torchtext 可以方便的完成模型训练的前期数据预处理工作,常见功能有:
- 将句子转化成分词列表
- 构建当前语料库中单词的词汇表,实现word和id之间的映射
- 将数据集转化为一个一个的batch,训练时直接使用
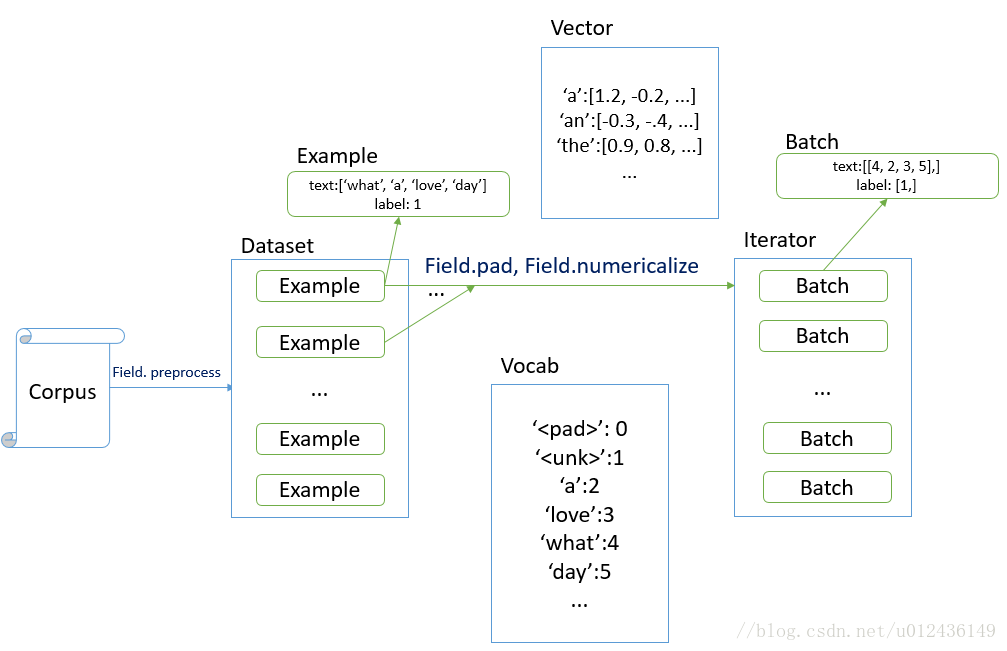
- 三大核心要素:
field、dataset、iteratorfield定义指定字段的处理方法dataset定义语料库iterator定义训练和测试模型时候的迭代器,里面是一个一个的batch
-
一般情况下定义两个field:
text_field和label_field分别定义文本域和标签域的处理方法,常见的属性为:- lower = False:是否把数据转化为小写
- sequential = True:是否把数据表示成序列,如果是False, 不能使用分词
- 特别注意
pad_token='<pad>'和unk_token='<unk>',在label中不建议使用,可以定义为None
def word_cut(text): text = re.compile(r'[^A-Za-z0-9\u4e00-\u9fa5]').sub(' ', text) # 将非中文字符、非a-z, 非A-Z,非0-9 全部替换为' ' return [word.strip() for word in jieba.cut(text) if word.strip()] text_field = data.Field(lower=True, tokenize=word_cut) label_field = data.Field(sequential=False, unk_token=None, pad_token=None)
-
之后传递
text_field和label_field的时候是传递了对象的引用,所以会直接修改两个field对象
-
dataset定义语料库,将文本转换为一个个example对象,准备好训练集和测试集之后,可以使用内置的split函数划分训练集和测试集,其中split参数如下
- path:数据所在的路径
- format:数据的格式,tsv为
\t分割的数据集 - skip_header:是否跳过第一行
- train、test:训练集和测试集文件名
- fields:
list(tuple(string, field)),string为文件中每一列的列名,field为之前创建的field对象,定义了该个字段的处理方法,None表示忽略这个字段
train_dataset, test_dataset = data.TabularDataset.splits( path='data', format='tsv', skip_header=True, train='train.tsv', test='test.tsv', fields=[ ('index', None), ('label', label_field), ('text', text_field) ] )
-
此时完成了将文本转化为语料库的工作,但此时语料库中为 一个分词后的句子 + 一个标签 的形式,还需要处理成模型的输入,需要建立当前字段的语料库,方法是field中定义的build_vocab函数
- 如果使用与训练词向量,需要在函数中指定vectors参数,该参数是一个Vectors对象
label_field.build_vocab(train_dataset, test_dataset) if args.static and args.pretrained_name and args.pretrained_path: vectors = Vectors(name=args.pretrained_name, cache=args.pretrained_path) text_field.build_vocab(train_dataset, test_dataset, vectors=vectors) else: text_field.build_vocab(train_dataset, test_dataset)
-
build_vocab完成之后,对应的field之中会创建一个vocab对象,为词汇表itos:一个list,获取对应index的word,word = itos[index]stoi:一个dict,获取对应word的index,index = stoi[word]len(field.vocab):返回词汇表的长度
-
模型中可以使用如下代码定义部分层
self.embedding = nn.Embedding(len(text_field.vocab), embedding_dimension) output_size = len(label_field.vocab) self.fc = nn.Linear(input_size, output_size)
- 需要注意,因为field在创建的时候默认的
pad_token='<pad>', unk_token='<unk>',如果不做处理的话output_size中会因为两个默认的token儿变大,所以定义field的时候可以将两个设置为None,参见 field
- 需要注意,因为field在创建的时候默认的
-
创建完语料库之后,需要对语料库batch化,使用
Iterator.splits方法划分训练集和测试集合的迭代器train_iter, test_iter = data.Iterator.splits( (train_dataset, test_dataset), batch_sizes=(args.batch_size, len(test_dataset)), sort_key=lambda x: len(x.text), **kwargs # device=-1, repeat=False, shuffle=True )
- 第一个tuple指明了划分的两个dataset,两个dataset里面有指向两个field的引用,所以里面iterator里面可以拿到词汇表
- batch_sizes指明了两个iterator的batch大小
- sort_key用于排序
-
创建完
torchtext的iterator对象之后,iter里面内置了__iter(self)__函数,使用方法为:for batch in train_iter: feature, target = batch.text, batch.label feature.data.t_() logits = model(feature)
-
模型训练完成之后需要模型在所有的数据上都能时候,而非训练测试两个数据。对于一般的数据处理思路如下:
- 首先将文本分词
- 将分词后的文本转化为数值tensor
- 将tensor放到模型中,获取预测结果
-
在 vocab 中提到了每个field在build_vocab完成之后会创建一个vocab对象,完成string和int之间的转化
# 保存词汇表 with open("data/vocab.pkl", "wb") as f: pickle.dump(vocab, f) # 读取词汇表 with open("data/vocab.pkl", "rb") as f: vocab = pickle.load(f)
-
利用vocab对象中的stoi属性获取单词在词汇表中的index
text = "外观漂亮,安全性佳,动力够强,油耗够低" text = re.compile(r'[^A-Za-z0-9\u4e00-\u9fa5]').sub(' ', text) words = [word.strip() for word in jieba.cut(text) if word.strip()] indexes = [vocab.stoi[word] for word in words] # list(int)