We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
现在 js 引擎基本都统一了代码的构建流程 初始代码 - parse - ast - 字节码 - 优化器 - 机器码
如何让我们写出的代码更符合引擎的优化规则,是在一些基础框架中需要考虑到的性能优化手段 这里主要分为两类:属性访问、函数执行
js 中没有数组,array 也是对象,对象的属性有三种模式
一个内存中对象都有三种属性
按照索引的大小排列,存储在 elements 中,会退化成稀疏数组 - 慢哈希
按照创建的顺序排列,存储在 properites 中,会退化成慢哈希
可以把 array 当做是实现了 Symbol.iterator 和 Array.prototype 里面一系列方法的特殊对象
对象和数组都可能会退化到哈希表存储模式,访问比索引慢,最重要的是无法应用 inline cache 但相对的这种字典存储方式可以节省内存
隐藏类,在 v8 object 中以 map 属性存在,存储了 js object 的属性描述,通常会构成 Transition tree
内联缓存优化,我理解是直接将属性索引地址嵌入字节码中,避免寻址过程的性能损耗
v8 根据反馈向量或类型范围确定优化与回退,同样适用于 inline cache
反馈向量其实就是一个表结构,它由很多项组成的,每一项称为一个插槽 (Slot),V8 会依次将执行 loadX 函数的中间数据写入到反馈向量的插槽中 每个插槽中包括了插槽的索引 (slot index)、插槽的类型 (type)、插槽的状态 (state)、隐藏类 (map) 的地址、还有属性的偏移量
例如一个属性查找过程为:V8 获取 o.x 的流程:查找对象 o 的隐藏类,再通过隐藏类查找 x 属性偏移量,然后根据偏移量获取属性值 那么如果反馈向量中记录了 offset(偏移量),就可以节省遍历 Transition tree 这个过程
// prototype 可以将慢对象转化为快速访问对象 function toFastProperties(obj) { /*jshint -W027*/ function f() {} f.prototype = obj; ASSERT("%HasFastProperties", true, obj); return f; eval(obj); }
v8 api ScriptCompiler::CreateCodeCache
// https://github.com/zertosh/v8-compile-cache/blob/master/v8-compile-cache.js var buffer = this._cacheStore.get(filename, invalidationKey); // vm 内部也是使用了v8::ScriptCompiler::CreateCodeCache var script = new vm.Script(wrapper, { filename: filename, lineOffset: 0, displayErrors: true, cachedData: buffer, produceCachedData: true, }); if (script.cachedDataProduced) { this._cacheStore.set(filename, invalidationKey, script.cachedData); } else if (script.cachedDataRejected) { this._cacheStore.delete(filename); }
v8 编译原理 shapes 和 inline caches v8 优化机制 v8-compile-cache 原理
坐的我好累,有时间再写
The text was updated successfully, but these errors were encountered:
No branches or pull requests
现在 js 引擎基本都统一了代码的构建流程
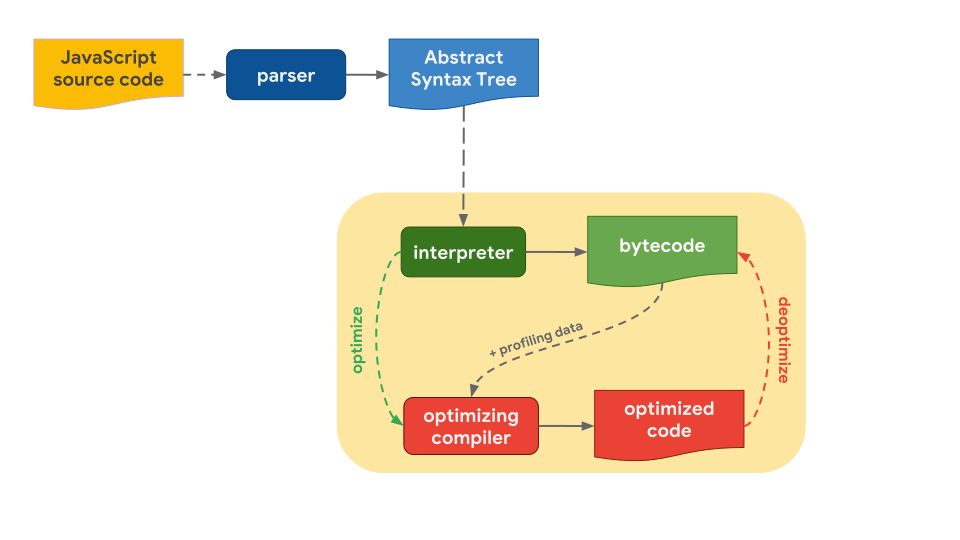
初始代码 - parse - ast - 字节码 - 优化器 - 机器码
如何让我们写出的代码更符合引擎的优化规则,是在一些基础框架中需要考虑到的性能优化手段
这里主要分为两类:属性访问、函数执行
属性访问
js 中没有数组,array 也是对象,对象的属性有三种模式
object
一个内存中对象都有三种属性
索引属性
按照索引的大小排列,存储在 elements 中,会退化成稀疏数组 - 慢哈希
命名属性
按照创建的顺序排列,存储在 properites 中,会退化成慢哈希
array
可以把 array 当做是实现了 Symbol.iterator 和 Array.prototype 里面一系列方法的特殊对象
慢哈希
对象和数组都可能会退化到哈希表存储模式,访问比索引慢,最重要的是无法应用 inline cache
但相对的这种字典存储方式可以节省内存
hidden class
隐藏类,在 v8 object 中以 map 属性存在,存储了 js object 的属性描述,通常会构成 Transition tree
inline cache
内联缓存优化,我理解是直接将属性索引地址嵌入字节码中,避免寻址过程的性能损耗
单态、多态、复合态
v8 根据反馈向量或类型范围确定优化与回退,同样适用于 inline cache
反馈向量
反馈向量其实就是一个表结构,它由很多项组成的,每一项称为一个插槽 (Slot),V8 会依次将执行 loadX 函数的中间数据写入到反馈向量的插槽中
每个插槽中包括了插槽的索引 (slot index)、插槽的类型 (type)、插槽的状态 (state)、隐藏类 (map) 的地址、还有属性的偏移量
例如一个属性查找过程为:V8 获取 o.x 的流程:查找对象 o 的隐藏类,再通过隐藏类查找 x 属性偏移量,然后根据偏移量获取属性值
那么如果反馈向量中记录了 offset(偏移量),就可以节省遍历 Transition tree 这个过程
优化技巧
优化 source code 经过 ast 到字节码这一过程
node 库,利用了 vm.script 生成代码,同时创建 code cache,这个方案需要同时设计硬盘缓存与内存缓存,以及更新机制
参考
v8 编译原理
shapes 和 inline caches
v8 优化机制
v8-compile-cache 原理
函数执行
坐的我好累,有时间再写
The text was updated successfully, but these errors were encountered: