This tutorial is from the Community part of tutorial for Hortonworks Sandbox - a single-node Hadoop cluster running in a virtual machine. Download the Hortonworks Sandbox to run this and other tutorials in the series.
This tutorial describes how to use RHadoop on Hortonworks Data Platform and how to facilitate using R on Hadoop to create a powerful analytics platform.
Clickstream data is an information trail a user leaves behind while visiting a website. It is typically captured in semi-structured website log files.
Clickstream data has been described in already exisiting tutorial 10 - Visualizing Website Clickstream Data. In this tutorial the same dataset will be used. So, it must be uploaded into omniturelogs table.
 R is a language for Stats, Math and Data Science created by statisticians for statisticians. It contains 5000+ implemented algorithms and impressive 2M+ users with domain knowledge worldwide. However, it has one big disadvantage - all data is placed into memory and processed in one thread.
R is a language for Stats, Math and Data Science created by statisticians for statisticians. It contains 5000+ implemented algorithms and impressive 2M+ users with domain knowledge worldwide. However, it has one big disadvantage - all data is placed into memory and processed in one thread.
Hadoop was developed in Java and Java is the main programming language for Hadoop. Although Java is main language, you can still use any other language to write MapReduce(MR): for example, Python, R or Ruby. It is called "Streaming API". Not all features available in Java will be available in R, because streaming works through "unix streams". Unfortunately, Streaming API is not easily used and that's why RHadoop has been created. It still uses streaming, but has the following advantages:
- no need to manage key change in Reducer
- no need to control functions output manually
- simple MapReduce API for R
- enables access to files on HDFS
- R code can be run on local env/Hadoop without changes
RHadoop is set of packages for R language, it contains the next packages currently (you install and load this package the same as you would for any other R package):
- rmr provides MapReduce interface; mapper and reducer can be described in R code and then called from R
- rhdfs provides access to HDFS; using simple R functions, you can copy data between R memory, the local file system, and HDFS
- rhbase required if you are going to access HBase
- plyrmr common data manipulation operations
To enable RHadoop on existing Hadoop cluster the following steps must be applied:
- install R on each node in Cluster
- on each node install RHadoop packages with dependencies
- set up env variables; run R from console and check that these variables are accessible
Environment variables required for RHadoop is 'HADOOP_CMD' and 'HADOOP_STREAMING', details are described in RHadoop Wiki. To facilitate development, RStudio server is recommended to be installed. It provides the same GUI for development as standalone RStudio. RStudio WebUI accessible just after instalation at ':8787', use login and password of any non-system user on this host.
We are going to predict number of visitors in the next period for each country/state using RHadoop. We will do it with linear regression
In the “Loading Data into the Hortonworks Sandbox” tutorial, we loaded website data files into Hortonworks. Omniture logs* – website log files containing information such as URL, timestamp, IP address, geocoded IP address, and user ID (SWID). First of all, we will create table with required data for us.

In omniture dataset we have information from 2012-03-01 till 2012-03-15 (Hive query select country, ts, count(*) from omniture2 group by country, ts), for many countries there are gaps, we are going to put 0 into these gaps and remove datasets with too small amount of elements, because of it's not enought for regression. The result of this query is following:
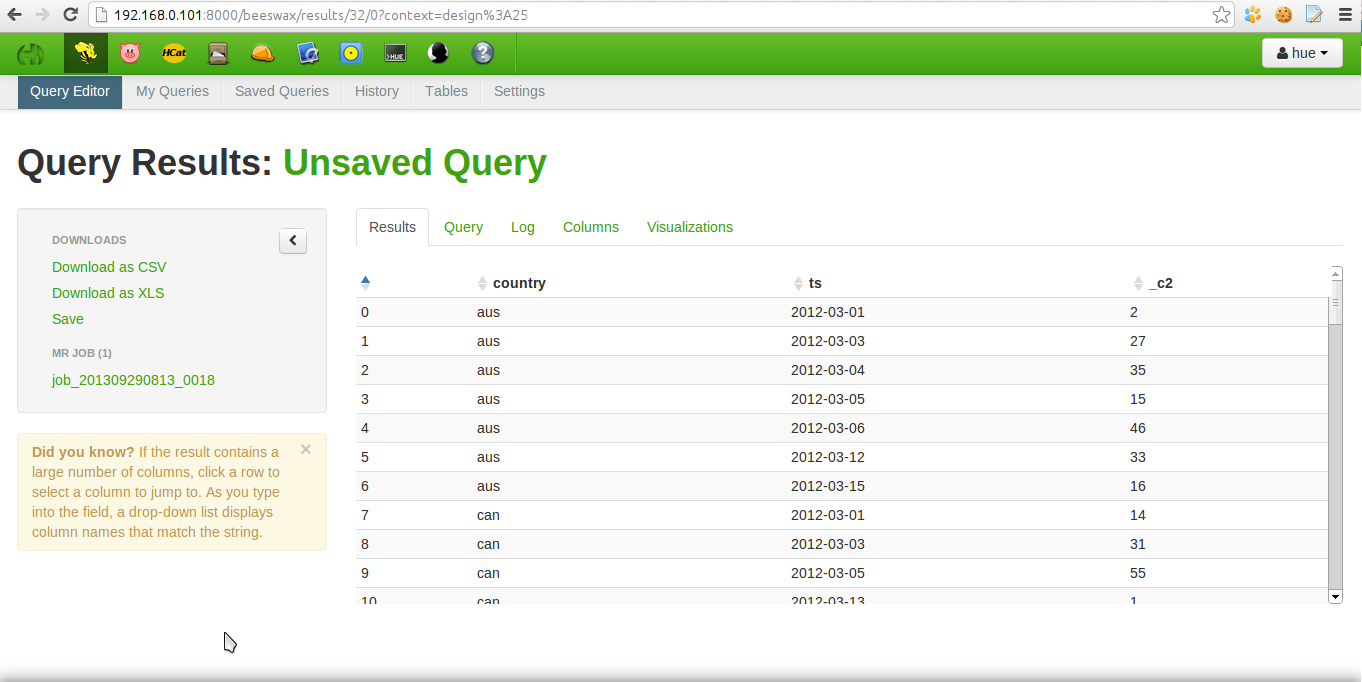
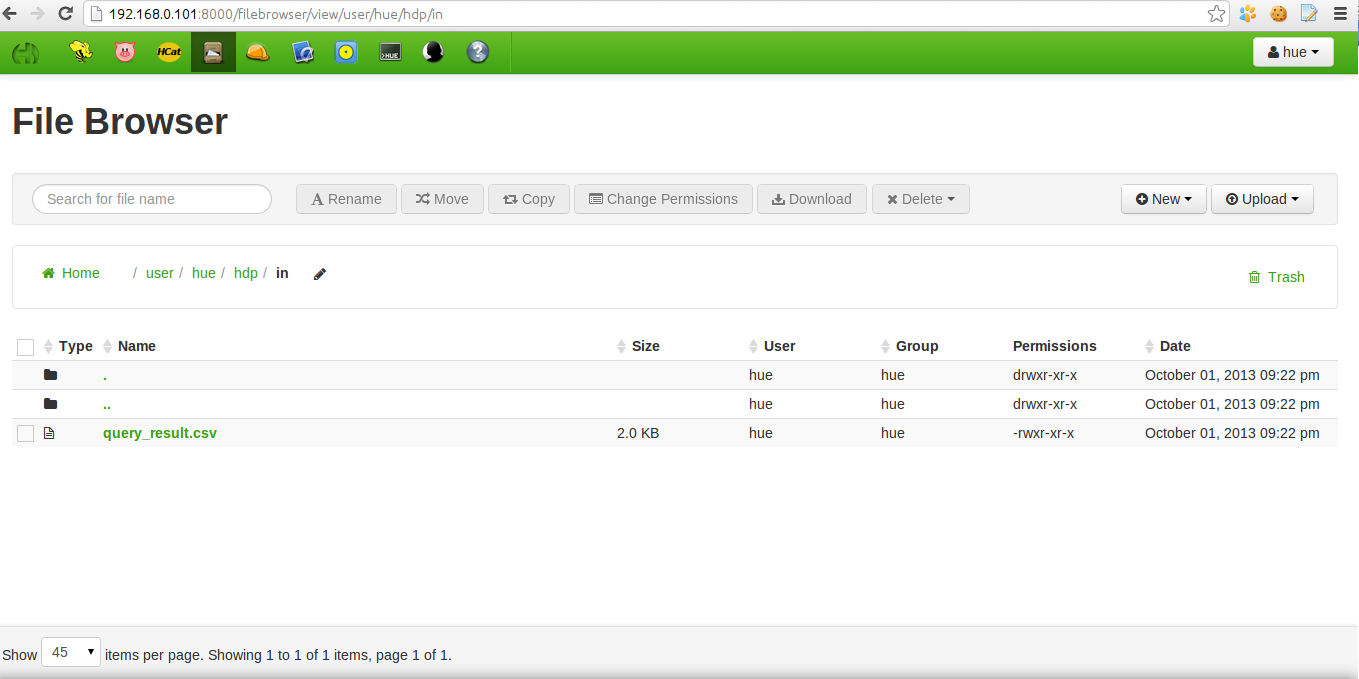
We need to save this result for the next step, just by clicking 'Download as CSV'. Save result to HDFS to the folder '/user/hue/hdp/in':
Please, don't guess all calculation here as academic research. This "prediction" has only one purpose to show the power of RHadoop. So, let's open RStudio and write first MapReduce with RHadoop. RStudio on local environment can be used as well as web UI (available at ':8787' under your non-system user). In the initial data set, number of clicks for each day (with possible gaps) is present from Mart 3 till Mart 15. The number of click for the Mart 16 is forecasted in the next program

The whole listing is following:
library(rmr2)
# utility function - insert new row into exist data frame
insertRow <- function(target.dataframe, new.day) {
new.row <- c(new.day, 0)
target.dataframe <- rbind(target.dataframe,new.row)
target.dataframe <- target.dataframe[order(c(1:(nrow(target.dataframe)-1),new.day-0.5)),]
row.names(target.dataframe) <- 1:nrow(target.dataframe)
return(target.dataframe)
}
mapper = function(null, line) {
# skip header
if( "ts" != line[[2]] )
keyval(line[[1]], paste(line[[1]],line[[2]], line[[3]], sep=","))
}
reducer = function(key, val.list) {
# not possible to build good enought regression for small datasets
if( length(val.list) < 10 ) return;
list <- list()
# extract country
country <- unlist(strsplit(val.list[[1]], ","))[[1]]
# extract time interval and click number
for(line in val.list) {
l <- unlist(strsplit(line, split=","))
x <- list(as.POSIXlt(as.Date(l[[2]]))$mday, l[[3]])
list[[length(list)+1]] <- x
}
# convert to numeric values
list <- lapply(list, as.numeric)
# create frames
frame <- do.call(rbind, list)
colnames(frame) <- c("day","clicksCount")
# set 0 count of clicks for missed days in input dataset
i = 1
# we must have 15 days in dataset
while(i < 16) {
if(i <= nrow(frame))
curDay <- frame[i, "day"]
# next Day in existing frame is not suspected
if( curDay != i ) {
frame <- insertRow(frame, i)
}
i <- i+1
}
# build lineral model for prediction
model <- lm(clicksCount ~ day, data=as.data.frame(frame))
# predict for the next day
p <- predict(model, data.frame(day=16))
keyval(country, p)
}
# call MapReduce job
mapreduce(input="/user/hue/hdp/in",
input.format=make.input.format("csv", sep = ","),
output="/user/hue/hdp/out",
output.format="csv",
map=mapper,
reduce=reducer
)
As soon as MapReduce job finishes, the result will be available at expected directory as several CSV formated files. Directory structure is regular for MapReduce jobs:
