![]()


With skore, data scientists can:
- Store objects of different types from their Python code: python lists,
scikit-learnfitted pipelines,plotlyfigures, and more. - Track and visualize these stored objects on a user-friendly dashboard.
- Export the dashboard to a HTML file.
These are only the first features: skore is a work in progress and aims to be an end-to-end library for data scientists.
Stay tuned, and join our Discord if you want to give us feedback!
First of all, we recommend using a virtual environment (venv). You need python>=3.9.
Then, you can install skore by using pip:
pip install -U skore🚨 For Windows users, the encoding must be set to UTF-8: see PYTHONUTF8.
- From your shell, initialize a
skoreproject, here namedproject.skore, that will be in your current working directory:
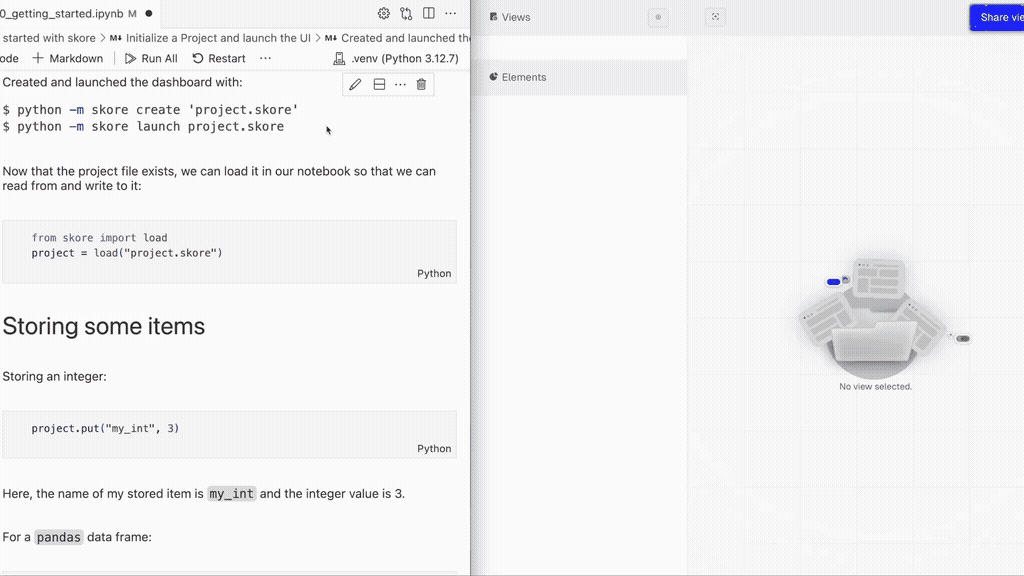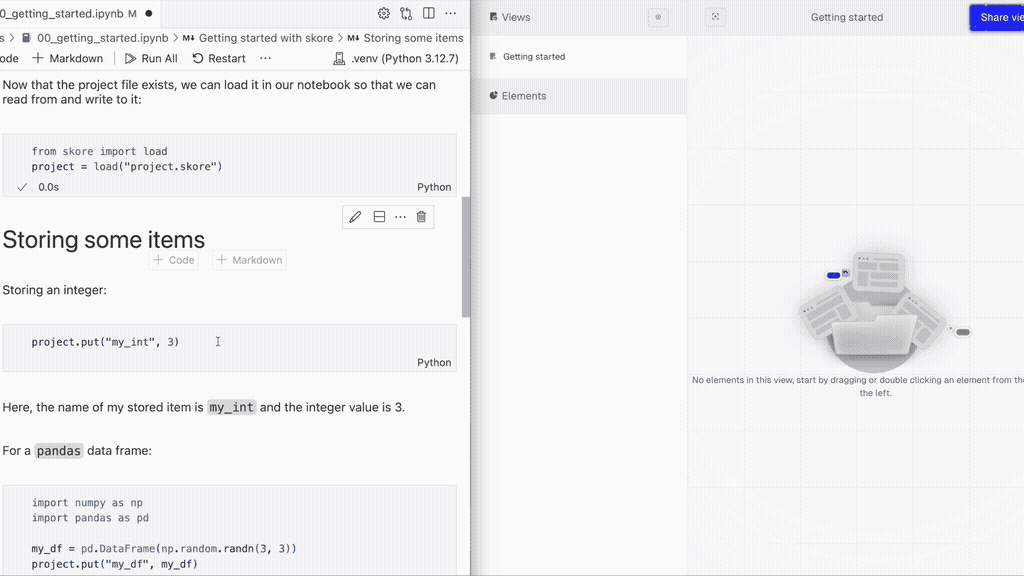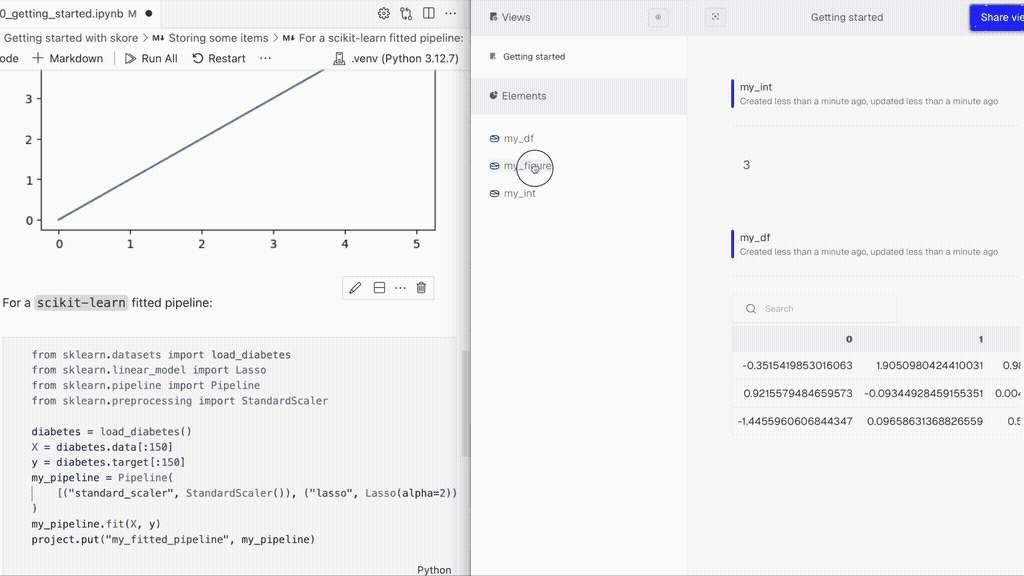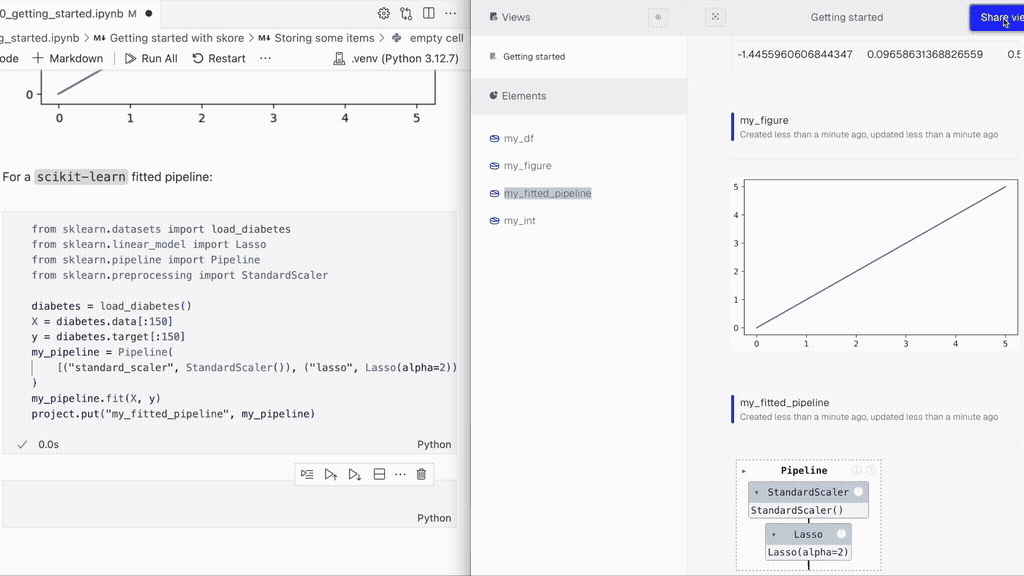
python -m skore create "project.skore"- Then, from your Python code (in the same directory), load the project and store an integer for example:
from skore import load
project = load("project.skore")
project.put("my_int", 3)- Finally, from your shell (in the same directory), start the UI locally:
python -m skore launch "project.skore"This will automatically open a browser at the UI's location:
- On the top left, create a new
View. - From the
Elementssection on the bottom left, you can add stored items to this view, either by double-cliking on them or by doing drag-and-drop.
💡 Note that after launching the dashboard, you can keep modifying the current items or store new ones from your python code, and the dashboard will automatically be refreshed.
Storing a pandas dataframe:
import numpy as np
import pandas as pd
my_df = pd.DataFrame(np.random.randn(3, 3))
project.put("my_df", my_df)Storing a matplotlib figure:
import matplotlib.pyplot as plt
x = [0, 1, 2, 3, 4, 5]
fig, ax = plt.subplots(figsize=(5, 3), layout="constrained")
ax.plot(x)
project.put("my_figure", fig)Storing a scikit-learn fitted pipeline:
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Lasso
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
diabetes = load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
my_pipeline = Pipeline(
[("standard_scaler", StandardScaler()), ("lasso", Lasso(alpha=2))]
)
my_pipeline.fit(X, y)
project.put("my_fitted_pipeline", my_pipeline)👨🏫 For a complete introductory example, see our basic usage notebook.
It shows you how to store all types of items: python lists and dictionaries, numpy arrays, pandas dataframes, scikit-learn fitted models, figures (matplotlib, altair, and plotly), etc.
The resulting skore report has been exported to this HTML file.
Thank you for your interest! See CONTRIBUTING.md.
| Type | Platforms |
|---|---|
| 🐛 Bug reports | GitHub Issue Tracker |
| ✨ Feature requests and ideas | GitHub Issue Tracker & Discord |
| 💬 Usage questions, discussions, contributions, etc | Discord |
Brought to you by