[SUGGESTIONS] floating point, dequantize and more #18
Comments
|
Much appreciated will get to it when I can |
|
I also suggest you to deeply check this paper (that describes many interesting audio restoration techniques) and, of course, try to collaborate with @abreuwallace that unofficially implemented it here. |
|
Changes made to v-1.1.0 to address some of the topics...cheers |
|
Bump. I recalled an old - but still valid - comparison about MP3 decoders quality:
...and this explains better why fp matters (google-translated from here):
It's unfortunally no longer used/developed (a 2006-source code version shared from Peter here), but someone like @buhadram (that recently forked mpglibdll) can be interested in implement such optimizations. I also suggest to check project like Audio Delossifier by @kroll-software that may help even more. Last but not least, the approach you're appying seems very similar to the well-known Spectral band replication but without the encoded-datas for recontruction. Anyway I believe that these types of alterations shouldn't be mandatory but, just like in stereotool, optionally activated by users. Hope that helps. |

|
Hi the code was updated in version 1.1.0 to use fp 64 cheers |
Nice. Please join the 3ad I've started @ hydrogenaudio 'cause others are asking me things that I sincerely don't know (note that there are many audio and codecs experts there). Thanks. |
|
Here are some other interesting projects to collaborate with: It would be also interesting to adopt better quality measurement method, such as the well-known Perceptual Evaluation of Audio Quality. You can evaluate to integrate it in fatllama too: https://github.com/search?q=PEAQ+audio&type=repositories&s=updated Last but not least, what about a "Jupyter Notebook" to let anyone test fatllama easily ? Hope that inspires ! |
|
Look and you shall find Another interesting - even if speech-oriented - project with many cool resources (= papers) linked in: EnglishSpeechUpsampler by @jhetherly.
|
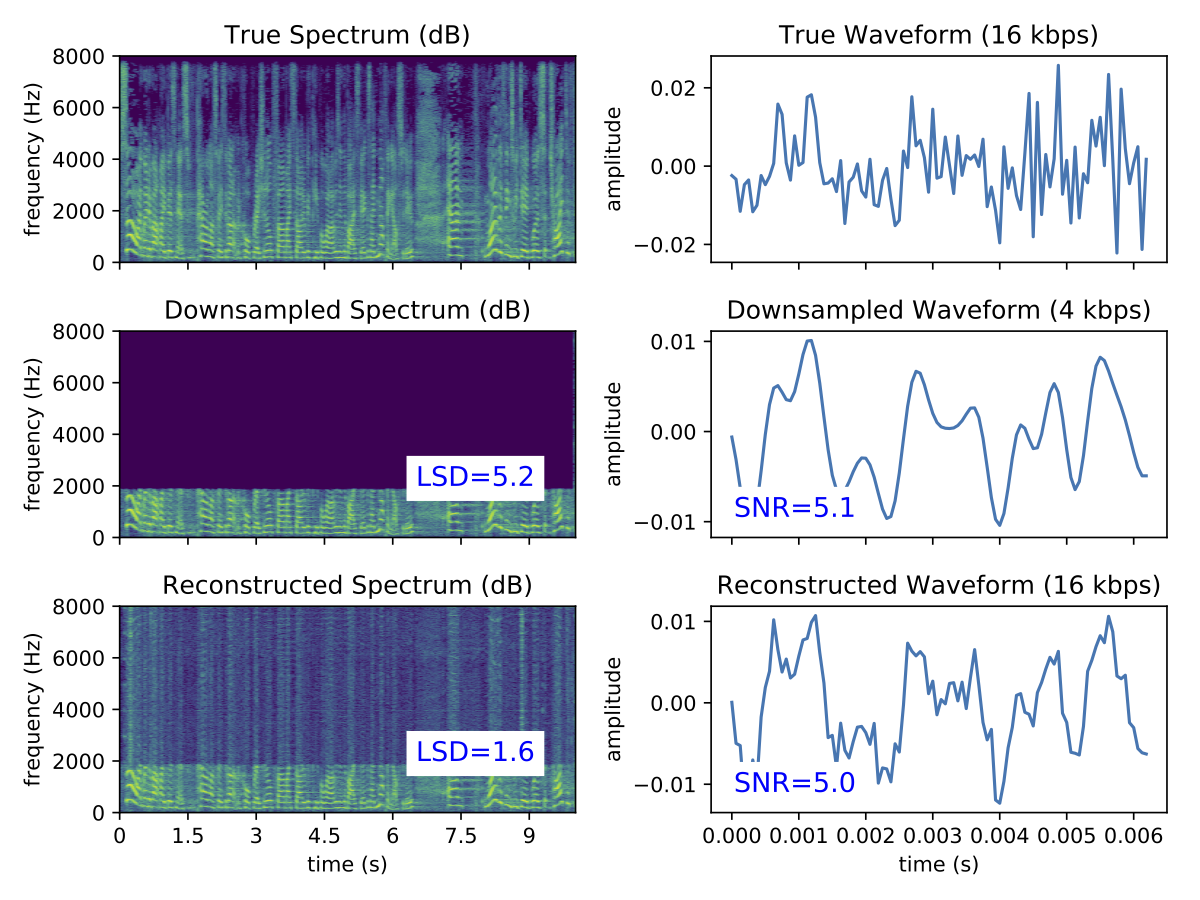
|
You can experiment with using transformer models to reconstruct frequencies for upscaling audio. For example, breathing sounds that are audible in CD quality but lost in MP3 could potentially be restored using a transformer model. While the model might introduce sounds that weren't present in the original recording, it can artificially enhance the details of the music. However, this approach requires significant effort and time to develop and fine-tune. |
|
Thanks for your knowledge sharing @ivandustin ! Seems that well-known @IAHispano choosed @haoheliu's AudioSR for their Audio Upscaler:
At the moment the best approach seems to be the Audio Delossifier by @kroll-software one, which is trainable. Anyway I would love to see a "scientific" (= spectral ?) quality comparison between all contenders... ...so I've decided to reorganize (and expand) the HyMPS' collection: AUDIO section \ AI-based category \ Enhancers page \ Upscalers Enjoy ! |

|
Well the HA discussion is going on and - as always - something interesting comes out: DeltaWave Audio Null Comparator: a free experimental software built to allow detailed comparison of two different captures of the same audio signal. It performs a wide range of measurements and comparisons, which could be very useful in testing the effectiveness and accuracy of fat llama: please check it out. EDIT
As already asked, a jupiter notebook (that let users run tests on Colab, for example) would be great for those - like me too - who don't own CUDA-enabled GPUs. Last but not least, I've also found this interesting repo by @franciscorafart that may help too. Hope that helps. |
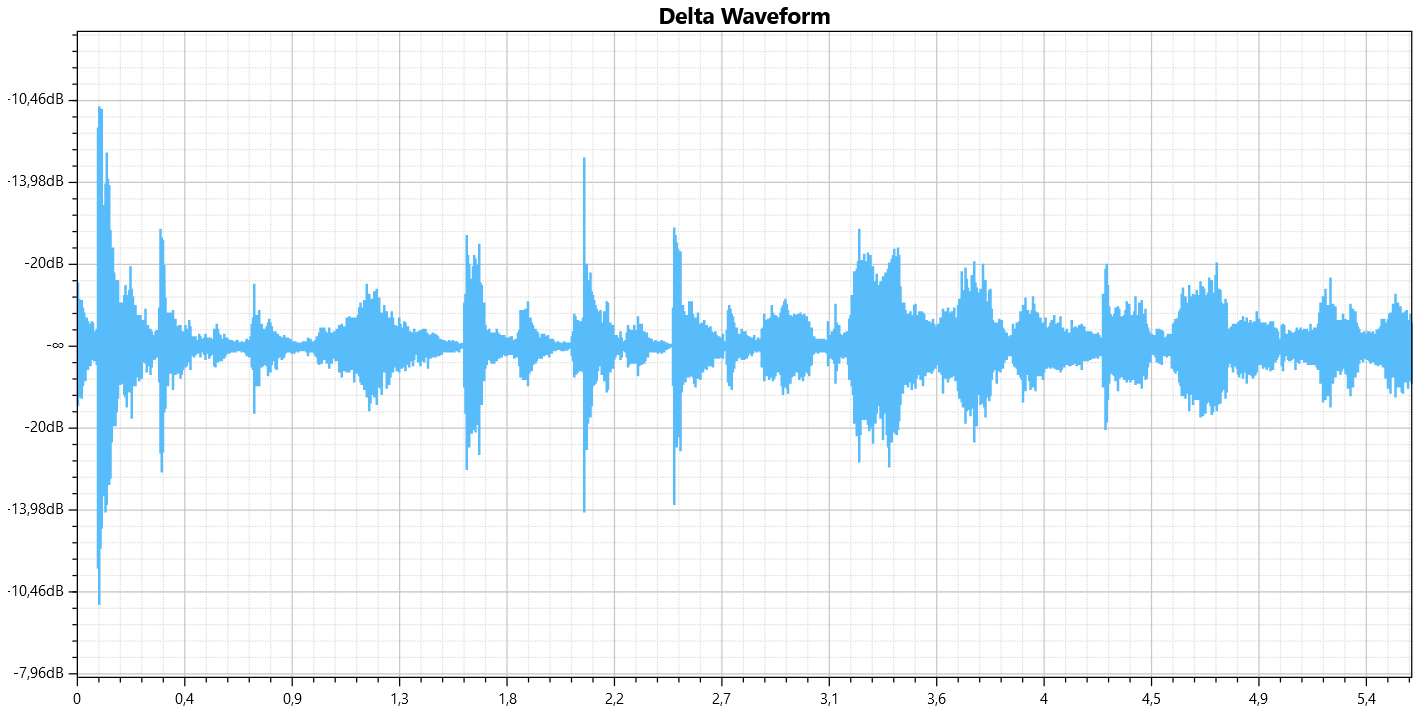
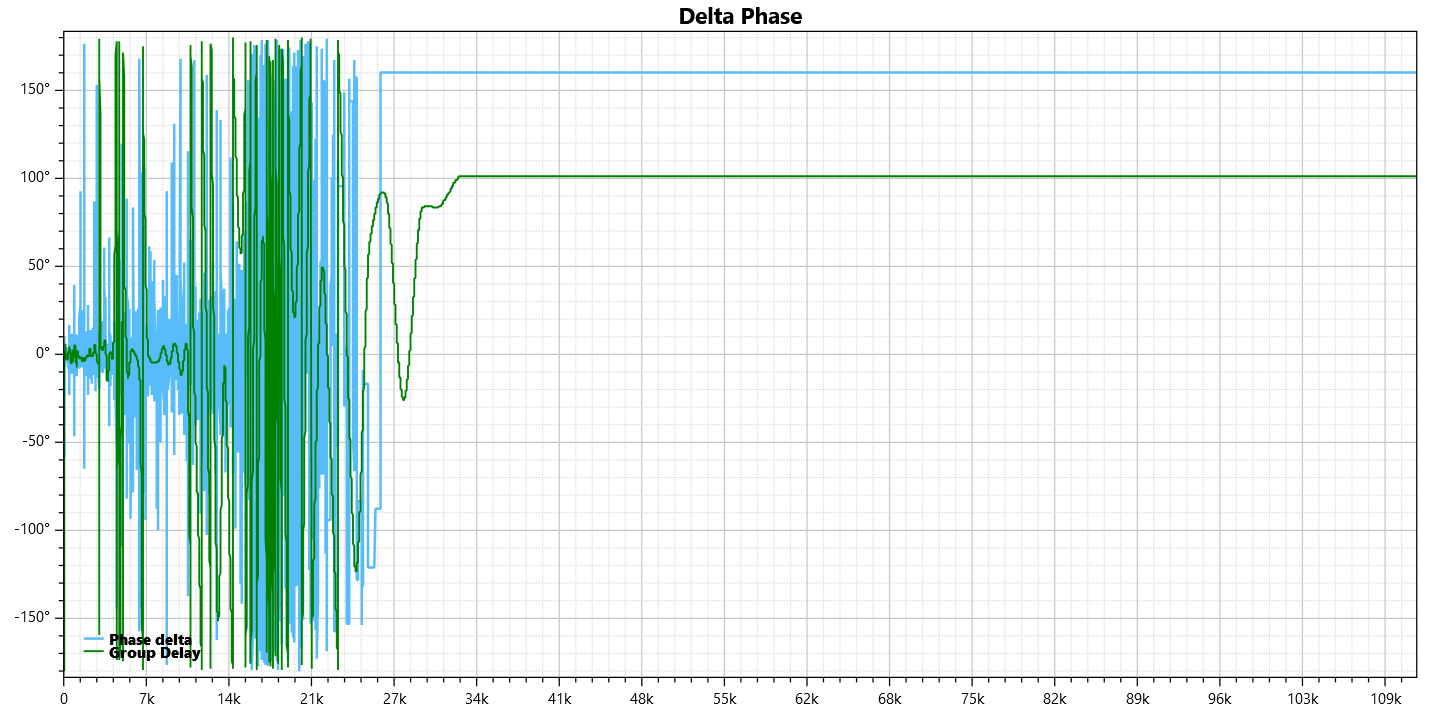

Hi there,
since I've some experiences in this field (audio delossify/upscale) I'd like to share what I have learned:
-drc_scale 0parameter when decoding lossy sources (even if it's AC3-specific feature);Last but not least, I've added your project to HyMPS project one (under AUDIO section \ Treatments page \ Enhancing subsection) so check out other interesting open projects to collaborate with.
Hope that helps/inspires !
EDIT
I've also opened a 3ad @ hydrogenaudio about Fat Llama, enjoy.
The text was updated successfully, but these errors were encountered: