diff --git "a/docs/cn/Pipeline \347\273\204\344\273\266/ONNX/ONNX \346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictor).md" "b/docs/cn/Pipeline \347\273\204\344\273\266/ONNX/ONNX \346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictor).md"
index c3b0cac33..c85cded15 100644
--- "a/docs/cn/Pipeline \347\273\204\344\273\266/ONNX/ONNX \346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictor).md"
+++ "b/docs/cn/Pipeline \347\273\204\344\273\266/ONNX/ONNX \346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictor).md"
@@ -26,6 +26,8 @@ Python 类名:OnnxModelPredictor
组件使用的是 ONNX 1.11.0 版本,当有 GPU 时,自动使用 GPU 进行推理,否则使用 CPU 进行推理。
+在 Windows 下运行时,如果遇到 ```UnsatisfiedLinkError```,请下载 [Visual C++ 2019 Redistributable Packages](https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads) 并重启,然后重新运行。
+
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/Pipeline \347\273\204\344\273\266/PyTorch/TorchScript \346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictor).md" "b/docs/cn/Pipeline \347\273\204\344\273\266/PyTorch/TorchScript \346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictor).md"
index 1471a8214..33d51aac7 100644
--- "a/docs/cn/Pipeline \347\273\204\344\273\266/PyTorch/TorchScript \346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictor).md"
+++ "b/docs/cn/Pipeline \347\273\204\344\273\266/PyTorch/TorchScript \346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictor).md"
@@ -22,7 +22,9 @@ Python 类名:TorchModelPredictor
- 输出列的数量需要与模型输出结果匹配。
- 输出类型可以是 Alink ```Tensor``` 类型或者 Alink 支持的类型,如果从模型预测输出的结果转换到指定类型失败那么将报错;暂不支持列表或字典类型。
-组件使用的是 PyTorch 1.8.1 版本,当有 GPU 时,自动使用 GPU 进行推理,否则使用 CPU 进行推理。
+组件使用的是 PyTorch 1.8.1 CPU 版本,如果需要使用 GPU 功能,可以自行替换插件文件。
+
+在 Windows 下运行时,如果遇到 ```UnsatisfiedLinkError```,请下载 [Visual C++ 2015 Redistributable Packages](https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads) 并重启,然后重新运行。
## 参数说明
diff --git "a/docs/cn/Pipeline \347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/Redis\350\241\250\346\237\245\346\211\276 (LookupRedis).md" "b/docs/cn/Pipeline \347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/Redis\350\241\250\346\237\245\346\211\276 (LookupRedis).md"
index 425683b4b..ce72d605a 100644
--- "a/docs/cn/Pipeline \347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/Redis\350\241\250\346\237\245\346\211\276 (LookupRedis).md"
+++ "b/docs/cn/Pipeline \347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/Redis\350\241\250\346\237\245\346\211\276 (LookupRedis).md"
@@ -18,10 +18,9 @@ Python 类名:LookupRedis
| selectedCols | 选择的列名 | 计算列对应的列名列表 | String[] | ✓ | | |
| clusterMode | Not available! | Not available! | Boolean | | | false |
| databaseIndex | Not available! | Not available! | Long | | | |
-| redisIP | Not available! | Not available! | String | | | |
+| pipelineSize | Not available! | Not available! | Integer | | | 1 |
| redisIPs | Not available! | Not available! | String[] | | | |
| redisPassword | Not available! | Not available! | String | | | |
-| redisPort | Not available! | Not available! | Integer | | | 6379 |
| reservedCols | 算法保留列名 | 算法保留列 | String[] | | | null |
| timeout | Not available! | Not available! | Integer | | | |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/ONNX/ONNX\346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/ONNX/ONNX\346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictBatchOp).md"
index 09285fe5c..a7b4eedbf 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/ONNX/ONNX\346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/ONNX/ONNX\346\250\241\345\236\213\351\242\204\346\265\213 (OnnxModelPredictBatchOp).md"
@@ -26,6 +26,8 @@ Python 类名:OnnxModelPredictBatchOp
组件使用的是 ONNX 1.11.0 版本,当有 GPU 时,自动使用 GPU 进行推理,否则使用 CPU 进行推理。
+在 Windows 下运行时,如果遇到 ```UnsatisfiedLinkError```,请下载 [Visual C++ 2019 Redistributable Packages](https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads) 并重启,然后重新运行。
+
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/PyTorch/PyTorch\346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/PyTorch/PyTorch\346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictBatchOp).md"
index cc1630885..820c7397f 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/PyTorch/PyTorch\346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/PyTorch/PyTorch\346\250\241\345\236\213\351\242\204\346\265\213 (TorchModelPredictBatchOp).md"
@@ -22,7 +22,9 @@ Python 类名:TorchModelPredictBatchOp
- 输出列的数量需要与模型输出结果匹配。
- 输出类型可以是 Alink ```Tensor``` 类型或者 Alink 支持的类型,如果从模型预测输出的结果转换到指定类型失败那么将报错;暂不支持列表或字典类型。
-组件使用的是 PyTorch 1.8.1 版本,当有 GPU 时,自动使用 GPU 进行推理,否则使用 CPU 进行推理。
+组件使用的是 PyTorch 1.8.1 CPU 版本,如果需要使用 GPU 功能,可以自行替换插件文件。
+
+在 Windows 下运行时,如果遇到 ```UnsatisfiedLinkError```,请下载 [Visual C++ 2015 Redistributable Packages](https://support.microsoft.com/en-us/help/2977003/the-latest-supported-visual-c-downloads) 并重启,然后重新运行。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/MetaPath\346\270\270\350\265\260 (MetaPathWalkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/MetaPath\346\270\270\350\265\260 (MetaPathWalkBatchOp).md"
index 3650fa01f..3d3134377 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/MetaPath\346\270\270\350\265\260 (MetaPathWalkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/MetaPath\346\270\270\350\265\260 (MetaPathWalkBatchOp).md"
@@ -5,8 +5,9 @@ Python 类名:MetaPathWalkBatchOp
## 功能介绍
- MataPathWalk是描述随机游走的一种算法。在给定的图上,每次迭代过程中,点都会按照一定的metaPath转移到它的邻居上,
- 转移到每个邻居的概率和连接这两个点的边的Type相关。通过这样的随机游走可以获得固定长度的随机游走序列,这可以类比自然语言中的句子。
+MataPathWalk [1] 是描述随机游走的一种算法。在给定的图上,每次迭代过程中,点都会按照一定的metaPath转移到它的邻居上,转移到每个邻居的概率和连接这两个点的边的Type相关。通过这样的随机游走可以获得固定长度的随机游走序列,这可以类比自然语言中的句子。
+
+[1] Dong et al. metapath2vec: Scalable Representation Learning for Heterogeneous Networks. KDD2017.
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/\351\232\217\346\234\272\346\270\270\350\265\260 (RandomWalkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/\351\232\217\346\234\272\346\270\270\350\265\260 (RandomWalkBatchOp).md"
index 278a94624..46359e906 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/\351\232\217\346\234\272\346\270\270\350\265\260 (RandomWalkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\345\233\276/\351\232\217\346\234\272\346\270\270\350\265\260 (RandomWalkBatchOp).md"
@@ -5,10 +5,12 @@ Python 类名:RandomWalkBatchOp
## 功能介绍
-RandomWalk是deepwalk中描述随机游走的一种算法。
+RandomWalk是deepwalk [1] 中描述随机游走的一种算法。
在给定的图上,每次迭代过程中,点都会转移到它的邻居上,转移到每个邻居的概率和连接这两个点的边的权重相关。
通过这样的随机游走可以获得固定长度的随机游走序列,这可以类比自然语言中的句子。
+[1] Bryan Perozzi et al. DeepWalk: online learning of social representations. KDD 2014.
+
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\350\256\255\347\273\203 (ItemCfTrainBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\350\256\255\347\273\203 (ItemCfTrainBatchOp).md"
index f0f4ac56c..78cd75023 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\350\256\255\347\273\203 (ItemCfTrainBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\350\256\255\347\273\203 (ItemCfTrainBatchOp).md"
@@ -5,9 +5,8 @@ Python 类名:ItemCfTrainBatchOp
## 功能介绍
-ItemCF 是一种被广泛使用的推荐算法,用给定打分数据训练一个推荐模型,
-用于预测user对item的评分、对user推荐itemlist,或者对item推荐userlist。
-
+ItemCF 是一种被广泛使用的协同过滤算法,用给定打分数据训练一个推荐模型,
+用于预测user对item的评分、对user喜欢的itemlist,或者对item推荐可能的userlist等。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\357\274\232ItemsPerUser\346\216\250\350\215\220 (ItemCfItemsPerUserRecommBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\357\274\232ItemsPerUser\346\216\250\350\215\220 (ItemCfItemsPerUserRecommBatchOp).md"
index f9843d508..3634df503 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\357\274\232ItemsPerUser\346\216\250\350\215\220 (ItemCfItemsPerUserRecommBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/ItemCf\357\274\232ItemsPerUser\346\216\250\350\215\220 (ItemCfItemsPerUserRecommBatchOp).md"
@@ -93,11 +93,11 @@ public class ItemCfItemsPerUserRecommBatchOpTest {
```
### 运行结果
-user|prediction_result
-----|-----------------
-1|{"item":"[3]","score":"[0.23533936216582085]"}
-2|{"item":"[3]","score":"[0.38953648389671724]"}
-2|{"item":"[3]","score":"[0.38953648389671724]"}
-4|{"item":"[2]","score":"[0.17950184794838112]"}
-4|{"item":"[2]","score":"[0.17950184794838112]"}
-4|{"item":"[2]","score":"[0.17950184794838112]"}
+user| prediction_result
+----|------------------------------
+1| MTable(1,2)(item,score)
3 | 0.2353
+2| MTable(1,2)(item,score)
3 | 0.3895
+2| MTable(1,2)(item,score)
3 | 0.3895
+4| MTable(1,2)(item,score)
2 | 0.1795
+4| MTable(1,2)(item,score)
2 | 0.1795
+4| MTable(1,2)(item,score)
2 | 0.1795
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/UserCf\350\256\255\347\273\203 (UserCfTrainBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/UserCf\350\256\255\347\273\203 (UserCfTrainBatchOp).md"
index bb85eca89..2042ad80f 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/UserCf\350\256\255\347\273\203 (UserCfTrainBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\216\250\350\215\220/UserCf\350\256\255\347\273\203 (UserCfTrainBatchOp).md"
@@ -5,9 +5,8 @@ Python 类名:UserCfTrainBatchOp
## 功能介绍
-UserCF 是一种被广泛使用的推荐算法,用给定打分数据训练一个推荐模型,
-用于预测user对item的评分、对user推荐itemlist,或者对item推荐userlist。
-
+UserCF 是一种被广泛使用的协同过滤算法,用给定打分数据训练一个推荐模型,
+用于预测user对item的评分、对user推荐itemlist,或者对item推荐userlist等。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleBatchOp).md"
index 571df831f..1f16ea163 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleBatchOp).md"
@@ -5,8 +5,7 @@ Python 类名:StratifiedSampleBatchOp
## 功能介绍
-
-本算子是对每个类别按照比例进行分层随机抽样。
+分层采样组件。给定输入数据,本算法根据用户指定的不同类别的采样比例进行随机采样。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\211\215N\344\270\252\346\225\260 (FirstNBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\211\215N\344\270\252\346\225\260 (FirstNBatchOp).md"
index 4caa76cd7..37fa6577d 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\211\215N\344\270\252\346\225\260 (FirstNBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\211\215N\344\270\252\346\225\260 (FirstNBatchOp).md"
@@ -32,8 +32,6 @@ df = pd.DataFrame([
["9.1,9.1,9.1"],
["9.2,9.2,9.2"]
])
-
-
# batch source
inOp = BatchOperator.fromDataframe(df, schemaStr='Y string')
@@ -76,8 +74,6 @@ public class FirstNBatchOpTest {
```
### 运行结果
-
-
|Y|
|---|
|0,0,0|
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\212\240\346\235\203\351\207\207\346\240\267 (WeightSampleBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\212\240\346\235\203\351\207\207\346\240\267 (WeightSampleBatchOp).md"
index 870ee6687..3890b7d44 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\212\240\346\235\203\351\207\207\346\240\267 (WeightSampleBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\212\240\346\235\203\351\207\207\346\240\267 (WeightSampleBatchOp).md"
@@ -5,8 +5,7 @@ Python 类名:WeightSampleBatchOp
## 功能介绍
-
-- 本算子是按照数据点的权重对数据按照比例进行加权采样,权重越大的数据点被采样的可能性越大。
+本算子是按照数据点的权重对数据按照比例进行加权采样,权重越大的数据点被采样的可能性越大。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\233\272\345\256\232\346\235\241\346\225\260\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleWithSizeBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\233\272\345\256\232\346\235\241\346\225\260\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleWithSizeBatchOp).md"
index 99feb9ac3..de04929dd 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\233\272\345\256\232\346\235\241\346\225\260\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleWithSizeBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\345\233\272\345\256\232\346\235\241\346\225\260\345\210\206\345\261\202\351\232\217\346\234\272\351\207\207\346\240\267 (StratifiedSampleWithSizeBatchOp).md"
@@ -5,8 +5,7 @@ Python 类名:StratifiedSampleWithSizeBatchOp
## 功能介绍
-
-本算子对输入数据的每个类别进行指定个数的分层随机抽样。
+固定条数分层随机采样组件。给定输入数据,本算法根据用户指定的不同类别的采样个数进行随机采样。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254CSV (ColumnsToCsvBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254CSV (ColumnsToCsvBatchOp).md"
index 3b2704eb5..20597d066 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254CSV (ColumnsToCsvBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254CSV (ColumnsToCsvBatchOp).md"
@@ -60,7 +60,8 @@ public class ColumnsToCsvBatchOpTest {
@Test
public void testColumnsToCsvBatchOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
BatchOperator data = new MemSourceBatchOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonBatchOp).md"
index 0b7510b91..89b3391bc 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonBatchOp).md"
@@ -56,7 +56,8 @@ public class ColumnsToJsonBatchOpTest {
@Test
public void testColumnsToJsonBatchOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
BatchOperator data = new MemSourceBatchOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
@@ -73,6 +74,6 @@ public class ColumnsToJsonBatchOpTest {
### 运行结果
|row|json|
- |---|----|
- | 1 |{"f0":"1.0","f1":"2.0"}|
- | 2 |{"f0":"4.0","f1":"8.0"}|
+|---|----|
+| 1 |{"f0":"1.0","f1":"2.0"}|
+| 2 |{"f0":"4.0","f1":"8.0"}|
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvBatchOp).md"
index f5fa4fcc0..92a339f47 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvBatchOp).md"
@@ -58,7 +58,8 @@ public class ColumnsToKvBatchOpTest {
@Test
public void testColumnsToKvBatchOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
BatchOperator data = new MemSourceBatchOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
@@ -75,7 +76,7 @@ public class ColumnsToKvBatchOpTest {
### 运行结果
|row|kv|
- |---|---|
- |1|f0:1.0,f1:2.0|
- |2|f0:4.0,f1:8.0|
+|---|---|
+|1|f0:1.0,f1:2.0|
+|2|f0:4.0,f1:8.0|
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleBatchOp).md"
index 589a393f4..64a6353d2 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleBatchOp).md"
@@ -58,7 +58,8 @@ public class ColumnsToTripleBatchOpTest {
@Test
public void testColumnsToTripleBatchOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
BatchOperator data = new MemSourceBatchOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorBatchOp).md"
index e1d642537..a137fe148 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorBatchOp).md"
@@ -6,7 +6,7 @@ Python 类名:ColumnsToVectorBatchOp
## 功能介绍
将数据格式从 Columns 转成 Vector
-
+数据格式可以为数值类型,如int,float,long,double,也可以为能够转换为数值类型的字符串。
## 参数说明
@@ -37,7 +37,6 @@ op = ColumnsToVectorBatchOp()\
.setSelectedCols(["f0", "f1"])\
.setReservedCols(["row"])\
.setVectorCol("vec")\
- .setVectorSize(5)\
.linkFrom(data)
op.print()
@@ -58,7 +57,8 @@ public class ColumnsToVectorBatchOpTest {
@Test
public void testColumnsToVectorBatchOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
BatchOperator data = new MemSourceBatchOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
@@ -66,7 +66,6 @@ public class ColumnsToVectorBatchOpTest {
.setSelectedCols("f0", "f1")
.setReservedCols("row")
.setVectorCol("vec")
- .setVectorSize(5)
.linkFrom(data);
op.print();
}
@@ -74,9 +73,9 @@ public class ColumnsToVectorBatchOpTest {
```
### 运行结果
-
-|row|vec|
- |---|-----|
- |1|$5$1.0 2.0|
- |2|$5$4.0 8.0|
+
+row|vec
+---|---
+1|1.0 2.0
+1|4.0 8.0
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleBatchOp).md"
index 0c7bb9b1d..343f770e0 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleBatchOp).md"
@@ -5,10 +5,7 @@ Python 类名:SampleBatchOp
## 功能介绍
-
-- 本算子对数据进行随机抽样,每个样本都以相同的概率被抽到。
-
-
+本算子对数据进行随机抽样,每个样本都以相同的概率被抽到。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\350\257\273\345\205\245 (AkSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\350\257\273\345\205\245 (AkSourceBatchOp).md"
index 3d21db8f8..c8a19c6f3 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\350\257\273\345\205\245 (AkSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\350\257\273\345\205\245 (AkSourceBatchOp).md"
@@ -7,6 +7,18 @@ Python 类名:AkSourceBatchOp
## 功能介绍
从文件系统读Ak文件。Ak文件格式是Alink 自定义的一种文件格式,能够将数据的Schema保留输出的文件格式。
+### 分区选择
+Export2FileSinkStreamOp组件能将数据分区保存,AkSourceBatchOp可以选择分区读取。
+分区目录名格式为"分区名=值",例如: month=06/day=17;month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+month | day
+---|---
+06 | 17
+06 | 18
+
+使用SQL语句查找分区,例如:AkSourceBatchOp.setPartitions("day = '17'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
+
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\350\257\273\345\205\245 (CsvSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\350\257\273\345\205\245 (CsvSourceBatchOp).md"
index 88b66c89a..9546e601a 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\350\257\273\345\205\245 (CsvSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\350\257\273\345\205\245 (CsvSourceBatchOp).md"
@@ -6,6 +6,16 @@ Python 类名:CsvSourceBatchOp
## 功能介绍
读CSV文件。支持从本地、hdfs、http读取
+### 分区选择
+分区目录名格式为"分区名=值",例如: city=beijing/month=06/day=17;city=hangzhou/month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+city | month | day
+---|---|---
+beijing | 06 | 17
+hangzhou | 06 | 18
+
+使用SQL语句查找分区,例如:CsvSourceBatchOp.setPartitions("city = 'beijing'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
## 参数说明
@@ -17,6 +27,7 @@ Python 类名:CsvSourceBatchOp
| handleInvalidMethod | 处理无效值的方法 | 处理无效值的方法,可取 error, skip | String | | "ERROR", "SKIP" | "ERROR" |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
| lenient | 是否容错 | 若为true,当解析失败时丢弃该数据;若为false,解析失败是抛异常 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| quoteChar | 引号字符 | 引号字符 | Character | | | "\"" |
| rowDelimiter | 行分隔符 | 行分隔符 | String | | | "\n" |
| skipBlankLine | 是否忽略空行 | 是否忽略空行 | Boolean | | | true |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\350\257\273\345\205\245 (LibSvmSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\350\257\273\345\205\245 (LibSvmSourceBatchOp).md"
index 783f56dcf..e2b92d515 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\350\257\273\345\205\245 (LibSvmSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\350\257\273\345\205\245 (LibSvmSourceBatchOp).md"
@@ -12,6 +12,7 @@ Python 类名:LibSvmSourceBatchOp
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| startIndex | 起始索引 | 起始索引 | Integer | | | 1 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\350\257\273\345\205\245 (TsvSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\350\257\273\345\205\245 (TsvSourceBatchOp).md"
index 7bf8ecc2b..f5a311952 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\350\257\273\345\205\245 (TsvSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\350\257\273\345\205\245 (TsvSourceBatchOp).md"
@@ -14,6 +14,7 @@ Python 类名:TsvSourceBatchOp
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| schemaStr | Schema | Schema。格式为"colname coltype[, colname2, coltype2[, ...]]",例如"f0 string, f1 bigint, f2 double" | String | ✓ | | |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| skipBlankLine | 是否忽略空行 | 是否忽略空行 | Boolean | | | true |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\350\257\273\345\205\245 (TextSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\350\257\273\345\205\245 (TextSourceBatchOp).md"
index ae253b03d..915d5f044 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\350\257\273\345\205\245 (TextSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\350\257\273\345\205\245 (TextSourceBatchOp).md"
@@ -5,8 +5,7 @@ Python 类名:TextSourceBatchOp
## 功能介绍
-
-按行读取文件数据
+按行读取文件数据。
## 参数说明
@@ -14,6 +13,7 @@ Python 类名:TextSourceBatchOp
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| textCol | 文本列名称 | 文本列名称 | String | | | "text" |
## 代码示例
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceBatchOp).md"
index 8dba64418..98e8777df 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceBatchOp).md"
@@ -5,12 +5,24 @@ Python 类名:ParquetSourceBatchOp
## 功能介绍
-读parquet文件数据。支持从本地、hdfs、http读取
+读parquet文件数据。支持从本地、hdfs、http读取,可以递归读取目录下全部文件,如果是分区目录,可以对分区进行选择。
+
+### 分区选择
+分区目录名格式为"分区名=值",例如: city=beijing/month=06/day=17;city=hangzhou/month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+city | month | day
+---|---|---
+beijing | 06 | 17
+hangzhou | 06 | 18
+
+使用SQL语句查找分区,例如:ParquetSourceBatchOp.setPartitions("city = 'beijing'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
## 代码示例
@@ -19,10 +31,10 @@ Python 类名:ParquetSourceBatchOp
### Python 代码
```python
filePath = 'https://alink-test-data.oss-cn-hangzhou.aliyuncs.com/iris.parquet'
-parquetSource = ParquetSourceStreamOp()\
+parquetSource = ParquetSourceBatchOp()\
.setFilePath(filePath)
parquetSource.print()
-StreamOperator.execute()
+
```
### Java 代码
```java
@@ -39,6 +51,28 @@ public class ParquetSourceStreamOpTest {
ParquetSourceBatchOp source = new ParquetSourceBatchOp()
.setFilePath(new FilePath(parquetName, new HttpFileReadOnlyFileSystem()));
source.print();
+
+ //选择分区示例
+ new ParquetSourceBatchOp()
+ .setFilePath(filepath)
+ .setPartitions("year>'9'")
+ .print();
+
+ new ParquetSourceBatchOp()
+ .setFilePath(filepath)
+ .setPartitions("city = 'beijing'")
+ .print();
+
+ new ParquetSourceBatchOp()
+ .setFilePath(filepath)
+ .setPartitions("year < '7' OR year > '9'")
+ .print();
+
+ new ParquetSourceBatchOp()
+ .setFilePath(new FilePath(parquetName2))
+ .setPartitions("year BETWEEN '9' AND '10'")
+ .print();
+
}
}
```
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/\345\206\205\345\255\230\346\225\260\346\215\256\350\257\273\345\205\245 (MemSourceBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/\345\206\205\345\255\230\346\225\260\346\215\256\350\257\273\345\205\245 (MemSourceBatchOp).md"
index d4954ae3a..9dfb88074 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/\345\206\205\345\255\230\346\225\260\346\215\256\350\257\273\345\205\245 (MemSourceBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/\345\206\205\345\255\230\346\225\260\346\215\256\350\257\273\345\205\245 (MemSourceBatchOp).md"
@@ -5,7 +5,7 @@ Python 类名:MemSourceBatchOp
## 功能介绍
-从内存中读取数据生成表
+从内存中读取数据生成表。
MemSourceBatchOp支持多个构造函数
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkBatchOp).md"
index 7a1ae0d5b..c2b0b93ef 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkBatchOp).md"
@@ -5,7 +5,7 @@ Python 类名:CsvSinkBatchOp
## 功能介绍
-写CSV文件。支持写到本地、hdfs。
+将输入数据写出到CSV文件。支持写到本地、hdfs。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
@@ -14,6 +14,7 @@ Python 类名:CsvSinkBatchOp
| fieldDelimiter | 字段分隔符 | 字段分隔符 | String | | | "," |
| numFiles | 文件数目 | 文件数目 | Integer | | | 1 |
| overwriteSink | 是否覆写已有数据 | 是否覆写已有数据 | Boolean | | | false |
+| partitionCols | 分区列 | 创建分区使用的列名 | String[] | | | null |
| quoteChar | 引号字符 | 引号字符 | Character | | | "\"" |
| rowDelimiter | 行分隔符 | 行分隔符 | String | | | "\n" |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkBatchOp).md"
index 37777ce3e..ec9816d39 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkBatchOp).md"
@@ -17,6 +17,7 @@ Python 类名:LibSvmSinkBatchOp
| labelCol | 标签列名 | 输入表中的标签列名 | String | ✓ | | |
| vectorCol | 向量列名 | 向量列对应的列名 | String | ✓ | | |
| overwriteSink | 是否覆写已有数据 | 是否覆写已有数据 | Boolean | | | false |
+| partitionCols | 分区列 | 创建分区使用的列名 | String[] | | | null |
| startIndex | 起始索引 | 起始索引 | Integer | | | 1 |
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkBatchOp).md"
index beb3a32c3..7615aa935 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkBatchOp).md"
@@ -14,11 +14,12 @@ Python 类名:TsvSinkBatchOp
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| numFiles | 文件数目 | 文件数目 | Integer | | | 1 |
| overwriteSink | 是否覆写已有数据 | 是否覆写已有数据 | Boolean | | | false |
+| partitionCols | 分区列 | 创建分区使用的列名 | String[] | | | null |
## 代码示例
-** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
### Python 代码
+** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
