Byte short int long float double boolean char

装箱就是 自动将基本数据类型转换为包装器类型;拆箱就是 自动将包装器类型转换为基本数据类型。 比如:把int转化成Integer,double转化成Double,等等。反之就是自动拆箱。
- 原始类型: boolean,char,byte,short,int,long,float,double
- 封装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
- 示例:
Integer i = 10;
这个过程中会自动根据数值创建对应的 Integer对象,这就是装箱。
那什么是拆箱呢?顾名思义,跟装箱对应,就是自动将包装器类型转换为基本数据类型:
Integer i = 10; //装箱
int n = i; //拆箱
- 对于short s1=1;s1=s1+1来说,在s1+1运算时会自动提升表达式的类型为int,那么将int赋予给short类型的变量s1会出现类型转换错误。
- 对于short s1=1;s1+=1来说 +=是java语言规定的运算符,java编译器会对它进行特殊处理,因此可以正确编译。
https://www.cnblogs.com/guodongdidi/p/6953217.html
- Integer是int的包装类,int则是java的一种基本数据类型
- Integer变量必须实例化后才能使用,而int变量不需要
- Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
- Integer的默认值是null,int的默认值是0
延伸: 关于Integer和int的比较 1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
2、Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同)
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
对于第4条的原因: java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
字节是存储容量的基本单位,字符是数子,字母,汉子以及其他语言的各种符号。1字节=8个二进制单位:一个一个字符由一个字节或多个字节的二进制单位组成。
基本类型保存原始值,引用类型保存的是引用值(引用值就是指对象在堆中所处的位置/地址)

https://blog.csdn.net/cey009008/article/details/46331619
重载(overload),Java中的方法重载发生在同一个类里面两个或者是多个方法的方法名相同但是参数不同的情况。
-1.可以在一个类中也可以在继承关系的类中;
-2.名相同;
- 3.参数列表不同(个数,顺序,类型) 和方法的返回值类型无关。
重写(override)又名覆盖,方法覆盖是说子类重新定义了父类的方法。方法覆盖必须有相同的方法名,参数列表和返回类型。覆盖者可能不会限制它所覆盖的方法的访问。:
- 1.不能存在同一个类中,在继承或实现关系的类中;
- 2.名相同,参数列表相同,方法返回值相同,
- 3.子类方法的访问修饰符要大于父类的。
- 4.子类的检查异常类型要小于父类的检查异常。
Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。java中也不可以覆盖private的方法,因为private修饰的变量和方法只能在当前类中使用,如果是其他的类继承当前类是不能访问到private变量或方法的,当然也不能覆盖。

https://www.cnblogs.com/yunche/p/9530927.html
- 1.使用new创建对象 使用new关键字创建对象应该是最常见的一种方式,但我们应该知道,使用new创建对象会增加耦合度。无论使用什么框架,都要减少new的使用以降低耦合度。
- 2.使用反射的机制创建对象 使用Class类的newInstance方法
- 3.采用clone clone时,需要已经有一个分配了内存的源对象,创建新对象时,首先应该分配一个和源对象一样大的内存空间。要调用clone方法需要实现Cloneable接口
- 4.采用序列化机制 使用序列化时,要实现实现Serializable接口,将一个对象序列化到磁盘上,而采用反序列化可以将磁盘上的对象信息转化到内存中。




https://github.com/gzc426/CS-Notes/edit/master/docs/notes/Java%20%E5%9F%BA%E7%A1%80.md
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 方法取得一个字符串引用。intern() 首先把 s1 引用的字符串放到 String Pool 中,然后返回这个字符串引用。因此 s3 和 s4 引用的是同一个字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s1.intern();
System.out.println(s3 == s4); // true如果是采用 "bbb" 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
- "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
- 而使用 new 的方式会在堆中创建一个字符串对象。
创建一个测试类,其 main 方法中使用这种方式来创建字符串对象。
public class NewStringTest {
public static void main(String[] args) {
String s = new String("abc");
}
}使用 javap -verbose 进行反编译,得到以下内容:
// ...
Constant pool:
// ...
#2 = Class #18 // java/lang/String
#3 = String #19 // abc
// ...
#18 = Utf8 java/lang/String
#19 = Utf8 abc
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
// ...在 Constant Pool 中,#19 存储这字符串字面量 "abc",#3 是 String Pool 的字符串对象,它指向 #19 这个字符串字面量。在 main 方法中,0: 行使用 new #2 在堆中创建一个字符串对象,并且使用 ldc #3 将 String Pool 中的字符串对象作为 String 构造函数的参数。
以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
在存储散列集合时〔如Set类),如果原对象equals新对象,但没有对 hashCode重写,即两个对象拥有不同的hashCode,则在集合中将会存储两个值相同的对象,从而导致混看。因此在重写 equals方法时,必须重写 hashCode
https://www.cnblogs.com/xiaoxi/p/6036701.html
String c = "xx" + "yy " + a + "zz" + "mm" + b; 实质上的实现过程是: String c = new StringBuilder("xxyy ").append(a).append("zz").append("mm").append(b).toString();
底层通过 StringBuilder实现
FileReader类是将文件按字符流的方式读取char数组或者String.FileInputStream则按字符流的方式读取文件byte数组。
- 1.首先获得一个文件句柄。 File fille= new File();file即为文件句柄。两人之间连 通电话网络了。接下来可以开始打电话了
- 2.通过这条线路读取甲方的信息: new FileInputStream(fe)目前这个信息已经 读进来内存当中了。接下来需要解读成乙方可以理解的东西
- 3.既然你使用了 FileInputStream()。那么对应的需要使用 InputStreamReader() 这个方法进行解读刚才装进来内存当中的数据
- 4.解读完成后要输出呀。那当然要转换成IO可以识别的数据呀。那就需要调用字节 码读取的方法 Bufferedreader()。同时使用 bufferedReader()的 readline()方 法读取txt文件中的每一行数据哈。


反射机制中可以获取private成员的值吗(没有set和get函数)
- Java运行时环境(JRE)。它包括Java虚拟机、Java核心类库和支持文件。它不包含开发工具(JDK)--编译器、调试器和其他工具。
- Java开发工具包(JDK)是完整的Java软件开发包,包含了JRE,编译器和其他的工具(比如:JavaDoc,Java调试器),可以让开发者开发、编译、执行Java应用程序。


1.final关键字提高了性能。JVM和Java应用都会缓存final变量。 2.final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销。 3.使用final关键字,JVM会对方法、变量及类进行优化。
static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。

答:垃圾回收器(garbage colector)决定回收某对象时,就会运行该对象的finalize()方法 但是在Java中很不幸,如果内存总是充足的,那么垃圾回收可能永远不会进行,也就是说filalize()可能永远不被执行,显然指望它做收尾工作是靠不住的。 那么finalize()究竟是做什么的呢?它最主要的用途是回收特殊渠道申请的内存。Java程序有垃圾回收器,所以一般情况下内存问题不用程序员操心。但有一种JNI(Java Native Interface)调用non-Java程序(C或C++),finalize()的工作就是回收这部分的内存。
finally 一定会被执行,如果 finally 里有 return 语句,则覆盖 try/catch 里的 return , 比较爱考的是 finally 里没有 return 语句,这时虽然 finally 里对 return 的值进行了修改,但 return 的值并不改变这种情况
无论是否抛出异常,finally代码块都会执行,它主要是用来释放应用占用的资源。finalize()方法是Object类的一个protected方法,它是在对象被垃圾回收之前由Java虚拟机来调用的。

- hashcode()
- equals()
- toString()
- getClass()
- wait
- notify()
- notifyAll()
- finalize()
- (1)对于==,如果作用于基本数据类型的变量(byte,short,char,int,long,float,double,boolean ),则直接比较其存储的"值"是否相等;如果作用于引用类型的变量(String),则比较的是所指向的对象的地址(即是否指向同一个对象)。
- (2)equals方法是基类Object中的方法,因此对于所有的继承于Object的类都会有该方法。在Object类中,equals方法是用来比较两个对象的引用是否相等,即是否指向同一个对象。
- (3)对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;而String类对equals方法进行了重写,用来比较指向的字符串对象所存储的字符串是否相等。其他的一些类诸如Double,Date,Integer等,都对equals方法进行了重写用来比较指向的对象所存储的内容是否相等。
- (4)StringBuffer 和StringBuilder,==和equal都是比较地址

Throwable.是ava话言中所有错误和异常的超类(万物即可抛).艺有两个子类:Eror、 Exception 异常种类
- Err:Eror为错误,是程序无法处理的,如 Out OfMemoryεror、 Thread Death等,出现这种况你唯一能做的就 是听之任之,交由M来处理,不过M在大多数情况下会选择终止程
- Exception: Exception.是程序可以处理的异常。E又分为两种 CheckedException(受捡异常),一种是
UncheckedException(不受检异常)
- CheckException发生在编译阶段,必须要使用ry- catch(或者 throws)否则编译不通过
- UncheckedException发生在运行期,具有不确症性,主要是由于程序的逻辑引起的,难以排查,如除0的产生的异常,我们一般都需要纵观全局才能够发现这类的异常错误,所以在程序设计中我们需要认真考虐,好好写代码,尽量处理异常,即使产生了异常,也能尽量保证程序朝着有利方向发展,ClassCastException(类转换异常) IndexOutOfBoundsException(数组越界) NullPointerException(空指针) ArrayStoreException(数据存储异常,操作数组时类型不一致)
Runtime:运行时,是一个封装了JVM的类。每一个JAVA程序实际上都是启动了一个JVM进程,每一个JVM进程都对应一个Runtime实例,此实例是由JVM为其实例化的。所以我们不能实例化一个Runtime对象,应用程序也不能创建自己的 Runtime 类实例,但可以通过 getRuntime 方法获取当前Runtime运行时对象的引用。一旦得到了一个当前的Runtime对象的引用,就可以调用Runtime对象的方法去控制Java虚拟机的状态和行为。 查看官方文档可以看到,Runtime类中没有构造方法,本类的构造方法被私有化了, 所以才会有getRuntime方法返回本来的实例化对象,这与单例设计模式不谋而合 public static Runtime getRuntime() 直接使用此静态方法可以取得Runtime类的实例
1.接口和抽象类的区别 1,抽象类里可以有构造方法,而接口内不能有构造方法。 2,抽象类中可以有普通成员变量,而接口中不能有普通成员变量。 3,抽象类中可以包含非抽象的普通方法,而接口中所有的方法必须是抽象的,不能有非抽象的普通方法。 4,抽象类中的抽象方法的访问类型可以是public ,protected和private,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。 5,抽象类中可以包含静态方法,接口内不能包含静态方法。 6,抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static类型,并且默认为public static final类型。 7,一个类可以实现多个接口,但只能继承一个抽象类。
- Java抽象类可以有构造函数吗? 可以有,抽象类可以声明并定义构造函数。因为你不可以创建抽象类的实例,所以构造函数只能通过构造函数链调用(Java中构造函数链指的是从其他构造函数调用一个构造函数),例如,当你创建具体的实现类。现在一些面试官问,如果你不能对抽象类实例化那么构造函数的作用是什么?好吧,它可以用来初始化抽象类内部声明的通用变量,并被各种实现使用。另外,即使你没有提供任何构造函数,编译器将为抽象类添加默认的无参数的构造函数,没有的话你的子类将无法编译,因为在任何构造函数中的第一条语句隐式调用super(),Java中默认超类的构造函数。
- Java抽象类可以实现接口吗?它们需要实现所有的方法吗? 可以,抽象类可以通过使用关键字implements来实现接口。因为它们是抽象的,所以它们不需要实现所有的方法。好的做法是,提供一个抽象基类以及一个接口来声明类型 。这样的例子是,java.util.List接口和相应的java.util.AbstractList抽象类。因为AbstractList实现了所有的通用方法,具体的实现像LinkedList和ArrayList不受实现所有方法的负担,它们可以直接实现List接口。这对两方面都很好,你可以利用接口声明类型的优点和抽象类的灵活性在一个地方实现共同的行为。Effective Java有个很好的章节,介绍如何使用Java的抽象类和接口,值得阅读。
- Java抽象类可以是final的吗? 不可以,Java抽象类不能是final的。将它们声明为final的将会阻止它们被继承,而这正是使用抽象类唯一的方法。它们也是彼此相反的,关键字abstract强制继承类,而关键字final阻止类被扩张。在现实世界中,抽象表示不完备性,而final是用来证明完整性。底线是,你不能让你的Java类既abstract又final,同时使用,是一个编译时错误。
- Java抽象类可以有static方法吗? 可以,抽象类可以声明并定义static方法,没什么阻止这样做。但是,你必须遵守Java中将方法声明为static的准则,
- 可以创建抽象类的实例吗? 不可以,你不能创建Java抽象类的实例,它们是不完全的。即使你的抽象类不包含任何抽象方法,你也不能对它实例化。将类声明为abstract的,就等你你告诉编译器,它是不完全的不应该被实例化。当一段代码尝试实例化一个抽象类时Java编译器会抛错误。
- 抽象类必须有抽象方法吗? 不需要,抽象类有抽象方法不是强制性的。你只需要使用关键字abstract就可以将类声明为抽象类。编译器会强制所有结构的限制来适用于抽象类,例如,现在允许创建一些实例。是否在抽象类中有抽象方法是引起争论的。我的观点是,抽象类应该有抽象方法,因为这是当程序员看到那个类并做假设的第一件事。这也符合最小惊奇原则。
- 何时选用抽象类而不是接口? 这是对之前抽象类和接口对比问题的后续。如果你知道语法差异,你可以很容易回答这个问题,因为它们可以令你做出抉择。当关心升级时,因为不可能在一个发布的接口中添加一个新方法,用抽象类会更好。类似地,如果你的接口中有很多方法,你对它们的实现感到很头疼,考虑提供一个抽象类作为默认实现。这是Java集合包中的模式,你可以使用提供默认实现List接口的AbstractList。
- Java中的抽象方法是什么? 抽象方法是一个没有方法体的方法。你仅需要声明一个方法,不需要定义它并使用关键字abstract声明。Java接口中所有方法的声明默认是abstract的。这是抽象方法的例子 public void abstract printVersion(); 现在,为了实现这个方法,你需要继承该抽象类并重载这个方法。
- Java抽象类中可以包含main方法吗? 是的,抽象类可以包含main方法,它只是一个静态方法,你可以使用main方法执行抽象类,但不可以创建任何实例。
https://www.cnblogs.com/acm-bingzi/p/javaAnnotation.html
http://www.importnew.com/24029.html
- (1)Java中的泛型是什么 ? 使用泛型的好处是什么? 这是在各种Java泛型面试中,一开场你就会被问到的问题中的一个,主要集中在初级和中级面试中。那些拥有Java1.4或更早版本的开发背景的人都知道,在集合中存储对象并在使用前进行类型转换是多么的不方便。泛型防止了那种情况的发生。它提供了编译期的类型安全,确保你只能把正确类型的对象放入集合中,避免了在运行时出现ClassCastException。
- (2)Java的泛型是如何工作的 ? 什么是类型擦除 ? 这是一道更好的泛型面试题。泛型是通过类型擦除来实现的,编译器在编译时擦除了所有类型相关的信息,所以在运行时不存在任何类型相关的信息。例如List在运行时仅用一个List来表示。这样做的目的,是确保能和Java 5之前的版本开发二进制类库进行兼容。你无法在运行时访问到类型参数,因为编译器已经把泛型类型转换成了原始类型。根据你对这个泛型问题的回答情况,你会得到一些后续提问,比如为什么泛型是由类型擦除来实现的或者给你展示一些会导致编译器出错的错误泛型代码。请阅读我的Java中泛型是如何工作的来了解更多信息。
