Memory leak in pd.read_csv or DataFrame #21353
Comments
|
@kuraga : Thanks for the updated issue! |
|
Seems like it's not
|
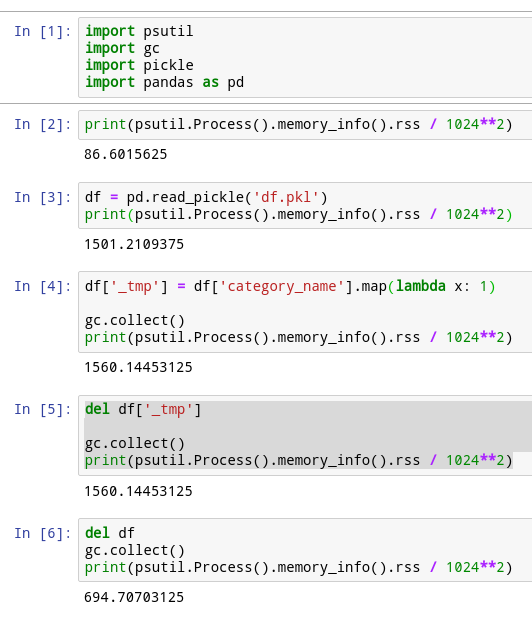
|
I have a similiar issue. I have tried to debug it with memory_profiler but I don't see the source of the leak. This snippet of the code is inside a loop and every time it increments the memory usage. I also tried to delete the history and history_group object and calling gc.collect() manually, but nothing seems to work. p.s: My pandas version is 0.23.1 |
|
Sorry, I was wrong. Not the read_csv which consumes the memory rather than a drop: And I think I found out that malloc_trim solves the problem, similar to this: #2659 @kuraga Maybe you should try it. |
|
I also noticed a memory leak in @gfyoung, could you please review the patch below? It might also help with the leak discussed here, although I am not sure if it is the same leak or not. The patch
--- parsers.pyx 2018-08-01 19:57:16.000000000 +0100
+++ parsers.pyx 2018-10-08 15:25:32.124526087 +0100
@@ -1054,18 +1054,6 @@
conv = self._get_converter(i, name)
- # XXX
- na_flist = set()
- if self.na_filter:
- na_list, na_flist = self._get_na_list(i, name)
- if na_list is None:
- na_filter = 0
- else:
- na_filter = 1
- na_hashset = kset_from_list(na_list)
- else:
- na_filter = 0
-
col_dtype = None
if self.dtype is not None:
if isinstance(self.dtype, dict):
@@ -1090,13 +1078,26 @@
self.c_encoding)
continue
- # Should return as the desired dtype (inferred or specified)
- col_res, na_count = self._convert_tokens(
- i, start, end, name, na_filter, na_hashset,
- na_flist, col_dtype)
+ # XXX
+ na_flist = set()
+ if self.na_filter:
+ na_list, na_flist = self._get_na_list(i, name)
+ if na_list is None:
+ na_filter = 0
+ else:
+ na_filter = 1
+ na_hashset = kset_from_list(na_list)
+ else:
+ na_filter = 0
- if na_filter:
- self._free_na_set(na_hashset)
+ try:
+ # Should return as the desired dtype (inferred or specified)
+ col_res, na_count = self._convert_tokens(
+ i, start, end, name, na_filter, na_hashset,
+ na_flist, col_dtype)
+ finally:
+ if na_filter:
+ self._free_na_set(na_hashset)
if upcast_na and na_count > 0:
col_res = _maybe_upcast(col_res)
@@ -2043,6 +2044,7 @@
# None creeps in sometimes, which isn't possible here
if not PyBytes_Check(val):
+ kh_destroy_str(table)
raise ValueError('Must be all encoded bytes')
k = kh_put_str(table, PyBytes_AsString(val), &ret) |
|
@zhezherun : That's a good catch! Create a PR, and we can review. |
|
Trying to patch is cool but fear that #2659 (comment)... |
* Move allocation of na_hashset down to avoid a leak on continue * Delete na_hashset if there is an exception * Clean up table before raising an exception Closes pandas-devgh-21353.
* Move allocation of na_hashset down to avoid a leak on continue * Delete na_hashset if there is an exception * Clean up table before raising an exception Closes pandas-devgh-21353.
* Move allocation of na_hashset down to avoid a leak on continue * Delete na_hashset if there is an exception * Clean up table before raising an exception Closes gh-21353.
|
@zhezherun , @TomAugspurger , thanks very much! But could you, please, describe the connection with @nynorbert 's observation:
So, we had memory leak in Pandas in addition to glibc's feature to not trim after Thanks. |
|
I don't know C, so no. Perhaps @nynorbert can clarify. |
* Move allocation of na_hashset down to avoid a leak on continue * Delete na_hashset if there is an exception * Clean up table before raising an exception Closes pandas-devgh-21353.
* Move allocation of na_hashset down to avoid a leak on continue * Delete na_hashset if there is an exception * Clean up table before raising an exception Closes pandas-devgh-21353.
|
|
|
Hi, I am facing this issue on google compute engine (Windows Server 2012 R2 Datacenter, 64 bit). How do I fix it? I have installed the latest version of Pandas. |
|
Theory: When reading large files with Python, pd.read_csv, csv.reader, plain python io, or with mmap it seems that the thread reading will hold memory. If the same thread does a new read, the already allocated memory will be used, if a new thread reads, it will aquire additional memory. With panda on google the reading of 3 files of app. 100 MB has required app 3GB that is not released. With csv.reader app 300MB, and plain read and mmap app 200MB. So multithreading read of the 3 files can result in extensive storage use (25GB+). This is not my home field, but it has been a frustrating week looking for leaks. If I'm wrong, sorry for the disturbance. (Python 3.7 and 3.8) |
|
@gberth If you use engine="python" do you see that same pattern? |
|
Sorry, no difference. If I ensure reading files twice in the same thread, it does not consume or hold more memory. Read in two different threads, and both holds 2GB+ as long as the threads live (at least looks like that to me) |
Code Sample, a copy-pastable example if possible
Problem description
Two issues:
pd.DataFrame()- ~53Mb.cc @gfyoung
Output of
pd.show_versions()(same for 0.21, 0.22, 0.23)
The text was updated successfully, but these errors were encountered: