Support the `{{.DB}}`, `{{.Table}}`, and `{{.Index}}` arguments
The three arguments represent the database name, table name, and chunk ID of the data file | `{{.DB}}.{{.Table}}.{{.Index}}` | | `--status-addr` | Dumpling's service address, including the address for Prometheus to pull metrics and pprof debugging | ":8281" | diff --git a/dynamic-config.md b/dynamic-config.md index d006a759ae8e6..cff4e08482ead 100644 --- a/dynamic-config.md +++ b/dynamic-config.md @@ -213,6 +213,9 @@ The following TiKV configuration items can be modified dynamically: | `{db-name}.{cf-name}.soft-pending-compaction-bytes-limit` | The soft limit on the pending compaction bytes | | `{db-name}.{cf-name}.hard-pending-compaction-bytes-limit` | The hard limit on the pending compaction bytes | | `{db-name}.{cf-name}.titan.blob-run-mode` | The mode of processing blob files | +| `{db-name}.{cf-name}.titan.min-blob-size` | The threshold at which data is stored in Titan. Data is stored in a Titan blob file when its value reaches this threshold. | +| `{db-name}.{cf-name}.titan.blob-file-compression` | The compression algorithm used by Titan blob files | +| `{db-name}.{cf-name}.titan.discardable-ratio` | The threshold of garbage data ratio in Titan data files for GC. When the ratio of useless data in a blob file exceeds the threshold, Titan GC is triggered. | | `server.grpc-memory-pool-quota` | Limits the memory size that can be used by gRPC | | `server.max-grpc-send-msg-len` | Sets the maximum length of a gRPC message that can be sent | | `server.snap-io-max-bytes-per-sec` | Sets the maximum allowable disk bandwidth when processing snapshots | diff --git a/enable-tls-between-clients-and-servers.md b/enable-tls-between-clients-and-servers.md index 34724f5cfbb93..3e47532a9bb88 100644 --- a/enable-tls-between-clients-and-servers.md +++ b/enable-tls-between-clients-and-servers.md @@ -1,16 +1,16 @@ --- title: Enable TLS Between TiDB Clients and Servers -summary: Use the encrypted connection to ensure data security. +summary: Use secure connections to ensure data security. aliases: ['/docs/dev/enable-tls-between-clients-and-servers/','/docs/dev/how-to/secure/enable-tls-clients/','/docs/dev/encrypted-connections-with-tls-protocols/'] --- # Enable TLS between TiDB Clients and Servers -Non-encrypted connection between TiDB's server and clients is allowed by default, which enables third parties that monitor channel traffic to know the data sent and received between the server and the client, including query content and query results. If a channel is untrustworthy (such as if the client is connected to the TiDB server via a public network), then a non-encrypted connection is prone to information leakage. In this case, for security reasons, it is recommended to require an encrypted connection. +By default, TiDB allows insecure connections between the server and clients. This enables third parties that monitor channel traffic to know and possibly modify the data sent and received between the server and the client, including query content and query results. If a channel is untrustworthy (such as if the client is connected to the TiDB server via a public network), an insecure connection is prone to information leakage. In this case, for security reasons, it is recommended to require a connection that is secured with TLS. -The TiDB server supports the encrypted connection based on the TLS (Transport Layer Security). The protocol is consistent with MySQL encrypted connections and is directly supported by existing MySQL clients such as MySQL Client, MySQL Shell and MySQL drivers. TLS is sometimes referred to as SSL (Secure Sockets Layer). Because the SSL protocol has [known security vulnerabilities](https://en.wikipedia.org/wiki/Transport_Layer_Security), TiDB does not support SSL. TiDB supports the following protocols: TLSv1.0, TLSv1.1, TLSv1.2 and TLSv1.3. +The TiDB server supports secure connections based on the TLS (Transport Layer Security) protocol. The protocol is consistent with MySQL secure connections and is directly supported by existing MySQL clients such as MySQL Client, MySQL Shell and MySQL drivers. TLS is sometimes referred to as SSL (Secure Sockets Layer). Because the SSL protocol has [known security vulnerabilities](https://en.wikipedia.org/wiki/Transport_Layer_Security), TiDB does not support SSL. TiDB supports the following protocols: TLSv1.2 and TLSv1.3. -When an encrypted connection is used, the connection has the following security properties: +When a TLS secured connection is used, the connection has the following security properties: - Confidentiality: the traffic plaintext is encrypted to avoid eavesdropping - Integrity: the traffic plaintext cannot be tampered @@ -20,8 +20,8 @@ To use connections secured with TLS, you first need to configure the TiDB server Similar to MySQL, TiDB allows TLS and non-TLS connections on the same TCP port. For a TiDB server with TLS enabled, you can choose to securely connect to the TiDB server through an encrypted connection, or to use an unencrypted connection. You can use the following ways to require the use of secure connections: -+ Configure the system variable `require_secure_transport` to require secure connections to the TiDB server for all users. -+ Specify `REQUIRE SSL` when you create a user (`create user`), or modify an existing user (`alter user`), which is to specify that specified users must use the encrypted connection to access TiDB. The following is an example of creating a user: ++ Configure the system variable [`require_secure_transport`](/system-variables.md#require_secure_transport-new-in-v610) to require secure connections to the TiDB server for all users. ++ Specify `REQUIRE SSL` when you create a user (`create user`), or modify an existing user (`alter user`), which is to specify that specified users must use TLS connections to access TiDB. The following is an example of creating a user: {{< copyable "sql" >}} @@ -47,27 +47,27 @@ See the following descriptions about the related parameters to enable secure con To enable secure connections with your own certificates in the TiDB server, you must specify both of the `ssl-cert` and `ssl-key` parameters in the configuration file when you start the TiDB server. You can also specify the `ssl-ca` parameter for client authentication (see [Enable authentication](#enable-authentication)). -All the files specified by the parameters are in PEM (Privacy Enhanced Mail) format. Currently, TiDB does not support the import of a password-protected private key, so it is required to provide a private key file without a password. If the certificate or private key is invalid, the TiDB server starts as usual, but the client cannot connect to the TiDB server through an encrypted connection. +All the files specified by the parameters are in PEM (Privacy Enhanced Mail) format. Currently, TiDB does not support the import of a password-protected private key, so it is required to provide a private key file without a password. If the certificate or private key is invalid, the TiDB server starts as usual, but the client cannot connect to the TiDB server through a TLS connection. -If the certificate parameters are correct, TiDB outputs `secure connection is enabled` when started; otherwise, it outputs `secure connection is NOT ENABLED`. +If the certificate parameters are correct, TiDB outputs `mysql protocol server secure connection is enabled` to the logs on `"INFO"` level when started. -For TiDB versions earlier than v5.2.0, you can use `mysql_ssl_rsa_setup --datadir=./certs` to generate certficates. The `mysql_ssl_rsa_setup` tool is a part of MySQL Server. +## Configure the MySQL client to use TLS connections -## Configure the MySQL client to use encrypted connections - -The client of MySQL 5.7 or later versions attempts to establish an encrypted connection by default. If the server does not support encrypted connections, it automatically returns to unencrypted connections. The client of MySQL earlier than version 5.7 uses the unencrypted connection by default. +The client of MySQL 5.7 or later versions attempts to establish a TLS connection by default. If the server does not support TLS connections, it automatically returns to unencrypted connections. The client of MySQL earlier than version 5.7 uses the non-TLS connections by default. You can change the connection behavior of the client using the following `--ssl-mode` parameters: -- `--ssl-mode=REQUIRED`: The client requires an encrypted connection. The connection cannot be established if the server side does not support encrypted connections. -- In the absence of the `--ssl-mode` parameter: The client attempts to use an encrypted connection, but the encrypted connection cannot be established if the server side does not support encrypted connections. Then the client uses an unencrypted connection. +- `--ssl-mode=REQUIRED`: The client requires a TLS connection. The connection cannot be established if the server side does not support TLS connections. +- In the absence of the `--ssl-mode` parameter: The client attempts to use a TLS connection, but the encrypted connection cannot be established if the server side does not support encrypted connections. Then the client uses an unencrypted connection. - `--ssl-mode=DISABLED`: The client uses an unencrypted connection. -MySQL 8.0 clients have two SSL modes in addition to this parameter: +MySQL 8.x clients have two SSL modes in addition to this parameter: - `--ssl-mode=VERIFY_CA`: Validates the certificate from the server against the CA that requires `--ssl-ca`. - `--ssl-mode=VERIFY_IDENTITY`: The same as `VERIFY_CA`, but also validating whether the hostname you are connecting to matches the certificate. +For MySQL 5.7 and MariaDB clients and earlier you can use `--ssl-verify-server-cert` to enable validation of the server certificate. + For more information, see [Client-Side Configuration for Encrypted Connections](https://dev.mysql.com/doc/refman/8.0/en/using-encrypted-connections.html#using-encrypted-connections-client-side-configuration) in MySQL. ## Enable authentication @@ -87,17 +87,15 @@ If the `ssl-ca` parameter is not specified in the TiDB server or MySQL client, t - To perform mutual authentication, meet both of the above requirements. -By default, the server-to-client authentication is optional. Even if the client does not present its certificate of identification during the TLS handshake, the TLS connection can be still established. You can also require the client to be authenticated by specifying `require x509` when creating a user (`create user`), granting permissions (`grant`), or modifying an existing user (`alter user`). The following is an example of creating a user: - -{{< copyable "sql" >}} +By default, the server-to-client authentication is optional. Even if the client does not present its certificate of identification during the TLS handshake, the TLS connection can be still established. You can also require the client to be authenticated by specifying `REQUIRE x509` when creating a user (`CREATE USER`), or modifying an existing user (`ALTER USER`). The following is an example of creating a user: ```sql -create user 'u1'@'%' require x509; +CREATE USER 'u1'@'%' REQUIRE X509; ``` > **Note:** > -> If the login user has configured using the [TiDB Certificate-Based Authentication for Login](/certificate-authentication.md#configure-the-user-certificate-information-for-login-verification), the user is implicitly required to enable the encrypted connection to TiDB. +> If the login user has configured using the [TiDB Certificate-Based Authentication for Login](/certificate-authentication.md#configure-the-user-certificate-information-for-login-verification), the user is implicitly required to enable the TLS connection to TiDB. ## Check whether the current connection uses encryption @@ -105,13 +103,22 @@ Use the `SHOW STATUS LIKE "%Ssl%";` statement to get the details of the current See the following example of the result in an encrypted connection. The results change according to different TLS versions or encryption protocols supported by the client. +```sql +SHOW STATUS LIKE "Ssl%"; +``` + ``` -mysql> SHOW STATUS LIKE "%Ssl%"; -...... -| Ssl_verify_mode | 5 | -| Ssl_version | TLSv1.2 | -| Ssl_cipher | ECDHE-RSA-AES128-GCM-SHA256 | -...... ++-----------------------+-------------------------------------------------------> +| Variable_name | Value > ++-----------------------+-------------------------------------------------------> +| Ssl_cipher | TLS_AES_128_GCM_SHA256 > +| Ssl_cipher_list | RC4-SHA:DES-CBC3-SHA:AES128-SHA:AES256-SHA:AES128-SHA2> +| Ssl_server_not_after | Apr 23 07:59:47 2024 UTC > +| Ssl_server_not_before | Jan 24 07:59:47 2024 UTC > +| Ssl_verify_mode | 5 > +| Ssl_version | TLSv1.3 > ++-----------------------+-------------------------------------------------------> +6 rows in set (0.0062 sec) ``` For the official MySQL client, you can also use the `STATUS` or `\s` statement to view the connection status: @@ -119,24 +126,22 @@ For the official MySQL client, you can also use the `STATUS` or `\s` statement t ``` mysql> \s ... -SSL: Cipher in use is ECDHE-RSA-AES128-GCM-SHA256 +SSL: Cipher in use is TLS_AES_128_GCM_SHA256 ... ``` ## Supported TLS versions, key exchange protocols, and encryption algorithms -The TLS versions, key exchange protocols and encryption algorithms supported by TiDB are determined by the official Golang libraries. +The TLS versions, key exchange protocols and encryption algorithms supported by TiDB are determined by the official Go libraries. The crypto policy for your operating system and the client library you are using might also impact the list of supported protocols and cipher suites. ### Supported TLS versions -- TLSv1.0 (disabled by default) -- TLSv1.1 (disabled by default) - TLSv1.2 - TLSv1.3 -The `tls-version` configuration option can be used to limit the TLS versions that can be used. +You can use the [`tls-version`](/tidb-configuration-file.md#tls-version) configuration option to limit the TLS versions that can be used. The actual TLS versions that can be used depend on the OS crypto policy, MySQL client version and the SSL/TLS library that is used by the client. diff --git a/encryption-at-rest.md b/encryption-at-rest.md index 14ec3d239083e..8671963d3118f 100644 --- a/encryption-at-rest.md +++ b/encryption-at-rest.md @@ -22,7 +22,7 @@ When a TiDB cluster is deployed, the majority of user data is stored on TiKV and TiKV supports encryption at rest. This feature allows TiKV to transparently encrypt data files using [AES](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard) or [SM4](https://en.wikipedia.org/wiki/SM4_(cipher)) in [CTR](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation) mode. To enable encryption at rest, an encryption key must be provided by the user and this key is called master key. TiKV automatically rotates data keys that it used to encrypt actual data files. Manually rotating the master key can be done occasionally. Note that encryption at rest only encrypts data at rest (namely, on disk) and not while data is transferred over network. It is advised to use TLS together with encryption at rest. -Optionally, you can use AWS KMS for both cloud and self-hosted deployments. You can also supply the plaintext master key in a file. +You can use Key Management Service (KMS) for both cloud and self-hosted deployments or supply the plaintext master key in a file. TiKV currently does not exclude encryption keys and user data from core dumps. It is advised to disable core dumps for the TiKV process when using encryption at rest. This is not currently handled by TiKV itself. @@ -59,7 +59,7 @@ TiKV currently supports encrypting data using AES128, AES192, AES256, or SM4 (on * Master key. The master key is provided by user and is used to encrypt the data keys TiKV generates. Management of master key is external to TiKV. * Data key. The data key is generated by TiKV and is the key actually used to encrypt data. -The same master key can be shared by multiple instances of TiKV. The recommended way to provide a master key in production is via AWS KMS. Create a customer master key (CMK) through AWS KMS, and then provide the CMK key ID to TiKV in the configuration file. The TiKV process needs access to the KMS CMK while it is running, which can be done by using an [IAM role](https://aws.amazon.com/iam/). If TiKV fails to get access to the KMS CMK, it will fail to start or restart. Refer to AWS documentation for [KMS](https://docs.aws.amazon.com/kms/index.html) and [IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/introduction.html) usage. +The same master key can be shared by multiple instances of TiKV. The recommended way to provide a master key in production is via KMS. Currently, TiKV supports KMS encryption on [AWS](https://docs.aws.amazon.com/kms/index.html), [Google Cloud](https://cloud.google.com/security/products/security-key-management?hl=en), and [Azure](https://learn.microsoft.com/en-us/azure/key-vault/). To enable KMS encryption, you need to create a customer master key (CMK) through KMS, and then provide the CMK key ID to TiKV using the configuration file. If TiKV fails to get access to the KMS CMK, it will fail to start or restart. Alternatively, if using custom key is desired, supplying the master key via file is also supported. The file must contain a 256 bits (or 32 bytes) key encoded as hex string, end with a newline (namely, `\n`), and contain nothing else. Persisting the key on disk, however, leaks the key, so the key file is only suitable to be stored on the `tempfs` in RAM. @@ -67,9 +67,44 @@ Data keys are passed to the underlying storage engine (namely, RocksDB). All fil Regardless of data encryption method, data keys are encrypted using AES256 in GCM mode for additional authentication. This required the master key to be 256 bits (32 bytes), when passing from file instead of KMS. -### Key creation +### Configure encryption + +To enable encryption, you can add the encryption section in the configuration files of TiKV and PD: + +``` +[security.encryption] +data-encryption-method = "aes128-ctr" +data-key-rotation-period = "168h" # 7 days +``` + +- `data-encryption-method` specifies the encryption algorithm. The possible values are `"aes128-ctr"`, `"aes192-ctr"`, `"aes256-ctr"`, `"sm4-ctr"` (only for v6.3.0 and later versions), and `"plaintext"`. The default value is `"plaintext"`, which means that encryption is disabled by default. + + - For a new TiKV cluster or an existing TiKV cluster, only data written after encryption has been enabled is guaranteed to be encrypted. + - To disable encryption after it is enabled, remove `data-encryption-method` from the configuration file or set its value to `"plaintext"`, and then restart TiKV. + - To change the encryption algorithm, replace the value of `data-encryption-method` with a supported encryption algorithm, and then restart TiKV. After the replacement, as new data is written in, the encryption files generated by the previous encryption algorithm are gradually rewritten to files generated by the new encryption algorithm. + +- `data-key-rotation-period` specifies how often TiKV rotates keys. + +If encryption is enabled (that is, the value of `data-encryption-method` is not `"plaintext"`), you must specify a master key in either of the following ways: + +- [Specify a master key via KMS](#specify-a-master-key-via-kms) +- [Specify a master key via a file](#specify-a-master-key-via-a-file) -To create a key on AWS, follow these steps: +#### Specify a master key via KMS + +TiKV supports KMS encryption for three platforms: AWS, Google Cloud, and Azure. Depending on the platform where your service is deployed, you can choose one of them to configure KMS encryption. + +> **Warning:** +> +> Currently, specifying a master key using Google Cloud KMS is experimental. It is not recommended that you use it in production environments. This feature might be changed or removed without prior notice. If you find a bug, you can report an [issue](https://github.com/pingcap/tidb/issues) on GitHub. + +
+
+**Step 1. Create a master key**
+
+To create a key on AWS, take the following steps:
1. Go to the [AWS KMS](https://console.aws.amazon.com/kms) on the AWS console.
2. Make sure that you have selected the correct region on the top right corner of your console.
@@ -85,19 +120,9 @@ aws --region us-west-2 kms create-alias --alias-name "alias/tidb-tde" --target-k
The `--target-key-id` to enter in the second command is in the output of the first command.
-### Configure encryption
+**Step 2. Configure the master key**
-To enable encryption, you can add the encryption section in the configuration files of TiKV and PD:
-
-```
-[security.encryption]
-data-encryption-method = "aes128-ctr"
-data-key-rotation-period = "168h" # 7 days
-```
-
-Possible values for `data-encryption-method` are "aes128-ctr", "aes192-ctr", "aes256-ctr", "sm4-ctr" (only in v6.3.0 and later versions) and "plaintext". The default value is "plaintext", which means encryption is not turned on. `data-key-rotation-period` defines how often TiKV rotates the data key. Encryption can be turned on for a fresh TiKV cluster, or an existing TiKV cluster, though only data written after encryption is enabled is guaranteed to be encrypted. To disable encryption, remove `data-encryption-method` in the configuration file, or reset it to "plaintext", and restart TiKV. To change encryption method, update `data-encryption-method` in the configuration file and restart TiKV. To change the encryption algorithm, replace `data-encryption-method` with a supported encryption algorithm and then restart TiKV. After the replacement, as new data is written in, the encryption file generated by the previous encryption algorithm is gradually rewritten to a file generated by the new encryption algorithm.
-
-The master key has to be specified if encryption is enabled (that is,`data-encryption-method` is not "plaintext"). To specify a AWS KMS CMK as master key, add the `encryption.master-key` section after the `encryption` section:
+To specify the master key using AWS KMS, add the `[security.encryption.master-key]` configuration after the `[security.encryption]` section in the TiKV configuration file:
```
[security.encryption.master-key]
@@ -111,6 +136,87 @@ The `key-id` specifies the key ID for the KMS CMK. The `region` is the AWS regio
You can also use [multi-Region keys](https://docs.aws.amazon.com/kms/latest/developerguide/multi-region-keys-overview.html) in AWS. For this, you need to set up a primary key in a specific region and add replica keys in the regions you require.
+
+
+
+**Step 1. Create a master key**
+
+To create a key on Google Cloud, take the following steps:
+
+1. Go to the [Key Management](https://console.cloud.google.com/security/kms/keyrings) page in the Google Cloud console.
+2. Click **Create key ring**. Enter a name for the key ring, select a location of the key ring, and then click **Create**. Note that the location of the key ring needs to cover the region where the TiDB cluster is deployed.
+3. Select the key ring you created in the previous step, and then click **Create Key** on the key ring details page.
+4. Enter a name for the key, set the key information as follows, and then click **Create**.
+
+ - **Protection level**: **Software** or **HSM**
+ - **Key Material**: **Generated key**
+ - **Purpose**: **Symmetric encrypt/decrypt**
+
+You can also perform this operation using the gcloud CLI:
+
+```shell
+gcloud kms keyrings create "key-ring-name" --location "global"
+gcloud kms keys create "key-name" --keyring "key-ring-name" --location "global" --purpose "encryption" --rotation-period "30d"
+```
+
+Make sure to replace the values of `"key-ring-name"`, `"key-name"`, `"global"`, and `"30d"` in the preceding command with the names and configurations corresponding to your actual key.
+
+**Step 2. Configure the master key**
+
+To specify the master key using Google Cloud KMS, add the `[security.encryption.master-key]` configuration after the `[security.encryption]` section:
+
+```
+[security.encryption.master-key]
+type = "kms"
+key-id = "projects/project-name/locations/global/keyRings/key-ring-name/cryptoKeys/key-name"
+vendor = "gcp"
+
+[security.encryption.master-key.gcp]
+credential-file-path = "/path/to/credential.json"
+```
+
+- `key-id` specifies the key ID of the KMS CMK.
+- `credential-file-path` specifies the path of the authentication credentials file, which currently supports two types of credentials: Service Account and Authentication User. If the TiKV environment is already configured with [application default credentials](https://cloud.google.com/docs/authentication/application-default-credentials), there is no need to configure `credential-file-path`.
+
+
+
+
+**Step 1. Create a master key**
+
+To create a key on Azure, refer to the instructions in [Set and retrieve a key from Azure Key Vault using the Azure portal](https://learn.microsoft.com/en-us/azure/key-vault/keys/quick-create-portal).
+
+**Step 2. Configure the master key**
+
+To specify the master key using Azure KMS, add the `[security.encryption.master-key]` configuration after the `[security.encryption]` section in the TiKV configuration file:
+
+```
+[security.encryption.master-key]
+type = 'kms'
+key-id = 'your-kms-key-id'
+region = 'region-name'
+endpoint = 'endpoint'
+vendor = 'azure'
+
+[security.encryption.master-key.azure]
+tenant-id = 'tenant_id'
+client-id = 'client_id'
+keyvault-url = 'keyvault_url'
+hsm-name = 'hsm_name'
+hsm-url = 'hsm_url'
+# The following four fields are optional, used to set client authentication credentials. You can configure them according to the requirements of your scenario.
+client_certificate = ""
+client_certificate_path = ""
+client_certificate_password = ""
+client_secret = ""
+```
+
+Except `vendor`, you need to modify the values of other fields in the preceding configuration to the corresponding configuration of the actual key.
+
+
+[JSON_CONTAINS(target, candidate[, path])](https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html#function_json-contains),
[JSON_EXTRACT(json_doc, path[, path] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html#function_json-extract),
[JSON_INSERT(json_doc, path, val[, path, val] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-insert),
[JSON_LENGTH(json_doc[, path])](https://dev.mysql.com/doc/refman/8.0/en/json-attribute-functions.html#function_json-length),
[JSON_MERGE(json_doc, json_doc[, json_doc] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-merge),
[JSON_OBJECT([key, val[, key, val] ...])](https://dev.mysql.com/doc/refman/8.0/en/json-creation-functions.html#function_json-object),
[JSON_REMOVE(json_doc, path[, path] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-remove),
[JSON_REPLACE(json_doc, path, val[, path, val] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-replace),
[JSON_SET(json_doc, path, val[, path, val] ...)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-set),
[JSON_TYPE(json_val)](https://dev.mysql.com/doc/refman/8.0/en/json-attribute-functions.html#function_json-type),
[JSON_UNQUOTE(json_val)](https://dev.mysql.com/doc/refman/8.0/en/json-modification-functions.html#function_json-unquote),
[JSON_VALID(val)](https://dev.mysql.com/doc/refman/8.0/en/json-attribute-functions.html#function_json-valid),
[value MEMBER OF(json_array)](https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html#operator_member-of) | | [Date and time functions](/functions-and-operators/date-and-time-functions.md) | [DATE()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date), [DATE_FORMAT()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_date-format), [DATEDIFF()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_datediff), [DAYOFMONTH()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_dayofmonth), [DAYOFWEEK()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_dayofweek), [DAYOFYEAR()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_dayofyear), [FROM_DAYS()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_from-days), [HOUR()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_hour), [MAKEDATE()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_makedate), [MAKETIME()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_maketime), [MICROSECOND()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_microsecond), [MINUTE()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_minute), [MONTH()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_month), [MONTHNAME()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_monthname), [PERIOD_ADD()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_period-add), [PERIOD_DIFF()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_period-diff), [SEC_TO_TIME()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_sec-to-time), [SECOND()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_second), [SYSDATE()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_sysdate), [TIME_TO_SEC()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_time-to-sec), [TIMEDIFF()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_timediff), [WEEK()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_week), [WEEKOFYEAR()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_weekofyear), [YEAR()](https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html#function_year) | -| [String functions](/functions-and-operators/string-functions.md) | [ASCII()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_ascii), [BIT_LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_bit-length), [CHAR()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_char), [CHAR_LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_char-length), [CONCAT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat), [CONCAT_WS()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat-ws), [ELT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_elt), [FIELD()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_field), [HEX()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_hex), [LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_length), [LIKE](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#operator_like), [LOWER()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_lower), [LTRIM()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_ltrim), [MID()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_mid), [NOT LIKE](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#operator_not-like), [NOT REGEXP](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_not-regexp), [REGEXP](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_regexp), [REPLACE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_replace), [REVERSE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_reverse), [RIGHT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_right), [RTRIM()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_rtrim), [SPACE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_space), [STRCMP()](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#function_strcmp), [SUBSTR()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_substr), [SUBSTRING()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_substring), [UPPER()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_upper) | +| [String functions](/functions-and-operators/string-functions.md) | [ASCII()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_ascii), [BIT_LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_bit-length), [CHAR()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_char), [CHAR_LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_char-length), [CONCAT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat), [CONCAT_WS()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_concat-ws), [ELT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_elt), [FIELD()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_field), [HEX()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_hex), [LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_length), [LIKE](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#operator_like), [LOWER()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_lower), [LTRIM()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_ltrim), [MID()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_mid), [NOT LIKE](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#operator_not-like), [NOT REGEXP](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_not-regexp), [REGEXP](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_regexp), [REGEXP_INSTR()](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-instr), [REGEXP_LIKE()](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-like), [REGEXP_REPLACE()](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-replace), [REGEXP_SUBSTR()](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#function_regexp-substr), [REPLACE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_replace), [REVERSE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_reverse), [RIGHT()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_right), [RLIKE](https://dev.mysql.com/doc/refman/8.0/en/regexp.html#operator_regexp), [RTRIM()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_rtrim), [SPACE()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_space), [STRCMP()](https://dev.mysql.com/doc/refman/8.0/en/string-comparison-functions.html#function_strcmp), [SUBSTR()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_substr), [SUBSTRING()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_substring), [UPPER()](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_upper) | | [Aggregation functions](/functions-and-operators/aggregate-group-by-functions.md#aggregate-group-by-functions) | [COUNT()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count), [COUNT(DISTINCT)](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_count-distinct), [SUM()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_sum), [AVG()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_avg), [MAX()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_max), [MIN()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_min), [VARIANCE()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_variance), [VAR_POP()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_var-pop), [STD()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_std), [STDDEV()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_stddev), [STDDEV_POP](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_stddev-pop), [VAR_SAMP()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_var-samp), [STDDEV_SAMP()](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_stddev-samp), [JSON_ARRAYAGG(key)](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_json-arrayagg), [JSON_OBJECTAGG(key, value)](https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html#function_json-objectagg) | | [Encryption and compression functions](/functions-and-operators/encryption-and-compression-functions.md#encryption-and-compression-functions) | [MD5()](https://dev.mysql.com/doc/refman/8.0/en/encryption-functions.html#function_md5), [SHA1(), SHA()](https://dev.mysql.com/doc/refman/8.0/en/encryption-functions.html#function_sha1), [UNCOMPRESSED_LENGTH()](https://dev.mysql.com/doc/refman/8.0/en/encryption-functions.html#function_uncompressed-length) | | [Cast functions and operators](/functions-and-operators/cast-functions-and-operators.md#cast-functions-and-operators) | [CAST()](https://dev.mysql.com/doc/refman/8.0/en/cast-functions.html#function_cast), [CONVERT()](https://dev.mysql.com/doc/refman/8.0/en/cast-functions.html#function_convert) | diff --git a/functions-and-operators/string-functions.md b/functions-and-operators/string-functions.md index 7c3762a95d949..d6c9f6bf1ad7b 100644 --- a/functions-and-operators/string-functions.md +++ b/functions-and-operators/string-functions.md @@ -28,36 +28,20 @@ The `ASCII(str)` function is used to get the ASCII value of the leftmost charact > > `ASCII(str)` only works for characters represented using 8 bits of binary digits (one byte). -Examples: +Example: ```sql -SELECT ASCII('A'); - -+------------+ -| ASCII('A') | -+------------+ -| 65 | -+------------+ +SELECT ASCII('A'), ASCII('TiDB'), ASCII(23); ``` -```sql -SELECT ASCII('TiDB'); - -+---------------+ -| ASCII('TiDB') | -+---------------+ -| 84 | -+---------------+ -``` +Output: ```sql -SELECT ASCII(23); - -+-----------+ -| ASCII(23) | -+-----------+ -| 50 | -+-----------+ ++------------+---------------+-----------+ +| ASCII('A') | ASCII('TiDB') | ASCII(23) | ++------------+---------------+-----------+ +| 65 | 84 | 50 | ++------------+---------------+-----------+ ``` ### [`BIN()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_bin) @@ -68,24 +52,34 @@ The `BIN()` function is used to convert the given argument into a string represe - If the argument is a negative number, the function converts the absolute value of the argument to its binary representation, inverts each bit of the binary value (changing `0` to `1` and `1` to `0`), and then adds `1` to the inverted value. - If the argument is a string containing only digits, the function returns the result according to those digits. For example, the results for `"123"` and `123` are the same. - If the argument is a string and its first character is not a digit (such as `"q123"`), the function returns `0`. -- If the argument is a string that consists of digits and non-digits, the function returns the result according to the consecutive digits at the beginning of the argument. For example, the results for `"123q123"` and `123` are the same. +- If the argument is a string that consists of digits and non-digits, the function returns the result according to the consecutive digits at the beginning of the argument. For example, the results for `"123q123"` and `123` are the same, but `BIN('123q123')` generates a warning like `Truncated incorrect INTEGER value: '123q123'`. - If the argument is `NULL`, the function returns `NULL`. -Examples: +Example 1: ```sql -SELECT BIN(123); +SELECT BIN(123), BIN('123q123'); +``` + +Output 1: -+----------+ -| BIN(123) | -+----------+ -| 1111011 | -+----------+ +```sql ++----------+----------------+ +| BIN(123) | BIN('123q123') | ++----------+----------------+ +| 1111011 | 1111011 | ++----------+----------------+ ``` +Example 2: + ```sql SELECT BIN(-7); +``` + +Output 2: +```sql +------------------------------------------------------------------+ | BIN(-7) | +------------------------------------------------------------------+ @@ -93,18 +87,6 @@ SELECT BIN(-7); +------------------------------------------------------------------+ ``` -```sql -SELECT BIN("123q123"); - -+----------------+ -| BIN("123q123") | -+----------------+ -| 1111011 | -+----------------+ -``` - -Return a string containing binary representation of a number. - ### [`BIT_LENGTH()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_bit-length) The `BIT_LENGTH()` function is used to return the length of a given argument in bits. @@ -1307,7 +1289,7 @@ Example 1: SELECT SUBSTRING_INDEX('www.tidbcloud.com', '.', 2); ``` -Result 1: +Output 1: ```sql +-----------------------------------------+ @@ -1323,7 +1305,7 @@ Example 2: SELECT SUBSTRING_INDEX('www.tidbcloud.com', '.', -1); ``` -Result 2: +Output 2: ```sql +------------------------------------------+ @@ -1352,7 +1334,7 @@ Example 1: SELECT TO_BASE64('abc'); ``` -Result 1: +Output 1: ```sql +------------------+ @@ -1368,7 +1350,7 @@ Example 2: SELECT TO_BASE64(6); ``` -Result 2: +Output 2: ```sql +--------------+ @@ -1388,19 +1370,108 @@ Remove leading and trailing spaces. ### [`UCASE()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_ucase) -Synonym for `UPPER()`. +The `UCASE()` function is used to convert a string to uppercase letters. This function is equivalent to the `UPPER()` function. + +> **Note:** +> +> When the string is null, the `UCASE()` function returns `NULL`. + +Example: + +```sql +SELECT UCASE('bigdata') AS result_upper, UCASE(null) AS result_null; +``` + +Output: + +```sql ++--------------+-------------+ +| result_upper | result_null | ++--------------+-------------+ +| BIGDATA | NULL | ++--------------+-------------+ +``` ### [`UNHEX()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_unhex) -Return a string containing hex representation of a number. +The `UNHEX()` function performs the reverse operation of the `HEX()` function. It treats each pair of characters in the argument as a hexadecimal number and converts it to the character represented by that number, returning the result as a binary string. + +> **Note:** +> +> The argument must be a valid hexadecimal value that contains `0`–`9`, `A`–`F`, or `a`–`f`. If the argument is `NULL` or falls outside this range, the function returns `NULL`. + +Example: + +```sql +SELECT UNHEX('54694442'); +``` + +Output: + +```sql ++--------------------------------------+ +| UNHEX('54694442') | ++--------------------------------------+ +| 0x54694442 | ++--------------------------------------+ +``` ### [`UPPER()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_upper) -Convert to uppercase. +The `UPPER()` function is used to convert a string to uppercase letters. This function is equivalent to the `UCASE()` function. + +> **Note:** +> +> When the string is null, the `UPPER()` function returns `NULL`. + +Example: + +```sql +SELECT UPPER('bigdata') AS result_upper, UPPER(null) AS result_null; +``` + +Output: + +```sql ++--------------+-------------+ +| result_upper | result_null | ++--------------+-------------+ +| BIGDATA | NULL | ++--------------+-------------+ +``` ### [`WEIGHT_STRING()`](https://dev.mysql.com/doc/refman/8.0/en/string-functions.html#function_weight-string) -Return the weight string for the input string. +The `WEIGHT_STRING()` function returns the weight string (binary characters) for the input string, primarily used for sorting and comparison operations in multi-character set scenarios. If the argument is `NULL`, it returns `NULL`. The syntax is as follows: + +```sql +WEIGHT_STRING(str [AS {CHAR|BINARY}(N)]) +``` + +- `str`: the input string expression. If it is a non-binary string, such as a `CHAR`, `VARCHAR`, or `TEXT` value, the return value contains the collation weights for the string. If it is a binary string, such as a `BINARY`, `VARBINARY`, or `BLOB` value, the return value is the same as the input. + +- `AS {CHAR|BINARY}(N)`: optional parameters used to specify the type and length of the output. `CHAR` represents the character data type, and `BINARY` represents the binary data type. `N` specifies the output length, which is an integer greater than or equal to 1. + +> **Note:** +> +> If `N` is less than the string length, the string is truncated. If `N` exceeds the string length, `AS CHAR(N)` pads the string with spaces to the specified length, and `AS BINARY(N)` pads the string with `0x00` to the specified length. + +Example: + +```sql +SET NAMES 'utf8mb4'; +SELECT HEX(WEIGHT_STRING('ab' AS CHAR(3))) AS char_result, HEX(WEIGHT_STRING('ab' AS BINARY(3))) AS binary_result; +``` + +Output: + +```sql ++-------------+---------------+ +| char_result | binary_result | ++-------------+---------------+ +| 6162 | 616200 | ++-------------+---------------+ +``` ## Unsupported functions diff --git a/hardware-and-software-requirements.md b/hardware-and-software-requirements.md index 8896807aa8663..b345b4fbadf3d 100644 --- a/hardware-and-software-requirements.md +++ b/hardware-and-software-requirements.md @@ -267,3 +267,32 @@ As an open-source distributed SQL database, TiDB requires the following network ## Web browser requirements TiDB relies on [Grafana](https://grafana.com/) to provide visualization of database metrics. A recent version of Microsoft Edge, Safari, Chrome or Firefox with Javascript enabled is sufficient. + +## Hardware and software requirements for TiFlash disaggregated storage and compute architecture + +The preceding TiFlash software and hardware requirements are for the coupled storage and compute architecture. Starting from v7.0.0, TiFlash supports the [disaggregated storage and compute architecture](/tiflash/tiflash-disaggregated-and-s3.md). In this architecture, TiFlash is divided into two types of nodes: the Write Node and the Compute Node. The requirements for these nodes are as follows: + +- Software: remain the same as the coupled storage and compute architecture, see [OS and platform requirements](#os-and-platform-requirements). +- Network port: remain the same as the coupled storage and compute architecture, see [Network](#network-requirements). +- Disk space: + - TiFlash Write Node: it is recommended to configure at least 200 GB of disk space, which is used as a local buffer when adding TiFlash replicas and migrating Region replicas before uploading data to Amazon S3. In addition, an object storage compatible with Amazon S3 is required. + - TiFlash Compute Node: it is recommended to configure at least 100 GB of disk space, which is mainly used to cache the data read from the Write Node to improve performance. The cache of the Compute Node might be fully used, which is normal. +- CPU and memory requirements are described in the following sections. + +### Development and test environments + +| Component | CPU | Memory | Local Storage | Network | Number of Instances (Minimum Requirement) | +| --- | --- | --- | --- | --- | --- | +| TiFlash Write Node | 16 cores+ | 32 GB+ | SSD, 200 GB+ | Gigabit Ethernet | 1 | +| TiFlash Compute Node | 16 cores+ | 32 GB+ | SSD, 100 GB+ | Gigabit Ethernet | 0 (see the following note) | + +### Production environment + +| Component | CPU | Memory | Disk Type | Network | Number of Instances (Minimum Requirement) | +| --- | --- | --- | --- | --- | --- | +| TiFlash Write Node | 32 cores+ | 64 GB+ | 1 or more SSDs | 10 Gigabit Ethernet (2 recommended) | 1 | +| TiFlash Compute Node | 32 cores+ | 64 GB+ | 1 or more SSDs | 10 Gigabit Ethernet (2 recommended) | 0 (see the following note) | + +> **Note:** +> +> You can use deployment tools such as TiUP to quickly scale in or out the TiFlash Compute Node, within the range of `[0, +inf]`. diff --git a/information-schema/information-schema-tidb-index-usage.md b/information-schema/information-schema-tidb-index-usage.md new file mode 100644 index 0000000000000..00e57aa9cd906 --- /dev/null +++ b/information-schema/information-schema-tidb-index-usage.md @@ -0,0 +1,103 @@ +--- +title: TIDB_INDEX_USAGE +summary: Learn the `TIDB_INDEX_USAGE` INFORMATION_SCHEMA table. +--- + +# TIDB_INDEX_USAGE + +
+
+For detailed information on using TiDB Operator, see the following documents:
+
+- [Deploy PD microservices](https://docs.pingcap.com/tidb-in-kubernetes/dev/configure-a-tidb-cluster#enable-pd-microservices)
+- [Configure PD microservices](https://docs.pingcap.com/tidb-in-kubernetes/dev/configure-a-tidb-cluster#configure-pd-microservices)
+- [Modify PD microservices](https://docs.pingcap.com/tidb-in-kubernetes/dev/modify-tidb-configuration#modify-pd-microservice-configuration)
+- [Scale PD microservice components](https://docs.pingcap.com/tidb-in-kubernetes/dev/scale-a-tidb-cluster#scale-pd-microservice-components)
+
+
+
+
+For detailed information on using TiUP Playground, see the following document:
+
+- [Deploy PD microservices](/tiup/tiup-playground.md#deploy-pd-microservices)
+
+
+- `[+region=us-east-1]` means placing data on nodes that have a `region` label as `us-east-1`.
- `[+region=us-east-1,-type=fault]` means placing data on nodes that have a `region` label as `us-east-1` but do not have a `type` label as `fault`.
| -| Dictionary format | If you need to specify different numbers of replicas for different constraints, you can use the dictionary format. For example:
- `FOLLOWER_CONSTRAINTS="{+region=us-east-1: 1,+region=us-east-2: 1,+region=us-west-1: 1}";` means placing one Follower in `us-east-1`, one Follower in `us-east-2`, and one Follower in `us-west-1`.
- `FOLLOWER_CONSTRAINTS='{"+region=us-east-1,+type=scale-node": 1,"+region=us-west-1": 1}';` means placing one Follower on a node that is located in the `us-east-1` region and has the `type` label as `scale-node`, and one Follower in `us-west-1`.
- `FOLLOWER_CONSTRAINTS="{+region=us-east-1: 1,+region=us-east-2: 1,+region=us-west-1: 1}";` means placing one Follower in `us-east-1`, one Follower in `us-east-2`, and one Follower in `us-west-1`.
- `FOLLOWER_CONSTRAINTS='{"+region=us-east-1,+type=scale-node": 1,"+region=us-west-1": 1}';` means placing one Follower on a node that is located in the `us-east-1` region and has the `type` label as `scale-node`, and one Follower in `us-west-1`.
\| (bitor), `~` (bitneg), `^` (bitxor) |
| [String functions](/functions-and-operators/string-functions.md) | `SUBSTR()`, `CHAR_LENGTH()`, `REPLACE()`, `CONCAT()`, `CONCAT_WS()`, `LEFT()`, `RIGHT()`, `ASCII()`, `LENGTH()`, `TRIM()`, `LTRIM()`, `RTRIM()`, `POSITION()`, `FORMAT()`, `LOWER()`, `UCASE()`, `UPPER()`, `SUBSTRING_INDEX()`, `LPAD()`, `RPAD()`, `STRCMP()` |
-| [Regular expression functions and operators](/functions-and-operators/string-functions.md) | `REGEXP`, `REGEXP_LIKE()`, `REGEXP_INSTR()`, `REGEXP_SUBSTR()`, `REGEXP_REPLACE()` |
+| [Regular expression functions and operators](/functions-and-operators/string-functions.md) | `REGEXP`, `REGEXP_LIKE()`, `REGEXP_INSTR()`, `REGEXP_SUBSTR()`, `REGEXP_REPLACE()`, `RLIKE` |
| [Date functions](/functions-and-operators/date-and-time-functions.md) | `DATE_FORMAT()`, `TIMESTAMPDIFF()`, `FROM_UNIXTIME()`, `UNIX_TIMESTAMP(int)`, `UNIX_TIMESTAMP(decimal)`, `STR_TO_DATE(date)`, `STR_TO_DATE(datetime)`, `DATEDIFF()`, `YEAR()`, `MONTH()`, `DAY()`, `EXTRACT(datetime)`, `DATE()`, `HOUR()`, `MICROSECOND()`, `MINUTE()`, `SECOND()`, `SYSDATE()`, `DATE_ADD/ADDDATE(datetime, int)`, `DATE_ADD/ADDDATE(string, int/real)`, `DATE_SUB/SUBDATE(datetime, int)`, `DATE_SUB/SUBDATE(string, int/real)`, `QUARTER()`, `DAYNAME()`, `DAYOFMONTH()`, `DAYOFWEEK()`, `DAYOFYEAR()`, `LAST_DAY()`, `MONTHNAME()`, `TO_SECONDS()`, `TO_DAYS()`, `FROM_DAYS()`, `WEEKOFYEAR()` |
| [JSON function](/functions-and-operators/json-functions.md) | `JSON_LENGTH()`, `->`, `->>`, `JSON_EXTRACT()`, `JSON_ARRAY()`, `JSON_DEPTH()`, `JSON_VALID()`, `JSON_KEYS()`, `JSON_CONTAINS_PATH()`, `JSON_UNQUOTE()` |
-| [Conversion functions](/functions-and-operators/cast-functions-and-operators.md) | `CAST(int AS DOUBLE), CAST(int AS DECIMAL)`, `CAST(int AS STRING)`, `CAST(int AS TIME)`, `CAST(double AS INT)`, `CAST(double AS DECIMAL)`, `CAST(double AS STRING)`, `CAST(double AS TIME)`, `CAST(string AS INT)`, `CAST(string AS DOUBLE), CAST(string AS DECIMAL)`, `CAST(string AS TIME)`, `CAST(decimal AS INT)`, `CAST(decimal AS STRING)`, `CAST(decimal AS TIME)`, `CAST(time AS INT)`, `CAST(time AS DECIMAL)`, `CAST(time AS STRING)`, `CAST(time AS REAL)`, `CAST(json AS JSON)`, `CAST(json AS STRING)`, `CAST(int AS JSON)`, `CAST(real AS JSON)`, `CAST(decimal AS JSON)`, `CAST(string AS JSON)`, `CAST(time AS JSON)`, `CAST(duration AS JSON)` |
+| [Conversion functions](/functions-and-operators/cast-functions-and-operators.md) | `CAST(int AS DOUBLE), CAST(int AS DECIMAL)`, `CAST(int AS STRING)`, `CAST(int AS TIME)`, `CAST(double AS INT)`, `CAST(double AS DECIMAL)`, `CAST(double AS STRING)`, `CAST(double AS TIME)`, `CAST(string AS INT)`, `CAST(string AS DOUBLE), CAST(string AS DECIMAL)`, `CAST(string AS TIME)`, `CAST(decimal AS INT)`, `CAST(decimal AS STRING)`, `CAST(decimal AS TIME)`, `CAST(decimal AS DOUBLE)`, `CAST(time AS INT)`, `CAST(time AS DECIMAL)`, `CAST(time AS STRING)`, `CAST(time AS REAL)`, `CAST(json AS JSON)`, `CAST(json AS STRING)`, `CAST(int AS JSON)`, `CAST(real AS JSON)`, `CAST(decimal AS JSON)`, `CAST(string AS JSON)`, `CAST(time AS JSON)`, `CAST(duration AS JSON)` |
| [Aggregate functions](/functions-and-operators/aggregate-group-by-functions.md) | `MIN()`, `MAX()`, `SUM()`, `COUNT()`, `AVG()`, `APPROX_COUNT_DISTINCT()`, `GROUP_CONCAT()` |
| [Miscellaneous functions](/functions-and-operators/miscellaneous-functions.md) | `INET_NTOA()`, `INET_ATON()`, `INET6_NTOA()`, `INET6_ATON()` |
diff --git a/tikv-configuration-file.md b/tikv-configuration-file.md
index 5477cd5dfcccc..4ddca277f7023 100644
--- a/tikv-configuration-file.md
+++ b/tikv-configuration-file.md
@@ -177,9 +177,9 @@ This document only describes the parameters that are not included in command-lin
### `grpc-stream-initial-window-size`
+ The window size of the gRPC stream
-+ Default value: `2MB`
-+ Unit: KB|MB|GB
-+ Minimum value: `"1KB"`
++ Default value: `2MiB`
++ Unit: KiB|MiB|GiB
++ Minimum value: `"1KiB"`
### `grpc-keepalive-time`
@@ -220,9 +220,9 @@ This document only describes the parameters that are not included in command-lin
### `snap-io-max-bytes-per-sec`
+ The maximum allowable disk bandwidth when processing snapshots
-+ Default value: `"100MB"`
-+ Unit: KB|MB|GB
-+ Minimum value: `"1KB"`
++ Default value: `"100MiB"`
++ Unit: KiB|MiB|GiB
++ Minimum value: `"1KiB"`
### `enable-request-batch`
@@ -283,9 +283,9 @@ Configuration items related to the single thread pool serving read requests. Thi
+ The stack size of the threads in the unified thread pool
+ Type: Integer + Unit
-+ Default value: `"10MB"`
-+ Unit: KB|MB|GB
-+ Minimum value: `"2MB"`
++ Default value: `"10MiB"`
++ Unit: KiB|MiB|GiB
++ Minimum value: `"2MiB"`
+ Maximum value: The number of Kbytes output in the result of the `ulimit -sH` command executed in the system.
### `max-tasks-per-worker`
@@ -348,9 +348,9 @@ Configuration items related to storage thread pool.
+ The stack size of threads in the Storage read thread pool
+ Type: Integer + Unit
-+ Default value: `"10MB"`
-+ Unit: KB|MB|GB
-+ Minimum value: `"2MB"`
++ Default value: `"10MiB"`
++ Unit: KiB|MiB|GiB
++ Minimum value: `"2MiB"`
+ Maximum value: The number of Kbytes output in the result of the `ulimit -sH` command executed in the system.
## `readpool.coprocessor`
@@ -402,9 +402,9 @@ Configuration items related to the Coprocessor thread pool.
+ The stack size of the thread in the Coprocessor thread pool
+ Type: Integer + Unit
-+ Default value: `"10MB"`
-+ Unit: KB|MB|GB
-+ Minimum value: `"2MB"`
++ Default value: `"10MiB"`
++ Unit: KiB|MiB|GiB
++ Minimum value: `"2MiB"`
+ Maximum value: The number of Kbytes output in the result of the `ulimit -sH` command executed in the system.
## storage
@@ -444,8 +444,8 @@ Configuration items related to storage.
### `scheduler-pending-write-threshold`
+ The maximum size of the write queue. A `Server Is Busy` error is returned for a new write to TiKV when this value is exceeded.
-+ Default value: `"100MB"`
-+ Unit: MB|GB
++ Default value: `"100MiB"`
++ Unit: MiB|GiB
### `enable-async-apply-prewrite`
@@ -456,9 +456,9 @@ Configuration items related to storage.
+ When TiKV is started, some space is reserved on the disk as disk protection. When the remaining disk space is less than the reserved space, TiKV restricts some write operations. The reserved space is divided into two parts: 80% of the reserved space is used as the extra disk space required for operations when the disk space is insufficient, and the other 20% is used to store the temporary file. In the process of reclaiming space, if the storage is exhausted by using too much extra disk space, this temporary file serves as the last protection for restoring services.
+ The name of the temporary file is `space_placeholder_file`, located in the `storage.data-dir` directory. When TiKV goes offline because its disk space ran out, if you restart TiKV, the temporary file is automatically deleted and TiKV tries to reclaim the space.
-+ When the remaining space is insufficient, TiKV does not create the temporary file. The effectiveness of the protection is related to the size of the reserved space. The size of the reserved space is the larger value between 5% of the disk capacity and this configuration value. When the value of this configuration item is `"0MB"`, TiKV disables this disk protection feature.
-+ Default value: `"5GB"`
-+ Unit: MB|GB
++ When the remaining space is insufficient, TiKV does not create the temporary file. The effectiveness of the protection is related to the size of the reserved space. The size of the reserved space is the larger value between 5% of the disk capacity and this configuration value. When the value of this configuration item is `"0MiB"`, TiKV disables this disk protection feature.
++ Default value: `"5GiB"`
++ Unit: MiB|GiB
### `enable-ttl`
@@ -514,7 +514,7 @@ Configuration items related to the sharing of block cache among multiple RocksDB
+ When `storage.engine="raft-kv"`, the default value is 45% of the size of total system memory.
+ When `storage.engine="partitioned-raft-kv"`, the default value is 30% of the size of total system memory.
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
## storage.flow-control
@@ -538,12 +538,12 @@ Configuration items related to the flow control mechanism in TiKV. This mechanis
### `soft-pending-compaction-bytes-limit`
+ When the pending compaction bytes in KvDB reach this threshold, the flow control mechanism starts to reject some write requests and reports the `ServerIsBusy` error. When `enable` is set to `true`, this configuration item overrides `rocksdb.(defaultcf|writecf|lockcf).soft-pending-compaction-bytes-limit`.
-+ Default value: `"192GB"`
++ Default value: `"192GiB"`
### `hard-pending-compaction-bytes-limit`
+ When the pending compaction bytes in KvDB reach this threshold, the flow control mechanism rejects all write requests and reports the `ServerIsBusy` error. When `enable` is set to `true`, this configuration item overrides `rocksdb.(defaultcf|writecf|lockcf).hard-pending-compaction-bytes-limit`.
-+ Default value: `"1024GB"`
++ Default value: `"1024GiB"`
## storage.io-rate-limit
@@ -552,7 +552,7 @@ Configuration items related to the I/O rate limiter.
### `max-bytes-per-sec`
+ Limits the maximum I/O bytes that a server can write to or read from the disk (determined by the `mode` configuration item below) in one second. When this limit is reached, TiKV prefers throttling background operations over foreground ones. The value of this configuration item should be set to the disk's optimal I/O bandwidth, for example, the maximum I/O bandwidth specified by your cloud disk vendor. When this configuration value is set to zero, disk I/O operations are not limited.
-+ Default value: `"0MB"`
++ Default value: `"0MiB"`
### `mode`
@@ -604,7 +604,7 @@ Configuration items related to Raftstore.
+ The storage capacity, which is the maximum size allowed to store data. If `capacity` is left unspecified, the capacity of the current disk prevails. To deploy multiple TiKV instances on the same physical disk, add this parameter to the TiKV configuration. For details, see [Key parameters of the hybrid deployment](/hybrid-deployment-topology.md#key-parameters).
+ Default value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `raftdb-path`
@@ -668,10 +668,10 @@ Configuration items related to Raftstore.
> This configuration item cannot be queried via SQL statements but can be configured in the configuration file.
+ The soft limit on the size of a single message packet
-+ Default value: `"1MB"`
++ Default value: `"1MiB"`
+ Minimum value: greater than `0`
-+ Maximum value: `3GB`
-+ Unit: KB|MB|GB
++ Maximum value: `3GiB`
++ Unit: KiB|MiB|GiB
### `raft-max-inflight-msgs`
@@ -687,9 +687,9 @@ Configuration items related to Raftstore.
### `raft-entry-max-size`
+ The hard limit on the maximum size of a single log
-+ Default value: `"8MB"`
++ Default value: `"8MiB"`
+ Minimum value: `0`
-+ Unit: MB|GB
++ Unit: MiB|GiB
### `raft-log-compact-sync-interval` New in v5.3
@@ -712,7 +712,7 @@ Configuration items related to Raftstore.
### `raft-log-gc-count-limit`
+ The hard limit on the allowable number of residual Raft logs
-+ Default value: the log number that can be accommodated in the 3/4 Region size (calculated as 1MB for each log)
++ Default value: the log number that can be accommodated in the 3/4 Region size (calculated as 1MiB for each log)
+ Minimum value: `0`
### `raft-log-gc-size-limit`
@@ -845,9 +845,9 @@ Configuration items related to Raftstore.
### `lock-cf-compact-bytes-threshold`
+ The size out of which TiKV triggers a manual compaction for the Lock Column Family
-+ Default value: `"256MB"`
++ Default value: `"256MiB"`
+ Minimum value: `0`
-+ Unit: MB
++ Unit: MiB
### `notify-capacity`
@@ -900,9 +900,9 @@ Configuration items related to Raftstore.
### `snap-apply-batch-size`
+ The memory cache size required when the imported snapshot file is written into the disk
-+ Default value: `"10MB"`
++ Default value: `"10MiB"`
+ Minimum value: `0`
-+ Unit: MB
++ Unit: MiB
### `consistency-check-interval`
@@ -990,7 +990,7 @@ Configuration items related to Raftstore.
### `store-io-pool-size` New in v5.3.0
+ The allowable number of threads that process Raft I/O tasks, which is the size of the StoreWriter thread pool. When you modify the size of this thread pool, refer to [Performance tuning for TiKV thread pools](/tune-tikv-thread-performance.md#performance-tuning-for-tikv-thread-pools).
-+ Default value: `0`
++ Default value: `1` (Before v8.0.0, the default value is `0`)
+ Minimum value: `0`
### `future-poll-size`
@@ -1014,7 +1014,7 @@ Configuration items related to Raftstore.
### `raft-write-size-limit` New in v5.3.0
+ Determines the threshold at which Raft data is written into the disk. If the data size is larger than the value of this configuration item, the data is written to the disk. When the value of `store-io-pool-size` is `0`, this configuration item does not take effect.
-+ Default value: `1MB`
++ Default value: `1MiB`
+ Minimum value: `0`
### `report-min-resolved-ts-interval` New in v6.0.0
@@ -1155,9 +1155,9 @@ Configuration items related to RocksDB
### `max-manifest-file-size`
+ The maximum size of a RocksDB Manifest file
-+ Default value: `"128MB"`
++ Default value: `"128MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `create-if-missing`
@@ -1191,14 +1191,14 @@ Configuration items related to RocksDB
+ The size limit of the archived WAL files. When the value is exceeded, the system deletes these files.
+ Default value: `0`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `max-total-wal-size`
+ The maximum RocksDB WAL size in total, which is the size of `*.log` files in the `data-dir`.
+ Default value:
- + When `storage.engine="raft-kv"`, the default value is `"4GB"`.
+ + When `storage.engine="raft-kv"`, the default value is `"4GiB"`.
+ When `storage.engine="partitioned-raft-kv"`, the default value is `1`.
### `stats-dump-period`
@@ -1211,17 +1211,17 @@ Configuration items related to RocksDB
### `compaction-readahead-size`
-+ Enables the readahead feature during RocksDB compaction and specifies the size of readahead data. If you are using mechanical disks, it is recommended to set the value to 2MB at least.
++ Enables the readahead feature during RocksDB compaction and specifies the size of readahead data. If you are using mechanical disks, it is recommended to set the value to 2MiB at least.
+ Default value: `0`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `writable-file-max-buffer-size`
+ The maximum buffer size used in WritableFileWrite
-+ Default value: `"1MB"`
++ Default value: `"1MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `use-direct-io-for-flush-and-compaction`
@@ -1231,9 +1231,9 @@ Configuration items related to RocksDB
### `rate-bytes-per-sec`
+ When Titan is disabled, this configuration item limits the I/O rate of RocksDB compaction to reduce the impact of RocksDB compaction on the foreground read and write performance during traffic peaks. When Titan is enabled, this configuration item limits the summed I/O rates of RocksDB compaction and Titan GC. If you find that the I/O or CPU consumption of RocksDB compaction and Titan GC is too large, set this configuration item to an appropriate value according the disk I/O bandwidth and the actual write traffic.
-+ Default value: `10GB`
++ Default value: `10GiB`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `rate-limiter-refill-period`
@@ -1259,23 +1259,23 @@ Configuration items related to RocksDB
### `bytes-per-sync`
+ The rate at which OS incrementally synchronizes files to disk while these files are being written asynchronously
-+ Default value: `"1MB"`
++ Default value: `"1MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `wal-bytes-per-sync`
+ The rate at which OS incrementally synchronizes WAL files to disk while the WAL files are being written
-+ Default value: `"512KB"`
++ Default value: `"512KiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `info-log-max-size`
+ The maximum size of Info log
-+ Default value: `"1GB"`
++ Default value: `"1GiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `info-log-roll-time`
@@ -1335,7 +1335,7 @@ Configuration items related to Titan.
>
> - To enhance the performance of wide table and JSON data writing and point query, starting from TiDB v7.6.0, the default value changes from `false` to `true`, which means that Titan is enabled by default.
> - Existing clusters upgraded to v7.6.0 or later versions retain the original configuration, which means that if Titan is not explicitly enabled, it still uses RocksDB.
-> - If the cluster has enabled Titan before upgrading to TiDB v7.6.0 or later versions, Titan will be retained after the upgrade, and the [`min-blob-size`](/tikv-configuration-file.md#min-blob-size) configuration before the upgrade will be retained. If you do not explicitly configure the value before the upgrade, the default value of the previous version `1KB` will be retained to ensure the stability of the cluster configuration after the upgrade.
+> - If the cluster has enabled Titan before upgrading to TiDB v7.6.0 or later versions, Titan will be retained after the upgrade, and the [`min-blob-size`](/tikv-configuration-file.md#min-blob-size) configuration before the upgrade will be retained. If you do not explicitly configure the value before the upgrade, the default value of the previous version `1KiB` will be retained to ensure the stability of the cluster configuration after the upgrade.
+ Enables or disables Titan.
+ Default value: `true`
@@ -1363,10 +1363,10 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `block-size`
+ The default size of a RocksDB block
-+ Default value for `defaultcf` and `writecf`: `"32KB"`
-+ Default value for `lockcf`: `"16KB"`
-+ Minimum value: `"1KB"`
-+ Unit: KB|MB|GB
++ Default value for `defaultcf` and `writecf`: `"32KiB"`
++ Default value for `lockcf`: `"16KiB"`
++ Minimum value: `"1KiB"`
++ Unit: KiB|MiB|GiB
### `block-cache-size`
@@ -1379,7 +1379,7 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
+ Default value for `writecf`: `Total machine memory * 15%`
+ Default value for `lockcf`: `Total machine memory * 2%`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `disable-block-cache`
@@ -1460,12 +1460,12 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `write-buffer-size`
+ Memtable size
-+ Default value for `defaultcf` and `writecf`: `"128MB"`
++ Default value for `defaultcf` and `writecf`: `"128MiB"`
+ Default value for `lockcf`:
- + When `storage.engine="raft-kv"`, the default value is `"32MB"`.
- + When `storage.engine="partitioned-raft-kv"`, the default value is `"4MB"`.
+ + When `storage.engine="raft-kv"`, the default value is `"32MiB"`.
+ + When `storage.engine="partitioned-raft-kv"`, the default value is `"4MiB"`.
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `max-write-buffer-number`
@@ -1482,18 +1482,18 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `max-bytes-for-level-base`
+ The maximum number of bytes at base level (level-1). Generally, it is set to 4 times the size of a memtable. When the level-1 data size reaches the limit value of `max-bytes-for-level-base`, the SST files of level-1 and their overlapping SST files of level-2 will be compacted.
-+ Default value for `defaultcf` and `writecf`: `"512MB"`
-+ Default value for `lockcf`: `"128MB"`
++ Default value for `defaultcf` and `writecf`: `"512MiB"`
++ Default value for `lockcf`: `"128MiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
-+ It is recommended that the value of `max-bytes-for-level-base` is set approximately equal to the data volume in L0 to reduce unnecessary compaction. For example, if the compression method is "no:no:lz4:lz4:lz4:lz4:lz4", the value of `max-bytes-for-level-base` should be `write-buffer-size * 4`, because there is no compression of L0 and L1 and the trigger condition of compaction for L0 is that the number of the SST files reaches 4 (the default value). When L0 and L1 both adopt compaction, you need to analyze RocksDB logs to understand the size of an SST file compressed from a memtable. For example, if the file size is 32 MB, it is recommended to set the value of `max-bytes-for-level-base` to 128 MB (`32 MB * 4`).
++ Unit: KiB|MiB|GiB
++ It is recommended that the value of `max-bytes-for-level-base` is set approximately equal to the data volume in L0 to reduce unnecessary compaction. For example, if the compression method is "no:no:lz4:lz4:lz4:lz4:lz4", the value of `max-bytes-for-level-base` should be `write-buffer-size * 4`, because there is no compression of L0 and L1 and the trigger condition of compaction for L0 is that the number of the SST files reaches 4 (the default value). When L0 and L1 both adopt compaction, you need to analyze RocksDB logs to understand the size of an SST file compressed from a memtable. For example, if the file size is 32 MiB, it is recommended to set the value of `max-bytes-for-level-base` to 128 MiB (`32 MiB * 4`).
### `target-file-size-base`
+ The size of the target file at base level. This value is overridden by `compaction-guard-max-output-file-size` when the `enable-compaction-guard` value is `true`.
-+ Default value: `"8MB"`
++ Default value: `"8MiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `level0-file-num-compaction-trigger`
@@ -1517,9 +1517,9 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `max-compaction-bytes`
+ The maximum number of bytes written into disk per compaction
-+ Default value: `"2GB"`
++ Default value: `"2GiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `compaction-pri`
@@ -1561,14 +1561,14 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `soft-pending-compaction-bytes-limit`
+ The soft limit on the pending compaction bytes. When `storage.flow-control.enable` is set to `true`, `storage.flow-control.soft-pending-compaction-bytes-limit` overrides this configuration item.
-+ Default value: `"192GB"`
-+ Unit: KB|MB|GB
++ Default value: `"192GiB"`
++ Unit: KiB|MiB|GiB
### `hard-pending-compaction-bytes-limit`
+ The hard limit on the pending compaction bytes. When `storage.flow-control.enable` is set to `true`, `storage.flow-control.hard-pending-compaction-bytes-limit` overrides this configuration item.
-+ Default value: `"256GB"`
-+ Unit: KB|MB|GB
++ Default value: `"256GiB"`
++ Unit: KiB|MiB|GiB
### `enable-compaction-guard`
@@ -1579,14 +1579,14 @@ Configuration items related to `rocksdb.defaultcf`, `rocksdb.writecf`, and `rock
### `compaction-guard-min-output-file-size`
+ The minimum SST file size when the compaction guard is enabled. This configuration prevents SST files from being too small when the compaction guard is enabled.
-+ Default value: `"8MB"`
-+ Unit: KB|MB|GB
++ Default value: `"8MiB"`
++ Unit: KiB|MiB|GiB
### `compaction-guard-max-output-file-size`
+ The maximum SST file size when the compaction guard is enabled. The configuration prevents SST files from being too large when the compaction guard is enabled. This configuration overrides `target-file-size-base` for the same column family.
-+ Default value: `"128MB"`
-+ Unit: KB|MB|GB
++ Default value: `"128MiB"`
++ Unit: KiB|MiB|GiB
### `format-version` New in v6.2.0
@@ -1627,14 +1627,14 @@ Configuration items related to `rocksdb.defaultcf.titan`.
> **Note:**
>
-> - Starting from TiDB v7.6.0, Titan is enabled by default to enhance the performance of wide table and JSON data writing and point query. The default value of `min-blob-size` changes from `1KB` to `32KB`. This means that values exceeding `32KB` is stored in Titan, while other data continues to be stored in RocksDB.
-> - To ensure configuration consistency, for existing clusters upgrading to TiDB v7.6.0 or later versions, if you do not explicitly set `min-blob-size` before the upgrade, TiDB retains the previous default value of `1KB`.
-> - A value smaller than `32KB` might affect the performance of range scans. However, if the workload primarily involves heavy writes and point queries, you can consider decreasing the value of `min-blob-size` for better performance.
+> - Starting from TiDB v7.6.0, Titan is enabled by default to enhance the performance of wide table and JSON data writing and point query. The default value of `min-blob-size` changes from `1KiB` to `32KiB`. This means that values exceeding `32KiB` is stored in Titan, while other data continues to be stored in RocksDB.
+> - To ensure configuration consistency, for existing clusters upgrading to TiDB v7.6.0 or later versions, if you do not explicitly set `min-blob-size` before the upgrade, TiDB retains the previous default value of `1KiB`.
