Static analysis and reporting for file-format reports generated by digital preservation tools, DROID and Siegfried.
Working example Siegfried: Siegfried Govdocs Select Results...
Working example DROID: DROID Govdocs Select Results...
Utility for the analysis of DROID CSV and Seigfried file-format reports. The tool has three purposes:
- break the export into its components and store them within a set of tables in a SQLite database for performance and consistent access;
- provide additional information about a collection's profile where useful;
- and query the SQLite database, outputting results in a visually pleasant report for further analysis by digital preservation specialists and archivists.
For departments on-boarding archivists or building digital capability, the report contains descriptions, written by archivists for each of the statistics output.

This Code4Lib article published early in 2022 describes some of the important information in file-format reports that appear, in-aggregate. It describes the challenges of accessing that information consistently also.
This utility was first written in 2013. The code was pretty bad, but worked. It wrapped a lot of technical debt into a small package.
The 2020/2021 refactor tries to do three things:
- Fix minor issues.
- Make compatible with Python 3 and temporarily, one last time with Python 2.
- Add unit tests.
Adding unit tests is the key to your contributions and greater flexibility with refactoring. One a release candidate is available of this work, there is more freedom to think about next steps including exposing queries more generically so that more folk can work with sqlitefid. And finding more generic API-like abstractions in general so the utility is less like a monolith and more like a configurable static analysis engine analogous to something you might work with in Python or Golang.
See the following blogs for more information:
- [2014-06-03] On the creation of this tool
- [2015-08-25] Creating a digital preservation rogues gallery
- [2016-05-23] Consistent and repeatable digital preservation reporting
- [2016-05-24] A multi-lingual lingua-franca and exploring ID methods
COPTR Link: DROID_Siegfried_Sqlite_Analysis_Engine
There are three components to the tool.
Adds identification data to an SQLite database that forms the basis of the entire analysis. There are five tables.
- DBMD - Database Metadata
- FILEDATA - File manifest and filesystem metadata
- IDDATA - Identification metadata
- IDRESULTS - FILEDATA/IDRESULTS junction table
- NSDATA - Namespace metadata, also secondary key (NS_ID) in IDDATA table
Will also augment DROID or Siegfried export data with additional columns:
- URI_SCHEME: Separates the URI_SCHEME from the DROID URI column. This is to enable the identification of container objects found in the export specifically, and the distinction of files stored in container objects from standalone files.
- DIR_NAME: Returns the base directory name from the file path to enable analysis of directory names, e.g. the number of directories in the collection.
Outputs an analysis from extensive querying of the SQLite database created by sqlitefid,
HTML is the default report output, with plain-text, and file-listings also available.
It is a good idea to run the analysis and > pipe the result to a file, e.g.
python demystify.py --export my_export.csv > my_analysis.htm.
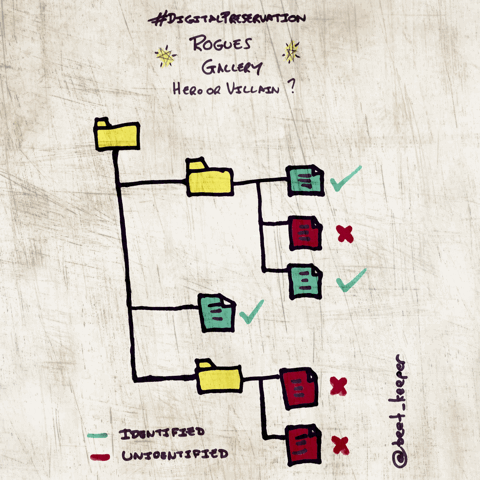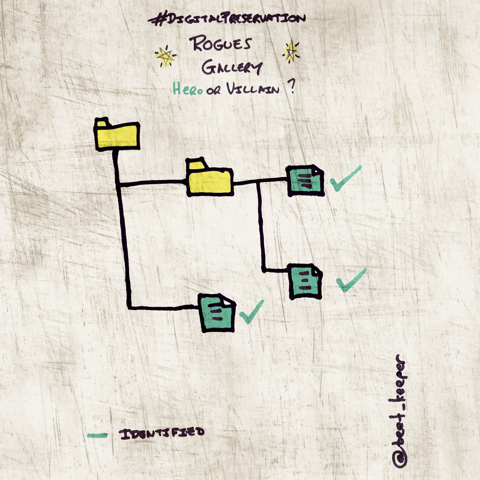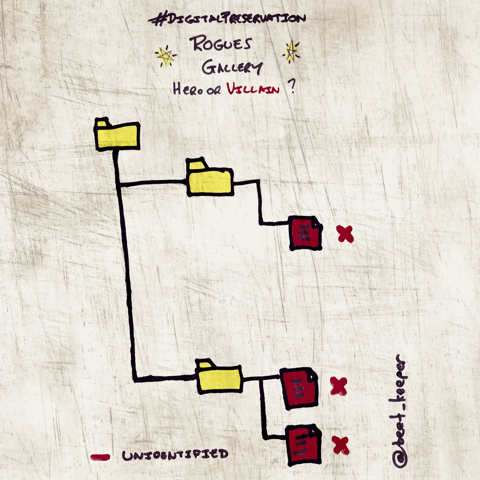
The following flags provide Rogue or Hero output:
--rogues
Outputs a list of files returned by the identification tool that might require more analysis e.g. non-IDs, multiple IDs, extension mismatches, zero-byte objects and duplicate files.
--heroes
Outputs a list of files considered to need less analysis.
The options can be configured by looking at denylist.cfg. More information
can be found here.
A string analysis engine created to highlight when string values, e.g. file paths might need more care taken of them in a digital preservation environment, e.g. so we don't lose diacritics during transfer - providing a checklist of items to look at.
Includes:
- Class to handle analysis of non-recommended filenames from Microsoft.
- Copy of a library from Cooper Hewitt to enable writing of plain text descriptions of Unicode characters.
The tool is designed to be easily modified to create your own output by using the Analysis Results class as a further abstraction layer (API).

The recent re-factor resulted in more generic python data structures being returned from queries and less (if not zero) formatted output. This means a little more work has to be put into presentation of results, but it is more flexible to what you want to do.
Tests are being implemented to promote the reliability of data returned.
There should be no dependencies associated with this tool. That being said,
you may need lxml for HTML output. An alternative may be found as the tool is
refactored.
If we can maintain a state of few repositories then it should promote use across a wide-number of institutions. This has been driven by my previous two working environments where installing Python was the first challenge... PIP and the ability to get hold of code dependencies another - especially on multiple user's machines where we want this tool to be successful.
Summary/Aggregate Binary / Text / Filename identification statistics are output with the following priority:
Namespace (e.g. ordered by PRONOM first [configurable])
- Binary and Container Identifiers
- XML Identifiers
- Text Identifiers
- Filename Identifiers
- Extension Identifiers
We need to monitor how well this works. Namespace specific statistics are also output further down the report.
- Internationalizing archivist descriptions here.
- Improved container listing/handling.
- Improved 'directory' listing and handling.
- Output formatting unit tests!
As you use the tool or find problems, please report them. If you find you are missing summaries that might be useful to you please let me know. The more the utility is used, the more we can all benefit.
I have started a discussion topic for improvements: here.
Installation should be easy. Until the utility is packaged, you need to do the following:
- Find a directory you want to install demystify to.
- Run
git clone. - Navigate into the demystify repository,
cd demystify. - Checkout the sub-modules (pathlesstaken, and sqlitefid):
git submodule update --init --recursive. - Install
lxml:python -m pip install -r requirements/production.txt. - Run tests to make sure everything works:
tox -e py39.
NB. tox is cool. If you're working on this code and want to format it
idiomatically, run tox -e linting. If there are errors, they will point to
where you may need to improve your code.
A virtual environment is recommended in some instances, e.g. you don't want to pollute your Python environment with other developer's code. To do this, for Linux you can do the following:
- Create a virtual environment:
python3 -m virtualenv venv-py3. - Activate the virtual environment:
source venv-py3/bin/activate.
Then follow the installation instructions above this.
See the Releases section on GitHub.
Copyright (c) 2013 Ross Spencer
This software is provided 'as-is', without any express or implied warranty. In no event will the authors be held liable for any damages arising from the use of this software.
Permission is granted to anyone to use this software for any purpose, including commercial applications, and to alter it and redistribute it freely, subject to the following restrictions:
The origin of this software must not be misrepresented; you must not claim that you wrote the original software. If you use this software in a product, an acknowledgment in the product documentation would be appreciated but is not required.
Altered source versions must be plainly marked as such, and must not be misrepresented as being the original software.
This notice may not be removed or altered from any source distribution.