by Renxi Wang, Xudong Han, Lei Ji, Shu Wang, Timothy Baldwin, Haonan Li
https://github.com/Reason-Wang/ToolGen
https://arxiv.org/abs/2410.03439
- Abstract
- 1 Introduction
- 2 Related Work
- 3 ToolGen
- 4 Tool Retrieval Evaluation
- 5 End-to-End Evaluation
- 6 Conclusions
- Appendix A. Real Tool Example
- Appendix B. Tool Virtualization Implementation
- Appendix C Constrained Beam Search Detail
- Appendix D Retry Mechanism
- Appendix E Ablation
- Appendix F Generalization
- Appendix G Adapt ToolBench Data to ToolGen
ToolGen: Integrating Tool Knowledge into Language Models
Background:
- Large language models (LLMs) have limitations in executing tasks without external tools
- Traditional methods rely on inputting tool descriptions as context, but are constrained by context length and require separate retrieval mechanisms
Introducing ToolGen:
- Paradigm shift: integrates tool knowledge directly into the LLM's parameters
- Each tool represented as a unique token
- Enables generation of tool calls and arguments in next token prediction capabilities
- Seamless blend of language generation and tool invocation
Benefits:
- No additional retrieval step required
- Significantly enhances performance and scalability
Experimental Results:
- Over 47,000 tools tested
- Superior results in both tool retrieval and autonomous task completion
- Sets the stage for new era of AI agents adapting to tools across diverse domains
Implications:
- Transforms tool retrieval into a generative process
- Enables end-to-end tool learning
- Opens opportunities for integration with advanced techniques like chain-of-thought and reinforcement learning.
Large Language Models (LLMs)
- Impressive capabilities as interactive systems
- Process external inputs, execute actions, and complete tasks autonomously
- Demonstrated by various methods: Gravitas [2023], Qin et al. [2023], Yao et al. [2023], Shinn et al. [2023], Wu et al. [2024a], Liu et al. [2024]
- Tool calling via APIs is a common and effective approach for interaction
Challenges with Existing Methods for Tool Retrieval and Execution
- Struggle to scale efficiently as the number of tools grows
- Combined method of tool retrieval and execution:
- Retrieval models rely on small encoders that fail to fully capture semantics
- Separating retrieval from execution introduces inefficiencies and potential misalignment
- LLMs have limited intrinsic knowledge of tool-related functionalities, resulting in suboptimal performance
Introducing ToolGen: A Novel Framework for Integrating Real-World Tool Knowledge into LLMs
- Expands LLM's vocabulary with tool-specific virtual tokens
- Trains the model to generate these tokens within conversational context
- Allows LLM to leverage pre-existing knowledge more effectively for retrieving and calling tools
- Each tool represented as a unique virtual token in the LLM's vocabulary
- Training stages: tool memorization, retrieval training, agent training
- Tool memorization: associates each virtual tool token with documentation
- Retrieval training: model learns to generate relevant tool tokens based on user queries
- Agent training: model acts as an autonomous agent, generating plans and tools, determining appropriate parameters for task completion
- Calling tools and receiving feedback from external environments allows efficient handling of user queries
Comparison with Traditional Paradigms
- ToolGen merges retrieval and generation into a single, cohesive model, setting the stage for advanced techniques like chain-of-thought reasoning and reinforcement learning in real-world applications
Contributions
- Novel framework, ToolGen, that integrates tool retrieval and execution into the LLM's generative process using virtual tokens
- Three-stage training process for efficient and scalable tool retrieval and API calling within ToolGen
- Experimental validation demonstrating comparable performance to current best tool retrieval methods with less cost and higher efficiency, surpassing traditional tool learning paradigms across large-scale tool repositories.
Tool Retrieval for LLM Agents
Importance of Tool Retrieval:
- Essential for LLM agents in real-world task execution
- Tools are usually represented by their documentation
Traditional Retrieval Methods:
- Sparse retrieval (e.g., BM25)
- Dense retrieval (e.g., DPR, ANCE)
- Rely on large document indices and external modules
- Lead to inefficiencies and difficulty in optimizing in an end-to-end agent framework
Alternative Retrieval Methods:
- Chen et al. (2024b): Rewrite queries, extract intent for unsupervised settings
- Xu et al. (2024): Iteratively refine queries based on tool feedback
- Generative Retrieval: Models directly generate relevant document identifiers
ToolGen Approach:
- Represent each tool as a unique token
- Tool retrieval and calling framed as generation task
- Simplifies retrieval, integrates with other LLM/LLM-based agent features (e.g., chain-of-thought reasoning, ReAct)
- Consolidates retrieval and task execution into a single LLM agent
- Reduces latency and computational overhead for more efficient and effective task completion
LLMs and Tools:
- LLMs have shown potential in mastering various tasks (Chen et al., 2023a; Zeng et al., 2023; Yin et al., 2024; Wang et al., 2024)
- Limited set of actions in existing works (Schick et al., 2023; Patil et al., 2023; Qin et al., 2023)
- Tool selection challenge in complex environments (ToolBench, Qin et al., 2023)
- Pipelined approaches face issues: error propagation and LLMs' inability to fully understand tools (Patil et al., 2023; Qin et al., 2023)
- Representing actions as tokens and converting them into generative tasks (RT2, Brohan et al., 2023; Self-RAG, Asai et al., 2023)
- ToolkenGPT: introduces tool-specific tokens to trigger tool usage (Hao et al., 2023)
Comparison with ToolkenGPT:
- Focus on real-world tools for complex tasks vs. simpler tools (YouTube channel search vs. math functions)
- Full-parameter fine-tuning vs. few-shot prompting
- Larger tool set (47,000 tools vs. 13–300)
Other Approaches:
- ToolPlanner and AutoACT use reinforcement learning or multi-agent systems for enhancing tool learning/task completion (Wu et al., 2024b; Qiao et al., 2024)
- Not compared with our method due to feedback mechanisms and potential integration for future work.
Introduction: Introduce notations utilized throughout the paper.
ToolGen Methodology:
- Tool Virtualization: Map tools into virtual tokens.
- Tool Memorization: Predict tool tokens based on their documentation.
- Retrieval Training: Learn to predict tool tokens from queries.
- End-to-end Agent Tuning: Fine-tune the retriever model using pipeline data (trajectories), resulting in the ToolGen Agent model.
Inference Approach: Detailed later in the paper.
Tool Learning with Large Tool Sets
- Goal: Resolve user query
qusing tools from a large tool setD={d1, d2, ..., dN} - Retriever (R): Retrieve
krelevant tools fromD, denoted asDk,R={dr1, dr2, …, drk} - Prompt: Concatenation of
qandDk,R, denoted asPromp= [q, Dk, R]
Iterative Four-Stage Paradigm for Task Completion
- Generate a plan (pi): -
- Select a tool (dsi): Choose an appropriate tool from the retrieved set
Dk,R - Determine tool parameters (ci): Set up necessary configurations or inputs for the selected tool
- Collect feedback (fi): Interact with the tool to obtain information on its performance and potential refinements
- Repeat steps 1-4 until the task is completed, generating final answer
a - Trajectory of Actions:
Traj=[Promp, (p1, dsi1, ci1, fi1), ... , (pt, dst, ci, ft), a] - Iterative Approach: Allows for dynamic adjustment and refinement at each step, improving task completion performance.
Atomic Indexing in ToolGen
Virtualization of Tools:
- Each tool is mapped to a unique new token through atomic indexing
- Expands the Language Model's (LLM) vocabulary to include the unique tool token
- Initializes the embedding for each tool token as the average embedding of its corresponding tool name, ensuring a semantically meaningful starting point
Token Set Definition:
- The token set is defined as T=Index(d)|∀d∈D, where:
- Index is the function mapping tools to tokens
- D is the set of all available tools
Comparison with Other Indexing Methods:
- Atomic indexing is more efficient and can mitigate hallucination compared to other indexing methods, such as:
- Semantic mappings
- Numeric mappings
- These are discussed in sections 4.3 and 5.4
Tool Memorization in LLMs
- Assign tokens to tools, but LLMs lack knowledge of them.
- To remedy this, fine-tune the LLM by providing tool descriptions as inputs and their tokens as outputs (tool memorization).
- Use loss function: L_tool = ∑d∈D - log pθ(Index(d) | ddo_c), where θ represents LLM parameters and ddo_c is a tool description.
- This process equips the LLM with basic knowledge of tools and their actions.
Training LLMs to Link User Queries and Tool Tokens:
We fine-tune LLMs by associating user queries with relevant tool tokens:
- Inputs are user queries
- Outputs are tool tokens
The equation, Retriever loss, is used for fine-tuning:
Retriever loss = ∑q∈Q∑d∈Dq - logpθ′(Index(d) | q)
Where:
Qis the set of user queriesDqis the set of tools relevant to each querypθ′(Index(d) | q)is the probability that tooldis generated given queryq, based on the LLM parameters after tool memorization (θ′)
This process produces ToolGen Retriever, capable of generating appropriate tool tokens for a user's query.
LLM Capabilities and Fine-Tuning Process
During retrieval training, the LLM generates tool tokens from queries. Subsequently, it is fine-tuned using agent task completion trajectories. The inference strategy resembles Agent-Flan (Chen et al., 2024c), but instead of generating Thought, Action, and Arguments together as ReAct, our process separates them. Our pipeline follows an iterative approach:
- The LLM first generates a Thought.
- This Thought triggers the generation of a corresponding Action token.
- Using this Action token, the model retrieves tool documentation.
- The LLM then generates necessary Arguments based on the documentation.
- This iterative process continues until the model produces a "finish" token or the maximum number of turns is reached.
- The generated trajectory is represented as
Traj=[q,(p1,Index(ds1),c1,f1),…,(pt,Index(dst),ct,ft),a]. In this structure, relevant tools are no longer required.
Constrained Beam Search for Action Token Restriction
To prevent action tokens outside the predefined tool set during inference, we implemented a constrained beam search generation that limits output tokens to the tool token set. This approach was applied both to tool retrieval, where the model selects tools based on queries, and to the end-to-end agent system, decreasing hallucination during action generation. Further details can be found in Section 5.4, and implementation specifics are explained in Appendix C.
(Note: Constrained Beam Search, implemented for tool retrieval and end-to-end agent system to limit hallucination during action generation)
ToolGen: Unified Tool Retrieval and Calling via Generation
Foundation Model:
- Pretrained Llama-3-8B (Dubey et al., 2024) with vocabulary size of 128,256
Expansion:
- Atomic indexing approach to expand vocabulary by an additional 46,985 tokens following tool virtualization process
- Final vocabulary size of 175,241
Fine-tuning:
- Llama-3 chat template with cosine learning rate scheduler
- Maximum learning 4×10−5
- Trained using Deepspeed ZeRO 3 (Rajbhandari et al., 2020) across 4×A100 GPUs
- 8 epochs for tool memorization, 1 epoch for retrieval training
Dataset:
- ToolBench: real-world tool benchmark with 16k tool collections and 47k unique APIs
- Each API documented with name, description, and parameters for calling the API
Baselines:
- BM25: classical unsupervised retrieval method based on TF-IDF
- EmbSim: sentence embeddings generated using OpenAI's sentence embedding model
- Re-Invoke: unsupervised retrieval method with query rewriting and document expansion
- IterFeedback: BERT-based retriever with iterative feedback for up to 10 rounds
- ToolRetriever: BERT-based retriever trained via contrastive learning
Settings:
- In-Domain Retrieval: retrieval search space restricted to tools within the same domain
- Multi-Domain Retrieval: search space expanded to include tools from all three domains
Metrics:
- Normalized Discounted Cumulative Gain (NDCG) a widely used metric in ranking tasks, including tool retrieval.
Tool Retrieval Results (Table 1)
- All trained models significantly outperform untrained baselines (BM25, EmbSim, Re-Invoke) across all metrics
- Benefit of training on tool retrieval data demonstrated
- Proposed ToolGen model: consistently achieves best performance in both settings
In-Domain Setting:
- ToolGen delivers competitive results, comparable to IterFeedback system
- Outperforms ToolRetriever by significant margin in all metrics
- Surpasses IterFeedback in several cases: NDCG@5 for domain I1 and NDCG@1,@3,@5 for I2
Multi-Domain Setting:
- ToolGen remains robust, outperforming ToolRetriever and other baselines
- Single model capable of handling complex real-world retrieval tasks with less defined domain boundaries.
ToolGen vs Alternative Indexing Approaches
Alternative Indexing Methods:
- Numeric: Map each tool to a unique number, providing no semantic information but distinct identifiers
- Hierarchical: Cluster tools into non-overlapping groups and recursively partition, forming a hierarchical structure
- Semantic: Map each tool to its name, using semantic content of names to guide the Language Model
Analysis of Subtokens:
- Atomic indexing: Each tool represented by a single token
- Numeric indexing: Tools encoded into N tokens based on number of tools
- Semantic indexing, Hierarchical indexing: Produce variable number of subtokens, with more outliers in semantic indexing
Evaluation of Indexing Methods:
- Semantic indexing demonstrates best retrieval performance across various metrics and scenarios
- Atomic indexing achieves better end-to-end results
Ablation Study:
- Removing retrieval training, tool memorization, and constrained beam search decreases ToolGen's performance
Ablation Study for ToolGen Performance:
- Retrieval training: crucial factor for tool retrieval performance as it aligns with query inputs and output tokenized tools
- Removing retrieval training leads to minor performance drop, plays a role in generalization (discussed further in Appendix F)
- Tool memorization: helps improve generalization but not major contributor to retrieval task performance
- Constrained beam search: prevents hallucinations and useful for end-to-end agent tasks. Not a major contributor to retrieval task but important for preventing incorrect outputs.
ToolGen Framework Adaptations
- Remove explicit tool selection from ToolBench data
- Fine-tune retrieval model using reformatted data
Baselines
- GPT-3.5: same as StableToolBench, using GPT-3.5 for tool calling capability
- ToolLlama-2: fine-tuned Llama-2 on ToolBench data
- ToolLlama-3: fine-tuned Llama-3 (same base model as ToolGen) on ToolBench dataset, named "ToolLlama" to distinguish from ToolLlama-2
Settings
- Ground truth tools defined based on ChatGPT selections for evaluation purposes
- Retrieval-based setting used for end-to-end experiments: ToolRetriever retrieves relevant tools for baselines, while ToolGen generates tool tokens directly
- Both models finetuned using cosine scheduler with maximum learning rate set to 4×10^-5
- Context length truncated to 6,144 and total batch size set to 512
- Flash-Attention and Deepspeed ZeRO 3 used for memory savings
- ToolGen separates Thought, Action, and Parameters steps, while ToolLlama completes them in a single round
- Maximum of 16 turns allowed for ToolGen, compared to ToolLlama's 6-turn limit
- Retry mechanism introduced to prevent early termination: models generate responses with higher temperature when "give up" or "I’m sorry" detected
Metrics
- Solvable Pass Rate (SoPR) and Solvable Win Rate (SoWR) used for end-to-end evaluation
- Results reported under two settings: Ground Truth Tools (G.T.) and Retriever (R.)
End-to-End Evaluation Performance (Table 4)
- ToolGen achieves best average SoPR score of 54.19 and highest SoWR of 49.70 using Ground Truth Tools (G.T.)
- In Retriever setting, ToolGen maintains lead with an average SoPR of 53.28 and SoWR of 51.51
- ToolLlama shows competitive performance, surpassing ToolGen on some individual instances
Ablation Study (Appendix G)
- Table 5 presents end-to-end evaluation for different indexing methods: Numeric, Hierarchical, Semantic, Atomic
- In Numeric setting: SoPR = 34.76, SoWR = 28.79
- In Hierarchical setting: SoPR = 50.20, SoWR = 29.51
- In Semantic setting: SoPR = 58.79, SoWR = 47.88
- In Atomic setting: SoPR = 58.08, SoWR = 47.58
Tool Retrieval Evaluation: End-to-End
Comparison of Indexing Methods for Agent Task:
- Atomic method: achieves best performance among four indexing methods in end-to-end agent task (Table 5)
- Hallucination rates: Atomic has lower hallucinations compared to other methods (Figure 4)
- Constrained decoding: removed, allowing free generation of Thought, Action, and Parameters
Impact of Indexing Methods on Performance:
- Atomic method: highest performance due to lower hallucination rates
- Other methods: higher hallucination rates lead to poorer performance (discussed in Section 5.4)
Impact of Constrained Decoding:
- With constrained decoding, ToolGen does not generate nonexistent tools
- Without constraint, ToolGen generates 7% non-tool tokens during Action generation stage with atomic indexing
- Semantic indexing results in even more nonexistent tool tokens for ToolGen
- ToolLlama and GPT-3.5 still generate hallucinations despite being provided with five ground truth tools in the prompt (Figure 4)
- Without any tools specified, ToolLlama generates over 50% nonexistent tool names.
Evaluation of Model Hallucination in Tool Generation
ToolGen Evaluation:
- Input query in ToolGen agent paradigm (Thought, Tool, Parameters)
- Report proportion of generated tools that do not exist in dataset out of all tool generation actions
Actions Decoding without Beam Search Constraints:
- Tested on ToolLlama and GPT-3.5 models
- Input query along with 5 ground truth tools
Hallucination Rates:
- Figure 4 shows hallucination rates of nonexistent tools for different models
- ToolGen, with constrained decoding, does not hallucinate at all
- ToolLlama and GPT-3.5 may still generate nonexistent tool names despite being provided with 5 ground truth tools
ToolGen Framework: Unifies tool retrieval and execution within large language models (LLMs) through embedding tool-specific virtual tokens into the model's vocabulary, transforming tool interactions into a generative task. A three-stage training process enables efficient tool handling in real-world scenarios, setting a new standard for scalable AI agents dealing with extensive tool repositories. Future advancements may include chain-of-thought reasoning, reinforcement learning, and ReAct, enhancing LLMs' autonomy and versatility in practical applications.
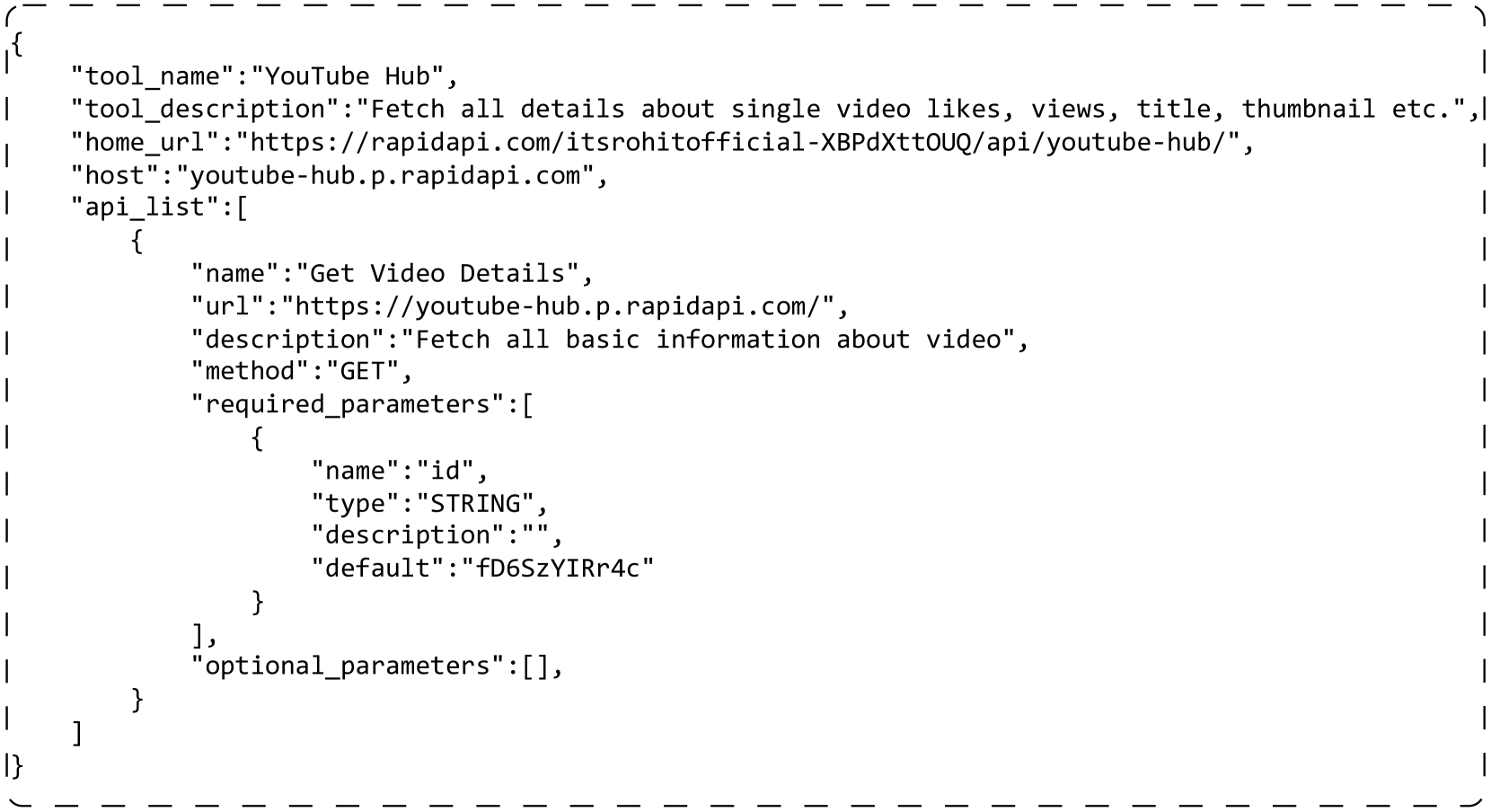
Tool Example (Figure 5) showcases a real tool that consists of various APIs.
- Tool Details: "tool_name" - name, "tool_description" - description of the tool's functionality
- API Fields: "name" - API name, "description" - API information, "method" - HTTP calling method, "required_parameters" - essential parameters for an API call, "optional_parameters" - optional additional parameters
Refer to caption Figure 5: A real tool example featuring one API with simplified fields.
{kind=link}
ToolGen Indexing Methods
Atomic indexing:
- Uses a single token to represent a tool (tool name + API name)
- Does not hallucinate nonexistent tools
- Example: <<Youtube Hub&&Get Video Details>>
Semantic indexing:
- Maps each tool to the ToolBench name (combination of tool name and API name)
- Tokenizes the name into multiple tokens for semantic meaning
- Example: get_video_details_for_youtube_hub
Numeric indexing:
- Assigns unique numbers to each tool
- Uses a 5-digit number representation (spaced)
- Example: 0 0 0 1 2 8
Hierarchical indexing:
- Maps each tool to a hierarchical, clustered representation
- Clusters tools into 10 categories per iteration
- Assigns numbers from root to leaf node in the clustering tree
- Example: 0 1 2 2 3 3 3
ToolGen: Unified Tool Retrieval and Calling via Generation
- During retrieval and end-to-end agent tasks, use constrained beam search to limit generated actions to valid tool tokens
- Build disjunctive trie for each node representing a tool token ID
- Children are all feasible ids following current id
- Determine possible next token IDs based on current searched IDs
- During beam search step, mask out unfeasible tokens' logits to force possible ids to be sampled or searched
Retrieval:
- Constraint directly applied during generation
End-to-End Agent Tasks:
- Decompose inference step into three conversational turns
- Detect when ToolGen needs to generate action, then apply constraint
Dataset Statistics:
- Table 6 shows dataset statistics for tool memorization and retrieval training
- I1: 49,936 samples
- I2: 194,086 samples
- I3: 222,783 samples
- All: 72,833 tools used, resulting in slightly more than the number of samples
ToolGen Inference Example:
- Figure 6 shows an example of ToolGen inference with no relevant tools for choice
- System prompt given first, followed by user's task query
- ToolGen generates thought, which hints model to generate action
- After generating action, user provides tool documentation for model input generation.
Techniques for Reproducibility:
- Fixing random seeds
- Setting temperatures to zero for decoding
Problems with Adopted Techniques:
- Models give up early, not trying enough
- Negative impact on end-to-end evaluation
Mitigating Negative Impact:
- Retry mechanism: regenerate turn when models try to give up or say sorry
Constrained Beam Search Algorithm:
- Build Disjunctive Trie
- Inputs: Set of tool token ids {Ids1,Ids2,…,Idsn}; Initial InputIds; Beam width k; Language model LM
- Output: Searched Beams
- Initialize Root←{}, Beams←[(InputIds, root of T)]
- while Beams is not empty do
- for each (beam, node) in Beams do
- if beam ends with eos_token_id then
- Output beam and remove beam from beams
- Continue
- end if
- score ← LM(beam)
- feasible_ids ← children of node in T
- Mask out ids not in feasible_ids from score
- Append (NewBeam, NewNode) to NewBeams for each id, group in zip(TopIds, Groups) do
- NewBeam ← beams[group] + [id]
- NewNode ← node.child(id)
- Append (NewBeam, NewNode) to NewBeams
- end for
- if beam ends with eos_token_id then
- Beams ← NewBeams
- for each (beam, node) in Beams do
- end while
Table 7: Ablation Results for ToolGen End-to-End Evaluation
Model Performance on Unseen Instructions (SoPR):
- ToolGen Agent shows slightly better performance without tool memorization or retrieval training
Model Performance on Unseen Tools (SoWR):
- Training without the first two stages causes a drop in both SoPR and SoWR
- This demonstrates that the first two stage training plays a role in the generalization capability of ToolGen
- Retrieval training is more significant compared to tool memorization
Ablation Results for Model Performance: | Model | SoPR | SoWR | I1-Inst. | I2-Inst. | I3-Inst. | Avg. | I1-Tool. | I1-Cat. | I2 Cat. | Avg. | |---|---|---|---|---|---|---|---|---|---|---|---| | ToolGen | 54.60 | 52.36 | 43.44 | 51.82 | 50.31 | 51.82 | 54.72 | 26.23 | 47.28 | 42.91 | | w/o retrieval training | 56.95 | 46.70 | 50.27 | 52.42 | 49.69 | 51.61 | 34.43 | 47.27 | - | - | | w/o memorization | 56.03 | 47.96 | 57.38 | 53.69 | 49.08 | 53.17 | 34.43 | 49.70 | - | - | | I1-Tool. | 56.54 | 49.46 | - | - | - | 52.66 | - | - | 51.96 | 50.83 | | I1-Cat. | 49.47 | 40.31 | - | - | - | 42.84 | - | 39.87 | - | 40.23 | | I2 Cat. | 58.86 | 46.19 | - | - | - | 51.70 | - | 42.74 | - | 49.46 | | I1-Inst. (ToolGen) | 50.31 | 54.72 | 50.31 | 54.72 | 43.44 | 51.82 | 39.87 | 38.56 | 42.74 | 43.43 | | I2-Inst. (ToolGen) | 40.51 | 39.87 | 40.51 | 39.87 | 51.82 | 46.19 | - | 36.29 | 37.90 | 38.28 | | I3-Inst. (ToolGen) | 37.90 | 39.53 | 37.90 | 39.53 | 47.28 | 39.32 | - | 36.13 | 36.66 | 36.83 |
ToolGen Agent Performance on Unseen Tools
Generalization Results:
- Table 8 shows end-to-end evaluation of models on unseen tools
- ToolGen underperforms ToolLlama, indicating worse generalization capability in completing full tasks
- Generalization problem is prevalent in generative retrieval and beyond the scope of this paper
ToolGen Performance:
- In Table 8, ToolGen:
- SoPR (Setting 1 - Tools): 52.32, 40.46, 39.65, 47.67, 39.24, 38.56, 37.90, 39.30
- SoWR (Setting 1 - Words): 56.54, 49.46, 51.96, 52.66, 40.51, 39.87, 37.90, 39.53
- Compared to:
- GPT-3.5 (SoPR: 58.90, SoWR: 57.59) and (Retrieval: 57.59, 61.76)
- ToolLlama (SoPR: 57.38, SoWR: 57.70) and (Retrieval: 45.43, 61.76)
ToolGen Data Adaptation from ToolBench:
- Adopt tool documentations for tool memorization training as input: documents -> tool tokens
- Use annotated data for retrieval training, converting queries to virtual tokens and relevant tools
- Convert interaction trajectories for end-to-end agent-tuning:
- Remove system prompted tools
- Replace tool names with virtual tool tokens
- Decompose ReAct into three conversational turns: Thought -> Action Prompt -> Action (Tool Tokens) -> Tool Parameters
- Table 6 in Appendix C shows the number of samples for each dataset.
Data Conversion for ToolGen:
- Memorization Training: user role as input, assistant role as output
- Retrieval Training: queries as input, virtual tokens representing tools as output
- End-to-End Agent-Tuning:
- Remove system prompted tools from trajectories
- Replace tool names with virtual tool tokens
- Decompose ReAct into three conversational turns for model training.
Adapted Data Examples:
- Figure 7 shows examples of tool memorization and retrieval training data (Figure 7)
- Figure 8 demonstrates an example of end-to-end agent-tuning data (Figure 8).