature(5), + 'image/object/bbox/xmin': dataset_util.float_list_feature([0.0]), + 'image/object/bbox/xmax': dataset_util.float_list_feature([1.0]), + 'image/object/bbox/ymin': dataset_util.float_list_feature([0.0]), + 'image/object/bbox/ymax': dataset_util.float_list_feature([1.0]), + 'image/object/class/label': dataset_util.int64_list_feature([2]), + 'image/object/mask': dataset_util.float_list_feature(flat_mask), + })) + writer.write(example.SerializeToString()) + writer.close() + + return path + + def test_build_tf_record_input_reader(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = input_reader_builder.build(input_reader_proto) + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + + self.assertTrue(fields.InputDataFields.groundtruth_instance_masks + not in output_dict) + self.assertEquals( + (4, 5, 3), output_dict[fields.InputDataFields.image].shape) + self.assertEquals( + [2], output_dict[fields.InputDataFields.groundtruth_classes]) + self.assertEquals( + (1, 4), output_dict[fields.InputDataFields.groundtruth_boxes].shape) + self.assertAllEqual( + [0.0, 0.0, 1.0, 1.0], + output_dict[fields.InputDataFields.groundtruth_boxes][0]) + + def test_build_tf_record_input_reader_and_load_instance_masks(self): + tf_record_path = self.create_tf_record() + + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + load_instance_masks: true + tf_record_input_reader {{ + input_path: '{0}' + }} + """.format(tf_record_path) + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + tensor_dict = input_reader_builder.build(input_reader_proto) + + with tf.train.MonitoredSession() as sess: + output_dict = sess.run(tensor_dict) + + self.assertEquals( + (4, 5, 3), output_dict[fields.InputDataFields.image].shape) + self.assertEquals( + [2], output_dict[fields.InputDataFields.groundtruth_classes]) + self.assertEquals( + (1, 4), output_dict[fields.InputDataFields.groundtruth_boxes].shape) + self.assertAllEqual( + [0.0, 0.0, 1.0, 1.0], + output_dict[fields.InputDataFields.groundtruth_boxes][0]) + self.assertAllEqual( + (1, 4, 5), + output_dict[fields.InputDataFields.groundtruth_instance_masks].shape) + + def test_raises_error_with_no_input_paths(self): + input_reader_text_proto = """ + shuffle: false + num_readers: 1 + load_instance_masks: true + """ + input_reader_proto = input_reader_pb2.InputReader() + text_format.Merge(input_reader_text_proto, input_reader_proto) + with self.assertRaises(ValueError): + input_reader_builder.build(input_reader_proto) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder.py" new file mode 100644 index 00000000..2b98d0aa --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder.py" @@ -0,0 +1,252 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A function to build localization and classification losses from config.""" + +import functools +from object_detection.core import balanced_positive_negative_sampler as sampler +from object_detection.core import losses +from object_detection.protos import losses_pb2 +from object_detection.utils import ops + + +def build(loss_config): + """Build losses based on the config. + + Builds classification, localization losses and optionally a hard example miner + based on the config. + + Args: + loss_config: A losses_pb2.Loss object. + + Returns: + classification_loss: Classification loss object. + localization_loss: Localization loss object. + classification_weight: Classification loss weight. + localization_weight: Localization loss weight. + hard_example_miner: Hard example miner object. + random_example_sampler: BalancedPositiveNegativeSampler object. + + Raises: + ValueError: If hard_example_miner is used with sigmoid_focal_loss. + ValueError: If random_example_sampler is getting non-positive value as + desired positive example fraction. + """ + classification_loss = _build_classification_loss( + loss_config.classification_loss) + localization_loss = _build_localization_loss( + loss_config.localization_loss) + classification_weight = loss_config.classification_weight + localization_weight = loss_config.localization_weight + hard_example_miner = None + if loss_config.HasField('hard_example_miner'): + if (loss_config.classification_loss.WhichOneof('classification_loss') == + 'weighted_sigmoid_focal'): + raise ValueError('HardExampleMiner should not be used with sigmoid focal ' + 'loss') + hard_example_miner = build_hard_example_miner( + loss_config.hard_example_miner, + classification_weight, + localization_weight) + random_example_sampler = None + if loss_config.HasField('random_example_sampler'): + if loss_config.random_example_sampler.positive_sample_fraction <= 0: + raise ValueError('RandomExampleSampler should not use non-positive' + 'value as positive sample fraction.') + random_example_sampler = sampler.BalancedPositiveNegativeSampler( + positive_fraction=loss_config.random_example_sampler. + positive_sample_fraction) + + if loss_config.expected_loss_weights == loss_config.NONE: + expected_loss_weights_fn = None + elif loss_config.expected_loss_weights == loss_config.EXPECTED_SAMPLING: + expected_loss_weights_fn = functools.partial( + ops.expected_classification_loss_by_expected_sampling, + min_num_negative_samples=loss_config.min_num_negative_samples, + desired_negative_sampling_ratio=loss_config + .desired_negative_sampling_ratio) + elif (loss_config.expected_loss_weights == loss_config + .REWEIGHTING_UNMATCHED_ANCHORS): + expected_loss_weights_fn = functools.partial( + ops.expected_classification_loss_by_reweighting_unmatched_anchors, + min_num_negative_samples=loss_config.min_num_negative_samples, + desired_negative_sampling_ratio=loss_config + .desired_negative_sampling_ratio) + else: + raise ValueError('Not a valid value for expected_classification_loss.') + + return (classification_loss, localization_loss, classification_weight, + localization_weight, hard_example_miner, random_example_sampler, + expected_loss_weights_fn) + + +def build_hard_example_miner(config, + classification_weight, + localization_weight): + """Builds hard example miner based on the config. + + Args: + config: A losses_pb2.HardExampleMiner object. + classification_weight: Classification loss weight. + localization_weight: Localization loss weight. + + Returns: + Hard example miner. + + """ + loss_type = None + if config.loss_type == losses_pb2.HardExampleMiner.BOTH: + loss_type = 'both' + if config.loss_type == losses_pb2.HardExampleMiner.CLASSIFICATION: + loss_type = 'cls' + if config.loss_type == losses_pb2.HardExampleMiner.LOCALIZATION: + loss_type = 'loc' + + max_negatives_per_positive = None + num_hard_examples = None + if config.max_negatives_per_positive > 0: + max_negatives_per_positive = config.max_negatives_per_positive + if config.num_hard_examples > 0: + num_hard_examples = config.num_hard_examples + hard_example_miner = losses.HardExampleMiner( + num_hard_examples=num_hard_examples, + iou_threshold=config.iou_threshold, + loss_type=loss_type, + cls_loss_weight=classification_weight, + loc_loss_weight=localization_weight, + max_negatives_per_positive=max_negatives_per_positive, + min_negatives_per_image=config.min_negatives_per_image) + return hard_example_miner + + +def build_faster_rcnn_classification_loss(loss_config): + """Builds a classification loss for Faster RCNN based on the loss config. + + Args: + loss_config: A losses_pb2.ClassificationLoss object. + + Returns: + Loss based on the config. + + Raises: + ValueError: On invalid loss_config. + """ + if not isinstance(loss_config, losses_pb2.ClassificationLoss): + raise ValueError('loss_config not of type losses_pb2.ClassificationLoss.') + + loss_type = loss_config.WhichOneof('classification_loss') + + if loss_type == 'weighted_sigmoid': + return losses.WeightedSigmoidClassificationLoss() + if loss_type == 'weighted_softmax': + config = loss_config.weighted_softmax + return losses.WeightedSoftmaxClassificationLoss( + logit_scale=config.logit_scale) + if loss_type == 'weighted_logits_softmax': + config = loss_config.weighted_logits_softmax + return losses.WeightedSoftmaxClassificationAgainstLogitsLoss( + logit_scale=config.logit_scale) + if loss_type == 'weighted_sigmoid_focal': + config = loss_config.weighted_sigmoid_focal + alpha = None + if config.HasField('alpha'): + alpha = config.alpha + return losses.SigmoidFocalClassificationLoss( + gamma=config.gamma, + alpha=alpha) + + # By default, Faster RCNN second stage classifier uses Softmax loss + # with anchor-wise outputs. + config = loss_config.weighted_softmax + return losses.WeightedSoftmaxClassificationLoss( + logit_scale=config.logit_scale) + + +def _build_localization_loss(loss_config): + """Builds a localization loss based on the loss config. + + Args: + loss_config: A losses_pb2.LocalizationLoss object. + + Returns: + Loss based on the config. + + Raises: + ValueError: On invalid loss_config. + """ + if not isinstance(loss_config, losses_pb2.LocalizationLoss): + raise ValueError('loss_config not of type losses_pb2.LocalizationLoss.') + + loss_type = loss_config.WhichOneof('localization_loss') + + if loss_type == 'weighted_l2': + return losses.WeightedL2LocalizationLoss() + + if loss_type == 'weighted_smooth_l1': + return losses.WeightedSmoothL1LocalizationLoss( + loss_config.weighted_smooth_l1.delta) + + if loss_type == 'weighted_iou': + return losses.WeightedIOULocalizationLoss() + + raise ValueError('Empty loss config.') + + +def _build_classification_loss(loss_config): + """Builds a classification loss based on the loss config. + + Args: + loss_config: A losses_pb2.ClassificationLoss object. + + Returns: + Loss based on the config. + + Raises: + ValueError: On invalid loss_config. + """ + if not isinstance(loss_config, losses_pb2.ClassificationLoss): + raise ValueError('loss_config not of type losses_pb2.ClassificationLoss.') + + loss_type = loss_config.WhichOneof('classification_loss') + + if loss_type == 'weighted_sigmoid': + return losses.WeightedSigmoidClassificationLoss() + + if loss_type == 'weighted_sigmoid_focal': + config = loss_config.weighted_sigmoid_focal + alpha = None + if config.HasField('alpha'): + alpha = config.alpha + return losses.SigmoidFocalClassificationLoss( + gamma=config.gamma, + alpha=alpha) + + if loss_type == 'weighted_softmax': + config = loss_config.weighted_softmax + return losses.WeightedSoftmaxClassificationLoss( + logit_scale=config.logit_scale) + + if loss_type == 'weighted_logits_softmax': + config = loss_config.weighted_logits_softmax + return losses.WeightedSoftmaxClassificationAgainstLogitsLoss( + logit_scale=config.logit_scale) + + if loss_type == 'bootstrapped_sigmoid': + config = loss_config.bootstrapped_sigmoid + return losses.BootstrappedSigmoidClassificationLoss( + alpha=config.alpha, + bootstrap_type=('hard' if config.hard_bootstrap else 'soft')) + + raise ValueError('Empty loss config.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder_test.py" new file mode 100644 index 00000000..24b96b40 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/losses_builder_test.py" @@ -0,0 +1,561 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for losses_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.builders import losses_builder +from object_detection.core import losses +from object_detection.protos import losses_pb2 +from object_detection.utils import ops + + +class LocalizationLossBuilderTest(tf.test.TestCase): + + def test_build_weighted_l2_localization_loss(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, localization_loss, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(localization_loss, + losses.WeightedL2LocalizationLoss)) + + def test_build_weighted_smooth_l1_localization_loss_default_delta(self): + losses_text_proto = """ + localization_loss { + weighted_smooth_l1 { + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, localization_loss, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(localization_loss, + losses.WeightedSmoothL1LocalizationLoss)) + self.assertAlmostEqual(localization_loss._delta, 1.0) + + def test_build_weighted_smooth_l1_localization_loss_non_default_delta(self): + losses_text_proto = """ + localization_loss { + weighted_smooth_l1 { + delta: 0.1 + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, localization_loss, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(localization_loss, + losses.WeightedSmoothL1LocalizationLoss)) + self.assertAlmostEqual(localization_loss._delta, 0.1) + + def test_build_weighted_iou_localization_loss(self): + losses_text_proto = """ + localization_loss { + weighted_iou { + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, localization_loss, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(localization_loss, + losses.WeightedIOULocalizationLoss)) + + def test_anchorwise_output(self): + losses_text_proto = """ + localization_loss { + weighted_smooth_l1 { + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, localization_loss, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(localization_loss, + losses.WeightedSmoothL1LocalizationLoss)) + predictions = tf.constant([[[0.0, 0.0, 1.0, 1.0], [0.0, 0.0, 1.0, 1.0]]]) + targets = tf.constant([[[0.0, 0.0, 1.0, 1.0], [0.0, 0.0, 1.0, 1.0]]]) + weights = tf.constant([[1.0, 1.0]]) + loss = localization_loss(predictions, targets, weights=weights) + self.assertEqual(loss.shape, [1, 2]) + + def test_raise_error_on_empty_localization_config(self): + losses_text_proto = """ + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + with self.assertRaises(ValueError): + losses_builder._build_localization_loss(losses_proto) + + +class ClassificationLossBuilderTest(tf.test.TestCase): + + def test_build_weighted_sigmoid_classification_loss(self): + losses_text_proto = """ + classification_loss { + weighted_sigmoid { + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSigmoidClassificationLoss)) + + def test_build_weighted_sigmoid_focal_classification_loss(self): + losses_text_proto = """ + classification_loss { + weighted_sigmoid_focal { + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.SigmoidFocalClassificationLoss)) + self.assertAlmostEqual(classification_loss._alpha, None) + self.assertAlmostEqual(classification_loss._gamma, 2.0) + + def test_build_weighted_sigmoid_focal_loss_non_default(self): + losses_text_proto = """ + classification_loss { + weighted_sigmoid_focal { + alpha: 0.25 + gamma: 3.0 + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.SigmoidFocalClassificationLoss)) + self.assertAlmostEqual(classification_loss._alpha, 0.25) + self.assertAlmostEqual(classification_loss._gamma, 3.0) + + def test_build_weighted_softmax_classification_loss(self): + losses_text_proto = """ + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + + def test_build_weighted_logits_softmax_classification_loss(self): + losses_text_proto = """ + classification_loss { + weighted_logits_softmax { + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue( + isinstance(classification_loss, + losses.WeightedSoftmaxClassificationAgainstLogitsLoss)) + + def test_build_weighted_softmax_classification_loss_with_logit_scale(self): + losses_text_proto = """ + classification_loss { + weighted_softmax { + logit_scale: 2.0 + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + + def test_build_bootstrapped_sigmoid_classification_loss(self): + losses_text_proto = """ + classification_loss { + bootstrapped_sigmoid { + alpha: 0.5 + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.BootstrappedSigmoidClassificationLoss)) + + def test_anchorwise_output(self): + losses_text_proto = """ + classification_loss { + weighted_sigmoid { + anchorwise_output: true + } + } + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss, _, _, _, _, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSigmoidClassificationLoss)) + predictions = tf.constant([[[0.0, 1.0, 0.0], [0.0, 0.5, 0.5]]]) + targets = tf.constant([[[0.0, 1.0, 0.0], [0.0, 0.0, 1.0]]]) + weights = tf.constant([[[1.0, 1.0, 1.0], [1.0, 1.0, 1.0]]]) + loss = classification_loss(predictions, targets, weights=weights) + self.assertEqual(loss.shape, [1, 2, 3]) + + def test_raise_error_on_empty_config(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + with self.assertRaises(ValueError): + losses_builder.build(losses_proto) + + +class HardExampleMinerBuilderTest(tf.test.TestCase): + + def test_do_not_build_hard_example_miner_by_default(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, _, _, _, hard_example_miner, _, _ = losses_builder.build(losses_proto) + self.assertEqual(hard_example_miner, None) + + def test_build_hard_example_miner_for_classification_loss(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + loss_type: CLASSIFICATION + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, _, _, _, hard_example_miner, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertEqual(hard_example_miner._loss_type, 'cls') + + def test_build_hard_example_miner_for_localization_loss(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + loss_type: LOCALIZATION + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, _, _, _, hard_example_miner, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertEqual(hard_example_miner._loss_type, 'loc') + + def test_build_hard_example_miner_with_non_default_values(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + num_hard_examples: 32 + iou_threshold: 0.5 + loss_type: LOCALIZATION + max_negatives_per_positive: 10 + min_negatives_per_image: 3 + } + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + _, _, _, _, hard_example_miner, _, _ = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertEqual(hard_example_miner._num_hard_examples, 32) + self.assertAlmostEqual(hard_example_miner._iou_threshold, 0.5) + self.assertEqual(hard_example_miner._max_negatives_per_positive, 10) + self.assertEqual(hard_example_miner._min_negatives_per_image, 3) + + +class LossBuilderTest(tf.test.TestCase): + + def test_build_all_loss_parameters(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + } + classification_weight: 0.8 + localization_weight: 0.2 + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + (classification_loss, localization_loss, classification_weight, + localization_weight, hard_example_miner, _, + _) = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + self.assertTrue(isinstance(localization_loss, + losses.WeightedL2LocalizationLoss)) + self.assertAlmostEqual(classification_weight, 0.8) + self.assertAlmostEqual(localization_weight, 0.2) + + def test_build_expected_sampling(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + } + classification_weight: 0.8 + localization_weight: 0.2 + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + (classification_loss, localization_loss, classification_weight, + localization_weight, hard_example_miner, _, + _) = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertTrue( + isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + self.assertTrue( + isinstance(localization_loss, losses.WeightedL2LocalizationLoss)) + self.assertAlmostEqual(classification_weight, 0.8) + self.assertAlmostEqual(localization_weight, 0.2) + + + def test_build_reweighting_unmatched_anchors(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_softmax { + } + } + hard_example_miner { + } + classification_weight: 0.8 + localization_weight: 0.2 + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + (classification_loss, localization_loss, classification_weight, + localization_weight, hard_example_miner, _, + _) = losses_builder.build(losses_proto) + self.assertTrue(isinstance(hard_example_miner, losses.HardExampleMiner)) + self.assertTrue( + isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + self.assertTrue( + isinstance(localization_loss, losses.WeightedL2LocalizationLoss)) + self.assertAlmostEqual(classification_weight, 0.8) + self.assertAlmostEqual(localization_weight, 0.2) + + def test_raise_error_when_both_focal_loss_and_hard_example_miner(self): + losses_text_proto = """ + localization_loss { + weighted_l2 { + } + } + classification_loss { + weighted_sigmoid_focal { + } + } + hard_example_miner { + } + classification_weight: 0.8 + localization_weight: 0.2 + """ + losses_proto = losses_pb2.Loss() + text_format.Merge(losses_text_proto, losses_proto) + with self.assertRaises(ValueError): + losses_builder.build(losses_proto) + + +class FasterRcnnClassificationLossBuilderTest(tf.test.TestCase): + + def test_build_sigmoid_loss(self): + losses_text_proto = """ + weighted_sigmoid { + } + """ + losses_proto = losses_pb2.ClassificationLoss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss = losses_builder.build_faster_rcnn_classification_loss( + losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSigmoidClassificationLoss)) + + def test_build_softmax_loss(self): + losses_text_proto = """ + weighted_softmax { + } + """ + losses_proto = losses_pb2.ClassificationLoss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss = losses_builder.build_faster_rcnn_classification_loss( + losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + + def test_build_logits_softmax_loss(self): + losses_text_proto = """ + weighted_logits_softmax { + } + """ + losses_proto = losses_pb2.ClassificationLoss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss = losses_builder.build_faster_rcnn_classification_loss( + losses_proto) + self.assertTrue( + isinstance(classification_loss, + losses.WeightedSoftmaxClassificationAgainstLogitsLoss)) + + def test_build_sigmoid_focal_loss(self): + losses_text_proto = """ + weighted_sigmoid_focal { + } + """ + losses_proto = losses_pb2.ClassificationLoss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss = losses_builder.build_faster_rcnn_classification_loss( + losses_proto) + self.assertTrue( + isinstance(classification_loss, + losses.SigmoidFocalClassificationLoss)) + + def test_build_softmax_loss_by_default(self): + losses_text_proto = """ + """ + losses_proto = losses_pb2.ClassificationLoss() + text_format.Merge(losses_text_proto, losses_proto) + classification_loss = losses_builder.build_faster_rcnn_classification_loss( + losses_proto) + self.assertTrue(isinstance(classification_loss, + losses.WeightedSoftmaxClassificationLoss)) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder.py" new file mode 100644 index 00000000..d334f435 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder.py" @@ -0,0 +1,53 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A function to build an object detection matcher from configuration.""" + +from object_detection.matchers import argmax_matcher +from object_detection.matchers import bipartite_matcher +from object_detection.protos import matcher_pb2 + + +def build(matcher_config): + """Builds a matcher object based on the matcher config. + + Args: + matcher_config: A matcher.proto object containing the config for the desired + Matcher. + + Returns: + Matcher based on the config. + + Raises: + ValueError: On empty matcher proto. + """ + if not isinstance(matcher_config, matcher_pb2.Matcher): + raise ValueError('matcher_config not of type matcher_pb2.Matcher.') + if matcher_config.WhichOneof('matcher_oneof') == 'argmax_matcher': + matcher = matcher_config.argmax_matcher + matched_threshold = unmatched_threshold = None + if not matcher.ignore_thresholds: + matched_threshold = matcher.matched_threshold + unmatched_threshold = matcher.unmatched_threshold + return argmax_matcher.ArgMaxMatcher( + matched_threshold=matched_threshold, + unmatched_threshold=unmatched_threshold, + negatives_lower_than_unmatched=matcher.negatives_lower_than_unmatched, + force_match_for_each_row=matcher.force_match_for_each_row, + use_matmul_gather=matcher.use_matmul_gather) + if matcher_config.WhichOneof('matcher_oneof') == 'bipartite_matcher': + matcher = matcher_config.bipartite_matcher + return bipartite_matcher.GreedyBipartiteMatcher(matcher.use_matmul_gather) + raise ValueError('Empty matcher.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder_test.py" new file mode 100644 index 00000000..66854491 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/matcher_builder_test.py" @@ -0,0 +1,99 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for matcher_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.builders import matcher_builder +from object_detection.matchers import argmax_matcher +from object_detection.matchers import bipartite_matcher +from object_detection.protos import matcher_pb2 + + +class MatcherBuilderTest(tf.test.TestCase): + + def test_build_arg_max_matcher_with_defaults(self): + matcher_text_proto = """ + argmax_matcher { + } + """ + matcher_proto = matcher_pb2.Matcher() + text_format.Merge(matcher_text_proto, matcher_proto) + matcher_object = matcher_builder.build(matcher_proto) + self.assertTrue(isinstance(matcher_object, argmax_matcher.ArgMaxMatcher)) + self.assertAlmostEqual(matcher_object._matched_threshold, 0.5) + self.assertAlmostEqual(matcher_object._unmatched_threshold, 0.5) + self.assertTrue(matcher_object._negatives_lower_than_unmatched) + self.assertFalse(matcher_object._force_match_for_each_row) + + def test_build_arg_max_matcher_without_thresholds(self): + matcher_text_proto = """ + argmax_matcher { + ignore_thresholds: true + } + """ + matcher_proto = matcher_pb2.Matcher() + text_format.Merge(matcher_text_proto, matcher_proto) + matcher_object = matcher_builder.build(matcher_proto) + self.assertTrue(isinstance(matcher_object, argmax_matcher.ArgMaxMatcher)) + self.assertEqual(matcher_object._matched_threshold, None) + self.assertEqual(matcher_object._unmatched_threshold, None) + self.assertTrue(matcher_object._negatives_lower_than_unmatched) + self.assertFalse(matcher_object._force_match_for_each_row) + + def test_build_arg_max_matcher_with_non_default_parameters(self): + matcher_text_proto = """ + argmax_matcher { + matched_threshold: 0.7 + unmatched_threshold: 0.3 + negatives_lower_than_unmatched: false + force_match_for_each_row: true + use_matmul_gather: true + } + """ + matcher_proto = matcher_pb2.Matcher() + text_format.Merge(matcher_text_proto, matcher_proto) + matcher_object = matcher_builder.build(matcher_proto) + self.assertTrue(isinstance(matcher_object, argmax_matcher.ArgMaxMatcher)) + self.assertAlmostEqual(matcher_object._matched_threshold, 0.7) + self.assertAlmostEqual(matcher_object._unmatched_threshold, 0.3) + self.assertFalse(matcher_object._negatives_lower_than_unmatched) + self.assertTrue(matcher_object._force_match_for_each_row) + self.assertTrue(matcher_object._use_matmul_gather) + + def test_build_bipartite_matcher(self): + matcher_text_proto = """ + bipartite_matcher { + } + """ + matcher_proto = matcher_pb2.Matcher() + text_format.Merge(matcher_text_proto, matcher_proto) + matcher_object = matcher_builder.build(matcher_proto) + self.assertTrue( + isinstance(matcher_object, bipartite_matcher.GreedyBipartiteMatcher)) + + def test_raise_error_on_empty_matcher(self): + matcher_text_proto = """ + """ + matcher_proto = matcher_pb2.Matcher() + text_format.Merge(matcher_text_proto, matcher_proto) + with self.assertRaises(ValueError): + matcher_builder.build(matcher_proto) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder.py" new file mode 100644 index 00000000..83b709ae --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder.py" @@ -0,0 +1,515 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A function to build a DetectionModel from configuration.""" + +import functools + +from object_detection.builders import anchor_generator_builder +from object_detection.builders import box_coder_builder +from object_detection.builders import box_predictor_builder +from object_detection.builders import hyperparams_builder +from object_detection.builders import image_resizer_builder +from object_detection.builders import losses_builder +from object_detection.builders import matcher_builder +from object_detection.builders import post_processing_builder +from object_detection.builders import region_similarity_calculator_builder as sim_calc +from object_detection.core import balanced_positive_negative_sampler as sampler +from object_detection.core import post_processing +from object_detection.core import target_assigner +from object_detection.meta_architectures import faster_rcnn_meta_arch +from object_detection.meta_architectures import rfcn_meta_arch +from object_detection.meta_architectures import ssd_meta_arch +from object_detection.models import faster_rcnn_inception_resnet_v2_feature_extractor as frcnn_inc_res +from object_detection.models import faster_rcnn_inception_v2_feature_extractor as frcnn_inc_v2 +from object_detection.models import faster_rcnn_nas_feature_extractor as frcnn_nas +from object_detection.models import faster_rcnn_pnas_feature_extractor as frcnn_pnas +from object_detection.models import faster_rcnn_resnet_v1_feature_extractor as frcnn_resnet_v1 +from object_detection.models import ssd_resnet_v1_fpn_feature_extractor as ssd_resnet_v1_fpn +from object_detection.models import ssd_resnet_v1_ppn_feature_extractor as ssd_resnet_v1_ppn +from object_detection.models.embedded_ssd_mobilenet_v1_feature_extractor import EmbeddedSSDMobileNetV1FeatureExtractor +from object_detection.models.ssd_inception_v2_feature_extractor import SSDInceptionV2FeatureExtractor +from object_detection.models.ssd_inception_v3_feature_extractor import SSDInceptionV3FeatureExtractor +from object_detection.models.ssd_mobilenet_v1_feature_extractor import SSDMobileNetV1FeatureExtractor +from object_detection.models.ssd_mobilenet_v1_fpn_feature_extractor import SSDMobileNetV1FpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v1_ppn_feature_extractor import SSDMobileNetV1PpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v2_feature_extractor import SSDMobileNetV2FeatureExtractor +from object_detection.models.ssd_mobilenet_v2_fpn_feature_extractor import SSDMobileNetV2FpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v2_keras_feature_extractor import SSDMobileNetV2KerasFeatureExtractor +from object_detection.models.ssd_pnasnet_feature_extractor import SSDPNASNetFeatureExtractor +from object_detection.predictors import rfcn_box_predictor +from object_detection.predictors.heads import mask_head +from object_detection.protos import model_pb2 +from object_detection.utils import ops + +# A map of names to SSD feature extractors. +SSD_FEATURE_EXTRACTOR_CLASS_MAP = { + 'ssd_inception_v2': SSDInceptionV2FeatureExtractor, + 'ssd_inception_v3': SSDInceptionV3FeatureExtractor, + 'ssd_mobilenet_v1': SSDMobileNetV1FeatureExtractor, + 'ssd_mobilenet_v1_fpn': SSDMobileNetV1FpnFeatureExtractor, + 'ssd_mobilenet_v1_ppn': SSDMobileNetV1PpnFeatureExtractor, + 'ssd_mobilenet_v2': SSDMobileNetV2FeatureExtractor, + 'ssd_mobilenet_v2_fpn': SSDMobileNetV2FpnFeatureExtractor, + 'ssd_resnet50_v1_fpn': ssd_resnet_v1_fpn.SSDResnet50V1FpnFeatureExtractor, + 'ssd_resnet101_v1_fpn': ssd_resnet_v1_fpn.SSDResnet101V1FpnFeatureExtractor, + 'ssd_resnet152_v1_fpn': ssd_resnet_v1_fpn.SSDResnet152V1FpnFeatureExtractor, + 'ssd_resnet50_v1_ppn': ssd_resnet_v1_ppn.SSDResnet50V1PpnFeatureExtractor, + 'ssd_resnet101_v1_ppn': + ssd_resnet_v1_ppn.SSDResnet101V1PpnFeatureExtractor, + 'ssd_resnet152_v1_ppn': + ssd_resnet_v1_ppn.SSDResnet152V1PpnFeatureExtractor, + 'embedded_ssd_mobilenet_v1': EmbeddedSSDMobileNetV1FeatureExtractor, + 'ssd_pnasnet': SSDPNASNetFeatureExtractor, +} + +SSD_KERAS_FEATURE_EXTRACTOR_CLASS_MAP = { + 'ssd_mobilenet_v2_keras': SSDMobileNetV2KerasFeatureExtractor +} + +# A map of names to Faster R-CNN feature extractors. +FASTER_RCNN_FEATURE_EXTRACTOR_CLASS_MAP = { + 'faster_rcnn_nas': + frcnn_nas.FasterRCNNNASFeatureExtractor, + 'faster_rcnn_pnas': + frcnn_pnas.FasterRCNNPNASFeatureExtractor, + 'faster_rcnn_inception_resnet_v2': + frcnn_inc_res.FasterRCNNInceptionResnetV2FeatureExtractor, + 'faster_rcnn_inception_v2': + frcnn_inc_v2.FasterRCNNInceptionV2FeatureExtractor, + 'faster_rcnn_resnet50': + frcnn_resnet_v1.FasterRCNNResnet50FeatureExtractor, + 'faster_rcnn_resnet101': + frcnn_resnet_v1.FasterRCNNResnet101FeatureExtractor, + 'faster_rcnn_resnet152': + frcnn_resnet_v1.FasterRCNNResnet152FeatureExtractor, +} + + +def build(model_config, is_training, add_summaries=True): + """Builds a DetectionModel based on the model config. + + Args: + model_config: A model.proto object containing the config for the desired + DetectionModel. + is_training: True if this model is being built for training purposes. + add_summaries: Whether to add tensorflow summaries in the model graph. + Returns: + DetectionModel based on the config. + + Raises: + ValueError: On invalid meta architecture or model. + """ + if not isinstance(model_config, model_pb2.DetectionModel): + raise ValueError('model_config not of type model_pb2.DetectionModel.') + meta_architecture = model_config.WhichOneof('model') + if meta_architecture == 'ssd': + return _build_ssd_model(model_config.ssd, is_training, add_summaries) + if meta_architecture == 'faster_rcnn': + return _build_faster_rcnn_model(model_config.faster_rcnn, is_training, + add_summaries) + raise ValueError('Unknown meta architecture: {}'.format(meta_architecture)) + + +def _build_ssd_feature_extractor(feature_extractor_config, + is_training, + freeze_batchnorm, + reuse_weights=None): + """Builds a ssd_meta_arch.SSDFeatureExtractor based on config. + + Args: + feature_extractor_config: A SSDFeatureExtractor proto config from ssd.proto. + is_training: True if this feature extractor is being built for training. + freeze_batchnorm: Whether to freeze batch norm parameters during + training or not. When training with a small batch size (e.g. 1), it is + desirable to freeze batch norm update and use pretrained batch norm + params. + reuse_weights: if the feature extractor should reuse weights. + + Returns: + ssd_meta_arch.SSDFeatureExtractor based on config. + + Raises: + ValueError: On invalid feature extractor type. + """ + feature_type = feature_extractor_config.type + is_keras_extractor = feature_type in SSD_KERAS_FEATURE_EXTRACTOR_CLASS_MAP + depth_multiplier = feature_extractor_config.depth_multiplier + min_depth = feature_extractor_config.min_depth + pad_to_multiple = feature_extractor_config.pad_to_multiple + use_explicit_padding = feature_extractor_config.use_explicit_padding + use_depthwise = feature_extractor_config.use_depthwise + + if is_keras_extractor: + conv_hyperparams = hyperparams_builder.KerasLayerHyperparams( + feature_extractor_config.conv_hyperparams) + else: + conv_hyperparams = hyperparams_builder.build( + feature_extractor_config.conv_hyperparams, is_training) + override_base_feature_extractor_hyperparams = ( + feature_extractor_config.override_base_feature_extractor_hyperparams) + + if (feature_type not in SSD_FEATURE_EXTRACTOR_CLASS_MAP) and ( + not is_keras_extractor): + raise ValueError('Unknown ssd feature_extractor: {}'.format(feature_type)) + + if is_keras_extractor: + feature_extractor_class = SSD_KERAS_FEATURE_EXTRACTOR_CLASS_MAP[ + feature_type] + else: + feature_extractor_class = SSD_FEATURE_EXTRACTOR_CLASS_MAP[feature_type] + kwargs = { + 'is_training': + is_training, + 'depth_multiplier': + depth_multiplier, + 'min_depth': + min_depth, + 'pad_to_multiple': + pad_to_multiple, + 'use_explicit_padding': + use_explicit_padding, + 'use_depthwise': + use_depthwise, + 'override_base_feature_extractor_hyperparams': + override_base_feature_extractor_hyperparams + } + + if is_keras_extractor: + kwargs.update({ + 'conv_hyperparams': conv_hyperparams, + 'inplace_batchnorm_update': False, + 'freeze_batchnorm': freeze_batchnorm + }) + else: + kwargs.update({ + 'conv_hyperparams_fn': conv_hyperparams, + 'reuse_weights': reuse_weights, + }) + + if feature_extractor_config.HasField('fpn'): + kwargs.update({ + 'fpn_min_level': + feature_extractor_config.fpn.min_level, + 'fpn_max_level': + feature_extractor_config.fpn.max_level, + 'additional_layer_depth': + feature_extractor_config.fpn.additional_layer_depth, + }) + + return feature_extractor_class(**kwargs) + + +def _build_ssd_model(ssd_config, is_training, add_summaries): + """Builds an SSD detection model based on the model config. + + Args: + ssd_config: A ssd.proto object containing the config for the desired + SSDMetaArch. + is_training: True if this model is being built for training purposes. + add_summaries: Whether to add tf summaries in the model. + Returns: + SSDMetaArch based on the config. + + Raises: + ValueError: If ssd_config.type is not recognized (i.e. not registered in + model_class_map). + """ + num_classes = ssd_config.num_classes + + # Feature extractor + feature_extractor = _build_ssd_feature_extractor( + feature_extractor_config=ssd_config.feature_extractor, + freeze_batchnorm=ssd_config.freeze_batchnorm, + is_training=is_training) + + box_coder = box_coder_builder.build(ssd_config.box_coder) + matcher = matcher_builder.build(ssd_config.matcher) + region_similarity_calculator = sim_calc.build( + ssd_config.similarity_calculator) + encode_background_as_zeros = ssd_config.encode_background_as_zeros + negative_class_weight = ssd_config.negative_class_weight + anchor_generator = anchor_generator_builder.build( + ssd_config.anchor_generator) + if feature_extractor.is_keras_model: + ssd_box_predictor = box_predictor_builder.build_keras( + conv_hyperparams_fn=hyperparams_builder.KerasLayerHyperparams, + freeze_batchnorm=ssd_config.freeze_batchnorm, + inplace_batchnorm_update=False, + num_predictions_per_location_list=anchor_generator + .num_anchors_per_location(), + box_predictor_config=ssd_config.box_predictor, + is_training=is_training, + num_classes=num_classes, + add_background_class=ssd_config.add_background_class) + else: + ssd_box_predictor = box_predictor_builder.build( + hyperparams_builder.build, ssd_config.box_predictor, is_training, + num_classes, ssd_config.add_background_class) + image_resizer_fn = image_resizer_builder.build(ssd_config.image_resizer) + non_max_suppression_fn, score_conversion_fn = post_processing_builder.build( + ssd_config.post_processing) + (classification_loss, localization_loss, classification_weight, + localization_weight, hard_example_miner, random_example_sampler, + expected_loss_weights_fn) = losses_builder.build(ssd_config.loss) + normalize_loss_by_num_matches = ssd_config.normalize_loss_by_num_matches + normalize_loc_loss_by_codesize = ssd_config.normalize_loc_loss_by_codesize + + equalization_loss_config = ops.EqualizationLossConfig( + weight=ssd_config.loss.equalization_loss.weight, + exclude_prefixes=ssd_config.loss.equalization_loss.exclude_prefixes) + + target_assigner_instance = target_assigner.TargetAssigner( + region_similarity_calculator, + matcher, + box_coder, + negative_class_weight=negative_class_weight) + + ssd_meta_arch_fn = ssd_meta_arch.SSDMetaArch + kwargs = {} + + return ssd_meta_arch_fn( + is_training=is_training, + anchor_generator=anchor_generator, + box_predictor=ssd_box_predictor, + box_coder=box_coder, + feature_extractor=feature_extractor, + encode_background_as_zeros=encode_background_as_zeros, + image_resizer_fn=image_resizer_fn, + non_max_suppression_fn=non_max_suppression_fn, + score_conversion_fn=score_conversion_fn, + classification_loss=classification_loss, + localization_loss=localization_loss, + classification_loss_weight=classification_weight, + localization_loss_weight=localization_weight, + normalize_loss_by_num_matches=normalize_loss_by_num_matches, + hard_example_miner=hard_example_miner, + target_assigner_instance=target_assigner_instance, + add_summaries=add_summaries, + normalize_loc_loss_by_codesize=normalize_loc_loss_by_codesize, + freeze_batchnorm=ssd_config.freeze_batchnorm, + inplace_batchnorm_update=ssd_config.inplace_batchnorm_update, + add_background_class=ssd_config.add_background_class, + explicit_background_class=ssd_config.explicit_background_class, + random_example_sampler=random_example_sampler, + expected_loss_weights_fn=expected_loss_weights_fn, + use_confidences_as_targets=ssd_config.use_confidences_as_targets, + implicit_example_weight=ssd_config.implicit_example_weight, + equalization_loss_config=equalization_loss_config, + **kwargs) + + +def _build_faster_rcnn_feature_extractor( + feature_extractor_config, is_training, reuse_weights=None, + inplace_batchnorm_update=False): + """Builds a faster_rcnn_meta_arch.FasterRCNNFeatureExtractor based on config. + + Args: + feature_extractor_config: A FasterRcnnFeatureExtractor proto config from + faster_rcnn.proto. + is_training: True if this feature extractor is being built for training. + reuse_weights: if the feature extractor should reuse weights. + inplace_batchnorm_update: Whether to update batch_norm inplace during + training. This is required for batch norm to work correctly on TPUs. When + this is false, user must add a control dependency on + tf.GraphKeys.UPDATE_OPS for train/loss op in order to update the batch + norm moving average parameters. + + Returns: + faster_rcnn_meta_arch.FasterRCNNFeatureExtractor based on config. + + Raises: + ValueError: On invalid feature extractor type. + """ + if inplace_batchnorm_update: + raise ValueError('inplace batchnorm updates not supported.') + feature_type = feature_extractor_config.type + first_stage_features_stride = ( + feature_extractor_config.first_stage_features_stride) + batch_norm_trainable = feature_extractor_config.batch_norm_trainable + + if feature_type not in FASTER_RCNN_FEATURE_EXTRACTOR_CLASS_MAP: + raise ValueError('Unknown Faster R-CNN feature_extractor: {}'.format( + feature_type)) + feature_extractor_class = FASTER_RCNN_FEATURE_EXTRACTOR_CLASS_MAP[ + feature_type] + return feature_extractor_class( + is_training, first_stage_features_stride, + batch_norm_trainable, reuse_weights) + + +def _build_faster_rcnn_model(frcnn_config, is_training, add_summaries): + """Builds a Faster R-CNN or R-FCN detection model based on the model config. + + Builds R-FCN model if the second_stage_box_predictor in the config is of type + `rfcn_box_predictor` else builds a Faster R-CNN model. + + Args: + frcnn_config: A faster_rcnn.proto object containing the config for the + desired FasterRCNNMetaArch or RFCNMetaArch. + is_training: True if this model is being built for training purposes. + add_summaries: Whether to add tf summaries in the model. + + Returns: + FasterRCNNMetaArch based on the config. + + Raises: + ValueError: If frcnn_config.type is not recognized (i.e. not registered in + model_class_map). + """ + num_classes = frcnn_config.num_classes + image_resizer_fn = image_resizer_builder.build(frcnn_config.image_resizer) + + feature_extractor = _build_faster_rcnn_feature_extractor( + frcnn_config.feature_extractor, is_training, + inplace_batchnorm_update=frcnn_config.inplace_batchnorm_update) + + number_of_stages = frcnn_config.number_of_stages + first_stage_anchor_generator = anchor_generator_builder.build( + frcnn_config.first_stage_anchor_generator) + + first_stage_target_assigner = target_assigner.create_target_assigner( + 'FasterRCNN', + 'proposal', + use_matmul_gather=frcnn_config.use_matmul_gather_in_matcher) + first_stage_atrous_rate = frcnn_config.first_stage_atrous_rate + first_stage_box_predictor_arg_scope_fn = hyperparams_builder.build( + frcnn_config.first_stage_box_predictor_conv_hyperparams, is_training) + first_stage_box_predictor_kernel_size = ( + frcnn_config.first_stage_box_predictor_kernel_size) + first_stage_box_predictor_depth = frcnn_config.first_stage_box_predictor_depth + first_stage_minibatch_size = frcnn_config.first_stage_minibatch_size + use_static_shapes = frcnn_config.use_static_shapes and ( + frcnn_config.use_static_shapes_for_eval or is_training) + first_stage_sampler = sampler.BalancedPositiveNegativeSampler( + positive_fraction=frcnn_config.first_stage_positive_balance_fraction, + is_static=(frcnn_config.use_static_balanced_label_sampler and + use_static_shapes)) + first_stage_max_proposals = frcnn_config.first_stage_max_proposals + if (frcnn_config.first_stage_nms_iou_threshold < 0 or + frcnn_config.first_stage_nms_iou_threshold > 1.0): + raise ValueError('iou_threshold not in [0, 1.0].') + if (is_training and frcnn_config.second_stage_batch_size > + first_stage_max_proposals): + raise ValueError('second_stage_batch_size should be no greater than ' + 'first_stage_max_proposals.') + first_stage_non_max_suppression_fn = functools.partial( + post_processing.batch_multiclass_non_max_suppression, + score_thresh=frcnn_config.first_stage_nms_score_threshold, + iou_thresh=frcnn_config.first_stage_nms_iou_threshold, + max_size_per_class=frcnn_config.first_stage_max_proposals, + max_total_size=frcnn_config.first_stage_max_proposals, + use_static_shapes=use_static_shapes) + first_stage_loc_loss_weight = ( + frcnn_config.first_stage_localization_loss_weight) + first_stage_obj_loss_weight = frcnn_config.first_stage_objectness_loss_weight + + initial_crop_size = frcnn_config.initial_crop_size + maxpool_kernel_size = frcnn_config.maxpool_kernel_size + maxpool_stride = frcnn_config.maxpool_stride + + second_stage_target_assigner = target_assigner.create_target_assigner( + 'FasterRCNN', + 'detection', + use_matmul_gather=frcnn_config.use_matmul_gather_in_matcher) + second_stage_box_predictor = box_predictor_builder.build( + hyperparams_builder.build, + frcnn_config.second_stage_box_predictor, + is_training=is_training, + num_classes=num_classes) + second_stage_batch_size = frcnn_config.second_stage_batch_size + second_stage_sampler = sampler.BalancedPositiveNegativeSampler( + positive_fraction=frcnn_config.second_stage_balance_fraction, + is_static=(frcnn_config.use_static_balanced_label_sampler and + use_static_shapes)) + (second_stage_non_max_suppression_fn, second_stage_score_conversion_fn + ) = post_processing_builder.build(frcnn_config.second_stage_post_processing) + second_stage_localization_loss_weight = ( + frcnn_config.second_stage_localization_loss_weight) + second_stage_classification_loss = ( + losses_builder.build_faster_rcnn_classification_loss( + frcnn_config.second_stage_classification_loss)) + second_stage_classification_loss_weight = ( + frcnn_config.second_stage_classification_loss_weight) + second_stage_mask_prediction_loss_weight = ( + frcnn_config.second_stage_mask_prediction_loss_weight) + + hard_example_miner = None + if frcnn_config.HasField('hard_example_miner'): + hard_example_miner = losses_builder.build_hard_example_miner( + frcnn_config.hard_example_miner, + second_stage_classification_loss_weight, + second_stage_localization_loss_weight) + + crop_and_resize_fn = ( + ops.matmul_crop_and_resize if frcnn_config.use_matmul_crop_and_resize + else ops.native_crop_and_resize) + clip_anchors_to_image = ( + frcnn_config.clip_anchors_to_image) + + common_kwargs = { + 'is_training': is_training, + 'num_classes': num_classes, + 'image_resizer_fn': image_resizer_fn, + 'feature_extractor': feature_extractor, + 'number_of_stages': number_of_stages, + 'first_stage_anchor_generator': first_stage_anchor_generator, + 'first_stage_target_assigner': first_stage_target_assigner, + 'first_stage_atrous_rate': first_stage_atrous_rate, + 'first_stage_box_predictor_arg_scope_fn': + first_stage_box_predictor_arg_scope_fn, + 'first_stage_box_predictor_kernel_size': + first_stage_box_predictor_kernel_size, + 'first_stage_box_predictor_depth': first_stage_box_predictor_depth, + 'first_stage_minibatch_size': first_stage_minibatch_size, + 'first_stage_sampler': first_stage_sampler, + 'first_stage_non_max_suppression_fn': first_stage_non_max_suppression_fn, + 'first_stage_max_proposals': first_stage_max_proposals, + 'first_stage_localization_loss_weight': first_stage_loc_loss_weight, + 'first_stage_objectness_loss_weight': first_stage_obj_loss_weight, + 'second_stage_target_assigner': second_stage_target_assigner, + 'second_stage_batch_size': second_stage_batch_size, + 'second_stage_sampler': second_stage_sampler, + 'second_stage_non_max_suppression_fn': + second_stage_non_max_suppression_fn, + 'second_stage_score_conversion_fn': second_stage_score_conversion_fn, + 'second_stage_localization_loss_weight': + second_stage_localization_loss_weight, + 'second_stage_classification_loss': + second_stage_classification_loss, + 'second_stage_classification_loss_weight': + second_stage_classification_loss_weight, + 'hard_example_miner': hard_example_miner, + 'add_summaries': add_summaries, + 'crop_and_resize_fn': crop_and_resize_fn, + 'clip_anchors_to_image': clip_anchors_to_image, + 'use_static_shapes': use_static_shapes, + 'resize_masks': frcnn_config.resize_masks + } + + if isinstance(second_stage_box_predictor, + rfcn_box_predictor.RfcnBoxPredictor): + return rfcn_meta_arch.RFCNMetaArch( + second_stage_rfcn_box_predictor=second_stage_box_predictor, + **common_kwargs) + else: + return faster_rcnn_meta_arch.FasterRCNNMetaArch( + initial_crop_size=initial_crop_size, + maxpool_kernel_size=maxpool_kernel_size, + maxpool_stride=maxpool_stride, + second_stage_mask_rcnn_box_predictor=second_stage_box_predictor, + second_stage_mask_prediction_loss_weight=( + second_stage_mask_prediction_loss_weight), + **common_kwargs) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder_test.py" new file mode 100644 index 00000000..87ac0a8b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/model_builder_test.py" @@ -0,0 +1,1570 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.models.model_builder.""" + +from absl.testing import parameterized + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.builders import model_builder +from object_detection.meta_architectures import faster_rcnn_meta_arch +from object_detection.meta_architectures import rfcn_meta_arch +from object_detection.meta_architectures import ssd_meta_arch +from object_detection.models import faster_rcnn_inception_resnet_v2_feature_extractor as frcnn_inc_res +from object_detection.models import faster_rcnn_inception_v2_feature_extractor as frcnn_inc_v2 +from object_detection.models import faster_rcnn_nas_feature_extractor as frcnn_nas +from object_detection.models import faster_rcnn_pnas_feature_extractor as frcnn_pnas +from object_detection.models import faster_rcnn_resnet_v1_feature_extractor as frcnn_resnet_v1 +from object_detection.models import ssd_resnet_v1_fpn_feature_extractor as ssd_resnet_v1_fpn +from object_detection.models import ssd_resnet_v1_ppn_feature_extractor as ssd_resnet_v1_ppn +from object_detection.models.embedded_ssd_mobilenet_v1_feature_extractor import EmbeddedSSDMobileNetV1FeatureExtractor +from object_detection.models.ssd_inception_v2_feature_extractor import SSDInceptionV2FeatureExtractor +from object_detection.models.ssd_inception_v3_feature_extractor import SSDInceptionV3FeatureExtractor +from object_detection.models.ssd_mobilenet_v1_feature_extractor import SSDMobileNetV1FeatureExtractor +from object_detection.models.ssd_mobilenet_v1_fpn_feature_extractor import SSDMobileNetV1FpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v1_ppn_feature_extractor import SSDMobileNetV1PpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v2_feature_extractor import SSDMobileNetV2FeatureExtractor +from object_detection.models.ssd_mobilenet_v2_fpn_feature_extractor import SSDMobileNetV2FpnFeatureExtractor +from object_detection.models.ssd_mobilenet_v2_keras_feature_extractor import SSDMobileNetV2KerasFeatureExtractor +from object_detection.predictors import convolutional_box_predictor +from object_detection.predictors import convolutional_keras_box_predictor +from object_detection.protos import model_pb2 + +FRCNN_RESNET_FEAT_MAPS = { + 'faster_rcnn_resnet50': + frcnn_resnet_v1.FasterRCNNResnet50FeatureExtractor, + 'faster_rcnn_resnet101': + frcnn_resnet_v1.FasterRCNNResnet101FeatureExtractor, + 'faster_rcnn_resnet152': + frcnn_resnet_v1.FasterRCNNResnet152FeatureExtractor +} + +SSD_RESNET_V1_FPN_FEAT_MAPS = { + 'ssd_resnet50_v1_fpn': + ssd_resnet_v1_fpn.SSDResnet50V1FpnFeatureExtractor, + 'ssd_resnet101_v1_fpn': + ssd_resnet_v1_fpn.SSDResnet101V1FpnFeatureExtractor, + 'ssd_resnet152_v1_fpn': + ssd_resnet_v1_fpn.SSDResnet152V1FpnFeatureExtractor, +} + +SSD_RESNET_V1_PPN_FEAT_MAPS = { + 'ssd_resnet50_v1_ppn': + ssd_resnet_v1_ppn.SSDResnet50V1PpnFeatureExtractor, + 'ssd_resnet101_v1_ppn': + ssd_resnet_v1_ppn.SSDResnet101V1PpnFeatureExtractor, + 'ssd_resnet152_v1_ppn': + ssd_resnet_v1_ppn.SSDResnet152V1PpnFeatureExtractor +} + + +class ModelBuilderTest(tf.test.TestCase, parameterized.TestCase): + + def create_model(self, model_config): + """Builds a DetectionModel based on the model config. + + Args: + model_config: A model.proto object containing the config for the desired + DetectionModel. + + Returns: + DetectionModel based on the config. + """ + return model_builder.build(model_config, is_training=True) + + def test_create_ssd_inception_v2_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_inception_v2' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + override_base_feature_extractor_hyperparams: true + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDInceptionV2FeatureExtractor) + self.assertIsNone(model._expected_loss_weights_fn) + + + + def test_create_ssd_inception_v3_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_inception_v3' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + override_base_feature_extractor_hyperparams: true + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDInceptionV3FeatureExtractor) + + def test_create_ssd_resnet_v1_fpn_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_resnet50_v1_fpn' + fpn { + min_level: 3 + max_level: 7 + } + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + encode_background_as_zeros: true + anchor_generator { + multiscale_anchor_generator { + aspect_ratios: [1.0, 2.0, 0.5] + scales_per_octave: 2 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + weight_shared_convolutional_box_predictor { + depth: 32 + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + random_normal_initializer { + } + } + } + num_layers_before_predictor: 1 + } + } + normalize_loss_by_num_matches: true + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_sigmoid_focal { + alpha: 0.25 + gamma: 2.0 + } + } + localization_loss { + weighted_smooth_l1 { + delta: 0.1 + } + } + classification_weight: 1.0 + localization_weight: 1.0 + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + + for extractor_type, extractor_class in SSD_RESNET_V1_FPN_FEAT_MAPS.items(): + model_proto.ssd.feature_extractor.type = extractor_type + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, extractor_class) + + def test_create_ssd_resnet_v1_ppn_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_resnet_v1_50_ppn' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + mean_stddev_box_coder { + } + } + matcher { + bipartite_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + weight_shared_convolutional_box_predictor { + depth: 1024 + class_prediction_bias_init: -4.6 + conv_hyperparams { + activation: RELU_6, + regularizer { + l2_regularizer { + weight: 0.0004 + } + } + initializer { + variance_scaling_initializer { + } + } + } + num_layers_before_predictor: 2 + kernel_size: 1 + } + } + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_l2 { + } + } + classification_weight: 1.0 + localization_weight: 1.0 + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + + for extractor_type, extractor_class in SSD_RESNET_V1_PPN_FEAT_MAPS.items(): + model_proto.ssd.feature_extractor.type = extractor_type + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, extractor_class) + + def test_create_ssd_mobilenet_v1_model_from_config(self): + model_text_proto = """ + ssd { + freeze_batchnorm: true + inplace_batchnorm_update: true + feature_extractor { + type: 'ssd_mobilenet_v1' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV1FeatureExtractor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + self.assertTrue(model._freeze_batchnorm) + self.assertTrue(model._inplace_batchnorm_update) + + def test_create_ssd_mobilenet_v1_fpn_model_from_config(self): + model_text_proto = """ + ssd { + freeze_batchnorm: true + inplace_batchnorm_update: true + feature_extractor { + type: 'ssd_mobilenet_v1_fpn' + fpn { + min_level: 3 + max_level: 7 + } + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV1FpnFeatureExtractor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + self.assertTrue(model._freeze_batchnorm) + self.assertTrue(model._inplace_batchnorm_update) + + def test_create_ssd_mobilenet_v1_ppn_model_from_config(self): + model_text_proto = """ + ssd { + freeze_batchnorm: true + inplace_batchnorm_update: true + feature_extractor { + type: 'ssd_mobilenet_v1_ppn' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV1PpnFeatureExtractor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + self.assertTrue(model._freeze_batchnorm) + self.assertTrue(model._inplace_batchnorm_update) + + def test_create_ssd_mobilenet_v2_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_mobilenet_v2' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV2FeatureExtractor) + self.assertIsInstance(model._box_predictor, + convolutional_box_predictor.ConvolutionalBoxPredictor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + + def test_create_ssd_mobilenet_v2_keras_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'ssd_mobilenet_v2_keras' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV2KerasFeatureExtractor) + self.assertIsInstance( + model._box_predictor, + convolutional_keras_box_predictor.ConvolutionalBoxPredictor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + + def test_create_ssd_mobilenet_v2_fpn_model_from_config(self): + model_text_proto = """ + ssd { + freeze_batchnorm: true + inplace_batchnorm_update: true + feature_extractor { + type: 'ssd_mobilenet_v2_fpn' + fpn { + min_level: 3 + max_level: 7 + } + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV2FpnFeatureExtractor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + self.assertTrue(model._freeze_batchnorm) + self.assertTrue(model._inplace_batchnorm_update) + + def test_create_ssd_mobilenet_v2_fpnlite_model_from_config(self): + model_text_proto = """ + ssd { + freeze_batchnorm: true + inplace_batchnorm_update: true + feature_extractor { + type: 'ssd_mobilenet_v2_fpn' + use_depthwise: true + fpn { + min_level: 3 + max_level: 7 + additional_layer_depth: 128 + } + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 320 + width: 320 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + normalize_loc_loss_by_codesize: true + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + SSDMobileNetV2FpnFeatureExtractor) + self.assertTrue(model._normalize_loc_loss_by_codesize) + self.assertTrue(model._freeze_batchnorm) + self.assertTrue(model._inplace_batchnorm_update) + + def test_create_embedded_ssd_mobilenet_v1_model_from_config(self): + model_text_proto = """ + ssd { + feature_extractor { + type: 'embedded_ssd_mobilenet_v1' + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + box_coder { + faster_rcnn_box_coder { + } + } + matcher { + argmax_matcher { + } + } + similarity_calculator { + iou_similarity { + } + } + anchor_generator { + ssd_anchor_generator { + aspect_ratios: 1.0 + } + } + image_resizer { + fixed_shape_resizer { + height: 256 + width: 256 + } + } + box_predictor { + convolutional_box_predictor { + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + loss { + classification_loss { + weighted_softmax { + } + } + localization_loss { + weighted_smooth_l1 { + } + } + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = self.create_model(model_proto) + self.assertIsInstance(model, ssd_meta_arch.SSDMetaArch) + self.assertIsInstance(model._feature_extractor, + EmbeddedSSDMobileNetV1FeatureExtractor) + + def test_create_faster_rcnn_resnet_v1_models_from_config(self): + model_text_proto = """ + faster_rcnn { + inplace_batchnorm_update: false + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_resnet101' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 14 + maxpool_kernel_size: 2 + maxpool_stride: 2 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + + for extractor_type, extractor_class in FRCNN_RESNET_FEAT_MAPS.items(): + model_proto.faster_rcnn.feature_extractor.type = extractor_type + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, faster_rcnn_meta_arch.FasterRCNNMetaArch) + self.assertIsInstance(model._feature_extractor, extractor_class) + + @parameterized.parameters( + {'use_matmul_crop_and_resize': False}, + {'use_matmul_crop_and_resize': True}, + ) + def test_create_faster_rcnn_resnet101_with_mask_prediction_enabled( + self, use_matmul_crop_and_resize): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_resnet101' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 14 + maxpool_kernel_size: 2 + maxpool_stride: 2 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + predict_instance_masks: true + } + } + second_stage_mask_prediction_loss_weight: 3.0 + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model_proto.faster_rcnn.use_matmul_crop_and_resize = ( + use_matmul_crop_and_resize) + model = model_builder.build(model_proto, is_training=True) + self.assertAlmostEqual(model._second_stage_mask_loss_weight, 3.0) + + def test_create_faster_rcnn_nas_model_from_config(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_nas' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 17 + maxpool_kernel_size: 1 + maxpool_stride: 1 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, faster_rcnn_meta_arch.FasterRCNNMetaArch) + self.assertIsInstance( + model._feature_extractor, + frcnn_nas.FasterRCNNNASFeatureExtractor) + + def test_create_faster_rcnn_pnas_model_from_config(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_pnas' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 17 + maxpool_kernel_size: 1 + maxpool_stride: 1 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, faster_rcnn_meta_arch.FasterRCNNMetaArch) + self.assertIsInstance( + model._feature_extractor, + frcnn_pnas.FasterRCNNPNASFeatureExtractor) + + def test_create_faster_rcnn_inception_resnet_v2_model_from_config(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_inception_resnet_v2' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 17 + maxpool_kernel_size: 1 + maxpool_stride: 1 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, faster_rcnn_meta_arch.FasterRCNNMetaArch) + self.assertIsInstance( + model._feature_extractor, + frcnn_inc_res.FasterRCNNInceptionResnetV2FeatureExtractor) + + def test_create_faster_rcnn_inception_v2_model_from_config(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_inception_v2' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 14 + maxpool_kernel_size: 2 + maxpool_stride: 2 + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, faster_rcnn_meta_arch.FasterRCNNMetaArch) + self.assertIsInstance(model._feature_extractor, + frcnn_inc_v2.FasterRCNNInceptionV2FeatureExtractor) + + def test_create_faster_rcnn_model_from_config_with_example_miner(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + feature_extractor { + type: 'faster_rcnn_inception_resnet_v2' + } + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + second_stage_box_predictor { + mask_rcnn_box_predictor { + fc_hyperparams { + op: FC + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + hard_example_miner { + num_hard_examples: 10 + iou_threshold: 0.99 + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + model = model_builder.build(model_proto, is_training=True) + self.assertIsNotNone(model._hard_example_miner) + + def test_create_rfcn_resnet_v1_model_from_config(self): + model_text_proto = """ + faster_rcnn { + num_classes: 3 + image_resizer { + keep_aspect_ratio_resizer { + min_dimension: 600 + max_dimension: 1024 + } + } + feature_extractor { + type: 'faster_rcnn_resnet101' + } + first_stage_anchor_generator { + grid_anchor_generator { + scales: [0.25, 0.5, 1.0, 2.0] + aspect_ratios: [0.5, 1.0, 2.0] + height_stride: 16 + width_stride: 16 + } + } + first_stage_box_predictor_conv_hyperparams { + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + initial_crop_size: 14 + maxpool_kernel_size: 2 + maxpool_stride: 2 + second_stage_box_predictor { + rfcn_box_predictor { + conv_hyperparams { + op: CONV + regularizer { + l2_regularizer { + } + } + initializer { + truncated_normal_initializer { + } + } + } + } + } + second_stage_post_processing { + batch_non_max_suppression { + score_threshold: 0.01 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + score_converter: SOFTMAX + } + }""" + model_proto = model_pb2.DetectionModel() + text_format.Merge(model_text_proto, model_proto) + for extractor_type, extractor_class in FRCNN_RESNET_FEAT_MAPS.items(): + model_proto.faster_rcnn.feature_extractor.type = extractor_type + model = model_builder.build(model_proto, is_training=True) + self.assertIsInstance(model, rfcn_meta_arch.RFCNMetaArch) + self.assertIsInstance(model._feature_extractor, extractor_class) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder.py" new file mode 100644 index 00000000..ce64bfe6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder.py" @@ -0,0 +1,127 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Functions to build DetectionModel training optimizers.""" + +import tensorflow as tf +from object_detection.utils import learning_schedules + + +def build(optimizer_config): + """Create optimizer based on config. + + Args: + optimizer_config: A Optimizer proto message. + + Returns: + An optimizer and a list of variables for summary. + + Raises: + ValueError: when using an unsupported input data type. + """ + optimizer_type = optimizer_config.WhichOneof('optimizer') + optimizer = None + + summary_vars = [] + if optimizer_type == 'rms_prop_optimizer': + config = optimizer_config.rms_prop_optimizer + learning_rate = _create_learning_rate(config.learning_rate) + summary_vars.append(learning_rate) + optimizer = tf.train.RMSPropOptimizer( + learning_rate, + decay=config.decay, + momentum=config.momentum_optimizer_value, + epsilon=config.epsilon) + + if optimizer_type == 'momentum_optimizer': + config = optimizer_config.momentum_optimizer + learning_rate = _create_learning_rate(config.learning_rate) + summary_vars.append(learning_rate) + optimizer = tf.train.MomentumOptimizer( + learning_rate, + momentum=config.momentum_optimizer_value) + + if optimizer_type == 'adam_optimizer': + config = optimizer_config.adam_optimizer + learning_rate = _create_learning_rate(config.learning_rate) + summary_vars.append(learning_rate) + optimizer = tf.train.AdamOptimizer(learning_rate) + + if optimizer is None: + raise ValueError('Optimizer %s not supported.' % optimizer_type) + + if optimizer_config.use_moving_average: + optimizer = tf.contrib.opt.MovingAverageOptimizer( + optimizer, average_decay=optimizer_config.moving_average_decay) + + return optimizer, summary_vars + + +def _create_learning_rate(learning_rate_config): + """Create optimizer learning rate based on config. + + Args: + learning_rate_config: A LearningRate proto message. + + Returns: + A learning rate. + + Raises: + ValueError: when using an unsupported input data type. + """ + learning_rate = None + learning_rate_type = learning_rate_config.WhichOneof('learning_rate') + if learning_rate_type == 'constant_learning_rate': + config = learning_rate_config.constant_learning_rate + learning_rate = tf.constant(config.learning_rate, dtype=tf.float32, + name='learning_rate') + + if learning_rate_type == 'exponential_decay_learning_rate': + config = learning_rate_config.exponential_decay_learning_rate + learning_rate = learning_schedules.exponential_decay_with_burnin( + tf.train.get_or_create_global_step(), + config.initial_learning_rate, + config.decay_steps, + config.decay_factor, + burnin_learning_rate=config.burnin_learning_rate, + burnin_steps=config.burnin_steps, + min_learning_rate=config.min_learning_rate, + staircase=config.staircase) + + if learning_rate_type == 'manual_step_learning_rate': + config = learning_rate_config.manual_step_learning_rate + if not config.schedule: + raise ValueError('Empty learning rate schedule.') + learning_rate_step_boundaries = [x.step for x in config.schedule] + learning_rate_sequence = [config.initial_learning_rate] + learning_rate_sequence += [x.learning_rate for x in config.schedule] + learning_rate = learning_schedules.manual_stepping( + tf.train.get_or_create_global_step(), learning_rate_step_boundaries, + learning_rate_sequence, config.warmup) + + if learning_rate_type == 'cosine_decay_learning_rate': + config = learning_rate_config.cosine_decay_learning_rate + learning_rate = learning_schedules.cosine_decay_with_warmup( + tf.train.get_or_create_global_step(), + config.learning_rate_base, + config.total_steps, + config.warmup_learning_rate, + config.warmup_steps, + config.hold_base_rate_steps) + + if learning_rate is None: + raise ValueError('Learning_rate %s not supported.' % learning_rate_type) + + return learning_rate diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder_test.py" new file mode 100644 index 00000000..343a858f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/optimizer_builder_test.py" @@ -0,0 +1,208 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for optimizer_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format + +from object_detection.builders import optimizer_builder +from object_detection.protos import optimizer_pb2 + + +class LearningRateBuilderTest(tf.test.TestCase): + + def testBuildConstantLearningRate(self): + learning_rate_text_proto = """ + constant_learning_rate { + learning_rate: 0.004 + } + """ + learning_rate_proto = optimizer_pb2.LearningRate() + text_format.Merge(learning_rate_text_proto, learning_rate_proto) + learning_rate = optimizer_builder._create_learning_rate( + learning_rate_proto) + self.assertTrue(learning_rate.op.name.endswith('learning_rate')) + with self.test_session(): + learning_rate_out = learning_rate.eval() + self.assertAlmostEqual(learning_rate_out, 0.004) + + def testBuildExponentialDecayLearningRate(self): + learning_rate_text_proto = """ + exponential_decay_learning_rate { + initial_learning_rate: 0.004 + decay_steps: 99999 + decay_factor: 0.85 + staircase: false + } + """ + learning_rate_proto = optimizer_pb2.LearningRate() + text_format.Merge(learning_rate_text_proto, learning_rate_proto) + learning_rate = optimizer_builder._create_learning_rate( + learning_rate_proto) + self.assertTrue(learning_rate.op.name.endswith('learning_rate')) + self.assertTrue(isinstance(learning_rate, tf.Tensor)) + + def testBuildManualStepLearningRate(self): + learning_rate_text_proto = """ + manual_step_learning_rate { + initial_learning_rate: 0.002 + schedule { + step: 100 + learning_rate: 0.006 + } + schedule { + step: 90000 + learning_rate: 0.00006 + } + warmup: true + } + """ + learning_rate_proto = optimizer_pb2.LearningRate() + text_format.Merge(learning_rate_text_proto, learning_rate_proto) + learning_rate = optimizer_builder._create_learning_rate( + learning_rate_proto) + self.assertTrue(isinstance(learning_rate, tf.Tensor)) + + def testBuildCosineDecayLearningRate(self): + learning_rate_text_proto = """ + cosine_decay_learning_rate { + learning_rate_base: 0.002 + total_steps: 20000 + warmup_learning_rate: 0.0001 + warmup_steps: 1000 + hold_base_rate_steps: 20000 + } + """ + learning_rate_proto = optimizer_pb2.LearningRate() + text_format.Merge(learning_rate_text_proto, learning_rate_proto) + learning_rate = optimizer_builder._create_learning_rate( + learning_rate_proto) + self.assertTrue(isinstance(learning_rate, tf.Tensor)) + + def testRaiseErrorOnEmptyLearningRate(self): + learning_rate_text_proto = """ + """ + learning_rate_proto = optimizer_pb2.LearningRate() + text_format.Merge(learning_rate_text_proto, learning_rate_proto) + with self.assertRaises(ValueError): + optimizer_builder._create_learning_rate(learning_rate_proto) + + +class OptimizerBuilderTest(tf.test.TestCase): + + def testBuildRMSPropOptimizer(self): + optimizer_text_proto = """ + rms_prop_optimizer: { + learning_rate: { + exponential_decay_learning_rate { + initial_learning_rate: 0.004 + decay_steps: 800720 + decay_factor: 0.95 + } + } + momentum_optimizer_value: 0.9 + decay: 0.9 + epsilon: 1.0 + } + use_moving_average: false + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + optimizer, _ = optimizer_builder.build(optimizer_proto) + self.assertTrue(isinstance(optimizer, tf.train.RMSPropOptimizer)) + + def testBuildMomentumOptimizer(self): + optimizer_text_proto = """ + momentum_optimizer: { + learning_rate: { + constant_learning_rate { + learning_rate: 0.001 + } + } + momentum_optimizer_value: 0.99 + } + use_moving_average: false + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + optimizer, _ = optimizer_builder.build(optimizer_proto) + self.assertTrue(isinstance(optimizer, tf.train.MomentumOptimizer)) + + def testBuildAdamOptimizer(self): + optimizer_text_proto = """ + adam_optimizer: { + learning_rate: { + constant_learning_rate { + learning_rate: 0.002 + } + } + } + use_moving_average: false + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + optimizer, _ = optimizer_builder.build(optimizer_proto) + self.assertTrue(isinstance(optimizer, tf.train.AdamOptimizer)) + + def testBuildMovingAverageOptimizer(self): + optimizer_text_proto = """ + adam_optimizer: { + learning_rate: { + constant_learning_rate { + learning_rate: 0.002 + } + } + } + use_moving_average: True + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + optimizer, _ = optimizer_builder.build(optimizer_proto) + self.assertTrue( + isinstance(optimizer, tf.contrib.opt.MovingAverageOptimizer)) + + def testBuildMovingAverageOptimizerWithNonDefaultDecay(self): + optimizer_text_proto = """ + adam_optimizer: { + learning_rate: { + constant_learning_rate { + learning_rate: 0.002 + } + } + } + use_moving_average: True + moving_average_decay: 0.2 + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + optimizer, _ = optimizer_builder.build(optimizer_proto) + self.assertTrue( + isinstance(optimizer, tf.contrib.opt.MovingAverageOptimizer)) + # TODO(rathodv): Find a way to not depend on the private members. + self.assertAlmostEqual(optimizer._ema._decay, 0.2) + + def testBuildEmptyOptimizer(self): + optimizer_text_proto = """ + """ + optimizer_proto = optimizer_pb2.Optimizer() + text_format.Merge(optimizer_text_proto, optimizer_proto) + with self.assertRaises(ValueError): + optimizer_builder.build(optimizer_proto) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder.py" new file mode 100644 index 00000000..b48ed7ef --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder.py" @@ -0,0 +1,124 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Builder function for post processing operations.""" +import functools + +import tensorflow as tf +from object_detection.core import post_processing +from object_detection.protos import post_processing_pb2 + + +def build(post_processing_config): + """Builds callables for post-processing operations. + + Builds callables for non-max suppression and score conversion based on the + configuration. + + Non-max suppression callable takes `boxes`, `scores`, and optionally + `clip_window`, `parallel_iterations` `masks, and `scope` as inputs. It returns + `nms_boxes`, `nms_scores`, `nms_classes` `nms_masks` and `num_detections`. See + post_processing.batch_multiclass_non_max_suppression for the type and shape + of these tensors. + + Score converter callable should be called with `input` tensor. The callable + returns the output from one of 3 tf operations based on the configuration - + tf.identity, tf.sigmoid or tf.nn.softmax. See tensorflow documentation for + argument and return value descriptions. + + Args: + post_processing_config: post_processing.proto object containing the + parameters for the post-processing operations. + + Returns: + non_max_suppressor_fn: Callable for non-max suppression. + score_converter_fn: Callable for score conversion. + + Raises: + ValueError: if the post_processing_config is of incorrect type. + """ + if not isinstance(post_processing_config, post_processing_pb2.PostProcessing): + raise ValueError('post_processing_config not of type ' + 'post_processing_pb2.Postprocessing.') + non_max_suppressor_fn = _build_non_max_suppressor( + post_processing_config.batch_non_max_suppression) + score_converter_fn = _build_score_converter( + post_processing_config.score_converter, + post_processing_config.logit_scale) + return non_max_suppressor_fn, score_converter_fn + + +def _build_non_max_suppressor(nms_config): + """Builds non-max suppresson based on the nms config. + + Args: + nms_config: post_processing_pb2.PostProcessing.BatchNonMaxSuppression proto. + + Returns: + non_max_suppressor_fn: Callable non-max suppressor. + + Raises: + ValueError: On incorrect iou_threshold or on incompatible values of + max_total_detections and max_detections_per_class. + """ + if nms_config.iou_threshold < 0 or nms_config.iou_threshold > 1.0: + raise ValueError('iou_threshold not in [0, 1.0].') + if nms_config.max_detections_per_class > nms_config.max_total_detections: + raise ValueError('max_detections_per_class should be no greater than ' + 'max_total_detections.') + + non_max_suppressor_fn = functools.partial( + post_processing.batch_multiclass_non_max_suppression, + score_thresh=nms_config.score_threshold, + iou_thresh=nms_config.iou_threshold, + max_size_per_class=nms_config.max_detections_per_class, + max_total_size=nms_config.max_total_detections, + use_static_shapes=nms_config.use_static_shapes) + return non_max_suppressor_fn + + +def _score_converter_fn_with_logit_scale(tf_score_converter_fn, logit_scale): + """Create a function to scale logits then apply a Tensorflow function.""" + def score_converter_fn(logits): + scaled_logits = tf.divide(logits, logit_scale, name='scale_logits') + return tf_score_converter_fn(scaled_logits, name='convert_scores') + score_converter_fn.__name__ = '%s_with_logit_scale' % ( + tf_score_converter_fn.__name__) + return score_converter_fn + + +def _build_score_converter(score_converter_config, logit_scale): + """Builds score converter based on the config. + + Builds one of [tf.identity, tf.sigmoid, tf.softmax] score converters based on + the config. + + Args: + score_converter_config: post_processing_pb2.PostProcessing.score_converter. + logit_scale: temperature to use for SOFTMAX score_converter. + + Returns: + Callable score converter op. + + Raises: + ValueError: On unknown score converter. + """ + if score_converter_config == post_processing_pb2.PostProcessing.IDENTITY: + return _score_converter_fn_with_logit_scale(tf.identity, logit_scale) + if score_converter_config == post_processing_pb2.PostProcessing.SIGMOID: + return _score_converter_fn_with_logit_scale(tf.sigmoid, logit_scale) + if score_converter_config == post_processing_pb2.PostProcessing.SOFTMAX: + return _score_converter_fn_with_logit_scale(tf.nn.softmax, logit_scale) + raise ValueError('Unknown score converter.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder_test.py" new file mode 100644 index 00000000..c39fbfb4 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/post_processing_builder_test.py" @@ -0,0 +1,107 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for post_processing_builder.""" + +import tensorflow as tf +from google.protobuf import text_format +from object_detection.builders import post_processing_builder +from object_detection.protos import post_processing_pb2 + + +class PostProcessingBuilderTest(tf.test.TestCase): + + def test_build_non_max_suppressor_with_correct_parameters(self): + post_processing_text_proto = """ + batch_non_max_suppression { + score_threshold: 0.7 + iou_threshold: 0.6 + max_detections_per_class: 100 + max_total_detections: 300 + } + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + non_max_suppressor, _ = post_processing_builder.build( + post_processing_config) + self.assertEqual(non_max_suppressor.keywords['max_size_per_class'], 100) + self.assertEqual(non_max_suppressor.keywords['max_total_size'], 300) + self.assertAlmostEqual(non_max_suppressor.keywords['score_thresh'], 0.7) + self.assertAlmostEqual(non_max_suppressor.keywords['iou_thresh'], 0.6) + + def test_build_identity_score_converter(self): + post_processing_text_proto = """ + score_converter: IDENTITY + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + _, score_converter = post_processing_builder.build(post_processing_config) + self.assertEqual(score_converter.__name__, 'identity_with_logit_scale') + + inputs = tf.constant([1, 1], tf.float32) + outputs = score_converter(inputs) + with self.test_session() as sess: + converted_scores = sess.run(outputs) + expected_converted_scores = sess.run(inputs) + self.assertAllClose(converted_scores, expected_converted_scores) + + def test_build_identity_score_converter_with_logit_scale(self): + post_processing_text_proto = """ + score_converter: IDENTITY + logit_scale: 2.0 + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + _, score_converter = post_processing_builder.build(post_processing_config) + self.assertEqual(score_converter.__name__, 'identity_with_logit_scale') + + inputs = tf.constant([1, 1], tf.float32) + outputs = score_converter(inputs) + with self.test_session() as sess: + converted_scores = sess.run(outputs) + expected_converted_scores = sess.run(tf.constant([.5, .5], tf.float32)) + self.assertAllClose(converted_scores, expected_converted_scores) + + def test_build_sigmoid_score_converter(self): + post_processing_text_proto = """ + score_converter: SIGMOID + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + _, score_converter = post_processing_builder.build(post_processing_config) + self.assertEqual(score_converter.__name__, 'sigmoid_with_logit_scale') + + def test_build_softmax_score_converter(self): + post_processing_text_proto = """ + score_converter: SOFTMAX + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + _, score_converter = post_processing_builder.build(post_processing_config) + self.assertEqual(score_converter.__name__, 'softmax_with_logit_scale') + + def test_build_softmax_score_converter_with_temperature(self): + post_processing_text_proto = """ + score_converter: SOFTMAX + logit_scale: 2.0 + """ + post_processing_config = post_processing_pb2.PostProcessing() + text_format.Merge(post_processing_text_proto, post_processing_config) + _, score_converter = post_processing_builder.build(post_processing_config) + self.assertEqual(score_converter.__name__, 'softmax_with_logit_scale') + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder.py" new file mode 100644 index 00000000..1d03b641 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder.py" @@ -0,0 +1,348 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Builder for preprocessing steps.""" + +import tensorflow as tf + +from object_detection.core import preprocessor +from object_detection.protos import preprocessor_pb2 + + +def _get_step_config_from_proto(preprocessor_step_config, step_name): + """Returns the value of a field named step_name from proto. + + Args: + preprocessor_step_config: A preprocessor_pb2.PreprocessingStep object. + step_name: Name of the field to get value from. + + Returns: + result_dict: a sub proto message from preprocessor_step_config which will be + later converted to a dictionary. + + Raises: + ValueError: If field does not exist in proto. + """ + for field, value in preprocessor_step_config.ListFields(): + if field.name == step_name: + return value + + raise ValueError('Could not get field %s from proto!', step_name) + + +def _get_dict_from_proto(config): + """Helper function to put all proto fields into a dictionary. + + For many preprocessing steps, there's an trivial 1-1 mapping from proto fields + to function arguments. This function automatically populates a dictionary with + the arguments from the proto. + + Protos that CANNOT be trivially populated include: + * nested messages. + * steps that check if an optional field is set (ie. where None != 0). + * protos that don't map 1-1 to arguments (ie. list should be reshaped). + * fields requiring additional validation (ie. repeated field has n elements). + + Args: + config: A protobuf object that does not violate the conditions above. + + Returns: + result_dict: |config| converted into a python dictionary. + """ + result_dict = {} + for field, value in config.ListFields(): + result_dict[field.name] = value + return result_dict + + +# A map from a PreprocessingStep proto config field name to the preprocessing +# function that should be used. The PreprocessingStep proto should be parsable +# with _get_dict_from_proto. +PREPROCESSING_FUNCTION_MAP = { + 'normalize_image': + preprocessor.normalize_image, + 'random_pixel_value_scale': + preprocessor.random_pixel_value_scale, + 'random_image_scale': + preprocessor.random_image_scale, + 'random_rgb_to_gray': + preprocessor.random_rgb_to_gray, + 'random_adjust_brightness': + preprocessor.random_adjust_brightness, + 'random_adjust_contrast': + preprocessor.random_adjust_contrast, + 'random_adjust_hue': + preprocessor.random_adjust_hue, + 'random_adjust_saturation': + preprocessor.random_adjust_saturation, + 'random_distort_color': + preprocessor.random_distort_color, + 'random_jitter_boxes': + preprocessor.random_jitter_boxes, + 'random_crop_to_aspect_ratio': + preprocessor.random_crop_to_aspect_ratio, + 'random_black_patches': + preprocessor.random_black_patches, + 'rgb_to_gray': + preprocessor.rgb_to_gray, + 'scale_boxes_to_pixel_coordinates': ( + preprocessor.scale_boxes_to_pixel_coordinates), + 'subtract_channel_mean': + preprocessor.subtract_channel_mean, + 'convert_class_logits_to_softmax': + preprocessor.convert_class_logits_to_softmax, +} + + +# A map to convert from preprocessor_pb2.ResizeImage.Method enum to +# tf.image.ResizeMethod. +RESIZE_METHOD_MAP = { + preprocessor_pb2.ResizeImage.AREA: tf.image.ResizeMethod.AREA, + preprocessor_pb2.ResizeImage.BICUBIC: tf.image.ResizeMethod.BICUBIC, + preprocessor_pb2.ResizeImage.BILINEAR: tf.image.ResizeMethod.BILINEAR, + preprocessor_pb2.ResizeImage.NEAREST_NEIGHBOR: ( + tf.image.ResizeMethod.NEAREST_NEIGHBOR), +} + + +def build(preprocessor_step_config): + """Builds preprocessing step based on the configuration. + + Args: + preprocessor_step_config: PreprocessingStep configuration proto. + + Returns: + function, argmap: A callable function and an argument map to call function + with. + + Raises: + ValueError: On invalid configuration. + """ + step_type = preprocessor_step_config.WhichOneof('preprocessing_step') + + if step_type in PREPROCESSING_FUNCTION_MAP: + preprocessing_function = PREPROCESSING_FUNCTION_MAP[step_type] + step_config = _get_step_config_from_proto(preprocessor_step_config, + step_type) + function_args = _get_dict_from_proto(step_config) + return (preprocessing_function, function_args) + + if step_type == 'random_horizontal_flip': + config = preprocessor_step_config.random_horizontal_flip + return (preprocessor.random_horizontal_flip, + { + 'keypoint_flip_permutation': tuple( + config.keypoint_flip_permutation), + }) + + if step_type == 'random_vertical_flip': + config = preprocessor_step_config.random_vertical_flip + return (preprocessor.random_vertical_flip, + { + 'keypoint_flip_permutation': tuple( + config.keypoint_flip_permutation), + }) + + if step_type == 'random_rotation90': + return (preprocessor.random_rotation90, {}) + + if step_type == 'random_crop_image': + config = preprocessor_step_config.random_crop_image + return (preprocessor.random_crop_image, + { + 'min_object_covered': config.min_object_covered, + 'aspect_ratio_range': (config.min_aspect_ratio, + config.max_aspect_ratio), + 'area_range': (config.min_area, config.max_area), + 'overlap_thresh': config.overlap_thresh, + 'clip_boxes': config.clip_boxes, + 'random_coef': config.random_coef, + }) + + if step_type == 'random_pad_image': + config = preprocessor_step_config.random_pad_image + min_image_size = None + if (config.HasField('min_image_height') != + config.HasField('min_image_width')): + raise ValueError('min_image_height and min_image_width should be either ' + 'both set or both unset.') + if config.HasField('min_image_height'): + min_image_size = (config.min_image_height, config.min_image_width) + + max_image_size = None + if (config.HasField('max_image_height') != + config.HasField('max_image_width')): + raise ValueError('max_image_height and max_image_width should be either ' + 'both set or both unset.') + if config.HasField('max_image_height'): + max_image_size = (config.max_image_height, config.max_image_width) + + pad_color = config.pad_color or None + if pad_color: + if len(pad_color) == 3: + pad_color = tf.to_float([x for x in config.pad_color]) + else: + raise ValueError('pad_color should have 3 elements (RGB) if set!') + return (preprocessor.random_pad_image, + { + 'min_image_size': min_image_size, + 'max_image_size': max_image_size, + 'pad_color': pad_color, + }) + + if step_type == 'random_crop_pad_image': + config = preprocessor_step_config.random_crop_pad_image + min_padded_size_ratio = config.min_padded_size_ratio + if min_padded_size_ratio and len(min_padded_size_ratio) != 2: + raise ValueError('min_padded_size_ratio should have 2 elements if set!') + max_padded_size_ratio = config.max_padded_size_ratio + if max_padded_size_ratio and len(max_padded_size_ratio) != 2: + raise ValueError('max_padded_size_ratio should have 2 elements if set!') + pad_color = config.pad_color + if pad_color and len(pad_color) != 3: + raise ValueError('pad_color should have 3 elements if set!') + kwargs = { + 'min_object_covered': config.min_object_covered, + 'aspect_ratio_range': (config.min_aspect_ratio, + config.max_aspect_ratio), + 'area_range': (config.min_area, config.max_area), + 'overlap_thresh': config.overlap_thresh, + 'clip_boxes': config.clip_boxes, + 'random_coef': config.random_coef, + } + if min_padded_size_ratio: + kwargs['min_padded_size_ratio'] = tuple(min_padded_size_ratio) + if max_padded_size_ratio: + kwargs['max_padded_size_ratio'] = tuple(max_padded_size_ratio) + if pad_color: + kwargs['pad_color'] = tuple(pad_color) + return (preprocessor.random_crop_pad_image, kwargs) + + if step_type == 'random_resize_method': + config = preprocessor_step_config.random_resize_method + return (preprocessor.random_resize_method, + { + 'target_size': [config.target_height, config.target_width], + }) + + if step_type == 'resize_image': + config = preprocessor_step_config.resize_image + method = RESIZE_METHOD_MAP[config.method] + return (preprocessor.resize_image, + { + 'new_height': config.new_height, + 'new_width': config.new_width, + 'method': method + }) + + if step_type == 'ssd_random_crop': + config = preprocessor_step_config.ssd_random_crop + if config.operations: + min_object_covered = [op.min_object_covered for op in config.operations] + aspect_ratio_range = [(op.min_aspect_ratio, op.max_aspect_ratio) + for op in config.operations] + area_range = [(op.min_area, op.max_area) for op in config.operations] + overlap_thresh = [op.overlap_thresh for op in config.operations] + clip_boxes = [op.clip_boxes for op in config.operations] + random_coef = [op.random_coef for op in config.operations] + return (preprocessor.ssd_random_crop, + { + 'min_object_covered': min_object_covered, + 'aspect_ratio_range': aspect_ratio_range, + 'area_range': area_range, + 'overlap_thresh': overlap_thresh, + 'clip_boxes': clip_boxes, + 'random_coef': random_coef, + }) + return (preprocessor.ssd_random_crop, {}) + + if step_type == 'ssd_random_crop_pad': + config = preprocessor_step_config.ssd_random_crop_pad + if config.operations: + min_object_covered = [op.min_object_covered for op in config.operations] + aspect_ratio_range = [(op.min_aspect_ratio, op.max_aspect_ratio) + for op in config.operations] + area_range = [(op.min_area, op.max_area) for op in config.operations] + overlap_thresh = [op.overlap_thresh for op in config.operations] + clip_boxes = [op.clip_boxes for op in config.operations] + random_coef = [op.random_coef for op in config.operations] + min_padded_size_ratio = [tuple(op.min_padded_size_ratio) + for op in config.operations] + max_padded_size_ratio = [tuple(op.max_padded_size_ratio) + for op in config.operations] + pad_color = [(op.pad_color_r, op.pad_color_g, op.pad_color_b) + for op in config.operations] + return (preprocessor.ssd_random_crop_pad, + { + 'min_object_covered': min_object_covered, + 'aspect_ratio_range': aspect_ratio_range, + 'area_range': area_range, + 'overlap_thresh': overlap_thresh, + 'clip_boxes': clip_boxes, + 'random_coef': random_coef, + 'min_padded_size_ratio': min_padded_size_ratio, + 'max_padded_size_ratio': max_padded_size_ratio, + 'pad_color': pad_color, + }) + return (preprocessor.ssd_random_crop_pad, {}) + + if step_type == 'ssd_random_crop_fixed_aspect_ratio': + config = preprocessor_step_config.ssd_random_crop_fixed_aspect_ratio + if config.operations: + min_object_covered = [op.min_object_covered for op in config.operations] + area_range = [(op.min_area, op.max_area) for op in config.operations] + overlap_thresh = [op.overlap_thresh for op in config.operations] + clip_boxes = [op.clip_boxes for op in config.operations] + random_coef = [op.random_coef for op in config.operations] + return (preprocessor.ssd_random_crop_fixed_aspect_ratio, + { + 'min_object_covered': min_object_covered, + 'aspect_ratio': config.aspect_ratio, + 'area_range': area_range, + 'overlap_thresh': overlap_thresh, + 'clip_boxes': clip_boxes, + 'random_coef': random_coef, + }) + return (preprocessor.ssd_random_crop_fixed_aspect_ratio, {}) + + if step_type == 'ssd_random_crop_pad_fixed_aspect_ratio': + config = preprocessor_step_config.ssd_random_crop_pad_fixed_aspect_ratio + kwargs = {} + aspect_ratio = config.aspect_ratio + if aspect_ratio: + kwargs['aspect_ratio'] = aspect_ratio + min_padded_size_ratio = config.min_padded_size_ratio + if min_padded_size_ratio: + if len(min_padded_size_ratio) != 2: + raise ValueError('min_padded_size_ratio should have 2 elements if set!') + kwargs['min_padded_size_ratio'] = tuple(min_padded_size_ratio) + max_padded_size_ratio = config.max_padded_size_ratio + if max_padded_size_ratio: + if len(max_padded_size_ratio) != 2: + raise ValueError('max_padded_size_ratio should have 2 elements if set!') + kwargs['max_padded_size_ratio'] = tuple(max_padded_size_ratio) + if config.operations: + kwargs['min_object_covered'] = [op.min_object_covered + for op in config.operations] + kwargs['aspect_ratio_range'] = [(op.min_aspect_ratio, op.max_aspect_ratio) + for op in config.operations] + kwargs['area_range'] = [(op.min_area, op.max_area) + for op in config.operations] + kwargs['overlap_thresh'] = [op.overlap_thresh for op in config.operations] + kwargs['clip_boxes'] = [op.clip_boxes for op in config.operations] + kwargs['random_coef'] = [op.random_coef for op in config.operations] + return (preprocessor.ssd_random_crop_pad_fixed_aspect_ratio, kwargs) + + raise ValueError('Unknown preprocessing step.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder_test.py" new file mode 100644 index 00000000..89de2b43 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/preprocessor_builder_test.py" @@ -0,0 +1,598 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for preprocessor_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format + +from object_detection.builders import preprocessor_builder +from object_detection.core import preprocessor +from object_detection.protos import preprocessor_pb2 + + +class PreprocessorBuilderTest(tf.test.TestCase): + + def assert_dictionary_close(self, dict1, dict2): + """Helper to check if two dicts with floatst or integers are close.""" + self.assertEqual(sorted(dict1.keys()), sorted(dict2.keys())) + for key in dict1: + value = dict1[key] + if isinstance(value, float): + self.assertAlmostEqual(value, dict2[key]) + else: + self.assertEqual(value, dict2[key]) + + def test_build_normalize_image(self): + preprocessor_text_proto = """ + normalize_image { + original_minval: 0.0 + original_maxval: 255.0 + target_minval: -1.0 + target_maxval: 1.0 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.normalize_image) + self.assertEqual(args, { + 'original_minval': 0.0, + 'original_maxval': 255.0, + 'target_minval': -1.0, + 'target_maxval': 1.0, + }) + + def test_build_random_horizontal_flip(self): + preprocessor_text_proto = """ + random_horizontal_flip { + keypoint_flip_permutation: 1 + keypoint_flip_permutation: 0 + keypoint_flip_permutation: 2 + keypoint_flip_permutation: 3 + keypoint_flip_permutation: 5 + keypoint_flip_permutation: 4 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_horizontal_flip) + self.assertEqual(args, {'keypoint_flip_permutation': (1, 0, 2, 3, 5, 4)}) + + def test_build_random_vertical_flip(self): + preprocessor_text_proto = """ + random_vertical_flip { + keypoint_flip_permutation: 1 + keypoint_flip_permutation: 0 + keypoint_flip_permutation: 2 + keypoint_flip_permutation: 3 + keypoint_flip_permutation: 5 + keypoint_flip_permutation: 4 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_vertical_flip) + self.assertEqual(args, {'keypoint_flip_permutation': (1, 0, 2, 3, 5, 4)}) + + def test_build_random_rotation90(self): + preprocessor_text_proto = """ + random_rotation90 {} + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_rotation90) + self.assertEqual(args, {}) + + def test_build_random_pixel_value_scale(self): + preprocessor_text_proto = """ + random_pixel_value_scale { + minval: 0.8 + maxval: 1.2 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_pixel_value_scale) + self.assert_dictionary_close(args, {'minval': 0.8, 'maxval': 1.2}) + + def test_build_random_image_scale(self): + preprocessor_text_proto = """ + random_image_scale { + min_scale_ratio: 0.8 + max_scale_ratio: 2.2 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_image_scale) + self.assert_dictionary_close(args, {'min_scale_ratio': 0.8, + 'max_scale_ratio': 2.2}) + + def test_build_random_rgb_to_gray(self): + preprocessor_text_proto = """ + random_rgb_to_gray { + probability: 0.8 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_rgb_to_gray) + self.assert_dictionary_close(args, {'probability': 0.8}) + + def test_build_random_adjust_brightness(self): + preprocessor_text_proto = """ + random_adjust_brightness { + max_delta: 0.2 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_adjust_brightness) + self.assert_dictionary_close(args, {'max_delta': 0.2}) + + def test_build_random_adjust_contrast(self): + preprocessor_text_proto = """ + random_adjust_contrast { + min_delta: 0.7 + max_delta: 1.1 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_adjust_contrast) + self.assert_dictionary_close(args, {'min_delta': 0.7, 'max_delta': 1.1}) + + def test_build_random_adjust_hue(self): + preprocessor_text_proto = """ + random_adjust_hue { + max_delta: 0.01 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_adjust_hue) + self.assert_dictionary_close(args, {'max_delta': 0.01}) + + def test_build_random_adjust_saturation(self): + preprocessor_text_proto = """ + random_adjust_saturation { + min_delta: 0.75 + max_delta: 1.15 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_adjust_saturation) + self.assert_dictionary_close(args, {'min_delta': 0.75, 'max_delta': 1.15}) + + def test_build_random_distort_color(self): + preprocessor_text_proto = """ + random_distort_color { + color_ordering: 1 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_distort_color) + self.assertEqual(args, {'color_ordering': 1}) + + def test_build_random_jitter_boxes(self): + preprocessor_text_proto = """ + random_jitter_boxes { + ratio: 0.1 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_jitter_boxes) + self.assert_dictionary_close(args, {'ratio': 0.1}) + + def test_build_random_crop_image(self): + preprocessor_text_proto = """ + random_crop_image { + min_object_covered: 0.75 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.25 + max_area: 0.875 + overlap_thresh: 0.5 + clip_boxes: False + random_coef: 0.125 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_crop_image) + self.assertEqual(args, { + 'min_object_covered': 0.75, + 'aspect_ratio_range': (0.75, 1.5), + 'area_range': (0.25, 0.875), + 'overlap_thresh': 0.5, + 'clip_boxes': False, + 'random_coef': 0.125, + }) + + def test_build_random_pad_image(self): + preprocessor_text_proto = """ + random_pad_image { + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_pad_image) + self.assertEqual(args, { + 'min_image_size': None, + 'max_image_size': None, + 'pad_color': None, + }) + + def test_build_random_crop_pad_image(self): + preprocessor_text_proto = """ + random_crop_pad_image { + min_object_covered: 0.75 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.25 + max_area: 0.875 + overlap_thresh: 0.5 + clip_boxes: False + random_coef: 0.125 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_crop_pad_image) + self.assertEqual(args, { + 'min_object_covered': 0.75, + 'aspect_ratio_range': (0.75, 1.5), + 'area_range': (0.25, 0.875), + 'overlap_thresh': 0.5, + 'clip_boxes': False, + 'random_coef': 0.125, + }) + + def test_build_random_crop_pad_image_with_optional_parameters(self): + preprocessor_text_proto = """ + random_crop_pad_image { + min_object_covered: 0.75 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.25 + max_area: 0.875 + overlap_thresh: 0.5 + clip_boxes: False + random_coef: 0.125 + min_padded_size_ratio: 0.5 + min_padded_size_ratio: 0.75 + max_padded_size_ratio: 0.5 + max_padded_size_ratio: 0.75 + pad_color: 0.5 + pad_color: 0.5 + pad_color: 1.0 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_crop_pad_image) + self.assertEqual(args, { + 'min_object_covered': 0.75, + 'aspect_ratio_range': (0.75, 1.5), + 'area_range': (0.25, 0.875), + 'overlap_thresh': 0.5, + 'clip_boxes': False, + 'random_coef': 0.125, + 'min_padded_size_ratio': (0.5, 0.75), + 'max_padded_size_ratio': (0.5, 0.75), + 'pad_color': (0.5, 0.5, 1.0) + }) + + def test_build_random_crop_to_aspect_ratio(self): + preprocessor_text_proto = """ + random_crop_to_aspect_ratio { + aspect_ratio: 0.85 + overlap_thresh: 0.35 + clip_boxes: False + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_crop_to_aspect_ratio) + self.assert_dictionary_close(args, {'aspect_ratio': 0.85, + 'overlap_thresh': 0.35, + 'clip_boxes': False}) + + def test_build_random_black_patches(self): + preprocessor_text_proto = """ + random_black_patches { + max_black_patches: 20 + probability: 0.95 + size_to_image_ratio: 0.12 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_black_patches) + self.assert_dictionary_close(args, {'max_black_patches': 20, + 'probability': 0.95, + 'size_to_image_ratio': 0.12}) + + def test_build_random_resize_method(self): + preprocessor_text_proto = """ + random_resize_method { + target_height: 75 + target_width: 100 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.random_resize_method) + self.assert_dictionary_close(args, {'target_size': [75, 100]}) + + def test_build_scale_boxes_to_pixel_coordinates(self): + preprocessor_text_proto = """ + scale_boxes_to_pixel_coordinates {} + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.scale_boxes_to_pixel_coordinates) + self.assertEqual(args, {}) + + def test_build_resize_image(self): + preprocessor_text_proto = """ + resize_image { + new_height: 75 + new_width: 100 + method: BICUBIC + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.resize_image) + self.assertEqual(args, {'new_height': 75, + 'new_width': 100, + 'method': tf.image.ResizeMethod.BICUBIC}) + + def test_build_rgb_to_gray(self): + preprocessor_text_proto = """ + rgb_to_gray {} + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.rgb_to_gray) + self.assertEqual(args, {}) + + def test_build_subtract_channel_mean(self): + preprocessor_text_proto = """ + subtract_channel_mean { + means: [1.0, 2.0, 3.0] + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.subtract_channel_mean) + self.assertEqual(args, {'means': [1.0, 2.0, 3.0]}) + + def test_build_ssd_random_crop(self): + preprocessor_text_proto = """ + ssd_random_crop { + operations { + min_object_covered: 0.0 + min_aspect_ratio: 0.875 + max_aspect_ratio: 1.125 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.0 + clip_boxes: False + random_coef: 0.375 + } + operations { + min_object_covered: 0.25 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.25 + clip_boxes: True + random_coef: 0.375 + } + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.ssd_random_crop) + self.assertEqual(args, {'min_object_covered': [0.0, 0.25], + 'aspect_ratio_range': [(0.875, 1.125), (0.75, 1.5)], + 'area_range': [(0.5, 1.0), (0.5, 1.0)], + 'overlap_thresh': [0.0, 0.25], + 'clip_boxes': [False, True], + 'random_coef': [0.375, 0.375]}) + + def test_build_ssd_random_crop_empty_operations(self): + preprocessor_text_proto = """ + ssd_random_crop { + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.ssd_random_crop) + self.assertEqual(args, {}) + + def test_build_ssd_random_crop_pad(self): + preprocessor_text_proto = """ + ssd_random_crop_pad { + operations { + min_object_covered: 0.0 + min_aspect_ratio: 0.875 + max_aspect_ratio: 1.125 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.0 + clip_boxes: False + random_coef: 0.375 + min_padded_size_ratio: [1.0, 1.0] + max_padded_size_ratio: [2.0, 2.0] + pad_color_r: 0.5 + pad_color_g: 0.5 + pad_color_b: 0.5 + } + operations { + min_object_covered: 0.25 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.25 + clip_boxes: True + random_coef: 0.375 + min_padded_size_ratio: [1.0, 1.0] + max_padded_size_ratio: [2.0, 2.0] + pad_color_r: 0.5 + pad_color_g: 0.5 + pad_color_b: 0.5 + } + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.ssd_random_crop_pad) + self.assertEqual(args, {'min_object_covered': [0.0, 0.25], + 'aspect_ratio_range': [(0.875, 1.125), (0.75, 1.5)], + 'area_range': [(0.5, 1.0), (0.5, 1.0)], + 'overlap_thresh': [0.0, 0.25], + 'clip_boxes': [False, True], + 'random_coef': [0.375, 0.375], + 'min_padded_size_ratio': [(1.0, 1.0), (1.0, 1.0)], + 'max_padded_size_ratio': [(2.0, 2.0), (2.0, 2.0)], + 'pad_color': [(0.5, 0.5, 0.5), (0.5, 0.5, 0.5)]}) + + def test_build_ssd_random_crop_fixed_aspect_ratio(self): + preprocessor_text_proto = """ + ssd_random_crop_fixed_aspect_ratio { + operations { + min_object_covered: 0.0 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.0 + clip_boxes: False + random_coef: 0.375 + } + operations { + min_object_covered: 0.25 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.25 + clip_boxes: True + random_coef: 0.375 + } + aspect_ratio: 0.875 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.ssd_random_crop_fixed_aspect_ratio) + self.assertEqual(args, {'min_object_covered': [0.0, 0.25], + 'aspect_ratio': 0.875, + 'area_range': [(0.5, 1.0), (0.5, 1.0)], + 'overlap_thresh': [0.0, 0.25], + 'clip_boxes': [False, True], + 'random_coef': [0.375, 0.375]}) + + def test_build_ssd_random_crop_pad_fixed_aspect_ratio(self): + preprocessor_text_proto = """ + ssd_random_crop_pad_fixed_aspect_ratio { + operations { + min_object_covered: 0.0 + min_aspect_ratio: 0.875 + max_aspect_ratio: 1.125 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.0 + clip_boxes: False + random_coef: 0.375 + } + operations { + min_object_covered: 0.25 + min_aspect_ratio: 0.75 + max_aspect_ratio: 1.5 + min_area: 0.5 + max_area: 1.0 + overlap_thresh: 0.25 + clip_boxes: True + random_coef: 0.375 + } + aspect_ratio: 0.875 + min_padded_size_ratio: [1.0, 1.0] + max_padded_size_ratio: [2.0, 2.0] + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, + preprocessor.ssd_random_crop_pad_fixed_aspect_ratio) + self.assertEqual(args, {'min_object_covered': [0.0, 0.25], + 'aspect_ratio': 0.875, + 'aspect_ratio_range': [(0.875, 1.125), (0.75, 1.5)], + 'area_range': [(0.5, 1.0), (0.5, 1.0)], + 'overlap_thresh': [0.0, 0.25], + 'clip_boxes': [False, True], + 'random_coef': [0.375, 0.375], + 'min_padded_size_ratio': (1.0, 1.0), + 'max_padded_size_ratio': (2.0, 2.0)}) + + def test_build_normalize_image_convert_class_logits_to_softmax(self): + preprocessor_text_proto = """ + convert_class_logits_to_softmax { + temperature: 2 + } + """ + preprocessor_proto = preprocessor_pb2.PreprocessingStep() + text_format.Merge(preprocessor_text_proto, preprocessor_proto) + function, args = preprocessor_builder.build(preprocessor_proto) + self.assertEqual(function, preprocessor.convert_class_logits_to_softmax) + self.assertEqual(args, {'temperature': 2}) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder.py" new file mode 100644 index 00000000..157c94fb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder.py" @@ -0,0 +1,59 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Builder for region similarity calculators.""" + +from object_detection.core import region_similarity_calculator +from object_detection.protos import region_similarity_calculator_pb2 + + +def build(region_similarity_calculator_config): + """Builds region similarity calculator based on the configuration. + + Builds one of [IouSimilarity, IoaSimilarity, NegSqDistSimilarity] objects. See + core/region_similarity_calculator.proto for details. + + Args: + region_similarity_calculator_config: RegionSimilarityCalculator + configuration proto. + + Returns: + region_similarity_calculator: RegionSimilarityCalculator object. + + Raises: + ValueError: On unknown region similarity calculator. + """ + + if not isinstance( + region_similarity_calculator_config, + region_similarity_calculator_pb2.RegionSimilarityCalculator): + raise ValueError( + 'region_similarity_calculator_config not of type ' + 'region_similarity_calculator_pb2.RegionsSimilarityCalculator') + + similarity_calculator = region_similarity_calculator_config.WhichOneof( + 'region_similarity') + if similarity_calculator == 'iou_similarity': + return region_similarity_calculator.IouSimilarity() + if similarity_calculator == 'ioa_similarity': + return region_similarity_calculator.IoaSimilarity() + if similarity_calculator == 'neg_sq_dist_similarity': + return region_similarity_calculator.NegSqDistSimilarity() + if similarity_calculator == 'thresholded_iou_similarity': + return region_similarity_calculator.ThresholdedIouSimilarity( + region_similarity_calculator_config.thresholded_iou_similarity.threshold + ) + + raise ValueError('Unknown region similarity calculator.') diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder_test.py" new file mode 100644 index 00000000..ca3a5512 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/builders/region_similarity_calculator_builder_test.py" @@ -0,0 +1,67 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for region_similarity_calculator_builder.""" + +import tensorflow as tf + +from google.protobuf import text_format +from object_detection.builders import region_similarity_calculator_builder +from object_detection.core import region_similarity_calculator +from object_detection.protos import region_similarity_calculator_pb2 as sim_calc_pb2 + + +class RegionSimilarityCalculatorBuilderTest(tf.test.TestCase): + + def testBuildIoaSimilarityCalculator(self): + similarity_calc_text_proto = """ + ioa_similarity { + } + """ + similarity_calc_proto = sim_calc_pb2.RegionSimilarityCalculator() + text_format.Merge(similarity_calc_text_proto, similarity_calc_proto) + similarity_calc = region_similarity_calculator_builder.build( + similarity_calc_proto) + self.assertTrue(isinstance(similarity_calc, + region_similarity_calculator.IoaSimilarity)) + + def testBuildIouSimilarityCalculator(self): + similarity_calc_text_proto = """ + iou_similarity { + } + """ + similarity_calc_proto = sim_calc_pb2.RegionSimilarityCalculator() + text_format.Merge(similarity_calc_text_proto, similarity_calc_proto) + similarity_calc = region_similarity_calculator_builder.build( + similarity_calc_proto) + self.assertTrue(isinstance(similarity_calc, + region_similarity_calculator.IouSimilarity)) + + def testBuildNegSqDistSimilarityCalculator(self): + similarity_calc_text_proto = """ + neg_sq_dist_similarity { + } + """ + similarity_calc_proto = sim_calc_pb2.RegionSimilarityCalculator() + text_format.Merge(similarity_calc_text_proto, similarity_calc_proto) + similarity_calc = region_similarity_calculator_builder.build( + similarity_calc_proto) + self.assertTrue(isinstance(similarity_calc, + region_similarity_calculator. + NegSqDistSimilarity)) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/__init__.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/__init__.py" new file mode 100644 index 00000000..8b137891 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/__init__.py" @@ -0,0 +1 @@ + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/anchor_generator.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/anchor_generator.py" new file mode 100644 index 00000000..f2797ef7 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/anchor_generator.py" @@ -0,0 +1,150 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Base anchor generator. + +The job of the anchor generator is to create (or load) a collection +of bounding boxes to be used as anchors. + +Generated anchors are assumed to match some convolutional grid or list of grid +shapes. For example, we might want to generate anchors matching an 8x8 +feature map and a 4x4 feature map. If we place 3 anchors per grid location +on the first feature map and 6 anchors per grid location on the second feature +map, then 3*8*8 + 6*4*4 = 288 anchors are generated in total. + +To support fully convolutional settings, feature map shapes are passed +dynamically at generation time. The number of anchors to place at each location +is static --- implementations of AnchorGenerator must always be able return +the number of anchors that it uses per location for each feature map. +""" +from abc import ABCMeta +from abc import abstractmethod + +import tensorflow as tf + + +class AnchorGenerator(object): + """Abstract base class for anchor generators.""" + __metaclass__ = ABCMeta + + @abstractmethod + def name_scope(self): + """Name scope. + + Must be defined by implementations. + + Returns: + a string representing the name scope of the anchor generation operation. + """ + pass + + @property + def check_num_anchors(self): + """Whether to dynamically check the number of anchors generated. + + Can be overridden by implementations that would like to disable this + behavior. + + Returns: + a boolean controlling whether the Generate function should dynamically + check the number of anchors generated against the mathematically + expected number of anchors. + """ + return True + + @abstractmethod + def num_anchors_per_location(self): + """Returns the number of anchors per spatial location. + + Returns: + a list of integers, one for each expected feature map to be passed to + the `generate` function. + """ + pass + + def generate(self, feature_map_shape_list, **params): + """Generates a collection of bounding boxes to be used as anchors. + + TODO(rathodv): remove **params from argument list and make stride and + offsets (for multiple_grid_anchor_generator) constructor arguments. + + Args: + feature_map_shape_list: list of (height, width) pairs in the format + [(height_0, width_0), (height_1, width_1), ...] that the generated + anchors must align with. Pairs can be provided as 1-dimensional + integer tensors of length 2 or simply as tuples of integers. + **params: parameters for anchor generation op + + Returns: + boxes_list: a list of BoxLists each holding anchor boxes corresponding to + the input feature map shapes. + + Raises: + ValueError: if the number of feature map shapes does not match the length + of NumAnchorsPerLocation. + """ + if self.check_num_anchors and ( + len(feature_map_shape_list) != len(self.num_anchors_per_location())): + raise ValueError('Number of feature maps is expected to equal the length ' + 'of `num_anchors_per_location`.') + with tf.name_scope(self.name_scope()): + anchors_list = self._generate(feature_map_shape_list, **params) + if self.check_num_anchors: + with tf.control_dependencies([ + self._assert_correct_number_of_anchors( + anchors_list, feature_map_shape_list)]): + for item in anchors_list: + item.set(tf.identity(item.get())) + return anchors_list + + @abstractmethod + def _generate(self, feature_map_shape_list, **params): + """To be overridden by implementations. + + Args: + feature_map_shape_list: list of (height, width) pairs in the format + [(height_0, width_0), (height_1, width_1), ...] that the generated + anchors must align with. + **params: parameters for anchor generation op + + Returns: + boxes_list: a list of BoxList, each holding a collection of N anchor + boxes. + """ + pass + + def _assert_correct_number_of_anchors(self, anchors_list, + feature_map_shape_list): + """Assert that correct number of anchors was generated. + + Args: + anchors_list: A list of box_list.BoxList object holding anchors generated. + feature_map_shape_list: list of (height, width) pairs in the format + [(height_0, width_0), (height_1, width_1), ...] that the generated + anchors must align with. + Returns: + Op that raises InvalidArgumentError if the number of anchors does not + match the number of expected anchors. + """ + expected_num_anchors = 0 + actual_num_anchors = 0 + for num_anchors_per_location, feature_map_shape, anchors in zip( + self.num_anchors_per_location(), feature_map_shape_list, anchors_list): + expected_num_anchors += (num_anchors_per_location + * feature_map_shape[0] + * feature_map_shape[1]) + actual_num_anchors += anchors.num_boxes() + return tf.assert_equal(expected_num_anchors, actual_num_anchors) + diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler.py" new file mode 100644 index 00000000..a38f82f6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler.py" @@ -0,0 +1,264 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Class to subsample minibatches by balancing positives and negatives. + +Subsamples minibatches based on a pre-specified positive fraction in range +[0,1]. The class presumes there are many more negatives than positive examples: +if the desired batch_size cannot be achieved with the pre-specified positive +fraction, it fills the rest with negative examples. If this is not sufficient +for obtaining the desired batch_size, it returns fewer examples. + +The main function to call is Subsample(self, indicator, labels). For convenience +one can also call SubsampleWeights(self, weights, labels) which is defined in +the minibatch_sampler base class. + +When is_static is True, it implements a method that guarantees static shapes. +It also ensures the length of output of the subsample is always batch_size, even +when number of examples set to True in indicator is less than batch_size. +""" + +import tensorflow as tf + +from object_detection.core import minibatch_sampler +from object_detection.utils import ops + + +class BalancedPositiveNegativeSampler(minibatch_sampler.MinibatchSampler): + """Subsamples minibatches to a desired balance of positives and negatives.""" + + def __init__(self, positive_fraction=0.5, is_static=False): + """Constructs a minibatch sampler. + + Args: + positive_fraction: desired fraction of positive examples (scalar in [0,1]) + in the batch. + is_static: If True, uses an implementation with static shape guarantees. + + Raises: + ValueError: if positive_fraction < 0, or positive_fraction > 1 + """ + if positive_fraction < 0 or positive_fraction > 1: + raise ValueError('positive_fraction should be in range [0,1]. ' + 'Received: %s.' % positive_fraction) + self._positive_fraction = positive_fraction + self._is_static = is_static + + def _get_num_pos_neg_samples(self, sorted_indices_tensor, sample_size): + """Counts the number of positives and negatives numbers to be sampled. + + Args: + sorted_indices_tensor: A sorted int32 tensor of shape [N] which contains + the signed indices of the examples where the sign is based on the label + value. The examples that cannot be sampled are set to 0. It samples + atmost sample_size*positive_fraction positive examples and remaining + from negative examples. + sample_size: Size of subsamples. + + Returns: + A tuple containing the number of positive and negative labels in the + subsample. + """ + input_length = tf.shape(sorted_indices_tensor)[0] + valid_positive_index = tf.greater(sorted_indices_tensor, + tf.zeros(input_length, tf.int32)) + num_sampled_pos = tf.reduce_sum(tf.cast(valid_positive_index, tf.int32)) + max_num_positive_samples = tf.constant( + int(sample_size * self._positive_fraction), tf.int32) + num_positive_samples = tf.minimum(max_num_positive_samples, num_sampled_pos) + num_negative_samples = tf.constant(sample_size, + tf.int32) - num_positive_samples + + return num_positive_samples, num_negative_samples + + def _get_values_from_start_and_end(self, input_tensor, num_start_samples, + num_end_samples, total_num_samples): + """slices num_start_samples and last num_end_samples from input_tensor. + + Args: + input_tensor: An int32 tensor of shape [N] to be sliced. + num_start_samples: Number of examples to be sliced from the beginning + of the input tensor. + num_end_samples: Number of examples to be sliced from the end of the + input tensor. + total_num_samples: Sum of is num_start_samples and num_end_samples. This + should be a scalar. + + Returns: + A tensor containing the first num_start_samples and last num_end_samples + from input_tensor. + + """ + input_length = tf.shape(input_tensor)[0] + start_positions = tf.less(tf.range(input_length), num_start_samples) + end_positions = tf.greater_equal( + tf.range(input_length), input_length - num_end_samples) + selected_positions = tf.logical_or(start_positions, end_positions) + selected_positions = tf.cast(selected_positions, tf.float32) + indexed_positions = tf.multiply(tf.cumsum(selected_positions), + selected_positions) + one_hot_selector = tf.one_hot(tf.cast(indexed_positions, tf.int32) - 1, + total_num_samples, + dtype=tf.float32) + return tf.cast(tf.tensordot(tf.cast(input_tensor, tf.float32), + one_hot_selector, axes=[0, 0]), tf.int32) + + def _static_subsample(self, indicator, batch_size, labels): + """Returns subsampled minibatch. + + Args: + indicator: boolean tensor of shape [N] whose True entries can be sampled. + N should be a complie time constant. + batch_size: desired batch size. This scalar cannot be None. + labels: boolean tensor of shape [N] denoting positive(=True) and negative + (=False) examples. N should be a complie time constant. + + Returns: + sampled_idx_indicator: boolean tensor of shape [N], True for entries which + are sampled. It ensures the length of output of the subsample is always + batch_size, even when number of examples set to True in indicator is + less than batch_size. + + Raises: + ValueError: if labels and indicator are not 1D boolean tensors. + """ + # Check if indicator and labels have a static size. + if not indicator.shape.is_fully_defined(): + raise ValueError('indicator must be static in shape when is_static is' + 'True') + if not labels.shape.is_fully_defined(): + raise ValueError('labels must be static in shape when is_static is' + 'True') + if not isinstance(batch_size, int): + raise ValueError('batch_size has to be an integer when is_static is' + 'True.') + + input_length = tf.shape(indicator)[0] + + # Set the number of examples set True in indicator to be at least + # batch_size. + num_true_sampled = tf.reduce_sum(tf.cast(indicator, tf.float32)) + additional_false_sample = tf.less_equal( + tf.cumsum(tf.cast(tf.logical_not(indicator), tf.float32)), + batch_size - num_true_sampled) + indicator = tf.logical_or(indicator, additional_false_sample) + + # Shuffle indicator and label. Need to store the permutation to restore the + # order post sampling. + permutation = tf.random_shuffle(tf.range(input_length)) + indicator = ops.matmul_gather_on_zeroth_axis( + tf.cast(indicator, tf.float32), permutation) + labels = ops.matmul_gather_on_zeroth_axis( + tf.cast(labels, tf.float32), permutation) + + # index (starting from 1) when indicator is True, 0 when False + indicator_idx = tf.where( + tf.cast(indicator, tf.bool), tf.range(1, input_length + 1), + tf.zeros(input_length, tf.int32)) + + # Replace -1 for negative, +1 for positive labels + signed_label = tf.where( + tf.cast(labels, tf.bool), tf.ones(input_length, tf.int32), + tf.scalar_mul(-1, tf.ones(input_length, tf.int32))) + # negative of index for negative label, positive index for positive label, + # 0 when indicator is False. + signed_indicator_idx = tf.multiply(indicator_idx, signed_label) + sorted_signed_indicator_idx = tf.nn.top_k( + signed_indicator_idx, input_length, sorted=True).values + + [num_positive_samples, + num_negative_samples] = self._get_num_pos_neg_samples( + sorted_signed_indicator_idx, batch_size) + + sampled_idx = self._get_values_from_start_and_end( + sorted_signed_indicator_idx, num_positive_samples, + num_negative_samples, batch_size) + + # Shift the indices to start from 0 and remove any samples that are set as + # False. + sampled_idx = tf.abs(sampled_idx) - tf.ones(batch_size, tf.int32) + sampled_idx = tf.multiply( + tf.cast(tf.greater_equal(sampled_idx, tf.constant(0)), tf.int32), + sampled_idx) + + sampled_idx_indicator = tf.cast(tf.reduce_sum( + tf.one_hot(sampled_idx, depth=input_length), + axis=0), tf.bool) + + # project back the order based on stored permutations + reprojections = tf.one_hot(permutation, depth=input_length, + dtype=tf.float32) + return tf.cast(tf.tensordot( + tf.cast(sampled_idx_indicator, tf.float32), + reprojections, axes=[0, 0]), tf.bool) + + def subsample(self, indicator, batch_size, labels, scope=None): + """Returns subsampled minibatch. + + Args: + indicator: boolean tensor of shape [N] whose True entries can be sampled. + batch_size: desired batch size. If None, keeps all positive samples and + randomly selects negative samples so that the positive sample fraction + matches self._positive_fraction. It cannot be None is is_static is True. + labels: boolean tensor of shape [N] denoting positive(=True) and negative + (=False) examples. + scope: name scope. + + Returns: + sampled_idx_indicator: boolean tensor of shape [N], True for entries which + are sampled. + + Raises: + ValueError: if labels and indicator are not 1D boolean tensors. + """ + if len(indicator.get_shape().as_list()) != 1: + raise ValueError('indicator must be 1 dimensional, got a tensor of ' + 'shape %s' % indicator.get_shape()) + if len(labels.get_shape().as_list()) != 1: + raise ValueError('labels must be 1 dimensional, got a tensor of ' + 'shape %s' % labels.get_shape()) + if labels.dtype != tf.bool: + raise ValueError('labels should be of type bool. Received: %s' % + labels.dtype) + if indicator.dtype != tf.bool: + raise ValueError('indicator should be of type bool. Received: %s' % + indicator.dtype) + with tf.name_scope(scope, 'BalancedPositiveNegativeSampler'): + if self._is_static: + return self._static_subsample(indicator, batch_size, labels) + + else: + # Only sample from indicated samples + negative_idx = tf.logical_not(labels) + positive_idx = tf.logical_and(labels, indicator) + negative_idx = tf.logical_and(negative_idx, indicator) + + # Sample positive and negative samples separately + if batch_size is None: + max_num_pos = tf.reduce_sum(tf.to_int32(positive_idx)) + else: + max_num_pos = int(self._positive_fraction * batch_size) + sampled_pos_idx = self.subsample_indicator(positive_idx, max_num_pos) + num_sampled_pos = tf.reduce_sum(tf.cast(sampled_pos_idx, tf.int32)) + if batch_size is None: + negative_positive_ratio = ( + 1 - self._positive_fraction) / self._positive_fraction + max_num_neg = tf.to_int32( + negative_positive_ratio * tf.to_float(num_sampled_pos)) + else: + max_num_neg = batch_size - num_sampled_pos + sampled_neg_idx = self.subsample_indicator(negative_idx, max_num_neg) + + return tf.logical_or(sampled_pos_idx, sampled_neg_idx) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler_test.py" new file mode 100644 index 00000000..1df28e4c --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/balanced_positive_negative_sampler_test.py" @@ -0,0 +1,204 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.balanced_positive_negative_sampler.""" + +import numpy as np +import tensorflow as tf + +from object_detection.core import balanced_positive_negative_sampler +from object_detection.utils import test_case + + +class BalancedPositiveNegativeSamplerTest(test_case.TestCase): + + def test_subsample_all_examples_dynamic(self): + numpy_labels = np.random.permutation(300) + indicator = tf.constant(np.ones(300) == 1) + numpy_labels = (numpy_labels - 200) > 0 + + labels = tf.constant(numpy_labels) + + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler()) + is_sampled = sampler.subsample(indicator, 64, labels) + with self.test_session() as sess: + is_sampled = sess.run(is_sampled) + self.assertTrue(sum(is_sampled) == 64) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 32) + self.assertTrue(sum(np.logical_and( + np.logical_not(numpy_labels), is_sampled)) == 32) + + def test_subsample_all_examples_static(self): + numpy_labels = np.random.permutation(300) + indicator = np.array(np.ones(300) == 1, np.bool) + numpy_labels = (numpy_labels - 200) > 0 + + labels = np.array(numpy_labels, np.bool) + + def graph_fn(indicator, labels): + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler( + is_static=True)) + return sampler.subsample(indicator, 64, labels) + + is_sampled = self.execute(graph_fn, [indicator, labels]) + self.assertTrue(sum(is_sampled) == 64) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 32) + self.assertTrue(sum(np.logical_and( + np.logical_not(numpy_labels), is_sampled)) == 32) + + def test_subsample_selection_dynamic(self): + # Test random sampling when only some examples can be sampled: + # 100 samples, 20 positives, 10 positives cannot be sampled + numpy_labels = np.arange(100) + numpy_indicator = numpy_labels < 90 + indicator = tf.constant(numpy_indicator) + numpy_labels = (numpy_labels - 80) >= 0 + + labels = tf.constant(numpy_labels) + + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler()) + is_sampled = sampler.subsample(indicator, 64, labels) + with self.test_session() as sess: + is_sampled = sess.run(is_sampled) + self.assertTrue(sum(is_sampled) == 64) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 10) + self.assertTrue(sum(np.logical_and( + np.logical_not(numpy_labels), is_sampled)) == 54) + self.assertAllEqual(is_sampled, np.logical_and(is_sampled, + numpy_indicator)) + + def test_subsample_selection_static(self): + # Test random sampling when only some examples can be sampled: + # 100 samples, 20 positives, 10 positives cannot be sampled. + numpy_labels = np.arange(100) + numpy_indicator = numpy_labels < 90 + indicator = np.array(numpy_indicator, np.bool) + numpy_labels = (numpy_labels - 80) >= 0 + + labels = np.array(numpy_labels, np.bool) + + def graph_fn(indicator, labels): + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler( + is_static=True)) + return sampler.subsample(indicator, 64, labels) + + is_sampled = self.execute(graph_fn, [indicator, labels]) + self.assertTrue(sum(is_sampled) == 64) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 10) + self.assertTrue(sum(np.logical_and( + np.logical_not(numpy_labels), is_sampled)) == 54) + self.assertAllEqual(is_sampled, np.logical_and(is_sampled, numpy_indicator)) + + def test_subsample_selection_larger_batch_size_dynamic(self): + # Test random sampling when total number of examples that can be sampled are + # less than batch size: + # 100 samples, 50 positives, 40 positives cannot be sampled, batch size 64. + numpy_labels = np.arange(100) + numpy_indicator = numpy_labels < 60 + indicator = tf.constant(numpy_indicator) + numpy_labels = (numpy_labels - 50) >= 0 + + labels = tf.constant(numpy_labels) + + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler()) + is_sampled = sampler.subsample(indicator, 64, labels) + with self.test_session() as sess: + is_sampled = sess.run(is_sampled) + self.assertTrue(sum(is_sampled) == 60) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 10) + self.assertTrue( + sum(np.logical_and(np.logical_not(numpy_labels), is_sampled)) == 50) + self.assertAllEqual(is_sampled, np.logical_and(is_sampled, + numpy_indicator)) + + def test_subsample_selection_larger_batch_size_static(self): + # Test random sampling when total number of examples that can be sampled are + # less than batch size: + # 100 samples, 50 positives, 40 positives cannot be sampled, batch size 64. + # It should still return 64 samples, with 4 of them that couldn't have been + # sampled. + numpy_labels = np.arange(100) + numpy_indicator = numpy_labels < 60 + indicator = np.array(numpy_indicator, np.bool) + numpy_labels = (numpy_labels - 50) >= 0 + + labels = np.array(numpy_labels, np.bool) + + def graph_fn(indicator, labels): + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler( + is_static=True)) + return sampler.subsample(indicator, 64, labels) + + is_sampled = self.execute(graph_fn, [indicator, labels]) + self.assertTrue(sum(is_sampled) == 64) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) >= 10) + self.assertTrue( + sum(np.logical_and(np.logical_not(numpy_labels), is_sampled)) >= 50) + self.assertTrue(sum(np.logical_and(is_sampled, numpy_indicator)) == 60) + + def test_subsample_selection_no_batch_size(self): + # Test random sampling when only some examples can be sampled: + # 1000 samples, 6 positives (5 can be sampled). + numpy_labels = np.arange(1000) + numpy_indicator = numpy_labels < 999 + indicator = tf.constant(numpy_indicator) + numpy_labels = (numpy_labels - 994) >= 0 + + labels = tf.constant(numpy_labels) + + sampler = (balanced_positive_negative_sampler. + BalancedPositiveNegativeSampler(0.01)) + is_sampled = sampler.subsample(indicator, None, labels) + with self.test_session() as sess: + is_sampled = sess.run(is_sampled) + self.assertTrue(sum(is_sampled) == 500) + self.assertTrue(sum(np.logical_and(numpy_labels, is_sampled)) == 5) + self.assertTrue(sum(np.logical_and( + np.logical_not(numpy_labels), is_sampled)) == 495) + self.assertAllEqual(is_sampled, np.logical_and(is_sampled, + numpy_indicator)) + + def test_subsample_selection_no_batch_size_static(self): + labels = tf.constant([[True, False, False]]) + indicator = tf.constant([True, False, True]) + sampler = ( + balanced_positive_negative_sampler.BalancedPositiveNegativeSampler()) + with self.assertRaises(ValueError): + sampler.subsample(indicator, None, labels) + + def test_raises_error_with_incorrect_label_shape(self): + labels = tf.constant([[True, False, False]]) + indicator = tf.constant([True, False, True]) + sampler = (balanced_positive_negative_sampler. + BalancedPositiveNegativeSampler()) + with self.assertRaises(ValueError): + sampler.subsample(indicator, 64, labels) + + def test_raises_error_with_incorrect_indicator_shape(self): + labels = tf.constant([True, False, False]) + indicator = tf.constant([[True, False, True]]) + sampler = (balanced_positive_negative_sampler. + BalancedPositiveNegativeSampler()) + with self.assertRaises(ValueError): + sampler.subsample(indicator, 64, labels) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher.py" new file mode 100644 index 00000000..c5dfb712 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher.py" @@ -0,0 +1,136 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Provides functions to batch a dictionary of input tensors.""" +import collections + +import tensorflow as tf + +from object_detection.core import prefetcher + +rt_shape_str = '_runtime_shapes' + + +class BatchQueue(object): + """BatchQueue class. + + This class creates a batch queue to asynchronously enqueue tensors_dict. + It also adds a FIFO prefetcher so that the batches are readily available + for the consumers. Dequeue ops for a BatchQueue object can be created via + the Dequeue method which evaluates to a batch of tensor_dict. + + Example input pipeline with batching: + ------------------------------------ + key, string_tensor = slim.parallel_reader.parallel_read(...) + tensor_dict = decoder.decode(string_tensor) + tensor_dict = preprocessor.preprocess(tensor_dict, ...) + batch_queue = batcher.BatchQueue(tensor_dict, + batch_size=32, + batch_queue_capacity=2000, + num_batch_queue_threads=8, + prefetch_queue_capacity=20) + tensor_dict = batch_queue.dequeue() + outputs = Model(tensor_dict) + ... + ----------------------------------- + + Notes: + ----- + This class batches tensors of unequal sizes by zero padding and unpadding + them after generating a batch. This can be computationally expensive when + batching tensors (such as images) that are of vastly different sizes. So it is + recommended that the shapes of such tensors be fully defined in tensor_dict + while other lightweight tensors such as bounding box corners and class labels + can be of varying sizes. Use either crop or resize operations to fully define + the shape of an image in tensor_dict. + + It is also recommended to perform any preprocessing operations on tensors + before passing to BatchQueue and subsequently calling the Dequeue method. + + Another caveat is that this class does not read the last batch if it is not + full. The current implementation makes it hard to support that use case. So, + for evaluation, when it is critical to run all the examples through your + network use the input pipeline example mentioned in core/prefetcher.py. + """ + + def __init__(self, tensor_dict, batch_size, batch_queue_capacity, + num_batch_queue_threads, prefetch_queue_capacity): + """Constructs a batch queue holding tensor_dict. + + Args: + tensor_dict: dictionary of tensors to batch. + batch_size: batch size. + batch_queue_capacity: max capacity of the queue from which the tensors are + batched. + num_batch_queue_threads: number of threads to use for batching. + prefetch_queue_capacity: max capacity of the queue used to prefetch + assembled batches. + """ + # Remember static shapes to set shapes of batched tensors. + static_shapes = collections.OrderedDict( + {key: tensor.get_shape() for key, tensor in tensor_dict.items()}) + # Remember runtime shapes to unpad tensors after batching. + runtime_shapes = collections.OrderedDict( + {(key + rt_shape_str): tf.shape(tensor) + for key, tensor in tensor_dict.items()}) + + all_tensors = tensor_dict + all_tensors.update(runtime_shapes) + batched_tensors = tf.train.batch( + all_tensors, + capacity=batch_queue_capacity, + batch_size=batch_size, + dynamic_pad=True, + num_threads=num_batch_queue_threads) + + self._queue = prefetcher.prefetch(batched_tensors, + prefetch_queue_capacity) + self._static_shapes = static_shapes + self._batch_size = batch_size + + def dequeue(self): + """Dequeues a batch of tensor_dict from the BatchQueue. + + TODO: use allow_smaller_final_batch to allow running over the whole eval set + + Returns: + A list of tensor_dicts of the requested batch_size. + """ + batched_tensors = self._queue.dequeue() + # Separate input tensors from tensors containing their runtime shapes. + tensors = {} + shapes = {} + for key, batched_tensor in batched_tensors.items(): + unbatched_tensor_list = tf.unstack(batched_tensor) + for i, unbatched_tensor in enumerate(unbatched_tensor_list): + if rt_shape_str in key: + shapes[(key[:-len(rt_shape_str)], i)] = unbatched_tensor + else: + tensors[(key, i)] = unbatched_tensor + + # Undo that padding using shapes and create a list of size `batch_size` that + # contains tensor dictionaries. + tensor_dict_list = [] + batch_size = self._batch_size + for batch_id in range(batch_size): + tensor_dict = {} + for key in self._static_shapes: + tensor_dict[key] = tf.slice(tensors[(key, batch_id)], + tf.zeros_like(shapes[(key, batch_id)]), + shapes[(key, batch_id)]) + tensor_dict[key].set_shape(self._static_shapes[key]) + tensor_dict_list.append(tensor_dict) + + return tensor_dict_list diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher_test.py" new file mode 100644 index 00000000..61b4390b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/batcher_test.py" @@ -0,0 +1,158 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.batcher.""" + +import numpy as np +import tensorflow as tf + +from object_detection.core import batcher + +slim = tf.contrib.slim + + +class BatcherTest(tf.test.TestCase): + + def test_batch_and_unpad_2d_tensors_of_different_sizes_in_1st_dimension(self): + with self.test_session() as sess: + batch_size = 3 + num_batches = 2 + examples = tf.Variable(tf.constant(2, dtype=tf.int32)) + counter = examples.count_up_to(num_batches * batch_size + 2) + boxes = tf.tile( + tf.reshape(tf.range(4), [1, 4]), tf.stack([counter, tf.constant(1)])) + batch_queue = batcher.BatchQueue( + tensor_dict={'boxes': boxes}, + batch_size=batch_size, + batch_queue_capacity=100, + num_batch_queue_threads=1, + prefetch_queue_capacity=100) + batch = batch_queue.dequeue() + + for tensor_dict in batch: + for tensor in tensor_dict.values(): + self.assertAllEqual([None, 4], tensor.get_shape().as_list()) + + tf.initialize_all_variables().run() + with slim.queues.QueueRunners(sess): + i = 2 + for _ in range(num_batches): + batch_np = sess.run(batch) + for tensor_dict in batch_np: + for tensor in tensor_dict.values(): + self.assertAllEqual(tensor, np.tile(np.arange(4), (i, 1))) + i += 1 + with self.assertRaises(tf.errors.OutOfRangeError): + sess.run(batch) + + def test_batch_and_unpad_2d_tensors_of_different_sizes_in_all_dimensions( + self): + with self.test_session() as sess: + batch_size = 3 + num_batches = 2 + examples = tf.Variable(tf.constant(2, dtype=tf.int32)) + counter = examples.count_up_to(num_batches * batch_size + 2) + image = tf.reshape( + tf.range(counter * counter), tf.stack([counter, counter])) + batch_queue = batcher.BatchQueue( + tensor_dict={'image': image}, + batch_size=batch_size, + batch_queue_capacity=100, + num_batch_queue_threads=1, + prefetch_queue_capacity=100) + batch = batch_queue.dequeue() + + for tensor_dict in batch: + for tensor in tensor_dict.values(): + self.assertAllEqual([None, None], tensor.get_shape().as_list()) + + tf.initialize_all_variables().run() + with slim.queues.QueueRunners(sess): + i = 2 + for _ in range(num_batches): + batch_np = sess.run(batch) + for tensor_dict in batch_np: + for tensor in tensor_dict.values(): + self.assertAllEqual(tensor, np.arange(i * i).reshape((i, i))) + i += 1 + with self.assertRaises(tf.errors.OutOfRangeError): + sess.run(batch) + + def test_batch_and_unpad_2d_tensors_of_same_size_in_all_dimensions(self): + with self.test_session() as sess: + batch_size = 3 + num_batches = 2 + examples = tf.Variable(tf.constant(1, dtype=tf.int32)) + counter = examples.count_up_to(num_batches * batch_size + 1) + image = tf.reshape(tf.range(1, 13), [4, 3]) * counter + batch_queue = batcher.BatchQueue( + tensor_dict={'image': image}, + batch_size=batch_size, + batch_queue_capacity=100, + num_batch_queue_threads=1, + prefetch_queue_capacity=100) + batch = batch_queue.dequeue() + + for tensor_dict in batch: + for tensor in tensor_dict.values(): + self.assertAllEqual([4, 3], tensor.get_shape().as_list()) + + tf.initialize_all_variables().run() + with slim.queues.QueueRunners(sess): + i = 1 + for _ in range(num_batches): + batch_np = sess.run(batch) + for tensor_dict in batch_np: + for tensor in tensor_dict.values(): + self.assertAllEqual(tensor, np.arange(1, 13).reshape((4, 3)) * i) + i += 1 + with self.assertRaises(tf.errors.OutOfRangeError): + sess.run(batch) + + def test_batcher_when_batch_size_is_one(self): + with self.test_session() as sess: + batch_size = 1 + num_batches = 2 + examples = tf.Variable(tf.constant(2, dtype=tf.int32)) + counter = examples.count_up_to(num_batches * batch_size + 2) + image = tf.reshape( + tf.range(counter * counter), tf.stack([counter, counter])) + batch_queue = batcher.BatchQueue( + tensor_dict={'image': image}, + batch_size=batch_size, + batch_queue_capacity=100, + num_batch_queue_threads=1, + prefetch_queue_capacity=100) + batch = batch_queue.dequeue() + + for tensor_dict in batch: + for tensor in tensor_dict.values(): + self.assertAllEqual([None, None], tensor.get_shape().as_list()) + + tf.initialize_all_variables().run() + with slim.queues.QueueRunners(sess): + i = 2 + for _ in range(num_batches): + batch_np = sess.run(batch) + for tensor_dict in batch_np: + for tensor in tensor_dict.values(): + self.assertAllEqual(tensor, np.arange(i * i).reshape((i, i))) + i += 1 + with self.assertRaises(tf.errors.OutOfRangeError): + sess.run(batch) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder.py" new file mode 100644 index 00000000..f20ac956 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder.py" @@ -0,0 +1,151 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Base box coder. + +Box coders convert between coordinate frames, namely image-centric +(with (0,0) on the top left of image) and anchor-centric (with (0,0) being +defined by a specific anchor). + +Users of a BoxCoder can call two methods: + encode: which encodes a box with respect to a given anchor + (or rather, a tensor of boxes wrt a corresponding tensor of anchors) and + decode: which inverts this encoding with a decode operation. +In both cases, the arguments are assumed to be in 1-1 correspondence already; +it is not the job of a BoxCoder to perform matching. +""" +from abc import ABCMeta +from abc import abstractmethod +from abc import abstractproperty + +import tensorflow as tf + + +# Box coder types. +FASTER_RCNN = 'faster_rcnn' +KEYPOINT = 'keypoint' +MEAN_STDDEV = 'mean_stddev' +SQUARE = 'square' + + +class BoxCoder(object): + """Abstract base class for box coder.""" + __metaclass__ = ABCMeta + + @abstractproperty + def code_size(self): + """Return the size of each code. + + This number is a constant and should agree with the output of the `encode` + op (e.g. if rel_codes is the output of self.encode(...), then it should have + shape [N, code_size()]). This abstractproperty should be overridden by + implementations. + + Returns: + an integer constant + """ + pass + + def encode(self, boxes, anchors): + """Encode a box list relative to an anchor collection. + + Args: + boxes: BoxList holding N boxes to be encoded + anchors: BoxList of N anchors + + Returns: + a tensor representing N relative-encoded boxes + """ + with tf.name_scope('Encode'): + return self._encode(boxes, anchors) + + def decode(self, rel_codes, anchors): + """Decode boxes that are encoded relative to an anchor collection. + + Args: + rel_codes: a tensor representing N relative-encoded boxes + anchors: BoxList of anchors + + Returns: + boxlist: BoxList holding N boxes encoded in the ordinary way (i.e., + with corners y_min, x_min, y_max, x_max) + """ + with tf.name_scope('Decode'): + return self._decode(rel_codes, anchors) + + @abstractmethod + def _encode(self, boxes, anchors): + """Method to be overriden by implementations. + + Args: + boxes: BoxList holding N boxes to be encoded + anchors: BoxList of N anchors + + Returns: + a tensor representing N relative-encoded boxes + """ + pass + + @abstractmethod + def _decode(self, rel_codes, anchors): + """Method to be overriden by implementations. + + Args: + rel_codes: a tensor representing N relative-encoded boxes + anchors: BoxList of anchors + + Returns: + boxlist: BoxList holding N boxes encoded in the ordinary way (i.e., + with corners y_min, x_min, y_max, x_max) + """ + pass + + +def batch_decode(encoded_boxes, box_coder, anchors): + """Decode a batch of encoded boxes. + + This op takes a batch of encoded bounding boxes and transforms + them to a batch of bounding boxes specified by their corners in + the order of [y_min, x_min, y_max, x_max]. + + Args: + encoded_boxes: a float32 tensor of shape [batch_size, num_anchors, + code_size] representing the location of the objects. + box_coder: a BoxCoder object. + anchors: a BoxList of anchors used to encode `encoded_boxes`. + + Returns: + decoded_boxes: a float32 tensor of shape [batch_size, num_anchors, + coder_size] representing the corners of the objects in the order + of [y_min, x_min, y_max, x_max]. + + Raises: + ValueError: if batch sizes of the inputs are inconsistent, or if + the number of anchors