Attention mask? #88
Comments
|
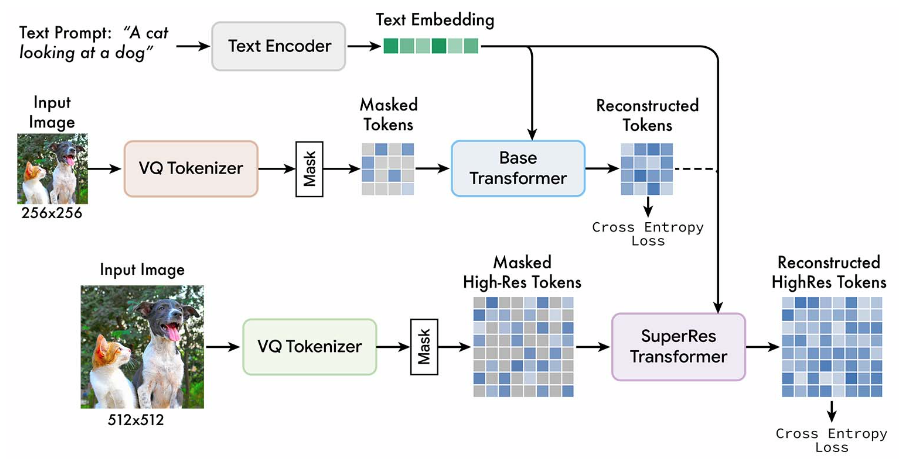
these authors reckon it's better to train on an unmasked text embeddings (even though that risks learning from PAD token embeddings): as for inference: the user needs to be able to match whatever approach was used during training. I thought Muse was a bit wackier though. it actually masks vision tokens: |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Like in Stable Diffusion, no attention mask appears to be used for input tokens:
open-muse/muse/pipeline_muse.py
Lines 93 to 101 in 2a03657
But according to third party analysis this appears to have been a mistake all along. Do we have insight on whether attention masks would help for better prompt-image alignment?
The text was updated successfully, but these errors were encountered: