Balthasar Bickel, Johanna Nichols, Taras Zakharko, Alena Witzlack-Makarevich, Kristine Hildebrandt, Michael Rießler, Lennart Bierkandt, Fernando Zúñiga and John B. Lowe
This work is licensed under a Creative Commons Attribution 4.0 International License
AUTOTYP is provided as a series of tabular datasets based on the relational data model. All data
files are located under data. To support different types of users and use cases, the data is
provided using a variety of formats:
- An R workspace file
data/autotyp.RDatafor convenient import into R - A series of JSON files in
data/jsonfor use with other processing environments (e.g. Python) - A series of CSV files in
data/csvfor quick visual exploration or use with a spreadsheet tool - A CLDF dataset in
data/cldf(CLDF export code contributed by Robert Forkel)
Human-readable descriptions of the datasets in YAML format
are located in metadata and are organized according to the module (see
Dataset overview). These description files can be either parsed for automated
processing or opened in a text editor/viewer for visual inspection.
Note that AUTOTYP table fields can contain nested tables or repeated data values (see
Data architecture for details). In the R export, such fields are represented
as lists of tables/values and can be intuitively manipulated with the unnest() functionality in
the tidyverse framework (see example). In the JSON export, such fields are transparently
represented as objects or lists (you can use functionality like json_normalize() to produce
simple tables out of nested structures). In the CSV export, such data is "unnested" to produce one
value per cell, with outer rows replicated — see
PredicateClasses.csv for an example.
# load the tibble package for improved data display
library(tibble)
# load the dataset
load("data/autotyp.RData")
# inspect the Register dataset
Register
# inspect the PredicateClasses dataset
PredicateClasses
# unnest the individual predicate meanings to produce one normalized table
unnest(PredicateClasses, IndividualPredicates)Using the JSON dataset:
import json
# load the Register dataset
with open("data/json/Register.json") as json_file:
register_data = json.load(json_file)
# inspect the first record
print(register_data[0])Using the CLDF dataset:
from pycldf import Dataset
autotyp = Dataset.from_metadata("data/cldf/StructureDataset-metadata.json")AUTOTYP differs from traditional topological databases in that in most cases, data is entered in a fairly raw format (comparable to reference grammar descriptions) and needs to be aggregated and reshaped for most analytical purposes. For example, we do not enter alignment statements ('S=A≠P' or 'nominative-accusative alignment', etc.) but enter individual case markers with the roles they cover and the conditions under which they occur. Alignment statements can then be derived (i.e. aggregated and/or reshaped) from the data using scripts. The raw data supports a variety of such derivations (apart from alignment statements, one might be interested in whether or not there is a split in case marking, or how many cases can code the same generalized semantic argument role etc.). As a result, AUTOTYP usually contains several alternative derivations from the same raw data.
In the current release, primary (hand entered) datasets and fields are declared as such with
kind: manual data entry in the dataset metadata, while derived data is declared as
kind: computed. The full summary of primary and derived datasets and variables can be found in
variables_overview.csv. Primary datasets can also contain derived
(computed) variables; these are usually quick summaries such as counts or convenience types/labels
that enhance the primary raw data. Derived datasets only contain derived variables.
All the code used to create the derived datasets and derived variables as well their metadata is
available in aggregation-scripts and referenced in the dataset descriptions (metadata).
You can use the available aggregations or write your own code to aggregate the data in a way that
best suits your research purpose. Of course, it is also possible to explore the data tables without
writing any code, e.g. for exploring, looking things up in particular languages, copying data to
your own spreadsheet, etc. — we provide every dataset as a convenient CSV file for this purpose.
Another way in which AUTOTYP differs from traditional databases is that most variables were not
predefined but were developed in a technique we call autotypologizing (Bickel & Nichols 2002,
Witzlack-Makarevich et al. 2021): the values of the variables (features, categories, types) and
their definitions are constantly revised and expanded during data collection until they stabilize.
For example, instead of surveying the presence/absence of a predefined category like 'aspect', we
develop a list of categories as we encounter them in our survey work and equate them (or not) to
cross-linguistically stable types on the basis of an evolving analysis. The result is a list of
categories and definitions which are stored in separate definition tables (see the module
Definitions). Category values defined in the definition tables are then utilized in various
datasets across the database, allowing for quick cross-referencing and queries.
AUTOTYP has been developed for over 20 years, in a series of loosely related projects. Each project
is associated with one or more database modules, such as GrammaticalRelations or Morphology.
Because the projects were carried out with specific purposes in mind and at different times,
the variables do not necessarily form a tightly integrated and internally consistent system.
The variables sometimes assume different basic notions, reflecting different research questions or
a different stage in our theoretical research. For example, some datasets make reference to an open
list of semantic roles (e.g. LocusOfMarkingPerMicrorelation) that we used in one project,
while other datasets (e.g. GrammaticalRelations) makes reference to a Dowty-style approach with a
fixed roster of generalized roles that we adopted in another project.
Another perennial concern of typological databases is empty/missing cells ("NA"s in R parlance). In the current release, we do not distinguish between different types of empty values. That is, an empty value can mean 'logically impossible to fill' (e.g. fusion of case marker when there is no case marker), or 'we don't know', or 'nobody knows'. We hope to improve this in future releases.
Finally, a note on the nature and quality of our data. We sometimes deliberately deviate from the analysis provided in reference grammars because we find our analyses are better supported by the data in the grammar or text collections. Because of this and because the analyses evolve slowly together with autotypologizing variables, simple reliability tests were not really feasible during the development of AUTOTYP. However, during the process, all analyses and definitions were extensively discussed in project teams until we reached consensus. Also, in several areas, such as in work on agreement and case morphology or on NP structure, data was collected in independent projects and was then extensively tested for consistency, discussing and resolving any mismatches in the analyses. Some of the datasets contain auxiliary notes with analysis details and examples.
AUTOTYP is a relational database organized into separate tabular datasets. Each row in a dataset
represents an observation of some kind, e.g. information associated with a language for Register
or a single grammatical relation for GrammaticalRelations. Columns (fields) in the datasets
represent the variables that encode information. Most of these variables refer to some fact about
linguistic structure (variables proper), but some have a bookkeeping function (e.g. language or
construction identifiers, names or labels) or store relevant comments and notes. Different datasets
are implicitly connected by referring to a common set of IDs (such as language IDs) or concepts
(e.g. generalized semantic roles, marker position types). The latter shared concepts are
accompanied by auxiliary definition datasets (module Definitions) that list possible values and
their definitions. We plan to make the relationships between these variables more explicit in
future versions of the database, by exposing the links in the metadata.
One important aspect of the AUTOTYP data architecture is that table cells can contain nested tables
or repeated values (we follow the terminology established by other databases such as
Google BigQuery). This allows us to
represent complex data in a more natural fashion. As an example, consider the dataset
PredicateClasses (module GrammaticalRelations). Every entry in PredicateClasses describes a
language-specific predicate (valence) type: a (potentially open) set of predicates identified by
their valency frame. One type of information we want to provide for each of these predicate classes
is the semantic field — and we do it by providing a set of simple translation equivalents that
approximate the meaning of the verbs that make up the predicate class. For instance, the German
language has a small class of predicates that require accusative subject, these encompass verbs
experience and existence, with the translation equivalents including 'feel_itchy', 'feel_cold' and
'exist'.
The classical relational (normalized) data model would require three tables to represent this information: one listing only the individual predicate classes, one listing the meanings, and a third one matching predicate classes to the meanings (with each row listing one meaning per predicate class). However, from the practical standpoint, it makes a lot of sense to treat the sets of meanings directly as a property of the predicate class instead:
| Language | PredicateClass | Meanings |
|---|---|---|
| German | Sacc verbs | [feel_itchy, feel_cold, exist] |
| German | control and raising verbs | [try, promise, believe, ...] |
| ... |
Using a list of values in a table cell allows us to represent such data within a single dataset
(rather than three), improve the clarity, as well package the maximal amount of relevant information
closely together. Such data arrangement is also convenient to work with: it is easier to make sense
out of a single table with nested data than trying to follow three different linked tables. R
frameworks such as tidyverse (nest(), unnest(), dplyr predicates) make it possible to
transform and aggregate data of this kind in a natural and intuitive fashion, and similar tools are
available for other data analysis environments (e.g. Python pandas) as well.
Variables (fields) in AUTOTYP datasets can are one of the following types (as specified by the YAML
metadata field data):
integer- an integer numbernumber- a (possibly fractional) numberlogical- atrue/falsevaluestring- a label-like short text value (single line, no consecutive whitespaces), open-endedvalue-list- a categorical value from a controlled list of values (YAML metadata fieldvaluesdescribes the possible values)comment- a free-text comment fieldtable- a nested table field (YAML metadata fieldfieldslists the nested fields)list-of<data>- a repeated field of typedata
AUTOTYP defines multiple categorical values that encode categories and types. These definitions are
provided as part of the module Definitions. Many datasets rely on these value definitions to
encode the presence of categories in a way that permits compatible coding and quick
cross-referencing. For instance, the definition table Position establishes a set of values for
describing the location of a grammatical marker in relation to its phonological host. These values
are then used across multiple datasets (e.g. GrammaticalMarkers,
MaximallyInflectedVerbSynthesis etc.). Note that most of these values are not a-priory defined,
but produced through the process of autotypology — the set of defined values is extended when new
phenomena is discovered that cannot be adequately described with the existing set.
For variables that rely on shared definitions, the dataset metadata will specify their type as
value-list and values will list the values and their explanations. Such variables are presented
in the R export as factors. A future release of AUTOTYP will make the relationship between the
variables more explicit by annotating defined values as a separate data type.
AUTOTYP uses verbose variable names that aim to be self-explanatory. The name generally includes the
topic (subject) of coding and the coded property, assembled together into a phrase-like identifier
following the CamelCase convention, e.g. PredicateClassDiscourseFrequency,
VerbAgreementMarkerPosition. The name characters are limited to the ASCII letter range, with
some variables including an optional numerical suffix (e.g. VerbAgreementMarkerPositionBinned4).
In exceptional cases, an underscore is used to delimit the name components (e.g. ISO639_3).
The names in generally follow one of following patterns:
-
Categorical statements or descriptive properties are named using composite nominal phrases ( e.g.
PredicateClassDiscourseFrequency,VerbAgreementMarkerPosition) -
Binned variable statements are identified with a name suffix 'BinnedX' (e.g.
VerbAgreementMarkerPositionBinned4is a coarsely coded variant ofVerbAgreementMarkerPosition) -
Binary (TRUE/FALSE) variables are named using phrases containing words "is" or "has" to denote the presence of certain properties (e.g.
VerbHasAnyIncorporation,MarkerIsFlexive) -
Count variables have the suffix "Count" (e.g.
MarkerExpressedCategoriesCount,VerbInflectionMaxFormativeCount)
AUTOTYP is organized into a series of thematic modules, each hosting one or more datasets. Currently available modules are:
Register- general language information (identity, genealogy, geography etc.)Definitions- value definitions concepts and types used across the database (such as semantic roles etc.). The tables in this module merely provide value definitions, they are not typological data.Categories- information about selected grammatical categoriesSentence- some aspects of clause/sentence syntaxNP- some aspects of the NP syntaxMorphology- selected information on morphology and grammatical markersGrammaticalRelation- selected information on grammatical relations and valence framesWord- aspects of wordhoodPerLanguageSummaries- various aggregated per language data summaries from different modules
Detailed list of datasets is available in the overview of available datasets.
The current release includes over 200 primary (hand-entered) typological variables (not counting auxiliary variables, comments, bookkeeping and recodings) that describe 1,225 languages over approximately 270,000 data points. Together with the derived (aggregated) data, we provide over 2,000,000 data points. The following table breaks down the data coverage per AUTOTYP module:
| Module | Primary variables | Derived variables | Number of languages covered | Number of primary typological datapoints |
|---|---|---|---|---|
| 1 | 550 | 229 | 0 | |
| Categories | 14 | 7 | 505 | ~4,000 |
| GrammaticalRelations | 64 | 111 | 818 | ~110,000 |
| Morphology | 50 | 244 | 1004 | ~110,000 |
| NP | 13 | 121 | 485 | ~9,000 |
| Sentence | 47 | 0 | 468 | ~8,000 |
| Word | 36 | 3 | 76 | ~25,000 |
| Total | 225 | 1036 | 1171 | ~270,000 |
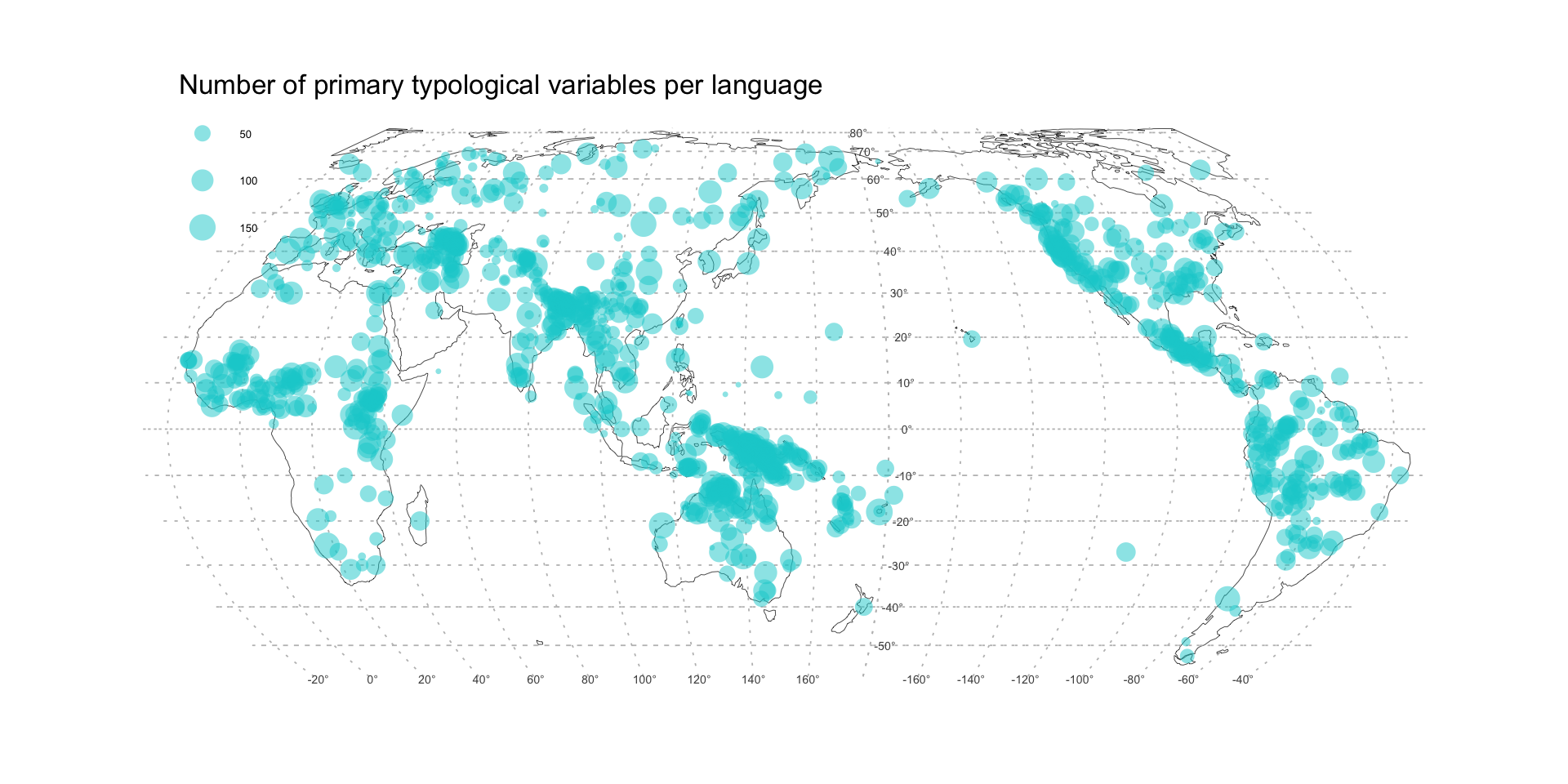
The following map shows how the primary data are distributed over the world. Points are sized in proportion to the number of primary typological variables available for each language
Each dataset is associated with a metadata file that provides detailed descriptions of the dataset
and its fields. The metadata files are stored in
YAML format in the directory metadata/. A tabular
overview is also available in the file variables_overview.csv.
The following metadata fields are provided:
-
description: free-text description in markdown format -
data: data type (see Data types in variables) -
kind: whether the data is entered manually or derived -
variant_of(optional): specifies the name of the base variable if the current variable is a logical recoding of another one (e.g. binning of fine-grained types into broader ones). This can be used to detect variables that represent the same data at different granularity levels -
values(optional): list of values and their definitions for value list data. Most of the time, this is taken from the corresponding definition table (see theDefinitionsmodule).
The sources for all entries can be retrieved from the .bib file via the language identifier
(LID) which comes with every entry. There may be gaps, in which case the references listed in
Glottolog are likely to correspond to what we relied on.
This work is licensed under a Creative Commons Attribution 4.0 International License
Please use the AUTOTYP database issue tracker at https://github.com/autotyp/autotyp-data/issues
Bickel, Balthasar, Nichols, Johanna, Zakharko, Taras, Witzlack-Makarevich, Alena, Hildebrandt, Kristine, Rießler, Michael, Bierkandt, Lennart, Zúñiga, Fernando & Lowe, John B. 2023. The AUTOTYP database (v1.1.1). https://doi.org/10.5281/zenodo.7976754
@misc{AUTOTYP,
author = {
Bickel, Balthasar and
Nichols, Johanna and
Zakharko, Taras and
Witzlack-Makarevich, Alena and
Hildebrandt, Kristine and
Rießler, Michael and
Bierkandt, Lennart and
Zúñiga, Fernando and
Lowe, John B
},
doi = {10.5281/zenodo.7976754},
title = {The AUTOTYP database (v1.1.1)},
url = {https://doi.org/10.5281/zenodo.7976754},
year = {2023}
}}Please make sure to always include the correct database version number and DOI with your citation. We use Zenodo to archive database releases which ensures that the results can always be reproduced. Please take extra care when citing unreleased versions (e.g. a github revision) as these are not guaranteed to be archived. We recommend only using released database versions for publications.
Bickel, Balthasar & Johanna Nichols. 2002. Autotypologizing databases and their use in fieldwork. In Austin et al. (eds.), Proceedings of the International LREC Workshop on Resources and Tools in Field Linguistics, Las Palmas, 26-27 May 2002. Nijmegen: MPI for Psycholinguistics [PDF].
Bickel, Balthasar & Johanna Nichols. 2006. Oceania, the Pacific Rim, and the theory of linguistic areas. Proc. Berkeley Linguistics Society 32. 3–15. [PDF]
Nichols, Johanna, Alena Witzlack-Makarevich & Balthasar Bickel. 2013. The AUTOTYP genealogy and geography database: 2013 release. Electronic database [PDF].
Schiering, René, Kristine Hildebrandt & Balthasar Bickel. 2012. Stress-timed = word-based? Testing a hypothesis in Prosodic Typology. Language Typology and Universals 65. 157–168.
Witzlack-Makarevich, Alena, Johanna Nichols, Kristine Hildebrandt, Taras Zakharko & Balthasar Bickel. 2022. Managing AUTOTYP Data: design principles and implementation. In Berez-Kroeker et al. (eds.), Open Handbook of Linguistic Data Management, Cambridge, MA: MIT Press [PDF].