[[toc]]
[toc]
Goroutine是很重要的,接触了Go语言,使用这个语言越多,越发现这门语言跟c语言很像:平坦的内存,指针,翻译机器指令等等。
Go的
runtime提供了一些基本的操作系统抽象,goroutine对应进程,channel对应进程间通信,另外Go有自己的虚拟内存管理,所以如果用Go来编写内核,进程调度和内存管理这些繁琐的东西就直接可以用现成的了,那么因此是不是可以实现 cubos-go
在java/c++中我们要实现并发编程的时候,我们通常需要自己维护一个线程池,并且需要自己去包装一个又一个的任务,同时需要自己去调度线程执行任务并维护上下文切换,这一切通常会耗费程序员大量的心智。那么能不能有一种机制,程序员只需要定义很多个任务,让系统去帮助我们把这些任务分配到CPU上实现并发执行呢?
Go语言中的goroutine就是这样一种机制,goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可以了.
先看一个需求,统计1~900000000000中有哪些素数
传统方法:使用一个循环,判断哪些数是素数
使用并发或并行的方式,==将统计素数的任务分配个多个goroution完成==(速度最少提高四倍,分配给四个CPU)
#进程
在学习goroutine中我们需要熟悉下操作系统的进程
-
进程:进程就是程序在操作系统中的一次执行过程,是系统进行资源调度和分配的基本单位
-
线程:线程是进程的一个执行实例,是程序执行的一个最小单位,它是比进程跟小能够独立完成的基本单位。
比如打开网盘,此时打开网盘是一个进程,如果我们在网盘中下载多个视频,此时下载就叫做线程,线程吃的资源更小
一个进程可以创建或者销毁多个线程,同一个进程中的多个线程可以==并发==进行
一个程序至少有一个进程,一个进程至少有一个线程
#Go语言协程和Go主线程
Go语言主线程(也称为线程,也可以理解为进程),一个Go语言线程上可以起多个协程,协程是轻量级的线程
编译器优化
Go语言协程特点(重要):
- 有独立的栈空间
- 共享程序堆空间
- 调度由用户控制
- 协程是轻量级的线程
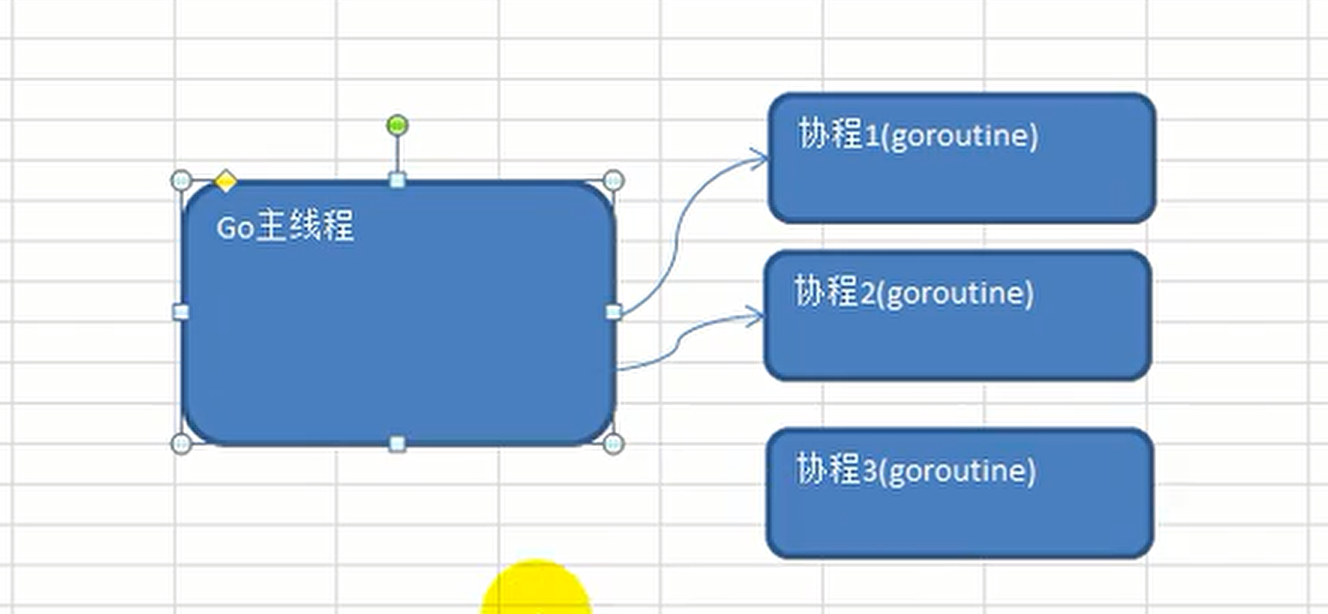
Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。
一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
启动goroutine的方式非常简单,只需要在调用的函数(普通函数和匿名函数)前面加上一个go关键字。
举个例子如下:
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
hello()
fmt.Println("main goroutine done!")
}这个示例中hello函数和下面的语句是串行的,执行的结果是打印完Hello Goroutine!后打印main goroutine done!。
接下来我们在调用hello函数前面加上关键字go,也就是启动一个goroutine去执行hello这个函数。
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
go hello() // 启动另外一个goroutine去执行hello函数
fmt.Println("main goroutine done!")
}这一次的执行结果只打印了main goroutine done!,并没有打印Hello Goroutine!。为什么呢?
📜 对上面的解释:
在程序启动时,Go程序就会为
main()函数创建一个默认的goroutine。当
main()函数返回的时候该goroutine就结束了,所有在main()函数中启动的goroutine会一同结束.
所以我们要想办法让main函数等一等hello函数,最简单粗暴的方式就是time.Sleep了。
func hello() {
fmt.Println("Hello Goroutine!")
}
func main() {
go hello() // 启动另外一个goroutine去执行hello函数
fmt.Println("main goroutine done!")
time.Sleep(time.Second)
}执行上面的代码你会发现,这一次先打印main goroutine done!,然后紧接着打印Hello Goroutine!。
首先为什么会先打印main goroutine done!是因为我们在创建新的goroutine的时候需要花费一些时间,而此时main函数所在的goroutine是继续执行的。
在Go语言中实现并发就是这样简单,我们还可以启动多个goroutine。让我们再来一个例子: (这里使用了sync.WaitGroup来实现goroutine的同步)
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
go hello(i) //这个岂不是启动了十次
}
wg.Wait() // 等待所有登记的goroutine都结束
}多次执行上面的代码,会发现每次打印的数字的顺序都不一致。这是因为10个goroutine是并发执行的,而goroutine的调度是随机的。
- 如果主协程退出了,其他任务还执行吗(运行下面的代码测试一下吧)
package main
import (
"fmt"
"time"
)
func main() {
// 合起来写
go func() {
i := 0
for {
i++
fmt.Printf("new goroutine: i = %d\n", i)
time.Sleep(time.Second)
}
}()
i := 0
for {
i++
fmt.Printf("main goroutine: i = %d\n", i)
time.Sleep(time.Second)
if i == 2 {
break
}
}
}OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大。所以在Go语言中一次创建十万左右的goroutine也是可以的。
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
G很好理解,就是个goroutine的,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。P管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。M(machine)是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
-
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©