diff --git a/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
index 613a45d2e..546ea6ebb 100644
--- a/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/all-columns-anomalies.mdx
@@ -24,7 +24,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
-- elementary.all_columns_anomalies:
timestamp_column: column name
column_anomalies: column monitors list
- dimensions: list
+ dimensions: sql expression
exclude_prefix: string
exclude_regexp: regex
where_expression: sql expression
diff --git a/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
index e48b157fc..fd88dbab9 100644
--- a/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/column-anomalies.mdx
@@ -22,7 +22,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
tests:
-- elementary.column_anomalies:
column_anomalies: column monitors list
- dimensions: list
+ dimensions: sql expression
timestamp_column: column name
where_expression: sql expression
anomaly_sensitivity: int
diff --git a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
index fffea01c1..b564514fc 100644
--- a/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
+++ b/docs/data-tests/anomaly-detection-tests/volume-anomalies.mdx
@@ -24,7 +24,7 @@ No mandatory configuration, however it is highly recommended to configure a `tim
tests:
- -- elementary.volume_anomalies:
+ - elementary.volume_anomalies:
timestamp_column: column name
where_expression: sql expression
anomaly_sensitivity: int
diff --git a/docs/data-tests/how-anomaly-detection-works.mdx b/docs/data-tests/how-anomaly-detection-works.mdx
index 4a2817968..f2c2663f1 100644
--- a/docs/data-tests/how-anomaly-detection-works.mdx
+++ b/docs/data-tests/how-anomaly-detection-works.mdx
@@ -54,7 +54,7 @@ If a value in the detection set is an outlier to the expected range, it will be
### Expected range
Based of the values in the training test, we calculate an expected range for the monitor.
-Each data point in the detection period will be compared to the expected range calculated based on it’s training set.
+Each data point in the detection period will be compared to the expected range calculated based on its training set.
### Training period
diff --git a/docs/data-tests/introduction.mdx b/docs/data-tests/introduction.mdx
index 1f28c4238..f844d255b 100644
--- a/docs/data-tests/introduction.mdx
+++ b/docs/data-tests/introduction.mdx
@@ -41,7 +41,7 @@ Tests to detect anomalies in data quality metrics such as volume, freshness, nul
title="Event freshness anomalies"
href="/data-tests/anomaly-detection-tests/event-freshness-anomalies"
>
- Monitors the gap between the latest event timestamp and it's loading time, to
+ Monitors the gap between the latest event timestamp and its loading time, to
detect event freshness issues.
diff --git a/docs/features/alerts-and-incidents/alert-configuration.mdx b/docs/features/alerts-and-incidents/alert-configuration.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/cloud/guides/alert-rules.mdx b/docs/features/alerts-and-incidents/alert-rules.mdx
similarity index 94%
rename from docs/cloud/guides/alert-rules.mdx
rename to docs/features/alerts-and-incidents/alert-rules.mdx
index 3716c2893..199820163 100644
--- a/docs/cloud/guides/alert-rules.mdx
+++ b/docs/features/alerts-and-incidents/alert-rules.mdx
@@ -2,7 +2,7 @@
title: "Alert rules"
---
-Elementary cloud allows you to create rules that route your alerts.
+Elementary Cloud allows you to create rules that route your alerts.
Each rule is a combination of a filter and a destination.
The Slack channel you choose when connecting your Slack workspace is automatically added as a default alert rule, that sends all the alerts to that channel without any filtering.
diff --git a/docs/features/alerts-and-incidents/alerts-and-incidents-overview.mdx b/docs/features/alerts-and-incidents/alerts-and-incidents-overview.mdx
new file mode 100644
index 000000000..c20f9a1f0
--- /dev/null
+++ b/docs/features/alerts-and-incidents/alerts-and-incidents-overview.mdx
@@ -0,0 +1,37 @@
+---
+title: Alerts and Incidents Overview
+sidebarTitle: Alerts & incidents overview
+---
+
+
+
+Alerts and incidents in Elementary are designed to shorten your time to response and time to resolution when data issues occur.
+
+- **Alert -** Notification about an event that indicates a data issue.
+- **[Incident](/features/alerts-and-incidents/incidents) -** A data issue that starts with an event, but can include several events grouped to an incident. An incident has a start time, status, severity, assignee and end time.
+
+Alerts provide information and context for recipients to quickly triage, prioritize and resolve issues.
+For collaboration and promoting ownership, alerts include owners and tags.
+You can create distribution rules to route alerts to the relevant people and channels, for faster response.
+
+An alert would either open a new incident, or be automatically grouped and added to an ongoing incident.
+From the alert itself, you can update the status and assignee of an incident. In the [incidents page](/features/alerts-and-incidents/incident-management),
+you will be able to track all open and historical incidents, and get metrics on the quality of your response.
+
+## Alerts & incidents core functionality
+
+- **Alert distribution rules** -
+- **Incident status and assignee** -
+- **Owners and subscribers** -
+- **Severity and tags** -
+- **Alerts customization** -
+- **Group alerts to incidents** -
+- **Alerts suppression** -
+
+## Alert types
+
+
+
+## Supported alert integrations
+
+
\ No newline at end of file
diff --git a/docs/features/alerts-and-incidents/effective-alerts-setup.mdx b/docs/features/alerts-and-incidents/effective-alerts-setup.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/alerts-and-incidents/incident-management.mdx b/docs/features/alerts-and-incidents/incident-management.mdx
new file mode 100644
index 000000000..dac4ae81a
--- /dev/null
+++ b/docs/features/alerts-and-incidents/incident-management.mdx
@@ -0,0 +1,54 @@
+---
+title: Incident Management
+sidebarTitle: Incident management
+---
+
+
+
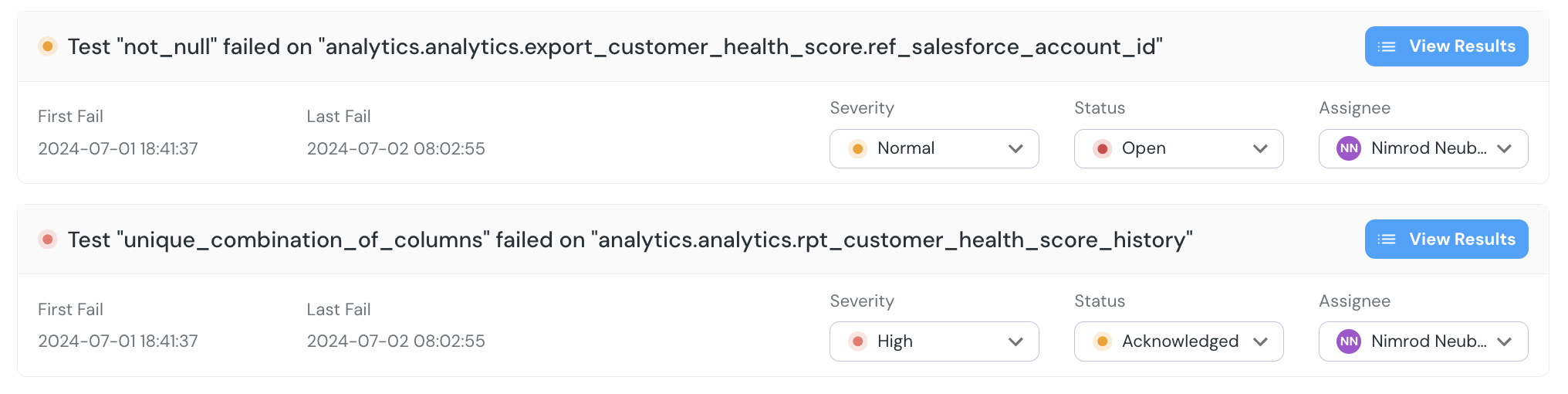
+The `Incidents` page is designed to enable your team to stay on top of open incidents and collaborate on resolving them.
+The page gives a comprehensive overview of all current and previous incidents, where users can view the status, prioritize, assign and resolve incidents.
+
+## Incidents view and filters
+
+The page provides a view of all incidents, and useful filters:
+
+- **Quick Filters:** Preset quick filters for all, unresolved and “open and unassigned” incidents.
+- **Filter:** Allows users to filter incidents based on various criteria such as status, severity, model name and assignee.
+- **Time frame:** Filter incidents which were open in a certain timeframe.
+
+
+
+
+## Interacting with Incidents
+
+An incident has a status, assignee and severity.
+These can be set in the Incidents page, or from an alert in integrations that support alert actions.
+
+- **Incident status**: Will be set to `open` by default, and can be changed to `Acknowledged` and back to `Open`. When an alert is manually or automatically set as `Resolved`, it will close and will no longer be modified.
+- **Incident assignee**: An incident can be assigned to any user on the team, and they will be notified.
+ - If you assign an incident to a user, it is recommended to leave the incident `Open` until the user changes status to `Acknowledged`.
+- **Incident severity**: Users can set a severity level (High, Low, Normal, Critical) to an incident. _Coming soon_ Severity will be automated by an analysis of the impacted assets.
+
+## Incidents overview and metrics
+
+The top bar of the page present aggregated metrics on incidents, to provide an overall status.
+You will also be able to track your average resolution time.
+
+_ _Coming soon_ _ The option to create and share a periodic summary of incidents will be supported in the future.
+
+
+
+

+
+
+
 -
-
-## Supported automated monitors
-
-### Volume
-
-Monitors how much data was added / removed / updated to the table with each update.
-The monitor alerts you if there is an unexpected drop or spike in rows.
-
-### Freshness
-
-Monitors how frequently a table is updated, and alerts you if there is an unexpected delay.
-
-### Schema changes
-
-_Coming soon_
diff --git a/docs/features/ci.mdx b/docs/features/ci.mdx
index c17753e90..588ea4df6 100644
--- a/docs/features/ci.mdx
+++ b/docs/features/ci.mdx
@@ -1,7 +1,6 @@
---
title: "Elementary CI"
sidebarTitle: "Elementary CI"
-icon: "code-pull-request"
---
@@ -15,7 +14,7 @@ You'll also be able to see if any of your dbt tests are failing or your models a
-
-
-## Supported automated monitors
-
-### Volume
-
-Monitors how much data was added / removed / updated to the table with each update.
-The monitor alerts you if there is an unexpected drop or spike in rows.
-
-### Freshness
-
-Monitors how frequently a table is updated, and alerts you if there is an unexpected delay.
-
-### Schema changes
-
-_Coming soon_
diff --git a/docs/features/ci.mdx b/docs/features/ci.mdx
index c17753e90..588ea4df6 100644
--- a/docs/features/ci.mdx
+++ b/docs/features/ci.mdx
@@ -1,7 +1,6 @@
---
title: "Elementary CI"
sidebarTitle: "Elementary CI"
-icon: "code-pull-request"
---
@@ -15,7 +14,7 @@ You'll also be able to see if any of your dbt tests are failing or your models a
 -Elementary CI automations will help you make changes with confidence and seeing the full picture before merging your pull request.
+Elementary CI automations help you make changes with confidence by providing a comprehensive view before merging your pull request.
## Want to join the beta?
diff --git a/docs/features/catalog.mdx b/docs/features/collaboration-and-communication/catalog.mdx
similarity index 84%
rename from docs/features/catalog.mdx
rename to docs/features/collaboration-and-communication/catalog.mdx
index 5f61a58b4..3004b4018 100644
--- a/docs/features/catalog.mdx
+++ b/docs/features/collaboration-and-communication/catalog.mdx
@@ -1,13 +1,11 @@
---
title: "Data Catalog"
-icon: "folder-tree"
-iconType: "solid"
---
On the Catalog tab you can now explore your datasets information - descriptions, columns, columns descriptions, latest update time and datasets health.
-From the dataset you can navigate directly to it’s lineage and test results.
+From the dataset you can navigate directly to its lineage and test results.
The catalog content is generated from the descriptions you maintain in your dbt project YML files.
diff --git a/docs/features/data-observability-dashboard.mdx b/docs/features/collaboration-and-communication/data-observability-dashboard.mdx
similarity index 97%
rename from docs/features/data-observability-dashboard.mdx
rename to docs/features/collaboration-and-communication/data-observability-dashboard.mdx
index 7dd10b357..afb567124 100644
--- a/docs/features/data-observability-dashboard.mdx
+++ b/docs/features/collaboration-and-communication/data-observability-dashboard.mdx
@@ -1,6 +1,5 @@
---
title: Data Observability Dashboard
-icon: "browsers"
---
Managing data systems can be a complex task, especially when there are hundreds (or even thousands) of models being orchestrated separately across multiple DAGs. These models serve different data consumers, including internal stakeholders, clients, and reverse-ETL pipelines.
diff --git a/docs/features/config-as-code.mdx b/docs/features/config-as-code.mdx
index 804899bdf..de7526a49 100644
--- a/docs/features/config-as-code.mdx
+++ b/docs/features/config-as-code.mdx
@@ -1,11 +1,10 @@
---
-title: "Configuration as Code"
-icon: "code"
+title: "Configuration-as-Code"
---
-All Elementary configuration is managed in your dbt code.
+All Elementary configurations are managed in your dbt code.
Configuring observability becomes a part of the development process that includes version control, continuous integration, and a review process.
-In Elementary Cloud, you can save time by adding tests in bulk from the UI that will be added to your code. Additionally, you can allow data analysts to create quality tests without writing any code. Elementary will take care of it for them and open pull requests for them.
+In Elementary Cloud, you can save time by adding tests in bulk from the UI that will be added to your code. Additionally, you can allow data analysts to create quality tests without writing any code. Elementary will take care of it for them and open pull requests on their behalf.
diff --git a/docs/features/data-governance/define-ownership.mdx b/docs/features/data-governance/define-ownership.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/data-governance/leverage-tags.mdx b/docs/features/data-governance/leverage-tags.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/data-governance/overview-and-best-practices.mdx b/docs/features/data-governance/overview-and-best-practices.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/column-level-lineage.mdx b/docs/features/data-lineage/column-level-lineage.mdx
similarity index 63%
rename from docs/features/column-level-lineage.mdx
rename to docs/features/data-lineage/column-level-lineage.mdx
index d94b067ed..a88474b56 100644
--- a/docs/features/column-level-lineage.mdx
+++ b/docs/features/data-lineage/column-level-lineage.mdx
@@ -1,38 +1,42 @@
---
-title: Column Level Lineage
-sidebarTitle: Column Level Lineage
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
---
+
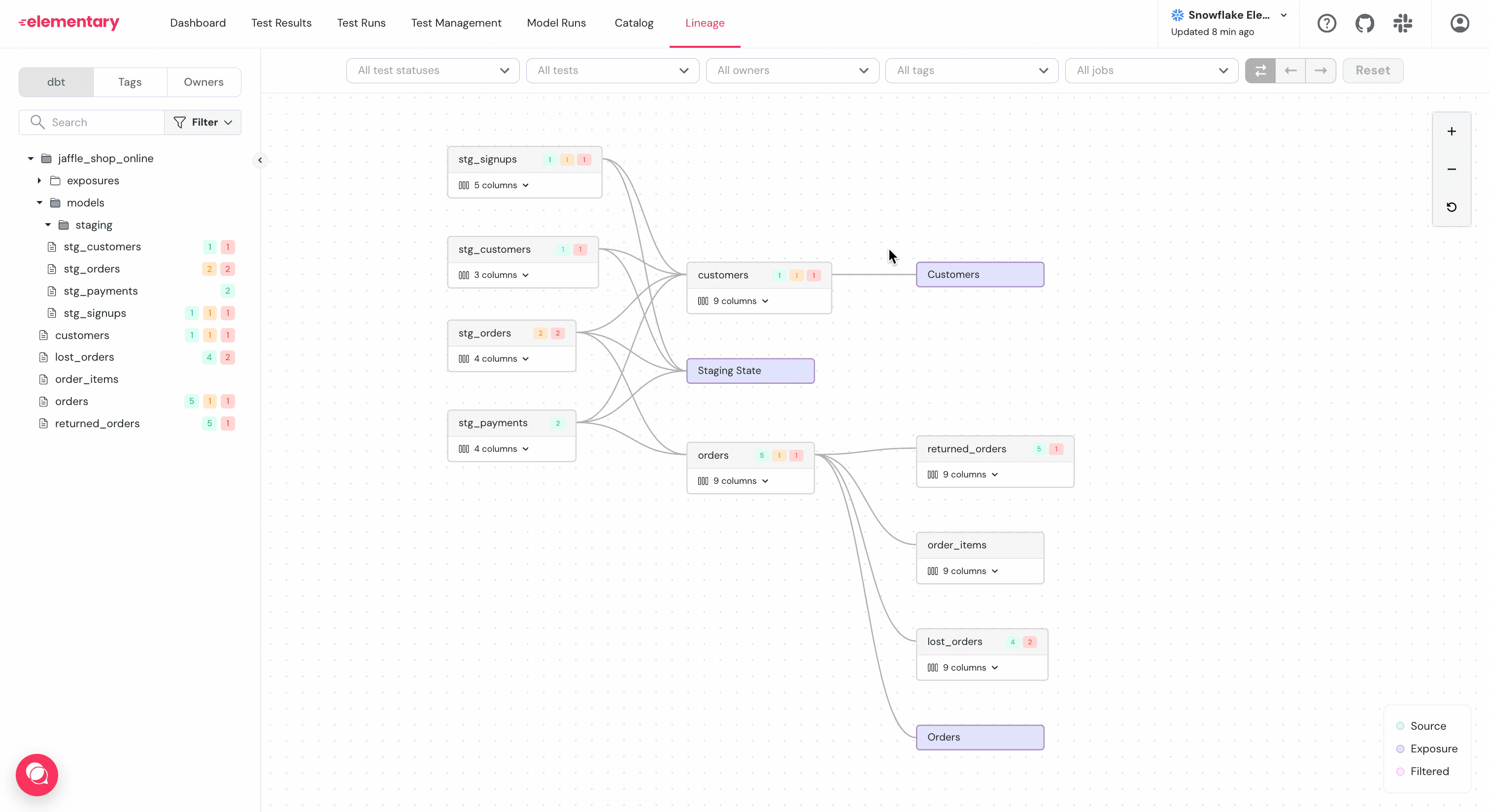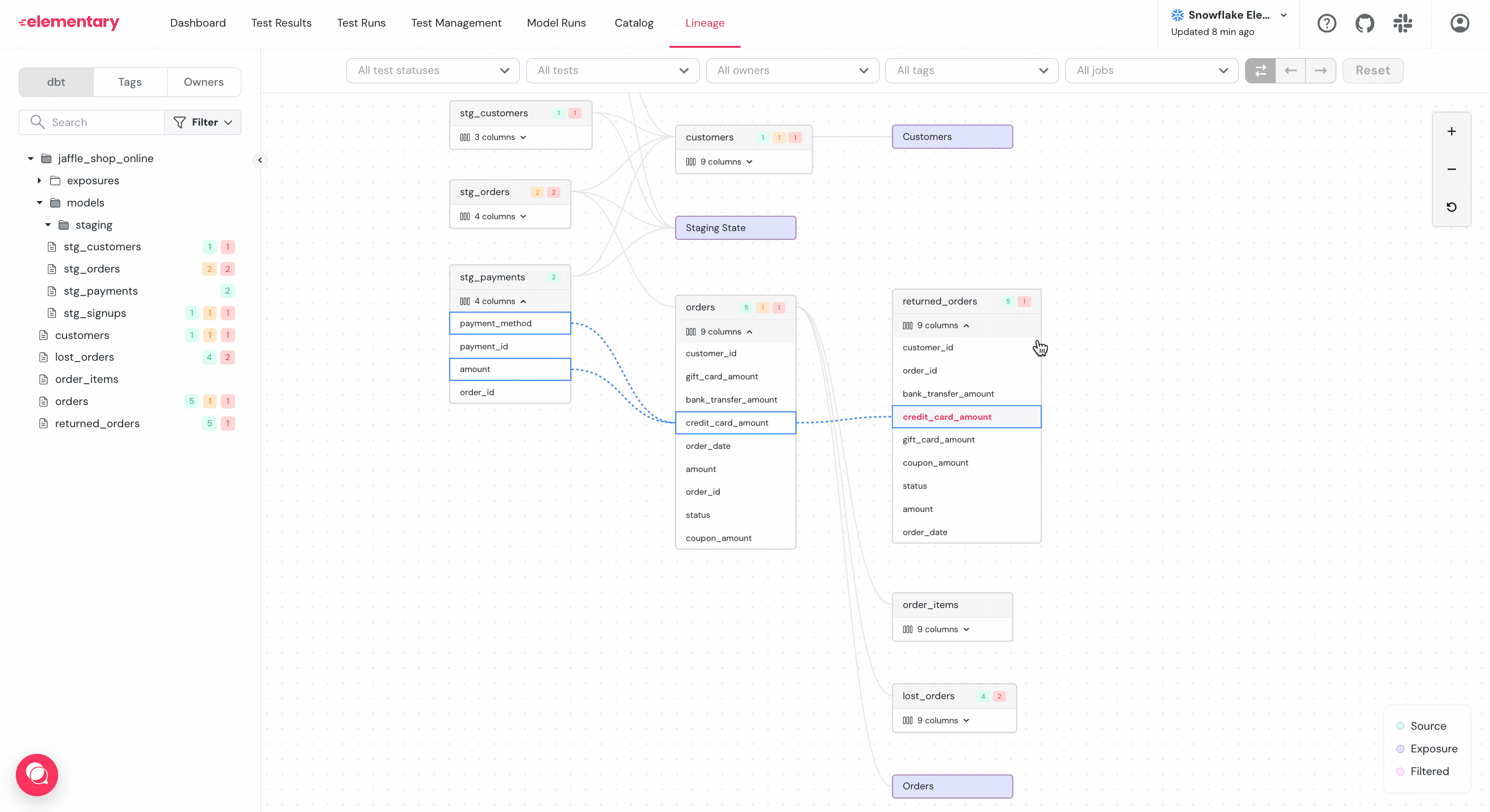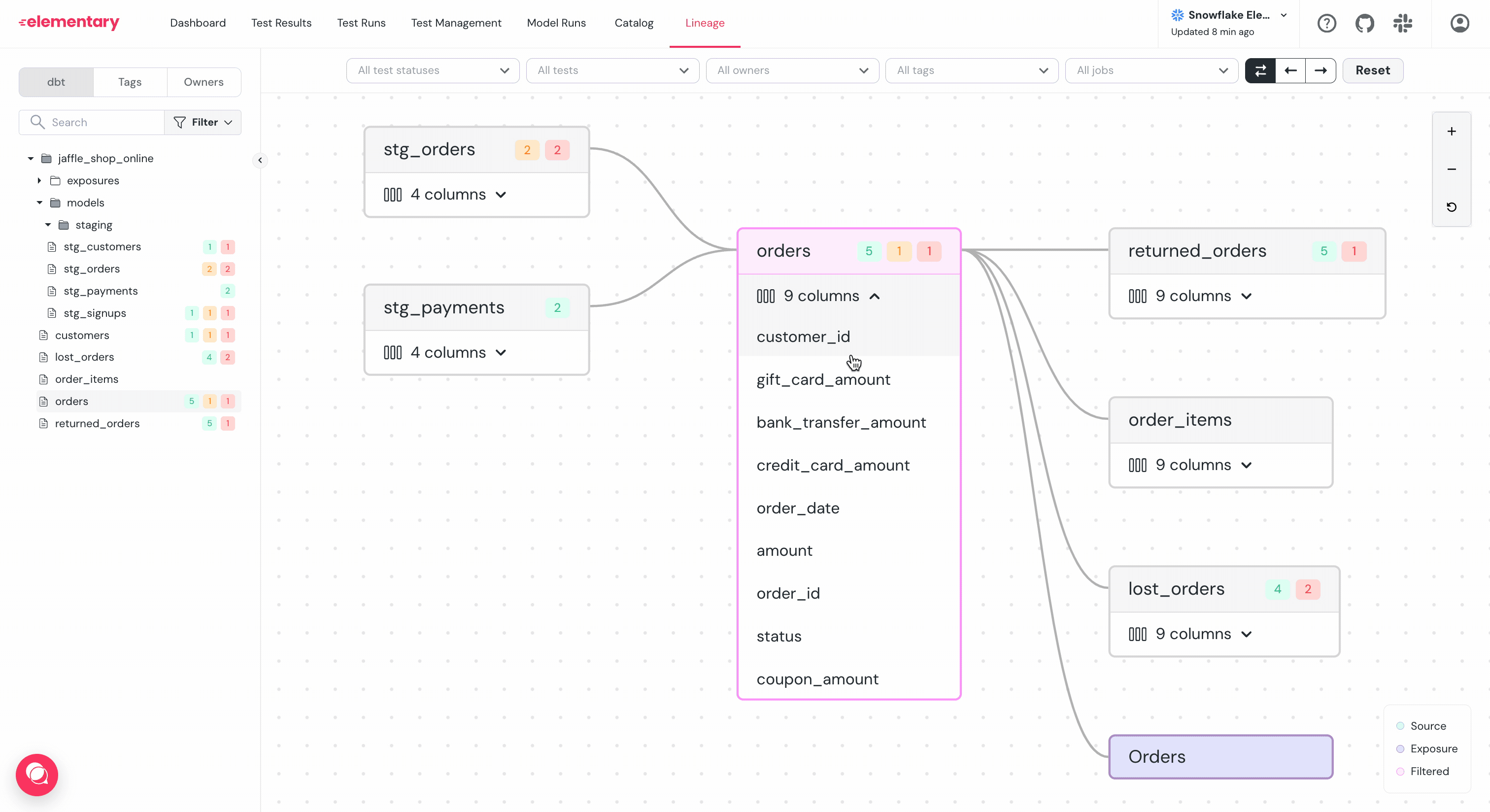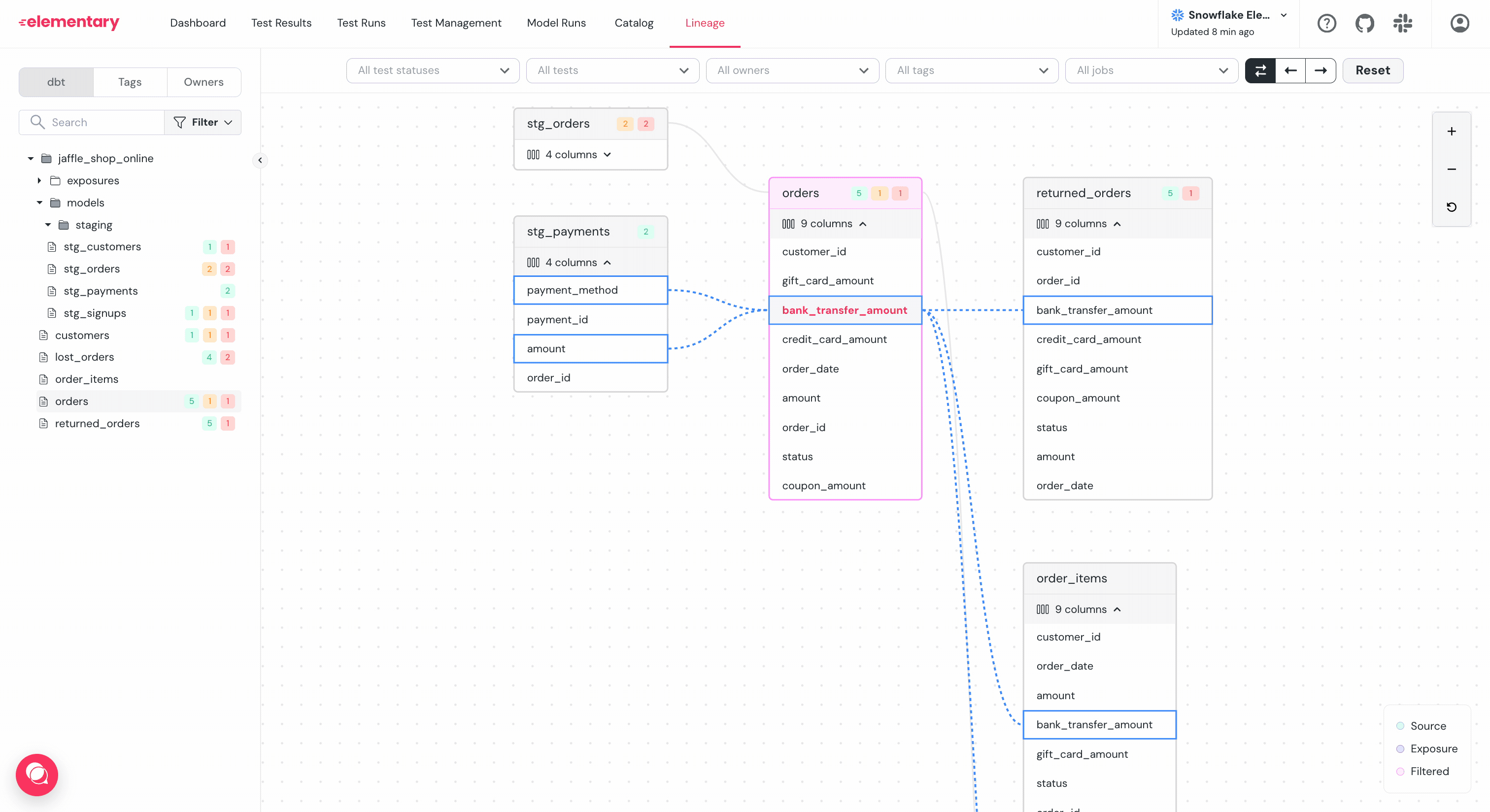
The table nodes in Elementary lineage can be expanded to show the columns. When you
select a column, the lineage of that specific column will be highlighted.
-Column level lineage is useful for answering questions such as:
+Column-level lineage is useful for answering questions such as:
- Which downstream columns are actually impacted by a data quality issue?
- Can we deprecate or rename a column?
- Will changing this column impact a dashboard?
-
-
-Elementary CI automations will help you make changes with confidence and seeing the full picture before merging your pull request.
+Elementary CI automations help you make changes with confidence by providing a comprehensive view before merging your pull request.
## Want to join the beta?
diff --git a/docs/features/catalog.mdx b/docs/features/collaboration-and-communication/catalog.mdx
similarity index 84%
rename from docs/features/catalog.mdx
rename to docs/features/collaboration-and-communication/catalog.mdx
index 5f61a58b4..3004b4018 100644
--- a/docs/features/catalog.mdx
+++ b/docs/features/collaboration-and-communication/catalog.mdx
@@ -1,13 +1,11 @@
---
title: "Data Catalog"
-icon: "folder-tree"
-iconType: "solid"
---
On the Catalog tab you can now explore your datasets information - descriptions, columns, columns descriptions, latest update time and datasets health.
-From the dataset you can navigate directly to it’s lineage and test results.
+From the dataset you can navigate directly to its lineage and test results.
The catalog content is generated from the descriptions you maintain in your dbt project YML files.
diff --git a/docs/features/data-observability-dashboard.mdx b/docs/features/collaboration-and-communication/data-observability-dashboard.mdx
similarity index 97%
rename from docs/features/data-observability-dashboard.mdx
rename to docs/features/collaboration-and-communication/data-observability-dashboard.mdx
index 7dd10b357..afb567124 100644
--- a/docs/features/data-observability-dashboard.mdx
+++ b/docs/features/collaboration-and-communication/data-observability-dashboard.mdx
@@ -1,6 +1,5 @@
---
title: Data Observability Dashboard
-icon: "browsers"
---
Managing data systems can be a complex task, especially when there are hundreds (or even thousands) of models being orchestrated separately across multiple DAGs. These models serve different data consumers, including internal stakeholders, clients, and reverse-ETL pipelines.
diff --git a/docs/features/config-as-code.mdx b/docs/features/config-as-code.mdx
index 804899bdf..de7526a49 100644
--- a/docs/features/config-as-code.mdx
+++ b/docs/features/config-as-code.mdx
@@ -1,11 +1,10 @@
---
-title: "Configuration as Code"
-icon: "code"
+title: "Configuration-as-Code"
---
-All Elementary configuration is managed in your dbt code.
+All Elementary configurations are managed in your dbt code.
Configuring observability becomes a part of the development process that includes version control, continuous integration, and a review process.
-In Elementary Cloud, you can save time by adding tests in bulk from the UI that will be added to your code. Additionally, you can allow data analysts to create quality tests without writing any code. Elementary will take care of it for them and open pull requests for them.
+In Elementary Cloud, you can save time by adding tests in bulk from the UI that will be added to your code. Additionally, you can allow data analysts to create quality tests without writing any code. Elementary will take care of it for them and open pull requests on their behalf.
diff --git a/docs/features/data-governance/define-ownership.mdx b/docs/features/data-governance/define-ownership.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/data-governance/leverage-tags.mdx b/docs/features/data-governance/leverage-tags.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/data-governance/overview-and-best-practices.mdx b/docs/features/data-governance/overview-and-best-practices.mdx
new file mode 100644
index 000000000..e69de29bb
diff --git a/docs/features/column-level-lineage.mdx b/docs/features/data-lineage/column-level-lineage.mdx
similarity index 63%
rename from docs/features/column-level-lineage.mdx
rename to docs/features/data-lineage/column-level-lineage.mdx
index d94b067ed..a88474b56 100644
--- a/docs/features/column-level-lineage.mdx
+++ b/docs/features/data-lineage/column-level-lineage.mdx
@@ -1,38 +1,42 @@
---
-title: Column Level Lineage
-sidebarTitle: Column Level Lineage
+title: Column-Level Lineage
+sidebarTitle: Column level lineage
---
+
The table nodes in Elementary lineage can be expanded to show the columns. When you
select a column, the lineage of that specific column will be highlighted.
-Column level lineage is useful for answering questions such as:
+Column-level lineage is useful for answering questions such as:
- Which downstream columns are actually impacted by a data quality issue?
- Can we deprecate or rename a column?
- Will changing this column impact a dashboard?
-
-  -
-
### Filter and highlight columns path
-To help navigate graphs with large amount of columns per table, use the `...` menu right to the column:
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+- **Filter**: Will show a graph of only the selected column and its dependencies.
+- **Highlight**: Will highlight only the selected column and its dependencies.
-- **Filter**: Will show a graph of only the selected column and it's dependencies.
-- **Highlight**: Will highlight only the selected column and it's dependencies.
+
-### Column level lineage generation
+### Column-level lineage generation
Elementary parses SQL queries to determine the dependencies between columns.
Note that the lineage is only of the columns that directly contribute data to the column.
-For example for the query:
+For example, for the query:
```sql
create or replace table db.schema.users as
@@ -46,4 +50,4 @@ where user_type != 'test_user'
The direct dependency of `total_logins` is `login_events.login_time`.
The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
-If you want a different approach in your Elementary Cloud instance - Contact us.
+If you want a different approach in your Elementary Cloud instance - contact us.
diff --git a/docs/features/exposures-lineage.mdx b/docs/features/data-lineage/exposures-lineage.mdx
similarity index 53%
rename from docs/features/exposures-lineage.mdx
rename to docs/features/data-lineage/exposures-lineage.mdx
index c99f90666..634427c2d 100644
--- a/docs/features/exposures-lineage.mdx
+++ b/docs/features/data-lineage/exposures-lineage.mdx
@@ -1,17 +1,17 @@
---
-title: Lineage to Downstream Dashboards
-sidebarTitle: BI Integrations
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
---
Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
These downstream data consumers are called _exposures_.
-Elementary lineage graph presents downstream exposures of two origins:
+The Elementary lineage graph presents downstream exposures of two origins:
-1. Elementary Cloud Automated BI integrations
+1. Elementary automated BI integrations
2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
-
+
```yaml
exposures:
@@ -41,29 +41,24 @@ exposures:
-### Automated BI lineage
+### Automated lineage to the BI
-Elementary will automatically and continuously extend the column-level-lineage to the dashboard level of your data visualization tool.
+Elementary will automatically and continuously extend the column-level lineage to the dashboard level of your data visualization tool.
-
+frameborder="0"
+allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+allowfullscreen
+alt="Elementary Lineage"
+>
### Supported BI tools:
-
-
-### Why is lineage to exposures useful?
-
-- **Incidents impact analysis**: You could explore which exposures are impacted by each data issue.
-- **Exposure health**: By selecting an exposure and filtering on upstream nodes, you could see the status of all it’s upstream datasets.
-- **Prioritize data issues**: Prioritize the triage and resolution of issues that are impacting your critical downstream assets.
-- **Change impact**: Analyze which exposures will be impacted by a planned change.
-- **Unused datasets**: Detect datasets that no exposure consumes, that could be removed to save costs.
+
\ No newline at end of file
diff --git a/docs/features/data-lineage/lineage.mdx b/docs/features/data-lineage/lineage.mdx
new file mode 100644
index 000000000..2420ccf77
--- /dev/null
+++ b/docs/features/data-lineage/lineage.mdx
@@ -0,0 +1,42 @@
+---
+title: End-to-End Data Lineage
+sidebarTitle: Lineage overview
+---
+
+
+
+Elementary offers automated [Column-Level Lineage](/features/column-level-lineage) functionality, enriched with the latest test and monitors results.
+It is built with usability and performance in mind.
+The column-level lineage is built from the metadata of your data warehouse, and integrations with [BI tools]((/features/exposures-lineage#automated-bi-lineage)) such as Looker and Tableau.
+
+Elementary updates your lineage view frequently, ensuring it is always current.
+This up-to-date lineage data is essential for supporting several critical workflows, including:
+
+- **Effective Data Issue Debugging**: Identify and trace data issues back to their sources.
+- **Incidents impact analysis**: You could explore which downstream assets are impacted by each data issue.
+- **Prioritize data issues**: Prioritize the triage and resolution of issues that are impacting your critical downstream assets.
+- **Public assets health**: By selecting an exposure and filtering on upstream nodes, you can see the status of all its upstream datasets.
+- **Change impact**: Analyze which exposures will be impacted by a planned change.
+- **Unused datasets**: Detect datasets that are not consumed downstrean, and could be removed to reduce costs.
+
+
+
+## Node info and test results
+
+To view additional information in the lineage view, use the `...` menu to the right of the column:
+
+- **Test results**: Access the table's latest test results in the lineage view.
+- **Node info**: See details such as description, owner and tags. If collected, it will include the latest job info.
+
+
+## Job info in lineage
+
+You can [configure Elementary to collect jobs information](/cloud/guides/collect-job-data) to present in the lineage _Node info_ tab. Job names can also be used to filter the lineage graph.
diff --git a/docs/features/data-tests.mdx b/docs/features/data-tests.mdx
deleted file mode 100644
index 0c3ef16d8..000000000
--- a/docs/features/data-tests.mdx
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: "Elementary Data Tests"
-icon: "monitor-waveform"
-sidebarTitle: "Data Tests"
----
-
-Elementary provides tests for detection of data quality issues.
-Elementary data tests are configured and executed like native tests in your dbt project.
-
-Elementary tests can be used in addition to dbt tests, packages tests (such as dbt-expectations), and custom tests.
-All of these test results will be presented in the Elementary UI and alerts.
-
-
diff --git a/docs/features/data-tests/custom-sql-tests.mdx b/docs/features/data-tests/custom-sql-tests.mdx
new file mode 100644
index 000000000..4f7205478
--- /dev/null
+++ b/docs/features/data-tests/custom-sql-tests.mdx
@@ -0,0 +1,6 @@
+---
+title: Custom SQL Tests
+sidebarTitle: Custom SQL test
+---
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/data-tests/data-tests-overview.mdx b/docs/features/data-tests/data-tests-overview.mdx
new file mode 100644
index 000000000..c848aa572
--- /dev/null
+++ b/docs/features/data-tests/data-tests-overview.mdx
@@ -0,0 +1,15 @@
+---
+title: Data Tests Overview
+sidebarTitle: Overview and configuration
+---
+
+Data tests are useful for validating and enforcing explicit expectations on your data.
+
+Elementary enables data validation and result tracking by leveraging dbt tests and dbt packages such as dbt-utils, dbt-expectations, and Elementary.
+This rich ecosystem of tests covers various use cases, and is widely adopted as a standard for data validations.
+Any custom dbt generic or singular test you develop will also be included.
+
+Additionally, users can create custom SQL tests in Elementary.
+
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/data-tests/dbt-tests.mdx b/docs/features/data-tests/dbt-tests.mdx
new file mode 100644
index 000000000..1578b4b26
--- /dev/null
+++ b/docs/features/data-tests/dbt-tests.mdx
@@ -0,0 +1,24 @@
+---
+title: dbt, Packages and Elementary Tests
+sidebarTitle: dbt tests
+---
+
+_🚧 Under construction 🚧_
+
+
+## Elementary dbt package tests
+
+The Elementary dbt package also provides tests for detection of data quality issues.
+Elementary data tests are configured and executed like native tests in your dbt project.
+
+
+
+
+## Supported dbt packages
+
+Elementary collects and monitors the results of all dbt tests.
+
+The following packages are supported in the tests configuration wizard:
+
+- dbt expectations
+- dbt utils
\ No newline at end of file
diff --git a/docs/features/data-tests/schema-validation-test.mdx b/docs/features/data-tests/schema-validation-test.mdx
new file mode 100644
index 000000000..8b30d021d
--- /dev/null
+++ b/docs/features/data-tests/schema-validation-test.mdx
@@ -0,0 +1,6 @@
+---
+title: Schema Validation Tests
+sidebarTitle: Schema validation
+---
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/elementary-alerts.mdx b/docs/features/elementary-alerts.mdx
index 4e6f06cc7..e69de29bb 100644
--- a/docs/features/elementary-alerts.mdx
+++ b/docs/features/elementary-alerts.mdx
@@ -1,14 +0,0 @@
----
-title: "Alerts"
-icon: "bell-exclamation"
----
-
-
-
-## Alerts destinations
-
-
-
-## Alerts configuration
-
-
diff --git a/docs/features/lineage.mdx b/docs/features/lineage.mdx
deleted file mode 100644
index db015dc93..000000000
--- a/docs/features/lineage.mdx
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: End-to-End Data Lineage
-sidebarTitle: Data Lineage
----
-
-Elementary Cloud UI and Elementary OSS Report include a rich data lineage graph.
-The graph is enriched with the latest test results, to enable easy impact and root cause analysis of data issues.
-
-In Elementary Cloud lineage includes [Column Level Lineage](/features/column-level-lineage) and [BI integrations](/features/exposures-lineage#automated-bi-lineage).
-
-## Node info and test results
-
-To see additional information in the lineage view, use the `...` menu right to the column:
-
-- **Test results**: Access the table latest test results in the lineage view.
-- **Node info**: See details such as description, owner and tags. If collected, it will include the latest job info.
-
-
-
-## Job info in lineage
-
-You can configure Elementary to collect jobs names and information to present in the lineage _Node info_ tab. Job names can also be used to filter the lineage graph.
-
-Read how to configure jobs info collection for [Elementary Cloud](/cloud/guides/collect-job-data) or [OSS](/oss/guides/collect-job-data).
diff --git a/docs/features/multi-env.mdx b/docs/features/multi-env.mdx
index fb6d55921..4fb533ac2 100644
--- a/docs/features/multi-env.mdx
+++ b/docs/features/multi-env.mdx
@@ -1,11 +1,10 @@
---
title: "Multiple Environments"
-icon: "rectangle-history-circle-plus"
---
-An environment in Elementary is a combination of dbt project and target.
-For example: If you have a single dbt project with three targets, prod, staging and dev, you could create 3 environments in Elementary and monitor these envs.
+An environment in Elementary is a combination of a dbt project and a target.
+For example: If you have a single dbt project with three targets, prod, staging and dev, you can create 3 environments in Elementary and monitor these environments.
If you have several dbt projects and even different data warehouses, Elementary enables monitoring the data quality of all these environments in a single interface.
diff --git a/docs/features/performance-monitoring/performance-monitoring.mdx b/docs/features/performance-monitoring/performance-monitoring.mdx
new file mode 100644
index 000000000..77ce069ba
--- /dev/null
+++ b/docs/features/performance-monitoring/performance-monitoring.mdx
@@ -0,0 +1,39 @@
+---
+title: Performance Monitoring
+sidebarTitle: Performance monitoring
+---
+
+Monitoring the performance of your data pipeline is critical for maintaining data quality, reliability, and operational efficiency.
+Proactively monitoring performance issues enables to detect bottlenecks and opportunities for optimization, prevent data delays, and avoid unnecessary costs.
+
+Elementary monitors and logs the execution times of:
+- dbt models
+- dbt tests
+
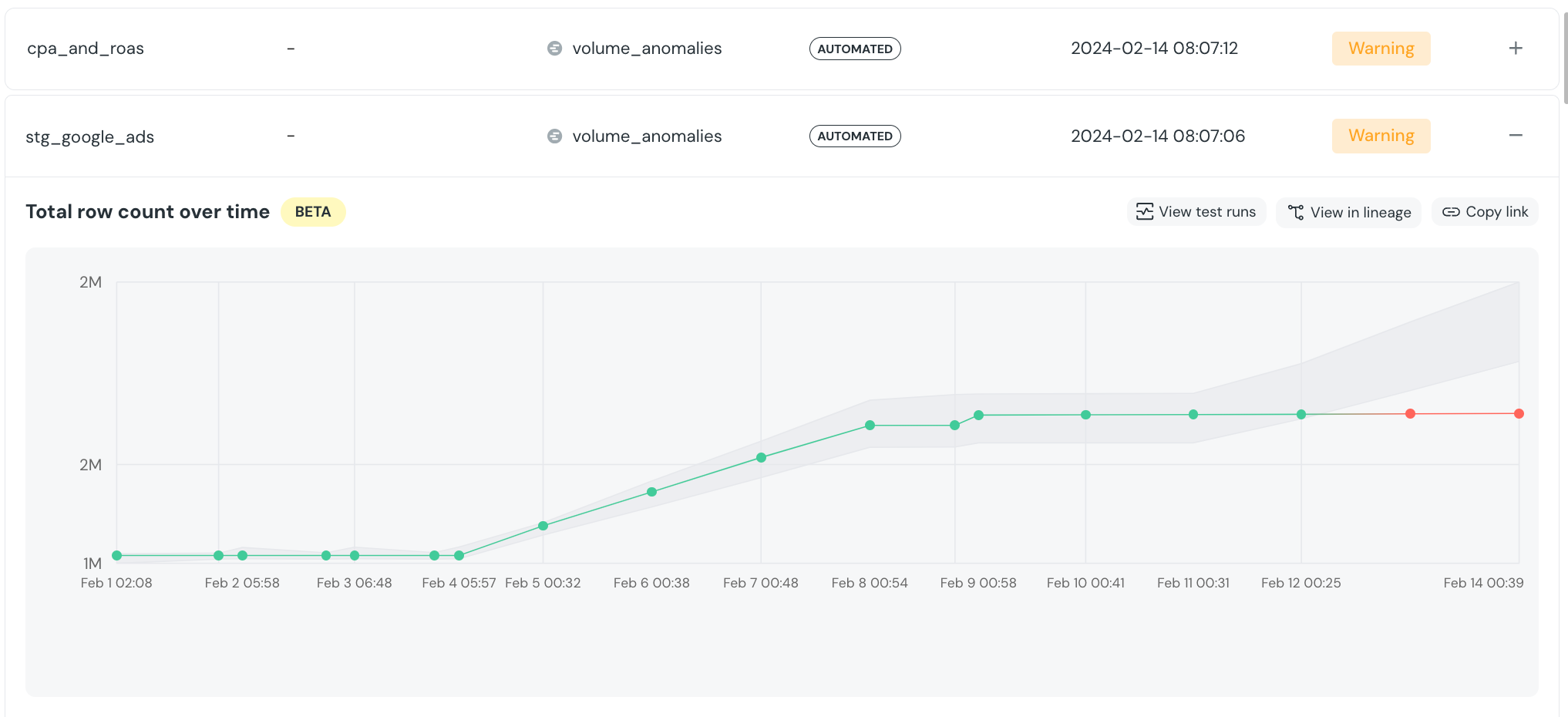
+## Models performance
+
+Navigate to the `Model Duration` tab.
+
+The table displays the latest execution time, median execution time, and execution time trend for each model. You can sort the table by these metrics and explore the execution times over time for the models with the longest durations
+
+It is also useful to use the navigation bar to filter the results, and see run times per tag/owner/folder.
+
+
+
+## Tests performance
+
+Navigate to the `Test Execution History` tab.
+
+On the table you can see the median execution time and fail rate per test.
+You can sort the table by this time column, and detect tests that are compute heavy.
+
+It is also useful to use the navigation bar to filter the results, and see run times per tag/owner/folder.
\ No newline at end of file
diff --git a/docs/introduction.mdx b/docs/introduction.mdx
index 1fc128423..8bd67abcd 100644
--- a/docs/introduction.mdx
+++ b/docs/introduction.mdx
@@ -12,7 +12,8 @@ icon: "fire"
alt="Elementary banner"
/>
-
+
+
Elementary includes two products:
diff --git a/docs/key-features.mdx b/docs/key-features.mdx
index 581b8d25d..75068c125 100644
--- a/docs/key-features.mdx
+++ b/docs/key-features.mdx
@@ -72,3 +72,43 @@ icon: "stars"
Explore and discover data sets, manage your documentation in code.
+
+
+
+#### Anomaly Detection
+
+
+ Out-of-the-box ML-powered monitoring for freshness and volume issues on all production tables.
+ The monitors track updates to tables, and will detect data delays, incomplete updates, and significant volume changes.
+ By qurying only metadata (e.g. information schema, query history), the monitors don't add compute costs.
+
+
+
+ ML-powered anomaly detection on data quality metrics such as null rate, empty values, string length, numeric metrics (sum, max, min, avg), etc.
+ Elementary also supports monitoring for anomalies by dimensions.
+ The monitors are activated for specific data sets, and require minimal configuration (e.g. timestamp column, dimensions).
+
+
+#### Schema Validation
+
+
+ Elementary offers a set of schema tests for validating there are no breaking changes.
+ The tests support detecting any schema changes, only detecting changes from a configured baseline, JSON schema validation,
+ and schema changes that break downstream exposures such as dashboards.
+
+
+
+ Coming soon!
+
+
+#### Data Tests
+
+Custom SQL Tests
+
+dbt tests
+
+Python tests
+
+#### Tests Coverage
+
+#### Performance monitoring
diff --git a/docs/mint.json b/docs/mint.json
index 9d9bb9820..a4b1acf83 100644
--- a/docs/mint.json
+++ b/docs/mint.json
@@ -29,7 +29,7 @@
},
"tabs": [
{
- "name": "Data tests",
+ "name": "Elementary Tests",
"url": "data-tests"
},
{
@@ -61,7 +61,6 @@
"pages": [
"introduction",
"quickstart",
- "cloud/general/security-and-privacy",
{
"group": "dbt package",
"icon": "cube",
@@ -75,27 +74,98 @@
]
},
{
- "group": "Features",
+ "group": "Cloud Platform",
"pages": [
- "features/data-tests",
- "features/automated-monitors",
- "features/elementary-alerts",
- "features/data-observability-dashboard",
+ "cloud/introduction",
+ "cloud/features",
+ "features/integrations",
+ "cloud/general/security-and-privacy"
+ ]
+ },
+ {
+ "group": "Anomaly Detection Monitors",
+ "pages": [
+ "features/anomaly-detection/monitors-overview",
{
- "group": "End-to-End Lineage",
- "icon": "arrow-progress",
- "iconType": "solid",
+ "group": "Automated monitors",
"pages": [
- "features/lineage",
- "features/exposures-lineage",
- "features/column-level-lineage"
+ "features/anomaly-detection/automated-monitors",
+ "features/anomaly-detection/automated-freshness",
+ "features/anomaly-detection/automated-volume"
]
},
+ "features/anomaly-detection/opt-in-monitors",
+ {
+ "group": "Configuration and Feedback",
+ "pages": [
+ "features/anomaly-detection/monitors-configuration",
+ "features/anomaly-detection/monitors-feedback",
+ "features/anomaly-detection/disable-or-mute-monitors"
+ ]
+ }
+ ]
+ },
+ {
+ "group": "Data Tests",
+ "pages": [
+ "features/data-tests/data-tests-overview",
+ "features/data-tests/dbt-tests",
+ "features/data-tests/custom-sql-tests",
+ "features/data-tests/schema-validation-test"
+ ]
+ },
+ {
+ "group": "Data Lineage",
+ "pages": [
+ "features/data-lineage/lineage",
+ "features/data-lineage/column-level-lineage",
+ "features/data-lineage/exposures-lineage"
+ ]
+ },
+ {
+ "group": "Alerts and Incidents",
+ "pages": [
+ "features/alerts-and-incidents/alerts-and-incidents-overview",
+ {
+ "group": "Setup & configure alerts",
+ "pages": [
+ "features/alerts-and-incidents/effective-alerts-setup",
+ "features/alerts-and-incidents/alert-rules",
+ "features/alerts-and-incidents/owners-and-subscribers",
+ "features/alerts-and-incidents/alert-configuration"
+ ]
+ },
+ "features/alerts-and-incidents/incidents",
+ "features/alerts-and-incidents/incident-management"
+ ]
+ },
+ {
+ "group": "Performance & Cost",
+ "pages": [
+ "features/performance-monitoring/performance-monitoring"
+ ]
+ },
+ {
+ "group": "Data Governance",
+ "pages": [
+ "features/data-governance/overview-and-best-practices",
+ "features/data-governance/define-ownership",
+ "features/data-governance/leverage-tags"
+ ]
+ },
+ {
+ "group": "Collaboration & Communication",
+ "pages": [
+ "features/collaboration-and-communication/data-observability-dashboard",
+ "features/collaboration-and-communication/catalog"
+ ]
+ },
+ {
+ "group": "Additional features",
+ "pages": [
"features/config-as-code",
- "features/catalog",
"features/multi-env",
- "features/ci",
- "features/integrations"
+ "features/ci"
]
},
{
@@ -181,7 +251,7 @@
]
},
{
- "group": "Communication & collaboration",
+ "group": "Alerts & Incidents",
"pages": [
"cloud/integrations/alerts/slack",
"cloud/integrations/alerts/ms-teams",
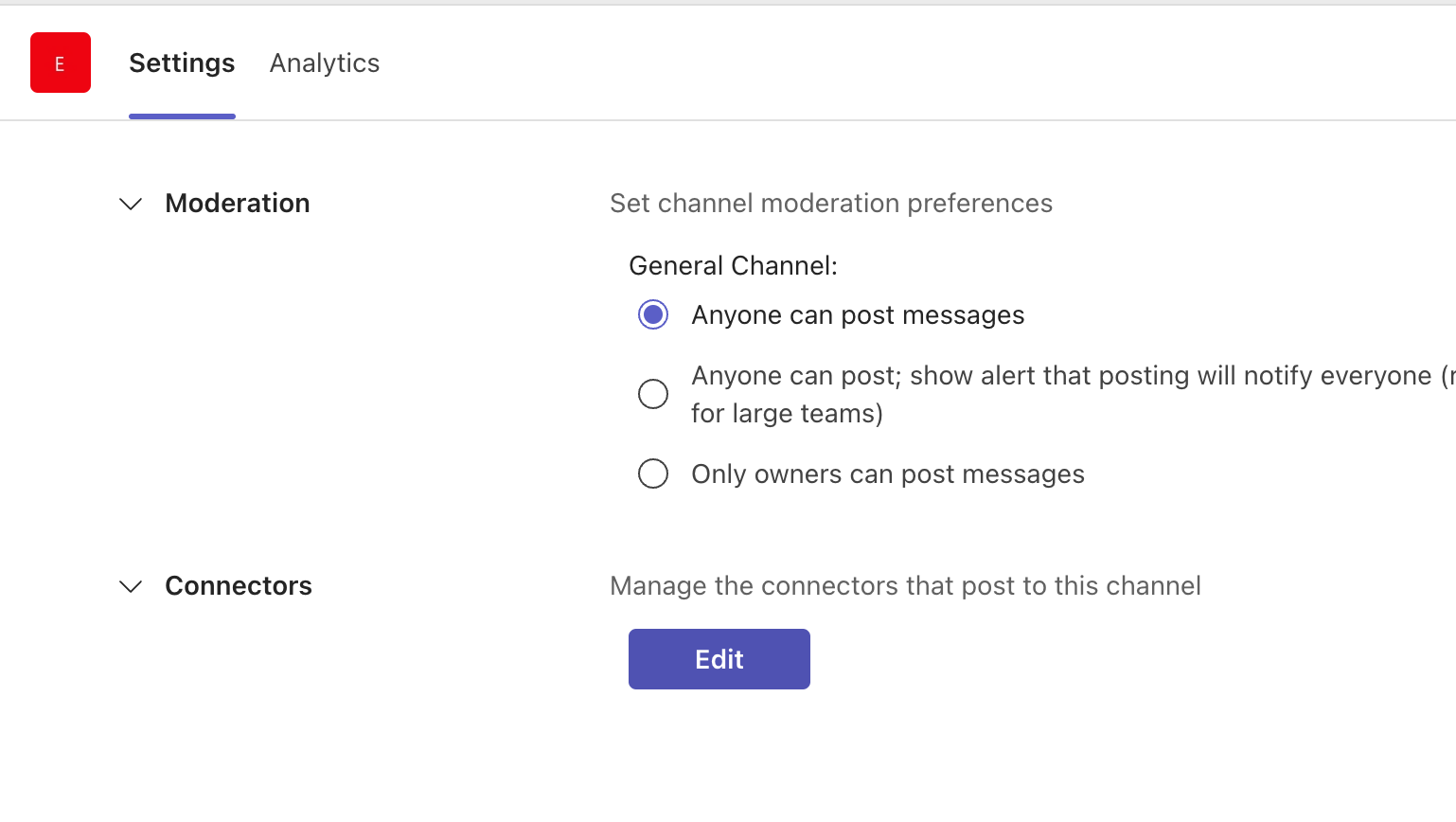
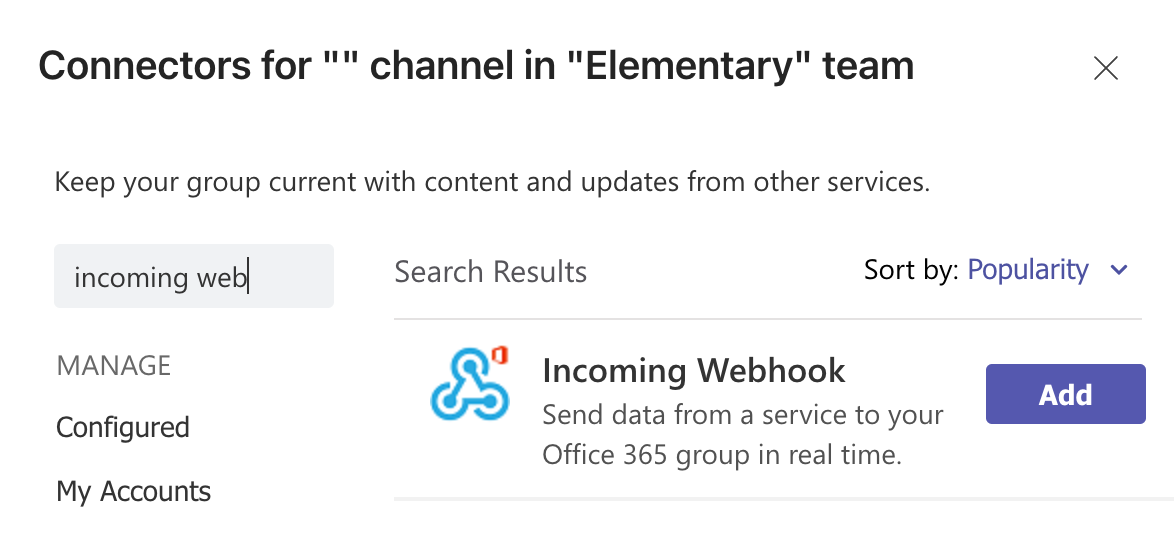
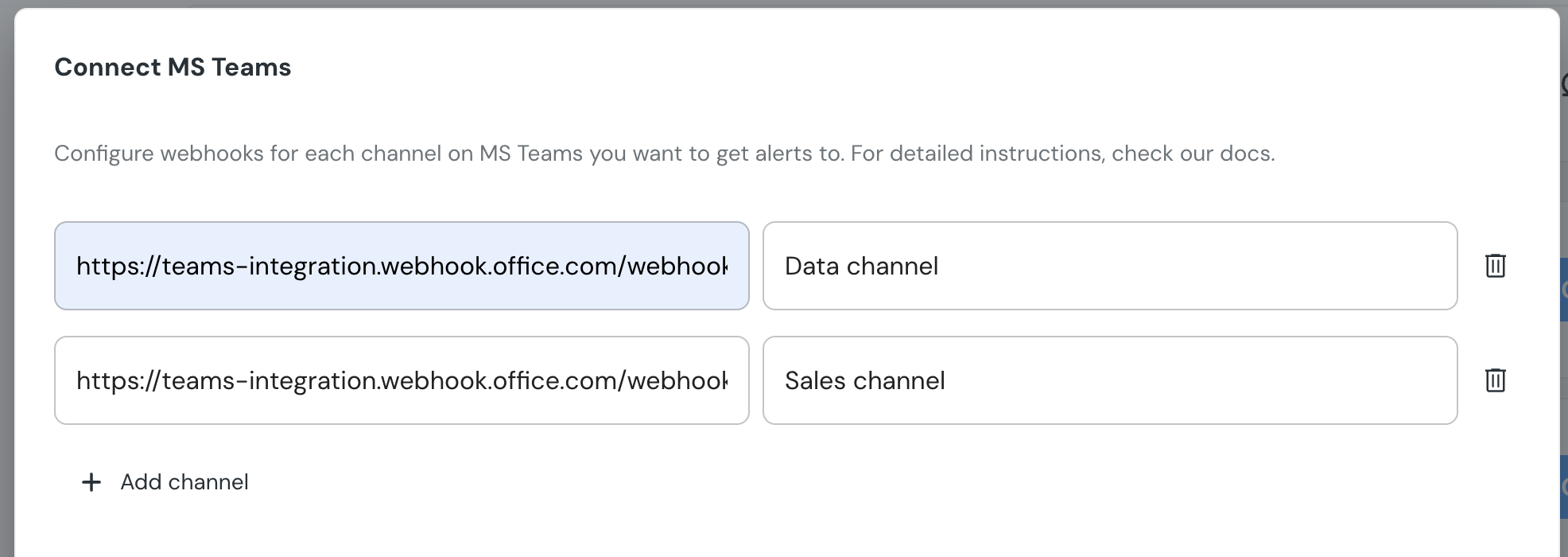
@@ -197,6 +267,7 @@
{
"group": "Resources",
"pages": [
+ "resources/business-case-data-observability-platform",
"overview/cloud-vs-oss",
"resources/pricing",
"resources/community"
@@ -240,7 +311,8 @@
"data-tests/anomaly-detection-configuration/ignore_small_changes",
"data-tests/anomaly-detection-configuration/fail_on_zero",
"data-tests/anomaly-detection-configuration/detection-delay",
- "data-tests/anomaly-detection-configuration/anomaly-exclude-metrics"
+ "data-tests/anomaly-detection-configuration/anomaly-exclude-metrics",
+ "data-tests/anomaly-detection-configuration/exclude-final-results"
]
},
"data-tests/anomaly-detection-tests/volume-anomalies",
@@ -262,7 +334,9 @@
},
{
"group": "Other Tests",
- "pages": ["data-tests/python-tests"]
+ "pages": [
+ "data-tests/python-tests"
+ ]
},
{
"group": "Elementary OSS",
@@ -308,7 +382,10 @@
},
{
"group": "Configuration & usage",
- "pages": ["oss/cli-install", "oss/cli-commands"]
+ "pages": [
+ "oss/cli-install",
+ "oss/cli-commands"
+ ]
},
{
"group": "Deployment",
@@ -369,7 +446,8 @@
]
}
],
- "footerSocials": {
+ "footerSocials":
+ {
"website": "https://www.elementary-data.com",
"slack": "https://elementary-data.com/community"
},
@@ -383,5 +461,43 @@
"gtm": {
"tagId": "GTM-TKR4HS3Q"
}
- }
+ },
+ "redirects": [
+ {
+ "source": "/features/lineage",
+ "destination": "/features/data-lineage/lineage"
+ },
+ {
+ "source": "/features/exposures-lineage",
+ "destination": "/features/data-lineage/exposures-lineage"
+ },
+ {
+ "source": "/features/column-level-lineage",
+ "destination": "/features/data-lineage/column-level-lineage"
+ },
+ {
+ "source": "/features/automated-monitors",
+ "destination": "/features/anomaly-detection/automated-monitors"
+ },
+ {
+ "source": "/features/data-tests",
+ "destination": "/features/data-tests/dbt-tests"
+ },
+ {
+ "source": "/features/elementary-alerts",
+ "destination": "/features/alerts-and-incidents/alerts-and-incidents-overview"
+ },
+ {
+ "source": "/cloud/guides/alert-rules",
+ "destination": "/features/alerts-and-incidents/alert-rules"
+ },
+ {
+ "source": "/features/catalog",
+ "destination": "/features/collaboration-and-communication/catalog"
+ },
+ {
+ "source": "/features/data-observability-dashboard",
+ "destination": "/features/collaboration-and-communication/data-observability-dashboard"
+ }
+ ]
}
diff --git a/docs/resources/business-case-data-observability-platform.mdx b/docs/resources/business-case-data-observability-platform.mdx
new file mode 100644
index 000000000..a78f11580
--- /dev/null
+++ b/docs/resources/business-case-data-observability-platform.mdx
@@ -0,0 +1,25 @@
+---
+title: "When do I need a data observability platform?"
+sidebarTitle: "When to add data observability"
+---
+
+
+### If the consequences of data issues are high
+If you are running performance marketing budgets of $millions, a data issue can result in a loss of hundreds of thousands of dollars.
+In these cases, the ability to detect and resolve issues fast is business-critical. It typically involves multiple teams and the ability to measure, track, and report on data quality.
+
+### If data is scaling faster than the data team
+The scale and complexity of modern data environments make it impossible for teams to manually manage quality without expanding the team. A data observability platform enables automation and collaboration, ensuring data quality is maintained as data continues to grow, without impacting team efficiency.
+
+### Common use cases
+If your data is being used in one of the following use cases, you should consider adding a data observability platform:
+- Self-service analytics
+- Data activation
+- Powering AI & ML products
+- Embedded analytics
+- Performance marketing
+- Regulatory reporting
+- A/B testing and experiments
+
+## Why isn't the open-source package enough?
+The open-source package was designed for engineers that want to monitor their dbt project. The Cloud Platform was designed to support the complex, multifaceted requirements of larger teams and organizations, providing a holistic observability solution.
\ No newline at end of file
diff --git a/docs/resources/how-does-elementary-work b/docs/resources/how-does-elementary-work
new file mode 100644
index 000000000..937fb3500
--- /dev/null
+++ b/docs/resources/how-does-elementary-work
@@ -0,0 +1,28 @@
+---
+title: "How does Elementary work"
+sidebarTitle: "Elementary Could Platform"
+---
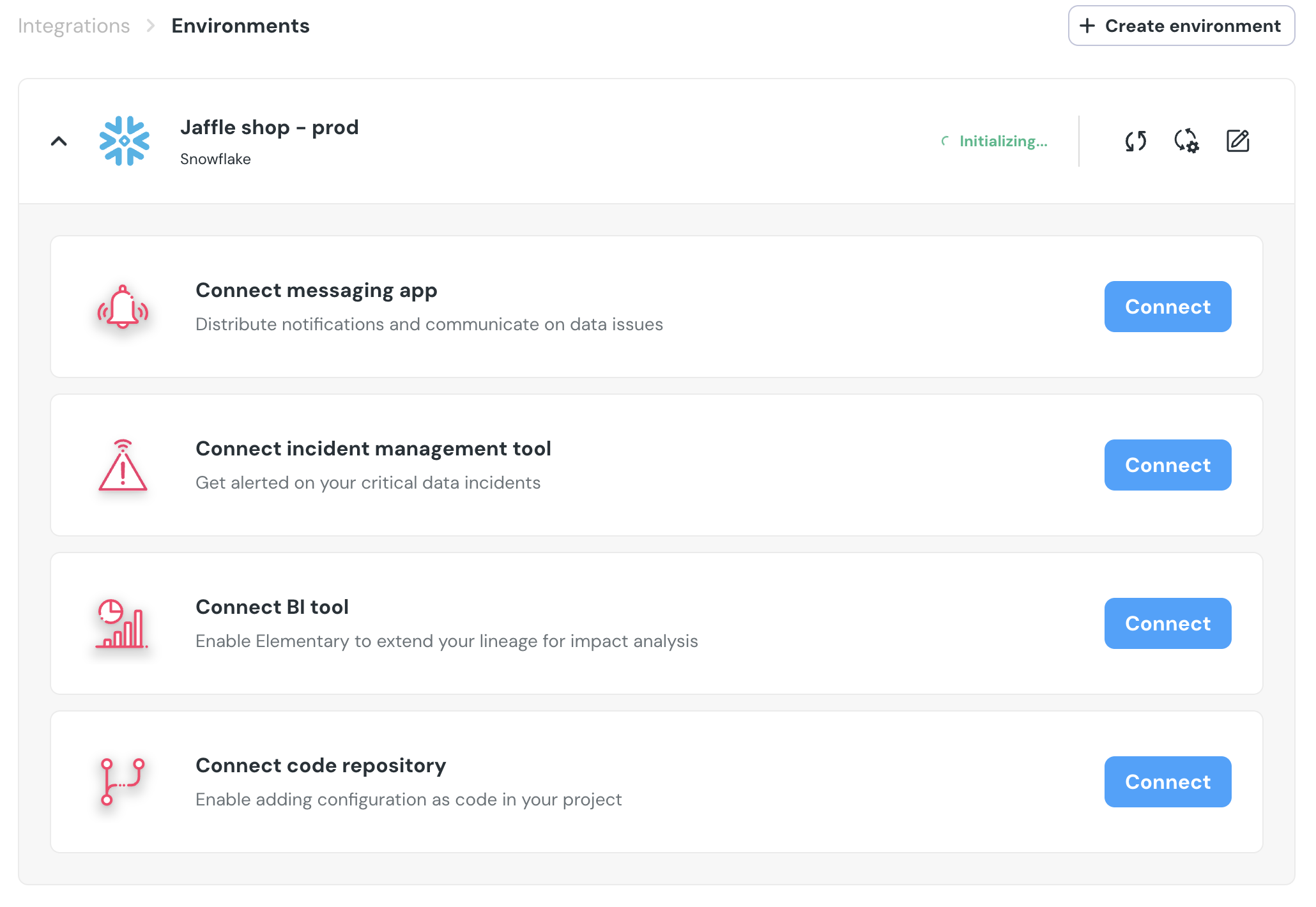
+## Cloud platform architecture
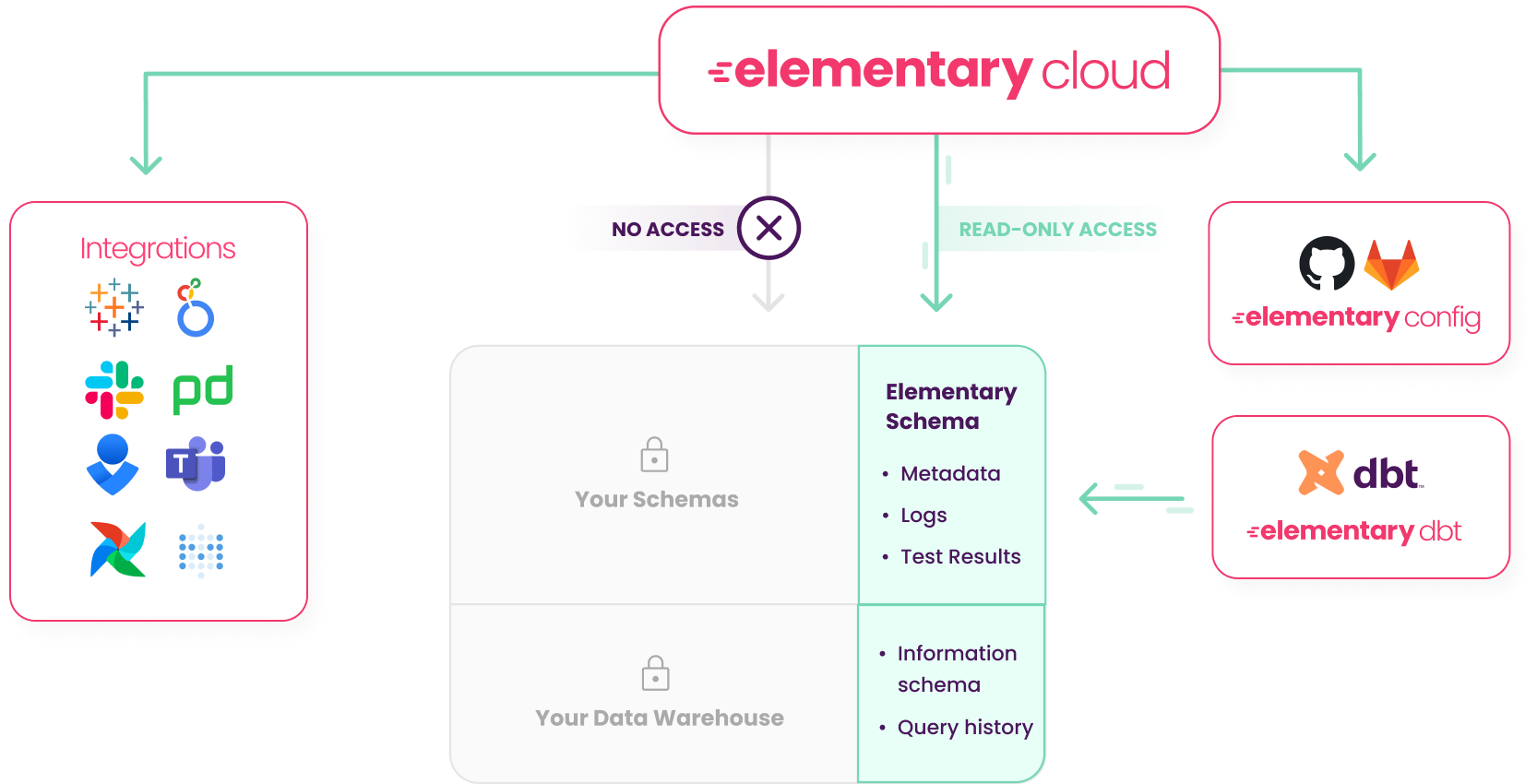
+The Elementary open-source package creates a schema that collects the test results and the models from your dbt projects. The platform is part of your package and it runs in your dbt pipeline and it writes to its own data set in the data warehouse and then the platform syncs that data set to the cloud. It also integrates directly with your data warehouse so it has access to the information schema, the query history and the metadata.
+
+We also integrate with your dbt code repository - so we understand how it’s built including tags, owners, which tables are part of your dbt project and what tables are not, and we see daily usage by connecting to your BI.
+
+
+
-
-
### Filter and highlight columns path
-To help navigate graphs with large amount of columns per table, use the `...` menu right to the column:
+To help navigate graphs with large amount of columns per table, use the `...` menu to the right of the column:
+
+- **Filter**: Will show a graph of only the selected column and its dependencies.
+- **Highlight**: Will highlight only the selected column and its dependencies.
-- **Filter**: Will show a graph of only the selected column and it's dependencies.
-- **Highlight**: Will highlight only the selected column and it's dependencies.
+
-### Column level lineage generation
+### Column-level lineage generation
Elementary parses SQL queries to determine the dependencies between columns.
Note that the lineage is only of the columns that directly contribute data to the column.
-For example for the query:
+For example, for the query:
```sql
create or replace table db.schema.users as
@@ -46,4 +50,4 @@ where user_type != 'test_user'
The direct dependency of `total_logins` is `login_events.login_time`.
The column `login_events.user_type` filter the data of `total_logins`, but it is an indirect dependency and will not show in lineage.
-If you want a different approach in your Elementary Cloud instance - Contact us.
+If you want a different approach in your Elementary Cloud instance - contact us.
diff --git a/docs/features/exposures-lineage.mdx b/docs/features/data-lineage/exposures-lineage.mdx
similarity index 53%
rename from docs/features/exposures-lineage.mdx
rename to docs/features/data-lineage/exposures-lineage.mdx
index c99f90666..634427c2d 100644
--- a/docs/features/exposures-lineage.mdx
+++ b/docs/features/data-lineage/exposures-lineage.mdx
@@ -1,17 +1,17 @@
---
-title: Lineage to Downstream Dashboards
-sidebarTitle: BI Integrations
+title: Lineage to Downstream Dashboards and Tools
+sidebarTitle: Lineage to BI
---
Some of your data is used downstream in dashboards, applications, data science pipelines, reverse ETLs, etc.
These downstream data consumers are called _exposures_.
-Elementary lineage graph presents downstream exposures of two origins:
+The Elementary lineage graph presents downstream exposures of two origins:
-1. Elementary Cloud Automated BI integrations
+1. Elementary automated BI integrations
2. Exposures configured in your dbt project. Read about [how to configure exposures](https://docs.getdbt.com/docs/build/exposures) in code.
-
+
```yaml
exposures:
@@ -41,29 +41,24 @@ exposures:
-### Automated BI lineage
+### Automated lineage to the BI
-Elementary will automatically and continuously extend the column-level-lineage to the dashboard level of your data visualization tool.
+Elementary will automatically and continuously extend the column-level lineage to the dashboard level of your data visualization tool.
-
+frameborder="0"
+allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture"
+allowfullscreen
+alt="Elementary Lineage"
+>
### Supported BI tools:
-
-
-### Why is lineage to exposures useful?
-
-- **Incidents impact analysis**: You could explore which exposures are impacted by each data issue.
-- **Exposure health**: By selecting an exposure and filtering on upstream nodes, you could see the status of all it’s upstream datasets.
-- **Prioritize data issues**: Prioritize the triage and resolution of issues that are impacting your critical downstream assets.
-- **Change impact**: Analyze which exposures will be impacted by a planned change.
-- **Unused datasets**: Detect datasets that no exposure consumes, that could be removed to save costs.
+
\ No newline at end of file
diff --git a/docs/features/data-lineage/lineage.mdx b/docs/features/data-lineage/lineage.mdx
new file mode 100644
index 000000000..2420ccf77
--- /dev/null
+++ b/docs/features/data-lineage/lineage.mdx
@@ -0,0 +1,42 @@
+---
+title: End-to-End Data Lineage
+sidebarTitle: Lineage overview
+---
+
+
+
+Elementary offers automated [Column-Level Lineage](/features/column-level-lineage) functionality, enriched with the latest test and monitors results.
+It is built with usability and performance in mind.
+The column-level lineage is built from the metadata of your data warehouse, and integrations with [BI tools]((/features/exposures-lineage#automated-bi-lineage)) such as Looker and Tableau.
+
+Elementary updates your lineage view frequently, ensuring it is always current.
+This up-to-date lineage data is essential for supporting several critical workflows, including:
+
+- **Effective Data Issue Debugging**: Identify and trace data issues back to their sources.
+- **Incidents impact analysis**: You could explore which downstream assets are impacted by each data issue.
+- **Prioritize data issues**: Prioritize the triage and resolution of issues that are impacting your critical downstream assets.
+- **Public assets health**: By selecting an exposure and filtering on upstream nodes, you can see the status of all its upstream datasets.
+- **Change impact**: Analyze which exposures will be impacted by a planned change.
+- **Unused datasets**: Detect datasets that are not consumed downstrean, and could be removed to reduce costs.
+
+
+
+## Node info and test results
+
+To view additional information in the lineage view, use the `...` menu to the right of the column:
+
+- **Test results**: Access the table's latest test results in the lineage view.
+- **Node info**: See details such as description, owner and tags. If collected, it will include the latest job info.
+
+
+## Job info in lineage
+
+You can [configure Elementary to collect jobs information](/cloud/guides/collect-job-data) to present in the lineage _Node info_ tab. Job names can also be used to filter the lineage graph.
diff --git a/docs/features/data-tests.mdx b/docs/features/data-tests.mdx
deleted file mode 100644
index 0c3ef16d8..000000000
--- a/docs/features/data-tests.mdx
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: "Elementary Data Tests"
-icon: "monitor-waveform"
-sidebarTitle: "Data Tests"
----
-
-Elementary provides tests for detection of data quality issues.
-Elementary data tests are configured and executed like native tests in your dbt project.
-
-Elementary tests can be used in addition to dbt tests, packages tests (such as dbt-expectations), and custom tests.
-All of these test results will be presented in the Elementary UI and alerts.
-
-
diff --git a/docs/features/data-tests/custom-sql-tests.mdx b/docs/features/data-tests/custom-sql-tests.mdx
new file mode 100644
index 000000000..4f7205478
--- /dev/null
+++ b/docs/features/data-tests/custom-sql-tests.mdx
@@ -0,0 +1,6 @@
+---
+title: Custom SQL Tests
+sidebarTitle: Custom SQL test
+---
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/data-tests/data-tests-overview.mdx b/docs/features/data-tests/data-tests-overview.mdx
new file mode 100644
index 000000000..c848aa572
--- /dev/null
+++ b/docs/features/data-tests/data-tests-overview.mdx
@@ -0,0 +1,15 @@
+---
+title: Data Tests Overview
+sidebarTitle: Overview and configuration
+---
+
+Data tests are useful for validating and enforcing explicit expectations on your data.
+
+Elementary enables data validation and result tracking by leveraging dbt tests and dbt packages such as dbt-utils, dbt-expectations, and Elementary.
+This rich ecosystem of tests covers various use cases, and is widely adopted as a standard for data validations.
+Any custom dbt generic or singular test you develop will also be included.
+
+Additionally, users can create custom SQL tests in Elementary.
+
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/data-tests/dbt-tests.mdx b/docs/features/data-tests/dbt-tests.mdx
new file mode 100644
index 000000000..1578b4b26
--- /dev/null
+++ b/docs/features/data-tests/dbt-tests.mdx
@@ -0,0 +1,24 @@
+---
+title: dbt, Packages and Elementary Tests
+sidebarTitle: dbt tests
+---
+
+_🚧 Under construction 🚧_
+
+
+## Elementary dbt package tests
+
+The Elementary dbt package also provides tests for detection of data quality issues.
+Elementary data tests are configured and executed like native tests in your dbt project.
+
+
+
+
+## Supported dbt packages
+
+Elementary collects and monitors the results of all dbt tests.
+
+The following packages are supported in the tests configuration wizard:
+
+- dbt expectations
+- dbt utils
\ No newline at end of file
diff --git a/docs/features/data-tests/schema-validation-test.mdx b/docs/features/data-tests/schema-validation-test.mdx
new file mode 100644
index 000000000..8b30d021d
--- /dev/null
+++ b/docs/features/data-tests/schema-validation-test.mdx
@@ -0,0 +1,6 @@
+---
+title: Schema Validation Tests
+sidebarTitle: Schema validation
+---
+
+_🚧 Under construction 🚧_
\ No newline at end of file
diff --git a/docs/features/elementary-alerts.mdx b/docs/features/elementary-alerts.mdx
index 4e6f06cc7..e69de29bb 100644
--- a/docs/features/elementary-alerts.mdx
+++ b/docs/features/elementary-alerts.mdx
@@ -1,14 +0,0 @@
----
-title: "Alerts"
-icon: "bell-exclamation"
----
-
-
-
-## Alerts destinations
-
-
-
-## Alerts configuration
-
-
diff --git a/docs/features/lineage.mdx b/docs/features/lineage.mdx
deleted file mode 100644
index db015dc93..000000000
--- a/docs/features/lineage.mdx
+++ /dev/null
@@ -1,32 +0,0 @@
----
-title: End-to-End Data Lineage
-sidebarTitle: Data Lineage
----
-
-Elementary Cloud UI and Elementary OSS Report include a rich data lineage graph.
-The graph is enriched with the latest test results, to enable easy impact and root cause analysis of data issues.
-
-In Elementary Cloud lineage includes [Column Level Lineage](/features/column-level-lineage) and [BI integrations](/features/exposures-lineage#automated-bi-lineage).
-
-## Node info and test results
-
-To see additional information in the lineage view, use the `...` menu right to the column:
-
-- **Test results**: Access the table latest test results in the lineage view.
-- **Node info**: See details such as description, owner and tags. If collected, it will include the latest job info.
-
-
-
-## Job info in lineage
-
-You can configure Elementary to collect jobs names and information to present in the lineage _Node info_ tab. Job names can also be used to filter the lineage graph.
-
-Read how to configure jobs info collection for [Elementary Cloud](/cloud/guides/collect-job-data) or [OSS](/oss/guides/collect-job-data).
diff --git a/docs/features/multi-env.mdx b/docs/features/multi-env.mdx
index fb6d55921..4fb533ac2 100644
--- a/docs/features/multi-env.mdx
+++ b/docs/features/multi-env.mdx
@@ -1,11 +1,10 @@
---
title: "Multiple Environments"
-icon: "rectangle-history-circle-plus"
---
-An environment in Elementary is a combination of dbt project and target.
-For example: If you have a single dbt project with three targets, prod, staging and dev, you could create 3 environments in Elementary and monitor these envs.
+An environment in Elementary is a combination of a dbt project and a target.
+For example: If you have a single dbt project with three targets, prod, staging and dev, you can create 3 environments in Elementary and monitor these environments.
If you have several dbt projects and even different data warehouses, Elementary enables monitoring the data quality of all these environments in a single interface.
diff --git a/docs/features/performance-monitoring/performance-monitoring.mdx b/docs/features/performance-monitoring/performance-monitoring.mdx
new file mode 100644
index 000000000..77ce069ba
--- /dev/null
+++ b/docs/features/performance-monitoring/performance-monitoring.mdx
@@ -0,0 +1,39 @@
+---
+title: Performance Monitoring
+sidebarTitle: Performance monitoring
+---
+
+Monitoring the performance of your data pipeline is critical for maintaining data quality, reliability, and operational efficiency.
+Proactively monitoring performance issues enables to detect bottlenecks and opportunities for optimization, prevent data delays, and avoid unnecessary costs.
+
+Elementary monitors and logs the execution times of:
+- dbt models
+- dbt tests
+
+## Models performance
+
+Navigate to the `Model Duration` tab.
+
+The table displays the latest execution time, median execution time, and execution time trend for each model. You can sort the table by these metrics and explore the execution times over time for the models with the longest durations
+
+It is also useful to use the navigation bar to filter the results, and see run times per tag/owner/folder.
+
+
+
+## Tests performance
+
+Navigate to the `Test Execution History` tab.
+
+On the table you can see the median execution time and fail rate per test.
+You can sort the table by this time column, and detect tests that are compute heavy.
+
+It is also useful to use the navigation bar to filter the results, and see run times per tag/owner/folder.
\ No newline at end of file
diff --git a/docs/introduction.mdx b/docs/introduction.mdx
index 1fc128423..8bd67abcd 100644
--- a/docs/introduction.mdx
+++ b/docs/introduction.mdx
@@ -12,7 +12,8 @@ icon: "fire"
alt="Elementary banner"
/>
-
+
+
Elementary includes two products:
diff --git a/docs/key-features.mdx b/docs/key-features.mdx
index 581b8d25d..75068c125 100644
--- a/docs/key-features.mdx
+++ b/docs/key-features.mdx
@@ -72,3 +72,43 @@ icon: "stars"
Explore and discover data sets, manage your documentation in code.
+
+
+
+#### Anomaly Detection
+
+
+ Out-of-the-box ML-powered monitoring for freshness and volume issues on all production tables.
+ The monitors track updates to tables, and will detect data delays, incomplete updates, and significant volume changes.
+ By qurying only metadata (e.g. information schema, query history), the monitors don't add compute costs.
+
+
+
+ ML-powered anomaly detection on data quality metrics such as null rate, empty values, string length, numeric metrics (sum, max, min, avg), etc.
+ Elementary also supports monitoring for anomalies by dimensions.
+ The monitors are activated for specific data sets, and require minimal configuration (e.g. timestamp column, dimensions).
+
+
+#### Schema Validation
+
+
+ Elementary offers a set of schema tests for validating there are no breaking changes.
+ The tests support detecting any schema changes, only detecting changes from a configured baseline, JSON schema validation,
+ and schema changes that break downstream exposures such as dashboards.
+
+
+
+ Coming soon!
+
+
+#### Data Tests
+
+Custom SQL Tests
+
+dbt tests
+
+Python tests
+
+#### Tests Coverage
+
+#### Performance monitoring
diff --git a/docs/mint.json b/docs/mint.json
index 9d9bb9820..a4b1acf83 100644
--- a/docs/mint.json
+++ b/docs/mint.json
@@ -29,7 +29,7 @@
},
"tabs": [
{
- "name": "Data tests",
+ "name": "Elementary Tests",
"url": "data-tests"
},
{
@@ -61,7 +61,6 @@
"pages": [
"introduction",
"quickstart",
- "cloud/general/security-and-privacy",
{
"group": "dbt package",
"icon": "cube",
@@ -75,27 +74,98 @@
]
},
{
- "group": "Features",
+ "group": "Cloud Platform",
"pages": [
- "features/data-tests",
- "features/automated-monitors",
- "features/elementary-alerts",
- "features/data-observability-dashboard",
+ "cloud/introduction",
+ "cloud/features",
+ "features/integrations",
+ "cloud/general/security-and-privacy"
+ ]
+ },
+ {
+ "group": "Anomaly Detection Monitors",
+ "pages": [
+ "features/anomaly-detection/monitors-overview",
{
- "group": "End-to-End Lineage",
- "icon": "arrow-progress",
- "iconType": "solid",
+ "group": "Automated monitors",
"pages": [
- "features/lineage",
- "features/exposures-lineage",
- "features/column-level-lineage"
+ "features/anomaly-detection/automated-monitors",
+ "features/anomaly-detection/automated-freshness",
+ "features/anomaly-detection/automated-volume"
]
},
+ "features/anomaly-detection/opt-in-monitors",
+ {
+ "group": "Configuration and Feedback",
+ "pages": [
+ "features/anomaly-detection/monitors-configuration",
+ "features/anomaly-detection/monitors-feedback",
+ "features/anomaly-detection/disable-or-mute-monitors"
+ ]
+ }
+ ]
+ },
+ {
+ "group": "Data Tests",
+ "pages": [
+ "features/data-tests/data-tests-overview",
+ "features/data-tests/dbt-tests",
+ "features/data-tests/custom-sql-tests",
+ "features/data-tests/schema-validation-test"
+ ]
+ },
+ {
+ "group": "Data Lineage",
+ "pages": [
+ "features/data-lineage/lineage",
+ "features/data-lineage/column-level-lineage",
+ "features/data-lineage/exposures-lineage"
+ ]
+ },
+ {
+ "group": "Alerts and Incidents",
+ "pages": [
+ "features/alerts-and-incidents/alerts-and-incidents-overview",
+ {
+ "group": "Setup & configure alerts",
+ "pages": [
+ "features/alerts-and-incidents/effective-alerts-setup",
+ "features/alerts-and-incidents/alert-rules",
+ "features/alerts-and-incidents/owners-and-subscribers",
+ "features/alerts-and-incidents/alert-configuration"
+ ]
+ },
+ "features/alerts-and-incidents/incidents",
+ "features/alerts-and-incidents/incident-management"
+ ]
+ },
+ {
+ "group": "Performance & Cost",
+ "pages": [
+ "features/performance-monitoring/performance-monitoring"
+ ]
+ },
+ {
+ "group": "Data Governance",
+ "pages": [
+ "features/data-governance/overview-and-best-practices",
+ "features/data-governance/define-ownership",
+ "features/data-governance/leverage-tags"
+ ]
+ },
+ {
+ "group": "Collaboration & Communication",
+ "pages": [
+ "features/collaboration-and-communication/data-observability-dashboard",
+ "features/collaboration-and-communication/catalog"
+ ]
+ },
+ {
+ "group": "Additional features",
+ "pages": [
"features/config-as-code",
- "features/catalog",
"features/multi-env",
- "features/ci",
- "features/integrations"
+ "features/ci"
]
},
{
@@ -181,7 +251,7 @@
]
},
{
- "group": "Communication & collaboration",
+ "group": "Alerts & Incidents",
"pages": [
"cloud/integrations/alerts/slack",
"cloud/integrations/alerts/ms-teams",
@@ -197,6 +267,7 @@
{
"group": "Resources",
"pages": [
+ "resources/business-case-data-observability-platform",
"overview/cloud-vs-oss",
"resources/pricing",
"resources/community"
@@ -240,7 +311,8 @@
"data-tests/anomaly-detection-configuration/ignore_small_changes",
"data-tests/anomaly-detection-configuration/fail_on_zero",
"data-tests/anomaly-detection-configuration/detection-delay",
- "data-tests/anomaly-detection-configuration/anomaly-exclude-metrics"
+ "data-tests/anomaly-detection-configuration/anomaly-exclude-metrics",
+ "data-tests/anomaly-detection-configuration/exclude-final-results"
]
},
"data-tests/anomaly-detection-tests/volume-anomalies",
@@ -262,7 +334,9 @@
},
{
"group": "Other Tests",
- "pages": ["data-tests/python-tests"]
+ "pages": [
+ "data-tests/python-tests"
+ ]
},
{
"group": "Elementary OSS",
@@ -308,7 +382,10 @@
},
{
"group": "Configuration & usage",
- "pages": ["oss/cli-install", "oss/cli-commands"]
+ "pages": [
+ "oss/cli-install",
+ "oss/cli-commands"
+ ]
},
{
"group": "Deployment",
@@ -369,7 +446,8 @@
]
}
],
- "footerSocials": {
+ "footerSocials":
+ {
"website": "https://www.elementary-data.com",
"slack": "https://elementary-data.com/community"
},
@@ -383,5 +461,43 @@
"gtm": {
"tagId": "GTM-TKR4HS3Q"
}
- }
+ },
+ "redirects": [
+ {
+ "source": "/features/lineage",
+ "destination": "/features/data-lineage/lineage"
+ },
+ {
+ "source": "/features/exposures-lineage",
+ "destination": "/features/data-lineage/exposures-lineage"
+ },
+ {
+ "source": "/features/column-level-lineage",
+ "destination": "/features/data-lineage/column-level-lineage"
+ },
+ {
+ "source": "/features/automated-monitors",
+ "destination": "/features/anomaly-detection/automated-monitors"
+ },
+ {
+ "source": "/features/data-tests",
+ "destination": "/features/data-tests/dbt-tests"
+ },
+ {
+ "source": "/features/elementary-alerts",
+ "destination": "/features/alerts-and-incidents/alerts-and-incidents-overview"
+ },
+ {
+ "source": "/cloud/guides/alert-rules",
+ "destination": "/features/alerts-and-incidents/alert-rules"
+ },
+ {
+ "source": "/features/catalog",
+ "destination": "/features/collaboration-and-communication/catalog"
+ },
+ {
+ "source": "/features/data-observability-dashboard",
+ "destination": "/features/collaboration-and-communication/data-observability-dashboard"
+ }
+ ]
}
diff --git a/docs/resources/business-case-data-observability-platform.mdx b/docs/resources/business-case-data-observability-platform.mdx
new file mode 100644
index 000000000..a78f11580
--- /dev/null
+++ b/docs/resources/business-case-data-observability-platform.mdx
@@ -0,0 +1,25 @@
+---
+title: "When do I need a data observability platform?"
+sidebarTitle: "When to add data observability"
+---
+
+
+### If the consequences of data issues are high
+If you are running performance marketing budgets of $millions, a data issue can result in a loss of hundreds of thousands of dollars.
+In these cases, the ability to detect and resolve issues fast is business-critical. It typically involves multiple teams and the ability to measure, track, and report on data quality.
+
+### If data is scaling faster than the data team
+The scale and complexity of modern data environments make it impossible for teams to manually manage quality without expanding the team. A data observability platform enables automation and collaboration, ensuring data quality is maintained as data continues to grow, without impacting team efficiency.
+
+### Common use cases
+If your data is being used in one of the following use cases, you should consider adding a data observability platform:
+- Self-service analytics
+- Data activation
+- Powering AI & ML products
+- Embedded analytics
+- Performance marketing
+- Regulatory reporting
+- A/B testing and experiments
+
+## Why isn't the open-source package enough?
+The open-source package was designed for engineers that want to monitor their dbt project. The Cloud Platform was designed to support the complex, multifaceted requirements of larger teams and organizations, providing a holistic observability solution.
\ No newline at end of file
diff --git a/docs/resources/how-does-elementary-work b/docs/resources/how-does-elementary-work
new file mode 100644
index 000000000..937fb3500
--- /dev/null
+++ b/docs/resources/how-does-elementary-work
@@ -0,0 +1,28 @@
+---
+title: "How does Elementary work"
+sidebarTitle: "Elementary Could Platform"
+---
+## Cloud platform architecture
+The Elementary open-source package creates a schema that collects the test results and the models from your dbt projects. The platform is part of your package and it runs in your dbt pipeline and it writes to its own data set in the data warehouse and then the platform syncs that data set to the cloud. It also integrates directly with your data warehouse so it has access to the information schema, the query history and the metadata.
+
+We also integrate with your dbt code repository - so we understand how it’s built including tags, owners, which tables are part of your dbt project and what tables are not, and we see daily usage by connecting to your BI.
+
+
+  +
+
+
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
\ No newline at end of file
+
+
+
+## How it works?
+1. You install the Elementary dbt package in your dbt project and configure it to write to it's own schema, the Elementary schema.
+2. The package writes test results, run results, logs and metadata to the Elementary schema.
+3. The cloud service only requires `read access` to the Elementary schema, not to schemas where your sensitive data is stored.
+4. The cloud service connects to sync the Elementary schema using an **encrypted connection** and a **static IP address** that you will need to add to your allowlist.
+
+
+##
+
+
+[Read about Security and Privacy](/cloud/general/security-and-privacy)
\ No newline at end of file
 +
+  +
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
index bf9a777ac..1c369051d 100644
--- a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
+++ b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
@@ -51,6 +51,14 @@
}
>
+
+
\ No newline at end of file
diff --git a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
index bf9a777ac..1c369051d 100644
--- a/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
+++ b/docs/_snippets/cloud/integrations/cards-groups/alerts-destination-cards.mdx
@@ -51,6 +51,14 @@
}
>
+  -Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that would trigger a sync after your jobs are done.
+Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that will trigger a sync after your jobs are done.
-- Make sure the webhook is triggered on `Run completed` events
+- Make sure the webhook is triggered on `Run completed` events.
- Select **only** the main jobs of the relevant environment.
-Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that would trigger a sync after your jobs are done.
+Heading to dbt Cloud, you can [create a webhook subscription](https://docs.getdbt.com/docs/deploy/webhooks#create-a-webhook-subscription) that will trigger a sync after your jobs are done.
-- Make sure the webhook is triggered on `Run completed` events
+- Make sure the webhook is triggered on `Run completed` events.
- Select **only** the main jobs of the relevant environment.
 +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+