一开始分享时调用wxapi.sendReq接口,返回总是false,去官网文档中心了看了下,有一句检查发送时的缩略图大小是否超过32k ,于是查看图片的文件大小不超过32K啊,为什么还是不行呢?后来发现是图片解码后的占用内存,而不是文件的物理存储空间。举个实例:
一张200 * 200的png图片,解码后的大小为 200 * 缩放系数 * 200 * 缩放系数
如果把图片放到drawable或者raw这样不带dpi的文件夹,inDensity使用默认值160
否则的话根据文件夹确定,如果放在xhdpi=320,xxhdpi=480,以此类推
而ARGB_8888(也就是我们最常用的Bitmap 的格式)的一个像素占用 4byte
所以刚才的图片放在xhdpi目录下,使用小米note pro(densityDpi=640)的占用内存为
可通过getByteCount() 得到图片在内存中的占用大小
//不使用系统默认的分辨率值和图片所存的文件夹,解码后200*200的图片占用内存大小还是200*200*4byte
BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds = false;
options.inSampleSize = 1;
options.inDensity = 160;
options.inTargetDensity = 160;//注意不要设置成inScreenDensity,但API>=19的手机占用内存正常是因为scale在native层因density==screenDensity而使用了默认值1.0- ALPHA_8 每个像素占用1byte内存
- ARGB_4444:每个像素占用2byte内存
- ARGB_8888:每个像素占用4byte内存
- RGB_565:每个像素占用2byte内存
Android默认的色彩模式为ARGB_8888
-
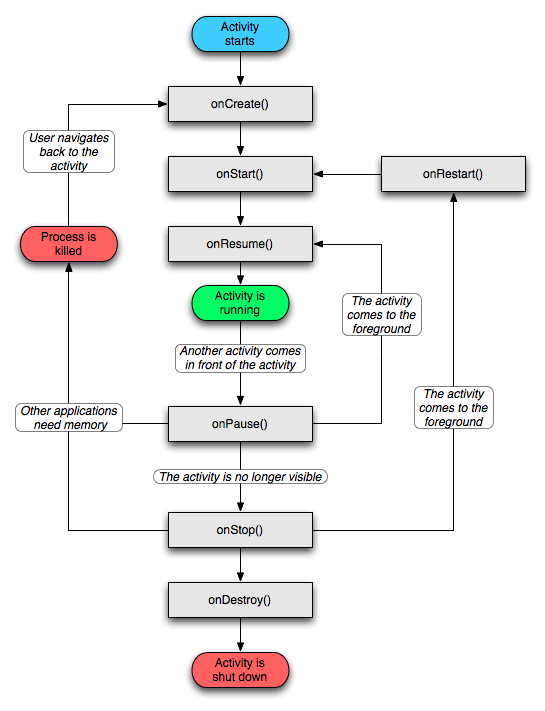
onStart和onStop是从Activity是否可见这个角度来回调的,而onResume和onPause是从Activity是否位于前台这个角度来回调的。
其中onStart和onResume都表示Activity已经可见,但是onStart的时候Activity还在后台,onResume的时候Activity才显示到前台 -
onPause必须先执行完,新Activity的onResume才会执行。
-
系统只在Activity异常终止的时候才会调用onSaveInstanceState和onRestoreInstanceState来存储和恢复数据,其他情况下不会触发这个过程。
- standard:标准模式,也是系统的默认模式。每次启动一个Activity都会重新创建一个新的实例,不管这个实例是否已经存在。
- singleTop:栈顶复用模式。这种模式下,如果新Activity已经位于任务栈的栈顶,那么此Activity不会被重新创建,同时它的onNewIntent方法会被回调。如果已存在,但不在栈顶,那么新Activity仍会被创建。
- singleTask:栈内复用模式。只要Activity在一个栈中存在,那么多次启动此Activity都不会重新创建实例,和singleTop一样,系统也会回调onNewIntent。比如Activity A是singleTask模式的,系统首先会寻找是否存在A想要的任务栈,如果不存在,则重新创建一个任务栈,然后创建A的实例后把A放到栈中。如果存在A所需的任务栈,这时要看A是否在栈中有实例存在,如果有实例存在,那么系统就会把A调到栈顶并调用它的onNewIntent方法,如果实例不存在,就创建A的实例并把A压入栈中。
比如目前任务栈S1中的情况为ABC,这时候Activity D以singleTask模式请求启动,其所需要的任务栈为S2,由于S2和D的实例都不存在,所以系统会先创建任务栈S2,然后再创建D的实例并将入栈到S2。
另一种情况,假设D所需的任务栈为S1,其他情况如上,那么由于S1已经存在,所需系统会直接创建D的实例并将其入栈到S1。
如果D所需的任务栈为S1,并且当前任务栈S1的情况为ADBC,根据栈内复用原则,此时D不会重新创建,系统会把D切换到栈顶并调用其onNewIntent方法,同时由于singleTask默认具有clearTop的效果,会导致栈内所有在D上面的Activity全部出栈,于是最终S1中的情况为AD.
- singleInstance:单实例模式。除了具有singleTask模式的所有特性外,具有此种模式的Activity只能单独地位于一个任务栈中。
Activity所需的任务栈,与TaskAffinity参数相关,默认情况下,所有Activity所需的任务栈的名字为应用的包名。另外任务栈分为前台任务栈和后台任务栈。
可通过 adb shell dumpsys activity命令查看任务栈
- FLAG_ACTIVITY_CLEAR_TOP:具有此标记位的Activity,当它启动时,在同一个任务栈中所有位于它上面的Activity都要出栈。这个标记位一般会和singleTask启动模式一起出现。
- FLAG_ACTIVITY_EXCLUDE_FROM_RECENTS:具有此标记的Activity不会出现在历史Activity的列表中。它等同于在XML中指定Activity的属性
android:excludeFromRecents="true"
方法:给四大组件在AndroidManifest.xml中指定android:process属性,除此之外没有其他方法。其实还有一种非常规的多进程方法,就是通过JNI在native层去fork一个新的进程。
Android系统会为每个应用分配一个唯一的UID,具有相同UID的应用才能共享数据。具有相同的ShareUID并且签名相同才可以互相访问对方的私有数据,不管是否跑在同一进程,如果是跑在同一进程中,除了能共享data目录、组件信息,还可以共享内存数据。
一般来说,使用多进程会造成如下几方面的问题:
- 静态成员和单例模式完全失效。
- 线程同步机制完全失效。
- SharedPreferences的可靠性下降。
- Application会多次创建。
原因:Android为每个进程分配一个独立的虚拟机,不同的虚拟机在内存分配上有不同的地址空间。
AIDL的使用流程:首先创建一个Service和一个AIDL接口,接着创建一个类继承自AIDL接口中的Stub类并实现Stub中的抽象方法,在Service的onBind方法中返回这个类的对象,然后客户端就可以绑定服务端Service,建立连接后就可以访问远程服务端的方法了。
启动一个Activity,我们一般都是通过调用startActivity方法,startActivity方法虽有好几种重载方式,但最终都会调用startActivityForResult方法。
启动Activity真正的实现由ActivityManagerNative.getDefault()的startActivity方法来完成。
ActivityMangerService(简称AMS)继承自ActivityManagerNative,而ActivityManagerNative继承自Binder并实现了IActivityManager这个Binder接口,因此AMS也是一个Binder,所以只需查看AMS的startActivity方法即可。
绕过一大圈,Activity的启动过程最终回到了ActivityThread中的内部类ApplicationThread中,ApplicationThread通过scheduleLaunchActivity方法来启动Activity,而scheduleLaunchActivity的实现很简单,就是发送一个启动Activity的消息交由Handler处理,这个Handler的名字叫H。然后从Handler H可知,Activity的启动过程由ActivityThread的handleLaunchActivity方法来实现,performLaunchActivity方法最终完成了Activity对象的创建和启动过程
思路:通过两个布尔值变量来分别控制 Fragment 是否初始化和是否已经加载过数据。
-
设定两个标识
private boolean isViewPrepared; // 标识fragment视图已经初始化完毕 private boolean hasFetchData; // 标识已经触发过懒加载数据 -
创建懒加载的数据加载方法
/** 懒加载的方式获取数据,仅在满足fragment可见和视图已经准备好的时候调用一次 */ protected void lazyFetchData() { Log.v(TAG, getClass().getName() + "------>lazyFetchData"); }
-
以上两个标识的判定
- 在onViewCreated方法中(即表明视图已经准备完毕)isViewPrepared = true;
- 在onDestroyView方法中(view被销毁后,将可以重新触发数据懒加载,因为在ViewPager下,fragment不会再次新建并走onCreate的生命周期流程,将从onCreateView开始)hasFetchData = false; isViewPrepared = false;
-
判定是否需要加载数据
private void lazyFetchDataIfPrepared() { // 用户可见fragment && 没有加载过数据 && 视图已经准备完毕 if (getUserVisibleHint() && !hasFetchData && isViewPrepared) { hasFetchData = true; //已加载过数据 lazyFetchData(); } }
-
lazyFetchDataIfPrepared方法的调用时机
- onViewCreated方法中调用lazyFetchDataIfPrepared方法,此时只有首页会符合条件
- setUserVisibleHint
@Override public void setUserVisibleHint(boolean isVisibleToUser) { super.setUserVisibleHint(isVisibleToUser); Log.v(TAG, getClass().getName() + "------>isVisibleToUser = " + isVisibleToUser); if (isVisibleToUser) {//当前为显示页面时 lazyFetchDataIfPrepared(); } }
-
子类Fragment根据需要重载lazyFetchData方法(访问网络加载数据)
@Override protected void lazyFetchData() { ((DiscoverPresenter) mPresenter).getData(); }
- Activity组件只有一种运行模式,即Activity处于启动模式。但Service有两种状态:启动状态和绑定状态
- Service本身是运行在主线程中的。

广播的注册有两种方式,既可以在AndroidManifest.xml文件中静态注册,也可以在代码中动态注册。
以类似数据库中表的方式将数据暴露,提供给第三方使用
PendingIntent表示一种待定状态的意图,将在某个待定的时刻发生。
PendingIntent与Intent的区别在于,PendingIntent是在将来的某个不确定的时刻发生,而Intent是立刻发生。
PendingIntent支持三种待定意图:启动Activity、启动Service和发送广播
Window有三种类型:
- 应用Window:对应着一个Activity
- 子Window:不能单独存在,需要附属在特定的父Window中,如Dialog
- 系统Window:需要声明权限才能创建的Window,如Toast和系统状态栏
Window是分层的,每个Window都有对应的z-ordered,层级大的会覆盖在层级小的Window的上面
- 应用Window的层级范围:1~99
- 子Window的层级范围:1000~1999
- 系统Window的层级范围:2000~2999
这些层级范围对应着WindowManager.LayoutParams的type参数。
Window是一个抽象的概念,每一个Window都对应着一个View和一个ViewRootImpl,Window和View是通过ViewRootImpl来建立联系,因此Window并不是实际存在的,它是以View的形式存在,View才是Window存在的实体。实际使用中无法直接访问Window,对Window的访问必须通过WindowManager。
View是Android中的视图的呈现方式,但是View不能单独存在,它必须附着在Window这个抽象概念之上,因此有视图的地方就有Window。
Window是一个抽象类,它的具体实现是PhoneWindow。要创建一个Window,只需通过WindowManager即可完成。WindowManager是外界访问Window的入口,Window的具体实现位于WindowManagerService中,WindowManager和WindowManagerService的交互是一个IPC过程。
Android的动画可分为三种:View动画、帧动画和属性动画
View动画:平移、缩放、旋转和透明度
LayoutAnimation作用于ViewGroup,为ViewGroup指定一个动画,这样当它的子元素出场时都会有这种动画效果。如ListView上每个item都以一定的动画形式出现。
属性动画总结: 我们对object的属性abc做动画,如果想让动画生效,必须同时满足两个条件
- object必须提供setAbc方法,如果动画的时候没有传递初始值,那么还要提供getAbc方法,因为系统要去取abc属性的初始值(如果这条不满足,程序直接Crash)
- object的setAbc对属性abc所做的改变必须能够通过某种方法反映出来,比如会带来UI的改变之类的(如果这条不满足,动画无效果但不会Crash)

- View的位置主要由它的四个顶点来决定,分别对应于View的四个属性:top、left、right、bottom
- 从Android3.0开始,View增加了额外的几个参数:x、y、translationX和translationY
x、y:是View的左上角的坐标
translationX、translationY:是View的左上角相对于父容器的偏移量
x = left + translationX
y = top + translationY
需要注意的是,View在平移的过程中,top和left表示的是原始左上角的位置信息,其值并不会发生改变,此时发生改变的是x、y、translationX和translationY这四个参数
- 通过View本身提供的scrollTo/scrollBy方法
- 通过动画给View施加平移效果
- 通过改变View的LayoutParams使得View重新布局
- scrollTo:是指移动到指定的(x,y)坐标点
- scrollBy:在当前位置的基础上再偏移(x,y)
假如一个View,调用两次scrollTo(-10, 0),第一次向右滚动10,第二次就不滚动了,因为mScrollX和x
相等了,当我们调用两次scrollBy(-10, 0),第一次向右滚动10,第二次再向右滚动10,它是相对View的
上一个位置来滚动的。
从源码中看出,scrollBy实际上是调用了 scrollTo(mScrollX + x, mScrollY + y);
mScrollX + x和mScrollY + y,即表示在原先偏移的基础上再发生偏移,通俗的说就是相对我们当前位
置偏移。
假设有个View叫SView,如果想把SView从(0, 0)移动到(100, 100)。注意,这里说的(0, 0)和(100, 100),指的是SView左上角的坐标。那么偏移量就是原点(0, 0)到目标点(100, 100)的距离,即(0,0)-(100,100)=(-100,-100)。只需要调用SView.scrollTo(-100,-100)就可以了。请再次注意,scrollTo(int x, int y)的两个参数x和y,代表的是偏移量,这时的参照物是(0, 0)点。也就是说scrollTo永远都相对于(0,0)点。
scrollBy()的参照物是(0, 0)点加上偏移量之后的坐标。这么描述比较抽象,举个例子。假设SView调用了scrollTo(-100, -100),此时SView左上角的坐标是(100, 100),这时再调用scrollBy(-20, -20),此时SView的左上角就被绘制到了(120, 120)这个位置。
滑动过程中View内部的两个属性mScrollX和mScrollY的改变规则:
可以通过 getScrollX 和 getScrollY 方法分别得到,在滑动过程中,mScrollX的值总是等于 View 左边缘和 View 内容左边缘在水平方向的距离,而 mScrollY 的值总是等于 View 上边缘和 View 内容上边缘在竖直方向的距离。
View 边缘是指 View 的位置,由四个顶点组成,而 View 内容边缘是指 View 中的内容的边缘,scrollTo 和 scrollBy 只能改变 View 内容的位置而不能变 View 在布局中的位置。
mScrollX 和 mScrollY 的单位为像素,并且当 View 左边缘在 View 内容左边缘的右边时,mScrollX为正值,反之为负值;当View上边缘在 View 内容上边缘的下边时,mScrollY 为正值,反之为负值。即,若从左向右滑动,mScrollX 为负值,反之为正值;若从上往下滑动,mScrollY 为负值,反之为正值。(总结:即将显示的内容是顺着坐标系方向走的话,其值就是正,否则为负)

主要是操作View的translationX和translationY属性,既可以采用传统的View动画,也可以采用属性动画。
将一个View在100ms内从原始位置向右平移100像素
ObjectAnimator.ofFloat(targetView,"translationX",0,100).setDuration(100).start();
改变布局参数,即改变 LayoutParams,如把一个Button向右平移100px,只需将这个 Bution 的LayoutParams 里的 marginLeft 参数的值增加100px即可
MarginLayoutParams layoutParams = (MarginLayoutParams) mButton.getLayoutParams();
layoutParams.width +=100;
layoutParams.leftMargin +=100;
mButton.requestLayout();
//或者mButton.setLayoutParams(layoutParams);-
scrollTo/scrollBy:操作简单,适合对View内容的滑动;
优点:可以比较方便地实现滑动效果并且不影响内部元素的单击事件。
缺点:只能滑动View的内容,并不能滑动View本身。
-
动画:操作简单,主要适用于没有交互的 View 和实现复杂的动画效果;
优点:一些复杂的效果必须要通过动画才能实现。
缺点:使用View动画或者在Android3.0以下使用属性动画,均不能改变View本身的属性。
-
改变布局参数:操作稍微复杂,适用于有交互的 View。
实现弹性滑动方法很多,其共同的思想是:将一次大的滑动分成若干个小的滑动,并且在一个时间段完成。 如 Scroller,Handler#postDelayed,Thread#sleep。
Scroller 工作原理概括:Scroller 本身并不能实现 View 的滑动,需要配合 View 的 computeScroll 方法才能完成弹性滑动的效果,它不断的让View重绘,而每一次重绘距滑动起始时间会有一个时间间隔,通过这个时间间隔 Scroller 就能得出 View 当前的滑动位置,知道了滑动位置就可以用scrollTo方法来完成View的滑动。就这样,View 的每一次重绘都会导致 View 进行小幅度的滑动,而多次的小幅度滑动组成了弹性滑动,这就是Scroller 的工作机制。

动画本身就是一种渐进的过程,因此通过它来实现滑动天然就具有弹性效果。
可以利用动画的特性来实现一些动画不能实现的效果,模仿scroller来实现 View 的弹性滑动
final int startX = 0;
final int deltaX = 100;
final ValueAnimator animator = ValueAnimator.ofInt(0,1).setDuration(1000);
animator.addUpdateListener(new ValueAnimator.AnimatorUpdateListener() {
@Override
public void onAnimationUpdate(ValueAnimator valueAnimator) {
float fraction = animator.getAnimatedFraction();
mButton.scrollTo(startX + (int)(deltaX * fraction),0);
}
});
animator.start();延时策略,其核心思想是通过发送一系列延时消息从而达到一种渐进式的效果,具体来说可以使用 Handler 或 View 的 postDelayed 方法,也可用线程的sleep方法。
public boolean dispatchTouchEvent(MotionEvent ev)
用来进行事件的分发。如果事件能够传递给当前View,那么此方法一定会被调用,返回结果受当前View的onTouchEvent和下级View的dispatchTouchEvent方法的影响,表示是否消耗当前事件。
public boolean onInterceptTouchEvent(MotionEvent ev)
在上述方法内部调用,用来判断是否拦截某个事件,如果当前View拦截了某个事件,那么在同一个事件序列当中,此方法不会被再次调用,返回结果表示是否拦截当前事件。
public boolean onTouchEvent(MotionEvent ev)
在dispatchTouchEvent方法中调用,用来处理点击事件,返回结果表示是否消耗当前事件,如果不消耗,则在同一个事件序列中,当前View无法再次接收到事件。
对于一个根ViewGroup来说,当点击事件发生后,首先会传递给它,这时它的dispatchTouchEvent就会被调用,如果这个ViewGroup的onInterceptTouchEvent方法返回true就表示它要拦截当前事件,接着事件就会交给这个ViewGroup处理,即它的onTouchEvent就会被调用;如果这个ViewGroup的onInterceptTouchEvent方法返回false就表示它不拦截当前事件,这时当前事件就会继续传递给它的子元素,接着子元素的dispatchTouchEvent方法就会被调用,如此反复直到事件被最终处理。

当一个点击事件产生后,它的传递过程遵循如下顺序: Activity->Window->ViewGroup->View
总结:
- 某个View一旦决定拦截,那么这个事件序列都只能由它来处理(如果事件序列能够传递给它的话),并且它的onInterceptTouchEvent不会再被调用
- 某个View一旦开始处理事件,如果它不消耗ACTION_DOWN事件(onTouchEvent返回了false),那么同一事件序列中的其他事件都不会再交给它来处理,并且事件将重新交给它的父元素去处理,即父元素的onTouchEvent会被调用。(好比上级交给程序员一件事,如果这件事没有处理好,短期内上级就不敢再把事情交给这个程序员做了)
- ViewGroup默认不拦截任何事件。Android源码中ViewGroup的onInterceptTouchEvent方法默认返回false
- View没有onInterceptTouchEvent方法,一旦有点击事件传递给它,那么它的onTouchEvent方法就会被调用

