diff --git a/docs/MatrixOne/Overview/matrixone-introduction.md b/docs/MatrixOne/Overview/matrixone-introduction.md
index 2126857d46..9867c1f955 100644
--- a/docs/MatrixOne/Overview/matrixone-introduction.md
+++ b/docs/MatrixOne/Overview/matrixone-introduction.md
@@ -4,9 +4,9 @@ MatrixOne is a hyper-converged cloud & edge native distributed database with a s
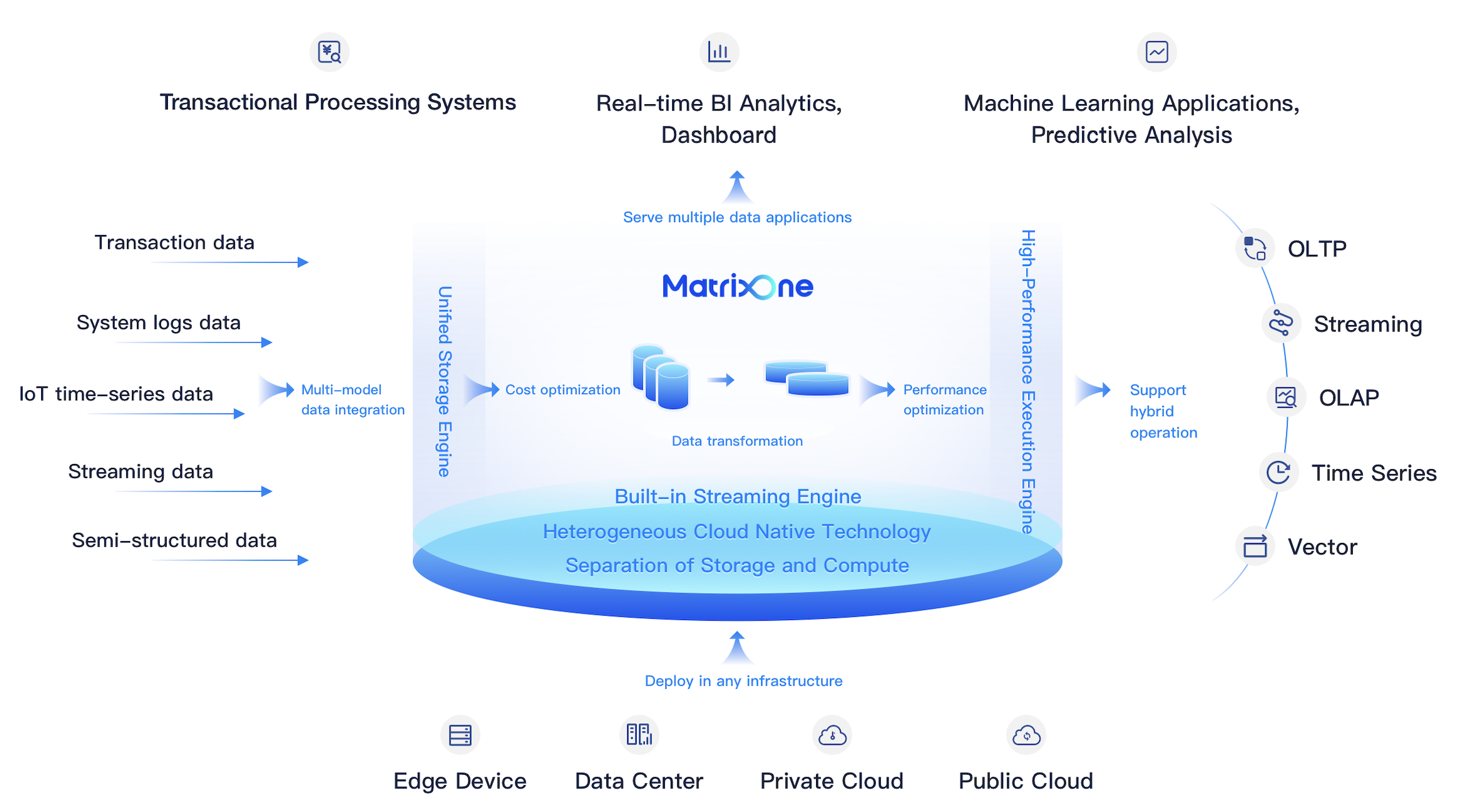
MatrixOne touts significant features, including real-time HTAP, multi-tenancy, stream computation, extreme scalability, cost-effectiveness, enterprise-grade availability, and extensive MySQL compatibility. MatrixOne unifies tasks traditionally performed by multiple databases into one system by offering a comprehensive ultra-hybrid data solution. This consolidation simplifies development and operations, minimizes data fragmentation, and boosts development agility.
-
+
-MatrixOne is optimally suited for scenarios requiring real-time data input, large data scales, frequent load fluctuations, and a mix of procedural and analytical business operations. It caters to use cases such as mobile internet apps, IoT data applications, real-time data warehouses, SaaS platforms, and more.
+MatrixOne is designed for scenarios that require real-time data ingestion, large-scale data management, fluctuating workloads, and multi-modal data management. It is particularly suited for environments that combine transactional and analytical workloads, such as generative AI applications, mobile internet applications, IoT data processing, real-time data warehouses, and SaaS platforms.
## **Key Features**
diff --git a/docs/MatrixOne/Tutorial/search-picture-demo.md b/docs/MatrixOne/Tutorial/search-picture-demo.md
index 7683cfac99..37d8b2b947 100644
--- a/docs/MatrixOne/Tutorial/search-picture-demo.md
+++ b/docs/MatrixOne/Tutorial/search-picture-demo.md
@@ -1,242 +1,238 @@
-# Example of application basis for graph search
+# Basic example of image search application using images (text)
-Currently, graphic and text search applications cover a wide range of areas. In e-commerce, users can search for goods by uploading images or text descriptions; in social media platforms, content can be found quickly through images or text to enhance the user's experience; and in copyright detection, image copyright can be identified and protected. In addition, text search is widely used in search engines to help users find specific images through keywords, while graphic search is used in machine learning and artificial intelligence for image recognition and classification tasks.
+At present, related applications of image search and text search cover a wide range of fields. In e-commerce, users can search for products by uploading images or text descriptions; on social media platforms, users can quickly find relevant content through images or text. , enhance the user experience; in terms of copyright detection, it can help identify and protect image copyrights; in addition, text-based image search is also widely used in search engines to help users find specific images through keywords, while image-based image search is used in Used for image recognition and classification tasks in the field of machine learning and artificial intelligence.
-The following is a flow chart of a graphic search:
+The following is a flow chart for searching pictures using pictures (text):
-

+
-

-
-

+