+> - A value smaller than `32KiB` might affect the performance of range scans. However, if the workload primarily involves heavy writes and point queries, you can consider decreasing the value of `min-blob-size` for better performance.
+ The smallest value stored in a Blob file. Values smaller than the specified size are stored in the LSM-Tree.
-+ Default value: `"32KB"`
++ Default value: `"32KiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `blob-file-compression`
@@ -1649,31 +1649,36 @@ Configuration items related to `rocksdb.defaultcf.titan`.
### `zstd-dict-size`
-+ The zstd dictionary compression size. The default value is `"0KB"`, which means to disable the zstd dictionary compression. In this case, Titan compresses data based on single values, whereas RocksDB compresses data based on blocks (`32KB` by default). When the average size of Titan values is less than `32KB`, Titan's compression ratio is lower than that of RocksDB. Taking JSON as an example, the store size in Titan can be 30% to 50% larger than that of RocksDB. The actual compression ratio depends on whether the value content is suitable for compression and the similarity among different values. You can enable the zstd dictionary compression to increase the compression ratio by configuring `zstd-dict-size` (for example, set it to `16KB`). The actual store size can be lower than that of RocksDB. But the zstd dictionary compression might lead to about 10% performance regression in specific workloads.
-+ Default value: `"0KB"`
-+ Unit: KB|MB|GB
++ The zstd dictionary compression size. The default value is `"0KiB"`, which means to disable the zstd dictionary compression. In this case, Titan compresses data based on single values, whereas RocksDB compresses data based on blocks (`32KiB` by default). When the average size of Titan values is less than `32KiB`, Titan's compression ratio is lower than that of RocksDB. Taking JSON as an example, the store size in Titan can be 30% to 50% larger than that of RocksDB. The actual compression ratio depends on whether the value content is suitable for compression and the similarity among different values. You can enable the zstd dictionary compression to increase the compression ratio by configuring `zstd-dict-size` (for example, set it to `16KiB`). The actual store size can be lower than that of RocksDB. But the zstd dictionary compression might lead to about 10% performance regression in specific workloads.
++ Default value: `"0KiB"`
++ Unit: KiB|MiB|GiB
### `blob-cache-size`
+ The cache size of a Blob file
-+ Default value: `"0GB"`
++ Default value: `"0GiB"`
+ Minimum value: `0`
-+ Recommended value: After database stabilization, it is recommended to set the RocksDB block cache (`storage.block-cache.capacity`) based on monitoring to maintain a block cache hit rate of at least 95%, and set `blob-cache-size` to `(total memory size) * 50% - (size of block cache)`. This is to ensure that the block cache is sufficiently large to cache the entire RocksDB, while maximizing the blob cache size. However, to prevent a significant drop in the block cache hit rate, do not set the blob cache size too large.
-+ Unit: KB|MB|GB
++ Recommended value: `0`. Starting from v8.0.0, TiKV introduces the `shared-blob-cache` configuration item and enables it by default, so there is no need to set `blob-cache-size` separately. The configuration of `blob-cache-size` only takes effect when `shared-blob-cache` is set to `false`.
++ Unit: KiB|MiB|GiB
+
+### `shared-blob-cache` (New in v8.0.0)
+
++ Controls whether to enable the shared cache for Titan blob files and RocksDB block files.
++ Default value: `true`. When the shared cache is enabled, block files have higher priority. This means that TiKV prioritizes meeting the cache needs of block files and then uses the remaining cache for blob files.
### `min-gc-batch-size`
+ The minimum total size of Blob files required to perform GC for one time
-+ Default value: `"16MB"`
++ Default value: `"16MiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `max-gc-batch-size`
+ The maximum total size of Blob files allowed to perform GC for one time
-+ Default value: `"64MB"`
++ Default value: `"64MiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `discardable-ratio`
@@ -1699,9 +1704,9 @@ Configuration items related to `rocksdb.defaultcf.titan`.
### `merge-small-file-threshold`
+ When the size of a Blob file is smaller than this value, the Blob file might still be selected for GC. In this situation, `discardable-ratio` is ignored.
-+ Default value: `"8MB"`
++ Default value: `"8MiB"`
+ Minimum value: `0`
-+ Unit: KB|MB|GB
++ Unit: KiB|MiB|GiB
### `blob-run-mode`
@@ -1742,9 +1747,9 @@ Configuration items related to `raftdb`
### `max-manifest-file-size`
+ The maximum size of a RocksDB Manifest file
-+ Default value: `"20MB"`
++ Default value: `"20MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `create-if-missing`
@@ -1775,29 +1780,29 @@ Configuration items related to `raftdb`
+ The size limit of the archived WAL files. When the value is exceeded, the system deletes these files.
+ Default value: `0`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `max-total-wal-size`
+ The maximum RocksDB WAL size in total
-+ Default value: `"4GB"`
- + When `storage.engine="raft-kv"`, the default value is `"4GB"`.
++ Default value:
+ + When `storage.engine="raft-kv"`, the default value is `"4GiB"`.
+ When `storage.engine="partitioned-raft-kv"`, the default value is `1`.
### `compaction-readahead-size`
+ Controls whether to enable the readahead feature during RocksDB compaction and specify the size of readahead data.
-+ If you use mechanical disks, it is recommended to set the value to `2MB` at least.
++ If you use mechanical disks, it is recommended to set the value to `2MiB` at least.
+ Default value: `0`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `writable-file-max-buffer-size`
+ The maximum buffer size used in WritableFileWrite
-+ Default value: `"1MB"`
++ Default value: `"1MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `use-direct-io-for-flush-and-compaction`
@@ -1817,23 +1822,23 @@ Configuration items related to `raftdb`
### `bytes-per-sync`
+ The rate at which OS incrementally synchronizes files to disk while these files are being written asynchronously
-+ Default value: `"1MB"`
++ Default value: `"1MiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `wal-bytes-per-sync`
+ The rate at which OS incrementally synchronizes WAL files to disk when the WAL files are being written
-+ Default value: `"512KB"`
++ Default value: `"512KiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `info-log-max-size`
+ The maximum size of Info logs
-+ Default value: `"1GB"`
++ Default value: `"1GiB"`
+ Minimum value: `0`
-+ Unit: B|KB|MB|GB
++ Unit: B|KiB|MiB|GiB
### `info-log-roll-time`
@@ -1880,24 +1885,24 @@ Configuration items related to Raft Engine.
### `batch-compression-threshold`
+ Specifies the threshold size of a log batch. A log batch larger than this configuration is compressed. If you set this configuration item to `0`, compression is disabled.
-+ Default value: `"8KB"`
++ Default value: `"8KiB"`
### `bytes-per-sync`
+ Specifies the maximum accumulative size of buffered writes. When this configuration value is exceeded, buffered writes are flushed to the disk.
+ If you set this configuration item to `0`, incremental sync is disabled.
-+ Default value: `"4MB"`
++ Default value: `"4MiB"`
### `target-file-size`
+ Specifies the maximum size of log files. When a log file is larger than this value, it is rotated.
-+ Default value: `"128MB"`
++ Default value: `"128MiB"`
### `purge-threshold`
+ Specifies the threshold size of the main log queue. When this configuration value is exceeded, the main log queue is purged.
+ This configuration can be used to adjust the disk space usage of Raft Engine.
-+ Default value: `"10GB"`
++ Default value: `"10GiB"`
### `recovery-mode`
@@ -1908,7 +1913,7 @@ Configuration items related to Raft Engine.
### `recovery-read-block-size`
+ The minimum I/O size for reading log files during recovery.
-+ Default value: `"16KB"`
++ Default value: `"16KiB"`
+ Minimum value: `"512B"`
### `recovery-threads`
@@ -2066,7 +2071,7 @@ Configuration items related to TiDB Lightning import and BR restore.
+ The garbage ratio threshold to trigger GC.
+ Default value: `1.1`
-### `num-threads` New in v6.5.8 and v7.6.0
+### `num-threads` New in v6.5.8, v7.1.4, v7.5.1, and v7.6.0
+ The number of GC threads when `enable-compaction-filter` is `false`.
+ Default value: `1`
@@ -2091,7 +2096,7 @@ Configuration items related to BR backup.
+ The threshold of the backup SST file size. If the size of a backup file in a TiKV Region exceeds this threshold, the file is backed up to several files with the TiKV Region split into multiple Region ranges. Each of the files in the split Regions is the same size as `sst-max-size` (or slightly larger).
+ For example, when the size of a backup file in the Region of `[a,e)` is larger than `sst-max-size`, the file is backed up to several files with regions `[a,b)`, `[b,c)`, `[c,d)` and `[d,e)`, and the size of `[a,b)`, `[b,c)`, `[c,d)` is the same as that of `sst-max-size` (or slightly larger).
-+ Default value: `"144MB"`
++ Default value: `"144MiB"`
### `enable-auto-tune` New in v5.4.0
@@ -2139,12 +2144,13 @@ Configuration items related to log backup.
### `initial-scan-pending-memory-quota` New in v6.2.0
+ The quota of cache used for storing incremental scan data during log backup.
-+ Default value: `min(Total machine memory * 10%, 512 MB)`
++ Default value: `min(Total machine memory * 10%, 512 MiB)`
### `initial-scan-rate-limit` New in v6.2.0
+ The rate limit on throughput in an incremental data scan during log backup, which means the maximum amount of data that can be read from the disk per second. Note that if you only specify a number (for example, `60`), the unit is Byte instead of KiB.
+ Default value: 60MiB
++ Minimum value: 1MiB
### `max-flush-interval` New in v6.2.0
@@ -2174,17 +2180,17 @@ Configuration items related to TiCDC.
### `old-value-cache-memory-quota`
+ The upper limit of memory usage by TiCDC old values.
-+ Default value: `512MB`
++ Default value: `512MiB`
### `sink-memory-quota`
+ The upper limit of memory usage by TiCDC data change events.
-+ Default value: `512MB`
++ Default value: `512MiB`
### `incremental-scan-speed-limit`
+ The maximum speed at which historical data is incrementally scanned.
-+ Default value: `"128MB"`, which means 128 MB per second.
++ Default value: `"128MiB"`, which means 128 MiB per second.
### `incremental-scan-threads`
@@ -2268,14 +2274,14 @@ Suppose that your machine on which TiKV is deployed has limited resources, for e
#### `foreground-write-bandwidth` New in v6.0.0
+ The soft limit on the bandwidth with which transactions write data.
-+ Default value: `0KB` (which means no limit)
-+ Recommended setting: Use the default value `0` in most cases unless the `foreground-cpu-time` setting is not enough to limit the write bandwidth. For such an exception, it is recommended to set the value smaller than `50MB` in the instance with 4 or less cores.
++ Default value: `0KiB` (which means no limit)
++ Recommended setting: Use the default value `0` in most cases unless the `foreground-cpu-time` setting is not enough to limit the write bandwidth. For such an exception, it is recommended to set the value smaller than `50MiB` in the instance with 4 or less cores.
#### `foreground-read-bandwidth` New in v6.0.0
+ The soft limit on the bandwidth with which transactions and the Coprocessor read data.
-+ Default value: `0KB` (which means no limit)
-+ Recommended setting: Use the default value `0` in most cases unless the `foreground-cpu-time` setting is not enough to limit the read bandwidth. For such an exception, it is recommended to set the value smaller than `20MB` in the instance with 4 or less cores.
++ Default value: `0KiB` (which means no limit)
++ Recommended setting: Use the default value `0` in most cases unless the `foreground-cpu-time` setting is not enough to limit the read bandwidth. For such an exception, it is recommended to set the value smaller than `20MiB` in the instance with 4 or less cores.
### Background Quota Limiter
@@ -2301,7 +2307,7 @@ Suppose that your machine on which TiKV is deployed has limited resources, for e
> This configuration item is returned in the result of `SHOW CONFIG`, but currently setting it does not take any effect.
+ The soft limit on the bandwidth with which background transactions write data.
-+ Default value: `0KB` (which means no limit)
++ Default value: `0KiB` (which means no limit)
#### `background-read-bandwidth` New in v6.2.0
@@ -2310,7 +2316,7 @@ Suppose that your machine on which TiKV is deployed has limited resources, for e
> This configuration item is returned in the result of `SHOW CONFIG`, but currently setting it does not take any effect.
+ The soft limit on the bandwidth with which background transactions and the Coprocessor read data.
-+ Default value: `0KB` (which means no limit)
++ Default value: `0KiB` (which means no limit)
#### `enable-auto-tune` New in v6.2.0
@@ -2374,24 +2380,24 @@ Configuration items related to [Load Base Split](/configure-load-base-split.md).
+ Controls the traffic threshold at which a Region is identified as a hotspot.
+ Default value:
- + `30MiB` per second when [`region-split-size`](#region-split-size) is less than 4 GB.
- + `100MiB` per second when [`region-split-size`](#region-split-size) is greater than or equal to 4 GB.
+ + `30MiB` per second when [`region-split-size`](#region-split-size) is less than 4 GiB.
+ + `100MiB` per second when [`region-split-size`](#region-split-size) is greater than or equal to 4 GiB.
### `qps-threshold`
+ Controls the QPS threshold at which a Region is identified as a hotspot.
+ Default value:
- + `3000` when [`region-split-size`](#region-split-size) is less than 4 GB.
- + `7000` when [`region-split-size`](#region-split-size) is greater than or equal to 4 GB.
+ + `3000` when [`region-split-size`](#region-split-size) is less than 4 GiB.
+ + `7000` when [`region-split-size`](#region-split-size) is greater than or equal to 4 GiB.
### `region-cpu-overload-threshold-ratio` New in v6.2.0
+ Controls the CPU usage threshold at which a Region is identified as a hotspot.
+ Default value:
- + `0.25` when [`region-split-size`](#region-split-size) is less than 4 GB.
- + `0.75` when [`region-split-size`](#region-split-size) is greater than or equal to 4 GB.
+ + `0.25` when [`region-split-size`](#region-split-size) is less than 4 GiB.
+ + `0.75` when [`region-split-size`](#region-split-size) is greater than or equal to 4 GiB.
## memory New in v7.5.0
@@ -2403,4 +2409,4 @@ Configuration items related to [Load Base Split](/configure-load-base-split.md).
### `profiling-sample-per-bytes` New in v7.5.0
+ Specifies the amount of data sampled by Heap Profiling each time, rounding up to the nearest power of 2.
-+ Default value: `512KB`
++ Default value: `512KiB`
diff --git a/tiproxy/tiproxy-grafana.md b/tiproxy/tiproxy-grafana.md
index 0d77836e7d694..8339349dfe150 100644
--- a/tiproxy/tiproxy-grafana.md
+++ b/tiproxy/tiproxy-grafana.md
@@ -47,6 +47,7 @@ TiProxy has four panel groups. The metrics on these panels indicate the current
- CPS by Instance: command per second of each TiProxy instance
- CPS by Backend: command per second of each TiDB instance
- CPS by CMD: command per second grouped by SQL command type
+- Handshake Duration: average, P95, and P99 duration of the handshake phase between the client and TiProxy
## Balance
@@ -59,3 +60,10 @@ TiProxy has four panel groups. The metrics on these panels indicate the current
- Get Backend Duration: the average, p95, p99 duration of TiProxy connecting to a TiDB instance
- Ping Backend Duration: the network latency between each TiProxy instance and each TiProxy instance. For example, `10.24.31.1:6000 | 10.24.31.2:4000` indicates the network latency between TiProxy instance `10.24.31.1:6000` and TiDB instance `10.24.31.2:4000`
- Health Check Cycle: the duration of a cycle of the health check between a TiProxy instance and all TiDB instances. For example, `10.24.31.1:6000` indicates the duration of the latest health check that TiProxy instance `10.24.31.1:6000` executes on all the TiDB instances. If this duration is higher than 3 seconds, TiProxy may not be timely to refresh the backend TiDB list
+
+## Traffic
+
+- Bytes/Second from Backends: the amount of data, in bytes, sent from each TiDB instance to each TiProxy instance per second.
+- Packets/Second from Backends: the number of MySQL packets sent from each TiDB instance to each TiProxy instance per second.
+- Bytes/Second to Backends: the amount of data, in bytes, sent from each TiProxy instance to each TiDB instance per second.
+- Packets/Second to Backends: the number of MySQL packets sent from each TiProxy instance to each TiDB instance per second.
diff --git a/tiproxy/tiproxy-overview.md b/tiproxy/tiproxy-overview.md
index c67f44c6798a9..32eda9fb4040f 100644
--- a/tiproxy/tiproxy-overview.md
+++ b/tiproxy/tiproxy-overview.md
@@ -11,7 +11,7 @@ TiProxy is an optional component. You can also use a third-party proxy component
The following figure shows the architecture of TiProxy:
-
+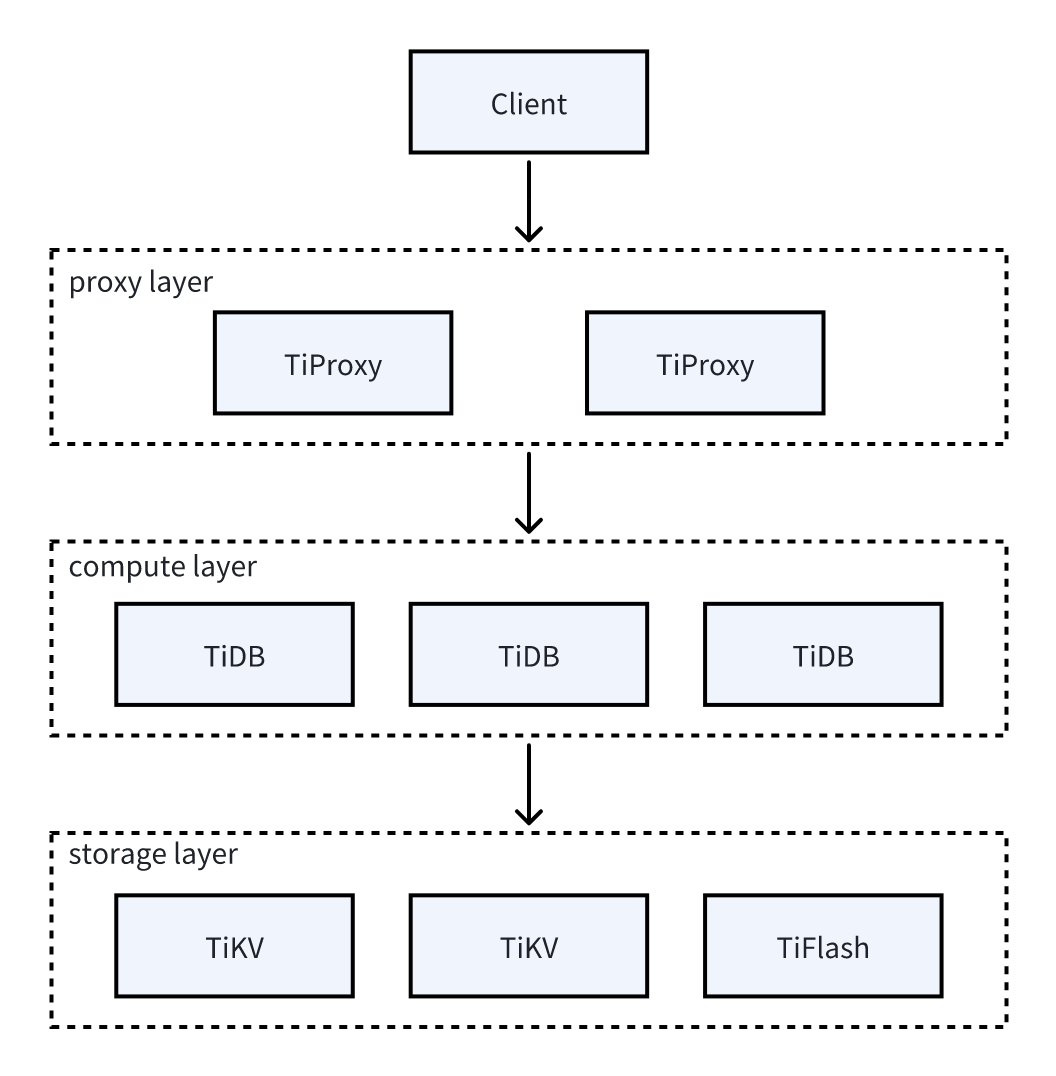 ## Main features
@@ -23,7 +23,7 @@ TiProxy can migrate connections from one TiDB server to another without breaking
As shown in the following figure, the client originally connects to TiDB 1 through TiProxy. After the connection migration, the client actually connects to TiDB 2. When TiDB 1 is about to be offline or the ratio of connections on TiDB 1 to connections on TiDB 2 exceeds the set threshold, the connection migration is triggered. The client is unaware of the connection migration.
-
+
## Main features
@@ -23,7 +23,7 @@ TiProxy can migrate connections from one TiDB server to another without breaking
As shown in the following figure, the client originally connects to TiDB 1 through TiProxy. After the connection migration, the client actually connects to TiDB 2. When TiDB 1 is about to be offline or the ratio of connections on TiDB 1 to connections on TiDB 2 exceeds the set threshold, the connection migration is triggered. The client is unaware of the connection migration.
-
+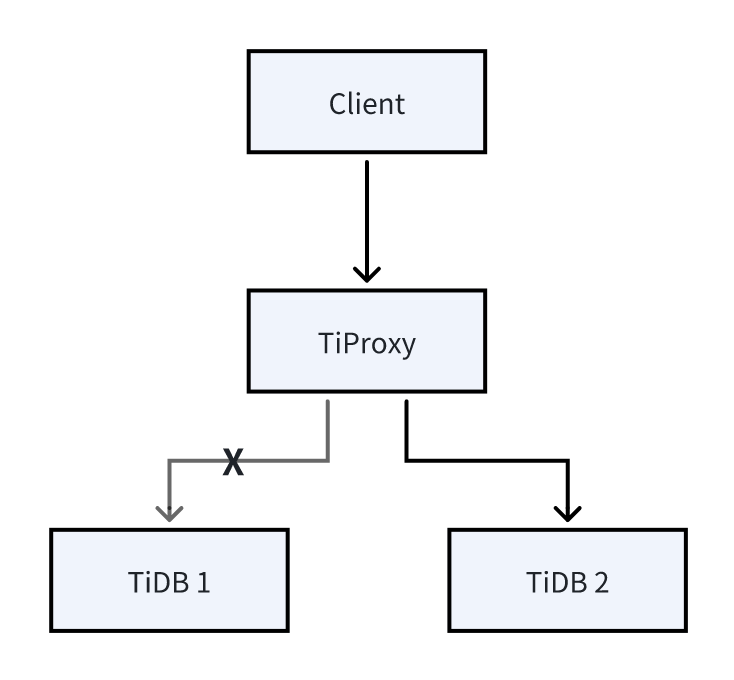 Connection migration usually occurs in the following scenarios:
@@ -59,7 +59,7 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
### Deploy TiProxy
-1. Generate a self-signed certificate.
+1. Before TiUP v1.15.0, you need to manually generate a self-signed certificate.
Generate a self-signed certificate for the TiDB instance and place the certificate on all TiDB instances to ensure that all TiDB instances have the same certificate. For detailed steps, see [Generate self-signed certificates](/generate-self-signed-certificates.md).
@@ -67,8 +67,8 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
When using TiProxy, you also need to configure the following items for the TiDB instances:
- - Configure the [`security.session-token-signing-cert`](/tidb-configuration-file.md#session-token-signing-cert-new-in-v640) and [`security.session-token-signing-key`](/tidb-configuration-file.md#session-token-signing-key-new-in-v640) of TiDB instances to the path of the certificate. Otherwise, the connection cannot be migrated.
- - Configure the [`graceful-wait-before-shutdown`](/tidb-configuration-file.md#graceful-wait-before-shutdown-new-in-v50) of TiDB instances to a value greater than the longest transaction duration of the application. Otherwise, the client might disconnect when the TiDB server is offline. For details, see [TiProxy usage limitations](#limitations).
+ - Before TiUP v1.15.0, configure the [`security.session-token-signing-cert`](/tidb-configuration-file.md#session-token-signing-cert-new-in-v640) and [`security.session-token-signing-key`](/tidb-configuration-file.md#session-token-signing-key-new-in-v640) of TiDB instances to the path of the certificate. Otherwise, the connection cannot be migrated.
+ - Configure the [`graceful-wait-before-shutdown`](/tidb-configuration-file.md#graceful-wait-before-shutdown-new-in-v50) of TiDB instances to a value greater than the longest transaction duration of the application. Otherwise, the client might disconnect when the TiDB server is offline. You can view the transaction duration through the [Transaction metrics on the TiDB monitoring dashboard](/grafana-tidb-dashboard.md#transaction). For details, see [TiProxy usage limitations](#limitations).
A configuration example is as follows:
@@ -100,7 +100,7 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
```yaml
component_versions:
- tiproxy: "v0.2.0"
+ tiproxy: "v1.0.0"
server_configs:
tiproxy:
security.server-tls.ca: "/var/ssl/ca.pem"
@@ -202,3 +202,8 @@ The following table lists some supported connectors:
| Python | PyMySQL | 0.7 |
Note that some connectors call the common library to connect to the database, and these connectors are not listed in the table. You can refer to the above table for the required version of the corresponding library. For example, MySQL/Ruby uses libmysqlclient to connect to the database, so it requires that the libmysqlclient used by MySQL/Ruby is version 5.5.7 or later.
+
+## TiProxy resources
+
+- [TiProxy Release Notes](https://github.com/pingcap/tiproxy/releases)
+- [TiProxy Issues](https://github.com/pingcap/tiup/issues): Lists TiProxy GitHub issues
diff --git a/tiproxy/tiproxy-performance-test.md b/tiproxy/tiproxy-performance-test.md
index 90b3c648cfee3..7cc0992afd228 100644
--- a/tiproxy/tiproxy-performance-test.md
+++ b/tiproxy/tiproxy-performance-test.md
@@ -9,33 +9,34 @@ This report tests the performance of TiProxy in the OLTP scenario of Sysbench an
The results are as follows:
-- The QPS upper limit of TiProxy is affected by the type of workload. Under the basic workloads of Sysbench and the same CPU usage, the QPS of TiProxy is about 20% to 40% lower than that of HAProxy.
-- The number of TiDB server instances that TiProxy can hold varies according to the type of workload. Under the basic workloads of Sysbench, a TiProxy can hold 4 to 10 TiDB server instances of the same model.
-- The performance of TiProxy is more affected by the number of vCPUs, compared to HAProxy. When the returned data is 10,000 rows and the CPU usage is the same, the QPS of TiProxy is about 30% lower than that of HAProxy.
+- The QPS upper limit of TiProxy is affected by the type of workload. Under the basic workloads of Sysbench and the same CPU usage, the QPS of TiProxy is about 25% lower than that of HAProxy.
+- The number of TiDB server instances that TiProxy can hold varies according to the type of workload. Under the basic workloads of Sysbench, a TiProxy can hold 5 to 12 TiDB server instances of the same model.
+- The row number of the query result set has a significant impact on the QPS of TiProxy, and the impact is the same as that of HAProxy.
- The performance of TiProxy increases almost linearly with the number of vCPUs. Therefore, increasing the number of vCPUs can effectively improve the QPS upper limit.
+- The number of long connections and the frequency of creating short connections have minimal impact on the QPS of TiProxy.
## Test environment
### Hardware configuration
-| Service | Machine Type | CPU Architecture | Instance Count |
+| Service | Machine type | CPU model | Instance count |
| --- | --- | --- | --- |
-| TiProxy | 4C8G | AMD64 | 1 |
-| HAProxy | 4C8G | AMD64 | 1 |
-| PD | 4C8G | AMD64 | 3 |
-| TiDB | 8C16G | AMD64 | 8 |
-| TiKV | 8C16G | AMD64 | 8 |
-| Sysbench | 8C16G | AMD64 | 1 |
+| TiProxy | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
+| HAProxy | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
+| PD | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 3 |
+| TiDB | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 8 |
+| TiKV | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 8 |
+| Sysbench | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
### Software
| Service | Software version |
| --- | --- |
-| TiProxy | v0.2.0 |
+| TiProxy | v1.0.0 |
| HAProxy | 2.9.0 |
-| PD | v7.6.0 |
-| TiDB | v7.6.0 |
-| TiKV | v7.6.0 |
+| PD | v8.0.0 |
+| TiDB | v8.0.0 |
+| TiKV | v8.0.0 |
| Sysbench | 1.0.17 |
### Configuration
@@ -102,73 +103,73 @@ sysbench $testname \
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 20 | 43935 | 0.45 | 0.63 | 210% | 900% |
-| 50 | 87870 | 0.57 | 0.77 | 350% | 1700% |
-| 100 | 91611 | 1.09 | 1.79 | 400% | 1800% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 20 | 41273 | 0.48 | 0.64 | 190% | 900% |
+| 50 | 100255 | 0.50 | 0.62 | 330% | 1900% |
+| 100 | 137688 | 0.73 | 1.01 | 400% | 2600% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 20 | 43629 | 0.46 | 0.63 | 130% | 900% |
-| 50 | 102934 | 0.49 | 0.61 | 320% | 2000% |
-| 100 | 157880 | 0.63 | 0.81 | 400% | 3000% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 20 | 44833 | 0.45 | 0.61 | 140% | 1000% |
+| 50 | 103631 | 0.48 | 0.61 | 270% | 2100% |
+| 100 | 163069 | 0.61 | 0.77 | 360% | 3100% |
### Read Only
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 71816 | 11.14 | 12.98 | 340% | 2500% |
-| 100 | 79299 | 20.17 | 23.95 | 400% | 2800% |
-| 200 | 83371 | 38.37 | 46.63 | 400% | 2900% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 50 | 72076 | 11.09 | 12.75 | 290% | 2500% |
+| 100 | 109704 | 14.58 | 17.63 | 370% | 3800% |
+| 200 | 117519 | 27.21 | 32.53 | 400% | 4100% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 74945 | 10.67 | 12.08 | 250% | 2500% |
-| 100 | 118526 | 13.49 | 18.28 | 350% | 4000% |
-| 200 | 131102 | 24.39 | 34.33 | 390% | 4300% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 50 | 75760 | 10.56 | 12.08 | 250% | 2600% |
+| 100 | 121730 | 13.14 | 15.83 | 350% | 4200% |
+| 200 | 131712 | 24.27 | 30.26 | 370% | 4500% |
### Write Only
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 100 | 67762 | 8.85 | 15.27 | 310% | 3200% |
-| 300 | 81113 | 22.18 | 38.25 | 390% | 3900% |
-| 500 | 79260 | 37.83 | 56.84 | 400% | 3800% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 100 | 81957 | 7.32 | 10.27 | 290% | 3900% |
+| 300 | 103040 | 17.45 | 31.37 | 330% | 4700% |
+| 500 | 104869 | 28.59 | 52.89 | 340% | 4800% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 100 | 74501 | 8.05 | 12.30 | 220% | 3500% |
-| 300 | 97942 | 18.36 | 31.94 | 280% | 4300% |
-| 500 | 105352 | 28.44 | 49.21 | 300% | 4500% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 100 | 81708 | 7.34 | 10.65 | 240% | 3700% |
+| 300 | 106008 | 16.95 | 31.37 | 320% | 4800% |
+| 500 | 122369 | 24.45 | 47.47 | 350% | 5300% |
### Read Write
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 60170 | 16.62 | 18.95 | 280% | 2700% |
-| 100 | 81691 | 24.48 | 31.37 | 340% | 3600% |
-| 200 | 88755 | 45.05 | 54.83 | 400% | 4000% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 50 | 58571 | 17.07 | 19.65 | 250% | 2600% |
+| 100 | 88432 | 22.60 | 29.19 | 330% | 3900% |
+| 200 | 108758 | 36.73 | 51.94 | 380% | 4800% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 58151 | 17.19 | 20.37 | 240% | 2600% |
-| 100 | 94123 | 21.24 | 26.68 | 370% | 4100% |
-| 200 | 107423 | 37.21 | 45.79 | 400% | 4700% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 50 | 61226 | 16.33 | 19.65 | 190% | 2800% |
+| 100 | 96569 | 20.70 | 26.68 | 290% | 4100% |
+| 200 | 120163 | 31.28 | 49.21 | 340% | 5200% |
## Result set test
@@ -202,21 +203,21 @@ sysbench oltp_read_only \
TiProxy test results:
-| Range Size | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage | Inbound Network (MiB/s) | Outbound Network (MiB/s) |
-| --- | --- | --- | --- | --- | --- | --- | --- |
-| 10 | 92100 | 1.09 | 1.34 | 330% | 3700% | 150 | 150 |
-| 100 | 57931 | 1.73 | 2.30 | 370% | 2800% | 840 | 840 |
-| 1000 | 8249 | 12.12 | 18.95 | 250% | 1300% | 1140 | 1140 |
-| 10000 | 826 | 120.77 | 363.18 | 230% | 600% | 1140 | 1140 |
+| Range size | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage | Inbound network (MiB/s) | Outbound network (MiB/s) |
+|------------|---------|------------------|------------------|-------------------|------------------------|-------------------------|--------------------------|
+| 10 | 80157 | 1.25 | 1.61 | 340% | 2600% | 140 | 140 |
+| 100 | 55936 | 1.79 | 2.43 | 370% | 2800% | 820 | 820 |
+| 1000 | 10313 | 9.69 | 13.70 | 310% | 1500% | 1370 | 1370 |
+| 10000 | 1064 | 93.88 | 142.39 | 250% | 600% | 1430 | 1430 |
HAProxy test results:
-| Range Size | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage | Inbound Network (MiB/s) | Outbound Network (MiB/s) |
-| --- | --- | --- | --- | --- | --- | --- | --- |
-| 10 | 93202 | 1.07 | 1.30 | 330% | 3800% | 145 | 145 |
-| 100 | 64348 | 1.55 | 1.86 | 350% | 3100% | 830 | 830 |
-| 1000 | 8944 | 11.18 | 14.73 | 240% | 1400% | 1100 | 1100 |
-| 10000 | 908 | 109.96 | 139.85 | 180% | 600% | 1130 | 1130 |
+| Range size | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage | Inbound network (MiB/s) | Outbound network (MiB/s) |
+|------------|--------|------------------|------------------|-------------------|------------------------|-------------------------|--------------------------|
+| 10 | 94376 | 1.06 | 1.30 | 250% | 4000% | 150 | 150 |
+| 100 | 70129 | 1.42 | 1.76 | 270% | 3300% | 890 | 890 |
+| 1000 | 9501 | 11.18 | 14.73 | 240% | 1500% | 1180 | 1180 |
+| 10000 | 955 | 104.61 | 320.17 | 180% | 1200% | 1200 | 1200 |
## Scalability test
@@ -241,9 +242,73 @@ sysbench oltp_point_select \
### Test results
-| vCPU | Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- | --- |
-| 2 | 40 | 58508 | 0.68 | 0.97 | 190% | 1200% |
-| 4 | 80 | 104890 | 0.76 | 1.16 | 390% | 2000% |
-| 6 | 120 | 155520 | 0.77 | 1.14 | 590% | 2900% |
-| 8 | 160 | 202134 | 0.79 | 1.18 | 800% | 3900% |
+| vCPU | Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|------|---------|---------|------------------|------------------|-------------------|------------------------|
+| 2 | 40 | 58508 | 0.68 | 0.97 | 190% | 1200% |
+| 4 | 80 | 104890 | 0.76 | 1.16 | 390% | 2000% |
+| 6 | 120 | 155520 | 0.77 | 1.14 | 590% | 2900% |
+| 8 | 160 | 202134 | 0.79 | 1.18 | 800% | 3900% |
+
+## Long connection test
+
+### Test plan
+
+This test aims to verify that a large number of idle connections have minimal impact on the QPS when the client uses long connections. This test creates 5000, 10000, and 15000 idle long connections, and then executes `sysbench`.
+
+This test uses the default value for the `conn-buffer-size` configuration:
+
+```yaml
+proxy.conn-buffer-size: 32768
+```
+
+Use the following command to perform the test:
+
+```bash
+sysbench oltp_point_select \
+ --threads=50 \
+ --time=1200 \
+ --report-interval=10 \
+ --rand-type=uniform \
+ --db-driver=mysql \
+ --mysql-db=sbtest \
+ --mysql-host=$host \
+ --mysql-port=$port \
+ run --tables=32 --table-size=1000000
+```
+
+### Test results
+
+| Connection count | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiProxy memory usage (MB) | TiDB overall CPU usage |
+|------------------|-------|------------------|------------------|-------------------|---------------------------|------------------------|
+| 5000 | 96620 | 0.52 | 0.64 | 330% | 920 | 1800% |
+| 10000 | 96143 | 0.52 | 0.65 | 330% | 1710 | 1800% |
+| 15000 | 96048 | 0.52 | 0.65 | 330% | 2570 | 1900% |
+
+## Short connection test
+
+### Test plan
+
+This test aims to verify that frequent creation and destruction of connections have minimal impact on the QPS when the client uses short connections. This test starts another client program to create and disconnect 100, 200, and 300 short connections per second while executing `sysbench`.
+
+Use the following command to perform the test:
+
+```bash
+sysbench oltp_point_select \
+ --threads=50 \
+ --time=1200 \
+ --report-interval=10 \
+ --rand-type=uniform \
+ --db-driver=mysql \
+ --mysql-db=sbtest \
+ --mysql-host=$host \
+ --mysql-port=$port \
+ run --tables=32 --table-size=1000000
+```
+
+### Test results
+
+| New connections per second | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|----------------------------|--------|------------------|------------------|-------------------|------------------------|
+| 100 | 95597 | 0.52 | 0.65 | 330% | 1800% |
+| 200 | 94692 | 0.53 | 0.67 | 330% | 1800% |
+| 300 | 94102 | 0.53 | 0.68 | 330% | 1900% |
diff --git a/tiup/tiup-playground.md b/tiup/tiup-playground.md
index 4ae07c8131ffc..314c07bde839b 100644
--- a/tiup/tiup-playground.md
+++ b/tiup/tiup-playground.md
@@ -172,3 +172,16 @@ You can specify a `pid` in the `tiup playground scale-in` command to scale in th
```shell
tiup playground scale-in --pid 86526
```
+
+## Deploy PD microservices
+
+Starting from v8.0.0, PD supports the [microservice mode](/pd-microservices.md) (experimental). You can deploy the `tso` microservice and `scheduling` microservice for your cluster using TiUP Playground as follows:
+
+```shell
+./tiup-playground v8.0.0 --pd.mode ms --pd.api 3 --pd.tso 2 --pd.scheduling 3
+```
+
+- `--pd.mode`: setting it to `ms` means enabling the microservice mode for PD.
+- `--pd.api num`: specifies the number of APIs for PD microservices. It must be at least `1`.
+- `--pd.tso num`: specifies the number of instances to be deployed for the `tso` microservice.
+- `--pd.scheduling num`: specifies the number of instances to be deployed for the `scheduling` microservice.
\ No newline at end of file
diff --git a/troubleshoot-lock-conflicts.md b/troubleshoot-lock-conflicts.md
index 7e6a978d0ca74..fc1399896168c 100644
--- a/troubleshoot-lock-conflicts.md
+++ b/troubleshoot-lock-conflicts.md
@@ -86,13 +86,14 @@ For example, to filter transactions with a long lock-waiting time using the `whe
{{< copyable "sql" >}}
```sql
-select trx.* from information_schema.data_lock_waits as l left join information_schema.tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
+select trx.* from information_schema.data_lock_waits as l left join information_schema.cluster_tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
```
The following is an example output:
```sql
*************************** 1. row ***************************
+ INSTANCE: 127.0.0.1:10080
ID: 426831815660273668
START_TIME: 2021-08-06 07:16:00.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
@@ -106,6 +107,7 @@ CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
*************************** 2. row ***************************
+ INSTANCE: 127.0.0.1:10080
ID: 426831818019569665
START_TIME: 2021-08-06 07:16:09.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
diff --git a/tune-tikv-thread-performance.md b/tune-tikv-thread-performance.md
index 43a6b4ef98fc1..36dfc3dd5ce5a 100644
--- a/tune-tikv-thread-performance.md
+++ b/tune-tikv-thread-performance.md
@@ -61,7 +61,7 @@ Starting from TiKV v5.0, all read requests use the unified thread pool for queri
* The Raftstore thread pool.
- The Raftstore thread pool is the most complex thread pool in TiKV. The default size (configured by `raftstore.store-pool-size`) of this thread pool is `2`. For the StoreWriter thread pool, the default size (configured by `raftstore.store-io-pool-size`) is `0`.
+ The Raftstore thread pool is the most complex thread pool in TiKV. The default size (configured by `raftstore.store-pool-size`) of this thread pool is `2`. For the StoreWriter thread pool, the default size (configured by `raftstore.store-io-pool-size`) is `1`.
- When the size of the StoreWriter thread pool is 0, all write requests are written into RocksDB in the way of `fsync` by the Raftstore thread. In this case, it is recommended to tune the performance as follows:
diff --git a/upgrade-tidb-using-tiup.md b/upgrade-tidb-using-tiup.md
index 9b0ce992c17e7..7bdb7fbce7205 100644
--- a/upgrade-tidb-using-tiup.md
+++ b/upgrade-tidb-using-tiup.md
@@ -26,6 +26,31 @@ This document is targeted for the following upgrade paths:
> - If your cluster to be upgraded is v3.1 or an earlier version (v3.0 or v2.1), the direct upgrade to v7.6.0 is not supported. You need to upgrade your cluster first to v4.0 and then to v7.6.0.
> - If your cluster to be upgraded is earlier than v6.2, the upgrade might get stuck when you upgrade the cluster to v6.2 or later versions in some scenarios. You can refer to [How to fix the issue](#how-to-fix-the-issue-that-the-upgrade-gets-stuck-when-upgrading-to-v620-or-later-versions).
> - TiDB nodes use the value of the [`server-version`](/tidb-configuration-file.md#server-version) configuration item to verify the current TiDB version. Therefore, to avoid unexpected behaviors, before upgrading the TiDB cluster, you need to set the value of `server-version` to empty or the real version of the current TiDB cluster.
+> - Setting the [`performance.force-init-stats`](/tidb-configuration-file.md#force-init-stats-new-in-v657-and-v710) configuration item to `ON` prolongs the TiDB startup time, which might cause startup timeouts and upgrade failures. To avoid this issue, it is recommended to set a longer waiting timeout for TiUP.
+> - Scenarios that might be affected:
+> - The original cluster version is earlier than v6.5.7 and v7.1.0 (which does not support `performance.force-init-stats` yet), and the target version is v7.2.0 or later.
+> - The original cluster version is equal to or later than v6.5.7 and v7.1.0, and the `performance.force-init-stats` configuration item is set to `ON`.
+>
+> - Check the value of the `performance.force-init-stats` configuration item:
+>
+> ```
+> SHOW CONFIG WHERE type = 'tidb' AND name = 'performance.force-init-stats';
+> ```
+>
+> - You can increase the TiUP waiting timeout by adding the command-line option [`--wait-timeout`](/tiup/tiup-component-cluster.md#--wait-timeout). For example, execute the following command to set the waiting timeout to 1200 seconds (20 minutes).
+>
+> ```shell
+> tiup update cluster --wait-timeout 1200 [other options]
+> ```
+>
+> Generally, a 20-minute waiting timeout is sufficient for most scenarios. For a more precise estimate, search for `init stats info time` in the TiDB log to get the statistics loading time during the previous startup as a reference. For example:
+>
+> ```
+> [domain.go:2271] ["init stats info time"] [lite=true] ["take time"=2.151333ms]
+> ```
+>
+> If the original cluster is v7.1.0 or earlier, when upgrading to v7.2.0 or later, because of the introduction of [`performance.lite-init-stats`](/tidb-configuration-file.md#lite-init-stats-new-in-v710), the statistics loading time is greatly reduced. In this case, the `init stats info time` before the upgrade is longer than the loading time after the upgrade.
+> - If you want to shorten the rolling upgrade duration of TiDB and the potential performance impact of missing initial statistical information during the upgrade is acceptable for your cluster, you can set `performance.force-init-stats` to `OFF` before the upgrade by [modifying the configuration of the target instance with TiUP](/maintain-tidb-using-tiup.md#modify-the-configuration). After the upgrade is completed, you can reassess and revert this setting if necessary.
## Upgrade caveat
Connection migration usually occurs in the following scenarios:
@@ -59,7 +59,7 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
### Deploy TiProxy
-1. Generate a self-signed certificate.
+1. Before TiUP v1.15.0, you need to manually generate a self-signed certificate.
Generate a self-signed certificate for the TiDB instance and place the certificate on all TiDB instances to ensure that all TiDB instances have the same certificate. For detailed steps, see [Generate self-signed certificates](/generate-self-signed-certificates.md).
@@ -67,8 +67,8 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
When using TiProxy, you also need to configure the following items for the TiDB instances:
- - Configure the [`security.session-token-signing-cert`](/tidb-configuration-file.md#session-token-signing-cert-new-in-v640) and [`security.session-token-signing-key`](/tidb-configuration-file.md#session-token-signing-key-new-in-v640) of TiDB instances to the path of the certificate. Otherwise, the connection cannot be migrated.
- - Configure the [`graceful-wait-before-shutdown`](/tidb-configuration-file.md#graceful-wait-before-shutdown-new-in-v50) of TiDB instances to a value greater than the longest transaction duration of the application. Otherwise, the client might disconnect when the TiDB server is offline. For details, see [TiProxy usage limitations](#limitations).
+ - Before TiUP v1.15.0, configure the [`security.session-token-signing-cert`](/tidb-configuration-file.md#session-token-signing-cert-new-in-v640) and [`security.session-token-signing-key`](/tidb-configuration-file.md#session-token-signing-key-new-in-v640) of TiDB instances to the path of the certificate. Otherwise, the connection cannot be migrated.
+ - Configure the [`graceful-wait-before-shutdown`](/tidb-configuration-file.md#graceful-wait-before-shutdown-new-in-v50) of TiDB instances to a value greater than the longest transaction duration of the application. Otherwise, the client might disconnect when the TiDB server is offline. You can view the transaction duration through the [Transaction metrics on the TiDB monitoring dashboard](/grafana-tidb-dashboard.md#transaction). For details, see [TiProxy usage limitations](#limitations).
A configuration example is as follows:
@@ -100,7 +100,7 @@ This section describes how to deploy and change TiProxy using TiUP. For how to d
```yaml
component_versions:
- tiproxy: "v0.2.0"
+ tiproxy: "v1.0.0"
server_configs:
tiproxy:
security.server-tls.ca: "/var/ssl/ca.pem"
@@ -202,3 +202,8 @@ The following table lists some supported connectors:
| Python | PyMySQL | 0.7 |
Note that some connectors call the common library to connect to the database, and these connectors are not listed in the table. You can refer to the above table for the required version of the corresponding library. For example, MySQL/Ruby uses libmysqlclient to connect to the database, so it requires that the libmysqlclient used by MySQL/Ruby is version 5.5.7 or later.
+
+## TiProxy resources
+
+- [TiProxy Release Notes](https://github.com/pingcap/tiproxy/releases)
+- [TiProxy Issues](https://github.com/pingcap/tiup/issues): Lists TiProxy GitHub issues
diff --git a/tiproxy/tiproxy-performance-test.md b/tiproxy/tiproxy-performance-test.md
index 90b3c648cfee3..7cc0992afd228 100644
--- a/tiproxy/tiproxy-performance-test.md
+++ b/tiproxy/tiproxy-performance-test.md
@@ -9,33 +9,34 @@ This report tests the performance of TiProxy in the OLTP scenario of Sysbench an
The results are as follows:
-- The QPS upper limit of TiProxy is affected by the type of workload. Under the basic workloads of Sysbench and the same CPU usage, the QPS of TiProxy is about 20% to 40% lower than that of HAProxy.
-- The number of TiDB server instances that TiProxy can hold varies according to the type of workload. Under the basic workloads of Sysbench, a TiProxy can hold 4 to 10 TiDB server instances of the same model.
-- The performance of TiProxy is more affected by the number of vCPUs, compared to HAProxy. When the returned data is 10,000 rows and the CPU usage is the same, the QPS of TiProxy is about 30% lower than that of HAProxy.
+- The QPS upper limit of TiProxy is affected by the type of workload. Under the basic workloads of Sysbench and the same CPU usage, the QPS of TiProxy is about 25% lower than that of HAProxy.
+- The number of TiDB server instances that TiProxy can hold varies according to the type of workload. Under the basic workloads of Sysbench, a TiProxy can hold 5 to 12 TiDB server instances of the same model.
+- The row number of the query result set has a significant impact on the QPS of TiProxy, and the impact is the same as that of HAProxy.
- The performance of TiProxy increases almost linearly with the number of vCPUs. Therefore, increasing the number of vCPUs can effectively improve the QPS upper limit.
+- The number of long connections and the frequency of creating short connections have minimal impact on the QPS of TiProxy.
## Test environment
### Hardware configuration
-| Service | Machine Type | CPU Architecture | Instance Count |
+| Service | Machine type | CPU model | Instance count |
| --- | --- | --- | --- |
-| TiProxy | 4C8G | AMD64 | 1 |
-| HAProxy | 4C8G | AMD64 | 1 |
-| PD | 4C8G | AMD64 | 3 |
-| TiDB | 8C16G | AMD64 | 8 |
-| TiKV | 8C16G | AMD64 | 8 |
-| Sysbench | 8C16G | AMD64 | 1 |
+| TiProxy | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
+| HAProxy | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
+| PD | 4C8G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 3 |
+| TiDB | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 8 |
+| TiKV | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 8 |
+| Sysbench | 8C16G | Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz | 1 |
### Software
| Service | Software version |
| --- | --- |
-| TiProxy | v0.2.0 |
+| TiProxy | v1.0.0 |
| HAProxy | 2.9.0 |
-| PD | v7.6.0 |
-| TiDB | v7.6.0 |
-| TiKV | v7.6.0 |
+| PD | v8.0.0 |
+| TiDB | v8.0.0 |
+| TiKV | v8.0.0 |
| Sysbench | 1.0.17 |
### Configuration
@@ -102,73 +103,73 @@ sysbench $testname \
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 20 | 43935 | 0.45 | 0.63 | 210% | 900% |
-| 50 | 87870 | 0.57 | 0.77 | 350% | 1700% |
-| 100 | 91611 | 1.09 | 1.79 | 400% | 1800% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 20 | 41273 | 0.48 | 0.64 | 190% | 900% |
+| 50 | 100255 | 0.50 | 0.62 | 330% | 1900% |
+| 100 | 137688 | 0.73 | 1.01 | 400% | 2600% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 20 | 43629 | 0.46 | 0.63 | 130% | 900% |
-| 50 | 102934 | 0.49 | 0.61 | 320% | 2000% |
-| 100 | 157880 | 0.63 | 0.81 | 400% | 3000% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 20 | 44833 | 0.45 | 0.61 | 140% | 1000% |
+| 50 | 103631 | 0.48 | 0.61 | 270% | 2100% |
+| 100 | 163069 | 0.61 | 0.77 | 360% | 3100% |
### Read Only
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 71816 | 11.14 | 12.98 | 340% | 2500% |
-| 100 | 79299 | 20.17 | 23.95 | 400% | 2800% |
-| 200 | 83371 | 38.37 | 46.63 | 400% | 2900% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 50 | 72076 | 11.09 | 12.75 | 290% | 2500% |
+| 100 | 109704 | 14.58 | 17.63 | 370% | 3800% |
+| 200 | 117519 | 27.21 | 32.53 | 400% | 4100% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 74945 | 10.67 | 12.08 | 250% | 2500% |
-| 100 | 118526 | 13.49 | 18.28 | 350% | 4000% |
-| 200 | 131102 | 24.39 | 34.33 | 390% | 4300% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 50 | 75760 | 10.56 | 12.08 | 250% | 2600% |
+| 100 | 121730 | 13.14 | 15.83 | 350% | 4200% |
+| 200 | 131712 | 24.27 | 30.26 | 370% | 4500% |
### Write Only
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 100 | 67762 | 8.85 | 15.27 | 310% | 3200% |
-| 300 | 81113 | 22.18 | 38.25 | 390% | 3900% |
-| 500 | 79260 | 37.83 | 56.84 | 400% | 3800% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 100 | 81957 | 7.32 | 10.27 | 290% | 3900% |
+| 300 | 103040 | 17.45 | 31.37 | 330% | 4700% |
+| 500 | 104869 | 28.59 | 52.89 | 340% | 4800% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 100 | 74501 | 8.05 | 12.30 | 220% | 3500% |
-| 300 | 97942 | 18.36 | 31.94 | 280% | 4300% |
-| 500 | 105352 | 28.44 | 49.21 | 300% | 4500% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 100 | 81708 | 7.34 | 10.65 | 240% | 3700% |
+| 300 | 106008 | 16.95 | 31.37 | 320% | 4800% |
+| 500 | 122369 | 24.45 | 47.47 | 350% | 5300% |
### Read Write
TiProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 60170 | 16.62 | 18.95 | 280% | 2700% |
-| 100 | 81691 | 24.48 | 31.37 | 340% | 3600% |
-| 200 | 88755 | 45.05 | 54.83 | 400% | 4000% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|---------|--------|------------------|------------------|-------------------|------------------------|
+| 50 | 58571 | 17.07 | 19.65 | 250% | 2600% |
+| 100 | 88432 | 22.60 | 29.19 | 330% | 3900% |
+| 200 | 108758 | 36.73 | 51.94 | 380% | 4800% |
HAProxy test results:
-| Threads | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- |
-| 50 | 58151 | 17.19 | 20.37 | 240% | 2600% |
-| 100 | 94123 | 21.24 | 26.68 | 370% | 4100% |
-| 200 | 107423 | 37.21 | 45.79 | 400% | 4700% |
+| Threads | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage |
+|---------|---------|------------------|------------------|-------------------|------------------------|
+| 50 | 61226 | 16.33 | 19.65 | 190% | 2800% |
+| 100 | 96569 | 20.70 | 26.68 | 290% | 4100% |
+| 200 | 120163 | 31.28 | 49.21 | 340% | 5200% |
## Result set test
@@ -202,21 +203,21 @@ sysbench oltp_read_only \
TiProxy test results:
-| Range Size | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage | Inbound Network (MiB/s) | Outbound Network (MiB/s) |
-| --- | --- | --- | --- | --- | --- | --- | --- |
-| 10 | 92100 | 1.09 | 1.34 | 330% | 3700% | 150 | 150 |
-| 100 | 57931 | 1.73 | 2.30 | 370% | 2800% | 840 | 840 |
-| 1000 | 8249 | 12.12 | 18.95 | 250% | 1300% | 1140 | 1140 |
-| 10000 | 826 | 120.77 | 363.18 | 230% | 600% | 1140 | 1140 |
+| Range size | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage | Inbound network (MiB/s) | Outbound network (MiB/s) |
+|------------|---------|------------------|------------------|-------------------|------------------------|-------------------------|--------------------------|
+| 10 | 80157 | 1.25 | 1.61 | 340% | 2600% | 140 | 140 |
+| 100 | 55936 | 1.79 | 2.43 | 370% | 2800% | 820 | 820 |
+| 1000 | 10313 | 9.69 | 13.70 | 310% | 1500% | 1370 | 1370 |
+| 10000 | 1064 | 93.88 | 142.39 | 250% | 600% | 1430 | 1430 |
HAProxy test results:
-| Range Size | QPS | Avg latency(ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU Usage | Inbound Network (MiB/s) | Outbound Network (MiB/s) |
-| --- | --- | --- | --- | --- | --- | --- | --- |
-| 10 | 93202 | 1.07 | 1.30 | 330% | 3800% | 145 | 145 |
-| 100 | 64348 | 1.55 | 1.86 | 350% | 3100% | 830 | 830 |
-| 1000 | 8944 | 11.18 | 14.73 | 240% | 1400% | 1100 | 1100 |
-| 10000 | 908 | 109.96 | 139.85 | 180% | 600% | 1130 | 1130 |
+| Range size | QPS | Avg latency (ms) | P95 latency (ms) | HAProxy CPU usage | TiDB overall CPU usage | Inbound network (MiB/s) | Outbound network (MiB/s) |
+|------------|--------|------------------|------------------|-------------------|------------------------|-------------------------|--------------------------|
+| 10 | 94376 | 1.06 | 1.30 | 250% | 4000% | 150 | 150 |
+| 100 | 70129 | 1.42 | 1.76 | 270% | 3300% | 890 | 890 |
+| 1000 | 9501 | 11.18 | 14.73 | 240% | 1500% | 1180 | 1180 |
+| 10000 | 955 | 104.61 | 320.17 | 180% | 1200% | 1200 | 1200 |
## Scalability test
@@ -241,9 +242,73 @@ sysbench oltp_point_select \
### Test results
-| vCPU | Threads | QPS | Avg latency(ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU Usage |
-| --- | --- | --- | --- | --- | --- | --- |
-| 2 | 40 | 58508 | 0.68 | 0.97 | 190% | 1200% |
-| 4 | 80 | 104890 | 0.76 | 1.16 | 390% | 2000% |
-| 6 | 120 | 155520 | 0.77 | 1.14 | 590% | 2900% |
-| 8 | 160 | 202134 | 0.79 | 1.18 | 800% | 3900% |
+| vCPU | Threads | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|------|---------|---------|------------------|------------------|-------------------|------------------------|
+| 2 | 40 | 58508 | 0.68 | 0.97 | 190% | 1200% |
+| 4 | 80 | 104890 | 0.76 | 1.16 | 390% | 2000% |
+| 6 | 120 | 155520 | 0.77 | 1.14 | 590% | 2900% |
+| 8 | 160 | 202134 | 0.79 | 1.18 | 800% | 3900% |
+
+## Long connection test
+
+### Test plan
+
+This test aims to verify that a large number of idle connections have minimal impact on the QPS when the client uses long connections. This test creates 5000, 10000, and 15000 idle long connections, and then executes `sysbench`.
+
+This test uses the default value for the `conn-buffer-size` configuration:
+
+```yaml
+proxy.conn-buffer-size: 32768
+```
+
+Use the following command to perform the test:
+
+```bash
+sysbench oltp_point_select \
+ --threads=50 \
+ --time=1200 \
+ --report-interval=10 \
+ --rand-type=uniform \
+ --db-driver=mysql \
+ --mysql-db=sbtest \
+ --mysql-host=$host \
+ --mysql-port=$port \
+ run --tables=32 --table-size=1000000
+```
+
+### Test results
+
+| Connection count | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiProxy memory usage (MB) | TiDB overall CPU usage |
+|------------------|-------|------------------|------------------|-------------------|---------------------------|------------------------|
+| 5000 | 96620 | 0.52 | 0.64 | 330% | 920 | 1800% |
+| 10000 | 96143 | 0.52 | 0.65 | 330% | 1710 | 1800% |
+| 15000 | 96048 | 0.52 | 0.65 | 330% | 2570 | 1900% |
+
+## Short connection test
+
+### Test plan
+
+This test aims to verify that frequent creation and destruction of connections have minimal impact on the QPS when the client uses short connections. This test starts another client program to create and disconnect 100, 200, and 300 short connections per second while executing `sysbench`.
+
+Use the following command to perform the test:
+
+```bash
+sysbench oltp_point_select \
+ --threads=50 \
+ --time=1200 \
+ --report-interval=10 \
+ --rand-type=uniform \
+ --db-driver=mysql \
+ --mysql-db=sbtest \
+ --mysql-host=$host \
+ --mysql-port=$port \
+ run --tables=32 --table-size=1000000
+```
+
+### Test results
+
+| New connections per second | QPS | Avg latency (ms) | P95 latency (ms) | TiProxy CPU usage | TiDB overall CPU usage |
+|----------------------------|--------|------------------|------------------|-------------------|------------------------|
+| 100 | 95597 | 0.52 | 0.65 | 330% | 1800% |
+| 200 | 94692 | 0.53 | 0.67 | 330% | 1800% |
+| 300 | 94102 | 0.53 | 0.68 | 330% | 1900% |
diff --git a/tiup/tiup-playground.md b/tiup/tiup-playground.md
index 4ae07c8131ffc..314c07bde839b 100644
--- a/tiup/tiup-playground.md
+++ b/tiup/tiup-playground.md
@@ -172,3 +172,16 @@ You can specify a `pid` in the `tiup playground scale-in` command to scale in th
```shell
tiup playground scale-in --pid 86526
```
+
+## Deploy PD microservices
+
+Starting from v8.0.0, PD supports the [microservice mode](/pd-microservices.md) (experimental). You can deploy the `tso` microservice and `scheduling` microservice for your cluster using TiUP Playground as follows:
+
+```shell
+./tiup-playground v8.0.0 --pd.mode ms --pd.api 3 --pd.tso 2 --pd.scheduling 3
+```
+
+- `--pd.mode`: setting it to `ms` means enabling the microservice mode for PD.
+- `--pd.api num`: specifies the number of APIs for PD microservices. It must be at least `1`.
+- `--pd.tso num`: specifies the number of instances to be deployed for the `tso` microservice.
+- `--pd.scheduling num`: specifies the number of instances to be deployed for the `scheduling` microservice.
\ No newline at end of file
diff --git a/troubleshoot-lock-conflicts.md b/troubleshoot-lock-conflicts.md
index 7e6a978d0ca74..fc1399896168c 100644
--- a/troubleshoot-lock-conflicts.md
+++ b/troubleshoot-lock-conflicts.md
@@ -86,13 +86,14 @@ For example, to filter transactions with a long lock-waiting time using the `whe
{{< copyable "sql" >}}
```sql
-select trx.* from information_schema.data_lock_waits as l left join information_schema.tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
+select trx.* from information_schema.data_lock_waits as l left join information_schema.cluster_tidb_trx as trx on l.trx_id = trx.id where l.key = "7480000000000000415F728000000000000001"\G
```
The following is an example output:
```sql
*************************** 1. row ***************************
+ INSTANCE: 127.0.0.1:10080
ID: 426831815660273668
START_TIME: 2021-08-06 07:16:00.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
@@ -106,6 +107,7 @@ CURRENT_SQL_DIGEST_TEXT: update `t` set `v` = `v` + ? where `id` = ? ;
DB: test
ALL_SQL_DIGESTS: ["0fdc781f19da1c6078c9de7eadef8a307889c001e05f107847bee4cfc8f3cdf3","06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7"]
*************************** 2. row ***************************
+ INSTANCE: 127.0.0.1:10080
ID: 426831818019569665
START_TIME: 2021-08-06 07:16:09.081000
CURRENT_SQL_DIGEST: 06da614b93e62713bd282d4685fc5b88d688337f36e88fe55871726ce0eb80d7
diff --git a/tune-tikv-thread-performance.md b/tune-tikv-thread-performance.md
index 43a6b4ef98fc1..36dfc3dd5ce5a 100644
--- a/tune-tikv-thread-performance.md
+++ b/tune-tikv-thread-performance.md
@@ -61,7 +61,7 @@ Starting from TiKV v5.0, all read requests use the unified thread pool for queri
* The Raftstore thread pool.
- The Raftstore thread pool is the most complex thread pool in TiKV. The default size (configured by `raftstore.store-pool-size`) of this thread pool is `2`. For the StoreWriter thread pool, the default size (configured by `raftstore.store-io-pool-size`) is `0`.
+ The Raftstore thread pool is the most complex thread pool in TiKV. The default size (configured by `raftstore.store-pool-size`) of this thread pool is `2`. For the StoreWriter thread pool, the default size (configured by `raftstore.store-io-pool-size`) is `1`.
- When the size of the StoreWriter thread pool is 0, all write requests are written into RocksDB in the way of `fsync` by the Raftstore thread. In this case, it is recommended to tune the performance as follows:
diff --git a/upgrade-tidb-using-tiup.md b/upgrade-tidb-using-tiup.md
index 9b0ce992c17e7..7bdb7fbce7205 100644
--- a/upgrade-tidb-using-tiup.md
+++ b/upgrade-tidb-using-tiup.md
@@ -26,6 +26,31 @@ This document is targeted for the following upgrade paths:
> - If your cluster to be upgraded is v3.1 or an earlier version (v3.0 or v2.1), the direct upgrade to v7.6.0 is not supported. You need to upgrade your cluster first to v4.0 and then to v7.6.0.
> - If your cluster to be upgraded is earlier than v6.2, the upgrade might get stuck when you upgrade the cluster to v6.2 or later versions in some scenarios. You can refer to [How to fix the issue](#how-to-fix-the-issue-that-the-upgrade-gets-stuck-when-upgrading-to-v620-or-later-versions).
> - TiDB nodes use the value of the [`server-version`](/tidb-configuration-file.md#server-version) configuration item to verify the current TiDB version. Therefore, to avoid unexpected behaviors, before upgrading the TiDB cluster, you need to set the value of `server-version` to empty or the real version of the current TiDB cluster.
+> - Setting the [`performance.force-init-stats`](/tidb-configuration-file.md#force-init-stats-new-in-v657-and-v710) configuration item to `ON` prolongs the TiDB startup time, which might cause startup timeouts and upgrade failures. To avoid this issue, it is recommended to set a longer waiting timeout for TiUP.
+> - Scenarios that might be affected:
+> - The original cluster version is earlier than v6.5.7 and v7.1.0 (which does not support `performance.force-init-stats` yet), and the target version is v7.2.0 or later.
+> - The original cluster version is equal to or later than v6.5.7 and v7.1.0, and the `performance.force-init-stats` configuration item is set to `ON`.
+>
+> - Check the value of the `performance.force-init-stats` configuration item:
+>
+> ```
+> SHOW CONFIG WHERE type = 'tidb' AND name = 'performance.force-init-stats';
+> ```
+>
+> - You can increase the TiUP waiting timeout by adding the command-line option [`--wait-timeout`](/tiup/tiup-component-cluster.md#--wait-timeout). For example, execute the following command to set the waiting timeout to 1200 seconds (20 minutes).
+>
+> ```shell
+> tiup update cluster --wait-timeout 1200 [other options]
+> ```
+>
+> Generally, a 20-minute waiting timeout is sufficient for most scenarios. For a more precise estimate, search for `init stats info time` in the TiDB log to get the statistics loading time during the previous startup as a reference. For example:
+>
+> ```
+> [domain.go:2271] ["init stats info time"] [lite=true] ["take time"=2.151333ms]
+> ```
+>
+> If the original cluster is v7.1.0 or earlier, when upgrading to v7.2.0 or later, because of the introduction of [`performance.lite-init-stats`](/tidb-configuration-file.md#lite-init-stats-new-in-v710), the statistics loading time is greatly reduced. In this case, the `init stats info time` before the upgrade is longer than the loading time after the upgrade.
+> - If you want to shorten the rolling upgrade duration of TiDB and the potential performance impact of missing initial statistical information during the upgrade is acceptable for your cluster, you can set `performance.force-init-stats` to `OFF` before the upgrade by [modifying the configuration of the target instance with TiUP](/maintain-tidb-using-tiup.md#modify-the-configuration). After the upgrade is completed, you can reassess and revert this setting if necessary.
## Upgrade caveat