This is me trying to write an efficient (near-realtime, ideally!) implementation of triangle-based image approximation, as popularized by Roger Alsing's EvoLisa project. The general idea is to find a relatively small set of overlapping, flat-shaded, semi-transparent triangles that best approximates a given image. The results are impressive; usually only a few hundred triangles are necessary. Roger's original code was written in C# (!!!) and performed all processing in a single CPU thread (!!!) using GDI for rendering (!!!!!). Its results are impressive, but convergence can take days.
I'd like to think that I could do better.
I'm starting from an existing CUDA implementation by Joy Ding and Drew Robb, which uses particle swarm optimization instead of Alsing's naive random-walk. Ding & Robb's code [link? -ed] was designed to be launched from Python from a Linux host, so my first step has been adapting the code to C++. From there I intend to profile and optimize the kernels.
Here's the Mona Lisa approximated with 500 triangles over 2400 iterations. Each frame represents 100 iterations of the algorithm. This sequence took about 3m20s minutes to evolve on my laptop's 650M:
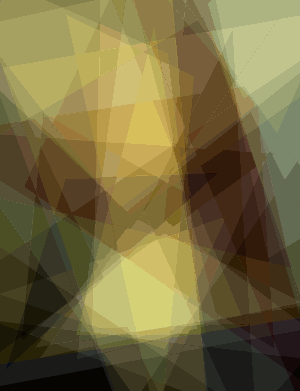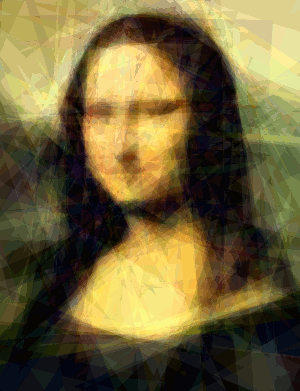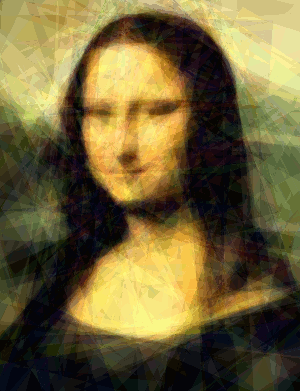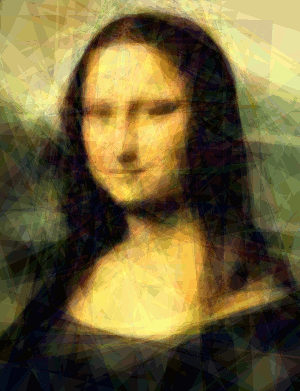
- 2014-07-03: Since textures shared between CUDA and OpenGL must be backed by CUDA Arrays, I tried converting the PSO implementation to write to surface memory (CUDA's name of R/W textures) instead of raw device memory. The bad news is that performance dropped by about 50%; the good news is that it turns out the texture I need to share with OpenGL doesn't need to be generated nearly as often as I feared. So, I'll keep the intermediate rendering as pitched device memory, and only use array/surface memory when necessary. I'm also working on moving the entire PSO iteration process to the GPU; currently there's way too much pointless copying back and forth between host and device memory.
- 2014-06-23: Work is coming along on the GUI front. I have all the relevant components (Qt5, CUDA, and OpenGL) playing nicely with each other in a testbed; all that remains is to hook up the actual EvoLisa logic. To that end, I've extracted all the relevant code into a single module that can be trivially shared between the command-line and GUI projects.
- 2014-06-04: I took another detour into even more boring work, and started putting together a GUI for the program. I really, really do not enjoy GUI programming, which means I'm strongly motivated to finish this part quickly and get back to optimizations.
- 2014-05-29: Boring work complete! All relevant previously-hard-coded settings and constants can now be overriden on the command line. This let me write a fancy Python script to run the code on a corpus of test images, dump all the output into a single folder, and generate pretty graphs to track the speed and quality of convergence for each image. As soon as I actually start running this script on a regular basis and archiving the results, it will give me an easy way to gauge the impact of individual code changes. On the actual algorithm front, I made a few minor changes: I removed the unused alpha channel from the triangle particles (reducing the optimization problem from 10 dimensions to 9), and removed some suspicious-looking code that allowed color channels to have negative values (which works, technically, but is kind of cheating as far as I'm concerned). Much to my surprise, this cut convergence time by 60%, and improved quality by nearly 0.5 dB! My theory is that it lets each generation stabilize on a local maximum in fewer iterations.
- 2014-05-19: I started tracking the Peak Signal-to-Noise Ratio (PSNR) at each generation instead of the squared error sum, since the former is theoretically comparable across multiple images while the latter is not. This should let me better evaluate the effect of future codes changes on image quality. As for the error function itself, I tried applying a non-uniform scale to the color channels when computing per-pixel error (so that green error is weighted more heavily than red error, and red more than blue), but strangely it didn't seem to help. I also simplified the error calculation to use 30% fewer ALU ops, but the register pressure was worse. The next step is probably some boring work, like adding command-line arguments to enable better automated testing.
- 2014-05-16: I found a memory stomp introduced in one of my previous changes; hooray for Nsight! Fixing it increased my register pressure and pushed me back to 50% occupancy, but noticeably improved long-term convergence quality. I also keep better track of the best solution found so far, which further improves visual quality. I fixed a number of race conditions in the per-thread-block score updates, but the algorithm is still flagrantly violating CUDA's "Thou Shalt Not Share Data Directly Between Thread Blocks" rule; only a substantial rewrite will fix that. Finally, I tried tweaking the image difference equation to ignore luminance. I'm not convinced it's a quality improvement, but between all these changes, Lisa is looking fine.
- 2014-05-14: Reading Ding & Robb's paper revealed some easy improvements, mostly having to do with parameter tuning. My neighborhood size and alpha limit were both too large, and appropriate values can apparently be determined as functions of particle count and triangle count respectively. The PSO dampening factor also seems to have two optimal values to choose from, depending on the preference for short-term or long-term convergence quality. I'd like to roll all of this into one giant "perf/quality" knob, but for now if I tune everything for short-term performance it's about 33% faster than yesterday's build. I also located an even better resource than the paper: Ding & Robb themselves!
- 2014-05-13: Today I completed a quick optimization pass over the kernels. I hoisted some loop invariants, converted double-precision literals to single-precision, and inserted explicit fused multiply-adds where appropriate. Collectively, this made everything run about 4x faster. Along the way I found a typo in the triangle-scoring function whose correction led to significantly better algorithmic convergence. So, 4x faster and better results; score! Nsight reports that occupancy is still at 62.5% (limited by register pressure), so there's still work to be done there. The instruction issue rate is also sitting at around 20% due to texture stalls, which is alarming. And I still haven't even started on some algorithmic improvements I have in mind...
- 2014-05-09: Fixed some dumb Python->C++ conversion errors. I'm now more or less reproducing Ding & Robb's results. My next step will be to actually read their paper, to gain a better understanding of their Particle Swarm Optimization implementation and the tweakable parameters they expose. I also profiled the kernel using NVVP: the actual image rendering is negligent compared to the iterated PSO kernel, as expected. The PSO kernel is running at about 50% occupancy, and seems to include far more int<->float conversion instructions than I would have expected. Finally, the application currently isn't launching enough thread blocks to saturate a modern GPU. Any of these could be easy low-hanging fruit for optimization.
- 2014-05-08: First successful run. Results are definitely not matching those described by Ding & Robb in their paper; the approximation does converge to a point, but seems to quickly hit a brick wall.
In no particular order; just listed here so I don't forget:
- Investigate triangle selection method for each iteration. Currently, a triangle is selected randomly from the first iIter/2 entries. Would it be preferable to run each triangle at least once before random selection? Would it be helpful to sort the triangles by score or area, and favor the iteration of triangles whose current contribution to the final image is negligible?
- The PSO kernel currently assigns one particle to each thread block, to process over all covered pixels. I wonder if it would be any better to assign each thread block a region of pixels to process for all particles. My informal estimate is that this would cut memory traffic to 1/6th of its current level, with a number of other advantages to boot.
- Continue to investigate improvements to the image difference method. The current squared-scaled-distance approach is probably naive. Possible alternatives include Root Mean Squared Deviation and Mean Structual Similarity.
Here's what I use to build and run Mona.
- Windows 7
- Visual Studio 2010
- CUDA Toolkit 6.0
- NVIDIA GPU (currently requires Compute Capability 3.0 or later)
- Qt 5.3 (optional -- for GUI frontend)
- Gnuplot 4.6.5 (optional -- for generating graphs)
- Python 3.4 (optional -- for running test scripts)
Other configurations may work, with some coaxing. This is just the only CUDA-capable system I have available to test with.
Much thanks to:
- Roger Alsing for the original EvoLisa algorithm.
- Joy Ding and Drew Robb for their CUDA implementation of PSO EvoLisa, and accompanying paper.
- Sean Barrett for stb_image and stb_image_write