```python
df = pd.DataFrame([
["0L", "1L", 0.6],
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/Text\346\226\207\344\273\266\345\257\274\345\207\272 (TextSinkBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/Text\346\226\207\344\273\266\345\257\274\345\207\272 (TextSinkBatchOp).md"
index 013e7810a..8a9b6b473 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/Text\346\226\207\344\273\266\345\257\274\345\207\272 (TextSinkBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/Text\346\226\207\344\273\266\345\257\274\345\207\272 (TextSinkBatchOp).md"
@@ -13,6 +13,7 @@ Python 类名:TextSinkBatchOp
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| numFiles | 文件数目 | 文件数目 | Integer | | | 1 |
| overwriteSink | 是否覆写已有数据 | 是否覆写已有数据 | Boolean | | | false |
+| partitionCols | 分区列 | 创建分区使用的列名 | String[] | | | null |
## 代码示例
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\345\215\241\346\226\271\351\200\211\346\213\251\345\231\250 (ChiSqSelectorBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\345\215\241\346\226\271\351\200\211\346\213\251\345\231\250 (ChiSqSelectorBatchOp).md"
index 8ec8bc40d..be2e8ebd7 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\345\215\241\346\226\271\351\200\211\346\213\251\345\231\250 (ChiSqSelectorBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\345\215\241\346\226\271\351\200\211\346\213\251\345\231\250 (ChiSqSelectorBatchOp).md"
@@ -6,7 +6,7 @@ Python 类名:ChiSqSelectorBatchOp
## 功能介绍
-针对table数据,进行特征筛选
+针对table数据,进行特征筛选。计算features和label列两两的卡方值,取最大的n个feature作为结果。
## 参数说明
diff --git "a/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTBatchOp).md" "b/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTBatchOp).md"
index 71c08c23d..145f0106d 100644
--- "a/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTBatchOp).md"
+++ "b/docs/cn/\346\211\271\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTBatchOp).md"
@@ -6,7 +6,13 @@ Python 类名:DCTBatchOp
## 功能介绍
-对数据进行离散余弦变换。
+DCT(Discrete Cosine Transform), 又叫做离散余弦变换,是对数据进行离散余弦变换,可以用来做视频编码,图像压缩等,经过变换后数据会有更好的聚集性。
+输入是vector列,vector的size为n, 那经过变换后的输出变成size为n的vector。
+
+### 算法原理
+DCT变换就是输入信号为实偶函数的DFT变换
+
+











df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
StreamOperator data = new MemSourceStreamOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonStreamOp).md"
index af4bfdfb5..357dc9b81 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254JSON (ColumnsToJsonStreamOp).md"
@@ -58,7 +58,8 @@ public class ColumnsToJsonStreamOpTest {
@Test
public void testColumnsToJsonStreamOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
StreamOperator data = new MemSourceStreamOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvStreamOp).md"
index 24523ace1..d04bc519b 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254KV (ColumnsToKvStreamOp).md"
@@ -57,7 +57,8 @@ public class ColumnsToKvStreamOpTest {
@Test
public void testColumnsToKvStreamOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
StreamOperator data = new MemSourceStreamOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleStreamOp).md"
index 59190e7a7..d046ed7f3 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\344\270\211\345\205\203\347\273\204 (ColumnsToTripleStreamOp).md"
@@ -60,7 +60,8 @@ public class ColumnsToTripleStreamOpTest {
@Test
public void testColumnsToTripleStreamOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
StreamOperator data = new MemSourceStreamOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorStreamOp).md"
index 29f5a57c5..6ecf2cb16 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\346\225\260\346\215\256\346\240\274\345\274\217\350\275\254\346\215\242/\345\210\227\346\225\260\346\215\256\350\275\254\345\220\221\351\207\217 (ColumnsToVectorStreamOp).md"
@@ -6,7 +6,7 @@ Python 类名:ColumnsToVectorStreamOp
## 功能介绍
将数据格式从 Columns 转成 Vector
-
+数据格式可以为数值类型,如int,float,long,double,也可以为能够转换为数值类型的字符串。
## 参数说明
@@ -37,7 +37,6 @@ op = ColumnsToVectorStreamOp()\
.setSelectedCols(["f0", "f1"])\
.setReservedCols(["row"])\
.setVectorCol("vec")\
- .setVectorSize(5)\
.linkFrom(data)
op.print()
@@ -60,7 +59,8 @@ public class ColumnsToVectorStreamOpTest {
@Test
public void testColumnsToVectorStreamOp() throws Exception {
List df = Arrays.asList(
- Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0)
+ Row.of("1", "{\"f0\":\"1.0\",\"f1\":\"2.0\"}", "$3$0:1.0 1:2.0", "f0:1.0,f1:2.0", "1.0,2.0", 1.0, 2.0),
+ Row.of("2", "{\"f0\":\"4.0\",\"f1\":\"8.0\"}", "$3$0:4.0 1:8.0", "f0:4.0,f1:8.0", "4.0,8.0", 4.0, 8.0)
);
StreamOperator data = new MemSourceStreamOp(df,
"row string, json string, vec string, kv string, csv string, f0 double, f1 double");
@@ -68,7 +68,6 @@ public class ColumnsToVectorStreamOpTest {
.setSelectedCols("f0", "f1")
.setReservedCols("row")
.setVectorCol("vec")
- .setVectorSize(5)
.linkFrom(data);
op.print();
StreamOperator.execute();
@@ -77,9 +76,9 @@ public class ColumnsToVectorStreamOpTest {
```
### 运行结果
-
-|row|vec|
-|---|-----|
-|1|$5$1.0 2.0|
-|2|$5$4.0 8.0|
+
+row|vec
+---|---
+1|1.0 2.0
+1|4.0 8.0
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\347\261\273\345\236\213\350\275\254\346\215\242 (TypeConvertStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\347\261\273\345\236\213\350\275\254\346\215\242 (TypeConvertStreamOp).md"
index 6a57f35ab..0ee606e4f 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\347\261\273\345\236\213\350\275\254\346\215\242 (TypeConvertStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\347\261\273\345\236\213\350\275\254\346\215\242 (TypeConvertStreamOp).md"
@@ -5,12 +5,10 @@ Python 类名:TypeConvertStreamOp
## 功能介绍
+类型转换是用来列类型进行转换的组件。本组件可一次性转化多个列到指定的数据类型,但是这些列的数据类型只能为同一种,并且为JDBC Type。
-类型转换是用来列类型进行转换的组件
+组件支持的目标类型为 STRING, VARCHAR, FLOAT, DOUBLE, INT, BIGINT, LONG, BOOLEAN。
-组件可一次性转化多个列到指定的数据类型,但是这些列的数据类型只能为同一种,并且为JDBC Type。
-
-支持的目标类型为 STRING, VARCHAR, FLOAT, DOUBLE, INT, BIGINT, LONG, BOOLEAN。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
@@ -50,14 +48,50 @@ StreamOperator.execute()
```
+### Java 代码
+```java
+import org.apache.flink.types.Row;
+
+import com.alibaba.alink.operator.stream.StreamOperator;
+import com.alibaba.alink.operator.stream.source.MemSourceStreamOp;
+import com.alibaba.alink.operator.stream.dataproc.TypeConvertStreamOp;
+import org.junit.Test;
+
+import java.util.Arrays;
+import java.util.List;
+
+public class TypeConvertStreamOpTest {
+ @Test
+ public void testTypeConvertStreamOp() throws Exception {
+ List inputData = Arrays.asList(
+ Row.of("Ohio", 2000L, 1.5),
+ Row.of("Ohio", 2001L, 1.7),
+ Row.of("Ohio", 2002L, 3.6),
+ Row.of("Nevada", 2001L, 2.4),
+ Row.of("Nevada", 2002L, 2.9),
+ Row.of("Nevada", 2003L,3.2)
+ );
+ StreamOperator memSourceStreamOp = new MemSourceStreamOp(inputData, "f1 string, f2 bigint, f3 double");
+ new TypeConvertStreamOp()
+ .setSelectedCols("f2")
+ .setTargetType("double")
+ .linkFrom(memSourceStreamOp)
+ .print();
+
+ StreamOperator.execute();
+ }
+}
+```
+
### 运行结果
```
-['f1', 'f2', 'f3']
-['Ohio', 2000.0, 1.5]
-['Ohio', 2001.0, 1.7]
-['Ohio', 2002.0, 3.6]
-['Nevada', 2001.0, 2.4]
-['Nevada', 2002.0, 2.9]
-['Nevada', 2003.0, 3.2]
+f1 |f2 |f3
+---|---|---
+Ohio|2000.0000|1.5000
+Ohio|2001.0000|1.7000
+Ohio|2002.0000|3.6000
+Nevada|2001.0000|2.4000
+Nevada|2002.0000|2.9000
+Nevada|2003.0000|3.2000
```
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleStreamOp).md"
index 6eb3e4839..217a39716 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\244\204\347\220\206/\351\232\217\346\234\272\351\207\207\346\240\267 (SampleStreamOp).md"
@@ -5,8 +5,7 @@ Python 类名:SampleStreamOp
## 功能介绍
-
-- 随机采样是对数据进行随机抽样,每个样本都以相同的概率被抽到。
+随机采样组件。本算法是对数据进行随机抽样,每个样本都以相同的概率被抽到。
## 参数说明
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (AkSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (AkSourceStreamOp).md"
index a2fa6c25b..b8c3602de 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (AkSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/AK\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (AkSourceStreamOp).md"
@@ -7,6 +7,18 @@ Python 类名:AkSourceStreamOp
## 功能介绍
以流式的方式读Ak文件。Ak文件格式是Alink 自定义的一种文件格式,能够将数据的Schema保留输出的文件格式。
+### 分区选择
+Export2FileSinkStreamOp组件能将数据分区保存,AkSourceStreamOp可以选择分区读取。
+分区目录名格式为"分区名=值",例如: month=06/day=17;month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+ month | day
+---|---
+06 | 17
+06 | 18
+
+使用SQL语句查找分区,例如:AkSourceStreamOp.setPartitions("day = '17'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
+
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (CsvSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (CsvSourceStreamOp).md"
index ebdb3f823..ab3da8bb8 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (CsvSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/CSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (CsvSourceStreamOp).md"
@@ -5,7 +5,18 @@ Python 类名:CsvSourceStreamOp
## 功能介绍
-读CSV文件数据
+读CSV文件数据。
+
+### 分区选择
+分区目录名格式为"分区名=值",例如: city=beijing/month=06/day=17;city=hangzhou/month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+city | month | day
+---|---|---
+beijing | 06 | 17
+hangzhou | 06 | 18
+
+使用SQL语句查找分区,例如:CsvSourceStreamOp.setPartitions("city = 'beijing'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
@@ -16,6 +27,7 @@ Python 类名:CsvSourceStreamOp
| handleInvalidMethod | 处理无效值的方法 | 处理无效值的方法,可取 error, skip | String | | "ERROR", "SKIP" | "ERROR" |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
| lenient | 是否容错 | 若为true,当解析失败时丢弃该数据;若为false,解析失败是抛异常 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| quoteChar | 引号字符 | 引号字符 | Character | | | "\"" |
| rowDelimiter | 行分隔符 | 行分隔符 | String | | | "\n" |
| skipBlankLine | 是否忽略空行 | 是否忽略空行 | Boolean | | | true |
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (LibSvmSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (LibSvmSourceStreamOp).md"
index 921464538..fdb2af180 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (LibSvmSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/LibSvm\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (LibSvmSourceStreamOp).md"
@@ -12,6 +12,7 @@ Python 类名:LibSvmSourceStreamOp
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| startIndex | 起始索引 | 起始索引 | Integer | | | 1 |
## 代码示例
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TsvSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TsvSourceStreamOp).md"
index c33620ccc..9d700f538 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TsvSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/TSV\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TsvSourceStreamOp).md"
@@ -14,6 +14,7 @@ Python 类名:TsvSourceStreamOp
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| schemaStr | Schema | Schema。格式为"colname coltype[, colname2, coltype2[, ...]]",例如"f0 string, f1 bigint, f2 double" | String | ✓ | | |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| skipBlankLine | 是否忽略空行 | 是否忽略空行 | Boolean | | | true |
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TextSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TextSourceStreamOp).md"
index 24f20a55b..47d064510 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TextSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/Text\346\226\207\344\273\266\346\225\260\346\215\256\346\272\220 (TextSourceStreamOp).md"
@@ -12,6 +12,7 @@ Python 类名:TextSourceStreamOp
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
| ignoreFirstLine | 是否忽略第一行数据 | 是否忽略第一行数据 | Boolean | | | false |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
| textCol | 文本列名称 | 文本列名称 | String | | | "text" |
## 代码示例
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceStreamOp).md"
index 28f9e7033..0ed6788b3 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\205\245/parquet\346\226\207\344\273\266\350\257\273\345\205\245 (ParquetSourceStreamOp).md"
@@ -5,12 +5,24 @@ Python 类名:ParquetSourceStreamOp
## 功能介绍
-读parquet文件数据。支持从本地、hdfs、http读取
+读parquet文件数据。支持从本地、hdfs、http读取,可以递归读取目录下全部文件,如果是分区目录,可以对分区进行选择。
+
+### 分区选择
+分区目录名格式为"分区名=值",例如: city=beijing/month=06/day=17;city=hangzhou/month=06/day=18。
+Alink将遍历目录下的分区名和分区值,构造分区表:
+
+city | month | day
+---|---|---
+beijing | 06 | 17
+hangzhou | 06 | 18
+
+使用SQL语句查找分区,例如:ParquetSourceStreamOp.setPartitions("city = 'beijing'"),分区选择语法参考[《Flink SQL 内置函数》](https://www.yuque.com/pinshu/alink_tutorial/list_sql_function),分区值为String类型。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| filePath | 文件路径 | 文件路径 | String | ✓ | | |
+| partitions | 分区名 | 1)单级、单个分区示例:ds=20190729;2)多级分区之间用" / "分隔,例如:ds=20190729/dt=12; 3)多个分区之间用","分隔,例如:ds=20190729,ds=20190730 | String | | | null |
## 代码示例
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkStreamOp).md"
index dc0bea535..766265966 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/CSV\346\226\207\344\273\266\345\257\274\345\207\272 (CsvSinkStreamOp).md"
@@ -5,7 +5,7 @@ Python 类名:CsvSinkStreamOp
## 功能介绍
-写CSV文件
+将输入数据写出到CSV文件。
## 参数说明
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkStreamOp).md"
index 9d027cf01..3522218fe 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/LibSvm\346\226\207\344\273\266\345\257\274\345\207\272 (LibSvmSinkStreamOp).md"
@@ -5,7 +5,6 @@ Python 类名:LibSvmSinkStreamOp
## 功能介绍
-
写出LibSvm格式文件,支持写出到本地文件和HDFS文件。
## 参数说明
@@ -23,13 +22,8 @@ Python 类名:LibSvmSinkStreamOp
## 代码示例
### Python 代码
+** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
```python
-from pyalink.alink import *
-
-import pandas as pd
-
-useLocalEnv(1)
-
df_data = pd.DataFrame([
['1:2.0 2:1.0 4:0.5', 1.5],
['1:2.0 2:1.0 4:0.5', 1.7],
@@ -45,6 +39,7 @@ StreamOperator.execute()
```
### Java 代码
+** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
```java
import org.apache.flink.types.Row;
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkStreamOp).md"
index a80604a85..b6df00099 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\346\225\260\346\215\256\345\257\274\345\207\272/TSV\346\226\207\344\273\266\345\257\274\345\207\272 (TsvSinkStreamOp).md"
@@ -5,8 +5,7 @@ Python 类名:TsvSinkStreamOp
## 功能介绍
-
-写Tsv文件,Tsv文件是以tab为分隔符
+本组件将输入数据写出到Tsv文件,Tsv文件以tab为分隔符。
## 参数说明
@@ -19,13 +18,8 @@ Python 类名:TsvSinkStreamOp
## 代码示例
### Python 代码
+** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
```python
-from pyalink.alink import *
-
-import pandas as pd
-
-useLocalEnv(1)
-
df = pd.DataFrame([
["0L", "1L", 0.6],
["2L", "2L", 0.8],
@@ -54,6 +48,7 @@ StreamOperator.execute()
```
### Java 代码
+** 以下代码仅用于示意,可能需要修改部分代码或者配置环境后才能正常运行!**
```java
import org.apache.flink.types.Row;
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTStreamOp).md"
index 41e6a13bb..79864e3c0 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\347\211\271\345\276\201\345\267\245\347\250\213/\347\246\273\346\225\243\344\275\231\345\274\246\345\217\230\346\215\242 (DCTStreamOp).md"
@@ -6,7 +6,15 @@ Python 类名:DCTStreamOp
## 功能介绍
-对数据进行离散余弦变换。
+DCT(Discrete Cosine Transform), 又叫做离散余弦变换,是对数据进行离散余弦变换,可以用来做视频编码,图像压缩等,经过变换后数据会有更好的聚集性。
+输入是vector列,vector的size为n, 那经过变换后的输出变成size为n的vector。
+
+### 算法原理
+DCT变换就是输入信号为实偶函数的DFT变换
+
+
+
+
## 参数说明
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\344\272\214\345\210\206\347\261\273\350\257\204\344\274\260 (EvalBinaryClassStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\344\272\214\345\210\206\347\261\273\350\257\204\344\274\260 (EvalBinaryClassStreamOp).md"
index 1eb0434f0..9da51a493 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\344\272\214\345\210\206\347\261\273\350\257\204\344\274\260 (EvalBinaryClassStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\344\272\214\345\210\206\347\261\273\350\257\204\344\274\260 (EvalBinaryClassStreamOp).md"
@@ -5,91 +5,102 @@ Python 类名:EvalBinaryClassStreamOp
## 功能介绍
-二分类评估是对二分类算法的预测结果进行效果评估。
-支持Roc曲线,LiftChart曲线,K-S曲线,Recall-Precision曲线绘制。
+对二分类算法的预测结果进行效果评估。
-流式的实验支持累计统计和窗口统计,除却上述四条曲线外,还给出Auc/Kappa/Accuracy/Logloss随时间的变化曲线。
+### 算法原理
-给出整体的评估指标包括:AUC、K-S、PRC, 不同阈值下的Precision、Recall、F-Measure、Sensitivity、Accuracy、Specificity和Kappa。
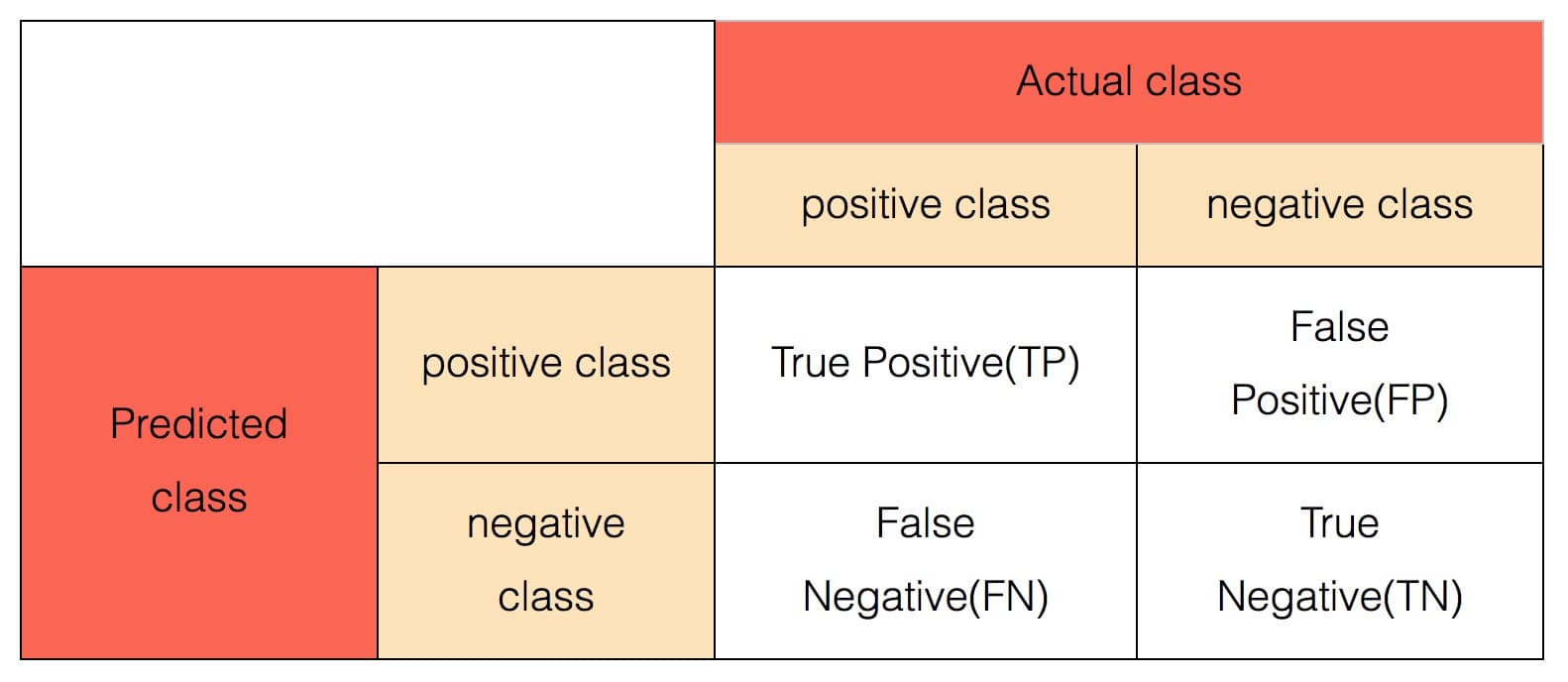
+在有监督二分类问题的评估中,每条样本都有一个真实的标签和一个由模型生成的预测。 这样每调样本点实际上可以划分为以下 4 个类别中的一类:
-#### 混淆矩阵
-
+- True Positive(TP):标签为正类,预测为正类;
+- True Negative(TN):标签为负类,预测为负类;
+- False Positive(FP):标签为负类,预测为正类;
+- False Negative(FN):标签为正类,预测为负类。
-#### Roc曲线
+通常,用 $TP, TN, FP, FN$ 分别表示属于各自类别的样本数。
+基于这几个数量,可以定义大部分的二分类评估指标。
-横坐标:FPR
+#### 精确率
-纵坐标:TPR
+$Precision = \frac{TP}{TP + FP}$
-#### AUC
+#### 召回率、敏感性
-Roc曲线下面的面积
+$Recall = \frac{TP}{TP + FN} = Sensitivity$
-#### K-S
+#### F-measure
-横坐标:阈值
+$F1=\frac{2TP}{2TP+FP+FN}=\frac{2\cdot Precision \cdot Recall}{Precision+Recall}$
-纵坐标:TPR和FPR
+#### 准确率
-#### KS
+$Accuracy=\frac{TP + TN}{TP + TN + FP + FN}$
-K-S曲线两条纵轴的最大差值
+#### 特异性
-#### Recall-Precision曲线
+$Specificity=\frac{TN}{FP+TN}$
-横坐标:Recall
+#### Kappa
-纵坐标:Precision
+$p_a =\frac{TP + TN}{TP + TN + FP + FN}$
-#### PRC
+$p_e = \frac{(TN + FP) * (TN + FN) + (FN + TP) * (FP + TP)}{(TP + TN + FP + FN) * (TP + TN + FP + FN)}$
-Recall-Precision曲线下面的面积
+$kappa = \frac{p_a - p_e}{1 - p_e}$
-#### 提升曲线
+#### 混淆矩阵
-横坐标:$$ \dfrac{TP + FP}{total} $$
+
-纵坐标:TP
+二分类模型除了给出每条样本的预测标签之外,通常还会给出每条样本预测为正类的概率$p$,而预测标签是根据这个概率与阈值的关系确定的。
+通常情况下,阈值会设为 0.5,概率大于 0.5 的预测为正类,小于 0.5 的预测为负类。
+有一些评估指标会考虑这个阈值从 0 到 1 变化时,各个指标的变化情况,计算更加复杂的指标。
-#### Precision
-$$ Precision = \dfrac{TP}{TP + FP} $$
+#### LogLoss
+$LogLoss = -\frac{1}{n}\sum_{i}[y_i \log(y'_i) + (1-y_i) \log(1 - y'_i)]$
-#### Recall
-$$ Recall = \dfrac{TP}{TP + FN} $$
+这里,$y_i\in [0,1]$表示样本$i$的真实标签(正类为 1,负类为0),$y'_i$表示样本$i$预测为正类的概率。
+#### ROC(receiver operating characteristic)曲线
-#### F-Measure
-$$ F1=\dfrac{2TP}{2TP+FP+FN}=\dfrac{2\cdot Precision \cdot Recall}{Precision+Recall} $$
+阈值从 0 到 1 变化时, 横坐标:$FPR = FP / (FP + TN)$ 和纵坐标:$TPR = TP / (TP + FN)$构成的曲线。
+#### AUC (Area under curve)
-#### Sensitivity
-$$ Sensitivity=\dfrac{TP}{TP+FN} $$
+ROC 曲线下的面积。
+#### K-S 曲线
-#### Accuracy
-$$ Accuray=\dfrac{TP + TN}{TP + TN + FP + FN} $$
+阈值从 0 到 1 变化时,横坐标阈值和纵坐标$TPR$和$FPR$构成的曲线。
+#### KS 指标
-#### Specificity
-$$ Specificity=\dfrac{TN}{FP+T} $$
+K-S 曲线 中,两条曲线在纵轴方向上的最大差值。
+#### Precision-Recall 曲线
-#### Kappa
-$$ p_a =\dfrac{TP + TN}{TP + TN + FP + FN} $$
+阈值从 0 到 1 变化时,横坐标 Precision 和纵坐标 Recall 构成的曲线。
-$$ p_e = \dfrac{(TN + FP) * (TN + FN) + (FN + TP) * (FP + TP)}{(TP + TN + FP + FN) * (TP + TN + FP + FN)} $$
+#### PRC 指标
-$$ kappa = \dfrac{p_a - p_e}{1 - p_e} $$
+Precision-Recall 曲线下的面积。
+#### 提升曲线(Lift Chart)
-#### Logloss
-$$ logloss=- \dfrac{1}{N}\sum_{i=1}^N \sum_{j=1}^My_{i,j}log(p_{i,j}) $$
+阈值从 0 到 1 变化时,横坐标$\frac{TP + FP}{N}$和纵坐标$TP$构成的曲线。
+### 使用方式
+
+该组件通常接二分类预测算法的输出端。
+
+使用时,需要通过参数 `labelCol` 指定预测标签列,通过参数 `predictionDetailCol` 指定预测详细信息列(包含有预测概率)。
+另外,需要指定参数 `timeInterval`,表示对数据按时间窗口来进行划分。
+在输出结果中既包含各个时间窗口内的统计指标,也包含此前所有数据的统计指标。
## 参数说明
+
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| labelCol | 标签列名 | 输入表中的标签列名 | String | ✓ | | |
@@ -98,8 +109,6 @@ $$ logloss=- \dfrac{1}{N}\sum_{i=1}^N \sum_{j=1}^My_{i,j}log(p_{i,j}) $$
| positiveLabelValueString | 正样本 | 正样本对应的字符串格式。 | String | | | null |
| timeInterval | 时间间隔 | 流式数据统计的时间间隔 | Double | | | 3.0 |
-
-
## 代码示例
### Python 代码
```python
diff --git "a/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\345\244\232\345\210\206\347\261\273\350\257\204\344\274\260 (EvalMultiClassStreamOp).md" "b/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\345\244\232\345\210\206\347\261\273\350\257\204\344\274\260 (EvalMultiClassStreamOp).md"
index e687fe561..7a0313ca7 100644
--- "a/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\345\244\232\345\210\206\347\261\273\350\257\204\344\274\260 (EvalMultiClassStreamOp).md"
+++ "b/docs/cn/\346\265\201\347\273\204\344\273\266/\350\257\204\344\274\260/\345\244\232\345\210\206\347\261\273\350\257\204\344\274\260 (EvalMultiClassStreamOp).md"
@@ -5,54 +5,71 @@ Python 类名:EvalMultiClassStreamOp
## 功能介绍
-多分类评估是对多分类算法的预测结果进行效果评估。
-支持Roc曲线,LiftChart曲线,K-S曲线,Recall-Precision曲线绘制。
+对多分类算法的预测结果进行效果评估。
-流式的实验支持累计统计和窗口统计,除却上述四条曲线外,还给出Auc/Kappa/Accuracy/Logloss随时间的变化曲线。
+### 算法原理
-给出整体的评估指标包括:AUC、K-S、PRC, 不同阈值下的Precision、Recall、F-Measure、Sensitivity、Accuracy、Specificity和Kappa。
+在多分类问题的评估中,每条样本都有一个真实的标签和一个由模型生成的预测。
+但与二分类问题不同,多分类算法中,总的类别数是大于2的,因此不能直接称作正类和负类。
-#### 混淆矩阵
-
+在计算评估指标时,可以将某个类别选定为正类,将其他值都看作负类,这样可以计算每个类别(per-class)的指标。
+进一步地,将每个类别各自的指标进行平均,可以得到模型总体的指标。
+这里的"平均"有三种做法:
-#### Precision
-$$ Precision = \dfrac{TP}{TP + FP} $$
+- Macro 平均:直接对各个类别的同一个指标求数值平均值,作为总体指标;
+- 加权平均:以样本中各个类别所占的比例为权重,对各个类别的同一个指标求加权平均值,作为总体指标;
+- Micro 平均:将各个类别看作正类时的 $TP, TN, FN$ 相加,得到总的 $TP, TN, FN$ 值,然后计算指标。在 Micro 平均时,micro-F1, micro-precision, micro-recall 都等于 accuracy。
+所支持的每类别指标与平均指标见下:
-#### Recall
-$$ Recall = \dfrac{TP}{TP + FN} $$
+#### 精确率
+$Precision = \frac{TP}{TP + FP}$
-#### F-Measure
-$$ F1=\dfrac{2TP}{2TP+FP+FN}=\dfrac{2\cdot Precision \cdot Recall}{Precision+Recall} $$
+#### 召回率、敏感性
+$Recall = \frac{TP}{TP + FN} = Sensitivity$
-#### Sensitivity
-$$ Sensitivity=\dfrac{TP}{TP+FN} $$
+#### F-measure
+$F1=\frac{2TP}{2TP+FP+FN}=\frac{2\cdot Precision \cdot Recall}{Precision+Recall}$
-#### Accuracy
-$$ Accuray=\dfrac{TP + TN}{TP + TN + FP + FN} $$
+#### 准确率
+$Accuracy=\frac{TP + TN}{TP + TN + FP + FN}$
-#### Specificity
-$$ Specificity=\dfrac{TN}{FP+T} $$
+#### 特异性
+$Specificity=\frac{TN}{FP+TN}$
#### Kappa
-$$ p_a =\dfrac{TP + TN}{TP + TN + FP + FN} $$
-$$ p_e = \dfrac{(TN + FP) * (TN + FN) + (FN + TP) * (FP + TP)}{(TP + TN + FP + FN) * (TP + TN + FP + FN)} $$
+$p_a =\frac{TP + TN}{TP + TN + FP + FN}$
+
+$p_e = \frac{(TN + FP) * (TN + FN) + (FN + TP) * (FP + TP)}{(TP + TN + FP + FN) * (TP + TN + FP + FN)}$
+
+$kappa = \frac{p_a - p_e}{1 - p_e}$
-$$ kappa = \dfrac{p_a - p_e}{1 - p_e} $$
+#### 混淆矩阵
+
+
+二分类模型除了给出每条样本$i$的预测标签之外,通常还会给出每条样本预测为为各个类别$j$的概率$p_{i,j}$。
+通常情况下,每条样本最大概率对应的类别为该样本的预测标签。
-#### Logloss
-$$ logloss=- \dfrac{1}{N}\sum_{i=1}^N \sum_{j=1}^My_{i,j}log(p_{i,j}) $$
+#### LogLoss
+$LogLoss=- \frac{1}{n}\sum_{i} \sum_{j=1}^M y_{i,j}log(p_{i,j})$
+
+### 使用方式
+
+该组件通常接多分类预测算法的输出端。
+
+使用时,需要通过参数 `labelCol` 指定预测标签列,通过参数 `predictionCol` 和 `predictionDetailCol` 指定预测结果列和预测详细信息列(包含有预测概率)。
## 参数说明
+
| 名称 | 中文名称 | 描述 | 类型 | 是否必须? | 取值范围 | 默认值 |
| --- | --- | --- | --- | --- | --- | --- |
| labelCol | 标签列名 | 输入表中的标签列名 | String | ✓ | | |
@@ -60,8 +77,6 @@ $$ logloss=- \dfrac{1}{N}\sum_{i=1}^N \sum_{j=1}^My_{i,j}log(p_{i,j}) $$
| predictionDetailCol | 预测详细信息列名 | 预测详细信息列名 | String | | | |
| timeInterval | 时间间隔 | 流式数据统计的时间间隔 | Double | | | 3.0 |
-
-
## 代码示例
### Python 代码
```python