- (3)什么是泛型中的限定通配符和非限定通配符 ? 这是另一个非常流行的Java泛型面试题。限定通配符对类型进行了限制。有两种限定通配符,一种是它通过确保类型必须是T的子类来设定类型的上界,另一种是它通过确保类型必须是T的父类来设定类型的下界。泛型类型必须用限定内的类型来进行初始化,否则会导致编译错误。另一方面表示了非限定通配符,因为<?>可以用任意类型来替代。更多信息请参阅我的文章泛型中限定通配符和非限定通配符之间的区别。
- (4)List<? extends T>和List <? super T>之间有什么区别 ? 这和上一个面试题有联系,有时面试官会用这个问题来评估你对泛型的理解,而不是直接问你什么是限定通配符和非限定通配符。这两个List的声明都是限定通配符的例子,List<? extends T>可以接受任何继承自T的类型的List,而List<? super T>可以接受任何T的父类构成的List。例如List<? extends Number>可以接受List或List。在本段出现的连接中可以找到更多信息。
- (5)如何编写一个泛型方法,让它能接受泛型参数并返回泛型类型? 编写泛型方法并不困难,你需要用泛型类型来替代原始类型,比如使用T, E or K,V等被广泛认可的类型占位符。泛型方法的例子请参阅Java集合类框架。最简单的情况下,一个泛型方法可能会像这样:
public V put(K key, V value) {
return cache.put(key, value);
}
- (6)Java中如何使用泛型编写带有参数的类? 这是上一道面试题的延伸。面试官可能会要求你用泛型编写一个类型安全的类,而不是编写一个泛型方法。关键仍然是使用泛型类型来代替原始类型,而且要使用JDK中采用的标准占位符。
- (7)编写一段泛型程序来实现LRU缓存? 对于喜欢Java编程的人来说这相当于是一次练习。给你个提示,LinkedHashMap可以用来实现固定大小的LRU缓存,当LRU缓存已经满了的时候,它会把最老的键值对移出缓存。LinkedHashMap提供了一个称为removeEldestEntry()的方法,该方法会被put()和putAll()调用来删除最老的键值对。当然,如果你已经编写了一个可运行的JUnit测试,你也可以随意编写你自己的实现代码。
- (8)你可以把List传递给一个接受List参数的方法吗? 对任何一个不太熟悉泛型的人来说,这个Java泛型题目看起来令人疑惑,因为乍看起来String是一种Object,所以List应当可以用在需要List的地方,但是事实并非如此。真这样做的话会导致编译错误。如果你再深一步考虑,你会发现Java这样做是有意义的,因为List可以存储任何类型的对象包括String, Integer等等,而List却只能用来存储Strings。
- (9)Array中可以用泛型吗? 这可能是Java泛型面试题中最简单的一个了,当然前提是你要知道Array事实上并不支持泛型,这也是为什么Joshua Bloch在Effective Java一书中建议使用List来代替Array,因为List可以提供编译期的类型安全保证,而Array却不能。
- (1)) 如何阻止Java中的类型未检查的警告? 如果你把泛型和原始类型混合起来使用,例如下列代码,Java 5的javac编译器会产生类型未检查的警告,例如
- (A)FileOutputStream(File name) 创建一个文件输出流,向指定的 File 对象输出数据。
- (B)FileOutputStream(FileDescriptor) 创建一个文件输出流,向指定的文件描述器输出数据。
- (C)FileOutputStream(String name) 创建一个文件输出流,向指定名称的文件输出数据。
- (D)FileOutputStream(String, boolean) 用指定系统的文件名,创建一个输出文件。
- 1、字节流在操作的时候本身是不会用到缓冲区(内存)的,是与文件本身直接操作的,而字符流在操作的时候是使用到缓冲区的
- 2、字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容
- 3、Reader类的read()方法返回类型为int :作为整数读取的字符(占两个字节共16位),范围在 0 到 65535 之间 (0x00-0xffff),如果已到达流的末尾,则返回 -1 inputStream的read()虽然也返回int,但由于此类是面向字节流的,一个字节占8个位,所以返回 0 到 255 范围内的 int 字节值。如果因为已经到达流末尾而没有可用的字节,则返回值 -1。因此对于不能用0-255来表示的值就得用字符流来读取!比如说汉字.
- (1) 父类静态代码块(包括静态初始化块,静态属性,但不包括静态方法)
- (2) 子类静态代码块(包括静态初始化块,静态属性,但不包括静态方法 )
- (3) 父类非静态代码块( 包括非静态初始化块,非静态属性 )
- (4) 父类构造函数
- (5) 子类非静态代码块 ( 包括非静态初始化块,非静态属性 )
- (6) 子类构造函数
List<String> rawList = new ArrayList()
https://blog.csdn.net/woshizisezise/article/details/79374460
public static <T> void show1(List<T> list){
for (Object object : list) {
System.out.println(object.toString());
}
}
public static void show2(List<?> list) {
for (Object object : list) {
System.out.println(object);
}
}
public static void test(){
List<Student> list1 = new ArrayList<>();
list1.add(new Student("zhangsan",18,0));
list1.add(new Student("lisi",28,0));
list1.add(new Student("wangwu",24,1));
//这里如果add(new Teacher(...));就会报错,因为我们已经给List指定了数据类型为Student
show1(list1);
System.out.println("************分割线**************");
//这里我们并没有给List指定具体的数据类型,可以存放多种类型数据
List list2 = new ArrayList<>();
list2.add(new Student("zhaoliu",22,1));
list2.add(new Teacher("sunba",30,0));
show2(list2);
}
从show2方法可以看出和show1的区别了,list2存放了Student和Teacher两种类型,同样可以输出数据,所以这就是T和?的区别啦
https://www.cnblogs.com/huangliting/p/5746950.html https://www.cnblogs.com/huangliting/p/5746950.html
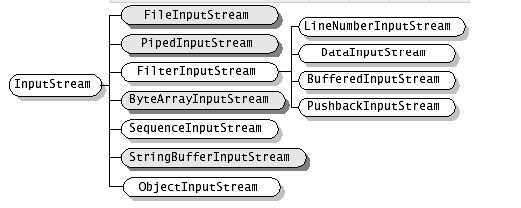
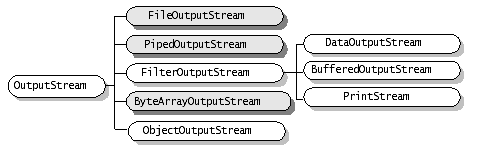

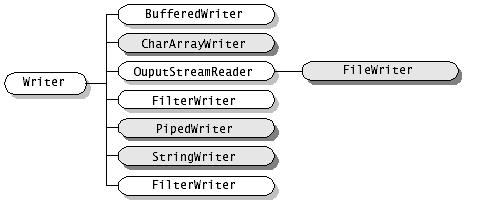
InputStream,OutputStream,Reader,writer都是抽象类。所以不能直接new
字节流和字符流使用是非常相似的,那么除了操作代码的不同之外,还有哪些不同呢? 区别:
字节流:处理字节和字节数组或二进制对象; 字符流:处理字符、字符数组或字符串。
一、字符(Reader和 Writer):中文,字符是只有在内存中才会形成的,操作字符、字符数组或字符串, 二、字节(InputStream 和OutputStream):音频文件、图片、歌曲,所有的硬盘上保存文件或进行传输的时候,操作字节和字节数组或二进制对象, *如果要java程序实现一个拷贝功能,应该选用字节流进行操作(可能拷贝的是图片),并且采用边读边写的方式(节省内存)。
面试和笔试经常考
类的加载顺序。
Math 类中提供了三个与取整有关的方法:ceil、floor、round,这些方法的作用与它们的英 文名称的含义相对应,例如,ceil 的英文意义是天花板,该方法就表示向上取整, Math.ceil(11.3)的结果为12,Math.ceil(-11.3)的结果是-11;floor 的英文意义是地板,该方法 就表示向下取整,Math.ceil(11.6)的结果为11,Math.ceil(-11.6)的结果是-12;最难掌握的是 round 方法,它表示“四舍五入”,算法为 Math.floor(x+0.5),即将原来的数字加上0.5后再向 下取整,所以,Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11。
作业帮面试题
char 型变量是用来存储 Unicode 编码的字符的,unicode 编码字符集中包含了汉字,所以, char 型变量中当然可以存储汉字啦。不过,如果某个特殊的汉字没有被包含在 unicode 编 码字符集中,那么,这个 char 型变量中就不能存储这个特殊汉字。补充说明:unicode 编 码占用两个字节,所以,char 类型的变量也是占用两个字节。