This tutorial is from the Hortonworks Sandbox - a single-node Hadoop cluster running in a virtual machine. Download to run this and other tutorials in the series.
This tutorial was derived from one of the lab problems in the Hortonworks Developer training class. The developer training class covers uses of the tools in the Hortonworks Data Platform and how to develop applications and projects using the Hortonworks Data Platform. You can find more information about the course at Hadoop Training for Developers
We value your feedback. When you’re done with this tutorial, please tell us what you think by filling out this survey . We really do pay attention and read your comments!
Apache HCatalog (running time: about 9 minutes)
For this tutorial, we will use a baseball statistics file. This file has all the statistics for each American player by year from 1871-2011. The data set is fairly large (over 95,000 records), but to learn Big Data you don't need to use a massive dataset. You need only use tools that scale to massive datasets.
The data files we are using in this tutorial come from Sean Lahman’s extensive historical baseball database (http://seanlahman.com/), and are being used under a Creative Commons Attribution-ShareAlike license: http://creativecommons.org/licenses/by-sa/3.0/
Download and unzip the data file from this URL:
http://seanlahman.com/files/database/lahman591-csv.zip
The zip archive includes many statistics files. We will only use the following two files:
- Master.csv
- Batting.csv
Start by selecting the File Browser from the top tool bar. The File Browser allows you to view the Hortonworks Data Platform (HDP) file store. The HDP file system is separate from the local file system.

Click Upload and select Files to upload files to HDFS.

A dialog box appears.
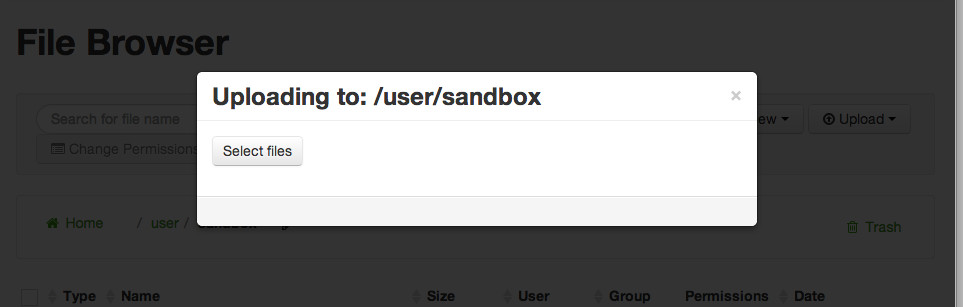
Click Upload a file, and you will get a dialog box. Navigate to where you stored the data files on your local disk. Select 'Batting.csv' and 'Master.csv' files and select Choose.
When you are done, you will see the two files in your directory.

Now that you've uploaded a file to HDFS, you will create an HCatalog table so that the data can be accessible to both Pig and Hive.
Select the HCat icon in the icon bar at the top of the page:
Select "Create a new table from file" from the ACTIONS menu on the left.

This action takes you to Step 1: Choose File. On this page, you will create a table for the batting.csv file, as follows:
- Name the table "batting_data"
- Leave the optional description blank
- Click 'Choose a file'Next

This action takes you to Step 2: Create a new table from a file.
Complete these steps:
- Scroll to the right and change column name R to "Runs" and also change its Column type to "int"
- Click Create Table
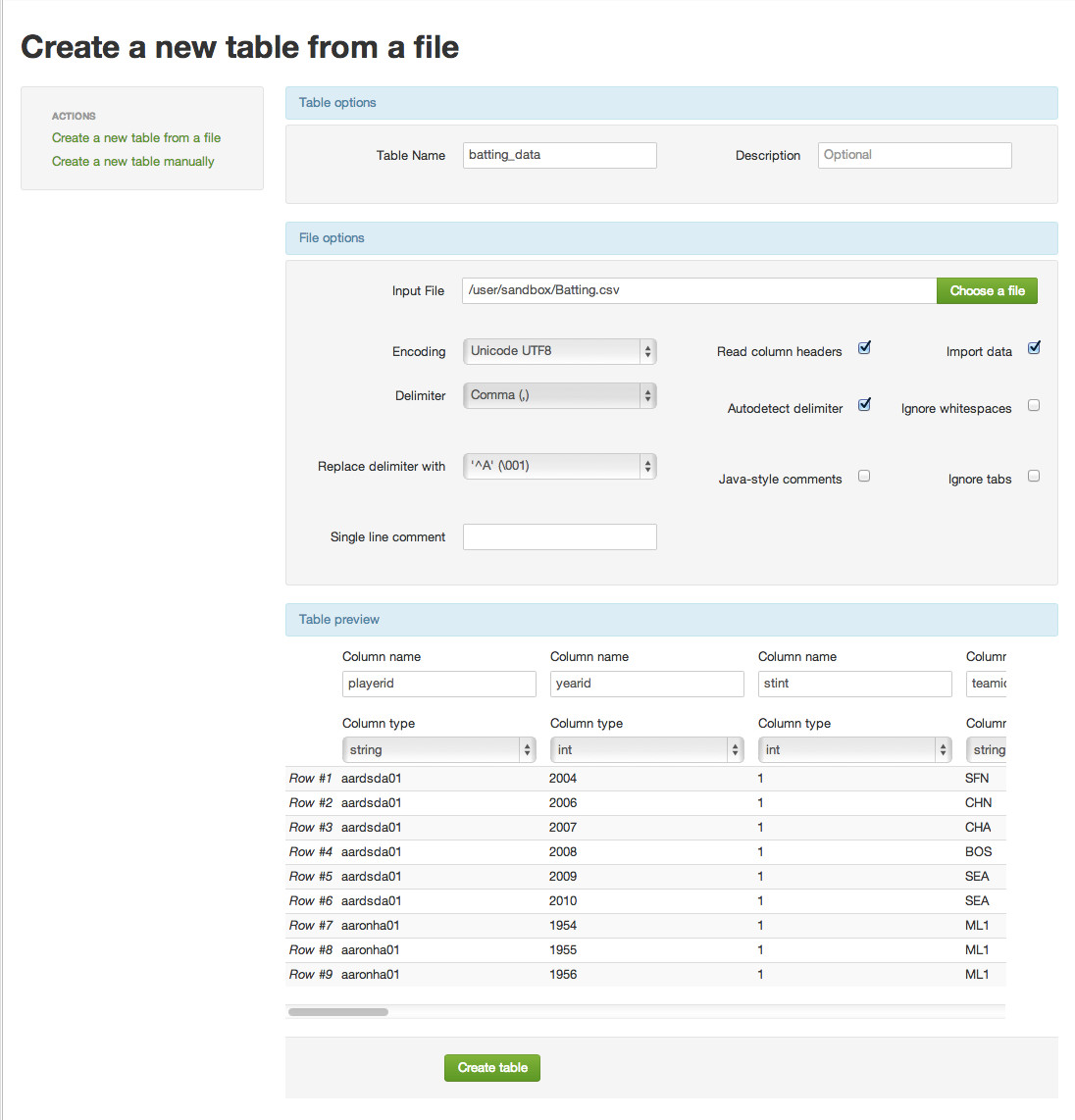
You will see a new table "batting_data" has been created:

Repeat above steps for the second data set (master.csv) and create a new table named "master_data". You do not need to make any changes in Step 2 and Step 3 for this table.

Now two tables have been created on input data, which Hive and Pig can use for further processing.
In the previous sections you:
- Uploaded your data file into HDFS
- Used Apache HCatalog to create tables
In this tutorial, you will use Apache Hive to perform basic queries on the data.
Apache Hive™ provides a data warehouse function to the Hadoop cluster. Through the use of HiveQL you can view your data as a table and create queries just as you would in a database.
To make it easy to interact with Hive, you can use a tool in the Hortonworks Sandbox called Beeswax. Beeswax provides an interactive interface to Hive where you can type in queries and Hive will evaluate them using a series of MapReduce jobs.
Open Beeswax. Click on the bee icon on the top bar.
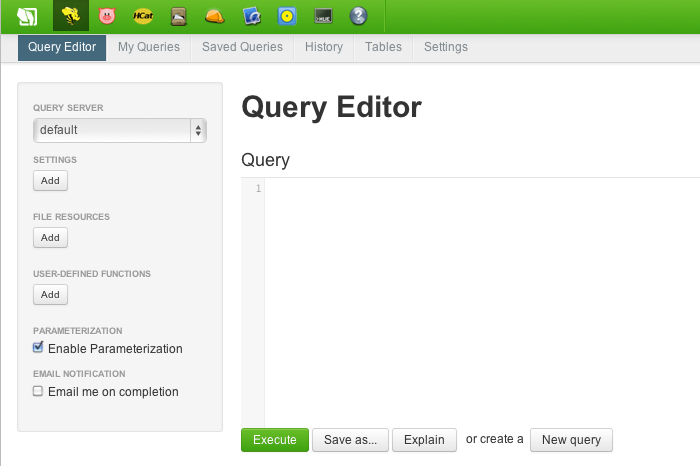
Notice the query window and execute button. Type your queries in the Query window. When you are done with a query, click the execute button.
Note: You can only type one query in the composition window at a given time. You cannot type multiple queries separated by semicolons.
Since you loaded your data and created your table in HCatalog, Hive automatically knows about the data.
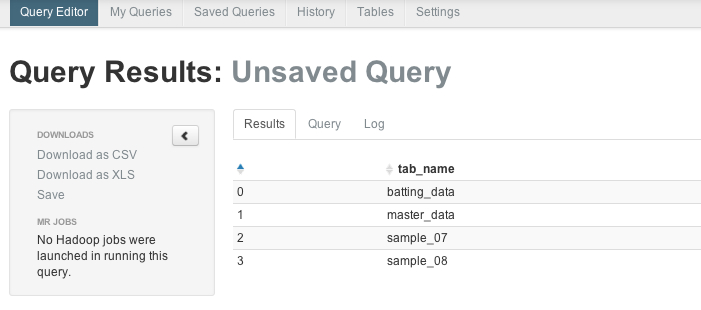
To see tables that Hive knows about, in Query Editor type the query:
show tables
and click on Execute.

Notice the tables that you previously created are in the list ("batting_data" and "master_data").
Hive inherits schema and location information from HCatalog. As a result, you do not have to provide this information in the Hive queries. If we did not have HCatalog, we would have to build the table using HiveQL and provide location and schema information.
To see the records type:
select * from batting_data
in Query Editor and click Execute.
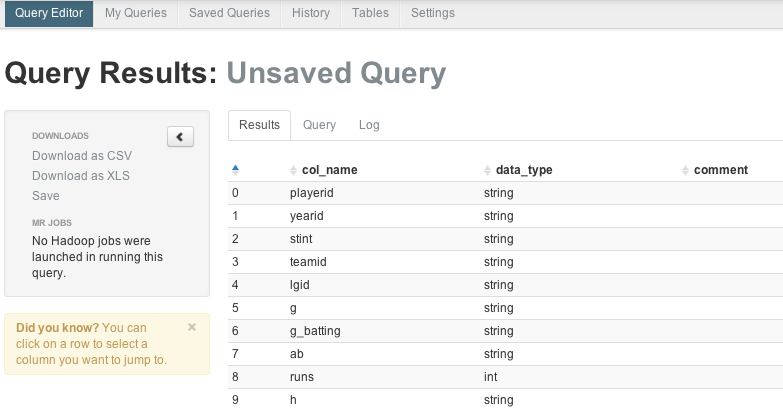
You can see the columns in the table by executing:
describe batting_data

You can make a join with other tables in Pig the same way you do with other database queries.
Let's make a join between batting_data and master_data tables:
Enter the following into the query editor:
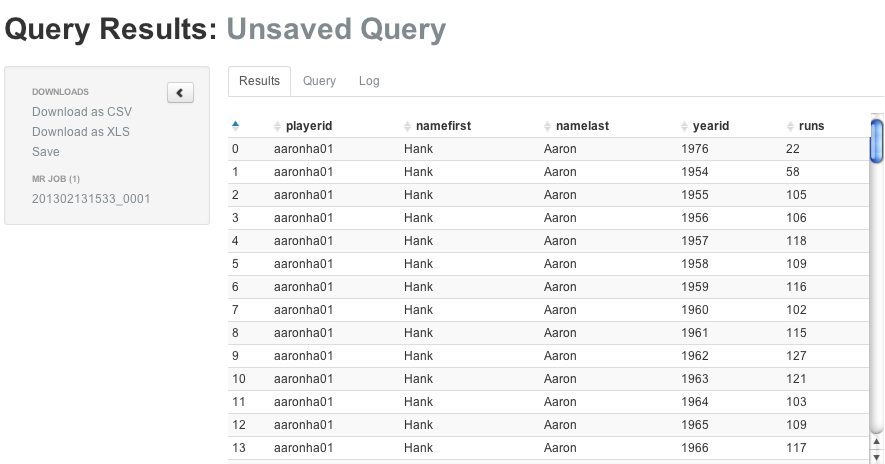
select a.playerid, a.namefirst, a.namelast, b.yearid, b.runsfrom master_data ajoin batting_data b ON (b.playerid = a.playerid)

This job is more complex so takes longer than previous queries. You can watch the job running in the log.

When the job completes, you can see the results.
In this tutorial, you will create and execute a Pig script.
To access the Pig interface, click the Pig icon on the icon bar at the top of your screen. This action brings up the Pig user interface. On the left is a list of your scripts and on the right is a composition box for your scripts.
A special feature of the interface is the Pig helper at the bottom. The
Pig helper provides templates for the statements, functions, I/O
statements, HCatLoader() and Python user defined functions.
At the bottom are status areas that show the results of script and log
files.
In this section, you will load the data from the table that is stored in HCatalog. Then you will make a join between two data sets on the Player ID field in the same way that you did in the Hive section.
Open the Pig interface by clicking the Pig icon at the top of the screen.

Title your script by filling in the title box.

The data is already in HDFS through HCatalog. HCatalog stores schema and location information, so we can use the HCatLoader() function within the Pig script to read data from HCatalog-managed tables. In Pig, you now only need to give the table a name or alias so that Pig can process the table.
Follow this procedure to load the data using HCatLoader:
- Use the right-hand pane to start adding your code at Line 1
- Open the Pig helper drop-down menu at the bottom of the screen to give you a template for the line.

Choose **PIG helper -> HCatalog->LOAD…**template. This action pastes the Load template into the script area.
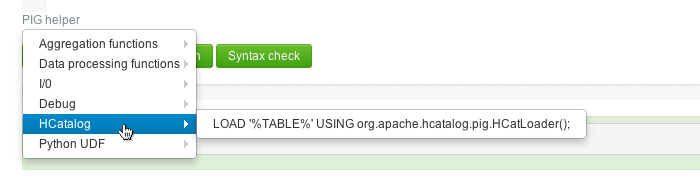
- The entry %TABLE% is highlighted in red. Type the name of the table ('batting_data') in place of %TABLE%(single quotes are required).
- Remember to add the "a = " before the template. This saves the results into "a".
- Make sure the statement ends with a semi-colon (;)
Repeat this sequence for "master_data" and add " b = "
The completed lines of code will be:
a = LOAD 'batting_data' using org.apache.hcatalog.pig.HCatLoader();
b = LOAD 'master_data' using org.apache.hcatalog.pig.HCatLoader();

It is important to note that at this point, we have merely defined the aliases for our tables to hold the data (alias "a" for batting data and alias "b" for master data). Data is not loaded or transformed until we execute an operational command such as DUMP or STORE
Next, you will use the JOIN operator to join both tables on the Player ID. Master.data has the player's first name and last name and player ID (among other fields). Batting.data has the player's run record and player ID (among other fields). You will create a new data set using the Pig Join function that will match the player ID field and include all of the data from both tables.
Complete these steps:
- Choose PIG helper->Data processing functions->JOIN template
- Replace %VAR% with "a". Repeat this step on the same line for "b".
- Again, add the trailing semi-colon to the code.
So, the final code will be:
a = LOAD 'batting_data' using org.apache.hcatalog.pig.HCatLoader();
b = LOAD 'master_data' using org.apache.hcatalog.pig.HCatLoader();
c = join a by playerid, b by playerid;

Now you have joined all the records in both of the tables on Player ID.
To complete the Join operation, use the DUMP command to execute the
results. This will show all of the records that have a common PlayerID.
The data from both tables will be merged into one row.
Complete this steps:
- Add the last line with PIG helper->I/O->DUMPtemplate and replace %VAR% with "c".
The full script should be:
a = LOAD 'batting_data' using org.apache.hcatalog.pig.HCatLoader();
b = LOAD 'master_data' using org.apache.hcatalog.pig.HCatLoader();
c = join a by playerid, b by playerid;dump c;

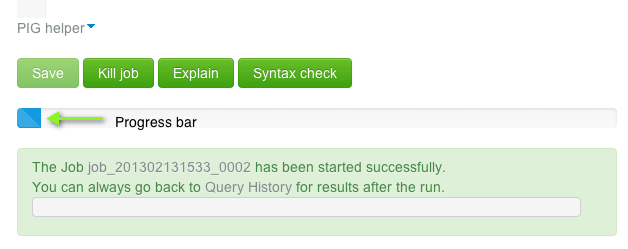
At the bottom of the screen, click Save and Execute to run the script. This action creates one or more MapReduce jobs.
Below the Execute button is a progress bar that shows the job's status. The progress bar can be blue (indicating job is in process), red (job has a problem), or green (job is complete).
When the job completes, check the results in the green box. You can also download results to your system by clicking the download icon. The result is that each line that starts with an open parenthesis "(" has data from both tables for each unique player ID.

Click the Logs link if you want to see what happened when your script ran, including any error messages. (You might need to scroll down to view the entire log.)

Congratulations! You have successfully completed HCatalog, Basic Pig & Hive Commands.