所谓外部拦截法是指点击事件都先经过父容器的拦截处理,如果父容器需要此事件就拦截,不需要就不拦截,这种方式比较符合点击事件的分发机制。外部拦截法需要重写父容器的onInterceptTouchEvent方法,在内部做相应的拦截即可。
public boolean onInterceptTouchEvent(MotionEvent event) {
boolean intercepted = false;
int x = (int) event.getX();
int y = (int) event.getY();
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN: {
intercepted = false;
break;
}
case MotionEvent.ACTION_MOVE: {
if (满足父容器的拦截要求) {
intercepted = true;
} else {
intercepted = false;
}
break;
}
case MotionEvent.ACTION_UP: {
intercepted = false;
break;
}
default:
break;
}
mLastXIntercept = x;
mLastYIntercept = y;
return intercepted;
}注意父容器中ACTION_DOWN事件必须返回false,即不拦截该事件。因为一旦父容器拦截了ACTION_DOWN,那么后续的ACTION_MOVE和ACTION_UP事件都会直接交由父容器处理,就无法再传递给子元素了。
内部拦截法是指父容器不拦截任何事件,所有的事件都传递给子元素,如果子元素需要此事件就直接消耗掉,否则就交由父容器处理,这种方法与Android中的事件分发机制不一致,需要配合requestDisallowInterceptTouchEvent方法才能正常工作。我们需要重写子元素的dispatchTouchEvent方法:
public boolean dispatchTouchEvent(MotionEvent event) {
int x = (int) event.getX();
int y = (int) event.getY();
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN: {
parent.requestDisallowInterceptTouchEvent(true);
break;
}
case MotionEvent.ACTION_MOVE: {
int deltaX = x - mLastX;
int deltaY = y - mLastY;
if (父容器需要此类点击事件) {
parent.requestDisallowInterceptTouchEvent(false);
}
break;
}
case MotionEvent.ACTION_UP: {
break;
}
default:
break;
}
mLastX = x;
mLastY = y;
return super.dispatchTouchEvent(event);
}除了子元素这样处理外,父元素也要默认拦截除ACTION_DOWN以外的其它事件,这样子元素调用parent.requestDisallowInterceptTouchEvent(false)方法时,父元素才能继续拦截所需的事件。因为ACTION_DOWN事件并不受FLAG_DISALLOW_INTERECPT这个标记位控制。父元素修改如下:
public boolean onInterceptTouchEvent(MotionEvent event) {
int action = event.getAction();
if (action == MotionEvent.ACTION_DOWN) {
return false;
} else {
return true;
}
}measure过程决定了View的宽/高,measure完成后,可以通过getMeasuredWidth和getMeasuredHeight方法来获取到View测量后的宽/高,在几乎所有的情况下它都等同于View最终的宽/高。
Layout过程决定了View的四个顶点的坐标和实际的View的宽/高,完成后,可以通过getTop、getBottom、getLeft和getRight来拿到View的四个顶点的位置,并可以通过getWidth和getHeight方法来拿到View的最终宽/高
MeasureSpec代表一个32位int值,高2位代表SpecMode(测量模式),低30位代表SpecSize(在某种测量模式下的规格大小)
- UNSPECIDIED:父容器不对View有任何限制,要多大给多大,这种情况一般用于系统内部,表示一种测量的状态
- EXACTLY:父容器已经检测出View所需要的精确大小,这个时候View的最终大小就是SpecSize所指定的值。它对应于LayoutParams中的match_parent和具体的数值这两种模式
- AT_MOST:父容器指定了一个可用大小即SpecSize,View的大小不能大于这个值,具体是什么值要不同View的具体实现。它对应于LayoutParams中的wrap_content
- 对于顶级View(即DecorView),其MeasureSpec由窗口的尺寸和其自身的LayoutParams来共同决定
- 对于普通View,其MeasureSpec由父容器的MeasureSpec和其自身的LayoutParams来共同决定
View的工作流程主要是指measure、layout、draw这三大流程,即测量、布局和绘制
measure过程:如果只是一个原始的View,那么通过measure方法就完成了其测量过程,如果是一个ViewGroup,除了完成自己的测量过程外,还会去遍历调用所有子元素的measure方法
在Activity执行onCreate、onStart和onResume时获取View宽高:
- Actiivty/View#onWindowFocusChanged:会被调用多次,当Activity的窗口得到焦点和失去焦点时均会被调用一次
- view.post(runnable)
- ViewTreeObserver
- view.measure方法:该方法比较复杂。
draw过程步骤如下:
- 绘制背景background.draw(canvas)
- 绘制自己(onDraw)
- 绘制children(dispatchDraw)
- 绘制装饰(onDrawScrollBars)
View有个特殊的方法setWillNotDraw。默认情况下,View没有启用这个优化标记位,但ViewGroup会默认启用这个优化标记位。当明确知道一个ViewGroup需要通过onDraw来绘制内容时,我们需要显式地关闭WILL_NOT_DRAW这个标记位
- 继承View重写onDraw方法
- 继承ViewGroup派生特殊的Layout
- 继承特定的View(如TextView)
- 继承特定的View(如LinearLayout)
这种方法主要用于实现一些不规则的效果,即这种效果不方便通过布局的组合方式来达到,往往需要静态或者动态地显示一些不规则的图形。采用这种方法需要自己支持wrap_content,并且padding也需要自己处理(因为如果View在布局中使用wrap_content,getDefaultSize()方法中AT_MOST与EXACTLY模式下,返回的都是specSize,这种情况下View的specSize等于parentSize)
这种方法主要用于实现自定义的布局,即除了LinearLayout、RelativeLayout、FrameLayout这几种系统的布局之外,我们重新定义一种新布局,当某种效果看起来很像几种View组合在一起时,可以用此方法实现。采用这种方式稍微复杂一些,需要合适地处理ViewGroup的测量、布局这两个过程,并同时处理子元素的测量和布局过程。
这种方法比较常见,一般用于扩展某种已有View的功能。这种方法不需要自己支持wrap_content和padding
这种方法也比较常见,当某种效果看起来很像几种View组合在一起的时候,可以采用这种方法。采用这种方法不需要自己处理ViewGroup的测量和布局这两个过程,与方法2的区别是,方法2能实现的效果方法4也都能实现,而方法2更接近View的底层。
- 让View支持wrap_content
因为直接继承View或者ViewGroup的控件,如果不在onMeasure中对wrap_content做特殊处理的话,在布局中使用wrap_content就相当于使用match_parent
-
如果有必要,让你的View支持padding
因为直接继承View的控件,如果不在draw中处理padding,那么padding就无法起作用。另外直接继承自ViewGroup的控件需要在onMeasure和onLayout中考虑padding和子元素的margin对其造成的影响,不然将导致padding和子元素的margin失效
-
尽量不要在View中使用Handler,没必要
因为View内部本身就提供了post系列的方法,完全可以替代Handler的作用,除非很明确使用Handler来发消息
- View中如果有线程或动画,需及时停止,参考View#onDetachedFromWindow
若不及时处理这种问题,会导致内存泄漏
- View带有滑动嵌套情形时,需要处理好滑动冲突

-
无/白色:绘制1次
-
蓝色:绘制2次(理想状态)
-
绿色:绘制3次
-
浅红:绘制4次(要优化了)
-
深红:绘制5次或5次以上。(必须要优化了)
引起过度绘制的两个主要因素:层级与背景图片
- 层级为透明时(不添加背景),不会引起过度绘制,但会引起测量、布局、绘画时间的显著提高。
- 改变View形状,也算是绘制一层。添加一个椭圆形的黑色背景,算作两层
- 值得注意的是,背景图片的绘制是及其耗时的
- 去除主题背景色
Android主题Window会被默认被添加一个纯色的背景,该背景被DecorView持有的。可以在主题中去掉
<item name="android:windowBackground">@null</item>
如果设成其他颜色,而有些activity是不需要主题背景色的,可以在onCreate方法中添加
getWindow().setBackgroundDrawableResource(android.R.color.transparent);
或
getWindow().setBackgroundDrawable(null);
- 去除其他非必要背景
- 按需显示占位背景图片
- 如在Adapter里中的ImageView在拿到图片时占位图才显示,否则把ImageView的Background设置为Transparent
- 对于使用Selector当背景的Layout(比如ListView的Item,会使用Selector来标记点击,选择等不同的状态),可以将normal状态的color设置为
@android:color/transparent来解决对应的问题
- 自定义控件使用
clipRect()和quickReject()优化- 当某些控件不可见时,如果还继续绘制更新该控件,就会导致过度绘制。但是通过 Canvas
clipRect()方法可以设置需要绘制的区域,当某个控件或者 View 的部分区域不可见时,就可以减少过度绘制。
- 当某些控件不可见时,如果还继续绘制更新该控件,就会导致过度绘制。但是通过 Canvas
- 使用merge减少层级
- Activity或Fragment的默认根布局是FrameLayout
- Merge只能作为XML布局的根标签使用,当Inflate以merge开头的布局文件时,必须指定一个父ViewGroup,并且必须设定attachToRoot为true。
- 各大布局性能比较
- 布局嵌套层数相同情况效率对比:LinearLayout ≈ FrameLayout > RelativeLayout
- 在布局层级一样的情况下 ,建议使用LinearLayout代替RelativeLayout, 因为LinearLayout性能要稍高一点
- 在完成相对较复杂的布局时,建议使用RelativeLayout,RelativeLayout可以简单实现LinearLayout嵌套才能实现的布局
- layout_weight属性的LinearLayout会在绘制时花费昂贵的系统资源,因为每一个子组件都需要被测量两次
- Layout尽量宽而浅,而不是窄而深
- 使用ViewStub标签来加载一些不常用的布局
View的onDraw方法要避免执行大量的操作
1.onDraw中不要创建新的局部对象,因为onDraw会被频繁调用,会导致产生大量的临时对象,不仅会占用过多的内存而且会导致系统更加频繁的gc
2.onDraw中不要做耗时的操作,会导致每帧的绘制时间超过16ms,造成绘制卡顿
-
单例造成的内存泄露
由于单例的静态特性使得单例的生命周期和应用的生命周期一样长,这就说明了如果一个对象已经不需要使用了,而单例对象还持有该对象的引用,那么这个对象将不能被正常回收,这就导致了内存泄漏。
解决方法是使用Application的context
-
非静态内部类创建静态实例造成的内存泄漏
因为非静态内部类默认会持有外部类的引用,而又使用了该非静态内部类创建了一个静态的实例
-
Handler造成的泄露
解决方式是使用弱引用
-
资源未关闭造成的内存泄漏
使用LeakCanary工具检测内存泄露
LeakCanary的使用是通过install方法即可,它会返回RefWatcher对象。该对象是通过RefWatcherBuilder类创建,运用Builder模式,如果不重写该类,会使用默认配置AndroidRefWatcherBuilder。
RefWatcherBuilder类里有
private ExcludedRefs excludedRefs;//排除列表
private HeapDump.Listener heapDumpListener;
private DebuggerControl debuggerControl;
private HeapDumper heapDumper;//是接口,其实现是AndroidHeapDumper
private WatchExecutor watchExecutor;//是接口,其实现是AndroidWatchExecutor
private GcTrigger gcTrigger;//触发GC玩了一款DancingLine游戏,发现广告特别多,然后有些关卡需要通过金币购买,分析可得它是通过SharedPreferences配置文件保存相关数据的,所以思路可以是程序启动时替换掉原字段值。有个data.save 文件放在assets目录下,其实该文件是个zip包。至于xml里的key可以用JustDecompile 反编译Assembly-CSharp.dll 来分析查看,通过分析可得,在Monetyzation 命名空间里的CoinsController 类里
当然除了通过Java方式的破解,还可以去修改Assembly-CSharp.dll 来破解。但有些Unity3D制作的游戏,在解包后发现已经被il2cpp过了,Managed文件夹下传统的dll被编译到lib下的libil2cpp.so 了,这样就不能再通过修改Assembly-CSharp.dll 来破解了。
Android为什么提供Handler机制->因为只能主线程访问UI->但是又不能在UI主线程进行耗时操作,否则会ANR->所以必须子线程获取数据后再去更新UI->这就需要Handler来传递数据更新UI了
为什么不允许子线程访问UI->Android的UI控件不是线程安全的->为什么不加锁呢->加锁会让UI访问的逻辑变得复杂,锁机制会降低UI访问的效率
ThreadLocal:当某些数据是以线程为作用域并且不同线程具有不同的数据副本时,可以考虑采用ThreadLocal
- Handler:分发和处理消息队列里的Message
- Looper:是MessageQueue的管理者,每个线程中只有一个Looper(但是工作线程默认不创建Looper),它是一个死循环,不断的从MessageQueue中取出Message,发送给Handler处理
- MessageQueue:消息队列,用来存放Message对象的数据结构。内部采用单链表(因单链表在插入和删除上比较有优势)的数据结构来存储消息列表,按照FIFO的原则存放消息。
总结表述:Handler将消息传递给Looper,然后Looper将消息放入MessageQueue里,Looper一直以死循环的方式在读取消息队列里的消息,并将其广播出去,相应的handler收到消息后,调用相应的handler对象的handleMessage()方法进行处理。
一个线程中只有一个Looper实例,一个MessageQueue实例,可以有多个Handler实例
Looper对象的创建是通过prepare函数来实现的,同时也会创建一个MessageQueue对象。Looper是MessageQueue的管理者。每一个MessageQueue都不能脱离Looper而存在,两者总是共存亡的。
Android系统会在启动的时候为UI主线程创建一个MessageQueue和Looper。即主线程中有默认的Looper和MessageQueue。但是,创建的工作线程默认是没有MessageQueue和Looper的。所以调用Looper.getMainLooper()得到主线程的Looper不为NULL,但调用Looper.myLooper() 得到当前线程的Looper就有可能为NULL
调用Looper.prepare()来创建MessageQueue后,必须调用Looper.loop()来真正进入消息循环
如何处理Message则由用户指定,三个判断,优先级从高到低:
- Message里面的Callback,一个实现了Runnable接口的对象,其中run函数做处理工作;
- Handler里面的mCallback指向的一个实现了Callback接口的对象,由其handleMessage进行处理;
- 处理消息Handler对象对应的类继承并实现了其中handleMessage函数,通过这个实现的handleMessage函数处理消息。
由此可见,我们实现的handleMessage方法是优先级最低的。
除Thread本身外,在Android中可以扮演线程角色的还有很多,如AsyncTask和IntentService,同时HandlerThread也是一种特殊的线程。
- AsyncTask:底层用到了线程池,封装了线程池和Handler,方便在子线程中更新UI
- IntentService:底层直接使用了线程,是一个服务,方便执行后台任务,内部采用HandlerThread来执行,当任务执行完毕后IntentService会自动退出。
- HandlerThread:底层直接使用了线程,是一种具有消息循环的线程,在它的内部可以使用Handler
- AsyncTask的对象必须在主线程中创建(因为内部用到的sHandler是一个静态的Handler,为了能够将执行环境切换到主线程,这就要求sHandler这个对象必须在主线程中创建。由于静态成员会在加载类的时候进行初始化,因此这就变相要求AsyncTask的类必须在主线程中加载)
- execute方法必须在UI线程调用
- 在Android1.6之前,AsyncTask是串行执行任务的,Android1.6的时候AsyncTask开始采用线程池里并行处理任务,但从Android3.0开始,为了避免AsyncTask所带来的并发错误,AsyncTask又采用一个线程来串行执行任务。尽管如此,在Android3.0以及后续的版本中,我们仍可以通过AsyncTask的executeOnExecutor方法来并行执行任务。
HandlerThread继承于Thread,它是一种可以使用Handler的Thread。
IntentService是一种特殊的Service,它继承了Service并且它是一个抽象类。IntentService可用于执行后台耗时的任务,当任务执行后它会自动停止,由于它是Service,因此它的优先级比单纯的线程高很多,不容易被系统杀死。
IntentService封装了HandlerThread和Handler。
RecyclerView提供了一种插拔式的体验,高度的解耦,异常的灵活,可用于替代ListView和GridView
- 通过布局管理器LayoutManager可以控制其显示方式,如列表,网格和瀑布流:LinearLayoutManager(支持横向和纵向)、GridLayoutManager和StaggeredGridLayoutManager
- 通过ItemDecoration,自定义绘制item之间的间隔(继承于
RecyclerView.ItemDecoration),support包中已自带DividerItemDecoration - 通过ItemAnimator控制item增删的动画
- 但item的点击事件必须自己写
- adapter继承于RecyclerView.Adapter
- 定义一个内部ViewHolder类,继承于RecyclerView.ViewHolder
- 重写onCreateViewHolder方法,可以根据getItemViewType方法,不同的类型使用不同的ViewHolder
- 重写onBindViewHolder方法绑定数据
- 继承于RecyclerView.ItemDecoration,然后重写onDraw方法,因为该方法先于drawChildren
- 重写getItemOffsets方法,可以通过outRect.set()为每个Item设置一定的偏移量,主要用于绘制Decorator
按照RecyclerView的设计,RecyclerView负责控制/框架,LayoutManager负责计算布局,假设将ItemClickListener放到RecyclerView上,如果要实现点击事件,首先需要确定每一个item的点击区域。但是RecyclerView无法知道每一个item的点击区域,因为LayoutManager是可以由开发者来实现的,也就是说两个View的区域是允许重叠的。如果点了A和B重叠区域到底是触发A还是B,又必须要由LayoutManager来决定。
而RecyclerView的目的是让开发者专注于每个Item和用户的交互,它并不是ListView的1:1重制版,所以谷歌还不如不写,将任务交给开发者,至少能保持源码的整洁。
RecyclerView和ListView的回收机制非常相似,但是ListView是以View作为单位进行回收,RecyclerView是以ViewHolder作为单位进行回收。Recycler是RecyclerView回收机制的实现类,它实现了四级缓存(ListView是两级):
- mAttachedScrap: 缓存在屏幕上的ViewHolder。
- mCachedViews: 缓存屏幕外的ViewHolder,默认为2个。ListView对于屏幕外的缓存都会调用getView()。
- mViewCacheExtensions: 需要用户定制,默认不实现。
- mRecyclerPool: 缓存池,多个RecyclerView共用。
结论:从性能上看,RecyclerView并没有带来显著的提升,但如果列表页展示界面,需要支持动画,或者频繁更新,局部刷新,建议使用RecyclerView,更加强大完善,易扩展;其它情况下两者都OK,但ListView在使用上会更加方便,快捷。
ConstraintLayout约束布局继承于ViewGroup,添加约束时,必须遵循以下几点:
- 每个View必须拥有至少两个约束:一个水平和一个垂直
- 只能在约束句柄和在同一平面的锚点之间创建约束,也就是说,view的垂直面(左边和右边)只能约束到另一个view的垂直面。baseline只能约束到其他baseline上
- 一个约束句柄只能用于一个约束,但是你可以创建多个约束到同一个锚点(从不同的view)
不应在ConstraintLayout中使用match_parent,而应该用**“match_constraint”(0dp)**代替
因为容器里面的控件如果设置了约束的话,控件的宽高会根据约束来确定,所以从名字上也可以看出是match_constraint,如果是match_parent的话,就该充满父容器的剩余可用大小了,所以match_parent就不被支持了。
margin和以往的使用一致,但不能为负值。当约束的widget为GONE时,可以使用相应的goneMargin,如app:layout_goneMarginLeft,不过要配合相应不带gone的margin一起使用,如android:layout_marginLeft,只有当约束的控件为GONE时,自身控件的goneMarginXXX属性才会启用。
Chains提供了在一个维度(水平或者垂直),管理一组控件的方式,链的属性由链头控制。有几种样式,默认是CHAIN_SPREAD
Guideline用于布局辅助,其属性是GONE,有水平和垂直两种
Android绘制视图都要通过三个阶段:测量->布局->绘制,而每个过程都是对视图树自顶向下的遍历操作,因此视图层次结构中嵌套越多,绘制视图所需的时间和计算功耗也越多。所以在布局时应该尽量保持层次结构宽而浅,而不是窄而深。
而ConstraintLayout 允许您构建复杂的布局,而不必嵌套 View 和 ViewGroup 元素,能够保持一个完全扁平的层次结构
BottomSheets需要配合CoordinatorLayout控件,其实也是依赖于Behavior机制的使用,有三个重要属性:
app:behavior_peekHeight="50dp"peekHeight是当Bottom Sheets关闭的时候,底部我们能看到的高度,默认是0不可见。app:behavior_hideable="true"hideable是当我们拖拽下拉的时候,bottom sheet是否能全部隐藏。- layout_behavior指向bottom_sheet_behavior,代表这是一个Bottom Sheets
setBottomSheetCallback可以监听回调的状态,onStateChanged监听状态的改变,onSlide是拖拽的回调,onStateChanged可以监听到的回调一共有5种:
- STATE_HIDDEN: 隐藏状态。默认是false,可通过
app:behavior_hideable属性设置。 - STATE_COLLAPSED: 折叠关闭状态。可通过
app:behavior_peekHeight来设置显示的高度,peekHeight默认是0。 - STATE_DRAGGING: 被拖拽状态
- STATE_SETTLING: 拖拽松开之后到达终点位置(collapsed or expanded)前的状态。
- STATE_EXPANDED: 完全展开的状态。
BottomSheets控件配合NestedScrollView、RecyclerView使用效果会更好
使用BottomSheetDialog时,继承于BottomSheetDialog即可,若要使用我们自己布局根元素的背景时,需要将BottomSheetDialog背景设为透明,方法如下:
((View) view.getParent()).setBackgroundResource(R.color.transparent);或
//使用主题,对android:colorBackground设置透明色即可
getWindow().findViewById(R.id.design_bottom_sheet).setBackgroundResource(R.color.transparent);通过show()方法展示出来的BottomSheetDialog,如果用户是通过向下滑动的方式隐藏的话,会发现无法展示了。这是由于其状态的问题造成的,因为我们在下滑隐藏BottomSheetDialog的时候,其状态变为了STATE_HIDDEN,但是其并没有销毁,重新show()的时候,自然也不会重建,每次需要展示时可以直接重新new一个对象出来。
新建一个继承于FloatingActionButton.Behavior的类,重写onStartNestedScroll、layoutDependsOn和onDependentViewChanged方法,然后在布局文件中就可以使用
app:layout_behavior='自定义Behavior类名全路径'
AppBarLayout必须是CoordinatorLayout的直接子View
然后,我们需要定义AppBarLayout与滚动视图之间的联系。在RecyclerView或者任意支持嵌套滚动的view比如NestedScrollView上添加app:layout_behavior。
support library包含了一个特殊的字符串资源@string/appbar_scrolling_view_behavior,它的值为android.support.design.widget.AppBarLayout$ScrollingViewBehavior,指向AppBarLayout.ScrollingViewBehavior,用来通知AppBarLayout这个特殊的view何时发生了滚动事件,这个behavior需要设置在触发滚动事件的view之上。
app:layout_scrollFlags属性里面必须至少启用scroll这个flag,这样这个view才会滚动出屏幕,否则它将一直固定在顶部。可以使用的其他flag有:
- enterAlways: 一旦向上滚动这个view就可见。
- enterAlwaysCollapsed: 顾名思义,这个flag定义的是何时进入(已经消失之后何时再次显示)。假设你定义了一个最小高度(minHeight)同时enterAlways也定义了,那么view将在到达这个最小高度的时候开始显示,并且从这个时候开始慢慢展开,当滚动到顶部的时候展开完毕。
- exitUntilCollapsed: 同样顾名思义,这个flag时定义何时退出,当你定义了一个minHeight,这个view将在滚动到达这个最小高度的时候消失。
CoordinatorLayout的工作原理是搜索定义了CoordinatorLayout Behavior 的子view,不管是通过在xml中使用app:layout_behavior标签还是通过在代码中对view类使用@DefaultBehavior修饰符来添加注解。当滚动发生的时候,CoordinatorLayout会尝试触发那些声明了依赖的子view。
要自己定义CoordinatorLayout Behavior,你需要实现layoutDependsOn() 和onDependentViewChanged()两个方法。比如AppBarLayout.Behavior 就定义了这两个关键方法。这个behavior用于当滚动发生的时候让AppBarLayout发生改变。
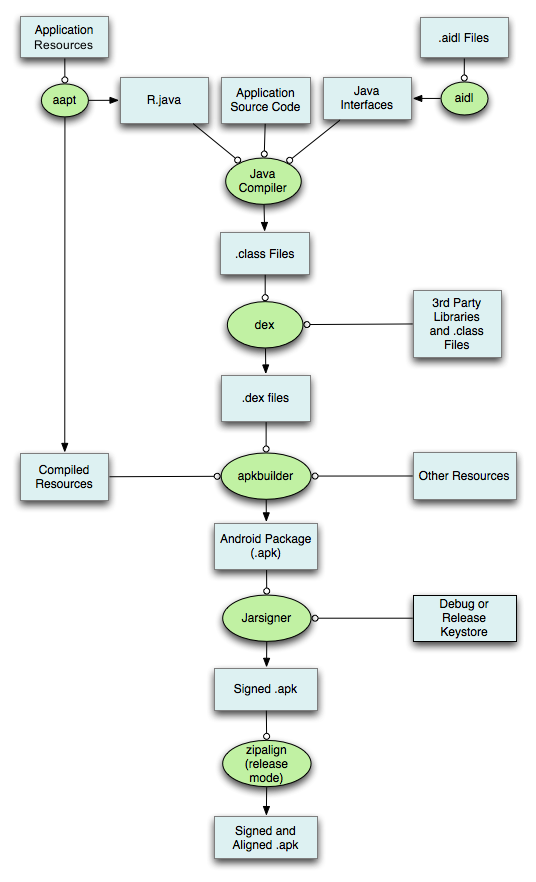
- 通过aapt打包res资源文件,生成R.java、resources.arsc和res文件(二进制 & 非二进制如res/raw和pic保持原样)
- 处理.aidl文件,生成对应的Java接口文件
- 通过Java Compiler编译R.java、Java接口文件、Java源文件,生成.class文件
- 通过dex命令,将.class文件和第三方库中的.class文件处理生成classes.dex
- 通过apkbuilder工具,将aapt生成的resources.arsc和res文件、assets文件和classes.dex一起打包生成apk
- 通过Jarsigner工具,对上面的apk进行debug或release签名
- 通过zipalign工具,将签名后的apk进行对齐处理。
在有Instant Run的环境下:一个新的App Server类会被注入到App中,与Bytecode instrumentation协同监控代码的变化。
同时会有一个新的Application类,它注入了一个自定义类加载器(Class Loader),同时该Application类会启动我们所需的新注入的App Server。于是,Manifest会被修改来确保我们的应用能使用这个新的Application类。
这里不必担心自己继承定义了Application类,Instant Run添加的这个新Application类会代理我们自定义的Application类,在attachBaseContext方法中先替换掉ClassLoader,然后再设置真正的Application类。自定义的ClassLoader名为IncrementalClassLoader,该ClassLoader很简单,就是BaseDexClassLoader的一个子类,并且将IncrementalClassLoader设置为原ClassLoader的parent,熟悉JVM加载机制的同学应该都知道,由于ClassLoader采用双亲委托模式,即委托父类加载类,父类找不到再自己去找。这样IncrementalClassLoader就变成了整个App的所有类的加载的ClassLoader,并且dexPath是/data/data/package_name/files/instant-run/dex目录下的dex列表。
至此,Instant Run已经可以跑起来了,在我们使用的时候,它会通过决策,合理运用冷温热拔插来协助我们大量地缩短构建程序的时间,其他细节可以参考从Instant run谈Android替换Application和动态加载机制。

热拔插:代码改变被应用、投射到APP上,不需要重启应用,不需要重建当前activity。
场景:适用于多数的简单改变(包括一些方法实现的修改,或者变量值修改)
温拔插:activity需要被重启才能看到所需更改。
场景:典型的情况是代码修改涉及到了资源文件,即resources。
冷拔插:app需要被重启(但是仍然不需要重新安装)
场景:任何涉及结构性变化的,比如:修改了继承规则、修改了方法签名等。
资源修复步骤:
- 构造一个新的AssetManager,并通过反射调用
addAssetPath,把这个完整的新资源包加入到AssetManager中。这样就得到了一个包含所有新资源的AssetManager - 找到所有之前引用到原有AssetManager的地方,通过反射,把引用处替换为新AssetManager
Gradle3.0.0变化很大,涉及访问 outputFile 对象的更复杂任务不再奏效。因为配置阶段期间不再创建变体特定的任务。不过仍适用于简单任务,如构建时更改APK名称。
3.0.0以前更改apk文件名及输出目录:
android.applicationVariants.all { variant ->
def version = android.defaultConfig.versionName
def time = new Date().format("MMdd_HHmm")
variant.outputs[0].outputFile = file("$project.buildDir/9158v${version}_${time}.apk")
}3.0.0及以上:
android.applicationVariants.all { variant ->
def version = android.defaultConfig.versionName
def time = new Date().format("MMdd_HHmm")
variant.getPackageApplication().outputDirectory = new File(project.buildDir.absolutePath)
variant.outputs[0].outputFileName = "9158v${version}_${time}.apk"
}
Header字段解析

为每个方法插入一段控制代码,侵入式打包
该方案基于的是Android dex分包方案,就是把多个dex文件塞入到app的classloader之中,但是Android dex拆包方案中的类是没有重复的,如果classes.dex和classes1.dex中有重复的类,当用到这个重复的类的时候,系统会选择哪个类进行加载呢?
一个ClassLoader可以包含多个dex文件,每个dex文件是一个Element,多个dex文件排列成一个有序的数组dexElements,当找类的时候,会按顺序遍历dex文件,然后从当前遍历的dex文件中找类,如果找到类则返回,如果找不到则从下一个dex文件继续查找。所以可以把有问题的类打包到一个dex(patch.dex)中去,然后把这个dex插入到Elements的最前面。
但是有一个问题,当两个调用关系的类不在同一个DEX时,就会产生异常报错。我们知道,在APK安装时,虚拟机需要将classes.dex优化成odex文件,然后才会执行。在这个过程中,会进行类的verify操作,如果调用关系的类都在同一个DEX中的话就会被打上CLASS_ISPREVERIFIED的标志,然后才会写入odex文件。
所以,为了可以正常的进行打补丁修复,必须避免类被打上CLASS_ISPREVERIFIED标志,单独放一个帮助类在独立的dex中让其他类调用。
为了解决QQ空间补丁技术由于插桩带来的效率问题,引入DEX差量包,基于 dexDiff 和 dexPatch。其主要的原理与QQ空间超级补丁技术基本相同,最大区别在于:不再将patch.dex增加到Elements数组中,而是差量的方式给出patch.dex;然后将patch.dex与应用的classes.dex合并,然后整体替换掉旧的dex,达到修复的目的。
通过hook本地方法,不侵入打包(提供了一种运行时在Native修改Filed指针的方式,实现方法的替换,达到即时生效无需重启)
阿里Hotfix 1.x在AndFix的基础上,增加了补丁管理后台;同时基于手淘的实践,针对AndFix做了大量优化, 性能上提高了兼容和稳定性;功能上支持新增类并提供了更小的补丁包(这是因为基于类方法作为粒度)
但阿里Hotfix 1.x仍存在很多限制:
- 不支持资源、so文件修复;不支持新增类方法/类字段,这是因为Hotfix 1.x本质上是Hook一个已存在的方法;
- 参数包括Long、Double、Float基本类型的方法不能被Patch,同时参数超过8的方法不能被Patch;
- 被反射调用的方法不能被Patch,具体来说是非静态方法的反射调用会提示IllegalArgumentException异常,当静态方法被反射调用,如果反射调用不涉及类对象,则可以被Patch;
- 构造方法不能被Patch,实际上不允许修改一个类字段(包括静态的和非静态的);
- 正在运行的方法不能被Patch,也就是说如果一个方法正在运行,然后方法的在Native层的结构被替换, 那么就很可能导致Crash。
最开始是手淘基于Xposed进行了改进,产生了针对Android Dalvik虚拟机运行时的Java Method Hook技术-Dexposed。该方案对底层Dalvik结构过于依赖,最终无法继续兼容Android 5.0以后的ART虚拟机,因此作罢。
后来支付宝提出了Andfix->阿里百川结合手淘使用Andfix经验,提出阿里百川Hotfix方案
最后手淘技术团队联合阿里云正式发布新一代非侵入式Android热修复方案:Sophix
代码修复有两大主要方案,一是阿里系的底层替换方案,另外一种是腾讯系的类加载方案
- 底层替换方案限制颇多,但时效性最好,加载轻快,立即见效
- 类加载方案时效性差,需要重新冷启动才能见效,但修复范围广,限制少
底层替换方案
底层替换方案是在已经加载了的类中直接替换掉原有方法,是在原有类的基础上进行修改的。因而无法实现对原有类进行方法和字段的增减,因为这样将破坏原有类的结构。
类加载方案
类加载方案的原理是在app重新启动后让Classloader去加载新的类。因为如果不重启,原来的类还在虚拟机中,就无法加载新类。

SF文件的操作:
①计算MANIFEST.MF文件的整体SHA值并用私钥签名,再经过BASE64编码后、记录在CERT.SF主属性块(在文件头上)的“SHA1-Digest-Manifest”属性值下。
②逐条计算MANIFEST.MF文件中每一条记录的SHA并用私钥签名,再经过BASE64编码后,记录在CERT.SF中的同名块中,属性的名字是“SHA1-Digest"
当采用自签名证书时,Android直接跳过验证,将证书加入了合法证书列表。这导致攻击者拿到.RSA / .DSA文件后,可以对其中的证书(除了证书拥有者公钥之外)随意篡改,包括证书序号、证书有效期、证书拥有者名字等等。而Android在安装APK时,仅仅使用了证书中的公钥,其它信息未使用也未作任何验证,只要使用公钥验证.SF文件的数字签名通过就可以正常安装使用。
Android源文件有其对应的数字摘要保证其完整性,并且有对CERT.SF的数字签名来保证其不可篡改。但是**/META-INFO文件夹中的内容没有采取任何的保护措施**,我们只要不触碰CERT.RSA中的证书公钥,以及其中的CERT.SF数字签名部分(当然这二者也保证了CERT.SF不能篡改),就可以对该文件夹做任意的恶意代码插入,并且能够保证插入代码后的apk能够正常安装,运行,而且可以和旧版本升级兼容。
HTTPS协议是具有安全性的SSL加密传输协议,如果是向ca申请证书的证书,用OkHttp或者HttpsURLConnection都可以直接访问,不需要做额外的事情,当然也可以使用自签名证书,这样的话服务器和客户端的证书要一致。
使用步骤:
-
配置HostnameVerifier
-
配置SSLSocketFactory
设置SSLSocketFoactory有两种:1.需要安全证书 2.不需要安全证书 SSLContext是负责证书管理和信任管理器的
-
先创建Java类,声明Native方法,编译成.class文件。
-
使用javah命令生成C/C++的头文件,例如:javah -jni com.android.TestJNI,则会生成一个以.h为后缀的文件com_android_TestJNI.h。
-
创建.h对应的源文件,然后实现对应的native方法
JNI中就有一个叫 JNINativeMethod的结构体来保存Java Native函数和JNI函数的一一对应关系,实现动态注册方就需要用到这个结构体。
如果要实现动态注册就必须实现JNI_OnLoad方法,这个是JNI的一个入口函数。在这里我们会去拿到JNI中一个很重要的结构体JNIEnv,env指向的就是这个结构体,通过env指针可以找到指定类名的类,并且调用JNIEnv的RegisterNatives方法来完成注册native方法和JNI函数的对应关系。
static JNINativeMethod gMethods[] = {
{"addIP", "(Ljava/lang/String;I)I", (void *) native_addIP},
{"startServer", "()I", (void *) native_startServer},
{"like", "(II)V", (void *) native_like}
};
#ifndef NELEM
#define NELEM(x) ((int)(sizeof(x) / sizeof((x)[0])))
#endifjint JNI_OnLoad(JavaVM *vm, void *reserved) {
workSock.setClientCallback(&javaRecvWork);
jvm = vm;
JNIEnv *env = nullptr;
if (vm->GetEnv((void **) &env, JNI_VERSION_1_4) != JNI_OK) {
return JNI_ERR;
}
if (env == nullptr) {
return JNI_ERR;
}
jclass jc = env->FindClass(JNI_REG_CLASS);
if (jc == nullptr) {
return JNI_ERR;
}
if (env->RegisterNatives(jc, gMethods, NELEM(gMethods)) < 0) {
return JNI_ERR;
}
return JNI_VERSION_1_4;
}回调Java层native方法时,需要先调用AttachCurrentThread,退出时调用DetachCurrentThread,形如
void CJavaRecvWork::onPhotoStatus(int photoStatus) {
int status = 0;
JNIEnv *env = 0;
status = (jvm)->AttachCurrentThread(&env, 0);
if (env == 0) return;
jmethodID mid = env->GetMethodID(jWorkSockClass, "onPhotoStatus", "(I)V");
if (mid == 0) return;
env->CallVoidMethod(jo, mid, photoStatus);
if (status > 0) jvm->DetachCurrentThread();
}对齐补齐规则
对齐原则:每一成员需对齐为后一成员类型的倍数
补齐原则:最终大小补齐为成员类型最大值的倍数
前提:在32位系统环境,编译选项为4字节对齐
struct A{
int a; //4
short b; //(4) + 2 = 6 下一元素为 int,需对齐为 4 的倍数, 6 + (2) = 8
int c; //(8) + 4 = (12)
char d; //(12) + 1 = 13, 需补齐为 4 的倍数,13 + (3) = 16
};
struct B{
int a; //4
short b; //(4) + 2 = 6,下一成员为 char 类型,不考虑对齐
char c; //(6) + 1 = 7,下一成员为 int 类型,需对其为 4 的倍数,7 + (1) = 8
int d; //(8) + 4 = 12,已是 4 的倍数
};因此,sizeof(A)=16 sizeof(B)=12
修改结构体的对齐值
- 使用伪指令#pragma pack (n),编译器将按照n个字节对齐
- 使用伪指令#pragma pack (),取消自定义字节对齐方式
优点:解耦合
缺点:接口和类多而且重复,而且V与P直接要相互通信,那么P就得持有V的实例,但如果V挂掉了,如果没有对V进行释放,还有导致内存溢出的问题(可以使用软引用,防止所持View都销毁,但presenter一直持有,导致内存泄漏)

一般MVP架构一共需要以下四步:
- 定义一个Interface接口XView,对应的Activity,Fragment实现这个Interface
- 编写Model,里面的业务逻辑主要包括网络请求获取数据,数据库读取等耗时操作,通过M层回调给P层通知V层更新UI
- 编写Presenter,P层持有V和M的引用,实现P层的回调,并且回调给V层更新
- Activity中调用P执行业务逻辑,更新UI
封装思路
Contract:契约类,一个功能模块中View接口、Model接口和请求数据回调统一在对应模块的Contract中定义,便于管理。
ViewInterface: view层接口,定义了view中的UI操作
ModelInterface: model层接口,定义了model负责的数据操作方法,如请求接口,操作数据库等
CallbackInterface: model层操作数据完成后的回调
BasePersenter: Persenter父类,主要是对相关view的获取,销毁等操作
View: view层实现类,主要就是Activity或Fragment,负责UI展示和事件响应
Model: model层实现类,就是依据业务,请求对应接口或数据库,并将结果返给回调CallBack
Persenter: persenter层类,负责业务逻辑处理,view将响应传给persenter,persenter负责调用model,并将结果返回给view供其展示
MVVM 模式将 Presenter 改名为 ViewModel,基本上与 MVP 模式完全一致。
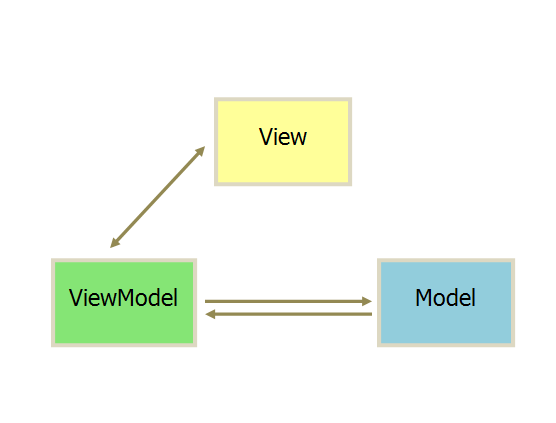
ViewModel大致上就是MVP的Presenter和MVC的Controller了,而View和ViewModel间没有了MVP的界面接口,而是直接交互,用数据“绑定”的形式让数据更新的事件不需要开发人员手动去编写特殊用例,而是自动地双向同步。数据绑定你可以认为是Observer模式或者是Publish/Subscribe模式,原理都是为了用一种统一的集中的方式实现频繁需要被实现的数据更新问题。
- 首先采集端向业务服务器发起创建房间的请求;
- 业务服务器通过 服务端 SDK 发起创建直播流的请求;
- 把返回的 JSON 返回给业务服务器,业务服务器返回给采集端并把播放地址记录在本地;
- 采集端获取到 JSON 后推流给 LiveNet,业务服务器不需要承担流媒体流量。
- 首先播放端对业务服务器发起查询房间列表请求,获取所有房间的播放地址;
- 播放端通过播放地址播放流媒体,业务服务器不需要承担流媒体流量。



视频的采集涉及两方面数据的采集:音频采集和图像采集
音频采集
音频的采集过程主要通过设备将环境中的模拟信号采集成 PCM 编码的原始数据,然后编码压缩成 MP3 等格式的数据分发出去。常见的音频压缩格式有:MP3,AAC,HE-AAC,Opus,FLAC,Vorbis (Ogg),Speex 和 AMR等。
音频采集和编码主要面临的挑战在于:延时敏感、卡顿敏感、噪声消除(Denoise)、回声消除(AEC)、静音检测(VAD)和各种混音算法等。
图像采集
图像的采集过程主要由摄像头等设备拍摄成 YUV 编码的原始数据,然后经过编码压缩成 H.264 等格式的数据分发出去。常见的视频封装格式有:MP4、3GP、AVI、MKV、WMV、MPG、VOB、FLV、SWF、MOV、RMVB 和 WebM 等。


-
美颜的主要原理是通过「磨皮+美白」来达到整体美颜的效果。磨皮的技术术语是「去噪」,也即对图像中的噪点进行去除或者模糊化处理,常见的去噪算法有均值模糊、高斯模糊和中值滤波等。因此这个环节中也涉及到人脸和皮肤检测技术。
-
滤镜,安卓有对iOS的GPUImage 库的移植,还有谷歌开源的Grafika库
-
连麦架构

基本原理
核心思想就是去除冗余信息:
- 空间冗余:图像相邻像素之间有较强的相关性
- 时间冗余:视频序列的相邻图像之间内容相似
- 编码冗余:不同像素值出现的概率不同
- 视觉冗余:人的视觉系统对某些细节不敏感
- 知识冗余:规律性的结构可由先验知识和背景知识得到
编码器的选择
- H.264
- HEVC/H.265
- VP8
- VP9
- FFmpeg
封装
就是媒体的容器,所谓容器,就是把编码器生成的多媒体内容(视频,音频,字幕,章节信息等)混合封装在一起的标准。
- AVI 格式(后缀为 .AVI)
- DV-AVI 格式(后缀为 .AVI)
- QuickTime File Format 格式(后缀为 .MOV)
- MPEG 格式(文件后缀可以是 .MPG .MPEG .MPE .DAT .VOB .ASF .3GP .MP4等)
- WMV 格式(后缀为.WMV .ASF)
- Real Video 格式(后缀为 .RM .RMVB)
- Flash Video 格式(后缀为 .FLV)
- Matroska 格式(后缀为 .MKV)
- MPEG2-TS 格式 (后缀为 .ts)
目前,我们在流媒体传输,尤其是直播中主要采用的就是 FLV 和 MPEG2-TS 格式,分别用于 RTMP/HTTP-FLV 和 HLS 协议。
推送协议
- RTMP
- WebRTC
- 基于 UDP 的私有协议
- RTMP是 Real Time Messaging Protocol(实时消息传输协议)的首字母缩写。该协议基于 TCP,是一个协议族,包括 RTMP 基本协议及 RTMPT/RTMPS/RTMPE 等多种变种。
- WebRTC,名称源自网页即时通信(英语:Web Real-Time Communication)的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的 API。
- 基于UDP私有协议,因为 UDP 在弱网环境下的优势通过一些定制化的调优可以达到比较好的弱网优化效果(省去弱网环节下的丢包重传可以降低延迟)
传输网络
传统CDN架构【树状结构】

CDN 节点的分类,主要分成两大类,骨干节点和 POP 节点,骨干节点又分为中心节点和区域节点。
- 骨干节点:中心节点,区域节点
- POP节点:边缘节点
直播CDN架构【网状结构】


握手时返回给对方的ACK序号,始终是上次收到的seq的值再加1
为什么要三次握手?
防止服务器端因为接收了早已失效的连接请求报文从而一直等待客户端请求,从而浪费资源。
“已失效的连接请求报文段”的产生在这样一种情况下:Client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。
为什么要四次挥手?
为了保证双方都能通知对方“需要释放连接”,即在释放连接后都无法接收或发送消息给对方
- 需要明确的是:TCP是全双工模式,这意味着是双向都可以发送、接收的
- 释放连接的定义是:双方都无法接收或发送消息给对方,是双向的
- 当主机1发出“释放连接请求”(FIN报文段)时,只是表示主机1已经没有数据要发送 / 数据已经全部发送完毕;
可能有人会有疑问,在TCP连接握手时为何ACK是和SYN一起发送,挥手时ACK却没有和FIN一起发送呢。原因是因为TCP是全双工模式,接收到FIN时意味将没有数据再发来,但是还是可以继续发送数据。
TCP如何保证可靠?
TCP为了保证不发生丢包,就给每个字节一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的字节发回一个相应的确认;如果发送端实体在合理的往返时延内未收到确认,那么对应的数据将会被重传。
冒泡排序算法的流程如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
public static void bubble_sort(int[] arr) {
int i, j, temp, len = arr.length;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
} 设置标志变量change
标志变量用于记录每趟冒泡排序是否发生数据元素位置交换。如果没有发生交换,说明序列已经有序了,不必继续进行下去了。
void bubble_sort(int arr[], int len) {
int i, j, change = 1;
for (i = 0; i < len - 1 && change != 0; i++) {
change = 0;
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
swap(arr[j], arr[j + 1]);
change = 1;
}
}
}1.时间复杂度
在设置标志变量之后:
当原始序列“正序”排列时,冒泡排序总的比较次数为n-1,移动次数为0,也就是说冒泡排序在最好情况下的时间复杂度为O(n);
当原始序列“逆序”排序时,冒泡排序总的比较次数为$\frac{n(n-1)}{2}$,移动次数为$\frac{3n(n-1)}{2}$次,所以冒泡排序在最坏情况下的时间复杂度为O(n²);
当原始序列杂乱无序时,冒泡排序的平均时间复杂度为O(n²)。
2.空间复杂度
冒泡排序排序过程中需要一个临时变量进行两两交换,所需要的额外空间为1,因此空间复杂度为O(1)
3.稳定性
冒泡排序在排序过程中,元素两两交换时,相同元素的前后顺序并没有改变,所以冒泡排序是一种稳定排序算法
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 以此类推,直到所有元素均排序完毕
/**
* 选择排序
*
* 1. 从待排序序列中,找到关键字最小的元素;
* 2. 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换;
* 3. 从余下的 N - 1 个元素中,找出关键字最小的元素,重复①、②步,直到排序结束。
* 仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
* @param arr 待排序数组
*/
public static void selectionSort(int[] arr){
for(int i = 0; i < arr.length-1; i++){
int min = i;
for(int j = i+1; j < arr.length; j++){ //选出之后待排序中值最小的位置
if(arr[j] < arr[min]){
min = j;
}
}
if(min != i){
int temp = arr[min]; //交换操作
arr[min] = arr[i];
arr[i] = temp;
System.out.println("Sorting: " + Arrays.toString(arr));
}
}
}①. 从第一个元素开始,该元素可以认为已经被排序
②. 取出下一个元素,在已经排序的元素序列中从后向前扫描
③. 如果该元素(已排序)大于新元素,将该元素移到下一位置
④. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
⑤. 将新元素插入到该位置后
⑥. 重复步骤②~⑤
/**
* 插入排序
*
* 1. 从第一个元素开始,该元素可以认为已经被排序
* 2. 取出下一个元素,在已经排序的元素序列中从后向前扫描
* 3. 如果该元素(已排序)大于新元素,将该元素移到下一位置
* 4. 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
* 5. 将新元素插入到该位置后
* 6. 重复步骤2~5
* @param arr 待排序数组
*/
public static void insertionSort(int[] arr){
for( int i=0; i<arr.length-1; i++ ) {
for( int j=i+1; j>0; j-- ) {
if( arr[j-1] <= arr[j] )
break;
int temp = arr[j]; //交换操作
arr[j] = arr[j-1];
arr[j-1] = temp;
System.out.println("Sorting: " + Arrays.toString(arr));
}
}
}对于一个数组,我们选定一个基准数据(例如:数组中的最后一个或者第一个元素),剩下的数据组成一个新的数组,然后遍历这个新数组中的每一个元素,分别与基准元素进行对比,分别将小于基准元素和不小于基准元素的数据区分开来,这个时候基准元素在总的数组中的位置就确定了。然后,在分别对这个两个数组进行相同的操作,直到每一个元素的位置都唯一确定下来。
①. 从数列中挑出一个元素,称为”基准”(pivot)。
②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
/**
* 快速排序(递归)
*
* ①. 从数列中挑出一个元素,称为"基准"(pivot)。
* ②. 重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
* ③. 递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
* @param arr 待排序数组
* @param low 左边界
* @param high 右边界
*/
public static void quickSort(int[] arr, int low, int high){
if(arr.length <= 0) return;
if(low >= high) return;
int left = low;
int right = high;
int temp = arr[left]; //挖坑1:保存基准的值
while (left < right){
while(left < right && arr[right] >= temp){ //坑2:从后向前找到比基准小的元素,插入到基准位置坑1中
right--;
}
arr[left] = arr[right];
while(left < right && arr[left] <= temp){ //坑3:从前往后找到比基准大的元素,放到刚才挖的坑2中
left++;
}
arr[right] = arr[left];
}
arr[left] = temp; //基准值填补到坑3中,准备分治递归快排
System.out.println("Sorting: " + Arrays.toString(arr));
quickSort(arr, low, left-1);
quickSort(arr, left+1, high);
}
基本思想:顺序查找也称为线形查找,属于无序查找算法。从数据结构线形表的一端开始,顺序扫描,依次将扫描到的结点关键字与给定值k相比较,若相等则表示查找成功;若扫描结束仍没有找到关键字等于k的结点,表示查找失败
也称为折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
**需要注意:**折半查找的前提条件是需要有序表顺序存储
/**
* 二分查找又称折半查找,它是一种效率较高的查找方法。 【二分查找要求】:1.必须采用顺序存储结构 2.必须按关键字大小有序排列。
*
* @param array 有序数组 *
* @param searchKey 查找元素 *
* @return searchKey的数组下标,没找到返回-1
*/
public static int binarySearch(int[] array, int searchKey) {
int low = 0;
int high = array.length - 1;
while (low <= high) {
int middle = (low + high) / 2;
if (searchKey == array[middle]) {
return middle;
} else if (searchKey < array[middle]) {
high = middle - 1;
} else {
low = middle + 1;
}
}
return -1;
}算法思想:将n个数据元素”按块有序”划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须”按块有序”;即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素
为什么二分查找算法一定要是折半,而不是折四分之一或者折更多呢?
二分查找中查找点计算如下:
可以改进为下面的计算方案:
也就是将上述的比例参数$\frac{1}{2}$改进为自适应的,根据关键字在整个有序表中所处的位置,让mid值的变化更靠近关键字key,这样也就间接地减少了比较次数。
斐波那契查找算法的核心在于:
1)当key=a[mid]时,查找就成功;
2)当key<a[mid]时,新范围是第low个到第mid-1个,此时范围个数为F[k-1]-1个;
3)当key>a[mid]时,新范围是第m+1个到第high个,此时范围个数为F[k-2]-1个。
就是说,如果要查找的记录在右侧,则左侧的数据都不用再判断了,不断反复进行下去,对处于当中的大部分数据,其工作效率要高一些
基本思想:对待查找的数据元素生成二叉查找树,然后将给定值和根结点的关键字进行比较,若相等,则查找成功,否则依据给定值小于或大于根结点的关键字,继续在左子树和右子树中进行查找,直至查找成功或者因左子树或右子树为空树为止,后者说明查找不成功。这个算法的查找效率很高,但是如果使用这种查找方法要首先创建二叉查找树。
其它数表查找还有
-
平衡查找树之2-3查找树(2-3 Tree)
-
平衡查找树之红黑树(Red-Black Tree)
-
B树和B+树查找(B Tree/B+ Tree)
算法思想:哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
算法流程:
- 用给定的哈希函数构造哈希表;
- 根据选择的冲突处理方法解决地址冲突;
- 常见的解决冲突的方法:拉链法和线性探测法。
- 在哈希表的基础上执行哈希查找。
-
单一职责原则(Single Responsibility Principle)
一个类应该仅有一个引起它变化的原因
-
开闭原则(Open Close Principle)
一个类应该对外扩展开放,对修改关闭
-
里氏替换原则(Liskov Substitution Principle)
所有引用基类的地方必须能透明地使用其子类的对象
-
依赖倒置原则(Dependence Inversion Principle)
要依赖于抽象,不要依赖于具体类,有以下几个关键点:
- 高层模块不应该依赖低层模块,两者都应该依赖于抽象
- 抽象不应该依赖于具体实现
- 具体实现应该依赖于抽象
-
接口隔离原则(Interface Segregation Principle)
客户端不应该依赖它不需要的接口
-
迪米特原则(Law of Demeter)
也称为最少知识原则(Least Knowledge Principle)
一个对象应该对其他对象有最少的了解
EventBus是一款针对Android的发布/订阅事件总线。它可以轻松的实现在Android各个组件之间传递消息,代码的可读性更好,耦合度更低。
EventBus中的观察者通常有四种线程模型,分别是PostThread(默认)、MainThread、BackgroundThread与Async。
- PostThread:该事件在哪个线程发布出来的,事件处理函数就会在这个线程中运行,也就是说发布事件和接收事件在同一个线程。在线程模型为PostThread的事件处理函数中尽量避免执行耗时操作,因为它会阻塞事件的传递,甚至有可能会引起ANR。
- MainThread:不论事件是在哪个线程中发布出来的,该事件处理函数都会在UI线程中执行。该方法可以用来更新UI,但是不能处理耗时操作。
- BackgroundThread:如果事件是在UI线程中发布出来的,那么该事件处理函数就会在新的线程中运行,如果事件本来就是子线程中发布出来的,那么该事件处理函数直接在发布事件的线程中执行。在此事件处理函数中禁止进行UI更新操作。
- Async:无论事件在哪个线程发布,该事件处理函数都会在新建的子线程中执行。同样,此事件处理函数中禁止进行UI更新操作。
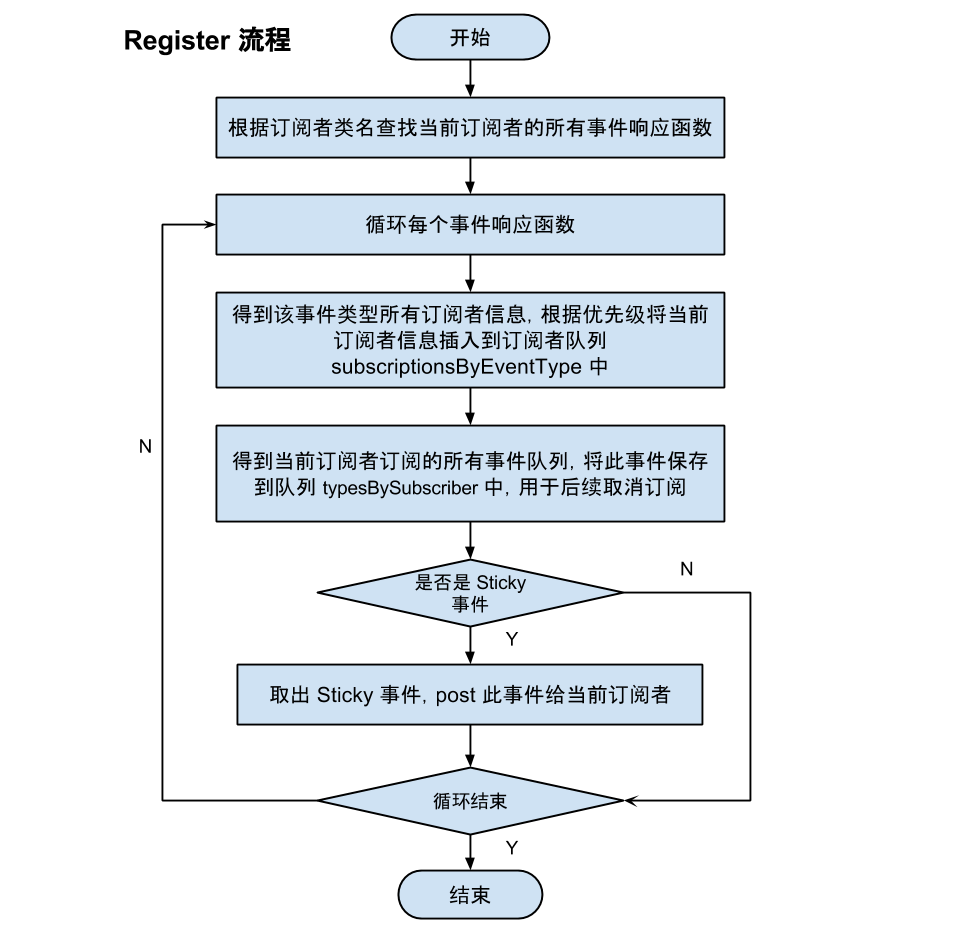
register 函数中会先根据订阅者类名去subscriberMethodFinder中查找当前订阅者所有事件响应函数,然后循环每一个事件响应函数,依次执行下面的 subscribe 函数:
subscribe
subscribe 函数分三步
第一步:通过subscriptionsByEventType得到该事件类型所有订阅者信息队列,根据优先级将当前订阅者信息插入到订阅者队列subscriptionsByEventType中;
第二步:在typesBySubscriber中得到当前订阅者订阅的所有事件队列,将此事件保存到队列typesBySubscriber中,用于后续取消订阅;
第三步:检查这个事件是否是 Sticky 事件,如果是则从stickyEvents事件保存队列中取出该事件类型最后一个事件发送给当前订阅者。
Fresco的MVC模型:
M -> DraweeHierarchy 保存和管理图像层次;
V -> DraweeView 显示DraweeHierarchy的顶层图像;
C -> DraweeController 管理其他组件,设置视图层次;
DraweeHolder:controller和hierarchy的持有类,DraweeView 通过此类和controller和hierarchy交互,起到解耦作用。
DraweeHierarchy :Fresco提供了诸如占位图(加载中,加载失败显示的图片),进度条,渐进式JPEG图,多图请求及图片复用等效果,也就是说根据图片加载过程中的不同状态要显示不同效果的图片,所以需要图像的分层管理。
public interface DraweeHierarchy {
Drawable getTopLevelDrawable();
}DraweeHierarchy代表了一个Drawee的层次,它内部维持了一个树状数据结构,DraweeHierarchy对外屏蔽了一切具体细节,只提供the top level drawable用于DraweeView的动态显示。
Fresco共用三级缓存,分别是 Bitmap缓存,未解码图片缓存, 文件缓存。
5.0以下系统:使用”ashmem”(匿名共享内存)区域存储Bitmap缓存,这样Bitmap对象的创建、释放将永远不会触发GC,关于”ashmem”存储区域,它是一个不在Java堆区的一片存储内存空间,它的管理由Linux内核驱动管理,且这块空间是可以多进程共享的,GC的活动不会影响到它。5.0以上系统,由于内存管理的优化,所以对于5.0以上的系统Fresco将Bitmap缓存直接放到了堆内存中。
Fresco为了更好地管理bitmap 对象(bitmap对象申请和释放会引起频繁的GC操作,从而引起界面卡顿), 引入了可关闭的引用(CloseableReference), 持有者在离开作用域的时候需要关闭该引用,而我们要获取的bitmap对象就是可关闭的引用。也就是说,我们只能在Fresco提供的作用域范围内使用Bitmap。
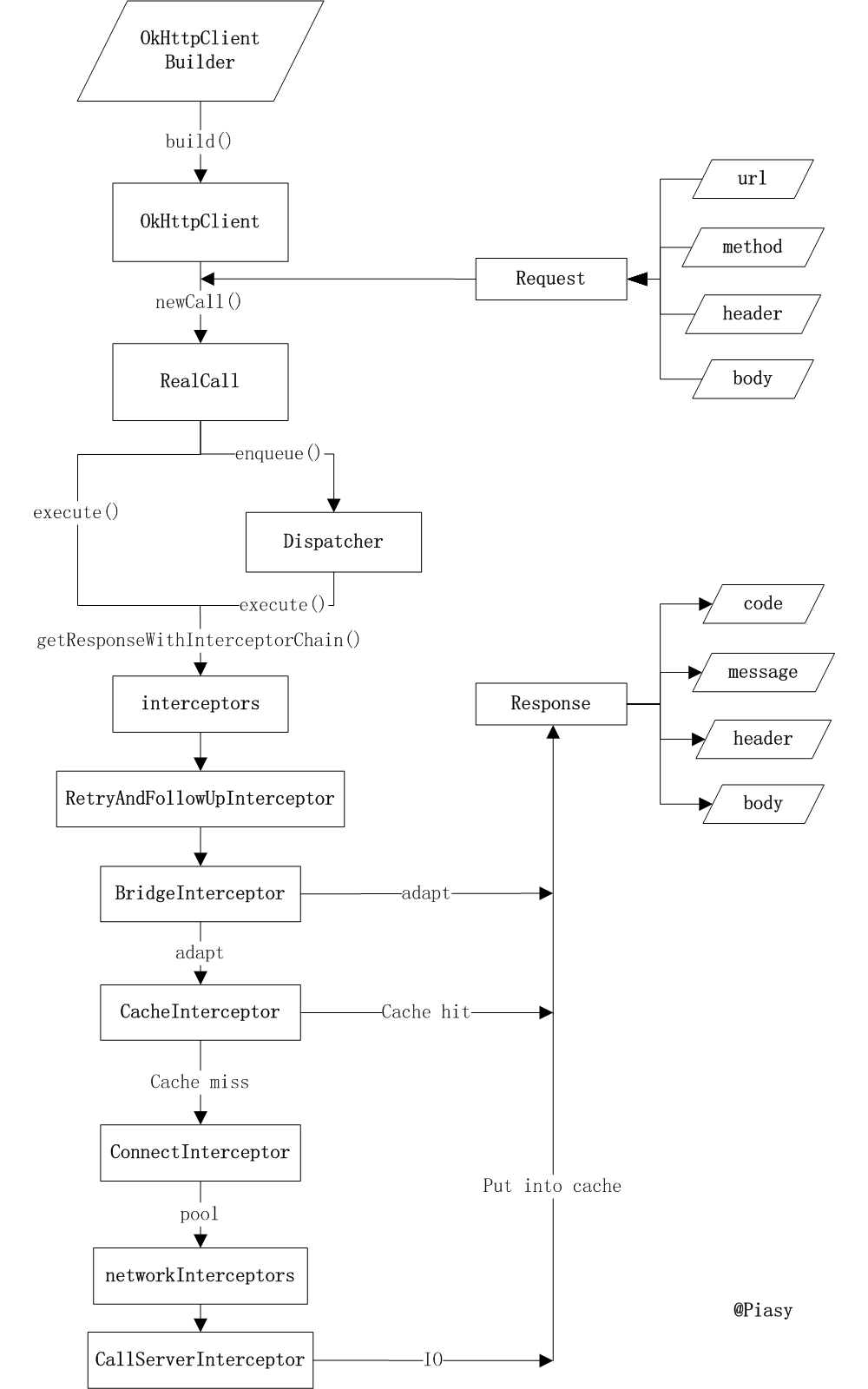
OkHttpClient实现Call.Factory,负责为Request创建Call;RealCall为具体的Call实现,其enqueue()异步接口通过Dispatcher利用ExecutorService实现,而最终进行网络请求时和同步execute()接口一致,都是通过getResponseWithInterceptorChain()函数实现;getResponseWithInterceptorChain()中利用Interceptor链条,分层实现缓存、透明压缩、网络 IO 等功能;
上面getResponseWithInterceptorChain()拦截器的依次顺序如下:
- 在配置
OkHttpClient时设置的interceptors; - 负责失败重试以及重定向的
RetryAndFollowUpInterceptor; - 负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应的
BridgeInterceptor; - 负责读取缓存直接返回、更新缓存的
CacheInterceptor; - 负责和服务器建立连接的
ConnectInterceptor; - 配置
OkHttpClient时设置的networkInterceptors; - 负责向服务器发送请求数据、从服务器读取响应数据的
CallServerInterceptor。
两个关键词:异步和简洁