inferred from encoded_boxes and anchors are + inconsistent. + """ + encoded_boxes.get_shape().assert_has_rank(3) + if encoded_boxes.get_shape()[1].value != anchors.num_boxes_static(): + raise ValueError('The number of anchors inferred from encoded_boxes' + ' and anchors are inconsistent: shape[1] of encoded_boxes' + ' %s should be equal to the number of anchors: %s.' % + (encoded_boxes.get_shape()[1].value, + anchors.num_boxes_static())) + + decoded_boxes = tf.stack([ + box_coder.decode(boxes, anchors).get() + for boxes in tf.unstack(encoded_boxes) + ]) + return decoded_boxes diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder_test.py" new file mode 100644 index 00000000..c087a325 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_coder_test.py" @@ -0,0 +1,61 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.box_coder.""" + +import tensorflow as tf + +from object_detection.core import box_coder +from object_detection.core import box_list + + +class MockBoxCoder(box_coder.BoxCoder): + """Test BoxCoder that encodes/decodes using the multiply-by-two function.""" + + def code_size(self): + return 4 + + def _encode(self, boxes, anchors): + return 2.0 * boxes.get() + + def _decode(self, rel_codes, anchors): + return box_list.BoxList(rel_codes / 2.0) + + +class BoxCoderTest(tf.test.TestCase): + + def test_batch_decode(self): + mock_anchor_corners = tf.constant( + [[0, 0.1, 0.2, 0.3], [0.2, 0.4, 0.4, 0.6]], tf.float32) + mock_anchors = box_list.BoxList(mock_anchor_corners) + mock_box_coder = MockBoxCoder() + + expected_boxes = [[[0.0, 0.1, 0.5, 0.6], [0.5, 0.6, 0.7, 0.8]], + [[0.1, 0.2, 0.3, 0.4], [0.7, 0.8, 0.9, 1.0]]] + + encoded_boxes_list = [mock_box_coder.encode( + box_list.BoxList(tf.constant(boxes)), mock_anchors) + for boxes in expected_boxes] + encoded_boxes = tf.stack(encoded_boxes_list) + decoded_boxes = box_coder.batch_decode( + encoded_boxes, mock_box_coder, mock_anchors) + + with self.test_session() as sess: + decoded_boxes_result = sess.run(decoded_boxes) + self.assertAllClose(expected_boxes, decoded_boxes_result) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list.py" new file mode 100644 index 00000000..c0196f05 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list.py" @@ -0,0 +1,207 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Bounding Box List definition. + +BoxList represents a list of bounding boxes as tensorflow +tensors, where each bounding box is represented as a row of 4 numbers, +[y_min, x_min, y_max, x_max]. It is assumed that all bounding boxes +within a given list correspond to a single image. See also +box_list_ops.py for common box related operations (such as area, iou, etc). + +Optionally, users can add additional related fields (such as weights). +We assume the following things to be true about fields: +* they correspond to boxes in the box_list along the 0th dimension +* they have inferrable rank at graph construction time +* all dimensions except for possibly the 0th can be inferred + (i.e., not None) at graph construction time. + +Some other notes: + * Following tensorflow conventions, we use height, width ordering, + and correspondingly, y,x (or ymin, xmin, ymax, xmax) ordering + * Tensors are always provided as (flat) [N, 4] tensors. +""" + +import tensorflow as tf + + +class BoxList(object): + """Box collection.""" + + def __init__(self, boxes): + """Constructs box collection. + + Args: + boxes: a tensor of shape [N, 4] representing box corners + + Raises: + ValueError: if invalid dimensions for bbox data or if bbox data is not in + float32 format. + """ + if len(boxes.get_shape()) != 2 or boxes.get_shape()[-1] != 4: + raise ValueError('Invalid dimensions for box data.') + if boxes.dtype != tf.float32: + raise ValueError('Invalid tensor type: should be tf.float32') + self.data = {'boxes': boxes} + + def num_boxes(self): + """Returns number of boxes held in collection. + + Returns: + a tensor representing the number of boxes held in the collection. + """ + return tf.shape(self.data['boxes'])[0] + + def num_boxes_static(self): + """Returns number of boxes held in collection. + + This number is inferred at graph construction time rather than run-time. + + Returns: + Number of boxes held in collection (integer) or None if this is not + inferrable at graph construction time. + """ + return self.data['boxes'].get_shape()[0].value + + def get_all_fields(self): + """Returns all fields.""" + return self.data.keys() + + def get_extra_fields(self): + """Returns all non-box fields (i.e., everything not named 'boxes').""" + return [k for k in self.data.keys() if k != 'boxes'] + + def add_field(self, field, field_data): + """Add field to box list. + + This method can be used to add related box data such as + weights/labels, etc. + + Args: + field: a string key to access the data via `get` + field_data: a tensor containing the data to store in the BoxList + """ + self.data[field] = field_data + + def has_field(self, field): + return field in self.data + + def get(self): + """Convenience function for accessing box coordinates. + + Returns: + a tensor with shape [N, 4] representing box coordinates. + """ + return self.get_field('boxes') + + def set(self, boxes): + """Convenience function for setting box coordinates. + + Args: + boxes: a tensor of shape [N, 4] representing box corners + + Raises: + ValueError: if invalid dimensions for bbox data + """ + if len(boxes.get_shape()) != 2 or boxes.get_shape()[-1] != 4: + raise ValueError('Invalid dimensions for box data.') + self.data['boxes'] = boxes + + def get_field(self, field): + """Accesses a box collection and associated fields. + + This function returns specified field with object; if no field is specified, + it returns the box coordinates. + + Args: + field: this optional string parameter can be used to specify + a related field to be accessed. + + Returns: + a tensor representing the box collection or an associated field. + + Raises: + ValueError: if invalid field + """ + if not self.has_field(field): + raise ValueError('field ' + str(field) + ' does not exist') + return self.data[field] + + def set_field(self, field, value): + """Sets the value of a field. + + Updates the field of a box_list with a given value. + + Args: + field: (string) name of the field to set value. + value: the value to assign to the field. + + Raises: + ValueError: if the box_list does not have specified field. + """ + if not self.has_field(field): + raise ValueError('field %s does not exist' % field) + self.data[field] = value + + def get_center_coordinates_and_sizes(self, scope=None): + """Computes the center coordinates, height and width of the boxes. + + Args: + scope: name scope of the function. + + Returns: + a list of 4 1-D tensors [ycenter, xcenter, height, width]. + """ + with tf.name_scope(scope, 'get_center_coordinates_and_sizes'): + box_corners = self.get() + ymin, xmin, ymax, xmax = tf.unstack(tf.transpose(box_corners)) + width = xmax - xmin + height = ymax - ymin + ycenter = ymin + height / 2. + xcenter = xmin + width / 2. + return [ycenter, xcenter, height, width] + + def transpose_coordinates(self, scope=None): + """Transpose the coordinate representation in a boxlist. + + Args: + scope: name scope of the function. + """ + with tf.name_scope(scope, 'transpose_coordinates'): + y_min, x_min, y_max, x_max = tf.split( + value=self.get(), num_or_size_splits=4, axis=1) + self.set(tf.concat([x_min, y_min, x_max, y_max], 1)) + + def as_tensor_dict(self, fields=None): + """Retrieves specified fields as a dictionary of tensors. + + Args: + fields: (optional) list of fields to return in the dictionary. + If None (default), all fields are returned. + + Returns: + tensor_dict: A dictionary of tensors specified by fields. + + Raises: + ValueError: if specified field is not contained in boxlist. + """ + tensor_dict = {} + if fields is None: + fields = self.get_all_fields() + for field in fields: + if not self.has_field(field): + raise ValueError('boxlist must contain all specified fields') + tensor_dict[field] = self.get_field(field) + return tensor_dict diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops.py" new file mode 100644 index 00000000..7c6d75c8 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops.py" @@ -0,0 +1,1136 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Bounding Box List operations. + +Example box operations that are supported: + * areas: compute bounding box areas + * iou: pairwise intersection-over-union scores + * sq_dist: pairwise distances between bounding boxes + +Whenever box_list_ops functions output a BoxList, the fields of the incoming +BoxList are retained unless documented otherwise. +""" +import tensorflow as tf + +from object_detection.core import box_list +from object_detection.utils import ops +from object_detection.utils import shape_utils + + +class SortOrder(object): + """Enum class for sort order. + + Attributes: + ascend: ascend order. + descend: descend order. + """ + ascend = 1 + descend = 2 + + +def area(boxlist, scope=None): + """Computes area of boxes. + + Args: + boxlist: BoxList holding N boxes + scope: name scope. + + Returns: + a tensor with shape [N] representing box areas. + """ + with tf.name_scope(scope, 'Area'): + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + return tf.squeeze((y_max - y_min) * (x_max - x_min), [1]) + + +def height_width(boxlist, scope=None): + """Computes height and width of boxes in boxlist. + + Args: + boxlist: BoxList holding N boxes + scope: name scope. + + Returns: + Height: A tensor with shape [N] representing box heights. + Width: A tensor with shape [N] representing box widths. + """ + with tf.name_scope(scope, 'HeightWidth'): + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + return tf.squeeze(y_max - y_min, [1]), tf.squeeze(x_max - x_min, [1]) + + +def scale(boxlist, y_scale, x_scale, scope=None): + """scale box coordinates in x and y dimensions. + + Args: + boxlist: BoxList holding N boxes + y_scale: (float) scalar tensor + x_scale: (float) scalar tensor + scope: name scope. + + Returns: + boxlist: BoxList holding N boxes + """ + with tf.name_scope(scope, 'Scale'): + y_scale = tf.cast(y_scale, tf.float32) + x_scale = tf.cast(x_scale, tf.float32) + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + y_min = y_scale * y_min + y_max = y_scale * y_max + x_min = x_scale * x_min + x_max = x_scale * x_max + scaled_boxlist = box_list.BoxList( + tf.concat([y_min, x_min, y_max, x_max], 1)) + return _copy_extra_fields(scaled_boxlist, boxlist) + + +def clip_to_window(boxlist, window, filter_nonoverlapping=True, scope=None): + """Clip bounding boxes to a window. + + This op clips any input bounding boxes (represented by bounding box + corners) to a window, optionally filtering out boxes that do not + overlap at all with the window. + + Args: + boxlist: BoxList holding M_in boxes + window: a tensor of shape [4] representing the [y_min, x_min, y_max, x_max] + window to which the op should clip boxes. + filter_nonoverlapping: whether to filter out boxes that do not overlap at + all with the window. + scope: name scope. + + Returns: + a BoxList holding M_out boxes where M_out <= M_in + """ + with tf.name_scope(scope, 'ClipToWindow'): + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + win_y_min, win_x_min, win_y_max, win_x_max = tf.unstack(window) + y_min_clipped = tf.maximum(tf.minimum(y_min, win_y_max), win_y_min) + y_max_clipped = tf.maximum(tf.minimum(y_max, win_y_max), win_y_min) + x_min_clipped = tf.maximum(tf.minimum(x_min, win_x_max), win_x_min) + x_max_clipped = tf.maximum(tf.minimum(x_max, win_x_max), win_x_min) + clipped = box_list.BoxList( + tf.concat([y_min_clipped, x_min_clipped, y_max_clipped, x_max_clipped], + 1)) + clipped = _copy_extra_fields(clipped, boxlist) + if filter_nonoverlapping: + areas = area(clipped) + nonzero_area_indices = tf.cast( + tf.reshape(tf.where(tf.greater(areas, 0.0)), [-1]), tf.int32) + clipped = gather(clipped, nonzero_area_indices) + return clipped + + +def prune_outside_window(boxlist, window, scope=None): + """Prunes bounding boxes that fall outside a given window. + + This function prunes bounding boxes that even partially fall outside the given + window. See also clip_to_window which only prunes bounding boxes that fall + completely outside the window, and clips any bounding boxes that partially + overflow. + + Args: + boxlist: a BoxList holding M_in boxes. + window: a float tensor of shape [4] representing [ymin, xmin, ymax, xmax] + of the window + scope: name scope. + + Returns: + pruned_corners: a tensor with shape [M_out, 4] where M_out <= M_in + valid_indices: a tensor with shape [M_out] indexing the valid bounding boxes + in the input tensor. + """ + with tf.name_scope(scope, 'PruneOutsideWindow'): + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + win_y_min, win_x_min, win_y_max, win_x_max = tf.unstack(window) + coordinate_violations = tf.concat([ + tf.less(y_min, win_y_min), tf.less(x_min, win_x_min), + tf.greater(y_max, win_y_max), tf.greater(x_max, win_x_max) + ], 1) + valid_indices = tf.reshape( + tf.where(tf.logical_not(tf.reduce_any(coordinate_violations, 1))), [-1]) + return gather(boxlist, valid_indices), valid_indices + + +def prune_completely_outside_window(boxlist, window, scope=None): + """Prunes bounding boxes that fall completely outside of the given window. + + The function clip_to_window prunes bounding boxes that fall + completely outside the window, but also clips any bounding boxes that + partially overflow. This function does not clip partially overflowing boxes. + + Args: + boxlist: a BoxList holding M_in boxes. + window: a float tensor of shape [4] representing [ymin, xmin, ymax, xmax] + of the window + scope: name scope. + + Returns: + pruned_boxlist: a new BoxList with all bounding boxes partially or fully in + the window. + valid_indices: a tensor with shape [M_out] indexing the valid bounding boxes + in the input tensor. + """ + with tf.name_scope(scope, 'PruneCompleteleyOutsideWindow'): + y_min, x_min, y_max, x_max = tf.split( + value=boxlist.get(), num_or_size_splits=4, axis=1) + win_y_min, win_x_min, win_y_max, win_x_max = tf.unstack(window) + coordinate_violations = tf.concat([ + tf.greater_equal(y_min, win_y_max), tf.greater_equal(x_min, win_x_max), + tf.less_equal(y_max, win_y_min), tf.less_equal(x_max, win_x_min) + ], 1) + valid_indices = tf.reshape( + tf.where(tf.logical_not(tf.reduce_any(coordinate_violations, 1))), [-1]) + return gather(boxlist, valid_indices), valid_indices + + +def intersection(boxlist1, boxlist2, scope=None): + """Compute pairwise intersection areas between boxes. + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding M boxes + scope: name scope. + + Returns: + a tensor with shape [N, M] representing pairwise intersections + """ + with tf.name_scope(scope, 'Intersection'): + y_min1, x_min1, y_max1, x_max1 = tf.split( + value=boxlist1.get(), num_or_size_splits=4, axis=1) + y_min2, x_min2, y_max2, x_max2 = tf.split( + value=boxlist2.get(), num_or_size_splits=4, axis=1) + all_pairs_min_ymax = tf.minimum(y_max1, tf.transpose(y_max2)) + all_pairs_max_ymin = tf.maximum(y_min1, tf.transpose(y_min2)) + intersect_heights = tf.maximum(0.0, all_pairs_min_ymax - all_pairs_max_ymin) + all_pairs_min_xmax = tf.minimum(x_max1, tf.transpose(x_max2)) + all_pairs_max_xmin = tf.maximum(x_min1, tf.transpose(x_min2)) + intersect_widths = tf.maximum(0.0, all_pairs_min_xmax - all_pairs_max_xmin) + return intersect_heights * intersect_widths + + +def matched_intersection(boxlist1, boxlist2, scope=None): + """Compute intersection areas between corresponding boxes in two boxlists. + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding N boxes + scope: name scope. + + Returns: + a tensor with shape [N] representing pairwise intersections + """ + with tf.name_scope(scope, 'MatchedIntersection'): + y_min1, x_min1, y_max1, x_max1 = tf.split( + value=boxlist1.get(), num_or_size_splits=4, axis=1) + y_min2, x_min2, y_max2, x_max2 = tf.split( + value=boxlist2.get(), num_or_size_splits=4, axis=1) + min_ymax = tf.minimum(y_max1, y_max2) + max_ymin = tf.maximum(y_min1, y_min2) + intersect_heights = tf.maximum(0.0, min_ymax - max_ymin) + min_xmax = tf.minimum(x_max1, x_max2) + max_xmin = tf.maximum(x_min1, x_min2) + intersect_widths = tf.maximum(0.0, min_xmax - max_xmin) + return tf.reshape(intersect_heights * intersect_widths, [-1]) + + +def iou(boxlist1, boxlist2, scope=None): + """Computes pairwise intersection-over-union between box collections. + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding M boxes + scope: name scope. + + Returns: + a tensor with shape [N, M] representing pairwise iou scores. + """ + with tf.name_scope(scope, 'IOU'): + intersections = intersection(boxlist1, boxlist2) + areas1 = area(boxlist1) + areas2 = area(boxlist2) + unions = ( + tf.expand_dims(areas1, 1) + tf.expand_dims(areas2, 0) - intersections) + return tf.where( + tf.equal(intersections, 0.0), + tf.zeros_like(intersections), tf.truediv(intersections, unions)) + + +def matched_iou(boxlist1, boxlist2, scope=None): + """Compute intersection-over-union between corresponding boxes in boxlists. + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding N boxes + scope: name scope. + + Returns: + a tensor with shape [N] representing pairwise iou scores. + """ + with tf.name_scope(scope, 'MatchedIOU'): + intersections = matched_intersection(boxlist1, boxlist2) + areas1 = area(boxlist1) + areas2 = area(boxlist2) + unions = areas1 + areas2 - intersections + return tf.where( + tf.equal(intersections, 0.0), + tf.zeros_like(intersections), tf.truediv(intersections, unions)) + + +def ioa(boxlist1, boxlist2, scope=None): + """Computes pairwise intersection-over-area between box collections. + + intersection-over-area (IOA) between two boxes box1 and box2 is defined as + their intersection area over box2's area. Note that ioa is not symmetric, + that is, ioa(box1, box2) != ioa(box2, box1). + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding M boxes + scope: name scope. + + Returns: + a tensor with shape [N, M] representing pairwise ioa scores. + """ + with tf.name_scope(scope, 'IOA'): + intersections = intersection(boxlist1, boxlist2) + areas = tf.expand_dims(area(boxlist2), 0) + return tf.truediv(intersections, areas) + + +def prune_non_overlapping_boxes( + boxlist1, boxlist2, min_overlap=0.0, scope=None): + """Prunes the boxes in boxlist1 that overlap less than thresh with boxlist2. + + For each box in boxlist1, we want its IOA to be more than minoverlap with + at least one of the boxes in boxlist2. If it does not, we remove it. + + Args: + boxlist1: BoxList holding N boxes. + boxlist2: BoxList holding M boxes. + min_overlap: Minimum required overlap between boxes, to count them as + overlapping. + scope: name scope. + + Returns: + new_boxlist1: A pruned boxlist with size [N', 4]. + keep_inds: A tensor with shape [N'] indexing kept bounding boxes in the + first input BoxList `boxlist1`. + """ + with tf.name_scope(scope, 'PruneNonOverlappingBoxes'): + ioa_ = ioa(boxlist2, boxlist1) # [M, N] tensor + ioa_ = tf.reduce_max(ioa_, reduction_indices=[0]) # [N] tensor + keep_bool = tf.greater_equal(ioa_, tf.constant(min_overlap)) + keep_inds = tf.squeeze(tf.where(keep_bool), squeeze_dims=[1]) + new_boxlist1 = gather(boxlist1, keep_inds) + return new_boxlist1, keep_inds + + +def prune_small_boxes(boxlist, min_side, scope=None): + """Prunes small boxes in the boxlist which have a side smaller than min_side. + + Args: + boxlist: BoxList holding N boxes. + min_side: Minimum width AND height of box to survive pruning. + scope: name scope. + + Returns: + A pruned boxlist. + """ + with tf.name_scope(scope, 'PruneSmallBoxes'): + height, width = height_width(boxlist) + is_valid = tf.logical_and(tf.greater_equal(width, min_side), + tf.greater_equal(height, min_side)) + return gather(boxlist, tf.reshape(tf.where(is_valid), [-1])) + + +def change_coordinate_frame(boxlist, window, scope=None): + """Change coordinate frame of the boxlist to be relative to window's frame. + + Given a window of the form [ymin, xmin, ymax, xmax], + changes bounding box coordinates from boxlist to be relative to this window + (e.g., the min corner maps to (0,0) and the max corner maps to (1,1)). + + An example use case is data augmentation: where we are given groundtruth + boxes (boxlist) and would like to randomly crop the image to some + window (window). In this case we need to change the coordinate frame of + each groundtruth box to be relative to this new window. + + Args: + boxlist: A BoxList object holding N boxes. + window: A rank 1 tensor [4]. + scope: name scope. + + Returns: + Returns a BoxList object with N boxes. + """ + with tf.name_scope(scope, 'ChangeCoordinateFrame'): + win_height = window[2] - window[0] + win_width = window[3] - window[1] + boxlist_new = scale(box_list.BoxList( + boxlist.get() - [window[0], window[1], window[0], window[1]]), + 1.0 / win_height, 1.0 / win_width) + boxlist_new = _copy_extra_fields(boxlist_new, boxlist) + return boxlist_new + + +def sq_dist(boxlist1, boxlist2, scope=None): + """Computes the pairwise squared distances between box corners. + + This op treats each box as if it were a point in a 4d Euclidean space and + computes pairwise squared distances. + + Mathematically, we are given two matrices of box coordinates X and Y, + where X(i,:) is the i'th row of X, containing the 4 numbers defining the + corners of the i'th box in boxlist1. Similarly Y(j,:) corresponds to + boxlist2. We compute + Z(i,j) = ||X(i,:) - Y(j,:)||^2 + = ||X(i,:)||^2 + ||Y(j,:)||^2 - 2 X(i,:)' * Y(j,:), + + Args: + boxlist1: BoxList holding N boxes + boxlist2: BoxList holding M boxes + scope: name scope. + + Returns: + a tensor with shape [N, M] representing pairwise distances + """ + with tf.name_scope(scope, 'SqDist'): + sqnorm1 = tf.reduce_sum(tf.square(boxlist1.get()), 1, keep_dims=True) + sqnorm2 = tf.reduce_sum(tf.square(boxlist2.get()), 1, keep_dims=True) + innerprod = tf.matmul(boxlist1.get(), boxlist2.get(), + transpose_a=False, transpose_b=True) + return sqnorm1 + tf.transpose(sqnorm2) - 2.0 * innerprod + + +def boolean_mask(boxlist, indicator, fields=None, scope=None, + use_static_shapes=False, indicator_sum=None): + """Select boxes from BoxList according to indicator and return new BoxList. + + `boolean_mask` returns the subset of boxes that are marked as "True" by the + indicator tensor. By default, `boolean_mask` returns boxes corresponding to + the input index list, as well as all additional fields stored in the boxlist + (indexing into the first dimension). However one can optionally only draw + from a subset of fields. + + Args: + boxlist: BoxList holding N boxes + indicator: a rank-1 boolean tensor + fields: (optional) list of fields to also gather from. If None (default), + all fields are gathered from. Pass an empty fields list to only gather + the box coordinates. + scope: name scope. + use_static_shapes: Whether to use an implementation with static shape + gurantees. + indicator_sum: An integer containing the sum of `indicator` vector. Only + required if `use_static_shape` is True. + + Returns: + subboxlist: a BoxList corresponding to the subset of the input BoxList + specified by indicator + Raises: + ValueError: if `indicator` is not a rank-1 boolean tensor. + """ + with tf.name_scope(scope, 'BooleanMask'): + if indicator.shape.ndims != 1: + raise ValueError('indicator should have rank 1') + if indicator.dtype != tf.bool: + raise ValueError('indicator should be a boolean tensor') + if use_static_shapes: + if not (indicator_sum and isinstance(indicator_sum, int)): + raise ValueError('`indicator_sum` must be a of type int') + selected_positions = tf.to_float(indicator) + indexed_positions = tf.cast( + tf.multiply( + tf.cumsum(selected_positions), selected_positions), + dtype=tf.int32) + one_hot_selector = tf.one_hot( + indexed_positions - 1, indicator_sum, dtype=tf.float32) + sampled_indices = tf.cast( + tf.tensordot( + tf.to_float(tf.range(tf.shape(indicator)[0])), + one_hot_selector, + axes=[0, 0]), + dtype=tf.int32) + return gather(boxlist, sampled_indices, use_static_shapes=True) + else: + subboxlist = box_list.BoxList(tf.boolean_mask(boxlist.get(), indicator)) + if fields is None: + fields = boxlist.get_extra_fields() + for field in fields: + if not boxlist.has_field(field): + raise ValueError('boxlist must contain all specified fields') + subfieldlist = tf.boolean_mask(boxlist.get_field(field), indicator) + subboxlist.add_field(field, subfieldlist) + return subboxlist + + +def gather(boxlist, indices, fields=None, scope=None, use_static_shapes=False): + """Gather boxes from BoxList according to indices and return new BoxList. + + By default, `gather` returns boxes corresponding to the input index list, as + well as all additional fields stored in the boxlist (indexing into the + first dimension). However one can optionally only gather from a + subset of fields. + + Args: + boxlist: BoxList holding N boxes + indices: a rank-1 tensor of type int32 / int64 + fields: (optional) list of fields to also gather from. If None (default), + all fields are gathered from. Pass an empty fields list to only gather + the box coordinates. + scope: name scope. + use_static_shapes: Whether to use an implementation with static shape + gurantees. + + Returns: + subboxlist: a BoxList corresponding to the subset of the input BoxList + specified by indices + Raises: + ValueError: if specified field is not contained in boxlist or if the + indices are not of type int32 + """ + with tf.name_scope(scope, 'Gather'): + if len(indices.shape.as_list()) != 1: + raise ValueError('indices should have rank 1') + if indices.dtype != tf.int32 and indices.dtype != tf.int64: + raise ValueError('indices should be an int32 / int64 tensor') + gather_op = tf.gather + if use_static_shapes: + gather_op = ops.matmul_gather_on_zeroth_axis + subboxlist = box_list.BoxList(gather_op(boxlist.get(), indices)) + if fields is None: + fields = boxlist.get_extra_fields() + fields += ['boxes'] + for field in fields: + if not boxlist.has_field(field): + raise ValueError('boxlist must contain all specified fields') + subfieldlist = gather_op(boxlist.get_field(field), indices) + subboxlist.add_field(field, subfieldlist) + return subboxlist + + +def concatenate(boxlists, fields=None, scope=None): + """Concatenate list of BoxLists. + + This op concatenates a list of input BoxLists into a larger BoxList. It also + handles concatenation of BoxList fields as long as the field tensor shapes + are equal except for the first dimension. + + Args: + boxlists: list of BoxList objects + fields: optional list of fields to also concatenate. By default, all + fields from the first BoxList in the list are included in the + concatenation. + scope: name scope. + + Returns: + a BoxList with number of boxes equal to + sum([boxlist.num_boxes() for boxlist in BoxList]) + Raises: + ValueError: if boxlists is invalid (i.e., is not a list, is empty, or + contains non BoxList objects), or if requested fields are not contained in + all boxlists + """ + with tf.name_scope(scope, 'Concatenate'): + if not isinstance(boxlists, list): + raise ValueError('boxlists should be a list') + if not boxlists: + raise ValueError('boxlists should have nonzero length') + for boxlist in boxlists: + if not isinstance(boxlist, box_list.BoxList): + raise ValueError('all elements of boxlists should be BoxList objects') + concatenated = box_list.BoxList( + tf.concat([boxlist.get() for boxlist in boxlists], 0)) + if fields is None: + fields = boxlists[0].get_extra_fields() + for field in fields: + first_field_shape = boxlists[0].get_field(field).get_shape().as_list() + first_field_shape[0] = -1 + if None in first_field_shape: + raise ValueError('field %s must have fully defined shape except for the' + ' 0th dimension.' % field) + for boxlist in boxlists: + if not boxlist.has_field(field): + raise ValueError('boxlist must contain all requested fields') + field_shape = boxlist.get_field(field).get_shape().as_list() + field_shape[0] = -1 + if field_shape != first_field_shape: + raise ValueError('field %s must have same shape for all boxlists ' + 'except for the 0th dimension.' % field) + concatenated_field = tf.concat( + [boxlist.get_field(field) for boxlist in boxlists], 0) + concatenated.add_field(field, concatenated_field) + return concatenated + + +def sort_by_field(boxlist, field, order=SortOrder.descend, scope=None): + """Sort boxes and associated fields according to a scalar field. + + A common use case is reordering the boxes according to descending scores. + + Args: + boxlist: BoxList holding N boxes. + field: A BoxList field for sorting and reordering the BoxList. + order: (Optional) descend or ascend. Default is descend. + scope: name scope. + + Returns: + sorted_boxlist: A sorted BoxList with the field in the specified order. + + Raises: + ValueError: if specified field does not exist + ValueError: if the order is not either descend or ascend + """ + with tf.name_scope(scope, 'SortByField'): + if order != SortOrder.descend and order != SortOrder.ascend: + raise ValueError('Invalid sort order') + + field_to_sort = boxlist.get_field(field) + if len(field_to_sort.shape.as_list()) != 1: + raise ValueError('Field should have rank 1') + + num_boxes = boxlist.num_boxes() + num_entries = tf.size(field_to_sort) + length_assert = tf.Assert( + tf.equal(num_boxes, num_entries), + ['Incorrect field size: actual vs expected.', num_entries, num_boxes]) + + with tf.control_dependencies([length_assert]): + _, sorted_indices = tf.nn.top_k(field_to_sort, num_boxes, sorted=True) + + if order == SortOrder.ascend: + sorted_indices = tf.reverse_v2(sorted_indices, [0]) + + return gather(boxlist, sorted_indices) + + +def visualize_boxes_in_image(image, boxlist, normalized=False, scope=None): + """Overlay bounding box list on image. + + Currently this visualization plots a 1 pixel thick red bounding box on top + of the image. Note that tf.image.draw_bounding_boxes essentially is + 1 indexed. + + Args: + image: an image tensor with shape [height, width, 3] + boxlist: a BoxList + normalized: (boolean) specify whether corners are to be interpreted + as absolute coordinates in image space or normalized with respect to the + image size. + scope: name scope. + + Returns: + image_and_boxes: an image tensor with shape [height, width, 3] + """ + with tf.name_scope(scope, 'VisualizeBoxesInImage'): + if not normalized: + height, width, _ = tf.unstack(tf.shape(image)) + boxlist = scale(boxlist, + 1.0 / tf.cast(height, tf.float32), + 1.0 / tf.cast(width, tf.float32)) + corners = tf.expand_dims(boxlist.get(), 0) + image = tf.expand_dims(image, 0) + return tf.squeeze(tf.image.draw_bounding_boxes(image, corners), [0]) + + +def filter_field_value_equals(boxlist, field, value, scope=None): + """Filter to keep only boxes with field entries equal to the given value. + + Args: + boxlist: BoxList holding N boxes. + field: field name for filtering. + value: scalar value. + scope: name scope. + + Returns: + a BoxList holding M boxes where M <= N + + Raises: + ValueError: if boxlist not a BoxList object or if it does not have + the specified field. + """ + with tf.name_scope(scope, 'FilterFieldValueEquals'): + if not isinstance(boxlist, box_list.BoxList): + raise ValueError('boxlist must be a BoxList') + if not boxlist.has_field(field): + raise ValueError('boxlist must contain the specified field') + filter_field = boxlist.get_field(field) + gather_index = tf.reshape(tf.where(tf.equal(filter_field, value)), [-1]) + return gather(boxlist, gather_index) + + +def filter_greater_than(boxlist, thresh, scope=None): + """Filter to keep only boxes with score exceeding a given threshold. + + This op keeps the collection of boxes whose corresponding scores are + greater than the input threshold. + + TODO(jonathanhuang): Change function name to filter_scores_greater_than + + Args: + boxlist: BoxList holding N boxes. Must contain a 'scores' field + representing detection scores. + thresh: scalar threshold + scope: name scope. + + Returns: + a BoxList holding M boxes where M <= N + + Raises: + ValueError: if boxlist not a BoxList object or if it does not + have a scores field + """ + with tf.name_scope(scope, 'FilterGreaterThan'): + if not isinstance(boxlist, box_list.BoxList): + raise ValueError('boxlist must be a BoxList') + if not boxlist.has_field('scores'): + raise ValueError('input boxlist must have \'scores\' field') + scores = boxlist.get_field('scores') + if len(scores.shape.as_list()) > 2: + raise ValueError('Scores should have rank 1 or 2') + if len(scores.shape.as_list()) == 2 and scores.shape.as_list()[1] != 1: + raise ValueError('Scores should have rank 1 or have shape ' + 'consistent with [None, 1]') + high_score_indices = tf.cast(tf.reshape( + tf.where(tf.greater(scores, thresh)), + [-1]), tf.int32) + return gather(boxlist, high_score_indices) + + +def non_max_suppression(boxlist, thresh, max_output_size, scope=None): + """Non maximum suppression. + + This op greedily selects a subset of detection bounding boxes, pruning + away boxes that have high IOU (intersection over union) overlap (> thresh) + with already selected boxes. Note that this only works for a single class --- + to apply NMS to multi-class predictions, use MultiClassNonMaxSuppression. + + Args: + boxlist: BoxList holding N boxes. Must contain a 'scores' field + representing detection scores. + thresh: scalar threshold + max_output_size: maximum number of retained boxes + scope: name scope. + + Returns: + a BoxList holding M boxes where M <= max_output_size + Raises: + ValueError: if thresh is not in [0, 1] + """ + with tf.name_scope(scope, 'NonMaxSuppression'): + if not 0 <= thresh <= 1.0: + raise ValueError('thresh must be between 0 and 1') + if not isinstance(boxlist, box_list.BoxList): + raise ValueError('boxlist must be a BoxList') + if not boxlist.has_field('scores'): + raise ValueError('input boxlist must have \'scores\' field') + selected_indices = tf.image.non_max_suppression( + boxlist.get(), boxlist.get_field('scores'), + max_output_size, iou_threshold=thresh) + return gather(boxlist, selected_indices) + + +def _copy_extra_fields(boxlist_to_copy_to, boxlist_to_copy_from): + """Copies the extra fields of boxlist_to_copy_from to boxlist_to_copy_to. + + Args: + boxlist_to_copy_to: BoxList to which extra fields are copied. + boxlist_to_copy_from: BoxList from which fields are copied. + + Returns: + boxlist_to_copy_to with extra fields. + """ + for field in boxlist_to_copy_from.get_extra_fields(): + boxlist_to_copy_to.add_field(field, boxlist_to_copy_from.get_field(field)) + return boxlist_to_copy_to + + +def to_normalized_coordinates(boxlist, height, width, + check_range=True, scope=None): + """Converts absolute box coordinates to normalized coordinates in [0, 1]. + + Usually one uses the dynamic shape of the image or conv-layer tensor: + boxlist = box_list_ops.to_normalized_coordinates(boxlist, + tf.shape(images)[1], + tf.shape(images)[2]), + + This function raises an assertion failed error at graph execution time when + the maximum coordinate is smaller than 1.01 (which means that coordinates are + already normalized). The value 1.01 is to deal with small rounding errors. + + Args: + boxlist: BoxList with coordinates in terms of pixel-locations. + height: Maximum value for height of absolute box coordinates. + width: Maximum value for width of absolute box coordinates. + check_range: If True, checks if the coordinates are normalized or not. + scope: name scope. + + Returns: + boxlist with normalized coordinates in [0, 1]. + """ + with tf.name_scope(scope, 'ToNormalizedCoordinates'): + height = tf.cast(height, tf.float32) + width = tf.cast(width, tf.float32) + + if check_range: + max_val = tf.reduce_max(boxlist.get()) + max_assert = tf.Assert(tf.greater(max_val, 1.01), + ['max value is lower than 1.01: ', max_val]) + with tf.control_dependencies([max_assert]): + width = tf.identity(width) + + return scale(boxlist, 1 / height, 1 / width) + + +def to_absolute_coordinates(boxlist, + height, + width, + check_range=True, + maximum_normalized_coordinate=1.1, + scope=None): + """Converts normalized box coordinates to absolute pixel coordinates. + + This function raises an assertion failed error when the maximum box coordinate + value is larger than maximum_normalized_coordinate (in which case coordinates + are already absolute). + + Args: + boxlist: BoxList with coordinates in range [0, 1]. + height: Maximum value for height of absolute box coordinates. + width: Maximum value for width of absolute box coordinates. + check_range: If True, checks if the coordinates are normalized or not. + maximum_normalized_coordinate: Maximum coordinate value to be considered + as normalized, default to 1.1. + scope: name scope. + + Returns: + boxlist with absolute coordinates in terms of the image size. + + """ + with tf.name_scope(scope, 'ToAbsoluteCoordinates'): + height = tf.cast(height, tf.float32) + width = tf.cast(width, tf.float32) + + # Ensure range of input boxes is correct. + if check_range: + box_maximum = tf.reduce_max(boxlist.get()) + max_assert = tf.Assert( + tf.greater_equal(maximum_normalized_coordinate, box_maximum), + ['maximum box coordinate value is larger ' + 'than %f: ' % maximum_normalized_coordinate, box_maximum]) + with tf.control_dependencies([max_assert]): + width = tf.identity(width) + + return scale(boxlist, height, width) + + +def refine_boxes_multi_class(pool_boxes, + num_classes, + nms_iou_thresh, + nms_max_detections, + voting_iou_thresh=0.5): + """Refines a pool of boxes using non max suppression and box voting. + + Box refinement is done independently for each class. + + Args: + pool_boxes: (BoxList) A collection of boxes to be refined. pool_boxes must + have a rank 1 'scores' field and a rank 1 'classes' field. + num_classes: (int scalar) Number of classes. + nms_iou_thresh: (float scalar) iou threshold for non max suppression (NMS). + nms_max_detections: (int scalar) maximum output size for NMS. + voting_iou_thresh: (float scalar) iou threshold for box voting. + + Returns: + BoxList of refined boxes. + + Raises: + ValueError: if + a) nms_iou_thresh or voting_iou_thresh is not in [0, 1]. + b) pool_boxes is not a BoxList. + c) pool_boxes does not have a scores and classes field. + """ + if not 0.0 <= nms_iou_thresh <= 1.0: + raise ValueError('nms_iou_thresh must be between 0 and 1') + if not 0.0 <= voting_iou_thresh <= 1.0: + raise ValueError('voting_iou_thresh must be between 0 and 1') + if not isinstance(pool_boxes, box_list.BoxList): + raise ValueError('pool_boxes must be a BoxList') + if not pool_boxes.has_field('scores'): + raise ValueError('pool_boxes must have a \'scores\' field') + if not pool_boxes.has_field('classes'): + raise ValueError('pool_boxes must have a \'classes\' field') + + refined_boxes = [] + for i in range(num_classes): + boxes_class = filter_field_value_equals(pool_boxes, 'classes', i) + refined_boxes_class = refine_boxes(boxes_class, nms_iou_thresh, + nms_max_detections, voting_iou_thresh) + refined_boxes.append(refined_boxes_class) + return sort_by_field(concatenate(refined_boxes), 'scores') + + +def refine_boxes(pool_boxes, + nms_iou_thresh, + nms_max_detections, + voting_iou_thresh=0.5): + """Refines a pool of boxes using non max suppression and box voting. + + Args: + pool_boxes: (BoxList) A collection of boxes to be refined. pool_boxes must + have a rank 1 'scores' field. + nms_iou_thresh: (float scalar) iou threshold for non max suppression (NMS). + nms_max_detections: (int scalar) maximum output size for NMS. + voting_iou_thresh: (float scalar) iou threshold for box voting. + + Returns: + BoxList of refined boxes. + + Raises: + ValueError: if + a) nms_iou_thresh or voting_iou_thresh is not in [0, 1]. + b) pool_boxes is not a BoxList. + c) pool_boxes does not have a scores field. + """ + if not 0.0 <= nms_iou_thresh <= 1.0: + raise ValueError('nms_iou_thresh must be between 0 and 1') + if not 0.0 <= voting_iou_thresh <= 1.0: + raise ValueError('voting_iou_thresh must be between 0 and 1') + if not isinstance(pool_boxes, box_list.BoxList): + raise ValueError('pool_boxes must be a BoxList') + if not pool_boxes.has_field('scores'): + raise ValueError('pool_boxes must have a \'scores\' field') + + nms_boxes = non_max_suppression( + pool_boxes, nms_iou_thresh, nms_max_detections) + return box_voting(nms_boxes, pool_boxes, voting_iou_thresh) + + +def box_voting(selected_boxes, pool_boxes, iou_thresh=0.5): + """Performs box voting as described in S. Gidaris and N. Komodakis, ICCV 2015. + + Performs box voting as described in 'Object detection via a multi-region & + semantic segmentation-aware CNN model', Gidaris and Komodakis, ICCV 2015. For + each box 'B' in selected_boxes, we find the set 'S' of boxes in pool_boxes + with iou overlap >= iou_thresh. The location of B is set to the weighted + average location of boxes in S (scores are used for weighting). And the score + of B is set to the average score of boxes in S. + + Args: + selected_boxes: BoxList containing a subset of boxes in pool_boxes. These + boxes are usually selected from pool_boxes using non max suppression. + pool_boxes: BoxList containing a set of (possibly redundant) boxes. + iou_thresh: (float scalar) iou threshold for matching boxes in + selected_boxes and pool_boxes. + + Returns: + BoxList containing averaged locations and scores for each box in + selected_boxes. + + Raises: + ValueError: if + a) selected_boxes or pool_boxes is not a BoxList. + b) if iou_thresh is not in [0, 1]. + c) pool_boxes does not have a scores field. + """ + if not 0.0 <= iou_thresh <= 1.0: + raise ValueError('iou_thresh must be between 0 and 1') + if not isinstance(selected_boxes, box_list.BoxList): + raise ValueError('selected_boxes must be a BoxList') + if not isinstance(pool_boxes, box_list.BoxList): + raise ValueError('pool_boxes must be a BoxList') + if not pool_boxes.has_field('scores'): + raise ValueError('pool_boxes must have a \'scores\' field') + + iou_ = iou(selected_boxes, pool_boxes) + match_indicator = tf.to_float(tf.greater(iou_, iou_thresh)) + num_matches = tf.reduce_sum(match_indicator, 1) + # TODO(kbanoop): Handle the case where some boxes in selected_boxes do not + # match to any boxes in pool_boxes. For such boxes without any matches, we + # should return the original boxes without voting. + match_assert = tf.Assert( + tf.reduce_all(tf.greater(num_matches, 0)), + ['Each box in selected_boxes must match with at least one box ' + 'in pool_boxes.']) + + scores = tf.expand_dims(pool_boxes.get_field('scores'), 1) + scores_assert = tf.Assert( + tf.reduce_all(tf.greater_equal(scores, 0)), + ['Scores must be non negative.']) + + with tf.control_dependencies([scores_assert, match_assert]): + sum_scores = tf.matmul(match_indicator, scores) + averaged_scores = tf.reshape(sum_scores, [-1]) / num_matches + + box_locations = tf.matmul(match_indicator, + pool_boxes.get() * scores) / sum_scores + averaged_boxes = box_list.BoxList(box_locations) + _copy_extra_fields(averaged_boxes, selected_boxes) + averaged_boxes.add_field('scores', averaged_scores) + return averaged_boxes + + +def pad_or_clip_box_list(boxlist, num_boxes, scope=None): + """Pads or clips all fields of a BoxList. + + Args: + boxlist: A BoxList with arbitrary of number of boxes. + num_boxes: First num_boxes in boxlist are kept. + The fields are zero-padded if num_boxes is bigger than the + actual number of boxes. + scope: name scope. + + Returns: + BoxList with all fields padded or clipped. + """ + with tf.name_scope(scope, 'PadOrClipBoxList'): + subboxlist = box_list.BoxList(shape_utils.pad_or_clip_tensor( + boxlist.get(), num_boxes)) + for field in boxlist.get_extra_fields(): + subfield = shape_utils.pad_or_clip_tensor( + boxlist.get_field(field), num_boxes) + subboxlist.add_field(field, subfield) + return subboxlist + + +def select_random_box(boxlist, + default_box=None, + seed=None, + scope=None): + """Selects a random bounding box from a `BoxList`. + + Args: + boxlist: A BoxList. + default_box: A [1, 4] float32 tensor. If no boxes are present in `boxlist`, + this default box will be returned. If None, will use a default box of + [[-1., -1., -1., -1.]]. + seed: Random seed. + scope: Name scope. + + Returns: + bbox: A [1, 4] tensor with a random bounding box. + valid: A bool tensor indicating whether a valid bounding box is returned + (True) or whether the default box is returned (False). + """ + with tf.name_scope(scope, 'SelectRandomBox'): + bboxes = boxlist.get() + combined_shape = shape_utils.combined_static_and_dynamic_shape(bboxes) + number_of_boxes = combined_shape[0] + default_box = default_box or tf.constant([[-1., -1., -1., -1.]]) + + def select_box(): + random_index = tf.random_uniform([], + maxval=number_of_boxes, + dtype=tf.int32, + seed=seed) + return tf.expand_dims(bboxes[random_index], axis=0), tf.constant(True) + + return tf.cond( + tf.greater_equal(number_of_boxes, 1), + true_fn=select_box, + false_fn=lambda: (default_box, tf.constant(False))) + + +def get_minimal_coverage_box(boxlist, + default_box=None, + scope=None): + """Creates a single bounding box which covers all boxes in the boxlist. + + Args: + boxlist: A Boxlist. + default_box: A [1, 4] float32 tensor. If no boxes are present in `boxlist`, + this default box will be returned. If None, will use a default box of + [[0., 0., 1., 1.]]. + scope: Name scope. + + Returns: + A [1, 4] float32 tensor with a bounding box that tightly covers all the + boxes in the box list. If the boxlist does not contain any boxes, the + default box is returned. + """ + with tf.name_scope(scope, 'CreateCoverageBox'): + num_boxes = boxlist.num_boxes() + + def coverage_box(bboxes): + y_min, x_min, y_max, x_max = tf.split( + value=bboxes, num_or_size_splits=4, axis=1) + y_min_coverage = tf.reduce_min(y_min, axis=0) + x_min_coverage = tf.reduce_min(x_min, axis=0) + y_max_coverage = tf.reduce_max(y_max, axis=0) + x_max_coverage = tf.reduce_max(x_max, axis=0) + return tf.stack( + [y_min_coverage, x_min_coverage, y_max_coverage, x_max_coverage], + axis=1) + + default_box = default_box or tf.constant([[0., 0., 1., 1.]]) + return tf.cond( + tf.greater_equal(num_boxes, 1), + true_fn=lambda: coverage_box(boxlist.get()), + false_fn=lambda: default_box) + + +def sample_boxes_by_jittering(boxlist, + num_boxes_to_sample, + stddev=0.1, + scope=None): + """Samples num_boxes_to_sample boxes by jittering around boxlist boxes. + + It is possible that this function might generate boxes with size 0. The larger + the stddev, this is more probable. For a small stddev of 0.1 this probability + is very small. + + Args: + boxlist: A boxlist containing N boxes in normalized coordinates. + num_boxes_to_sample: A positive integer containing the number of boxes to + sample. + stddev: Standard deviation. This is used to draw random offsets for the + box corners from a normal distribution. The offset is multiplied by the + box size so will be larger in terms of pixels for larger boxes. + scope: Name scope. + + Returns: + sampled_boxlist: A boxlist containing num_boxes_to_sample boxes in + normalized coordinates. + """ + with tf.name_scope(scope, 'SampleBoxesByJittering'): + num_boxes = boxlist.num_boxes() + box_indices = tf.random_uniform( + [num_boxes_to_sample], + minval=0, + maxval=num_boxes, + dtype=tf.int32) + sampled_boxes = tf.gather(boxlist.get(), box_indices) + sampled_boxes_height = sampled_boxes[:, 2] - sampled_boxes[:, 0] + sampled_boxes_width = sampled_boxes[:, 3] - sampled_boxes[:, 1] + rand_miny_gaussian = tf.random_normal([num_boxes_to_sample], stddev=stddev) + rand_minx_gaussian = tf.random_normal([num_boxes_to_sample], stddev=stddev) + rand_maxy_gaussian = tf.random_normal([num_boxes_to_sample], stddev=stddev) + rand_maxx_gaussian = tf.random_normal([num_boxes_to_sample], stddev=stddev) + miny = rand_miny_gaussian * sampled_boxes_height + sampled_boxes[:, 0] + minx = rand_minx_gaussian * sampled_boxes_width + sampled_boxes[:, 1] + maxy = rand_maxy_gaussian * sampled_boxes_height + sampled_boxes[:, 2] + maxx = rand_maxx_gaussian * sampled_boxes_width + sampled_boxes[:, 3] + maxy = tf.maximum(miny, maxy) + maxx = tf.maximum(minx, maxx) + sampled_boxes = tf.stack([miny, minx, maxy, maxx], axis=1) + sampled_boxes = tf.maximum(tf.minimum(sampled_boxes, 1.0), 0.0) + return box_list.BoxList(sampled_boxes) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops_test.py" new file mode 100644 index 00000000..727c198b --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_ops_test.py" @@ -0,0 +1,1108 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.box_list_ops.""" +import numpy as np +import tensorflow as tf + +from object_detection.core import box_list +from object_detection.core import box_list_ops +from object_detection.utils import test_case + + +class BoxListOpsTest(test_case.TestCase): + """Tests for common bounding box operations.""" + + def test_area(self): + corners = tf.constant([[0.0, 0.0, 10.0, 20.0], [1.0, 2.0, 3.0, 4.0]]) + exp_output = [200.0, 4.0] + boxes = box_list.BoxList(corners) + areas = box_list_ops.area(boxes) + with self.test_session() as sess: + areas_output = sess.run(areas) + self.assertAllClose(areas_output, exp_output) + + def test_height_width(self): + corners = tf.constant([[0.0, 0.0, 10.0, 20.0], [1.0, 2.0, 3.0, 4.0]]) + exp_output_heights = [10., 2.] + exp_output_widths = [20., 2.] + boxes = box_list.BoxList(corners) + heights, widths = box_list_ops.height_width(boxes) + with self.test_session() as sess: + output_heights, output_widths = sess.run([heights, widths]) + self.assertAllClose(output_heights, exp_output_heights) + self.assertAllClose(output_widths, exp_output_widths) + + def test_scale(self): + corners = tf.constant([[0, 0, 100, 200], [50, 120, 100, 140]], + dtype=tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.constant([[1], [2]])) + + y_scale = tf.constant(1.0/100) + x_scale = tf.constant(1.0/200) + scaled_boxes = box_list_ops.scale(boxes, y_scale, x_scale) + exp_output = [[0, 0, 1, 1], [0.5, 0.6, 1.0, 0.7]] + with self.test_session() as sess: + scaled_corners_out = sess.run(scaled_boxes.get()) + self.assertAllClose(scaled_corners_out, exp_output) + extra_data_out = sess.run(scaled_boxes.get_field('extra_data')) + self.assertAllEqual(extra_data_out, [[1], [2]]) + + def test_clip_to_window_filter_boxes_which_fall_outside_the_window( + self): + window = tf.constant([0, 0, 9, 14], tf.float32) + corners = tf.constant([[5.0, 5.0, 6.0, 6.0], + [-1.0, -2.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0], + [-100.0, -100.0, 300.0, 600.0], + [-10.0, -10.0, -9.0, -9.0]]) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.constant([[1], [2], [3], [4], [5], [6]])) + exp_output = [[5.0, 5.0, 6.0, 6.0], [0.0, 0.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], [0.0, 0.0, 9.0, 14.0], + [0.0, 0.0, 9.0, 14.0]] + pruned = box_list_ops.clip_to_window( + boxes, window, filter_nonoverlapping=True) + with self.test_session() as sess: + pruned_output = sess.run(pruned.get()) + self.assertAllClose(pruned_output, exp_output) + extra_data_out = sess.run(pruned.get_field('extra_data')) + self.assertAllEqual(extra_data_out, [[1], [2], [3], [4], [5]]) + + def test_clip_to_window_without_filtering_boxes_which_fall_outside_the_window( + self): + window = tf.constant([0, 0, 9, 14], tf.float32) + corners = tf.constant([[5.0, 5.0, 6.0, 6.0], + [-1.0, -2.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0], + [-100.0, -100.0, 300.0, 600.0], + [-10.0, -10.0, -9.0, -9.0]]) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.constant([[1], [2], [3], [4], [5], [6]])) + exp_output = [[5.0, 5.0, 6.0, 6.0], [0.0, 0.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], [0.0, 0.0, 9.0, 14.0], + [0.0, 0.0, 9.0, 14.0], [0.0, 0.0, 0.0, 0.0]] + pruned = box_list_ops.clip_to_window( + boxes, window, filter_nonoverlapping=False) + with self.test_session() as sess: + pruned_output = sess.run(pruned.get()) + self.assertAllClose(pruned_output, exp_output) + extra_data_out = sess.run(pruned.get_field('extra_data')) + self.assertAllEqual(extra_data_out, [[1], [2], [3], [4], [5], [6]]) + + def test_prune_outside_window_filters_boxes_which_fall_outside_the_window( + self): + window = tf.constant([0, 0, 9, 14], tf.float32) + corners = tf.constant([[5.0, 5.0, 6.0, 6.0], + [-1.0, -2.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0], + [-10.0, -10.0, -9.0, -9.0], + [-100.0, -100.0, 300.0, 600.0]]) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.constant([[1], [2], [3], [4], [5], [6]])) + exp_output = [[5.0, 5.0, 6.0, 6.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0]] + pruned, keep_indices = box_list_ops.prune_outside_window(boxes, window) + with self.test_session() as sess: + pruned_output = sess.run(pruned.get()) + self.assertAllClose(pruned_output, exp_output) + keep_indices_out = sess.run(keep_indices) + self.assertAllEqual(keep_indices_out, [0, 2, 3]) + extra_data_out = sess.run(pruned.get_field('extra_data')) + self.assertAllEqual(extra_data_out, [[1], [3], [4]]) + + def test_prune_completely_outside_window(self): + window = tf.constant([0, 0, 9, 14], tf.float32) + corners = tf.constant([[5.0, 5.0, 6.0, 6.0], + [-1.0, -2.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0], + [-10.0, -10.0, -9.0, -9.0], + [-100.0, -100.0, 300.0, 600.0]]) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.constant([[1], [2], [3], [4], [5], [6]])) + exp_output = [[5.0, 5.0, 6.0, 6.0], + [-1.0, -2.0, 4.0, 5.0], + [2.0, 3.0, 5.0, 9.0], + [0.0, 0.0, 9.0, 14.0], + [-100.0, -100.0, 300.0, 600.0]] + pruned, keep_indices = box_list_ops.prune_completely_outside_window(boxes, + window) + with self.test_session() as sess: + pruned_output = sess.run(pruned.get()) + self.assertAllClose(pruned_output, exp_output) + keep_indices_out = sess.run(keep_indices) + self.assertAllEqual(keep_indices_out, [0, 1, 2, 3, 5]) + extra_data_out = sess.run(pruned.get_field('extra_data')) + self.assertAllEqual(extra_data_out, [[1], [2], [3], [4], [6]]) + + def test_prune_completely_outside_window_with_empty_boxlist(self): + window = tf.constant([0, 0, 9, 14], tf.float32) + corners = tf.zeros(shape=[0, 4], dtype=tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('extra_data', tf.zeros(shape=[0], dtype=tf.int32)) + pruned, keep_indices = box_list_ops.prune_completely_outside_window(boxes, + window) + pruned_boxes = pruned.get() + extra = pruned.get_field('extra_data') + + exp_pruned_boxes = np.zeros(shape=[0, 4], dtype=np.float32) + exp_extra = np.zeros(shape=[0], dtype=np.int32) + with self.test_session() as sess: + pruned_boxes_out, keep_indices_out, extra_out = sess.run( + [pruned_boxes, keep_indices, extra]) + self.assertAllClose(exp_pruned_boxes, pruned_boxes_out) + self.assertAllEqual([], keep_indices_out) + self.assertAllEqual(exp_extra, extra_out) + + def test_intersection(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + exp_output = [[2.0, 0.0, 6.0], [1.0, 0.0, 5.0]] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + intersect = box_list_ops.intersection(boxes1, boxes2) + with self.test_session() as sess: + intersect_output = sess.run(intersect) + self.assertAllClose(intersect_output, exp_output) + + def test_matched_intersection(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0]]) + exp_output = [2.0, 0.0] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + intersect = box_list_ops.matched_intersection(boxes1, boxes2) + with self.test_session() as sess: + intersect_output = sess.run(intersect) + self.assertAllClose(intersect_output, exp_output) + + def test_iou(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + exp_output = [[2.0 / 16.0, 0, 6.0 / 400.0], [1.0 / 16.0, 0.0, 5.0 / 400.0]] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + iou = box_list_ops.iou(boxes1, boxes2) + with self.test_session() as sess: + iou_output = sess.run(iou) + self.assertAllClose(iou_output, exp_output) + + def test_matched_iou(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0]]) + exp_output = [2.0 / 16.0, 0] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + iou = box_list_ops.matched_iou(boxes1, boxes2) + with self.test_session() as sess: + iou_output = sess.run(iou) + self.assertAllClose(iou_output, exp_output) + + def test_iouworks_on_empty_inputs(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + boxes_empty = box_list.BoxList(tf.zeros((0, 4))) + iou_empty_1 = box_list_ops.iou(boxes1, boxes_empty) + iou_empty_2 = box_list_ops.iou(boxes_empty, boxes2) + iou_empty_3 = box_list_ops.iou(boxes_empty, boxes_empty) + with self.test_session() as sess: + iou_output_1, iou_output_2, iou_output_3 = sess.run( + [iou_empty_1, iou_empty_2, iou_empty_3]) + self.assertAllEqual(iou_output_1.shape, (2, 0)) + self.assertAllEqual(iou_output_2.shape, (0, 3)) + self.assertAllEqual(iou_output_3.shape, (0, 0)) + + def test_ioa(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + exp_output_1 = [[2.0 / 12.0, 0, 6.0 / 400.0], + [1.0 / 12.0, 0.0, 5.0 / 400.0]] + exp_output_2 = [[2.0 / 6.0, 1.0 / 5.0], + [0, 0], + [6.0 / 6.0, 5.0 / 5.0]] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + ioa_1 = box_list_ops.ioa(boxes1, boxes2) + ioa_2 = box_list_ops.ioa(boxes2, boxes1) + with self.test_session() as sess: + ioa_output_1, ioa_output_2 = sess.run([ioa_1, ioa_2]) + self.assertAllClose(ioa_output_1, exp_output_1) + self.assertAllClose(ioa_output_2, exp_output_2) + + def test_prune_non_overlapping_boxes(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + minoverlap = 0.5 + + exp_output_1 = boxes1 + exp_output_2 = box_list.BoxList(tf.constant(0.0, shape=[0, 4])) + output_1, keep_indices_1 = box_list_ops.prune_non_overlapping_boxes( + boxes1, boxes2, min_overlap=minoverlap) + output_2, keep_indices_2 = box_list_ops.prune_non_overlapping_boxes( + boxes2, boxes1, min_overlap=minoverlap) + with self.test_session() as sess: + (output_1_, keep_indices_1_, output_2_, keep_indices_2_, exp_output_1_, + exp_output_2_) = sess.run( + [output_1.get(), keep_indices_1, + output_2.get(), keep_indices_2, + exp_output_1.get(), exp_output_2.get()]) + self.assertAllClose(output_1_, exp_output_1_) + self.assertAllClose(output_2_, exp_output_2_) + self.assertAllEqual(keep_indices_1_, [0, 1]) + self.assertAllEqual(keep_indices_2_, []) + + def test_prune_small_boxes(self): + boxes = tf.constant([[4.0, 3.0, 7.0, 5.0], + [5.0, 6.0, 10.0, 7.0], + [3.0, 4.0, 6.0, 8.0], + [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + exp_boxes = [[3.0, 4.0, 6.0, 8.0], + [0.0, 0.0, 20.0, 20.0]] + boxes = box_list.BoxList(boxes) + pruned_boxes = box_list_ops.prune_small_boxes(boxes, 3) + with self.test_session() as sess: + pruned_boxes = sess.run(pruned_boxes.get()) + self.assertAllEqual(pruned_boxes, exp_boxes) + + def test_prune_small_boxes_prunes_boxes_with_negative_side(self): + boxes = tf.constant([[4.0, 3.0, 7.0, 5.0], + [5.0, 6.0, 10.0, 7.0], + [3.0, 4.0, 6.0, 8.0], + [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0], + [2.0, 3.0, 1.5, 7.0], # negative height + [2.0, 3.0, 5.0, 1.7]]) # negative width + exp_boxes = [[3.0, 4.0, 6.0, 8.0], + [0.0, 0.0, 20.0, 20.0]] + boxes = box_list.BoxList(boxes) + pruned_boxes = box_list_ops.prune_small_boxes(boxes, 3) + with self.test_session() as sess: + pruned_boxes = sess.run(pruned_boxes.get()) + self.assertAllEqual(pruned_boxes, exp_boxes) + + def test_change_coordinate_frame(self): + corners = tf.constant([[0.25, 0.5, 0.75, 0.75], [0.5, 0.0, 1.0, 1.0]]) + window = tf.constant([0.25, 0.25, 0.75, 0.75]) + boxes = box_list.BoxList(corners) + + expected_corners = tf.constant([[0, 0.5, 1.0, 1.0], [0.5, -0.5, 1.5, 1.5]]) + expected_boxes = box_list.BoxList(expected_corners) + output = box_list_ops.change_coordinate_frame(boxes, window) + + with self.test_session() as sess: + output_, expected_boxes_ = sess.run([output.get(), expected_boxes.get()]) + self.assertAllClose(output_, expected_boxes_) + + def test_ioaworks_on_empty_inputs(self): + corners1 = tf.constant([[4.0, 3.0, 7.0, 5.0], [5.0, 6.0, 10.0, 7.0]]) + corners2 = tf.constant([[3.0, 4.0, 6.0, 8.0], [14.0, 14.0, 15.0, 15.0], + [0.0, 0.0, 20.0, 20.0]]) + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + boxes_empty = box_list.BoxList(tf.zeros((0, 4))) + ioa_empty_1 = box_list_ops.ioa(boxes1, boxes_empty) + ioa_empty_2 = box_list_ops.ioa(boxes_empty, boxes2) + ioa_empty_3 = box_list_ops.ioa(boxes_empty, boxes_empty) + with self.test_session() as sess: + ioa_output_1, ioa_output_2, ioa_output_3 = sess.run( + [ioa_empty_1, ioa_empty_2, ioa_empty_3]) + self.assertAllEqual(ioa_output_1.shape, (2, 0)) + self.assertAllEqual(ioa_output_2.shape, (0, 3)) + self.assertAllEqual(ioa_output_3.shape, (0, 0)) + + def test_pairwise_distances(self): + corners1 = tf.constant([[0.0, 0.0, 0.0, 0.0], + [1.0, 1.0, 0.0, 2.0]]) + corners2 = tf.constant([[3.0, 4.0, 1.0, 0.0], + [-4.0, 0.0, 0.0, 3.0], + [0.0, 0.0, 0.0, 0.0]]) + exp_output = [[26, 25, 0], [18, 27, 6]] + boxes1 = box_list.BoxList(corners1) + boxes2 = box_list.BoxList(corners2) + dist_matrix = box_list_ops.sq_dist(boxes1, boxes2) + with self.test_session() as sess: + dist_output = sess.run(dist_matrix) + self.assertAllClose(dist_output, exp_output) + + def test_boolean_mask(self): + corners = tf.constant( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]]) + indicator = tf.constant([True, False, True, False, True], tf.bool) + expected_subset = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + boxes = box_list.BoxList(corners) + subset = box_list_ops.boolean_mask(boxes, indicator) + with self.test_session() as sess: + subset_output = sess.run(subset.get()) + self.assertAllClose(subset_output, expected_subset) + + def test_static_boolean_mask_with_field(self): + + def graph_fn(corners, weights, indicator): + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + subset = box_list_ops.boolean_mask( + boxes, + indicator, ['weights'], + use_static_shapes=True, + indicator_sum=3) + return (subset.get_field('boxes'), subset.get_field('weights')) + + corners = np.array( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]], + dtype=np.float32) + indicator = np.array([True, False, True, False, True], dtype=np.bool) + weights = np.array([[.1], [.3], [.5], [.7], [.9]], dtype=np.float32) + result_boxes, result_weights = self.execute(graph_fn, + [corners, weights, indicator]) + expected_boxes = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + expected_weights = [[.1], [.5], [.9]] + + self.assertAllClose(result_boxes, expected_boxes) + self.assertAllClose(result_weights, expected_weights) + + def test_dynamic_boolean_mask_with_field(self): + corners = tf.placeholder(tf.float32, [None, 4]) + indicator = tf.placeholder(tf.bool, [None]) + weights = tf.placeholder(tf.float32, [None, 1]) + expected_subset = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + expected_weights = [[.1], [.5], [.9]] + + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + subset = box_list_ops.boolean_mask(boxes, indicator, ['weights']) + with self.test_session() as sess: + subset_output, weights_output = sess.run( + [subset.get(), subset.get_field('weights')], + feed_dict={ + corners: + np.array( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]]), + indicator: + np.array([True, False, True, False, True]).astype(np.bool), + weights: + np.array([[.1], [.3], [.5], [.7], [.9]]) + }) + self.assertAllClose(subset_output, expected_subset) + self.assertAllClose(weights_output, expected_weights) + + def test_gather(self): + corners = tf.constant( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]]) + indices = tf.constant([0, 2, 4], tf.int32) + expected_subset = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + boxes = box_list.BoxList(corners) + subset = box_list_ops.gather(boxes, indices) + with self.test_session() as sess: + subset_output = sess.run(subset.get()) + self.assertAllClose(subset_output, expected_subset) + + def test_static_gather_with_field(self): + + def graph_fn(corners, weights, indices): + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + subset = box_list_ops.gather( + boxes, indices, ['weights'], use_static_shapes=True) + return (subset.get_field('boxes'), subset.get_field('weights')) + + corners = np.array([4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], + 4 * [4.0]], dtype=np.float32) + weights = np.array([[.1], [.3], [.5], [.7], [.9]], dtype=np.float32) + indices = np.array([0, 2, 4], dtype=np.int32) + + result_boxes, result_weights = self.execute(graph_fn, + [corners, weights, indices]) + expected_boxes = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + expected_weights = [[.1], [.5], [.9]] + self.assertAllClose(result_boxes, expected_boxes) + self.assertAllClose(result_weights, expected_weights) + + def test_dynamic_gather_with_field(self): + corners = tf.placeholder(tf.float32, [None, 4]) + indices = tf.placeholder(tf.int32, [None]) + weights = tf.placeholder(tf.float32, [None, 1]) + expected_subset = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + expected_weights = [[.1], [.5], [.9]] + + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + subset = box_list_ops.gather(boxes, indices, ['weights'], + use_static_shapes=True) + with self.test_session() as sess: + subset_output, weights_output = sess.run( + [subset.get(), subset.get_field('weights')], + feed_dict={ + corners: + np.array( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]]), + indices: + np.array([0, 2, 4]).astype(np.int32), + weights: + np.array([[.1], [.3], [.5], [.7], [.9]]) + }) + self.assertAllClose(subset_output, expected_subset) + self.assertAllClose(weights_output, expected_weights) + + def test_gather_with_invalid_field(self): + corners = tf.constant([4 * [0.0], 4 * [1.0]]) + indices = tf.constant([0, 1], tf.int32) + weights = tf.constant([[.1], [.3]], tf.float32) + + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + with self.assertRaises(ValueError): + box_list_ops.gather(boxes, indices, ['foo', 'bar']) + + def test_gather_with_invalid_inputs(self): + corners = tf.constant( + [4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0]]) + indices_float32 = tf.constant([0, 2, 4], tf.float32) + boxes = box_list.BoxList(corners) + with self.assertRaises(ValueError): + _ = box_list_ops.gather(boxes, indices_float32) + indices_2d = tf.constant([[0, 2, 4]], tf.int32) + boxes = box_list.BoxList(corners) + with self.assertRaises(ValueError): + _ = box_list_ops.gather(boxes, indices_2d) + + def test_gather_with_dynamic_indexing(self): + corners = tf.constant([4 * [0.0], 4 * [1.0], 4 * [2.0], 4 * [3.0], 4 * [4.0] + ]) + weights = tf.constant([.5, .3, .7, .1, .9], tf.float32) + indices = tf.reshape(tf.where(tf.greater(weights, 0.4)), [-1]) + expected_subset = [4 * [0.0], 4 * [2.0], 4 * [4.0]] + expected_weights = [.5, .7, .9] + + boxes = box_list.BoxList(corners) + boxes.add_field('weights', weights) + subset = box_list_ops.gather(boxes, indices, ['weights']) + with self.test_session() as sess: + subset_output, weights_output = sess.run([subset.get(), subset.get_field( + 'weights')]) + self.assertAllClose(subset_output, expected_subset) + self.assertAllClose(weights_output, expected_weights) + + def test_sort_by_field_ascending_order(self): + exp_corners = [[0, 0, 1, 1], [0, 0.1, 1, 1.1], [0, -0.1, 1, 0.9], + [0, 10, 1, 11], [0, 10.1, 1, 11.1], [0, 100, 1, 101]] + exp_scores = [.95, .9, .75, .6, .5, .3] + exp_weights = [.2, .45, .6, .75, .8, .92] + shuffle = [2, 4, 0, 5, 1, 3] + corners = tf.constant([exp_corners[i] for i in shuffle], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant( + [exp_scores[i] for i in shuffle], tf.float32)) + boxes.add_field('weights', tf.constant( + [exp_weights[i] for i in shuffle], tf.float32)) + sort_by_weight = box_list_ops.sort_by_field( + boxes, + 'weights', + order=box_list_ops.SortOrder.ascend) + with self.test_session() as sess: + corners_out, scores_out, weights_out = sess.run([ + sort_by_weight.get(), + sort_by_weight.get_field('scores'), + sort_by_weight.get_field('weights')]) + self.assertAllClose(corners_out, exp_corners) + self.assertAllClose(scores_out, exp_scores) + self.assertAllClose(weights_out, exp_weights) + + def test_sort_by_field_descending_order(self): + exp_corners = [[0, 0, 1, 1], [0, 0.1, 1, 1.1], [0, -0.1, 1, 0.9], + [0, 10, 1, 11], [0, 10.1, 1, 11.1], [0, 100, 1, 101]] + exp_scores = [.95, .9, .75, .6, .5, .3] + exp_weights = [.2, .45, .6, .75, .8, .92] + shuffle = [2, 4, 0, 5, 1, 3] + + corners = tf.constant([exp_corners[i] for i in shuffle], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant( + [exp_scores[i] for i in shuffle], tf.float32)) + boxes.add_field('weights', tf.constant( + [exp_weights[i] for i in shuffle], tf.float32)) + + sort_by_score = box_list_ops.sort_by_field(boxes, 'scores') + with self.test_session() as sess: + corners_out, scores_out, weights_out = sess.run([sort_by_score.get( + ), sort_by_score.get_field('scores'), sort_by_score.get_field('weights')]) + self.assertAllClose(corners_out, exp_corners) + self.assertAllClose(scores_out, exp_scores) + self.assertAllClose(weights_out, exp_weights) + + def test_sort_by_field_invalid_inputs(self): + corners = tf.constant([4 * [0.0], 4 * [0.5], 4 * [1.0], 4 * [2.0], 4 * + [3.0], 4 * [4.0]]) + misc = tf.constant([[.95, .9], [.5, .3]], tf.float32) + weights = tf.constant([.1, .2], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('misc', misc) + boxes.add_field('weights', weights) + + with self.assertRaises(ValueError): + box_list_ops.sort_by_field(boxes, 'area') + + with self.assertRaises(ValueError): + box_list_ops.sort_by_field(boxes, 'misc') + + with self.assertRaises(ValueError): + box_list_ops.sort_by_field(boxes, 'weights') + + def test_visualize_boxes_in_image(self): + image = tf.zeros((6, 4, 3)) + corners = tf.constant([[0, 0, 5, 3], + [0, 0, 3, 2]], tf.float32) + boxes = box_list.BoxList(corners) + image_and_boxes = box_list_ops.visualize_boxes_in_image(image, boxes) + image_and_boxes_bw = tf.to_float( + tf.greater(tf.reduce_sum(image_and_boxes, 2), 0.0)) + exp_result = [[1, 1, 1, 0], + [1, 1, 1, 0], + [1, 1, 1, 0], + [1, 0, 1, 0], + [1, 1, 1, 0], + [0, 0, 0, 0]] + with self.test_session() as sess: + output = sess.run(image_and_boxes_bw) + self.assertAllEqual(output.astype(int), exp_result) + + def test_filter_field_value_equals(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1], + [0, -0.1, 1, 0.9], + [0, 10, 1, 11], + [0, 10.1, 1, 11.1], + [0, 100, 1, 101]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('classes', tf.constant([1, 2, 1, 2, 2, 1])) + exp_output1 = [[0, 0, 1, 1], [0, -0.1, 1, 0.9], [0, 100, 1, 101]] + exp_output2 = [[0, 0.1, 1, 1.1], [0, 10, 1, 11], [0, 10.1, 1, 11.1]] + + filtered_boxes1 = box_list_ops.filter_field_value_equals( + boxes, 'classes', 1) + filtered_boxes2 = box_list_ops.filter_field_value_equals( + boxes, 'classes', 2) + with self.test_session() as sess: + filtered_output1, filtered_output2 = sess.run([filtered_boxes1.get(), + filtered_boxes2.get()]) + self.assertAllClose(filtered_output1, exp_output1) + self.assertAllClose(filtered_output2, exp_output2) + + def test_filter_greater_than(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1], + [0, -0.1, 1, 0.9], + [0, 10, 1, 11], + [0, 10.1, 1, 11.1], + [0, 100, 1, 101]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant([.1, .75, .9, .5, .5, .8])) + thresh = .6 + exp_output = [[0, 0.1, 1, 1.1], [0, -0.1, 1, 0.9], [0, 100, 1, 101]] + + filtered_boxes = box_list_ops.filter_greater_than(boxes, thresh) + with self.test_session() as sess: + filtered_output = sess.run(filtered_boxes.get()) + self.assertAllClose(filtered_output, exp_output) + + def test_clip_box_list(self): + boxlist = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5], + [0.6, 0.6, 0.8, 0.8], [0.2, 0.2, 0.3, 0.3]], tf.float32)) + boxlist.add_field('classes', tf.constant([0, 0, 1, 1])) + boxlist.add_field('scores', tf.constant([0.75, 0.65, 0.3, 0.2])) + num_boxes = 2 + clipped_boxlist = box_list_ops.pad_or_clip_box_list(boxlist, num_boxes) + + expected_boxes = [[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]] + expected_classes = [0, 0] + expected_scores = [0.75, 0.65] + with self.test_session() as sess: + boxes_out, classes_out, scores_out = sess.run( + [clipped_boxlist.get(), clipped_boxlist.get_field('classes'), + clipped_boxlist.get_field('scores')]) + + self.assertAllClose(expected_boxes, boxes_out) + self.assertAllEqual(expected_classes, classes_out) + self.assertAllClose(expected_scores, scores_out) + + def test_pad_box_list(self): + boxlist = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]], tf.float32)) + boxlist.add_field('classes', tf.constant([0, 1])) + boxlist.add_field('scores', tf.constant([0.75, 0.2])) + num_boxes = 4 + padded_boxlist = box_list_ops.pad_or_clip_box_list(boxlist, num_boxes) + + expected_boxes = [[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5], + [0, 0, 0, 0], [0, 0, 0, 0]] + expected_classes = [0, 1, 0, 0] + expected_scores = [0.75, 0.2, 0, 0] + with self.test_session() as sess: + boxes_out, classes_out, scores_out = sess.run( + [padded_boxlist.get(), padded_boxlist.get_field('classes'), + padded_boxlist.get_field('scores')]) + + self.assertAllClose(expected_boxes, boxes_out) + self.assertAllEqual(expected_classes, classes_out) + self.assertAllClose(expected_scores, scores_out) + + def test_select_random_box(self): + boxes = [[0., 0., 1., 1.], + [0., 1., 2., 3.], + [0., 2., 3., 4.]] + + corners = tf.constant(boxes, dtype=tf.float32) + boxlist = box_list.BoxList(corners) + random_bbox, valid = box_list_ops.select_random_box(boxlist) + with self.test_session() as sess: + random_bbox_out, valid_out = sess.run([random_bbox, valid]) + + norm_small = any( + [np.linalg.norm(random_bbox_out - box) < 1e-6 for box in boxes]) + + self.assertTrue(norm_small) + self.assertTrue(valid_out) + + def test_select_random_box_with_empty_boxlist(self): + corners = tf.constant([], shape=[0, 4], dtype=tf.float32) + boxlist = box_list.BoxList(corners) + random_bbox, valid = box_list_ops.select_random_box(boxlist) + with self.test_session() as sess: + random_bbox_out, valid_out = sess.run([random_bbox, valid]) + + expected_bbox_out = np.array([[-1., -1., -1., -1.]], dtype=np.float32) + self.assertAllEqual(expected_bbox_out, random_bbox_out) + self.assertFalse(valid_out) + + def test_get_minimal_coverage_box(self): + boxes = [[0., 0., 1., 1.], + [-1., 1., 2., 3.], + [0., 2., 3., 4.]] + + expected_coverage_box = [[-1., 0., 3., 4.]] + + corners = tf.constant(boxes, dtype=tf.float32) + boxlist = box_list.BoxList(corners) + coverage_box = box_list_ops.get_minimal_coverage_box(boxlist) + with self.test_session() as sess: + coverage_box_out = sess.run(coverage_box) + + self.assertAllClose(expected_coverage_box, coverage_box_out) + + def test_get_minimal_coverage_box_with_empty_boxlist(self): + corners = tf.constant([], shape=[0, 4], dtype=tf.float32) + boxlist = box_list.BoxList(corners) + coverage_box = box_list_ops.get_minimal_coverage_box(boxlist) + with self.test_session() as sess: + coverage_box_out = sess.run(coverage_box) + + self.assertAllClose([[0.0, 0.0, 1.0, 1.0]], coverage_box_out) + + +class ConcatenateTest(tf.test.TestCase): + + def test_invalid_input_box_list_list(self): + with self.assertRaises(ValueError): + box_list_ops.concatenate(None) + with self.assertRaises(ValueError): + box_list_ops.concatenate([]) + with self.assertRaises(ValueError): + corners = tf.constant([[0, 0, 0, 0]], tf.float32) + boxlist = box_list.BoxList(corners) + box_list_ops.concatenate([boxlist, 2]) + + def test_concatenate_with_missing_fields(self): + corners1 = tf.constant([[0, 0, 0, 0], [1, 2, 3, 4]], tf.float32) + scores1 = tf.constant([1.0, 2.1]) + corners2 = tf.constant([[0, 3, 1, 6], [2, 4, 3, 8]], tf.float32) + boxlist1 = box_list.BoxList(corners1) + boxlist1.add_field('scores', scores1) + boxlist2 = box_list.BoxList(corners2) + with self.assertRaises(ValueError): + box_list_ops.concatenate([boxlist1, boxlist2]) + + def test_concatenate_with_incompatible_field_shapes(self): + corners1 = tf.constant([[0, 0, 0, 0], [1, 2, 3, 4]], tf.float32) + scores1 = tf.constant([1.0, 2.1]) + corners2 = tf.constant([[0, 3, 1, 6], [2, 4, 3, 8]], tf.float32) + scores2 = tf.constant([[1.0, 1.0], [2.1, 3.2]]) + boxlist1 = box_list.BoxList(corners1) + boxlist1.add_field('scores', scores1) + boxlist2 = box_list.BoxList(corners2) + boxlist2.add_field('scores', scores2) + with self.assertRaises(ValueError): + box_list_ops.concatenate([boxlist1, boxlist2]) + + def test_concatenate_is_correct(self): + corners1 = tf.constant([[0, 0, 0, 0], [1, 2, 3, 4]], tf.float32) + scores1 = tf.constant([1.0, 2.1]) + corners2 = tf.constant([[0, 3, 1, 6], [2, 4, 3, 8], [1, 0, 5, 10]], + tf.float32) + scores2 = tf.constant([1.0, 2.1, 5.6]) + + exp_corners = [[0, 0, 0, 0], + [1, 2, 3, 4], + [0, 3, 1, 6], + [2, 4, 3, 8], + [1, 0, 5, 10]] + exp_scores = [1.0, 2.1, 1.0, 2.1, 5.6] + + boxlist1 = box_list.BoxList(corners1) + boxlist1.add_field('scores', scores1) + boxlist2 = box_list.BoxList(corners2) + boxlist2.add_field('scores', scores2) + result = box_list_ops.concatenate([boxlist1, boxlist2]) + with self.test_session() as sess: + corners_output, scores_output = sess.run( + [result.get(), result.get_field('scores')]) + self.assertAllClose(corners_output, exp_corners) + self.assertAllClose(scores_output, exp_scores) + + +class NonMaxSuppressionTest(tf.test.TestCase): + + def test_select_from_three_clusters(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1], + [0, -0.1, 1, 0.9], + [0, 10, 1, 11], + [0, 10.1, 1, 11.1], + [0, 100, 1, 101]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant([.9, .75, .6, .95, .5, .3])) + iou_thresh = .5 + max_output_size = 3 + + exp_nms = [[0, 10, 1, 11], + [0, 0, 1, 1], + [0, 100, 1, 101]] + nms = box_list_ops.non_max_suppression( + boxes, iou_thresh, max_output_size) + with self.test_session() as sess: + nms_output = sess.run(nms.get()) + self.assertAllClose(nms_output, exp_nms) + + def test_select_at_most_two_boxes_from_three_clusters(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1], + [0, -0.1, 1, 0.9], + [0, 10, 1, 11], + [0, 10.1, 1, 11.1], + [0, 100, 1, 101]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant([.9, .75, .6, .95, .5, .3])) + iou_thresh = .5 + max_output_size = 2 + + exp_nms = [[0, 10, 1, 11], + [0, 0, 1, 1]] + nms = box_list_ops.non_max_suppression( + boxes, iou_thresh, max_output_size) + with self.test_session() as sess: + nms_output = sess.run(nms.get()) + self.assertAllClose(nms_output, exp_nms) + + def test_select_at_most_thirty_boxes_from_three_clusters(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1], + [0, -0.1, 1, 0.9], + [0, 10, 1, 11], + [0, 10.1, 1, 11.1], + [0, 100, 1, 101]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant([.9, .75, .6, .95, .5, .3])) + iou_thresh = .5 + max_output_size = 30 + + exp_nms = [[0, 10, 1, 11], + [0, 0, 1, 1], + [0, 100, 1, 101]] + nms = box_list_ops.non_max_suppression( + boxes, iou_thresh, max_output_size) + with self.test_session() as sess: + nms_output = sess.run(nms.get()) + self.assertAllClose(nms_output, exp_nms) + + def test_select_single_box(self): + corners = tf.constant([[0, 0, 1, 1]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant([.9])) + iou_thresh = .5 + max_output_size = 3 + + exp_nms = [[0, 0, 1, 1]] + nms = box_list_ops.non_max_suppression( + boxes, iou_thresh, max_output_size) + with self.test_session() as sess: + nms_output = sess.run(nms.get()) + self.assertAllClose(nms_output, exp_nms) + + def test_select_from_ten_identical_boxes(self): + corners = tf.constant(10 * [[0, 0, 1, 1]], tf.float32) + boxes = box_list.BoxList(corners) + boxes.add_field('scores', tf.constant(10 * [.9])) + iou_thresh = .5 + max_output_size = 3 + + exp_nms = [[0, 0, 1, 1]] + nms = box_list_ops.non_max_suppression( + boxes, iou_thresh, max_output_size) + with self.test_session() as sess: + nms_output = sess.run(nms.get()) + self.assertAllClose(nms_output, exp_nms) + + def test_copy_extra_fields(self): + corners = tf.constant([[0, 0, 1, 1], + [0, 0.1, 1, 1.1]], tf.float32) + boxes = box_list.BoxList(corners) + tensor1 = np.array([[1], [4]]) + tensor2 = np.array([[1, 1], [2, 2]]) + boxes.add_field('tensor1', tf.constant(tensor1)) + boxes.add_field('tensor2', tf.constant(tensor2)) + new_boxes = box_list.BoxList(tf.constant([[0, 0, 10, 10], + [1, 3, 5, 5]], tf.float32)) + new_boxes = box_list_ops._copy_extra_fields(new_boxes, boxes) + with self.test_session() as sess: + self.assertAllClose(tensor1, sess.run(new_boxes.get_field('tensor1'))) + self.assertAllClose(tensor2, sess.run(new_boxes.get_field('tensor2'))) + + +class CoordinatesConversionTest(tf.test.TestCase): + + def test_to_normalized_coordinates(self): + coordinates = tf.constant([[0, 0, 100, 100], + [25, 25, 75, 75]], tf.float32) + img = tf.ones((128, 100, 100, 3)) + boxlist = box_list.BoxList(coordinates) + normalized_boxlist = box_list_ops.to_normalized_coordinates( + boxlist, tf.shape(img)[1], tf.shape(img)[2]) + expected_boxes = [[0, 0, 1, 1], + [0.25, 0.25, 0.75, 0.75]] + + with self.test_session() as sess: + normalized_boxes = sess.run(normalized_boxlist.get()) + self.assertAllClose(normalized_boxes, expected_boxes) + + def test_to_normalized_coordinates_already_normalized(self): + coordinates = tf.constant([[0, 0, 1, 1], + [0.25, 0.25, 0.75, 0.75]], tf.float32) + img = tf.ones((128, 100, 100, 3)) + boxlist = box_list.BoxList(coordinates) + normalized_boxlist = box_list_ops.to_normalized_coordinates( + boxlist, tf.shape(img)[1], tf.shape(img)[2]) + + with self.test_session() as sess: + with self.assertRaisesOpError('assertion failed'): + sess.run(normalized_boxlist.get()) + + def test_to_absolute_coordinates(self): + coordinates = tf.constant([[0, 0, 1, 1], + [0.25, 0.25, 0.75, 0.75]], tf.float32) + img = tf.ones((128, 100, 100, 3)) + boxlist = box_list.BoxList(coordinates) + absolute_boxlist = box_list_ops.to_absolute_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + expected_boxes = [[0, 0, 100, 100], + [25, 25, 75, 75]] + + with self.test_session() as sess: + absolute_boxes = sess.run(absolute_boxlist.get()) + self.assertAllClose(absolute_boxes, expected_boxes) + + def test_to_absolute_coordinates_already_abolute(self): + coordinates = tf.constant([[0, 0, 100, 100], + [25, 25, 75, 75]], tf.float32) + img = tf.ones((128, 100, 100, 3)) + boxlist = box_list.BoxList(coordinates) + absolute_boxlist = box_list_ops.to_absolute_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + + with self.test_session() as sess: + with self.assertRaisesOpError('assertion failed'): + sess.run(absolute_boxlist.get()) + + def test_convert_to_normalized_and_back(self): + coordinates = np.random.uniform(size=(100, 4)) + coordinates = np.round(np.sort(coordinates) * 200) + coordinates[:, 2:4] += 1 + coordinates[99, :] = [0, 0, 201, 201] + img = tf.ones((128, 202, 202, 3)) + + boxlist = box_list.BoxList(tf.constant(coordinates, tf.float32)) + boxlist = box_list_ops.to_normalized_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + boxlist = box_list_ops.to_absolute_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + + with self.test_session() as sess: + out = sess.run(boxlist.get()) + self.assertAllClose(out, coordinates) + + def test_convert_to_absolute_and_back(self): + coordinates = np.random.uniform(size=(100, 4)) + coordinates = np.sort(coordinates) + coordinates[99, :] = [0, 0, 1, 1] + img = tf.ones((128, 202, 202, 3)) + + boxlist = box_list.BoxList(tf.constant(coordinates, tf.float32)) + boxlist = box_list_ops.to_absolute_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + boxlist = box_list_ops.to_normalized_coordinates(boxlist, + tf.shape(img)[1], + tf.shape(img)[2]) + + with self.test_session() as sess: + out = sess.run(boxlist.get()) + self.assertAllClose(out, coordinates) + + def test_to_absolute_coordinates_maximum_coordinate_check(self): + coordinates = tf.constant([[0, 0, 1.2, 1.2], + [0.25, 0.25, 0.75, 0.75]], tf.float32) + img = tf.ones((128, 100, 100, 3)) + boxlist = box_list.BoxList(coordinates) + absolute_boxlist = box_list_ops.to_absolute_coordinates( + boxlist, + tf.shape(img)[1], + tf.shape(img)[2], + maximum_normalized_coordinate=1.1) + + with self.test_session() as sess: + with self.assertRaisesOpError('assertion failed'): + sess.run(absolute_boxlist.get()) + + +class BoxRefinementTest(tf.test.TestCase): + + def test_box_voting(self): + candidates = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.6, 0.6, 0.8, 0.8]], tf.float32)) + candidates.add_field('ExtraField', tf.constant([1, 2])) + pool = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5], + [0.6, 0.6, 0.8, 0.8]], tf.float32)) + pool.add_field('scores', tf.constant([0.75, 0.25, 0.3])) + averaged_boxes = box_list_ops.box_voting(candidates, pool) + expected_boxes = [[0.1, 0.1, 0.425, 0.425], [0.6, 0.6, 0.8, 0.8]] + expected_scores = [0.5, 0.3] + with self.test_session() as sess: + boxes_out, scores_out, extra_field_out = sess.run( + [averaged_boxes.get(), averaged_boxes.get_field('scores'), + averaged_boxes.get_field('ExtraField')]) + + self.assertAllClose(expected_boxes, boxes_out) + self.assertAllClose(expected_scores, scores_out) + self.assertAllEqual(extra_field_out, [1, 2]) + + def test_box_voting_fails_with_negative_scores(self): + candidates = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4]], tf.float32)) + pool = box_list.BoxList(tf.constant([[0.1, 0.1, 0.4, 0.4]], tf.float32)) + pool.add_field('scores', tf.constant([-0.2])) + averaged_boxes = box_list_ops.box_voting(candidates, pool) + + with self.test_session() as sess: + with self.assertRaisesOpError('Scores must be non negative'): + sess.run([averaged_boxes.get()]) + + def test_box_voting_fails_when_unmatched(self): + candidates = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4]], tf.float32)) + pool = box_list.BoxList(tf.constant([[0.6, 0.6, 0.8, 0.8]], tf.float32)) + pool.add_field('scores', tf.constant([0.2])) + averaged_boxes = box_list_ops.box_voting(candidates, pool) + + with self.test_session() as sess: + with self.assertRaisesOpError('Each box in selected_boxes must match ' + 'with at least one box in pool_boxes.'): + sess.run([averaged_boxes.get()]) + + def test_refine_boxes(self): + pool = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5], + [0.6, 0.6, 0.8, 0.8]], tf.float32)) + pool.add_field('ExtraField', tf.constant([1, 2, 3])) + pool.add_field('scores', tf.constant([0.75, 0.25, 0.3])) + refined_boxes = box_list_ops.refine_boxes(pool, 0.5, 10) + + expected_boxes = [[0.1, 0.1, 0.425, 0.425], [0.6, 0.6, 0.8, 0.8]] + expected_scores = [0.5, 0.3] + with self.test_session() as sess: + boxes_out, scores_out, extra_field_out = sess.run( + [refined_boxes.get(), refined_boxes.get_field('scores'), + refined_boxes.get_field('ExtraField')]) + + self.assertAllClose(expected_boxes, boxes_out) + self.assertAllClose(expected_scores, scores_out) + self.assertAllEqual(extra_field_out, [1, 3]) + + def test_refine_boxes_multi_class(self): + pool = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5], + [0.6, 0.6, 0.8, 0.8], [0.2, 0.2, 0.3, 0.3]], tf.float32)) + pool.add_field('classes', tf.constant([0, 0, 1, 1])) + pool.add_field('scores', tf.constant([0.75, 0.25, 0.3, 0.2])) + refined_boxes = box_list_ops.refine_boxes_multi_class(pool, 3, 0.5, 10) + + expected_boxes = [[0.1, 0.1, 0.425, 0.425], [0.6, 0.6, 0.8, 0.8], + [0.2, 0.2, 0.3, 0.3]] + expected_scores = [0.5, 0.3, 0.2] + with self.test_session() as sess: + boxes_out, scores_out, extra_field_out = sess.run( + [refined_boxes.get(), refined_boxes.get_field('scores'), + refined_boxes.get_field('classes')]) + + self.assertAllClose(expected_boxes, boxes_out) + self.assertAllClose(expected_scores, scores_out) + self.assertAllEqual(extra_field_out, [0, 1, 1]) + + def test_sample_boxes_by_jittering(self): + boxes = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], + [0.1, 0.1, 0.5, 0.5], + [0.6, 0.6, 0.8, 0.8], + [0.2, 0.2, 0.3, 0.3]], tf.float32)) + sampled_boxes = box_list_ops.sample_boxes_by_jittering( + boxlist=boxes, num_boxes_to_sample=10) + iou = box_list_ops.iou(boxes, sampled_boxes) + iou_max = tf.reduce_max(iou, axis=0) + with self.test_session() as sess: + (np_sampled_boxes, np_iou_max) = sess.run([sampled_boxes.get(), iou_max]) + self.assertAllEqual(np_sampled_boxes.shape, [10, 4]) + self.assertAllGreater(np_iou_max, 0.5) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_test.py" new file mode 100644 index 00000000..edc00ebb --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_list_test.py" @@ -0,0 +1,134 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.box_list.""" + +import tensorflow as tf + +from object_detection.core import box_list + + +class BoxListTest(tf.test.TestCase): + """Tests for BoxList class.""" + + def test_num_boxes(self): + data = tf.constant([[0, 0, 1, 1], [1, 1, 2, 3], [3, 4, 5, 5]], tf.float32) + expected_num_boxes = 3 + + boxes = box_list.BoxList(data) + with self.test_session() as sess: + num_boxes_output = sess.run(boxes.num_boxes()) + self.assertEquals(num_boxes_output, expected_num_boxes) + + def test_get_correct_center_coordinates_and_sizes(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + boxes = box_list.BoxList(tf.constant(boxes)) + centers_sizes = boxes.get_center_coordinates_and_sizes() + expected_centers_sizes = [[15, 0.35], [12.5, 0.25], [10, 0.3], [5, 0.3]] + with self.test_session() as sess: + centers_sizes_out = sess.run(centers_sizes) + self.assertAllClose(centers_sizes_out, expected_centers_sizes) + + def test_create_box_list_with_dynamic_shape(self): + data = tf.constant([[0, 0, 1, 1], [1, 1, 2, 3], [3, 4, 5, 5]], tf.float32) + indices = tf.reshape(tf.where(tf.greater([1, 0, 1], 0)), [-1]) + data = tf.gather(data, indices) + assert data.get_shape().as_list() == [None, 4] + expected_num_boxes = 2 + + boxes = box_list.BoxList(data) + with self.test_session() as sess: + num_boxes_output = sess.run(boxes.num_boxes()) + self.assertEquals(num_boxes_output, expected_num_boxes) + + def test_transpose_coordinates(self): + boxes = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + boxes = box_list.BoxList(tf.constant(boxes)) + boxes.transpose_coordinates() + expected_corners = [[10.0, 10.0, 15.0, 20.0], [0.1, 0.2, 0.4, 0.5]] + with self.test_session() as sess: + corners_out = sess.run(boxes.get()) + self.assertAllClose(corners_out, expected_corners) + + def test_box_list_invalid_inputs(self): + data0 = tf.constant([[[0, 0, 1, 1], [3, 4, 5, 5]]], tf.float32) + data1 = tf.constant([[0, 0, 1], [1, 1, 2], [3, 4, 5]], tf.float32) + data2 = tf.constant([[0, 0, 1], [1, 1, 2], [3, 4, 5]], tf.int32) + + with self.assertRaises(ValueError): + _ = box_list.BoxList(data0) + with self.assertRaises(ValueError): + _ = box_list.BoxList(data1) + with self.assertRaises(ValueError): + _ = box_list.BoxList(data2) + + def test_num_boxes_static(self): + box_corners = [[10.0, 10.0, 20.0, 15.0], [0.2, 0.1, 0.5, 0.4]] + boxes = box_list.BoxList(tf.constant(box_corners)) + self.assertEquals(boxes.num_boxes_static(), 2) + self.assertEquals(type(boxes.num_boxes_static()), int) + + def test_num_boxes_static_for_uninferrable_shape(self): + placeholder = tf.placeholder(tf.float32, shape=[None, 4]) + boxes = box_list.BoxList(placeholder) + self.assertEquals(boxes.num_boxes_static(), None) + + def test_as_tensor_dict(self): + boxlist = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]], tf.float32)) + boxlist.add_field('classes', tf.constant([0, 1])) + boxlist.add_field('scores', tf.constant([0.75, 0.2])) + tensor_dict = boxlist.as_tensor_dict() + + expected_boxes = [[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]] + expected_classes = [0, 1] + expected_scores = [0.75, 0.2] + + with self.test_session() as sess: + tensor_dict_out = sess.run(tensor_dict) + self.assertAllEqual(3, len(tensor_dict_out)) + self.assertAllClose(expected_boxes, tensor_dict_out['boxes']) + self.assertAllEqual(expected_classes, tensor_dict_out['classes']) + self.assertAllClose(expected_scores, tensor_dict_out['scores']) + + def test_as_tensor_dict_with_features(self): + boxlist = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]], tf.float32)) + boxlist.add_field('classes', tf.constant([0, 1])) + boxlist.add_field('scores', tf.constant([0.75, 0.2])) + tensor_dict = boxlist.as_tensor_dict(['boxes', 'classes', 'scores']) + + expected_boxes = [[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]] + expected_classes = [0, 1] + expected_scores = [0.75, 0.2] + + with self.test_session() as sess: + tensor_dict_out = sess.run(tensor_dict) + self.assertAllEqual(3, len(tensor_dict_out)) + self.assertAllClose(expected_boxes, tensor_dict_out['boxes']) + self.assertAllEqual(expected_classes, tensor_dict_out['classes']) + self.assertAllClose(expected_scores, tensor_dict_out['scores']) + + def test_as_tensor_dict_missing_field(self): + boxlist = box_list.BoxList( + tf.constant([[0.1, 0.1, 0.4, 0.4], [0.1, 0.1, 0.5, 0.5]], tf.float32)) + boxlist.add_field('classes', tf.constant([0, 1])) + boxlist.add_field('scores', tf.constant([0.75, 0.2])) + with self.assertRaises(ValueError): + boxlist.as_tensor_dict(['foo', 'bar']) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_predictor.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_predictor.py" new file mode 100644 index 00000000..91a6647e --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/box_predictor.py" @@ -0,0 +1,227 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Box predictor for object detectors. + +Box predictors are classes that take a high level +image feature map as input and produce two predictions, +(1) a tensor encoding box locations, and +(2) a tensor encoding classes for each box. + +These components are passed directly to loss functions +in our detection models. + +These modules are separated from the main model since the same +few box predictor architectures are shared across many models. +""" +from abc import abstractmethod +import tensorflow as tf + +BOX_ENCODINGS = 'box_encodings' +CLASS_PREDICTIONS_WITH_BACKGROUND = 'class_predictions_with_background' +MASK_PREDICTIONS = 'mask_predictions' + + +class BoxPredictor(object): + """BoxPredictor.""" + + def __init__(self, is_training, num_classes): + """Constructor. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + """ + self._is_training = is_training + self._num_classes = num_classes + + @property + def is_keras_model(self): + return False + + @property + def num_classes(self): + return self._num_classes + + def predict(self, image_features, num_predictions_per_location, + scope=None, **params): + """Computes encoded object locations and corresponding confidences. + + Takes a list of high level image feature maps as input and produces a list + of box encodings and a list of class scores where each element in the output + lists correspond to the feature maps in the input list. + + Args: + image_features: A list of float tensors of shape [batch_size, height_i, + width_i, channels_i] containing features for a batch of images. + num_predictions_per_location: A list of integers representing the number + of box predictions to be made per spatial location for each feature map. + scope: Variable and Op scope name. + **params: Additional keyword arguments for specific implementations of + BoxPredictor. + + Returns: + A dictionary containing at least the following tensors. + box_encodings: A list of float tensors. Each entry in the list + corresponds to a feature map in the input `image_features` list. All + tensors in the list have one of the two following shapes: + a. [batch_size, num_anchors_i, q, code_size] representing the location + of the objects, where q is 1 or the number of classes. + b. [batch_size, num_anchors_i, code_size]. + class_predictions_with_background: A list of float tensors of shape + [batch_size, num_anchors_i, num_classes + 1] representing the class + predictions for the proposals. Each entry in the list corresponds to a + feature map in the input `image_features` list. + + Raises: + ValueError: If length of `image_features` is not equal to length of + `num_predictions_per_location`. + """ + if len(image_features) != len(num_predictions_per_location): + raise ValueError('image_feature and num_predictions_per_location must ' + 'be of same length, found: {} vs {}'. + format(len(image_features), + len(num_predictions_per_location))) + if scope is not None: + with tf.variable_scope(scope): + return self._predict(image_features, num_predictions_per_location, + **params) + return self._predict(image_features, num_predictions_per_location, + **params) + + # TODO(rathodv): num_predictions_per_location could be moved to constructor. + # This is currently only used by ConvolutionalBoxPredictor. + @abstractmethod + def _predict(self, image_features, num_predictions_per_location, **params): + """Implementations must override this method. + + Args: + image_features: A list of float tensors of shape [batch_size, height_i, + width_i, channels_i] containing features for a batch of images. + num_predictions_per_location: A list of integers representing the number + of box predictions to be made per spatial location for each feature map. + **params: Additional keyword arguments for specific implementations of + BoxPredictor. + + Returns: + A dictionary containing at least the following tensors. + box_encodings: A list of float tensors. Each entry in the list + corresponds to a feature map in the input `image_features` list. All + tensors in the list have one of the two following shapes: + a. [batch_size, num_anchors_i, q, code_size] representing the location + of the objects, where q is 1 or the number of classes. + b. [batch_size, num_anchors_i, code_size]. + class_predictions_with_background: A list of float tensors of shape + [batch_size, num_anchors_i, num_classes + 1] representing the class + predictions for the proposals. Each entry in the list corresponds to a + feature map in the input `image_features` list. + """ + pass + + +class KerasBoxPredictor(tf.keras.Model): + """Keras-based BoxPredictor.""" + + def __init__(self, is_training, num_classes, freeze_batchnorm, + inplace_batchnorm_update, name=None): + """Constructor. + + Args: + is_training: Indicates whether the BoxPredictor is in training mode. + num_classes: number of classes. Note that num_classes *does not* + include the background category, so if groundtruth labels take values + in {0, 1, .., K-1}, num_classes=K (and not K+1, even though the + assigned classification targets can range from {0,... K}). + freeze_batchnorm: Whether to freeze batch norm parameters during + training or not. When training with a small batch size (e.g. 1), it is + desirable to freeze batch norm update and use pretrained batch norm + params. + inplace_batchnorm_update: Whether to update batch norm moving average + values inplace. When this is false train op must add a control + dependency on tf.graphkeys.UPDATE_OPS collection in order to update + batch norm statistics. + name: A string name scope to assign to the model. If `None`, Keras + will auto-generate one from the class name. + """ + super(KerasBoxPredictor, self).__init__(name=name) + + self._is_training = is_training + self._num_classes = num_classes + self._freeze_batchnorm = freeze_batchnorm + self._inplace_batchnorm_update = inplace_batchnorm_update + + @property + def is_keras_model(self): + return True + + @property + def num_classes(self): + return self._num_classes + + def call(self, image_features, **kwargs): + """Computes encoded object locations and corresponding confidences. + + Takes a list of high level image feature maps as input and produces a list + of box encodings and a list of class scores where each element in the output + lists correspond to the feature maps in the input list. + + Args: + image_features: A list of float tensors of shape [batch_size, height_i, + width_i, channels_i] containing features for a batch of images. + **kwargs: Additional keyword arguments for specific implementations of + BoxPredictor. + + Returns: + A dictionary containing at least the following tensors. + box_encodings: A list of float tensors. Each entry in the list + corresponds to a feature map in the input `image_features` list. All + tensors in the list have one of the two following shapes: + a. [batch_size, num_anchors_i, q, code_size] representing the location + of the objects, where q is 1 or the number of classes. + b. [batch_size, num_anchors_i, code_size]. + class_predictions_with_background: A list of float tensors of shape + [batch_size, num_anchors_i, num_classes + 1] representing the class + predictions for the proposals. Each entry in the list corresponds to a + feature map in the input `image_features` list. + """ + return self._predict(image_features, **kwargs) + + @abstractmethod + def _predict(self, image_features, **kwargs): + """Implementations must override this method. + + Args: + image_features: A list of float tensors of shape [batch_size, height_i, + width_i, channels_i] containing features for a batch of images. + **kwargs: Additional keyword arguments for specific implementations of + BoxPredictor. + + Returns: + A dictionary containing at least the following tensors. + box_encodings: A list of float tensors. Each entry in the list + corresponds to a feature map in the input `image_features` list. All + tensors in the list have one of the two following shapes: + a. [batch_size, num_anchors_i, q, code_size] representing the location + of the objects, where q is 1 or the number of classes. + b. [batch_size, num_anchors_i, code_size]. + class_predictions_with_background: A list of float tensors of shape + [batch_size, num_anchors_i, num_classes + 1] representing the class + predictions for the proposals. Each entry in the list corresponds to a + feature map in the input `image_features` list. + """ + raise NotImplementedError diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_decoder.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_decoder.py" new file mode 100644 index 00000000..9ae18c1f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_decoder.py" @@ -0,0 +1,41 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Interface for data decoders. + +Data decoders decode the input data and return a dictionary of tensors keyed by +the entries in core.reader.Fields. +""" +from abc import ABCMeta +from abc import abstractmethod + + +class DataDecoder(object): + """Interface for data decoders.""" + __metaclass__ = ABCMeta + + @abstractmethod + def decode(self, data): + """Return a single image and associated labels. + + Args: + data: a string tensor holding a serialized protocol buffer corresponding + to data for a single image. + + Returns: + tensor_dict: a dictionary containing tensors. Possible keys are defined in + reader.Fields. + """ + pass diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_parser.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_parser.py" new file mode 100644 index 00000000..3dac4de2 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/data_parser.py" @@ -0,0 +1,41 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== +"""Interface for data parsers. + +Data parser parses input data and returns a dictionary of numpy arrays +keyed by the entries in standard_fields.py. Since the parser parses records +to numpy arrays (materialized tensors) directly, it is used to read data for +evaluation/visualization; to parse the data during training, DataDecoder should +be used. +""" +from abc import ABCMeta +from abc import abstractmethod + + +class DataToNumpyParser(object): + __metaclass__ = ABCMeta + + @abstractmethod + def parse(self, input_data): + """Parses input and returns a numpy array or a dictionary of numpy arrays. + + Args: + input_data: an input data + + Returns: + A numpy array or a dictionary of numpy arrays or None, if input + cannot be parsed. + """ + pass diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm.py" new file mode 100644 index 00000000..68a56aa6 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm.py" @@ -0,0 +1,70 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""A freezable batch norm layer that uses Keras batch normalization.""" +import tensorflow as tf + + +class FreezableBatchNorm(tf.keras.layers.BatchNormalization): + """Batch normalization layer (Ioffe and Szegedy, 2014). + + This is a `freezable` batch norm layer that supports setting the `training` + parameter in the __init__ method rather than having to set it either via + the Keras learning phase or via the `call` method parameter. This layer will + forward all other parameters to the default Keras `BatchNormalization` + layer + + This is class is necessary because Object Detection model training sometimes + requires batch normalization layers to be `frozen` and used as if it was + evaluation time, despite still training (and potentially using dropout layers) + + Like the default Keras BatchNormalization layer, this will normalize the + activations of the previous layer at each batch, + i.e. applies a transformation that maintains the mean activation + close to 0 and the activation standard deviation close to 1. + + Arguments: + training: Boolean or None. If True, the batch normalization layer will + normalize the input batch using the batch mean and standard deviation, + and update the total moving mean and standard deviations. If False, the + layer will normalize using the moving average and std. dev, without + updating the learned avg and std. dev. + If None, the layer will follow the keras BatchNormalization layer + strategy of checking the Keras learning phase at `call` time to decide + what to do. + **kwargs: The keyword arguments to forward to the keras BatchNormalization + layer constructor. + + Input shape: + Arbitrary. Use the keyword argument `input_shape` + (tuple of integers, does not include the samples axis) + when using this layer as the first layer in a model. + + Output shape: + Same shape as input. + + References: + - [Batch Normalization: Accelerating Deep Network Training by Reducing + Internal Covariate Shift](https://arxiv.org/abs/1502.03167) + """ + + def __init__(self, training=None, **kwargs): + super(FreezableBatchNorm, self).__init__(**kwargs) + self._training = training + + def call(self, inputs, training=None): + if training is None: + training = self._training + return super(FreezableBatchNorm, self).call(inputs, training=training) diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm_test.py" new file mode 100644 index 00000000..504b9e71 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/freezable_batch_norm_test.py" @@ -0,0 +1,121 @@ +# Copyright 2018 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.freezable_batch_norm.""" +import numpy as np +import tensorflow as tf + +from object_detection.core import freezable_batch_norm + + +class FreezableBatchNormTest(tf.test.TestCase): + """Tests for FreezableBatchNorm operations.""" + + def _build_model(self, training=None): + model = tf.keras.models.Sequential() + norm = freezable_batch_norm.FreezableBatchNorm(training=training, + input_shape=(10,), + momentum=0.8) + model.add(norm) + return model, norm + + def _train_freezable_batch_norm(self, training_mean, training_var): + model, _ = self._build_model() + model.compile(loss='mse', optimizer='sgd') + + # centered on training_mean, variance training_var + train_data = np.random.normal( + loc=training_mean, + scale=training_var, + size=(1000, 10)) + model.fit(train_data, train_data, epochs=4, verbose=0) + return model.weights + + def test_batchnorm_freezing_training_true(self): + with self.test_session(): + training_mean = 5.0 + training_var = 10.0 + + testing_mean = -10.0 + testing_var = 5.0 + + # Initially train the batch norm, and save the weights + trained_weights = self._train_freezable_batch_norm(training_mean, + training_var) + + # Load the batch norm weights, freezing training to True. + # Apply the batch norm layer to testing data and ensure it is normalized + # according to the batch statistics. + model, norm = self._build_model(training=True) + for trained_weight, blank_weight in zip(trained_weights, model.weights): + weight_copy = blank_weight.assign(tf.keras.backend.eval(trained_weight)) + tf.keras.backend.eval(weight_copy) + + # centered on testing_mean, variance testing_var + test_data = np.random.normal( + loc=testing_mean, + scale=testing_var, + size=(1000, 10)) + + out_tensor = norm(tf.convert_to_tensor(test_data, dtype=tf.float32)) + out = tf.keras.backend.eval(out_tensor) + + out -= tf.keras.backend.eval(norm.beta) + out /= tf.keras.backend.eval(norm.gamma) + + np.testing.assert_allclose(out.mean(), 0.0, atol=1.5e-1) + np.testing.assert_allclose(out.std(), 1.0, atol=1.5e-1) + + def test_batchnorm_freezing_training_false(self): + with self.test_session(): + training_mean = 5.0 + training_var = 10.0 + + testing_mean = -10.0 + testing_var = 5.0 + + # Initially train the batch norm, and save the weights + trained_weights = self._train_freezable_batch_norm(training_mean, + training_var) + + # Load the batch norm back up, freezing training to False. + # Apply the batch norm layer to testing data and ensure it is normalized + # according to the training data's statistics. + model, norm = self._build_model(training=False) + for trained_weight, blank_weight in zip(trained_weights, model.weights): + weight_copy = blank_weight.assign(tf.keras.backend.eval(trained_weight)) + tf.keras.backend.eval(weight_copy) + + # centered on testing_mean, variance testing_var + test_data = np.random.normal( + loc=testing_mean, + scale=testing_var, + size=(1000, 10)) + + out_tensor = norm(tf.convert_to_tensor(test_data, dtype=tf.float32)) + out = tf.keras.backend.eval(out_tensor) + + out -= tf.keras.backend.eval(norm.beta) + out /= tf.keras.backend.eval(norm.gamma) + + out *= training_var + out += (training_mean - testing_mean) + out /= testing_var + + np.testing.assert_allclose(out.mean(), 0.0, atol=1.5e-1) + np.testing.assert_allclose(out.std(), 1.0, atol=1.5e-1) + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops.py" new file mode 100644 index 00000000..e520845f --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops.py" @@ -0,0 +1,282 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Keypoint operations. + +Keypoints are represented as tensors of shape [num_instances, num_keypoints, 2], +where the last dimension holds rank 2 tensors of the form [y, x] representing +the coordinates of the keypoint. +""" +import numpy as np +import tensorflow as tf + + +def scale(keypoints, y_scale, x_scale, scope=None): + """Scales keypoint coordinates in x and y dimensions. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + y_scale: (float) scalar tensor + x_scale: (float) scalar tensor + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'Scale'): + y_scale = tf.cast(y_scale, tf.float32) + x_scale = tf.cast(x_scale, tf.float32) + new_keypoints = keypoints * [[[y_scale, x_scale]]] + return new_keypoints + + +def clip_to_window(keypoints, window, scope=None): + """Clips keypoints to a window. + + This op clips any input keypoints to a window. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + window: a tensor of shape [4] representing the [y_min, x_min, y_max, x_max] + window to which the op should clip the keypoints. + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'ClipToWindow'): + y, x = tf.split(value=keypoints, num_or_size_splits=2, axis=2) + win_y_min, win_x_min, win_y_max, win_x_max = tf.unstack(window) + y = tf.maximum(tf.minimum(y, win_y_max), win_y_min) + x = tf.maximum(tf.minimum(x, win_x_max), win_x_min) + new_keypoints = tf.concat([y, x], 2) + return new_keypoints + + +def prune_outside_window(keypoints, window, scope=None): + """Prunes keypoints that fall outside a given window. + + This function replaces keypoints that fall outside the given window with nan. + See also clip_to_window which clips any keypoints that fall outside the given + window. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + window: a tensor of shape [4] representing the [y_min, x_min, y_max, x_max] + window outside of which the op should prune the keypoints. + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'PruneOutsideWindow'): + y, x = tf.split(value=keypoints, num_or_size_splits=2, axis=2) + win_y_min, win_x_min, win_y_max, win_x_max = tf.unstack(window) + + valid_indices = tf.logical_and( + tf.logical_and(y >= win_y_min, y <= win_y_max), + tf.logical_and(x >= win_x_min, x <= win_x_max)) + + new_y = tf.where(valid_indices, y, np.nan * tf.ones_like(y)) + new_x = tf.where(valid_indices, x, np.nan * tf.ones_like(x)) + new_keypoints = tf.concat([new_y, new_x], 2) + + return new_keypoints + + +def change_coordinate_frame(keypoints, window, scope=None): + """Changes coordinate frame of the keypoints to be relative to window's frame. + + Given a window of the form [y_min, x_min, y_max, x_max], changes keypoint + coordinates from keypoints of shape [num_instances, num_keypoints, 2] + to be relative to this window. + + An example use case is data augmentation: where we are given groundtruth + keypoints and would like to randomly crop the image to some window. In this + case we need to change the coordinate frame of each groundtruth keypoint to be + relative to this new window. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + window: a tensor of shape [4] representing the [y_min, x_min, y_max, x_max] + window we should change the coordinate frame to. + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'ChangeCoordinateFrame'): + win_height = window[2] - window[0] + win_width = window[3] - window[1] + new_keypoints = scale(keypoints - [window[0], window[1]], 1.0 / win_height, + 1.0 / win_width) + return new_keypoints + + +def to_normalized_coordinates(keypoints, height, width, + check_range=True, scope=None): + """Converts absolute keypoint coordinates to normalized coordinates in [0, 1]. + + Usually one uses the dynamic shape of the image or conv-layer tensor: + keypoints = keypoint_ops.to_normalized_coordinates(keypoints, + tf.shape(images)[1], + tf.shape(images)[2]), + + This function raises an assertion failed error at graph execution time when + the maximum coordinate is smaller than 1.01 (which means that coordinates are + already normalized). The value 1.01 is to deal with small rounding errors. + + Args: + keypoints: A tensor of shape [num_instances, num_keypoints, 2]. + height: Maximum value for y coordinate of absolute keypoint coordinates. + width: Maximum value for x coordinate of absolute keypoint coordinates. + check_range: If True, checks if the coordinates are normalized. + scope: name scope. + + Returns: + tensor of shape [num_instances, num_keypoints, 2] with normalized + coordinates in [0, 1]. + """ + with tf.name_scope(scope, 'ToNormalizedCoordinates'): + height = tf.cast(height, tf.float32) + width = tf.cast(width, tf.float32) + + if check_range: + max_val = tf.reduce_max(keypoints) + max_assert = tf.Assert(tf.greater(max_val, 1.01), + ['max value is lower than 1.01: ', max_val]) + with tf.control_dependencies([max_assert]): + width = tf.identity(width) + + return scale(keypoints, 1.0 / height, 1.0 / width) + + +def to_absolute_coordinates(keypoints, height, width, + check_range=True, scope=None): + """Converts normalized keypoint coordinates to absolute pixel coordinates. + + This function raises an assertion failed error when the maximum keypoint + coordinate value is larger than 1.01 (in which case coordinates are already + absolute). + + Args: + keypoints: A tensor of shape [num_instances, num_keypoints, 2] + height: Maximum value for y coordinate of absolute keypoint coordinates. + width: Maximum value for x coordinate of absolute keypoint coordinates. + check_range: If True, checks if the coordinates are normalized or not. + scope: name scope. + + Returns: + tensor of shape [num_instances, num_keypoints, 2] with absolute coordinates + in terms of the image size. + + """ + with tf.name_scope(scope, 'ToAbsoluteCoordinates'): + height = tf.cast(height, tf.float32) + width = tf.cast(width, tf.float32) + + # Ensure range of input keypoints is correct. + if check_range: + max_val = tf.reduce_max(keypoints) + max_assert = tf.Assert(tf.greater_equal(1.01, max_val), + ['maximum keypoint coordinate value is larger ' + 'than 1.01: ', max_val]) + with tf.control_dependencies([max_assert]): + width = tf.identity(width) + + return scale(keypoints, height, width) + + +def flip_horizontal(keypoints, flip_point, flip_permutation, scope=None): + """Flips the keypoints horizontally around the flip_point. + + This operation flips the x coordinate for each keypoint around the flip_point + and also permutes the keypoints in a manner specified by flip_permutation. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + flip_point: (float) scalar tensor representing the x coordinate to flip the + keypoints around. + flip_permutation: rank 1 int32 tensor containing the keypoint flip + permutation. This specifies the mapping from original keypoint indices + to the flipped keypoint indices. This is used primarily for keypoints + that are not reflection invariant. E.g. Suppose there are 3 keypoints + representing ['head', 'right_eye', 'left_eye'], then a logical choice for + flip_permutation might be [0, 2, 1] since we want to swap the 'left_eye' + and 'right_eye' after a horizontal flip. + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'FlipHorizontal'): + keypoints = tf.transpose(keypoints, [1, 0, 2]) + keypoints = tf.gather(keypoints, flip_permutation) + v, u = tf.split(value=keypoints, num_or_size_splits=2, axis=2) + u = flip_point * 2.0 - u + new_keypoints = tf.concat([v, u], 2) + new_keypoints = tf.transpose(new_keypoints, [1, 0, 2]) + return new_keypoints + + +def flip_vertical(keypoints, flip_point, flip_permutation, scope=None): + """Flips the keypoints vertically around the flip_point. + + This operation flips the y coordinate for each keypoint around the flip_point + and also permutes the keypoints in a manner specified by flip_permutation. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + flip_point: (float) scalar tensor representing the y coordinate to flip the + keypoints around. + flip_permutation: rank 1 int32 tensor containing the keypoint flip + permutation. This specifies the mapping from original keypoint indices + to the flipped keypoint indices. This is used primarily for keypoints + that are not reflection invariant. E.g. Suppose there are 3 keypoints + representing ['head', 'right_eye', 'left_eye'], then a logical choice for + flip_permutation might be [0, 2, 1] since we want to swap the 'left_eye' + and 'right_eye' after a horizontal flip. + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'FlipVertical'): + keypoints = tf.transpose(keypoints, [1, 0, 2]) + keypoints = tf.gather(keypoints, flip_permutation) + v, u = tf.split(value=keypoints, num_or_size_splits=2, axis=2) + v = flip_point * 2.0 - v + new_keypoints = tf.concat([v, u], 2) + new_keypoints = tf.transpose(new_keypoints, [1, 0, 2]) + return new_keypoints + + +def rot90(keypoints, scope=None): + """Rotates the keypoints counter-clockwise by 90 degrees. + + Args: + keypoints: a tensor of shape [num_instances, num_keypoints, 2] + scope: name scope. + + Returns: + new_keypoints: a tensor of shape [num_instances, num_keypoints, 2] + """ + with tf.name_scope(scope, 'Rot90'): + keypoints = tf.transpose(keypoints, [1, 0, 2]) + v, u = tf.split(value=keypoints[:, :, ::-1], num_or_size_splits=2, axis=2) + v = 1.0 - v + new_keypoints = tf.concat([v, u], 2) + new_keypoints = tf.transpose(new_keypoints, [1, 0, 2]) + return new_keypoints diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops_test.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops_test.py" new file mode 100644 index 00000000..1c09c55a --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/keypoint_ops_test.py" @@ -0,0 +1,200 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Tests for object_detection.core.keypoint_ops.""" +import numpy as np +import tensorflow as tf + +from object_detection.core import keypoint_ops + + +class KeypointOpsTest(tf.test.TestCase): + """Tests for common keypoint operations.""" + + def test_scale(self): + keypoints = tf.constant([ + [[0.0, 0.0], [100.0, 200.0]], + [[50.0, 120.0], [100.0, 140.0]] + ]) + y_scale = tf.constant(1.0 / 100) + x_scale = tf.constant(1.0 / 200) + + expected_keypoints = tf.constant([ + [[0., 0.], [1.0, 1.0]], + [[0.5, 0.6], [1.0, 0.7]] + ]) + output = keypoint_ops.scale(keypoints, y_scale, x_scale) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_clip_to_window(self): + keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + window = tf.constant([0.25, 0.25, 0.75, 0.75]) + + expected_keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.25], [0.75, 0.75]] + ]) + output = keypoint_ops.clip_to_window(keypoints, window) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_prune_outside_window(self): + keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + window = tf.constant([0.25, 0.25, 0.75, 0.75]) + + expected_keypoints = tf.constant([[[0.25, 0.5], [0.75, 0.75]], + [[np.nan, np.nan], [np.nan, np.nan]]]) + output = keypoint_ops.prune_outside_window(keypoints, window) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_change_coordinate_frame(self): + keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + window = tf.constant([0.25, 0.25, 0.75, 0.75]) + + expected_keypoints = tf.constant([ + [[0, 0.5], [1.0, 1.0]], + [[0.5, -0.5], [1.5, 1.5]] + ]) + output = keypoint_ops.change_coordinate_frame(keypoints, window) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_to_normalized_coordinates(self): + keypoints = tf.constant([ + [[10., 30.], [30., 45.]], + [[20., 0.], [40., 60.]] + ]) + output = keypoint_ops.to_normalized_coordinates( + keypoints, 40, 60) + expected_keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_to_normalized_coordinates_already_normalized(self): + keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + output = keypoint_ops.to_normalized_coordinates( + keypoints, 40, 60) + + with self.test_session() as sess: + with self.assertRaisesOpError('assertion failed'): + sess.run(output) + + def test_to_absolute_coordinates(self): + keypoints = tf.constant([ + [[0.25, 0.5], [0.75, 0.75]], + [[0.5, 0.0], [1.0, 1.0]] + ]) + output = keypoint_ops.to_absolute_coordinates( + keypoints, 40, 60) + expected_keypoints = tf.constant([ + [[10., 30.], [30., 45.]], + [[20., 0.], [40., 60.]] + ]) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_to_absolute_coordinates_already_absolute(self): + keypoints = tf.constant([ + [[10., 30.], [30., 45.]], + [[20., 0.], [40., 60.]] + ]) + output = keypoint_ops.to_absolute_coordinates( + keypoints, 40, 60) + + with self.test_session() as sess: + with self.assertRaisesOpError('assertion failed'): + sess.run(output) + + def test_flip_horizontal(self): + keypoints = tf.constant([ + [[0.1, 0.1], [0.2, 0.2], [0.3, 0.3]], + [[0.4, 0.4], [0.5, 0.5], [0.6, 0.6]] + ]) + flip_permutation = [0, 2, 1] + + expected_keypoints = tf.constant([ + [[0.1, 0.9], [0.3, 0.7], [0.2, 0.8]], + [[0.4, 0.6], [0.6, 0.4], [0.5, 0.5]], + ]) + output = keypoint_ops.flip_horizontal(keypoints, 0.5, flip_permutation) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_flip_vertical(self): + keypoints = tf.constant([ + [[0.1, 0.1], [0.2, 0.2], [0.3, 0.3]], + [[0.4, 0.4], [0.5, 0.5], [0.6, 0.6]] + ]) + flip_permutation = [0, 2, 1] + + expected_keypoints = tf.constant([ + [[0.9, 0.1], [0.7, 0.3], [0.8, 0.2]], + [[0.6, 0.4], [0.4, 0.6], [0.5, 0.5]], + ]) + output = keypoint_ops.flip_vertical(keypoints, 0.5, flip_permutation) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + def test_rot90(self): + keypoints = tf.constant([ + [[0.1, 0.1], [0.2, 0.2], [0.3, 0.3]], + [[0.4, 0.6], [0.5, 0.6], [0.6, 0.7]] + ]) + expected_keypoints = tf.constant([ + [[0.9, 0.1], [0.8, 0.2], [0.7, 0.3]], + [[0.4, 0.4], [0.4, 0.5], [0.3, 0.6]], + ]) + output = keypoint_ops.rot90(keypoints) + + with self.test_session() as sess: + output_, expected_keypoints_ = sess.run([output, expected_keypoints]) + self.assertAllClose(output_, expected_keypoints_) + + +if __name__ == '__main__': + tf.test.main() diff --git "a/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/losses.py" "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/losses.py" new file mode 100644 index 00000000..c7a85ac3 --- /dev/null +++ "b/1 \351\201\227\345\244\261\345\256\240\347\211\251\347\232\204\346\231\272\350\203\275\345\257\273\346\211\276/models/research/object_detection/core/losses.py" @@ -0,0 +1,674 @@ +# Copyright 2017 The TensorFlow Authors. All Rights Reserved. +# +# Licensed under the Apache License, Version 2.0 (the "License"); +# you may not use this file except in compliance with the License. +# You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# ============================================================================== + +"""Classification and regression loss functions for object detection. + +Localization losses: + * WeightedL2LocalizationLoss + * WeightedSmoothL1LocalizationLoss + * WeightedIOULocalizationLoss + +Classification losses: + * WeightedSigmoidClassificationLoss + * WeightedSoftmaxClassificationLoss + * WeightedSoftmaxClassificationAgainstLogitsLoss + * BootstrappedSigmoidClassificationLoss +""" +from abc import ABCMeta +from abc import abstractmethod + +import tensorflow as tf + +from object_detection.core import box_list +from object_detection.core import box_list_ops +from object_detection.utils import ops + +slim = tf.contrib.slim + + +class Loss(object): + """Abstract base class for loss functions.""" + __metaclass__ = ABCMeta + + def __call__(self, + prediction_tensor, + target_tensor, + ignore_nan_targets=False, + losses_mask=None, + scope=None, + **params): + """Call the loss function. + + Args: + prediction_tensor: an N-d tensor of shape [batch, anchors, ...] + representing predicted quantities. + target_tensor: an N-d tensor of shape [batch, anchors, ...] representing + regression or classification targets. + ignore_nan_targets: whether to ignore nan targets in the loss computation. + E.g. can be used if the target tensor is missing groundtruth data that + shouldn't be factored into the loss. + losses_mask: A [batch] boolean tensor that indicates whether losses should + be applied to individual images in the batch. For elements that + are True, corresponding prediction, target, and weight tensors will be + removed prior to loss computation. If None, no filtering will take place + prior to loss computation. + scope: Op scope name. Defaults to 'Loss' if None. + **params: Additional keyword arguments for specific implementations of + the Loss. + + Returns: + loss: a tensor representing the value of the loss function. + """ + with tf.name_scope(scope, 'Loss', + [prediction_tensor, target_tensor, params]) as scope: + if ignore_nan_targets: + target_tensor = tf.where(tf.is_nan(target_tensor), + prediction_tensor, + target_tensor) + if losses_mask is not None: + tensor_multiplier = self._get_loss_multiplier_for_tensor( + prediction_tensor, + losses_mask) + prediction_tensor *= tensor_multiplier + target_tensor *= tensor_multiplier + + if 'weights' in params: + params['weights'] = tf.convert_to_tensor(params['weights']) + weights_multiplier = self._get_loss_multiplier_for_tensor( + params['weights'], + losses_mask) + params['weights'] *= weights_multiplier + return self._compute_loss(prediction_tensor, target_tensor, **params) + + def _get_loss_multiplier_for_tensor(self, tensor, losses_mask): + loss_multiplier_shape = tf.stack([-1] + [1] * (len(tensor.shape) - 1)) + return tf.cast(tf.reshape(losses_mask, loss_multiplier_shape), tf.float32) + + @abstractmethod + def _compute_loss(self, prediction_tensor, target_tensor, **params): + """Method to be overridden by implementations. + + Args: + prediction_tensor: a tensor representing predicted quantities + target_tensor: a tensor representing regression or classification targets + **params: Additional keyword arguments for specific implementations of + the Loss. + + Returns: + loss: an N-d tensor of shape [batch, anchors, ...] containing the loss per + anchor + """ + pass + + +class WeightedL2LocalizationLoss(Loss): + """L2 localization loss function with anchorwise output support. + + Loss[b,a] = .5 * ||weights[b,a] * (prediction[b,a,:] - target[b,a,:])||^2 + """ + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + code_size] representing the (encoded) predicted locations of objects. + target_tensor: A float tensor of shape [batch_size, num_anchors, + code_size] representing the regression targets + weights: a float tensor of shape [batch_size, num_anchors] + + Returns: + loss: a float tensor of shape [batch_size, num_anchors] tensor + representing the value of the loss function. + """ + weighted_diff = (prediction_tensor - target_tensor) * tf.expand_dims( + weights, 2) + square_diff = 0.5 * tf.square(weighted_diff) + return tf.reduce_sum(square_diff, 2) + + +class WeightedSmoothL1LocalizationLoss(Loss): + """Smooth L1 localization loss function aka Huber Loss.. + + The smooth L1_loss is defined elementwise as .5 x^2 if |x| <= delta and + delta * (|x|- 0.5*delta) otherwise, where x is the difference between + predictions and target. + + See also Equation (3) in the Fast R-CNN paper by Ross Girshick (ICCV 2015) + """ + + def __init__(self, delta=1.0): + """Constructor. + + Args: + delta: delta for smooth L1 loss. + """ + self._delta = delta + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + code_size] representing the (encoded) predicted locations of objects. + target_tensor: A float tensor of shape [batch_size, num_anchors, + code_size] representing the regression targets + weights: a float tensor of shape [batch_size, num_anchors] + + Returns: + loss: a float tensor of shape [batch_size, num_anchors] tensor + representing the value of the loss function. + """ + return tf.reduce_sum(tf.losses.huber_loss( + target_tensor, + prediction_tensor, + delta=self._delta, + weights=tf.expand_dims(weights, axis=2), + loss_collection=None, + reduction=tf.losses.Reduction.NONE + ), axis=2) + + +class WeightedIOULocalizationLoss(Loss): + """IOU localization loss function. + + Sums the IOU for corresponding pairs of predicted/groundtruth boxes + and for each pair assign a loss of 1 - IOU. We then compute a weighted + sum over all pairs which is returned as the total loss. + """ + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, 4] + representing the decoded predicted boxes + target_tensor: A float tensor of shape [batch_size, num_anchors, 4] + representing the decoded target boxes + weights: a float tensor of shape [batch_size, num_anchors] + + Returns: + loss: a float tensor of shape [batch_size, num_anchors] tensor + representing the value of the loss function. + """ + predicted_boxes = box_list.BoxList(tf.reshape(prediction_tensor, [-1, 4])) + target_boxes = box_list.BoxList(tf.reshape(target_tensor, [-1, 4])) + per_anchor_iou_loss = 1.0 - box_list_ops.matched_iou(predicted_boxes, + target_boxes) + return tf.reshape(weights, [-1]) * per_anchor_iou_loss + + +class WeightedSigmoidClassificationLoss(Loss): + """Sigmoid cross entropy classification loss function.""" + + def _compute_loss(self, + prediction_tensor, + target_tensor, + weights, + class_indices=None): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing the predicted logits for each class + target_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing one-hot encoded classification targets + weights: a float tensor of shape, either [batch_size, num_anchors, + num_classes] or [batch_size, num_anchors, 1]. If the shape is + [batch_size, num_anchors, 1], all the classses are equally weighted. + class_indices: (Optional) A 1-D integer tensor of class indices. + If provided, computes loss only for the specified class indices. + + Returns: + loss: a float tensor of shape [batch_size, num_anchors, num_classes] + representing the value of the loss function. + """ + if class_indices is not None: + weights *= tf.reshape( + ops.indices_to_dense_vector(class_indices, + tf.shape(prediction_tensor)[2]), + [1, 1, -1]) + per_entry_cross_ent = (tf.nn.sigmoid_cross_entropy_with_logits( + labels=target_tensor, logits=prediction_tensor)) + return per_entry_cross_ent * weights + + +class SigmoidFocalClassificationLoss(Loss): + """Sigmoid focal cross entropy loss. + + Focal loss down-weights well classified examples and focusses on the hard + examples. See https://arxiv.org/pdf/1708.02002.pdf for the loss definition. + """ + + def __init__(self, gamma=2.0, alpha=0.25): + """Constructor. + + Args: + gamma: exponent of the modulating factor (1 - p_t) ^ gamma. + alpha: optional alpha weighting factor to balance positives vs negatives. + """ + self._alpha = alpha + self._gamma = gamma + + def _compute_loss(self, + prediction_tensor, + target_tensor, + weights, + class_indices=None): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing the predicted logits for each class + target_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing one-hot encoded classification targets + weights: a float tensor of shape, either [batch_size, num_anchors, + num_classes] or [batch_size, num_anchors, 1]. If the shape is + [batch_size, num_anchors, 1], all the classses are equally weighted. + class_indices: (Optional) A 1-D integer tensor of class indices. + If provided, computes loss only for the specified class indices. + + Returns: + loss: a float tensor of shape [batch_size, num_anchors, num_classes] + representing the value of the loss function. + """ + if class_indices is not None: + weights *= tf.reshape( + ops.indices_to_dense_vector(class_indices, + tf.shape(prediction_tensor)[2]), + [1, 1, -1]) + per_entry_cross_ent = (tf.nn.sigmoid_cross_entropy_with_logits( + labels=target_tensor, logits=prediction_tensor)) + prediction_probabilities = tf.sigmoid(prediction_tensor) + p_t = ((target_tensor * prediction_probabilities) + + ((1 - target_tensor) * (1 - prediction_probabilities))) + modulating_factor = 1.0 + if self._gamma: + modulating_factor = tf.pow(1.0 - p_t, self._gamma) + alpha_weight_factor = 1.0 + if self._alpha is not None: + alpha_weight_factor = (target_tensor * self._alpha + + (1 - target_tensor) * (1 - self._alpha)) + focal_cross_entropy_loss = (modulating_factor * alpha_weight_factor * + per_entry_cross_ent) + return focal_cross_entropy_loss * weights + + +class WeightedSoftmaxClassificationLoss(Loss): + """Softmax loss function.""" + + def __init__(self, logit_scale=1.0): + """Constructor. + + Args: + logit_scale: When this value is high, the prediction is "diffused" and + when this value is low, the prediction is made peakier. + (default 1.0) + + """ + self._logit_scale = logit_scale + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing the predicted logits for each class + target_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing one-hot encoded classification targets + weights: a float tensor of shape, either [batch_size, num_anchors, + num_classes] or [batch_size, num_anchors, 1]. If the shape is + [batch_size, num_anchors, 1], all the classses are equally weighted. + + Returns: + loss: a float tensor of shape [batch_size, num_anchors] + representing the value of the loss function. + """ + weights = tf.reduce_mean(weights, axis=2) + num_classes = prediction_tensor.get_shape().as_list()[-1] + prediction_tensor = tf.divide( + prediction_tensor, self._logit_scale, name='scale_logit') + per_row_cross_ent = (tf.nn.softmax_cross_entropy_with_logits( + labels=tf.reshape(target_tensor, [-1, num_classes]), + logits=tf.reshape(prediction_tensor, [-1, num_classes]))) + return tf.reshape(per_row_cross_ent, tf.shape(weights)) * weights + + +class WeightedSoftmaxClassificationAgainstLogitsLoss(Loss): + """Softmax loss function against logits. + + Targets are expected to be provided in logits space instead of "one hot" or + "probability distribution" space. + """ + + def __init__(self, logit_scale=1.0): + """Constructor. + + Args: + logit_scale: When this value is high, the target is "diffused" and + when this value is low, the target is made peakier. + (default 1.0) + + """ + self._logit_scale = logit_scale + + def _scale_and_softmax_logits(self, logits): + """Scale logits then apply softmax.""" + scaled_logits = tf.divide(logits, self._logit_scale, name='scale_logits') + return tf.nn.softmax(scaled_logits, name='convert_scores') + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing the predicted logits for each class + target_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing logit classification targets + weights: a float tensor of shape, either [batch_size, num_anchors, + num_classes] or [batch_size, num_anchors, 1]. If the shape is + [batch_size, num_anchors, 1], all the classses are equally weighted. + + Returns: + loss: a float tensor of shape [batch_size, num_anchors] + representing the value of the loss function. + """ + weights = tf.reduce_mean(weights, axis=2) + num_classes = prediction_tensor.get_shape().as_list()[-1] + target_tensor = self._scale_and_softmax_logits(target_tensor) + prediction_tensor = tf.divide(prediction_tensor, self._logit_scale, + name='scale_logits') + + per_row_cross_ent = (tf.nn.softmax_cross_entropy_with_logits( + labels=tf.reshape(target_tensor, [-1, num_classes]), + logits=tf.reshape(prediction_tensor, [-1, num_classes]))) + return tf.reshape(per_row_cross_ent, tf.shape(weights)) * weights + + +class BootstrappedSigmoidClassificationLoss(Loss): + """Bootstrapped sigmoid cross entropy classification loss function. + + This loss uses a convex combination of training labels and the current model's + predictions as training targets in the classification loss. The idea is that + as the model improves over time, its predictions can be trusted more and we + can use these predictions to mitigate the damage of noisy/incorrect labels, + because incorrect labels are likely to be eventually highly inconsistent with + other stimuli predicted to have the same label by the model. + + In "soft" bootstrapping, we use all predicted class probabilities, whereas in + "hard" bootstrapping, we use the single class favored by the model. + + See also Training Deep Neural Networks On Noisy Labels with Bootstrapping by + Reed et al. (ICLR 2015). + """ + + def __init__(self, alpha, bootstrap_type='soft'): + """Constructor. + + Args: + alpha: a float32 scalar tensor between 0 and 1 representing interpolation + weight + bootstrap_type: set to either 'hard' or 'soft' (default) + + Raises: + ValueError: if bootstrap_type is not either 'hard' or 'soft' + """ + if bootstrap_type != 'hard' and bootstrap_type != 'soft': + raise ValueError('Unrecognized bootstrap_type: must be one of ' + '\'hard\' or \'soft.\'') + self._alpha = alpha + self._bootstrap_type = bootstrap_type + + def _compute_loss(self, prediction_tensor, target_tensor, weights): + """Compute loss function. + + Args: + prediction_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing the predicted logits for each class + target_tensor: A float tensor of shape [batch_size, num_anchors, + num_classes] representing one-hot encoded classification targets + weights: a float tensor of shape, either [batch_size, num_anchors, + num_classes] or [batch_size, num_anchors, 1]. If the shape is + [batch_size, num_anchors, 1], all the classses are equally weighted. + + Returns: + loss: a float tensor of shape [batch_size, num_anchors, num_classes] + representing the value of the loss function. + """ + if self._bootstrap_type == 'soft': + bootstrap_target_tensor = self._alpha * target_tensor + ( + 1.0 - self._alpha) * tf.sigmoid(prediction_tensor) + else: + bootstrap_target_tensor = self._alpha * target_tensor + ( + 1.0 - self._alpha) * tf.cast( + tf.sigmoid(prediction_tensor) > 0.5, tf.float32) + per_entry_cross_ent = (tf.nn.sigmoid_cross_entropy_with_logits( + labels=bootstrap_target_tensor, logits=prediction_tensor)) + return per_entry_cross_ent * weights + + +class HardExampleMiner(object): + """Hard example mining for regions in a list of images. + + Implements hard example mining to select a subset of regions to be + back-propagated. For each image, selects the regions with highest losses, + subject to the condition that a newly selected region cannot have + an IOU > iou_threshold with any of the previously selected regions. + This can be achieved by re-using a greedy non-maximum suppression algorithm. + A constraint on the number of negatives mined per positive region can also be + enforced. + + Reference papers: "Training Region-based Object Detectors with Online + Hard Example Mining" (CVPR 2016) by Srivastava et al., and + "SSD: Single Shot MultiBox Detector" (ECCV 2016) by Liu et al. + """ + + def __init__(self, + num_hard_examples=64, + iou_threshold=0.7, + loss_type='both', + cls_loss_weight=0.05, + loc_loss_weight=0.06, + max_negatives_per_positive=None, + min_negatives_per_image=0): + """Constructor. + + The hard example mining implemented by this class can replicate the behavior + in the two aforementioned papers (Srivastava et al., and Liu et al). + To replicate the A2 paper (Srivastava et al), num_hard_examples is set + to a fixed parameter (64 by default) and iou_threshold is set to .7 for + running non-max-suppression the predicted boxes prior to hard mining. + In order to replicate the SSD paper (Liu et al), num_hard_examples should + be set to None, max_negatives_per_positive should be 3 and iou_threshold + should be 1.0 (in order to effectively turn off NMS). + + Args: + num_hard_examples: maximum number of hard examples to be + selected per image (prior to enforcing max negative to positive ratio + constraint). If set to None, all examples obtained after NMS are + considered. + iou_threshold: minimum intersection over union for an example + to be discarded during NMS. + loss_type: use only classification losses ('cls', default), + localization losses ('loc') or both losses ('both'). + In the last case, cls_loss_weight and loc_loss_weight are used to + compute weighted sum of the two losses. + cls_loss_weight: weight for classification loss. + loc_loss_weight: weight for location loss. + max_negatives_per_positive: maximum number of negatives to retain for + each positive anchor. By default, num_negatives_per_positive is None, + which means that we do not enforce a prespecified negative:positive + ratio. Note also that num_negatives_per_positives can be a float + (and will be converted to be a float even if it is passed in otherwise). + min_negatives_per_image: minimum number of negative anchors to sample for + a given image. Setting this to a positive number allows sampling + negatives in an image without any positive anchors and thus not biased + towards at least one detection per image. + """ + self._num_hard_examples = num_hard_examples + self._iou_threshold = iou_threshold + self._loss_type = loss_type + self._cls_loss_weight = cls_loss_weight + self._loc_loss_weight = loc_loss_weight + self._max_negatives_per_positive = max_negatives_per_positive + self._min_negatives_per_image = min_negatives_per_image + if self._max_negatives_per_positive is not None: + self._max_negatives_per_positive = float(self._max_negatives_per_positive) + self._num_positives_list = None + self._num_negatives_list = None + + def __call__(self, + location_losses, + cls_losses, + decoded_boxlist_list, + match_list=None): + """Computes localization and classification losses after hard mining. + + Args: + location_losses: a float tensor of shape [num_images, num_anchors] + representing anchorwise localization losses. + cls_losses: a float tensor of shape [num_images, num_anchors] + representing anchorwise classification losses. + decoded_boxlist_list: a list of decoded BoxList representing location + predictions for each image. + match_list: an optional list of matcher.Match objects encoding the match + between anchors and groundtruth boxes for each image of the batch, + with rows of the Match objects corresponding to groundtruth boxes + and columns corresponding to anchors. Match objects in match_list are + used to reference which anchors are positive, negative or ignored. If + self._max_negatives_per_positive exists, these are then used to enforce + a prespecified negative to positive ratio. + + Returns: + mined_location_loss: a float scalar with sum of localization losses from + selected hard examples. + mined_cls_loss: a float scalar with sum of classification losses from + selected hard examples. + Raises: + ValueError: if location_losses, cls_losses and decoded_boxlist_list do + not have compatible shapes (i.e., they must correspond to the same + number of images). + ValueError: if match_list is specified but its length does not match + len(decoded_boxlist_list). + """ + mined_location_losses = [] + mined_cls_losses = [] + location_losses = tf.unstack(location_losses) + cls_losses = tf.unstack(cls_losses) + num_images = len(decoded_boxlist_list) + if not match_list: + match_list = num_images * [None] + if not len(location_losses) == len(decoded_boxlist_list) == len(cls_losses): + raise ValueError('location_losses, cls_losses and decoded_boxlist_list ' + 'do not have compatible shapes.') + if not isinstance(match_list, list): + raise ValueError('match_list must be a list.') + if len(match_list) != len(decoded_boxlist_list): + raise ValueError('match_list must either be None or have ' + 'length=len(decoded_boxlist_list).') + num_positives_list = [] + num_negatives_list = [] + for ind, detection_boxlist in enumerate(decoded_boxlist_list): + box_locations = detection_boxlist.get() + match = match_list[ind] + image_losses = cls_losses[ind] + if self._loss_type == 'loc': + image_losses = location_losses[ind] + elif self._loss_type == 'both': + image_losses *= self._cls_loss_weight + image_losses += location_losses[ind] * self._loc_loss_weight + if self._num_hard_examples is not None: + num_hard_examples = self._num_hard_examples + else: + num_hard_examples = detection_boxlist.num_boxes() + selected_indices = tf.image.non_max_suppression( + box_locations, image_losses, num_hard_examples, self._iou_threshold) + if self._max_negatives_per_positive is not None and match: + (selected_indices, num_positives, + num_negatives) = self._subsample_selection_to_desired_neg_pos_ratio( + selected_indices, match, self._max_negatives_per_positive, + self._min_negatives_per_image) + num_positives_list.append(num_positives) + num_negatives_list.append(num_negatives) + mined_location_losses.append( + tf.reduce_sum(tf.gather(location_losses[ind], selected_indices))) + mined_cls_losses.append( + tf.reduce_sum(tf.gather(cls_losses[ind], selected_indices))) + location_loss = tf.reduce_sum(tf.stack(mined_location_losses)) + cls_loss = tf.reduce_sum(tf.stack(mined_cls_losses)) + if match and self._max_negatives_per_positive: + self._num_positives_list = num_positives_list + self._num_negatives_list = num_negatives_list + return (location_loss, cls_loss) + + def summarize(self): + """Summarize the number of positives and negatives after mining.""" + if self._num_positives_list and self._num_negatives_list: + avg_num_positives = tf.reduce_mean(tf.to_float(self._num_positives_list)) + avg_num_negatives = tf.reduce_mean(tf.to_float(self._num_negatives_list)) + tf.summary.scalar('HardExampleMiner/NumPositives', avg_num_positives) + tf.summary.scalar('HardExampleMiner/NumNegatives', avg_num_negatives) + + def _subsample_selection_to_desired_neg_pos_ratio(self, + indices, + match, + max_negatives_per_positive, + min_negatives_per_image=0): + """Subsample a collection of selected indices to a desired neg:pos ratio. + + This function takes a subset of M indices (indexing into a large anchor + collection of N anchors where M